


















































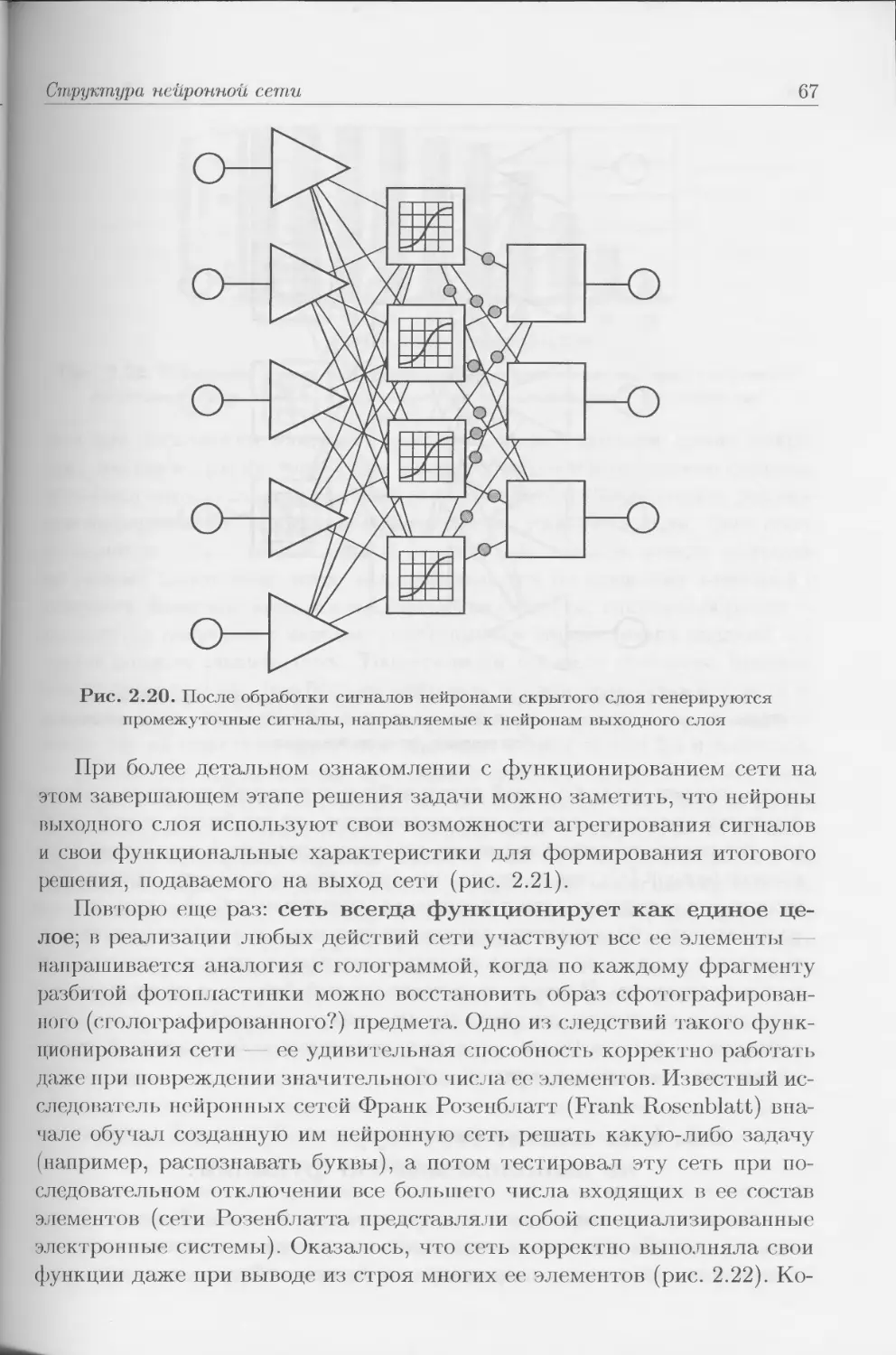








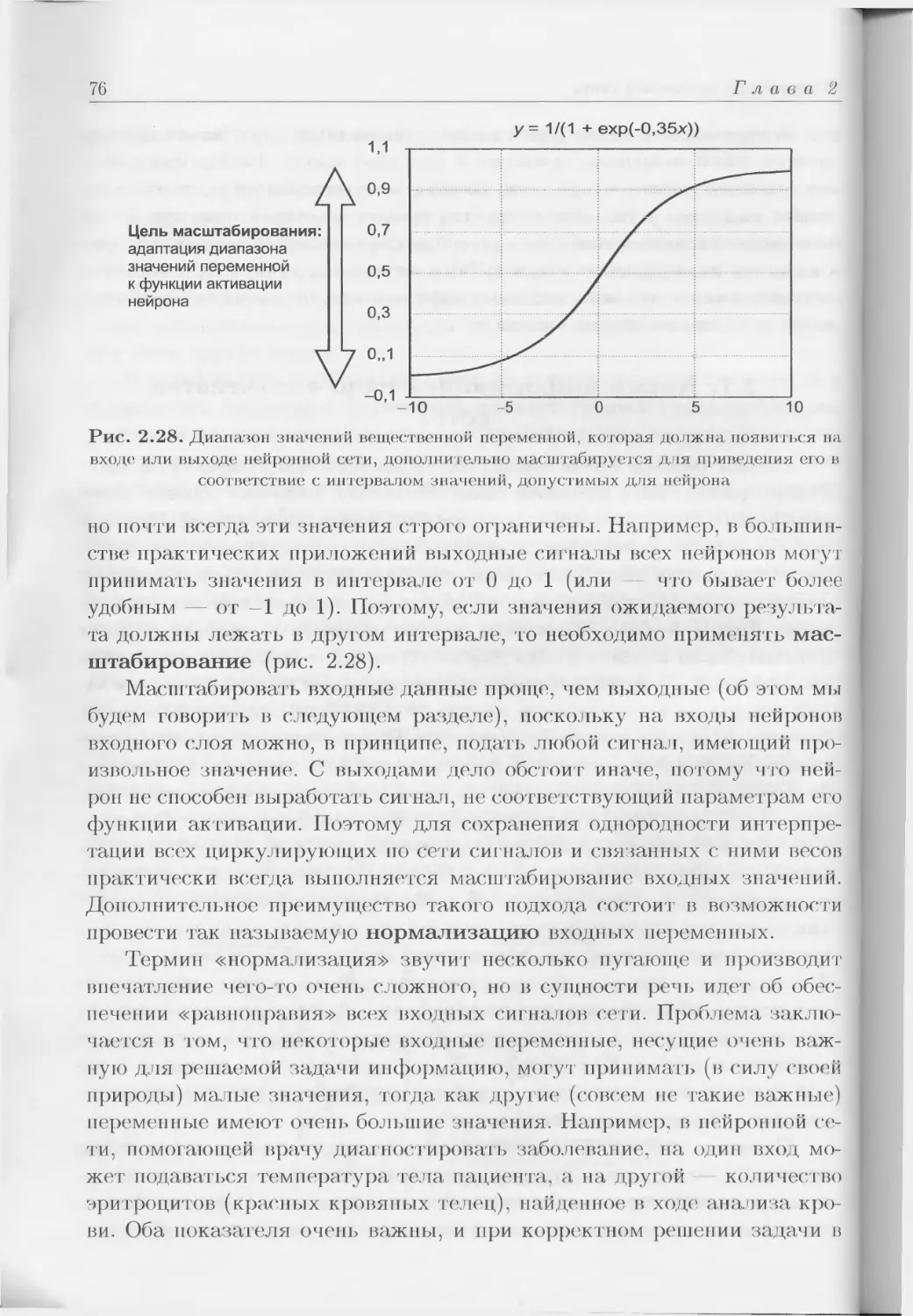







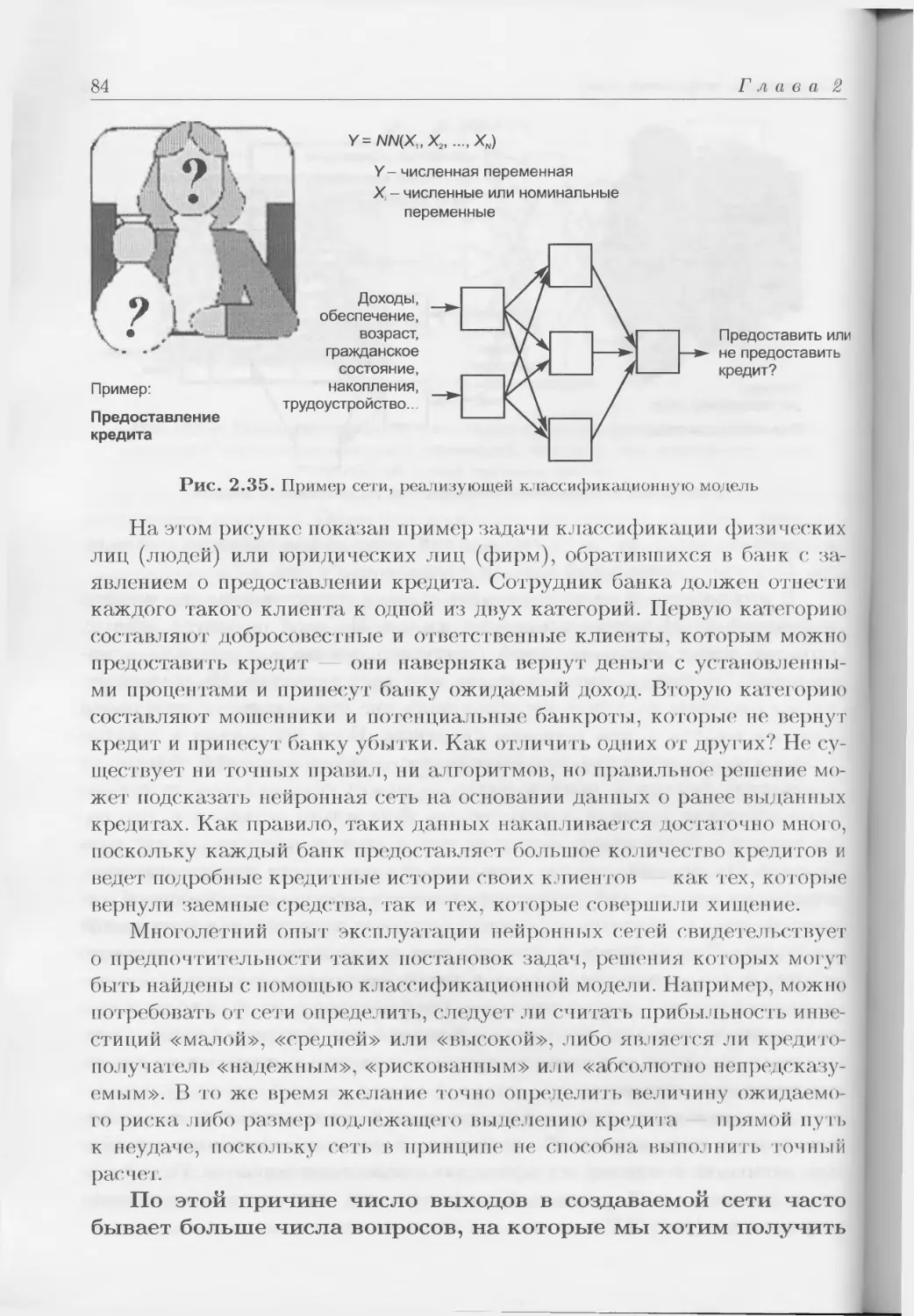
























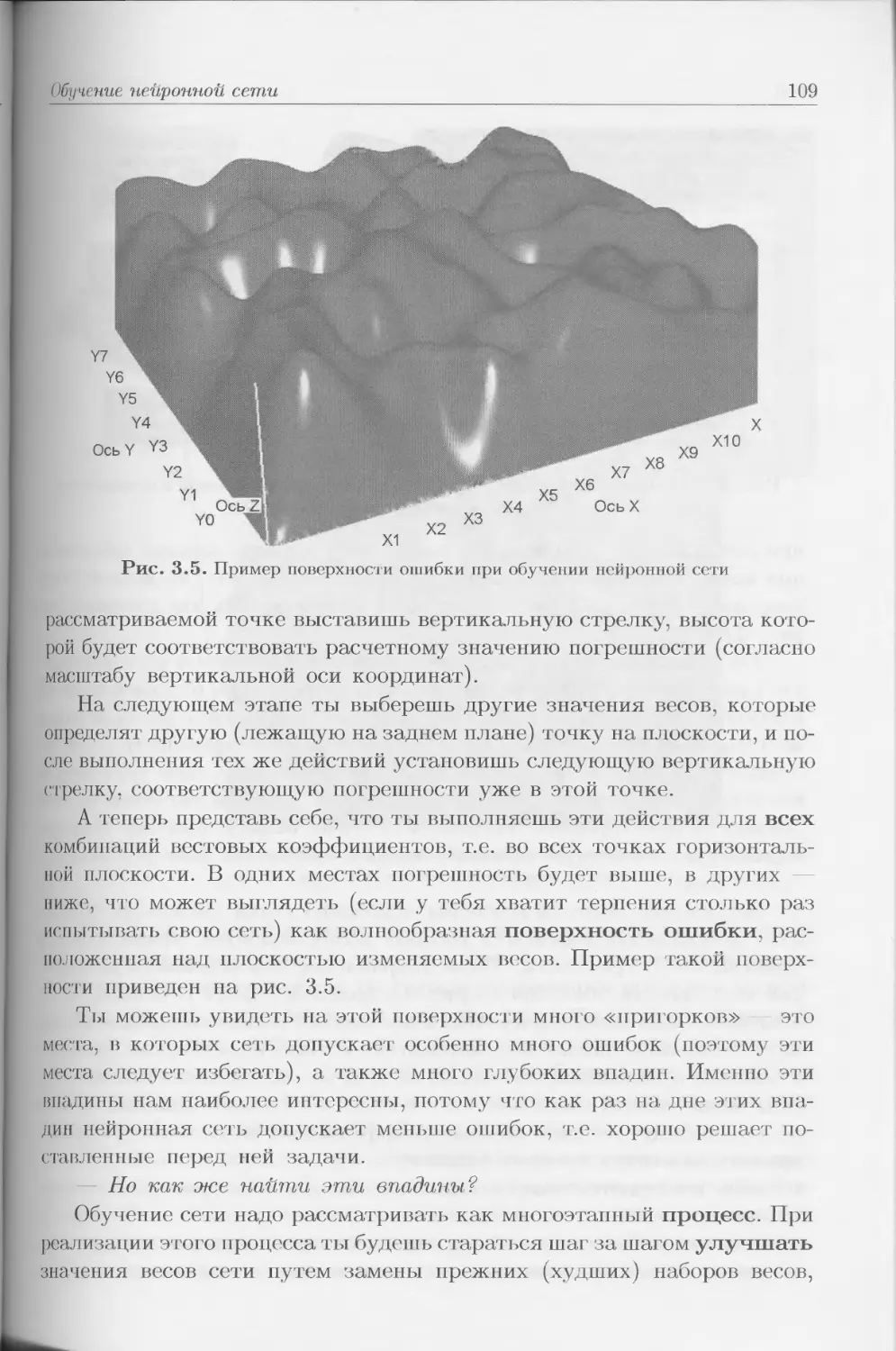




































































































































































































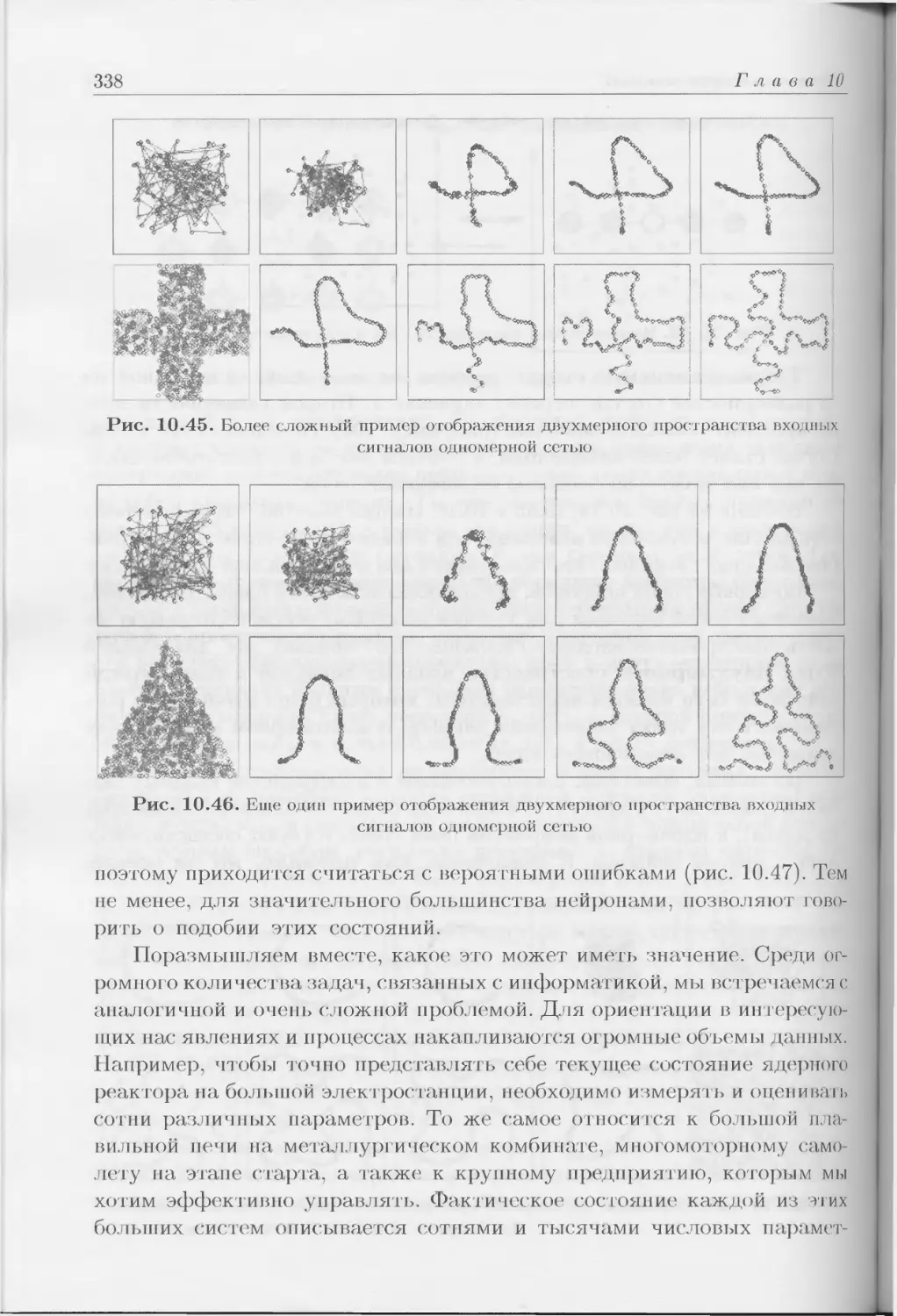







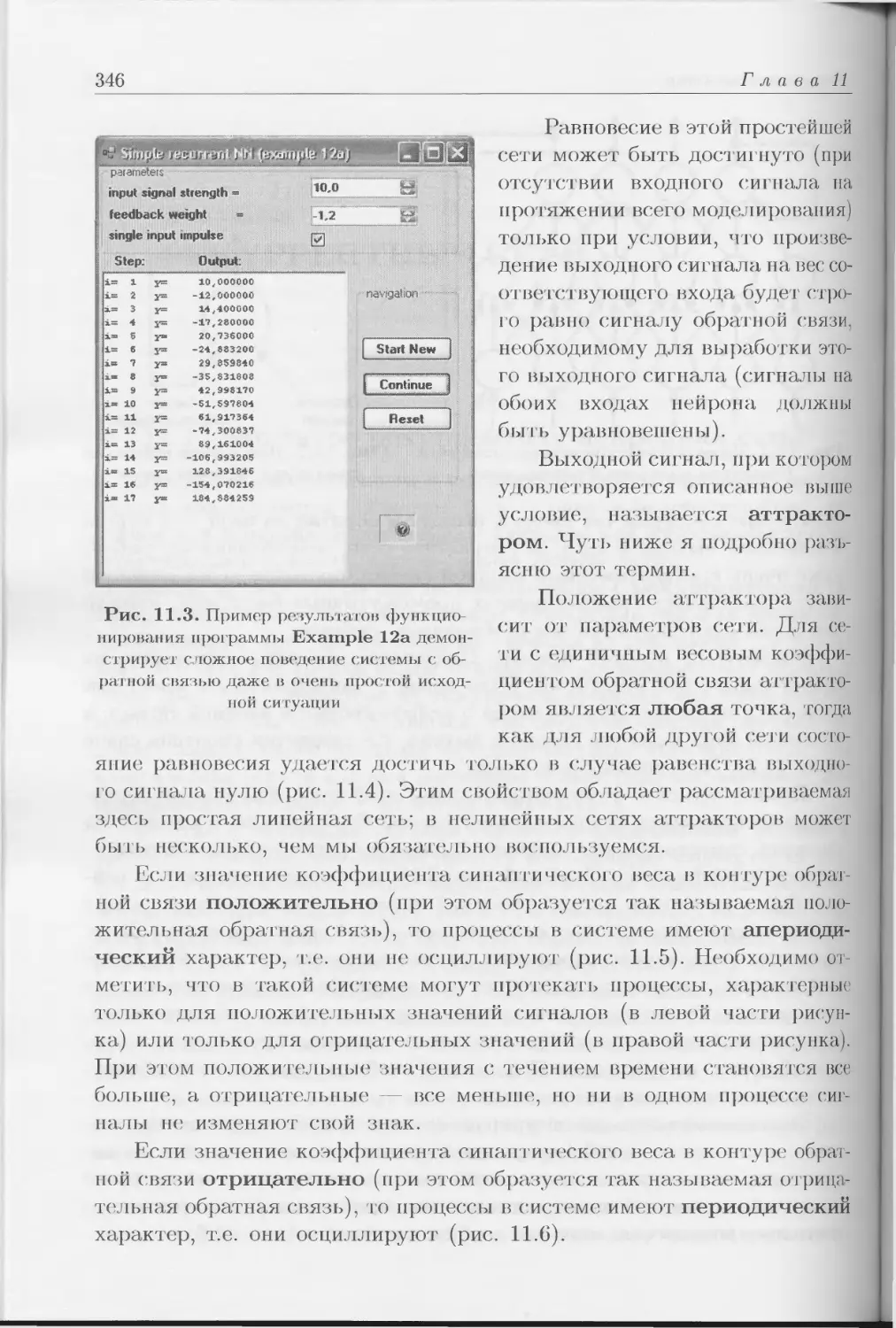

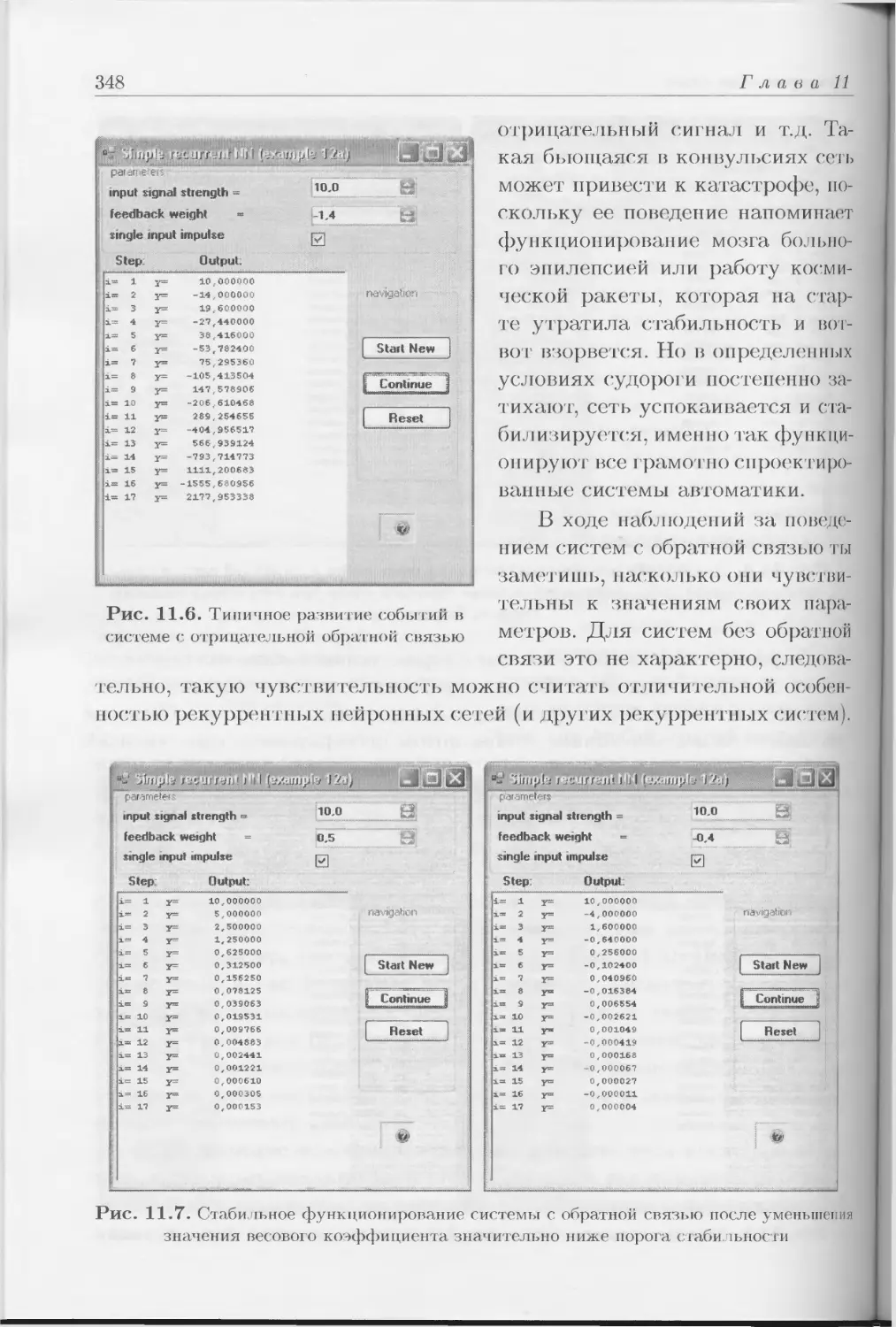





























































Author: Тадеусевич Р. Боровик Б. Гончаж Т Леппер Б.
Tags: компьютерные технологии эргономика программирование искусственный интеллект машинное обучение искусственные нейронные сети
ISBN: 978-5-9912-0163-6
Year: 2011




Рышард Тадеусевич
Варвара Боровик
Томаш Тонча»
Бартош Поппер
Элементарное
„ введение в технологию „
НЕЙРОННЫХ СЕТЕЙ
с примерами программ
РышапдТадеусевич
Барбара Боровик
Томаш Гончаж
Бартош Леппер
Элементарное
введение в технологию
НЕЙРОННЫХ СЕТЕЙ
с примерами программ
Москва
Горячая линия - Телеком
2011
УДК 681.322
ББК 30.17
Э45
Авторы: Рышард Тадеусевич, Барбара Боровик, Томаш Гончаж,
Бартош Леппер
Э45 Элементарное введение в технологию нейронных сетей с
примерами программ / Перевод с польск. И. Д. Рудинского. -
М.: Горячая линия - Телеком, 2011.- 408 с., ил.
ISBN 978-5-9912-0163-6.
Искусственные нейронные сети - одна из наиболее динамично
развивающихся и реально используемых на практике ветвей теории
искусственного интеллекта. В книге выдающегося европейского спе-
циалиста популярно и увлекательно освещаются возможности,
структура и особенности работы этих сетей. С помощью описывае-
мых в книге компьютерных программ читатель сможет самостоя-
тельно построить несложные нейронные сети, обучить их и провести
захватывающие эксперименты. Автор излагает материал без единой
формулы; он ведет диалог с читателем и постепенно подводит его к
пониманию механизмов функционирования человеческого мозга и к
осознанию перспектив их использования для управления современ-
ными техническими и экономическими системами.
Книга предназначена для широкого круга читателей, в первую
очередь для молодых специалистов, желающих понять сущность и
безграничные перспективы искусственных нейронных сетей.
ББК 30.17
Тадеусевич Рышард, Боровик Барбара,
Гончаж Томаш, Леппер Бартош
ЭЛЕМЕНТАРНОЕ ВВЕДЕНИЕ В ТЕХНОЛОГИЮ НЕЙРОННЫХ
СЕТЕЙ С ПРИМЕРАМИ ПРОГРАММ
Компьютерная верстка Е. В. Кормакова
Обложка художника В, Г. Ситникова
Подписано в печать 07.08.10. Формат 70х 100/16. Усл. печ. л. 25,5. Тираж 1000 экз. Изд. №9163
ООО «Научно-техническое издательство «Горячая линия-Телеком»
ISBN 978-5-9912-0163-6 Copyright © Р. Тадеусевич, 2007
© Рудинский И. Д., перевод с польск., 2010
© Оформление издательства «Горячая линия-Телеком», 2010
ПРЕДИСЛОВИЕ К РУССКОМУ
ИЗДАНИЮ
Представляемая российскому читателю книга возникла довольно не-
обычным образом. В начале 90-х гг. прошлого века редакция научно-
популярного ИТ*-ежемесячника Enter (выпускаемого в Польше, но с
удовольствием читаемого в нескольких соседних странах, в частности в
Словакии) обратилась ко мне с просьбой подготовить статью, в которой
предельно доходчиво было бы объяснено читателям журнала, что про-
исходит «с этими нейронными сетями», о которых столько говорят и
пишут.
В начале 90-х гг. возникла мода (если не сказать — эпидемия!) по-
всеместного применения так называемых «нейрокомпьютеров». В прин-
ципе эта мода существует и сейчас; именно ею объясняется тот инте-
рес, который ты, уважаемый читатель, проявил к этой книге. Правда,
по сравнению с девяностыми годами кое-что изменилось: по истечении
некоторого времени (когда угасла первая волна некритичного энтузи-
азма) футуристическое название «нейрокомпьютер» было отвергнуто,
а соответствующий инструментарий стали называть более взвешенно и
спокойно «нейронными сетями»; тем не менее мода на их применение
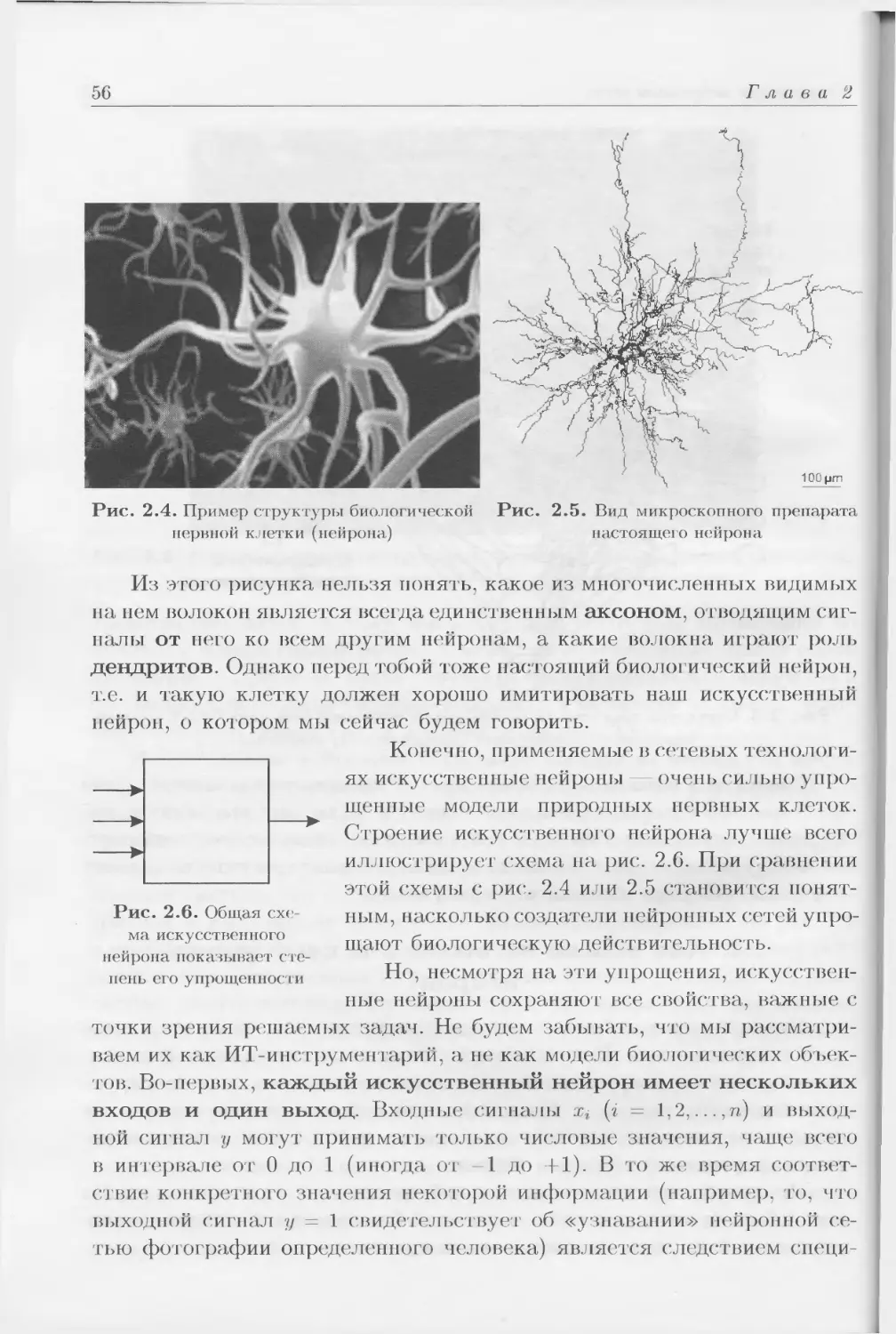
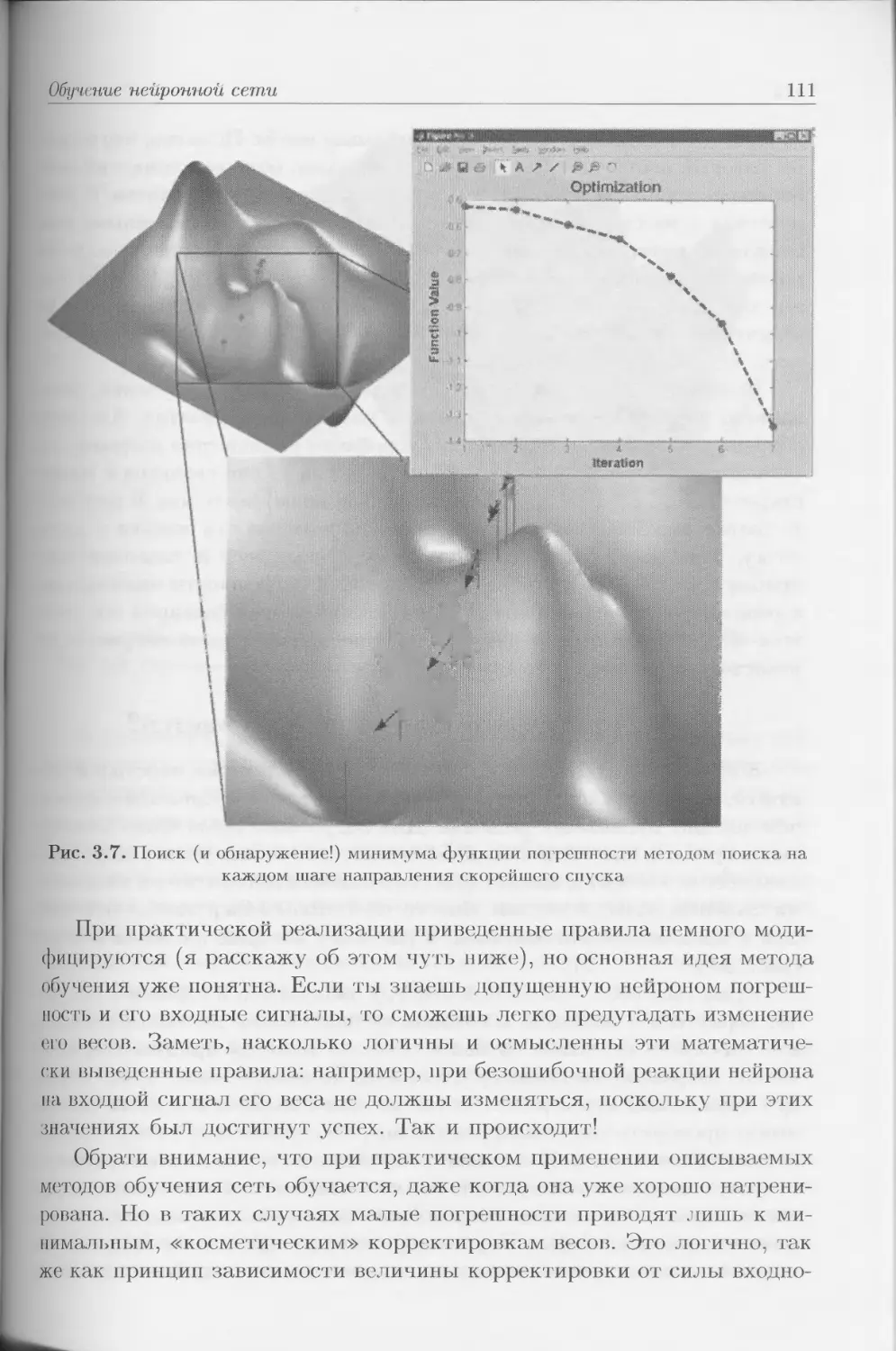
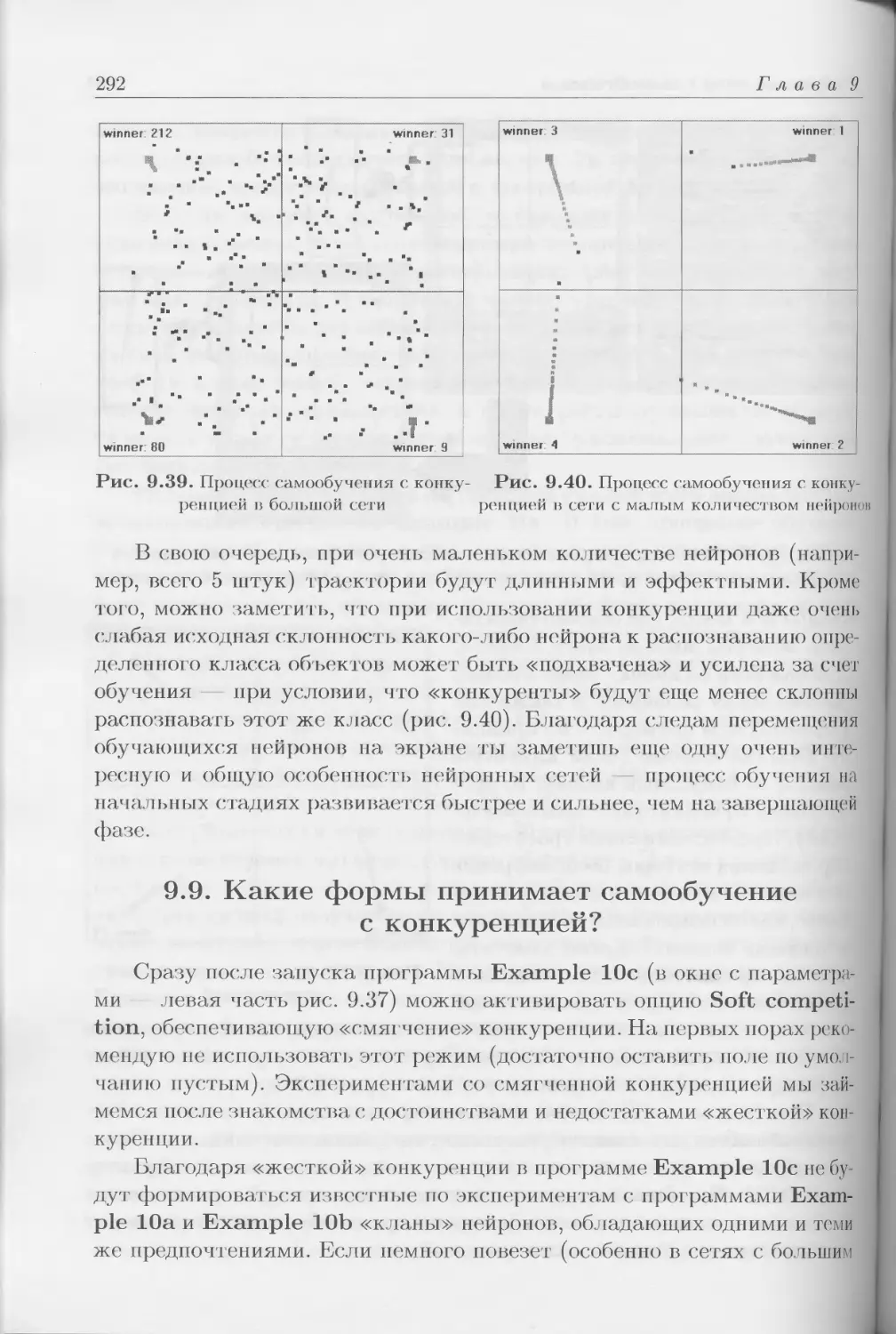
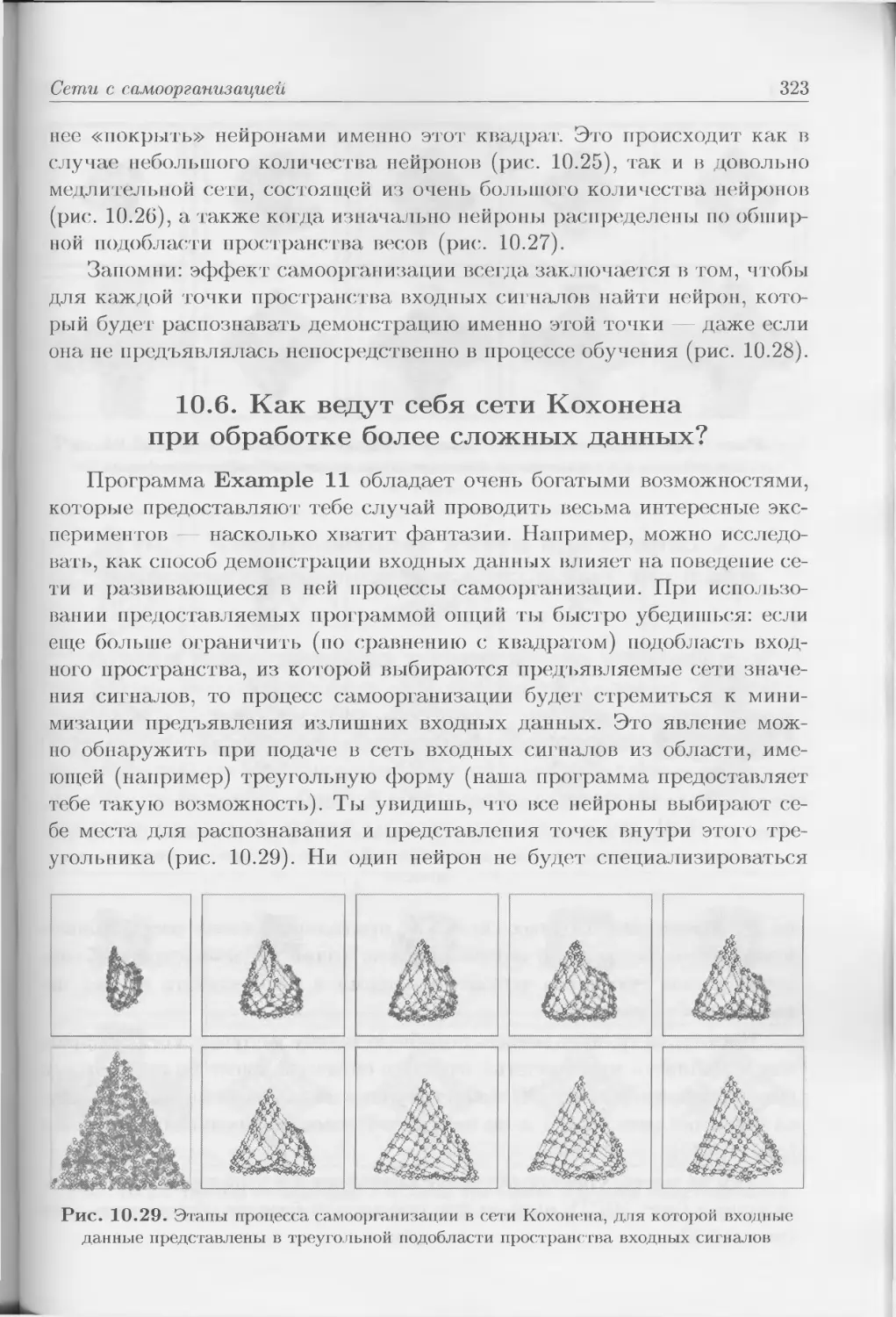
продолжается и даже расширяется (рис. П.1).
Мотив описываемого явления прост: по ряду причин, которые будут
раскрыты ниже, в 90-х гг. специалисты в различных областях знаний
«обнаружили», что нейронные сети могут быть очень эффективным ору-
дием для ИТ-решения стоящих перед ними задач. Я написал «обнаружи-
ли» в кавычках, поскольку «чудесные» свойства нового инструментария,
с энтузиазмом излагаемые и обсуждаемые в специализированных ИТ-
изданиях тех лет, были хорошо известны и ранее, но только очень узкому
кругу специалистов — биокибернетикам, а точнее, нейрокибернетикам.
Рис. П.1. Прибыль (млн долл.) от
продажи программных продуктов для
создания и использования нейронных
сетей. Данные характеризуют рынок
США. Для 2006 г. представлено оце-
ночное значение
OOOOOOCDOOOOOOOOOO
О О о о о о о о о о о о о о о о о
V- V- Х~ Х~ Х~ Г“ Х~ Х~ Х~ Х~ С\ (\1 С\ М (\ М W
Информационные технологии (Information Technology). Прим, перев.
4
Предисловие к русскому изданию
В то время я оказался одним из немногих польских специалистов
такого профиля, поскольку около 20 лет занимался моделированием че-
ловеческого мозга, а в начале 90-х гг. написал первую в Польше книгу
о нейронных сетях. Однако моя книга была узкопрофессиональной, по-
этому ее читали только научные сотрудники и студенты. Кстати говоря,
ту книгу продолжают читать и сейчас (о чем свидетельствуют много-
численные ссылки на нее в других книгах, научных статьях и диссер-
тациях). В настоящее время се электронная версия доступна в любой
точке земного шара в фондах Польской Интернет-библиотеки по адре-
су www.pbi.edu.pl или в фондах Академической цифровой библиотеки по
адресу http:/ abc.agh.edu.pl/. Поскольку книга вызывает большой инте-
рес, доступ к ней можно получить по прямому адресу http://winntbg.bg.
agh.edu.pl/skrypty/0001/. Тем нс менее, названная публикация предна-
значалась профессионалам, тогда как для людей, просто интересовав-
шихся нейронными сетями, по не имевших профессиональной подготов-
ки в этой области, в 90-х гг. не было никакой литературы. А интерес к
этим сетям, как я уже говорил, был большим и непрерывно возрастал.
Не скрою, я был очень польщен просьбой объяснить широкой обще-
ственности сущность нейронных сетей и с воодушевлением принялся за
работу. Вначале я думал, что на работу хватит одного вечера - вроде бы
проще простого популярно объяснить то, что хорошо знаешь и любишь!
Но материала для увлекательного рассказа о нейронных сетях неожи-
данно оказалось гораздо больше, чем можно было ожидать. В результа-
те популяризация нейронных сетей стала для меня не только приятным,
но и очень трудоемким занятием на протяжении следующих нескольких
лет. Сам не ожидал, сколько интересного можно рассказать (и практи-
чески показать!) об этих сетях любознательному читателю. В связи с
этим тематика разрасталась, перетекала в следующие номера журнала
(статьи о нейронных сетях публиковались из номера в номер на про-
тяжении двух лет!), а потом изданный материал, соответствующим об-
разом скомпонованный и переработанный, стал основой для написания
первой польской версии этой книги.
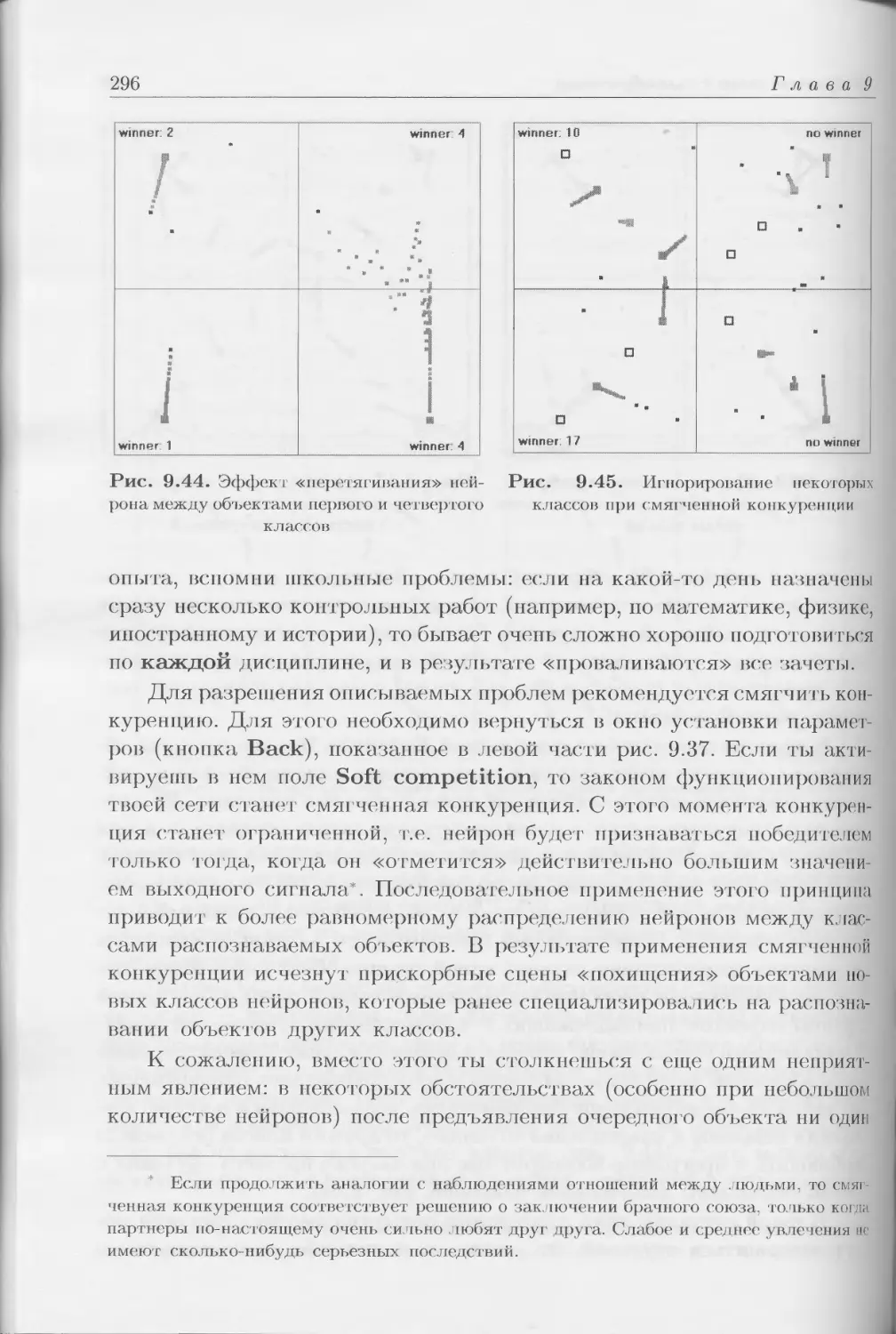
Сначала я намеревался разъяснить читателю только то, что в вос-
хищающих людей свойствах нейронных сетей отражаются лишь некото-
рые (причем очень скромные) фрагменты тех огромных и очень инте-
ресных знаний, которые в течение десятилетий накапливали исследова-
тели процессов обработки информации, обучения и формирования моде-
лей поведения, происходящих в потаенных уголках мозга людей и зверей
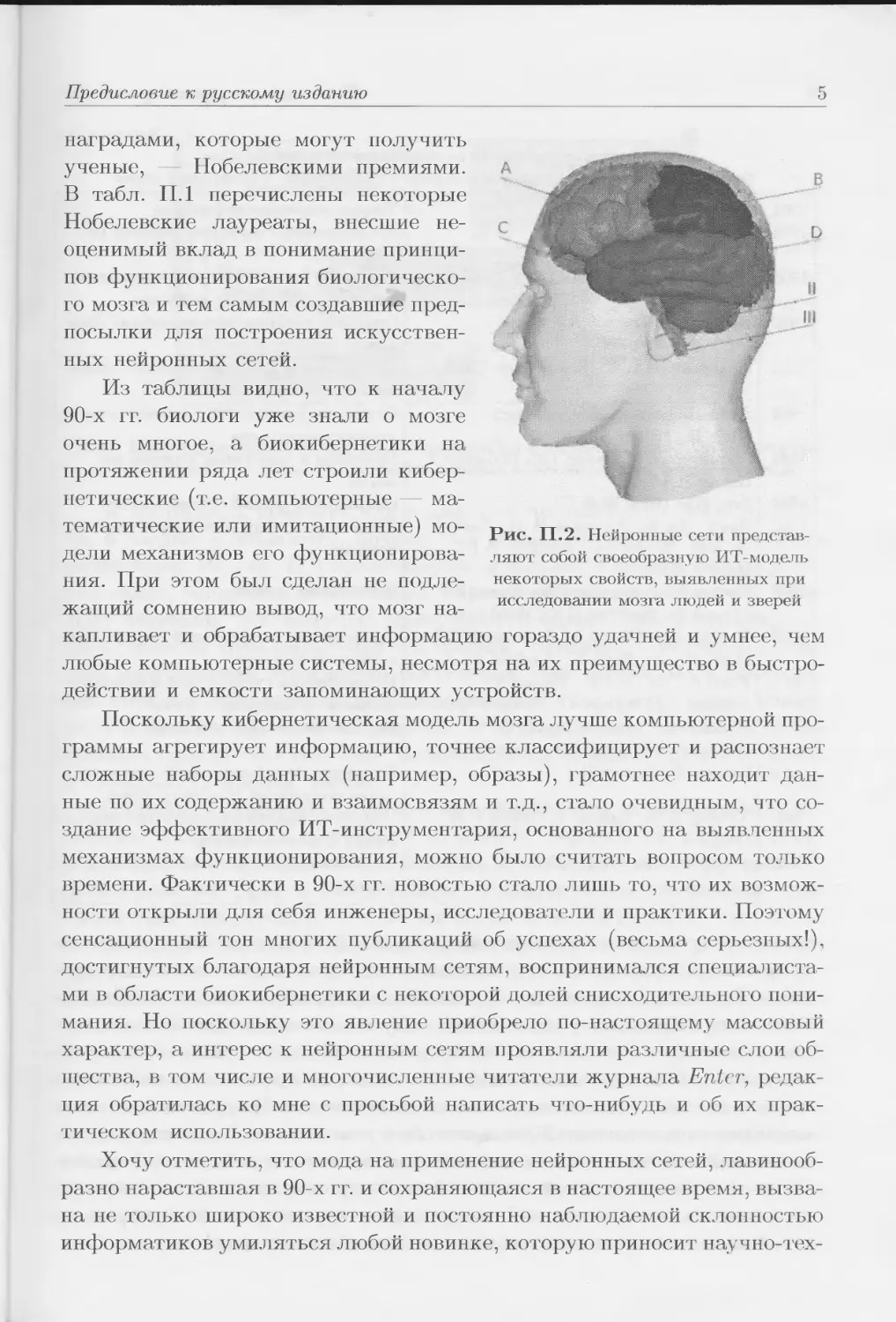
(рис. П.2).
Работы, начатые еше русским ученым, академиком И.П. Павловым,
увенчались целой серией открытий, отмеченных самыми почетными
Предисловие к русскому изданию
5
наградами, которые могут получить
ученые, - Нобелевскими премиями.
В табл. П.1 перечислены некоторые
Нобелевские лауреаты, внесшие не-
оценимый вклад в понимание принци-
пов функционирования биологическо-
го мозга и тем самым создавшие пред-
посылки для построения искусствен-
ных нейронных сетей.
Из таблицы видно, что к началу
90-х гг. биологи уже знали о мозге
очень многое, а биокибернетики на
протяжении ряда лет строили кибер-
нетические (т.е. компьютерные — ма-
тематические или имитационные) мо-
дели механизмов его функционирова-
ния. При этом был сделан не подле-
жащий сомнению вывод, что мозг на-
капливает и обрабатывает информацию гораздо уд ан ней и умнее, чем
любые компьютерные системы, несмотря на их преимущество в быстро-
действии и емкости запоминающих устройств.
Поскольку кибернетическая модель мозга лучше компьютерной про-
граммы агрегирует информацию, точнее классифицирует и распознает
сложные наборы данных (например, образы), грамотнее находит дан-
Рис. П.2. Нейронные сети представ-
ляют собой своеобразную ИТ-модель
некоторых свойств, выявленных при
исследовании мозга людей и зверей
ные по их содержанию и взаимосвязям и т.д., стало очевидным, что со-
здание эффективного ИТ-инструментария, основанного на выявленных
механизмах функционирования, можно было считать вопросом только
времени. Фактически в 90-х гг. новостью стало лишь то, что их возмож-
ности открыли для себя инженеры, исследователи и практики. Поэтому
сенсационный тон многих публикаций об успехах (весьма серьезных!),
достигнутых благодаря нейронным сетям, воспринимался специалиста-
ми в области биокибернетики с некоторой долей снисходи гельного пони-
мания. Но поскольку это явление приобрело по-настоящему массовый
характер, а интерес к нейронным сетям проявляли различные слои об-
щества, в том числе и многочисленные читатели журнала Enter, редак-
ция обратилась ко мне с просьбой написать что-нибудь и об их прак-
тическом использовании.
Хочу отметить, что мода на применение нейронных сетей, лавинооб-
разно нараставшая в 90-х гг. и сохраняющаяся в настоящее время, вызва-
на не только широко известной и постоянно наблюдаемой склонностью
информатиков умиляться любой новинке, которую приносит научно-тех-
6
Предисловие к русскому изданию
Таблица П.1
Нобелевские премии за исследования нервной системы,
результаты которых прямо или косвенно использованы в нейронных сетях
1904 1906 1906 1920 1932 1936 1944 1949 1963 1969 1970 1974 1977 1981 1981 1991 Павлов И.П. Гольи К. (Golgi С.) Рамон-и-Кайял С. (Ramon у Cajal S.) Крог С.A. (Krogh S.A.) Шеррингтон К.С. (Sherrington Ch. S.) Дейл Г., Хелле! Л.О. (Dale Н., Hallett L.O.) Эрлангер Дж., Гассер Г.С. (Erlanger J., Gasser H.S.) Гесс В.Р. (Hess W.R.) Экклз Дж.К., Ходжкин А.Л., Хакс- ли А.Ф. (Eccles J.C., Hodgkin A.L., Huxley A.F.) Гранит P., Хартлайн Г.К., Вальд Г. (Granit R., Hartline H.K., Wald G.) Кац Б., фон Ойлер У., Аксельрод Дж. (Katz В., von Euler U., Axelrod J.) Клод А., Де Дюв К., Пал аж Г. (Claude A., De Duve Ch., Palade G.) Жюльмен P., Шали А., Елоу P. (Guillemin R., Schally A., Yalow R.) Сперри P. (Sperry R.) Хубель Д.Х , Визель T. (Hubei D.H., Wiesel T.) Нейер E., Сакмен Б. (Nohcr E., Sak- mann B.) Теория условных рефлексов Исследование структуры нервной си- стемы Открытие того, что мозг представляет собой сеть отдельных нейронов Описание системы регулирования орга- низма Исследование системы нервного управ- ления работой мускулов Открытие химической трансмиссии нервных импульсов Процессы в одиночном нервном во- локне Открытие функций среднего мозга Механизм электрической активности нейрона Физиология зрения Трансмиссия гуморальной информации в нервных клетках Исследования структурной и функцио- нальной организации клетки Исследования гормонов мозга Открытие функциональной специали- зации полушарий головного мозга Открытие принципов обработки инфор- мации в системе зрения Функции ионных каналов в нервных клетках
нический прогресс и развитие цивилизации. Восхищение нейронными се-
тями имеет дополнительные, причем вполне конкретные и важные при-
чины. Главная предпосылка огромной популярности сетей действи-
тельно прекрасные результаты, получаемые с помощью этого нового
инструментария при решении многих задач, издавна считавшихся особо
сложными. Сенсационные сообщежия пионеров применения нейронных
сетей вдохновили многочисленных последователей. На протяжении всего
последнего десятилетия XX в. известия о том. кто и для чего успешно ис-
пользовал эти сети, появлялись как пресловутые «грибы после дождя>>.
По этой причине в одной из статей я перефразировал давно и звестное
шутливое высказывание, что в некоторых кругах незнание нейронных
сетей начинает трактоваться как светская бестактность!
Предисловие к русскому изданию
7
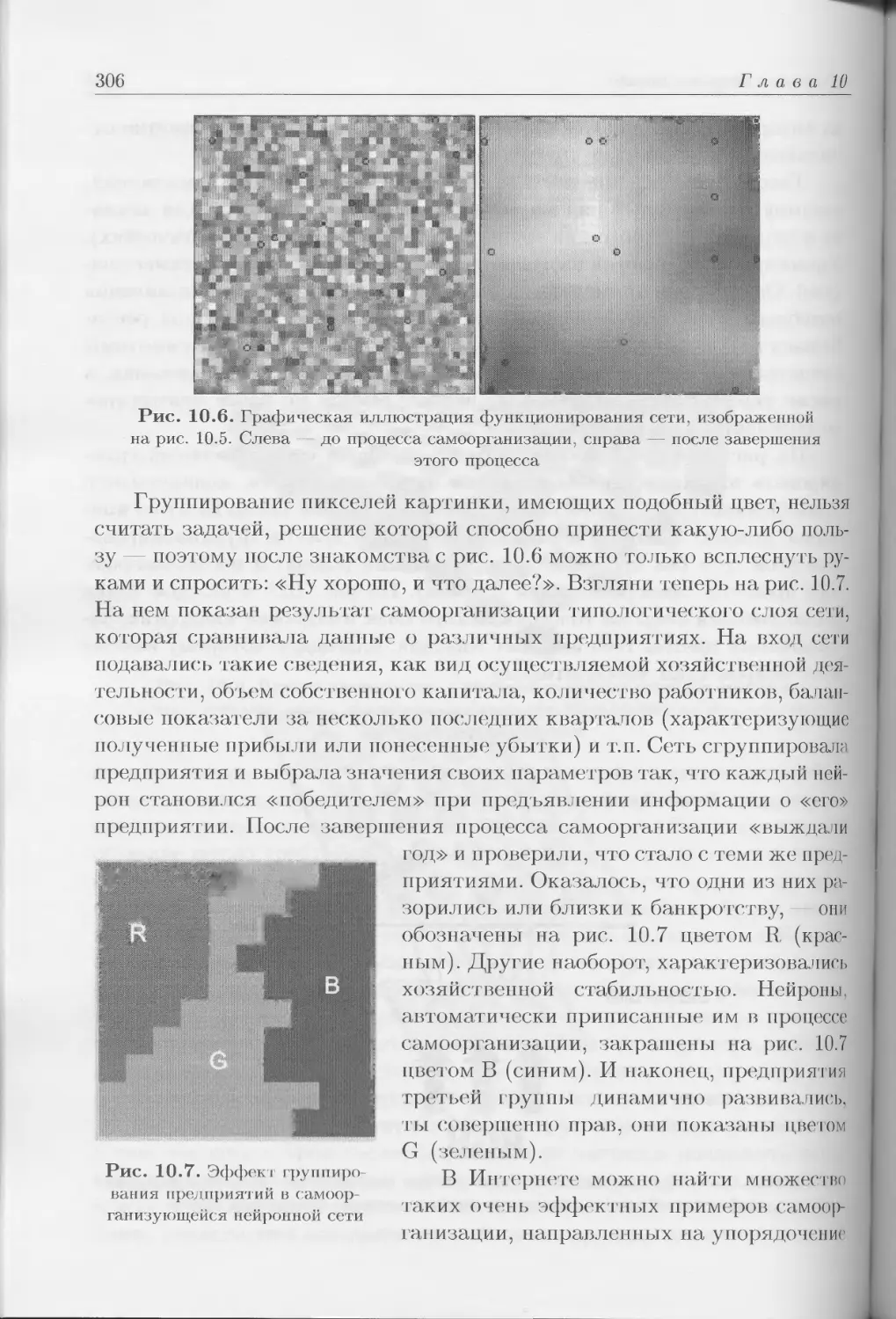
Степень сложность проблемы
Рис. П.З. Характеристика информационных задач с различной степенью сложности
и локализация тех задач, для решения которых особенно удобны нейронные сети
Я постараюсь показать, где и для чего применяются нейронные се-
ти, а заодно и объяснить, почему они обладают такими интересными
свойствами. На рис. П.З представлена довольно условная классифика-
ция задач, решаемых различными информационными системами. Каж-
дому очевидно, что среди них присутствуют более и менее сложные за-
дачи, поэтому горизонтальная ось графика отражает некоторую услов-
ную меру степени сложности. Несомненно, что точное масштабирова-
ние этой оси практически невозможно, поскольку не до конца понят-
но, как можно измерить сложность. В любом случае на рисунке обо-
значены задачи простые (они располагаются в левой части графика)
и сложные (в правой части).
Сложность решаемой задачи — не единственная мера проблем, с ко-
торыми сталкивается желающий ее решить информатик. Другое изме-
рение задачи — доступность знаний, на которые должно опираться бу-
дущее решение. Для некоторых задач правила точно определены, хотя
число этих правил либо степень их сложности могут быть сопряжены
с серьезными вычислительными трудностями. Например, разработчик
программного обеспечения для крупного банка должен немало порабо-
тать, хотя правила принятия решений хорошо известны и в меру просты:
если клиент вносит деньги, то содержимое его счета должно увеличить-
ся, а если клиент снимает деньги, то сальдо необходимо уменьшить. С
проблемами иного рода сталкивается физик, исследующий математиче-
скую модель внутреннего строения атома: уравнений мало, но их очень
трудно решить. Тем не менее, в обоих примерах мера сложности (в роли
которой выступает незнание правил) оказывается нулевой, посколь-
ку правила принятия решений известны и могут использоваться для
создания необходимого инструментария. Мы знаем, как использовать
компьютеры для решения задач, характеризующихся знанием всех пра-
8
Предисловие к русскому изданию
вил: необходимо построить соответствующий этим правилам алгоритм и
на его основе написать требуемую программу.
Но ситуация может оказаться более сложной. Часто встречаются за-
дачи, правила решения которых нам неизвестны, но их схемы решения
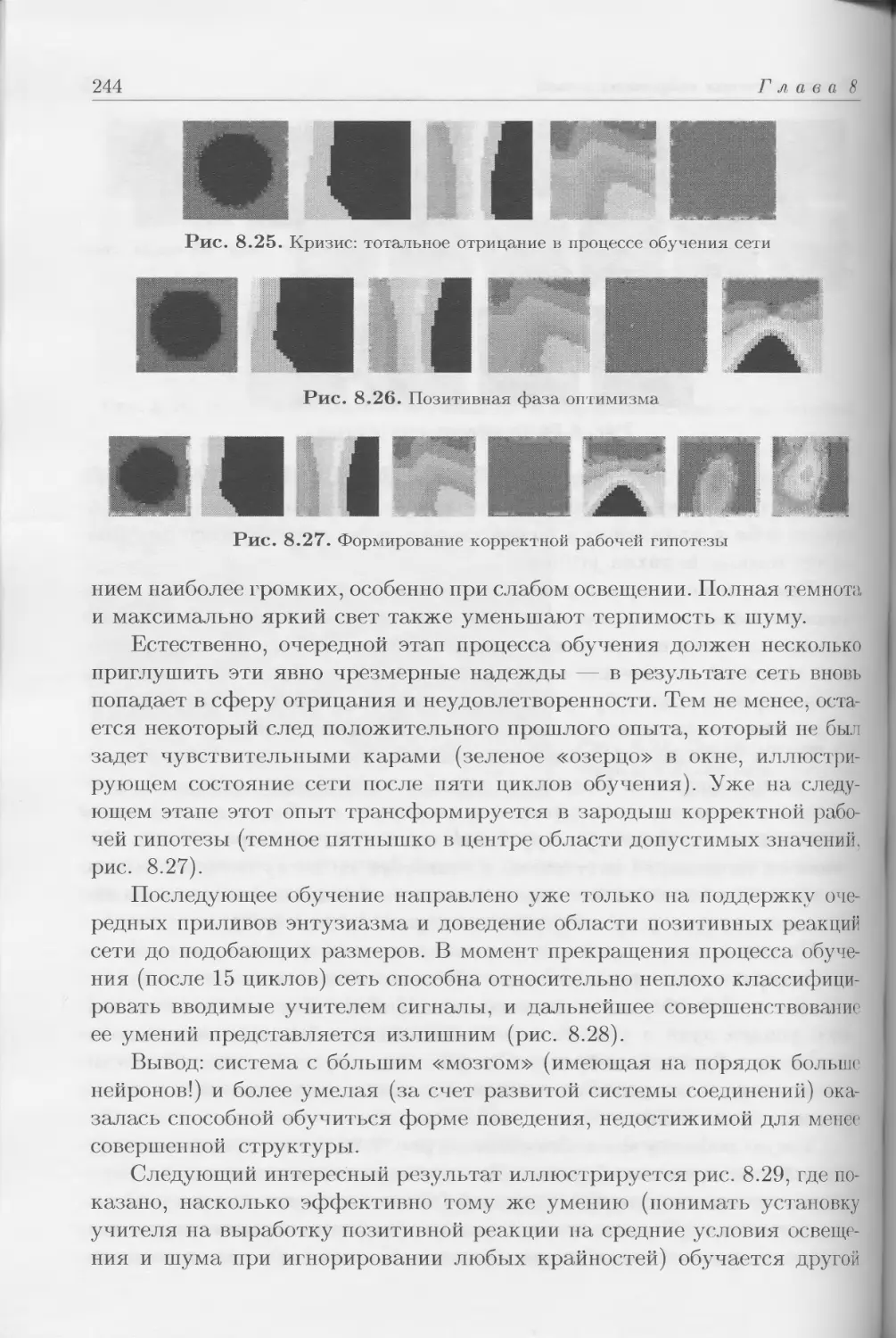
могут основываться на какой-либо повторяемости связанных с задачей
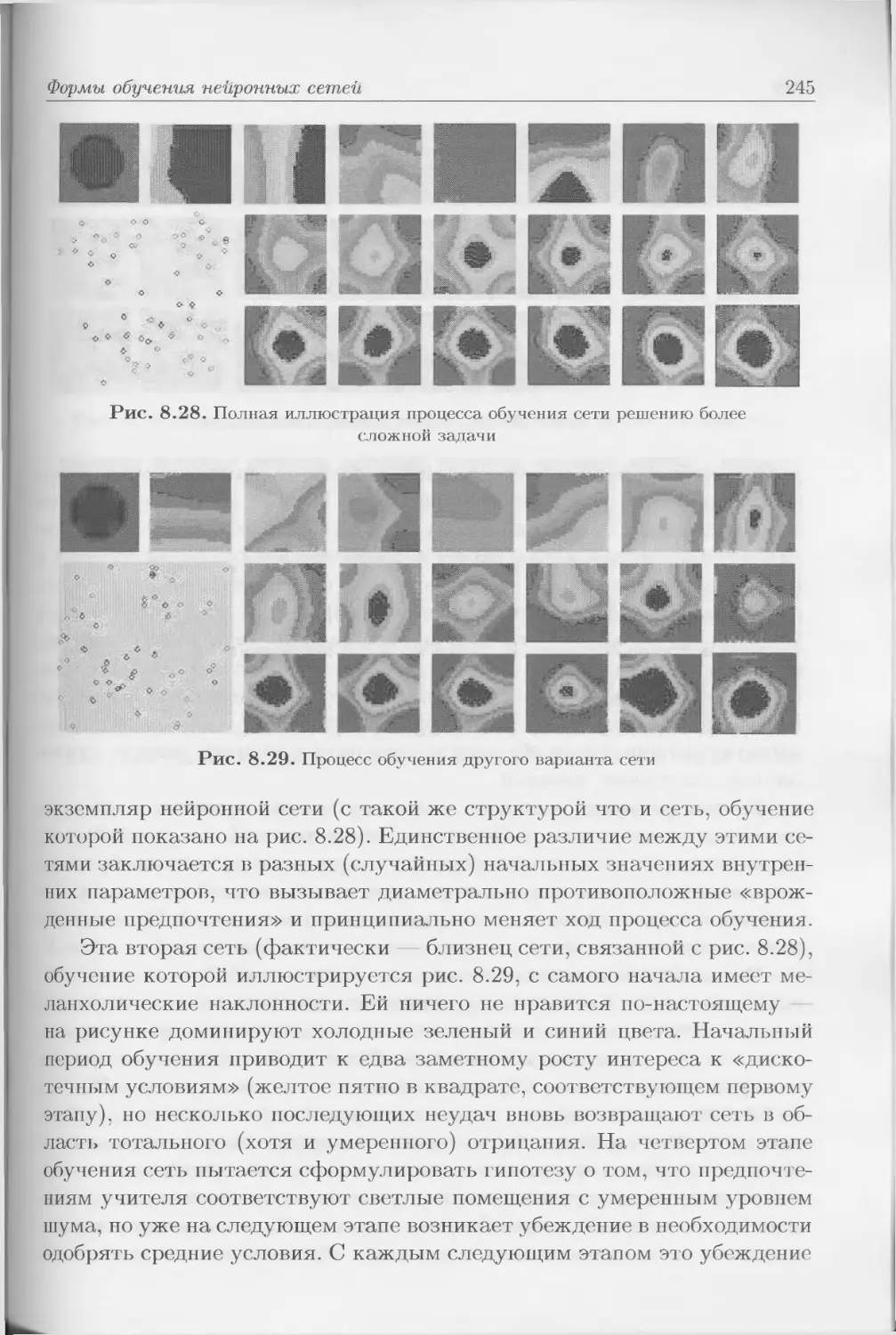
явлений или процессов. В этом случае мы имеем дело с ситуацией, симво-
лически локализованной в центральной части рис. П.З. Знания о прави-
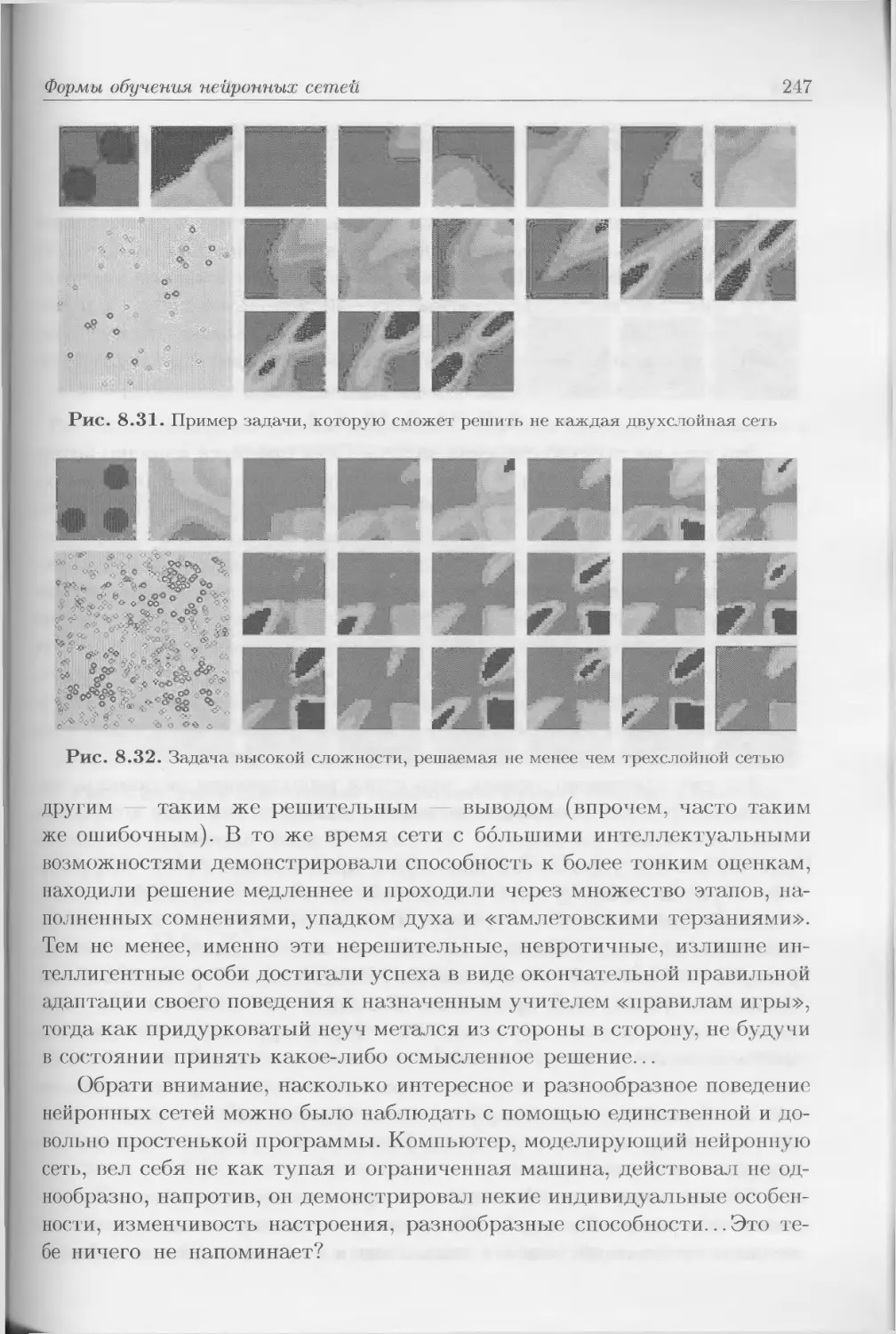
лах не полны, а отдельные правила могут быть не до конца известными,
тем не менее, существует возможность воспользоваться удобной техно-
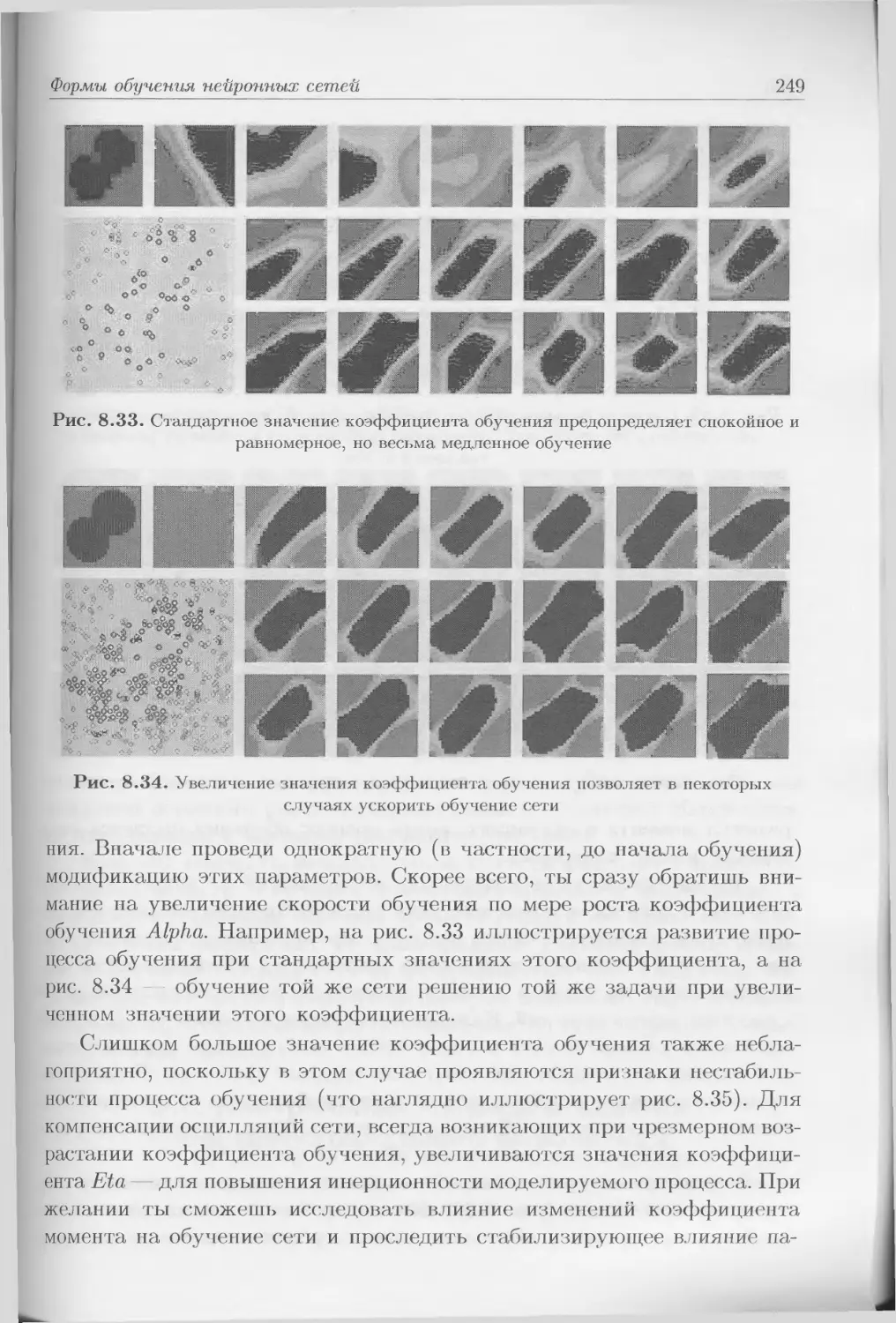
логией дедукции: попробовать вывести общее правило (или чаще всего
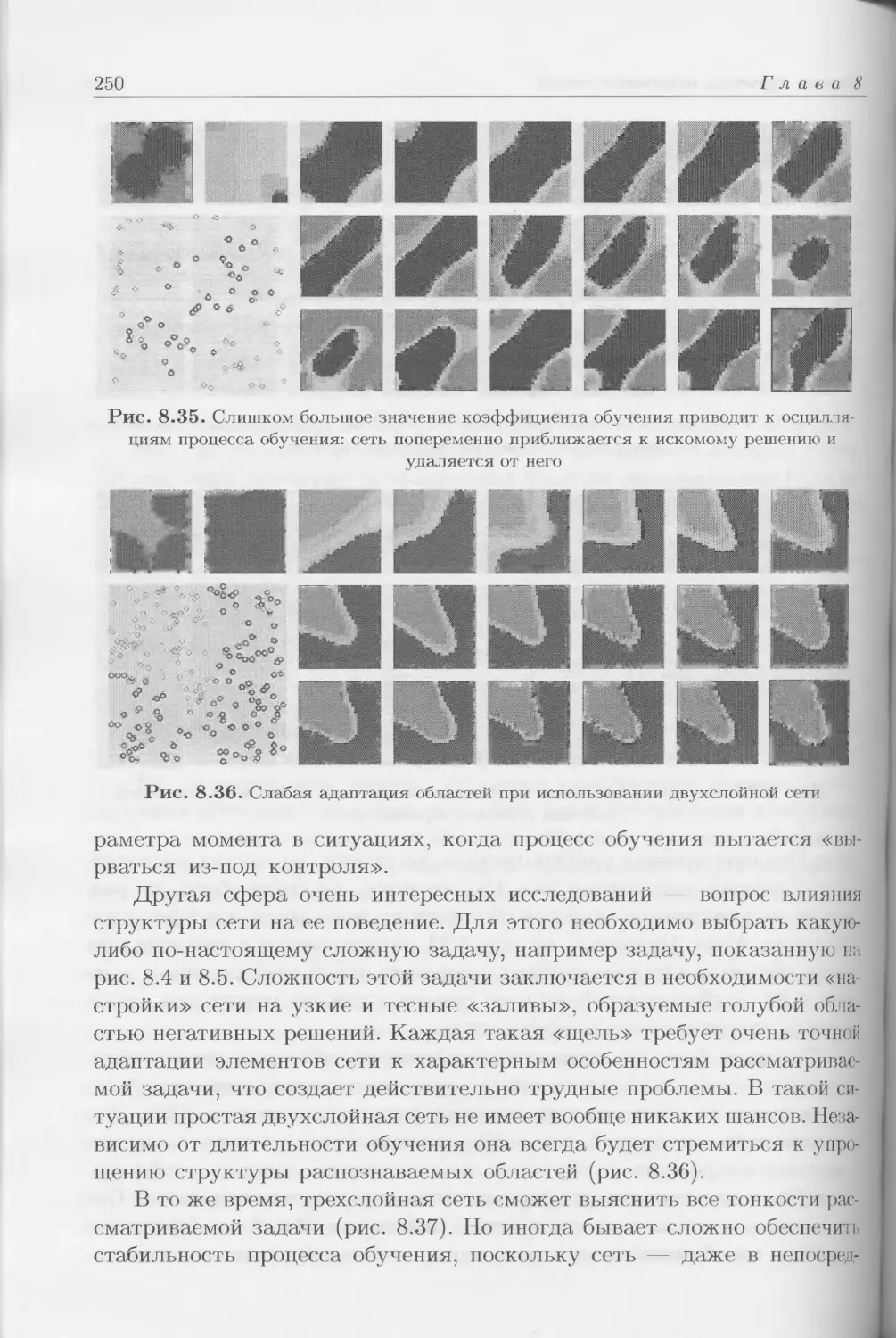
множество общих правил), которое впоследствии будет использоваться
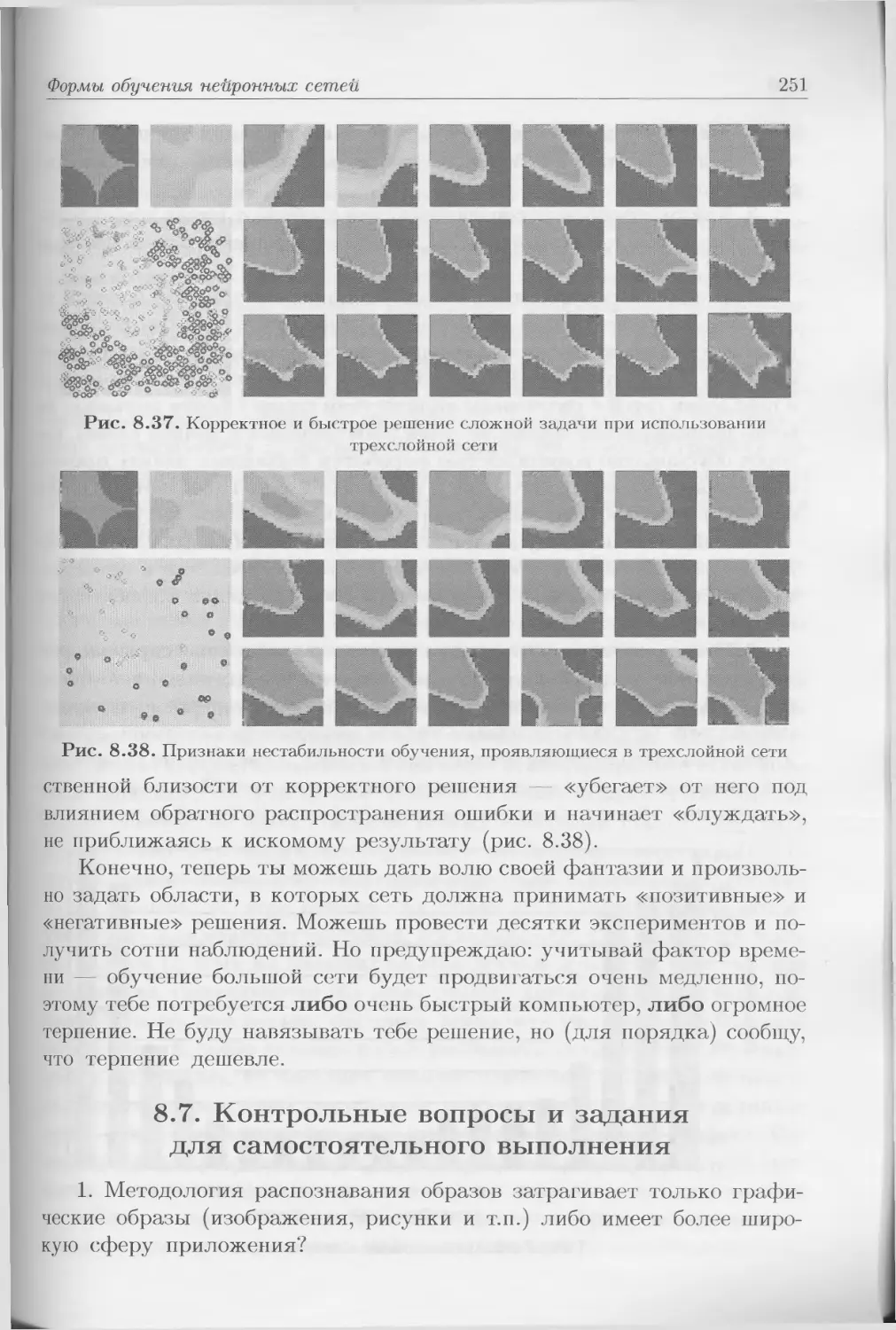
при решении каждой конкретной, но частной задачи. Правила, констру-
ируемые для такого класса задач, обычно учитывают факт неполноты и
неопределенности наших знаний. По этой причине для их решения ши-
роко применяются статистические методы (например, в экономике или
агротехнике), а также не алгоритмизированные, но базирующиеся на
многолетнем опыте и здравом смысле знания экспертов (например, в по-
пулярных медицинских экспертных системах, подсказывающих диагноз
или предлагающих наиболее подходящие методы лечения).
Однако существует еще более сложная ситуация, в которой нельзя
предложить каких-либо правил; все, чем мы располагаем, несколько
примеров задач, которые кто-то когда-то решил, но не может объяснить,
как был достигнут желаемый результат, потому что процессы анализа
ситуации и принятия решений лежали в неподконтрольной рассудку ин-
туитивной сфере. В первый момент читатель может возразить мол,
таких ситуаций не бывает или они крайне редки. Увы! Наш мозг решает
такие задачи непрерывно, например, те, которые в психологии называ-
ются задачами перцепции или восприятия. Субъективно вопрос очень
прост: предположим, ты идешь по улице и встречаешь свою знакомую.
Узнавание происходит немедленно — лицо, фигура — не возникает ни-
каких сомнений. Но представьте себе, что те же действия должен вы-
полнять компьютер, чтобы пускать в твой дом только знакомых людей.
Первый этап этой работы представить очень просто из-за широкой до-
ступности цифровых фотоаппаратов и видеокамер, так как полученные
с их помощью цифровые образы можно непосредственно ввести в ком-
пьютер (рис. П.4). Но встает вопрос чго делать дальше?
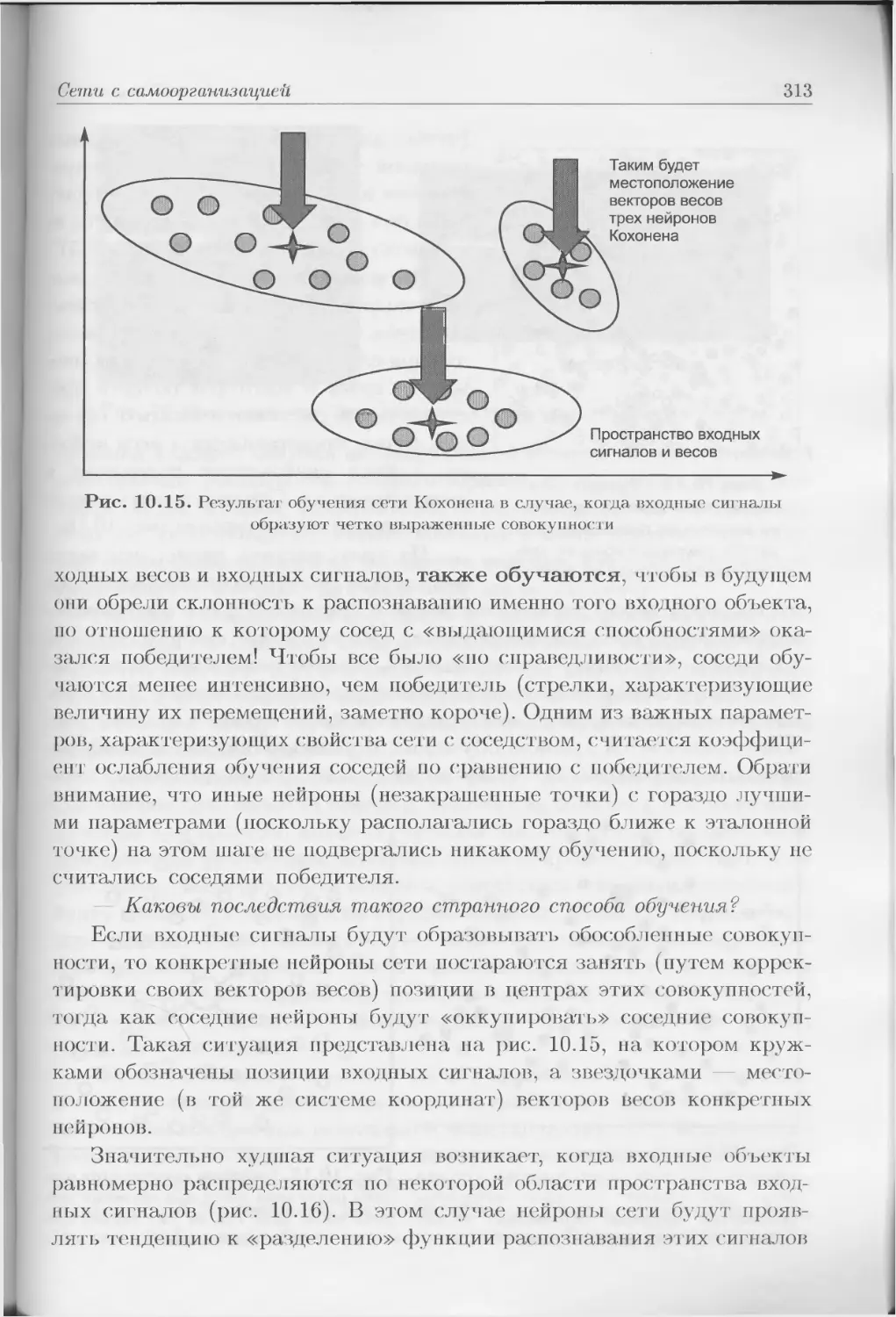
Образ, введенный в память компьютера, разложен па миллионы то-
чек (пикселей), а яркость или цвет каждой точки кодируется в циф-
ровой форме. Благодаря такой форме представления цифровой образ
может легко обрабатываться компьютером ведь это вычислительная
машина. Более того, легко убедиться, что в этих миллионах цифровых
Предисловие к русскому изданию
9
Рис. П.4. Введенный в компьютер цифровой образ представлен в удобной для
вычислений форме двумерной функции; характерные элементы образа можно легко
найти по экстремумам этой функции. Но очень сложно предложить алгоритм распознавания
человека, изображенного на снимке, по значениям этой функции
описаний конкретных пикселей содержится информация, необходимая
для распознавания человека с фотографии, — достаточно вывести ее
на экран или распечатать на принтере, чтобы понять: «Так это же Ле-
на!». Прекрасно, но как составить алгоритм, который сможет автомати-
чески заменить этим утверждением безликую серость миллионов циф-
ровых описаний отдельных точек? Более того, алгоритм должен рас-
познавать знакомое лицо независимо от положения в анфас или в
профиль, ближе или дальше оно расположено, лучше или хуже осве-
щено и т.д. Узнаванию человека не должны препятствовать переменные
элементы его мимики (например, наличие или отсутствие улыбки), раз-
личные головные уборы, разный фон и т.д. Для нашего мозга решение
таких проблем не составляет труда, но если мы пожелаем запрограм-
мировать эти умения в виде обобщенного компьютерного алгоритма, то
окажемся бессильными!
В аналогичных ситуациях для передачи определенных умений дру-
гим людям мы демонстрируем примеры. Например, показываем десятки
картинок и говорим: «Вот это буква А, и это тоже буква А, только
поменьше, и здесь тоже буква А, которая выглядит немного иначе, по-
тому что напечатана другим шрифтом, но читается, она точно так
же». При таком подходе мы предполагаем (чаще всего справедливо),
что обученный получатель информации сможет на основании множества
частных примеров самостоятельно сформировать какой-либо синтетиче-
ский способ поведения, который позволит ему эффективно распознавать
не только все показанные эталонные образы, но и другие образы той же
буквы (либо того же человека или другого распознаваемого объек га) при
условии, что они будут достаточно похожи на представленные примеры.
10
Предисловие к русскому изданию
Описанный подход называется индуктивным методом. Его отли-
чие от ранее упоминавшейся дедукции заключается в незнании како-
го-либо обобщенного правила, на основании которого могут решать-
ся конкретные частные задачи. Вместо этого мы располагаем некоторым
числом примеров корректного решения частных задач. Человеческий ра-
зум способен анализировать такие примеры, делать по ним выводы и
впоследствии обобщать эти выводы для решения не только эталонных
примеров, но и других задач, в какой-то степени подобных использо-
вавшимся в процессе обучения.
Как я уже говорил, специалистам в области нейрокибернетики уже
давно был известен огромный потенциал, который всегда характерен
для изучаемых биологами способностей человеческого мозга к обучению
и для нейронных методов обработки информации. Однако большинство
других ученых и практиков (особенно много лет применявших компью-
теры) полагали, что для эффективного решения любой теоретической
или прикладной задачи необходимо знать точный алгоритм функциони-
рования либо, как минимум, достаточно сильное дедуктивное правило.
Когда выяснилось, что нейронные сети способны решать различные за-
дачи без программирования, только методом вывода по аналогии, что
они могут самостоятельно формулировать заранее неизвестные прави-
ла поведения и решать задачи, для которых никто из людей не смог
бы предложить способ решения, возник огромный интерес. Научные со-
общения искрились, как фейерверки, а формулируемые в них выводы
зачастую свидетельствовали о некритичном увлечении авторов этим но-
вым инструментарием. Волна эффективных и эффектных успехов ней-
ронных сетей’ вновь пробудила надежды па то, что наконец-то найден
«философски^ камень», безуспешно искавшийся на протяжении многих
столетий алхимиками и астрологами, и что с помощью новой техноло-
гии отныне можно будет решать вне и всегда.
Нейрокибернетикам уже раньше были известны способности к обу-
чению и к обобщению знаний, свойственные моделям структуры и по-
ведения человеческого мозга, по они также понимали ограниченность
возможностей повой (как, впрочем, и любой другой1 технологии. По-
этому они отнеслись к упомянутым сообщениям с интересом (посколь-
ку человеческая изобретательность в использовании нейронных сетей
оказалась невероятно огромной), но вполне спокойно было попятно,
что после волны чрезмерного энтузиазма обязательно наступит период
разочарований. В то же время «неофиты нейрокомпьютинга», а также
внешние комментаторы их достижений (т.е. профессионалы в области
«наукозпапия» и околонаучные журналисты) утратили чувство меры
и при описании очередных успехов фонтанировали восторгом и гордо-
стью. Многие из этих комментаторов восхищались, в первую очередь,
Предисловие к русскому изданию
11
универсальностью новой технологии. Возможности и достоинства ней-
ронных сетей также привлекли внимание как инженеров-энтузиастов,
применивших их, в частности, для управления роботами, так и банки-
ров, которые использовали их для выявления и раскрытия банковских
афер. Нейронные сети нашли применение в астрофизике для модели-
рования возникновения Вселенной и в пищевой промышленности для
выпечки пирожных. Выяснилось, что нейронные сети можно использо-
вать практически везде, и почти в каждой сфере они оказываются более
эффективными, чем классические компьютерные методы, применявши-
еся в этих областях на протяжении многих лет. Многие традиционные
исследователи были шокированы.
Причины для выражения эмоций имелись у многих специалистов.
Если нейронная сеть эффективнее оценивала новые технологии выра-
щивания зерновых, чем привычные методы математической статистики,
удивлялись агротехники. Если нейронная сеть точнее контролировала
химическую реакцию, чем компьютерная модель баланса энергии и мас-
сы, восхищались технологи. Если нейронная сеть точнее прогнозировала
будущие цены товаров или курсы валют, недоумевали эксперты, при-
выкшие к методам традиционной эконометрики. Если нейрокомпьютер
лучше, чем классические сигнальные процессоры или новейшие цифро-
вые модули, контролировал автоматизированный процесс, это вызыва-
ло обеспокоенность у всех автоматчиков. Можно без конца перечислять
специалистов, для которых в девяностые годы нейронные сети не толь-
ко открыли совершенно новые шансы, но и стали серьезным вызовом
их вдруг устаревшим знаниям.
Именно в такой ситуации очень широкого интереса (зачастую со-
провождаемого беспокойством) и отсутствия достоверной информации,
о чем идет речь, как «оно» функционирует и почему так хорошо — меня
попросили рассказать, что представляют собой нейронные сети, и объ-
яснить их необыкновенные свойства.
Не скрою, решить задачу оказалось труднее, чем представлялось
на первый взгляд. Конечно, написанию статей (переработанные и су-
щественно дополненные версии которых составляю!' основу этой кни-
ги) предшествовали двадцать лет исследовательской работы по созда-
нию и непрерывному совершенствованию различных нейронных сетей,
Но специальные книги, которых я до этого времени написал более 50*,
Полный перечень моих книг, статей и иных публикаций можно найти в Интернете по
адресу http://iowv].ayhJ.ed'iL.pl/uczelnia/tad/. Представленные на этой странице материалы
доступны в семи языковых версиях, в том числе на русском и английском языках. Я
рассматриваю эту Интернет-страницу как дополнительный список литературы, которую
можно рекомендовать читателям, желающим углубить и расширить свои знания.
12
Предисловие к русскому изданию
не были пригодны для объяснения феномена нейронных сетей всем тем,
кто эти объяснения желал получить. Многочисленные научные статьи
по этой тематике также не годились, поскольку все они без исключе-
ния адресовались специалистам-биокибернетикам и предполагали, что
читатель хорошо ориентируется в обсуждаемой проблематике. На этот
раз я должен был подготовить популярный материал, т.е. доступный
и понятный для каждого. Задача казалась почти неразрешимой. Мож-
но ли ожидать о г избегающего математики медика такого понимания
сильно математизированной и объективно весьма сложной (даже для ин-
форматиков) теории нейронных сетей, что он начнет использовать эту
теорию для диагностирования заболеваний или для планирования лече-
ния своих пациентов? Могу ли я убедить председателя правления банка,
который хочет воспользоваться услугами нейронного консультанта при
предоставлении кредитов, что он должен вникнуть в множество дет а-
лей нейроанатомической и нейрофизиологической природы, составляю-
щих понятийную и концептуальную базу создания и применения (осо-
бенно обучения) сетей?
Работа, которую мне поручили, оказалась чрезвычайно важной и ак-
туальной. Люди все чаще интересовались нейронными сетями, поэтому
им надо было объяснить, что это такое и почему работает? Возможности
нейрокомпьютинга вызывали все больший энтузиазм, поэтому возникла
потребность в публикации, играющей роль «ушата холодной воды», что-
бы предупредить попытки решать с помощью нейронных сетей задачи,
для которых этот метод непригоден. Таким образом, я убедился в на-
сущной необходимости писать серию заказанных журналом Enter статей
(почти сразу стало ясно, что в одной статье охватить всю проблематику
не удастся). В статьях нельзя было использовать математику ведь
для мно1их людей, которым знания о нейронных сетях могли оказаться
полезными, любая математическая формула представляется непреодо-
лимым барьером. Эту цель удалось достичь — как в цикле тех, уже
далеких статей, так и в настоящей книге нет ни одной формулы. Лю-
дям, которые о биологии что-то слышали давно и немного, предстояло
объяснить, в какой степени и в каком смысле нейронные сети можно счи-
тать моделями реальных нейронных структур (в частности, фрагментов
человеческого мозга). Попятно, что это объяснение тоже должно было
обойтись без углубленного изложения анатомии и физиологии нервной
системы. Я не должен был сильно погружаться в проблематику нейрон-
ных сетей, поскольку частности (как и в любой другой области знаний)
сложны и интересны только специалистам, но хотел, чтобы читатель
моих статей понял, как функционируют нейронные сети и почему они
настолько полезны. И еще: я старался любой ценой избегать изложения
сведений, которые? нужно принимать «просто на веру».
Предисловие к русскому изданию
13
Почти неразрешимую, на первый взгляд, задачу удалось решить и,
как я говорил, вместо одной популярной статьи возник цикл из двух
десятков текстов, которые печатались в каждом номере журнала Enter
на протяжении почти двух лет. Публикации вызвали огромный интерес
как у взрослых читателей, так и у школьников. К моему удивлению,
именно молодежь из лицеев и колледжей очень живо восприняла обсуж-
даемую тематику и это стало самым радостным. Оказалось, что в
средней школе учится множество «фанатов» информатики, которые за-
читывались популярными статьями на модную тему. Когда стало понят-
ным, что эти публикации не требуют ни специальных знаний в области
информатики, ни знакомства с высшей математикой, ни ориентации в
тайнах биологии, число читающих мои статьи лицеистов выросло мно-
гократно, а издатели журнала Enter отметили существенное увеличение
объема продаж. Я получал от молодых читателей множество писем, в
которых высказывалось одно и то же мнение: « Читать о нейронных
сетях очень интересно и увлекательно, но еще лучше было бы поэкспе-
риментировать с ними на школьном или домашнем компьютере!».
Я решил удовлетворить пожелания и запросы моих читателей, при-
чем не только школьного возраста. Аналогичные просьбы направляли
мне даже пенсионеры, которые, получив в старости больше свободного
времени, также хотели узнать нечто новое и интересное. Так почему бы
не использовать для этого купленный для внука, но привлекательный и
для деда персональный компьютер? В одной из последних статей цикла,
опубликованных в журнале Enter, я привел список известных мне про-
грамм для построения и моделирования простейших нейронных сетей на
персональных компьютерах, а также источников, из которых их можно
получить. К сожалению, это решение оказалось не слишком удачным.
Как правило, пользователь готовых программ должен был обладать бо-
лее глубокими знаниями, чем те, которые он мог почерпнуть из моих
популярных статей. Кроме того, для получения полнофункциональных
версий программ необходимо было приобрести соответствующую лицен-
зию (на что школьники и другие любители чаще всего были просто не
способны), а бесплатно предоставлялись только очень ограниченные де-
монстрационные версии. В результате возможности использования гото-
вых программ оказались весьма далекими от того, что я хотел обеспе-
чить своим читателям, — радости самостоятельного экспериментирова-
ния с нейронными сетями, построенными своими руками.
Для разрешения сложившейся ситуации надо было самому написать
программы, которые помогли бы читателям (наряду с накоплением тео-
ретических знаний) получить практический опыт создания и примене-
ния нейронных сетей. Я занялся этим, когда по просьбе одного из из-
дателей решил собрать воедино и издать в виде книги опубликованные
14
Предисловие к русскому изданию
в Enter статьи. Данное издание подготовлено на основе выпущенной в
Польше книги «Элементарное введение в технологию нейронных сетей
с примерами программ»*. Название «Элементарное введение...» отра-
жало содержание ранее написанных статей (конечно, переработанное и
упорядоченное), тогда как программы, записанные на прилагавшуюся
к книге дискету, стали той новинкой, которая должна была удовлетво-
рить потребности, в первую очередь, молодых читателей, желавших не
только читать о нейронных сетях, но также самостоятельно строить и ис-
следовать их. Для достижения поставленной цели я написал около трид-
цати несложных программ (некоторые из них — совместно с доктором
наук П. Короходой (Р. Korohoda) с кафедры Электроники Краковской
горно-металлургическом академии;, которые предоставляли пользовате-
лю возможность познакомиться с функционированием нейронных сетей
путем самостоятельного выполнения простых вычислительных экспери-
ментов на любом доступном компьютере.
Первая версия этих программ была написана на языке Бейсик, точ-
нее, на его диалекте, используемом интерпретатором** QBASIC. Увы,
этот интерпретатор канул в прошлое вместе с операционной системой
MS DOS и довольно давно. С высоты сегодняшнего дня можно утвер-
ждать, что для «тех времен» программа на «старом, добром Веисике»
была неплохим решением. Как и для любого другого интерпретиру-
емого языка, Бейсик-программа представляет собой простой текстовый
файл, который можно просмотреть (и модифицировать!") с помощью про-
извольного текстового редактора, например Блокнота. Кстати говоря, я
не рекомендую открывать файл с текстом программы (на профессио-
нальном языке называемым исходным кодом) с помощью редактора типа
MS Word причины этого разъясняются в следующей главе. К сожа-
лению, розы без шипов не растут. Для выполнения такой программы
R. Tadeusiewicz, Elementarne wprowadzenie do techniki sieci neuronowych z przyka-
dowymi programami. Warszawa: PL J, 1998.
Интерпретатор программа- предназначенная для выполнения других программ.
Если это кажется тебе слишком сложным, не расстраивайся: читать книгу и пользоваться
упоминаемыми в ней программами можно и без этих знаний. Для гсх же, к го заинтере-
совался, сообщу, что программы делятся на две категории:
интерпретируемые, в которых сама программа хранится в текстовом файле, а ее
выполнение заключается в пошаговом считывании и исполнении интерпретатором каждой
команды;
компилируемые, в которых текст программы ( гак называемый исходный код) так-
же хранится в текстовом файле, но он «раз и навсегда» преобразуемся в формат, непосред-
ственно понимаемый процессором компьютера (так называемый машинный код) и чаще
всего хранимый в файле с расширением «.ехе».
Звучит знакомо, правда? Большинство файлов на жестком диске твоего компьютера,
скорее всего, откомпилированные программы.
Предисловие к русскому изданию
15
необходим уже упоминавшийся интерпретатор — программа QBASIC.
Да-да, если до этого времени ты не знал, что компьютер не может «про-
сто так» выполнить программу, написанную на любом языке програм-
мирования и хранящуюся в текстовом файле, то именно теперь одним
заблуждением стало меньше.
К сожалению, QBASIC был примитивной программой с сильно огра-
ниченными возможностями. Сегодня, когда нормой для пользователя
стали программы с богатым и дружественным оконным интерфейсом,
использование как среды QBASIC, так и написанных с его применени-
ем программ стало анахронизмом.
Программы, предназначенные для упрощения понимания и иллю-
страции содержания этой книги, созданы с применением совершенно
иной технологии. Они написаны на компилируемом языке С#. Это озна-
чает, что читатель получает готовые программы, которые можно устано-
вить на своем компьютере и выполнить нажатием нескольких клавиш,
так же как и большинство других программ. Написанные соавторами
этой книги Б. Боровик (В. Borowik), Т. Гончажем (Т. Gonciarz) и
Б. Пеппером (В. Lepper) специально для операционной системы Win-
dows, они обладают прозрачным и дружественным для пользователя
интерфейсом. Все программы можно скачать (легально и бесплатно) с
Интернет-с границы
http://www. agh. edu.pl/tad
Процесс скачивания и использования программ подробно описывает-
ся в гл. 4.
Однако возникает вполне обоснованный вопрос: Почему авторы пере-
шли на новую технологию программирования, если текст программы на
Бейсике можно было видеть «невооруженным глазом» и самостоятельно
разбираться — что и как она делает, тогда как программы, написанные
на языке С#, «прочитать» невозможно?
Прежде всего потому, что с новыми программами проще работать.
Более того, их применение адаптировано к навыкам и привычкам изба-
лованных пользователей современных компьютеров (ты один из таких
пользователей можешь не оправдываться!), привыкших к оперирова-
нию программами с помощью удобных средств системы Windows: быст-
рый и простой выбор из многоуровневого меню, попятные и уместные
подсказки, кнопки для щелканья мышкой и т.п. — это вам не много-
трудный ввод команд и данных с клавиатуры, бывший единственным
способом общения с программами на Бейсике!
