/
































































































































































































































































































































































































































































































































































































































































Tags: компьютерные технологии программирование язык программирования c++
ISBN: 5-8459-0686-5
Year: 2004




Text
Данный файл был взят с сайта:
-FVQHBook.IlGfe
Данный файл представлен исключительно в ознакомительных
целях. Уважаемый читатель! Если вы скопируете его, Вы должны
незамедлительно удалить его сразу после ознакомления с
содержанием. Копируя и сохраняя его Вы принимаете на себя всю
ответственность, согласно действующему международному
законодательству.
Все авторские права на данный файл сохраняются за
правообладателем. Любое коммерческое и иное использование
кроме предварительного ознакомления запрещено. Публикация
данного документа не преследует за собой никакой коммерческой
выгоды. Но такие документы способствуют быстрейшему
профессиональному и духовному росту читателей и являются
рекламой бумажных изданий таких документов.
Все авторские права сохраняются за правообладателем. Если
Вы являетесь автором данного документа и хотите дополнить его
или изменить, уточнить реквизиты автора или опубликовать
другие документы, пожалуйста, свяжитесь с нами по e-mail - мы
будем рады услышать ваши пожелания.
ProgBook.net - библиотека программиста.
В нашей библиотеке Вы найдете книги и статьи практически по
любому языку программирования.
параллельное
и распределенное
программирование
с использованием
Камерон
Хьюз
Трейси
Хьюз
Параллельное
и распределенное
программирование
с использованием
Parallel
and Distributed
Programming
Using
Cameron Hughes • Tracey Hughes
Л Addison-Wesley
Pearson Education
Boston • San Fransisco • New York • Toronto • Montreal
London * Munich • Paris • Madrid
Cape Town • Sydney • Tokyo • Singapore • Mexico City
Параллельное
и распределенное
программирование
с использованием
Камерон Хьюз • Трейси Хьюз
Москва • Санкт-Петербург • Киев
2004
ББК 32.973.26-018.2.75
Х98
УДК 681.3.07
Издательский дом “Вильямс”
Зав. редакцией С. Н. Тригуб
Перевод с английского и редакция Н. М. Ручко
По общим вопросам обращайтесь в Издательский дом “Вильямс” по адресу:
info@dialektika.com, http://www.dialektika.com
Хьюз, Камерон, Хьюз, Трейси.
Х98 Параллельное и распределенное программирование на C++. : Пер. с англ. — М. :
Издательский дом “Вильямс”, 2004. — 672 с.: ил. — Парал. тит. англ.
ISBN 5-8459-0686-5 (рус.)
В книге представлен архитектурный подход к распределенному и параллельному
программированию с использованием языка C++. Здесь описаны простые методы
программирования параллельных виртуальных машин и основы разработки кла-
стерных приложений. Эта книга не только научит писать программные компоненты,
предназначенные для совместной работы в сетевой среде, но и послужит надежным
“путеводителем” по стандартам для программистов, которые занимаются многоза-
дачными и многопоточными приложениями. Многолетний опыт работы привел ав-
торов книги к использованию агентно-ориентированной архитектуры, а для мини-
мизации затрат на обеспечение связей между объектами системы они предлагают
применить методологию “классной доски”.
Эта книга адресована программистам, проектировщикам и разработчикам про-
граммных продуктов, а также научным работникам, преподавателям и студентам, ко-
торых интересует введение в параллельное и распределенное программирование
с использованием языка C++.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками со-
ответствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы то
ни было форме и какими бы то ни было средствами, будь то электронные или механические, включая
фотокопирование и запись на магнитный носитель, если на это нет письменного разрешения издатель-
ства Addison-Wesley Publishing Company, Inc.
Authorized translation from the English language edition published by Addison-Wesley Publishing
Company, Inc , Copyright © 2004
.All rights reserved. No part of this book may be reproduced or transmitted in any form or by any
means, electronic or mechanical, including photocopying, recording or by any information storage
retrieval system, without permission from the Publisher.
Russian language edition published by Williams Publishing House according to the Agreement with
R&I Enterprises International, Copyright © 2004
ISBN 5-8459-0686-5 (pyc.)
ISBN 0-13-101376-9 (англ.)
© Издательский дом “Вильямс”, 2004
© Pearson Education, Inc., 2004
ОГЛАВЛЕНИЕ
Введение 16
Глава 1. Преимущества параллельного программирования 23
Глава 2. Проблемы параллельного и распределенного
программирования 42
Глава 3. Разбиение С++-программ на множество задач 57
Глава 4. Разбиение С++-программ на множество потоков 111
Глава 5. Синхронизация параллельно выполняемых задач 183
Глава 6. Объединение возможностей параллельного
программирования и С++-средств на основе PVM 211
Глава 7. Обработка ошибок, исключительных ситуаций
и надежность программного обеспечения 245
Глава 8. Распределенное объектно-ориентированное
программирование в C++ 268
Глава 9. Реализация моделей SPMD и MPMD с помощью
шаблонов и MPI-программирования 312
Глава 10. Визуализация проектов параллельных
и распределенных систем 336
Глава 11. Проектирование компонентов для поддержки
параллелизма 377
Глава 12. Реализация агентно-ориентированных архитектур 427
Глава 13. Реализация технологии “классной доски”
с использованием pvm-средств, потоков
и компонентов C++ 463
Приложение А 497
Приложение Б 507
Список литературы 657
Предметный указатель 660
СОДЕРЖАНИЕ
Введение 16
Этапы большого пути 17
Подход 18
Почему именно C++ 18
Библиотеки для параллельного и распределенного программирования 19
Новый единый стандарт спецификаций UNIX 19
Для кого написана эта книга 19
Среды разработки 20
Дополнительный материал 20
Глава 1. Преимущества паралельного программирования 23
1.1. Что такое параллелизм 25
1.1.1. Два основных подхода к достижению параллельности 26
1-2. Преимущества параллельного программирования 28
1.2.1. Простейшая модель параллельного программирования (PRAM) 29
