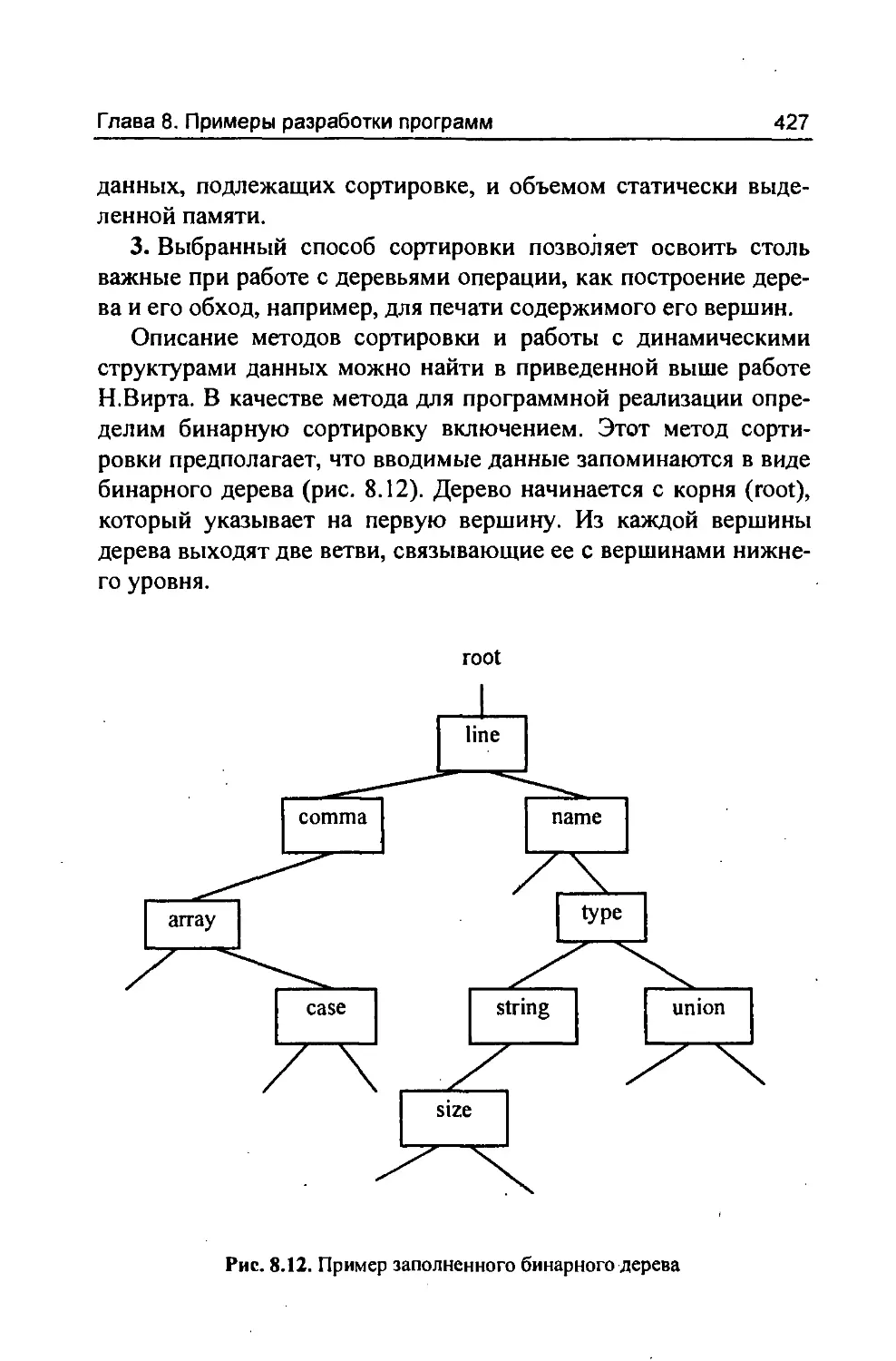
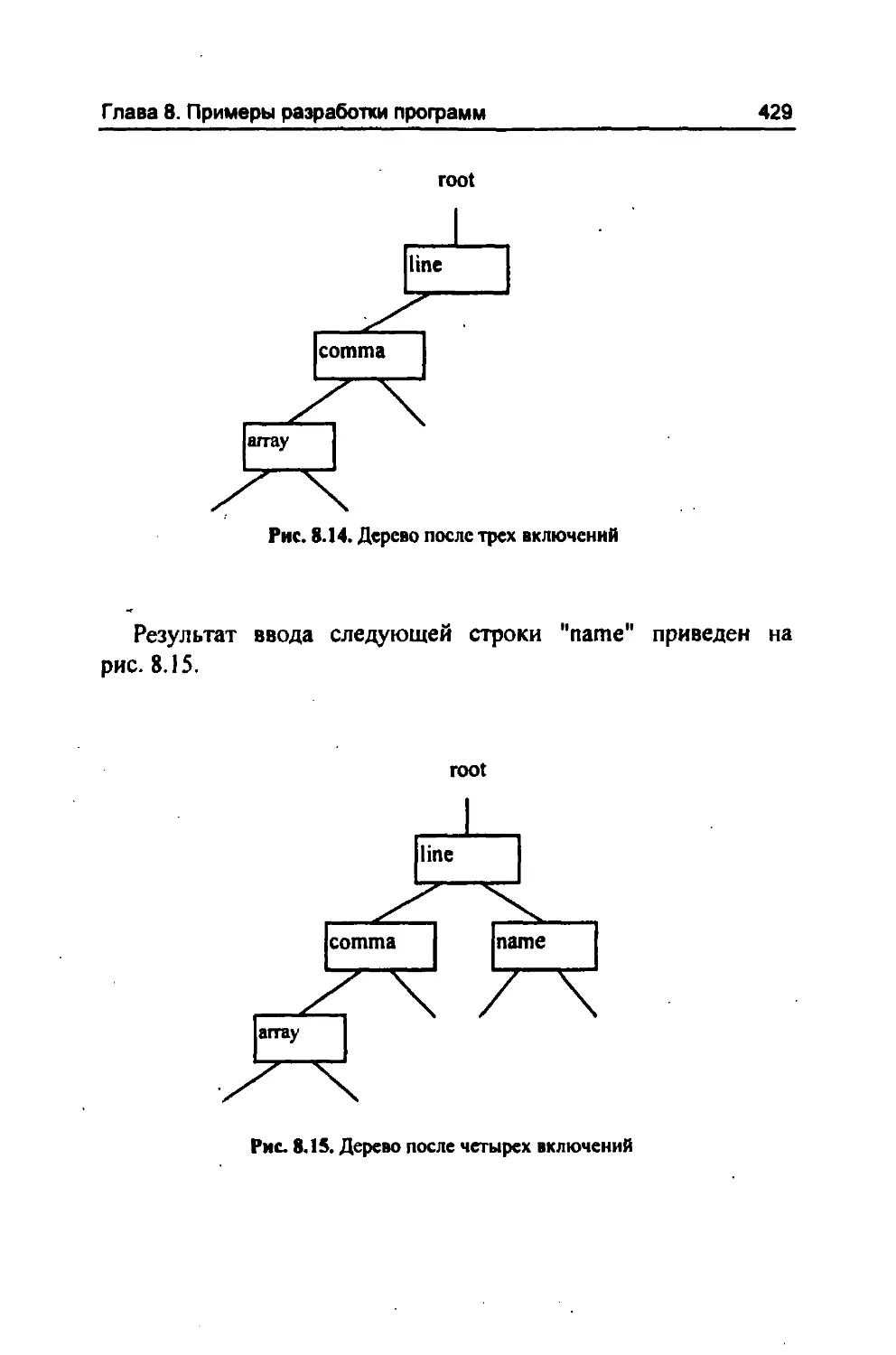
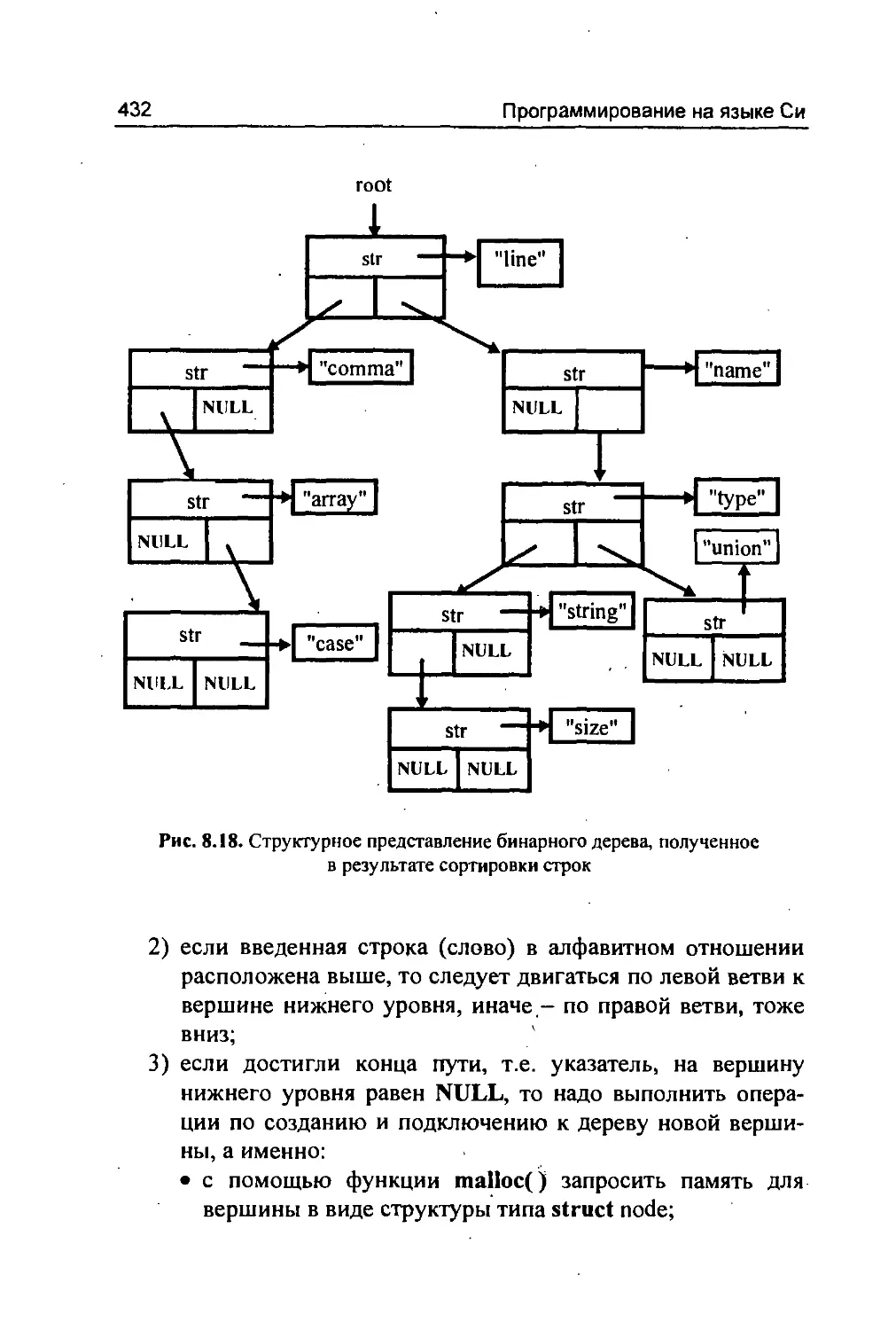
/



























































































































































































































































































































































































































































































































































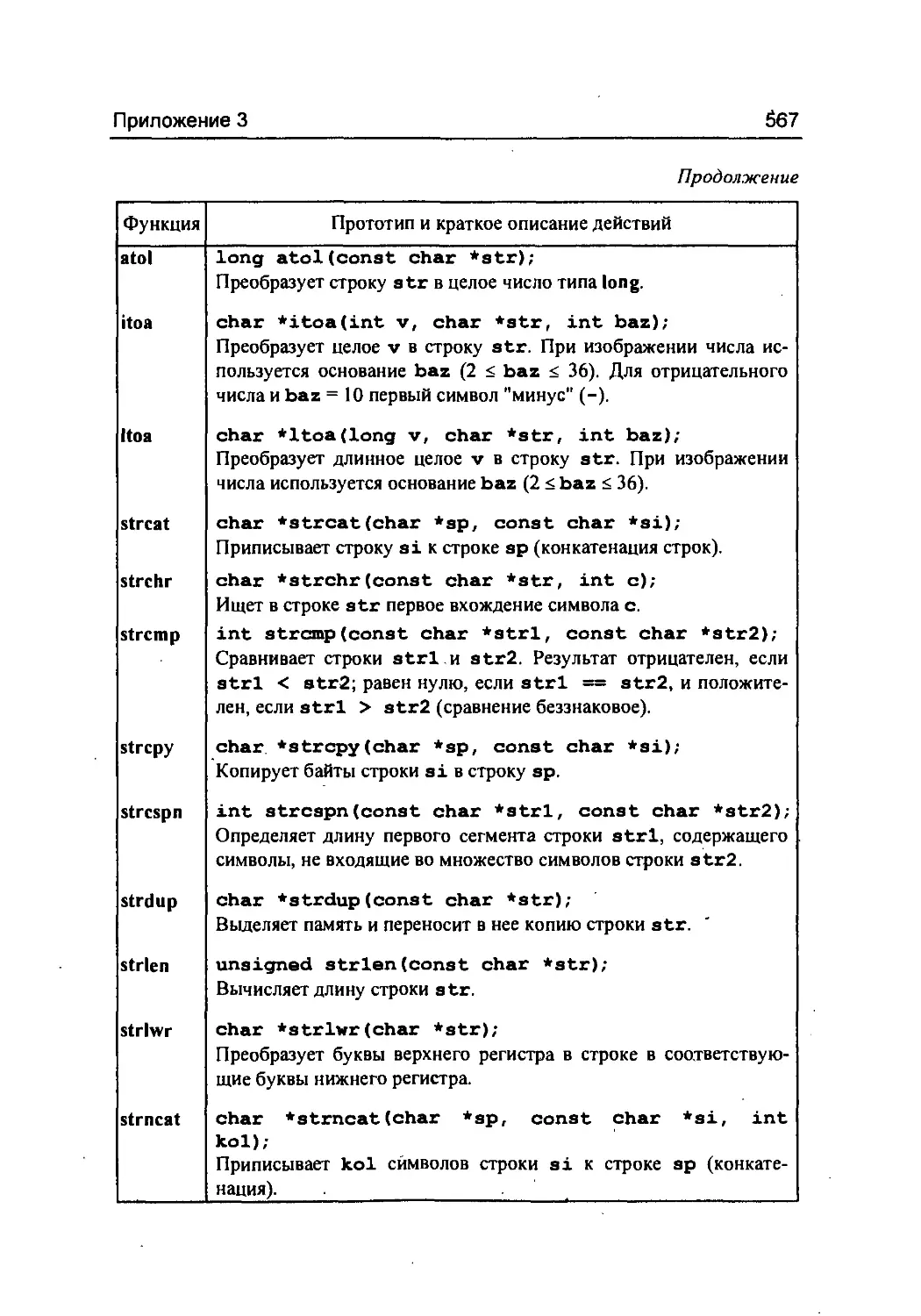

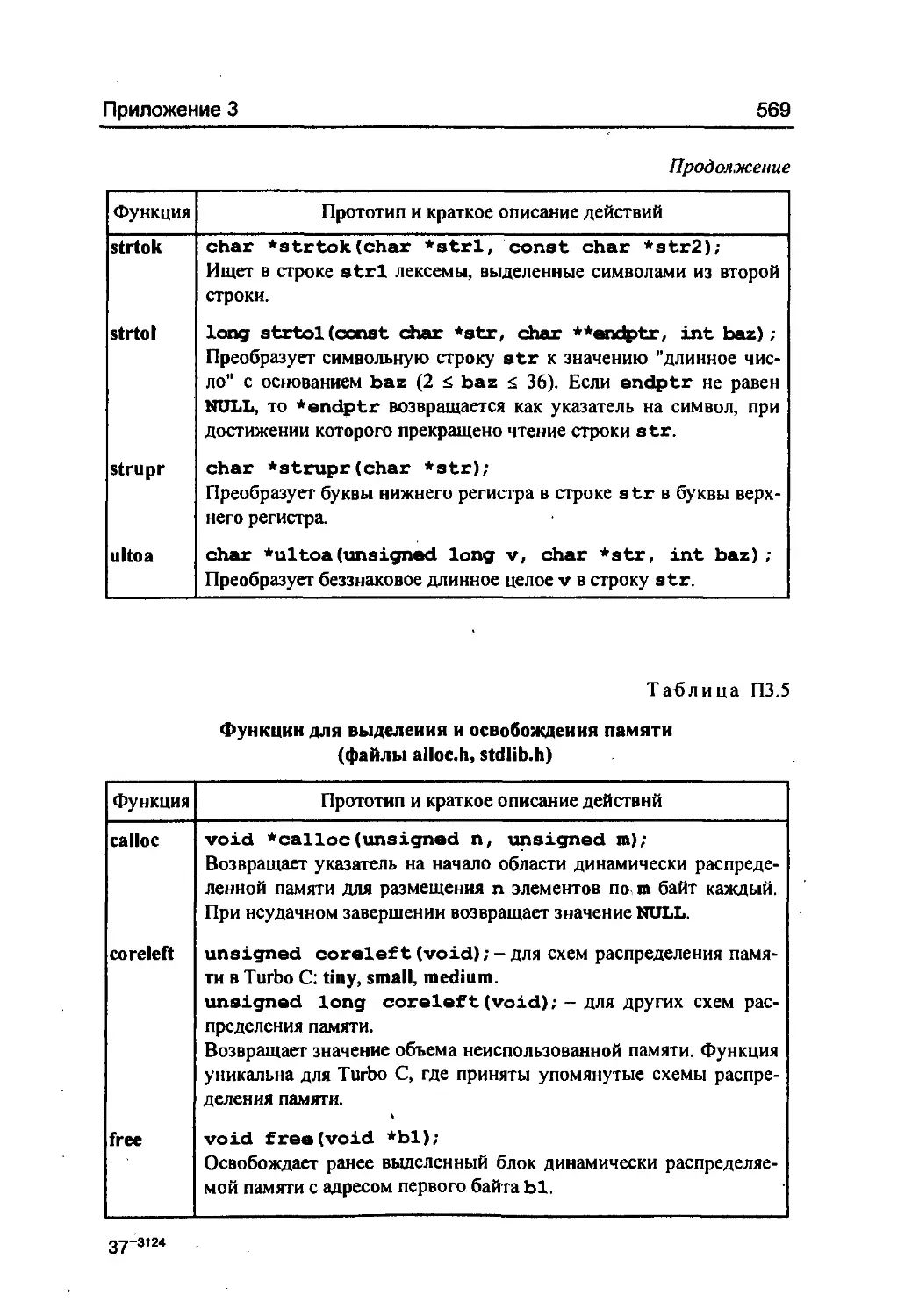



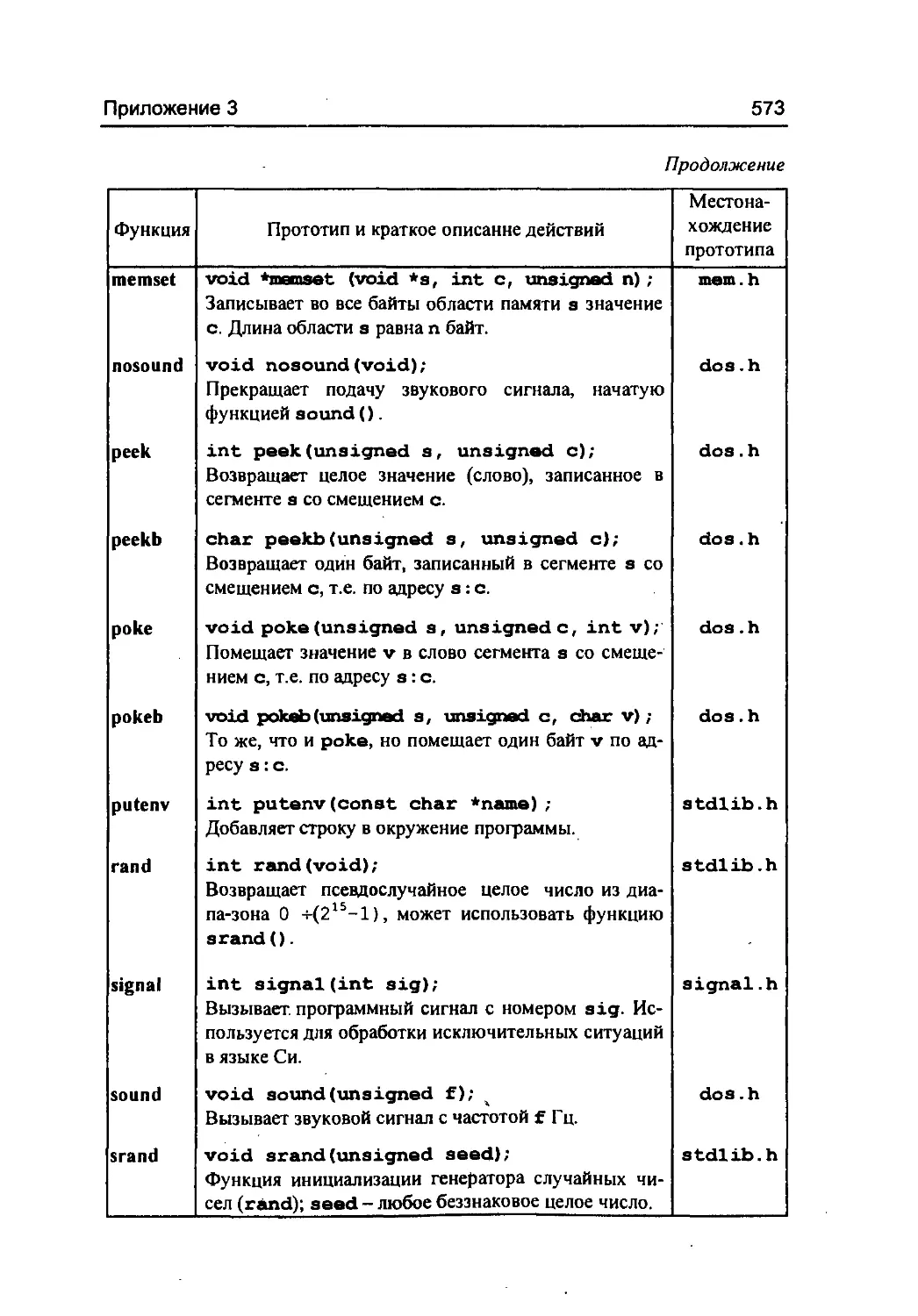




























Author: Фомин С.С. Подбельский В.В.
Tags: языки программирования компьютерные технологии программирование язык программирования c
ISBN: 5-279-02180-6
Year: 2004




Text
УДК 004.438Си (075.8)
ББК 32.973.26-018.1я73
П44
РЕЦЕНЗЕНТЫ:
кафедра «Информационные технологии»
Российского государственного технологического университета
имени К. Э. Циолковского;
Ю. Н. Патрикеев, кандидат технических наук, доцент
Подбельский В. В., Фомин С. С.
П44 Программирование на языке Си: Учеб, пособие. - 2-е доп.
изд. - М.: Финансы и статистика, 2004. - 600 с.: ил.
ISBN 5-279-02180-6
Пособие (1-е издание - 1998 г.) состоит из трех разделов. Первый раз-
дел — это полный курс программирования на стандартном языке Си. Рас-
сматриваются все средства языка Си, не зависящие от реализаций, суще-
ствующие в компиляторах на ПЭВМ; рабочих станциях и мощных сетевых
серверах. Второй раздел посвящен выполнению программ в разных опера-
ционных системах. Третий раздел - это практикум по языку Си. По каждой
теме практикума приведены методические рекомендации и варианты зада-
ний для организации индивидуальной работы в учебной группе или классе.
Д ля студентов и преподавателей вузов, а также для желающих освоить
самостоятельно программирование на языке Си.
2404000000 -193 _ УДК 004.438Си (075.8)
010(01)-2004 ББК 32.973.26-018.1я73
© В. В. Подбельский, С. С. Фомин, 1998
ISBN 5-279-02180-6 © В. В. Подбельский, С. С. Фомин, 1999
ПРЕДИСЛОВИЕ
Язык программирования Си создан в 1972 г. сотрудником
фирмы Bell Laboratories Деннисом Ритчи (Dennis М. Ritchie) при
разработке операционной системы UNIX. Язык проектировался
как инструмент для системного программирования с ориен-
тацией на разработку хорошо структурированных программ.
Удачное сочетание лаконичности конструкций и богатства вы-
разительных возможностей позволило языку Си быстро распро-
страниться и стать наиболее популярным языком прикладного и
системного программирования. Компиляторы языка Си работа-
ют почти на всех типах современных ЭВМ в операционных сис-
темах UNIX, MS-DOS, Mac OS, OS/2, Windows, Windows NT,
Solaris и др.
В отличие от многих языков программирования (Ада, Алгол-
60, Алгол-68 и т.д.), которые вступали в силу после принятия
соответствующих национальных и международных стандартов,
язык Си вначале был создан как рабочий инструмент, не пре-
тендующий на широкое применение. Стандарта на язык Си до
1989 г. не существовало, и в качестве формального описания
разработчики компиляторов использовали первое издание книги
Б.Кернигана и Д.Ритчи, вышедшее в США в 1978 г. (переведена
на русский язык в 1985 г. [1]). Роль неформального стандарта
языка Си сохранилась за этой книгой и. в настоящее время. Не
случайно в литературе и документации по компиляторам ссылка
на эту работу обозначается специальным сокращением K&R.
Второе издание книги Б.Кернигана и Д.Ритчи [2] описывает
язык Си в стандартизованном Американским институтом на-
циональных стандартов виде (стандарт ANSI языка Си). В на-
стоящее время, кроме стандарта ANSI С, разработан между-
народный стандарт ISO С (International Standard Organization С).
Обе версии стандарта близки друг к другу, и на различиях меж-
ду стандартами нет необходимости останавливаться до возник-
новения разногласий в толковании той или иной конструкции
4
Программирование на языке Си
языка либо при оценке стандартности конкретного компилято-
ра. Эти ситуации выходят за рамки курса по программированию
на языке Си. В случае необходимости получения справок по
стандартам языка Си следует обращаться к специальным пуб-
ликациям, например к "Толковому словарю стандарта языка Си"
Р. Жешке [5]. Неформальное применение книги K&R в качестве
стандарта до 1989 г. и последующая ее переработка авторами в
соответствии с принятым стандартом ANSI привели к тому, что
ее и сейчас можно рассматривать как достоверный источник
при получении справок по языку Си.
Настоящее пособие предназначено для изучения программи-
рования на стандартном языке Си. Ориентация сделана как на
изложение синтаксиса и семантики конструкций языка, так и на
их практическое использование при решении типовых задач
программирования. Первый раздел (главы 1 - 8) содержит мате-
риал, относящийся к синтаксису, семантике и особенностям
программирования на Си. После описания в главе 1 основных
понятий языка рассмотрены средства представлений базовых
конструкций структурного программирования, возможности
которых в главе 2 иллюстрируются на простых вычислительных
задачах. Глава 3 содержит подробное' описание препро-
цессорных средств компилятора языка Си, которые активно ис-
пользуются при последующем изложении методов и приемов
программирования на языке Си. Следующая глава посвящена
незаменимым в системном программировании понятиям - объ-
ектам и адресам (указателям). Аппарат указателей используется
затем при обработке массивов и строк. Центральное место за-
нимает глава 5, посвященная функциям. Здесь возможности
функций рассмотрены подробно и с нужной полнотой. Особое
внимание уделено взаимосвязи функций с указателями, а также
классам памяти, которые вводятся в связи с организацией мно-
гофайловых программ, включающих много функций. Глава 6
рассматривает структурированные данные (структуры и объе-
динения). Особенности работы с файлами, а также средства
ввода-вывода показаны на типовых задачах в главе 7. В главе 8
подробно рассмотрено несколько задач, иллюстрирующих не
Предисловие
5
только синтаксические возможности языка, но и основные
принципы построения достаточно крупных программ. Второй
раздел (глава 9) посвящен использованию компиляторов и ин-
тегрированных средств разработки программ на языке Си в раз-
ных операционных системах, причем большое внимание
уделено таким универсальным средствам различных сред про-
граммирования, как проекты многомодульных программ.
Приводимые в пособии программы сопровождаются резуль-
татами, полученными на ЭВМ. Программы выполнялись в ОС
UNIX (в частности, в FreeBSD) и на IBM PC в интегрированных
средах Turbo С 2.0 и Borland C++3.1. Более поздние версии
компиляторов использовать не требовалось. Обратим внимание
на тот факт, что большинство интегрированных сред, в назва-
нии которых указан язык Си++, компилируют и программы на
языке Си. Например, Borland C++ и Turbo C++ включают по 2
компилятора - для языка Си и для языка Си++. Подробнее об
этом говорится в главе 9.
В третьем разделе книги представлен "Практикум" - сборник
задач, снабженный вариантами типовых решений и рекоменда-
циями по программированию. Задачи сгруппированы по темам
и в совокупности представляют хорошую основу для организа-
ции практических работ группы студентов и самостоятельного
активного усвоения материала.
Целью настоящего пособия является изложение методики и
принципов корректного, структурированного программирова-
ния на языке Си. Программы, иллюстрирующие конструкции и
возможности языка, написаны максимально понятно для чита-
теля. Авторы нигде не гнались за эффективностью кода в ущерб
его структурированности и простоты. Возможности современ-
ных компиляторов языка Си такбвы, что они позволяют генери-
ровать весьма эффективный код по тексту хорошо структу-
рированной программы без специальных ухищрений програм-
миста, направленных на повышение быстродействия или незна-
чительную экономию памяти.
Книга написана на основе курсов лекций, которые авторы в
течение ряда лет читали в МИЭМе на факультете прикладной
6
Программирование на языке Си
математики, на факультете автоматики и вычислительной тех-
ники и факультете повышения квалификации инженеров. Мате-
риал пособия соответствует учебной программе дисциплины
"Алгоритмические языки и программирование". Изучение ука-
занной дисциплины, в частности языка Си, служит основой для
курсов по математическому обеспечению ЭВМ и сетей, по опе-
рационным системам, построению компиляторов и системному
программированию.
Авторы надеются, что книга поможет ликвидировать разрыв
между широко публикуемыми техническими руководствами по
реализации языка Си и потребностями в методическом обеспе-
чении учебного процесса. Для чтения книги достаточно знать
основы информатики. Поэтому пособие можно использовать
как в вузе, так и в курсах информатики школ, гимназий, лицеев
и техникумов. Необходимым условием освоения материала кни-
ги являются выполнение приведенных в ней примеров и реше-
ние задач практикума на любой ЭВМ, снабженной тран-
слятором с языка Си.
С.С.Фоминым написаны главы 7 и 9, В.В.Подбельским вы-
полнено общее редактирование, написаны главы 1-6. Глава 8 и '
практикум написаны авторами совместно. В подборе задач для
практикума принял участие С.Г.Чернацкий. В текст пособия по
предложению С.М.Лавренова включено несколько программ,
иллюстрирующих тонкие вопросы языка Си.
Повышению качества рукописи способствовали замечания
рецензентов, а также внимательный анализ текста, который
провели С.М.Лавренов и С.Г.Чернацкий. При печати и оформ-
лении рукописи авторам помогали Н.В.Васюкова, И.А.Моро-
зова, О.В.Шеханова и Юлия Кочнева. Авторы выражают им
глубокую благодарность.
Любые конструктивные замечания и предложения по улуч-
шению пособия авторы с благодарностью примут и учтут в
дальнейшем. Нам можно писать по адресу издательства либо по
электронной почте: vvp@extech.msk.su.
ПОЛНЫЙ КУРС
ПРОГРАММИРОВАНИЯ
НА СТАНДАРТНОМ
ЯЗЫКЕ Си
Глава 1
БАЗОВЫЕ ПОНЯТИЯ ЯЗЫКА
Начиная изучать новый для вас алгоритмический язык про-
граммирования, необходимо выяснить следующие вопросы:
1. Каков алфавит языка и как правильно записывать его лек-
семы1?
2. Какие типы данных приняты в языке и как они определя-
ются (описываются)?
3. Какие операции над данными допустимы в языке, как
строятся с их помощью выражения и как они выполняются?
4. Какова структура программы, в какой последовательности
размещаются операторы, описание и определения?
5. Как выводить (представлять пользователю) результаты ра-
боты программы?
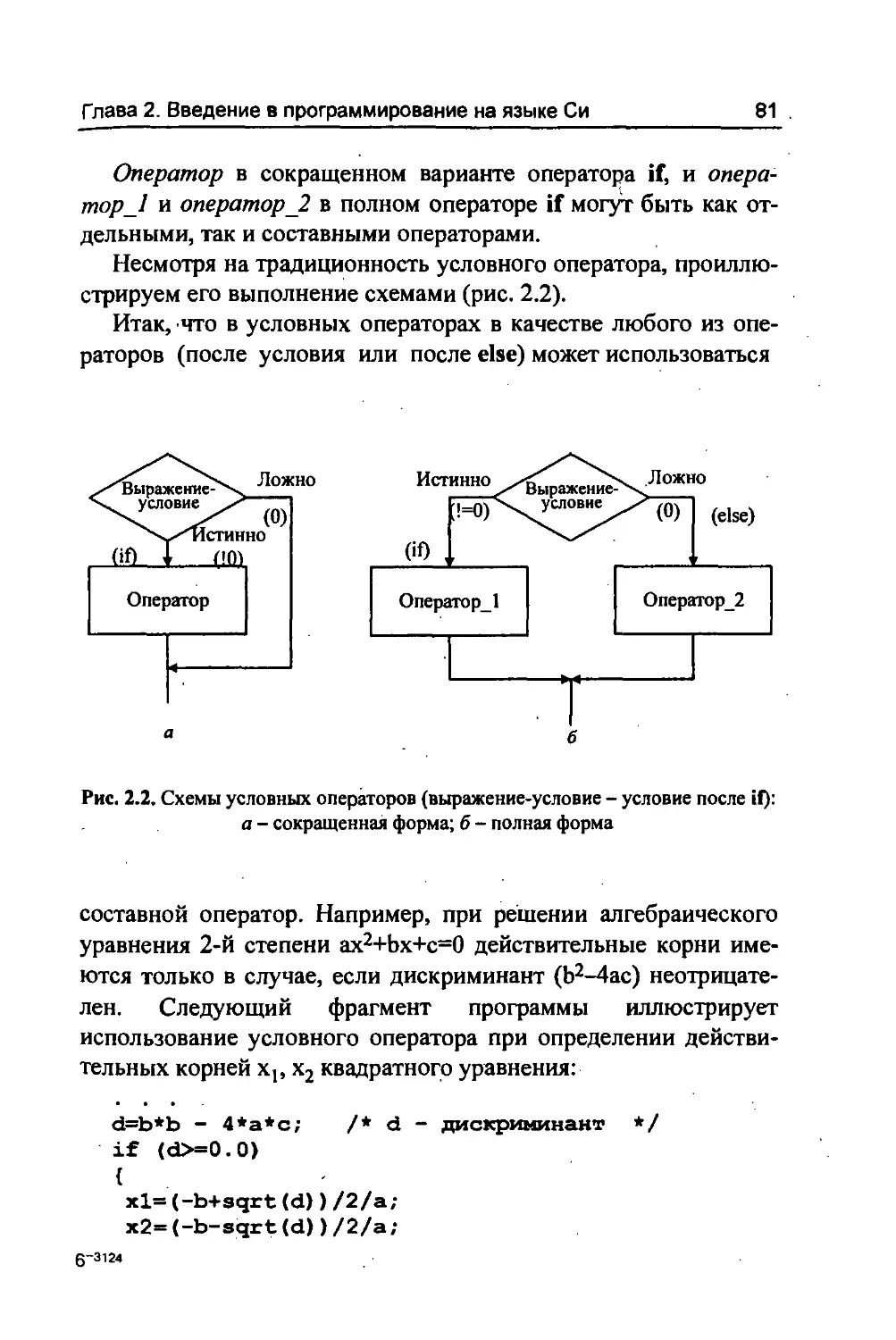
6. Как реализованы оператор присваивания, условные опера-
торы и операторы перехода?
7. Как вводить исходные данные для программы?
8. Какие специальные конструкции для организации циклов
есть в языке? .
9. Каков аппарат подпрограмм (процедур) и (или) подпро-
грамм-функций?
Затем следует приступать к составлению программ, углубляя
в ходе программирования знание языка. Изложение материала в
данйом пособии почти соответствует описанной схеме изучения
. алгоритмических языков. Введя основные средства языка Си,
будем рассматривать конкретные программы, а затем, переходя
к новым классам задач, введем все конструкции языка и те
средства, которые не упоминаются в перечисленных выше во-
просах.
1 Лексема - единица текста программы, которая при компиляции воспри-
нимается как единое целое и по Смыслу не может быть разделена на более
мелкие элементы.
10
Программирование на языке Си
, В начале первой главы рассмотрим алфавит, идентификато-
ры, константы, типы данных и операции языка. Этот базовый
материал необходим для всех следующих глав. Не освоив пере-
численных понятий, невозможно начинать программирование.
Традиционно перед изложением синтаксиса языка програм-
мирования авторы пособий дают неформальное введение, где
на примерах иллюстрируют основные принципы построения
программ на предлагаемом языке. Однако язык Си невелик, и
его лексические основы можно рассмотреть весьма подробно
уже в самом начале изучения. Поэтому начнем с алфавита и
лексем.
1.1. Алфавит, идентификаторы,
служебные слова
Алфавит. В алфавит языка Си входят:
• прописные и строчные буквы латинского алфавита
(A,B,...,Z, a, b,..., z)
• цифры: 0,1,2,3,4,5,6,7,8,9
• специальные знаки: " , {} | [] ()• + - / %
• неизображаемые символы ("обобщенные пробельные сим-
волы"), используемые для отделения лексем друг от друга
(например, пробел, табуляция, переход на новую строку).
В комментариях, строках и символьных константах могут
использоваться и другие литеры (например, русские буквы).
Комментарий формируется как последовательность знаков
(символов), ограниченная слева знаками /*, а справа - зна-
ками */. Например:
/* Это комментарий */
В стандартном языке Си комментарии запрещено вкладывать
друг в друга, т.е. запись
/* текст-1 /* текст-2 */ текст-3 */
ошибочна - ” текст-3” не считается комментарием.
Глава 1. Базовые понятия языка 11
В языке Си шесть классов лексем: свободно выбираемые и
используемые идентификаторы, служебные (ключевые) слова,
константы, строки (строковые константы), операции (знаки
операций), разделители (знаки пунктуации).
Идентификатор. Последовательность букв, цифр и симво-
лов подчеркивания , начинающаяся с буквы или символа
подчеркивания, считается идентификатором языка Си. Примеры
идентификаторов:
КОМ_1б, size88, _MIN, TIME, time
Прописные и строчные буквы различаются, т.е. два послед-
них идентификатора различны.
Идентификаторы могут иметь любую длину, но компилятор
учитывает не более 31-го символа от начала идентификатора. В
некоторых компиляторах это ограничение еще более жесткое, и
учитываются только первые 8 символов любого идентификато-
ра. В этом случае идентификаторы NUMBER_OF_ROOM и
NUMBER_OF_TEST в программе будут неразличимы. ,
Служебные (ключевые) слова. Идентификаторы, зарезер-
вированные в языке, т.е. такие, которые нельзя использовать в
качестве свободно выбираемых программистом имен, называют
служебными словами. Служебные слова определяют типы дан-
ных, классы памяти, квалификаторы типа, модификаторы, псев-
допеременные и операторы. В стандарте языка определены
следующие служебные слова:
auto break case char const continue default do
double else enum extern float for goto if
int long register return short signed sizeof static
struct switch typed ef union unsigned void volatile while
По смысловой нагрузке служебные слова группируются сле-
дующим образом.
12
Программирование на языке Си
Для обозначения типов данных используются спецификато-
ры типов и квалификаторы типов.
К спецификаторам типов относятся:
char - символьный;
double - вещественный двойной точности с плавающей
точкой;
enuin - перечисляемый тип (перечисление) - определе-
ние целочисленных констант, для каждой из ко-
торых вводятся имя и значение;
float - вещественный с плавающей точкой;
int - целый;
long - целый увеличенной длины (длинное целое);
short - целый уменьшенной длины (короткое целое);
struct - структура (структурный тип);
signed - знаковый, т.е. целое со знаком (старший бит
считается знаковым);
union - объединение (объединяющий тип);
unsigned - беззнаковый, т.е. целое без знака (старший бит
не считается знаковым);
void - отсутствие значения;
typedef - вводит синоним обозначения типа (определяет
сокращенное наименование для обозначения
типа).
Квалификаторы типа:
const - квалификатор объекта, имеющего постоянное
значение, т.е. доступного только для чтения;
volatile - квалификатор объекта, значение которого мо-
жет измениться без явных указаний программи-
ста.
Квалификаторы типа информируют компилятор о необходимо-
сти и (или) возможности особой обработки'объектов в процес-
се оптимизации кода программы.
Для обозначения классов памяти используются:
auto - автоматический;
Глава 1. Базовые понятия языка
13
extern - внешний;
register - регистровый;
static - статический.
Для построения операторов используются служебные слова:
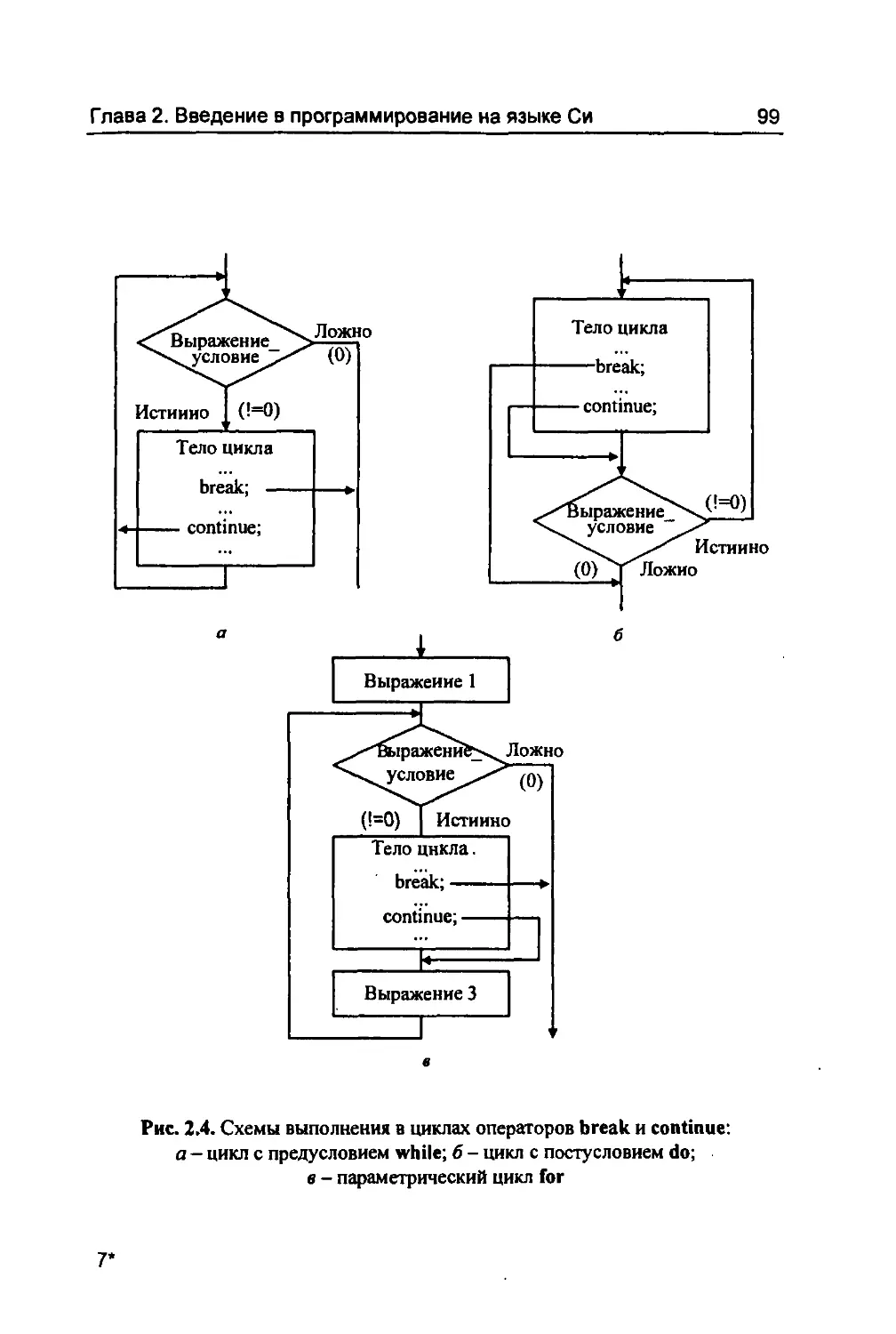
break continue - выйти из цикла или переключателя; - завершить текущую итерацию цикла (продол- жить цикл, перейдя к следующей итерации);
do - выполнять (заголовок оператора цикла с пост- условием);
for - для (заголовок оператора параметрического цикла);
goto if return switch while - перейти (безусловный переход); - если - обозначение условного оператора; - возврат (из функции); - переключатель; - пока (заголовок цикла с предусловием или за- вершение цикла do).
К служебным словам также отнесены следующие идентифи-
каторы:
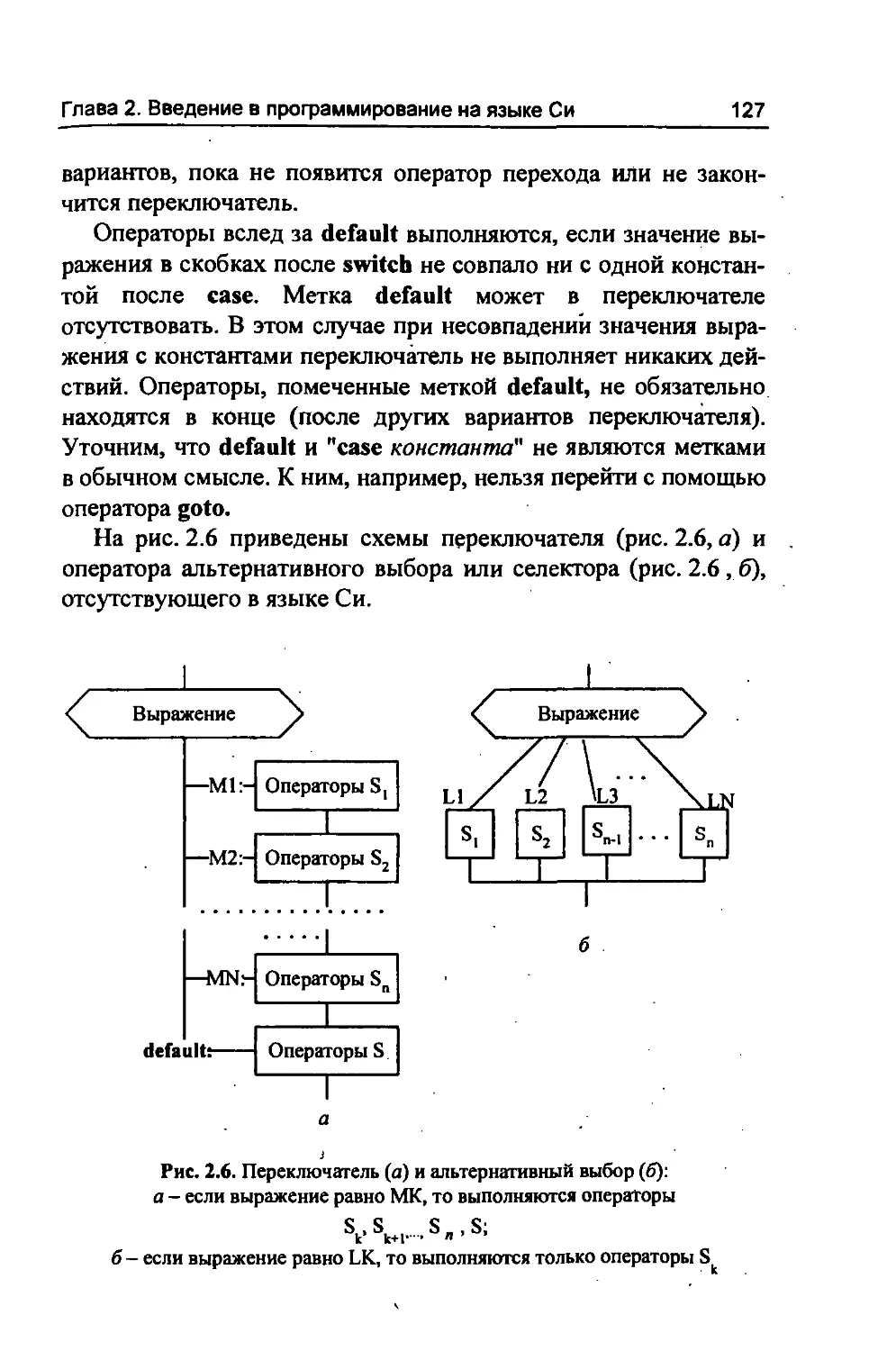
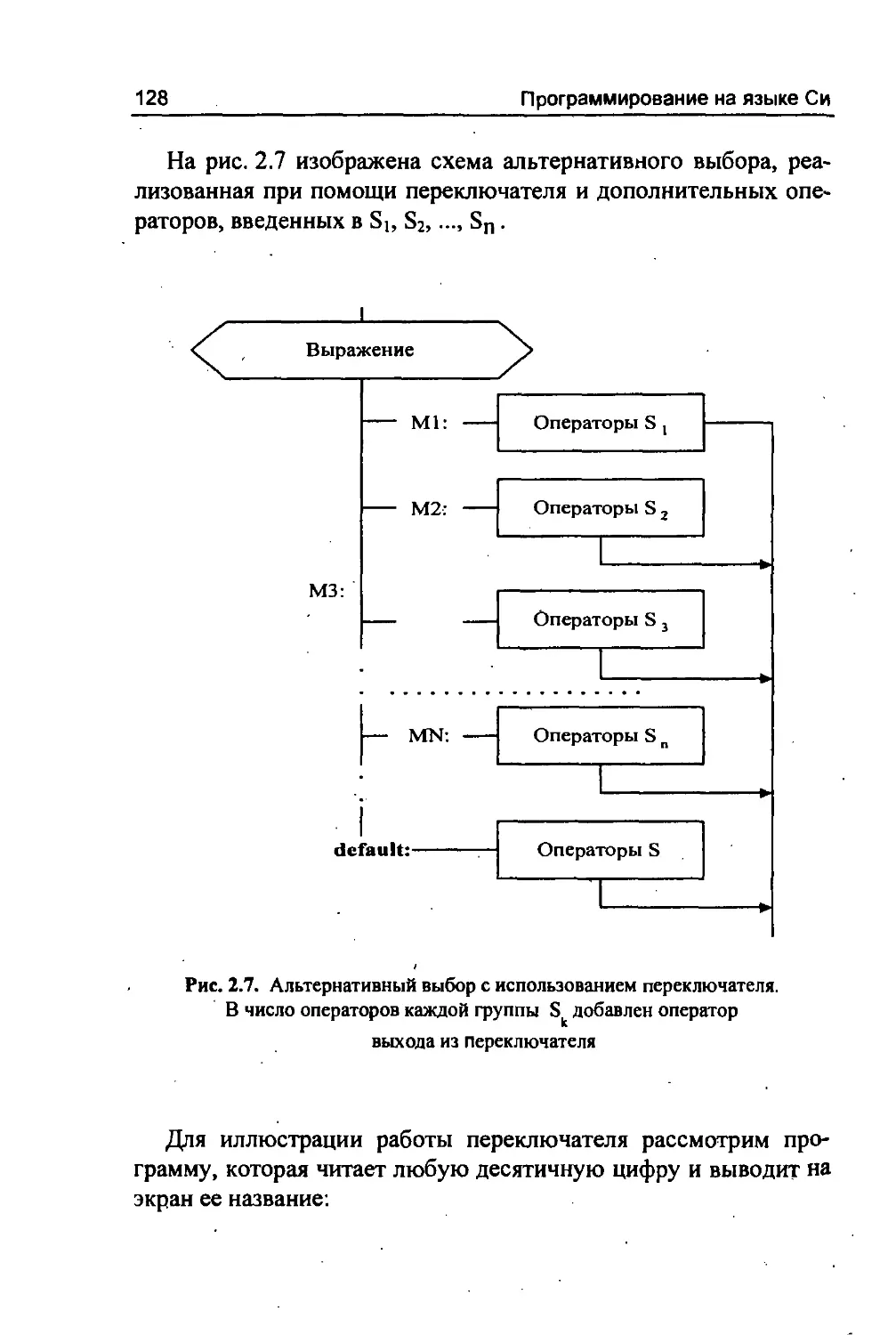
default - определяет действия при отсутствии нужного варианта в операторе switch;
case else - определяет вариант в операторе switch; - входит в оператор if, определяя альтернативную ветвь;
sizeof - операция определения размера операнда (в бай- тах).
В число служебных слов, определенных стандартом языка,
модификаторы не входят, однако их необходимо знать, работая
с конкретной реализацией языка. Практически во всех шестна-
дцатиразрядных реализациях компиляторов для IBM PC исполь-
зуются следующие модификаторы:
14
Программирование на языке Си
asm cdecl _cs _ds _es far
fortran huge interrupt near pascal _ss
Кроме основных (определенных стандартом языка) служеб-
ных слов и модификаторов, конкретные реализации языка Си
(конкретные компиляторы) содержат собственные расширения
списка служебных (ключевых) слов. Например, компилятор
Borland C++ для языка Си дополнительно вводит следующие
модификаторы (перечислены не все):
_cdecl _export _far _fastcall _loadds _near
pascal _saveregs _seg
Для работы с регистрами в том же компиляторе Borland C++
определен набор псевдопеременных, доступных из программ на
языке Си и запрещенных для использования в других целях:
AH AL _AX _BH _BL BP BX
— — — —
_CH _CL _cs _cx _DH _DI DL
_DS _DX JES _FLAGS _si _SP _SS
Конструкции языка, в которых используются служебные
слова, будем определять по мере необходимости. Можно было
бы не перечислять все служебные слова, а вводить их по мере
изложения языка, однако их запрещено использовать в качестве
имен, выбираемых программистом, и поэтому для предупреж-
дения возможных ошибок список служебных слов нужен уже на
данном этапе.
Глава 1. Базовые понятия языка
15
Добавим еще одно соглашение, обычно соблюдаемое авто-
рами компиляторов и стандартных библиотек языка Си. Иден-
тификаторы, начинающиеся с одного или двух символов
подчеркивания зарезервированы для использования в
библиотеках и компиляторах. Поэтому такие идентификаторы
не рекомендуется выбирать в качестве имен в прикладной про-
грамме на языке Си. Следующее соглашение относительно имен
относится уже не к стандарту и не к реализациям, а отображает
стиль оформления текста программы. Рекомендуется при про-
граммировании имена констант записывать целиком заглавны-
ми буквами.
1.2. Константы и строки
По определению, константа представляет значение, которое
не может быть изменено. Синтаксис языка определяет пять ти-
пов констант: символы, константы перечисляемого типа, веще-
ственные числа, целые числа и нулевой указатель ("null-
указатель"). (Стандарт ввел дополнительный тип констант
"символ расширенной формы представления", но сейчас его
поддерживает незначительное число компиляторов.) Все кон-
станты, кроме нулевого указателя, отнесены в языке Си к ариф-
метическим.
Символы, или символьные константы. Для изображения
отдельных знаков, имеющих индивидуальные внутренние коды,
используются символьные константы. Каждая символьная кон-
станта - это лексема, которая состоит из изображения символа и
ограничивающих апострофов. Например: 'А', 'а', 'В',('8', 'О','+',
ит.д.
Внутри апострофов можно записать любой символ, изобра-
жаемый на дисплее или принтере в текстовом режиме. Однако в
ЭВМ используются и коды, не имеющие графического пред-
ставления на экране дисплея, клавиатуре или принтере. Приме-
рами таких кодов служит код перехода курсора дисплея на
новую строку или код возврата царетки (возврат курсора к нача-
лу текущей строки). Для изображения в программе соответст-
16
Программирование на языке Си
вующих символьных констант используются комбинации из
нескольких символов, имеющих графическое представление.
Каждая такая комбинация начинается с символа 'V (обратная
косая черта - backslash). Такие наборы литер, начинающиеся с
символа 'V, в литературе по языку Си называют управляющими
последовательностями. Ниже приводится их список:
’\п'- перевод строки;
V - горизонтальная табуляция;
'\г* - возврат каретки (курсора) к началу строки;
'W - обратная косая черта \;
'\" - апостроф (одиночная кавычка);
- кавычка (символ двойной кавычки);
'\0'-нулевой символ;
'\а'- сигнал-звонЬк;
'\Ь'- возврат на одну позицию (на один символ);
'\f - перевод (прогон) страницы;
'\v'— вертикальная табуляция;
*\7 - знак вопроса.
Обратите внимание на то, что перечисленные константы изо-
бражаются двумя и более литерами, а обозначают они одну
символьную константу, имеющую индивидуальный двоичный
код. Управляющие последовательности являются частным слу-
чаем эскейп-последовательностей (ESC-sequence), к которым
также относятся лексемы вида '\ddd' либо ’\xhh* или '\Xhh'.
'\ddd' - восьмеричное представление любой символьной кон-
станты. Здесь d - восьмеричная цифра (от 0 до 7). Например,
'\017'или ^33'. . -
'\xhh' или '\Xhh* - шестнадцатеричное представление любой,
символьной константы. Здесь h - шестнадцатеричная цифра (от
О до F). Например,'\xOb','\х1 А'и т.д.
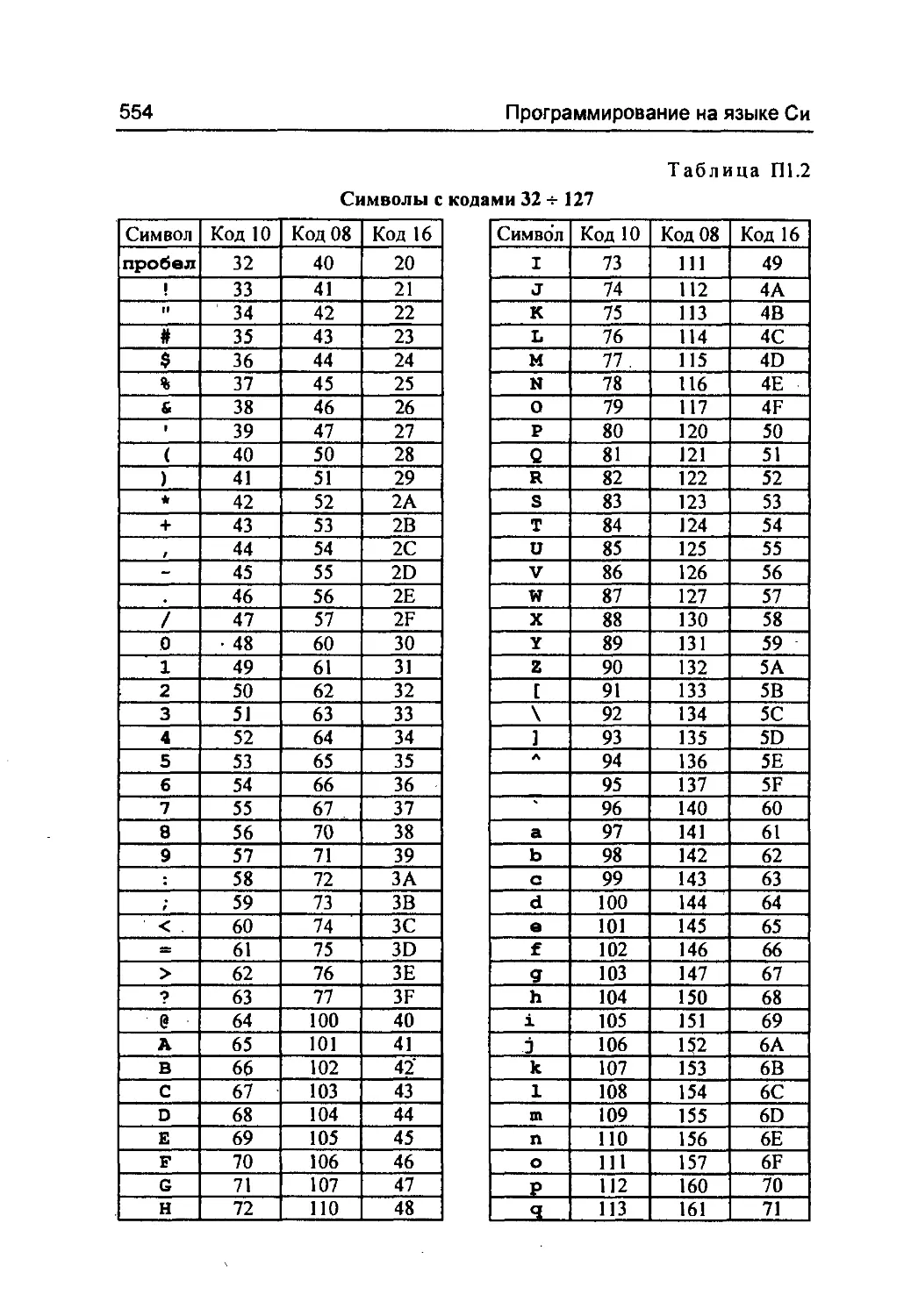
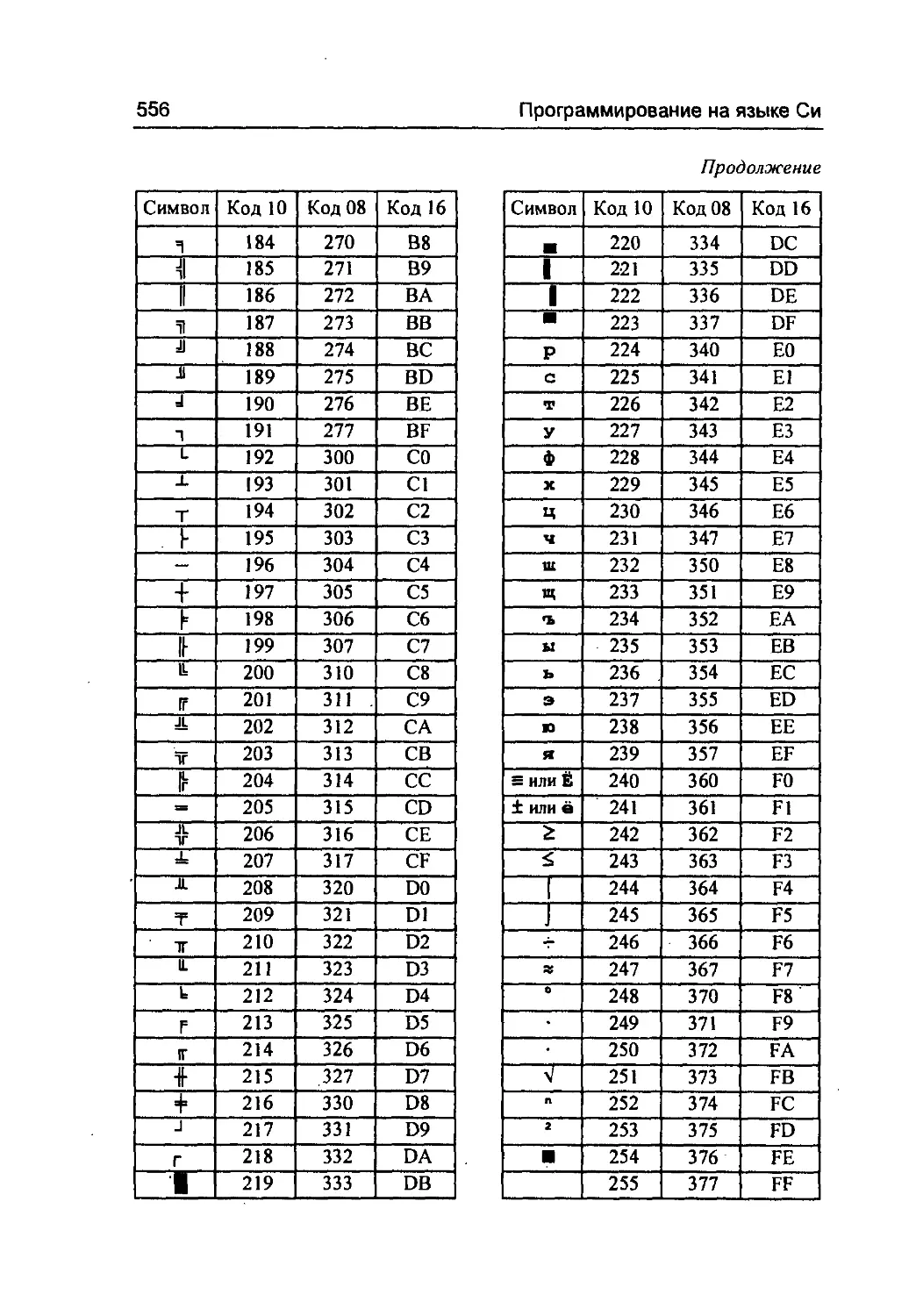
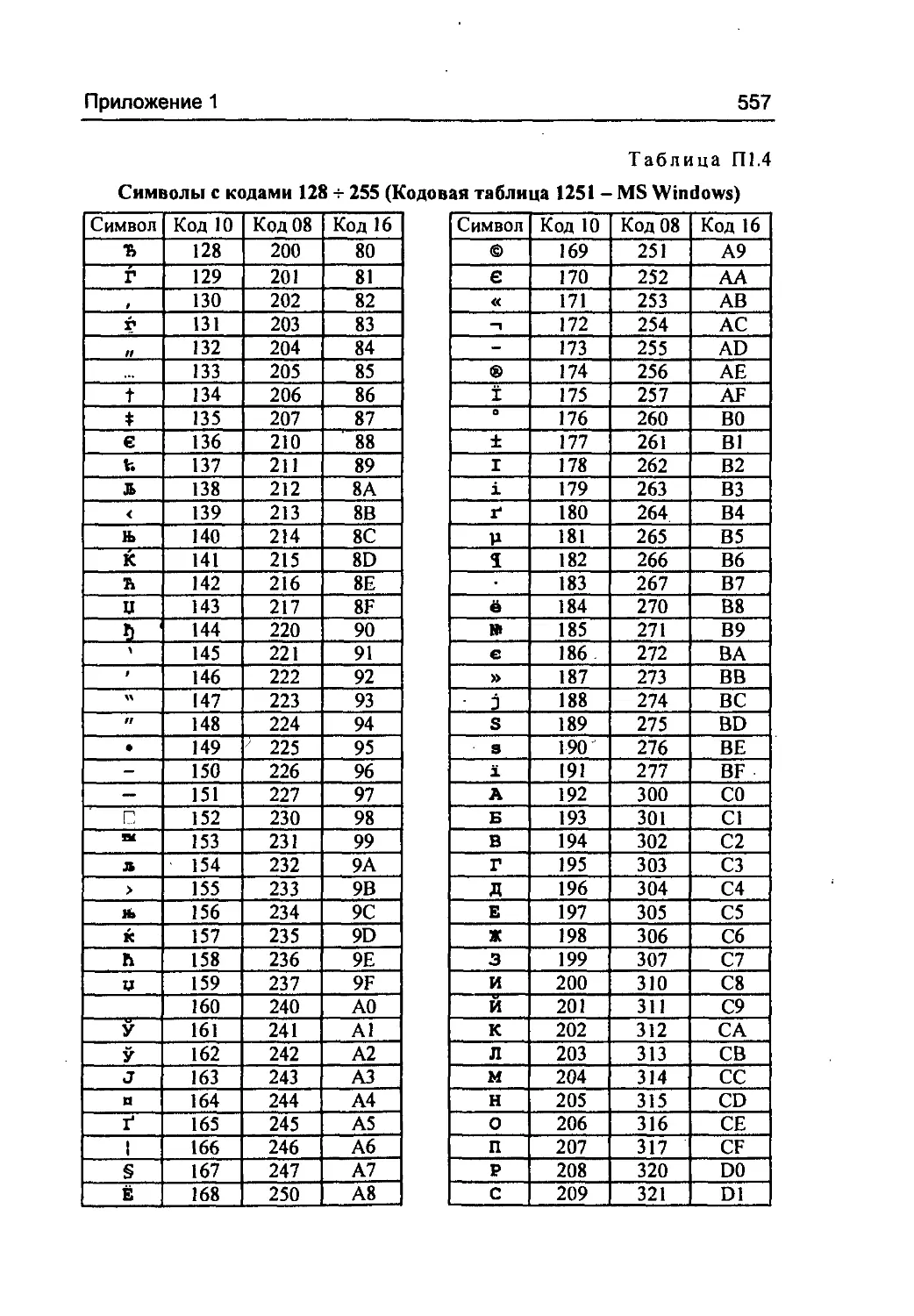
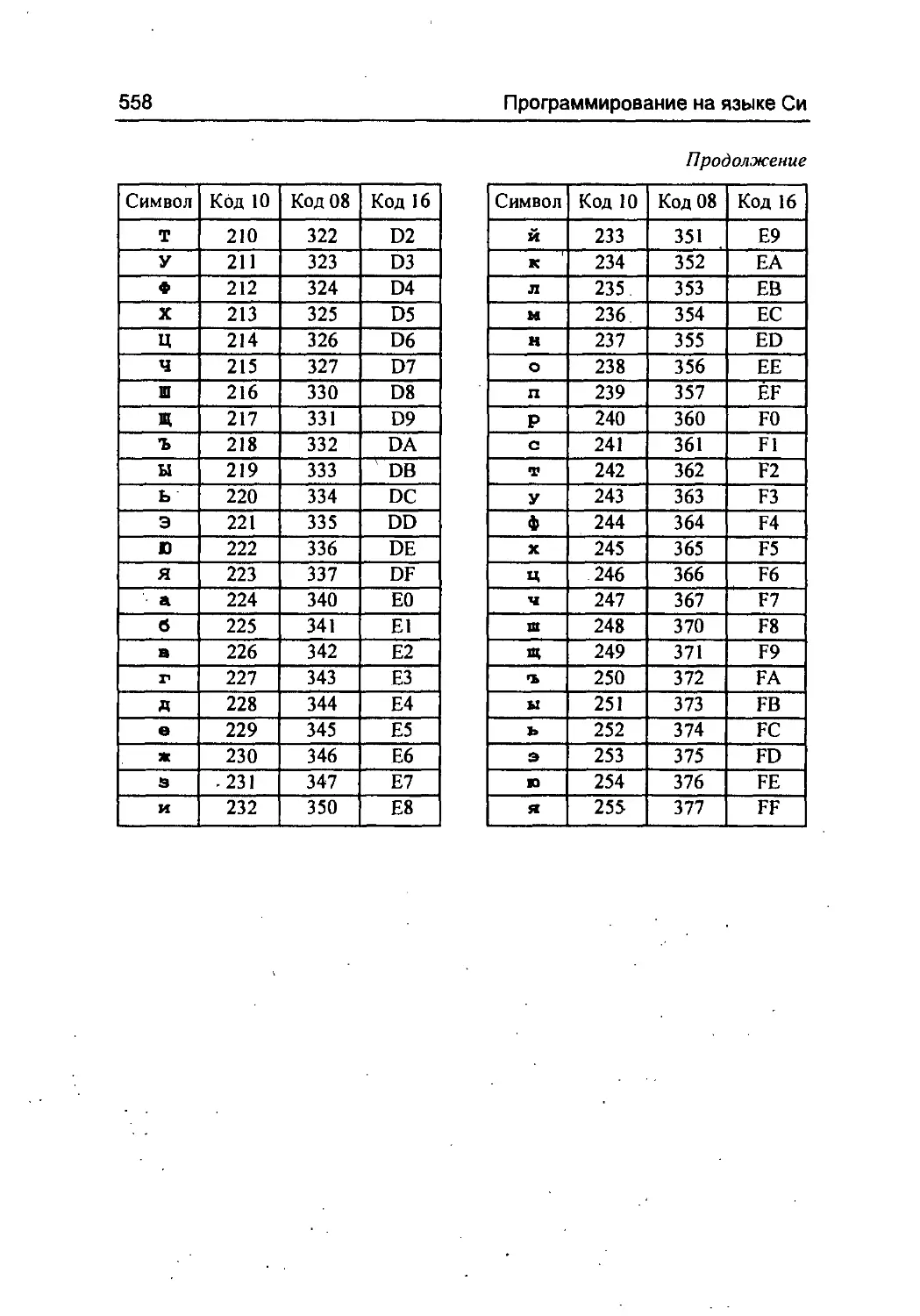
В Приложении 1 приведены таблицы числовых кодов симво-
лов. Зная значения кодов, можно изображать в виде эскейп-
последовательности любой символ, как воспроизводимый в тек-
стовом режиме на дисплее (принтере), так и неизображаемый
(управляющий).
Глава 1. Базовые понятия языка 17
Символьная константа (символ) имеет целый тип, т.е. симво-
лы можно использовать в качестве целочисленных операндов в
выражениях.
Целые константы. Синтаксисом языка определены целые
константы: десятичные, шестнадцатеричные и восьмеричные.
Основание определяется префиксом в записи константы. Для
десятичных констант префикс не используется. Десятичные це-
лые определены как последовательности десятичных цифр, на-
чинающиеся не с нуля (если это не число нуль):
44 684 0. 1024
Последовательность Цифр, начинающаяся с 0 и не содержа-
щая десятичных цифр старше 7, воспринимается как восьме-
ричная константа:
016 - восьмеричное представление десятичного целого 14.
Последовательность шестнадцатеричных цифр (0, 4,..., 9 ,А,
В, С, D, Е, F), перед которой записаны символы Ох или ОХ, счи-
тается шестнадцатеричной константой:
0x16 - шестнадцатеричное представление десятичного цело-
го 22;
0XFF - шестнадцатеричное представление десятичного цело-
го 255.
Каждая конкретная реализация языка вводит свои ограниче-
ния на предельные значения констант. Например, компилятор
Turbo С в отношении целых констант соответствует стандарту и
допускает целые десятичные от 0 до 32767, а длинные целые
(см. ниже тип long) - от 0 до 2147483647.
Вещественные константы. Для представления веществен-
ных (нецелых) чисел используются константы, представляемые
в памяти ЭВМ в форме с плавающей точкой. Каждая вещест-
венная константа состоит из следующих частей: целая часть
(десятичная целая константа); десятичная точка; дробная часть
(десятичная целая константа); признак показателя "е" или "Е";
показатель десятичной степени ^десятичная целая константа,
возможно, со знаком). При записи констант с плавающей точкой
могут опускаться целая или дробная часть (но не одновремен-
>3124
18
Программирование на языке Си
но); десятичная точка или символ экспоненты с показателем
степени (но не одновременно). Примеры констант с плавающей
точкой:
44. 3.14159 44е0 .314159Е1 0.0
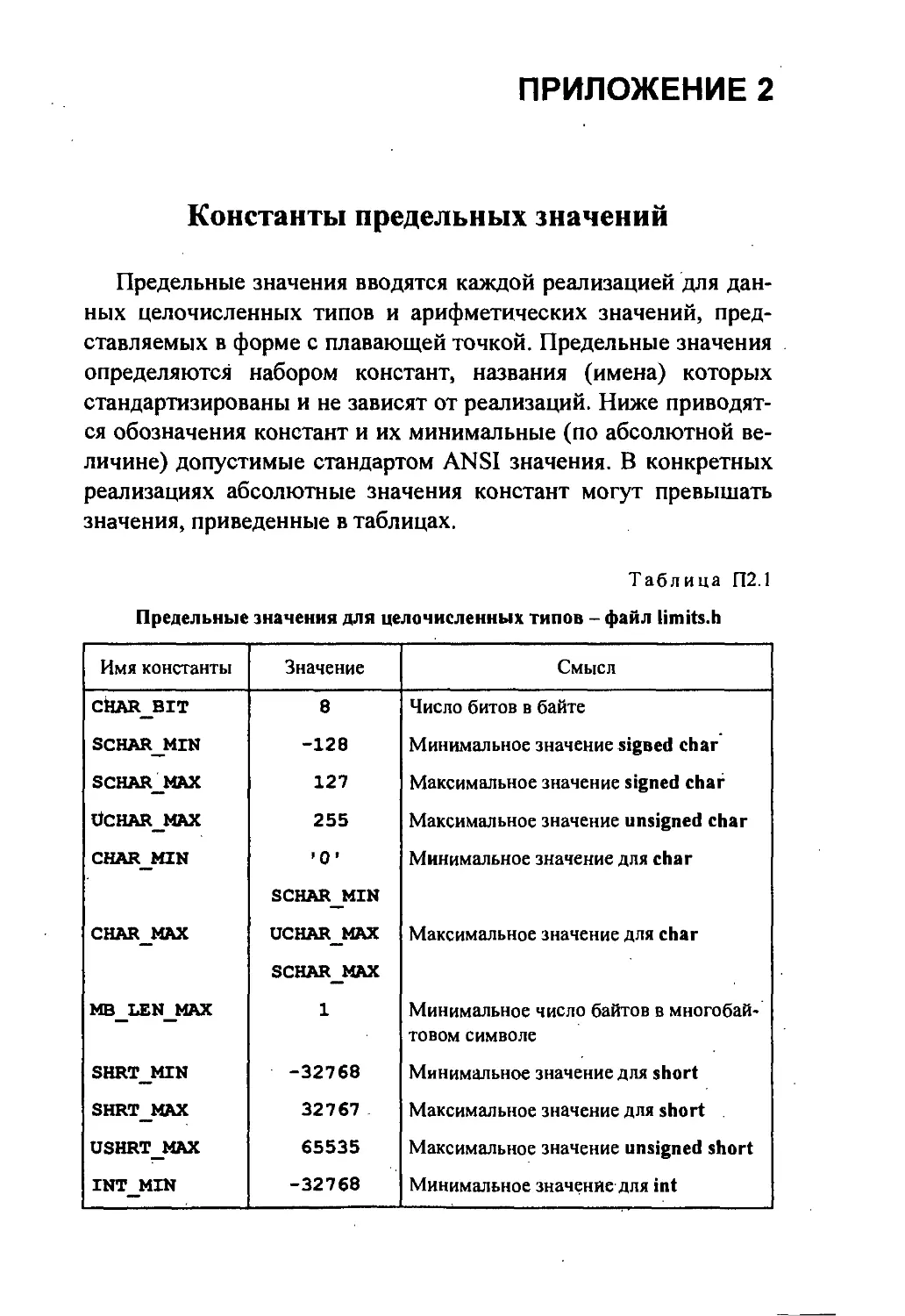
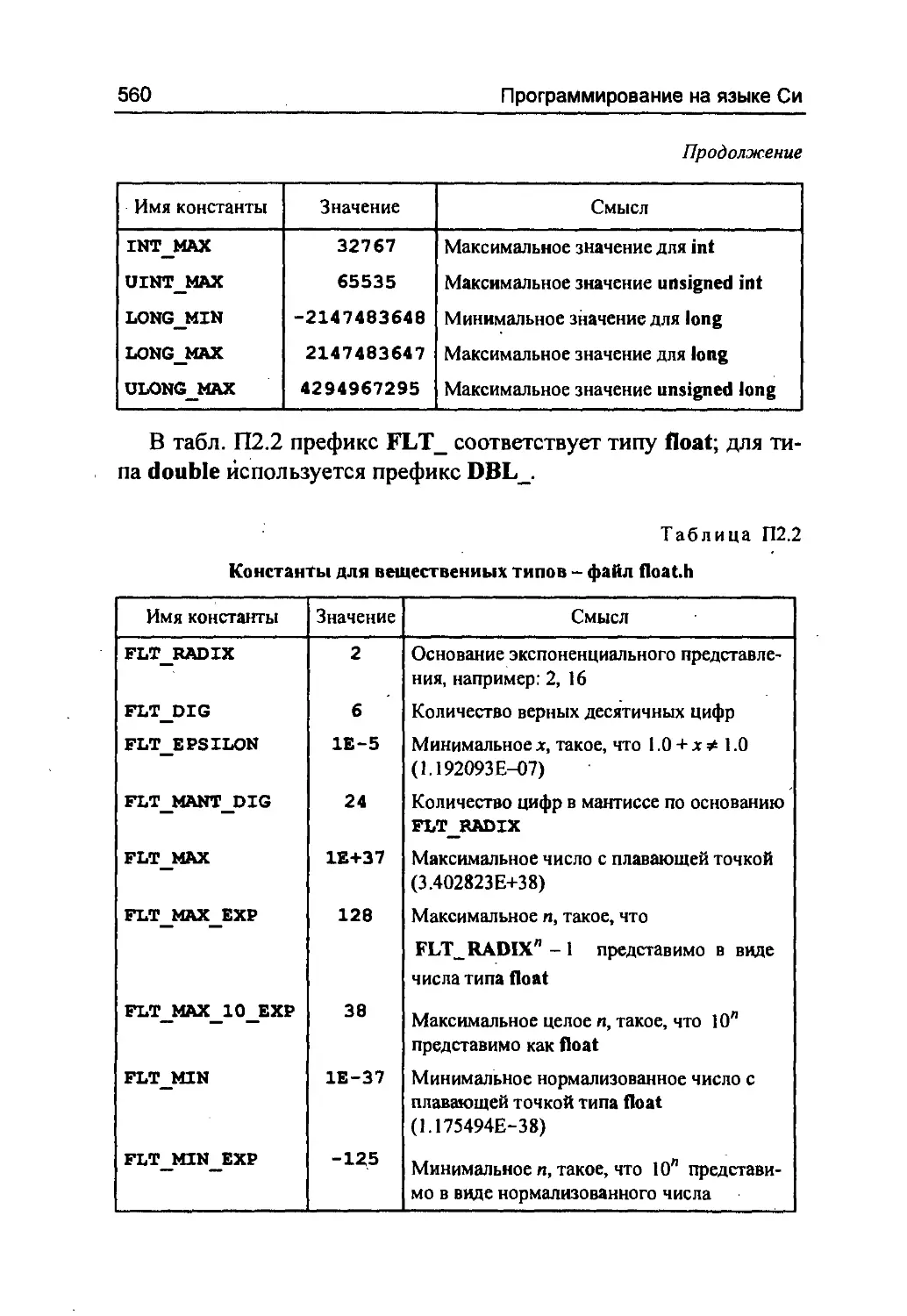
Предельные значения и типы арифметических констант.
Машинное представление (код) программы на языке Си пред-
полагает, что каждая константа, введенная в программе, зани-
мает в ЭВМ некоторый участок памяти. Размеры этого участка
памяти и интерпретация его содержимого определяются типом
соответствующей константы. В Приложении 2 приведены до-
пустимые стандартом предельные значения для разных типов
данных. Почти все компиляторы отводят символьным констан-
там (символам) по одному байту (восемь бит). Тем самым вво-
дится ограничение на все разнообразие символьных констант -
их внутренние коды должны находиться в диапазоне от 0 до
255. В языках многих стран мира не весь набор символов (букв
и знаков) может быть представлен с помощью одного байта. В
настоящее время ведется систематическая международная рабо-
та по созданию многобайтового универсального кода (unicode),
в рамках которого можно представлять символы почти всех ал-
фавитов. Однако рассмотрение многобайтовых кодов в рамках
настоящего пособия представляется нам преждевременным.
Для целых и вещественных констант каждая реализация
компилятора с языка Си может определять свои ограничения. В
табл. 1.1 приведены пределы, исходя из которых компиляторы,
реализованные на IBM-совместимых ПЭВМ, выбирают типы
целых констант. Например, все целые константы в диапазоне от
0 до 32767 имеют тип int, т.е. будут представлены в памяти уча-
стками в 2 байта (1 б бит).
В табл. 1.2 приведены сведения о представлении данных ве-
щественных типов.
Вещественная константа 3.141592653589793 будет восприня-
та как имеющая тип double, и ей будет выделено 8 байт (64 би-
та). Тот же тип выбирается для константы 3.14, так как по
умолчанию всем вещественным константам присваивается тип
double.
Глава 1. Базовые понятия языка
19
Таблица 1.1
Целые константы н выбираемые для них типы
Диапазоны значений констант Тип данных
десятичные восьмеричные шестнадцатеричные
отО до 32767 от 00 до 077777 от 0x0000 до 0x7FFF int
- от 0100000 до 0177777 от 0x8000 до OxFFFF uusigued iut
от 32768 до 2147483647 от 020000 до 017777777777 от 0x10000 до 0x7FFFFFFF loug
от 2147483648 до 4294967295 от 020000000000 до 037777777777 . от 0x80000000 до OxFFFFFFFF unsigned long
> 4294967295 >037777777777 > OxFFFFFFFF ошибка
Т аблица 1.2
Данные вещественных типов
Тип данных Размер, бит Диапазон абсолютных величин
float 32 от 3.4Е-38 до 3.4Е+38
double 64 от 1.7Е-308до 1.7Е+308
long double 80 от 3.4Е-4932 до 1.1Е+4932
Если программиста не устраивает тип, который компилятор
приписывает константе, то тип .можно явно указать в записи
константы с помощью суффиксов: F (или f) - float (для вещест-
венных), U (или u) - unsigned (для целых), L (или I) - long (для
целых и вещественных). Например:
3.14159F - константа типа float (выделяется 4 байта);
3.14L - константа типа long double (выделяется 10 байт).
С помощью суффикса U (или и) можно представить целую
константу в виде беззнакового целого. Например:
50000U - константа типа unsigned int.
2’
20
Программирование на языке Си
Константе 50000U выделяются 2 байта (вместо четырех, как
было бы при отсутствии суффикса (см. табл. 1.1). В этом случае,
т.е. для unsigned int, знаковый бит йспользуется для представ-
ления одного из разрядов кода числа и диапазон значений ста-
новится от 0 до 65535.
Суффикс L (или I) позволяет выделить целой константе 4
байта (32 бита):
500L - константа типа long, которой выделяется 4 байта;
0L - целая константа типа long длиной 4 байта.
Совместное использование в любом порядке суффиксов U
(или и) и L (или 1) позволяет приписать целой константе тип
unsigned long, и она займет в памяти 32 разряда (бита), причем
знаковый разряд будет использоваться для представления раз-
ряда кода (а не знака). Примеры:
0LU - целая константа типа unsigned long длиной 4 байта;
2424242424UL - константа типа unsigned long.
Нулевой указатель. Null-указатель, называемый нулевым
указателем, это единственная неарифметическая константа. Ее
роль и функциональные возможности станут ясны при изучении
аппарата указателей (см. следующие главы). В конкретных реа-
лизациях null-указатель может быть представлен либо как О,
либо как 0L, либо как именованная константа NULL. Здесь
нужно отметить, что значение константы NULL не обязано
быть нулем и имеет право не совпадать с кодом символа 'О'.
Константы перечисляемого типа. Целочисленные имено-
ванные константы можно вводить с помощью перечисления:
епшп тип перечисления {список именованных констант};
где епшп - служебное слово, вводящее перечисление;
тип_пёречисления - его название - необязательный про-
извольный идентификатор;
список именованных констант - разделенная запятыми
последовательность идентификаторов или именованных кон-
стант вида: имя_константы=значение константы
Глава 1. Базовые, понятия языке
21’
Примеры:
enum{ONE=l, TWO, THREE/FOUR) ;
enum DAY {SUNDAY, MONDAY, TUESDAY, WEDNESDAY,
THURSDAY, FRIDAY, SATURDAY};
enum BOOLEAN {NO, YES}; '
Если в списке нет ни одного элемента со знаком то значе-
ния констант начинаются с 0 и увеличиваются на 1 слева напра-
во. Таким образом, NO равно О, YES равно 1, SUNDAY имеет
значение 0 и FRIDAY имеет значение 5. Именованная константа
со знаком получает соответствующее значение (ONE=f1), а
следующие за ней именованные константы без явных значений
увеличиваются на 1 каждая. В нашем примере TWO равно 2,
THREE равно 3, FOUR равно 4.
Строки, или строковые константы. Формально строки (в
соответствии со стандартом) не относятся к константам языка
Си, а представляют собой отдельный тип его лексем. Для них в
литературе используется еще одно название "строковые лите-
ралы". Строковая константа определяется как последователь-
ность символов (см. выше символьные константы), заключенная
в двойные кавычки (не в апострофы):
"Образец строки"
Среди символов строки могут быть эскейп-последова-
тельности, т.е. сочетания знаков, соответствующие неизобра-
жаемым символам, или символам, задаваемым их внутренними
кодами. В этом случае, как и в представлениях отдельных сим-
вольных констант, их изображения начинаются с обратной ко-
сой черты' V :
"\п Текст \п разместится \п в 3-х строках дисплея"
Представления строковых констант в памяти ЭВМ подчиня-
ются следующим правилам. Все символы строки размещаются
.подряд, и каждый символ (в том числе представленный эскейп-
последовательностью) занимает ровно 1 байт. В конце записи
строковой константы компилятор помещает символ '\0*.
22
Программирование на языке Си
Таким образом, количество байтов, выделяемое в памяти
ЭВМ для представления значения строки, ровно на 1 больше,
чем число символов в записи этой строковой константы:
"Эта строка занимает в памяти ЭВМ 43 байта."
"Строка в 18 байт."
При работе с символьной информацией нужно помнить, что
длина константы 'F' равна 1 байту, а длина строки "F" равна 2
байтам.
При записи строковых констант возможно размещение одной
константы в нескольких строках текстового файла с програм-
мой. Для этого используется следующее правило.
Если в последовательности символов (литер) константы
встречается литера 'V, за которой до признака '\п' конца строки
текстового файла размещены только пробелы, то эти пробелы
вместе с символом 'V и окончанием '\п' удаляются, и продолже-
нием строковой константы считается следующая строка текста.
Например, следующий текст представляет одну строковую кон-
станту:
"Шалтай-Болтай \
сидел на стене."
В программе эта константа будет эквивалентна такой:
"Шалтай-Болтай сидел на стене."
Начальные (левые) пробелы в продолжении константы на
новой строке не удаляются, а считаются входящими в строко-
вую константу.
Две строковые константы, между которыми нет других раз-
делителей, кроме обобщенных пробельных символов (пробел,
табуляция, конец строки и т.д.); воспринимаются как одна стро-
ковая константа. Таким образом,
"Шалтай-Болтай" " свалился во сне."
воспринимается как одна константа:
"Шалтай-Болтай свалился во сне."
Глава 1. Базовые понятия языка
23
Тем же правилам подчиняются и строковые константы, раз-
мещенные на разных строках. Как одна строка будет воспринята
последовательность
"Вся королевская "
"конница, "
"вся' королевская "
"рать*
Эти четыре строковые константы эквивалентны одной:
"Вся королевская конница, вся королевская рать"
Обратите внимание, что в результирующую строку здесь не
включаются начальные пробелы перед каждой константой-
продолжением.
1.3. Переменные и именованные константы
Переменная как объект. Одним из основных понятий языка
Си является объект - именованная область памяти. Частный
случай объекта - переменная. Отличительная особенность пе-
ременной состоит в возможности связывать с ее именем различи
ные значения, совокупность которых определяется типом
переменной. При задании значения переменной в соответст-
вующую ей область памяти помещается код этого значения.
Доступ к значению переменной наиболее естественно обеспечи-
вает ее имя, а доступ к участку памяти возможен только по его
адресу. О взаимосвязях имен и адресов будет подробно гово-
риться в главе, посвященной указателям и работе с памятью
ЭВМ. Для целей первых глав будет вполне достаточно интер-
претировать понятие переменной как пару "имя - значение".
Определение переменных. Каждая переменная перед ее .ис-
пользованием в программе должна быть определена, т.е. для
переменной должна быть выделена память. Размер участка па-
мяти, выделяемой для переменной, и интерпретация содержи-
мого зависят от типа, указанного в определении переменной.
24 Программирование на языке Си
В соответствии с типами значений, допустимых в языке Си,
рассмотрим символьные, целые и, вещественные переменные
автоматической памяти. О классах памяти (один из которых
класс автоматической памяти) будем подробно говорить позже.
Сейчас достаточно ввести только переменные автоматической
памяти, которые существуют в том блоке, где они определены.
В наиболее распространенном случае таким блоком является
текст основной (main) функции программы.
Простейшая форма определения переменных:
тип списокименпеременных;
где имена переменных - это выбранные программистом иден-
тификаторы, которые в списке разделяются запятыми;
тип - один из уже упоминаемых (в связи с константами)
типов.
Определены целочисленные типы (перечислены в порядке
неубывания длины внутреннего представления):
char - целый длиной не менее 8 бит;
short int - короткий целый (допустима аббревиатура
short);
int -целый;
long - длинный целый.
Каждый из целочисленных типов может быть определен ли-
бо как знаковый signed либо как беззнаковый unsigned (по
умолчанию signed).
Различие между этими двумя типами - в правилах интерпре-
тации старшего бита внутреннего представления. Спецификатор
signed требует, чтобы старший бит внутреннего представления
воспринимался как знаковый; unsigned означает, что старший
бит внутреннего представления входит в код представляемого
числового значения, которое считается в этом случае беззнако-
вым. Выбор знакового или беззнакового представления опреде-
ляет предельные значения, которые можно представить с
помощью описанной переменной. Например, на IBM PC пере-
менная типа unsigned int позволяет представить числа от 0 до
65535, а переменной типа signed int (или просто int) соответст-
Глава 1. Базовые понятия языка
25
вуют значения в диапазоне от -32768 до +32767. Чтобы глубже
понять различие между целой величиной и целой величиной без
знака, следует обратить внимание на результат выполнения
унарной операции (минус) над целой величиной и целой ве-
личиной без знака. Для целой величины результат очевиден и
тривиален. Результатом при использовании целой величины без
знака является
2П - (значение величины без знака),
где п - количество разрядов, отведенное для представления ве-
личины без знака.
Например, если переменная к типа int равна 16, то значени-
ем -к будет -16. Если переменная Ь типа unsigned int равна 16,
то значением -Ь на IBM PC является 65520.
По умолчанию, при отсутствии в качестве префикса клю-
чевого слова unsigned любой целый тип считается знаковым
(signed). Таким образом, употребление совместно со служеб-
ными словами char, short, int, long префикса signed излишне.
Допустимо отдельное использование обозначений (специфи-
каторов) "знаковости". При этом
signed эквивалентно signed int; •>
unsigned эквивалентно unsigned int.
Примеры определений целочисленных переменных:
char symbol, сс;
unsigned char code;
int number, row;'
unsigned long long_number;
Обратите внимание на необходимость символа "точка с запя-
той" в конце каждого определения.
Стандартом языка введены следующие вещественные типы:
float - вещественный одинарной точности;
double - вещественный удвоенной точности;
long double - вещественный максимальной точности.
Значения всех вещественных типов в ЭВМ представляются с
"плавающей точкой", т.е. с мантиссой и порядком, как было
26
Программирование на языке Си
рассмотрено при определении констант (§1.2). Примеры опре-
делений вещественных переменных:
float х, X, ссЗ, pot_8;
double a, Stop, В4;
Предельные значения переменных. Предельные значения
констант (и соответствующих переменных) разработчики ком-
пиляторов вправе выбирать самостоятельно исходя из аппарат-
ных возможностей компьютера. Однако при такой свободе
выбора стандарт языка требует, чтобы для значений типа short
и int было отведено не менее 16 бит, для long - не менее 32 бит.
При этом размер long должен быть не менее размера int, a int -
не менее short. Предельные значения арифметических констант
и переменных для большинства компиляторов, реализованных
на IBM PC, приведены в табл. 1.3.
Предельные значения вещественных переменных совпадают
с предельными значениями соответствующих констант (см., на-
пример, табл. 1.2).
Т аблица 1.3
Основные типы данных
Тип данных Размер, бит Диапазон значений
Unsigned char 8 0...255
char 8 -128... 127
enum 16 -32768... 32767
unsigned int 16 0... 65535
short int (short) 16 -32768... 32767
unsigned short 16 0... 65535
int 16 -32768... 32767
unsigned long 32 0... 4294967295
long 32 -2147483648 ...2147483647
float 32 , 3.4Е-38... 3.4Е+38
donble 64 1.7Е-308... 1.7Е+ЗО8
long donble 80 3.4Е-4932... 1.1Е+4932
Глава 1. Базовые понятия языка
27
Предельные значения целочисленных переменных совпада-
ют с предельными значениями соответствующих констант (см.
табл. 1.1). Табл. 1.3 содержит и предельные значения для тех
типов, которые не включены в табл. 1.1.
Требования стандарта отображают таблицы Приложения 2.
Инициализация переменных. В соответствии с синтакси-
со\1 языка переменные автоматической памяти после определе-
ния по умолчанию имеют неопределенные значения. Надеяться
на то, что они равны, например, 0, нельзя. Однако переменным
можно присваивать начальные значения, явно указывая их в оп-
ределениях:
тип имя_ переменной=началъноезначение;
Этот прием назван инициализацией. В отличие от присваи-
вания, которое, осуществляется в процессе выполнения про-
граммы, инициализация выполняется при выделении для
переменной участка памяти. Примеры определений с инициали-
зацией:
float pi=3.1415, сс=1.23;
unsigned int year=1997;
Именованные константы. В языке Си, кроме переменных,
могут быть определены константы, имеющие фиксированные
названия (имена). В качестве имен констант используются про-
извольно выбираемые программистом идентификаторы, не сов-
падающие с ключевыми словами и с другими именами
объектов. Традиционно принято, что для обозначений констант
выбирают идентификаторы из больших букв латинского алфа-
вита и символов подчеркивания. Такое соглашение позволяет
при просмотре большого текста программы на языке Си легко
отличать имена переменных от названий констант.
Первая возможность определения именованных констант
была проиллюстрирована в §1.2, посвященном константам. Это
перечисляемые константы, вводимые с использованием слу-
жебного слова enum.
Вторую возможность вводить именованные константы обес-
печивают определения такого вида:
28
Программирование на языке Си
const тип имя константы^значение константы;
Здесь const - квалификатор типа, указывающий, что опреде-
ляемый объект имеет постоянное значение, т.е. доступен только
для чтения; тип - один из типов объектов; имяконстанты -
идентификатор; значение константы должно соответствовать
ее типу. Примеры.*
const double Е=2.718282;
const long №99999999;
const F=765;
В последнем определении тип константы не указан, по умол-
чанию ей приписывается тип int.
Третью возможность вводить именованные константы обес-
печивает препроцессорная директива
#define имяконстанты значение константы
Обратите внимание на отсутствие символа "точка с запятой"
в конце директивы. Подробному рассмотрению директивы
#define будут посвящены два параграфа главы 3. Здесь мы
только упоминаем о возможности с ее помощью определять
именованные константы. Кроме того, отметим, что в конкрет-
ные реализации компиляторов с помощью директив #define
включают целый, набор именованных констант с фиксирован-
ными именами (см. главу 3 и Приложение 2).
Отличие определения именованной константы
const double Е=2.718282;
от определения препроцессорной константы с таким же значе-
нием
#define EULER 2.718282
состоит внешне в том, что в определении константы Е явно за-
дается ее тип, а при препроцессорном определении константы
EULER ее тип определяется "внешним видом" значения кон-
станты. Например, следующее определение
#define NEXT 'Z'
Глава 1. Базовые понятия языка
29
вводит обозначение NEXT для символьной константы 'Z'. Это
соответствует такому определению:
const char NEXT = 'Z';
Однако различия между обычной именованной константой и
препроцессорной константой, вводимой директивой #define,
гораздо глубже и принципиальнее. До начала компиляции текст
программы на языке Си обрабатывается специальным компо-
нентом транслятора - препроцессором. Если в тексте встречает-
ся директива
#define EULER 2.718282
а ниже ее в тексте используется имя константы EULER, напри-
мер, в таком виде: 1
double mix = EULER;
d = alfa*EULER;
то препроцессор заменит каждое обозначение EULER на ее зна-
чение и сформирует такой текст:
double mix = 2.718282;
d = alfa*2.718282;
Далее текст от препроцессора поступает к компилятору, ко-
торый уже "и не вспомнит" о существовании имени EULER, ис-
пользованного в препроцессорной директиве #define. Конс-
танты, определяемые на препроцессорном уровне с помощью
директивы #define, очень часто используются для задания раз-
меров массивов, что будет продемонстрировано позже.
Итак, основное отличие констант, определяемых препроцес-
сорными директивами #define, состоит в том, что эти константы
вводятся в текст программы до этапа ее компиляции. Специаль-
ный компонент транслятора - препроцессор обрабатывает ис-
ходный текст программы, подготовленный программистом, и
делает в этом тексте замены и подстановки. Пусть в исходном
тексте встречается директива:
#define ZERO 0.0
30
Программирование на языке Си
Это означает, что каждое последующее использование в тек-
сте программы имени ZERO будет заменяться на 0.0.
Рис. 1.1 иллюстрирует некоторые принципы работы препро-
цессора. Его основное отличие от других компонентов трансля-
тора - обработка программы выполняется только на уровне ее
текста. На входе препроцессора - текст с препроцессорными
директивами, на выходе препроцессора - модифицированный
текст без препроцессорных директив. Этот выходной модифи-
цированный текст изменен по сравнению с входным текстом за
счет выполнения препроцессорных директив, но сами препро-
цёссорные директивы в выходном тексте отсутствуют. Полно-
стью все препроцессорные директивы будут рассмотрены позже
в главе 3. В связи с именованными константами здесь рассмат-
ривается только одна из возможностей директивы #define -
простая подстановка.
Текст до препроцессора (исходный текст программы):
#definePI 3.141593
#define ZERO 0.0
if (r>ZEROy* Сравнение с константой ZERO •/
/* Длина окружности радиуса г:*/
D=2*PI*r;
Текст после препроцессора:
if (г>0.0)/* Сравнение с константой ZERO ♦/
/*Длина окружности радиуса г: ♦/
D=2*3.141593*r;
Рис. 1.1. Обработка текста программы препроцессором
Глава 1. Базовые понятия языка
31
Имена PI и ZERO (см. рис. 1.1) после работы препроцессора
заменены в тексте программы на определенные в двух директи-
вах #define значения (3.141593 и 0.0). • '
Обратите внимание, что подстановка не выполняется в ком-
ментариях и в строковых константах. В примере на рис. 1.1
идентификатор ZERO остался без изменений в комментарии
(/* Сравнение с константой ZERO */).
Именно с помощью набора именованных препроцессорных
констант стандарт языка Си рекомендует авторам компиляторов
определять предельные значения всех основных типов данных.
Для этого в языке определен набор фиксированных имен, каж-
дое из которых является именем одной из констант, опреде-
ляющих то или иное предельное значение. Например:
FLT MAX - максимальное число с плавающей точкой
типа float;
CHAR BIT - количество битов & байте;
INT MIN - минимальное значение для данных типа int
Общий список стандартных препроцессорных именованных
констант для арифметических данных дан в Приложении 2.
Чтобы использовать в программе указанные именованные
препроцессорные константы, недостаточно записать их имена в
программе. Предварительно в текст программы необходимо
включить препроцессорную директиву такого вида:
#include <имя_заголовочного_файла>
где в качестве имени_заголовочного_файла подставляются:
limits.h - для данных целых типов;'
floath - для вещественных данных.
В заголовочный файл limits.h авторы компилятора помести-
ли набор препроцессорных директив, среди которых есть такие
(приведены значения в шестнадцатеричном виде для Turbo С):
«define CHAR_BIT 8
«define SHRT_MAX 0x7FFF
«define LONG MAX 0x7FFFFFFFL
32
Программирование на языке Си
В заголовочном файле float.h находятся директивы, опреде-
ляющие константы, связанные с представлением данных веще-
ственных типов. Например:
#define FLT_MIN 1.17549435E-38F
//define DBL_MIN 2.2250738585072014E-308
#define DBL_EPSILpN 2.2204460492503131E-16
Значения этих предопределенных на препроцессорном уров-
не констант в соответствии со стандартом языка в конкретных
компиляторах могут быть несколько иными, отличными от тех,
что приведены в-таблицах Приложения 2.
Подробно о возможностях препроцессорных средств будет
говориться в главе 3. Сейчас достаточно знать, что, записав в
тексте своей программы директиву
//include <Iimits.h>
можно использовать в программе стандартные именованные
константы CHARBIT, SHRTMIN и т.д. (см. Приложение 2),
а уж их значениямигбудут те числа, которые включили в дирек-
тивы //define авторы конкретного компилятора и конкретной
библиотеки.
Если включить в программу директиву
//include <float.h>
то станут доступными именованные константы предельных
значений числовых данных вещественных типов (см. Прило-
жение 2).
Такой подход к определению предельных значений с помо-
щью препроцессорных констант, сохраняемых в библиотечных
файлах; позволяет писать программы, не зависящие от реализа-
ции, что обеспечивает их достаточную мобильность. Програм-
мист использует в программе стандартные имена (обозначе-
ния) констант, а их значения определяются версией реализации,
т.е. конкретным компилятором и его библиотеками.
Глава 1. Базовые понятия языка
33
1.4. Операции
В этом параграфе достаточно лаконично определяются все
операции языка Си и приводится таблица их приоритетов. Хотя
в ближайших параграфах (где вводятся выражения и основные
операторы языка) нам понадобятся не все знаки операций и не-
редко будет достаточно интуитивного представления об их
старшинстве и ассоциативности, но материал этого параграфа
слишком важен, чтобы говорить о нем позже. В последующих
главах применение операций языка будет рассмотрено подроб-
но, но к таблице приоритетов стоит обращаться и при дальней-
шем чтении, и при написании программ.
Знаки операций. Для формирования и последующего вы-
числения выражений используются операции. Для изображения
одной операций в большинстве случаев используется несколько
символов. В табл. 1.4 приведены все знаки операций, опреде-
ленные стандартом языка. Операции в таблице разбиты на
группы в соответствии с их рангами.
За исключением операций "()" и все знаки опера-
ций распознаются компилятором как отдельные лексемы. В за-
висимости от контекста одна и та же лексема может обозначать
разные операции, т.е. один и тот же знак операции может упот-
ребляться в различных выражениях и по-разному интерпретиро-
ваться в зависимости от контекста. Например, бинарная опера-
ция & - это поразрядная конъюнкция, а унарная операция & -
это операция получения адреса.
Операции ранга 1 имеют наивысший приоритет. Операции
одного ранга имеют одинаковый приоритет, и если их в выра-
жении несколько, то они выполняются в соответствии с прави-
лом ассоциативности либо слева направо (->), либо справа
налево (<—). Если один и тот же знак операции приведен в таб-
лице дважды (например, знак *), то первое появление (с мень-
шим по номеру, т.е. старшим по приоритету, рангом)
соответствует унарной операции, а второе - бинарной.
Опишем кратко возможности отдельных операций.
3-3124
34
Программирование на языке Си
Таблица 1.4
Приоритеты (ранги) операций
Ранг Операции Ассоциа- тивность
1 О [] -> • —>
2 !- + -++ — & * (тип) sizeof <—
3 * / % (мультипликативные бинарные) —>
4 + - (аддитивные бинарные) —>
5 « » (поразрядного сдвига) —>
6 <<->=> (отношения) —>
7 — != (отношения) —>
8 & (поразрядная конъюнкция "И") —
9 Л (поразрядное исключающее "ИЛИ") —>
10 | (поразрядная дизъюнкция "ИЛИ") —>
11 && (конъюнкция "И") —>
12 || (дизъюнкция "ИЛИ”) —>
13 ?: (условная операция) <—
14 = *= /= %= += -=&=«=!= «= »= <—
15 , (операция "запятая") —>
Унарные (одноместные) операции. Для изображения од-
номестных префиксных и постфиксных операций используются
следующие символы:
& - операция получения адреса операнда (ранг 2);
* - операция обращения по адресу, т.е. раскрытия ссыл-
ки, иначе операция разыменования (доступа по ад-
ресу к значению того объекта, на который указывает
операнд). Операндом должен быть указатель (ранг
2);
- унарный минус, изменяет знак арифметического
операнда (ранг 2);
Глава 1. Базовые понятия языка
35
+ - унарный плюс, введен для симметрии с унарным
минусом (ранг 2);
~ - поразрядное инвертирование внутреннего двоичного
кода целочисленного аргумента - побитовое отрица-
ние (ранг 2);
! - НЕ - логическое отрицание значения операнда (ранг
2). Применяется к скалярным операндам. Целочис-
ленный результат 0 (если операнд ненулевой, т.е.
истинный) или 1 (если операнд нулевой, т.е. лож-
ный). Напомним, что в качестве логических значе-
ний в языке используют целые числа: 0 - ложь и не
нуль, т.е. (!0) - истина. Отрицанием любого ненуле-
вого числа будет 0, а отрицанием нуля будет 1. Та-
ким образом: !1 равно 0; !2 равно 0; !(-5) равно 0; !0
равно 1;
++ - увеличение на единицу (инкремент или автоувеличе-
ние - ранг 2); имеет две формы:
префиксная операция - увеличение значения опе-
ранда на 1 до его использования. Ассоциативность
справа в соответствии со стандартом;
постфиксная операция - увеличение значения
операнда на 1 после его использования. Ассоциатив-
ность слева в соответствии со стандартом.
Операнд для операции ++ (и для операции —) не
может быть константой либо произвольным выраже-
нием. Записи ++5 или 84++ будут неверными. ++(j+k)
также неверная запись. Операндами унарных опера-
ций ++ и — должны быть всегда модифицируемые
именующие выражения (L-value, left value, /-зна-
чение, леводопустимое выражение). Термины "лево-
допустимое выражение" и "/-значение" происходят
от объяснения действия операции присваивания Е =
D, в которой операнд Е слева от знака операции при-
сваивания может быть только модифицируемым /-
значением. Примером модифицируемого /-значения
служит имя переменной, которой выделена память.
3*
36
Программирование на языке Си
Таким образом, /-значение - ссылка на область памя-
ти, значение которой доступно изменениям;
- уменьшение на единицу (декремент или автоумень-
шение - ранг 2) - унарная операция, операндом ко-
торой должно быть леводопустимое выражение, т.е.
не константа и не выражение:
префиксная операция - уменьшение на 1 значения
операнда до его использования;
постфиксная операция - уменьшение на 1 значе-
ния операнда после его использования;
sizeof - операция (ранг 2) вычисления размера (в байтах) для
объекта того типа, который имеет операнд. Разреше-
ны два формата операции:
sizeof выражение
sizeof(тип).
sizeof не вычисляет значения выражения, а только определяет
его тип, для которого затем вычисляется размер.
Бинарные (двуместные) операции делятся на следующие
группы:
• аддитивные;
• мультипликативные;
• сдвигов;
• поразрядные;
• операции отношений;
• логические;
• присваивания;
• выбора компонента структурированного объекта;
• операция "запятая";
• скобки в качестве операций.
Аддитивные операции:
+ - бинарный плюс - сложение арифметических операндов
или сложение указателя с целочисленным операндом
(ранг 4)\
~ - бинарный минус - вычитание арифметических операн-
дов или вычитание указателей (ранг 4).