То, что современные и усовершенствованные программы откомпи-
лированы (и, следовательно, нечитаемы), не должно считаться боль-
шой проблемой: в конце концов, большинство читателей захочет просто
16
Предисловие к русскому изданию
установить эти программы и поэкспериментировагь с ними, а не изу-
чать их структуру. Понятно, что желающих «заглянуть под маску» бу-
дет гораздо меньше. Однако и для них ггайцется кое-что интересное. На
упомянутой выше Интернет-страпице http://www.agh.edu.pl/tad находят-
ся исходные тексты всех программ, а также средства для просмотра и
анализа этих текстов. Ну а самые отважные и наиболее опытные най-
дут на этой странице инструментарий для модификации и компиляции
исходного кода, а также для самостоятельного выполнения программ.
Для этого используется бесплатная среда программирования компании
Microsoft Visual Studio Express 2005. Я рекомендую инсталлировать
эту бесплатную среду на своем компьютере и тем читателям, которые
хотят только просмотреть исходный код наших программ: благодаря ей
использовать программы, иллюстрирующие описываемые в книге зада-
чи, станет намного проще.
Таким образом, книгу и размещенные в Интернете приложения к пей
можно использовать тремя способами. Если ты интересуешься нейрон-
ными сетями только с теоретической точки зрения и не имеешь жела-
ния «баловаться» какими-нибудь программами, достаточно прочитать
саму книгу. Если хочется узнать, как реализуются описанные в книге
решения, то можно скачать готовые протраммы, позволяющие строить
и исследовать нейронные сети. Так ты сможешь соединить теорию (вы-
читанную в книге) с практикой (полученной в результате применения
наших программ) и благодаря этому получить двоякие умения, связан-
ные с теорией нейронных сетей и методами их применения. Если же, в
довершение ко всему, ты еще и любитель программирования, пожалуй-
ста, изучай устройство наших программ. Мы ничего не скрываем!
Благодаря этому ты поймешь, как функционируют программы, и
сможешь менять их параметры. Если же возникнет желание модифици-
ровать исходный код наших npoi рамм и проверить «что будет, если ...»,
то ты вступишь в элитарный клуб создателей нейронных сетей, гораз-
до более престижный, чем клуб простых пользователей этих же се-
тей. Конечно, для успешной модификации программ ты должен уметь
программировать на языке С#. Желающим «всерьез» познакомиться
с этим языком рекомендую изучить соответствующую литературу. Она
не дефинитна. Перед тем как написать эти строки, я ввел в поиско-
вую систему Google комбинацию «С#» и получил в ответ 110 000 000
свыше ста миллионов!) ссылок на Интернет-страницы, содержащие
информацию об этом языке, в том числе и электронные учебники по
программированию на С#, бесплатные версии которых существую!' на
всех языках, в том числе и на русском.
Русское издание книги имеет несколько существенных отличий от
последнего польского издания.
Предисловие к русскому изданию 17
Во-первых, по сравнению с польским оригиналом сильно перерабо-
тано и актуализировано все содержание книги. Со времени публикации
польской версии прошло немало времени, а темпы научно-технического
прогресса в нашей области знаний остаются стремительными. Поэтому
русский вариант книги с содержательной точки зрения значительно бо-
гаче польского оригинала.
Во-вторых, изменены (к лучшему!) свыше 4/5 представленных в кни-
ге иллюстраций. Они стали более красивыми и современными, а также
полнее используют возможности полиграфии. Новые иллюстрации по-
явились потому, что с момента написания первой польской версии этой
книги я в течение 10 лет рассказывал студентам, что такое нейронные
сети и как их используют, а при подготовке к лекциям приходится го-
товить иллюстративный материал, значительно обогащающий учебный
процесс. И когда возникла необходимость работать над новым изданием
книги, лекционные презентации оказались очень кстати!
В-третьих, о чем уже говорилось, заменены все программы, иллю-
стрирующие решение рассматриваемых в книге задач. При разработ-
ке нового программного обеспечения использовались все возможности и
свойства современных компьютеров и наиболее широко распространен-
ных операционных систем (в первую очередь Windows). Использование
этих программ станет для читателя удобнее и проще, чем программ, на-
писанных на Бейсике для первой версии книги. Те читатели, которые
воспользуются возможностью доступа к исходным кодам применяемых
программ, дополнительно смогут повысить свою квалификацию в обла-
сти программирования на языке С#.
В-четвертых, книга по своей структуре стала более похожей на учеб-
ное пособие благодаря тому, что в конце каждой главы добавлены кон-
трольные вопросы и задания для самостоятельного выполнения. Это
позволит читателю оперативно контролировать расширение своих зна-
ний и даст повод дополнительно осмыслить (в меру возможности) по-
лученные сведения. В сумме читатель получит свыше ста заданий, над
решением которых придется поразмыслить. Это не маленькое и в чем-
то уникальное множество заданий, если принять во внимание мировые
информационные ресурсы по обсуждаемой тематике.
В-пятых, в книгу добавлена отсутствовавшая в польской версии биб-
лиография по нейронным сетям, благодаря которой читателю будет про-
ще получить дополнительную информацию.
Мне кажется, что благодаря всем этим изменениям каждый чита-
тель российского издания нашей книги без труда найдет способ попол-
нить свои теоретические знания и закрепить практические умения, а
также углубится в проблематику нейронных сетей настолько, насколь-
ко сможет и пожелает.
18
Предисловие к русскому изданию
Прежде чем мы перейдем к описанию и изучению различных ней-
ронных сетей, рассматриваемых в следующих главах нашей книги, хоте-
лось бы сердечно поблагодарить тех, кто имеет отношение к ее созданию.
В первую очередь, авторы выражают сердечную признательность про-
фессору И.Д. Рудинскому, который перевел книгу на русский язык и
высказал множество ценных советов и рекомендаций, позволивших кни-
ге попасть в руки российского читателя.
Мы также очень благодарны издательству «Горячая линия Теле-
ком» и лично Е.А. Занину, которые, невзирая на отсутствие внешнего
инвестора, приняли решение издать книгу за счет собственных средств
и на собственный риск. Без этого смелого решения книга никогда бы
не дошла до российского читателя.
И, наконец, мы считаем свои долгом выразить искреннюю благодар-
ность академику Польской академии наук, профессору Лешеку Рутков-
скому, который помог установить необходимые контакты и предоставил
возможность пройти путем, проложенным его великолепными книгами,
еще раньше переведенными и изданными в России. Это служит еще од-
ним доказательством целесообразности и полезности подобного обмена
интеллектуальными ценностями между нашими странами.
С чего-то надо начинать, и я утверждаю, что именно эта книга ока-
жется наилучшей стартовой площадкой для увлекательнейших приклю-
чений в нейронных сетях. Итак, приглашаю всех к погружению в сле-
дующие главы книги и к познанию (при ее посредничестве, а также с
помощью программ) захватывающего мира нейронных сетей мощного
орудия искусственного интеллекта, которое имело и имеет множество
ИТ-приложений, но также и интересного инструментария для изучения
нашего собственного мозга инструментария, который может стать под-
спорьем для понимания таинственного мира нашего интеллекта и нашей
далеко не познанной психики.
Рышард Тадеусевич,
заведующий кафедрой Автоматики
Краковской горно-металлургической академии,
академик Польской академии паук,
вице-президент Краковского отделения
Польской академии наук
февраль 2007 г.
Глава 1
ВВЕДЕНИЕ В ЕСТЕСТВЕННЫЕ И
ИСКУССТВЕННЫЕ НЕЙРОННЫЕ
СЕТИ
1.1. Для чего нужно изучать нейронные сети?
Эта книга написана, чтобы ты, мой дорогой читатель, легко, удоб-
но и приятно получил представление о нейронных сетях, как и почему
они функционируют, а так же, как их можно использовать. Если ты
читаешь сейчас мои слова, значит, тебе это интересно. Но книга не ма-
ленькая, и для ее изучения, наверняка, потребуется приложить опре-
деленные усилия. Ты можешь задаться вопросом: А нужно ли это де-
лать, и если да то зачем? Или лучше отложить книгу и заняться
любимой компьютерной игрой?
Самой простой ответ следующий: Да, нейронные сети изучать стоит,
поскольку ими интересуется множество ученых и практиков, потому
что с их помощью сделаны многочисленные открытия, а в будущем они
станут источником еще многих достижений. Если эти доводы все еще
не убедили тебя в том, что на знакомство с нейронными сетями име-
ет смысл потратить немного времени, вот еще один аргумент — о
них все говорят, нейронные сети попросту в Model
Но можно ли считать приведенные доводы достаточными? На про-
тяжении многих лет мы наблюдаем в информатике различные моды
и связанные с ними приливы-отливы интереса к различным частным
проблемам, влияющие на направления научных исследований, форми-
рующие представление о компьютерном рынке и концентрирующие на
конкретных задачах внимание программистов. Длительность таких мод-
пых увлечений бывает разной, в среднем от нескольких месяцев до
нескольких лет. В общем случае мода сохраняется до момента, пока но-
вое увлечение не направит массы «искателей золота» в новые регионы.
Можно привести множество примеров таких модных тем: не так давно
все поголовно «заразились» Интернетом (впрочем, «помешательство»
па интеллектуальных обозревателях все еще продолжается), в настоя-
щее время очень много говорится о так называемых технологиях распре-
20
Глава 1
деленных вычислений, все еще нс утихли волны моды на клеточные ав-
томаты и агентские технологии, своих верных «фанатов» имеют фрак-
талы и хаос, периодичес ки (как эпидемия чумы!) возвращаются увлече-
ния генетическими алгоритмами и теорией нечетких множеств.
Можно сказать, ччо в информатике цари г мода на изменчивость
увлечений!
С начала 90-х гг. XX в. возникла и держится до настоящего времени
мода на нейронные сети. Я уже написал кое-что об этой моде в предисло-
вии к российскому изданию, и если ты его все еще не прочитал (я знаю
людей, которые принципиально игнорируют любые предисловия...), то
настоятельно советую вернуться на несколько страниц и прочитать имен-
но это предисловие. В нем приводится немало интересных, важных и
полезных фактов, которые я не буду повторять в следующих главах,
ио которые тебе наверняка пригодятся, если ты всерьез интересуешься
нейронными сетями и чем более, если рассматриваешь их как инстру-
ментарий будущей работы.
Я написал, что нейронные сети модны. Если нечто входит в мо-
ду, то иногда оказывается полезным к пси присоединиться, поскольку в
модной области проще добиться признания, можно эффектнее нредста-
вигь полученные результаты, и даже скорее опубликовать статью или
получить заказы на программы либо гранты па проведение исследова-
ний. Поэтому модные темы нужно и можно изучать. На этом основании
к большому удовлетворению сторонников чезиса, что популярность ней-
ронных сетей вызвана модой подтверждаю, дей< гвительно такая мода
существует, и именно поэтому стоит заниматься нейронными сетями.
Я знаю, что следование моде не всегда и не для всех приемлемо. Сво-
бодный и ничем не стесненны г человеческий дух неохотно принимает1
любые ограничения и при первой возможности сбрасывает наброшенные
на него узы. Поэтому для многих людей известие о том, что некий «обч>-
ект» стал модным, само по себе оказывается достаточным поводом для
отторжения этой идеи или явления с чувством глубокого превосходства:
— Пусть там другие суетятся!
Конечно, с чакон мотивацией можно игнорировать моду и оставаться
на обочине, но даже тогда (или именно тогда) необходимо понимать,
от чего отказываешься. Безрассудное отрицание моды так же нелогично,
как и безрассудное следование ей.
Независимо от того, собираешься ли ты, дорогое читатель, приме-
нять нейронные сети в своей работе, хочешь просто поиграть с ними
либо сознательно намерен их игнорировать ты должен их изучить.
Но мода не единственное объяснение целесообразное! и знаком-
ства с нейронными сетями. Ниже в этой хлаве я постараюсь убедить
Введение в естественные и искусственные сети
Рис. 1.1. Человеческий
мозг оригинал и недося-
гаемый идеал для исследо-
вателей нейронных сетей
тебя в том, что сети интересный объект для исследований и прекрас-
ный инструментарий для множества приложений. Почему бы не уделить
некоторое время для знакомства с этим предметом хотя бы из любозна-
тельности либо для серьезного освоения? С большой вероятностью ты
увлечешься нейронными сетями и захочешь их использовать, но даже
если ты не почувствуешь их очарование, то сможешь, по крайней мере,
ответить любому на вопрос: «А почему Вы не применили для этого ней-
ронные сети?». На научных конференциях и на защитах диссертаций я
встречал много людей, которые с удовольствием задают такие вопросы,
поэтому имеет смысл держать наготове осмысленный ответ.
И еще один аргумент. Нейронные сети
представляют собой очень упрощенную (и
благодаря этому лучше охватываемую мыс-
лью и проще реализуемую на компьютере)
модель биологической нервной системы.
Принципы функционирования и структура
этих сетей отражают уже известные фак-
ты и правила функционирования реальной
биологической нервной ткани, а также ее
строение. Подробности мы рассмотрим во
второй главе, но забегая вперед, можно ска-
зать, что нейронные сети — это упрощенные
модели некоторых фрагментов нашего собственного мозга (рис. 1.1).
Если же ты задумывался когда-нибудь о своем собственном интел-
лекте, если хотел узнать что-либо о природе мышления, обучения, ас-
социативности — займись нейронными сетями, и наверняка найдешь в
них ответы на многие занимающие тебя вопросы, а при случае обна-
ружишь еще больше новых неожиданных и захватывающих загадок! В
процессе исследования нейронных сетей ты приблизишься к осознанию
некоторых особенностей собственного мозга, а при соответствующем при-
менении нейронных сетей начнешь лучше понимать мотивы поступков
других людей и научишься прогнозировать их поведение в тех или иных
обстоятельствах. Это пригодится в жизни!
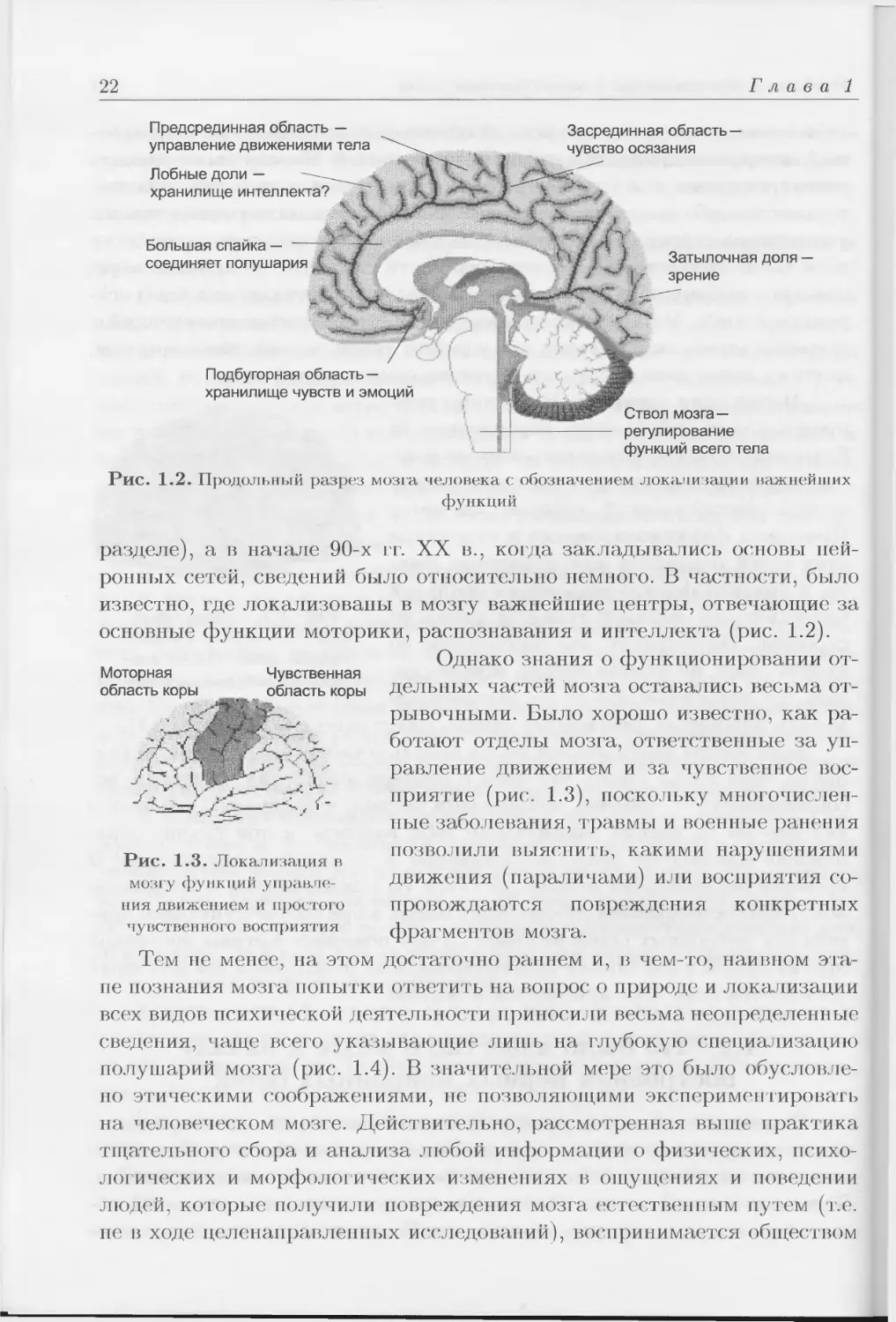
1.2. Что было известно о мозге к началу
построения первых нейронных сетей?
Строение мозга всегда привлекало внимание людей, однако, несмот-
ря па многолетние интенсивные исследования, мы так и не можем до
конца ни выяснить, ни понизь все феномены его функционирования.
Только в последние годы был достигнут существенный прогресс в об-
ласти изучения мозга (мы подробнее поговорим об этом в следую]цем
22
Глава 1
Предсрединная область —
управление движениями тела
Лобные доли —
хранилище интеллекта?
Большая спайка — —
соединяет полушария
Засрединная область—
чувство осязания
Затылочная доля —
зрение
Подбугорная область—
хранилище чувств и эмоций
Ствол мозга—
регулирование
функций всего тела
Рис. 1.2. Продольный разрез мозга человека с обозначением локализации важнейших
функций
разделе), а в начале 90-х it. XX в., когда закладывались основы ней-
ронных сетей, сведений было относительно немного. В частности, было
известно, где локализованы в мозгу важнейшие центры, отвечающие за
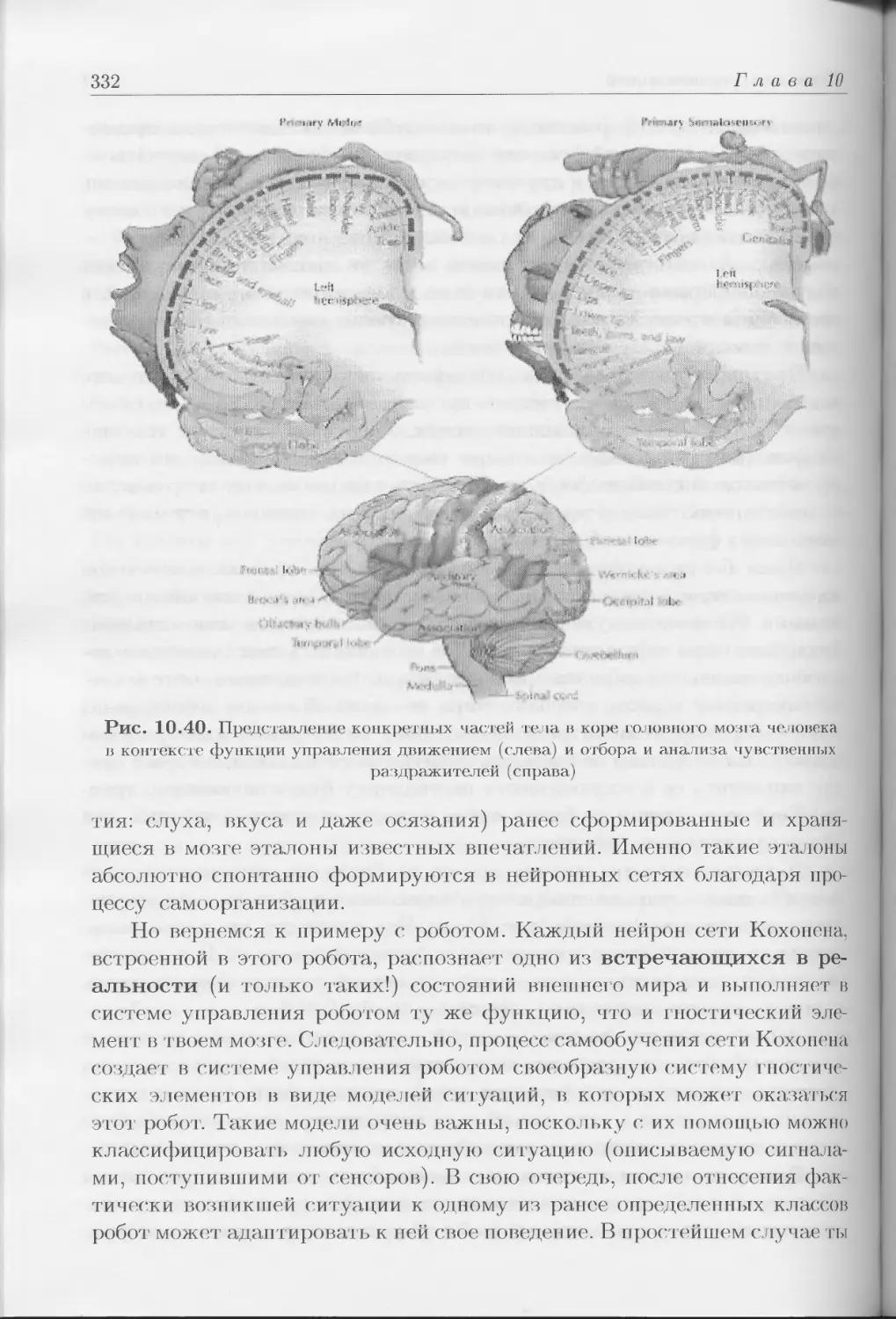
основные функции моторики, распознавания и интеллекта (рис. 1.2).
Моторная
Чувственная
Рис. 1.3. Локализация в
мозгу функций управле-
ния движением и простого
чувственного восприятия
Тем не менее, на этом
Однако знания о функционировании от-
дельных частей мозга оставались весьма от-
рывочными. Было хорошо известно, как ра-
ботают отделы мозга, ответственные за уп-
равление движением и за чувственное вос-
приятие (рис. 1.3), поскольку многочислен-
ные заболевания, травмы и военные ранения
позволили выяснить, какими нарушениями
движения (параличами) или восприятия со-
провождаются повреждения конкретных
фрагментов мозга.
достаточно раннем и, в чем-то, наивном эта-
пе познания мозга попытки ответить на вопрос о природе и локализации
всех видов психической деятельности приносили весьма неопределенные
сведения, чаще всего указывающие лишь на глубокую специализацию
полушарии мозга (рис. 1.4). В значительной мере это было обусловле-
но этическими соображениями, не позволяющими экспериментировать
на человеческом мозге. Действительно, рассмотренная выше практика
тщательного сбора и анализа любой информации о физических, психо-
логических и морфолотических изменениях в ощущениях и поведении
людей, которые получили повреждения мозга естественным путем (т.е.
не в ходе целенаправленных исследований), воспринимается обществом
Введение в естественные и искусственные сети
23
Левое полушарие управляет правой рукой, а правое — левой рукой
Левое полушарие
управляет функцией
речи и точным
пониманием, а также
математическими
способностями
Правое полушарие
управляет артистическими
способностями,
а также воображением
и художественными
фантазиями
Рис. 1.4. Распределение (в значительной степени гипотетическое) задач между
полушариями мозга
гораздо спокойнее, чем манипулирование электродами или скальпелем
в тканях здорового мозга для получения информации о функциониро-
вании его различных частей.
Конечно, в те годы можно было проводить опыты на животных —
и их проводили очень часто. Но умерщвление невинных зверюшек ради
удовлетворения нашей любознательности, даже если это благородный
интерес ученого, имело весьма неоднозначную моральную репутацию.
В довершение ко всему результаты опытов на животных не позволяли
делать прямые суждения о поведении и свойствах человеческого мозга.
Дистанция, отделяющая нас от зверей в этой области, гораздо больше,
чем при исследовании мышц, сердца или крови.
Итак, чем же располагали создатели первых искусственных нейрон-
ных сетей, желавшие наделить свои конструкции как можно большим
количеством свойств и характеристик, наблюдавшихся при функциони-
ровании реального биологического мозга?
Во-первых, они знали, что мозг состоит из отдельных ячеек (нейро-
нов), играющих роль биологических процессоров. Первое описание чело-
веческого мозга в виде взаимосвязанных, но вполне автономных элемен-
тов предложил испанский анатом С. Рамон-и-Кайял (Нобелевская пре-
мия за 1906 г.). Он также сформулировал концепцию нейронов, т.е. спе-
циализированных ячеек, перерабатывающих информацию, получающих
и анализирующих чувственное восприятие, вырабатывающих и рассыла-
ющих сигналы управления теми элементами человеческого организма,
которые контролируются мозгом (например, мышцами, железами и дру-
гими внутренними органами). Структуру нейрона мы обсудим во второй
главе, поскольку его технический аналог используется в качестве ос-
24
Глава 1
Рис. 1.5. Ключ к созданию концепции нейронных сетей выделение из нервной
ткани одиночных ячеек (нейронов), играющих роль биологических процессоров
новпого элемента рассматриваемых там структур нейронных сетей. На
рис. 1.5 демонстрируется, каким способом из густой сети нейронов, обра-
зующих кору головного мозга, удалось выделить одиночную ячейку. Я
уже говорил, что она представляет собой сложный биологический про-
цессор, ответственный за все функции и все действия нашей нервной
системы (причем не только мозга, но и, например, симпатической и пара-
симпатической систем, управляющих работой всех внутренних органов).
К моменту создания первых нейронных сетей о нейронах было из-
вестно уже довольно много, поскольку у некоторых видов животных
(например, у кальмара Loligio) они настолько велики, что умелым иссле-
дователям (Ходжкин и Хаксли, Нобелевская премия за 1963 г.) удалось
изучить биохимические и биоэлектрические изменения, происходящие в
них при передаче и обработке сигналов носителей нервной информа-
ции. Однако ключевым оказался вывод о возможности существенного
упрощения описания реального нейрона (на самом деле очень сложно-
го) путем замены принципов происходящей в нем обработки информации
несколькими простыми зависимоетями (описываемыми во второй главе).
Такой крайне упрощенный нейрон (рис. 1.6) все равно позволяет созда-
Входные
сигналы /—х
Переменные
«веса»
Рис. 1.6. Структура и основные
элементы искусственного нейрона
Выходной
сигнал
вать сети, обладающие интересными и по-
лезными свойствами; в то же время такой
нейрон можно легко построить.
Указанные на рис. 1.6 элементы (осо-
бенно таинственные «веса» внутри блока,
символизирующего нейрон) будут внима-
тельно рассматриваться в следующих гла-
вах, поэтому о них пока можно не думать.
Введение в естественные и искусственные сети
25
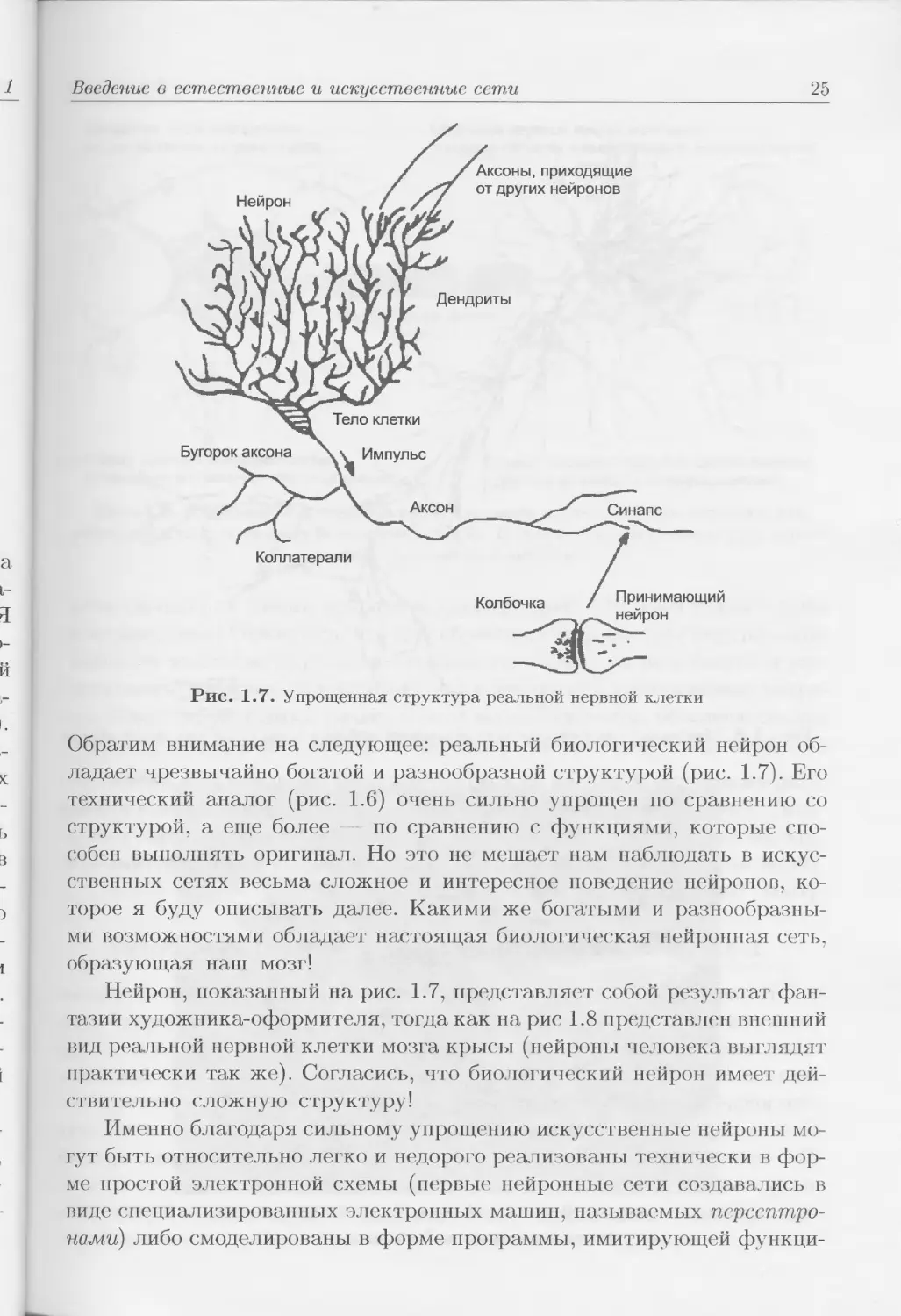
Рис. 1.7. Упрощенная структура реальной нервной клетки
Обратим внимание на следующее: реальный биологический нейрон об-
ладает чрезвычайно богатой и разнообразной структурой (рис. 1.7). Его
технический аналог (рис. 1.6) очень сильно упрощен по сравнению со
структурой, а еще более — по сравнению с функциями, которые спо-
собен выполнять оригинал. Но это не мешает нам наблюдать в искус-
ственных сетях весьма сложное и интересное поведение нейронов, ко-
торое я буду описывать далее. Какими же богатыми и разнообразны-
ми возможностями обладает настоящая биологическая нейронная сеть,
образующая наш мозг!
Нейрон, показанный па рис. 1.7, представляет собой результат фан-
тазии художника-оформителя, тогда как на рис 1.8 представлен внешний
вид реальной нервной клетки мозга крысы (нейроны человека выглядят
практически так же). Согласись, что биологический нейрон имеет дей-
ствительно сложную структуру!
Именно благодаря сильному упрощению искусственные нейроны мо-
гут быть относительно легко и недорого реализованы технически в фор-
ме простой электронной схемы (первые нейронные сети создавались в
виде специализированных электронных машин, называемых персептро-
нами) либо смоделированы в форме программы, имитирующей функци-
26
Глава 1
Рис. 1.8. Микроскопический препарат реального нейрона коры головного мозга крысы
онирование такой клетки на компьютере (персональном или любом дру-
гом). В современных системах практически всегда используется именно
программная реализация, которая представляет собой удобный и недо-
рогой йнструментарий, позволяющий моделировать как одиночные ней-
роны, так и целые нейронные сети.
1.3. Как создавались первые нейронные сети?
Но вернемся к обзору (биологических данных, на которых основыва-
лись создатели первых ш i [ровных сетей. Посмотрим, как нейрокиберне-
тики использовали эту информацию для повышения удобстве! и сниже-
ния стоимости применения полученных сетей. Я постараюсь доказать,
что исследователи знали достаточно много о том. какие действия мо-
жет выполнять биологический нейрон. Достаточно заглянуть в таблицу
П.1 предисловия, чтобы убедиться как много Нобелевских премий
получены на протяжении всего XX в. за открытия, прямо или косвен-
но связанные с нервной клеткой и ее функционированием. Важнейшие
знания, которые удалось получить биологам, относятся к местам пере-
Введение в естественные и искусственные сети
27
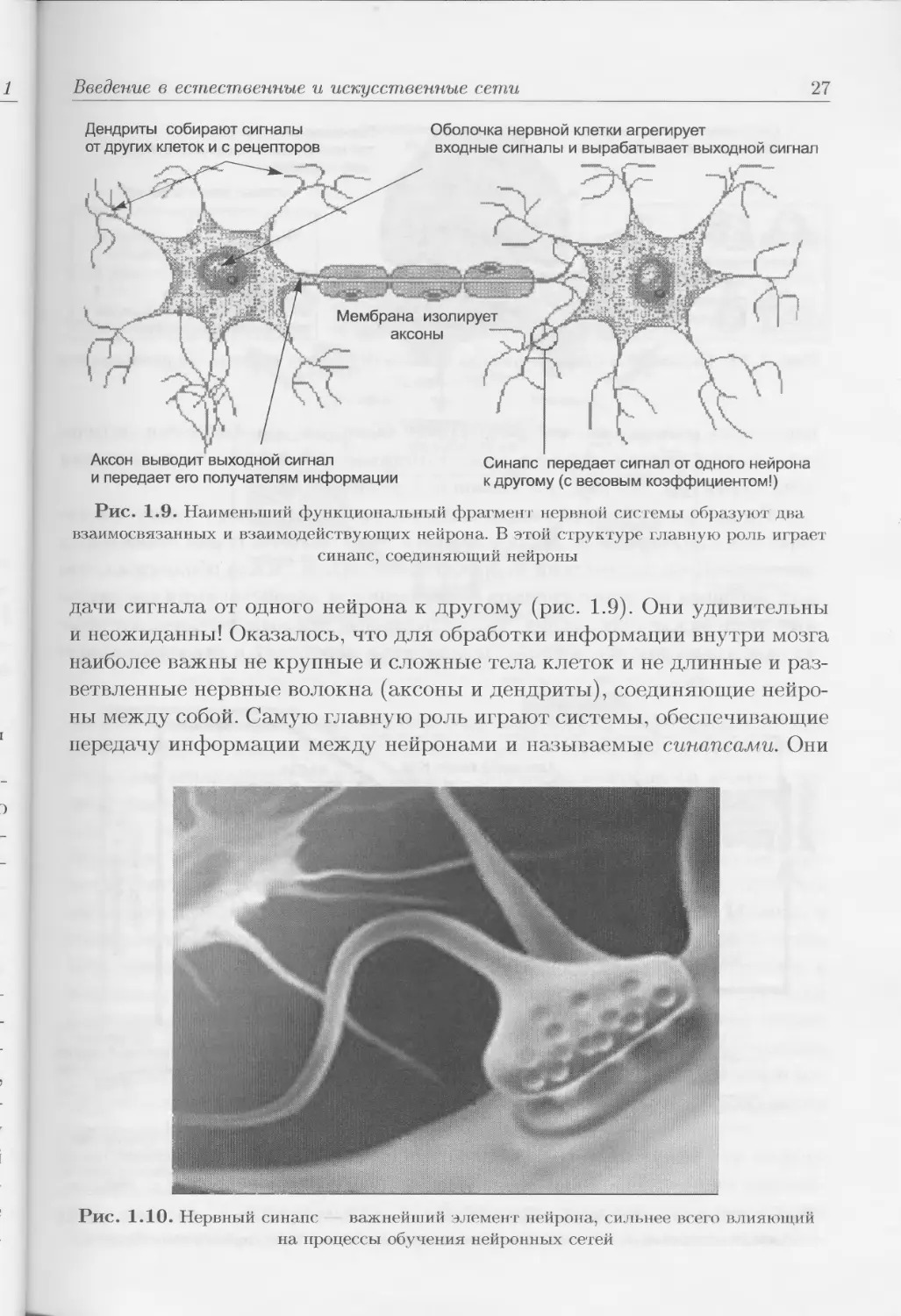
Дендриты собирают сигналы
от других клеток и с рецепторов
Оболочка нервной клетки агрегирует
входные сигналы и вырабатывает выходной сигнал
х/ . *
Мембрана изолирует
аксоны
Аксон выводит выходной сигнал
и передает его получателям информации
Синапс передает сигнал от одного нейрона
к другому (с весовым коэффициентом!)
Рис. 1.9. Наименьший функциональный фрагмент нервной системы образуют два
взаимосвязанных и взаимодействующих нейрона. В этой структуре главную роль играет
синапс, соединяющий нейроны
дачи сигнала от одного нейрона к другому (рис. 1.9). Они удивительны
и неожиданны! Оказалось, что для обработки информации внутри мозга
наиболее важны не крупные и сложные тела клеток и не длинные и раз-
ветвленные нервные волокна (аксоны и дендриты), соединяющие нейро-
ны между собой. Самую главную роль играют системы, обеспечивающие
передачу информации между нейронами и называемые синапсами. Они
Рис. 1.10. Нервный синапс важнейший элемент нейрона, сильнее всего влияющий
на процессы обучения нейронных сетей
28
Глава 1
Окончание аксона нейрона,
передающего информацию
Переменное количество
так называемого нейромедиатора
(«вес синапса»)
Тело нейрона,
получающего
информацию
Так называемая
постсинатптическая
мембрана, вырабатывающая
электрические сигналы
Рис. 1.11. Упрощенная схема структуры синапс а ( позволяет увидеть, где располагается
его «вес»)
настолько маленькие, что разрешение обычных для биологии оптиче-
ских микроскопов оказалось недостаточным для выявления и описания
этих структур. На рис. 1 9 синапсы еле видны.
Только электронные микроскопы показали, насколько сложной и ин-
тересной структурой обладают синапсы (рис. 1.10). В серии гениальных
экспериментов английский нейрофизиолог Джон Экклз обнаружил, что
для переноса нервного сигнала через синапсы задействуются специаль-
ные химические субстанции, так называемые нейромедиаторы, которые
из окончания аксона нейрона-передатчика переходят в так называемую
Глютаминат
Калиевый канал К+
АС
Л Го
o ro
g X
о
Киназа С
Киназа А
Автофосфориляция
Автофосфориляция
CREB
т mGluRs
Са/СаМ
Киназа
zif268
c-jun
c-fos
jun-B
un-D
Первый этап
(ранняя фаза LTP)
Транскрипция
калиевых каналов
и/или фрагментов
NMDA
каналов
и/или фрагментов
NMDA
NMDA
CAMP
\ DAC
Рис. 1.12. Биохимические механизмы, задействованные в процессе запоминания знаний
(довольно сложные, но в нейронных сетях они отображаются упрощенным образом)
Введение в естественные и искусственные сети
29
Долговременная память
Кора мозга
Декларативная память
Семантическая Эпизодическая
1. Do you
speak...
2. р£,ост
3. ?! =
Классическая
Оперативная память
Зрительно-пространственная память
Собственная
разработка
по материалам
С. Гринфилд
Рис. 1.13. Из всех видов человеческой памяти, выделяемых психологами, нейронные
сети моделируют только один вид — - недекларативную память
постсинаптическую мембрану нейрона-получателя информации (очень
упрощенная схема структуры синапса приведена на рис. 1.11). С очень
сильным упрощением можно сказать, обучение нейрона (и мозга в це-
лом) заключается в том, что один и тот же сиг пал, поступающий по ак-
сону от клетки, передающей информацию, может вбрасывать в синапс
большую или меньшую дозу нейромедиатора. Если в результате обу-
чения сигнал признается важным, то количество нейромедиатора уве-
личивается, а если не слишком значимым, го уменьшается. Именно в
этом заключается тайна обучения и памяти, хотя еще раз надо отме-
тить предельную упрощенность описанного механизма по отношению к
реальным биологическим процессам, протекающим в синапсе. Лучшим
подтверждением важност и и сложности обсуждаемого процесса может
служить факт присуждения в 1963 г. Дж. Экклзу Нобелевской премии
за открытие переноса информации между нейронами и за выявление ме-
ханизма изменений, происходящих в синапсе при обучении и получении
новой информации (см. табл. П.1 в предисловии).
Специалисты по нейронным сетям удачно использовали эту инфор-
мацию, благодаря чему созданные ими системы обрели одно из важней-
ших свойств способность к обучению. Конечно, для получения
инструментария, пригодного для решения практических задач приклад-
30
Глава 1
ной информатики, биологические основы обучения (объективно чрезвы-
чайно сложные и опирающиеся на весьма специфические биохимические
процессы) (рис. 1.12) также необходимо было многократно упростить.
Более того, было принято решение, чго предметом обучения в нейрон-
ных сетях будет лишь гот раздел знаний, который психологи Относят к
функции недекларативной памяти — отнюдь не единственному виду
человеческой памяти (рис. 1.13).
Рис. 1.14. Графический пример пространственной реконструкции связей
между элементами нервной системы
Введение в естественные и искусственные сети
31
Другой источник информации, на котором основывалась концепция
нейронных сетей в 90-х гг. XX в., выявленная в этот период внут-
ренняя структура мозга. Кропотливая работа нескольких поколений ги-
стологов, анализ тысяч микроскопных препаратов, сотни более или ме-
нее удачных попыток реконструкции трехмерной структуры соединений
нервных элементов ознаменовались получением схем, пример которых
представлен на рис. 1.14 (показан не самый эффектный фрагмент цен-
тральной нервной системы, точнее, спинного мозга).
1.4. Почему нейронные сети обладают
многослойной структурой?
Так же как в случае упомянутой выше информации о различных
свойствах реального биологического мозга, при построении искусствен-
ных нейронных сетей пришлось максимально упростить нейроанатоми-
ческие и цитологические знания о пространственной структуре межней-
ронных связей. В этом вопросе создатели сетей оказались особенно ра-
дикальными и решительными — они применили для конструирования
и формирования нейронных сетей наиболее удобное с прикладной точки
зрения, но предельно упрощенное правило. В частности, была выявле-
на регулярная многослойная структура межнейронных связей некото-
рых фрагментов коры головного мозга. Отнюдь не весь мозг обладает
многослойной структурой, но были обнаружены несколько характер-
ных примеров (рис. 1.15).
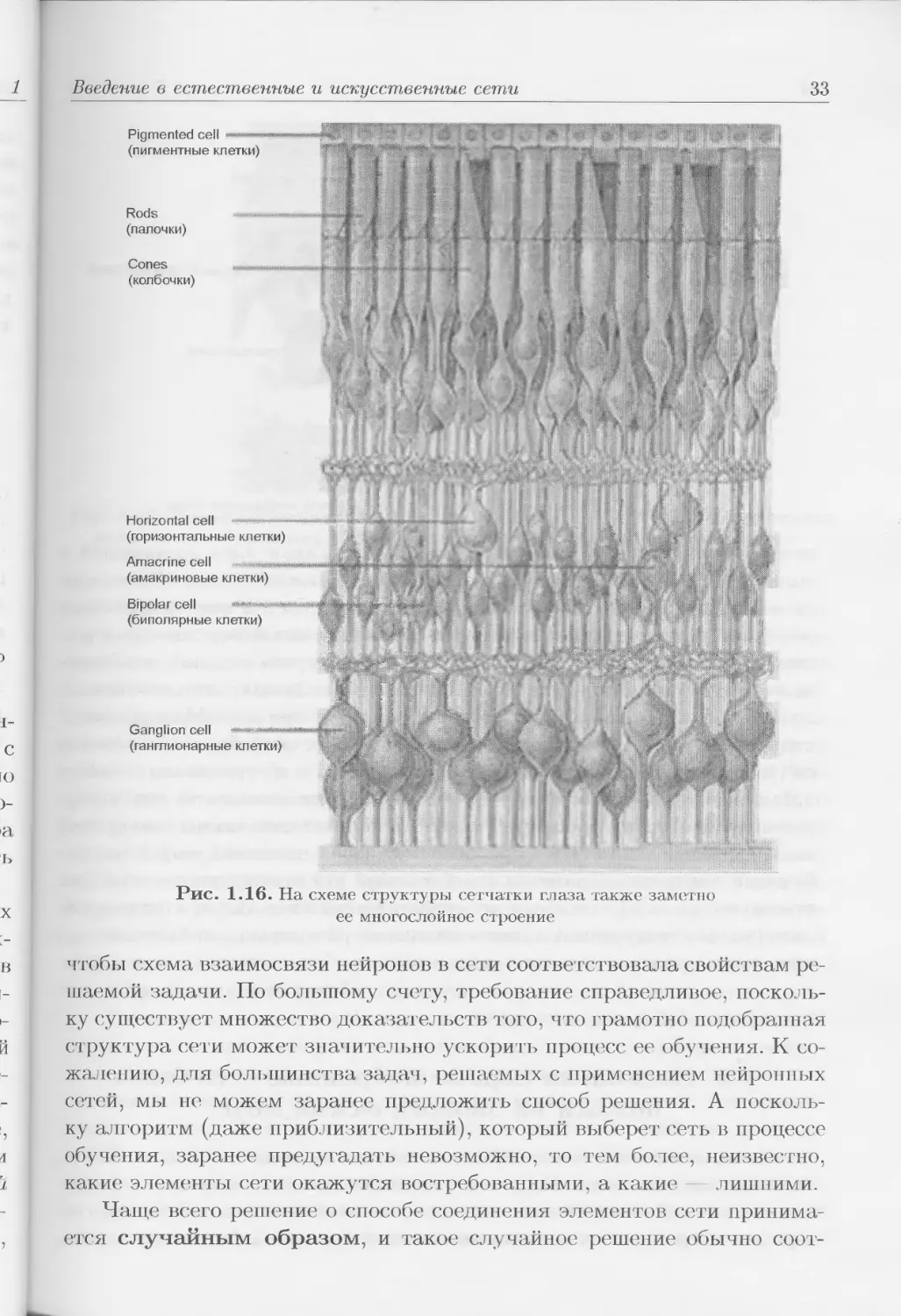
Многослойной структурой обладает и сетчатка глаза (рис. 1.16)
эмбриология свидетельствует, что она представляет собой трансформи-
рованный фра; мент коры головного мозга.
Поэтому следует признать, что при создании нейронных сетей в фор-
ме многослойных структур мы уступаем собственной любви к удобствам
(повторюсь, такие структуры проще всего реализовать технически). Од-
пако мы не совершаем какую-либо кардинальную ошибку, кощунствен-
ную с биологической точки зрения. Конечно, нейронные сети представ-
ляю г собой предельно упрощенные модели фрагментов реальной нерв-
ной ткани. Тем нс менее, они не настолько сильно отличаются от ори-
гинала, чтобы результаты модельных наблюдений не могли корректно
интерпретироваться в контексте потребностей нейрофизиологии.
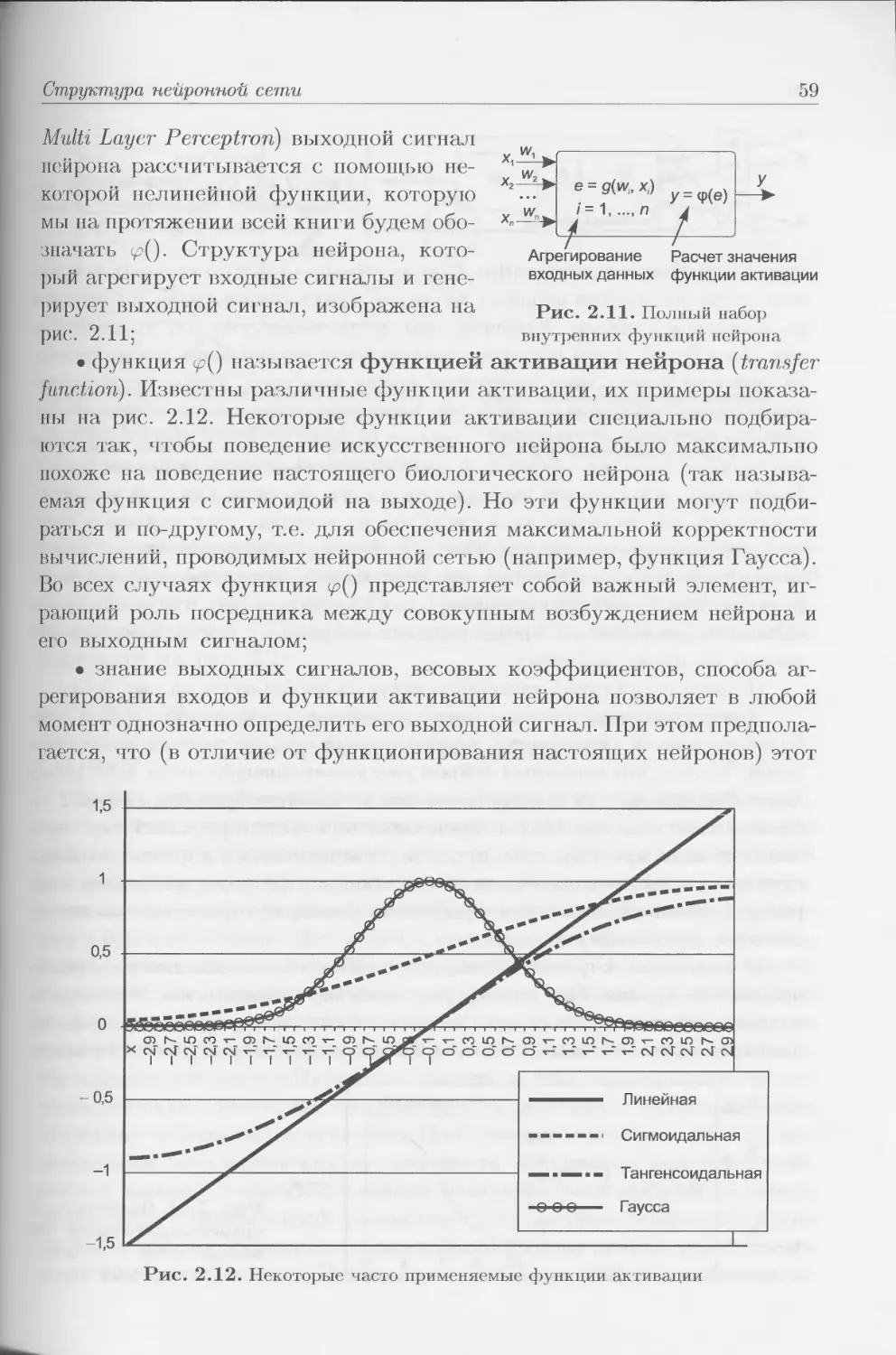
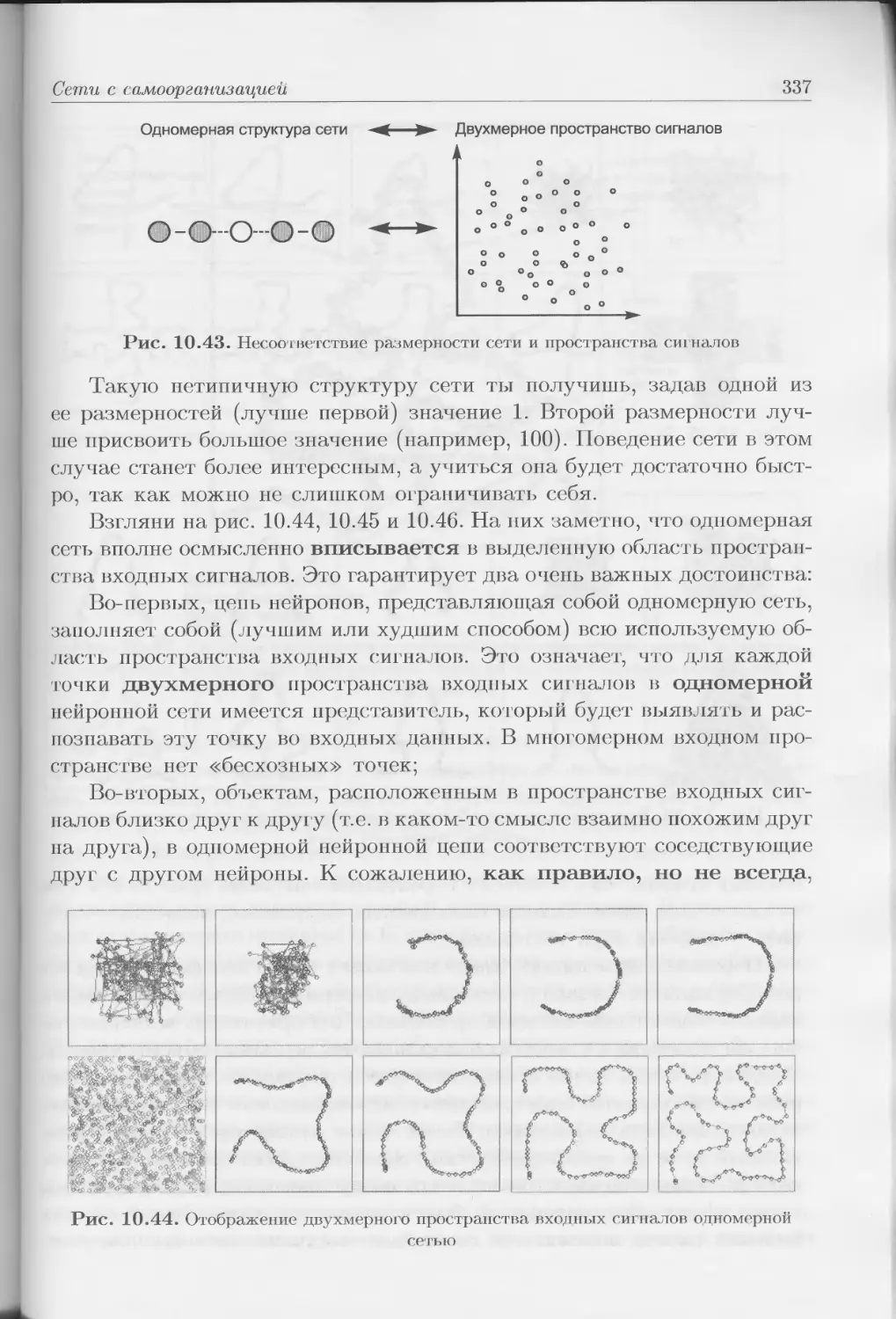
Типичная нейронная сеть имеет структуру, изображенную па
рис. 1.17.
Именно такую (многослойную) структуру сети относительно просто
и удобно реализовать в форме как электронной модели, так и имита-
ционной компьютерной программы. Исследователи привыкли к много-
32
Глава 1
Рис. 1.15. Многослойная структура коры заметна на срезах фрагментов зрительного
отдела головного мозга человека
слойной структуре и традиционно используют ее во всех искусствен-
ных нейронных сетях. Честно говоря, такая модель имеет мало общего с
биологическим оригиналом, но она практична и удобна. Соответственно
многослойная идеология повсеместно применяется без оглядки па био-
логические предпосылки и робкие замечания’о том, что архитектура
сети, более адекватная характеру конкретной задачи, может находить
гораздо лучшие варианты решения.
Также существует проблема взаимосвязи нейронов, расположенных
как в одном, так и в различных слоях. В реальном мозге схема меж-
нейронных соединении очень сложна, причем схемы разных фрагментов
могут существенно отличаться друг от друга. В XIX в. на основе вы-
явленных схем межнейронных соединении была построена первая топо-
логическая карга мозга, на которой указывались регионы с одинаковой
ци гоархитектоникой. Эта карга, названная планом полей Бродмана, се-
годня имеет, скорее, историческое значение, поскольку мы обладаем воз-
можностью различать мозговые структ^ы гораздо точнее. Тем не менее,
сам факт существования карты Бродмана свидетельствует об отсутствии
точного и однозначного ответа на вопрос: Как соединены между собой
нейроны в сети? Ответ зависит от тог о, какой фрал мент мозга мы прини-
маем во внимание. С другой стороны, можно было бы ввести требование,
Введение в естественные и искусственные сети
33
Rods
(палочки)
Cones
(колбочки)
Bipolar cell
(биполярные клетки)
Pigmented cell -
(пигментные клетки)
Ganglion cell '...„д
(ганглионарные клетки)
if
Рис. 1.16. На схеме структуры сетчатки глаза также заметно
ее многослойное строение
Horizontal cell
(горизонтальные клетки)
Amacrine cell
(амакриновые клетки)
чтобы схема взаимосвязи нейронов в сети соответствовала свойствам ре-
шаемой задачи. По большому счету, требование справедливое, посколь-
ку существует множество доказательств того, что грамотно подобранная
структура сети может значительно ускорить процесс ее обучения. К со-
жалению, для большинства задач, решаемых с применением нейронных
сетей, мы не можем заранее предложить способ решения. А посколь-
ку алгоритм (даже приблизительный), который выберет сеть в процессе
обучения, заранее предугадать невозможно, то тем более, неизвестно,
какие элементы сети окажутся востребованными, а какие лишними.
Чаше всего решение о способе соединения элементов сети принима-
ется случайным образом, и такое случайное решение обычно соот-
34
Глава 1
Входные сигналы (данные)
Выходные сигналы (результаты)
Рис. 1.17. Типичная структура многослойной нейронной сечи
ветствует схеме чипа «каждый с каждым». Такая идея однородной и
полной схемы соединений между элементами каждого слоя обеспечива-
ет минимизацию усилий по определению сети, по за счет увеличения
ресурсов (например, объема памяти в имитационной модели или коли-
чества потенциальных соединений в структуре микрочипа), необходи-
мых для отражения в сети всех связей, необходимых для решения за-
дачи. Необходимо отметить, что при отказе от принципа однородности
структуры только для описания топологии сети потребуются сотни ты-
сяч параметров. Это незамедлительно приведет к обесцениванию любых
попыток применения структур с какой-либо неординарной архитекту-
рой связей. В то же время решение об использовании схемы соединений
тина «каждый с каждым» представляет собой элементарный и не тре-
бующий длительных размышлений волевой акт конструктора сети. Так
проще, и поэтому (почти все поступают именно так. Возможность удоб-
ного (читай: бездумного) применения подобного упрощения обусловлена
чем, что в процессе обучения сечь «сама» выберет из доступных снача-
ла всех соединений те, которые окажутся действи юл ыю необходимыми,
и отбросит (обнулит) ненужные.
1.5. Насколько первые нейронные сети были
похожи на биологический мозг?
Итак, искусственные нейронные сети, созданные в 90-х гг. XX в.,
основы вались на накопленных к тому времени анатомических, физио-
логических и биохимических знаниях о человеческом мозге. Однако со-
здатели нейронных сетей использовали эти знания как источник вдохно-
Введение в естественные и искусственные сети
35
Рис. 1.18. Знания о биологических нейронах, «проникающие» в структуры современных
компьютеров (образ автора книги, сформированный студентами Краковской горно-
металлургической академии)
вения, а не как эталон для добросовестного воспроизведения. Поэтому
структура и принципы функционирования практически применявших-
ся искусственных нейронных сетей не являются точным отражением
биологических знаний даже тех, уже устаревших почти на два де-
сятка лет. Можно утверждать, что создатели современных нейронных
сетей в определенной степени базировались на элементах биологических
знаний, которые, тем не менее, чаще отступали на задний план и служи-
ли скорее источником вдохновения, а не эталоном для подражания. В то
же время формируемая нейрокибернетиком материя насквозь пропитана
информационными технологиями, поскольку нейронные сети создаются,
обучаются, исследуются и применяются на типовых современных ком-
пьютерах. Графической метафорой этого процесса может служить смон-
тированный студентами Краковской горно-металлургической академии
образ автора этой книги, представляющий его именно как исследовате-
ля нейронных сетей (рис. 1.18).
Поэтому во всех последующих рассуждениях мы будем помнить (и
принимать во внимание) то, что любая биологическая информация вна-
чале очень сильно препарировалась и упрощалась, и только после этого
превращалась в фундамент построения искусственных нейрокибернети-
ческих систем. Этот факт принципиально влияет на свойства исследу-
емых систем, которые оказываются нейронными больше по названию,
чем по степени подобия настоящему мозгу. Вопреки ожиданиям отме-
ченная особенность позитивно влияет на свойства и характеристики
нейронных сетей, рассматриваемых как один из инструментов поддерж-
36
Глава 1
ки процесса познания нашего биологического мозга. Мы обсудим этот
феномен в одном из следующих разделов книги.
Российское издание кпи!и увидит свет более чем через десять лет
после выхода первого польского издания. При подготовке згой новой
версии я не мог игнорировать то, что за эту декаду исследования мозга
существенно продвинулись вперед, а представления о цели и условиях
применения нейронных сетей также претерпели определенную эволю-
цию. Поэтому в следующем разделе мы обсудим современные проблемы
исследования нервной системы человека и попробуем выяснить, какую
роль могут играть нейронные сети в этих исследованиях.
1.6. Какими методами сегодня исследуется
мозг, и могут ли нейронные сети помочь
в познании тайн человеческого мышления?
Исследователь человеческого мозга в начале XXI в. вооружен несрав-
ненно более мощным инструментарием, чем первооткрыватели наших
знаний о структуре и функционировании нервной системы, составивших
фундамент первых нейронных сетей в 90-х гг. XX в. В первую очередь,
необходимо отмет ить расширение возможностей графического представ-
ления внутренних структур мозга благодаря применению компьютерной
томографии и ядериого магнитного резонанса. В прежние времена череп-
ная коробка, абсолютно непроницаемая для примитивных технологий
наблюдения (в том числе с применением рентгеновской техники), на-
дежно скрывала тайны внутренней структуры мозга живого и здорового
человека. Мозг становился доступным для исследований только после
смерти пациента тогда препарат мертвого мозга мог изучаться анато-
мами. Ученые, наблюдавшие срезы мозговых тканей под микроскопами,
пытались выявить и понять структуру центров обработки информации и
схему их соединений примерно с тем же успехом, если бы кто-то рассмат-
ривал срезы микросхем компьютера, изучал расположение проводов и
отдельных деталей и на этой базе пытался понять основы информатики.
Современные технологии позволяют спокойно заглянуть в мозг живого
человека и выявить, его структуру с удивительной точностью (рис. 1.19).
Современные диагностические технологии позволяют также обнару-
жить и локализовать места, мозговая активность которых в момент об-
следования оказывается особенно высокой (рис. 1.20). При сопоставле-
нии таких центров активности с видами деятельности, которые выпол-
няет обследуемый человек, выявляются мозговые структуры, участвую-
щие в решении конкретных задач. Такой подход позволяет легче понять
функциональные аспекты отдельных нервных структур.
Введение в естественные и искусственные сети
37
Рис. 1.19. Внутренние структуры мозга живого человека можно рассматривать сегодня
с удивительной точност] >ю
Перечисленные способы представления информации о структуре и
функционировании мозга помогают не только регистрировать его состо-
яние в каждый конкретный момент времени, но и отслеживать протека-
ющие в нем процессы. В частности, благодаря гибридным технологиям
усовершенствованного отображения внутренних нервных структур и от-
слеживания активности конкретных фрагментов этой системы сегодня
можно получать исключительно точные изображения, иллюстрирующие
усиление или ослабление активности фрагментов мозговой коры в той
или иной ситуации (рис. 1.21).
Более того, описанные выше изменения можно регистрировать и про-
сматривать динамическим образом (так же, как видеофильм или ком-
пьютерную анимацию). В книге невозможно продемонстрировать упо-
мянутые образы в движении, но можно показать результаты динамиче-
ских исследований аналогично тому, как иногда показывают последова-
тельность движений спортсмена или кадров мультфильма. На рис. 1.22
последовательность образов отражает изменение активности некоторых
внутренних анатомических структур мозга в период наблюдения. После-
довательная презентация таких образов с определенной скоростью созда-
ет так же, как в фильме или телепередаче, впечатление непрерывного
движения, благодаря чему исследователь может свободно отслеживать,
какие структуры и в какой очередности активизируются при вынолне-
38
Глава 1
Рис. 1.20. Метод проекций, демонстрирующий активность различных отделов мозга
при выполнении определенных действий
кии конкретных анализируемых действий.
Из представленных выше примеров результатов, полученных с по-
мощью современных методов исследования мозга, может показаться, что
по истечении последнего десятилетия XX в. (которое многими называет-
ся «десятилетием мозга») мы знаем о человеческом мозге столько, что
нераскрытых тайн в ном уже не осталось.
Чрезвычайно сильное заблуждение! Действительно, структуру мозга
мы уже изучили довольно подробно, о его функционировании знаем так-
же много. Однако возникла проблема, которая весьма часто проявляется
при исследовании особо сложных объектов: как реконструировать обраг
целого при наличии огромного количества отдельных и невзаимосвя-
занных частных результатов? Один из очень результативных методов,
используемых современной наукой, метод декомпозиции или, проще
говоря, деления на мелкие кусочки. Нам трудно ойисать большую систе-
му? Разделим ее на его гастей и исследуем каждый из них но отдельно-
сти! Не удается понять сложный процесс? Разложим его на несколько де-
сятков простых процессов, после чего изучим и опишем каждый из них!
Этот метод очень Эффективен, поскольку выделенные в рамках деком-
позиции подсистемы или подпроцессы всегда (в случае необходимости'
можно далее разделить на еще меньшие и простейшие.. .Но ври этом су-
ществует одна специфическая трудность: кто. когда и каким образом со-
берет воедино результаты исследования всех этих частей и фрагментов?
При анализе по-настоящему сложных систем синтез результатов част-
ных исследований непрост и нелегок, особенно если эти результаты по-
лучены с применением различных исследовательских технологий, снеци^
фичных для разных областей знания. Оказывается, очень сложно найги
кого-то, способного интегрировать например, основанную па рисунках
Введение в естественные и искусственные сети
39
Рис. 1.21. Мониторинг изменений, происходящих в мозгу при выполнении определенных
действий
анатомическую информацию, представленные в описательном виде фи-
зиологические данные и результаты биохимических исследований, полу-
ченные с применением аналитического оборудования. Поэтому везде, где
только можно, следует пользоваться компьютерным моделированием,
которое способно играть роль «общего знаменателя» для любой инфор-
мации- собираемой и накапливаемой из разных источников. Опыт под-
тверждает, что компьютерную модель, описывающую анатомию, удает-
ся совместить с компьютерным описанием физиологических процессов
и с компьютерным представлением биохимических реакций. В настоящее
40
Глава 1
Рис. 1.22. Пр<'зентация динамики процессов внутри мозга
время именно такая идея воплощается в жизнь при попы тке реконстру-
ировать совокупность знаний о различных биологических системах]
порознь исследовавшихся до этого разными специалистами.
। 1римснительно к нервной системе и особенно к человеческому мозгу
необходимо использовать несколько компьютерных моделей для инте-
грации результатов многочисленных исследований и получения шансов
на комплексное понимание функционирования этой необычайно слож-
ной системы. О некоторых моделях я расскажу чуть позже, но уже в
этой вводной главе хотелось бы отметить, что проще всего попытать-
ся описать паши знания о мозге как раз с помощью рассматриваемых
в нашей книге нейронных сетей. Конечно, мозг человека чрезвычайно
сложен, а нейронные сети по сравнению с ним совсем крошечные и.
кроме того, сильно упрощены. Но в науке довольно часто применение
Введение в естественные и искусственные сети
41
упрощенных моделей приводит к открытию закономерностей, которые
подтверждаются и соблюдаются в весьма широком масштабе. Напри-
мер, если химик в маленькой пробирке проведет некоторую реакцию, то
мы с полным основанием можем ожидать проведения такой же реакции
в огромном океане или внутри удаленной звезды и эти ожидания, как
правило, оправдываются. Но ведь с пробиркой манипулировать гораздо
ггроц^е, чем с океаном — о звездах и говорить не стоит! При постижении
научной истины упрощение очень часто оказывается ключом к успеху.
1.7. Насколько нейронные сети проще
биологических объектов?
Нейронные сети очень упрощены по сравнению с нервными си-
стемами большинства живых организмов. Это утверждение иллюстри-
руется рис. 1.23, на котором отмечены свойства некоторого множества
нейрокибернегических систем — как естественных, так и искусственных.
Горизонтальная ось характеризует степень структурной сложности каж-
дой системы (выражаемую количеством синапсов — т.е. мест, в которых
как биологические мозги, так и искусственные нейронные сети накапли-
вают информацию). В свою очередь, на вертикальной оси обозначается
скорость обработки информации каждой системой. Эта скорость выра-
жается в специальных единицах CPS {Connections Per Second, т.е. коли-
чество соединений в секунду), но для нас эти числовые значения пока
не имеют особого значения. Обе оси масштабированы по логарифмиче-
ской шкале, поэтому даже небольшое перемещение вверх или вправо
будет означать очень быстрое (сто- или даже тысячекратное) увеличение
соответствующей характеристики сложности системы или скорости
ее функционирования. Именно такой способ масштабирования графика
объясняет, почему па нем обозначены человек, пчела и муха, но нет со-
баки или копя на логарифмической шкале точки, соответствующее
размеру и четкости работы мозга собаки и человека расположатся на-
столько близко, что различить их на графике станет невозможно.
На представленном графике видно, что для всех живых существ от
пиявки до человека наблюдается практически пропорциональная
зависимость между объемом мозга и скоростью его работы. Это объяс-
няется параллельной работой всех биологических нейронов — они об-
рабатывают информацию одновременно, поэтому скорость функциони-
рования принципиально зависит от технологии их построения. В связи
с этим обычные цифровые устройства оказываются медленнее специ-
ализированных решений, которые, в свою очередь, не могут угнаться
за оптоэлектронными системами. На графике видно, что используемые
42
Глава 1
Рис. 1.23. Сложное 1ь и скорость функционирования различных нейрокибернетических
систем
в технике типовые нейронные сети, чаще всего базирующиеся на пер-
сональных компьютерах и рабочих станциях, располагаются в левом
нижнем углу, т.е. характеризуются минимальной степенью сложности!
(они в миллионы раз проще человеческого мозга) и очень низкой ско-
ростью обработки информации Для большинства практических прило-
жений этого достаточно, но для моделирования таким путем мозга в
целом нам еще очень далеко.
Л уже гФворйл, что мы и не стремимся (на современном этапе раз-
вития исследований) к моделированию мозга в целом. Задачи, кото-
рые решают сегодня нейрокибернетики, более скромные, но благодаря
этому полностью реальные. Цель заключается в использовании просто-
ты и ограниченного размера нейронных сетей (благодаря чему их лег-
ко строить, наблюдать и понимать) для осознания того, как система,
в чем-то имитирующая человеческий мозг, обретает способность полу-
чать информацию от учителя либо самостоятельно добывать ее (т.е. са-
мообучаться), формировать и обобщать знания, ассоциировать разроз-
ненные факты, классифицировать ощущения и принимать решения
словом, выполнять все те функции, которые психологи считают элемен-
Введение в естественные и искусственные сети
43
тами человеческого интеллекта, но которые нейробиологи еще нс смог-
ли связать с конкретными механизмами функционирования известных
анатомических структур.
Если ты захочешь познать и понять нейронные сети, то получишь
шанс включиться в эти исследования. Это территория, на которой все
еще имеется множество «белых пятен», ожидающих своих Колумбов. На
Земле уже не осталось неоткрытых островов или неизвестных народов
даже в глубинах тропических джунглей; для обследования далеких пла-
нет необходимо чрезвычайно дорогостоящее оборудование, а богатейшая
и не до конца открытая Вселенная нашего мозга ждет своих исследова-
телей и располагается так близко — буквально па расстоянии вытяну-
той руки. Если тебя привлекает карьера первооткрывателя и если тебе
интересен твой собственный мозг — не буду продолжать агитацию. Но
даже если тебе безразличен твой собственный интеллект и его удиви-
тельное вместилище биологический мозг, тебя, быть может, вооду-
шевят способности нейронных сетей как вычислительных устройств —
причем при решении задач, с которыми типовые компьютеры и обыч-
ные программы не очень хорошо справляются. Об этих достоинствах
нейронных сетей и об аргументах в пользу их изучения и применения
я писал в предисловии, но поскольку вопрос очень важен, позволю се-
бе еще раз вернуться к нему и добавить несколько козырей, которые
нужно обязательно принимать во внимание.
1.8. Каковы главные достоинства нейронных
сетей?
Как ты уже знаешь, нейронные сети представляют собой новый и с
многих точек зрения привлекательный ИТ-инструментарий, наследую-
щий структуру мозга и по этой причине принципиально отличающийся
от привычных для пас компьютерных приложений. В большинстве слу-
чаев сети оказываются средством преодоления многих барьеров и огра-
ничений, которые трудно обойти другими методами, причем средством
удобным и эффективным. По этой причине нейронными сетями интере-
суются и теоретики, и практики. Практические достоинства нейронных
сегей сводятся к двум основным положениям:
• они представляют собой удобное и недорогое многопроцессорное ре-
шение с большим числом элементов, параллельно обрабатывающих
поступающую информацию;
• они не требуют программирования и используют только процесс обу-
чения.
В дальнейшем мы подробно обсудим каждый тезис, а сейчас отметим
только основное значение каждого из них.
44
Глава 1
Первое достоинство удается использовать тогда, когда нейронные се-
ти создаются как специализированные устройства, например для очень
быстрого распознавания образов, понимания речи или управления мо-
бильным роботом. Основная идея заключается в том, что все нейроны,
объединенные в сеть, функционируют параллельно и решают задачу
как единый, хорошо слаженный коллектив. Благодаря такому «парал-
лельному» способу работы всего множества задействованных нейронов
отпадает необходимость ожидать результат решения задачи так же дол-
го, как в случае использования обычного компьютера, в котором все
действия должен выполни гь шаг за шагом, т.е. последовательно, един-
ственный процессор. Если тысячи составляющих сеть искусственных
нейронов будут выполнять назначенные им вычислительные задачи па-
раллельно, то скорость работы нейронной сети сможет в миллионы
раз превысить быстродействие современных компьютеров.
В будущем это достоинство может стать очень важным аргумен-
том в пользу нейронных сетей как исключительно быстродействующего
ИТ-инструментария, поскольку с весьма высокой вероятностью полу-
чат широкое распространение именно «массовые параллельные вычис-
ления» {massive parallel processing — запомни это понятие, часто исполь-
зуемое в специальной литературе). Однако в настоящее время существу-
ет очень мало вычислительных систем, использующих в качестве ком-
понентов искусственные нейроны. Поэтому я только упоминаю достоин-
ства параллельных вычислений и не развиваю далее эту тему. Очень
жаль, что я не могу предоставить тебе доступ к таким специализиро-
ванным вычислительным системам, например к тем, па которых мы
ведем различные исследования в Краковской горпо-металлур! и ческой
академии. В частности, мы изучаем возможность использования ней
рои пых сетей, реализованных в виде чрезвычайно быстродействующих
многопроцессорных вычислительных комплексов, для распознавания об-
разов в зрительных системах промышленных роботов. Эго воистину ум-
ные и забавные машины!
Ты можешь найти в Интерне тс предназначенные для читателей этой
книги интересные программы, имитирующие работу нейронных сетей на
любом доступном тебе компьютере, чуть позже я остановлюсь на этом
подробнее. Но чтобы не дразнить тебя описанием реальных специали-
зированных нейрокомпьютеров, имеющих ог ром ное быстродействие бла-
годаря параллельному функционированию электронных нейронов, я не
буду более упоминать о них и сконцентрируюсь на втором достоинстве,
т.е. на возможностях обучения нейронных сетей.
Это важный козырь, имеющий далеко идущие последствия. Посколь-
ку сеть может самостоятельно получать знания в процессе обучения.
Введение в естественные и искусственные сети
45
пользователь таких систем освобождается от трудоемкого и утомитель-
ного программирования. Даже если кто-то очень любит программиро-
вать компьютеры (а большинство пользователей современных информа-
ционных технологий это не любят, что доказывается популярностью го-
товых программ, написанных другими людьми), он все равно вшн-ужден
признать, что задачи решаются быстрее и удобнее, если можно обой-
тись без программирования. Для решения задачи с применением сети не
требуется писать программу, поскольку сеть сама обучится правильно-
му методу решения. Достаточно продемонстрировать сети примеры за-
дач с соответствуют,ими правильными решениями — метод и правила
решения нейронная сеть составит самостоятельно. Это дает огромный
выигрыш во времени и приносит значительную выгоду.
Но указанное достоинство нельзя считать единственным. Посколь-
ку сеть в состоянии самостоятельно научиться решать различные слож-
ные задачи, для которых я могу написать программы (но не буду это
делать, так как сеть справится самостоятельно с выбором метода ре-
шения), тот же метод обучения можно применить для задач, методы
решения которых мне неизвестны, но для которых у меня имеются
примеры решений, пригодные для обучения сети. Другими словами, бла-
годаря обучению нейронная сеть может расширять круг решаемых задач
даже в тех случаях, когда я могу помочь ей только демонстрацией полу-
ченных ранее решений. Ты понимаешь, конечно, насколько это расши-
ряет прикладные возможности информатики! Благодаря обучению ней-
ронных сетей мы получаем инструменты решения широчайшего спектра
задач, для которых можно сформулировать цели и продемонстрировать
частные решения, но нельзя предложить методы достижения этих целей.
В предисловии (повторно рекомендую тебе прочитать его, если не сделал
этого раньше) я говорил, что это относится, в первую очередь, к уме-
нию человека интуитивно решать задачи без ясного понимания способов
достижения успеха. В качестве примера таких умений приводилось рас-
познавание людей по их лицам. Человек решает задачу распознавания
очень легко, и почти не задумываясь. Но когда мы вводим фотографию
лица в компьютер, то становится совершенно непонятно, как (независи-
мо от угла наклона камеры, поворота головы, освещения и т.п.) иденти-
фицировать изображенного человека по информации о более или менее
темных (либо светлых) пикселях, из которых состоит образ.
Более того, обучение нейронных сетей может применяться при реше-
нии задач, для которых само существование метода решения может под-
вергаться сомнению. В качестве примера можно привести проблему про-
гнозирования различных будущих событий по событиям, имевшим место
в прошлом. Такие прогнозы важны и необходимы. Предсказание будуще-
46
Глава 1
го очень полезно и даже выгодно. Нам требуются экономические прогно-
зы например, для выяснения, какие акции будут дорожать, а какие
дешеветь). Крайне необходимы более эффективные методы прогнозиро-
вания погоды. Большое значение имеют демографические прогнозы. Мы
хотим предсказывать наводнения, землетрясения и прочие природные
катаклизмы. Таких примеров можно привести бесчисленное множество.
Думаю, ты легко согласишься, что при прогнозировании мы всегда
исходим из предположения о наличии в прошлых событиях определен-
ных предпосылок для предсказания будущего. Однако ни ты, ни я, ни
кто-либо другой нс знает точные правила прогнозирования будущего но
известному прошлому. Ну, может быть, за исключением простейших слу-
чаев полностью детерминированных процессов (таких, как равномернее
движение планет, при котором легко можно спрогнозировать положение
планеты хоть через тысячу лет) и простейших случаев, в которых из-
вестны причинно-следственные зависимости, например, если поставить
кастрюлю с водой па огонь, то через некоторое время вода закипит. В за-
дачах, для которых предположение о детерминизме по вполне обосно-
ванно (например, в экономических процессах), а также в случаях от-
сутствия или незнания правил, связывающих причины со следствиями,
прогнозирование оказывается весьма затруднительным. В то же время
из литературы известны многочисленные примеры успешного примене-
ния нейронных сетей для предсказания недетерминированных либо ли-
шенных явной причинно-следственной зависимости явлений и процессов.
При этом точност ь прогнозов, предложенных «сетевой гадалкой», часто
удивляла самих создателей использовавшихся нейронных сетей. Таким
способом удается получать достоверные прогнозы биржевой стоимости
различных акций, курсов валют, спроса на энергетические ресурсы, а
также метеорологические, гидрологические и многие другие прогнозы.
Во всех этих случаях ключом к успеху оказывалось большое количе-
ство ретроспективных дачных, которые' могли использоваться для де-
монстрации нейронной сети соответствующих примеров и обучения эф-
фективному прогнозированию. Принцип функционирования достаточно
прост: при наличии данных из прошлого их можно рассматривать как
примеры связей между пред шествующей последовательностью некото-
рых явление и последовавшим за ними (также известным, поскольку он
имел место в истории) интересующим нас итоговым фактом. Например,
при наличии информации о событиях прошлых лег можно легко ском-
поновать набор данных, содержащим наблюдения за последние две неде-
ли, предшествовавшие некоторому событию. Если таких данных собра-
но достаточно много, то можно обучить сеть предсказывать будущее но
известным фактам из прошлого независимо от харак тера связей меж-
ду фактическими показателями и прогнозируемым значением. Именно
Введение в естественные и искусственные сети
47
таких прогностических сетей построено очень много и большинство из
пих прекрасно работают!
1.9. Кто и для чего применяет нейронные сети
сегодня?
В уже цитировавшейся моей давней книге (Р. Тадеуссвич, Нейронные
сегпи. 3-е изд. Варшава: изд-во AOW, 1995) я перечислил более полу-
тора десятков реальных приложений нейронных сетей. Здесь я приведу
более свежие примеры и назову новейшие достижения, которые практи-
чески реализованы в последние годы:
Американское агентство по исследованию космического простран-
ства NASA использует нейронные сети для управления руксй робота, за-
дача которого заключается в захвате произвольно расположенных пред-
метов (в частности, речь идет о манипуляторе, применяемом при сты-
ковке космических кораблей. В условиях невесомости очень трудно удер-
живать элементы стыковочного узла в фиксированном положении, а на-
дежность захвата зависит от степени совпадения пространственной ори-
ентации оси предмета и элементов механической руки).
Нейронная сеть, созданная специалистами из New York University
Medical Center, также предназначена для управления рукой робота. Эта
сеть применяется как альтернатива сложных тензорных вычислений па-
раметров движения механической руки для значительного ускорения
функционирования системы управления, которая обретает способность
функционировать в реальном масш габе времени. Любые другие алгорит-
мы при реализации на тех же компьютерах не в состоянии обеспечить
необходимую скорост ь расчета всех необходимых координат, ускорений,
прилагаемых усилий и моментов вращения.
Фирма General Dynamics разработала для нужд военно-морского фло-
та США основанную не нейронных сетях систему классификации и рас-
познавания сигналов сонара. Эта система позволяет распознавать шу-
мы, характерные для двигателей различных типов гражданских и во-
енных судов. Удалось настолько точно обучить сеть, что опа оказалась
способной различать шумы равных судов одного и того же проекта и
позволяла идентифицировать названия кораблей. Эта же сеть с помо-
щью гидрофонов распознает некоторые надводные звуки, например шум
пролетающего вертолета.
Аналогичные достижения в области идентификации самолетов полу-
чили ученые из университета штата Пенсильвания (США) в сотрудниче-
стве с фирмой TRW. Построенная ими нейронная сеть может распозна-
вать самолеты с такой точностью, что для безошибочной идентификации
достаточно наблюдать деталь размером 18 дюймов с расстояния 50 миль.
48
Глава 1
В госпитале Anderson Memorial Hospital (штат Южная Каролина,
США) нейронная сеть используется для оптимизации процесса лечения;
как следует из публикации, сэкономлены миллионы долларов и спасены
жизни нескольких десятков человек. К сожалению, никакие подробно-
сти этого интересного мероприятия неизвестны.
Крупный производитель ракет фирма General Devices Space Systems
Division использует нейронные сети для управления работой 150 кла-
панов, подающих топливо и окислитель в двигатели ракеты «Атлас».
Оказалось, что хорошо обученная сеть, использующая данные о факти-
ческой флуктуации мощности двигателей, способна эффективнее управ-
лять клапанами, чем применявшаяся рапсе дорогая и сложная система
автоматики, основанная на алгоритмической обработке данных от сотен
датчиков.
Широко известное приложение нейронной сети используемая фир-
мой Eaton Corporation система управления, помогающая водителю боль-
шого грузового автомобиля (5 осей, 18 колес) выполнять некоторые особо
сложные маневры (например, движение задним ходом с прицепом).
Нейронные сети часто применяются в энергетике — особенно для
прогнозирования потребности в электрических мощностях. Одно из наи-
более известных внедрений в этой области связано с особенно сложной в
управлении электростанцией ВС Hydro (Ванкувер, Канада). Ее четыре
турбины имеют очень разные характеристики, поэтому решение зада-
чи их запуска и отключения в соответствии с изменениями потребления
электроэнергии оказывается исключительно сложным и неблагодарным
занятием.
Аналогичные сообщения появляются в периодических изданиях с за-
видной регулярностью. Позволю себе упомянуть без комментариев еще
несколько примеров:
Американские военно-воздушные силы применяют нейронные сети
для развития имитаторов полета;
Концерн Ford Motor Company задействовал нейронные сети в новой
системе диагностирования своих двигателей;
Фирма Halliburton использует нейронные сети для идентификации
образцов скальных пород, поднимаемых в ходе разведочного бурения
при поисках нефти и газа;
Авиакомпания TWA применяет нейронную сеть для поиска боепри-
пасов на своем терминале в аэропорту JFK (Нью Йорк, США).
Тебе недостаточно этих примеров? Загляни в любой номер какого-
нибудь специализированного журнала, посвященного использованию вы-
числительной техники. Ручаюсь, что в нем найдется, как минимум, од-
на статья о нейронных сетях! Можешь ввести запрос «Neural Networks»
Введение в естественные и искусственные сети
49
в Google или в другую поисковую Интернет-систему. В ответ получишь
ссылки на миллионы Интернет-страниц с описанием возможностей и
способов применения нейронных сетей, а также полученных результатов.
Поскольку в настоящее время нейронные сети применяются почти
всеми и почти для всего, становится актуальным следующий вопрос:
1.10. Смогут ли нейронные сети вытеснить
современные компьютеры?
Приведенный перечень удачных приложений нейронных сетей мож-
но продолжать бесконечно. Свидетельствует ли это о необходимости вы-
бросить такие привычные для нас «классические» компьютеры и решать
все вычислительные задачи исключительно с помощью сетей?
Конечно, нет. Сети представляют собой модный и удобный инстру-
ментарий, имеющий ряд очень серьезных ограничений. Сущность этих
ограничений станет понятной в ходе дальнейших рассуждений, когда
в следующих главах ты будешь знакомиться с конкретными сетевыми
структурами, методами их обучения и особенно способами их примене-
ния для решения конкретных задач. Но уже сейчас я назову несколько
характерных особенностей задач, которые практически невозможно
решить с помощью нейронных сетей.
Первый класс задач, при решении которых следует полностью от-
казаться от сетей, связан с символьными преобразованиями. С помо-
щью нейронных сетей чрезвычайно сложно осуществлять любую обра-
ботку символьной информации, поэтому необходимость работать с ин-
формацией в символьной форме должна рассматриваться как сигнал к
отказу от применения сетевых технологий. В этой связи можно приве-
сти предельно утрированный пример: нет никакого смысла применять
концепцию нейронных сетей для построения текстового редактора ли-
бо процессора формул.
Вторая «классическая» группа задач, при решении которых о се-
тях можно не вспоминать, это вычислительные задачи с высокой точ-
ностью результатов. Нейронная сеть работает «качественным» спосо-
бом, т.е. найденное сетью решение всегда имеет приближенный характер.
Для многих приложений такая небольшая точность оказывается вполне
удовлетворительной: при обработке сигналов, распознавании образов и
речи, прогнозировании биржевых котировок, управлении роботами, ап-
проксимации значений сложной функции и т.п. Однако характерные для
нейронной сети приближенные вычисления абсолютно недопустимы, на-
пример при обслуживании банковских счетов либо при проведении точ-
ных инженерных расчетов.
50
Глава 1
И, наконец, третья область, в которой не приходится ожидать хоро-
ших результатов применения нейронных сетей, связана с задачами мно-
гошаговою принятия решений — например, при выяснении истинности
или ложности определенных последовательностей ло! ических суждений.
Практически всегда сеть старается решить стоящую перед ней задачу за
один шаг. Если это еп удается (что считается большой удачей), то ре-
зультат становится доступным практически немедленно. Если же необ-
ходимо выполнить последовательность рассуждении и особенно если
необходимо обосновать каждое промежуточное решение с точки зрения
его влияния па итоговый результат (например, в экспертных системах),
то сеть оказывается совершенно беспомощной. Все попытки ее исполь-
зования в подобных ситуациях фатально обречены на неудачу.
1.11. Может быть, и не надо заниматься
нейронными сетями?
Из сказанного выше не следует делать поспешные выводы. Сеть нс
может самостоятельно обрабатывать символьную информацию, но спо-
собна поддерживать работу других систем в плане решения свойствен-
ных ей задач. Гримером могут служить сети Тойво Кохопспа {Tcuvo
Kohonen) либо классическая сеть NetTalk Теренса Сеиновского {Terence
Sejnowski), используемые в системах управления синтезатором речи дня
замены текста в символьном представлении последовательностью фо-
нем. Аналогично, из утверждения о непригодности сетей для управле-
ния кассовым терминалом на банковской стойке не следует их полная
бесполезность для банков, напротив, они оказались очень удобными для
проверки добросовестности заемщиков и для выбора условий обсуждае-
мого контракта. Подобные наблюдения очень многочисленны. Сформу-
лируем важный конкретный вывод:
Нейронная сеть пригодна для множества приложений, но
она не настолько универсальна, как классический компьютер.
Поэтому энтузиаст легко найдет задачи, при решении которых сеть ока-
жется полезнее классического компьютера, а скептик задачи, при ре-
шении которых сеть окажется поразительно беспомощной. Как всегда,
правда лежит посередине. В следующих главах мы постараемся вме-
сте найти эту золотую середину при подробном обсуждении нейросете-
вых технологий и методов обучения сетей, а также в ходе экспсримен-
зов с простыми программами, с помощью которых можно «пощупать
сеть своими руками».
В этой главе я познакомил тебя с происхождением нейронных сетей
и рассказал об их некоторых достоинствах. И первое, и второе может
Введение в естественные и искусственные сети
51
оказаться поводом для принятия тобой решения поближе познакомить-
ся с этим инструментарием. Я знаю людей, для которых красота точно-
го биржевого прогноза превалирует над любыми другими достоинства-
ми сети. Но позволь мне остаться при своих, давно сформировавшихся
предпочтениях. Поэтому при обсуждении нейронных сетей как средства
достижения различных, более или менее реальных практических целей
я буду демонстрировать тебе их привлекательность как следствие по-
добия живому мозгу структуры и принципов функционирования этих
сетей. Я приведу примеры успехов, достигнутых при решении своих за-
дач инженерами, геологами и врачами, и объясню, за счет чего сети
обеспечили получение выдающихся результатов. Я также обращу твое
внимание па последствия проводимых исследований поведения сетей в
процессах обучения и самостоятельного накопления знаний. Благодаря
доступу к нашим программам (Интернет-адрес представлен в предисло-
вии к книге) ты станешь не только свидетелем, но и деятельным участ-
ником удивительных опытов, которые позволят лучше понять сущность
нейронных сетей, а через них — и сущность твоего собственного моз-
га, таинственный и богатый различными способностями, о котором еще
Шекспир писал как о «хрупком пристанище души»...
Итак: теперь ты понимаешь, зачем надо заниматься нейрон-
ными сетями? Если да, и если желание не пропало, то книга поможет
реализовать это намерение. Приглашаю к знакомству со следующими
главами! Текст книги актуален и полон. Я постарался представить в
ней всю самую важную и новую информацию о нейронных сетях. Столь
же целенаправленно я освобождал книгу от многочисленных мелких,
по трудных для понимания подробностей, которыми изобилует любая
область вычислительных технологий и которые удается выразить толь-
ко с помощью математических формул. Я серьезно отнесся к принципу,
напечатанному па обложке прекрасной книги С.В. Хоукигпа «Краткая
история времени»: каждое приведенное в тексте уравнение уменьша-
ет количество читателей наполовину. Мне хочется, чтобы мою книгу
прочитали как можно больше людей, и среди них наверняка окажутся
те, кто признает нейронные сети удобным и полезным инструментари-
ем. По этой причине в основном тексте книги нет пи единой форму-
лы — если она отпугнет хоть одного читателя, я сочту это невосполни-
мой потерей. В то же время, каждая глава сопровождается отдельным
кадром, в котором собрана наиболее важная теоретическая информа-
ция. Этой информацией ты сможешь воспользоваться, если пожелаешь
узнать нейронные сети с менее яркой, но более серьезной и сильно ма-
тематизированной стороны.
52
Г л а в а 1
1.12. Контрольные вопросы и задания
для самостоятельного выполнения
1. Перечисли несколько проблемных областей современно! информа-
тики, которые считаются модными и в которых не применяются ней-
ронные сети.
2. Какие функции и свойства мозга были выявлены самыми первыми,
как добывалась и накапливалась эта информация?
3. Кто первый выяснил, что мозг состоит из огромного количества
объединенных между собой, но анатомически и физиологически само-
стоятельных нейронов?
4. Какое лабораторное животное использовалось для получения ос-
новной информации об электрохимических функциях мозга, благодаря
которой Ходжкин и Хаксли создали точную модель этих функций и по-
лучили за эту работу Нобелевскую премию?
5. Назови основные элементы природного (биологического) нейрона.
6. Почему синапсы играют такую важную роль в функционировании
нейронных систем (как биологических, так и искусственных)?
7. Что называется нейромедиаторами? Можешь ли ты привести на-
звания и характеристики каких-либо из этих полезных соединений?
8. По каким причинам искусственные нейронные сети имеют, чаще
всего, многослойную структуру?
9. Как объединяются между собой нейроны каждого слоя сети, и
почему используется именно такой способ соединения?
10. Приведи несколько примеров областей применения нейронных
сетей.
11. В чем заключаются преимущества нейронных сетей перед типо-
выми компьютерами; что считается их слабыми сторонами и недостатка-
ми?
СТРУКТУРА нейронной сети
2.1. Как устроена нейронная сеть?
Кто из нас не начинал познание мира с раскручивания будильника
или разборки магнитофона, чтобы увидеть их внутренности? Поэтому
прежде чем рассказать тебе о том, как функционирует и использует-
ся сеть, я постараюсь как можно проще и доступнее описать ее кон-
струкцию. Из предыдущей главы ты уже знаешь, что нейронная сеть
Параллельные Клегки Пэльджи
Клетки Пуркинье волокна
Молекулярный
слой
Звездообразная клегка
Восходящая
ветвь аксона
гранулярной
клетки
Гранулярный
слой
Сердцевинный
спой
4 ’
V
Параллельный
отвод
Корзинчатые
клетки -
Г ранупярные
клетки
Мшистые
волокна
Аксоны Пуркинье
Рис. 2.1. Схематичное представление коры мозжечка демонстрирует, что биологическая
нервная система состоит из множества соединенных между собой нейронов. Тот же
принцип реализуется и в искусственных нейронных сетях
54
Глава 2
Рис. 2.2. Искусственная сеть со структурой, соответствующей трехмерной карте мозга,
оказалась бы непригодно;! для практического использования
представляет собой систему, выполняющую некоторые вычисления по
принципу параллельной работы множества объединенных между собой
элементов нейронов. Такая структура была изначально обнаруже на в
биологической нервной системе (например, в мозжечке человека, фраг-
мент которого схематически изображен па рис. 2.1).
Искусственные нейронные сети также состоят из множества нейро-
нов, только искусственных следовательно, сильно упрощенных по
сравнению с оригиналом, а также гораздо проще (если не сказать
примитивнее) соединенных между собой. Если попытаться сконструи-
ровать искусственную нейронную сеть по образу и подобию реальной
нервной системы, то созданная система окажется практически непро-
зрачной и, вдобавок, ее будет очень трудно контролировать. На рис. 2.2
в приближенной форме показано, как выглядела бы искусственная нед-
ронная сеть, построенная по структурным схемам реальных нервных
систем. Легко заметить, что такая структура непригодна для исполь-
зования в каких-либо экспериментах. Напротив, в ней легко потеряться,
как в дремучем лесу!
Поэтому искусственные нейронные сети конструируются так, чтобы
их структура была удобна для наблюдения и дешева с позиций прак-
тической реализации?. Как следствие, искусственпые сети строятся, во-
первых, плоскими (а не трехмерными!) и имеют принудительно регу-
лярную структуру. В такой структуре выделяются слои нейронов с четко
определенным назначением, которые соединяются друг с другом по про-
стому (ходя и избыточному) приппипу «каждый с каждым» (рис. 2.3).
Структура нейронной сети
55
РАДИАЛЬНЫЙ СЛОЙ
Каждый нейрон представляет
обнаруженную совокупность данных
Рис. 2.3. Структура практически используемой нейронной сети типа GRNN (сильно
упрощена по отношению к биологическому оригиналу)
Свойства и возможности нейронных сетей предопределяются тремя
факторами: из каких элементов состоит сеть (т.е. как выглядят и как
функционируют искусственные нейроны); как эти элементы соединяют-
ся между собой; каким способом задаются параметры сети в процессе
обучения. Обсудим каждый из этих факторов.
2.2. Как можно изготовить искусственный
нейрон?
Искусственные нейроны основные «кирпичики», из которых стро-
ятся нейронные сети. Познакомимся с ними немного поближе. В преды-
дущей главе ты уже разглядывал несколько рисунков, демонстрирую-
щих структуру типичного биологического нейрона, но еще одна иллю-
страция не повредит, поэтому посмотри на рис. 2.4, как выглядит (ко-
нечно, упрощенно) еще один нейрон.
Не думай, что все настоящие нейроны выглядят именно так. На
рис. 2.5 изображен еще один настоящий биологический нейрон, препа-
рированный из коры головного мозга крысы.
56
Глава 2
Рис. 2.4. Пример структуры биологической
нервной клетки (нейрона)
Рис. 2.5. Вид микроскопного препарата
настоящего нейрона
Из этого рисунка нельзя попять, какое
из многочисленных видимых
на пом волокон является всегда единственным аксоном, отводящим сиг-
налы от него ко всем другим нейронам, а какие волокна играют роль
дендритов. Однако перед тобой тоже настоящим биологический нейрон,
т.е. и такую клетку должен хорошо имитировать наш искусственный
нейрон, о котором мы сейчас будем говорить.
Рис. 2.6. Общая схе-
ма искусственного
нейрона показывает сте-
пень его упрощенности
Конечно, применяемые в сетевых технологи-
ях искусственные нейроны очень сильно упро-
щенные модели природных нервных клеток.
Строение искусственного нейрона лучше всего
иллюстрирует схема на рис. 2.6. При сравнении
этой схемы с рис. 2.4 или 2.5 становится понят-
ным, насколько создатели нейронных сетей упро-
щают биологическую действительность.
Но, несмотря на эти упрощения, искусствен-
ные нейроны сохраняют’ все свойства, важные с
точки зрения решаемых задач. Не будем забывать, что мы рассматри-
ваем. их как ИТ-инструментарий, а н< как модели биологических объек-
тов. Во-первых, каждый искусственный нейрон имеет нескольких
входов и один выход. Входные сигналы т,- (г = 1,2, ...,п) и выход-
ной сигнал у могут принимать только числовые значения, чаще всего
в интервале от 0 до I (иногда от -1 до fl). В го же время соответ-
ствие конкретного значения некоторой информации (например, то, что
выходной сигнал у — 1 свидетельствует об «узнавании» нейронной се-
тью фотографии определенного человека) является следствием снеди-
Структура нейронной сети
57
Рис. 2.7. Основные сигналы нейрона
Рис. 2.8. Добавление в структуру нейро-
на весовых коэффициентов превращает его
в обучающуюся систему
ильного соглашения. Чаще всего конкретные значения приписываются
входным и выходным сигналам сети так, что большее значение имеет
то, па каком входе или выходе возник сигнал (т.е. сам факт появления
сигнала обращает внимание на номер конкретного входа или выхода),
а масштабирование сигналов применяется дополнительно и только в
случае необходимости; при этом значения циркулирующих в сети сигна-
лов пе должны выходить за установленные пределы, например от 0 до 1.
Во-вторых, входные сигналы каждого нейрона подвергаются обра-
ботке, в результате которой вырабатывается выходной сигнал (один для
каждого нейрона), который и передается па входы других нейронов или
на выход сети в качестве решения рассматриваемой задачи. Таким об-
разом, работа сети сводится к параллельному функционированию всех
ее нейронов, каждый из которых преобразует свои входные сигналы х^
в выходной сигнал у^ в зависимости от своей структуры и результатов
обучения. Упомянутые свойства нейрона иллюстрируются рис. 2.7.
В-третьих, нейроны могут обучаться. Для этого предназначены ко-
эффициенты Wi, называемые синаптическими весами. В первой главе
ты читал, что эти веса отражают сложные биохимические и биоэлектри-
ческие процессы, реально протекающие в синапсах биологических ней-
ронов. В настоящий момент для нас наиболее интересна возможность
модификации синаптических весов (точнее, изменения их значений), со-
ставляющая основу обучения сети. Структура способного к обучению
нейрона изображена на рис. 2.8.
Подведем промежуточный итог. Мы можем утверждать, что искус-
ственные нейроны представляют собой элементарные процессоры со
следующими свойствами:
• каждый нейрон получает' несколько входных сигналов х^ и фор-
мирует на их основе свой «отклик» т.е. вырабатывает один выходной
сигнал; с каждым входом нейрона связан параметр, называемый весом
(в англоязычной литературе weight) w>. Это название говорит, что пара-
метр выражает степень важности информации, поступающей в нейрон
по соответствующему (т.е. г-му) входу;
• сигнал, поступающий по конкретному входу, вначале модифи-
цируется с применением веса этого входа. Чаще всего модификация
58
Глава 2
1
п
Агрегирование
входных данных
Рис. 2.9. Агрегирование входных данных
как первая внутренняя функция нейрона
x2J^
e = g(w,x)
/= 1...п
ХоеО —
Рис. 2.10. Применение дополнительного
парамечра порога (bias)
заключается в простом умножении значения сигнала на вес входа,
и в дальнейших расчетах сигнал участвует уже в модифицированном
виде: усиленном (если вес больше единицы i или ослабленном (ес-
ли вес меньше единицы). Сигнал может принимать инвертированный
вид, если его вес имеет отрицательное значение. Пользователи нейрон-
ных сете? называют входы с отрицательными весами тормозящими
входами, тогда как входы с положительными весами называются воз-
буждающими входами;
• входные сигналы (модифицированные соответствующими весами)
агрегируются нейроном рис. 2.9). По большому счету, в сетях могут
применяться различные способы ai ротирован ия входных сигналов, но
чаще всего соответствующие сигналы просто суммируются для полу-
чения некоторого вспомогательного внутреннего сигнала, называемого
совокупным возбуждением нейрона или постсинаптическим воз-
буждением. Б англоязычной ли тературе этот сигнал обозначается тер
мипом net value;
• иногда (по во всех типах сетей, но довольно часто) к полученной
таким способом сумме сигналов нейрон добавляет некоторую дополни-
тельную компоненту, независимую от входных сигналов и называемую
порогом (bras). При использовании порога он тоже подвергается обуче-
нию. Поэтому иногда можно рассматривать порог как синаптический вес
дополнительного входа, на который подается постоянно равный 1 внут-
ренний сигнал. Благодаря порогу свойства нейрона могут формировать-
ся в процессе обучения гораздо более свободно (без его использования
график функции агрегирования всегда должен проходив через начало
координат, что иногда оказывается неприятным бременем). Структура
нейрона с учетом порота изображена на рис. 2.10;
• сумма входных сигналов, умноженных на соответствующие? веса, с
возможно) добавленным пороюм может непосредственно передаваться
на выход? нейрона и рассматриваться как его выходной сигнал. Для
многих типов сети этого вполне достаточно. Например, таким способом
функционируют так называемые линейные сети (в частности, сети тина
ADALINE ADAptive LINEar}. В то же время в сетях с более разнооб-
разными возможностями в частности, в очень популярных сетях MLP
Структура нейронной сети
59
Multi Layer Perceptron) выходной сигнал
псйрона рассчитывается с помощью не-
которой нелинейной функции, которую
мы на протяжении всей книги будем обо-
значать <р(). Структура нейрона, кото-
рый агрегирует входные сигналы и гене-
рирует выходпог сигнал, изображена на
рис. 2.11;
e = g(w„x,) у = ф(е)
/=1,...,л i
Агрегирование Расчет значения
входных данных функции активации
Рис. 2.11. Полный набор
внутренних функций нейрона
, w2
2---
W
П--
• функция </?() называется функгщей активации нейрона (transfer
function). Известны различные функции активации, их примеры показа-
ны па рис. 2.12. Некоторые функции активации специально подбира-
ются так, чтобы поведение искусственного нейрона было максимально
похоже на поведение настоящего биологического нейрона (так называ-
емая функция с сигмоидой на выходе). Но эти функции могут подби-
раться и по-другому, т.е. для обеспечения максимальной корректности
вычислений, проводимых нейронной сетью (например, функция Гаусса).
Во всех случаях функция <^() представляет собой важный элемент, иг-
рающий роль посредника между совокупным возбуждением нейрона и
его выходным сигналом;
• знание выходных сигналов, весовых коэффициентов, способа аг-
регирования входов и функции активации нейрона позволяет в любой
момент однозначно определить его выходной сигнал. При этом предпола-
гается, что (в отличие от функционирования настоящих нейронов) этот
Рис. 2.12. Некоторые часто применяемые функции активации
60
Глава 2
Рис. 2.13. Структура нейрона как
элементарного процессора основы
структуры нейронной сети
процесс протекает мгновенно. Соответственно в искусственных нейрон-
ных сетях изменение входных сигналов практически сразу отражается
па выходном сигнале. Конечно, это чисто теоретическое предположе-
ние, поскольку даже в случае элекгроппой реализации искусствснно-
му нейрону необходимо некоторое время для того, чтобы соответству-
ющая схема рассчитала значение выходного сигнала по обновленным
значениям входных сигналов. Гораздо больше времени необходимо для
реализации того же эффекта в имитационной модели нейронной сети.
Компьютер, па котором моделируется сеть, должен каждый раз пере-
считывать все значения всех сигналов на выходах всех нейронов сети,
что даже при очень высоком быстродействии суперкомпьютеров может
затянуться надолго. Поэтому мое заявление о мгновенном функциони-
ровании сети нужно рассматривать как указание на то, что мы нс будем
обращать внимание на время реакции нейрона сейчас оно для нас
просто не имеет значения.
Полная структура одиночного нейрона изображена на рис. 2.13.
Представленный на этом рисунке нейрон представляет собой наи-
более типичный «кирпичик», используемый при построении нейронных
сетей. Точнее, это т ипичный нейрон уже упоминавшейся сети MLP (Multi
Layer Perceptron)^ важнейшие элементы которой изображены на рис. 2.14.
Можно заметить, что MLP-нейрон характеризуется функцией агрегиро-
вания в виде простого суммирования умноженных на «веса» входных
сигналов, а также использованием нелинейной функции активации с ха-
рактерной «сигмоидов» (т.е. графиком, форма которого похожа на ла-
тинскую букву «S») на выходе.
В некоторых случаях в сетях применяются так называемые ради-
альные нейроны. Они характеризуются нетипичным способом агреги-
рования входных данных, используют нетипичную (гауссовскую) функ-
цию активации и обучают* я тоже нестандартно. Мы не будем пока знако-
w2
У
Рис. 2.14. Наиболее часто
применяемый элемент ней-
ронных сетей — нейрон
типа MLP
Структура нейронной сети
61
Агрегирование входных сигналов в нейроне
этого типа заключается в расчете расстояния
между текущим входным вектором X
и сформированным в процессе обучения
центроидом некоторого подмножества Т
Также нелинейная функция перехода
в этих нейронах имеет отличающуюся
форму - «колоколообразной» гауссоиды
т.е. это не монотонная функция
Рис. 2.15. Структура и особые свойства радиального нейрона, обозначаемого RBF
миться с этими специфичными нейронами, которые используются, глав-
ным образом, для построения особых, так называемых RBF-сетей (Radial
Basis Function), но на рис. 2.15 ты можешь увидеть структуру ради-
ального нейрона и сравнить ее со структурой типового нейрона, изоб-
раженного на рис. 2.14.
2.3. Почему не используется точная модель
биологического нейрона?
Все искусственные нейроны (как сигмоидальные, так и радиальные),
описываемые в этой главе и используемые в последующих частях пашей
книги, являются упрощенными моделями биологических нейронов. Я
уже несколько раз повторял эту фразу, но теперь постараюсь показать,
насколько сильно упрощены искусственные нейроны по сравне-
нию с биологическими. Для этого я воспользуюсь примером, заимство-
ванным из исследовании де Шуттера (de Schutter). Этот ученый в тече-
ние многих лет старался максимально точно и максимально достоверно
(в мельчайших подробностях!) отразить в компьютерной модели все, что
мы знаем о структуре и функционировании только одного нейрона
так называемой клетки Пуркинье. Модель де Шуттера базировалась на
электрических элементах, которые (в соответствии с исследованиями
Ходжкина и Хаксли, получивших Нобелевскую премию в 1963 г.) мо-
делировали биоэлектрическую активность конкретных волокон (денд-
ритов и аксона), а также клеточной мембраны тела нейрона. В работе
де Шуттера с необычайной точностью была воспроизведена структура
реальной клетки Пуркинье, а также были учтены результаты исследо-
ваний Нейера и Сакмана (Нобелевская премия за 1991 г.), посвященных
62
Глава 2
Рис. 2.16. Использовавшаяся в исследованиях де Шуттера модель нейрона,
максимально подобная биолоя индскому орш и валу
функционированию так называемых ионных каналов. Структура моде-
лируемой клетки, а также схемы электрических элементов, использо-
ванных в модели де Шуттера, изображены на рис. 2.16.
Построенная де Шуттером модель оказалась чрезвычайно сложной
и дорогостоящей с вычислительной точки зрения. Достаточно сказать,
что для построения этой модели было использовано:
• 1600 так называемых компартменчпов I фрагментов клетки, рассмат-
риваемых как однородные структуры и содержащие конкретные хи-
мические соединения в строго определенных концентрациях);
• 8021 модель ионных каналов;
• 10 чипов различных сложных математических описаний этих ионных
каналов, зависящих от напряжения;
• 32000 дифференциальных уравнений (!);
• 19200 параметров, необходимых для оценивания настроек моде-
ли; точное описание морфологии клетки, реконструированной с по-
мощью микроскопа.
Структура нейронной сети
63
-И mV
-20 mV
-26 mV
-32 mV
-38 mV
Л4т¥
-SO mV
Рис. 2.17. Некоторые результаты исследований де Шуттера. В верхней части
электрическая активность моделируемой клетки, в нижней части биохимические
явления (перенос ионов кальция)
Не приходится удивляться, что для моделирования полутора десят-
ков секунд «жизни» такой нервной клетки потребовалось несколько де-
сятков часов непрерывной работы большого суперкомпьютера. Следует
признать чрезвычайную неэффскгность полученных результатов моде-
лирования. Некоторые из них приведены па рис. 2.17.
Тем не менее, из этих исследований сделаны однозначные выводы:
попытка точного моделирования структуры и функционирования насто-
ящего биологического нейрона оказалась удачной, но слишком дорогой
и трудоемкой, чтобы аналогичным образом создавать практически по-
лезные нейронные сети. Поэтому мы будем далее использовать исклю-
чительно упрощенные модели в надежде на то что, невзирая на эти у про-
64
Глава 2
тения нейронная сеть сможет нс только эффективно решать поставлен-
ные задачи, но и поможет нам (в процессе наблюдения за ее функцио-
нированием) формулировать интересные выводы о ра юте человеческого
(например, твоего!) мозга. Очень скоро ты в этом убедишься!
2.4. Как функционирует сеть, состоящая
из искусственных нейронов?
Из приведенного выше описания следует, что каждый нейрон рас-
полагает некоторой внутренней памятью (представленной текущими
значениями весов и порога), а также определенными возможностями
преобразования входных сигналов в выходной сигнал. Несмотря па
сильную ограниченность этих возможностей (благодаря которой нейрон
оказывается относительно недорогим процессором, и мы можем стро-
ить сети из сотен или тысяч таких элементов), они оказываются до-
статочными для построения систем, способных решать очень сложные
задачи обработки данных.
Поскольку информационные ресурсы каждого (/.«дельного нейрона
в сети всегда ограниченны (ведь единственный нейрон имеет немного
настраиваемых весов), а вычислительные возможност и такого «одиноч-
ки» весьма слабы (только агрегирование сигналов и расчет’ выходного
сигнала), нейронная сеть чаще всего должна состоять из боль-
шого числа нейронов и может функционировать только как
единое целое. Следовательно, все обсуждавшиеся в предыдущей главе
возможности и свойства нейронных сетей представляют собой резуль-
тат коллективного функционирования очень многих объединенных
между собой элементов (всей сети, а не отдельных нейронов)- В связи с
этим представляется вполне обоснованным использование термина МРР
(Massive Parallel Processing — Массовая параллельная обработка), кото-
рым иногда называется вся наша область информатики.