1.2.2. Простейшая классификация схем параллелизма 30
1-3. Преимущества распределенного программирования 31
1.3.1. Простейшие модели распределенного программирования 32
1.3.2. Мультиагентные распределенные системы 32
1-4. Минимальные требования 33
1.4.1. Декомпозиция 33
1.4.2. Связь 34
1.4.3. Синхронизация 34
1 -5. Базовые уровни программного параллелизма 34
1.5.1. Параллелизм на уровне инструкций 34
1.5.2. Параллелизм на уровне подпрограмм 35
8 Содержание
1.5.3. Параллелизм на уровне объектов 35
1.5.4. Параллелизм на уровне приложений 35
1.6. Отсутствие языковой поддержки параллелизма в C++ 36
1.6.1. Варианты реализации параллелизма с помощью C++ 36
1.6.2. Стандарт MPI 37
1.6.3. Pvm: стандарт для кластерного программирования 38
1.6.4. Стандарт CORBA 38
1.6.5. Реализации библиотек на основе стандартов 39
1.7. Среды для параллельного и распределенного программирования 40
1.8. Резюме 40
Глава 2. Проблемы параллельного и распределенного
программирования 42
2.1. Кардинальное изменение парадигмы 44
2.2. Проблемы координации 44
2.3. Отказы оборудования и поведение ПО 51
2.4. Негативные последствия излишнего параллелизма и распределения 52
2.5. Выбор архитектуры 53
2.6. Различные методы тестирования и отладки 54
2.7. Связь между параллельным и распределенным проектами 55
2.8. Резюме 56
Глава 3. Разбиение С++-программ на множество задач 57
3.1. Определение процесса 58
3.1.1. Два вида процессов 59
3.1.2. Блок управления процессами 59
3.2. Анатомия процесса 60
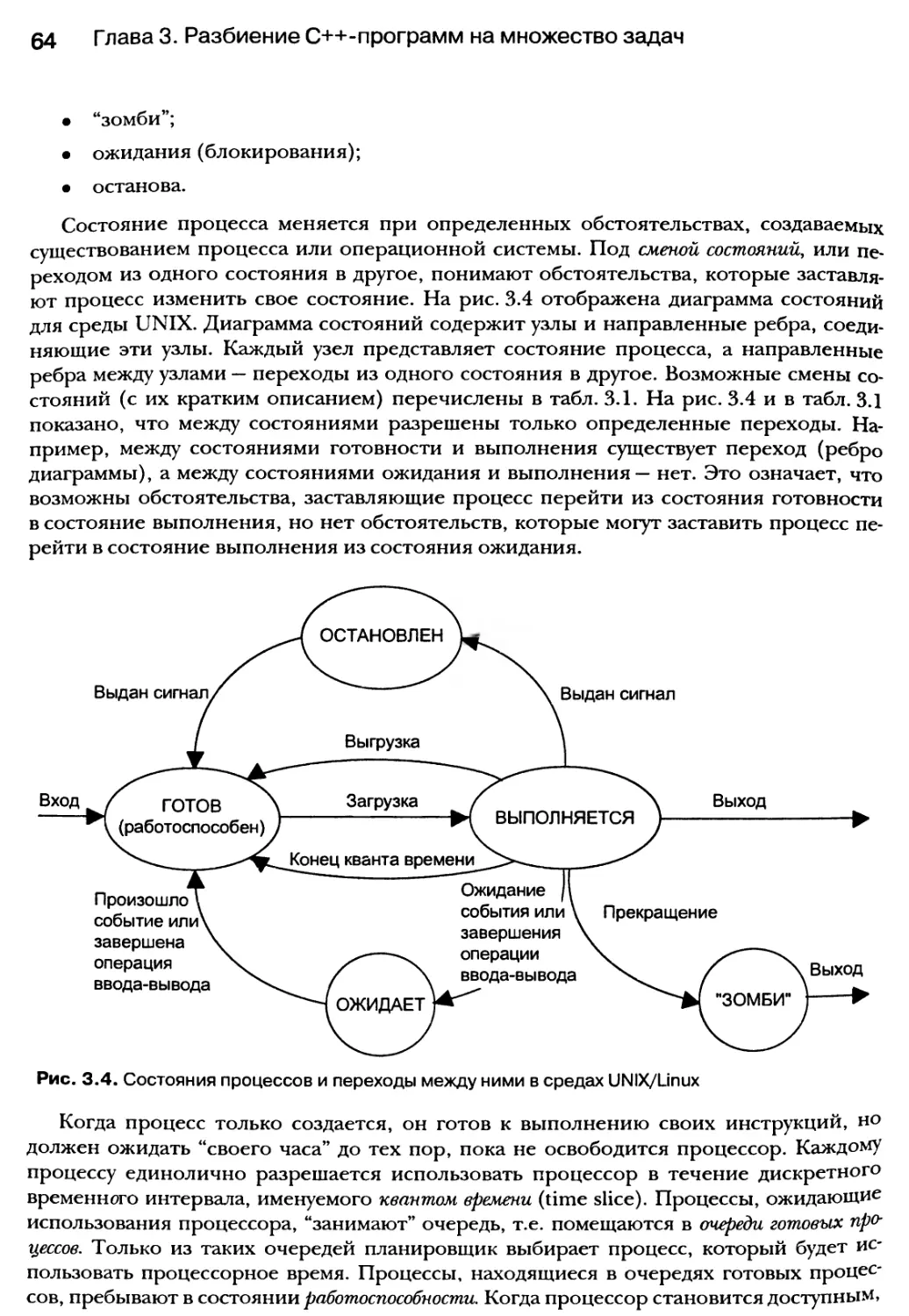
3.3. Состояния процессов 63
3.4. Планирование процессов 66
3.4.1. Стратегия планирования 67
3.4.2. Использование утилиты PS 69
3.4.3. Установка и получение приоритета процесса 71
3.5. Переключение контекста 73
3.6. Создание процесса 74
3.6.1. Отношения между родительскими и сыновними процессами 74
3.6.2. Использование системной функции fork() 78
3.6.3. Использование семейства системных функций ехес 78
3.6.4. Использование функции system() для порождения процессов 83
3.6.5. Использование posix-функций для порождения процессов 83
Содержание $
3.6.6. Идентификация родительских и сыновних процессов с помощью
функций управления процессами 8С
3.7. Завершение процесса 82
3.7.1. Функции exit(), kill() и abort() 9С
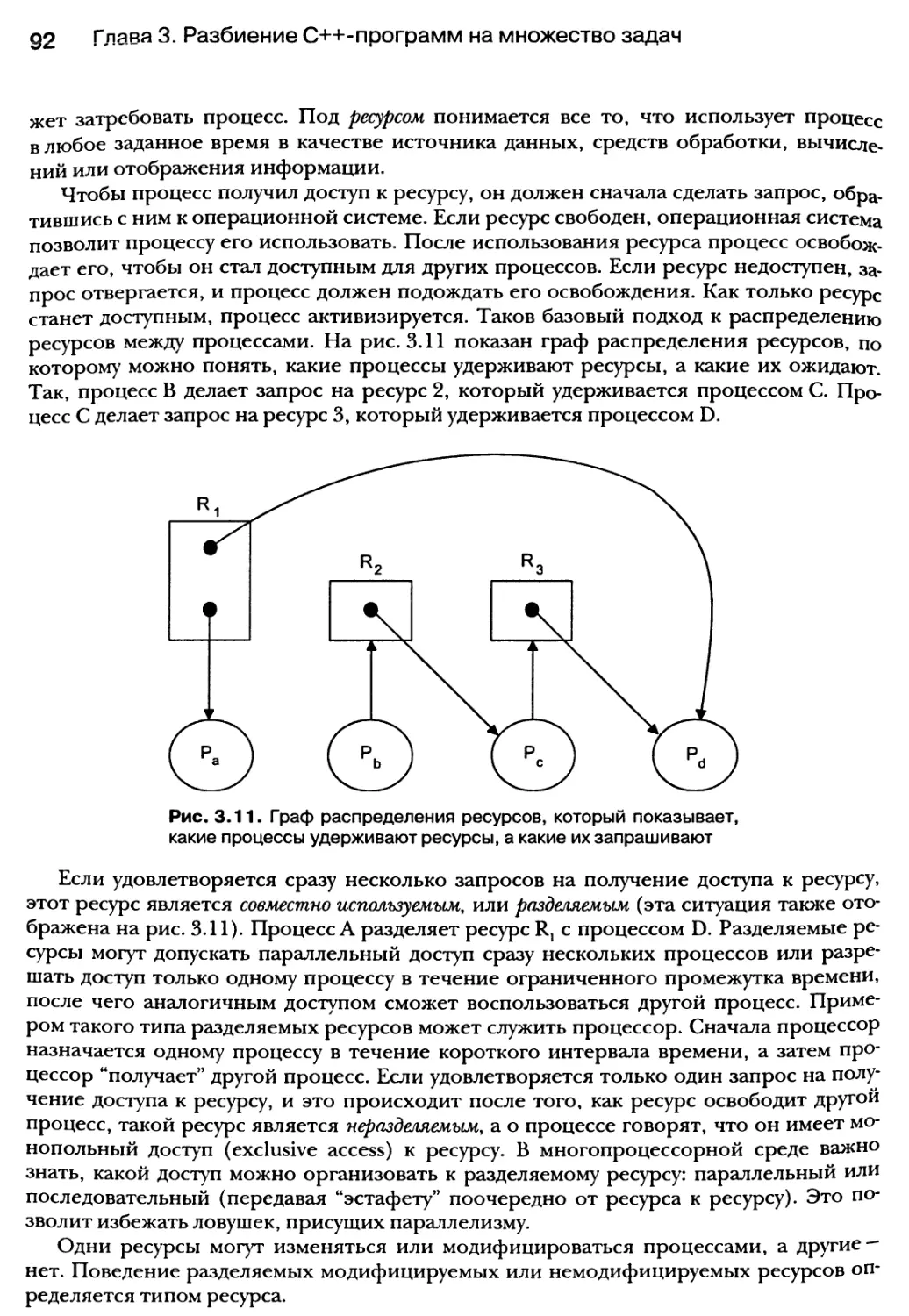
3.8. Ресурсы процессов 91
3.8.1. Типы ресурсов 93
3.8.2. Posix-функции для установки ограничений доступа к ресурсам 94
3.9. Асинхронные и синхронные процессы 97
3.9.1. Создание синхронных и асинхронных процессов с помощью
функций fork(), ехес(), system() и posix_spawn() 99
3.9.2. Функция wait() 99
3.10. Разбиение программы на задачи 101
3.10.1. Линии видимого контура 108
3.11. Резюме 109
Глава 4. Разбиение С++-программ на множество
потоков 111
4.1. Определение потока 113
4.1.1. Контекстные требования потока 114
4.1.2. Сравнение потоков и процессов 115
4.1.3. Преимущества использования потоков 116
4.1.4. Недостатки использования потоков 117
4.2. Анатомия потока 119
4.2.1. Атрибуты потока 121
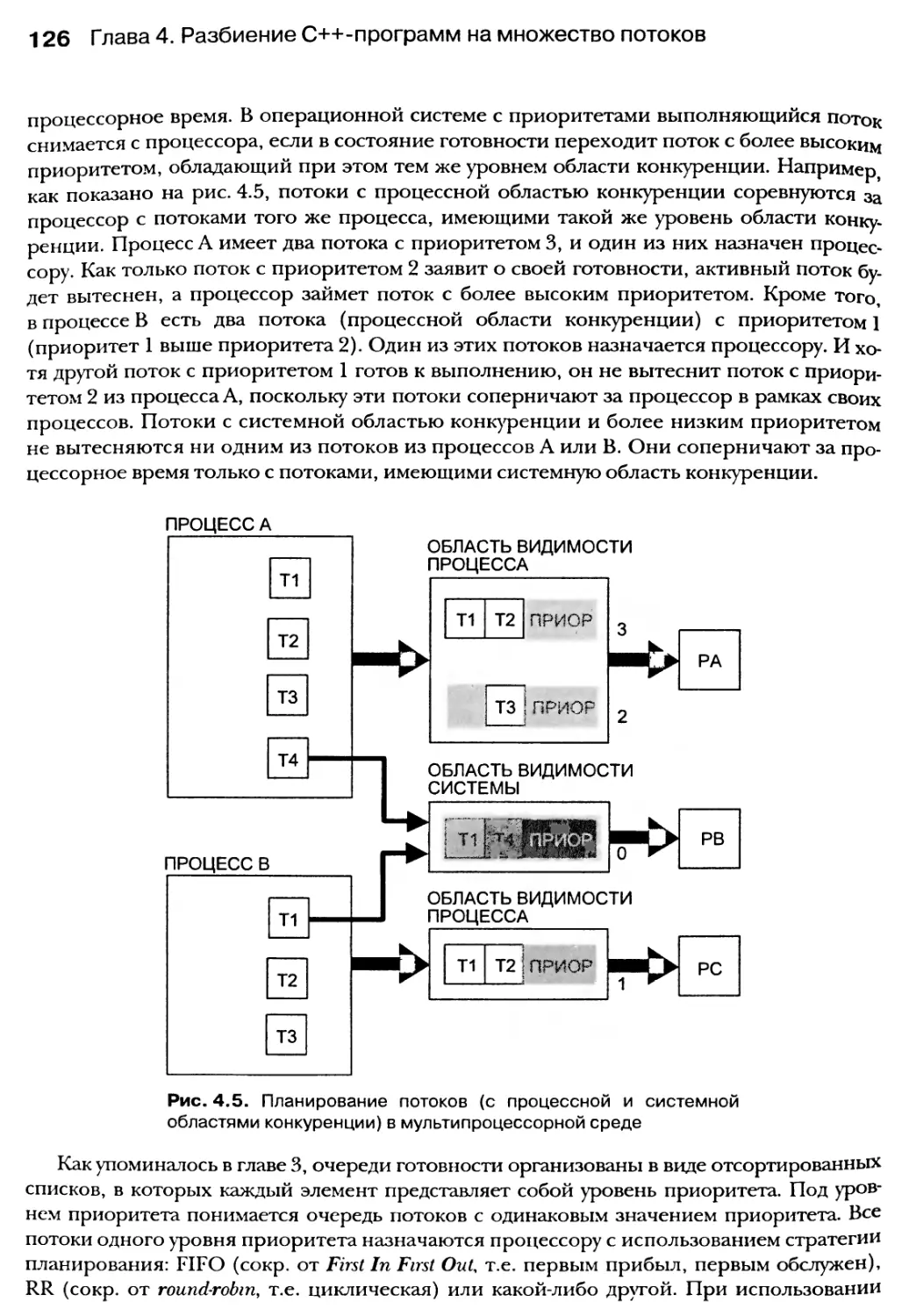
4.3. Планирование потоков 123
4.3.1. Состояния потоков 124
4.3.2. Планирование потоков и область конкуренции 125
4.3.3. Стратегия планирования и приоритет 125
4.4. Ресурсы потоков 128
4.5. Модели создания и функционирования потоков 129
4.5.1. Модель делегирования 130
4.5.2. Модель с равноправными узлами 132
4.5.3. Модель конвейера 132
4.5.4. Модель “изготовитель-потребитель” 133
4.5.5. Модели SPMD и MPMD для потоков 133
4.6. Введение в библиотеку PTHREAD 134
4.7. Анатомия простой многопоточной программы 136
4.7.1. Компиляция и компоновка многопоточных программ 137
4.8. Создание потоков 138
4.8.1. Получение идентификатора потока 141
4.8.2. Присоединение потоков 141
10 Содержание
4.8.3. Создание открепленных потоков 142
4.8.4. Использование объекта атрибутов 143
4.9. Управление потоками 145
4.9.1. Завершение потоков 145
4.9.2. Управление стеком потока 154
4.9.3. Установка атрибутов планирования и свойств потоков 157
4.9.4. Использование функции sysconf() 162
4.9.5. Управление критическими разделами 164
4.10. Безопасность использования потоков и библиотек 170
4.11. Разбиение программы на несколько потоков 172
4.11.1. Использование модели делегирования 173
4.11.2. Использование модели сети с равноправными узлами 177
4.11.3. Использование модели конвейера 177
4.11.4. Использование модели “изготовитель-потребитель” 178
4.11.5. Создание многопоточных объектов 180
Резюме 181
Глава 5. Синхронизация параллельно выполняемых
задач 183
5.1. Координация порядка выполнения потоков 185
5.1.1. Взаимоотношения между синхронизируемыми задачами 185
5.1.2. Отношения типа старт-старт (СС) 186
5.1.3. Отношения типа финиш-старт (ФС) 187
5.1.4. Отношения типа старт-финиш (СФ) 188
5.1.5. Отношения типа финиш-финиш (ФФ) 188
5.2. Синхронизация доступа к данным 189
5.2.1. Модель PRAM 189
5.3. Что такое семафоры 193
5.3.1. Операции по управлению семафором 193
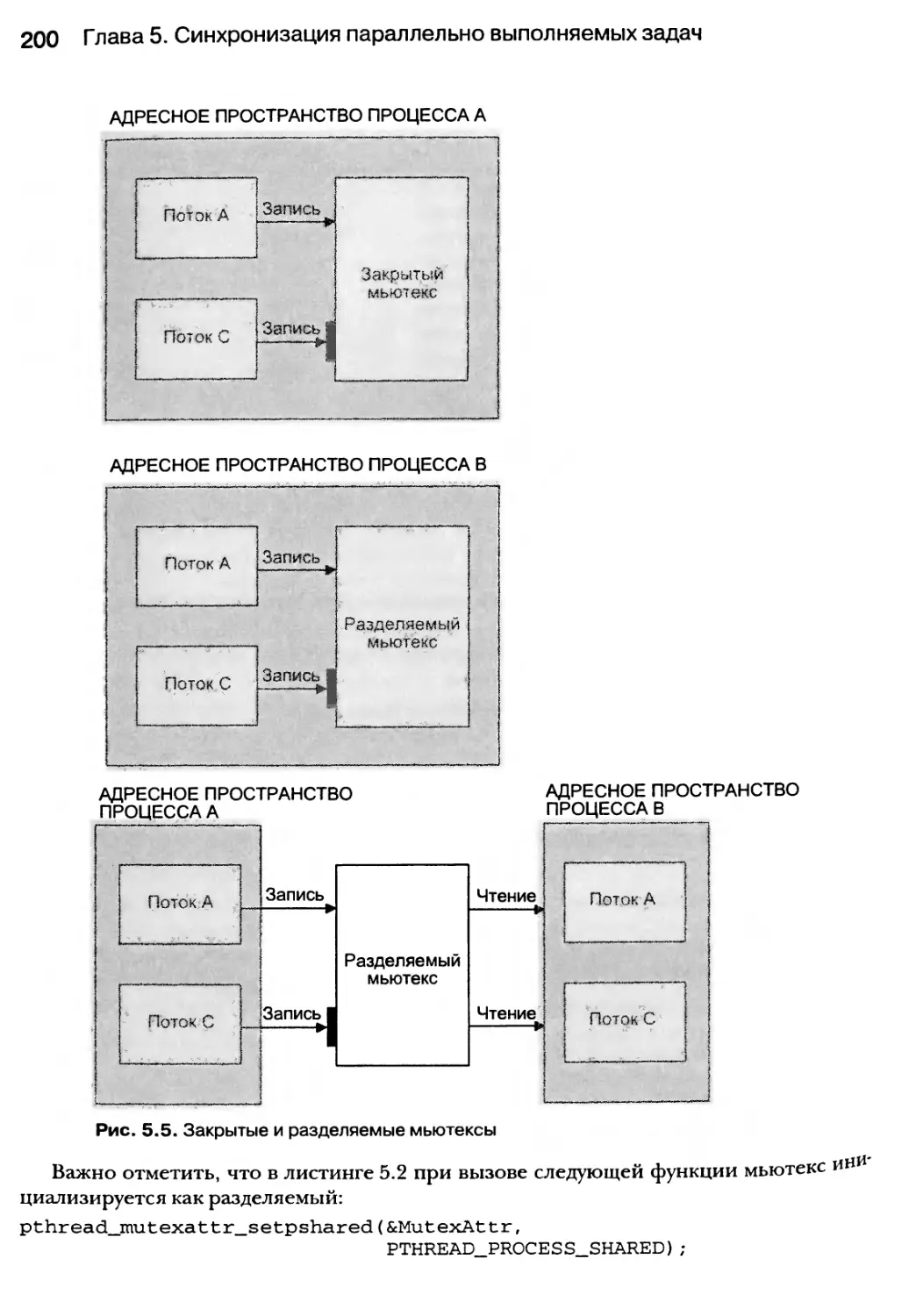
5.3.2. Мьютексные семафоры 194
5.3.3. Блокировки для чтения и записи 201
5.3.4. Условные переменные 205
5.4. Объектно-ориентированный подход к синхронизации 210
5.5. Резюме 210
Глава 6. Объединение возможностей параллельного
программирования и С++-средств на основе PVM 211
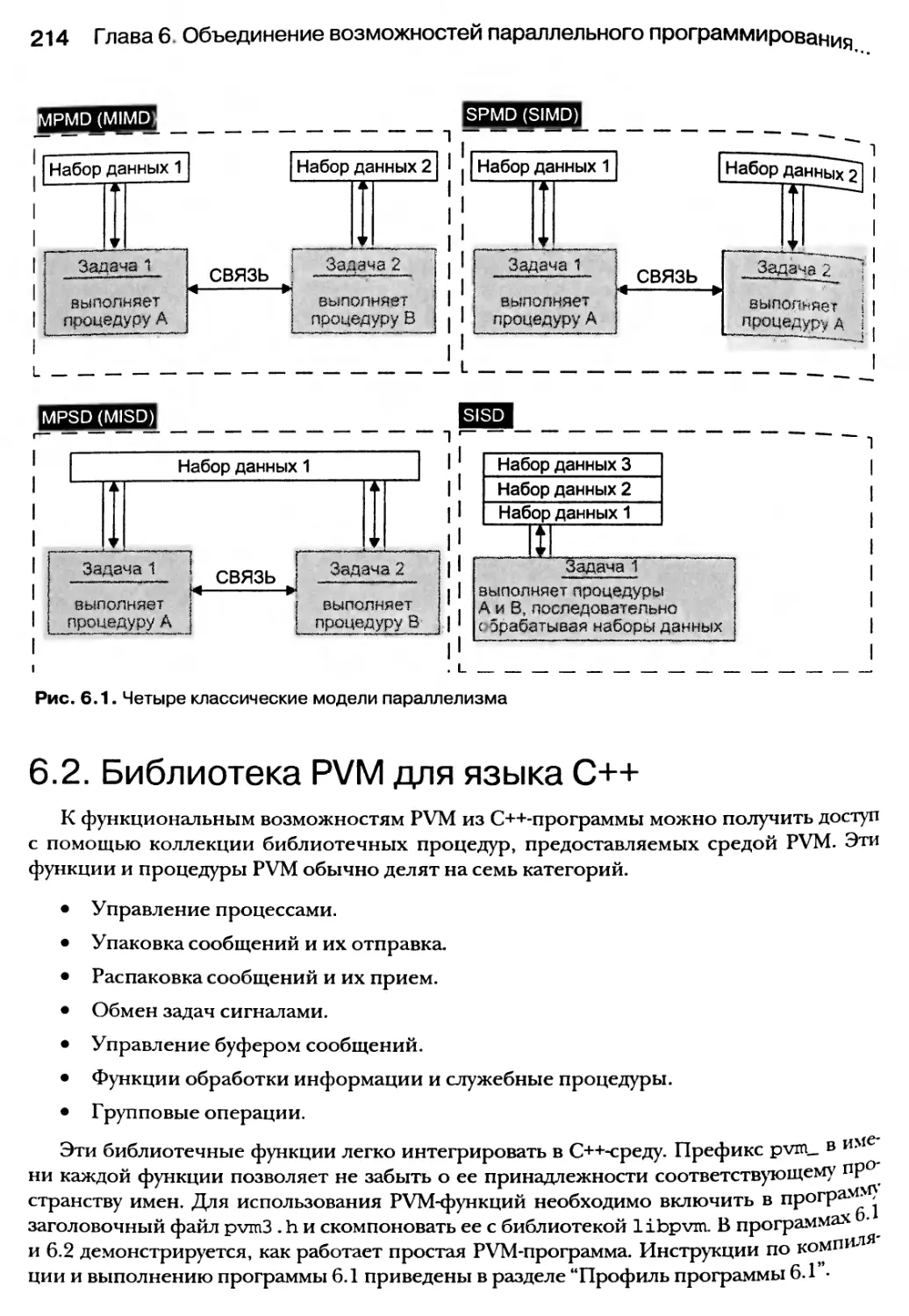
6.1. Классические модели параллелизма, поддерживаемые системой PVM 213
6.2. Библиотека PVM для языка C++ 214
6.2.1. Компиляция и компоновка С++/РУМ-программ 217
6.2.2. Выполнение PVM-программы в виде двоичного файла 218
Содержание 11
6.2.3. Требования к PVM-программам 220
6.2.4. Объединение динамической С++-библиотеки с библиотекой PVM 222
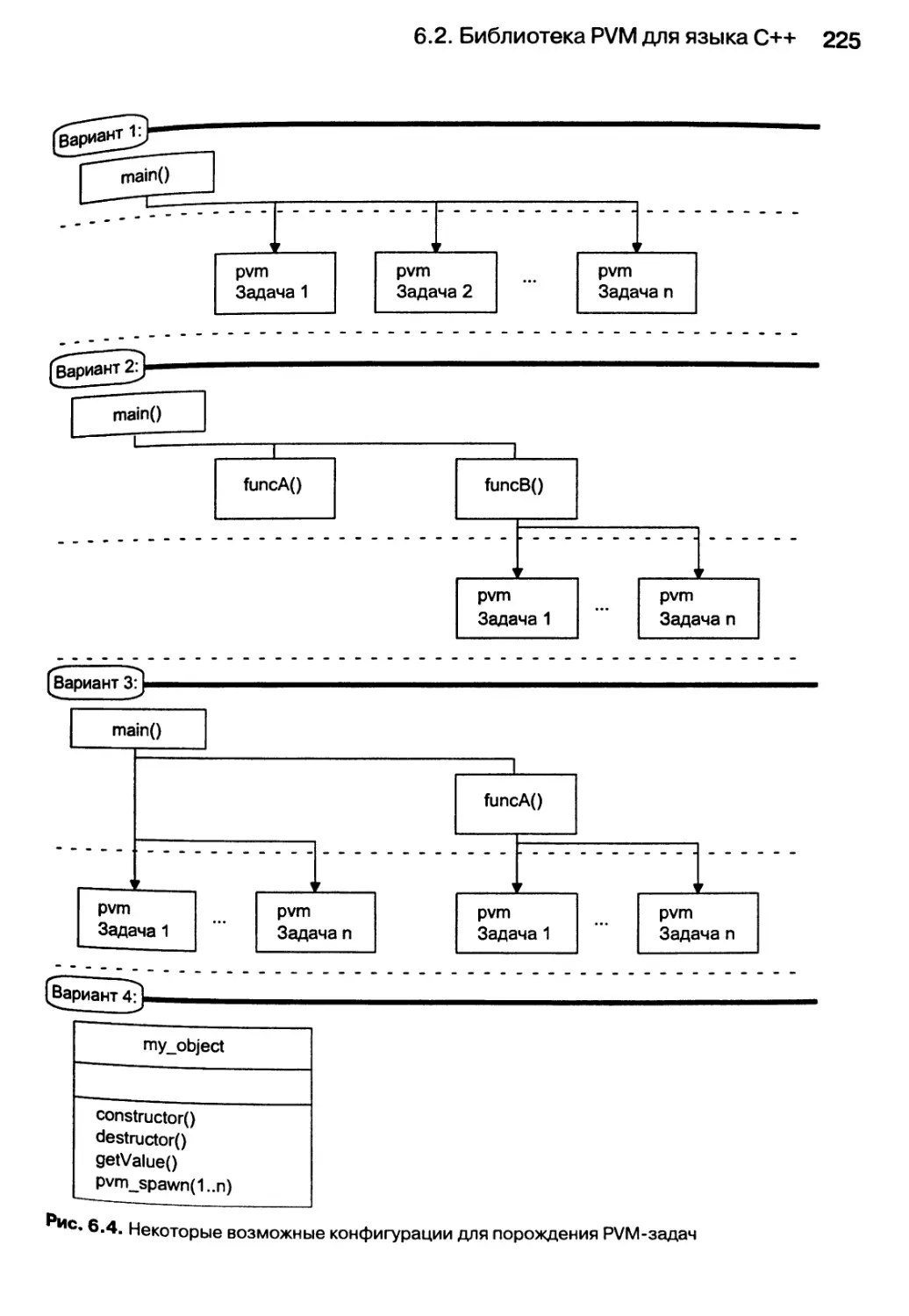
6.2.5. Методы использования PVM-задач 223
6.3. Базовые механизмы PVM 233
6.3.1. Функции управления процессами 234
6.3.2. Упаковка и отправка сообщений 236
6.4. Доступ к стандартному входному потоку (STDIN) и стандартному
выходному потоку (STDOUT) со стороны pvm-задач 242
6.4.1. Получение доступа к стандартному выходному потоку (COUT)
из сыновней задачи 243
6.5. Резюме 243
Глава 7. Обработка ошибок, исключительных ситуаций
и надежность программного обеспечения 245
7.1. Надежность программного обеспечения 247
7.2. Отказы в программных и аппаратных компонентах 249
7.3. Определение дефектов в зависимости от спецификаций ПО 251
7.4. Обработка ошибок или обработка исключительных ситуаций? 251
7.5. Надежность ПО: простой план 255
7.5.1. План А: модель возобновления, план Б: модель завершения 255