Глава 1. Базовые понятия языка
37
Мультипликативные операции:
* - умножение операндов арифметического типа {ранг S);
/ - деление операндов арифметического типа (ранг 3).
При целочисленных операндах абсолютное значение
результата округляется до целого. Например, 20/3 рав-
но 6, -20/3 равно -6, (-20)/3 равно -6, 20/(-3) равно -6;
% - получение остатка от деления целочисленных операн-
дов (деление по модулю - ранг 3). При неотрицатель-
ных операндах остаток положительный. В противном
случае остаток определяется реализацией. В компиля-
торе Turbo С:
13%4 равняется 1, (-13)%4 равняется -1;
13%(—4) равно +1, а (-13)%(-4) равняется -1.
При ненулевом делителе для целочисленных операн-
дов всегда выполняется соотношение: (a/b)*b + а%Ь
равно а.
Операции сдвига (определены только для целочисленных
операндов). Формат выражения с операцией сдвига:
операнд левый операция сдвига операнд_правый
« - сдвиг влево битового представления значения левого
целочисленного операнда на количество разрядов, рав-
ное значению правого целочисленного операнда
(ранг 5);
» - сдвиг вправо битового представления значения левого
целочисленного операнда на количество разрядов, рав-
ное значению правого целочисленного операнда
(ранг 5).
Поразрядные операции:
& - поразрядная конъюнкция (И) битовых представлений
значений целочисленных операндов (ранг 8);
I - поразрядная дизъюнкция (ИЛИ) битовых представле-
ний значений целочисленных операндов (ранг J О')',
А - поразрядное исключающее ИЛИ битовых представле-
ний значений целочисленных операндов (ранг 9).
38
Программирование на языке Си
Результат выполнения операций сдвига и поразрядных опе-
раций:
4«2 равняется 16;
5>>1 равняется 2;
6&5 равняется 4;
615 равняется' 7;
6*5 равняется 3.
Напоминаем, что двоичный код для 4 равен 100, для 5 - это
101, для 6 - это 110 и т.д. При сдвиге влево на две позиции код
100 становится равным 10000 (десятичное значение равно 16).
Остальные результаты операций сдвига и поразрядных опера-
ций могут быть прослежены аналогично.
Обратите внимание, что сдвиг влево на п позиций эквивален-
тен умножению значения на 2", а сдвиг кода вправо уменьшает
соответствующее значение в 2" раз с отбрасыванием дробной
части результата. (Поэтому 5»1 равно 2.)
Операции отношений (сравнения):
< меньше, чем (ранг 6);
, > больше, чем (ранг 6);
< = меньше или равно (ранг 6);
> = больше или равно (ранг 6);
— равно (ранг 7);
!= не равно (ранг 7).
Операнды операций отношений должны быть арифметиче-
ского типа или могут быть указателями. Результат целочислен-
ный: 0 (ложь) или 1 (истина). Последние две операции
(операции сравнения на равенство) имеют более низкий при-
оритет по сравнению с остальными операциями отношений. Та-
ким образом, выражение (х < В — А < х) есть 1, когда значение
х находится в интервале от А до В и А<В либо х, А, В равны.
(Вначале вычисляются х < В и А < х, ак результатам применя-
ется операция сравнения на равенство —.)
Логические бинарные операции:
&& - конъюнкция (И) арифметических операндов или от-
ношений (ранг 11). Целочисленный результат 0
(ложь) или 1 (истина);
Глава 1. Базовые понятия языка
39
I I - дизъюнкция (ИЛИ) арифметических операндов или
отношений (ранг 12). Целочисленный результат О
(ложь) или 1 (истина).
(Вспомните о существовании унарной операции отрицания'!'.)
Результаты отношений и логических операций:
3<5 равняется 1;
3>5 равняется 0;
3=5 равняется 0;
31=5 равняется 1;
3!—5 || 3==5 равняется!;
3+4>5 && 3+5>4 && 4+5>3 равняется 1.
Операции присваивания (ранг 14)
В качестве левого операнда в операциях присваивания может
использоваться только модифицируемое именующее выраже-
ние (/-значение), т.е. ссылка на некоторую именованную об-
ласть памяти, значение которой доступно изменениям.
Перечислим операции присваивания, отметив, что сущест-
вуют одна простая операция присваивания и ряд составных опе-
раций:
= - простое присваивание: присвоить значение выраже-
ния-операнда из правой части операнду левой части.
Пример: Р = 10.3 - 2*х;
*= - присваивание после умножения: присвоить операнду
левой части произведение значений обоих операндов.
Р *= 2 эквивалентно Р = Р * 2;
/= - присваивание после деления: присвоить операнду ле-
вой части частное от деления значения левого опе-
ранда на значение правого. Р /= 2.2 - d эквивалентно
Р = Р / (2.2 - d);
%= - присваивание после деления по модулю: присвоить
операнду левой части остаток от целочисленного де-
ления значения левого операнда на значение правого
операнда. N %= 3 эквивалентно N = N % 3;
+= - присваивание после суммирования: присвоить опе-
ранду левой части сумму значений обоих операндов
А += В эквивалентно А = А + В;
40
Программирование на языке Си
-= - присваивание после вычитания: присвоить операнду
левой части разность значений левого и правого опе-
рандов. X -= 4.3 - Z эквивалентно X = X - (4.3 - Z);
«= - присваивание после сдвигов разрядов влево: присво-
ить целочисленному операнду левой части значение,
полученное сдвигом влево его битового представле-
ния на количество разрядов, равное значению пра-
вого целочисленного операнда. Например, а «= 4
эквивалентно а = а « 4;
»= - присваивание после сдвигов разрядов вправо: присво-
ить целочисленному операнду левой части значение,
полученное сдвигом вправо его битового представле-
ния на количество разрядов, равное значению пра-
вого целочисленного операнда. Например, а »= 4
эквивалентно а = а » 4;
&= - присваивание после поразрядной конъюнкции: при-
своить целочисленному операнду левой части значе-
ние, полученное поразрядной конъюнкцией (И) его
битового представления с битовым представлением
целочисленного операнда правой части е &= 44 экви-
валентно е = е & 44;
1= - присваивание после поразрядной дизъюнкции: при-
своить целочисленному операнду левой части значе-
ние, полученное поразрядной дизъюнкцией (ИЛИ)
его битового представления с битовым представле-
нием целочисленного операнда правой части а | = b
эквивалентно а = а | Ь;
А= - присваивание после исключающего поразрядного
“ИЛИ"-, присвоить целочисленному операнду левой
части значение, полученное применением поразряд-
ной операции исключающего ИЛИ к битовым пред-
ставлениям значений обоих операндов zA=x+y
эквивалентно г = г А (х + у).
Обратите внимание, что для всех составных операций при-
сваивания форма присваивания El ор= Е2 эквивалентна Е1 =
El op (Е2), где ор - обозначение операции.
Глава 1. Базовые понятия языка
41
Операции выбора компонентов структурированного объ-
екта:
. (точка) - прямой выбор (выделение) компонента структу-
рированного объекта, например объединения или
структуры {ранг 7). Формат применения опера-
ции:
имя структурированного объекта, имя компо-
нента
-> - косвенный выбор (выделение) компонента струк-
турированного объекта, адресуемого указателем
(ранг 1). При использовании операции требуется,
чтобы с объектом был связан указатель
(указателям посвящена гл. 4.). В этом случае фор-
мат применения операции имеет вид:
указательнаструктурированныйобъект ->
имякомпонента
Так как операции выбора компонентов структурированных
объектов используются со структурами и объединениями, то
необходимые пояснения и примеры приведем позже, введя пе-
речисленные понятия и, кроме того, аккуратно определив указа-
тели.
Запятая в качестве операции (ранг 15)
Несколько выражений, разделенных запятыми вычисля-
ются последовательно слева направо. В качестве результата со-
храняются тип и значение самого правого выражения. Таким
образом, операция "запятая" группирует вычисления слева на-
право. Тип и значение результата определяются самым правым
из разделенных запятыми операндов (выражений). Значения
всех левых операндов игнорируются. Например, если перемен-
ная х имеет тип int, то значением выражения (х=3, 3*х) будет 9,
а переменная х примет значение 3.
Скобки в качестве операций
Круглые () и квадратные [ ] скобки играют роль бинарных
операций (ранг 7) при вызове функций и индексировании эле-
ментов массивов. Для программиста, начинающего использо-
42
Программирование нв языке Си
вать язык Си, мысль о том, что скобки в ряде случаев являются
бинарными операциями, часто даже не приходит в голову. И это
даже тогда, когда он практически в каждой программе обраща-
ется к функциям или применяет индексированные переменные.
Итак, отметим, что скобки могут служить бинарными опера-
циями, особенности и возможности которых достойны внима-
ния.
Круглые скобки обязательны в обращении к функции:
имяфункции(списокаргументов)
где операндами служат имяфункции и список аргументов. Ре-
зультат вызова определяется (вычисляется) в теле функции,
структуру которого задает ее определение.
В выражении
имя_массива[индекс]
операндами для операции [ ] служат имямассива и индекс.
Подробнее с индексированными переменными мы познакомим-
ся на примерах в главе 2 и более подробно в следующих главах.
Условная трехместная операция (ранг 13). В отличие от
унарных и бинарных операций условная тернарная операция
используется с тремя операндами. В изображении условной
операции применяются два символа '?' и и три выражения-
операнда:
выражение ! ? выражение_ 2 : выражение_3
Первым вычисляется значение выражения !. Если оно ис-
тинно, т.е. не равно нулю, то вычисляется значение выраже-
ния?, которое становится результатом. Если при вычислении
выражения ! получится 0, то в качестве результата берется
значение выражения ?. Классический пример:
х < 0 ? -х : х;
Выражение возвращает абсолютную величину переменной х.
Операция явного преобразования типа. Операция преобра-
зования (приведения) типа (ранг 2) имеет следующий формат:
(имя_типа) операнд
Глава 1. Базовые понятия языка
43
Такое выражение позволяет преобразовывать значение опе-
ранда к заданному типу. В качестве операнда используется
унарное выражение, которое в простейшем случае может быть
переменной, константой или любым выражением, заключенным
в круглые скобки. Например, преобразования (Iong)8 (вну-
треннее представление результата имеет длину 4 байта) и
(char)8 (внутреннее представление результата имеет длину 1
байт) изменяют длину внутреннего представления целых кон-
стант, не меняя их значений.
В этих преобразованиях константа не меняла значения и ос-
тавалась целочисленной. Однако возможны более глубокие
преобразования, например, (long double)6 или (float)4 не только
изменяют длину константы, но и структуру ее внутреннего
представления. В результатах будут выделены порядок и ман-
тисса, значения будут вещественными.
Преобразования типов арифметических данных нужно при-
менять аккуратно, так как возможно изменение числовых зна-
чений. При преобразовании больших целочисленных констант к
вещественному типу (например, к типу float) возможна потеря
значащих цифр (потеря точности). Если вещественное значение
преобразуется к целому, то возможна ошибка при выходе полу-
ченного значения за диапазон допустимых значений для целых.
В этом случае результат преобразования не всегда предсказуем
и целиком зависит от реализации.
1.5. Разделители
Этот параграф может быть опущен при первом чтении, так
как смысл почти всех разделителей становится очевиден при
разборе той или иной конструкции языка. Однако полнота из-
ложения сведений о лексемах и их назначениях требует систе-
матического рассмотрения разделителей именно здесь, что мы и
делаем. В дальнейшем этот раздел можно использовать для
справок. В некоторых примерах этого параграфа пришлось ис-
пользовать понятия, вводимые в следующих главах (например,
структурный тип или прототип функции).
44
Программирование на языке Си
Разделители, или знаки пунктуации, входят в число лексем
языка:
[] (){},;:...* = #
Квадратные скобки. Для ограничения индексов одно- и
многомерных массивов, а также при записи индексированных
элементов используются квадратные скобки [ ]. Примеры:
int А[5]; А - одномерный массив из пяти элементов;
int х, е[3][2]; е - двумерный массив (матрица) размером 3x2.
Выражение с индексированными элементами:
е[0][0] = х = А[2] J 4;
означает, что начальному элементу массива е, переменной х и
третьему элементу массива А присваивается значение 4. Так как
индексы в массивах всегда начинаются с 0, то элемент А[2] со-
ответствует третьему элементу массива.
Круглые скобки. Назначение круглых скобок ():
1) выделяют выражения-условия (в операторе "если"):
if (х < 0) х = -х;
/♦абсолютная величина арифметической переменной*/
2) входят как обязательные элементы в определение и описа-
ние (в прототип) любой функции, где выделяют соответственно
список формальных параметров и список спецификаций пара-
метров:
float F(float х, int k) /* Определение функции*/
{ тело_функции }
float F(float, int); /* Описание функции - ее
.прототип */
3) круглые скобки обязательны при определении указателя
на функцию:
int (*pfunc)( ); /* Определение указателя pfunc
на функцию */
Глава 1. Базовые понятия языка
45
4) группируют выражения, изменяя естественную последова-
тельность выполнения операций:
у = (а + Ь) /с; /* Изменение приоритета
операций */
5) входят как обязательные элементы в операторы циклов:
for (i=0, j=l; i<j; i+=2, j++) тело_ця*ла;
while ( i<j ) тело_цикла;
do тело_цихла while ( k>0 );
6) необходимы при явном преобразовании типа. Примеры:
long i = 12L; /* Определение переменной */
float brig; /* Определение переменной */
brig = (float)i; /* Явное приведение типа */
brig получает значение 12L, преобразованное к типу float;
7) применение круглых скобок настоятельно рекоменду-
ется в макроопределениях, обрабатываемых препроцессором
(см. гл. 3):
fdefine R(x,y) sqrt((x)*(x) + (у) *(у))
Это позволяет использовать в качестве параметров макровызо-
вов арифметические выражения любой сложности и не сталки-
ваться с нарушениями приоритетов операций.
Фигурные скобки. Для обозначения соответственно начала
и конца составного оператора или блока используют фигурные
скобки {}. Пример использования составного оператора в ус-
ловном операторе:
if (d > х) { d—; х++; }
Пример блока - тело любой функции:
float absx (float х)
(
return х>О.О?х:-х;
)
Обратите внимание на отсутствие точки с запятой после закры-
вающейся скобки обозначающей конец составного операто-
ра или блока.
46
Программирование на языке Си
Фигурные скобки используются для выделения списка ком-
понентов в определениях структурных и объединяющих типов:
/* Определение структурного типа cell: */
struct cell
{
char *b;
int ее;
double U[6];
};
/* Определение объединяющего типа mix: */
union mix
unsigned int ii;
char cc[2];
};
Обратите внимание на необходимость точки с запятой после
определения каждого типа.
Фигурные скобки используются при инициализации масси-
вов и структур при их определении:
/* Инициализация массива: */
int month [ ] ={ 1, 2, 3, 4, 5, б, 7, 8, 9, 10,
11, 12 };
/* Инициализация структуры stock типа mixture */
struct mixture
int ii;
double dd;
char cc; }
stock = { 666, 3.67, *\t' };
В примере mixture - имя структурного типа с тремя компо-
нентами разных типов, stock - имя конкретной структуры типа
mixture. Компоненты ii, dd, сс структуры stock получают значе-
ния при инициализации из списка В фигурных скобках.
(Подробно о структурах см. в гл. 6.)
Запятая. Запятая может быть использована в качестве опе-
рации, а может применяться как разделитель. В последнем слу-
чае она разделяет элементы списков. Во-первых, это списки
Г лава 1. Базовые понятия языка
47
начальных значений элементов массивов и компонентов струк-
тур при их инициализации (примеры только что даны).
Другой пример списков - списки формальных и фактических
параметров и их спецификаций в функциях.
Третье использование запятой как разделителя - в заголовке
оператора цикла:
for (x=pl,у=р2,i=2; i<n; z=x+y, х=у, y=z, i++);
(В данном примере после выполнения цикла значением пере-
менной z будет величина, равная n-му члену последовательно-
сти чисел Фибоначчи, определенной по значениям первых двух
pl и р2.)
Запятая как разделитель используется также в описаниях и
определениях объектов (например, переменных) одного типа:
int i, n;
float x, у, z, pl, p2;
Запятая в качестве операции уже рассматривалась. Следует
обратить внимание на необходимость с помощью круглых ско-
бок отделять запятую-операцию от запятой-разделителя. На-
пример, для элементов следующего массива m используется
список с тремя начальными значениями:
int i=l, m[ ]={ i, (i=2,i*i), i };
В данном примере запятая в круглых скобках выступает в роли
знака операции. Операция присваивания "=" имеет более высо-
кий приоритет, чем операция "запятая". Поэтому вначале i по-
лучает значение 2, затем вычисляется произведение i*i, и этот
результат служит значением выражения в скобках. Однако зна-
чением переменной i остается 2. Значениями т[0], т[1], т[2]
будут соответственно 1, 4, 2.
Точка с запятой. Каждый оператор, каждое определение и
каждое описание в программе на языке Си завершает точка с
запятой Любое допустимое выражение, за которым следует
воспринимается как оператор. Это справедливо и для пусто-
го выражения, т.е. отдельный символ "точка с запятой" считает-
48
Программирование на языке Си
ся пустым оператором. Пустой оператор иногда используется
как тело цикла. Примером может служить цикл for, приведен-
ный выше для иллюстрации особенностей использования запя-
той в качестве разделителя. (Вычисляется n-й член
последовательности чисел Фибоначчи.)
Примеры операторов-выражений:
х++; /* Результат - только изменение Значения
переменной i */
F(z,4); /* Результат определяется телом функции
с именем F */
Двоеточие. Для отделения метки от помечаемого ею опера-
тора используется двоеточие
метка: оператор;
Многоточие. Это три точки без пробелов между ними.
Оно используется для обозначения переменного числа парамет-
ров у функции при ее определении и описании (при задании ее
прототипа). При работе на языке Си программист постоянно
использует библиотечные функции со списком параметров пе-
ременной длины для форматных ввода и вывода. Их прототипы
выглядят следующим образом:
int printf (const char * format,...);
int scanf (const char * format,...);
Здесь с помощью многоточия указана возможность при об-
ращении к. функциям использовать разное количество парамет-
ров (не меньше одного, так как параметр format должен быть
указан всегда и не может опускаться).
Подготовка своих функций с переменным количеством па-
раметров на языке Си требует применения средств адресной
арифметики, например макросов, предоставляемых заголовоч-
ным файлом stdarg.h. О возможностях упомянутых макросов
подробно говорится в главе 5.
Звездочка. Как уже упоминалось, звездочка используется
в качестве знака операции умножения и знака операции разы-
Г лава 1. Базовые понятия языка
49
менования (получения доступа через указатель). В описаниях и
определениях звездочка означает, что описывается (определя-
ется) указатель на значение использованного в объявлении типа:
/♦Указатель на величину типа int*/
int * point;
/* Указатель на указатель на объект типа char */
char * * refer;
Обозначение присваивания. Как уже упоминалось, для
обозначения операции присваивания используется символ
Кроме того, в определении объекта он используется при его
инициализации:
/* инициализация структуры */
struct {char х, int у} А={ 'z', 1918 };
/* инициализация переменной */
int F = 66;
Признак препроцессорных средств. Символ (знак номе-
ра или диеза в музыке) используется для обозначения директив
(команд) препроцессора. Если этот символ является первым от-
личным от пробела символом в строке программы, то строка
воспринимается как директива препроцессора. Этот же символ
используется в качестве одной из препроцессорных операций
(см. гл. 3).
Без одной из препроцессорных директив обойтись совер-
шенно невозможно - препроцессорная команда
#include <stdio.h>
включает в текст программы средства связи с библиотечными
функциями ввода-вывода.
Директива //define уже введена при рассмотрении именован-
ных препроцессорных констант. Остальные директивы и опера-
ции препроцессора можно рассматривать позже, что и будет
сделано в главе 3.
4-3124
50
Программирование на языке Си
1.6. Выражения и приведение
арифметических типов
Введя константы, переменные, разделители и знаки опера-
ций, охарактеризовав основные типы данных и рассмотрев пе-
ременные, можно конструировать выражения. Каждое выраже-
ние состоит из одного или нескольких операндов, символов
операций и ограничителей, в качестве которых чаще всего вы-
ступают круглые скобки (). Назначение любого выражения -
формирование некоторого значения. В зависимости от типа
формируемых значений определяются типы выражений. Если
значениями выражения являются целые и вещественные числа,
то говорят об арифметических выражениях.
В арифметических выражениях допустимы следующие опе-
рации: '
+ - сложение (или унарная операция +);
- вычитание (или унарная операция изменения знака);
* - умножение;
/ - деление;
% - деление по модулю (т.е. получение остатка от цело-
численного деления первого операнда на второй).
Операндами для перечисленных операций служат константы
и переменные арифметических типов, а также выражения, за-
ключенные в круглые скобки.
Примеры выражений с двумя операндами:
а+Ь 12.3-х 3.14159*Z k/3 16%i
Нужно быть аккуратным, применяя операцию деления 7' к
целочисленным операндам. Например, как мы уже упоминали
выше, за счет округления результата значением выражения 5/3
будет 1, а соответствует ли это замыслам программиста, зависит
от смысла той конкретной конструкции, в которой это выраже-
ние используется.
Чтобы результат выполнения арифметической операции был
вещественным, необходимо, чтобы вещественным был хотя бы
Глава 1. Базовые понятия языка
51
один из операндов. Например, значением выражения 5.0/2 будет
2.5, что соответствует смыслу обычного деления.
Операции *, /, % (см. табл. 1.4) имеют один ранг (3), опе-
рации +, - также один ранг (4), но более низкий. Арифметиче-
ские операции одного ранга выполняются слева направо. Для
изменения порядка выполнения операций обычным образом
используются скобки. Например, выражение (d+b)/2.0 позволяет
получить среднее арифметическое операндов d и Ь.
Как уже говорилось, введены специфические унарные опера-
ции ++ (ийкремент) и — (декремент) для изменения на 1 опе-
ранда, который в простейшем случае должен быть переменной
(леводопустимым значением). Каждая из этих операций может
быть префиксной и постфиксной: ;
• выражение ++т увеличивает на 1 значение т, и это по-
лученное значение используется как значение выражения
++т (префиксная форма);
• выражение —к уменьшает на 1 значение к, и это новое
значение используется как значение выражения —к
(префиксная форма);
• выражение i++ (постфиксная форма) увеличивает на 1
значение i, однако значением выражения i++ является пре-
дыдущее значение i (до его увеличения);
• выражение)— (постфиксная форма) уменьшает на 1
значение), однако значением выражения j— является пре-
дыдущее значение j (до его уменьшения).
Например, если п равно 4, то при вычислении выражения п++*2
результат равен 8, а п примет значение 5. При п, равном 4, зна-
чением выражения ++п*2 будет 10, а п станет равно 5.
Внешнюю неоднозначность имеют выражения, в которых
знак унарной операции ++ (или —) записан непосредственно
рядом со знаком бинарной операции +:
х+++Ь или z—d
В этих случаях трактовка выражений однозначна и полно-
стью определяется рангами операций (бинарные аддитивные + и
- имеют ранг 4; унарные ++ и — имеют ранг 2). Таким образом:
4*
52
Программирование на языке Си
х+++Ь эквивалентно (х++)+Ь
z---d эквивалентно (z—)-d
Отношения и логические выражения. Отношение опреде-
тяется как пара арифметических выражений, соединенных
'разделенных) знаком операции отношения. Знаки операций
этношения (уже были введены выше):
== равно; •= неравно;
< меньше, чем; <= меньше или равно;
> больше, чем; >= больше или равно.
Примеры отношений:
а-Ь>6.3
(х-4)*3=12
6 <=44
Логический тип в языке Си отсутствует, поэтому принято,
что отношение имеет ненулевое значение (обычно 1), если оно
истинно, и равно 0, если оно ложно. Таким образом, значением
отношения 6<=44 будет 1.
Операции >, >=, <, <= имеют один ранг 6 (см. табл. 1.4).
Операции сравнения на равенство == и ! = также имеют одина-
ковый, но более низкий ранг 7, чем остальные операции отно-
шений. Арифметические операции имеют более высокий ранг,
чем операции отношений, поэтому в первом примере для выра-
жения а-b не нужны скобки. .
Логических операций в языке Си три:
! - отрицание, т.е. логическое НЕ (ранг 2)
&& - конъюнкция, т.е. логическое И (ранг /7);
I I - дизъюнкция, т.е. логическое ИЛИ (ранг 12).
Они перечислены по убыванию старшинства (ранга). Как
правило, логические операции применяются к отношениям. До
выполнения логических операций вычисляются значения отно-
шений, входящих в логическое выражение. Например, если а, Ь,
с - переменные, соответствующие длинам сторон треугольника,
то для них должно быть истинно, т.е. не равно 0, следующее
логическое выражение:
а+Ь>с && а+с>Ь && Ь+с>а
Глава 1. Базовые понятия языка
53
Несколько операций одного ранга выполняются слева напра-
во, причем вычисления прерываются, как только будет опреде-
лена истинность (или ложность) результата, т.е. если в
рассмотренном примере а+b окажется не больше с, то осталь-
ные отношения не рассматриваются - результат ложен.
Так как значением отношения является целое (0 или 1), то
ничто не противоречит применению логических операций к це-
лочисленным значениям. При этом принято, что любое ненуле-
вое положительное значение воспринимается как истинное, а
ложной считается только величина, равная нулю. Значением !5
будет 0, значением 4 && 2 будет 1 и т.д.
Присваивание (выражение и оператор). Как уже говори-
лось, символ "=" в языке Си обозначает бинарную операцию, у
которой в выражении должно быть два операнда - левый
(модифицируемое именующее выражение - обычно перемен-
ная) и правый (обычно выражение). Если z - имя переменной,
то
z = 2.3 + 5.1
есть выражение со значением 7.4. Одновременно это значение
присваивается и переменной z. Только В том случае, когда в
конце выражения с операцией присваивания помещен символ
это выражение становится оператором присваивания. Таким
образом,
z = 2.3 + 5.1;
есть оператор простого присваивания переменной z значения,
равного 7.4.
Тип и значение выражения с операцией присваивания опре-
деляются значением выражения, помещенного справа от знака
'='. Однако этот тип может не совпадать с типом переменной из
левой части выражения. В этом случае при определении значе-
ния переменной выполняется преобразование (приведение) ти-
пов (о правилах приведения см. ниже в этом параграфе).
Так как выражение справа от знака '=' может содержать, в
свою очередь, операцию присваивания, то в одном операторе
присваивания можно присвоить значения нескольким перемен-
54
Программирование на языке Си
ным, т.е. организовать "множественное" присваивание, напри-
мер:
с = х = d = 4.0 + 2.4;
Здесь значение 6.4 присваивается переменной d, затем 6.4
как значение выражения с операцией присваивания "d=4.0+2.4"
присваивается х и, наконец, 6.4 как значение выражения "x=d"
присваивается с. Естественное ограничение - слева от знака '=' в
каждой из операций присваивания может быть только леводо-
пустимое выражение (в первых главах книги - имя перемен-
ной).
В языке Си существует целый набор "составных операций
присваивания" (ранг 14 в табл. 1.4). Как уже говорилось в §1.4,
каждая из составных операций присваивания объединяет неко-
торую бинарную логическую или арифметическую операцию и
собственно присваивание. Операция составного присваивания
является основой оператора составного присваивания:
имя_переменной ор=выражение;
где ор - одна из операций *, /, %, +, -, &, Л, |, «, ». Если
рассматривать конструкцию "ор=" как две операции, то вначале
выполняется ор, а затем '='. Например,
х*=2; z+=4; i/=x+4*z;
При выполнении каждого из этих операторов операндами
для операции ор служат переменная из левой части и выраже-
ние из правой. Результат присваивается переменной из левой
части.
Таким образом, первый пример можно рассматривать как
обозначение требования "удвоить значение переменной х"; вто-
рой пример - "увеличить на 4 значение переменной z"; третий
пример - "уменьшить значение переменной i в (x+4*z) раз".
Этим операторам эквивалентны такие операторы простого при-
сваивания:
х=х*2; z=z+4; i=i/(x+4*z);
Глава 1. Базовые понятия языка
55
В последнем из них пришлось ввести скобки для получения
правильного результата. Обратите внимание на то, что перейти
от простого оператора присваивания к составному можно толь-
ко в тех случаях, когда одна переменная используется в обеих
частях. Более того, для некоторых операций эта переменная
должна быть обязательно первым (левым) операндом. Напри-
мер, на удастся заменить составными следующие простые опе-
раторы присваивания:
a=b/a; x=z%x.
Приведение типов. Рассматривая операцию деления, мы
отметили, что при делении двух целых операндов результат по-
лучается целым. Например, значением выражения 5/2 будет 2, а
не 2.5. Для получения вещественного результата нужно выпол-
нять деление не целых, а вещественных операндов, например,
записав 5.0/2.0, получим значение 2.5.
Если операндами являются безымянные константы, то заме-
нить целую константу (как мы только что сделали) на вещест-
венную совсем не трудно. В том случае, когда операндом
является именованная константа, переменная или выражение в
скобках, необходимо для решения той же задачи использовать
операцию явного приведения (преобразования) типа. Например,
рассмотрим такой набор определений и операторов присваива-
ния:
int n=5, к=2;
double d;
int m;
d-(double) n/ (double) k;
n=n/k;
В этом фрагменте значением d станет величина 2.5 типа
double, а значением переменной m станет целое значение 2.
Операция деления является только одной из бинарных опе-
раций. Почти для каждой из них операнды могут иметь разные
типы. Однако не всегда программист должен в. явном виде ука-
зывать преобразования типов. Если у бинарной операции опе-
ранды имеют разные типы (а должны в соответствии с
56
Программирование на языке Си
синтаксисом выражения иметь один тип), то компилятор вы-
полняет преобразование типов автоматически, т.е. приводит оба
операнда к одному типу. Например, для тех же переменных зна-
чение выражения d+k будет иметь тип double за счет неявного
преобразования, выполняемого автоматически без указания
программиста. Рассмотрим правила, по которым такие приведе-
ния выполняются.
Правила преобразования типов. При вычислении выраже-
ний некоторые операции требуют, чтобы операнды имели соот-
ветствующий тип, а если требования к типу не выполнены,
принудительно вызывают выполнение нужных преобразований.
Та же ситуация возникает при инициализации, когда тип ини-
циализирующего выражения приводится к типу определяемого
объекта. Напомним, что в языке Си присваивание является би-
нарной операцией, поэтому сказанное относительно преобразо-
вания типов относится и ко всем формам присваивания, однако
при присваиваниях значение выражения из правой части всегда
приводится к типу переменной из левой части, независимо от
соотношения этих типов.
Правила преобразования в языке Си для основных типов оп-
ределены стандартом языка. Эти стандартные преобразования
включают перевод "низших" типов в "высшие".
Среди преобразований типов выделяют:
• преобразования - в арифметических выражениях;
• преобразования при присваиваниях;
• преобразования указателей.
Преобразование типов указателей будет рассмотрено в гла-
ве 4. Здесь рассмотрим преобразования типов при арифметиче-
ских операциях и особенности преобразований типов при прис-
ваиваниях. .
При преобразовании типов нужно различать преобразования,
изменяющие внутреннее представление данных, и преобразова-
ния, изменяющие только интерпретацию внутреннего представ-
ления. Например, когда данные типа unsigned int переводятся в
тип int, менять их внутреннее представление не требуется - из-
меняется только интерпретация. При преобразовании значений
Глава 1. Базовые понятия языка
57
типа float в значение типа int недостаточно изменить только
интерпретацию, необходимо изменить длину участка памяти
для внутреннего представления и кодировку. При таком преоб-
разовании из float в int возможен выход за диапазон допусти-
мых значений типа int, и реакция на эту ситуацию существенно
зависит от конкретной реализации. Именно поэтому для сохра-
нения мобильности программ в них рекомендуется с осторож-
ностью применять преобразование типов.
Рассмотрим последовательность выполнения преобразования
операндов в арифметических выражениях.
1. Все короткие целые типы преобразуются в типы не мень-
шей длины в соответствии с табл. 1.5. Затем оба значения, уча-
ствующие в операции, принимают одинаковый тип в соот-
ветствии со следующими ниже правилами.
2. Если один из операндов имеет тип long double, то второй
тоже будет преобразован в long double.
3. Если п. 2 не выполняется и один из операндов есть double,
другой приводится к типу double.
4. Если п. 2 - 3 не выполняются и один из операндов имеет
тип float, то второй приводится к типу float.
5. Если п. 2 - 4 не выполняются (оба операнда целые) и один
операнд unsigned long int, то оба операнда преобразуются к ти-
пу unsigned long int.
6. Если п. 2 - 5 не выполняются и один операнд есть long,
другой преобразуется к типу long.
7. Если п. 2 - 6 не выполняются и один операнд unsigned, то
другой преобразуется к типу unsigned.
8. Если п. 2 - 7 не выполнены, то оба операнда принадлежат
типу int.
Используя арифметические выражения, следует учитывать
приведенные правила и не попадать в "ловушки" преобразова-
ния типов, так как некоторые из них приводят к потерям ин-
формации, а другие изменяют интерпретацию битового (внут-
реннего) представления данных.
58
Программирование на языке Си
На рис. 1.2 стрелками отмечены "безопасные" арифметиче-
ские преобразования, гарантирующие сохранение точности и
неизменность численного значения.
Таблица 1.5
Правила стандартных арифметических преобразований
Исходный тип Преобразованный тип • Правила преобразований
char int Расширение нулем или знаком в за- висимости от умолчания для char
unsigned char int Старший байт заполняется нулем
signed char int Расширение знаком
short int Сохраняется то же значение
unsigned short unsigned int Сохраняется то же значение
enum int Сохраняется то же значение
битовое поле int . Сохраняется то же значение
Рис. 1.2. Арифметические преобразования типов, гарантирующие
сохранение значимости
Глава 1. Базовые понятия языка
59
При преобразованиях, которые не отнесены схемой (рис. 1.2)
к безопасным, возможны существенные информационные поте-
ри. Для оценки значимости таких потерь рекомендуется прове-
рить обратимость преобразования типов. Преобразование цело-
численных значений в вещественные осуществляется настолько
точно, насколько это предусмотрено аппаратурой. Если кон-
кретное целочисленное значение не может быть точно пред-
ставлено как вещественное, то младшие значащие цифры
теряются и обратимость невозможна.
Приведение вещественного значения к целому типу выпол-
няется за счет отбрасывания дробной части. Преобразование
целой величины в вещественную также может привести к поте-
ре точности.
Выражения с поразрядными операциями. Поразрядные
операции позволяют конструировать выражения, в которых об-
работка операндов выполняется на битовом уровне (пораз-
рядно). Рассмотрим возможности операций над битами:
~ - поразрядное отрицание (дополнение или инвертиро-
вание битов) (ранг 2);
» - сдвиг вправо последовательности битов (ранг 5)',
« - сдвиг влево последовательности битов (ранг 5);
А - поразрядное исключающее ИЛИ (ранг 9);
| - поразрядное ИЛИ (поразрядная дизъюнкция) (ранг
Ю)-
& - поразрядное И (поразрядная конъюнкция) (ранг 8).
Операция поразрядного отрицания (дополнения или инвер-
тирования битов) обозначается символом и является унар-
ной (одноместной), т.е. действует на один операнд, который
должен быть целого типа. Значение операнда в виде внутренне-
го битового представления обрабатывается таким образом, что
формируется значение той же длины (того же типа), что и опе-
ранд. В битовом представлении результата содержатся 1 во всех
разрядах, где у операнда 0, и 0 в тех разрядах, где у операнда 1.
Например:
unsigned char Е='\0301', F;
F=-E;
60
Программирование на языке Си
Значением F будет восьмеричный код '\076' символа '>' (см.
Приложение 1). Действительно, битовые представления значе-
ний Е и F можно изобразить так:
11000001 - для значения переменной Е, т.е. для *\0301'
00111110 - для значения переменной F, т.е. для '\076'
За исключением дополнения, все остальные поразрядные
операции бинарные (двухместные).
Операции сдвигов » (вправо) и « (влево) должны иметь
целочисленные операнды. Над битовым представлением значе-
ния левого операнда выполняется действие - сдвиг. Правый
операнд определяет величину поразрядного сдвига. Например:
5<<2 будет равно 20
5>>2 будет равно 1
Битовые представления тех же операций сдвига можно изо-
бразить так:
101 «2 равно 10100, т.е. 20;
101»2 равно 001, т.е. 1.
При сдвиге влево на N позиций двоичное представление ле-
вого операнда сдвигается, а освобождающиеся слева разряды
заполняются нулями. Такой сдвиг эквивалентен умножению
значения операнда на 2N .
Сдвиг вправо на N позиций несколько сложнее. Тут следует
отметить две особенности, Первое - это исчезновение младших
разрядов, выходящих за разрядную сетку. Вторая особенность -
отсутствие стандарта на правило заполнения освобождающихся
левых разрядов. В стандарте языка сказано, что когда левый
операнд есть целое значение с отрицательным знаком, то при
сдвиге вправо заполнение освобождающихся левых разрядов
определяется реализацией. Здесь возможны два варианта: осво-
бождающиеся разряды заполняются значениями знакового раз-
ряда (арифметический сдвиг вправо) или освобождающиеся
слева разряды заполняются нулями (логический сдвиг вправо).
Прй положительном левом операнде сдвиг вправо на N пози-
ций эквивалентен уменьшению значения левого операнда в 2N
Глава 1. Базовые понятия языка
61
раз с отбрасыванием дробной части результата. (Поэтому 5»2
равно 1.)
Операция "поразрядное исключающее ИЛИ". Эта операция
имеет очень интересные возможности. Она применима к целым
операндам. Результат формируется при поразрядной обработке
битовых кодов операндов. В тех разрядах, где оба операнда
имеют одинаковые двоичные значения (1 и 1 или 0 и 0), резуль-
тат принимает значение 0. В тех разрядах, где биты операндов
не совпадают, результат равен 1. Пример использования:
char а=’А'; /* внутренний код 01000001 */
char z= * Z'; /* внутренний код 01011010 */
а=аЛ z; /* результат: 00011011 */
z=aA z; /* результат: 01000001 */
а=ал z; /* результат: 01011010 */
Переменные a и z "обменялись" значениями без использова.
ния вспомогательной переменной!
Поразрядная дизъюнкция (поразрядное ИЛИ) применима к
целочисленным операндам. В соответствии с названием она по-
зволяет получить 1 в тех разрядах результата, где не одновре-
менно равны 0 биты обоих операндов. Например:
5 |6 равно 7 (для 5-код 101, для 6-код НО);
10 | 8 равно 10 (для 10-код 1010, для 8-код 1000).
Поразрядная конъюнкция (поразрядное И) применима к це-
лочисленным операндам. В битовом представлении результата
только те биты равны 1, которым соответствуют единичные би-
ты обоих операндов. Примеры:
5&6 равно 4 (для 5-код 101, для 6 - код ПО);
10&8 равно 8 (для 10 - код 1010, для 8 - код 1000).
Условное выражение. Как уже говорилось в §1.4, операция,
вводимая двумя лексемами '?' и':' (она имеет ранг 13), является
уникальной. Во-первых, в нее входит не одна, а две лексемы, во-
вторых, она трехместная, т.е. должна иметь три операнда. С ее
помощью формируется условное выражение, имеющее такой
вид:
62
Программирование на языке Си
операнд ! ? операнд_2: операндЗ
Все три операнда - выражения. Операнд ! - это арифмети-
ческое выражение и чаще всего - отношение либо логическое
выражение. Типы операнда_2 и операндаЗ могут быть разны-
ми (но они должны быть одного типа или должны автоматиче-
ски приводиться к одному типу).
Первый операнд является условием, в зависимости от кото-
рого вычисляется значение выражения в целом. Если значение
первого операнда отлично от нуля (условие истинно), то вычис-
ляется значение операнда_2, и оно становится результатом.
Если значение первого операнда равно 0 (т.е. условие ложно),
то вычисляется значение операнда З, и оно становится резуль-
татом.
Примеры применения условного выражения мы уже приво-
дили в § 1.4.
Глава 2
ВВЕДЕНИЕ
В ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ Си
2.1. Структура и компоненты
простой программы
В первой главе мы рассмотрели лексемы языка, способы оп-
ределения констант и переменных, правила записи и вычисле-
ния выражений. Несколько слов было сказано об операции
присваивания, об операторе присваивания и о том, что каждое
выражение превращается в оператор, если в конце выражения
находится разделитель "точка с запятой". В этой главе перейдем
собственно к программированию, т.е. рассмотрим операторы,
введем элементарные средства ввода-вывода, опишем структуру
однофайловой программы и на несложных примерах вычисли-
тельного характера продемонстрируем особенности программи-
рования на языке Си.
Текст программы и препроцессор. Каждая программа на
языке Си есть последовательность препроцессорных директив,
описаний и определений глобальных объектов и функций. Пре-
процессорные директивы (в гл. 1 мы рассмотрели директивы
#include и #define) управляют преобразованием текста прог-
раммы до ее компиляции. Определения вводят функции и объ-
екты. Объекты необходимы для представления в программе об-
рабатываемых данных. Функции определяют потенциально
возможные действия программы. Описания уведомляют компи-
лятор о свойствах и именах тех объектов и функций, которые
определены в других частях программы (например, ниже по ее
тексту или в другом файле).
Программа на языке Си должна быть оформлена в виде од-
ного или нескольких текстовых файлов. Текстовый файл разбит
на строки. В конце каждой строки есть признак ее окончания
(плюс управляющий символ перехода к началу новой строки).
Просматривая текстовый файл на экране дисплея, мы видим по
64
Программирование на языке Си
следовательность строк, причем признаки окончания строк не-
видимы, но по ним производится разбивка текста редактором.
Определения и описания программы на языке Си могут раз-
мещаться в строках текстового файла достаточно произвольно
(в свободном формате.) Для препроцессорных директив суще-
ствуют ограничения. Во-первых, препроцессорная директива
обычно размещается в одной строке, т.е. признаком ее оконча-
ния является признак конца строки текста программы. Во-
вторых, символ вводящий каждую директиву препроцессора,
должен быть первым отличным от пробела символом в строке с
препроцессорной директивой.
Подробному изучению возможностей препроцессора и всех
его директив будет посвящена глава 3. Сейчас достаточно рас-
смотреть только основные принципы работы препроцессора и
изложить общую схему подготовки исполняемого модуля про-
граммы, написанной на языке Си. Исходная программа, подго-
товленная на языке Си в виде текстового файла, проходит три
обязательных этапа обработки (рис. 2.1):
• препроцессорное преобразование текста;
• компиляция;
• компоновка (редактирование связей или сборка).
Только после успешного завершения всех перечисленных
этапов формируется исполняемый машинный код программы.
Задача препроцессора - преобразование текста программы
до ее компиляции. Правила препроцессорной обработки опре-
деляет программист с помощью директив препроцессора. Каж-
дая препроцессорная директива начинается с символа В этой
главе нам будет достаточно двух директив: #include и ^define.
Препроцессор "сканирует" исходный текст программы в по-
иске строк, начинающихся с символа Такие строки воспри-
нимаются препроцессором как команды (директивы), которые
определяют действия по преобразованию текста. #define указы-
вает правила замены в тексте. Простые примеры использования
этой директивы для задания именованных констант были при-
ведены в § 1.3. Директива #include определяет, какие текстовые
файлы нужно включить в этом месте текста программы.
Глава 2. Введение в программирование на языке Си
65
Рис. 2.1. Схема подготовки исполняемой программы
Директива #include <...> предназначена для включения в
текст программы текста файла из каталога "заголовочных фай-
лов", поставляемых вместе со стандартными библиотеками
компилятора. Каждая библиотечная функция, определенная
стандартом языка Си, имеет соответствующее описание
(прототип библиотечной функции плюс определения типов, пе-
ременных, макроопределений и констант) в одном из заголо-
вочных файлов. Список заголовочных файлов для стандартных
библиотек определен стандартом языка.
Важно понимать, что употребление в программе препроцес-
сррной директивы
5-3124
66
Программирование на языке Си
#include < имя заголовочного файла >
не подключает к программе соответствующую стандартную
библиотеку. Препроцессорная обработка выполняется на уровне
исходного текста программы. Директива #include только позво-
ляет вставить в текст программы описания из указанного заго-
ловочного файла. Подключение к программе кодов библио-
течных функций (см. рис. 2.1) осуществляется только на этапе
редактирования связей (этап компоновки), т.е. после компиля-
ции, когда уже получен машинный код программы. Доступ к
кодам библиотечных функций нужен только на этапе компо-
новки. Именно поэтому компилировать программу и устранять
синтаксические ошибки в ее тексте можно без стандартной биб-
лиотеки, но обязательно с заголовочными файлами.
Здесь следует отметить еще одну важную особенность. Хотя
в заголовочных файлах содержатся описания всех стандартных
функций, в код программы включаются только те функции, ко-
торые используются в программе. Выбор нужных функций вы-
полняет компоновщик на этапе, называемом "редактирование
связей".
Термин "заголовочный файл" (header file) в применении к
файлам, содержащим описания библиотечных функций стан-
дартных библиотек, не случаен. Он предполагает включение
этих файлов именно в начало программы. Мы Настоятельно ре-
комендуем, чтобы до обращения к любой функции она была
определена или описана в том же файле, где помещен текст
программы. Описание или определения функций должны быть
"выше" по тексту, чем вызовы функций. Именно поэтому заго-
ловочные файлы нужно помещать в начале текста программы,
т.е. заведомо раньше обращений к соответствующим библио-
течным функциям.
Хотя заголовочный файл может быть включен в програм-
му не в ее начале, а непосредственно перед обращением к нуж-
ной библиотечной функции, такое размещение директив
#include <...> не рекомендуется.
Структура программы. После выполнения препроцессор-
ной обработки в тексте программы не остается ни одной пре-
Глава 2. Введение в программирование на языке Си
67
процессорной директивы. Теперь программа представляет со-
бой набор описаний и определений. Если не рассматривать (в
этой главе) определений глобальных объектов и описаний, то
программа будет набором определений функций.
Среди этих функций всегда должна присутствовать функция
с фиксированным именем main. Именно эта функция является
главной функцией программы, без которой программа не может
быть выполнена. Имя этой главной функции для всех программ
одинаково (всегда main) и не может выбираться произвольно.
Таким образом, исходный текст программы в простом случае
(когда программа состоит только из одной функции) имеет та-
кой вид:
директивы препроцессора
void main()
{
определенияобъектов;
исполняемые операторы;
}
Две директивы препроцессора #define и #include мы уже
ввели. Для целей этой главы их вполне достаточно. Напомним
только, что директивы препроцессора могут размещаться не
только в начале программы. Они при необходимости могут
быть помещены в любом месте текста программы. Однако заго-
ловочные файлы, с которыми всегда приходится иметь дело,
рекомендуется помещать в начале текста программы. Именно
эта особенность отмечена в предложенном формате программы.
Теперь можно писать несложные программы на языке Си.
Перед именем каждой функции программы следует поме-
щать сведения о типе возвращаемого функцией значения (тип
результата). Если функция ничего не возвращает, то указывает-
ся тип void. Функция main() является той функцией програм-
мы, которая запускается на исполнение по командам
операционной системы. Возвращаемое функцией main() значе-
ние также передается операционный системе. Если программист
не предполагает, что операционная система будет анализиро-
5*
68
Программирование на языке Си
вать результат выполнения его программы, то проще всего ука-
зать, что возвращаемое значение отсутствует, т.е. имеет тип
void. Если сведения о типе результата отсутствуют, то считается
по умолчанию, что функция main возвращает целочисленное
значение типа int.
Каждая функция (в том числе и main) в языке Си должна
иметь набор параметров. Этот набор может быть пустым, тогда
в скобках после имени функции помещается служебное слово
void либо скобки остаются пустыми. В отличие от обычных
функций главная функция main() может использоваться как с
параметрами, так и без них. Состав списка параметров функции
main() и их назначение будут рассмотрены в главе 5. Сейчас
только отметим, что параметры функции main() позволяют ор-
ганизовать передачу данных из среды выполнения в исполняе-
мую программу, минуя средства, предоставляемые стандартной
библиотекой ввода-вывода.
Вслед за заголовком void main() размещается тело функции.
Тело функции - это блок, последовательность определений,
описаний и исполняемых операторов, заключенная в фигурные
скобки. Определения и описания в блоке будем размещать до
исполняемых операторов. Каждое определение, описание и ка-
ждый оператор завершается символом (точка с запятой).
Определения вводят объекты, необходимые для представле-
ния в программе обрабатываемых данных. Примером таких
объектов служат именованные константы и переменные разных
типов. Описания уведомляют компилятор о свойствах и именах
объектов и функций, определенных в других частях программы.
Операторы определяют действия программы на каждом шаге ее
выполнения.
Чтобы привести пример простейшей осмысленной програм-
мы на языке Си, необходимо ввести оператор, обеспечивающий
вывод данных из ЭВМ, например на экран дисплея. К сожале-
нию (или как особенность языка), такого оператора в языке Си
НЕТ! Все возможности обмена данными с внешним миром про-
грамма на языке Си реализует с помощью библиотечных функ-
ций ввода-вывода.
Глава 2. Введение в программирование на языке Си
69
Для подключения к программе описаний средств ввода-
вывода из стандартной библиотеки компилятора используется
директива #include <stdio.h>.
Название заголовочного файла stdio.h является аббревиату-
рой: std - standard (стандартный), i - input (ввод), о - output
(вывод), h - head (заголовок).
Функция форматированного вывода. Достаточно часто
для вывода информации из ЭВМ в программах используется
функция printf( ). Она переводит данные из внутреннего кода в
символьное представление и выводит полученные изображения
символов результатов на экран дисплея. При этом у программи-
ста имеется возможность форматировать данные, т.е. влиять на
их представление на экране дисплея.
Возможность форматирования условно отмечена в самом
имени функции с помощью литеры f в конце ее названия (print
formatted).
Оператор вызова функции printf( ) можно представить так:
printf (форматнаястрока, список аргументов)',
Форматная строка ограничена двойными кавычками (см.
строковые константы, §1.2) и может включать произвольный
текст, управляющие символы и спецификации преобразования
данных. Список аргументов (с предшествующей запятой) мо-
жет отсутствовать. Именно такой вариант использован в клас-
сической первой программе на языке Си [1, 2]: .
#include <stdio.h>
void main( )
(
printf ("\n Здравствуй, Мир!\п");
1
Директива #include <stdio.h> включает в текст программы
описание (прототип) библиотечной функции printf(). (Если
удалить из текста программы эту препроцессорную директиву,
то появятся сообщения об ошибках и исполнимый код про-
граммы не будет создан. Среди параметров функции printf()
есть в этом примере только форматная строка (список аргумен-
70
Программирование на языке Си
тов отсутствует). В форматной строке два управляющих симво-
ла '\п' - "перевод строки". Между ними текст, который выво-
дится на экран дисплея:
Здравствуй, Мир!
Первый символ '\п' обеспечивает вывод этой фразы с начала
новой строки. Второй управляющий символ '\п' переведет кур-
сор к началу следующей строки, где и начнется вывод других
сообщений (не связанных с программой) на экран дисплея.
Итак, произвольный текст (не спецификации преобразования
и не управляющие символы) непосредственно без изменений
выводится на экран. Управляющие символы (перевод строки,
табуляция и т.д.) позволяют влиять на размещение выводимой
информации на экране дисплея.
Спецификации преобразования данных предназначены для
управления формой внешнего представления значений аргумен-
тов функции printff). Обобщенный формат спецификации пре-
образования имеет вид: %флажки ширина_поля.точность
модификатор спецификатор
Среди элементов спецификации преобразования обязатель-
ными являются только два - символ '% ' и спецификатор.
В задачах вычислительного характера этой главы будем ис-
пользовать спецификаторы:
d - для целых десятичных чисел (тип int);
и - для целых десятичных чисел без знака (тип unsigned);
f - для вещественных чисел в форме с фиксированной точкой
(типы float и double);
е - для вещественных чисел в форме с плавающей точкой (с
мантиссой и порядком) - для типов double и float.
В список аргументов функции printf() включают объекты,
значения которых должны быть выведены из программы. Это
выражения и их частные случаи - переменные и константы. Ко-
личество аргументов и их типы должны соответствовать после-
довательности спецификаций преобразования в форматной
строке. Например, если вещественная переменная summa имеет
значение 2102.3, то при таком вызове функции
Глава 2. Введение в программирование на языке Си
71
printf("\n summa=%f", summa);
на экран с новой строки будет выведено:
summa=2102.3
После выполнения операторов
float с, е;
int к;
с=48.3; к=-83; е=1б.ЗЗ;
printf ("\nc=%f\tk=%d\te=%e", с, к, е);
на экране получится такая строка:
0=48.299999 к=-83 е=1.б3300е+01
Здесь обратите внимание на управляющий символ ’\t*
(табуляция). С его помощью выводимые значения в строке ре-
зультата отделены друг от друга.
Для вывода числовых значений в спецификации преобразо-
вания весьма полезны "ширинаполя" и "точность".
Ширина_поля - целое положительное число, определяющее
длину (в позициях на экране) представления выводимого значе-
ния.
Точность - целое положительное число, определяющее ко-
личество цифр в дробной части внешнего представления веще-
ственного числа (с фиксированной точкой) или его мантиссы
(при использовании формы с плавающей точкой).
Пример с теми же переменными:
printf ("\nc=%5.2\tk=%5d\te=%8.2f\te=%ll.4е", с,
к, е, е);
Результат на экране:
с=48.30 к= -83 е= 16.33 е= 1.6330е+01
В качестве модификаторов в спецификации преобразования
используются символы:
h - для вывода значений типа short int;
1 - для вывода значений типа long;
L - для вывода значений типа long double.
72
Программирование на языке Си
Примеры на использование модификаторов здесь приводить
не будем, но они нам понадобятся в следующей программе, где
будут продемонстрированы их возможности.
Хотя в разделе, посвященном символам и строковым кон-
стантам (§1.2),упоминалось о возможностях записи управляю-
щих последовательностей и эскейп-последовательностей внутри
строк, остановимся еще раз на этом вопросе в связи с формат-
ной строкой. При необходимости вывести на экран (на печать)
парные кавычки или апострофы их представляют с помощью
соответствующих последовательностей: \" или V, т.е. заменяют
парами литер. Обратная косая черта 'V для однократного вывода
на экран должна быть дважды включена в форматную строку.
При необходимости вывести символ % его в форматную
строку включают дважды: % %.
Программы печати предельных констант. Введенных
средств препроцессора и языка вполне достаточно для програм-
мы, выводящей на печать (на экран дисплея) значения констант,
определяющие в конкретной системе (для конкретного компи-
лятора) пределы изменения данных разных типов. Таблица
стандартных обозначений предельных констант есть в Прило-
жении 2. В главе 1 (§1.3) приведены некоторые из них. Там же,
говоря об именованных константах, мы отметили, что среди
стандартных заголовочных файлов компилятора всегда есть
файлы limits.h и float.h, включающие препроцессорное опре-
деление предельных констант. Следующая программа печатает
некоторые из значений предельных констант для целых ти-
пов, определенных конкретной реализацией компилятора с
языка Си.
#include <stdio.h>
#include <limits.h> /* Определение предельных
целочисленных констант*/
void main( )
{ printf("\nCHAR_BIT=%d", CHAR_BIT);
printf("\nSCHAR_MIN=%d\t\tSCHAR_MAX=%d",
SCHAR_MIN, SCHAR_MAX);
printf("\nUCHAR_MAX=%d", UCHAR_MAX);
printf("\nINT_MIN=%d\t\tINT_MAX=%d", INT_MIN,
Глава 2. Введение в программирование на языке Си
73
INT_MAX);
printf("\nLONG_MIN=%ld\tLONG_MAX=%ld",
LONG-MIN, LONG_MAX);
)
Результат выполнения программы с компилятором Turbo С:
CHAR_BIT=8
SCHAR_MIN=-128
UCHAR_MAX=255
INT—MIN=-32768
LONG—MIN=-214 74 83 648
SCHAR_MAX=127
INT—MAX=32767
LONG—MAX=2147483647
В вызовах функции printf() нужно обратить внимание на
спецификации преобразования. Все константы целочисленные,
поэтому используется спецификатор'd*. Для величин типа long
потребовался модификатор 'Г, т.е. константы LONG_MIN и
LONG_MAX выводятся с использованием спецификаций пре-
образования %ld. Во всех спецификациях преобразования от-
сутствуют сведения о длине изображения выводимых значений.
Количество позиций в изображениях констант зависит от их
значений. Управляющие последовательности '\п* и V обеспе-
чивают при выводе соответственно переходы на новые строки и
табуляцию.
Для вывода вещественных значений с мантиссой и порядком
в форматной строке функции printf() нужно использовать спе-
цификацию %е. Следующая программа выводит на экран зна-
чения некоторых из предельных вещественных констант:
finclude <stdio.h>
#include <float.h> /* Определение предельных
вещественных констант*/
void main( )
{
printf("\nFLT_EPSILON=%e", FLT_EPSILON);
printf("\nDBL_EPSILON=%e", DBL_EPSILON);
printf("\nFLT_MIN=%e\tFLT_MAX=%e", FLT_MIN,
FLT-MAX);
printf("\n \t \t \tDBL_MAX=%e", DBL—MAX);
printf("\nFLT_MANT_DIG=%d", FLT_MANT_DIG);
printf("\nDBL_MANT_DIG=%d", DBL_MANT_DIG);
)
74
Программирование на языке Си
Результаты выполнения программы с компилятором Turbo С:
FLT_EPSILON=1.1920936-07
DBL_EPSILON=2.220446е-16
FLT_MIN=1.1754946-38 FLT_MAX=3.402823е+38
DBL_MAX=1.797б93е+308
FLT_MANT_DIG=2 4
DBL_MANT_DIG=53
Отметим применение символа табуляции ’\t* для размещения
информации, выводимой на дисплей. Больше в использовании
функции printf(), кроме спецификации %е, ничего нового нет.
Стоит пояснить смысл напечатанных констант. FLT_EPSILON
и DBL_EPSILON - максимальные значения типов float и
double, сумма каждого из которых со значением 1.0 не отли-
чается от 1.0. Предельные константы FLT_EPSILON , и
DBLEPSILON называют "машинными нулями" относительно
вещественного значения 1.0. FLT_MIN, FLT_MAX и
DBL_MAX - предельные значения для вещественных данных.
FLT_MANT_DIG, DBL_MANT_DIG - количество двоич-
ных цифр (бит) в мантиссах соответственно чисел типа
float и double.
Применимость вещественных данных. Даже познакомив-
шись с различиями в диапазонах представления вещественных
чисел, начинающий программист не сразу осознает различия
между типами float, double и long double. Сразу бросается в
глаза разное количество байтов, отводимых в памяти для веще-
ственных данных перечисленных типов. На IBM PC:
• для float - 4 байта;
• для double - 8 байт;
• для long double - 10 байт.
Обратив внимание на значения предельных констант, отме-
чают (см. Приложение 2), что максимальные значения, которые
можно представить вещественными числами, определены кон-
стантами:
FLT_MAX приблизительно равно 1Е+37 (для float);
DBL_MAX приблизительно равно 1Е+308 (для double).
Глава 2. Введение в программирование на языке Си
75
Затем обращают внимание на количество верных десятичных
цифр в мантиссах:
FLTJDIG равно 6 (для float);
DBL_DIG равно 10 (для double).
Наконец, оценят минимальные нормализованные числа:
FLTMIN приблизительно равно 1Е-37 (для float);
DBLMIN приблизительно равно 1Е-308 (для double).
Можно и дальше продолжать сравнение констант, перечис-
ленных в описании языка (см. Приложение 2), но нужно сделать
выводы относительно применимости вещественных констант и
переменных разных типов. По умолчанию все константы, не
относящиеся к целым типам, принимают тип double. У про-
граммиста это соглашение часто вызывает недоумение - а не
лучше ли всегда работать с вещественными данными типа float
и только при необходимости переходить к double или long
double? Ведь значения больше 1Е+38 и меньше 1Е-38 встреча-
ются довольно редко.
Следующая программа (предложена С.М.Лавреновым) ил-
люстрирует опасности, связанные с применением данных типа
float даже в несложных арифметических выражениях:
finclude <stdio.h>
void main( )
{
float a, b, c, tl, t2, t3;
a=95.0;
b=0.02;
tl= (a+b) * (a+b) ;
t2=-2.0*a*b-a*a;
t3=b*b;
c=(tl+t2)/t3;
printf("\nc=%f\n", c) ;
1
Результат выполнения программы:
с=2.44140б
Если в той же программе переменной а присвоить значение
100.0, то результат будет еще хуже:
76
Программирование на языке Си
с=0.000000.
Таким образом, запрограммированное с использованием пе-
ременных типа float несложное алгебраическое выражение
(a+b)2 - (а2 + 2аЬ)
Р
никак "не хочет" вычисляться и принимать свое явное теорети-
ческое единичное значение.
Если заменить в программе только одну строку, т.е. так оп-
ределить переменные:
double a, b, с, tl, t2, t3;
значение выражения вычисляется совершенно точно:
с=1.000000
Приведенный пример и общие положения вычислительной
математики заставляют существенно ограничить применение
переменных типа float. Тип float можно выбирать для представ-
ления исходных данных или окончательных результатов, полу-
чаемых в программе. Однако применение данных типа float в
промежуточных вычислениях (особенно в итерационных алго-
ритмах) следует ограничить и всегда использовать double либо
long double.
К сожалению, ни double, ни long double не снимают полно-
стью проблем конечной точности представления вещественных
чисел в памяти ЭВМ. Существенное различие в порядках значе-
ний операндов арифметических выражений может привести к
подобным некорректным результатам и при использовании
типов double и long double.
Выделение лексем из текста программы. В главе 1 мы
ввели понятие лексемы, перечислили их группы (идентифика-
торы, знаки операций и т’д.) и определили состав каждой из
групп лексем. Первая задача, которую решает компилятор, - это
лексический анализ текста программы. В результате лексиче-
ского анализа из сплошного текста выделяются лекси-
Глава 2. Введение в программирование на языке Си
77
ческие единицы (лексемы). Программисту полезно знать, каки-
ми правилами при этом руководствуется компилятор.
Компилятор просматривает символы (литеры) текста про-
граммы слева направо. При этом его первая задача - выделить
лексемы языка. За очередную лексическую единицу принимает-
ся наибольшая последовательность литер, которая образует
лексему. Таким образом, из последовательности intjine компи-
лятор не станет выделять как лексему служебное слово int, а
воспримет всю последовательность как введенный пользовате-
лем идентификатор.
В соответствии с тем же принципом выражение d+++b трак-
туется как d++ +b, а выражение Ь-->с эквивалентно (Ь—)>с.
Следующая программа иллюстрирует сказанное:
#include <stdio.h>
void main()
{ int n=10,m=2;
printf("\nn+++m=%d",n+++m);
printf("\nn=%d, m=%d",n,m);
printf ("\nnf—>n=%d",m—>n) ;
printf("\nn=%d, m=%d",n,m);
printf("\nn—>m=%d",n—>m);
printf("\nn=%d, m=%d",n,m);
)
Результат выполнения программы:
n+++m=12
n=ll,m=2
m—>n=0
n=ll,m=l
n—>m=l
n=10,m=l <
Результаты вычисления выражений n+++m, n—>m, m—>n
полностью соответствуют правилам интерпретации выражений
на основе таблицы рангов операций (см. табл. 1.4). Унарные
операции ++ и — имеют ранг 2. Аддитивные операции + и -
имеют ранг 4. Операции отношений имеют ранг 6.
78
Программирование на языке Си
2.2. Элементарные средства программирования
Деление операторов языка Си на группы. Если вспомнить
вопросы, перечисленные в начале главы 1, то окажется, что мы
уже получили ответы на многие из них. Введен алфавит языка и
его лексемы; приведены основные типы данных, константы и
переменные; определены все операции; рассмотрены правила
построения арифметических выражений, отношений и логиче-
ских выражений; описана структура программы; рассмотрены
средства вывода из ЭВМ арифметических значений с помощью
функции printf( ); определен оператор присваивания.
В этом и следующих параграфах второй главы мы ответим на
остальные вопросы, сформулированные в главе 1, и этого будет
достаточно, чтобы писать на языке Си программы для решения
задач вычислительного характера.
Вернемся вновь к структуре простой программы, состоящей
только из одной функции с именем main().
директивы препроцессора
void main()
{ определения объектов;
исполняемые операторы;
Как мы уже договорились, пока нам будет достаточно двух
препроцессорных директив //include <...> и //define. В качестве
определяемых объектов будем вводить переменные и константы
базовых типов. А вот об исполняемых операторах в теле функ-
ции нужно говорить подробно.
Каждый исполняемый оператор определяет действия про-
граммы на очередном шаге ее выполнения. У оператора (в от-
личие от выражения) нет значения. По характеру действий раз-
личают два типа операторов: операторы преобразования данных
и операторы управления работой программы.
Наиболее типичные операторы преобразования данных -
операторы присваивания и произвольные выражения, завер-
шенные символом "точка с запятой":
Глава 2. Введение в программирование на языке Си
79
i++; /*Арифметическое выражение - оператор*/
x*=i; /*Оператор составного присваивания*/
i=x-4*i; /*Оператор простого присваивания*/
Так как вызов функции является выражением с операцией
"круглые скобки" и операндами "имя функции", "список факти-
ческих параметров", к операторам преобразования данных мож-
но отнести и оператор вызова или обращения к функции:
ггияфунющы (список фактических-Параметров);
Мы уже использовали обращение к библиотечной функции
printf(), параметры которой определяли состав и представление
на экране дисплея выводимой из программы информации. С
точки зрения процесса преобразования информации функция
printf() выполняет действия по перекодированию данных из их
внутреннего представления в последовательность кодов, при-
годных для вывода на экран дисплея.
Операторы управления работой программы называют управ-
ляющими конструкциями программы. К ним относятся:
• составные операторы;
• операторы выбора;
• операторы циклов;
• операторы перехода.
К составным операторам относят собственно составные опе-
раторы и блоки. В обоих случаях это последовательность опера-
торов, заключенная в фигурные скобки. Отличие блока от
составного оператора - наличие определений в теле блока. На-
пример, приведенный ниже фрагмент программы - составной
оператор:
{
п++;
summa+=(float)n;
)
а этот фрагмент - блок:
{
int п=0;
п++;
80
Программирование на языке Си
summa+=(float)n;
)
Наиболее часто блок употребляется в качестве тела функции.
Операторы выбора - это условный оператор (if) и переклю-
чатель (switch).
Операторы циклов в языке Си трех видов - с предусловием
(while), с постусловием (do) и параметрический (for).
Операторы перехода выполняют безусловную передачу
управления: goto (безусловный переход), continue (завершение
текущей итерации цикла), break (выход из цикла или переклю-
чателя), return (возврат из функции).
Перечислив операторы управления программой, перейдем к
подробному рассмотрению тех из них, которых будет достаточ-
но для программирования простейших алгоритмов.
Условный оператор имеет сокращенную форму:
if (выражение _условие) оператор;
где в качестве выражения_условия могут использоваться:
арифметическое выражение, отношение и логическое выраже-
ние. Оператор, включенный в условный, выполняется только в
случае истинности (т.е. при ненулевом значении) выраже-
ния_условия. Пример:
if (х < 0 && х > -10) х=-х:
Кроме сокращенной формы, имеется еще и полная форма ус-
ловного оператора:
if (выражение-условие)
оператор I;
else
оператор_2;
Здесь в случае истинности выражения-условия выполняется
только оператор_1, при нулевом значении выражения-условия
выполняется только оператор_2. Например:
if (х > 0)
Ь=Х ;
else
Ь=-х;
Глава 2. Введение в программирование на языке Си
81
Оператор в сокращенном варианте оператора if, и опера-
тор_1 и оператор_2 в полном операторе if могут быть как от-
дельными, так и составными операторами.
Несмотря на традиционность условного оператора, проиллю-
стрируем его выполнение схемами (рис. 2.2).
Итак, что в условных операторах в качестве любого из опе-
раторов (после условия или после else) может использоваться
Рис. 2.2. Схемы условных операторов (выражение-условие - условие после if):
а - сокращенная форма; б - полная форма
составной оператор. Например, при решении алгебраического
уравнения 2-й степени ах2+Ьх+с=0 действительные корни име-
ются только в случае, если дискриминант (Ь2-4ас) неотрицате-
лен. Следующий фрагмент программы иллюстрирует
использование условного оператора при определении действи-
тельных корней хь х2 квадратного уравнения:
d=b*b - 4*а*с; /* d - дискриминант */
if (d>=0.0)
{ '
xl=(-b+sqrt(d))/2/а;
х2=(-b-sqrt(d))/2/а;
6-3124
82
Программирование на языке Си
printf("\п Корни: xl=%e, х2=%е", х1, х2) ;
}
else
printf("\п Действительные корни отсутствуют.");
Во фрагменте предполагается, что переменные d, b, a, xl, х2
- вещественные (типа float либо double). До приведенных опе-
раторов переменные а, Ь, с получили конкретные значения, для
которых выполняются вычисления. В условном операторе после
if находится составной оператор, после else - только один опе-
ратор - вызов функции printf(). При вычислении корней ис-
пользуется библиотечная функция sqrt() из стандартной
библиотеки компилятора. Ее прототип находится в заголовоч-
ном файле math.h (см. Приложение 3).
Метки и пустой оператор. Метка - это идентификатор, по-
мещаемый слева от оператора и отделенный от него двоеточием
Например,
СОН: Х+=-8;
Чтобы можно было поставить метку в любом месте про-
граммы (или задать пустое тело цикла), в язык Си введен пустой
оператор, изображаемый только одним символом Таким об-
разом, можно записать такой помеченный пустой оператор:
МЕТКА:;
Оператор перехода. Оператор безусловного перехода имеет
следующий вид:
goto идентификатор;
где идентификатор - одна из меток программы. Например:
goto СОН; или goto МЕТКА;
Введенных средств языка Си вполне достаточно для написа-
ния примитивных программ, которые не требуют ввода исход-
ных данных. Алгоритмы такого сорта достаточно редко
применяются, но для иллюстрации некоторых особенностей
разработки и выполнения программ рассмотрим следующую
задачу.
Глава 2. Введение в программирование на языке Си
83
Программа оценки машинного нуля. В вычислительных
задачах при программировании итерационных алгоритмов, за-
вершающихся при достижении заданной точности, часто нужна
оценка "машинного нуля", т.е. числового значения, меньше ко-
торого невозможно задавать точность данного алгоритма. Абсо-
лютное значение "машинного нуля" зависит от разрядной сетки
применяемой ЭВМ, от принятой в конкретном трансляторе точ-
ности представления вещественных чисел и от значений, ис-
пользуемых для оценки точности. Следующая программа
оценивает абсолютное значение "машинного нуля" относитель-
но близких (по модулю) к единице переменных типа float:
1
2
3
4
5
б
7
8
9
10
11
12
13
14
/* Оценка "машинного нуля" */
#include <stdio.h>
void main( )
{ int k; /*k - счетчик итераций*/
float e,el;/*el - вспомогательная переменная*/
е=1.0; /*е - формируемый результат*/
к=0;
М:е=е/2.0;
е1=е+1.0;
к=к+1;
if (el>1.0) goto М;
printf ("\п число делений на 2: %6d\n", к);
printf ("машинный нуль: %е\п", е);
}
В строках программы слева помещены порядковые номера,
которых нет в исходном тексте. Номера добавлены только для
удобства ссылок на операторы. Строка 1 - комментарий с на-
званием программы. Комментарии в строках 4, 5, 6 поясняют
назначение переменных. Объяснить работу программы проще
всего с помощью трассировочной таблицы (табл. 2.1).
Во втором столбце таблицы указаны номера строк с испол-
няемыми операторами. Значения переменных даны после вы-
полнения соответствующего оператора. Только что измененное
значение переменной в таблице выделено. После подготови-
тельных присваиваний (строки 6, 7) циклически выполняются
6*
84
Программирование на языке Си
операторы 8-11 до тех пор, пока истинно отношение е1>1.0,
проверяемое в условном операторе. При каждой итерации зна-
чение переменной е уменьшается вдвое, и, наконец, прибавле-
ние (в строке 9) к 1.0 значения е не изменит результата, т.е. el
станет равно 1.0.
При использовании компилятора Turbo С получен следую-
щий результат:
Число делений на 2: 24
Машинный нуль: 5.960464е-08
При использовании в строке 5 для определения переменных
е, el типа double, т.е. при использовании двойной точности, по-
лучен иной результат:
Число делений на 2: 53
Машинный нуль: 1.110223е-16
Оба результата близки к значениям, приведенным в Прило-
жении 2, для предельных констант FLTEPSILON и
DBL_EPSILON.
Таблица 2.1
Трассировочная таблица
Шаг Номер Значения переменных
выполнения строки е к el
г 6 1.0 - -
2 7 1.0 fl -
3 8 0.5 0 -
4 9 0.5 0 1.5
5 10 0.5 1 1.5
б 11 0.5 1 1.5
7 8 0.25 1 1.5
8 9 0.25 1 L25
9 10 0.25 1 1.25
10 11 0.25 2 1.25
11 8 0.125 2 1.25
Глава 2. Введение в программирование на языке Си
85
Ввод данных. Для ввода данных с клавиатуры ЭВМ в про-
грамме будем использовать функцию (описана в заголовочном
файле stdio.h):
scanf (форматная строка, списокаргументов)',
Функция scanf( ) выполняет "чтение" кодов, вводимых с кла-
виатуры. Это могут быть как коды видимых символов, так и
управляющие коды, поступающие от вспомогательных клавиш
и от их сочетаний. Функция scanf() воспринимает коды, преоб-
разует их во внутренний формат и передает программе. При
этом программист может влиять на правила интерпретации
входных кодов с помощью спецификаций форматной строки.
(Возможность форматирования условно отмечена в названии
функции с помощью литеры f в конце имени.)
И форматная строка, и список аргументов для функции
scanf() обязательны. Форматную строку для функции scanf()
будем формировать из спецификаций преобразования вида:
% * ширина_поля модификатор спецификатор
Среди элементов спецификации преобразования обязательны
только % и спецификатор. Для ввода числовых данных исполь-
зуются спецификаторы:
d - для целых десятичных чисел (тип int);
и - для целых десятичных чисел без знака (тип unsigned int); ч
f - для вещественных чисел (тип float);
е - для вещественных чисел (тип float).
Ширина_поля - целое положительное число, позволяющее
определить, какое количество байтов (символов) из входного
потока соответствует вводимому значению. Этим элементом мы
сейчас не будем пользоваться.
Звездочка в спецификации преобразования позволяет про-
пустить во входном потоке байты соответствующего вводимого
значения. (Сейчас, когда уже забыли о подготовке данных на
перфокартах и перфолентах, звездочка при вводе почти не ис-
пользуется. Она может быть полезной при чтении данных из
файлов, когда нужно пропускать те или иные значения.)
86
Программирование на языке Си
В качестве модификаторов используются символы:
h - для ввода значений типа short int (hd);
1 - для ввода значений типа long int (Id) или double (If, le);
L - для ввода значений типа long double (Lf, Le).
В ближайших программах нам не потребуются ни ни мо-
дификаторы. Информацию о них приводим только для полноты
сведений о спецификациях преобразования данных при вводе.
В отличие от функции printf() аргументами для функции
scanf( ) могут быть только адреса объектов программы, в част-
ном случае - адреса ее переменных. Не расшифровывая понятие
адреса (адресам и указателям будет посвящена гл. 4), напомним,
что в языке Си имеется специальная унарная операция & полу-
чения адреса объекта:
& имяобъекта
Выражение для получения адреса переменной будет таким:
& имя переменной
Итак, для обозначения адреса перед именем переменной за-
писывают символ &. Если name - имя переменной, то &name -
ее адрес.
Например, для ввода с клавиатуры значений переменных n, z,
х можно записать оператор:
scanf ("%d%f%f",Ьп,&z,&х);
В данном примере спецификации преобразования в формат-
ной строке не содержат сведений о размерах полей и точностях
вводимых значений. Это разрешено и очень удобно при вводе
данных, диапазон значений которых определен не строго. Если
переменная п описана как целая, z и х - как вещественные типа
float, то после чтения с клавиатуры последовательности симво-
лов 18 18 -0.431 переменная п получит значение 18, z-
значение 18.0, х-значение -0.431.
При чтении входных данных функция scanf() (в которой
спецификации не содержат сведений о длинах вводимых значе-
ний) воспринимает в качестве разделителей полей данных
"обобщенные пробельные символы" - собственно пробелы,
Глава 2. Введение в программирование на языке Си
87
символы табуляции, символы новых строк. Изображения этих
символов на экране отсутствуют, но у них имеются коды, кото-
рые "умеет" распознавать функция scanf(). При наборе входной
информации на клавиатуре функция scanf() начинает ввод дан-
ных после нажатия клавиши <Enter> (переход на новую строку).
До этого набираемые на клавиатуре символы помещаются в
специально выделенную операционной системой область памя-
ти - в буфер клавиатуры и одновременно отображаются на эк-
ране в виде строки ввода. До нажатия клавиши <Enter>
разрешено редактировать (исправлять) данные, подготовленные
в строке ввода.
Рассмотрим особенности применения функции scanf() для
ввода данных и принципы построения простых программ на ос-
нове следующих несложных задач вычислительного характера.
Вычисление объема цилиндра. В предыдущих задачах не
требовалось вводить исходные данные. После выполнения про-
граммы на экране появлялся результат. Более общий случай -
программа, требующая ввода исходных данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/♦Вычисление объема прямого цилиндра*/
#include <stdio.h>
void main( )
{
double h, r, v;
const float PI = 3.14159;
/*h - высота цилиндра, г -радиус цилиндра*/
/*v - объем цилиндра, PI - число "пи" */
printf("\п Радиус цилиндра г= ;
scanf("%lf", &r);
printf("Высота цилиндра h= "); .
scanf("%lf"r &h);
v = h * PI * r * r;
printf("Объем цилиндра: %10.4f" ,v) ;
}
В тексте программы несколько особенностей. Определена
константа PI, т.е. со значением 3.14159 связано имя PI, которое
до конца выполнения программы будет именовать только это
значение.
88
Программирование на языке Си
Перед каждым вводом помещены (строки 9, И) вызовы
функции printf( ), выводящей на экран запрос-подсказку, вслед
за которой на экране отображается набираемое на клавиатуре
вводимое значение. Функция scanf() считывает только это зна-
чение, как только будет нажата клавиша "Ввод" (Enter), что
воспринимается как признак конца строки ввода. Поэтому оче-
редной вызов функции printf( ) выводит данные на следующую
строку. Обратите внимание на спецификации преобразования
%lf. Если бы переменные h и г имели тип float, то в форматных
строках функций scanf() нужно было бы применять специфи-
кации %f или %е. Текст на экране при выполнении программы
может быть таким:
радиус цилиндра г= 2.0
высота цилиндра h= 4.0
объем цилиндра: 50.2654
Здесь пользователь ввел 2.0 для г и 4.0 для h. Другой вариант:
радиус цилиндра г= 4.0
высота цилиндра h= 2.0
объем цилиндра: 100.5309
Еще раз обратите внимание на использование в функции
scanf() не имен переменных, а их адресов &r, &h.
Сумма членов ряда Фибоначчи. Ряд Фибоначчи определен,
если известны первые два его члена f,, f2, так как очередной
член fj =f и + fj.2 для i>2. Необходимо вычислить сумму задан-
ного количества (к) первых членов ряда Фибоначчи, если из-
вестны первые два: р = F| и г = F2. Следующая программа
решает эту задачу:
/♦Вычисление суммы членов ряда Фибоначчи*/
2 #include <stdio.h>
3
void main( )
4 {
5
6
7
8 Ml:
int к, i;/*к-число членов; i-номер члена */
float s,p,r,f; /* s - искомая сумма */
/♦Члены: p -первый; г - второй; f - i-й*/
printf("\п Введите число членов ряда к=");
Глава 2. Введение в программирование на языке Си
89
9 scanf("%d",&Jc);
10 if ( Jc > 2 ) goto М2 ;
11 printf ("\n Ошибка! Jc должно быть >2 ! ") ;
12 goto Ml;
13 М2: printf("\n Первый член ряда p=");
14 scanf("%f",&p);
15 printf("\n Второй член ряда r=");
16 scanf("%f",&r);
17 i = 3;
18 s = p + r;
19 M: f = p + r;
20 s = s + f;
21 p = r;
22 r = f;
23 i = i + 1;
24 if ( i <= Jc ) goto M;
25 printf("\n Сумма членов ряда: %10.3f", s);
26 }
Обратите внимание на строки 10-12, где выполняется про-
верка введенного значения к. Программа может правильно ра-
ботать только при к>2, поэтому только в этом случае
выполняется переход из строки 10 к метке М2 (строка 13). В
противном случае печатается сообщение об ошибке (в стро-
ке 11), и после перехода к метке Ml запрашивается новое зна-
чение к. (Для полного понимания работы программы целе-
сообразно составить трассировочную таблицу, выбрав подхо-
дящие значения к, р, г.)
Результат (текст на экране) может быть, например, таким:
Введите число членов ряда Jc=-4
Ошибка! к должно быть > 2 !
Введите число членов ряда к=10
Первый член ряда р=4.О
Второй член ряда г=5.О
Сумма членов ряда: 660.000
Особенность и недостаток программы состоят в том, что она
никогда не закончит вычислений, если не ввести допустимого
значения к>2.
90
Программирование на языке Си
2.3. Операторы цикла
Три формы операторов цикла. Как и в других языках про-
граммирования, в языке Си существуют специальные средства
для организации циклов (операторы циклов), позволяющие уп-
ростить их программирование. В большинстве языков програм-
мирования оператор цикла состоит из двух элементов -
заголовка и тела. Тело включает операторы, выполняемые в
цикле, заголовок организует циклическое выполнение операто-
ров тела. В соответствии с названием заголовок размещается
непосредственно перед телом цикла. В языке Си равноправно
используются три разных оператора цикла, обозначаемых соот-
ветственно служебными словами while, for, do.
Циклы while и for построены по схеме
заголовок цикла
тело_цикла
Цикл do имеет другую структуру - тело цикла как бы обрам-
лено (сверху и снизу) конструкциями, организующими цикли-
ческое выполнение тела. Поэтому говорить о заголовке цикла
do в языке Си, по-видимому, некорректно.
Введем форматы перечисленных операторов цикла и приве-
дем примеры их использования. Предварительно отметим, что
во всех трех операторах цикла тело цикла - это либо отдельный,
либо составной оператор, т.е. последовательность операторов,
заключенная в операторные скобки {}. Тело цикла может быть
и пустым оператором, т.е. изображаться только как
Цикл while (цикл с предусловием) имеет вид:
while {выражение_условие)
телоцикла
В качестве выражения^условия чаще всего используется от-
ношение или логическое выражение. Если оно истинно, т.е. не
равно 0, то тело цикла выполняется до тех пор, пока выраже-
ние_условие не станет ложным.
Глава 2. Введение в программирование на языке Си
91
Обратите внимание, что проверка истинности выражения
осуществляется до каждого выполнения тела цикла (до каждой
итерации). Таким образом, для заведомо ложного выраже-
нияусловия тело цикла не выполнится ни разу. Выраже-
ние условие может быть и арифметическим выражением. В этом
случае цикл выполняется, пока значение выражения_условия не
равно 0.
Цикл do (цикл с постусловием) имеет вид:
do
телоцикла
while (выражениеусловие)-,
Выражениеусловие логическое или арифметическое, как и в
цикле while. В цикле do тело цикла всегда выполняется по
крайней мере один раз. После каждого выполнения тела цикла
проверяется истинность выражения условия (на равенство 0), и
если оно ложно (т.е. равно 0), то цикл заканчивается. В против-
ном случае тело цикла выполняется вновь.
Цикл for (называемый параметрическим) имеет вид:
for (выражение _1; выражение условие; выражение_3)
телоуикла
Первое и третье выражения в операторе for могут состоять
из нескольких выражений, разделенных запятыми. Выраже-
ние! определяет действия, выполняемые до начала цикла, т.е.
задает начальные условия для цикла; чаще всего это выражение
присваивания. Выражение условие - обычно логическое или
арифметическое. Оно определяет условия окончания или про-
должения цикла. Если оно истинно (т.е. не равно 0), то выпол-
няется тело цикла, а затем вычисляется выражение_3.
Выражение_3 обычно задает необходимые для следующей ите-
рации изменения параметров или любых переменных тела цик-
ла. После выполнения выражения З вычисляется истинность
выраженияусловия, и все повторяется... Таким образом, вы-
ражение_1 вычисляется только один раз, а выражение условие
и выражение_3 вычисляются после каждого выполнения тела
Цикла. Цикл продолжается до тех пор, пока не станет ложным
92
Программирование на языке Си
выражениеусловие. Любое из трех, любые два или все три вы-
ражения в операторе for могут отсутствовать, но разделяющие
их символы должны присутствовать всегда. Если отсутствует
выражение условие, то считается, что оно истинно и нужны
специальные средства для выхода из цикла.
Схемы организации циклов while, do и for даны на рис. 2.3.
Проиллюстрируем особенности трех типов цикла на примере
вычисления приближенного значения
2 3 со п
г 1 X X X X
е =1 + — + — + — +...= > —
I! 2! 3!
для заданного значения х. Вычисления будем продолжать до тех
пор, пока очередной член ряда остается больше заданной точно-
сти. Обозначим точность через eps, результат - Ь, очередной
член ряда - г, номер члена ряда - i. Для получения i-ro члена
ряда нужно (i-I)-fi член умножить на х и разделить на i, что по-
зволяет исключить операцию возведения в степень и явное вы-
числение факториала. Опустив определения переменных, опера-
торы ввода и проверки исходных данных, а также вывода ре-
зультатов, запишем три фрагмента программ.
/* Цикл с предусловием */
i = 2;
Ь = 1.0;
г = х;
while( г > eps || г < -eps )
{
b=b+r;
r=r*x/i;
}
Так как проверка точности проводится до выполнения тела
цикла, то для окончания цикла абсолютное значение очередного
члена должно быть меньше или равно заданной точности.
/* Цикл с постусловием */
i=l ;
Ь=0.О;
Глава 2. Введение в программирование на языке Си
93
в
Рис. 2.3. Схемы организации циклов while, do, for:
а - цикл с предусловием while; б - цикл с постусловием do;
в - параметрический цикл for
94
Программирование на языке Си
г=1.О;
do {
. b=b+r;
r=r*x/i;
}
while( г >= eps I| г <= -eps );
Так как проверка точности осуществляется после выполнения
тела цикла, то условие окончания цикла - абсолютное зна-
чение очередного члена строго меньше заданной точности. Со-
ответствующие изменения внесены и в операторы, выполняе-
мые до цикла.
/* Параметрический цикл */
i=2;
Ь=1.О;
Г=Х ;
for( ; г > eps | | г < -eps ; )
{
b=b+r;
r=r*x/i;
}
Условие окончания параметрического цикла такое же, как и
в цикле while.
Все три цикла записаны по возможности одинаково, чтобы
подчеркнуть сходство циклов. Однако в данном примере цикл
for имеет существенные преимущества. В заголовок цикла (в
качестве выражения !) можно ввести инициализацию всех пе-
ременных:
for ( i=2, b=1.0, r=x; r>eps || r<-eps ; )
{
b=b+r;
r=r*x/i;
}
В выражениеЗ можно включать операцию изменения счет-
чика членов ряда:
Глава 2. Введение в программирование на языке Си
95
for( i=2, Ь=1.0, r=x; r>eps || r<-eps; i++)
{
b=b+r;
г=г*х/i;
}
Можно еще более усложнить заголовок, перенеся в него все
исполнимые операторы тела цикла:
for(i=2, b=1.0, r=x; r>eps || r<-eps;
b+=r, r*=x/i, i++);
В данном случае тело цикла - пустой оператор. Для сокра-
щения выражения_3 в нем использованы составные операции
присваивания и операция ++.
Приближенное значение экспоненты. Приведем полный
текст программы для приближенного вычисления экспоненты:
1 /*Приближенное Значение экспоненты*/
2 #include <stdio.h>
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void main( )
{
int i; /*i - счетчик членов ряда*/
double eps,b=l.0,r,x;/*exp - абс. точность*/
/*Ь-Значение экспоненты; r-очередной член*/
/* х-вводимое Значение показателя экспоненты*/
printf("\п Введите Значение х=") ;
scanf("%lf",£х);
do {
printf("\п Введите точность eps=");
scanf("%lf",£eps);
}
while( eps <= 0.0 );
for( i=2, r=x; r > eps || r < -eps; i++ )
{
b=b+r;
r=r*x/i;
}
printf(” Результат: %f\n”,b);
printf(" Погрешность: %f\n",r);
printf(" Число членов ряда: %d\n",i);
}
96
Программирование на языке Си
В программе переменная b инициализирована (строка 6), т.е.
ей еще в процессе выделения памяти присваивается конкретное
начальное значение (1.0). При вводе значения переменной eps
предусмотрена защита от неверного задания точности (строки
11-5-15), для чего использован цикл do. В соответствии с прави-
лами его работы выполняются операторы из строк 12 и 13, а за-
тем проверяется введенное значение точности. Если значение
eps недопустимо (eps<=0.0), то операторы тела цикла (строки
12, 13) выполняются снова. Цикл не закончится до тех пор, пока
не будет введено допустимое значение точности.
Результаты выполнения программы:
Введите значение х=1
Введите точность ерз=0.01
Результат: 2.708333
Погрешность: 0.008333
Число членов ряда: 6
Другой вариант выполнения программы:
Введите значение х=1
Введите точность ерз=-0.3
Введите точность ерз=0.0001
Результат: 2.718254
Погрешность: 0.000025
Число членов ряда: 9
В последнем варианте вначале введено неверное значение
eps=-Q.3 и ввод пришлось повторить. Отметим, что в качестве
погрешности выводится последнее значение учтенного члена
ряда, что не вполне корректно.
Оператор break. Как видно из предыдущего примера, при-
нятый способ проверки исходных данных с повторным запро-
сом значения точности eps не очень удобен, так как на экране
отсутствует сообщение об ошибке. В примере, рассмотренном в
предыдущем параграфе (сумма членов ряда Фибоначчи), на эк-
ран выводится конкретное указание о сделанной ошибке
("Ошибка! к должно быть > 2 !"), что упрощает ее исправление.
Однако в этом случае в программе использованы метки и опера-
Глава 2. Введение в программирование на языке Си
97
тор перехода, что считается некорректным с точки зрения
структурного программирования.
Добиться такого же результата можно, не нарушая принципов
структурного программирования и применяя оператор цикла,
если использовать в его теле оператор прерывания break. Этот
оператор (рис. 2.4) прекращает выполнение оператора цикла и
передает управление следующему за ним (за циклом) оператору.
Необходимость в использовании оператора прерывания в те-
ле цикла возникает, когда условие продолжения итераций нуж-
но проверять не в начале цикла (как в циклах for и while) и не в
конце тела цикла (как в цикле do), а в середине тела цикла.
Наиболее естественна в этом случае такая структура тела цикла:
{
операторы
if (условие) break;
операторы
}
Рассмотрим пример с использованием оператора прерывания
break в цикле ввода исходных данных.
Сумма отрезка степенного ряда. Введя значения перемен-
п
ных п и g, вычислить сумму с = g' , где п>0. Задачу решает
1=1
следующая программа:
1
2
3
4
5
6
7
8
9
10
11
12
13
/* Сумма степенного ряда */
#iriclude <stdio.h>
void main( )
{
double g,c,p; /* с - сумма, p - член ряда
int i,n;
printf("\n Введите Значение g=u);
scanf("%lf”,£g);
while(1)
{
printf("\n Введите значение n=") ;
scanf(”%d",£n);
if( n > 0 ) break;
*/
7-3124
98
Программирование на языке Си
14 15 16 17 18 19 20 21 22 printf("Ошибка! п должно быть >0! \п") ; } for( с=0.0, р=1.0, i=l; i <= n; i++ ) { p*=g; c+=p ; } printf("\n Сумма c=%f",c); }
Для защиты от неверных исходных данных использован цикл
(строки 9-5-15), в заголовке которого после while записано заве-
домо истинное выражение 1, т.е. цикл может быть прерван
только за счет выполнения операторов его тела. В строке 13
оператор break выполняется в случае истинности условия
"п>0". При этом цикл заканчивается, и следует переход к опера-
тору строки 16. Таким образом, сообщение об ошибке, выводи-
мое функцией printf() из строки 14, печатается для каждого
неположительного значения п.
Вычисляя сумму ряда (строки 16+20), очередной его член
получаем, умножая предыдущий на g (строка 18). Тем самым
устранена необходимость явного возведения в степень. В вы-
ражении! оператора for формируются начальные значения
переменных, изменяемых при выполнении цикла. В строках 18,
19 использованы составные операции присваивания.
Приведем результаты выполнения программы для Turbo С:
Введите значение д=8.8
Введите Значение п=-15
Ошибка! п должно быть >0!
Введите значение п=15
Сумма с=165816655682177404000
Полученное значение суммы довольно трудно прочесть. По-
видимому, в этой задаче следует применять печать результата в
экспоненциальной форме, т.е. в printf() из строки 21 исполь-
зовать спецификацию преобразования %е. При этом получится
такой результат:
Введите значение п=15
Сумма с=1;658167е+14.
Глава 2. Введение в программирование на языке Си
99
Рис. 2.4. Схемы выполнения в циклах операторов break и continue:
а — цикл с предусловием while; 6 - цикл с постусловием do;
в - параметрический цикл for
7’
100
Программирование на языке Си
Оператор continue. Еще одну возможность влиять на вы-
полнение операторов тела цикла обеспечивает оператор перехо-
да к следующей итерации цикла continue (см. рис. 2.4). Как
указано в описании языка Си, "оператор continue противополо-
жен по действию оператору break". Он позволяет в любой точке
тела цикла прервать текущую итерацию и перейти к проверке
условий продолжения цикла, определенных в предложениях for
или while. В соответствии с результатами проверки выполнение
цикла либо заканчивается, либо начинается новая итерация.
Оператор continue удобен, когда от итерации к итерации изме-
няется последовательность выполняемых операторов тела
цикла, т.е. когда тело цикла содержит ветвления. Рассмотрим
пример.
Суммирование положительных чисел. Вводя последова-
тельность чисел, заканчивающуюся нулем, получить сумму и
количество только положительных из них. Следующая про-
грамма решает эту задачу:
#include <stdio.h>
/* Сумма положительных чисел */
void main( )
{
double s,x;/*x - очередное число, s - сумма*/
int k; /*k - количество положительных */
printf("\пВведите последовательность чисел"
" с 0 в конце:\п");
for( х=1.0, s=0.0, k=0; х != 0.0; )
{
scanf("%lf",£х);
if( х <= 0.0 ) continue;
k++; s+=x;
}
printf("\n CyMMa=%f,
количество положительных=%с!",з,к) ;
}
Результат выполнения программы:
Введите последовательность чисел с 0 в конце:
б -3.0 14.0 -5 -4 10 0.0
Сумма=30.000000, количество положительных=3
Глава 2. Введение в программирование на языке Си
101
Недостаток приведенной программы состоит в том, что нет
защиты от неверно введенных данных. Например, не преду-
смотрены действия, когда в последовательности отсутствует
нулевой элемент. Обратите внимание на объединение двух
строк в функции printf().
2.4. Массивы и вложение операторов цикла
Массивы и переменные с индексами. Математическим по-
нятием, которое привело к появлению в языках программирова-
ния понятия "массив", являются матрица и ее частные случаи:
вектор-столбец или вектор-строка. Элементы матриц в матема-
тике принято обозначать с использованием индексов. Сущест-
венно, что все элементы матриц либо вещественные, либо целые
и т.п. Такая "однородность" элементов свойственна и массиву,
определение которого описывает тип элементов, имя массива и
его размерность, т.е. число индексов, необходимое для обозна-
чения конкретного элемента. Кроме того, в определении указы-
вается количество значений, принимаемых каждым индексом.
Например, int а[10]; определяет массив из 10 элементов а[0],
а[1], ..., а[9]. float Z[13][[6]; определяет двумерный массив, пер-
вый индекс которого принимает 13 значений от 0 до 12, второй
индекс принимает 6 значений от 0 до 5. Таким образом, элемен-
ты двумерного массива Z можно перечислить так:
Z[0][0], Z[0][l], Z[0] [2],...,Z[12][4], Z[12][5]
В соответствии с синтаксисом Си в языке существуют только
одномерные массивы, однако элементами одномерного массива,
в свою очередь, могут быть массивы. Поэтому двумерный мас-
сив определяется как массив массивов. Таким образом, в при-
мере определен массив Z из 13 элементов-массивов, каждый из
которых, в свою очередь, состоит из 6 элементов типа float. Об-
ратите внимание, что нумерация элементов любого массива все-
гда начинается с 0, т.е. индекс изменяется от 0 до N-1, где N -
количество значений индекса.
102
Программирование на языке Си
Ограничений на размерность массивов, т.е. на число индек-
сов у его элементов, в языке Си теоретически нет. Стандарт
языка Си требует, чтобы транслятор мог обрабатывать опреде-
ления массивов с размерностью до 31. Однако чаще всего ис-
пользуются одномерные и двумерные массивы. Продемон-
стрируем на простых вычислительных задачах некоторые прие-
мы работы с массивами.
Вычисление среднего и дисперсии. Введя значение п из
диапазона (0<п<=100) и значения п первых элементов массива
х[0], х[1],...,х[п-1], вычислить среднее и оценку дисперсии зна-
чений введенных элементов массива. Задачу решает следующая
программа:
1 /* Вычисление среднего и дисперсии */
2 #include <stdio.h>
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void main ( )
{ /*п - количество элементов */
int i,j,n;/*b-среднее,d-оценка дисперсии; */
float a,b,d,x[100],e; /*а,е-вспомогательные*/
while (1)
{
printf("\n Введите Значение n=");
scanf("%d", £n);
if( n > 0 && n <= 100 ) break;
printf("\n Ошибка? Необходимо 0<n<101 ");
} /* Конец цикла ввода значения п */
printf("\п Введите Значения элементов:\п");
for( b=0.0,i=0; i<n; i++)
{
printf("x[%d] =", i);
scanf("%f", Sx[i]);
b+=x[i];/* Вычисление суммы элементов */
}
b/=n;/* Вычисление среднего */
for(j=0,d=0.0; j<n; j++)
{
a=x[j]-b;
Глава 2. Введение в программирование на языке Си
103
25
26
27
28
29
d+=a*a;
} /* Оценка дисперсии*/
d/=n;
printf("\п Среднее =%f, дисперсия=%£",b,d);
}
В программе определен (строка 6) массив х со 100 элемента-
ми, хотя в каждом конкретном случае используются только пер-
вые п из них. Ввод значения п сопровождается проверкой
допустимости вводимого значения (строки 7ч-13). В качестве
условия после while записано заведомо истинное выражение 1,
поэтому выход из цикла (оператор break) возможен только при
вводе правильного значения п, удовлетворяющего неравенству
0<п<101. Следующий цикл (строки 15-5-20) обеспечивает ввод п
элементов массива и получение их суммы (Ь). Затем в цикле
(строки 22-5-26) вычисляется сумма d квадратов отклонений эле-
ментов от среднего значения. Возможен следующий результат
работы программы:
Введите значение п=5
Введите значение элементов:
х[0] = 4
х[1] = 5
х[2] =6
х[3] = 7
х[4] = 8
Среднее=6.000000, дисперсия=2.000000
Вложенные циклы. В теле цикла разрешены любые испол-
нимые операторы, в том числе и циклы, т.е. можно конструиро-
вать вложенные циклы. В математике вложенным циклам
соответствуют, например, кратные суммы или произведения.
В качестве примера рассмотрим фрагмент программы для
получения суммы такого вида:
104
Программирование на языке Си
Введем следующие обозначения: а - двумерный массив, со-
держащий значения элементов матрицы; р - произведение эле-
ментов строки матрицы; с - сумма их значений; s - искомая
сумма (результат). Опустив определения переменных и опера-
торы ввода-вывода, запишем текст на языке Си:
double а[10][5];
for( s=0.0,j=0; j<10; j++)
{
for( p=l.0,c=0.0,i=0; i<5; i++)
{
P*=a[j][i];
c+=a[j][i];
}
s+=c+p;
}
При работе с вложенными циклами следует обратить внима-
ние на правила выполнения операторов break и continue. Каж-
дый из них действует только в том операторе, в теле которого
он непосредственно использован. Оператор break прекращает
выполнение ближайшего внешнего для него оператора цикла.
Оператор continue передает управление на ближайшую внеш-
нюю проверку условия продолжения цикла.
Для иллюстрации рассмотрим фрагмент другой программы
для вычисления суммы произведений элементов строк той же
матрицы:
1
2
3
4
5
6
7
8
9
10
11
double а[10][5];
for (j=O,s=O.O; j<10; j++)
{
for (i=0,p=1.0; i<5; i++)
{
if (a[j][i] == 0.0) break;
p*=a[j][i];
)
if (i <5) continue;
s+=p;
)
Глава 2. Введение в программирование на языке Си
105
Внутренний цикл по i прерывается, если (строка 6) обнару-
живается нулевой элемент матрицы. В этом случае произведе-
ние элементов столбца заведомо равно нулю, и его не нужно
вычислять. Во внешнем цикле (строка 9) проверяется значение
i. Если i<5, т.е. элемент a[j][i] оказался нулевым, то оператор
continue передает управление на ближайший оператор цикла
(строка 4), и, таким образом, не происходит увеличение s (стро-
ка 10) на величину "недосчитанного" значения р. Если внутрен-
ний цикл завершен естественно, то i равно 5, и оператор
continue не может выполняться.
Упорядочение в одномерных массивах. Задаче упорядоче-
ния или сортировке посвящены многочисленные работы мате-
матиков и программистов. Для демонстрации некоторых
особенностей вложения циклов и работы с массивами рассмот-
рим простейшие алгоритмы сортировки. Необходимо, введя
значение переменной 1<п<=100 и значения п первых элементов
массива а[0],а[1],...,а[п-1], упорядочить эти первые элементы
массива по возрастанию их значений. Текст первого варианта
программы:
/* Упорядочение элементов массива */•
#include <stdio.h>
main( )
{
int n,i,j;
double a[100],b;
while(1)
{
printf("\n Введите количество элементов n=") ;
scanf("%d",&n);
if (n > 1 && n <= 100) break;
printf("Ошибка! Необходимо 1<п<=100!");
}
* printf("\n Введите значения элементов "
"массива:\п");
for(j=0; j<n; j++)
{
printf("a[%d]=", j+1) ;
scanf("%lf",&a[j]);
)
106
Программирование на языке Си
for(i=0; i<n-l; i++)
for(j=i+l; j<n; j++)
if(a[i]>a[j])
{
b=a[i];
a[i]=a[j];
a[j]=b;
}
printf("\n Упорядоченный массив: \n");
for(j=0; j<n; j++)
printf("a[%d]=%f\n",j+l,a[j]);
Результаты выполнения программы:
Введите количество элементов п=-15
Ошибка! Необходимо 1<п<=100!
Введите количество элементов п=3
Введите значения элементов массива:
а[1] = 88.8
а[2] = -3.3
а[3] = 0.11
Упорядоченный массив:
а[1] = -3.3
а[2] = 0.11
а[3] = 88.8
Обратите внимание, что при заполнении массива и при печа-
ти результатов его упорядочения индексация элементов выпол-
нена от 1 до п, как это обычно принято в математике. В
программе на Си это соответствует изменению индекса от 0 до
(п-1).
В программе реализован алгоритм прямого упорядочения -
каждый элемент a[i], начиная с а[0] и кончая а[п-2], сравнива-
ется со всеми последующими, и на место a[i] выбирается мини-
мальный. Таким образом, а[0] принимает минимальное зна-
чение, а[1] - минимальное из оставшихся и т.д. Недостаток это-
го алгоритма состоит в том, что в нем фиксированное число
сравнений, не зависимое от исходного расположения значений
элементов. Даже для уже упорядоченного массива придется вы-
полнить то же самое количество итераций (п-1)*п/2, так как
Глава 2. Введение в программирование на языке Си
107
условия окончания циклов не связаны со свойствами, т.е. с раз-
мещением элементов массива.
Алгоритм попарного сравнения соседних элементов позволя-
ет в ряде случаев уменьшить количество итераций при упорядо-
чении. В цикле от 0 до п-2 каждый элемент a[i] массива
сравнивается с последующим a[i+l] (0<i<n-l). Если a[i]>a[i+l],
то значения этих элементов меняются местами. Упорядочение
заканчивается, если оказалось, что a[i] не больше a[i+l] для всех
i. Пусть к - количество перестановок при очередном просмотре.
Тогда упорядочение можно осуществить с помощью такой по-
следовательности операторов:
do {
for (i=0,k=0; i<n-l; i++)
if ( a[i] > a[i+l] )
{
b=a[i];
a[i]=a[i+l];
a[i+l]=b;
k=k+l;
} •
n— ;
}
while( k > 0 ) ;
Здесь количество повторений внешнего цикла зависит от ис-
ходного расположения значений элементов массива. После пер-
вого завершения внутреннего цикла элемент а[п-1] становится
максимальным. После второго окончания внутреннего цикла на
место а[п-2] выбирается максимальный из оставшихся элемен-
тов и т.д. Таким образом, после j-ro выполнения внутреннего
цикла элементы a[n-j],...,a[n-l] уже упорядочены, и следующий
внутренний цикл достаточно выполнить только для 0<i<(n-j-l).
Именно поэтому после каждого окончания внутреннего цикла
значение п уменьшается на 1.
В случае упорядоченности исходного массива внешний цикл
повторяется только один раз, при этом выполняется (n-1) срав-
нений, к остается равным 0. Для случая, когда исходный массив
упорядочен по убыванию, количество итераций внешнего цикла
108
Программирование на языке Си
равно (п-1), а внутренний цикл последовательно выполняется
(п-1)*п/2 раз.
Имеется возможность улучшить и данный вариант алгоритма
упорядочения (см., например, Кнут Д. "Искусство программи-
рования. ТЗ. Сортировка и поиск". М.: Мир, 1980), однако рас-
смотренных примеров вполне достаточно для знакомства с
особенностями применения массивов и индексированных пере-
менных.
Инициализация массивов. При определении массивов воз-
можна их инициализация, т.е. присваивание начальных значе-
ний их элементам. По существу (точнее по результату),
инициализация - это объединение определения объекта с одно-
временным присваиванием ему конкретного значения. Исполь-
зование инициализации позволяет изменить формат
определения массива. Например, можно явно не указывать ко-
личество элементов одномерного массива, а только перечислить
их начальные значения в списке инициализации:
double d[ ]={1.0, 2.0, 3.0, 4.0, 5.0};
В данном примере длину массива компилятор вычисляет по
количеству начальных значений, перечисленных в фигурных
скобках. После такого определения элемент d[0] равен 1.0, d[l]
равен 2.0 и т.д. до d[4], который равен 5.0.
Если в определении массива явно указан его размер, то коли-
чество начальных значений не может быть больше количества
элементов в массиве. Если количество начальных значений
меньше, чем объявленная длина массива, то начальные значения
получат только первые элементы массива (с меньшими значе-
ниями индекса):
int М[8]={8,4,2};
В данном примере определены значения только переменных
М[0], М[ 1 ] и М[2], равные соответственно 8, 4 и 2. Элементы
М[3],..., М[7] не инициализируются.
Правила инициализации многомерных массивов соответст-
вуют определению многомерного массива как одномерного,
элементами которого служат массивы, размерность которых на
Глава 2. Введение в программирование на языке Си
109
единицу меньше, чем у исходного массива. Одномерный массив
инициализируется заключенным в фигурные скобки списком
начальных значений. В свою очередь, начальное значение, если
оно относится к массиву, также представляет собой заключен-
ный в фигурные скобки список начальных значений. Например,
присвоить начальные значения вещественным элементам дву-
мерного массива А, состоящего из трех "строк" и двух
"столбцов", можно следующим образом:
double А[3][2]={{10,20}, {30,40}, {50,60}};
Эта запись эквивалентна последовательности операторов
присваивания: А[0][0]=10; А[0][1]=20; А[1][0]=30; А[1][1]=40;
А[2][0]=50; А[2][1]=60;. Тот же результат можно получить с
одним списком инициализации:
double А[3][2]={10,20,30,40,50,60};
С помощью инициализаций можно присваивать значения не
всем элементам многомерного массива. Например, чтобы ини-
циализировать только элементы первого столбца матрицы, ее
можно описать так:
double Z[4][6]={{1}, {2}, {3}, {4}};
Следующее описание формирует "треугольную" матрицу в
целочисленном массиве из 5 строк и 4 столбцов:
int х[5][4]={{1), {2,3}, {4,5,6}, {7,8,9,10} };
В данном примере последняя пятая строка х[4] остается не-
заполненной. Первые три строки заполнены не до конца. Схема
размещения элементов массива изображена на рис.2.5.
Строка 0 1 2 3 4
Столбец °И |г |з 0 И И3 oh |г|з ° i Иг |з ° | Нг |з
Значение 1 ы-1- гр i-l- 4!5 i6 ь 7р|9Н0 - •-
Рис. 2.5. Схема "треугольного" заполнения матрицы
110
Программирование на языке Си
2.5. Функции
Определение функций. Как уже было отмечено, каждая
программа на языке Си - это совокупность функций. В опреде-
лении функции указываются последовательность действий, вы-
полняемых при обращении к функции, имя функции, тип
результата (возвращаемого значения) и совокупность формаль-
ных параметров, заменяемых при обращении к функции факти-
ческими параметрами (аргументами).
"Описание и определение функций - это та область, где
стандартом ANSI в язык внесены самые существенные измене-
ния" [2]. Так как многие компиляторы были написаны до ввода
стандартов, а многие современные компиляторы позволяют ис-
пользовать два варианта определения и описания функций, не
будем ограничиваться только вариантом, рекомендуемым стан-
дартом языка. Это целесообразно, так как "достандартный"
(нестандартный) вариант часто встречается в опубликованных
ранее текстах программ и нужно уметь их читать. Начнем в ис-
торической последовательности с нестандартного определения
функции, однако отметим еще раз, что стандарт допускает два
варианта определения.
Действия, выполняемые при обращении к функции, задает ее
тело - составной оператор (блок), обязательным элементом ко-
торого служат внешние фигурные скобки { }. Имя функции, тип
результата, совокупность параметров и их свойства задают за-
головок функции. Структура классического (нестандартного)
определения функции:
тип_резулыпата
имя-функции (список-формальных-Параметров)
спецификациЯ-формальныХ-Параметров
{
определения объектов
исполняемые-Операторы
}
Глава 2. Введение в программирование на языке Си
111
Здесь первые три строки - заголовок, последние четыре -
тело функции.
В этой главе будем рассматривать функции, возвращающие
значения целого или вещественного типа. Таким образом, типом
результата может быть char, int, long, float, double или long
double. Могут быть добавлены signed и unsigned. Если тип ре-
зультата не указан, то по умолчанию предполагается целый тип
int. Допустимы функции, не возвращающие результата. В этом
случае для них должен быть использован тип void.
Имя неглавной функции - это произвольно выбираемый
идентификатор. Имя функции не должно совпадать со служеб-
ными словами, именами библиотечных функций и с другими
именами в программе. Список формальных параметров - набор
идентификаторов, отделяемых друг от друга запятыми. Специ-
фикация формальных параметров определяет их свойства и во
многом подобна определениям и описаниям. В данной главе
будем считать, что параметр может быть специфицирован либо
как простая переменная целого или вещественного типа, либо
как одномерный массив (целый или вещественный).
Пример рассмотренного определения функции:
double f (a,b,d)
int a;
float b;
double d;
{ /* тело функции */}
В настоящее время более широко используется и рекоменду-
ется стандартом языка Си определение функции, в котором спи-
сок формальных параметров объединен с их спецификацией.
Структура стандартного определения функции:
тип_резулыпата
имя_функции (спецификация_формалъных_параметров)
{
определения _объектов;
исполняемые_рператоры;
112
Программирование на языке Си
Пример той же функции:
double f (int a, float b, double d)
{/*тело функции*/}
Принципиально важным оператором тела функции является
оператор возврата из функции в точку ее вызова:
return выражение;
или
return;
Выражение в операторе возврата задает возвращаемое функ-
цией значение. Для функции, не возвращающей никакого зна-
чения (указан тип void), выражение в операторе return
отсутствует. В теле такой функции оператор return может во-
обще отсутствовать. В этом случае компилятор предполагает,
что оператор return находится в самом конце тела функции.