Обратимся ненадолго к работе сети в целом. Из сказанного выше
следует, что и программа функционирования, и содержимое базы зна-
ний, и входные данные для вычислений, а также сам процесс вы-
числений оказываются распределенными по всей сети. Невозможно
указать место, в котором храни гея та или иная конкретная информация,
хотя сети используются в качестве запоминающих устройств (особенно
ассоциативной памяти) и очень хорошо выполняют эту функцию. Точно
так же невозможно локализовать в конкретном месте сети какого-либо
фрагмента алгоритма ее функционирования. В частности, нельзя ука-
зать, какие элементы сети отвечают ва предварительную обработку и
анализ входных данных, а какие формируют итоговое решение.
Структура нейронной сети
65
Рис. 2.18. Начало функционирования нейронной сети связано с появлением на ее
входах сигналов (серые точки), несущих информацию о новой, подлежащей решению
задаче
Посмотрим, как это все работает, и какую роль играют конкретные
элементы в функционировании сети в целом. Предположим, что значе-
ния всех весовых коэффициентов сети уже заданы, т.е. процесс обуче-
ния завершен. Процесс обучения сети (очень важный, но и очень непро-
стой для понимания) мы будем рассматривать в следующих главах. Нач-
нем наш анализ с момента постановки перед сетью новой задачи. В этот
момент па все входы сени подастся новая комбинация входных сигналов.
Па рис. 2.18 эти сигналы обозначены серыми точками, размещенными в
соответствующих местах на схеме сети.
Входные сигналы попадают на нейроны входного слоя, которые, как
правило, их не обрабатывают, а только перераспределяю']1 — т.е. рас-
сылают по всем нейронам скрытого слоя (рис. 2.19). Отметим, что осо-
бая роль таких нейронов-распределителей (не обрабатывающих инфор-
мацию) обозначается па схемах нейронных сетей особым символом (на-
пример, на наших рисунках они обозначены треугольниками в отли-
чие от квадратов, которыми обозначены другие нейроны).
Следующий этап активизация нейронов скрытого слоя. Эти ней-
роны, используя свои веса (т.е. задействуя накопленную в них информа-
66
Глава 2
Рис. 2.19. Входные < и гнали (никак не преобразованиьте во .входном слое) рассылатотся
всем нейронам скрытого слоя
пию), вначале модифицируют входные сигналы, а потом агрегируют их с
учетом своих характеристик (представленных на рис. 2.20 в виде сигмо-
идальных функций ) и рассчитывают выходные сигналы, передаваемые
на нейроны выходного слоя. Этот этап обработки информации нейронной
сетью имеет особо важное значение. Извне сети скрытый слой практиче-
ски незаметен (его сигналы не наблюдаю гея ни па входе, пи на выходе
сети этим объясняется название слоя), но именно в нем выполняет-
ся большая часть работы но решению задачи. Наибольшее число связей
и соответствующих им весовых коэффициентов обычно рас полагаетс я
между входным и скрытым слоями. Поэтому можно утверждать, что
большая часть знаний, накопленных в процессе обучения, локализует-
ся именно в скрытом слое. Сигналы, генерируемые нейронами скрытого
слоя, не имеют никакой прямой интерпретации в отличие от входных
и выходных сигналов, каждый из которых обозначает что-то конкретное
в коп тексте решаемой задачи. Но по аналогии с: производственным про-
цессом можно утверждать, что нейроны скрытого слоя вырабатывают
«полуфабрикаты» их сигналы так характеризуют решаемую задачу,
что процесс «монтажа конечно! о продукта», т.е. получения итогового ре-
шения нейронами выходного слоя, существенно облегчается (рис. 2.20).
Структура нейронной сети
67
Рис. 2.20. После обработки сигналов нейронами скрытою слоя генерируются
промежуточные сигналы, направляемые к нейронам выходного слоя
При более детальном ознакомлении с функционированием сети на
этом завершающем этапе решения задачи можно заметить, что нейроны
выходного слоя используют свои возможности агрегирования сигналов
и свои функциональные характеристики для формирования итогового
решения, подаваемого на выход сети (рис. 2.21).
Повторю еще раз: сеть всегда функционирует как единое це-
лое; в реализации любых действий сети участвуют все ее элементы
напрашивается аналогия с голограммой, когда по каждому фрагменту
разбитой фотопластинки можно восстановить образ сфотографирован-
ною ((-голографированного?) предмета. Одно из следствий такого функ-
ционирования сети ее удивительная способность коррект но работать
даже при повреждении значительного числа ее элементов. Известный ис-
следователь нейронных сетей Франк Розенблатт (Frank Rosenblatt) вна-
чале обучал созданную им нейронную сеть решать какую-либо задачу
Iнапример, распознавать буквы), а потом тестировал эту сеть при по-
следовательном отключении все большего числа входящих в ее состав
элементов (сети Розенблатта представляли собой специализированные
электронные системы). Оказалось, что сеть корректно выполняла свои
функции даже при выводе из строя многих ее элементов (рис. 2.22). Ко-
68
Глава 2
Рис. 2.21. Нейроны выходного слоя, используя информацию, предварительно
обработанную в скрытом слое, рассчитывают итоговые результаты, вродетавляюгцие
собой решение исходной задачи
нечцр, повреждение большей части нейронов и связей снижало качество
функционирования сети, но это проявлялось во все более частых ошиб-
ках при распознавании (например, при демонстрации буквы О сеть назы-
вала ее буквой D), тем не менее, опа продолжала работать. Можно срав-
нить такое поведение сети с наверняка известным тебе фактом, что для
подавляющего большинства других электронных устройств (компьютер,
телевизор и т.п.) для выхода из строя достаточно отказа единственного
важного элемента. И еще один установленный факч в мозгу взрослого
человека ежедневно погибает (по разным причинам) несколько тысяч
нейронов тем не менее, мозг как единое1 целое безотказно функцио-
нирует на протяжении многих лет.
2.5. Как влияет структура нейронной сети
на выполняемые ею функции?
Рассмотрим теперь связь между структурой сети и решаемыми этой
сетью задачами. Ты уже знаешь, что сеть состоит из нейронов, (войства
которых мы обсуждали в предыдущем разделе. Структура сети образу-
Структура нейронной сети
69
Рис. 2.22. Нейронная <еть обладает потрясающим свойством: опа может корректно
функционировал» даже в случае повреждения большого числа ее элементов!
елся при соединении (согласно принятой схеме) выходов одних нейро-
нов с входами других, благодаря чему формируется целостная система,
способная параллельно и полностью согласованно обрабатывать различ-
ную информацию. По причинам, которые мы уже обсуждали, чаще всего
выбирается сеть с многослойной структурой, а связи между нейрона-
ми разных слоев чаще всего устанавливаются по принципу «каждый с
каждым». Конечно, конкретная топология сети (т.е. главным образом
количество нейронов в каждом слое) должна определяться задачей, ко-
торую должна решить сеть. Теоретически правило довольно простое:
чем сложнее задача, тем больше нейронов должно входить в сеть для ее
решения, поскольку, чем больше нейронов в сети тем выше ее «интел-
лект». Но на практике все не так однозначно, как могло бы показаться.
К счастью, обозначенная проблема в действительности нс настоль-
ко остра. В богатейшей библиографии по нейронным сетям можно найти
множество работ, доказывающих, что решения о структуре сети вли-
яют на ее поведение гораздо слабее, чем это представляется на
первый взгляд. Это парадоксальное утверждение объясняется тем, что
функционирование сети предопределяется, в первую очередь, процессом
ее обучения, а не структурой (фактически числом использованных
для ее построения элементов). Следовательно, сеть с заведомо худшей
структурой может при хорошем обучении эффективнее решать постав-
ленные перед пей задачи, чем слабо натренированная сеть с оптимально
подобранной структурой. Известны эксперименты, в которых структура
сети выбиралась абсолютно случайным образом (точнее, случайным
образом выбирались соединяемые друг с другом элементы и способ их
соединения), но сеть все равно оказывалась способной решать постав-
ленные перед пей трудные задачи!
Из последнего утверждения следуют довольно важные и интерес-
ные выводы. Если сеть может получить корректные результаты даже
в случае, когда ее структура выбирается случайным образом, то про-
цесс обучения способен всякий раз настолько хорошо адаптировать ее
70
Глава 2
Рис. 2.23. Схема связей coin, элементы которой соединялись между собой
с применением случайных. правил. Удивительно то, что такая сеть может (после
обучения) целенаправленно и успешно функционироват ь
параметры к операциям, необходимым для выполнения заданного алго-
ритма, что корректное решение задачи может быть найдено, несмотря
на абсолютно случайную структуру сети. Эти эксперименты, впервые
проведенные Франком Розенблаттом в начале 0-х гг. XX в., были очень
эффектными: исследователь бросал игральные кости или вытаскивал
билетик и в зависимости от выпавшего исхода соединял элементы се-
чи между собо 4 или нет. Возникавшая структура связей была абсолютно
хаотичной (рис. 2.23) — тем не менее, сеть после обучения могла очень
осмысленно решать предьявленные ей задачи.
Результаты исследований Розенблатта были настолько удиви тель-
ными, что поначалу ученые не верили в их реальность. Но впоследствии
эти эксперименты были многократно воспроизведены (между прочим, в
СССР академик В.М. Глушков специально для этого построил нейрон-
ную сеть, названную Альфа). Опыты доказали, что сеть со случайными
межнейронными связями может научиться корректно решать задачи, .хо-
тя, конечно, процесс обучения такой сети оказывается дольше и слож-
нее, чем обучение сети, структура которой целенаправленно выбирается
исходя из специфики задачи, которую требуется решить.
Полученными Розенблаттом результатами заищгересовались также
философы они сочли, что таким способом был доказан некоторый
тезис, высказанный еш-е Аристотелем и позднее развитый Локком. Речь
идет о концепции, согласно которой мышление зарождается как чистая
Структура нейронной сети
71
доска, которая заполняется только в процессе обучения и накопления
опыта. Розенблатт доказал техническую осуществимость этой концеп-
ции, по крайней мерс, в форме нейронной сети. Самостоятельное зна-
чение имеет попытка ответить на вопрос: соответствует ли это процес-
сам в биологическом мозге человека? Действительно ли как утверждал
Локк, врожденные способности — ничто, а приобретенные в процес-
се обучения знания все?
Точный ответ нам пока не известен. Мы можем с полной уверен-
ностью сказать, что нейронные сети могут приобретать все свои зна-
ния в процессе обучения и не обязаны заранее иметь какую-либо точно
определенную структуру, адаптированную к решению конкретных за-
дач. Конечно, сеть должна быть достаточно сложной, чтобы в процессе
обучения в ее структуре можно было «выкристаллизовать» необходи-
мые связи и подструктуры. Слишком маленькая сеть не сможет ничему
научиться, поскольку для этого ее «интеллектуальный потенциал» ока-
жется недостаточным — но дело не в структуре, а в числе элементов.
Крысу никто не обучает теории относительности, хотя ее можно вы-
дрессировать на поиск пути в сложном лабиринте. Точно также никто
не рождается «запрограммированным» на то, чтобы стать гениальным
хирургом или обязательно строителем мостов (на это нацелены соот-
ветствующие учебные заведения), хотя некоторым людям интеллекта
хватает только для погрузки песка в тачку, да и то под контролем. Увы,
это реалии нашего бытия, и никакие высокопарные заявления о равен-
стве возможностей не в состоянии их изменить. Одни имеют достаточные
интеллектуальные ресурсы, другие — нет; одни обладают мощной фигу-
рой и развитой мускулатурой, а другие как будто всю жизнь провели
перед монитором компьютера...
В сетях ситуация аналогична — мы не можем сделать так, чтобы сеть
изначально обладала какими-либо особыми способностями. Мы можем
лишь очень быстро соорудить кибернетического кретина, который пико-
ила ничему не научится, потому что его возможности слишком ограни-
ченны. Таким образом, структура сети может быть произвольной, глав-
ное опа не должна быть слишком большой, что тоже вредно. Но об
этом мы поговорим подробнее чуть ниже.
2.6. Как «по-умному» выбирать структуру
сети?
Независимо от представленных соображений о возможности научить
эффективному функционированию сеть, структура которой необяза-
тельно оптимизирована под решаемую задачу, сеть должна иметь хоть
72
Глава 2
какую-то структуру. Легко показать, что изначальный выбор разум-
ной структуры, неплохо адаптированной к специфике решаемой зада-
чи, может существенным образом сократить длительность обучения и
улучшить его итоговые результаты. Поэтому я позволю себе сформу-
лировать некоторые рекомендации по выбору структуры сети, хотя их
нельзя при знать универсальными рецептами па все случаи жизни. Я
считаю себя обязанным дать тебе несколько советов, поскольку хорошо
известны тс муки, которыми часто сопровождается свободный, ничем
не ограниченный заранее выбор решения. Ощущения начинающего кон-
структора нейронной сети в ситуации, когда он может выбрать любую ее
структуру, подобны ощущениям начинающего пользователя персональ-
ного компьютера, с беспокойством вглядывающегося в появившееся на
экране системное сообщение:
Press any key...
Где эта любая клавиша, которую я должен нажать?!
Над этим можно смеяться, по я очень часто наблюдаю своих сту-
дентов и аспирантов напряженно размышляющих, что это такое
любая структура сети9
Сейчас я немного расскажу о возможных и часто применяемых струк-
турах сети, но сразу хочу отметить, что мои соображения и рекомендаг
иии не исчерпывают все возможности, напротив, любой исследователь
может и должен стать своеобразным Демиургом, основателем и созда-
телем новых миров, поскольку свойства сетей с различными структу-
рами исследованы недостаточно; этой работе пригодится любая пара...
мозговых полушарий.
Вначале я выделю два класса наиболее часто применяемых струк-
тур нейронных сетей, с одной стороны, мы будем рассматривать струк-
туры без обратных связей, а с другой стороны, сети с обратными
связями. Сети первого класса часто определяются англоязычным тер-
мином feedforward, который звучит несколько странно и даже чуть-
чуть таинственно. Тем не менее, он короче и удобнее принятого понятия
«сети с однонаправленным распространением сигналам. Сети второго
класса могут содержать обратные связи, по которым сигналы могут об-
ращаться в течение сколько угодно долгого времени Такие сети назы-
ваются рекуррентными.
Сети feedforward представляют? собой структуры, в которых задано
строго определенное направление распространения сигнала от неко-
торого заранее* определенного входа, через кот орый в сеть вводятся сиг-
налы носит ели входных данных, определяющих решаемую задачу, к вы-
ходу, на кот орый сеть выводи г найденное решение (рис. 2.24). Такие сети
применяются чаще всего и оказываются наиболее эффективными. Их бо-
Структура нейронной сети
73
?Х?Х1Х1Х1>?
QQQQQQ
збобоЪ
txtxtxtxtxr
Рис. 2.24. Пример структуры сети типа
feedforward. Нейроны, обозначенные окруж-
ностями. соединяются так, что сигналы
перелаются только от входа к выходу
Рис. 2.25. Пример структуры рекуррент-
ной сети. Пунктирные линии обратные
связи, делающие сеть рекуррентной
лее подробному обсуждению мы посвятим часть этой и несколько следу-
ющих глав.
Рекуррентные сети имеют межнейронные обратные связи мно-
гочисленные и сложные замкнутые петли, в которых импульсы могут
долго ходить по кругу и изменяться, прежде чем сеть достигнет некото-
рого устойчивого состояния, если такое состояние в принципе достижимо
(рис. 2.25).
Анализ свойств и способностей
рекуррентных сетей намного более
сложен, чем сетей с прямым распро-
странением сигнала, но их вычисли-
тельные возможности удивительно
отличаются от возможностей сетей
других типов. Например, рекуррент-
ные сети способны решать оптимиза-
ционные задачи, г.е. находить паилуч-
шие решения. Сети типа feedforward в
принципе не умеют этого делать.
Особое место среди рекуррентных
сетей занимают сечи, связанные с име-
нем Хопфилда и имеющие особенно
много обратных связей. Честно гово-
ря, в сетях Хопфилда все нейроны со-
единены между собой по принципу об-
Рис. 2.26. Сеть Хопфилда, в
которой все нейроны связаны
между собой обратными связями
74
Глава 2
ратной связи; других межнейронных связей в этих сетях просто нет
(рис. 2.26).
В свое время настоящей сенсацией стало полученное с помощью Се-
ти Хонфилда (этой «предельно рекуррентной» сета) решения знаме-
ни гой задачи коммивояжера, что открыло для этих сетей обширный
и важный класс так называемых TVF-совершенных задач, о которых я
расскажу тебе как-нибудь в другой раз. Но, несмотря на это сенсаци-
онное достижение, сети Хонфилда не стали такими же популярными,
как сет и других т ипов.
Построить сеть с обратными связями, конечно, гораздо сложнее, чем
создать сеть feedforward. Кроме того, намного труднее управлять сетью,
в которой одновременно реализуется парочка тысяч параллельных ди-
намических процессов, чем сетью, в которой сигналы чинно и спокойно
передаются от входа к выходу. По этой причине имеет смысл начать
знакомство с нейронными сетями именно с сетей однонаправленного рас-
пространения сигнала с последующем — плавным и постепенным
переходом к рекуррентным сетям. Если ты уже слышал о самых из-
вестных среди них, т.е. о сетях Хонфилда, и хочешь поскорее добраться
именно до них, то можешь перейти Сразу к соответствующему описа-
нию в одиннадцатое главе. Тем не менее (я это настоятельно рекомен-
дую), лучше систематически читать главу за главой, но в этом случае
ты должен запастись терпением.
Сконцентрируем свое внимание на сетях feedforward. Для описания
этих структур используется удобная и универсальная многослойная
модель. В ней предполагается, что нейроны группируются в определен-
ные комплексы (слои), организованные так, что главные связи 1и соот-
ветственно пути передачи сигналов} соединяют между собой элементы
соседних слоев. Мы уже обсуждали в этой главе многослойную ст рукту-
ру, по не помешает приглядеться к ней еще раз (рис. 2.27).
Скрытый слой
(один или два)
Входной слои
Выходной слой
Функционирование сети зависит от:
• применяемой модели нейрона;
• топологии (структуры) сети;
• значений параметров нейрона,
рассчитанных в результате обучения
Рис. 2.27. Пример структуры простейшей многослойной нейронной сети
Структура нейронной сети
75
В предыдущей главе я уже писал о различных способах соединения
между собой нейронов, лежащих в соседних слоях. Выбор способа
прерогатива конструктора сети, по чаще всего применяется схема «каж-
дый с каждым» в расчете на то, что процесс обучения Приведет к «са-
мокристаллизации» необходимого множества связей па входах, которые
окажутся излишними с точки зрения решения задачи, в процессе обу-
чения появятся нулевые весовые коэффициенты, что практически разо-
рвет эти ненужные соединения.
2.7. Какой информацией надо «потчевать»
сеть?
Самым первым среди слоев, составляющих нейронную сеть, необ-
ходимо рассмотреть входной слой. Этот слой получает данные извне
сети (таким путем описывается подлежащая решению задача). При про-
ектировании входного слоя создателю сети проще принимать решение
число элементов этого слоя точно предопределяется объемом входных
данных, которые необходимо принимать во внимание при решении за-
дачи. Другой вопрос, что иногда трудно определить, сколько и каких
данных нужно вводить в сеть для ее успешной и результативной рабо-
ты. Например, при нейросетевом прогнозировании курсов биржевых ак-
ций некоторые исследователи получают результаты, приносящие очень
большие прибыли инвесторам, которые на основании полученных про-
гнозов принимают решения о приобретении или продаже конкретных
ресурсов. Но в публикациях на эту тему очень скупо говорится о дан-
ных, использованных в качестве исходной точки проведенных расчетов.
Как правило, рассказывается о применении сети и об ее обучении (опи-
сываются даже соответствующие алгоритмы/, приводятся полученные
результаты (какие прибыли получены благодаря удачным инвестициям,
как точно сеть прогнозирует изменение курсов акций, очень хорошо «вы-
глядят» красивые графики фактических изменений и линии прогноза).
Тем не менее, о входных данных упоминается очень скупо общеизвест-
ные истины об использовании информации о ранее зарегистрированных
изменениях курсов и о результатах финансового анализа деятельности
участников рынка. Как обрабатывались данные, какие из них и в ка-
кой степени использовались авторы «забывают» или «стесняются»
написать. Какие рассеянные!
С вводом данных в нейронную сеть (а также с получением сетью
решений о чем речь пойдет в следующей главе) связано одно обсто-
ятельство, на которое необходимо обратить внимание. Нейроны облада-
ют возможностью вырабатывать решение в форме числовых значений.
76
Глава 2
Цель масштабирования:
адаптация диапазона
значений переменной
к функции активации
нейрона
Рис. 2.28. Диапазон значении вещественной переменной, которая должна появиться на
входе или выходе нейронной сет и, дополнит ельно масштабируется для при ведения его в
соответствие' с интервалом значении, допустимых для нейрона
но почти всегда эти значения строго ограничены. Например, в бо.иыиип-
стве практических приложений выходные сигналы всех нейронов могу г
принимать значения в интервале от 0 до 1 (или что бывает более
удобным — от -1 до 1). Поэтому, если значения ожидаемого результа-
та должны лежать в другом интервале, то необходимо применять мас-
штабирование (рис. 2.28).
Масштабировать входные данные проще, чем выходные (об этом мы
будем Говорить в следующем разделе), поскольку па входы нейронов
входного слоя можно, в принципе, подать любой сигнал, имеющий про-
извольное значение. С выходами дело обстоит иначе, потому что ней
рон не способен выработать сигнал, не соответствующий параметрам его
функции активации. Поэтому для сохранения однородности интерпрс-
тании всех циркулирующих по сети сигналов и связанных с ними весов
практически всегда выполняется масштабирование входных значений,
Дополнительное преимущество такого подхода состоит в возможности
провести так называемую нормализацию входных переменных.
Термин «нормализация» звучит несколько пугающе и производит
впечатление чего-то очень сложного, но в сущности речь идет об обес-
печении «равноправия» всех входных сигналов сети. Проблема заклю-
чается в том, что некоторые входные переменные несущие очень важ-
ную для решаемой задачи информацию, могут принимать (в силу своей
природы) малые значения, тогда как другие (совеем не такие важные)
переменные имеют очень большие значения. Например, в нейронной се-
ти, помогающей врачу диагностировать заболевание, па од,ин вход мо-
жет подаваться температура тела пациента. а на другой количество
эритроцитов (красных кровяных телец), найденное в ходе анализа кро-
ви. Оба показателя очень важны, и при корректном решении задачи в
Структура нейронной сети
77
одном случае может быть определяющим первы 1 из них, а в другом
случае второй. Однако температура тела человека характеризуется
небольшими значениями (как ты наверняка знаешь, у здорового челове-
ка она равна 36,6 °C), и даже ее небольшие изменения (на пару граду-
сов в большую или меньшую сторону) могут свидетельствовать об очень
серьезном заболевании. В то же время количество красных клеток (под-
считываемых в одном миллилитре крови) примерно равно 5 млн., и его
изменение даже на один миллион не должно вызывать серьезного бес-
покойства. При отсутствии масштабирования нейрон, «увидевший» на
одном своем входе огромные числовые значения количество эритроци-
тов, а на другом — маленькие значения температуры, принимал бы во
внимание4 только первый показатель при полном игнорировании второ-
го. Благодаря нормализации (п результате которой диапазоны измене-
ния всех входных переменных становятся одинаковыми) обе переменные
обретают равноправие, и сеть функционирует более эффективно.
2.8. Как объяснить сети, где живет слон?
Следующая задача гораздо серьезнее. Данные, которые должны об-
рабатываться сетью, (либо искомые результаты ес функционирования)
не всегда имеют исключительно числовую природу и это становит-
ся источником осложнений. К сожалению, в нашем мире не все удает-
ся измерить и выразить числом. Многие сведения, которые мы хотели
бы видеть па входе или выходе сети, имеют качественный, описатель-
ный. либо как это чаще всего называется номинальный характер.
В качестве их значений выступают некоторые названия, а не чис-
ла. Для разъяснения сути проблемы обратимся к примеру. Представь
себе, что сеть должна принять решение являются ли некоторые жи-
вотные опасными для человека или нет рмы специально разместили в
Интернете несколько программ, с помощью которых ты вскоре будешь
самостоятелыю решать такие задачи h
Например, для решения задачи может потребоваться подать на один
из входов сети информацию, из какой части света происходит живот-
ное. Если из входных данных следует, что животное большое и обладает
хоботом, понятно, что это слон. Но представляет он угрозу для чело-
века или нет, зависит от континента, на котором этот слон прожива-
ет. Известно, что азиатские слоны добродушны и миролюбиво трудятся
вместе с людьми. В то же время африканские' слоны агрессивны, и все
попытки их приручения оканчиваются неудачей. Поэтому для приня-
тия решения об опасности животного необходимо значение переменной,
определяющей его происхождение. Проблема заключается в том. что
78
Глава 2
Переменная «Происхождение»
может принимать следующие
значения:
{Азия, Америка, Европа}
Применяем следующую
схему кодирования’
Азия: {1, 0, 0};
Америка: {0, 1, 0};
Европа: {0, 0, 1}
Одна переменная -
три нейрона!
Рис. 2.29. Способ кодирования номинальной переменной па входе нейронной сети
названия континентов известны, но непонятно, как подать на вход се-
ти, например, название «Азия»?
Для решения этой проблемы используется способ, называемый «один
из А», где N обозначает число различных допустимых значений (назва-
ний), которые может принимать поминальная переменная. Способ коди-
рования по методу «один из 7V» для простого примера, в котором N = 3,
показан на рис. 2.29. Принцип прост: каждой номинальной переменной,
которая должна отражаться па входе сети, во входном слое соответству-
ет столько нейронов, сколько разных значений может принимать эта
переменная (т.е. N). Если в рассматриваемом примере мы предположим,
что животные происходят только из Азии, Америки и Европы, то для
представления па входе се ти переменной «Происхождение» нам потребу-
ются три нейрона. В этой ситуации для информирования сети о том, что
в текущий момент переменная «Происхождение» имеет значение «Аме-
рика», мы подадим сигнал 0 па первый из трех входов, сигнал 1 на
второй и снова 0 на третий вход.
Поскольку ты читаешь эту книгу, то наверняка обладаешь быстрым
и пытливым умом и при упоминании о методе «од,ин из Л» с чувством
некоторого превосходства задался вопросом: Зачем бее так усложнять?
У меня есть лучшее решение! Пусть Азии соответствует значение 7,
Америке 2. а, Европе 3, и подадим эти значения, на единственный
вход сет,и! Либо, если значения входного сигнала должны лежать в
интервале от 0 до 1, пусть будет Азия 0, Америка 1.2. а Европа
1. Почему никто до меня do этого не додумался?
К сожалению, предложенное (гипотетически 1 тобой решение не слиш-
ком удачно. Нейронные сети очень чувствительны к взаимным зави-
симостям между входными значениями. Если принять первое из твоих
правил, то нейронная сеть в процессе обучения будет пытаться каким-
нибудь способом использовать факт (выведенный ею из множества обу-
Структура нейронное сети
79
чающих данных), что Европа в три раза больше чем Азия; естественно,
это приведет к полному абсурду. Еще худшая ситуация возникнет в слу-
чае масштабирования входных данных, потому что сеть сочтет возмож-
ным «пересчитать» Америку в Европу (умножением па 2), по Азию не
удастся пи во что «пересчитать», поскольку умножение на ноль любого
числа даст в результате тот же ноль.
Одним словом, ты вынужден согласиться с необходимостью пред-
ставления номинальны! переменных способом «один из А», хотя он уве-
личивает количество входов сети и связей между входным и последу-
ющими слоями. Особенно неприятен второй факт, потому что каждой
межнейронной связи соответствует свой весовой коэффициент, значение
которого придется долго и упорно искать в процессе обучения. Поэто-
му дополнительные входы и связи усложняют обучение. Однако иного
(лучшего) решения нет, и тебе придется (повторю еще раз) применять
схему «один из А» и многократно увеличивать количество входов, свя-
занных с каждой номинальной переменной, если только ты не изобре-
тешь какой-нибудь действительно эффективный революционный метод
кодирования этих переменных.
Замечание. Не бывает правил без исключений. При использовании
схемы «один из А» исключительным оказывается случай А = 2. Для
таких «двоичных номинальных переменных» (примером которых может
быть переменная «Пол человека») можно, например, использовать коды
Мужчина = 0 и Женщина — 1 (или наоборот), и сети этого будет до-
статочно. Однако, по сути, такие двоичные коды то самое типичное
«исключение, которое подтверждает правило», состоящее в необходи-
мости кодировать данные качественного типа по принципу «один из А».
2.9. Как интерпретировать результаты
функционирования сети?
Теперь поговорим о выходном слое, который генерируют итоговые
решения рассматриваемой задачи. Эти решения передаются во внешнюю
среду в виде выходных сигналов сети в целом. Интерпретация выход-
ных сигналов имеет огромное значение, поскольку мы должны знать
и понимать, о чем сеть хочет нас проинформировать. Количество вы-
ходных нейронов определить проше, чем количество входных нейронов,
потому что мы обычно знаем, сколько и каких решении можно полу-
чить. Сомнения типа «надо добавлять еще один сигнал или нет», кото-
рые отвлекали паше внимание при проектировании входного слоя, здесь
отсутствуют. Подходы к выбору способов кодирования выходных сигна-
лов аналогичны способам при кодировании входных шн налов: числовые
80
Глава 2
Рис. 2.30. Идеальная ситуация, связанная с использованием идеальной переменной
па выходе нейронной сети
переменные необходимо масштабировать так, чтобы выходные нейро-
ны могли сгенерировать значение, соответствующее истинному решению
рассматриваемой задачи, а значения номинальных переменных необхо-
димо представлять па выходе сети по принципу «один из 7V». Тем не
менее, на выходе сети можно столкнуться с парой проблем, специфич-
ных именно для этою слоя. Уделим этим проблемам помпою внимания.
Первая проблема тесно связана с применением схемы «один из У».
Ты помнишь, что согласно этому принципу сигнал с максимальным, зна-
чением (как правило. 1) может появиться па выходе только одного ней-
рона — приписанного к соответствующему символьному значению но-
минальной переменной. Все остальные нейроны из грутщы, представля-
ющей одну и ту же входную переменную, должны иметь пулевые зна-
чения. Эту идеальную ситуацию четкого указания сетью конкретного
значения выходной номинальной переменной иллюстрирует рис. 2.30.
Рисунок предполагает, что решаемая сетью задача (в некотором смысле)
обратна задаче с рис. 2.29: там нужно было подать па вход информацию
о континенте, на котором проживает классифицируемый зверь (чтобы
принять решение, опасен он для человека или нет), тогда как во вновь
рассматриваемой задаче входу сети демонстрируется* живот ное, а сеть
должна определить, на каком континенте оно проживает.
К сожалению, изображенная па рис. 2.30 ситуация возможна только
в теории (а па практике опа встречается только как результат счастливо-
го стечения обстоятельств). В деист вигильности из-за ограниченной точ-
«Демоистрация» животного нейронной сетью заключается в том, что па не йро-
ны входного слоя подается некоторая и- формация об его внешнем виде и строении тела
(форма го ловы, цвет шерсти, строение лап, вид хвоста и т.н.). На рисунке “та информация
представляется ст репками соединяющими части тела животного с входными нейронами,
на которые подается соответствующая информация.
Структура нейронной сети
81
Рис. 2.31. Факти ческое распределение значений сигналов в нейронной сети
с номинальной переменной на выходе
ности функционирования сети (эту проблему мы обсудим позднее) почти
всегда на выходах всех нейронов, приписанных к конкретной выходной
номинальной переменной, появляются какие-нибудь ненулевые сигналы.
Эта ситуация иллюстрируется рис. 2.31. И как мы должны поступать?
Так вот, для получения однозначных ответов в таких ситуациях при-
меняются дополнительные критерии обработки полученных сетью ре-
зультатов в виде порога принятия и порога отклонения решения. Сущ-
ность этой концепции сводится к так называемому пост-процессингу
{post-processing): рассчитанные оконечными нейронами выходные сигна-
лы принимаются или отклоняются путем сравнения их фактических
значений с упомянутыми порогами (рис. 2.32).
Значения порога принятия и порога отклонения могут подбираться в
зависимости от текущих потребностей, так же как и правила поведения
в случае, когда на одном или нескольких нейронах появляется сигнал
Рис. 2.32. Окончательный результат свидетельствует, что значения номинальной
переменной можно однозначно определить даже при неточных значениях на выходах
нейронов
82
Глава 2
Рис. 2.33. Пример распределения выходных сигналов, когда лучше вообще не
определять значения номинально# пере менной, чем допустить возможность очень
вероятной в этой ситуации ошибки
отсутствия решения. Опыт подсказывает, что сети не должны предъяв-
ляться слишком высокие требования, т.е. нс надо «силой» добиваться
однозначного значения выходной переменно i номинального типа в слабо
определенной ситуации, пример которой показан па рис. 2.33.
Будет гораздо более честным признать неспособность сети однознач-
но классифицировать входной сигнал, чем принимать конкретное ре-
шение в условиях, когда эго решение может с высокой вероятностью
оказаться ошибочным:.
2.10. Что лучше
получить от сети
число или
решение?
При использовании нейронных сетей всегда нужно помнить, что по-
лученные сетью результаты (даже если они представляют собой чис-
ла, имеющие содержательную интерпретацию) всегда оказываются при-
ближенными. Качество этого приближения может быть разным, но о
точности порядка нескольких знаков после запятой не может быть ре-
чи хорошо, если полученный нейроном результат обладает точностью
выше двух цифр (т.е. погрешность может достигать нескольких процен-
тов). Такова природа этого инструментария. Понимание неизбежности
этих ограничений вынуждает интерпретировать выходные сигналы со-
ответствующим образом, что необходимо для разумного использования
получаемой информации. Кроме того, приходится обдумывать целесо-
образность применения гой или иной модели нейронных вычислений.
В общем случае нейронные сети могут представлять собой модели двух
типов: регрессионные и классификационные. Регрессионной назы-
вается модель, на выходе которой мы ожидаем ’и требуем) получить
Структура нейронной сети
83
У=Л/Л/(Х1,Х2, ...,Х„)
регрессионной сети:
Оценивание жилищ
У-численная переменная
X, - численные или номинальные
переменные
Площадь,
гараж,
возраст,
отопление,
местоположение,
этаж...
Рис. 2.34. Пример сети, реализующей регрессионную модель
конкретное число, рассматриваемое как решение рассматриваемой зада-
чи. Интерпретацию такой модели иллюстрирует рис. 2.34.
В изображенной на этом рисунке модели представлены (по мнению
нейронной сети) оценки стоимости жилья. На вход подаются данные,
которые могут иметь числовой (например, площадь в м2) или номи-
нальный (например, имеется гараж или нет) характер. На выходе се-
ти мы ожидаем получить числовое значение цены, которую наверняка
удастся выручить при продаже квартиры. Всем продавцам и покупа-
телям квартир известно, что рыночная стоимость квартиры зависит от
множества факторов, причем никто не может сформулировать точные
экономические правила, позволяющие изначально установить, что од-
на квартира будет стоить «столько-то», а другая, например, в два раза
больше. На первый взгляд, стоимость жилья нельзя спрогнозировать,
поскольку цена всякий раз устанавливается в результате свободной ры-
ночной игры и суверенных решений продавца и покупателя конкретной
квартиры. Тем не менее, нейронная сеть после достаточно длительного
обучения (па основании данных о ранее заключенных сделках купли-
продажи квартир) оказывается способной построить настолько хорошую
регрессионную модель решения этой задачи, что фактические цены сле-
дующих сделок отличаются от «угаданного» сетью прогноза на какие-
то несколько процентов.
Альтернативная (классификационная) модель связана с получени-
ем от сети информации об отнесении объекта, описываемого входны-
ми данными, к одному из нескольких известных классов. Естествен-
но, па выходе сети, решающей такую задачу, находится поминальная
переменная (рис. 2.35).
84
Глава 2
Пример:
Предоставление
кредита
Y-численная переменная
X, - численные или номинальные
переменные
Доходы,
обеспечение,
возраст,
гражданское
состояние,
накопления,
трудоустройство...
Предоставить или
не предоставить
кредит?
Рис. 2.35. Пример сети, реализующей классификационную модель
V
На этом рисунке показан пример задачи классификации физических
лиц (люден । или юридических лиц (фирм), обратившихся в банк с за-
явлением о предоставлении кредита. Сотрудник банка должен отнести
каждого такого клиента к одной из двух категорий. Первую категорию
составляют добросовестные и ответственнее клиенты, которым можно
предоставить кредит они наверняка вернут деньги с установленны-
ми процентами и принесут банку ожидаемы • доход. Вторую категорию
составляют мошенники и потенциальные банкроты, которые не вернут
кредит и принесут банку убытки. Как отличи ть одних от других? Не су-
ществует пи точных правил, ни алгоритмов, но правильное решение мо-
жет* подсказать нейронная сеть па основании данных о ранее выданных
кредитах. Как правило, таких данных накапливаемся достаточно много,
поскольку каждый банк пре'доставляет большое количество кредитов и
ведет подробные кредитпые истории своих клиентов как тех, которые
вернули заемные средства, так и тех, которые совершили хищение.
Многолетний опыт* эксплуатации нейронный сетей свидетельствует
о предпочтительности таких постановок задач, решения которых могут
быть найдены с иомошыо классификационной модели. Например, можно
потребовать от сети определять, следует* ли считать прибыльность инве-
стиций «малой», «средней» или «высокой», либо является ли кредито-
получатель «надежным», «рискованным» или «абсолютно непредсказу-
емым». В то же время желание точно определить величину ожидаемо-
го риска либо размер подлежащего выделению кредита прямой пут ь
к неудаче, поскольку сеть в принципе не способна выполнить точный
расчет.
По этой причине число выходов в создаваемой сети часто
бывает больше числа вопросов, на которые мы хотим получить
Структура нейронной сети
85
У=Л/Л/(Х1)Х2, ...,Х„)
Пример:
Прогноз
курса валюты
$/рубль(0
$/рубль(Х -1)
€/рубль(Х)
€/рубль(Х -1)
У- численная переменная
X, - численные или номинальные
переменные
$/рубль(/ +1)
или
сигнал:
повышение или
понижение?
Рис. 2.36. Задача прогнозирования курсов валют одна из задач, при решении
которых создатель нейронной сети может выбирать между регрессионной
и классификационной моделями
ответы. Это объясняется необходимостью для многих выходных сигна-
лов искусственно вводить несколько нейронов, обслуживающих каждый
выход — например, для того чтобы предусматриваемый диапазон зна-
чений выходного сигнала был разделен на значимые для пользователя
поддиапазоны. В такой ситуации мы уже не должны принуждать сеть
формировать на выходе конкретное «угаданное» значение. Сеть функ-
ционирует так, что конкретные выходные нейроны отвечают за сиг-
нализацию принадлежности найденного решения к одному из
поддиапазонов, как правило, нам этого оказывается достаточно. Та-
кую классификационную сеть гораздо легче сконструировать и обучить,
тогда как создание сети, из которой «выжимаются» точные решения
магемах ических задач, представляется «искусством ради искусства»
трудоемкой забавой с минимальной прикладной полезностью. Сформу-
лированные выводы иллюстрирует рис. 2.36, на котором показана одна
из классических задач, решаемых нейронными сетями, прогнозиро-
вание валютных курсов.
Из рисунка понятно, что задача может решаться двумя способами:
либо мы будем строить прогностическую модель (которая попытается
предсказать, сколько рублей дадут за доллар завтра) либо удовлетво-
римся моделью, которая сможет только сигнализировать на следу-
ющий день следует ожидать повышение или понижение курса родной
валюты? Вторую задачу сеть решит гораздо легче, причем прогноз из-
менения курса может оказаться очень полезным, например, если кто-то
намеревается покупать доллары для заграничной поездки.
86
Глава 2
2.11. Что лучше иметь — одну сеть
с несколькими выходами или несколько сетей
с одним выходом?
С выходным слоем нейронной сети ассоциируется еще одна пробле-
ма, которую можно решить двумя способами, причем выбор какого-либо
из этих спос обов оказывается предметом свободного решения конструк-
тора сети. Как известно, мы всегда можем построить сечь с любым ко-
личеством выходов, которое зависит от того, сколько выходных данных
мы хотим получить в процессе решения конкретной задачи. Но не всегда
решение о количестве выходов бывает оптимальным, поскольку процесс
обучения сети с несколькими выходами должен привести — путем под-
бора значений внутрисетевых весов к определенным компромиссам,
которые всегда ухудшают результат.
Компромиссы, о которых идет речь, могут выражаться в том, что
при выборе задач конкретных нейронов скрытого слоя необходимо учи-
тывать (путем подбора значений его весовых коэффициентов) роль, ко-
торую будет играть этот нейрон в расчете выходных значений несколь-
ких выходных нейронов (поскольку его выходной сигнал подается на эти
нейроны). Может случиться гак, что роль этого скрытого нейрона будет
оптимальной с позиций расчета какого-либо одного выходного сигнала
и совершенно при расчете другого выходного сигнала. В такой ситуа-
ции веса этого скрытого нейрона будут непрерывно меняться в процессе
обучения из-за необходимости адаптироваться то к одной, то к другой
роли с очевидными последствиями в виде длительного и мало эффек-
тивного обучения. Поэтому часто оказываемся целесообразным разло-
жить сложную проблему и вместо одной сети с несколькими выходами
построить несколько самостоятельных сетей, которые будут использо-
вать один и тот же набор входных данных, различные скрытые слои
и одиночные выходы (рис. 2.37).
Тем не менее, это правило не следует трактовать слишком догма-
тично, поскольку иногда сеть с несколькими выходами обучается лучгйе
сети с одним выходом. Этот внешне парадоксальный вывод обосновыва-
ется тем, что описанный выше потенциальный «конфликт» (связанный
с функционированием скрытых нейронов и с определением их роли в
выработке нескольких различных выходных сигналов) может вообще не
возникнуть. Напротив, при обучении сети иночда наблюдаемся эффект
своеобразной синергии, заключающийся в том, что при выборе (в процес-
се обучения) параметров скрытого нейрона, оптимальных относитель-
но «интересов» нескольких нейронов выходного слоя, успех достигается
быстрее и эффективнее, чем в отдельных семях, Индивидуально пастра-
Структура нейронной сети
87
Предположим, что мы обучаем
одну нейронную сеть
с двумя выходами А и В
В такой ситуации лучше построить
две отдельные сети:
В нейронах обоих скрытых слоев
должна накапливаться информация,
необходимая для расчета значений А и В
Иногда это может быть удобно, если выходы
синергично связаны между собой; тогда
при совершенствовании работы сети для отыскания
корректных значений А накапливаются знания,
необходимые для расчета значений В
Но чаще оказывается, что выходы конфликтуют
между собой - при «улучшении» значений,
необходимых для расчета А, «ухудшаются» значения,
необходимые для расчета В - и наоборот
Каждая из них сможет
оптимально настроиться
на расчет искомых значений А и В
Рис. 2.37. В одной сети с несколькими выходами скрытые нейроны должны обучаться
так, чтобы обслуживать оба выхода. Иногда вместо использования одной сети с несколь-
кими выходами лучше задействовать несколько раздельных сетей с теми же самыми
входными сигналами, но только с одним выходом, поскольку скрытые нейроны могут
специанизироваты я
иваемых па каждый выходной сигнал. Поэтому не следует изначально
настраиваться на то, что лучшим окажется то или иное решение — луч-
ше всего исследовать оба решения и обоснованно выбрать одно из них.
11 все же мои собственные наблюдения (основанные на опыте собствен-
норучного создания со ген сел ей для различных приложений, а также на
консультировании десятков работ студентов и аспирантов) свидетель-
ствуют, что гораздо чаще оптимальным решением оказывается спектр
сетей с одиночными выходами, хотя биологические сети чаще всего ор-
ганизованы по принципу агрегатов с несколькими выходами.
Ты уже знаешь, ч то кажцая сеть с прямым распространением сигна-
ла (feedforward) должна иметь, как минимум, два рассмотренных выше
слоя входной и выходной. Но существуют и такие сети, которые име-
ют только одни обучаемый слой, их называют однослойными сетями
(рис. 2.38). Конечно, обучается выходной слой, поскольку (ты это тоже
уже знаешь) входной слой не подвергается обучению ни в одной сети.
Одпако многие сети (особенно решающие более сложные задачи)
должны иметь в своем составе дополнительные слои элементов, посред-
88
Глава 2
Рис. 2.38. Пример однослойной сети
пинающих между входом и выхо-
дом. Чаще всего такие слои назы-
ваю гея скрытыми слоями. Это
название звучит необычно и таин-
ственно, и при первой встрече с
проблематикой скрытых слоев мо-
жет возникнуть вполне объяснимое
беспокойство. Я постараюсь объяс-
нит?) тебе как можно скорее, что
представляют собой эти слои, и по-
чему они «скрытые».
2.12. Что скрывается в «скрытых» слоях?
Если совсем коротко, то скрытые слои представляют собой средство
такой обработки входных сигналов I полученных входным слоем), после
которой выходной слой сможет легче пай ги искомый ответ (решение про-
блемы). Пользователь (который ставит задачи и контролирует коррект-
ность их решения сетью) не может непосредственно наблюдать функ-
ционирование этих дополнительных (не всегда присутствующих) слоев.
Он не имеет доступа ни к входам нейронов этих слоев (для подачи па
них сигналов необходимо воспользоваться нейронами входного слоя), ни
к их выходам (результаты функционирования нейронов скрытого слоя
проявляются косвенно через отклики, Генерируемые и передаваемые
нейронами выходного слоя). Следовательно, пользователь сети не мо-
жет напрямую контролировать работу нейронов слоев-посредников
именно в этом смысле эти слои называются скрытыми.
Тем не менее, эти дополнительные (скрытые) слои играют в нейрон-
ных сетях очень важную и ответственную роль. Они создают дополни-
тельную структуру обработки информации, а роль скрытых слоев проще
всего обсудить на примере сетей, решающих довольно популярную зада-
чу распознавания образов. На вход такой сети (точнее, па входы ней-
ронов ее первого слоя) подается цифровое описание образа. Это не может
быть картинка, полученная с обычного фотоаппарата, вводимая в ком-
пьютер с помощью сканера или устройства типа Frame Grabber. Причина
достаточно проста: поскольку на вход таков системы- подается само изоб-
ражение, а не какое-то его изощренное описание (см. рис. 2.30), размеры
и организация входного слоя нейронов (т.е. их группирование в столбцы
и строки) соответствуют структуре самого изображения. Проще говоря,
каждой точке образа приписан входной нейрон, сети, который анализиру-
ет и сигнализирует состояние этой точки. Образ, полученный с цифрово-
го фотоаппарата или сканера, представляет собой множество пикселей,
Структура нейронной сети
89
Эти нейроны
сигнализируют
о распознавании
конкретных символов
Рис. 2.39. Пример сети, распознающей простые образы
по ведь этих пикселей миллионы! Практически невозможно построить
искусственную сеть, содержащую миллионы входных нейронов, хотя бы
потому, что такая сеть должна будет иметь миллиарды (!) связей, и для
каждой из них потребуется определять весовой коэффициент.
Но мы можем представить себе систему, на вход которой будет пода-
ваться очень упрощенный цифровой образ (например, букв), состоящий
из небольшого числа пикселей (рис. 2.39).
На выходе такой сети должны формироваться решения о распознава-
емом объекте, например сеть может быть организована так, что каждому
конкретному выходному нейрону условно приписывается определенное
решение: «распознана буква 4», «распознана буква В» и т.п., а величи-
на сигнала интерпретируется как степень уверенности соответствующего
решения. Легко заметить, что при таком подходе сеть может давать мно-
гозначные ответы («Входной образ в степени 0,7 похож, на букву А, но
в степени 0,4 напоминает букву В»\. Эго одно из интересных и полез-
ных свойств нейронных сетей, благодаря которому ее функционирование
напоминает работу так называемых систем нечеткой (fuzzy) логики, по
подробное обсуждение этого аспекта выходит за рамки пашей книги.
В обсуждаемой сети нейроны скрытого слоя играют роль посредни-
ков. Они имеют прямой доступ к входным данным, т.е. просматривают
поданное па вход сети изображение, а по их выходным сигналам следу-
ющие слои принимают конкретные решения о распознавании того или
ино1 о образа. По этой причине считается, что роль нейронов скрытого
слоя заключается в формировании такой комбинации предварительно
90
Глава 2
обработанных входных данных, которрй смогут воспользоваться ней-
роны выходного слоя при выработке итогового решения.
Полезность этих слоев-посредников обусловлена тем, что после пред-
варительного преобразования входных данных сеть может гораздо проще
решить поставленную перед пей задачу, чем в случае прямой обработки
исходных данных. Например, в рассматриваемой задаче распознавания
образов трудно найти правило идентификации представленного объекта
непосредственно по светлым и темным пикселям изображения (именно
такой информацией располагает сеть без скрытого слоя). Вывести пра-
вило корректного распознавания па таком низком уровне чрезвычайно
сложно, поскольку идентифицируемые объекты могут иметь множество
вариантов изображения, различающихся формой, но имеющих одина-
ковое значение. Один и то же объект (например, буква А) может вы-
глядеть по-разному в рукописном виде, в напечатанном тексте или на
развевающемся транспаранте. Даже буква, отпечатанная одним и тем
же шрифтом, может представляться двумя разными образами (некото-
рые точки которых буду! иметь совершенно разные значения пикселей)
в результате такой банальной и ничуть не мешающей человеку погреш-
ности, как небольшое (‘мешение листа бумаги в процессе печати. Если в
такой ситуации сеть будет принимать во внимание только степень окрас-
ки каждого пикселя (белый он или черный), то решения о распознава-
нии образов букв могут изменяться самым драматичным образом. Мало
того, при обработке изображений с малой разрешающей спосрбностыо
возникает дополнительная проблема: совершенно разные объекты мо-
гут описываться на таких цифровых образах очень большими подмно-
жествами одинаковых пикселей.
В подобной ситуации было бы наивным ожидать, что нейронная сеть
сможет «одним прыжком» преодолеть все трудности, разделяющие «сы-
рое» исходное изображение и итоговое решение. Накопленный опыт сви-
детельствует о невозможности обучить распознаванию образов простую
сеть без скрытого слоя. Такая сеть «неспособна понять», что один и тог
же набор пикселей может соответствовать разным объектам, а разные
наборы одному и тому же объекту.
Как правило, сеть со скрытым слоем оказывается в состоянии ре-
шать задачи, оказавшиеся не по силам сетям с меньшим числом слоев.
При решении таких задач нейроны скрытого слоя находят некоторые
вспомогательные значения, существенно упрощающие решение исходной
задачи. Например в обсуждаемой задаче распознавания образов нейро-
ны скрытого слоя могут обнаруживать и кодировать некоторые общие
признаки, описывающие структуру изображения и представленного на
нем объекта. Эти признаки должны лучше соответствоват ь требованиям
Структура нейронной сети
91
окончагелыюго распознавания образа, чем само оригинальное изобра-
жение например они могут не зависеть (в какой-то степени) от распо-
ложения или масштаба распознаваемых объектов. В качестве примера
признаков, описывающих элементы изображения букв и облегчающих
их распознавание, можно указать:
• наличие или отсутствие в изображении буквы замкнутых контуров
(они присутствуют в буквах О, D, А и в некоторых других, по от-
сутствуют в буквах I, Т, S, N и т.д.);
• наличие в контуре буквы разрыва снизу (А, X, К), сверху (U, v-
V, К) или сбоку (Е, F);
• наличие у буквы в целом закругленной (О. S, С) или угловатой (Е,
W, Т, А) формы.
Конечно, можно выделить очень много признаков, как отличающих
буквы друг от друга, так и затрудняющих их распознавание (вид шриф-
та в печатном или рукописном тексту, размер символов, их наклон, рас-
тянутость и т.д.). Необходимо отметить, что конструктор сети не обя-
зан сам указывать значимые признаки образа — сеть должна самосто-
ятельно приобретать требуемые навыки в процессе обучения. Нет ника-
кой гарантии, что предназначенная для распознавания букв нейронная
сеть научит свой скрытый слой выявлению и демонстрации именно тех
признаков, которые я перечислил выше. Можно даже заключить пари,
что сеть не сможет самостоятельно обнаружить конкретно эти призна-
ки. Тем не менее, опыт многочисленных исследователей свидетельствует
о способности сетей, решающих задачи распознавания, самостоятель-
но находить признаки, эффективно облегчающие распознавание. При
этом создатель сетц часто оказывается не в состоянии попять, какой
смысл имеет тот или иной признак, закодированный в скрытом слое.
Таким образом, использование скрытого слоя оказывается целесооб-
разным со всех точек зрения, поскольку благодаря этому слою нейрон-
ная сеть может вести себя гораздо более «интеллектуально». Но сети на-
до предоставить соответствующие возможности, в первую очередь, путем
введения в ее структуру элементов, которые омотут выявлять необхо-
димые «описательные признаки образа». Необходимо отметить, что ха-
рактер выявляемых признаков предопределяется не структурой сети, а
Только процессом обучения. Если представить себе сеть, которая должна
распознавать образы, то выявляемые нейронами скрытого слоя призна-
ки будут автоматически адаптироваться к виду распознаваемых образов.
Например, если мы поручим сети выявлять на аэрофотоснимках обра-
зы замаскированных пусковых ракетных установок, то станет понятной
главная задача скрытого слоя обеспечить независимоеть от располо-
жения объекта, поскольку подозрительная ст руктура должна раснозпа-
92
Глава 2
ваться одинаково независимо от ее локализации в любой части изображе-
ния. Если же сеть должна распознавать буквы, чо она не должна терять
информацию об их расположении (какую пользу принесет сеть, которая
проинформирует нас о наличии буквы «А» где-то на отсканированной
странице, мы должны знать, где именно она находится, точнее, в каком
контексте применяется). В эюм случае задача скрытого слоя заключает-
ся в выявлении признаков, позволяющих безотказно распознавать буквы
независимо от их размера и шрцфха. Что интересно, обе задачи может
решать (после соответствующей тренировки) одна и та же сеть. Хотя ко-
нечно, сеть, распознающая чанки, не сможет читать письма, а обученная
распознавать оттиски пальцев, не справится с узнаванием лиц.
2.13. Сколько потребуется нейронов
для построения хорошей сети?
Из представленных рассуждений напрашивается простой вывод
наиболее широкими прикладными возможностями обладают сети как
минимум с трехслойной структурой (выделен ны ч входной слой для при-
ема сигналов, скрытый слой для выявления из входных сигналов необхо-
димых признаков, выходной слои дня принятия и вывода окончательно-
го решения). В такой структуре некоторые элементы оказываются пред-
определенными: количество входных и выходных элементов, а также
принцип соединений (каждый с каждым) между слоями. Но существуют
и переменные элементы, которые приходится выбирать самосчоятель-
но: количество скрытых слоев (один или несколько?) и количество
элементов в скрытом слое (слоях?) (рис. 2.40).
Несмотря на уже многолетнюю историю развития нашей технологии,
все еще не удалось сформулировать точную теорию нейронных сетей.
Рис. 2.40. Наиболее серьезная проблема при выборе сгруктуры нейронной сети
связана с определением количества, элементов в скрытом слое
... а маленькая сеть может оказаться
слишком примитивной для того, чтобы
справиться с трудностями решаемой задачи
Структура нейронной сети
93
По этой причине количество слоев и элементов выбирается либо слу-
чайным образом, либо методом проб и ошибок. Довольно часто оказы-
вается, что представления конструктора сети о требуемом количестве
скрытых нейронов и об их размещении в один или несколько скрытых
слоев1 не оказывают принципиального влияния на способ функцио-
нирования сети, поскольку в процессе обучения она имеет возможность
(корректировать возможные структурные недостатки путем подбора со-
ответствующих параметров связей. Тем нс менее, я хочу предостеречь
тебя от двух видов ошибок, которые становятся ловушками для многих
особенно начинающих) исследователей нейронных сечей.
Первая ошибка заключается в проектировании сети со слишком ма-
лым числом элементов если скрытый слой не предусматривается или
насчитывает недостаточное количество нейронов, то процесс обучения
будет неудачным по определению. В этом случае сеть не сможеэ' отоб-
разить в своей (слишком бедной) структуре все особенности решаемой
задачи. Чуть ниже я продемонстрирую тебе примеры того, как слиш-
ком малая и примитивная сеть оказывается неспособной решать неко-
торые задачи даже после долгого и тщательного обучения. Нейронные
сети в этом плане похожи на людей — далеко не все оказываются до-
статочно способными решать стоящие перед ними задачи. К счастью,
всегда можно относительно просто определить, насколько интеллекту-
альна сечь, так как видна ее структура и легко подсчитать количество
нейронов. Фактически мерой способностей сети выступает количество
скрытых нейронов. У людей выявить способности гораздо сложнее!
К сожалению, несмотря на возможность создавать сети большей или
меньшей размерности, иногда проектируются слишком низкоинтеллск-
туальные сети. Попытки применения таких сетей для достижения какой-
либо конкретной цели всегда обречены на неудачу, поскольку «нейрон-
ный 1упица» со слишком малым количеством скрытых нейронов нико-
гда не решит стоящие перед ним задачи независимо от труда, затра-
ченного па его обучение.
Увы, существует также опасность «переусердствовать» с увеличе-
нием интеллектуального потенциала сети. Образно говоря, результатом
избыточной интеллектуальности сети совсем не обязательно станет
большая успешность решения стоящих перед сетью задач. Удиви тель-
ный эффект может проявиться в том, что сеть (вместо планомерно-
го накопления необходимых знаний) начинает обманывать своего учи-
теля и совсем не обучается! В первый момент это звучит совершен-
но неправдоподобно, но такова горькая правда. Сеть, имеющая слиш-
ком много скрытых слоев или слишком много нейронов в скрытых сло-
ях, начинает проявлять склонность к упрощению решаемой задачи и,
94
Г л а в а 2
Рис. 2.41. Максимально упрощенная схема процесса обучения нейронной сети
как следствие, старается «идти по самому легкому пути». Чтобы по-
пять суть этого явления, поговорим немного о том, как протекает про-
цесс обучения (рис. 2.41).
Мы подробно обсудим детали этого процесса в одной из следующих
глав. Но уже сейчас я должен сообщить тебе, что для обучения сети на ее
вход подаются сигналы, для которых известны правильные решения
они содержатся в обучающей выборке. Дня каждой комбинации вход-
ных данных сеть вырабатывает на выходе свой вариант решения. Чаще
всего предложенное сетью решение отличается от правильного (эта-
лонного) решения, содержащегося в обучающей выборке, а разность
этих решений характеризует величину погрешности (ошибки), которую
допустила сеть. На основании значения погрешности обучающий алго-
ритм изменяет веса всех нейронов сети так. чтобы в будущем сеть не
допускала те же ошибки.
Представленная схема процесса обучения демонстрирует стремле-
ние сети не допускать ошибки при предъявлении ей обучающих
данных. Соответственно, хорошо обучающаяся сеть ищет такое прави-
ло обработки входных сигналов, применение которого позволит выраба-
тывать корректные решения. Если сети удается найти такое правило,
то в будущем она сможет решать как задачи, предъявлявшиеся ей в
составе обучающей выборки, так и другие аналогичные задачи, кото-
рые будут предъявляться в процессе нормальной эксплуатации. В этом
случае мы говорим, что сеть демонстрирует способность к обучению
и к обобщению (генерализации) результатов обучения, что считает-
ся несомненным успехом.
К сожалению, слишком «интеллектуальная» сеть, обладающая из-
рядными ресурсами памяти в виде большого количества скрытых ней-
ронов (с соответственно настроенными весами), может легко избавиться
от ошибок в процессе обучения благодаря прямому запоминанию всей
обучающей выборки. В этом случае сеть необычайно быстро достигает
больших успехов в обучении, поскольку она знает и выдает правильное
решение каждой предъявляемой ей задачи. Увы, при таком способе «фо-
Структура нейронной сети
95
парафирования» обучающей выборки сеть не предпринимает никаких
попыток обобщать полученные знания. Они лишь пытается достичь успе-
ха благодаря применению правила «при таком-то входе такой-то выход».
В результате такого некорректного функционирования сеть точно и
быс тро запоминает всю так называемую обучающую последовательность
(т.е. множество примеров того, как следует решать предъявляемые сети
задачи), но фатально компрометирует себя при первой же попытке те-
стирования, т.е. при решении задачи аналогичного класса, но несколь-
ко отличающейся от уже знакомых учебных задач. Например, при обу-
чении сечи распознаванию букв мы очень быстро достигаем успеха (сеть
безошибочно узнает все демонстрируемые ей «учебные» символы), по
попытка предъявить ей букву, написанную несколько иным почерком
или напечатанную другим шрифтом, завершается полным провалом
никакого распознавания (нули па всех выходах сети) либо абсолютно
случайные решения. В таких случаях анализ накопленных сетью зна-
ний показывает, что она действует по простейшим (сформированным ею)
правилам вида «Если эти два пикселя черные, а на выходах тех пяти
нейронов нули, то символ распознается как буква А». Конечно, такие
примитивные правила не выдерживают испытаний при решении новой
задачи, и сеть не оправдывает наши ожидания.
Описанное явление «обучения зазубриванием» отсутствует в сетях с
меньшим скрытым слоем, поскольку из-за ограниченного объема памяти
сеть должна постараться и выработать при меньшем количестве доступ-
пых элементов скрытого слоя такие правила преобразования входного
сигнала, которые удастся корректно применять для решения различных
задач одного и того же класса. Обычно для этого требуется гораздо более
медленный и трудоемкий процесс обучения (примеры, на которых обу-
чается есть, должны демонстрироваться не один раз иногда несколь-
ко десятков или даже несколько тысяч раз). Конечный результат ока-
зывается гораздо лучше. После завершения правильно организованного
обучения (т.е. в момент, когда можно констатировать хорошую работу
сечи при решении обучающих примеров), мы выдвигаем предположение,
что сеть сможет также хорошо решать аналогичные (но не идентичные)
задачи, которые будут предъявляться ей в процессе тестирования. Так
происходит не всегда, но довольно часто, и в этом заключаются наши
ожидания, связанные с обучением сети.
В заключение, запомни следующее правило: не надейся на чудо;
предположение, что простая сеть с малым количеством скрытых ней-
ронов сможет решать сложные задачи нереалистично. Однако в сетях
со слишком большим количеством скрытых слоев или скрытых нейронов
также существенно снижается качество обучения. Оптимальный размер
скрытого слоя находится где-то между этими крайностями.
96
Глава 2
Рис. 2.42. Пример зависимости погрешности сети от количества скрытых нейронов
На рис. 2.42 показано, как изменяется погрешность функционирова-
ния сети при различном количестве (крытых нейронов использовались
данные компьютерных экспериментов). График подтверждает наличие
множества сетей, функционирующих почти одинаково хорошо, несмотря
па различное количество скрытых нейронов в такой широкий «опти-
мум» попасть не так уж сложно. В то же время (и это гоже видно па
рисунке!, следует избегать крайности, т.е. слишком большие и слишком
малые сети. Особенно вредно применение дополнительных (избыточных)
скрытых слоев. Не следует удивляться тому, что зачастую лучшие pt-
зультаты демонстрирует сеть с меньшим количеством скрытых слоев
(поскольку ее можно «нормально» обучить), чем теоретически лучшая
сеть с большим количеством скрытых слоев (процесс обучения которой
«застревает» в излишних подробностях). Поэтому следует применять се-
ти с одним скрытым слоем (в исключительных случаях с двумя сло-
ями!), а искушение использовать сеть с большим числом скрытых слоев
безжалостно подавлят ь ст рогим постом и купанием в ледяной воде.
2.14. Контрольные вопросы и задания
для самостоятельного выполнения
1. Назови несколько наиболее существенных различий между искус-
ственными нейронными сетями и реальнььми биологическими структу-
рами, которые можно идс птифинировать в мозгу человека и животных.
Постарайся ответить, какие из этих различий можно считать результа-
том капитуляции (нам не удается построить достаточно сложный ис-
кусственный нейрон, поэтому приходится довольствоваться суррогатом),
Структура нейронной сети
97
а какие представляют собой результат свободного и целенаправленного
выбора создателей нейронных сетей?
2. Объясни понятие «синаптический вес» с учетом роли, какую
этот вес играет в искусственных нейронных сетях, а также с учетом
биологических свойств, которые он описывает. В электронных системах,
моделирующих нейронные сети, эти веса иногда бывают дискретными,
те. могут принимать только некоторые значения (например, целочис-
ленные), а не произвольные. Как влияет, по твоему мнению, эта дис-
кретизация па функционирование сети?
3. Нарисуй схему преобразования искусственным нейроном входной
информации в выходной сигнал и объясни, чем могут отличаться друг от
друга разные варианты искусственных нейронов (линейные, MLP, RBF)?
4. Объясни шаг за шагом функционирование сети, состоящей из ис-
кусственных нейронов. Почему скрытый слой имеет такое название?
5. Объясни взаимосвязь структуры нейронной сети и выполняемых
этой сетью функций. Какие сетевые структуры встречаются чаще все-
го, и каковы их свойства? Как выяснить возможность решения конкрет-
ных вычислительных задач сетью, элементы которой соединены между
собой произвольным (случайным) образом?
6. О чем свидетельствует факт высокой устойчивости сети к выходу
из строя ее элементов и к повреждениям структуры?
7. Почему в нейронных сетях необходимо настолько радикально от-
делять числовые данные от качественных данных (номинальных дан-
ных)? Существует мнение, что если на входе или па выходе сети ис-
пользуются номинальные данные, то процесс ее обучения будет длиться
дольше (из-за большого количества подлежащих определению синапти-
ческих весов). Насколько это мнение обосновано?
8. Сеть, на выходе которой данные кодируются но принципу «один
из N», может иногда отказываться выдавать ответ на заданный ей во-
прос. Что может быть следствием такого поведения? Чем можно считать
указанную особенность — достоинством или недостатком сети?
9. Можно ли считать задачу анализа временных серий и связанного с
ним прогнозирования (рис. 2.36) более похожей па регрессионную задачу
;,рис. 2.34) чем па задачу классификации (рис. 2.35)? Какие аргументы
свидетельствуют в пользу первого, а какие — в пользу второго решения?
10. Можно ли из информации, представленной на рис. 2.37 (и из свя-
занного с этим рисунком текста), сделать вывод об абсолютной неже-
лательности применения нейронных сетей с несколькими выходами? В
частности, если на выходе сети вырабатываются значения номинальной
неременной но принципу «один из IV», то можно ли вместо одной сети с N
выходами использовать для решения задачи N сетей с одним выходом?
98
Глава 2
11. Задание для наиболее подготовленных. Представим себе,
что в нашем распоряжении имеемся некоторое множество входных дан-
ных для задачи классификации, которую мы собираемся решать с при-
менением нейронных сете й. Высказываются некоторые сомнения в по-
лезности этой информации в контексте искомой классификации. На-
пример, можно ли по результатам анализа крови отиести конкретного
пациента к категории лиц, хорошо переносящих предлагаемое лечение,
или наоборот, этот результат ничего не проясняет по существу вопроса?
При наличии таких сомнительных входных данных мы можем колебать-
ся — следует ли подавать их на вход сети. Если эти данные окажутся
непригодными, то сети придется повторно выводить свое решающее пра-
вило без учета этих данных «сомнительного качества». Может быть,
не следует «примешивать» к решению задачи переменные, значения ко-
торых с высокой вероятностью окажутся бесполезными? Сформулируй
и обоснуй свое мнение.
12. Задание для наиболее подготовленных. В ли тературе, посвя-
щенной проблематике нейронных сетей, часто предлагается определять
структуру нейронной сети (особенно количество скрытых слоев и конфи-
гурацию скрытых нейронов) с использованием так называемого генети-
ческого алгоритма, имитирующего в компьютере процесс биологической
эволюции. В результате этой эволюции «выживают наиболее приспо-
собленные» (в нашем случае «выживет» сеть, обладающая паилучшими
свойствами в контексте решаемой задачи). Постарайся побольше узнать
об этом методе, после ч&о сформулируй свое отношение к нему: имеет
ли смысл стараться «вывести эволюционным путем» сеть с наилучшими
свойствами либо лучше не использовать этот метод? Приведи аргумен-
ты «за» и «против» каждого решения.
Глава 3
ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ
3.1. Кто такой учитель, который будет обучать
сеть?
В цикле функционирования нейронной сети можно выделить этап
обучения, на котором сеть накапливает знания для будущей работы, и
этап нормального функционирования (иногда называемый тести-
рованием)^ на котором сеть должна решать конкретные новые задачи
(поскольку нас не интересуют задачи, использовавшиеся для обучения
сети — их решения уже известны). Ключом к пониманию функциони-
рования сети и ее возможностей оказывается именно процесс обучения.
Мы начнем знакомство с сетью с обсуждения этого процесса, а опи-
сание функционирования обученных сетей различных типов отложим
до следующей главы.
Существуют два варианта обучения: с учителем и без учителя.
Обучению без учителя посвящен второй раздел этой главы, а сначала
мы рассмотрим модель обучения с учителем. Такое обучение заключа-
ется в предъявлении сети примеров корректного функционирования, ко-
торые она впоследствии должна воспроизводить в своей текущей работе
в процессе тестирования). Пример необходимо понимать как сформи-
рованную учителем комбинацию входных и выходных сигналов, показы-
вающую отклик сети, который должен быть выдан в ответ на соответ-
ствующую конфигурацию входных данных. Сеть наблюдает связи между
введенными входными данными и ожидаемым результатом (т.е. сигна-
лом, который она должна выработать па выходе) и учится следоват ь
продемонстрированным примерам функционирования.
Запомни: при обучении с учителем мы всегда работаем с парой зна-
чений примером входного сигнала и требуемым (эталонным) выход-
ным сигналом, т.е. ожидаемой реакцией сети на этот входной сигнал.
Конечно, сеть может иметь много входов и много выходов, тогда упомя-
нутая пара представляет собой, в сущности, два множества значений:
100
Глава 3
Vanables 6
Cases
1Ф1Й FEMP PRZEM LUDN jpRED W iOPAD DNI DESZ
70.3 213 582 6 7.05 36 1од
02 61 91 132 8.2 48.52 100 13„
00 56.7 453 716 8.7 20.66 67 12
04 51.9 454 515 9 12.95 86 17
65; 49.1 412 158 9 4S.17 127 56
06 54 80 80 9 40.25 114 36
5'?. < 434 Hi 2>
08 68.4 136 529 8.8 54.47 116 14
09 75.5 207 335 9 59.8 123 10
ТО • - - <ОЧ 4-3, i-4 LIS 24
11 50.6 3344 3369 10.4 34.44 122 110 *
Это входные данные
Это корректные
значения решений
Рис. 3.1. Пример обучающей выборки
множество комбинации входных данных и множество значений, которые
должны появиться на выходах сети как полное решение задачи. Но они
всегда присутствуют вместе: исходные данные задачи и ее решение.
Теперь выясним, кто такой «учитель» в мезоде обучения «с учите-
лем»*. Это название необязательно обозначает человека, ко горы соб-
ственноручно тренирует сеть (хотя при чтении следующих глав у тебя
будет возможность поразвлечься персональным «натаскиванием» сво-
их сетей). На практике гораздо чаще роль учителя исполняет тот же
компьютер, который моделирует рассматриваемую нейронную сеть,
так удобнее и проще. К сожалению, нейронные сети не слишком быст-
ры, и для хорошего обучения сети решению какой-нибудь сложной за-
дачи потребуются несколько сотен, а иногда несколько тысяч демон-
страций! У кого найдется столько сил и терпения, чтобы вышколить
такого невежду!? Поэтому мы говорим учитель, а всегда имеем в ви-
ду компьютерную программу с составленной человеком так называемой
обучающей выборкой.
Что представляет собой обучающая выборка? Взгляни на рис. 3.1.
На нем изображена таблица с примерами данных. Это сведения о
загрязненности воздуха в различных американских городах, но па их
месте могут быть любые другие данные'. Важно, чтобы эти данные бы-
ли реальными, взятыми из настоящей базы данных. Я сознательно
оставил на рис. 3.1 элементы оригинального оки! программы, обслу-
живавшей эту базу. Из накопленных в базе сведений можно выделить
те, которые будут рассматриваться в качестве' входных для сети (столб-
цы таблицы, обозначенные черной стрелкой в нижней части рис. 3.1).
В русскоязычной литературе метод обучения с учителем ино1да называется «обу-
чением под над юром» — Прим, перев.
Обучение нейронной сети
101
В представленном на рисунке примере данные предполагается исполь-
зовать для прогнозирования степени загрязненности воздуха, поэтому
нам необходимы сведения о численности городского населения, уровне
индустриализации, атмосферных условиях и т.д. По таким входным дан-
ным сеть должна будет предсказывать среднюю степень загрязненности
воздуха в каждом городе.
Для городов, в которых степень загрязненности воздуха еще не ис-
следовалась, значение этого показателя надо будет угадать именно
для этого потребуются сети, которые мы вместе будем обучать. На этапе
обучения ты сможешь воспользоваться уже известном информацией
[хранящейся в базе данных) о загрязненности воздуха в некоторых го-
родах. Эта информация располагается в соответствующем столбце таб-
лицы, отмеченном на рис. 3.1 стрелкой справа.
На рис. 3.1 есть все необходимое для обучения сети: множество дан-
ных, в котором содержатся соответствующие пары входных и выходных
данных: видны причины (численность населения, индустриализация, ат-
мосферные условия) и следствие (степень загрязненности воздуха). Сеть
воспользуется этой информацией с применением одной из известных
стратегий обучения и научится правильно функционировать (т.е. угады-
вать загрязненность воздуха в городах, в которых еще не проводились
инструментальные измерения). Чуть позже мы подробно обсудим неко-
торые стратегии обучения, но пока снова обратимся к рис. 3.1. Один из
столбцов таблицы виден хуже, поскольку информация в нем выделена
серым цветом (а не черным, как в остальных столбцах"!. Такой способ
окраски, вроде бы, свидетельствует о меньшей важности этого столбца.
Так и есть: «серый» столбец содержит названия городов. В базе данных
эта информация играет очень важную роль, поскольку именно по назва-
ниям городов в базу вносятся новые данные и выбираются необходимые
сведения*. Но нейронной сети названия городов не нужны (загрязнен-
ность воздуха не зависит от названия конкретного города). Поэтому
мы не будем использовать их для обучения сети, несмотря на наличие
в базе данных. Такой избыточной информации (игнорируемой при обу-
чении сети) в базе данных может быть много.
Запомни, что «учителем» сети чаще всего выступает какое-либо мно-
жество данных, которое не используется «как есть», а готовится к ро-
ли обучающей выборки путем соответствующего конфигурирования дан-
ных. Необходимо однозначно указать, какая именно информация будет
задействована в качестве входных, а какая в качестве выходных дан-
ных, с последующей разумной селекцией: сеть не должна «засоряться»
В теории баз данных подобные показатели называются ключевыми. — Прим.
персе.
102
Глава 3
имеющимися у тебя, по бесполезными (безусловно или предположитель-
но) для решения задачи данными!
3.2. Может ли сеть обучаться самостоятельно?
Наряду с описанной выше схемой обучения с учителем также приме-
няется ряд методов так называемого обучения без учителя (или само-
обучения сети). Эти методы предполагают подачу на вход сети только
последовательности входных данных без какой-либо информации о тре-
буемых или ожидаемых выходных сигнала!*. Оказывается, что спроек-
тированная соответствующим образом нейронная сеть может самостоя-
тельно (на основании одних лишь наблюдений входных сигналов) по-
строить осмысленный алгоритм своего функционирования. Чаще все-
го этот алгоритм связан с автоматическим выявлением повторяющих-
ся классов (возможно, с некоторыми вариациями* входных сигналов, и
сеть учится (абсолютно спонтанно, без явного «натаскивания») распо-
знавать эти эталоны сигналов.
Для самообучения сети также необходима обучающая выборка с тем
отличием, что это множество будет содержать данные, предназначенные
для подачи только на вход сети. Эталонные выходные сигналы отсут-
ствуют, поскольку технология обучения без учителя применяется, когда
мы не знаем, что хотим получить от сети, анализирующей какие-
либо данные. Если в качестве4 примера взять данные с рис. 3.1, то для
обучения без учителя мы использовали бы только столбцы, соответствуя
ющие входным данным, и не сообщали сети информацию из столбца,
отмеченного красной стрелкой. Сеть, которая получает знания таким
путем, не сможет прогнозировать загрязненность воздуха она попро-
сту не обладает необходимой информацией. Но в ходе анализа данных по
различным городам сеть сможет, например, выделить (абсолю тно само-
стоятельно!) группу больших промышленных городов и научиться отли-
чать их от маленьких городков, расположенных в сельскохозяйственных
регионах. Такие различия удается выявлять на множестве входных дан-
ных на том основании, что большие промышленные города похожи друг
на друга, а маленькие сельскохозяйственные городки, в свою очередь,
гоже имеют много общих черт. На основании этого принципа сеть смо-
жет совершенно самостоятельно выделять города с хорошим и плохим
состоянием атмосферы и выполнять иную классификацию и все это
только на базе наблюдаемых значений входных данных.
Обрати внимание на то, что самообучение сети очень интересно с
точки зрения аналогии между таким функционированием сети и чело-
веческим мышлением: человек тоже обладает1 способностью спонтанно
Обучение нейронной сети
103
классифицировать встречаемые объекты и явления (некоторые исследо-
ватели называют это «формированием понятий»), а после формирования
классов может распознавать следующие объекты по их принадлежности
к одному из ранее выделенных классов. Самообучение также интересно с
позиций прикладной полезности, поскольку нс требует явного пополне-
ния сети какими-либо внешними знаниями (они могут быть недоступны
либо их сбор слишком трудоемок) сеть накапливает всю необходимую
информацию самостоятельно. В одной из следующих глав мы очень
подробно рассмотрим в том ч*исле и с применением соответствующих
программ), в чем заключается самообучение сети.
Теперь можешь представить себе (скорее, для забавы и развития во-
ображения, чем с какой-либо реальной целью), что оснащенная теле-
камерой самообучающаяся сеть может быть отправлена беспилотным
космическим кораблем на Марс. Мы не знаем, какие там условия, и
тем более не знаем, какие объекты наш зонд должен там распознавать.
Волее того, мы даже не представляем, сколько классов объектов там
существует! Ничего страшного, сеть справится (рис. 3.2). Космический
корабль совершает мягкую посадку, и сеть начинает самообучаться. Вна-
чале она ничего не распознает, только наблюдает. Но со временем про-
цесс спонтанной самоорганизации приводит к тому, что сеть становится
способной выявлять и отличать друг от друга различные тины регистри-
руемых входных сигналов: отдельные скалы и камни, отдельные виды
растений и живых организмов (конечно, если они существуют на Марсе).
Если мы предоставим сети достаточно времени, то она сможет научиться
отличать марсиан от марсианок несмотря на то, что создатель сети
щжс не подозревал об их существовании!
Конечно, описанный самообучающийся космический спускаемый ап-
парат исключительно гипотетическое творение. Но сети, самостоя-
тельно формирующие классы объектов и распознающие различные эта-
лоны, реально существуют и широко применяются. Например, пас мо-
жет интересовать, сколько существует форм некоторой мало известной
болезни и чем эти формы разлягся? Заболевание вызывается одним бо-
лезнетворным микробом или несколькими? Чем они отличаются друг
от друга? Как лечить больного?
Для получения ответов па поставленные вопросы следует взять са-
мообучающуюся нейронную сеть и достаточно долго демонстрировать ей
описания зарегистрированных пациентов и их симптомов. Через некото-
рое время сеть начнет выдавать информацию о числе выявленных симп-
томатических групп и признаков, а также о критериях, но которым мож-
но относить пациентов к той или иной группе. Исследователю остается
только присвоить каждой группе солидно звучащее латинское название
104
Глава 3
Рис. 3.2. Космический спускаемый аппарат с самообучающейся нейронной сетью в
качестве орудия поиска знаний об объектах, существование которых создатель сети не
мог предвидс сь заранее
болезни и можно бежать к портному па примерку фрака, обязатель-
ного для торжественного вручения Нобелевской премии!
Конечно, описанный метод самообучения имеет (как и все в этом
несовершенном мире) определенные недостатки но я расскажу о них
чуть позже, когда ты уже будешь ясно понимать* схему функционирова-
ния сети. Тем не менее, у этого метода столько несомненных достоинств,
что приходится только удивляться его относительно невысокой популяр-
ности!
3.3. Где и как нейронные сети накапливают
полученные знания?
Вернемся к процессу обучения с учителем. Каким образом сеть по-
лучает и накапливает знания? Ключевую роль играют представленные
в предыдущей главе веса входов каждого нейрона. Напомним: каждый
нейрон имеет несколько входов, с помощью которых он получает сиг-
налы от других нейронов или исходные данные для расчетов. < 1 каж-
дым входом связан параметр, называемый весом; каждый входной сиг-
нал вначале умножается на значение веса, и только потом суммирует-
ся с другими сигналами. При изменении значений весов роль нейрона
в сети тоже несколько меняется и, следовательно, сеть в целом начи-
нает функционировать по-другому. Таким образом, искусство обу-
чения сети заключается в таком подборе весов, при котором
Обучение нейронной сети
105
каждый нейрон будет выполнять строго определенную и ожи-
даемую от него функцию.
Сеть может состоять из нескольких тысяч нейронов, каждый из кото-
рых имеет сотни входов понятно, что вручную за один раз присвоить
значения такому числу весов даже случайным способом просто невоз-
можно. Но мы можем спроектировать и реализовать процесс обучения,
при котором сеть начинает функционировать с некоторыми случайными
начальными значениями весов и последовательно улучшает эти зна-
чения. На каждом шаге процесса обучения изменяются значения весов
одного или нескольких нейронов. При этом правила этих изменений под-
бираются так, чтобы каждые нейрон сам мог определить необходимость
модификации каких-либо своих весов, направление изменения (увеличе-
ние или уменьшение значения), а также величину корректировки. Конеч-
но, для определения необходимости изменений весов нейрон может вос-
пользоваться информацией, полученной от учителя (при использовании
соответствующего способа обучения). Тем не менее, сам процесс модифи-
кации весов (именно они играют в сети роль запоминающих устройств)
протекает в каждом нейроне спонтанно и независимо, благодаря че-
му отпадает необходимость прямого и непрерывного контроля со сторо-
ны лица, управляющего обучением. Более того, процесс обучения одного
нейрона независим от обучения любого другого нейрона, поэтому парал-
лельно могут обучаться все нейроны сети (конечно, при построении сети
в виде электронной схемь , а не имитационной программы). Эго обеспе-
чивает высокую скорость обучения и удивительно быстрое повышение
«квалификации» сети, которая мудреет буквально па наших глазах!
Отмечу еще раз ключевой момент: учитель не должен вникать в по-
дробности процесса обучения достаточно, чтобы он дал сети эталон
корректного функционирования. Сеть сравнит свое решение, выработан-
ное при использовании входных данных очередного элемента обучаю-
щей выборки, с соответствующим этому элементу выходным (эталон-
ным, т.е. безусловно* корректным) сигналом. Алгоритмы обучения по-
(гроепы так, что знаний о значении допущенной сетью погрешности
Учитель сети не обязан быть идеальным. Он может иногда ошибаться и подавать
для некоторых данных неверные решения сеть все равно научится находить коррект-
ные ответы на задаваемые ей вопросы. Это удивительное свойство нейронных сетей, ко-
торые после обучения оказываются способными ошибаться реже ненадежного учителя,
было открыто и описано Ф. Розенблаттом при исследовании построенного им персептро-
на. Выявленная особенность имеет большое практическое значение, поскольку довольно
часто при формировании обучающей выборки некоторые примеры (в частности, резуль-
таты. полученные на каком-либо реальном объекте^ оказываются не совсем достоверны-
ми. Упомянутая устойчивость сетей к ошибкам учителя позволяет1 эффективно обучать
их даже тогда, когда некоторые (конечно, не слишком многочисленные) примеры из
обучающей выборки содержат ошибки!
106
Глава 8
OateSet ГЛ ч
—' ---------- - ...ixs?*a.Lx;;.b. - i..J.-.-^g:-_
л- ;а| х|
F~ @Г § £»« Р @]3 ЦГ 3
Рис. 3.3. rJ и повой шаг обучения нейронной сети
оказываются достаточными для корректировки значений ее весов, при-
чем каждый nei рон самостоятельно (под управлением упомянутого ал-
горитма) корректирует свои веса на всех входах, если только он получит
сообщение о допущенной им ошибке*. Эго очень простой и одновремен-
но очень эффективный механизм (рис. 3.3). Его систематическое приме-
нение позволяет сети шаг за шагом улучшать свое функционирование
вплоть до момента, когда она сможет решить все задачи обучающей вы-
борки. В результате обобщения полученных в процессе обучения знаний
сеть обретет способность решать и другие аналогичные задачи, которые
будут ставиться перед ней па этапе тестирования.
Описанный выше способ обучения сети применяется чаще всего, по
для решения некоторых задач (например, распознавания образов) сети
не нужны точные значения ожидаемого выходного сигнала для эф-
фективного обучения достаточно самой общей информации о том, кор-
ректно принятое сетью решение или пет. Иногда речь идет о сигналах
«кнута» и «пряника», в соответствии с которыми каждый нейрон сети
самостоятельно модифицирует свое функционирование. Эта аналогия с
дрессировкой зверей совсем не случайна!
3.4. Как организовать обучение сети?
Необходимые изменения значений весовых коэффициентов конкрет-
ных нейронов рассчитываю 1ся по специальным правилам (иногда они
называются парадигмами сети). Количество применяемых в настоящее
Обучение нейронной сети
107
время правил и их вариантов просто астрономическое, поскольку прак-
тически каждый исследователь старался внести свой вклад в теорию
нейронных сетей в форме нового обучающего правила. Некоторое пред-
ставление о разнообразии правил дает обзор алгоритмов обучения, пред-
ставленный в моей книге «Нейронные сети» (к электронной версии кото-
ром, расположенной в Интернете по адресу http://winntbg.bg.agh.edu.pl/
skrypty/0001/ (увы, польскоязычной I, я постоянно отсылаю наиболее за-
интересованных читателей). Здесь же я кратко (без применения мате-
матики, как мы договорились в начале книги) объясню два основных
обучающих правила: правило наискорейшего спуска, лежащее в осно-
ве большинства алгоритмов обучения с учителем, и правило Хебба
простейший пример обучения без учителя.
Согласно правилу наискорейшего спуска, каждый нейрон, полу-
чивший на своих входах некоторые сигналы (с входа сети или от дру-
гих нейронов, расположенных в предшествующих слоях), вырабатыва-
ет свой выходной сигнал с использованием накопленных знаний (на-
помним, что эти знания представляются текущими значениями коэф-
фициентов усиления (весов) каждого входа и (возможно) значением по-
рога). Способы выработки нейронами значений выходных сигналов по
значениям входных сигналов подробно обсуждались в предыдущей гла-
ве. Значение выходного сигнала, выработанного нейроном на текущем
шаге процесса обучения, сравнивается с соответствующим эталонным
значением, заданным учителем в обучающей выборке. Если эти значе-
ния различаются (а в начале обучения различия выявляются практи-
чески всегда откуда нейрон может знать, что мы от него хотим?), то
нейрон вычисляет разность между своим выходным сигналом и значе-
нием, которое по мнению учителя должно быть получено, а также
определяет (с помощью метода наискорейшего спуска, о котором я сей-
час расскажу), как надо изменить значения весов для более быстрого
уменьшения этой погрешности.
В дальнейших рассуждениях мы воспользуемся понятием поверх-
ности ошибки, которое сейчас введем и подробно обсудим. Ты уже
зшпчпь. что функционирование сети зашГсй’г от значений весовых коэф-
фициентов нейронов, входящих в ее состав. Если известны значения всех
весовые коэффициентов каждого нейрона сечи, то ее поведение можно
предсказать. В частности, такой сети можно предъявить (по очереди) все
доступные примеры задач и их решения, входящие в состав обучающей
выборки. Каждый раз сечь будет вырабатывать свое решение предъяв-
ленной задачи — его можно сравнить с эталоном правильного решения
и рассчитать допущенную сетью погрешность. Обычно в качестве ме-
ры этой погрешности выступает разность между откликом сети и эта-
лонным результатом, представленным в обучающей выборке. Обычно
108
Глава 3
Рис. 3.4. Способ конструирования поверхности ошибки (при
начинать с объяснений на светлом фоне)
чтении рекомендую
комплексная оценка функционирования сети при фиксированных зна-
чениях весовых коэффициентов ее нейронов рассчитывается как сум-
ма квадратов погрешностей допущенных сетью при решении каждого
конкретного примера из обучающей выборки. Погрешности возводятся в
квадрат перед суммированием для предотвращения эффекта взаимной
компенсации положи тельных и отрицательных отклонений. Кроме то-
го, при возведении в квадрат сеть получает особо высокие «штрафы» за
большие погрешности (двукратно большей погрешности соответствует
четырехкратно большая компонента в сумме квадратов).
На рис. 3.4 показана ситуация, которая может сложиться в очень ма-
ленькой сети, имеющем всего два весовых коэффициента. Таких сетей не
бывает, по представь себе именно ее потому что только для такой кро-
шечной сети мы сможем графически отобразить ее поведение без погру-
жения в сложное многомерное пространство. Каждому состоянию луч-
шей или худшей обученности это i с еги сопоставляется некоторая точка
на горизонтальной плоскости, показанная на рисунке вместе с ее коор-
динатами, которые определяются значениями рассматриваемых весовых
коэффициентов. Теперь представь себе, что в сети заданы значения ве-
совых коэффициентов, соответствующие «более близкой к нам» точке
на переднем плане. При проверке такой сети с помощью всех элементов
обучающей выборки ты рассчитаешь суммарную погрешность сети и в
Обучение нейронной сети
109
Рис. 3.5. Пример поверхности ошибки при обучении нейронной сети
рассматриваемой точке выставишь вертикальную стрелку, высота кото-
рой будет соответствовать расчетному значению погрешности (согласно
масштабу вертикальной оси координат).
На следующем этапе ты выберешь другие значения весов, которые
определят другую (лежащую на заднем плане) точку на плоскости, и по-
сле выполнения тех же действий установишь следующую вертикальную
стрелку, соответствующую погрешности уже в этой точке.
А теперь представь себе, что ты выполняешь эти действия для всех
комбинаций вестовых коэффициентов, т.е. во всех точках горизонталь-
ной плоскости. В одних местах погрешность будет выше, в других
ниже, что может выглядеть (если у тебя хватит терпения столько раз
испытывать свою сеть) как волнообразная поверхность ошибки, рас-
положенная над плоскостью изменяемых весов. Пример такой поверх-
ности приведен на рис. 3.5.
Ты можешь увидеть па этой поверхности много «пригорков» это
моста, в которых сеть допускает особенно много ошибок (поэтому эти
места следует избегать), а также много глубоких впадин. Именно эти
впадины нам наиболее интересны, потому что как раз на дне этих впа-
дин нейронная сеть допускает меньше ошибок, т.е. хорошо решает по-
ставленные перед пей задачи.
Но как же найти эти впадины?
Обучение сети надо рассматривать как многоэтапный процесс. При
реализации этого процесса ты будешь стараться шаг за шагом улучшать
значения весов сети путем замены прежних (худших) наборов весов,
по
Глава 3
Соответствующее
ему значение
погрешности
Направление
скорейшего
уменьшения
погрешности
Перемещение
по поверхности
пофешности
Старый (худший)
вектор весов
Миграция
в пространстве
весов
Новый (л/чшим
зектор весов
Рис. 3.6. Сущность процесса обучения заключается в перемещении в направлении
понижения поверхности ошибки
при которых сеть допускала большие погрешности, новым и наборами,
при которых можно надеяться на лучшие результаты (по нельзя быть
уверенным в них!). Я постарался проиллюстрировать это утверждение
рис. 3.6.
Ты начинаешь с ситуации, показанной в левом нижнем углу рисунка,
т.е. имеешь некоторый «старый» набор (вектор) весов, обозначенный на
плоскости параметров светлым кружком в темпом контуре. Для этого
вектора весов рассчитывается допускаемая сетью погрешность ей со-
ответствует т очка на поверхности ошибки в левом верхнем углу рисун-
ка, в которую «упирается» светлая стрелка. Об этой ситуации нельзя
сказать ничего хорошего: погрешность очень велика, поэтому текущие
параметры сети следует признать очень плохими. Их надо улучшить.
Как1?
Вот именно. Методы обучения нейронных сетей позволяют опреде-
лить направление изменения весовых коэффициентов, приводящего к
уменьшению погрешности. Такое направление наискорейшего уменьше-
ния погрешности показано на рис. 3.6 большой черной стрелкой. К со-
жалению, подробности применения методов обучения невозможно объяс-
нить без применения выспи й математики и таких поня тий, как градиент
и частная производная^ но выводы из этих весьма сложных математиче-
ских манипуляций оказываются довольно понятными. Каждый нейрон
сети модифицирует свои весовые коэффициенты (и, возможно, порог) с
применением двух простых правил:
• веса изменяются тем сильнее, чем больше обнаруженная погреш-
ность:
• веса входов, па которые Ьыли поданы большие значения входных сиг-
налов, изменяются сильнее, чем веса входов со слабыми сигналами.
Обучение нейронной сети
111
Рис. 3.7. Поиск (и обнаружение!) минимума функции погрешности методом поиска на
каждом шаге направления скорейшего спуска
При практической реализации приведенные правила немного моди-
фицируются (я расскажу об этом чуть ниже), но основная идея метода
обучения уже понятна. Если ты знаешь допущенную нейроном погреш-
ность и его входные сигналы, то сможешь легко предугадать изменение
сю весов. Заметь, насколько логичны и осмысленны эти математиче-
ски выведенные правила: например, при безошибочной реакции нейрона
па входной сигнал его веса не должны изменяться, поскольку при этих
значениях был достигнут успех. Так и происходит!
Обрати внимание, что при практическом применении описываемых
методов обучения сеть обучается, даже когда она уже хорошо натрени-
рована. Но в таких случаях малые погрешности приводят лишь к ми-
нимальным, «косметическим» корректировкам весов. Это логично, так
же как принцип зависимости величины корректировки от силы входно-
112
Глава 3
го сигнала, подаваемого с рассматриваемым весом. Понятно, что входы,
на которые поступаю г более мощные сигналы, больше влияют на оши-
бочное поведение нейрона, поэтому их надо сильнее «изменить». В соот-
ветствии с рассматриваемым алгоритмом, остаются неизменными веса
входов, на которые в текущий момент времени не подаются сигналы (их
расчетные значения оказались пулевыми). Действительно, мы не зна-
ем, хороши ли актуальные значения весов или нет, поскольку они не
участвовали в формировании выходного сигнала (безусловно, ошибоч-
ного, если его чадо поправлять).
Возвратимся к презентации одного шага процесса обучения, пока-
занного на рис. 3.6, и посмотрим, как развиваются события. Алгоритм
обучения, нашедший направление скорейшего уменьшения погрешности,
организует перемещение в пространстве весов оно сводится к замене
старого (худшего) вектора весов новым (лучшим) вектором. В результа-
те такого перемещения мы «скользим» по поверхности ошибки в новую
точку, чаще всего расположенную ниже предыдущей и, следовательно,
приближающей сеть к той низине, в которой погрешности минимальны,
а решения самые лучшие. Такой оптимистичный сценарий постепен-
ного и эффективного продвижения к зоне минимальных погрешностей
представлен на рис. 3.7.
3.5. Почему это иногда не получается?
К сожалению, обучение не всегда оказывается таким простым и при-
ятным, как показано на рис. 3.7. Иногда сеть долго «дергается», прежде
чем находит правильное решение. Для подробного объяснения возника-
ющих проблем нам снова понадобились бы долгие экскурсы в дифферен-
циальное исчисление, анализ чувствительности алгоритмов и иные весь-
ма сложные области знаний. Вместо того чтобы «нагружать» тебя выс-
шей и прикладной математикой, я расскажу историю о слепом кенгуру
(рис. 3.8).
Представь себе, что слепой кенгуру заблудился в горах и очень хо-
чет вернуться в свои дом. о котором он знает лишь то, что он располо-
жен на самом дне самой глубокой долины. Кенгуру придумал простой
метод. Зверек по-настояшему слеп, и он не может увидеть всю карти-
ну окружающих его гор (точно так же как алгоритм обучения сети не
может проверить значения функции погрешности во всех гонках при лю-
бых значениях весов). Но он может определить своими лапками, в какую
сторону понижается поверхность земли (подобно тому, как алгоритм обу-
чения определяет, в каком направлении надо изменять веса для умень-
шения погрешности). Поэтому кенгуру находит правильное направление
и прыг! скачет изо всех сил (как он думает, в сторону своего домика).
Обучение нейронной сети
113
*
Рис. 3.8. Обучение нейронной сети как блуждание слепого кенгуру в поисках своего
дома
К сожалению, нашего кенгуру (так же как и алгоритм обучения ней-
ронной сети) поджидают различные неожиданности. Если ты вниматель-
но посмотришь на рис. 3.8, то заметишь, что неосторожный прыжок мо-
жет привести кенгуру на дно оврага, который пересекает путь домой.
Еще одна вполне реальная ситуация (не изображенная на этом рисун-
ке. но легко представляемая) в некотором направлении профиль по-
верхности может полого понижаться, но потом он вдруг резко начнет
повышаться. В таком случае длинный г рыжок вроде бы в правильном
направлении способен ухудшить положение кенгуру он окажется вы-
ше (т.е. дальше от цели), чем в момент старта!
Успех несчастного конгурепка зависит, главным образом, от пра-
вильного выбора длины шага. Если он будет перемещаться короткими
прыжками, то дорога домой займет очень много времени. Но если он
решится на длинный прыжок, а на пути встретятся овраги или ямы,
то сделает себе только хуже!
При обучении сети создатель алгоритма также должен принять ре-
шение о величине изменений весов при определенных значениях входных
сигналов и уровнях погрешности. Для этого используется так называе-
мый коэффициент обучения (learning rate). На первый взгляд, его значе-
ние может выбираться произвольно, но каждое конкретное решение име-
114
Глава 3
ет определенные последствия. Выбор слишком малого коэффициента
делает процесс обучения слишком медленным (па каждом шаге веса кор-
ректируются незначительно, поэтому для достижения искомой точпост и
придется выполнить огромное число таких шажков). В свою очередь,
выбор слишком большого коэффициента обучения приводит к слиш-
ком резким изменениям параметров сети, которые в предельном случае
могут дестабилизировать процесс обучения (сеть «мечется», так как не
может найти правильные значения весов они изменяются слишком
быстро для припелыюго «попадания» в искомое решение).
На обсуждаемую проблему можно взглянуть с еще одной точки зре-
ния. Большие значения коэффициента обучения соответствуют позиции
очень требовательного и сурового учителя, которыт слишком жестко на-
казывает ученика за совершаемые ошибки. Такой учитель редко дости-
гает хороших результатов, потому что вводит учеников в замешательство
и вызывает чрезмерный стресс. В свою очередь, малые значения коэф-
фициента обучения соответствуют характеристике слишком «добрень-
кого» учителя; его ученики прогрессируют слишком медленно, потому
что наставник недостаточно заставляет их работать.
ри обучении как сети, гак и учеников необходим компромиссный
выбор, учитывающий и достоинства быстрой работы, и соображения без-
о п ас пости (в силу которых необходима стабильность процесса обучения).
Тем не менее, можно помочь самому себе одним хитрым способом, о ко-
тором я расскажу в следующем разделе.
3.6. Для чего используется момент?
Для повышения скорости обучения при сохранении стабильности се-
ти в алгоритме обучения может быть задействован дополнительный эле-
мент, называемым моментом. Образно говоря, момент повышает инер-
ционность процесса обучения изменения весов становятся зависимы-
ми как от погрешностей, допущенных сетью в текущим момент времени,
так и от развития этого процесса в предшествующей период.
Рис. 3.9 позволяет сравнить процесс обучения с учетом момента и
без него. На рисунке показано изменение трех весовых коэффициентов
(его пало воспринимать как развитие процесса в трехмерном простран-
стве весов). Большие темные точки соответсьтвуют стартовым позициям
(определяемым исходными, т.е. присвоенными до обучения значениями
весов), меньшие светлые точки значениям весовых коэффициентов,
последовательно получаемым в процессе обучения. Предположим, что
минимум функции погрешности достигается в точке «+», а серый эл-
липс очерчивает контур постоянной погрешности ‘ множество значений
Обучение нейронной сети
115
Рис. 3.9. Изменение весовых коэффициентов
сети в процессе обучения без учета коэффици-
ент момента (слева) и с коэффициентом мо-
мента равным 0,5 (справа) при том же числе
шагов
весовых коэффициентов, для которых процесс обучения приводит к од-
ному и тому же уровню погрешности). Рисунок однозначно свидетель-
ствует: учет момента действительно «успокаивает» процесс обучения
(значения коэффициентов изменяются не так резко и часто) и повыша-
ет его эффективность (точки графика быстрее приближаются к точке
«+», в которой располагается искомое решение задачи). В настоящее
время для обучения сети, как правило, учитывается момент, посколь-
ку это ускоряет поиск корректных решений и не слишком повышает
затраты на обучение сети.
Другой способ совершенствования процесса обучения основан на при-
менении переменных значений коэффициентов обучения малых в на-
чале процесса (когда сеть только выбирает направление своей деятель-
ности), больших в середине обучения (когда надо пусть приближенно,
но побыстрее адаптировать параметры сети к заданным принципам ее
функционирования) и снова меньших под конец процесса обучения (ко-
гда сеть окончательно настраивает свои параметры (fine tuning), и слиш-
ком резкие изменения могут повредить уже сформированную структуру
знаний). Отметим, что эти технологии обработки информации, обладаю-
щие математически выверенной структурой и эмпирически доказанной
эффективностью, очень напоминают подходы к обучению, выработанные
опытными учителями-практиками и применяемые к ученикам с низкой
психологическо! устойчивостью! Вне всякого сомнения это еще один
нс первый и не последний) пример удивительной аналогии между пове-
дением нейронной сети и человеческим мышлением.
3.7. С чего начинать обучение нейронной сети?
Любой создатель алгоритма обучения нейронной сети обязательно
сталкивается с проблемой выбора начальных (стартовых) значений ве-
совых коэффициентов. Приведенное выше описание алгоритма обуче-
ния показывает, как можно улучшить значения этих коэффициентов.
Но процесс обучения надо с чего-то начать, поскольку уже в момент
предъявления первого элемента обучающей выборки каждый весовой ко-
116
Глава 3
эффициент сети должен иметь какое-то конкретное значение — без это-
го невозможно рассчитать значения выходных сигналов всех нейронов и
сравнить их с заданными учителем эталонными значениями для выяв-
ления погрешности. Где взять эти начальные значения каждого веса?
Теория обучения нейронных сетей утверждает, что при выполнении
некоторых (довольно простых) условий лилейная сеть может обучиться
и найти окончательные значения весовых коэффициентов : позволяющие
получить правильное решение поставленной задачи, если оно существу-
ет) независимо от начальных значении этих параметров. С нелинейны-
ми сетями ситуация сложнее, поскольку в них процесс обучения может
выйги в точки так называемых локальных минимумов функции погреш-
ности. Практически это означает, что при старте с разных исходных по-
зиций (т.е. с различными наборами значений весовых коэффициентов)
мы можем получать разные параметры обученной сети лучше или
хуже пригодные для решения предъявленной задачи. Это теория, но она
ничего не говорит о выборе удачных стартовых точек...
К сожалению, здесь мы должны обратиться за помощью к эмпири-
ке. Простая и широко применяемая практика- заключается в том. что
начальные значения весовых коэффициентов выбираются случайным
способом. Поскольку все задаваемые параметры получают случайные
исходные значения, обучение стартует из любого, не предсказуемого за-
ранее места в пространстве весов. В первый момент это может показать-
ся странным, но напрашивается вполне логичное объяснение если
неизвестно, где находится искомый минимум функции погрешности, то
лучшим решением оказывается случайный кьтбор!
В имитационных программах и( пользуется специальная инструкция,
«рассеивающая» по сети случайные начальные значения коэффициен-
тов, При этом следует избегать слишком большие значения (чаще все-
го используется интервал от —ОД до +0,1. из которого числа выбира-
ются случайным способом). Кроме того, в многослойных сетях не сле-
дует выбирать нулевое значение, поскольку такой вес блокирует обу-
чение более глубоких слоев (сигналы не проходят через соединение с
нулевым весом, чго практически означает «отсечение» части сети от
последующего обучения).
Об успехах обучения свидетельствует уменьшение погрешности. Этот
проносе сначала развивается очень быстро, потом замедляется и через
некоторое число шагов вообще прекращается. Необходимо помнить, что
процесс обучения, направленный на «натаскивание» одной и той же сети
на решение4 одной и той же задачи, может развиваться по-разному. На
рис. 3.10 показаны три варианта, развития одного и того же процесса,
которые различаются как скоростью обучения, гак и конечным резуль-
татом (в виде значения коэффициента погрешности, ниже которого не
Обучение нейронной сети
117
Число примеров
Рис. 3.10. Уменьшение погрешности в процессе обучения для различных вариантов
обучения одной и той же сети
удается опуститься даже при продолжении интенсивного обучения). По-
скольку все графики относятся к одной и той же сети и одной и той
же задаче, а отличаются только начальными (случайно выбранными до
обучения) значениями весовых коэффициентов, можно говорить об от-
ражении на графиках «врожденных способностей» сети.
В сетях некоторых типов (например, в сети Кохонена) дополнительно
требуется нормировать начальные значения весовых коэффициентов, по
мы поговорим об этом требовании при обсуждении соответствующих се-
тей.
3.8. Как долго надо обучать сеть?
К сожалению, ответ на этот вопрос неутешителен. За использование
процесса обучения вместо «ручного» программирования сети приходится
платить длительностью обучения и с этим придется смириться, посколь-
ку никакой реальной альтернативы не существует. Более того — труд-
но предугадать, как долго потребуется обучать каждую конкретную
сеть, прежде чем она начнет проявлять признаки хоть сколько-нибудь
осмысленного поведения. Иногда это происходит молниеносно, но чаще
всего приходится долго и терпеливо предъявлять элементы обучающей
выборки, прежде чем сеть начнет чуть-чуть понимать, чего мы от нее
хотим. Также придется смириться с фактом, что вследствие случай-
ного выбора начальных значений весовых коэффициентов результаты
обучения одной и той же сети при одних и тех же данных, использу-
емых в качестве обучающей последовательности, могут нес колько раз-
личаться разве что у кого- нибудь хватит времени па многократное
118
Глава 3
обучение сети с последующим выбором наилучшего варианта. С прак-
тическое точки зрения такой подход оказывается слишком трудоемким,
поскольку проводимые нами исследования многократно подтверждают
непреложный факт: одноразовое обучение сети, содержащей несколько
тысяч элементов, длится несколько десятков часов!
И это не единичный результат. Например, из опубликованного в еже-
месячнике Electronic Design обзора явствует, что число презентаций эле-
ментов обучающей выборки, необходимых для обеспечения корректного
решения сетью некоторых задач, равно:
• для распознавания кенийского алфавита 1013;
• для распознавания речи 1012;
• для распознавания рукописного текста — 1012;
• для синтеза речи 1010;
• для финансового прогнозирования — 109.
Другие авторы приводят аналогичные результаты.
Дня повышения скорости обучения разрабатываются новые (отлича-
ющиеся от описываемого нами классического дельта-алгоритма) методы
обучения сети. Считается, что длительность обучения сети алгоритмом
наискорейшего спуска в показательном степени возрастает с увеличени-
ем количества элементов сети, что может оказаться в будущем факто-
ром. принципиально ограничивающим размерность создаваемых сетей.
3.9. Как обучать скрытые слои?
В завершение обсудим проблему обучения сети связанную с нали-
чием в ней скрытых слоев. Как я уже отмечал в предыдущей главе,
скрытым чаще всего называется любой слой за исключением входно-
го и выходного. Суть проблемы обучения скрытого слоя заключается
в невозможности прямого определения погрешности расположенных в
этом слое нейронов — учитель подает эталонные значения только для
сигналов выходного слоя, тогда как сигналы, выработанные нейрона-
ми скрытого слоя (которые в начале обучения тоже, безусловно, име-
ют погрешность), попросту не с чем сравнить. Определенным решени-
ем этой проблемы едал метод гак называемого обратного распростра-
нения ошибки (backpi’opagation)^ впервые предложенный Паулем Вербо-
вом (Гаи1 Werbos) и позднее популяризованный Дэвидом Румельхаргом
(David Rumelhart), с именем которого этот метод чаще всего и ассоцииру-
ется.
Метод обратного распространения основан на отображении предпо-
лагаемых значений погрешностей более глубоких (скрытых) слоев сети
путем переноса на них погрешностей, допущенных в выходном слое. С
Обучение нейронной сети
119
большим упрощением (допустимым па данный момент, потому что в сле-
дующих главах мы будем анализировать этот процесс более подробно)
можно описать указанную процедуру следующим образом: погрешности
всех нейронов, на которые направил свой выходной сигнал некоторый
нейрон скрытого слоя, суммируются с учетом весов связей между этим
нейроном и соответствующими получателями его выходного сигнала. Та-
ким образом, «ответственность» за погрешность распределяется между
нейронами скрытого слоя пропорционально силе их влияния (характе-
ризуемой весом связи’ на выработку сигналов выходного слоя (т.е. на
погрешность, выявляемую при оценке отклика сети).
Последовательное применение этого принципа при пошаговом про-
движении от выхода ко входу сети позволяет найти предполагаемые по-
грешности всех нейронов и выработать предпосылки для корректировки
весовых коэффициентов каждого из них. Конечно, описанная процеду-
ра никогда не обеспечит идеально точный расчет погрешности нейронов
промежуточных слоев, поэтому при обучении такой сети корректиров-
ки оказываются менее точными и удачными, чем при обучении сети без
скрытых слоев. На практике это проявляется упоминавшимся выше зна-
чительным удлинением процесса обучения. Но если принять во внима-
ние значительно более широкие возможности многослойных сетей, то
большие затраты на обучение сети следует признать целесообразными,
даже если ожидаемый результат (в виде корректно функционирующей
сети) удается получить после нескольких десятков тысяч презентаций
элементов обучающей выборки.
С многократным предъявлением всех элементов обучающей выборки
в процессе обучения связан целый ряд дополнительных проблем. Необ-
ходимость такого «цикличного» предъявления этой выборки связана с
тем, что даже при ангельском терпении учителя для обучения сети уда-
ется собрать несколько десятков, иногда несколько сотен, в редких слу-
чаях пару тысяч примеров, но никак не сотни тысяч или миллионы,
а именно столько шагов временами требуется для «дрессировки» сети.
Поэтому мы не имеем иного выхода приходится многократно предъ-
являть сети одни и те же объекты (т.е. комбинации входных сигналов и
соответствующих им эталонных ответов). Однако следует признать чрез-
вычайно неблагоприятной демонстрацию элементов обучающей выбор-
ки в одной и той же последовательности. Такое периодическое обучение
может привести к цикличности изменения значений весовых коэффици-
ентов.. что тормозит процесс обучения и становится причиной многих (в
том числе известных мне лично) неудач. Таким образом, очень большое
значение приобретает рандомизация процесса обучения — случайное пе-
ремешивание обучающей выборки и непрерывное изменение последова-
тельности предъявления сети ее элементов. Это несколько усложняет
120
Глава 3
процесс* обучения, по в большинстве; случаев оказывается предпосылкой
получения хороших результатов.
3.10. Каким образом сеть может
самообучаться?
Этот вопрос мы уже вкратце обсуждали в разд. 3.2 («обучение без
учителя»). Концепция подлежащей решению задачи сводится к требо-
ванию, чтобы сеть самостоятельно нашла способ ее решения без каких-
либо готовых эталонов и примеров. Но возможно ли это? Имеем ли мы
основания ожидать от сети самосовершенствования без единой рекомен-
дации с нашей стороны?
Так вот, при выполнении нескольких простых условии спонтанная
самоорганизация нейронной сети оказывается вполне возможной и даже
относительно легко достижимой. Самая простая концепция самообуче-
ния сети основана на обнаруженном американским физиологом и пет
хологом Дональдом Хеббом (Donald Hebb) явлении усиления связей
между нейронами (либо их группами так называемыми центрами) при
условии их одновременного возбуждения. Так (по мнению Хебба) воз-
никают ассоциации, формируются рефлексы, а также простые формы
моторных и чувственных умений.
При переносе теории Хебба па нейронные сети информатики пред-
ложили метод самообучения, согласно которому сети пред появляется по-
следовательность входных сигналов без каких-либо указаний о спо-
собах их обработки. Сечь просто наблюдает окружающую среду и по-
лучает различные сигналы, никто не информирует ее о значении демон-
стрируемых объектов и зависимостях между ними. Сеть самостоятельно
(па основании полученных ею сигналов) постепенно выявляет значение
каждого объекта и обнаруживает их взаимосвязи. Таким способом сеть
не только получает знания, в известной степени она их создает! По-
знакомимся с этим интересным процессом более подробно.
В результате последовательной подачи на вход сети комбинации ис-
ходных данных в ней формируется определенное распределение вход-
ных сигналов не которые нейроны сети возбуждаются очень ейльно,
другие слабее, а на третьих входные сигналы могут быть просто отри-
цательными. Такое поведение можно иптерпретировагь следующим об-
разом: первые нейроны распознают входные нейроны как «свои» (т.е.