7.6. Использование объектов отображения для обработки ошибок 256
7.7. Механизмы обработки исключительных ситуаций в C++ 259
7.7.1. Классы исключений 260
7.8. Диаграммы событий, логические выражения и логические схемы 264
7.9. Резюме 267
Глава 8. Распределенное объектно-ориентированное
программирование в C++ 268
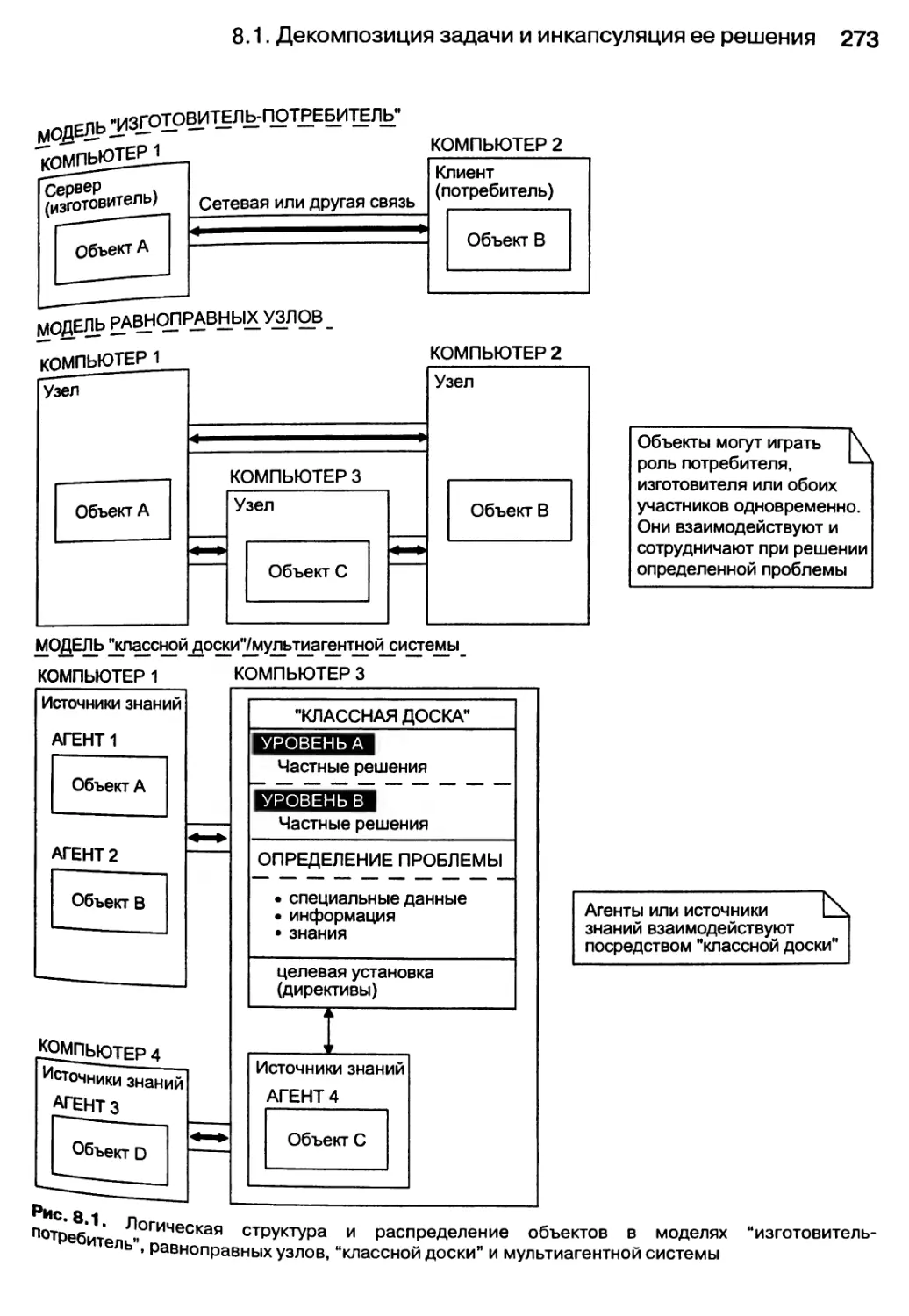
8.1. Декомпозиция задачи и инкапсуляция ее решения 271
8.1.1. Взаимодействие между распределенными объектами 272
8.1.2. Синхронизация взаимодействия локальных и удаленных объектов 274
8.1.3. Обработка ошибок и исключений в распределенной среде 275
8.2. Доступ к объектам из других адресных пространств 275
8.2.1. IOR-доступ к удаленным объектам 277
8.2.2. Брокеры объектных запросов (ORB) 278
8.2.3. Язык описания интерфейсов (IDL): более “пристальный” взгляд
на CORBA-объекты 282
8.3. Анатомия базовой CORBA-программы потребителя 286
8.4. Анатомия базовой CORBA-программы изготовителя 288
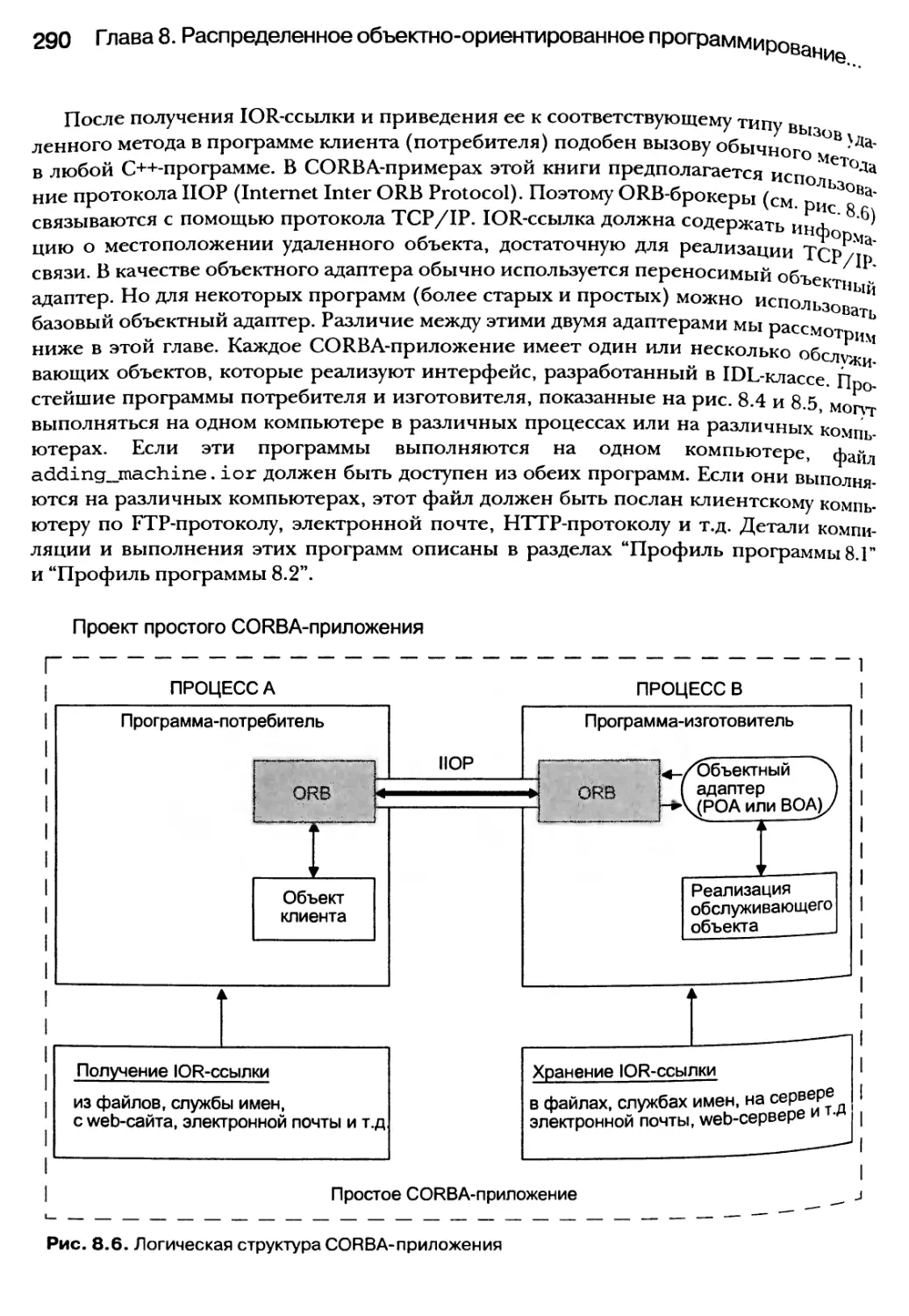
8.5. Базовый проект CORBA-приложения 289
12 Содержание
8.5.1. IDL-компилятор 292
8.5.2. Получение IOR-ссылки для удаленных объектов 293
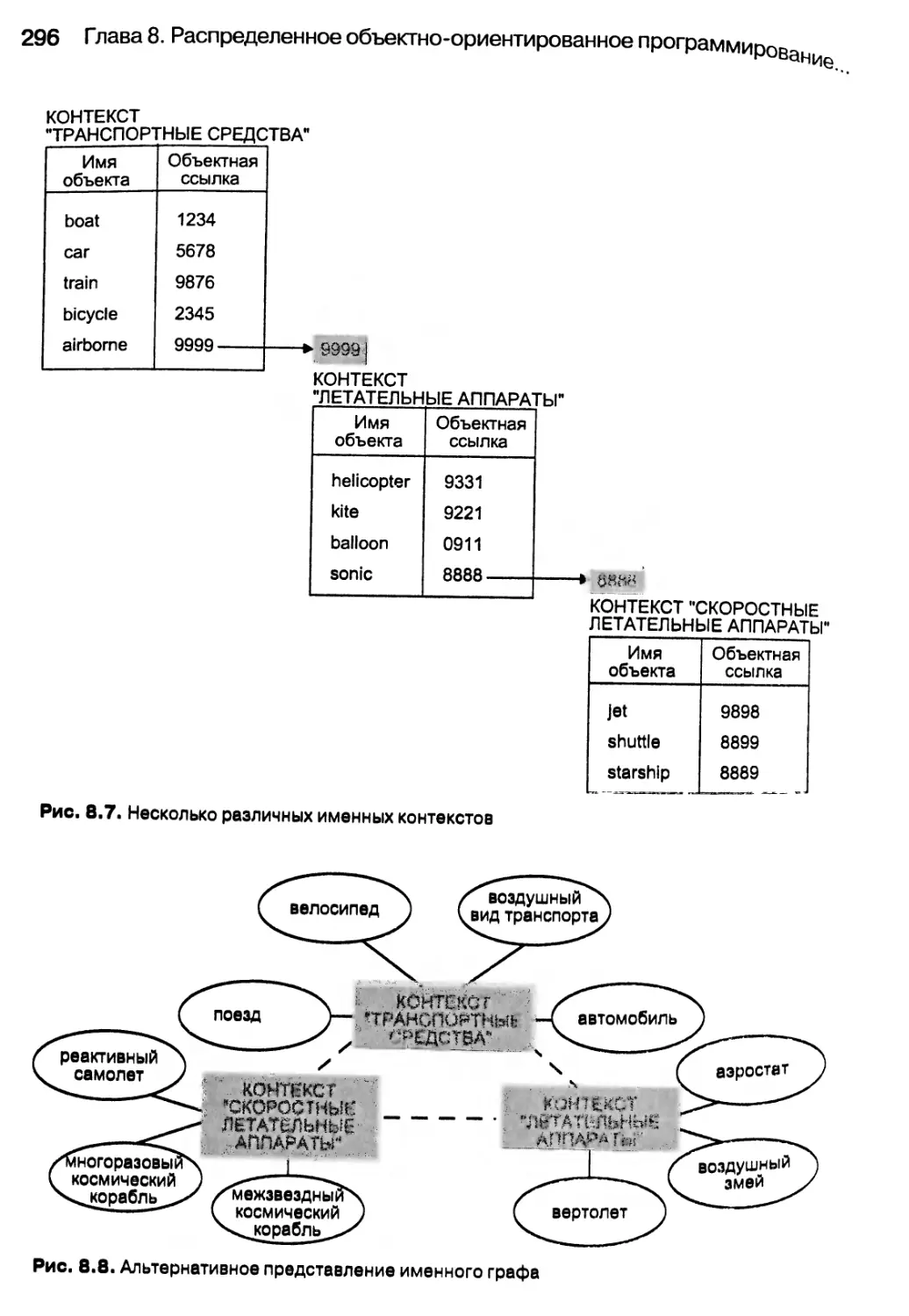
8.6. Служба имен 294
8.6.1. Использование службы имен и создание именных контекстов 298
8.6.2. Служба имен “потребитель-клиент” 300
8.7. Подробнее об объектных адаптерах 303
8.8. Хранилища реализаций и интерфейсов 305
8.9. Простые распределенные Web-службы, использующие CORBA-спецификацию 306
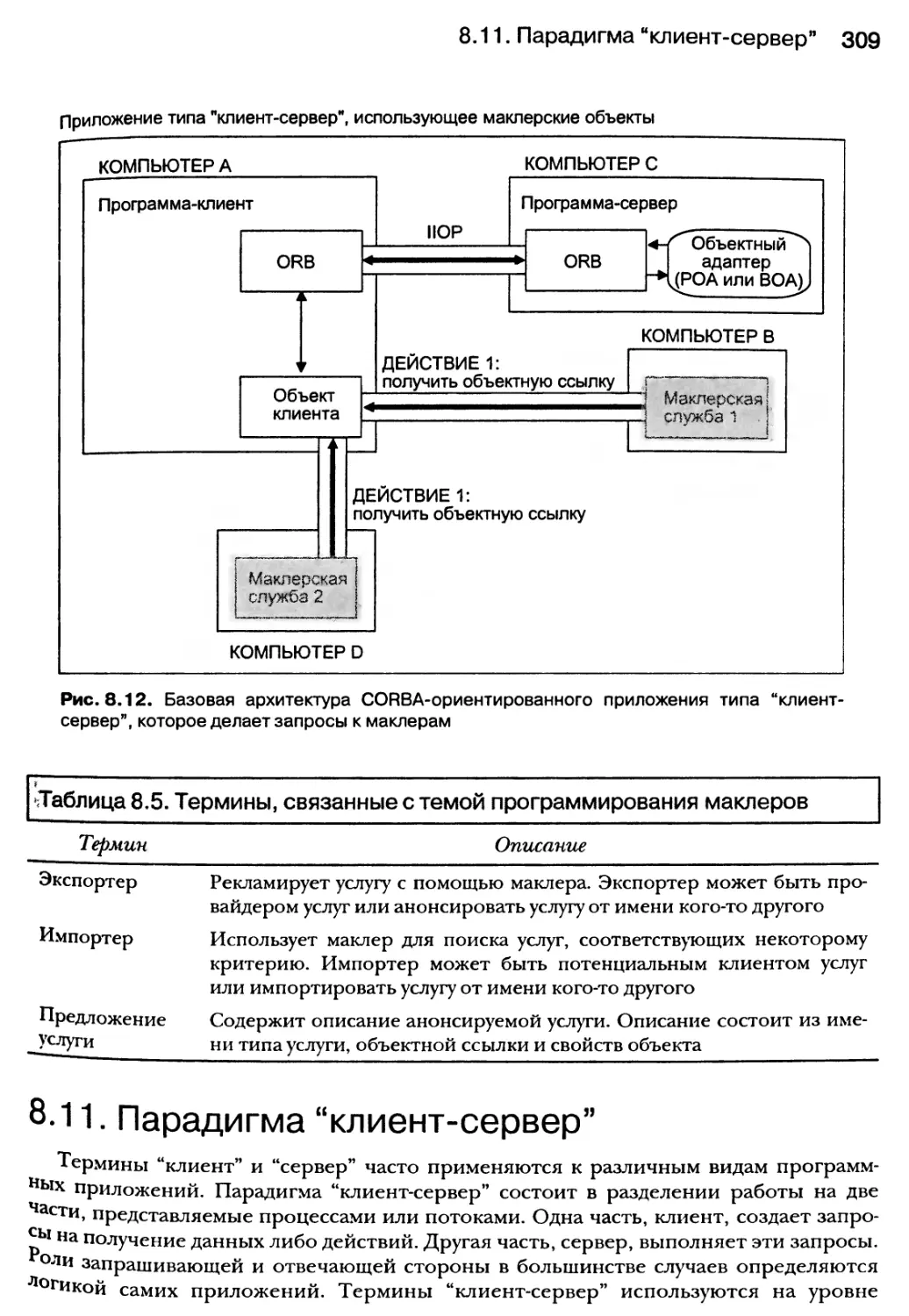
8.10. Маклерская служба 307
8.11. Парадигма “клиент-сервер” 309
8.12. Резюме 311
Глава 9. Реализация моделей SPMD и MPMD с помощью
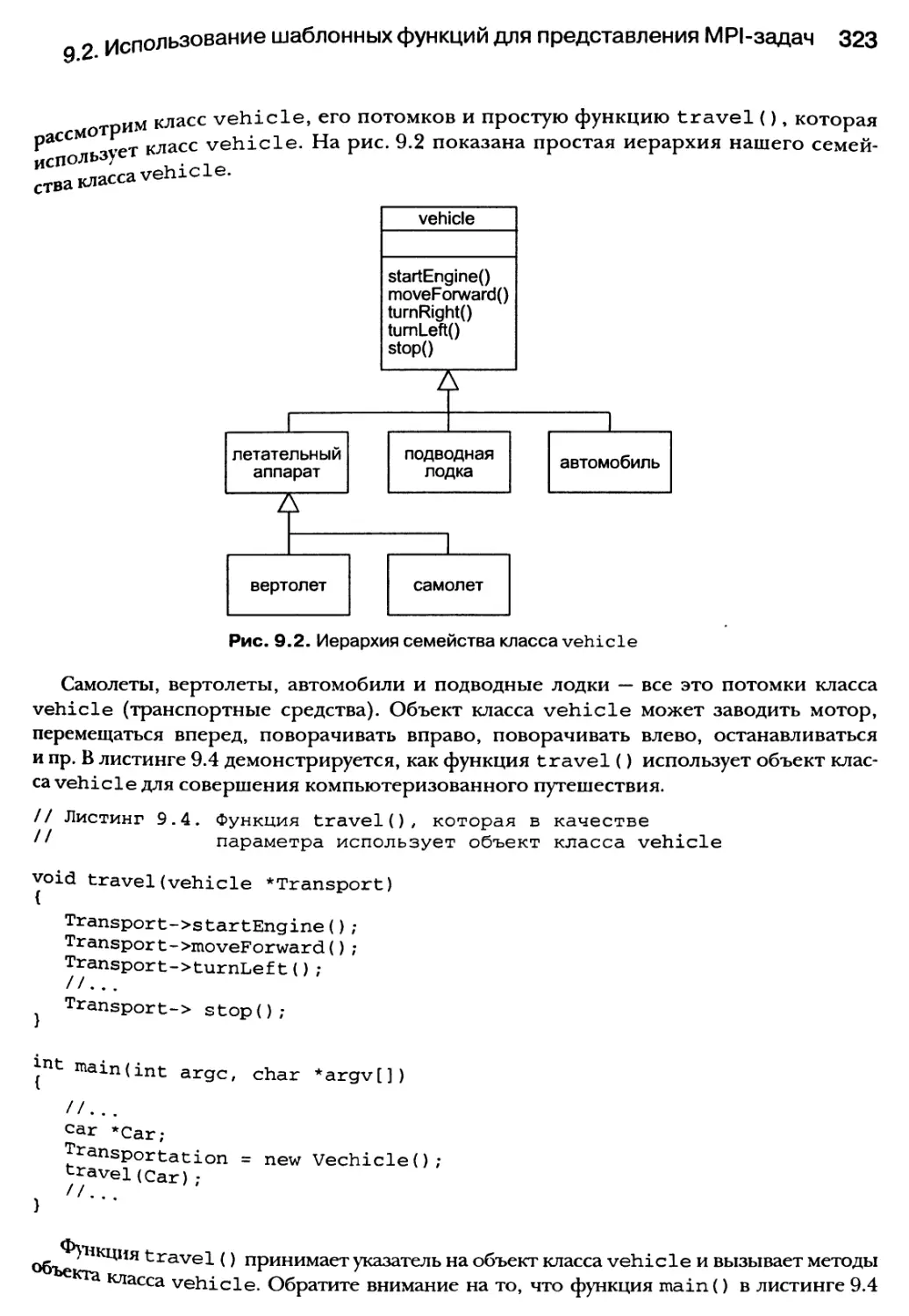
шаблонов и МР1-программирования 312
9.1. Декомпозиция работ для МР1-интерфейса 314
9.1.1. Дифференциация задач по рангу 315
9.1.2. Группирование задач по коммуникаторам 317
9.1.3. Анатомия MPI-задачи 319
9.2. Использование шаблонных функций для представления МР1-задач 320
9.2.1. Реализация шаблонов и модель SPMD (типы данных) 321
9.2.2. Использование полиморфизма для реализации MPMD-модели 322
9.2.3. Введение MPMD-модели с помощью функций-объектов 327
9.3. Как упростить взаимодействие между MPI-задачами 328
9.3.1. Перегрузка операторов “«” и “»” для организации взаимодействия
между MPI-задачами 332
9.4. Резюме 335
Глава 10. Визуализация проектов параллельных
и распределенных систем ззб
10.1. Визуализация структур 338
10.1.1. Классы и объекты 338
10.1.2. Отношения между классами и объектами 347
10.1.3. Организация интерактивных объектов 353
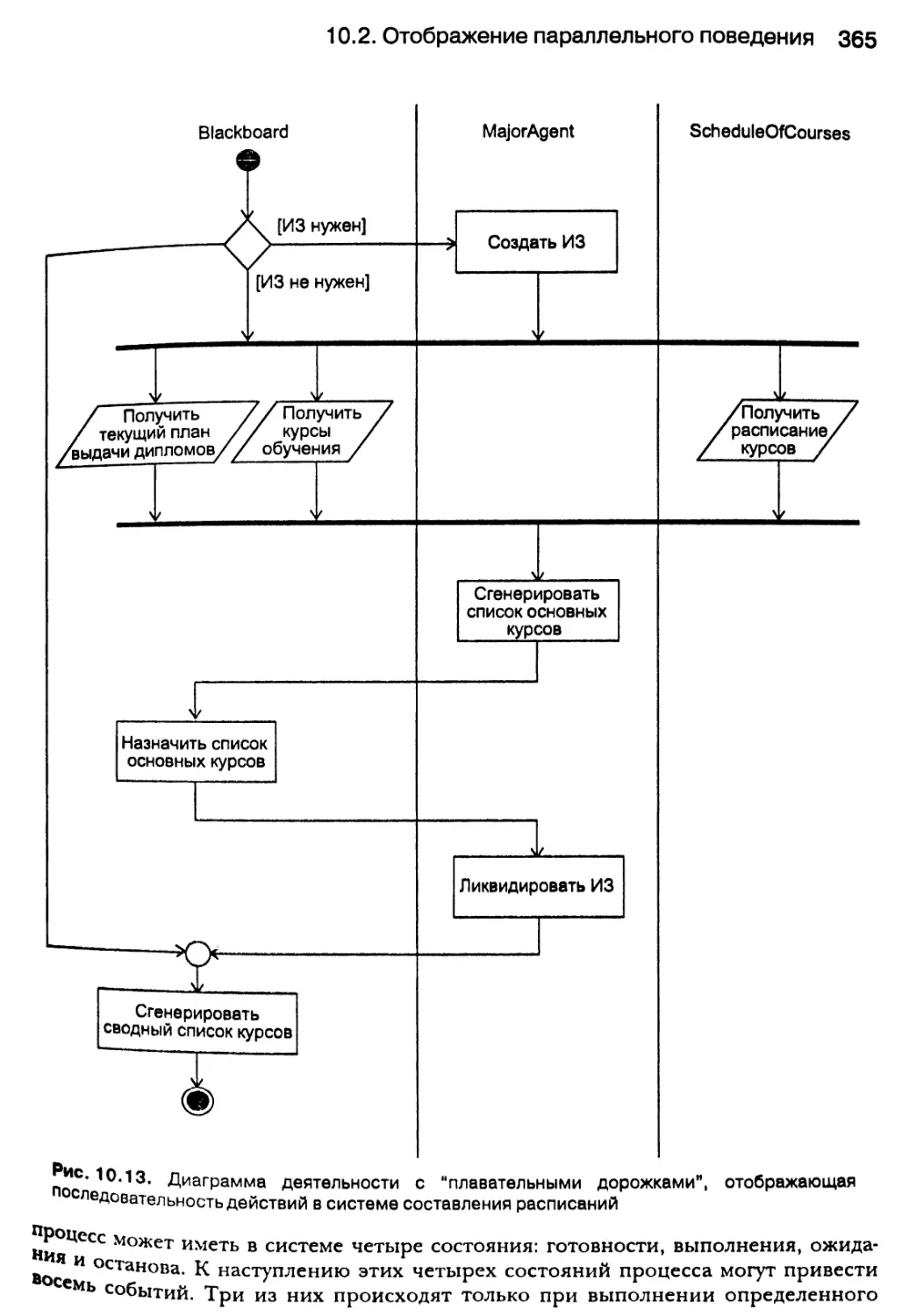
10.2. Отображение параллельного поведения 354
10.2.1. Сотрудничество объектов 354
10.2.2. Последовательность передачи сообщений между объектами 359
10.2.3. Деятельность объектов 360
10.2.4. Конечные автоматы 364
10.2.5. Распределенные объекты 371
Содержание 13
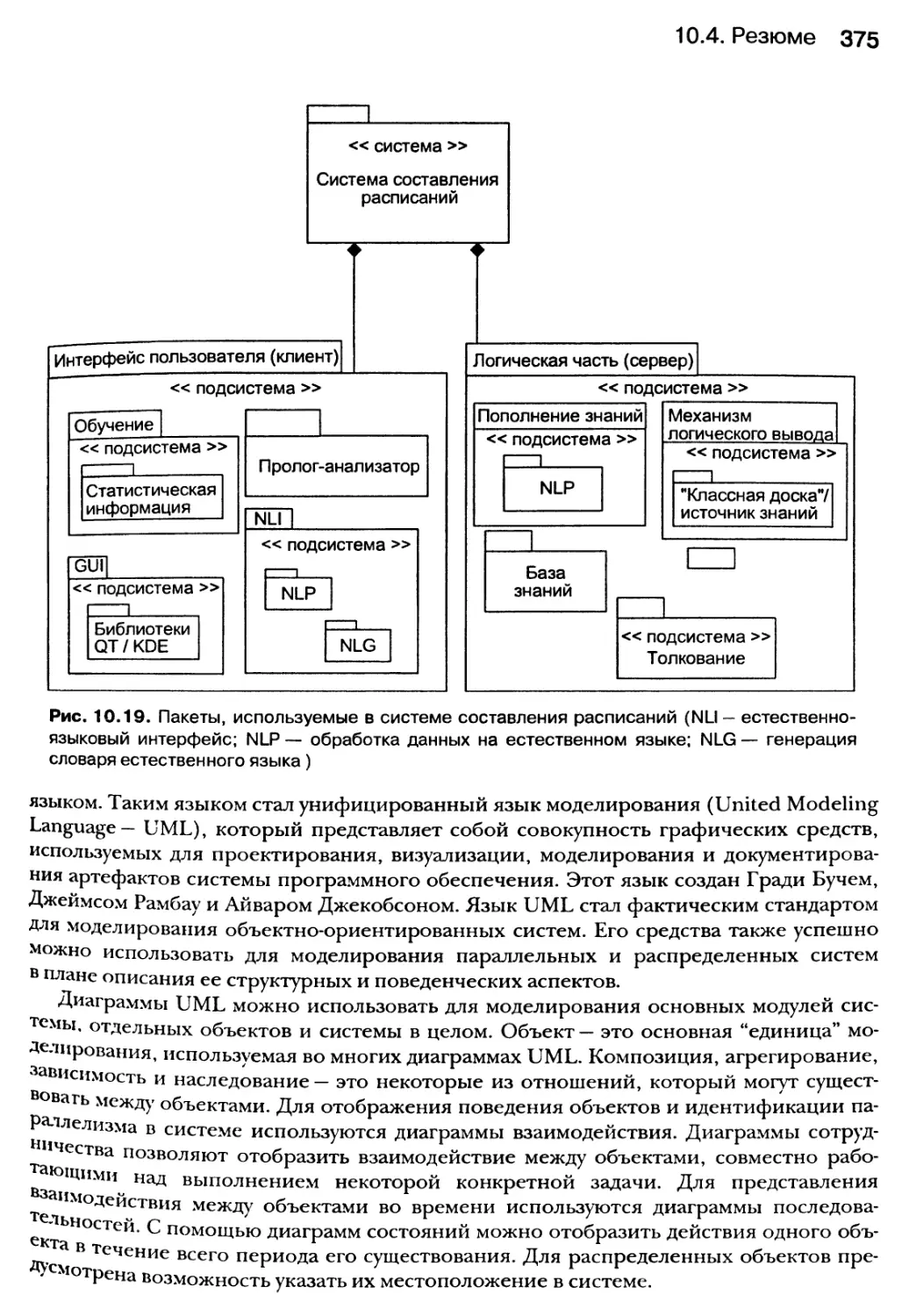
10.3. Визуализация всей системы 371
10.3.1. Визуализация развертывания систем 372
10.3.2. Архитектура системы 373
10.4. Резюме 374
Глава 11. Проектирование компонентов для поддержки
параллелизма 377
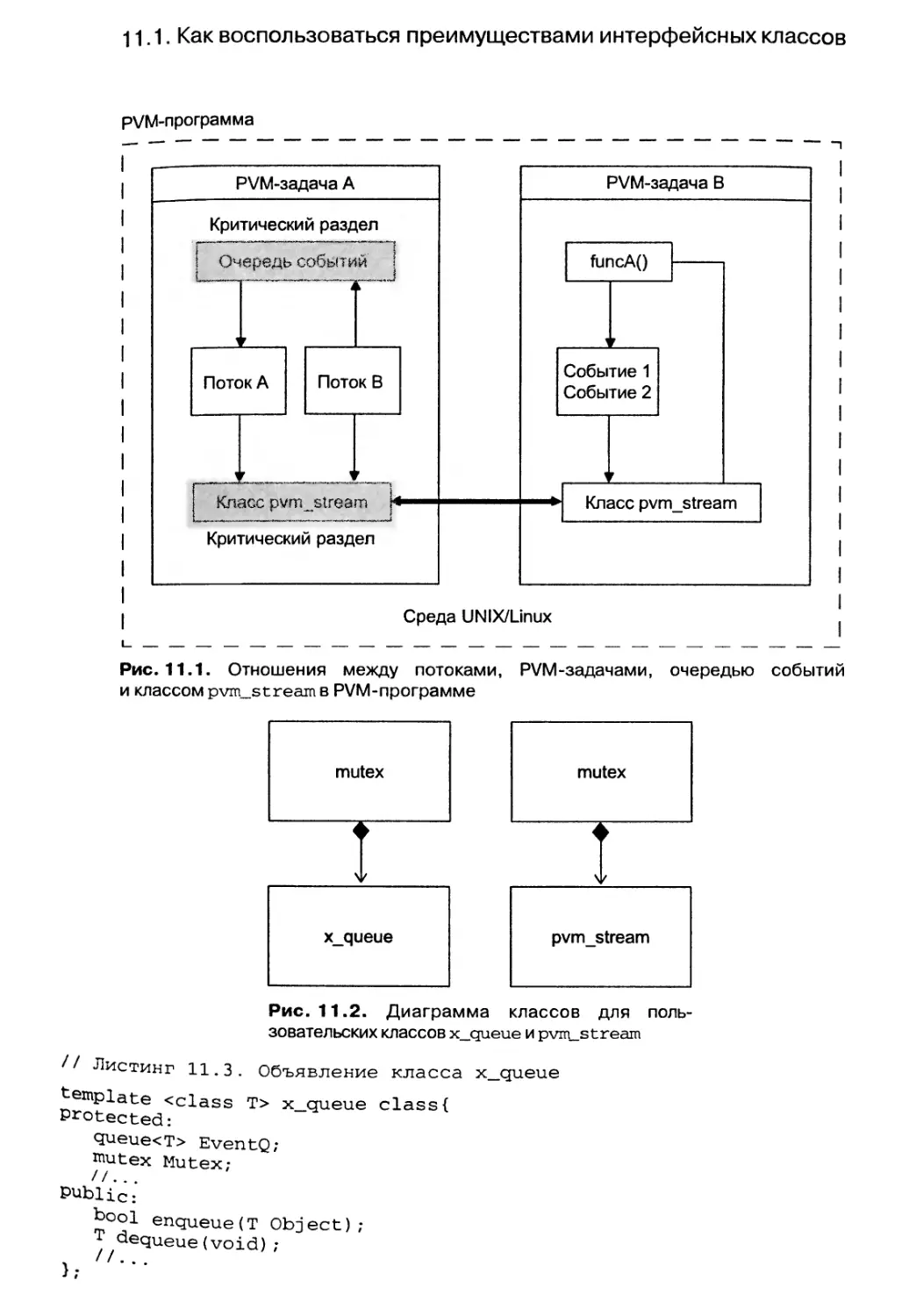
11.1. Как воспользоваться преимуществами интерфейсных классов 380
11.2. Подробнее об объектно-ориентированном взаимном исключении
и интерфейсных классах 385
11.2.1. “Полуширокие” интерфейсы 386
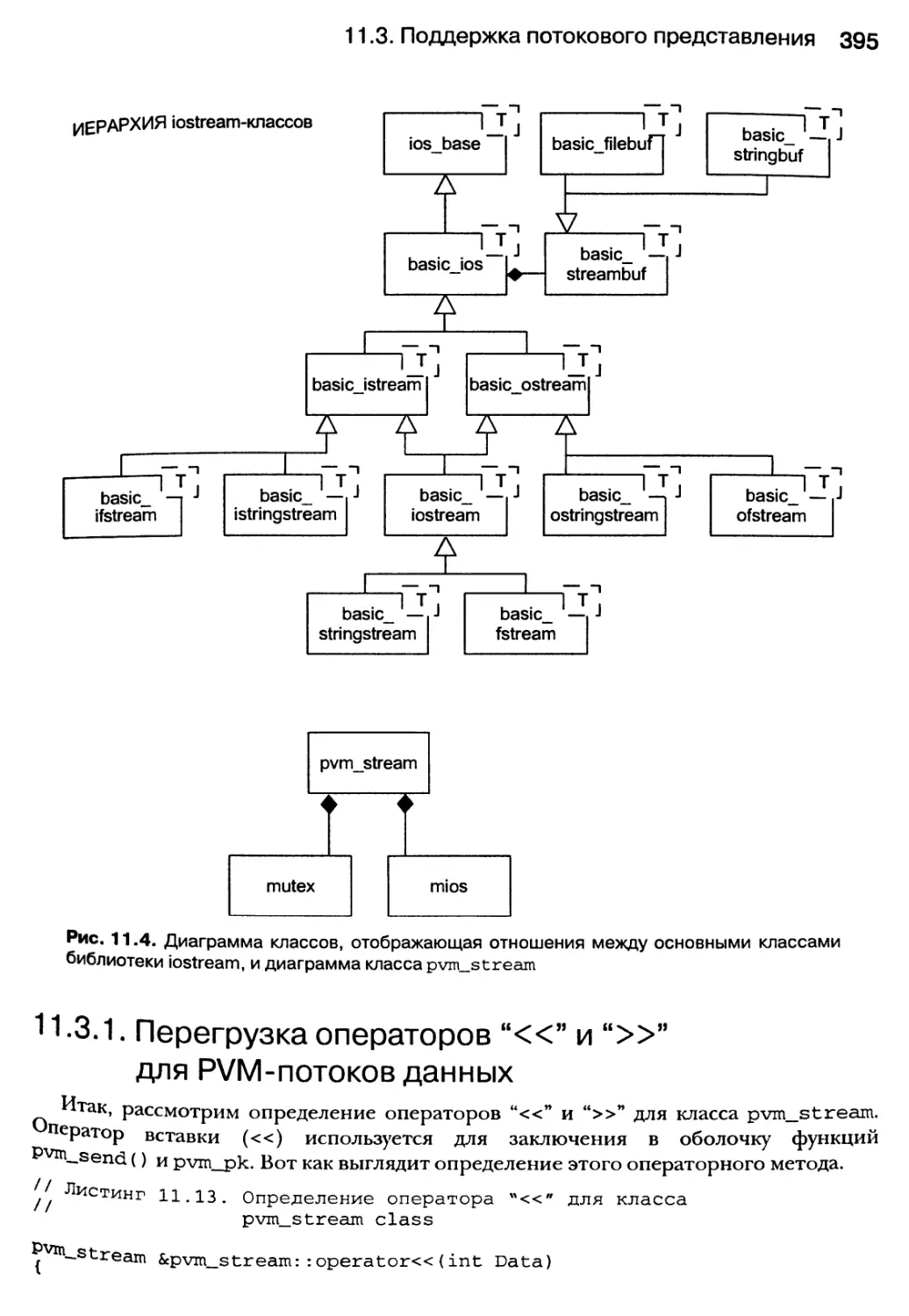
11.3. Поддержка потокового представления 393
11.3.1. Перегрузка операторов “«” и “»” для PVM-потоков данных 395
11.4. Пользовательские классы, создаваемые для обработки PVM-потоков данных 398
11.5. Объектно-ориентированные каналы и FIFO-очереди как базовые
элементы низкого уровня 401
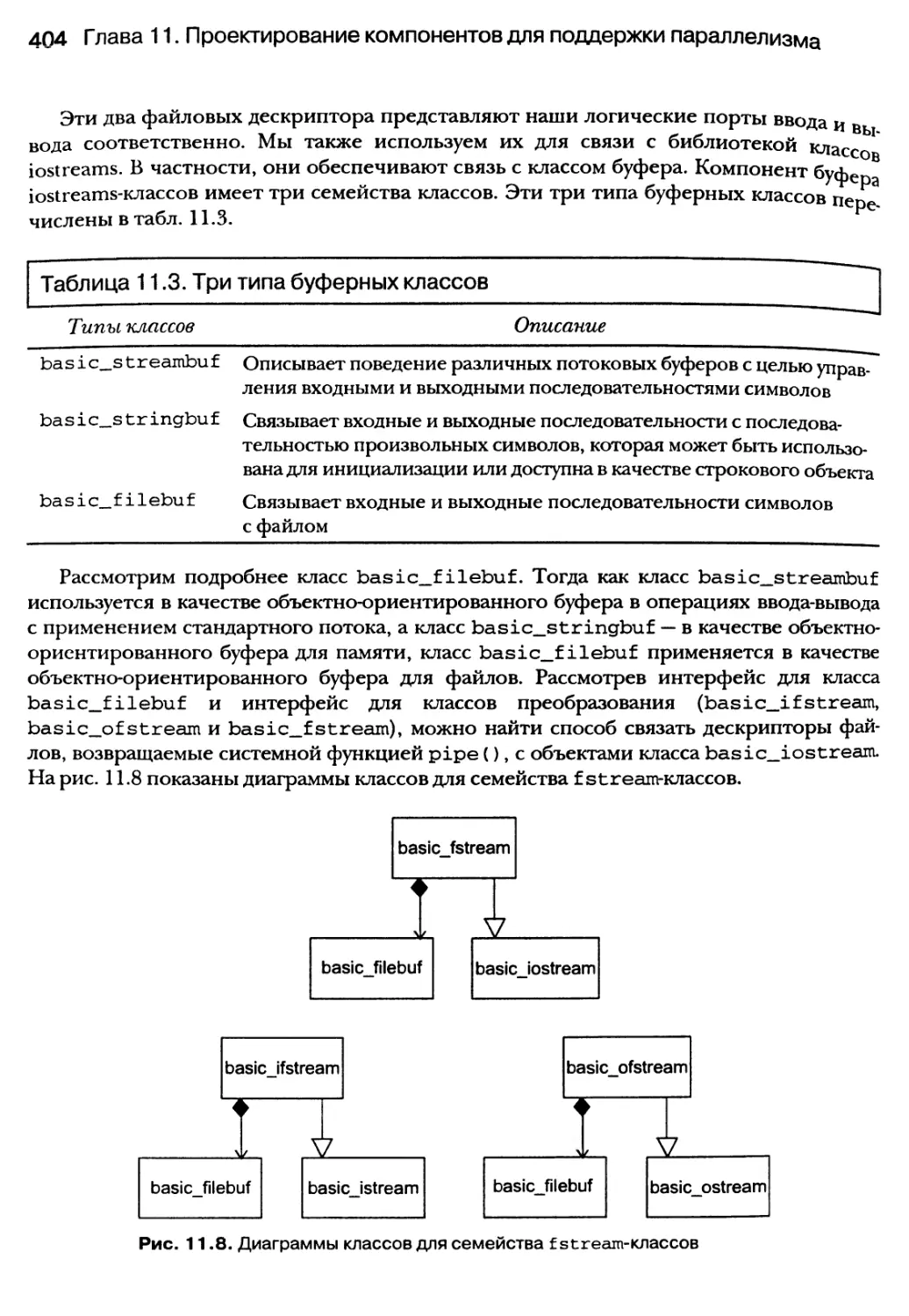
11.5.1. Связь каналов с iostream-объектами с помощью дескрипторов файлов 405
11.5.2. Доступ к анонимным каналам с использованием итератора
OSTREAMJTERATOR 408
11.5.3. FIFO-очереди (именованные каналы), iostreams-классы и итераторы
типа ostream_iterator 415
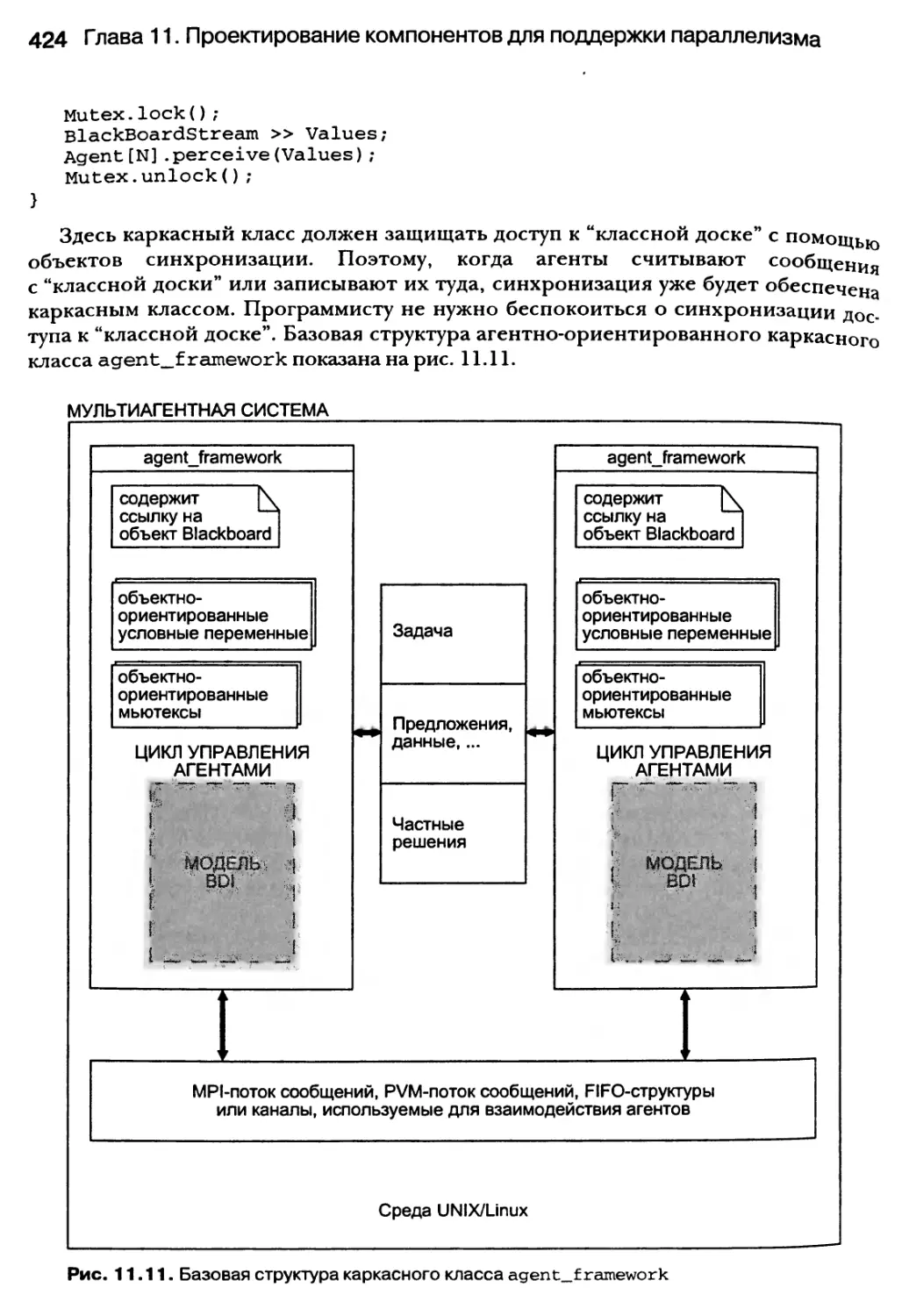
11.6. Каркасные классы 421
11.7. Резюме 425
Глава 12. Реализация агентно-ориентированных
архитектур 427
12.1. Что такое агенты 429
12.1.1. Агенты: исходное определение 429
12.1.2. Типы агентов 430
12.1.3. В чем состоит разница между объектами и агентами 431
12.2. Понятие об агентно-ориентированном программировании 432
12.2.1. Роль агентов в распределенном программировании 434
12.2.2. Агенты и параллельное программирование 436
12.3. Базовые компоненты агентов 437
12.3.1. Когнитивные структуры данных 438
12.4. Реализация агентов в C++ 444
12.4.1. Типы данных предположений и структуры убеждений 444
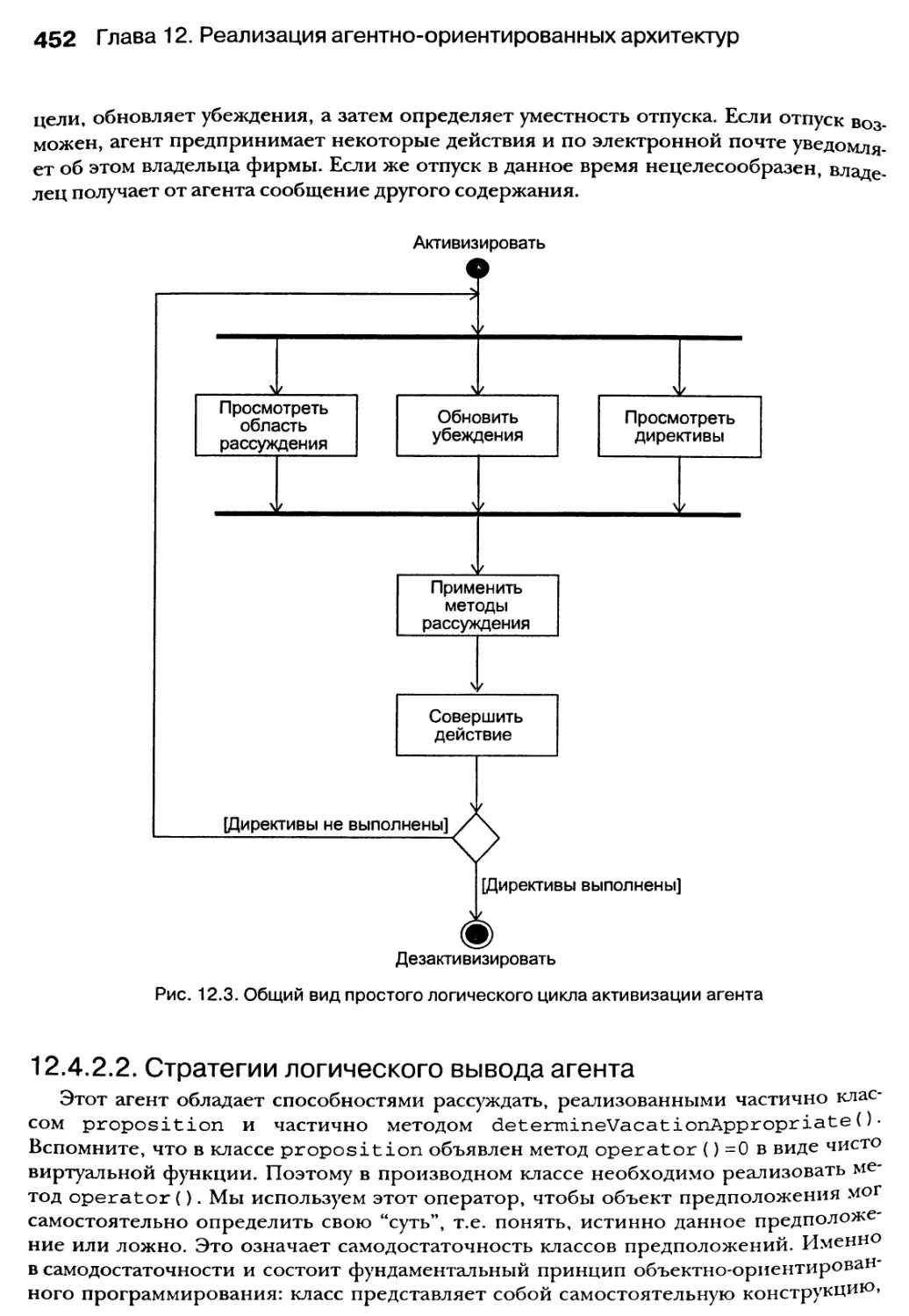
12.4.2. Класс агента 449
12.4.3. Простая автономность 460
12.5. Мультиагентные системы 461
12.6. Резюме 462
14 Содержание
Глава 13. Реализация технологии “классной доски”
с использованием PVM-средств, потоков
и компонентов C++ 463
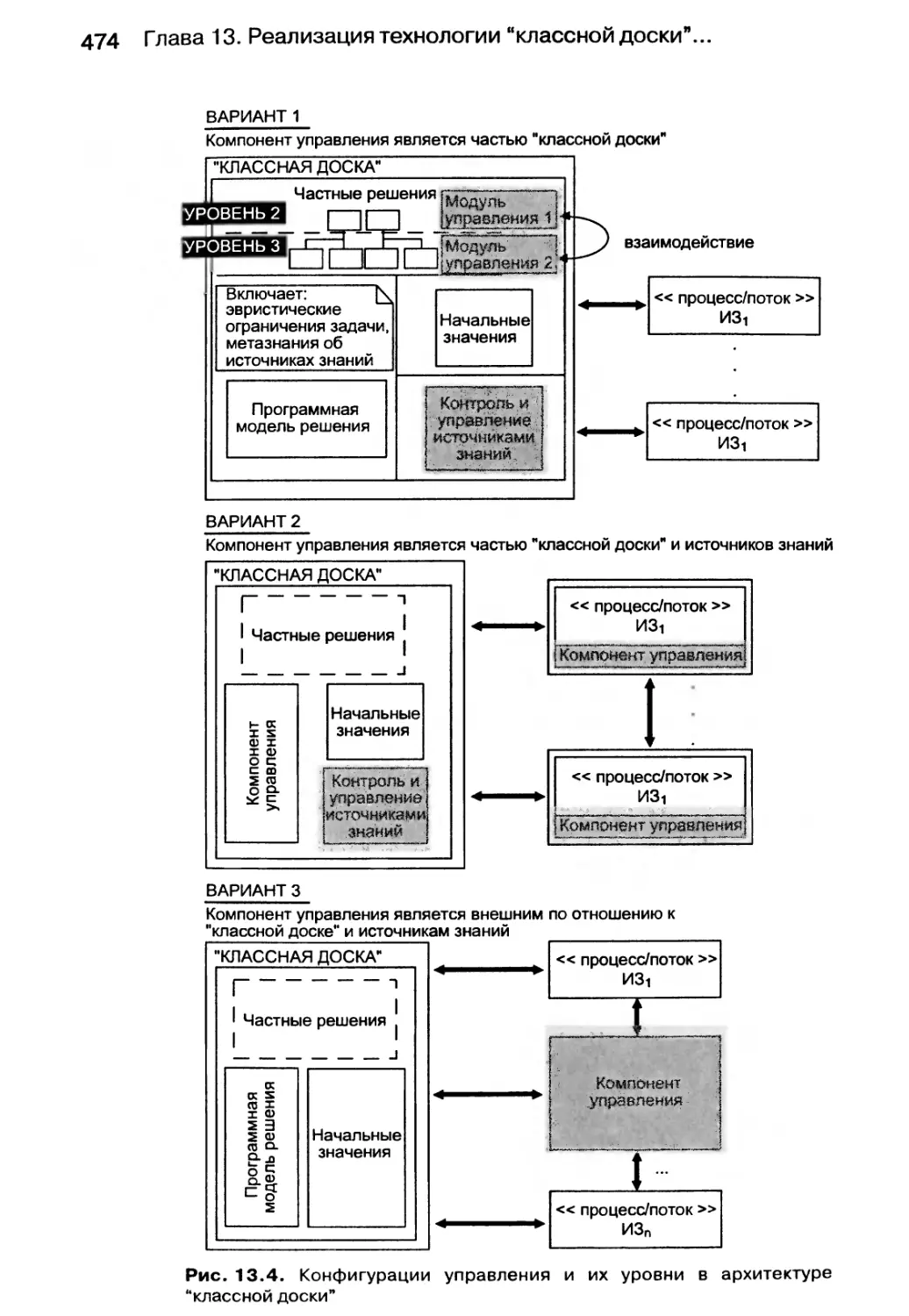
13.1. Модель “классной доски” 465
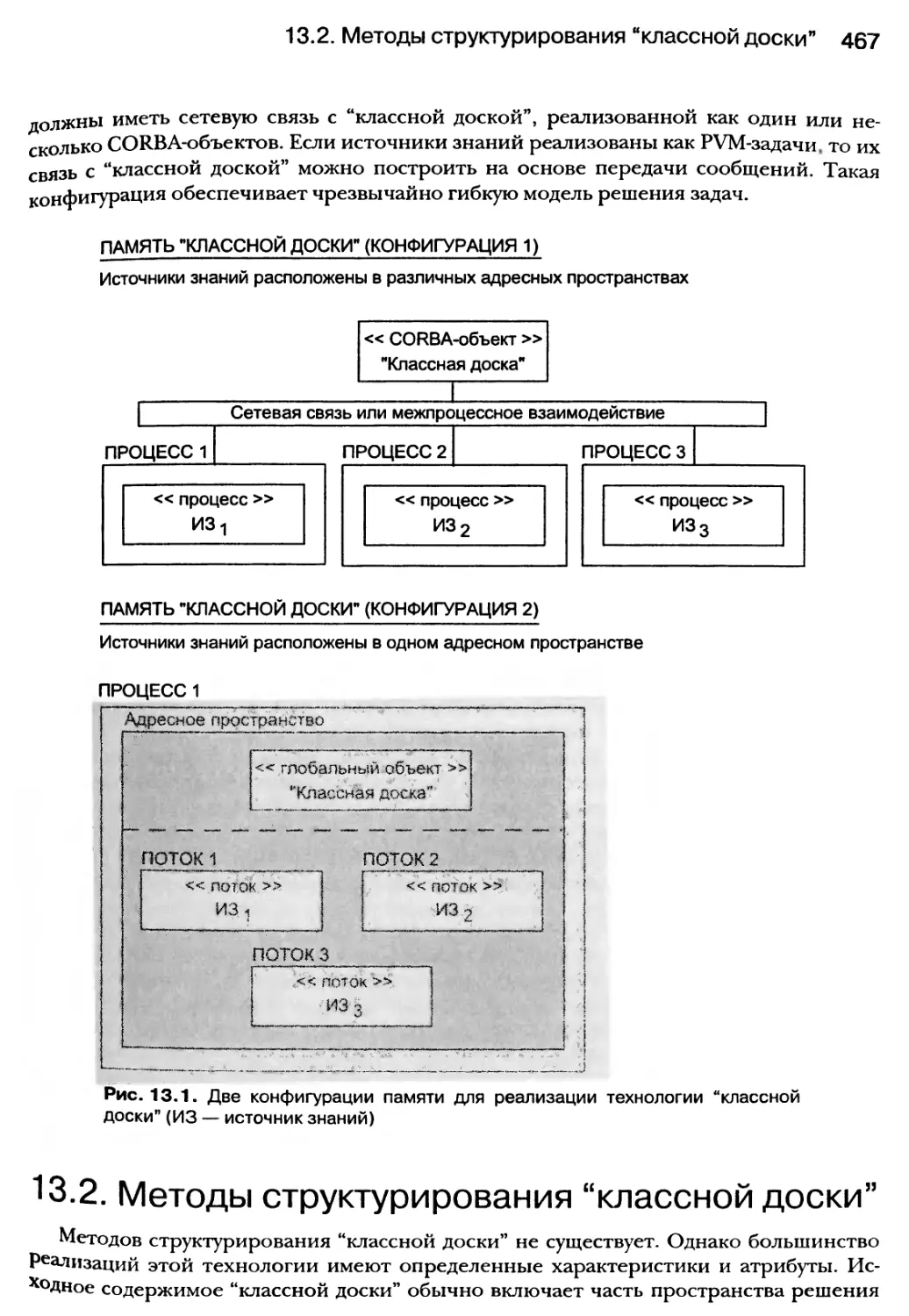
13.2. Методы структурирования “классной доски” 467
13.3. Анатомия источника знаний 470
13.4. Стратегии управления для “классной доски” 471
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 475
13.5.1. Пример использования corba-объекта “классной доски” 475
13.5.2. Реализация интерфейсного класса blackboard 478
13.5.3. Порождение источников знаний в конструкторе “классной доски” 480
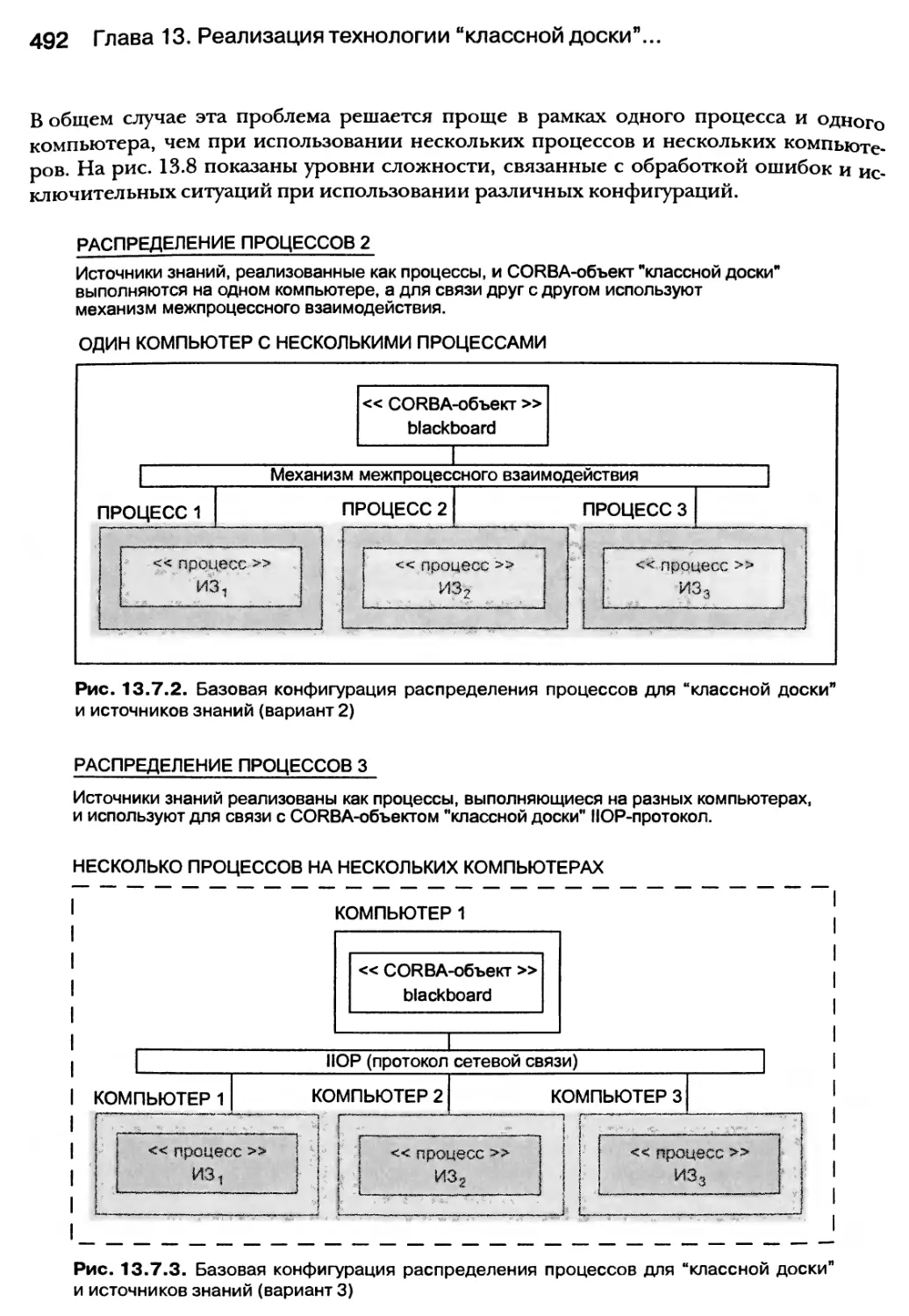
13.6. Реализация модели “классной доски” с помощью глобальных объектов 490
13.7. Активизация источников знаний с помощью потоков 494
13.8. Резюме 495
Приложение А 497
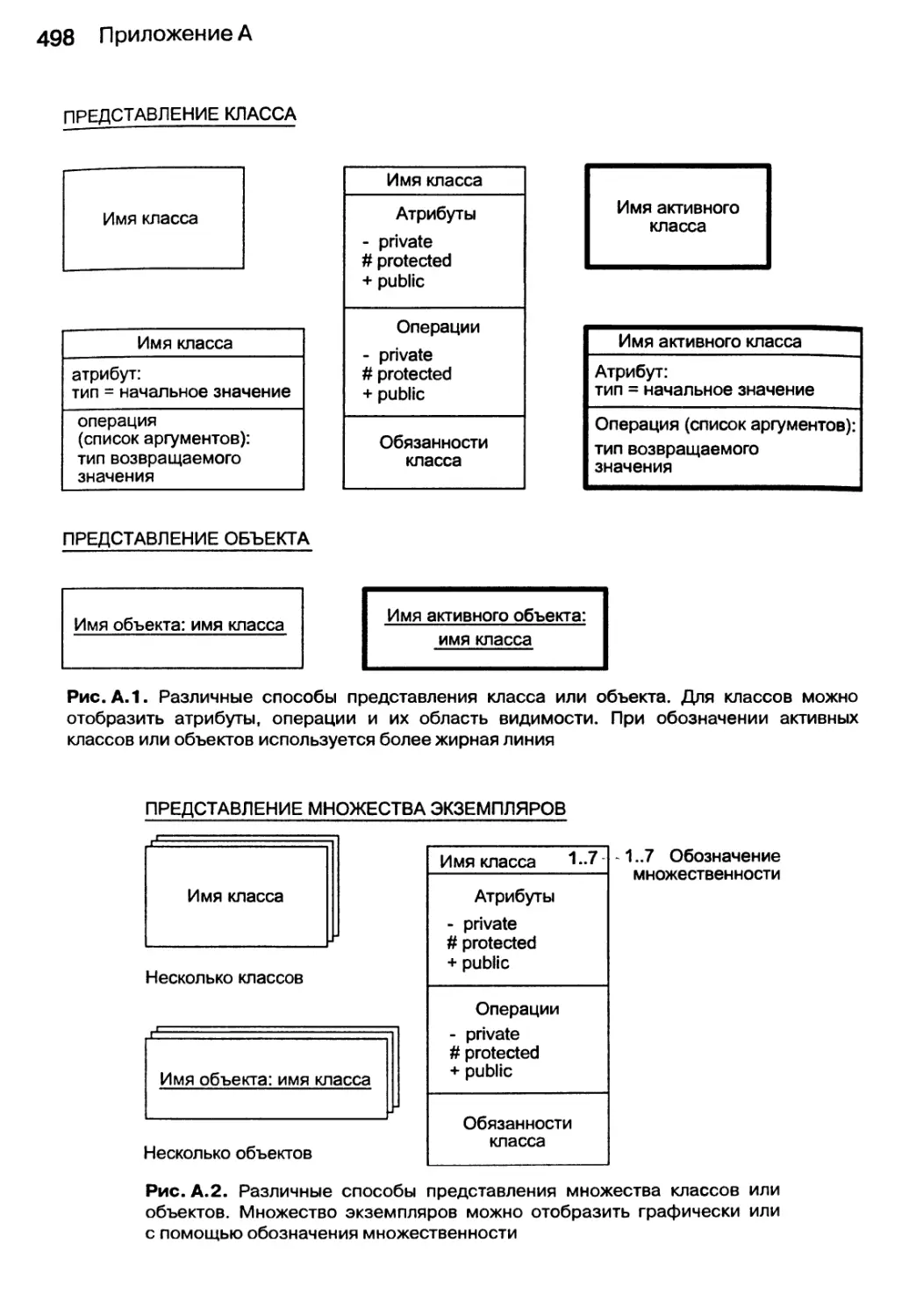
А. 1. Диаграммы классов и объектов 497
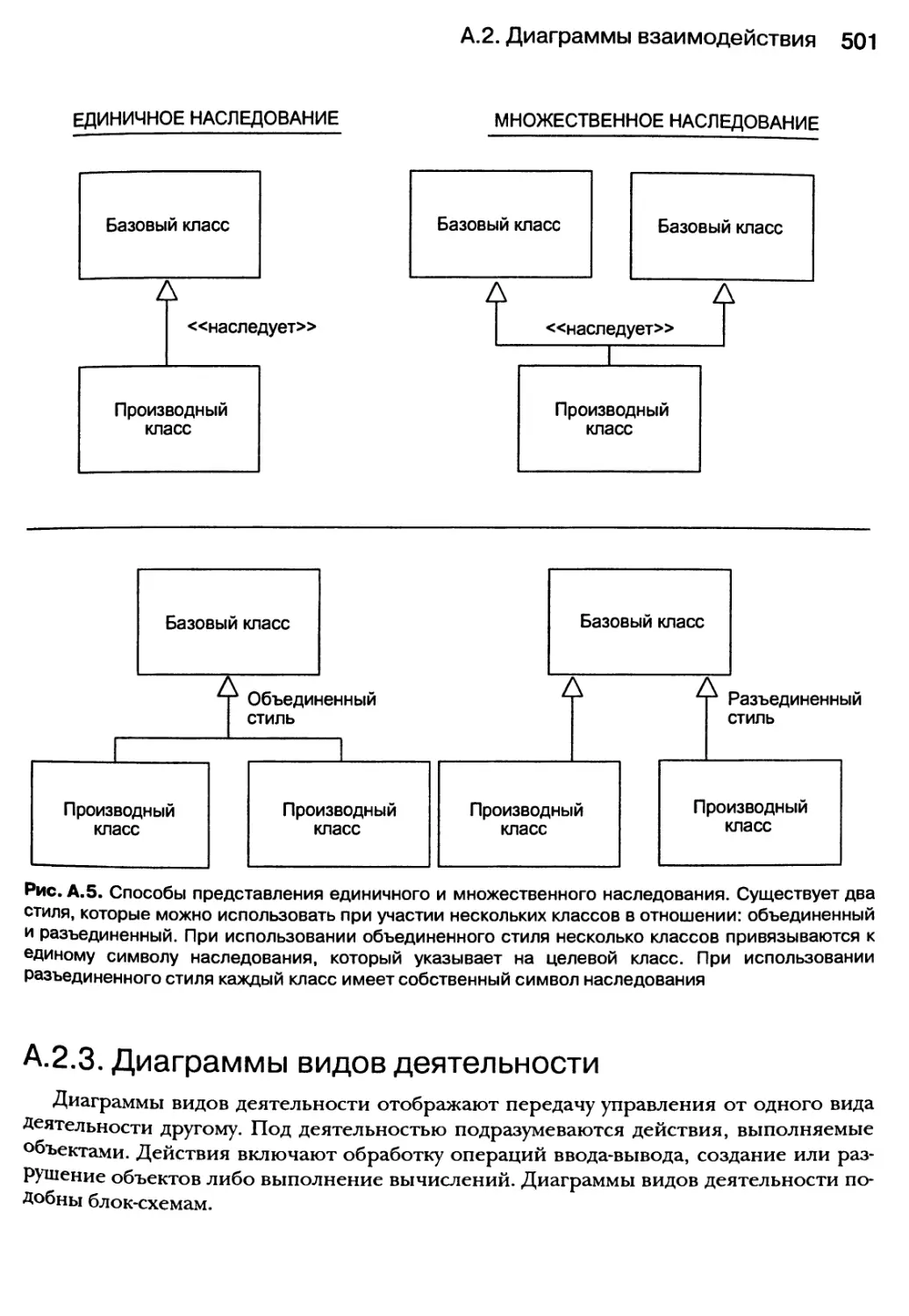
А.2. Диаграммы взаимодействия 499
А.2.1. Диаграммы сотрудничества 499
А.2.2. Диаграммы последовательностей 499
А.2.3. Диаграммы видов деятельности 501
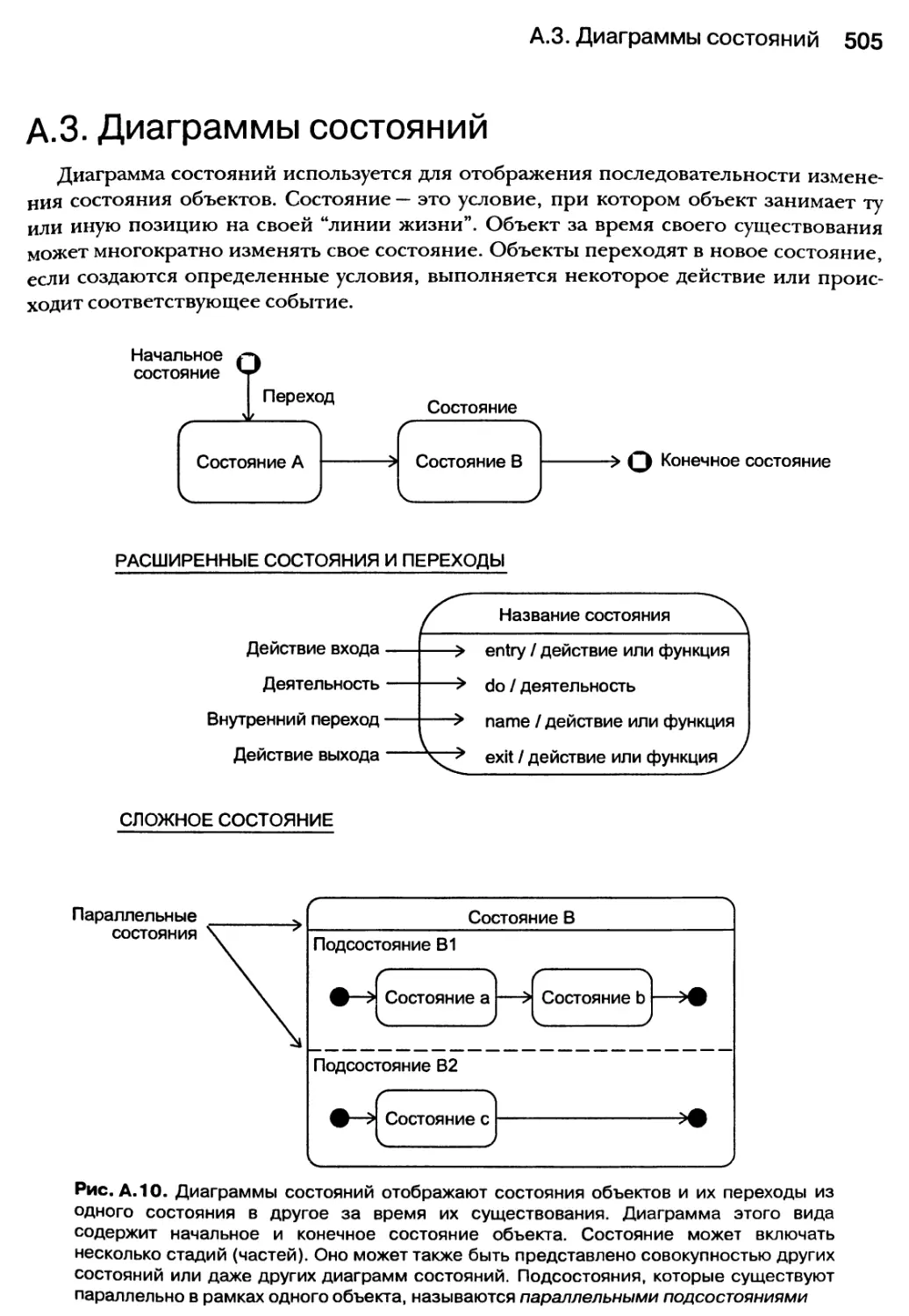
А.З. Диаграммы состояний 505
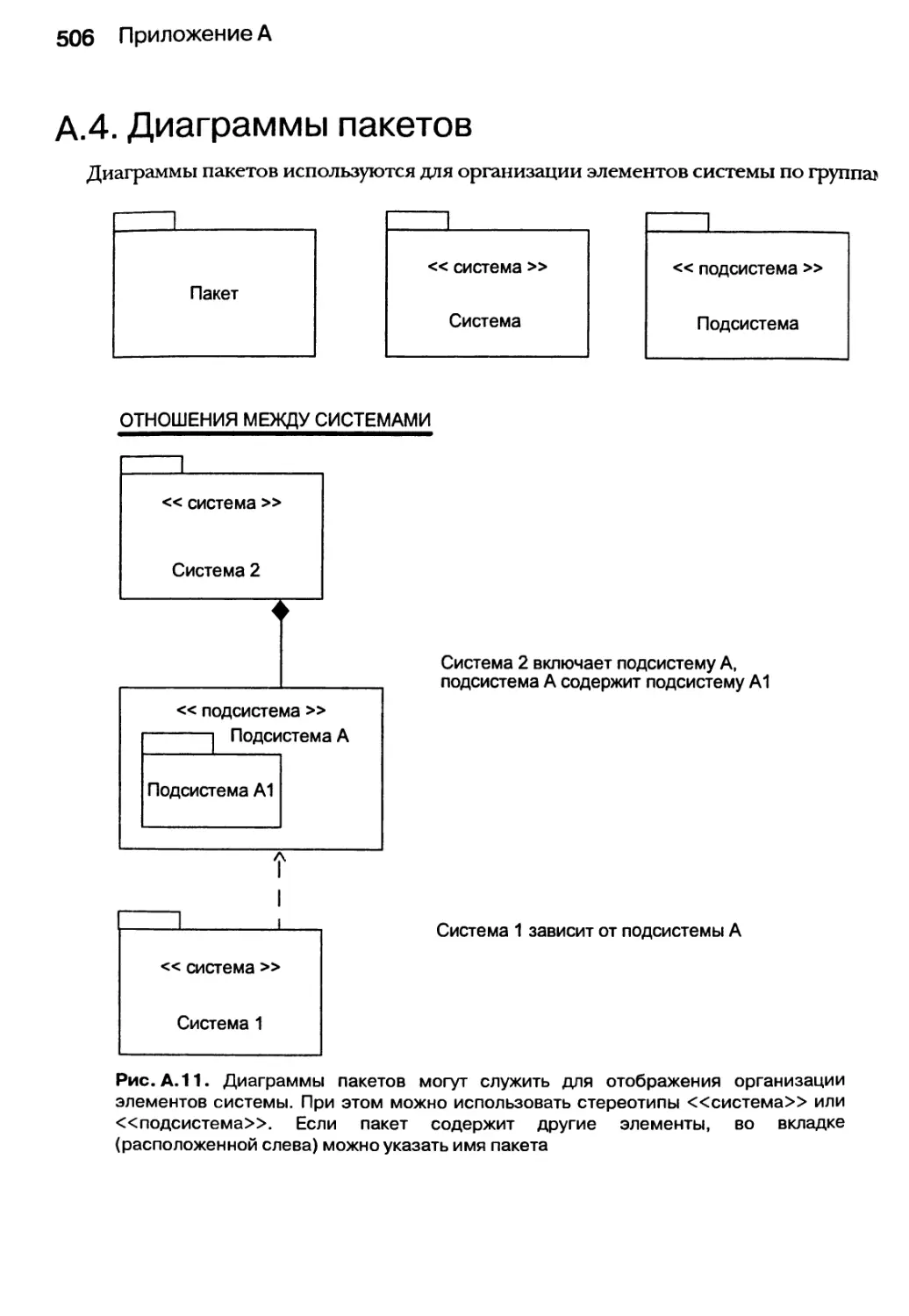
А.4. Диаграммы пакетов 506
Приложение Б 507
Список литературы 657
Предметный указатель 660
Эта книга посвящена всем программистам, “безвредным”хакерам,
инженерам-полуночникам и бесчисленным добровольцам, которые
без устали и сожаления отдают свой талант, мастерство, опыт и время,
чтобы сделать открытые программные продукты реальностью
и совершить революцию в Linux. Без их вклада кластерное, МРР-, SMP-
и распределенное программирование не было бы столь доступным для всех
желающих, каким оно стало в настоящее время.