Применение оператора return допустимо и в функции
main( ). Если программист явно не поместил в функцию main( )
оператор return, то компилятор поместит его в конце текста
функции main(). В отличие от "неглавных" функций, откуда
возврат выполняется в вызывающую функцию, выполнение
оператора return; или return выражение; в функции main()
приводит к завершению программы. Управление при таком вы-
ходе передается вызывающей программе, например операцион-
ной системе, которая может анализировать значение
выражения, использованного в операторе возврата.
Приведем примеры определения функций и проиллюстриру-
ем некоторые их особенности.
Функция для вычисления объема цилиндра. Пусть у
функции имеются два параметра, значение большего из которых
считается радиусом цилиндра, а меньший определяет значение
высоты цилиндра.
Пусть g и h - параметры; тогда объем цилиндра равен
g*g*h*PI, если g>h, или g*h*h*PI, если g<h, где PI - число п.
Текст нестандартного (старомодного) определения функции:
Глава 2. Введение в программирование на языке Си
113
float volume (g,h)
float g,h;
{ ' .
float b; /* b - вспомогательная переменная */
if ( g < h)
{
b=h;
h=g;
g=b;
}
return 3.14159*g*g*h;
}
Первые две строки — заголовок функции с именем volume;
далее - тело функции. Параметры специфицированы как веще-
ственные типа float. Для возврата из функции и передачи ре-
зультата в точку вызова в теле функции используется оператор
return 3.14159*g*g*h;
Операторов return в теле функции может быть несколько.
Например, для решения той же задачи определим другую функ-
цию (в рекомендуемом современном формате):
float w(float g, float h)
{
if ( g >= h )
return 3.14159*g*g*h;
else
return 3.14159*g*h*h;
}
Функция для вычисления скалярного произведения век-
торов. Скалярное произведение двух векторов n-мерного ли-
нейного пространства вычисляется по формуле
п
<=1
Функция для вычисления указанного произведения может
быть определена следующим нестандартным образом:
8'3124
114
Программирование на языке Си
/* Скалярное произведение п-мерных векторов */
float S_Product(n,a,b)
int n; /* Размерность пространства векторов */
float а[ ],b[ ]; /* Массивы координат векторов*/
{ int i; /* Параметр цикла */
float z; /* Формируемая сумма */
for (i=0, z=0.0; i<n; i++)
z+=a[i]*b[i];
return z; /* Возвращаемый результат */
}
Приведя второй после volume() пример нестандартного оп-
ределения функции, мы настоятельно рекомендуем читателю
использовать только предлагаемую стандартом форму заголов-
ка.
Первый параметр п специфицирован как целая переменная
типа int. В спецификации массивов-параметров типа float пре-
делы изменения индексов не указаны, что позволяет при обра-
щении к функции использовать вместо а и b в качестве
фактических параметров одномерные массивы такого же типа
любых размеров (с любым количеством элементов). Конкрет-
ные пределы изменения их индексов задает фактический пара-
метр, заменяющий формальный параметр int п.
Современный формат (введенный стандартом) предусматри-
вает такую запись заголовка:
float ScalarProduct (int n, float a[ ], float b[ ])
Тело функции остается одинаковым при обоих форматах оп-
ределения заголовка.
Обращение к функции и ее прототип. Как уже говорилось,
для обращения к функции используется элементарное (пер-
вичное) выражение, называемое "вызов функции":
имя_функций (список фактических параметров)
Значение этого выражения - возвращаемое функцией значе-
ние (определяется в теле функции выполненным оператором
return). Список фактических параметров (аргументов) - это
Глава 2. Введение в программирование на языке Си
115
список выражений, заменяющих формальные параметры функ-
ции. Соответствие между формальными и фактическими пара-
метрами устанавливается по порядку их расположения в
списках. Если формальных параметров у функции нет, то не
должно быть и фактических параметров при обращении к этой
функции. Фактические параметры (аргументы) передаются из
вызывающей программы в функцию по значению, т.е. вычисля-
ется значение каждого аргумента, и именно оно используется в
теле функции вместо заменяемого формального параметра.
Примеры вызовов определенных выше функций для вычисле-
ния объема цилиндра:
volume(3.05,х*2)
w(z-1.0,1е-2)
При работе с функциями тип возвращаемого функцией зна-
чения определяется только типом результата, указанным в оп-
ределении функции перед ее именем. Как уже упоминалось, в
языке Си ранее было принято, что если в определении функции
тип результата опущен, то предполагается, что функция воз-
вращает целочисленное значение. Это же соглашение справед-
ливо и в вызывающей программе, где используется обращение к
функции. Если возвращаемое функцией значение отлично от
целочисленного, то эту функцию нужно обязательно специаль-
ным образом описать до обращения к ней. В версиях языка Си
до его стандартизации описание функции имело вид:
тип_резулътата имя_функции();
Такое описание не определяет функцию, не указывает коли-
чество и типы ее параметров, а только описывает тип возвра-
щаемого значения. Например,
float volume(); ...
... z=volume(z-1.0,le-2);
Переменная z получит вещественное значение (объем цилин-
дра), вычисленное с помощью функции volume( ). Если описа-
ние float volume(); опустить, то в вызывающей программе
8*
116
Программирование на языке Си
функция volume() воспринимается как целочисленная, т.е.
результат будет неверен.
Стандарт языка Си предусматривает обязательное описание
функции со стандартным заголовком с помощью прототипа.
Прототип в отличие от старомодного описания включает спе-
цификацию параметров:
тип_резулътата имя_функции
(спецификация формальныхпараметров);
Здесь спецификация формальных параметров представляет
собой список типов и, возможно, имен параметров функции.
Прототип функции схож с ее заголовком. Но имеются два
существенных отличия. Во-первых, прототип всегда заканчива-
ется признаком конца оператора (символ Во-вторых, в про-
тотипе могут не указываться имена специфицируемых
параметров. Прототип может не использоваться только в том
случае, когда определение функции находится в том же файле,
где размещена вызывающая ее программа, и это определение
помещено выше вызывающей программы. Прототипы введен-
ных выше функций могут быть такими:
float w(float, float);
Scalar_Product (int n, float a[ ], float b[ ]);
Имена формальных параметров в прототипе функции w() не
указаны, специфицированы только их типы.
Отметим, что применение прототипа предполагает только
стандартную форму записи заголовка функции. Использование
прототипа несовместимо со "старомодным" видом заголовка.
Мы настоятельно рекомендуем стандартный вид заголовка и
применение прототипов.
И прототипы функций, и старомодные описания функций
необходимо размещать наряду с определением объектов в теле
функций до исполняемых операторов.
Приведем примеры программ, состоящих более чем из одной
функции.
Глава 2. Введение в программирование на языке Си
117
Вычисление биномиального коэффициента. Как известно,
т’(и-т)!’
где n > m > 0; n, m - целые.
Составим программу для вычисления биномиального коэф-
фициента С", в которой используем функцию для вычисления
факториала:
#include <stdio.h>
int fact(int k) /* Вычисление факториала k!*/
{
int j, i; /* Вспомогательные переменные */
for(i=l, j=l; i<=k; i++) /*Цикл вычисления*/
j *=i ;
return j;
} /* Конец определения функции */
/* Вычисление биномиального коэффициента: */
void main( )
{
int п, m, nmc, nm; /*nm - значение (n-m) */
/* nmc - значение биномиального коэффициента */
while (1)
{
printf("\пВведите n=");
scanf("%d",&n);
printf("Введите m=");
scanf ("%d", &m) ;
if (m>=0 && n>=m && n<10) break;
printf ("Ошибка• Необходимо 0<=m<=n<lC>") ;
}
nm=n-m;
nmc=fact(n)/fact(m)/fact(nm);
printf ("\n Биномиальный коэффициент=|^", nmc);
} /* Конец основной программы */
В основной программе функция fact() не описана. Ее прото-
тип здесь не нужен, так как определение функции находится в
том же файле, что и функция main(), вызывающая fact(), при-
чем определение размещено выше вызова. Пример выполнения
программы:
118
Программирование на языке Си
Введите п=4
Введите ш=5
Ошибка ! Необходимо 0<ш<=п<10
Введите п=4
Введите ш=2
Биномиальный коэффициент =6
Вычисление объема цилиндра с использованием приведен-
ной выше функции w():
#include <stdio.h>
/* Вычисление объема цилиндра: */
void main( )
{
float w(float, float); /* Прототип функции */
float а,Ь; /* Исходные данные */
int j; /* Счетчик попыток ввода */
for (j=0; j<5; j++)
{ /* Цикл ввода данных */
printf("\n Введите a=");
scanf("%f",&a);
printf(" Введите b=");
scanf("%f",&b);
if (a>0.0&&b>0.0) break;
printf("\n Ошибка, нужно a>0 и b>0!\n");
)
if (j = 5)
(
printf("\n ОчЕНЬ ПЛОХО вводите данные!!"),*
return; /* Аварийное окончание программы*/
}
printf("\п Объем цилиндра =%f", w(a,b));
} /* Конец основной программы */
/* Функция для вычисления объема цилиндра: */
float w(float g, float h)
{
if ( g >= h )
return(3.14159*g*g*h);
else
return(3.14159*g*h*h);
)
Глава 2. Введение в программирование на языке Си
119
В основной программе использован оператор return, преры-
вающий исполнение программы. Оператор return выполняется
после цикла ввода исходных данных, если количество неудач-
ных попыток ввода (значений а и Ь) равно 5. Задан прототип
функции w( ), т.е. задан ее прототип, что необходимо, так как
она возвращает значение, отличное от int, и определена стан-
дартным образом позже (ниже), чем обращение к ней. Обраще-
ние к функции w() использовано в качестве фактического
параметра функции printf( ).
Пример выполнения программы;
Введите а=2.О
Введите Ь=-44.3
Ошибка, нужно а>0 и Ь>0
Введите а=2.0
Введите Ь=3.0
Обт>ем цилиндра=56.548520
Вычисление площади треугольника. Для определения
площади треугольника по формуле Герона
S - р(р - А\р - В\р - С)
достаточно задать длины его сторон А, В, С и, вычислив полу-
периметр р=(А+В+С)/2, вычислить значение площади по фор-
муле. Однако для составления соответствующей программы
необходима функция вычисления квадратного корня. Предпо-
ложив, что такой функции в библиотеке стандартных математи-
ческих функций нет, составим ее сами. В основу положим метод
Ньютона:
х, = (х,-! + z / х,-!) / 2, i= 1,2,
где z - подкоренное выражение; х0 - начальное приближение.
Вычисления будем проводить с фиксированной относитель-
ной точностью е. Для простоты условием прекращения счета
будет выполнение неравенства
< £. Для вычисления
абсолютного значения введем еще одну функцию с именем
120
Программирование на языке Си
abs() (хотя такая функция, так же как функция для вычисления
квадратного корня, есть в стандартной библиотеке). Программа
может быть такой:
/* Вычисление площади треугольника */
#include <stdio.h> /*Для средств ввода-вывода*/
#include <stdlib.h> /* Для функции exit( ) */
void main( )
{
float a,b,c,p,s;
float sqr(float); /* Прототип функции */
printf("\n Сторона a= ");
scanf("%f",&a); /
printf("Сторона b= ");
scanf("%f",£b);
printf("Сторона c= ");
scanf("%f",&c);
if(a+b <= с I I a+c <= b | | b+c <= a)
{
printf("\n Треугольник построить нельзя*");
return; /* Аварийное окончание работы */
)
p=(a+b+c)/2; /* Полупериметр */
s=sqr(р*(р-а)*(р-b)*(р-с));
printf("Площадь треугольника: %f",s);
} /* Конец основной программы */
/* Определение функции
вычисления квадратного корня */
float sqr(float х)
{ /* х-подкоренное выражение */
/♦Прототип функции вычисления модуля: */
float abs(float);
double г,q;
const double REL=0.00001;
/* REL-относительная точность */
if (x < 0.0)
{ '
printf("\n Отрицательное подкоренное"
" выражение");
exit(l); /* Аварийное окончание.программы */
)
if (х = 0.0) return х ;
Глава 2. Введение в программирование на языке Си
121
/* Итерации вычисления корня: */
г=х; /* г - очередное приближение */
do {
q=r; /* q - предыдущее приближение */
r=(q+x/q)/2;
}
while (abs((r-q)/г) > REL);
return r;
} /* Конец определения функции sqr */
/* Определение функции */
/* для получения абсолютного значения: */
float abs(float z)
{
if(z > 0) return z;
else return(-z);
} /* Конец определения функции abs */
В программе используются три функции. Основная функция
main( ) вызывает функцию sqr( ), прототип которой размещен
выше вызова. Функция abs( ) не описана в основной программе,
так как здесь к ней нет явных обращений. Функция abs() вызы-
вается из функции sqr(), поэтому ее прототип помещен в тело
функции sqr().
В процессе выполнения программы может возникнуть ава-
рийная ситуация, когда введены такие значения переменных а,
Ь, с, при которых они не могут быть длинами сторон одного
треугольника. При обнаружении такой ситуации выдается пре-
дупреждающее сообщение "Треугольник построить нельзя!" и
основная функция main() завершается оператором return. В
функции sqr() также есть защита от неверных исходных дан-
ных. В случае отрицательного значения подкоренного выраже-
ния (х) нужно не только прервать вычисление значения корня,
но и завершить выполнение программы с соответствующим
предупреждающим сообщением. Оператор return для этого не-
удобен, так как позволяет выйти только из той функции, в кото-
рой он выполнен. Поэтому вместо return; при. отрицательном
значении х в функции sqr( ) вызывается стандартная библиотеч-
ная функция exit(), прекращающая выполнение программы.
Прототип (описание) функции exit( ) находится в заголовочном
122'
Программирование на языке Си
файле stdlib.h, который включается в начало текста программы
препроцессорной директивой.
Пример результатов выполнения программы:
, Сторона Сторона Сторона Площадь а=2.0 Ь=3.0 с=4.0 треугольника: 2.904737
Скалярное произведение векторов. Выше была определена
функция Scalar_Product() для вычисления скалярного произве-
дения векторов, в которой параметрами являлись массивы.
Следующая программа использует эту функцию:
/* Скалярное произведение векторов */
#include <stdio.h>
fdefine MAX_INDEX 5
void main( )
{
/* Прототип функции: */
float Scalar_Product(int, float[ ], float[ ]);
int n,i;
float x[MAX_INDEX],y[MAX_INDEX];
printf("\n Размерность векторов n= ;
scanf("%d",&n);
if(n < 1 || n >MAX_INDEX)
{
printf("\n Ошибка в данных!");
return; /* Аварийное завершение */
}
printf("Введите %d координ. х: ",п);
for (i=0; i<n; i++)
scanf("%f",&x[i]);
printf("Введите %d координ. у: ",n);
for (i=0; i<n; i++)
scanf("%f",&y[i]);
printf("\n Результат: %7.3f",
Scalar_Product(n,x,у));
}
/* Определение функции scalar: */
float Scalar_Product(int n, float a[],float b[])
I * Скалярное произведение п-мерных векторов */
Глава 2. Введение в программирование на языке Си
123
/* п - размерность пространства векторов */
/* а[ ] ,Ь[ ] - массивы координат векторов */
( int i; /* Параметр цикла */
double z; /* Формируемая сумма */
for (i=O,z=O.O; i < n; i++)
z += a[i]*b[i];
return z; /* Возвращаемый результат */
}
В начале программы с помощью #define введена препро-
цессорная константа MAX_INDEX. Далее определены массивы,
у которых пределы изменения индексов заданы на препроцес-
сорном уровне. Именно эти пределы проверяются после ввода
размерности векторов (п). В теле функции main() приведен
прототип функции Scalar_Product(). Обратите внимание, что в
прототипе отсутствуют имена формальных параметров. Тот
факт, что два параметра являются одномерными массивами,
отображен спецификацией float[].
Результаты выполнения программы:
Размерность векторов п=2
Введите 2 координ. х: 1 3.1
Введите 2 координ. у: 1 2.1
Результат: 7.510
Другая попытка выполнить программу:
Размерность векторов п=0
Ошибка в данных!
Диаметр множества точек. Как еще один пример использо-
вания функций с массивами в качестве параметров рассмотрим
программу определения диаметра множества точек в многомер-
ном евклидовом пространстве. Напомним, что диаметром назы-
вается максимальное расстояние между точками множества, а
расстояние в евклидовом пространстве между точками х={ х, } ;
У ={у,} i=l,...,n, определяется как
Jn
Eu-z)2.
i=l
124
Программирование на языке Си
Введем ограничения на размерность пространства:
N_MAX<=10 и количество точек К_МАХ<=100. Текст про-
граммы может быть таким:
#include <stdio.h>
#include <math.h> /* для функции sqrt( ) */
/* Функция для вычисления
расстояния между двумя точками */
float distance(float х[ ], float у[ ], int n)
{
int i;
float r,s=O.O;
for(i=0;i<n;i++)
{
r=Y[i]-x[i] ;
s+=r*r;
}
s=sqrt(s);
return s;
}
#define K_MAX 100
#define N_MAX 10
void main( )
{
float dist, dist_max,d;
int i, j, i_max, m_max, n, k, m;
float a[K_MAX][N_MAX];
/* a[][] - Массив фиксированных размеров */
while(1)
{
printf("\n Количество точек k=");
scanf("%d", &k);
printf("Размерность пространства n=");
scanf("%d", &n);
if(k>0 && k<=K_MAX && n>0 && n<=N_MAX) break;
printf("ОШИБКА В ДАННЫХ!");
}
for(i=0;i<k;i++)
{ /* Пикл ввода координат точек */
printf("Введите %d координ. "
"точки %d:\n",n,i+l);
for(j=0;j<n;j++)
/* Цикл ввода координат одной точки */
Глава 2. Введение в программирование на языке Си
125
scanf("%f",&a[i][j]) ;
}
dist_max=O.О;
i_max=O;
m_max=O;
for(i=O;i<k-l;i++)
{ /* Цикл сравнения точек */
for(m=i+l;m<k;m++)
{
dist=distance(a[i], a[m],n);
if(dist>dist_max)
{
dist_max=dist;
i_max=i;
m_max=m;
}
}
} /* Конец цикла no i */
printf("Результат:\nflnaMerp=%f",dist_max);
printf("\n Номера точек : %d,%d",
i_max+l,m_max+l);
}
Результаты выполнения программы:
Количество точек к=4
Размерность пространства Введите 3 координ. точки 111 п=3 1:
Введите 3 -1 -1 координ.- -1 точки 2:
Введите 3 2 2 координ. 2 точки 3:
Введите 3 координ. точки 4:
-2 -2 -2
Результат:
Диаметр = 6.928203
Номера точек: 3, 4
В программе особый интерес представляет обращение к
функции distance( ), где в качестве фактических параметров ис-
пользуются индексированные элементы a[i], а[ш]. Каждый из
них по определению есть одномерный массив из п элементов,
126
Программирование на языке Си
что и учитывается в теле функции. Для задания размеров масси-
ва а[ ][] и предельных значений переменных кип используются
препроцессорные константы К_МАХ и N_MAX. Их нельзя оп-
ределить как переменные, т.е. ошибочной будет последователь-
ность:
int К_МАХ=100; Ы_МАХ=10;
float а [К MAX] [N МАХ] ;
—
При определении массивов их размеры можно задавать толь-
ко с помощью константных выражений.
2.6. Переключатели
Основным средством для организации мультиветвления слу-
жит оператор-переключатель, формат которого имеет вид:
8У/ИсЪ(выражение)
{ case константа!: операторы_1 ;
case константа2: операторы_2;
default: операторы-,
)
В этом операторе используются три служебных слова:
switch, case, default. Первое из них идентифицирует собственно
оператор-переключатель. Служебное слово case с последующей
константой является в некотором смысле меткой. Константы
могут быть целыми или символьными и все должны быть раз-
личными (чтобы метки были различимы). Служебное слово
default также обозначает отдельную метку. При выполнении
оператора (рис. 2.6, а) вычисляется выражение, записанное по-
сле switch, и его значение последовательно сравнивается с кон-
стантами, которые помещены вслед за case. При первом же
совпадении выполняются операторы, помеченные данной мет-
кой. Если выполненные операторы не предусматривают какого-
либо перехода (т.е. среди них нет ни goto, ни return, ни exit( ),
ни break), то далее выполняются операторы всех следующих
Глава 2. Введение в программирование на языке Си
127
вариантов, пока не появится оператор перехода или не закон-
чится переключатель.
Операторы вслед за default выполняются, если значение вы-
ражения в скобках после switch не совпало ни с одной констан-
той после case. Метка default может в переключателе
отсутствовать. В этом случае при несовпадений значения выра-
жения с константами переключатель не выполняет никаких дей-
ствий. Операторы, помеченные меткой default, не обязательно
находятся в конце (после других вариантов переключателя).
Уточним, что default и "case константа" не являются метками
в обычном смысле. К ним, например, нельзя перейти с помощью
оператора goto.
На рис. 2.6 приведены схемы переключателя (рис. 2.6, а) и
оператора альтернативного выбора или селектора (рис. 2.6 , б),
отсутствующего в языке Си.
Рис. 2.6. Переключатель (а) и альтернативный выбор (б):
а - если выражение равно МК, то выполняются операторы
S^.S^, S , S;
к к+1.. "
б - если выражение равно LK, то выполняются только операторы Sk
128
Программирование на языке Си
На рис. 2.7 изображена схема альтернативного выбора, реа-
лизованная при помощи переключателя и дополнительных опе-
раторов, введенных в Sb S2,..., Sn.
Рис. 2.7. Альтернативный выбор с использованием переключателя.
В число операторов каждой группы Sfc добавлен оператор
выхода из переключателя
Для иллюстрации работы переключателя рассмотрим про-
грамму, которая читает любую десятичную цифру и выводит на
экран ее название:
Глава 2. Введение в программирование на языке Си
129
#include <stdio.h>
void main( )
{
int i;
while(1)
{
printf("\n Введите десятичную цифру: ");
scanf ("%d", &i) ,*
printf ("\t\t'’) ;
switch( i )
<
case 1: printf("%d -один \n",i);
break;
case 2: printf ("%d - два \r)" ,i) ;
break;
case 3: printf("%d - три \n",i);
break;
case 4: printf("%d - четыре \n",i);
break;
case 5: printf("%d - пять \n",i);
break;
case 6: printf("%d - шесть \n",i);
break;
case 7: printf("%d - семь \n",i);
break;
case 8: printf ("%d - восемь \n",i);
break;
case 9: printf("%d - девять \n",i);
break;
case 0: printf("%d - нуль \n",i);
break;
default: printf("%d - это не цифра! \n",i);
return;
} /* Конец переключателя */
} /* Конец цикла */
}
Пример результатов выполнения программы:
Введите десятичную цифру: 3
3 - три
Введите десятичную цифру: 8
8 - восемь
9-312“
130
Программирование на языке Си
Введите десятичную цифру: -7
-7 - это не цифра!
Программа прекращает выполнение, как только будет введен
символ, отличный от цифры. Завершение программы обеспечи-
вает оператор return; который в данном случае передает управ-
ление операционной системе, так как выполняет выход из
функции main().
Переключатель вместе с набором операторов break реализу-
ет в этой программе альтернативный выбор (см. рис. 2.7). Если
удалить все операторы break, то работа переключателя в этой
программе будет соответствовать схеме рис. 2.6, а.
Несколько "меток" case с разными значениями констант мо-
гут помечать один оператор внутри переключателя, что позво-
ляет еще больше разнообразить схемы построения операторов
switch.
Глава 3
ПРЕПРОЦЕССОРНЫЕ СРЕДСТВА
В предыдущих главах мы познакомились с некоторыми базо-
выми понятиями и основными средствами (может быть, не са-
мыми эффективными) программирования языка Си. Начиная с
данной главы, начнем подробное изучение тех особенностей и
возможностей, которыми Си отличается от других языков про-
граммирования и которые принесли ему заслуженную популяр-
ность и любовь профессиональных программистов.
Несколько нетрадиционно для пособий по языку Си начнем
дальнейшее изложение материала с возможностей препроцессо-
ра. Это позволит в следующих главах продемонстрировать эф-
фективность препроцессорных средств и их применимость при
решении разнородных задач. Откладывать, как часто принято,
изучение препроцессора на конец курса по языку Си, по нашему
мнению, не совсем удачно. Даже в начальных (вступительных)
главах 1 и 2 пришлось затронуть некоторые важные вопросы
препроцессорной обработки. Введены константы, определяемые
директивой #define, проиллюстрированы некоторые правила
включения в программу текстов заголовочных файлов для связи
со стандартной библиотекой компилятора. Этих сведений впол-
не достаточно, чтобы программировать на языке Си, вводить с
помощью #define собственные обозначения констант и не ис-
пытывать затруднений в использовании стандартных библиотек.
К сожалению, именно на таком уровне использования пре-
процессора остаются многие программисты, не обратившие
внимания на другие возможности препроцессорной обработки
текста программы. А возможности препроцессора весьма инте-
ресные, особенно в областях макрообработки и условной ком-
пиляции. Введя в этой главе препроцессорные средства, мы
сможем в следующих главах показать способы и возможности
их применения при решении задач разных классов.
Прежде чем перейти к изложению материала, отметим, что
препроцессор обрабатывает почти любые тексты, а не только
тексты программ на языке Си. Обработка программ - это основ-
9*
132
Программирование на языке Си
ная задача препроцессора, однако он может преобразовывать
произвольные тексты, и этой возможностью программисту не
следует пренебрегать в своей работе.
Итак, на входе препроцессора - текст с препроцессорными
директивами, на выходе препроцессора - текст без препроцес-
сорных директив (см. рис. 1.1).
3.1. Стадии и команды препроцессорной
обработки
В интегрированную среду подготовки программ на Си или в
компилятор языка как обязательный компонент входит препро-
цессор. Назначение препроцессора - обработка исходного тек-
ста программы до ее компиляции (см. рис. 2.1).
Стадии препроцессорной обработки. Препроцессорная об-
работка включает несколько стадий, выполняемых последова-
тельно. Конкретная реализация может объединять несколько
стадий, но результат должен быть таким, как если бы они вы-
полнялись в следующем порядке:
• все системно-зависимые обозначения (например, системно-
зависимый индикатор конца строки) перекодируются в
стандартные коды;
• каждая пара из символов ’V и "конец строки" вместе с про-
белами между ними убираются, и тем самым следующая
строка исходного текста присоединяется к строке, в кото-
рой находилась эта пара символов;
• в тексте (точнее, в тексте каждой отдельной строки) распо-
знаются директивы и лексемы препроцессора, а каждый
комментарий заменяется одним символом пустого проме-
жутка;
• выполняются директивы препроцессора и производятся
макроподстановки;
• эскейп-последовательности в символьных константах и
символьных строках, например ’\п* или '\xF2', заменяются
на их эквиваленты (на соответствующие числовые коды);
Глава 3. Препроцессорные средства
133
• смежные символьные строки (строковые константы) кон-
катенируются, т.е. соединяются в одну строку;
• каждая препроцессорная лексема преобразуется в текст на
языке Си.
Поясним, что понимается под препроцессорными лексемами
или лексемами препроцессора (preprocessing token). К ним отно-
сятся символьные константы, имена включаемых файлов, иден-
тификаторы, знаки операций, препроцессорные числа, знаки
препинания, строковые константы (строки) и любые символы,
отличные от пробела.
Знакомство с перечисленными стадиями препроцессорной
обработки объясняет, как реализуются некоторые правила син-
таксиса языка. Например, становится понятным смысл утвер-
ждений: "каждая символьная строка может быть перенесена в
файле на следующую строку, если использовать символ или
"две символьные строки, записанные рядом, воспринимаются
как одна строка". Отметим, что после "склеивания" строк в со-
ответствии с приведенными правилами каждая полученная
строка обрабатывается препроцессором отдельно.
Рассмотрим подробно стадию обработки директив препро-
цессора. При ее выполнении возможны следующие действия:
• замена идентификаторов (обозначений) заранее подготов-
ленными последовательностями символов;
• включение в программу текстов из указанных файлов;
• исключение из программы отдельных частей ее текста (ус-
ловная компиляция);
• макроподстановка, т.е. замена обозначения параметризо-
ванным текстом, формируемым препроцессором с учетом
конкретных параметров (аргументов).
Директивы препроцессора. Для управления препроцессо-
ром, т.е. для задания нужных действий, используются команды
(директивы) препроцессора, каждая из которых помещается на
отдельной строке и начинается с символа #.
Обобщенный формат директивы препроцессора:
134
Программирование на языке Си
# имя_директивы лексемы препроцессора
Перед символом и после него в директиве разрешены
пробелы. Пробелы также разрешены перед лексема-
ми препроцессора, между ними и после них. Окончанием пре-
процессорной директивы служит конец текстовой строки (при
наличии символа 'V, обозначающего перенос строки, окончани-
ем препроцессорной директивы будет признак конца следую-
щей строки текста).
Определены следующие препроцессорные директивы:
# define - определение макроса или препроцессорного
идентификатора;
# inchide - включение текста из файла;
# undef - отмена определения макроса или идентифика-
тора (препроцессорного);
# if - проверка условия-выражения;
# ifdef - проверка определенности идентификатора;
# ifndef - проверка неопределенности идентификатора;
# else - начало альтернативной ветви для #if;
# endif - окончание условной директивы #if;
# elif - составная директива #else/#if;
# line - смена номера следующей ниже строки;
# еггог - формирование текста сообщения об ошибке
трансляции;
# pragma - действия, предусмотренные реализацией;
# - пустая директива.
Кроме препроцессорных директив имеются три препроцес-
сорные операции, которые будут подробно рассмотрены вместе
с командой ^define:
d efined - проверка истинности операнда;
# # - конкатенация препроцессорных лексем;
# - преобразование операнда в строку символов.
Глава 3. Препроцессорные средства
135
Директива #define имеет несколько модификаций. Они пре-
дусматривают определение макросов и препроцессорных иден-
тификаторов, каждому из которых ставится в соответствие
некоторая символьная последовательность. В последующем
тексте программы препроцессорные идентификаторы заменя-
ются на заранее запланированные последовательности симво-
лов. Примеры определения констант с помощью #define при-
ведены в главе I.
Директива ^include позволяет включать в текст программы
текст из указанного файла.
Директива ttundef отменяет действие директивы ttdefine,
которая определила до этого имя препроцессорного иденти-
фикатора.
Директива #if и ее модификации ttifdef, #ifndef совместно с
директивами #else, #endif, #elif позволяют организовать услов-
ную обработку текста программы. При использовании этих
средств компилируется не весь текст, а только те его части, ко-
торые выделены с помощью перечисленных директив.
'Директива #line позволяет управлять нумерацией строк в
файле с программой. Имя файла и желаемый начальный номер
строки указываются непосредственно в директиве #line (под-
робнее см. §3.6).
Директива #еггог позволяет задать текст диагностического
сообщения, которое выводится при возникновении ошибок.
Директива #pragma вызывает действия, зависящие от реали-
зации, т.е. запланированные авторами компилятора.
Директива # ничего не вызывает, так как является пустой ди-
рективой, т.е. не дает никакого эффекта и всегда игнорируется.
Рассмотрим возможности перечисленных директив и пре-
процессорных операций при решении типичных задач, пору-
чаемых препроцессору. Одновременно на примерах поясним,
что понимается под препроцессорными лексемами в обобщен-
ном формате препроцессорных директив.
136
Программирование на языке Си
3.2. Замены в тексте
Директива #define. Как уже иллюстрировалось на примере
именованных констант (§1.3 и 2. Г), для замены выбранного про-
граммистом идентификатора заранее подготовленной последо-
вательностью символов используется директива (обратите
внимание на пробелы):
#define идентификатор строка_замещения
Директива может размещаться в любом месте обрабатывае-
мого текста, а ее действие в обычном случае распространяется
от точки размещения до конца текста. Директива, во-первых,
определяет идентификатор как препроцессорный. В результате
работы препроцессора вхождения идентификатора, определен-
ного командой #define, в тексте программы заменяются строкой
замещения, окончанием которой обычно служит признак конца
той "физической" строки, где размещена команда #define. Сим-
волы пробелов, помещенные в начале и в конце строки замеще-
ния, в подстановке не используются. Например:
Исходный текст Результат препроцессорной обработки
#define begin {
ttdefine end } >
void main() void main()
begin {
операторы операторы
end j
В данном случае программист решил использовать в качест-
ве операторных скобок идентификаторы begin, end. До компи-
ляции препроцессор заменяет все вхождения этих
идентификаторов стандартными скобками { и }. Соответствую-
щие указания программист дал препроцессору с помощью ди-
ректив #define.
Цепочка подстановок. Если в строке замещения команды
#define в качестве отдельной лексемы встречается препроцес-
сорный идентификатор, ранее определенный другой директивой
Глава 3. Препроцессорные средства
137
tfdefine, то выполняется цепочка последовательных подстано-
вок. В качестве примера рассмотрим, как можно определить
диапазон (RANGE) возможных значений любой целой перемен-
ной типа int в следующей программе:
#include <limits.h>
#define RANGE ((INT_MAX) - (INT_MIN)+1)
/♦RANGE - диапазон значений для int */
int RANGE_T = RANGE/8;
Препроцессор последовательно, строку за строкой, просмат-
ривает текст и, обнаружив директиву #include <limits.h>, встав-
ляет текст из файла limits.h. Там определены константы
INT_MAX (предельное максимальное значение целых вели-
чин), INT_MIN (предельное минимальное значение целых ве-
личин). Тем самым программа принимает, например, такой вид:
#define INTJMAX 32767
#define INT_MIN -32768
#define RANGE ((INT_MAX)-(INT_MIN)+1).
/♦RANGE - диапазон значений для int*/
int RANGE_T = RANGE/8;
Обратите внимание, что директива #include исчезла из про-
граммы, но ее заменил соответствующий текст.
Обнаружив в тексте (добытом из файла limits.h) директивы
^define..., препроцессор выполняет соответствующие подста-
новки, и программа принимает вид:
#define RANGE ((32767)-(-32768)+1)
/♦RANGE - диапазон Значений для int*/
int RANGE Т = RANGE/8;
138
Программирование на языке Си
Подстановки изменили строку замещения препроцессорного
идентификатора RANGE в директиве #define, размещенной ни-
же, чем текст, включенный из файла limits.h. "Продвигаясь" по
тексту программы, препроцессор встречает препроцессорный
идентификатор RANGE и выполняет подстановку. Текст про-
граммы приобретает следующий вид:
/♦RANGE - диапазон значений для int*/
int RANGE_T = ((32767)-(-32768)+1)/8 ;
Теперь все директивы #define удалены из текста. Получен
текст, пригодный для компиляции, т.е. создана "единица транс-
ляции". Подстановка строки замещения вместо идентификатора
RANGE выполнена в выражении RANGE/8, однако внутри
комментария идентификатор RANGE остался без изменений и
не изменился идентификатор RANGE_T.
Этот пример иллюстрирует выполнение "цепочки" подстано-
вок и ограничения на замены: замены не выполняются внутри
комментариев, внутри строковых констант, внутри символьных
констант и внутри идентификаторов (не может измениться часть
идентификатора). Например, RANGE_T остался без изменений.
Для еще одной иллюстрации перечисленных ограничений рас-
смотрим такой фрагмент программы:
#define п 24
char с = ’\п'; /* Символьная константа*/
/* \п - эскейп-последовательность:*/
. . . "\п Строковая константа". . .
с=1п1>'\п1?'п':'\п';
int k=n;
В ходе препроцессорной обработки этого текста замена п на
24 будет выполнена только один раз в последнем определении,
которое примет вид:
int k=24;
Глава 3. Препроцессорные средства
139
Все остальные вхождения символа п в текст программы пре-
процессор просто "не заметит".
Вернемся к формату директивы #define.
Если строка замещения оказывается слишком длинной, то,
как уже говорилось, ее можно продолжить в следующей строке
текста. Для этого в конце продолжаемой строки помещается
символ ’V. В ходе одной из стадий препроцессорной обработки
этот символ вместе с последующим символом конца строки бу-
дет удален из текста программы. Пример:
#define STRING "\n Game Over! - \
Игра закончена! "
printf(STRING);
На экран будет выведено:
Game Over! - Игра закончена!
С помощью команды #define удобно выполнять настройку
программы. Например, если в программе требуется работать с
массивами, то их размеры можно явно определять на этапе пре-
процессорной обработки:
Исходный текст Результат препроцессорной обработки
#define К 40
void main( ) void main( )
( {
int M[K][К]; int M[40][40];
float A[2*K+1], float A[2*40+l],
float B[K+3][K-3]; float B[40+3][40-3];
При таком описании очень легко изменять предельные раз-
меры сразу всех массивов, изменив только одну константу
(строку замещения) в директиве #define.
Предусмотренные директивой #define препроцессорные. за-
мены не выполняются внутри строк, символьных констант и
комментариев, т.е. не распространяются на тексты, ограничен-
ные кавычками ("), апострофами (') и разделителями (/*, */). В
140
Программирование на языке Си
то же время строка замещения может содержать перечисленные
ограничители, например, как это было в замене препроцессор-
ного идентификатора STRING.
Если в программе нужно часто печатать или выводить на эк-
ран дисплея значение какой-либо переменной и, кроме того,
снабжать эту печать одним и тем же пояснительным текстом, то
удобно ввести сокращенное обозначение оператора печати, на-
пример:
#define РК printf("\п Номер элемента=%с1. " , N) ;
После этой директивы использование в программе оператора
РК; будет эквивалентно (по результату) оператору из строки
замещения. Например, последовательность операторов
int N = 4;
РК;
приведет к выводу такого текста:
Номер элемента=4.
Если в строку замещения входит идентификатор, определен-
ный в другой команде #define, то в строке замещения выполня-
ется следующая замена (цепочка подстановок). Например,
программа, содержащая команды:
#define К 50
#define РЕ printf ("\п Число элементов K=%d",K);
РЕ;
выведет на экран такой текст:
Число элементов К=50
Обратите внимание, что идентификатор К внутри строки за-
мещения, обрамленной кавычками ("), не заменен на 50.
Строку замещения, связанную с конкретным препроцессор-
ным идентификатором, можно сменить, приписав уже опреде-
ленному идентификатору новое значение другой командой
#define:
Глава 3. Препроцессорные средства
141
#define М 16
/* Идентификатор М определен как 16 */
#define М 'С
/* М определен как символьная константа 'С'
*/
fdefine М "С"
/* М определен как символьная строка */
/* с двумя элементами: 'С и '\0’ */
Однако при таких сменах значений препроцессорного иден-
тификатора компилятор Borland C++ выдает предупреждающее
сообщение на каждую следующую директиву #define:
Warning ..: Redefinition of 'M' is not identical
Замены в тексте можно отменять с помощью команды
#undef идентификатор
После выполнения такой директивы идентификатор для пре-
процессора становится неопределенным, и его можно опреде-
лять повторно. Например, не вызовут предупреждающих
сообщений директивы:
#define М 16
#undef М
#define М ’С
#undef М
#define М "С"
Директиву #undef удобно использовать при разработке
больших программ, когда они собираются из отдельных "кусков
текста", написанных в разное время или разными программи-
стами. В этом случае могут встретиться одинаковые обозначе-
ния разных объектов. Чтобы не изменять исходных файлов,
включаемый текст можно "обрамлять" подходящими директи-
вами #define, #undef и тем самым устранять возможные ошиб-
ки. Приведем пример:
А = 10; / Основной текст */
#define А X
142
Программирование на языке Си
А = 5; / Включенный текст */
#undef А
В = А; / Основной текст */
При выполнении программы переменная В примет значение
10, несмотря на наличие оператора присваивания А = 5; во
включенном тексте.
3.3. Включение текстов из файлов
Для включения текста из файла, как мы уже неоднократно
показывали, используется команда //include, имеющая три фор-
мы записи:
//include < имя_файла > /* Имя в угловых скобках */
//include "имяфайла" /* Имя в кавычках */
//include имямакроса
/* Макрос, расширяемый до обозначения файла*/
где имя макроса - это введенный директивой //define препро-
цессорный идентификатор либо макрос, при замене которого
после конечного числа подстановок будет получена последова-
тельность символов <имя_файлс1> либо "имя файла". (О макро-
сах см. ниже в §3.5.)
До сих пор мы в программах и примерах фрагментов про-
грамм использовали только первую форму команды //include.
Существует правило, что если имя файла - в угловых скобках,
то препроцессор разыскивает файл в стандартных системных
каталогах. Если имя файла заключено в кавычки, то вначале
препроцессор просматривает текущий каталог пользователя и
только затем обращается к просмотру стандартных системных
каталогов.
Г лава 3. Препроцессорные средства
143
Начиная работать с языком Си, пользователь сразу же стал-
кивается с необходимостью использования в программах
средств ввода-вывода. Для этого в начале текста программы по-
мещают директиву:
#include <stdio.h>
Выполняя эту директиву, препроцессор включает в програм-
му средства связи с библиотекой ввода-вывода. Поиск файла
stdio.h ведется в стандартных системных каталогах.
По принятому соглашению суффикс .h приписывается тем
файлам, которые содержат прототипы библиотечных функций,
а также определения и описания типов и констант, используе-
мых при работе с библиотеками компилятора. Эти файлы в ли-
тературе по языку Си принято называть заголовочными.
Кроме такого в некоторой степени стандартного файла, ка-
ким является stdio.h, в заголовок программы могут быть вклю-
чены любые другие файлы (стандартные или подготовленные
специально). Перечень обозначений заголовочных файлов для
работы с библиотеками компилятора утвержден стандартом
языка. Ниже приведены названия этих файлов, а также краткие
сведения о тех описаниях и определениях, которые в них вклю-
чены. Большинство описаний - прототипы стандартных функ-
ций, а определены в основном константы (например, NULL,
EOF), необходимые для работы с библиотечными функциями.
Все имена, определенные в стандартных заголовочных файлах,
являются зарезервированными именами:
assert.h - Диагностика программ
ctype.h - Преобразование и проверка символов
errao.h - Проверка ошибок
float.h - Работа с вещественными данными
limits.h - Предельные значения целочисленных данных
locate.h - Поддержка национальной среды
, math.h - Математические вычисления
setjump.h - Возможности нелокальных переходов
signaLh - Обработка исключительных ситуаций
144
Программирование на языке Си
stdarg.h - Поддержка переменного числа параметров
• stddef.h - Дополнительные определения
stdio.h - Средства ввода-вывода
stdlib.h - Функции общего назначения
(работа с памятью)
string.h - Работа со строками символов
time.h - Определение дат и времени
В конкретных реализациях количество и наименования заго-
ловочных файлов могут быть и другими. Например, в компиля-
торах для MS-DOS активно используются заголовочные файлы
с названиями mem.h, alloc.h, conio.h, dos.h и др. Кроме того,
почти в каждой операционной системе имеется библиотека гра-
фических функций, для связи с которыми вводится соответст-
вующий заголовочный файл. Например, в компиляторах Turbo
С и Borland C++ для связи с графической библиотекой применя-
ется заголовочный файл с названием graphics.h.
Стандартные заголовочные файлы могут быть нечаянно или
нарочно включены в текст программы в любом порядке и по
несколько раз без отрицательных побочных эффектов. Однако
действие включаемого заголовочного файла распространяется
на текст программы только в пределах одного модуля от места
размещения директивы #include и до конца текстового файла (и
всех включаемых в программу текстов).
Заголовочные нестандартные файлы оказываются весьма
эффективным средством при модульной разработке крупных
программ, когда связь между модулями, размещаемыми в раз-
ных файлах, реализуется не только с помощью параметров, но и
через внешние объекты, глобальные для нескольких или всех
модулей. Описания таких внешних объектов (переменных, мас-
сивов, структур и т.п.) и прототипы функций помещаются в од-
ном файле, который с помощью директив #include включается
во все модули, где необходимы внешние объекты. В тот же
файл можно включить и директиву подключения файла с опи-
саниями библиотеки функций ввода-вывода. Заголовочный
файл может быть, например, таким:
Глава 3. Препроцессорные средства
145
#include <stdio.h> /* Включение средств обмена */
/* Целые внешние переменные */
extern int ii, jj, 11;
/* Вещественные внешние переменные */
extern float аа, ЬЬ;
Если в программе используется несколько функций, то часто
удобно текст каждой из них хранить в отдельном файле. При
подготовке программы в виде одного модуля программист
включает в нее тексты всех функций с помощью команд
^include.
В главе 8 приведены примеры разработки таких программ.
Одним из примером служит задача формирования гистограммы
с целью оценки последовательности псевдослучайных чисел.
При разработке программы выделены шесть функций и введены
внешние переменные, которые должны быть доступны для этих
функций. Список не главных функций (их прототипы) получил-
ся (см. гл. 8) таким:
void count(void);
void estimate (double ♦, double ♦, double ♦);
void compare (double, double);
double gauss (double, double);
int pseudorand (void);
В тексты всех перечисленных функций, а также в функцию
main() помещены прототипы вызываемых функций. Кроме
того, в каждой функции описаны со спецификатором extern все
внешние объекты, доступ к которым нужен в теле функции (о
внешних объектах, спецификаторе extern и классах памяти под-
робно будет говориться в §5.7).
Такое размещение описаний и определений допускает произ-
вольный порядок размещения текстов функций в программном
файле. Если в качестве имен файлов с текстами функций про-
граммы выбраны идентификаторы, близкие к именам функций,
то возможен следующий текст программы (одни процессорные
команды):
#include "main.с"
#include "count.с"
1 0'3124
146
Программирование на языке Си
finclude "estimate.с”
♦include "compare.с"
#include "gauss.с"
#include "pseudo.c"
Имена файлов соответствуют именам функций с добавкой
расширения ".с". Единственное исключение - имя файла
"pseudo.c". Здесь имя функции pseudorand() укорочено, чтобы
программа могла выполняться и для реализации под MS-DOS,
где имена файлов не должны превышать восьми символов.
Как иллюстрирует этот пример, исходный текст программы
может быть настолько сокращен, что будет содержать только
директивы препроцессора.
Препроцессор включает настоящие (реальные) тексты всех
функций в программу и как единое целое (модуль) передает по-
лученный текст на компиляцию.
3.4. Условная компиляция
Директивы ветвлений. Условная компиляция обеспечива-
ется в языке Си следующим набором директив, которые, не
точно соответствуя названию, управляют не компиляцией, а
препроцессорной обработкой текста:
#if целочисленное_константное-выражение
#ifdef идентификатор
#ifndef идентификатор
#else
tfendif
#elif
Первые три директивы выполняют проверку условий, две
следующие - позволяют определить диапазон действия прове-
ряемого условия. (Директиву #elif рассмотрим несколько поз-
же.) Общая структура применения директив условной ком-
пиляции такова:
Глава 3. Препроцессорные средства
147
текст!
#else
текст_2
tfendif
Конструкция #else текст_2 необязательна. Текст ! вклю-
чается в компилируемый текст только при истинности прове-
ряемого условия (обозначено многоточием после #if). Если
условие ложно, то при наличии директивы #else на компиляцию
передается текст_2. Если директива #else и текст_2 отсутст-
вуют, то весь текст от #if до #endif при ложном условии опуска-
ется. Различие между формами команд #if состоит в
следующем.
В первой из перечисленных директив
#if целочисленноеконстантноевыражение
проверяется значение константного выражения, в которое могут
входить целые константы и идентификаторы. Идентификаторы
могут быть определены на препроцессорном уровне, и тогда их
значение определяется подстановками. В противном случае
считается, что идентификаторы имеют нулевые значения. Если
константное выражение отлично от нуля, то считается, что про-
веряемое условие истинно. Например, в результате выполнения
директив:
#if 5+4
текст!
tfendif
текст ! всегда будет включен в компилируемую программу.
В директиве
#ifdef идентификатор
проверяется, определен ли с помощью директивы #define к те-
кущему моменту идентификатор, помещенный после #ifdef.
Если идентификатор определен, т.е. является препроцессорным,
ТО текст ! используется компилятором.
148
Программирование на языке Си
В директиве
ftifndef идентификатор
проверяется обратное условие - истинным считается неопреде-
ленность идентификатора, т.е. тот случай, когда идентификатор
не был использован в команде #define или его определение бы-
ло отменено командой tfundef.
Условную компиляцию удобно применять при отладке про-
грамм для включения или исключения средств вывода кон-
трольных сообщений. Например,
#define DEBUG
#ifdef DEBUG
printf ( " Отладочная печать ");
#endif
Таких вызовов функции printf(), появляющихся в программе
в зависимости от определенности идентификатора DEBUG, мо-
жет быть несколько, и, убрав либо поместив в скобки коммен-
тария /*...*/ директиву #define DEBUG, сразу же отключаем все
отладочные средства.
Файлы, предназначенные для препроцессорного включения в
программу, обычно снабжают защитой от повторного включе-
ния. Такое повторное включение может произойти, если не-
сколько файлов, в каждом из которых, в свою очередь,
запланировано препроцессорное включение одного и того же
файла, объединяются в общий текст программы. Например, та-
кими средствами защиты снабжены все заголовочные файлы
стандартной библиотеки. Схема защиты от повторного включе-
ния может быть такой:
/* Файл с именем filename */
/* Проверка определенности _FILE_NAME */
#ifndef _FILE_NAME
.../* Включаемый текст файла filename */
/* Определение FILE_NAME */
# define _FILE_NAME
#endif
Глава 3. Препроцессорные средства
149
Здесь _FILE_NAME - зарезервированный для файла filename
препроцессорный идентификатор, который желательно не ис-
пользовать в других текстах программы.
Для организации мультиветвлений во время обработки пре-
процессором исходного текста программы введена директива
#eli f целочисленное константное -выражение
Требования к целочисленному константному выражению
те же, что и в директиве #if.
Структура исходного текста с применением этой директивы
такова:
#if условие
текстдля!/
#elif выражение!
текст _1
#elif выражение?
текст_2
#else
текст_для_случая_е1$е
#endif
Препроцессор проверяет вначале условие в директиве #if. Ес-
ли оно ложно (равно 0), - вычисляется выражение !, если при
этом оказывается, что и значением выражения ! также являет-
ся 0, - вычисляется выражение ?, и т.д. Если все выражения
ложны (равны 0), то в компилируемый текст включается
текст для случая еЬе. В противном случае, т.е. при появлении
хотя бы одного истинного выражения (в #if или в #elif),
начинает обрабатываться текст, расположенный непосредствен-
но за этой директивой, а все остальные директивы не рассмат-
риваются.
Таким образом, препроцессор обрабатывает всегда только
один из участков текста, выделенных директивами условной
компиляции.
150
Программирование на языке Си
Операция defined. При условной обработке текста (при ус-
ловной компиляции с использованием директив #if, #elif) для
упрощения записи сложного условия выбора можно использо-
вать унарную препроцессорную операцию
defined операнд
где операнд - либо идентификатор, либо заключенный в скобки
идентификатор, либо обращение к макросу (см. §3.5). Если
идентификатор операнда до этого определен с помощью коман-
ды #define как препроцессорный, то выражение defined операнд
принимает значение 1L, т.е. считается истинным. В противном
случае его значение равно 0L.
Выражение
#if defined операнд
эквивалентно выражению
tfifdef операнд
Но в таком простом случае никакие достоинства операции
defined не проявляются. Поясним с помощью примера полезные
возможности операции defined. Предположим, что некоторый
важныйтекст должен быть передан компилятору только в
том случае, если идентификатор Y определен как препроцес-
сорный, а идентификатор N не определен. Директивы препро-
цессора могут быть записаны следующим образом:
#if defined Y && 'defined N
важный_текст
tfendif
Обработку препроцессор ведет следующим образом. Во-
первых, определяется истинность выражений defined Y и
defined N. Получаем два значения, каждое 0L или 1L. К резуль-
татам применяется операция && (конъюнкция), и при истинно-
сти ее результата важный текст передается компилятору.
Не используя операцию defined, то же самое условие можно
записать таким наглядным способом:
Глава 3. Препроцессорные средства
151
#ifdefY
#ifndefN
важныйтекст
#endif
#endif
Таким образом, из примера видно, что:
#if defined эквивалентно #ifdef
#if {defined эквивалентно #ifndef
Стандарт языка Си не определил defined в качестве ключе-
вого слова. В тексте программы его можно использовать в каче-
стве идентификатора, свободно применяемого программистом
для обозначения объектов, defined имеет специфическое значе-
ние только при формировании выражений-условий, проверяе-
мых в директивах #if и #elif. В то же время идентификатор
defined запрещено использовать в директивах #define и tfundef.
3.5. Макроподстановки средствами
препроцессора
Макрос, по определению, есть средство замены одной после-
довательности символов на другую. Для выполнения замен
должны быть заданы соответствующие макроопределения. Про-
стейшее макроопределение мы уже ввели, рассматривая замены
в тексте с помощью директивы
#define идентификатор строка замещения
С помощью директивы #define программист может вводить
собственные обозначения базовых или производных типов. На-
пример, директива
#define REAL long double
вводит название (имя) REAL для типа long donble. Далее в тек-
сте программы можно определять конкретные объекты, исполь-
зуя REAL в качестве обозначения их типа (long double):
152
Программирование на языке Си
REAL х, array [6];
) Идентификатор в команде #define может определять, как мы
видели, имя константы, если строка замещения задает значе-
ние этой константы. В более общем случае идентификатор слу-
жит обозначением некоторого выражения, например:
#define RANGE ((INT_MAX)-(INT_MIN)+1)
Идентификаторы, входящие в строку замещения, в свою оче-
редь, могут быть определены как препроцессорные, и их значе-
ния будут подставлены вместо них (вместо INT_MAX и
INT_MIN в нашем примере).
Допустимость выполнять с помощью tfdefine “цепочки” под-
становок расширяет возможности этой директивы, однако она
имеет существенный недостаток - строка замещения фиксиро-
вана. Большие возможности предоставляет макроопределение с
параметрами
^define имя(списокпараметров) строка замещения
Здесь имя - имя макроса (идентификатор),
список параметров - список разделенных запятыми
идентификаторов. Между именем макроса и скобкой, откры-
вающей список параметров, не должно быть пробелов.
Для обращения к макросу ("для вызова макроса") использу-
ется конструкция ("макровызов") вида:
имя макроса (список аргументов)
В списке аргументы разделены запятыми. Каждый аргумент
- препроцессорная лексема.
Классический пример макроопределения:
#define тах(а,Ь) (а < Ь ? Ь : а)
позволяет формировать в программе выражение, определяющее
максимальное из двух значений аргументов. При таком опреде-
лении вхождение в программу макровызова
max(X,Y)
заменяется выражением
Глава 3. Препроцессорные средства
153
(X<Y? Y:X)
а использование конструкции вида
max(Z,4)
приведет к формированию выражения
(Z<4? 4:Z)
В первом случае при истинном значении X < Y возвращается
значение Y, иначе - значение X. Во втором примере значение
переменной Z сравнивается с константой 4 и выбирается боль-
шее из значений.
Не менее часто используется определение
#define ABS(X) (Х<0? -(X):Х)
С его помощью в программу можно вставлять выражение для
определения абсолютных значений переменных. Конструкция
ABS(E-Z)
заменяется выражением
(E-ZCO? -(E-Z):E-Z)
в результате вычисления которого определяется абсолютное
значение выражения Е-Z. Обратите внимание на скобки. Без
них могут появиться ошибки в результатах.
Следует отметить, что последовательные препроцессорные
подстановки выполняются в строке замещения, но не действуют
на параметры макроса.
Моделирование многомерных массивов. В качестве еще
одной области эффективного использования макросов укажем
на проблему представления многомерных массивов в языке Си.
Массивы мы будем подробно рассматривать в следующих гла-
вах, а пока остановимся только на вопросе применения макро-
средств для удобной адресации элементов матрицы. Напомним
общие принципы представления массивов в языке Си.
1. Основным понятием в языке Си является одномерный
массив, а возможности формирования многомерных массивов
(особенно с переменными размерами) весьма ограниченны.
154
Программирование на языке Си
2. Нумерация элементов массивов в языке Си начинается с
нуля, т.е. для обращения к начальному (первому) элементу мас-
сива требуется нулевое значение индекса.
При работе с матрицами обе указанные особенности масси-
вов языка Си создают по крайней мере неудобства. Во-первых,
при обращении к элементу матрицы нужно указывать два ин-
декса - номер строки и номер столбца элемента матрицы. Во-
вторых, нумерацию строк и столбцов матрицы принято начи-
нать с 1.
Применение макросов для организации доступа к элементам
массива позволяет программисту обойти оба указанных затруд-
нения, правда, за счет нетрадиционных обозначений индексиро-
ванных элементов. (Индексы в макросах, представляющих
элементы массивов матриц, заключены в круглые, а не в квад-
ратные скобки.) Рассмотрим следующую программу:
# define N 4 /* Число строк матрицы */
# define М 5 /* Число столбцов матрицы */
# define A(i,j) x[M*(i-l) + (j-1)]
tfinclude <stdio.h>
void main ( )
{
/* Определение одномерного массива */
double x [N*M] ;
int i, j , Jc;
for (Jc=O; Jc < N*M; Jc++)
x [ Jc ] =Jc;
for (i=l; i<=N; i++) /* Перебор строк */
{
printf ("\n Строка %d:”, i);
/* Перебор элементов строки */
for (j«l; j<=M; j++)
printf(" %6.1f", A(i, j));
}
)
Результат выполнения программы:
Строка 1: 0.0 1.0 2.0 3.0 4.0
Строка 2: 5.0 6.0 7.0 8.0 9.0
Строка 3: 10.0 11.0 12.0 13.0 14.0
Строка 4: 15.0 16.0 17.0 18.0 ’ 19.0
Глава 3. Препроцессорные средства
155
В программе определен одномерный массив х[ ], количество
элементов в котором зависит от значений препроцессорных
идентификаторов N и М.
Значения элементам массива х[ ] присваиваются в цикле с
параметром к. Никаких новинок здесь нет. А вот далее для дос-
тупа к элементам того же массива х[ ] используются макровызо-
вы вида A(i, j), причем i изменяется от 1 до N, а переменная j
изменяется во внутреннем цикле от 1 до М. Переменная i соот-
ветствует номеру строки матрицы, а переменная j играет роль
второго индекса, т.е. указывает номер столбца. При таком под-
ходе программист оперирует с достаточно естественными обо-
значениями A(i,j) элементов матрицы, причем нумерация
столбцов и строк начинается с 1, как и предполагается в мат-
ричном исчислении.
В тексте программы за счет макрорасширений в процессе
препроцессорной обработки выполняются замены параметризо-
ванных обозначений A(i, j) на x[5*(i-l)+(j-l)], и далее действия
выполняются над элементами одномерного массива х[ ]. Но
этих преобразований программист не видит и может считать,
что он работает с традиционными обозначениями матричных
элементов. Использованный в программе оператор (вызов
функции)
printf ("% 6.If", A (i, j));
после макроподстановок будет иметь вид:
printf ("% 6.If", х[5*(i-1)+(j-1)]);
На рис. 3.1 приведена иллюстративная схема одномерного
массива х[ ] и виртуальной (существующей только в воображе-
нии программиста, использующего макроопределения) матрицы
для рассмотренной программы.
Отлнчия макросов от функций. Сравнивая макросы с
функциями, заметим, что в отличие от функции, определение
которой всегда присутствует в одном экземпляре, тексты, фор-
мируемые макросом, вставляются в программу столько раз,
сколько раз используется макрос. Обратим внимание на еще
одно отличие: функция определена для данных того типа, кото-
156
Программирование на языке Си
i-я строка к. 0.0 1.0 2.0 3.0 4.0 Матрица А С размерами 4x5
5.0 6.0 7.0 8.0 9.0
10.0 11.0 12.0 13.0 14.0
15.0 16.0 17.0 18.0 19.0
Рис. 3.1. Имитация матрицы с помощью макроопределения
и одномерного массива:
А (1,1) соответствует х[5*(1-1)+(1-1)] = = х[0]
А (1,2) соответствует х[5*(1-1)+(2-1)] = = х[1]
А (2,1) соответствует х[5*(2-1)+(1-1)] = = х[5]
А (3,4) соответствует х[5*(3-1)+(4-1)] = = х[13]
рый указан в спецификации ее параметров и возвращает значе-
ние только одного конкретного типа. Макрос пригоден для об-
работки параметров любого типа, допустимых в выражениях,
формируемых при обработке строки замещения. Тип получае-
мого значения зависит только от типов параметров и от самих
выражений. Таким образом, макрос может заменять несколько
функций. Например, приведенные макросы тах() и ABS() вер-
но работают для параметров любых целых и вещественных ти-
пов, а результат зависит только от типов параметров.
Отметим как рекомендацию, что для устранения неодно-
значных или неверных использований макроподстановок пара-
метры в строке замещения и ее саму полезно заключать в
скобки.
Еще одно отличие: фактические параметры функций - это
выражения, а аргументы вызова макроса - препроцессорные
Глава 3. Препроцессорные средства
157
лексемы, разделенные запятыми. Аргументы макрорасширени-
ям не подвергаются.
Препроцессорные операции в строке замещения. В после-
довательности лексем, образующей строку замещения, преду-
сматривается использование двух операций - и первая
из которых помещается перед параметром, а вторая - между
любыми двумя лексемами. Операция требует, чтобы текст,
замещающий данный параметр в формируемой строке, заклю-
чался в двойные кавычки.
В качестве полезного примера с операцией рассмотрим
следующее макроопределение:
#define print (A) printf (#A"=%f', А)
К макросу print (А) можно обращаться, подставляя вместо
параметра А произвольные выражения, формирующие резуль-
таты вещественного типа. Пример:
print (sin (а/2)); - обращение к макросу;
printf ("sin (a/2)""=%f, sin (а/2)); - макрорасширение.
Фрагмент программы:
double а=3.14159;
print (sin (а/2));
Результат выполнения (на экране дисплея):
sin (а/2)=1.0
Операция допускаемая только между лексемами строки
замещения, позволяет выполнять конкатенацию лексем, вклю-
чаемых в строку замещения.
Чтобы пояснить роль и место операции рассмотрим, как
будут выполняться макроподстановки в следующих трех макро-
определениях с одинаковым списком параметров и одинаковы-
ми аргументами.
#define zero (a, b, с, d) a (bed)
#define one (a, b, с, d) a (b с d)
tfdefine two (a, b, c, d) a (b##c##d)
158
Программирование на языке Си
Макровызов:
Результат макроподстановки:
zero(sin, х, + , у)
one(sin, х, +, у)
two(sin, x, +, у)
sin(bed)
sin(x + y)
sin(x+y)
В случае zero() последовательность "bed" воспринимается
как отдельный идентификатор. Замена параметров b, с, d не вы-
полнена. В строке замещения макроса опе() аргументы отделе-
ны пробелами, которые сохраняются в результате. В строке
замещения для макроса two() использована операция что
позволило выполнить конкатенацию аргументов без пробелов
между ними.
3.6. Вспомогательные директивы
В отличие от директив #include, #define и всего набора ко-
манд условной компиляции (#if...) рассматриваемые в данном
параграфе директивы не так часто используются в практике
программирования.
Препроцессорные обозначения строк. Для нумерации
строк можно использовать директиву
#line константа
которая указывает компилятору, что следующая ниже строка
текста имеет номер, определяемый целой десятичной констан-
той. Директива может одновременно изменять не только номер
строки, но и имя файла:
#line константа "имя_файла"
Как пишут в литературе по языку Си [5], директиву #line
можно "встретить" сравнительно редко, за исключением случая,
когда текст программы на языке Си генерирует какой-то другой
препроцессор.
Смысл директивы #line становится очевидным, если рас- г
смотреть текст, который препроцессор формирует и передает на
Глава 3. Препроцессорные средства
159
компиляцию. После препроцессорной обработки каждая строка
имеет следующий вид:
имяфайла номер_строки текст_на_языке_Си
Например, пусть препроцессор получает для обработки файл
"www.c" с таким текстом:
«define N 3 /* Определение константы */
void main ( )
(
#line 23 "file.с"
double z[3*N];
)
После препроцессора в файле с именем "www.i" будет полу-
чен следующий набор строк:
www.с 1:
www.с 2: void main( )
www.c 3: {
www.c 4:
file.с 23: double z[3*3]
file.c 24: )
Обратите внимание на отсутствие в результирующем тексте
препроцессорных директив и комментария. Соответствующие
строки пусты, но включены в результирующий текст. Для них
выделены порядковые номера (1 и 4). Следующая строка за ди-
рективой #line обозначена в соответствии со значением кон-
станты (23) и указанным именем файла "file.c".
Реакция на ошибки. Обработка директивы
#егтог последовательность_лексем
приводит к выдаче диагностического сообщения в виде, опре-
деленном последовательностью лексем. Естественно примене-
ние директивы #еггог совместно с условными
препроцессорными командами. Например, определив некото-
рую препроцессорную переменную NAME
«define NAME 5
160 Программирование на языке Си
в дальнейшем можно проверить ее значение и выдать сообще-
ние, если у NAME окажется другое значение:
#if (NAME »= 5)
terror NAME должно быть равно 5 !
Сообщение будет выглядеть так:
Error <лмя_фалла> <номер_строжи>:
Error directive: NAME должно быть равно 5 !
В интегрированной среде (например, Turbo С) сообщение
будет выдано на этапе компиляции в таком виде:
Fatal <имя_файла> <номер_строки>:
Error directive: NAME должно быть равно 5 <
В случае выявления такой аварийной ситуации дальнейшая
препроцессорная обработка исходного текста прекращается, и -
только та часть текста, которая предшествует условию по-
падает в выходной файл препроцессора.
Пустая директива. Существует директива, использование
которой не вызывает никаких действий. Она имеет вид:
#
Прагмы. Директива
tfpragma последовательность_лексем
определяет действия, зависящие от конкретной реализации
компилятора. Например, в некоторые компиляторы входит ва-
риант этой директивы для извещения компилятора о наличии в
тексте программы команд на языке ассемблера.
Возможности команды #pragma могут быть весьма разнооб-
разными и важными. Стандарта для них не существует. Если
конкретный препроцессор встречает прагму, которая ему неиз-
вестна, он ее просто игнорирует как пустую директиву. В неко-
торых реализациях включена прагма
#pragma pack(n)
где п может быть 1, 2 или 4.
Глава 3. Препроцессорные средства
161
Прагма "pack" позволяет влиять на упаковку смежных эле-
ментов в структурах и объединениях (см. гл. 6).
Соглашение может быть таким:
раск(1) - выравнивание элементов по границам байтов;
раск(2) - выравнивание элементов по границам слов;
раск(4) - выравнивание элементов по границам двойных слов.
В некоторые компиляторы включены прагмы, позволяющие
изменять способ передачи параметров функциям, порядок по-
мещения параметров в стек и т.д.
3.7. Встроенные (заранее определенные)
макроимена
Существуют встроенные (заранее определенные) макроиме-
на, доступные препроцессору во время обработки. Они позво-
ляют получить следующую информацию:
__LINE _ - десятичная константа - номер текущей обраба-
тываемой строки файла с программой на Си.
Принято, что номер первой строки исходного
файла равен 1;
_FILE___- строка символов - имя компилируемого файла.
Имя изменяется всякий раз, когда препроцес-
сор встречает директиву tfinclude с указанием
имени другого файла. Когда включения файла
по команде tfinclude завершаются, восстанав-
ливается предыдущее значение макроимени
__FILE_;
__DATE____- строка символов в формате: "месяц число год",
определяющая дату начала обработки исходно-
го файла. Например, после препроцессорной
обработки текста программы, выполненной 10
марта 1997 года, оператор
printf(_DATE___);
станет таким:
ir3124 0rintf("Mar 10 1997");
162
Программирование на языке Си
__TIME_____строка символов вида "часы:минугы:секунды",
определяющая время начала обработки пре-
процессором исходного файла;
__STDC_____- константа, равная 1, если компилятор работает
в соответствии с ANSI-стандартом. В против-
ном случае значение макроимени_________________STDC__ не
определено. Стандарт языка Си предполагает,
что наличие имени_____STDC____определяется
реализацией, так как макрос___STDC____отно-
сится к нововведениям стандарта.
В конкретных реализациях набор предопределенных имен
шире. Например, в препроцессор компилятора Borland C++ до-
полнительно включены:
__ВСОРТ__ - имя, определенное равным 1, если при
компиляции используется оптимизация;
__BCPLUSPLUS_____- числовое значение соответствует версии
компилятора (определен для компилято-
f ра Си++);
__CDECL____ - идентифицирует порядок передачи пара-
метров функциям, значение 1 соответст-
вует порядку, принятому в языке Си (в
отличие от языка Паскаль);
__CONSOLE_____ - определено для 32-разрядного компиля-
тора и установлено в 1 для программ
консольного приложения;
__DLL___ - соответствует работе в режиме Windows
DLL;
__MSDOS____ - равно 1 для 16-разрядных компиляторов
Borland C++, устанавливается в 0 для 32-
разрядного компилятора;
__МТ____ - макрос доступен только для 32-разряд-
ного компилятора;
__OVERLAY_____ - значение равно 1 в оверлейном режиме;
Глава 3. Препроцессорные средства
163
PASCAL— __TCPLUSPLUS__ - противоположен CDECL ; . - числовое значение соответствует версии компилятора (определено для компиля- тора Си++);
__TLS__ - определен как истинный для 32- разрядного компилятора;
TURBOC— - числовое значение, равное 0x0400 для компилятора Borland C++ 4.0 (0x0460 - для Borland C++ 4.5 и т.д.);
WINDOWS WIN32 - означает генерацию кода для Windows; - определен для 32-разрядного компилято- ра и установлен в 1 для консольных при- ложений.
Для получения более полных сведений о предопределенных
препроцессорных именах следует обращаться к документации
по конкретному компилятору.
11
Глава 4
УКАЗАТЕЛИ, МАССИВЫ, СТРОКИ
В предыдущих главах были введены все базовые (основные)
типы языка Си. Для их определения и описания используются
служебные слова: char, short, int, long, signed, unsigned, float,
double, enum, void.
В языке Си, кроме базовых типов, разрешено вводить и ис-
пользовать производные типы, каждый из которых получен на
основе более простых типов. Стандарт языка определяет три
способа получения производных типов:
• массив элементов заданного типа;
• указатель на объект заданного типа;
• функция, возвращающая значение заданного типа.
С массивами и функциями мы уже немного знакомы по ма-
териалам главы 2, а вот указатели требуют особого рассмотре-
ния. В языке Си указатели введены как объекты, значениями
которых служат адреса других объектов либо функций. Рас-
смотрим вначале указатели на объекты.
4.1. Указатели на объекты
Адреса и указатели. Начнем изучение указателей, обратив-
шись к понятию переменной. Каждая переменная в программе -
это объект, имеющий имя и значение. По имени можно обра-
титься к переменной и получить (а затем, например, напечатать)
ее значение. В операторе присваивания выполняется обратное
действие - имени переменной из левой части оператора при-
сваивания ставится в соответствие значение выражения его пра-
вой части. С точки зрения машинной реализации имя
переменной соответствует адресу того участка памяти, который
для нее выделен, а значение переменной - содержимому этого
участка памяти. Соотношение между именем и адресом условно
представлено на рис. 4.1.
Глава 4. Указатели, массивы, строки
165
Е - имя
Программный
уровень
Переменная Значение
Участок Содержимое
памяти ----------------
Машинный
уровень
&Е - адрес
Рис. 4.1. Соотношение между именем и адресом
На рис. 4.1 имя переменной явно не связано с адресом, одна-
ко, например, в операторе присваивания Е=С+В; имя перемен-
ной Е адресует некоторый участок памяти, а выражение С+В
определяет значение, которое должно быть помещено в этот
участок памяти. В операторе присваивания адрес переменной из
левой части оператора обычно не интересует программиста и
недоступен. Чтобы получить адрес в явном виде, в языке Си
применяют унарную операцию &. Выражение &Е позволяет
получить адрес участка памяти, выделенного на машинном
уровне для переменной Е.
Операция & применима только к объектам, имеющим имя и
размещенным в памяти. Ее нельзя применять к выражениям,
константам, битовым полям структур (см. гл. 6), регистровым
переменным или внешним объектам (файлам - см. гл. 7), с ко-
торыми может взаимодействовать программа.
Рис. 4.2, взятый с некоторыми изменениями из [6], хорошо
иллюстрирует связь между именами, адресами и значениями
переменных. На рис. 4.2 предполагается, что в программе ис-
пользована, например, такая последовательность определений (с
инициализацией):
char ch='G';
int date=1937;
float summa=2.015E-6;
166
Программирование на языке Си
Машинный адрес: i । 1А2В 1 [ 1А2С 1 [ 1A2D 1 [ 1А2Е 1 1 1A2F 1 1 [ 1А30 1 | 1А31 1 !,А32 । । ।
1 1 । 1 1 байт 1 1 1 байт 1 1 1 байт 1 1 1 байт 1 1 1 байт 1 1 1 байт 1 1 1 байт 1 । । 1 байт I 1 1
1 Значение в I памяти: ] 1 1 !'G' 1 1 । 1937 । । 1 1 1 1 2.015*10"6 1 1 1 1 1 1 1 1
1 Имя: 1 ' ch 1 ' date 1 ' 1 summa 1 “ 1 1 1
Рис. 4.2. Разные типы данных в памяти ЭВМ
В соответствии с приведенным рисунком переменные раз-
мещены в памяти, начиная с байта, имеющего шестнадцатерич-
ный адрес 1А2В. Целые переменные занимают по 2 байта,
вещественные с плавающей точкой требуют участков памяти по
4 байта, символьные переменные занимают по одному байту.
При таких требованиях к памяти в данном примере &ch=l А2В
(адрес переменной ch); &date—1А2С; &summa—1А2Е. Адреса
имеют целочисленные беззнаковые значения, и их можно обра-
батывать как целочисленные величины.
Имея возможность с помощью операции & определять адрес
переменной или другого объекта программы, нужно уметь его
сохранять, преобразовывать и передавать. Для этих целей в язы-
ке Си введены переменные типа "указатель", которые для крат-
кости будем называть просто указателями, если это не приводит
к неоднозначности или путанице. Указатель в языке Си можно
определить как переменную, значением которой служит адрес
объекта конкретного типа. Кроме того, значением указателя
может быть заведомо не равное никакому адресу значение, при-
нимаемое за нулевой адрес. Для его обозначения в ряде заголо-
вочных файлов, например в файле stdio.h, определена специ-
альная константа NULL.
Как и всякие переменные, указатели нужно определять и
описывать, для чего используется, во-первых, разделитель '*'. В
Глава 4. Указатели, массивы, строки
167
описании и определении переменных типа "указатель" необхо-
димо сообщать, на объект какого типа ссылается описываемый
указатель. Поэтому, кроме разделителя '*', в определения и опи-
сания указателей входят спецификации типов, задающие типы
объектов, на которые ссылаются указатели. Примеры определе-
ния указателей:
char *z;
/* z — указатель на объект символьного типа */
int *k,*i;
/* k, i - указатели на объекты целого типа */
float *f;
/* f — указатель на объект вещественного типа */
Итак, в определениях и описаниях указателей применяется
разделитель '*', который является в этом случае знаком унарной
операции косвенной адресации, иначе называемой операцией
разыменования или операцией раскрытия ссылки или обраще-
ния по адресу. Операндом операции разыменования всегда яв-
ляется указатель. Результат этой операции - тот объект,
который адресует указатель-операнд. Таким образом, *z обо-
значает объект типа char (символьная переменная), на который
указывает z; *k - объект типа int (целая переменная), на кото-
рый указывает к, и т.д. Обозначения *z, *i, *f имеют права пе-
ременных соответствующих типов. Оператор *z- засылает
символ "пробел" в тот участок памяти, адрес которого опреде-
ляет указатель z. Оператор *k=*i=0; заносит целые нулевые зна-
чения в те участки памяти, адреса которых заданы указателями
k, i. Обратите внимание на то, что указатель может ссылаться на
объекты того типа, который присутствует в определении указа-
теля. Исключением являются указатели, в определении которых
использован тип void - отсутствие значения. Такие указатели
могут ссылаться на объекты любого типа, однако к ним нельзя
применять операцию разыменования, т.е. операцию '*'.
Скрытую в операторе присваивания Е=В+С; работу с адре-
сом переменной левой части можно сделать явной, если .за-
менить один оператор присваивания следующей после-
довательностью:
168
Программирование на языке Си
/* Определения переменных и указателя т: */
int Е,С,В,*т;
/* Значению т присвоить адрес переменной Е: */
m—&Е;
/* Переслать значение выражения С+В в участок
памяти с адресом равным значению ш: */
*ш=В+С;
Данный пример не объясняет необходимости применения
указателей, а только иллюстрирует их особенности. Возможно-
сти и преимущества указателей проявляются при работе с
функциями, массивами, строками, структурами и т.д. Перед тем,
как привести более содержательные примеры использования
указателей, остановимся подробнее на допустимых действиях с
указателями.
Операции над указателями. В языке Си допустимы сле-
дующие (основные) операции над указателями: присваивание;
получение значения того объекта, на который ссылается указа-
тель (синонимы: косвенная адресация, разыменование, раскры-
тие ссылки); получение адреса самого указателя; унарные
операции изменения значения указателя; аддитивные операции
и операции сравнений. Рассмотрим перечисленные операции
подробнее.
Операция присваивания предполагает, что слева от знака
операции присваивания помещено имя указателя, справа - ука-
затель, уже имеющий значение, либо константа NULL, опреде-
ляющая условное нулевое значение указателя, либо адрес
любого объекта того же типа, что и указатель слева.
Если для имен действуют описания предыдущих примеров,
то допустимы операторы:
i=&date;
k=i ;
z=NULL;
Комментируя эти операторы, напомним, что выражение
* имя указателя позволяет получить значение, находящееся по
адресу, который определяет указатель. В предыдущих примерах
было определено значение переменной date (1937), затем ее ад-
Глава 4. Указатели, массивы, строки
169
рес присвоен указателю i и указателю к, поэтому значением *к
является целое 1937. Обратите внимание, что имя переменной
date и разыменования *i, *к указателей i, к обеспечивают в этом
примере доступ к одному и тому же участку памяти, выделен-
ному только для переменной date. Любая из операций
*к=выражение, *\=выражение, АаХе=выражение приведет к из-
менению содержимого одного и того же участка в памяти ЭВМ.
Иногда требуется присвоить указателю одного типа значение
указателя (адрес объекта) другого типа. В этом случае исполь-
зуется "приведение типов", механизм которого понятен из сле-
дующего примера:
char *z; /* z - указатель на символ */
int *k; /* k - указатель на целое */
z=(char *)k; /* Преобразование указателей */
Подобно любым переменным переменная типа указатель
имеет имя, собственный адрес в памяти и значение. Значение
можно использовать, например, печатать или присваивать дру-
гому указателю, как это сделано в рассмотренных примерах.
Адрес указателя может быть получен с помощью унарной опе-
рации &. Выражение &.имя указателя определяет, где в памяти
размещен указатель. Содержимое этого участка памяти является
значением указателя. Соотношение между именем, адресом и
значением указателя иллюстрирует рис. 4.3.
Указатель А
* А - объект,
адресуемый
указателем А
&А - адрес указателя Значение Адрес объекта Значение
указателя (Значение объекта
———, указателя А) L— .
Рис. 4.3. Имя, адрес и значение указателя
• 170
Программирование на языке Си
С помощью унарных операций '++' и '—' числовые (ариф-
метические) значения переменных типа указатель меняются по-
разному в зависимости от типа данных, с которыми связаны эти
переменные. Если указатель связан с типом char, то при выпол-
нении операций '++' и 1—' его числовое значение изменяется на
1 (указатель z в рассмотренных примерах). Если указатель свя-
зан с типом int (указатели i, к), то операции ++i, i++, —к, к—
изменяют числовые значения указателей на 2. Указатель, свя-
занный с типом float или long, унарными операциями '++', '—’,
изменяется на 4. Таким образом, при изменении указателя на
единицу указатель "переходит к началу" следующего (или пре-
дыдущего) поля той длины, которая определяется типом.
Аддитивные операции по-разному применимы к указателям,
точнее, имеются некоторые ограничения при их использовании.
Две переменные типа указатель нельзя суммировать, однако к
указателю можно прибавить целую величину. При этом вычис-
ляемое значение зависит не только от значения прибавляемой
целой величины, но и от типа объекта, с которым связан указа-
тель. Например, если указатель относится к целочисленному
объекту типа long, то прибавление к нему единицы увеличивает
реальное значение на 4, т.е. выполняется "переход" к адресу
следующего в памяти объекта типа long.
В отличие от операции сложения операция вычитания при-
менима не только к указателю и целой величине, но и к двум
указателям на объекты одного типа. С ее помощью можно нахо-
дить разность (со знаком) двух указателей (одного типа) и тем
самым определять "расстояние" между размещением в памяти
двух объектов. При этом "расстояние" вычисляется в единицах,
кратных "длине" отдельного элемента данных того типа, к кото-
рому отнесен указатель.
Например, после выполнения операторов
int х[5] , *i, *k, j;
i=fix[0] k=fix[4] ; j=k-i;
j принимает значение 4, а не 8, как можно было бы предполо-
жить исходя из того, что каждый элемент массива х[ ] занимает
два байта.
Глава 4. Указатели, массивы, строки
171
В данном примере разность указателей присвоена перемен-
ной типа int. Однако тип разности указателей определяется по-
разному в зависимости от особенностей компилятора. Чтобы
сделать язык Си независимым от реализаций, в заголовочном
файле stddef.h определено имя (название) ptrdifft, с помощью
которого обозначается тип разности указателей в конкретной
реализации.
В следующей программе используется рассмотренная воз-
можность однозначного задания типа разности указателей. Про-
грамма будет корректно выполняться со всеми компиляторами,
соответствующими стандартам языка Си.
#include <stdio.h>
#include <stddef.h>
void main()
{
int x[5];
int *i,*k;
ptrdiff_t j;
i=&x[0];
k«fix[4];
j=k-i;
printf("\nj=%d",(int)j);
)
Результат будет таким:
j=4
Арифметические операции и указатели. Унарные адрес-
ные операции и '*' имеют более высокий приоритет, чем
арифметические операции. Рассмотрим следующий пример, ил-
люстрирующий это правило:
float а=4.0, *u, z;
u=&z ;
*u=5;
а=а + *u + 1;
/* а равно 10, и — не изменилось, z равно 5 */
При использовании адресной операции '*' в арифметических
выражениях следует остерегаться случайного сочетания знаков
172
Программирование на языке Си
операций деления 7* и разыменования так как комбинацию
7*' компилятор воспринимает как начало комментария. Напри-
мер, выражение
а/*и
следует заменить таким:
а/(*и)
Унарные операции и '++' или '—' имеют одинаковый при-
оритет и при размещении рядом выполняются справа налево.
Добавление целочисленного значения п к указателю, адре-
сующему некоторый элемент массива, приводит к тому, что
указатель получает значение адреса того элемента, который от-
стоит от текущего на п позиций (элементов). Если длина эле-
мента массива равна d байтов, то численное значение указателя
изменяется на (d*n). Рассмотрим следующий фрагмент про-
граммы, иллюстрирующий перечисленные правила:
int х[4]={ 0, 2 4, 6 ), *i, у;
i=fix[O]; /* 1 равно адресу элемента х[0] */
y=*i; /* У равно 0; i равно fix[0] */
y=*i++; /* У равно 0; i равно fix[l] */
y=++*i; /* У равно 3; i равно* fix[l] */
y=*++i; /* У равно 4; i равно fix [2] */
y=(*i)++; /* У равно 4; i равно fix [2] */
y=++(*i);' /* У равно 6; i равно fix [2] */
Указатели и отношения. К указателям применяются опера-
ции сравнения ’>', '>=', '==', '<=', '<’. Таким образом, указа-
тели можно использовать в отношениях. Но сравнивать указа-
тели допустимо только с другими указателями того же типа или
с константой NULL, обозначающей значение условного нулево-
го адреса.
Приведем пример, в котором используются операции над
указателями и выводятся (печатаются) получаемые значения.
Обратите внимание, что для вывода значений указателей
(адресов) в форматной строке функции printf() используется
спецификация преобразования %р.
Г лава 4. Указатели, массивы, строки
173
#include <stdio.h>
float х[ ] = { 10.0, 20.0, 30.0, 40.0, 50.0 };
void main( )
{
float *ul, *u2;
int i;
printf("\n Адреса указателей: &ul=%p &u2=%p",
&ul, &u2 ) ;
printf("\n Адреса элементов массива: \n");
for(i=0; i<5; i++)
{
if (i==3) printf("\n");
printf(" &x[%d] = %p", i, &x[i]);
}
printf("\n Значения элементов массива: \n");
for(i=0; i<5; i++)
{
if (i==3) printf("\n");
printf(" x[%d] = %5.1f ", i, x[i]);
}
for(ul=&x[0], u2=&x[4]; u2>=&x[0]; ul++, u2—)
{
printf("\n ul=%p *ul=%5.1f u2=%p
*u2=%5.If",ul,*ul,u2,*u2);
printf("\n u2-ul=%d", u2-ul);
}
J
При печати значений разностей указателей и адресов в функ-
ции printf( ) использована спецификация преобразования %d -
вывод знакового десятичного целого.
Возможный результат выполнения программы (конкретные
значения адресов могут быть другими):
Адреса указателей: &ul=FFF4 &u2=FFF2
Адреса элементов массива:
&х[0]=00А8 &х[1]=00АС &х[2]=00В0
&х[3]=00В4 &х[4]=00В8
Значения элементов массива:
х[0]=10.0 х[1]=20.0 х[2]=30.0
х[3]=40.0 х[4]=50.0
ul=00A8 *ul=10.0 u2=00B8 *u2=50.0
u2-ul=4
174
Программирование на языке Си
ul=00AC
u2-ul=2
ul=00B0
u2-ul=0
ul=00B4
u2-ul=-2
ul=00B8
u2-ul=-4
*ul=20.0 u2=00B4 *u2=40.0
*ul=30.0 u2=00B0 *u2=30.0
*ul=40.0 u2=00AC *u2=20.0
*ul=50.0 u2=00A8 *u2=10.0
На рис. 4.4 приводится схема размещения в памяти массива
float х[5] и указателей до начала выполнения цикла изменения
указателей.
Рис. 4.4. Схема размещения в памяти массива и указателей
Глава 4. Указатели, массивы, строки
175
4.2. Указатели и массивы
Указатели и доступ к элементам массивов. По определе-
нию, указатель - это либо объект со значением "адрес объекта"
или "адрес функции", либо выражение, позволяющее получить
адрес объекта или функции. Рассмотрим фрагмент:
int х,у;
int *р =&х;
р=&у;
Здесь р - указатель-объект, а &х, &у - указатели-выражения,
т.е. адреса-кОнстанты. Мы уже знаем, что р - переменная того
же типа, что и значения &х, &у. Различие между адресом (т.е.
указателем-выражением) и указателем-объектом заключается в
возможности изменять значения указателей-объектов. Именно
поэтому указатели-выражения называют указателями-
константами или адресами, а для указателя объекта используют
название указатель-переменная или просто указатель.
В соответствии с синтаксисом языка Си имя массива без ин-
дексов является указателем-константой, т.е. адресом его первого
элемента (с нулевым индексом). Это нужно учитывать и пом-
нить при работе с массивами и указателями.
Рассмотрим задачу "инвертирования" массива символов и
различные способы ее решения с применением указателей
(заметим, что задача может быть легко решена и без указателей
- с использованием индексации). Предположим, что длина мас-
сива типа char равна 80.
Первое решение задачи инвертирования массива:
char z[80],s;
char *d,*h;
/* d и h - указатели на символьные объекты */
for (d=z, h=&z[79]; d<h; d++,h—)
{
s=*d;
*d=*h;
*h=s ;
}
176
Программирование на языке Си
В заголовке цикла указателю d присваивается адрес первого
(с нулевым индексом) элемента массива z. Здесь можно было
бы применить и другую операцию, а именно: d=&z[0]. Указа-
тель h получает значение адреса последнего элемента массива z.
Далее работа с указателями в заголовке ведется, как с обычны-
ми целочисленными переменными. Цикл выполняется до тех
пор, пока d<h. После каждой итерации значение d увеличивает-
ся, значение h уменьшается на 1. При первой итерации в теле
цикла выполняется обмен значений z[0] и z[79], так как d - ад-
рес z[0], h - адрес z[79]. При второй итерации значением d явля-
ется адрес z[l], для h - адрес z[78] и т.д.
Второе решение задачи инвертирования массива:
char z[80] , s, *d, *h;
for (d=z, h=&z[79]; d<h;)
{
s=*d; *d++=*h; *h— = s;
}
Приращение указателя d и уменьшение указателя h перене-
сены в тело цикла. Напоминаем, что в выражениях *d++ и *h—
операции увеличения и уменьшения на 1 имеют тот же приори-
тет, что и унарная адресная операция Поэтому изменяются
на 1 не значения элементов массива, на которые указывают d и
h, а сами указатели. Последовательность действий такая: по
значению указателя d (или h) обеспечивается доступ к элементу
массива; в этот элемент заносится значение из правой части
оператора присваивания; затем увеличивается (уменьшается) на
1 значение указателя d (или h).
Третье решение задачи инвертирования массива (исполь-
зуется цикл с предусловием):
char zteO]^ s, *d, *h;
d=z ;
h=&z[79];
while (d < h)
{
s=*d; *d++ = *h; *h— = s;
}
Глава 4. Указатели, массивы, строки
177
Четвертое решение задачи инвертирования массива
(имитация индексированных переменных указателями со сме-
щениями):
char z[80],s;
int i;
for (i=0; i<40; i++)
{
s = *(z+i) ;
*(z+i) = *(z+(79-i));
*(z+(79-i)) = s;
}
Последний пример демонстрирует возможность использова-
ния вместо индексированного элемента z[i] выражения *(z+i). В
языке Си, как мы упоминали, имя массива без индексов есть
адрес его первого элемента (с нулевым значением индекса).
Прибавив к имени массива целую величину, получаем адрес со-
ответствующего элемента, таким образом, &z[i] и z+i - это две
формы определения адреса одного и того же элемента массива,
отстоящего на i позиций от его начала.
Итак, в соответствии с синтаксисом языка операция индек-
сирования El[Е2] определена таким образом, что она эквива-
лентна *(Е1+Е2), где Е1 - имя массива, Е2 - целое. Для
многомерного массива правила остаются теми же. Таким об-
разом, E[n][m][k] эквивалентно *(E[n][m]+k) и, далее
*(*(*(E+n)+m)+k).
Отметим, что имя массива не является переменной типа ука-
затель, а есть константа - адрес начала массива. Таким обра-
зом, к имени массива не применимы операции '++' (увеличения),
'—' (уменьшения), имени массива нельзя присвоить значение,
т.е. имя массива не может использоваться в левой части опера-
тора присваивания.
В рассмотренных примерах указатели относились к символь-
ным переменным, и поэтому их приращения были единичными.
Однако это обеспечивалось только особенностями представле-
ния в памяти символов - каждый символ занимает в памяти
один байт, и поэтому адреса смежных элементов символьного
массива отличаются на 1. В случае массивов с другими элемен-
12-3124
178 Программирование на языке Си
тами (другого типа) единичному изменению указателя, как уже
отмечалось, соответствует большее изменение адреса.
В следующей программе продемонстрируем еще раз особен-
ности изменения указателей при переходе от элемента к элемент
ту в массивах с элементами разных типов:
#include <stdio.h>
/* Изменение значений указателей на элементы
массива */
void main( ) .
{
char z[5]; int m[5]; float a[5];
char *uz; int *um; float *ua;
printf("\n Адреса элементов символьного "
"массива:\n");
for (uz=z; uz <= &z[4]; uz++)
printf(" %10p",uz);
printf("\n Адреса элементов целочисленного "
"массива:\n");
for.(um=m; um <= &m[4]; um++)
printf ("%10p",um);
printf("\n Адреса элементов вещественного "
"массива:\n");
for (ua=a; ua <= &a[4]; ua++)
printf(" %10p",ua);
}
Результат выполнения программы:
Адреса элементов символьного массива :
FFFO FFF1 FFF2 FFF3 FFF4
Адреса элементов целочисленного массива:
FFF6 FFF8 FFFA FFEC FFFE
Адреса элементов вещественного массива:
FFDO FFD4 FFD8 FFDC FFE0
Как подтверждает рассмотренный пример, изменение указа-
теля на 1 приводит к разным результатам в зависимости от типа
объекта, с которым связан указатель. Значение указателя изме-
няется на длину участка памяти, выделенного для элемента, свя-
занного с указателем. Символы занимают в памяти по одному
байту, поэтому значение указателя uz изменяется на 1 при пере-
Глава 4. Указатели, массивы, строки
179
ходе к соседнему элементу символьного массива. Для целочис-
ленного массива переход к соседнему элементу изменяет указа-
тель um на 2. Для массива вещественных элементов с
плавающей точкой переход к соседнему элементу изменяет ука-
затель иа на 4.
Массивы динамической памяти. В соответствии со стан-
дартом языка массив представляет собой совокупность элемен-
тов, каждый из которых имеет одни и те же атрибуты
(характеристики). Все элементы размещаются в смежных участ-
ках памяти подряд, начиная с адреса, соответствующего началу
массива, т.е. значению & имя массива [0].
При традиционном определении массива:
тип имя_массива [количество_элементов\,
имя_массива становится указателем на область памяти, выде-
ляемой для размещения элементов массива. Количест-
во_элементов в соответствии с синтаксисом языка должно быть
константным выражением. Тип явно определяет размеры памя-
ти, выделяемой для каждого элемента массива.
Таким образом, общее количество элементов массива и раз-
меры памяти, выделяемой для него, полностью и однозначно
заданы определением. Это не всегда удобно. Иногда нужно,
чтобы память для массива выделялась в таких размерах, какие
нужны для решения конкретной задачи, причем потребности в
памяти заранее не известны и не могут быть фиксированы.
Формирование массивов с переменными размерами можно
организовать с помощью указателей и средств для динамиче-
ского выделения памяти. Начнем рассмотрение указанных
средств с библиотечных функций, описанных в заголовочных
файлах alloc.h и stdlib.h стандартной библиотеки (файл alloc.h
не является стандартным). В табл. 4.1 приведены сведения об
этих библиотечных функциях. Функции malloc(), calloc() и
realloc() динамически выделяют память в соответствии со зна-
чениями параметров и возвращают адрес начала выделенного
участка памяти. Для универсальности тип возвращаемого зна-
чения каждой из этих функций есть void*. Этот указатель
12*
180
Программирование на языке Си
(указатель такого типа) можно преобразовать к указателю лю-
бого типа с помощью операции явного приведения типа (тип *).
Функция free( ) решает обратную задачу - освобождает па-
мять, выделенную перед этим с помощью одной из трех функ-
ций calloc(), malloc( ) или realloc( ). Сведения об этом участке
памяти передаются в функцию free() с помощью указателя -
параметра типа void *. Преобразование указателя любого типа к
типу void * выполняется автоматически, поэтому вместо фор-
мального параметра void *Ы можно подставить в качестве фак-
тического параметра указатель любого типа без операции
явного приведения типов.
Таблица 4.1
Функции для выделения и освобождения памяти
Функция Прототип и краткое описание
malloc void * malloc (uusigned s); Возвращает указатель на начало области (блока) динамической памяти длиной в s байт. При неудачном завершении возвращает значение NULL.
calloc void * calloc (uusigned n, unsigned m); Возвращает указатель на начало области (блока) обнуленной динамической памяти, выделенной для размещения п элементов по m байт каждый. При неудачном завершении возвращает зна- чение NULL.
realloc void * realloc (void * bl, unsigned ns); Изменяет размер блока ранее выделенной динамической памяти до размера ns байт. Ы - адрес начала изменяемого блока. Если Ы равен NULL (память не выделялась), то функция выполняет- ся как malloc.
free void * free (void * bl); Освобождает ранее выделенный участок (блок) динамической памяти, адрес первого байта которого равен значению Ы.
Следующая программа иллюстрирует на несложной задаче
особенности применения функций выделения (шаПос) и осво-
бождения (free) динамической памяти. Решается следующая
Глава 4. Указатели, массивы, строки
181
задача: ввести и напечатать в обратном порядке набор вещест-
венных чисел, количество которых заранее не фиксировано, а
вводится до начала ввода самих числовых значений. Текст про-
граммы может быть таким: ,
#include <stdio.h>
#include <stdlib.h>
void main ( )
{
I * Указатель для выделяемого блока памяти */
float *t;
int i,n;
printf("\nn="); /* n - число элементов */
scanf("%d”,&n);
t=(float *)malloc(n*sizeof(float));
for(i=0; i<n; i++) /* Цикл ввода чисел */
{ printf("x[%d]=",i);
scanf("%f",&t[i]) ;
}
/* Цикл печати результатов */
for(i=n-l; i>=0; i—)
{
if (i%2=0) printf("\n");
printf("\tx[%d]=%f",i,t[i]) ;
J
free (t); /* Освобождение памяти */
}
Результат выполнения программы (компилятор ВС++3.1 и
компилятор из операционной системы Free BSD UNIX):
n=4
x[0]=10
x[l]=20
x[2]=30
x[3]=40
x[3]=40.000000 x[2]=30.000000
x[l]=20.000000 x[0]=10.000000
В программе int n - количество вводимых чисел типа float, t
- указатель на начало области, выделяемой для размещения п
вводимых чисел. Указатель t принимает значение адреса облас-
182
Программирование на языке Си
ти, выделяемой для п штук значений типа float. Обратите вни-
мание на приведение типа (float*) значения, возвращаемого
функцией malloc(). Доступ к участкам выделенной области па-
мяти выполняется с помощью операции индексирования: t[i] и
t[i-1]. Остальное очевидно из текста программы. Оператор
free(t); содержит вызов функции, освобождающей выделенную
ранее динамическую память и связанной с указателем t.
Следующее замечание не имеет никакого отношения к стан-
дартам языка Си. Выше указано, что результат выполнения про-
граммы получен при использовании компилятора языка Си,
включенного в интегрированную среду программирования
Borland C++3.1 и компилятора из операционной системы Free
BSD UNIX. Необходимость в этом замечании связана с давним
затруднением, которое сопровождает уже несколько поколений
компиляторов разных фирм. Функция scanf() "отказывается"
вводить значения индексированных элементов динамических
вещественных массивов. Например, при попытке выполнить
программу в интегрированной среде Turbo C++1.01 выдается
сообщение:
x[0]=scanf: floating point formats not linked
Abnormal program termination
Обойти это затруднение можно двумя путями. Во-первых,
можно использовать вспомогательную переменную для ввода,
например, так:
float W;
for (i=0; i<n; i++)
{
printf ("x[%d]=", i);
scanf ("%f", &W);
t[ij=W; .
}
Во-вторых, можно воспользоваться компилятором, библио-
течная функция которого не выдает такой ошибки. Такой ком-
пилятор языка Си включен в интегрированную среду
Borland C++3.1. (Однако и этот улучшенный компилятор
Глава 4. Указатели, массивы, строки
183
"спотыкается" при вводе значений элементов многомерных мас-
сивов динамической памяти, которые мы рассмотрим ниже в
этом параграфе.) Устойчиво работает компилятор в системе
Free BSD UNJX.
Массивы в каноническом смысле, вводимые с помощью оп-
ределения массива, отличаются от массивов динамической па-
мяти. Наиболее существенным отличием является отсутствие
"имени собственного" у динамического массива. Чтобы проде-
монстрировать важность этого различия, рассмотрим стандарт-
ную процедуру определения количества элементов кано-
нического массива с помощью операции sizeof.
Напомним, что операция sizeof имеет две формы вызова:
sizeof (тип)
sizeof выражение
В качестве типа могут использоваться типы любых объектов
(нельзя использовать тип функции), за исключением типа void.
В результате выполнения операции sizeof вычисляется размер в
байтах ее операнда. Если операнд есть выражение, то вычисля-
ется его значение, для этого значения определяется тип, Для ко-
торого и вычисляется длина в байтах. Например:
sizeof (long) обычно равно 4;
sizeof (long double) обычно равно 10.
Чтобы в программе вычислить количество элементов кано-
нически определенного конкретного массива, удобно использо-
вать операцию sizeof, применяя ее дважды - к имени массива и
к его нулевому элементу. Если операндом для sizeof служит имя
массива (без индексов), то возвращается значение "длины" па-
мяти, отведенной для массива в целом. Таким образом, значени-
ем выражения
sizeof (имя_массива) /sizeof (имя_массива[0))
будет количество элементов в массиве.
В следующем фрагменте "перебираются" все элементы мае- •
сива х:
184
Программирование на языке Си
float х[8];
for (i=0; sizeof(х)/sizeof(х[О’])>i; i++)
....x[i]...
Если применить операцию sizeof к тому указателю, который
получил значение адреса начала памяти, выделенной для дина-
мического массива с помощью одной из функций табл. 4.1, то
будет вычислен размер не динамического участка памяти, а
только размер самого указателя. Для иллюстрации этого поло-
жения рассмотрим фрагмент программы:
double *pointer;
pointer=(double*) mallee(100);
... sizeof(pointer)
Независимо от значения параметра функции malloc() значе-
ние выражения sizeof(pointer) всегда будет одинаковым - рав-
ным величине участка памяти для переменной (для указателя)
pointer.
Массивы указателей и моделирование многомерных мас-
сивов. Хотя синтаксисом языка Си массив определяется как
одномерная совокупность его элементов, но каждый элемент
может быть, в свою очередь, массивом. Именно так конструи-
руются многомерные массивы. Язык Си не накладывает явных
ограничений на размерность массива, однако каждая реализация
обычно вводит такое ограничение. Максимальное значение раз-
мерности массивов определяет константа (препроцессорная),
определенная в заголовочном файле стандартной библиотеки.
Обычно это предельное значение размерности массивов уста-
навливается равным 12.
В главе 3 матрицы имитировались с применением одномер-
ных массивов и макроопределений, обеспечивающих доступ к
элементам с помощью двух индексов.
В главе 2 рассматривались двумерные массивы фиксирован-
ных размеров и приводились примеры их использования для
представления: матриц. Однако матрицы (двумерные массивы)
имели фиксированные размеры. Очевидного способа прямого
определения многомерных массивов с несколькими перемен-
Глава 4. Указатели, массивы, строки
185
ными размерами в языке Си не существует. Решение, как и для
случая одномерных массивов динамической памяти, находится
в области системных средств (библиотечных функций) для ди-
намического управления памятью. Но прежде чем рассматри-
вать их возможности для многомерных массивов, необходимо
ввести массивы указателей.
Массив указателей фиксированных размеров вводится од-
ним из следующих определений:
тип * имямассива [размер];
тип * имя массива [ ]=инициализатор;
тип * имя массива [размер]=инициализатор;
где тип может быть как одним из базовых типов, так и произ-
водным типом;
имя массива - свободно выбираемый идентификатор;
размер - константное выражение, вычисляемое в процес-
се трансляции;
инициализатор - список в фигурных скобках значений
типа тип*.
Примеры:
int data[6]; /* обычный массив */
int *pd[6]; /* массив указателей */
int *pi[ ]={ &data[0], &data[4], &data[2] };
Здесь каждый элемент массивов pd и pi является указателем
на объекты типа int. Значением каждого элемента pd[j] и pi[k]
может быть адрес объекта типа int. Все 6 элементов массива pd
указателей типа int * не инициализированы. В массиве pi три
элемента, которые инициализированы адресами конкретных
элементов массива data.
Интересные возможности массива указателей появляются в
тех случаях, когда его элементы адресуют либо элементы дру-
гого массива, либо указывают на начало одномерных массивов
соответствующего типа. В таких случаях очень красиво реша-
ются задачи сортировки сложных объектов с разными размера-
ми. Например, можно ввести массив указателей, адресовать с
помощью его элементов строки матрицы и затем решать задачи
186
Программирование на языке Си
упорядочения строк матрицы, не переставляя строки двумерно-
го массива, представляющего матрицу. Если с двумерным мас-
сивом связать несколько одномерных массивов указателей,
то можно упорядочить строки матрицы одновременно по раз-
ным правилам, "добираясь" до строк с помощью разных масси-
вов указателей.
В качестве простого примера рассмотрим программу одно-
временного упорядочения и по возрастанию, и по убыванию
одномерного массива без перестановки его элементов.
finclude <stdio.h>
fdefine В 6
void main( )
{
float array[ ]={5.0, 2.0, 3.0, 1.0, 6.0, 4.0};
float * pmin[B];
float * pmax[B];
float * e;
int i,j;
for (i=0; i<B; i++)
pmin[i]=pmax[i]=&array[ i ] ;
for (i=0; i<B-l; i++)
for (j=i+l; j<B; j++)
{
if (*pmin[i]<*pmin[j])
{
e=pmin[i];
pmin[i]=pmin[j];
pmin[j]=e;
)
if (*pmax[i]>*pmax[j])
{
e=pmax[i];
pmax[i]=pmax[ j ] ;
pmax[j]=e;
}
}
printf("\n По убыванию: \n");
for (i=0; i<B; i++)
printf("\t%5.3f",*pmin[i]);
printf("\n По возрастанию: \n");
for (i=0; i<B; i++)
printf("\t%5.3f",*pmax[i]);
}
Глава 4. Указатели, массивы, строки
187
Результаты выполнения программы:
По убыванию:
6.000 5.000 4.000 3.000 2.000 1.000
По возрастанию:
1.000 2.000 3.000 4.000 5.000 6.000
В программе с помощью перестановки значений элементов
массива указателей pmin[6] определяется последовательность
"просмотра" элементов массива аггау[6] в порядке убывания их
значений. Массив указателей ртах[6] решает такую же задачу,
но для "просмотра" массива аггау[6] в порядке возрастания их
значений. Рис. 4.5 иллюстрирует исходную и результирующую
адресации элементов массива аггау[6] элементами массивов ука-
зателей. Для "обмена" значений элементов массивов ртах[6] и
pmin[6] введен вспомогательный указатель float * е.
Рис. 4.5. Массивы указателей в задаче упорядочения:
а - массивы до упорядочения; б - массивы после упорядочения
188
Программирование на языке Си
"Матрица" со строками разной длины. Массив в языке Си
должен иметь элементы одного типа и, естественно, одного
размера. В ряде случаев возникает необходимость обрабаты-
вать, подобно элементам массива, объекты разного размера.
Например, попытка оформить в виде двумерного массива стро-
ки чисел с разным количеством числовых значений при обыч-
ном подходе потребует определить двумерный массив с Мак-
симально допустимыми размерами. Наличие более коротких
строк не может уменьшить общих размеров массива - излишние
требования к памяти налицо. Использование массивов указа-
телей и средств динамического выделения памяти позволяет
обойти указанные затруднения и более рационально распре-
делить память. Для иллюстрации этих возможностей рассмот-
рим следующую задачу, очень схожую с задачей, рассмотрен-
ной ранее.
Необходимо ввести и распечатать в обратном порядке набор
строк числовых значений. Количество строк в наборе вводится в
начале работы программы, а длина каждой строки (т.е. количе-
ство чисел - элементов в ней) вводится перед каждой последо-
вательностью числовых значений элементов строки.
Программа для решения задачи может быть такой:
#include <stdio.h>
#include <alloc.h>
void main( )
{
double ** line;
/* line - указатель для блока памяти,
выделяемого для массива указателей */
int i,j, n;
double dd;
int * m; /* Указатель для блока памяти */
printf("\п\пВведите количество строк п=");
scanf("%d",&n);
line=(double**)calloc(n,sizeof(double*));
m=(int *)mallbc(sizeof(int)*n);
Глава 4. Указатели, массивы, строки
189
/* Цикл по количеству строк*/
for(i=0;i<n;i++)
{
printf("Введите длину строки m[%d]=",i);
scanf("%d",&m[i]);
line[i]=(double*)calloc(m[i],sizeof(double));
for(j=0;j<m[i];j++)
{
printf("line[%d][%d]=",i,j);
scanf("%le",&dd);
line[i][j]=dd;
)
}
printf("\п₽езультаты обработки:");
for(i=n-l;i>=0;i—)
<
printf("\пСтрока %d, элементов %d:\n",i,m[i]);
for(j=0;j<m[i];j++)
printf("\t%f", line[i][j]);
free(line[i]); /* Освободить память строки */
}
/* Освободить память от массива указателей: */
free(line);
/* Освободить память от массива int: */
free(m);
}
Результаты выполнения программы (Free BSD UNIX):
Введите количество строк п=5
Введите длину строки т[0]=4
line[0][0]=0.0
line[0][1]=0.1
line[0][2]=0.2
line[0][3]=0.3
Введите длину строки m [1]=3
linefl][0]=1.0
linefl][1J-1.1
line[l][2]=1.2
190
Программирование на языке Си
Введите длину строки m [2]=1
line[2][0]=2.0
Введите длину строки m [3]=4
line[3][0]=3.0
line[3][1]=3.1
line[3][2]=3.2
line[3][3]=3.3
Введите длину строки m [4]=2
line [4][0]=4.0
line [4][Ц=4.1
Результат обработки:
Строка 4, 4.000000 элементов 2: 4.100000
Строка 3, 3.000000 элементов 4: 3.100000 3.200000 3.300000
Строка 2, 2.000000 элементов 1:
Строка 1, 1.000000 элементов 3: 1.100000 1.200000
Строка 0, 0.000000 элементов 4: 0.100000 0.200000 0.300000
Приведенным результатам выполнения программы соответ-
ствует рис. 4.6, где условно изображены все массивы, динами-
чески формируемые в процессе выполнения программы.
В программе использованы:
line - указатель на массив указателей типа double *, каж-
дый из которых, т.е. line[i], адресует динамически выделяемый
участок памяти длиной в m[i] элементов типа double.
m - указатель на массив целых (int), значение каждого
элемента равно длине массива, на который указывает 1 ine[i].
Глава 4. Указатели, массивы, строки
191
Указатель Указатель
Рис. 4.6. Схема "матрицы” со строками разной длины для случая:
число строк п=5, количество элементов в строках: 4, 3,1, 4, 2
Для иллюстрации разных функций выделения памяти в про-
грамме использованы calloc() и malloc(). Различие между ними
заключается в количестве и смысле параметров (см. табл. 4.1), а
также в том, что функция calloc() обнуляет содержимое выде-
ленного блока памяти.
При выходе из программы все блоки динамически выделяе-
мой памяти рекомендуется явным образом освобождать. Для
этих целей используется несколько вызовов функции free(). В
Цикле по i после печати очередной строки функция free (line[ij)
освобождает участок памяти, адресуемой указателем line[i]. По-
сле окончания цикла освобождаются блоки, выделенные для
массива указателей free(Iine) и массива целых free(m).
192
Программирование на языке Си
4.3. Символьная информация и строки
Для представления текстовой информации в языке Си ис-
пользуются символы (константы), символьные переменные и
строки (строковые константы), для которых в языке Си не вве-
дено отдельного типа в отличие от некоторых других языков
программирования.
Символьные константы были рассмотрены в главе 1. Для
символьных данных введен базовый тип char. Описание сим-
вольных переменных имеет вид:
char списокимен _переменных;
Например:
char а,z;
Ввод-вывод символьных данных. Для ввода и вывода сим-
вольных значений в форматных строках библиотечных функций
printf() и scanf() используется спецификация преобразования
%с. Некоторые особенности работы с символьными данными
уже рассматривались выше. Смотрите, например, разные спосо-
бы "инвертирования" массива символов в §4.2. Продолжая эту
тему, рассмотрим следующую задачу.
Ввести предложение, слова в котором разделены пробелами
и в конце которого стоит точка. Удалить повторяющиеся пробе-
лы между отдельными словами (оставить по одному пробелу),
вывести отредактированное предложение на экран.
Текст программы:
/* Удаление повторяющихся пробелов */
tfinclude <stdio.h>
void main( )
{
char z, s; /* z — текущий вводимый символ */
printf("\n Напишите предложение с точкой ’’
"в конце:\п");
for (z=s=' ' ; z!='.'; s=z)
{ /* s - предыдущий символ */
scanf("%c",&z);
if (z==' ' && s=' ') continue;
Глава 4. Указатели, массивы, строки
193
printf ("%c’',z) ;
} /* Конец цикла обработки */
} /* Конец программы */
В программе две символьные переменные: z - для чтения
очередного символа и s - для хранения предыдущего. В заго-
ловке цикла переменные z и s получают значения "пробел".
Очередной символ вводится как значение переменной z, и пара
z, s анализируется. Если хотя бы один из символов значений па-
ры отличен от пробела, то значение z печатается. В заголовке
цикла z сравнивается с символом "точка" и при несовпадении
запоминается как значение s. Далее цикл повторяется до появ-
ления на входе точки, причем появление двух пробелов (z и s)
приводит к пропуску оператора печати.
Пример работы программы:
Напишите предложение с точкой в конце:
YYYYY УУУУУ hhhhh ttttt.
YYYYY ууууу hhhhh ttttt.