такие, которые они склонны принять), вторые трактуют их «без-
различно», а у третьих эти сигналы вызывают «отвращение». После
расчета выходных сигналов всех нейронов сети изменяются веса каж-
дого нейрона, причем величина корректировки определяется произве-
дением входного сигнала, поданного на соответствующий вход (вес
Обучение нейронной сети
121
которого изменяется), на выходной сигнал нейрона, веса которого
модифицируются. Легко заметить, что таким образом реализуется по-
стулат Хебба: в результате выполнения этой процедуры усиливаются
связи mi >кду источниками с ильных сигналов и нейронами, которые на
них сильно реагируют1.
Детальный анализ процесса самообучения методом Хебба позволяет
утверждать, что в результате последовательного применения описанно-
го алгоритма начальные (чаще всего случайные) «предпочтения» ней-
ронов систематически усиливаются и поляризуются. Если какой-то ней-
рон обладал «врожденной склонностью» к принятого сигналов опреде-
ленного рода, то по мере предъявления очередных входных комбина-
ций он научился все точнее и увереннее распознавать «свои» сигналы.
После длительного самообучения в сети формируются (совершенно са-
мостоятельно) эталоны конкретных типов сигналов, поступающих на
ее вход. В результате этого процесса похожие друг на друга сш налы
будут по мере прогресса обучения все более успешно группироваться
и распознаваться одними нейронами, тогда как другие типы входных
сигналов станут «объектом заинтересованности» иных нейронов. В ре-
зультате сеть сама (исключительно по наблюдениям входных сигналов)
«поймет», сколько классов похожих друг на друга сигналов появляет-
ся на ее входах и сама припишет каждому из этих классов нейроны,
которые смогут их различать, распознавать и сигнализировать. Всего
лишь и в то же время так много!
3.11. Как проводить самообучение сети?
К сожалению, описанный выше процесс самообучения сети имеет
свои недостатки. По сравнению с процессом обучения с учителем са-
мообучение протекает гораздо медленнее. Поэтому при наличии выбора
лучше применять обучение с учителем, чем самообучение. Более того,
без учителя мы никогда нс знаем заранее, какой именно нейрон бу-
дет специализироваться на распознавании конкретного класса сигналов
;например, первый может настойчиво распознавать букву R второй
букву D, третин букву G. но никакая сила не заставит эти нейро-
ны расположиться в алфавитном порядке). Эго создает определенные
проблемы при использовании и ин терпретации результатов работы сети,
например, в системе управления роботом. Отмеченная проблема имеет
еще более принципиальный характер и еще более неприятные послед-
ствия нет никакой гарантии, что при развитии своих начальных (слу-
чайных!) предпочтений каждый нейрон получит настолько узкую специ-
ализацию. которая позволит каждому из них указывать на свой класс
входных сигналов. Напротив, с весьма высокой вероятностью несколько
122
Глава 3
нейронож «захотят» распознавать один и тот же класс сигналов, напри-
мер букву А, но пи один «не решится» распознавать букву В. Поэтому
сеть с самообучением должна быть больше сети, решающей ту же зада-
чу, но обучаемой класс ическим способом, т.е. с участием учителя Соч-
ные оценки дать затруднительно, но наблюдения (как мои собственные,
так и студентов, выполняющих магистерские работы в нашей лабора-
тории) свидетельствуют, что сеть с самообучением должна иметь, как
минимум, в три раза больше элементов (особенно в выходном слое)
по сравнению с количеством вариантов ответов, которые сеть должна
выдавать после завершения обучения.
Щепетильный и очень важный вопрос выбор начальных значе-
ний весов сети с самообучением. Эти значения сильно влияют на ито-
говое поведение сети, поскольку процесс обучения только углубляет и
усиливает определенные тенденции, присутствующие1 в сети с самого
начала. Поэтому качество этих исходных («врожденных») свойств су-
щественно отражается на возможностях сети после завершения обуче-
ния. Если мы не знаем заранее, какую задачу должна будет решать
сеть, то сложно предлагать какой-либо конкретный механизм выбора
начальных значений весов. Тем не менее, если полностью положить-
ся на волю случая, то сеть Iособенно небольших размеров! может ока-
заться неспособной в достаточной степени разнообразить свое функци-
онирование в начальный период обучения, и все последующие усилия
по представлению в структуре сети всех классов входных сигналов мо-
гут оказаться напрасными. Однако можно предложить некоторый ме-
ханизм предварительного «распределения» значений весов на началь!
ной фазе обучения. Этот метод, называемый «convex combination» (кон-
векспое сращивание) (он подробно описывается в моей книге «Нейрон-
ные сети», электронная версия которой доступна в Интернете по адре-
су http://winntbg.bg.agh.edu.pl/skrypty/OOOl/), модифицирует начальные
значения весов так, чтобы повысит}» вероятность равномерного покры-
тия нейронами всех типовых ситуации, появляющихся во входном на-
боре данных. Если данные, используемые па нкчаА!?ной фазе обучения,
не будут существенно отличаться от тех, которые сети предстоит ана-
лизировать и распознавать по запершс-унии обучения, то метод «convex
combination» автоматически создаст удобную стартовую позицию для!
последующего самообучения и обеспечит относительно высокое качество
решения обученной сетью большинства прикладных задач.
Обучение нейронной сети
123
3.12. Контрольные вопросы и задания
для самостоятельного выполнения
1. Каким условиям должен удовлетворять набор данных, чтобы он
мог использоваться в качестве обучающей выборки для нейронной сети?
2. Чем отличается обучение сети «с учителем» от обучения «без учи-
теля»?
3. По какому принципу алгоритм обучения находит направление и
величину корректировки весов на каждом шаге процесса обучения?
4. Каким способом необходимо выбирать значения весовых коэффи-
циентов сети, чтобы инициализировать процесс ее обучения?
5. Когда процесс обучения останавливается сам?
6. Каковы причины неудач при обучении сети и как эти неудачи
можно предотврат ить?
7. На чем основан механизм обобщения знаний, полученных нейрон-
ной сетью в процессе обучения?
8. Как можно получить данные, необходимые для определения в про-
цессе обучения величин изменений весовых коэффициентов нейронов,
лежащих в скрытых слоях?
9. Для чего предназначен коэффициент момента, и чего можно до-
стичь с его помощью?
10. Насколько длительное обучение необходимо нейронной сети? От
чего зависит длительность обучения?
11. Почему применительно к сетям с самообучением часто речь идет
о «выявлении знаний», а не о простом обучении сети?
12. Задание для наиболее подготовленных. Постарайся сфор-
мулировать правило, в соответствии с которым можно будет изменять
коэффициент обучения (learning rate) в процессе обучения так, чтобы
ускорять обучение в безопасной ситуации и замедлять в момент, когда
стабильность обучения оказывается под угрозой.
Подсказка. Рассмотри изменения значений погрешностей, допус-
каемых сетью на последовательных шагах процесса обучения.
Глава 4
ФУНКЦИОНИРОВАНИЕ
ПРОСТЕЙШЕЙ НЕЙРОННОЙ СЕТИ
4.1. Как перейти от теории к практике, или
как использовать программы, предназначенные
для читателей этой книги?
Предыдущие три главы были написаны для предоставления тебе ос-
новных теоретических знаний о нейронных сетях. С этой £лавы начина-
ется практическое изучение сетей. Теперь я буду стараться иллюстри-
ровать все свои выводы с помощью простых программ, которые позво-
лят тебе своими руками «ощутить» функционирование нейронных сетей
и понять основные правила их использования. Все программы (а так-
же необходимые для их выполнения данные) доступны в Интернете по
адресу http://www. agh. edu.pl/tad.
По этому адресу твой Интернет-броузер найдет страницу, которая
детально, таг за шагом описывает все действия, необходимые для по-
лучения (бесплатно и легально!) программ, которыми мы вместе будем
пользоваться при чтении книги. Благодаря этим программам ты не дол-
жен будешь слепо верить в написанное мною о нейронных сетях. С помо-
щью программ ты сможешь самостоятельно выявлять на своем компью-
тере различные' свойства нейронных сетей и при этом получать огром-
ное удовольствие. Нет повода для беспокойства: все, что потребуется,
выполнить одну или две программы-инсталляторы. Если ты уже уста-
навливал что-либо на свой компьютер, то, безусловно, эго сделаешь. Па
всякий случаи, подробная инструкция по инсталляции тоже находится
на указанной WWW-странице — поскольку программное обеспечение
время от времени обновляется, поэтому слишком подробное описание
его в книге может быстро потерять актуальность. Тем не менее, я поз-
волю себе привести несколько скучных (к сожалению!) подробностей
о том, что ты должен сделать.
Скачать сами программы с указанной выше страницы очень про-
сто это действие выполняется одним щелчком мыши (в случае необ-
Функционирование простейшей нейронной сети
125
ходимосчи попроси помочь кого-нибудь, уже имеющего опыт скачивания
ресурсов из Интернета). Эти программы написаны па языке С#. Для их
выполнения па твоем компьютере должны быть установлены библиоте-
ки. которые называются .Net Framework (версия 2.0). Если ты пока
еще не понимаешь, о чем идет речь, не беспокойся, все необходимое про-
граммное обеспечение находи гея в Интерне те по указанному адресу.
Первый шаг, который надо сделать — инсталлировать упомянутые
библиотеки. Этот шаг может оказаться ненужным, если эти библиоте-
ки уже установлены на твой компьютер. Если ты в этом уверен, то шаг
инсталляции .Net Framework можно пропустить, по па всякий слу-
чай я рекомендую его выполнить. Если необходимые программы дей-
ствительно установлены, то инсталлятор сам обнаружит это и выдаст
соочвечствующсе сообщение. Но по указанному выше Интернет-адресу
moi ут храниться более новые версии библиотек. В этом случае инстал-
лятор выполнит свою работу и это хорошо, потому что всегда полез-
но заменить устаревшее программное обеспечение современным. Новые
версии программ могут пригодиться тебе для различных целей, не обя-
зательно связанных с чтением этой книги и выполнением описанных
в ней экспериментов.
Очень важное замечание: Все программное обеспечение, доступ-
ное па странице http://www.agh.edu.pl/tad, легально и бесплатно в рам-
ках образовательной лицензии, предоставленной компанией Microsoft™.
Эта лицензия позволяет бесплатно использовать и развивать технологию
.Net в случае ее применения не с коммерческой целью. Это означает,
что ты можешь пользоваться указанным программным обеспечением без
каких-либо ограничений в рамках описанных в книге экспериментов, а
также можешь использовать его для написания твоих собственных про-
грамм при условии, что нс будешь их продавать.
Вернемся к процессу инсталляции необходимого тебе программного
обеспечения.
После завершения установки библиотек .Net Framework как обяза-
тельно* компоненты всех последующих действий воспользуйся инструк-
циями на указанной Иптсрпет-странице для установки программ, необ-
ходимых для выполнения рассматриваемых в книге примеров. Снова
запустится инсталлятор, который позволит тебе автоматически (т.е. с
твоей точки зрения совсем безболезненно) установить написанные нами
программы. Этими программами ты воспользуешься во время чтения
книги, потому что благодаря им сможешь не только теоретически по-
знакомиться с нейронными сетями, но и практически с ними «поиграть»
(т.е. провести необходимые эксперименты :-) и приобрести очень полез-
ную практику применения механизмов нейронных вычислений. Когда
126
Глава 4
Ш|
Г*ИЙИ
Select Installation Folder
*
Г ill 1 tebVDfTj/ - LZdJ/Jpl^S
r
The installer will install Neural Networks - Examples to rhe following folder
Tо install in this folder, click "Next" Tо install to a different folder, enter it below or click "Browse
Folder
CAF'rogram FilesKFlyszard TadeusiewiczXNeural Networks - Examples
Browse .
Disk Cost
i
*
Inctail Neural Networks - Examples for yourself, or for anyone who uses this computer
l
Everyone
r* Just me
I
Cancel
< Back
Next >
i
Рис. 4.1. Инсталлятор задаст тебе только два вопроса
инсталлятор завершит свою работу, ты получишь доступ к ним через
меню Пуск так же, как к большинству дру] их программ.
Для того чтобы убедить недоверчивых в простоте инсталляции, па
рис. 4.1 показан единственный «сложный» момент этой процедуры, ко-
гда инсталлятор спрашивает пользователя, куда стаповить программы
и кому они должны быть доступны. Даже в этом случае логичнее всего
согласиться с значениями, принятыми по умолчанию, и просто щелк-
нуть на кнопку Next.
Для наиболее верных адептов информатики (а ты один из них пе
правда ли?) предназначены остальные две опции: скачивание исходных
кодов и инсталляция интегрированной среды инструментального про-
1раммного обеспечения Visual Studio.NET.
Первая опция позволяет скопировать на жесткий диск твоего ком-
пьютера понятные для человека (15 первую очередь для тебя!) тексты
всех программ, исполняемые версии которых ггы будешь использовать
при чтении книги. Эго очень интересная возможность, позволяющая те-
бе узнать, как устроены эти программы и почему они работают именно
так, как нам требуется. Наличие исходных кодов позволит тебе если
хватит смелости внести собственные изменения в любую программу.
Хочу ясно и однозначно сказать: для обычного использования опи-
сываемых в книге программ доступ к их исходным кодам совершенно
не нужен. Но при их наличии ты сможешь научиться большему и бе-
Функционирование простейшей нейронной сети
127
лее интересно использовать приготовленные для тебя ресурсы. Стоит
попробовать, тем более, что для получения этих кодов не надо прикла-
дывать практически никаких усилий.
Последняя опция — Инсталляция интегрированной среды ин-
струментального программного обеспечения Visual Studio.
NET предназначена, в первую очередь, для тех, кто захочет модифи-
цировать наши программы для проведения своих собственных экспери-
ментов или даже написать свои оригинальные программы. Одним сло-
вом это опция для амбициозных. Но при желании этим программным
обеспечением смогут воспользоваться и те, кто хочег только просмат-
ривать исходные коды. Имеет смысл потратить 10 15 дополнительных
минут, чтобы просмотр текстов программ стал гораздо более удобным.
Visual Studio.NET —- очень развитая интегрированная среда написа-
ния программ (Integrated Development Environment IDE), приспособ-
ленная для удобного просмотра и редактирования кода. Инсталляция
Visual Studio.NET позволит тебе выполнять множество дополнитель-
ных действий, таких как подключение внешних объектов, легкая диа-
гностика приложений и быстрая генерация окончательно скомпилиро-
ванных версий программ.
Запомни, что инсталляция как исходных кодов, так и Visual Studio.
NET - полностью добровольное дело, и ты сам должен решить, про-
водить ее или нет. Для выполнения программ, с помощью которых ты
сможешь собственными руками создавать и исследовать описываемые в
книге нейронные сети, достаточно установить .Net Framework (первый
шаг) и сами программы (второй шаг).
Ну хорошо, скопировал и инсталлировал все необходимое — что
дальше ?
Для того чтобы воспользоваться каким-либо примером программы,
необходимо выбрать соответствующую инструкцию в меню Пуск/Про-
граммы/Neural Networks — Examples. После запуска нужной про-
граммы в компьютере ты сможешь создавать и анализировать любую
описываемую в книге нейронную сеть. Вначале эго будет сеть с запро-
граммированной мной размерностью и структурой, но после по1руже-
пия в исходный код ты сможешь абсолютно все модифицировать и из-
менять. Запущенная программа позволит сети жить на твоем компью-
тере, ты сможешь обучать ее, тестировать, анализировать, т.е. иссле-
довать. Думаю, что такой способ выявления свойств нейронных се-
тей путем их построения и включения в работу — может оказаться
более привлекательным и расширяющим кругозор, чем любая лекция
или теоретический вывод.
Функционирование нейронной сети сильно зависит от ее структуры
и предназначения, поэтому мы должны будем рассмотреть в следую-
128
Глава 4
ших главах несколько конкретных частных случаев. Поскольку проще
всего понять работу сети, которая служит для распознавания обра-
зов (помимо всего, именно эта область известна мне лучше вес то), нач-
нем обсуждение с нее.
Как уже говорилось выше, такая сеть нолудает на свой вход образ,
а на выходе должна выдать ответ, к какому из выделенных ранее клас-
сов принадлежит изображенный объект (пример такой сети приведен на
рис. 2.34). Задачи распознавания образов решаются сетями, классифи-
цирующими геометрические фигуры, печатные и рукописные1 символы,
контуры самолетов или лица людей.
Как работает такая сеть?
Для ответа на этот вопрос начнем с предельно упрощенной сети
состоящей из единственного нейрона.
Как это? Ведь его и сетью назвать нельзя! В сети должно быть
много нейронов, и они должны соединяться между собой!
Ничего страшного. Оказывается, что даже такой cyppoiar сети мо-
жет делать интересные вещи!
4.2. Чего можно ожидать от единственного
нейрона?
Как ты, безусловно, помнишь, нейрон получает сигналы со своих вхо-
дов, умножает их на весовые* коэффициенты (индивидуально подобран-
ные для каждою входа в процессе обучения) и суммирует полученные
произведения. Сконцентрируемся на некоторое время па этой упрощен-
ной модели. Ты также знаешь, что практически во всех нейронах эта
сумма сигналов преобразуется в выходной сигнал с применением спе-
циально подобранной (как правило, нелинейной) функции. Но поверь
мне, что в нашем первом упрощенном нейроне мы сможем обойтись без
этой функции. Исследуем вначале поведение этого простейшего линей-
ного нейрона. Ог чего зависит величина его выходного сигнала?
Легко показат ь, что она зависит от степени согласованности меж-
ду входными сигналами и весовыми коэффициентами на соот-
ветствующих входах. Конечно, эго правило идеально точно отражает
отношения только между нормализованными входными сигналами и
значениями весов (я сейчас подробно объясню, что под этим понима-
ется). Но Даже без нормализации величина выходного сигнала нейрйна,
может рассматриваться как мера подобия между множеством вход-
ных сигналов и множеством соответствующих им весов.
Можно сказать, что не трон обладает собственной памят ью и храпит
в ней представление знаний, т.е. эталон входных данных (в форме теку-
щих значений весов), к которым он чувствителен. Если входные сигналы
Функционирование простейшей нейронной сети 129
согласуются с хранимым эталоном, то нейрон «распознает» их как ито-
го лакомое и реагирует выдачей сильного выходного сигнала. При от-
сутствии связи между входными сигналами и запомненным эталоном вы-
ходной сигнал нейрона будет близок к нулю (распознавание отсутству-
ет). Также возможна ситуация полной противоположности между вход-
ными сигналами и значениями весов в этом случае? нейрон с линейной
функцией активации вырабатывает на своем выходе отрицательный
сигнал, тем более сильный, чем сильнее противоречие между «представ-
лением» нейрона о внешнем сигнале и его фактическим значением.
Вначале рекомендую тебе познакомиться с простой программой
ExampleOla. Можешь просто запустить эту программу и провести не-
сколько экспериментов, па которые опа ориентирована. Но будет гораз-
до больше пользы, если т ы решишься немного изменить, подправить и
дополнить эту программу. При таком подходе ты узнаешь сети намного
полисе.
Подготовленная для тебя программа создает на компьютере модель
искусственного нейрона. Этому нейрону поручается решение легкой и
приятной задачи: его обязанность — «рассматривать» (на основании опи-
сания! и оценивать цветки. У твоего нейрона будет всего два входа и,
как у любого нейрона, один выход.
На первый вход нейрона ты будешь подавать сигнал о запахе цвет-
ка (Fragrant). Большое положительное значение этого сигнала означает,
что цветок обладает сильным и приятным запахом. Большое отрица-
тельное значение сигнала информирует, что запах тебе не нравится (как
известно, существуют и такие пвегы!). В то же время произвольное ма-
лое' значение (положительное или отрицательное) соответствует слабо-
му запаху «демонстрируемого» цветка. Практически это означает, что
нейрон лишь в незначительной степени будет учитывать это свойство
запах! при выработке своих решений.
Па второй вход нейрона ты будешь подавать информацию об окраске
цветка (Colorful). Мы не будет здесь различать, о каком именно цвете
идет речь (для этого потребовалось бы большое число входов). Снова
воспользуемся едиш твенпым числом, большое положительное значение
которого соответствует твоему мнению о красивой окраске цветка, а
отрицательное значение твоему негативному отношению к его окрас-
ке*. Близкое к нулю значение будет характеризовать «никакую» окраску,
мало существенную для оценивания цветка.
Нейрон должен рассматривать демонстрируемый тобой цветок и
«выражать собственное мнение». Это мнение будет представляться сиг-
налом на выходе нейрона. Программа выведет числовое значение сигна-
ла в соответствующем окошке. Выработанный нейроном положительный
130
лава
°- ^ZunjlhijilLlJJ fcZ'UMpki O'JdJ ,„ J
^Ттд-- - -- T_-l_ _- - 1 1 - И l_ Л. - . - - - - -- - - - — - 1,1- niK -— Т-I---^*T"
/f he neuron that you will be examining will divide the objects you will show it into the ones Д
that it likes and the ones it dislikes.
Let's assume that the recognized objects are flowers
Объяснение
назначения
программы.
Просто
прочитай его
____I
Feature weights
Here you enter the neuron’s weight coefficients for the individual object features. Positive
coefficient means approval to the attribute, and negative one will indicate that the given
\attribute should be disliked by the neuron
Now, enter if you want the neuron to like the flower that is:
Fragrant: JOjO gg
Colorful:
Evaluated object
After setting the weights yout can perform experiments. Eneter if the flower is:
Fragrant:
Colorful:
Neuron’s response
The neuron’s response value is:
It means that the neuron’s attitude against the flower is:
Recalculate!
Рис. 4.2. Окно программы Example Ola сразу после ее запуска
сигнал будет означать, что твой цветок ему понравился. Если же выход-
ной сигнал будет отрицательным цветок пришелся нейрону «нс но
вкусу». Во всех прочих ситуациях (когда значение выходного сигнала
близко к пулю) цветок нейрону безразличен.
Положи тельные или отрицательные сигналы, которые ты будешь
«предъявлять» нейрону, характеризуют твои оценки качеств цветка.
Именно этими сигналами ты сможешь информировать моделируемы]!
на компьютере нейрон: «Вот этот цветок обладает сильным запахом,
который мне нравится, но окраска у него блеклая». Но моделируемый
нейрон может иметь собственное мнение, что ему нравится, а что нет,
поэтому его решения могут тебя удивить!
Наличие у нейрона «собственного разума» подтверждается наличи-
ем у него весов, связанных с каждым входом. Значения этих весов опре-
деляют в соответствии с названием что нейрон считает более ве-
сомым: например- если вес первого входа больше веса второго входа, то
нейрон будет более чувствительным к запаху и менее чувствительным
к окраске цветка. Ты сам будешь устанавливать значения этих весов,
поэтому можешь поэкспериментировать — даже сделать свой нейрон
дальтоником, и он вообще нс будет обращать внимание на окраску цвет-
ка (для этого значение весового коэффициента при втором входе должно
быть близким к нулю). И это еще нс все! Благодаря возможности произ-
вольно выбирать значения весов ты можешь построить нейрон, которым
Функционирование простейшей нейронной сети
131
У Jly t, J . J tS1
—. ..... ...hi..it i ..it»..и, . мгаа> a, .< » «шЯЕйЛмЭ
The neuron that you will be examining will divide the objects you will show it into the ones
that it likes and the ones it dislikes.
Let’s assume that the recognized objects are flowers.
Feature weights
Here you enter the neuron’s weight coefficients for the individ ual object features. Positive
coefficient means approval to the attribute, and negative one will indicate that the given
attribute should be disliked by the neuron.
Evaluated object
After setting the weights, yout can oetform experiments. Eneter if the flower is-
Fragrant 10,0 Colorful: lOO
•»> И» < «»*« ».».<« fc>»» » 11 mwwwiiV»»»?
Neuron's response
The neuron's response value is: 0
It means that the neuron's attitude against the flower is: indifferent [ Recalculate!
Изменяем
предпочтения
нейрона
Рис. 4.3. Начальный этап диалога с программой Example 01а
будет обладать предельно странным вкусом: например, если вес первого
входа будет отрицательным, то нейрон будет сильнее всего любить гот
цветок, который имеет наименее приятный запах!
Но уже достаточно этих теоретических разглагольствований. Мы пи-
сали программы не для того, чтобы рассказывать тебе об их рабо-
те, а чтобы ты сам мог ими воспользоваться! Итак к делу! После
запуска программы Example 01а на мониторе высветится окно, по-
казанное на рис. 4.2, а в его верхней части — текст с объяснением,
что ты должен делать.
Мигающий курсор сигнализирует, что программа ожидает — от те-
бя! ввода значения весового коэффициента того входа нейрона, кото-
рый связан со свойством запах {Fragrant}. Можешь ввести это значение
путем занесения в указанное поле выбранного тобой числа, либо можешь
выбрать одно из значений в окошке (перебирая их с помощью стрелок
«Вверх» и «Вниз»), либо можешь сделать то же самое мышкой (щелкая
по кнопкам стрелок рядом с окошком, в котором задастся значение).
После ввода значения для свойства запах перейди к следующему полю,
которое отвечает за другое свойство цветка окраску {colorful).
Предположим, твой нейрон должен любить яркие и благоухающие
цветы, но решительно отдавать предпочтение окраске. Окно программы
для ввода осмысленных ответов должно выглядеть так, как показано на
рис. 4.3.
132
Глава 4
Теперь укажем
нашему нейрону
какое-нибудь
направление
Вроде бы нейрон
удовлетворился.
Кто сказал,
что цветы
любят только
женщины?
Рис. 4.4. Завершающий этап диалога с программой Example 01а
Кликни эту кнопку,
чтобы увидеть
отклик нейрона
Обсуждаемая программа (как, впрочем, и все последующие?) предо-
ставляют возможность в любой момент скорректировать введенную то-
бой информацию (уточнить введенные данные, изменить решение и т.п.).
Программа старается оперативно актуализировать результаты проводи-
мых вычислений.
После ввода данных о «предпочтениях» нейрона (фактически зна-
чении его весовых коэффициентов) самое время проверить функциони-
рование нейрона. Ты можешь вводить различные комбинации входных
компонент так, как показано на рис. 4.4. а программа рассчитает и сооб-
щит тебе, какой выходной сигнал выработал нейрон, и что он означает.
Не забывай о возможности в любой момент изменить как предпочтения
нейрона, так и описание цветка!
Примечание для любознательных. Ты, конечно, заметил, что
если для ввода данных используется мышка или клавиши управления
курсором (на которых обозначены стрелки), то для получения результа-
та нс обязательно всякий раз щелкать по кнопке Recalculate он пере-
считывается автоматически. Но если ты вводишь числа с клавиатуры,
на эту кнопку приходится нажимать. Причина в том, что в этом слу-
чае компьютер не знает, в какой момент ты закончил ввод, а в какой
просто решил сбегать за бутербродом с колбаской.
На следующем этапе мы будем ставить нейрон в нетипичные ситу-
ации. Сущность эксперимента, показанного на рис. 4.3, заключается в
Функционирование простейшей нейронной сети
133
Какой странный
этот цветок...
Он мне нравится
чуть меньше, но
все равно красивый!
Рис. 4.5. Программа Example 01а попала в нетипичную ситуацию
проверке реакции нейрона на появление объекта, отличающегося от за-
помненного им «идеала» (очень яркого и благоухающего цветка). Мы
предъявили ему по-настоящему яркий, но лишенный запаха цветок. Как
видно, нейрону этот цветок тоже поправился!
Изменениями параметров оцениваемого цветка можно изучать пове-
дение нейрона в любых других обстоятельствах. Примеры таких экспе-
риментов показаны на рис. 4.6. Мы проверили, что сделает нейрон при
vou want the neuron to like the (tower that is’
1.0 [Й Colorful
you want the i leuron to like the Hower that is
Colorful:
you4 can experiments И thMI6(M4rh
: 1.0 ' Colorful 0.0 -
Этот цветок
бесцветный,
но хоть немного
пахнет
some
response value is:
the neuron's alytude-egainsHhe
flcwei is
Фу! На какой
мусорной свалке
ты его нашел?
Этот цветок
не только бесцветный,
но и отвратительно
пахнет
sense
response value is:
the neuron’s attitude' against Hie
Так уж и быть,
пусть остается...
Но на день рождения
хочу более красивый!
Рис. 4.6. Пример другого эксперимента с применением программы Example Ola
131
Глава 4
Рис. 4.7. Еще один пример эксперимента с программой Example 01а
предъявлении ему благоухающего, по практически бесцветного цветка
(этот экземпляр понравился), а потом выдали ему блеклый и, вдобавок,
дурно пахну тип цветок (вот это уже не понравилось).
Теперь предъявим нейрону более серьезную задачу: проверим, как
он среагирует па дурно пахнущий, но очень ярко окрашенный цветок
(рис. 4.7).
Ты видишь, что возможности для экспериментов достаточно обшир-
ны. Теперь попробуй изменить предпочтения нейрона и проверить, как
будет вести себя в разных ситуациях нейрон, который любит, например,
дурно пахнущие цветы (в этом случае весовой коэффициент, отвечаю-
щий за запах, должен быть отрицательным).
4.3. Что еще можно наблюдать в ходе
экспериментов?
Рекомендую уделить счце немного времени экспериментам с програм-
мой Example 01а. При вводе различных значении входных коэффици-
ентов (причем не только целых чисел) и входных сигналов ты быстро
поймешь, что исследуемым нейрон действует по очень простому правилу.
Он рассматривает свои веса как «эталоны» подлежащего распознаванию
входного ( игпала. В момент подачи на вход нейрона комбинации сигна-
лов, которая соответствует введенным ранее весам, он находит в этой
комбинации «что-то знакомое» и с энтузиазмом реагирует па выходе
Функционирование простейшей нейронной сети
135
Рис. 4.8. Представление свойств нейрона как точки и как вектора
в пространстве свойств
формируется сильный сигнал. При вводе малых значений входных сиг-
налов нейрон проявляет безразличие, а при вводе отрицательных зна-
чений — отвращение. Такова его природа!
При ближайшем рассмотрении оказывается, что поведение нейро-
на определяется, главным образом, углом между вектором весов и
вектором входных сигналов. Проверь это, используя следующую про-
грамму, которая тоже будет выявлять цветочные предпочтения нейро-
на — только на этот раз эталон «идеального цветка» будет дополнитель-
но обозначен точкой (или вектором) в так называемом пространстве вхо-
дов.
Понятие пространства входов (и связанного с ним пространства ве-
сов) достаточно важное, но при этом довольно простое. Поэтому имеет
смысл сконцентрироваться на них на какое-то время. На самом деле
вопрос совсем не сложен, хотя на первый взгляд он производит впе-
чатление «тайного знания».
Если ты задаешь конкретные предпочтения нейрона, т.е. указыва-
ешь любит ли он (и is какой степени) благоухающие цветы и (независи-
мо от этого) яркие цветы, то в сущности формируешь компоненты неко-
торого вектора, так называемого вектора весов. Можешь нарисовать
две координатные оси и на одной из них (например, горизонтальной) от-
менить значения веса первого свойства (запаха), а на второй (вертикаль-
ной I значения веса второго свойства (рис. 4.8). Если захочешь обозна-
чить предпочтения конкретного нейрона, можно отметить его положение
на каждой оси, и точка с указанными координатами будет соответство-
вать рассматриваемому нейрону. Например, «безразличный к окраске»
нейрон, «ценяший» только запах цветка, будет представляться точкой,
рас положенной в правой части плоскости (большое значение первой ком-
поненты), но на горизонтальной оси координат (нулевое или совсем ма-
136
Г Л (L в (I 1^.
лое значение второй компоненты). В свою очередь, нейрон, которому
ты хочешь приписать любовь к орхидеям очень красочным цветам
с мизерным, иногда очень противным запахом, будет лежать довольно
высоко на вертикальной оси (высокая оценка свойства «окраска») либо
даже слева от нее (согласие на присутствие неприятного запаха).
Аналогично можно поступить с каждым конкретным объектом (цвет-
ком), который ты «предъявишь» нейрону для оценивания: его окраску
надо отложить на вертикальной оси, а запах на горизонтальней оси.
Если эт о будет ландыш, то ему будет соот ветствовать точка в самой пра-
вой части плоскости (трудно представить себе более прекрасный запах),
но расположенная довольно низко (окраска не самое выдающееся ка-
чество этого цветка). Если же ты решишь показать нейрону гвоздику
точка будет лежач ь высоко (как правило, гвоздика отличается краси-
вой окраской) и, скорее всего, слева от вертикальной оси (запах гвоздик
трудно признать приятным). В левом нижнем углу системы координат
будет располагаться росянка (насекомоядное растение, привлекающее
мух видом, напоминающим гниющее мясо, и таким же запахом), тогда
как величавые розы, наверняка, займут правый верхний угол.
При обсуждении нейронных сетей удобно обозначать конкретные объ-
ект ы «например, оцениваемые цветы, а также «представление» нейрона
об образе идеального цветка) не только в виде точек в пространстве сиг-
налов, но и в виде векторов. Каждые вектор получается соединением
обозначенной па графике точки с началом координат. Именно так Дей-
ствует программа Example 01b, которую так же, как и предыдущую
программу, ты найдешь в своем меню Пуск*. При использовании этой
программы обрати внимание па следующие факты:
• величина выходного сигнала нейрона зависит, главным образом, от
угла между входным вектором (представляюшим входные сигналы]
и вектором весов («идеальным эталоном», апробированным нейро-
ном). Это иллюстрируется рис. 4.9;
• если угол между входным вектором и вектором весов мал (т.е. век-
торы расположены близко друг к другу), го нейрон выдаст сильный
положительный сигнал;
• если угол между входным вектором и вектором весов велик (т.е.
векторы расположены под углом. значительно превышающий 90°);
то нейрон выдает сильный отрицательный сигнал;
• если угол между входным вектором и вектором весов близок к 90'.
то йейроЦ выдает слабый нейтральный сигнал (близкий к пулю!
независимо от направления входного век гора.
Если ты еще не инсталлировал обсуждаемые проГрамКгы, то сделай это именно
сейчас приключения только начинаются...
Функционирование простейшей нейронной сети
137
А Значения весов нейрона
для свойства цвет, а также
значение этого свойства
для конкретного цветка
Точка, представляющая
свойства нейрона
Окраска
цветка
«Любимый»
цвет нейрона
«Любимый»
запах нейрона
Точка, представляющая
свойства цветка
Угол, определяющий отклик нейрона
Запах Значения весов нейрона
цветка для свойства залах, а также
значение этого свойства
для конкретного цветка
Рис. 4.9. Взаимное расположение вектора весов и вектора входных сигналов
как фактор, предопределяющий величину выходного сигнала нейрона
Ты можешь самостоятельно исследовать с помощью программы
Example 01b все отмеченные свойства и характерные особенности по-
ведения нейрона. Конечно, формируемые этой программой рисунки не
настолько графически совершенны, как рис. 4.9, но они достаточно чи-
табельны для получения тобой собственных впечатлений о функциони-
ровании такого одиночного нейрона.
Здесь «расположены» Здесь можно Аналогичный элемент ты обнаружишь во многих
веса входов нейрона увидеть наших программах. Если поместить на нем курсор мышки
(клик правой кнопкой) их значения и немного подождать, то сможешь прочитать подсказки
Рис. 4.10. Окно программы Example 01b с обозначенным aj алойным объектом
138
Глава 4
«Цветок» мы разместим
здесь (клик левой кнопкой)
Здесь ты можешь
увидеть его координаты
Здесь программа показывает
выходной сигнал нейрона
Рис. 4.11. Представление положения входного вектора, для которого выходной сигнал
положителен
Интерфейс программы интуитивно понятен. Ты должен только щел-
ка ть мышкой по плоскости изображенного слева графика. Вначале щелк-
ни правой кнопкой мыши для фиксации положения выбранной гобой
. . , . .. м .. { , ,и.
Click to perform ез penmerrt1 See emanations.
I he rptjrnn that you will be eoriwi ng twill d v^de the objects you
ивГ show it «nto the ones that it likes and the ones it dislikes'
F-*3t ле weights (rnodel object)
w(2) =
Evaluated ob^ct
X(1) ®
3,2
М2)«
Neuron’s response:
Graph
’ ra Key:
- Le M odel object
Evaluated ot’ieci
54
-58,899402
ГЛ
7 4
Наш «цветок». На этот раз нейрон его не потеряет,
поэтому на экране он показан голубым цветом
Рис. 4.12. Представление нФЛожения входного вектора, для которою выходной сигнал
отрицателен
Функционирование простейшей нейронной сети
139
5,4
х(2Ь
I?
Neuron’s response:
0,91183189
Click to perorm experiment! See expies ons
The neuror that you wip be examiraig will divide the obi sc*s you
will show t into the one; thar it I kes and the one? it dislikes.
Evaluated object
xil)= -6,1
Pealu'e weights [model
w[1]= 5,9
Graph
Key:
-J Model object
Ev akiateo object
ob^c i
w[2]' =
Рис. 4.13. Представление положения входного вектора, для которого
выходной сигнал нейтрален
точки, соответствующей конкретным значениям весовых коэффициен-
тов нейрона (рис. 4.10). Программа покажет эту точку и ее координаты.
Конечно, ты в любой момент можешь сменить эту точку достаточно
щелкнуть мышкой в другом месте графика или вручную модифициро-
вать ее координаты, так же как это делалось в программе Example 01а.
Теперь щелкни на графике левой кнопкой для выбора местоположения
«цветка» и получи ответ программы. Если нейрону предъявленный цве-
ток «нравится» (в правой части экрана появится значение выходного
сигнала, по которому легко понять «мнение» нейрона о твоем цветке),
то соответствующая точка на графике будет помечена красным цве-
том (как вершины гор на карте на рис. 4.11). Если отношение нейрона
к цветку отрицательно, точка будет синей (как дно океана на карте на
рис. 4.12). Если же реакция нейрона нейтральна, то соответствующая
точка па графике буде бледно голубой (рис. 4.13). Через некоторое вре-
мя ты, безусловно, сформируешь собственное мнение о форме областей в
пространстве входных сигналов, соответствующих конкретным решени-
ям. Для лучшего понимания структуры этих областей можешь попробо-
вать «проползти» мышкой по графику с какой-либо нажатой кнопкой
так ты сможешь наблюдать плавное изменение результатов.
4.4. Как справиться с большим количеством
входов нейрона?
Приведенные выше примеры были предельно простыми, так как опи-
сывали один нейрон всего с двумя входными сигналами. В реальных
приложениях нейронных сетей мы, как правило, имеем дело с задача-
ми с огромным количеством входов (потому что искомое решение чаще
всего зависит от большого количества разнообразных входных данных).
140
Глава 4
Рис. 4.14. Начало диалога с программой Example 01с
В этих приложениях также задействовано множество нефронов для
обеспечения такой степени сложности проводимых сетью вычислений,
которая необходима для корректного решения рассматриваемой задачи.
Именно в этом месте «закапчиваются шутки (о нейронных сетях) и
начинаются ступеньки»*. Нарисовать это невозможно (поскольку никто
не может представить себе точку в пространстве, имеющем полтора де-
сятка координат!), и поэтому всем кажется очень сложным понять, как
работает такая сеть. На самом деле, все не так страшно. Сейчас ты в
этом убедишься. Запусти программу Example 01с (рис. 4.14).
Вначале программа запросит ввести число входов нейрона. Ты смо-
жешь согласиться со значением по умолчанию (5) и щелкнуть Next.
Далее, так же как в программе Example 01а, необходимо ввести значе-
ния весовых коэффициентов, т.е. эталон сигнала, на который твой ней-
рон должен реагировать. Размести эти значение в столбце, обозначенном
Эта очень популярная в Полый»' поговорка может быть не совсем понятной для
россиянина, поэтому я позволю себе принесли соответствующее предание (прекрасно по-
нимаю, что к нейронным сетям оно имеет очень косвенное отношение). В одном из Вар-
шавских кафе на втором паже была комната, в которой любили встречайся артис 1ы.
А поскольку длина артиста требует алкогольной подпитки время там проходило очень
весело, с обильным «увлажнением» рас сказываемых баек хорошей водкой и коньяком
К сожалению, любое веселье когда-нибудь закапчивается, и возникала необходимость
спуститься со второго этажа но крутой лестнице'. Для многих участников этот спуск ча-
сто заканчивался болезненным падением вследствие фатального разбалансирования (под
действием алкоголя) артистических нейронных сетей. Поэтому поговорка «заканчивают-
ся шутки и начинаются ступенькй» понимается в Польше как напоминание, что после
приятного и необременительного времяпровождения приходится возвращаться к делам
менее веселым, но необходимым.
Функционирование простейшей нейронной сети
141
сУ г
Perform experiments
Enter the input weights and signal
values in the table below.
Output
Input signal strength.
Г.
Memory trace strength:
Г"
m г....№.
imiV .ifa.
г
Веса Входной сигнал
Рис. 4.15. Продолжение диалога с программой Example О1с
w(i) (рис. 4.15). После этого введи значения входных сигналов в столбец
x(i) — программа самостоятельно рассчитает и сообщит тебе значение
выходного сигнала. Не правда ли, совсем просто?
Не обращай пока внимание на сообщения программы о каких-то си-
лах (strength быть может, речь идет о силах тьмы?). Со временем ты
узнаешь, для чего они могут пригодиться.
В процессе экспериментирования с этой программой ты заметишь,
что несмотря на перемещение в пятимерном пространстве весов и сиг-
налов (таким пространством даже Альберт Эйнштейн не занимался он
остановился на четырех измерениях), поведение нейрона относительно
легко предсказуемо. Если значения последовательно вводимых компо-
нент вектора входных сигналов будут похожи на значения соответству-
ющих координат вектора весов (программа услужливо напоминает эти
координаты при вводе входных сигналов), то значение выходного сигна-
ла нейрона будет большим. Это вполне объяснимо и довольно очевидно:
похожие значения компонент весов и соот ветствующих компонент вход-
ных сигналов означает близость вектора весов к вектору входного сигна-
ла. В свою очередь, если значения компонент вектора входного сигнала
будут близки соответствующим значениям компонент вектора весов, но
с обратным знаком, то вектор входного сигнала будет направлен в сто-
142
Глава 4
рону, противоположную вектору весов. Результат очевиден в качестве
реакции па такое возбуждение нейрон будет выдавать сильный отрица-
тельный сигнал. И, наконец, если при вводе входных сигналов ты не
будешь стараться соблюдать какое-то соответствие между ними и векто-
ром весов, то с большой вероятностью тво! многомерный нейрон проявит
к таким сигналам полное безразличие и станет вырабатывать па своем
выходе очень небольшие (по абсолютной величине) выходные сигналы.
При проведении экспериментов ты заметишь еще одну закономер-
ность. Большие значения выходного сигнала нейрона можно получить
двумя способами: либо подачей на его входы значений, близких к зна-
чениям соответствующих этим входам весов (что можно было ожи-
дать), либо подачей очень больших значений сигналов на входы с по-
ложительными значениями весов. Первый способ получения больших
значений выходного сигнала интеллигентен... и элегантен. Но тот же (а
иногда даже лучший) эффект можно получить с применением грубом
силы, т.е. второго способа. По этой причине при вводе входных сигналов
необходимо стремиться к тому, чтобы их «сила» всегда оставалась при-
мерно одинаковой (для этого компьютер выводит значение параметра,
характеризующего фактическую «силу» сигнала). Только в этом слу-
чае ты сможешь корректно интерпретировать и сравнивать результаты.
Аналогично, при сравнении поведения различных нейронов (имеющих
различные векторы весов) при одних и тех же входных сигналах необ-
ходимо стремиться к примерно одинаковым значениям «силы запомнен-
ного сигнала», т.е. длины вектора весов. В сети с большим количеством
нейронов значение «силы» входных сигналов радикально уменьшается,
поскольку одни и те же сильные или слабые сигналы подаются на
все нейроны, а результат определяется разностью выходных сигналов,
выработанных нейронами с большей и меньшей «приспособленностью» к
входному сигналу. Пучь ниже мы обсудим этот вопрос подробнее. Но ври
исследовании поведения одиночного нейрона проблема разной величины
входных сигналов может несколько искажать образ и затруднять интер-
претацию результатов. Поэтому договоримся о следующем: при выборе
входных сигналов для экспериментов с нейроном ты будешь старать-
ся задавать такие значения, чтобы сумма их квадратов (приближенная,
поскольку высокая точность здесь нс требуется) принимала раз и на-
всегда установленное значение — например, между 5 и 35. Поскольку
программа рассчитывает силу сигнала как корень квадратный из сум-
мы квадратов его координат (именно такой вид имеет формула расчета
Длины вектора), то сила сигналов должна лежать в интервале между
квадратными корнями из 5 и 35, т.е. где-то между 2 и 6.
Почему имеггно столько? Потому что при экспериментировании с
программой я убедился: при подаче случайных малых нелых значений
Функционирование простейшей нейронной сети
143
на пять входов нейрона оценка силы, как правило, будет принимать при-
мерно такие значения. Но при желании ты можешь выбрать любое иное
значение и, пожалуйста, придерживайся потом именно его. Таким же
ограничением следует руководствоваться при выборе значений весовых
коэффициентов (оно пригодится тебе в будущем поверь мне!), бла-
годаря этому облегчается проверка «соответствия» вводимых входных
сигналов значениям весов.
4.5. Как ведет себя простая линейная
нейронная сеть?
Предположим, что нейронов не-
сколько и они образуют сеть. Пусть
наша сеть будет пока однослойной
(т.е. нейроны соединены не между со-
бой, а только с входом и выходом,
рис. 4.16).
Вводимые тобой сигналы будут
подаваться непосредственно на входы
всех нейронов, а выходные сигналы
этих нейронов будут, в свою очередь,
рассматриваться как отклик всей се-
ти поставленную перед ней задачу.
Как функционирует такая сеть
Рис. 4.16. Структура, однослойной
нейронной сети
»
Любой нейрон имеет свой собственный набор весовых коэффици-
ентов, поэтому он готов распознавать какое-то конкретное множество
входных сигналов. При этом каждый нейрон, разумеется, имеет свой,
уникальный эталон распознавания. Поэтому, когда ты подаешь на вход
сечи какой-либо входной сигнал, каждый нейрон вырабатывает незави-
симо от других нейронов собственный выходной сигнал, которыл ока-
жется большим для одного нейрона (который распознает «свой» эталон)
и меньшим для всех остальных элементов сети. При наблюдении выход-
ных сигналов всех нейронов можно легко сориентироваться, какой эта-
лон «выбран» сетью |на основании того, какой нейрон выдал наиболь-
ший сигнал). Ты также можешь оценить, насколько сеть «уверена» в сво-
ем решении Для этого необходимо сравнить выходной сигнал нейрона-
«победителя» с выходными сигналами Остальных нейронов сети.
Иногда именно это свойство сети, позволяющее выявлять неопреде-
ленные и неоднозначные ситуации, оказывается наиболее практически
полезным. Нет ничего вреднее алгоритма, чрезвычайно уверенно и одно-
значно высказывающего некоторое мнение на основании неполных дан-
пых и методов приближенного вывода. Если такой алгоритм применяет-
144
Глава 4
ся с умом, то он тоже может оказаться полезным. Однако люди склонны
тем больше доверять компьютеру, чем меньше его понимают. Предста-
вим себе глупца, вооруженного экспертной системой с почти случайным
выбором решения, образ мартышки с бритвой на фоне такого ужаса
покалкется детской страшилкой...
4.6. Как построить простую линейную
нейронную сеть?
Обратимся к следующей простой программе. Она называется Exam-
ple 02 и призвана помочь тебе поиграть с очень маленькой нейронной
сетью. Очень рекомендую тебе после знакомства с этой сетью самосто-
ятельно написать аналогичную программу для решения какой-либо ре-
альной задачи.
Описываемая программой Example 02 сеть распознает животных.
Выделяются три категории зверей (млекопитающее, рыба, птица),
поэтому сеть состоит из трех нейронов. При распознавании учитыва-
ются пять свойств, поэтому каждый нейрон имеет пять входов. На эти
входы подаются следующие данные:
• сколько у животного ног;
• живет ли око в воде, умеет ли летать:
• покрыто ли оно перьями;
• рождается ли оно из яиц.
Дня каждого конкретного нейрона я заранее задал значения весов
так, чтобы комбинация весов соответст вовала эталону одного из живот-
ных. Итак, для первого нейрона, который должен распознавать млеко-
питающее, установлены следующие веса входов:
4 млекопитающее имеет четыре ноги;
0,01 млекопитающее иногда живет в воде (тюлень), хотя для ви-
да в целом это нетипично;
0,01 млекопитающее ино1да умеет летать (летучая мышь), хотя
для вида в целом это нетипично;
— 1 млекопитающее не имеет' перьев;
1,5 млекопитающее живородящее, и это его важная особенность.
Для второго нейрона для распознавания птицы, веса такие:
2 — у птицы две ноги;
-1 птицы не живут в воде (утка плавает только на поверхности!);
2 птица, как правило, эго для нее важно умеет летать
(исключение: страус);
2,5 птица покрыта перьями и это ее важная особенность;
2 птица яйцекладущее животное.
Функционирование простейшей нейронной сети
145
The neural network in this example uses, five features to re* ognze three classes ot animal; Its
we ght coefficients are pi edefrned and shown tn the table below
T о test the network beha юг, enter the input s ignals in the rightmost column and read the
output va.ues from the bottom ow
Feature mammal bird i fish Input vector
number df ieg’i 4 2 1 0
lives in water 0.01 1 3.5 0
can fly СД1 2 0.01 0
I 1 has feathers -1 co СЛ '2 0
egg laying -1,5 2 1.5 0
Output Recalculate output! I
□ Show the winner
Рис. 4.17. Начало работы программы Example02
И для третьего нейрона, идентифицирующего рыбу, выбраны веса:
1 у рыбы нет ног;
3,5 рыба живет в воде, и это ее важнейшее свойство;
0,01 — рыба, как правило, не умеет летать (исключение летучая
рыбка);
- 2 рыба никогда не покрыта перьями или чем-либо их напомина-
ющим;
1,5 рыба, как правило, яйцекладущее животное*; впрочем, для
рыбы это не настолько важное свойство, как для птицы, исключение
составляют живородящие рыбы.
Программа Example 02 после запуска выводит на экран информа-
цию о приведенных выше значениях весовых коэффициентов всех входов
каждого нейрона (рис. 4.17) и предоставляет тебе возможность провести
ряд очень забавных экспериментов, которые описываются в следующем
разделе.
4.7. Как использовать представленную
нейронную сеть?
Как я уже говорил, программа Example02 предполагает наличие
у сети трех выходов, связанных с распознаванием трех видов объектов
(животных): млекопитающих, птиц и рыб. Поскольку сеть однослой-
ная, то она содержит только три нейрона- хотя в будущем ты познако-
мишься с сетями, в которых количество нейронов значительно больше
Просто рыбьи яйца называются икрой! Прим, перев.
146
Глава 4
количества выходов. С учетом простоты структуры описываемой сети
ты можешь олень легко Расширить ее до любого количества выходов.
В рассматриваемом примере на вход сети подается только нять сит-
палов, соответствующих конкретным свойствам распознаваемых объек-
тов. Конечно, самым банальным образом ты можешь увеличить коли-
чество таких свойств, если в стоящей перед тобой задаче будет больше
входных данных. Все входные сигналы подаются на каждый нейрон, что
отвечает так называемому «принципу лени»: если тебе не хочется раз-
думывать, на какие конкретные выходы сел и влияют какие входные сиг-
налы, то лучше всего выбрать способ коммутации «каждый с каждым».
В нейронных сетях так поступают практически всегда, поэтому имеет
смысл начинать привыкать к такому подходу.
Для тебя будет очень полезно немного поразмышлять над тем, как
будут подаваться входные сигналы в сеть. Среди них имеются сиг-
налы числового характера (информация о числе ног у животного), а
также сит налы, отражающие свойства логического харак тера (живет ли
живот ное в воде, умеет ли летать, покры то ли перьями, размножается
ли яйцами). Относительно последних сигналов необходимо договорить-
ся, каким способом они будут представляться в сети, поскольку ней-
роны оперируют — я раньше уже обращал па это внимание значе-
ниями сигналов, а не символами (такими, как истина и ложь). По-
скольку решение не столь очевидно, позволь поделиться с тобой неко-
торыми соображениями.
Если ты считаешь себя информатиком (подозреваю, что это неда-
леко от истины, поскольку ты интересуешься нейронными сетями), то
прекрасно понимаешь, что понятия истина и ложь очень хорошо опи-
сываются в двоичной форме: 1 истина, О ложь. Если же ты Крутой
информатик -к тому же, рассекающий в Ассемблере), и каждую ночь те-
бе снятся регистры микропроцессора, шестнадцатеричны* дамп памяти
и апплеты Java, то именно такое представление истины и лжи будет для
тебя очевидным, единственно правильным и абсолютно естественным.
Я должен тебе кое-что разъяснить. При по1ружении в сфе ру нейрон-
ных сетей ты будешь вынужден несколько модифицировать некоторые
прежние привычки. Сейчас ты встретишься с этой необходимостью в
первый, но не в последний раз!
Запомни, что нуль в нейронной сети оказывается весьма глупым
сигналом (сигналом, которого нет, которьй не приносит никакой инфор-
мации). Это обусловлено способом функционирования нейронов, кото-
рые умножают с игналы на веса и суммируют их. Но умножение па пуль
всегда приносит один и тог же неинтересный результат независимо от
значения веса, которое отражает накопленные нейроном знания!
Функционирование простейшей нейронной сети
147
Использование нуля в качестве значения входного сигнала лишит те-
бя определенных возможностей влияния на поведение сети, что неразум-
но и нецелесообразно. Поэтому в наших программах мы придерживаемся
правила, которое я рекомендую тебе всегда применять в нейронных се-
тях: истина обозначается сигналом +1, а ложь сигналом -1. Такие
«биполярные» сигналы действительно лучше решают свои задачи!
Дополнительное преимущество биполярной нейронной сети — воз-
можность применения (при вводе данных) произвольных значений
входных сигналов, которые могут отражать представления пользовате-
ля сети о важности тех или иных сведений. Например, ты можешь при
вводе описания трески признать существенным факт ее жизни в воде
и подать на соответствующий вход сигнал +2 вместо +1 (что можно
интерпретировать как возглас «ну да, конечно!», вместо холодного «да,
это правда»). В других случаях ты можешь вводить значения, меньшие
единицы (например, при вводе ответа на вопрос «умеет ли летать1!».
Относительно летучей рыбки могут быть некоторые сомнения — стоит
ли давать ответ +1 (который бесспорен при описании орла), поэтому
уместны некие колебания на уровне +0,2, что интерпретируется как
«немножко..»). Действительно, возможности здесь безграничны, напри-
мер при вводе сигнала, соответствующего понятию «имеет хвост», для
змеи следовало бы задать значение +10 {«исключительно длинный!»).
Поскольку ты уже знаешь, как вводятся сигналы в сеть, давай попро-
буем вместе провести несколько простых экспериментов. Введи описа-
ния нескольких произвольно выбранных животных и проверь, насколь-
ко правильно сеть распознает их. При этом ты сможешь заметить, что в
сети, состоящей из нескольких элементов, нормализация входных сигна-
лов (т.е. забота о примерном равенстве их «силы») имеет гораздо мень-
шее значение. В частности, именно к такому выводу ты придешь при
вводе для лисы следующего набора значений:
4 (ноги);
- 1 (не живет в воде);
- 1 (нс летает);
0,9 (не покрыта перьями разве что только в момент поимки
гуся...);
- 1 (не откладывает яйца);
или такого набора значений:
8 (у лисы четыре ноги, но это так важно, что не грех сказать дважды);
6 (не терпит воду, особенно в лунках и прорубях!);
-3 (абсолютно не летает, хотя иногда очень хочет...);
5 (рыжая шубка важный опознавательный знак);
148
Г лава
а jjnjpk Iblisdr ЛзОГп! pZiinjpk 92 J
Bl®
The neural network in this example uses five features to recogtnze three classes of animals Its
weight coefficients are predefined and shown in the table below.
Tо test the network behavior enter the input signals in the rightmost column arid read tr.e
output values from the bottom low
Feature mammal bird fish Input vector
number of legs 4 2 -1 4
lives in water 0 01 1 3,5 -1
can fly 0,01 2 0 01 -1
[ “ 1 has feathers -1 egg laying -1,5 2,5 2 -2 15 -1 -1
Output 18,48 2,5 -7,01 Recalculate output1
[J Show the winner
Рис. 4.18. Распознавание с помощью сети типичного млекопитающего
9 (не обкладывает яйца и категорически отвергает малейшие' подо-
зрения в этом!).
Необходимо отметить, что программа Example02 может не толь-
ко корректно распознавать типовые ситуации правильно идентифици-
ровать каждого типичного Представителя млекопитающих, птиц и рыб
(рис. 4.18, 4.19 и 4.20)). Сеть достаточно разумно ведет себя в нетипич-
ных ситуациях, например она распознает как млекопитающее тюленя,
летучую мышь и даже утконоса (странное австралийское млекопитаю-
jj/nph lifjj'jj fjjuriil нашшк 92j
The neural network in this example uses five features to recognize three classes ot animals. Its
weight coefficients are predefined and shown in the table below
Tо test the network behavior enter the input signals in the rightmost column and read the
output values from the bottom row.
Feature mamro al bird fish Input veci or
number of legs 4 2 -1 2
lives m water 0,01 1 3.5 -1
can fly 001 2 0.01 2
has feathers -1 2,5 -2 2
egg laving -1.5 2 1.5 1
Output 4,51 16 -7,98 Recalculate output!
П Show the winner
Рис. 4.19. Функционирование программы в процессе рас познавания птицы
Функционирование простейшей нейронной сети
149
The neural network in this example uses five featui es to recogn.ze thi ее classes of animals Its
weight coefficients are predefined and shown in the table below.
i
To test the network behavior,, enter the input signals in the rightmost column and read the
output va'ues from the bottom ‘ow
I Show the winer **
Рис. 4.20. Функционирование программы в процессе распознавания рыбы
щее, которое откладывает яйца), а в качестве птицы — не летающего
страуса! Не страшны сети и летучие рыбки, которых она также распо-
знает «без промаха». Убедись в этом сам!
В то же время, сеть попадет в ловушку ври демонстрации ей змеи
(нет ног, живет на суше и откладывает яйца???). В таком случае все ней-
роны с волнением извещают, что ЭТО не является обычным животным
'все выходные сигналы имеют отрицательные значения). В контексте
принятых принципов классификации выглядит вполне осмысленно.
Описанная сеть очень примитивна и иногда ошибается, например она
упорно считает черепаху млекопитающим (четыре ноги, живет на су-
ше, но откладывает яйца — возникают сомнения...), а также относит
к млекопитающим двоякодышащих рыб (во время засухи они живут на
суше — можешь проворить), по это уже такая своеобразная красота ней-
ронных сетей они умеют мыслить очень оригинально. Если кто-то из
читателей пи разу не ошибался, пусть первый бросит в монитор камнем!
4.8. Как и для чего в нейронную сеть вводится
конкуренция?
В практических приложениях иногда используется дополнительный
механизм «конкуренции» между нейронами, который в некот орых слу-
чаях позволяет существенно улучшить результаты функционирования
сети. Мы сможем наблюдать работу сети с конкуренцией {competition
network), если введем в уже знакомую нам структуру для распознава-
ния животных элемент, сравнивающий между собой выходные сигналы
150
Глава 4
а:.г 3‘шрЬ 1шу;л гниги! bzanipb fJ>;
The neural network in this example uses five features to recogn ze three classes of animals. Its
weight coefficients are predefined and shown in the table below.
T о test the network behavior enter the input signals in the rightmost column and read the
output Values from the bottom row
Feature mammal bird fish Input vector
number of legs 4 2 -1 2
lives in water 0 01 -1 3,5 . . -1
can fly 0,01 2 0 01 -1
has feathers 1 2,5 2 2
| egg-laying -1.5 2 1,5 \ 2
Output 2,98 6,51 Recalculate output!
Show the winner
Winner
And Hie winner is Neuron 2
Because of this, the network claims Th IS IS 3 bird
Threshold 5,0
Рис. 4.21. Пример функционирования программы Example 02 с включенном
конкуренцией нейронов
всех нейронов и выбирающий из них «победителя». Победителем в та-
кой конкуренции становится нейрон с наибольшим значением выходного
сигнала. Выбор победителя может иметь различные последствия I напри-
мер, только этому нейрону будет1 предоставлено право обучения это
характерно для сетей Кохонена, о которых я буду рассказывать очень
подробно, но гораздо ниже). Чаще всего победитель выбирается для уси-
ления поляризации выходных сигналов сети, например только нейрон-
«победитель» имеет право отправить свой сигнал во внешнюю среду, то-
гда как сигналы всех остальных нейронов обнуляются. Такой принцип
функционирования сети, называемый WTA ( Winner Takes All— победи-
тель получает все), облегчает интерпретацию поведения сети (особенно
если опа имеет несколько входов), но несет1 в себе ряд упомянутых выше
опасностей. Лучше всего сам изучи работу такой сети — для этого введи
элемент1 конкуренции в уже апробированную программу, моделирующую
распознавание животных. Запусти еще раз npoj рамму Example02, по в
этот раз поставь галочку в поле Show the winner. В этом случае про-
грамма после «прохождения» сигналов по сет и выделит нейрон, имею-
щий наибольший выходной сигнал, т.е. вынесет однозначный «вердикт».
Пример такого функционирования показан на рис. 4.21.
Обрати внимание: при наличии конкуренции в качестве базы для
принятия решений рассматриваются только положи юльные выходные
Функционирование простейшей нейронной сети
151
7- -у . ' к-*, • ' ' р .
°- ’Ллр'и linW лДЬ-I’jjk р/шьр’у fJ2j
The neural network in this- example use^ five featuies to recognize three classes of animals Its
weight coeffic ents are preclef ned and jhewn in tne table below.
T о test the netwrrk behavior, enter the input signals in the rightmost column and read the
output vaiues from the bottom row
Feature mammal bird hsh Input vector
number nf legs 4 2 1 T
lives in water 0.01 1-1 3,5 -2
can fly 0.01 j2 0.01 -2
has feathers -1 2.5 [-2 -2
egg-laying -1.5 2 1.5 2
Recalculate output!
Output -1.04 -3 -0,02
yj Sho w the winne;
Winner
And the winner is
Because of ths, the network claims This is something strange*
Threshold 5,0 Й
(There is no winner)
Рис. 4.22. Сеть с конкуренцией пытается распознать змею
сигналы. Если все выходные сигналы будут меньше заданного в про-
грамме «порога» (ты можешь выбрать его произвольно, достаточно из-
менить значение в поле Threshold) , то в качестве выходного сигнала
будет выработан сигнал об отсутствии решения (рис. 4.22).
Очень рекомендую тебе воспользоваться программой Example 02 и
провести ряд экспериментов с описанной сетью в режиме конкуренции.
Ты убедишься, что эта сеть в отличие от ранее использовавшейся
«обычной» линейной сети обладает несколькими симпатичными осо-
бенностями: она выдает более категоричные ответы, более того, тексто-
вые (а не только числа, требующие дополнительной интерпретации). Тем
нс менее, эта сеть тоже имеет ряд серьезных ограничений, с которыми
ты познакомишься при чтении следующих глав книги.
4.9. Как еще можно использовать нейронную
сеть?
Обсуждавшаяся выше сеть предназначалась для распознавания не-
которых наборов данных, рассматривавшихся как множества свойств
идентифицируемых индивидов. Но это не единственно возможное при-
менение простых однослойных сетей, состоящих из нейронов с линейной
функцией активации. Сети такого типа широко применяются для мно-
гих других целей, например для фильтрации сигналов (особенно в каче-
152
Глава 4
стве адаптивных фильтров, свойства которых изменяются в зависимости
от ситуации). Известны их многочисленные приложения в различных
системах преобразования сигналов (речи, музыки, видео, Медицинских
данных в электро- и эхокардиографах, системах ультразвукового ис-
слсдования). В частности, нейронные сети могут выделять спектр сигна-
ла или раскладывать входные данные с применением так называемого
метода анализа главных компонент PC A {Principal Components Analysis).
Я перечислил в качестве примеров лишь несколько задач, но приложе-
ния любой сети даже такой простой, как описанная выше — могут
быть очень разнообразными.
В любой ситуации решающее значение имеет принятый набор ве-
сов всех используемых нейронов. Изменение набора весов приводит к
изменению функционирования сети точно так же, как при изменении
программы мы заставляем по-другому работать обычный компьютер.
В рассматривавшихся примерах применялись случайно выбранные зна-
чения весов (точнее, мы сами решали, какие коэффициенты весов дол-
жен иметь каждый нейрон), чго может интерпретироваться как навя-
зывание сети модели ее функционирования. I ри небольшом количестве
нейронов в сети, а также для простой и в меру очевидной ичтерпрета-
нии ее весов (как в рассматривавшемся примере распознавания живот-
ных) такое «ручное программирование» сети вполне допустимо и может
давать хорошие результаты. Но в большинстве практических приложе-
ний сети содержат большое количество элементов. В сетях такой раз-
мерности практически невозможно выявить роль и задачи каждого кон-
кретного йейрона. По этой причине более полезными оказываются сети,
которые сами выбирают значения своих весовых коэффициентов в про-
цессе обучения. В следующей главе мы вплотную займемся важнейшей
проблематикой обучением сети.
4.10. Контрольные вопросы и задания
для самостоятельного выполнения
1. Какими свойствами должны обладать веса нейрона и его входные
сигналы, чтобы нейрон выработал:
а) сильный позитивный выходной сигнал?
б) сильный негативный выходной сигнал’?
в) выходной сигнал, значение которого близко к нулю?
2. Как добиться, чтобы нейрон придавал большее значение одно-
му из своих входов например, чтобы окраска цветка была для ней-
рона важнее запаха)?
3. Как можно интерпретировать положительные и отрицательные
веса, приписанные конкретным входам нейрона?
Функционирование простейшей нейронной сети
153
4. Как можно интерпретировать положительные и отрицательные
сигналы, поступающие на конкретные входы нейрона?
5. На все входы нейрона поданы только отрицательные сигналы.
Обязательно ли этот нейрон выработает отрицательный выходной сиг-
нал?
6. Ограничено ли число входных сигналов нейрона?
7. Проверь, кем — млекопит ающим или рыбой — признает дельфи-
на сеть, моделируемая программой Example 02?
8. Что достигается благодаря введению в нейронную сеть конкурен-
ции?
9. Проверь, в какую группу животных занесет летучую мышь сеть,
моделируемая программой Example 02?
10. Проверь, сможет ли сеть, моделируемая программой Example
02, понять, что динозавр не был пи млекопитающим, ни птицей, ни ры-
бой (поскольку он считается земноводным, а такая категория сети неиз-
вестна)? К каким известным сети животным динозавр окажется наибо-
лее близким?
11. Всегда ли сеть с конкуренцией выявляет «победителя»?
12. Задание для наиболее подготовленных. Усложни сеть, пред-
назначенную для распознавания животных, и добавь в нее новые клас-
сы зверей (например, хищников и травоядных), а также введи допол-
нительные данные для описания свойств животного (например, остроту
зубов/клюва и способность быстро бегать/летать/плавать).
Глава 5
ОБУЧЕНИЕ ПРОСТЫХ ЛИНЕЙНЫХ
ОДНОСЛОЙНЫХ НЕЙРОННЫХ
СЕТЕЙ
5.1. Как построить обучающую выборку?
В этой главе ты узнаешь, как обучается простейшая сеть. Знаю-знаю.
мы об этом уже говорили, но теоретические знания, основанные на зна-
комстве с описанием алгоритма, — это одно, а практические умения, ос-
пованные на получении результатов «собственными руками», совсем
другое дело. Мы продолжим экспериментировать с линейными селя-
ми — в их сослав входят проел ei шие нейроны, которые ты исследовал в
предыдущей главе; из этих нейронов ты построил и немного изучил про-
стую линейную сеть, и поэтому, наверняка, уже понимаешь, как ведут
себя такие нейроны и сети. В шестой главе я расскажу тебе о нелинейных
сетях, и тогда ты практически познакомишься с их свойствами и функ-
ционированием. Поэтому позволь вначале (по принципу разделения) по-
дробно объяснить смысл прилагательного линейный, характеризующе-
го все рассматриваемые в этой главе сети. Пока поверь мне на слово:
линейные сети юраздо проще нелинейных; им легче ставить задачи при
обучении и оценивать их эффективность. Начнем с простейшей задачи
обучения одиночного нейрона. Для ее решения ты будешь использовать
программу Example 03, выполняющую имитационное моделирование и
автоматический тренинг одиночного линейного нейрона (рис. 5.1).
Рис. 5.1. Структура и основные элемен-
ты искусе I венного нейрона, подвергающе-
гося обучению
Прежде чем ты установишь па
свой компьютер, апробируешь и I не-
сомненно) улучшишь нашу обучаю-
щую программу — одно вводное за-
мечание. При проведении эксперта
ментов, направленных на изучение
функционирования одиночного ней-
рона и всей сели (в предыдущей гла-
ве), ты воспользовался возмож-
ностью ручного ввода всех необхо-
Обучение простых линейных однослойных нейронных сетей
155
димых сигналов, что обеспечило полный контроль над ходом экспери-
мента. Тогда это было легко, приятно и удобно. Однако при первых же
попытках обучения несколько больших сетей сложность задач возрас-
тает «нежности» заканчиваются. В некоторых случаях нам потребу-
ются сотни и тысячи экспериментов, прежде чем из первородного хаоса
начнет выявляться нечто осмысленное. Конечно, можно предст авить се-
бе мазохиста, который несколько тысяч раз «высасывает из пальца» и
вручную вводит одни и те же данные, необходимые для обучения сети
корректному решению какой-либо задачи. Но я уверен, что такие сума-
сшедшие окажутся в подавляющем меньшинстве среди читателей этой
книги.
Поэтому с самого начала договоримся, что процесс обучения должен
опираться на хранящейся в компьютере, заранее подготовленной так на-
зываемой обучающей выборке. Эта выборка должна содержать как
входные сигналы (для всех нейронов сети), так и эталоны корректных
(ожидаемых) выходных сигналов, с которыми обучающий алгоритм бу-
дет сравнивать результаты фактического функционирования сети. В на-
ших программах используется следующий формат записей обучающей
выборки:
комментарий (облегчающий понимание происходящего'
набор входных сигналов
набор эталонных выходных сигналов
Договоримся, что набор входных сигналов будет состоять из пяти-
элементных векторов (порций по пять сигналов для пяти входов рас-
сматриваемого нейрона), тогда как эталонный выходной сигнал будет
один (поскольку в наличии имеется только один нейрон). Эти пара-
метры сети указаны в первой строке файла, содержащего обучающую
выборку. Выборка может иметь произвольную длину (чем больше при-
меров правильно решенных задач ты предъявишь сети — тем лучше),
поэтому иногда файл с перечисленной выше информацией может быть
по-настоящему большим. Но для начала, при знакомстве с программой
обучения одиночного нейрона я предлагаю следующий короткий файл:
5, 1
A typical object that should be accepted
3, 4, 3, 4, 5
1
A typical object that should be rejected
1, -2, 1, -2, -4
-1
An untypical object that should be accepted
4, 2, 5, 3, 2
0.8
An untypical object that should be rejected
156
Глава 5
О, -1, О, -3, -3
-0.8
Приведенная обучающая последовательность для программы Exam-
ple 03 хранится в файле Default teaching set.txt. Эта программа знает
об этом, поэтому я предлагаю начать работу именно с этим сЪайлом. Ко-
нечно, ты можешь создать свой собственный. совершенно иной файл с
данными для обучения сети и подключить его к описываемой програм-
ме. Таким способом ты научишь нейрон распознавать другие эталоны
или даже заставишь его построить модель какого-либо явления (чтобы
он аппроксимировал какую-то зависимость между входными сигналами
и выходным сигналом, например, при обработке медицинских наблюде-
ний или физических измерений). Только не забывай, что имеешь дело с
линейным нейроном, который сможет в лучшем случае научиться об-
рабатывать сигналы подобно тому, как это делают1 методы корреляции
и многомерной линейной регрессии «математические методы, применя-
емые учеными для статистического описания результатов эксперимен-
тальных исследований) — его возможности ограничены! С более «ум-
ными» нейронами и более универсальными нелинейными сетями ты
тоже познакомишься, но не сразу...
Тем не менее, предлагаю для первого раза воспользоваться моим
файлом. Конечно, как только ты познакомишься с программой и убе-
дишься в ее нормальном функционировании, сможешь сколько угодно
экспериментировать с собственными данными. Но когда я знаю, на ка-
ких данных ты обучаешь свою сеть, есть возможность описать то, что
ты видишь в процессе обучения, и объяснить получаемые результаты.
5.2. Как можно обучать одиночный нейрон?
Начнем с попытки запуска программы Example 03. Обрати внима-
ние на то, что делает эта программа: она считывает данные из фай-
ла (который как мы договорились называется Default teaching
set.txt) и сразу пытается самостоятельно классифицировать объекты,
описание которых (в виде входных сигналов нейрона) последователен^
записаны в файл. Если классификация оказывается неудачной (нейрон
в этом убедится сам), то программа модифицирует весовые коэффици-
енты моделируемого нейрона (в соответствии с алгоритмом, подробно
обсуждавшимся в одной из предыдущих глав). Таким способом нейрон
учится лучше решать поставлю иную задачу. В процессе имитации обуче-
ния ты сможешь отслеживать на экране компьютера последовательность
изменения весовых коэффициентов и погрешности на каждом шаге. По-
нятно, что вначале погрешность велика (рис. 5.-2).
Обучение простых линейных однослойных нейронных сетей
157
item лйугль
Енос 0,951575
< Sack
Next >
r. .,S »1.Wi
" " " > I > i »»'w К ...
I?
Restart teaching | TCHCh ГПОГС!
—____.—-> UuuatttftГГгтТптгт.1Т1ТТП I urffiMBSiP
*>ЙЙ1.||Й1|Га1.. it,iCnTinfcawtii.jrix
Teaching
Step 1 Comment: A typical object that should be accepted
Before teaching
| Input number (i) 11 12 3 4 5 I
Original ir.puts (u[i|) +3,000 +4,000 +3,000 +4 000 +5,003
Normalized npucsbO +0,348 +0,462 +0,346 +0,462 +0,577 I
Weights +0,003 . -0,001 -0.057 -0,034 -0,043 |
Output [<0573059
Correct output
Aftef teaching
Input number (i) 1 2 |3 j4 y5 1
Weights (w[i]) ' <045 +0,048 -0,020 +0,015 |+0,019 I
Correct output 1
Output: 0 0484247
Teact jig ratio 0,100
Значения
весовых
коэффициентов
до и после обучения
на текущем шаге
Клик на эту кнопку
вызывает пошаговое
обучение нейрона
Переход
к «тестированию»
Рис. 5.2. Начало процесса обучения нейрона
Если теперь подвергнуть сеть «тестированию» (на эту фазу можно
перейти в любой момент обучения достаточно щелкнуть по кнопке
Next), то выявятся ее истинные умения. Однако в начале обучения ты
с сожалением убедишься, что твоя надежда на узнавание нейроном де-
монстрируемых ему объектов фатально не оправдывается (рис. 5.3).
i
i
Experiments
Those are the objects our neuron should already know:
xl2) И|РВ1 | ±L L<) Output Comment
... 1 £ W ’W ‘ -w *
г 2 1 -2 4 1 A typical object that should be reieoted
4 t- 5 3 2 0,8 An untypical obiecl that should be accepted
0 •1 0 -3 3 -0.8 An untypical object that should be rejected
Here vou can enter the feature walue§ for the object tn be recognized:
|»fW до*w< Input number (i| 1 |2 3 4 5
Input weight (w(i)i +0 045 j+0,048 !-0,020 !+0,015 |+0,019
Reeak uiatel
Response:
Input signal 'x(il)
0 048424854
После единственного
шага обучения
результат
неудовлетворительный!
Ты можешь
«дообучить»
нейрон при
возвращении
в окно Teaching
ш iSiai «.a/
з
Рис. 5.3. Неудачный результат тестирования слабо обученного нейрона (сеть очень
плохо распознает предъявленный объект)
158
Глава 5
Нпхг'ЛГ 1j-UJ9Jj '^ZcJJJpb (Jjj
fliaigl
Teaching
Step 45 Comment: A typical object that should be accepted
Before teaching
Input number (ij 1 2 3 4 5 к
Original inputs (u(ij) +3 000 +4,000 +3 000 +4,000 +5000
Normalized inputs (x(i)l +0,346 +0,462 +0,346 +0.462 +0 577 gHj V
Weights Mi)) +0 208 +0,452 +0,182 +0.505 +0 678
Output 0,968403 Correct output: 1 Erro 0.0315966
After teaching
Input number (i) 1 !2 3 4
Weights MO) +0.209 +0.454 1+0,183 +0.507 +o ЩЦ
Error 0,028437
Output 0,971563 Correct output
Рис. 5.4. Один из поздних этапов процесса обучения характеризуется малым
значением погрешности и незначительным ее уменьшением после завершения этапа
Успехи обучения можно
оперативно наблюдать
при отслеживании
значений погрешности
Для придания поведению нейрона осмысленности его надо несколь-
ко подучить. При нажатии кнопки Back ты Перейдешь в предыдущее
окно Teaching и терпеливо продолжишь обучение нейрона, для этого
необходимо многократно щелкнуть по кнопке Teach more!. Если че-
рез некоторое время ты заметишь уменьшение выдаваемых программой
значении погрешности до разумных пределов, причем изменение (сни-
жение) этих значении от шага к шагу уже будет не так велико (рис. 5.4),
то можно прервать процесс обучения и попробовать оценить знания се-
ти с помощью нового тесла. Результаты должны улучшиться — как при
предъявлении сети одного из элементов обучающей выборки (рис. 5.5),
так и при демонстрации ей совершенно нового (не входившего в обучаю-
щую последовательность и поэтому не известного сети объекта. По этот
объект должен оыть похож па объекты обучающей выборки рис. 5.6).
В процессе обучения ты можешь воспользоваться1 историей его развития,
доказываемой по твоему желанию) в виде графика пошаговых измене-
ний погрешности сети. Этот полезный и поучительный график можно
вывести на экран в любой момент нажатием кнопки History.
Обучение простых линейных однослойных нейронных сетей
159
Рис. 5.5. В поздние периоды процесса обучения сеть без труда сдает тест
на отклонение объекта, который должен быть отклонен
Программа покажет тебе не только погрешности (как элементы,
сильнее всего влияющие на процесс обучения), но и значения весовых
коэффициентов до и после коррекции на очередном шаге обучения. Ты
помнишь (из предыдущих глав), что хорошо обученный нейрон должен
сформировать у себя (в форме соответствующих значений весовых ко-
эффициентов) «эталон» распознаваемого объекта, поэтому можешь сра-
зу же оценить, в ту ли сторону развивается процесс, или он «пошел
вразнос» (увы, и это случается...).
Рис. 5.6. В поздние периоды обучения тест демонстрирует способность к обобщению,
поскольку она решительно отклоняет объект, который только похож на подлежащий
отклонению объект из обучающей выборки
160
Глава 5
Длительность обучения (в этапах)
Рис. 5.7. Уменьшение погрешности в процессе обучения при различных
начальных значениях весов исследуемой сети
Учти, что при небольшом количестве элементов обучающей выбор-
ки, особенно при их циклически повторяющемся предъявлении нейрону
(без рекомендованного в одной из предыдущих глав и очень полезного
«тасования» этих элементов) нельзя требовать от нейрона слишком мно-
гого. Такой подход, конечно, не даст хороших результатов при обучении
решению сложных задач, но выполнению простых задании подобных
описываемому файлом Default teaching set.txt) нейрон обучается па
удивление быстро и эффективно.
Обрати внимание на динамику процесса обучения. Уже несколько
первых предъявление обучающих данных существенно повышают эф-
фективность функционирования нейрона. Потом скорость обучения сни-
жается, но погрешность работы сети на очередных шагах обучения про-
должает уменьшаться. Взгляни на рис. 5.7, иллюстрирующий типичное
изменение погрешности в процессе обучения как одиночного нейрона,
гак и целой сети. Постарайся представить, как должен выглядеть гра-
фик процесса обучения в твоих собственных экспериментах? Также убе-
дись в том, что, несмотря на применение всегда одной и той же обуча-
ющей выборки, ты будешь получать в разных экспериментах различ-
ные варианты развития процесса обучения, поскольку нейрон каждый
раз будет стартовать с различных (случайно выбираемых) начальных
значений весовых коэффициентов.
Программа Example 03 достаточно «дружественна» к пользовате-
лю. С ее помощью ты сможешь свободно экспериментировать с нейро-
ном, например прерывать процесс обучения и подвергать нейрон «тести-
рованию» для проверки его поведения при подаче пробных сигналов
лучше всего подобных, но не идентичных содержащимся в обучающем
выборке. В любой момент ты можешь возобновить прерванный процесс
Обучение простых линейных однослойных нейронных сетей
161
обучения и немного «поднатаскать» нейрон перед очередным экзаменом.
Такая последовательность действий (обучение тестирование) может
повторяться многократно. Советую тебе каждый раз удлинять перио-
ды обучения между очередными проверками, поскольку по мере смены
очередных «эпох» (т.е. циклов демонстрации всех элементов обучающей
выборки) изменения в процессе обучения будут становиться все менее за-
метными. Имеет смысл посвятить таким экспериментам некоторое вре-
мя, поскольку они дают очень конкретное и детальное представление
[причем на очень простом и удобном для понимания примере) об одном
из наиболее удивительных свойств нейронных сетей — способности к
обучению и к обобщению полученных знаний.
5.3. Может ли нейрон обладать врожденными
способностями?
Я также советую тебе проверить, как влияют на результаты обуче-
ния «врожденные способности» нейрона. Для этого необходимо несколь-
ко раз запустить процесс обучения с самого начала и отследить проис-
ходящие изменения. Из-за случайности выбора начальных значений ве-
совых коэффициентов ты будешь наблюдать различные темпы обучения
нейрона при одних и тех же входных данных. Иногда нейрон обучается
практически молниеносно (если попадается такой способный «от рож-
дения»), а иногда его «тренинг» длится очень долго, причем в процессе
обучения даже встречаются периоды ухудшения результатов (погреш-
ность возрастает, несмотря на интенсивное обучение). Это случается, ко-
гда нейрону приходится преодолевать некие «врожденные склонности».
Эффект случайности развития и непредсказуемости результатов обуче-
ния может быть очень сильным — чтобы в него поверить, нужно увидеть
все своими глазами. Поэтому не жалей времени и проведи несколько экс-
периментов с программой Example 03, всякий раз изменяя в ее тексте
допустимый диапазон случайных исходных значений весовых коэффи-
циентов*. В частности, можно изменить используемые по умолчанию па-
раметры инициализации весов нейрона в методе InitializeTeaching() клас-
са ProgramLogic. Например, вместо команды
_examinedNeuron.Randomize(_randomGenerator, -0.1, 0.1);
можно применить команду
Для проведения таких опытов необходимо заглянуть в исходный код программы,
изменить одну из ее команд и повторно откомпилировать программу Example 03. Это
означает, что такой эксперимент ориентирован на наиболее подготовленных читателей
нашей книги. Но я надеюсь, что с учетом приводимых рекомендаций и инструкций ты
сможешь справиться с этой проблемой.
162
Глава 5
_(ixaniincdN(‘uron.Ran(iomizc(_randomGencrator, -0.4, 0.4);
Как следствие, начальные значения весов будут выбираться из го-
раздо более широкого диапазона, что очень существенно отразится на
процессе обучения и на ею результатах.
После нескольких запусков процесса обучения с одной и той же обу-
чающей выборкой ты легко заметишь, насколько сильным может ока-
заться влияние случайно выбранных начальных значении весов. Каж-
дый раз нейрон будет обучаться совершенно иначе! Таким способом ты
наглядно познакомишься еще с одним, иногда демонизируемым {«свобо-
да поведения автомата? Ъ>) свойством нейронных сетей их индетер-
минизмом, т.е. непредсказуемостью как развития процесса обучения,
так и его результатов.
Прими во внимание следующее обстоятельство: сеть, которую ты ис-
пользуешь для описываемых в этой главе экспериментов, совсем неве-
лика и не очень сложна, а решаемая ею задача просто легкая. Однако в
большой сети при решении по-настоящему сложной задачи суммирова-
ние' множества случайных эффектов (подобных описанному выше) мо-
жет привести к абсолютно непредсказуемому поведению сечи которая
этим отличается от «обученных грамоте», привычных к полной и без-
условной повторяемости поведения регулярных вычислителыгых алго-
ритмов, применяемых в типовых компьютерных программах.
5.4. Насколько строго надо обучать нейрон?
Предложенная выше простенькая демонстрационная программка
должна рассматриваться как «экспериментальный полигон», на кото-
ром ты сможешь исследовать еще один важный фактор развития про-
цесса обучения коэффициент, определяющий скорость обучения. Этот
коэффициент можно изменить в поле Teaching ratio в окне Teaching
программы Example 03. При увеличении значения коэффициента обу-
чения, например при вводе
Teaching ratio = 0,3
вместо используемого по умолчанию
Teaching ratio = 0,1
можно ускорить обучение, но процесс станет более «нервным» (с резки-
ми колебаниями значений весов и внезапными скачкообразными изме-
нениями в любую сторону допускаемых сетью погрешностей). Можешь
проверить несколько различных значений и отследить их влияние на
процесс обучения. Но не забывай: если введешь слийгком большое зна-
чение этого коэффициента, то процесс обучения станет хаотичным и по
принесет никаких позитивных результатов, поскольку нейрон будет «ме-
таться» из одной крайности в другую, а конечный эффект окажется ила-
Обучение простых линейных однослойных нейронных сетей
163
чсвным — вместо последовательного улучшения своих показателей ней-
рон будет характеризоваться все большими погрешностями. Это стоит
увидеть собственными глазами!
В свою очередь, слишком малое значение коэффициента обучения
приведет к существенному замедлению обучения его прогресс может
стать практически незаметным. В такой ситуации вполне вероятно, что
потенциальный пользователь нейронной сети разочаруется в ней и нач-
нет искать более эффективные технологии и алгорит мы.
Описываемые эксперименты требуют соответствующей интерпрета-
ции с учетом реальных процессов обучения, в которых участвуют не ис-
кусственные нейроны, а настоящие мозги школьников и студентов. Лег-
ко понять, что значение коэффициента обучения характеризует степень
«строгости» учителя. Малые значения этого коэффициента соответству-
ют ситуации, когда учитель добр и ласков — он замечает и коррек-
тирует погрешности обучения, но не использует силу для скорейшего
достижения требуемых результатов. Проведенные тобой эксперименты
ясно свидетельствуют: такое благодушие не приносит ожидаемый эф-
фект. Однако слишком большое значение коэффициента обучения, т.е.
чрезмерная строгость учителя, тоже бывает вредным. Обрушивающие-
ся на ученика суровые наказания, решительный и жесткий нагоняй за
каждую оплошность ведут к раздражительности обучаемого, которая
выражается в резких изменениях весовых коэффициентов нейрона без
реального развития процесса обучения.
5.5. Как обучать простую сеть?
Перейдем теперь от обучения одиночного нейрона к обучению це-
лой сети. Написанная для этого программа Example 04 очень похожа
на представленную выше программу обучения одиночного нейрона, по-
этому тебе будет легко ее использовать. Для экспериментов по обуче-
нию сети потребуется файл с обучающей выборкой. Я подготовил такой
файл. Он тоже называется Default teaching set.txt, но размещается
так, чтобы обеспечить его связь с программой Example 04. Этот файл
содержит следующие данные:
5, 3
A typical object that should be accepted by the first neuron
3, 4, 3, 4, 5
1, -1, -1
A typical object that should be accepted by the second neuron
1, -2, 1, -2, -4
-1, 1, -1
A typical object that should be accepted by the third neuron
164
Глава 5
-1, -1, 1
An untypical object that should be accepted by the first neuron
4, 2, 5, 3, 2
0.8, -1, -1
An untypical object that should be accepted by the second neuron
0, -1, 0, -3, -3
-1, 0.8, -1
An untypical object that should be accepted by the third neuron
- 5, 1, -1, 4, 2
- 1, -1, 0.8
An untypical object that should be rejected by all neurons
- 1, -1, -1, -1, -1
- 1, -1, "I
Программа, с которой ты сейчас будешь взаимодействовать, инфор-
мирует о состоянии процесса обучения и значениях каждой переменной
чуть менее подробно, чем программа Example 03, поскольку при боль-
шем числе нейронов слишком подробное описание функционирования
каждого нейрона окажется избыточным. Программа завалила бы тебя
информационной лавиной, из которой практически невозможно извлечь
наиболее существенные данные. Поэтому ознакомление с процессом обу-
чения с помощью программы Example 04 носит синтетический харак-
тер — выдается информация сразу обо всех трех нейронах рассматри-
ваемой сети в виде, показанном на рис. 5.8.
*
i
Teaching
Step 1 Comment* A typical object that should be accepted by the first neuron
Input data
Input number fi| 1 2 3 4 5
Original input? (u|i)) +3.000 -4000 +3,000 +4 000 +5.000
Normalized inputs (x(i)) +0.346 +0,462 +0,346 +0,462 +0.577
Сигналы
на выходах
трех нейронов
i
I eachrtg srogr^s
| I Output number (j) | I1 2 3
Value befoie teaching +0 035 +0.000 +0.057
Value expected fzfij) +1.000 -1 000 I -1 000
Error before teaching (e(i)) +0,365 1.000 -1.057
Value after teat htng fy’fiJJ +0132 -0100 -0.049
Error after teaching (e’filj +0868 -0.900 -0.951
Teach more?
History
Restart teaching
ф T eaching ratio
1,—- -
< Back Next > |
1
Рис. 5.8. Описание состояния сети на момент начата Процесса обучения в нрырамме
Example 04
Обучение простых линейных однослойных нейронных сетей
165
Teaching
Step 226 Comment: A typical object that should be accepted by the second neuron
Input date
Input number (t) 11 2 3 4 5
. Chginal inputs (uftjj ♦1.000 -2.000 +1,000 •2.000 -4.000 1
j Noi maltzed nputs (xfij) +0,196 -0.392 +0.196 -0.392 •0784 |
reading progress
Output number lj] 1 2 3
Value before teaching (v(i j -0603 юж •0,887
Value expected friiJj -1.000 +1000 1.000
Error before teaching leQ] -0,397 +0,120 0113
Value after teaching i/(p) -0,643 +0892 -0898
Error after teacl >.ng fe'($j •0,357 ♦0.108 0.102
—
Restart teaching
__ -ь-____—,
Tea :hng ratio; 0.100 Ц
j i------------_
Teach more! |
Рис. 5.9. Описание состояния сети на момент окончания процесса обучения
в программе Example 04
Такой подход не препятствует изучению наиболее существенного для
нас аспекта — развития процесса обучения, в чем можно убедиться при
сравнении рис. 5.8 с рис. 5.9.
По указанным выше причинам рассматриваемая программа Exam-
ple 04 также синтетическим способом демонстрирует поведение сети па
фазе тестирования (рис. 5.10), что тоже не препятствует получению от-
вета на вопрос — правильно функционирует сеть или нет?
На рис. 5.10 заметно, что после обучения сеть неплохо справляется
даже с объектом, не представленным в обучающей выборке, но похожим
на объект, позитивно распознаваемый конкретным (в этом случае пер-
вым) нейроном. Обрати внимание, что в процессе тестирования только
первый нейрон выработал положительное значение выходного сигнала.
Это решительно и однозначно указывает на успешность распознавания.
Тем не менее, из-за нетипичности ситуации второй и третий нейроны,
которые должны были ясно «откреститься» от этого объекта, имели со-
мнения
их отклики оказались неуверенными и нерешительными.
166
Глава 5
Experiments
Those are the objects oui t <etwofk $hoUd already know
ми МЛ М3| M4J х(51 У(1) У(2) ИЗ) Comment
1 * 3 4 5 1 4 4 A typical IM b? $c<w»ed by the fat nexr n
h ii- -2 h -2 -4 -1 и |4 A typical object that should be accepted by the second neuion
1 I -3 2 •5 3 1 1 4 1 A typical object that should be accepted by the thud neuron
4 2 5 3 2 0.8 Ь1 4 An untypical object that should be accepted by the first neuron
1° 4 0 •3 -3 4 0.8 4 An untypical object that should be accepted by the second neuron
Ь5 1 -1 4 2 4 1 0.8 An untypical object that should be accepted by the third neuron
4 -1 -1 •1 4 4 4 4 An untypical object that should be rejected by all neurons
Here you can ei itei the feature value:, tot the object to be recognized:
хП) x[2) x(3j x(4) x(5)
40 3 0 fjjio £3 3.0 4.0
Here are the network output values:
а.^аЛкл......хх,...др^-.иоозоох*1--1’НУГпм’Г1ИГ«Г~1Ш MiT
Рис. 5.10. Процесс тестирования сети в программе Example 04
Такая неуверенность встречается довольно часто. Если мы ожидаем
от сети обобщения полученных в процессе обучения знаний, то прак-
тически всегда сталкиваемся с неопределенным поведением. Дело в том.
что сети легче выработать позитивное решение например, корректно
распознать объект), чем уверенно и безошибочно отклонить его из-за
невозможности отнести к одному из известных классов.
При наблюдении за процессом обучения заметно, что одни зада-
чи, предъявляемые в процессе обучения, сеть решает легко и быстро,
а с другими справляется с большим трудом. В частности, применитель-
но к рассмотренному выше файлу Default teaching set.txt легкими
оказываются все задачи, которые сводятся к необходимости позитивно-
го распознавания конкретными нейронами конкретных (типичных или
нетипичных) эталонов. В то же время, труден для освоения пример,
объект которого все нейроны должны отклонить. На рис. 5.11 пока-
зан один из поздних этапов процесса обучения, когда позитивное рас-
познавание конкретных объектов происходит практически безошибочно,
а объект, который должен быть отклонен, все еще доставляет немало
хлопот.
Более того, можно заметить, что каждая неудачная попытка адапти-
ровать сеть к решению именно этой трудной задачи приводит к ухудше-
нию уже относительно неплохого состояния обученности сети решению
основных задач (т.е. распознаванию типичных объектов).
Обучение простых линейных однослойных нейронных сетей
167
QJ IVj Jnri.-
МяЯНЯЯМИМННвВНН
.* .ж
Z
it
< Back
Next >
Restart teaching | Teach ГТЮГе!
w-
Teaching
Step 546 Comment: An untypical object that should be rejected by all neurnns
-1,000
Original iepute fu(ij)
. .. • I
Normalized inputs (x|t)J -0,447
2 3 4 |5 1
-1,000 -1,000 -1,000 -1,080
[-0,447 -0.447 1 -0,447 -0,447 j
’eaching progress
Output number (j)
Value before leaching [yljjJ -1,054 i+0,379 ! +0,226
Value expelled (z[|j) 4 да -1,000 -1,000
Error before teaching (e(lJ) *0054 4,379 -1.226
Value after teaching -1 049 [ +0,241 1 +0,104 ]
j
Error after teaching (e(j)) *0049 -1.241 -1.104
1
Рис. 5.11. Обучение сети в случае распознавания проблемных объектов
Если ты реально попадешь в такую ситуацию, то вместо длительных,
утомительных и безрезультатных попыток обучить сеть подумай, мож-
но ли переформулировать задачу так, чтобы исключить возникновение
этой проблемы. Как правило, исключение из обучающей выборки одно-
го или нескольких подобных примеров радикально улучшает и ускоряет
процесс обучения. Насколько это повышает эффективность обучения,
сможешь убедиться сам, если исключишь соответствующий фрагмент
из файла Default teaching set.txt и вновь проведешь обучение сети,
но уже без этого проблемного элемента. Безусловно, ты заметишь бла-
гоприятные изменения как в скорости, так и в эффективности обучения.
5.6. Каковы возможности применения таких
простых нейронных сетей?
Ты, конечно, не удивишься (и, надеюсь, не смутишься) сообщению,
что исследуемая тобой сеть не считается самым крупным и самым слож-
ным нейрокомпьютером в мире. Правду говоря, она настолько проста,
168
Глава 5
что некоторые читатели сочли ее вообще примитивной. Тем не менее,
даже эта простейшая сеть демонстрировала очень интересные формы
поведения и оказалась способной вполне достойно справляться с доволь-
но сложными задачами, потому что коллективное функционирование
нескольких нейронов открывает весьма широкую область очень разных
приложений.
В этом месте я позволю себе сформулировать одно замечание об-
щего характера. Легко заметить, что возможности одиночного нейрона
и целой сети довольно похожи. Соответственно, сеть можно рассматри-
вать как совокупность взаимодействующих нейронов, а знания о пове-
дении одиночных нейронов можно естественным образом перенести на
всю сеть. Тем не менее, существуют уникальные сетевые возможности,
недоступные одиночному нейрону. Например, даже простейшие (обсуж-
даемые в этой главе) сети позволяют смело браться за решение мно-
гомерных задач, которые нередко оказываются «не по зубам» другим
математическим и вычислительным методам. Ты можешь убедиться в
этом сам. если увеличишь размерность сети, задавая большие значе-
ния для количества входов и количества выходов, и попробуешь при-
менить полученную сеть для решения какой-либо практической задачи.
Ь частности, сеть можно использовать для моделирования каких-либо
сложных систем, в которых определенное количество входных сигна-
лов может вызвать один из некоторого множества выходных сигналов.
В существовании огромного числа таких приложений ты убедишься, ес-
ли организуешь с помощью Google поиск по ключевым словам «Neural
Networks Modeling». Минуту назад я получил информацию о найденных
в Интернете 30 миллионах ссылок на страницы с такими словами. Очень
сомневаюсь- что одиночные нейроны используются так же широко!
Помимо создания нейронных моделей сложных систем мы можем
применять аналогичные простые линейные сети для адаптивной обра-
ботки сигналов. Это тоже огромная и очень популярная область да-
же говорить не буду, сколько страниц выдала поисковая система Google
при вводе ключевых слов «Signal Processing». Дело в том, что цифровая
техника открыла возможности компьютерной «в том числе и нейронной]
обрабочки очень многих и разнообразных сигналов, например передава
емой по телефону речи, фото- и видеоизображений, данных современной
медицинской аппаратуры о состоянии организма пациента, результатов
научных экспериментов (как правило, состояших из громадного чисп
сигналов), записей контрольно-измерительной аппаратуры в системах
промышленной автоматики и т.д. и т.п.
Думаю, настало время более подробно рассмотреть эту обширнук. ,
важную и интересную отрасль. Сейчас мы познакомимся с проблема™-
Обучение простых линейных однослойных нейронных сетей
169
кой фильтрагщи сигналов (т.е. удалением из этих сигналов помех, за-
трудняющих их получение, анализ и интерпретацию), которая представ-
ляет собой очень привлекательное поле приложения нейронных сетей.
5.7. Может ли сеть научиться фильтровать
сигналы?
Представь себе некоторый сигнал с наложившимся на него шумом.
Специалисты по телекоммуникации, автоматике, электронике и меха-
нотропике ежедневно мучаются с такими сигналами обычное дело.
Если спросить такого специалиста, как очистить сигнал от шума, то он
с чувством собственного достоинства изречет: необходим фильтр. При
последующем углублении в эту проблему ты узнаешь, что фильтром
называют устройство (чаще всего электронное), которое полезный
сигнал пропускает, а шум — задерживает. Операция фильтрации очень
эффективна, поэтому у нас есть нормально работающие телефоны, ра-
диоприемники, телевизоры и т.д. Однако любой специалист подтвердит:
хороший фильтр удается построить только тогда, когда в шуме обна-
руживается некоторое свойство, отсутствующее в полезном сигнале. Ес-
ли нечто обладает этим свойством оно задерживается фильтром как
шум, а если не обладает то пропускается. Просто и эффективно!
Но для реализации такого подхода ты должен многое знать о шуме,
который искажает твой сигнал. В противном случае построить фильтр
невозможно: как он сможет понять, что пропускать, а что нет?
К сожалению, часто неизвестны ни источник шума, ни его свой-
ства. Если ты отправляешь в космос исследовательский корабль, кото-
рый должен высылать на Землю сигналы с описанием планетоподобного
объекта, очень трудно предвидеть, что может прицепиться к полезному
сигналу за время его путешествия через миллиарды километров меж-
звездного пространства. Как в этом случае строить фильтр?!
Так вот, полезный сигнал удается отделять от неизвестных помех
с помощью адаптивной фильтрации. В этом случае адаптация заклю-
чается в обучении приемника сигналов заранее неизвестным принципам
отделения сигнала от шума. В частности, нейронную сеть можно на-
тренировать так, чтобы она фильтровала сигнал и отсеивала шум. Для
этого в качестве входных сигналов рассматриваются примеры искажен-
ного сообщения, а в качестве выходных сигналов используются примеры
«чистого» сообщения. Через некоторое время сеть научится выделять
неискаженные входные сигналы из зашумленных сообщений и сможет
использоваться в качестве фильтра.
Рассмотрим конкретный пример. Пусть задан некоторый эталонный
си!нал, например фрагмент синусоиды (как «чистый», так и искажен-
170
Глава 5
Рис. 5.12. Искаженный сигнал, который должна фильтровать нейронная сеть
ный). Такие сигналы в виде файла, позволяющего обучать сеть, могут
быть сгенерированы программой Example 05. Эта программа автома-
тически создает файл с данными под названием teaching set, который
ты можешь использовать для обучения простой сети. Окно для моди-
фикации параметров, необходимых для генерации файла, появится на
экране сразу после запуска программы Example 05. Это окно изоб-
ражено на рис. 5.12. Программа попросит тебя сообщить ей через ок-
но размерность сети (Networks size) ожидаемый уровень шума (Noise
level measure), частоту (Frequency) и количество шагов процесса обу-
чения (Number of teaching steps). Один взгляд на все это может от-
бить желание общаться с этой программой, поскольку требования зву-
чат таинственно и непонятно; в конце концов, откуда ты можешь знать
необходимые значения?
Но все не так плохо. Если хорошо присмотреться к этому окну, то
можно заметить значения, уже вписанные в каждую позицию. Эти зна-
чения подобраны и апробированы мной так. чтобы программа нормаль-
но работала и демонстрировала интересные эффекты. Поэтому при от-
сутствии собственных идей можешь для начала воспользоваться этими
значениями по умолчанию и просто (ничего более не делая) принять
Обучение простых линейных однослойных нейронных сетей
173
Рис. 5.14. Попытка фильтрации сигнала после первого шаха обучения
к
$
Symulahon rode
172
Глава 5
Рис. 5.15. Попытка фильтрации сигнала после пяти шагов обучения
Menu About ,
л
Progress
Step: 20 / 50
Show signal
3 reference
1 noisy
Рис. 5.16. Попытка фильтрации сигнала после двадцати шагов обучения
Simulation mode
Choos© case
Weights
Обучение простых линейных однослойных нейронных сетей
173
их щелчком по кнопке Apply. Конечно, позднее (если захочешь и смо-
жешь) ты имеешь право изменить любое значение, хотя бы для того
чтобы проверить «что будет, если...».
Программа предоставляет тебе очень большую свободу выбора зна-
чений. В любой момент ты можешь удалить ранее введенные значения
(кнопка Cancel) либо мгновенно восстановить все значения по умол-
чанию (кнопка Default).
Несмотря на пугающий вид, с программой Example 05 легко по-
дружиться, и с ее помощью ты сможешь наблюдать функционирование
сети, которая сама научится фильтровать сигнал. В ходе эксперимен-
тов сеть будет улучшать сигнал от шага к шагу, но в любой момент ты
сможешь увидеть отфильтрованный сигнал (рис. 5.12) и оригинальный,
т.е. зашумленный сигнал (рис. 5.13). Для этого необходимо выбрать со-
ответствующую опцию (reference или noisy) в группе Show signal в
правой части экрана программы.
Теперь вместе разберемся с работой программы. Первые результа-
ты фильтрации после небольшого числа шагов выглядят не слишком
обещающими (рис. 5.14 и 5.15), но терпеливое обучение сети (благодаря
многократным щелчкам по кнопке Next) приводит, в конце концов, к
практически идеальной фильтрации сигнала (рис. 5.16).
Процесс обучения может развиваться автоматически или прерывать-
ся после каждого шага. Это означает, что по твоему желанию програм-
ма откроет все свои тайны либо автоматически пройдет несколько де-
сятков этапов обучения — сеть усовершенствует свое функционирова-
ние, а ты спокойно познакомишься с итоговым результатом. Ты смо-
жешь задать режим обучения выбором соответствующей опции в груп-
пе Symulation mode (Auto либо Manual). Вначале при проведе-
нии первых экспериментов рекомендую тебе наблюдать пошаговое
развитие процесса обучения сети, для этого необходимо выбрать режим
Manual. В следующих экспериментах можно изменить количество ша-
гов (воспользуйся для этого опцией Menu >Configuration в верхней
папели окна нашей программы) и попробовать более длительное обуче-
ние, например 50 или 100 шагов в режиме Auto. Результаты будут очень
поучительными, поэтому имеет смысл немного потрудиться!
Представленные примеры свидетельствуют: сеть действительно обу-
чается и совершенствует свое функционирование настолько, что через
некоторое (достаточно короткое!) время она начинает весьма успешно
устранять случайные помехи, обнаруживаемые в оригинальном сигнале.
Эффективность фильтра, создаваемого в процессе обучения сети, можно
оценить при совмещении отфильтрованного сигнала с образом исходно-
ю (до начала фильтрации) сигнала (рис. 5.17).
174
Глава 5
Start
Choose case
a
"I
Vi
Show signal
__ reference
Options
S emulation mode
Weights
Progress
Step 20 7 50
Рис. 5.17. Оценка эффективности фильтрации сигнала после двадцати шагов обучения
Merc About
Next
Beset
F^viqaUun
В процессе экспериментирования с программой ты убедишься — сеть
действительно может научиться фильтровать сигнал, и через некоторое
время начинает решать эту задачу вполне удовлетворительно. Легко за-
метить, что труднее всего обучить сеть выделять сигнал в тех местах,
в которых значения сигнала малы (и особенно, если они равны пулю1,
поэтому в программе Example 05 предусмотрены две версии обучения
сети вначале оригинальным с инусоидальным сигналом, а потом сме-
шенным синусоидальным сигналом, чтобы обрабатываемые сетью сиг-
налы были только положительными. Нужная версия выбирается с по-
мощью окна Choose case в правой части экрана. Вначале результаты
второго варианта обучения (которому в окне Choose case соответствует
режим With shift т.е. «со смещением») выглядят хуже (рис. 5.18), по
терпеливое обучение сети дает в этом случае гораздо лучшие результа-
ты, чем при обучении без смещения (см. рис. 5.19).
Наблюдение за поведением сети в каждом из этих вариантов поможет
тебе в будущем выявлять и анализировать причины возможных неудач
при использовании сети для решения более сложных задач.
Надеюсь, что созерцание процесса обучения сети, предназначенной
для фильтрации сигнала, тебе поправилось и помогло лучше понять,
что и как делает нейронная сеть для улучшения своего функцией иро!
вания. Тем не менее, при всей привлекательности задач, которые мы
Обучение простых линейных однослойных нейронных сетей
175
Start
Next
r______________ I
Stop I
Reset
Options j
Simulation mod**
: I
5
Choose case
Weight?
i? г
’
$ Iww signal
Й reference
noisy
<
Рюдад s
j
Step; 1/50
Рис. 5.18. Попытка фильтрации смещенного сигнала после первого шага обучения
Рис. 5.19. Попытка фильтрации смещенного сигнала после двадцати шагов обучения
176
Г л а в а
совместно решали, я должен открыть одну тайну: линейные сети — все
го лишь начальная подготовка к настоящим нейронным сетям. Неболь
шая разминка. Сети не могут быть исключительно однослойными (если
хочешь узнать почему, загляни в заключительную часть третьей гла
вы упоминавшейся выше моей книги «Нейронные сети» — это нельзя
объяснить без математики, а я обещал не использовать ее здесь), в т
время как кора головного мозга имеет МНОГОСЛОЙНУЮ структуру
Настоящие приключения начнутся только тогда, когда ты построишь
и активизируешь свою первую многослойную сеть, состоящую из пели
нейных нейронов. Как ты догадываешься, это произойдет совсем ско
ро в следующей главе.
5.8. Контрольные вопросы и задания
для самостоятельного выполнения
1. Почему при обучении сети решению более сложных задан мы ис-
пользуем обучающую выборку, хранящуюся в файле на диске, а нс вво
дим соответствующие данные с помощью клавиатуры или мышки?
2. В чем причина того, что график на рис. 5.4 (как и многие дру-
гие графики изменения погрешности, который ты наблюдал в процес
се обучения сети) наряду с отчетливой тенденцией к понижению, ха
рактеризующей прогресс обучения и систематическое уменьшение по-
грешности, имеет «выбросы» вверх? Неужели нейрон время от време-
ни внезапно глупеет?
3. Попробуй оценить (на основании результатов экспериментов, опи-
санных в этой главе), в какой степени на итоговое поведение сети влияет
процесс обучения, а в какой степени - «врожденные способности», обу-
словленные случайной инициализацией параметров сети. Можно ли и
этого сделать какие-либо практические выводы о влиянии твоего обра-
зования на твою жизненную карьеру?
4. Попробуй установить опытным путем (многократно запуская про-
грамму Example 03) наиболее благоприятное значение коэффициента
обучения {Teaching ratio) для задачи, которую решает описываемая здеа
сеть. Как ты думаешь, при решении другой задачи, характеризуемой с<
вершенно иной обучающей выборкой, оптимальное значение коэффици-
ента обучения будет таким же или изменится?
5. Подумай, в каких случаях можно применять большие значения ко-
эффициента обучения {Teaching ratio): для задач, легко решаемых ней-
ронной сетью, или для более трудных и сложных задач?
6. Придумай и составь другую обучающую выборку для программь
Example 04, запиши ее в файл Default teaching set.txt с помощью ре-
дактора Блокнот операционной системы Windows либо (лучше всего) с
Обучение простых линейных однослойных нейронных сетей 177
применением специализированного инструментария типа Visual Studio.
Постарайся превратить программу Example 04 в универсальное сред-
ство для решения различных задач, определяемых свободно подбирае-
мыми тобой обучающими выборками.
7. Подготовь несколько файлов с различными обучающими выборка-
ми и попытайся оценить, насколько хорошо обучается сеть решению раз-
ных задач. Определи, как уровень сложности задачи I измеряемый сте-
пенью подобия наборов данных, описывающих объекты (особенно нети-
пичные), которые должны различаться сетью) влияет па длительность
обучения и величину погрешностей, допускаемых сетью после заверше-
ния процесса обучения. Постарайся сформулировать настолько сложную
задачу, что сеть не сможет научиться решать ее независимо от длитель-
ности процесса обучения.
8. Исследуй процесс обучения программы Example 04 в зависимо-
сти от начальных значений весов, коэффициента обучения и различных
модификаций обучающей выборки.
9. Нейронная сеть, обучаемая адаптивной фильтрации сигнала, все-
гда использует искаженный помехой сигнал и его «чистый» эталон. По-
чему для обучения сети никогда не используется эталон помехи (шума)?
10. На рис. 5.18 и 5.19 видно, что с помощью программы Example 05
верхняя часть графика фильтруется лучше нижней части. Почему?
11. Задание для наиболее подготовленных. Программа Exam-
ple 03 использует обучение нейронной сети для создания классифи-
катора (т.е. сети, которая после предъявления ей некоторого набора
входных сигналов вырабатывает на выходе сигнал, интерпретируемый
как признание объекта, описываемого этими сигналами, либо как его
отклонение). Исследуй поведение этой программы при обучении ее более
сложному делу: расчету по входным данным определенного выходного
значения. Такая сеть сможет работать как модель какого-либо просто-
го физического или экономического явления. Ниже приводится пример
набора данных в формате Default teaching set.txt, для которого ты
можешь попробовать построить такую модель (для уменьшения количе-
ства входных данных сеть имеет всего два входа):
2, 1
Observation 1
3, 4,
-0.1
Observation 2
1, -2
0.7
Observation 3
4, 2
-0.2
178
Глава 5
Observation 4
О, -1
0.3
Observation 5
4, -5
1.9
Observation 6
- 3, -3
0.6
Observation 7
- 2, -4
1
Observation 8
3, -2
0.9
Observation 9
- 1, "I
0.2
Проверь, правильно ли программа находит решения для других (нс
использовавшихся в процессе обучения) комбинаций данных при усло-
вии, что обучающие данные соответствовали уравнению у = 0,1Х] — 0,ЗС2.
12. Задание для наиболее подготовленных. Программа Exam-
ple 05 иллюстрирует способ функционирования адаптивного фильтра,
основанного на принципе обучения нейронной сети, но не является при-
кладной программой для практического применения. Тем не менее, га
же самая сеть может применяться для фильтрации других сигналов,
например данных электрокардиограммы. Наверняка, ты не имеешь под
рукой цифровое представление этого сигнала, по попытайся модифи-
цировать сеть для обработки других сигналов — например, отфиль-
труй звуковой фрагмент, представленный в формате WAV- либо МРЗ-
файла. Если же тебе по душе решение особо сложных задач, проду-
май, как использовать принцип адаптивной не цюсетевой фильтрации
для обработки изображений ?
Глава 6
НЕЛИНЕЙНЫЕ НЕЙРОННЫЕ СЕТИ
6.1. Зачем нужны нелинейности в сети?