ВВЕДЕНИЕ
В этой книге представлен архитектурный подход к распределенному и парал-
лельному программированию с использованием языка C++. Особое внимание
уделяется применению стандартной С++-библиотеки, алгоритмов и контей-
нерных классов в распределенных и параллельных средах. Кроме того, мы подроб-
но разъясняем методы расширения возможностей языка C++, направленные на ре-
шение задач программирования этой категории, с помощью библиотек классов
и функций. При этом нас больше всего интересует характер взаимодействия
средств C++ с новыми стандартами POSIX и Single UNIX применительно к органи-
зации многопоточной обработки. Здесь рассматриваются вопросы объединения
С++-программ с программами, написанными на других языках программирования,
для поиска “многоязычных” решений проблем распределенного и параллельного
программирования, а также некоторые методы организации программного обеспе-
чения, предназначенные для поддержки этого вида программирования.
В книге показано, как преодолеть основные трудности параллелизма, и описано,
что понимается под производным распараллеливанием. Мы сознательно уделяем
внимание не методам оптимизации, аппаратным характеристикам или производи-
тельности, а способам структуризации компьютерных программ и программных сис-
тем ради получения преимуществ от параллелизма. Более того, мы не пытаемся при-
менить методы параллельного программирования к сложным научным и математиче-
ским алгоритмам, а хотим познакомить читателя с мультипарадигматическим
подходом к решению некоторых проблем, которые присущи распределенному и па-
раллельному программированию. Чтобы эффективно решать эти задачи, необходимо
сочетать различные программные и инженерные подходы. Например, методы объ-
ектно-ориентированного программирования используются для решения проблем
“гонки” данных и синхронизации их обработки. При многозадачном и многопоточ-
ном управлении мы считаем наиболее перспективной агентно-ориентированную ар-
хитектуру. А для минимизации затрат на обеспечение связей между объектами мы
привлекаем методологию “классной доски” (стратегия решения сложных системных
задач с использованием разнородных источников знаний, взаимодействующих через
общее информационное поле). Помимо объектно-ориентированного, агентно-
Введение 17
ориентированного и AI-ориентированного (AI— сокр. от artificial intelligence— искусст-
венный интеллект) программирования, мы используем параметризованное
(настраиваемое) программирование для реализации обобщенных алгоритмов, кото-
рые применяются именно там, где нужен параллелизм. Опыт разработки программ-
ного обеспечения всевозможных форм и объемов позволил нам убедиться в том, что
для успешного проектирования программных средств и эффективной их реализации
без разносторонности (универсальности) применяемых средств уже не обойтись.
Предложения, идеи и решения, представленные в этой книге, отражают практиче-
ские результаты нашей работы.
Этапы большого пути
При написании параллельных или распределенных программ, как правило, необ-
ходимо “пройти” следующие три основных этапа.
1. Идентификация естественного параллелизма, который существует в контексте
предметной области.
2. Разбиение задачи, стоящей перед программным обеспечением, на несколько
подзадач, которые можно выполнять одновременно, чтобы достичь требуемого
уровня параллелизма.
3. Координация этих задач, позволяющая обеспечить корректную и эффективную
работу программных средств в соответствии с их назначением.
гонка данных
частичный отказ
взаимоблокировка
регистрация завершения работы
проблема многофазной синхронизации
локализация ошибок
Эти три этапа достигаются при условии параллельного решения следующих проблем:
обнаружение взаимоблокировки
бесконечное ожидание
отказ средств коммуникации
отсутствие глобального состояния
несоответствие протоколов
отсутствие средств централизованного
распределения ресурсов
В этой книге разъясняются все названные проблемы, причины их возникновения
и возможные пути решения.
Наконец, в некоторых механизмах, выбранных нами для обеспечения паралле-
лизма, в качестве протокола используется TCP/IP (Transmission Control
Protocol/Internet Protocol— протокол управления передачей/протокол Internet).
В частности, имеются в виду следующие механизмы: библиотека MPI (Message Passing
Interface — интерфейс для передачи сообщений), библиотека PVM (Parallel Virtual
Machine — параллельная виртуальная машина) и библиотека MICO (или CORBA —
Common Object Request Broker Architecture — технология построения распределен-
ных объектных приложений). Эти механизмы позволяют использовать наши подходы
в среде Internet/Intranet, а это значит, что программы, работающие параллельно, мо-
гут выполняться на различных сайтах Internet (или корпоративной сети intranet)
и общаться между собой посредством передачи сообщений. Многие эти идеи служат
18 Введение
в качестве основы для построения инфраструктуры Web-служб. В дополнение к MPI-
и PVM-процедурам, используемые нами CORBA-объекты, размещенные на различных
серверах, могут взаимодействовать друг с другом через Internet. Эти компоненты
можно использовать для обеспечения различных Intemet/Intranet-служб.
Подход
При решении проблем, которые встречаются при написании параллельных
или распределенных программ, мы придерживаемся компонентного подхода.
Наша главная цель — использовать в качестве строительных блоков параллелизма
каркасные классы. Каркасные классы поддерживаются объектно-ориентирован-
ными мьютексами, семафорами, конвейерами и сокетами. С помощью интер-
фейсных классов удается значительно снизить сложность синхронизации задач
и их взаимодействия. Для того чтобы упростить управление потоками и процес-
сами, мы используем агентно-ориентированные потоки и процессы. Наш основ-
ной подход к глобальному состоянию и связанные с ним проблемы включают
применение методологии “классной доски”. Для получения мультипарадигмати-
ческих решений мы сочетаем агентно-ориентированные и объектно-
ориентированные архитектуры. Такой мультипарадигматический подход обеспе-
чивают средства, которыми обладает язык C++ для объектно-ориентированного,
параметризованного и структурного программирования.
Почему именно C++
Существуют С++-компиляторы, которые работают практически на всех извест-
ных платформах и в операционных средах. Национальный Институт Стандарти-
зации США (American National Standards Institute — ANSI) и Международная ор-
ганизация по стандартизации (International Organization for Standardization — ISO)
определили стандарты для языка C++ и его библиотеки. Существуют устойчиво
работающие, так называемые открытые (open source) (т.е. лицензионные про-
граммы вместе с их исходными текстами, не связанные ограничениями на даль-
нейшую модификацию и распространение с сохранением информации о первич-
ном авторстве и внесенных изменениях), а также коммерческие реализации этого
языка. Язык C++ был быстро освоен научными работниками, проектировщиками
и профессиональными разработчиками всего мира. Его использовали для реше-
ния самых разных (по объему и форме) проблем: для написания как отдельных
драйверов устройств, так и крупномасштабных промышленных приложений.
Язык C++ поддерживает мультипарадигматический подход к разработке про-
граммных продуктов и библиотек, которые делают средства параллельного и рас-
пределенного программирования легко доступными.
Введение 19
Библиотеки для параллельного
и распределенного программирования
Для параллельного программирования на основе C++ используются такие библио-
теки, как MPICH (реализация библиотеки MPI), PVM и Pthreads (POSIX1 Threads). Для
распределенного программирования применяется библиотека MICO (С++-реализация
стандарта CORBA). Стандартная библиотека C++ (C++ Standard Library) в сочетании
с CORBA и библиотекой Pthreads обеспечивает поддержку концепций агентно-
ориентированного программирования и программирования на основе методологии
“классной доски”, которые рассматриваются в этой книге.
Новый единый стандарт спецификаций UNIX
Новый единый стандарт спецификаций UNIX (Single UNIX Specifications
Standard) версии 3 — совместный труд Института инженеров по электротехнике
и электронике (Institute of Electrical and Electronics Engineers — IEEE2) и организации
Open Group — был выпущен в декабре 2001 года. Новый единый стандарт специфика-
ций UNIX реализует стандарты POSIX и способствует повышению уровня переноси-
мости программных продуктов. Его основное назначение — дать разработчикам про-
граммного обеспечения единый набор API-функций (Application Programming
Interface — интерфейс прикладного программирования, т.е. набор функций, предос-
тавляемый для использования в прикладных программах), поддерживаемых каждой
UNIX-системой. Этот документ обеспечивает надежный “путеводитель” по стандар-
там для программистов, которые занимаются многозадачными и многопоточными
приложениями. В этой книге, рассматривая темы создания процессов, управления
процессами, использования библиотеки Pthreads, новых процедур posix_spawn (),
POSIX-семафоров и FIFO-очередей (/irst-m, yirst-out — “первым поступил, первым об-
служен”), мы опираемся исключительно на новый единый стандарт спецификаций
UNIX. В приложении Б представлены выдержки из этого стандарта, которые могут
быть использованы в качестве справочника для изложенного нами материала.
Для кого написана эта книга
Эта книга предназначена для проектировщиков и разработчиков программного
обеспечения, прикладных программистов и научных работников, преподавателей
и студентов, которых интересует введение в параллельное и распределенное про-
граммирование с использованием языка C++. Для освоения материала этой книги чи-
тателю необходимо иметь базовые знания языка C++ и стандартной С++-библиотеки
классов, поскольку учебный курс по программированию на C++ и по объектно-1
ориентированному программированию здесь не предусмотрен. Предполагается, что
читатель должен иметь общее представление о таких принципах объектно-|
1 POSIX— Portable Operating System Interface for computer environments— интерфейс переносимой one\
рационной системы (набор стандартов IEEE, описывающих интерфейсы ОС для UNIX).
2 IEEE— профессиональное объединение, выпускающие свои собственные стандарты; членами /£££|
являются ANSI и ISO.
20 Введение
ориентированного программирования, как инкапсуляция, наследование и полимор-
физм. В настоящей книге излагаются основы параллельного и распределенного про-
граммирования в контексте C++.
Среды разработки
Примеры и программы, представленные в этой книге, разработаны и протестиро-
ваны в Linux- и UNIX-средах, а именно — под управлением Solaris 8, Aix и Linux (SuSE,
Red Hat). MPI- и PVM-код разработан и протестирован на 32-узловом Linux-ориенти-
рованном кластере. Многие программы протестированы на серверах семейства Sun
Enterprise 450. Мы использовали Sun C++ Workshop (С++-компилятор компании Port-
land Group) и проект по свободному распространению программного обеспечения
GNU C++. Большинство примеров должны выполняться как в UNIX-, так и Linux-
средах. Если конкретный пример не предназначен для выполнения в обеих назван-
ных средах, этот факт отмечается в разделе “Профиль программы”, которым снабжа-
ются все законченные примеры программ этой книги.
Дополнительный материал
Диаграммы UML
Для построения многих диаграмм в этой книге применяется стандарт UML
(Unified Modeling Language — унифицированный язык моделирования). В частности,
для описания важных архитектур параллелизма и межклассовых взаимоотношений
используются диаграммы действий, развертывания (внедрения), классов и состояний.
И хотя знание языка UML не является необходимым условием, все же некоторый
уровень осведомленности в этом вопросе окажется весьма полезным. Описание
и разъяснение символов и самого языка UML приведено в приложении А.
Профили программы
Каждая законченная программа в этой книге сопровождается разделом “Профиль
программы”, который содержит описание таких особенностей реализации, как тре-
буемые заголовки, библиотеки, инструкции по компиляции и компоновке. Профиль
программы также включает подраздел “Примечания”, содержащий специальную ин-
формацию, которую необходимо принять во внимание при выполнении данной про-
граммы. Если код не сопровождается профилем программы, значит, он предназначен
только для демонстрации.
Параграфы
Мы посчитали лишним включать сугубо теоретические замечания в такую книгу-
введение, как эта. Но в некоторых случаях без теоретических или математических
выкладок было не обойтись, и тогда мы сопровождали такие выкладки подробными
разъяснениями, оформленными в виде параграфов (например, § 6.1).
Введение 21
Тестирование кода и его надежность
Несмотря на то что все примеры и приложения, приведенные в этой книге, были
протестированы для подтверждения их корректности, мы не даем никаких гарантий,
что эти программы полностью лишены изъянов или ошибок, совместимы с любым кон-
кретным стандартом, годятся для продажи или отвечают вашим конкретным требова-
ниям. На эти программы не следует полагаться при решении проблем, если существует
вероятность, что некорректный способ получения результатов может привести к мате-
риальном}7 ущербу. Авторы и издатели этой книги не признают какую бы то ни было от-
ветственность за прямой или косвенный ущерб, который может явиться результатом
использования примеров, программ или приложений, представленных в этой книге.
Ждем ваших отзывов!
Вы, читатель этой книги, и есть главный ее критик и комментатор. Мы ценим ваше
мнение и хотим знать, что было сделано нами правильно, что можно было сделать
лучше и что еще вы хотели бы увидеть изданным нами. Нам интересно услышать
и любые другие замечания, которые вам хотелось бы высказать в наш адрес.
Мы ждем ваших комментариев и надеемся на них. Вы можете прислать нам бумаж-
ное или электронное письмо, либо просто посетить наш Web-сервер и оставить свои
замечания там. Одним словом, любым удобным для вас способом дайте нам знать, нравит
ся или нет вам эта книга, а также выскажите свое мнение о том, как сделать наши книги
более интересными для вас.
Посылая письмо или сообщение, не забудьте указать название книги и ее авторов,
а также ваш обратный адрес. Мы внимательно ознакомимся с вашим мнением и обязательно
учтем его при отборе и подготовке к изданию последующих книг. Наши координаты:
E-mail: info@dialektika.com
WWW: http://www.dialektika.com
Информация для писем из:
России: 115419, Москва, а/я 783
Украины: 03150, Киев, а/я 152
Благодарности
Мы никогда бы не смогли “вытянуть” этот проект без помощи, поддержки, конст-
руктивной критики и материальных ресурсов многих наших друзей и коллег. В част-
ности, мы хотели бы поблагодарить Терри Льюиса (Terry Lewis) и Дага Джонсона
(Doug Johnson) из компании OSC (Ohio Super-Computing) за предоставление доступа
к 32-узловому Linux-ориентированному кластеру; Марка Уэлтона (Mark Welton) из
компании YSU за экспертный анализ и помощь при конфигурировании кластера для
поддержки наших PVM- и MPI-программ; Сэлу Сандерс (Sal Sanders) из компании YSU,
позволившую нам работать на Power-PC с установленными Mac OSX и Adobe
Illustrator; Брайана Нельсона (Brian Nelson) из YSU за разрешение протестировать
многие наши многопоточные и распределенные программы на многопроцессорных
вычислительных машинах Sun Е-250 и Е-450. Мы также признательны Мэри Энн
Джонсон (Mary Ann Johnson) и Джеффри Тримблу (Jeffrey Trimble) из YSU MAAG за
помощь в получении справочной информации; Клавдию М. Стэнзиоло (Claudio М.
Stanziola), Полетт Голдвебер (Paulette Goldweber) и Жаклин Хэнсон (Jacqueline
Hansson) из объединения IEEE Standards and Licensing and Contracts Office за получе-
ние разрешения на переиздание фрагментов нового стандарта Single-UNIX/POSIX;
Эндрю Джози (Andrew Josey) и Джину Пирсу (Gene Pierce) из организации Open
Group за аналогичное содействие. Большое спасибо Тревору Уоткинсу (Trevor
Watkins) из организации Z-Group за помощь в тестировании примеров программ; ис-
пользование его распределенной Linux-среды было особенно важным фактором
в процессе тестирования. Особую благодарность заслужили Стив Тарасвеки (Steve
Tarasweki) за согласие написать рецензию на эту книгу (несмотря на то, что она была
еще в черновом варианте); доктор Юджин Сантос (Eugene Santos) за то, что он указал
нужное направление при составлении категорий структур данных, которые можно
использовать в PYM (Parallel Virtual Machine — параллельная виртуальная машина);
доктор Майк Кресиманно (Mike Crescimanno) из организации Advanced Computing
Work Group (ACWG) при компании YSU за разрешение представить некоторые мате-
риалы из этой книги на одном из совещаний ACWG. Наконец, мы хотим выразить
признательность Полю Петрелия (Paul Petralia) и всему составу производственной
группы (особенно Гейлу Кокеру-Богусу (Gail Cocker-Bogusz)) из компании Prentice Hall
за их терпение, поддержку, энтузиазм и высокий профессионализм.
ПРЕИМУЩЕСТВА
ПАРАЛЛЕЛЬНОГО
ПРОГРАММИРОВАНИЯ
В этой главе...
1.1. Что такое параллелизм
1.2. Преимущества параллельного программирования
1.3. Преимущества распределенного программирования
1.4. Минимальные требования
1.5. Базовые уровни программного параллелизма
1.6. Отсутствие языковой поддержки параллелизма в C++
1.7. Среды для параллельного и распределенного
программирования
1.8. Резюме
“Я допускаю, что параллелизм лучше всего поддерживать с помощью
библиотеки, причем такую библиотеку можно реализовать без существенных
расширений самого языка программирования.”
— Бьерн Страуструп, создатель языка C++
Для того чтобы в настоящее время разрабатывать программное обеспечение, не-
обходимы практические знания параллельного и распределенного программиро-
вания. Теперь перед разработчиками приложений все чаще ставится задача, что-
бы отдельные программные составляющие надлежащим образом выполнялись в Internet
или Intranet. Если программа (или ее часть) развернута в одной или нескольких таких сре-
дах, то к ней предъявляются самые жесткие требования по части производительности.
Пользователь всегда надеется, что результаты работы программ будут мгновенными
и надежными. Во многих ситуациях заказчик хотел бы, чтобы программное обеспече-
ние удовлетворяло сразу многим требованиям. Зачастую пользователь не видит ничего
необычного в своих намерениях одновременно загружать программные продукты
и данные из Internet. Программное обеспечение, предназначенное для приема телетекста,
также должно быть способно на гладкое воспроизведение графических изображений и
звука после цифровой обработки (причем без прерывания). Программное обеспечение
Web-сервера нередко выдерживает сотни тысяч посещений в день, а часто посещаемые
почтовые серверы— порядка миллиона отправляемых и получаемых сообщений. При
этом важно не только количество обрабатываемых сообщений, но и их содержимое.
Например, передача данных, содержащих оцифрованные музыку, видео или графиче-
ские изображения, может “поглотить” всю пропускную способность сети и причинить
серьезные неприятности программному обеспечению сервера, которое не было спро-
ектировано должным образом. Обычно мы имеем дело с сетевой вычислительной
1.1. Что такое параллелизм 25
средой, состоящей из компьютеров с несколькими процессорами. Чем больше функций
возлагается на программное обеспечение, тем больше к нему предъявляется требова-
ний. Чтобы удовлетворить минимальные требования пользователя, современные про-
граммы должны быть еще более производительными и интеллектуальными. Программ-
ное обеспечение следует проектировать так, чтобы можно было воспользоваться
преимуществами компьютеров, оснащенных несколькими процессорами. А поскольку
сетевые компьютеры — это скорее правило, чем исключение, то целью проектирова-
ния программного обеспечения должно быть его корректное и эффективное выпол-
нение при условии, что некоторые его составляющие будут одновременно выпол-
няться на различных компьютерах. В некоторых случаях используемые компьютеры
могут иметь совершенно различные операционные системы с разными сетевыми
протоколами! Чтобы справиться с описанными реалиями, ассортимент разработок
программных продуктов должен включать методы реализации параллелизма посред-
ством параллельного и распределенного программирования.
1.1. Что такое параллелизм
Два события называют одновременными, если они происходят в течение одного и того
же временного интервала. Если несколько задач выполняются в течение одного и того
же временного интервала, то говорят, что они выполняются параллельно. Для нас термин
параллельно необязательно означает “точно в один момент”. Например, две задачи могут
выполняться параллельно в течение одной и той же секунды, но при этом каждая из них
выполняется в различные доли этой секунды. Так, первая задача может отработать
в первую десятую часть секунды и приостановиться, затем вторая может отработать
в следующую десятую часть секунды и приостановиться, после чего первая задача может
возобновить выполнение в течение третьей доли секунды, и т.д. Таким образом, эти за-
дачи могут выполняться по очереди, но поскольку продолжительность секунды с точки
зрения человека весьма коротка, то кажется, что они выполняются одновременно. По-
нятие одновременности (параллельности) можно распространить и на более длинные ин-
тервалы времени. Так, две программы, выполняющие некоторую задачу в течение одно-
го и того же часа, постепенно приближаясь к своей конечной цели в течение этого часа,
могут (или могут не) работать точно в одни и те же моменты времени. Мы говорим, что
данные две программы для этого часа выполняются параллельно, или одновременно.
Другими словами, задачи, которые существуют в одно и то же время и выполняются
в течение одного и того же интервала времени, являются параллельными. Параллельные
задачи могут выполняться в одно- или многопроцессорной среде. В однопроцессорной
среде параллельные задачи существуют в одно и то же время и выполняются в течение
одного и того же интервала времени за счет контекстного переключения. В многопро-
цессорной среде, если свободно достаточное количество процессоров, параллельные
задачи могут выполняться в одни и те же моменты времени в течение одного и того же
периода времени. Основной фактор, влияющий на степень приемлемости для паралле-
лизма того или иного интервала времени, определяется конкретным приложением.
Цель технологий параллелизма — обеспечить условия, позволяющие компьютер-
ным программам делать больший объем работы за тот же интервал времени. Поэтому
проектирование программ должно ориентироваться не на выполнение одной задачи
в некоторый промежуток времени, а на одновременное выполнение нескольких за-
дач, на которые предварительно должна быть разбита программа. Возможны ситуа-
ции, когда целью является не выполнение большего объема работы в течение того же
26 Глава 1. Преимущества параллельного программирования
интервала времени, а упрощение решения с точки зрения программирования. Иногда
имеет смысл думать о решении проблемы как о множестве параллельно выполняемых
задач. Например (если взять для сравнения вполне житейскую ситуацию), проблему
снижения веса лучше всего представить в виде двух параллельно выполняемых задач:
диета и физическая нагрузка. Иначе говоря, для решения этой проблемы предполагает^
ся применение строгой диеты и физических упражнений в один и тот же интервал вре-
мени (необязательно точно в одни и те же моменты времени). Обычно не слишком полезно
(или эффективно) выполнять одну подзадачу в один период времени, а другую — совер-
шенно в другой. Именно параллельность обоих процессов дает естественную форму ис-
комого решения проблемы. Иногда к параллельности прибегают, чтобы увеличить бы-
стродействие программы или приблизить момент ее завершения. В других случаях па-
раллельность используется для увеличения продуктивности программы (объема
выполняемой ею работы) за тот же период времени при вторичности скорости ее рабо-
ты. Например, для некоторых Web-сайтов важно как можно дольше удерживать пользо-
вателей. Поэтому здесь имеет значение не то, насколько быстро будет происходить под-
ключение (регистрация) и отключение пользователей, а сколько пользователей сможет
этот сайт обслуживать одновременно. Следовательно, цель проектирования программ-
ного обеспечения такого сайта — обрабатывать максимальное количество подключений
за как можно больший промежуток времени. Наконец, параллельность упрощает само
программное обеспечение. Зачастую сложную последовательность операций можно уп-
ростить, организовав ее в виде ряда небольших параллельно выполняемых операций.
Независимо от частной цели (ускорение работы программ, обработка увеличенной на-
грузки или упрощение реализации программы), наша главная цель — усовершенство-
вать программное обеспечение, воспользовавшись принципом параллельности.
1.1.1. Два основных подхода к достижению
параллельности
Параллельное и распределенное программирование— это два базовых подхода
к достижению параллельного выполнения составляющих программного обеспечения
(ПО). Они представляют собой две различные парадигмы программирования, которые
иногда пересекаются. Методы параллельного программирования позволяют распределить
работу программы между двумя (или больше) процессорами в рамках одного физиче-
ского или одного виртуального компьютера. Методы распределенного программирования
позволяют распределить работу программы между двумя (или больше) процессами,
причем процессы могут существовать на одном и том же компьютере или на разных.
Другими словами, части распределенной программы зачастую выполняются на разных
компьютерах, связываемых по сети, или по крайней мере в различных процессах. Про-
грамма, содержащая параллелизм, выполняется на одном и том же физическом или
виртуальном компьютере. Такую программу можно разбить на процессы (process) или
потоки (thread). Процессы мы рассмотрим в главе 3, а потоки — в главе 4. В изложении
материала этой книги мы будем придерживаться того, что распределенные программы
разбиваются только на процессы. Многопоточность ограничивается параллелизмом.
Формально параллельные программы иногда бывают распределенными, например, при
PVM-программировании (Parallel Virtual Machine — параллельная виртуальная машина).
Распределенное программирование иногда используется для реализации параллелизма,
как в случае с MPI-программированием (Message Passing Interface — интерфейс для
1.1. Что такое параллелизм 27
передачи сообщений). Однако не все распределенные программы включают паралле-
лизм. Части распределенной программы могут выполняться по различным запросам
и в различные периоды времени. Например, программу календаря можно разделить
на две составляющие. Одна часть должна обеспечивать пользователя информацией,
присущей календарю, и способом записи данных о важных для него встречах, а другая
часть должна предоставлять пользователю набор сигналов для разных типов встреч.
Пользователь составляет расписание встреч, используя одну часть ПО, в то время как
другая его часть выполняется независимо от первой. Набор сигналов и компонентов
расписания вместе образуют единое приложение, которое разделено на две части,
выполняемые по отдельности. При чистом параллелизме одновременно выполняе-
мые части являются компонентами одной и той же программы. Части распределен-
ных приложений обычно реализуются как отдельные программы. Типичная архитек-
тура построения параллельной и распределенной программ показана на рис. 1.2.
Рис.Д/1. Типичная архитектура построения параллельной и распределенной программ
28 Глава 1. Преимущества параллельного программирования
Параллельное приложение, показанное на рис. 1.2, состоит из одной программы,
разделенной на четыре задачи. Каждая задача выполняется на отдельном процессоре,
следовательно, все они могут выполняться одновременно. Эти задачи можно реализо-
вать в 1.2, состоит из трех отдельных программ, каждая из которых выполняется на от-
дельном компьютере. При этом программа 3 состоит из двух отдельных частей (задачи А и
задачи D), выполняющихся на одном компьютере. Несмотря на это, задачи А и D являются
распределенными, поскольку они реализованы как два отдельных процесса. Задачи парал-
лельной программы более тесно связаны, чем задачи распределенного приложения.
В общем случае процессоры, связанные с распределенными программами, находятся
на различных компьютерах, в то время как процессоры, связанные с программами,
реализующими параллелизм, находятся на одном и том же компьютере. Конечно же,
существуют гибридные приложения, которые являются и параллельными, и распреде-
ленными одновременно. Именно такие гибридные объединения становятся нормой.
1.2. Преимущества параллельного
программирования
Программы, надлежащее качество проектирования которых позволяет воспользо-
ваться преимуществами параллелизма, могут выполняться быстрее, чем их последо-
вательные эквиваленты, что повышает их рыночную стоимость. Иногда скорость мо-
жет спасти жизнь. В таких случаях быстрее означает лучше. Иногда решение некоторых
проблем представляется естественнее в виде коллекции одновременно выполняемых
задач. Это характерно для таких областей, как научное программирование, математи-
ческое и программирование искусственного интеллекта. Это означает, что в некото-
рых ситуациях технологии параллельного программирования снижают трудозатраты
разработчика ПО, позволяя ему напрямую реализовать структуры данных, алгоритмы
и эвристические методы, разрабатываемые учеными. При этом используется специа-
лизированное оборудование. Например, в мультимедийной программе с широкими
функциональными возможностями с целью получения более высокой производи-
тельности ее логика может быть распределена между такими специализированны-
ми процессорами, как микросхемы компьютерной графики, цифровые звуковые
процессоры и математические спецпроцессоры. К таким процессорам обычно
обеспечивается одновременный доступ. МРР-компьютеры (Massively Parallel
Processors — процессоры с массовым параллелизмом) имеют сотни, а иногда и тысячи
процессоров, что позволяет их использовать для решения проблем, которые про-
сто не реально решить последовательными методами. Однако при использовании
МРР-компьютеров (т.е. при объединении скорости и “грубой силы”) невозможное
становится возможным. К категории применимости МРР-компьютеров можно от-
нести моделирование экологической системы (или моделирование влияния раз-
личных факторов на окружающую среду), исследование космического пространства
и ряд тем из области биологических исследований, например проект моделирова-
ния генома человека. Применение более совершенных технологий параллельного
программирования открывает двери к архитектурам ПО, которые специально раз-
рабатываются для параллельных сред. Например, существуют специальные муль-
тиагентные архитектуры и архитектуры, использующие методологию “классной
доски”, разработанные специально для среды с параллельными процессорами.
1.2. Преимущества параллельного программирования 29
1.2.1. Простейшая модель параллельного
программирования (PRAM)
В качестве простейшей модели, отражающей базовые концепции параллельного
программирования, рассмотрим модель PRAM (Parallel Random Access Machine — па-
раллельная машина с произвольным доступом). PRAM — это упрощенная теоретиче-
ская модель с п процессорами, которые используют общую глобальную память. Про-
стая модель PRAM изображена на рис. 1.2.
Все процессоры имеют доступ для чтения и запи-
си к общей глобальной памяти. В PRAM-среде возмо-
жен одновременный доступ. Предположим, что все
процессоры могут параллельно выполнять различ-
ные арифметические и логические операции. Кроме
того, каждый из теоретических процессоров
(см. рис. 1.2) может обращаться к общей памяти в од-
ну непрерываемую единицу времени. PRAM-модель об-
ладает как параллельными, так и исключающими ал-
горитмами считывания данных. Параллельные алго-
Рис. 1.2. Простая модель PRAM
ритмы считывания данных позволяют одновременно
обращаться к одной и той же области памяти без ис-
кажения (порчи) данных. Исключающие алгоритмы считывания данных использу-
ются в случае, когда необходима гарантия того, что никакие два процесса никогда
не будут считывать данные из одной и той же области памяти одновременно. PRAM-
модель также обладает параллельными и исключающими алгоритмами записи дан-
ных. Параллельные алгоритмы позволяют нескольким процессам одновременно
записывать данные в одну и ту же область памяти, в то время как исключающие ал-
горитмы гарантируют, что никакие два процесса не будут записывать данные в одну
и ту же область памяти одновременно. Четыре основных алгоритма считывания
и записи данных перечислены в табл. 1.1.
Таблица 1.1. Четыре базовых алгоритма считывания и записи данных
Типы алгоритмов
Описание
EREW CREW ERCW CRCW Исключающее считывание/исключающая запись Параллельное считывание/исключающая запись Исключающее считывание/параллельная запись Параллельное считывание/параллельная запись
В этой книге мы будем часто обращаться к этим типам алгоритмов для реализации
параллельных архитектур. Архитектура, построенная на основе технологии “классной
Доски , — это одна из важных архитектур, которую мы реализуем с помощью PRAM-
Модели (см. главу 13). Необходимо отметить, что хотя PRAM — это упрощенная теоре-
тическая модель, она успешно используется для разработки практических программ,
и эти программы могут соперничать по производительности с программами, которые
были разработаны с использованием более сложных моделей параллелизма.
30 Глава 1. Преимущества параллельного программирования
1.2.2. Простейшая классификация схем параллелизма
PRAM — это способ построения простой модели, которая позволяет предста-
вить, как компьютеры можно условно разбить на процессоры и память и как эти
процессоры получают доступ к памяти. Упрощенная классификации схем функцио-
нирования параллельных компьютеров была предложена М. Флинном (М. J. Flynn)1.
Согласно этой классификации различались две схемы: SIMD (Single-Instruction,
Multiple-Data — архитектура с одним потоком команд и многими потоками данных)
и MIMD (Multiple-Instruction, Multiple-Data — архитектура со множеством потоков
команд и множеством потоков данных). Несколько позже эти схемы были расши-
рены до SPMD (Single-Program, Multiple-Data — одна программа, несколько потоков
данных) и MPMD (Multiple-Programs, Multiple-Data — множество программ, множест-
во потоков данных) соответственно. Схема SPMD (SIMD) позволяет нескольким
процессорам выполнять одну и ту же инструкцию или программу при условии, что
каждый процессор получает доступ к различным данным. Схема MPMD (MIMD) по-
зволяет работать нескольким процессорам, причем все они выполняют различные
программы или инструкции и пользуются собственными данными. Таким образом,
в одной схеме все процессоры выполняют одну и ту же программу или инструкцию,
а в другой все процессоры выполняют различные программы или инструкции. Ко-
нечно же, возможны гибриды этих моделей, в которых процессоры могут быть раз-
делены на группы, из которых одни образуют SPMD-модель, а другие — MPMD-
модель. При использовании схемы SPMD все процессоры просто выполняют одни
и те же операции, но с различными данными. Например, мы можем разбить одну
задачу на группы и назначить для каждой группы отдельный процессор. В этом слу-
чае каждый процессор при решении задачи будет применять одинаковые правила,
обрабатывая при этом различные части этой задачи. Когда все процессоры спра-
вятся со своими участками работы, мы получим решение всей задачи. Если же при-
меняется схема MPMD, все процессоры выполняют различные виды работы, и, хо-
тя при этом все они вместе пытаются решить одну проблему, каждому из них выде-
ляется свой аспект этой проблемы. Например, разделим задачу по обеспечению
безопасности Web-сервера по схеме MPMD. В этом случае каждому процессору ста-
вится своя подзадача. Предположим, один процессор будет отслеживать работу
портов, другой — курировать процесс регистрации пользователей, а третий — ана-
лизировать содержимое пакетов и т.д. Таким образом, каждый процессор работает
с нужными ему данными. И хотя различные процессоры выполняют разные виды
работы, используя различные данные, все они вместе работают в одном направле-
нии — обеспечивают безопасность Web-сервера. Принципы параллельного про-
граммирования, рассматриваемые в этой книге, нетрудно описать, используя моде-
ли PRAM, SPMD (SIMD) и MPMD (MIMD). И в самом деле, эти схемы и модели ус-
пешно используются для реализации практических мелко- и среднемасштабных
приложений и вполне могут вас устраивать до тех пор, пока вы не подготовитесь
к параллельному программированию более высокой степени организации.
1 M.J. Flynn. Very high-speed computers. Из сборников объединения, IEEE, 54, 1901-1909 (декабрь 1966).
1.3. Преимущества распределенного программирования 31
1.3. Преимущества распределенного
программирования
Методы распределенного программирования позволяют воспользоваться пре-
имуществами ресурсов, размещенных в Internet, в корпоративных Intranet и локаль-
ных сетях. Распределенное программирование обычно включает сетевое программи-
рование в той или иной форме. Это означает, что программе, которая выполняется
на одном компьютере в одной сети, требуется некоторый аппаратный или программ-
ный ресурс, который принадлежит другому компьютеру в той же или удаленной сети.
Распределенное программирование подразумевает общение одной программы с дру-
гой через сетевое соединение, которое включает соответствующее оборудование
(от модемов до спутников). Отличительной чертой распределенных программ явля-
ется то, что они разбиваются на части. Эти части обычно реализуются как отдельные
программы, которые, как правило, выполняются на разных компьютерах и взаимо-
действуют друг с другом через сеть. Методы распределенного программирования
предоставляют доступ к ресурсам, которые географически могут находиться на боль-
шом расстоянии друг от друга. Например, распределенная программа, разделенная на
компонент Web-сервера и компонент Web-клиента, может выполняться на двух раз-
личных компьютерах. Компонент Web-сервера может располагаться, допустим, в Аф-
рике, а компонент Web-клиента — в Японии. Часть Web-клиента может использовать
программные и аппаратные ресурсы компонента Web-сервера, несмотря на то, что их
разделяет огромное расстояние, и почти наверняка они относятся к различным се-
тям, функционирующим под управлением различных операционных сред. Методы
распределенного программирования предусматривают совместный доступ к дорого-
стоящим программным и аппаратным ресурсам. Например, высококачественный го-
лографический принтер может обладать специальным программным обеспечением
сервера печати, которое предоставляет соответствующие услуги для ПО клиента. ПО
клиента печати размещается на одном компьютере, а ПО сервера печати — на другом.