Помимо scanf() и printf() для ввода и вывода символов в
библиотеке предусмотрены специальные функции обмена:
getchar() - функция без параметров. Позволяет читать из
входного потока (обычно с клавиатуры) по одному символу за
обращение. Как и при использовании функции scanf(), чтение
вводимых данных начинается после нажатия клавиши <Enter>.
Это дает возможность исправлять вводимую информацию
(стирая последние введенные символы с помощью клавиши
<Backspace>) до начала ее чтения программой;
putchar(X) - выводит символьное значение X в стандартный
выходной поток (обычно на экран дисплея).
Проиллюстрируем применение этих функций на следующей
задаче: "Ввести предложение, в конце которого стоит точка, и
подсчитать общее количество символов, отличных от пробела
(не считая точки)".
/* Подсчет числа отличных от пробелов символов*/
#include <stdio.h>
void main( )
{
13'3124
194
Программирование на языке Си
char z; /* z — вводимый символ */
int к; /* к - количество значащих символов */
printf("Напишите предложение с точкой в "
"конце:\п");
for (k=0; (z=getchar( ))>='.'; )
if (z?=' ') k++;
printf ("\n Количество символов=%<3" ,k) ;
} /* Конец программы */
В заголовке цикла for выражение z=getchar() заключено в
скобки, так как операция присваивания (см. табл. 1.4 на с. 34)
имеет более низкий ранг, чем операции сравнения. Если скобки
опустить, то последовательность операций будет такой: функ-
ция getchar() введет значение символа и выполнит его сравне-
ние с символом Результат сравнения присвоится переменной
z. По смыслу же необходимо введенный символ присвоить пе-
ременной z и сравнить его с точкой.
Результат выполнения программы:
Напишите предложение с точкой в конце:
123456789 0.
Количество символов=10
Внутренние коды и упорядоченность символов. В языке
принято соглашение, что везде, где синтаксис позволяет исполь-
зовать целые числа, можно использовать и символы, т.е. данные
типа char, которые при этом представляются числовыми значе-
ниями своих внутренних кодов. Такое соглашение позволяет
сравнительно просто упорядочивать символы, обращаясь с ни-
ми как с целочисленными величинами. Например, внутренние
коды десятичных цифр в таблицах кодов ASCII упорядочены по
числовым значениям, поэтому несложно перебирать символы
десятичных цифр в нужном порядке.
Следующая программа печатает цифры от 0 до 9 и шестна-
дцатеричные представления их внутренних кодов.
/* Печать десятичных цифр: */
#include <stdio.h>
void main( )
Глааа 4. Указатели, массивы, строки
195
{
char z;
for (z=*0'; z<=*9’; z++)
{
if (z='O5 || z=*=’5’) printf ("\n") ;
printf(” %c-%x ”, z, z) ;
}
} /* Конец программы */
Результат выполнения программы:
0-30 1-31 2-32 3-33 4-34
5-35 б-Зб 7-37 8-38 9-39
Обратите внимание на то, что символьная переменная z явля-
ется операндом арифметической операции выполняемой
над числовым представлением ее внутреннего кода. Для изо-
бражения значения символов в форматной строке функции
printf() используется спецификация %с. Шестнадцатеричные
коды выводятся с помощью спецификации %х. В Приложении 1
можно посмотреть, что именно такими являются шестнадцате-
ричные коды символов. Для 'О' - код 30, для 'Г - код 31 и т.д.
Воспользовавшись упорядоченностью внутренних кодов
букв латинского алфавита, очень просто его напечатать:
/* Печать латинского алфавита: */
#include <stdio.h>
void main( )
{
char z;
for (z=’A'; z<=’Z'; z++)
printf("%c",z);
} /* Конец•программы * /
Результат выполнения программы:
ABODEFGHIJKI24NOPQRSTUVWXYZ
Строки, или строковые константы. В программе строки,
или строковые константы, представляются последовательно-
стью изображений символов, заключенной в кавычки (не в апо-
строфы), например "любые_символы". Среди символов строки
13*
196
Программирование на языке Си
могут быть эскейп-последовательности, соответствующие ко-
дам неизображаемых (специальных) символьных констант.
Примеры строк:
"1234567890"
"\t Состав президиума"
" Начало строки \п и конец строки".
Строки уже многократно встречались в функциях printf() и
scanf(). (
Однако у строк есть некоторые особенности. Транслятор от-
водит каждой строке отдельное место в памяти ЭВМ даже в тех
случаях, когда несколько строк полностью совпадают (стандарт
языка Си предполагает, что в конкретных реализациях это пра-
вило может не выполняться). Размещая строку в памяти, транс-
лятор автоматически добавляет в ее конце символ *\0', т.е.
нулевой байт. В записи строки может быть и один символ: "А",
однако в отличие от символьной константы 'А' (использованы
апострофы) длина строки "А" равна двум байтам. В отличие от
других языков (например, от Паскаля) в языке Си нет отдельно-
го типа для строк. Принято, что строка - это массив символов,
т.е. она всегда имеет тип char[ ]. Таким образом, строка счита-
ется значением типа "массив символов". Количество элементов
в таком массиве на 1 больше, чем в изображении соответст-
вующей строковой константы, так как в конец строки добав-
лен нулевой байт '\0'.
Присвоить значение массиву символов (т.е. строке) с помо-
щью обычного оператора присваивания нельзя. Поместить
строку в массив можно либо с помощью инициализации (при
определении символьного массива), либо с помощью функций
ввода. В функции scanf() или printf() для символьных строк
используется спецификация преобразования %s.
При определении массива типа char с одновременной ини-
циализацией можно не указывать пределы изменения индекса.
Сказанное иллюстрирует следующая программа:
/* Печать символьной строки */
#include <stdio.h>
void main( )
Г/iaea 4. Указатели, массивы, строки
197
{
char В[ ]="Сезам, откройся!";
printf("%s",В);
} /* Конец программы */
Результат выполнения программы:
Сезам, откройся!
В программе длина массива В - 17 элементов, т.е. длина
строки, помещаемой в массив (16 символов), плюс нулевой байт
окончания строки. Именно 17 байтов выделяется при инициали-
зации массива в приведенном примере. Инициализация массива
символов с помощью строковой константы представляет собой
сокращенный вариант инициализации массива и введена в язык
для упрощения. Можно воспользоваться обычной инициализа-
цией, поместив начальные значения элементов массива в фи-
гурные скобки и не забыв при этом поместить в конце списка
начальных значений специальный символ окончания строки '\0'.
Таким образом, в программе была бы допустима такая инициа-
лизация массива В:
char В[ ]={,C,,,e,,'B,,,a,,'м,,,,,,' ,,,о,,,т',
'K'j'p'j'o'j'ft'j'c'j'a'j'i'j'XO' };
Соглашение о признаке окончания строки нужно соблюдать,
формируя в программах строки из отдельных символов. В каче-
стве примера рассмотрим следующую задачу: "Ввести предло-
жение, заканчивающееся точкой, слова в котором отделены
пробелами. Напечатать последнее слово предложения".
Анализ условия задачи позволяет выявить следующие оши-
бочные ситуации и особые случаи: отсутствие точки в конце
предложения; пробел или пробелы перед первым словом пред-
ложения; несколько пробелов между словами; пробелы перед
завершающей предложение точкой; отсутствие слов в предло-
жении (только точка). Чтобы не усложнять решение задачи,
примем соглашение о том, что вводимое предложение всегда
размещается на одной строке дисплея, т.е. длина его не пре-
вышает 80 символов. Это позволит легко выявлять отсутствие
точки в конце предложения и ограничивает длину любого слова
198
Программирование на языке Си
предложения. Чтобы учесть особые ситуации с пробелами, не-
обходимо при анализе очередного введенного символа
(переменная s) рассматривать и предыдущий символ
(переменная ss). Для выявления отсутствия слов в предложении
будем вычислять длину к каждого очередного вводимого слова.
Если к=0, а вводится символ то это признак пустого пред-
ложения.
Текст программы:
/* Напечатать последнее слово в предложении* */
#include <stdio.h>
void main( )
{
char s,ss; / * s - вводимый символ */
/* ss — предыдущий введенный символ */
char А[80]; /* Массив для слова */
int i,k; /* k - длина слова */
printf("Напишите предложение с точкой в "
"конце:\п");
for (i=0,s=' ' ,k=0; i<=79; i++)
(
ss=s; s=getchar( );
if (s=' ') continue;
if (s=='.') break;
if (ss==' ') k=0;
A[k]=s; k++;
}
/♦Выход по точке или по окончании ввода строки*/
if (i==80 | | k=0)
printf(" Неверное предложение \n") ;
else
{
A[k]='\0'; /* Конец строки */
printf("Последнее слово: %s",A);
}
} /* Конец программы */
Чтение вводимых данных выполняется посимвольно в цикле
с параметром i. Если вводится пробел, то оператор continue вы-
зывает переход к следующей итерации. Если введена точка, то
цикл прерывается. При этом в первых к элементах массива А[]
Глава 4. Указатели, массивы, строки
199
запоминается последнее слово предложения. Если введенный
символ отличен от точки и пробела, то анализируется предыду-
щий символ. Если это пробел, то начинается ввод следующего
слова и устанавливается нулевое значение к. В следующих опе-
раторах введенный символ записывается в к-й элемент массива
Айк увеличивается на 1. Выход из цикла возможен при появ-
лении точки или после ввода 80 символов. Последнее выполня-
ется при отсутствии в предложении точки. В этом ошибочном
случае i=80. Когда в предложении нет слов, к остается равным
нулю. Если i<80 и к не равно 0, то в к-й элемент массива А за-
писывается признак конца строки (последнего слова предложе-
ния), и она как единое целое выводится на печать.
Результат выполнения программы:
Напишите предложение с точкой в конце:
Орфографический словарь.
Последнее слово: словарь
Как еще раз иллюстрирует приведенная программа, работа с
символьными строками - это работа с массивами типа char.
При этом следует обращать внимание на обязательное присут-
ствие в конце строки (в последнем занятом элементе массива)
символа '\0' и не допускать его случайного уничтожения при
обработке.
В качестве следующей задачи рассмотрим проверку вводи-
мой цифровой информации: "Необходимо, введя строку, напе-
чатать порядковый номер (позицию) каждого символа, который
отличен от пробела или цифры". Задачу решает следующая про-
грамма:
/* Проверка вводимых числовых данных: */
#include <stdio.h>
void main( )
{
char z[ ]="0123456789
char s;
int i, j;
printf("Введите строку символов:\n ;
for (i=l; (s=getchar( ))!='\n'; i++)
200
Программирование на языке Си
(
for (j=0; j<ll; j++)
if (s == z[j]) break;
if (j == 11)
printf("Ошибка в символе %c с номером "
"%d\n", s,i);
} /* Конец цикла ввода */
} /* Конец программы */
В программе (в цикле по i) выполняется ввод отдельных
символов до появления неизображаемого символа *\п' - перевод
строки. Каждый введенный символ s сравнивается в цикле по j с
элементами массива z, содержащего все допустимые символы.
Если выявлено совпадение, то при выходе из цикла j не равно
11. При естественном завершении цикла (не найдено Совпаде-
ния) j оказывается равным 11, и печатается номер ошибочного
символа.
Пример результата выполнения программы:
Введите строку символов: 124Е-22 16
Ошибка в символе Е с номером 4
Ошибка в символе - с номером 5
Строки и указатели. Мы уже рассмотрели взаимосвязь ука-
зателей с массивами, так что возможность связать указатель с
каждой строкой нас уже не удивит. Рассмотрим следующие два
определения:
char А[20];
/* Массив, в который можно записать строку */
char *В;
/* Указатель, с которым можно связать строку */
Массив А получает память автоматически при обработке оп-
ределения. Строке, с которой мы хотим связать указатель В, па-
мять при обработке определения указателя не выделяется.
Поэтому если далее следуют операторы
scanf("%s", А); /* Оператор верен */
scanf("%s",В); /* Оператор не корректен */
Глава 4. Указатели, массивы, строки
201
то первый из них допустим, а второй приводит к ошибке во
время выполнения программы - попытка ввода в неопределен-
ный участок памяти. До выполнения второго из этих операто-
ров ввода с указателем В нужно связать некоторый участок па-
мяти. Для этого существует несколько возможностей. Во-пер-
вых, переменной В можно присвоить адрес уже определенного
символьного массива. Во-вторых, указатель В можно "на-
строить" на участок памяти, выделяемый с помощью средств
динамического распределения памяти (см. табл. 4.1). Например,
оператор
B=(char *) malloc(80);
выделяет 80 байт н связывает этот блок памяти с указателем В.
Только теперь применение приведенного выше оператора ввода
допустимо. Прототипы функции malloc() и других функций
распределения памяти находятся в файле stdlib.h.
С помощью указателей типа char* удобно получать доступ к
строкам в виде массивов символов. Типичная задача - обработ-
ка слов или предложений, каждое из которых представлено в
массиве типа char в виде строки (т.е. в конце представления
предложения или слова находится нуль-символ '\0'). Использо-
вание указателей, а не массивов с фиксированными размерами
особенно целесообразно, когда предложения или слова должны
быть разной длины. В следующей программе определен и при
инициализации связан с набором строк одномерный массив
point[ ] указателей типа char*. Функция printf() и специфика-
тор преобразования %s допускают использование в качестве
параметра указатель на строку. При этом на дисплей (в выход-
ной поток) выводится не значение указателя point[i], а содержи-
мое адресуемой им строки.
Текст программы:
#include <stdio.h>
void main( )
{
char * point[ ]={"thirteen","fourteen",
"fifteen","sixteen","seventeen","eighteen",
"ninteen"};
202
Программирование на языке Си
int i,n;
n=sizeof(point)/sizeof(point[0]);
for(i=0;i<n;i++)
printf("\n%s",point[i]);
Результат выполнения программы:
thirteen
fourteen
fifteen
sixteen
seventeen
eighteen
nineteen
Глава 5
ФУНКЦИИ
5.1. Общие сведения о функциях
Определение функции. В соответствии с синтаксисом в
языке Си определены три производных типа: массив, указатель,
функция. В этой главе рассмотрим функции.
О функциях в языке Си нужно говорить, рассматривая это
понятие с двух сторон. Во-первых, функция, как мы только что
сказали, - это один из производных типов (наряду с массивом и
указателем). С другой стороны, функция - это минимальный
исполняемый модуль программы на языке Си. Синонимами это-
го второго понятия в других языках программирования являют-
ся процедуры, подпрограммы, подпрограммы-функции, про-
цедуры-функции. Все функции в языке Си имеют рекомендуе-
мый стандартами языка единый формат определения:
тип имяфункции (спецификация параметров)
телофункции
Первая строка - это, по существу, заголовок функции, кото-
рый отличается от ее прототипа только отсутствием точки с за-
пятой в конце и обязательным присутствием имен формальных
параметров.
Здесь тип либо void (для функций, не возвращающих значе-
ния), либо обозначение типа возвращаемого функцией значения.
В предыдущих главах рассмотрены функции, возвращающие
значения базовых типов (char, int, double и т.д.).
Имя функции либо main - для основной (главной) функции
программы, либо произвольно выбираемое программистом имя
(идентификатор), не совпадающее со служебными словами и с
именами других объектов (и функций) программы.
Спецификация параметров - это либо пусто, либо список
формальных параметров, каждый элемент которого имеет вид:
204
Программирование на языке Си
обозначение типа имя параметра
Примеры спецификаций параметров уже приводились для
случаев, когда параметры были базовых типов или массивами.
Список параметров функции может заканчиваться запятой с по-
следующим многоточием Многоточие обозначает возмож-
ность обращаться к функции с большим количеством фактичес-
ких параметров, чем явно указано в спецификации параметров.
Такая возможность должна быть "подкреплена" специальными
средствами в теле функции. В следующих параграфах этой гла-
вы особенности подготовки функций с переменным количест-
вом параметров будут подробно рассмотрены. Сейчас отметим,
что мы уже хорошо знакомы с двумя библиотечными функция-
ми, допускающими изменяемое количество фактических пара-
метров. Вот их прототипы:
int printf (const char * format,...);
int scanf (const char * format,...);
Указанные функции форматированного вывода и формати-
рованного ввода позволяют применять теоретически неогра-
ниченное количество фактических параметров. Обязательным
является только параметр char * format - "форматная строка",
внутри которой с помощью спецификаций преобразования оп-
ределяется реальное количество параметров, участвующих в
обменах.
Телофункции - это часть определения функции, ограничен-
ная фигурными скобками и непосредственно размещенная вслед
за заголовком функции. Тело функции может быть либо состав-
ным оператором, либо блоком. Напоминаем, что в отличие от
составного оператора блок включает определения объектов (пе-
ременных, массивов и т.д.). Особенность языка Си состоит в
невозможности внутри тела функции определить другую функ-
цию. Другими словами, определения функций не могут быть
вложенными.
Обязательным, но не всегда явно используемым оператором
тела функции является оператор возврата из функции в точку
вызова, имеющий две формы:
Глава 5. Функции
205
return;
return выражение;
Первая форма соответствует завершению функции, не воз-
вращающей никакого значения, т.е. функции, перед именем ко-
торой в ее определении указан тип void. Выражение во второй
форме оператора return должно иметь тип, указанный перед
именем функции в ее определении, либо иметь тип, допускаю-
щий автоматическое преобразование к типу возвращаемого
функцией значения.
Мы отметили обязательность оператора возврата из тела
функции, однако оператор return программист может явно не
использовать в теле функции, возвращающей значение типа
void (ничего не возвращающей). В этом случае компилятор ав-
томатически добавляет оператор return в конец тела функции
перед закрывающейся фигурной скобкой
Итак, в языке Си допустимы функции с параметрами и без
параметров, функции, возвращающие значения указанного типа
и ничего не возвращающие.
Завершая рассмотрение определения функции, укажем на
допустимость в языке Си "старой" формы:
тип имяфункции (списокпараметров)
спецификация параметров;
тело функции
Следующие два определения функций эквивалентны, но мы
рекомендуем использовать только первую стандартную форму:
double f (int n, float x) double f (n, x)
{ int n;
/* Тело функции */ float x;
} {
/* Тело функции */
}
Как видно из примера, в устаревшей форме определения
функций список параметров не содержит сведений об их типах.
Эти сведения помещаются во вторую часть заголовка функции.
Тело функции в обоих формах определения одинаково.
206
Программирование на языке Си
Описание функции н ее тип. Для корректного обращения к
функции сведения о ней должны быть известны компилятору,
т.е. до вызова функции в том же файле стандартом рекоменду-
ется помещать ее определение или описание. Двум формам
(стандартной и старомодной) определения функции соответст-
вуют две формы их описания. Для функции, определенной
стандартным образом, описанием служит ее прототип:
тип имя_функции (спецификация параметров);
В отличие от заголовка функции в ее прототипе могут не
указываться имена формальных параметров. Например, допус-
тимы и эквивалентны следующие прототипы одной и той же
функции:
double f (int n, float x);
double f (int, float);
При старом формате определения функции используется ста-
ромодный способ описания функции, не содержащий специфи-
кации параметров:
тип имя функции ();
Например, для некоторой функции old() в программе может
быть использовано следующее описание:
double oldf( );
При таком описании функции компилятор ничего "не знает"
о типах ее параметров и не сможет выполнить проверку совмес-
тимости списков фактических и формальных параметров. По-
этому рекомендуется для описания функции всегда применять
ее прототип, что возможно только при стандартном определе-
нии функции.
Прототип очень плохо заменяется старомодным описанием
функции, особенно при необходимости использовать ее тип в
определении того или иного элемента программы. Тип функции
складывается из типа возвращаемого значения и спецификации
параметров. Например, рассмотрим стандартный прототип и
старомодное описание:
Глава 5. Функции
207
double f (int, float);
void w( );
Тип функции f() - это функция, возвращающая значения ти-
па double и имеющая параметры типов int и float. Тип функции
w() (вводимый старомодным описанием) опознать практически
невозможно. Служебное слово void определяет только тип воз-
вращаемого значения. Таким образом, w() - это функция, не
возвращающая значения и имеющая неизвестное количество
параметров неизвестного типа. Именно поэтому при определе-
нии типа "функция" нужно всегда использовать прототип, а не
старомодное описание.
Вызов функции. Для обращения к функции используется
выражение с операцией "круглые скобки":
обозначение функции (списокфактическихпараметров)
Операндами операции '()' служат обозначение функции и
списокфактическихпараметров. Наиболее естественное и
понятное обозначение функции - это ее имя. Кроме того, функ-
цию можно обозначить, разыменовав указатель на нее. Так как
указатели на функции мы еще не ввели (см. следующие пара-
графы этой главы), то ограничимся пока для обозначения функ-
ций их именами.
Список фактических параметров, называемых аргументами,
- это список выражений, количество которых равно числу фор-
мальных параметров функции (исключение составляют функ-
ции с переменным количеством параметров). Соответствие
между формальными и фактическими параметрами устанавли-
вается по их взаимному расположению в списках. Порядок вы-
числения значений фактических параметров (слева направо или
справа налево) стандарт языка Си не определяет.
Между формальными и фактическими параметрами должно
быть соответствие по типам. Лучше всего, когда тип фактиче-
ского параметра совпадает с типом формального параметра. В
противном случае компилятор автоматически добавляет коман-
ды преобразования типов, что возможно только в том случае,
208
Программирование на языке Си
если такое приведение типов допустимо. Например, пусть опре-
делена функция с прототипом:
int g(int, long);
Далее в программе использован вызов:
g(3.0+m, б.4е+2)
Оба фактических параметра в этом вызове имеют тип double.
Компилятор, ориентируясь на прототип функции, автоматиче-
ски предусмотрит такие преобразования:
g((int)(3.0+m), (long) б.4е+2)
Так как вызов функции является выражением, то после вы-
полнения операторов тела функции в точку вызова возвращает-
ся некоторое значение, тип которого строго соответствует типу,
указанному перед именем функции в ее определении (и прото-
типе). Например, функция
float ft(double х, int n)
{
if (x<n) return x;
return n;
}
всегда возвращает значение типа float. В выражения, помещен-
ные в операторы return, компилятор автоматически добавит
средства для приведения типов, т.е. получим (невидимые про-
граммисту) операторы:
return (float) х;
return (float) n;
Особое внимание, нужно уделить правилам передачи пара-
метров при обращении к функциям. Синтаксис языка Си преду-
сматривает только один способ передачи параметров - передачу
по значениям. Это означает, что формальные параметры функ-
ции локализованы в ней, т.е. недоступны вне определения
функции и никакие операции над формальными параметрами в
теле функции не изменяют значений фактических параметров.
Глава 5. Функции
209
Передача параметров по значению предусматривает сле-
дующие шаги:
1. При компиляции функции (точнее, при подготовке к ее
выполнению) выделяются участки памяти для формаль-
ных параметров, т.е. формальные параметры оказываются
внутренними объектами функции. При этом для парамет-
ров типа float формируются объекты типа double, а для
параметров типов char и short int создаются объекты типа
int. Если параметром является массив, то формируется
указатель на начало этого массива и он служит представ-
лением массива-параметра в теле функции.
2. Вычисляются значения выражений, использованных в ка-
честве фактических параметров при вызове функции.
3. Значения выражений - фактических параметров заносятся
в участки памяти, выделенные для формальных парамет-
ров функции. При этом float преобразуется в double, а
char и short int - в тип int (см. п. 1).
4. В теле функции выполняется обработка с использованием
значений внутренних объектов-параметров, и результат
передается в точку вызова функции как возвращаемое ею
значение.
5. Никакого влияния на фактические параметры (на их зна-
чения) функция не оказывает.
6. После выхода из функции освобождается память, выделен-
ная для ее формальных параметров.
Вызов функции всегда является выражением, однако разме-
щение такого выражения в тексте программы зависит от типа
возвращаемого функцией значения. Если в качестве типа воз-
вращаемого значения указан тип void, то функция является
функцией без возвращаемого результата. Такая функция не мо-
жет входить ни в какие выражения, требующие значения, а
должна вызываться в виде отдельного выражения-оператора:
имя функции (списокфактическихпараметров) ;
14'3124
210
Программирование на языке Си
Например, следующая функция возвращает значение типа void:
void print(int gg, int mm, int dd)
{
printf("\n год: %d",gg);
printf(",\t месяц: %d,",mm);
printf (",\t день: %d.*', dd) ;
}
Обращение к ней
print(1966, 11, 22);
приведет к такому выводу на экран:
год: 1966, месяц: 11, день: 22,
Может оказаться полезной и функция, которая не только не
возвращает никакого значения (имеет возвращаемое значение
типа void), но и не имеет параметров. Например, такая:
#include <stdio.h>
void Real_Time (void)
{
printf("\n Текущее время: %s",_____TIME___
" (час: мин: сек.)");
}
При обращении
Real_Time ( );
в результате выполнения функции будет выведено на экран
дисплея сообщение:
Текущее время: 14:16:25 (час: мин: сек.)
5.2. Указатели в параметрах функций
Указатель-параметр. В предыдущем параграфе мы доста-
точно подробно рассмотрели механизм передачи параметров
при вызове функций. Схема передачи параметров по значениям
не оставляет никаких надежд на возможность непосредственно
изменить фактический параметр за счет выполнения операторов
Глава 5. Функции
211
тела функции. И это действительно так. Объект вызывающей
программы, использованный в качестве фактического парамет-
ра, не может быть изменен из тела функции. Однако существует
косвенная возможность изменять значения объектов вызываю-
щей программы действиями в вызванной функции. Эту возмож-
ность обеспечивает аппарат указателей. С помощью указателя в
вызываемую функцию можно передать адрес любого объекта из
вызывающей программы. С помощью выполняемого в тексте
функции разыменования указателя мы получаем доступ к адре-
суемому указателем объекту из вызывающей программы.
Тем самым, не изменяя самого параметра (указатель-пара-
метр постоянно содержит только адрес одного и того же объек-
та), можно изменять объект вызывающей программы.
Продемонстрируем изложенную схему на простом примере:
#include <stdio.h>
void positive(int * m) /* Определение функции */
{
*m = *m > 0 ? *m : —*m;
}
void main()
{
int k=-3;
positive(&k);
printf("\nk=%d", k);
}
Результат выполнения программы:
k=3
Параметр функции positive() - указатель типа int *. При об-
ращении к ней из основной программы main() в качестве фак-
тического параметра используется адрес &к переменной типа
int. Внутри функции значение аргумента (т.е. адрес &к) "запи-
сывается" в участок памяти, выделенный для указателя int *m.
Разыменование *m обеспечивает доступ к тому участку памяти,
на который в этот момент "смотрит" указатель т. Тем самым в
выражении
14*
212
Программирование на языке Си
*т = *т>0 ? *т :- *т
все действия выполняются над значениями той переменной ос-
новной программы (int к), адрес которой (&к) использован в
качестве фактического параметра.
Графически иллюстрирует взаимосвязь функции positive() и
основной программы рис. 5.1. При обращении к функции
positive() она присваивает абсолютное значение той перемен-
ной, адрес которой использован в качестве ее параметра.
Функция positive ()
Основная программа
*(&к) - переменная к
Рис. 5.1. Схема "настройки" параметра-указателя
Пояснив основные принципы воздействия с помощью указа-
телей из тела функции на значения объектов вызывающей про-
граммы, напомним, что этой возможностью мы уже неодно-
кратно пользовались, обращаясь к функции scanf(). Функция
scanf() имеет один обязательный параметр - форматную строку
и некоторое количество необязательных параметров, каждый из
которых должен быть адресом того объекта, значение которого
вводится с помощью функции scanf(). Например:
long 1;
double d;
scanf("%ld%le", &1, &d);
Глава 5. Функции
213
Здесь в форматной строке спецификаторы преобразования
%ld и %1е обеспечивают ввод (чтение) от клавиатуры соответ-
ственно значений типов long int и double. Передача этих значе-
ний переменным long 1 и double d обеспечивается с помощью
их адресов &I и &d, которые используются в качестве фактиче-
ских параметров функции scanf().
Имитация подпрограмм. Подпрограммы отсутствуют в
языке Си, однако если использовать обращение к функции в
виде оператора-выражения, то получим аналог оператора вызо-
ва подпрограммы. (Напомним, что выражение приобретает ста-
тус оператора, если после него стоит точка с запятой.) Выше
были приведены в качестве примеров функции
void print(int gg, int mm, int) и void Real Time(void),
каждая из которых очень похожа на подпрограммы других язы-
ков программирования.
К сожалению, в языке Си имеется еще одно препятствие для
непосредственного использования функции в роли подпрограм-
мы - это рассмотренная выше передача параметров только зна-
чениями, т.е. передаются значения переменных, а не их адреса.
Другими словами, в результате выполнения функции нельзя из-
менить значения ее фактических параметров. Таким образом,
если Z() - функция для вычисления периметра и площади тре-
угольника по длинам сторон Е, F, G, то невозможно, записав
оператор-выражение Z(E, F, G, РР, SS); получить результаты
(периметр и площадь) в виде значений переменных РР и SS.
Так как параметры передаются только значениями, то после вы-
полнения функции Z() значения переменных РР и SS останутся
прежними.
Возможно следующее решение задачи. В определении функ-
ции параметры, с помощью которых результаты должны пере-
даваться из функции в точку вызова, описываются как ука-
затели. Тогда с помощью этих указателей может быть реализо-
ван доступ из тела функции к тем объектам вызывающей про-
граммы, которые адресуются параметрами-указателями. Для
пояснения сказанного рассмотрим следующую программу:
214
Программирование на языке Си
#include <stdio.h>
void main ()
{
float x,y;
/* Прототип функции */
void aa(float *, float *);
printf("\n Введите: x=");
scanf("%f",&x);
printf(" Введите: y=");
scanf("%fH,&y);
/* Вызов функции */
aa(&x,&y) ;
printf (" \n Результат: x=%f y=%f", x, y) ;
}
/* Функция, меняющая местами
значения переменных, на которые указывают
фактические параметры: */
void aa(float * b, float * с)
/* Ь и с - указатели */
(
float е; /* Вспомогательная переменная */
е=*Ь;
*Ь=*с;
* с=е ;
}
В основной программе описаны переменные х, у, значения
которых пользователь сводит с клавиатуры. Формальными па-
раметрами функции аа() служат указатели типа float *. Задача
функции - поменять местами значения тех переменных, на ко-
торые указывают ее параметры-указатели. При обращении к
функции аа() адреса переменных х, у используются в качестве
фактических параметров. Поэтому после выполнения програм-
мы возможен, например, такой результат:
Введите: х=33.3
Введите: у=6б.б
Результат: х=бб.600000 у=33.300000
Имитация подпрограммы (функция) для вычисления пери-
метра и площади треугольника:
Глава 5. Функции
215
#include <math.h> /* для функции sqrt( ) */
#include <stdio.h>
void main( )
(
float x,y,z,pp,ss;
/* Прототип: */
int triangle(float, float, float,
float *, float *);
printf("\n Введите: x=");
scanf("%f",&x);
printf("\t y=");
scanf("%f",&y);
printf("\t z=");
scanf("%f",&z);
if (triangle(x,y,z,&pp,&ss) == 1)
(
printf(" Периметр = %f",pp);
printf(", площадь = %f",ss);
}
else
printf("\n Ошибка в данных ");
}
/* Определение функции: */
int triangle(float a,float b,
float c,float * perimeter,
float * area)
(
float e;
*perimeter=*area=O.0;
if (a+b<=c || a+c<=b || b+c<=a)
return 0;
*perimeter=a+b+c;
e=*perimeter/2;
*area=sqrt(e*(e-a)*(e-b)*(e-c));
return 1 ;
}
Пример результатов выполнения программы:
Введите х=3
у=4
z=5
Периметр=12.000000 площадь=б.000000
216
Программирование на языке Си
5.3. Массивы и строки как параметры
функций
Массивы в параметрах. Если в качестве параметра функции
используется обозначение массива, то на самом деле внутрь
функции передается только адрес начала массива. Применяя
массивы в качестве параметров для функций из главы 2, мы не
отмечали этой особенности. Например, заголовок функции для
вычисления скалярного произведения векторов выглядел так:
float Scalar_Product(int n, float a[ ], float b[ ])...
Но заголовок той же функции можно записать и следующим
образом:
float Scalar_Product(int n, float *a, float *b)...
Конструкции
float b[ ]; и float *b;
совершенно равноправны в спецификациях параметров. Однако
в первом случае роль имени b как указателя не так явственна.
Во втором варианте все более очевидно - b явно определяется
как указатель типа float *. .
В теле функции Scalar_Product() из главы 2 обращение к
элементам массивов-параметров выполнялось с помощью ин-
дексированных элементов a[i] и b[i]. Однако можно обращаться
к элементам массивов, разыменовывая соответствующие значе-
ния адресов, т.е. используя выражения *(a+i) и *(i+b).
Так как массив всегда передается в функцию как указатель,
то внутри функции можно изменять значения элементов масси-
ва-фактического параметра, определенного в вызывающей про-
грамме. Это возможно и при использовании индексирования, и
при разыменовании указателей на элементы массива.
Для иллюстрации указанных возможностей рассмотрим
функцию, возводящую в квадрат значения элементов одномер-
ного массива, и вызывающую ее программу:
Глава 5. Функции
217
#include <stdio.h>
/* Определение функции: */
void quart(int n, float * x)
(
int i ;
for(i=0;i<n;i++)
/* Присваивание после умножения: */
* (x+i)*=*(x+i) ;
}
void main()
{
/* Определение массива: */
float z[ ]={1.0, 2.0, 3.0, 4.0};
int j ;
quart(4,z); /* Обращение к функции */
/* Печать измененного массива */
for(j=0;j<4;j++)
printf("\nz[%d]=%f",j,z[j]);
}
Результат выполнения программы:
z[0]=l.000000
z[l[=4.000000
z[2]=9.000000
z[3]=16.000000
Чтобы еще раз обратить внимание на равноправие парамет-
ров в виде массива и указателя того же типа, отметим, что заго-
ловок функции в нашей программе может быть и таким:
void quart (int n, float x [ ])
В теле функции разыменовано выражение, содержащее имя
массива-параметра, т.е. вместо индексированной переменной
x[i] используется *(x+i). Эту возможность мы уже неоднократно
отмечали. Более интересная возможность состоит в том, что
можно изменять внутри тела функции значение указателя на
массив, т.е. в теле цикла записать, например, такой оператор:
*х*=*х++;
Обратите внимание, что неверным для нашей задачи будет
такой вариант этого оператора:
218
Программирование на языке Си
*х++*=*х++; /*ошибка!*/
В этом ошибочном случае "смещение" указателя х вдоль
массива будет при каждой итерации цикла не на один элемент
массива, а на 2, так как х изменяется и в левом, и в правом опе-
рандах операции присваивания.
Следует отметить, что имя массива внутри тела функции не
воспринимается как константный (не допускающий изменений)
указатель, однако такая возможность отсутствует в основной
программе, где определен соответствующий массив (факти-
ческий параметр). Если в цикле основной программы вместо
значения z[j] попытаться использовать в функции printf() вы-
ражение *z++, то получим сообщение об ошибке, т.е. следую-
щие операторы не верны:
for (j=0; j<4; j++)
printf("\nz[%d]=%f", j, *z++);
Сообщение об ошибке при компиляции выглядит так:
Error. . . Lvalue required
Подводя итоги, отметим, что, с одной стороны, имя массива
является константным указателем со значением, равным адресу
нулевого элемента массива. С другой стороны, имя массива, ис-
пользованное в качестве параметра, играет в теле функции роль
обычного (неконстантного) указателя, т.е. может использовать-
ся в качестве леводопустимого выражения. Именно поэтому в
спецификациях формальных параметров эквивалентны, как ука-
зано выше, например, такие формы:
double х[ ] и double *х
Строки как параметры функций. Строки в качестве фак-
тических параметров могут быть специфицированы либо как
одномерные массивы типа char [ ], либо как указатели типа
char *. В обоих случаях с помощью параметра в функцию пере-
дается адрес начала символьного массива, содержащего строку.
В отличие от обычных массивов для параметров-строк нет не-
Глава 5. Функции
219
обходимости явно указывать их длину. Признак '\0', размещае-
мый в конце каждой строки, позволяет всегда определить ее
длину, точнее, позволяет перебирать символы строки и не вый-
ти за ее пределы. Как примеры использования строк в качестве
параметров функций рассмотрим несколько функций, решаю-
щих типовые задачи обработки строк. Аналоги большинства из
приводимых ниже функций имеются в библиотеке стандартных
функций компилятора (см. Приложение 3). Их прототипы и
другие средства связи с этими функциями находятся в заголо-
вочных файлах string.h и stdlib.h. Однако для целей темы, по-
священной использованию строк в качестве параметров, удобно
заглянуть "внутрь" таких функций.
Итак, в иллюстративных целях приведем определения функ-
ций для решения некоторых типовых задач обработки строк.
Будем для полноты картины использовать различные способы
задания строк-параметров.
Функция вычисления длины строки. Следующая ниже
функция имеет самую старомодную и не рекомендуемую стан-
дартом форму заголовка (в стандартной библиотеке ей соответ-
ствует функция strlen(), см. Приложение 3):
int 1еп(е)
char е[ ];
{
int m;
for (m=0; e[m]<='\0'; m++);
return m;
}
В соответствии с ANSI-стандартом и со стандартом ISO заго-
ловок должен иметь, например, такой вид:
int len (char е[ ])
В этом примере и в заголовке, и в теле функции нет даже
упоминаний о родстве массивов и указателей. Однако компиля-
тор всегда воспринимает массив как указатель на его начало, а
индекс как смещение относительно начала массива. Следующий
220
Программирование на языке Си
вариант той же функции (теперь заголовок соответствует стан-
дартам языка) явно реализует механизм работы с указателями:
int len (char *s)
{
int m;
for (m=0; *s++!='\0'; m++)
return m;
}
Для формального параметра-указателя s внутри функции вы-
деляется участок памяти, куда записывается значение фактиче-
ского параметра. Так как s не константа, то значение этого
указателя может изменяться. Именно поэтому допустимо выра-
жение s++.
Функция инвертирования строки-аргумента с парамет-
ром-массивом (заголовок соответствует стандарту):
void invert(char е[ ])
{
char s;
int i, j, m;
/*m - номер позиции символа '\0' в строке е */
for (m=0; e[m]!='\0'; m++) ;
for (i=0, j=m-l; i<j; i++, j--)
(
s=e[i]z
e[i]=e[j];
e[j]=s;
}
В определении функции invert() с помощью ключевого слова
void указано, что функция не возвращает значения.
В качестве упражнения можно переписать функцию invert(),
заменив параметр-массив параметром-указателем типа char*.
При выполнении функции invert() строка - фактический па-
раметр, например, "сироп" превратится в строку "порис". При
этом символ '\0' остается на своем месте в конце строки. Пример
использования функции invert():
Глава 5. Функции
221
#include <stdio.h>
void main( )
{
char ct[ ]="0123456789";
/* Прототип функции: */
void invert(char [ ]);
/* Вызов функции: */
invert(ct);
printf("\n%s",ct);
Результат выполнения программы:
9876543210
Функция поиска в строке ближайшего слева вхождения
другой строки (в стандартной библиотеке имеется подобная
функция strstr(), см. Приложение 3):
/*Поиск строки СТ2 в строке СТ1 */
int index (char * СТ1, char * CT2)
{
int i, j, ml, m2;
/* Вычисляются ml и m2 - длины строк */
for (ml=0; CTl[ml] !=’\0'; ml++);
for (m2=0; CT2[m2] !='\0'; m2++);
if (m2>ml)
return -1;
for (i=0; i<=ml-m2; i++)
{
for (j=0; j<m2; j++) /*Цикл сравнивания */
if (CT2[j] <=CTl[i+j])
break;
if (j==m2)
return i;
} /* Конец цикла no i */
return -1;
Функция index() возвращает номер позиции, начиная с кото-
рой СТ2 полностью совпадает с частью строки СТ1. Если стро-
ка СТ2 не входит в СТ1, то возвращается значение -1.
222
Программирование на языке Си
Пример обращения к функции index():
#include <stdio.h>
void main( )
{
char Cl[ ]="сумма масс";
/* Прототип функции: */
int index(char [ ], char [ ]);
char C2[ ]="иа";
char C3[ ]="ам";
printf("\пДля %s HHAOKC«%d",C2,index(Cl,C2)) ;
printf("\пДля %s MHfleKc=%d",C3,index(Cl,C3));
}
Результат выполнения программы:
Для ма индекс=3
Для ан индекс=-1
В функции index() параметры специфицированы как указа-
тели на тип char, а в теле функции обращение к символам строк
выполняется с помощью индексированных переменных. Вместо
параметров-указателей подставляют в качестве фактических
параметров имена символьных массивов С1[], С2[ ], С3[ ]. Ни-
какой неточности здесь нет: к массивам допустимы обе формы
обращения - и с помощью индексированных переменных, и с
использованием разыменования указателей.
Функция сравнения строк. Для сравнения двух строк можно
написать следующую функцию (в стандартной библиотеке име-
ется близкая к этой функция strcmp(), см. Приложение 3):
int row(char Cl[ ], char C2[ ])
{
int i,ml,m2; /* ml,m2 - длины строк C1,C2 */
for (ml=0;*(Cl+ml)= '\0 ' ; ml++);
for (m2=0;*(C2+m2)= '\0'; m2++);
if (ml!=m2) return -1;
for (i=0; i<ml; i++)
if (*C1++ != *C2++) return (i+1);
return 0;
Г лава 5. Функции
223
В теле функции обращение к элементам массивов-строк реа-
лизовано через разыменование указателей. Функция row() воз-
вращает: значение -1, если длины строк-аргументов С.1, С2 раз-
личны; 0 - если все символы строк совпадают. Если длины
строк одинаковы, но символы не совпадают, то возвращается
порядковый номер (слева) первых несовпадающих символов.
Особенность функции row() - спецификация параметров как
массивов и обращение к элементам массивов внутри тела функ-
ции с помощью разыменования. При этом за счет операций
С1++ и С2++ изменяются начальные "настройки" указателей на
массивы. Одновременно в той же функции к тем же массивам-
параметрам выполняется обращение и с помощью выражений
*(Cl+ml) и *(С2+т2), при вычислении которых значения С1 и
С2 не меняются.
Функция соединения строк. Следующая функция позволяет
"присоединить" к первой строке-аргументу вторую строку-
аргумент (в стандартной библиотеке есть подобная функция
strncat(), см. Приложение 3):
/* Соединение (конкатенация) двух строк: */
void cone(char *С1, char *С2)
(
int i,m; /* m - длина 1-й строки */
for (m=0; *(Cl+m)•=1\0'; m++);
for (i=0; *(C2+i)!='\0'; i++)
*(Cl+m+i)=*(C2+i);
*(Cl+m+i)=1\0';
)
Результат возвращается как значение первого аргумента С1.
Второй аргумент С2 не изменяется. Обратите внимание на то,
что при использовании функции сопс() длина строки, заме-
няющей параметр С1, должна быть достаточной для приема ре-
зультирующей строки.
Функция выделения подстроки. Для выделения из строки
С1 фрагмента заданной длины (подстроки) можно предложить
такую функцию:
224
Программирование на языке Си
void substr(char *С1, char *С2, int n, int k)
/* Cl - исходная строка */
/* C2 - выделяемая подстрока */
/* n - начало выделяемой подстроки */
/* к - длина выделяемой подстроки */
{
int i,m; /* m - длина исходной строки */
for (m=0; Cl[m]!='\O'; m++);
if (n<0 || n>m || k<0 || k>m-n)
{
C2[0]='\0’;
return;
}
for (i=n; i<k+n; i++)
C2[i-n]=Cl[i-1];
C2[i-n]='\0';
return;
}
Результат выполнения функции - строка С2[ ] из к символов,
выделенных из строки С1[ ], начиная с символа, имеющего но-
мер п. При неверном сочетании значений параметров возвраща-
ется пустая строка, использованная в качестве параметра С2.
Функция копирования содержимого строки. Так как в язы-
ке Си отсутствует оператор присваивания для строк, то полезно
иметь специальную функцию, позволяющую "переносить” со-
держимое строки в другую строку (такая функция strcpy() есть
в стандартной библиотеке, но она имеет другое возвращаемое
значение):.
/* Копирование содержимого строки С2 в С1 */
void copy(char *С1, char *С2)
7* С2 - оригинал, С1 - копия */
{
int i;
for (i=0; C2[i]!=’\0'; i++)
Cl[i]=C2[i];
Cl[i]='\O';
Пример использования функции copy():
Глава 5. Функции
225
#include <stdio.h>
void main()
{
char X[ ]="SIC TRANSIT GLORIA MUNDI!";
/* Прототип функции: */
void copy(char[ ], char[ ]);
char В[100];
/* Обращение к функции: */'
copy (В,Х);
printf("%s\n", В);
}
Результат выполнения тестовой программы :
SIC TRANSIT GLORIA MUNDI!
Другой вариант функции копирования строки:
void copy(char Cl[ ], char С2[ ])
(
int i=0;
do
{
Cl[i] =C2[i];
}
while (Cl[i++]!='\0');
} В * * * * * * * * * * *
В той же функции операция присваивания может быть пере-
несена в выражение-условие продолжения цикла. Ранги опера-
ций требуют заключения выражения-присваивания в скобки:
void copy(char *С1, char *С2)
(
int i=0;
while ((Cl[i] = C2[i]) != '\0')
}
Так как ненулевое значение в выражении после while счита-
ется истинным, то явное сравнение с ’\0’ необязательно и воз-
можно следующее упрощение функции:
15~3’24
226
Программирование на языке Си
void copy(char * Cl, char * С2)
(
int i=0;
while (Cl[i] = C2[i])
i++;
И, наконец, наиболее короткий вариант:
void copy (char * Cl, char * C2)
(
while (*C1++ = *C2++);
Резюме по строкам-параметрам. Часть из приведенных
функций для работы со строками, а именно функции: конкате-
нации строк сопс(), 'инвертирования строки invert( ), копирова-
ния одной строки в другую сору(), выделения подстроки
stibstr(); предусматривают изменение объектов вызывающей
программы. Это возможно и допустимо только потому, что па-
раметрами являются указатели. Это либо имена массивов, либо
указатели на строки. Как уже говорилось, параметры-указатели
позволяют функции получить непосредственный доступ к объ-
ектам той программы, из которой функция вызвана. В приве-
денных определениях функций этот доступ осуществляется как
с помощью индексированных переменных, так и с помощью
разыменования указателей. На самом деле компилятор языка
Си, встречая, например, такое обращение к элементу массива
s[i], всегда заменяет его выражением *(s+i), т.е. указателем s со
смещением i.
Такую замену, т.е. использование указателей со смещениями
вместо индексированных переменных, можно явно использо-
вать в определениях функций. Иногда это делает нагляднее
связь между функцией и вызывающей ее программой.
В заключение параграфа продемонстрируем возможности
библиотеки стандартных функций для задач обработки строк,
точнее, перепишем функцию конкатенации строк, используя
библиотечную функцию strlen(), позволяющую вычислить
длину строки-параметра.
Глава 5. Функции
227
Функция для сцепления (конкатенации) строк:
#include <string.h>
void concat(char * Cl, char * C2)
{
int m, i ;
m=strlen (Cl); i=0;
while ((*(Cl+m+i) ж *(C2+i))•='\0')
i++;
} .
Вместо функции strlen( ) можно было бы использовать опре-
деленную выше функцию 1еп(). При обращении к функции
concat(), а также при использовании похожей на нее библио-
течной функции strcat() нужно, чтобы длина строки, использо-
ванной в качестве первого параметра, была достаточной для
размещения результирующей (объединенной) строки. В против-
ном случае результат выполнения непредсказуем.
5.4. Указатели на функции.
Указатели при вызове функций. До сих пор мы рассматри-
вали функцию как минимальный исполняемый модуль про-
граммы, обмен данными с которым происходит через набор
параметров функции и с помощью значений, возвращаемых
функцией в точку вызова. Теперь перейдем к вопросу о том, по-
чему в языке Си функция введена как один из производных ти-
пов. Необходимость в таком типе связана, например, с
задачами, в которых функция (или ее адрес) должна выступать в
качестве параметра другой функции или в качестве значения,
возвращаемого другой функцией. Обратимся к уже рассмотрен-
ному ранее выражению "вызов функции" (точнее, к более об-
щему варианту вызова):
обозначение функции (списокфактическихпараметров)
где обозначение функции (только в частном случае это иден-
тификатор) должно иметь тип "указатель на функцию, возвра-
щающую значение конкретного типа".
15*
228
Программирование на языке Си
В соответствии с синтаксисом языка указатель на функцию -
это выражение или переменная, используемые для представле-
ния адреса функции. По определению, указатель на функцию
содержит адрес первого байта или первого слова выполняемого
кода функции (арифметические операции над указателями на
функции запрещены).
Самый употребительный указатель на функцию - это ее имя
(идентификатор). Именно так указатель на функцию вводится в
ее определении:
тип имяфункции (спецификация параметров)
телофункции
Прототип
тип имя функции (спецификация_параметров);
также описывает имя функции именно как указатель на функ-
цию, возвращающую значение конкретного типа.
Имя функции в ее определении и в ее прототипе - указатель-
константа. Он навсегда связан с определяемой функцией и не
может быть "настроен" на что-либо иное, чем ее адрес. Для
идентификатора имя_функции термин "указатель" обычно не
используют, а говорят об имени функции.
Указатель на функцию как переменная вводится отдельно от
определения и прототипа какой-либо функции. Для этих целей
используется конструкция:
тип (*имя_указателя) (спецификация параметров);
где тип - определяет тип возвращаемого функцией значения;
имя_указателя - идентификатор, произвольно выбранный
программистом;
спецификациЯ-Параметров - определяет состав и типы
параметров функции.
Например, запись
int (*point) (void);
определяет указатель-переменную с именем point на функции
без параметров, возвращающие значения типа int.
Глава 5. Функции
229
Важнейшим элементом в определении указателя на функции
являются круглые скобки. Если записать
int * funct (void);
то это будет не определением указателя, а прототипом функции
без параметров с именем funct, возвращающей значения типа
int*.
В отличие от имени функции (например, funct) указатель
point является переменной, т.е. ему можно присваивать значения
других указателей, определяющих адреса функций программы.
Принципиальное требование - тип указателя-переменной дол-
жен полностью соответствовать типу функции, адрес которой
ему присваивается.
Мы уже говорили, что тип функции определяется типом воз-
вращаемого значения и спецификацией ее параметров. Таким
образом, попытка выполнить следующее присваивание
point=funct; /★ Ошибка - несоответствие типов */
будет ошибочной, так как типы возвращаемых значений для
point и funct различны.
Неконстантный указатель на функцию, настроенный на адрес
конкретной функции, может быть использован для вызова этой
функции. Таким образом, при обращении к функции перед
круглыми скобками со списком фактических параметров можно
помещать: имя функции (т.е. константный указатель); указа-
тель-переменную того же типа, значение которого равно адресу
функции; выражение разыменования такого же указателя с та-
ким же значением. Следующая программа иллюстрирует три
способа вызова функций.
#include <stdio.h>
void fl (void)
{
printf ("\n Выполняется f1( ) ") ;
)
void f2 (void)
{ .
printf ("\n Выполняется f2( )");
}
230
Программирование на языке Си
void main ()
{
void (*point) (void);
/♦point - указатель-переменная на функцию */
f2 (); /* Явный вызов функции f2()*/
point=f2; /* Настройка указателя на f2()*/
(♦point)(); /* Вызов f2() по ее адресу
с разыменованием указателя */
point=f1; /* Настройка указателя на fl()*/
(♦point)(); /* Вызов fl() по ее адресу
с разыменованием указателя */
point (); /* Вызов fl() без разыменования
указателя */
)
Результат выполнения программы:
Выполняется f2( )
Выполняется f2( )
Выполняется fl( )
Выполняется f1( )
Все варианты обращения к функциям с использованием ука-
зателей-констант (имен функций) и указателей-переменных
(неконстантных указателей на функции) в программе продемон-
стрированы и снабжены комментариями. Приведем общий вид
двух операций вызова функций с помощью неконстантных ука-
зателей:
(*имя_указателя) (списокфактическихпараметров)
имя_указателя (список_фактических_параметров)
В обоих случаях тип указателя должен соответствовать типу
вызываемой функции, и между формальными и фактическими
параметрами должно быть соответствие. При использовании
явного разыменования обязательны круглые скобки, т.е. в на-
шей программе будет ошибочной запись
♦point (); /* Ошибочный вызов */
Это полностью соответствует синтаксису языка. Операция
'()' - "круглые скобки" имеет более высокий приоритет, чем
Глава 5. Функции
231
операция разыменования В этом ошибочном вызове вначале
выполнится вызов point(), а уж к результату будет применена
операция разыменования.
При определении указателя на функции он может быть ини-
циализирован. В качестве инициализирующего выражения дол-
жен использоваться адрес функции того же типа, что и тип
определяемого указателя, например:
int fic (char); /* Прототип функции */
int (*pfic) (char)=fic;
/* pfic - указатель на функцию */
Массивы указателей на функции. Такие массивы по смыс-
лу ничем не отличаются от массивов других объектов, однако
форма их определения несколько необычна:
тип (*имя массива [размер]) (спецификация параметров);
где тип определяет тип возвращаемых функциями значений;
имя массива - произвольный идентификатор;
размер - количество элементов В массиве;
спецификация параметров - определяет состав и типы
параметров функций.
Пример:
int (*parray [4]) (char);
где parray - массив указателей на функции, каждому из которых
можно присвоить адрес определенной выше функции int fic
(char) и адрес любой функции с прототипом вида
int имя-функции (char);
Массив в соответствии с синтаксисом языка является произ-
водным типом наряду с указателями и функциями. Массив
функций создать нельзя, однако, как мы показали, можно опре-
делить массив указателей на функции. Тем самым появляется
возможность создавать "таблицы переходов" (jump tables), или
"таблицы передачи управления". С помощью таблицы перехо-
дов удобно организовывать ветвления с возвратом по результа-
232
Программирование на языке Си
там анализа некоторых условий. Для этого все ветви обработки
(например, N+1 штук) оформляются в виде однотипных функ-
ций (с одинаковым типом возвращаемого значения и одинако-
вой спецификацией параметров). Определяется массив указа-
телей из N+1 элементов, каждому элементу которого присва-
ивается адрес конкретной функции обработки. Затем формиру-
ются условия, на основе которых должна выбираться та или
иная функция (ветвь) обработки. Вводится индекс, значение ко-
торого должно находиться в пределах от 0 до N включительно,
где (N+1) - количество ветвей обработки. Каждому условию
ставится в соответствие конкретное значение индекса. По кон-
кретному значению индекса выполняются обращение к элемен-
ту массива указателей на функции и вызов соответствующей
функции обработки:
имя массива [индекс] (списокфактическихпараметров);
(★имя массива [индекс]) (список фактических параметров);
Описанную схему использования массивов указателей на
функций удобно применять для организации меню, точнее, про-
грамм, которыми управляет пользователь с помощью меню.
#include <stdlib.h> /* Для функции exit ( ) */
#include <stdio.h>
#define N 2
void actO(char * name)
{
printf("%s: Работа завершена!\n",name);
exit(0);
}
void actl(char * name)
{
printf("%s: работа l\n",name);
}
void act2(char * name)
{
printf("%s: работа 2\n",name);
}
void main()
{/* Массив указателей на функции: */
Глава 5. Функции
233
void (* pact[])(char *)={actO,actl,act2};
char string[12];
int number;
printf("\п\пВводите имя: ");
scanf("%s",string);
printf("Вводите номера работ от 0 до %d:\n",N);
While (1)
{
scanf("%d",Snumber);
/* Ветвление по условию */
pact[number](string);
)
)
Пример выполнения программы:
Вводите имя: Peter
Вводите номера работы от 0 до 2:
1
Peter: работа 1
1
Peter: работа 1
2
Peter: работа 2
О
Peter: Работа Завершена*
В программе для упрощения нет защиты от неверно введен-
ных данных, т.е. возможен выход индекса за пределы, опреде-
ленные для массива pact[ ] указателей на функции . При такой
ситуации результат непредсказуем.
Указатели на функции как параметры позволяют созда-
вать функции, реализующие тот или иной метод обработки дру-
гой функции, которая заранее не определена. Например, можно
определить функцию для вычисления определенного интеграла.
Подынтегральная функция может быть передана в функцию вы-
числения интеграла с помощью параметра-указателя. Пример
функции для вычисления определенного интеграла с помощью
формулы прямоугольников:
double rectangle
(double (* pf)(double), double a, double b)
234
Программирование на языке Си
int N=20;
int i;
double h,s=0.0;
h=(b-a)/N;
for (i=0; i<N; i++)
s+=pf(a+h/2+i*h);
return h*s;
Параметры функции rectangle(): pf- указатель на функцию с
параметром типа double, возвращающую значение типа double.
Это указатель на функцию, вычисляющую значение подынте-
гральной функции при заданном значении аргумента. Парамет-
ры а, b - пределы интегрирования. Число интервалов разбиения
отрезка интегрирования фиксировано: N=20. Пусть текст функ-
ции под именем rect.c сохранен в каталоге пользователя.
Предложим, что функция rectangle() должна быть использо-
вана для вычисления приближенных значений интегралов
(Абрамов С.А., Зима Е.В. Начала информатики. - М.: Наука,
1989.-С. 83):
1/2
и J4cos2x<&
о
Программа для решения этой задачи может иметь следую-
щий вид:
#include <math.h>
#include <stdio.h>
#include "rect.c" /* Включение определения
функции rectangle! ) */
double ratio(double x) /* Подынтегральная
функция */
{
double z; /* Вспомогательная переменная * I
z=x*x+l;
return x/(z*z);
}
double cos4_2(double v) /* Подынтегральная
функция */
Глава 5.- Функции
235
{
double w; /* Вспомогательная переменная */
w=cos(v);
return 4*w*w;
}
void main()
{
double a,b,c;
a=-1.0;
b=2. 0 ;
c=rectangle(ratio,a,b);
printf("\n Первый интеграл:
printf("\n Второй интеграл: %f",
rectangle(сов4_2,0.0,0.5));
)
Результат выполнения программы:
Первый интеграл: 0.149847
Второй интеграл: 1.841559
Комментарии к тексту программы могут быть следующими.
Директива #include "rect.c" включает на этапе препроцессорной
обработки в программу определение функции rectangle().
Предполагается, как упомянуто выше, что текст этого опреде-
ления находится в файле rect.c. В языке Си, как говорилось в
главе 3, существует соглашение об обозначении имен включае-
мых файлов. Если имя файла заключено в угловые скобки '< >',
то считается, что это один из файлов стандартной библиотеки
компилятора. Например, файл <math.h> содержит средства свя-
зи с библиотечными математическими функциями. Файл, назва-
ние которого помещено в кавычках " ", воспринимается как
файл из текущего каталога. Именно там в этом примере препро-
цессор начинает разыскивать файл rect.c.
Определения функций ratio() и cos4_2(), позволяющих вы-
числять значения подынтегральных выражений по заданному
значению аргумента, ничем не примечательны. Их прототипы
соответствуют требованиям спецификации первого параметра
функции rectangle():
double имя (double)
236
Программирование на языке Си
В основной программе main() функция rectangle() вызыва-
ется дважды с разными значениями параметров. Для разнообра-
зия вызовы выполнены по-разному, но каждый раз первый пара-
метр - это имя конкретной функции, т.е. константный указатель
на функцию.
Указатель на функцию как возвращаемое функцией зна-
чение. При организации меню в тех случаях, когда количество
вариантов и соответствующее количество действий определя-
ются не в точке исполнения, а в "промежуточной" функции,
удобно возвращать из этой промежуточной функции адрес той
конкретной функции, которая должна быть выполнена. Этот
адрес можно возвращать в виде значения указателя на функцию.
Рассмотрим программу, демонстрирующую особенности та-
кой организации меню.
В программе определены три функции: первые две функции
fl () и f2() с прототипом вида
int f (void); ,
(пустой список параметров, возвращается значение типа int) и
третья функция menu() с прототипом
int (*menu(void)) (void);
которая возвращает значение указателя на функции с пустыми
списками параметров, возвращающие значения типа int.
При выполнении функции menu() пользователю дается воз-
можность выбора из двух пунктов меню. Пунктам меню соот-
ветствуют определенные выше функции fl () и f2(), указатель
на одну из которых является возвращаемым значением. При не-
верном выборе номера пункта возвращаемое значение становит-
ся равным NULL.
В основной программе определен указатель г, который мо-
жет принимать значения адресов функций fl() и f2(). В беско-
нечном цикле выполняются обращения к функции menu( \ и
если результат равен NULL, то программа печатает "The End" и
завершает выполнение. В противном случае вызов
t=(*r) ( );
Глава б. Функции
237
обеспечивает исполнение той из функций fl () или f2(), адрес
которой является значением указателя г.
Текст программы' :
#include <stdio.h>
int fl(void)
{
printf(" The first actions: ");
return 1;
)
int f2(void)
{
printf(" The second actions: ");
return 2;
)
int (* menu(void))(void)
{
int choice; /* Номер пункта меню */
/* Массив указателей на функции: */
int (* menu_items[])() = {fl, f2);
printf("\n Pick the menu item (1 or 2): ");
scanf("%d",bchoice);
if (choice < 3 && choice > 0)
return menu_iterns[choice - 1];
else
return NULL;
)
void main()
{
int (*r)(void); /* Указатель на функции */
int t;
while (1)
( /* Обращение к меню: */
r=menu();
if (r == NULL)
(
printf("\nThe End!");
return;
)
' Исходный вариант программы предложен С.М.Лавреновым.
238
Программирование на языке Си
/* Вызов выбранной функции */
t=(*r) () ;
printf("\tt=
Результаты выполнения программы:
Pick the menu item (1 or 2): 2
The second actions: t=2
Pick the menu item (1 or 2): 1
The first actions: t=l
Pick the menu item (1 or 2): 24
The End!
В функции menu() определен массив menu_items[ ] указате-
лей на функции. В качестве инициализирующих значений в
списке использованы имена функций fl () и f2():
int (* menu_items[ ]) () = {fl, f2};
Такое определение массива указателей на функции по мень-
шей мере не очень наглядно. Упростить такие определения
можно с .помощью вспомогательных обозначений (имен), вво-
димых спецификатором typedef. Например, то же самое опреде-
ление массива указателей можно ввести так:
typedef int (*Menu_action) (void);
Menu action menu items [ ] = {fl, f2};
Здесь typedef вводит обозначение Menu action для типа "ука-
затель на функции с пустым списком параметров, возвращаю-
щие значения типа int".
Библиотечные функции с указателями на функции в па-
раметрах. Эти функции играют важную роль при решении за-
дач на языке Си. В стандартную библиотеку компилятора с
языка Си включены по крайней мере следующие функции:
qsort () - функция быстрой сортировки массива;
search () - функция поиска в массиве элемента с заданны-
ми свойствами.
Глава 5. Функции
239
У каждой из этих функций один из параметров - указатель на
функцию. Для функции быстрой сортировки нужен указатель на
функцию, позволяющую задать правила упорядочения (срав-
нения) элементов. В функции поиска параметр - указатель на
функцию позволяет задать функцию, с помощью которой про-
граммист должен сформулировать требования к искомому эле-
менту массива.
Опыт работы на языке Си показал, что даже не новичок в об-
ласти программирования испытывает серьезные неудобства,
разбирая синтаксис определения конструкций, включающих
указатели на функции. Например, не каждому сразу становится
понятным такое определение прототипа функции:
void qsort(void * base, sizet nelem, sizet width,
int (*fcmp)(const void * pl, const void * p2));
Это прототип функции быстрой сортировки, входящей в
стандартную библиотеку функций. Прототип находится в заго-
ловочном файле stdlib.h. Функция qsort() сортирует содержи-
мое таблицы (массива) однотипных элементов, неоднократно
вызывая функцию сравнения, подготовленную пользователем.
Для вызова функции сравнения ее адрес должен заместить ука-
затель fcmp, специфицированный как формальный параметр.
При использовании qsort() программист должен подготовить
таблицу сортируемых элементов в виде одномерного массива
фиксированной длины и написать функцию, позволяющую
сравнивать два любых элемента сортируемой таблицы. Остано-
вимся на параметрах функции qsort():
base - указатель на начало таблицы (массива) сорти-
. руемых элементов (адрес нулевого элемента
массива);
nelem - количество сортируемых элементов в таблице
(целая величина, не большая размера массива) -
сортируются первые nelem элементов от начала
массива;
width - размер элемента таблицы (целая величина, оп-
ределяющая в байтах размер одного элемента
массива);
240
Программирование на языке Си
fcmp - указатель на функцию сравнения, получающую
в качестве параметров два указателя pl, р2 на
элементы таблицы и возвращающую в зависи-
мости от результата сравнения целое число:
если *р1 < *р2, функция fcmp () возвращает
отрицательное целое < 0;
если *pl — *р2, fcmp () возвращает 0;
если *pl > *р2, fcmp () возвращает положи-
тельное целое > 0.
При сравнении символ "меньше, чем" (<) означает, что после
сортировки левый элемент отношения *р1 должен оказаться в
таблице перед правым элементом *р2, т.е. значение *р1 должно
иметь меньшее значение индекса в массиве, чем *р2. Аналогич-
но (но обратно) определяется расположение элементов при вы-
полнении соотношения "больше, чем" (>).
В следующей программе функция qsort() используется для
упорядочения массива указателей на строки разной длины.
Упорядочение должно быть выполнено таким образом, чтобы
последовательный перебор массива указателей позволял полу-
чать строки в алфавитном порядке. Сами строки в процессе сор-
тировки не меняют своих положений. Изменяются только
значения указателей в массиве.
#include <stdio.h>
♦include <stdlib.h> /*
♦include <string.h> /*
Для функции qsort() */
Для сравнения строк:
strcmp () */
/* Определение функции для сравнения: */
int compare(const void *a, const void *b)
{
unsigned long *pa = (unsigned long *)a,
*pb = (unsigned long *)b;
Return strcmp((char *)*pa, (char *)*pb);
}
void main()
{
char *pc[] = {
"One - 1",
"Two - 2",
Глава 5. Функции
241
"Three - 3",
"Four - 4 ",
"Five - 5",
"Six - 6",
"Seven - 7",
"Eight - 8" } ;
/* Размер таблицы: */
int n = sizeof(pc)/sizeof(pc[0J);
int i;
printf("\n До сортировки:");
for (i = 0; i < n; i++)
printf("\npc [%d] = %p -> %s",
i,pc[i],pc[i]);
/* Вызов функции упорядочения: */
qsort((void *)
pc,I * Адрес начала сортируемой таблицы *I
n,/* Число элементов сортируемой таблицы */
sizeof(рс[0]), /* Размер одного элемента */
compare /* Имя функции сравнения
(указатель) */
) ;
printf("\n\n После сортировки:");
for (i = 0; i < n; i++)
printf("\npc [%d] = %p -> %s",
i,pc[i],pc[i]);
)
Результаты выполнения программы:
до сортировки:
рс [0] = 00В8 -> One - 1
рс [1] = оосо -> Two - 2
рс [2] = 00С8 -> Three - 3
рс [3] = 00D2 -> Four - 4
рс [4] = 00DC -> Five - 5
рс [5] = 00Е5 -> Six - 6
рс [б] = 00ED -> Seven - 7
рс [7] = 00F7 -> Eight - 8
после сортировки:
рс
рс
рс
[0] = 00F7 -> Eight - 8
[1] = 00DC -> Five - 5
[2] = 00D2 -> Four - 4
16-3’2*
242
Программирование на языке Си
рс [3] = 00В8 -> One - 1
рс [4] = 00ED -> Seven - 7
рс [5] = 00Е5 -> Six - 6
рс [6] = 00С8 -> Three - 3
рс [7] = 00С0 -> Two - 2
Вывод адресов, т.е. значений указателей pc[i], выполняется в
шестнадцатеричном виде с помощью спецификации преобразо-
вания %р.
Обратите внимание на значения указателей pc[i]. До сорти-
ровки разность между рс[1] и рс[0] равна длине строки "One -
1" и т.д. После упорядочения рс[0] получит значение, равное
исходному значению рс[7], и т.д.
Для выполнения сравнения строк (а не элементов массива
рс[ ]) в функции сошраге() использована библиотечная функ-
ция strcmp(), прототип которой в заголовочном файле string.h
имеет вид:
int strcmp(const char *sl, const char *s2);
Функция strcmp() сравнивает строки, связанные с указате-
лями si и s2. Сравнение выполняется посимвольно, начиная с
начальных символов строк и до тех пор, пока не встретятся не-
совпадающие символы либо не закончится одна из строк.
Прототип функции strcmp() требует, чтобы параметры име-
ли тип (const char *). Входные параметры функции compare()
имеют тип (const void *), как предусматривает определение
функции qsort(). Необходимые преобразования для наглядно-
сти выполнены в два этапа. В теле функции compare() опреде-
лены два вспомогательных указателя типа (unsigned long *),
которым присваиваются значения адресов элементов!, сортируе-
мой таблицы (элементов массива рс[ ]) указателей. В свок\ оче-
редь, функция strcmp() получает разыменования этих ука-
зателей, т.е. адреса символьных строк. Таким образом, выпол-
няется сравнение не элементов массива char * рс[ ], а тех строк,
адреса которых являются значениями pc[i]. Однако функция
qsort() работает с массивом рс[ ] и меняет местами только зна-
Глава 5. Функции
243
чения его элементов. Последовательный перебор массива рс[ ]
позволяет в дальнейшем получить строки в алфавитном поряд-
ке, что иллюстрирует результат выполнения программы. Так
как pc[i] - указатель на некоторую строку, то по спецификации
преобразования %s выводится сама строка.
Если не использовать вспомогательных указателей pa, pb, то
функцию сравнения строк можно вызвать из тела функции
compare( ):таким оператором:
return strcmp((char *)(*(unsigned long *)a),
(char *)(*(unsigned long *)b));
где каждый указатель (void *) вначале преобразуется к типу
(unsigned long *).
Последующее разыменование "достает" из нескольких смеж-
ных байтов значение соответствующего указателя pc[i], затем
преобразование (char *) формирует такой указатель на строку,
который нужен функции strcmp().
5.5. Функции с переменным количеством
параметров
В языке Си допустимы функции, количество параметров у
которых при компиляции функции не фиксировано. Кроме того,
могут быть неизвестными и типы параметров. Количество и ти-
пы параметров становятся известными только в момент вызова
функции, когда явно задан список фактических параметров. При
определении и описании таких функций, имеющих списки па-
раметров неопределенной длины, спецификация формальных
параметров заканчивается запятой и многоточием. Формат про-
тотипа функции с переменным списком параметров:
тип имя (спецификация явных параметров,...);
где тип - тип возвращаемого функцией значения;
имя - имя функции;
16’
244
Программирование на языке Си*
спецификация явных параметров - список специфика-
ций параметров, количество и типы которых фиксированы и
известны в момент компиляции. Эти параметры можно назвать
обязательными.
Каждая функция с переменным количеством параметров
должна иметь хотя бы один обязательный параметр. После спи-
ска явных (обязательных) параметров ставится запятая, а затем
многоточие, извещающее компилятор, что дальнейший кон-
троль соответствия количества и типов параметров при обра-
ботке вызова функции проводить не нужно. Сложность в том,
что у переменного списка параметров нет даже имени, поэтому
не понятно, как найти его начало и конец.
Каждая функция с переменным списком параметров должна
иметь механизм определения их количества и их типов. Прин-
ципиально различных подходов к созданию этого механизма
два. Первый подход предполагает добавление в конец списка
реально использованных (необязательных) фактических пара-
метров специального параметра-индикатора с уникальным зна-
чением, которое будет сигнализировать об окончании списка.
При таком подходе в теле функции параметры последовательно
перебираются, и их значения сравниваются с заранее известным
концевым признаком. Второй подход предусматривает передачу
в функцию сведений о реальном количестве фактических пара-
метров. Эти сведения о реальном количестве используемых
фактических параметров можно передавать в функцию с помо-
щью одного из явно задаваемых (обязательных) параметров. В
обоих подходах - и при задании концевого признака, и при ука-
зании числа реально используемых фактических параметров -
переход от одного фактического параметра к другому выполня-
ется с помощью указателей, т.е. с использованием адресной
арифметики. Проиллюстрируем сказанное примерами.
Доступ к адресам параметров из списка. Следующая про-
грамма включает функцию с изменяемым списком параметров,
первый из которых (единственный обязательный) определяет
число действительно используемых при вызове необязательных
фактических параметров.
Глава 5. Функции
245
#include <stdio.h>
/*Функция суммирует значения своих параметров
типа int */
long symma(int k,...)
/* k - число суммируемых параметров */
{
int *pick = &k; /* Настроили указатель
на параметр к*/
long total(= 0;
for(; к; к—)
total += *(++pick);
return total;
}
void main()
{
printf("\n summa(2, 6, 4) « %d",summa(2,6,4));
printf("\n summa(6, 1, 2, 3, 4, 5, 6) = %d",
summa(6,1,2,3,4,5,6));
}
Результат выполнения программы:
summa(2, 6, 4) = 10
summa(6,. 1, 2, 3, 4, 5, 6) = 21
Для доступа к списку параметров используется указатель
pick типа int *. Вначале ему присваивается адрес явно заданного
параметра к, т.е. он устанавливается на начало списка парамет-
ров в памяти. Затем в цикле указатель pick перемещается по ад-
ресам следующих фактических параметров, соответствующих
неявным формальным параметрам. С помощью разыменования
*(++pick) выполняется выборка их значений. Параметром цикла
суммирования служит аргумент к, значение которого уменьша-
ется на 1 после каждой итерации и, наконец, становится нуле-
вым. Особенность функции - возможность работы только с
целочисленными фактическими параметрами, так как указатель
pick после обработки значения очередного параметра
"перемещается вперед" на величину sizeof(int) и должен быть
всегда установлен на начало следующего параметра.
Недостаток функции - возможность ошибочного задания не-
верного количества реально используемых параметров.
246
Программирование на языке Си
Следующий пример содержит функцию для вычисления
произведения переменного количества параметров. Признаком
окончания списка фактических параметров служит параметр с
нулевым значением.
#include <stdio.h>
/* Функция вычисляет произведение параметров:*/
double prod(double arg, ...)
{
double aa = 1.0; /* Формируемое произведение*/
double *prt — &arg; /* Настроили указатель
на параметр arg */
if (*prt == 0.0)
return 0.0;
for (; *prt; prt++)
aa *= *prt;
return aa;
}
void main()
{
double prod(double,...);/* Прототип функции */
printf("\n prod(2e0, 4e0, 3e0, OeO) — %e",
prod(2e0,4e0,3e0,OeO));
printf("\n prod(1.5, 2.0, 3.0, 0.0) = %f",
prod(1.5,2.0,3.0,0.0));
printf("\n prod(1.4, 3.0, 0.0, 16.0, 84.3,
0.0)=%f",
prod(1.4,3.0,0.0,16.0,84.3,0.0));
printf( "\n prod(OeO) = %e",prod(OeO));
}
Результат выполнения программы:
prod(2e0, 4e0, ЗеО, 0e0)'= 2.400000e+01
prod(1.5, 2.0, 3.0, 0.0) = 9.000000
prod(1.4, 3.0, 0.0, 16.0, 84.3, 0.0) = 4.200000
prod(OeO) га 0.000000e+00
В функции prod() перемещение указателя prt по списку фак-
тических параметров выполняется всегда за счетщзменения prt
на величину sizeof(double). Поэтому все фактические парамет-
ры при обращении к функции prod() должны иметь тип double.
Глава 5. Функции
247
В вызовах функции проиллюстрированы некоторые варианты
задания параметров. Обратите внимание на вариант с нулевым
значением параметра в середине списка. Параметры вслед за
этим значением игнорируются. Недостаток функции - неопре-
деленность действий при отсутствии в списке фактических па-
раметров параметра с нулевым значением.
Чтобы функция с переменным количеством параметров мог-
ла воспринимать параметры различных типов, необходимо в
качестве исходных данных каким-то образом передавать ей ин-
формацию о типах параметров. Для однотипных параметров
возможно, например, такое решение - передавать с помощью
дополнительного обязательного параметра признак типа пара-
метров. Определим функцию, выбирающую минимальное из
значений параметров, которые могут быть двух типов: или
только long, или только int. Признак типа параметра будем пе-
редавать как значение первого обязательного параметра. Второй
обязательный параметр указывает количество параметров, из
значений которых выбирается минимальное. В следующей про-
грамме предложен один из вариантов решения сформулирован-
ной задачи:
#include <stdio.h>
void main()
{ /* Прототип функции: */
long minimum(char, int ,...);
printf("\n\tminimum('1',3,10L,20L,30L) = %ld",
minimum('1',3,10L,20L,30L));
printf("\n\tminimum('i',4,11, 2, 3, 4) = %ld",
minimum('i',4,11,2,3,4));
printf( "\n\tminimum('k', 2, 0, 64) = %ld",
minimum('k',2,0,64));
}
/* Определение функции о переменным списком
параметров */
long minimum(char z, int k,...)
{
if (z = 'i')
{
int *pi » &k + 1; /* Настроились на первый
необязательный параметр */
248
Программирование на языке Си
int min = *pi; /* Значение первого
необязательного параметра */
for(; к; к—, pi++)
min = min > *pi ? *pi : min;
return (long)min;
}
if (z == •!•)
{
long *pl = (long*)(&k+l);
long min = *pl; /* Значение первого
необязательного параметра */
for(; к; к—, pl++)
min = min > *pl ? *pl : min;
return (long)min;
}
printf("\пОшибка? Неверно задан 1-й пара-
метр : ") ;
return 2222L;
}
Результат выполнения программы:
minimum('1', 3, 10L, 20L, 30L) =10
minimum('i', 4, 11, 2, 3, 4) =2
Ошибка! Неверно задан 1-й параметр:
minimum('к',2,0,64)=2222
В приведенных примерах функций с изменяемыми списками
параметров перебор параметров выполнялся с использованием
адресной арифметики и явным применением указателей нужных
типов. К проиллюстрированному способу перехода от одного
параметра к другому нужно относиться с осторожностью. Дело
в том, что порядок размещения параметров в памяти ЭВМ зави-
сит от реализации компилятора. В компиляторах имеются оп-
ции, позволяющие изменять последовательность размещения
параметров. Стандартная для языка Си на IBM PC последова-
тельность: меньшее значение адреса у первого параметра функ-
ции, а остальные размещены подряд в соответствии с уве-
личением адресов. Противоположный порядок обработки и раз-
мещения будет у функций, определенных и описанных с моди-
фикатором pascal. Этот модификатор и его антипод -
Глава 5. Функции
249
модификатор cdecl являются дополнительными ключевыми
словами, определенными для ряда компиляторов. Не останавли-
ваясь подробно на возможностях, предоставляемых модифика-
тором pascal, отметим два факта. Во-первых, применение
модификатора pascal необходимо в тех случаях, когда функция,
написанная на языке Си, будет вызываться из программы, под-
готовленной на Паскале. Во-вторых, функция с модификатором
pascal не может иметь переменного списка параметров, т.е. в ее
определении и в $е прототипе нельзя использовать многоточие.
Макросредства для переменного числа параметров. Вер-
немся к особенностям конструирования функций со списками
параметров переменной длины и различных типов. Предложен-
ный выше способ передвижения по списку параметров имеет
один существенный недостаток - он ориентирован на конкрет-
ный тип машин и привязан к реализации компилятора. Поэтому
функции могут оказаться немобильными.
Для обеспечения мобильности программ с функциями,
имеющими изменяемые списки параметров, в каждый компиля-
тор стандарт языка предлагает включать специальный набор
макроопределений, которые становятся доступными при вклю-
чении в текст программы заголовочного файла stdarg.h. Макро-
команды, обеспечивающие простой и стандартный (не
зависящий от реализации) способ доступа к конкретным спи-
скам фактических параметров переменной длины, имеют сле-
дующий формат:
void va_start(va_list param, последний явный параметр)-,
type va_arg(va_list param, type)-,
void va_end(va_list param)’,
Кроме перечисленных макросов, в файле stdarg.h определен
специальный тип данных va_list, соответствующий потребно-
стям обработки переменных списков параметров. Именно тако-
го типа должны быть первые фактические параметры,
используемые при обращении к макрокомандам va_start(),
va_arg(), va_end(). Кроме того, для обращения к макросу
va_arg() необходимо в качестве второго параметра использо-
250
Программирование на языке Си
вать обозначение типа {type) очередного параметра, к которому
выполняется доступ. Объясним порядок использования пере-
численных макроопределений в теле функции с переменным
количеством параметров (рис. 5.2). Напомним, что каждая из
функций с переменным количеством параметров должна иметь
хотя бы один явно специфицированный формальный параметр,
за которым после запятой стоит многоточие. В теле функции
обязательно определяется объект типа va_list. Например, так:
va_list factor;
Определенный таким образом объект factor обладает свойства-
ми указателя. С помощью макроса va_start() объект factor свя-
зывается с первым необязательным параметром, т.е. с началом
.списка неизвестной длины. Для этого в качестве второго аргу-
мента при обращении к макросу va_start() используется по-
следний из явно специфицированных параметров функции
(предшествующий многоточию):
va_start (factor, последний явный параметр)',
Рассмотрев выше способы перемещения по списку парамет-
ров с помощью адресной арифметики, мы понимаем, что указа-
тель factor сначала "нацеливается" на адрес последнего явно
специфицированного параметра, а затем перемещается на его
длину и тем самым устанавливается на начало переменного
списка параметров. Именно поэтому функция с переменным
списком параметров должна иметь хотя бы один явно специфи-
цированный параметр.
Теперь с помощью разыменования указателя factor мы мо-
жем получить значение первого фактического параметра из пе-
ременного списка. Однако нам не известен тип этого факти-
ческого параметра. Как и без использования макросов, тип па-
раметра нужно каким-то образом передать в функцию. Если это
сделано, т.е. определен тип type очередного параметра, то об-
ращение к макросу
va_arg (factor, type)
Глава 5. Функции
251
Реальные фактические параметры
обязательные необязательные
int int float int char inti ] long double
N К sum Z cc ro smell
va_list factor; /* Определили указатель */
va_start (factor, sum); /* Настройка указателя (см. ниже) */
| N | К | sum | Z | ее | го | smell |
Л
factor---------------------
int ix;
ix=va_arg (factor, int); /* Считали в ix значение Z типа int,
одновременно сместили указатель на длину переменной типа int */
| N | К | sum | Z | сс | го | smell |
factor---------------:----------------
char сх;
cx=va_arg (factor, char); /* Считали в сх значение сс типа char и
сместили указатель на длину объекта типа char */
| N | К | sum | Z | сс | го | smell ~]
А
factor----------------------------------------
int * pr;
pr=va_arg(factor, int); /* Считали в pr адрес го типа int* массива типа
int [ ] и сместили указатель factor на размер указателя int* */
| N | К | sum | Z | сс , | го | smell |
factor --------------------------------------------------
long double рр;
pp=va_arg (factor, long double); /* Считали значение smell */
Рис. 5.2. Схема обработки переменного списка параметров
с помощью макросов стандартной библиотеки
252
Программирование на языке Си
позволяет, во-первых, получить значение очередного (сначала
первого) фактического параметра типа type. Вторая задача мак-
рокоманды va_arg() - заменить значение указателя factor на
адрес следующего фактического параметра в списке. Теперь,
узнав каким-то образом тип, например typel, этого следующего
параметра, можно вновь обратиться к макросу:
va_arg (factor, typel)
Это обращение позволяет получить значение следующего
фактического параметра и переадресовать указатель factor на
фактический параметр, стоящий за ним в списке, и т.д.
Примечание. Реализация компиляторов Turbo C++ и Borland
C++ запрещает использовать с макрокомандой va_arg( ) ти-
пы char, unsigned char, float. Данные типа char и unsigned
char преобразуются при передаче в функцию с переменным
количеством параметров в тип int, а данные типа float при-
водятся к типу double. Именно поэтому при выводе с помо-
щью printf() данных как типа float, так и типа double
используются одни и те же спецификаторы %f и %е. Вывод
данных типа char и unsigned char можно выполнять и по
спецификации %d, и по спецификации %с.
Макрокоманда va_end() предназначена для организации
корректного возврата из функции с переменным списком пара-
метров. Ее единственным параметром должен быть указатель
типа va_list, который использовался в функции для перебора
параметров. Таким образом, для наших иллюстраций вызов
макрокоманды должен иметь вид:
va_end (factor);
Макрокоманда va_end() должна быть вызвана после того,
как функция обработает весь список фактических параметров.
Макрокоманда va_end() обычно модифицирует свой аргу-
мент (указатель типа va_list), и поэтому его нельзя будет по-
вторно использовать без предварительного вызова макроса
va_start().
Глава 5. Функции
253
Примеры функций с переменным количеством парамет-
ров. Для иллюстрации особенностей использования описанных
макросов рассмотрим функцию, формирующую в динамической
памяти массив из*элементов типа double. Количество элементов
определяется значением первого обязательного параметра
функции, имеющего тип int. Значения параметров массива пе-
редаются в функцию с помощью переменного числа необяза-
тельных параметров типа double. Текст функции вместе с
основной программой, из которой выполняется ее вызов:
#include <stdarg.h> /* Для макросредств */
#include <stdlib.h> /* Для функции calloc( ) */
double * set_array (int k, ...)
{
int i ;
va_list par; /* Вспомогательный указатель */
double * rez; /* Указатель на результат */
rez=calloc(k,sizeof(double));
if (rez == NULL)
return NULL;
va_start (par, k); /* "Настройка" указателя */
/* Цикл "чтения" параметров: */
for (i=0; i<k; i++)
rez[i]=va arg (par, double);
\ —
va_end . (par);
return rez;
}
#include <stdio.h>
void main( )
{
double * array; int j;
int n=5;
printf("\n");
array=set_array (n, 1.0, 2.0, 3.0, 4.0, 5.0);
if (array == NULL) return;
for {j=0; j<n; j++)
printf ("\t%f", array [j]);
free(array);
}
254
Программирование на языке Си
Результат выполнения программы:
1.000000 2.000000 3.000000 4.000000 5.000000
В теле функции обратите внимание на применение функции
са!1ос(), позволяющей выделить память для массива. Первый
параметр функции са!1ос() - количество элементов массива,
второй - размер в байтах одного элемента. При неудачном вы-
делении памяти функция са!1ос() возвращает нулевое значение
адреса, что проверяет следующий ниже условный оператор.
В функциях с переменным количеством параметров есть
один уязвимый пункт - если при "чтении" параметров с помо-
щью макроса va_arg() указатель выйдет за пределы явно ис-
пользованного списка фактических параметров, то результат,
возвращаемый макросом va_arg(), не определен. Таким обра-
зом, в нашей функции set_array() количество явно заданных
параметров переменного списка ни в коем случае не должно
быть меньше значения первого фактического параметра (заме-
няющего int к).
В основной программе main() определен указатель double *
array, которому присваивается результат (адрес динамического
массива), возвращаемый функцией set_array(). Затем с помо-
щью указателя array в цикле выполняется доступ к элементам
массива, и их значения выводятся на экран дисплея.
В следующей программе в качестве еще одной иллюстрации
механизма обработки переменного списка параметров исполь-
зуется функция для конкатенации любого количества символь-
ных строк. Строки, предназначенные для соединения в одну
строку, передаются в функцию с помощью списка указателей-
параметров. В конце списка неопределенной длины всегда по-
мещается нулевой указатель NULL.
#include <stdio.h>
#include <string.h> /*
#include <stdarg.h> /*
#include <stdlib.h> /*
char *concat(char *sl,
Для функций обработки
строк */
Для макросредств *'/
Для функции malloc( ) */
. . .)
Глава 5. Функции
255
{
va_list par;/* Указатель на параметры списка */
char *ср = si;
char *string;
int len = strlen(sl);/* Длина 1-го параметра */
va_start(par, si); /* Начало переменного
списка */
/* Цикл вычисления общей длины параметров-
строк : * /
while (ср = va_arg(par, char *))
len += strlen(ср);
/* Выделение памяти для результата: */
string = (char *)malloc(len +1);
strcpy(string, si); /* Копируем 1-й параметр */
va_start(par, si); /* Начало переменного
списка */
/* Цикл конкатенации параметров строк: */
while (ср = va_arg(par, char *))
strcat(string, ср); /* Конкатенация двух
строк */
va_end(par);
return string;
}
void main()
{
char* concat(char* si, ...); /* Прототип
функции */
char* s; /* Указатель для результата */
s=concat("\nNulla ","Dies ",’'Sine ", "Lineal",
NULL);
s = concat(s,
" - Ни одного дня без черточки!",
"\n\t",
"(Плиний Старший о художнике Апеллесе)",
NULL);
printf("\n%s",s);
}
Результат выполнения программы:
Nulla Eti.es Sine Linea! - Ни одного дня без черточки!
(Плиний Старший о художника Апеллесе)
256
Программирование на языке Си
В приведенной функции concat() количество параметров пе-
ременно, но их тип заранее известен и фиксирован. В ряде слу-
чаев полезно иметь функцию, параметры которой изменяются
как по числу, так и по типам. В этом случае, как уже говори-
лось, нужно сообщать функции о типе очередного фактического
параметра. Поучительным примером таких функций служат
библиотечные функции форматного ввода-вывода языка Си:
int printf (const char* format,...);
int scanf (const char* format,...);
В обеих функциях форматная строка, связанная с указателем
format, содержит спецификации преобразования (%d - для де-
сятичных чисел, %е - для вещественных данных в форме с пла-
вающей точкой, %f - для вещественных значений в форме с
фиксированной точкой и т.д.). Кроме того, эта форматная стро-
ка в функции printf( ) может содержать произвольные символы,
которые выводятся на дисплей без какого-либо преобразования.
Чтобы продемонстрировать особенности построения функций с
переменным числом параметров, классики языка Си [1] реко-
мендуют самостоятельно написать функцию, подобную функ-
ции printf(). Последуем их совету, но для простоты разрешим
использовать только спецификации преобразования "%d" и
"%Г.
/* Упрощенный аналог printf( ).
По мотивам K&R, [2], стр. 152 */
#include <stdio.h>
#include <stdarg.h> /* Для макросредств
переменного списка параметров */
void miniprint(char *format, ...)
va_list ар;/* Указатель на необязательный
параметр*/
char *р; /* Для просмотра строки format */
int ii; /* Целые параметры */
double dd; /* Параметры типа double */
va_start(ар,format);/‘Настроились на первый
параметр */
for (р = format; *р; р++)
Глава 5. Функции
257
{
if (*р != '%')
{
printf("%с",*р);
continue;
} •
switch (*++р)
{ case 'd': ii = va_arg(ap,int);
printf("%d",ii);
break;
case 'f': dd = va_arg(ap,double);
printf(”%f”,dd);
break;
default: printf("%c", *p) ;
} /* Конец переключателя */
}/* Конец цикла просмотра строки-формата */
va_end(ар);/‘Подготовка к завершению функции*/
}
void main()
{
void miniprint(char *, ...); /* Прототип */
int k = 154;
double e = 2.718282;
miniprint("\пЦелое k= %d,\t4nono e= %f",k,e);
}
Результат выполнения программы;
Целое k= 154, число е= 2.718282
Интересной особенностью предложенной функции
miniprint() и ее серьезных прародителей - библиотечных функ-
ций языка Си printf() и scanf() - является использование одно-
го явного параметра и для задания типов последующих
параметров, и для определения их количества. Для этого в стро-
ке, определяющей формат вывода, записывается последова-
тельность спецификаций, каждая из которых начинается
символом Предполагается, что количество спецификаций
равно количеству параметров в следующем за форматом списке.
Конец обмена и перебора параметров определяется по достиже-
нию конца форматной строки, когда *р= = '\0'.
17~3124
258
Программирование на языке Си
5.6. Рекурсивные функции
Рекурсивной называют функцию, которая прямо или косвен-
но сама вызывает себя. Именно возможность прямого или кос-
венного вызова позволяет различать прямую или косвенную
рекурсию.
При каждом обращении к рекурсивной функции создается
новый набор объектов автоматической памяти, локализованных
в теле функции.
Рекурсивные алгоритмы эффективны, например, в тех зада-
чах, где рекурсия использована в определении обрабатываемых
данных. Поэтому серьезное изучение рекурсивных методов
нужно проводить, вводя динамические структуры данных с ре-
курсивной структурой. Рассмотрим вначале только принципи-
альные возможности, которые предоставляет язык Си для
организации рекурсивных алгоритмов.
Еще раз отметим, что различают прямую и косвенную рекур-
сии. Функция называется косвенно рекурсивной в том случае,
если она содержит обращение к другой функции, содержащей
прямой или косвенный вызов определяемой (первой) функции.
В этом случае по тексту определения функции ее рекурсивность
(косвенная) может быть не видна. Если в теле функции явно ис-
пользуется вызов этой же функции, то имеет место прямая ре-
курсия, т.е. функция, по определению, рекурсивная (иначе -
самовызываемая или самовызывающая: self-calling). Классиче-
ский пример - функция для вычисления факториала неотрица-
тельного целого числа.
long fact(int k)
{ if (k < 0) return 0;
if (k = 0) return 1;
return k * fact(k-l);
}
Для отрицательного аргумента результат (по определению
факториала) не существует. В этом случае функция возвратит
нулевое значение. Для нулевого параметра функция возвращает
Глава 5. Функции
259
значение 1, так как, по определению, 0! равен 1. В противном
случае вызывается та же функция с уменьшенным на 1 значени-
ем параметра и результат умножается на текущее значение па-
раметра. Тем самым для положительного значения параметра к
организуется вычисление произведения
к * (к-1) * (к-2) *...*3*2*1*1
Обратите внимание, что последовательность рекурсивных
обращений к функции fact() прерывается при вызове fact(O).
Именно этот вызов приводит к последнему значению 1 в произ-
ведении, так как последнее выражение, из которого вызывается
функция, имеет вид: l*fact(l-l)
В языке: Си отсутствует операция возведения в степень, и
следующая рекурсивная функция вычисления целой степени
вещественного ненулевого числа может оказаться полезной
(следует отметить, что в стандартной библиотеке есть функция
pow() для возведения в степень данных типа double. См. При-
ложение 3):
double expo(double a, int n)
{ if (n == 0) return 1;
if (a = 0.0) return 0;
if (n > 0) return a * expo(a, n-1);
if (n < 0) return expo(a, n+1) / a;
)
При обращении вида expo(2.0, 3) рекурсивно выполняются
вызовы функции ехро() с изменяющимся вторым аргументом:
ехро(2.0,3), ехро(2.0,2), ехро(2.0,1), ехро(2.0,0). При этих вызо-
вах последовательно вычисляется произведение
2.0 * 2.0 * 2.0 * 1
и формируется нужный результат.
Вызов функции для отрицательного значения степени, на-
пример,
expo(5.0,-2)
эквивалентен вычислению выражения
expo(5.0,0) /5.0 /5.0
17*
260
Программирование на языке Си
Отметим математическую неточность, В функции ехро() для
любого показателя при нулевом основании результат равен ну-
лю, хотя возведение в нулевую степень нулевого основания
должно Приводить к ошибочной ситуации.
В качестве еще одного примера рекурсии рассмотрим функ-
цию определения с заданной точностью eps корня уравнения
fix) ~0 на отрезке [а, 6]. Предположим для простоты, что ис-
ходные данные задаются без ошибок, т.е. eps > 0,fia) * fib) < 0,
b > а, и вопрос о возможности существования нескольких кор-
ней на отрезке [а, 6] нас не интересует. Не очень эффективная
рекурсивная функция для решения поставленной задачи содер-
жится в следующей программе:
#include <stdio.h>
#include <math.h> /*Для математических функций*/
#include <stdlib.h> /* Для функции exit() */
/* Рекурсивная функция для определения корня ма-
тематической функции методом деления пополам: */
double recRoot(double f(double), double a,
double b, double eps)
{
double fa = f(a), fb = f(b), c, fc;
if (fa * fb > 0)
(
printf("\пНеверен интервал локализации "
"корня!");
exit(1);
}
с = (а + b) /2.0;
fc = f(с);
if (fc ==0.0 || b - a < eps)
return с; \
return (fa * fc < 0.0) ? recRoot(f, a, c,eps) .*
recRoot(f, c, b,eps);
}
int counter=0; /*Счетчик обращений к тестовой
функции */
void main()
{
double root,
A=0.1, /* Левая граница интервала */
Глава 5. Функции
261
В = 3.5, /* Правая граница интервала */
EPS = 5е-5; /* Точность локализации корня */
double giper(double); /* Прототип тестовой
функции */
root « recRoot(giper, А, В, EPS);
printf("\пЧисло обращений к тестовой функции ”
’’= %d",counter);
printf("\пКорань « %f",root);
}
/* Определение тестовой функции: */
double ^iper(double х)
{
counter++; /*Счетчик обращений - глобальная
переменная */
return (2.0/х * cos(x/2.0));
}
Результат выполнения программы:
Число обращений к тестовой функции = 54
Корень = 3.141601
В рассматриваемой программе пришлось использовать биб-
лиотечную функцию exit(), прототип которой размещен в заго-
ловочном файле stdlib.h Функция exit() позволяет завершить
выполнение программы и возвращает операционной системе
значение своего параметра.
Неэффективность предложенной программы связана, напри-
мер, с излишним количеством обращений к программной реали-
зации функции, для которой определяется корень. При каждом
рекурсивном вызове recRoot() повторно вычисляются значения
f(a), f(b), хотя они уже известны после предыдущего вызова.
Предложите свой вариант исключения лишних обращений к f()
при сохранении рекурсивности.
В литературе по программированию рекурсиям уделено дос-
таточно внимания как в теоретическом плане, так и в плане рас-
смотрения механизмов реализации рекурсивных алгоритмов.
Сравнивая рекурсию с итерационными методами, отмечают, что
рекурсивные алгоритмы наиболее пригодны в случаях, когда
поставленная задача или используемые данные определены ре-
262
Программирование на языке Си
курсивно (см., например, Вирт Н. Алгоритмы + структуры дан-
ных = программы - М.: Мир, 1985. - 406 с.). В тех случаях, ко-
гда вычисляемые значения определяются с помощью простых
рекуррентных соотношений, гораздо эффективнее применять
итеративные методы. Таким образом, определение корня мате-
матической функции, возведение в степень и вычисление фак-
ториала только иллюстрируют схемы организации рекурсивных
функций, но не являются примерами эффективного применения
рекурсивного подхода к вычислениям.
В следующей главе, посвященной структурам и объединени-
ям, мы рассмотрим (§6.4) динамические информационные
структуры, которые включают рекурсивность в само определе-
ние обрабатываемых данных. Именно для таких данных приме-
нение рекурсивных алгоритмов не имеет конкуренции со
стороны итерационных методов.
5.7. Классы памяти и организация программ
Локализация объектов. До сих пор в примерах программ
мы использовали в основном только два класса памяти - авто-
матическую и динамическую память. (В последнем примере из
§5.6 использована глобальная переменная int counter, которая
является внешней по отношению к функциям программ
main(), giper().) Для обозначения автоматической памяти мо-
гут применяться спецификаторы классов памяти auto или
register. Однако и без этих ключевых слов-спецификаторов
класса памяти любой объект (например, массив или перемен-
ная), определенный внутри блока (например, внутри тела функ-
ции), воспринимается как объект автоматической памяти.
Объекты автоматической памяти существуют только внутри
того блока, где они определены. При выходе из блока "память,
выделенная объектам типа auto или register, освобождается, т.е.
объекты исчезают. При повторном входе в блок для тех же объ-
ектов выделяются новые участки памяти, содержимое которых
никак не зависит от "предыстории". Говорят, что объекты авто-
Глава 5. Функции
263
магической памяти локализованы внутри того блока, где они
определены, а время их существования (время "жизни") опреде-
ляется присутствием управления внутри этого блока. Другими
словами, автоматическая память всегда внутренняя, т.е. к ней
можно обратиться только в том блоке, где она определена.
Пример:
#include <stdio.h>
/* Переменные автоматической памяти */
void autofunc(void)
(
int К=1;
printf("\tK=%d",К);
K++;
return;
)
void main()
{
int i;
for (i=0;i<5;i++)
autofunc();
)
Результат выполнения программы:
K=1 K=1 K=1 K=1
Результат выполнения этой программы очевиден, и его мож-
но было бы не приводить, если бы не существовало еще одного
класса внутренней памяти - статической внутренней памяти.
Рассмотрим программу очень похожую на приведенную:
#include <stdio.h>
/* Локальные переменные статической памяти */
Void stat(void)
{
static int K=1;
printf("\tK=%d",K);
K++;
return;
)
void main()
264
Программирование на языке Си
{'
int i;
for (i=0;i<5;i++)
stat () ;
)
Результат выполнения программы:
К=1 К=2 К=3 К=4 К-5
Отличие функций autofunc() и stat() состоит в наличии спе-
цификатора static при определении переменной int К, локализо-
ванной в теле функции stat(). Переменная К в функции
autofunc() - это переменная автоматической памяти, она опре-
деляется и инициализируется при каждом входе в функцию. Пе-
ременная static int К получает память и инициализируется
только один раз. При выходе из функции stat() последнее зна-
чение внутренней статической переменной К сохраняется до
последующего вызова этой же функции. Сказанное иллюстри-
рует результат выполнения программы.
Глобальные объекты. О локализации объектов и о внутрен-
ней памяти блоков мы только что поговорили. Следует обратить
внимание на возможность использовать внутри блоков объекты,
которые по месторасположению своего определения оказыва-
ются глобальными по отношению к операторам и определениям
блока. Напомним, что блок - это не только тело функции, но и
любая последовательность определений и операторов, заклю-
ченная в фигурные скобки.
Выше в рекурсивной программе для вычисления приближен-
ного значения корня математической функции переменная
counter для подсчета количества обращений к тестовой функции
giper() определена как глобальная для всех функций програм-
мы. Вот еще один пример программы с глобальной переменной:
#include <stdio.h>
int N=5; /* Глобальная переменная */
void func(void)
(
printf("\tN=%d",N);
Глава 5. Функции
265
N-- ;
return;
)
void main()
{
int i;
for (i=0;i<5;i++)
{
func();
N+=2 ;
}
Результат выполнения программы:
N=5 N=6 N=7 N=8 N=9
Переменная int N определена вне функций main() и func() и
является глобальным объектом по отношению к каждой из них.
При каждом вызове func() значение N уменьшается на 1, в ос-
новной программе - увеличивается на 2, что и определяет ре-
зультат.
Глобальный объект может быть "затенен" или "скрыт" внут-
ри блока определением, в котором для других целей использо-
вано имя глобального объекта. Модифицируем предыдущую
программу:
#include <stdio.h>
int N=5; /* Глобальная переменная */
void func(void)
{
printf("\tN=%d",N);
N— ;
return;
}
void Aiain ()
{
int N; /* Локальная переменная */
for (N=0;N<5;N++)
func();
)
266
Программирование на языке Си
Результат выполнения программы:
N=5 N=4 N=3 N=2 N=1
Переменная int N автоматической памяти из функции main()
никак не влияет на значение глобальной переменной int N. Это
разные объекты, которым выделены разные участки памяти.
Внешняя переменная N "не видна" из функции main(), и это
результат определения int N внутри нее.
Динамическая память - это память, выделяемая в процессе
выполнения программы. А вот на вопрос: "Глобальный или ло-
кальный объект размещен в динамической памяти?" попытаем-
ся найти правильный ответ.
После выделения динамической памяти она сохраняется до
ее явного освобождения, что может быть выполнено только с
помощью специальной библиотечной функции free().
Если динамическая память не была освобождена до оконча-
ния выполнения программы, то она освобождается автоматиче-
ски при завершении программы. Тем не менее явное осво-
бождение ставшей ненужной памяти является признаком хоро-
шего стиля программирования.
В процессе выполнения программы участок динамической
памяти доступен везде, где доступен указатель, адресующий
этот участок. Таким образом, возможны следующие три вариан-
та работы с динамической памятью, выделяемой в некотором
блоке (например, в теле неглавной функции):
• указатель (на участок динамической памяти) определен как
локальный объект автоматической памяти. В этом случае
выделенная память будет недоступна при выходе за преде-
лы блока локализации указателя, и ее нужно освободить
перед выходом из блока;
• указатель определен как локальный объект статической
памяти. Динамическая память, выделенная однократно в
блоке, доступна через указатель при каждом повторном
входе в блок. Память нужно освободить только по оконча-
нии ее использования;
Глава 5. Функции
267
• указатель является глобальным объектом по отношению к
блоку. Динамическая память доступна во всех блоках, где
"виден" указатель. Память нужно освободить только по
окончании ее использования.
Проиллюстрируем второй вариант, когда объект динамиче-
ской памяти связан со статическим внутренним (лока-
лизованным) указателем:
#include <stdio.h>
#include <alloc.h> /* Для функций malloc( ),
fгее( ) */
void dynam(void)
{
static char *uc=NULL; /* Внутренний
указатель */
/* Защита от многократного выделения памяти: */
if (uc == NULL)
(
uc=(char*)malloc(1);
*uc='A';
)
printf("\t%c",*uc);
(*uc)++;
return;
)
void main( )
{
int i ;
for (i=0; i<5; i++)
dynam( );
)
Результат выполнения программы:
ABODE
Некоторая небрежность предыдущей программы - выделен-
ный функцией malloc() участок памяти явно не освобождается
функцией free().
В следующей программе указатель на динамический участок
памяти - глобальный объект:
268
Программирование на языке Си
#include <stdio.h>
#include <alloc.h> /* Для функций malloc( ),
fгее( ) */
char * uk=NULL; /* Глобальный указатель */
void dynaml (void)
{
printf * uk);
(* uk)++;
}
void main (void)
{
int i;
uk=(char*) malloc (1);
*uk=’A';
for (i=0; i<5; i++)
{
dynaml( );
(*uk)++;
}
free(uk);
)
Результат выполнения программы:
A c E G I
Динамический объект создается в основной функции и свя-
зывается с указателем uk. Там же он явным присваиванием по-
лучает начальное значение 'А'. За счет глобальности указателя
динамический объект доступен в обоих функциях main() и
dynaml(). При выполнении цикла в функции main() и внутри
функции dynaml() изменяется значение динамического объекта.
Приводить пример для случая, когда указатель, адресующий
динамически выделенный участок памяти, является объектом
автоматической памяти, нет необходимости. Заканчивая обсуж-
дение этой темы, отметим, что динамическая память после вы-
деления доступна везде (в любой функции и в любом файле),
где указатель, связанный с этой памятью, определен или описан
как внешний объект. Следует только четко определить понятие
внешнего объекта, к чему мы сейчас и перейдем. \
Глава 5. Функции
269
Внешние объекты. Здесь в конце главы, посвященной
функциям, самое подходящее время, чтобы взглянуть в целом
на программу, состоящую из набора функций, размещенных в
нескольких текстовых файлах. Именно такой вид обычно имеет
более или менее серьезная программа на языке Си. Отдельный
файл с текстами программы иногда называют программным мо-
дулем, но нет строгих терминологических соглашений относи-
тельно модулей или файлов с текстами программы. На рис. 5.3
приведена схема программы, текст которой находится в двух
файлах. Программа, как мы уже неоднократно говорили, пред-
ставляет собой совокупность функций. Все функции внешние,
так как внутри функции по правилам языка Си нельзя опреде-
лить другую функцию. У всех функций, даже размещенных в
разных файлах, должны быть различные имена. Одинаковые
имена функций должны относиться к одной и той же функции.
Кроме функций, в программе могут использоваться внеш-
ние_объекты - переменные, указатели, массивы и т.д. Внешние
объекты должны быть определены вне текста функций.
Внешние объекты могут быть доступны из многих функций
программы, однако эта доступность не всегда реализуется авто-
матически - в ряде случаев нужно дополнительное вмешатель-
ство программиста. Если объект определен в начале файла с
программой, то он является глобальным для всех функций, раз-
мещенных в файле, и доступен в них без всяких дополнитель-
ных предписаний. (Ограничение - если внутри функции имя
глобального объекта использовано в качестве имени внутренне-
го объекта, то внешний объект становится недостижимым, т.е.
"невидимым" в теле именно этой функции.) На рис. 5.3:
• объект X: доступен в fl 1(), fl 2() как глобальный; досту-
пен как внешний в файле 2 только в тех функциях, где бу-
дет помещено описание extern X;
• объект Y: доступен как глобальный в f21() и f22(); досту-
пен как внешний в тех функциях файла 1, где будет поме-
щено описание extern Y;
• объект Z: доступен как глобальный в f22() и во всех функ-
циях файла 1 и файла 2, где помещено описание extern Z.
270
Программирование на языке Си
--------Файл 1
Объект X (определение)
— функция fl —
прототип fl 2
вызов fl 2-------
--------Файд 2 ------
Объект У(определение)
— функция f21(...) —
прототип fl 1
------вызов fl 1
прототип f22
------вызов f22(...)
— функция fl2(.„) —
---вызов fl 1
Объект /(определение)
— функция f22(...) —
прототип fl 2
------вызов fl 2
Рис. 5.3. Схема программы, размещенной в двух файлах
Если необходимо, чтобы внешний объект был доступен для
функций из другого файла или функций, размещенных выше
определения объекта, то он должен быть перед обращением до-
полнительно описан с использованием дополнительного ключе-
вого слова extern. (Наличие этого слова по умолчанию
предполагается и для всех функций, т.е. не требуется в их про-
тотипах.) Такое описание, со спецификатором слова extern, мо-
жет помещаться в начале файла, и тогда объект доступен во
всех функциях файла. Однако это описание может быть разме-
щено в теле одной функции, тогда объект доступен именно' в
ней.
Описание внешнего объекта не есть его определение. Пом-
ните: в определении объекту всегда выделяется память, и он
может быть инициализирован. Примеры определений:
Глава 5. Функции
271
double summa [5];
char D_Phil [ ]="Doctor of Philosophy";
long M=1000;
В описаниях инициализация невозможна, нельзя указать и
количество элементов массивов:
extern double summa [ ];
extern char D_Phil [ ];
extern long M;
Содержательные примеры, иллюстрирующие особенности
применения внешних объектов в "многофайловых" программах,
приведены в главе 8.
5.8. Параметры функции main()
В соответствии с синтаксисом языка Си основная функция
каждой программы может иметь такой заголовок:
int main (int argc, char *argv [ ], char *envp[ ])
Параметр argv - массив указателей на строки; argc - пара-
метр типа int, значение которого определяет размер массива
argv, т.е. количество его элементов, envp - параметр-массив ука-
зателей на-, символьные строки, каждая из которых содержит
описание одной из переменных среды (окружения). Под средой
понимается та программа (обычно это операционная система),
которая "запустила" на выполнение функцию main( ).
Назначение параметров функции main() - обеспечить связь
выполняемой программы с операционной системой, точнее, с
командной строкой, из которой запускается программа и в ко-
торую можно вносить данные и тем самым передавать испол-
няемой программе любую информацию.
Если внутри функции main() нет необходимости обращаться
к информации из командной строки, то параметры обычно
опускаются.
272
Программирование на языке Си
Если программист "запускает" программу на языке Си из ин-
тегрированной среды разработки (например, Turbo С), то он
редко использует командную строку и должен предпринимать
специальные меры, чтобы увидеть эту строку или внести в нее
нужную информацию. (В Turbo С нужно в главном меню вы-
брать пункт RUN, а затем в ниспадающем меню выбрать пункт
ARGUMENTS...).
При запуске программы из операционной системы команд-
ная строка явно доступна, и именно в ней записывается имя вы-
полняемой программы. Вслед за именем можно разместить
нужное количество "слов", разделяя их друг от друга пробела-
ми. Каждое "слово" из командной строки становится строкой-
значением, на которую указывает очередной элемент параметра
argv[i], где 0<i<argc. Здесь нужно сделать одно уточнение.
Как и в каждом массиве, в массиве argv[] индексация эле-
ментов начинается с нуля, т.е. всегда имеется элемент argv[0].
Этот элемент является указателем на полное название запускае-
мой программы. Например, если из командной строки выполня-
ется обращение к программе EXAMPLE из каталога CATALOG,
размещенного на диске С, то вызов в MS-DOS выглядит так:
С:\CATALOG\EXAMPLE.EXE
Значение argc в этом случае будет равно 1, а строка, которую
адресует указатель argv[0], будет такой:
"С:\CATALOG\EXAMPLE.EXE"
В качестве иллюстрации сказанного приведем программу,
которая выводит на экран дисплея всю информацию из команд-
ной строки, размещая каждое "слово" на новой строке экрана.