Линейные системы (не только нейронные сети, но абсолютно все
системы такого типа) обладают множеством симпатичных свойств. Их
поведение хорошо и легко прогнозируется, а математическое описание
очень простое и всегда поддается решению. Закономерно встает вопрос:
есть ли смысл покидать эту удобную и приятную позицию ради поиска
счастья в сложной и непонятной области нелинейных сетей?
Увы, такая необходимость существует.
— Но почему???
Поводов несколько (в следующих разделах этой главы ты познако-
мишься со всеми), но в этот момент я укажу основную причину: просто-
напросто класс задач, которые может решать сеть, состоящая из
линейных нейронов, гораздо уже класса задач, решаемых нели-
нейной сетью. Первая сеть может решать только такие задачи, кото-
рые основаны на линейном отображении множества входных сигналов
во множество выходных сигналов. Вторая (т.е. нелинейная) сеть не на-
кладывает подобные ограничения.
Если ты разбираешься в математике, то последние две фразы тебе
все прояснили. Но я предполагаю, что ты не обязан быт ь специалистом
по математике, поэтому в книге не используется ни одна математиче-
ская формула. Соответственно нельзя оставлять тебя в таком важном
вопросе один на один с высказанными выше утверждениями, поскольку
они наверняка остаются для тебя не совсем понятными. Неужели что-то
чрезвычайное кроется в факте, что сеть, состоящая из линейных ней-
ронов, реализует исключительно линейные отображения? На первый
взгляд, очередное «масло масляное».
Если бы ты разбирался в математике, то в качестве объяснения мож-
но было бы сказать следующее: линейное отображение можно предста-
вить в такой форме, что получаемые нейронной сетью (и рассматрива-
емые как векторы) решения будут выводиться из подаваемых на вход
180
Глава 6
сети данных с помощью некоторой определенной матрицы трансфор-
мации. Но, скорее всего, ты ассоциируешь термин «матрица» с восьми
известным одноименным фильмом, что еще больше сбивает с толка.
Попробую охарактеризовать представление линейных и нелиней-
ных отображений с учетом их фундаментальных свойств, называемых
однородностью и аддитивностью. Совершенно не обязательно запоми-
нать эти мудреные названия, постарайся понять их смысл.
Однородность линейного отображения означает, что в этом отобра-
жении следствие всегда пропорционально причине. Независимо от того,
какие понятия ты связываешь с причиной и со следствием, отобра-
жение, позволяющее предсказать следствие по известной причине (либо
угадать причину наблюдаемого следствия), будет однородным, если,
например, двукратное увеличение причины вызовет ровно в два раза
большее следствие. Однако пропорциональное увеличение следствия
при соответствующем увеличении причины не может считаться призна-
ком всех возможных зависимостей. Напротив, наблюдения за окружаю-
щим миром дают тебе множество примеров непропорциональных зависи-
мостей. Например, из школьной практики известно: чем больше учишь-
ся, тем лучшие оценки получаеть. Поэтому между длительностью обу-
чения и значениями полученных тобой оценок существует какая-то за-
висимость, которую можно представить в виде некоторого отображения.
Тем не менее, нельзя сказать, что если ты потратишь па учебу в два
раза больше времени, то получишь ровно в два раза лучшие оценки! По-
этому зависимость между усилиями, затраченными на обучение, и вы-
ставленными тебе оценками оказывается нелинейной, поскольку соот-
ветствующее отображение не обладает обязательным условием линей-
ности свойствам однородное ! и.
Второе условие линейности — аддитивность (от английского слова
add складывать). Этот трудно выговариваемый термин также име-
ет простое объяснение. При исследовании зависимости, которая долж-
на описывать интересующее отображение, ты можешь вначале выявить
следствие реализации какой-либо одной, а потом следствие реали-
зации другой причины. Когда мы знаем последствия раздельной ])са-
лизации этих двух причин, то можно попытаться предсказать эффект
их совместного проявления. Если при таком совместном проявлении ре-
зультат будет точно равен сумме следствий раздельной реализации,]то
исследуемое явление (и описывающее его отображением называется ад-
дитивным. Увы, опят!? можно указать огромное число явлений и про-
цессов, в которых такое простое суммирование следствий при сумми-
ровании причин оказывается некорректным. Если ты нальешь в вазу
воду, то сможешь держать в ней цветы. Если ваза упадет со стола, т
опа окажется на полу. Но если ты нальешь в вазу воду и сбросишь е<
Нелинейные нейронные сети
181
со стола, то держать в ней цветы уже не сможешь, потому что вода вы-
льется, а ваза, скорее всего, разобьется. Таким образом, явление превра-
щения вазы в мелкие осколки нелинейно, и это следствие невозможно
предсказать как простую сумму следствий предшествующих действий,
рассматриваемых по отдельности.
При построении математических описаний каких-либо систем, про-
цессов или явлений мы широко используем линейные зависимости их
намного легче применять. При реализации этих математических форма-
лишов нейросетевыми технологиями получаем легкую, простую и сим-
патичную линейную сеть.
К сожалению, очень многие системы, процессы и явления не удается
«втиснуть» в узкие рамки линейных отображений. Для их описания мы
вынуждены использовать сложные нелинейные математические модели
либо (что проще и удобнее) строить нелинейные нейронные сети, кото-
рые будут достоверно имитировать функционирование исходных объек-
тов. В таких обстоятельствах нейронная сеть оказывается чрезвычайно
мощным и очень полезным орудием. Зависимость между выходными сиг-
налами (откликами сети) и входными сигналами (т.е. исходными данны-
ми для проводимых вычислений) при достаточно большой и многослой-
ной нелинейной сети может иметь практически произвольный характер.
Это утверждение лежит в основе одной из фундаментальных матема-
тических теорем об интерполяции и экстраполяции функций, носящей
имя великого русского математика А.Н. Колмогорова.
Наша книга не самое лучшее место для подробного обсуждения
этой темы, имеющей сильно теоретический и математический характер;
поэтому предлагаю принять эту теорему «па веру». Могу только доба-
вить, что преимущество нелинейных сетей перед линейными — не столь-
ко предмет академического интереса (типа памятных «научных» дис-
куссий, какой праздник важнее Пасха или Рождество Христово).
сколько оценка практической полезности рассматриваемых инструмен-
тов. В действительности, существует обширная группа практических
задач, которые могут быть решены только с помощью нелинейных се-
тей, поскольку линейные сети оказываются неэффективными. Одна из
программ, с которой ты будешь экспериментировать при чтении этой
главы, проиллюстрирует обсуждаемую проблематику более детально,
но вначале познакомимся с несколькими другими программами, демон-
стрирующими функционирование нелинейной сети и ее возможности.
6.2. Как функционирует нелинейный нейрон?
Начнем с простой программы, имитирующей работу одиночного
нелинейного нейрона. Структура такого нейрона показана на рис. 6.1.
182
Глава t
Рис. 6.1. Структура нелинейногр ней-
рона как дополнение линейного нейро-
на нелинейной функцие-i активации
Программа для моделирования этого нейрона Example Оба анало-
гии на (с некоторыми упрощениями) программе Example 01с. с помо-
щью котором ты ранее исследовал функционирование линейного нейро-
на. Этот пример поможет тебе познакомиться с работой простого нейрона
с нелинейной (в рассмагриваемом случае — пороговой! функцией акти-
вации. Программа допускает возможность использования так называе-
мой униполярной или биполярной функции. Ты должен будешь с самого
начала выбрать одну из них в поле Neuron type (см. рис. б.Зщ). Также
можно задать количество входов нейрона, но на первый раз я рекомен-
дую воспользоваться значением по умолчанию 4 и перейти к слепну-
щему окну щелчком по кнопке Next. Устрашающие названия функций
активации на самом дело I оворя г об очень прост ых вещах: выходной сиг-
нал нейрона с униполярной функцией всегда неотрицателен ( чаще все-
го он принимает значение 0 или 1, но некоторые типы нейронов могут
вырабатывать любые значения сигналов внутри этого интервала). При
использовании биполярной функции возможны как положительные, так
и отрицательные значения выходного сигнала (чаще всего —1 и +1, по
и туг встречаются нейроны с промежуточными значениями). Различи?]
между униполярной и биполярной функциями показаны на рис. 6.2. До-
бавлю лишь небольшое пояснение.
Настоящим биологическим нейронам неизвестно понятие «отрица-
тельный сигнал». Значения любых сигналов в твоем мозге всетда по-
ложительны (либо равны нулю, когда думать совсем не хочется!), по-
этому униполярная функция оказывается гораздо ближе биологической
реальности. Тем не менее, при использовании искусственных нейронных
сетей мы всегда больше заботимся об удобстве вычислительного инстру-
ментария, чем о соблюдении максимального подобия биологическому
Рис. 6.2. Нел инейные функции активации нейрона: униполярная (Слева) и биполярная
(справа)
Нелинейные нейронные сети
183
оригиналу. По этой причине при построении искусственных нейронов
чаще всею допускается некоторая «избыточность». Мы стараемся пре-
дупредить возникновение ситуаций, в которых в сети вырабатываются
выходные сигналы со значением 0 особенно, если получателями та-
ких сигналов (генерируемых одними нейронами) должны быть другие
нейроны той же сети. Как ты помнишь, сеть плохо обучается на сигна-
лах с пулевыми значениями. (Помнишь эксперименты по фильтрации
сигналов с помощью сети, предложенной в предыдущей главе? В них
эта особенность была видна как на ладони!). Соответственно, наряду
с элементами, вырабатывающими сигналы 0 и 1, в искусственные ней-
ронные сети вводятся биполярные структуры. В таких нейронах тоже
рассматриваются два уровня значений, но теперь они обозначаются — 1
и +1. Просто, не правда ли? Взгляни еще раз на рис. 6.2.
Пользование программой Example Оба просто и интуитивно понят-
но. При работе с ней ты отметишь большую категоричность решений
по сравнению с рассмотренным выше линейным нейроном (рис. 6.3,6).
Линейные нейроны (и построенные из них сети) реагируют на подава-
емые сигналы мягко и взвешенно: одни комбинации входных сигналов
вызывают сильную реакцию (высокий уровень выходного сигнала), дру-
гие вызывают гораздо более слабую реакцию, а к третьим сеть остается
практически безразличной (выходной сигнал близок к нулю). В отличие
от «чувствительных» линейных нейронов, нелинейные нейроны с поро-
говой функцией активации действуют но принципу «все или ничего». На
некоторую комбинацию входных сигналов нейрон может реагировать од-
нозначно негативно (вырабатывается выходной сигнал, равный —1), но
иногда при минимальных изменениях входных сигналов реакция нейро-
на становится решительно и однозначно позитивной ^выходной сигнал
меняется на 0 или +1) (см. рис. 6.4).
Описываемая программа Example Оба предельно проста и даже при-
митивна. Тем не менее, эта модель (из всех рассмотренных нами к те-
кущему моменту) наиболее близка к технологии и принципам функцио-
нирования нейронов реального человеческого мозга. Несколько простых
экспериментов, подобных проводившимся ранее с линейными нейронами,
помогут тебе попять работу программы. Ничего особо примечательного
или в чем-то интересного. Так себе, простенькая пороговая функция. И
нее же, чуть-чуть фантазии — и ты представляешь себе эксперименты
с настоящей нервной клеткой...
... В никелированном заэюиме аппарата видна вскрытая черепная
коробка, а в ее глубине пульсирует в ритме сердечных сокращений се-
рая складчатая поверхность мозга. Микроскопический электрод углуб-
ляется, в ткань, и на мониторах появляются характерные формы нерв-
184
Глава 6
Категорический ответ
нелинейного нейрона
типа «все или ничего»
а)
[ни
Select the number of inputs and neuron type
In this application you will examine u non- linear neuron
First, you need to select the number of inputs The mere inputs the neuron will have the more
numbers ycu will need to supply for the we gth coefficients ‘and the input signal values You also have
to ch. lose what type of neuron you . </ant to exami ne an un'po'ar or a bipolar neuron.
И you don’t know what to do, just accept the default value and click "Next" After performing some
expenments, you always can go back and select a different number of inputs and/or neuron type
Number of inputs
4 ti
Neuron type
(•) Unipola»
О Bipolar
Рис. 6.3. Начало диалога (ft) и следующий этап диалога (б) с программой
Example Оба
ных сигналов — всегда очень крутых, иглообразных импульсов, иден-
тичных во всех отделах мозга и в любых ситуациях, но каждый раз
имеющих разные значения.
Незаметное изменение регулировки стимулятора, высылающего
электрические сигналы вглубь ткани, и импульсы исчезают. Немно-
го другая комбинация сигналов и импульс появляется вновь. Труд-
но поверить, но именно так функционирует человеческий мозг. Тео'-
мозг. Именно в этот момент. В миллиардах клеток вырабатывают^
и исчезают электрические импульсы. Всего лишь и в то же время пин
много!
Нелинейные нейронные сети
185
2
Experiment 'esuR
Memory trace s’renqth:
Input signal strength.
Perform experiments
Exoe-itr er;? data
Enter the inpu* weights and signal
values n the table bel jw
2
Output-
Незначительное
изменение
входного сигнала x(3)
вызвало позитивную
реакцию нейрона
Рис. 6.4. Чувствительность нелинейного нейрона к изменению входных сигналов
Здесь умещается все: решение уравнения и большая любовь. Пони-
мание сущности бытия и желание совершить самое страшное пре-
ступление. Запах весеннего луга и панорама звездного неба. Все невыска-
занные слова и сокровенные желания. Идея. Пришедшая в голову мину-
ту назад, и возвращающиеся в снах детские воспоминания... Импуль-
сы, только импульсы или их отсутствие. Все или ничего. 1 или
0. Как в компьютере...
Фантазия вещь прекрасная и захватывающая, но она не пополняет
знания. Поэтому вернемся к реальностям и продолжим эксперименты.
6.3. Как функционирует сеть, состоящая
из нелинейных нейронов?
В представленной выше программе Example Оба выходной сигнал
нейрона мог принимать два значения, ассоциируемых с принятием (узна-
ванием) некоторого набора входных сигналов либо с его однозначным
отклонением. Такое; принятие или отклонение часто связано с распо-
знаванием какого-то объекта или ситуации. Поэтому сети, состоящие
из таких нейронов, часто называются персептронами (perception
восприятие, отцушение).
Нейроны персептронного типа формируют па своих выходах толь-
ко два вида сигналов: 1 или 0. Это соответствует (вполне очевидно)
уже упоминавшемуся и известному из нейрофизиологии принципу «все
186
Глава 6
или ничего», лежащему в основе функционирования реального биоло-
гического нейрона. Так работает программа Example Оба, и из таких
нейронов ты будешь строить все следующие исследуемые в нашей кни-
ге сети. Теперь наслало время познакомиться с функционированием и
обучением совокупности биполярных нейронов на примере' состоящей из
них простой однослойной нелинейной сети. Эту сеть ойисывает очеред-
ная программа Example 06b. Для обучения сети можешь использовать
файл под названием Default teaching set 06b.txt, по умолчанию при-
меняемый программой Example 06b. В частности, файл может содер-
жать следующие данные:
5, 3
A typical object that should be recognized by the first neuron
3, 4, 3, 4, 5
1, "I, -1
A typical object that should be recognized by the second neuron
1, -2, 1, -2, -4
-1, 1, “I
A typical object that should be recognized by the third neuron
-3, 2, -5, 3, 1
-1, "I, 1
Структуру такого факта мы уже обсуждали, по-моему, повторять ос
описание нет необходимости; но в случае появления каких-либо сомне-
нии, советую заглянуть в предыдущую главу.
При сравнении представленного файла с уже использованными ты
заметишь, что для очень быстрого обучения нелинейной сети требуется
совсем небольшое число примеров достаточно лишь запустить про-
грамму. Как правило*, для ликвидации выявленных погрешностей тре-
буется лишь один шаг обучения (рис. 6.5).
В среднем после б 7 шагов сеть оказывается полностью обученной
и может подвергаться тестированию. Результаты тестирования свиде-
тельствуют, что сеть не только быстро обучается, но и хорошо обобщает
полученные знания (рис. 6.6).
Способность обобщать знания для нейронных сетей чрезвычайно
важна и необходима. Какой был бы толк от нейронной сети, которую
вначале необходимо обучать демонстрацией последовательности задач (
их решениями только для того, чтобы убедиться в се умении решать
задачи, но только показанные) ранее. Задачи включенные в обучаю-
щую выборку, решать уже не требуется их решения известны. Нам
Условная форма этого утверждения обусловлена гем, что при использовании nei
ронных сетей никогда пи в чем нельзя бьпь абсолютно уверенным любая попытку
любой шаг процесса обучения может все изменить, поскольку на окончательный резуль-
тат сильно влияют случайные факторы, которые не повторяется дважды. Совсем так
же как в жизни, в твоей жизни!
Нелинейные нейронные сети
187
' a j -г
'Г‘
Teaching
Step 1 Comment: A typical object that should be recognized by the first neuron
input data
input number (i) ' 1 2 I3 Д-- 5
Original inputs (u(i)) +3,000 т4,000 +3,000 +4,000 +5,000
| Normalized inputs (x(i)) +0,346 +0,462 +0,346 +0,462 +0,577
I
I
j
I
Teaching progress
Output number (,) 1 2 3
/alue before teaching (yu)) -Г000 +1.000 -1.000
Value expected (zfj)) +1 000 1 DOO -1.00U
Error before teaching (e(j)) +2000 -2,000 +0 00C
/alue after teach ng (y(j)) I- —— — Error after teach ng (e‘(j)) +1,000 -1.000 -1,000
+0,000 +0,000 +0 000
History
V Teaching raho: 0100
Teach more!
Restart teaching
< Dack
Next >
Рис. 6.5. Уже на первом шаге обучения йеливейной сети удается устранить
большинство ногрешностей
необходим инструментарий, который вначале научится решать задачи
из обучающей выборки, а потом сможет также решать другие задачи.
К счастью, нейронная сеть может обобщать знания, что выражается в
способности решать задачи, отсутствовавшие в обучающей выборке, но
в некотором смысле подобные учебным задачам (с аналогичной зави-
симостью между входами и выходами).
Свойство обобщения знаний одно из важнейших особенностей ней-
ронной сети. Поэтому рекомендую тебе проверить, насколько сильно
можно искажать входные данные по сравнению с данными, на которых
izApdiiiicriu*
Tho->t аге the ои ect» ou. rietwork al ould al eidy know
x(2> x(3) x(4) x(5) ytn У12) y(3) Com*npnt
F 4 4 *1 A tynital etijeef that ihoiJd be reaogni»9C! try the fit*'
p 2 1 -2 -4 -1 1 i-1 A tvnical nbied that should be -ecogn.’ed by the second neuron I
|-3 2 -5 :3 1 -1 -1 1 м typral cbj₽ct that should be -ecogr .zed by the third neuron
Here you can enter the feature values for the object to be recognized-
"x(1) ' x(2) x(3) >(4) x(5)
1.0 2.0 |r3.0 £?4.0 fe»5 0 fc*
Here err the network output vaJr les
< Back
Рис. 6.6. Нелинейная сеть хорошо обобщает знания, полученные в процессе обучения
188
Глава 6
обучалась есть, при сохранении осмысленности результатов ее функци-
онирования и признания эффекта обобщения, а не абсолютно свободной
фантазии, на которую сеть также способна! Мои совет - попробуй раз-
личными способами «поиздеваться» над нелинейной сетью. Наверняка
ты признаешь ее превосходство над линейными сетями!
6.4. Как представить функционирование
нелинейных нейронов?
Результаты функционирования нелинейных нейронов и построенных
из них сетей удобно интерпретировать в так называемом пространстве
входных сигналов с указанием, на какие значения эчих сигналов ней-
рон реагирует позитивно (т.е. вырабатывает сигнал +1), а на какие
негативно (т.е. вырабатывает сигнал -1).
Поразмышляем, как интерпретировать графическое представление
данных в пространстве входных сигналов?
Любая точка внутри большого квадрата, который сейчас бу-
дет нарисован нро!раммой Example 06с, символизирует комбинацию
двух показателей (соответствующих горизонтальной и вертикальной ко-
ординатам положения этой точки ). Э i и пока-зачсли отображают текущие
значения входных сигналов нейронной сети. Для наглядности представь
себе, что исследуемая сеть — это мозг гипоте тического зверька, имеюще-
го два рецептора, например примитивного зрения и слуха. Чем сильнее
сигнал, получаемый органом зрения, тем правее располагается точка.
Чем сильнее звук тем выше будет лежать 'точка (рис. 6.7).
Левый нижний угол квадрата соответствует ситуации «тихо и зем-
но» (спальня), а правый верхний максимально шумному и максималь-
но освещенному окружению (Центральная площадь в полдень). Левый
верхний угол может быть дискотекой («темно и громко»), а правый
Здесь светло и шумно
Свет
А здесь данные для конкретной
окружающей среды, в которую
мы помещаем нашего зверька
Рис. 6.7. Экспериментальный мир зверька, мозгом которого является исследуемый
нейрон
Нелинейные нейронные сети
189
Рис. 6.8. Способ обозначе-
ния «самочувствия» зверька
нижний — пляэесем («светло и тихо»).
Попробуй сам найти аналогии для оста-
льных областей внутри квадрата.
К каждой обсуждаемой ситуации мо-
делируемый зверек может относиться по-
зитивно (в этом случае цвет точки будет
ярко красным) или негативно (точка бу-
дет голубой) (рис. 6.8).
Теперь представь себе, что «мозг» мо-
делируемого зверька состоит всего лишь
из одного, по нелинейного нейрона. Ко-
нечно, это должен быть двухвходовый нейрон, поскольку входная ин-
формация поступает с двух рецепторов «зрения» и «слуха». Вначале
для каждого из этих рецепторов необходимо ввести произвольные значе-
ния весовых коэффициентов. Например, положительный первый весовой
коэффициент будет указывать на любовь твоего зверька к яркому све-
ту, а отрицательное значение этого коэффициента будет склонять его к
сидению в темном месте. Точно также можешь поступить со второй коор-
динатой вектора весов и указать, будет ли зверек предпочитать тишину
или окажется любителем концертов группы Metallica.
Таким способом ты «запрограммируешь» мозг своего «животного»,
который позднее будешь тестировать подачей на его рецепторы различ-
ных (конечно, тоже парных) комбинаций входных сигналов. Каждая по-
данная на вход комбинация сигналов может рассматриваться как опи-
сание некоторой «среды», в которую ты пытаешься поместить зверька.
Свойства этой «среды» символизирует точка на плоскости рисунка: зна-
чение первого сигнала (освещенность) соответствует абсциссе этой точ-
ки, а значение второго сигнала (громкость) — ее ординате. Для такой
точки (т.е. для соответствующей комбинации входных сигналов) ней-
рон вырабатывает свое решение в одних случаях +1, а в других 1.
Иными словами, в одних условиях зверьку «комфортно», а в других
нет. Построим карту предпочтений исследуемого нейрона, на которой
закрасим красным точки, «удовлетворившие» нейрон (если он вырабо-
тал сигнал +1), и голубым точки, «отброшенные» нейроном (если он
выработал сигнал 1). Впрочем, зачем раскрашивать карту вручную
лучше воспользуйся пашей программой Example 06с, которая соста-
вит карту сама. Конечно, вначале ты должен ввести значения весовых
коэффициентов, определяющих предпочтения нейрона (рис. 6.9).
После этого ты сможешь сколько угодно проверять, какое значение
(+1 или -1) будет генерировать на своем выходе нейрон в любой точке
пространства входных сигналов. Программа очень услужлива и преду-
190
Глава 6
SygntHy
Show one random point
Show multiple points
Show the entire plane
Параметры, описывающие
нелинейный нейрон
Каждая точка внутри квадрата символизирует
комбинацию двух данных (соответствующих
горизонтальной и вертикальной координатам
местоположения точки), представляющих собой
текущие входные сигналы нейронной сети
Рис. 6.9. Задание параметров нейрона в программе Example 06с
прецительна. Мало того, что она пунктуально выполняет все необходи-
мые вычисления и строит описанную выше каргу, так еще и самое!оя-
тельпо генерирует все необходимые входные сигналы и высвечивает их
координаты в нижней правой части окна (рис. 6.10).
Пока у тебя не пропало желание рассматривать каждую представля-
емую программой точку — щелкай по кнопке Show one random point и
ммммн
Point: (9,22127,-1.81526) Result 1
Neuron
Transfer function type Bipolar
w(1)= 20 w(2)= "30 &
Рис. 6.10. Представление (с помощью цветА) откликов нейрона на поданным входной
сигнал
Нелинейные нейронные сети
191
Рис. 6.11. Вид экрана программы Example 06с после множества предъявлений
входных сигналов
проверяй положение повой точки на экране (па пес указывают прое кции
координат па оси, что позволяет легко выделить эту точку из множества
появившихся ранее). Возникает повод для размышлений, почему нейрон
принял или отклонил соответствующую комбинацию входных сигналов.
Для облегчения поиска ответа числовые данные о сгенерированной по-
следней точке высвечиваются в строке под рисунком. Но поскольку для
эффективного построения карты, показывающей области позитивных и
негативных откликов нейрона, потребуется большое число точек, ты мо-
жешь в любой момент щелкнуть по кнопке Show multiple points. Про-
грамма перейдет в режим непрерывной работы, в котором точки будут
генерироваться автоматически и последовательно наноситься на «кар-
ту» (в любой момент можно вернуться в предыдущий режим щелчком
на кнопке Stop). Через некоторое время прорисуются контуры области,
в которой нейрон реагирует позитивно, и второй области, в которой ней-
рон вырабатывает негативный отклик (рис. 6.11).
Легко заметить, что гранила между этими областями представля-
ет собой прямую линию. Поэтому мы говорим, что одиночный нейрон
осуществляет линейную дискриминацию пространства входных
сигналов. Звучит заумно и таинственно, а означает лишь то, что ты
видишь на экране при проведении описываемых экспериментов.
Если ты хочешь посмотреть, как будет выглядеть карта откликов
нейрона без приложения усили г к генерации точек, то программа Exam-
ple 06с предоставил и такую возможность. Для этого используй кноп-
ку Show the entire plane (рис. 6.12). Очень интересные результаты
могут принести изменения нелинейной функции акт ивации нейрона пу-
192
Глава 6
Рис. 6.12. Вид экрана программы Example 06с в виде карты откликов нейрона
чем выбора одной из доступных в перечне Transfer function type (в
группе опций, связанных с нейроном). Рекомендую поэксперимепч кро-
вать с этими функциями.
6.5. Каковы возможности многослойной
нелинейной сети?
Одиночный нейрон или один слой нейронов) может разделять вход-
ные сигналы только таким способом граница (в двухмерном простран-
стве, т.е. при двух входных сигналах, подаваемых в сеть) всегда будет
прямой линией. При соответствующем комби пировании таких линейно
разграниченных областей можно получить практически любые значения
агрегированных выходных сигналов в произвольных точках простран-
ства входных сигналов. Поэтому в литературе, посвященной нейронным
сетям, часто появляются ошибочные утверждения, что с помощью нейро-
нов можно насколько угодно точно аппроксимировать любую функции».
Эго в принципе невозможно сделать с одним слоем нейронов, посколь-
ку теоремы Цибепко. Хорника, Ланедеса и Фарбера, а также многие
аналогичные научные выводы относятся только к многослойным сетям.
Использование нескольких слоев оказывается необходимым, поскольку
структурные элементы функции, создаваемой обучающимися нейрона-
ми, должны в итоге собираться воедино, как минимум, одним выход-
ным нейроном (чаше всего имеющим линейную функцию активации). По
этой причине сети предстающие в роли универсальных анпроксимато-
ров, имеют несколько слоев два или даже три. Помимо всего прочего,
лихие утверждения о возможности нейросетевой аппроксимации любой
Нелинейные нейронные сети
193
функции, дразнят математиков они стараются придумать такую див-
ную функцию, которая окажется нейронной сети «не но зубам». Увы, ма-
тематики правы, существуют (и не в единственном числе!) такие против-
ные функции, перед которыми нейронные сети оказываются беспомощ-
ными. Но Природа добрее математиков. Реальные процессы (физиче-
(кие, химические, биологические, технические, экономические, социаль-
ные и иные, происходящие в окружающем нас мире) описываются функ-
циями с некоторой степенью регулярности а их нейронные сети обслу-
живают без особого труда, особенно с применением нескольких слоев.
Неоспорим факт, что многослойная сеть обладает гораздо более об-
ширными возможностями, чем обсуждавшаяся выше однослойная сеть.
Те области, в которых нейроны будут позитивно реагировать на вход-
ные сигналы, могут иметь достаточно сложную форму. При использова-
нии двухслойных сетей это, наверняка, выпуклые многоугольники (ли-
бо их многомерные аналоги — так называемые симплексы), а при на-
личии большего числа слоев — произвольные многоугольники (в том
числе и не выпуклые) и даже не связанные между собой (состоящие
из нескольких отдельных «островов»). Думаю, что все это лучше уви-
деть па экране, чем описывать или рисовать, поэтому мы приготовили
программу Example 06d.
Запусти эту программу и поэкспериментируй с ней. Ты сможешь по-
лучать карты откликов, аналогичные составлявшимся предыдущей про-
граммой, но быстрее и проще. Но самое важное — программа Example
06d позволяет1 исследовать сети с произвольным количеством слоев. Ес-
ли ты выберешь однослойную сеть, то увидишь уже знакомый образ ли-
нейной дискриминации (рис. 6.12). Если выберешь двухслойную сеть,
увидишь, что сеть выделяет в пространстве входных сигналов непре-
рывную выпуклую подобласть, ограниченную плоскостями (уже упоми-
навшийся симплекс) (рис. 6.13). Для сети, имеющей три (и более) слоя,
пет никаких ограничений. Область, выделяемая сетью в пространстве
входных сигналов, может быть сколько угодно сложной, не обязательно
выпуклой и не обязательно непрерывной (рис. 6.14). С помощью про-
граммы Example 06d ты сможешь познакомиться с широким спектром
областей откликов (поскольку программа случайно выбирает свойства
конкретной сети) и убедиться, насколько разнообразными бывают фор-
мы этих областей. Для управления ходом экспериментов тебе предо-
ставлена возможность изменять параметры сети, в т ом числе определя-
ющие количество слоев (Number of layers), функцию активации ней-
рона (Transfer function type), количество выходов сети (Number of
outputs). Программа обладает множеством интересных функциональ-
ных возможностей, обсуждать которые у пас просто нет времени. Но
194
Глава 6
а - j J'; ‘ 1У Й ill
* Л s^JJ ldljiJ ii ЛРЧН JJjT Jj --’.If J
, ............ z ............ . U J . . . . ‘ > i i 4 I ..•
N et work n a.ramet e rs
Transfer function type Bipolar
View perametsrs
pl Show the "neuron lines'*
Create new random network
Number of layers 1
Number of outputs 1
Weights range 0,1
7 Different bias range 0,1
10 (1)
t .. ^1 . И 10 (1)
10 (1)
10 (1)
J Use brightness scaling
Рис. 6.13. Пример пространства откликов однослойной нейронной сети
Network parameters
Transter function type' Bipolar
Number of layers 1 10
Number ot outputs 1 I |10
Weights range 0,1 10
Different bias range 0,1 10
v Show the "neuron lines" Г2 Use brightness scaling
Create new random network
Рис. 6.14. Пример пространстве! откликов двухслойной нейронной сети
я советую тебе попытаться обнаружить «зашитые» в программе функ-
ции, а если ты интересуешься программированием, то проанализируй
ее исходный код получишь удовольствие от знакомства с примером
«искусства программирования».
При знакомстве с рисунками, ci оперированными программой Exam-
ple 06d. легко заметить, как по мере роста количества слоев се-
ти расширяются возможности обработки входной информации
и возможности реализации сложных алгоритмов, выражающих
зависимости между входными и выходными сигналами. В обсуж-
давшихся ранее линейных сетях такая особенность не наблюдалась: ли-
нейная сеть независимо от количества слоев всегда реализует
Нелинейные нейронные сети
195
i /Wrjvm П
lew
Create new random network
Рис. 6.15. Пример пространства откликов трехслойной нейронной сети
..... -
hl; Л *
ч par «г
Transfer function tvpe Number с/ layers Bipolar 1 10 (3)
Number of outputs 1 10 (1)
Weights range 0,1 10 (1)
; ”] Different bias range 0,1 10 (1)
v ; Show the “heurpn lines" {__I Use brightness scaling
только и исключительно линейные операции преобразования
входных данных в выходные. Поэтому смысл построения многослой-
ных линейных сетей практически отсутствует. В нелинейных сетях —
все с точностью до наоборот. Здесь увеличение количества слоев од-
на из основных процедур, выполняемых для повышения эффективно-
сти функционирования сети.
6.6. Как протекает обучение нелинейного
нейрона?
Теперь перейдем к проблеме геометрической интерпретации процес-
са обучения нелинейной сети. Как всегда, начнем с простейшего слу-
чая, т.е. процесса обучения одиночного нейрона. Мы знаем, что сущ-
ность функционирования такого нейрона заключается в декомпозиции
пространства входных сигналов на две области с помощью линейной по-
верхности (на плоском рисунке она будет представлена прямой линией,
а в n-мерном пространстве возникают интересные создания, называемые
линейными многообразиями п — 1 порядка, или короче — гиперплоско-
стями). Эта поверхность должна быть расположена так, чтобы она как
можно точнее разделяла точки пространства входных сигналов, в кото-
рых сеть должна вырабатывать противоположные отклики.
Познакомься со следующей программой (Example Обе), которая
позволит тебе исследовать процесс обучения нелинейного нейрона и пе-
ремещение разделяющей липни, изначально устанавливаемой случай-
ным образом, вплоть до момента ее фиксации (автоматической!) в таком
месте, где она лучше всего разделяет две группы точек, для которых в
процессе обучения вводились противоположные решения.
196
Глава 6
One cycle
Step number. 0
Опция Custom set позволяет загрузить
собственный файл с данными
(в рассматриваемом случае
Sample teaching set 06e.txt)
Standard set
Vertical gap size
0
Number of steps to pe
Teaching petfi
Perceptron
Custom set
Load from file
1 (0,99) ----------
Changing these settini is will restart
Tec Г .
•f, P-
! File F^dir Format View f-idp
' //ob jecI I, (1 ass 1
0.1, 0.4
1
0.6, 0.5
2,
class
//obje.1
0.2, 0.7
1
//objec t
-0.6,
1
j//object 2,
1-0.5, -0.5
5,
1,
-0.2
//object 5,
-0.9, -0.7
class
class
class
class
1
1
2
2
2
Рис. 6.16. Пример формирования собственного файла с входными данными
для программы Example Обе
Вначале программа демонстрирует на экране два множества точек
(каждое из которых содержит 10 объекте^), составляющих обучающую
выборку. Точки, принадлежащие одному множеству, изображаются ма-
ленькими черными окружностями, а точки другого множества — та-
кими же окружностями, только белыми. Эти множества образуют две
четко различающихся совокупности, но для усложнения задачи в каж-
дом множестве содержи тся дополнительно но одной «каверзной» точке,
выразительно выдвинутой в направлении противоположного множества.
Проведение разделительной линии вначале между множествами в че-
лом, а потом точно между «каверзными», близкими друг к другу точ-
ками главная цель процесса обучения. Координаты точек ты можешь
задавать самостоятельно, для этого необходимо создать соответствую^
щий файл с входными данными для программы Example Обе, после
чего выбрать опцию C ustom set в группе Teaching set для его за-
грузки (рис. 6.16). Пример такого набора данных представлен в файле
Sample teaching set 06e.txt.
Тем не менее, при самом первом «запуске» программы я рекомен-
дую использовать параметры, установленные по умолчанию (для это-
го надо выбрать опцию Standard set). При выборе этой опции можно
дополнительно изменить расположение множеств (Vertical gap size),
которые можно приблизить друг к другу (задача нейрона в этом случае
усложняется) либо отдалип> с помощью соответствующего «движка».
После запуска программы и выбора опции Standard set ты увидишь па
экране образ, показанный на рис. 6.17.
Нелинейные нейронные сети
197
Рис. 6.17. Начальное состояние процесса обучения в программе Example Обе после
выбора опции Standard set для входных данных
На этом экране видны упомянутые выше точки и начальное (случай-
ное, поэтому каждый раз иное) положение разделяющей линии на стыке
двух полуплоскостей, окрашенных разными цветами. Конечно, началь-
ное положение разделяющей линии опрделястся начальными параметра-
ми нейрона.
Как обычно в задачах обучения, в рассматриваемом случае роль ней-
рона заключается в подборе таких значение весовых коэффициентов,
при которых формируемые на его выходе сигналы будут соответство-
вать характеристикам точек обучающей выборки, заданным учителем.
На экране постоянно высвечивается расположение обоих множеств то-
чек, на которых обучается нейрон, а также демонстрируется прохож-
дение разделительной линии — она может смещаться в процессе обу-
чения. Исходное размещение этой линии зависит от случайных началь-
ных значений, приписанных всем весам нейрона. Такая первичная «ран-
домизация» весов считается наиболее разумным подходом, поскольку
мы не знаем заранее, какие значения будут наиболее подходящими для
корректного решения, и, соответственно, не можем предложить более
осмысленный метод выбора стартовой позиции, чем случайный набор
весов. По этой же причине мы не можем предугадать, какое оконча-
тельное положение займет линия, разделяющая рассматриваемые точ-
ки, так как ее начальная позиция (и связанные с ней изменения по мере
обучения) оказывается следствием случайно выбранной исходной точ-
ки процесса обучения.
В ходе наблюдений за тем, как разделит ель пая линия постепенно ме-
няет свое положение и «втискивается» между разграничиваемыми мно-
жествами точек, ты можешь очень много узнать о природе процессов обу-
чения нейронов с нелинейными характеристиками. Очередной «цикл»
198
Глава 6
обучения, состоящий из заданного количества шагов, начинается после
каждого щелчка но кнопке One cycle. Программа позволяет изменить
количество шагов обучения, которые выполняются в одном «цикле», пе-
ред выводом очередного положения разделительной линии. Эго имеет
большое практическое значение, поскольку процесс обучения развива-
ется вначале быстро (каждый очередной шаг обучения приносит легко
заметное перемещение разделительной линии), но потом развитие за-
медляется. Поэтому вначале следует задавать небольшое количество
шагов । например, 1, 5 или 10), а позднее нужно совершать достаточно
большие «скачки» (но 100-500 шагов) между очередными просмотрами
(рис. 6.18). Чтобы избавить тебя от необходимости щелкать по кнопке
One cycle, предусмотрена кнопка Continuous. После щелчка по пей
программа делает все самостоятельно вплоть до очередного щелчка во
этой кнопке. Каждый раз программа показывает, сколько всего шагов
обучения пройдено (информация Step number:... в нижней части окна
программы), поэтому ты можешь оперативно контролировать процесс
обучения па всем его протяжении.
Посмотри па рис. 6.18. Начальное положение разделительной линии
сильно отличается от искомого положения, при котором, как мьг ожи-
даем, с одно! стороны барьера будут располагаться все точки, принад-
лежащие к первому множеству, а с другой стороны все точки вто-
рого множества. Первый этап обучения на рис. 6.18 он очень корот-
кий всего три демонстрации) привел к вполне осязаемому улучше-
нию результатов. Тенденция сохраняется и на следующих шагах все
большее число точек разделяется правильно. К сожалению, 51-й шаг
принес ухудшение, после него много точек оказалось «не со стороны»
разделительной линии. Сеть пошла на поводу у «каверзных» точек (ко-
торые разделить особенно трудно) и ухудшила свое функционирование
относительно точек, входящих в основные множества легко разделяе-
мых данных. Увы, такие кризисы в процессе обучения — не редкость.
Очередные 10 шагов улучшают ситуацию, а следующие этаны приводят
к заметному повышению результатов.
На рис. 6.19 видно, что процесс обучения завершился полным усшн
хом, поскольку итоговая линия (на границе красной и синей полуплос-
костей) идеально точно разделяет множества точек. Необходимо отмс-
тить, что по достижении искомого решения продолжение обучения не
приносит1 ничего нового, например разделигельные линии после 16(Ю
и 3600 шагов полностью совпадают. Так происходит всегда, посколь-
ку после полного обучения нейрон уже не изменяет свои корректные
(о чем свидетельствует успешная классификация точек) значения ве-
совых коэффициентов.
Нелинейные, нейронные сети
199
Srpp number 15
Step number 38
Рис. 6.18. Изменения положения раздели гель пой линии на начальном этапе процесса
обучения нейрона
Рис. 6.19. Изменения положения
разделительной линии на конеч-
ном этапе процесса обучения ней-
рона
Step number 16DQ
Step number ЗЯПГ1
6.7. Какие исследования можно проводить
в процессе обучения нейрона?
Описанная в предыдущем разделе программа Example Обе позво-
ляет самостоятельно проводить различные исследования. Ты должен
только выбрать и ввести соответствующие значения параметров. Про-
грамма предоставляет возможность изменять положение отдельных то-
чек или целых обучающих множеств. Можно применить один из двух
известных из литературы методов обучения нелинейного нейрона: либо
персептронный (основа обучения сравнение выходного сигнала ней-
рона с эталонным сю налом, заданным «учителем» (в рассматриваемом
случае включенным в обучающую выборку)), либо так называемый
метод Бидроу-Хоффа. Второй метол, с водится к обучению только линей-
ной части (основа обучения «net value»). Выбор одного из этих методов
200
Глава 6
осуществляется в группе Teaching method указанием какого-либо из
них в качестве используемого в текущем сеансе.
При проведении собственных исследований ты заметишь, что вто-
рой метод обучения, ассоциирующийся с фамилиями его создателей <ид-
роу (В. Widrow) и Хоффа (М. Hoff), иногда оказывается более эффек-
тивным (вероятно, уже в первых экспериментах ты обнаружишь, что
близкое к идеальному разделе ше находится с применением этого ме-
тода гораздо быстрее, чем с применением персептронного метода). Но
в методе Видроу-Хоффа нет критерия завершения обучения, поэтому
нейрон никогда не перестает обучаться. После достижения корректно-
го решения он ухудшает свои характеристики, потом улучшает их, по-
том снова ухудшает...
Наверное, ты замечал, что точно также поступает множество лю-
дей? В частности, такая особенность поведения была присуща известно-
му польскому художнику Александру Геримскому. Он никогда не бы-
вал полностью удовлетворен своими картинами, поэтому после созда-
ния очередного шедевра сразу начинал корректировать его что-то
стирал, что-то подрисовывал и через некоторое время картина ока-
зывалась безвозвратно испорченной. Все сохранившиеся произведения
Мастера уцелели только поюму, что его друзья силой забирали из ма-
стерской «незавершенные» работы!
6.8. Контрольные вопросы и задания
для самостоятельного выполнения
1. Назови, как минимум, три достоинства применения нелинейных
нейронов для решения сложных вычислительных задач.
2. Какую функцию активации униполярную или биполярную
имеет линейный нейрон?
3. В чем заключаются достоинства нейрона с биполярной функцией
активации? Используются ли эти функции в мозгу человека и живот-
ных?
4. На рис. 2.12 на стр. 59 показаны наиболее часто применяемые на
практике фупкции активации нейронов. Какие из них униполярные, а
какие биполярные?
5. На чем основано явление обобщения знаний, наблюдаемое в обу-
чающихся нейронных сетях?
6. Какие ограничения налагаются на задачи, решаемые с помощью
одно-, двух- и трехслойной нелинейной нейронной сети?
7. Что необходимо изменить в определении нейронной сети, чтобы
описанный в разделе 6.4 «Дверок» мог попадать в промежуточные со-
Нелинейные нейронные сети
201
Что сделать, чтобы между состояниями:
полного счастья
абсолютной
депрессии
существовали промежуточные состояния,
которые мы будем обозначать различной
окраской - подобно тому, как на
географических картах обозначаются
промежуточные высоты между
вершинами (энтузиазмом)
и дном (меланхолией)
Желательное для нас состояние
представлено примером карты:
Рис. 6.20. Иллюстрация к заданию № 7
стояния между «полным счастьем» и «полной депрессией», примеры
которых показаны на рис. 6.20?
8. Нарисуй график изменения погрешности сети в процессе обучения
па основании экспериментов по классификации точек, принадлежащих
двум разным множествам. Какие выводы можно сделать при анализе
формы этого графика?
9. Почему при повторении попыток обучения одной и той же сети с
использованием одних и тех же обучающих данных процесс обучения
развивается, как правило, по-разному?
10. Задание для наиболее подготовленных. Попробуй доказать
теорему (самую настоящую!) о том, что многослойная линейная сеть
может реализовать только те же самые простые отображения, что и
однослойная сеть, и по этой причине строить многослойные линейные
сети нет никакого смысла.
11. Задание для наиболее подготовленных. Напиши программу,
которая позволит обучать многослойную нейронную сеть распознава-
нию классов точек, произвольно размещаемых па экране щелчком мы-
ши.
12. Более сложное задание для самых подготовленных. Напи-
ши про] рамму, которая позволит сети классифицировать точки в про-
странстве входных сигналов при использовании не двух, а пяти классов
по аналогии с программой, описанной в этой главе).
Глава 7
ОБРАТНОЕ РАСПРОСТРАНЕНИЕ
7.1. Что называется обратным
распространением?
В предыдущей главе мы рассматривали некоторые аспекты функ-
ционирования и обучения однослойной нейронной сети, построенной
из нелинейных элементов. Сейчас мы продолжим это обсуждение, но
рассмотрим работу многослойных нелинейных сетей. Как ты знаешь,
такие сети обладают существенно большими и интересными возмож-
ностями. в чем ты мог убедиться в ходе экспериментов с программой
Example 06d.
Ты уже понял, что мы будем ci роить многослойные сети из .нели-
нейных нейронов. Ты знаещь, как обучается нелинейный нейрон (вспом-
ни программу Example Обе). Но тебе еще неизвестна (даже если ты
об этом слышал, то вряд ли ощутил «на собственной шкуре») основ-
ная проблема обучения таких сетей проблема так называемых скры-
тых слоев (рис. 7.1).
В чем же смысл этой проблемы?
Правила обучения, с которыми ты познакомился в предыдущих гла-
вах, были основаны на простом но очень эффективном принципе: каж-
дый нейрон сети сам корректирует уровень собственных знаний (т.е. из-
меняет значения весовых коэс >фициентов на всех своих входах) с уче-
том известного значения допущенной им погрешности. При рабо-
те с однослойной сетью ситуация была простой и очевидной: выходной
сигнал каждого нейрона сравнивался с предложенным учителем пра-
вильным значением, что создавало достаточный базис для корреюиров-
ки весов. В многослойной сети все не так просто. Погрешность нейронов
последнего (выходного) слоя можно оценить в меру простая м и легким
способом, как и прежде, путем сравнения выработанного каждым ней-
роном сигнала с эталонным сигналом, предложенным учителем.
Обратное распространение
203
Входные сигналы (данные)
Входной
слой
Первый
скрытый
слой
п-й скрытый
слой
Выходной
слой
Выходные сигналы (данные)
Рис. 7.1. Скрьг1ые слои в многослойной нейронной сети
А как быть с нейронами предшествующих слоев? Их погрешности
необходимо оценивать математически, поскольку напрямую измерить их
не удается, мы не знаем, какими ДОЛЖНЫ быть значения соответству-
ющих сигналов, поскольку учитель не задает эти промежуточные зна-
чения и концентрируется исключительно на конечном результате.
Метод, который повсеместно применяется для «отгадывания» по-
грешностей нейронов скрытых слоев, называется backpropagation (метод
обратного распространения ошибки). Этот метод настолько распростра-
нит, что в большинстве программ для создания и обучения нейронных
сетей оп используется по умолчанию. В то же время существует много
других методов обучения, например ускоренная версия этого алгоритма,
называемая quickpropagation, а также методы, основанные па более слож-
ных математических инструментах, таких, как алгоритм сопряженных
градиентов или алгоритм Левенберга — Марквардта. Перечисленные
методы (а также еще, как минимум, дюжина других, не менее изыс-
канных) обладают таким достоинством, как высокая скорость работы.
Однако это достоинство проявляется лишь в случае, когда подлежащая
решению задача (понятно, что сеть выясняет способ ее решения в процес-
се обучения) удовлетворяет различным, иногда достаточно серьезным
математическим требованиям. Увы, далеко не всегда, даже если нам в
общих чертах понятна задача, которую должна решить сеть, мы можем
определить, удовлетворяет опа эт им сложным тр< бовапиям или нет.
Ну и что это практически означает?
Нс более и не менее чем следу юную ситуацию:
Мы должны решить сложную задачу, поэтому берем нейронную сеть
и начинаем обучать ее с применением одного из этих изящных и совре-
менных методов, например алгоритма Левенберга Марквардта. Если
204
Глава 1
нам посчастливилось получить именно ту задачу, решение которой сеть
легко найдет с применением именно этого алгоритма, то сеть обучится в
течение очень короткого времени. Но если задача «нс подходи т» к этому
современному алгоритму обучения, он будет бесконечно водить пас во-
круг да около, а сеть так ничему не научится, потому что определенные
теоретические требования не были выполнены. Иное дело представляе-
мый в этой главе метод обратного распространения. Он обладает од-
ним очень привлекательным свойством: независимость от каких бы то ни
было теоретических условий. Это означает, что в отличие о г многочис-
ленных быстрых алгоритмов, работающих иногда, алгоритм обратною
распространения результативен всегда. Конечно, в некоторых случаях
он может выполняться до раздражения медленно, но никогда не подве-
дет. Познакомиться с алгоритмом обратного распространения стоит хотя
бы потому, что многие профессиональные пользователи нейронных сетей
часто возвращаются к нему как к испытанному и надежному партнеру.
С методом образ ного распространен^ ты познакомишься в дина-
мике, изучая работу очередной специально написанной программы. Но
прежде чем мы к нет обратимся, я должен вернуться к одному част-
ному вопросу, который раньше рассматривался как второстепенный. а
сейчас приобретает особую важность. Эго форма нелинейной функ-
ции активации исследуемых нейронов.
7.2. Как изменять «порог» нелинейной
функции активации нейрона?
В предыдущей главе мы рассматривали нейроны, действующие по
принципу «все или ничего». Они могли функционировать на основе ло-
гической категоризации входных сигналов (истина или ложь, 1 или 01.
либо па базе «биполярной» характеристики (принятие или отклонение,
+1 или —1). В обоих рассматриваемых случаях переход между двумя
граничными состояниями имел скачкообразный характер: либо входные
Сигналы (точнее, их взвешенная сумма) «превышали порог», и тогда вы-
ходной сигнал мгновенно принимал значение +1, либо входные chi налы
оказывались слишком слабыми («предпороповое возбуждение»), и от-
клик представлял собой отсутствие реакции (сигнал 0) либо однозначно
негативный ответ (-1). Волее того, мы придерживались принципа нуле-
вого порога, согласно которому положи тельной сумме входных сигналов
соответствовал сигнал +1, а отрипатсльпой сигнал 0 (или -1), что
несколько oi раничивало возможности рассматриваемых сетей. Поэтому
при обсуждении формы функции активации нелинейного нейрона так ж»
необходимо рассмотрет ь вопрос выбора значения порога, поскольку в
общем случае он совсем не обязан быть пулевым.
Обратное распространение
205
Draw
BIAS Current RIAS
Chai adenstic 1 || ffl ’2.80
Characteristic 2 3 1 -1.40
Characteristic 3 □ Q 0 00
Charadennttc 4 £i '1 * Kj
Characteristic 5 в ff 12 гео
Color
Рис. 7.2. Семейство пороювых функций активации нейрона при различных значениях
переменной BIAS (экран программы Example 07а)
С этого момента в рассматриваемых нами нелинейных моделях ней-
ронов порог будет свободным, соотвегствующим мобильным функци-
ям активации с возможностью подбора точки переключения с помощью
параметра, чаще всего обозначаемого в программах моделирования се-
рей идентификаторов BIAS. С помощью программы Example 07а ты
сможешь нарисовать себе семейство пороговых функций активации ней-
ронов с изменяющимся значением BIAS, что позволит получить очень
хорошее представление о роли этого фактора в формировании поведе-
ния одиночных нейронов и сетей в целом. Программа демонстрирует,
каким может быть поведение нейрона со свободно выбираемым порогом
(рис. 7.2).
7.3. Какая форма нелинейной функции
активации нейрона применяется наиболее
часто?
Функция активации настоящего биологического нейрона оказывает-
ся более сложной. Между состоянием полного максимального (по тер-
минологии физиологов «столбнячного») возбуждения и предпорого-
вым состоянием (характеризующимся отсутствием какой-либо активно-
сти) «распределено» множество промежуточных состояний, характери-
зующихся наличием импульсов переменной частоты. С некоторым упро-
щением можно сказать, что чем сильнее будет входной раздражитель,
достигающий конкретного нейрона через все его входы, гем больше ока-
206
Глава 7
жется частота i мпульсов на выходе этого нейрона. Поэтому следует при-
знать, что вся информация в нашем мозгу передается с применением
метода РСМ*, который был изобретен Природой... на несколько милли-
ардов лет раньше инженеров по телекоммуникациям!
Однако подробное обсуждение проблематики кодирования нейрон-
ных сигналов в биологическом мозге выходит за рамки этой книги, по-
этому если тема кажется тебе интересной, загляни в мою книгу «Про-
блемы биокибернетики». С точки зрения содержания текущего раздела
важен только один вывод: можно (и необходимо!) применять нейронные
сети, выходные сигналы которых непрерывно изменяются в интер-
валах ог 0 до 1 либо от -1 до +1.
Такие нейроны с непрерывными нелинейными функциями актива-
ции выгодно отличаются как от линейных нейронов, которыми мы до-
статочно долго занимались в первых главах, так и от рассмотренных в
предыдущей главе дискретных нелинейных нейронов, имевших толь-
ко два допустимых значения выходного сигнала. Я не смогу представить
здесь все достоинства (в частности, потому что многие из них удается
объяснить только в форме определенных математических теорем а
я обещал, что не включу в эту книгу ни одну формулу). Тем не менее,
даже при поверхностном взгляде очевидны широчайшие возможности
нелинейных нейронов с непрерывными функциями активации. С одной
стороны, это нелинейные структуры, которые способны (в отличие ог
линейных нейронов) объединяться в многослойные сети, позволяющие
(путем обучения) формировать абсолютно любые зависимости меж-
ду входом и выходом. С другой стороны, сигналы в таких сетях мо-
гут иметь любые непрерывные значения. Это позволяет применять
их для решения задач в которых результат работы нейрокомпьютера
не обязан ограничиваться исключительно двоичными значениями типа
«да — пет», но может представлять собой некоторое числовое значение,
например ожидаемый прирост стоимости акций (в модных в последнее
время сетях, используемых для анализа рынка и предсказания (про-
гнозирования) его изменении).
Несколько менее очевиден, но также важен другой аргумент в поль-
зу отказа от простоя «скачкообразной» функции активации. Для эф-
фективного обучения многослойной нейронной сети НЕОБХОДИМО
чтобы функции активации входящих в нее нейронов были непрерыв-
ными и дифференцируемыми**. Доказать важность этих свойств
Это современный метод импульс пою кодирования сигналов, используемый в на-
стоящее время в электронике, авч ома гике, робоютехнике, йнформатике и телекоммуни-
каци ях.
**
Конечно, оба термина непрерывность и дифференцируемое!ь обозначают
Обратное распространение
207
довольно просто, но я по считаю эту книгу подходящим местом для
публикации такого доказательства. Тем не мечсе, сам факт необходимо
запомнить: функция активации нейрона в многослойной обуча-
емой сети должна быть достаточно «гладкой», если мы желаем
обеспечить беспроблемное обучение.
Существует множество функции, пригодных для исполнения роли
функции перехода моделируемых нами нейронов, по наибольшей попу-
лярностью пользуется логистическая кривая, известная также (по
форме ее графика) под названием «сигмоида». Эта функция обладает
следующими достоинствами:
• обеспечивает плавный переход между значениями 0 и 1;
• имеет гладкую и легкую для практических вычислений производ-
ную;
• имеет один параметр (чаще всего называемый «ВЕТА»), значение
которого позволяет свободно выбирать форму кривой — от очень
плоской и близкой к линейной функции до очень крутого «релей-
ного» перехода от 0 к 1.
Программа Example 07b позволит1 тебе поближе познакомиться с
этой функцией. Легко заметить, что при построении нелинейной функ-
ции активации нейрона учитывается также возможность перемещения
точки «переключения» между значениями 0 и 1 с помощью параметра
BIAS, по дополнительно гы можешь подобрать крутизну кривой и об-
щую степень нелинейного поведения нейрона (рис. 7.3).
Логистическая кривая, со свойствами которой ты познакомился в
ходе экспериментов с представленной выше программой, широко приме-
няется в естественно-научных дисциплинах. Когда-нибудь я напишу об
этом подробнее, но сейчас скажу только одно: любое развитие (напри-
мер, развитие новой фирмы или технологии протекает согласно гра-
фику логистической кривой. По мере накопления опыта, капиталов и
прочих ресурсов развитие начинает ускоряться, и кривая довольно кру-
то идет вверх. D момент наибольшего успеха, в наиболее крутой точке
направленного вверх отрезка линии происходит перелом, и кривая изги-
бается в горизонтальном направлении. Эю вначале незаметно, а затем
все более радикально тормозится дальнейший рост кривой наступа-
ет «насыщение». Конец любого развития представляет собой стагнацию,
после которой (па логистической кривой это уже не видно) приходит
неуклонный спад. Но это тема совсем иной беседы...
математические понятия, по мы решили, что «в твоем классе математика нс преподается».
Но даже если ты в настоящий момент не понимаешь, о чем идет речь, то это нисколько не
станет препятствием для восприятия последующего текста упомянутыми свойствами
мы далее пользоваться (в явном виде) не будем.
208
Глава 1
Рис. 7.3. Различные формы логистической кривой (экран программы Example 07b)
Вариан т сигмоиды для биполярных сигналов (симметрично располо-
женных между —1 и +1) называется гиперболическим тангенсом. На-
звание звучит несколько устрашающе, во в деветви гсльпосги это очень
симпатичная функция. Лучше всего познакомься с ней самостоятельно
с помощью следующей программы Example 07с. Не правда ли, в этот
функции пег ничего, вызывающего опасения?
Поскольку ты уже знаешь, как выглядят функции активации нели-
нейных нейронов, пора строить из них сеть и начинать ее обучение.
Рис. 7.4. Различные формы функции гиперболического тангенса (экран программы
Example 07с)
Обратное распространение
209
7.4. Как функционирует многослойная сеть,
состоящая из нелинейных нейронов?
Многослойные сечи, состоящие из нелинейных нейронов, считаются
в настоящее время основным нейронным инструментарием для решения
практических задач. Для реализации таких сетей написано большое чис-
ло пакетов прикладных программ, которыми (в случае необходимости)
ты можешь легко воспотЯьзоваться. О готовых программах (как общедо-
ступных — public domain, гак и очень многочисленных коммерческих)
для моделирования сетей различных типов мы поговорим в другой раз, а
сейчас я предлагаю воспользоваться двумя простыми программами: пер-
вая вначале продемонстрирует тебе, как функционирует многослойная
сеть (программа Example 08а), а потом — уже в следующем разделе —
программа Example 08b познакомит со способом обучения таких сетей.
При внимательном чтении этих двух разделов книги в ходе эксперимен-
тов с применением предложенных программ ты сможешь попять смысл
знаменитого метода backpropagation. Очень рекомендую не спешить и
очень внимат ельно прочитать, осмыслить и собст венноручно опробовать
все, о чем идет речь, поскольку обратное распространение считает-
ся ядром и сущностью нейросетевой технологии. Если ты изучишь
и хорошо поймешь суть этого метода, большинст во проблем, ассоцииру-
емых с нейронными сетями, покажутся простыми и очевидными. Если
же не втянешься в это увлекательное занятие и не проникнешься его
духом, то, скорее всего, так и не сможешь полностью понять, «ктао там
в траве шевелится». Конечно, можно прожит ь и без этого, но стоит ли?
Перед запуском очередных программ прочитай несколько дополни-
тельных примечаний об их работе, увы, взаимодействие с этими програм-
мами уже не так очевидно, как с простенькими программами в предыду-
щих главах.
Программа Example 08а подробно демонстрирует функционирова-
ние сети, которая состоит из всего четырех нейронов (рис. 7.5). Они объ-
единены в три слоя: входной слой, не подлежащий обучению (в верх-
ней части экрана), выходной слой (сигналы которого передаются на вы-
ход сети для оценивания и использования для обучения, он расположен
в нижней части экрана) и вамый важный скрытый слой, представ-
лении 1 в центральной части, экрана. Нейроны и сигналы в сети будут
обозначаться двумя номерами: номером слоя и номером нейрона (или
сигнала) внутри слоя.
Теперь несколько слов о работе программы и об ее обслуживании.
Вначале программа просит ввести значения весовых коэффициентов
каждого нейрона сети (рис. 7.5). Ты должен ввести только 12 значении,
210
Глава 1
Рис. 7.5. Задание параметров и входных сигналов для сети в программе Example 08а
поскольку, как уже говорилось, сеть состоит' из четырех нейронов (два
в скрытом слое и два в выходном слое), причем каждый из них имеет
по три входа (два от нейронов предыдущего слоя и один дополни тель-
ный вход тоже снабженный весовым коэффициентом связанный
с «порогом», который представляется в рассматриваемой сети генера-
тором искусственного постоянного сигнала BIAS). При вводе этих ко-
эффициентов ты осознаешь удобство случайного назначения начальных
значений весовых коэффициентов в реальных сетях с сотнями нейро-
нов и тысячами весов с их автоматической корректировкой в процес-
се обучения. В обсуждаемой программе мы предоставили возможность
«вручную» задавать значения всех параметров, чтобы ты смог прове-
рять, насколько результаты работы сети совпадают с ожидаемыми то-
бой значениями. Для этого ты можешь задавать произвольные значения
входных сигналов и наблюдать сигналы, как на входах, так и на вы-
ходах нейронов. Вначале выбирай в качестве весовых коэффициентов и
входных сигналов простые целые числа это облегчит проверку сте-
пени совпадения результатов рабочая сеч и с твоими представлениями о
пик, а также позволит оценить, насколько хорошо ты понимаешь ло-
гику се функционирования.
После ввода значений коэффициентов необходимо ввести значения
обоих входных сигналов, которые должны быть поданы па вход сети
(рис. 7.5). В этот момент программа уже полностью готова к работе. Ко-
нечно, ты уже сориентировался в представлении структуры сети (места
расположения каждого нейрона и места обозначения каждого сигнала,
рис. 7.6).
Обратное распространение
211
Weights
“ "i"oooj ........iddd| [sLooo]
iodo' .............2'0601 I’..........<000
Neurun(1,1)
Surn
Output
Neurun (1,2)
Sum
Output Г □
bias;
["ji'dddj
Weig*’ Is
” 1 000
1 000
1.00П
2 ООП
000
1.Л00 Места, в которых программа
выведет рассчитанные сигналы
Neuro" (2.1)
Sum
Nburon (2 2)
Sunn
Output
BIAS
-1.000
Output
Output (2 1)
Calculate
Рис. 7.6. Начало демонстрации сети в программ» Example 08а
Рис. 7.7. Иллюстрация функционирования линейной (сум’мирующеЙ
взвешенные сигналы) пасли нейронов первого слоя
Для начала и проведения процесса моделирования передачи и обра-
ботки сигналов в исследуемой сечи щелкни по кнопке Calculate. Вна-
чале для каждого слоя рассчитываются и высвечиваются (на красном
фоне) суммы значений входных сигналов, умноженных на соот-
ветствующие весовые коэффициенты (вместе с компонентой BIAS).
Далее демонстрируются расчетные значения выходных сигналов («от-
клики») каждого нейрона (вначале тоже на красном фоне), полученные
212
Глава 7
Рис. 7.8. Завершающий этап выполнения программы — все сигналы рассчитаны
в результате пропуска суммирован пых входных сигналов через функ-
цию активации, имеющую сигмоидальную форму. Пути распространения
этих сигналов показаны па рис. 7.7 в виде стрелок.
На следующем этапе отклики нейронов низшего слоя становятся
входными сигналами для нейронов высшего слоя, и весь процесс повто-
ряется (рис. 7.8).
Последовательное нажатие кнопки Calculate позволит тебе просле-
ди Пэ перемещение сигналов между нейронами от входа к выходу рас-
сматриваемой модели сети. Ты можешь изменять входные значения и
наблюдать выходные сигналы столько раз, сколько тебе потребуется для
лучшего понимания происходящего в сети. Советую уделить некоторое
время детальному анализу и осмыслению каждого числа на экране (быть
может, с ручным пересчетом их значений на калькуляторе для провер-
ки, насколько твои знания о нейронных сетях позволяют точно прогно-
зировать их поведение). Только таким способом ты сможешь узнать и
осознать, как в действительности работает сеть.
7.5. Как можно обучать многослойную сеть?
После того как ты выведаешь все секреты описанной выше много-
слойной сет и, значения всех весов и входных сигналов которой были
введены твоими собственными руками, попробуй ввести и запустить ту
же сеть, по в режиме обучения. Для этого предназначена программа
Example 08b. После вызова этой программы необходимо ввести значе-
ния двух коэффициентов, определяющих развитие процесса обучения.
Обратное распространение
213
Первый из них характеризует величину поправки, которая будет вво-
дился после обнаруже ния каждой очередной погрешности и тем самым
будет обусловливать скорость обучения. Чем больше значение этого ко-
эффициента, тем сильнее и быстрее будут изменяться веса нейронов при
выявлении погрешностей в процессе обучения. Этот коэффициент дол-
жен выбираться очень вдумчиво, поскольку как слишком большое, так
и слишком малое его значение фатально повлияет на успешность обуче-
ния. В англоязычной литературе этот коэффициен т называется learning
rate {коэффициент обучения). К счастью, ты не должен задумываться,
чему должен быть равен эт о г коэффициент, я нашел наиболее подходя-
щее значение, которое предложит тебе программа по умолчанию. Если
захочешь, можешь заменить это значение любым другим и потом удив-
ляться, как все «пошло вразнос». В конце концов, ты живешь в свобод-
ной стране и волен делать все, что пожелаешь!
Второй коэффициент характеризует1 «степень консерватизма» про-
цесса обучения. В англоязычной литературе этот коэффициент назы-
вается momentum, что можно перевести как инерция или фактор дви-
жения. Ты можешь использовать эти понятия, по лучше называть его
так, как принято в большинстве публикаций по нейронным сетям — ко-
эффициент момента. В программе оставлено оригинальное английское
название. Чем больше значения коэффициента момента, тем стабильнее
и безопаснее процесс обучения. Однако слишком большое значение мо-
жет создавать проблемы для поиска сетью наилучших (оптимальных)
значений весовых коэффициентов каждого нейрона сети. Я также подо-
брал относительно неплохое значение этого коэффициента. Тебе остает-
ся просто подтвердить предлагаемые по умолчанию значения щелчком
по кнопке Intro (рис. 7.9). Но можешь испытать судьбу и поискать луч-
шее значение. Желаю успеха, и пусть тебе сопутствует удача!
Рис. 7.9. Задание параметров, определяющих эффективность обучения в программе
Example 08b
214
Глава 1
После ввода выбранных тобой (или предложенных мной) значений
коэффициентов программа высвечивает на экране окно, уже известное
тебе из предыдущих экспериментов, в котором показываются все ней-
роны, значения сигналов, весовые коэффициенты и погрешности. Для
облегчения взаимодействия в программу добавлен вспомогательный эле-
мент, информирующий тебя (сообщениями в нижней части экрана) о дей-
ствиях в текущий момент. Эю г информатор оказался очень полезным
и даже необходимым, поскольку задача повои программы более слож-
ная — она должна обучать сеть.
7.6. Что надо наблюдать в процессе обучения
многослойной сети?
Задача моделируемой сети заключается в правильном распознава-
нии входных сигналов. Идеальное распознавание заключается в выра-
ботке выходным сигналом сигнала 1 на нейроне, приписанном к соот-
ветствующему классу (в нашем случае левым или правым нейро-
ном). Понятно, что другой нейрон в тот же момент времени должен
выработать сигнал 0. Но для оценивания корректности функциониро-
вания сети достаточно выдвинуть более мягкое условие — погрешность
на любом выходе пе должна превышать* 0,5, потому что в этом слу-
чае классификация входного сигнала пе будет отличаться от указан-
ной учителем. Следовательно, понятие погрешность (измеряемая как
разность между фактическими значениями сигналов па выходе сечи и
значениями, указанными учителем в качестве эталона не эквивалентно
оценке корректности решения сетью поставленной задачи, по-
скольку последняя связана с обобщенным поведением сети в целом, а нс
со значениями конкретных сигналов. Поэтому можно чаще «отпускать
мелкие грехи», допущенные сетью, если ей удастся выдавать правиль-
ные решения. Но в ходе экспериментов с описываемой программой ты
заметишь, что процесс обучения с применением метода обратного рас-
пространения не склонен к толерантности. Если па выходе должен быть
сигнал 1, а нейрон выработал 0,99 э го считается подлежащей коррек-
тировке погрешностью, даже если ученик размазывает слезы по щекам
Например, для появившихся на некотором этане процесса обучения входных сиг
налов, равных 4,437 и 1,034 отклики сети равны 0,529 и0,451, что квалифицирусня
как ошибка, поскольку объект с представленными коордипагами должен быть отнесен ко
второму классу, тогда как сигнал на выходе второго нейрона оказывается меньше сигнала
на выходе первого нейрона. В го же время следующий предлагаемый программой объект
из обучающей выборки с координатами -3,720 и4,937 вызывает отклики 0,399 иО.593.
поэтому его распознавание может считаться корректным (этот объект тоже припал лежит
ко второму классу), хотя величина среднеквадратичной по грешное! и в обоих случаях при-
мерно равна (постарайся понаблюдать подобную ситуацию во время твоих экспериментов)
Обратное распространение
215
и дрыгает ногами! (прошу прощеная, меня понесло дрыганье ногами
в программе не предусмотрено).
Как оказалось, такое стремление к совершенству оправданно, по-
скольку при уточнении своих сигналов в соответсгвии с указаниями у1 и
теля сеть стремится все более эффек гивпо достигать поставленные перед
пей дели. Возникает’ очень интересная аналогия с обучением в школе:
как правило, сведения, получаемые при изучении какой-либо конкрет-
ной дисциплины (например, геометрии) не применяются непосредствен-
но на практике, поскольку в действительности мы почти не имеем дела
с идеальными геометрическими фигурами. Тем не менее, знания, по-
лученные применительно к этим эталонным образцам, пригодятся для
решения практических задач (например, для определения прощади сет-
ки, необходимой для ограждения садового участка конкретной формы).
Если кто-т о не уделяет должного внимания решению бессмысленных, на
первый взгляд, теоретических задач и считает достаточным получать ба-
зовые знания по принципу «если сильно заставят», то он рискует часто
оказываться в будущем в затруднительном положении при необходимо-
сти решать реальные практические проблемы. Чем лучше ты научишься
решать математические задачи, гем эффективнее будешь справляться
с практическими ситуациями.
Не подлежит сомнению, что изучение «идеализированной» физики
помогает понимать очень «прикладную» технологию, изучение биологии
необходимо для занятий растениеводством и животноводством, изучение
географии помогает осваивать окружающую среду и т.н. Как мы видим,
в нейронных сетях складывается аналогичная ситуация. Стремление до-
стичь идеальных целей, поставленных перед сетью учителем в процес-
се обучения, приближает ее к достойному исполнению предназначенной
роли — эффективного инст рументария решения практических задач.
Но вернемся к обсуждению рассматриваемой программы. В процессе
обучения сети твоя роль будет ограничена наблюдением. Воспользуй-
ся правом надзирать, нажимать любую клавишу и внимательно следить
за происходящим на экране. Все начальные значения весов, входные
сигналы и эталоны правильных решений программа сгенерирует са-
мостоятельно. Некоторые из этих данных будут выбираться случайным
способом (начальные значения весов и входные сигналы), по эталоны
правильных решений, по которым сеть будет обучаться, отнюдь не слу-
чайны! Попробуй сам попять из текста программы или по наблюдениям
за ее работой, по какому принципу она функционирует я не хочу ли-
шать тебя удовольствия самостоятельного познания истины. По правде
говоря, знать это т принцип не обязательно сеть сама найдет в процессе
обучения необходимые зависимости и начнет корректно классифициро-
216
Глава 7
-1 ObB
tote
Рис. 7.10. Представление структуры сети
вать сигналы. Убедись, что она сможет это делать даже тогда, когда ты
будешь готов расписаться в собственном бессилии!
Теперь несколько слов о работе программы и о диалоге с пей.
Вначале программа показываем па экране только структуру сети, о
чем услужливо информирует красная надпись в верхней части экрана
(рис. 7.10).
Обрати внимание, что источники «псевлосигналов» В AS па этот раз
показаны на желтом фоне для более четкого отделения их от источ-
ников (и значений) настоящих сигналов, участвующих в процессе обу-
чения. На следующем шаге после щелчка на кнопке Intro программа
покажет тебе исходные значения весовых коэффициентов, назна-
ченные каждому входу каждого нейрона случайным способом (рис. 7.11).
После того как ты вдоволь налюбуешься сетью и ее параметрами,
следующий щелчок ча кнопке Intro выведет На экран значения вход-
ных сигналов нейронов, обозначенных номерами (0,0) и (0,1) (рис. 7.12).
С этого момента начинается процесс обучения, но твоя активная
роль ограничивается последовательными щелчками мышкой на кнопке
Next step для активации и моделирования обучения исследуемое сети
‘.рис. 7.13).
Сначала будут показаны сигналы, рассчитанные для каждого ней-
рона при передаче возбуждений от ад ода к выходу. Эю так называемая
фаза «прямого распространения» входные сигналы преобразуются
нейронами в выходные сигналы, и такой процесс последовательно повто-
ряется во всех слоях от входа к выходу. Эту фазу ты уже наблюдал
Обратное распространение
217
Presentation of network
Looming rote 0.700
Momentum 0.300
Ini г О
Neuron < 1 1)
Sun.
Output:
Error in.
Error out • ( :
Neuron [1.2)
Sum:
Error in
Oupui
Error out
BIAS
-idol
Neuron (21)
Sum
£#oe.lh
ие iron (2 2)
Sum.
Error in.:
E AS 000
Output:
Outpv*
Рис. 7.11. Сеть и ее параметры
в ходе экспериментов с программой Example 08а. Используемая сей-
час программа позволяет так же дегалыю отслеживать развитие этого
процесса. Рассчитываются и выводятся па экран суммы значений вход-
ных сигналов, умноженных па соответствующие весовые коэффициен-
ты (в том числе компонента BIAS), после чего демонстрируются под-
свеченные красным расчетные значения выходных сигналов («откли-
ки») каждого нейрона, выработанные после прохождения суммирован-
3
ГеПМ1С>Г
Input signals
I earning rate
Momentum 0 3t"J
m»ro
Inp <tb
Input ft. I)
?.58<
nput (1,2)
-0.04^
WeiqHs
0,107
0,074
1.103
1656
-08?
Neuro i (1.1)
Sum.
Error, г
Neuron (i 2)
Sum
Error in.
Output
Erroi out
Output:
Error out
BIAS -1.000
Wpighte
41712
0.65”!
0.1ЙЯ.
1.176
-0.7
0,3^1
Na коп (2.1)
Sum:
Error m
Neuron (7 2)
Sum
Error и
BIAS -t.ouo
’ 045
O1 itpul
Ouipi?
Рис. 7.12. Появление входных сигналов
218
Глава 1
Weigh”
0.712 0.621 О,'В?
1.176. ;07
Neurhr (2 1)
Stir-
1 jut put:
8IAS -1.000
Neuror (2,2)
Sum ’* Error in
fSSE
Рис. 7.13. Вид экране! в процессе моделирования обучения сети
иых входных сигналов через сигмоидальную функцию активации. Оче-
видно, что очклики нейронов низшего слоя оказываются входными сиг-
налами для нейронов следующего слоя, в связи с чем ты можешь щед-
кать по кнопке Next step и наблюдать перемещение сигналов по нейро-
нам от входа к выходу моделируемой сечи. В результате после выпол-
нения определенного числа шагов сеть приобретает вид, показанный па
рис. 7.14.
Ne'.KCir>(1
Sum: Ч ?7?32 Error in..
Output t? 316977 Error out
Weighs
0712 0 62 0.16’1
Neuron (1.2) RIAS -1 000
Sum Output: 4L07620 Error «л
0,460958 Errpr qlH
1.176 -0.? 0.341
Neurnn(2,1)
S-шт 0 ’1630 Error in.
Output
Outputs
Output (2,1} 0 471206 Error out.
Neuron (2.2) Sum Output. •PJIW Error in HAS 1 OOC
04241 I
Output (2,21 0424071 Error out
Next •teral’un Nr»xt Мер
Рис. 7.14. Сеть после завершения этапа прямого распространения
Обратное распространение
219
reretioi.
Learning rote
0 700
Momentu г
Р ЗИГ
Inputs
2 584
fnpu»(l,2)
-0645
Weights
0.187
0 074
1.193
-0.656
0.62
-1.095
Neuron (1.))
Sun 0,77232 Error щ
Output 0 31597? Error ou*
Wights
-0Л2 0 521 0.189
Neuron (1,7)
Sun 4 37620 Ena in.:
Bias -1,003
Ou'p'jt- 04W1 и fl Erro' out.
1176 -0.7 034i
Neuron 2,i)
Sum И01153О Error in.-
Outpu1 0.47 206
Neuron (2 2)
Sum iO. 30608 Error m
BIAS -toot
Ou put' Ц4Р4С71
Output;;
Output (?,’) 0,471206 i Correct > «. Error out. L* 522P9’1
. “""""""""""“г* ... . л.-.у;.-
C'utpu (2;2j '3 4240'1 Cu-rect 0.0 Сто1, out -g4?4₽?
1
lnput(1,l)
Next iteration Next step
Рис. 7.15. Сопоставление результатов функционирования сети с эталоном,
пред.'южснным учителем
После появления сигналов па обоих выходах сети наступает (после
очередного щелчка по кнопке Next step) «момент истины» в пиж-
пей части экрана высвечиваются ожидаемые сигналы (т.е. эталоны
корректных решений* па каждом выходе (рис. 7.15). После этого рас-
считываются погрешности на каждом вьгходе сечи, а также рассчи-
тывается и выводится на экран среднеквадратичная погрешность
обоих выходов. В конце концов, выставляется итоговая оценка функ-
ционирования сети в целом (рис. 7.16).
Сначала оценка (выставленная красным — а каким же еще? цве-
том в нижней части экрана), наверняка, будет «BAD», но вскоре сеть
начнет обучаться и станет получать желаемые оценки «GOOD». В мо-
мент, когда сеть (как единое целое) допустит ошибку, будут рассчитаны
погрешности каждого нейрона. Первыми находятся погрешности выход-
ных нейронов сети. Потом эти noipcni пости пересчитываюгСя на соот-
ветствующие им значения на входах нейронов (именно для этого необ-
ходима дифференцируемость функции активации). Эти погрешности,
перенесенные на входы, показаны па рис. 7.17.
Теперь начинается важнейший этап — распространение ошибки
на нейроны низшего (скрытого!) слоя. Соответствующие значения
появляются вначале у выходов, а потом у входов нейронов этого слоя
(рис. 7.18).
После того как все нейроны получили «свою долю» расчетной ошиб-
ки, па следующем шаге работы программы корректируются значения
220
Глава 7
Luomang rat<i - ’00 Mum en-urr. 0 300
inpu«
input fl.I) 2-ЗЙ4
Wei'jl-'*
018? 6in?4 1 193
Input ' I "J '0 ’45
-CSSS -Г'? -1336
fteuran [1Л]
'.Vetgh*s
-6 ?r?
C * ?2'j2 Euv'in
0-31597 ? Error cut
0631 1Ш9
Г-Cll IV<, (1 2j
Sum -0U?S3C Ertw r .
BIAS " SCO
'jutfrit 0.4г<< 398 Error out
1178 -C: 7 C341
Neu~xt 2,
Neura-i (2 2j
-91193’3
0<«(хГ<
jj 42-sO’i
BIAS
Outpjt(3,t
0.4flS06
?ог-'ай
14 Error от « .£»?«
Output re.
.42437'
6,5
Ewsu -3.42487
Mi 41 JxSUStt!»3 Er»Or
Next iteration
I---------------------s
Next step
5,4*>?^
Cfli.t-iliftitriH
.343
Рис. 7.16. Расчет погрешностей нейронов выходного слоя и
среднеквадратичной погрешности сети в целом
весовых коэффициентов каждого нейрона сети. Новые коэффициен-
ты высвечиваются под ранее использовавшимися значениями, благодаря
чему ты можешь узнать, насколько и в каком направлении изменились
параметры в процессе обучения .рис. 7.19).
tte'st-on 1
inputs
Input (1,1 j ’,584
We.ghts
Г С.182 0,024 1.193
Learning ate 0.7CO Momemum
Input (1,2) -0W5
•0.666 -0.62 C*1,(®5
Neuron (1.1)
Sum -0.72232 Error in
Output 031397? Erro-out.
Weights
-0.212 0.621 0.189
Neuron (1.2)
Sum 0 'I 20 Er-or h.
BIAS -LOCO
Output. 0.490968 Error oul
1.126 -а? ели
Neui-X (2,1)
Sum
Output
Output >
Output (2.1)
-011530 Error in 0. »1?69
11471206 .................
0.47,206 o-rect 1.0 Error out 3.626’93
Mean Squared Error * 4793003
Clansiticaiio”
HAP
Neuron (2,2)
Sum
Output:
-0.39608 Error rn -0.1C3C?
0.424071 4....................
•IAS
-1.DCC
Output (2.2) 0.424071 Corned 00 Error out -C.42407
Next iteration
Next step
Рис. 7.17. Пере нос погрешностей на входы нейронов
Обратное распространение
221
Nwrcr ( I J)
Sun -0 -7252 Error ir-; -0.046S0
dipt? 0.3183* tine-mil u?’:6I
Wetgr>f$
-0.712 OS9? oj«g
Neuron (1,2)
Sum: E. or in 0uJ8b25
BIAS -1.000
Output' Й.4Й0968 Errr-rut 01^4324
1 J 76 Д?: 0.34 J
MewoT.(2,l)
Sun 'Eiii-iDO Ector; in 0,131769:
Output. 447(206
Outputs
£>utnift</t) 8471206 Gon-ей JJ| Errorlcut №576,<,3
Neuron (2 2)
Sum: J,30gfi0 Errbrw -O.ifl^f :.
BIA' -1 ООО
Qu'put: •-W
C<utput.(2.2) 8.424071 Corest 0;0i Error out. 8 ГЧ0'
Рис. 7.18. Результат обратного распространения ошибки
Это очень важный момент эксперимента с программой. На экране
представлено много информации, но видно все — входные и выходные
сигналы, погрешности, старые и повью значения весов... Внимательно
изучи и обдумай все доступные данные чем лучше поймешь проис-
ходящее, тем более успешно в будущем ты станешь применять нейронные
сети.
------------.---------------------------------------------
New wbi^hfe!
Й,М5Й6 П ПТОЛЯ-, ЙВ67721
Neuron (1 I)
Sum 8 э,7232 Error in. Ч?О46ЬО
Output' Ц316977 Errs-out’ -0.21 Б61 ,
We ghlB
8.7’2 0.621 IP 89
-П TSSI 0.45Б7&
___________________________________________________________________4
Newer ft,?)
Sue 8 Er-йг in. 0838825
BIAS -1 000
Ou*put: О 1BT95( Er-pr oui 8 * 843? t
1.176 -0.7 n <41
Nr wwe'gN'
•0 46925 0.47911'Ч 0.. 140068 Сflin’Sl ОЗР’О
Neurnn (2,1)
Sum
Output:
8.11 «0 Error .n 0 131/5?
0.471206
Neuron (2,2)
Slim: 0 306P6 Error in 41,10367
BIAS ’000
(Jutpul X474071
Output”
Ot/put(2,n 0.471206 Correct 1.8 Error out. ОбЗО’ЭЗ Output (2,2) 0 424071 Curred C O. Erro-out •0 424П?
Mnnn Squared Error 8.4793009 Ce4sification. BAD | J" ,, ,, "3
Next iteration Next stro |
Рис. 7.19. Изменение весовых коэффициентов
222
Глава 1
Дальнейшие эксперименты с программой можешь вести двумя спо-
собами. Если тебе захочется еще раз отследить все развитие очередной
итерации процесса обучения (прохождение сигналов в прямом направ-
лении, обратное распространение ошибки, корректировку весов и т.д.),
то необходимо щелкать ио кнопке Next step. Но можно ускорить веся
процесс за счет реализации следующей итерации целиком, т.е. «скачко-
образного» выполнения программы вплоть до момента расчета новых
значений всех сигналов, ошибок и весовых коэффициентов. Для этого
используется кнопка Next iteration.
На текущем этапе такой режим работы наиболее удобен, посколь-
ку осмысленного поведения сети удастся добиться выполнением очень
большого числа полных итераций процесса обучения. С помощью про-
граммы Example 08b ты сможешь легко и удобно наблюдать развитие
процесса обучения, изменения весов, а также важнейший элемент ал-
горитма процесс обратного распространения рассчитанных в выход-
ном слое значений ошибок. Ты увидишь и исследуешь, как фактические
значения ошибок выходных нейронов и рассчитанные в процессе обрат-
ною распространения ошибки нейронов остальных («скрытых») слоев
позволяют скорректировать значения весовых коэффициентов каждо-
го нейрона сети. Ты также проследишь, насколько успешно корректи-
ровка весов продвигает процесс обучения сети. Советую уделить долж-
ное внимание этим экспериментам. Пример итогового эффекта обуче-
ния представлен па рис. 7.20.
Learning1 ale 0.700 Moment! m 0.300
Biput (1,2) 2,168013
1.563628 -C 07528 -0.5583'
Ite'nfor 305
Inputs
Input (1.П 224215
Weigh1-,
-2 98004 0.29 ’09 106МБ7
0876 |-0№ n, (161 2?k
Neuron ( I, I)
Sum 6.057145 Error in. Э.-й83738
Cj itout 0.837664 Eifor out. nCul07(itl
Wo-ghts
-2.99235 i520128 O'p'fiJf
Newweiohts
-2 99872 1.61 16»9 -aS36S1
Neuron (2.1)
Sum ’2.37221 Error in' -0.00665
Output 00Й6315
ЦбЗбТЗ -0.ЙЙЙ65 -0 55175
Neuron 11 2)
Sum *11229 Error in ODOO-"
BIAS 1 000
Output: 0.042*4(4 Error out.’ *0.01906
3.178890 1 36904 0.73035
J.18S131 *1 36387 0,71*97
Neuron (2,2)
Sum 2 362'786 f rror in 0 00*5 4
6’AS "’ООО
Output 0 9155Г5
Outputs
O' ilpul (2,1) 0,085315 Correct 0.0 Enorout -0.00531 Output (2,2) 0.9’5505 Cored 1.0 Lrroi out 0 08^494
..„I 1^
Menn Squared Error 0.0849062 Ctasi ificaliun GOOD
Next iteration
Рис. 7.20. Окончательный результат процессе! обучения
Next step
Обратное распространение
223
Знакомство с программой Example 08b, конечно, потребовало от
тебя приложения определенных усилии Эта программа относительно ве-
лика и достаточно сложна. Взамен ты получил собственный и легко мо-
дифицируемый) инструментарий для глубокого и основательно! о позна-
ния технологии backpropagation одного из важнейших методов обуче-
ния современных пег ровных сетей. Ты также обрел нечто гораздо более
цепное знания, серьезное и основательное понимание функционирова-
ния сети, обучаемой с применением метода обратного распространения
ошибки. Насколько ценны и полезны эти знания — убедишься уже очень
скоро!
7.7. Контрольные вопросы и задания
для самостоятельного выполнения
1. Почему метод обратного распространения называется именно так?
Что и для чего «распространяется обратно»?
2. Что такое и для чего используется BIAS? Чем обеспечивается воз-
можность обучения этого параметра?
3. Почему в процессе работы сети для каждого нейрона высвечивают-
ся два значения (Sum и Output)? Как эти значения связаны между со-
бой?
4. Как влияют па процесс обучения сети коэффициенты Learning
rate и Momentum? Вспомни теоретические сведения об этом и поста-
райся проследить влияние названных параметров в процессе Экспери-
ментирования с программой.
5. Как следует понимать процесс передачи ошибки с выхода нейро-
на (на котором она рассчитывается) к его входу (где она используется
для корректировки весов)?
6. Какой из нейронов скрытого слоя будет больше обременен ошиб-
кой, допущенной некоторым нейроном выходного слоя? От чего это зави-
сит?
7. Возможна ли ситуация, в которой нейроны выходного слоя до-
пускают погрешности, а некоторому нейрону скрытого слоя алгоритм
обратного распространения «отписывает» нулевую ошибку (вследствие
чего этот нейрон не изменяет свои весовые} коэффициенты)?
8. Как рассчитывается совокупная оценка корректности функциони-
рования сети в целом? Можно ли как-то иначе оценивать ее работу (т.е.
не по индивидуальным показателям работы нейронов)?
9. Задание для наиболее подготовленных. Добавь в програм-
му модуЛь, который будет показывать в виде графиков изменение} по-
грешности сети в целом и отдельных ее нейронов. Всегда ли улучшение
224
Глава 7
функционирования сети связано с минимизацией погрешностей, допус-
каемых всеми нейронами сети?
10. Задание для наиболее подготовленных. Попробуй расши-
ригь описанные в этой главе программы, используя большее 'тело вход-
пых и выходных сигналов, а также большее числа нейронов, объединен-
ных (если хочешь рассматривать это задание как особый вызов твоим
знаниям) в более чем один скрытый слой.
11. Задание для наиболее подготовленных. При испольвовании
сети с большим числом входов постарайся обнаружить явление избавле-
ния процесса обучения от непригодной информации. Для этого поданаи
па один из дополнительных входов бесполезную информацию, не име-
ющую никакой связи с ожидаемый реакцией сети (например, результаты
работы генератора случайных чисел). На остальные входы должны по-
даваться все сигналы, необходимые для решения сетью поставленной
задачи! ? ы должен увидетц, что уже очень скоро в процессе обучения
весовые коэффициенты всех соединений, ведущих от такого «тунеядству-
ющего» входа к скрытым нейронам примут близкие к нулевым значения,
т.е. бессодержательный вход окажется практически «ампутированным»!
12. Более сложное задание для самых подготовленных. В про-
граммах, рассмотренных в этой главе, функционирование сети демон-
стрировалось путем вывода в соответствующих позициях экрана зна-
чений параметров и сигналов. Такой способ представления позволял
проверить 'например, с помощью калькулятора), что и как делает сеть,
по был в целом пе очень наглядным для качественного оценивания про-
текающих в сети процессов. Спроектируй и напиши версию программы,
которая будет представлять все значения в графической форме более
простой и удобной для интерпретации.
Глава 8
ФОРМЫ ОБУЧЕНИЯ
НЕЙРОННЫХ СЕТЕЙ
8.1. Как использовать многослойную
нейронную сеть для распознавания образов?
Многослойные нейронные сети, о которых мы так много говорили
в предыдущей главе, могут применяться для достижения различных
целей. Мне представляется удобным рассмотреть их функционирова-
ние и поведение при решении задачи распознавания образов. Нейронная
сеть (либо другая автоматическая распознающая система) в этом случае
должна принимать решение о принадлежности исследуемых объектов к
определенным классам. Могут рассматриваться объекты различных ти-
пов, например гщфровые изображения, полученные с помощью циф-
ровых фото- или видеокамер, либо аналоговые изображения, обработан-
ные сканером или устройством «frame grabber». Цифровое и аналоговое
изображения представлены на рис. 8.1 для того, чтобы ты лучше пони-
мал обсуждаемую проблему, а также для уменьшения самоуверенности
тех, кто считает слово «цифровое» аналогом слова «лучшее».
Но мы не собираемся в этой книге подробно изучать проблематику
распознавания образов, поскольку книга посвящена не им, а нейронным
Аналоговая фотография
Цифровая фотография
Рис. 8.1. Сопоставление цифрового и аналогового изображений
226
Глава 8
Рис. 8.2. Внешний вид «перс гптрош»
Розенблатта — первой нейронной сети
для распознавания образов
сетям. Тем не менее, считаю нужным напомнить с задачи распозна-
вания образов началось развитие нашей дисциплины, и от этой задачи
берет свое начало ее название. На рис. 8.2 показана первая (историче-
ская!) нейронная сеть, построенная Франком Розенблаттом и предназна-
ченная именно для распознавания образов (отсюда ее название «Персеп-
трон»). Снимок довольно старый «начала 70-х гг. XX в.), поэтому он не
слишком хорошего качества, но посмотри на него с уважением это
след одного из самых первых достижений в области знаний, о которой
идет речь в нашей книге.
Понятие «образ» в проблематике распознавания позднее было обоб-
щено так. что современные нейронные сети могут также распознавать
образцы звукового сигнала ( например, голосовые команды), сей-
смические (либо иные геофизические) сигналы, помогающие выявлять
геологические слои, симптомы пациентов, заболевания которых необ-
ходимо диагностировать, экономические оценки фирм, пытающихся
получить банковские кредиты, и многие другие данные. Во всех этих
задачах речь идет о распознавании образов, но эти образы оказывают-
ся соответственно звуковыми, геоипформационными, диагностическими,
экономическими и т.п.
Чаще всего нейронная сеть для распознавания образов имеет не-
сколько входов, на которые подаются сигналы, соответствующие опре-
деленным свойствам распознаваемых объектов. Например, это могут
быть коэффициенты, описывающие форму показываемых камерой де-
талей машин или текстуру изучаемой с помощью УЗИ (ультразвуко-
вого исследования) ткани печени. Как правило, таких входов бывает
много (например, в задачах распознавания речи я сам использую ней-
ронную сеть с 98 входами), поскольку надо детально «продемонстриро-
вать» сети все свойства распознаваемого объекта чтобы опа смогла
научиться правильно распознавать его. Однако количество свойств, ко-
Формы обучения нейронных сетей
227
торыми характеризуется образ, гораздо меньше количества элементов
(пикселей) самого изображения. Для того чтобы предъявить распозна-
ющей сети непосредственно само цифровое изображение, количество ее
входов (равное числу пикселей такого изображения) должно достигать
сотен тысяч и даже миллионов! Поэтому практически неизвестны при-
меры реализации нейронных сетей, которые получали бы на свои входы
анализируемый образ как таковой; чаще всего сети демонстрируются
упомянутые свойства образа, обнаруженные и извлеченные с помощью
программ, предварительно анализирующих исходные изображения без
использования нейронных сетей. Иногда такой прием называется пре-
процессингом этих образов.
Распознающая нейронная сеть также имеет много входов. В общем
случае, каждому входу поручается распознавание определенного эле-
мента. Например, в системе автоматического распознавания алфавитно-
числовых символов (для решения так называемой задачи OCR) исполь-
зуется свыше 60 входов, каждый из которых приписан к своему символу,
например первый нейрон должен сигнализировать о появлении буквы А,
второй В и т.д. Речь об этом шла во второй главе, поэтому для припо-
минания внешнего вида выходного сигнала сети, распознающей образы,
ты можешь взглянуть на рис. 2.30, 2.31 и 2.33.
Обычно между входом и выходом располагается хотя бы один скры-
тый слой. Именно этот слой мы вскоре изучим более подробно. В общем
случае скрытый слой может состоять из большего или меньшего количе-
ства нейронов. Традиционная интерпретация явлений, происходящих в
нейронных сетях, свидетельствует о росте «интеллекта» нейронной сети
по мере увеличения количества нейронов в скрытом слое. Но ты очень
скоро убедишься, что чрезмерный «врожденный интеллект» нейронной
сети иногда приносит вред, поскольку такая «шибко умная» сеть часто
оказывается слишком непослушной!
8.2. Как запрограммировать нейронную сеть
для распознавания образов?
В примере, который мы сейчас вместе рассмотрим, будет исследо-
ваться всего лишь двухвходовая сеть. На практике редко удается вы-
явить что-либо интересное на основании только двух свойств. Нейронные
сети широко применяются, главным образом, для анализа многомер-
ных данных, т.е. таких входных сигналов, для представления которых
необходимо очень много входов. Но для нашего примера в наличии всего
двух входов есть иметь одно несомненное достоинство: каждый распо-
знаваемый объект можно представить точкой на плоскости. Одна
228
Глава 8
Сигнал на
входе № 2
Сигнал на входе № 1
Рис. 8.3. Способ представления входных и выходных сигналов в сети с двумя входами
и одним выходом
координата этой точки соответствует первому свойству распознаваемого
объекта, а другая значению второго свойства (рис. 8.3).
Ты помнишь, что выше мы уже рассматривали аналогичную ситуа-
цию (в разд. 6.4). Я предложил тогда представить двумерное простран-
ство входных сигналов так, будто исследуемая сеть является мозгом ги-
потетического зверька, обладающего двумя рецепторами, например при-
митивного зрения и слуха. Чем сильнее зрительный сигнал, тем правее
располагается точка. Чем громче звук, тем выше она будет лежать. Эта
аналогия и связанный с ней рис. 6.8 очень пригодится при рассмотре-
нии примера в этом разделе.
Благодаря принятому соглашению каждый «предъявляемый» сети
образ (каждую ситуацию, в которую будет попадать «зверек») мож-
но отобразить на экране точкой с соответствующими координатами ли-
бо подсвеченным пикселем в том месте экрана, координаты которого
будут отвечать свойствам рассматриваемой «ситуации». Конечно, при
ограниченных размерах экрана мы должны договориться, что значения
рассматриваемых свойств не должны быть произвольными, а лежать в
заранее заданном интервале. В частности, в рассматриваемом примере
видимые на экране значения обеих координат (свойств), составляющих
основу процесса распознавания образов, будут лежать в интервале от
-5 до +5. Это ограничение ты должен соблюдать при формулировании
предъявляемых сети задач.
Конечно, любая сеть имеет выход, необходимый для наблюдения за
ее поведением. В рассматриваемом примере мы предполагаем наличие
у сети только одного выхода. Интерпретация вырабатываемого им вы-
ходного сигнала также была представлена в разд. 6.4 (см. рис. 6.8). На-
помню: к каждой предъявляемой на вход сети ситуации «зверек» может
относиться позитивно (в этом случае точка будет красной) или негативно
(точка будет синей). Создавая для «подопытного животного» различные
Формы обучения нейронных сетей
229
Данные о конкретной
Звук А
окружающей среде
*****
**«<**••«
S* *5 ****** « • « * * *
Ж Ж « Ж * * * * * Ж #*
**»♦»♦ • Ж ******
ЖяЯ************
*«»»»»»#»«♦»**
♦ *»»»♦»♦*>»****
******** *******
**** « • • Ж
********
*#»»» • ♦ •
**♦*«*«
«««*****
*******
*******
******
##«*«*
С Ж Ж Ж Ж
************* ♦
ж************
************
***********
« « »Й « Й *
*******
»****««**
»»»»«»*»**#
*»»♦»»♦»♦**»
«»*«««*»«****
**************
»»»»»»»»******
* # о •**«*»«»**#
**»•*•***»**<.**
************ «Ж****»*»**»»** « * * *
** * л * ♦ * ******** * * ж * * ж ж * a ж ж ж * * ж *
*,*»««*»*»#»«»***»»*»♦*»♦♦*<**»
* Ж Ж ** ****** ***************** * * *
ж**********************»»♦«»ж * *
жж ж ж ж ****** ж** *******•* *»♦***»*
ж * ж ж♦♦♦♦»#* ** ***** * * ж * * * « ж « ж ж ж ж
Свет
Рис. 8.5. Та же карта, что и на
рис. 8.4, но в сглаженной форме
Рис. 8.4. Пример карты демонстрирует, к каким
условиям (т.е. областям пространства входных сиг-
налов) моделируемый «зверек» должен относиться
позитивно, а к каким негативно
ситуации (т.е. подавая па вход нейронной
сети комбинации исходных
данных, соответствующие различным точкам в пространстве входных
сигналов), ты сможешь составить «карту» мест, в которых твой «зве-
рек» должен чувствовать себя комфортно или не очень. Такая «карта»
будет представлять совокупность точек, именно в таком виде ее демон-
стрирует программа, которую мы вместе сейчас запустим (рис. 8.4). Для
удобства восприятия книжных рисунков все «карты» изображаются на
них несколько сглаженными (рис. 8.5).
Также возможны промежуточные состоя-
ния (по мере усложнения сети их число будет
увеличиваться), характеризующиеся частич-
пым неприятием (светло-синий цвет), безраз-
личным отношением (светло-зеленый цвет)
либо частичным одобрением (желтый, перехо-
дящий в светло-красный цвет) см. рис. 8.6.
Так же, как и на карпе в твоем географиче-
ском атласе, от синих глубин печали до
ярко-красного высочайшего энтузиазма!
Так как сеть имеет только один выход, ее
функционирование легко и удобно показывать
па экране. Каждую демонстрируемую точку,
соответствующую определенной комбинации
Рис. 8.6. Пример кар-
ты «предпочтений» моде-
лируемого «зверька» на
некотором этапе обучения
входных координат, ты сможешь соотнести с классом «одобряемых»
(красный цвет) или «отрицаемых» (синии цвет) точек. Конечно, дан-
ные этих точек будет необходимо ввести в программу, о чем речь пой-
дет несколько позже.
230
Глава 8
Такие карты ты сможешь рассматривать в процессе обучения се-
ти. Конечно, они будут изменяться, поскольку в результате обучения
сеть сможет перестать «любить» то, что она раньше «обожала», либо
ей «понравятся» какие-нибудь условия, которые сначала безоговороч-
но отклонялись. Ты убедишься в увлекательности отслеживания пере-
хода сети от начальной нерешительности и неопределенноеги к выра-
ботке «рабочих гипотез», которые позднее перерастут в «абсолютную
уверенность». Несомненно, обучение сети с большим числом входов не
так наглядно, хотя (как я уже упоминал) реальные сети, как прави-
ло, имеют более одного выхода.
Рассматриваемый пример (с одним выходом) обладает еще одним
дополнительным достоинством. В частности, нам не придется выбирать,
какая сеть лучше: та, которая уверенно указывает па несколько возмож-
ных решений о классификации входного сигнала (в том числе истинное,
или которая все решения считает слабыми и неуверенными (хотя среди
этих малых значений подавляющее большинство приходится на выход-
ной нейрон, указывающий па правильно распознанный объект). В сетях
с несколькими выходами такие проблемы весьма распространены. Как
следствие, затрудняется оценивание фактического состояния сети и его
изменение в процессе обучения, а также предсказание возможной реак-
ции сети на нетипичные задачи (т.е. ухудшаются возможности обобще-
ния знаний) и т.п. В сети с одним выходом ситуация примитивна она
всегда ясна и определенна: распознавание либо корректно, либо пет.
8.3. Как выбирать структуру нейронной сети
в ходе экспериментов?
Программа Example 09 позволит тебе экспериментировать с распо-
знающей сетью. Вначале на экране высветится панель ввода царамет-
ров, описывающих структуру создаваемой сечи (рис. 8.7). Как обычно,
предлагаются значения параметров по умолчанию, которые можно мо-
дифицировать. что мы и сделаем.
Предположим, что исследуемая сеть должна иметь структуру
2 — ххх — 1,
где числа обозначают количество нейронов в каждом слое: два на входе,
один на выходе и некоторое количество (ххх его необходимо опреде-
лить) в середине. При выборе конкретной сети ты должен будешь ука-
зать только количество этих внутренних нейронов и способ их упорядо-
чения (в один или несколько скрытых слоев).
В зависимости от числа, введенного в поле Layers, ты сможешь за-
дать количество нейронов в каждом слое. При выборе количества ело-
Формы обучения нейронных сетей
231
Рис. 8.7. Пример описания структуры сети в программе Example 09
Рис. 8.8. Описание структуры сети в
программе Example 09 при выборе
только двух слоев
ев помни, что принимаются во внимание только слои с обучающими-
ся нейронами -- т.е. учитывается одноэлементный выходной слой, но
не учитываются два входных нейрона, которые только принимают и
«распределяют» входные сигналы. Поэтому, если ты изъявишь желание
исследовать однослойную сеть, го получишь структуру
2 — 1,
для которой количество нейронов в скрытом слое вводить не требуется.
Если же тебе необходима двухслойная сеть, то получишь структуру вида
2 — х — 1.
В этом случае автоматически откроется поле ввода количества нейронов
в скрытом слое (Neurons in first hidden layer) (рис. 8.8).
Наконец, если тебе потребуется трехслойная сеть (либо в случае при-
нятия исходных значений по умолчанию), то возникает структура
2 — х — у — 1,
и ты должен будешь ввести количество нейронов в обоих скрытых сло-
ях (в полях Neurons in first hidden layer и Neurons in second hidden
layer).
Описываемая программа не позволяет исследовать более чем трех-
232
Глава 8
слойную сеть. Это серьезное ограничение, которое можно изменить пу-
тем корректировки исходного текста программы (к которому у тебя есть
доступ). Указанное ограничение обусловлено соображениями вычисли-
тельного характера программа «обсчитывает» большую сеть медлен-
но. Ты убедишься, что выполнение нескольких сотен шагов обучения ivb
процессе работы с программой становится ясно, что несколько сотен ша-
гов для получения ощутимых результатов обучения совсем немного!)
будет иметь вполне ощутимую длительность, даже если твой компью-
тер новый и быстродействующий.
8.4. Как подготовить задачу распознавания
образов?
После выбора размеров сети, и, если необходимо,количества нейро-
нов в каждом слое начинается самый интересный этап работы с про-
граммой — формулирование задачи, которую должна решить сеть.
Как ты уже знаешь, суть задачи распознавания заключается в том,
что на некоторые комбинации сигналов сеть должна реагировать пози-
тивно (т.е. «распознавать» соответствующие ситуации как благоприят-
ные для нее образы), тогда как на другие комбинации сигналов реакция
сети должна быть негативной (отклонение соответствующих образов и
отказ их распознавания в качестве «любимых»). Информация о том, что
сеть должна любить, а что нет, задается обучающей выборкой. Эта вы-
борка содержит некоторое число точек, обе координаты которых извест-
ны. Благодаря такому подходу известно местоположение каждой точки
на экране и соответствующий корректный отклик сети позитивный
(красные точки) или негативный (синие точки1 (рис. 8.9).
Тебе решать, в каких местах экрана бу-
дут располагаться точки с ожидаемой пози-
тивной реакцией сети, а в каких точки с
ожидаемой негативной реакцией. Я мог бы по-
зволить тебе вводить исходные данные, «высо-
санные из пальца», в виде троек чисел две
исходные координаты и эталонный отклик се-
ти, по для формулирования осмысленной за-
дачи т ы должен был бы немало потрудиться.
Кроме того, созданный в виде «карты предпо-
чтении» образ окажется сложным для интер-
претации.
Поэтому я решил: программа Example 09
будет автоматически генерировать обучающую
Рис. 8.9. Пример обучаю-
щей выборки, сгенерирован-
ной программой Example 09
Формы обучения нейронных сетей
233
1В
Y caoru
:0.3=J
Neurons .n first hidden layer: Neurone in econd t.id fen layo'
= 0
C.rUe 1
CSrcie?
0,03
I,OU
4.00
1 00
Circle 3
i Ney
Leyes_.
X cor-rd.
Koo
fes -KX-tfe
«00
Radius
Рис. 8.10. Пример определения структуры сети и формирования областей для
распознавания (а) и «карточка» областей, в которых сеть (после обучения) должна
вырабатывать позитивные или негативные решения (б)
последовательность; ты должен только указать, где должны распола-
гаться позитивные, а где — негативные отклики сети. И вновь я оказал-
ся перед необходимостью принять решение вместо тебя. Можно было
бы позволить создание абсолютно произвольных областей позитивных и
негативных решений, которые впоследствии станут объектами изучения
и эталонами распознавания, но такой подход потребовал бы дополнить
программу серьезным графическим редактором, с которым очень непро-
сто взаимодействовать. Поэтому я выбрал компромиссное решение
области позитивных решений, т.е. фрагменты пространства входных сиг-
налов, в которых сеть должна отвечать «да» (красные точки на экране),
будут представлять собой внутренние зоны трех окружностей. Это
весьма серьезное ограничение, которое позволит тебе быстро и удобно
формулировать задачи для сети и (благодаря возможности конструиро-
вать свои области из произвольно выбираемых окружностей, любой
величины и расположенных в какой угодно области пространства вход-
ных сигналов) решать по-настоящему интересные и сложные задачи.
Координаты этих трех окружностей можно задать в том же окне (по-
являющемся на экране сразу после запуска программы Example 09),
в котором ты определяешь структуру сети (рис. 8.10,а). Первые две ко-
ординаты х и у описывают местоположение центра окружности, а тре-
тье число ее радиус. Эти параметры задаются для каждой из трех
окружностей (Circle 1, 2, 3).
Ты полностью свободен в выборе этих значений, но как уже гово-
рилось, в процессе распознавания будет участвовать только та часть
плоскости, для которой обе координаты лежат в интервале (—5, +5).
Это означает, что весьма разумным решением для размещения точек,
описывающих свойства объектов и предназначенных для позитивного
234
Глава 8
распознавания, будет, например, окружность с параметрами
О, О, 3,
тогда как окружность с параметрами
10, 10, 3
вообще не будет видна на экране, и ее использование лишено смысла.
Параметры подлежащей решению задачи можно увидеть па следую-
щей панели, предназначенной для моделирования поведения сети. Для
перехода к этой панели шелкни по кнопке Next в нижней части ок-
на (см. рис. 8.10,а). Результаты реализации твоих решений выводятся в
виде «карты» областей, в которых сеть (после обучения) должна выра-
батывать позитивные или негативные отклики (рис. 8.10,6).
Таким способом ты сможешь в любой момент проверить, соответ-
ствуют ли действительности твои предположения о форме заданных об-
ластей или нет. Если не удается сразу сформулировать задачу, отра-
жающую твои представления, то можно вернуться к предыдущей па-
нели щелчком по кнопке Back (рис. 8.10,6) для изменения координат
и радиусов окружностей.
В процессе обучения сети точки видимой на экране плоскости выби-
раются случайным образом. Затем с помощью твоей карты определяется
их принадлежность одному из классов, после чего комбинация из коор-
динат выбранной точки и корректного (эталонного) отклика сети будет
подана на вход сети в качестве элемента обучающей последовательности.
Обрати внимание на одну очевидную деталь. Если при формулирова-
нии задачи большую часть выведенного на экран окна занимают красные
точки (соответствующие позитивным откликам), то сеть в процессе обу-
чения будет от носительно редко получать примеры объектов для выра-
ботки негативных решений — это может сильно замедлить обучение. По-
хожие проблемы (только «с обратным знаком») возникнут в сети, обуча-
емой на примерах «с избытком» синих точек (соответствующих негатив-
ным откликам). Необходимо стремиться примерно к равному представ-
лению на экране «красного» и «синего». В этом случае процесс обучения
будет максимально эффективным к твоему глубокому удовлетворению.
При игнорировании этой рекомендации ты получишь сеть, которая ни-
чему не сможет научиться, и только потеряешь драгоценное время.
После формулирования сбалансированной (в упомянутом выше смы-
сле) задачи в виде удовлетворяющих тебя областей, можно начинать
процесс обучения. Для этого щелкни по кнопке Start (рис. 8.10,6).
Вначале программа покажет, какие решения принимает необученная
сеть при случайных значениях весовых коэффициентов всех ее нейронов.
Как правило, это начальное распределение решений никак не связано с
поставленной тобой задачей, и действительно, откуда сеть до обучения
Формы обучения нейронных сетей
235
Области, Решения, принимаемые сетью Кризис обучения Отучение сети
Окончательное совершенствование
процесса распознавания
Конструктивная фаза
процесса обучения
Обучающая
последовательность
Рис. 8.11. Способ представления последовательных этапов проиесса обучения
программой Example 09
может узнать, чего ты от нее хочешь? Тем не менее, имеет смысл при-
смотреться к исходной карте «врожденных предпочтений» сети и срав-
нить ее с образом, который ты построил при формулировании задачи.
Последующий процесс обучения будет сильно зависеть от того, насколь-
ко эти две «карты» похожи друг на друга. При большом подобии сеть
обучается быстро и интенсивно. Если же различия велики (как правило,
так и бывает), то сеть обучается медленно и (особенно в начальный пе-
риод) прогресс почти незаметен. Все понятно: вначале необходимо изба-
вить сеть от «вредных врожденных привычек» (ох, непросто это сделать,
очень непросто!), и только потом разворачивается процесс настоящего
накопления знаний и совершенствования умений (рис. 8.11).
Теперь несколько слов о структуре формируемого программой и вы-
водимого на экран изображения. На нем видны созданные в процессе
моделирования и заполненные цветными пятнами небольшие квадраты,
отображающие «уровень информированности» нейронной сети на каж-
дом этапе обучения. Каждая точка внутри каждого квадрата сим-
волизирует, как ты уже знаешь, комбинацию двух координат ее местопо-
ложения (полученных сетью в качестве входных сигналов), а цвет точки
характеризует отклик моделируемой сети. Начнем с обсуждения значе-
ния первых двух квадратов, расположенных в левой верхней части экра-
на. Первый квадрат демонстрирует, чему ты пытаешься научить сеть.