Как правило, для обслуживания множества клиентов печати достаточно только одно-
го сервера печати. Распределенные вычисления можно использовать для создания
определенного уровня избыточности вычислительных средств на случай аварии. Если
разделить программу на несколько частей, каждая из которых будет выполняться на
отдельном компьютере, то некоторым из этих частей мы можем поручить одну и ту же
работу. Если по какой-то причине один компьютер откажет, его программу заменит
аналогичная программа, выполняющаяся на другом компьютере. Ни для кого не сек-
рет, что базы данных способны хранить миллионы, триллионы и даже квадриллионы
единиц информации. И, конечно же, нереально каждому пользователю иметь копию
подобной базы данных. А ведь пользователи и компьютер, содержащий базу данных,
зачастую находятся не просто в разных зданиях, а в разных городах или даже странах.
Но именно методы распределенного программирования дают возможность пользова-
телям (независимо от их местонахождения) обращаться к таким базам данных.
32 Глава 1. Преимущества параллельного программирования
1.3.1. Простейшие модели распределенного
программирования
Возможно, самой простой и распространенной моделью распределенной обра-
ботки данных является модель типа “клиент/сервер”. В этой модели программа раз-
бивается на две части: одна часть называется сервером, а другая — клиентом. Сервер
имеет прямой доступ к некоторым аппаратным и программным ресурсам, которые
желает использовать клиент. В большинстве случаев сервер и клиент располагаются
на разных компьютерах. Обычно между клиентом и сервером существует отношение
типа “множество-к-одному”, т.е., как правило, один сервер отвечает на запросы мно-
гих клиентов. Сервер часто обеспечивает опосредованный доступ к огромной базе
данных, дорогостоящему оборудованию или некоторой коллекции приложений. Кли-
ент может запросить интересующие его данные, сделать запрос на выполнение вы-
числительной процедуры или обработку другого типа. В качестве примера приложе-
ния типа “клиент/сервер” приведем механизм поиска (search engine). Механизмы
(или машины) поиска используются для поиска заданной информации в Internet или
корпоративной Intranet. Клиент служит для получения ключевого слова или фразы,
которая интересует пользователя. Часть ПО клиента затем передает сформирован-
ный запрос той части ПО сервера, которая обладает средствами поиска информации
по заданному пользователем ключевому слову или фразе. Сервер либо имеет прямой
доступ к информации, либо связан с другими серверами, которые имеют его. В иде-
альном случае сервер находит запрошенное пользователем ключевое слово или фразу
и возвращает найденную информацию клиенту. Несмотря на то что клиент и сервер
представляют собой отдельные программы, выполняющиеся на разных компьютерах,
вместе они составляют единое приложение. Разделение ПО на части клиента и сер-
вера и есть основной метод распределенного программирования. Модель типа
“клиент/сервер” также имеет другие формы, которые зависят от конкретной среды.
Например, термин “изготовитель-потребитель” (producer-consumer) можно считать
близким родственником термина “клиент/сервер”. Обычно клиент-серверными при-
ложениями называют большие программы, а термин “изготовитель-потребитель” от-
носят к программам меньшего объема. Если программы имеют уровень операционной
системы или ниже, к ним применяют термин “изготовитель-потребитель”, если вы-
ше — то термин “клиент/сервер” (конечно же, исключения есть из всякого правила).
1.3.2. Мультиагентные распределенные системы
Несмотря на то что модель типа “клиент/сервер” — самая распространенная мо-
дель распределенного программирования, все же она не единственная. Используются
также агенты — рациональные компоненты ПО, которые характеризуются самонаве-
дением и автономностью и могут постоянно находиться в состоянии выполнения.
Агенты могут как создавать запросы к другим программным компонентам, так и отве-
чать на запросы, полученные от других программных компонентов. Агенты сотруд-
ничают в пределах групп для коллективного выполнения определенных задач. В та-
кой модели не существует конкретного клиента или сервера. Это — модель сети с рав-
ноправными узлами (peer-to-peer), в которой все компоненты имеют одинаковые
права, и при этом у каждого компонента есть что предложить другому. Например,
агент, который назначает цены на восстановление старинных спортивных машин, мо-
жет работать вместе с другими агентами. Один агент может быть специалистом по мо-
1.4. Минимальные требования 33
торам, другой — по кузовам, а третий предпочитает работать как дизайнер по интерье-
рам. Эти агенты могут совместно оценить стоимость работ по восстановлению автомо-
биля. Агенты являются распределенными, поскольку все они размещаются на разных
серверах в Internet. Для связи агенты используют согласованный Internet-протокол. Для
одних типов распределенного программирования лучше подходит модель типа
“клиент/сервер”, а для других — модель равноправных агентов. В этой книге рассматри-
ваются обе модели. Большинство требований, предъявляемых к распределенному про-
граммированию, удовлетворяется моделями “клиент/сервер” и равноправных агентов.
1.4. Минимальные требования
Параллельное и распределенное программирование требует определенных за-
трат. Несмотря на описанные выше преимущества, написание параллельных и рас-
пределенных программ не обходится без проблем и необходимости наличия предпо-
сылок. О проблемах мы поговорим в главе 2, а предпосылки рассмотрим в следующих
разделах. Написанию программы или разработке отдельной части ПО должен пред-
шествовать процесс проектирования. Что касается параллельных и распределенных
программ, то процесс проектирования должен включать три составляющих: декомпо-
зиция, связь и синхронизация (ДСС).
1.4.1. Декомпозиция
Декомпозиция — это процесс разбиения задачи и ее решения на части. Иногда
части группируются в логические области (т.е. поиск, сортировка, вычисление, ввод
и вывод данных и т.д.). В других случаях части группируются по логическим ресурсам
(т.е. файл, связь, принтер, база данных и т.д.). Декомпозиция программного решения
часто сводится к декомпозиции работ (work breakdown structure — WBS). Декомпози-
ция работ определяет, что должны делать разные части ПО. Одна из основных про-
блем параллельного программирования — идентификация естественной декомпози-
ции работ для программного решения. Не существует простого и однозначного под-
хода к идентификации WBS. Разработка ПО — это процесс перевода принципов, идей,
шаблонов, правил, алгоритмов или формул в набор инструкций, которые выполняют-
ся, и данных, которые обрабатываются компьютером. Это, в основном, и составляет
процесс моделирования. Программные модели — это воспроизведение в виде ПО не-
которой реальной задачи, процесса или идеала. Цель модели— сымитировать или
скопировать поведение и характеристики некоторой реальной сущности в конкрет-
ной предметной области. Процесс моделирования вскрывает естественную декомпо-
зицию работ программного решения. Чем лучше модель понята и разработана, тем
более естественной будет декомпозиция работ. Наша цель — обнаружить параллелизм
и распределение с помощью моделирования. Если естественный параллелизм не на-
блюдается, не стоит его навязывать насильно. На вопрос, как разбить приложение на
параллельно выполняемые части, необходимо найти ответ в период проектирования,
и правильность этого ответа должна стать очевидной в модели решения. Если модель
задачи и решения не предполагает параллелизма и распределения, следует попытать-
ся найти последовательное решение. Если последовательное решение оказывается
неудачным, эта неудача может дать ключ к нужному параллельному’ решению.
34 Глава 1. Преимущества параллельного программирования
1.4.2. Связь
После декомпозиции программного решения на ряд параллельно выполняемых частей
обычно возникает вопрос о связи этих частей между собой. Как же реализовать связь, если
эти части разнесены по различным процессам или различным компьютерам? Должны ли
различные части ПО совместно использовать общую область памяти? Каким образом
одна часть ПО узнает о том, что другая справилась со своей задачей? Какая часть должна
первой приступить к работе? Откуда один компонент узнает об отказе другого компо-
нента? На эти и многие другие вопросы необходимо найти ответы при проектировании
параллельных и распределенных систем. Если отдельным частям ПО не нужно связы-
ваться между собой, значит, они в действительности не образуют единое приложение.
1.4.3. Синхронизация
Декомпозиция работ, как уже было отмечено выше, определяет, что должны делать
разные части ПО. Когда множество компонентов ПО работают в рамках одной зада-
чи, их функционирование необходимо координировать. Определенный компонент
должен “уметь” определить, когда достигается решение всей задачи. Необходимо также
скоординировать порядок выполнения компонентов. При этом возникает множество
вопросов. Все ли части ПО должны одновременно приступать к работе или только
некоторые, а остальные могут находиться пока в состоянии ожидания? Каким двум
(или больше) компонентам необходим доступ к одному и тому же ресурсу? Кто имеет
право получить его первым? Если некоторые части ПО завершат свою работу гораздо
раньше других, то нужно ли им “поручать” новую работу? Кто должен давать новую
работу в таких случаях? ДСС (декомпозиция, связь и синхронизация) — это тот мини-
мум вопросов, которые необходимо решить, приступая к параллельному или распре-
деленному программированию. Помимо сути проблем, составляющих ДСС, важно
также рассмотреть их привязку. Существует несколько уровней параллелизма в разра-
ботке приложений, и в каждом из них ДСС-составляющие применяются по-разному.
1.5. Базовые уровни программного параллелизма
В этой книге мы исследуем возможности параллелизма в пределах приложения
(в противоположность параллелизму на уровне операционной системы или аппарат-
ных средств). Несмотря на то что параллелизм на уровне операционной системы или
аппаратных средств поддерживает параллелизм приложения, нас все же интересует
само приложение. Итак, параллелизм можно обеспечить на уровне:
• инструкций;
• подпрограмм (функций или процедур);
• объектов;
• приложений.
1.5.1. Параллелизм на уровне инструкций
Параллелизм на уровне инструкций возникает, если несколько частей одной инст-
рукции могут выполняться одновременно. На рис. 1.3 показан пример декомпозиции
одной инструкции с целью достижения параллелизма выполнения отдельных операций.
1.5. Базовые уровни программного параллелизма 35
На рис. 1.8 компонент (А + В) можно вычислить одновременно с компонентом
(Q _ о) • Этот вид параллелизма обычно поддерживается директивами компилятора
и не попадает под управление С++-программиста.
X = (А + В ) * ( С - D )
Х1 = а + в х2 s с -d Параллельное выполнение
1J..... Синхронизация
X = х2 • х2
Рис. 1.3. Декомпозиция одной инструкции
1.5.2. Параллелизм на уровне подпрограмм
ДСС-структуру программы можно представить в виде ряда функций, т.е. сумма ра-
бот, из которых состоит программное решение, разбивается на некоторое количест-
во функций. Если эти функции распределить по потокам, то каждую функцию в этом
случае можно выполнить на отдельном процессоре, и, если в вашем распоряжении
будет достаточно процессоров, то все функции смогут выполняться одновременно.
Подробнее потоки описываются в главе 4.
1.5.3. Параллелизм на уровне объектов
ДСС-структуру программного решения можно распределить между объектами.
Каждый объект можно назначить отдельному потоку или процессу. Используя стан-
дарт CORBA (Common Object Request Broker Architecture — технология построения
распределенных объектных приложений), все объекты можно назначить различным
компьютерам одной сети или различным компьютерам различных сетей. Более де-
тально технология CORBA рассматривается в главе 8. Объекты, реализованные в раз-
личных потоках или процессах, могут выполнять свои методы параллельно.
1.5.4. Параллелизм на уровне приложений
Несколько приложений могут сообща решать некоторую проблему. Несмотря на
то что какое-то приложение первоначально предназначалось для выполнения от-
дельной задачи, принципы многократного использования кода позволяют приложе-
ниям сотрудничать. В таких случаях два отдельных приложения эффективно работа-
ют вместе подобно единому распределенному приложению. Например, буфер обмена
(Clipboard) не предназначался для работы ни с каким конкретным приложением, но его
успешно использует множество приложений рабочего стола. О некоторых вариантах
применения буфера обмена его создатели в процессе разработки даже и не мечтали.
Второй и третий уровни — это основные уровни параллелизма, поэтому методам
их реализации и уделяется основное внимание в этой книге. Уровня операционной
системы и аппаратных средств мы коснемся только в том случае, когда это будет не-
обходимо в контексте проектирования приложений. Получив соответствующую ДСС-
структуру для проекта, предусматривающего параллельное или распределенное про-
граммирование, можно переходить к следующему этапу — рассмотрению возможно-
сти его реализации в C++.
36 Глава 1. Преимущества параллельного программирования
1.6. Отсутствие языковой поддержки
параллелизма в C++
Язык C++ не содержит никаких синтаксических примитивов для параллелизма.
С++-стандарт ISO также отмалчивается на тему многопоточности. В языке C++ не пре-
дусмотрено никаких средств, чтобы указать, что заданные инструкции должны вы-
полняться параллельно. Включение встроенных средств параллелизма в других язы-
ках представляется как их особое достоинство. Бьерн Страуструп, создатель языка
C++, имел свое мнение на этот счет:
Можно организовать поддержку параллелизма средствами библиотек, которые будут
приближаться к встроенным средствам параллелизма как по эффективности, так и по
удобству применения. Опираясь на такие библиотеки, можно поддерживать различные
модели, а не только одну, как при использования встроенных средств параллелизма.
Я полагаю, что большинство программистов согласятся со мной, что именно такое
направление (создание набора библиотек поддержки параллелизма) позволит ре-
шить проблемы переносимости, используя тонкий слой интерфейсных классов.
Более того, Страуструп говорит: “Я считаю, что параллелизм в C++ должен быть
представлен библиотеками, а не как языковое средство”. Авторы этой книги находят
позицию Страуструпа и его рекомендации по реализации параллелизма в качестве
библиотечного средства наиболее подходящими с практической точки зрения. В на-
стоящей книге рассмотрен только этот вариант, и такой выбор объясняется доступно-
стью высококачественных библиотек, которые успешно можно использовать для реше-
ния задач параллельного и распределенного программирования. Библиотеки, которые
мы используем для усиления языка C++ с этой целью, реализуют национальные и между-
народные стандарты и используются тысячами С++-программистов во всем мире.
1.6.1. Варианты реализации параллелизма
с помощью C++
Несмотря на существование специальных версий языка C++, предусматривающих
“встроенные” средства параллельной обработки данных, мы представляем методы
реализации параллелизма с использованием стандарта ISO (International Organization
for Standardization — Международная организация по стандартизации) для C++. Мы
находим библиотечный подход к параллелизму (при котором используются как сис-
темные, так и пользовательские библиотеки) наиболее гибким. Системные библио-
теки предоставляются средой операционной системы. Например, поточно-
ориентированная библиотека POSIX (Portable Operating System Interface — интер-
фейс переносимой операционной системы) содержит набор системных функций,
которые в сочетании с языковыми средствами C++ успешно используются для
поддержки параллелизма. Библиотека POSIX Threads является частью нового еди-
ного стандарта спецификаций UNIX (Single UNIX Specifications Standard) и включе-
на в набор стандартов IEEE, описывающих интерфейсы ОС для UNIX (IEEE Std.
1003.1-2001). Создание нового единого стандарта спецификаций UNIX финансиру-
ется организацией Open Group, а его разработка поручена организации Austin
Common Standards Revision Group. В соответствии с документами Open Group но-
вый единый стандарт спецификаций UNIX:
1.6. Отсутствие языковой поддержки параллелизма в C++ 37
• предоставляет разработчикам ПО единый набор API-функций, которые долж-
ны поддерживаться каждой UNIX-системой;
• смещает акцент с несовместимых реализаций систем UNIX на соответствие
единому набору функций API;
• представляет собой кодификацию и юридическую стандартизацию общего ядра
системы UNIX;
• в качестве основной цели преследует достижение переносимости исходного
кода приложения.
Новый единый стандарт спецификаций UNIX, версия 3, включает стандарт IEEE Std.
1003.1-2001 и спецификации Open Group Base Specifications Issue 6. Стандарты IEEE
POSIX в настоящее время представляют собой часть единой спецификации UNIX,
и наоборот. Сейчас действует единый международный стандарт для интерфейса пе-
реносимой операционной системы. С++-разработчикам это только на руку, поскольку
данный стандарт содержит API-функции, которые позволяют создавать потоки
и процессы. За исключением параллелизма на уровне инструкций, единственным
способом достижения параллелизма с помощью C++ является разбиение программы
на потоки или процессы. Именно эти средства и предоставляет новый стандарт. Раз-
работчик может использовать:
• библиотеку POSIX Threads (или Pthreads);
• POSIX-функцию spawn ();
• семейство функций exec ().
Все эти средства поддерживаются системными API-функциями и системными биб-
лиотеками. Если операционная система отвечает 3-й версии нового единого стандар-
та UNIX, то С++-разработчику будут доступны эти API-функции (они рассматриваются
в главах 3 и 4 и используются во многих примерах этой книги). Помимо библиотек
системного уровня, для поддержки параллелизма в C++ могут применяться такие биб-
лиотеки пользовательского уровня, как MPI (Message Passing Interface — интерфейс
для передачи сообщений), PVM (Parallel Virtual Machine — параллельная виртуальная
машина) и CORBA (Common Object Request Broker Architecture — технология по-
строения распределенных объектных приложений).
1.6.2. Стандарт MPI
Интерфейс MPI — стандартная спецификация на передачу сообщений — был раз-
раоотан с целью достижения высокой производительности на компьютерах с массовым
параллелизмом и кластерах рабочих станций (рабочая станция — это сетевой компью-
тер, использующий ресурсы сервера). В этой книге используется MPICH-реализация
стандарта MPI. MPICH — это свободно распространяемая переносимая реализация ин-
терфейса MPI. MPICH предоставляет С++-программисту набор API-функций и биб-
лиотек, которые поддерживают параллельное программирование. Интерфейс МР1
особенно полезен для программирования моделей SPMD (Single-Program, Multiple-
Data— одна программа, несколько потоков данных) и MPMD (Multiple-Program,
Multiple-Data — множество программ, множество потоков данных). Авторы этой кни-
ги используют MPICH-реализацию библиотеки MPI для 32-узлового Linux-ориенти-
рованного кластера и 8-узлового кластера, управляемого операционными системами
38 Глава 1. Преимущества параллельного программирования
Linux и Solaris. И хотя в C++ нет встроенных примитивов параллельного программи-
рования, С++-программист может воспользоваться средствами обеспечения паралле-
лизма, предоставляемыми библиотекой MPICH. В этом и состоит одно из достоинств
языка C++, которое заключается в его фантастической гибкости.
1.6.3. PVM: стандарт для кластерного
программирования
Программный пакет PVM позволяет связывать гетерогенную (неоднородную) кол-
лекцию компьютеров в сеть для использования ее в качестве единого мощного парал-
лельного компьютера. Общая цель PVM-системы — получить возможность совместно
использовать коллекцию компьютеров для организации одновременной или парал-
лельной обработки данных. Реализация библиотеки PVM поддерживает:
• гетерогенность по компьютерам, сетям и приложениям;
• подробно разработанную модель передачи сообщений;
• обработку данных на основе выполнения процессов;
• мультипроцессорную обработку данных (МРР, SMP) ’;
• “полупрозрачный” доступ к оборудованию (т.е. приложения могут либо игно-
рировать, либо использовать преимущества различий в аппаратных средствах);
• динамически настраиваемый пул (процессоры могут добавляться или удаляться
динамически, возможен также их смешанный состав).
PVM — это самая простая (по использованию) и наиболее гибкая среда, доступная для
решения задач параллельного программирования, которые требуют применения различ-
ных типов компьютеров, работающих под управлением различных операционных систем.
PVM-библиотека особенно полезна для объединения в сеть нескольких однопроцессор-
ных систем с целью образования виртуальной машины с параллельно работающими про-
цессорами. Методы использования библиотеки PVM в С++-коде мы рассмотрим в главе 6.
PVM — это фактический стандарт для реализации гетерогенных кластеров, который легко
доступен и широко распространен. PVM прекрасно поддерживает модели параллельно-
го программирования MPMD (MIMD) и SPMD (SIMD). Авторы этой книги для реше-
ния небольших и средних по объему задач параллельного программирования исполь-
зуют PVM-библиотеку, а для более сложных и объемных — MPI-библиотеку. Обе биб-
лиотеки PVM и MPI можно успешно сочетать с C++ для программирования кластеров.
1.6.4. Стандарт CORBA
CORBA— это стандарт для распределенного кроссплатформенного объектно-
ориентированного программирования. Выше упоминалось о применении CORBA для
поддержки параллелизма, поскольку реализации стандарта CORBA можно использо-
вать для разработки мультиагентных систем. Мультиагентные системы предлагают
важные сетевые модели распределенного программирования с равноправными узлами
МРР - Massively Parallel Processors (процессоры с массовым параллелизмом), SMP- symmetric multi-
processor (симметричный мультипроцессор).
1.6. Отсутствие языковой поддержки параллелизма в C++ 39
/oeer-to-peer). В мультиагентных системах работа может быть организована параллельно.
Это одна из областей, в которых параллельное и распределенное программирование пе-
пекрываются. Несмотря на то что агенты выполняются на различных компьютерах, это
происходит в течение одного и того же промежутка времени, т.е. агенты совместно ра-
ботают над общей проблемой. Стандарт CORBA обеспечивает открытую, независимую
от изготовителя архитектуру и инфраструктуру, которую компьютерные приложения
используют для совместного функционирования в сети. Используя стандартный прото-
кол ПОР (Internet InterORB Protocol — протокол, определяющий передачу сообщений
между сетевыми объектами по TCP/IP), CORBA-ориентированная программа
(созданная любым производителем на любом языке программирования, выполняемая
практически на любом компьютере под управлением любой операционной системы
в любой сети) может взаимодействовать с другой CORBA-ориентированной програм-
мой (созданной тем же или другим производителем на любом другом языке програм-
мирования, выполняемой практически на любом компьютере под управлением любой
операционной системы в любой сети). В этой книге мы используем М1СО-реализацию
стандарта CORBA. MICO— свободно распространяемая и полностью соответствую-
щая требованиям реализация стандарта CORBA, которая поддерживает язык C++.
1.6.5. Реализации библиотек на основе стандартов
Библиотеки MPICH, PVM, MICO и POSIX Threads реализованы на основе стандар-
тов. Это означает, что разработчики ПО могут быть уверены, что эти реализации ши-
роко доступны и переносимы с одной платформы на другую. Эти библиотеки исполь-
зуются многими разработчиками ПО во всем мире. Библиотеку POSIX Threads можно
использовать с C++ для реализации многопоточного программирования. Если про-
грамма выполняется на компьютере с несколькими процессорами, то каждый поток
может выполняться на отдельном процессоре, что позволяет говорить о реальной
параллельности программирования. Если же компьютер содержит только один про-
цессор, то иллюзия параллелизма обеспечивается за счет процесса переключения
контекстов. Библиотека POSIX Threads позволяет реализовать, возможно, самый
простой способ введения параллелизма в С++-программу. Если для использования
библиотек MPICH, PVM и MICO необходимо предварительно побеспокоиться об их
установке, то в отношении библиотеки POSIX Threads это излишне, поскольку среда
любой операционной системы, которая согласована с POSIX-стандартом или новой
спецификацией UNIX (версия 3), оснащена реализацией библиотеки POSIX Threads.
Все библиотеки предлагают модели параллелизма, которые имеют незначительные
различия. В табл. 1.2 показано, как каждую библиотеку можно использовать с C++.
Таблица 1.2. Использование библиотек MPICH, PVM, MICO и POSIXThreads с C++
Библиотека Использование с C++ i
MPICH Поддерживает крупномасштабное сложное программирование класте- ров. Предпочтительно используется для модели SPMD. Также поддер- живает SMP-, МРР- и многопользовательские конфигурации
PVM Поддерживает кластерное программирование гетерогенных сред. Легко используется для однопользовательских (мелко- и среднемасштабных) кластерных приложений. Также поддерживает МРР-конфигурации .
40 Глава 1. Преимущества параллельного программирования
Окончание табл. 1.2
Библиотека Использование с C++
MICO Поддерживает и распределенное, и параллельное программирование. Содержит эффективные средства поддержки агентно- ориентированного и мультиагентного программирования
POSIX Поддерживает параллельную обработку данных в одном приложении на уровне функций или объектов. Позволяет воспользоваться преимущест- вами SMP- и МРР-конфигурации
В то время как языки со встроенной поддержкой параллелизма ограничены при-
менением конкретных моделей, С++-разработчик волен смешивать различные модели
параллельного программирования. При изменении структуры приложения С++-
разработчик в случае необходимости выбирает другие библиотеки, соответствующие
новому сценарию работы.
1.7. Среды для параллельного
и распределенного программирования
Наиболее распространенными средами для параллельного и распределенного
программирования являются кластеры, SMP- и МРР-компьютеры.
Кластеры — это коллекции, состоящие из нескольких компьютеров, объединенных
сетью для создания единой логической системы. С точки зрения приложения такая
группа компьютеров выглядит как один виртуальный компьютер. Под МРР-
конфигурацией (Massively Parallel Processors — процессоры с массовым параллелизмом)
понимается один компьютер, содержащий сотни процессоров, а под SMP-конфи-
гурацией (symmetric multiprocessor — симметричный мультипроцессор) — единая сис-
тема, в которой тесно связанные процессоры совместно используют общую память
и информационный канал. SMP-процессоры разделяют общие ресурсы и являются
объектами управления одной операционной системы. Поскольку эта книга представ-
ляет собой введение в параллельное и распределенное программирование, нас будут
интересовать небольшие кластеры, состоящие из 8-32 процессоров, и многопроцес-
сорные компьютеры с двумя-четырьмя процессорами. И хотя многие рассматривае-
мые здесь методы можно использовать в МРР- или больших SMP-средах, мы в основ-
ном уделяем внимание системам среднего масштаба.
1.8. Резюме
В этой книге представлен архитектурный подход к параллельному и распределен-
ному программированию. При этом акцент ставится на определении естественного
параллелизма в самой задаче и ее решении, который закрепляется в программной
модели решения. Мы предлагаем использовать объектно-ориентированные методы,
которые бы позволили справиться со сложностью параллельного и распределенно-
го программирования, и придерживаемся следующего принципа: функция следует за
формой. В отношении языка C++ используется библиотечный подход к обеспечению
1.8. Резюме 41
поддержки параллелизма. Рекомендуемые нами библиотеки базируются на националь-
ных и международных стандартах. Каждая библиотека легко доступна и широко исполь-
зуется программистами во всем мире. Методы и идеи, представленные в этой книге, не
зависят от конкретных изготовителей программных и аппаратных средств, общедос-
тупны и опираются на открытые стандарты и открытые архитектуры. С++-программист
и разработчик ПО может использовать различные модели параллелизма, поскольку
каждая такая модель обусловливается библиотечными средствами. Библиотечный
подход к параллельному и распределенному программированию дает С++-программисту
гораздо большую степень гибкости по сравнению с использованием встроенных средств
языка. Наряду с достоинствами, параллельное и распределенное программирование не
лишено многих проблем, которые рассматриваются в следующей главе.
ПРОБЛЕМЫ
ПАРАЛЛЕЛЬНОГО
И РАСПРЕДЕЛЕННОГО
ПРОГРАММИРОВАНИЯ
В этой главе...
2.1. Кардинальное изменение парадигмы
2.2. Проблемы координации
2.3. Отказы оборудования и поведение ПО
2.4. Негативные последствия излишнего
параллелизма и распределения
2.5. Выбор архитектуры
2.6. Различные методы тестирования и отладки
2.7. Связь между параллельным и распределенным
проектами
2.8. Резюме
“Стремление обозначать точные значения любой физической величины
(температура, плотность, напряженность потенциального поля или что-либо
еще...) есть не что иное как смелая экстраполяция.”
— Эрвин Шредингер (Erwin Shrodinger), Causality and Wave Mechanics
В базовой последовательной модели программирования инструкции компью-
терной программы выполняются поочередно. Программа выглядит как кули-
нарный рецепт, в соответствии с которым для каждого действия компьютера
задан порядок и объемы используемых “ингредиентов”. Разработчик программы раз-
бивает основную задачу ПО на коллекцию подзадач. Все задачи выполняются по по-
рядку, и каждая из них должна ожидать своей очереди. Все программы имеют начало,
середину и конец. Разработчик представляет каждую программу в виде линейной по-
следовательности задач. Эти задачи необязательно должны находиться в одном фай-
ле, но их следует связать между собой так, чтобы, если первая задача по какой-то при-
чине не завершила свою работу, то вторая вообще не начинала выполнение. Другими
словами, каждая задача, прежде чем приступить к своей работе, должна ожидать до
тех пор, пока не получит результатов выполнения предыдущей. В последовательной
Модели зачастую устанавливается последовательная зависимость задач. Это означает,
что задаче А необходимы результаты выполнения задачи В, а задаче В нужны резуль-
таты выполнения задачи С, которой требуется что-то от задачи D и т.д. Если при вы-
полнении задачи В по какой-то причине произойдет сбой, задачи С и D никогда не
Приступят к работе. В таком последовательном мире разработчик привычно ориен-
тирует ПО сначала на выполнение действия 1, затем — действия 2, за которым должно
следовать действие 3 и т.д. Подобная последовательная модель настолько закрепилась
44 Глава 2. Проблемы параллельного и распределенного программирования
в процессе проектирования и разработки ПО, что многие программисты считают ее
незыблемой и не допускают мысли о возможности иного положения вещей. Решение
каждой проблемы, разработка каждого алгоритма и планирование каждой структуры
данных — все это делалось с мыслью о последовательном доступе компьютера к каж-
дой инструкции или ячейке данных.
2.1. Кардинальное изменение парадигмы
В мире параллельного программирования все обстоит по-другому. Здесь сразу не-
сколько инструкций могут выполняться в один и тот же момент времени. Одна инструк-
ция разбивается на несколько мелких частей, которые будут выполняться одновремен-
но. Программа разбивается на множество параллельных задач. Программа может со-
стоять из сотен или даже тысяч выполняющихся одновременно подпрограмм. В мире
параллельного программирования последовательность и местоположение составляю-
щих ПО не всегда предсказуемы. Несколько задач могут одновременно начать выполне-
ние на любом процессоре без какой бы то ни было гарантии того, что задачи закрепле-
ны за определенными процессорами, или такая-то задача завершится первой, или все
они завершатся в таком-то порядке. Помимо параллельного выполнения задач, здесь
возможно параллельное выполнение частей (подзадач) одной задачи. В некоторых
конфигурациях не исключена возможность выполнения подзадач на различных про-
цессорах или даже различных компьютерах. На рис. 2.1 показаны три уровня парал-
лелизма, которые могут присутствовать в одной компьютерной программе.
Модель программы, показанная на рис. 2.1, отражает кардинальное изменение па-
радигмы программирования, которая была характерна для “раннего” сознания про-
граммистов и разработчиков. Здесь отображены три уровня параллелизма и их рас-
пределение по нескольким процессорам. Сочетание этих трех уровней с базовыми
параллельными конфигурациями процессоров показано на рис. 2.2.
Обратите внимание на то, что несколько задач может выполняться на одном про-
цессоре даже при наличии в компьютере нескольких процессоров. Такая ситуация
создается системными стратегиями планирования. На длительность выполнения за-
дач, подзадач и инструкций оказывают влияние и выбранные стратегии планирова-
ния, и приоритеты процессов, и приоритеты потоков, и быстродействие устройств
ввода-вывода. На рис. 2.2 следует обратить внимание на различные архитектуры, ко-
торые программист должен учитывать при переходе от последовательной модели
программирования к параллельной. Основное различие в моделях состоит в переходе
от строго упорядоченной последовательности задач к лишь частично упорядоченной
(или вовсе неупорядоченной) коллекции задач. Параллелизм превращает ранее из-
вестные величины (порядок выполнения, время выполнения и место выполнения)
в неизвестные. Любая комбинация этих неизвестных величин является причиной из-
менения значений программы, причем зачастую непредсказуемым образом.
2.2. Проблемы координации
Если программа содержит подпрограммы, которые могут выполняться параллель-
но, и эти подпрограммы совместно используют некоторые файлы, устройства или об-
ласти памяти, то неизбежно возникают проблемы координации. Предположим, у нас
2.2. Проблемы координации 45
есть программа поддержки электронного банка, которая позволяет снимать деньги со
счета и класть их на депозит. Допустим, что эта программа разделена на три задачи
(обозначим их А, В и С), которые могут выполняться параллельно.
Параллелизм на уровне инструкций
Эти компоненты инструкции
могут выполняться параллельно.
X
Рис. 2.1. Три уровня параллелизма, которые возможны в одной компьютерной программе
Задача А получает запросы от задачи В на выполнение операций снятия денег со
счета. Задача А также получает запросы от задачи С положить деньги на депозит. За-
дача А принимает запросы и обрабатывает их по принципу “первым пришел — пер-
вым обслужен”. Предположим, на счете имеется 1000 долл., при этом задача С требует
Положить на депозит 100 долл., а задача В желает снять со счета 1100 долл. Что про-
изойдет, если обе задачи В и С попытаются обновить один и тот же счет одновременно?
46 Глава 2. Проблемы параллельного и распределенного программирования
Параллелизм
Однопроцессорный
компьютер
Рис. 2.2. Три уровня параллелизма в сочетании с базовыми параллельными
конфигурациями процессоров
2.2. Проблемы координации 47
Каким будет остаток на счете? Очевидно, остаток на счете в каждый момент времени
не может иметь более одного значения. Задача А применительно к счету должна вы-
полнять одновременно только одну транзакцию, т.е. мы сталкиваемся с проблемой
координации задач. Если запрос задачи В будет выполнен на какую-то долю секунды
быстрее, чем запрос задачи С, то счет приобретет отрицательный баланс. Но если за-
дача С получит первой право на обновление счета, то этого не произойдет. Таким об-
разом, остаток на счете зависит от того, какой задаче (В или С) первой удастся сде-
лать запрос к задаче А. Более того, мы можем выполнять задачи В и С несколько раз
с одними и теми же значениями, и при этом иногда запрос задачи В будет произведен
на какую-то долю секунды быстрее, чем запрос задачи С, а иногда — наоборот. Оче-
видно, что необходимо организовать надлежащую координацию действий.
Для координации задач, выполняемых параллельно, требуется обеспечить связь
между ними и синхронизацию их работы. При некорректной связи или синхрониза-
ции обычно возникает четыре типа проблем.
Проблема №1: “гонка” данных
Если несколько задач одновременно попытаются изменить некоторую общую об-
ласть данных, а конечное значение данных при этом будет зависеть от того, какая за-
дача обратится к этой области первой, возникнет ситуация, которую называют со-
стоянием “гонок” (race condition). В случае, когда несколько задач попытаются обно-
вить один и тот же ресурс данных, такое состояние “гонок” называют “гонкой” данных
(data race). Какая задача в нашей программе поддержки электронного банка первой
получит доступ к остатку на счете, определяется результатом работы планировщика
задач операционной системы, состоянием процессоров, временем ожидания и слу-
чайными причинами. В такой ситуации создается состояние “гонок”. И какое значе-
ние в этом случае должен сообщать банк в качестве реального остатка на счете?
Итак, несмотря на то, что мы хотели бы, чтобы наша программа позволяла одно-
временно обрабатывать множество операций по снятию денег со счета и вложению
их на депозит, нам нужно координировать эти задачи в случае, если окажется, что
операции снятия и вложения денег должны быть применены к одному и тому же сче-
ту. Всякий раз когда задачи одновременно используют модифицируемый ресурс, к ре-
сурсному доступу этих задач должны быть применены определенные правила и стра-
тегии. Например, в нашей программе поддержки банковских операций со счетами мы
могли бы всегда выполнять любые операции по вложению денег до выполнения каких
бы то ни было операций по их снятию. Мы могли бы установить правило, в соответ-
ствии с которым доступ к счету одновременно могла получать только одна транзак-
ция. И если окажется, что к одному и тому же счету одновременно обращается сразу
несколько транзакций, их необходимо задержать, организовать их выполнение в со-
ответствии с некоторым правилом очередности, а затем предоставлять им доступ
к счету по одной (в порядке очереди). Такие правила организации позволяют добить-
ся надлежащей синхронизации действий.
Проблема №2: бесконечная отсрочка
Такое планирование, при котором одна или несколько задач должны ожидать до тех
Пор, пока не произойдет некоторое событие или не создадутся определенные условия,
Может оказаться довольно непростым для реализации. Во-первых, ожидаемое событие
48 Глава 2. Проблемы параллельного и распределенного программирования
или условие должно отличаться регулярностью. Во-вторых, между задачами следует на-
ладить связи. Если одна или несколько задач ожидают сеанса связи до своего выполне-
ния, то в случае, если ожидаемый сеанс связи не состоится, состоится слишком поздно
или не полностью, эти задачи могут так никогда и не выполниться. И точно так же, если
ожидаемое событие или условие, которое (по нашему мнению) должно произойти (или
наступить), но в действительности не происходит (или не наступает), то приостанов-
ленные нами задачи будут вечно находиться в состоянии ожидания. Если мы приоста-
новим одну или несколько задач до наступления события (или условия), которое ни-
когда не произойдет, возникнет ситуация, называемая бесконечной отсрочкой (indefinite
postponement). Возвращаясь к нашему примеру электронного банка, предположим, что,
если мы установим правила, предписывающие всем задачам снятия денег со счета нахо-
диться в состоянии ожидания до тех пор, пока не будут выполнены все задачи вложе-
ния денег на счет, то задачи снятия денег рискуют стать бесконечно отсроченными.