#include <stdio.h>
void main (int argc, char * argv [ ])
(
int i;
for (i=0; i<argc; i++)
printf("\n argv [%d] -> %s", i, argv [i];
)
Глава 5. Функции
273
Пусть программа запускается из такой командной строки:
C:\WP\test66 11 22 33
Результат выполнения программы:
argv [0] -> C:\WP\test66.exe
argv [1] ~> 11
argv [2] -> 22
argv [3] -> 33
В главной программе main( ) разрешено использовать и тре-
тий параметр char * envp[ ]. Его назначение - передать в про-
грамму всю информацию об окружении, в котором выполняется
программа. Следующий пример иллюстрирует возможности
этого третьего параметра основной функции main().
#include <stdio.h>
void main (int argc, char *argv[], char *envp[])
{
int h;
printf("\пПрограмма '%s’ "
"\пЧисло параметров при запуске: %d",
argv[O], argc-1);
for (n=l; n<argc; n++)
printf("\n%d-M параметр: %s", n, argv[n]);
printf("\п\пСписюк переменных окружения:");
for (n=0; envp[n]; n++)
printf("\n%s7, envpfn]);
}
Пусть программа "запущена" на выполнение в MS-DOS под
Windows 95 из такой командной строки:
C:\WWP\TESTPROG\MAINENVP.EXE qqq www
Результаты выполнения программы:
Программа ' С: \WWP\TESTPROG\MAINENVP. EXE ’
Число параметров при запуске: 2
1-й параметр: qqq
18~3124
274
Программирование на языке Си
2-й параметр: www
Список переменных окружения:
ТМР=С: \WINDOWS\TEMP
PROMPT=$p$g
winbootdir=C: \ WINDOWS
COMSPEC=C:\WINDOWS\COMMAND.COM
TEMP»c:\windows\temp
CLASSPATH».;c:\cafe\java\lib\classes.zip
HOMEDRIVE=c:
HOMEPATH»\cafe\java
JAVA_HOME»c:\cafe\java
windir»C: \WINDOWS
NWLANGUAGE=English
PATH»C:\CAFE\BIN;C:\CAFE\JAVA\BIN;C:\BC5\BIN;
C:\WINDOWS;C:\WINDOWS\COMMAND;C:\NC;
C:\ARC;C:\DOS;C:\VLM;C:\TC\BIN
CMDLINE=tc
Через массив указателей envp[] программе доступен набор
символьных строк, образующих окружение программы. Чаще
всего каждая строка содержит такую информацию:
имя_переменной = значение переменной
Например, в приведенных результатах имя переменной ТМР
связано с именем каталога для временных данных. Изменив
значение переменной ТМР, можно "заставить" программу ис-
пользовать для хранения временных данных другой каталог.
Для работы со строками окружения в программах на языке Си
используют функции getenvO и putenvO-
Не рассматривая смысл остальных переменных окружения,
выведенных программой mainenvp.exe, отметим, что перемен-
ные окружения широко используются при исполнении про-
грамм в операционной системе Unix.
Глава 6
СТРУКТУРЫ И ОБЪЕДИНЕНИЯ
6.1. Структурные типы и структуры
Производные типы. Из базовых типов (и типов, определен-
ных программистом) можно формировать производные типы, к
которым относятся: указатели, массивы, функции, структуры и
объединения. Указатели, массивы, структуры и объединения
являются производными типами данных. Иногда в качестве
производного типа в руководствах по языку Си указывают стро-
ки, однако напоминаем, что в соответствии с синтаксисом языка
строковый тип в нем отсутствует. Строка определяется как ча-
стный случай одномерного массива, т.е. как массив с элемента-
ми типа char, последний элемент которого равен '\0'.
Указатели и массивы подробно рассмотрены в предыдущих
главах. Эта глава посвящена структурам и объединениям. Пре-
жде чем рассматривать их особенности и возможности, введем
некоторые терминологические соглашения стандарта, которые
не всегда понятны сами собой.
Данные базовых типов (int, float, ...) считаются скалярными
данными. Массивы и структуры являются агрегирующими ти-
пами данных в отличие от объединений и скалярных данных,
которые относятся к неагрегирующим типам. С массивами и
скалярными данными мы уже хорошо знакомы, поэтому разли-
чие между агрегирующими и неагрегирующими типами пояс-
ним на примере массивов и скалярных данных базовых типов.
Обычно агрегирующий тип включает несколько компонентов.
Например, массив long В[12] состоит из 12 элементов, причем
каждый элемент имеет тип long. Язык Си позволяет определять
и одноэлементные массивы. Так, массив float А[1] состоит из
одного элемента А[0]. Однако одноэлементные массивы есть
слишком частный случай обыкновенных массивов со многими
элементами. Итак, в общем случае массив есть агрегирующий
тип данных, состоящий из набора однотипных элементов, раз-
18*
276
Программирование на языке Си
мощенных в памяти подряд в соответствии с ростом индекса.
Для агрегирующего типа данных (например, для массива) в ос-
новной памяти ЭВМ выделяется такое количество памяти, что-
бы сохранять (разместить) одновременно значения всех
элементов. Этим свойством массивов мы уже неоднократно
пользовались. Например, следующее выражение позволяет вы-
числить количество элементов массива В[ ]:
sizeof (В) / sizeof (В [0])
Для данных неагрегирующих типов в основной памяти ЭВМ
выделяется область памяти, достаточная для размещения только
одного значения. С тем, как это происходит для скалярных ти-
пов, мы уже хорошо знакомы. С особенностями выделения па-
мяти для объединений познакомимся в этой главе.
Структурный тип. Этот тип (производный агрегирующий)
задает внутреннее строение определяемых с его помощью
структур. Сказанное требует пояснений. Начнем с понятия
структуры. Структура - это объединенное в единое целое
множество поименованных элементов (компонентов) данных. В
отличие от массива, всегда состоящего из однотипных элемен-
тов, компоненты структуры могут быть разных типов и все
должны иметь различные имена. Например, может быть введена
структура, описывающая товары на складе, с компонентами:
• название товара (char*);
• оптовая (закупочная) цена (long);
• торговая наценка в процентах (float);
• объем партии товара (int);
• дата поступления партии товара (char [9]).
В перечислении элементов структуры "товары на складе" до-
бавлены выбранные программистом типы этих элементов. В
соответствии со смыслом компоненты могут иметь любой из
типов данных, допустимых в языке. Так как товаров на складе
может быть много, для определения отдельных структур, со-
держащих сведения о конкретных товарах, программист вводит
производный тип, называемый структурным. Для нашего при-
мера его можно ввести, например, так:
Глава 6. Структуры и объединения
277
Struct goods {
char* name; /* Наименование */
long price; /* Цена оптовая */
float percent; /* Наценка в % * /
int vol; /* Объем партии */
char date [9] ; }; /* Дата поставки I партии */
Здесь struct - спецификатор структурного типа (служебное
слово); goods - предложенное программистом название (имя)
структурного типа. (Используя транслитерацию английского
термина "tag", название структурного типа в русскоязычной ли-
тературе п<? языку Си довольно часто называют тегом.) В фи-
гурных скобках размещаются описания. элементов, которые
будут входить в каждый объект типа goods. Итак, формат опре-
деления структурного типа таков:
struct имя структурного_типа
{ определения элементов };
где struct - спецификатор структурного типа;
имя структурного типа - идентификатор, произвольно
выбираемый программистом;
определения_элементов - совокупность одного или более
описаний объектов, каждый из которых служит прототипом для
элементов структур вводимого структурного типа.
Следует обратить внимание, что определение структурного
типа (в отличие от определения функции) заканчивается точкой
с запятой.
Конструкция struct имя структурного типа играет ту же
роль, что и спецификаторы типов, например, double или int. С
помощью struct goods можно либо определить конкретную
структуру (как, например, объект структурного типа struct
goods), либо указатель на структуры такого типа. Пример:
/* Определение структуры с именем food */
struct goods food;
/* Определение указателя point_to на структуры*/
struct goods *point_to;
278
Программирование на языке Си
Кроме такого прямого определения поименованного струк-
турного типа может быть введен безымянный структурный тип
и не полностью определенный (незавершенный) структурный
тип. О безымянном структурном типе речь пойдет в этом пара-
графе чуть позже при определении структур как объектов. Не
полностью определенный, т.е. незавершенный структурный тип,
потребуется в следующем параграфе при рассмотрении указате-
лей на структуры, вводимые в качестве элементов структур.
Кстати, отметим, что незавершенным может быть не только
структурный тип. В общем смысле незавершенным считается
любое определение, в котором не содержится достаточно ин-
формации о размере будущего объекта.
Еще одну возможность ввести структурный тип дает служеб-
ное слово typedef, позволяющее ввести собственное обозначе-
ние для любого определения типа. В случае структурного типа
он может быть введен и поименован следующим образом:
typedef struct {определения элементов}
обозначение структурного типа;
Пример:
typedef struct
{ double real;
double imag;
}
complex;
Приведенное определение вводит структурный тип struct
{double real; double imag;} и присваивает ему обозначение
(название, имя) complex. С помощью этого обозначения можно
вводить структуры (объекты) так же, как с обычным именем
структурного типа (например, struct goods в предыдущем при-
мере). Пример:
/* Определены две структуры: */
complex sigma, alfa;
Структурный тип, которому программист назначает имя с
помощью typedef, может в то же время иметь второе имя, вво-
Глава 6. Структуры и объединения
279
димое стандартным образом после служебного слова struct. В
качестве примера введем определение структурного типа
"рациональная дробь". Будем считать, что рациональная дробь -
это пара целых чисел (m;n), где число п отлично от нуля. Опре-
деление такой дроби:
typedefrstruct rational_fraction
{ int numerator; /* Числитель */
int denominator; /* Знаменатель */
} fraction;
f.
Здесь fraction - обозначение структурного типа, вводимое с
помощью typedef. Имя rational_fraction введено для того же
структурного типа стандартным способом. После такого опре-
деления структуры типа "рациональная дробь" могут вводиться
как с помощью названия fraction, так и с помощью обозначения
того же типа struct rational_fraction.
С помощью директивы #define можно вводить имена типов
подобно тому, как это делается с помощью typedef. Например,
сведения о книге могут быть введены таким образом:
#define BOOK struct \
{ char author[20]; /* Автор */ \ .
char title [80] ; /* Название */ \
int year; /* Год издания */ \
}
Здесь BOOK - препроцессорный идентификатор, вслед за
которым в нескольких строках размещена "строка замещения".
Обратите внимание на использование символа продолжения 'V
для переноса строковой константы. Кроме того, отметим отсут-
ствие точки с запятой после закрывающей скобки '}'• Далее в
программе можно определять конкретные объекты-структуры
или указатели с помощью имени BOOK, введенного на препро-
цессорном уровне:
BOOK ss, *pi;
После препроцессорных замен и исключения комментариев
это предложение примет вид (с точностью до размещения по
строкам):
280
Программирование на языке Си
struct
{
char author[20];
char title [80];
int year;
}
ss, *pi;
(Смотрите ниже определение структур и определение указате-
лей на структуры.)
Определение структур. Определения элементов (компонен-
тов) структурного типа внешне подобны определениям данных
соответствующих типов. Однако имеется существенное отли-
чие. При. определении структурного типа его компонентам не
выделяется память, и их нельзя инициализировать. Другими
словами, структурный тип не является объектом.
Из нашего примера определения структурного типа с назва-
нием goods следует, что наименование товара будет связано с
указателем типа char*, имеющим имя паше. Оптовая цена еди-
ницы товара будет значением элемента типа long с названием
price. Торговая наценка будет значением элемента типа float с
именем percent и т.д. Все это следует из приведенного опреде-
ления структурного типа с названием goods. Но прежде чем
элементы, введенные в определении структурного типа, смогут
получить значения, должна быть определена хотя бы одна
структура (т.е. структурированный объект) этого типа. Напри-
мер, следующее определение вводит две структуры, т.е. два
объекта, типа goods:
struct goods coat, tea;
Итак, если структурный тип определен и известно его имя, то
формат определения конкретных структур ^объектов структур-
ного типа) имеет вид:
struct имя структурного типа списокструктур;
где список структур - список выбранных пользователем имен
(идентификаторов).
Глава 6. Структуры и объединения
281
Выше показано, что для структурного типа, имя которого
введено с помощью служебного слова typedef, определение
структур не должно содержать спецификатора типа struct. На-
пример, указатель на структуры для представления комплекс-
ных чисел с помощью определенного выше обозначения
структурного типа complex можно определить так:
complex *p_comp;
Выше был определен структурный тип "рациональная
дробь", для которого введены два имени. С их помощью так
вводятся конкретные структуры:
/* Две структуры: */
struct rational_fraction ratio_l, ratio_2;
/* Две структуры: */
fraction zin, rat_X_Y;
Кроме изложенной последовательности определения струк-
тур (определяется структурный тип, затем с использованием его
имени определяются структуры) в языке Си имеются еще две
схемы их определения. Во-первых, структуры могут быть опре-
делены одновременно с определением структурного типа:
struct имя структурного типа
{ определения-Элементов }
список структур;
Пример одновременного определения структурного типа и
структур (объектов):
Struct"student
{
char name [15] ; /* Имя */
char surname [20] ; /* Фамилия */
int year; /* Курс */
} student_l, student_2, student_3;
Здесь определен структурный тип с именем student и три
конкретные структуры student_l, student_2, student_3, которые
являются полноправными объектами. В каждую из этих трех
282
Программирование на языке Си
структур входят элементы, позволяющие представить, имя
(паше), фамилию (surname), курс (year), на котором обучается
студент,
После приведенного определения в той же программе можно
определять любое количество структур, используя структурный
тип student:
struct student leader, freshman;
Следующий вариант определения структур является некото-
рым упрощением приведенного варианта. Дело в том, что мож-
но определять структуры, приведя "внутреннее строение"
структурного типа, но не вводя его названия. Такой безымянный
структурный тип обычно используется в программе для одно-
кратного определения структур:
struct
{определенияэлементов}
список_структур',
В качестве примера определим структуры,, описывающие
конфигурацию персонального компьютера с такими характери-
стиками:
• тип процессора (char [10]);
• рабочая частота в МГц (int);
• объем основной памяти в Мбайтах (int);
• емкость жесткого диска в Мбайтах (int).
Пример определения структур безымянного типа:
struct {
char processor [10] ;
int frequency;
int memory;
int disk;
} IBM_486, IBM_386, Compaq;
В данном случае введены три структуры (три объекта) с име-
нами 1ВМ 486, IBM_386, Compaq. В каждую из определенных
структур входят элементы, в которые можно будет занести све-
дения о характеристиках конкретных ПЭВМ. Структурный тип
"компьютер" не именован. Поэтому, если в программе потребу-
Глава 6. Структуры и объединения
283
ется определять другие структуры с таким же составом элемен-
тов, то придется полностью повторить приведенное выше опре-
деление структурного типа.
Выделение памяти для структур. Мы уже договорились,
что определение структурного типа не связано с выделением
памяти, а при каждом определении структуры (объекта) ей вы-
деляется память в таком количестве, чтобы могли разместиться
данные всех элементов. На рис. 6.1 приведены условные схемы
распределения памяти для одного из объектов (структур) типа
goods. На первой схеме элементы структуры размещены подряд
без пропусков между ними. Однако никаких гарантий о таком
непрерывном размещении элементов структур стандарт языка
Си не дает. Причиной появления неиспользованных участков
памяти ("дыр") могут явиться требования выравнивания данных
по границам участков адресного пространства. Эти требования
зависят от реализации, от аппаратных возможностей системы и
иногда от режимов (опций) работы компилятора. На рис. 6.1
условно изображен и второй вариант с пропуском участка памя-
ти между элементами float percent и int vol. Пропуск ("дыра")
может быть и после последнего элемента структуры. В этом
случае память для следующего объекта, определенного в про-
грамме, будет выделена не сразу после структуры, а с проме-
жутком, оставляемым для выравнивания по принятой границе
участка адресного пространства.
Необходимость в выравнивании данных зависит от конкрет-
ной задачи. Например, доступ к целым значениям выполняется
быстрее, если они имеют четные адреса, т.е. выравнены по гра-
ницам машинных слов. Противоположное требование состоит в
плотной "упаковке" информации, когда идет борьба за умень-
шение объема, занимаемого в памяти структурой или массивом
структур. Влиять на размещение структур можно с помощью
препроцессорной директивы #pragma (см. гд. 3).
В зависимости от наличия "пропусков" между элементами
изменяется общий объем памяти, выделяемый для структуры.
Реальный размер памяти в байтах, выделяемый для структуры,
можно определить с помощью операции
284
Программирование на языке Си
sizeof (имяструктуры)
sizeof (имя_структурного_типа)
Для нашего примера одинаковые результаты дадут операции:
sizeof (struct goods)
sizeof (tea)
sizeof coat
В последнем выражении имя структуры coat только для раз-
нообразия помещено без скобок. Напомним, что операция опре-
деления размера имеет две формы:
sizeof (имятипаданных)
sizeof выражение
В случае операнда-выражения его не обязательно заключать
в скобки и его значение не вычисляется. Для него определяется
тип и оценивается его размер (в байтах).
Определение структурного типа:
struct goods { char* name; long price; float percent;
int vol; char date [9]
};
Элементы размещены подряд
Названия элементов: их типы: байты: name price percent vol date
char* long float int char|9]
<— 4—> <—4—> <—4—> e—2—> < 9 >
Названия
элементов:
их типы:
байты:
Размещение элементов с выравниванием данных
name price percent "ды- ра" vol date
char* long float int char|9]
<—4~* 4—> h—4— Г"2-^ n—9—H
Рис. 6.1. Размещение структуры типа goods в памяти
(размеры в байтах для разных реализаций могут быть другими)
Глава 6. Структуры и объединения
285
Инициализация и присваивание структур. Инициализация
структур похожа на инициализацию массивов. Непосредственно
в определении конкретной структуры после ее имени и знака
в фигурных скобках размещается список начальных значений
элементов. Например:
struct goods coat={
"пиджак черный", 400000, 7.5, 220, "12.01.97" };
complex sigma={1.3, 12.6};
Сравнивая структуры с массивами, нужно обратить внимание
на одну особенность, связанную с операцией присваивания. Ес-
ли определены два массива одного и того же типа и одинаковых
размеров, то присвоить элементам одного массива значения
элементов другого массива можно только с помощью явного
перебора элементов, например, в цикле
float z[5], х[5]={1.0, 2.0, 3.0, 4.0, 5.0 };
int j;
for (j=0; j<sizeof(x)/sizeof(x[0]); j++)
z[j]®x[j];
Попытка использовать имена массивов без индексов в опера-
ции присваивания будет обречена на провал (ведь имя массива
есть неизменяемый указатель):
z=x; /* Ошибка в операции */
В то же время стандарт языка Си разрешает присваивание
структур. Если не обращать внимание на смысл имен введенных
выше структур типа struct goods (tea - чай; coat - пиджак), то
допустимо следующее присваивание:
tea=coat;
Определив структуру типа complex, можно выполнить, на-
пример, такое присваивание (структура sigma того же типа оп-
ределена и инициализирована выше):
complex sport;
sport—sigma;
286
Программирование на языке Си
Отметим, что для структур не определены операции сравне-
ния даже на равенство. И сравнивать структуры нужно только
поэлементно.
Доступ к элементам структур. Наиболее наглядно и естест-
венно доступ к элементам структур обеспечивается с помощью
уточненных имен. Конструкция
имяструктуры. имяэлемента
играет роль названия (имени) объекта того типа, к которому от-
несен элемент в соответствии с определением структурного ти-
па. В нашем примере с инициализацией структуры типа struct
goods:
coat.name - указатель типа char* на строку "пиджак чер-
ный";
coat.price - переменная типа long со значением 400000;
coat.percent - переменная типа float со значением 7.5;
coat.vol - переменная типа int со значением 220;
coat.date - массив типа char [9], содержащий "12.01.97".
Обратите внимание, что перед точкой стоит не название
структурного типа, а имя конкретной структуры, для которой ее
определением выделена память.
Уточненное имя - это выражение с двумя операндами и опе-
рацией "точка" между-ними. Операция "точка" называется опе-
рацией доступа к элементу структуры (или объединения). У
нее самый высокий ранг наряду со скобками (и операцией
"стрелка" для доступа к элементам структуры через адресую-
щий ее указатель, см. табл. 1.4).
Уточненное имя используется для выбора правого операнда
операции "точка" из структуры (или объединения), задаваемой
левым операндом. Левый операнд должен иметь структурный
тип, а правый операнд должен быть именем компонента
(элемента) этой структуры. Тип результата операции "точка",
т.е. тип уточненного имени, - это тип именуемого ею компонен-
та (элемента) структуры. Именно такие типы указаны в приве-
денных выше примерах, т.е. coat.vol - объект типа int и т.д.
Глава 6. Структуры и объединения
287
Если при определении структуры она инициализирована, то
ее элементы получают соответствующие начальные значения. С
помощью уточненных имен эти значения могут быть, например,
выведены на экран дисплея.
Пример программы с инициализацией структуры и выводом
значений ее элементов:
#include <stdio.h>
void main( )
{ struct goods {
char* name;
long price;
float percent;
int vol;
char date[9];
};
struct goods coat={
"пиджак черный", 400000, 7.5, 220, "12.01.97"};
printf("\n Товар на складе:")
printf("\n Наименование: %s.", coat.name);
printf("\n Оптовая цена: %ld руб.",
coat.price);
printf("\n Наценка: %4.1f %%.", coat.percent);
printf("\n Объем партии: %d штук.", coat.vol);
printf("\n Дата поставки: %s.", coat.date);
}
Результат выполнения программы:
Товар на складе:
Наименование: пиджак черный.
Оптовая цена: 400000. руб.
Наценка: 7.5 %
Объем партии: 220 штук.
Дата поставки: 12.01.97.
Уточненные имена элементов структур обладают всеми пра-
вами объектов соответствующих типов. Их можно использовать
в выражениях, их значения можно вводить с клавиатуры и т.д.
Например, с помощью следующих операторов можно изменить
торговую наценку (элемент coat.price) и вычислить розничную
цену на определенный в программе товар (пиджак черный):
288
Программирование на языке Си
printf("\п Введите торговую наценку:");
scanf("%f", &coat.percent);
printf("Цена товара: %ld руб.",
(long)(coat.price*(1.0+coat.percent/100));
Обратите внимание, что в качестве фактического параметра
функции scanf() используется адрес элемента percent структуры
coat. Для этого операция получения адреса & применяется к
уточненному имени coat.percent. При вычислении розничной
цены товара приходится вводить явное приведение типов (long),
так как результат умножения элемента coat.price на веществен-
ное выражение 1.0+coat.percent/100 имеет по умолчанию тип
double.
Следующая программа выполняет сложение комплексных
чисел, для представления которых использован структурный
тип, имя которого вводит спецификатор typedef:
#include <stdio.h>
typedef struct (
double real;
double imag;
} complex;
void main( )
{
complex x, y, z;
printf("\n Введите два комплексных числа:");
printf("\п Вещественная часть: ");
scanf(" %lf", &x.real);
printf(" Мнимая часть:");
scanf(" %lf", &x.imag);
printf(" Вещественная часть:");
scanf(" %lf",' &y.real);
printf(" Мнимая часть:");
scanf (" %lf", &y.imag);
z.real=x.real+y.real;
z.imag=x.imag+y.imag;
prinf("\n Результат: z.real=%f z.imag=%f",
z.real, z.imag);
)
Глава 6. Структуры и объединения
289
Возможный результат выполнения программы:
Введите два комплексных числа-.
Вещественная часть: 1.3
Мнимая часть: 0.84
Вещественная часть: 2.2
Мнимая часть: 6.16
Результат: z.real= 3.500000 z.imag=7.000000
6.2. Структуры, массивы и указатели
Массивы и структуры в качестве элементов структур. Не
акцентируя особого внимания на проблеме, в примерах преды-
дущего параграфа мы использовали в качестве элементов струк-
тур символьные массивы. Никаких особенных сложностей в
этом нет. Массив, как и любые другие данные, может быть эле-
ментом структуры, и для обращения к каждому элементу такого
массива потребуется индексирование. Приведем примеры.
Пусть нужна структура, описывающая размещение в простран-
стве материальных точек (точечных масс). Компонентами такой
структуры могут быть:
• значение массы (double);
• массив координат (float [3]).
Проиллюстрируем основные особенности работы с такими
структурами. Введя величину и координаты точечной массы,
вычислим ее удаление от начала координат (модуль радиус-
вектора).
#include <stdio.h>
#include <math. h> /* Для функции sqrt( ) */
void main( )
{
struct {
double mass;
float coord [3] ;
} point={12.3, {1.0, 2.0, —3.0}};
int i;
float s=0.0;
for (i=0, i<3; i++)
19-S124
290
Программирование на языке Си
s+=point.coord [i]* point.coord [i];
printf ("\n Длина радиус-вектора: %f"( sqrt(s));
}
Результат выполнения программы:
Длина радиус-вектора: 3.741657
Для структуры point структурный тип введен как безымян-
ный. Структура point получает значения своих элементов в ре-
зультате инициализации. В списке начальных значений ис-
пользовано вложение инициализаторов, так как элементом
структуры является массив. Можно обратить внимание на ин-
дексирование при обращении к элементу внутреннего массива
coord[3]. Индексы записываются после имени массива-элемента,
а не после имени структуры.
Так как элементами структур могут быть данные любых ти-
пов, то естественным образом допускается вложение структур,
т.е. элементом структуры может быть другая (и только другая,
не та же самая!) структура. В качестве примера еще раз рас-
смотрим структурный тип для представления сведений о сту-
денте. Дополнительно к тем элементам, которые уже были (имя,
фамилия, курс), введем в качестве элемента структуру с именем
(названием) структурного типа struct birth. В ней будут сохра-
няться сведения о рождении - место рождения и дата рождения.
В свою очередь, дату рождения представим структурой (типа
date) с элементами число, месяц, год.
В тексте программы перечисленные структурные типы
должны быть размещены в такой последовательности, чтобы
использованный в определении структурный тип был уже опре-
делен ранее:
/* Определение структурных типов: */
struct date { /* тип "дата" */
int day; /* число */
int month; /* месяц */
int year; /* год */
};
struct birth { /* тип "данные о рождении" */
char place [20] /* место рождения */
Глава 6. Структуры и объединения
291
struct date dd; /* дата рождения */
} ;
struct student { /* тип "студент" */
char name [15] ; /* имя */
char surname [20] ; /* фамилия */
int year; /* курс */
struct birth bit;/* данные о рождении*/
};
/* Работа с конкретным студентом: */
void main( )
(
/* Конкретная структура: */
struct student stud= ("Павел", "Иванов", 1,
"Петербург", 22, 11, 1888 };
printf("\п Введите курс студента: ") ;
scanf("%d", &stud.year);
printf("Сведения о студенте:");
printf("\п Фамилия: %s", stud.surname);
printf("\n Имя:%з", stud.name);
printf ("\n Курс: %d-n", stud.year);
printf("\n Место рождения: %d",
stud.bir.place);
printf("\n Дата рождения: %d.%d.%d",
stud.bir.dd.day, stud.bir.dd.month,
stud.bir.dd.year);
)
Результаты выполнения программы:
Введите курс студента:3
Сведения о студенте:
Фамилия: Иванов
Имя: Павел
Курс: 3-й
Место рождения: Петербург
Дата рождения: 22.11.1888
Конкретная структура-объект stud типа struct student получа-
ет значение элементов при инициализации. Затем с помощью
scanf() изменяется элемент stud.year (Иванов Павел перешел
уже на 3-й курс!). Содержимое структуры выводится на дис-
19*
292
Программирование на языке Си
плей, причем для доступа к элементам вложенных структур ис-
пользуются уточненные имена с нужным количеством "точек".
Массивы структур. Определяются массивы структур так
же, как и массивы других типов данных. Естественное отличие
- служебное слово struct в названии структурного типа (если
обозначение типа не введено с помощью typedef). Для введен-
ных выше структурных типов можно определить:
struct goods list [MAX_GOODS];
complex set [80];
Эти предложения определяют list как массив, состоящий из
MAX GOODS элементов - структур типа goods, a set - массив
структур типа complex, состоящий из 80 элементов. (Иден-
тификатор MAX GOODS должен быть именем константы.)
Имена list и set не являются именами структур, это имена
массивов, элементами которых являются структуры. list[O] -
есть структура типа goods, listfl ] - вторая структура типа goods
из массива listf ] и т.д.
Для доступа к компонентам структур, входящих в массив
структур, используются уточненные имена с индексированием
первого имени (имени массива). Например:
set[4].real - первый компонент (с именем real) типа double
структуры типа complex, входящей в качестве пятого (от начала)
элемента в массив структур setf ];
list[O].price - второй компонент (с именем price) типа long
структуры типа goods, входящей в качестве первого элемента (с
нулевым индексом) в массив структур listf ]
На рис. 6.2 условно изображена схема размещения в памяти
массива listf ]. Его элементы (как и элементы любого другого
массива) размещаются в основной памяти подряд в соответст-
вии с возрастанием индекса.
Еще раз обратите внимание на индексирование в уточненном
имени при обращении, к компонентам структур, принадлежащих
массиву. Индекс записывается непосредственно после имени
массива структур. Тем самым из массива выделяется нужная
структура, а уже с помощью точки и последующего имени
Глава 6. Структуры и объединения
293
идентифицируется соответствующий компонент структуры. Бу-
дет ошибкой поместить индекс после всего уточненного имени.
Например, запись:
list.percent[8] /* Ошибка ! */
- ошибочное имя; percent - переменная типа float, а не массив.
Определение массива структур:
struct goods list [MAX GOODS];
list[0].name listfO],price listfO].percent listfO].vol listfO].date \ list[O]
char* long float int char|9] J
listfl].name listfl ]. price listfl ]. percent listfl ]. vol listfl].date ( lirtrn
char* tong float int charf9| J
listf99].name listfO].price listfO].percent listfO].vol listfO].date \ i;jrnnl
char* __long_ float int char|9] J
Рис. 6.2. Массив структур (MAX_GOODS= 100)
Как и массивы других типов, массив структур при определении
может быть инициализирован. Инициализатор массива структур
должен содержать в фигурных скобках список начальных зна-
чений структур массива. В свою очередь, каждое начальное
значение для структуры - это список значений ее компонентов
(также в фигурных скобках).
В следующей программе вводится и инициализируется мас-
сив структур, каждая из которых описывает точечную массу
(материальную точку). Для определенной таким образом систе-
мы материальных точек вычисляется центр масс (координаты
хс, Ус, zc центра масс).
Если т\, пг2, ...,тп- массы материальных точек; х, у,, zt - ко-
ординаты отдельной точки (i=l, п), то имеем:
п
т = У, т< - общая масса системы точек.
z=i
294
Программирование на языке Си
Координаты центра масс:
п п п
Текст программы с массивом структур:
#include <stdio.h>
/* Определение структурного типа: */
struct particle {
double mass;
float coord [3] ;
};
void main ( )
{ /* Определение массива структур: */
struct particle mass_point[ ]={
20.0, {2.0, 4.0, 6.0},
40.0, {6.0, -2.0, 8.0},
10.0, {1.0, 3.0, 2.0}
};
int N; /* N - число точек */
/* Структура для формирования результатов: *
struct particle center= { /* центр масс */
0.0, {0.0, 0.0, 0.0}
};
int i ;
N=sizeof(mass_point) / sizeof(mass_point[0]);
for (i=0; i<N; i++)
{
center.mass+=mass_point[i].mass;
center.coord[0] += mass_point[i].coord[0] *
mass_point[i].mass;
center.coord[l] += mass_point[i].coord[l] *
mass_point[i].mass;
center.coord[2] += mass_point[i].coord[2] *
mass_point[i].mass;
}
printf("\n Координаты центра масс:");
for (i=0; i<3; i++)
{
center.coord[i]/=center.mass;
Глава 6. Структуры и объединения
295
printf("\п Координата %d: %f", (i+1),
center, coord [i]);
}
}
Результат выполнения программы:
Координаты центра масс:
Координата 1: 4.142857
Координата 2: 0.428571
Координата 3: 6.571429
Указатели иа структуры. Эти указатели определяются, как
и указатели на данные других типов. Как обычно, для структур-
ных типов название типа состоит из двух слов - служебного
слова struct и имени уже определенного структурного типа, на-
пример:
struct goods *p_goods;
struct studest *p_stu, *p_stu2;
Указатели на структуры могут вводиться и для безымянных
структурных типов:
struct { /* Безымянный структурный тип */
char processor [10] ; /* Тип процессора */
int frequency; /* Частота в МГц */
int memory; /* Память в Мбайт */
int disk; /* Емкость диска в Мбайт */
} *point_IBM, *point_2;
И как обычно, если название структурного типа введено с
помощью typedef, то при определении указателей название это-
го типа может использоваться без предшествующего служебно-
го слова struct:
complex *сс, *ss, comp;
При определении указателя на структуру он может быть
инициализирован. Наиболее корректно в качестве инициализи-
рующего значения применять адрес структурного объекта того
же типа, что и тип определяемого указателя:
296
Программирование на языке Си
struct particle
{
double mass
float coord [3];
} dot [3], point, *pinega;
/* Инициализация указателей: */
struct particle *p_d=Sdot [11 ,
*pinta=Spoint;
Значение указателя на структуру может быть определено и с
помощью обычного присваивания:
pinega=&dot [0];
Указатели как средство доступа к компонентам структур.
Указатель на структуру, настроенный на конкретную структуру
(конкретный объект) того же типа, обеспечивает доступ к ее
элементам двумя способами:
( * указатель на структуру ). имяэлемента
или
указатель на структуру -> имя элемента
Первый способ традиционный. Он основан на обратимости
операций разыменования ’*’ и получения адреса Обозначив
знак равенства последовательностью можно таким образом
формально напомнить эти правила на конкретном примере:
если ' '
*
pinega = = &dot [0],
то
♦pinega = = dot[0].
Доступ к элементам структуры dot[0] с помощью разымено-
вания адресующего его указателя pinega можно в соответствии с
приведенными соотношениями реализовать с помощью таких
конструкций:
(♦pinega).mass = = dot[0]. mass
(♦pinega).coord [0] = = dot[0].coord[0]
Глава 6. Структуры и объединения
297
(*pinega).coord [1] = = dot[0].coord[l]
(*pinega).coord [2] = = dot[0].coord[2]
Важным является наличие скобок, ограничивающих опера-
цию разыменования (*pinega). Скобки необходимы, так как би-
нарная операция "точка" имеет более высокий ранг, чем унарная
операция разыменования (см. табл. 1.4 приоритетов операций в
гл. 1).
Присвоить элементам структуры dot[0] значения можно, на-
пример, с помощью таких операторов присваивания:
(*pinega) . mass = 33.3;
(*pinega).coord[l] = 12.3;
Второй способ доступа к элементам структуры с помощью
"настроенного" на нее указателя предусматривает применение
специальной операции "стрелка" (->). Операция "стрелка" име-
ет самый высший ранг (см. табл. 1.4) наряду со скобками и опе-
рацией "точка". Операция "стрелка" обеспечивает доступ к
элементу структуры через адресующий ее указатель того же
структурного типа. Формат применения операции в простейшем
случае:
указатель _на-Структуру -> имя элемента
Операция "стрелка" двуместная. Применяется для доступа к
элементу (к. компоненту), задаваемому правым операндом, той
структуры, которую адресует левый операнд. В качестве левого
операнда должен быть указатель на структуру: в качестве пра-
вого - обозначение (имя) компонента этой структуры.
Операция "стрелка" (->) иногда называется операцией кос-
венного выбора компонента' (элемента) структурированного
объекта, адресуемого указателем.
Примеры:
pinega -> mass эквивалентно (*pinega) mass
pinega -> coord[0] эквивалентно (*pinega) coord[0]
Если в программе (см. выше) определены структура point ти-
па struct particle и на нее настроен указатель:
298
Программирование на языке Си
struct particle *pinta = &point;
то будут справедливы следующие равенства:
pinta -> mass == (*pinta).mass
pinta -> coord == (*pinta).coord
Изменить значения элементов структуры point в этом случае
можно, например, такими операторами:
pinta -> mass =18.4;
for (i=0; i<3; i++)
pinta -> coord[i] = 0.1*i;
Тип результата операции "стрелка" (->) совпадает с типом
правого операнда, т.е. того элемента структуры, на который
"нацелена"стрелка.
Операции иад указателями на структуры. Эти операции
не отличаются от операций над другими указателями на данные.
(Исключение составляет операция "стрелка" (->), но ее мы уже
рассмотрели). Если присвоить указателю на структуру конкрет-
ного структурного типа значение адреса одного из элементов
массива структур того же типа, то, изменяя значение указателя
(например, с помощью операций ++ или —), можно равномерно
"перемещаться" по массиву структур.
В качестве иллюстрации рассмотрим следующую задачу.
Вычислить сумму заданного количества комплексных чисел,
представленных в программе массивом аггау[ ] структур.
#include <stdio.h>
void main ( )
{ , •
struct complex
{ /* Определение структурного типа complex*/
float x; /* Вещественная часть */
float у; /* Мнимая часть */
} array [ ] = {1.0, 2.0, 3.0, -4.0, -5.0,
-6.0, -7.0, -8.0};
struct complex summa = {0.0, 0.0};
struct complex * point = & array [0];
Глава 6. Структуры и объединения
299
int k, i;
к = sizeof (array) / sizeof (array [0]);
for (i=0; i<k; i++)
{
summa.x += point -> x;
summa.у += point -> y;
point++;
}
printf(" \n Сумма: real=%f,\t imag=%f",
summa.x, summa.у);
Результат выполнения программы:
Сумма: real= -8.000000, imag=-l6.000000
В программе введен тип struct complex. Определены: массив
структур аггау[ ], структура summa, где формируется результат,
и указатель point, в начале программы настроенный на первый
(нулевой) элемент массива структур, а затем в цикле "про-
бегающий" по всему массиву. Доступ к структуре summa реали-
зован с помощью уточненных имен (операция "точка"). Доступ
к элементам структур, входящих в массив, осуществляется через
указатель point и с помощью операции "стрелка" (->).
Указатели на структуры как компоненты структур. В со-
ответствии с синтаксисом языка компонентами структур могут
быть данные любых типов, за исключением структур того же
типа, что и определяемый структурный тип. Например, элемен-
том структуры, как уже говорилось, может быть структура, тип
которой уже определен. Обычна конструкция:
struct mix {int N; double * d;};
struct hole {
struct^mix exit;
float b;
};
Здесь ранее определенная структура типа struct mix является
элементом структуры типа struct hole.
300
Программирование на языке Си
В то же время элементом структуры может быть указатель на
структуру того же типа, что и определяемый структурный тип:
ч struct element {
/* Структурный тип "химический элемент" */
int number /* Порядковый номер *
double mass; /* Атомный вес */
char name[16] /* Название элемента */
struct element * next;
};
В структурном типе "химический элемент" есть компонент
next - указатель на структуру того же типа. С его помощью
можно формировать списки (цепочки) интересующих нас эле-
ментов. Например, можно связать все элементы одной группы
периодической таблицы химических элементов либо предста-
вить в виде единого списка всю таблицу Д. И. Менделеева.
При определении структурных типов может потребоваться
организация взаимных перекрестных связей между структурами
двух или более разных типов. В этом случае невозможно вы-
полнить требование об определенности всех связываемых
структурных типов. Выходом из тупиковой ситуации служит
применение указателей на структуры. Например:
struct part { /* Структурный тип */
double modul;
struct cell * element_cell;
struct part * element_part;
};
struct cell { /* Структурный тип */
long summa;
struct cell * one;
struct part * two;
]
В данном примере для организации перекрестных ссылок в
структурах типа struct part использованы в качестве элементов
указатели на объекты типа struct cell. В структуры типа struct
cell входят указатели на структуры типа struct part.
Глава 6. Структуры и объединения
301
6.3. Структуры и функции
Для "взаимоотношения" структур и функций имеются две
основные возможности: структура может быть возвращаемым
функцией значением и структура может использоваться в пара-
метрах функции. Кроме того, в обоих случаях могут использо-
ваться указатели на объекты структурных типов. Итак,
рассмотрим все перечисленные варианты.
/ * Определение структурного типа: */
struct person {char * name; int age; };
• Функция может возвращать структуру как результат:
/* Прототип функции: */
struct person f (int N)
• Функция может возвращать указатель на структуру:
/* Прототип функции: */
struct person * ff (void);
• Параметром функции может быть структура:
/* Прототип функции: */
void fff (struct person str);
• Параметром функции может быть указатель на объект
структурного типа:
/* Прототип функции: */
void ffff (struct person * pst);
При вызове функции fff() выделяется память для формаль-
ного параметра, т.е. для вспомогательного объекта типа struct
person. В этот объект переносится значение фактического пара-
метра, заменяющего формальный параметр - структуру str. Да-
лее выполняются действия, предусмотренные операторами тела
функции fff(). Эти действия не могут изменять структуру, ис-
пользованную в качестве фактического параметра.
В случае, когда параметром служит указатель на объект
структурного типа, действиями внутри тела функции ffff()
можно изменить ту структуру вызывающей функции, которая
адресуется фактическим параметром pst.
302
Программирование на языке Си
Имитация абстрактных типов данных. При решении кон-
кретных прикладных задач бывает удобным выделить набор
типов данных, наиболее полно соответствующих понятиям и
объектам предметной области. Такие типы данных обычно от-
сутствуют в языке программирования, но их можно сконструи-
ровать и ввести как производные типы. Одновременно с такими
специализированными данными (точнее, с производными типа-
ми для их представления) для каждого типа вводится набор
операций, удобный для обработки этих данных. Тип данных и
набор операций над объектами этого типа совместно определя-
ют абстрактный тип данных, ориентированный на представле-
ние понятий предметной области решаемой задачи. В языке Си
программист имеет возможность вводить абстрактные типы
данных с помощью структур, отображающих собственно дан-
ные, и функций, определяющих операции над данными.
В качестве примера введем абстрактный тип данных для ра-
циональных дробей. Выше в §6.1 введен и поименован с помо-
щью typedef как fraction структурный тип для представления
рациональных дробей.
Определим функции, реализующие операции над рациональ-
ными дробями:
input() - ввод дроби;
out() - вывод дроби на дисплей;
add() - сложение;
sub() - вычитание;
mult() - умножение;
divide() - деление.
Этот набор операций можно легко расширить, введя, напри-
мер, функции для приведения дробей к одному знаменателю,
для сокращения дроби, для выделения целой части неправиль-
ной дроби и т.д. Но для демонстрации особенностей примене-
ния структур в функциях при определении абстрактного типа
данных перечисленного набора операций вполне достаточно.
Оформим определение структурного типа "рациональная
дробь" и набор прототипов перечисленных выше функций для
операций над дробями в виде следующего файла:
Глава 6. Структуры и объединения
303
/* Файл fract.h - абстрактный тип
"рациональная дробь" */
typedef struct rational_fraction
{
int numerator; /* Числитель */
int denominator; /* Знаменатель */
} fraction; /♦ Обозначение структурного типа */
/* Прототипы функций для работы с дробями: */
void input (fraction * pd);
void out (fraction dr);
fraction add (fraction drl, fraction dr2);
void sub (fraction drl, fraction dr2,
fraction * pdr);
fraction * mult (fraction drl, fraction dr2);
fraction divide (fraction *pdl, fraction *pd2);
Обратите внимание, что применение typedef позволило уп-
ростить название структурного типа. Вместо конструкции struct
rational fraction в прототипах функций и далее в программе ис-
пользуется более короткое обозначение fraction.
Определения функций, реализующих перечисленные опера-
ции над рациональными дробями, объединим в один файл сле-
дующего вида:
/♦Файл fract.c - определения функций
для работы с дробями */
#include <stdio.h>
#include <stdlib.h> /*'Для exit() и malloc() */
void input (fraction * pd) /* Ввод дроби */
{
int N;
printf("\n Числитель:");
scanf("%d", pd -> numerator);
printf("Знаменатель:");
scanf("%d", &N);
if (N == 0)
{
printf("\n Ошибка* Нулевой знаменатель!");
exit (0); /* Завершение программы */
)
pd -> denominator=N;
)
304
Программирование на языке Си
/* Изобразить дробь на экране: */
void out (fraction dr)
{
printf("Рациональная дробь:");
printf("%d/%d",.dr.numerator, dr.denominator);
)
/* Сложение дробей: */
fraction add (fraction drl, fraction dr2)
{
fraction dr;
dr.numerator = drl.numerator * dr2.denominator
+ drl.denominator * dr2.numerator;
dr.denominator = drl.denominator *
dr2.denominator;
return dr;
)
/* Вычитание дробей: */
void sub (fraction drl, fraction dr2,
fraction * pdr)
{
pdr -> numerator=drl.numerator * dr2.numerator
- dr2.numerator * drl.denominator;
pdr -> denominator=drl.denominator *
dr2.denominator;
)
/* Умножение дробей: */
fraction * mult (fraction drl, fraction dr2)
{
fraction * mul;
mul=(fraction *) malloc (sizeof (fraction));
mul -> numerator=drl.numerator *
dr2.numerator;
mul -> denominator=drl.denominator *
dr2.denominator;
return mul;
}
/* Деление дробей: */
fraction divide (fraction * pdl, fraction * pd2)
{
fraction d;
d.numerator = pdl ~> numerator * pd2 ->
Глава 6. Структуры и объединения
305
denominator;
d.denominator = pdl -> denominator * pd2 ->
numerator;
return d;
}
Приведенный набор функций демонстрирует все возможные
сочетания возвращаемых значений и параметров функций при
работе со структурами. Обратите внимание, что функции add(),
divide() возвращают структуру типа fraction, которую нужно
"разместить" в соответствующей структуре вызывающей про-
граммы. Функция sub() предусматривает передачу результата
через параметр-указатель fraction * pdr. Функция muit() форми-
рует динамический объект типа fraction и возвращает его адрес.
В основной программе после обращения к muit( ) корректно бу-
дет освободить динамическую память с помощью функции
free(). t
Следующая программа демонстрирует работу с рациональ-
ными дробями с помощью введенных функций:
#include "fract.h" /* Файл прототипов */
#include "fract.c" /* Файл определений функций */
void main ( )
{
fraction а, b, с; /* Определили три
дроби-структуры */
fraction *р; /* Указатель на дробь */
printf("\п Введите дроби:"); х
input(&а);
input(&Ь); . ,
с = add(а, Ь); out(с); /* Сложение дробей */ /* Вывод дроби */
р = mult(а, Ь); /* Умножение дробей */
out(*р); /* Вывод дроби, адресуемой указателем */
free(р); /* Освободить память */
с = divide(&а, &Ь) ; /* Деление дробей */
out j(c) ; /* Вывод дроби .*/
)
20’3124
306
Программирование на языке Си
Результаты выполнения программы:
Введите дроби:
Числитель: 5
Знаменатель: 4
Числитель: 2
Знаменатель: 3
Рациональная дробь:
Рациональная дробь:
Рациональная дробь:
23/12
10/12
15/8
Обратите внимание на необходимость явного освобождения
памяти после выполнения функции mult(), внутри тела которой
для результата (для структуры типа fraction) явно выделяется
память, и указатель на этот участок памяти передается в вызы-
вающую программу. После печати результата out(*p) библио-
течная функция free(p) освобождает память.
6.4. Динамические информационные
структуры
Статическое и динамическое представление данных. В
языках программирования типы данных и определения пере-
менных (как объектов заданных типов) нужны для того, чтобы
определить требования к памяти для каждого из этих объектов и
фиксировать диапазон (пределы) значений, которые могут при-
нимать эти объекты (переменные). Для базовых типов (int, long,
double и т.д.) требования к памяти и диапазоны возможных зна-
чений определяются реализацией языка (компилятора). Из базо-
вых типов формируются производные, такие, как массивы и
структурные типы. Для производных типов требования к памяти
заложены в их определениях. Таким образом, определив массив
или структурный тип, программист зафиксировал требования к
памяти в самом определении. Например, на основании опреде-
ления double array[18] в памяти для массива йггау[ ] будет выде-
лено не менее 18* sizeof (double) байт.
Глава 6. Структуры и объединения
307
С помощью определения
struct mixture
{
int ii;
long 11;
char cc [8];
};
не только задается состав структурного типа с названием struct
mixture, но и утверждается, что каждый объект структурного
типа struct mixture потребует для размещения не менее
sizeof (int) + sizeof (long) + 8* sizeof (char)
байт. Точный объем позволяет определить операция
sizeof (struct mixture).
Вводимые таким образом объекты позволяют представить
только статические данные. Однако во многих задачах требует-
ся использовать более сложные данные, представление которых
(конфигурация, размеры, состав) может изменяться в процессе
выполнения программы. О таких изменяемых данных говорят,
используя принятый в информатике термин "динамические ин-
формационные структуры ".
Односвязный список. Наиболее простая динамическая ин-
формационная структура - это односвязный список, элементами
(звеньями) которого служат объекты, например, такого струк-
турного типа:
struct имя структурного типа
{
элементы структуры', /* данные */
struct имя структурного типа * указатель',
};
В каждую структуру такого типа входит указатель на объект
того же типа, что и определяемая структура.
Чтобы продемонстрировать некоторые особенности обработ-
ки простых динамических информационных структур, разрабо-
20*
308
Программирование на языке Си
таем программу, в которой определим структурный тип для
представления звеньев односвязного списка и решим такую
простейшую задачу: "Ввести с клавиатуры произвольное коли-
чество структур, объединяя их в односвязный список, а затем
вывести на экран дисплея содержимое введенного списка в по-
рядке формирования его звеньев".
Анализ динамических информационных структур удобнее
всего выполнять с помощью их графического изображения. На
рис. 6.3 приведены схема односвязного списка и обозначения,
которые будут использованы в программе. Для работы со спи-
ском понадобятся три указателя: beg - на начало списка; end -
на последний элемент, уже включенный в список; гех - указа-
тель для "перебора" элементов списка от его начала .
Начало списка
beg ---------►! данные! указатель I
| данные | указатель |
гех --------► . ..
, I , ,
| данные | указатель"!
end---------►! данные [указатель I
(последний элемент списка)
Рис. 6.3. Односвязный динамический список
Следующая программа решает сформулированную задачу.
#include <stdlib.h>
#include <stdio.h>
/* Определение структурного типа "Звено списка":*/
struct cell {
char sign [10] ;
int weight;
struct cell * pc;
};
Глава 6. Структуры и объединения
309
void main()
{
/* Указатель для перебора Звеньев списка: */
struct cell * rex;
struct cell * beg=NULL; /* Начало списка */
struct cell * end=NULL; /* Конец списка */
printf("\пВведите Значения структур:\n");
/* Цикл ввода и формирования списка */
do
( /* Выделить память для очередного эвена
списка: */
rex=(struct cell *)malloc(
sizeof(struct cell));
/* Ввести значения элементов Эвена: */
printf("sign=");
scanf("%s",& rex->sign);
printf("weight=");
scanf("%d",& rex->weight);
if (rex->weight == 0)
{
free(rex);
break; /* Выход из цикла ввода списка */
)
/* Включить эвено в список: */
if (beg==NULL && end=NULL) /* Список пуст*/
beg=rex;
else /* Включить звено в уже существующий
список */
end->pc=rex;
end=rex;
end->pc=NULL;
)
while(1); /* Конец ввода списка */
/* Напечатать список */
printf("\пСодержимое списка:");
rex=beg;
while (rex?=NULL)
{
printf("\nsign=%s\tweight=%d",rex->sign,
rex->weight);
rex=rex->pc;
)
)
310
Программирование на языке Си
Пример выполнения программы:
Введите данные о структурах:
Sign=sigma
weight=16
Sign=omega
weight=44
Sign=alfa
weight=0
Содержимое списка:
Sign=sigma weight=16
Sign=omega weight=44
Обратите внимание, что при вводе данных о третьем элемен-
те списка введено нулевое значение переменной weight и соот-
ветствующий элемент в список не включен.
В программе ввод данных, т.е. заполнение односвязного спи-
ска структур, выполняется в цикле. Условием окончания цикла
служит нулевое значение, введенное для элемента int weight,
очередной структуры.
Формирование списка структур происходит динамически.
Указатели beg, end инициализированы нулевыми значениями -
вначале список пуст.
Обратите внимание на преобразование типов (struct cell *)
при выделении памяти для структуры типа struct cell. Функция
malloc() независимо or типа параметров всегда возвращает ука-
затель типа void *, а слева от знака присваивания находится
указатель гех типа struct cell *.
Используется явное приведение типов, хотя это не обяза-
тельно - тип void * совместим по операции присваивания с ука-
зателем на объект любого типа.
Остальные особенности программы поясняются коммента-
риями в ее тексте.
Рекурсия при обработке списка. Даже такая простая струк-
тура, как динамический односвязный список, представляет со-
бой конструкцию, которую удобно обрабатывать с помощью
рекурсивных процедур. Рассмотрим ту же задачу об односвяз-
Глава 6. Структуры и объединения
311
ном списке, но оформим формирование списка и вывод списка
на экран дисплея в виде рекурсивных функций. Сделаем это с
целью показать на этом простом примере особенности рекур-
сивной обработки динамических информационных структур.
В каждом звене списка содержатся полезная информация
(данные) и ссылка (адрес) на следующее звено списка. Если та-
кая ссылка нулевая, то список пройден до конца. Для начала
просмотра списка нужно знать только адрес его первого эле-
мента.
Рассмотрим, какие действия должны выполнять функция ре-
курсивного формирования списка и функция его рекурсивного
просмотра с выводом данных о звеньях списка на экран дис-
плея.
Функция рекурсивного заполнения списка ниже в программе
имеет прототип:
struct cell * input (void);
Она возвращает указатель на сформированный и заполнен-
ный данными с клавиатуры динамический список. Предполага-
ется, что при каждом вызове этой функции формируется новый
список. Функция заканчивает работу, если для очередного звена
списка введено нулевое значение переменной weight. В против-
ном случае заполненная с клавиатуры структура подключается к
списку, а ее элементу struct cell * рс присваивается значение,
которое вернет функция input(), рекурсивно вызванная из тела
функции. После этого функция возвращает адрес очередного
звена списка, т.е. значение указателя struct cell * рс.
Прежде чем рассматривать текст функции input( ), помещен-
ный в приведенной ниже программе, еще раз сформулируем ис-
пользованные в ней конструктивные решения.
1. При каждом обращении к этой функции в основной памя-
ти формируется новый список, указатель на начало кото-
рого возвращает функция.
2. Выделение памяти для звеньев списка и заполнение значе-
ниями элементов звеньев (структур) зависит от тех значе-
ний, которые пользователь присваивает элементам.
312
Программирование на языке Си
3. Если для очередного звена списка вводится нулевое значе-
ние элемента weight, то звено не подключается к списку,
процесс формирования списка заканчивается. Такой набор
данных, введенных для элемента очередного звена, счита-
ется терминальным.
4. Если нулевое значение элемента weight введено для перво-
го звена списка, то функция input( ) возвращает значение
NULL.
5. Список определяется рекурсивно как первое (головное)
звено, за которым следует присоединяемый к нему список.
6. Псевдокод рекурсивного алгоритма формирования списка:
Если введены терминальные данные для звена
Освободить память, выделенную для звена
Вернуть нулевой указатель
Иначе:
Элементу связи звена присвоить результат
формирования продолжения списка
(использовать тот же алгоритм)
Все-если
Вернуть указатель на звено.
Текст функции input( ) на языке Си почти полностью соот-
ветствует приведенному псевдокоду и учитывает перечислен-
ные конструктивные решения. Для структуры типа struct ceil
выделяется память. После того как пользователь введет значе-
ния данных, выполняется их анализ. В случае терминальных
значений библиотечная функция free(p) освобождает память от
ненужного звена списка и выполняется оператор return NULL;.
В противном случае элементу связи (указатель struct cell * р)
присваивается результат рекурсивного вызова функции input().
Далее все повторяется для-нового экземпляра этой функции.
Когда при очередном вызове input() пользователь введет тер-
минальные данные, функция input() вернет значение NULL,
которое будет присвоено указателю связи предыдущего звена
списка, и выполнение функции будет завершено.
Глава 6. Структуры и объединения
313
Функция рекурсивного просмотра и печати списка имеет та-
кой прототйп:
void output (struct cell * p);
Исходными данными для ее работы служит адрес начала
списка (или адрес любого его звена), передаваемый как значе-
ние указателя - параметра struct cell * р. Если параметр имеет
значение NULL - список исчерпан, исполнение функции пре-
кращается. В противном случае выводятся на экран значения
элементов той структуры, которую адресует параметр, и функ-
ция output() рекурсивно вызывается с параметром р -> рс. Тем
самым выполняется продвижение к следующему элементу спи-
ска. Конец известен - функция печатает "Список исчерпан!" и
больше не вызывает сама себя, а завершает работу.
Текст программы с рекурсивными функциями:
/* Определение структурного типа "Звено списка":*/
struct cell
{
char sign[10];
int weight;
struct cell * pc;
};
#include <stdlib.h>
#include <stdio.h>
/* Функция ввода и формирования списка: */
struct cell * input(void)
{
struct cell * p;
p=(struct cell *)malloc(sizeof(struct cell));
printf("sign=");
scanf("%s",b p->sign);
printf("weight=");
scanf("%d",b p->weight); .
if (p -> weight == 0)
{
free (p);
return NULL;
)
314
Программирование на языке Си
р -> рс = input(); /* Рекурсивный вызов */
return р;
}
/* Функция "печати" списка: */
void output(struct cell *p)
{
if (p == NULL}
(
printf("\пСписок исчерпан!");
return;
)
printf("\nsign=%s\tweight=%d",p->sign,
p->weight);
output(p -> pc); /* Рекурсивный вызов */
}
void main()
{
struct cell * beg=NULL; /* Начало списка */
printf("\пВведите данные структур:\n");
beg=input(); /* Ввод списка. */
/♦Напечатать список: */
printf("\пСодержимое списка:");
output(beg);
)
Возможный результат выполнения программы:
Введите данные структур:
Sign=Zoro
weight=1938
Sign=Zodiac
weight=1812
Sign=0
weight=0
Содержимое списка:
Sign=Zoro weight=1938
Sign=Zodiac weight=1812
Список исчерпан!
Глава 6. Структуры и объединения
315
6.5. Объединения и битовые поля
Объединения. Со структурами в "близком родстве" находят-
ся объединения, которые вводятся (описываются, определяют-
ся) с помощью служебного слова union.
Объединение можно рассматривать как структуру, все эле-
менты которой имеют нулевое смещение от ее начала. При та-
ком размещении разные элементы занимают в памяти один и
тот же участок. Тем самым объединения обеспечивают возмож-
ность доступа к одному и тому же участку памяти с помощью
переменных (и/или массивов и структур) разного типа. Необхо-
димость в такой возможности возникает, например, при выде-
лении из внутреннего представления целого числа его
отдельных байтов. Для иллюстрации сказанного введем такое
объединение:
union {
char hh[2];
int ii;
} CC;
Здесь:
• union - служебное слово, вводящее тип данных
"объединение" или объединяющий тип данных;
• СС - имя конкретного объединения;
• символьный массив char hh[2] и целая переменная int ii -
элементы (компоненты) объединения.
Схема размещения объединения СС в памяти ЭВМ приведе-
на на рис. 6.4.
Для обращения к элементу объединения используются те же
конструкции, что и для обращения к элементу структуры:
имя объединения. имяэлемента
( * указатель на объединение ). имя элемента
указатель на объединение -> имя элемента
Смысловое отличие объединения от структуры состоит в
том, что записать информацию в объединение можно с помо-
щью одного из его элементов, а выбрать данные из того же уча-
316
Программирование на языке Си
стка памяти можно с помощью другого элемента того же объе-
динения. Например, оператор
CC.ii = 15;
записывает значение 15 в объединение, а с помощью конструк-
ций CC.hhfO], CC.hh[ 1] можно получить отдельные байты внут-
реннего представления целого числа 15.
Определение объединения:
union {charhh[2]; int ii; } сс;
(Массив символов)
«—hh[OJ—►
*—hh[l]—►
Участок памяти,
выделенный <— Байт—►
объединению СС:___________
«— Байт—►
(Целая переменная)
Рис. 64. Схема размещения объединения в памяти
Как и данные других типов, объединение - это конкретный
объект, которому выделено место в памяти. Размеры участка
памяти, выделяемого для объединения, должны быть достаточ-
ны для размещения самого большого элемента объединения. В
нашем примере элементы int ii и char hh[2] имеют одинаковую
длину, но это не обязательно. Основное свойство объединения
состоит в том, что все его элементы размещаются от начала од-
ного и того же участка памяти. А размеры участка памяти, от-
водимого для объединения, определяются размером самого
большого из элементов. Например, для объединения
union
double dd;
float aa;
int j j;
uu;
Глава 6. Структуры и объединения
317
Размеры объекта-объединения uu равны размерам самого
большого из элементов, т.е.:
sizeof(uu) == sizeof(double)
Объединяющий тип. В рассмотренных примерах определе-
ны объединения, но явно не обозначены объединяющие типы.
Именованный объединяющий тип вводится с помощью опреде-
ления такого вида:
union имя объединяющего типа
{
определен ия_элементов
};
где union - спецификатор типа;
имя объединяющего типа - выбираемый программистом
идентификатор;
определение элементов - совокупность описаний объек-
тов, каждый из которых служит прототипом одного из элемен-
тов объединений вводимого объединяющего типа.
Конструкция union имя объединяющего типа играет роль
имени типа, т.е. с ее помощью можно вводить объединения-
объекты.
Как и для структурных типов, с помощью typedef можно
вводить обозначения объединяющих типов, не требующие при-
менения union:
typedef union имя объединяющего типа
{
определения_элементов
} обозначение объединяющего типа;
Пример:
typedef union uni
. {
double dou;
int in[4];
char ch[8] ;
} uni name;
318
Программирование на языке Си
На основе такого определения типа можно вводить конкрет-
ные объединения двумя способами:
union uni snow, ray;
uni_name yet, zz4;
Объединения не относятся ни к скалярным данным, ни к
данным агрегирующих типов.
Пример. Для демонстрации возможностей, предоставляемых
объединениями, рассмотрим функцию bioskey() из стандартной
библиотеки (прототип функции в заголовочном файле bios.h)
компилятора Turbo С:
int bioskey(int) ;
В MS-DOS принято, что каждое нажатие на любую значи-
мую клавишу клавиатуры ПЭВМ приводит ц занесению в буфер
клавиатуры двух байтов, младший из которых (по адресу) со-
держит ASCII-код клавиши, а старший содержит код, называе-
мый скэн-кодом клавиши. Функция bibskey() имеет один
параметр, определяющий режим ее выполнения. При обраще-
нии bioskey(O) функция при пустом буфере ожидает нажатия
любой клавиши, т.е. появления в буфере некоторого кода. Если
в буфере уже есть коды, то bioskey(O) выбирает из буфера кла-
виатуры очередной двухбайтовый код и возвращает его в виде
целого числа. Обращение bioskey(l) позволяет проверить нали-
чие хотя, бы одного кода в буфере. Если буфер не пуст,
bioskey(l) возвращает значение очередного кода из буфера, но
не удаляет этот код из буфера. ’
Следующая программа позволяет получать и печатать ука-
занные выше коды, поступающие в буфер клавиатуры ПЭВМ,
работающей под управлением операционной системы MS-DOS:
/* Печать scan и ASCII кодов клавиатуры IBM PC*/
#include <stdio.h> /* Для функции printf( ) */
#.include <bios.h> /* Для функции bioskey ( ) */
void main( )
{
union •
{
Глава 6. Структуры и объединения
319
char hh[2];
int ii;
) ас;
unsigned char sen, asc;
printf("\n\n Выход no Ctrl+Z.");
printf("\n Нажав клавишу, получите ее"
" двубайтовый код.\п");
printf("\n SCAN || ASCII");
printf("\n (10) (16) (10) (16)");
do /* Цикл до Ctrl+Z */
{
printf("\n");
cc.ii=bioskey(0);
asc=cc.hh[0];
scn=cc.hh[l];
printf (" %4d %3xH | |%4d %3xH I",sen, sen,
asc, asc);
)
while(asc ’=26 || sen *= 44);
)
Обратите внимание на спецификацию преобразования %х,
она предназначена для шестнадцатеричного представления пе-
ресылаемого значения. Для каждого байта, получаемого из бу-
фера клавиатуры, печатается его десятичное и шестнадцате-
ричное представления. Выход из программы осуществляется
при нажатии клавиш Ctrl+Z. В этом случае в программу посту-
пает двухбайтовый код "44+26". Нажатие любой другой клави-
ши вызывает чтение очередного кода.
Пример результатов работы с программой:
Выход по Ctrl+Z.
Нажав клавишу, получите ее двубайтовый код.
SCAN || ASCII
(10) (16) I | (Ю) (16)
16 ЮН | | 113 71Н
17 ПН | | 119 77Н
18 12Н || 101 65Н
19 13Н I | 114 72Н
320
Программирование на языке Си
20 21 14Н | 15Н | 1 . Иб I 121 74Н 79Н
55 37Н | 1 42 2 ah
40 28Н | | 39 27Н
39 27Н | 1 ' 59 ЗЬН
38 26Н | 1 76 4сН
44 2сН j 1 26 1аН
В данной программе используется объединение с именем сс,
в которое с помощью целочисленного элемента cc.ii помещает
результат функция bioskey(O). Затем отдельные байты этого це-
лого числа (для доступа к которым используется char hh[2] -
второй элемент объединения) печатаются как скэн- и ASCII-
коды. Цикл do будет прерван при появлении ASCII-кода 26 и
скэн-кода 44 (сочетание клавиш Ctrl и Z), после чего программа
заканчивает работу.
В объединения, кроме переменных и массивов, могут вхо-
дить и структуры. Однако, прежде чем привести содержатель-
ный пример, остановимся на еще одном важном понятии - на
битовых полях.
Битовые поля. Битовое поле может быть только элементом
структуры или объединения и вне объектов этих типов не
встречается. Битовые поля не имеют адресов и не могут объе-
диняться в массивы. Назначение битовых полей - обеспечить
удобный доступ к отдельным битам данных. Кроме того, с по-
мощью битовых полей можно формировать объекты с длиной
внутреннего представления, не кратной байту. Это позволяет
плотно "упаковывать" информацию, что экономит память.
Описание структуры с битовыми полями должно иметь такой
формат:
struct { mun i имяполя! : ширина поля !;
тип_2 имя_поля_2 : ширина_поля_2‘,
} имя структуры ;
где mun i - тип поля, который может быть только int, воз-
можно, со спецификатором unsigned или signed;
Глава 6. Структуры и объединения
321
ширинаполя - целое неотрицательное десятичное число,
значение которого обычно (в зависимости от реализации ком-
пилятора) не должно превышать длины слова конкретной ЭВМ.
Разрешается поле без имени (для чего указываются только
двоеточие и ширина), с помощью которого в структуру вводятся
неиспользуемые биты (промежуток между значимыми полями).
Нулевая ширина поля вводится, когда необходимо, чтобы сле-
дующее в данной структуре поле разместилось с начала очеред-
ного слова конкретной ЭВМ.
Вместо служебного слова struct может употребляться union.
В этом случае определяется объединение с битовыми полями.
Для обращения к полям используются те же конструкции,
что и для обращения к обычным элементам структур:
имя структуры. имяполя}
(* указатель на структуру). имя_поля_1
указатель на структуру -> имя_поля_1
Например, для структуры хх с битовыми полями:
struct {
int а:10; <
int b: 14;
} хх ;
правомочны такие операторы:
хх.а=1; хх.Ь=48; или хх.а=хх.Ь=0;
От реализации зависит порядок размещения в памяти полей
одной структуры. Поля могут размещаться как слева направо,
так и справа налево. Для компиляторов, работающих под управ-
лением MS-DOS на IBM PC, поля, которые размещены в начале
описания структуры, имеют младшие адреса. Таким образом,
для примера:
struct {
int х:5;
int у:3; } hh;
hh.x=4; hh.y=2;
21-3124
322
Программирование на языке Си
в одном байте формируется последовательность битов, приве-
денная на рис. 6.5.
Номера битов:
Битовые поля:
7 6 5 4 3 2 1 0
0 1 0 0 0 1 0 0
<---- hh.y ----------------- hh.x-----------►
Рис. 6.5. Размещение битовых полей в байте
В качестве иллюстрации возможностей объединений и
структур с битовыми полями рассмотрим следующую програм-
му. В ней вводятся значения двух целых переменных типи
остатки от их деления на 16 заносятся соответственно в четыре
младших и четыре старших разряда одного байта. Таким обра-
зом выполняется некоторая кодировка введенных значений пе-
ременных тип. Затем печатается изображение содержимого
сформированного байта. Особенности программы объяснены в
комментариях и поясняются результатами выполнения. Обрати-
те внимание на использование объединений. В функции cod()
запись данных производится в элементы (битовые поля) струк-
туры hh, входящей в объединение un, а результат выбирается из
того же объединения un в виде одного байта. В функции binar()
происходит обратное преобразование - в нее как значение па-
раметра передается байт, содержимое которого побитово
"расшифровывается" за счет обращения к отдельным полям
структуры byte, входящей в объединение cod.
Текст программы:
/* Структуры, объединения и битовые поля */
#include <stdio.h>
void main (void)
(
unsigned char k;
int m,n;
Глава 6. Структуры и объединения
323
void binar(unsigned char); /* Прототип
функции */
unsigned char cod(int,int); /* Прототип
функции */
printf("\n m=");
scanf("%d",&m);
printf(" n=");
scanf("%d",&n);
k=cod(m,n);
printf(" cod=%u",k);
binar(k);
}
I * Упаковка в один байт остатков от деления
на 16 двух целых чисел */
unsigned char cod(int a, int b)
{
union
(
unsigned char z;
struct
(
unsigned int x :4; /* Младшие биты */
unsigned int у :4; /* Старшие биты */
) hh;
) un ;
un.hh.x=a%16;
un.hh.y=b%16;
return un. z;
)
/* binar - двоичное представление байта */
void binar(unsigned char ch)
(
union
(
unsigned char ss;
struct
{
unsigned aO :1; unsigned al : 1;
unsigned a2 :1; unsigned a3 :1;
unsigned a4 :1; unsigned a5 : 1 ;
unsigned a6 :1; unsigned a 7 :1;
} byte;
) cod ;
21
324
Программирование на языке Си
cod.s s=ch;
printf("\n Номера битов: 1»
"7 6 5 4 3 2 1 0") ;
printf("\n Значения битов: %d %d
"%d %d " %d %d %d %d",
cod.byte.a7, cod.byte.a6, cod.byte.a5,
cod.byte.a4, cod.byte.a3, cod.byte.a2,
cod.byte.al, cod.byte.aO);
}
Результаты выполнения программы на IBM PC:
Первый вариант:
m=l
n=3
cod=4 9
Номера битов: 76543210
Значения битов: 00110001
Второй вариант:
т=0
п=1
cod=16
Номера битов: 76543210
Значения битов: 00010000
Глава 7
ВВОД и вывод
В стандарте языка Си отсутствуют средства ввода-вывода.
Все операции ввода-вывода реализуются с помощью функций,
находящихся в библиотеке языка Си, поставляемой в составе
конкретной системы программирования Си.
Особенностью языка Си, который впервые был применен
при разработке операционной системы UNIX, является отсутст-
вие заранее спланированных структур файлов. Все файлы рас-
сматриваются как неструктурированная последовательность
байтов. При таком подходе к организации файлов удалось рас-
пространить понятие файла и на различные устройства. В UNIX
конкретному устройству соответствует так называемый "спе-
циальный файл", а одни и те же функции библиотеки языка Си
используются как для обмена данными с файлами, так и для об-
мена с устройствами.
Примечание. В UNIX эти же функции используются также
для обмена данными между процессами (выполняющимися
программами).
Библиотека языка Си поддерживает три уровня ввода-
вывода: потоковый ввод-вывод, ввод-вывод нижнего уровня и
ввод-вывод для консоли и портов. Последний уровень, обеспе-
чивающий удобный специализированный обмен данными с дис-
плеем и портами ввода-вывода, мы рассматривать не будем в
силу его системной зависимости. Например, он различен для
MS-DOS, Windows и UNIX.
7.1. Потоковый ввод-вывод
На уровне потокового ввода-вывода обмен данными произ-
водится побайтно. Такой ввод-вывод возможен как для собст-
венно устройств побайтового обмена (печатающее устройство,
дисплей), так и для файлов на диске, хотя устройства внешней
памяти, строго говоря, являются устройствами поблочного об-
мена, т.е. за одно обращение к устройству производится счи-
326
Программирование на языке Си
тывание или запись фиксированной порции данных. Чаще всего
минимальной порцией данных, участвующей в обмене с внеш-
ней памятью, являются блоки в 512 байт или 1024 байта. При
вводе с диска (при чтении из файла) данные помещаются в бу-
фер операционной системы, а затем побайтно или определен-
ными порциями передаются программе пользователя. При
выводе данных в файл они накапливаются в буфере, а при за-
полнении буфера записываются в виде единого блока на диск
за одно обращение к последнему. Буферы операционной систе-
мы реализуются в виде участков основной памяти. Поэтому пе-
ресылки между буферами ввода-вывода и выполняемой прог-
раммой происходят достаточно быстро в отличие от реальных
обменов с физическими устройствами.
Функции библиотеки ввода-вывода языка Си, поддержи-
вающие обмен данными с файлами на уровне потока, позволяют
обрабатывать данные различных размеров и форматов, обеспе-
чивая при этом буферизованный ввод и вывод. Таким образом,
поток - это файл вместе с предоставляемыми средствами буфе-
ризации.
При работе с потоком можно производить следующие дейст-
вия:
• открывать и закрывать потоки (связывать указатели на по-
токи с конкретными файлами);
• вводить и выводить: символ, строку, форматированные
данные, порцию данных произвольной длины;
• анализировать ошибки потокового ввода-вывода и условие
достижения конца потока (конца файла);
• управлять буферизацией потока и размером буфера;
• получать и устанавливать указатель (индикатор) текущей
позиции в потоке.
Для того чтобы можно было использовать функции библио-
теки ввода-вывода языка Си, в программу необходимо включить
заголовочный файл stdio.h (#include <stdio.h>), который содер-
жит прототипы функций ввода-вывода, а также определения
констант, типов и структур, необходимых для работы функций
обмена с потоком.
Глава 7. Ввод и вывод
327
На рис. 7.1 показаны возможные информационные обмены
исполняемой программы на локальной (несетевой) ЭВМ.
Рис. 7.1. Информационные обмены исполняемой программы
на локальной ЭВМ
7.1.1. Открытие и закрытие потока
Прежде чем начать работать с потоком, его необходимо ини-
циализировать, т.е. открыть. При этом поток связывается в ис-
полняемой программе со структурой предопределенного типа
FILE. Определение структурного типа FILE находится в заго-
ловочном файле stdio.h. В структуре FILE содержатся компо-
ненты, с помощью которых ведется работа с потоком, в
частности: указатель на буфер, указатель (индикатор) текущей
позиции в потоке и другая информация.
При открытии потока в программу возвращается указатель
на поток, являющийся указателем на объект структурного типа
FILE. Этот указатель идентифицирует поток во всех после-
дующих операциях.
328
Программирование на языке Си
Указатель на поток, например fp, должен быть объявлен в
программе следующим образом:
#include <stdio.h>
FILE *fp;
Указатель на поток приобретает значение в результате вы-
полнения функции открытия потока:
fp - fopen {имя файла, режим открытия)',
Параметры имя файла и режим открытия являются указа-
телями на массивы символов, содержащих соответственно имя
файла, связанного с потоком, и строку режимов открытия. Од-
нако эти параметры могут задаваться и непосредственно в виде
строк при вызове функции открытия файла:
fp = fopen("t.txt", "г");
где t. txt - имя некоторого файла, связанного с потоком;
г - обозначение одного из режимов работы с файлом (тип
доступа к потоку).
Стандартно файл, связанный с потоком, можно открыть в
одном из следующих шести режимов:
"w" - новый текстовый (см. ниже) файл открывается для
записи. Если файл уже существовал, то предыдущее
содержимое стирается, файл создается заново;
"г" - существующий текстовый файл открывается только
для чтения;
"а" -текстовый файл открывается (или создается, если
файла нет) для добавления в него новой порции ин-
формации (добавление в конец файла). В отличие от
режима "w" режим "а" позволяет открывать уже
существующий файл, не уничтожая его предыдущей
версии, и писать в продолжение файла;
"w+" - новый текстовый файл открывается для записи и
последующих многократных исправлений. Если
файл уже существует, то предыдущее содержимое
стирается. Последующие после открытия файла за-
пись и чтение из него допустимы в любом месте
Глава 7. Ввод и вывод
329
файла, в том числе запись разрешена и в конец фай-
да, т.е. файл может увеличиваться ("расти");
"г4-" - существующий текстовый файл открывается как для
чтения, так и для записи в любом месте файла; од-
нако в этом режиме невозможна запись в конец
файла, т.е. недопустимо увеличение размеров фай-
ла;
"а+" -текстовый файл открывается или создается (если
файла нет) и становится доступным для изменений,
т.е. для записи и для чтения в любом месте; при
этом в отличие от режима "w+" можно открыть су-
ществующий файл и не уничтожать его содержи-
мого; в отличие от режима "г+" в режиме "а+"
можно вести запись в конец файла, т.е. увеличивать
его размеры.
Поток можно открыть в текстовом либо двоичном (би-
нарном) режиме.
В текстовом режиме прочитанная из потока комбинация
символов CR (значение 13) и LF (значение 10), то есть управ-
ляющие коды "возврат каретки" и ^'перевод строки", преобразу-
ется в один символ новой строки *\п' (значение 10, совпадающее
с LF). При записи в поток в текстовом режиме осуществляется
обратное преобразование, т.е. символ новой строки *\п' (LF) за-
меняется последовательностью CR и LF.
Если файл, связанный с потоком, хранит не текстовую, а
произвольную двоичную информацию, то указанные преобразо-
вания не нужны и могут быть даже вредными. Обмен без такого
преобразования выполняется при выборе двоичного или бинар-
ного режима, который обозначается буквой Ь. Например, "г+Ь"
или "wb". В некоторых компиляторах текстовый режим об-
мена обозначается буквой t, т.е. записывают "a+t" или "rt".
Если поток открыт для изменений, т.е. в параметре режима
присутствует символ "+", то разрешены как вывод в поток, так
и чтение из него. Однако смена режима (переход от записи к
чтению и обратно) должна происходить только после установки
указателя потока в нужную позицию (см. §7.1.3).
330
Программирование на языке Си
При открытии потока могут возникнуть следующие ошибки:
указанный файл, связанный с потоком, не найден (для режима
"чтение"); диск заполнен или диск защищен от записи и т.п. Не-
обходимо также отметить, что при выполнении функции
fopen() происходит выделение динамической памяти. При ее
отсутствии устанавливается признак ошибки "Not enough
memory" (недостаточно памяти). В перечисленных случаях ука-
затель на поток приобретает значение NULL. Заметим, что ука-
затель на поток в любом режиме, отличном от аварийного,
никогда не бывает равным NULL.
Приведем типичную последовательность операторов, кото-
рая используется при открытии файла, связанного с потоком:
if ((fp = fopen("t.txt", "w")) == NULL)
{
perror("ошибка при открытии файла t.txt \n");
exit(0);
)
где NULL - нулевой указатель, определенный в файле stdio.h.
Для вывода на экран дисплея сообщения об ошибке при от-
крытии потока используется стандартная библиотечная функция
реггог(), прототип которой в stdio.h имеет вид:
void perror (const char * s);
Функция perror() выводит строку символов, адресуемую
указателем s, за которой размещаются: двоеточие, пробел и со-
общение об ошибке. Содержимое и формат сообщения опре-
деляются реализацией системы программирования. Текст сооб-
щения об ошибке выбирается функцией perrorQ на осно-
вании номера ошибки. Номер ошибки заносится в переменную
int errno (определенную в заголовочном файле errno.h) рядом
функций библиотеки языка Си, в том числе и функциями ввода-
вывода.
После того как файл открыт, с ним можно работать, записы-
вая в него информацию или считывая ее (в зависимости от ре-
жима).
Глава 7. Ввод и вывод
331
Открытые на диске файлы после окончания работы с ними
рекомендуется закрыть явно. Для этого используется библио-
течная функция
int fclose (указатель на поток );
Открытый файл можно открыть повторно (например, для из-
менения режима работы с ним) только после того, как файл бу-
дет закрыт с помощью функции fclose().
7.1.2. Стандартные файлы и функции
для работы с ними
Когда программа начинает выполняться, автоматически от-
крываются пять потоков, из которых основными являются:
• стандартный поток ввода (на него ссылаются, используя
предопределенный указатель на поток stdin);
• стандартный поток вывода (stdout);
• стандартный поток вывода сообщений об ошибках
(stderr).
По умолчанию стандартному потоку ввода stdin ставится в
соответствие клавиатура, а потокам stdout и stderr соответству-
ет экран дисплея.
Для ввода-вывода данных с помощью стандартных потоков в
библиотеке языка Си определены следующие функции:
• getchar( )/putchar() - ввод-вывод отдельного символа;
• gets( )/puts() - ввод-вывод строки;
• scanf( )/printf() - ввод-вывод в режиме форматирования
данных.
Ввод-вывод отдельных символов. Одним из наиболее эф-
фективных способов осуществления ввода-вывода одного сим-
вола является использование библиотечных функций getchar()
и putchar( ). Прототипы функций getchar( ) и putchar() имеют
следующий вид:
int getchar(void);
int putchar(int с);
332
Программирование на языке Си
Функция getchar( ) осуществляет ввод одного символа. При
обращении она возвращает в вызвавшую ее функцию один вве-
денный символ.
Функция putchar() выводит в стандартный поток один сим-
вол, при этом также возвращает в вызвавшую ее функцию толь-
ко что выведенный символ.
Обратите внимание на то, что функция getchar() вводит оче-
редной байт информации (символ) в виде значения типа int. Это
сделано для того, чтобы гарантировать успешность распознава-
ния ситуации "достигнут конец файла". Дело в том, что при
чтении из файла с помощью функции getchar() может быть
достигнут конец файла. В этом случае операционная система в
ответ на попытку чтения символа передает функции getchar()
значение EOF (End of File). Константа EOF определена в заго-
ловочном файле stdio.h и в разных операционных системах
имеет значение 0 или -1. Таким образом, функция getchar()
должна иметь возможность прочитать из входного потока не
только символ, но и целое значение. Именно с этой целью
функция getchar() всегда возвращает значение типа int.
Применение в программах константы EOF вместо конкрет-
ных целых значений, возвращаемых при достижении конца
файла, делает программу мобильной (не зависимой от конкрет-
ной операционной системы).
В случае ошибки при вводе функция getchar() также воз-
вращает EOF.
Строго говоря, функции getchar() и putchar() функциями не
являются, а представляют собой макросы, определенные в заго-
ловочном файле stdio.h следующим образом:
#define getqhar() getc(stdin)
#define putchar(c) putc ((c), stdout)
Здесь переменная с определена как int с.
Функции getc() и putc( ), с помощью которых определены
функции getchar( ) и putchar(), имеют следующие прототипы;
int getc (FILE ‘stream);
int putc (int c, FILE ‘stream);
Глава 7. Ввод и вывод
333
Указатели на поток, задаваемые в этих функциях в качестве
параметра, при определении макросов getchar() и putchar()
имеют соответственно предопределенные значения stdin (стан-
дартный ввод) и stdout (стандартный вывод).
Интересно отметить, что функции getc() и putc(), в свою
очередь, также реализуются как макросы. Соответствующие
строки легко найти в заголовочном файле stdio.h.
Не разбирая подробно эти макросы, заметим, что вызов биб-
лиотечной функции getc( ) приводит к чтению очередного байта
информации из стандартного ввода с помощью системной
функции (ее имя зависит от операционной системы) лишь в том
случае, если буфер операционной системы окажется пустым.
Если буфер не пуст, то в программу пользователя будет передан
очередной символ из буфера. Это необходимо учитывать при
работе с программой, которая использует функцию getchar()
для ввода символов.
При наборе текста на клавиатуре коды символов записыва-
ются во внутренний буфер операционной системы, Одновре-
менно они отображаются (для визуального контроля) на экране
дисплея. Набранные на клавиатуре символы можно редактиро-
вать (удалять и набирать новые). Фактический перенос симво-
лов из внутреннего буфера в программу происходит при нажа-
тии клавиши <Enter>. При этом код клавиши <Enter> также за-
носится во внутренний буфер. Таким образом, при нажатии на
клавишу 'А' и клавишу <Enter> (завершение ввода) во внутрен-
нем буфере оказываются: код символа 'А' и код клавиши <Enter>.
Об этом необходимо помнить, если вы рассчитываете на
ввод функцией getchar() одиночного символа.
Приведем фрагмент программы, в которой функция
getchar(.) используется для временной приостановки работы
программы с целью анализа промежуточных значений контро-
лируемых переменных.
#include <stdio.h>
int main()
{
printf("a");
334
Программирование на языке Си
getchar(); /*. #1 */
printf("b");
getcharO ; /* #2 */
printf("c");
return 0;
}
Сначала на экран выводится символ 'а', и работа программы
приостанавливается до ввода очередного (в данном случае -
любого) символа. Если, как это делается обычно, нажать, на-
пример, клавишу <q> и затем клавишу <Enter> (для завершения
ввода), то на следующей строке появятся символы be, и про-
грамма завершит свою работу. Первая (в программе) функция
getchar() (#1) прочитала из внутреннего буфера код символа 'q',
и следующая за ней функция printf( ) вывела на экран символ
Ъ'. Остановки работы программы не произошло, потому что
вторая функция getchar() (#2) прочитала код клавиши <Enter>
из внутреннего буфера, а не очередной символ с клавиатуры.
Произошло это потому, что к моменту вызова функции
getchar( ) внутренний буфер не был пуст.
Приведенная программа будет работать правильно, если в
момент остановки программы нажимать только клавишу
<Enter>.
Функция putchar() служит для вывода на устройство стан-
дартного вывода одного символа, заданного в качестве парамет-
ра. Ниже приведены примеры задания выводимого символа:
1
2
3
4
5
int с;
с = getchar( ) ;
putchar(c);
putchar('А');
putchar('\007’);
putchar('\t');
В строке 2 фрагмента программы на экран дисплея выводит-
ся символ, введенный в предыдущей строке функцией
getchar( ). В строке 3 выводится символ 'А', в строке 4 выводит-
ся управляющий символ, заданный кодом 007 (звуковой сиг-
нал). В последней строке выводится неотображаемый (управ-
Глава 7. Ввод и вывод
335
ляющий) символ табуляции, перемещающий курсор в следую-
щую позицию табуляции. Обычно эти позиции задаются сле-
дующим числовым рядом: 1,9,17,25...
Приведем в качестве примера применения функций
getchar() и putchar() программу копирования данных из стан-
дартного ввода в стандартный вывод, которую можно найти
практически в любом пособии по программированию на Си:
# include <s tdio.h>
int main()
{
int c;
while ((c = getchar()) != EOF)
putchar(c);
return 0;
}
Эта же программа с использованием функций getc() и putc()
будет выглядеть так:
♦include <stdio.h>
int main ()
{
int с ;
while ((с = getc(stdin)) != EOF)
putc(c, stdout);
return 0;
}
Для завершения приведенной выше программы копирования
необходимо ввести с клавиатуры сигнал прерывания Ctrl+C
(одновременно нажать клавиши <Ctrl> и <С>).
В [1, §1.5] приведены примеры использования функций
getchar() и putchar() для подсчета во входном потоке числа
отдельных введенных символов, строк и слов.
Ввод-вывод строк. Одной из наиболее популярных опера-
ций ввода-вывода является операция ввода-вывода строки сим-
волов. В библиотеку языка Си для обмена данными через
стандартные потоки ввода-вывода включены функции ввода-
вывода строк gets() и puts(),' которые удобно использовать при
336
Программирование на языке Си
создании диалоговых систем. Прототипы этих функций имеют
следующий вид:
char * gets (char * s); /* Функция ввода */
int puts (char * s); /* Функция вывода */
Обе функции имеют только один аргумент - указатель s на
массив символов. Если строка прочитана удачно, функция
gets( ) возвращает адрес того массива s, в который производился
ввод строки. Если произошла ошибка, то возвращается NULL.
Функция puts() в случае успешного завершения возвращает
последний выведенный символ, который всегда является сим-
волом '\п'. Если произошла ошибка, то возвращается EOF.
Приведем простейший пример использования этих функций.
#include <stdio.h>
char strl[ ] = "Введите фамилию сотрудника:";
int main()
{
char name[80];
puts(strl);
gets(name);
return 0;
}
Напомним, что любая строка символов в языке Си должна
заканчиваться нуль-символом '\0'. В последний элемент массива
strl нуль-символ будет записан автоматически во время транс-
ляции при инициализации массива. Для функции puts() нали-
чие нуль-символа в конце строки является обязательным. В
противном случае, т.е. при отсутствии в символьном массиве
символа '\0', программа может завершиться аварийно, так как
функция puts() в поисках нуль-символа будет перебирать всю
доступную память байт за байтом, начиная в нашем примере с
адреса strl. Об этом необходимо помнить, если в программе
происходит формирование строки для вывода ее на экран дис-
плея. Функция gets( ) завершает свою работу при вводе символа
'Vn', .который автоматически передается от клавиатуры в ЭВМ
при нажатии на клавишу <Enter>. При этом сам символ ’\п* во
Ввод и вывод
337
вводимую строку не записывается. Вместо него в строку поме-
щается нуль-символ '\0'. Таким образом, функция gets() произ-
водит ввод "правильной" строки, а не просто последователь-
ности символов.
Здесь следует обратить внимание на следующую особен-
ность ввода данных с клавиатуры. Функция gets() начинает об-
работку информации от клавиатуры только после нажатия
клавиши <Enter>. Таким образом, она "ожидает", пока не будет
набрана нужная информация и нажата клавиша <Enter>. Только
после этого начинается ввод данных в программу.
Форматный ввод-вывод. В состав стандартной библиотеки
языка Си включены функции форматного ввода-вывода. Ис-
пользование таких функций позволяет создавать программы,
способные обрабатывать данные в заданном формате, а также
осуществлять элементарный синтаксический анализ вводимой
информации уже на этапе ее чтения. Функции форматного вво-
да-вывода предназначены для ввода-вывода отдельных симво-
лов, строк, целых восьмеричных, шестнадцатеричных,
десятичных чисел и вещественных чисел всех типов.
Для работы со стандартными потоками в режиме форматного
ввода-вывода определены две функции:
printf() - форматный вывод;
scanf() - форматный ввод.
Форматный вывод в стандартный выходной поток. Про-
тотип функции printf( ) имеет вид:
int printf(const char * format,...);
При обращении к функции printf() возможны две формы за-
дания первого параметра:
int printf ( форматная строка, список аргументов)',
int printf ( указатель_на_форматную строку,
списокаргументов)',
В обоих случаях функция printf() преобразует данные из
внутреннего представления в символьный вид в соответствии с
22“3124
338
Программирование на языке Си
форматной строкой и выводит их в выходной поток. Данные,
которые преобразуются и выводятся, задаются как аргументы
функции printf().
Возвращаемое значение функции printf() - число напеча-
танных символов; а в случае ошибки - отрицательное число.
Форматная строка ограничена двойными кавычками и мо-
жет включать произвольный текст, управляющие символы и
спецификации преобразования данных. Текст и управляющие
символы из форматной строки просто копируются в выходной
поток. Форматная строка обычно размещается в списке факти-
ческих параметров функции, что соответствует первому вариан-
ту вызова функции printf(). Второй вариант предполагает, что
первый фактический параметр - это указатель типа char *, а
сама форматная строка определена в программе как обычная
строковая константа или переменная.
В список аргументов функции printf() включают выраже-
ния, значения которых должны быть выведены из программы.
Частные случаи этих выражений - переменные и константы.
Количество аргументов и их типы должны соответствовать по-
следовательности спецификаций преобразования в форматной
строке. Для каждого аргумента должна быть указана точно одна
спецификация преобразования.
Если аргументов недостаточно для данной форматной стро-
ки, то результат зависит от реализации (от операционной систе-
мы и от системы программирования). Если аргументов больше,
чем указано в форматной строке, "лишние" аргументы игнори-
руются. Гарантируется, что при любом количестве параметров и
любом их типе после выполнения функции printf() дальнейшее
выполнение программы будет корректным.
Списокаргументов (с предшествующей запятой) может от-
сутствовать,
Спецификация преобразования имеет следующую форму:
% флаги ширина _поля.точностъ модификатор спецификатор
. Символ % является признаком спецификации преобразова-
ния. В спецификации преобразования обязательными являются
только два элемента: признак % и спецификатор.
Глава 7. Ввод и вывод 339
Спецификация преобразования не должна содержать внутри
себя пробелов. Каждый элемент спецификации является оди-
ночным символом или числом.
Предупреждение. Спецификации преобразований должны
соответствовать типу указанных аргументов. При несовпаде-
нии не будет выдано сообщений об ошибках во время ком-
пиляции или выполнения программы, но в выводе
результатов выполнения программы может содержаться
"мусор".
Начнем рассмотрение составных элементов спецификации
преобразования с обязательного элемента - спецификатора,
который определяет, как будет интерпретироваться соответст-
вующий аргумент: как символ, как строка или как число
(табл. 7.1).
Таблица 7.1
Спецификаторы форматной строки для функции форматного вывода
Спе- цифи- катор Тип аргумента Формат вывода
d int, char, nnsigned Десятичное целое со знаком
i int, char, unsigned Десятичное целое со знаком
u int, char, unsigned Десятичное целое без знака
о int, char, nnsigned Восьмеричное целое без знака
X int, char, unsigned Шестнадцатеричное целое без знака; при выводе ис- пользуются символы "O...9a...f"
X int, char, unsigned Шестнадцатеричное целое без знака; при выводе ис- пользуются символы "0...9A...F
f double,- float Вещественное значение со знаком в виде: 3HaK_4uc4adddd.dddd, где dddd - одна или более десятичных цифр. Количе- ство цифр перед десятичной точкой зависит от вели- чины выводимого числа, а количество цифр после десятичной точки зависит от требуемой точности. Знак_числа при отсутствии модификатора '+' изобра- жается только для отрицательного числа
22*
340
Программирование на языке Си
Продолжение
Спе- цифи- катор Тип аргумента Формат вывода
е double, float Вещественное значение в виде: знакчислатМййезнакххх, где m.dddd - изображение мантиссы числа; m - одна десятичная цифра; dddd - последовательность десятичных цифр; е - признак порядка; знак - знак порядка; ххх - десятичные цифры для представления поряд- ка числа; знакчисла при отсутствии модификатора '+' изо- бражается только для отрицательного числа
Е double, float Идентичен спецификатору "е", за исключением того, что признаком порядка служит "Е"
g double, float Вещественное значение со знаком печатается в форма- те спецификаторов "Г или "е" в зависимости от того, какой из них более компактен для данного значения и точности. Формат спецификатора "е" используется то- . гда, когда значение показателя меньше -4 или больше заданной точности. Конечные нули отбрасываются, а десятичная точка появляется, если за ней следует хотя бы одна цифра
G double, float Идентичен формату спецификатора "g", за исключени- ем того, что признаком порядка служит "Е"
С int, char, unsigned Одиночный символ
S char * Символьная строка. Символы печатаются либо до пер- вого нулевого символа ('\0') или печатается то количе- ство символов, которое задано в поле точность спе- цификации преобразования
р void * Значение адреса. Печатает адрес, указанный аргумен- том (представление адреса зависит от реализации)
Приведем примеры использования различных спецификато-
ров. В каждой строке вызова функции printf() в качестве ком-
ментариев приведены результаты выйода. Переменная code
Глава 7. Ввод и вывод
341
содержит код возврата функции prints ) - число напечатанных
символов при выводе значения переменной f.
#include <stdio.h>
int main()
{
int number = 27;
float f = 123.456;
char str[4] = "abc";
char c = 'a';.
int code;
printf("%d\n", number); /* 27 */
printf("%o\n", number); /* 33 */
printf("%x\n", number); /* lb */
code = printf("%f\n", f) ; /* 123.456001 */
printf("code = %d\n", code); /* code = 11 */
printf("%e\n", f); /* 1.23456e+02 */
printf("%c\n", c); /* a */
printf("%s\n", str); /* abc ♦/
return 0;
}
Необязательные элементы спецификации преобразования
управляют другими параметрами форматирования.
Флаги управляют выравниванием вывода и печатью знака
числа, пробелов, десятичной точки, префиксов восьмеричной и
шестнадцатеричной систем счисления. Флаги могут отсутство-
вать, а если они есть, то могут стоять в любом порядке.- Смысл
флагов следующий:
Выводимое изображение значения прижимается к
левому краю поля. По умолчанию, т.е. при отсут-
ствии этого флага, происходит выравнивание по
правой границе поля.
+ Если выводимое значение имеет знак (любой: '+'
или то он выводится. Без этого флага знак
выводится только при отрицательном значении.
пробел Используется для вставки пробела на месте знака
перед положительными числами.
342
Программирование на языке Си
# Если этот флаг используется с форматами "о", "х”
или "X", то любое ненулевое значение выводится
с предшествующим 0, Ох или ОХ соответственно.
При использовании флага # с форматами "Г, "g",
"G" десятичная точка будет выводиться, даже
если в числе нет дробной части.
Примеры использования флагов:
"%+d" - вывод знака '+' перед положительным целым де-
1 сятичным числом;
"% d" - добавление (вставка) пробела на месте знака пе-
ред положительным числом (использован флаг
пробел после символа %);
"%#о" - печать ведущих нулей в изображениях восьме-
ричных чисел.
Ширина_поля, задаваемая в спецификации преобразования
положительным целым числом, определяет минимальное коли-
чество позиций, отводимое для представления выводимого зна-
чения. Если число символов в выводимом значении меньше, чем
ширина_поля, выводимое значение дополняется пробелами до
заданной минимальной длины. Если ширинаполя задана с на-
чальным нулем, не занятые значащими цифрами выводимого
значения позиции слева заполняются нулями.
Если число символов в изображении выводимого значения
больше, чем определено в ширине_поля, или ширина поля не
задана, печатаются все символы выводимого значения.
Точность указывается с помощью точки и необязательной
последовательности десятичных цифр (отсутствие цифр эквива-
лентно 0).
Точность задает:
• минимальное число цифр, которые могут быть выведены
при использовании спецификаторов d, i, о, и, х или X;
• число цифр, которые будут выведены после десятичной
точки при спецификаторах е, Е и f;
• максимальное число значащих цифр при спецификаторах g
и G;
Глава 7. Ввод и вывод
343
• максимальное число символов, которые будут выведены
при спецификаторе s.
Непосредственно за точностью может быть указан модифи-
катор, который определяет тип ожидаемого аргумента и зада-
ется следующими символами:
h - указывает, что следующий после h спецификатор d, i,
о, х или X применяется к аргументу типа short или
unsigned short;
1 - указывает, что следующий после 1 спецификатор d, i,
о, х или X применяется к аргументу типа long или
unsigned long;
L - указывает, что следующий после L спецификатор е, Е,
f, g или G применяется к аргументу типа long double.
Примеры указания ширины _поля и точности:
%d - вывод десятичного целого в поле, достаточном
для представления всех его цифр и знака;
%7d - вывод десятичного целого в поле из 7 позиций;
%f - вывод вещественного числа с целой и дробной
частями (выравнивание по правому краю; количе-
ство цифр в дробной части определяется реализа-
цией и обычно равно 6);
%7f - вывод вещественного числа в поле из 7 позиций;
%.3f - вывод вещественного числа с тремя цифрами по-
сле десятичной точки;
%7.3f - вывод вещественного числа в поле из 7 позиций и
тремя цифрами после десятичной точки;
%.0f - вывод вещественного числа без десятичной точки
и без дробной части;
%15s - печать в выводимой строке не менее 15 символов;
%. 12s - печать строки длиной не более 12 символов
("лишние" символы не выводятся);
%12.12s - печать всегда в поле из 12 позиций, причем лиш-
ние символы не выводятся, используется всегда 12
позиций. Таким образом, точное количество вы-
водимых символов можно контролировать, зада-
344
Программирование на языке Си
вая и ширинуполя, и точность (максимальное
количество символов);
%-15s - выравнивание выводимой строки по левому краю;
%08f - вывод вещественного числа в поле из 8 позиций.
Не занятые значащими цифрами позиции запол-
няются нулями.
Функция форматного вывода printf() предоставляет множе-
ство возможностей по форматированию выводимых данных,
однако наибольший интерес представляют построение столбцов
данных и их выравнивание по левому или правому краю задан-
ного поля.
В программе, приводимой ниже, на экран дисплея выводится
список товаров в магазине. В каждой строке в отдельных полях
указываются: номер товара (int), код товара (int), наименование
товара (строка символов) и цена товара (float).
#include <stdio.h>
int main()
{
int i ;
int number[3]={1, 2, 3}; /* Номер товара */
int code[3]={10, 25670, 120}; /* Код товара */
/* Наименование товара: */
char design[3][30]={{"лампа"}, {"стол"},
{"очень большое кресло"}};
/* Цена: */
float price[3]={52.700, 240.000, 824.000};
"for (i=0; i<=2; i++)
printf("%-3d %5d %-20s %8.3f\n",
number[i], codefi], design[i], price[i]);
return 0;
}
Результат выполнения программы:
1 10 лампа 52.700
2 25670 стол 240.000
3 120 очень большое кресло 824.000
Форматная строка в параметрах функции printf() обеспечи-
вает следующие преобразования выводимых значений:
Глава 7. Ввод и вывод
345
1) переменная number[i] типа int выводится в поле шириной
3 символа и прижимается к левому краю (%-3d);
2) переменная code[i] типа int выводится в поле шириной 5
символов и прижимается (по умолчанию) к правому краю
(%5d);
3) строка из массива design[i] выводится в поле шириной 20
символов и прижимается к левому краю (%-20s). Если в
данной спецификации преобразования будет указано
меньшее, чем 20, количество позиций, то самая длинная
строка будет все равно выведена, однако последний стол-
бец не будет выровнен;
4) переменная price[i] типа float выводится в поле шириной
8 символов, причем после десятичной точки выводятся 3
символа, и выводимое значение прижимается к правому
краю.
Между полями, определенными спецификациями преобразо-
ваний, выводится столько пробелов, сколько их явно задано в
форматной строке между спецификациями преобразования. Та-
ким образом, добавляя пробелы между спецификациями преоб-
разования, можно производить форматирование всей выводи-
мой таблицы.
Напомним, что любые символы, которые появляются в фор-
матной строке и не входят в спецификации преобразования, ко-
пируются в выходной поток. Этим обстоятельством можно вос-
пользоваться для вывода явных разделителей между столбцами
таблицы. Например, для этой цели можно использовать символ
'*' или В последнем случае форматная строка в функции
printf() будет выглядеть так: "%-3d | %5d | %-20s | %8.3Лп", и
результат работы программы будет таким:
1 I 10 I лампа | 52.700
2 | 25670 | стол | 240.000
3 | 120 | очень большое кресло | 824.000
Форматный ввод из входного потока. Форматный ввод из
входного потока осуществляется функцией scanf(). Прототип
функции scanf() имеет вид:
346
Программирование на языке Си
int scanf(const char * format,...);
При обращении к функции scanf() возможны две формы за-
дания первого параметра:
int scanf ( форматная строка, список аргументов );
int scanf (указатель_на_форматную_строку,
списокаргументов);
Функция scanf() читает последовательности кодов символов
(байты) из входного потока и интерпретирует их в соответствии
с форматной строкой как целые числа, вещественные числа,
одиночные символы, строки. В первом варианте вызова функ-
ции форматная строка размещается непосредственно в списке
фактических параметров. Во втором варианте вызова предпола-
гается, что первый фактический параметр - это указатель типа
char *, адресующий собственно форматную строку. Форматная
строка в этом случае должна быть определена в программе как
обычная строковая константа или переменная.
После преобразования во внутреннее представление данные
записываются в области памяти, определенные аргументами,
которые следуют за форматной строкой. Каждый аргумент дол-
жен быть указателем на переменную, в которую будет записа-
но очередное значение данных и тип которой соответствует
типу, указанному в спецификации преобразования из формат-
ной строки.
Если аргументов недостаточно для данной форматной стро-
ки, то результат зависит от реализации (от операционной систе-
мы и от системы программирования). Если аргументов больше,
чем требуется в форматной строке, "лишние" аргументы игно-
рируются.
Последовательность кодов символов, которую функция
scanf() читает из входного потока, как правило, состоит из по-
лей (строк), разделенных символами промежутка или обобщен-
ными пробельными символами. Поля просматриваются и вво-
дятся функцией scanf() посимвольно. Ввод поля прекращается,
если встретился пробельный символ или в спецификации
Глава 7. Ввод и вывод
347
преобразования точно указано количество вводимых символов
(см. ниже).
Функция scanf( ) завершает работу, если исчерпана формат-
ная строка. При успешном завершении scanf( ) возвращает ко-
личество преобразованных и введенных полей (точнее,
количество объектов, получивших значения при вводе). Значе-
ние EOF возвращается при возникновении ситуации "конец
файла"; значение -1 - при возникновении ошибки преобразова-
ния данных.
Форматная строка ограничена двойными кавычками и мо-
жет включать: I
• пробельные символы, отслеживающие разделение входно-
го потока на поля. Пробельный символ указывает на то, что
из входного потока надо считывать, но не сохранять все
последовательные пробельные символы вплоть до появле-
ния непробельного символа. Один пробельный символ в
форматной строке соответствует любому количеству по-
следовательных пробельных символов во входном потоке;
• обычные символы, отличные от пробельных и символа '%'.
Обработка обычного символа из форматной строки сводит-
ся к чтению очередного символа из входного потока. Если
прочитанный символ отличается от обрабатываемого сим-
вола форматной строки, функция завершается с ошибкой.
Несовпавший символ и следующие за ним входные симво-
лы остаются непрочитанными;
• спецификации преобразования.
Спецификация преобразования имеет следующую форму:
% * ширина поля модификатор спецификатор
Все символы в спецификации преобразования являются не-
обязательными, за исключением символа '%', с которого она
начинается (он и является признаком спецификации преобразо-
вания), и спецификатора, позволяющего указать ожидаемый
тип элемента во входном потоке (табл. 7.2).
Необязательные элементы спецификации преобразования
имеют следующий смысл:
348
Программирование на языке Си
* - звездочка, следующая за символом процента, запрещает
запись значения, прочитанного из входного потока по
адресу, задаваемому аргументом. Последовательность
кодов из входного потока прочитывается функцией
scanfiQ, но не преобразуется и не записывается в пере-
менную, определенную очередным аргументом.
Ширинаполя - положительное десятичное целое, опреде-
ляющее максимальное число символов, которое может
быть прочитано из входного потока. Фактически может
быть прочитано меньше символов, если встретится про-
бельный символ или символ, который не может быть
преобразован по заданной спецификации.
Модификатор - позволяет задать длину переменной, в кото-
рую предполагается поместить вводимое значение. Мо-
дификатор может принимать следующие значения:
L - означает, что соответствующий спецификации пре-
образования аргумент должен указывать на объект
типа long double;
1 - означает, что аргумент должен быть указателем на
переменную типа long, unsigned long или double;
h - означает, что аргумент должен быть указателем на
тип short.
Приведем примеры ввода данных из входного потока с по-
мощью функции scanf().
Предположим, что необходимо ввести со стандартного ввода
следующие данные: десятичное число, одиночный символ и
строку. Пусть во входном потоке присутствует дополнительная
информация, необходимая для пояснения или идентификации
вводимых данных. Например, вводимые данные могут иметь
такой формат:
code: цифра строка! символ строка!
Набранные жирным шрифтом элементы (цифра, символ и
строка!) должны быть введены в программу, а элементы, на-
бранные курсивом, будут использоваться для контроля (code:) и
комментария (строка!).
Глава 7. Ввод и вывод
349
Таблица 7.2
Спецификаторы форматной строки для функции форматного ввода
Спе- цифи- катор Ожидаемый тип вводимых данных Тип аргумента
d Десятичное целое int *
о Восьмеричное целое int *
X Шестнадцатеричное целое int *
i Десятичное, восьмеричное или шестнадцате- ричное целое int *
и Десятичное целое без знака unsigned int *
с, f, g Вещественное значение вида: [+[-]dddd [E|e[+|-]dd], состоящее из необяза- тельного знака (+ или -), последовательности из одной или более десятичных цифр, возмож- но, содержащих десятичную точку, и необяза- тельного порядка (признак "е" или "Е", за которым следует целое значение, возможно, со знаком). (Для ввода значений переменных типа double используются спецификаторы "%1е", "%lf, "%lg". Для ввода значений переменных типа long double используются спецификато- ры "%Le", "%Lf, "%Lg".) float *
С Очередной читаемый символ должен всегда восприниматься как значимый символ. Про- пуск начальных пробельных символов в этом' случае подавляется. (Для ввода ближайшего, отличного от пробельного, символа необходи- мо использовать спецификацию "%ls".) char *
S Строка символов, ограниченная справа и слева пробельными символами. Для чтения строк, не ограниченных пробельными символами, вме- сто спецификатора s следует использовать на- бор символов в квадратных скобках. Символы из входного потока читаются до первого сим- вола, отличного от символов в квадратных скобках. Если же первым символом в квадрат- ных скобках задан символ ,Л1, то символы из входного потока читаются до первого символа из квадратных скобок. Указатель char * на массив симво- лов, достаточный для размещения входной строки, плюс завершаю- щий символ кон- ца строки ('\0'), который добавля- ется автоматиче- ски
350
Программирование на языке Си
Контроль заключается в том, что во входном потоке должна
присутствовать именно строка "code:" (без кавычек). Строка
строка1 используется для комментирования вводимых данных,
может иметь произвольную длину и пропускается при вводе.
Отметим, что строка 1 и строка2 не должны содержать внутри
себя пробелов. Текст программы приводится ниже:
#inciude <stdio.h>
int main()
{
int i ;
int ret; /* Код возврата функции scanf() */
char c, s[80];
ret=scanf("code: %d %*s %c %s", &i, &c, s);
printf("\n i=%d c=%c s=%s", i, c, s) ;
printf("\n \t ret = %d\n", ret);
return 0;
}
Рассмотрим форматную строку функции scanf():
"code: %d %*s %c %s"
Строка "code:" присутствует во входном потоке для контроля
вводимых данных и поэтому указана в форматной строке. Спе-
цификации преобразования задают следующие действия:
%d - ввод десятичного целого;
%*s - пропуск строки {строка! в приведенной выше форме
ввода);
%с - ввод одиночного символа; -
%s - ввод строки.
Приведем результаты работы программы для трех различных
наборов входных данных.
1. Последовательность символов исходных данных:
code: 5 поле2 D asd
Результат выполнения программы:
i=5 c=D s=asd
ret=3
Глава 7. Ввод и вывод
351
Значением переменной ret является код возврата функции
scanf(). Число 3 говорит о том, что функция scanf() ввела
данные без ошибки и было обработано 3 входных поля
(строки "code:" и "поле2" пропускаются при вводе).
2. Последовательность символов исходных данных:
code: 5 D asd
Результат выполнения программы:
i=5 с=а s=sd
ret=3
Обратите внимание на то, что во входных данных пропу-
щена строка перед символом D, использующаяся как ком-
ментарий. В результате символ D из входного потока был
(в соответствии с форматной строкой) пропущен, а из
строки "asd" в соответствии с требованием спецификации
преобразования %с был введен символ 'а' в переменную с.
Остаток строки "^sd" (sd) был введен в массив символов s.
Код возврата (ret=3) функции scanf() говорит о том, что
функция завершила свою работу без ошибок и обработала
3 поля.
3. Последовательность символов исходных данных:
cod: 5 поле2 D asd
Результат выполнения программы:
i=40 с= s= )
ret=0
Вместо предусмотренной в форматной строке последова-
тельности символов в данных входного потока допущена ошиб-
ка (набрано слово cod: вместо code:). Функция scanf()
завершается аварийно (код возврата равен 0). Функция printf()
в качестве результата напечатала случайные значения перемен-
ных i, с и s ("мусор").
Необходимо иметь в виду, что функция scanf(), обнаружив
какую-либо ошибку при преобразовании данных входного по-
тока, завершает свою работу, а необработанные данные остают-
352
Программирование на языке Си
ся во входном потоке. Если функция scanf() применяется для
организации диалога с пользователем, то, будучи активизирова-
на повторно, она дочитает из входного потока "остатки" преды-
дущей порции данных, а не начнет анализ новой порции,
введенной пользователем.
Предположим, что программа запрашивает у пользователя
номер дома, в котором он живет. Программа обрабатывает код
возврата функции scanf() в предположении, что во входных
данных присутствует одно поле.