Согласно методу, описанному в предыдущем разделе, ты изначально за-
даешь, какие условия должен искать, а какие избегать моделируе-
мый «зверек»; это графически отображается в виде «карты» эталон-
ного поведения. Другой выделенный квадрат (второй слева в верхнем
236
Глава 8
ряду) показывает «врожденные» склонности сети. В каждом экспери-
менте сеть может иметь иные исходные (выбираемые случайным спосо-
бом) значения своих параметров, в связи с чем ее начальное поведение
предсказать невозможно.
Следующие картинки, соответствующие очередным фазам процес-
са обучения, представляются на экране также в виде квадратов (см.
рис. 8.11). Они могут выводиться через различные промежутки време-
ни, поскольку ты сам будешь решать, сколько шагов обучения должно
быть выполнено перед очередной демонстрацией результатов (для это-
го предназначено поле Iterations), наверное, ты заметил, что под полем
Iterations расположено дополнительное поле Total Iterations. Его зна-
чение информирует, сколько всего шагов пройдено к текущему моменту.
Перед выполнением заданного тобой (либо оставшегося неизменным
с предыдущей фазы) числа шагов можно модифицировать значения ко-
эффициентов, определяющих скорость обучения (коэффициент обуче-
ния Alpha и коэффициент момента Eta) — окна, содержащие эти зна-
чения, все время видны на экране. Ты можешь задавать их абсолютно
произвольно, но на первых порах лучше не изменять эти параметры и
использовать значения, предложенные программой по умолчанию. Позд-
нее, когда ты осознаешь достоинства (и недостатки...) типового процес-
са обучения, можешь попытаться изменить эти параметры и оценить
результаты введенных изменений.
8.5. Какие формы обучения можно наблюдать
в сети?
Описываемая программа Example 09 предоставляет возможность
провести очень интересные исследования форм обучения нейронных се-
тей. Эти эксперименты очень увлекательны, и я сам посвятил много
часов подбору различных задач и наблюдению за обучением сети с раз-
личными значениями параметров. Позволь поделиться с тобой некото-
рыми соображениями. Вскоре уже ты сможешь рассказать мне и другим,
как протекало обучение исследовавшихся тобой сетей.
Обучаемость живых организмов (и особенно нейронные механизмы,
лежащие в основе процесса обучения) «всегда» были объектом внимания
ученых-биологов. Многолетнее накопление и систематизация наблюде-
ний за различными формами обучения людей и животных позволили со-
брать обширную базу знаний, позволяющих выявить важнейшие особен-
ности этого процесса. Собранные сведения применяются и для обучении
людей, и для дрессировки животных. Тем не менее, это бихевиористи-
ческие знания о поведении, но не о механизмах его формирования.
Формы обучения нейронных сетей
237
Неоднократно предпринимались попытки выяснить сущность процесса
обучения результаты тысяч нейрофизиологических и биохимических
опытов оказались гораздо скромнее. К счастью, в настоящее время по-
явилась возможность проверять различные концепции функционирова-
ния нервной системы в том числе в процессе обучения и накопления зна-
ний) путем их моделирования с применением нейронных сетей. Для это-
го используются программы, аналогичные программе Example 09. Она
имитирует процесс обучения и генерирует рисунки, изучение которых
способно доставить массу незабываемых впечатлений. Рассмотрим вме-
сте одну ситуацию, остальные ты сможешь исследовать самостоятельно!
Напомню, что обучение нейронной сети заключается в подаче на ее
входы случайно подобранных комбинаций входных сигналов и в принуж-
дении ее к такому функционированию, которое приводило бы к выра-
ботке требуемых выходных сигналов. Подобный сценарий в приложении
его к условиям рассматриваемого примера («зверек» с двумя органами
чувств) сводится к многократному созданию для нашего «подопытного
животного» различных ситуаций, т.е. к подаче на входы сети (рецепторы
«зверька») случайных, но известных сигналов. Сеть реагирует на них в
соответствии с накопленными в ней знаниями, т.е. одни условия «одоб-
ряет», другие — нет. В то же время, «учитель» (в роли которого высту-
пает проводящий обучение компьютер) на основании карты требуемого
поведения сети вырабатывает эталонные сигналы — будто говорит: Это
тебе должно понравн/тъсл, а то — нет!
Развитие такого обучения можно наблюдать в динамике (на экране
компьютера), поскольку полное представление о нем дает картинка в
виде большого квадрата в левом нижнем углу экрана. В этом квадрате
последовательно высвечиваются точки, соответствующие поданным на
вход обучаемой сети комбинациям входных сигналов. Заметно, что эти
точки случайно распределяются по всей плоскости. Каждая точка за-
крашена красным или синим цветом. Именно этот цвет указание учи-
теля: это хорошо, а это - нет. Сеть учитывает эти указания и корректи-
рует допущенные погрешности изменением значений своих параметров
(синаптических весов). Для корректировки применяется рассматривав-
шийся ранее алгоритм обратного распространения ошибки.
Время от времени процесс обучения прерывается, и сеть подвергает-
ся «тестированию», в ходе которого она должна выработать свои оценки
в каждой предъявленной точке. Результаты теста выводятся програм-
мой в виде «карт» цветных точек отдельными квадратами, располага-
ющимися (слева направо, как в комиксе) вначале в верхней, а потом в
нижней части изображения, формируемого npoi раммой Example 09. Ты
должен каждый раз указывать, после выполнения какого числа шагов
будет проводиться очередное тестирование.
238
Глава 8
Рис. 8.12. Вид модели
окружающей среды
и заданных учи ге-
лем предпочтений
Мы начнем презентацию с примера обучения односло14ной сети, име-
ющей структуру
2 — 1.
Перед этой сетью поставлена очень простая задача: разделить об-
ласть всех возможных входных сигналов на две подобласти «одоб-
ряемую» и «отвергаемую» — с помощью (почти) прямой линии. Для
достижения искомой цели необходимо при описании задачи ввести сле-
дующие координаты окружностей'':
100, 100, 140
0, 0, 0
0, 0, О
В результате возникает «карл а» заданных
учителем форм поведения сети (рис. 8.12), име-
ющая простую и удобно интерпретируемую
структуру - «зверек» должен предпочитать и
искать обстановку, в которой светло и громко.
Напомню, что программа Example 09 вна-
чале проверяет естественные («врожденные»;
предпочтения сети. На экране появится второй
квадрат (рис. 8.13), который следует интерпре-
тировать как комплексные результаты модели-
рования поведения «зверька» до начала обуче-
ния. Программа попросту создаст для него все
возможные ситуации (т.е. исследует все точки
внутри квадрата и в каждой точке выяснит от-
клик сети. При позитивной реакции точка закрашивается красным.
В случае негативного отклика точка становится синий. Промежуточные
состояния характеризуются переходной окраской. Можно заметить, что
«зверек» до начала процесса обучения «любит» укромные уголки, пре-
красно чувствует себя в темноте и тишине, но вполне допускает и осве-
щенные места, причем, чем светлее — тем громче! Образно говоря -
любитель дискотек и спален (ну и животное нам попалось :-).
Если ты воспроизведешь описываемые эксперименты на своем ком-
пьютере, то (вне всякого сомнения!) получишь иную картину исходных
предпочтений сети, поскольку — это уже привычно они выбираются
случайным способом. Детали не столь существенны. Видно, что нсле-
вое (с точки зрения учителя) и фактическое состояния сильно отлича-
Обрати внимание на «фокус» с вводом координат окружностей с нулевым ради-
усом он применяется, если нам достаточно одной окружности, и дальнейшее услож-
нение задачи не требуется.
Формы обучения нейронных сетей
239
Рис. 8.13. Сопоставление заданных
учителем и «врожденных» предпо-
чтений сети
8.14. Состояние после завершения
первого этапа обучения сети
Рис.
ются друг от друга. Для описываемых здесь экспериментов это норма,
поэтому интенсивное обучение сети - насущная необходимость.
Для вывода на экран следующей карты распределения решений сети
ты должен ввести желательное (по твоему мнению) число шагов обуче-
ния. Совет: при исследовании небольших сетей «подсматривай» за про-
цессом обучения часто, например через каждые 10 шагов. Но при изу-
чении объемных сетей с «насыщенными» скрытыми слоями результа-
ты обучения будут заметными только при более длительном обучении.
Итак, от тебя требуется только вводить длительности циклов обучения,
а потом наблюдать, сравнивать, анализировать и делать выводы. Та-
ким способом можно узнать о сетях гораздо больше, чем при чтении
умных книжек и научных статей!
Предлагаю теперь внимательно присмотреться к последовательности
обучения при выполнении нескольких примеров, подготовленных специ-
ально для этой книги хотя ты, проходя по моим следам, получишь на
своем компьютере несколько иные результаты. По крайней мере, будет
понятно, чего следует ожидать!
На первом этапе обучения выведенный на экран квадрат (рис. 8.14)
очень похож на тот, который соответствовал начальным («врожденным»)
свойствам системы. Это означает, что, несмотря на интенсивный тренинг,
сеть не желает «поступаться своими убеждениями». Такое исходное пре-
бывание в заблуждении достаточно типично для обучения нейронных
сетей и находит свое отражение в обучении людей и животных.
Следующий этап добавляет в картинку очередной квадрат и демон-
стрирует некую промежуточную фазу процесса обучения. Сеть начинает
вполне ощутимо менять свое поведение, но она еще далека от оконча-
тельного решения разделительная линия между областями позитив-
ных и негативных решений проходит практически горизонтально
(рис. 8.15). Сети в этот момент кажется, что она понимает учителя:
она должна любить громкие места. Увы, это мнение ошибочно, и необ-
ходимы дальнейшие корректировки.
Только после следующей «порции знаний» характер поведения се-
ти начинает приближаться к эталонному, хотя фактическое положение
разделительной линии все еще отличается о г идеального (рис. 8.16).
240
Глава 8
Рис. 8.15. Следующий этап процесса обучения
Рис. 8.16. После трех этапов обучения сеть близка к успеху
Рис. 8.17. Кризис в процессе обучения как следствие чрезмерной строгости учителя
Результат можно было бы признать прекрасным, особенно если при-
нять во внимание факт его достижения за очень короткое время. В прин-
ципе, на этом обучение следовало бы прекратить, но для целей экспе-
римента предположим, что строгий учитель добивается абсолютного со-
вершенства и требует вносить коррективы после каждой, даже самой
маленькой погрешности.
Результатом оказывается внезапный кризис. Сеть ухудшает свое
поведение (после четвертого этапа процесса обучения разделительная
линия удаляется от эталона, рис. 8.17).
После такого кризиса необходимо весьма длительное, многоэтапное
обучение для достижения сетью такого уровня совершенства ее поведе-
ния, который соответствует задаваемым учителем эталонам. Необходи-
мо зафиксировать и запомнить факт: чрезмерная строгость учителя па
этапе, когда знания сети еще не полностью сформировались и стабилизи-
ровались, практически всегда вредна и может привести даже к полной
потере сетью всех благоприобретенных навыков.
Полный набор результатов 12 этапов обучения рассматривавшейся
простой сети решению задачи «зверька» показан па рис. 8.18.
Прервем выполнение программы и вернемся (кнопка Back' к экра-
ну, в котором устанавливаются новые параметры задачи. При сохране-
нии той же (однослойной 1 структуры сети сформулируем более слож-
ную задачу. Попробуем, чтобы моделируемы!] зверек стал поклонником
«золотой середины» все крайние ситуации должны отклоняться, а
Формы обучения нейронных сетпей
241
Рис. 8.18. Окончательный результат процесса обучения сети
«подопытное животное» должно стремиться к средним условиям. Этого
легко достичь вписыванием в соответствующие окна координат одной
Рис. 8.19. Эта-
лон новой задачи
для обучения сети
окружности и ее центра:
О, О, 3.5
Остальные две окружности вновь обнуляем вводом
параметров:
О, О, О
о, о, о
в этом случае образ эталонного пове-
дения сети иллюстрируется рис. 8.19.
При наблюдении за функционированием сети по
рис. 8.20 (структура которого аналогична рис. 8.18) заметны метания
сети и резкие изменения ее поведения в попытках избежать учительских
наказаний — увы, все безуспешно...
Несмотря на подбор параметров сети и на демаркацию границы меж-
ду областями позитивных и негативных реакций, сеть все равно попа-
дет в ловушку, связанную с восприятием как позитивной обстановки
с какими-нибудь предельными значениями свойств. Например, на не-
скольких идущих друг за другом картинках видно, как моделируемый
«зверек» пытается укрыться в темноте и выбирает в качестве главно-
го указателя небольшое число света в представленных учителем при-
мерах — именно за это он будет наказываться на следующих этапах
обучения. Прежде чем я прервал эксперимент, зверек «успел сформули-
ровать» еще одну некорректную гипотезу: он стал избегать области, в
которых стоит устрашающая тишина (ошибочно полагая, что сущность
стоящей перед ним задачи сводится к поиску наиболее шумной обла-
сти). Увы, это очередное заблуждение...
Причина неудач весьма прозаична — моделируемая сеть оказалась
слишком примитивной для обучения такой сложной форме поведения.
242
Глава Ь
Рис. 8.20. Безуспешные попытки обучения при использовании слишком примитивной
структуры сети
Рис. 8.21. Способ задания зна-
чений для «более интеллектуаль-
ной» сети
как «выбор золотой середины». Для использовавшейся в эксперименте
сети единственной доступной формой разделения входных сигналов бы-
ла их линейная дискриминация для рассматриваемого примера она
оказалась слишком простой и недостаточной.
Поэтому следующий эксперимент будет заключаться в применении
для решения поставленной задачи сети с большим числом элементов и
более сложной структурой. Например, для описания этой сети можно
использовать данные, показанные на рис. 8.21.
Необходимо отметить, что после объявления о наличии в сети более
одного слоя программа задала дополнительный вопрос о количестве ней-
ронов в этом дополнительном слое! При построении еще более сложной
сети таких дополнительных вопросов будет еще больше!
Как ты знаешь, чем больше слоев и нейронов имеет сеть, тем вы-
ше будет ее «интеллектуальный потенциал». Такая сеть по-настоящему
сможет использовать свой «врожденный интеллект». Теперь посмотрим,
как такая сеть обучается. Исходное распределение цветных пятен, по-
Формы обучения нейронных сетей
243
Рис. 8.22. Пример начального со-
стояния более сложной сети
Рис. 8.23. Начальный этап обучения сети
Рис. 8.24. Очередной этап обучения
казанных на рис. 8.22, свидетельствует об изначальном энтузиазме этой
сети по отношению ко всему. Моделируемый «зверек» прекрасно чув-
ствует себя в практически любой ситуации, но меньше всего ему нра-
вятся темные и тихие уголки.
Тем не менее, первый опыт, полученный в процессе обучения, пока-
зывает «зверьку» мир совсем не таким прекрасным — рядом со сладким
ядрышком ореха всегда лежит горькая скорлупа. Сеть реагирует типо-
вым способом — вначале она усиливает свои исходные предпочтения:
после первого этапа обучения гораздо меньше любит темные закутки,
но все еще очень далека от итогового успеха (рис. 8.23).
Но последующее обучение сети приводит нашего «зверька» к очеред-
ным разочарованиям. Множатся штрафы за излишнее доверие и чрез-
мерный энтузиазм, на которые сеть реагирует все более недоверчивым
отношением к коварному миру. Заметно, что после второго этапа обу-
чения от начального энтузиазма и симпатии ко всему остается только
легкая тяга к тихим солнечным полянкам (небольшое желтое пятнышко
в нижнем правом углу последнего квадрата на рис. 8.24 I.
Но такое поведение также вызывает критику учителя, поэтому по-
сле завершения очередного этапа обучения сеть впадает в полное от-
рицание ей абсолютно ничего не нравится! Такое состояние пол-
ного упадка духа и уныния очень типично для большинства экспери-
ментов по обучению нейронных сетей как правило, оно предвосхи-
щает попытки создания позитивного (с точки зрения учителя) образа
ученика (рис. 8.25)...
Такую попытку мы наблюдаем на рис. 8.26, иллюстрирующем чет-
вертый этап процесса обучения. Достаточно несколько продемонстриро-
ванных учителем примеров ситуаций (на которые сеть должна реагиро-
вать позитивно), и начинается очередная фаза оптимизма и энтузиазма,
характеризующаяся одобрением практически всех ситуаций за исключе-
244
Глава 8
Рис. 8.25. Кризис: тотальное отрицание в процессе обучения сети
Рис. 8.26. Позитивная фаза оптимизма
Рис. 8.27. Формирование корректной рабочей гипотезы
нием наиболее громких, особенно при слабом освещении. Полная темнота
и максимально яркий свет также уменьшают терпимость к шуму.
Естественно, очередной этап процесса обучения должен несколько
приглушить эти явно чрезмерные надежды — в результате сеть вновь
попадает в сферу отрицания и неудовлетворенности. Тем не менее, оста-
ется некоторый след положительного прошлого опыта, который пе был
задет чувствительными карами (зеленое «озерцо» в окне, иллюстри-
рующем состояние сети после пяти циклов обучения). Уже на следу-
ющем этапе этот опыт трансформируется в зародыш корректной рабо-
чей гипотезы (темное пятнышко в центре области допустимых значений,
рис. 8.27).
Последующее обучение направлено уже только на поддержку оче-
редных приливов энтузиазма и доведение области позитивных реакций
сети до подобающих размеров. В момент прекращения процесса обуче-
ния (после 15 циклов) сеть способна относительно неплохо классифици-
ровать вводимые учителем сигналы, и дальнейшее совершенствование
ее умений представляется излишним (рис. 8.28).
Вывод: система с большим «мозгом» (имеющая на порядок больше
нейронов!) и более умелая (за счет развитой системы соединений) ока-
залась способной обучиться форме поведения, недостижимой для менее
совершенной структуры.
Следующий интересный результат иллюстрируется рис. 8.29, где по-
казано, насколько эффективно тому же умению (понимать установку
учителя на выработку позитивной реакции па средние условия освеще-
ния и шума при игнорировании любых крайностей) обучается другой
Формы обучения нейронных сетей
245
л °
О,
Рис. 8.28. Полная иллюстрация процесса обучения сети решению более
сложной задачи
Рис. 8.29. Процесс обучения другого варианта сети
экземпляр нейронной сети (с такой же структурой что и сеть, обучение
которой показано на рис. 8.28). Единственное различие между этими се-
тями заключается в разных (случайных) начальных значениях внутрен-
них параметров, что вызывает диаметрально противоположные «врож-
денные предпочтения» и принципиально меняет ход процесса обучения.
Эта вторая сеть (фактически близнец сети, связанной с рис. 8.28),
обучение которой иллюстрируется рис. 8.29, с самого начала имеет ме-
ланхолические наклонности. Ей ничего не нравится по-настоящему
на рисунке доминируют холодные зеленый и синий цвета. Начальный
период обучения приводит к едва заметному росту интереса к «диско-
течным условиям» (желтое пятно в квадрате, соответствующем первому
этапу), но несколько последующих неудач вновь возврашают сеть в об-
ласть тотального (хотя и умеренного) отрицания. На четвертом этапе
обучения сеть пытается сформулировать гипотезу о том, что предпочте-
ниям учителя соответствуют светлые помещения с умеренным уровнем
шума, но уже на следующем этапе возникает убеждение в необходимости
одобрять средние условия. С каждым следующим этапом это убеждение
246
Глава 8
Рис. 8.30. Пример задачи для двухслойной сети
усиливается и конкретизируется. Как следствие, на рисунке появляет-
ся красный цвет категоричного одобрения, область которого все лучше
соответствует региону, заданному учителем как зона эталонного одобре-
ния. В то же время выражающие неуверенность и сомнения зеленый и
желтый цвета исчезают в пользу все более отчетливо кристаллизующе-
гося разделения на области однозначно хороших и однозначно плохих
условий. На последних этапах «меланхоличная» сеть учится действо-
вать практически так же, как и первая сеть (как мы помним, страдав-
шая сначала чрезмерным энтузиазмом). Это доказывает, что «врожден-
ные предпочтения» не являются определяющими, цель может быть
достигнута терпеливым обучением, хотя пути к знаниям зависят от раз-
личных стартовых позиций.
Используя предложенную программу, можно провести множество
различных экспериментов. Некоторые из них показаны на рис. 8.30-8.32.
Осмысление развития показанных на этих рисунках процессов обучения,
воспроизведение их на своем компьютере, проведение собственных иссле-
дований заманчивое поле для удивительных открытий. Пусть у тебя
хватит отваги проложить на этом поле собственную тропу!
И в завершение главы — еще одно примечание. Сравни рис. 8.28
8.32 с рис. 8.20. Ты заметишь, насколько поведение сети с большими
«интеллектуальными возможностями» отличается от поведения прими-
тивной сети, совершенно не способной обучиться более сложным принци-
пам функционирования. Обрати внимание, что тот «нейронный балбес»
не был в состоянии освоить корректные реакции, тем не менее, его дей-
ствия в любой ситуации были очень категоричными и решительными.
Весь мир для него представлялся «исключительно черно-белым» од-
на часть ситуаций оценивалась как «однозначно положительные», а вто-
рая часть —- как «однозначно отрицательные». Если такое категоричное
суждение не подтверждалось в процессе обучения, то оно заменялось
Формы обучения нейронных сетей
217
Рис. 8.31. Пример задачи, которую сможет решить не каждая двухслойная сеть
Рис. 8.32. Задача высокой сложности, решаемая не менее чем трехслойной сетью
другим таким же решительным - выводом (впрочем, часто таким
же ошибочным). В то же время сети с большими интеллектуальными
возможностями демонстрировали способность к более тонким оценкам,
находили решение медленнее и проходили через множество этапов, на-
полненных сомнениями, упадком духа и «гамлетовскими терзаниями».
Тем не менее, именно эти нерешительные, невротичные, излишне ин-
теллигентные особи достигали успеха в виде окончательной правильной
адаптации своего поведения к назначенным учителем «правилам игры»,
тогда как придурковатый неуч метался из стороны в сторону, не будучи
в состоянии принять какое-либо осмысленное решение...
Обрати внимание, насколько интересное и разнообразное поведение
нейронных сетей можно было наблюдать с помощью единственной и до-
вольно простенькой программы. Компьютер, моделирующий нейронную
сеть, вел себя не как тупая и ограниченная машина, действовал не од-
нообразно, напротив, он демонстрировал некие индивидуальные особен-
ности, изменчивость настроения, разнообразные способности... Это те-
бе ничего не напоминает?
248
Глава 8
8.6. Что еще можно наблюдать в исследуемой
сети?
В принципе я мог бы на этом завершить обсуждение и предоставить
тебе возможность самостоятельно выявить все потенциальные «фишки»
программы Example 09. Но все-таки мне хочется подсказать, какие об-
ласти пространства входных сигналов стоит использовать, прежде чем
ты «набьешь собственную руку». Мой опыт подсказывает, что очень ин-
тересное развитие процесса обучения можно наблюдать, эксперименти-
руя с «болванчиком», образованным окружностями с параметрами
0, 0, 34, 0, 10, 4, 1
Это уже достаточно сложная задача. Сети придется изрядно потру-
диться, чтобы обнаружить правильный принцип распознавания (для ре-
шения такой задачи сеть должна быть трехслойной, а число элементов
в скрытых слоях больше, например 7 элементов в первом слое и 5
во втором). В то же время эта задача вполне компактна, что позволяет
хорошо представлять ее на экране видеомонитора и легко оценивать по-
лучаемые результаты. Я не включил в книгу полученные мной решения
этих примеров, потому что не хочу лишать тебя удовольствия получить
их самостоятельно. Но я подскажу, какие результаты следует ожидать,
если ты решишься применить описываемую программу для более углуб-
ленных исследований свойств сети и ее чувствительности к некоторым
параметрам, определяющих развитие процесса обучения.
Ты уже прекрасно знаешь, что перед выполнением заданного чис-
ла шагов обучения программа позволяет изменить значения коэффици-
ентов, влияющих на скорость обучения. Первый параметр, обозначен-
ный на панели управления как Alpha, представляет собой коэффици-
ент обучения {learning rate). Увеличение значения этого коэффициента
повышает интенсивность обучения. Иногда это улучшает итоговые ре-
зультаты, но чаще ухудшает их, поэтому имеет смысл проверить это
утверждение «на собственной шкуре». Второй параметр, обозначаемый
на панели управления программы Example 09 символом Eta, опре-
деляет инерционность обучения. Этот параметр, чаще всего называе-
мый в литературе коэффициентом момента. заставляет сеть быть бо-
лее «консервативной» и дольше сохранять выбранное ранее направле-
ние изменений весовых коэффициентов. И опять же в одних случа-
ях увеличение значения этого коэффициента улучшает обучение, а в
других — только мешает.
Оба названных коэффициента все время доступны на панели управ-
ления программы Example 09, поэтому ты можешь изменять их зна-
чения в процессе обучения и накапливать очень интересные наблюде-
Формы обучения нейронных сетей
249
Рис. 8.33. Стандартное значение коэффициента обучения предопределяет спокойное и
равномерное, но весьма медленное обучение
Рис. 8.34. Увеличение значения коэффициента обучения позволяет в некоторых
случаях ускорить обучение сети
ния. Вначале проведи однократную (в частности, до начала обучения!
модификацию этих параметров. Скорее всего, ты сразу обратишь вни-
мание па увеличение скорости обучения по мере роста коэффициента
обучения Alpha. Например, на рис. 8.33 иллюстрируется развитие про-
цесса обучения при стандартных значениях этого коэффициента, а на
рис. 8.34 — обучение той же сети решению той же задачи при увели-
ченном значении этого коэффициента.
Слишком большое значение коэффициента обучения также небла-
гоприятно, поскольку в этом случае проявляются признаки нестабиль-
ности процесса обучения (что наглядно иллюстрирует рис. 8.35). Для
компенсации осцилляций сети, всегда возникающих при чрезмерном воз-
растании коэффициента обучения, увеличиваются значения коэффици-
ента Eta — для повышения инерционности моделируемого процесса. При
желании ты сможешь исследовать влияние изменений коэффициента
момента на обучение сети и проследить стабилизирующее влияние па-
250
Г л а ь a 8
Рис. 8.35. Слишком большое значение коэффициента обучения приводит к осцилля-
циям процесса обучения: сеть попеременно приближается к искомому решению и
удаляется от него
Рис. 8.36. Слабая адаптация областей при использовании двухслойной сети
раметра момента в ситуациях, когда процесс обучения пытается «вы-
рваться из-под контроля».
Другая сфера очень интересных исследований вопрос влияния
структуры сети на ее поведение. Для этого необходимо выбрать какую-
либо по-настоящему сложную задачу, например задачу, показанную на
рис. 8.4 и 8.5. Сложность этой задачи заключается в необходимости «на-
стройки» сети на узкие и тесные «заливы», образуемые голубой обла-
стью негативных решений. Каждая такая «щель» требует очень точной
адаптации элементов сети к характерным особенностям рассматривав
мой задачи, что создает действительно трудные проблемы. В такой си-
туации простая двухслойная сеть не имеет вообще никаких шансов. Неза-
висимо от длительности обучения она всегда будет стремиться к упро-
щению структуры распознаваемых областей (рис. 8.36).
В то же время, трехслойная сеть сможет выяснить все тонкости рас-
сматриваемой задачи (рис. 8.37). Но иногда бывает сложно обеспечить
стабильность процесса обучения, поскольку сеть даже в непосред-
Формы обучения нейронных сетей
251
Рис. 8.37. Корректное и быстрое решение сложной задачи при использовании
трехслойной сети
Рис. 8.38. Признаки нестабильности обучения, проявляющиеся в трехслойной сети
ственпой близости от корректного решения — «убегает» от него под
влиянием обратного распространения ошибки и начинает «блуждать»,
не приближаясь к искомому результату (рис. 8.38).
Конечно, теперь ты можешь дать волю своей фантазии и произволь-
но задать области, в которых сеть должна принимать «позитивные» и
«негативные» решения. Можешь провести десятки экспериментов и по-
лучить сотни наблюдений. Но предупреждаю: учитывай фактор време-
ни — обучение большой сети будет продвигаться очень медленно, по-
этому тебе потребуется либо очень быстрый компьютер, либо огромное
терпение. Не буду навязывать тебе решение, но (для порядка) сообщу,
что терпение дешевле.
8.7. Контрольные вопросы и задания
для самостоятельного выполнения
1. Методология распознавания образов затрагивает только графи-
ческие образы (изображения, рисунки и т.п.) либо имеет более широ-
кую сферу приложения?
252
Глава 8
2. В какой форме вводятся образы (или информация о других распо-
знаваемых объектах) в нейронную сеть, выполняющую функции класси-
фикатора?
3. Каким способом распознающие сети сообщают (чаще всего) поль-
зователю результаты своей работы, в частности, решение о распознанном
объекте?
4. Попробуй сопоставить выводы, сделанные в ходе наблюдений за
описываемым в этой главе процессом обучения сети и ее функционирова-
нием при решении различных генерируемых программой задач (с одной
стороны) и представленной в шестой главе теоретической информацией
о поведении сетей с различным количеством слоев. Обрати внимание на
более разнообразное поведение сетей (описываемых в данной главе), ко-
торое обусловлено возможностью выработки нейронами любых проме-
жуточных выходных сигналов, а не только 0 или 1 (соответствующих
синему и красному цветам на генерируемых программой рисунках).
5. Найди связь между количеством нейронов в скрытых слоях слож-
ной многослойной сети с количеством несвязных областей в простран-
стве входных сигналов, в которых сеть после обучения вырабатывает
противоположные решения (0 или 1).
6. Пример зависимости между количеством нейронов в скрытом слие
и корректностью решения обученной сетью некоторых задач показан на
рис. 8.39. Левую часть этого графика относительно легко интерпрети-
ровать: сеть со слишком малым числом нейронов недостаточно «умна»
для корректного решения поставленной задачи, а увеличение количества
нейронов ведет к улучшению функционирования сети. Как можно интер-
претировать факт (также многократно зафиксированный в разливных
Рис. 8.39. Иллюстрация к заданию № 6
Формы обучения нейронных сетей
253
нейронных сетях), что чрезмерное увеличение количества скрытых ней-
ронов парадоксально ухудшает качество работы сети?
7. Коэффициент обучения {learning rate) считается мерой интенсив-
ности изменений весов сети в случае ее некорректного функционирова-
ния. Согласно распространенной интерпретации этого коэффициента его
большие значения соответствуют действиям «строгого и требовательно-
го учителя», а малые значения моделируют «понимающего и снисходи-
тельного учителя». Попробуй обосновать положение о том, что процесс
обучения развивается наиболее эффективно при использовании умерен-
ных (не больших и не маленьких) значений обсуждаемого коэффици-
ента. Постарайся собрать и упорядочить информацию на эту тему в
ходе экспериментов с программой Example 09. Построй графики из-
менения качества функционирования сети после определенного числа
шагов обучения (например, после 500, 1000 и 5000 шагов) в зависимости
от значения коэффициента обучения.
8. В публикациях по тематике нейронных сетей предлагаются раз-
личные алгоритмы обучения, в которых значения коэффициента обуче-
ния изменяются в процессе обучения. Как ты думаешь, в каких условиях
эти значения должны увеличиваться, а в каких — уменьшаться?
9. В некоторых теориях обучения нейронных сетей рекомендуется
выбирать коэффициент обучения в начале процесса небольшим, по-
скольку сеть вначале совершает много серьезных ошибок. Если мы бу-
дем сильно корректировать значения весов пропорционально этим боль-
шим ошибкам, то сеть начнет «биться в конвульсиях» в устранении
одних ошибок, но из-за слишком резких изменений станет допускать
другие ошибки (в следующих обучающих последовательностях). Поэто-
му па первых порах сети необходим «удобный и деликатный детский
сад». Позднее, по мере накопления сетью все больших умений можно
увеличить коэффициент обучения, поскольку сеть уже совершает мень-
ше ошибок (к тому же меньших по абсолютной величине), поэтому для
повышения интенсивности обучения следует «несколько закрутить гай-
ки». Наконец, под занавес обучения, когда сеть уже накопила большой
объем знаний, снова рекомендуется уменьшить коэффициент обучения,
чтобы случайные, не имеющие прямого отношения к решаемой задаче
погрешности (например, связанные с особенно сложными или нетипич-
ными объектами классификации) не портили суммарный эффект. Из-
вестно, что улучшение функционирования сети в одной точке всегда при-
водит к какому-нибудь (пусть даже самому минимальному) ухудшению
ее работы в других точках. Попробуй провести серию экспериментов,
подтверждающих эту теорию либо доказывающих ее ошибочность.
254
Г -п а в a 8
-б -+ —2 С’ 2 + в
Рис. 8.40. Иллюстрация к заданию № 11. Задача «двух спиралей»: обучающая
выборка (слева) и два примера ее решения
10. Последствия излишне большого значения коэффициента обуче-
ния (угрожающего стабильности процесса) компенсируется увеличением
значения коэффициента момента, характеризующего степень «консер-
ватизма» процесса обучения. Спланируй и проведи серию эксперимен-
тов, позволяющих вычертить график изменения минимальных значений
коэффициента момента при различных значениях коэффициента обу-
чения, совместно обеспечивающих наилучшее (быстрое, но стабильное)
развитие процесса обучения.
11. Задание для наиболее подготовленных. Модифицируй ис-
пользуемую в этой главе программу обучения сети так, чтобы области
принадлежности объектов к различным классам (области, в которых
«зверек» счастлив либо несчастен) можно было бы выделять на экране,
рисуя их границы с помощью графического редактора. Применяя такой
инструментарий, попробуй построить сеть, которая сможет научиться
решать особенно сложную задачу распознавания областей позитивных и
негативных решений, имеющих форму двух спиралей (рис. 8.40).
12. Задание для наиболее подготовленных. Спроектируй и по-
строй модель «зверька» с большим числом рецепторов («органов чувств,
получающих информацию о различных свойствах «окружающей сре-
ды»), имеющего возможность совершать более сложные действия (на-
пример, перемещаться в своей «среде» в поисках необходимых ему опре-
деленных условий либо конкретных объектов еды и т.п.). Наблюдение
за функционированием обучающейся нейронной сети как за «мозгом»
такого зверька, а также за его поведением в различных средах может
оказаться захватывающим интеллектуальным приключением!
Глава 9
НЕЙРОННЫЕ СЕТИ
С САМООБУЧЕНИЕМ
9.1. На чем основана идея самообучения сети?
уже видел (и даже опробовал в нескольких npoi раммах!), как в
соответствии с указаниями учителя нейронная сеть шаг за шагом совер-
шенствует свое функционирование так, что через некоторое время ее по-
ведение начинает соответствовать представленным учителем эталонам.
Теперь я покажу тебе, что сеть Может обучаться совершенно са-
мостоятельно, т.е. без учителя. Эту возможность мы уже обсуждали
в разд. 3.2, по теперь наступило время познакомиться с деталями. Ты
должен знать о существовании различных методов такого самообучения
алгоритмы Хебба, Ойя, Кохонена и т.д.). но в этой книге мы не изучаем
подробности реализации алгоритмов, а стараемся понять их сущность.
Для этого предлагаю воспользоваться программой Example 10а.
В этой программе мы будем иметь дело с нейронной сетью, состо-
ящей из одного, но иногда довольно обширного слоя (рис. 9.1). На все
нейроны этого слоя подаются одни и те же входные сигналы, и каждый
нейрон вырабатывает (независимо от каких-либо условий) значение сте-
пени своего возбуждения, равное произведению входного сигнала (оди-
накового для всех нейронов) па свои (заданные отдельно для каждого
элемента) весовые коэффициенты.
Как ты помнишь, возбуждение
нейрона тем сильнее, чем выше согла-
сованность между введенными в теку-
щий момент входными сигналами и их
внутренним эталоном. Когда весовые
коэффициенты нейрона известны, то
можно сразу сказать, па какие вход-
ные сигналы он будет* реагировать по-
зитивно, а на какие негативно. Ес-
ли предположить двухмерность вход-
ных сигналов (т.е. каждый сигнал
Рис. 9.1. Структура однослойной
сети, которая может самообучаться
256
Глава 9
Рис. 9.2. Интерпретация взаимного расположения вектора весов и вектора входною
сигнала
состоит из двух компонент), то их можно обозначать точками на плоско-
сти, называемой в этом случае пространством входных сигналов. В этом
случае весовые коэффициенты каждою нейрона также двухмерпц (ве-
сов должно быть ровно столько, сколько компонент в сигнале), и их
также можно обозначать точками на плоскости, лучше всего на той
же плоскости. Таким способом в пространстве входных сигналов появ-
ляются точки, харак теризующие расположение каждого нейрона и соот-
ветствующие их внутренним знаниям (отраженных в значениях весовых
коэффициентов). Это показано на рис. 9.2, который уже приводился в
одной из предыдущих глав но теперь ты (обогащенный полученным опы-
том) наверняка будешь смотреть на него по-довому.
Принцип самообучения заключается в том, что вначале все нейро-
ны получают случайные значения весовых коэффициентов. Па рисун-
ке, генерируемом программой Example 10а, это отображается «обла-
ком» беспорядочно разбросанных точек. Каждая точка представляет
один нейрон; как обычно, расположение точек обусловлено значения-
ми весовых коэффициентов (окно в правой части рис. 9.3). Также как и
в .предыдущих программах, окно в левой части рис. 9.3 становится до-
ступным сразу после запуска программы; отто предназначено для моди-
фикации параметров сети. Можно варьировать значения двух парами г-
ров: количество нейронов в сети (поведение большего числа нейронов
более интересно, по его сложнее отслеживать) и так называемый па-
раметр Etha, который характеризует интенсивноеть процесса обучения
(большим значениям соответствует более быстрое и энергичное обуче-
ние). Эти параметры ты можешь изменить в любой момент, но сначала
рекомендую принять значения но умолчанию. Такие установки выбра-
ны нами в результате предварительного тестирования работы програм-
Нейронные сети с самообучением
257
' Organ Й ing Neural Network
in this example, you will examine нвИ-ieernin 3
neural network. Neurons have two inpi its so we
can display them blet as po-nts ot two dimensional
space
You will be ab e to teach the network by cbo^ sing
learning objects (from appropriate quartet)
In this setup panel you can change some network
and learning parameters, or use default
piesettir gs at the beginning.
Press Next if you accept settings. You can always
change th.s parameters by clicking Back.
Number of Neuron? : Etha factor
® P Rendumize ГзсГ~3 |Koi?“±|
dS*l
Next, >
Рис. 9.3. Стартовое окно с параметрами (слева) и расположение точек, представляющих
нейроны в программе Example 10а после выбора значений сети и выбора Next (окно
справа)
мы. К описанию каждого параметра и к методике «оперирования» ими
мы вернемся чуть ниже.
После запуска программы в твоем распоряжении будет сеть из 30
нейронов, характеризующаяся весьма умеренным стремлением к уче-
бе. Все веса каждого нейрона этой сети получают случайные значения.
В такую случайным способом инициализированную сеть начинают no-
ci унать входные сигналы, представляющие собой описания обрабатыва-
емых сетью объектов. Ты сможешь влиять на появление этих объектов
в программе Example 10а. Эго немного противоречит идее самообуче-
ния (если сеть должна обучаться самостоятельно, то ты вроде бы
должен сидеть сложа руки!), но только в следующие эксперимен-
тах процесс представления объектов обучающей выборки (при отсут-
ствии указании по их обработке) будет развиваться случайным спосо-
бом, без малейшего внешнего воздействия. В программе Example 10а
мы осознанно отступили от этого идеала, для того чтобы ты смог на-
блюдать, как способ появления обучающих объектов (какие-то чаще,
какие-то реже...) влияет па «самостоятельное получение» сетью необ-
ходимых ей знаний (рис. 9.3).
В этом месте я вынужден тебя некоторым образом предостеречь.
В процессе самообучения все получаемые сетью знания должны сод ер-
258
Глава 9
жаться в демонстрируемых входных объектах, точнее в том, что эти объ-
екты образуют некие классы подобия. Эго означает наличие объектов,
которые взаимно похожи друг на друга (будем называть их Марси-
анами), но отличны от объектов, принадлежащих другому клас-
су (назовем объекты второго класса Марсианками). Эго означает, что
при предъявлении сети обучающих объектов ни ты («высасывающий из
пальца» их описание), пи автоматический генератор (который заменит
тебя в следующей программе) — никто не может демонстрировать се-
ти объекты с совершенно случайными координатами в пространстве
входных сигналов. Предъявляемые объекты должны заметно концентри-
роваться вокруг определенных, поддающихся выявлению центров, кото-
рым можно будет дать имена и смысловую интерпретацию («типичный
Марсианин», «типичная Марсианка» и т.д.).
В процессе функционирования программы Example 10а ты каж-
дый раз должен решать, что надо предъявить сети, но это будет очень
«грубый» выбор объекта, поскольку его параметры будут1 выбираться
автоматически. В частности, т ебе предоставляется возможность выбрать
квадрант*, в котором должен располагаться очередной предъявляемый
объект1. Для этого достаточно щелкнуть мышкой па соответствующий
квадрант. Таким способом ты сможешь управлять демонстрацией сети
объектов обучения. Например, можешь договориться (сам с собой!), что
объекты первого квадранта будут Марсианами, вт орого Марсианка-
ми, третьего — Марсианятами, а четвертого Марсиаморами**. При
* Понятие «квадрант» (как часть пространства, определенного в двухмерной системе
координат) заимствовано из математики, а я обещал не обращаться к этой дисциплине при
написании киши. Поэтому, если ты еще не изучал на занятиях по математике (либо изу-
чал, но успел ^абы ть), ч го такое система координат и какие квадранты она выделяет в про-
странстве описываемых сигналов, то прими к сведению: квадранты нумеруются, начиная
с правого верхнего угла рассматриваемого пространства. Этот правый верхний квадрант, в
которых обе откладываемые на осях координаты принимают только положительные зна-
чения, считается первым. Следующие квадранты нумеруются в направлении против
часовой стрелки. Поэтому второй квадрант располагается в левом верхнем углу, тре-
тий непосредственно под вторым и т.д. Для того чтобы увидеть способ размещения квад-
рантов с их номерами, переверни несколько страниц книги вперед и взгляни на рис. 9.12.
В правом нижнем углу представленного на этом рисунке окна программы расположены
четыре кнопки с условными поморами, точно соответствующими структуре используемых
нами четырех квадрантов. Каковы функции этих кнопок, я расскажу ниже, сейчас про-
сто присмотрись к их размещению и запомни нумерацию. Это облегчит понимание моего
рассказа.
Марсиаморы представители обитающих на Марсе существ третьего пола. Веем
известно, что жители Марса для заведения потомства объединяются в треугольники и в
результате такой сложной эротической жизни, до сих пор не создали техническую циви-
лизацию, не строят большие сооружения, поэтому попытки наблюдения за ними с Земли
до настоящего времени не увенчались успехом.
Нейронные сети с самообучением
259
некотором воображении ты можешь
взглянуть на окно, формируемое
программой Example 10а так, как
это показано на рис. 9.4. На нем я
постарался показать марсиан в си-
стеме координат вместо точек,
представляющих их измеренные
свойства.
Из рисунка видно, что каждый
марсианин в чем-то индивидуален,
по все они похожи друг* на друга.
По этой причине их описания пред-
ставляются в одном и том же про-
странстве входных сигналов (что
облегчит нейронной сети выяснение
облика «тиничиого марсианина»).
Поскольку каждый марсианин об-
ладает и иди виду ал ы i ым и особен-
ностями, отличающими его от ос-
Neural Network (exam
Reset
Click a qi iarter for learninn object
< Back
ста входных сигналов в виде «Марсиан»
будут не-
тальных сородичей, представляю- Рис. 9.4. Представление точек простран-
щие каждую особь точки
сколько отличаться друг от друса они будут размещаться в разных
местах пашей системы координат. Но свойств, по которым марсиане по-
хожи друг па друга, больше, чем свойств, определяющих их индивиду-
алыгые различия, поэтому соогветствующие нашим «инопланетянам»
точки будут группироваться в конкретных подобластях рассматривае-
мого пространства входных сигналов.
При генерации объектов для процесса обучения ты Сможешь решать,
кгго должен быть предъявлен на очередном шаге Марсианин, Марси-
анка, Марсианенок или Марсиамора. Но ты пе будешь вводить никакие
конкретные данные но демонстрируемому объекту (от тебя не требует-
ся задавать цвет глаз или рост жителя Красной планеты) программа
сделает это автоматически. На каждом шаге процесса самообучения тебе
будет задан вопрос, с образом какого марсианина ты хочешь иметь дело
(т.е. В каком квадранте должен располагаться объект)? После принятия
решения и выбора соответствующего квадранта программа сгенерирует’
объект требуемого класса и «продемонстрирует» его сети. Каждый сле-
дующий марсианин будет немного отличаться от предыдущих, по ты лег-
ко заметишь, что их свойства (отображаемые локализацией соответству-
ют,их точек в пространстве входных сигналов) концентрируюгея вокруг
определенных «протот ипов». Возможно, процесс «созидания» и демон-
страции сети объектов кажется тебе сейчас ггесколько усложненным, но
260
Глава 9
N*ural
Continue |
Reset
Press Continue
< Hack
Рис. 9.5. Ситуация после появления
обучающего объекта («марсианина»)
уже вскоре после начала работы с
программой Example 10а ты вы-
работаешь необходимые навыки.
Кроме того, программа будет вы-
давать подсказки, которые помогут
лучше ориентироваться в текущей
ситуации.
В момент появления на входе
сети очередно! о сигнала, принадле-
жащего обучающей выборке, ои
отобразится на экране в виде зе-
леного квадрата попробуй угадать,
почему я выбрал именно зеленый
цвет?), размеры которого гораздо
больше размеров точки, обознача-
ющей местоположение любого ней-
рона «рис. 9.5). При получении это-
го сигнала на свои входы каждый
нейрон самообучающейся сети рас
считывает (на основании* компонент
этого входного сигнала и значений
своих весов) свой выходной сигнал. Эти выходные сигналы могут быть
положи тельными (объект «понравился» нейрону такие тючки обозна-
чаются на экране' красным цветом) либо отрицательными (объект «нс
поправился» нейрону такие точки обозначаются га экране синим цве-
том). Если выходные сигналы (как положительные, так и отрицатель-
ные) некоторых нейронов имеют малые значения, то соответствующие
точки становятся серыми, и это интерпретируется как «безразличное1
отношение» нейрона к введенному объекту.
На основе полученных входных и рассчитанных выходных сигналов
все нейроны самообучающейся сети корректируют1 свои веса. Во вре-
мя корректировки поведение каждого нейрона зависит от значения вы-
ходного сигнала, которым он отреагировал на возбуждение. Если этот
выходной сигнал был сильно позитивным (чему на экране соответству-
ет красный цвет), то веса изменяются в сторону приближения нейро-
на к понравившейся ему точке. Это означает, что в случае повторно-
го предъявления той же точки нейрон отреагирует с еще большим эн-
тузиазмом (выходной сигнал будет иметь еще большее положительное
значение). В свою очередь, если нейрон демонстрировал по отношению
к предъявленному эталону негативное отношение (чему на экране со-
ответствует синий цвет), то он будет «отталкиваться» от эталона в
Нейронные сети с самообучением
261
Рис. 9.6. Корректировка весов в резуль- Рис. 9.7. Следующая итерация процесса
тате самообучения самообучения
;*S₽lf«Organu mg Neurat M^tWOFk (ex.mpl.10.) BE®i
Continue Reset . &
Press Continue
< Back
результате соответствующей корректировки весов следующая реакция
на входной сигнал такого типа окажется еще более негативной. В про-
грамме Example 10а можно заменить эффект «побега» негативно на-
строенных нейронов за пределы областей, в которых представлены со-
ответствующие им точки. В этом случае нейрон перестает высвечивать-
ся на экране. Подобное поведение считается абсолютно естественным,
поскольку в процессе самообучения пеиронпой сети применяются, как
правило, одинаково сильные «при гяжепие» и «отталкивание».
Процессы перемещения точек, обозначающих местоположение век-
торов весов нейронов, можно наблюдать в мельчайших подробностях.
На каждом шаге программа демонстрирует образ, на котором показаны
как прежние (цветные), так и новые (пустые в середине квадраты) точ-
ки, соответствующие нейронам (рис. 9.6). Более того, прежнее и новое
местоположения каждой точки соединены штриховой линией, что поз-
воляет отслеживать «траекторию» обучения нейронов.
На следующем шаге «новые» веса нейронов становятся «старыми»,
и после демонстрации очередной точки весь цикл повторяется с самого
начала (рис. 9.7), а сети предъявляется новый объект (возможно, при-
надлежащий другому классу (рис. 9.8).
Если этот процесс будет повторяться достаточно долго, то в каждом
квадранте сформируется совокупность нейронов, специализированных
262
Глава 9
Рис. 9.8. Интерпретация следующей иге-
рации процесса самообучения (см. рис. 9.7)
Рис. 9.9. Завершающая фаза процесса
самообучения
па распознавании типичного объекта именно «своей» группы (рис. 9.9).
Таким способом сеть совершенно самостоятельно приобретает навыки
распознавания всея встречающихся видов объектов. При наблюдении
за процессом самообучения ты, безусловно, заметишь, что он углубля-
ет и усиливает только «врожденные склонности» нейронной сети, кото-
рые выражаются исходным (случайным!) распределением векторов ве-
сов. Именно эти исходные различия обусловливают различную (пози-
тивную или негативную) реакцию разных нейронов па один и гот же
входной объект. Веса каждого нейрона корректируются с учетом именно
его реакции. В результате сеть обучается распознавать появляющиеся
на ее входе типичные элементы и эффективно совершенствует свои спо-
собности к распознаванию без какого-либо вмешательства учителя,
который может даже пе знать, сколько объект ов придется распознавать
и какими свойствами они будут обладать.
Для того чтобы процесс обучения протекал эффективно, популяция
нейронов изначально должна быть достаточно разнородна. Если значе-
ния весов выбираются так, чтобы обеспечить необходимую разнород-
ность, то самообучение окажется относительно простым и беспроблем-
ным. Если же все нейроны будут иметь подобные «врожденные склон-
ности», то будет очень сложно научить сеть «обслуживать» все классы
подаваемых на ее вход объектов. В таком случае более вероятным пред-
Нейронные сети с самообучением
263
In ths example^ you will examinfe self-learning
neural network Meun» is h& в tea inputs so we
car display thwrti later as points: uf two dimens'oriol
space
rau whI be able teach th? network by choosing
learning objects (from appropriate quarter)
{ In this eu iis 05 nei ynu can cnange зспе network
and teaming parameters, or use defaif t
preset! ir gs at the begim ling
Press Ned if you accept settings You canalways
change this
paramei вгс bv clicking Заек
4W
к/ 1
Reset
Click a quarter for learning object
Number of Neurons:
Ethat actor
a L______iVJWl* _ КДййййМЬк
Рис. 9.10. Стартовое окно с параметрами (слева) и пример случайного выбора началь-
ных значений векторов весов в программе Example 10ах после выбора параметров сети
и активации поля Density. В этом случае после нажатия на кнопку Next мы получаем
задачу с небольшим разбросом начальных значений весов (окно справа)
вставляется явление так называемого «овечьего стада» — коллективного
интереса всех нейронов к единственному объекту и полного невнимания
ко всем остальным объектам. Чаще всего в такой ситуации все нейроны
специализируются па распознавании единственного класса объектов и
совершенно игнорируют все другие классы.
В программе Example 10а разнообразие рассматривалось как оче-
видное и непременное свойство. Но поскольку влияние случайности ис-
ходного распределения нейронов остается вопросом принципиального
значения, мы подготовили версию этой программы под названием Exam-
ple 10ах, в которой ты должен затребовать либо случайное рассеивание
нейронов (равномерно по всему пространству входных сигналов), либо
выбор их исходного расположения из определенной достаточно узкой
области. Для этого необходимо соответствующим образом активировать
поле {checkbox) Density на стартовой панели программы (левое окно
на рис. 9.10). Вначале лучше выбрать широкое распределение нейро-
нов, для чего поле Density должно оставаться пустым. Когда ты пой-
мешь основные особенности процесса самообучения сети и будешь готов
к познанию чего-либо принципиально нового, активируй это поле. Тогда
гы убедишься, насколько важно для сети исходное случайное распреде-
264
Глава 9
Continue
Reset
Press Continue
< Beck
Рис. 9.11. Самообучение в программе
Example Юах — все нейроны согласован-
но притягиваются одним аттрактором*
Reset I «*
...-------1
Press Continue
Continue
< Back,
Рис. 9.12. Самообучение в программе
Example 10ах все нейроны одинаково
отталкиваются одним и тем же аттрактором
лепие параметров (весов) нейронов. Несколько примеров самообучения
сети в случае недостаточного разнообразия исходных значений весовых
коэффициентов нейронов показаны на рис. 9.10 9.12.
* Понятие аттрактор ввели в математику исследователи динамических < ис гем. Та-
кие системы могут изменять свои состояния (поэтому они называются динамическими)
Математически развитая теория динам и ческих систем предназначена (среди прочего) для
прогнозирования этих изменений как при подаче в систему определенных управляющих
сигналов (для этого создана очень обширная теория управления^, так и для случаев, котла
системе! предоставлена самой себе (тут следует упомянуль о так называемой теории хаоса
описывающей особенно интересное спонтанное поведение динамических систем). Послг-
довадельность состояний, в которые поочередно переходит1 динамическая система, можно
представить в виде линии, по которой перемещается эта система. Такая линия называем я
траекторией динамической системы. При исследовании динамических систем мы убежда-
емся. что очень часто их траектории направлены па достижение некоторой целевой точки
(или процесса). Если при старте из различных исходных условий динамическая система
приходит (по различным траекториям в конкретное конечное состояние, то это состоя-
ние называется аттрактором. Аттрактор «притягивает» ггроходящие поблизости к нему
траектории, на что указывает его название (attract притягивать). Одна динамическая
система может иметь несколько аттракторов. В этом случае каждый аттрактор обладает
своей зоной действия, называемой бассейном притяжения. Это множество таких началь-
ных условий при которых траектория системы приводит к соответствующему аттрактору.
Применительно к рассматриваемым нами нейронным сетям понятие аттрактор вве-
дено для описания того, как появляющиеся входные сигналы притягивают значения весо-
вых коэффициентов.
Нейронные сети с самообучением
265
Используя программы Example 10а и Example Юах, можно про-
вести серию специализированных экспериментов, например изучить по-
следствия более «энергичного» самообучения при изменении (особенно
при увеличении, но очень осторожном!) значения коэффициента обуче-
ния Etha.
Другие интересные явления можно наблюдать при фиксации (путем
выбора изначально заданного значения) параметра Randomize. В этом
случае сеть всякий раз будет стартовать с одним и тем же исходным
распределением весовых коэффициентов, что позволит отследить, какое
влияние на окончательное расположение нейронов оказывают (опреде-
ляемая твоими решениями!) последовательность и частота демонстра-
ции объектов из разных квадрантов. Следующий параметр, с которым
ты можешь экспериментировать — количество нейронов (Number of
Neurons), которое характеризует количество отображаемых на экране
точек. Ты, конечно, уже понял, что эти параметры можно изменять в
окне, всегда выводимом на экран сразу после запуска программы
(рис. 9.3 и 9.10 — стартовое окно с параметрами, показанное в левых
частях этих рисунков).
В контексте описываемых экспериментов можно усмотреть очень ин-
тересные аналогии между исходным распределением нейронов и врож-
денными способностями и талантами, а также между последовательно-
стью демонстрации объектов и личным опытом конкретного человека.
9.2. Как протекает длительное самообучение
сети?
Программа Example 10а позволяла очень детально отследить раз-
витие процесса самообучения нейронной сети. Но она оказывается до-
вольно неудобной в ситуации, когда хочется узнать «чем все это закон-
чится», необходимо слишком много раз нажимать на кнопку Conti-
nue. Поэтому мы написали программу Example 10b, которая пе тре-
бует таких усилий — основной процесс самообучения протекает в ней
«почти» автоматически. Так же как и в предыдущих примерах, после
запуска программы и выбора стартовых значений параметров (по умол-
чанию или по твоему усмотрению) па экране появляется окно, в кото-
ром можно наблюдать за ходом эксперимента. Процесс самообучения
развивается «почти» автоматически, потому что нажатие и отпускание
кнопки Start позволяет наблюдать за процессом самообучения «шаг за
шагом» надо же приглядеться, что происходит! Если ты нажмешь на
кнопку Start и не отпустишь ее, то процесс самообучения будет раз-
виваться автоматически. В любой момент можно вернуться к режиму
266
Глава 9
’ Hedral Network
frgdmzing Neural Ni
In this example, vou will examine self-ieanii.ng
neural netwcr к Neurons I mve tw inputs so we
can display them later as points of two d-mensional
space.
You will be able to teach the network by choosing
learning objects (from appropriate quarter)
In this setup panel you can chai ige some network
and learning parameters, or use default
presettings at the beginning
Press Next if you accept sett ngs You can always
change this parameters by clicwng Back.
r7 Randomize
r~ „
I Density
Number of Neurons
|ho“ 3
Etha taolnri
Irmo3
Pre ss/Hold Start Г RND Learn ng
< Back
_........1_____________|
Next >
Рис. 9.13. Начало самообучения сети, состоящей из 10 нейронов
«шаг за шагом» либо вновь «ускорить» процесс, используя описанный
выше прием. Таким способом (без приложения каких-либо усилий) мож-
но пе только наблюдать процесс самообучения сети в течение дли тельно-
го времени, но и обнаружить в нем несколько интересных особен поен й.
о которых мы сейчас поговорим;
Прежде всего, при запуске программы в обсуждаемом режиме необ-
ходимо выбрать размер исследуемо!* нейронной сет и. Программ^ позво-
ляет моделировать сеть с произвольным числом нейронов. Рекомендую
начать с небольшой сети (рис. 9.13 и 9.14). Теоретически можно наблю-
дать поведение даже одиночного нейрона. Однако, поскольку сеть бу-
дет стараться создать четыре обособленных сообществ нейронов (по од-
ному в каждом квадранте), пет никакого смысла строить сет ь менее чем
из ретырех нейронов. Все заботы о моделировании программа берет на
себя, тебе остается только наблюдать за развитием процесса самообуче-
ния и делить выводы. Для облегчения наблюдения за событиями в сети
в углу каждого квадранта высвечиваемся дополнительная информация в
виде трех чисел. Они информируют, сколько раз демонстрировалс я объ-
ект обучающей последовательности, принадлежащий этому квадранту^
с начала обучения и (из-за доминирующей роли первых предъявлений
в ходе первых девяти презентаций i число в скобках), и сколько нейро
пов располагается в текущий момент рассмат риваемом квадранте (число
Нейронные сети с самообучением
267
StlMkRanizihe N«»un
13(1) 2 в 18(4). 3
«1 о* 15(1)4 м 20(3). 4
Start Reset
Presb/Hnld Start
3 4
i RND Learn, ng
Нажатием кнопки с номером
соответствующего квадранта
ты исключишь выбор обучающих
объектов из этого квадранта
Активация этого параметра
приводит к случайному выбору места
появления обучающего объекта
< Back
Рис. 9.14. Завершающий этап самообучения сети, состоящей из 10 нейронов
после запятой). Например, запись
10 (3), 1
означает, что в рассматриваемом квадранте обучающий объект появлял-
ся десять раз (в том числе трижды в первых девяти презентациях) и
что в текущий момент в нем находится один нейрон. Такая информа-
ция особенно полезна при большом количестве нейронов (когда сложно
определить па взгляд, сколько их располагается в том или ином месте),
и если нейроны концентрируются в небольшой области пространства и
заслоняю г друг друга (что затрудняет1 оценивать ситуацию).
Очень интересный материал для размышлений дает наблюдение за
последствиями (случайной) асимметрии, заключающейся в более частой
демонстрации объектов из какого-либо квадранта. Эта асимметрия мо-
жет быть общей либо затрагивать только объекты, предъявлявшиеся в
начале обучения.
Далее ты сможешь наблюдать поведение больших сетей, состоящих
из нескольких сотен (не более 1000) нейронов. Это по-настоящему
увлекательно — наблюдать за параллельным обучением, например, 700
нейронов (рис. 9.15 и 9.16)! Программа сама генерирует исходное распре-
деление весов каждого не!фона и также самостоятельно демонстрирует
эталоны входных сигналов (как точки, расположенные в центрах соот-
ветствующих, случайно выбираемых квадрантов). После каждой демон-
268
Глава 9
0(0), 56 а. о □ □ В A * a. Q * V X* \ * * Иг а. о!Х " л. ° 0 « Ту гу 8 н. » В-а °* « о а из о ° «в -кя-Й/ий а ® а в ~ й ф a as tv а в _ “ *» J * в> ® а а-Цг'’ & * а. 3" в % в- а 9 а п
cP ° о, «* омОБ » . ° о а „ Ч» и ~ “ж» __ О ₽1 0 в »--о “а “ —.g • -Я * ** *-—в п ° О В и ° ж- ^--'8. ' о « _ -и ..а ' e.-J « » 0(0), 68 Г •''/ * \ \ i(i). 66
Рис. 9.15. Начальный этап самообучения
сети, сое тоящсь и < 300 нейронов
Рис. 9.16. Завершающий этап самообуче-
ния сети, состоящей из 300 нейронов
страции п?1 экран выводится «траектория» перемещения векторов весов
под влиянием самообучения, после чего сети Предъявляется следующий
объект и т.д. Как уже отмечалось, при поочередном нажатии и отпуска-
нии кнопки Start процесс самообучения развивается «шаг за шагом», тл.
приостанавливается после демонстрации каждого следующего объект,
это позволяет, присмо греться к событиям, происходящим в сети. Позднее
эти паузы прекращаются, и процесс самообучения несется вперед «род-
ным ходом». Чтобы не рассеивать твое внимание (особенно когда мы
будем рассматривать более сложные примеры самообучения), в даль-
нейшей части текущей главы на рисунках будет представляться только
важнейшая часть окна программы (т.е. «карга» распределения точек].
Процесс самообучения (также как процесс обучения с учителем) мо-
жет происходить при разных значениях коэффициента обучения. На
рис. 9.15 показано поведение сети с очень большим значением этого
коэффициента. Такая «особь» с огромным энтузиазмом воспринимает
окружающий мир: любая новая идея или концепция сразу же овладе-
вает ею без остатка. В результате возникающий аттрактор притягивает
к себе огромное количество нейронов, которые рьяно и усердно стара-
ются как можно скорее обрести способность к 'точному распознаванию
и локализации именно этого нового объекта. Конечно, такое поведение
сети обеспечивает ее быстрое обучение, но очень быстро приводит к «ис-
тощению» ее познавательных способностей. Достаточно небольшого (от-
носительно количества нейронов в сети) числа аттракторов, чтобы все
без остатка нейроны оказались вовлеченными в их распознавание. При
появлении новых эталонных объектов возможности для адаптации ока-
зываются исчерпанными, сеть уже не в состоянии осознать или воспри-
Нейронные сети с самообучением
269
пять новые идеи. По-другому ведет
себя сеть с малым коэффициентом
обучения. На первых порах, при по-
явлении нового эталонного обтек-
ла реакции сети спокойны и взве-
шенны (рис. 9.17). Соответственно
успехи обучения не слишком стре-
мительны, что можно было бы счи-
тать недостатком (рис. 9.18, на ко-
тором показана та же фаза процес-
са самообучения этой «спокойной»
Сети, что и па рис. 9.16). Но благо-
даря «отсутствию суеты» сеть рас-
полагает определенным запасом
нейронов, не получивших оконча-
тельную специализацию и способ-
ных реагировать на новые эталон-
ов), 7?
га
а
ISS.
. "В
и
В !
"cfeV
»В
в ®
ш ч
йи
в
б
* «В
ПН. 61
S*
ЕЮ
□
а
□а
о
еГ
«1
Е
WJ
*4j
.....Ж-.
if
сГ
0*
в»
в*
в
0
и«
в»
G«
rftj а
0«
Q’«4 в.. вв° аО
В. з °
0(0) 82
Рис. 9.17. Плавное и неторопливое нача-
ло самообучения в системе с небольшим
значением коэффициента обучения Etha
о с
D Q
Ш
ц Q
В
ч
ь
о
й
а й
и
□
В
0
□
Ш °
м
р
в
о
в
в
в
0
о
'3
И
о
Й Ш>
« а
b
в
Z п ш J5
Я ‘
гаа
а
а
□
----П—
° °
u а
□
а
о
В
□
В-»
□
о
в
«
%
□
a
о
0
в
пыс сигналы, т.е. на новые идеи, новые впечатления и новые понятия.
А это уже новое качество!
Напрашивается аналогия с человеческим повелением. Встречаются
люди, которые некритично и с энтузиазмом воспринимают первую по-
павшуюся идею (например, политическую), быстро проникаются ею и
идентифицируют себя с ее содержанием. Позднее такие фанатики ока-
зываются неспособными к осмыслению новых концепций или взглядов,
0(0), 0 268(9). 300
0(0), 0 0(0) 0
0(0), 0 268(9). 0
89/(0). 300 0(0). 0
Рис. 9.18. Этап процесса самообучения, аналогичный показанному па рис. 9.14,
по на этот раз для сети с малым значением коэффициента обучения. Заметны
многочисленные «незадействованные» нейроны
270
Глава 9
для этого в их мозгу просто «не осталось свободного места». Возможно,
этим объясняется феномен патологических маньяков или террористов,
которые после быстрого впитывания какой-либо демагогической идео-
логии (фанатичные формы ислама, фашизм, сталинизм) проникаются
ее целями до такой степени, что во имя своих (либо навязанных им) це-
лей становятся способными убивать и мучить людей. В то же время та-
кие естественные и общезначимые идеи, как сострадание, гуманизм либо
обычные правила приличия не имеют для фанатиков никакого значения.
При проведении экспериментов с такой излишне нейронной воспри-
имчивой сетью иногда наблюдается интересное явление: если «фанатич-
ная» сеть в течение дли гелыюго времени не получает сигналы со сторо-
ны «своего» аттрактора, то опа может очень резко изменить свое «ми-
ровоззрение». В результате вся совокупность точек, связанных рапсе с
одним и том же эталоном ( либо с одной, всеохватной идеей), внезапно на-
чинает мигрироват ь по направлению к совершенно другому эталону, для
того чтобы вскоре отождествиться с ним так же окончат ельно и беспово-
ротно, как и с только что покинутым предыдущим эталоном (рис. 9.19).
В этом пет ничего удивительного, если присмотреться к поведению неко-
торых людей. Литература полна рассказами о таких «обращенных фана-
тиках», которые (увы!) пе становятся спокойными и добропорядочными
гражданами, а бросаются из одной крайности в другую. К сожалению,
новейшая история дает нам множество примеров, в которых одержимые
какой-либо идеей фанатики внцчале уничтожали защитников действу-
ющего режима, а после захвата власти начинали также активно «изво-
дить» своих бывших сторонников.
Рис. 9.19. Удовлетворенность всех нейронов объектами только одного класса (слева)
и уход пт этого единственного аттрактора с переходом всех нейронов к распознаванию
объектов другого класса (справа). Такие явления характерны для сетей с большими
значениями коэффициента обучения. Перемещения обуслов лены тем, что объекты
обучающей последовательности принадлежащие к одному классу) не идентичны между
собой поэтому сеть непрерывно дообучается
Нейронные сети с самообучением
271
В то же время модель сети с малым значением коэффициента обу-
чения (см. рис. 9.17) напоминает' человека, который не вспыхивает и
не горячится, у которого каждая новая идея должна созреть, выкри-
сталлизоваться, окрепнуть только после этого она будет тщательно и
качественно реализована. Эти люди часто воспринимают ся окружающи-
ми как медлительные и порой (абсолютно безосновательно!) пе слишком
умными. Но если такой человек сформулирует свои предпочтения, то он
не может изменять их легко и быстро, а часто остается верным своим
идеалам даже после длительного «промывания мозгов».
9.3. Можно ли успехи самообучения считать
повышением интеллекта сети?
Я сейчас расскажу, что можно исследовагь с помощью описывае-
мой программы, а также предложу несколько простых, по поучитель-
ных экс периментов для самостоятельного выполнения. Думаю, что эти
эксперименты будут интересны тебе пе только как средство познания
ейойств процесса самообучения нейронных сетей, но и для формулиро-
вания выводов более общей природы, например о том, как ты сам до-
бываешь и пополняешь свои знания. Я также опишу, как пользовать-
ся программой Example 10b, хотя полностью уверен что после нача-
ла экспериментов ты самостоятельно обнаружишь множество дополни-
тельных возможностей.
После инициализации процесса обучения с некоторым числом ней-
ронов присмотрись к тому, как нейроны «узнают» о наличии некот о-
рых характерных объектов среди повторяющихся входных данных. Дей-
ствительно, очень скоро в изначально хаот инном множестве точек, пред-
ставляющих местоположение весов нейронов, ты заметишь стремление
к декомпозиции всей популяции нейронов па столько подгрупп, сколько
классов объектов появляется па входе сети. Это очень легко проверить,
если 13 процессе имитации самообучения щелкнуть по кнопке с номером
конкретного квадранта (or 1 до 4). После этого в процессе обучения на
экране будут показываться то лько объекты не во всех четырех, а только
в трех (либо в двух или даже в одном) квадрантах. Объекты квадранта,
па помер которого ты щелкнешь, будут игнорироваться, а сам квадрант
помечен более темным цветом. Эта опция программы позволит* тебе про-
верять, насколько эффективно сеть самоеюятельно определяет, сколько
(и каких) классов объектов она должна распознавать (рис. 9.20 и 9.21).
Обрати внимание, что в начальный период обучения сеть частич-
но «использует» те нейроны, которые потенциально могли бы распозна-
вать обьекты отсутствующего класса (рис. 9.21). В результате сеть все
272
Глава 9
Рис. 9.20. Начальный этап процесса само-
обучения, во время которого игнорируются
объекты из второго квадранта
0(0) 1 е 14(3). 109 QB
ег 10(41 136 Р «в 11(2), 5-4
Рис. 9.21. Завершающий этап процес са са-
мообучения, во время которого игнориру-
ются объекты из второго квадранта
больше «концентрирует внимание» на тех объектах, которые фактиче-
ски предъявляю гея и должны распознаваться. Тем не менее, даже на
завершающем этапе, когда сеть уже только совершенствует полученную
специализацию на распознавании и идентификации объектов, регуляр-
но появлявшихся в процессе самообучения (три заметно плотные сово-
купности точек па рис. 9.21), в игнорировавшемся области (в которой не
было пи одного аттрактора) остается некоторое количество «дежурных»
нейронов. Они рассеяны случайным образом; по мерс развития процесса
самообучения их количество будет уменьшаться. Но еще длительное вре-
мя после завершения основного обучения при появлении нового объекта
в ранее «пезадействоваппой» области очень быст ро найдутся нейреньц
которые начнут специализироваться па его идентификации. Только по-
сле очень длительного систематического обучения, когда сеть накопит
чрезвычайно богатый «жизненный опыт», этот «свободный ресурс» бу-
дет исчерпан, поскольку все нейроны раньше или позже окажутся втяну-
тыми в «орбиту влияния» фактически существующих аттракторов. Если
после такой стабилизации сети появится совершенно новый объект, той
сети уже не окажется свободных нейронов для его восприятия и распо-
знавания. Это означает, что длительное самообучение приводит к утрате
способности адаптироваться к следующим «новинкам». Но это известно
нам из повседневною опыта: молодые люди очень легко адаптируются
к новым условиям и приобретают новые умения (например, пользовать-
ся Интернетом), тогда как взрослые опытные и специализированные
на выполнении конкретных функции и на идентификации определен
пых ситуаций обучаются с трудом, плохо воспринимают перемены и
Нейронные сети с самообучением
273
склонны негативно реагировать на новые явления и процессы. Как ви-
дишь, нейронная сеть ведет себя точно так же.
Детали развития обсуждаемых процессов зависят от начального рас-
пределения значений весовых коэффициентов нейронов (т.е. от «врож-
денных свойств» каждой особи), а также от последовательности предъ-
явления конкретных объектов обучающей выборки (т.е. от «жизненного
опыта» каждой особи). Одни дольше сохраняют юношескую способность
удивляться новинкам и с энтузиазмом реагировать па них, другие очень
скоро застываюг в своих убеждениях и фобиях. Ты можешь убедиться в
этом, наблюдая за процессом моделирования. Программа Example 10b
построена так, что щелчок по кнопке Reset приводит к рестарту про-
цесса самообучения (с тем же количеством нейронов), но с новыми слу-
чайно выбранными начальными значениями весов каждого нейрона и
с повой (случайной и отличающейся от предыдущей) последовательно-
стью обучающих объектов, принадлежащих к фактически выбранным
квадрантам. Последовательное нажатие кнопок с номерами квадрантов
позволяет произвольно запускать и прекращать презентацию объектов
соответствующих классов (в том числе в процессе обучения), Фактиче-
ски весь эксперимент протекает пол, твоим полным контролем.
После неоднократного возобновления процесса обучения ты заме-
тишь, что стремление к самоорганизации (в смысле спонтанного «же-
лания» нейронов идентифицировать себя с определенным классом по-
ступающих .входных сигналов) может считаться неотъемлемым свой-
ством самообучающейся нейронной сети — независимо от числа клас-
сов, численности популяции нейронов и начального распределения зна-
чений весовых коэффициентов. Ты также заметишь, что сети с большим
количеством нейронов («более талантливые») дольше сохраняют спо-
собность к восприятию новых знаний и к приобретению новых умений.
Следовательно, окостенение в старых убеждениях и навыках нельзя счи-
тать сколько бы d и говорили проявлением приходящей с года-
ми мудрости; оно оказывается всего лишь результатом недостаточного
«врожденного интеллекта».
9.4. На что еще надо обратить внимание
в процессе самообучения сети?
Применяя программу Example 10b, ты можешь выполнить очень
много различных экспериментов. Прежде всего, рекомендую проанали-
зировать влияние способа представления объектов обучающей
последовательности на процесс самообучения сети.
Увы, в программе отсутствуют механизмы, которые преподносили
бы тебе соответствующие факты «на тарелочке». Но при многократных
274
Глава 9
19(2). 1 % % 20(3). 5 а» в
4(2). 0 *Ь ъ 15(2). 4
Рис. 9.22. Неравномерность представ-
ления классов как следствие процесса
самообучения
наблюдениях за моделируемым про-
цессом самообучения ты, конечно,
заметил, что классы, объекты кото-
рых демонстрируются чаще всего,
притягивают к себе гораздо больше
нейронов, чем классы, представите-
ли которых демонстрируются реже
(обрати внимание на результаты для
первого и второго квадрантов на
рис. 9.22). Ино1да для некоторых де-
монстрируемых классов может про-
сто не хватить нейринов, «желаю-
щих» их распознавать, особенно в се-
тях с небольшим числом элементов
• см. третий квадрант па рис. 9.22).
Это серьезная проблема, о которой
я говорил в одной из предыдущих глав. Поэтому сети с самообучени-
ем должны содержать намного больше нейронов, чем решающие ту же
задачу распознавания и классификации сети, обучаемые под надзором
учителя.
При исследовании процесса самообучения на нескольких примерах
ты также отметишь особое значение первого «опыта», приобретенною
сетью. Это видно из рис. 9.23, на котором показаны образы начала (слева
вверху) и окончания (справа внизу) процесса самообучения. В этом про-
цессе па первых девяти шагах алгоритма были случайно выбраны толь-
ко объекты из третьего квадранта. Обрати внимание, насколько сильно
такой выбор отразился па итоговом распределении количества нейро-
нов в каждом квадранте!
Обрати внимание, что доминирующее влияние «первого опыта» на
последующее формирование понятийного аппарата и привычек можно
наблюдать и у людей. Если некоторые квадранты изначально исклю-
чались («недостаточный детский опыт»), а потом были активированы,
то представление этих ранее игнорировавшихся впечатлений или поня-
тий (представленных в нашей модели квадрантами, в которых появ-
ляются сигналы» отражается на поведении сети ограниченным пред-
ставлением именно этих понятий (либо их полным отсутствием) или
нечувствительностью к отдельным сигналам. Такое наблюдение пояс-
няет1, почему так сложно корректировать последствия «трудного дег-
ства» в зрелом возрасте.
При неоднократном последовательном наблюдении процессов «при-
тяжения» одних нейронов и «отталкивания» других постарайся пред-
ставить себе, что происходит в твоем собственном мозге при анализе и
Нейронные сети с самообучением
275
3(UX 57 6(0). 160
ж в. ж • ж » в сз Ж % В W '4s %,ж Г И w 33S
* л ' ц, в Ч й1 J
1 t? Й В* О в а** « й «
17(Я) 424 4(0). 59
Рис. 9.23. Иллюстрапия процесса самообучения с исходными предпочтениями
для третьего класса
распознавании новых ситуаций. Особенно интересные аналогии с реаль-
ными нейронными сетями можно отмени!ь при моделировании сети с
большим количеством нейронов (взгляни на рис. 9.23, представляющий
самообучение сети из 700 нейронов). Массовое перемещение «состояний
осведомленности» многих нейронов в направлении ночек, соответствую-
щих полученным входным раздражителям (с целью превратиться впо-
следствии в детекторы именно этих классов входных сигналов) вне
всякого сомнения, это надо видеть собственными глазами!
При желании можно наблюдать за «революциями», совершающими-
ся в множестве нейронов на первых шагах процесса самообучения. Луч-
ше всего это заметно при проведении эксперимент а в режиме «шаг за
шагом», Информация о частоте демонстрации объектов в начальный пе-
риод обучения высвечивается в каждом квадранте, поэтому ты можешь
без труда выявлять и анализировать основные зависимости между ча-
276
Глава 9
стотой предъявления конкретного объекта в обучающей выборке и ко-
личеством нейронов, готовых его распознавать. Обсуждаемый эффект
особенно заметен при сравнении результатов нескольких сеансов моде-
лирования, поскольку нельзя забывать о том, что на результаты каждо-
го отдельно взятого сеанса сильно влияют начальное распределение
значений весовых коэффициентов и последовательность предьявле-
ния объектов обучающей выборки. Еще раз напомню: оба этих фак гора
в наших программах формируются механизмом случайного выбора.
9.5. «Мечты» и «фантазии», возникающие
при самообучении сети
ч «Д © 1 Л U ОВПВП Q) Q 22(0), 16 1 1 • м 1
ез а в в 1 ь- 57(1), 71 м “ В 25(1), 71
Рис. 9.24. Формирование нейро-
нов, которые готовы выявляй ь объ-
екты с о средними (относитсльно ре-
ально cyin.ec I вующих) характери-
стиками (так называемые фантомы)
После того как ты наглядный*
ся на процесс формирования и со-
вершенствования (уточнения) спон-
танно обнаруживаемых сетью «по-
нятий», тгридс г время заняться бо-
лее тонкими явлениями. Конечно
(особенно при анализе примеров с
большим количеством нейронов),
твое внимание1 привлечет факт, что
наряду с основным процессом обра-
зования сообществ нейронов, рас-
познающих главные предъявляе-
мые объекты, возникают свособраз-
ные «тропинки» нейронов, которые
стремятся выявлять и распозна-
вать входные объекты с промежу-
точными з н ач (ч I и я м и свойств
(рис. 9.24). Дальнейший прощ сс са-
мообучения приводит к поглощению
этих «детекторов фантомов» «настоящими» центрами идептисЬикации
реальных объектов. Тем нс менее, этап сетевого фантазирования на
гему возможных, но пе суще ствуютцих в действительности раздражите-
лей повторяется с удивительной регулярностью.
Подумай что это означает? Если сечи предъявляются эталонные
изображения рыбы и женщины, то она сможет распознавать как женщи-
ну, так и рыбу. Следовательно, в соответствующих точках пространства
входных сигналов будут располагаться нейроны, отвечающие за «уши-
вание» появляющихся па входе образов женщин и ооразов рыб. Но в
сети также появятся нейроны, которые «распознают» (точнее, окажут-
ся готовыми распознавать русалок существ с рыбьим хвостом, но
Нейронные сети с самообучением
277
Рис. 9.25. Представление реальных и вымышленных объектов
в самообучающейся нейронной сети
телом и головой женщины. Во время обучения такие существа сети не
демонстрировались, тем не мопсе, сеть подготовила некоторые нейроны
к их идентификации, т.е. «придумала» русалок самостоятельно.
Аналогично, та же сеть, дополнительно обученная распознаванию
птиц, также самостоятельно вырабатывает способность соединить свой-
ства птицы (крылья) со свойствами женщины (голова, тело, платье).
В результате в сети формируется образ... ангела (рис. 9.25).
При повторении различных экспериментов ты убедишься в том, что
любая «молодая» (т.е. не до конца обученная) нейронная сеть будет
проявлять тенденцию к «придумыванию» подобных фантастических су-
ществ. Если последующие опыты будут настаивать на существовании
женщин и па существовании рыб, но на отсутствии существ, облада-
ющих свойствами и женщины и рыбы (таких, как сказочные русалки или
сирены), то соответствующие нейроны переквалифицируются (хоть и без
особого желания — по ходу моделирования это заметно) па распознава-
ние реальных существ, а не вымышленных фантомов. Если же подобное
гибридное животное реально существует (млекопитающее с крыльями
278
Глава 9
3(2). 5?
5ML 128
3(1), 50
5(2). 65
СГ
Рис. 9.26. Произвольное возникновение и разрушение связей в процессе самообучения
летучая мышь), то пред ьявлепис на вход сети соответствующих эталон-
ных объектов значительно облегчит их выявление и классификацию.
Обрати внимание: эта склонность к «выдумыванию» иесуществую-
ших объектов, представляющих собой некоторую комбинацию элементов
достаточно далеких друг от друга впечатление и знаний, (Двойственна
только «молол,ым» сетям, пребывающим на начальной стадии самообу-
чения. Возможно, это в какой-то степени объясняет известную любовь
детишек к сказкам и легендам, которые скучны (а иногда просто раз-
дражают) взрослых и более опытных людей? Быть может, в этом за-
ключается феномен богатейшей поэтизированное фантазии, свойствен-
ной очень молодым цивилизациям (например, Древней Греции) в про-
тивоположность махровому прагматизму старых и окостеневших сооб-
ществ конца XX начала XXI века? Или при наблюдении (рис. 9.26)
за возникающими в процессе самообучения топкими цепочками нейро-
нов, пытающимися долго, вопреки очевидным фак гам сохранить не су-
ществующие в действительное! и связи между вымышленными и кон-
кретно локализуемыми явлениями, не выявляем ли мы нейронные осно-
вы формирования в человеческом сознании молниеносных ассоциаций,
отдаленных аналогий, неожиданных метафор? Можно ли считать такие
импульсивно создаваемые «мостики» (рвущиеся, как паутина, под на-
пором новых фактов и ассоциаций), фантасмагорические грезы, фанта-
стические комбинации свойств реальных объектов, создаваемые самими
нейронными механизмами для отображения чего-то несуществующего,
но красивого и интересного сущностью поэзии, искусства и креативной
части пауки? Возможно, именно в этот момент ты постигаешь глубин-
ные причины известного факта, что поэты (как и настоящие ученые)
всегда остаются немного детьми...
Иногда во время экспериментов ты будешь видеть, что некоторые1
(как правило, одиночные) нейроны упрямо остаются вне областей, в ко-
торых концентрируются эталонные объекты. В общем случае эти нейро-
ны не имеют практического значения, поскольку подавляющее больший-
Нейронные сети с самообучением
279
Это сообщества,
каждое из которых
насчитывает примерно
по сто нейронов
Рис. 9.27. Одиночные нейроны вне глобальных сообществ на поздних этапах процесса
самообучения (после выполнения примерно двухсот шагов)
ство элементов сети прилежно обучаются и послушно совершенствуют
по; [ученную специализацию в направлении идеального решения зада-
чи — выявления и идентификации объектов, регулярно появляющихся
в моделируемом мире. Но оторванные от действительности щ ироны про-
должают упорствовать (рис. 9.27) в своих фантазиях о крылатых змеях
и многоглавых драконах, как будто видят один и тот же посещающий
их снова и снова сон...
Продолжим обзор возможных экспериментов. При внимательном на-
блюдении за начальными фазами процесса самообучения в некоторых
(достаточно редких) случаях мож1 о заметить еще одно интересное явле-
ние. После демонстрации эталонного обьекта, локализованного в неко-
торой точке пространства входных сигналов, отдельные нейроны (как
правило, очень немногие, что тем более заслуживает внимания) рез-
ко изменяют свое исходное «приличное» положение для перехода в по-
вое место (очень далекое от предыдущей позиции и от начала коорди-
нат) по направлению к предъявленному входному объекту. Я не слу-
чайно оговорился, это явление наблюдается очень редко, поскольку оно
сильно зависит от исходного распределения значений весовых коэффи-
циентов синаптических весов (в конце концов, не каждый рождается
поэтом...). При терпеливом повторении экспериментов ты, безусловно,
с ним столкнешься (рис. 9.28). Как правило, такие «взбунтовавшиеся»
нейроны успокаиваются за пределами рамки, ограничивающей рисунок.
Поэтому их можно зафиксировать главным образом но линиям, не закан-
чивающимся привычным пустым квадратиком, они должны находиться
вне пределов высвеченной на экране области.
Нейроны, далеко разбежавшиеся в начале процесса самообучения,
на следующих этапах неуклонно стягиваются в зону реального распо-
280
Глава 9
Пунктирные и не завершенные
пустым квадратиком линии
свидетельствуют о «побеге»
нейронов за пределы видимой
части экрана
Рис. 9.28. Эффект дальнего побега на начальном этане процесса самообучения
ложения пред'ья пленного эталона и окончательно остаются в этой об-
ласти. На эти нейроны можно было бы вообще не обращать внимания,
если бы не факт, что они представляют очень известное из психологии
явление гигантоманию (рис. 9.29). Очень важно’, что такой «выско-
чивший» за пределы области обзора нейрон становится, по суч и дела,
своеобразным эталоном (внутренним представлением) объекта, облада-
ющим примерно теми же характеристиками, как и реально предъявлен-
ный в начале обучения эталонный объект, но значения всех свойств ока-
зываются значительно большими. Этакий нейронный Гулливер. Если
сечи предьявляется изображение льва, то в результате увеличения его
свойств возникает представление о монстре огромных размеров, с гро-
Нейрон, страдающий
«гигантоманией»
Рис. 9.29. Эффект «гигантомании» в несколько меньшем масштабе, чем на рис 9 28.
но также весьма заметный
Нейронные сети с самообучением
281
«
»
а
й
0(0). 52
Нейрон,
помнящий
внешним
облик льва
1
&
0(0). в?
й
> г
0
Й
а
й
-а
%
! О
« 8
Л
& *
\ *
9
£3
„ *
'’* & 8
0 * *
• Й»
е
а<
8 . Ч*
П. Xх-
к
%
®ч
* ' •*>
a© us
; 8 Ч
' - • 1 •
I X
* 4
1 * ш
i»
« <
"Г®“—с—‘
>8<Л \
*
*
\ »; „
* Ъ X
«
8 й
в,
'»
о,
а "*
А М
X
r*"Mr'V
%(« \ °
V* 43
©
' 1
g 1
% й
8
4
Ч Й
i < ъй
Другой нейрон, помнящим льва
Образ суперльва,
сформированный & ЧЕЙ V \
одним из нейронов / \^г,
dS±
J 'ч~~*
«Л.-
:3^м>>
у>ч
Рис. 9.30. Интерпретация явления «гигантомании»
а„
Чй Ж
„ ®. *
fee 3- ,
8.
%
а
*
и* &
Я»
Реальный облик льва,
продемонстрированный
в качестве обучающего
примера
1(1) 82 '
мадными клыками и когтями, взлохмаченной гривой, ужасным рыком,
обжигающим дыханием и т.н. (рис. 9.30). Такие гипертрофированные
представления сохраняются не очень долго, поскольку их «проверяет па
прочность» и приводит к реальным масштабам сама жизнь и накаплива-
емый опыт. Но для наивной и горячей Молодости, только вступающей в
мир новых ощущений, Первая Девушка всегда самая-самая.. .Теперь
ты понимаешь, что созданная мной и исследуемая тобой нейронная сеть
поступает точно так же?
Наиболее грустное явление можно наблюдать под занавес процесса
самообучения. Большинство нейронов уже входит в сплоченные сооб-
щества, теснящиеся в местах расположения входных объектов (каждый
уже выбрал себе Господина и преданно ему служит...). И в это время
(иногда из-за пределов области обзора) появляются этакие «неадапти-
рованные» одиночные точки, явно сопротивляющиеся неуклонному стя-
гиванию их в зону распознавания реальных объектов (рис. 9.31). Их
мировоззрение отличается от взглядов большинства; еще хуже то, что
повседневная жизнь доказывает правоту «общества». Тем не менее, оди-
ночки склонны упрямо следовать своим прекрасным фантазиям и не хо-
тят признавать реалии окружающего мира, для которого важны совсем
282
Глава 9
Возвращающиеся
нейроны
Рис. 9.31. Притяжение к реальному аттрактору нейронов, убежавших на начальном
этапе процесс,а обучения и создавших фиктивное представление данных (описанное
выше под названием «гигантомания»)
другие цепное'! и... Но оставим романтические отступления и вернемся
к нейронной сети. Терез некоторое время «взбунтовавшиеся» нейрон™
вливаются в общую массу, присоединяются к большинству, выводятся
на путь истинный. Однако в их бунте остается что-то прекрасное. И
еще: если во «внешне м мире», поставляющем в сеть «входные впечат-
ления», появляется нечто повое и неожиданное, то именно эти нс адап-
тировавшиеся вовремя нейроны первыми получают шанс та получение
Большого приза сытое большинство идеально адаптированных кон-
формистов в расчет не принимается. Жаль только, чю это происходи!
очень редко — даже в нейронных сетях!
9.6. Запоминание и забывание
До сих пор мы занимались главным образом зайоминанЛем информа-
ции и получением знаний в процессе самообучения. Но из повседневною
опыта тебе, конечно, известно еще одно весьма частое явление за-
бывание. Оно весьма неприятно (особенно перед важным экзаменом),
но с биологической точки зрения просто необходимо. Любое окружение,
в котором существует конкретный организм (например, ты...), подвер-
жено непрерывным изменениям, поэтому способы функционирования,
выработанные и доказавшие свою эффективность на конкретном жиз-
ненном этапе, в свете нового опыта становятся неактуальными (ино-
гда — просто вредными). Именно по этой (среди прочих) причине мы
вынуждены неустанно получать новые знания и вырабатывать новые
умения, одновременно забывая прежние, которые могут мешать или
вводить в заблуждение.
Нейронные сети с самообучением
283
Постарайся зафиксировать и про-
анализировать это явление в модели-
руемой нейронной сети. При проведе-
нии опытов с небольшим количеством
самообучающихся нейронов можно
заметить, что новые предъявляемые
об'ьекты могут «оттягивать» о г дру-
гих, реже демонстрируемых классов
нейроны, которые кажутся уже впол-
не обученными. В крайних случаях
происходит сво< юбразпое «пох и ще-
ни.е» часто предъявляемыми новыми
объектами тех нейронов, которые ра-
нее полностью идентифицировались с
другими эталонами, по какой-то при-
чине переставшими демонстрировать-
ся сети. На рис. 9.32 показана ситуа-
9(1), 2 о »-и 12(4}. 5 1
* 8(0) 2 а 6(4). 1
Рис. 9.32. Начало процесса запомина-
ния, характерного для самообучения.
В настоящий момент ешь обладает еще
«старыми знаниями», поэтому луч-
ше всего рас*познается первый класс
ния, в которой сеть относительно неплохо распознает все четыре предъ-
являемых ей эталона. Обрати внимание па наиболее часто демонстрируе-
мы/ объект 1 (в первом квадранте). В этот момент процесс самообучения
(целенаправленно) искажается — продолжают предъявляв ься все эта-
лоны, кроме объек гов первого класса. Через очень короткое время начи-
нается «грабеж». Нейроны, ранее распознававшие объекты первого клас-
са, поспешно переквалифицируются и начинают специализироваться па
других классах (в рассматриваемом примере на четвертом классе,
41 о заметно в левой части рис. 9.33). Класс, который ранее распознавал-
ся особенно хорошо, забывается. Не Полностью, поскольку даже после
15(1). 2 12(4). 3 Ml у й
а 14(0). 2 « 35(4). 3
12(1). 2 П(1). 1 S
□ и 36(6), 2 к 34(1). 5
Рис. 9.33. Постепенное запоминание первого класса в ситуации, когда память о нем
не усиливается систематически при последующем самообучении
284
Глава 9
очень длительного обучения в памяти остается некоторый след, не даю-
щий забыть славное прошлое (правая часть рис. 9.33). Но этот след слаб
(всего один нейрон) и сильно искажен (этот нейрон сильно сместился по
сравнению с исходным местоположением).
Обрати внимание на аналогию с твоим собственным сознанием
например, во время каникул ты можешь заинтересоваться ботаникой и
запомнить названия многих растений, а также научиться идентифици-
ровать и классифицировать их. Но если ты не будешь возвращаться к
этим знаниям и закреплять их, то приобретенные понятия и критерии
распознавания окажутся «затертыми» новой информацией « например, о
распознавании новых моделей автомобиле! ). Итог: в начале следующе-
го л эта ты с волнением воскликнешь: Какой прекрасный луг! Сколько
иветов! Когда-то я знал, как каждый из них называется...
9.7. Все ли входные данные приводят
к самообучению сети?
Но оставим в стороне обсуждавшуюся в предыдущем разделе груст-
ную проблему забывания и вернемся к анализу процесса самообучения
нейронной сети. При экспериментировании с программой Example 10b
ты мог заметить и наблюдать одно тревожное явление: вследствие спон-
танности процесса самообучения одни классы объектов могут быт ь пред-
ставлены в нейронной сети сильнее (их объекты распознаются и иден-
тифицируются большим числом нейронов), а другие классы — слабее
либо вообще отсутствуют! Это серьезный недостаток рассматриваемых
нами методов самообучения, о котором мы поговорим в разд. 9.8.
Теперь я хочу еще раз от мет и гь и показать тебе, чт о процессы са-
моорганизации и самообучения развиш!отся только тогда, когда во
входной последовательности обучающих данных существует некоторая
предопределенная закономерность, па которую сеть может опереться.
В предыдущих экспериментах с программой Example 10b ты сталки-
вался с «приличными» и хорошо сбалансированными ситуациями, по-
скольку демонстрировавшиеся сети объекты принадлежали к одному из
нескольких (обычно четырех) конкретных классов и занимали в про-
странстве входных сигналов хорошо взаимно отсепарированные места,
расположенные в центрах соответствующих квадрантов системы коор-
динат. Эти объекты предъявлялись совершенно случайно, по они рас-
полагались в не совсем случайных местах. Каждая предъявляемая се-
ти точка находилась (в пределах определенного разброса) вблизи цен-
тра соответствующего квадранта, т.е. это был какой-то (необязательно
полностью типичный, который должен располагаться строго в центре
Нейронные сети с самообучением
285
квадранта) пример Марсианина, Марсианки и т.д. При таком представ-
лении объектов ты наблюдал хорошо известное явление: самообучение
сети приводило к формированию сообществ нейронов, все более точно
и результативно специализирующихся на распознавании соответствую-
щих эталонов благодаря многократной демонстрации объектов «своего»
класса, немного отличающихся друг от друга, но являющихся вариан-
тами одного и того же идеального эталона.
Посмотрим на поведение сети, в которой процесс обучения связан
с полностью случайным выбором местоположения демонстрируемых
точек. Для этого вернемся к нашему примеру с космическим кораблем,
отправленному на Марс. Предположим, что ‘марсиане не существуют,
и спускаемый аппарат получает с помощью своих камер только изоб-
ражения случайных структур, образуемых вихрями марсианской пы-
ли. Такую ситуацию легко смоделировать — соответствующая возмож-
ность предус мотрена в программе Example 10b. Достаточно активиро-
вать опцию RND learning (т.е. щелкнуть мышке! в чек-боксе, кото-
рый до этого момента оставался пустым). С этого момента уже невоз-
можно (да и не нужно) узнать, из какого квадранта выбирается де-
монстрируемый объект (при условии, что выбор разрешен из всех че-
тырех квадрантов (рис. 9.34)), обучающий объект будет появляться то
тут, то там в любом месте пространства входных сигналов без какой-
либо системы и порядка.
Естественно, подобное отсутствие порядка приведет к полному от-
сутствию во входной последовательности какой-либо информации.
Один раз нейроны будут притягиваться к центральной части плоскости,
другой раз — к ее периферии (рис. 9.35).
В такой ситуации процесс самообучения не приведет к объединению
нейррнов в какие-либо обособленные друг от друга сообщества они
начнут группироваться в одну большую окружность, поскольку именно
па ней будут располагаться локальные усредненные эталоны сигна-
лов. Достаточно дотп ос наблюдение за процессом самообучения в этом
странном случае свидетельствует, что окружность незначительно мо-
дифицирует свои размеры и расположение по мере предъявления оче-
редных образцов (рис. 9.36), по до выделения каких-нибудь локальных
групп нейронов дело все равно не доходит — для формирования таких
ipynn нет входных данных.
Вывод из этого эксперимента будет частично оптимистичным и ча-
стично пессимистичным.
Оптимистичная часть вывода заключается в следующем: Процесс
самообучения нейронной сети может помочь обнаружить неизвестные
ранее закономерности, содержащиеся в данных на входе сети, причем
286
Глава 9
Start Reset
Press/Holtj Start
* AND Learning
Активация этого параметра
приводит к случайному
выбору места появления
каждого следующего
обучающего объекта
Рис. 9.34. Начало Процессе! самообучения со
случайно выбираемыми входными об се к-
тами
10(2). 43
11(2) 94
Рис. 9.35. Хаотичные перемещения ней-
ронов при случайном предъявлении объ-
ектов
6(2) 23
18(3). 134
Рис. 9.36. Один из поздних этапов хаотичною обучения
Нейронные сети с самообучением
287
пользователь нс обязан знать ни сами эти закономерности, ни их ко-
личество. Иногда можно встретить утверждение, что сеть может отве-
чать на незаданные вопросы, либо (при еще более высоком уровне обоб-
щения) что сети не только накапливают знания в процессе обучения,
но и самостоятельно находят знания. Этот факт очень радует пас, по-
тому что в информатике создано множество прекрасных инструментов
для формулирования мудрых ответов на мудрые вопросы (например,
Интернет' и системы управления базами данных). Ипотда также удает-
ся получить мудрый ответ на глупый вопрос — это тоже очень прият-
ное свойство. Добавлю, что в некоторых случаях задачи поиска ответов
на пезаданные вопросы объединяются под общим англоязычным назва-
нием Data Mining. В частности, такой подход применяется при выяв-
лении особенностей поведения покупателеч в супермаркетах либо при
определении предпочтений абонентов систем мобильной связи. Специ-
алисты в области маркетинга извлекают пользу из любого сообщения
о повторяемом и массовом поведении клиентов, поэтому такие знания
ищутся особенно интенсивно.
Пессимистичная часть вывода заключается в следующем: Если сеть
подвергается самообучению с применением данных, не содержащих ни-
какой цепной информации (например, полностью случайных входных
сигналов, пе имеющих никаких явных или скрытых значений), то сколь-
ко угодно длит ельное самообучение сети пе приведе т к достижению ос-
м ыс jIе и по 1 о резул ьт ата.
Почему этот вывод я считаю пессимистичным? Потому что сеть ни-
когда не (‘может заменить пас в вопросах изобретения абсолютно новых
(как говорится, возникших «на пустом месте») объектов!
А может, это самый оптимистичный вывод?
9.8. Что может дать введение конкуренции
в сеть?
Самообучению могут подвергаться сети любого тина, но особенно ин-
тересные результ аты дает интеграция самообучения с процессом конку-
ренции Конкурешщя (соперничество) между нейронами не является
для тебя новым понятием. В разд. 4.8 я описывал структуру и функ-
ционирование сетей, нейроны которых «конкурируют» и «соперничают»
между собой (вспомнил?). Если нет запусти программу Example 02b.
В сетях с конкуренцией все нейроны получают входные сигналы (как
правило, одни и те же, поскольку такие сети обычно состоят из одно-
го слоя). Каждый нейрон рассчитывает сумму этих сигналов (конечно,
умноженных на соответствующие свои для каждого нейрона весо-
вые коэффициенты), после чего проводится «конкурс». Он заключается
288
Глава 9
в сравнении рассчитанных каждым нейроном выходных значений и вы-
бора из них «победите ля», т.е. нейрона с самой сильной реакцией на
полученный входной сигнал.
Ты помнишь, что степень возбуждения нейрона характеризуется со-
гласованностью между текущими входными сигналами и внутренним
эталоном. Если нам известны значения весовых коэффициентов нейрона
(соответствующие его расположению в пространстве входных сигналов),
то можно заранее определить нейрона-победителя в случае предьявле-
ния выборок входных сигналов из конкретных областей этого простран-
ства. Угадать победителя легко, поскольку в конкуренции между ней-
ронами победит только тот, внутренние знания которого в наибольшей
степени согласуются с текущими входными ситнягами. На выходе се-
ти появится сигнал только нейрона-победителя, а проигравшие будут
вынуждены промолчать. Конечно, такой «успех» нейрона краткосрочен,
потому что в следующий момент возникнет новая комбинация входных
сигналов, и в конкуренции «победит» дру! ой нейрон. В этом нет ничего
удивительного, поскольку карта размещения значений весовых коэффи-
циентов позволяет легко выяснить, какой нейрон станет победителем
при демонстрации того или иного входного сигнала им окажется тот
нейрон, вектор весовых коэффициентов которого расположен ближе все-
го к вектору предъявленного входного ейгнала.
Победа конкретного нейрона имеет несколько следствий Во-первых,
в большинст ве сетей такого типа только один нейрон вырабатыва-
ет ненулевой выходной сигнал (как правило, значение этого сигнала
равно 1). Выходные сигналы всех остальных нейронов искусственно об-
нуляются, такой подход в литературе обозначается аббревиатурой WTA
(Winner Takes All победитель получает все).
Но этого недостаточно, процесс обучения (точнее, самообучения)
ограничивается обычно самим «победителем». Его (и только его!)
весовые коэффициенты изменяются, причем этот процесс протекает так
и в таком направлении, чтобы гга следующем коггкурсе с гем же входным
сигналом нейроп-«победитель» выиграл еще более убедительно!
Ну и какой в этом смысл?
Для ответа гга поставленный вопрос приглядимся, что происходит в
самообучающейся сети с конкуренцией. На входе сети появляется объ-
ект, представленный некоторой комбинацией входных сигналов. Эти сиг-
налы подаются на все нейроны и вызывают у них «случайное возбуж-
дение». В простейшем случае величина этого возбуждения рассчитыва-
ется по принципу умножения входных сигналов на весовые коэффици-
енты каждого нейрона, но можно представить себе тот же принцип с
применением, например, нейронов с нелинейными функциями актива-
Нейронные сети с самообучением
289
ции. Чем больше веса нейронов похожи на входные сигналы, тем силь-
нее «случайное возбуждение» на выходе соответствующего нейрона. Мы
уже говорили о том, что наборы весов можно трактовать как «эталоны»
входных сигналов, к которым чувствителен нейрон. Поэтому, чем ближе
входной сигнал к эталону, хранимому рассматриваемым нейроном, тем
сильнее будет выходная реакция. Следовательно, если в некоторый мо-
мент один из нейронов становится «победителем», то его «внутренний
эталон» сильнее всего похож на текущий входной сигнал.
А почему он должен быть на него похож?
В начале процесса обучения это может обусловливаться только слу-
чайной инициализацией весов. В любой нейронной сети исходные зна-
чения весовых коэффициентов присваиваются каждому нейрону случай-
ным способом. Позднее эти значения оказываются более или мспсс по-
хожими на комбинации входных сигналов, получаемые сетью в процессе
обучения в виде последовательности распознаваемых объектов. Поэто-
му некоторые нейроны исключительно по воле случая обладают
«врожденной склонностью» к распознаванию одних объектов и таким
же случайным «нежеланием» распознавать другие объекты. Впослед-
ствии, по морс развития процесса обучения и пошагового увеличения
степени подобия хранящихся в нейронах «внутренних эталонов» опре-
деленным типовым объектам, особенно часто предъявляемым на вход
сети, случайность исчезает, и нейроны все точнее специализируются па
распознавании конкретных классов объектов.
На этом этапе нейрон, который один раз победил при попытке распо-
знавания буквы А, с большой вероятностью победит в следующий раз
когда па входе сети вновь появится буква А, пусть даже написанная
другой рукой. Но вначале ситуация всегда случайна нейроны сами
решают, какие из пих должны распознавать А, какие В, а какие сиг-
нализировать, что предъявленный знак вообще не является буквой (а,
например, отпечатком грязного пальца). Процесс самообучения всегда
усиливает и кристаллизует только врожденные склонности (повто-
рю еще раз: возникшие случайно в результате предварительной генера-
ции начальных значений весов).
Но так происходит в любой сети с самообучением, какое же влияние
на эти процессы оказывает конкуренция?
Вследствие конкуренции процесс самообучения может стать
более эффективным и экономным.
Если начальные значения весовых коэффициентов нейронов выбра-
ны случайным способом, то «склонность» к распознаванию одного и то-
го же класса объектов может проявиться одновременно у нескольких
нейронов. Нормальный, т.е. не связанный с конкуренцией процесс само-
обучения будет развивать эти склонности параллельно у всех нейронов,
290
Глава 9
поэтому поведение элементов сети не будет дифференцироваться. Ско-
рее, наоборот, будет нарастать унификация. Ты неоднократно наблюдал
это явление в ходе экспериментов с программой Example 10b.
Если мы вводим конкуренцию, то ситуация изменяется. Какой-ни-
будь нейрон всегда будет хоть немножко лучше (по сравнению с «кон-
курентами») приспособлен к распознаванию демонстрируемого в теку-
щий момент объекта. В результате именно этот нейрон, весовые коэф-
фициенты которого случайным образом оказались наиболее похожими
на свойства предъявленного эталона, станет «победителем». Обучение
этого (и только этого!) нейрона приведет к усилению и стабилизации
его «врожденных склонностей», а «конкуренты-неудачники» останут-
ся позади и смогут соревноваться за право распознавания других, еще
«не запятых» объектов.
Развитие самообучения с конкуренцией удобнее всего наблюдать при
использовании программы Example 10с. В этой программе обучение
с конкуренцией применяется для решения задачи, аналогичной распо-
знаванию Марсиан, Марсианок, Марсиапяг и Марсиамор в предыдущих
двух программах. Но поскольку принцип обучения изменился, в ходе
наблюдений ты столкнешься с совершенно иными явлениями.
Вначале программа (так же как в предыдущих примерах) выведет па
экран окно с параметрами, в котором ты можешь задать, среди прочего,
количество нейронов в обучаемой сети. На первых норах рекомендую из-
менять значение только этого параметра, потому что если сразу начнешь
манипулировать всеми параметрами, сразу же запутаешься.
Принципы выбора количества нейронов достаточно просты: при не-
большой размерности сет и (например, 30 нейронов) явления самообуче-
ния с конкуренцией выглядят* гораздо эффектнее. В этом случае4 замет-
но, как все нейроны «стоят», и только победитель подвергается обуче-
нию. Для лучшей визуализации этого факта мы предусмотрели сохра-
нение па экране следа перемещения обучаемого нейрона, что позволяет
отслеживать его «траекторию». На рисунках, генерируемых программой
Example 10с, введено еще одно новшество: в момент, когда нейрон до-
стигает своей цели (месторасположения эталонного объекта), изобража-
ющая его точка превращается в большой красный квадрат. Это событие
можно считать сигналом о завершении процесса самообучения, по край-
ней мере, для соответствующего класса (рис. 9.37).
После инициализации процесса самообучения ты увидишь, что к
каждой точке появления объектов, принадлежащих к демонстрируемым
сети классам, будет «притягиваться» единственный нейрон, который
через некоторое время станет идеальным детектором элементов соответ-
ствующего класса (о чем свидетельствует появление большого красного
Нейронные сети с самообучением
291
(n in-e rncsmple, vnu wifi examine self teaming
neurar rslwo'kfW’'A) Ne irons have two mnuis
w we tan < pte, them lelui a. pain's of two
o_nensioraltpat
Vcu wil be able to tearto toe network c choosing
learmrq abyeus it om appropriate quarter i
In '4s setup par>~|усц con charge some йлггк
end eanwu, parameter., or use tie a ih
pro «ring* el toe begems g
Pre s f-lexl i' you eixep settings ot eon eiwoys
cbenge tor parameters by dk.> nq Раск.
Number of He roru Etoe factor
f Soft competition [jO ~.l |d.lO
| NW> ~|
Рис. 9.37. Окно с параметрами программы Example 10с и способ представ.: юн и я
процесса самообучения в сети с конкуренцией до и после достижения искомою успеха
квадрата в место, где обычно появля-
лись объекты именно этого класса).
При нажат ии па кнопку Start процесс
самообучения развивается также как
в предыдущем примере по принци-
пу «шаг за шагом» (если кликнешь
Start и нс отпустишь кнопку, то про-
цесс самообучения станет автоматиче-
ским). При отслеживании траекторий
перемещения векторов весов нейронов
(с учетом сообщений в каждом квад-
ранте, какой нейрон стал победителем
в текущий момент) можно заметить,
что на протяжении всего текущего
этапа самообучения в каждом квад-
Рис. 9.38. Процесс самообучения с
конкуренцией
ранте победителем становится один и тот же нейрон, поэтому только он
непрерывно приближается к демонстрируемому эталону, пока не найдет
желанную позицию и не успокоится в ней (рис. 9.38).
При большом количестве нейронов процесс самообучения с конку-
ренцией наблюдать сложнее, поскольку он (в отличие от классического
самообучения больших сетей) имеет очень локальный характер
(рис. 9.39). Причина в том, что расстояние между густо рассеянными
нейронами очень мало, поэтому «траектория» обученного победителя
оказывается короткой и мало заметной.
292
Глава 9
Рис. 9.39. Процесс самообучения с конку-
ренцией в большой сети
Рис. 9.40. Процесс самообучения с конку-
ренцией
в сети с малым количеством
нейронов
В свою очередь, при очень маленьком количестве нейронов (напри-
мер, всего 5 штук) траектории будут длинными и эффектными. Кроме
того, можно заметить, что при использовании конкуренции даже очень
слабая исходная склонность какого-либо нейрона к распознаванию опре-
деленного класса объектов может быть «подхвачена» и усилена за счет
обучения — при условии, что «конкуренты» будут еще менее склошты
распознавать этот' же класс (рис. 9.40). Благодаря следам перемещения
обучающихся негроиов на экране ты заметишь еще одну очень инте-
ресную и общую особенность нейронных сетей процесс обучения на
начальных стадиях развивает ся быстрее и си льнее, чем па завершающей
фазе.
9.9. Какие формы принимает самообучение
с конкуренцией?
Сразу после запуска программы Example 10с (в окно с параметра-
ми левая часть рис. 9.37) можно активировать опцию Soft competi-
tion, обеспечивающую «смягчение» конкуренции. На первых порах реко-
мендую не использовать этот режим (достаточно оставить поле по умол-
чанию пустым). Экспериментами со смягченной конкуренцией мы зай-
мемся после знакомства с достоинствами и недостатками «жесткой» кон-
куренции.
Благодаря «жесткой» конкуренции в программе Example 10с не бу-
дут формироваться известные по экспериментам с программами Exam-
ple 10а и Example 10b «кланы» нейронов, обладающих одними и теми
же предпочтениями. Если немного повезет (особенно в сетях с большим
Нейронные сети с самообучением
293
избытком нейронов по отношению к числу распознаваемых классов), то
удастся избежать появления «мертвых зон», т.е. входных объектов, ко-
торые не хочет распознавать пи один нейрон. Использование конкурен-
ции позволяет с высокой вероятностью утверждать, что в сети не будет
групп нейронов, распознающих один и тог же класс, и нс будет классов,
ис распознаваемых ни одним нейроном. Совсем как в известной посло-
вице: «Всякая невеста для своего жениха родится»*.
Поскольку при обучении с конкуренцией все нейроны (кроме побе-
дителя) не изменяют свое местоположение, они остаются готовыми к
«настройке» па другие эталоны. По этой причине в ситуации, когда
в процессе обучения внезапно появляются объекты совершенно иных
классов, в сети сразу находятся свободные нейроны, которые могут
сразу же приступить к распознаванию новых классов и к системати-
ческому совершенствованию Способностей к их идентификации. Это хо-
рошо видно па экране, поскольку в программу Example 10с встроена
возможность представлять уже обученной сечи новые, ранее неизвест-
ные обьекты. Тако . эффект возникает при нажатии (в любой момент
моделирования) кнопки new pattern. При многократном нажатии па
эту кнопку твоя сеть в результате самообучения получит’ возможность
распознавать гораздо больпгее число классов, чем непрерывно эксплуа-
тировавшиеся до настоящего момента гетырс типа марсиан (только нс
требуй от меня назвать, кого эти классы могут1 представлять — после
придумывания Марсиамор моя фантазия исчерпалась!). Благодаря са-
мообучению с конкуренцией каждый из многочисленных классов вход-
пых объектов обретает своего «ангела хранителя» в виде нелрона, ко-
торый с этого момента будет отождествляться с соответствующим клас-
сом (рис. 9.41), и еще останется немного свободных (не задействован-
ных) нейронов «про запас», т.е. для распознавания объектов, которые
(возможно) появятся в будущем.