Мы исходили из предположения о гарантированном существовании задач вложе-
ния денег на счет. Но если ни один из запросов на пополнение счетов не поступит, то
что тогда заставит выполниться задачи снятия денег? И, наоборот, что, если будут без
конца поступать запросы на пополнение одного и того же счета? Ведь тогда не смо-
жет “пробиться” к счету ни один из запросов на снятие денег. Такая ситуация также
может вызвать бесконечную отсрочку задач снятия денег.
Бесконечная отсрочка возникает при отсутствии задач вложения денег на счет или
их постоянном поступлении. Необходимо также предусмотреть ситуацию, когда запро-
сы на вложение денег поступают корректно, но нам не удается надлежащим образом ор-
ганизовать связь между событиями и задачами. По мере того как мы будем пытаться
скоординировать доступ параллельных задач к некоторому общему ресурсу данных, сле-
дует предусмотреть все ситуации, в которых возможно создание бесконечной отсрочки.
Методы, позволяющие избежать бесконечных отсрочек, рассматриваются в главе 5.
Проблема №3: взаимоблокировка
Взаимоблокировка — это еще одна “ловушка”, связанная с ожиданием. Для демонст-
рации взаимоблокировки предположим, что в нашей программе поддержки электрон-
ного банка три задачи работают не с одним, а с двумя счетами. Вспомним, что задача А
получает запросы от задачи В на снятие денег со счета, а от задачи С — запросы на вло-
жение денег на депозит. Задачи А, В и С могут выполняться параллельно. Однако задачи В
и С могут обновлять одновременно только один счет. Задача А предоставляет доступ задач
В и С к нужному счету по принципу “первым пришел — первым обслужен”. Предположим
также, что задача В имеет монопольный доступ к счету 1, а задача С — монопольный дос-
туп к счету 2. При этом задаче В для выполнения соответствующей обработки также ну-
жен доступ к счету 2 и задаче С — доступ к счету 1. Задача В удерживает счет 1, ожидая,
пока задача С не освободит счет 2. Аналогично задача С удерживает счет 2, ожидая, пока
задача В не освободит счет 1. Тем самым задачи В и С рискуют попасть в тупиковую си-
туацию, которую в данном случае можно назвать взаимоблокировкой (deadlock). Ситуация
взаимоблокировки между задачами В и С схематично показана на рис. 2.3.
Форма взаимоблокировки в данном случае объясняется наличием параллельно вы-
полняемых задач, имеющих доступ к совместно используемым данным, которые им раз-
решено обновлять. Здесь возможна ситуация, когда каждая из задач будет ожидать до
тех пор, пока другая не освободит доступ к общим данным (общими данными здесь яв-
ляются счет 1 и счет 2). Обе задачи имеют доступ к обоим счетам. Может случиться так,
2.2. Проблемы координации 49
вместо получения доступа одной задачи к двум счетам, каждая задача получит доступ
одному из счетов. Поскольку задача В не может освободить счет 1, пока не получит
К туп к счету 2, а задача С не может освободить счет 2, пока не получит доступ к счету 1,
огоамма обслуживания счетов электронного банка будет оставаться заблокированной.
Пбпатите внимание на то, что задачи В и С могут ввести в состояние бесконечной отсроч-
ки и другие задачи (если таковые имеются в системе). Если другие задачи ожидают полу-
чения доступа к счетам 1 или 2, а задачи В и С “скованы” взаимоблокировкой, то те другие
задачи будут ожидать условия, которое никогда не выполнится. При координации парал-
лельно выполняемых задач необходимо помнить, что взаимоблокировка и бесконечная
отсрочка — это самые опасные преграды, которые нужно предусмотреть и избежать.
Рис. 2.3. Ситуация взаимоблокировки между задачами В и С
Проблема №4: трудности организации связи
Многие распространенные параллельные среды (например, кластеры) зачастую
состоят из гетерогенных компьютерных сетей. Гетерогенные компьютерные сети— это
системы, которые состоят из компьютеров различных типов, работающих в общем
случае под управлением различных операционных систем и использующих различ-
ные сетевые протоколы. Их процессоры могут иметь различную архитектуру, обраба-
тывать слова различной длины и использовать различные машинные языки. Помимо
разных операционных систем, компьютеры могут различаться используемыми стра-
тегиями планирования и системами приоритетов. Хуже того, все системы могут раз-
личаться параметрами передачи данных. Это делает обработку ошибок и исключи-
тельных ситуаций (исключений) особенно трудной. Неоднородность системы может
усугубляться и другими различиями. Например, может возникнуть необходимость
в организации совместного использования данных программами, написанными на
различных языках или разработанных с использованием различных моделей ПО.
^едь общее системное решение может быть реализовано по частям, написанным на
языках Fortran, C++ и Java. Это вносит проблемы межъязыковой связи. И даже если
распределенная или параллельная среда не является гетерогенной, остается проблема
50 Глава 2. Проблемы параллельного и распределенного программирования
взаимодействия между несколькими процессами или потоками. Поскольку каждый про-
цесс имеет собственное адресное пространство, то для совместного использования пе-
ременных, параметров и значений, возвращаемых функциями, необходимо применять
технологию межпроцессного взаимодействия (interprocess communication — IPC), или
МПВ-технологию. И хотя реализация МПВ-методов необязательно является самой
трудной частью разработки системы ПО, тем не менее они образуют дополнительный
уровень проектирования, тестирования и отладки в создании системы.
POSIX-спецификация поддерживает пять базовых механизмов, используемых для
реализации взаимодействия между процессами:
• файлы со средствами блокировки и разблокировки;
• каналы (неименованные, именованные и FIFO-очереди);
• общая память и сообщения;
• сокеты;
• семафоры.
Каждый из этих механизмов имеет достоинства, недостатки, ловушки и тупики,
которые проектировщики и разработчики ПО должны обязательно учитывать, если
хотят создать надежную и эффективную связь между несколькими процессами. Орга-
низовать взаимодействие между несколькими потоками (которые иногда называются
облегченными процессами) обычно проще, чем между процессами, так как потоки ис-
пользуют общее адресное пространство. Это означает, что каждый поток в программе
может легко передавать параметры, принимать значения, возвращаемые функциями,
и получать доступ к глобальным данным. Но если взаимодействие процессов или по-
токов не спроектировано должным образом, возникают такие проблемы, как взаимо-
блокировки, бесконечные отсрочки и другие ситуации “гонки” данных. Необходимо
отметить, что перечисленные выше проблемы характерны как для распределенного,
так и для параллельного программирования.
Несмотря на то что системы с исключительно параллельной обработкой отлича-
ются от систем с исключительно распределенной обработкой, мы намеренно не про-
водили границ}7 между проблемами координации в распределенных и параллельных
системах. Частично мы можем объяснить это некоторым перекрытием существующих
проблем, и частично тем, что некоторые решения проблем в одной области часто
применимы к проблемам в другой. Но главная причина нашего “обобщенного” подхо-
да состоит в том, что в последнее время гибридные (параллельно-распределенные)
системы становятся нормой. Современное положение в параллельном способе обра-
ботке данных определяют кластеры и сетки. Причудливые кластерные конфигурации
составляют из готовых продуктов. Такие архитектуры включают множество компью-
теров со многими процессорами, а однопроцессорные системы уже уходят в прошлое.
В будущем предполагается, что чисто распределенные системы будут встраиваться в
виде компьютеров с несколькими процессорами. Это означает, что на практике проек-
тировщик или разработчик ПО будет теперь все чаще сталкиваться с проблемами рас-
пределения и параллелизма. Вот потому-то мы и рассматриваем все эти проблемы в од-
ном пространстве. В табл. 2.1 представлены комбинации параллельного и распределен-
ного программирования с различными конфигурациями аппаратного обеспечения.
В табл. 2.1 обратите внимание на то, что существуют конфигурации, в которых па-
раллелизм достигается за счет использования нескольких компьютеров. В этом случае
подходит применение библиотеки PVM. И точно так же существуют конфигурации,
2.3. Отказы оборудования и поведение ПО 51
которых распределение может быть достигнуто лишь на одном компьютере за счет
азбиения логики ПО на несколько процессов или потоков. Именно факт использо-
вания множества процессов или потоков говорит о том, что работа программы носит
“паспределенный” характер. Комбинации параллельного и распределенного про-
граммирования, представленные в табл. 2.1, подразумевают, что проблемы конфигу-
рации, обычно присущие распределенному программированию, могут возникнуть
в ситуациях, обусловленных параллельным программированием, и, наоборот, про-
блемы конфигурации, обычно связанные с параллельным программированием, могут
возникнуть в ситуациях, обусловленных распределенным программированием.
Таблица 2.1. Комбинации параллельного и распределенного программирования
с различными конфигурациями аппаратного обеспечения
Один компьютер Множество компьютеров
Параллельное програм- мирование Оснащен множеством процес- Использует такие библиотеки, как соров. Использует логическое PVM. Требует организации взаи- разбиение на несколько пото- модействия посредством передачи ков или процессов. Потоки или сообщений, что обычно связано процессы могут выполняться на с распределенным программиро- различных процессорах. Для ванием координации задач требуется МПВ-технология
Распределенное
программи-
рование
Наличие нескольких процес-
соров не является обязатель-
ным. Логика ПО может быть
разбита на несколько процес-
сов или потоков. Для коорди-
нации задач требуется МПВ-
технология
Реализуется с помощью сокетов
и таких компонентов, как CORBA
ORB (Object Request Broker — бро-
кер объектных запросов). Может
использовать тип взаимодействия,
который обычно связан с парал-
лельным программированием
Независимо от используемой конфигурации аппаратных средств, существует два
базовых механизма, обеспечивающих взаимодействие нескольких задач: общая па-
мять и средства передачи сообщений. Для эффективного использования механизма
общей памяти программисту необходимо предусмотреть решение проблем “гонки”
Данных, взаимоблокировки и бесконечных отсрочек. Схема передачи сообщений
Должна предполагать возникновение таких “накладок”, как прерывистые передачи,
бессмысленные (искаженные), утерянные, ошибочные, слишком длинные, просро-
ченные (с нарушением сроков), преждевременные сообщения и т.п. Эффективное
использование обоих механизмов подробно рассматривается ниже в этой книге.
2.3. Отказы оборудования и поведение ПО
При совместной работе множества процессоров над решением некоторой задачи
Возможен отказ одного или нескольких процессоров. Каким в этом случае должно
быть поведение ПО? Программа должна остановиться или возможно перераспреде-
ление работы? Что случится, если при использовании мультикомпьютерной системы
Канал связи между несколькими компьютерами временно выйдет из строя? Что про-
изойдет, если поток данных будет настолько медленным, что процессы на каждом
52 Глава 2. Проблемы параллельного и распределенного программирования
конце связи превысят выделенный им лимит времени? Как ПО должно реагировать
на подобные ситуации? Если, предположим, во время работы системы, состоящей из
50 компьютеров, совместно работающих над решением некоторой проблемы, про-
изойдет отказ двух компьютеров, то должны ли остальные 48 взять на себя их функ-
ции? Если в нашей программе электронного банка при одновременном выполнении
задач по снятию и вложению денег на счет две задачи попадут в ситуацию взаимобло-
кировки, то нужно ли прекратить работу серверной задачи? И что тогда делать с за-
блокированными задачами? А как быть, если задачи по снятию и вложению денег на
счет будут работать надлежащим образом, но по какой-то причине будет
“парализована” серверная задача? Следует ли в этом случае прекратить выполнение
всех “повисших” задач по снятию и вложению денег на счет? Что делать с частичными
отказами или прерывистой работой? Подобные вопросы обычно не возникают при
работе последовательных программ в одно-компьютерных средах. Иногда отказ сис-
темы является следствием административной политики или стратегии безопасности.
Например, предположим, что система содержит 1000 подпрограмм, и некоторым из
них требуется доступ к файлу для записи в него информации, но они по какой-то причи-
не не могут его получить. В результате возможны взаимоблокировка, бесконечная от-
срочка или частичный отказ. А как быть, если некоторые подпрограммы блокируются
из-за отсутствия у них прав доступа к нужным ресурсам? Должна ли в таких случаях
“вырубаться” вся система целиком? Насколько можно доверять обработанной инфор-
мации, если в системе произошли сбои в оборудовании, отказ каналов связи или их ра-
бота была прерывистой? Тем не менее эти ситуации очень даже характерны (можно
сказать, являются нормой) для распределенных или параллельных сред. В этой книге
мы рассмотрим ряд архитектурных решений и технологий программирования, которые
позволят программному обеспечению системы справляться с подобными ситуациями.
2.4. Негативные последствия излишнего
параллелизма и распределения
При внедрении технологии параллелизма всегда существует некоторая “точка на-
сыщения”, по “ту сторону” которой затраты на управление множеством процессоров
превышают эффект от увеличения быстродействия и других достоинств параллелиз-
ма. Старая поговорка “процессоров никогда не бывает много” попросту не соответст-
вует истине. Затраты на организацию взаимодействия между компьютерами или
обеспечение синхронизации процессоров выливаются “в копеечку”. Сложность син-
хронизации или уровень связи между процессорами может потребовать таких затрат
вычислительных ресурсов, что они отрицательно скажутся на производительности
задач, совместно выполняющих общую работу. Как узнать, на сколько процессов, за-
дач или потоков следует разделить программу? И, вообще, существует ли оптимальное
количество процессоров для любой заданной параллельной программы? В какой
“точке” увеличение процессоров или компьютеров в системе приведет к замедлению
ее работы, а не к ускорению? Нетрудно предположить, что рассматриваемые числа
зависят от конкретной программы. В некоторых областях имитационного моделиро-
вания максимальное число процессоров может достигать нескольких тысяч, в то вре-
мя как в коммерческих приложениях можно ограничиться несколькими сотнями. Для
ряда клиент-серверных конфигураций зачастую оптимальное количество составляет
восемь процессоров, а добавление девятого уже способно ухудшить работу сервера.
2.5. Выбор архитектуры 53
Всегда необходимо отличать работу и ресурсы, задействованные в управлении па-
аллельными аппаратными средствами, от работы, направленной на управление па-
раллельно выполняемыми процессами и потоками в ПО. Предел числа программных
процессов может быть достигнут задолго до того, как будет достигнуто оптимальное
количество процессоров или компьютеров. И точно так же можно наблюдать сниже-
ние эффективности оборудования еще до достижения оптимального количества па-
раллельно выполняемых задач.
2.5. Выбор архитектуры
Существует множество архитектурных решений, которые поддерживают паралле-
лизм. Архитектурное решение можно считать корректным, если оно соответствует
декомпозиции работ (work breakdown structure — WBR) программного обеспечения
(ДР ПО). Параллельные и распределенные архитектуры могут быть самыми разнооб-
разными. В то время как некоторые распределенные архитектуры прекрасно работа-
ют в Web-среде, они практически обречены на неудачу в среде с реальным масштабом
времени. Например, распределенные архитектуры, которые рассчитаны на длинные
временные задержки, вполне приемлемы для Web-среды и совершенно неприемлемы
для многих сред реального времени. Достаточно сравнить распределенную обработку
данных в Web-ориентированной системе функционирования электронной почты
с распределенной обработкой данных в банкоматах, или автоматических кассовых
машинах (automated teller machine— ATM). Задержка (время ожидания), которая
присутствует во многих почтовых Web-системах, была бы попросту губительной для
таких систем реального времени, как банкоматы. Одни распределенные архитектуры
(имеются в виду некоторые асинхронные модели) справляются с временными за-
держками лучше, чем другие. Кроме того, необходимо самым серьезным образом под-
ходить к выбору соответствующих архитектур параллельной обработки данных. На-
пример, методы векторной обработки данных наилучшим образом подходят для ре-
шения определенных математических задач и проблем имитационного
моделирования, но они совершенно неэффективны в применении к мультиагентным
алгоритмам планирования. Распространенные архитектуры ПО, которые поддержи-
вают параллельное и распределенное программирование, показаны в табл. 2.2.
Четыре базовые модели, перечисленные в табл. 2.2, и их вариации обеспечивают
основу для всех параллельных типов архитектур (т.е. объектно-ориентированного,
агентно-ориентированного и “классной доски”), которые рассматриваются в этой
книге. Разработчикам ПО необходимо подробно ознакомиться с каждой из этих мо-
делей и их приложением к параллельному и распределенному программированию.
Мы считаем своим долгом предоставить читателю введение в эти модели и дать биб-
лиографические сведения по материалам, которые позволят найти о них более де-
тальную информацию. В каждой работе или при решении проблемы лучше всего ис-
кать естественный или присущий им параллелизм, а выбранный тип архитектуры
Должен максимально соответствовать этому естественному параллелизму. Например,
Параллелизм в решении, возможно, лучше описывать с помощью симметричной мо-
дели, или модели сети с равноправными узлами (peer-to-peer model), в которой все
сотрудники (исполнители) считаются равноправными, в отличие от несимметричной
Модели “управляющий/рабочий”, в которой существует главный (ведущий) процесс,
Управляющий всеми остальными процессами как подчиненными.
54 Глава 2. Проблемы параллельного и распределенного программирования
Таблица 2.2. Распространенные архитектуры ПО, используемые для
поддержки параллельного и распределенного программирования
Модель Архитектура Распределенное программирование Параллельное программирование
Модель ведущего узла, именуемая также: • главный/подчиненный; • управляющий/рабочий; • клиент/сервер Модель равноправных узлов Главный узел управляет задачами, т.е. контроли- рует их выполнение и передает работу подчи- ненным задачам Все задачи, в основ- ном, имеют одинако- вый ранг, и работа ме- жду ними распределя- ется равномерно
Векторная или конвейер- ная (поточная)обработка Один исполнительный узел соответствует каждому элементу массива (вектора) или шагу конвейера
Дерево с родительскими и дочерними элементами Динамически генерируе- мые исполнители в отношении типа “родитель/потомок”. Этот тип архитектуры полезно использовать в алгоритмах следующих типов: • рекурсия; • “разделяй и властвуй”; • И/ИЛИ • древовидная обработка
2.6. Различные методы тестирования и отладки
При тестировании последовательной программы разработчик может отследить ее
логику в пошаговом режиме. Если он будет начинать тестирование с одних и тех же
данных при условии, что система каждый раз будет пребывать в одном и том же со-
стоянии, то результаты выполнения программы или ее логические цепочки будут
вполне предсказуемыми. Программист может отыскать ошибки в программе, исполь-
зуя соответствующие входные данные и исходное состояние программы, путем про-
верки ее логики в пошаговом режиме. Тестирование и отладка в последовательной
модели зависят от степени предсказуемости начального и текущего состояний про-
граммы, определяемых заданными входными данными.
С параллельным и распределенным программированием все обстоит иначе. Здесь
трудно воспроизвести точный контекст параллельных или распределенных задач из-
за разных стратегий планирования, применяемых в операционной системе, дина-
мически меняющейся рабочей нагрузки, квантов процессорного времени, приори-
тетов процессов и потоков, временных задержек при их взаимодействии и собственно
2.7. Связь между параллельным и распределенным проектами 55
выполнении, а также различных случайных изменений ситуаций, характерных для
параллельных или распределенных контекстов. Чтобы воспроизвести точное состоя-
ние в котором находилась среда при тестировании и отладке, необходимо воссоздать
каждую задачу, выполнением которой была занята операционная система. При этом
должен быть известен режим планирования процессорного времени и точно воспро-
изведены состояние виртуальной памяти и переключение контекстов. Кроме того,
следует воссоздать условия возникновения прерываний и формирования сигналов,
а в некоторых случаях — даже рабочую нагрузку7 сети. При этом нужно понимать, что
и сами средства тестирования и отладки оказывают немалое влияние на состояние
среды. Это означает, что создание одинаковой последовательности событий для тес-
тирования и отладки зачастую невозможно. Необходимость воссоздания всех пере-
численных выше условий обусловлено тем, что они позволяют определить, какие
процессы или потоки следует выполнять и на каких именно процессорах. Смешанное
выполнение процессов и потоков (в некоторой неудачной “пропорции”) часто явля-
ется причиной возникновения взаимоблокировок, бесконечных отсрочек, “гонки”
данных и других проблем. И хотя некоторые из этих проблем встречаются и в после-
довательном программировании, они не в силах зачеркнуть допущения, сделанные
при построении последовательной модели. Тот уровень предсказуемости, который
имеет место в последовательной модели, недоступен для параллельного программи-
рования. Это заставляет разработчика овладевать новыми тактическими приемами
для тестирования и отладки параллельных и распределенных программ, а также тре-
бует от него поиска новых способов доказательства корректности его программ.
2.7. Связь между параллельным
и распределенным проектами
При создании документации на проектирование параллельного или распределен-
ного ПО необходимо описать декомпозицию работ и их синхронизацию, а также
взаимодействие между задачами, объектами, процессами и потоками. При этом про-
ектировщики должны тесно контактировать с разработчиками, а разработчики —
с теми, кто будет поддерживать систему7 и заниматься ее администрированием. В идеале
это взаимодействие должно осуществляться по действующим стандартам. Однако найти
единый язык, понятный всем сторонам и позволяющий четко представить мультипара-
Дигматическую природу всех этих систем, — труднодостижимая цель. Мы остановили
свой выбор на языке UML (Unified Modeling Language — унифицированный язык моде-
лирования). В табл. 2.3 перечислено семь UML-диаграмм, которые часто используются
При создании многопоточных, параллельных или распределенных программ.
Семь диаграмм, перечисленных в табл. 2.3, представляют собой лишь подмноже-
ство диаграмм, которые предусмотрены языком UML, но они наиболее всего подхо-
дят к тому’, что мы хотим подчеркнуть в наших проектах параллельного ПО. В частно-
СТи- UML-диаграммы деятельности, развертывания и состояний весьма полезны для
°Писания взаимодействующего поведения параллельной и распределенной подсис-
тем обработки данных. Поскольку UML— это фактический стандарт, используемый
ПРИ создании взаимодействующих объектно-ориентированных и агентно-
°рИентированных проектов, при изложении материала в этой книге мы опираемся
Именно на него. Описание обозначений и символов, используемых в перечисленных
вЬнпе диаграммах, содержится в приложении А.
56 Глава 2. Проблемы параллельного и распределенного программирования
Таблица 2.3. UML-диаграммы, используемые при создании многопоточных,
параллельных или распределенных программ
UML-диаграммы Описание
Диаграмма
(видов)
деятельности
Диаграмма
взаимодействия
Диаграмма
(параллел ьных)
состояний
Диаграмма
последователь-
ностей
Диаграмма
сотрудничества
Диаграмма
развертывания
(внедрения)
Диаграмма
компонентов
Разновидность диаграммы состояний, в которой большинство со-
стояний (или все) представляют виды деятельности, а большинство
переходов (или все) активизируются при выполнении некоторого
действия в исходных состояниях
Тип диаграммы, которая отображает взаимодействие между объек-
тами. Взаимодействия описываются в виде сообщений, которыми
они обмениваются. К диаграммам взаимодействия относятся диа-
граммы сотрудничества, диаграммы последовательностей и диа-
граммы (видов)деятельности
Диаграмма, которая показывает последовательность преобразований
объекта в процессе его реакции на события. При использовании диа-
граммы параллельных состояний эти преобразования могут проис-
ходить в течение одного и того же интервала времени
Диаграмма взаимодействия, в которой отображается организация
структуры объектов, принимающих или отправляющих сообщения
(с акцентом на упорядочении сообщений по времени)
Диаграмма взаимодействия, в которой отображается организация
структуры объектов, принимающих или отправляющих сообщения
(с акцентом на структурной организации)
Диаграмма, которая показывает динамическую конфигурацию узлов
обработки, аппаратных средств и программных компонентов в системе
Диаграмма взаимодействия, в которой отображается организация
физических модулей программного кода (пакетов) в системе и зави-
симости между ними
2.8. Резюме
При создании параллельного и распределенного ПО разработчиков ожидает мно-
жество проблем. Поэтому при проектировании ПО им необходимо искать новые архи-
тектурные подходы и технологии. Многие фундаментальные допущения, которых при-
держивались разработчики при построении последовательных моделей программиро-
вания, совершенно неприемлемы в области создания параллельного и распределенного
ПО. В программах, включающих элементы параллелизма, программисты чаще всего
сталкиваются со следующими четырьмя проблемами координации: “гонка” данных,
бесконечная отсрочка, взаимоблокировка и проблемы синхронизации при взаимо-
действии задач. Наличие параллелизма и распределения оказывает огромное влияние
на все аспекты жизненного цикла разработки ПО: начиная эскизным проектом и за-
канчивая тестированием готовой системы и подготовкой документации. В этой книге
мы представляем архитектурные подходы к решению многих упомянутых проблем,
используя преимущества мультипарадигматических средств языка C++, которые по-
зволяют справиться со сложностью параллельных и распределенных программ.
РАЗБИЕНИЕ С++-
ПРОГРАММ НА
МНОЖЕСТВО ЗАДАЧ
В этой главе...
3.1. Определение процесса
3.2. Анатомия процесса
3.3. Состояния процессов
3.4. Планирование процессов
3.5. Переключение контекста
3.6. Создание процесса
3.7. Завершение процесса
3.8. Ресурсы процессов
3.9. Асинхронные и синхронные процессы
3.10. Разбиение программы на задачи
3.11. Резюме
Коль выполнение параллельных процессов возможно на более низком
(нейронном) уровне, то на символическом уровне мышление человека
с принципиальной точки зрения можно рассматривать как последовательную
машину, которая использует временно создаваемые последовательности
процессов, выполнение которых длится сотни миллисекунд.
— Герберт Саймон (Herbert A. Simon), The Machine As Mind
Параллельность в С++-программе достигается путем ее (программы) разложения
на несколько процессов или потоков. Несмотря на существование различных
вариантов организации логики С++-программы (например, с помощью объек-
тов, функций или обобщенных шаблонов), под параллелизмом все же понимается ис-
пользование множества процессов и потоков. Прочитав эту главу, вы поймете, что та-
кое процесс и как С++-программы можно разделить на несколько процессов.
3.1. Определение процесса
Процесс (process) — это некоторая часть (единица) работы, создаваемая операци-
онной системой. Важно отметить, что процессы и программы — необязательно экви-
валентные понятия. Программа может состоять из нескольких процессов. В некото-
рых ситуациях процесс может быть не связан с конкретной программой. Процессы —
это артефакты операционной системы, а программы — это артефакты разработчика.
Такие операционные системы, как UNIX/Linux позволяют управлять сотнями или
даже тысячами параллельно загружаемых процессов.
3.1. Определение процесса 59
Чтобы некоторую часть работы можно было назвать процессом, она должна иметь
адресное пространство, назначаемое операционной системой, и идентификатор, или
идентификационный номер (id процесса). Процесс должен обладать определенным
статусом и иметь свой элемент в таблице процессов. В соответствии со стандартом
pOSlX он должен содержать один или несколько потоков управления, выполняющих-
ся в рамках его адресного пространства, и использовать системные ресурсы, требуе-
мые для этих потоков. Процесс состоит из множества выполняющихся инструкций,
размещенных в адресном пространстве этого процесса. Адресное пространство про-
цесса распределяется между инструкциями, данными, принадлежащими процессу,
и стеками, обеспечивающими вызовы функций и хранение локальных переменных.
3.1.1. Два вида процессов
При выполнении процесса операционная система назначает ему некоторый процес-
сор. Процесс выполняет свои инструкции в течение некоторого периода времени. За-
тем он выгружается, освобождая процессор для другого процесса. Планировщик опера-
ционной системы переключается с кода одного процесса на код другого, предоставляя
каждому процессу шанс выполнить свои инструкции. Различают пользовательские про-
цессы и системные. Процессы, которые выполняют системный код, называются систем-
ными и применяются к системе в целом. Они занимаются выполнением таких служеб-
ных задач, как распределение памяти, обмен страницами между внутренним и вспомо-
гательным запоминающими устройствами, контроль устройств и т.п. Они также
выполняют некоторые задачи “по поручению” пользовательских процессов, например,
делают запросы на ввод-вывод данных, выделяют память и т.д. Пользовательские про-
цессы выполняют собственный код и иногда обращаются к системным функциям. Вы-
полняя собственный код, пользовательский процесс пребывает в пользовательском режи-
ме (user mode). В пользовательском режиме процесс не может выполнять определенные
привилегированные машинные команды. При вызове системных функций (например
read(), write () или open ()) пользовательский процесс выполняет инструкции опе-
рационной системы. При этом пользовательский процесс “удерживает” процессор до
тех пор, пока не будет выполнен системный вызов. Для выполнения системного вызова
процессор обращается к ядру операционной системы. В это время о пользователь-
ском процессе говорят, что он пребывает в привилегированном режиме, или режиме ядра
(kernel mode), и не может быть выгружен никаким другим пользовательским процессом.
3.1.2. Блок управления процессами
Процессы имеют характеристики, используемые для идентификации и определе-
ния их поведения. Ядро поддерживает необходимые структуры данных и предостав-
ляет системные функции, которые дают возможность пользователю получить доступ
к этой информации. Некоторые данные хранятся в блоках управления процессами
(process control block — РСВ), или БУЛ. Данные, хранимые в БУП-блоках, описывают
Процесс с точки зрения потребностей операционной системы. С помощью этой ин-
формации операционная система может управлять каждым процессом. Когда операци-
онная система переключается с одного процесса на другой, она сохраняет текущее со-
ст°яние выполняющегося процесса и его контекст в области сохранения БУП-блока,
Чтобы надлежащим образом возобновить выполнение этого процесса в следующий раз,
60 Глава 3. Разбиение С++-программ на множество задач
когда ему снова будет выделен центральный процессор (ЦП). БУП-блок считывается
и обновляется различными модулями операционной системы. Модули “отвечают” за
контроль производительности операционной системы, планирование, распределе-
ние ресурсов и доступ к механизму обработки прерываний и/или модифицируют
БУП-блок. Блок БУИ содержит следующую информацию:
• текущее состояние и приоритет процесса;
• идентификатор процесса, а также идентификаторы родительского и сыновне-
го процессов;
• указатели на выделенные ресурсы;
• указатели на область памяти процесса;
• указатели на родительский и сыновний процесс;
• процессор, занятый процессом;
• регистры управления и состояния;
• стековые указатели.
Среди данных, содержащихся в БУП-блоке, есть такие, которые “отвечают” за
управление процессом, т.е. отражают его текущее состояние и приоритет, указывают на
БУП-блоки родительского и сыновнего процессов, а также выделенные ресурсы и па-
мять. Кроме того, этот блок включает информацию, связанную с планированием,
привилегиями процессов, флагами, сообщениями и сигналами, которыми обменива-
ются процессы (имеется в виду межпроцессное взаимодействие — znter/?rocess
communication, или IPC). С помощью информации, связанной с управлением процес-
сами, операционная система может координировать параллельно выполняемые про-
цессы. Стековые указатели и содержимое регистров пользователя, управления и со-
стояния содержат информацию, связанную с состоянием процессора. При выполнении
процесса соответствующая информация размещается в регистрах ЦП. При переклю-
чении операционной системы с одного процесса на другой вся информация из этих
регистров сохраняется. Когда процесс снова получает ЦП во “временное пользова-
ние”, ранее сохраненная информация может быть восстановлена. Есть еще один вид
информации, который связан с идентификацией процесса. Имеется в виду идентифика-
тор процесса (id), или PID, и идентификатор родительского процесса (PPID). Эти
идентификационные номера (которые представлены положительными целочислен-
ными значениями) уникальны для каждого процесса.
3.2. Анатомия процесса
Адресное пространство процесса делится на три логических раздела: текстовый (для
кода программы), информационный (для данных программы) и стековый (для стеков про-
граммы). Логическая структура процесса показана на рис. 3.1. Текстовый раздел
(расположенный в нижней части адресного пространства) содержит подлежащие вы-
полнению инструкции, которые называются программным кодом. Раздел данных
(расположенный над текстовым разделом) содержит инициализированные глобальные,
внешние и статические переменные процесса. Раздел стеков содержит локально созда-
ваемые переменные и параметры, передаваемые функциям. Поскольку7 процесс может
3.2. Анатомия процесса 61
вызывать как системные функции, так и функции, определенные пользователем, в стеко-
вом разделе поддерживаются два стека: стек пользователя и стек ядра. При вызове функции
создается стековый фрейм функции, который помещается в стек пользователя или стек ядра
в зависимости от того, в каком режиме пребывает процесс в данный момент: в пользова-
тельском или привилегированном (режиме ядра). Стековый раздел имеет тенденцию
расти в направлении раздела данных. При выходе из функции ее стековый фрейм из-
влекается из стека. Разделы кода, данных и стеков, а также блок управления процессом
образуют часть того, из чего складывается образ процесса (process image).
ИДЕНТИФИКАЦИЯ ПРОЦЕССА
ИНФОРМАЦИЯ О СОСТОЯНИИ ПРОЦЕССА
- БУП
ИНФОРМАЦИЯ ОБ УПРАВЛЕНИИ ПРОЦЕССОМ
РАЗДЕЛ
СТЕКОВ
Стек ядра
ОБРАЗ
ПРОЦЕССА
Стек пользователя
РАЗДЕЛ ДАННЫХ
• инициализированные
глобальные переменные
* внешние переменные
« статические переменные
РАЗДЕЛ КОДА
• код программы
Рис. 3.1. Адресное пространство процесса делится на три логических
раздела: текстовый, информационный и стековый. Так выглядит
логическая структура процесса
Адресное пространство процесса виртуально. Применение виртуальной памяти по-
зволяет отделить адреса, используемые в текущем процессе, от адресов, реально дос-
тупных во внутренней памяти. Тем самым значительно увеличивается задействованное
пространство адресов памяти по сравнению с реально доступными адресами. Разделы
виртуального адресного пространства процесса представляют собой смежные блоки па-
мяти. Каждый такой раздел и физическое адресное пространство разделены на участки
памяти, именуемые страницами. У каждой страницы есть уникальный номер страничного
блока (page frame number). В качестве индекса для входа в таблицы страничных блоков
(page frame table) используется номер виртуального страничного блока. Каждый элемент таб-
лицы страничных блоков содержит номер физического страничного блока, что позволяет
Установить соответствие между виртуальными и физическими страничными блоками. Это
соответствие отображено на рис. 3.2. Как видите, виртуальное адресное пространство
Непрерывно, но устанавливаемое с его помощью соответствие физическим страницам
Не является упорядоченным. Другими словами, при последовательных виртуальных ад-
ресах соответствующие им физические страницы не будут последовательными.
62 Глава 3. Разбиение С++-программ на множество задач
Несмотря на то что виртуальное адресное пространство каждого процесса защи-
щено, т.е. приняты меры по предотвращению доступа к нему со стороны другого про-
цесса, текстовый раздел процесса может совместно использоваться несколькими
процессами. На рис. 3.2 также показано, как два процесса могут разделять один и тот
же программный код. При этом в элементах таблиц страничных блоков обоих про-
цессов хранится один и тот же номер физического страничного блока. Как показано
на рис. 3.2, виртуальный страничный блок с номером 0 процесса А соответствует фи-
зическому страничному блоку с номером 5, что также справедливо и для виртуального
страничного блока с номером 2 процесса В.
ВИРТУАЛЬНОЕ АДРЕСНОЕ
ПРОСТРАНСТВО ПРОЦЕССА В
- РАЗДЕЛ СТЕКОВ
- РАЗДЕЛ ДАННЫХ
- РАЗДЕЛ КОДА
ВИРТУАЛЬНОЕ АДРЕСНОЕ
ПРОСТРАНСТВО ПРОЦЕССА А
Рис. 3.2. Соответствие последовательных виртуальных страничных блоков страницам
физической памяти (НСБ — номер страничного блока; НВСБ— номер виртуального
страничного блока)
3.3. Состояния процессов 63
Чтобы операционная система могла управлять всеми процессами, хранимыми во
внутренней памяти, она создает и поддерживает таблицы процессов (process table). В дей-
ствительности операционная система содержит отдельные таблицы для всех объектов,
которыми она управляет. Следует иметь в виду, что операционная система управляет не
только процессами, но и всеми ресурсами компьютера, т.е. устройствами ввода-вывода,
памятью и файлами. Часть памяти, устройств и файлов управляется от имени пользова-
тельских процессов. Эта информация отмечена в БУП-блоках как ресурсы, выделенные
процессу. Таблица процессов должна иметь соответствующую структуру для каждого об-
раза процесса в памяти. Каждая такая структура содержит идентификаторы (id) самого
процесса и родительского процесса, идентификаторы реального и эффективного пользо-
вателей, идентификатор группы, список подвешенных сигналов, местоположение тексто-
вого, информационного и стекового разделов, а также текущее состояние процесса. Если
операционной системе нужен доступ к определенному процессу, в таблице процессов ра-
зыскивается информация о нем, а затем в памяти размещается его образ (рис. 3.3).
ТАБЛИЦЫ ПРОЦЕССОВ
Рис. 3.3. Операционная система управляет таблицами. Каждая структура в массиве
таблиц процессов представляет процесс в системе
З.з. Состояния процессов
Во время выполнения процесса его состояние изменяется. Под состоянием процес-
са подразумевается его текущий режим, или статус. В среде UNIX процесс может пре-
бывать в одном из следующих состояний:
• выполнения;
• работоспособности (готовности);
64 Глава 3. Разбиение С++-программ на множество задач
• “зомби”;
• ожидания (блокирования);
• останова.