#include <stdio.h>
int main ()
{
int number;
printf("Введите номер дома: ");
while (scanf("%d", &number) •= 1)
printf("Ошибка. Введите номер дома: ");
printf("Номер вашего дома %d\n", number);
return 0;
}
При правильном вводе данных (введено целое десятичное
число) результат будет следующий:
Введите номер дома: 25
Номер вашего дома 25
Предположим, что пользователь ошибся и ввел, например,
следующую последовательность символов "@%". (Эти символы
будут введены, если нажаты клавиши '2' и '5', но на верхнем ре-
гистре, т.е. одновременно была нажата клавиша <Shift>.) В этом
случае получится следующий результат:
Введите номер дома: 6%
Ошибка. Введите номер дома:
Ошибка. Введите номер дома:
Ошибочный символ @ прерывает работу функции scanf( ),
но сам остается во входном потоке, и вновь делается попытка
его преобразования при повторном вызове функции в теле цик-
ла while. Однако эта и последующие попытки ввода оказывают-
Глава 7. Ввод и вывод
353
ся безуспешными, и программа переходит к выполнению беско-
нечного цикла.' Необходимо до предоставления пользователю
новой попытки ввода номера дома убрать ненужные символы из
входного потока. Это предусмотрено в следующем варианте той
же программы:
#include <stdio.h>
int main()
{
int. number;
printf("Введите номер дома: ");
while (scanf("%d", Snumber) •= 1)
{
/* Ошибка. Очистить входной поток: */
while (getchar() •= J\n')
. £
printf("Ошибка. Введите номер дома: ");
}
printf("Номер вашего Дома %d\n", number);
return 0;
}
Теперь при неправильном вводе данных результат будет та-
ким:
Введите номер дома: @% .
Ошибка. Введите номер дома: 25
Номер вашего дома 25
7.1.3. Работа с файлами на диске
Аналогичным образом (так же как это делается при работе со
стандартными потоками ввода-вывода stdin и stdout) можно
осуществлять работу с файлами на диске. Для этой цели в биб-
лиотеку языка Си включены следующие функции:
fgetc(), getc() - ввод (чтение) одного символа из файла;
fputc(), putc() - запись одного символа в файл;
fprintf() - форматированный вывод в файл;
fscanf() - форматированный ввод (чтение) из файла;
23"3124
354
Программирование на языке Си
fgets() - ввод (чтение) строки из файла;
fputs() - запись строки в файл.
Различие между функциями fgetc(), getc() и fputc(), putc()
здесь не рассматривается, и поэтому в примерах мы будем ис-
пользовать только одну из них.
Двоичный (бинарный) режим обмена с файлами. Двоич-
ный режим обмена организуется с помощью функций getc( ) и
putc(), обращение к которым имеет следующий формат:
с= getc(fp);
putc(c, fp);
где fp - указатель на поток;
с - переменная типа int для приема очередного символа
из файла или для записи ее значения в файл.
Прототипы функции:
int getc ( FILE *stream );
int putc ( int c, FILE *stream );
В качестве примера использования функций getc( ) и putc()
рассмотрим программы ввода данных в файл с клавиатуры и
программу вывода их на экран дисплея из файла.
Программа ввода читает символы с клавиатуры и записывает
их в файл. Пусть признаком завершения ввода служит посту-
пивший от клавиатуры символ Имя файла запрашивается у
пользователя. Если при вводе последовательности символов
была нажата клавиша <Enter>, служащая разделителем строк
при вводе с клавиатуры, то в файл записываются управляющие
коды "Возврат каретки" (CR - значение 13) и "Перевод строки"
(LF - значение 10). Код CR в дальнейшем при выводе вызывает
перевод маркера (курсора) в начало строки экрана дисплея. Код
LF служит для перевода маркера на новую строку дисплея. Зна-
чения этих кодов в тексте программы обозначены соответствен-
но идентификаторами CR и LF, т.е. CR и LF - именованные
константы. Запись управляющих кодов CR и LF в файл позволя-
ет при последующем выводе файла на экран отделить строки
друг от друга.
Глава 7. Ввод и вывод
355
В приводимых ниже программах используются уже рассмот-
ренные выше функции getchar(), putchar() для посимвольного
обмена со стандартными потоками stdin, stdout.
/* Программа ввода символов */
tinclude <stdio.h>
int main()
{
FILE *fp; /* Указатель на поток */
char с;
/* Восьмеричный код "Возврат каретки": */
const char CR='\015';
/* Восьмеричный код "Перевод строки": */
const char LF = ’\012’;
char fname[20]; /* Массив для имени файла */
/* Запрос имени файла: */
puts("введите имя файла: \п");
gets(fname);
/* Открыть файл для записи: */
if ((fp = fopen(fname,"w")) = NULL)
{
perror(fname);
return 1;
/* Цикл ввода и записи в файл символов: */
while ((с = getchar()) •= '#')
{
if (с == '\п')
) (
putc(CR, fp);
putc(LF, fp) ;
else putc(c, fp);
}
/* Цикл ввода завершен; закрыть файл: */
fclose(fp);
return 0;
)
Следующая программа читает поток символов из ранее соз-
данного файла и выводит его на экран дисплея:
23‘
356
Программирование на языке Си
/* Программа вывода символьного файла
на экран дисплея */
♦include <stdio.h>
int main ()
{
FILE *fp; /* Указатель на поток */
char с;
char fname[20]; /* Массив для имени файла */
/* Запрос имени файла: */
puts("введите имя файла: \п ");
gets(fname);
/* Открыть файл для чтения: */
if ((fp = fopen(fname,"г")) = = NULL)
{
perror(fname);
return 1;
}
/* Цикл чтения из файла и вывода символов
на экран: */
while ((с = getc(fp)) •= EOF)
putchar(c);
fclose(fp); /* Закрыть файл */
return 0;
}
Программу чтения символов из файла можно усовершенст-
вовать, добавив возможность вывода информации на экран пор-
циями (кадрами):
/★ Усовершенствованная программа вывода
символьного файла на экран дисплея по кадрам */
♦include <stdio.h>
int main ()
{
FILE *fp; /* Указатель на поток) */
char с;
/★ Восьмеричный код "Перевод строки": */
const char LF='\012';
int MAX=10; /* Размер кадра */
int nline; /* Счетчик строк */
char fname[10]; /* Массив для имени файла */
Глава 7. Ввод и вывод
357
/* Запрос имени файла: */
puts("введите имя файла \п");
gets(fname);
/* Открыть файл для чтения: */
if ((fp = fopen(fname,"г")) = = NULL)
{
perror(fname);
return 1;
)
while (1)
{ /* Цикл вывода на экран */
nline = 1;
while (nline<MAX) /* Цикл вывода кадра */
(
с = getc(fp);
if (с == EOF)
{
fclose(fp);
return 0;
}
if (c = LF) nline++;
putchar(c);
} /* Конец цикла вывода кадра*/
getchar(); /* Задержка вывода до
нажатия любой клавиши */
) /♦ Конец цикла вывода */
} /* Конец программы */
В этой программе после вывода очередного кадра из МАХ
строк для перехода к следующему кадру необходимо нажать
любую клавишу.
Используя двоичный обмен с файлами, можно сохранять на
диске информацию, которую нельзя непосредственно вывести
на экран дисплея (целые и вещественные числа во внутреннем
представлении).
Необходимые примеры и разъяснения приводятся в главе 8
при описании программы обслуживания базы данных о сотруд-
никах предприятия. Функции save() и load( ) из этого примера
(см. §8.2) позволяют сохранить во внешней памяти и загрузить
из внешней памяти базу данных о сотрудниках предприятия.
358
Программирование на языке Си
Строковый обмен с файлами. Для работы с текстовыми
файлами, кроме перечисленных выше, удобно использовать
функции fgets() и fputs(). Прототипы этих функций в файле
stdio.h имеют следующий вид:
int fputs(const char *s, FILE *stream);
char * fgets(char *s, int n, FILE *stream);
Функция fputs() записывает ограниченную символом '\0'
строку (на которую указывает s) в файл, определенный указате-
лем stream на поток, и возвращает неотрицательное целое. При
ошибках функция возвращает EOF. Символ '\0' в файл не пере-
носится, и символ '\п' не записывается в конце строки вместо '\0'.,
Функция fgets() читает из определенного указателем stream
файла не более (п-1) символов и записывает их в строку, на ко-
торую указывает s. Функция прекращает чтение, как только про-
чтет (п-1) символов или встретит символ новой строки '\п', ко-
торый переносится в строку s. Дополнительно в конец каждой
строки записывается признак окончания строки '\0'. В случае
успешного завершения функция возвращает указатель s. При
ошибке или при достижении конца файла, при условии, что из
файла не прочитан ни один символ, возвращается значение
NULL. В этом случае содержимое массива, который адресуется
указателем s, остается без изменений. Напомним, что в отличие
от fgets() функция gets() отбрасывает символ '\п'.
Проиллюстрируем возможности указанных функций на про-
грамме, которая переписывает текст из одного файла в другой.
На этом же примере еще раз проиллюстрируем особенность
языка Си - возможность передачи информации в выполняемую
программу из командной строки (см. §5.8).
В стандарте языка Си определено, что любая программа на
языке Си при запуске на выполнение получает от операционной
системы информацию в виде значений двух аргументов - argc
(сокращение от argument count - счетчик аргументов) и argv
(сокращение от argument vector). Первый из них определяет ко-
личество строк, передаваемых в виде массива указателей argv.
По принятому соглашению argv[0] это всегда указатель на стро-
Глава 7. Ввод и вывод
359
ку, содержащую полное имя файла с выполняемой программой.
Остальные элементы массива argv[l],...,argv[argc-l] содержат
ссылки на параметры, записанные через пробелы в командной
строке после имени программы. (Третий параметр char * envp[ ]
мы уже рассмотрели в §5.8, но он используется весьма редко.)
Предположим, что имя выполняемой программы copyfile.exe
и мы хотим с ее помощью переписать содержимое файла fl .dat
в файл f2.txt. Вызов программы из командной строки имеет вид:
>copyfile.exe fl.dat f2.txt
Текст программы может быть таким:
#include <stdio.h>
main(int argc, char *argv[ ])
t
char cc[256];/* Массив для обмена с файлами */
FILE *fl, *f2; /* Указатели на потоки */
if (argc •= 3) /* Проверка командной строки */
{
printf("\п Формат вызова программы: ");
printf("\n copyfile.ехе"
printf("\п файл-источник файл-приемник");
return 1;
1
if ((fl = fopen(argv[l], "г")) == NULL)
/* Открытие входного файла */
{
perror(argv[1]);
return 1;
}
if ((f2 = fopen (argv [2] , "w")) == NULL)
/* Открытие выходного файла */
{
perror(argv[2]);
return 1;
}
while (fgets(cc, 256, fl) •= NULL)
fputs(cc, f2);
fclose(fl);
fclose(f2);
return 0;
1
360
Программирование на языке Си
Обратите внимание, что значение argc явно не задается, а оп-
ределяется автоматически. Так как argv[0] определено всегда, то
значение argc не может быть меньше 1. При отсутствии в ко-
мандной строке двух аргументов (имен файлов ввода-вывода)
значение argc оказывается не равным трем, и поэтому на экран
выводится поясняющее сообщение:
Формат вызова программы:
copyfile.exe ' файл-источник файл-приемник
Если имя входного файла указано неудачно или нет места на
диске для создания выходного файла, то выдаются соответст-
вующие сообщения:
Ошибка при открытии файла fl.dat
или
Ошибка при открытии файла f2.txt
Режим форматного, обмена с файлами. В некоторых случа-
ях информацию удобно записывать в файл в виде, пригодном
для непосредственного (без преобразования) отображения на
экран дисплея, т.е. в символьном виде. Например, для сохране-
ния результатов работы программы, чтобы затем распечатать их
на бумагу (получить "твердую" копию) или когда необходимо
провести трассировку программы - вывести значения некото-
рых переменных во время выполнения программы для их по-
следующего анализа. В этом случае можно воспользоваться
функциями форматного ввода (вывода) в файл fprintf() и
fscanf(), которые имеют следующие прототипы:
int fprintf (указатель на поток, форматная-строка,
список-переменных);
int fscanf (указательнапоток, форматная строка,
список адресов переменных)',
Как и в функциях printf() и scanf(), форматная строка мо-
жет быть определена вне вызова функции, а в качестве фактиче-
ского параметра в этом случае будет указатель на нее.
Глава 7. Ввод и вывод
361
От рассмотренных выше функций prints ), scanf() для фор-
матного обмена с дисплеем и клавиатурой функции fprintf() и
fscanf() отличаются лишь тем, что в качестве первого парамет-
ра в них необходимо задавать указатель на поток, с которым
производится обмен. В качестве примера приведем программу,
создающую файл int.dat и записывающую в него символьные
изображения чисел от 1 до 10 и их квадратов [9]:
#include <stdio.h>
int main()
{
FILE *fp; /* Указатель на поток */
int п;
if ((fp = fopen("int.dat","w")) = NULL)
(
perror("int.dat");
return 1;
} . -
for (n=l; n<ll; n++)
fprintf(fp, "%d %d\n", n, n*n);
fclose(fp);
return 0;
1
В результате работы этой программы в файле int.dat форми-
руется точно такая же "картинка", как и в том случае, если бы
мы воспользовались вместо функции fprintf() функцией
printf() для вывода результатов непосредственно на экран дис-
плея. В этом легко убедиться, воспользовавшись соответствую-
щей обслуживающей программой операционной системы для
вывода файла int.dat на экран дисплея. Несложно и самим напи-
сать такую программу, используя для форматного чтения дан-
ных из файла функцию fscanf():
#include <stdio.h>
int main ()
{
FILE *fp; /* Указатель на .поток */
int n, nn, i;
if ((fp = fopen("int.dat","r")) == NULL)
{
362
Программирование на языке Си
perrorCint.dat") ;
return 1;
}
for (i=l; i<ll; i++)
{
fscanf(fp, "%d %d", &n, Snn) ;
printf(" %d %d \n",n, nn);
}
fclose(fp);
return 0;
}
Позиционирование в потоке. В начале главы были рас-
смотрены посимвольный, построчный й форматный обмены с
файлами, организованными в виде потока байтов. Эти средства
позволяли записать в файл данные и читать из него информа-
цию только последовательно.
Операция чтения (или записи) для потока всегда производит-
ся, начиная с текущей позиции в потоке. Начальная позиция
чтения/записи в потоке устанавливается при открытии потока и
может соответствовать начальному или конечному байту потока
в зависимости от режима открытия потока. При открытии пото-
ка в режимах "г" и "w" указатель текущей позиции чте-
ния/записи в потоке устанавливается на начальный байт потока,
а при открытии в режиме "а" - в конец файла (за конечным бай-
том). При выполнении каждой операции ввода-вывода указатель
текущей позиции в потоке перемещается на новую текущую
позицию в соответствии с числом прочитанных (записанных)
байтов.
Рассмотрим средства позиционирования в потоке, позво-
ляющие перемещать указатель (индикатор) текущей позиции в
потоке на нужный байт. Эти средства дают возможность рабо-
тать с файлом на диске, как с обычным массивом, осуществляя
доступ к содержимому файла в произвольном порядке.
В библиотеку языка Си включена функция fseek() для пере-
мещения (установки) указателя текущей позиции в потоке на
нужный байт потока (файла). Она имеет следующий прототип:
int fseek (указатель на поток, смещение, начало отсчета)’,
Глава 7. Ввод и вывод
363
Смещение задается переменной или выражением типа long и
может быть отрицательным, т.е. возможно перемещение по
файлу в прямом и обратном направлениях. Начало отсчета зада-
ется одной из предопределенных констант, размещенных в за-
головочном файле stdio.h:
SEEK_SET (имеет значение 0) - начало файла;
SEEK CUR (имеетзначение 1)-текущая позиция;
SEEK_END (имеет значение 2) - конец файла.
Здесь следует напомнить некоторые особенности данных ти-
па long. Этот тип определяется для целочисленных констант и
переменных, которым в памяти должно быть выделено больше
места, чем данным типа int. Обычно переменной типа long вы-
деляется 4 байта, чем и определен диапазон ее значений. Опи-
сание данных типа long:
long А, р, Z[16];
Константа типа long записывается в виде последовательно-
сти десятичных цифр, вслед за которыми добавляется раздели-
тель L или 1. Примеры констант типа long:
01 0L 10L 688L 331
В текстах программ лучше использовать L, чтобы не путать 1
с цифрой 1.
Функция fseek() возвращает 0, если перемещение в потоке
(файле) выполнено успешно, в противном случае возвращается
ненулевое значение.
Приведем примеры использования функции fseek(). Пере-
мещение к началу потока (файла) из произвольной позиции:
fseek(fp, 0L, SEEK_SET) ;
Перемещение к концу потока (файла) из произвольной пози-
ции:
fseek(fp, 0L, SEEK_END);
В обоих примерах смещение задано явно в виде нулевой де-
сятичной константы 0L типа long.
364
Программирование на языке Си
При использовании сложных типов данных (таких, как
структура) можно перемещаться в потоке (файле) на то количе-
ство байтов, которое занимает этот тип данных. Пусть, напри-
мер, определена структура:
struct str
} st;
Тогда при следующем обращении к функции fseek() указа-
тель текущей позиции в потоке будет перемещен на одну струк-
туру назад относительно текущей позиции:
fseek(fp, -(long)sizeof(st), SEEK_CUR);
Для иллюстрации работы с файлом в режиме произвольного
доступа рассмотрим пример небольшого трехъязычного слова-
ря, содержащего названия цифр от 1 до 9 на английском, немец-
ком и французском языках. Для обслуживания словаря необ-
ходимы 2 программы: программа загрузки словаря в файл на
диске и программа поиска слова в словаре (в ней используется
функция fseek()).
"База данных" словаря организована в файле vac.dat. Функ-
ция загрузки запрашивает названия для цифр от ! до 9. Назва-
ния конкретной цифры (в предположении, что каждое название
не превышает 9 букв) на всех трех языках записываются в од-
ной строке через пробелы. Сформированная строка по нажатию
клавиши <Enter> прочитывается в массив символов buff ]. Текст
программы:
#include <stdio.h>
int main ()
(
int i, k;
int n;
char buf[30]; /* Буфер */
char * c;
int *pti;
FILE *fp; /* Указатель на поток */
/* Открыть файл для записи */
Глава 7. Ввод и вывод
365
if ((fp = fopen("vac.dat","w")) == NULL)
{
perror("vac.dat");
return 1;
}
for (i=l; i<=9; i++)
{ /* Очистить буфер: */
for (k=0; k<30; k++)
buf[k] = ' ’;
/* Запрос названий цифр */
n = i;
pti = &n;
printf("\n Введите названия цифры %d:\n", i) ;
scanf("%s %s %s", buf, buf+10, buf+20);
/* Запись в файл цифры */
с = (char *)pti;
for (k=0; к <2; k++)
putc(*c++, fp);
/* Запись в файл названий цифр */
. с — buf;
for (к=0; к<30; к++)
putc(*c++, fp);
}
fclose(fp);
return 0;
}
Введенные данные (представление цифры в формате целого
числа и названия цифр на трех языках) побайтно выводятся в
файл vac.dat, образуя в нем "записи", структура которых показа-
на на рис. 7.2.
2 байта 10 байт 10 байт 10 байт
Цифра
Названия цифр на разных языках
Рис. 7.2. Состав записи "Цифра1
366
Программирование на языке Си
Следующая программа перевода (trans) запрашивает сначала
язык, на котором нужно выводить названия цифр, а затем в цик-
ле запрашиваются цифры. Язык идентифицируется первой бук-
вой своего русского наименования: 'а' или 'А' - для английского;
'н' или 'Н' - для немецкого; 'ф' или 'Ф' - для французского. При-
знаком завершения программы служит ввод цифры 0. Текст
программы trans:
/* Программа перевода trans.с */
#include <stdio.h>
int main ()
{
int i, k;
char * c;
long pos; /* Смещение в файле */
char buf[30];
char In;•
FILE *fp; /* Указатель на поток */
int lang; /* Индикатор "язык" */
/* Открыть файл: */
if ((fp = fopen("vac.dat","г")) — NULL)
{
perror("vac.dat");
return 1;
)
/* Запросить язык: */
lang = -1;
while (lang == -1)
{
puts("\n Введите первую букву названия"
" языка: (а,н,ф)");
scanf ("%с"?, &1п) ;
if ((In =='а')I I (In = 'A')) lang = 0;
else
if ((In =='н')11(1п =='H')) lang = 1;
else
if ((In—’ф’) I I (In ='♦’)) lang = 2 ;
)
while (1) /* Цикл перевода */
{
с = buf;
Глава 7. Ввод и вывод
367
puts("введите цифру (0 - для завершения):");
scanf("%d", &к);
if (к = = 0)
{
fclose(fp);
return 0;
}
/* Вычислить смещение */
pos = (к-1)*32+2+lang*10;
fseek(fp, pos, SEEK_SET);
/* Выбрать перевод */
for (i=0; i<=9; i++)
*c++=getc(fp);
c++;
*c = 1\0';
printf("%d->%s\n", k, buf);
}
fclose(fp);
return 0;
}
При вычислении позиции (pos) в файле, с которой начинает-
ся строка перевода, участвуют следующие составляющие:
к-1 - выбирает подстроку (длиной 32 байта), в которой со-
держится перевод;
2 - учитывает длину поля цифры (2 байта);
lang* 10 - задает смещение до требуемого значения цифры в
подстроке перевода.
На рис. 7.3 показаны составляющие смещения для искомого
поля с переводом на немецкий язык.
pos
2 байта 10 байт 10 байт 10 байт
(k-l)*32
Рис. 7.3. Составляющие смещения для записей в файле словаря
368
Программирование на языке Си
Предлагаем самостоятельно разработать функцию поиска в
файле заданной подстроки и на ее основе написать программу
перевода названий цифр с одного языка на другой. В табл. 7.3
приводятся названия цифр от ! до 9 на трех языках.
Таблица 7.3
Трехъязычный словарь "Цифры"
№ Английский язык Немецкий язык Французский язык
1 ONE EINS UN
2 TWO ZWEI DEUX
3 THREE DREI TROIS
4 FOUR VIER QUATRE
5 FIVE FUNF CINQ
6 SIX SECHS SIX
7 SEVEN SIEBEN SEPT
8 EIGHT ACHT HUIT
9 . NINE NEUN NEUF
Кроме рассмотренной функции fseek(), в библиотеке функ-
ций языка Си находятся следующие функции для работы с ука-
зателями текущей позиции в потоке:
long ftell(FILE *) - получить значение указателя текущей по-
зиции в потоке;
void rewind(FILE *) - установить указатель текущей позиции
в потоке на начало потока.
Необходимо иметь в виду, что недопустимо использовать
функции работы с указателем текущей позиции в потоке для
потока, связанного не с файлом, а с устройством. Поэтому при-
менение описанных выше функций с любым из стандартных
потоков приводит к неопределенным результатам.
Глава 7. Ввод и вывод
369
7.2. Ввод-вывод нижнего уровня
Ввод-вывод, ориентированный на поток, обычно применяет-
ся для выполнения достаточно стандартных операций ввода-
вывода. Применение рассмотренных выше функций обмена с
потоками гарантирует успешность переноса программы (в от-
ношении ввода-вывода) в различные операционные системы.
Функции ввода-вывода более низкого уровня позволяют
пользоваться средствами ввода-вывода операционной системы
непосредственно. При этом не выполняются буферизация и фор-
матирование данных. Программы, использующие низкоуровне-
вый ввод-вывод, переносимы в рамках некоторых систем про-
граммирования Си, в частности, относящихся к UNIX.
Учитывая близость функций низкоуровневого- ввода-вывода к
средствам ввода-вывода операционной системы, можно реко-
мендовать их применение для разработки собственной подсис-
темы ввода-вывода, например ориентированной на работу со
сложными структурами данных (списки, деревья, сложные за-
писи и т.п.).
При низкоуровневом открытии файла с ним связывается не
указатель файла (потока), а дескриптор (handle) файла. Деск-
риптор является целым значением, характеризующим размеще-
ние информации об открытии файла во внутренних таблицах
операционной системы. Дескриптор файла используется при
последующих операциях с файлом.
В библиотеку языка Си включены следующие основные
функции ввода-вывода нижнего уровня:
• open( )/close() - открыть / закрыть файл;
• creat( ) - создать файл;
• read( )/write() - читать / писать данные;
• sopen() - открыть файл в режиме разделения, т.е. для од-
новременного доступа со стороны нескольких процессов
(работающих программ);
• eof() - проверить достижение конца файла;
• lseek( ) - изменить текущую позицию в файле;
• tell() - получить значение текущей позиции в файле.
24-3124
370
Программирование на языке Си
Для работы с функциями нижнего уровня в программу долж-
ны включаться соответствующие заголовочные файлы. Имена
этих файлов могут быть различными в разных операционных
системах. Поэтому перед написанием программ, использующих
функции ввода-вывода нижнего уровня, или при переносе про-
грамм в другую операционную систему необходимо ознако-
миться с документацией по библиотеке Си для данной опе-
рационной системы.
Функции нижнего уровня в отличие от функций для работы с
потоком не требуют включения в программу заголовочного
файла stdio.h. Однако, этот файл содержит определения ряда
констант (например, признак конца файла EOF), которые могут
оказаться полезными. В случае применения этих констант файл
stdio.h должен быть включен в программу.
7.2.1. Открытие/закрытие файла
До выполнения операций ввода-вывода в файл (из файла) на
низком уровне необходимо открыть или создать файл одной из
следующих функций: open(), sopen() или creat().
Функция sopen() используется в том случае, ко(да необхо-
димо дать возможность одновременного доступа к файлу для
нескольких выполняющихся программ. Разумеется, речь идет о
доступе к файлу в режиме чтения. Обычно файл блокируется
для доступа со стороны других выполняющихся программ, и
именно функция sopen() необходима для разрешения одновре-
менного доступа.
При открытии файла в программу возвращается дескриптор
файла, значение которого является целочисленным. В отличие
от дескриптора указатель на поток есть указатель на структуру
типа FILE, определенного в заголовочном файле stdio.h.
Формат вызова функции ореп(), в результате выполнения
которой приобретает значение дескриптор файла:
fd = open ( имя файла, флаги, права доступа );
Глава 7. Ввод и вывод
•371
В программе дескриптор файла fd должен быть определен
как int fd. Параметр имя файла является указателем на массив
символов, содержащий имя файла.
Второй параметр флаги определяет режим открытия файла,
который является выражением, сформированным (с помощью Т
- побитовой операции ИЛИ) из одной или более предопреде-
ленных констант, размещенных в заголовочном файле fcntl.hrB
некоторых реализациях UNIX эти константы находятся в файле
sys/file.h.
Примечание. Обратите внимание иа то, что в UNIX при об-
разовании полного имени файла применяется символ 'У
(прямой слэш), а не обратный слэш ('\'), как в MS-DOS.
Приведем в алфавитном порядке список констант, задающих
режим открытия файла, с кратким описанием их назначения:
O_APPEND - открыть файл для добавления (для записи в
конец файла);
O_BINARY - открыть файл в бинарном режиме (см.
§7.1.1);
O_CREAT - создать и открыть новый файл;
O_EXCL - если он указан вместе с флагом O_CREAT и
файл уже существует, то функция открытия
файла завершается с ошибкой. Этот флаг по-
зволяет избежать непреднамеренного унич-
тожения уже существующего файла;
O_RDONLY - открыть файл только для чтения;
O_RDWR - открыть файл и для чтения, и для записи;
О_ТЕХТ - открыть файл в текстовом режиме (см.
§7.1.1);
O_TRUNC - открыть существующий файл и стереть его
содержимое (подготовить для записи новой
информации).
Обратите внимание на то, что режим открытия файла должен
быть задан обязательно, так как его значение по умолчанию не
устанавливается.
24*
372
Программирование на языке Си
Третий параметр - права доступа должен применяться толь-
ко в режиме открытия файла O_CREAT, т.е. только при созда-
нии нового файла.
В операционных системах MS-DOS и Windows для задания
параметра права доступа используются следующие предопре-
деленные константы:
S_IWRITE - разрешить запись в файл;
S_IREAD - разрешить чтение из файла;
S_IREAD|S_IWRITE - разрешить и чтение, и запись (совпа-
дает с SJWRITE).
Перечисленные константы размещены в заголовочном файле
stat.h, находящемся в каталоге sys системы программирования
Си. Обычно его подключение осуществляется директивой
#include <sys\stat.h>.
Если параметр права_доступа не указан, то устанавливается
разрешение только на чтение из файла. Чаще всего в операци-
онных системах MS-DOS и Windows этот параметр не исполь-
зуется.
В UNIX в силу того, то она является многопользовательской,
система защиты файлов более развита. Права доступа к файлам
устанавливаются для трех категорий пользователей:
• владелец файла;
• участник группы пользователей;
• прочие пользователи.
Права доступа к конкретному файлу устанавливаются вла-
дельцем файла специальными командами. Права доступа ото-
бражаются при просмотре оглавления каталога командой Is -1 в
виде символьной строки, которая формируется по следующему
правилу: для каждой группы пользователей в строке прав дос-
тупа выделяется 3 символа, каждый из которых может прини-
мать следующие значения:,
г - разрешено чтение из файла;
w - разрешена запись в файл;
х - разрешено выполнение файла (для файлов, хранящих
исполняемую программу).
Глава 7. Ввод и вывод
373
Символы г, w, х задаются строго на своих местах в указан-
ном порядке (rwx). Если какой-либо из типов доступа к файлу
запрещен, на месте соответствующего символа записывается
символ (минус). Таким образом, если для владельца файла
разрешены все виды доступа к файлу (rwx), для участника
группы пользователей - только чтение и выполнение (r-х), а для
прочих пользователей - только выполнение (--х), то строка прав
доступа будет выглядеть так:
rwxr-x—X
От этой строки символов легко перейти к собственно пара-
метру правадоступа, являющемуся целым числом. Если на
соответствующем месте в строке указан символ, отличный от
то записывают 'Г, иначе - записывают 'О'. Получившееся двоич-
ное число (111101001) переводят в восьмеричное, записав в ви-
де восьмеричной цифры каждую группу из трех двоичных цифр,
начиная с самой правой группы: 0751. Это число и следует ука-
зать в качестве параметра права доступа в функции ореп().
Приведем несколько примеров открытия файла.
1. Открыть файл для чтения:
fd = open("t.txt", O_RDONLY);
2. Открыть существующий файл для записи новых данных:
fd = open("new.txt",
O_WRONLY|O_CREAT|O_TRUNC,0600);
Параметр права доступа, заданный восьмеричной константой
0600 (для UNIX), в символьном изображении имеет вид rw-,
т.е. для владельца файла разрешены чтение и запись, для двух
других категорий пользователей не разрешен ни один из видов
доступа к файлу. Если файл с именем new.txt существует, то
перед записью новых данных он будет усечен до нулевого раз-
мера (очищен). При открытии файла с указанными параметрами
в других ОС параметр права доступа опускается.
3. Открыть файл для добавления:
fd=open("t.txt",
O_WRONLYIO_APPEND|O_CREAT,0600);
374
Программирование на языке Си
4. Открыть файл для чтения и записи:
fd = open("t.txt", O_RDWR);
5. Создать новый файл для записи:
if ((fd = open("tmpfile",
O_WRONLY|O_CREAT| O_EXCL,
0666)) == -1)
puts("tmpfile уже существует\п");
В операционной системе UNIX такая последовательность опе-
раторов открывает новый файл для записи. Если файл не суще-
ствует, то он создается. Иначе функция завершается неудачей.
Флаг O EXCL специально задан для предотвращения непредна-
меренного уничтожения уже существующего файла. Этот флаг
используется совместно с O CREAT. Права доступа (rw-rw-rw-)
разрешают чтение и запись в файл для всех категорий пользова-
телей. В других ОС параметр права доступа должен быть опу-
щен.
Приведем более полный пример создания файла (MS-DOS,
Windows):
#include <stdio.h>
#include <stdlib.h>
#include <io.h>
#include <errno.h>
#include <fcntl.h>
#include <sys\stat.h>
void main( )
<
int fd; /♦ Дескриптор файла ♦/
if ((fd = open("tmpfile",
O_RDWR|O_CREAT|O_EXCL,
S_IREAD|S_IWRITE)) < 0)
(. ’
if (errno == EEXIST)
fprintf(stderr, "файл tempfile"
" уже' существует\п") ;
exit(errno);
}
}
Глава 7. Ввод и вывод
375
Создаваемый файл в соответствии с выбранными флагами
открывается для чтения и записи. Права доступа (rw-) по-
зволяют только владельцу работать с файлом (читать и писать).
Для идентификации ошибок, возникающих при открытии
файла, используется именующее выражение (переменная)
еггпо, определенное в заголовочном файле errno.h. При выпол-
нении функций стандартной библиотеки в область памяти, име-
нуемой еггпо, записываются коды ошибок. Предопределенная в
errno.h константа EEXIST означает, что файл, указанный в
функции ореп( ), уже существует. В этом примере для вывода
сообщения об ошибке применена функция форматного вывода в
файл fprintf(), в которой использован предопределенный деск-
риптор файла stderr стандартного потока для вывода сообще-
ний об ошибках. '
Кроме функции ореп( ), для открытия файла можно исполь-
зовать функцию creat(), упомянутую в начале параграфа.
Функция creat( ) полностью эквивалентна такому вызову функ-
ции ореп():
open (имя файла, O_CREAT|O_TRUNC|O_WRONLY);
Функция creat() создает новый файл и открывает его для за-
писи. Наличие в библиотеке наряду с функцией ореп( ) функции
creat() вызвано требованиями совместимости с ранними вер-
сиями UNIX, имевшими только три основных режима открытия
файла (O RDONLY, O WRONLY, OJRDWR), что вынуждало
использовать для создания нового файла специальную функцию
creat().
Так же как и при использовании потоков, в начале работы
каждой программы автоматически открываются файлы стан-
дартного ввода, стандартного вывода и стандартного вывода
сообщений об ошибках. Эти файлы имеют значения дескрипто-
ров файлов 0, 1 и 2, которые можно использовать при обменах
на нижнем уровне со стандартными файлами.
Необходимо иметь в виду, что в каждой операционной сис-
теме имеется ограничение на количество одновременно откры-
тых в программе файлов. Обычно их число устанавливается от
376
Программирование на языке Си
20 до 40. Во время работы программы, в которой обрабатывает-
ся большое количество файлов, необходимо своевременно за-
крывать ненужные файлы. Для закрытия файла на нижнем
уровне служит функция close(), прототип которой имеет вид:
int close (дескриптор файла)',
Функция close() при успешном завершении возвращает 0. В
случае ошибки возвращается -1.
При завершении программы все открытые файлы автомати-
чески закрываются.
7.2.2. Чтение и запись данных
Ввод-вывод данных на нижнем уровне осуществляется
функциями read() и write( ). Прототипы этих функций имеют
следующий вид:
int read(int fd, char *buffer, unsigned int count);
int write(int fd, char *buffer, unsigned int count);
Обе функции возвращают целое число - количество действи-
тельно прочитанных или записанных байтов,.
Функция read( ) читает количество байтов, заданное третьим
параметром count, из файла, открытого с дескриптором файла
fd, в буфер, определенный указателем buffer. При достижении
конца файла функция read() возвращает значение 0. В случае
возникновения ошибки при чтении из файла функция read()
возвращает значение -1.
Операция чтения, так же как и для потокового ввода-вывода,
начинается с текущей позиции в файле. После завершения опе-
рации чтения текущая позиция будет определять первый непро-
читанный символ.
Если файл открыт в текстовом режиме, то происходят точно
такие же преобразования при вводе последовательности симво-
лов CR и LF в символ '\n* (LF), как и при работе с потоком. Ука-
занное преобразование приводит к тому, что в возвращаемом
Глава 7. Ввод и вывод
377
значении вместо двух символов CR и LF учитывается только
один символ '\n' (LF).
Функция write( ) записывает последовательность байтов, ко-
личество которых задано третьим параметром count, в файл, ''от-
крытый с дескриптором файла fd, из буфера, определенного
указателем buffer. Запись производится с текущей позиции. Ес-
ли файл открыт в текстовом режиме, то количество реально за-
писанных байтов может превышать count за счет преобразова-
ний всех символов '\п' в последовательности символов CR, LF.
Таким образом, count будет содержать только количество сим-
волов, взятых из буфера.
Если при выполнении операции записи возникла ошибка, то
функция write() возвращает значение -1, а глобальная пере-
менная еггпо получает одно из следующих значений, заданных
предопределенными константами в заголовочном файле
errno.h:
EACCES - файл защищен для записи (доступен только для
чтения);
ENOSPC - исчерпано свободное пространство на внешнем
устройстве;
EBADF - недействительный дескриптор файла.
Приведем два примера применения функций низкоуровнево-
го ввода-вывода.
Пример 1.
Копирование последовательности отдельных символов иЬ
стандартного ввода в стандартный вывод:
#include <io.h>
int main( )
{
char c[2];
while ((read(O, c, 1)) > 0)
write(1, c, 1);
return 0;
}
В текст программы включается заголовочный файл io.h, со-
держащий прототипы функций read() и write(). При вызове
378
Программирование на языке Си
этих функций для файлов стандартного ввода и стандартного
вывода используются соответственно значения дескрипторов
стандартных файлов 0 и 1. Прочитанный символ и код клавиши
<Enter>, который служит признаком завершения набора вводи-
мой последовательности символов, записываются в одномерный
массив с[ ] из 2 байтов, откуда они затем функцией write() вы-
водятся на экран дисплея.
Запустив программу на выполнение, можно вводить одиноч-
ные символы с клавиатуры, завершая ввод каждого из них на-
жатием на клавишу <Enter>. Результат работы программы
может выглядеть так:
V
V
w
w
е
е
<Ctrl+C>
Первый символ из пары одинаковых символов (v-v; w-w и
т.д.) - это символ, введенный с клавиатуры и выведенный сис-
темой ввода-вывода на экран (стандартный режим ввода данных
с клавиатуры). Второй символ пары выведен на устройство
стандартного вывода функцией write(). Программа копирова-
ния завершает работу при вводе сигнала прерывания (одновре-
менном нажатии клавиш <Ctrl> и <С>).
Пример 2.
Копирование произвольного файла
Программа получает имена файлов из командной строки при
запуске и позволяет копировать произвольные файлы, (см. ана-
лог этой программы в §7.1.3).
#include <stdio.h>
#include <fcntl.h>
#include <io.h>
int main(int argc, char *argv[ ])
<
int fdin, fdout; /♦ Дескрипторы файлов ♦/;
Глава 7. Ввод и вывод 379
int п; /♦ Количество прочитанных байтов */
char buff[BUFSIZ];
if ( argc >= 3)
{
printf("Формат вызова программы:");
printf("\n %s файл_источник файл_приемник",
argv[O]);
return 1;
1
if ((fdin = open(argv[l], O_RDONLY)) == -1)
{
perror(argv[1]);
return 1;
}
if ((fclout = open(argv [2] ,
O_WRONLY|O_CREAT|O_TRUNC) ) == -1)
(
perror(argv[2]);
return 1;
}
/* Файлы открыты - можно копировать ♦/
while ((n = read(fdin, buff, BUFSIZ)) > 0 )
write(fdout, buff, n);
return 0;
}
Константа BUFSIZ (размер буфера для потокового ввода-
вывода) определена в заголовочном файле stdio.h. Ее значение
для MS-DOS равно 512 байт.
Для применения этой программы в ОС MS-DOS необходимо
вначале построить исполняемую программу (см. гл. 9), напри-
мер, copyf.exe. Вызов программы из командной строки будет
иметь вид:
>copyf fl.dat f2.dat
где fl. dat - файл-источник;
f2. dat - файл-приемник.
Если ошибок при исполнении программы нет, файл будет
скопирован, но никаких сообщений на экране дисплея не поя-
вится..
380
Программирование на языке Си
7.2.3. Произвольный доступ к файлу
В приведенных выше программах с функциями ввода-вывода
, низкого уровня обмен с файлом осуществлялся последователь-
но. При необходимости файл можно читать на низком уровне и
в произвольном порядке. Так же, как это делалось при работе с
потоками, можно изменять значение указателя текущей позиции
чтения/записи в файле. Для этой цели служит функция Iseek( ).
Прототип этой функции имеет следующий вид:
long Iseek (int fd, long offset, int origin);
Функция lseek() изменяет текущую позицию в файле, свя-
занном с дескриптором fd, на новую, определяемую смещением
(второй параметр - offset) относительно выбранной Точки от-
счета (третий параметр - origin). .
Точка отсчета задается одной из предопределенных кон-
стант, размещенных в заголовочном файле io.h (MS-DOS) или
файле unistd.h (UNIX):
SEEK_SET (имеет значение 0) - начало файла;
SEEK_CUR (имеетзначение 1)-текущая позиция;
SEEK_END (имеет значение 2) - конец файла.
При удачном завершении функция Iseek() возвращает новую
текущую позицию чтения/записи, представляющую собой сме-
щение от начала файла. Попытка переместиться за пределы
файла считается ошибкой. Код ошибки заносится в глобальную
Переменную errno, определенную в заголовочном файле
errno. h.
Для определения текущей позиции в файле можно использо-
вать функцию tell( ), прототип которой имеет следующий вид:
long tell (int fd);
Приведем примеры использования функции Iseek( ).
Пример 1.
Установка текущей позиции в файле на его начало:
Iseek(fd, OL, SEEK_SET);
Глава 7. Ввод и вывод
381
Пример 2.
Установка текущей позиции для последующего добавле-
ния данных в файл (позиция в конце файла):
lseek(fd, OL, SEEK_END);
Пример 3.
Модификация записей в существующем файле
В качестве еще одного примера использования функции
Iseek() приведем фрагмент программы, производящей модифи-
кацию записей в существующем файле. Запись - это объект
(последовательность байтов) в файле, являющаяся сложным
структурным элементом в контексте программы, обрабатываю-
щей эти записи. Логическая структура записи может быть лю-
бой: некоторой последовательностью байтов, строкой,
структурой и т.д. В следующем фрагменте программы предпо-
лагается, что все записи имеют одинаковый размер (в байтах) и
размещены в файле подряд.
/* Прочитать запись в буфер ♦/
read(fd, buff, sizeof( запись ));
/* Вернуть указатель в файле на место,
с которого начиналось чтение записи */
Iseekffd, -sizeof( запись ), SEEK_CUR);
/♦ Откорректировать запись в буфере ♦/
/* Поместить запись на прежнее место */
write(fd, buff, sizeof( запись ));
Буфер buff может быть определен как массив символов, дос-
таточный для размещения одной записи.
Глава 8
ПРИМЕРЫ РАЗРАБОТКИ ПРОГРАММ
Изучение программирования на конкретном алгоритмиче-
ском языке требует не только освоения его конструкций, но
и знакомства с принципами разработки достаточно больших
программ. В предыдущих главах, посвященных синтаксису и
семантике языка Си, мы в качестве иллюстраций использо-
вали тексты небольших программ. В этой главе мы поместили
более крупные программы, изучение которых позволит полу-
чить достаточно полное представление об особенностях проек-
тирования, разработки и кодирования реальных программ на
языке Си.
8.1. Программа с объектами разных классов
памяти
Постановка задачи. В качестве иллюстрации возможностей
применения в одной программе объектов разных классов памя-
ти рассмотрим следующую достаточно.реальную задачу.
Пусть задан следующий способ получения равномерно рас-
пределенных псевдослучайных чисел (Gruenberger F., Babcock
D. Computing with minicomputers. Los Angeles, 1973) :
а=(xy +y; +Zj mod 16384,
Где Xj = (2Xj_]) mod 16381;
y-j = mod 16363;
Zj = (2zj-i) mod 16349.
Для j > 0 и aQ =o =y0 =z0=l.
В приведенных соотношениях mod - обозначение деления по
модулю. В языке Си деление по модулю целых чисел реализует-
ся с помощью операции
Глава 8. Примеры разработки программ
383
Получаемые значения распределены достаточно равно-
мерно в диапазоне от 0 до 16383. Известно, что для получения
величин, распределенных по нормальному закону из равномер-
но распределенных величин, можно использовать, например,
такое приближенное соотношение :
. Л+12
где L = 1, 13,25,...
Используя приведенные соотношения, нужно получить за-
данное количество N псевдослучайных чисел S ,i = \,N и
оценить для полученной совокупности выборочное среднее
(математическое ожидание) т и выборочную дисперсию V:
Введя или определив предельные значения элементов Smu,
Smax в выборке {5j} из N элементов, сформировать гистограмму
с заданным количеством К интервалов равной ширины.
Сравнить гистограмму, построенную для выборки псевдо-
случайных чисел, с кривой нормального (Гауссова) распределе-
ния, которая описывается уравнением:
где х - аргумент; V- дисперсия; т - математическое ожидание.
Гистограмма характеризуется следующими данными: Sm2(1 и
Smax ~ предельные значения псевдослучайных чисел; N - общее
384 Программирование на языке Си
количество помещаемых в гистограмму значений; К - количест-
во равных интервалов разбиения оси абсцисс гистограммы; rij -
количество значений Sj, относящихся к j-му интервалу, где
j = VK.
к
Естественно соотношение: N = У'и; .
j=i
На основании анализа гистограммы можно по-другому и с
меньшей точностью оценить среднее значение тд и дисперсию
Vg исходной последовательности псевдослучайных чисел {5\}.
Для пояснения рассмотрим изображение гистограммы на
рис.8.1. По оси абсцисс гистограммы - получаемые значения Si
псевдослучайных чисел. По оси ординат - количество значе-
ний Si, относящихся кj-му интервалу (сгруппированных в нем).
Количество интервалов К гистограммы фиксировано, интервалы
имеют равную ширину:
Рис. 8.1. Гистограмма для псевдослучайных чисел
Глава 8. Примеры разработки программ
385
Среднее значение абсциссы j-ro интервала :
=Smin+(7-1)А + -^; у = й.
Cj представляет собой среднее значение данных (т.е. вели-
чин Si), отнесенных кj-му интервалу гистограммы. Для каждо-
го j-ro интервала количество значений S, равно и,, поэтому для
оценки среднего значения mg выборки {S^} по данным гисто-
граммы применимо соотношение :
1 к
т =—У и,С. .
Оценить выборочное значение дисперсии по данным гисто-
граммы можно так :
7V-1
Получаемое таким образом значение Vg оказывается немного
больше оценки выборочной дисперсии Vдля всей выборки {Si}.
Более точное значение оценки дисперсии dg получается с по-
мощью поправки Шеппарда (равной h! 12), т.е.:
Здесь h - ширина интервала гистограммы.
Программная реализация. Рассмотрим основные принципы
построения программы для решения поставленной задачи.
Программу построим в виде набора функций, не обязательно
размещенных в одном файле (рис. 8.2). Связи между функциями
реализуем не только с помощью параметров, но и с применени-
ем внешних объектов (указателей, массивов, переменных), ко-
25-3124
386 Программирование на языке Си
торые нужно сделать' доступными в тех функциях, где к ним
потребуется обращаться.
Статические внешние объекты
N К smin gisto smax sum sum2
Память для К элементов гистограммы
void main () { void count(void); void estimate (double *, double *, double *); void compare(double, double); void estimate(double *mg, double *vg, double *dg) { }
void count (void) { int pseudorand(void); } void compare (double mat, double dis) { double gauss(double, double, double);
int pseudorand(void) { static unsigned x, y, z, s; } double gauss (double x, double m, double v)’ { }
Рис. 8.2. Состав программы для оценки последовательности
псевдослучайных чисел
Глава 8. Примеры разработки программ
387
Алгоритм получения псевдослучайных нормально распреде-
ленных чисел оформим в виде функции pseudorand( ) без пара-
метров, возвращающей целочисленные значения в диапазоне от
О до 16383. Так как при получении очередного (/-го) псевдослу-
чайного значения Si необходимо использовать предыдущие
значения последовательностей Xi~i, yi-i, Zi-ъ Si-i, то в теле
функции предусмотрим их сохранение в статических (static)
переменных. Предлагаемый вариант функции:
int pseudorand(void)
{
static unsigned int x=l, y=l, z=l, s=l;
int i;
long sa — 0;
for (i = 0; i < 12; i++)
(
x=(2*x)%16381;
y=(2*y)%16363;
z=(2*z)%16349;
s=(x+y+z+s)%16384;
sm+=s;
}
return sm/12;
Разработаем функцию count( ) для "заполнения" К элементов
массива гистограммы с одновременным вычислением сумм
N N
1=1 1=1
Исходные данные для функции count( ):
N- количество формируемых псевдослучайных чисел;
АГ- число интервалов гистограммы;
smin - минимально допустимое значение анализируемых
псевдослучайных чисел;
smax - максимально допустимое значение анализируемых
псевдослучайных чисел.
25*
388
Программирование на языке Си
Результаты, формируемые функцией count( ):
gisto[X] - массив значений nj - количества псевдослучайных
чисел Sj, сгруппированных в К интервалов гистограммы;
sum - сумма всех N анализируемых псевдослучайных чисел
Si,
sum2 - сумма квадратов всех N анализируемых псевдослу-
чайных чисел.
Как исходные данные функции count(), так и результаты ее
выполнения нужны в следующей функции estimate(), назначе-
ние которой - собственно вычисление оценок средних и дис-
персий анализируемой совокупности из N псевдослучайных
чисел. Исходя из этого определим переменные N, К, smin, smax,
sum, sum2 как внешние объекты, а участок памяти для гисто-
граммы будем формировать динамически по известному значе-
нию К перед обращением к функции count( ). Для связи с этим
участком памяти определим внешний указатель int * gisto.
Текст функции :
void count (void)
{ /* Формирование гистограммы и вычисление сумм */
extern long N;
extern int К;
extern int smin;
extern int smax;
extern int *gisto;
extern double sum;
extern double sum2;
int pseudorand(void); /* Прототип */
double h; /* Интервал гистограммы */
int j, i;
double d;
sum = sum2 = 0.0;
h — (smax-smin)/К;
for (i=0; i<N; i++)
{ d = pseudorand( );
j = (int)((d-smin)/h);
if (j<K && j>=0)
/* Заполнение интервала гистограммы */
gisto[j]++;
Глава 8. Примеры разработки программ
389
else
printf("\nj=%d d=%8.Of", j, d);
sum+=d;
sum2+=d*d;
)
}
На основе данных гистограммы следующая функция
estimate() будет вычислять оценку математического ожидания
mg и две оценки дисперсии vg и dg (последняя с учетом поправ-
ки Шеппарда).
Исходные данные для функции estimate( ):
К - число интервалов гистограммы;
gisto[X] - массив значений в интервалах гистограммы
(доступен в функции с помощью внешнего указателя gisto);
smin, smax - пределы гистограммы (по абсциссе);
N- количество анализируемых псевдослучайных чисел, по-
мещенных в гистограмму.
Результаты, формируемые функцией estimate( ):
mg - оценка математического ожидания по данным из гисто-
граммы (double *);
vg - оценка дисперсии по гистограмме (double *);
dg - уточненная оценка дисперсии по гистограмме (double *).
Исходные Данные передаются в функцию estimate() через
внешние переменные. Для передачи результатов из функции
estimate() будем использовать аппарат параметров. Как неодно-
кратно подчеркивалось, это потребует работы с указателями и
адресами, так как параметры в функциях на языке Си переда-
ются только по значениям.
void estimate(double *mg, double *vg, double *dg)
<
extern int K;
extern int * gisto;
extern long N;
extern int smin;
extern int smax;
int j ;
390
Программирование на языке Си
double-h, сj, с;
double sm=0.0, sm2—0.0;
h = (smax-smin)/К;
for ( j=0; j<K; j++)
{ cj = smin + j*h + h/2;
c = gisto[j] * cj ;
sm+=c;
sm2+=c*cj ;
}
*mg=sm/N;
*vg=(sm2-sm*sm/N)/(N-l);
*dg=*vg-h/12;
}
Обратите внимание на операцию разыменования, применяе-
мую к параметрам-указателям mg, vg, dg. При обращении к
функции estimate() вместо формальных параметров должны
подставляться адреса тех объектов (переменных), в которые
функция поместит результаты вычислений.
Введем функцию, реализующую вычисления по аналитиче-
скому выражению для кривой нормального (Гауссова) распре-
деления :
#include <math.h>
double gauss (double x, double m, double v)
<
const double PI=3.14159265358979;
double z, e ;
z=sqrt(2*PI*v);
e=(x-m)*(x-m)/(2 *v);
return exp(-e)/z;
}
При известных значениях математического ожидания (m) и
дисперсии (v) по заданному значению аргумента (х) функция
вычисляет точку кривой нормального распределения.
Функция gauss() используется в следующей функции
compare(), где выполняется сравнение сформированной гисто-
граммы с теоретической гауссовой кривой. Функция compare()
печатает (выводит на экран) таблицу со значениями из гисто-
граммы и теоретической кривой. Теоретическая кривая строится
Глава 8. Примеры разработки программ
391
для полученных оценок математического ожидания и дисперсии
анализируемой последовательности из п псевдослучайных чи-
сел. с
void compare (double mat, double dis)
{ /* Сравнение гистограммы с кривой Гаусса */
double h, сj, dj, cko = 0, raz;
extern int * gisto;
extern int K;
extern int smin;
extern int smax;
double gauss(double,gauss,double);/*Прототип*/
long nn = 0;
int j ;
for (j=0; j<K; j++)
. nn+=gisto[j];
h=(smax-smin)/К;
printf("\пСравнительная таблица\п");
printf(" j I cj | gisto[j] |"
" gauss(cj) | delta\n");
for (j=0; j<K; j++)
<
cj = smin + j*h + h/2;
dj = gauss(cj,mat,dis)*nn*h;
printf("%2d %7.1f %d %7.0f % 12.le\n",
j, cj, gisto[j], dj, gisto[j]-dj);
raz = gisto[j]-dj;
cko+=raz * raz;
}
cko = sqrt(cko)/K;
printf ("\ncko=»%f \n" , cko);
}
Кроме печати таблицы, в цикле вычисляется среднее квадра-
тическое отклонение данных гистограммы от теоретических
значений гауссовой кривой:
где rij - значение ординаты гистограммы;
у, - теоретическое значение, полученное для х=С, (i=l, К).
392
Программирование на языке Си
Теперь все готово к разработке функции main(), которая,
вызывая по мере необходимости определенные выше функции,
решает основную задачу - печатает таблицу гистограммы и вы-
числяет оценки математических ожиданий и дисперсий анали-
зируемой последовательности из п псевдослучайных чисел.
Исходные данные для программы :
N- количество анализируемых псевдослучайных чисел;
К - число интервалов гистограммы.
Для обмена с функциями нужно до заголовка main() опреде-
лить объекты внешней памяти.
Текст основной функции программы :
#lnclude <stdio.h>
#include <stdlib.h>
/* Определение внешних объектов: */
long N;
int К;
int smin = 0;
int smax — 16384;
int * gisto = NULL;
double sum — 0.0;
double sum2 ~ 0.0;
/* Прототипы функций: */
void estimate (double *, double *, double *);
' void compare(double, double);
void count(void);
int main ( )
( int j;
double mean, variance, mgist, vgist, dgist, cj;
printf("\n N=") ;
scanf ("%ld", &N) ;
if ( N <= 0)
{
printf("\n Ошибка в данных!");
return -1 ;
} .
printf("\n K=");
scanf("%d", &K);
if ( К <= 0) •
Глава 8. Примеры разработки программ
393
{
printf("\пОшибка в данных!");
return 1;
}
/* Память для гистограммы: */
gisto = (int*)calloc(K,2);
if (gisto==NULL)
{
printf("\n Нет памяти!");
return 1;
}
count( );
mean — sum/N;
variance = (sum2-sum*sum/N)/(N-l);
printf("\n Среднее по выборке MEAN: %f\n",
mean);
printf("Дисперсия по выборке VAR: %f\n",
variance);
estimate(&mgist, &vgist, &dgist);
printf("Среднее по гистограмме MGIST: %f\n",
mgist) ;
printf("Дисперсия по гистограмме VGIST: %f\n",
vgist);
printf("Дисперсия с поправкой DGIST: %f\n",
dgist);
compare(mean, variance);
free(gisto);
}
В программе введена защита от неверно вводимых значений
N и К, а также проверяется успешность выделения динами-
ческой памяти для массива гистограммы.
Результаты выполнения программы :
№10000
К=20
Среднее по выборке MEAN: 8176.704700
Дисперсия по выборке VAR: 1867412.218920
Среднее по гистограмме MGIST: 8175.831300
Дисперсия по гистограмме VGIST: 1924404.997440
Дисперсия с поправкой DGIST: 1924336.747440
394
Программирование на языке Си
Сравнительная таблица
j <=j gisto[j] gauss(cj) delta
0 409.5 0 0 -2.3e-04
1 1228.5 0 0 -5.8e-03
2 2047.5 3 0 2.9e+00
3 2866.5 7 1 5.7e+00
4 3685.5 27 11 1.6e+01
5 4504.5 71 65 6.4e+00
6 5323.5 265 270 -5.4e+00
7 6142.5 727 790 -6.3e+01
8 6961.5 1594 1610 -1.6e+01
9 7780.5 2317 2293 2.4e+01
10 8599.5 2390 2279 l.le+02
11 9418.5 1512 1582 -7.0e+01
12 10237.5 750 7 67 -1.7e+01
13 11056.5 232 260 -2.8e+01
14 11875.5 75 61 1.4e+01
15 12694.5 25 10 1.5e+01
16 13513.5 5 1 3.8e+00
17 14332.5 0 0 -9.4e-02
18 15151.5 0 0 -5.3e-03
19 15970.5 0 0 -2.1e-04
око = 7.715622
Обратите внимание на выравнивание значений в столбцах
выводимой таблицы. Для этого выравнивания в обращении к
функции printf() аккуратно подобраны спецификации преобра-
зования числовых значений (см. сотраге()). Например, пробел
в спецификации "% 12.1е" обеспечивает пустую позицию на
месте знака положительного числа.
Глава 8. Примеры разработки программ
395
8.2. Структуры и обработка списков
в основной памяти
Постановка задачи. Рассмотрим задачу, в которой весьма
целесообразен структурный тип данных. Предположим, что в
памяти ЭВМ необходимо хранить сведения о сотрудниках неко-
торого учреждения и иметь возможность выдавать справки по
личному составу, а также корректировать сохраняемые данные
при изменениях сведений. Таким образом, нужна несложная
база данных о сотрудниках. Для каждого сотрудника должно
быть указано (в скобках определен тип переменной):
• фамилия (char[ ]);
• название отдела (char[ ]);
• номер отдела (int);
• оклад (int);
• код должности (int);
• название должности (char[ ]);
• дата поступления на работу (char[ ]).
Предположим также, что штатным расписанием установлена
граница - не более 100‘ сотрудников, а при работе с этой базой
данных потребуются следующие функции:
• ввод сведений о новом сотруднике;
• удаление сведений о сотруднике;
• вывод на экран дисплея текущего состояния базы данных с
ранжированием информации о сотрудниках по одному из
следующих признаков:
- по окладам;
- по отделам;
- по алфавиту (по фамилиям);
- по датам поступления на работу.
Сведения о сотруднике для данной задачи будем определять
с помощью структуры такого структурного типа:
struct person
{
char names[20];
/* Ф, И. О.
396
Программирование на языке Си
char depname[15]; /* Название отдела */ */
int depnumb; /* Номер отдела
int price; /* Оклад */
int job; /* Код должности */
char jobname[15] ; /* Название должности */
char date[10];/* Дата поступления на работу */
};
Напомним, что приведенное описание не определяет струк-
туру с именем person. Вводится только "формат" входящих в
структуру данных, и этот формат как структурный тип обозна-
чается именем person.
В нашей задаче запись о сотруднике учреждения (эта запись
оформляется в виде конкретной структуры) должна быть эле-
ментом массива, содержащего сведения о всех сотрудниках.
Массив структур определяется следующим образом:
struct person st[100];
Это определение отводит память для 100 индексированных
переменных с общим именем st, каждая из которых является
структурой типа person. Заметим, что, как и все массивы, масси-
вы структур индексируются, начиная с 0.
Если необходимо вывести на экран дисплея значение зара-
ботной платы сотрудника, идущего в списке под номером 4, это
можно сделать следующим образом:
printf("%d", st[3].price);
Как и другие объекты программ на языке Си, структуры
имеют адрес - номер байта, начиная с которого структура раз-
мещается в основной памяти. Со структурой можно связать ука-
затель, объявив его стандартным образом. Например:
struct person *point;
где point - указатель на структуру типа person.
Описав указатель на структуру, можно присвоить ему адрес
конкретной структуры того же типа: point = &st[3];. После тако-
го определения значения указателя появляется еще одна воз-
Глава 8. Примеры разработки программ
397
можность доступа к элементам структуры. Ее обеспечивает опе-
рация позволяющая обратиться к любому элементу струк-
туры, с которой в данный момент связан указатель. Например, к
тому же элементу st[3].price можно теперь обратиться, исполь-
зуя конструкцию point->price.
Напомним возможность применения указателя в уточненном
имени элемента структуры. Операция раскрытия ссылки позво-
ляет обратиться к объекту, который адресует указатель, в част-
ном случае - на структуру. Таким образом, выражение
(*point).price (обратите внимание на необходимость скобок, так
как операция раскрытия ссылки относится только к указа-
телю point и ее приоритет ниже, чем у операции '.') эквива-
лентно point->price и st[3].price.
После того как определен состав сведений об одном сотруд-
нике и эта информация описана в виде структурного типа, необ-
ходимо определить способ хранения структур. Одним из вари-
антов хранения совокупности однотипных структур является
массив фиксированного размера. Однако такая форма реализа-
ции базы данных не всегда удобна. Во время работы с массива-
ми, в которых записи размещены последовательно и, как
правило, упорядочены по некоторому признаку, возникают про-
блемы, связанные с реорганизацией таких массивов при добав-
лении или удалении записей. Реорганизации массива можно
избежать, если хранить записи базы данных в связных списках.
Техника работы со связными списками предполагает в слу-
чае ввода новой записи запрашивать для нее у операционной
системы дополнительный объем памяти, а при удалении записи
- возвращать соответствующий участок памяти операционной
системе.
При программировании на языке Си для этой цели можно
(как мы демонстрировали выше) использовать соответственно
функции malloc(), calloc( ) и free(), но в рассматриваемом слу-
чае, учитывая небольшой объем базы данных и учебный харак-
тер программы, будем использовать связный список с
фиксированным количеством (100) элементов, формируя его из
заранее выделенного массива. Чтобы записи с информацией о
398
Программирование на языке Си
сотрудниках можно было связать в список, необходимо в струк-
туру, которая описывает сведения об одном сотруднике, ввести
указатель на следующий элемент списка. Довольно часто ис-
пользуют двунаправленные списки, в которых каждый элемент
списка содержит указатели как на предыдущий, так и на после-
дующий элемент. Схема двунаправленного связного списка, со-
стоящего из трех элементов, приведена на рис. 8.3.
Рис. 8.3. Пример двунаправленного связного списка из трех
элементов в основной памяти
В примере предполагается использовать структурный тип
person. Для того чтобы можно было связать отдельные струк-
туры в список, в структурный тип необходимо добавить два
указателя:
• на предыдущий элемент списка (prior);
• на следующий элемент списка (next).
Полное описание структурного типа person будет иметь вид:
Глава 8. Примеры разработки программ
399
struct person
{ -
char name[20] ; /* Ф. И. О. */
char depname[15] ; /* Название отдела */
int depnumb; /* Номер отдела */
int price; /* Оклад */
int job; /* Код должности */
char jobname[15]; /* Название должности */
char date[10];/* Дата поступления на работу */
/* Указатель на предыдущий элемент: */
struct person *prior;
/* Указатель на следующий элемент: */
struct person *next;
};
Последние две строки (см. рис. 8.3) определяют указатели
(prior и next) на структуры типа person, т.е. в качестве элементов
структуры используются указатели на структуру того же типа.
Так как список сотрудников располагается в основной памяти в
массиве, содержащем фиксированное количество (100) экземп-
ляров структур типа person, а функции динамического распре-
деления памяти не используются, примем следующие техни-
ческие решения:
• при подготовке массива структур (т.е. при инициализации
базы данных) все элементы массива объединяются в спи-
сок свободных элементов;
• список занятых элементов вначале пуст;
• при заполнении базы данных в качестве буферного исполь-
зуется первый из свободных элементов массива структур, в
него записываются сведения об очередном сотруднике. За-
тем этот элемент включается в список занятых элементов.
Таким образом, в массиве структур будут находиться два
связных списка: список свободных элементов и список за-
нятых элементов.
Замечание. Вводимый список сотрудников должен быть
упорядочен по алфавиту;
• при удалении сведений о сотруднике из базы данных осво-
бодившийся элемент удаляется из списка занятых элемен-
тов и возвращается в список свободных элементов.
400
Программирование на языке Си
На рис. 8.4 изображен в рабочем состоянии массив структур,
содержащий сведения о сотрудниках. Указатели в первых и по-
следних элементах списков, не указывающие соответственно на
предыдущий и следующий элементы, получают значение, рав-
ное NULL.
Начало
списка
занятых
элементов
bbeg
Конец
списка
занятых
элементов
Начало
списка
свободных
элементов
Конец
списка
свободных
элементов
fend
Inull | Il-Hi1 |2|4tP |981NLU.|
|null|9?|—H | iooIinulZ]
«—Список занятых элементов—► <—Список свободных—♦
элементов
Рис. 8.4. Рабочее состояние массива структур
(в списке свободных элементов сейчас только 2 элемента)
Схема, приведенная на рис. 8.5, поясняет процесс удаления
элемента из списка занятых элементов. Был удален элемент под
номером 2. Физически он остается на месте, но входит после
, удаления в другой список (свободных элементов), так как указа-
тели на предыдущий и последующий элементы получили дру-
гие значения.
Теперь можно приступить к разработке функций, реализую-
щих операции по обслуживанию базы данных. Для этого пона-
добятся следующие функции:
main() - главная функция;
init() - инициализация (подготовка) базы данных;
input() - ввод сведений о новом сотруднике;
delete() - удаление сведений о сотруднике;
print( ) - распечатка базы данных;
save() - запись базы данных в файл;
load() - загрузка базы данных из файла.
Глава 8. Примеры разработки программ
401
Начало Начало Конец
списка списка списка
занятых свободных занятых
элементов элементов элементов
Конец
списка
свободных
элементов
fend
Рис. 8.5. Состояние массива структур после удаления
элемента 2 из списка занятых элементов
Функция main(). В функции main() реализован механизм
управления базой данных с помощью меню. Текст функции
main() может быть таким (назначение отдельных переменных и
частей программы поясняется в комментариях):
#include <stdio.h>
/* Определения глобальных объектов программы: */
/* Опредение структурного типа "сотрудник": */
struct person
{
char name[20]; /* Фамилия */
char depname[15]; /* Название отдела */
int depnumb; /* Код отдела: */
/* 1 - маркетинг */
/* 2 — реклама */.
/* 3 - бухгалтерия */
int price; /* Оклад */
int job; /* Код должности: */
/* 1 - менеджер */
, /* 2 - агент */
/* 3 - эксперт */
/* 4 - консультант */
char jobname[15]; /* Должность */
char date[10]; /* Дата поступления на
работу: день.месяц.год */
26-3U4
402
Программирование на языке Си
struct person *prior; /* Указатель на
предыдущий элемент списка */
struct person *next; /* Указатель на
следующий элемент списка */
} st[100]; /* Определен массив структур */
/* Управляющие переменные: */
/* Число элементов в массиве структур: */
const int М=100;
struct control
{
int nb; /* Число занятых элементов */
int nf; /* Число свободных элементов */
/* Указатели на структуры: */
struct person *bbeg; /* Начало списка
занятых элементов */
struct person *bend; /* Конец списка
занятых элементов */
struct person *fbeg; /* Начало списка
свободных элементов */
struct person *fend; /* Конец списка
свободных элементов */
} Ctrl;
/* Прототипы вызываемых функций: */
int init(void);
int input(void);
int delete(void);
struct person *find(char *nam);
int fr(struct person *ptr);
int print(void);
int save(void);
int'load(void);
/* Текст главной функции: */
void main(void)
{
char numb[10]; /* Номер работы из меню * /
/* Вывод меню на экран: */
while (1)
{ /* Бесконечный цикл работы с базой данных*/
printf("1.Ввод сведений о новом сотруднике \п") ;
printf("2.Удаление сведений о сотруднике \п") ;
printf("3.Печать содержимого базы данных \п") ;
printf("4.Сохранение базы данных в файле \п");
Г лава 8. Примеры разработки программ 403
printf("5.Загрузка базы данных из файла \п");
printf("б.Инициализация базы данных \п");
printf("7.Окончание работы \п");
/* Ввод и обработка номера работы */
printf("\n\n Введите номер пункта меню\п");
scanf("%s", numb );
switch( numb[0] )
{
case '1':
input( ) ;/* Ввод данных о новом сотруднике*/
break ;
case 2 ' :
delete( );/*Удаление сведений о сотруднике*/
break ;
case '3':
printf );/* Печать содержимого базы данных*/
break ;
case '4' :
savef );/* Сохранение базы данных в файле */
break ;
case ’ 5' :
load( ); /* Загрузка базы данных из файла */
break ;
case 1 б'
init( ); /* Инициализация базы данных */
break ;
case '7'
return ; /* Выход ив программы */
default:
printf("Неверно указан номер пункта меню\п");
}
} /* Конец цикла */
)
Примечание. Имена всех переменных, встречающихся до
void main(), являются внешними для остальных функций
программы, и их не надо описывать в функциях еще раз, если
главная функция, внешние переменные и остальные функции
программы будут собраны в один файл (исходный модуль).
Функция init() - "Инициализировать базу данных". Пер-
вое действие, которое должен выполнить пользователь при ра-
боте с базой данных, - это подготовить ее к работе (инициали-
26*
404
Программирование на языке Си
зировать). Функция init() связывает все элементы массива
структур в "список свободных элементов" и устанавливает на-
чальные значения управляющих переменных.
В тексте функции для доступа к элементам структуры ис-
пользована операция ("стрелка"). Напомним, что она изо-
бражается двумя символами: ("минус") и ">" ("больше,
чем") и называется операцией косвенного выбора элемента
структуры, адресуемой указателем. Операция используется с
указателем на структуру для доступа к элементу структуры.
Выражение point -> prior обеспечивает доступ к элементу
prior той структуры, которую адресует указатель point. Иными
словами, point -> prior эквивалентно st[i],prior, если ранее вы-
полнен оператор point=&st[i]; Ниже приводится текст функции
init():
int init(void)/* Инициализировать базу данных */
{
struct person *point=st; /* Указатель на
текущий элемент */
int i;
ctrl.nb =0; /* Число занятых элементов */
ctrl.nf =0; /* Число свободных элементов */
Ctrl.bbeg=NULL;
Ctrl.bend=NULL; /* Списка занятых
элементов нет */
Ctrl.fbeg=st; /* st - адрес начала
массива структур */
Ctrl.fend = st;
point = st;
printf("\n\n Инициализация массива. \n");
for (i=0; i<M-l; i++ )
{
if ( ctrl.nf?=0 ) /* He первый элемент: */
{
point -> prior = point-1;
point -> next = point+1;
}
else /* Первый элемент: */
{
point -> prior = NULL;
point —> next = point+1;
Глава 8. Примеры разработки программ
405
}
point++;
Ctrl.nf++;
Ctrl.fend++;
} /* Конец цикла инициализации (М-1)
элементов массива */
/* Инициализация последнего элемента в массиве*/
ctrl.nf++;
point -> prior=point-l;
point -> next= NULL;
return 0;
}
В этой функции для каждого элемента массива в цикле зада-
ются значения указателей на предыдущий и следующий элемен-
ты. Для первого элемента указатель prior устанавливается рав-
ным NULL. Для последнего элемента указатель next устана-
вливается также равным NULL (для этих элементов нет соот-
ветственно предыдущего и следующего элементов).
Функция delete() - "Удалить все сведения о сотруднике
из базы данных". В работе функции delete() можно выделить
два этапа:
• поиск нужного элемента в списке занятых элементов;
• удаление найденного элемента (возврат элемента в список
свободных элементов).
Действия по поиску нужного элемента в списке целесообраз-
но оформить в виде отдельной функции find(), текст которой
приводится ниже. Аргументом (ключом) поиска элемента явля-
ется фамилия сотрудника, Для сравнения строк (фамилия, вве-
денная с терминала, и фамилия в структуре) используется стан-
дартная библиотечная функция strcmp(), параметрами которой
являются указатели на сравниваемые строки. Функция
strcmp(), описанная в заголовочном файле string.h, возвращает
0, если строки совпадают. Для сравнения строк можно было бы
использовать функцию row(), текст которой приведен в §5.3,
где рассматриваются строки как параметры функций.
Функция поиска элемента в списке занятых find() должна
возвращать указатель на найденный элемент либо NULL, если
406
Программирование на языке Си
элемент в списке не обнаружен. Конструкция struct person *
перед именем функции find() сообщает компилятору языка Си,
что функция возвращает указатель именно на структуру типа
person. Приведем текст функции find():
#include <string.h> /* Для функции strcmp’ */
struct person *find(char *nam)
{
int i;
struct person *ptf; /* Вспомогательный указа-
тель на начало списка занятых элементов */
ctrl.ptf = bbeg;
for (i=0; i<ctrl.nb; i++) /* nb - число
занятых элементов */
{
if ((strcmp(nam, ptf->name)) == 0)
return ptf;
ptf = ptf->next; /* Перемещаем указатель на
следующий элемент списка */
}
/* Просмотрен весь список Занятых элементов */
return NULL;
)
При выполнении функции delete() удаления элемента из
списка занятых производятся следующие действия:
• запрос фамилии;
• поиск фамилии в списке занятых элементов;
• удаление найденного элемента из списка занятых;
• возврат освобожденного элемента в список свободных.
Текст функции delete() может быть таким:
/* Удаление элемента из списка занятых: */
int delete(void)
{
char nam[20]; /* фамилия */
int i;
struct person *ptr; /* Указатель на
удаляемый элемент */
printf("\п\п Функция удаления элемента \п");
if (ctrl.nb = = 0)
Глава 8. Примеры разработки программ
407
{
printf(" список занятых элементов пуст \п") ;
return -1;
}
/* Запрос фамилии */
printf(” Введите : Ф.И.О. \п");
scanf("%s", nam);
/* Поиск фамилии: */
if ((ptr=find(nam))==0)/* Фамилия не найдена*/
{
printf(" фамилия не найдена\п");
return -1;
} _
/* Фамилия найдена, удалить элемент: */
if (ptr == Ctrl.bbeg)
{ /* Это первый элемент */
if (ctrl.nb = = 1)
{ /* Единственный элемент в списке занятых */
' Ctrl.bend = NULL;
fr(ptr) ;
return 0;
)
else
{ /* He единственный элемент */
Ctrl.bbeg = ptr->next;
Ctrl.bbeg->prior = NULL;
f r (ptr) ;
return 0;
)
)
else
{ /* Это не первый элемент */
if (ptr = = Ctrl.bend)
{/* Это последний элемент (не единственный)*/
ptr->prior->next = NULL;
Ctrl.bend = ptr->prior;
fr(ptr);
return 0;
}
else
{ /* Элемент в середине */
ptr->prior->next = ptr—>next;
ptr->next->prior = ptr->prior;
408
Программирование на языке Си
fг (ptr) ;
return 0;
)
}
}
В функции delete() использовано обращение к функции fr(),
текст которой приведен ниже. Функция fr() "привязывает" ос-
вобожденный элемент к списку свободных элементов, делая его
головным, и корректирует глобальные управляющие перемен-
ные и указатели. Встретившийся в функции delete() оператор
ptr->prior—>next = ptr->next;
имеет следующий смысл (рис. 8.6 ч- 8.9). Так как операция
"стрелка" (->) выполняется слева направо, то оператор можно
записать так:
(ptr->prior)->next = ptr->next;
Это означает, что в поле next элемента, стоящего слева от
удаляемого, заносится адрес элемент», который находится спра-
ва от удаляемого (рис. 8.7 + 8.9). На рис. 8.7 изображено исход-
ное состояние массива структур, а на рис. 8.8 и рис. 8.9 - изме-
нение значений указателей после удаления элемента из списка
занятых элементов и возврата его в список свободных эле-
ментов.
Аналогично следует понимать и выражение
ptr->next->prior=ptr->prior;
ptr
Рис. 8.6. Связи элемента, на который ссылается указатель ptr
(N - next, Р - prior)
. ,.OQa 8. Примеры разработки программ
409
bbeg
bend
fbeg
fend
Рис. 8.7. Исходное Состояние массива структур
(N - next, Р - prior)
bbeg
bend
fbeg
fend
InULLI |Nt*.T*|p| | null]
ptr (удаленный)
Рис. 8.8. Изменение значений указателей после удаления элемента
bbeg
fbeg
bend
fend
I I 1 Г------------------ I I . . . 1
I null] |n| |null| |n| |lp| |null| | p| 1М~>-~(р| I null]
Рис. 8.9. Изменение значений указателей после возврата элемента
' в список свободных
410
Программирование на языке Си
Функция Тг() - "Возвратить освобожденный элемент в
список свободных элементов". Эта вспомогательная функция
используется в функции delete():
/* Освобождение удаляемого элемента: */
int fг(struct person *ptr)
{
if (ctrl.nb == M ) /* Были Заняты все элементы
массива */
(
ptr->prior = NULL;
ptr->next = NULL;•
Ctrl.fbeg->prior = ptr;
Ctrl.fbeg = ptr;
}
else
(
ptr->prior = NULL;
ptr—>next = ctrl.fbeg;
Ctrl.fbeg->prior = ptr;
ctrl.fbeg = ptr;
}
ctrl.nb—
ctrl.nf++;
return 0;
}
Функция input() - "Ввести в базу данных сведения о но-
вом сотруднике". Функция input() должна вводить информа-
цию о новом сотруднике, сохраняя алфавитный порядок записей
в базе данных. При реализации этой функции возникают труд-
ности: буквы национального алфавита (в данном случае кирил-
лицы) в международной таблице кодов не упорядочены по
возрастанию внутренних кодов, что требует для операций упо-
рядочения дополнительных перекодировок с применением про-
межуточных словарей. Чтобы в рассматриваемой задаче не
отвлекаться на решение этой проблемы, договоримся, что при
вводе новой записи в уже существующую базу данных добав-
ляемый элемент подсоединяется к хвостовому элементу списка
занятых элементов. Однако при этом необходимо помнить, что
Глава 8. Примеры разработки программ
411
алфавитный порядок в списке занятых элементов будет нару-
шен.
Как было решено ранее, информацию о новом сотруднике
будем вводить в первый свободный элемент списка с после-
дующей привязкой этого элемента к списку занятых. Приведем
текст функции input():
/* Вставка нового элемента в список занятых
элементов: */
int input(void)
{
struct person *ptr; /* Вспомогательный
указатель */
printf("\n\n Функция вставки элемента \n ");
if (ctrl.nf = = 0}
{
printf(" Свободных элементов нет\п");
return -1;
}
ptr = fbeg;
I * Запрос Ф.И.О. */
printf(" Введите: Ф.И.О. \n");
scanf("%s", fbeg->name);
printf("Введите код отдела \n");
printf("1 - Маркетинг\п 2 - Реклама\п");
printf("3 — Бухгалтерия\п ");
scanf("%d", &ptr->depnumb);
printf("Введите название отдела: \n");
scanf("%s", ptr->depname);
printf("Введите оклад \n");
scanf("%d", &ptr->price);
printf("Введите код должности: \n");
printf("1 - менеджер\п 2 — агент\п");
printf("3 - эксперт\п 4 - ст. консультант\п");
scanf("%d", &ptr->job);
printf("Введите наименование должности: \n");
scanf("%s", ptr->jobname);
printf ("Введите дату поступления на работу: \n") ;
printf("по формату: ДД.ММ.ГГ\п") ;
scanf("%s", ptr->date);
/* Подключение элемента к списку занятых
элементов */
412
Программирование на языке Си
if (ctrl.nf==l) /* Занимаем последнее место */
{
ctrl.fbeg = NULL;
ptr->next = NULL;
ptr—>prior = Ctrl.bend;
Ctrl.bend->next = ptr;
. Ctrl.bend = ptr;
Ctrl;fend = NULL;
}
else
{
if (ctrl.nb == 0)
Ctrl.bbeg = ptr; .
ctrl.fbeg = ptr->next;
ptr->next = NULL;
ptr->prior = ctrl.bend;
Ctrl.bend->next = ptr;
ctrl.bend = ptr;
Ctrl.fbeg->prior = NULL; /* Новый первый в
списке свободных элементов */
}
Ctrl.nb++;
Ctrl.nf—;
return 0;
)
Функция print() - "Печать списка занятых элементов".
Реализуем функцию печати списка занятых элементов в том по-
рядке, в котором они связаны. В качестве упражнений само-
стоятельно разберите варианты функции печати с ранжирова-
нием выводимой информации по окладу, кодам отделов, кодам
должностей, дате поступления на работу.
Функция print() может быть реализована следующим обра-
зом:
/* Печать информации из базы данных: */
int print(void)
{
int i ;
struct person *ptr; /* Вспомогательный
указатель */,
ptr = Ctrl.bbeg;
Глава 8. Примеры разработки программ
413
printf("База данных \"сотрудники\" \n\n\n");
if (ctrl.nb =0) /* База данных пуста */
<
printf("База данных пуста \п");
return -1;
}
for ( i = 0; i < ctrl.nb; i++ )
{
printf("%d фамилия: %s\n", i, ptr->name);
printf("отдел %s\n", ptr->depname);
printf("код отдела %d\n", ptr->depnumb);
printf("оклад %d\n", ptr->price);
printf("код должности : %d\n", ptr->job);
printf("должность : %s\n", ptr->jobname);
printf("дата поступления: %s\n", ptr->date);
ptr - ptr->next;
}
printf("\n\n Общее число Записей =%d\n", i);
return 0;
}
Сохранение (восстановление) базы данных. Поскольку в
рассматриваемом примере база данных реализована в виде дву-
направленного списка в основной памяти и она стирается (ее со-
держимое исчезает) при завершении работы программы, необ-
ходимо предусмотреть как сохранение базы данных во внешней
памяти, так и загрузку базы данных из внешней памяти в сле-
дующем сеансе работы с ней.
Перед разработкой функции "выгрузка" базы данных в файл
на диске необходимо определить формат и состав выгружаемых
данных.
Собственно база данных (в виде двух независимых двуна-
правленных списков - списка занятых элементов и списка сво-
бодных элементов) располагается в массиве st структур типа
struct person (см. главную программу). Информация о количе-
стве элементов в этих списках, а также указатели на начало и
конец списков располагаются в структуре Ctrl типа struct
control.
414
Программирование на языке Си
Рассмотрим один из простейших вариантов создания на дис-
ке резервной копии базы данных о сотрудниках учреждения. Он
состоит в том, что сначала необходимо записать в файл управ-
ляющую информацию (содержимое структуры Ctrl), а за ней -
весь массив структур (байт за байтом), тем более что в рассмат-
риваемом примере он невелик (7 Кбайт). При восстановлении
базы данных из файла на диске читается управляющая инфор-
мация и размещается в структуре Ctrl, затем читается информа-
ция, расположенная в файле за управляющей информацией, и
размещается в области основной памяти, отведенной под массив
структур st.
Такая схема копирования (восстановления) обладает сущест-
венным недостатком: вместе с содержательной информацией в
файл записываются и значения указателей (адреса основной па-
мяти), содержащиеся в элементах списков базы данных. Таким
образом, при принятой схеме копирования (восстановления)
программа обслуживания базы данных будет работать при вы-
полнении условия неизменности адреса загрузки программы в
основную память. При работе на персональном компьютере в
операционных системах MS-DOS и UNIX (однопользова-
тельский режим) вызванная для выполнения программа будет
загружена на то же самое место в основной памяти только в том
случае, если между сеансами работы с программой не произво-
дились "системные" работы, повлекшие за собой перераспреде-
ление основной памяти.
Однако, несмотря на неполную надежность восстановления,
приведем исходные тексты функций save() - "выгрузить базу
данных в файл на диске" и Ioad() - "восстановить базу данных
из файла". В этих функциях показано, как можно выгрузить (и
затем восстановить) из основной памяти в файл на диске содер-
жимое переменных различных типов.
Операция sizeof, примененная в функциях save() и load(),
вычисляет длину операнда в байтах. Операторы с = (char *)pti;
и с = (char *)ptr; производят явное преобразование указателя pti
на целое и указателя ptr на структуру соответственно в указате-
ли на символы, что позволяет использовать последние в Качест-
Глава 8. Примеры разработки программ
415
ве аргументов в функциях putc() H,getc() для побайтного обме-
на с файлом.
В функции save() производится запись в файл на диске всех
элементов массива структур. Запись производится функцией
putc() побайтно. Поэтому в программе необходимо описать
указатель на символы, т.е. типа char*. Для работы с массивом
структур необходим указатель на структуру типа person, содер-
жащую сведения о сотруднике учреждения, и указатель потока,
связанный с файлом, в котором производится сохранение базы
данных. Назовем этот файл bd.dat.
Приведем текст функции save():
/* Выгрузка в файл всего массива структур */
int save(void)
{
int i, k;
struct person *ptr; /* Указатель на структуру
типа person */
char *c; /* Указатель на символ */
int *pti; /* Указатель на целое */
FILE *fp; /* Указатель на поток */
/* Открыть файл для записи: */
if ((fp = fopen ("bd. dat" , "w")) —NULL)
{
perror("bd.dat");
return -1;
} •
if (ctrl.nb == 0) /* База данных пуста */
{
puts("База данных пуста \п");
puts("Запись на диск не производится \п");
return -1;
}
else
{
puts(" Производится запись БД в файл ") ;
ptr = st; /* Начато массива структур */
/* Запись управляющей информации: */
pti = &ctrl.nb; /* Начато блока управляющей
информации */
с = (char *)pti; /* Настройка указателя */
416 Программирование на языке Си
/* Цикл ввода управляющей информации: */
for (i=0; i<sizeof(ctrl); i++)
putc(*c++, fp) ;
/* Цикл вывода в файл всего массива структур: */
с = (char *)ptr; /* Настройка указателя */
for(к =0; к < sizeof(st); к++)
putc(*c++, fp);
i fclose(fp);
return 0;
}
Функция load() может быть реализована следующим обра-
зом:
/* Ввод (восстановление) из файла всего массива
структур */
int load(void)
{
int i ;
struct person *ptr; /‘Указатель на структуру*/
int *pti;
char *c, d;
FILE *fp; /* Указатель на поток */
/* Открыть файл для чтения: */
if ((fp = fopen("bd.dat","г"))== NULL )
.{
perror("bd.dat");
return -1;
}
if( ctrl.nb = = 0 )
puts(" База данных пуста \n");
if(Ctrl.nb != 0) /* База данных не пуста */
{
puts("База в основной памяти не пуста\п");
puts("Производить загрузку? [у,п]:");
d = getchar( );
if (d = = 'N' || d = = 'n' )
{
puts("Запрос на загрузку базы отменен\п");
return 1;
}
)
Глава 8. Примеры разработки программ
417
puts("Производится загрузка базы данных\п");
/* Чтение управляющей информации: */
pti = &ctrl.nb;
с = (char
/* Цикл ввода в список из файла */
for(i=0; i<sizeof(ctrl); i++)
*a++=getc(fp);
ptr = st; /* Начало массива структур */
с = (char *)ptr;
/* Цикл ввода всего массива */
for(i =0; i < sizeof(st); i++)
(
if ((*c=getc(fp)) •= EOF)
C++;
else
{
fclose(fp);
return 0;
}
}
return 0;
}
Перед восстановлением базы данных с диска проверяют,
пуст ли список занятых элементов в основной памяти. Если нет,
то выдается запрос "Производить загрузку?". В случае неполо-
жительного ответа, обозначаемого латинской буквой N или п,
загрузка информации в БД из файла не производится.
Для того чтобы программа обслуживания базы данных стала
не зависимой от адреса загрузки в основную память, модерни-
зируем функции save() и load( ) следующим образом:
• будем выгружать (записывать) в файл не весь массив
структур, а только список занятых элементов;
• после чтения содержимого файла в массив структур скор-
ректируем значения указателей, образующих связи в связ-
ных списках базы данных, т.е. установим реальные адреса
в указателях.
На рис. 8.10 показаны состояние списка занятых элементов в
массиве структур до выгрузки в файл, структура файла с ин-
формацией из базы и состояние массива структур после восста-
27~3124
418
Программирование на языке Си
новления базы данных из файла. В общем случае элементы спи-
ска, содержащего сведения о сотрудниках, к концу сеанса рабо-
ты с базой данных могут располагаться не в соседних элементах
массива. Однако после выгрузки в файл эти элементы окажутся
рядом. Читая из файла в массив структур список занятых эле-
ментов байт за байтом, мы размещаем элементы списка с начала
массива структур, т.е. элементы списка, в котором хранятся све-
дения о сотрудниках, в общем случае попадают на новые места
в массиве структур, и требуется корректировка адресов в эле-
ментах этого списка. Эта процедура аналогична процедуре ини-
циализации массива структур перед началом работы с базой
данных. Началом списка свободных элементов будет первый
элемент массива структур, не занятый загруженной из файла
информацией.
Исходное
состояние
массива
структур
|null| i |Nf
♦|F|2|Nfj----»|p|3|NULl]: ...
Файл
Сохранение \
(запись) \ ‘-4 ’•
информация » I NJj ЕЩЕ И Р| 3 l^LLl
Восстановление
(чтение)
Массив
структур
после
восстановления
базы данных
из файла
Рис. 8.10. Второй вариант схемы сохранения (восстановления) базы данных
Глава 8. Примеры разработки программ
419
Приведем текст функции save2() - "сохранить в файле на
диске только список занятых элементов":
/* Запись в файл только Занятых элементов */
int save2(void)
{
int size;/* Размер элемента списка в байтах */
int i, к;
struct person *ptr; /* Указатель на структуру
типа person */
char *с; /* Указатель на символ */
int *pti; /* Указатель на целое */
FILE *fp; /* Указатель на поток */
/* Открыть файл для записи: */
if ((fp = fopen("bd.dat","w"))== NULL)
{
perror("bd.dat");
return -1;
}
if (ctrl.nb == 0) /* База данных пуста */
{
puts("База данных пуста \п");
puts("Запись на диск не производится \п");
return -1;
}
else
{
puts("\n Производится запись БД в файл ");
size = sizeof(st) /М;
/* size - длина одного элемента в байтах */
/* М - число элементов в массиве структур*/
ptr = st; /* Начало массива структур */
/* Запись управляющей информации: */
pti = &ctrl.nb; /* Начало блока управляющей
информации */
с = (char *)pti;
/* Цикл ввода управляющей информации: */
for (i=0; i<sizeof(Ctrl); i++)
putc(*c++, fp);
/* Цикл вывода в файл списка занятых
элементов */
for (k=0; k<ctrl.nb; k++)
{
27’
420
Программирование на языке Си
с =. (char *)ptr;
/* Цикл вывода одного элемента списка */
for (i=0; i<size; i++)
putc(*C++, fp);
/♦Установка указателя на следующий элемент*/
ptr = ptr->next;
}
fclose(fp);
return 0;
}
}
Приведем текст функции Ioad2() - "загрузить в основную
память (прочитать из файла) базу данных из файла с корректи-
ровкой адресов, содержащихся в указателях элементов списков
базы данных".
/* Загрузка (чтение) базы данных из файла
с корректировкой указателей */
int load2(void)
{
int i, k;
struct person *ptr;/* Указатель на структуру*/
int *pti;
char *c, d;
FILE *fp; /* Указатель на файл (поток) */
/* Открыть файл для чтения: */
if ((fp=fopen("bd.dat","г"))== NULL )
{
puts("Ошибка при открытии файла \п");
return 1;
}
if (cnrl.nb == 0)
puts(" База данных пуста \п");
if (nb •= 0) /* База данных не пуста */
{
puts("База в основной памяти не пуста\п");
puts("Производить загрузку? [у,п]:");
d = getchar( );
if (d=='N' || d=='n' )
{
puts("Запрос на загрузку базы отменен\п");
return 1;
Глава 8. Примеры разработки программ
421
}
}
puts("Производится загрузка базы данных\п");
/* Чтение управляющей информации */
pti = &ctrl.nb;
с = (char *)pti;
for (i=0; Ksizeof (Ctrl) ; i++)
*c++=getc(fp);
/* Цикл чтения списка из файла */
ptr = st; /* Начало массива структур */
for (k=0; Ksizeof(st)/M*ctrl.nb; k++)
{
c = (char *)ptr;
/* Цикл чтения одного элемента */
for- (i=0; Ksizeof (st) /М; i++)
{
if ((*c=getc(fp)) »= EOF)
C++;
else
{
fclose(fp);
return 0;
}
}
ptr++; /* Загружаем в последовательные
элементы массива */
} /* Конец цикла по к */
Ctrl.bend = ptr; /* Указатель на последний
занятый элемент */
ptr++; /* Первый свободный элемент */
Ctrl.fbeg = ptr;
ptr->prior = NULL;
/* Корректировка указателей в списке занятых
элементов */
ptr = st;
for (i=0; Kctrl.nb; i++)
{
/* Первый элемент ? */
if (ctrl.nf = 0)
{
ptr->prior — NULL;
ptr->next = ptr+1;
}
422
Программирование на языке Си
else
{
ptr->prior = ptr-1;
ptr->next = ptr+1;
}
ptr++
}
/* Последний элемент */
ptr->prior = ptr-1;
ptr->next NULL;
return 0;
}
В качестве упражнения рекомендуем разработать более на-
дежную схему и формат хранения базы данных и соответст-
вующие функции сохранения (восстановления). В качестве
возможного варианта формата хранения базы данных в файле на
диске можно использовать следующий:
#1
пате=фамилия
йерпате=название_отдела
йерпитЪ=код_отдела
рпсе=зарплата
\оЬ=код_должности
jonam с-должностъ
da.te=dama приема на^работу
#2
фамилия
где
#1, #2,... - номера записей;
name=, depname=, ... - имена полей в структуре, содержащей
сведения о сотрудниках учреждения;
фамилия, название отдела, ... - содержимое полей струк-
туры в символьном виде.
Файл в таком формате и символьном представлении значе-
ний полей структур легко прочитать и модифицировать с помо-
Глава 8. Примеры разработки программ
423
щью любого текстового редактора. Имена полей можно исполь-
зовать для контроля правильности обработки записи при вводе
(см. гл. 7, форматный ввод). Список занятых элементов базы
данных формируется в момент ввода данных из файла.
Для того чтобы подготовить программный комплекс к по-
следующей обработке (трансляция, сборка), в простейшем слу-
чае необходимо с помощью текстового редактора собрать все
функции в одйн файл (набор данных). Этот файл должен иметь
следующую структуру:
• объектов, используемых во вспомогательных функциях
(массив структур типа struct person, управляющие пере-
менные в структуре Ctrl);
• описание внешних переменных;
• функция main();
• функция init();
• функция find();
• функция fr();
• функция delete();
• функция input();
• функция print();
• функция save() или функция save2( );
• функция load() или функция load2( ).
Подробно подготовка программного комплекса для работы с
базой данных о сотрудниках учреждения описана в главе 9.
8.3. Сортировка на основе бинарного дерева
Статические и динамические данные. В предыдущих гла-
вах были рассмотрены как элементарные типы данных (целые,
вещественные, символьные), так и более сложные производные
типы (массивы, указатели, объединения и структуры). Для объ-
ектов перечисленных основных тиров при определении задают-
ся диапазон изменения соответствующих им значений и размер
выделяемой для них памяти. В силу этого такие объекты могут
считаться статическими. Однако для решения ряда задач, воз-
424
Программирование на языке Си
никающих при построении информационных систем, разработ-
ке баз данных, построении протоколов передачи данных в теле-
коммуникационных сетях и т. п., требуются информационные
объекты с более сложной структурой. В процессе обработки
этих информационных объектов могут изменяться не только
значения объектов, но даже их конфигурация. Такие объекты
(мы уже рассматривали их в §6.4) называют динамическими
информационными структурами (см. Вирт Н. Алгоритмы и
структуры данных. - М.: Мир, 1989 - С. 213). Следует заметить,
что компоненты динамических информационных структур на
нижних уровнях детализации представляют собой статические
объекты, принадлежащие к одному из основных типов данных.
Таким образом, основные типы данных используются для фор-
мирования более сложных информационных конструкций.
В §8.2 был приведен пример применения для построения ба-
зы данных, сложных данных в виде двунаправленного линейно-
го списка. Особенностью реализации такой базы данных в §8.2
является выделение для ее работы статического массива струк-
тур. Внутри массива существовали два списка - свободных и
занятых элементов. Такой подход позволяет полностью контро-
лировать память, выделенную под массив структур на этапе
трансляции программы. Однако, если мы заранее не можем оп-
ределить объем обрабатываемых данных, то применение стати-
ческого массива не всегда оправдано. На практике под
динамические информационные структуры выделяют память
также динамически по мере возникновения потребности в со-
хранении очередной порции данных. Динамическая память вы-
деляется операционной системой по запросу программы из так
называемого динамического сегмента, входящего в адресное
пространство исполняемой программы.
Исполняемую программу на языке Си после компиляции и
загрузки в память условно можно разделить на 4 части: область
команд, стек, область статических данных и область динами-
ческих данных. Область команд содержит машинные команды.
Стек используется для временного хранения данных и адресов
Глава 8. Примеры разработки программ
425
возврата при вызове функций. Область статических данных
обеспечивает хранение значений переменных программы, а в
области динамических данных размещаются при исполнении
программы дополнительные данные, которые могут понадо-
биться в процессе ее работы. На рис. 8.11 приведена одна из
схем распределения адресного пространства выполняемой про-
граммы.
Область стека
(расширяется вниз)
Старшие адреса
Область динамических данных
(расширяется вверх)
Область статических данных
Область команд
Младшие адреса
Рис. 8.11. Схема распределения оперативной памяти процесса
Управление динамической памятью. Как мы уже упоми-
нали, в библиотеке языка Си есть функции выделения и осво-
бождения динамической памяти. Благодаря наличию таких
функций отпадает необходимость заранее резервировать для
программы всю доступную память, что оказывается полезным в
ситуациях, когда требуемый объем памяти заранее не известен
или зависит от конкретного применения программы.
Работа с динамической памятью (выделение памяти, измене-
ние размера ранее занятого участка, освобождение памяти) про-
изводится с помощью функций шаПос(), calloc(), realloc(),
free(), описанных в §4.2. Использование функций malloc(),
calloc(), free() выше продемонстрировано на многочисленных
примерах. Остановимся на особенностях функции realloc().
Функция realloc() может быть использована для изменения
размера ранее занятого участка памяти. При этом адрес начала
426
Программирование на языке Си
участка может измениться. Описание (прототип) функции
realloc():
void *realloc (void *oldptr, unsigned int new_size);
где oldptr-указатель на участок памяти, ранее выделенный с
помощью функции malloc() или са!1ос();
newsize - размер требуемой памяти.
Стандарт языка Си [5] рекомендует для устранения влияния
"перемещений" выделяемого с помощью realloc( ) участка па-
мяти следующим образом использовать функцию realloc():
pt = realloc (oldptr, new_size);
if (pt ’= NULL)
oldptr=pt;
Например, если oldptr указывал на часть связного списка и
для этой части функцией realloc() нужно выделить новый уча-
сток памяти, то старое значение oldptr может оказаться невер-
ным (не будет адресовать новое продолжение списка).
Применение описанной схемы (т.е. явное присваивание oldptr
нового адреса) позволит избежать возможных ошибок и сохра-
нить связность списка.
Необходимо отметить, что все функции, за исключением
функции free(), возвращают значение указателя, равное NULL,
если для выделения запрошенного участка памяти не хватает.
Сортировка с помощью бинарного дерева. Рассмотрим
применение функций работы с динамической памятью и дина-
мическими информационными структурами на примере сорти-
ровки с помощью бинарного дерева. Выбор этого способа
сортировки определен следующими соображениями.
1. Структуры данных типа "дерево" являются динамически-
ми и важны при построении информационных и телекоммуни-
кационных систем.
2. При сортировке произвольного набора данных заранее не
известен его объем, и применение статической памяти, которая
выделяется на этапе трансляции, может оказаться неоправдан-
ным в силу возникающих несоответствий, между количеством
Глава 8. Примеры разработки программ
427
данных, подлежащих сортировке, и объемом статически выде-
ленной памяти.
3. Выбранный способ сортировки позволяет освоить столь
важные при работе с деревьями операции, как построение дере-
ва и его обход, например, для печати содержимого его вершин.
Описание методов сортировки и работы с динамическими
структурами данных можно найти в приведенной выше работе
Н.Вирта. В качестве метода для программной реализации опре-
делим бинарную сортировку включением. Этот метод сорти-
ровки предполагает, что вводимые данные запоминаются в виде
бинарного дерева (рис. 8.12). Дерево начинается с корня (root),
который указывает на первую вершину. Из каждой вершины
дерева выходят две ветви, связывающие ее с вершинами нижне-
го уровня.
Рис. 8.12. Пример заполненного бинарного дерева
428
Программирование на языке Си
При построении дерева на рис. 8.12 был использован произ-
вольный набор английских слов, записанный в файл. Слова рас-
полагаются в файле в следующем порядке:
line, comma, array, name, type,
string, union, size, case.
Выбранный метод сортировки определяет следующую про-
цедуру формирования дерева. На первом от корня месте распо-
лагается первое слово, введенное из исходного файла. От него
проводятся две ветви (левая и правая), ведущие к двум верши-
нам нижнего уровня. Если следующее слово в алфавитном по-
рядке выше первого слова, то оно располагается в вершине
нижнего уровня, к которой ведет левая ветвь (рис. 8.13).
Рис. 8.13. Размещение в дереве нового слова
Следующий этап построения дерева вновь начинаем с корне-
вой вершины. Сравниваем слова "array" и "line". Строка "array"
выше в алфавитном порядке строки "line", поэтому переходим к
вершине нижнего уровня по левой ветви. Сравниваем строки
"array" и "comma". Строка "array" также выше в алфавитном по-
рядке строки "comma", поэтому от вершины, содержащей стро-
ку "comma", вновь спускаемся к вершине нижнего уровня по
левой ветви. Итог третьего этапа показан на рис. 8.14.
Глава 8. Примеры разработки программ
429
root
Рис. 8.14. Дерево после трех включений
Результат ввода следующей строки "name" приведен на
рис. 8.15.
root
Рис. 8.15. Дерево после четырех включений
430
Программирование на языке Си
Первое же сравнение строк "line" и "name" показывает, что
"name" располагается в алфавитном порядке ниже "line", поэто-
му из вершины "line" необходимо выйти по правой ветви. Эта
ветвь не ведет ни к какой вершине, поэтому к ней и присоеди-
няется вершина нижнего уровня со строкой "name" (см.
рис. 8.15).
Итогом описанного процесса будет бинарное дерево, пока-
занное на рис. 8.12.
После того как мы построили бинарное дерево на бумаге, пе-
рейдем к его описанию на языке Си. Каждая вершина должна
содержать символьный массив для представления слова в виде
строки и указатели на две вершины нижнего уровня - для левой
и правой ветвей. Определение структурного типа для структур,
представляющих вершины дерева, может быть, например, та-
ким:
struct node
{
char str[MAXLINE];
struct node *left;
struct node *right;
1;
С учетом приведенного определения структурного типа вер-
шину дерева можно изобразить графически (рис. 8.16).
str[MAXLINE]
left | right
Рис. 8.16. Структурное представление вершины бинарного дерева
Как правило, заранее не известны длина каждого конкретно-
го слова - массива str и количество слов в исходном файле. В
силу этого целесообразно динамически выделять память как для
каждой вершины дерева, так и для собственно массива, храня-
щего слово в виде строки.
Глава 8. Примеры разработки программ
431
Модифицируем описание структурного типа, соответствую-
щего вершине дерева, следующим образом:
struct node
{
char *str;
struct node *left;
struct node *right;
1;
Теперь в структуре типа struct node вместо массива симво-
лов фиксированной длины для слова из сортируемого файла ис-
пользуется указатель на строку. Память для каждой строки
(массива типа char[ ]) необходимо запрашивать у операционной
системы в соответствии с длиной конкретного слова.
Приведенному описанию соответствует графическое пред-
ставление, изображенное на рис. 8.17.
Рис. 8.17. Модифицированное структурное представление вершины
бинарного дерева
С учетом приведенного определения структурного типа для
вершин бинарного дерева нарисуем еще раз (рис. 8.18) дерево,
приведенное выше на рис. 8.12.
На рис. 8.18 указателям, не содержащим адреса какой-либо
вершины, присвоено значение NULL; указатель root типа struct
node * содержит адрес начальной вершины дерева.
Уточним алгоритм ввода очередного слова и построения со-
ответствующей вершины.
Введя слово, необходимо, двигаясь от начальной вершины:
1) сравнить введенное слово со словом, хранящимся в дан-
ной вершине дерева (на него указывает str);
432
Программирование на языке Си
root
Рис. 8.18. Структурное представление бинарного дерева, полученное
в результате сортировки строк
2) если введенная строка (слово) в алфавитном отношении
расположена выше, то следует двигаться по левой ветви к
вершине нижнего уровня, иначе,- по правой ветви, тоже
вниз;
3) если достигли конца пути, т.е. указатель, на вершину
нижнего уровня равен NULL, то надо выполнить опера-
ции по созданию и подключению к дереву новой верши-
ны, а именно:
• с помощью функции 1паПос() запросить память для
вершины в виде структуры типа struct node;
Глава 8. Примеры разработки программ
433
• с помощью функции malloc() запросить память для
представления очередного слова в виде строки;
• записать в полученный участок памяти введенную стро-
ку (слово);
• установить значения указателей новой вершины (в
структуре типа struct node):
- указатель str - на участок памяти, выделенный для
очередной строки со словом;
- указателям left и right присвоить значение NULL, так
как ни один из них пока не адресует вершину нижне-
го уровня;
• записать в указатель left или right предыдущей вершины
(на пройденном от начальной вершины пути) адрес уча-
стка памяти, выделенного под новую вершину дерева.
Объединим действия, описанные выше в пункте 3, в функ-
цию new_node() - "Создать новую вершину". Алгоритм в це-
лом, т.е. действия пунктов 1-5-3, оформим в виде функции
add_node(), которая будет вызывать функцию new_node().
Главная функция, в которой будет вызываться функция
add_node( ), должна выполнить следующие действия:
• получить имя файла с данными для сортировки;
• открыть файл для чтения;
• инициализировать нулевым значением (NULL) указатель
root на начальную вершину дерева;
• в цикле (до исчерпания данных из файла): читать очеред-
ную строку (слово) из файла и вызывать для каждой стро-
ки функцию add_node(). • .
Теперь можно приступить к написанию текстов всех указан-
ных функций. Начнем с функции main( ):
#include <stdio.h>
#define MAXLINE 80
/* Определение структурного типа "node" */
struct node
(
char’* s tr;
struct node *left;
28-3'2*
434
Программирование на языке Си
struct node *right;
} ;
int main (int argc, char *argv[ ])
{
struct node *add_node(struct node *root,
char *line) /* Прототип */;
void print(struct node *ptr);
struct node *root = NULL;
FILE *fp;
char line[MAXLINE];
if ((fp = fopen(argv[l],"r")) != NULL)
(
while (fgets(line, MAXLINE, fp))
root = add_node(root,' line);
}
else
<
perror( argv[l]);
return -1;
)
print(root);
return 0;
)
Текст функции main() не сложен и не требует пояснений.
Функция print(), вызываемая перед оператором return, предна-
значена для печати результатов сортировки; она рассматривает-
ся ниже.
Функции add_node( ), которая вызывается в теле цикла while,
необходимо передать два параметра: прочитанную из файла
строку (слово) line[ ] и указатель root на корневую вершину в
дереве, так как при включении в дерево новой вершины про-
смотр дерева каждый раз начинается с корневой вершины.
Ниже приводится текст функции add_node( ).
#inclUde <string.h>
#include <stdio.h>
struct node
(
char *str;
struct node *left;
Глава 8. Примеры разработки программ
435
struct node *right;
In-
struct node *add_node(struct node *root,
char *line)
<
struct node **prior;
struct node *ptr; /* Указатель на текущую
вершину */
struct node *new_node(char *line);
if (root != NULL)
(
ptr = root;
while (ptr != NULL)
/* Введенная строка выше в алфавитном порядке */
if (strcmp(line, ptr->str) <= 0)
( /* Идем по левой ветви */
prior = fiptr->left;
ptr = ptr->left;
)
else
( /* Новая строка ниже в алфавитном
порядке; идем по правой ветви */
prior = fiptr->right;
ptr = ptr->right;
} /♦ Конец цикла */
♦prior = new_node(line);
return root;
} /* end if */
return new_node(line);
}
Если указатель root на корневую вершину дерева имеет зна-
чение NULL (дерево пустое), то вызывается функция
new_node( ), которая создает первую (корневую) вершину дере-
ва и записывает в указатель root адрес этой вершины.
Если же указатель root имеет значение, отличное от NULL (в
дереве существует хотя бы одна вершина), то выполняется цикл
спуска по ветвям дерева до вершины, содержащей нулевой ад-
рес в соответствующей ветви, и вызывается функция
new_node(). для создания новой вершины. Рассмотрим подроб-
28*
436
Программирование на языке Си
нее этот процесс для случая, когда в дереве присутствуют две
вершины (рис. 8.19) и "подключается" слово "array".
Цифрами 1 и 2 показаны те вершины и указатели ветвей, ад-
реса которых содержат указатели ptr и prior, соответственно,
после первого (1) и второго (2) выполнение цикла while. Указа-
тель ptr содержит адрес текущей вершины.
root
Рис. 8.19. Подключение к дереву новой вершины
Конструкция **prior определяет переменную prior как указа-
тель на указатель. Перед чтением третьего слова из файла ука-
затель prior будет содержать адрес элемента ptr->left, в который
вместо NULL необходимо записать адрес новой вершины дере-
ва, так как введенное слово (array) находится выше в алфавит-
ном порядке, чем слово из второй вершины дерева (comma).
Указателю ptr присваивается после второго выполнения цикла
значение NULL, так как ниже второй вершины других вершин
нет.
Глава 8. Примеры разработки программ
437
Напомним, что функция new_node( ) должна выполнить сле-
дующие действия:
• запросить динамическую память для новой вершины дере-
ва (для структуры struct node);
• проинициализировать указатели left и right созданной
структуры значениями NULL;
• запросить память в виде массива типа char[ ] для сохране-
ния введенной из файла строки (слова);
• вернуть в функцию add_node() адрес участка памяти, где
размещена новая вершина.
В функцию new_node( ) необходимо передать один аргумент
- вновь введенную строку из файла. Текст функции new_node()
приводится ниже.
#include <alloc.h>
#include <string.h>
#include <stdio.h>
struct node
{
char *str;
struct node *left;
struct node *right;
) ;
struct node *new_node(char *line)
(
struct node *ptr;
ptr = (struct node*)
malloc(sizeof(struct node));
ptr->str = (char *)malloc(strlen(line) + 1);
strcpy(ptr->str, line);
ptr->left=ptr->right = NULL;
return ptr;
)
Операция sizeof, используемая при вызове функции malloc(),
вычисляет в байтах длину структуры, описывающей вершину
дерева. Выражение (strlen(line)+l) в следующей строке в каче-
стве параметра функции malloc() задает размер необходимой
для хранения введенной строки, добавляя один байт для записи
в конце строки '\0'.
438
Программирование на языке Си
Печать результатов сортировки. Для того чтобы напеча-
тать в алфавитном порядке результаты сортировки слов, вклю-
ченных в вершины дерева, необходима функция обхода дерева
по определенному маршруту. Сначала рассмотрим пример не-
большого бинарного дерева, приведенный на рис. 8.20.
Такое дерево легко получится при вводе, например, такой
последовательности букв латинского алфавита: D, В, С, F, А, Е,
G (введены все буквы в диапазоне от А до G). Рассматривая это
дерево, можно заметить, что буквы А и G (открывающая и за-
крывающая отсортированную последовательность) расположе-
ны на третьем (нижнем) уровне, соответственно слева и справа.
Для того чтобы напечатать буквы в алфавитном порядке, необ-
ходимо спуститься от корня дерева по левым ветвям до самой
нижней вершины. Там и будет первый элемент отсортирован-
ной последовательности букв. Увидев, что левый указатель ра-
вен NULL, напечатаем А и проверим указатель правой ветви.