К сожалению, чистый процесс самообучения с «жесткой» конкурен-
цией также может приводить к некоторым сбоям. При инициализации
самообучения сети с небольшим количеством нейронов для каждого из
предьявляемых и сначала немногочисленных (в нашей программе че-
тырех) классов находится нейрон, который будет распознавать и пред-
ставлять этот класс. Но при возникновении (после нажатия на кнопку
new pattern) новых классов объектов «победителем» в распознавании
какою-либо из тгих может стать нейрон, ранее специализировавшийся
Ты, конечно, понимаешь, что если бы не конкуренция типа WTA (обусловленная
обязательной в наших странах, по биологически совсем не оправданной моногамией), то
все девушки достались бы исключительно интеллектуальной элите общества, т.е. инфор-
матикам: а гак время от времени и другим счастье улыбается...
294
Глава 9
Рис. 9.41. Возможность обучения сети
с конкуренций рас познаванию нескольких
эталонов
на одном из старых классов. В результате некоторый класс объектов,
уже хорошо натренированный и «обеспеченный» нейронным представи-
телем, внезапно останется сиротой*! Эго соответствует ситуации, хоро-
шо известной тебе из повседневной жизни: старые знания и привычки
вытесняются новыми.
На рис. 9.42 отмеченный эффект иллюстрируется примером крайней
ситуации все нейроны, ранее обученные распознаванию конкретных
классов, «переориентировались» на вновь предъявленные объекты. Та-
кую ситуацию нельзя назвать типичной. Как правило, размерность сети
настолько превышает число распознаваемых классов, что эффект «су-
пружеской измены» проявляется очень редко не более одного или
двух раз па несколько десятков классов (рис. У.43). Этим можно объ-
яснить факт, что в повседневной практике, связанной с использовани-
Если продолжить шутливые аналогии матримониального характера то мы наб по-
даем механизм супружеской измены и развода.
Нейронные сети с самообучением
295
Рис. 9.42. Эффект зам&цекйя ранее вы-
работанных умений в результате получения
новых знаний
Рис. 9.43. Эффект утраты незначитель-
ной части ранее полученных знаний в сети
с «жесткой» конкуренцией
ем пашей собственной нейронной сети бесценного мозга. только
отдельные (к счастью, немногочисленные) сведения внезапно исчезают
из памяти, вытесненные другими, более яркими и интенсивными впе-
чатлениями. К сожалению, из памяти обычно стираются следы наибо-
лее существенных знаний и как раз тогда, когда они становятся осо-
бенно востребоваг i ны м и!
В ходе экспериментов с программой Example 10с ты, конечно, об-
наружил и другие предпосылки к «похищений» новыми обьектами ней-
ронов, уже состоящих в стабильной связи с другими классами. Из при-
веденных рисунков видно, что такая ситуация может возникнуть и при
наличии большого количества нейронов, все еще не получивших никакой
специализации па каком-либо из демонстрируемых объектов, но распо-
ложенных на значительном удалении от областей размещения предъяв-
ляемых эталонов. В обсуждаемой программе эго явление усиливается
вследствие демонстрации вначале одной группы объектов, а затем (по-
сле идентификации нейронов с элементами первой групды) другой
груптгьт объектов, принадлежащих к новым классам, Именно эти объек-
ты временами безнаказанно отбираю г нейроны у ранее демонстрировав-
шихся классов. Если бы все объекты демонстрировались одновременно,
то началось бы нормальное соперничество, выражающееся в «перетяги-
вании» нейронов в направлении то одного, то другого класса (это можно
наблюдать в программе Example 10с при запуске процесса обучения с
очень небольшим количеством нейронов, рис. 9.44).
В такой ситуации даже длительные попытки самообучения сети мо-
гут завершиться неудачей. Эго также известно тебе из повседневного
296
Глава 9
Рис. 9.44. Эффект «перетягивания» ней-
рона между объектами первого и четвертою
классов
Рис. 9.45. Игнорирование нг которых
классов при смягченной конкуренции
опыта, вспомни школьные проблемы: если па какой-то день назначены
сразу несколько контрольных работ I например, по математике, физике,
иностранному и истории), то бывает очень сложно хорошо подготовиться
по каждой дисциплине, и в результате «проваливаются» есе зачеты.
Для разрешения описываемых проблем рекомендуется смя! чиа ь кон-
куренцию. Для этого необходимо вернуться в окно установки парамет-
ров (кнопка Back), показанное в левой части рис. 9.37. Если ты акти-
вируешь в нем поле Soft competition, то законом функционирования
твоей сети станет смягченная конкуренция. С этого момента конкурен-
ция станет ограниченной, т.е. нейрон будет признаваться победителем
только то] да, когда он «отметится» действительно большим значени-
ем выходного сигнала*. Последовательное применение этого принципа
приводит к более равномерному распределению нейронов между клас-
сами распознаваемых обьектов. В результате применения смягченной
конкуренции исчезнут прискорбные сиены «похищения» объектами но-
вых классов нейронов, которые ранее специализировались на распозна-
вании объектов других классов.
К сожалению, вместо этого ты столкнешься с еще одним неприят-
ным явлением: в некоторых обстоятельствах (особенно при небольшом
количестве нейронов) после предъявления очередного объекта ни один
Если продолжить аналогии с наблюдениями отношений между людьми, то смяг-
ченная конкуренция соответствует решению о заключении брачного союза, только когда
партнеры по-насгояпдему очень сильно любят друг друга. Слабое и среднее увлечения не
имеют сколько пибудь серьезных последствий.
Нейронные сети с самообучением
297
нейрон не получит статус победителя* (рис. 9.45).
При использовании программы Example 10с в режиме смягчен-
ной конкуренции ты сможешь детально исследовать это явление. За-
дача окажется не сложной, поскольку программа в этом режиме рас-
ставляет специальные маркеры, обозначающие местоположение этало-
нов игнорируемых классов (тех, для которых ни один нейрон нс был
выбран победителем).
Ты убедишься, что при отсутствии острой конкуренции будешь ча-
сто встречаться с таким игнорированием объектов, особенно при модели-
ровании малых сетей (состоящих из небольшого количества нейронов).
В подобных случаях для большинства классов в сети формируются —
совершенно самостоятельно! эталоны, позволяющие в будущем ав-
томатически распознавать соответствующие классы сигналов. Но для
класса-«пеудачпика», с которым ни один нейрон нс хочет связываться,
в сети вообще не будут сформированы специализированные детекторы.
Ну и что?
Ну и ничего!
Или ты никогда не встречал человека, который прекрасно разби-
рается в истории, географии, английском языке — а вот математика
«никак не лезет ему в голову»?
9.10. Контрольные вопросы и задания
для самостоятельного выполнения
1. Попробуй сформулировать — кому, когда и для чего необходи-
мо самообучение нейронной сети?
2. Каким фактором обусловливается цвет (красный или синий) то-
чек, представляющих нейроны в прохрамме Example 10а?
3. На основании описанных в книге и проведенных тобой наблюде-
ний и экспериментов попробуй сформулировать собственные выводы о
влиянии па получаемые знания врожденных талант ов (представляемых
исходным случайным распределением векторов весов нейронов) и жиз-
ненного опыта (представляемого процессом самообучения). Считаешь ли
ты, что поведение систем с малым количеством нейронов (примитивных
животных) сильнее зависит от инстинктов и врожденных свойств, тогда
как на поведение более сложных систем, насчитывающих большое коли-
чество нейронов (например, людей) оказывают сильное влияние факто-
Этому эффекту также легко найти аналогию в отношениях между людьми. Навер-
няка в твоем окружении есть «старые девы» или «вечные кавалеры». Их существование
результат объединения принципа конкуренции (моногамия) и ее ослабленной версии
(только очень сильное чувство способно довести до женитьбы).
298
Глава 9
ры, связанные с личным опытом и целенаправленным обучением? Поста-
райся привести конкретные аргументы в пользу этого утверждения (или
против него) в аспекте самообучения сетей различных размерностей.
4. Расскажи о свойствах самообучающихся сетей при особенно ма-
лых и особенно больших значениях коэффициента обучения Etha. Как
ты думаешь, происходят ли аналогичные явления в мозге животных?
При формулировании ответа на вопрос прими во внимание, что обучае-
мость мозга (которую можно считать аналогом коэффициента обучения
Etho) уменьшается с возрастом. Это означает, что молодой щенок (мо-
дель которого представляется сетью с большим значением Etha) ведет
себя иначе, чем взрослый пес (у которого значение Etha иногда может
уменьшаться до нуля). Постарайся выделить позитивные и негативные
последствия обсуждаемого явления.
5. Может ли самообучающаяся нейронная сеть, способности которой
к «фантазированию» описывались в данной главе, выдумать какое-либо
абсолютно новое понятие, не имеющее никакого аналога в реальном мире
(точнее в пространстве входных сигналов, в котором «существуют»
используемые для обучения объекты)?
6. Можешь ли ты вообразить себе реальную ситуацию, соответству-
ющую опыту из раздела 9.7? Попробуй описать такую Ситуацию и поду-
май, как бы опа повлияла на функционирование мозга дрессированного
животного либо на сознание подвергнутого подобным воздействиям че-
ловека (особенно маленького ребенка).
7. Можно ли описанным в разд. 9.6 механизмом забывания (обу-
словленным «переучиванием» нейронов) объяснить все феномены, свя-
занные с этим тягостным (особенно перед экзаменом) процессом? И неза-
висимо от механизма полезным или вредным с биологических пози-
ций является забывание сведений, которые не актуализируются путем
предъявления решаемых с их использованием задач?
8. Какие неблагоприятные явления, характерные для процесса са-
мообучения сети, удастся исключить за счет введения Механизма кон-
куренции, а какие не удается?
9. В сетях с конкуренцией наряду с обсуждавшимся в этой 1лаве
принципом WTA (Winner Takes All— победитель получает все) ипенда
применяется принцип WTM (Winner Takes Most— победитель получает
больше). Подумай, что это может означать, а потом проверь истинность
твоих догадок с помощью Интернета.
10. Предположим, что ты хочешь построить самообучающуюся сеть
которая должна эффективно распознавать эталоны восьми различных
классов. Постарайся экспериментально определить, насколько больше
нейронов (по сравнению с их минимальным числом, равным восьми
Нейронные сети с самообучением
299
должна иметь такая сеть в начале процесса самообучения, чтобы в ней не
игнорировался ни один класс и, в то же время, чтобы после завершения
обучения число «незадействованпых» нейронов не было слишком боль-
шим?
11. Задание для наиболее подготовленных. Создай версию про-
граммы Example 10b, которая позволяла бы изначально запрограм-
мировать изменение параметра Etha (в зависимости от количества по-
казанных к текущему моменту объектов обучающей последовательно-
сти), а также позволяла бы планировать появление конкретных объек-
тов только в определенные периоды «жизни» сети (например, одни объ-
екты только в «детстве», а другие только на более поздних этапах,
т.е. В «зрелом возрасте» обучающейся сопи). Проведи серию экспери-
ментов с такой «лучше отражающей реальную жизнь» программой, по
результатам которых запиши свои наблюдения и постарайся сформу-
лировать все возможные выводы. В какой из периодов наблюдаемые в
сети явления имеют аналоги в реальной жизни, а в какие обусловле-
ны лишь тем, что построенная и исследуемая сеть представляет собой
слишком сильное упрощение реальных нервных структур, из которых
состоит мозг человека и животных?
12. Задание для наиболее подготовленных. Создай версию про-
граммы Example 10с, в которой конкуренция дополнялась бы исполь-
зованием фактора «совести». Реализация этого фактора означает, что
часто выигрывающий нейрон но мере развития процесса обучения на-
чинает1 испытывать «угрызения совести» и позволяет выигрывать дру-
гим нейронам. Сравни поведение моделей сетей с «конкуренцией и со-
вестью» и «чистой острой конкуренцией». Какие выводы можно сфор-
мулировать? Эти выводы относятся только к сфере нейронных сетей
либо их можно спроецировать на явления и процессы (например, эко-
номические) в реальной жизпи?
Глава 10
СЕТИ С САМООРГАНИЗАЦИЕЙ
10.1. Структура нейронной сети,
функционирующей по принципу
самоорганизации
Нейронная сеть может обучаться с учителем или самостоятельно
это ты уже знаешь. Теперь настало время познакомиться с сетями, ко-
торые не только самостоятельпо (т.е. без учителя) обучаются, но еще и
так согласовывают (путем взаимного влияния) функционирование всех
нейронов, что их совместная деятельность приобретает некоторое по-
вое качество. Речь идет об автоматически формируемом сетЫо сложном
отображении [mapping] множества входных сигналов во множество вы-
ходных сигналов. В общем случае, это отображение нельзя заранее спро-
гнозировать или как-то специально определить, поэтому обсуждаемые-
нами в этой главе сети будут гораздо более самостоятельными и незави-
симыми, чем те, о которых мы уже говорили выше. Свойства этих новых
сетей лишь в небольшой степени предопределяются создателем сети, то-
гда как суть их функционирования и итоговое отображение (представ-
ляющее собой результат их работы) зависят, главным образом, ог про-
цесса самоорганизации. Детали этого процесса представлены в очеред
ной программе. Но прежде чем приступить к описанию экспериментов,
я вкратце расскажу, для чего может пригодиться самоорганизация. Го-
раздо полезнее п( просто рассматривать картинки, но попытаться пред-
ставить себе сети с самоорганизацией в качестве инструментария для
достижения серьезный целей.
Отображение считается сложным математическим понятием, обла-
дающим (в зависимости от обстоятельств) различными свойствами и ха-
рактеристиками. ёдесь я постараюсь максимально наглядно (но, к сожа-
лению, не совсем строго) изложить сут ь этого понятия, опустив подроб-
ности. Не знаю, насколько у меня эго получится, поэтому договоримся:
если при чтении пояснений ты решишь, что они (‘лишком сложны (или
Сети с самоорганизацией
301
Рис. 10.1. Функционирование робота заключается
в преобразовании сигналов X в действия Y
Рис. 10.2. Общее представле-
ние отображения
скучны...), то можешь без сожаления пропустить всю теорию и продол-
жить чтение со следующего раздела в нем приводятся конкретные и
точные инструкции по построению сети с самоорганизацией и по иссле-
дованию ее свойств. Если же у тебя хватит сил прочитать теоретиче-
ское введение, то узнаешь, для чего создаются сети с самоорганизацией.
Прожить без этого можно, ио при последующем чтении и наблюдении за
работой такой сети ты получишь большее удовлетворение от понимания,
как опа функционирует и для чего может пригодиться.
Мне кажется, что если ты читаешь эти строки, движимый жаждой
познания, то поймешь более сложные вещи, о которых я сейчас расскажу.
И запомни — ты сам этого хотел!
Начнем с констатации факта: мы одень часто нуждаемся в преобра-
зовании входных сигналов в выходные сигналы по определенным прави-
лам. Например, при построении робо тов для решения конкретных задач
необходимо обеспечить, чтобы их системы управления могли коррект-
ным способом преобразовывать получаемые от сенсоров (видеокамер,
микрофонов, датчиков контакта, ультразвуковых датчиков движения и
т.п.) сит налы в команды управления работой приводных механизмов пог,
захватов, элементов рук и т.п. (рис. 10.1).
Именно такое преобразование произвольных входных сш налов в тре-
буемые выходные сигналы называется отображением ( рис. 10.2).
Конечно, это отображение не может быть абсолютно произвольным,
поскольку в этом случае оно окажется практически непригодным. Для
того чтобы робот правильно двигался, осмысленно решал задачи, кор-
рек тио реагировал на команды, о тображение, связывающее регистриру-
емые сенсорами раздражители с определенными движениями (соверша-
емыми с помощью исполнительных механизмов), должно быть соответ-
ствующим образом подобрано, детально продумано и тщательно запро-
граммировано. Поэт ому перед конст руктором робота (так же как и перед
302
Глава 10
конструкторами многих других систем автоматики) встает сложная за-
дача: определить требуемое отображение, которое (по сути дела) пред-
ставляет собой основное содержание «мозга», т.е. системы управления
роботом.
Если входной сигнал один, го задача достаточно проста, а искомое
отображение представляет собой известную всем со школьной скамьи
функцию. Если же робот обладает несколькими «органами чувств»
(т.е. сенсорами, которых всегда несколько), и когда исполнительных
механизмов тоже несколько (а их должно быть несколько, чтобы робот
мог сделать что-нибудь интересное), то задача становится очень слож-
ной, хлопотной и трудоемкой. В принципе можно попытаться «вручную»
определить и задать все необходимые отображения, но для решения
больших и сложных задач на это придется потратить всю оставшуюся
жизнь.
В такой ситуации приходят на помощь именно нейронные сети с са-
моорганизацией. Пример структуры такой сети приведен на рис. 10.3.
Топологический слой
Рис. 10.3. Структура нейронной сети с самоорганизацией
Сети с самоорганизацией
303
Как правило, сети с самоорганизацией имеют довольно много вхо-
дов. На рис. 10.3 показано всего три входа, по только чтобы по слишком
усложнять рисунок при тридцати входах путаницу было бы невозмож-
но отслсдить! Практически применяемые сети такого типа имеют обычно
от полутора до нескольких десятков входов, а их полезность в коп тексте
различных приложений обычно тем больше, чем больше входных сигна-
лов такая сеть сможет обработать. Но самое важное и сложное в другом:
обычно такие сети имеют еще больше выходов, поскольку они состоят из
множества нейронов, образующих так называемый топологический слой.
Определение «множество нейронов» здесь обозначает не менее несколь-
ких десятков, часто несколько сотен, нередко даже несколько тысяч ней-
ронов это действительно намного больше, чем в любых других уже
известных тебе сетях. Как понять, что именно в качестве результата сво-
его труда сеть представляет нам в этом огромном топологическом слое?
На помощь к нам приходит концепция, которая уже неоднократно
упоминалась в книге, — идея соперничества нейронов и выбора победи-
теля. После подачи в сеть любого конкретного входного сигнала каж-
дый нейрон топологического слоя рассчитывает свой выходной сигнал
в качестве отклика па этот раздражитель. Обычно один из этих сиг-
налов оказывается наибольшим и выработавший его нейрон становит-
ся победителем (рис. 10.4).
Процесс самоорганизации, о котором я буду подробно рассказывать
в следующих разделах, характеризуется (среди прочего) тем, что такой
«победоносный» нейрон только один раз может так явно и однозначно
взять верх над «конкурентами». Проблемы с выбором победителя могут
возникнуть только в ситуации, когда сеть (после завершения процесса
самоорганизации) получит на входе какой-нибудь абсолютно нетипич-
ный сигнал (непохожий ни на один сигнал, предъявлявшийся в составе
обучающей последовательности). В такой совсем редкой ситуации все
нейроны топологического слоя будут вырабатывать очень слабьте и по-
чти неразличимые сигналы.
10.2. На чем основана самоорганизация
и для чего она может пригодиться?
Даже те небольшие знания, которые ты получил в предыдущем раз-
деле, позволят сориентироваться в способностях сетей с самоорганиза-
цией. Последние формируют1 абсолютно самостоятельно, только па осно-
ве полученных входных данных определенные отображения множества
входных сигналов во множество выходных сигналов. При этом получае-
мые отображения, удовлетворяющие некоторым универсальным крите-
риям (о них чуть ниже), никак не задаются изначально ни создателем
304
Глава 10
Рис. 10.4. Пример распределена я значений выходных сигналов нейронов
топологического слоя с указанием «победителя», выявленного по результатам
оценивания этих сигналов
сети, ии пользователем. Структура и свойства необходимого нам отобра-
жения должны сложиться самостоятельно как результат скоординиро-
ванного процесса самообучения всех элементов сети. Такое спонтанное'
создание сетью требуемого отображения сигналов и называется само-
организацией. Строго говоря, это всего лишь еще одна форма самообу-
чения, но если принять во внимание ее результаты (а их будет много,
поскольку используемая в этой главе программа предоставит тебе мно-
жество необыкновенно красивых рисунков), то охотно признаешь, что
в этом случае мы имеем дело с гораздо более высоким уровнем адап-
тации сети, при котором оптимизируются пе только параметры каждого
отдельно взят ого нейрона, но и как раз в этом заключается новизна
координируется деятельность нейронов путем привнесения в работу спи
очень нужных эффектов группирования и коллективности.
Поясним введенные понятия. Эффек г группирования заключается
в том, что сеть в процессе самоорганизации пытается разложить вход-
ные данные для выявления среди них некоторых классов подобия.
В ходе этой операции входные объекты (описываемые входными chi на-
лами) разделяются автоматически на такие группы, элементы каждой
Сети с самоорганизацией
305
из которых взаимно похожи друг па друга и в то же время заметно от-
личаются от элементов других i рулп.
Такое группирование данных очень удобно для многих приложений,
поэтому создан целый ряд математизированных технологий для анали-
за и создания именно таких групп данных (чаще всего статистических).
Упомянутые технологии называются кластерным анализом (cluster ana-
lysis). Они широко применяются в экономике (например, для выявления
подобных друг другу предприятий» в ходе анализа возможной рента-
бельности инвестиций и в медицине (для исследования, какие симптомы
свидетельствуют о различных формах одного и того же заболевания, а
какие указывают на присутствие нового, возможно, ранее неизвестно-
го болезнетворного фактора).
На рис. 10.5 представлен пример нейронной сети, способной груп-
пировать входные сигналы (пиксели цветной картинки, кодируемые с
применением трех цветовых компонен т RGB Red-Green-Blue) по кри-
терию подобия цветов. На рис. 10.6 показан результат функционирова-
ния этой сети без процесса самоорганизации (слева) и после заверше-
ния процесса самоорганизации (справа). На рис. 10.6 в каждой точке
расположения нейрона топологического слоя изображен квадратик, за-
крашенный цветом того входного ггикселя, благодаря которому именно
этот нейрон стал «победителем».
Рис. 10.5. Сеть, группирующая входные Сигналы (компоненты гипового кодирования
цифрового образа) в коллекции, соответствующие возможным цветам
306
Глава 10
Рис. 10.6. Графическая иллюстрация функционирования сети, изображенной
на рис. 10.5. Слева — до процесса самоорганизации, справа — после завершения
этого процесса
Группирование пикселей картинки, имеющих подобный цвет, нельзя
считать задачей, решение которой способно принести какую-либо поль-
зу — поэт ому после знакомства с рис. 10.6 можно только всплеснуть ру-
ками и спросить: «Ну хорошо, и что далее?». Взгляни теперь на рис. 10.7.
На нем показан резулыат самоорганизации типологического слоя сети,
которая сравнивала данные о различных предприятиях. На вход сети
подавались такие сведения, как вид осущест вляемой хозяйственной дея-
тельности, объем собственною капитала, количество работников, балан-
совые показатели за несколько последних кварталов (характеризующие
полученные прибыли или понесенные убытки) и т.п. Сеть сгруппировала
предприятия и выбрала значения своих параметров так, что каждый пей
рон становился «победителем» при нредьявлении информации о «его»
предприятии. После завершения процесса самоорганизации «выждали
Рис. 10.7. Эффект группиро-
вания предприятий в самоор-
ганизующейся нейронной сети
год» и проверили, что стало с теми же пред-
приятиями. Оказалось, что одни из них ра-
зорились или близки к банкротству, они
обозначены па рис. 10.7 цветом R (крас-
ным). Другие наоборот, характеризовались
хозяйственной стабильностью. Нейроны,
автоматически приписанные им в процессе
самоорганизации, закрашены на рис. 10.7
цветом В (синим). И наконец, предприятия
третьей группы динамично развивались,
ты совершенно прав, они показаны цветом
G (зеленым).
В Интернете можно найти множество!
таких очень эффект пых примеров самоор-
ганизации, направленных па упорядочение
Сети с самоорганизацией
307
некоторых данных. Достаточно в окно поиска системы Google ввести
запрос «сети с самоорганизацией», а лучше всего повсеместно приме-
няемое сокращение SOM (Self-Organizing Maps). После получения спис-
ка ссылок ты очень быстро убедиться, что описываемые здесь задачи
группирования входных данных в классы подобия потребованы и име-
ют многочисленные практические приложения.
Итак, нейронные сети с самоорганизацией представляют собой очень
привлекательный инструментарий для решения задач группирования
входных данных и формирования из этих данных классов подобия. При-
влекательность нейронного подхода к рассмагриваемой проблематике
основана, главным образом, на возможности осуществления абсолют-
но автоматического и спонтанного процесса самоорганизации. При этом
создатель сети не должен формулировать никаких указаний, посколь-
ку вся необходимая информация содержится в самих входных данных
(из которых сеть самостоятельно извлечет знания о взаимном подобии
одних элементов и различии других). Болес того, после обучения сети
группированию входных данных возникают очень полезные системы
нейроны-«победители», которые специализировались па распознавании
конкретных классов входных сигналов, становятся их детекторами и мо-
гут использоваться для выявления соответствующих объектов.
После такого (по правде говоря очень краткого и поверхностного)
рассказа об эффекте группирования в нейронных сетях с самооргани-
зацией, скажу несколько слов об упомянутой выше коллективности
функционирования сети.
Сети с самоорганизацией устроены так, что объект распознавания
одного нейрона в значительной мере зависит от объектов, распознава-
емых нейронами из его непосредственного окружения. Фактически со-
вокупность нейронов (т.е. их коллектив) способен более полно и ком-
плексно обрабатывать информацию, чем каждый нейрон по отдельно-
сти. Взгляни на рис. 10.8.
На нем показаны результаты моих исследований, связанных с распо-
знаванием самоорганизующейся нейронной сетью пред ьявлявшихся ей
образов простых геометрических фигур. В местах, где сеть расставила
(абсолютно самостоятельно!) нейроны, распознающие конкретные фор-
мы показанных геометрических образов, нарисованы соответствующие
фшуры. Совершим краткую прогулку по этой карте, и ты убедишься,
что размещение нейронов именно в этих местах совсем пе случайно!
Начнем согласно нанесенным на рисунок красным стрелкам
с нейрона, ставшего «победителем» при демонстрации сети квадрата.
Неподалеку от пего расположен нейрон, распознающий пятиугольник,
чуть вдалеке нейрон, связанный с восьмиугольником. Все правишь-
308
Глава 10
Рис. 10.8. Эффект распознавания геометрических фигур в самоорганизующейся
нейронной сети
но: пятиугольник больше похож на квадрат, чем восьмиугольник! Непо-
далеку от последнего расположился нейрон, распознающий круг. От
него короткая дорожка ведет к нейрону, связанному с эллипсом, ко-
торый (в свою очередь) весьма близок к нейрону, распознающему по-
лукруг. Полукруг имеет явное сходство с еще меньшей частью круга,
называемой сектором, а от него уже недалеко до треугольника...
Как видишь, эффект коллективного функционирования нейронов со-
чи с самоорганизацией очень интересен. Волсе того, этот эффект созда-
ет предпосылки к более общим рассуждениям. Система, т.е. именно со-
вокупность взаимосвязанных и взаимодействующих элементов, создает
возможность получения новых форм поведения и новых видов деятель-
ности — гораздо более сложных, чем можно было ожидать от каждого
нейрона в от дельности. Например, каждое отдельное насекомое доста-
точно глупо и примитивно, но совокупность насекомых (пчелиная семья,
муравейник, термитник и т.п.) способна к выполнению целенаправлен-
ных, сложных и, вне всякого сомнения, осмысленных действий. Когда-
нибудь (уже не в этой книге) я подробно опишу собственный опыт ком-
пьютерного моделирования пчелиной семьи...
Но вернемся к сетям с самоорганизацией. Можно утверждать, что
они представляют собой удобный, полезный и широко применяемый ин-
струментарий и, кроме того (а может быть, в первую очередь) очень
интересный объект исследований. С деталями процесса самоорганиза-
ции, развивающегося в нейронных сетях, ты познакомишься в следу-
ющих разделах этой главы и как обычно сможешь провести се-
рию экспериментов со специально подготовленной для этою програм-
мой. Ключом для осмысления и применения сетей с самоорганизацией
станет понятие соседства нейронов.
Сети с самоорганизацией
309
10.3. Как определяется соседство в сети?
Для хорошего понимания структуры (и функционирования!) сети с
самоорганизацией попробуем вначале сравнить ее деятельность с воз-
можностями простых сетей с самообучением, рассмотренных в предыду-
щей главе. Вследствие огромного влияния случайных начальных значе-
ний па развитие простого самообучения создатель обычной самообучаю-
щейся сети не оказывает какого-либо воздействия па обучение каждого
конкретного нейрона. Иногда распределение нейронов, соответствующих
(после завершения самообучения) определенным событиям или явлени-
ям, оказывается очень невыгодным и неблагоприятным, но у тебя нет
возможности изменить что-либо без «ручного» вмешательства в поведе-
ние сети (что в общем случае достаточно проблематично и, кроме того,
противоречит принципу самообучения). В свою очередь, введение в сеть
одной лишь конкуренции может привести к обучению только неко-
торых (обычно очень немногочисленных) нейронов с большими «врож-
денными способностями», остальные останутся «неучами» и окажутся
(с точки зрения целей организации сети) фактически потерянными. Ты
мог наблюдать это явление в программе Example 10с, которая выда-
вала среди прочею — информацию о конкретных нейронах, ставших
«победителями» в конкретных классах объектов и «завоевавших» пра-
во распознавать соответствующие элементы. Номера этих нейронов вы-
свечивались хаотично, без какой-либо связи с локализацией распозна-
ваемых объектов. В то же время, приписывание конкретному нейрону
функции выявления определенных входных объектов может оказаться
важным фактором, увеличивающим или уменьшающим полезность сети.
Например, если некоторые входные сигналы в каком-то смысле подоб-
ны друг другу, то может оказаться удобным, чтобы их распознавали
нейроны-соседи, расположенные в сети недалеко друг от друга. Именно
так функционирует сеть с самоорганизацией, результат работы которой
показан на рис. 10.8. Тем не менее, на «чистую» самообучающуюся сеть
ты пе сможешь оказать никакого влияния и будешь вынужден принять
все происходящее в пей с покорностью и смирением.
Универсальный рецепт от всех названных «недугов» — ввести в са-
мообучающуюся сещ> еще один механизм, т.е. соседство. Впервые со-
седство цейронов в сети применил «в 70-х гг. XX в.) финский ученый
'lof.BO Кохопен. Поэтому в специальной литературе сети с использо-
ванием этого механизма (а обычно и конкуренции между нейронами)
называют сетями Кохонена.
Теперь посмотрим, в чем заключается соседство, а потом я расска-
жу о его достоинствах.
310
Глава 10
Рис. 10.9. Нейрон и его соседи в сети Рис. 10.10. Расширенное соседство в сети
Кохсшела Кохонеяа
До этого момента мы рассматривали нейроны сети как элементы,
в значительной степени независимые друг от друга. Конечно, они со-
единялись между собой и обменивались сигналами (сеть есть сеть!) но
их взаимоположение в слоях не имело никакого значения. Для по-
рядка (а также для организации вычислений в имитационных програм-
мах) вводилась нумерация нейронов не более того. Напротив, в рас-
сматриваем ых сейчас сетях с самоорганизацией очень важным оказыва-
ется признание каких-либо нейронов топологического слоя соседству-
ющими между собой, поскольку эго будет' принципиально влиять па
поведение сети в целом.
Чаще всего нейроны топологического слоя ассоциируются с точка-
ми какой-либо карт ы, изображенной на экране компьютера, поэтому мы
обычно рассматриваем двухмерное соседство: нейроны воспринима-
ются так, бу;гго они расположены в узлах регулярной решетки, сосгоя-
щей из строк и столбцов. В такой сетке каждый нейрон имеет, как ми-
нимум, четырех соседей: двух но горизонтали (слева и справа) и двух
по вертикали (сверху и снизу) (рис. 10.9).
В случае необходимости соседство можно трактовать шире: допу-
стить наличие соседей по диагонали (рис. 10.10) либо признать сосе-
дями также нейроны, расположенные в более удаленных строках и ш
столбцах (рис. 10.11). Определение степени соседства зависит исключи-
тельно от тебя, например можно так описать сеч ь, ч то соседство будет
одномерным (в этом случае нейроны образуют протяженную цепь, и
каждый нейрон будет иметь в соседях как предшествующие ему в цепи,
гак и следующие за ним нейроны) (рис. 10.12).
В специализированных приложениях сетей с самоорганизацией мож-
но ввести трехмерное соседство (в этом случае нейроны со своими соседя-
ми выглядят как атомы в кристаллической решетке, наверное, чы видел
такие изображения и можешь себе их припомнить, а мне почему-то со-
всем не хочется нечто подобное сейчас рисовать). Бывает чакже четы-
рех-, пяти- и более мерное соседство (угадай, почему их вообще никто ш
Сети с самоорганизацией
311
Рис. 10.11. Расширенная сфера соседства
в сети Кохонеиа
Рис. 10.12. Частный случай: одномерное
соседство
изображает?). Однако в подавляющем большинстве практических при-
ложений используются одно- и двухмерные соседства, поэтому во всех
последующих рассуждениях мы ограничимся ими.
Несомненно, соседство затрагивает все нейроны сети: большинство
нейронов имеет полный комплект соседей и, в свою очередь, каждый
нейрон выступает в роли соседа для других нейронов. Только нейро-
ны, расположенные по краям сети, имеют неполный комплект соседей,
но эту ситуацию можно исправить, если принять специальное соглаше-
ние (например, «замыкая» сеть так, чтобы нейроны верхнего края сети
считались соседями нейронов нижнего края; аналогично «замыкаются»
левый и правый края сети).
10.4. Что следует за признанием какого-либо
нейрона соседом?
Факт признания некоторых нейронов соседями имеет очень большое
значение. Если в процессе обучения конкретный нейрон становится по-
бедителем и подвергается обучению, то вместе с ним обучаются и его
соседи. Я сейчас покажу, как это происходит, но вначале напомню, как
обучаются одиночные нейроны в самообучающихся сетях (рис. 10.13).
Теперь взгляни на рис. 10.14. Обрати внимание1: нейрон-победитель
(закрашенный черным цветом) подвергается обучению, носкольку имен-
но его исходные весовые коэффициенты были подобны компонентам
си] нала, предъявленного в процессе обучения (темно-серая точка). Со-
ответственно «врожденные» предпочтения этого нейрона усиливаются и
конкретизируются (что ты уже многократно наблюдал в других само-
312
Глава 10
Значение А
второго
веса
нейрона
Процесс самообучения заключается в том, что
вектор весов W выбранного для обучения нейрона
притягивается к вектору входного сигнала X,
ставшего причиной обучения
Перемещение
вектора весов
в результате обучения
Точка, представляющая вектор весов W
нейрона перед обучением
Значение второй
компоненты
сигнала
q Местоположение вектора весов W'
нейрона после обучения
Точка, представляющая
входной сигнал X
Значение первой компоненты сигнала
Значение первого
веса нейрона
Рис. 10.13. Процесс самообучения одиночного нейрона
Рис. 10.14. Схема процесса обучения, распространенного па соседей «победигеля»
обучающихся сетях). На рисунке описываемая процедура выглядит как
притяжение «победителя» к точке расположения эталонного объекта
его вектор весов (и точка, представляющая этот вектор на рисунке) силь-
но перемещается в направлении точки, отображающей входной сигнал.
Соседи пейрона-«иобедителя» (светло-серые точки) независимо от их ис-
Сети с самоорганизацией
313
Пространство входных
сигналов и весов
Таким будет
местоположение
векторов весов
трех нейронов
Кохонена
Рис. 10.15. Результат обучения сети Кохонена в случае, когда входные сигналы
образуют четко выраженные совокупности
ходных весов и вводных сигналов, также обучаются, чтобы в будущем
они обрели склонность к распознаванию именно того входного объекта,
по отношению к которому сосед с «выдающимися способностями» ока-
зался победи гелем! Чтобы все было «по справедливости», соседи обу-
чаются менее интенсивно, чем победитель (стрелки, характеризующие
величину их перемещений, заметно короче). Одним из важных парамет-
ров, характеризующих свойства сечи с соседством, считается коэффици-
ент ослабления обучения соседей но сравнению с победителем. Обрати
внимание, что иные нейроны (незакрашенные точки) с гораздо лучши-
ми параметрами (поскольку располагались гораздо ближе к эталонной
точке) на этом шаге не подвергались никакому обучению, поскольку не
считались соседями победителя.
Каковы последствия такого странного способа обучения?
Если входные сигналы будут образовывать обособленные совокуп-
ности, то конкретные нейроны сети постараются занять «путем коррек-
тировки своих векторов весов) позиции в центрах этих совокупностей,
тогда как соседние нейроны будут «оккупировать» соседние совокуп-
ности. Такая ситуация представлена на рис. 10.13, на котором круж-
ками обозначены позиции входных сигналов, а звездочками место-
положение (в той же системе координат) векторов весов конкретных
нейронов.
Значительно худшая ситуация возникает, когда входные объекты
равномерно распределяются по некоторой области пространства вход-
ных сигналов (рис. 10.16). В этом случае нейроны сети будут прояв-
лять тенденцию к «разделению» функции распознавания этих сигналов
314
Глава 10
Рис. 10.16. Обучение сети
множеством данных, пример-
но равномерно распределенных
внутри некоторой области про-
странства входных сигналов
им вектором весов) займет
(чтобы каждое подмножество входных
сигналов получило своего «ангела-хра-
нителя» в виде нейрона, который будет
выявлять и распознавать все сигналы из
соответствующей подобласти, рис. 10.17).
Изучение этого рисунка необходимо
сопроводить небольшим комментарием.
Для тебя, возможно, не совсем очевидно,
что при случайном формировании мно-
жества точек в некоторой области про-
странства и систематического обуче-
ния точка, представляющая веса нейро-
на, займет центральное положение в
этом множестве. Справедливость такого
утверждения иллюстрирует рис. 10.18.
Из этого рисунка видно, что когда
нейрон (как обычно, представленный сво-
положение в центре «облака» распознавае-
мых им точек, продолжение обучения уже не сможет намного сдвинут!)
его с занятой позиции различные объекты обучающей последоватсль-
ности будут вызывать взаимно компенсируемые перемещения. Для огра-
ничения масштабов такой «осцилляции» нейрона в сетях Кохоиепа чаще
всего применяется правило обучения с уменьшающимся коэффи-
циентом обучения. По этому правилу наиболее значительные пере-
Рис. 10.17. Локализация векторов весов
нейронов (большие кру1и) в местах, где они
могут представлять некоторые подгруппы
(множества одинаково окрашенных малых
кругов входных данных
Рис. 10.18. Взаимная компенсация вли-
яния различных точек при обучении ней-
рона после тоТо, как он уже займет цен-
тральное положение
Сети с самоорганизацией
315
Q л с xtt&t G @ 0 •
г jsocc ООО к 6 • я
со асэдИ®®
& <ИММ» в
<з и о © о с о о о с
© > С О О С I-
еоЯГвзв®
< соШ**оот
с @ ® ® е ® © © © '© ©Ф $
6с©W® й
е«ас«й€»е.а с®@
«ееее<»Феее*«©
gw сэййис
O»«*-W.;‘0fK{4 3iJ
® ® @ qdHkp ® е ® «• б
за® <©*• - Ит
*:»е<Ф
е®< ос^г .ш*з©*ф
tetmmmi
©©<>*« Фее© «*®
£$$&<ФЭОО^ФСФ
еееее®эео*н e.j
e®Qoe wmeoe
Рис. 10.19. Сокращение сферы соседства в процессе обучения сети Кохонена
мещения каждого нейрона по направлению к месту его окончательной
локализации совершаются, главным образом, на начальных этапах обу-
чения (когда значение коэффициента обучения еще достаточно велико).
В то же время объекты, демонстрируемые в конце процесса обучения,
уже очень слабо влияют на положение нейрона, который к определен-
ному моменту выбирает для себя окончательную точку.
Наряду с ослаблением коррекций по мере развития обучения в се-
ти наблюдается еще один процесс: систематическое сокращение сферы
соседства. Вначале обусловленные соседством изменения затрагивают
па каждом шаге большое число нейронов, но постепенно это соседство
сужается, а к концу обучения каждый нейрон становится одиноким и
лишенным соседей (рис. 10.19).
При осмыслении всех изложенных сейчас сведений ты заметишь: по-
сле завершения обучения нейроны топологического слоя разделят меж-
ду собой пространство входных сигналов так, что каждая область этого
пространства будет представляться одним нейроном. Более того, если
учитывать соседство, то те нейроны, которых ты «назначил соседями»,
будут проявлять склонность к распознаванию близких, т.е. подобных
друг другу входных объектов. Это окажется очень полезным и удоб-
ным свойством, поскольку такая самоорганизация является ключом к
особенно «интеллектуальным» приложениям сетей в качестве самоорга-
низующихся отображений. Мы обосновали эту возможность в первых
разделах этой главы.
В ходе наблюдения за процессом обучения сети Кохонена ты столк-
нешься с еще одной трудное гыо, которую необходимо прояснить до нача-
ла анализа конкретных результатов моделирования. При исследовании
получаемых результатов (представленных в виде изменения местополо-
жения точек, соответствующих конкретным нейронам) ты должен иметь
возможность отслеживать все происходящее с соседними нейронами.
На рис. 10.14 можно было легко сопоставить события, происходящие с
316
Глава 10
Рис. 10.20. Выполнение одного шага обучения в сети Кохонена с указанием (с
помощью красных линий) соседних нейронов
псйроном-«победитслсм» и его соседями из-за небольшого количества
точек, поэтому следить за соседями с помощью изменения их окрас-
ки было легко и удобно. Но при моделировании больших сетей иногда
ты будешь иметь дело с сотнями нейронов, и такая технология пред-
ставления результатов станет непригодной. Поэтому для визуализации
функционирования сетей Кохонена повсеместно применяется способ вы-
черчивания «карты» расположения нейронов с обозначением отношений
соседства (рис. 10.20).
На рисунке можно заметить: точки, соответствующие соседним ней-
ронам, соединены линиями. Если в процессе обучения точки перемеща-
ются, то перемещаются и соединяющие их линии. Конечно, это справед-
ливо для всех нейронов и всех отношений соседства, но па рис. 10.20
для максимальной наглядности я показал только те линии, которые
связывают текущего пейрона-«победителя» с его соседями и скрыл все
остальные соединения. Как это выглядит в масштабах всей сети? Сейчас
увидишь на примере подготовленной для тебя программы Example 11.
10.5. Что могут сети Кохонена?
Программа Example 11 иллюстрирует функционирование сети Ко-
хопепа. Но для ее освоения я сделаю несколько общих замечаний.
Сразу после запуска программы па экране появится окно, в котором
можно задать размеры сети: по горизонтали (Net size X) и по вертикали
Сети с самоорганизацией
317
ИИлинил^Т?
In this example we test simple Self-Orgemzing Net This involves creating the SOM with 2 input
nodes and (Net size X) x (Net size X) mao nodes. The map nodes are then randomly initialled to
values betws en -(Range of initial rai 'dom weigl its) and +(Range ol initial random weights). The
two input nodes represent X and Y values between -10 ana 10 If you continuously train tl is SOM
with random X, Y it should unravel itself and flatten out into a grid pattern. The center ol the
pattern wll be 0. 0.
Здесь ты можешь задать
размеры сети'
по горизонтали (Net size X)
и по вертикали (Net size Y)
Числовой диапазон,
из которого будут выбираться
начальные значения
весовых коэффициентов
Net size X: Net size Y;
Я
Range of initial landom weights.
Рис. 10.21. Начальный диалог с программой Example 11
(Net size Y) (рис. 10.21). Ты выбираешь размер сети самостоятельно, по
для большей прозрачност и результатов начни эксперименты с не очень
больших сетей, например 5x5 нейронов. Такая сеть довольно прими-
тивна, и при решении более сложных задач от нее будет мало толку,
по она обучится настолько быстро, что уже через минуту ты увидишь
конечный результат. Потом наступит время сетей большего размера. Ис-
ходный код программы не накладывает каких-либо конкретных ограни-
чений па размер сети, тем по менее, область допустимых значений этих
параметров ограничена интервалом от 1 до 100. При обучении больших
сетей на не слишком быстродействующем оборудовании приходится ожи-
дать результаты часами. Из предыдущих экспериментов ты знаешь, что
для их окончательного обучения необходимо от нескольких сотен
до нескольких тысяч шагов. Наряду с обоими размерами сети ты
можешь определить в стартовом окне (рис. 10.21) диапазон изменения
чисел, из которого должны выбираться начальные значения весовых ко-
эффициентов (Range of initial random weights). На первое время ре-
комендую использовать значения по умолчанию, а в следующих опытах
ты сможешь безопасно и увлекательно поэкспериментировать с иными
(большими) числами это поможет попять, как влияют на функциони-
рование сети «врожденные» способности ее нейронов.
После выбора размеров сети и диапазона Изменения начальных зна-
чений щелчком по кнопке Next ты перейдешь к следующему окну
рис. 10.22), в котором будешь следить за развитием процесса обучения.
П этом окне позиции конкретных нейронов в пространстве входных сиг-
318
Глава 10
All Refactions: 940
AJphaC
io 10
EpsAJphe
0.9997 M
Teaching parameters
Iterations
30( Й
Alpha''
0.02 g|
EpsNeighb:
[0999 ПЦ
Figure:___
Sqare
Ne.ghbou'
[3.0
Начальные
местоположения
нейронов
Кадры, отражающие
последовательность
этапов процесса
обучения
Область презентации echins
обучающей start |
последовательности
Reset
< Баск
Рис. 10.22. Структура экрана программы Example 11
налов обозначаются голубыми кругами, а красные линии между окруж-
ностями указывают на «соседство» нейронов (в соответствии с принци-
пами их связи между собой (см. рис. 10.20)). Там, где в пространстве
входных сигналов показан голубой круг, располагается нейрон, распо-
знакици* соответствующий объект (локализованный в этой точке либо
в ее ближайшем окружении, поскольку нейронные сети всегда им сил
склонность к некоторому обобщению полученных знании). В экспери-
ментах сетЯхМ Кохонена всегда предъявляются точки, случайным спосо-
бом выбираемые из некоторой подобласти пространства входных сигна-
лов. В результате голубые области будут систематически расширяться
и распространяться по всему пространству входных сигналов, точнее,
по тому его фрагменту, из которого происходят предъявляемые в про-
цессе самообучения входные объекты. В то же время, точки простран-
ства входных сигналов, которые не будут демонстрирова ться в процессе
обучения, не «притягивают» к себе никаких нейронов. Для демонстра-
ции этого эффекта мы предусмотрели в программе Example 11 три ва-
рианта представления обучающей последовательности: объекты могут
выбираться из всей видимой области пространства (эта опция названа
«квадрат»), но могут выбираться и 5 подобласти в форме креста или тре-
угольника. Благодаря этому ты сможешь убедиться: сеть действитель-
но находит отображения только для тех входных сигналов, которые ей
предъявлялись. В областях, не затронутых обучением, не появится ни
один символ, обозначающий присутствие нейрона!
Вид фигуры, из области которой будут «рекрут ироваться» точки для
демонстрации сети на каждом этапе обучения, ты сможешь выбрать и*
Сети с самоорганизацией
319
выпадающего списка Figure в группе параметров обучения (Teaching
parameters) после задания количества шагов выполнения программы
(параметр Iterations). В этой группе настраиваются и другие парамет-
ры процесса самообучения, но вначале я рекомендую использовать их
значения по умолчанию.
Теперь достаточно нажать Start для начала обучения сети. В окне,
расположенном в левом нижнем углу (картинка в зеленой рамке), по-
явится изображение всех точек, которые будут предъявляться сети (их
количество ты определил параметром Iterations). Все точки окрашены
одним и тем же цветом из-за отсутствия учителя, который бы класси-
фицировал их каким-нибудь образом. Ты можешь сразу увидеть, из ка-
кой подобласти пространства входных сигналов выбираются объекты, и
сравнить форму этой подобласти с итоговым результатом обучения.
После выполнения заданного тобой количества шагов программа вы-
ведет на экран новую карту, изображающую расположение нейронов (и
их связей с соседями согласно принятой топологии сети) на фоне все-
го пространства входных сигналов. Поскольку предыдущая карта также
остается видимой (программа выводит па экран результаты нескольких
последних этапов процесса обучения), ты сможешь оперативно наблю-
дать развитие этого процесса. Результат последнего завершенного этапа
легко узнать по красному цвету его рамки; это необходимо, поскольку
после выполнения нескольких этапов все рамки окажутся занятыми, и
места на экране начнут использоваться по принципу «ротации».
Вначале, пока процесс обучения не приведет к наведению хоть како-
го-нибудь порядка, нейроны располагаются в пространстве входных сиг-
налов весьма хаотично, поэтому голубые кружочки кажутся разбросан-
ными абсолютно случайно, а соединяющие соседей линии — направлен-
ными совершенно бессистемно (рис. 10.23).
Как я только что сказал, начальные зна-
чения выбираются из заданного тобой диа-
пазона. Поскольку поначалу рекомендуется
использовать малые начальные значения
весовых коэффициентов (например, не более
предлагаемого программой значения 0,01),
неупорядоченная совокупность голубых ква-
дратиков (символизирующих нейроны) рас-
положится в густо заполненной центральной
области пространства входных сигналов
(так, как па рис. 10.22), и визуально воспри-
нимать его будет сложно. Но чтобы ты смог
хорошенько присмотреться к исходному со-
стоянию сети перед обучением, я выбрал (до
Рис. 10.23. Пример графиче-
ского представления исходного
распределения весов нейронов
320
Глава 10
начала моделирования, стартовые позиции которою показаны на
рис. 10.23) широкий (точнее, равный 7) диапазон разброса весовых коэф-
фициентов. Прекрасно понимаю, что использовать такую сеть будет про-
блематично*, по хочу, чтобы ты лично сам убедился в абсолютной хаотич-
ности исходного состояния сети (особенно линий, задающих отношения
соседства).
После каждого вывода на экран карты расположения нейронов мож-
но изменить количество шагов, которые должны быть выполнены для
получения очередной схемы распределения точек. Вначале можно вос-
пользоваться установками по умолчанию, а потом (когда уже хорошо
«прочувствуешь» работу программы) ты сможешь по собственному же-
ланию удлинять или сокращать промежутки времени между очередными
презентациями результатов обучения и наблюдать за более эффектным
(большие скачки, основанные на выполнении нескольких десятков или
сотен шагов, и резкие изменения состояния сети) или более плавным
(мелкие шажки) развитием этого процесса. Под конец обучения, когда
«прогресс» развития сети станет почти незаметным, имеет смысл вы-
полнять очень большие прыжки (например, по 100 или 300 шагов), но
помни, что в этом случае при моделировании больших сетей придется
некоторое время тратить па ожидание результатов!
Наша цель заключается в наблюдении и исследовании процесса са-
моорганизации сети Кохопспа. Вначале посмотрим, как самоорганизация
развивается в простых условиях. Если моделирующая npoi рамма начнет
генерировать и предъявлять сети точки, расположенные в разных местах
пространства входных сигналов (ты сможешь контролировать этот про-
цесс по изображенной в левом нижнем углу экрана карте, па которой
будут демонстрироваться предъявляемые сети точки см. рис. 10.22),
то вскоре ты заметишь перемещение голубых кружочков, обозначающих
веса нейронов. Эти кружочки, вначале расположенные абсолютно хао-
тично, постепенно станут равномерно распределяться по выбранной под-
области пространства входных сигналов. Более того, па их размещение
будут влиять отношения соседства ты увидишь, что отображающие
эти отношения линии начнут формирование регулярной сетки. С точ-
ки зрения наблюдателя сетка, состоящая из узлов (нейронов) и связей
(линия соседства), начнет «растягиваться». В результате этого процесса
векторы весов нейронов 'топологическою слоя будут перемещаться в та-
кие места, где каждый из них окаже тся пент ром (эталоном) некоторою
фрагмента пространства входных сигналов. Математически строго этот
процесс описывается так называемой «мозаикой Вороного». Учитывая,
что мы отказались в пашей популярной книге от формул, можно при-
нять, что входящие в состав сети нейроны просто постепенно спсциали-
Сети с самоорганизацией
321
Рис. 10.24. Начальные этаны процесса самоорганизации, развивающегося в сети
Кохонена
Рис. 10.25. Этапы процесса самоорганизации, развивающегося в относительно
небольшой сети Кохонена, цля которой входные данные представлены в квадратной
подобласти пространс г ва входных сигналов
Рис. 10.26. Этапы процесса самоорганизации, развивающегося в большой сети
Кохонена, для которой входные данные представлены в квадратной подобласти
пространства входных сигналов
зируются в представлении и распознавании различных групп входных
сигналов. В результате через некоторое время каждому достаточно ча-
сто появляющемуся входному сигналу будет соответствовать точно один
322
Глава 10
Рис. 10.27. Самоорганизация сети, стартующая с широкого исходного распределения
значений весов
Распознает сигналы
из этого региона Этот нейрон
Распознает сигналы А этот его сосед
из этого региона
Рис. 10.28. Результат
процесса самоорганизации
пейрон сети, специализировавшийся на его представлении и распознава-
нии. На начальном этане (рис. 10.24) доминирующим оказывается про-
цесс, в результате которого случайное распределение точек и линий за-
меняется предварительным упорядочением элементов сети.
Впоследствии процесс обучения становится менее интенсивным; он
ориентируется на максимальную равномерность распределения точек.
Важно, что сеть вырабатывает внутреннее представление (в виде соот-
ветствующих распределений весовых коэффициентов нейронов) только
о той подобласти пространства входных сигналов, в которой распола-
гаются предъявляемые ей точки. Ты убедишься: если входные сигна-
лы происходят из ограниченной области значении входных сигналов,
имеющей форму квадрата, то сеть Кохонена старается как можно том-
Сети с самоорганизацией
323
нее «покрыть» нейронами именно этот квадрат. Это происходит как в
случае небольшого количества нейронов (рис. 10.25), так и в довольно
медли гельвой сети, состоящей из очень большого количества нейронов
(рис. 10.26 I, а также когда изначально нейроны распределены по обшир-
ной подобласти прсйстрапства весов (рис. 10.27).
Запомни: эффект самоорганизации всегда Заключается в том, чтобы
для каждой точки пространства входных сигналов найти нейрон, кото-
рый будет распознавать демонстрацию именно этой точки — даже если
она не предъявлялась непосредственно в процессе обучения (рис. 10.28).
10.6. Как ведут себя сети Кохонена
при обработке более сложных данных?
Программа Example 11 обладает очень богатыми возможностями,
которые предоставляют тебе случай проводить весьма интересные экс-
периментов насколько хватит фантазии. Например, можно исследо-
вать, как способ демонстрации входных данных влияет на поведение се-
ти и развивающиеся в ней процессы самоорганизации. При использо-
вании предоставляемых программой опций ты быстро убедишься: если
еще больше ограничить (по сравнению с квадратом) подобласть вход-
ного пространства, из которой выбираются предъявляемые сети значе-
ния сигналов, то процесс самоорганизации будет стремиться к мини-
мизации предъявления излишних входных данных. Это явление мож-
но обнаружить при подаче в сеть входных сигналов из области, име-
ющей [например) треугольную форму (наша программа предоставляет
тебе такую возможность). Ты увидишь, что все нейроны выбирают се-
бе места для распознавания и представления точек внутри этого тре-
угольника (рис. 10.29). Ни один нейрон не будет специализироваться
Рис. 10.29. Этапы процесса самоорганизации в сети Кохонена, для которой входные
данные представлены в треугольной подобласти пространства входных сигналов
324
Глав а 10
Рис. 10.30. Неудачный процесс самоорганизации в ситуации, когда выделенная
подобласти» пространства входных сигналов имеет крестообразную форму
♦зг*-
$ А
ьЬ .4 »'
A V Л
’ г Ч Ъ в <! «Г
у*'-» cj w t?\ ’ j.) /
!r а й E> .
'АЛГ
’l t v, v
nA
Рис. 10.31. Этапы процесса успешной самоорганизации в сети Кохонена, для которой
входные данные представлены в крестообразной подобласти пространства- входных
сигналов
па распознавании входных сигналов, приходящих извне рассматривав
мой фихуры, в процессе обучения такие точки не демонстрировались,
поэтому они считаются несуществующими и распознавать их нет ни-
какой необходимости!
Несколько труднее4 решить подобную задачу в случае, когда выбран-
ная подобласть пространства входных сигналов имеет более сложную
форму, например креста. В такой ситуации на начальной стадии процес-
са обучения сечь можеч' и не найти требуемое распределение нейронов
(рис. 10.30).
Тем не менее, упорное обучение позволяет и в этой ситуации добить-
ся успеха (рис. 10.31), причем тем проще, чем больше размерность сети
рис. 10.32).
Сети с. самоорганизацией
325
Рис. 10.32. Пример успешной самоорганизации в большой сети Кохонена, для которой
входные данные представлены в крестообразной подобласти пространства входных
сигналов
10.7. Что происходит в сети при слишком
широком распределении начальных значений
весов?
Большой разброс начальных значений вфо^вых коэффициентов мо-
делируемых нейронов представляет собой фактор, не совсем благоприят-
ствующий получению хороших результатов самоорганизации (рис. 10.33).
В таких случаях часто наблюдается (несмотря на длительное обучение)
последовательное игнорирование самоорганизующейся сетью некоторых
фрагментов активных областей пространства входных сигналов (обрати
внимание на правый нижний угол треугольника на рис. 10.34).
Рис. 10.33. Пример возникновения проблем при поиске успешной самоорганизации
в сиучае слишком большого разброса начальных значений весовых коэффициентов
нейронов
326
Глава 10
Рис. 10.34. Пример игнорирования части входных данных, иногда наблюдаемого
в случае слишком большого разброса начальных значений весовых коэффициентов
нейронов
Рис. 10.35. Явле ние «скручивания» сети Кохонена
Рис. 10.36. Друхая форма «скручивания» сели Кохонена
Сети с самоорганизацией
327
Рис. 10.37. Редко наблюдаемый случай «скручивания» сети Кохонена, отображающей
крестообразную область пространства входных сигналов
Настоятельно рекомендую: после того как насмотришься на «нор-
мальную» работу сети, инициируй обучение с очень большим разбро-
сом случайных начальных значений весовых коэффициентов (например,
равным 5) для какого-нибудь несложного случая (лучше всего неболь-
шой сети, например 5x5, чтобы быстро получить июговый эффект).
Весьма вероятно, что ты заметишь интересное явление, иногда возни-
кающее в предварительно обученной сети Кохонена и заключающееся в
«завивании» или в «скручивании» сети (рассказать о нем сложно, лучше
увидеть собственными глазами на рис. 10.35, 10.36 и 10.37). В свободное
время поразмышляй, в чем причина подобного недостатка и почему про-
цесс самообучения пе способствует выходу сети из этого «тупика»?
10.8. Можно ли изменять форму
самоорганизации в процессе самообучения
сети?
Интересные опыты можно провести с применением программы
Example 11 благодаря возможности изменения «на ходу» формы под-
области пространства, из которой выбираются входные данные. Напри-
мер, можно начать процесс обучения с выбором данных из «квадратной»
области, а потом, когда искомое состояние будет почти достигнуто, из-
менить свое решение и начать адаптацию сети к треугольной области
входных дачных. Результат такого эксперимента показан на рис. 10.38.
Такую операцию не всегда удается провести абсолютно безболезнен-
но временами в окончательной структуре сети остается след ранее
использовавшейся фигуры. Это заметно па рис. 10.39, где показано раз-
витие особо извращенного обучения: вначале сеть адаптировала свою
328
Глава 10
Рис. 10.38. Смена целей самоорганизации в процессе обучения
Рис. 10.39. Иногда сменА целей самоорганизации в процессе обучения ос гавляет
неустранимые следы
деятельность к области в форме треугольника, потом ее заставили ис-
кать распределение в квадратной обласчи, а в конце опять пришлось
вернуться к обработке данных, происходящих из «зоны треугольника».
Представленные примеры свидетельствую^* что нейроны в сеч и Ко-
хонсна учатся (абсолютно самостоятельно, без какого-либо вмешатель-
ства учителя!) отображать в своей внутренней памяти (представленной
весовыми коэффициентами появляющиеся эталоны типовых вводных
сигналов.
10.9. Ну и для чего все это может пригодиться?
Думаю, у тебя уже сложилось мпс'пие о во зможностях сеч и Кохоне-
на. По вновь встает важный и конкретный вопрос для чего можно ее
практически использовать? В начале главы я уже рассказывал тебе об
очображениях 'например, в робототехнике), которые сеть Кохонена мог-
Сети с самоорганизацией
329
ла бы формировать самостоятельно. Теперь, с учетом полученных зна-
ний о функционировании сети, этот пример можно проанализировать
более подробно. Представь себе робота с двумя сенсорами (поскольку
исследовавшиеся тобой сети обрабатывали только два входных сигна-
ла). Пусть один из сенсоров получает информацию об освещенности, а
второй — о громкости звуков. Соответственно, каждая гонка простран-
ства входных сигналов будет соответствовать окружающей робота сре-
де с конкретной комбинацией свойств одна будет светлая и тихая,
другая — темная и шумная и т.п.
— Ну как? На что-то похоже?
И очень хорошо, должно было напомнить!
Робот, оснащенный сетью Кохонена, начинает свое функционирова-
ние с наблюдения за окружающей средой. Иногда в этом окружении свет-
ло, иногда темно, иногда шумно, иногда тихо, по оказывается, что одни
комбинации встречаются роботу, а другие нет. Робот спокойно классифи-
цирует поступающие данные, накапливает знания о них, специализи-
рует свои нейроны и через некоторое время получает натренированную
сеть Кохонена, в которой каждой практически встречающейся ситуации
соответствует распознающий и идентифицирующий ее нейрон.
Давай поразмышляем, что это означает. То, что возникает в сети
Кохонена, играющей роль «мозга» робота, представляет собой внутрен-
нюю модель внешнего мира. В тебе есть такая же модель. В пей
есть нейрон, распознающий лицо твоей мамы, есть нейрон, связанный
с идентификацией дороги домой, есть нейрон, ответственный за узна-
вание твоего любимого пирожного, и нейрон, который сигнализирует о
появлении самого ненавистного соседского нса, покусавшего тебя целых
два раза. Каждому сознательному впечатлению, каждой известной тебе
ситуации в мозге соответствует модель, которая эту ситуацию выявляет
и распознает. Выдающийся нейрофизиолог профессор Конорский свя-
зал эти внутренние модели определенных фрагментов внешнего мира
с конкретными областями человеческого мозга, получившими название
гностических элементов.
Практически все твое восприятие, вся способность к познанию и рас-
познаванию окружающего мира основана на готовых эталонах соответ-
ствующих впечатлений, сформировавшихся в мозге в результате попа-
дания в различные жизненные ситуации эти эталоны и есть гности-
ческие элементы. Сигналы, которые воспринимаются твоими глазами,
ушами, носом и другими органами чувств, служат в таких ситуациях
для активации соответствующего гностического элемента. Из тысяч мо-
делей, заготовленных в твоем мозге, выбирается и инициируется имен-
но та, которая лучше всего отражает полученное впечатление или сло-
жившуюся ситуацию. Благодаря исключительно этому механизму твое
330
Глава 10
распознавал ие впечатлены й оказывается столь быстрым, корректным и
надежным. Если же в мозге отсутствует дакая готовая, ранее сформиро-
ванная модель, то ситуация рассматривается как сложная, а ориентация
в ней часто бывает замедленной и ошибочной.
В доказательство можно привести согни доводов, но — чтобы нс тя-
нуть время и позволить тебе как можно скорее вернуться к эксперимен-
там с нейронными сетями, упомяну только три из них. Наиболее важ-
ные свидетельства реального существования впу1реиних моделей внеш-
него мира получены в экспериментах на животных. Например, прово-
дились опыты но ограничению зрительного восприятия мира котятами.
Эти опыты заключались в том, что когда у котенка открывались гла-
за (как известно, котята рождаются слепыми и обретают способность
видеть окружающий мир только через несколько дней), ему позволя-
ли смотреть только на какую-то единственную геомет рическую фшуру,
например на верт икалытую линию. Во всех прочих обстоятельствах, ко-
хда котенок мог увидеть что-то другое (например, во время кормления),
свет выключался. Через месяц подобной тренировки кол енок выпускал-
ся в «обычный мир>>. Оказалось, что при наличии совершенно здоро-
вых и нормальных глаз котенок вел себя как незрячий. Он не видел
препятствия, миску с молоком и даже человека,. Его мозг располагал
только моделями Демонстрировавшихся ранее простых геометрических
фигур, но в нем нс было места для эталонов кресла, горшка или дру-
гого котенка. Восприятие такого животного было полностью наруше-
но, и требовалось длительное обучение, чтобы зрительное восприятие
кота пришло в норму.
Подобные явления наблюдаются и у людей свидетельствуют ан-
тропологов, которые изучали жизнь пигмеев. Естественная среда оби-
тания этого племени африканских карликов густые джунгли, в ко-
торых невозможно увидеть что-нибудь на большом расстоянии. Пигмеи,
выведенные на открытое пространство, полностью утрачивали способ-
ность к ориентации. Обычные для нас простейшие действия, связанные
с вглядыванием вдаль (такие, как изменение перспективы, связанное с
приближением какого-либо животного), они воспринимали как необъж-
нимые и могущественные чудеса {еще мгновение назад эта зебра была
меньше собаки, а сейчас увеличилась до размеров лошади!). В их мозгах
отсугствовали модели, связанные с восприяшем зрительных впечатле-
ний на открытом пространстве.
Иногда ты самостоятельно можешь оценить значение внутренних мо-
делей рас познаваемого внешнего мира, если только обратишь в тимание
на простые и, па первый взгляд, очевидные явления. Например, ты бе!
проблем воспринимаешь любую информацию па русском языке, а ес-
Сети с самоорганизацией
331
ли занимаешься информатикой, то для тебя не составит труда прочи-
тать текст, записанный буквами латинского алфавита, па английском,
немецком, французском и других языках. Если гы хоть немного знаешь
какой-то из этих языков, то достаточно одного взгляда — и уже в мозгу
буквы соединяются в слова, из слов вырастают понятия, из понятий
знания... А все потому, что в твоем мозге па протяжении многих лет
обучения сформировались модели букв, слов, понятий и впечатлений, в
связи с чем чтение знакомых элементов просто «вызывает» их гото-
вых к немедленному использованию.
Противоположная ситуация возникает, когда ты встречаешь в тексте
неизвестное слово либо пытаешься прочитать сообщение на неизвестном
языке. С трудом произносишь его вслух, очень много времени тратишь
на фонетический разбор, пе говоря уже о полном непонимании смыс-
ла незнакомой комбинации букв. Простота и скорость чтения мгновенно
исчезают, поскольку в твоем мозге нет готовых эталонов, нет моделей
этих слов, фраз и сообщений.
Я мог бы расширить эту тему и показать, как при анализе текстов
на неизвестном языке (папример, па венгерском), по записанных зна-
комыми буквами, могуч1 использоваться хранящиеся в мозге эталоны
букв, благодаря чему можно запомнить неизвестный текст и позднее по-
просить переводчика разъяснить его смысл. Гораздо хуже, если в тво-
ей внутренней модели внешнего мира нет даже эталонов необходимых
букв (например, если встретилась надпись иа японском или арабском
языке). Ты не только не сможешь понять смысл надписи, по даже про-
сто запомнить ее и воспроизвести переводчику будет неимоверно труд-
но! Твой мозг просто не будет иметь в запасе никаких пригодных для
этого гностических элементов.
В твоем мозге хранится и другое отображение, которое образует
«карту» твоего тела па поверхности коры мозга в области извилин, на-
зываемых gyrus postcentralis (рис. 10.40). Что интересно: эта карта совер-
шенно не соответствует пропорциям и форме твоего тела! В частности,
па поверхности мозга ладони и лицо занимают гораздо больше места,
чем весь корпус вместе с конечностями (рис. 10.41)!
Это объясняется фактом, который я упоминал раньше в контексте
искусственных самоорганизующихся нейронных сетей: для управления
движениями руки и лица (мимика, речь), а также детя получения осяза-
тельных импульсов с этих частей тела необходимо значительно больше
мозговых клеток, поскольку эти действия выполняются очень часто.
Прошу прощения за столь детальное обсуждение примеров, но ты
должен понять и запомнить, какое серьезное и принципиальное зна-
чение имеют для зрения (или любого другого чувственного восприя-
332
Глава 10
Рис. 10.40. Представление конкретных частей тела в коре головного мозга человека
в контексте функции управления движением (слева) и отбора и анализа чувственных
раздражителей (справа)
тия: слуха, вкуса и даже осязания) рапсе сформированные и храня-
щиеся в мозге эталоны известных впечатлений. Именно такие эталоны
абсолютно спонтанно формируются в нейронных сетях благодаря про-
цессу самоорганизации.
Но вернемся к примеру с роботом. Каждый нейрон сети Кохонена
встроенной в этого робота, распознает одно из встречающихся в ре-
альности (и только таких!) состояний внешнею мира и выполняет в
системе управления робсГгом ту же функцию, что и гностический эле-
мент? в твоем мозге. Следовательно, процесс самообучения сети Кохонена
создает в системе управления роботом своеобразную систему гностиче-
ских элементов в виде моделей Ситуаций, в которых может оказаться
этот робот. Такие модели очень важны, поскольку с их помощью можно
классифицировать любую исходную ситуацию (описываемую сигнала-
ми, поступившими от сенсоров). В свою очередь, после отнесения фак-
тически возникшей ситуации к одному из ранее определенных классов
робот может адаптировать к ней свое поведение. В простейшем случае ты
Сети с самоорганизацией
333
Рис. 10.41. Изображение человечка, у которого размеры отдельных частей тела
пропорциональны ве личине их представления в мозге
сам можешь определить, что робот обязан делать в каждой конкретной
ситуации, например в нормальных условиях (светло и тихо) робот дол-
жен двигаться вперед, если свет погаснет остановиться, если услышит
шум, то пятиться назад и т.п. Важно то, что ты не должен формулиро-
вать подробные команды роботу по его действиям в каждой возможной
ситуации. На основании соседства нейронов, распознающих аналогич-
ные ситуации, можно ограничиться такими указаниями для избранных,
наиболее типичных ситуаций, а обученная сеть Кохонена — «мозг» робо-
та сама выяснит, что нужно делать. Если робот поймет, что примени-
тельно к фактически сложившейся ситуации у него нет готового рецепта
поведения, то он самостоятельно выявит (на основании принципа сосед-
ства элементов нейронной сети) ближайшую к ней типовую ситуацию.
Если в памяти робота хранится конкретная инструкция по поведению в
этой ближайшей ситуации, то наверняка в сложившихся условиях име-
ет смысл ситуации рекомендовано быстро ехать вперед (пропуск), то во
всех не определенных пользователем «соседних» ситуациях следует так-
же ехать вперед, но (на всякий случай) с пониженной скоростью.
Если подобным образом ты задашь реакцию робота только для не-
скольких модельных ситуаций, то он сможет принимать решения (луч-
шие или худшие) в любой складывающейся ситуации. Необходимо под-
черкнуть, что эти решения будут касаться не только тех объектов, ко-
торые предъявлялись сети в процессе самообучения. При обучении сети
Кохонена (так же как и любых других нейронных сетей) мы наблюдаем
процессы усреднения и обобщения знаний.
334
Г л а в a 10
Относительно усреднения необходимо отмсти ть еще один факт. В хо-
де обучения сечи могу г демонстрироваться объекты, несколько отличаю-
щиеся друг от друга, т.е. харак юризующиеся некоторым разбросом зна-
чений параметров. Тем не менее, сеть запомнит для чих (в виде комплек-
са значений весовых коэффициентов соответствующих нейронов некий
усредненный эталон «типового входного сигнала», который сеть выра-
ботает (абсолютно самостоятельно!) по результатам обучения. Конечно,
таких типовых эталонных сигналов (и связанных с ними моделируемых
состояний окружающей среды) будет много, точнее столько, сколько
нейронов содержит сеть. Но в любом случае эталонов будет меньше, чем
возможных состояний окружающей среды, поскольку при произвольно
изменяющихся параметрах ситуаций, в которые попадает робот, таких
состояний будет бесконечное множество!
В свою очередь, благодаря обобщению знаний в процессе «тестиро-
вания» (т.е. в период нормальной эксплуатации робота) сеть может ока-
заться в ситуации с такой комбинацией параметров, которая ни разу не
встречалась в период обучения. Том не менее, каждый нейрон сети (да-
же впервые столкнувшийся с этим набором сигналов) будет пытаться
отнести ее к своей группе путем сравнения с «собственным» эталоном.
Естественно, победит тог нейрон, чей эталон окажется наиболее близким
к фактически сложившейся ситуации. Такое поведение предопределяет-
ся автоматическим обобщением знаний получаемых при обучении ели,
и очень часто приноси г прекрасные результаты.
Рассмотренный пример с роботом, который благодаря сети Кохонена
адаптирует свое поведение к состоянию окружающей среды, требовал от
тебя воображения, по в повседневных делах людям не требуется особен-
но много интеллекгуальных мобильных роботов. Если бы ты решил за-
рабатывать себе на жизнь созданием и продажей сетей Кохонена, боюсь,
на виллу с бассейном и шикарный автомобиль (которых ты, несомнен-
но, достоин) может не хватить... Увы, даже самые гениальные техниче-
ские системы не приносят их создателям сверхдоходов, если не найдутся
желающие их купить и эксплуат ировать. Возможно, в твоем мозге уже
сформирована модель этой ситуации? Если да, то поразмышляй: кто и
для чего по-настоящему может применять сети Кохонена?
Все идеи перечислить я не смогу при всем желании их слитком
много, по несколько наиболее интерес пых (в качестве отправных точек),
пожалуйста. В предыдущем абзаце речь шла о деньгах. Деньги, как из-
вестно, хранятся в банках, откуда их иногда крадут...
Только не подумай, что я агитирую строить мобильного робота, ко-
торый под управлением сети Кохонена будет металлическим голосом
орать в окошко кассы: «Руку вверх! Это ограбление! Деньги на сгпол!».
Сети с, самоорганизацией
335
Я предлагаю тебе подумать о возможностях сетей Кохонена с точки зре-
ния защиты банков от нападений. Причем не от грабежей в стиле при-
митивных кинофильмов — с бандитами в масках, стрельбой и бешеной
погоней по узким улицам. К счастью, такие нападения случаются редко,
и полиция научилась им противодействовать. В паше время настоящим
бедствием для банков стали преступления, совершаемые в «белых пер-
чатках», например невозврат полученных кредитов.
Банк живет благодаря выдаче денег в долг, поэтому он не может
гнать в шею каждого, кто обращается за получением кредита хоть
это и гарантирует 100% безопасности. Увы, часть получателей кредитов
не возвращают выданные им деньги - и это приводит к убыткам (как
правило, значительно большим, чем от нападений с пистолетом в руке).
Как узнать, кому безопасно одалживать деньги, а кому нет?
Все просто нужно только построить модель добропорядочного
заемщика, который на кредитные деньги построит прибыльное предпри-
ятие и вернет банку деньги с процентами, а также модель мошенника,
который рассчитывает получить деньги и исчезнуть с ними в голубом
тумане. К сожалению, люди очень разные, также различны жизненные
и экономические ситуации. Поэтому потребуются тысячи моделей доб-
ропорядочных заемщиков и, как минимум, столько же (если не больше)
моделей мошенников и растратчиков. Ни один человек решить такую
задачу не в состоянии.
Почему не вспомнить здесь о возможностях нейронных сетей? До-
статочно хорошенько помозговать, как провести самообучение и как ин-
терпретировать результаты, и после продажи этой гениальной системы
нескольким банкам можно отправляться на заслуженный отдых где-
нибудь на тропических островах.
Что, не хватает данных? Я должен подробно описать, что и как
делать ?
Ты представляешь, насколько тесно стало бы на коралловых пля-
жах Мальдивских островов, если бы я раскрыл здесь все подробности и
каждый, кто прочитал эту книжку, стал бы миллионером? Порабо-
тай своей головой сам!
10.10. Как можно использовать сеть в качестве
инструмента для преобразования размерности
пространства входных сигналов?
После быстротечной экскурсии к синему морю и шумящим пальмам
вернемся к обсуждению научных проблем. Уникальной особенностью се-
ти Кохонена считается наличие в ее откликах топологического пред-
ставления пространства входных сигналов. Естественно, речь идет
336
Глава 10
Двухмерное пространство сигналов
Двухмерная структура сети
Рис. 10.42. Соответствие размерности сети и пространства сигналов
о соседстве и его последствиях. На рисунках, которые ты уже видел
и которые увидишь во время самостоятельного применения описанной
программы, соответствующие нейронам синие точки соединяются меж-
ду собой красными линиями. Ты уже знаешь, что такими линиями со-
единены нейроны-соседи. Сначала эти линии, так же как и сами точки,
расположены совершенно случайно. В чем сущность этой сетки? Опа
отражает следующую закономерность: соседние нейроны будут стре-
миться к выявлению и распознаванию соседствующих друг с другом
точек в пространстве входных сигналов! Благодаря этой закономерно-
сти порядок, обусловленный близостью друг к другу некоторых точек
(соответствующих входным сигналам) вследствие очень небольших раз-
личий их координат, будет перенесен па сеть, в которой близкие точки
будут распознаваться только близкими друг к другу нейронами.
На всех представленных до настоящего момента рисунках два поня-
тия (близости (подобия) входных сигналов и близости (соседства) ней-
ронов в сети) могли связываться и ассоциироваться между собой вполне
естественным способом, поскольку пространство входных сигналов (и,
конечно, пространство весов) было двухмерным (как на рис. 10.13 или
10.16), и топология сети тоже была двухмерной (как на рис. 10.9 или
10.11). Существовало логичное соответствие между такими понятиями,
как «входной сигнал, лежащий выше предыдущего» (в том смысле, что
он имеет большее значение второй координаты) и «входной нейрон, ле-
жшций выше предыдущего» (в том смысле, что он лежит согласно
условной нумерации — в предыдущей строке (рис. 10.42).
Но такую ситуацию нельзя считать единственно возможной. Легко
представить себе одномерную сеть, которая будет учиться распознавать
двухмерные сигналы (рис. 10.43).
Можешь исследовать поведение сети, выполняющей такую своеоб-
разную конверсию двухмерного пространства входных сигналов в одно-
мерную структуру сети, поскольку наша программа позволяет строить
одномерные сети (цепочки нейронов).
Сети с самоорганизацией
337
Одномерная структура сети
Двухмерное пространство сигналов
Рис. 10.43. Несоответствие размерности сети и пространства сш налов
Такую нетипичную структуру сети ты получишь, задав одной из
ее размерностей (лучше первой) значение 1. Второй размерности луч-
ше присвоить большое значение (например, 100). Поведение сети в этом
случае станет более интересным, а учиться она будет достаточно быст-
ро, так как можно не слишком ограничивать себя.
Взгляни на рис. 10.44, 10.45 и 10.46. На них заметно, что одномерная
сеть вполне осмысленно вписывается в выделенную область простран-
ства входных сигналов. Это гарантирует два очень важных достоинства:
Во-первых, цепь нейронов, представляющая собой одномерную сеть,
заполняет собой (лучшим или худшим способом) всю используемую об-
ласть пространства входных сигналов. Это означает, что для каждой
точки двухмерного пространства входных сигналов в одномерной
нейронной сети имеется представитель, который будет выявлять и рас-
познавать эту точку во входных данных. В многомерном входном про-
странстве нет «бесхозных» точек;
Во-вторых, объектам, расположенным в пространстве входных сиг-
налов близко друг к другу (т.е. в каком-то смысле взаимно похожим друг
на друга), в одномерной нейронной цепи соответствуют соседствующие
друг с другом нейроны. К сожалению, как правило, но не всегда,
Рис. 10.44. Отображение двухмерного пространства входных сигналов одномерной
сетью
338
Глава 10
Рис. 10.45. Болес сложный пример отображения двухмерного пространства входных
сигналов одномерной сетью
Рис. 10.46. Еще один пример отображения двухмерного пространства входных
сигналов одномерной ceino
поэтому приходи гея считаться с вероятными ошибками (рис. 10.471 Тем
по менее, для значительного большинства нейронами, позволяют гово-
рить о подобии этих состоянии.
Поразмышляем вместе, какое эго может иметь значение. Среди ог-
ромного количества задач, связанных с информач икон, мы встречаемся с
аналогичной и очень сложной проблемой. Дня ориентации в интересую-
щих пас явлениях и процессах накапливаются огромные объемы данных.
Например, чтобы точно представлять себе текущее состояние ядерно,го
реактора па большой электростанции, необходимо измерять и оценивать
согни различных параметров. То же самое относится к большой пла-
вильной печи па металлургическом комбинате, многомоторному само-
лечу на этапе старта. а также к крупному предприятию, которым мы
хотим эффективно управлять. Фактическое состояние каждой из этих
больших систем описывается сотнями и тысячами числовых парамет-
Сети с самоорганизацией
339
Точки,
представляющие
похожие
входные
сигналы
Точки,
представляющие
похожие
входные
сигналы
Удаленные нейроны,
распознающие похожие
входные сигналы
Соседние нейроны,
распознающие похожие
входные сигналы
Рис. 10.47. Примеры корректного и некорректного отображения отношений между
объектами многомерною пространства, представляемыми нейронами сети малой
размерности
ров, следовательно, мы можем представить это состояние точкой в очень
многомерном пространстве. Такое многомерное пространство необходи-
мо, поскольку результат каждого измерения, эффект каждого наблю-
дения, сих нал каждого анализатора должен откладываться на отдель-
ной оси. По мере развития того или иного процесса значения всех пара-
метров изменяются, соответственно изменяется пространственное рас-
положение точки, характеризующей текухцее состояние. В связи с этим
для комплексного оценивания безопасности самолета, стабильности ре-
актора, надежности печи или рентабельности предприятия необходимо
непрерывно отслеживать местоположеххие точки-состояния в многомер-
ном пространстве. Точнее, речх> идет о позиционировании точки, пред-
ставляющей текущее состояние объекта, относительно областей, кото-
рым мы можем приписать конкретное практическое значение: стабиль-
ная работа реактора — или симптомы его перегрева, высокое качество
вырабатываемою сырья или его неудачный состав, благоприятное
развитие предприятия или угроза банкротства.
Если мы желаем наблюдать» и контролировать некоторый процесс,
то должны обладать актуальной и полной информацией о его состоянии,
направлении изменения, конечной цели. При попытке решать подобные
340
Глава 10
проблемы в современной технике мы чаще всего используем решения, ос-
нованлые на старательном накоплении всех оригинальных данных и их
предоставлении лицу, уполномоченному принимать решения. В резуль-
тате возникают известные тебе по фильмам огромные центры управле-
ния атомными электростанциями^ стены которых увешаны различными
экранами и индикаторами, кабины нилотов сверхзвуковых истребителей,
в которых каждый сантиметр поверхности заполнен какими-то устрой-
ствами, датчиками и хронометрами, а также километры компьютерных
распечаток с громадным числом числовых таблиц и i рафиков, над ко-
торыми стонут и мучаются бизнесмены.
Увы, с практической точки зрения такие решения фатально неэф-
фективны. Объяснение простое: ни один человек не может эффективно
наблюдать, контролировать и анализировать тысячи параметров. Если
честно, то оператору ядериого реактора, пилоту самолета или директору
фирмы совершенно не нужны подробные и ночные данные. Каждому из
них необходима комплексная, обобщенная информация: все нормально
или что-то не в порядке. Именно такую информацию способна выра-
ботать сеть Кохонена.
Представь себе: ты создал сеть, в которой к каждому нейрону посту-
пает несколько сотен или даже несколько тысяч сигналов, отражающих
все собранные измерительные данные. Такую сеть ничуть не труднее
запрограммировать, чем сеть с двумя входами потребуется бблщие
места в компьютерной памяти и оолыпе времени на моделирование ее
работы. Также представь, что эта сеть предусматривает двухмерное со-
седство нейронов его можно использовать так, чтобы выходной сигнал
каждого нейрона высвечивался в определенном (заранее установленном)
месте на экране, а сигналы соседей соответственно в соседних ("греках
или столбцах (чтобы визуализировать их отношения). После обучения
этой сети по методу Кохонена ты получишь инструмент для своеобраз-
ного «распределения» многомерных, сложных для оценивания данных
по плоскости одного экрана, который легко охватить взглядом, легко
оценить и легко интерпрет ировать. Образ на экране счанеч источником
данных, которые можно интерпретировать следующим способом:
Каждой встретившейся на практике комбинации входных сигналов
будет сооч веточ вовать только нейрон («победитель»), который будет вы-
являть и распознавать именно эту комбинацию. Если ты будешь высве-
чзтвать на экране выходной сигнал только этого нейрона, то получишь
образ в виде перемещающейся светящейся точки. Если на основании
предыдущих экспериментов ты выяснишь, какие области экрана отве-
чают нормальным состояниям исследуемого процесса, а какие угро-
жающим состояниям, то по наблюдениям за текущим местоположением
Сети с самоорганизацией
341
светящейся точки и за направлением ее перемещения сможешь получить
комплексную оценку состояния и перспектив изучаемой системы.
Ты можешь выводить на экран выходные сигналы нейронов без их
дискриминации, обусловленной принципом конкуренции. Можно дого-
вориться, что различным значениям выходных сигналов будут соответ-
ствовать разные цвета. В этом случае вариации наблюдаемого процесса
отразятся па экране изменяющейся разноцветной мозаикой. Опа содер-
жит гораздо больше информации о состоянии процесса, и после некото-
рой практики позволит тебе формулировать достаточно глубокие и точ-
ные выводы о наблюдаемых тенденциях; тем не менее, па первый взгляд
эта мозаика может показаться мало информативной.
Можно предложить много способов визуализации результатов функ-
ционирования сети Кохонена. Обрати внимание на их общую особен-
ность: эти образы всегда двухмерны, их легко охватить взглядом и от-
носительно просто интерпретировать. Эти образы не содержат информа-
цию о конкретных значениях тех или иных параметров (в случае необхо-
димости эти значения всегда можно получить другим способом), но де-
монстрируют интегрированное, комплексное представление, которое так
необходимо лицу, принимающему решения и оценивающему их послед-
ствия. Эти образы понижают степень подробности анализируемых дан-
ных, но благодаря обсуждавшимся выше явлениям усреднения и обоб-
щения их применение позволяет получать очень хорошие результаты.
10.11. Контрольные вопросы и задания
для самостоятельного выполнения
1. В чем разница между самообучением и самоорганизацией?
2. Сети Кохонена часто называют инструментом, позволяющим «за-
глянуть вглубь многомерных пространств данных». Сможешь ли ты обос-
новать это определение?
3. Одно из приложений сети Кохонена их использование как «де-
тектора новостей». В этом качестве сеть должна сигнализировать о по-
явлении комбинации входных сигналов, которая некогда прежде не ре-
гистрировалась (пи в точно такой, ни в любой подобной форме). Авто-
матическое обнаружение такой ситуации очень важно, например, для
выявления кражи кредитной карты или мобильного телефона вор
чаще всего пользуется ими иначе, чем законный владелец. Подумай,
каким способом сеть Кохонена сообщит о встрече с сигналом, имею-
щим признаки «новинки»?
4. Исследуй развитие процесса самоорганизации после изменения
формы подобласти пространства входных сигналов, из которой выбира-
342
Глава 10
ются в случайном порядке демонстрируемые входные сигналы и кото-
рая заполняется «сеткой», расплетаемой нейронной сетью. Программа
позволяет' тебе выбрать форму этой области квадрат, треугольник
или крест. Изучи последствия сделанного выбора. Если ты умеешь про-
граммировать, то можешь доработать программу для добавления еще
каких-нибудь новых форм.
5. Исследуй, какое влияние оказывает на процесс самоорганизации
коэффициент обучения нейрона-победителя, называемый в программе
AlphaO. Увеличение или уменьшение этого коэффициента вызывает со-
ответственно ускорение или замедление обучения. По мере выполнения
программы значение коэффициента AlphaO автоматически уменьшает-
ся (см. ниже), в результате чего процесс обучения (сначала быстрый и
динамичный) становится все плавным. Ты можешь и это изменить, а
потом проанализировать достигнутый эффект.
6. Исследуй, какое влияние оказывает на процесс самоорганизации
коэффициент обучения нейронов, соседствующих с нейроном-победите-
лем. Этот коэффициент называется в программе Alphal. Чем больше
значение этого коэффициента, гем более заметен эффект «притяжейия»
соседей к нейрону-победителю. Изучи и опиши последствия изменений
значения этого коэффициента (а также отношения AlphaO/Alphal) и
их влияние на поведение Сети.
7. Исследуй, какое влияние оказывает на процесс самоорганизации
сети изменение сферы соседства. Это значение определяет число ней-
ронов-соседей, т.е. как много нейронов подвергается принудительному
обучению при самообучении «победителя». Размер сферы соседства дол-
жен зависеть от размеров сети, именно по такому принципу он авто-
матически выбирается в применяемой программе. Предлагаю тебе экс-
периментально проверить его воздействие на поведение сети. Учти, что
большие значения сферы соседства сильно замедляют процесс обучения.
8. Исследуй, какое влияние оказывает на поведение и процесс само-
организации сети изменение коэффициента EpsAlpha, управляющего
пошаговым уменьшением коэффициентов обучения AlphaO и Alphal.
Обрати внимание: чем меньше значение этого коэффициента, тем ради-
кальнее будут уменьшаться коэффициенты обучения, и тем быстрее бу-
дет стабилизироваться процесс. Можешь задать коэффициент EpsAlpha
равным 1 (при этом коэффициенты обучения вообще не будут изменять-
ся) либо несколько большим единицы и понаблюдай за обучением сети
с течением времени (ой, что будет твориться!).
9. Исследуй, какое влияние оказывает на поведение и процесс са-
моорганизации сети изменение сферы соседства. Можно изменять зна-
чение коэффициента EpsNeighb, который управляет сокращением (от
Сети с самоорганизацией
343
шага к шагу) размера этой сферы. Сравни результаты изменения этого
коэффициента с процессами, которые ты наблюдал при эксперименти-
ровании с коэффициентом EpsAlpha.
10. Исследуй, к чему приведут попытки «переобученная» сети, кото-
рая вначале активно училась заполнять область пространства входных
сигналов, напоминающую, например, крест, а потом переключилась на
квадрат или треугольник. Не забывай, что в экспериментах с «переобу-
чением» после изменения формы области необходимо увеличить значе-
ния коэффициентов AlphaO и Alphal, а также сферу соседства.
11. Задание для наиболее подготовленных. Модифицируй про-
грамму для возможности решения задач, в которых сеть Кохонена стал-
кивается с явлением сильной неравномерности вероятности демон-
страции точек из различных регионов пространства входных сигналов.
Проведи самообучение и убедись, что в натренированной сети значи-
тельно преобладают нейроны, специализировавшиеся на распознавании
сигналов из регионов, наиболее часто представлявшихся в обучаю-
щей выборке. Сравни этот эффект со структурой карты мозговой ко-
ры, представленной па рис. 10.40. Какие выводы напрашиваются по ре-
зультатам этого опыта?
12. Задание для наиболее подготовленных. Напиши программу
для моделирования поведения робота, описанного в разд. 10.9. Проведи
эксперименты, имитирующие накопление умений отождествления сен-
сорных раздражителей (описывающих состояние внешней среды) с бла-
гоприятными для робота действиями (вызывающими выгодные для пето
изменения в моделируемом окружении). Исследуй, какое представление
знаний о моделируемой окружающей среде будет получено и исполь-
зовано «мозгом» робота его самоорганизующейся нейронной сетью.
Внеси несколько разнообразных изменений в характеристики окружаю-
щей среды (которую ты моделируешь, поэтому можешь назначить любые
правила ее формирования) и проследи, какие из этих изменений робот
сможет «обнаружить» своей самоорганизующейся нейронной сетью, а
какие окажутся слишком сложными для обработки?
Глава 11
РЕКУРРЕНТНЫЕ СЕТИ
11.1. Что такое рекуррентная нейронная сеть?
Благодаря рассмотренным в предыдущих главах примерам ты уже
знаешь, как обучается нейронная сеть одно- или многослойная, ли-
нейная или нелинейная, обучаемая с учителем или добывающая знания
«собственными руками», короче говоря, почти любая.
Почти, потому что ты еще не познакомился с рекуррентными се-
тями, содержащими обратные связи. Обратными связями пазывают-
ся соединения, которые возвращают сигналы из удаленных (от входа
нейронов сети к нейронам входного слоя или предшествующих скрытых
слоев (рис. 11.1). Несмотря на кажущуюся простоту, это очень важное
нововведение. Ты скоро убедишься, что сеть с обратными связями об-
ладает гораздо более богатыми вычислительными возможностями, чем
классическая сеть I в которой разрешено только однонаправленное рас-
пространение сигналов о г входа к выходу).
В сетях с обратными связями считаются нормальными явления и
процессы, которые невозможно увидеть в однонаправленных сетях. Од-
нократно возбужденная сеть с обратными связями может генерировать
целую последовательность сигналов и явлений, поскольку выходные сиг-
налы (представляющие собой результат обработки сигналов на некото-
ром n-м шаге) при попадании па входы нейронов приводят к выработке
новых (как правило, совершенно других) выходных сигналов на (п + 1)-м
шаге. Такое усложненное, «пикническое» продвижение сигналов в ре-
куррентных сетях приводит к специфическим явлениям и процессам,
например к затухающим или нарастающим осцилляциям, к стремитель-
ному усилению или к такому же стремительному угасанию сигналов или
к таинственным, хаотическим изменениям (создающим впечатление раз-
вития абсолютно недетерминированных процессов).
Подобные циклические сети с обратными связями пока еще не полу-
чили широкого распространения, поскольку их довольно сложно анали-
зировать. Трудности связаны с тем, что сигналы могут долго кружить по
Рекуррентные сети
345
<?????$
Рис. 11.2. Простейшая нейронная
структура с обратной связью
Рис. 11.1. Пример структуры рекуррентной сети.
Пунктиром выделены обратные' связи
замкнутым коп гурам (от входа к выходу и обратно на вход с новым
изменением выхода и т.н.). В результате сеть, отвечающая на любой,
даже очень кратковременный вводной сигнал, проходит через длинную
последовательность разнообразных промежуточных состояний, прежде
чем в пей сформируются все необходимые сигналы.
Рассмотрим простои пример. Представь себе сеть, состоящую из
единственного нейрона (чтобы было проще линейного). Он имеет два
входа с помощью первого входа в нейрон вводится входной сигнал, а
па второг вход подается сигнал с выхода, т.е. создается обратная связь
(рис. 11.2). Но может быть проще?
Познакомимся с функционированием этой сети. Как обычно, пред-
jiaiaio воспользоват ься простой программой Examplel2a, в которой ты
сможешь самостоятельно задавать параметры рассматриваемой сети
весовой коэффициент (feedback weight), с помощью которого в ней-
рон будет вводиться сигнал обратной связи, а также входной сигнал
(input signal strength), с которого сеть будет начинать свою работу.
Дополнительно можно определить (путем активизации поля single-in-
put -impuls), должен ли входной сигнал непрерывно подаваться на вход
сети, или он будет' подан однократно в момент начал а моделирования.
Программа будет пошагово рассчитывать сигналы, кружащие ио сети,
и отображать ее поведение. С помощью этой программы легко обнару-
жить несколько закономерностей:
Описываемая сеть демонстрирует существенно более сложную дина-
мику: после однократной (импульсной ) подачи входного сигнала на вы-
ходе сети инициируется длительный процесс, на протяжении которого
выходной сигнал miioi ократно изменяется, прежде чем будет достигнуто
состояние равновесия, если оно вообще достижимо (рис. 11.3).
346
Глава 11
Рис. 11.3. Пример результатов функцио-
нирования программы Example 12а демон-
стркрует сложное поведение системы с об-
раз ной с ня 5ыо даже в очень простой исход-
ной ситуации
Равновесие в этой простейшей
сети может быть достигнуто (при
отсутствии входного сигнала на
протяжении всего моделирования)
только при условии, что произве-
дение выходного сигнала на вес со-
ответствующего входа будет стро-
го равно сигналу обратной связи,
необходимому для выработки это-
го выходного сигнала (сигналы на
обоих входах нейрона должны
быть уравновешены).
Выходной сигнал, при котором
удовлетворяется описанное выше
условие, называй гея аттракто-
ром. Чуть ниже я подробно разъ-
ясню этот термин.
Положение агтрак гора зави-
сит от параметров сети:. Для се-
ти с единичным весовым коэффи-
циентом обратной связи аттракто-
ром является любая точка, тогда
как для любой другой сети сосю-
яние равновесия удается достичь только в случае равенства выходно-
го сигнала пулю (рис. 11.4). Этим свойством обладает рассматриваемая
здесь простая линейная сеть; в нелинейных сетях аттракторов может
быть несколько, чем мы обязательно воспользуемся.
Если значение коэффициента синаптического веса в контуре обрат-
ной связи положительно (при этом образуется так называемая поло-
жительная обратная связь), то процессы в системе имеют апериоди-
ческий характер, т.е. они не осциллируют (рис. 11.5). Необходимо от-
метить, что в такой системе могут протекать процессы, характерные
только для положительных значений сигналов (в левой части рисун-
ка) или только для отрицательных значений (в правой части рисунка).
При этом положительные значения с течением времени становятся все
больше, а отрицательные — все меньше, но пи в одном процессе сиг-
налы не изменяют свой знак.
Если значение коэффициента синап гического веса в контуре обрат-
ной связи отрицательно (при этом образуется так называемая отрица-
тельная обратная связь), то процессы в системе имеют периодический
характер, т.е. они осциллируют (рис. 11.6).
Рекуррентные сети
347
parameters'
input signal strength ~
feedback weight ~
single input impulse
Step: Output
•i»gle input impulse
Output:
lux
1=
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,000000
0,030000
0,000000
0,000000
0,000000
0,000000
navigation
Start New
C&iiiii- «Л '<
Continue I
шшгш * аияа
Reset
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
12,300000
navgahon
Рис. 11.4. Два сло< оба достижения состояния равновесий в линейной сети: нулевые
сигналы (слева) либо единичное усиление обратной связи при отсутствии входного
сигнала (справа)
$
Характер осцилляций в системе с отрицательной обрат ной связью за-
висит от параметров сети. Иногда «судороги» стремительно нарастают,
сеть мечется от больших (но модулю) отрицательных к еще большим
положительным значениям, чтобы потом сгенерировать еще больший
pa'amelers
input signal strength
feedback weight
single input impulse
Step:
1=
5
6
7
6
9
10
11
12
13
14
15
16
17
r=-
10,000000
14,000000
19,600000
27,440000
38,416000
53,782400
75,295360
105,413504
147,578908
206,610468
289,254655
404,956517
566,939124
793,714773
1111,200683
1555,680956
2177,953338
лил
Output
•AV.)
navigation
Start New
Heset
&
Continue
G‘J JjiHpfy г^сиггУш j b I k/'iHipb 12uj
par. arnetets
input signal strength -
feedback weight =
single npul impulse
Step Output:
’x= 17
-10,000000
-16,000000
-25,600000
-40,960000
-65,536000
-104,857600
-167,772160
-268,435456
-429,496730
-687,194767
-1099,511628
-1759,218604
-2814,74976?
-4503,599627
-7205,759404
-11520,215046
-18446 744074
navigation
Start New
Reset
1
2
3
Рис. 11.5. Типичное развитие событий в системе с положительной обратной связью
348
Глава 11
яга
Рис. 11.6. Т и пи иное ра-зви г не событий в
системе с отрицательной обратной связью
отрицательный сигнал и т.д. Та-
кая бьющаяся в конвульсиях Сеть
может привести к катастрофе, по-
скольку ее поведение напоминает
функционирование мозга больно-
го эпилепсией или работу косми-
ческой ракеты, которая па стар-
те утратила стабильность и жи-
вот взорвется. Но в определенных
условиях судороги постепенна, за-
тихают, сеть успокаивается и ста-
билизируется, именно так функци-
онируют все грамот но енроект ирО-
вацные системы автоматики.
В ходе наблюдений за поведе-
нием систем с обратной связью ты
заметишь, насколько они чувстви-
тельны к значениям своих пара-
метров. Для систем без обратной
связи это по характерно, следова-
тельно, такую чувствительность можно считать отличительной особен-
ностью рекуррентных нейронных сетей (и других рекуррентных систем).
Step
Output
10,000000
5,00000ft
2,500000
1,250000
0,625000
0,312500
0,156250
0,078125
0,039063
0,019531
0,009766
0,004885
0,002441
0,001221
0,000610
0,000305
0,000153
ДшрЬ rjUJjfdBi I Ij I
pabmete»’
input signal strength =
feedback weight
single input impulse
navigation
Start New
Reset
i Continue j
ГctC
parameters :nput signal strength = feedback we ght <= -0,4 single input impulre Step Output
: 1= 1 y^“ 10,000000
1= 2 ysi -4,000000 navigation
: 1» з ysz 1,600000
i= 4 утя -0,640000
i= 5 yss 0,256000
is 6 y= -0,102400 Start New
1= 7 0,040960 -ft,016384
i= 8 yn
i 1= 9 0,006554 Continue i
; i= 10 У= -0,002621
I i= 11 Y" 0,003049 Reset
i i= 12 yss -0,000419 M.MMfl
> 1= 13 y= 0,000168
: 1= 14 y= -0,000067
’ i= 15 yr? 0,000027
' i= 16 yes -0,U00011
! is: 17 0,000004 HHMWWM
Рис. 11.7. Стаби льное функционирование системы с обратной связью после уменьшения
значения весового коэффициента значительно ниже порога стабильности
Рекуррентные сети
349
Шу’
input signal strength
feedback weight
single input impulse
Step
Output.
10,0
Рис. 11.8. Поведение системы с обрат-
ной связью при непрерывном поступле-
нии в нее постоянного входного сигнала
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
10,000000
5,000000
7,500000
5,250000
6,575000
6,562500
6,716750
6,640625
6,679666
6,660156
6,669922
6,666059
6,667460
6,666260
6,666370
6,666565
6 666713
Если это поле
активировано,то
входной сигнал
подается в сеть
непрерывно
Проанализируем описанное
выше явление с численной точки
зрения. При выполнении несколь-
ких пробных прогонов ты убедишь-
ся в следующем: если абсолют-
ное значение весового коэффи-
циента обратной связи превышает
некоторое заданное значение, оп-
ределенное как порог стабильно-
сти, то в системе как с отрица-
тельной, так и с положительной
обратной связью абсолютные зна-
чения вырабаты ваем ых сип 1алов
будут непрерывно увеличиваться
(см. рис. 11.5 и 11.6). Это явление
известно как нестабильное пове-
дение сети.
Если же абсолютное значение
весового коэффициента обратной
связи меньше этого порогового зна-
чения, то система как с отрица-
тельной, так и с положительной обратной связью будет стремиться к
состоянию равновесия (рис. 11.7).
Входной сигнал может подаваться в сеть непрерывно, т.е. па протя-
жении всего периода моделирования (программа предоставляет такую
возможность, достаточно дезактивировать поле singleJnputJmpuls).
В этом случае равновесное состояние тоже может быть достигнуто, но
при другом значении выходного сигнала (конечно, зависящем от значе-
ния подаваемого входного сигнала) (рис. 11.8).
11.2. Каковы свойства сетей с обратной связью?
Из приведенных выше рассуждений можно сделать ряд выводов, ко-
торые пригодятся нам в будущем.
Распространение входных сигналов но сети с обратной связью может
демонстрировать два вида изменчивости: если весовой коэффициент об-
ратной связи положителен (т.е. существует положительная обратная
связь), то сигнал изменяется апериодически (в одном направлении),
тогда как при отрицательном весовом коэффициенте обратной связи (от-
рицательная обратная связь, иначе называемая управляющей) возни-
кают осцилляции выходной сигнал попеременно принимает большие
350
Глава 11
и меньшие (иногда положительные и отрицательные) значения. У нели-
нейного нейрона может наблюдаться еще одна форма поведения — хао-
тичное изменение сигналов со всеми чудесами, присущими современ-
ной теории хаоса («эффект бабочки», удивительные аттракторы, фрак-
талы, множества Мандельброта и т.п.), но это тема совсем другой бесе-
ды. Но если тебе интересно, что скрывается за этими названиями, впиши
какое-нибудь из них в окно запроса поисковой системы Google и посмот-
ри список найденных источников он заслуживает внимания!
Вне зависимости от декомпозиции форм поведения сети на периоди-
ческие и апериодические ты, конечно, заметил, что в функционировании
сети с обратной связью можно выделить стабильное поведение (значе-
ния сигналов ограниченны и, как правило, через некоторое число шагов
«сходятся» к конкретному конечному значению) и нестабильное пове-
дение (абсолютная величина сигнала с каждым шагом увеличивается и,
в конце концов, «вырывается» за пределы допустимых значений). Ими-
тационная компьютерная программа при этом аварийно завершает свою
работу с выдачей сообщения об ошибке «переполнение разрядной сетки»,
но в системе, построенной в виде электронной или электромеханической
схемы, в такой ситуации непременно что-нибудь сгорит или взорвется!
Возможно, тебя заинтересует факт, что в реальных нейронных сетях
такие явления происходят ежедневно, просто ты никогда не смотрел на
них с соответствующей точки зрения.
Положи гельная обрат ная связь проявляется в следующем: чем боль-
ше думаешь о какой-либо проблеме, гем сильнее она увлекает, тем боль-
ше ею занимаешься пока она не поглощает тебя целиком. Наверняка
ты попадал в такие ситуации, не правда ли? Это типичный эффект уси-
ления положительных значений сигналов в системе с положительной
обратной связью, идентичный показанному в левой части рис. 11.5.
Точно также ты наблюдал и обратный эффект: при негативном от-
ношении к какому-либо вопросу (например, к конкретному виду раз-
влечений или к одному из школьных предметов...) последующий жиз-
ненный опыт чаще всего будет укреплять твое убеждение в его ник-
чемности, непривлекательности и бесполезности. Обрати внимание на
сходство этой ситуации с развитием процесса, показанного в правой ча-
сти рис. 11.5. Если такой замкнутый круг положительной обратной свя-
зи не будет разорван, то он может довести даже до психического рас-
стройства. Это особенно небезопасно в случае формирования отноше-
ния к какому-нибудь человеку. Состояние, характеризуемое увеличени-
ем отрицательных значений, психиатры называют маниакальным пси-
хозом, тогда как увеличение положительных значений повсеместно из-
вестно, как острая влюбленность, — но неизвестным причинам она счи-
тается неизлечимой :-).
Рекуррентные сети
351
Заметим, что в реальных нейронных сетях также встречается (к
счастью, довольно редко) явление нестабильности. Психиатры называ-
ют его судорожным припадком, а вызывающую это явление болезнь
эпилепсией. Эпилепсия очень i розное заболевание, характеризующе-
еся внезапными изменениями мозговых сигналов (их можно обнаружить
при регистрации электрических потенциалов, вырабатываемых при ра-
боте мозга, на поверхности черепа при снятии так называемой электро-
энцефалограммы) и резкими сокращениями мускулов, приводящими к
неконтролируемым и очень сильным конвульсиям всего тела. В прошлом
эта болезнь вызывала у окружающих жуткий страх или рассматрива-
лась как доказательство посещения человека злыми или добрыми ду-
хами («пляска Святого Вита»). По свидетельствам современников, эпи-
лепсией счрадал Юлий Цезарь можешь завтра рассказать прияте-
лям, что моделировал на своем компьютере его мозг (это приведет их
в остолбенение, при котором коэффициенты синаптических весов равны
нулю).
Предлагаю самостоятельно придумать или наити в ходе компьютер-
ных экспериментов порог стабильности рассматриваемой простейшей си-
стемы с обратной связью. Постарайся установить, какие факторы приво-
дят к стабильности или нестабильности поведения системы. Поскольку
чуть ниже я буду обсуждать этот вопрос, предлагаю на время оторвать-
ся от книжки и поэкспериментировать с программой Example 12а, а
позднее сравнить твои открытия со знаниями, накопленным^ поседев-
шей ог мудрости ТЕОРИЕЙ.
В ходе экспериментов с программой ты наверняка заметил, что из-
менения выходных сигналов сети зависят, главным образом, от значений
ее коэффициентов; в то же время, входной сигнал отражается па выход-
ных сигналах значительно слабее даже если он подается непрерывно,
а не только в момент начала моделирования (при дезактивации поля,
обозначенного singleJnput_impuls). При исследовании поведения се-
ти (или в ходе размышлений над применяемым алгоритмом) гы быстро
поймешь: по-настоящему важную роль играет соотношение абсолютно-
го значения весового коэффициента обратной связи и единицы. При ко-
эффициентах, меньших 1, процесс всегда стабилен он апериодический
при положительных значениях и осциллирующий при отрицательных
значениях. При коэффициентах, больших 1, процесс всегда нестабилен.
В то же время, когда коэффициент точно равен 1, мы имеем дело с уди-
вительной ситуацией: при положительной обратной связи аттрактором
сети становится любой входной сигнал, а при отрицательной обратной
связи осцилляции становятся постоянными они не увеличиваются и
не затухают. Такое состояние называется порогом стабильности.
352
Глава 11
В более развитых сетях условия стабильное! и оказываются значи-
тельно сложнее; для определения порога стабильности приходится ис-
пользовать очень серьезные математические методы (определители Гур-
вича, диаграммы Найквиста, теорему Ляпунова и т.д.). Соответственно,
теория нейронных сетей с обратной связью в течение многих лет оста-
ется очень привлекательным полем деятельности для многочисленных
теоретиков, занимающихся динамикой сложных систем.
11.3. Кому нужны такие сети с петлями?
Ситуации в сети, состоящей из одного линейного нейрона, очень про-
сты их легко прогнозировать, поэтому какие-либо интересные прак-
тические приложения такой системы придумать сложно. Поэтому от
применявшейся выще программы Example 12а не удастся получить
сколько-нибудь полезные результаты. Только большие сети с обратной
связью, содержащие от полутора до нескольких десятков нейронов (осо-
бенно нелинейных!) могут демонстрировать по-настоящему интересное
и сложное поведение — это и есть ключ к их практическому приме-
нению. Только нс забывай: в сетях с большим количеством иёйродюв,
обменивающихся своими выходными сигналами через обратные связи,
возникают ситуации, гораздо более сложные, чем стабильное и неста-
бильное поведение одиночного нейрона (искренне надеюсь, собствс ино-
ручно тобою исследованное). В такой сложной сети состояния равнове-
сия могут достигаться при различных наборах значений выходных сш-
налов (не обязательно имеющих малоинтересное значение 0). При этом
можно подобрать такую комбинацию связей и параметров сети, при ко-
торой достигаемые состояния равновесия будут соответствовать
решениям конкретных задач.
В этом Суть большинства небанальных приложений рассматривае-
мых сетей. В частпост и, можно построить сети, в которых состояние рав-
новесия соответствует решен и го неко торой оптимизационной задачи
(поиска паи лучшего решения, обеспечивающего максимальную прибыль
или минимальные убытки с учетом ограничений, например ограничен-
ной мощности управляющих сигналов или ограниченного обьема инве-
стиций). Известны приложения сетей с обратной связью для решения
задачи коммивояжера, предпринимались попытки решать задачу опти-
мального распределения ограниченных ресурсов (например, воды), из-
вестны (некоторые весьма удачные!) случаи использования этих се-
тей для оптимального подбора структуры так называемого портфеля
акций при игре на бирже и т.н. Этими исследованиями занимались мои
сотрудники, студенты магистратуры и аспиранты, некоторые экспери-
менты я проводил лично. Но не об этом я буду рассказывать дальше.
Рекуррентные сети
353
ты должен развивать свое мышление и познавать тайны функциониро-
вания нейронных сетей, а не приемы азартной игры на бирже, где даже
при поддержке интеллектуальных нейронных сетей люди чаще проиг-
рывают, а не выигрывают.
Поэтому в дальнейшей части главы мы будем рассматривать пример
другой задачи, в которой достижение сетью одного из многих возможных
состояний равновесия может интерпретироваться как решение практи-
чески важной для современной информатики проблемы — построения
так называемой ассоциативной памяти.
Запоминающие устройства такого типа (ассоциативные, контекст-
ные, семантически адресованные) издавна остаются мечтой всех инфор-
матиков, которым надоел примитивизм современных методов поиска ин-
формации в типовых базах данных. Познакомимся поближе с процесса-
ми, развивающимися в этих нейросетевых запоминающих устройствах.
Ты прекрасно понимаешь, что в настоящее время накопление и хра-
пение в компьютере даже миллионов записей с любой информацией не
представляет никакой сложности. Проблемы начинаются, когда возни-
кает необходимость быстро получить какие-либо конкретные сведения.
Если известен пароль, ключевое слово или конкретное значение иско-
мого поля, отличающее требуемую запись от всех остальных, задача ре-
шается просто. Компьютер найдет и предоставит необходимую инфор-
мацию, а если ты заранее позаботился об упорядочении (индексирова-
нии) базы данных, сделает это очень быстро и аккуратно. Наверняка
ты много раз выполнял эту процедуру при вводе различных запросов в
поисковую систему Google и получении ответов (пе всегда удачных...)
из глубин Интернета.
чтуация осложняется, когда вместо ключевого слова или другого
элемента, идентифицирующего необходимые данные, у тебя есть только
общее представление о тематике необходимой информации. Поскольку
ты пе знаешь, как точно выглядит требуемая запись, типовые поиско-
вые системы, используемые для поиска в базах данных или в Интер-
нете, оказываются ненадежными и крайне неэффективными. Они либо
засыпают тебя ворохом ненужных сведений, либо вообще оказываются
неспособными найти что-то полезное (хотя тщательный просмотр базы
свидетельствует о наличии и доступности искомых данных). Конечно,
из двух плохих оказывается лучшим сценарий получения излишних дан-
ных (среди которых прячется искомая информация), но как ее извлечь?