Состояние процесса меняется при определенных обстоятельствах, создаваемых
существованием процесса или операционной системы. Под сменой состояний, или пе-
реходом из одного состояния в другое, понимают обстоятельства, которые заставля-
ют процесс изменить свое состояние. На рис. 3.4 отображена диаграмма состояний
для среды UNIX. Диаграмма состояний содержит узлы и направленные ребра, соеди-
няющие эти узлы. Каждый узел представляет состояние процесса, а направленные
ребра между узлами — переходы из одного состояния в другое. Возможные смены со-
стояний (с их кратким описанием) перечислены в табл. 3.1. На рис. 3.4 и в табл. 3.1
показано, что между состояниями разрешены только определенные переходы. На-
пример, между состояниями готовности и выполнения существует переход (ребро
диаграммы), а между состояниями ожидания и выполнения — нет. Это означает, что
возможны обстоятельства, заставляющие процесс перейти из состояния готовности
в состояние выполнения, но нет обстоятельств, которые могут заставить процесс пе-
рейти в состояние выполнения из состояния ожидания.
Рис. 3.4. Состояния процессов и переходы между ними в средах UNIX/Linux
Когда процесс только создается, он готов к выполнению своих инструкций, но
должен ожидать “своего часа” до тех пор, пока не освободится процессор. Каждому
процессу единолично разрешается использовать процессор в течение дискретного
временного интервала, именуемого квантом времени (time slice). Процессы, ожидающие
использования процессора, “занимают” очередь, т.е. помещаются в очереди готовых про-
цессов. Только из таких очередей планировщик выбирает процесс, который будет ис-
пользовать процессорное время. Процессы, находящиеся в очередях готовых процес-
сов, пребывают в состоянии работоспособности. Когда процессор становится доступным,
3.3. Состояния процессов 65
["таблица 3.1 • Переходы процессов из одного состояние в другое
Переходы между состояниями Описание
ГОТОВЫЙ->ВЫПОЛНЯЮЩИЙСЯ (загрузка) Процесс назначается процессору
выполняющийся^готовый Квант времени процесса, который назначен
(конец кванта времени) процессору, истек. Процесс возвращается назад в очередь готовых процессов
выполняющийся-»готовый Процесс выгружается до истечения его кванта
(досрочная выгрузка) времени. (Это возможно в случае, если стал го- товым процесс с более высоким приоритетом.) Выгруженный процесс помещается назад в оче- редь готовых процессов
выполняющийся-» Процесс отказывается от процессора до истече-
ОЖИДАЮЩИЙ (блокировка) ния его кванта времени. Процессу, возможно, нужно подождать наступления некоторого собы- тия, или он вызывает системную функцию, на- пример, делает запрос на ввод-вывод данных. Процесс помещается в очередь ждущих процессов
ОЖИДАЮЩИЙ-»ГОТОВЫЙ Событие, наступления которого ожидал процесс,
(разблокировка) произошло, или завершилось выполнение сис- темной функции, например, удовлетворен за- прос на ввод-вывод данных
ВЫПОЛНЯЮЩИЙСЯ-» Процесс отказывается от процессора из-за по-
ОСТАНОВЛЕННЫЙ лучения им сигнала останова
ОСТАНОВЛЕННЫЙ—»ГОТОВЫЙ Процесс получил сигнал продолжать и возвра- щается назад в очередь готовых процессов
ВЫПОЛНЯЮЩИЙСЯ-»“ЗОМБИ” Процесс прекращен и ожидает, пока родитель- ский процесс не извлечет из таблицы процес- сов его статус завершения
“ЗОМБИ”—>ВЫХОД Родительский процесс извлекает из таблицы процессов статус завершения и процесс-зомби покидает систему
ВЫПОЛНЯЮЩИЙСЯ->выход Процесс завершен, но он покидает систему по- сле того как родительский процесс извлечет из таблицы процессов его статус завершения
Диспетчер (dispatcher) назначает его работоспособному (готовому) процессу, который
занимает его в течение своего кванта времени. По истечении этого кванта времени
Процесс покидает процессор, независимо от того, выполнил он все свои инструкции
или нет. Этот процесс снова помещается в очередь готовых процессов (как в “зал ожи-
дания”) ожидать следующего сеанса работы процессора. Тем временем из очереди вы-
бирается новый процесс, котором}7 выделяется его квант процессорного времени. Сис-
темные процессы не выгружаются, т.е., “заполучив” процессор, они выполняются до
полного завершения. Если квант времени еще не исчерпан, но процесс не в состоянии
Продолжить выполнение, он может добровольно отказаться от процессорного времени.
66 Глава 3. Разбиение С++-программ на множество задач
Причины отказа могут быть разными. Например, процесс может сделать запрос на по-
лучение доступа к устройству ввода-вывода, вызвав системную функцию, или ему необ-
ходимо подождать освобождения объекта (переменной) синхронизации. Процессы, ко-
торые не могут продолжать выполнение из-за необходимости ожидать некоторого со-
бытия, “засыпают”, т.е. переходят в состояние ожидания. Они помещаются в очередь
ждущих процессов. После наступления ожидаемого ими события они удаляются из этой
очереди и возвращаются в очередь готовых процессов. Текущий процесс, т.е. процесс,
занимающий процессорное время, может быть лишен его еще до исчерпания кванта
времени, если заявит о своей готовности процесс с более высоким приоритетом
(например, системный процесс). Выгруженный досрочно процесс сохраняет статус
работоспособного и поэтому снова помещается в очередь готовых процессов.
Выполняющийся процесс может получить сигнал остановить выполнение. Состоя-
ние останова отличается от состояния ожидания, потому что при этом не был исчер-
пан квант времени и процесс не делал никакого системного запроса. Процесс мог по-
лучить сигнал остановиться либо по причине пребывания в режиме отладки, либо из-
за возникновения особой ситуации в системе. Получив сигнал остановиться, процесс
переходит из состояния выполнения в состояние останова. Позже процесс может быть
“разбужен” или ликвидирован.
Выполнив все свои инструкции, процесс покидает систему. В этом случае процесс
удаляется из таблицы процессов, его БУП-блок разрушается, и все занимаемые им ре-
сурсы освобождаются и возвращаются в системный пул доступных ресурсов. Процесс,
который неспособен продолжать выполнение, но при этом не может выйти из систе-
мы, считается “зомбированным”. Зомбированный процесс не использует никаких
системных ресурсов, но сохраняет свою структуру в таблице процессов. Если в табли-
це процессов окажется слишком много зомбированных процессов, это негативно от-
разится на производительности системы и может вызвать ее перезагрузку.
3.4. Планирование процессов
Если готовых к выполнению процессов больше одного, планировщик должен оп-
ределить, какой из них первым назначить процессору. С этой целью планировщик
поддерживает структуры данных, которые позволяют наиболее эффективным обра-
зом распределять между процессами процессорное время. Каждый процесс получает
класс (тип) приоритета и размещается в соответствующей очереди вместе с другими
работоспособными процессами того же приоритетного класса. Поэтому существует
несколько приоритетных очередей, которые представляют различные классы при-
оритетов, используемые системой. Эти приоритетные очереди упорядочиваются
и помещаются в массив распределения, именуемый также многоуровневой приоритетной
очередью (multilevel priority queue), показанной на рис. 3.5. Каждый элемент этого мас-
сива связан с конкретной приоритетной очередью. Для выполнения процессором
планировщик назначает тот процесс, который стоит в головной части непустой оче-
реди, имеющей самый высокий приоритет.
Приоритеты могут быть динамическими или статическими. Однажды установлен-
ный статический приоритет процесса изменить нельзя, а динамические — можно.
Процессы с самым высоким приоритетом могут монополизировать использование
процессора. Если же приоритет процессора динамический, то его начальный уровень
может быть заменен более высоким значением, в результате чего такой процесс будет
3.4. Планирование процессов 67
сведен в очередь с более высоким приоритетом. Кроме того, процесс, который
монополизирует процессор, может получить более низкий приоритет, или же другие
онессы могут получить более высокий приоритет, чем процесс-монополист. В сре-
дах UNIX/Linux для уровней приоритетов предусмотрен диапазон от -20 до 19. Чем
выше значение уровня, тем ниже приоритет процесса.
При назначении приоритета пользовательскому процессу следует учитывать, на что
именно этот процесс тратит большую часть времени. Одни процессы отличаются по-
вышенной интенсивностью использования процессорного времени (они используют
процессор в течение всего кванта процессорного времени). У других же большая часть
времени уходит на ожидание выполнения операций ввода-вывода или наступления не-
которых иных событий. Если такой процесс готов к использованию процессора, ему
следует немедленно предоставить процессор, чтобы он мог сделать следующий запрос
к устройствам ввода-вывода. Процессы, которые взаимодействуют между собой, могут
требовать довольно высокий приоритет, чтобы рассчитывать на приличное время ре-
акции. Системные процессы имеют более высокий приоритет, чем пользовательские.
Рис. 3.5. Многоуровневая приоритетная очередь (массив распределения), каждый элемент
которой указывает на очередь готовых процессов с одинаковым уровнем приоритета
3-4.1. Стратегия планирования
Процессы размещаются в приоритетных очередях в соответствии со стратегией
Планирования. В системах UNIX/Linux используются две стратегии планирования:
А*О (сокр. от First In First Out, т.е. первым прибыл, первым обслужен) и RR (сокр. от
68 Глава 3. Разбиение С++-программ на множество задач
rtmnd-robin, т.е. циклическая). Схема действия стратегии FIFO показана на рис. 3.6, а.
При использовании стратегии FIFO процессы назначаются процессору в соответст-
вии со временем поступления в очередь. После истечения кванта времени процесс
помещается в начало (головную часть) своей приоритетной очереди. Когда ждущий
процесс становится работоспособным (готовым к выполнению), он помещается в ко-
нец своей приоритетной очереди. Процесс может вызвать системную функцию и от-
казаться от процессора в пользу другого процесса с таким же уровнем приоритета.
Такой процесс также будет помещен в конец своей приоритетной очереди.
а) FIFO-планирование
ОЧЕРЕДЬ ГОТОВЫХ ПРОЦЕССОВ
ОЧЕРЕДЬ ЖДУЩИХ ПРОЦЕССОВ завершена
б) RR-планирование
ОЧЕРЕДЬ ГОТОВЫХ ПРОЦЕССОВ
Рис. 3.6. Схемы действия FIFO- и RR-стратегий планирования При использовании
стратегии FIFO процессы назначаются процессору в соответствии со временем поступления
в очередь. При использовании стратегии RR процессы назначаются процессору по правилам
FIFO-стратегии, но с одним отличием: после истечения кванта времени процесс помещается
не в начало, а в конец своей приоритетной очереди
3.4. Планирование процессов 69
В соответствии с циклической стратегией планирования (RR) все процессы счи-
таются равноправными (см. рис. 3.6, б). RR-планирование совпадает с FIFO-плани-
ованием с одним исключением: после истечения кванта времени процесс помещает-
ся не в начало, а в конец своей приоритетной очереди, и процессору назначается сле-
дующий (по очереди) процесс.
3.4.2. Использование утилиты ps
Утилита ps генерирует отчет, который содержит статистические данные о выпол-
нении текущих процессов. Эту информацию можно использовать для контроля за их
состоянием. В табл. 3.8 перечислены общие заголовки и описаны выходные данные,
генерируемые утилитой ps для сред Solaris/Linux. В любой многопроцессорной сре-
де утилита ps успешно применяется для мониторинга состояния процессов, степени
использования ЦП и памяти, приоритетов и времени запуска текущих процессов.
Ниже приведены командные опции, которые позволяют управлять информацией, со-
держащейся в отчете (с их помощью можно уточнить, что именно и какие процессы
вас интересуют). В среде Solaris по умолчанию (без командных опций) отображается
информация о процессах с тем же идентификатором эффективного пользователя
и управляющим терминалом инициатора вызова. В среде Linux по умолчанию ото-
бражается информация о процессах, id пользователя которых совпадает с id инициа-
тора запуска. В обеих средах в этом случае отображаемая информация, ограниченная
следующими составляющими: PID, TTY, TIME и COMMAND. Перечислим опции, кото-
рые позволяют получить информацию о нужных процессах.
- t term Список процессов, связанных с терминалом, заданным значением term
”е Все текущие процессы
“а (Linux) Все процессы с терминалом tty за исключением лидеров сеанса
(Solaris) Большинство часто запрашиваемых процессов за исключением
лидеров группы и процессов, не связанных с терминалом
Все текущие процессы за исключением лидеров сеанса
т (Linux) Все процессы, связанные с данным терминалом
а (Linux) Все процессы, включая процессы остальных пользователей
r (Linux) Только выполняющиеся процессы
Таблица 3.2. Общие заголовки, используемые для утилиты ps в средах Solaris/Linux
Заголовки Описание
Пользовательское имя владельца процесса
ID процесса
ID родительского процесса
ID лидирующего процесса в группе
ID лидера сеанса
USER, UID
PID
PPID
PGID
SID
70 Глава 3. Разбиение С++-программ на множество задач
Окончание табл. 3.2
Заголовки Описание
%CPU Коэффициент использования времени ЦП (в процентах) процессом в течение последней минуты
RSS %МЕМ Объем реального ОЗУ, занимаемый процессом в данный момент (в Кбайт) Коэффициент использования реального ОЗУ процессом в течение по- следней минуты
SZ Размер виртуальной памяти, занимаемой данными и стеком процесса (в Кбайт или страницах)
WCHAN Адрес события, в ожидании которого процесс пребывает в состоянии ожидания
COMMAND CMD ТТ, TTY S, STAT TIME Имя команды и аргументы Управляющий терминал процесса Текущее состояние процесса Общее время ЦП, используемое процессом (HH:MM:SS)
STIME, START NI PRI C, CP Время или дата старта процесса Фактор уступчивости процесса Приоритет процесса Коэффициент краткосрочного использования ЦП для вычисления пла- нировщиком значения PRI
ADDR Адрес памяти, выделенной процессу
LWP ID потока
NLWP Количество потоков
Синопсис
(Linux)
ps -[опции в стиле Unix98]
[опции в стиле BSD]
- -[GNU-опции в длинном формате]
(Solaris)
ps [-aAdeflcjLPy][-о format][-t termlist][-u userlist]
[-G grouplist] [-p proclist] [-g pgrplist] [-s sidlist]
В следующий список включены командные опции, которые используются для
управления отображаемой информацией о процессах:
- f полные распечатки
- 1 в длинном формате
- j в формате задания
Приведем пример использования утилиты ps в средах Solaris/Linux:
ps -f
По этой команде будет отображена полная информация о процессах, которая выводится
по умолчанию в каждой среде. На рис. 3.7 показан результат выполнения этой команды
3.4. Планирование процессов 71
еде Solaris. Командные опции можно использовать тандемом (одна за другой). На
рис 3 7 также показан результат совместного использования опций -1 и - f в среде Solaris:
ps
Командная опция 1 позволяет отобразить дополнительные заголовки: F, S, С, PRI, NI,
дрШ и WCHAN. При использовании командной опции Р отображается заголовок PSR, озна-
чающий номер процессора, которому назначается (или за которым закрепляется) процесс.
//SOLARIS
$ ps - f
UID PID PPID c STIME TTY TIME CMD
cameron 2214 2212 0 21:03:35 pts/12 0:00 -ksh
cameron 2396 2214 2 11:55:49 pts/12 0:01 nedit
F s UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
8 S cameron 2214 2212 0 51 20 70e80f00 230 70e80f6c 21:03:35 pts/12 0:00 -ksh
8 S cameron 2396 2214 1 53 24 70d747b8 843 70152aba 11:55:49 pts/12 0:01 nedit
Рис. 3.7. Результат выполнения команд ps -f и ps -IfB среде Solaris
На рис. 3.8 показан результат выполнения утилиты ps с использованием командных
опций Тих в среде Linux. Данные, выводимые с помощью заголовков %CPU, %МЕМ и STAT,
отображаются для процессов. В многопроцессорной среде с помощью этой информации
можно узнать, какие процессы являются доминирующими с точки зрения использования
времени ЦП и памяти. Заголовок STAT отображает состояние или статус процесса.
Ниже приведены символы, обозначающие статус, и дано соответствующее описание.
Заголовок STAT позволяет узнать дополнительную информацию о статусе процесса.
D (BSD) Ожидание доступа к диску
Р (BSD) Ожидание доступа к странице
X (System V) Ожидание доступа к памяти
W (BSD) Процесс выгружен надиск
К (AIX) Доступный процесс ядра
N (BSD) Приоритет выполнения понижен
> (BSD) Приоритет выполнения повышен искусственно
< (Linux) Процесс с высоким приоритетом
L (Linux) Страницы заблокированы в памяти
Эти символы должны предшествовать коду статуса. Например, А:ли перед кодом
статуса стоит символ N, значит, процесс выполняется с более низким уровнем при-
оритета. Если код статуса процесса отображен символами SW<, это означает, что про-
цесс пребывает в ждущем режиме, выгружен и имеет высокий уровень приоритета.
3.4.3. Установка и получение приоритета процесса
Уровень приоритета процесса можно изменить с помощью функции nice (). Каж-
дый процесс имеет фактор уступчивости (nice value), который используется для вы-
деления уровня приоритета вызывающего процесса. Процесс наследует приоритет
процесса, который его создал. Чтобы понизить приоритет процесса, следует увели-
Ч1,Ть его фактор уступчивости. Лишь процессы привилегированных пользователей
яДра системы могул’ увеличивать уровни своих приоритетов.
72 Глава 3. Разбиение С++-программ на множество задач
//Linux
[tdhughesOcolony]$ ps Tux
USER PID %CPU %MEM vsz RSS TTY STAT START TIME COMMAND
tdhughes 19259 0.0 0.1 2448 1356 pts/4 S 20:29 0:00 -bash
tdhughes 19334 0.0 0.0 1732 860 pts/4 s 20:33 0:00 /homeItdhughes/pv
tdhughes 19336 0.0 0.0 1928 780 pts/4 s 20:33 0:00 /home1tdhughes/pv
tdhughes 19337 18.0 2.4 26872 24856 pts/4 R 20:33 0:47 /home/tdhughes/pv
tdhughes 19338 18.0 2.3 26872 24696 pts/4 R 20:33 0:47 /home1tdhughes/pv
tdhughes 19341 17.9 2.3 26872 24556 pts/4 R 20:33 0:47 /home1tdhughes/pv
tdhughes 19400 0.0 0.0 2544 692 pts/4 R 20:38 0:00 ps Tux
tdhughes 19401 0.0 0.1 2448 1356 pts/4 R 20:38 0:00 -bash
Рис. 3.8. Результат выполнения команды ps Tux в среде Linux
Синопсис
#include <unistd.h>
int nice(int incr);
Чем ниже фактор уступчивости, тем выше уровень приоритета процесса. Параметр
incr содержит значение, добавляемое к текущему фактору уступчивости вызывающего
процесса. Значение параметра incr может быть отрицательным или положительным,
а фактор уступчивости представляет собой неотрицательное число. Положительное
значение incr увеличивает фактор уступчивости, а значит, понижает уровень приори-
тета. Отрицательное значение incr уменьшает фактор уступчивости, тем самым по-
вышая уровень приоритета. Если значение incr изменяет фактор уступчивости выше
или ниже соответствующих предельных величин, он будет установлен равным самому
высокому или самому низкому пределу соответственно. При успешном выполнении
функция nice () возвращает новый фактор уступчивости процесса, в противном слу-
чае — число -1, а прежнее значение фактора уступчивости при этом не изменяется.
Синопсис
#include <sys/resource.h>
int getpriority(int which, id_t who);
int setpriority(int which, id t who, int value);
Функция setpriority () устанавливает фактор уступчивости для заданного про-
цесса, группы процессов или пользователя. Функция getpriority () возвращает
приоритет заданного процесса, группы процессов или пользователя. Синтаксис ис-
пользования функций setpriority () и getpriority () для установки и считыва-
ния фактора уступчивости текущего процесса демонстрируется в листинге 3.1.
// Листинг 3.1. Использование функций setpriority() и
// getpriority()
#include <sys/resource.h>
//. . .
id_t pid = 0;
int which = PRIO—PROCESS;
int value = 10;
int nice—value;
int ret;
nice—value = getpriority(which,pid);
3.5. Переключение контекста 73
if(nice_value < value){
r = setpriority(which,pid,value);
зге ь
}
//•••
В листинге 3.1 возвращается и устанавливается приоритет вызывающего процесса.
Если фактор уступчивости вызывающего процесса оказывается меньше 10, он уста-
навливается равным 10. Процесс задается значениями, хранимыми в параметрах
which и who (см. соответствующий синопсис). Параметр which может определять
процесс, группу процессов или пользователя и иметь следующие значения.
PRIO__PROCESS Означает процесс
PRIO_PGRP Означает группу процессов
PRIO—USER Означает пользователя
В зависимости от значения параметра which параметр who содержит идентифи-
кационный номер (id) процесса, группы процессов или эффективного пользователя.
В листинге 3.1 параметру which присваивается значение PRIO_PROCESS. В листин-
ге 3.1 параметр who устанавливается равным 0, означая тем самым текущий процесс.
Параметр value для функции setpriority () определяет новое значение фактора
уступчивости для заданного процесса, группы процессов или пользователя. Факторы
уступчивости в среде Linux должны находиться в диапазоне от -20 до 19. В листин-
ге 3.1 фактор уступчивости устанавливается равным 10, если текущее его значение
оказывается меньше 10. В отличие от функции nice (), значение, передаваемое
функции setpriority (), является фактическим значением фактора уступчивости,
а не смещением, которое суммируется с текущим фактором уступчивости.
Если процесс имеет несколько потоков, модификация приоритета процесса повлия-
ет на приоритет всех его потоков. При успешном выполнении функции
getpriority() возвращается фактор уступчивости заданного процесса, а при успеш-
ном выполнении функции setpriority () — значение 0. В случае неудачи обе функции
возвращают число -1. Однако число -1 является допустимым значением фактора уступ-
чивости для любого процесса. Чтобы уточнить, не было ли ошибок при выполнении
функции getpriority (), имеет смысл протестировать внешнюю переменную errno.
3.5. Переключение контекста
Переключение контекста происходит в момент, когда процессор переключается
с одного процесса на другой. При переключении контекста система сохраняет кон-
текст текущего процесса и восстанавливает контекст следующего процесса, выбран-
ного для использования процессора. БУП-блок прерванного процесса при этом об-
новляется, а также изменяется значение поля состояния процесса (т.е. признак со-
стояния выполнения заменяется признаком другого состояния: готовности,
блокирования или “зомби”). Сохраняется и обновляется содержимое регистров про-
цессора, состояние стека, данные об идентификации (и привилегиях) пользователя
и процесса, а также о стратегии планирования и учетная информация.
Система должна отслеживать статус устройств ввода-вывода процесса и других ре-
сурсов, а также состояние всех структур данных, связанных с управлением памятью.
Ь1груженный (прерванный) процесс помещается в соответствующую очередь.
74 Глава 3. Разбиение С++-программ на множество задач
Переключение контекста происходит в случаях, когда:
• процесс выгружается;
• процесс добровольно отказывается от процессора;
• процесс делает запрос к устройству ввода-вывода или должен ожидать наступ-
ления события;
• процесс переходит из пользовательского режима в режим ядра.
Когда выгруженный процесс снова выбирается для использования процессора, его
контекст восстанавливается, и выполнение продолжается с точки, на которой он был
прерван в предыдущем сеансе.
3.6. Создание процесса
Чтобы выполнить любую программу, операционная система должна сначала создать
процесс. При создании нового процесса в главной таблице процессов создается новая
структура. Создается и инициализируется новый блок БУП, и в его раздел идентифика-
ции процесса записывается уникальный идентификационный номер процесса (id) и id
родительского процесса. Программный счетчик устанавливается указателем на входную
точку программы, а указатели системных стеков устанавливаются таким образом, чтобы
определить стековые границы для процесса. Процесс инициализируется любыми тре-
буемыми атрибутами. Если процессу не присвоено значение приоритета, то по умолча-
нию ему присваивается самое низкое значение. Изначально процесс не обладает ника-
кими ресурсами, если нет явного запроса на ресурсы или если они не были унаследова-
ны от процесса-создателя. Процесс “входит” в состояние выполнения и помещается
в очередь готовых к выполнению процессов. Для него выделяется адресное пространство,
размер которого определяется по умолчанию на основе типа процесса. Кроме того,
размер можно установить по запросу от создателя процесса. Процесс-создатель может
передать системе размер адресного пространства в момент создания процесса.
3.6.1. Отношения между родительскими и сыновними
процессами
Процесс, который создает, или порождает, другой процесс, является родительским
(parent) процессом по отношению к порожденному, или сыновнему (child) процессу.
Процесс init— родитель (или предок) всех пользовательских процессов — первый
процесс, видимый системой UNIX после ее загрузки. Процесс init организует сис-
тему, при необходимости выполняет другие программы и запускает демон-программы
(daemon), т.е. сетевые программы, работающие в фоновом режиме. Идентификатор
процесса init (PID) равен 1. Сыновний процесс имеет собственный уникальный
идентификатор PID, БУП-блок и отдельную структуру в таблице процессов. Сынов-
ний процесс также может породить новый процесс. Выполняющееся приложение
может создать дерево процессов. Например, родительский процесс выполняет поиск
накопителя на жестких дисках для заданного HTML-документа. Имя этого HTML-
документа записано в глобальной структуре данных, подобной списку, который со-
держит все запросы на документы. После успешного обнаружения документ удаляется
из списка запросов, и его путь (маршрут в сети) записывается в другую глобальную
структуру данных, которая содержит пути найденных документов. Чтобы обеспечить
3.6. Создание процесса 75
Приемлемую реакцию на пользовательские запросы, для процесса предусматривается
ограничение в виде пяти необработанных запросов в списке. По достижении этого
предела порождаются два новых процесса. Если порожденный процесс в свою оче-
редь достигнет установленного предела, он создаст еще два новых процесса. Созда-
ваемое таким способом дерево процессов показано на рис. 3.9. Любой процесс может
иметь только один родительский, но множество сыновних процессов.
процессов. При определенных условиях
Рис. 3.9. Дерево
процесс порождает два новых потомка
Сыновний процесс может быть создан с собственным исполняемым образом или
в виде дубликата родительского процесса. При создании в качестве дубликата предка
сыновний процесс наследует множество его атрибутов, включая среду, приоритет, стра-
тегию планирования, ограничения по ресурсам, открытые файлы и разделы общей па-
мяти. Если сыновний процесс перемещает указатель текущей позиции в файле или за-
крывает файл, то результаты этих действий будут видны родительскому процессу. Если
родителю выделяются любые дополнительные ресурсы уже после создания процесса-
потомка, то они не будут доступны потомку. В свою очередь, если сыновний процесс ис-
пользует какие-либо ресурсы, они также будут недоступны для процесса-родителя.
Некоторые атрибуты родителя не наследуются потомком. Как упоминалось выше,
сЫновний процесс не наследует PID родителя и его БУП-блок. Потомок не наследует
Никаких файловых блокировок, созданных родителем или необработанными сигна-
^аМи. Для сыновнего процесса используются собственные значения таких временных
^рактеристик, как коэффициент загрузки процессора и время создания. Несмотря на
Чт° сыновние процессы связаны определенными отношениями с родителями, они
76 Глава 3. Разбиение С++-программ на множество задач
все же функционируют как отдельные процессы. Их программные и стековые счет-
чики действуют раздельно. Поскольку разделы данных копируются, а не используются
совместно, процесс-потомок может изменять значения своих переменных, не оказы-
вая влияния на родительскую копию данных. Родительский и сыновний процесс со-
вместно используют раздел программного кода и выполняют инструкции, располо-
женные непосредственно после вызова системной функции, создавшей сыновний
процесс. Они не выполняют эти инструкции на этапе блокировки из-за соперничества
за процессор со всеми остальными процессами, загруженными в память.
После создания образ сыновнего процесса может быть заменен другим исполняе-
мым образом. Разделы программного кода, данных и стеков, а также его “куча” памяти
перезаписывается новым образом процесса. Новый процесс сохраняет свои иденти-
фикационные номера (PID и PPID). Атрибуты, сохраняемые новым процессом после
замены его исполняемого образа, перечислены в табл. 3.3. В ней также указаны сис-
темные функции, которые возвращают эти атрибуты. Переменные среды также со-
храняются, если во время замены исполняемого образа процесса не были заданы но-
вые переменные среды. Файлы, которые были открыты до момента замены испол-
няемого образа, остаются открытыми. Новый процесс будет создавать файлы с теми
же файловыми разрешениями. Время ЦП при этом не сбрасывается.
Таблица 3.3. Атрибуты, сохраняемые новым процессом после замены его
исполняемого образа образом нового процесса
Сохраняемые атрибуты Функция
Идентификатор (ID) процесса getpid()
ID родительского процесса getppid()
ID группы процессов getpgidO
Сеансовое членство getsid()
Идентификатор эффективного пользователя getuid()
Идентификатор эффективной группы getgid()
Дополнительные ID групп getgroups()
Время, оставшееся до сигнала тревоги alarm()
Фактор уступчивости nice()
Время, используемое до настоящего момента times ()
Маска сигналов процесса sigprocmask()
Ожидающие сигналы sigpending()
Предельный размер файла ulimit()
Предельный объем ресурсов getrlimit()
Маска создания файлового режима umask()
Текущий рабочий каталог getcwd()
Корневой каталог
3.6. Создание процесса 77
3.6.1.1. Утилита pstree
Утилита pstree в среде Linux отображает дерево процессов (точнее, она отобра-
жает выполняющиеся процессы в форме древовидной структуры). Корнем этого де-
рева является процесс init.
Синопсис
pstree [-а] [-с] [-h | -Hpid] [-1] [-n] [-р] [-u] [-G] | -U]
[pid | user]
pstree -V
При вызове этой утилиты можно использовать следующие опции.
- а Отобразить аргументы командной строки.
- h Выделить текущий процесс и его предков.
- Н Аналогично опции -h, но выделению подлежит заданный процесс.
- п Отсортировать процессы с одинаковым предком по значению PID, а не
по имени.
- р Отобразить значения PID.
На рис. 3.10 показан результат выполнения команды pstree -h в среде Linux.
ka:~ # pstree -h
init-+-applix
-atd
-axmain
-axnet
-cron
-gpm
-inetd
-9*[kdeinit]
-kdeinit -+-kdeinit
| -kdeinit----------bash----gimp script-fu
'-kdeinit--bash -+-man----sh--sh less
'-pstree
-kdeinit---cat
-kdm-+-X
' -kdm--------kde----ksmserver
-kflushd
-khubd
-klogd
-knotify
-kswapd
-kupdate
-login---bash
-Ipd
-mdrecoveryd
-5*[mingetty]
-nscd----nscd--5* [nscd]
-sshd
-syslogd
-usbmgr
'-xconsole
рИс. 3.10. Результат выполнения команды pstree -h в среде Linux
78 Глава 3. Разбиение С++-программ на множество задач
3.6.2. Использование системной функции fork()
Системная функция (или системный вызов) fork() создает новый процесс, кото-
рый представляет собой дубликат вызывающего процесса, т.е. его родителя. При ус-
пешном выполнении функция fork() возвращает родительскому и сыновнему про-
цессам два различных значения. Сыновнему возвращается число 0, а родительскому —
значение PID сыновнего процесса. Родительский и сыновний процессы продолжают
выполняться с инструкции, непосредственно следующей за функцией fork(). В слу-
чае неудачного выполнения (оно выражается в том, что сыновний процесс не был
создан) родительскому процессу возвращается число -1.
Синопсис
#include <unistd.h>
pid t fork (void);
Неудачный исход функции fork () возможен в случае, если система не обладает ре-
сурсами для создания еще одного процесса. Это происходит при превышении ограни-
чения (если оно существует) на количество сыновних процессов, которое может поро-
ждать родитель, или на количество выполняющихся процессов в масштабе всей систе-
мы. В этом случае устанавливается переменная ermo, которая означает наличие ошибки.
3.6.3. Использование семейства системных функций ехес
Семейство функций ехес предназначено для замены образа вызывающего процесса
образом нового процесса. При вызове функции fork () создается новый процесс, кото-
рый является точной копией родительского процесса, а функция ехес () заменяет об-
раз “скопированного” процесса образом копии. Образ нового процесса представляет
собой обычный выполняемый файл, который немедленно запускается на выполнение.
Этот файл можно задать с помощью имени и пути доступа к нему. Функции семейства
ехес могут передать новому процессу аргументы командной строки, а также установить
переменные среды. Если функция выполнилась успешно, она не возвращает никакого
значения, поскольку образ процесса, который содержал обращение к функции ехес,
уже перезаписан. В случае неудачи вызывающему процессу возвращается число -1. Все
функции ехес () могут иметь неудачный исход при следующих условиях:
• разрешения не признаны,
разрешение на поиск отвергается для каталога выполняемых файлов;
разрешение на выполнение отвергается для выполняемого файла;
• файлы не существуют',
выполняемый файл не существует;
каталог не существует;
• файл невозможно выполнить',
файл невозможно выполнить, поскольку он открыт для записи другим процессом;
файл не является выполняемым;
3.6. Создание процесса 79
с символическими ссылками',
проблемы
к исполняемому файлу символические ссылки образуют циклы;
при анализе пути
символические ссылки делают путь к исполняемому файлу слишком длинным.
функции семейства ехес используются совместно с функцией fork(). Функция
fork () создает и инициализирует сыновний процесс “по образу и подобию” роди-
тельского. Образ сыновнего процесса затем заменяет образ своего предка посредст-
вом вызова функции ехес (). Пример использования функций fork () и ехес () по-
казан в листинге 3.2.
// Листинг 3.2. Использование системных функций
,, fork() и ехес()
RtValue = fork();
if(RtValue == 0){
execl("/path/direct","direct"
}
В листинге 3.2 демонстрируется вызов функции fork (). Значение, которое она воз-
вращает, сохраняется в переменной RtValue. Если значение RtValue равно 0, зна-
чит, это — сыновний процесс, и в нем вызывается функция execl () с параметрами.
Первый параметр содержит путь к выполняемому модулю, второй — инструкцию для
выполнения, а третий — аргумент. Второй параметр, direct, представляет собой имя
утилиты, которая перечисляет все каталоги и подкаталоги из данного каталога. Всего
существует шесть версий функций ехес, предназначенных для использования раз-
личных соглашений о вызовах.
3.6.3.1. Функции execl ()
Функции execl (), execle () и execlp () передают аргументы командной строки
в виде списка. Количество аргументов командной строки должно быть известно во
время компиляции.
• int execl(const char *path,const char *arg0,.../*,
(char *)0 * /) ;
Здесь path — путевое имя выполняемой программы. Его можно задать в виде
полного составного имени либо относительного составного имени из текущего
каталога. Последующие параметры представляют собой список аргументов ко-
мандной строки, от arg0 до argn. Всего может быть п аргументов. Этот список
завершается NULL-указателем.
• int execle(const char *path,const char *arg0
(char *)0 *, char *const envp[]*/);
Эта функция аналогична функции execl () с одним отличием: она имеет до-
полнительный параметр, envp [ ]. Этот параметр указывает на новую среду для
нового процесса, т.е. envp [ ] — это указатель на строковый массив с завершаю-
щим нулевым символом. Каждая его строка, также завершающаяся нулевым
символом, имеет следующую форму:
name=value
80 Глава 3. Разбиение С++-программ на множество задач
Здесь паше — имя переменной среды, a value — сохраняемая строка. Значение
параметру envp [ ] можно присвоить следующим образом:
char *const envp[] = {"PATH=/opt/kde2:/sbin",
"HOME=/home",NULL};
Здесь PATH и HOME — переменные среды.
• int execlp(const char *file,const char *arg0,.../*,
(char *)0 * /) ;
Здесь file — имя выполняемой программы. Для определения местоположения
выполняемых программ используется переменная среды PATH. Остальные па-
раметры представляют собой список аргументов командной строки (см. описа-
ние функции execl ()).
Вот примеры применения синтаксиса функций execl () с различными аргументами:
char *const args[] = {"directNULL};
char *const envp[] = {"files=50",NULL};
execl("/path/direct","direct", ".",NULL);
execle("/path/direct","direct", ".",NULL,envp);
execlp("direct","direct",".",NULL);
Здесь в каждом примере вызова execl-функции активизированный процесс выпол-
няет программу direct.
Синопсис
#include <unistd.h>
int execl(const char *path,const char *arg0,.../*, (char *)0 * /) ;
int execlefconst char *path,const char *arg0,.../*, (char *)0 *,char *const envp[]*/);
int execlp(const char *file,const char *arg0,.../*, (char *)0 * /) ;
int int execv(const char *path,char *const arg[]); execve(const char *path,char *const arg[], char *const envp[]);
int execvpfconst char *file,char *const arg[]);
3.6.3.2. Функции execv ()
Функции execv (), execve () и execvp () передают аргументы командной строки
в векторе указателей на строки с завершающим нулевым символом. Количество аргу-
ментов командной строки должно быть известно во время компиляции. Элемент
argv [ 0 ] обычно представляет собой команду.
• int execv(const char *path,char *const arg[]);
Здесь path — путевое имя выполняемой программы. Его можно задать в виде
полного составного имени либо относительного составного имени из текущего
каталога. Последующий параметр представляет вектор (с завершающим нуле-
вым символом), содержащий аргументы командной строки, представленные
в виде строк с завершающими нулевыми символами. Всего может быть п аргу-
3.6. Создание процесса 81
ментов. Этот вектор завершается NULL-указателем. Элементу arg[] можно
присвоить значение таким образом:
char *const arg[] = {"traverse",”.", 1000", NULL};
Вот пример вызова этой функции:
execvf’traverse", arg) ;
В этом случае утилита traverse перечислит все файлы в текущем каталоге,
размер которых превышает 1000 байт.
• int execve(const char *path,char *const arg[],
char *const envp[]);
Эта функция аналогична функции execv (), с одним отличием: она имеет до-
полнительный параметр, envp [ ], который описан выше.