Он также равен NULL, поэтому поднимемся к предыдущей
вершине и напечатаем В. Спускаемся от В по правой ветви к С и
видим, что вниз по левой ветви от С указатель равен NULL,
следовательно, печатаем С. Далее идем вверх к В (эта буква уже
напечатана), поднимаемся к D и печатаем ее.
root
I
D
/ \
В F
/ \ / \
А С Е G
/\/\/\/\
Рис. 8.20. Пример бинарного дерева
Аналогичным образом обходим правое от D поддерево. В
итоге получается маршрут, изображенный на рис. 8.21.
Глава 8. Примеры разработки программ
439
Ниже приводится текст функции print( ), осуществляющей
обход дерева и печать строк из вершин в алфавитном порядке.
Для запоминания указателей на предыдущие узлы в функции
организован стек глубиной 10 элементов в виде массива из 10
указателей на структуру типа struct node.
Оператор stack[i++] = ptr; заносит в стек значение указателя
ptr и затем (постфиксная операция ++) увеличивает значение
индекса (i) массива на 1. После этого stackfi] становится первым
свободным элементом стека. Для выборки из стека значения
указателя необходимо сначала уменьшить индекс i на единицу,
с тем, чтобы stackfi] был не первым свободным элементом мас-
сива, а последним записанным:
ptr=stack[—i] ;
Root
Рис. 8.21. Обход бинарного дерева при печати
Текст функции print():
#include <stdio.h>
struct node
(
char *str;
struct node *left;
struct node *right;
};
void print(struct node *ptr)
440
Программирование на языке Си
int i = 0;
struct node *stack[10]; /* Внимание: число
уровней, на которых расположены
вершины в бинарном дереве, - не более 10
(в рассматриваемом примере 3 уровня */
while(1)
{ •
while (ptr •= NULL)
{
stack[i++] = ptr;
ptr = ptr->left;
J
ptr = stack[—i];
if (i < 0) break;
printf("%s", ptr->str);
ptr = ptr->right;
)
Подробно процесс подготовки и выполнение программы
сортировки на основе бинарного дерева в операционных систе-
мах UNIX, MS-DOS и Windows обсуждаются в главе 9.
ВЫПОЛНЕНИЕ
ПРОГРАММ
В РАЗНЫХ
ОПЕРАЦИОННЫХ
СИСТЕМАХ
Глава 9
ПОДГОТОВКА И ВЫПОЛНЕНИЕ
ПРОГРАММ
Упрощенная схема подготовки программ, существующая во
многих операционных системах, изображена на рис. 9.1 (см.
также §2.1, рис. 2.1):
Рис. 9.1. Упрощенная схема подготовки исполняемой программы
Текст программы, набранный в любом текстовом редакторе
и сохраненный в файле в виде последовательности кодов сим-
волов, называется исходным модулем. Имена файлов, как пра-
вило, имеют сложную структуру: кроме собственно имени
файла (произвольно назначаемого пользователем) указывается
расширение, задающее тип файла. Файлы, содержащие тексты
программ и функций на языке Си, обычно имеют расширение
"с". В тех операционных системах, где на уровне файловой сис-
темы не различаются строчные и прописные буквы (MS-DOS
или Windows), расширение может иметь и такой вид - "С". В
любом случае имя файла от его расширения отделяется точкой.
Исходные модули обрабатываются компилятором, в резуль-
тате чего получается промежуточный модуль, называемый объ-
ектным модулем. Объектный модуль состоит из двух
основных частей: тела модуля, представляющего собой про-
грамму в кодах команд конкретной ЭВМ, и заголовка, содер-
жащего внешние имена (имена переменных, используемых в
444
Программирование на языке Си
данном модуле, но определенных в других модулях). Эта ин-
формация необходима для построения из набора объектных мо-
дулей программы или программной системы, готовой к
выполнению.
Объектные модули обрабатываются компоновщиком, кото-
рый строит исполняемую программу, содержащую только ко-
манды ЭВМ. В зависимости от операционной системы испол-
няемую программу могут называть исполняемым файлом, ехе-
модулем, загрузочным модулем и т.п. При построении испол-
няемой программы к объектным модулям, полученным из ис-
ходных модулей программной системы, подключаются объект-
ные модули из одной или нескольких библиотек, содержащих,
например, объектные модули функций ввода-вывода, вспомога-
тельных библиотечных функций (обработка строк, массивов,
выделение динамической памяти и т.д.).
Существование промежуточного объекта (модуля) в цепочке
построения готовой к выполнению программы позволяет:
• сделать систему программирования гибкой и удобной в
эксплуатации за счет предварительной разработки библио-
тек объектных модулей, содержащих множество вспомога-
тельных функций;
• разрабатывать и использовать собственные библиотеки
объектных модулей, содержащие функции, общие для от-
дельных частей программной системы;
• при модификации программной системы перестраивать
только части, подвергшиеся доработке.
На различных этапах разработки программы или программ-
ной системы программистом может применяться разная техно-
логия сборки готовой к выполнению программы, например:
• главная функция и все подготовленные программистом
вспомогательные функции программной системы находят-
ся в одном текстовом файле;
• главная функция и вспомогательные функции находятся в
разных текстовых файлах, но собираются в один исходный
модуль с помощью препроцессорных команд #include;
• главная функция и вспомогательные функции находятся в
разных текстовых файлах, транслируются отдельно, и ис-
Глава 9. Подготовка и выполнение программ
445
полняемая программа собирается компоновщиком из объ-
ектных модулей;
• вспомогательные функции транслируются отдельно, отла-
живаются на тестовых примерах, и из них формируют лич-
ную библиотеку объектных модулей, которая применяется
для сборки программной системы.
Пример размещения текста программы в нескольких файлах
приведен в §8.1. Программа для исследования псевдослучайной
последовательности может быть собрана в один файл с помо-
щью директив ^include. Рассмотрим вариант такого же по-
строения программной системы с объединением всех исходных
модулей в один файл с помощью препроцессорных директив
^include на примере работы с базой данных о сотрудниках
предприятия из §8.2.
Исходный модуль, объединяющий все функции и объекты
программы, будет иметь следующую структуру:
• определения внешних переменных, т.е. объектов, исполь-
зуемых во вспомогательных функциях (массив структур st
типа struct person, управляющие переменные);
• главная функция и вспомогательные функции:
• main() {...} /* главная функция */
• init() {...} /* инициализировать базу данных */
• find() {...} /* поиск в списке занятых элементов */
• fr() {...} /* возвратить освобожденный элемент в
список свободных элементов */
• delete() {...} /* удалить сведения о сотруднике */
• input() {...} /* ввод данных о новом сотруднике */
• print() {...} /* печать содержимого базы данных */
• save() {...} /* сохранить базу данных в файле */
• load() {...} /* загрузить базу данных из файла */
Собрать в один файл все модули программы можно с помо-
щью препроцессора, если включить в текст основной функции
набор препроцессорных директив:
/* Определения внешних переменных, т.е.
объектов, используемых во вспомогательных
функциях (массив структур st типа struct
446
Программирование на языке Си
person, управляющие переменные) */
#include
♦include
♦include
*include
#inelude
#include
#include
♦include
"init.c"
"find.c"
"fr.c"
"delete.c"
"input.c"
"print.c"
"save.c"
"load.c"
main()
{................)
В фазе препроцессорной обработки компилятором будет со-
бран модуль, содержащий исходные тексты всех функций про-
граммной . системы. Способ препроцессорной сборки более
удобен по сравнению со способом размещения исходных моду-
лей в одном файле, так как каждая функция находится в отдель-
ном файле, что облегчает модификацию текстов функций.
Однако оба эти способа являются технологичными только для
малых (или очень малых) программных систем.
Даже небольшая программная система, если она хорошо
спроектирована, часто содержит значительное количество
функций и текстов определений и описаний внешних
(глобальных) объектов, размещенных в отдельных файлах. Не-
обходимо заметить, что сопряжение функций по данным с по-
мощью внешних переменных (объектов) или с помощью пара-
метров, передаваемых в функции, следует предусмотреть на эта-
пе разработки исходного текста программной системы.
Развитие любой программной системы приводит к тому, что
в итоге ее структура становится сложной, и программисту труд-
но удержать в голове логическую схему этой структуры. Посто-
янно. следить за файлами, которые требуют перекомпиляции
после внесения изменений, становится невозможным.
Современные операционные системы и системы программи-
рования предлагают пользователю средства, в той или иной
степени решающие задачу автоматизации процедуры поддерж-
ки разрабатываемой программной системы.
Глава 9. Подготовка и выполнение программ 447
Рассмотрим соответствующие инструментальные средства в
таких популярных операционных системах, как UNIX, MS-DOS,
Windows.
9.1. Подготовка программ в операционной
системе UNIX
В UNIX для документирования взаимосвязей между модуля-
ми и для автоматизации построения программной системы слу-
жит команда make. Исходной информацией для команды make
служит описание взаимосвязей модулей, на основе которого ко-
манда make собирает программную систему. При дальнейших
модификациях текстов отдельных частей системы описание
взаимосвязей модулей позволяет команде make перестраивать
при сборке программной системы только ту часть системы, ко-
торая подверглась модификации.
Прежде чем перейти к рассмотрению работы команды make,
построим программу сортировки на основе бинарного дерева,
описанную в главе 8, традиционным способом, вводя необхо-
димые команды через командную строку.
Программа сортировки состоит из 4 функций, размещенных
в отдельных файлах:
• tree.c - главный модуль;
• add_node.c - функция заполнения новой вершины дерева;
• new_node.c - функция создания новой вершины дерева;
• print.c - функция обхода и печати содержимого вер-
шин дерева.
Схема подготовки исполняемой программы в UNIX приведе-
на на рис. 9.2.
От традиционной для почти всех операционных систем схе-
мы подготовки исполняемых программ схема на рис. 9.2 отли-
чается тем, что в UNIX трансляция исходного модуля ведется на
язык ассемблера и исполняемый модуль, если не указано друго-
го, имеет стандартное имя a.out Выбор фиксированного имени
объясняется тем, что UNIX в свое время создавалась для удоб-
ной разработки и отладки программ. В режиме отладки нет не-
448
Программирование на языке Си
обходимости хранить промежуточные версии исполняемых
программ и вполне можно называть их одним именем'.
Рис. 9.2. Схема подготовки исполняемой программы в UNIX:
*.с - исходный модуль на языке Си;
*.а - модуль на ассемблере;
*.о - объектный модуль;
a.out - стандартное имя исполняемого модуля
(исполняемой программы); ’
сс - компилятор языка Си;
as - компилятор языка ассемблера;
Id - компоновщик (редактор связей).
Компилятор Си позволяет за одни вызов выполнить всю це-
почку преобразования исходного модуля в исполняемую про-
грамму. Для задания последовательности преобразований в
команде вызова компилятора сначала указываются ключи ком-
пилятора, а затем ключи и параметры компоновщика.
Формат команды сс, вызывающей компилятор языка Си,
предусматривает задание следующих параметров (в форматах
команд операционных систем принято помещать необязатель-
ные элементы в квадратные скобки [ ]):
сс [-ключи] исходные модули [ключикомпоновщика}
[объектные модули} [библиотеки}
где
ключи — однобуквенные параметры, задающие режимы работы
компилятора. Перед каждым ключом должен стоять знак
минус ('-'). После некоторых ключей могут указываться
дополнительные параметры. Приведем некоторые (наи-
более часто употребляемые) ключи команды сс:
Глава 9. Подготовка и выполнение программ
449
- с - транслировать исходный модуль в объектный;
- р - провести только препроцессорную обработку исходного
модуля;
- s - транслировать исходный модуль в модуль на языке ас-
семблера;
- о имяисполняемойпрограммы — при необходимости тран-
слировать и задать произвольное (отличное от стан-
дартного "a.out ") имя для исполняемой программы;
исходные модули - полные имена (с расширением "с") одного
или нескольких исходных модулей;
объектные_модули - полные имена (с расширением "о") тех
модулей, которые будут использованы при построении
исполняемой программы;
ключикомпоновщика - задают режимы работы компоновщика
(для нас представляет интерес ключ -1, определяющий
имя библиотеки объектных модулей):
- 1библиотека_объектных_модулей
Примечание. Способ указания имени библиотеки объектных
модулей объясняется ниже в разделе "Библиотеки объектных
модулей" (9.1.2).
Если программа состоит из одного исходного модуля, то для
построения исполняемого модуля достаточно выполнить ко-
манду (% - приглашение от операционной системы):
%сс main.с
Исходный модуль будет последовательно преобразован (см.
рис. 9.2) в модуль на языке ассемблера, объектный модуль, ис-
полняемый модуль. Исполняемый модуль получит стандартное
имя a.out. При повторном вызове компилятора языка Си коман-
дой сс и указании в качестве параметра команды имени другого
исходного модуля вновь полученный исполняемый модуль так-
же будет иметь имя a.out, но будет соответствовать другому
исходному (только что обработанному) модулю.
Для того чтобы определить произвольное имя исполняемого
модуля, необходимо в команде вызова компилятора указать
ключ -о и сразу за ним через пробег задать имя исполняемого
модуля:
29’3124
450
Программирование на языке Си
%сс -о begin main.с
Построение исполняемого модуля можно провести в два эта-
па с промежуточным получением объектного модуля:
%сс -с main.с
%сс -о begin main.о
В первой строке применен ключ -с, в результате чего про-
цесс обработки исходного модуля прервется, когда будет полу-
чен объектный модуль (main.о).
Во второй строке определено имя исполняемого модуля
begin и в качестве параметра команды сс указано имя объект-
ного модуля (main.о), полученного на предыдущем этапе.
Для построения исполняемого модуля разработанной в гла-
ве 8 программы сортировки на основе бинарного дерева необ-
ходимо в простейшем случае перечислить при вызове команды
сс в качестве параметров имена всех исходных модулей функ-
ций, из которых состоит программа сортировки:
%сс -о tree tree.с add_node.c new_node.c print.с
Однако для того чтобы при внесении изменений в исходные
тексты отдельных функций не транслировать повторно и те ис-
ходные модули, в которые не вносились изменения, целесооб-
разно получить объектные модули, а затем построить
исполняемую программу из полученных объектных модулей.
Таким образом, для построения исполняемого модуля разра-
ботанной в главе 8 программы сортировки на основе бинарного
дерева необходимо:
1) подготовить объектные модули всех функций (символ '%'
в начале строки является подсказкой операционной системы):
%сс -с tree.с
%сс -с add_node.c
%сс -с new_node.c
%сс -с print.с
В результате выполнения приведенных команд транслятор,
вызываемый 4 раза, создаст четыре объектных модуля: free.o,
addnode.o, new_node.o, print.o;
Глава 9. Подготовка и выполнение программ
451
2) построить из полученных в результате трансляции объект-
ных модулей исполняемый модуль:
%сс -о tree tree.о add_node.o new_node.o print.о
Напомним, что ключ -о и следующий за ним параметр tree
задают имя исполняемой программе, отличное от a.out. Далее
следует список объектных модулей, участвующих в построении
исполняемого модуля программы сортировки.
При внесении изменений в один из модулей, например в мо-
дуль add_node.c, необходимо получить обновленный вариант
объектного модуля add_node.o и собрать новый вариант испол-
няемого модуля.
%сс -с add_node.с
%сс -о tree tree.о add_node.o new_node.o print.о
При внесении изменений в несколько модулей необходимо
вести учет этих изменений либо транслировать заново все вхо-
дящие в программный комплекс модули. Только в этом случае
можно быть уверенным в том, что построенный исполняемый
модуль учитывает все последние изменения в функциях и го-
ловном модуле.
9.1.1. Команда make
Команда make позволяет документировать взаимосвязи ме-
жду модулями и освобождает пользователя от рутинной работы
по слежению за изменениями в модулях.
Команда make при вызове обновляет (перестраивает) испол-
няемый модуль, причем транслируются только те функции, в
исходные тексты которых были внесены изменения.
Исходными данными для команды make служит файл опи-
саний зависимостей модулей. Описания зависимостей модулей
и соответствующих действий хранятся в так называемом таке-
файле, который по умолчанию называется makefile или
Makefile. В этом случае он может не указываться при вызове
команды make. При выборе для таЛе-файла (файла зависимо-
29*
452
Программирование на языке Си
стей) произвольного имени часто назначают имена, начинаю-
щиеся с заглавной буквы, так как при просмотре содержимого
каталога (в UNIX для просмотра используется команда Is -1) они
будут располагаться в верхней части списка модулей каталога,
что облегчает поиск и распознавание /иаЛе-файлов.
Приведем текст файла зависимостей модулей для программы
сортировки на основе бинарного дерева. В простейшем случае
/иа£е-файл будет выглядеть так:
tree: tree.о add_node.o new_node.o print.о
сс -о tree tree.о add_node.о new_node.о print.о
В первой строке первым параметром перед символом ука-
зывается имя так называемого целевого файла, а после символа
приводится список имен файлов, от которых зависит целевой
файл. Эта строка информирует команду make о необходимости
выполнить команду, записанную в следующей строке, если ка-
кой-либо из объектных модулей (файлы *.о) имеет более позд-
нюю дату модификации по сравнению с целевым файлом tree,
являющимся в нашем примере исполняемым модулем програм-
мы сортировки.
Если какой-либо из исходных модулей на препроцессорном
уровне включает файл с текстом части программы, то описание
зависимостей файлов необходимо дополнить соответствующей
строкой по следующему образцу:
prog.о а.о: def.h
Здесь указано, что объектные модули prog.o и а.о зависят от
включаемого (директивой ^include) файла def.h.
Помимо описаний зависимостей, команда make использует в
процессе своего выполнения набор так называемых встроенных
правил. Одно из основных правил: повторно должны быть от-
компилированы лишь те исходные модули, дата последней мо-
дификации которых оказалась старше даты создания
соответствующего им объектного модуля. Компилируются^ ко-
нечно, и те исходные модули, для которых соответствующие
объектные модули не существуют. Таким образом, команда
make осуществляет лишь те минимальные действия, без кото-
Глава 9. Подготовка и выполнение программ
453
рых невозможно было бы получить новую версию целевого
файла.
Формат файла описаний зависимостей модулей. Файл
описаний зависимостей модулей представляет собой текстовый
файл, содержащий последовательность строк, которые являются
набором спецификаций взаимозависимостей, используемых
командой make при ее выполнении. Спецификация взаимозави-
симостей имеет следующую структуру:
• имя целевого файла;
• последовательность имен файлов, от которых зависит це-
левой файл;
• последовательность команд UNIX, которая должна быть
выполнена, если дата последней модификации хотя бы од-
ного из файлов, от которых зависит целевой файл, старше
даты модификации целевого файла.
Формат спецификации взаимозависимостей следующий:
targetlf target! ... ]:[:] [depend 1 .. .][# ...]
[(tab)commands] [#]
где (квадратные скобки означают необязательность элементов)
target... - целевые файлы, имена которых разделяются
пробелами;
: (или ::) - разделитель - в первом случае (для ':') после-
дующая последовательность команд UNIX
(commands) должна содержаться в одной
строке файла описаний, а во втором она мо-
жет располагаться в нескольких строках;
depend ... - последовательность имен файлов, от которых
зависит целевой файл (разделяются пробела-
ми);
(tab) - символ "Табуляция", которым предваряются
командные строки UNIX;
commands - команды UNIX, с помощью которых должен
быть получен целевой файл;
# - признак начала комментария (комментарий -
часть строки от символа до конца строки).
454
Программирование на языке Си
Примечание. Если список имен файлов, от которых зависит
целевой файл, не умещается на одной строке, для обозначе-
ния переноса части списка на другую строку можно восполь-
зоваться символом 'V, например:
tree: tree.о \
add_node.o \
newnode.o \
print.o
команды UNIX
Формат команды make. Команда make имеет следующий
формат:
make [-f таке)11е][ключи][имена][макро_определения]
Квадратные скобки, выделяющие параметры, означают их
необязательность. Параметры в команде отделяются друг от
друга пробелами.
Первый параметр с ключом -f задает имя файла зависимо-
стей модулей, если это имя отлично от makefile или Makefile.
Из множества ключей, определяющих режим работы коман-
ды make, упомянем следующие, необходимые для отладки
дагйе-файла:
- р - вывести в стандартный поток вывода полный список
зависимостей модулей;
- i - игнорировать коды возврата выполненных команд
(позволяет отладить сложный дааА’е-файл);
- п - вывести в стандартный поток вывода строки с коман-
дами UNIX, не выполняя их.
Параметр имена позволяет задавать имена целевых файлов.
Коротко остановимся на некоторых возможностях команды
make, которые не используются в нашем примере.
Макроопределения. Команда make позволяет использовать
при записи спецификаций взаимозависимостей макроопределе-
ния. Это дает возможность добиться большей наглядности фай-
ла описаний взаимозависимостей и использовать один и тот же
файл описаний для различных имен целевых файлов и файлов,
от которых зависит целевой файл.
Глава 9. Подготовка и выполнение программ
455
Макроопределения записываются в соответствии со сле-
дующим форматом:
имямакроса = значение
где имя макроса - имя макроса команды make;
значение - строка символов, которая подставляется вме-
сто конструкции $(имя_макроса) при ее использовании в стро-
ках файла взаимозависимостей.
Пример макроопределения:
СС=сс
После такого макроопределения контекст вида $(СС) будет
заменен в строках дааА’е-файла на сс.
Введем в качестве первой строки в приведенный выше файл
описаний взаимозависимостей для целевого файла tree следую-
щее макроопределение:
OBJECTS=tree.о add_node.о new_node.о print.о
Тогда позже в том же файле для указания объектных моду-
лей, перечисленных справа от знака равенства, можно приме-
нять конструкцию $(OBJECTS).
Теперь файл взаимозависимостей для программы сортировки
на основе бинарного дерева будет выглядеть так:
OBJECTS=add_node.о new_node.о print.о
tree: tree.о $(OBJECTS)
сс -о tree tree.с S(OBJECTS)
Встроенные правила. В процессе выполнения команда
make использует набор так называемых встроенных правил.
Одним из подмножеств этого набора являются правила автома-
тического установления взаимосвязей между файлами по суф-
фиксам их имен. Например, когда в команде make в качестве
параметра задано имя файла с суффиксом '.с', автоматически
выполняется вызов компилятора языка Си, который строит ис-
полняемый модуль из исходного модуля, находящегося в задан-
ном файле. Таблицу встроенных правил команды make,
соответствующих конкретной реализации UNIX, можно найти в
456
Программирование на языке Си
документации по операционной системе. Здесь стандартные
встроенные правила мы рассматривать не будем.
Программист может изменить встроенное правило, для чего
новый вариант правила необходимо включить в файл описаний
зависимостей, т.е. во входные данные для make.
Простейшее правило, описывающее процедуру подготовки
исполняемого модуля из исходного модуля (расширение имени
'с', суффикс имени '.с'), будет выглядеть так:
.с:
сс -о $@ $*.с
где $@ - внутренний макрос команды make, предназначен-
ный для спецификации полного имени целевого файла;
$* - внутренний макрос, определяющий префикс име-
ни файла.
Это правило, включенное в файл описаний зависимостей мо-
дулей, заменит внутреннее правило команды make для суффик-
са '.с'
Если теперь ввести команду make с указанием имени целе-
вого файла (исполняемой программы)
%mak.e prog
то исходный файл prog.c будет скомпилирован, а исполняемый
модуль получит имя prog.
С помощью команды make может быть решено множество
задач, связанных с программированием как на языках высокого
уровня, так и на командных языках, например, на командном
языке UNIX (sh, csh, ksh,...). Однако основное применение
make - учет взаимозависимостей между исходными текстами
модулей в больших программных комплексах.
9.1.2. Библиотеки объектных модулей
При разработке программной системы объектные модули
функций, входящих в ее состав, целесообразно размещать в
библиотеках объектных модулей, а в командной строке вызова
компилятора указывать эти библиотеки. Использование библио-
Глава 9. Подготовка и выполнение программ
457
тек позволяет не задавать непосредственно в командной строке
все необходимые для построения исполняемой программы объ-
ектные модули. Компоновщик на этапе построения исполняе-
мой программы будет выбирать из библиотеки только те объек-
тные модули функций, которые необходимы.
Стандартные библиотеки. Стандартные библиотеки UNIX
хранятся в каталогах /lib или /usr/lib. Ссылка на библиотеки
осуществляется при помощи ключа компоновщика -1, который
задается в команде сс вызова компилятора языка Си после всех
ключей и параметров компилятора. Непосредственно за ключом
(без пробела) указывается идентификатор библиотеки, например
%сс .... -1х
где х - часть имени библиотеки (полное имя библиотеки в дан-
ном случае libx.a; стандартный префикс для библиотеки "lib";
стандартное расширение имени для библиотеки 'а'). Обратите
внимание, что libx.a есть название библиотеки, а не отдельного
модуля, поэтому суффикс '.а' не обозначает "модуль на ассемб-
лере", как, например, на рис. 9.2.
Стандартная библиотека языка Си просматривается компо-
новщиком автоматически, т.е. указание этой библиотеки в ко-
мандной строке вызова компилятора Си не требуется. Эта биб-
лиотека хранится в файле /lib/libc.a.
Библиотека математических функций хранится в файле
/lib/libm.a, поэтому указание библиотеки в команде вызова ком-
пилятора будет таким: -1ш. Напомним, что ключ -1, являющий-
ся ключом компоновщика, необходимо разместить в командной
строке вызова компилятора Си после всех других ключей и па-
раметров, так как просмотр библиотеки должен происходить
после компиляции, когда становится известно, какие функции
из библиотеки нужны для построения исполняемого модуля.
Создание и сопровождение собственных библиотек. В
UNIX для создания и сопровождения библиотек объектных мо-
дулей служит программа ar (abchivator - архиватор). Для биб-
лиотек в UNIX принят термин "архив"; отсюда в качестве
расширения имени библиотеки используется буква 'а'.
458
Программирование на языке Си
При создании библиотеки необходимо иметь в виду, что
компоновщик просматривает библиотечный файл только один
раз. Если объектный модуль функции ссылается на другие име-
на из той же библиотеки, то он должен быть расположен в биб-
лиотеке до этих объектных модулей. Некоторые версии UNIX
содержат программу ranlib, которая создает оглавление биб-
лиотеки, что позволяет компоновщику Id обращаться к элемен-
там библиотеки в произвольном порядке. В других версиях
UNIX (например, UNIX System V) функция построения оглав-
ления библиотеки встроена в программы аг и Id.
Главное назначение программы аг - создание и обновление
библиотечных файлов, используемых компоновщиком, однако
ее можно применять и для любых других аналогичных целей.
Формат команды аг:
аг -ключ [ключ...] [позиционное имя} архив имя. . .
Параметры в команде отделяются пробелами.
Параметр позиционное имя не является обязательным. Клю-
чей может быть несколько, тогда они записываются без пробе-
лов и только с одним знаком
Параметр архив задает имя архивного файла.
Параметр имя... является списком имен объектных модулей,
которые либо находятся в архиве, либо должны быть туда по-
мещены.
Ключи программы аг имеют следующий смысл:
- d -исключить указанные (с помощью параметра имя...}
файлы из архивного файла;
- г -заменить указанные (параметром имя...} файлы в ар-
хивном файле. Если вместе с ключом г задается необя-
зательный ключ и, то заменяются только файлы,
имеющие более поздние даты модификации, чем фай-
лы в архиве. Этот же ключ используется для включе-
ния в библиотеку новых файлов, т.е. файлы, указанные
параметром имя... и отсутствующие в библиотеке, до-
бавляются в архив. Обычно новые файлы помещаются
в конец архива. Если указать имя файла из архива в
Глава 9. Подготовка и выполнение программ
459
параметре позиционное_имя, то можно новые файлы
поместить до или после этого файла. Для этого необ-
ходимо соответственно добавить к ключу -г необяза-
тельные литеры b (before) или a (after);
- t - вывести в стандартный поток вывода оглавление ар-
хивного файла. При задании параметра имя... печата-
ется информация только об указанных этим парамет-
ром файлах. Этот же ключ используется для включе-
ния в библиотеку новых файлов, т.е. файлы, указанные
параметром имя... и отсутствующие в библиотеке, до-
бавляются в архив;
- р - вывести в стандартный поток вывода указанные
(параметром имя...) файлы из архива;
- х - извлечь из архива указанные (параметром имя...) фай-
лы. Если не задан параметр имя..., из архива извлека-
ются все файлы. В любом случае собственно архивный
файл не изменяется;
- v - выдавать пояснительные сообщения;
- с - создать архивный файл. Обычно программа аг при
необходимости создает архивный файл сама. Данный
ключ подавляет информационное сообщение, выда-
ваемое при создании архивного файла.
Для размещения в личной библиотеке объектных модулей
функций программы сортировки на основе бинарного дерева (из
гл. 8) необходимо выполнить следующую команду:
%ar -rv libtree.a add_node.o new_node.o print.о
Здесь libtree.a - имя библиотеки (архивного файла).
Ключ -г задает режим замены объектных модулей, храня-
щихся в библиотеке, на объектные модули, список которых
приведен в командной строке вызова архиватора аг после имени
библиотеки. Так как в момент обработки указанной команды
библиотеки не существовало, она будет создана автоматически.
Ключ -v определяет режим вывода пояснительных сообщений о
работе архиватора аг.
460
Программирование на языке Си
После занесения объектных модулей в библиотеку необхо-
димо при помощи программы ranlib скорректировать (или соз-
дать) оглавление библиотеки, выполнив команду
%ranlib libtree.a.
Программа ranlib впервые появилась в версии 7 UNIX фир-
мы AT&T и существует в таких реализациях операционной
системы UNIX, как FreeBSD и Solaris. Рекомендуется при ра-
боте в других реализациях UNIX ознакомиться со справочной
литературой, в которой описывается работа с библиотеками.
Наиболее простой способ получения информации о наличии
программы ranlib в составе ОС состоит в поиске этой програм-
мы в каталогах /bin, /usr/bin, /etc. Если эта программа найдена,
прочтите ее описание, которое можно получить на экране дис-
плея по "самой полезной" команде ОС UNIX - команде man,
позволяющей быстро получить справку по многим компонен-
там, командам и программам UNIX. Например, справку о про-
грамме ranlib можно получить так:
%man ranlib
Проверим созданную библиотеку, распечатав ее оглавление:
%ar -t libtree.a
___. SYMDEF
add_node.о
new_node.о
print.о
Первая строка - вызов программы-архиватора (аг). Послед-
ние 4 строки - это результат работы команды аг. Оглавление
библиотеки содержится в разделе библиотеки_.SYMDEF. Ос-
тальные строки - это имена объектных модулей, находящихся в
библиотеке. После того как библиотека объектных модулей
создана, можно построить исполняемый модуль программы
сортировки на основе бинарного дерева с помощью команды:
%сс -о tree tree.с -Itree
Здесь транслируется головной модуль (tree.с), объектные мо-
дули на этапе компоновки выбираются из библиотеки libtree.a, и
Глава 9. Подготовка и выполнение программ
461
строится исполняемая программа с именем tree. Ключ компо-
новщика -1 позволяет задать имя библиотеки объектных моду-
лей (полное имя библиотеки: libtree.a).
Предположим, что в исходный текст одной из функций
(например, add_node()) были внесены изменения. Тогда для по-
строения обновленного варианта исполняемой программы не-
обходимо выполнить следующие команды:
%сс -с add_node.c
%ar -rv libtree.a add_node.о
%сс -о tree tree.о -Itree
На этот раз нет необходимости в повторной трансляции го-
ловного модуля (он не подвергался правке), поэтому в послед-
ней строке задано имя уже существующего объектного модуля
tree. о.
Применим в той же задаче сортировки на основе бинарного
дерева команду make для поддержания личной библиотеки объ-
ектных модулей в таком состоянии, когда она всегда содержит
объектные модули, полученные из последних версий соответст-
вующих исходных модулей. Выше был приведен пример файла
зависимостей команды make, в котором все объектные модули,
используемые для построения исполняемого модуля программы
сортировки, указывались в командной строке вызова компиля-
тора. В варианте таке-^гмла, ориентированном на применение
личной библиотеки объектных модулей, появляются 2 целевых
файла: исполняемая программа сортировки (tree) и библиотека
объектных модулей (libtree.a), причем исполняемая программа
зависит от содержимого (объектных модулей) библиотеки.
Взаимозависимость этих объектов определяется следующим
образом:
tree: tree.о \
add_node.о \
new node.о \
print.о \
libtree.а
libtree.a: libtree.a(add_node.о) \
libtree.a(new_node.о) \
libtree.a(print.о)
462
Программирование на языке Си
Обратите внимание, как указаны зависимость целевого файла
tree от библиотеки libtree.a и, в свою очередь, ее зависимость от
объектных модулей. Объектный модуль из библиотеки libtree.a
указывается так:
имя_бибпиотеки( имямодуля).
Для окончательного оформления дааАг-файла используем два
встроенных макроса команды make:
$@ - задает имя текущего целевого файла (в нашем случае -
последнего (libtree.a));
$? - значение этого макроса вычисляется командой make -
это имена всех модулей, которые подвергались изменениям.
Приведем один из вариантов полного текста таке-файла
(напомним, что его имя по умолчанию - makefile), позволяю-
щего обновлять целевые файлы (исполняемую программу и
библиотеку объектных модулей) в соответствии с изменениями
в исходных текстах функций, входящих в состав программы
сортировки на основе бинарного дерева:
tree: tree.о \
add_node.о \
new_node.о \
print.о \
libtree.а
libtree.a: libtree.a(add_node.о) \
libtree.a(new node.о) \
/ —
libtree.a(print.о)
ar -rv $@ $?
ranlib $@
сс -о tree tree.с -Itree
Теперь для того, чтобы построить исполняемый модуль, учи-
тывающий все внесенные изменения в любые функции про-
граммы сортировки, необходимо просто набрать на клавиатуре
команду make.
После внесения изменений, например, в исходный текст
функции new_node() и при выполнении команды make получим
на экране дисплея следующий протокол:
Глава 9. Подготовка и выполнение программ
463
%make
сс -о -с new_node
ar -rv ' libtree.a new_node.o
г - new_node.о
ranlib libtree.a
сс -о tree tree.с -Itree
Строка, следующая за командой вызова архиватора аг (г -
new_node.o), - это сообщение архиватора о замене объектного
модуля new node.o в библиотеке libtree.a.
9.2. Сборка и выполнение программ в
интегрированной среде Turbo С 2.0
9.2.1. Состав системы программирования Turbo С 2.0
В современных операционных системах в состав систем про-
граммирования обычно входит интегрированная среда. Такая
среда содержит все необходимые средства разработки про-
грамм. Не выходя из среды, можно создавать, редактировать,
компилировать, выполнять, отлаживать программы на том язы-
ке программирования, для которого эта среда построена.
Интегрированная среда Turbo С 2.0 является удобным сред-
ством для разработки программ на языке Си. Эта среда, как и
другие интегрированные среды, функционирующие в операци-
онной системе MS-DOS, предназначена для работы в текстовом
режиме дисплея. Работа среды базируется на технике меню и
окон, причем для каждого выделенного пункта меню можно по-
лучить контекстно-зависимую подсказку.
В системе программирования Turbo С 2.0 компоненты обыч-
но размещаются в следующих каталогах:
• LIB - содержит стандартную библиотеку объектных моду-
лей языка Си, библиотеки объектных модулей математиче-
ских функций, функций графики и др.;
• INCLUDE - заголовочные файлы системы программирова-
ния Си;
464
Программирование на языке Си
• EXAMPLES - содержит исходные тексты функций (под-
каталог SOURCE), в основном математических, и про-
граммы (подкаталог TEST) для тестирования функций из
подкаталога SOURCE;
• ОСНОВНОЙ КАТАЛОГ (в который была установлена сис-
тема программирования Turbo С) - содержит следующие
программы и файлы:
ТС.EXE - исполняемая программа интегрированной
среды;
ТСС.EXE - компилятор Lattice С Compiler для работы
из командной строки;
СРР.ЕХЕ - препроцессор языка Си;
THELP.COM - резидентный справочник по интегриро-
ванной системе Turbo С 2.0 и языку Си. Справочник за-
пускается командой thelp.com для работы в фоновом
режиме, т.е. после его запуска на дисплей не выводится
никакой информации. Переход к работе со справочни-
ком производится по нажатию клавиши 5 на цифровой
клавиатуре и ведется в отдельном окне. Выход из спра-
вочника производится по клавише <Esc>.
Для нормального функционирования интегрированной среды
Turbo С 2.0 достаточно IBM PC/XT с 640 Кбайт оперативной
памяти. Работоспособный вариант среды Turbo С 2.0 занимает
на жестком диске менее 1 Мбайта.
Переход в интегрированную среду Turbo С 2.0 осуществля-
ется по команде tc.exe (или просто tc).
9.2.2. Экран интегрированной среды Turbo С 2.0
При выполнении команды вызова интегрированной среды на
экране дисплея появляется окно, показанное на рис. 9.3.
Основными структурными компонентами экрана интегриро-
ванной среды являются:
1 - строка меню, расположенная в верхней части экрана и
содержащая основное меню среды Turbo С 2.0;
2 - окно редактирования (Edit) исходного текста;
Глава 9. Подготовка и выполнение программ
465
3 - строка заголовка, в которой отображаются координаты
курсора: номер строки, номер позиции в строке и имя редакти-
руемого файла (курсор на экране изображается мигающим сим-
волом "подчеркивание");
4 - окно сообщений (Message), в которое помещаются тексты
сообщений об ошибках, выявленных при трансляции исходных
текстов или построении исполняемой программы;
5 - строка подсказки, содержащая информацию о назначении
функциональных клавиш.
1
Рис. 9.3. Структура экрана интегрированной среды Turbo С 2.0
Функциональные клавиши среды Turbo С 2.0:
F1 - контекстно-зависимая подсказка (выводится справ-
ка о функции команды основного меню или вспомо-
гательного меню, которая в данный момент выбрана
(подсвечена цветовым маркером); при повторном
нажатии клавиши <F1> выводится окно Главной по-
мощи: команды меню, "горячие" клавиши, команды
управления редактором текстов, процедура установ-
ки Turbo С, справки по синтаксису языка Си;
F5 - расширение (распахивание) выбранного (активного)
окна на всю доступную область экрана, располо-
зо-3’24
466
Программирование на языке Си
женную между строкой меню (1) и строкой под-
сказки (5);
F6 - осуществляет переключение между окнами
"Редактирование" (Edit) и "Сообщения" (Message);
F9 - скомпилировать и построить исполняемую про-
грамму;
F10 - переход в главное меню; выбранный пункт главного
меню выделяется цветовым маркером; перемещение
по главному меню осуществляется с помощью кла-
виш со стрелками.
9.2.3. Система меню среды Turbo С 2.0
Строка меню (1) содержит основную группу команд. Приве-
дем описание этих команд и команд, содержащихся в меню
нижнего уровня. Поясним те из них, которые необходимы для
проведения минимальных действий по созданию и отладке про-
стейших программ. При выборе пункта меню и нажатии на кла-
вишу <Enter> может появиться в отдельном окне так называе-
мое "ниспадающее" меню нижнего уровня, каждый пункт кото-
рого может либо порождать, в свою очередь, меню следующего
уровня, либо вызывать определенные действия (трансляция, ис-
полнение программы и т.д.), либо устанавливать (определять)
некоторый параметр среды, например имя ехе-файла, путь к ка-
талогу с заголовочными файлами и т.п. Для ссылки в нашем
описании на пункт главного меню будем использовать название
этого пункта. Для ссылки на пункты меню нижних уровней
применим следующую схему: укажем последовательно назва-
ния тех пунктов в системе меню, через которые необходимо
пройти, для того чтобы достичь обозначаемый пункт. В качест-
ве разделителей имен пунктов меню будем использовать символ
'|' (вертикальная черта). Например, для ссылки на пункт меню
Change directory (сменить рабочий каталог), который входит в
подменю File главного меню, будем пользоваться записью
File,Change directory. Напомним, что для перехода в главное
меню используется функциональная клавиша <F10>.
Глава 9. Подготовка и выполнение программ
467
Начальную информацию о командах и режимах интегриро-
ванной среды можно получить по функциональной клавише
<F1>, ну и, конечно же, в документации по системе программи-
рования Turbo С 2.0.
Ниже приводятся перечень основных команд интегрирован-
ной среды и краткое описание их функций.
1. File - ссылается на группу команд, позволяющих:
• загрузить с диска файл для редактирования (Load);
• создать новый текстовый файл (New);
• сохранить редактируемый файл под новым именем
(Write to);
• выбрать текущий каталог для данного сеанса работы
(Directory);
• сменить рабочий каталог (Change directory);
• осуществить временный выход в MS-DOS (Dos Shell -
возврат в среду по команде exit);
• выход из среды Turbo С (Exit).
2. Edit - редактировать файл. Ниже будут приведены основ-
ные команды редактирования.
3. Run - группа команд, предназначенных для запуска про-
граммы и просмотра результатов работы:
• выполнить программу (Run);
• выполнить программу заново (Program reset);
• выполнять программу по шагам с заходом в функции
(Step over) или без захода в функции (Trace into);
• перейти к просмотру результатов работы программы
(User screen).
4. Compile - команды, связанные с трансляцией и сборкой
(компоновкой) программы:
• компилировать программу в объектный файл (Compile
to OBJ);
• вызвать подсистему (Make EXE file) для построения
исполняемого файла на основе файла проекта (см. сле-
дующий пункт Project). Если был определен файл про-
екта (файл с расширением 'prj') в меню Project|Project
name, то подсистема Маке использует список модулей
30*
468
Программирование на языке Си
из этого файла. Иначе используется файл с текстом ос-
новной программы на Си (Primary С file - см. ниже)
или файл, находящийся в окне редактирования;
• собрать (скомпоновать) исполняемый (с расширением
'ехе') файл независимо от того, устарел исполняемый
файл или нет (LINK EXE file);
• перекомпилировать все файлы в проекте вне зависимо-
сти от даты и времени создания (Build all);
• задать имя программы, которая будет скомпилирована в
объектный модуль (Primary С file);
• вывести информацию о текущем файле (Get info).
5. Project - определяет имя файла проекта и некоторые ре-
жимы работы подсистемы Маке» Указанная подсистема (она
аналогична по назначению команде make системы UNIX) пред-
назначена для слежения за тем, чтобы исполняемая программа
была построена из исходных модулей последних версий. Под-
система make позволяет:
• задать файл проекта (Project name), содержащий имена
файлов, которые необходимо скомпилировать или по-
строить. Имя файла проекта переходит к файлу с рас-
ширением 'ехе' (исполняемому файлу). В своей прос-
тейшей форме файл проекта содержит просто список
имен исходных модулей компонентов программы;
• установить условия прерывания процесса построения
подсистемой Маке исполняемой программы из объект-
ных модулей (Break make on errors). Поясним возмож-
ности этого пункта. При компиляции и компоновке
программы могут появиться:
О „"Предупреждения" (Warnings) - компилятор выдал
предупреждения;
О "Ошибки" (Errors) - компилятор обнаружил ошиб-
ки и выдал сообщения о них;
О "Фатальные ошибки" (Fatal errors) - выявлены
ошибки, влияющие на все компоненты исполняемой
программы.
Глава 9. Подготовка и выполнение программ
469
В качестве условия прерывания построения программы
можно указывать предельные количества предупрежде-
ний, ошибок и фатальных ошибок;
• установить режим автоматическогоя слежения за тем,
чтобы исполняемая программа была построена из ис-
ходных модулей последних версий (Auto dependencies
On). Если режим установлен (On), то подсистема Маке
открывает объектный, модуль и читает информацию в
заголовке модуля. Затем проверяются дата и время соз-
дания исходных модулей, из которых создаются объ-
ектные модули. Если эта информация различается, то
исходные модули компилируются и исполняемая про-
грамма перестраивается. Если режим не установлен
(Off), то такая проверка не производится;
• очистить имя проекта и закрыть окно сообщений (Clear
Project);
• стереть сообщения об ошибках в окне сообщений
"Message" (Remove message).
6. Options - команды, устанавливающие: режимы работы для
компилятора и компоновщика; параметры среды; каталоги; ар-
гументы исполняемой программы:
• установить параметры: аппаратной конфигурации, режимы
отладки, режим оптимизации кода, управления выдачей
сообщений (Compiler);
• установить режимы работы компоновщика (Linker) - ука-
зать возможность подстановки перед стандартными биб-
лиотеками собственных библиотек объектных модулей,
включить (выключить) режим уведомления о дублирую-
щихся внешних именах в объектных модулях;
• установить параметры среды (Environment) - параметры
просмотра сообщений об ошибках, режим сохранения па-
раметров среды, режим создания резервных копий редак-
тируемых файлов. Основные параметры, устанавливаемые
в этом пункте меню:
О установить (выключить) режим просмотра окна сооб-
щений, когда подсвечиваются строки в исходном фай-
470
Программирование на языке Си
ле, на которые ссылается сообщение (Message
tracking);
0 включить (выключить) режим автоматического сохра-
нения параметров конфигурации среды (Config
autosave);
О включить (выключить) режим создания резервных ко-
пий редактируемых файлов (Backup source files);
• определить полные пути к каталогам системы программи-
рования (Directories), которые содержат: заголовочные
файлы, библиотеки, рабочий каталог, каталог, где хранятся
компоненты системы программирования Си. Подробно ус-
тановка путей к этим каталогам описывается ниже;
• задать параметры командной строки (Arguments). В окне,
появившемся при выборе этого пункта меню, указываются
параметры, которые передаются исполняемой программе
при ее выполнении из среды Turbo С, - аргументы функ-
ции main();
• сохранить параметры среды (Save options) в файле на дис-
ке. При установке параметров можно изменять имя файла,
в котором они сохраняются. При последующей загрузке
среды значения ее параметров выбираются именно из это-
го файла;
• выбрать и загрузить один из нескольких файлов парамет-
ров среды, созданных по команде Options|Save options.
7. Debug - команды, позволяющие установить ряд парамет-
ров, используемых при отладке программы.
8. Break/Watch - команды, позволяющие вставить, удалить
контрольные точки в программе и сформировать выражения,
используемые для наблюдения за переменными программы во
время ее работы.
9.2.4. Настройка среды Turbo С
Прежде чем начинать работу по вводу текстов функций про-
граммной системы, их отладке и сборке, необходимо настроить
параметры среды Turbo С 2.0:
Глава 9. Подготовка и выполнение программ
471
• создать и указать в среде рабочий каталог, в котором будут
находиться компоненты разрабатываемых программ и го-
товые к выполнению программы;
• задать полные имена каталогов (пути), содержащих заго-
ловочные файлы и библиотеки системы программирования
Си;
• настроить параметры управления проектом.
Создание рабочего каталога. Предположим, что’ система
программирования Turbo С 2.0 была установлена на диске D: в
каталоге ТС20. В этом же каталоге создадим средствами MS-
DOS рабочий каталог и назовем его WORK.
Теперь простейший вход в интегрированную среду
Turbo С 2.0. - это выполнение команды (в MS-DOS):
>tc.ехе
После этой команды начнется диалог с интегрированной
средой и перед вами появится экран, изображенный на рис. 9.3.
Установка в среде Turbo С 2.0 полных имен каталогов.
Перед началом работы необходимо задать полные имена вспо-
могательных и рабочего каталогов. Для этого необходимо пе-
рейти в меню Options|Directories (рис. 9.4) и, выбирая после-
довательно следующие пункты меню
• Include directories
• Library directories
• Output directory
• Turbo C directory
ввести соответственно следующие имена каталогов:
D:\TC20\INCLUDE
D:\TC20\LIB
D:\TC20\WORK
D:\TC20
Здесь Include и Lib - это стандартные для интегрированной
среды (для компилятора) имена каталогов, в которых соответст-
венно размещены включаемые (заголовочные) текстовые файлы
и библиотечные модули;
472
Программирование на языке Си
IQpticns
File Edit Run Compile Project
Line 1 Col 1 Insert Indent Tab
Debug Break/watch
---------iQNAME.C
Compiler
Linker
Environment
Include directories: Library directories: Cutout directory: D:\TC20\INCLUDE D:\TC20\LIB D:\TC20\WORK
Il Turbo C directory: D:\TC20
Fick file name: Current pick file:
Рис. 9.4. Окно установки имен каталогов
При выборе каждого из указанных пунктов меню на экране
появляется вспомогательное окно с заголовком, совпадающим с
пунктом меню (например, Include directories), в котором необ-
ходимо набрать полное имя соответствующего каталога. Набор
имени завершается нажатием на клавишу <Enter>. После этого
имя каталога отображается в строке пункта меню (например,
как на рис. 9.4 "Include directories: D:\TC20\INCLUDE"). В итоге
после ввода всех имен меню Options,Directories будет выгля-
деть так, как показано на рис. 9.4.
"Каталог для результатов" (Output directory) определяет то
место, где запоминаются объектные модули (файлы с расшире-
нием "obj") и исполняемые модули. В нашем примере это рабо-
чий каталог WORK в каталоге ТС20. Подсистема управления
проектом именно здесь ищет объектные модули во время по-
строения исполняемой программы.
Настройка параметров управления проектом. В совре-
менных интегрированных средах в той или иной степени реали-
зованы идеи, на основе которых работает команда make в
системе UNIX. Используя информацию (о дате и времени соз-
дания), хранящуюся в объектных и исполняемых модулях, под-
системы управления проектами интегрированных сред позво-
ляют перекомпилировать и перестроить устаревшие объекты.
Подсистема управления проектом в интегрированной систе-
ме Turbo С 2.0 может действовать на основе простейшей ин-
Глава 9. Подготовка и выполнение программ
473
формации о программной системе - на основе просто списка
имен исходных файлов, содержащих компоненты программной
системы.
тги Edit
Line 1*
RunCompile
Col 1 Insert
lBlrHSI Options Debug Break/wat ch
Remove messages
Fl-Helo F5-Zoom F6-Switch F7-Trace FB-Steo F9-Make FlO-Henu
9.5. Окно определения проекта
Для настройки подсистемы управления проектом необходи-
мо выполнить следующие действия:
1. Задать имя файла проекта в пункте меню Project|Project
name (рис. 9.5). Во вспомогательном окне "Project Name" необ-
ходимо ввести имя файла проекта (например, tree.prj) програм-
мы сортировки на основе бинарного дерева, описанной в гла-
ве 8. Точно так же, как и в случае определения имен каталогов
(см. §9.2.3), введенное имя отображается в строке пункта меню:
Project name TREE.PRJ
Расширение имени файла проекта (prj) задается для фай-
лов проектов по умолчанию.
2. В этом же меню (Project) выбрать пункт меню "Auto
dependencies" и нажать клавишу <Enter>. Индикатор режима,
заданный в этой же строке, изменит свое значение. Значений
может быть два: On - включено и Off - выключено. В первом
случае проверяется соответствие объектных модулей и испол-
474
Программирование на языке Си
няемой программы последним версиям исходных модулей, пе-
речисленных в файле проекта. В случае необходимости устарев-
шие компоненты перекомпилируются и компонуются автомати-
чески; во втором случае проверки не производятся и все исход-
ные тексты, обозначенные в файле проекта, транслируются
заново.
3. Создать собственно файл проекта с помощью встроенного
редактора:
• войти в режим редактирования (F10|Edit);
• набрать в окне редактирования, например, такой текст:
D:\TC20\WORK\TREE.С
D:\TC20\WORK\ADD_NODE.С
D:\TC20\WORK\NEW_NODE.С
D:\TC20\WORK\PRINT.С
• запомнить файл проекта под именем tree.prj, для чего вы-
полнить команду:
F10|File|Write to
и в появившемся окне ввести:
D:\TC20\WORK\TREE.PRJ
ИЛИ ТОЛЬКО
TREE.PRJ
если уже ранее был задан рабочий каталог (в меню
Options|Directories|Output directory).
Сборка и выполнение программы. После настройки среды
Turbo С можно приступить к вводу текста и отладке головной
программы main() и вспомогательных функций. Для этого не-
обходимо перейти в режим редактирования (F10|Edit). В первой
строке окна редактирования (она постоянно находится на своем
месте) отображаются: номер строки, номер позиции в строке,
режимы редактирования и имя файла. При открытии нового
файла ему присваивается имя NONAME.C. В процессе редакти-
рования можно пользоваться командами редактирования, спи-
сок которых выдается по команде HELP (функциональная
клавиша <F1>).
Глава 9. Подготовка и выполнение программ
475
Команды редактирования объединены в следующие группы,
из которых приведем основные (частично эти команды совпа-
дают с командами текстовых редакторов UNIX):
1. Команды управления курсором: На символ влево Ctrl-S ИЛИ 4-
На символ вправо Ctrl-D или ->
На слово влево Ctrl-A
На слово вправо Ctrl-F
На строку вверх Ctrl-E или Т
На строку вниз Ctrl-Х или Ф
Перемещение текста на строку вверх Ctrl-W
Перемещение текста на строку вниз Ctrl-Z
Перемещение текста на страницу вверх Ctrl-R или PgUp
Перемещение текста на страницу вниз Ctrl-C или PgDn
2. Команды вставки и удаления: Включить (выключить) режим вставки Ctrl-V или Ins
Вставить строку Ctrl-N
Удалить строку Ctrl-Y
Удалить часть строки от курсора до конца строки Ctrl-Q Y
Удалить символ слева от курсора Ctrl-H или Backspace
Удалить символ Ctrl-G или Del
Удалить слово справа 3. Команды обработки блоков текста: Ctrl-T
Пометить начало блока Ctrl-K В
Пометить конец блока Ctrl-K К
Пометить одно слово Ctrl-K C
Переместить блок Ctrl-K V
Удалить блок Ctrl-K Y
Читать блок с диска Ctrl-K R
476
Программирование на языке Си
Записать блок на диск Ctrl-K W
Снять выделение блока Ctrl-K Н
Печатать блок Ctrl-K Р
4. Дополнительные команды: Перейти в главное меню Ctrl-K D или F10
Сохранить редактируемый файл и про- должать его редактировать F2
Создать новый файл F3
Взять для редактирования предыдущий файл Alt-F3
Найти последовательность символов Ctrl-Q F
Найти и заменить последовательность Ctrl-Q A
символов
Прекратить операцию Esc
Примечания.
1. Запись "Ctrl-A" означает одновременное кратковре-
менное нажатие клавиш <Ctrl> и <А>, а запись "Ctrl-K В" -
кратковременное одновременное нажатие клавиш <Ctrl> и
<К>, а затем - нажатие одной клавиши <В>.
2. Для получения справки по синтаксису языка Си (это
может понадобиться при вводе исходных текстов программ)
необходимо поставить маркер на строку, содержащую наз-
вание объекта языка Си, и нажать клавиши "Ctrl-Fl". На-
пример, подведя курсор к служебному слову int и нажав
"Ctrl-Fl", получим достаточно полную информацию о типе
int и близких к нему целых типах.
Введя текст функции, можно приступить к ее отладке. Для
этого служит команда Compile|Compile to obj. При выполнении
компиляции появляется окно отладки, содержащее информацию
о компилируемом модуле: имя файла, количество откомпилиро-
ванных строк, число обнаруженных предупреждений и ошибок.
В нижней строке окна компиляции фиксируется результат ком-
пиляции: Warnings (предупреждения), Errors (ошибки), Success
(успех), а также сообщение "Press any key" (нажмите любую
Глава 9. Подготовка и выполнение программ
477
клавишу). При нажатии произвольной клавиши окно Компиля-
ции закрывается. Сообщения об ошибках (Errors) и предупреж-
дения (Warnings) отображаются в окне сообщений. После
завершения трансляции окно сообщений находится в активном
режиме, и клавишами со стрелками "вверх" и "вниз" можно
просматривать сообщения об ошибках и предупреждения. Син-
хронно с просматриваемыми сообщениями об ошибках будет
перемещаться подсветка строки в окне редактирования. Нажав
клавишу <F1>, можно получить краткую справку о сути ошибки
или предупреждения.
Для выхода из режима просмотра сообщений об ошибках и
перехода в режим редактирования необходимо выполнить ко-
манду F10|Edit (редактировать) в главном меню либо просто
нажать клавишу <Enter>, "находясь" на том сообщении, кото-
рое вас заинтересовало. Если ошибка синтаксическая, то авто-
матически произойдет переход к той строке текста программы,
в которой компилятор ошибку распознал. Не возвращаясь в ок-
но сообщений, можно перейти к позиции следующей ошибки с
помощью клавиш Alt-F8 (подсказка с указанием назначения
клавиши, как обычно, в нижней строке экрана). Исправив
эшибку, необходимо снова откомпилировать исходный текст
функции. При наличии нескольких ошибок необходимо анали-
шровать первые 2-3 ошибки; остальные могут быть следствием
нескольких первых ошибок. Процесс отладки продолжается до
появления в окне отладки (в последней строке) сообщения
'Success: Press any key".
Исправив синтаксические ошибки поочередно во всех функ-
диях, можно выполнить команду Compile|Make EXE file для
построения исполняемой программы в соответствии с файлом
проекта. Если в окне сборки (имя окна "Linking") появится со-
общение Success (успех), то можно вызвать построенную
собранную) программу для выполнения.
Программа сортировки на основе бинарного дерева получает
пз командной строки имя файла, в котором содержатся слова
щя сортировки. Готовую к выполнению программу сортировки
ложно выполнить вне среды Turbo С, набрав в командной стро-
478
Программирование на языке Си
ке операционной системы после подсказки MS-DOS (например,
’>') имя исполняемой программы и ее аргументы:
>tree f
где f- имя файла с данными для сортировки.
Программу сортировки на основе бинарного дерева можно
вызвать для выполнения и из среды Turbo С. Для передачи про-
грамме имени файла, содержащего слова для сортировки, необ-
ходимо указать его в качестве аргумента вызываемой
программы в пункте меню Options|Arguments. Затем можно
выполнить программу при помощи команды Run|Run. Резуль-
таты работы программы отображаются на так называемом экра-
не пользователя. Для просмотра экрана пользователя
необходимо выполнись команду Run|User screen или исполь-
зовать сочетание клавиш Alt-F5. Для возврата обратно в среду
необходимо нажать произвольную клавишу.
Поскольку в среде Turbo С для рассматриваемой программы
сортировки на основе бинарного дерева был определен файл
проекта (tree.prj), то при попытке построить по команде
Compile|Make EXE file программу сортировки еще раз (не вно-
ся в исходные тексты функций никаких изменений) будет выда-
но следующее сообщение в окне "Построение" (Making):
D:\TC20\WORK\TREE.EXE
is up to date (программа tree.exe не устарела),
означающее, что программа сортировки собрана из последних
вариантов входящих в нее функций и в перестройке не нуждает-
ся. При внесении изменений в одну или несколько функций
именно они будут откомпилированы, и программа сортировки
будет построена заново.
Заметим, что выполнение команды Compile|Build all приво-
дит к полной перестройке всех компонентов программы незави-
симо от их соответствия или несоответствия последним версиям
исходных модулей.
Глава 9. Подготовка и выполнение программ
479
9.3. Сборка и выполнение программ
в интегрированной среде Borland C++ 3.1
Технические характеристики современных персональных
компьютеров улучшаются с каждым годом. В соответствии с
ростом возможностей развиваются и операционные системы:
MS-DOS, MS Windows З.хх, MS Windows-95 и т.д. Несмотря на
то, что в каждой среде (MS-DOS или Windows) работает кон-
кретная (и не одна) система программирования, существует оп-
ределенная преемственность между "младшими" и "старшими"
версиями любой системы программирования, так как лучшие
решения "младших" версий закрепляются и повторяются в
"старших" версиях. Поэтому опыт, приобретенный при работе в
одной интегрированной системе, помогает разобраться в работе
другой системы.
Круг задач, затронутых в данном пособии, и приведенные
примеры могут быть выполнены в различных операционных
системах. Как можно подготовить исполняемые модули про-
грамм в UNIX и MS-DOS, было показано в предыдущих разде-
лах главы 9. Однако нельзя не упомянуть какую-либо систему
программирования для MS Windows.
Рассмотрим одну из первых систем программирования Си
для MS Windows, а именно: систему программирования Borland
C++3.1 фирмы Borland International, Inc. Эта система програм-
мирования вполне может функционировать на IBM РС/386 с
тактовой частотой 40 МГц и объемом оперативной памяти 4
Мбайта. На жестком диске стандартный вариант системы зани-
мает около 35 Мбайт.
9.3.1. Состав системы программирования
Borland C++ 3.1
В системе программирования Borland C++ 3.1 компоненты
обычно размещаются в следующих каталогах:
1. BGI - система поддержки графического интерфейса фир-
мы Borland.
480
Программирование на языке Си
2. BIN - основной каталог:
• динамически подключаемые библиотеки (*.dll);
• файлы конфигурации для компилятора,, подсистемы
Help и т.п.;
• автономный препроцессор и компилятор для запуска из
командной строки;
• исполняемые модули для запуска интегрированной сре-
ды в MS-DOS и MS Windows;
• файлы инициализации, содержащие параметры на-
стройки для интегрированной среды и ее компонентов;
• вспомогательные подсистемы, например подсистема
управления проектами Маке.
3. CRTL. - ряд каталогов с исходными текстами функций
стандартной библиотеки языков Си и Си++ (C/C++ Runtime Lib-
rary Version 5.0).
4. DOC - файлы документации по интегрированной среде и
ее компонентам.
5. EXAMPLES - исходные тексты и файлы проектов для не-
скольких несложных программных систем.
6. INCLUDE - заголовочные файлы системы программиро-
вания.
7(. LIB - библиотеки объектных модулей.
8. OWL - подсистема для разработки интерфейсов приклад-
ных программ, предназначенных для работы в MS Windows
(Object-Windows Library).
Для запуска варианта интегрированной среды для MS
Windows необходимо выполнить программу bcw.exe.
9.3.2. Экран интегрированной среды
После запуска интегрированной среды на экране дисплея
появится окно, изображенное на рис. 9.6.
Основные структурные элементы окна:
1 - главное меню; •
Глава 9. Подготовка и выполнение программ
481
2 - окно, на фоне которого создаются окна, содержащие ис-
ходные тексты модулей, вспомогательные окна (окно проекта,
окно сообщений об обнаруженных ошибках и т.д.).
Рис. 9.6. Основное окно интегрированной среды Borland C++ 3.1
Работа с этими окнами ведется так же, как и с любым другим
окном в среде MS Windows.
9.3.3. Система меню интегрированной среды
Основные команды интегрированной среды сосредоточены в
главном меню. Перечислим функции основных команд главного
меню:
1. File
• создание нового исходного текста (New);
• загрузка существующего текста (Open);
• сохранение исходного текста после редактирования
(Save, Save as);
31 ~3124
482
Программирование на языке Си
• печать исходного текста (Print);
• выход из интегрированной среды (Exit).
2. Edit
• отмена сделанных модификаций (Undo);
• "вырезание" помеченного блока (Cut);
• копирование (Сору) помеченного блока в буфер обмена
(Clipboard);
• вставка (Paste) помеченного блока из буфера обмена в
текст, начиная с текущей позиции курсора.
3. Search
• поиск и замена строк в исходном тексте;
• переход к строке текста с заданным номером.
4. Run
• выполнение исполняемой программы (Run);
• аргументы исполняемой программы (Arguments);
• отладчик (Debugger);
• аргументы отладчика (Debugger arguments).
5. Compile
• компиляция (Compile);
• построение исполняемой программы на основе файла
проектов (Маке);
• компоновка (Link);
• построение исполняемой программы без учета соответ-
ствия объектных и исполняемых модулей последним
версиям исходных модулей (Build all).
6. Project
• открыть (или создать новый) проект (Open project);
• закрыть проект (Close project);
• добавить имя компонента в проект (Add item);
• удалить имя компонента из проекта (Delete item).
7. Browse - группа команд, позволяющих просмотреть ие-
рархию классов (для C++), функции и переменные программной
системы.
8. Options - задает режимы работы компонентов интегриро-
ванной среды и параметры ее работы:
Глава 9. Подготовка и выполнение программ 483
• параметры компилятора (Compiler);
• параметры подсистемы управления проектом (Маке);
• параметры компоновщика (Linker);
• параметры библиотекаря (Librarian);
• имена основных каталогов (Directories);
• характеристики основных ресурсов (Resources);
• параметры среды (Environments);
• команда сохранения настроек и установок для парамет-
ров среды (Save).
9. Window - информация об открытых окнах и способах их
расположения.
10. Help - подсистема оперативной помощи по интегрирован-
ной среде и элементам языка программирования.
9.3.4. Настройка интегрированной среды
Borland C++ 3.1
Так же как и для интегрированной среды Turbo С 2.0, укажем
минимально необходимые действия по настройке среды Borland
C++ 3.1, достаточные для создания, отладки, компоновки и вы-
полнения программ на языке Си. В качестве примера программ-
ной системы используем неоднократно рассмотренную нами
программу сортировки на основе бинарного дерева.
Задание полных имен основных и рабочего каталогов.
Задание полных имен основных и рабочего каталогов произво-
дится в окне, которое открывается по команде
Options|Directories (рис. 9.7).
В подокнах устанавливаются, например, такие имена:
1. Include Directories: p:\borlandc\include
2. Library Directories: p:\borlandc\lib
3. Output Directories: d:\tc20\work\bcw
31
484
Программирование на языке Си
? Help
Рис. 9.7. Окно установки полных имен основных и рабочего каталогов
В рабочем каталоге (Output Directory) размещаются объект-
ные и исполняемые модули создаваемой программной системы.
Примечания:
1) Система программирования Borland C++ 3.1 в этом при-
мере была установлена на диске р: в каталоге borlandc;
2) Рабочий каталог "\tc20\work\bcw" был предварительно
создан на диске d:.
Выбор стандарта языка Си. Интегрированная среда языка
Borland C++- 3.1 позволяет выбрать один из четырех вариантов
языков Си и Си++:
• Borland С+-+;
• Ansi - устанавливается соответствие стандарту ANSI;
• Unix - устанавливается соответствие компиляторам, функ-
ционирующим в UNIX System V;
• K&R - устанавливается соответствие описанию языка Си,
приведенному в [1].
Выбор варианта стандарта производится по команде
Options|Compiler|Source.
На рис. 9.8 выбран вариант языка, соответствующий стан-
дарту ANSI. Для этого необходимо "щелкнуть" левой кнопкой
мыши в зоне ромба слева от слова "Ansi".
Глава 9. Подготовка и выполнение программ
485
Source Options
Key Words
О Borland C++
<$> ^nsil
О Unix V
О Kernighan and Ritchie
Source Options
П Nested Comments
Identifier Length 32
? Help
Phc. 9.8. Окно выбора стандарта языка Си
Установка параметров подсистемы Маке. Подсистема
управления проектом (подсистема Маке) позволяет автомати-
чески следить за тем, чтобы исполняемая программа была по-
строена из исходных модулей последних версий. На рис. 9.9 по-
казано окно установки параметров подсистемы Маке, которое
отображается при выполнении команды Options|Make.
Параметры подсистемы Маке позволяют определить:
• тип ошибок, при появлении которых прекращается по-
строение исполняемого модуля (группа параметров Break
Make On - прервать процесс построения). На рис. 9.9 ус-
тановлен режим прерывания процесса построения про-
граммной системы по первой обнаруженной ошибке
(Errors);
• действия, которые необходимо выполнить после компиля-
ции (группа параметров After Compiling - действия после
завершения компиляции). На рис. 9.9 установлен режим
запуска компоновщика (Run Linker);
• режим учета взаимозависимостей модулей, включенных в
файл проекта (Check auto-dependencies). Включение (вы-
ключение) режима производится "щелчками" левой кнопки
мыши в зоне прямоугольника слева от наименования ре-
жима.
486
Программирование на языке Си
Маке ,
Break Make On
<С> Warning» <$> y£rror»j О Fatal errors О All sources processed After Compiling ^0K J^Cancel
О Stop <$> Run linker О Run librarian ? Help
[✓1 Check auto-dependencies
Рис. 9.9. Окно установки параметров подсистемы Маке
Создание проекта. Определение (создание нового) проекта
производится в окне, появляющемся по команде Project|Open
project (рис. 9.10).
File Name
tc20\work\bcw\tree prj
Path: d:\tc20\work\bcw
Filet Directories
11 [al l-bl [c] [dl [el I-f-1 hl I IH
^Cancel
7 Help
Рис. 9.10. Окно определения проекта
Глава 9. Подготовка и выполнение программ 487
С помощью подокна Directories (каталоги) производится вы-
бор рабочего каталога, а в поле File Name (имя файла) вводится
имя проекта, например tree.prj. В переменной Path (путь) ото-
бражается полное имя рабочего каталога, где хранится файл
проекта. По завершении определения проекта следует нажать
кнопку ОК.
Если проект создается заново, то необходимо указать исход-
ные файлы, из которых строится исполняемый модуль. Указа-
ние производится в окне формирования проекта (рис. 9.11),
которое вызывается по команде Project|Add item.
Рис. 9.11. Окно формирования проекта
В поле File Name (имя файла) необходимо установить рас-
ширение файла *.с и нажать мышью кнопку +Add для добавле-
ния этого расширения в список возможных расширений имен
файлов.
В подокне Files (файлы) появляются имена файлов с расши-
рением *.с из рабочего каталога. Для занесения имени нужного
исходного модуля в файл проектов необходимо в подокне Files
"щелкнуть" левой кнопкой на имени файла (оно будет выделе-
488
Программирование на языке Си
но) и нажать мышью кнопку +Add. Эту операцию следует про-
делать со всеми файлами, которые необходимо включить в про-
ект. Для завершения формирования проекта следует нажать
мышью кнопку Done.
После закрытия окна формирования проекта можно увидеть
окно проекта (рис. 9.12), в котором указаны все исходные моду-
ли проекта tree.prj.
нпнв Project: tree QQ
1 File Name Lines Code Data Location
1 tree.с 31 94 17 ♦
add node.c 40 91 0
new node.c 26 54 0
print.c 27 72 3 ♦
Рис. 9.12. Окно проекта
Задание аргументов командной строки. Так как имя фай-
ла, содержащего слова для сортировки, программа tree.exe берет
из командной строки, то перед выполнением программы необ-
ходимо задать имя файла в окне, появляющемся по команде
Run|Arguments (рис. 9.13). В этом случае задано имя файла - f.
- Рис. 9.13. Задание аргументов командной строки
Глава 9. Подготовка и выполнение программ
489
Сохранение параметров настройки интегрированной
среды. Для того чтобы параметры интегрированной среды, ус-
тановленные при ее настройке, сохранились и были доступны в
следующем сеансе, необходимо выполнить команду
Options|Save.
Сборка и выполнение программы. Перед построением ис-
полняемого модуля программы сортировки на основе бинарно-
го дерева необходимо исправить синтаксические ошибки в
функциях программы: tree.c, addnode.c, newnode.c и print.c.
Компиляция исходных модулей производится по команде
Compile|Compile.
Сборка (компоновка) исполняемого модуля программы сор-
тировки выполняется по команде Compile|Make. При этом ис-
пользуется файл проекта tree.prj. На рис. 9.14 приводится окно
построения программы. Сообщение "Success" в строке Status
информирует о том, что исполняемый модуль построен без
ошибок.
Рис. 9.14. Окно построения программы
490
Программирование на языке Си
Для выполнения программы сортировки необходимо выпол-
нить команду Run|Run. В окне выполнения (окне результатов)
можно увидеть отсортированный список слов (рис. 9.15).
— - (Inactive D:\TC2 0\WORK\0CW\TREE.EXE) DD
array
case
comma
name
size
string
type
union ♦
1 l±l
Рис. 9.15. Результат выполнения программы сортировки
По завершении просмотра окно результатов следует закрыть
(кнопка в левом верхнем углу окна).
Работа в интегрированной среде в последующих сеансах.
В последующих сеансах работы в интегрированной среде с уже
существующей программой перед построением исполняемого
модуля программы необходимо выбрать существующий проект
для этой программы. Выбор проекта производится по команде
Project|Open project. После выбора проекта можно произвести
повторное построение исполняемого модуля, если в исходные
тексты программных модулей были внесены изменения.
Информацию об открытых окнах и их расположении на эк-
ране можно получить по команде Window. Работа с окнами
проводится традиционными для MS Windows приемами.
ПРАКТИКУМ
ПО ПРОГРАММИРОВАНИЮ
НА ЯЗЫКЕ Си
Глава 10
ЗАДАЧИ ПО ПРОГРАММИРОВАНИЮ
10.1. Ознакомительная работа
Приемы и техника работы с реальными программными сред-
ствами могут быть освоены только за экраном компьютера в
диалоге с той или иной системой программирования. Знакомст-
во с многочисленными реализациями компиляторов языка Си и
интегрированными инструментальными средами разработки
программ выходит за рамки нашего пособия. Однако мы счита-
ем, что начинающий программист должен подходить к компью-
теру с конкретным, пусть даже очень простым заданием. В
качестве такого первоначального ознакомительного задания мы
предлагаем решение следующей задачи.
Написать программу, оценивающую значение машинного
нуля относительно заданного вещественного числа. Выполнить
программу нужно для разных представлений вещественных чи-
сел (float, double, long double) и оформить результаты в виде
приведенной ниже таблицы. В качестве основы для построения
предлагаемой программы можно использовать приведенную в
главе 2 программу для оценки машинного нуля относительно
числа 1.0. Усовершенствованный вариант той же программы (но
уже позволяющий выполнять оценки относительно разных зна-
чений, вводимых пользователем) имеет следующий вид:
#define REAL float
#define type(x) t(x)
#define t(z) #z
#define Kmax 10000
#include <stdio.h>
void main()
(
REAL e,el,s;
int k = 0; /* Количество итераций */
printf("\n Представление вещественных чисел:"
type (REAL) ) ;
494
Программирование на языке Си
printf("\п Введите начальное Значение:");
/* Для double: %lf; для long double: %Lf */
/*%1е" - для double; "%Le" - для long double*/
scanf("%f", &s);
if (s <= 0.0)
{
printf("\n Ошибка: начальное Значение < 0’");
return 1;
}
e = s;
do
{ /*Цикл с постусловием */
k++;
e /= 2.0;
el = s+e;
}
while(el > s && k < Kmax);
printf("\n Число итераций: %d", k) ;
printf("\n Машинный нуль: %e", e);
/* Для double: %le; для long double: %Le */
)
Программа позволяет обратить внимание на следующие во-
просы программирования:
• точность представления вещественных данных разных
типов;
• возможности макросредств (препроцессорные подста-
новки);
• спецификации преобразований при форматированном об-
мене (вводе-выводе) вещественных данных разных типов.
Результаты выполнения программы (для типа float):
Представление вещественных чисел:float
Введите начальное Значение: 1.0
Число итераций: 24
Машинный нуль: 5.960464е-08
Изменим директиву препроцессора, определяющую препро-
цессорный идентификатор REAL:
#define REAL double
Глава 10. Задачи по программированию
495
Заменим спецификации преобразования: %f на %lf, а %е на %1е
(см. текст программы).
В результате выполнения программы получим:
Представление вещественных чисел:double
Введите начальное Значение: 1.0
Число итераций: 53
Машинный нуль: 1.110223е-1б
Затем определим новое значение для REAL:
#define REAL long double
и получим решение той же задачи для вещественных данных
типа long double (если в дополнение к REAL изменим специфи-
кацию формата в scanf() и в printf() на %Lf и %Le).
В программе удачно использованы макроподстановки. В за-
висимости от значения REAL в функции печати printf(), где
стоит макровызов type(REAL), появляется строка "float" либо
"double", либо "long double". Последовательность подстановок
такая (когда REAL замещается значением float):
type(REAL) -> type(float) -> t(float) -> "float"
Обратите внимание, что если вместо макросов t(z) и type(x) оп-
ределить, например, один макрос
#define type(x) #х,
то последовательность будет неверной:
type(REAL) -> "REAL"
В этом случае будет печататься не имя типа (например,
double), а обозначение REAL.
По результатам выполнения программы заполните следую-
щую табл. 10.1.
496
Программирование на языке Си
Т аблица 10.1
Таблица результатов оценок “машинного нуля”
Значения S Внутреннее представление
float double long double
К M-zero К M-zero К M-zero
1 24 5.960464е-08 53 1.110223е-16 64 ' 5.42101 le-20
10
1000
1е-20
1е20
В табл. 10.1: S - начальное значение; К - число итераций;
M-zero - оценка машинного нуля относительно значения S.
10.2. Итерационные методы и ряды
Вычислить m значений заданной функции f(x) на интервале
[а,Ь]. Результаты оформить в виде табл. 10.2. Столбцы таблицы:
1 - значение xt; 2 - значение функции вычисленное с ис-
пользованием библиотечных функций компилятора; 3 - значе-
ние функции f2(Xj), вычисленное с помощью явного разложения
в ряд (итерационный процесс до достижения машинного нуля);
4 - M-zero - значение машинного нуля относительно f2(x<), т.е.
точность вычислений; 5 - количество итераций или количество
членов ряда в разложении функции.
Таблица 10.2
xi fl(Xi) Точность (M-zero) Число итераций
x0=a
xm.i=b
Глава 10. Задачи по программированию
497
Вычисления проводить для float, double и long double.
Ограничения.
• Переменных с индексами (и массивы) не использовать.
• Факториалы и высокие (больше 2) степени в выражениях
для членов ряда в явном виде не применять.
• Количество т точек на интервале [а,Ь] не. меньше 10. Раз-
биение (расположение точек на оси х) может быть равно-
мерным либо по предложенному вами правилу (детерми-
нированному или случайному).
• Для тригонометрических функций в программе приводить
значение аргумента к величине 0<=x<=7t/2.
• Для показательных функций выделять целую часть аргу-
мента, а разложение выполнять для дробной части.
Комментарий по итерационным методам (см.: Трифо-
нов Н.П., Пасхин Е.Н. Практикум работы на ЭВМ. - М.: Наука,
1982. С. 13-16):
1. Для уравнения у = tfx (х>0, к>0, к - целое) можно запи-
сать F(x,y) = \-x/)f=0, откуда получим по формуле Лагранжа:
уп^=уп (1+Х)"7^ •
Здесь для начального приближения у&>0 необходимо выпол-
нение условия у„<(к+1)х.
Если использовать F(x,y)=^ -х=0, то получим итерационную
формулу Ньютона:
справедливую для уо>О.
Нужная точность оценивается соотношением ly^s-yn^s, где £
обычно заранее задано. Однако в работе выполнять вычисление
нужно с точностью до "машинногонуля".
32“3124
498
Программирование на языке Си
2. Для многих функций требуется использование формулы
Маклорена (частный случай разложения в ряд Тейлора):
/(Х) = £И*(Х) + ЛЛХ) ’
к=0
где ик(х)=акхк и коэффициенты таковы:
^ло).«,=т.
Остаточный член:
Лл(х) = (^ТЩ/("+,)(0х)’ (°<0<1)-
Примеры разложения в ряд Тейлора:
3 5 2л+1
у = sin(x) = х- — + ..+(-1) —|х| < 00 ,
у = cos(x) = 1
х2 + X4
7Г+4!
X2"
2и!
н
< оо,
х , X X X X ||
и = е =1+ —+ — + —+...+—+,. х < оо
1! 2! 3! я!
у = 1п(1 + х) = х - +(-l)"+I |х| < i ,
2 п
х3 х5 x2n+1
у = sh(x) = х + — + —+...+--------+..., Ixl < оо,
z 3! 5! (2и+1)!
у = ch(x) = 1 + — + —+...+-—+..., Ixl < оо.
2! 4! 2п! 11
Глава 10. Задачи по программированию
499
Указанные разложения малоэффективны при больших по
модулю значениях аргумента, так как ряды в этих случаях схо-
дятся медленно.
Рекомендации.
1. Для тригонометрических функций следует автоматически
приводить значение аргумента к величине 0<х<л72. В этом слу-
чае справедлива оценка остаточного члена 7?„: , J, поэто-
му счет можно прекращать при |ы„|<£.
2. Для показательной функции можно представить значение
аргумента в виде х=Е(х)+г, где Е(х) - целая часть х, г - дробная
часть (0<г<1). В этом случае ех = еЕ(-х^ег; еЕ<х> вычисляется как
г "г2
е = г + — + —+... с остаточным членом |7?„|<(ы„|, что справедливо
для |г|<1, поэтому счет следует вести до [ип1<£, используя в каче-
стве £ оценку машинного нуля.
Для функции sh(x) остаточный член Я„ <-у- для 0<х<п.
2
Для функции ch(x) остаточный член Rn <—и„ при 0<|х|<и.
Таким образом, для функций ch(x), sh(x) при больших значе-
ниях х рекомендуется вначале получить грубое приближение
для п<х, а затем продолжать вычисления до "машинного нуля".
Варианты заданий по итерационным методам и рядам.
Ниже приведена табл. 10.3, содержащая варианты заданий.
Таблица 10.3
Варианты заданий по итерационным методам и рядам
№ /(*) a;b № а; b
1 е~х 4х 1;3 19 1ф) 1;1.5
2 3;4 20 l+ln2(jc) 0.4; 1
3 x<fx 4;5 21 1+ег 0.5; 1
32*
500
Программирование на языке Си
Продолжение
№ a; b № f(x) a; b
4 1/V7 5;7 22 е^/2 2;3
5 i/V? 6;8 23 cos(*)e'r 1;2
6 (2х + 1)/у7 8;9 24 l/(l+e'r) 3;4
7 № 0.5;l 25 sin(jc)sh(jc) 1;5
8 д/х2 + 1 2.5;3 26 0.5+sh2(jr) 2;3
9 Vx •COSX 1;1.5 27 уГх~- ch(*) 3;4
10 3.5;4 28 l/(l-bch2(jc)) 2;4
11 ег • sinx 0;л/4 29 - y[x~- sh(*) 1;5
12 д/х •COSX л/9;л/4 30 e'rch(*) 1;4
13 sin( х + 0.5) л/18;л/3 31 ln(x2) 1; 1.4
14 sin(jc2) л/4;л/2 32 *+1П X 1; 5
15 sin(x)/* 0.2;0.4 33 l/(l+sin x) л/3;л/6
16 cos( x)/x2 л/16;л/4 34 sin* + y/x л/6; л/4
17 x + sin(*) 0.4;0.6 35 *(l-cos) 0.4; 0.8
18 x2 - cos(*) л/4;л/2
Пример выполнения задания.
Вычислить табл. 10.3 из 11 значений заданной функции
/(х) = у/х-sh(x) на интервале [а,Ь], где а = 1, b = 5. Столбцы
табл. 10.2 следующие:
1 - значение х,;
2-значение fi(x), вычисленное с использованием библио-
течных функций и компилятора;
3 - значение f2(x), вычисленное с помощью явного разло-
жения в ряд или итерационного процесса (до достижения
"машинного нуля");
Глава 10. Задачи по программированию
501
4-значение "машинного нуля" относительно f(xi), т.е. точ-
ность вычислений;
5 - количество итераций или количество членов ряда в раз-
ложении функции.
С применением библиотечных функций можно записать:
у = sqrt(x) * sinh(x).
Для вычисления приближенного значения Vx воспользуемся
формулой Ньютона:
1 х
Уп+1 =т(Уя+—),я = 0>1)...
z Уп
В качестве начального приближения возьмем уо=х. В качест-
ве условия окончания процесса используем равенство:
Уп+l Уп •
Для вычисления гиперболического синуса sh(x) используем
ряд Тейлора:
х3 х5
sh(x) = х + — + — +...
v 1 3! 5!
Условием окончания вычислений гиперболического синуса
пусть будет "неизменность" накопленной суммы после добавле-
ния очередного члена ряда.
Точность результатов будем оценивать как разность между
значением функции, вычисленным с помощью библиотечных
функций, и значением, полученным с помощью приведенных
формул.
Числом итераций будем считать максимальное из двух зна-
чений - количество итераций по формуле Ньютона и количест-
во членов, использованных в разложении sh(x) в ряд.
Используемые переменные:
yt - значение Vx • sh(x), полученное с помощью биб-
лиотечных функций;
502
Программирование на языке Си
ус - значение Jx sh(x), вычисленное с помощью явно-
го разложения в рядвЬ(х) и по формуле Ньютона
для Vx ;
а - точность подсчета;
sq - текущее значение приближения при вычисле-
нии Vx ;
sqO - предыдущее значение приближения для Vx ;
sh - текущее значение члена ряда при вычислении функ-
ции у = sh(x);
sum - сумма ряда, подсчитанная при разложении функции
У = sh(x);
sm - предыдущее значение суммы ряда sum;
shn - счетчик элементов ряда разложения функции
У = sh(x);
sqn - счетчик итераций при вычислении функции
y = sqrt(x);
х - значения х„ в которых производятся вычисления
значений Vx-sh(x).
Псевдокод программы:
Цикл для х от 1 до 5 при изменении х с шагом 0.4.
Вычислить yt- "табличное"значение sqrt(x)*sinh(x)
в точке х.
Найти значение функции у= у/х в точке х, т.е. sq.
Найти значение функцииy=sh(x) в точке х, т.е. sum.
Вычислить для х значение ус = sq*sum.
Оценить точность вычислений.
Конец-цикла.
Вывести результаты.
Глава 10. Задачи по программированию
503
Текст программы:
/* Вычисление функции: у = sqrt(х)*sinh(х) */
#include <stdlib.h>
#include <math.h>
#include <stdio.h>
void main()
{
double yt,yc,a,x;
double sq, sqO, sh, sum, sm;
unsigned long sqn,n,shn;
printf("\n\t Вычисление функции: у ="
"sqrt(x)*sinh(x)\n\n");
printf("x \t f1(x) \t f2(x)\t To4HOCTb\t"
" Итерации\п");
for ( x=l.0; x <= 5.01; x+=0.4)
{/* цикл no x */
yt=sqrt(x)*sinh(x); /* Библиотечные функции*/
sqn=0; /* Счетчик итераций */
sq=x; /* Начальное приближение для корня */
do
{ /* Цикл вычисления квадратного корня */
sqn++; /* Счетчик итераций */
sqO = sq;
sq =(sqO+х/(sqO))/2;
}
while(sq ’= sqO);
shn = 1; /* Счетчик членов ряда */
sh = x; /* Значение первого члена ряда */
sum = 0;
п = 1;
do
{/♦Цикл вычисления гиперболического синуса*/
sm=sum;
sum += sh;
sh = sh* ((x*x) / ((n+1) * (n+2))) ;
n += 2 ;
shn++; /* Номер члена ряда */
' }
while(sm ’= sum);
yc = sq*sum;
/* Точность - сравнение с библиотечными
504
Программирование на языке Си
функциями:*/
а = ус - yt;
printf\t%lf \t%lf \t%le \t%ld \n",
к, yc, yt, a, shn>sqn?shn:sqn);
} /* Конец цикла по x */
}
Результаты:
Вычисление функции: у = sqrt(х)*sinh(х)
X fl(x) f2 (х) Точность Итерации
1 1.175201 1.175201 2.220446е-16 11
1.4 2.2532 2.2532 -4,440892е-16 12
1.8 3.947341 3.947341 0.000000е-00 13
2.2 6.610955 6.610955 0.000000е-00 14
2.6 10.794931 10.794931 0.000000е-00 15
3 17.351468 17.351468 3.552714е-15 15
3.4 27.594767 27.594767 3.552714е-15 16
3.8 43.547521 43.547521 -7.105427е-15 17
4.2 68.317789 68.317789 0.000000е-00 17
4.6 106.674264 106.674264 0.000000е-00 18
5 165.923423 165.927423 0.000000е-00 19
10.3. Работа со строками. Указатели,
динамические одномерные массивы
Порядок выполнения задания (общая схема алгоритма):
1. Запросить у пользователя максимально возможную по ус-
ловиям задачи длину LenMax строки.
2. Создать динамический символьный массив данного разме-
ра (LenMax).
3. Запросить у пользователя исходную строку и записать ее в
массив, созданный в п. 2.
4. Если длина введенной строки меньше LenMax, изменить
количество памяти, выделенной под массив в п.2, (уменьшить
размер массива).
Глава 10. Задачи по программированию
505
5. Выполнить действия, необходимые для решения задачи.
6. В процессе решения создать динамический массив нуж-
ной длины, содержащий результирующую строку, либо не-
сколько массивов (в зависимости от условий задачи).
7. Освободить память, выделенную под все созданные во
время работы динамические массивы, за исключением массива
(массивов), содержащего результирующую строку (строки).
8. Напечатать (вывести на дисплей) результирующую строку
(строки).
Примечание. Если введенная пользователем исходная стро-
ка содержит символы, не являющиеся допустимыми, выдать
сообщение об ошибке и первый недопустимый символ. Пре-
кратить решение задачи.
В соответствии с целями практикума в конкретных условиях
при выполнении заданий данного §10.3 могут быть введены
следующие ограничения:
• Не применять индексированных переменных для доступа к
элементам массивов-строк, а использовать разыменование
указателей.
• Не использовать стандартные (библиотечные) функции
str...() для работы со строками, а явно выполнять все дей-
ствия по конкатенации, копированию, сравнению и пр.
10.3.1. Варианты задач по обработке строк*
Вариант 1 ("Палиндромы").
Проверить, является ли выражение, состоящее только из
прописных букв заданной строки, палиндромом (палиндром -
слово или выражение, читающееся слева направо и справа нале-
во одинаково, например, "кабак" или "нажал кабан на бакла-
жан"). Если да, то напечатать полученный палиндром. В
противном случае вывести строку, состоящую из символов ис-
ходной строки с удаленными прописными символами.
Условия задач подобраны С.Г.Чернацким.
506
Программирование на языке Си
Допустимые символы - цифры; прописные и строчные ла-
тинские буквы.
Примеры:
Исходная строка Результат
lrK4ABAfgK BuRAtino AT&T KABAK - палиндром utino - не палиндром Недопустимый символ - '&'
Вариант 2.
Имеется строка, содержащая буквы и цифры. Преобразуйте
эту строку так, чтобы сначала в ней шли все цифры, а потом -
все буквы исходной строки.
Допустимые символы - цифры; прописные и строчные ла-
тинские буквы.
Примеры:
Исходная строка ad2e57b6 Tom&Jerry Результат 2576adeb Недопустимый символ - '&'
Вариант 3.
Имеется строка, содержащая буквы и цифры. Преобразуйте
эту строку так, чтобы сначала в ней шли все буквы, встречаю-
щиеся в исходной строке, но в обратном порядке, а потом - все
цифры исходной строки в прямом порядке.
Вариант', сначала все буквы, потом цифры в обратном по-
рядке.
Допустимые символы - цифры; прописные и строчные ла-
тинские буквы.
Примеры:
Исходная строка
ad2e57b6
KARABAS/ВARABAS
Результат
beda2576
Недопустимый символ - '/'
Вариант 4.
Имеется строка, содержащая буквы и цифры. Преобразуйте
эту строку так, чтобы сначала в ней шли все цифры исходной
Глава 10. Задачи по программированию
507
строки, а потом - все буквы исходной строки, но в обратном
порядке.
Допустимые символы - цифры; прописные и строчные ла-
тинские буквы.
Примеры:
Исходная строка ad2e57b6 Стрижем.Kozloff. Результат 2576beda Недопустимый символ - '.1
Вариант 5.
С клавиатуры вводятся:
• предложение, слова в котором разделены символом под-
черкивания ('_');
• маска (шаблон) для выбора из предложения нужных слов
(содержит буквы и символ-заполнитель '*', который заме-
няет любое сочетание букв, в том числе пустое).
Необходимо выбрать из предложения все слова, соответст-
вующие маске (шаблону).
Допустимые символы - прописные русские буквы; символ-
разделитель
Пример.
ВЫРАЖЕ НИЕ_Е СТЬ_ПРАВИЛО_ПОЛУЧЕНИЯ_ЗНАЧЕНИЯ
Маска Подходящие слова
* Я ПОЛУЧЕНИЯ | ЗНАЧЕНИЯ
* Н*Е ВЫРАЖЕНИЕ
* РА* ВЫРАЖЕНИЕ | ПРАВИЛО
* Е* ВЫРАЖЕНИЕ | ЕСТЬ | ПОЛУЧЕНИЯ | ЗНАЧЕНИЯ
Вариант 6.
Пусть цифрам от 1 до 9 соответствуют буквы от А (а) до I (i).
С клавиатуры вводится строка. Составьте новую строку из
цифр, соответствующих только данным буквам (прописным и
строчным), отсортированным по возрастанию.
Допустимые символы - прописные и строчные латинские
буквы.
508
Программирование на языке Си
Пример.
Исходная строка: SHiFROVkaOtSHPlonA
Результат: 1168899 (выделены буквы: HiFaHIA)
Вариант 7.
С клавиатуры вводится строка. Выберите из нее все буквы от
А(а) до I(i) (строчные преобразуйте в прописные) и отсортируй-
те их в алфавитном порядке.
Допустимые символы - прописные и строчные латинские
буквы.
Пример.
Исходная строка: SHiFROVkaOtSHPlonA
Результат: AAFHHII
Вариант 8.
С клавиатуры вводится строка. Выберите из нее все буквы от
J (j) до S (s) (строчные преобразуйте в прописные) и отсорти-
руйте их в алфавитном порядке.
Допустимые символы - прописные и строчные латинские
буквы.
Пример.
Исходная строка: SHiFROVkaOtSHPlonA
Результат: knoooprss
Вариант 9.
С клавиатуры вводится строка. Выберите из нее все буквы от
Q (q) до Z (z) (строчные преобразуйте в прописные) и отсорти-
руйте их в алфавитном порядке.
Допустимые символы - прописные и строчные латинские
буквы.
Пример.
Исходная строка: SHiFROVkaOtSHPlonA
Результат: rsstv
Глава 10. Задачи по программированию
509
Вариант 10 ("Треугольник Паскаля").
Имеется некоторое предложение (слова разделяются симво-
лами подчеркивания Используя треугольник Паскаля, за-
шифруйте исходное предложение по следующему правилу:
• из предложения выделяется очередное слово;
• из треугольника Паскаля выбирается строка с номером,
равным числу букв в слове;
• k-я буква исходного слова заменяется на букву, отстоящую
от исходной на число букв, указанное в k-м столбце вы-
бранной строки треугольника Паскаля (отсчет производит-
ся по часовой стрелке, как показано на схеме).
Треугольник Паскаля
1
1 1
12 1
13 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
АБВГДЕЖЗ
И
й
к
л
м
н
о
п
ЧЦХФУТСР
Допустимые символы - прописные русские буквы; символ-
разделитель
Пример:
Исходная строка:
"А_РОЗА_УПАЛА_НА_ЛАПУ_АЗОРА"
Зашифрованная строка:
"Б_ССКБ_ФУЖПБ_ОБ_МГТФ_БЛФФБ"
Вариант 11.
Имеется некоторое предложение, все слова которого разде-
лены символами подчеркивания ('_'). Используя треугольник
Паскаля, зашифруйте исходное предложение по следующему
правилу:
• из предложения выделяется очередное слово;
• из треугольника Паскаля выбирается строка с номером,
равным числу букв в слове;
510
Программирование на языке Си
• k-я буква исходного слова заменяется на набор одинаковых
букв в количестве, указанном в k-м столбце выбранной
строки треугольника Паскаля.
Треугольник Паскаля
1
1 1
12 1
13 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
Допустимые символы - прописные русские буквы; символ-
разделитель
Пример.
Исходная строка:
"А_РОЗА_УПАЛА_НА_ЛАПУ_АЗОРА"
Зашифрованная строка:
"А_РОООЗЗЗА_УППППААААААЛЛЛЛА_НА_ЛАААПППУ_АЗЗЗЗ
ООООООРРРРА"
Вариант 12.
Проверить, является ли заданная строка зашифрованной по
алгоритму, приведенному в варианте 11. Если да - выдать рас-
шифрованную строку, если нет - вывести сообщение об ошибке
с печатью первого ошибочного слова.
Допустимые символы - прописные русские буквы; символ-
разделитель
Примеры:
Зашифрованная строка:
НА_ДВВВВООООООРРРРЕ_ОССССЕЕЕЕЕЕННННЬ
Результат расшифровки:
НА_ДВОРЕ_ОСЕНЬ
Зашифрованная Строка:
НА_ДВВВВ0000РРРРЕ_ЗИИИМИМА
Результат расшифровки:
Ошибка слово * ДВВВВООООРРРРЕ' не является
зашифрованным.
Глава 10. Задачи по программированию
511
Вариант 13.
Выберите 10 произвольных букв русского алфавита (введите
с клавиатуры). Введите произвольное русское слово. С помо-
щью ключа длиной от трех до восьми символов, также вводимо-
го пользователем с клавиатуры, произведите шифровку слова в
числовую комбинацию, как показано в следующем примере.
Допустимые символы - прописные русские буквы (для букв
алфавита и слова), цифры (для ключа).
Пример.
Пусть задан набор русских букв:
ВЕЖМНОПРСТ
Поставим им в соответствие цифры от 0 до 9:
ВЕЖМНОПРСТ
0123456789
Пусть введено какое-нибудь русское слово, например
МНОЖЕСТВО.
Переведем буквы этого слова в цифры, соответствующие
этим буквам. В данном случае
МНОЖЕСТВО
345218905
Запрашиваем у пользователя цифровой ключ (3+8 символов).
Пусть пользователь ввел
1243
Теперь подставляем ключ под очередные числа, в которые
переведено наше число, и оставляем число единиц результата
(десятки отбрасываем). В нашем примере:
МНОЖЕСТВО
345218905
+ 12 4 3
+ 12 4 3
+ 1
469520336
Окончательный ответ:
469520336
512
Программирование на языке Си
Примечание. Если длина ключа не кратна длине слова, то
оставшиеся цифры ключа отбрасываются (как в примере).
Вариант 14.
Напишите дешифратор, преобразующий исходную строку,
зашифрованную по принципу, указанному в варианте 13 и со-
держащую цифры, в слово на русском языке, используя вводи-
мый набор из десяти допустимых символов.
Допустимые символы - прописные русские буквы (для алфа-
вита), цифры (для шифра и ключа).
Пример.
Десять русских букв: ВЕЖМНОПРСТ
Строка шифра: 469520336
Ключ (3-8 символов): 1243
Расшифрованная строка: МНОЖЕСТВО
Вариант 15.
Пусть задано некоторое слово. Начать просмотр этого слова
слева направо до тех пор, пока не встретятся повторяющиеся
буквы. Если такие буквы встретились, пропустить их и продол-
жить просмотр с конца слова в обратном порядке (справа нале-
во), пока снова не встретится набор повторяющихся букв. Если
такой набор встретился, продолжить просмотр с того места, ко-
торое следует за первым набором повторяющихся букв и т.д.
"Протокол" просмотра строки вывести на экран; вместо после-
довательности повторяющихся букв выводить один символ
подчеркивания.
Допустимые символы - прописные русские буквы.
Пример.
Исходное слово: НОННИЛЛИОН
"Протокол" просмотра: НО_НОИ_И
Вариант 16.
Найти в исходной строке все вхождения (но не более девяти)
заданной подстроки и заменить их на другую строку с указани-
ем номера очередного вхождения.
Допустимые символы - прописные русские буквы; символ-
разделитель
Глава 10. Задачи по программированию
513
Пример.
Исходная строка: ПОЛИЛИ_ЛИЛИЮ
Какую подстроку заменить: ЛИ
На какую подстроку заменить: СТО
Результат: ПОСТО1СТО2_СТОЗСТО4Ю
Вариант 17 ("Анаграммы")*
По заданному с клавиатуры слову построить все его ана-
граммы, т.е. слова (возможно, бессмысленные), состоящие из
всех букв исходного слова, но расположенных в произвольном
порядке. Например, "бук" и "куб" - анаграммы.
В качестве разделителя при выводе использовать символ
подчеркивания ('_'). (Для простоты можно вводить слово, не со-
держащее повторяющиеся буквы.)
Допустимые символы - прописные русские буквы.
Пример.
Введите исходное слово: КЛУБА
Анаграммы: КЛУБА КАБУЛ ..._БУЛКА_. . .
Вариант 18.
По заданному с клавиатуры слову напечатать все слова
(возможно, бессмысленные), которые можно составить из букв
введенного слова. В качестве разделителя при выводе получен-
ных слов использовать символ подчеркивания ('_'). (Для просто-
ты можно вводить слова, не содержащие повторяющиеся
буквы.)
Допустимые символы - прописные русские буквы.
Пример.
Исходное слово: БАРСУК
Полученные слова: Б_А_Р_..._АР_..._БАР_...
_СУК_..._БРУС_..._КРАБ_...
Вариант 19.
1. Зашифруйте вводимое с клавиатуры предложение сле-
дующим образом: сначала выбираются два произвольных слова
из базы, находящейся в тексте программы или вводимой с кла-
виатуры, затем слово из шифруемого предложения, потом опять
зз~3124
514
Программирование на языке Си
два слова из базы, после чего - опять слово из предложения и
т.д. "База" - набор слов, допустимых при выполнении програм-
мы, либо набор пар слов, как в приведенном ниже примере.
2. Напишите дешифратор.
Допустимые символы - прописные русские буквы; символ-
разделитель
Пример.
Шифруемое предложение:
ДЕЛ0_ЗАК0НЧЕ Н0_ХАДС0Н__РАССКАЗАЛ_ВСЕ_БЕ РЕ ГИТЕСЬ
База шифра:
С_ДИЧЬЮ_Я_ПОЛАГАЮ_ГЛАВА_ПРЕДПРИЯ ТИЯ_
ПО_СВЕДЕНИЯМ_О_МУХОБОЙКАХ_ФАЗАНЬИХ_КУРОЧЕК
Результат шифровки:
С_ДИЧЬЮ_ДД Л0_Я_П0ЛДГАЮ_ЗАК0НЧЕ НО_
ГЛАВА_ПРЕДПРИЯТИЯ_ХАДСОБ_ПО_СВЕДЕНИЯМ_
РАССКАЗАЛ_О_МУХОБОЙКАХ_ВСЕ_
ФАЗАНЬИХ_КУРОЧЕК_ББ РЕ ГИТЕ СЬ
Вариант 20.
В программе английским буквам поставлены в соответствие
наиболее часто ими передаваемые звуки, записанные русскими
буквами, например а - э, b - б, с - с, d - д, е - э, f — ф, g - г,
h - (пустой символ), i - и, j - ж и т.д. С клавиатуры задается не-
которое предложение на английском языке. (Слова разделяются
символами подчеркивания: Программа выводит "по ее мне-
нию" правильный вариант произношения каждого слова. Если
пользователь соглашается с вариантом произношения, предло-
женным программой, он нажимает <Enter>. Если не соглашается^
- вводит свой вариант произношения.
Допустимые символы - прописные английские буквы; сим-
вол-разделитель
Пример.
(В кавычках - выводимые программой произношения)
Введите предложение на английском языке:
THIS_IS_A_TABLE
THIS - "тис" -> Зис
Глава 10. Задачи по программированию
515
IS - "ИС" -> из
А - "э" ->
TABLE - "тэбле" -> тэйбл
THIS IS A TABLE -> Зис из э тэйбл
Вариант 21.
Имеется некоторая база данных, в которой некоторым анг-
лийским словам поставлены в соответствие их русские эквива-
ленты, например "THIS" - "ЭТО", "IS" - "", "А" - "", "TABLE" -
"СТОЛ" и т.д. С клавиатуры задается некоторое предложение на
английском языке (слова разделяются символами подчеркива-
ния: Программа ищет каждое слово у себя в базе данных и
выдает его перевод. Если введенное слово в базе не обнаружено,
в результирующую строку записывается исходное английское
слово.
Допустимые символы - прописные английские буквы; сим-
вол-разделитель
Пример выполнения программы:
Введите предложение на английском языке:
THIS_IS_A_T ABLE
Перевод:
ЭТО_СТОЛ
Если, например, в базе нет перевода слова TABLE, результат
выполнения программы должен быть таким:
Введите предложение на английском языке:
THIS_IS_A_TABLE
Перевод:
3T0_TABLE
Вариант 22.
С клавиатуры вводится исходная строка. Если в строке име-
ются цифры, то она считается зашифрованной и нужно выпол-
нять пункт 2 этого задания.
1. Если исходная строка не содержит цифр (т.е. символов с
кодами 48(0xJ+57(0x)), то она по определению считается неза-
шифрованной. Вам необходимо заменить все символы с кодами
33(0x21)-г99(0х63) на их двузначные коды.
33*
516
Программирование на языке Си
Символы с другими кодами выводятся без изменения.
Допустимые символы - символы с кодами от 33(0x21) до
255(0xFF), за исключением цифр (48(0x30X57(0x39)).
Пример выполнения программы:
Введите исходную строку: Hello!
Строка не зашифрована. Шифр: 72е11оЗЗ
2. Если исходная строка содержит цифры, то она по опреде-
лению считается зашифрованной. Напишите дешифратор. При
невозможности дешифрации напечатайте сообщение об ошибке
и укажите место в строке, где произошла ошибка.
Примерный диалог с программой:
Введите исходную строку: 72е11оЗЗ
Строка зашифрована. Расшифровка: Hello!
Введите исходную строку: 72е131о33
Строка зашифрована.
Ошибка в исходной строке: 72е13
Вариант 23.
Из двух заданных с клавиатуры слов составить различные
виды кроссвордов. При невозможности составить кроссворд (во
введенных словах нет ни одной одинаковой буквы) напечатать
сообщение об ошибке.
Допустимые символы - прописные русские буквы.
Пример выполнения программы:
Введите два слова, разделенных пробелом:
КАРАБАС БАРАБАС
Кроссворд 1: Кроссворд...:
Б Б
КАРАБАС А
Р ... Р
А А
Б Б
А КАРАБАС
С С
Глава 10. Задачи по программированию
517
Вариант 24.
С клавиатуры вводится предложение, слова в котором разде-
лены символом подчеркивания Подсчитайте число вхожде-
ний в предложение используемых букв, запишите результат в
строку (парами: буква - цифра) и напечатайте ее.
Допустимыми являются все символы, за исключением цифр.
Пример выполнения программы:
Введите предложение: КАРАБАС_БАРАБАС
Результат: А6БЗК1Р2С2
Вариант 25.
С клавиатуры вводится заданное количество слов. Найти все
пары слов, одно из которых оканчивается на то же сочетание
букв, на которое начинается другое, и вывести результат нало-
жения этих слов друг на друга.
Допустимые символы — прописные русские буквы.
Пример выполнения программы:
Введите количество слов: 7
Введите слова, разделенные пробелами:
ТИНА КОМА ПЛОТ КАМА ОМАР МАЗ ТОК
Результат:
КОМАР
ПЛОТИНА
КАМАЗ
Вариант 26.
С клавиатуры вводятся четыре массива слов:
1) существительные в именительном падеже единственного
числа (СТОЛЯР-КРАСНОДЕРЕВЩИК, ТОРМОЗ, ДИСКОВОД, ...);
2) глаголы несовершенного вида в 1-м лице единственного
числа (ЕСТ, САЖАЕТ, ТРАВИТ, ВАРИТ, КОСИТ, ПИЛИТ, ...);
3) качественные прилагательные во множественном числе
(ЯДОВИТЫЕ, ПРЕКРАСНЫЕ, КОШМАРНЫЕ, НЕВЗРАЧНЫЕ,
УБОЙНЫЕ, УБОГИЕ, ...);
4) существительные в винительном падеже множественного
числа (КОЛОНКИ, ДИСКЕТЫ, ВЕТВИ, ЗАБОРЫ, БАНКИ,...).
518
Программирование на языке Си
Выбирая из каждого массива с помощью датчика случайных
чисел по одному слову, составить и напечатать заданное коли-
чество текстовых строк.
Допустимые символы - прописные русские буквы.
Пример диалога с программой:
Введите массив существительных:
СТОЛЯР-КРАСНОДЕРЕВЩИК
ТОРМОЗ
ДИСКОВОД
Введите массив глаголов:
ЕСТ
САЖАЕТ
ТРАВИТ
ВАРИТ
КОСИТ
ПИЛИТ
Введите количество предложений: 2
Результат:
СТОЛЯР-КРАСНОДЕРЕВЩИК ТРАВИТ ЯДОВИТЫЕ ЗАБОРЫ.
ДИСКОВОД ПИЛИТ НЕВЗРАЧНЫЕ ДИСКЕТЫ.
Вариант 27.
С клавиатуры вводится предложение. Выведите это предло-
жение на экран, расположив буквы "по вашей любимой функ-
ции" (экспонента, квадратный корень и т.п.).
Допустимые символы - прописные русские буквы; знаки
препинания.
Пример (выбрана синусоида):
БАТЬ ОЛЕБ Л_ВЕ
ЛЕ СЯ _К АТ ЩА ЛИ
О И Ь Е К
К _ _ СВ И
К Я Я А Й
ОЛ ЬС .3 С
ЕБАТ ТАК ИНУС
Глава 10. Задачи по программированию
519
Вариант 28.
С клавиатуры вводится предложение, слова в котором разде-
лены символом подчеркивания Напечатайте все предложе-
ния, которые получаются при перестановке слов исходного
предложения.
Допустимые символы - прописные русские буквы; символ -
разделитель
Пример.
Исходное предложение: КОШКА_СЪЕЛА_МЫШКУ
Перестановки: СЪЕЛА_КОШКА_МЫШКУ
МЫШКУ_СЪЕЛА_КОШКА
КОШКА_МЫШКУ_СЪЕЛА
Вариант 29.
С клавиатуры или из файла вводится текст - некоторая ста-
тья. После этого задается содержимое письма, которое вы хоти-
те "скроить" из текста предложенной статьи. Вам необходимо
выяснить, можно ли слова письма "вырезать" из текста статьи.
Если некоторое слово "вырезать" возможно - напечатать его
большими буквами, если нет - маленькими. Границы "вырезов"
отмечать символом
Допустимые символы - прописные русские буквы; символы-
разделители или пробел).
Пример.
Текст:
ЕСЛИ КТО-НИБУДЬ БУДЕТ СТАРАТЬСЯ ВНУШИТЬ ВАМ,
ЧТО ТА ОТРАСЛЬ ПРОМЫШЛЕННОСТИ, В КОТОРОЙ ВЫ
ЛИЧНО ЗАИНТЕРЕСОВАНЫ, НАХОДИТСЯ ПОД ЗАЩИТОЙ
ПРОТЕКЦИОННЫХ ТАРИФОВ, ДЕРЖИТЕСЬ ПОДАЛЬШЕ ОТ
ТАКИХ ЛЮДЕЙ, ИБО РАССУДОК ДОЛЖЕН ВАМ ПОДСКАЗАТЬ,
ЧТО ПОДОБНАЯ СИСТЕМА В КОНЦЕ КОНЦОВ ПОДОРВЕТ
НАШ ИМПОРТ И НАРУШИТ НОРМАЛЬНУЮ ЖИЗНЬ НАШЕГО
ОСТРОВА, ИНТЕРЕСЫ КОТОРОГО ДОРОГИ ВСЕМ НАМ.
Письмо:
ЕСЛИ РАССУДОК И ЖИЗНЬ ДОРОГИ ВАМ ДЕРЖИТЕСЬ
ПОДАЛЬШЕ ОТ ТОРФЯНЫХ БОЛОТ.
520
Программирование на языке Си
Результат:
ЕСЛИ I РАССУДОК | И | ЖИЗНЬ | ДОРОГИ I ВАМ |
ДЕРЖИТЕСЬ ПОДАЛЬШЕ ОТ | торфяных болот
10.3.2. Рекомендации по обработке строк
Кратко напомним некоторые особенности обработки строк,
хотя все средства языка, необходимые для выполнения заданий
со строками, уже были рассмотрены в первых главах пособия.
1. Определение символьного массива фиксированного раз-
мера:
char Array [25] ;
Нельзя размер массива задавать с помощью переменной, т.е.
будет ошибкой определение (если N - непрепроцессорный
идентификатор):
char Array [N]
2. Определение динамического массива:
char *р;
int N = 25;
р = (char*) malloc(N);
3. Обращение к элементу массива:
выражения Аггау[0] и *Аггау - эквивалентны. Также эквива-
лентны выражения:
Array[i], *(Array+i), *(i+Array), i[Array]
Для динамического массива, адресованного указателем р, эк-
вивалентны выражения:
Р[0], *р;
p[i], *(p+i), *(i+p), i[p]
4. Переход к соседнему (i+l)-My элементу динамического
массива:
следующие выражения эквивалентны:
p[i+l] , p++[i], *(р++ +i)
Глава 10. Задачи по программированию
521
Неверно: Array++[i] - имя массива есть константа, по опре-
делению ее нельзя изменять.