Много неблагодарной и ненужной работы.
А ведь твое мышление действует совсем иначе. Человеку достаточно
мелкого фрагмента сообщения, чтобы в мгновение ока найти всю необ-
ходимую информацию. Иногда благодаря лишь одному слову, какому-то
354
Глава 11
образу, идее, математическому выражению в сознании формируется пол-
ный комплект сведений, ссылок, суждений и выводов. В другой раз едва
различимым запах, несколько нот мелодии, заход солнца вызывают в
памяти целую серию образов, воспоминаний, эмоций и чувств...
Итак, твоя память способна отыскать информацию по небольшому
фрагменту или добраться до псе, отталкиваясь от другой, связанной (
ней информации. Наши компьютеры пока па это не способны. Но сможет
ли решить такую задачу нейронная сеть?
Попробуй, и тогда сам узнаешь.
Чуть ниже мы подробно обсудим постановку задачи и детали се
практической реализации, но прежде — несколько вводных замечаний.
Проблематика создания ассоциативной памяти представляет собой об-
ласть обширной сферы знаний, известной под названием когнитиви-
стика {cognitive science). В последнее время интерес к когнитивистике
постоянно раст ет, особенно среди философов, педагогов и психологов. Нс
остаются в стороне и другие специалисты особенно физики, ежеднев-
но занимающиеся теоретическим описанием простых физических систем
(таких, как элементарные частицы) или специализирующиеся в обоб-
щенном описании систем, состоящих из множества взаимодействующих
элементов (в рамках гак называемой статистической термодинамики).
Результаты поиска в библиотеке или в Интернете удивя! тебя от ромпым
количеством физиков, опубликовавших множество серьезных (с матема-
тических позиций) работ, описывающих поведение сетей с обрат ной свя-
зью, и процессов, направленных на эфе активное управление их функци-
онированием. Среди прочего, па этом принципе действуют так называе-
мые машины Больцмана (использующие аналогию между процессами
в нейронных сетях и термодинамическими явлениями, описываемыми
распределением Больцмана) и алгоритмы «имитации отжига», о ко-
торых мы поговорим в другой раз. Когнитивистикой и моделирование^
нейронных сетей занимаются выдающиеся польские ученые профессор
Лешек Рутковский* и профессор Юзеф Корбич. Я имею честь назы-
вать их обоих своими друзьями и охотно бы написал, что именно они
внесли основной вклад в развитие этой теории. Но, следуя принципу
«amicus Plato, sed magnis arnica veritas»**, должен признать: наиболь-
ший вклад в развитие сетей с обратной связью внес другой физик
американец Джон Хопфилд.
См. изданные па русском языке книги: Д. Рутковская. М. Пилиньский, Л. Рут-
ковский. Нейронные сети, генетические алгоритмы и нечеткие системы. М.: Горячая
линия Телеком. 2005; Л. Рутковский. Методы и технологии искусственного интеллек-
та. М.: Горячая линия Телеком. 2010. Прим, перее.
Лат. Платон мне друг, но истина дороже. Прим, персе.
Рекуррентные сети
355
11.4. Какова структура сети Хопфилда?
Несомненно, сети Хопфилда можно считать важнейшим и наиболее
часто практически применяемым подклассом рекуррентных нейронных
сетей, поэтому я счел необходимым рассказать тебе именно о них. В ка-
честве самой общей характеристики можно сказать, что сети Хопфилда
представляют собой крайнюю противоположность сетям с однонаправ-
летшым распространением сигналов (класса feedforward), которые пол-
ностью лишены обратных связей, обсуждавшихся в предыдущих главах.
Сети, в которых допускаются обратные связи (опи называются рекур-
рентными}, могу г содержать определенное количество (большее или
меньшее) таких связей. В сети Хопфилда обратные связи присутству-
ют обязательно (рис. 11.9).
Все связи в это] сети являются обратными, все выходные сигна-
лы используются в качестве входных, и все входы каждого нейрона
принимают сигналы обратных связей. В сети Хопфилда каждый нейрон
связан со всеми остальными нейронами сети по принципу двухсторонней
обратной связи так, что эта сеть считается обратно связанной в полной и
предельно возможной степени. Таким образом, сеть Хопфилда представ-
ляет собой абсолютную противоположность всем обсуждавшимся ранее
сетям, которые все без исключения были сетями feedforward, в которых
любые обратные связи были попросту недопустимыми.
Сети Хопфилда оказываются очень важными, потому что происхо-
дящие в них процессы всегда стабильны. Их можно применять для ре-
шения различных задач без опасения внезапной катастрофы. Стабиль-
ность процессов в сети Хопфилда достигается благодаря выполнению
трех простых операций:
Введена очень регулярная (и простая в реализации как в форме
компьютерной программы, так и в виде специализированных электрон-
ных или оптоэлектронных схем) внутренняя структура сети, в которой
все нейроны соединены между собой по принципу «каждый с каждым».
Вспомни: такое же простое (по довольно дорогое!) правило внутрисе-
тевых соединений применялось в сетях, с которыми ты познакомился
ранее. Например, в сеаи с обучением по методу обратного распростра-
нения ошибки (backpropagation) соединения между нейронами скрыто-
го и выходного слоя также были организованы по принципу «каждый
с каждым». Поэтому сеть Хопфилда следует в этом вопросе хорошо
апробированным образцам с одной лишь разницей: соединенные друг с
другом нейроны не образуют отдельные слои, а составляют единую со-
вокупность, одновременно играя роль и источников и приемников ин-
формации (рис. 11.10).
356
Глава 11
Рис. 11.9. Структура простой сети Хопфилда
Весовой
коэффициент W.
Весовой
коэффициент И<
W = W
* г ху ух
Рис. 11.10. Структура сети
Хопфилда, подчеркивающая
равноправие всех входящих в
псе нейронов и симметрию их
связей
Запрещены обратные связи
охватывающие одиночные нейроны.
Следовательно, выходной сигнал
конкретного нейрона не может на-
прямую подаваться па его вход
обрати внимание на соблюдение это-
го правила в структуре сети, пока-
занной на рис. 11.9. Тем не менее,
не исключается влияние выходного
сигнала некоторого нейрона на соб-
ственное значение в будущем, по-
скольку может существовать обрат-
ная связь через дополнительные
нейрон ы-«посредники», по влияние
этих «посредников» оказывается
исключительно стабилизирующим.
Вводимые весовые коэффициен-
ты должны быть симметричными: если соединение между нейроном с
номером х и нейроном с номером у характеризуется определенным ве-
совым коэффициентом w, то точно такое же значение w должен иметь
весовой коэффициент соединения между нейроном с номером у и ней-
роном с номером х (рис. 11.11).
Все эти условия очень легко выполняются. Два первые условия опре-
деляют регулярную и простую в реализации структуру соединений эле-
ментов сети, а последнее условие автоматически выполняется при обу-
чении сети по методу Дональда Хебба (этот метод обсуждался в гл. 3,
поэтому мы не будем рассматривать его повторно). Благодаря простоте
построения и применения, сети Хопфилда получили широкое распро-
странение. Эти сети имеют многочисленные приложения, в том числе
для решения оптимизационных задач (о чем я уже упоминал), а так
Рекуррентные сети
357
Рис. 11.12. Пример шагающего робота, конечности которого подчиняются
цикличес ким ритмам, генерируемым сетью Хопфилда
же для генерации определенных последовательностей сигналов, следу-
ющих друг за другом в заданном (по модифицируемом) порядке. Это
позволяет формировать и высылать па различные объекты управляю-
щие сигналы. По такому принципу функционируют нейронные системы,
управляющие перестановкой ног шагающих роботов — двуногих, четве-
роногих и шестиногих (рис. 11.12).
«Мозг», управляющий движениями такой искусственной многонож-
ки, всегда содержит сеть с обратными связями, необходимыми для само-
стоятельного вырабатывания циклически изменяющихся управляющих
сигналов. Обрати внимание: независимо от количества пог шагание
всегда циклический процесс, в котором каждая конечность последова-
тельно поднимается вверх, переносится вперед, опускается вплоть до
получения стабильного контакта с поверхностью, перемешается назад
с целью активного переноса «тела» шагающего чудища вперед, а по-
том в течение некоторого времени играет роль только опоры, тогда как
движение обеспечивают другие конечности. Но шагание но неровной по-
верхности требует не только циклической генерации описанных выше
движений, оно дополнительно должно учитывать механизм адаптации
к изменяющейся ситуации например, если какая-нибудь нога попадет
в расщелину). По этой причине в качестве «мозга» шагающего робота
должно использоваться устройство, способное не только генерировать
цикличное поведение, но и способное обучаться адаптации к перемен-
ным ситуациям. Чаще всего в роли такого механизма выступает именно
сеть Хопфилда или ее какая-нибудь простая модификация.
358
Глава 11
Обучающиеся шагающие автоматы очень интересны; в будущем они
найдут широкое применение при обследовании далеких планет, глубо-
ких пещер или дна океанов. В следующем разделе я расскажу тебе, для
чего лучше всего применять сеть Хопфилда. В частности, мы вместе
построим ассоциативную память.
11.5. Как нейронная сеть играет роль
ассоциативной памяти?
Программа Examplel2b содержит модель сети Хопфилда, задача
которой заключается в запоминании и отображении простых образов.
Главное достоинство этой памяти в том, что она способна отобразить
информацию (образ) на основании сильно искаженного или зашумлен-
ного сигнала. Для этого в ней применяется способ, который чаще всего
называется автоассогщагщя*. Благодаря автоассоциации сеть Хопфил-
да может автоматически пополнять недостающие данные. На рис. 11.13
показан многократно воспроизведенный в различных книгах и разме-
щенный в Интернете (я заимствовал его с сайта www.es.pomona.edu, а мог
бы скачать с сайта eduai.hacker.lt) образ, демонстрирующий возможности
сети Хопфилда при устранении искажений и при отображении полных
данных по их отдельным фрагментам.
В каждой из трех строк этого рисунка слева приведен образ, предъ-
явленный сети в качестве входных данных, в центре — промежуточное
состояние (когда сет ь ищет в своей памяти нужный эталон) и справа
итоговый эффект, т.е. результат «вспоминания» требуемого эталона. Ко-
нечно, для «воспоминаний» соответствующие эталоны (образы) должны
быть зафиксированы в памяти сети путем обучения. На этане обучения
сети демонстрировались образы паука, двух бутылок и собачьей мор-
ды сеть запомнила их в качестве эталонов и приготовилась вспоми-
нать. Однако уже после завершения обучения сеть оказалась способной
на удивительные действия. Когда ей продемонстрировали сильно «за-
шумленный» образ паука (верхняя строка рис. 11.13), то был отображен
эталонный образ насекомого. При предъявлении изображения одной бу-
тылки сеть вспомнила, что при обучении ей всегда показывали образ
Авто ассоциация такой способ функционирования сети, при котором определен-
ное сообщение ассоциируется само с собой. Благодаря автоассоциации предъявление даже
небольшого фрагмента хранимой информации позволяет вызвать из памяти и отобразить
эту информацию (в частности, образ) целиком и со всеми подробностями. Альтернати-
вой автоассоциации считается гетероассоциация она заключается в том, что одпо
сообщение (например, фотография любимой бабушки) вызывает связанные с ней воспо-
минания (о вкусе пирожков, которые она пекла). Сети Хопфилда могут функционировал,
и как автоассоциативная, и как гетероассоциативная память, но первый вид проще, по-
этому мы говорим именно о нем.
Рекуррентные сети
359
двух бутылок. И, наконец, оказа-
лось достаточным предъявить соба-
чье ухо — на экране был отображен
полный образ пса.
Показанные па рис. 11.13 кар-
тинки хороши, но их отображение
не связано с решением какой-либо
серьезной практической задачи.
Тем пе менее, автоассоциативная
память может применяться для до-
стижения многих серьезных и прак-
тически значимых целей. Например,
сеть может отобразить точный вид
подлетающего самолета в ситуации,
когда видеокамера зарегистрирова-
ла далеко не полный его образ из-за
сильной облачности. Такая задача
очень важна для систем противо-
воздушной обороны необходимо
быстро решать проблему «свой
чужой». Сеть, работающая в режи-
ме автоассоциативной памяти, мо-
жет дополнять неполные запросы ]
Рис. 11.13. Примеры функционирования
сети Хопфштда в режиме ассоциагивной
иамя! и
информационной системе или ба-
зе данных. Как известно, хорошая база содержит много полезной ин-
формации, по получить точный ответ можно только при корректной
формулировке запроса. Если запрос будет сформулирован неграмотным
или небрежным пользователем и не будет соответствовать изначально
заданной схеме, то база данных не сможет ответить па него. Автоассо-
циативная память постарается «договориться» с системой управления
базой данных, благодаря чему информация будет искаться корректно
даже при неточном (хотя и однозначном) запросе пользователя. Сеть
попытается самостоятельно догадаться обо всех недостающих подробно-
стях (о которых должен был сообщить, по не сделал этого рассеянный
или недоученный пользователь). В такой ситуации автоассоциативная
сеть Хопфилда играет роль посредника между пользователем и базой
данных, подобно опытному школьному библиотекарю, который сможет
помочь ученику (забывшему автора и название нужной ему книжки, но
представляющему, о чем в ней написано) выбрать необходимый учебник.
Автоассоциативная сеть имеет множество других приложений. В част-
ности, она умеет устранять искажения и помехи в различных сигналах
(даже тогда, когда уровень «зашумления» входного сигнала исключает
360
Глава 11
практическое использование любых других методов фильтрации). Выда-
ющаяся эффективность сетей Хопфилда в подобных случаях обусловле-
на тем, что сеть отображает эталонную форму сигнала (чаще всего обра-
за), хранящуюся в ее памяти, а полученный искаженный входной сигнал
должен только сориентировать сеть, «направить ее па путь истинный»
к нужному эталону — среди всех образов, которые могут приниматься
в расчет.
Мне кажется, что рассуждений уже достаточно, пора переходить к
практическим занятиям с применением программы Examplel2b. Для
лучшей наглядности и читабельности результатов программа бу дел де-
монстрировать их в графическом виде, но ты должен помнить это
не единственная возможность, поскольку такие сети могут запоминать и
отображать любую информагщю при условии, что мы сумеем догово-
риться о формах отображения и презентации результатов функциониро-
вания сети.
Вначале выяснихм связь между моделируемо! сетью Хопфилда и об-
рабатываемыми iipoi раммой картинками. Каждый нейрон сети связав
с одной точкой (пикселем) образа. Если нейрон выработал выходной
сигнал 4-1, то соответствующий пиксель будет черным, а если сигнал
-1 белым. Выработка других значений не предусмотрела; посколь-
ку нейроны сети Хопфилда сильно нелинейны, опи могут находиться
только в этих двух (-1-1 или —1) состояниях. Рассматриваемая сеть со-
стоит из 96 нейронов, которые (исключительно для более наглядного
представления результатов) упорядочены в форме матрицы из 12 строк
и 8 столбцов. Соответственно, каждое конкретное состояние сети (пони-
маемое как множество выработанных нейронами сети выходных сигна-
лов) может рассматриват ься как монохромная картинка размером 12x8
пикселов (рис. 11.14).
Здесь показан
выходной сигнал
нейрона № 1
Здесь показан
выходной сигнал
нейрона № 8
Здесь показан
выходной сигнал
нейрона № 8
Здесь показан
выходной сигнал
нейрона № 2
-
ж
Здесь показан
выходной сигнал
нейрона № 16
Здесь показан
выходной сигнал
нейрона № 96
Здесь показан
выходной сигнал
имеющий значение +1
Здесь показан
выходной сигнал
имеющий значение -1
Рис. 11.14. Пример распределения выходных сигналов нейронов сети
Рекуррентные сети
361
Рассматриваемые картинки могли бы быть полностью произвольны-
ми, но для удобства формулирования решаемых сетью задач пусть это
будут образы символов (их легко вводить с помощью клавиатуры) ли-
бо абсолютно абстрактные картинки, генерируемые программой в соот-
ветствии с определенными математическими критериями (о которых я
подробнее расскажу чуть ниже).
Рис. 11.15. Набор эталонов, подго-
товленных для запоминания в сети
Хопфилда
Программа запоминает некоторое
число таких картинок (введенных тобой
или сгенерированных автоматически) и
самостоятельно (без твоего участия!) вы-
водит их па экран в качестве эталонов
для будущего отображения («вспомина-
ния»). На рис. 11.15 показано, как может
выглядеть подготовленный для запоми-
нания набор эталонов. Конечно, множество запомненных сетью эталонов
может содержать любые другие буквы или цифры, которые ты можешь
ввести с клавиатуры, поэтому изображенный па рис. 11.15 набор нужно
рассматривать только как один из многих возможных примеров.
Прежде чем я расскажу тебе, как вводить в программу другие этало-
ны, познакомься подробнее с работой программы и получаемыми резуль-
татами.
После ввода (или генерации) всех эталонов iipoi рамма Examplel2b
задает параметры (весовые коэффициенты) всех нейронов так, чтобы
именно эти картинки стали для сети точками равновесия (аттрактора-
ми). На каких принципах основан этот процесс и как он протекает, ты
можешь прочитать в уже упоминавшейся моей книге «Нейронные сети».
Здесь я не буду описывать этот процесс, поскольку теория обучения сети
Хопфилда достаточно сложна и сильно математизирована, а я обещал
не приводить в этой книге математические формулы. Впрочем, подроб-
ности знать не обязательно, достаточно (после завершения ввода этало-
нов) щелкнуть по кнопке Hebbian learning (рис. 11.16). Автоматически
начнется процесс обучения, после которого сеть сможет вспоминать хра-
нящиеся в ее памяти эталоны. Как следует из надписи на кнопке, для
обучения применяется метод Хебба, который мы обсуждали ранее (см.
гл. 3), но в данный момент детали процесса обучения для нас не так
существенны. Достаточно запомнить, что в процессе обучения формиру-
ются такие значения весовых коэффициентов всех нейронов сети, при
которых она достигает равновесия в момент появления на входе обра-
зов, соответствующих запомненным эталонам.
После обучения сеть готова к «тестированию». Можешь провести его
самостоятельно. Для этого вначале выбери (мышкой) эталон, степень
362
Глава 77
j
f
I
Add potterrs (max 20]
ф Letter: x
О Digit:
Add
Load hl, унЬ pad sms
Path:
Load
Ui or pwudoronttam path m g Aotoa^ssootwe prnce? ses
Generate
Number of pattern(s):
I Recall entry pattern!»
i_____
Hebbian learning
i riYrt rt ii ittii
Exit
Input pattern!» for teaching or recalling:
Clear
Save in a file ]
Enlarged selected input
Enlarged selected output
Noise Inverse
, " .--- -.L
%
Most similar pattern(s):
Г umber (s):
DP or H value* 34
t Remove
Undo the last operation
Dot product (DP) *.? Hamming distance (H)
Recoiled entry pattern(s):
5*ve in » (ila
ч
'
Рис. 11.16. Э’жпо.ны. которые должна запомнить сеть, вводятся в поле Add pattern
владения которым ты хочешь проверить. Эталоны и их номера в этот
момент видны в окне Input pattern(s) for teaching or recalling из
них и выбирается проверяемый элемент. Зыбор (т.е. щелчок мышкой! на
любом из этих эталонов приведет к появлению его увеличенною изоб-
ражения 1з окпе Enlarged selected input, а избранная мера подобия
этою эталона по отношению к остальным эталонам появи тся непосред-
ственно под миниатюрными изображениями всех эталонов в окне Input
pattern(s) for teaching or recalling (см. рис. 11.16). Степень подобия
картинок можно измерить двумя способами, поэтому под окном Input
pattern(s) for teaching or recalling расположены два поля выбора:
DP скалярное произведение и Н расстояние Хэмминга. Что эго
означает расскажу несколько ниже, а пока достаточно запомнить:
критерий DP показывает, насколько два образа подобны друг другу:
при этом большое значение DP под каким-либо изображением означа-
ет, что его легко спутать с выбранным тобой образом. В свою очередь,
расстояние Хэмминга (как следует из названия меры) характеризует
степень различия между образами. Следовательно, если под каким-то
образом высветится большое значение меры Н, то этот образ распола-
гается па безопасном удалении от выбранного тобой изображения. В то
же время малое значение Н свидетельствует о возможности перепутать
эталон с выбранной картинкой.
После выбора запомненного сетью образа, который ты хочешь про-
верить, можно подвергнуть испытаниям его эталон. Несложно «узнать»
картинку по ее идеальному отображению, и совсем другое дело, если
Рекуррентные сети
363
изображение будет случайно искажено! Именно тогда сеть должна бу-
дет проявить все свои ассоциативные способности, что и требуется.
Впиши в расположенное в правой части экрана окошко (обозначенное
символом %), какой процент точек эталонного изображения программа
должна изменить, прежде чем образ будет предложен сети для «узна-
вания». В это окошко можно вписать любое целое число от 0 до 99
именно такой процент точек эталона программа изменит перед началом
тестирования. Для ввода в образ заданного числа изменений ты должен
щелкнуть по кнопке Noise (шум или искажение). Чтобы еще больше
усложнить задачу, можно дополнительно инвертировать картинку (т.е.
получить ее негативное изображение) щелчком по кнопке Inverse.
Выбранное и целенаправленно искаженное изображение появится в
окне Enlarged selected input. Присмотрись к нему: смог бы ты сам
определить, из какого эталона оно получено? Дополнительно можешь
проверить: нс стал ли твой «модифицированный» эталон после всех из-
менений больше похож на какой-либо из образов-«ко1 курентов»? Для
оценивания ситуации пригодятся значения мер его «сходства» с дру-
гими эталонами, приведенные под их миниатюрными изображениями в
окне Input pattern(s) for teaching or recalling.
Рекомендация: вначале пе слишком сильно деформируй образ, по-
скольку в искаженном изображении не только сети, по и тебе трудно бу-
дет распознать его исходную форму. Мой опыт свидетельствует, что сеть
хорошо справляется с искажениями, пе превышающими 10%. Неплохие
результаты также достигаются (на первый взгляд, парадоксально) при
очень большом числе измененных точек. Причина в том, что в такой си-
туации образ сохраняет свою структуру, но большинство светлых точек
становятся темными, и наоборот. Например, при выборе 99% изменяе-
мых точек образ замещается своим почти идеально точным негативом.
Но негативное изображение песет, в сущности, ту же информацию, что
хорошо заметно в моделируемой сети. Если число изменений несколь-
ко меньше 99%, то сформированный образ также хорошо распознается
сетью небольшие изменения в негативе не помешают сети «узнать»
знакомый образ. К фатальным результатам приводят попытки узнать
эталон при числе искажений от 30 до 70% сеть пытается что-то рас-
познать, но чаше всего эталон выявляется только после большого чис-
ла итераций, а реконструкция искаженного изображения оказывается
неполной — многие помехи не удается устранить.
Таким образом, в начале процесса тестирования сети ты должен со-
здать слабо (см. пример в левой части рис. 11.17) или сильно искажен-
ное изображение эталона, которое становится отправной точкой для его
узнавания обученной сетью.
364
Глава 11
начинается процесс узнавания све-
дений, хранящихся в сети: слабо ис-
каженный эталон буквы В (слева)
и сильно искаженный эталон буквы
В (справа
Рис. 11.18. Бысггрое восстановление слабо иска-
женного эталона в сети Хопфилда, работающей как
ассоциативная память
Процесс узнавания сетью запомненного эталона сводится к подаче
выходных сигналов на се входы, где они преобразуются (не фонами в
новые выходные сигналы, которые вновь по обратным связям направ-
ляю гея на входы сети и т.д. Этот процесс автоматически прерывается,
когда па очередной итерации не происходит никаких изменений выход-
ных сигналов (сеть «узнала» соответствующий образ). Как правило,
этот узнанный образ совпадает с идеальным эталоном, искаженную вер-
сию которого ты представил сети. К сожалению, гак бывает пе всегда.
Если образ, с которого начинается процесс «узнавания», мало от-
личается от эталона, то искомый результат может быть получен прак-
тически мгновенно. Это иллюстрируется рис. 11.18, па котором демон-
стрируется процесс распознавания конкретной формы буквы В в сла-
бо искаженном образе (показанном в левой части рис. 11.17). Очеред-
ные картинки па рис. 11.18 (и на всех следующих рисунках этой главы)
представляют расчетные и моделируемые комбинации выходных сигна-
лов исследуемой сети. На рис. 11.18 видно, что выходной сигнал сети
достиг требуемого состояния (идеальное отображение эталона) уже по-
сле1 первой итерации.
Несколько более сложные процессы развивались в исследуемой се-
ти при узнавании сильно искаженного эталона, показанного в правой
части рис. 11.17. В этом случае сети потребовались две итерации для
достижения желаемого успеха (рис. 11.19).
Рис. 11.19. Восстановление сетью Хопфилда сильно искаженного эталона
Рекуррентные сети
365
Одно из интересных свойств сети
Хопфилда, с которым ты познакомишь-
ся при проведении самостоятельных
экспериментов с программой, считается
способность запоминать как оригиналь-
ные сигналы (связанные с очередными
эталонами), так и негативные отраже-
ния ранее запомненных эталонов. Мож-
но математически доказагь, что это про-
исходит всегда. В результате каждого
Рис. 11.20. Восстановление
ассоциат явной памятью нега-
лива запомненного эталона
этапа обучения, приводящего к запоминанию определенного эталона, в
сети, автоматически возникает аттрактор, соответствующий негативному
эталону. Следовательно, процесс узнавания образа может завершиться
отысканием как оригинального эталона, так и его негатива. Поскольку
негатив содержит ту же информацию, что и оригинальный сигнал (един-
ственное отличие заключается в том, что в точках, где оригинальный
сигнал имеет значение +1, в негативном отражении присутствует —1,
и наоборот), то отыскание сетью негатива эталонного изображения то-
же считается успехом. Например, на рис. 11.20 можно увидеть процесс
восстановления очень сильно искаженного эталона буквы В, который
завершился отысканием негатива этог буквы.
11.6. Как работает программа, позволяющая
тебе самостоятельно исследовать
функционирование сети Хопфилда?
Описанные выше явления (а также многие другие) ты можешь само-
стоятельно наблюдать и исследовать с помощью программы Example
12b. Эта программа начинает свою работу с принятия от тебя (либо по
твоему желанию с автоматической генерации) эталонов, которые должна
запомнить сеть. Ты уже знаешь, что в их роли могут выступать обра-
зы вводимых с клавиатуры букв или цифр, либо абстрактные образы,
самостоятельно созданные программой (об этом мы чуть ниже погово-
рим подробнее). Для большей наглядности миниатюрных изображений
эталонов на экране, а также с учетом ограниченной емкости ассоциатив-
ной (как и любой другой) памяти программа Examplel2b ограничивает
максимальное число запоминаемых сетью входных эталонов двадцатью
элементами. Ты можешь ввести столько эталонов, сколько захочешь,
по самоограничение «аппетитов» принесет положительный эффект. Чем
меньше эталонов, тем быстрее обучается сеть и тем быстрее она функци-
онирует (ты сможешь провести за то же время больше экспериментов),
366
Глава И
Рис. 11.21. Искажение эталона вследствие диафонии
а также, что еще важнее, тем меньше ошибается. При наличии более
16 эталонов сеть начинает смешивать и накладывать друг па друга на-
копленные сведения (из-за ограниченного числа нейронов, запоминаю-
щих введенные эталоны). В результате, при распознавании образов бу-
дут заметны серьезные ошибки. Эти ошибки проявляются присутствием
в воспроизводимых эталонах гак называемой диафонии, заключающей-
ся во включении в состав демонстрируемого образа элементов других
образов. Эффект диафонии показан па рис. 11.21. На этом и на сле-
ду ющих рисунках применяется несколько отличающийся от использо-
вавшегося ранее способ демонстрации процесса функционирования се-
ти. Слева направо приводятся:
• отображаемый эталон без искажений;
• образ после целенаправленного ввода в него искажений програм-
мой Examplel2b;
• последовательные этапы узнавания эталона сетью.
Такой способ демонстрации оказывается удобным при оперировании
многочисленными образами различной структуры. Как правило, для
комментария достаточно возможности сравнения оригинального эталона
(крайняя слева картинка) с окончательным результатом работы сети,
«узнавшей» эталон (крайняя справа картинка).
Из рис. 11.21 видно, что загрузка сети чрезмерным числом этало-
нов всегда приводит к неустранимым нарушениям ее функционирова-
ния. Эти нарушения проявляютс я в демонстрации найденного эталона в
искаженном виде, заметно отличающемся от оригинала, использовавше-
гося при обучении. Эго явление наблюдается даже тогда, когда процесс
узнавания стартует с практически неискаженного образа (рис. 11.22),
поскольку в структуре запомненного сетью эталона навсегда остаются
следы от других эталонов.
Обрати внимание на еш,е одно интересное явление, заметное на
рис. 11.21. На первой итерации (сразу после ввода в сеть сильно ис-
каженного изображения буквы X) программа вывела идеальный образ
эталона, но последующая обработка привела к его искажению «эхом»
воспоминаний о других запомненных сетью символах. Это соответствует
явно знакомой ситуации, когда при решении сложной задачи ты у беж да-
Рекуррентные сети
367
восстановить, даже если он подается на вход сети в неискаженном виде
ешься в истинности самой первой пришедшей в голову идеи, а последу-
ющие решения, полученные самыми разными способами, оказываются
хуже первого интуитивного решения.
Но вернемся к детальному описанию работы программы Example
12b. Как я уже говорил, после запуска программа собирает данные для
запоминания эталонов. Опа выдает запрос о вводе образа (рис. 11.23),
который может (но пе обязан) сохраниться в памяти. Эталоны для за-
поминания ты вводишь в групповом поле Add pattern (max 20). Мож-
но добавить букву (вводя ее в редактируемое поле Letter:) или цифру
(вводя ее в редактируемое поле Digit:). Выбор введенного тобой симво-
ла необходимо подтвердить щелчком по кнопке Add, после чего миниа-
тюрное изображение этого символа появится в графическом окне Input
pattern(s) for teaching or recalling:. Групповое поле Add pattern
(max 20) позволяет тебе ввести не более 20 эталонов (рис. 11.23). Про-
грамма предоставляет тебе возможность полностью контролировать со-
храненные в памяти эталоны при нажатии па клавишу соответству-
ющей буквы или цифры опа покажет тебе точную структуру символа
в поле Enlarged selected input.
После ввода подлежащих запоминанию эталонов (все они появят-
ся в окне Input pattern(s) for teaching or recalling) ты можешь
указать мышкой па любой из них и инвертировать (щелчком по кноп-
кам Inverse и Save) либо удалить (кнопка Remove). Последняя опе-
рация бывает единственным выходом, если при вводе очередного эта-
лона ты обнаружишь слишком сильное его сходство с ранее введен-
ными изображениями.
Эталоны могут генерироваться автоматически (об этом я расскажу
чуть ниже), но они имеют, к сожалению, плохо читаемую форму не
рекомендую на первых порах использовать их слишком активно. Лучше
всего начать с нескольких букв (я сформировал набор А, В, С, I, X).
После ввода каждой буквы в редактируемое поле Letter: не забывай
нажимать на кнопку Add.
После завершения ввода (и возможной модификации) множества эта-
лонов для запоминания сетью (показанных в графическом окне Input
368
Глава 11
Onhogonal or pseudorandom patterns
Generate
Numbar of pattern^]: 1
Au to as socialise processes
Hebbian learning
Fiet'-all щгНеггф)
Exit
Add pattern (max 20)
Lood file wtth patterns
[ Load ~1 Path:
Рис. 11.23. Способ ввода данных в ассоциативную намять с возможностью
модификации или отклонения каждого введенною вручную символа
pattern(s) for teaching or recalling) щелкни по кнопке Hebbian learn-
ing. Эту кнопку можно использовать часто, особен ио когда ты хочешь
научить сеть распознаванию нового набора эталонов. После щелчка на
Hebbian learning практически сразу активируется кнопка Recall ent-
ry pattern(s), позволяющая завершить обучение и начать тестирова-
ние способностей сети.
Теперь можешь приступать к проверке как сеть справляется с
узнаванием каждого запомненного эталона. При нажатии на кнопку Re-
call entry pattern(s) в момент, когда пе выделен пи один элемент в окне
Input pattern(s) for teaching or recalling, запускается процедура рас-
познавания всех тех входных эталонов, миниатюрные изображения ко-
торых представлены в окне Input pattern(s) for teaching or recalling.
Распознанные образы высвечиваются в окне Recalled entry pattern(s).
Наблюдения за тем, как сеть справляется с запоминанием символов
и с их узнаванием, очень интересны. В частности, сеть хорошо и эффек-
тивно распознает В, несколько хуже С, I и X, но при воспроизведении
А регулярно проявляется диафония (рис. 11.24).
Наверняка ты заметил: после щелчка на изображении любого эта-
лона в окне Input pattern(s) for teaching or recalling активируют-
ся кнопки Noise и Inverse в правой части экрана Enlarged selected
input. Редактируемое поле, обозначенное символом % и расположенное
под кнопкой Noise, предназначено для вписывания доли точек, кото-
рые должны измениться. Как я уже говорил, в это поле можно вписать
Рекуррентные сети
369
0 ЙЙй produrl №f *J О Hamming distance (Hl
ЯесаНЫ »rwr> гаЙШиЫЬ
Save irt a file
Рис. 11.24. Отображение всех запомненных сетью эталонов
любое целое число от 0 до 99. После нажатия кнопки Noise програм-
ма случайным образом изменит указанное количество точек эталона и
вставит увеличенное изображение полученного искаженного образа в по-
ле Enlarged selected input (рис. 11.25). При нажатии па кнопку Save
(расположенную под окном Enlarged selected input) этот искаженный
образ будет вставлен в набор запоминаемых эталонов, демонстрируемый
в окне Input pattern(s) for teaching or recalling.
Рядом с кнопкой Noise расположена кнопка Inverse, выполняю-
щая аналогичную функцию. При нажатии на кнопку Inverse выбран-
ный тобой эталон инвертируется, т.е. темные пиксели становятся свет-
лыми и наоборот. Так же как в случае с кнопкой Noise, инвертиро-
ванную версию изображения (полученную в результате нажатия кнопки
Inverse) необходимо зафиксировать щелчком по кнопки Save. Резуль-
тат последних изменений можно отменить щелчком по кнопке Undo the
last operation, которая восстанавливает состояние до нажатия кнопки
Save. Нажатие кнопки Undo the last operation также отменяет ре-
зультат удаления выбранного эталона (кнопка Remove). В общем слу-
чае нажатие кнопки Undo the last operation аннулирует последнюю
выполненную операцию типа Save или Remove.
Наличие или отсутствие взаимного подобия запомненных эталонов
основная проблема, которой мы должны уделить особое внимание. При
обсуждении рис. 11.21 и 11.22 ты заметил, что эталоны сигналов иногда
370
Глава 11
i Undo the last operation j
»’ Dot product (DP) О Hamming distance [Hl
Recalled entry pattern(s):
Save in <i file
ю %
Most
о
Number(s).
DP or Н value: 40
Remove i
Enlarged selected output
DP or H value between
the two enlarged patterns:
82
Рис. 11.25. Возможность сравнения образов в окнах Enlarged selected input и En-
larged selected output, а также меры подобия между ними (DP or Н value between
the two enlarged patterns)
накладываются друг па друга, эго приводит к диафонии. Такие явле-
ния усиливаются по мере увеличения взаимного подобия запомненных
образов. Это вполне логично чем сильнее подобие этанонов, тем боль-
ше «следы памяти» (которые — все! расположены в одной и той же
сети!) накладываются друг па друга. Если некоторый нейрон в одной
ситуации должен вырабатывать +1 (пос кольку является частью запом-
ненной буквы А), в другой ситуации — -1 (поскольку является частью
запомненной буквы В), а потом снова 4-1 (поскольку является частью
запомненной буквы С), то задача становится сложной и трудно разре-
шимой. В случае больших различи * между запомненными образами за-
дача упрощается, поскольку число «конфликтпых» точек уменьшается.
Если же эталоны сильно похожи друг па друга, то их описание в фор-
ме весовых коэффициентов отдельных нейронов настолько смешивают-
ся между собой в нейронной памяти, что в обученной сети возникают
проблемы с корректным узнаванием хотя бы какого-то из запомненных
эталонов (рис. 11.26).
Рис. 11.26. Эффект совмещения следов памяти при сильном смешении сигналов
Рекуррентные сети
371
По этой причине для наблюдения за функционированием сети в бо-
лее или менее благоприятных условиях ты должен постараться подо-
брать (по крайней мере, вначале) очень хорошо различаемые эта-
лоны. Программа может помочь двумя способами.
Первый способ заключается в том, что при вводе новых эталонов про-
грамма сразу же рассчитывает и сообщает тебе степень подобия между
новым и ранее запомненными образами. Следовательно, можно опера-
тивно контролировать эффекты наложения образов при «ручном» вводе
символов с клавиатуры. Это легко и просто, поскольку щелчок мышкой
па миниатюре любого ранее введенного эталона (видимой в графическом
окне Input pattern(s) for teaching or recalling) приводит к появлению
под каждой картинкой (имеющей свой индивидуальный номер) числа,
характеризующего степень подобия выбранного образа каждому
из ранее введенных эталонов. Нс забывай, что мера подобия может
рассчитываться как DP (в этом случае, чем больше значение, тем ху-
же степень подобия избранного и ранее введенного э галона велика)
либо как расстояние Хэммиша н (чем больше значение, тем лучше
расстояние между избранным и ранее введенным эталоном велико).
Дополнительно в окне Enlarged selected input будет показано уве-
личенное изображение выбранного гобой обьекта, а в правой части этого
окна под кнопками Noise и Inverse располагается групповое попе Most
similar pattern(s), в котором высвечивается информация об эталоне,
на который больше всего похож выбранный тобой образ. Это поле поз-
воляет предугадать возможную опасность (программа сообщает помер
эталона, с которым можно перепутать выбранную картинку). Номер та-
кого «потенциально опасного» эталона выводится в поле Numbers, а в
редактируемом поле DP or Н value: будет показано значение исполь-
зуемой меры подобия (т.е. максимальное значение скалярного произве-
дения или минимальное расстояние Хэмминга).
11.7. Несколько интересных примеров
Я прекрасно понимаю, что приведенное описание обслуживания и
функционирования программы Examplel2b могло тебе несколько на-
скучить, поэтому пришло время для вознаграждения. Приступим к сов-
местным экспериментам с программой. Ты увидишь, какие интересные
результаты она позволяет получить, а потом сможешь самостоятельно
продолжить исследования с учетом нескольких практических рекомен-
даций.
Проанализируем ситуацию, показанную на рис. 11.27. В верхней ча-
сти экрана видны заранее введенные мной эталоны букв А, В, С и D.
В текущий момент вводится образ буквы Е, которая оказывается слабо
372
Глава 11
Add pattern [max 20)
© Loner e J
О В«9Й
Orthogonal or pseudorandom patterns
Generate
Number of patterns) 1
«am*.**
Woassocialive processes
Het
Recall
------------j
Здесь показан номер
наиболее похожего эталона
(риск перепутать с ним
Exit
Load tile with patterns
Load Path:
рассматриваемый образ
является наибольшим)
Input pattem(s) for teaching or recalling
[ clear Save in a file
DP
Здесь показаны
номера эталонов
Здесь показаны меры
подобия этих эталонов
введенному символу
Здесь показаны
миниатюрные изображения
ранее введенных символов
Enlarged selected input
Undo the last operation
Norse
Inverse
attern(s):
Most stmtia
) rve
Number(s):
DP or H value; 7*
Remove
Enlarged selected output
OP or Н value between
the two enlarged patterns:
Рис. 11.27. Способ информирования о степени подобия нового образа
ранее запомненным эталонам
отличающейся от рапсе запомненных эталонов. Мера се подобия букве
А равна 22 (эго еще совсем неплохой результат), но с эталоном буквы
В буква Е связана с «силой» в 74 единицы, а с С и D силой в 56 еди-
ниц. В правой части окна ты увидишь (в поле Most similar pattern(s))
предупреждение программы о том, что вводимый образ может ошибоч-
но приниматься за букву В ;ничего удивительною...). Конечно, реше-
ние ты принимаешь самостоятельно, но я в своих экспериментах такой
эталон отбросил бы самым решительным образом. Достойно внимания:
применение инверсии (т.е. негативного изображения рассматриваемого
символа-неудачника) не изменяет степень его подобия ранее запомнен-
ным эталонам (рис. 11.28).
Вернемся к техническим деталям. В качестве основной меры подо-
бия вновь введенного образа ранее запомненным эталонам программа
рассматривает скалярное произведение (Dot Product, DP) векто-
ров, описывающих сравниваемые образы в пространстве входных сигна-
лов. Точнее, принимается во внимание абсолютное значение скалярного
произведения (па самом деле эта подробность пе так важна). Об этом
напоминает точка в поле выбора около надписи Dot product, (DP) в
центре экрана. Достаточно нажать на другую (расположенную рядом)
Рекуррентные сети
373
Clear
Save in a file Enlarged «elected input
Input pat!ein[$j for teaching or recalling
(уД Dot product [UPJ О Hamming distance flJ)
Recalled entry patternfs]:
Save in a file
Мез t similar
Numbers J:
DP or H value: Z$
Remove .
Undo the last operation !
Enlarged «elected output
Noise ! Inverse
I_________।______________.
Рис. 11.28. Инверсный образ имеет ту же степень подобия ранее запомненным
эталонам, что и оригинальный эталон
Enlarged selected < utput
Save in a file
Dot product (DP) Hamming distance (HJ
Recalled entry pattern(s}.
Рис. 11.29. М^ры подобия сигналов, выраженные расстоянием Хемминга
кнопку выбора с надписью Hamming distance (Н), программа пере-
строится на другой способ оценивания степени подобия эталонов и бу-
дет рассчитывать расстояние Хэмминга (рис. 11.29).
Таким образом, кнопки выбора Dot product (DP) и Hamming
distance (H) определяют, какая мера — DP или Н будет высвечи-
ваться под каждым миниатюрным изображением эталона.
Обрати внимание: на рис. 11.29 числа под каждым эталоном различ-
ны - теперь тот эталон, который наиболее похож па выбранный образ,
характеризуется наименьшим расстоянием до него. Ты уже знаешь,
как интерпретировать эту информацию, поскольку черная точка стоит
теперь в поле выбора возле надписи Hamming distance (Н), а не возле
надписи Dot product (DP)*, как прежде.
Для чего в программе реализованы две меры оценивания подобия?
В зависимости от складывающейся ситуации эти две меры предо-
ставляют различную информацию и могут применяться для достиже-
ния двух разных целей.
Скалярное произведение показывает, в какой степени элементы выбранного образа
повторяются в запомненных ранее эталонах, а расстояние Хэмминга в скольких точках
два изображения отличаются друг от друга.
374
Глава 11
Input patlernls) lor teaching or recalling:
Clear I | Save in a tile i Enlarged selected input
Dot product (DP) ‘ Hamming distance (Hj
Recalled entry pattern(s):
Save in a ,file*} Enlarged selected output
Рис. 11.30. Изменение расстояния Хэмминга в случае инверсии символа
------------ -----------*
Noise Invei se
%
Most sHtnia»
1
Number(s j:
DP or H value: 59
Undo the last operation
При генерации новых изображений лучше основываться на наблюде-
ниях (и максимизации скалярного произведения). Расстояние Хэммиша
может ввесм и в заблуждение: в частности, оно чувствительно к операции
инверсии эталона (см. рис. 11.30 и сравни его с рис. 11.27, 11.28 и 11.29)
при вводе и оценивании новых эталонов это крайне нежелательно.
В то же время, при наблюдении за функционированием сети, при
отслеживании ее усилии узнать какой-либо эталон расстояние Хэм-
минга более удобно. Оно позволяет оценить, в правильном ли направле-
нии развивается процесс поиска, приближаемся сеть к искомому эталону
или удаляется от пего. Э го бывает очень эмоциональным (особенно koi да
ты встретишься с интересным явлением) бегством сети ом1 «настоящего»
эталона и «узнаванием» совсем другой ранее запомненной информации.
Познакомься с примером на рис. 11 31.
Пример отражает ситуацию ввода в сеть искаженного входного сиг-
нала. В оригинальный образ 1 введено 20 случайных изменений, в ре-
зультате искаженный образ стад меньше похож на свой эталон и еще
меньше похож на другие эталоны. Это заметно как по внешнему виду
изображения, так и но рассчитанному программой расстоянию Хэммин-
га.
Теперь стартует динамический процесс, связанный с функциониро-
ванием обратных связей сети. Вначале сеть формирует образ, который
опасно сближаемся с эталоном 3, но потом становится заметным «при-
тяжение» сети к аттрактору, связанному с эталоном 9. Обрати внимание
на числа, высвечиваемые под набором эмалонов как в графическом окне
Input pattern(s) for teaching or recalling, гак и в окне Recalled entry
pattern(s). Они характеризуют расстояния Хэмминга (а на рис. 11.32
скалярные произведения) между мскущим значением па выходе сети и
всеми рассматриваемыми эталонами. Рисунок поможем1 гобе сориентиро-
ваться в соответствии конкретных сигналов наборам расстояний. Сравни
значения расстояний Хэмминга между искаженным образом «1» и каж-
дым эталоном как в окне Input pattern(s) for teaching or recalling,
Рекуррентные сети
375
Искаженный образ «1»
Здесь показаны миниатюрные изображения
ранее введенных символов. Под каждой
миниатюрой приведено расстояние Хэмминга
между этим эталоном и искаженным образом «1».
похож на первый эталон («1»).
Расстояние Хэмминга между ними
равно 19
Dot ptoduct (DP)
Recalled entry pattern(s):
(?) Hamming distance (HJ
i tile
H H HQ HO
Здесь показаны
номера эталонов
Кнопки выбора меры подобия
Возможность сравнения в окнах Enlarged selected input и Enlarged selected
output миниатюр ранее отмеченных образов и значение меры подобия
между ними (DP or Н value between the two enlarged patterns).
В рассматриваемом случае - расстояние Хэмминга равно 45
Рис. 11.31. Неудач ное завершение поиска эталона при заданном расстоянии Хеммиига
Искаженный образ «1»
Здесь показаны миниатюрные изображения
ранее введенных символов. Под каждой
миниатюрой приведено расстояние Хэмминга
между этим эталоном и искаженным образом «1»
Noise
20 %
Most similar
Искаженный образ «1» больше всего
ji {£) Dot product (DP) 0
Recalled entry pattern(s): k
ГТ IT 96 IT %
Hamming distance (H J
Здесь показаны
номера эталонов
Кнопки выбора меры подобия
похож на первый эталон («1»),
Их скалярное произведение равно 58
Возможность сравнения в окнах Enlarged selected input и Enlarged selected
output миниатюр ранее отмеченных образов и значение меры подобия
между ними (DP or Н value between the two enlarged patterns).
В рассматриваемом случае - скалярное произведение равно 6
Рис. 11.32. Неудачное завершение поиска эталона при заданном значении скалярного
произведения
376
Глава 11
так и в окис Recalled entry pattern(s). Обрати внимание: вначале рас-
стояние Хэмминга между корректной версией эталона 1 и сигналом, по-
данным на вход сети, равно 19. До остальных эталонов безопасно да-
леко — от 37 до 50 единиц. Программа указывает на большее рассто-
яние гам, где сигнал и эталон мало подобны друг другу (0 и 1), и на
меньшее расстояние гам, где можно найти некоторое сходство. Согла-
сись, все разумно и логично.
Описанный эксперимент ты можешь легко воспроизвести па своем
компьютере. Также можешь получить сот ни аналогичных результатов с
другими эталонами и другими сигналами. Этим экспериментам стоит по-
святить некоторое время, поскольку их развитие и осмысление получен-
ных результатов создаст основу для очень интересных выводов. Быть мо-
жет, именно так рож даются в твоем мозгу новые идеи и неожиданные ас-
социации?
Опыты с сетью Хопфилда продемонстрируют, что задача задаче
рознь. Некоторые эталоны узнаются легко и без особых хлопот, а дру-
гие упорно вводят в заблуждение (рис. 11.33). Поэтому в следующем
разделе я расскажу тебе о хорошо узнаваемых образах (хотя польза от
этого, скорее всего, будет невелика).
Рекуррентные сети
377
11.8. Как и для чего можно использовать
автоматическую генерацию эталонов для сети
Хопфилда?
Как я уже говорил, при конструировании эталонов (которые сеть
должна запомнить) необходимо руководствоваться значениями скаляр-
ных произведений они помогут получить совокупность эталонов, име-
ющих наименьшую степень диафонии. Ты знаешь, что корректно скон-
струированный набор эталонов должен характеризоваться минимальны-
ми значениями этих произведений (по принципу «каждый с каждым»).
Идеальными считаются эталоны, имеющие нулевые значения скаляр-
ного произведения. Такой набор эталонов с нулевыми значениями ска-
лярных произведений во всех парах типа «каждый с каждым» назы-
вается в математике ортогональной системой. Эта система обладает
целым рядом удивительных теоретических свойств, приводящих матема-
тиков в состояние, близкое к экстазу. Об этом можно написать несколько
толстых томов с одними формулами и уравнениями, перемежающимися
такими словами, как ортогональный базис системы координат, инва-
риант,ность трансформации, декорреляция переменных, трансформа-
ция канонических компонент, и диагонализация м,ат,рицы ковариации
(все это па самом доле имеет глубокий смысл и тесную связь с ис-
пользуемой тобой программой), по тебе здесь и сейчас знать это со-
вершенно не обязательно. В то же время, ты должен понимать, что
при приближении (как минимум!) эталонов к описанному идеалу про-
цессы обучения и эксплуатации сети будут развиваться максимально
благоприятным образом.
К сожалению, практически невозможно собственноручно сконстру-
ировать набор ортогональных эталонов. Можешь попробовать прибли-
зиться к этому идеалу, но всегда образы знаков, генерируемых клави-
атурой компьютера, окажутся в чем-то подобными друг другу, т.е. их
скалярные произведения будут отличаться от нуля. Но ты можешь по-
ручить это задание программе Examplel2b. Программа умеет строить
ортогональные эталоны, и этим она очень помогает тебе в твоей работе.
В верхней части экрана расположено групповое поле Orthogonal and
pseudorandom patterns, а в нем редактируемое поле Number of
pattern(s), в которое ты должен вписать число символов, которое долж-
на автоматически сгенерировать программа. Не забывай: для подтвер-
ждения своего решения ггеобходимо кликнуть кнопку Generate. Вве-
денное в поле Number of pattern(s) число должно быть подобрано
так, чтобы суммарное количество эталонов (вместе с введенными ранее
буквами и цифрами) не превысило максимально допустимое значение,
378
Глава 11
Г Dot product (DPJ Hamming distance (H)
Рис. 11.34. Набор ортогональных эталонов, сформированных автоматически
Input pattern(s) for teaching or recalling:
Clear |
IT
14
DP 4
Save m a file
Norse Inverse
%
Most similar pattemls}
Numberfc):
DP or H value* 26
uptsabori
<*..? Dot product (DP) О Hamming distance (H)
Рис. 11.35. Ав гомати чески сформированный набор псевдослучайных эталонов
(начинающихся символом X)
Dot product (DP) ' Hamming distance (H)
Mos# simfef prdte?m|sj'
1 я
Number(s):
DP or H value 34
Remove
Рис. 11.36. Abj соматически сформированный набор псевдослучайных эталонов
(начинающихся последовав ел внос тыо символов X, Y, Z)
т.е. 20. Нажатие кнопки Generate (так же, как при нажатии кнопки
Add) приведет’ к появлению в графическом окне Input pattern(s) for
teaching or recalling: миниатюрных изображений (в заданном тобой
количестве) сгенерированных программой взаимно ортогональных эта-
лонов. Автоматически создавать и добавлять такие эталоны можно с
самого начала работы с сетью (рис. 11.34), но можно применить комби-
нированный способ вначале ты вводишь один или несколько эталонов
с клавиатуры, а потом передаешь управление машине (рис. 11.35, 11.36).
В первом случае (когда с самого начала все эталоны генерируют-
ся автоматически) программа построит набор взаимно ортогональных
Рекуррентные сети
379
Input pattem(s) tor teaching or renaming
Save in a hie
Clear
I
O’: Dot product (DP) ( Hamming distance (H)
Recalled entry patternfsjr
Eniaigeo selected input
Noise Inverse
15 %
Mm# мш!йг D^ttem(3]
n
N umber (s J.
DP or It value 12
Undo the last operation
Save in a file Enlaced selected owpuf
М4А-ЫЛ.*&1МН,«ллл-%%-»<ъ-л^Й 3|кал4л№ ~л.\<
2
96 I?P 96
DP or H value between
the two enlarged patterns*
72
Рис. 11.37. Корректное отображение искаженного образа с использованием
ортогопал ьн ых э i ал тонов
образов, что очень облегчит функционирование нейронной памяти. При
абсолютно автоматической генерации эталоны буцут проще и более регу-
лярными, чем при инициализации этого процесса ручным вводом какого-
либо знака. Во втором случае (когда перед автоматической гспсраци-
ей ты введешь один или несколько символов с клавиатуры) программа
сгенерирует не взаимно ортогональные, а псевдослучайные образы (см.
рис. 11.35 и 11.36). Обрати внимание на малые значения скалярных про-
изведений.
Ортогональные эталоны очень удобны при эксплуатации cein как
ассоциативной памяти, поскольку при их использовании (гак же как и
псевдослучайных эталонов) существует возможность узнать оригиналь-
ный образ даже в сильно искаженном входном сигнале (рис. 11.37,11.38).
Конечно, сказанное относится к любому запомненному эталону, но при
работе со сгенерированными программой псевдослучайными образами
довольно сложно сориентироваться — действительно ли сетью выбран
именно тот сигнал, который вводился как эталон до искажения обра-
за (дело в том, что псевдослучайные образы часто выглядят, скажем,
довольно экзотически).
Способность правильно узнавать нужные образы в очень сильно ис-
каженных изображениях сетью Хопфилда, запомнившей ортогональные
или псевдослучайные эталоны, имеет свои пределы (рис. 11.39, 11.40).
Если оригинальное изображение искажено слишком сильно, то возмож-
ность его узнавания будет безвозвратно утрачена. Это явление имеет
380
Глава И
Input pattern(s) for teaching or recalling:
Clear
Save in a file
17
H 46
18
Enlarged selected input
Norse Inverse
28 %
Most similar patter rifs);
Number(s):
DP or H value. 42
Undo the last operation
Remove
Dot product (DP) 0 Hamming distance (H)
Recalled entry pattern(s):
Save in a file 1
Enlarged selected output
DP or H value between
the two enlarged patterns
26
Рис. 11.38. Корректное отображение эталона буквы Z, в которой случайно изменены
26 точек (т.е. степень искажения равна 28 %)
Inverse
Input pattern(s) for teaching or recalling;
Noise
%
20
Most simitar pattern^]
Numbers).
DP or H value. 41
4
Undo the last operation
H 4? H 51 H 45 H 47 H 49 H 45
Save in a file Enlarged selected output
H 4? H 47
О Dot product (DP) Hamming distance (H)
Recalled entry pattern(s)
1 2
f! 0
DP or H value between
the two enlarged patterns
21
Рис. 11.39. Неточное отображение ортогонального эталона, в котором случайно
изменены 19 точек (т.е. степень искажения равна 20 %)
весьма критический характер. Например, на рис. 11.38 и 11.40 показано,
что сеть с псевдослучайными эталонами способна необычайно быстро и
корректно узнать эталон буквы Z, в которой случайным способом из-
менены 26 и 24 точки.
Можно многократно повторять эксперименты и всякий раз получать
Рекуррентные сети
381
2b Ж
similar гшчстзк]
N umber р] *
DP or H value* 39
Рис. 11.40. Корректное отображение эталона буквы Z, в которой случайно изменены
24 точки (т.е. степень искажения равна 25 %)
Input patternfs] tor teaching or recalling;
\ Clear Save in a hie
C Dat product (DP] (£> Hamming distance (HJ
Recalled entry pattern(s).
Save tn a trie 1
Enlarged selected input
Noise Inverse
-----------1 I__________J
26 %
Mast similar pMlernpl1
Number (sj:
DP or H value; 39
“ I
Rcinovc
Г Undo the last operation
Enlarged selected output
DP or H value between
the two enlarged patterns.
31
Рис. 11.41. Абсолютно некорректное отображение эталона буквы Z, в которой
случайно изменены 25 точек (т.е. степень искажения равна 26 %)
другой результат, поскольку в каждом случае искаженный эталон будет
выглядеть иначе, а изменяемые точки выбираются случайным способом.
Но часто достаточно изменить одну-единственную точку (т.е. исказить
в образе эталона не 24, а 25 пикселов), чтобы сеть перестала правильно
«узнавать» искаженный образ из-за появления небольших, но неустра-
нимых ошибок (рис. 11.41).
382
Глава 11
Add pattern (ma и ДИ
Leiter z
О Digit:
Add
ШЖ^дапа! or pseudorandom patterns
Generate |
Number of pattern! >): 19
A<M ^associative processes
Inverse
t »ad fihi rmh patterns
[ Load ] Rath:]
Clear
Save in a file
Enlarged selected input
input pattern(s) for teaching or recalling;
io
c
9
6
19
H 4-1
К
H 46
н 5:
H 40
H 46
Dot product (DP) Hamming distance (H)
Recalled entry pattern(s);
H 45 H 5
H 4<?
H 50
13
H 44 H 4 г
16 17
Noise
30
Moil similar pattern}®}-
DR or H value between
the two enlarged patterns:
28
1
H 0
4
и 0
Enlarged selected output
i
I
i
Рис. 11.42. Инцидспталыю корректное отображение эталона буквы Z
H 6 H
4
При еще большей степени разрушения исходного эталона процесс
узнавания затягивается, а копенный результат пце более ухудшается
(вплоть до того, что начиная с некоторого уровня деформации образа
процесс узнавания просто разваливается, и сеть генерирует на своем
выходе сплошной мусор). Но и в такой ситуации могут наблюдаться
по какому-нибудь стечению обстоятельств необычайно эффектные
случаи молниеносных успехов правильного узнавания эталонов в очень
сильно искаженных образах (рис. 11.42).
Если у тебя возникнет желание поэкспериментировать с ранее со-
зданным (и сохраненным па диске своего компьютера) набором эталонов,
то можешь воспользоваться групповым полем Load file with patterns.
Кнопка Load открывает диалоговое окно выбора файла с эталонами,
которые необходимо загрузить в программу. Если путь доступа к файлу
с эталонами (он имеет расширение .PTN) будет найден, то программа
покажет этот путь в редактируемом поле Path:, а миниатюрные изоб-
ражения содержащихся в этом файле эталонов появятся в графическом
окне Input pattern(s) for teaching or recalling:.
Рекуррентные сети
383
11.9. Какие исследования можно проводить
с применением ассоциативной памяти?
С применением программы Example 12b ты можешь провести серию
экспериментов, направленных на лучшее понимание возможностей ассо-
циативной памяти (в роли которой выступает сеть Хопфилда). Я уже
рассказал о том, как можно сохранять информацию в этой памяти, и как
память эту информацию использует. Сейчас поговорим о емкости запо-
минающего устройства, построенного па базе нейросетевых технологий.
Нормальные (оперативные или постоянные) запоминающие устрой-
ства твоего компьютера имеют конкретную ограниченную емкость. В та-
ких устройствах любое сообщение хранится в конкретном месте, для до-
ступа (прямого или косвенного) к которому необходимо указать точный
адрес. Аналогично хранится информация на жестком диске и па опти-
ческих носителях. Соответственно, количество данных, которые могут
храниться на любом таком устройстве, строго предопределяется количе-
ством адресуемых элементов этих устройств. Поэтому на вопрос о емко-
сти «традиционных» запоминающих устройств можно ответить быстро и
конкретно.
По-другому складывается ситуация с памятью, построенной на сети
Хопфилда. В ней нет отдельно адресуемых мест для храпения данных,
поскольку в запоминании (и узнавании) любого образа участвуют все
нейроны сети. Это означает, что в каждом нейроне различные эталоны
«накладываются» друг на друга, что Создаст определенные проблемы
«вспомни явление диафонии). Более того, способ воспроизведения (счи-
тывания) информации из нейронной памяти диаметрально отличается от
способа, используемого в обычных компьютерах. Вместо ввода названия
переменной или файла, в котором хранится какая-либо информация (в
сущности, оба способа связаны с указанием адреса, синонимом которого
является это название), для доступа к ассоциативной памяти необходи-
мо ввести саму информацию — пусть даже неполную или искаженную.
В связи с этим необычайно трудно сориентироваться, сколько данных
можно «впихнуть» в сеть, а сколько в нее пе поместятся.
Конечно, для решения этого вопроса создана строгая и точная тео-
рия, которая объясняет все возникающие проблемы. Если ты всерьез
захочешь с ней познакомиться — обратись к уже многократно упомя-
нутой моей книге «Нейронные сети»*.
Но задача нашей книги познакомить тебя с основными понятиями
и концепциями нейронных сетей в ходе экспериментов. Соответственно,
Или к другим русскоязычным! изданиям, перечисленным в списке литерату-
ры. — Прим, персе.
384
Глава 11
Dot product (DP) Hamming distance (H)
Recalled entry pattern(s).
Save in a file
Enlarged selected output
Noise Inverse
45 %
Ым'4 similar
1
Number(s).
DP or H value 46
Undo the last operation
i г
H 0 H Q
DP or H v alue between
the two enlarged patterns:
43
Рис. 11.43. Безотказное отображение информации при небольшом количестве
завом пен пых этапонов
постараемся ответить на вопрос о емкости нейронной памяти экспери-
ментальным путем. Таким способом тоже можно получить максимально
точную информацию, по поскольку ты добудешь ее лично в резуль-
тате собственноручно проведенных исследований понимание станет
полноценным, а это очень важно.
Первый и наиболее существенный фактор, обусловливающий про-
стоту и надежность отображения сетью запомненных сигналов ко-
личество данных, сохраняемых в сети в виде так называемых «следов
памяти». При сохранении в сети небольшого количества эталонов (па-
пример, трех) информация узнается четко и безошибочно даже при
очень сильных искажениях фис. 11.43).
Но эффект работы сети также зависит от степени различия запом-
ненных эталонов. На рис. 11.44 показаны результаты эксперимента, в
котором сеть имела дело тоже с небольшим количеством эталонов
но вследствие их сильного сходства нс смогла корректно узнать предъ-
явленный входной образ.
Следовательно, для выяснения максимальной емкости сети необ-
ходимо оперировать максимально различающимися сигналами — луч-
ше всего ортогональными или псевдослучайными. Тогда ты это уже
знаешь можно получить хорошие результаты работы сети даже при
максимальном суммарном количестве эталонов, которое в используемой
программе равно 20 (рис. 11.45).
При неидеалыю ортогональных эталонах (например, псевдослучай-
ных, т.е. сформированных в ходе автоматической генерации после рум-
Рекуррентные сети
385
Input patbun(s) for teaching or recalling:
Clear Save tn a file
Enlarged selected input
Masi similar pattem(s|:
Number(sj
DP or H value 9
Remove
Undo the last operation
О Dot product (OP) Hamming distance (H)
Recalled entry pattein(s):
н о ы 0
i Save in a file
Рис. 11.44. Неудачное узнавание образа при небольшом числе очень похожих друг на
друга эталонов
Input patternls) for teaching or recalling
Enlarged selected output
Enlarged selected input
12 Z
Most sirml н pa<fe}n(slr
Numberfs}:
DP or H value: 39
‘ Dot product (DPJ Hamming distance (H)
Recalled entry pattern(s)
Save in a
1 2
h о н a
DP or H value between
the two enlarged patterns:
11
Рис. 11.45. Корректное узнавание сильно искаженного образа при максимальном
числе псевдослучайных эталонов
ного ввода двух символов) результаты тоже могут оказаться неплохими
при условии выбора максимально различающихся между собой исход-
ных знаков и не очень сильных искажений демонстрируемых образов
(рис, 11.46). Тем не менее, попытка предъявления сети более искаженной
картинки тут же выявит наличие в сети сильной диафонии (рис. 11.47).
386
Глава И
14 %
Most smilar paHoJhl sj'
Humberts):
DP or H value 44
f Remove |
Undo the last operation
Рис. 11.46. Успех при запоминании большого числа не совсем ортогональных эталонов
Input pattern(s) for teaching or recalling.
Clear
15 Ж
Most similar paHern(s):
Number(s): 18
DP or H value 39
Remove
Undo the last operation
Inverse
Dot product (DPI £? Hamming distance (H)
Recalled entry pattern(s):
^Save in a file
1
и i н о :-i о
Enlarged selected output
DP or H value between
the two enlarged patterns
14
Рис. 11.47. Диафония, проявляющаяся при сильных искажениях входного сигнала
Корректное узнавание сигнала в системе с автоматичес ки сгенериро-
ванными программой ортогональными или почти ортогональными эта-
лонами может несколько смазываться тем, что при большом количестве
запомненных эталонов проблемы узпавапия входных сигналов становят-
ся гораздо более серьезными, чем при небольшом количестве хранимой
информации. Тем не менее, на рис. 11.48 ты можешь заметить: при нали-
чии достаточно заметной части неортогональных эталонов (даже когда
Рекуррентные сети
387
Input pattern! s| for teaching or recalling:
Enlarged selected input
Dot product (DP) Hamming distance (H)
Recalled entry pattem(s):
Enlarged selected output
Noise j J Inverse
5 j X
Most similar pattemh):
N umber (s): 1
DP or H value 23
Undo the last operation
Save in a file
DP or H value between
the two enlarged patterns
14
Рис. 11.48. Сильная диафония при минимальных искажениях эталона в сети, нс
удовлетворяющей условию ортогональности
оставшиеся эталоны ортогональны) в сети проявляется очень неприят-
ная диафония уже при самых незначительных искажениях входного сиг-
нала.
11.10. Что еще можно наблюдать
в ассоциативной памяти?
Узнавание сетью правильной формы эталона по его искаженному
изображению, предъявленному сети в качестве входного сигнала,— ди-
намичный процесс, очень похожий на наблюдавшийся в одноэлементной
сети (которую ты исследовал с применением первой в этой главе про-
граммы Examplel2a). Последовательность этапов процесса узнавания
выводятся на экран в форме графических образов, что позволяет от-
слеживать, как искаженный образ в графическом окне Recalled entry
pattern(s) постепенно «проявляется из хаоса». Щелкни мышкой на лю-
бом образе и проанализируй числа, характеризующие степень подобия
сгенерированных сетью образов хранимым эталонам, это поможет лучше
осознать развитие процесса выявления правильного эталона.
Из предыдущего обсуждения ты помнишь, что программа Example
12b позволяет исследовать этот процесс двумя способами с помощью
скалярных произведений и расстояний Хэмминга. Как при вводе дан-
ных, так и при реконструкции образа достаточно нажать соответствую-
щую кнопку выбора, чтобы (при неизменных прочих условиях) вместо
числовых характеристик скалярного произведения (Dot product,DP)
388
Глава 11
на экран были выведены значения расстояния Хэмминга (Hamming
distance, Н), и наоборот. Благодаря этой возможности ты можешь оце-
нивать, как изменяется (численно и качественно) расстояние между со-
здаваемыми сетью последовательными приближениями искомого образа
и каждым хранящимся в нейронной памяти эталоном (либо как изме-
няются значения скалярных произведений, по в этом случае для интер-
претации результатов уже потребуются определенные математические
знания). Ты сможешь выработать собственное мнение о динамике про-
цесса извлечения знаний из ассоциативной памяти, а также о процессах
изменения состояний и выходных сигналов нейронов в сетях Хопфилда.
Программа Examplel2b предоставляет тебе и другие инструменты
для отслеживания процесса узнавания эталонов и для выяснения причин
того или иного развития этого процесса. Во-первых, в правой части окна
Recalled entry pattern(s) располагается графическое окно Enlarged
selected output. В этом окис выводится увеличенный образ, выбранный
из окна Recalled entry pattern(s). Если ты обозначил мышкой один
образ в окне Input pattern(s) for teaching or recalling: и один образ
в окис Recalled entry pattern(s), то в правой части окна Enlarged
selected output в редактируемом поле DP or Н value between the
two enlarged patterns: появится значение меры подобия между этими
выбранными эталонами (выраженное с помощью скалярного произведе-
ния или расстояния Хэмминга). При наблюдении за эволюцией обраба-
тываемого сетью образа можно пе только познакомиться с ее работой,
по и получить ответ па вопрос: почему сеть работает именно так?, хотя
для этого потребуется большое терпение и много времени. Процесс по-
иска сетью требуемого эталона заверпяается, к of да очередная итерация
нс вносит в образ никаких изменений (в этот момент состояние сети ста-
билизируется). Работа сети также может прекратиться в случае (очень
редко наблюдаемом на практике) возникновения осцилляций. Если оче-
редные шаги проходят яерез одни и те же последовательности состоя-
ний, то процесс завершается, хотя результаты в такой ситуации могут'
оказаться весьма странными.
Очень интересно наблюдал ь иногда происходящие «скачкообразные»
события когда сеть вместо постепенного выявления нужного эталона
вдруг ассоциирует деформированный образ с совершенно иным этало-
ном, и начинает деловито полировать и чистить этот фальшивый эталон
(рис. 11.32). Часто в результате такого «приключения» в сели форми-
руется совершенно повое впечатление о несуществующем эталоне в ви-
де гибрица реальных элементов, скомпонованных необычным образом,
пе имеющим ничего общего с реальной действительностью (рис. 11.27).
Возникают этакие сказочные чудовища или ужастики из ночного кошма-
Рекуррентные сети
389
ра типа крылатых змей или трехголовых собак, — только составлен-
ные из элементов доступного сети мира (т.е. фрагментов введенных сим-
волов). Это стоит увидеть, чтобы понять, как сильно отличается функ-
ционирование нейронной сети от тупого и лишенного фантазии выпол-
нения обычных алгоритмов!
Все остальное ты откроешь сам в процессе работы с программой.
Успехов!
11.11. Контрольные вопросы и задания
для самостоятельного выполнения
1. Постарайся кратко (максимум десятью предложениями) описать
все различия между нейронной сетью с однонаправленным распростра-
нением сигналов (часто называемой англоязычным термином feedfor-
ward) и сетью с обратными связями.
2. Постарайся найти формулу для предсказания равновесного (ста-
билизировавшегося) выходного сигнала в сети, моделируемой програм-
мой Examplel2a при различных значениях параметров (коэффициен-
тов синаптических весов) и при различных значениях входного сигна-
ла. Сравни результаты твоих рассуждений с результатами, полученны-
ми программным путем.
3. Прочитай какую-либо статью в Интернете или в книге по теории
хаоса. Как ты думаешь, что связывает эту теорию и описываемые ею
явления с рекуррентными нейронными сетями?
4. Найди в Интернете или в какой-нибудь публикации записи пе-
ременных во времени электрических потенциалов человеческого мозга,
так называемую электроэнцефалограмму (ЭЭГ). Как ты думаешь, рас-
пределений: эт их сигналов свидетельствует о наличии или об отсутствии
обратных связей в мозгу человека?
5. Как ты считаешь, в человеческой памяти (которая, вне всякого
сомнения, имеет1 ассоциативный характер) встречаются явления, ана-
логичные диафонии сети Хопфилда? Если да, то как они субъективно
ощущаются и оцениваются людьми?
6. На основе проведенных экспериментов сформулируй собственное
мнение какая из применяемых мер подобия (DP или Н) позволя-
ет эффективнее прогнозировать успешность или возможные проблемы
узнавания сетью образов?
7. Между количеством нейронов в сети Хопфилда и количеством эта-
лонов, которые можно эффективно запомнить в этой сети (с минималь-
ной вероятностью проявления диафонии), существует определенная, ма-
тематически выводимая зависимость. Не вдаваясь в подробности, можно
сказать: чем больше нейронов насчитывает сеть, тем больше эталонов
390
Глава 11
она может запомнить, хотя для запоминания каждого конкретного эта-
лона задействуются все нейроны сети. С учетом этого факта поразмыш-
ляй о запоминающей способности человеческого мозга, который состо-
ит из примерно ста миллиардов нейронов. Можно ли чем-то обосновать
факт, что одни люди обладают лучшей, а другие худшей памятью?
8. Все без исключения обсуждавшиеся в нашей книге сети Хопфил-
да были автоассодиативными сетями, т.е. их ассоциативная память
применялась только для узнавания ранее запомненных эталонов. Поду-
май, какую структуру должна иметь гстероассоциагивная сеть, предна-
значенная для запоминания ассоциаций различных образов (например,
упрощенного изображения какого-либо предмета и буквы, с которой на-
чинаемся название этого предмета).
9. При исследовании сети Хопфилда мы использовали очень про-
стые эталоны по сути, предельно схематичные контуры букв и цифр.
Несомненно, гораздо интереснее было бы экспериментировать с сетью,
оперирующее образами, аналогичными показанным на рис. 11.13. Как
ты думаешь, почему эта идея не была реализована?
10. При построении больших сетей Хопфилда (состоящих из большо-
го коли честна нейронов) некоторый компьютерный ресурс исчерпывает-
ся очень быстро. Как ты думаешь какой и почему именно он?
11. Задание для наиболее подготовленных. Создай версию про-
граммы Examplel2a, в которой вместо таблицы выходных сит палов, вы-
рабатываемых семью па каждом шаге моделирования, будем1 демонстри-
роваться график изменения выходного сигнала. Какая проблема будем1
преодолеваться труднее всего, и каким способом ты с пей справишься?
12. Задание для наиболее подготовленных. Создай версию про-
граммы Examplel2b с сильно увеличенной матрицей нейронов, пред-
ставляющих запомненные образы (например, ее можно увеличи ть в три
раза в каждом направлении). Используй усовершенствованный тобой ин-
струментарий для проведения экспериментов, описанных в этой главе, и
сопоставь результаты наблюдений с зависимостью, приведенной в зада-
нии № 7.
ЗАКЛЮЧЕНИЕ
Книга, которую ты только что закончил читать, ввела тебя в бога-
тый, интересный и иногда футуристический мир нейронных сетей. Тебя
нс должны ни удивить, пи опечалить мои слова о том, что все усвоенное
в результате прочтения книги — только «верхушка айсберга». Огромная
часть обширнейших знаний, накопленных людьми в области нейронных
сетей, все еще скрыта от глаз и остается погруженной в окружающий
тебя «Океан Незнания». Но сведения, почерпнутые из этой книги, мне
кажутся наиболее интересными и полезными. Знание свойств одиночного
нейрона (которые ты изучил очень подробно!) позволят понять функ-
ционирование любых сетей, состоящих из таких элементов, даже если
они будут иметь совершенно иные топологии, отличающиеся от рассмот-
ренных в книге. Ты узнал и подробно исследовал, как функционирует
и обрабатывает информацию сеть с топологией многослойного персеп-
трона. Это только одна из множества сетей, по чаще всего используемая
в большинстве практических приложений и известная своей эффектив-
ной работой. Но если кто-то покажет тебе сеть другой топологии ты
сориентируешься, что и как она делает, поскольку правила функциони-
рования различных сетей опираются па очень близкие концепции.
Идем дальше. Ты познакомился с функционированием алгоритма
обратного распространения ошибки (backpropagation) наиболее часто
и широко применяемым инструментом обучения сетей. Благодаря это-
му ты сможешь лучше понять работу других алгоритмов обучения, на-
пример основанных па математическом методе сопряженных градиентов.
В ходе экспериментов, которые мы вместе проводили при чтении книги,
ты уже знаешь, как развивается процесс самоорганизации в сети Кохоне-
на (это еще одна сеть, очень часто применяемая на практике!). Конечно,
твои знания о нейронных сетях все еще фрагментарны и отрывочны, но
благодаря наличию этих знаний можно смело обращаться к любым дру-
гим инструментам самообучения — уже понятно, что в них происходит.
Аналогично, знакомство со свойствами рекуррентных сетей Хопфилда
(тоже одних из наиболее популярных!) позволит понять способ функцио-
нирования иных рекуррентных сетей, особенно таких, которые работают
в режиме ассоциативной памяти.
Этот краткий обзор показывает, что ты узнал из книги достаточно
много, чтобы ощущать себя готовым к дальнейшим, уже самостоятель-
ным «путешествиям» по планете нейронных сетей. Обрати внимание: я
392
Заключение
много раз отмечал, что полученные тобой из книги знания о нейронных
сетях чаще всего применяются на практике. Другие топологии сетей,
другие методы обучения, другие принципы функционирования присут-
ствуют, как правило, в нечастых работах очень амбициозных исследова-
телей. Подавляющее большинство достижений, отмеченных в последнее
время в области нейронных сетей, получено с применением именно тех
инструментов, с которыми ты познакомился на страницах нашей книри
(ну, или с их незначительными модификациями...).
Книга окончена, по тяга к знаниям осталась. Возможно, тебя вол-
нует вопрос: Что дальше?
Твоя ситуация в этот момент напоминает ситуацию моряка, кото-
рый смотрит с палубы своего корабля в бездонное звездное небо. Его
взору открыты сотни звезд, так же как в литературе можно найти сот-
ни описаний различных нейронных сетей. Но чтобы безопасно довести
корабль до порта, необязательно помнить названия и свойства всех ви-
димых зве^ц. Достаточно знать несколько звезд, таких как Polaris (По-
лярная звезда, лежащая па земной оси) или Дельта Ориона (централь-
ная звездочка «пояса» Ориона, почти идеально расположенная в плос-
кости экватора), чтобы определить местоположение корабля и проло-
жить правильный курс.
По моему мнению, ты уже имеешь право считать себя моряком в
огромном Океане Незнания. Рассматривай эту книгу как яхту, па кото-
рой ты сможешь переплыть этот океан. Но прежде тем предприметь это
путешествие, прими к сведению несколько советов и предостережений.
Нс забывай: каждый моряк должен со знавать глубину той бездпы, кото-
рая разверзнется под его ногами при попытке сделат ь слишком широкий
шаг за пределы безопасной палубы корабля. Ты должен знать: Океан
Незнания огромен, а нвоя яхта (но сравнению с ним) очень маленькая.
Помни об этом непрерывно, иначе пренебрежение опасностью может при-
вести к такой стремительной катастрофе, что ты даже не успеешь попять
ее причину. Но твоя яхта не какая-нибудь случайная плоскодонка.
Она хоть и невелика, но стабильна и безопасна. Поэтому, вооруженный
знаниями, почерпнутыми со страниц этой книги, ты можешь гордо под-
нять голову и смело взглянуть па бесчисленные публикации, в которых
мудрые исследователи (и маниакальные графоманы...) описывают раз-
личные нейронные сети. Наверное, их больше чем звезд на небе в ясную
ночь, а ты знаешь лишь некоторые. При изучении следующих работ не
удивляйся, если тебе будут незнакомы какие-то применяемые методы
или непонятен избранный автором путь.
Но помни: все, чему я научил тебя в этой книге и что ты познал
сам при проведении собственноручных экспериментов это твои ну-
Заключение
393
теводные звезды, которые всегда будут указывать путь в безопасную
гавань. Им можно доверять!
Опытный моряк всегда берет с собой карту, на которой обозначе-
ны глубины и мели пересекаемого океана. Я тоже постараюсь предло-
жить тебе карту, на которой будет точно указано чего ты не знаешь
о нейронных сетях по прочтении этой книги и что должен сделать в
первую очередь, если возникнет желание заниматься этими интересней-
шими средствами информатики всерьез, а не только из любопытства.
Во-первых, главный недостаток твоих знаний заключается в том,
что, знакомясь с нейронными сетями на практике, ты абсолютно ниче-
го не знаешь об их теории. В тексте кнйги (в соответствии с обещанием,
данным на первых страницах) не было нй одной математической фор-
мулы. Это не означает, что в сфере нейронных сетей можно добиваться
успехов без знания математики. Соответствующие формулы применя-
лись, но не па страницах книги, а в текстах использовавшихся тобой
программ, которые только благодаря этим формулам могли так инте-
ресно и эффективно работать. Если ты желаешь не просто скользить по
поверхности проблематики нейронных сетей, но и постигнуть глубину
описанного мной Океана Незнания, то проигнорированная в книге тео-
рия окажется для тебя абсолютно необходимой*.
Во-вторых, ты знаешь о существовании многослойных нейронных се-
тей персептронной структуры, но ничего не знаешь о сетях типа RBF,
с которыми гы тоже должен познакомиться (хотя они используются
несколько реже). После этого можешь изучить сети GRNN, PNN, ART,
CNN, СР. BSB, ВАМ, нелинейные сети РСА, LVQ и многие другие.
Тебе эти сокращения ничего не говорят? Ну и что?
Вот именно! Ты должен накопить, как минимум, такие знания, бла-
годаря которым будешь точно понимать каждое приведенное сокраще-
ние, только тогда тебя смогут признать опытным экспертом обсужда-
емой здесь сферы информатики.
Я несколько раз упоминал о том, что наряду с методом backpropaga-
tion существую!' и применяются другие методы обучения сетей. Их ве-
ликое множество, и непрерывно создаются новые. Эксперюм ты смо-
жешь считаться только тогда, когда будешь знать, по крайней мере,
дюжину таких методов!
Ты познакомился с нейронами, которые преобразуют входные сиг-
налы в выходные без учета временных характеристик этих сигналов.
По всей книге мы предполагали, что каждый сигнал представляет собой
* Самые элементарные математические формулы, применяемые в теории нейронных
сетей, приведены в приложениях к книге. Прим, пере в.
394
Заключение
простое число. В то же время, новейшие исследования в области нейрон-
ных сетей все чаще основываются на факте, что естественные (биоло-
гические) нейроны при решении стоящих перец ними задач высылают и
получают серии необыкновенно слабо модулированных импульсов. Если
хочешь познакомиться с последними достижениями в этой сфере, то за-
помни название «импульсные нейроны» (Spiking Neurons). В некоторых
современных работах исследуются свойства именно таких нейронов.
И, в завершение, еще одно суждение. На протяжении всей книги в
качестве структуры рассматривавшихся нейронных сетей мы исполь-
зовали многослойное объединение нейронов со связями типа «каждый
с каждым». Но применяются сетевые структуры абсолютно иной топо-
логии. В качестве их наиболее яркого (т.е. максимально удаленного от
модели многослойного персептрона) примера можно назвать так назы-
ваемые клеточные нейронные сети, объединяющие свойства известных
тебе нейронных сетей со свойствами клеточных автоматов, ставших ши-
роко известными благодаря популярной игре «Жизнь» (Life)*.
Я перечислил только некоторые проблемы, с которыми ты должен
познакомиться, если захочешь превратиться из начинающего поклонни-
ка нейросетевых технологий в опытного «гуру». Для получения необхо-
димых знаний можешь воспользоваться книгами, указанными в списке
литературы. Но настоящим Мастером ты станешь только тогда, когда
сконструируешь свою собственную, не известную ранее нейронную сеть.
На уже знакомом небосводе нашей науки засияет новая звезда. Искрение
желаю: пусть опа будет прекрасной и яркой!
Автор Дж. Конуэй. Впервые на русском языке опубликована в книге М. Гартнера
«Математические цосути» (Мир, 1972). В Интернете есть большое число программ для
игры в «Жизнь». Прим. ред.
Приложения
Приложение 1. Математическая модель нейрона
Для описания зависимости между входом и выходом нейрона удобно ис-
пользовать векторную запись. Множество входных сигналов можно предста-
вить вектором
где т символ транспонирования. Аналогично можно записать вектор ве-
совых коэффициентов, которые представляют знания, полученные нейро-
ном в процессе обучения:
W = <Wi,W2,...,Wn)T.
Представленные векторы можно интерпретировать как точки в п-мер-
ном пространстве. Все возможные точки, представляющие входные сигналы
и весовые коэффициенты, образуют соответственно пространство входных
сигналов и пространство весов.
Математическое описание нейрона сводится к построению функции,
связывающей входные сигналы и весовые коэффициенты способом, позво-
ляющим рассчитать выходной сигнал нейрона. Выходной сигнал связан с
входным сигналом функцией /, определяющей функционирование нейрона:
Конкретная форма зависимости, описывающей функционирование ней-
рона, зависит от целей применения сети.
Приложение 2. Линейные и нелинейные нейроны
Линейные нейроны. Зависимость между входами (тг, i = 1,2, ...,п) и
выходом (?/) линейного нейрона имеет вид
п
У = ^w.Xi
i=1
либо в векторной форме
у = WTX.
Элемент, описываемый представленной линейной зависимостью, обла-
дает интересным свойством выделять те входные векторы, которые похожи
на вектор весовых коэффициентов. Это обусловлено особенностью скаляр-
ного произведения: выходной сигнал будет тем сильнее, чем больше распо-
396
Приложения
ложение входного вектора X в пространстве входов будет похоже на распо-
ложение вектора весовых коэффициентов W в пространстве весов. Таким
образом, даже одиночный нейрон сможет распознавать определенный класс
входных векторов, причем о распознавании «своего» вектора будет свиде-
тельствовать увеличение входного сигнала.
Нелинейные нейроны. В нелинейном нейроне входная информация
обрабатывается способом, который можно описать уравнением
У =
где р выбранная нелинейная функция, а сигнал е чаще всего соответ-
ствует совокупному возбуждению нейрона, рассчитываемому по формуле,
используемой в линейной модели:
либо с добавлением постоянной компоненты
(bias):
гак называемого порога
п
е = иухг + О.
г= 1
Для расчета, случайного возбуждающего сигнала е применяются и дру-
гие функции (например, основанные па произведении компонент, по мы их
сейчас обсуждать не будем». Любая функция, объединяющая входные сиг-
наль! х в единое возбуждающее воздействие, применяется только на на-
чальном этапе обработки информации нейроном. Специфические свойства
этого элемента определяются функцией </?, характеризующей нелинейную
зависимость между случайным входным сигналом с и откликом у. Следо-
вательно, обсуждавшийся выше линейный нейрон может рассматриваться
как компонента структуры нелинейного нейрона.
Наиболее из веста а так называемая пороговая функция:
' 1, если е 0;
С | 0, если с < 0,
и сигмоидальная функция, выведенная из логистической функции,
_ 1
1 + схр(—/Зе)
Приложение 3. Математические функции, часто
используемые в нелинейных нейронах
Функция гиперболического тангенса
у = tanh(/5te)
exp (/Зе) — ехр( -/Зе)
ехр(/3е) + ехр(—/?с)
Приложения
397
Функция «signum»
{1, если о > 0;
0, если е = 0;
— 1, если е < 0.
Модифицированная функция «signum»
[ 1, если с > 0;
( — 1, если е < 0.
Функция единичного порога
( 1,сслис 0;
(0, если е 0.
Персеи трот тая функция
( е, если е > 0;
у = <
[ 0, если с 0.
Функция ВАМ (Biderctional Associative Memory}
{1, если с > 0;
если е = 0;
-1, если с < 0.
Функция BSB (Brain State in a Box)
{1. «'ели е > 1;
е, если 1 > е > -1;
— 1, если с < —1.
Приложение 4. Какова роль «учителя» при обучении
нейронной сети?
Необходимо уточнить, какой смысл вкладывается в понятие «учитель,
трен лруюш.ий сеть». Это объект, который пред ьявляет сети примеры за-
дач вместе с их решениями. Обучение сети заключается в наследовании
способа функционирования учителя, поэтому очень удобным оказываемся
понятие «обучающая последовательность». Это последовательно предъ-
являемые элементы множества примеров, но которым обучается сеть.
Предположим, что рассматриваемая сеть имеет п входов и к выходов.
Очевидно, что это связано с наличием в такой сетй п Нейронов во входном
слое и к нейронов в выходном слое. При таких предположениях обучающая
последовательность для обучения одиночного нейрон8 имеет вид
где пары данных, демонстрируемых на входе и выходе сети
(нейрона) на j-м шаге процесса обучения; Х^ — n-мерный вектор входных
данных па j-м шаге; z® ожидаемый отклик нейрона на j-м шаге; N
число примеров, предъявляемых на этапе обучения.
398
Приложения
Применительно к многослойной сети в целом обучающая последова-
тельность имеет виц
и = Z<n), (Х(2\ Z<2)),(X(7V), Z(/v)}},
где А'1-'1 — л-мериым вектор входных данных на j-м шаге; Z'zl — /с-мерный
вектор ожидаемого отклика нейронов выходного слоя сети на j-м шаге.
В типичных условиях функционирование «учи геля» заключается ис-
ключительно в предъявлении сети обучающей последовательности, поэтому
роль учителя может исполнять компьютер, оборудованный соответствую-
щей базой данных.
Приложение 5. Элементы технологии самообучения
сети
При обучении без учителя (иначе называемом самообучением сети) ни-
кто гге предлагает сети правильные ответы. Сеть должна самостоятельно
пайги интересующие категории или свойства во мнЬжеСтве входных дан-
ных. Самообучение сет и похоже на функционирование человеческого мозга.
Человек гоже обладает способностью спонтанно классифицировать встре-
чаемые объекты и явления, а позднее распознавать новые объекты с
точки зрения их принадлежности к одному из ранее выделенных классов.
Метод самообучения основан на правиле Хебба: оно предполагает1 усиле-
ние связей между источниками сильных сигналов и нейронами, которые на
них сильно реагируют1. В результате обучения похожие друг на друга сиг-
налы будут распознаваться одними и игнорироваться другими нейронами
(отрицательные выходные значения). После выработки выходных сигналов
всеми нейронами сети, все веса каждого нейрона и вменяются, причем вели-
чина изменения рассчитывается из произведения входного сигнала, подан-
ного на соответствующий вход (весовой коэффициент кот орого изменяется)
на выходной сигнал нейрона. Для более подробного описания этого про-
цесса ггсобходимо вначале ввести понятие обучающей последовательности.
Эю множество примеров, по которым обучается сеть. Обучающая после-
довательность имеет вид
U = {X(1),X(2),...,X(/V)}
где Х^; вектор входных данных на _/-м шаге: N — количество примеров,
демонстрируемых на этапе обучения.
Правило обучения для m-го нейрона на j-м шаге обучения определим
следующим образом:
_ (™)0) I СП О)
т У-т >
где
О) _ (™)СЯ О)
i/m / v г ' '?
г— L
Приложения
399
Другое название обучения по правилу Хебба корреляционное обу-
чение {correlation learning), поскольку оно направлено на такую адаптацию
весов, при которой достигается наилучшая корреляция между входными
сигналами и запомненным в форме значений весов «эталоном» сигнала, на
который соответствующий нейрон должен реагировать.
Приложение 6. Технология обучения, применяемая
в нейронных сетях
Обсуждение алгоритмов обучения с учителем начнем с демонстрации
способа обучения одиночного нелинейного нейрона. Основная формула, ис-
пользуемая для обучения нейронных сетей, имеет вид
Дг/;0) =
1 de^ г
Из этой формулы следует, что изменение Д w • весового коэффициента w' ‘1
на г-м входе нейрона после предъявления Дго объекта обучающей последо-
вательности (см. Приложение 7) пропорционально погрешности £ ’допу-
щенной нейроном па этом этапе процесса обучения:
^v) _ z(j) _ Hj)
где, очевидно,
Следовательно, если нейрон не допускает ошибки при обучении, то его
веса не изменяются. Благодаря такому приему процесс самостоятельно за-
вершается при Достижении искомого результата. Корректировка весово-
го коэффициента на некотором входе Aw' также пропорциональна вели-
чине сигнала на этом входе Таким образом, изменению и актуализа-
ции в процессе обучения подвергаются веса только активных входов. Коэф-
фициент т/ называется коэффициентом обучения {learning rate)] он влия-
ет на скорость обучения.
Для упрощения расчета производной
как правило, логистическая функция
dj{e}
de[J}
в качестве <Де) используется,
•/ \ 1
у = Я ----------гтт’
1 + ехр(- be)
для которой
dj{e)
de(3^
Соответственно, получаем итоговую формулу обучения одиночного нейрона
(а также любой однослойной сети) в виде
Awp) — h{z^ — уи}){1 — у^)х^у^.
400
Приложения
В многослойных сетях события развиваются иначе, поэтому мы рас-
смотрим в отдельном приложении перенос обсуждавшегося здесь принципа
обучения на многослойную сеть.
Приложение 7. Ускорение процесса обучения
Метод учета момента {momentum} заключается в придании процессу
обучения некоторой инерции изменения весов зависят как от погреш-
ности, допущенной сетью па текущем шаге, так и от развития процесса
обучения на предыдущих шагах. Эту инерционность можно описать сле-
дующей зависимостью:
+г/2двд(т)0-1).
dCrn
Параметр z/2 принимает значения от 0 до 1; часто используется значение 0,9.
Приложение 8. Обучение многослойных сетей методом
обратного распространения ошибки
Алгоритм, описанный в Приложении 6, неприменим для обучения мно-
гослойных сетей, поскольку в этом случае нельзя напрямую определить
отклики (выходные сигналы) нейронов скрытых слоев и соответствен-
но определить погрешность 6^. По этой причине для корректировки весов
нейронов скрытых слоев также применяется формула
Aw(m)b) = -п<5(Л vU>)
где т номер рассматриваемого нейрона, но вместо простого выражения
x(j) _
т Um
мы должны использовать более сложную конструкцию. Пусть рассматри-
ваемый нейрон скрытого слоя высылает выходной сигнал только на ней-
роны выходного слоя, для которых значения ошибок легко определя-
ются гг ходе сравнения их сигналов с информацией, полученной от учи-
теля. Ошибку 8^\ допущенную рассматриваемым нейроном, мы находим
путем суммироваггия с учетом весовых коэффициентов связей между
этим нейроном и нейронами выходного слоя, на которые подается выра-
ботанный выходной сигнал:
хО) _ c(j)
°т - / , wm , (,) °к '
к
В этой формуле используются обозначения, показанные на рис. П.8.1.
Описанный подход известен как метод обратного распространения ошиб-
ки. Согласно этому методу распределяемые в обратном (от выхода к вхо-
ду сети) ошибки умножаются гга те же коэффициенты, на которые умно-
жались сигналы при продвижении сигнала в прямом (от входа к выхо-
ду сети) направлеггии.
Приложения
401
Рис. П.8.1. Определение обозначений в формуле обратного распространения ошибки
Метод обратного распределения ошибки можно применять к сети в це-
лом при соблюдении соответствующей последовательности расчета ошибок.
Приложение 9. Обучение сети как минимизация
функции погрешности
Цель процесса обучения заключается в достижении согласия между вы-
ходом нейрона и ожидаемым откликом для каждого примера, со-
держащегося в обучающей последовательности. При отсутствии та-
кого условия сеть, созданная для распознавания букв, очень быстро найдет
«решение», в соответствии с которым абсолютно каждый демонстрируемый
объект будет «распознаваться» как буква А. Конечно, в подавляющем боль-
шинстве случаев решение будет ошибочным, но как замечательно будет рас-
познаваться буква А независимо от шрифта и почерка автора!
Конечно, приведенный пример некорректпого функционирования сети
очевидно абсурден*, но эксперименты с нейронными сетями свидетельству-
ют об их невероятной склонности к получению «решений», заключающихся
в минимизации усилий по решению поставленных задач поэтому ника-
кие средства профилактики не будут излишними.
По этой причине в процессе обучения сети мы так определяем меру
ошибки (называемую функцией издержек, критериальной функцией или
функцией погрешности), чтобы она учитывала поведение сети при демон-
страции всех примеров, входящих в состав обучающей последовательности:
Q = I
J-1
где
Ситуация с «обученной» таким способом сетью аналогична ситуации, известной
из шутливого вопроса: Какие часы лучше — которые всегда отстают или которые иде-
ально точно показывают время, но только два раза в сутки? Понятно, что во втором
случае имеются в виду стоящие часы.
402
Приложения
Функция Q широко известна из метода наименьших квадратов; в па-
шем случае опа адаптирована к потребностям процесса обучения сети. Эта
функция для j-ro шага обучения принимает вид
QU) = |(гС7) -уО))2.
С использованием меры погрешности Q можно скорректировать вектор
весов AW так, чтобы как можно быстрее перемещаться вниз по поверхности
ошибки. Согласно градиентной стратегии процесса обучения (градиентная
минимизация функции погрешности), необходимо на J-м шаге изменять г-ю
компоненту вектора W на некоторую величину Дш?, пропорциональную г-й
компоненте градиента функции Q в этой точке:
гг-*?+1) - w-j) = = -т)
Знак «—» в формуле характеризует направление скорейшего уменьше-
ния функции Q. Значение Q зависит от ?/, а у = (/?(е) представляет собой
функцию, зависящую от совокупного возбуждения е, которое (в свою оче-
редь) непосредственно определяется весовыми коэффициентами Wi. Поэто-
му градиент Q можно разложить на производные составной функции:
dQ^ _ dQ^ dy^ де^
dwi dykfi de^ dwi
при очевидном
= -(г“ - >,<«) =
a./’1
()yU)
(3wi
dy(^ dy№
deW de(fi
При объединении этих выражений мы получим формулу, уже извест-
ную из Приложения 6:
' 1 de^ г
Библиография
1. Simon Haykin, Neural Networks: A Comprehensive Foundation, 2nd Edition, Prentice
Hall, 1999.
2. Kevin Gurney, An Introduction to Neural Networks, UCL Press, 1 Gunpowder Square,
London, 1999.
3. Jeannette Lawrence, Introduction to Neural Networks, California Scientific, Nevada City,
1998.
4. Robert J. Schalkoff, Artificial Neural Networks, McGraw-Hill, 1997.
5. Paul D. McNelis, Neural Networks In Finance: Gaining Predictive Edge in the Market,
Academic Press, 2004.
6. James A. Anderson, Edward Rosenfeld (Editors), Talking Nets: An Oral History of
Neural Networks,, MIT Press, 2000.
7. Marvin Minsky, The Emotion Machine, Simon & Schuttcr. 2005.
8. Martin T. Hagan, Howard B. Dernuth, Mark H. Beale, Neural Network Design, Martin
Hagan, 2002.
9. Simon S. Haykin, Jose C. Principe, Terrence J. Sejnowski, John McWhirter (Editors),
New Directions in Statistical Signal Processing: From Systems to Brain, MIT Press, 2006.
10. Stephen T. Welstead, Neural Network and Fuzzy Logic Applications in C/C++, Wiley,
1994.
11. Paul Smolensky, Geraldine Legendre, Harmonic Mind: From Neural Computation to
Optimality-theoretic Grammar, MIT Press, 2005.
12. Brian D. Ripley, Pattern Recognition and Neural Networks, MIT Press, 2005.
13. Laurene Fausett, Fundamentals of Neural Networks: Architectures, Algorithms, and
Applications, Prentice Hall, 1994.
14. Richard E. Neapolitan, Learning Bayesian Networks, Prentice Hall, 2003.
15. Earl Gose, Richard Johnsonbaugh, Steve Jost, Pattern Recognition and Image Analysis
Prentice Hall, 1996.
16. Jeff Hawkins, Sandra Blakeslee, On Intelligence: How a New Understanding of the Brain
Will Lead to the Creation of Truly Intelligent Machines, Henry Holt & Co, 2004.
17. Vladimir S. Cherkassky, Filip Mulicr, Learning from Data: Concepts, Theory, and
Methods, John Wiley, 2007.
18. Mukesh Kharc, Artificial Neural Networks in Vehicular Pollution Modeling, Springer
Vcrlag, 2007.
19. Fei-Yuc Wang, Derong Liu, Advances in Computational Intelligence: Theory And Ap-
plications, World Scientific Pub Co Inc, 2006.
20. Ke-lin Du, M. N. S. Swamy, Neural Networks in a Softcomputing Framework, Springer
Vcrlag, 2006.
21. Christopher M. Bishop, Neural Networks for Pattern Recognition, Oxford Univ Press,
1995.
22. Барский А.Б. Нейронные сети: распознавание, управление, принятие решений.
М.: Финансы и статистика, 2003.
23. Борисов В.В., Круглов В.В., Федулов А.С. Нечеткие модели и сети. М.: Го-
рячая линия Телеком, 2007.
24. Галушкин Л.И. Нейрокомпьютеры и их применение на рубеже тысячелетий в
Китае. В 2-х томах. М.: Горячая линия Телеком, 2004.
404
Библиография
25. Галушкин А.И. Синтез многослойных систем распознавания образов. М.: Энер-
гия, 1974.
26. Горбань А.Н. Обучение нейронных сетей. — М.: СП ПараГраф. 1990.
27. Горбань А., Дунин-Барковский В., Кирдии А. и др. Нейроинформатика. Ново-
сибирск: Наука. Сибирское предприятие РАН. 1998.
28. Горбань А.Н., Россией Д.А. Нейронные сети на персональных компьютерах.
Новосибирск: Наука, 1996.
29. Комашинский В., Смирнов Д. Нейронные сети и их применение в системах управ-
ления и связи. М.: Горячая линия Телеком, 2002.
30. Круглов В., Борисов В. Искусственные нейронные сети. Теория и практика.
М.: Горячая линия Телеком, 2002.
31. Круглов В., Дли М., Голунов Р. Нечеткая логика и искусственные нейронные
сети. М.: Изд-во Физматлит, 2000.
32. Нейронные сети. STATISTICA Neural Networks: Пер. с англ. М.: Горячая линия
Телеком, 2000.
33. Осовский С. Нейронные сети для обработки информации. - М.: Финансы и стати-
стика, 2002.
34. Редько В. Эволюция, нейронные сечи, интеллект. Модели и концепции эволюци-
онной кибернетики. М.: КомКнига, 2005.
35. Рутковская Д., Пилиньский М., Рутковский Л. Нейтронные сети, генетические
алгоритмы и нечеткие системы. М.: Горячая линия Телеком, 2007.
36. Рутковский Л. Методы и технологии искусственного интеллекта. М.: Горя-
чая линия Телеком, 2010.
37. Усков А.А., Кузьмин А.В. Интеллектуальные технологии управления. Искусствен-
ные нейронные сети и нечеткая логика. М.: Горячая линия Телеком, 2004.
38. Ту Дж., Гонсалес Р. Принципы распознавания образов. М.: Мир, 1978.
39. Хайкип С. Нейронные сети: полный курс. СПб: Изд. дом «Вильямс», 2006.
40. Цыпкин Я. Основы теории обучающихся систем. М.: Наука, 1968.
41. Шамис А. Пути моделирования мышления. Активные синергические нейронные
сети, мышление и творчество, формальные модели поведения и «распознавания с пони-
манием». М.: КомКнига, 2006.
42. Яхьяева Г. Нечеткие множества и нейронные сети: учебное пособие для вузов.
М.: Бином, 2006.
ОГЛАВЛЕНИЕ
ПРЕДИСЛОВИЕ К РУССКОМУ ИЗДАНИЮ............................ 3
Глава 1. ВВЕДЕНИЕ В ЕСТЕСТВЕННЫЕ И ИСКУССТВЕННЫЕ
НЕЙРОННЫЕ СЕТИ................................................... 19
1.1. Для чего нужно изучать нейронные сети?................. 19
1.2. Что было известно о мозге к началу построения первых нейронных
сетей?..................................................... 21
1.3. Как создавались первые нейронные сети?................. 26
1.4. Почему нейронные сети обладают' многослойной структурой?.. 31
1.5. Насколько первые нейронные сети были похожи па биологический
мозг?...................................................... 34
1.6. Какими методами сегодня исследуется мозг, и могут ли нейронные
сети помочь в познании тайп человеческого мышления?........ 36
1.7. Насколько нейронные сети проще биологических объектов?. 41
1.8. Каковы главные достоинства нейронных сетей?............ 43
1.9. Кто и для чего применяет нейронные сети сегодня?....... 47
1.10. Смогут ли нейронные сети вытеснить современные компьютеры? .... 49
1.11. Может быть, и не надо заниматься нейронными сетями?.... 50
1.12. Контрольные вопросы и задания для самостоятельного выполнения . 52
Глава 2. СТРУКТУРА НЕЙРОННОЙ СЕТИ............................. 53
2.1. Как устроена нейронная сеть?........................... 53
2.2. Как можно изготовить искусственный нейрон?............. 55
2.3. Почему не используется точная модель биологического нейрона? .... 61
2.4. Как функционирует сеть, состоящая из искусственных нейронов?.... 64
2.5. Как влияет структура нейронной сети на выполняемые ею функции? 68
2.6. Как «по-умному» выбирать структуру сети?............... 71
2.7. Какой информацией надо «потчевать» сеть?............... 75
2.8. Как объяснить сети, где живет слон?.................... 77
2.9. Как интерпретировать результаты функционирования сети?.... 79
2.10. Что лучше получить от сети число или решение?.......... 82
2.11. Что лучше иметь одну сеть с несколькими выходами или несколько
сетей с одним выходом?..................................... 86
2.12. Что скрывается в «скрытых» слоях?...................... 88
2.13. Сколько потребуется нейронов для построения хорошей сети?. 92
2.14. Контрольные вопросы и задания для самостоятельного выполнения . 96
406
Оглавление
Глава 3. ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ................................ 99
3.1. Кто такой учитель, который будет обучать сеч ь?.......... 99
3.2. Может ли сеть обучаться самостоятельно?................. 102
3.3. Где и как нейронные сети накапливают полученные знания?. 104
3.4. Как организовать обучение сети?......................... 106
3.5. Почему это иногда по получается?........................ 112
3.6. Для чего используется момент?........................... 114
3.7. С чего начинать обучение нейронной сети?................ 115
3.8. Как долго надо обучать сеть?............................ 117
3.9. Как обучать скрытые слои?............................... 118
3.10. Каким образом сеть может самообучаться?................. 120
3.11. Как проводить самообучение сети?........................ 121
3.12. Контрольные вопросы и задания для самостоятельного выполнения . 123
Глава 4. ФУНКЦИОНИРОВАНИЕ ПРОСТЕЙШЕЙ НЕЙРОННОЙ
СЕТИ........................................................... 124
4.1. Как перейти от теории к практике, или как использовать программы,
предназначенные для читателей этой книги?.................. 124
4.2. Чего можно ожидать от единственного нейрона?............ 128
4.3. Что еще можно наблюдать в ходе экспериментов?........... 134
4.4. Как справиться с большим количеством входов нейрона?.... 139
4.5. Как ведет себя простая линейная нейронная сеч ь?........ 143
4.6. Как построить простую линейную нейронную сеть?.......... 144
4.7. Как использовать представленную нейронную сеть?......... 145
4.8. Как и для чего в нейронную сеть вводится конкуренция?... 149
4.9. Как еще можно использовать нейронную сеть?.............. 151
4.10. Контрольные вопросы и задания для самостоятельного выполнения . 152
Глава 5. ОБУЧЕНИЕ ПРОСТЫХ ЛИНЕЙНЫХ ОДНОСЛОЙНЫХ
НЕЙРОННЫХ СЕТЕЙ................................................ 154
5.1. Как построить обучающую выборку?........................ 154
5.2. Как можно обучать одиночный нейрон?..................... 156
5.3. Может ли нейрон обладать врожденными способностями?..... 161
5.4. Насколько строго надо обучать нейрон?................... 162
5.5. Как обучать простую сечь?............................... 163
5.6. Каковы возможности применения таких простых нейронных сетей? .. 167
5.7. Может ли сеть научиться фильтровать сигналы?............ 169
5.8. Контрольные вопросы и задания для самостоятельного выполнения . 176
Глава 6. НЕЛИНЕЙНЫЕ НЕЙРОННЫЕ СЕТИ............................. 179
6.1. Зачем нужны нелинейности в сети?........................ 179
6.2. Как функционирует нелинейный нейрон?.................... 181
Оглавление
407
6.3. Как функционирует сеть, состоящая из нелинейных нейронов?... 185
6.4. Как представить функционирование нелинейных нейронов?. 188
6.5. Каковы возможности многослойной нелинейной сети?...... 192
6.6. Как протекает обучение нелинейного нейрона?........... 195
6.7. Какие исследования можно проводить в процессе обучения нейрона?. 199
6.8. Контрольные вопросы и задания для самостоятельного выполнения . 200
Глава 7. ОБРАТНОЕ РАСПРОСТРАНЕНИЕ............................ 202
7.1. Что называется обратным распространением?............. 202
7.2. Как изменять «порог» нелинейной функции активации нейрона?.. 204
7.3. Какая форма нелинейной функции активации нейрона применяется
наиболее часто?............................................ 205
7.4. Как функционирует многослойная сеть, состоящая из нелинейных ней-
ронов? .................................................... 209
7.5. Как можно обучать многослойную сеть?.................. 212
7.6. Что надо наблюдать в процессе обучения многослойной сети?... 214
7.7. Контрольные вопросы и задания для самостоятельного выполнения . 223
Глава 8. ФОРМЫ ОБУЧЕНИЯ НЕЙРОННЫХ СЕТЕЙ...................... 225
8.1. Как использовать многослойную нейронную сеть для распознавания
образов?................................................... 225
8.2. Как запрограммировать нейронную сеть для распознавания образов? 227
8.3. Как выбирать структуру нейронной сети в ходе экспериментов?. 230
8.4. Как подготовить задачу распознавания образов?......... 232
8.5. Какие формы обучения можно наблюдать в сети?.......... 236
8.6. Что еще можно наблюдать в исследуемой сети?........... 248
8.7. Контрольные вопросы и задания для самостоятельного выполнения . 251
Глава 9. НЕЙРОННЫЕ СЕТИ С САМООБУЧЕНИЕМ...................... 255
9.1. На чем основана идея самообучения сети?............... 255
9.2. Как протекает длительное самообучение сети?........... 265
9.3. Можно ли успехи самообучения считать повышением интеллекта сети? 271
9.4. На что еще надо обратить внимание в процессе самообучения сети?.. 273
9.5. «Мечты» и «фантазии», возникающие при самообучении сети..... 276
9.6. Запоминание и забывание............................... 282
9.7. Все ли входные данные приводят к самообучению сети?... 284
9.8. Что может дать введение конкуренции в сеть?........... 287
9.9. Какие формы принимает самообучение с конкуренцией?.... 292
9.10. Контрольные вопросы и задания для самостоятельного выполнения . 297
Глава 10. СЕТИ С САМООРГАНИЗАЦИЕЙ............................ 300
10.1. Структура нейронной сети, функционирующей по принципу самоорга-
низации .................................................... 300
408
Оглавление
10.2. На чем основан а самоорганизация и для чего она может пригодиться? 303
10.3. Как определяется соседство в сети?........................ 309
10.4. Что следует за признанием какого-либо нейрона соседом?.... 311
10.5. Что могут сети Кохонена?.................................. 316
10.6. Как ведут себя сети Кохонена при обработке более сложных данных? 323
10.7. Что происходит в сети при слишком широком распределении началь-
ных значений весов?............................................. 325
10.8. Можно ли изменять форму самоорганизации в процессе самообучения
сети?........................................................... 327
10.9. Ну и для чего все это может пригодиться?.................. 328
10.10. Как можно использовать сеть в качестве инструмента дня преобразо-
вания размерности пространства входных сигналов?................. 335
10.11. Контрольные вопросы и задания для самостоятельного выполнения . 341
Глава 11. РЕКУРРЕНТНЫЕ СЕТИ...................................... 344
11.1. Что такое рекуррентная нейронная сеть?.................... 344
11.2. Каковы свойства сетей с обратной связью?................ 349
11.3. Кому нужны такие сети с петлями?.......................... 352
11.4. Какова структура сети Хопфилда?........................... 355
11.5. Как нейронная сеть играет роль ассоциативной памяти?...... 358
11.6. Как работает программа, позволяющая тебе самостоятельно исследо-
вать функционирование сети Хопфилда?............................ 365
11.7. Несколько интересных примеров............................. 371
11.8. Как и для чего можно использовать автоматическую генерацию эта-
лонов для сети Хопфилда?........................................ 377
11.9. Какие исследования можно проводить с применением ассоциативной
памяти?......................................................... 383
11.10. Что еще можно наблюдать в ассоциативной памяти?........... 387
11.11. Контрольные вопросы и задания для самостоятельного выполнения . 389
Заключение................................................. 391
Приложение 1. Математическая модель нейрона........................ 395
Приложение 2. Линейные и нелинейные нейроны........................ 395
Приложение 3. Математические функции, часто используемые в нелинейных
нейронах ........................................................... 396
Приложение 4. Какова роль «учителя» при обучении нейронной сети?... 397
Приложение 5. Элементы технологии самообучения сети................ 398
Приложение 6. Технология обучения, применяемая в нейронных сетях... 399
Приложение 7. Ускорение процесса обучения.......................... 400
Приложение 8. Обучение многослойных сетей методом обратного распространения
ошибки ............................................................. 400
Приложение 9. Обучение сети как минимизация функции погрешности.... 401
Библиография............................................... 403
РышардТадеусевич
Барбара Боровик
Томаш Гончаж
Бартош Пеппер
Элементарное
„введение в технологию „
нейронных сетей
с примерами программ
Искусственные нейронные сети ~ одна из наиболее динамично
развивающихся и реально используемых на практике ветвей теории
искусственного интеллекта. В книге выдающегося европейского
специалиста популярно и увлекательно освещаются возможности,
структура и особенности работы этих сетей. С помощью описываемых в
книге компьютерных программ читатель сможет самостоятельно
построить несложные нейронные сети, обучить их и провести
захватывающие эксперименты. Автор излагает материал без единой
формулы; он ведет диалог с читателем и постепенно подводит его к
пониманию механизмов функционирования человеческого мозга и к
осознанию перспектив их использования для управления современными
техническими и экономическими системами.
Книга предназначена для широкого круга читателей, в первую
очередь для молодых специалистов, желающих понять сущность и
безграничные перспективы искусственных нейронных сетей.
Сайт издательства:
www.techbook.ru