5. Варианты перебора элементов массива.
int i;
for (i = 0; : i < 25; i++) {Array[i]...}
for (i = 0; : i < 25; i++) {*(Array+i)...}
for (i = 0; : i < 25; i++) {*(p+i) . . . }
for (i = 0; : i < 25; i++) {p[i]...}
Опасный вариант (можно забыть начало массива):
for (i = 0; i < 25; i++)
{ *p++...}
6. Строки в языке Си "размещаются" в символьных массивах.
Признаком окончания строки служит '\0'.
Если определен массив
char string[25] = "это строка";
то в массиве string[ ] длиной 25 байт будет размещена строка
длиной в 11 байт и string[ 10] = = '\0'.
Строки могут быть заданы в программе и так:
char *ps = "строка"; /* Длина строки 7 байт;
ps[6]=='\0'; *(ps+6)= ' \0' */
char str [ ] = "это строка"; /* Строка и
массив одинаковой длины */
7. Для ввода строк (набираемых на клавиатуре) удобно ис-
пользовать функцию char* gets(char* s), которая размещает
введенную последовательность символов в область памяти, ад-
ресуемую указателем s. При этом признак конца ввода '\п', до-
бавляемый во входной поток при нажатии клавиши <Enter>,
функция gets() заменяет признаком конца строки '\0'.
Использование для ввода строк функции scanf("%s"...) не
позволяет вводить последовательности символов, в которых со-
держатся пробелы или обобщенные пробельные символы. Ввод
по спецификации %s выполняется до ближайшего пробела.
8. Вычислить длину (1еп) строки, находящуюся в массиве
string или адресуемую указателем char * string; можно так:
522
Программирование на языке Си
int len;
for (len=0; *(string+len)•=’\0'; len ++) ;
Еще более удобно применять функции для работы со стро-
ками из стандартной библиотеки. Они описаны в заголовочном
файле string.h (см. Приложение 3). Например, для определения
длины строки используйте функцию с прототипом unsigned
strlen(char *str). (Возвращает длину строки без учета завер-
шающего строку символа '\0'.)
9. Копировать строку из массива string или из строки, адре-
суемой указателем char * string, в новый массив, адресуемый
указателем char * s, можно таким образом:
int j ;
char *s; s = (char *)malloc(len);
for (j=0; j <= len; j++)
*(s+j)=*(string+j);
здесь len - длина исходной строки.
Вариант, смещающий указатель с начала области памяти:
char *а; а = (char *)malloc(1еп5);
for (; *a++=*s++;);
10. Функции с параметрами-строками:
1) применение указателей
int length (const char *s) /* const - защита
от изменения фактического параметра */
int i;
{ for (i=0; *(s+i)!='\0’; i++)
/* Даже выражение *(s++) не меняет
"настройку" параметра на внешний массив */
return i; /* Длина строки */
}
2) применение массива
int length (char а[ ]) /*а - есть const по
синтаксису массива */
{ int i=0;
while (a[i++) •= '\0’);
return i-1; /* Длина (строки) */
}
Глава 10. Задачи по программированию
523
10.3.3. Пример выполнения задания
по обработке строк
Ввести символьную строку и разделить ее на части фиксиро-
ванной длины. Вывести на экран полученные части строки "в
столбик", т.е. каждую часть с новой строки дисплея. Пусть в
каждой части строки будет не более трех символов.
Текст программы:
/* Динамические символьные массивы, указатели
и строки */
#include <stdio.h>
#include <string.h>
void main ()
{
int LenMax, Len = 0;
char *h, *input;
int ks; /* Количество "частей" строки */
/* Указатель на массив указателей на части: */
char * * с;
int п = 0;
int j = 0;
int i;
printf("\n Введите максимальный размер"
" строки: ");
scanf("%d", &LenMax);
/* Выделить память для вводимой строки: */
input = (char *)malloc(LenMax);
printf("\n Введите строку:");
/* Удаление символа '\п' из входного потока: */
get char () ;
/* Чтение строки: */
while ((*(input+Len++)=getchar())!='\п’);
Len—;
/* Len - количество введенных символов */
/* Добавить признак конца строки: */
*(input+Len)=’\0';
/* Выделить память для введенной строки: */
h=(char *)malloc(Len+1);
/* Копируем информацию из исходной строки */
while I*(h+j++)=*input++);
/* Удаление из памяти исходной строки: */
524
Программирование на языке Си
free(input);
ks = (Len+2)/3; /* Количество частей */
с = (char **)calloc (ks, sizeof(char *));
/* Деление строки на ks "частей" */
for(j =0; j < ks; j++)
{ /* Память для части: */
*(c+j) = (char *)malloc(4);
for (i = 0; (i < 3 && *(h+n)); i++)
*(*(c+j)+i) = * (h+n++) ;
* (* (c+j)+i) = '\0 ' ;
)
/* Удаление из памяти обработанной строки: */
free(h);
/* Вывод "частей" исходной строки */
for (j = 0; j < ks; j++)
(
printf("\n %s", *(c+j));
}
/* Освободить память от динамических массивов:*/
for (j = 0; j < ks; j++)
free(*(c+j));
free(c) ;
Пример выполнения программы:
Введите максимальный размер строки: 60
Введите строку: World_Wide_Web •
Wor
ld_
Wid
e_W
eb!
В программе следует обратить внимание на ряд особенно-
стей.
Чтение символов входного потока выполняется двумя раз-
ными функциями. В цикле (окончанием которого служит появ-
ление символа '\п') с помощью getchar() читается
последовательность символов в область памяти, адресуемую
указателем char* input. Перед этим с помощью функции
scanf("%d",&LenMax) считывается значение LenMax. Здесь
Глава 10. Задачи по программированию
525
возникает одно неудобство. Функция scanf() при вводе
"оставляет" во входном потоке признак '\п' конца вводимой по-
следовательности. Если затем следует ввод с помощью функции
getchar(), то первым считанным значением будет '\п'. Именно
поэтому перед циклом с помощью getchar() из входного потока
удаляется ненужный символ '\п'.
Следующая особенность - отсутствие индексированных пе-
ременных. Для доступа к элементам массивов, в которых раз-
мещаются символы строк, используются разыменования
указателей и выражений с указателями, например: *(*(c+j)+i). В
качестве упражнения рекомендуем написать вариант программы
с индексированными переменными для доступа к отдельным
символам строк.
Еще одна особенность - отсутствие обращений к стандарт-
ным функциям для работы со строками. Программу можно уп-
ростить, если использовать функции для определения длины
строк strlen(), для копирования строк strcpy() и др.
10.4. Многомерные динамические массивы
с переменными размерами
Порядок выполнения задания (общая схема алгоритма):
1. Ввести размеры многомерных массивов.
2. Сформировать динамические массивы заданных размеров
с помощью функций malloc() и/или са11ос().
3. Заполнить массивы значениями, т.е. определить значения
элементов массивов (удобнее сделать это не вручную, т.е. не
вводя значения элементов с клавиатуры, а алгоритмически).
4. Выполнить действия над массивами, необходимые для
решения конкретной поставленной задачи, сформировать новый
массив-результат (или новые массивы).
5. Напечатать в наглядном виде массив-результат.
6. Удалить динамические массивы с помощью функции
free().
526
Программирование на языке Си
Входные данные:
• размеры массивов;
• данные, определяющие значения элементов массивов.
Выход: Представление на экране одного или нескольких
массивов-результатов.
Схема обработки многомерного динамического массива
(для матрицы).
1. Определяем указатель на массив указателей на объекты
заданного типа {тип **uk).
2. Вводим размеры матрицы N, М.
3. Создаем динамический массив из N указателей на указате-
ли:
uk = (/«wz? **)malloc(N*sizeof(ww« *));
или
uk = {тип **) calloc(N, sizeof(ww« *));
4. В цикле создаем N массивов-строк (по М элементов в каж-
дом)
for (...) uk[i] = {тип *)malloc(M*sizeof(ww«);
или
for (...) uk[i] = {тип *) calloc(M, sizeof(ww«));
5. Обработка массива (работа с индексированными элемен-
тами uk[i] [j]...);
6. В цикле удаление N массивов-строк:
for (... i ...) free(uk[i]);
7. Удаление массива указателей:
free(uk);
Каждое задание данного подраздела логически делится на
две части:
\ 1) формирование многомерного массива требуемых разме-
ров и определение значений его элементов;
2) решение задачи, для которой один или более массивов
(заполненных при выполнении первой части задания) являются
исходными данными.
Глава 10. Задачи по программированию
527
10.4.1. Варианты задач для 1-й части задания
по многомерным массивам
(правила формирования многомерного массива)
1. Ввести предельные значения xmin , хтах , ymin , утах и коли-
чество значений пх и пу , принимаемых соответственно пере-
менными
Xi (xmin <х, <хтт\ i = \,nx ;
У/ (ут.„ ^yj ^Утт\ j = ^ny .
Сформировать матрицу А с размерами пк на пу и присвоить ее
элементам значения
где функции F{xi,yt') могут быть определены следующими
аналитическими соотношениями:
F\ (*, ’ У))= 89 xi У., + 2-3 ~8 х. у2, ;
^2 (*,> .У,) = sin Д', -cosx,;
рз(х^уу)=(5Х1+7у,-25)е^' 'У1 ;
Л, (х,, yt) = х, у} - 0.5 х2 - 0.04 уj;
F5 (х„у^=^2-^-a)2 -by} +aXiyt,
где a = |0,2 ч- 0.4 j, b = |0,8 4-1.0j.
2. Ввести значение и - размерность вектора
А = {а,, а2,..., а„} и значения его элементов а,, / = !,«.
528
Программирование на языке Си
Сформировать квадратную матрицу В с размерами и на и и оп-
ределить значения ее элементов по следующему правилу:
2^7 , если у#/
at. для i=j.
3. Введя размеры и, т матрицы = определить зна-
чения ее элементов xzy (z=l, и;у=1, mj с помощью датчика
псевдослучайных чисел из библиотеки стандартных функций
компилятора. "Заполнение" матрицы выполнять по строкам, т.е.
последовательно определять значения: хи, х12,... х„т_,, х„т.
4. Введя значения и и т , сформировать матрицу Z = {z(J1 с
размерами и на т. Считая, что каждые т членов последователь-
ности
X/ = [1003 %,_] +19] mod 7777, (z = 1,2,..., х0 - задано).
определяют значения элементов очередной строки матрицы,
определить значения элементов матрицы Z = {z/7}.
Предварительно ввести значение х0 .
5. Ввести размеры и, т матрицы А = | и определить зна-
чения ее элементов по следующему правилу:
[ 6(z-l)+ </(n + l-zj /-1
а, = exp < —*-J-------- • -с 1,
7 [ п mJ
где b, с, d - величины, значения которых должны быть опреде-
лены, например, таким образом: b = 1,5; с = 3,0; d = 0,5.
6. Введя значение и, сформировать квадратную матрицу
(часть треугольника Паскаля):
Со° с‘ . z-чЛ— I Сл-1 С”
с' z-iW—l •• сл+1
С п-1 с* с2л-2 сп С2л-1
с° '-п C'n+i . I с2и-1 с2л
Глава 10. Задачи по программированию
529
где С,' - С° = 1, а остальные элементы определяются рекур-
рентной формулой: с; = с+ с .
7. Введя значения т, и, г, определить трехмерный массив
= I, значения элементов которого:
т
Pijk = —-exp-
J _________ __ ______
-----(у-Л) >, zdei = l,m; j= 1,п; к = 1,г.
п-т-г
10.4.2. Варианты для 2-й части задания по
многомерным массивам
1. Из матрицы А с размерами ЗТУна 3 М сформировать матри-
цу В с размерами 7V на М. Каждый элемент матрицы В вычис-
ляется как определитель матрицы третьего порядка,
составленной из элементов матрицы А, лежащих на пересечении
строк (3/ - 2), (3/- 1), (3/) и столбцов (Зу - 2), (Зу- 1), (Зу).
2. По заданной матрице А вычислить значения элементов
равновеликой ей матрицы В по следующему правилу: если эле-
мент матрицы А больше нуля, соответствующий элемент матри-
цы В равен единице, в противном случае - равен 0.
3. Сформировать матрицу, элементами которой являются
средние арифметические элементов исходной матрицы (без
элемента, соответствующего формируемому). Например, пер-
вым элементом полученной матрицы будет среднее арифмети-
ческое всех элементов исходной матрицы без первого элемента,
вторым - без второго и т.д.
4. По заданной квадратной матрице вычислить обратную
матрицу. Правильность выполнения проверить путем умноже-
ния исходной матрицы на обратную (должна получиться еди-
ничная матрица).
5. Так переставить строки и столбцы квадратной матрицы А,
чтобы алгебраические суммы произведений элементов /-го
34-3,24
530
Программирование на языке Си
столбца и i-й строки убывали при изменении i от 1
>1
до п, где п - размер матрицы.
6. Считая, что элементами матрицы А с размерами п на т яв-
ляются координаты п точек /«-мерного евклидового пространст-
ва, определить диаметр этого множества точек и найти две
точки, наименее удаленные друг от друга.
7. В прямоугольной матрице определить элемент, который по
модулю наименее отличается от среднего арифметического всех
элементов матрицы..
8. Считая, что элементами матрицы являются координаты т
точек «-мерного евклидового пространства, определить мини-
мальный «-мерный гиперпараллелепипед, содержащий все т то-
чек. Вычислить объем найденного гиперпараллелепипеда и вы-
вести его "проекции" на оси координат.
9. Считая, что « первых элементов каждой строки матрицы А
с размерами т на (п+1) являются координатами, а (п+1)-й эле-
мент - "весом" точки в п-мерном пространстве, определить
центр тяжести точек и расстояния от всех точек до найденного
центра тяжести.
10. По заданной прямоугольной матрице А с размерами п на
т сформировать матрицу В, каждый элемент ^которой равен
произведению средних арифметических значений элементов
"диагоналей", проходящих в матрице А через элемент atJ .
11. Сформировав равновеликие прямоугольные матрицы А и
В, построить результирующую матрицу С по правилу.
если«/у<^, тосу=ау+6у;
если а(/££>,, , тос^=ау-^.
12. Вычислить различные нормы прямоугольной матри-
цы: Л
Глава 10. Задачи по программированию
531
т-норма:;||<=т(ах^;|^|,
J
/-норма: рЦ, =тахУ|а,;|,
Л-норма: ||4 = р|аг?|2 .
V 'J
13. На основе прямоугольной матрицы получить два вектора:
вектор, сформированный путем суммирования элементов строк
матрицы; вектор, полученный путем умножения матрицы на
первый вектор. i
14. В массиве матриц транспонировать каждую матрицу.
Размерности всех матриц и их количество одинаковы. Обратите
внимание, что исходными данными для задачи служит трехмер-
ный массив.
15. Считая, что две прямоугольные матрицы с размерами п
на т представляют распределение тепла в одном и том же пря-
моугольном сечении (в точках сечения), определить градиенты
изменения температуры во всех точках (т.е. сформировать мат-
рицу приращений температуры).
16. Упорядочить матрицу (ее строки) по неубыванию наи-
больших элементов строк.
17. Целочисленную матрицу отсортировать следующим об-
разом: элементы с четными значениями должны быть упорядо-
чены внутри строк по убыванию, элементы с нечетными
значениями - по возрастанию. Четные и нечетные элементы не
должны меняться местами друг с другом.
18. Сформировать матрицу наибольших общих делителей
элементов двух исходных целочисленных матриц.
19. Вычислить заданную пользователем с клавиатуры сте-
пень п предварительно сформированной матрицы В:
В‘=В; В2=ВВ; В3=В2В.
34
532
Программирование на языке Си
20. Упорядочить строки матрицы по возрастанию значений
сумм их элементов.
21. Из заданной матрицы сформировать новую, удалив стро-
ку и столбец, которым принадлежит минимальный (один любой
из минимальных, если их несколько) элементов.
22. Вычислить суммы элементов строк квадратной матрицы
и сформировать из этих сумм вектор. Умножить исходную мат-
рицу на этот вектор-столбец и умножить этот вектор (считая его
строкой) на исходную матрицу. Вывести полученные одномер-
ные массивы.
10.4.3. Пример выполнения задания
по многомерным динамическим массивам
Условие задачи. Введя целое значение переменной и, сфор-
мировать единичную диагональную матрицу с размерами п на п
и вывести ее на экран дисплея.
В отличие от основных задач этого параграфа в данном слу-
чае для простоты не требуется обрабатывать сформированную
матрицу. В приводимой ниже программе реализовано в соответ-
ствии с условиями задачи только формирование матрицы. Этого
достаточно для демонстрации механизмов построения много-
мерных динамических массивов и работы с их элементами.
/* Единичная диагональная матрица с изменяемым
порядком */
#include <stdio.h>
void main()
{
int n; /*Порядок матрицы */
int j,i;
/* Указатель на массив указателей */
float ** matr;
/* Определяются размеры массива: */
printf("\п Введите порядок матрицы: ");
scanf("%d", &n);
/* Создаем массив для указателей float *: */
matr = (float **)malloc(sizeof(float)*n);
Глава 10. Задачи по программированию
533
if (matr = NULL)
{
printf("\n He создан динамический "
"массив!");
return; /* Завершение программы */
)
for(i = 0; i < n; i++)
{
/* Строка-массив элементов типа float */
matr[i] = (float *)malloc(sizeof(float*)*n);
if (matr[i] == NULL)
{
printf("\nHe создан динамический "
"массив!");
return; /* Завершение программы */
)
for(j = 0; j<n; j++)/* Заполнение матрицы */
if(i ’= j)
/* Формирование нулевых элементов */
matr[i] [ j] = 0.0 ,•
else
/* Формирование диагонали */
matr[i][j] =1.0;
)
for(i =0; i < n; i++)
{ /* Цикл перебора строк */
printf("\n строка %d:", i+1);
for(j =0; j < n; j++)
/‘Печать элементов строки */
printf("\t %e", matr[i][j]);
)
for(i =0; i < n; i++)
free(matr[i]);
free(matr);
Результат выполнения программы:
Введите порядок матрицы: 4
Строка 1:1 0 0 0
Строка 2: 0 1 0 0
Строка 3: 0 0 1 0
Строка 4: 0 0 0 1
534
Программирование на языке Си
Примечание. Для освоения механизмов моделирования
многомерных массивов с помощью препроцессорных
средств целесообразно решить ту же задачу, но для пред-
ставления матриц использовать одномерные массивы и орга-
низовать доступ к их элементам с помощью
макроопределений (см. §3.5).
10.5. Функции и указатели
Первая часть задания. Оформить в виде функции с прото-
типом
double function (double х);
итерационный алгоритм, запрограммированный в соответствии
с заданием §10.2 для функции f(x) из табл. 10.3. Используя соз-
данную функцию, вычислить грубое приближение интеграла:
(f(x)dx«^^(y0+2yi+...2yi+...+2ym^l +ут),
1=0
b-a
где Л - ---
т
Здесь [а, 6] - отрезок, определенный для функции f(x) из за-
дания 2 (см. табл. 10.3);
т - количество интервалов равномерного разбиения
отрезка [а,6] (см. задание из §10.2).
Вторая часть задания. Здесь предусматривается монотон-
ное увеличение количества интервалов разбиения исходного
интервала [а,Ь]. Требуется написать функцию для вычисления с
максимально возможной точностью определенного интеграла
на заданном интервале [а,Ь] от функции, указатель на которую
передается как значение параметра. Прототип функции для вы-
числения интеграла:
double integral (double(*pXdouble), double a, double b,
unsigned int *N, double *H);
Глава 10. Задачи по программированию
535
Использовать один из следующих численных методов интег-
рирования:
1. Метод (формула) Симпсона (парабола, проведенная через
3 ординаты на концах двух соседних интервалов). Справедлива
для четного количества и равных отрезков, на которые разбива-
ется интервал [а, £]:
* h
|/(х)<Лс * -(у0 + 4у, + 2у2 + 4у3 + 2у4 +...+2у„_2 + 4у„_, + у„),
а
2. Метод (формула) трапеций:
h h
j/(x)dx « ~(у0 + 2у, +...+2у„_, + у„ ),
3. Метод (формула) Ньютона (правило трех восьмых). Для п,
кратного 3:
]/(х)<Лс» ~(у0 + 3^! + Зу2 + 2у3 + Зу4 + Зу5
+ 2у6 +...+2у„_3 + Зу„_2 + Зу„_, + уп),
, Ь-а
где h =--- .
п
4. Метод Гаусса (вариант повышенной сложности). См., на-
пример, "квадратуру Гаусса" в "Справочнике по математике"
И.Н. Бронштейна, К.А. Семендяева. - М.: Наука, 1981.
С помощью разработанных функций function(), integral)
вычислить значение определенного интеграла для функции f(x)
из задания §10.2 на интервале [а,Ь], определенного там же.
536
Программирование на языке Си
С помощью параметров unsigned int *N и double *Н вер-
нуть в основную программу количество отрезков, на которые
разбивается интервал интегрирования [а, 6], и величину каждого
отрезка.
Пояснения.
При вычислении сравнивать два последующих результата,
удваивая количество шагов следующего счета. Увеличивая ко-
личество интервалов, сохранять предыдущие значения {у,} в
массиве. Это уменьшит время счета, но потребует модификации
алгоритма и динамического выделения памяти для массивов.
Возмох на нехватка памяти, следует предусмотреть защиту.
В качестве основы для выполнения задания можно использо-
вать следующую программу. В ней определенный интеграл вы-
числяется для функции у = sh(x) на интервале [2,3] методом
трапеций при фиксированном числе шагов. Точность не оцени-
вается.
/♦ Вычисление определенного интеграла
от гиперболического синуса */
#include <stdio.h>
I * Вычисление гиперболического синуса: */
double fsinh(double x)
{
int i=0;
double v,s,ss,u;
v = s = x;
do /* Цикл до машинного нуля */
{
i++ ;
ss = s;
u = v;
v = u*x*x/(i*2)/(i*2+l);
s = ss + v;
}
while(s •= ss);
return s;
}
/* Функция для вычисления интеграла методом
трапеций с фиксированным.числом шагов: */
Глава 10. Задачи по программированию
537
double integral(double (*f)(double), double a,
double b)
{
int n=50;
int i;
double h = (b-a)/n;
double s, x = a;
s = f (a) + f (b) ;
for (i = 1; i < n; i++)
{
x = x + h;
s '+= f(x)*2;
}
return s*h/2;
}
void main()
(
double a=2.0, b=3.0;
printf("\n интеграл = %le",
integral(fsinh,a,b));
}
Результат выполнения программы:
Интеграл: 6.305676е+00
10.6. Функции и массивы
Обобщенная формулировка задания. Написать функцию
для вычисления массива значений первой производной функции
f(x) в заданных точках х/ оси аргумента на интервале [а, £>]. Ука-
затель на дифференцируемую функцию передается как значе-
ние параметра. Оценить и выбрать внутри функции величину
шагов Д„ необходимых для оценки значений производной в
точке х/ (см. ниже приближенные формулы).
Прототип исследуемой функции (от которой берется произ-
водная):
double function(double х);
538
Программирование на языке Си
Возможны два варианта решения поставленной задачи.
1. Прототип функции для вычисления массива производных
с произвольным (неравномерным) разбиением интервала [a,Z>]:
double *derivatives(
double (*f) (double),/* f - указатель на функцию */
double x[ ] /* Массив значений аргумента х± */
int k, /* Количество Значений аргумента */
double D[ ]); /* Значения шагов Д± */
2. Прототип функции для вычисления массива производных
с равномерным разбиением интервала [a,Z>]:
double ‘derivatives(
double (*f) (double) ,/* f - указатель на функцию */
/* Границы интервала по х±: * /
double a, double Ь,
int к, / *Количество значений аргумента */
double D[ ]) ;/* Значения шагов */
Приближенные формулы вычисления, / (х0) - первой про-
изводной функции у=/(х) в точке х0 (рис. 10.1.):
Рис. 10.1. Иллюстрация х формулам оценки значений производной
Глава 10. Задачи по программированию
539
2Д
У о = f'(x0) = ~ Sy., + 8^, -у+2) J
12Д
У<> = Лх0) = Ц-у0 +нУ,
Д
Уо =f (хо) = гг(~3>'о +4>'| -Уг);
2Д
У о =f (*о) = 77г(-3>’-1 -1Оуо + 18у, -6у2 +к).
Массив-результат со значениями первой производной следу-
ет формировать как динамический массив внутри функции
derivatives(). Функция должна возвращать его адрес, т.е. указа-
тель на него типа double * (его адрес).
Массив-результат double d[ ] для значений шагов Д, нужно
определить в вызывающей функции.
Используя функцию derivatives(), вычислить значение пер-
вой производной для функции f(x) из задания §10.2 в точках из
интервала [а,Ь], заданного там же. Заполнить табл. 10.4.
Т аблица 10.4
Аргумент х, ♦ Значение ФУНКЦИИ f(Xj) Первая производная Шаг А;
"аналитическое" значение f«(x) приближенное значение Ш
хо=а
Хт-1~Ь
540
Программирование на языке Си
"Аналитическое" значение производной fa'(xj) для табл. 10.4
вычислить, предварительно выполнив дифференцирование по
аргументу х функции f(x). Полученное аналитическое выраже-
ние для производной fa'(x) оформить в виде дополнительной
функции с прототипом
double dir(double х) ;
Выбрать или разработать самостоятельно метод подбора ша-
га Aj вдоль оси аргумента при вычислении производной fn'(x).
Например, используйте последовательное уменьшение величи-
ны А, до достижения "машинной точности". Учтите, что это
достижение (сходимость) не гарантируется, поэтому необходи-
мо, по крайней мере, ограничить количество итераций либо вве-
сти ограничение на величину Aj
10.7. Работа со структурами
1. Выбрать предметную область для базы данных и предло-
жить структуру для описания отдельных записей базы данных.
Выбранная структура должна иметь не менее пяти полей (эле-
ментов) двух или более типов.
Пример. Структура "Государство"
Элементы (поля, компоненты) структуры:
• название страны;
• столица;
• государственный язык;
• численность населения;
• площадь территории.
2. Написать функцию для формирования одномерного мас-
сива структур, значения которых вводятся из стандартного
входного потока (с клавиатуры). При вводе структур можно
реализовать один из следующих механизмов:
• ввод заранее заданного количества структур;
• ввод до появления структуры с заданным признаком;
• диалог с пользователем о необходимости продолжать ввод.
Глава 10. Задачи по программированию
541
3. Написать функцию для записи в файл массива структур.
4. Написать функцию чтения в массив структур из файла.
5. Написать функцию дополнения уже существующего мас-
сива структур новыми структурами.
6. Написать функцию поиска структуры с заданным значени-
ем выбранного элемента.
7. Написать функцию постраничного вывода на экран дис-
плея содержимого массива структур.
8. Написать функцию поиска структур (записей) с заданными
признаками (например, выбор структур по заданному диапазону
значений элемента).
9. Написать функцию упорядочения массива структур по за-
данному полю (элементу). Например, упорядочить государства
по численности населения или в алфавитном порядке названий
стран.
10. Написать функцию полного обновления файла, например,
массив структур переписывается в файл после упорядочения.
Продемонстрировать:
• сохранение данных в файле после завершения программы;
• разные упорядочения совокупности структур;
• поиск подходящих структур (по значению элемента, по
диапазону значений элемента).
10.7.1. Варианты структур для выполнения работы
1. "Человек":
фамилия; имя; пол; национальность; вероисповедание;
рост; вес; дата рождения (год, месяц, число); номер теле-
фона; домашний адрес (почтовый йндекс, страна, область,
район, город, улица, дом, квартира).
2. "Школьник":
фамилия; имя; отчество; класс; пол; дата рождения (год,
месяц, число); домашний адрес (см. п. 1).
542
Программирование на языке Си
3. "Покупатель"-.
фамилия; имя; отчество; адрес: штат (губерния, область);
город; улица; номер дома; номер квартиры; номер кредит-
ной карточки или номер счета.
4. "Пациент"-.
фамилия; имя; год рождения; номер телефона; домашний
адрес (см. п. 1); номер медицинской карты; группа крови.
5. "Спортивная команда"-.
название; из какого города; сколько игр сыграла; сколько
набрала очков (проиграла, выиграла, ничья); количество
игроков.
6. "Стадион "-.
название; виды спорта; год постройки; адрес; вместимость
(зрителей); количество арен, площадок.
7. "Владелецавтомобиля"-.
имя; номер автомобиля; номер техпаспорта; дата рожде-
ния; телефон; отделение регистрации ГИБДД.
8. "Автомобиль":
марка; цвет; серийный номер; регистрационный номер;
количество дверей; год выпуска; цена.
9. "Фильм":
название; режиссер (фамилия, имя); страна; год выпуска;
стоимость (расходы на выпуск); доход.
10. "Музыкальный товар":
носитель (грампластинка, аудиокассета, лазерный диск);
порядковый номер в каталоге; название; исполнитель (фа-
милия, имя); время звучания; количество произведений;
цена по каталогу. .
11. "Альбом вокально-инструментальной группы":
название группы; название альбома; количество песен на
диске/кассете; год выпуска альбома; фирма-произво-
дитель.
Глава 10. Задачи по программированию
543
12. "Государство”'.
название страны; столица; государственный язык; населе-
ние (число жителей); площадь территории; денежная еди-
ница; курс валюты относительно рубля (доллара);
государственный строй.
В качестве основы для программы данного раздела можно
взять набор функций базы данных по сотрудникам предприятия
из главы 8.
10.8. Списки и деревья
В соответствии с индивидуальным заданием необходимо
создать программную систему для обслуживания конкретной
сложной динамической структуры данных (списка, дерева или
стека). Указанные в задании действия (создание пустой струк-
туры данных, ее инициализация и т.п.) должны быть оформлены
в виде отдельных функций, каждая из которых должна быть за-
писана в свой файл. Память под очередной элемент динамиче-
ской структуры данных следует выделять динамически.
Выполнение действий по обслуживанию динамической
структуры данных должно производиться в режиме диалога с
пользователем, например, так, как это делается при работе с ба-
зой данных, рассмотренной в главе 8.
В основной программе необходимо предусмотреть вызов
функций, реализующих обслуживание структуры данных, и ин-
дикацию их работы (начало работы, конец работы, код возвра-
та). Способ передачи параметров в функции - на усмотрение
разработчика программы. Для каждой функции разработать
систему кодов возврата, отражающую результат выполнения
действий внутри функции, например, успешное выполнение,
неправильный номер элемента, неправильный параметр, исчер-
пана динамическая память и т.п. В основной программе после
вызова каждой функции необходимо предусмотреть анализ ко-
дов возврата и соответствующие реакции.
544
Программирование на языке Си
В конкретном задании (см. ниже) информационная динами-
ческая струетура может быть списком, бинарным деревом, сте-
ком или деревом с особым строением узлов и связей. В
зависимости от типа конкретной информационной структуры
могут быть целесообразны разные операции по ее обработке.
Ниже приведены три группы вариантов динамических струетур,
и для каждой группы предложен список функций, реализующих
подходящий набор операций.
10.8.1. Списки
Разработать комплекс функций для обслуживания сложных
структур данных в виде разнообразных списков: однонаправ-
ленных, двунаправленных, с ключами, без ключей, кольцевых,
неоднородных и т.п.
В помещенных ниже изображениях используются следую-
щие обозначения: D - данные, next (либо N) - указатель на сле-
дующий элемент, Р - указатель на предыдущий элемент; К -
ключ; begin - указатель на начало списка.
Вариант 1. Однонаправленный список
begin —►! D | next -]-->| D | next -|---► D NULL |
Вариант 2. Однонаправленный список из элементов с клю-
чами
К D next
» К D next-f
»|К |D |NULL
Вариант 3. Кольцевой список
Вариант 4. Кольцевой список из элементов с ключами
begin —Ц К | D ] next-|-► [к | Ь | next-|-k| К | D | next-|—
t_____________—__________—J
Глава 10. Задачи по программированию
545
Вариант 5. Двунаправленный список с элементами без клю-
чей
begin —NULL ( D | N~|?=4. Р [ D | N^ZZtt-P | D | NULL |
Вариант 6. Двунаправленный список из элементов с клю-
чами
begin—<NULL | К | D | Nj?±|. Р | К | D | Р | К | D | NULL|
Вариант 7. Однонаправленный неоднородный (гетероген
ный) список с однородными подспйсками
Вариант 8. Однонаправленный неоднородный (гетероген-
ный) список с однородными подсписками из элементов с клю-
чами
7235"3124
546
Программирование на языке Си
Вариант 9. Кольцевой неоднородный (гетерогенный) список
с однородными подсписками
begin
Вариант 10. Кольцевой неоднородный (гетерогенный) спи-
сок с однородными подсписками из элементов с ключами
begin
Вариант И. Двунаправленный неоднородный (гетероген-
ный) список с однородными подсписками
Глава 10. Задачи по программированию
547
Вариант 12. Двунаправленный неоднородный (гетероген-
ный) список с однородными подсписками из элементов с клю-
чами
В программах для приведенных вариантов заданий исполь-
зуйте следующие обозначения:
begin - указатель на начало списка;
D - поле данных (строка произвольной длины либо
указатель на строку);
К - поле ключа - дополнительное поле элемента спи-
ска, заполняемое уникальным значением. Правило
формирования ключа предлагается выбрать само-
стоятельно. Простейшие варианты ключей:
• номер элемента в списке;
• номер элемента при его создании;
• ...
N, next - указатель на следующий элемент списка;
Р - указатель на предыдущий элемент списка;
NULL - нулевой указатель (используется, если для кон-
кретного элемента списка отсутствуют последую-
щий или предыдущий элементы).
Для каждого из вариантов необходимо разработать следую-
щие функции:
1. Создание (пустого списка).
2. Добавление элемента:
• в начало списка;
* в конец списка;
• после элемента с заданным номером;
1/г35’
548
Программирование на языке Си
• (*) после элемента с заданным ключом.
3. Печать списка (вывод на экран дисплея):
• номер элемента;
• содержимое поля данных;
• (*) содержимое поля ключа;
• значение указателя на следующий элемент;
• (**) значение указателя на предыдущий элемент.
4. Удаление элемента из списка:
• из начала;
• из конца;
• с заданным номером;
• (*) с заданным ключом.
5. Запись списка в файл.
6. Уничтожение списка.
7. Восстановление (чтение) списка из файла.
8. Упорядочение элементов в списке по выбранному признаку:
• используя информацию в поле данных;
• (*) используя информацию в поле ключа.
9. Изображение структуры списка на экране дисплея.
Примечания:
1. Звездочкой (*) обозначены функции списков для эле-
ментов с ключами.
2. Двумя звездочками (**) обозначены функции для дву-
направленных списков.
3. Для неоднородных списков функции обслуживания
должны разрабатываться применительно, к определенному
однородному подсписку.
Вариант 13. Стек.
Глава 10. Задачи по программированию 549
Необходимо разработать следующие функции:
1. Создание пустого стека.
2. Добавление элемента в стек.
3. Печать стека (вывод на дисплей).
4. Извлечение (удаление) элемента из стека.
5. Запись стека в файл.
6. Уничтожение стека.
7. Восстановление (чтение) стека из файла.
8. Упорядочивание элементов в стеке по выбранному при-
знаку (использовать содержимое поля данных).
9, Изображение структуры стека на экране.
10.8.2. Деревья
Бинарное дерево.
Каждая вершина бинарного дерева содержит:
• 2 указателя (на каждый альтернативный путь поиска - на
поддерево);
• данные - указатель на объект, содержащий данные, при-
надлежащие этой вершине.
Для реализации структур данных типа дерева предлагаются 4
варианта (А, Б, В и Г) их организации:
Вариант 1 (А)
Рис. 10.2. Древовидная структура типа А
550
Программирование на языке Си
В древовидной структуре типа А, представленной на
рис. 10.2, каждая вершина содержит 3 поля: поле данных и два
поля указателей на другие вершины. Левый указатель служит
для ссылки на вершину нижнего уровня, а правый - на сосед-
нюю вершину того же уровня. Указателям, не ссылающимся на
другие вершины, присваивается значение NULL (на рис. 10.2
они помечены крестиками).
Вариант 2 (Б)
Древовидная структура, типа Б (рис. 10.3) строится из вер-
шин, состоящих из двух полей: поля данных и указателя. Указа-
тель ссылается на вспомогательный список, с помощью
которого устанавливается связь текущей вершины с вершиной
нижнего уровня. Каждый элемент этого списка содержит указа-
тели на соседний Элемент вспомогательного списка и на одну
вершину нижнего уровня.
Вариант 3 (В)
Рис. 10.4. Древовидная структура типа В
Глава 10. Задачи по программированию 551
В древовидной структуре типа В (рис. 10.4) вершина состоит
всегда из 4 элементов: поля данных и 3 указателей на возмож-
ные вершины нижнего уровня. Указателям, не ссылающимся на
вершины, присваивается значение NULL.
Вариант 4 (Г)
Рис. 10.5. Древовидная структура типа Г
В древовидной структуре типа Г (рис. 10.5) каждая вершина
содержит следующие поля:
• поле данных;
• поле, в котором указано число координирующих вспомога-
тельных полей;
• вспомогательные поля, содержащие указатель на вершину
более высокого уровня (предыдущую) и указатели на вер-
шины нижнего уровня.
Если с текущей вершиной не связаны вершины нижнего
уровня, то в структуре даннь!х, описывающей вершину, соот-
ветствующие вспомогательные поля отсутствуют. Для корневой
вершины нет вершины более высокого уровня, поэтому соот-
ветствующему указателю (помечен как 'х') должно быть при-
своено значение NULL.
Для каждого из приведенных выше вариантов необходимо
разработать следующие функции:
1. Создание пустого дерева.
2. Добавление вершины к указанной вершине дерева.
552
Программирование нв языке Си
3. Распечатка (вывод на дисплей) структуры дерева.
4. Удаление заданного элемента из дерева с уничтожением
поддерева подчиненных вершин.
5. Запись дерева в файл.
6. Уничтожение дерева.
7. Восстановление (чтение) дерева из файла.
8. Изображение структуры дерева на экране.
ПРИЛОЖЕНИЕ 1
Таблицы кодов ASCII
Таблица П1.1
Коды управляющих символов (0 -г- 31)
Символ Код 10 Код 08 Код 16 Клавиши Значение
nul 0 0 00 A(? Нуль
soh 1 1 01 AA Начало заголовка
stx 2 2 02 AB Начало текста
etx 3 3 03 Ac Конец текста
eot 4 4 04 AD Конец передачи
enq 5 5 05 AE Запрос
ack 6 6 06 AJ. Подтверждение
bel 7 7 07 AG Сигнал (звонок)
ba 8 10 08 AH Забой (шаг назад)
ht 9 11 09 1 AI Горизонтальная табуляция
If 10 12 0A AJ . Перевод строки
vt 11 13 OB AK Вертикальная табуляция
ff ' 12 14 ОС AL Новая страница
cr 13 15 0D AM Возврат каретки
so 14 16 0E AN Выключить сдвиг
si 15 17 OF AO Включить сдвиг
die 16 20 10 AP Ключ связи данных
del 17 21 11 AQ Управление устройством 1
dc2 18 22 12 AR Управление устройством 2
dc3 19 23 13 AS Управление устройством 3
dc4 20 24 14 AT Управление устройством 4
nak 21 25 15 AU Отрицательное подтверждение
syn 22 26 - 16 AV Синхронизация
etb 23 27 17 AW Конец передаваемого блока
can 24 30 18 Ax Отказ
em 25 31 19 AY Конец среды
sub 26 32 1A AZ Замена
esc 27 33 IB A[ Ключ
fs ' 28 34 1C A\ Разделитель файлов
gs 29 35 ID A] Разделитель группы
rs 30 36 IE A A Разделитель записей ’
US 31 37 IF A Разделитель модулей
В графе "Клавиши" обозначение А соответствует нажатию клавиши
Ctrl, вместе с которой нажимается соответствующая "буквенная" кла-
виша, формируя код символа.
З6“3124
554
Программирование на языке Си
Таблица П1.2
Символы с кодами 32 -s-127
Символ Код 10 Код 08 Код 16 Символ Код 10 Код 08 Код 16
пробел 32 40 20 I 73 111 49
1 33 41 21 J 74 112 4A
1» 34 42 22 К 75 113 4B
# 35 43 23 L 76 114 4C
$ 36 44 24 М 77 . 115 4D
% 37 45 25 N 78 116 4E
& 38 46 26 О 79 117 4F
39 47 27 Р 80 120 50
( 40 50 28 Q 81 121 51
) 41 51 29 R 82 122 52
* 42 52 2А S 83 123 53
+ 43 53 2В Т 84 124 54
! 44 54 2С и 85 125 55
- 45 55 2D V 86 126 56
46 56 2Е W 87 127 57
/ 47 57 2F X 88 130 58
0 • 48 60 30 Y 89 131 59
1 49 61 31 Z 90 132 5A
2 50 62 32 [ 91 133 5B
3 51 63 33 \ 92 134 5C
4 52 64 34 ] 93 135 5D
5 53 65 35 Л 94 136 5E
6 54 66 36 95 137 5F
7 55 67 37 4 96 140 60
8 56 70 38 а 97 141 61
9 57 71 39 ь 98 142 62
58 72 ЗА с 99 143 63
59 73 ЗВ d 100 144 64
< 60 74 ЗС е 101 145 65
= 61 75 3D f 102 146 66
> 62 76 ЗЕ 9 103 147 67
63 77 3F h 104 150 68
е 64 100 40 i 105 151 69
А 65 101 41 j 106 152 6A
В 66 102 42 k 107 153 6B
С 67 103 43 1 108 154 6C
D 68 104 44 m 109 155 6D
Е 69 105 45 n 110 156 6E
F 70 106 46 о 111 157 6F
G 71 107 47 p 112 160 70
Н 72 110 48 3— 113 161 71
Приложение 1
555
Символ Код 10 Код 08 Код 16
г 114 162 72
9 115 163 73
t 116 164 74
U 117 165 75
V 118 166 76
W 119 167 77
X 120 170 78
Продолжение
Символ Код 10 Код 08 Код 16
У 121 171 79
Z 122 172 7А
( 123 173 7В
124 174 7С
) 125 175 7D
126 176 7Е
del 127 177 7F
Таблица П1.3
Символы с кодами 128 -s- 255 (Кодовая таблица 866 - MS-DOS)
Символ Код 10 Код 08 Код 16 Символ Код 10 Код 08 Код 16
А 128 200 80 ь 156 234 9С
Б 129 201 81 э 157 235 9D
В 130 202 82 ю 158 236 9Е
Г 131 203 83 я 159 237 9F
Д . 132 204 84 а 160 240 АО
Е 133 205 85 б 161 241 А1
Ж 134 206 86 в 162 242 А2
3 135 207 87 г 163 243 АЗ
и 136 210 88 д 164 244 А4
й 137 211 89 е 165 245 А5
к 138 212 8А ж 166 246 А6
л 139 213 8В 3 167 247 А7
м 140 214 8С и 168 250 А8
н 141 215 8D й 169 251 А9
о 142 216 8Е к 170 252 АА
п 143 217 8F л 171 253 АВ
р 144 220 90 м 172 254 АС
с 145 221 91 н 173 255 AD
т 146 222 92 о 174 256 АЕ
У 147 223 93 п 175 257 AF
* 148 224 94 176 260 ВО
X 149 225 95 й 177 261 В1
ц 150 226 96 178 262 В2
ч 151 227 97 1 179 263 ВЗ
ш 152 230 98 1 180 264 В4
ц 153 231 99 i 181 265 В5
ъ 154 232 9А Л 182 266 В6
ы 155 233 9В 3 183 267 В7
36*
556
Программирование на языке Си
Символ Код 10 Код 08 Код 16
=1 184 270 В8
185 271 В9
II 186 272 ВА
11 187 273 ВВ
Ji 188 274 ВС
Л 189 275 BD
190 276 BE
т 191 277 BF
L 192 300 СО
Л 193 301 С1
т 194 302 С2
195 303 СЗ
—• 196 304 С4
+ 197 305 С5
h 198 306 С6
IF 199 307 С7
it 200 310 С8
(г 201 311 . С9
JL 202 312 СА
if 203 313 СВ
11= 204 314 СС
= 205 315 CD
JL 1Г 206 316 СЕ
X 207 317 CF
JL 208 320 DO
T 209 321 D1
T 210 322 D2
IL 211 323 D3
L 212 324 D4
r 213 325 D5
IT 214 326 D6
215 327 D7
+ 216 330 D8
J 217 331 D9
Г 218 332 DA
1 219 333 DB
Продолжение
Символ Код 10 Код 08 Код 16
220 334 DC
1 221 335 DD
1 222 336 DE
223 337 DF
р 224 340 ЕО
с 225 341 El
т 226 342 Е2
У 227 343 ЕЗ
ф 228 344 Е4
X 229 345 Е5
Ц 230 346 Е6
ч 231 347 Е7
ш 232 350 Е8
щ 233 351 Е9
234 352 ЕА
ы 235 353 ЕВ
ь 236 354 ЕС
э 237 355 ED
ю 238 356 ЕЕ
я 239 357 EF
= или Ё 240 360 F0
± или ё 241 361 F1
£ 242 362 F2
243 363 F3
1 244 364 F4
J 245 365 F5
-г 246 366 F6
247 367 F7
0 248 370 F8
249 371 F9
250 372 FA
251 373 FB
п 252 374 FC
2 253 375 FD
254 376 FE
255 377 FF
Приложение 1
557
Таблица П1.4
Символы с кодами 128 -ь 255 (Кодовая таблица 1251 - MS Windows)
Символ Код 10 Код 08 Код 16
Ъ 128 200 80
Г 129 201 81
130 202 82
г 131 203 83
п 132 204 84
133 205 85
t 134 206 86
ф 135 207 87
е 136 210 88
V. 137 211 89
А 138 212 8А
< 139 213 8В
н> 140 214 8С
к 141 215 8D
ь 142 216 8Е
ц 143 217 8F
6 144 220 90
145 221 91
г 146 222 92
\\ 147 223 93
// 148 224 94
• 149 2 225 95
— 150 226 96
— 151 227 97
п 152 230 98
ВС 153 231 99
Л 154 232 9А
> 155 233 9В
ж 156 234 9С
к 157 235 9D
h 158 236 9Е
и 159 237 9F
160 240 АО
У 161 241 А1
У 162 242 А2
J 163 243 АЗ
в 164 244 А4
г 165 245 А5
1 166 246 А6
§ 167 247 А7
Ё 168 250 А8
Символ Код 10 Код 08 Код 16
© 169 251 А9
е 170 252 АА
« 171 253 АВ
“1 172 254 АС
- 173 255 AD
® 174 256 АЕ
I 175 257 AF
о 176 260 ВО
± 177 261 В1
I 178 262 В2
1 179 263 ВЗ
I* 180 264 В4
р 181 265 В5
I 182 266 В6
183 267 В7
ё 184 270 В8
№ 185 271 В9
е 186 272 ВА
» 187 273 ВВ
• j 188 274 ВС
S 189 275 BD
9 190 276 BE
1 191 277 BF
А 192 300 СО
Б 193 301 С1
В 194 302 С2
Г 195 303 СЗ
д 196 304 С4
Е 197 305 С5
Ж 198 306 С6
3 199 307 С7
и 200 310 С8
й 201 311 С9
к 202 312 СА
л 203 313 СВ
м 204 314 СС
н 205 315 CD
0 206 316 СЕ
п 207 317 CF
₽ 208 320 DO
с 209 321 D1
558
Программирование на языке Си
Символ Код 10 Код 08 Код 16
т 210 322 D2
У 211 323 D3
ф 212 324 D4
X 213 325 D5
Ц 214 326 D6
Ч 215 327 D7
Ш 216 330 D8
ц 217 331 D9
ъ 218 332 DA
ы 219 333 DB
ь 220 334 DC
э 221 335 DD
ю 222 336 DE
я 223 337 DF
- а 224 340 E0
б 225 341 El
в 226 342 E2
г 227 343 E3
д 228 344 E4
е 229 345 E5
ж 230 346 E6
3 .231 347 E7
и 232 350 E8
Продолжение
Символ Код 10 Код 08 Код 16
Й 233 351 Е9
X 234 352 ЕА
Л 235 353 ЕВ
M 236 354 ЕС
H 237 355 ED
о 238 356 ЕЕ
П 239 357 EF
p 240 360 F0
c 241 361 F1
T 242 362 F2
У 243 363 F3
Ф 244 364 F4
X 245 365 F5
Ц 246 366 F6
4 247 367 F7
Ш 248 370 F8
Ж 249 371 F9
250 372 FA
Ы 251 373 FB
b 252 374 FC
3 253 375 FD
Ю 254 376 FE
я 255 377 FF
ПРИЛОЖЕНИЕ 2
Константы предельных значений
Предельные значения вводятся каждой реализацией для дан-
ных целочисленных типов и арифметических значений, пред-
ставляемых в форме с плавающей точкой. Предельные значения
определяются набором констант, названия (имена) которых
стандартизированы и не зависят от реализаций. Ниже приводят-
ся обозначения констант и их минимальные (по абсолютной ве-
личине) допустимые стандартом ANSI значения. В конкретных
реализациях абсолютные Значения констант могут превышать
значения, приведенные в таблицах.
Таблица П2.1
Предельные значения для целочисленных типов - файл limits.h
Имя константы Значение Смысл
CHAR_BIT 8 Число битов в байте
SCHAR_MIN -128 Минимальное значение signed char
SCHAR_MAX 127 Максимальное значение signed char
UCHAR_MAX 255 Максимальное значение unsigned char
CHAR_MIN ’0’ Минимальное значение для char
SCHAR_MIN
CHAR_MAX UCHAR_MAX Максимальное значение для char
SCHAR_MAX
MB LEN MAX 1 Минимальное число байтов в многобай-
товом символе
SHRT_MIN -32768 Минимальное значение для short
SHRT_MAX 32767 Максимальное значение для short
USHRT_MAX 65535 Максимальное значение unsigned short
INT_MIN -32768 Минимальное значение для int
560
Программирование на языке Си
Продолжение
Имя константы Значение Смысл
INTJMAX UINT_MAX LONG_MIN LONG_MAX ULONG_MAX 32767 65535 -2147483648 2147483647 4294967295 Максимальное значение для int Максимальное значение unsigned int Минимальное значение для long Максимальное значение для long Максимальное значение unsigned long
В табл. П2.2 префикс FLT_ соответствует типу float; для ти-
па double йспользуется префикс DBL_.
Таблица П2.2
Константы для вещественных типов - файл floath
Имя константы Значение Смысл
FLT_RADIX 2 Основание экспоненциального представле- ния, например: 2, 16
FLT_DIG 6 Количество верных десятичных цифр
FLT_E₽SILON IE-5 Минимальное х, такое, что 1.0 + х * 1.0 (1.192093Е-07)
FLT_MANT_DIG 24 Количество цифр в мантиссе по основанию FLT_RADIX
FLT_MAX 1E+37 Максимальное число с плавающей точкой (3.402823Е+38)
FLT_MAX_EXP 128 Максимальное и, такое, что FLT_RADIX" - 1 представимо в виде числа типа float
FLT_MAX_10_EXP 38 Максимальное целое и, такое, что 10" представимо как float
FLT_MIN IE-37 Минимальное нормализованное число с плавающей точкой типа float (1.175494Е-38)
FLT_MIN_EXP -125 Минимальное л, такое, что 10" представи- мо в виде нормализованного числа
Приложение 2
561
Продолжение
Имя константы Значение Смысл
FLT_MIN_1О_ЕХР 38 Максимальное целое и, такое, что 10" представимо как float
DBL_DIG 10 Количество верных десятичных цифр для типа double
DBL_EPSILON IE-16 Минимальное х, такое, что 1.0 + х * 1.0, где х принадлежит типу double (2.220446Е-16)
DBL_MANT_DIG 53 Количество цифр по основанию FLT_RADIX в мантиссе для чисел типа double
DBL_MAX 1E+308 Максимальное число с плавающей точкой типа double (1.797693Е+308)
DBL_MAX_EXP 1024 Максимальное и, такое, что FLT_ RADIX" - 1 представимо в виде числа типа double
DBL_MAX_1O_EXP 308 Максимальное целое п, такое, что 10" представимо как double
DBL_MIN IE-308 Минимальное нормализованное число с плавающей точкой типа double (2.225074Е-308)
DBL_MIN_EXP -1021 Минимальное п, такое, что 10" представи- мо в виде нормализованного числа типа double
DBL_MIN_1O_EXP -307 Минимальное отрицательное целое и, та- кое, что 10" - в области определения чи- сел типа double
В скобках для некоторых констант приведены значения из
реализации Borland 3.1 C++
ПРИЛОЖЕНИЕ 3
Стандартная библиотека функций языка Си
Таблица П3.1
Математические функции (файл math.h)
Функция Прототип и краткое описание действий
abs int abs(int i); Возвращает абсолютное значение целого аргумента i.
acos double acos(double x); Функция арккосинуса. Значение аргумента должно находиться в диапазоне от -1 до +1.
asin double asin(double х); Функция арксинуса. Значение аргумента должно находиться в диапазоне от -1 до +1.
atari double atan(double х); Функция арктангенса.
atan2 double atan2(double у, double х); Функция арктангенса от значения у/х.
cabs double cabs(struct complex znum); Вычисляет абсолютное значение комплексного числа znum. Оп- ределение структуры (типа) complex - в файле math. h.
Ceil double ceil(double x); Вычисляет ближайшее целое, не меньшее, чем аргумент х.
COS double costdouble х); Фуикция косинуса. Угол (аргумент) задается в радианах.
exp double exp(double х); Вычисляет значение е* (экспоненциальная функция).
tabs double fabs(double x); Возвращает абсолютное значение вещественного аргумента х двойной точности.
floor double floor(double х); Находит наибольшее целое, не превышающее значение х.. Воз- вращает его в форме double.
Приложение 3
563
Продолжение
Функция Прототип и краткое описание действий
fmod double fmod(double x, double y); Возвращает остаток от деления нацело х на у.
frexp double frexp(douhle value, int *exp); Разбивает число с плавающей точкой value на нормализованную мантиссу и целую часть как степень числа 2. Целочисленная сте- пень записывается в область памяти, на которую указывает ехр, а мантисса используется как значение, которое возвращает функция.
hypot double hypot(double х, double у); Вычисляет гипотенузу z прямоугольного треугольника по значе- ниям катетов х, у (z^ = + у2).
labs long labs(long х); Возвращает абсолютное значение целого аргумента long х.
Idexp double Idexp(double v, int e); Возвращает значение выражения v*2e.
log double log(double x); Возвращает значение натурального логарифма (In х).
loglO double loglO(double x); Возвращает значение десятичного логарифма (log ] о х)-
rnodf double modf(double value, double *iptr); Разделяет число с плавающей точкой value на целую и дробную части. Целая часть записывается в область Памяти, на которую указывает iptr, дробная часть является значением, возвращаемым функцией.
Poly double poly(double х, int n, double c[ ]); Вычисляет значение полинома: c[n]xn + c[n - l]x" ' 1 + ... + c[l]x + o[0]
pow double pow(double x, double y); Возвращает значение xy, т.е. x в степени у.
powlO double powlO(int p); Возвращает значение 1 O’1.
sin double sin(double x); Функция синуса. Угол (аргумент) задается в радианах.
sinh double sinh(double х); Возвращает значение гиперболического синуса для х.
564
Программирование на языке Си
Продолжение
Функция Прототип и краткое описание действий
sqrt tan tanh double sqrt (double х); Возвращает положительное значение квадратного корня . double tan(double х); Функция тангенса. Угол (аргумент) задается в радианах. double tanh(double х); Возвращает значение гиперболического тангенса для х.
Таблица П3.2
Функции и макросы проверки и преобразования символов
(файл ctype.h)
Функция Прототип н краткое описание действий
isalnum int isalnum(int c); Дает значение не нуль, если с - код буквы или цифры (А 4- Z, а 4- z, 0 + 9), и нуль - в противном случае.
isalpha int isalpha(int с); Дает значение не нуль, если с - код буквы (А 4- Z, а 4- z), и нуль - в противном случае.
isascii int isascii(int с)) Дает значение не нуль, если с есть код ASCII, т.е. принимает зна- чение от 0 до 127, в противном случае - нуль.
iscntrl int iscntrl(int с); Дает значение не нуль, если с - управляющий символ с кодами 0x00 OxOlF или 0x7F, и нуль - в противном случае.
isdigit int isdigit(int с); Дает значение не нуль, если с - цифра (0 4- 9) в коде ASCII, и нуль - в противном случае.
isgraph int isgraph(int с); Дает значение не нуль, если с - видимый (изображаемый) символ с кодом (0x21 4- 0х7Е), и нуль - в противном случае.
islower int islower(int с); Дает значение не нуль, если с - код буквы на нижнем регистре (а 4- z), и нуль - в противном случае.
Приложение 3
565
Продолжение
Функция ' Прототип и краткое описание действий
isprint int isprint(int с); Дает значение не нуль, если с - печатный символ с кодом (0x20 -=- 0х7Е), и нуль - в противном случае.
ispunct int ispunct(int с); Дает значение не нуль, если с - символ-разделитель (т.е. соответ- ствует iscntrl или isspace) и нуль - в противном случае.
isspace int isspace(int с); Дает значение не нуль, если с - обобщенный пробел: пробел, символ табуляции, символ новой строки или новой страницы, символ возврата каретки (0x09 + 0x00,0x20), и нуль-в про- тивном случае.
supper int isupper(int с); Дает значение не нуль, если с - код буквы на верхнем регистре (А + Z), и нуль - в противном случае.
isxdigit int isxdigit(int с); Дает значение не нуль, если с - код шестнадцатеричной цифры (0 + 9, А + F, а + f), и нуль - в противном случае.
toascii int toascii(int с),- Преобразует целое число с в символ кода ASCII, обнуляя все би- ты, кроме младших семи. Результат от 0 до 127.
tolower int tolower(int с); Преобразует код буквы с к нижнему регистру, не буквенные ко- ды не изменяются.
toupper int toupper(int с); Преобразует код буквы с к верхнему регистру, не буквенные ко- ды не изменяются.
Таблица ПЗ.З
Функции ввода-вывода для стандартных потоков (файл stdio.h)
Функция Прототип и краткое описание действий
getch int getch(void); Считывает один символ с клавиатуры без отображения на экране.
566
Программирование на языке Си
Продолжение
Функция Прототип и краткое описание действий
getchar int getchar(void); Считывает очередной символ из стандартного входного потока (stdin).
gets char *gets(char *s); Считывает строку s из стандартного входного потока (stdin).
printf int printf(const char *format [, argument,...]); Функция форматированного вывода в стандартный поток stdout.
putchar int putchar(int с); Записывает символ с в стандартный поток вывода (stdout).
puts int puts(const char *s); Записывает строку s в стандартный поток вывода (stdout).
scanf int scanf(const char *format[, address, ...]); Функция форматированного ввода из стандартного потока stdin.
sprintf int- sprintf(char *s, const char *format[, argument, ...]); Функция форматированной записи в строку s.
sscanf int sscanf(const char *s, const char *fonnat[, address, ...]); Функция форматированного Чтения из строки s.
ungetch int ungetch(int c); Возвращает символ с в стандартный поток ввода stdin, заставляя его быть следующим считываемым символом.
Таблица П3.4
Функции для работы со строками
(файлы string.h, stdlib.h)
Функция Прототип и краткое описание действий
atof double atof(const char *str); Преобразует строку str в вещественное число типа double.
atoi int atoi(const char *str); Преобразует строку str в целое число типа int.
Приложение 3
667
Продолжение
Функция Прототип и краткое описание действий
atol long atol(const char *str); Преобразует строку str в целое число типа long.
itoa char *itoa(int v, char *str, int baz); Преобразует целое v в строку str. При изображении числа ис- пользуется основание baz (2 < baz < 36). Для отрицательного числа и baz = 10 первый символ "минус" (-).
Itoa char *ltoa(long v, char *str, int baz); Преобразует длинное целое v в строку str. При изображении числа используется основание baz (2 < baz < 36).
strcat char *strcat(char *sp, const char *si); Приписывает строку si к строке sp (конкатенация строк).
strchr char *strchr(const char *str, int c); Ищет в строке str первое вхождение символа с.
strcmp int strcmp(const char *strl, const char *str2); Сравнивает строки strl .H str2. Результат отрицателен, если strl < str2; равен нулю, если strl = str2, и положите- лен, если strl > str2 (сравнение беззнаковое).
strcpy char *strcpy(char *sp, const char *si); Копирует байты строки si в строку sp.
strcspn int strcspn(const char *strl, const char *str2); Определяет длину первого сегмента строки strl, содержащего символы, не входящие во множество символов строки str2.
strdup char *strdup(const char *str); Выделяет память и переносит в нее копию строки str.
strlen unsigned strlen(const char *str); Вычисляет длину строки str.
strlwr char *strlwr(char *str); Преобразует буквы верхнего регистра в строке в соответствую- щие буквы нижнего регистра.
strncat char *strncat (char *sp, const char *si, int koi); Приписывает koi сймволов строки si к строке sp (конкате- нация).
568
Программирование на языке Си
Продолжение
Функция Прототип и краткое описание действий
strncmp int strncoip (const char *strl, const char *str2, int koi); Сравнивает части строк strl и str2, причем рассматриваются первые koi символов. Результат отрицателен, если strl < str2; равен нулю, если strl == str2, и положителен, если strl > str2.
strncpy char *strncpy (char *sp, const char *si, int koi); Копирует koi символов строки si в строку sp ("хвост" отбрасы- вается или дополняется пробелами).
strnicmp int strnicmp(char *strl, const char *str2, int koi); Сравнивает не более koi символов строки strl и строки str2, не делая различия регистров (см. функцию strncmp ()).
strnset char *strnset(char *str, int c, int kol); Заменяет первые koi символов строки str символом с.
strpbrk char *strpbrk(const char *strl,const char *str2) ; Ищет в строке strl первое появление любого из множества символов, входящих в строку str2.
strrchr char *strrchr(const char *str, int c); Ищет в строке str последнее вхождение символа с.
strset char *strset(char *str, int с); Заполняет строку str заданным символом с. т.
strspn int strspn(const char *strl, const char *str2); Определяет длину первого сегмента строки strl, содержащего только символы, из множества символов строки str2.
strstr char *strstr(const char *strl, const char *str2); Ищет в строке strl подстроку str2. Возвращает указатель на тот элемент в строке strl, с которого начинается подстрока str2.
strtod double strtod(const char *str, char **endptr); Преобразует символьную строку str в число двойной точности. Если endptr не равен NULL, то *endptr возвращается как ука- затель на символ, при достижении которого прекращено чтение строки str.
Приложение 3
569
Продолжение
Функция Прототип и краткое описание действий
strtok char «strtok(char *strl, const char *str2); Ищет в строке strl лексемы, выделенные символами из второй строки.
strtot long strtol(const char «str, char ««endptr, int baz); Преобразует символьную строку str к значению "длинное чис- ло" с основанием baz (2 £ baz < 36). Если endptr не равен NULL, то «endptr возвращается как указатель на символ, при достижении которого прекращено чтение строки str.
strupr char «strupr(char «str); Преобразует буквы нижнего регистра в строке str в буквы верх- него регистра.
ultoa char «ultoa(unsigned long v, char *str, int baz); Преобразует беззнаковое длинное целое v в строку str.
Таблица П3.5
Функции для выделения и освобождения памяти
(файлы alloc.h, stdlib.h)
Функция Прототип и краткое описание действий
calloc void «calloc(unsigned n, unsigned m); Возвращает указатель на начало области динамически распреде- ленной памяти для размещения п элементов по, ш байт каждый. При неудачном завершении возвращает значение NULL.
coreleft unsigned coreleft (void); - для схем распределения памя- ти в Turbo С: tiny, small, medium. unsigned long coreleft (void); - для других схем рас- пределения памяти. Возвращает значение объема неиспользованной памяти. Функция уникальна для Turbo С, где приняты упомянутые схемы распре- деления памяти.
free void free (void *Ы); Освобождает ранее выделенный блок динамически распределяе- мой памяти с адресом первого байта Ы.
37-Э124
570
Программирование на языке Си
Продолжение
Функция Прототип и краткое описание действий
malloc void ‘malloc(unsigned s); Возвращает указатель на блок динамически распределяемой па- мяти длиной s байт. При неудачном завершении возвращает зна- чение NULL.
realloc void ‘realloc(void *Ы, unsigned ns); Сохраняя содержимое, изменяет размер участка динамической памяти с адресом начала Ы, делая его равным ns (байт). Если Ы равен NULL, то функция выполняется как malloc (). При не- удачном завершении возвращает значение NULL.
Таблица П3.6
Функции для работы с терминалом в текстовом режиме
(файл conio.ti)
Функция Прототип и краткое описание действий
clreol void clreol(void) ; Стирает символы от позиции курсора до конца строки в тексто- вом окне.
clrscr void clrscr(void); Очищает экран.
cgets char *cgets(char *str); Выводит на экран строку str.
cprintf int cprintf(const char ‘format[, argument,...]); Выводит форматированную строку в текстовое окно, созданное функцией window ().
cputs int cputs(char *str); Помещает в символьный массив str строку с клавиатуры (кон- соли).
cscanf int cscanf(const char ‘format[, address, ...]); Функция форматированного ввода, которая используется при работе с терминалом в текстовом режиме
delline void delline(void); Удаляет строку в текстовом окне (где находится курсор).
Приложение 3
571
Продолжение
Функция Прототип и краткое описание действий
gotoxy void gotoxy(int x, int y); Перемещает курсор в позицию текстового окна с координатами (Х.У).
highvideo void highvideo(void); Повышает яркость символов, выводимых на экран после ее вы- зова.
movetext int movetext(int xO,int yO,int xl,int y2,int x,int y); Переносит текстовое окно в область экрана, правый верхний угол которой имеет координаты (х, у). Координаты угловых то- чек окна - (хО, уО), (xl, yl).
normvideo void normvideo(void); Устанавливает нормальную яркость выводимых на экран симво- лов.
textattr void textattr(int newattr); Устанавливает атрибуты (фон, цвет) символов, выводимых на экран.
textbackg round void textbackground(int с); Устанавливает цвет фона по значению параметра с.
textcolor void textcolor(int с); Устанавливает цвет символов по значению параметра с.
textmode void textmode(int m); Переводит экран в текстовый режим по значению параметра т.
wherex int wherex(void); Возвращает значение горизонтальной координаты курсора.
wherey int wherey(void); Возвращает значение вертикальной координаты курсора.
window void window(int xO,int yO,int xl,int yl); Создает текстовое окно по координатам угловых точек (хО, уО), (xl, yl).
Функции из табл. П3.6 поддерживаются только на IBM PC (в
MS-DOS) и совместимых с ним компьютерах.
37
572
Программирование на языке Си
Таблица П3.7
Специальные функции
Функция Прототип и краткое описание действий Местона- хождение прототипа
delay void delay(unsigned x); Приостанавливает выполнение программы на х мсек. dos .h
getenv char *getenv(const char ‘name); Ищет в списке переменных среды имя, заданное па- раметром паше. В случае нахождения возвращает указатель на строку, являющуюся значением этой переменной среды. stdlib.h
kbhit int kbhit(void); Возвращает ненулевое целое, если в буфере клавиа- туры присутствуют коды нажатия клавиш, в против- ном случае - нулевое значение. conio.h
memcmp int memcmp (const void *sl, const void *s2, unsigned n); Сравнивает посимвольно две области памяти si и s2 длиной п байт. Возвращает значение меньше нуля, если si < s2, нуль, если si == s2, и больше ну- ля, если si > s2. mem.h
memcpy void *memcpy(void *p, const void *i, unsigned n); Копирует блок длиной n байт йз области памяти i в область памяти р. mem.h
memicmp int memicmp (const void *sl, const void *s2, unsigned n); Подобна memcmp, за тем исключением, что игнори- руются различия между буквами верхнего и нижнего регистра. mem. h
memmove void *memmove (void *dest, const void *src, int n); Копирует блок длиной n байтов из src в dest. Возвращает указатель des t. mem.h
Приложение 3
573
Продолжение
Функция Прототип и краткое описание действий Местона- хождение прототипа
memset void *manset (void *s, int c, unsigned n) ; Записывает во все байты области памяти s значение с. Длина области s равна п байт. mem. h
nosound void nosound(void); Прекращает подачу звукового сигнала, начатую функцией sound (). dos .h
peek int peek(unsigned s, unsigned c); Возвращает целое значение (слово), записанное в сегменте s со смещением с. dos. h
peekb char peekb(unsigned s, unsigned c); Возвращает один байт, записанный в сегменте s со смещением с, т.е. по адресу s: с. dos. h
poke void poke (unsigned s, unsigned c, int v); Помещает значение v в слово сегмента s со смеще- нием с, т.е. по адресу s: с. dos .h
pokeb void pokeb(unsigned s, unsigned c, char v) ; To же, что и poke, но помещает один байт v по ад- ресу s: с. dos. h
putenv int putenv(const char *name); Добавляет строку в окружение программы. stdlib.h
rand int rand(void); Возвращает псевдослучайное целое число из диа- па-зона 0 +(215-1), может использовать функцию srand(). stdlib.h
signal int signal(int sig); Вызывает, программный сигнал с номером sig. Ис- пользуется для обработки исключительных ситуаций в языке Си. signal.h
sound void sound(unsigned f); Вызывает звуковой сигнал с частотой f Гц. dos .h
srand void srand(unsigned seed); Функция инициализации генератора случайных чи- сел (rand); seed - любое беззнаковое целое число. stdlib.h
574
Программирование на языке Си
Таблица П3.8
Функции для работы с файлами, связанными с потоками (файл stdio.h)
Функция Прототип и краткое описание действий
clearerr void clearerr(FILE «stream); Сбрасывает индикаторы достижения конца файла и обнаружения ошибки для файла, связанного с потоком stream.
fclose int fclose(FILE «stream); Закрывает файл, связанный с Потоком stream.
feof int feof(FILE «stream); Проверяет, достигнут ли конец файла, связанного с потоком stream.
ferror int ferror(FILE «stream); Проверяет, не возникла ли ошибка записи или чтения при доступе к файлу, связанному с потоком stream.
fgetc int fgetc(FILE «stream); Считывает символ из файла, связанного с потоком stream.
fgetpos int fgetpos(FILE «stream, fpos_t *pos); Копирует значение указателя текущей позиции в файле, связанном с потоком stream, в объект, на который указывает pos. Тип при- нимающей переменной задан в заголовочном файле stdio.h.
fgets char «fgets(char «string, int n, FILE «stream); Читает не более п-1 символов из файла, связанного с потоком stream, в массив, адресуемый указателем string. За последним символом, помещенным в массив, записывается '\0'.
fopen FILE «fopen(const char «filename, const char «mode); Открывает файл, на имя которого указывает filename, в режиме, задаваемом mode, и связывает его с потоком. Указатель на поток является значением, возвращаемым функцией.
fprintf int fprintf(FILE «stream, const char «format [, argument,...]); Функция форматного вывода в файл, связанный с потоком stream (см. printf()).
fputc int fputc(int с, FILE «stream); Выводит символ с в файл, связанный с потоком stream.
Приложение 3
575
Продолжение
Функция Прототип и краткое описание действий
fputs int fputs(const char ‘string, FILE ‘string); Записывает символьную строку, на которую указывает string, в файл, связанный с потоком stream.
fscanf int fscanf(FILE ‘stream, const char ‘format [, argument,... |); Функция форматного ввода из файла, связанного с потоком stream (см. scanfO).
fseek int fseek(FILE ‘stream, long offset, int point); Перемещает указатель текущей позиции в файле, связанном с по- током stream, на offset байт относительно точки отсчета, опреде- ленной значением point (0 - от начала файла, 1 - от текущей позиции, 2 - от конца файла).
ftell long ftell(FILE ‘stream); Возвращает значение указателя текущей позиции в файле, связан- ном с потоком stream.
Таблица П3.9
Функции низкого уровня для работы с файлами
(файлы io.h, fcntl.h, unistd.h)
Функция Прототип и краткое описание действий
dose int close(int handle); Закрывает файл, связанный с дескриптором handle.
creat int creat(const char *path, int mode); Создает новый файл в режиме, заданном в mode.
eof int eof(int handle); Проверяет, достигнут ли конец файла, связанного с дескриптором handle.
Iseek long Iseek(int handle, long offset, int point); Перемещает указатель текущей позиции в файле, связанном с де- скриптором handle на offset байтов относительно точки отсчета, определенной значением point (0 - от начала файла, 1 - от теку- щей позиции, 2 - от конца файла).
576
Программирование на языке Си
Продолжение
Функция Прототип и краткое описание действий
open int open(const char *path, int access [, unsigned node]); Открывает файл, на имя которого указывает path а режиме, за- данном в access. Возвращает дескриптор файла. Mode определяет тип файла и права доступа.
read int read(int handle, void *buf, unsigned len); Читает len байтов из файла, связанного с дескриптором handle в буфер, на который указывает buf.
so pen int sopen(const char *path, int access, int shflag, [, unsigned mode]); Открывает файл, на имя которого указывает path, для совместно- го использования несколькими процессами. Access - режим доступа; shflag - режим разделения файла; mode определяет тип файла и права доступа. Возвращает дескриптор файла.
tell long tell(int handle); Возвращает значение указателя текущей позиции в файле, связан- ном с дескриптором handle.
write int write(int handle, void *buf, unsigned nbyte); . Записывает nbyte байтов из буфера, на который указывает buf, в файл, связанный с дескриптором handle.
ЛИТЕРАТУРА
1. Керниган Б., Ритчи Д., Фыоер А. Язык программирования
Си. Задачи по языку Си / Пер. с англ. - М.: Финансы и стати-
стика, 1985. - 279 с.
2. Кернигаи Б., Ритчи Д. Язык программирования Си / Пер. с
англ. - М.: Финансы и статистика, 1992. - 272 с.
3. Болски М.И. Язык программирования Си / Пер. с англ.
Справочник. - М.: Радио и связь, 1988. - 96 с.
4. Хэнкок Л., Кригер М. Введение в программирование на язы-
ке Си / Пер. с англ. - М.: Радио и связь, 1986. - 192 с.
5. Жешке Рекс. Толковый словарь стандарта языка Си / Пер. с
англ. - Санкт-Петербург: Питер, 1994. - 222 с.
6. Уэйт М., Прата С., Мартин Д. Язык Си. Руководство для
начинающих / Пер. с англ. - М.: Мир, 1988. - 512 с.
7. Банахан М., Раттер Э. Введение в операционную систему
UNIX / Пер. с англ. - М.: Радио и связь, 1985. - 344 с.
8. Белецкий Я. Энциклопедия языка Си / Пер. с англ - М.: Мир,
1992.-687 с.
9. Джехани Н. Программирование на языке Си / Пер. с англ. -
М.: Радио и связь, 1988. - 272 с.
10. Юлин В.А., Булатова И.Р. Приглашение к Си. - Минск:
Вышейшая школа, 1990. - 224 с.
11. Уинер Р. Язык Турбо Си / Пер. с англ. - М.: Мир, 1991. -
380 с.
12. Романовская Л.М., Русс Т.В., Свитковский С.Г. Про-
граммирование в среде Си для ПЭВМ ЕС - М.: Финансы и
статистика, 1991. - 352 с.
13. Трой Д. Программирование на языке Си для персонального
компьютера IBM PC. - М.: Радио и связь, 1991. - 430 с.
14. Бочков С.О., Субботин Д.М. Язык программирования Си
для персонального компьютера. - М.: СП "Диалог", 1990. -
384 с.
15. Дерк Луис С и C++. Справочник / Пер. с нем. - М.: Вос-
точная книжная компания, 1997. - 592 с.
16. Тоидо К., Гимпел С. Язык Си / Пер. с англ. Книга ответов.
- М.: Финансы и статистика, 1994. - 160 с.
Указатель операций и разделителей
, операция "запятая" 34, 36,
41
разделитель "запятая" 47
; разделитель "точка с за-
пятой" 25, 28, 47, 68
• операция логического от-
рицания 34, 35, 52
• = операция отношения "не-
равенство" 34,38,52,172
# препроцессорная опера-
ция над параметром
макроса 49, 64, 157, 160
## препроцессорная операция
конкатенации лексем в
макросе 157
% операция вычисления ос-
татка от деления 34, 37,
50, 54
%= операция вычисления ос-
татка с присваиванием
34, 39
& операция получения адре-
са 33, 34, 165
поразрядная операция И
34. 37, 59
&& логическая операция И
34, 38
&= поразрядная операция И с
присваиванием 34, 40,
54
О операция "вызов функ-
ции" 34,41, 110, 207
разделитель "скобки" 44,
50, 297
операция явного преобра-
зования типов 34,42
* операция разыменования
34,176, 216, 296
операция умножения 34,
37, 50, 54
определение указателя 34,
44, 49, 164
* = операция умножения с
присваиванием 34, 39
+ операция сложения 34, 50,
54
операция "унарный плюс"
34, 35
++ операция увеличения на 1
(инкремент) 34, 35, 51
+= операция сложения с при-
сваиванием 34, 39
- , операция вычитания 34,
50
операция "унарный ми-
нус"25, 34, 50
— операция уменьшения на
1(декремент) 34, 36, 51
- = операция вычитания с
присваиванием 34, 40
- > операция доступа к ком-
поненту по указателю
на структурированный
объект 34,297
операция доступа к ком-
поненту по имени
структурированного
объекта 34,41, 286, 297
Указатель операций и разделителей
579
... многоточие 44, 48, 204,
243,250
/ операция деления (слэш)
34, 37, 50, 54
/* комментарий (начало) 10
*/ комментарий (конец) 10
/= операция деления с при-
сваиванием 34, 39, 54
: признак битового поля
320
спецификатор метки 48
< операция отношения
"меньше, чем" 34, 38,
52, 172
« операция "поразрядный
сдвиг влево" 34, 37, 54,
59, 60
«= операция "поразрядный
сдвиг влево" с присваи-
ванием 34, 40
<= операция отношения
"меньше или равно" 34,
38, 52, 172
= операция присваивания
27, 34, 39, 44, 53
= операция отношения "сра-
внение на равенство"
34,38, 52, 172
> операция отношения
"больше, чем" 34, 38,
52, 172
>= операция отношения
"больше или равно" 34,
38,52,172
» операция "поразрядный
сдвиг вправо" 34, 37, 54,
59, 60
»= операция "поразрядный
сдвиг вправо". с при-
сваиванием 34, 40
?: операция условного вы-
ражения (условная опе-
рация) 33, 34, 61
[] операция индексации 33,
34,41,44,101
описание массива 44, 108
\ обратный слэш 16, 22
Л операция "поразрядное
исключающее ИЛИ" 34,
37, 54, 59
А= операция "поразрядное
исключающее ИЛИ" с
присваиванием 34, 40
_ подчеркивание (литера)
И, 15
{} фигурные скобки 20, 44,
45, 204, 264
I поразрядная операция
ИЛИ 34, 37, 54, 59
| = поразрядная операция
ИЛИ с присваиванием
34, 40
I | логическая операция ИЛИ
34, 39, 52
~ операция "дополнения"
34, 35, 59
Предметный указатель
A-Z
ANSI-стандарт 110, 162, 219,
484, 560
ASCII-код 194,318, 554, 565
ESC-sequence, см. Эскейп-по-
следовательность
/-значение 35, 36, 39
MS-DOS 144, 272, 318, 379,
440,480
UNIX 181,325,372,414, 452
Windows 162, 274, 325, 372,
440, 447, 479, 490
А
Абстрактный тип 302
Агрегирующий тип 318
Аддитивная операция 34, 36,
51,77, 170
Адрес, см. Операция получе-
ния адреса
Алфавит языка Си 10
Аргумент функции, см. Фак-
тические параметры; Фор-
мальные параметры
Арифметический тип, см. Тип
арифметический
Арифметическое выражение,
см. Выражение арифмети-
ческое
Арифметическое преобразо-
вание, см. Операция пре-
образования
Б
Бинарные операций 33, 34, 36,
38,41,51,53,60, 297
Бинарное дерево 426, 447, 550
Бинарный режим 329, 354
Битовое поле 320
Блок 24, 45, 68, 79, 110, 204,
261
Буфер ввода-вывода 326
- клавиатуры 87, 318
- операционной системы 326
Буферизация 326, 369
В
Ввод 69, 85, 192,213,325
Вещественная константа, см.
Константа вещественная
Вложение блоков, см. Блок
- инициализаторов 290
- комментариев, см. Ком-
ментарий
- операторов цикла 101
- определений функций 204
- переключателей, см. Опе-
ратор switch
Предметный указатель
581
- составных операторов, см.
Составной оператор
- структур 290
- условных операторов, см.
Условный оператор
Возвращаемое значение, см.
Значение, возвращаемой
функцией
Восьмеричная константа, см.
Константа восьмеричная
Время существования пере-
менных 263
Вывод 69, 192,252, 325, 331
Выражение 36, 42, 50, 77, 112,
126, 169, 183, 207, 284, 404
- арифметическое 62, 80, 91
- леводопустимое, см. Лево-
допустимое выражение
- логическое 62, 90
- модифицируемое име-
нующее 53, см. также I-
значение
- первичное 114
- постфиксной формы 51
- префиксной формы 51
- присваивания 91, см.
также Операция присваи-
вания
- пустое 47
- условное 61
- целочисленное констант-
ное 146
Вычитание, см. Операция вы-
читания
Г
Глобальный объект 63, 144,
264, 265,401,446
- переменная 262, 377, 408
д
Двоичный режим обмена с
файлами, см. Бинарный ре-
жим
Декремент, см. Операция "де-
кремент"
Деление, см. Операция деле-
ния
Десятичная константа, см.
Константа десятичная
Динамическая память 180,
262, 266, 305
— выделение, см. Память,
динамическое выделение
— управление 185
Динамическое представление
данных 306
Динамические массивы 182,
254, см. также Массив ди-
намический
- объекты 268, 305
- односвязные списки 310
- структуры 262
— информационные 306, 311
Директива препроцессора 28,
49, 64, 78, 122, 133, 445
- #160
582
Программирование на языке Си
- //define 29, 64, 123, 134,
279, 332
- #elif 134, 146, 149
- #else 134, 146, 149
- #endif 134,146,150
- #error 134, 159
- #if 134, 146, 149
- #ifdef 134, 146, 151
- //ifndef 134, 146, 151
- //include 31, 49, 64, 134,
142
- //line 134, 158
- //pragma 134, 160
- //undef 134, 141, 151
Доступ к адресам параметров
244
— значению переменной 23
— кодам библиотечных фун-
кций 66
— объекту 211, 226
— отдельным битам 320
— участку памяти 23, 169,
182,211
- - файлу 362, 380
— элементам массива 175,
184,254
— элементам структур 286,
296, 299,404
3
Заголовок переключателя, см.
Оператор switch
- функции 110, 204
- цикла, см. Цикл
Заголовочный файл 31, 66,
144, 326, 377
- - alloc.h 144, 179, 570
— assert.h 143
— conio.h 144, 570 572
— ctype.h 143, 565
- - dos.h 144, 572, 574
- - errno.h 143, 330, 375
- - float.h 31, 72, 143, 561
— graphics.h 144
- - limits.h 31, 72, 137, 143,
560
— locate.h 143
-- math.h 82, 143,235, 563
— mem.h 144, 572
— setjump.h 143
— signal.h 143, 574
— stdarg.h 48, 144, 249
- - stddef.h 144, 171
-- stdlib.h 122, 144, 179, 201,
219, 566, 570
— stdio.h 49, 69, 85, 144, 166,
326, 566
— string.h 144, 219, 405, 567
— time.h 144
Зарезервированное слово, см.
Служебное слово
Знаки операций 11, 33, 52, 76,
133
Значение, возвращаемое
функцией 68, 114, 205, 210,
338
Предметный указатель
583
- леводопустимое, см. /-зна-
чение
- указателя 168, 178, 217,
296, 368, 426
— нулевое, см. Нулевой ука-
затель
И
Идентификатор 11, 82, 136
- библиотеки 457
- процессорный 136, 150,
279,
Имя
- директивы 134
- заголовочного файла 31, 66
- исполняемой программы
449
- компонента 41
- константы 20, 28
- макроса 142, 455
- массива 42, 175, 179, 218
- объединения 315
- объекта 86
— глобального 265
— структурированного 41
- параметра 204
- переменной 23, 27, 35, 54,
86,164
- препроцессорного иденти-
фикатора 135
- структуры 284, 286, 321
- типа 42
— объединяющего 317
— структурного 277, 307
- указателя 168, 228
- уточненное 286
- файла 135, 142, 235, 328,
360,371
- функции 42, 79, 114, 203,
228,
— главной 67, 68
— неглавной 114
- элемента 296, 315
Индексация 106, 272, см.
также Операция [ J
Инициализатор 185, 293
Инициализация 27
- массива 46, 108, 197
- переменной 27, 49
- структуры 46, 285
Инкремент, см. Операция "ин-
кремент"
Исполняемый оператор, см.
Оператор
К
Класс памяти 12, 24, 262
- auto 11, 12, 262
- extern И, 13, 145,269,388
- register 11, 13, 262
- static И, 13, 264, 387
- автоматической 12, 262
Ключевое слово, см. Служеб-
ное слово
Кодировка ASCII, см. ASCII-
код
584
Программирование на языке Си
Команда препроцессора, см.
Директива препроцессора
Комментарий /**/10“
Компоновка 64, 482, 489
Константа 15
- арифметическая 18
- вещественная 17
- восьмеричная 17
- десятичная 17
- именованная 27
- литерная, см. Константа
символьная
- неарифметическая, см. Ну-
левой указатель
- перечисляемого типа 20
- предельная, см. Предель-
ные значения констант
- предопределенная, см.
Предопределенные кон-
станты
- препроцессорная 29, 131,
184
- с плавающей точкой, см.
Константа вещественная
- символьная 15, 18
- строковая 21, 195
— на нескольких строках 22,
279
- указатель, см. Указатель-
константа
- целая 17, 19
- шестнадцатеричная 17
Л
Леводопустимое выражение,
35, 54 см. также /-значе-
ние
Лексема 9, 11, 33, 44, 76
- препроцессора 133
- строки замещения 157
Лексический элемент, см.
Лексема
Литерал, см. Константа
Литерная константа, см. Кон-
станта символьная
Логическая операция, см.
Операция логическое И
(ИЛИ, НЕ)
М
Макроопределение, 151, 156,
249, 454 см. также Дирек-
тива препроцессора
#define
- va_arg()249,252
- va_end()249, 252
- va_start( ) 249, 252
Макрос, см. Макроопределе-
ние
Массив 41, 101, 164
- динамический 179, 254
- доступ к элементам, см.
Доступ к элементам мас-
сива
- и указатель 175
- имя, см. Имя массива
Предметный указатель
585
- инициализация, см. Ини-
циализация массива
- многомерный 44, 108, 184
- определение, см. Опреде-
ление массива
- параметр 216
- символьный 177, 196
- структур 292
- указателей 185
— на строки 201, 271
- - на функции 231
Метка 48, 82
- case в переключателе 126
- default в переключателе
126
Минус, см. Операция "минус
унарный"
Многомерный массив, см.
Массив многомерный
Модификатор 11, 13, 248 см.
также Служебное слово
- спецификации преобразо-
вания 70, 86, 338, 348
- cdecl 14,249
- const 12, 14
- pascal 14, 248
- volatile 12, 14
H
Неоднозначность 51
Нулевой указатель (NULL) 15,
20, 254,312, 330
38'3124
О
Обмен с файлами, бинарный,
см. Бинарный режим
- двоичный, см. Бинарный
режим
- строковый 358
- форматный 360
Обобщенный пробельный
символ 10, 22
Объединение 12, 315
Объединяющий тип 12, 315
Объект 23, 41, 63, 145, 164
Оператор 9, 33, 47, см. также
Служебное слово
- break 11, 13, 80,96'
- continue 11, 13, 80, 100
- do 11, 13,80,90
- else 11, 80
- for 11, 13,, 80,90
- goto 11, 13, 80
- if 11, 13, 80
- return 11, 13, 80, 112
- switch 11, 13, 80, 126
- while 11, 13, 80, 90
- безусловного перехода, см.
Оператор goto
- возврата из функции, см.
Оператор return
- выбора, см. Метка case в
переключателе
- выражение 48.
- переключатель, см. Опера-
тор switch
586
Программирование на языке Си
- присваивания, см. Опера-
ция присваивания
- пустой 48
- составной, см. Составной
оператор
- условный, см. Оператор if
- цикла, см. Цикл
Операционная система MS-
DOS, см. MS-DOS
— MS Windows, см. Windows
- - UNIX, см. UNIX
Операция 33
- #49,64,157,160
- ##157
- defined 134, 150
- () 34, 41, 110,207
- [] 33, 34, 41, 44, 101
- { } 20, 44, 45, 204, 264
- sizeof 11, 13, 34, 36, 183,
245,284,414
- аддитивная 34,36, 51
- бинарная 34, 36, 38,41
- больше или равно (>=) 34,
38,52,172
- больше, чем (>) 34, 38, 52,
172
- получения адреса (&) 33,
34, 165
- вычисления остатка (%)
34, 37, 50, 54
- вычитания (-) 34, 50
- декремент (—) 34, 36, 51
- деления (/) 34, 37, 50, 54
- доступа к компоненту по
имени структурированного
объекта 34,'Ml, 286, 297
- запятая (,) 34, 36, 41
- индексации 33, 34, 41, см.
также Операция [ ]
- инкремент (++) 34, 35, 51
- логическое И (&&) 34, 38
-- ИЛИЦ 1)34,39, 52
- - НЕ (!) 34, 35, 52
- меньше или равно (<=) 34,
38, 52, 172
- меньше, чем (<) 34, 38, 52,
172
- минус унарный (-) 34, 50
- мультипликативная 34, 37
- над указателями 168
- не равно (!=) 34, 38, 52, 172
- отношения 34, 38, 52, 62
- плюс унарный (+) 34, 35
- поразрядное И (&) 34,3 7,59
-----с присваиванием (&=)
34, 40, 54
-- ИЛИЦ) 34, 37, 54, 59
-----с присваиванием (| =)
34, 40
-----ИСКЛЮЧАЮЩЕЕ (А)
34, 37, 54, 59
- - НЕ (~) 34, 35, 59
— обратимость 59
— операндов в арифмети-
ческих выражениях 57
— типов 42, 56
Предметный указатель
587
— указателей 169, 172, 180
- постфиксная 35, 36, 51, 439
- префиксная 35, 36, 51
- приведения, см. Операция
преобразования
- приоритет, см. Приоритет
операций
- присваивания (=) 27, 34,
39, 44, 53
- разыменования (*) 34, 176,
216, 296
- сдвига влево («) 34, 37,
54, 59, 60
- сдвига вправо (») 34, 37,
54, 59, 60
- сложения (+) 34, 50, 54
- сравнения на равенство
(==)34, 38, 52, 172
- умножения (*) 34, 37, 50,
54
- условная (?:) 33, 34, 61
- функция 34, 41, 110, 207
- явного преобразования ти-
па 34,42, 180
Описание 47, 68
- внешнего объекта 270
- и определение, см. Опре-
деление и -описание
- символьной переменой 192
- структуры 320
- указателя 167
- функции 206
Определение 23, 68
- и описание 44
- массива 217, 23 8, 293
- объединения 316
- переменной 23, 45
- указателя 167
— на структуру 277
— на функцию 44, 227
- функции 65, 110, 116, 203
— с переменным числом па-
раметров 247
Остаток, см. Операция взятия
остатка
Отношения, см. Операция от-
ношения
П
Память, выделение автомати-
ческое, см. Класс памяти
автоматической
— динамическое 179, 188,
201,330
- локальная, см. Класс па-
мяти auto
- регистровая, см. Класс па-
мяти register
- ЭВМ 18,21
Параметр фактический, см.
Фактические параметры
- формальный, см. Фор-
мальные параметры
Переключатель, см. Оператор
switch
Переменная 23
38
588
Программирование на языке Си
- автоматической памяти 24,
см. также Класс памяти
auto
- вещественная 26
- глобальная, см. Глобальная
переменная
- индексированная 42, см.
также Индексация
- как объект 23
- локальная 263, см. также
Класс памяти static
- регистровая, см. Класс па-
мяти register
- статическая 264, см. так-
же Класс памяти static
- целочисленная 24
Перечислимая константа, см.
Константа перечисляемого
типа
Перечисляемый тип 12, 20
Плюс, см. Операция плюс
унарный
Побочные эффекты 144
Поле битовое, см. Битовое
поле
Поразрядные операции, см.
Операция поразрядное И
(ИЛИ, НЕ)
Предельные значения для ве-
щественных типов 561
-----констант 18, 26, 32, 72,
561
-----переменных 26
-----целочисленных типов
560
Преобразование, см. Опера-
ция преобразования
Предопределенные дескрип-
торы файлов 375
- значения указателя 333
- константы 363, 371, 377,
380
- указатели на поток 326,
327, 333
Препроцессор 29, 63, 132
- директивы, см. Директивы
препроцессора
- команды, см. Директивы
препроцессора
Префиксная операция, см.
Операция префиксная
Приведение, см. Операция
преобразования
Приоритет операций 33, 38,
47, 171, 176, 230, 397
Присваивание, см. Операция
присваивания
- множественное 54
Пробельный символ 347
- обобщенный 10, 22
Производные типы 151, 164,
185,203,227, 231,275
Прототип 43, 180, 206, см.
также Описание функции
Предметный указатель
589
Р
Разделитель 11, 43
- пробельный, см. Обобщен-
ный пробельный символ
Разыменование указателей
(обращение по указателю),
см. Операция разыменова-
ния
Ранги операций, см. Приори-
тет операций
Рекурсивная функция 258, 311
Рекурсия 258, 310
С
Сдвиг влево, см. Операция
сдвига влево
— с присваиванием 34, 40
- вправо, см. Операция сдви-
га вправо
— с присваиванием 34, 40
Символ '\0' 16, 21, 196, 219,
275, 336, 437
- '\п' 16, 22, 73, см. также
Эскейп-последователь-
ность
- подчеркивания11, 27
Скэн-код 318
Слово зарезервированное, см.
Служебное слово
- ключевое, см. Служебное
слово
Сложение, см. Операция сло-
жения
Служебное слово И, 13, 14,
25
— auto, см. Класс памяти
auto
— break, см. Оператор
break
— case, см. Метка case в пе-
реключателе
— cdecl, см. Модификатор
cdecl
— char, см. Тип char
— const, см. Модификатор
const
— continue, см. Оператор
continue
— default, см. Метка default
в переключателе
— delete, см. Операция
delete
— do, см. Оператор do
— double, см. Тип double
— else, см. Оператор else
— enum, см. Перечислимые
константы
— extern, см. Класс памяти
extern
— far, см. Модификатор far
— float, см. Тип float
— for, см. Оператор for
— goto, см. Оператор goto
— if, см. Оператор if
— int, см. Тип int
— long, см. Тип long
590
Программирование на языке Си
— pascal, см. Модификатор
pascal
- - register, см. Класс памяти
register
— return, см. Оператор
return
— short, см. Тип short
- - signed 11, 12, 24
— sizeof, см. Операция sizeof
— static, см. Класс памяти
static
— struct, см. также Струк-
турный тип
— switch, см. Оператор
switch
— typedef, см. Специфика-
тор typedef
— union, см. также Объе-
диняющий тип
— unsigned, см. - Тип
unsigned
— void, см. Тип void
— volatile, см. Модификатор
volatile
— while, см. Оператор while
Составной оператор 79, 81,
90, 110
Спецификатор 24
- typedef 11, 12, 238,278
Спецификация преобразова-
ния 70, 85
Список инициализации, см.
Инициализация
Сравнение, см. Операция
сравнения на равенство
Стандартный поток 331
Строка замещения 136, 139,
.157
- форматная 69, 337, 346
Строковая константа, см.
Константа строковая
Структура 12, 275, см. также
Структурный тип
Структурный тип 12,43, 276
Т
Тег, см. Структурный тип
Тело функции 44, 68, 203
- цикла 45, 90, см. также
Цикл
Тип 12
- char22, 12,24,26, 111
- double 11, 12, 18,25,26
- float 11, 19,25
- int 11, 19,24,26
- long 11, 24, 26
- long double 11, 12, 25, 26
- short 11,24,26
- unsigned 11, 19, 24
- void 11, 12,67
- void* 167, 179, 180
- агрегирующий, см. Агре-
гирующий. тип
- арифметический 37, 50
- базовый 192
Предметный указатель
591
- беззнаковый, см. Тип
unsigned
- возвращаемого значения,
см. Значение, возвращае-
мое функцией
- данных И, 12, 19, 26, 249,
302, 395
- знаковый, см. Тип signed
- объединяющий, см. Объе-
диняющий тип
- переменной 23, 75
- перечисляемый, см. Пере-
числяемый тип
- производный, см. Произ-
водные типы
- результата, см. Тип воз-
вращаемого значения
- скалярный, см. Скалярный
тип
- структурный, см. Струк-
турный тип
- указателя 56, 164, 166
— void*, см. Тип void*
- функции 203, 206, 207
- чисел с плавающей точкой,
см. Тип float, Тип double
Точность простая, см. Тип
float
- двойная, см. Тип double
У
Указатель 34, 41, 49, 164, 166,
175
- значение 168, см. также
Значение указателя
- и массив 175, 188, 231, см.
также Массив и указатель
- инициализация 197, см.
также Инициализация
массива
- константа 175, 177, 220,
228
- константный, см. Указа-
тель-константа
- массив 184, см. также
Массив указателей
- на массив 175
- на объект 164, 167, 327
- на поток 326, 327, 333
- на строку 200, 201, 243,
358,431
- на структурированный
объект 41
- на структуру 296
- на указатель 49
- на функцию 227, 228, 236,
239
- нулевой, см. Нулевой ука-
затель
- объект 175
- параметр 210
- переменная 169,175
- пустой, см. Нулевой ука-
затель
- родовой, см. Тип void*
Умножение, см. Операция
умножения
592
Программирование на языке Си
Унарные операции 25, 34,
172, 176
Управляющая последователь-
ность 16
Условная операция, см. Опе-
рация условная
- трехместная 42
Условный оператор, см. Опе-
ратор if
Уточненное имя , см. Имя
уточненное
Ф
Файл заголовочный, см. Заго-
ловочный файл
- стандартный 331
- текстовый 63, 328, 453
Фактические параметры 79,
110, 114, 156, 180, 207, 251
Формальные параметры 115,
207, 209
Форматирование данных при
вводе-выводе 337
Форматная строка 69, 204,
338, 344, 347,360
Флаг форматирования 341
Функция 203
- main( ) 67, 121, 123
- описание, см. Описание
функции
- определение, см. Опреде-
ление функции
- прототип,см. Прототип
- рекурсивная, см. Рекур-
сивная функция
- с переменным числом па-
раметров 247
- самовызывающая, см. Ре-
курсивная функция
- указатель, см. Указатель на
функцию
Функция библиотечная 563
- bioskey( ) 318,
- calloc() 180
- close() 376
- creat( ) 370
- exit( ) 121, 261
- fclose()331
- fopen() 328
- free( ) 180
- fseek() 362
- getchar() 193, 332
- getenv() 274
- lseek()380
- malloc() 180, 310
- open()370
- perror()330
- printf() 69, 79
- putchar() 193, 332
- putenv() 274
- qsort() 238, 239, 240
- read() 376
- scanf() 85, 346
- strcmp( ) 222, 240, 242
- strcpy( ) 224
- strlen()219
Предметный указатель
593
- strncat( ) 223 - strstr()221 - va_arg(), см. Макроопре- деление va_arg() - va_end(), см. Макроопре- деление va_end() - va_start(), см. Макрооп- ределение va_start( ) - write() 377 ц Целая константа, см. Кон- станта целая Целочисленный тип, см. также Тип int- (long, short, unsigned) Цикл 90 - бесконечный 236, 353 - итерационный, см. Опера- тор for - с постусловием, см. Опе- ратор do - с предусловием, см. Опе- ратор while III Шестнадцатеричная констан- та, см. Константа шестнад- цатеричная Э Эскейп-последовательность 16,21,72, 132, 196 Эффекты побочные, см. По- бочные эффекты Я Явное преобразование типа, см. Операция явного пре- образования типа
ОГЛАВЛЕНИЕ
ПРЕДИСЛОВИЕ................................. 3
РАЗДЕЛ I. ПОЛНЫЙ КУРС ПРОГРАММИРОВАНИЯ
НА ЯЗЫКЕ СИ................................. 7
Глава 1. БАЗОВЫЕ ПОНЯТИЯ ЯЗЫКА.............. 9
1.1. Алфавит, идентификаторы, служебные слова. 10
Алфавит/10). Идентификатор (11). Служебные (ключе-
вые) слова/11)
1.2. Константы и строки................ 15
Символы или символьные константы (15). Целые кон-
станты.(17). Вещественные константы (17). Предельные
значения и типы арифметических констант (18). Нулевой
указатель (20). Константы перечисляемого типа (20).
Строки, или строковые константы (21)
1.3. Переменные и именованные константы........... 23
Переменная как объект (23). Определение переменных
(23). Предельные значения переменных (26). Инициали-
зация переменных (27). Именованные константы (27)
1.4. Операции.................................. 33
Знаки операций (33). Унарные/одноместные) операции
(34). Бинарные (двуместные) операции (36)
1.5. Разделители................................. 43
Квадратные скобки (44). Круглые скобки (44). Фигур-
ные скобки (45). Запятая (46). Точка с запятой (47).
Двоеточие (48). Многоточие (48). Звездочка (48). Обо-
значение присваивания (49). Признак препроцессорных
средств(49)
1.6. Выражения и приведение арифметических
типов............................................. 50
Отношения и логические выражения (52). Присваивание
(выражение и оператор) (53). Приведение типов (55).
Правила преобразования типов (56). Выражения с пораз-
рядными операциями (59). Условное выражение (61)
Оглавление
595
Глава 2. ВВЕДЕНИЕ В ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ Си............................. 63
2.1. Структура и компоненты простой программы.... 63
Текст программы и препроцессор (63). Структура прог-
раммы (66). Функция форматированного вывЬда (69).
Программы печати предельных констант (72). Примени-
мость вещественных данных (74). Выделение лексем из
текста программы (76)
2.2. Элементарные средства программирования........ 78
Деление операторов языка Си на группы.(78). Метки и
пустой оператор (82). Оператор перехода (82). Програм-
ма оценки машинного нуля (83). Ввод данных (85). Вы-
числение объема цилиндра (87). Сумма членов ряда Фи-
боначчи (88)
2.3. Операторы цикла.............................. 90
Три формы операторов цикла (90). Приближенное зна-
чение экспоненты (95). Оператор break (96). Сумма от-
резка степенного ряда (97). Оператор continue (100).
Суммирование положительных чисел (100)
2.4. Массивы и вложение операторов цикла...........101
Массивы и переменные с индексами (101. Вычисление
среднего и дисперсии (102). Вложенные циклы (ЮЗ).
Упорядочение в одномерных массивах (105). Инициали-
зация массивов (108)
2.5. Функции...................................... 110
Определение функций (110). Функция для вычисления
объема цилиндра (112). Функция для вычисления скаляр-
ного произведения векторов (113). Обращение к функции
и ее прототип (114). Вычисление биномиального коэффи-
циента (117). Вычисление объема цилиндра (118). Вычи-
сление площади треугольника (119). Скалярное произве-
дение векторов (122). Диаметр множества точек (123)
2.6. Переключатели...................126
Глава 3. ПРЕПРОЦЕССОРНЫЕ СРЕДСТВА...... . 131
3.1. Стадии и команды препроцессорной обработки.. 132
Стадии препроцессорной обработки (132). Директивы
препроцессора(133)
596
Программирование на языке Си
Глава 3. ПРЕПРОЦЕССОРНЫЕ СРЕДСТВА
3.2. Замены в тексте..........................136
Директива #define (136). Цепочка подстановок (136).
3.3. Включение текстов из файлов..............142
3.4. Условная компиляция..................... 146
Директивы ветвлений (146). Операция defined (150)..
3.5. Макроподстановки средствами препроцессора.... 151
Моделирование многомерных массивов (153). Отличия
макросов от функций (155). Препроцессорные операции
в строке замещения (157)
3.6. Вспомогательные директивы................158
Препроцессорные обозначения строк (158). Реакция на
ошибки (159). Пустая директива (160). Прагмы (160)
3.7. Встроенные (заранее определенные)
макроимена................................... 161
Глава 4.УКАЗАТЕЛИ, МАССИВЫ, СТРОКИ................164
4.1. Указатели на объекты................... 164
Адреса и указатели (164). Операции над указателями
(168). Арифметические операции и указатели (171). Ука-
затели и отношения (172)
4.2. Указатели и массивы..................... 175
Указатели и доступ к элементам массивов (175). Масси-
вы динамической памяти (179). Массивы указателей и
моделирование многомерных массивов (184). "Матрица"
со строками разной длины (188)
4.3. Символьная информация и строки...........192
Ввод-вывод символьных данных (192). Внутренние коды
и упорядоченность символов (194). Строки, или строко-
вые константы (195). Строки и указатели (200)
Глава 5. ФУНКЦИИ..................................203
5.1. Общие сведения о функциях........................203
Определение функции (203). Описание функции и ее типх
(206). Вызов функции (207)
5.2. Указатели в параметрах функций...........210
Указатель-параметр (210). Имитация подпрограмм (213)
Оглавление
597
Глава 5. ФУНКЦИИ
5.3. Массивы и строки как параметры функций......216
Массивы в параметрах (216). Строки как параметры
функций (218). Резюме по строкам-параметрам (226)
5.4. Указатели на функцЦи.......................227
Указатели при вызове функций (227). Массивы указате-
лей на функции (231). Указатели на функции как пара-
метры (233). Указатель на функцию как возвращаемое
функцией значение (236). Библиотечные функции с ука-
зателями на функции в параметрах (238)
5.5. Функции с переменным количеством
параметров....................................... 243
Доступ к адресам параметров из списка (244). Макро-
средства для переменного числа параметров (249). При-
меры функций с переменным количеством параметров
(253)
5.6. Рекурсивные функции.................. 258
5.7. Классы памяти и организация программ....262
Локализация объектов (262). Глобальные объекты (264).
Динамическая память (266). Внешние объекты (269)
5.8. Параметры функции main( )..............271
Глава 6. СТРУКТУРЫ И ОБЪЕДИНЕНИЯ................275
6.1. Структурные типы и структуры...........275
Производные типы (275). Структурный тип (276). Опре-
деление структур (280). Выделение памяти для структур
(283). Инициализация и присваивание структур (285).
Доступ к элементам структур (286)
6.2. Структуры, массивы и указатели..............289
Массивы и структуры в качестве элементов структур
(289). Массивы структур (292). Указатели на структуры
(295). Указатели как средство доступа к компонентам
структур (296). Операции над указателями на структуры
(298). Указатели на структуры как компоненты структур
(299)
6.3. Структуры и функции........................ 301
‘ Имитация абстрактных типов данных (302)
598
Программирование на языке Си
Глава 6. СТРУКТУРЫ И ОБЪЕДИНЕНИЯ
6.4. Динамические информационные структуры...306
Статическое и динамическое представление данных (306).
Односвязный список (307). Рекурсия при обработке спи-
ска (310)
6.5. Объединения и битовые поля...............315
Объединения (315). Объединяющий тип (317). Битовые
поля (320)
Глава 7. ВВОД И ВЫВОД............................ 325
7.1. Потоковый ввод-вывод.................... 325
7.1.1. Открытие и закрытие потока........ 327
7.1.2. Стандартные файлы и функции для работы с ними.. 331
7.1.3. Работа с файлами на диске..........353
7.2. Ввод-вывод нижнего уровня.............. 369
7.2.1. Открытие/закрытие файла............370
7.2.2. Чтение и запись данных........... 376
7.2.3. Произвольный доступ к файлу....... 380
Глава 8. ПРИМЕРЫ РАЗРАБОТКИ ПРОГРАММ...............382
8.1. Программа с объектами разных классов
памяти........................................382
Постановка задачи (382). Программная реализация (385)
8.2. Структуры и обработка списков в основной
памяти...............,........................395
Постановка задачи (395). Функция main() (401). Функ-
ция init() - "Инициализировать базу данных" (403). Функ-
ция delete() - "Удалить все сведения о сотруднике из
базы данных" (405). Функция fr() - "Возвратить освобо-
жденный элемент в список свободных элементов" (410)..
Функция input() - "Ввести в базу данных сведения о но-
вом сотруднике" (410). Функция print() - "Печать списка
занятых элементов (412). Сохранение (восстановление)
базы данных (413)
8.3. Сортировка на основе бинарного дерева.........423
Статические и динамические данные (423). Управление
динамической памятью (425). Сортировка с помощью
бинарного дерева (426). Печать результатов сортировки (438)
Оглавление
599
РАЗДЕЛ II. ВЫПОЛНЕНИЕ ПРОГРАММ В
РАЗНЫХ ОПЕРАЦИОННЫХ СИСТЕМАХ. .. 441
Глава 9. ПОДГОТОВКА И ВЫПОЛНЕНИЕ •
ПРОГРАММ............................................. 443
9.1. Подготовка программ в операционной
системе UNIX................................447
9.1.1. Команда make..................... 451
9.1.2. Библиотеки объектных модулей............456
9.2. Сборка и выполнение программ в
интегрированной среде Turbo С 2.0...........463
9.2.1. Состав системы программирования Turbo С 2.0. 463
9.2.2. Экран интегрированной среды Turbo С 2.0.464
9.2.3. Система меню среды Turbo С 2.0..........466
9.2.4. Настройка среды Turbo С.................470
9.3. Сборка и выполнение программ в
интегрированной среде Borland C++3.1...... 479
9.3.1. Состав системы программирования Borland C++ 3.1.. 479
9.3.2. Экран интегрированной среды.................480
9.3.3. Система меню интегрированной среды..........481
9.3.4. Настройка интегрированной среды Borland C++3.1... 483
РАЗДЕЛ III. ПРАКТИКУМ ПО ПРОГРАММИРОВАНИЮ
НА ЯЗЫКЕ СИ................................. 491
Глава 10. ЗАДАЧИ ПО ПРОГРАММИРОВАНИЮ......................493
10.1. Ознакомительная работа...................... 493
10.2. Итерационные методы и ряды...................496
10.3. Работа со строками. Указатели, динамические
одномерные массивы.......................... 504
10.3.1. Варианты задач по обработке строк......505
10.3.2. Рекомендации по обработке строк........520
10.3.3. Пример выполнения задания по обработке строк... 523
10.4. Многомерные динамические массивы с
переменными размерами....................... 525
10.4.1. Варианты задач для 1-й части задания по
многомерным массивам...............................527
600
Программирование на языке Си
Глава 10. ЗАДАЧИ ПО ПРОГРАММИРОВАНИЮ
10.4.2. Варианты для 2-й части задания по многомерным
массивам......................... 529
10.4.3. Пример выполнения задания по многомерным
динамическим массивам............................532
10.5. Функции и указатели.......................... 534
10.6. Функции и массивы............................. 537
10.7. Работа со структурами..........................540
10.7.1. Варианты структур для выполнения работы.541
10.8. Списки и деревья...............................543
10.8.1. Списки................................ 544
10.8.2. Деревья................................ 549
Приложение 1. Таблицы кодов ASCII.......................553
Приложение 2. Константы предельных значений.............559
Приложение 3. Стандартная библиотека функций 562
языка Си..........................
ЛИТЕРАТУРА............................................. 577
УКАЗАТЕЛЬ ОПЕРАЦИЙ И РАЗДЕЛИТЕЛЕЙ.......................578
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ....................................580
Учебное издание
Подбельский Вадим Валериевич
Фомин Сергей Сергеевич
ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ СИ
Редактор Л. Д. Григорьева
Художественный редактор Ю. И. Артюхов
Технические редакторы Е. В. Кузьмина, Т. С. Маринина
Корректоры Т. М. Колпакова, Н. П. Сперанская, Г. В. Хлопцева
Оригинал-макет выполнен Н. В. Васюковой, О. В. Шехановой
Художественное оформление Н. М. Биксентеева
ИБ № 3477
Подписано в печать 10.08.2004. Формат 60x88/16
Гарнитура «Таймс». Печать офсетная
Усл. п. л. 36,75. Уч.-изд. л. 29,89
Тираж 4000 экз. Заказ 2724. «С» 193
Издательство «Финансы и статистика»
101000, Москва, ул. Покровка, 7
Телефон (095) 925-35-02, факс (095) 925-09-57
E-mail: mail@fmstat.ru http://www.finstat.ru
ГП Псковской области «Великолукская городская типография»
Комитета по средствам массовой информации
182100, Великие Луки, ул. Полиграфистов, 78/12
Тел./факс: (811-53) 3-62-95
E-mail: VTL@MART.RU