• int execvp(const char *file,char *const arg[]);
Здесь file— имя выполняемой программы. Последующий параметр пред-
ставляет собой вектор (с завершающим нулевым символом), содержащий ар-
гументы командной строки, представленные в виде строк с завершающими
нулевыми символами. Всего может быть п аргументов. Этот вектор заверша-
ется NULL-указателем.
Вот примеры применения синтаксиса функций execv () с различными аргументами:
char *const arg[] = {"traverse",".", 1000",NULL};
char *const envp[] = {"files=50",NULL};
execv("/path/traverse",arg);
execve("/path/traverse",arg,envp);
execvp("traverse",arg);
Здесь в каждом примере вызова execv-функции активизированный процесс вы-
полняет программу traverse.
3.6.3.3. Определение ограничений для функций ехес ()
Существуют ограничения на размеры вектора argv [ ] и массива envp [ ], переда-
ваемые функциям семейства ехес. Для определения максимального размера аргумен-
тов командной строки и размера переменных среды при использовании ехес-
функций (которые принимают параметр envp [ ]) можно использовать функцию
sysconf (). Чтобы эта функция возвратила размер, ее параметру паше необходимо
Передать значение _SC_ARG_MAX.
Синопсис
#include <unistd.h>
Jlong sysconf (int name);______________________________________________
Еще одним ограничением при использовании функций семейства ехес и других
Функций, применяемых для создания процессов, является максимальное количество
одновременно выполняемых процессов, которое допустимо для одного пользователя,
тобы функция sysconf () возвратила это число, ее параметру name необходимо пе-
редать значение _SC_CHILD_MAX.
82 Глава 3. Разбиение С++-программ на множество задач
3.6.3.4. Чтение и установка переменных среды
Переменные среды представляют собой строки с завершающими нулевыми симво-
лами, в которых хранится такая системная информация, как пути к каталогам, содер-
жащим команды, библиотеки, функции и процедуры, используемые процессом. Их
также можно использовать для передачи любых определенных пользователем данных
между родительскими и сыновними процессами. Они обеспечивают механизм пре-
доставления процессу специальной информации без необходимости жесткого ее связы-
вания с кодом программы. Переменные среды предопределены системой и совместно
используются всеми ее оболочками и процессами. Эти переменные инициализируются
файлами запуска. Чаще всего используются следующие системные переменные.
$НОМЕ Полное составное имя каталога пользователя.
$РАТН Список каталогов для поиска выполняемых файлов при выполнении команд.
$MAIL Полное составное имя почтового ящика пользователя.
$USER Идентификатор (id) пользователя.
$ SHELL Полное составное имя командной оболочки зарегистрированного пользователя.
$TERM Тип терминала пользователя.
Переменные среды могут храниться в файле или в списке, принадлежащем среде.
Этот список среды содержит указатели на строки с завершающими нулевыми симво-
лами. Когда процесс начинает выполняться, переменная
extern char **environ
будет указывать на список среды. Строки, составляющие список среды, имеют сле-
дующий формат:
name=value
Процессы, инициализированные с помощью функций execl (), execlpO,
execv () и execvp (), наследуют конфигурацию среды родительского процесса. Про-
цессы, инициализированные с помощью функций execve () и execle (), сами уста-
навливают среду.
Существуют функции и утилиты, которые позволяют опросить, добавить или мо-
дифицировать переменные среды. Функция getenv() используется для определения
факта установки заданной переменной. Интересующая вас переменная задается с по-
мощью параметра паше. Если заданная переменная не установлена, функция возвра-
щает значение NULL. В противном случае (если переменная установлена), функция
возвращает указатель на строку, содержащую ее значение.
Синопсис
#include <stdlib.h>
char *getenv(const char *name);
int setenv(const char *name, const char *value,
int overwrite);
void unsetenv(const char *name) ;
Рассмотрим пример:
string Path;
Path = getenv("PATH");
3.6. Создание процесса 83
Здесь строке Path присваивается значение, содержащееся во встроенной перемен-
НОЙ среды PATH.
функция setenvO используется для изменения значения существующей пере-
менной среды или добавления новой переменной в среду вызывающего процесса.
Параметр name содержит имя переменной среды, которую надлежит добавить или
изменить. Заданной переменной присваивается значение, переданное в параметре
value. Если переменная, заданная параметром name, уже существует, ее прежнее
значение заменяется значением, заданным параметром value при условии, если па-
раметр overwrite содержит ненулевое значение. Если же значение overwrite рав-
но 0, содержимое заданной переменной среды не модифицируется. Функция
setenv () возвращает 0 при успешном выполнении, в противном случае — значение -
1. Функция unsetenv () удаляет переменную среды, заданную параметром name.
3.6.4. Использование функции systemO для
порождения процессов
Функция systemO используется для выполнения команды или запуска програм-
мы. Функция system () выполняет функцию fork(), а затем сыновний процесс вы-
зывает функцию ехес () с оболочкой, выполняя заданную команду или программу.
Синопсис
#include <stdlib.h>
int system(const char *string);
В качестве параметра string можно передать системную команду или имя выпол-
няемого файла. При удачном исходе функция возвращает статус завершения команды
или значение, возвращаемое программой (если таковое предусмотрено). Ошибки мо-
гут возникнуть на нескольких уровнях, т.е. ошибка может произойти при выполнении
функции fork () или ехес () либо заданная оболочка может оказаться неподходящей
для выполнения команды или программы.
Функция system () возвращает значение родительскому процессу. При неудачном
исходе функции ехес () возвращается число 127, а при обнаружении других оши-
бок — число -1. Эта функция не влияет на состояние ожидания сыновних процессов.
3.6.5. Использование POSIX-функций для порождения
процессов
Подобно созданию процессов с помощью функций systemO и fork-exec, функ-
Чии posix_spawn() создают новые сыновние процессы из заданных образов про-
весов. Однако функции posix_spawn () позволяют при этом реализовать более
Многослойные “рычаги” управления, т.е. они управляют следующими атрибутами сы-
новних процессов, унаследованных от родительского процесса:
• Дескрипторы файлов;
• стратегия планирования;
• идентификатор группы процессов;
84 Глава 3. Разбиение С++-программ на множество задач
• идентификатор пользователя и группы;
• маска сигналов.
Функции posix_spawn() позволяют управлять тем, будут ли сигналы, проигно-
рированные родительским процессом, игнорироваться его потомком или устанавли-
ваться для выполнения действий, заданных по умолчанию. Управление дескриптора-
ми файлов позволяет сыновнему процессу получить самостоятельный доступ к потоку
данных, независимо открытому родителем. Возможность установить для сыновнего
процесса идентификатор группы повлияет на то, как управление сыновней задачей
будет связано с управлением родителем. Наконец, стратегию планирования сыновне-
го процесса можно установить отличной от стратегии планирования его родителя.
Синопсис
#include <spawn.h>
int posix—spawn(pid_t *restrict pid, const char *restrict path,
const posix_spawn_file_actions_t *file—actions,
const posix_spawnattr_t *restrict attrp,
char *const argvfrestrict],
char *const envp[restrict]);
int posix_spawnp(pid_t *restrict pid, const char *restrict file,
const posix_spawn_file_actions—t *file—actions,
const posix—spawnattr_t *restrict attrp,
char *const argv[restrict] ,
char *const envp[restrict]);
Различие между этими двумя функциями состоит в том, что функции posix_spawn ()
передается параметр path, а функции posix— spawnp () — параметр file. Параметр path
в функции posix— spawn () принимает полное или относительное составное имя выпол-
няемого файла, а параметр file в функции posix_spawnp () — только имя выполняе-
мой программы. Если этот параметр содержит символ “косая черта”, то содержимое па-
раметра file используется в качестве составного путевого имени. В противном случае
путь к выполняемому файлу определяется с помощью переменной среды PATH.
Параметр file_ actions представляет собой указатель на структуру
posix—spawn—file_асtions—t:
s t rue t po s ix_spawn—f i1e_ac t ions_t{
{
int ___allocated;
int ___used;
struct ___spawn_action *actions;
int ___pad [16] ;
};
Структура posix— spawn_file_actions—t содержит информацию о действиях,
выполняемых в новом процессе над дескрипторами файлов. Параметр
file_actions используется для преобразования родительского набора дескрипто-
ров открытых файлов в набор дескрипторов файлов для порожденного сыновнего
процесса. Эта структура может содержать ряд файловых операций, предназначенных
для выполнения в последовательности, в которой они были добавлены в объект деИ'
ствий над файлами. Эти файловые операции выполняются над дескрипторами от-
крытых файлов родительского процесса и позволяют копировать, добавлять, удалять
3.6. Создание процесса 85
или закрывать дескрипторы заданных файлов от имени сыновнего процесса даже до
его создания. Если параметр f ile_actions содержит нулевой указатель, то дескрип-
торы файлов, открытые родительским процессом, останутся открытыми для его по-
томка без каких-либо модификаций. Функции, используемые для добавления действий
над файлами в объект типа posix_spawn_f ile_actions, перечислены в табл. 3.4.
int
pos ix_spawn_f i le_ac t i ons_addc lose
(pos ix_spawn_f i 1 e_ac t i ons_t
*file_actions,
int fildes);
Таблица 3.4. Функции, используемые для добавления действий над файлами
в объект типа posix„spawn_f ile_actions
Функции Описание
Добавляет действие close () в объект
действий над файлами, заданный па-
раметром f ile_actions. В результа-
те при порождении нового процесса
с помощью этого объекта будет закрыт
файловый дескриптор fildes
int
pos ix_spawn_f i 1 e_ac t i ons_addopen
(posix_spawn_f ile_actions__t
*file_actions,
int fildes,
const char *restrict path,
int oflag, mode_t mode);
int
pos ix_spawn_f i 1 e_ac t i ons_adddup2
(pos ix_spawn_f i 1 e_ac t i ons_t
*file_actions,
int fildes, int new fildes);
int
pos ix_spawn_f i le_ac t i ons_des troy
(posix_spawn_fi1e_actions_t
*file_actions);
int
Posix_spawn_f ile_actions_init
(posix_spawn_file_actions_t
*file_actions);
Добавляет действие open () в объект
действий над файлами, заданный па-
раметром file_actions. В результа-
те при порождении нового процесса
с помощью этого объекта будет открыт
файл, заданный параметром path,
с использованием дескриптора fildes
Добавляет действие dup2 () в объект
действий над файлами, заданный па-
раметром file_actions. В результа-
те при порождении нового процесса
с помощью этого объекта будет создан
дубликат файлового дескриптора
fildes с использованием файлового
дескриптора newf ildes
Разрушает объект, заданный парамет-
ром f ile_ actions, что приводит
к деинициализации этого объекта. За-
тем его можно инициализировать по-
вторно с помощью функции
posix_spawn_ file_actions—ini t ()
Инициализирует объект, заданный
параметром f ile_actions. После
инициализации этот объект не будет
содержать действий, предназначенных
для выполнения над файлами
Параметр attrp указывает на структуру pos ix_spawnattr_t:
struct posix_spawnattr_t
short int __flags;
pid-t __pgrp;
86 Глава 3. Разбиение С++-программ на множество задач
sigset_t __sd;
sigset_t __ss;
struct sched_param ___sp;
int __policy;
int __pad [16] ;
};
Эта структура содержит информацию о стратегии планирования, группе процессов,
сигналах и флагах для нового процесса. Ниже следует описание отдельных атрибутов
этой структуры.
__flags Используется для индикации того, какие атрибуты процесса должны
быть модифицированы в порожденном процессе.
Эти атрибуты организованы поразрядно по принципу включающего ИЛИ:
POSIX_SPAWN_RESETIDS
POSIX_SPAWN_SETPGROUP
POSIX_SPAWN_SETSIGDEF
POSIX_SPAWN_SETSIGMASK
POSIX_SPAWN_SETSCHEDPARAM
POSIX_SPAWN_SETSCHEDULER
__pgrp Идентификатор группы процессов, подлежащих объединению с новым
процессом.
__sd Представляет множество сигналов, подлежащих обработке по умолча-
нию новым процессом.
__ss Представляет маску сигналов, подлежащую использованию новым
процессом.
__sp Представляет параметр планирования, подлежащий назначению ново-
му процессу.
—policy Представляет стратегию планирования, предназначенную для нового
процесса.
Функции, используемые для установки и считывания отдельных атрибутов, содер-
жащихся в структуре posix_spawnattr_t, перечислены в табл. 3.5.
Таблица 3.5. Функции, используемые для установки и считывания отдельных
атрибутов структуры posix spawnattr t
Функции Описание
int posix_spawnattr_getflags (const posix_spawnattr_t *restrict attr, short *restrict flags); int posix_spawnattr_setflags (posix_spawnattr_t *attr, short flags); Возвращает значение атрибута flags, хра- нимого в объекте, заданном параметром attr Устанавливает значение атрибута flags, хранимого в объекте, заданном параметром attr, равным значению параметра flags __
3.6. Создание процесса 87
Продолжение табл. 3.5
Функции
int posix_spawnattr_getpgroup
(const posix_spawnattr_t
*restrict attr,
pid_t *restrict pgroup);
int posix_spawnattr_setpgroup
(posix_spawnattr_t *attr,
pid_t pgroup);
int
posix_spawnattr_getschedparam
(const posix_spawnattr_t
*restrict attr,
struct sched_param
Restrict
schedparam);
int
pos ix_spawna 11r_s e t s chedparam
(posix—spawnattr_t *attr,
const struct sched_param
*restrict
schedparam) ;
int
pos ix_spawna t tr_ge t s chedpol icy
(const posix_spawnattr_t
*restrict attr,
int *restrict schedpolicy);
int
pos ix_spawnattr_setschedpolicy
(posix_spawnattr_t *attr,
int schedpolicy);
int
posix_spawnattr_getsigdefault
(const posix_spawnattr_t
*restrict attr,
sigset_t *restrict
sigdefault);
int
Posix_spawnattr_setsigdefault
(posix—spawnattr_t *attr,
const sigset_t *restrict
sigdefault);
lnt Posix—spawnattr_getsigmask
(const posix—spawnattr_t
Restrict attr,
__ sigset_t Restrict sigmask);
Описание
Возвращает значение атрибута ___pgroup,
хранимого в объекте, заданном параметром
attr, и сохраняет его в параметре pgroup
Устанавливает значение атрибута_pgroup,
хранимого в объекте, заданном параметром
attr, равным параметру pgroup, если
в атрибуте __flags установлен признак
POSIX_SPAWNJSETPGROUP
Возвращает значение атрибута_sp, храни-
мого в объекте, заданном параметром attr,
и сохраняет его в параметре schedparam
Устанавливает значение атрибута_sp, хра-
нимого в объекте, заданном параметром
attr, равным параметру schedparam, если
в атрибуте __flags установлен признак
POSIX_SPAWN_SETSCHEDPARAM
Возвращает значение атрибута ___policy,
хранимого в объекте, заданном параметром
attr, и сохраняет его в параметре
schedpolicy
Устанавливает значение атрибута_policy,
хранимого в объекте, заданном параметром
attr, равным параметру schedpolicy, если
в атрибуте_flags установлен признак
POSIX_SPAWN_SETSCHEDULER
Возвращает значение атрибута_sd, храни-
мого в объекте, заданном параметром attr,
и сохраняет его в параметре sigdefault
Устанавливает значение атрибута_sd, хра-
нимого в объекте, заданном параметром
attr, равным параметру sigdefault, если
в атрибуте __flags установлен признак
POSIX_SPAWN_SETSIGDEF
Возвращает значение атрибута _ss, храни-
мого в объекте, заданном параметром attr,
и сохраняет его в параметре sigmask
88 Глава 3. Разбиение С++-программ на множество задач
Окончание табл. 3.5
Функции Описание
int posix_spawnattr_setsigmask (posix_spawnattr_t *restrict attr, const sigset_t *restrict sigmask); int posix_spawnattr_destroy (posix_spawnattr_t *attr); int posix_spawnattr_init (posix_spawnattr_t *attr); Устанавливает значение атрибута ss, хра- нимого в объекте, заданном параметром attr, равным параметру sigmask, если в ат- рибуте flags установлен признак POSIX_S PAWN-SETSIGMASK Разрушает объект, заданный параметром attr. Этот объект можно затем снова ини- циализировать с помощью функции posix_spawnattr_init() Инициализирует объект, заданный парамет- ром attr, значениями, действующими по умолчанию для всех атрибутов, содержащих- ся в этой структуре
Пример использования функции posix__spawn () для создания процесса приведен
в листинге 3.3.
// Листинг 3.3. Порождение процесса с помощью
// функции posix_spawn(), которая
// вызывает утилиту ps
#include <spawn.h>
#include <stdio.h>
#include <errno.h>
#include <iostream>
{
//. . .
posix_spawnattr_t X;
posix_spawn_file_actions_t Y;
pid_t Pid;
char *const argv[] = {"/bin/ps-If", NULL};
char *const envp[] = {"PROCESSES=2"};
posix_spawnattr_init(&X);
posix—spawn_file_actions_init(&Y);
posix_spawn(&Pid,"/bin/ps",&Y,&X,argv,envp);
perror("posix_spawn");
cout « "spawned PID: " « Pid « endl;
//. . .
return(0) ;
}
В листинге 3.3 инициализируются объекты posix_spawnattr_t и posix_spawn_
f ile_actions_t. Функция posix_spawn () вызывается с такими аргументами: Pid,
путь " /bin/ps", Y, X, массив argv (который содержит команду в качестве первого
элемента и опцию в качестве второго) и массив envp, содержащий список перемен-
ных среды. При успешном выполнении функции posix_spawn () значение, храни-
мое в параметре Pid, станет идентификатором (PID) порожденного процесса,
а функция perror () отобразит следующий результат:
posix_spawn: Success
3.7. Завершение процесса 89
Затем будет выведено значение Pid. В данном случае порожденный процесс выпол-
няет следующую команду:
/bin/ps -If
При успешном выполнении POSIX-функции возвращают (обычным путем) число О
и в параметре pid идентификатор (id) сыновнего процесса (для родительского про-
цесса). В случае неудачи сыновний процесс не создается, следовательно, значение
pid не имеет смысла, а сама функция возвращает значение ошибки.
При использовании spawn-функций ошибки могут возникать на трех уровнях. Во-
первых, это возможно, если окажутся недействительными объекты f ile_actions или
attr objects. Если это произойдет после успешного (казалось бы) завершения функ-
ции (т.е. после порождения сыновнего процесса), такой сыновний процесс может полу-
чить статус завершения со значением 127. Если ошибка связана с функциями управле-
ния атрибутами порожденных процессов, возвращается код ошибки, сгенерированный
конкретной функцией (см. табл. 3.4 и 3.5). Если spawn-функция успела успешно завер-
шиться, то сыновний процесс может иметь статус завершения со значением 127.
Ошибки также возникают при попытке породить сыновний процесс. Эти ошибки
будут такими же, как при выполнении функций fork () или ехес (). В этом случае
они (ошибки) займут место значений, возвращаемых spawn-функциями. Если сынов-
ний процесс генерирует ошибку, родительский процесс не получает “дурного извес-
тия” автоматически. Для извещения родителя об ошибке сыновнего процесса необ-
ходимо использовать другие механизмы, поскольку информация об этом не сохраня-
ется в статусе завершения потомка. С этой целью можно использовать механизм
межпроцессного взаимодействия либо специальный флаг, устанавливаемый сынов-
ним процессом и видимый для его родителя.
3.6.6. Идентификация родительских и сыновних
процессов с помощью функций управления
процессами
Существуют две функции, которые возвращают значение идентификатора (PID) вызы-
вающего процесса и значение идентификатора (PPID) родительского процесса. Функция
getpid () возвращает идентификатор вызывающего процесса, а функция getppid () —
идентификатор процесса, который является родительским для вызывающего процесса.
Эти функции всегда завершаются успешно, поэтому коды ошибок не определены.
Синопсис
^include <unistd.h>
Pid_t getpid(void);
getppid (void) ;
3-7. Завершение процесса
Когда процесс завершается, его блок БУП разрушается, а используемое им адрес-
Н°е пространство и ресурсы освобождаются. Код завершения помещается в главную
Таблицу процессов. Как только родительский процесс примет этот код, соответст-
90 Глава 3. Разбиение С++-программ на множество задач
вующяя структура таблицы процессов будет удалена. Процесс завершается, если со-
блюдены следующие требования.
• Все инструкции выполнены.
• Процесс явным образом передает управление родительскому процессу или вы-
зывает системную функцию, которая завершает процесс.
• Сыновние процессы могут завершаться автоматически при завершении роди-
тельского процесса.
• Родительский процесс посылает сигнал о завершении своих сыновних процессов.
Аварийное завершение процесса может произойти в случае, если процесс выпол-
няет недопустимые действия.
• Процесс требует больше памяти, чем система может ему предоставить.
• Процесс пытается получить доступ к неразрешенным ресурсам.
• Процесс пытается выполнить некорректную инструкцию или запрещенные
вычисления.
Завершение процесса может быть инициировано пользователем, если этот про-
цесс является интерактивным.
Родительский процесс несет ответственность за завершение (освобождение) своих
потомков. Родительский процесс должен ожидать до тех пор, пока не завершатся все его
сыновние процессы. Если родительский процесс выполнит считывание кода завершения
сыновнего процесса, процесс-потомок покидает систему нормально. Процесс остается в
“зомбированном” состоянии до тех пор, пока его родитель не примет соответствующий
сигнал. Если родитель никогда не примет сигнал (поскольку он уже успел сам завершиться
и выйти из системы или не ожидал завершения сыновнего процесса), процесс-потомок
остается в “зомбированном” состоянии до тех пор, пока процесс init (исходный сис-
темный процесс) не примет его код завершения. Большое количество “зомбированных”
процессов может негативно отразиться на производительности системы.
3.7.1. Функции exit (), kill () и abort ()
Для самостоятельного завершения процесс может вызвать одну из двух функций:
exit () и abort (). Функция exit() обеспечивает нормальное завершение вызы-
вающего процесса. При этом будут закрыты все дескрипторы открытых файлов, свя-
занные с процессом. Функция exit () сбросит на диск все открытые потоки, содер-
жащие еще не переписанные буферизованные данные, после чего открытые потоки
будут закрыты. Параметр status принимает статус завершения процесса, возвра-
щаемый ожидающему родительскому процессу, который затем перезапускается. Па-
раметр status может принимать такие значения: 0, EXIT_FAILURE или
EXIT—SUCCESS. Значение 0 говорит об успешном завершении процесса. Ожидающий
родительский процесс имеет доступ только к младшим восьми битам значения пара-
метра status. Если родительский процесс не ожидает завершения сыновнего про-
цесса, его (ставшего “зомбированным”) “усыновляет” процесс init.
Функция abort () вызывает аварийное окончание вызывающего процесса, что по
последствиям равноценно результату выполнения функции fcloseO для всех от-
крытых потоков. При этом ожидающий родительский процесс получит сигнал о про-
3.8. Ресурсы процессов 91
крашении выполнения сыновнего процесса. Процесс может прибегнуть к прежде-
временному прекращению только в случае, если он обнаружит ошибку, с которой не
сможет справиться программным путем.
Синопсис
#include <stdlib.h>
void exit(int status);
void abort(void) ;
функцию kill() можно использовать для принудительного завершения другого
процесса. Эта функция отправляет сигнал процессам, заданным параметром pid. Пара-
метр sig — это сигнал, предназначенный для отправки заданному процессу. Возможные
сигналы перечислены в заголовке <signal.h>. Для уничтожения процесса параметр
sig должен иметь значение SIGKILL. Чтобы иметь право отсылать сигнал процессу,
вызывающий процесс должен обладать соответствующими привилегиями, либо его ре-
альный или идентификатор эффективного пользователя должен совпадать с реальным
или сохраненным пользовательским идентификатором процесса, который принимает
этот сигнал. Вызывающий процесс может иметь разрешение на отправку процессам
только определенных (а не любых) сигналов. При успешной отправке сигнала функция
возвращает вызывающему процессу значение 0, в противном случае — число -1.
Вызывающий процесс может отправить сигнал одному или нескольким процессам
при таких условиях.
pid > 0 Сигнал будет отослан процессу, идентификатор (PID) которого равен
значению параметра pid.
pid = 0 Сигнал будет отослан всем процессам, у которых идентификатор груп-
пы процессов совпадает с идентификатором вызывающего процесса.
pid = -1 Сигнал будет отослан всем процессам, для которых вызывающий про-
цесс имеет разрешение отправлять этот сигнал.
pid < -1 Сигнал будет отослан всем процессам, у которых идентификатор груп-
пы процессов равен абсолютному значению параметра pid, и для кото-
рых вызывающий процесс имеет разрешение отправлять этот сигнал.
Синопсис
^include <signal.h>
jjit kill (pid t pid, int sig) ;
3.8. Ресурсы процессов
При выполнении возложенной на процесс задачи часто приходится записывать
Данные в файл, отправлять их на принтер или отображать полученные результаты на
экране. Процессу могут понадобиться данные, вводимые пользователем с клавиатуры
Или содержащиеся в файле. Кроме того, процессы в качестве ресурса могут использо-
вать другие процессы, например, подпрограммы. Подпрограммы, файлы, семафоры,
Мьютексы, клавиатуры и экраны дисплеев — все это примеры ресурсов, которые мо-
92 Глава 3. Разбиение С++-программ на множество задач
жет затребовать процесс. Под ресурсом понимается все то, что использует процесс
в любое заданное время в качестве источника данных, средств обработки, вычисле-
ний или отображения информации.
Чтобы процесс получил доступ к ресурсу, он должен сначала сделать запрос, обра-
тившись с ним к операционной системе. Если ресурс свободен, операционная система
позволит процессу его использовать. После использования ресурса процесс освобож-
дает его, чтобы он стал доступным для других процессов. Если ресурс недоступен, за-
прос отвергается, и процесс должен подождать его освобождения. Как только ресурс
станет доступным, процесс активизируется. Таков базовый подход к распределению
ресурсов между процессами. На рис. 3.11 показан граф распределения ресурсов, по
которому можно понять, какие процессы удерживают ресурсы, а какие их ожидают.
Так, процесс В делает запрос на ресурс 2, который удерживается процессом С. Про-
цесс С делает запрос на ресурс 3, который удерживается процессом D.
Рис. 3.11. Граф распределения ресурсов, который показывает,
какие процессы удерживают ресурсы, а какие их запрашивают
Если удовлетворяется сразу несколько запросов на получение доступа к ресурсу,
этот ресурс является совместно используемым, или разделяемым (эта ситуация также ото-
бражена на рис. 3.11). Процесс А разделяет ресурс R, с процессом D. Разделяемые ре-
сурсы могут допускать параллельный доступ сразу нескольких процессов или разре-
шать доступ только одному процессу в течение ограниченного промежутка времени,
после чего аналогичным доступом сможет воспользоваться другой процесс. Приме-
ром такого типа разделяемых ресурсов может служить процессор. Сначала процессор
назначается одному процессу в течение короткого интервала времени, а затем про-
цессор “получает” другой процесс. Если удовлетворяется только один запрос на полу-
чение доступа к ресурсу, и это происходит после того, как ресурс освободит другой
процесс, такой ресурс является неразделяемым, а о процессе говорят, что он имеет мо-
нопольный доступ (exclusive access) к ресурсу. В многопроцессорной среде важно
знать, какой доступ можно организовать к разделяемому ресурсу: параллельный или
последовательный (передавая “эстафету” поочередно от ресурса к ресурсу). Это по-
зволит избежать ловушек, присущих параллелизму.
Одни ресурсы могут изменяться или модифицироваться процессами, а другие —
нет. Поведение разделяемых модифицируемых или немодифицируемых ресурсов оп-
ределяется типом ресурса.
3.8. Ресурсы процессов 93
§3
1 Граф распределения ресурсов
Г афы распределения ресурсов — это направленные графы, которые показывают, как
определяются ресурсы в системе. Такой граф состоит из множества вершин V
и множества ребер Е. Множество вершин делится на две категории:
Р={Р,Л- -Рп}
R={R„R2. -.RJ
Множество Р— это множество всех процессов, a R — это множество всех ресурсов
в системе. Ребро, направленное от процесса к ресурсу, называется ребром запроса,
а ребро, направленное от ресурса к процессу, называется ребром назначения. Направ-
ленные ребра обозначаются следующим образом:
р R Ребро запроса: процесс Р( запрашивает экземпляр типа ресурса R.
r р. Ребро назначения: экземпляр типа ресурса R выделен процессу Pj
Каждый процесс в графе распределения ресурсов отображается кругом, а каждый
ресурс — прямоугольником. Поскольку может быть много экземпляров одного типа ре-
сурса, то каждый из них представляется точкой внутри прямоугольника. Ребро запро-
са указывает на периметр прямоугольника ресурса, а ребро назначения берет начало
из точки и касается периметра круга процесса.
Граф распределения ресурсов, показанный на рис. 3.11, отображает следующее.
Множества Р, R и Е
p={pa,p„,pc,pd}
R={R„R2, R,}
E={R,-»P„ R,->Pd, Pb->R2,R2^Pc,Pc^R,)R3-»Pd}
3.8.1. Типы ресурсов
Существуют три основных типа ресурсов: аппаратные, информационные и про-
граммные. Аппаратные ресурсы представляют собой физические устройства, подклю-
ченные к компьютеру (например, процессоры, основная память и все устройства вво-
да-вывода, включая принтеры, жесткий диск, накопитель на магнитной ленте, диско-
вод с zip-архивом, мониторы, клавиатуры, звуковые, сетевые и графические карты, а
также модемы. Все эти устройства могут совместно использовать несколько процессов.
Некоторые аппаратные ресурсы прерываются, чтобы разрешить доступ к ним раз-
личных процессов. Например, прерывания процессора позволяют различным про-
цессам выполняться по очереди. Оперативное запоминающее устройство, или ОЗУ
(RAM), — это еще один пример ресурса, разделяемого посредством прерываний. Ко-
гда процесс не выполняется, некоторые страничные блоки, которые он занимает, мо-
гут быть выгружены во вспомогательное запоминающее устройство, а на их место за-
гружены данные, относящиеся к другому процессу. В любой момент времени весь
Диапазон памяти может быть занят страничными блоками только одного процесса.
римером разделяемого, но непрерываемого ресурса может служить принтер. При
совместном использовании принтера задания, посылаемые на печать каждым процес-
с°м, хранятся в очереди. Каждое задание печатается до конца, и только потом начи-
94 Глава 3. Разбиение С++-программ на множество задач
нает выполняться следующее задание. Принтер не прерывается ни одним ждущим за-
данием, если не отменяется текущее задание.
Информационные ресурсы — к ним относятся данные (например, объекты), систем-
ные данные (например, переменные среды, файлы и дескрипторы) и такие глобально
определенные переменные, как семафоры и мьютексы, — являются разделяемыми ре-
сурсами, которые могут быть модифицированы процессами. Обычные файлы и фай-
лы, связанные с физическими устройствами (например, принтером), могут откры-
ваться с учетом ограничивающего типа доступа со стороны процессов. Другими сло-
вами, процессы могут обладать правом доступа только для чтения, или только для
записи, или для чтения и записи. Сыновний процесс наследует ресурсы родительско-
го процесса и права доступа к ним, существующие на момент создания процесса-
потомка. Сыновний процесс может переместить файловый указатель, закрыть, моди-
фицировать или перезаписать содержимое файла, открытого родителем. Доступ к со-
вместно используемым файлам и памяти с разрешением записи должен быть синхро-
низирован. Для синхронизации доступа к разделяемым ресурсам данных можно ис-
пользовать такие разделяемые данные, как семафоры и мьютексы.
Разделяемые библиотеки могут служить примером программных ресурсов. Разделяемые
библиотеки предоставляют общий набор функций для процессов. Процессы могут
также совместно использовать приложения, программы и утилиты. В этом случае
в памяти находится только одна копия программного кода, например, приложения
(приложений). При этом должны существовать отдельные копии данных, по одной
для каждого пользователя (процесса). К неизменяемому программному коду (который
также именуется реентерабельным, или повторно используемым) могут получать доступ
несколько процессов одновременно.
3.8.2. POSIX-функции для установки ограничений
доступа к ресурсам
В библиотеке POSIX определены функции, которые ограничивают возможности
процесса по использованию определенных ресурсов. Так, операционная система ус-
танавливает ограничения на возможности процесса по использованию системных ре-
сурсов, а именно:
• размер стека процесса;
• размер создаваемого файла и файла ядра;
• объем времени ЦП, выделенный процессу (размер кванта времени);
• объем памяти, используемый процессом;
• количество дескрипторов открытых файлов.
Операционная система устанавливает жесткие ограничения на использование ресур-
сов процессом. Процесс может установить или изменить мягкие ограничения ре-
сурсов, но это значение не должно превысить жесткий предел, установленный опе-
рационной системой. Процесс может понизить свой жесткий предел, но его значение
не должно быть меньше мягкого предела. Операция по понижению процессом своего
жесткого предела необратима. Его могут повысить только процессы, обладающие
специальными привилегиями.
3.8. Ресурсы процессов 95
Синопсис
#include <sys/resource.h>
int setrlimit(int resource, const struct rlimit *rlp);
int getrlimit(int resource, struct rlimit *rlp);
int getrusage(int who, struct rusage *r_usage);
функция setrlimit () используется для установки ограничений на потребление
заданных ресурсов. Эта функция позволяет установить как жесткий, так и мягкий
пределы. Параметр resource представляет тип ресурса. Значения типов ресурсов
(и их краткое описание) приведено в табл. 3.6. Жесткие и мягкие пределы заданного
ресурса представляются параметром rip, который указывает на структуру rlimit,
содержащую два объекта типа rlim_t.
struct rlimit
{
rlim_t rlim_cur;
r1im_t r1im_max;
};
Тип rlim_t — это целочисленный тип без знака. Член rlim_cur содержит значе-
ние текущего, или мягкого предела, а член rlim_шах — значение максимума, или же-
сткого предела. Членам rlim_cur и rlim_max можно присвоить любые значения,
а также символические константы, определенные в заголовке <sys/resource. h>.
RLIM_INFINITY Отсутствие ограничения.
RLIM_SAVED—МАХ Непредставимый хранимый жесткий предел.
RLIM_SAVED—CUR Непредставимый хранимый мягкий предел.
Как жесткий, так и мягкий пределы можно установить равными значению
RLIM__INFINITY, которое подразумевает, что ресурс неограничен.
Таблица 3.6. Значения параметра resource
Определение ресурса Описание
RLIMIT—CORE Максимальный размер файла ядра в байтах, который может быть создан процессом
RLIMIT—CPU Максимальный объем времени ЦП в секундах, которое может быть использовано процессом
RLIMIT—DATA Максимальный размер раздела данных процесса в байтах
RLIMIT—FSIZE Максимальный размер файла в байтах, который может быть соз- дан процессом
RLIMIT-NOFILE Увеличенное на единицу максимальное значение, которое систе- ма может назначить вновь созданному дескриптору файла
RLIMIT-STACK Максимальный размер стека процесса в байтах
^RLIMIT—as Максимальный размер доступной памяти процесса в байтах
gg Глава 3. Разбиение С++-программ на множество задач
Функция getrlimit () возвращает значения мягкого и жесткого пределов задан-
ного ресурса в объекте rip. Обе функции возвращают значение 0 при успешном за-
вершении и число -1 в противном случае. Пример установки процессом мягкого пре-
дела для размера файлов в байтах приведен в листинге 3.4.
// Листинг 3.4. Использование функции setrlimitO для
// установки мягкого предела для размера
// файлов
#include <sys/resource.h>
//. . .
struct rlimit R_limit;
struct rlimit R_limit—values;
//. . .
R_limit.rlim_cur = 2000;
R_limit.rlim_max = RLIM_SAVED_MAX;
setrlimit(RLIMIT_FSIZE,&R_limit);
getrlimit(RLIMIT_FSIZE,&R_limit—values);
cout « "мягкий предел для размера файлов: "
<< R_limit_values. rlim_cur
« endl;
//. . .
В листинге 3.4 мягкий предел для размера файлов устанавливается равным 2000
байт, а жесткий предел — максимально возможному значению. Функции setrlimit ()
передаются значения RLIMIT_FSIZE и R_limit, а функции getrlimit () — значения
RLIMIT__FSIZE и R_limit_values. После их выполнения на экран выводится уста-
новленное значение мягкого предела.
Функция getrusage () возвращает информацию об использовании ресурсов вы-
зывающим процессом. Она также возвращает информацию о сыновнем процессе, за-
вершения которого ожидает вызывающий процесс. Параметр who может иметь сле-
дующие значения:
RUSAGE_SELF
RUSAGE_CHILDREN
Если параметру who передано значение RUSAGE_SELF, то возвращаемая инфор-
мация будет относиться к вызывающему процессу. Если же параметр who содержит
значение RUSAGE_CHILDREN, то возвращаемая информация будет относиться к по-
томку вызывающего процесса. Если вызывающий процесс не ожидает завершения
своего потомка, информация, связанная с ним, отбрасывается (не учитывается)-
Возвращаемая информация передается через параметр r_usage, который указыва-
ет на структуру rusage. Эта структура содержит члены, перечисленные и описан-
ные в табл. 3.7. При успешном выполнении функция возвращает число 0, в против-
ном случае — число -1.
3.9. Асинхронные и синхронные процессы 97
Таблица 3.7. Члены структуры rusage
Член структуры Описание
^struct timeval ru_utime Время, потраченное пользователем
struct timeval ru_sutime Время, использованное системой
long rujnaxrss Максимальный размер, установленный для резидент- ной программы
long ru_maxixrss Размер разделяемой памяти
long ru_maxidrss Размер неразделяемой области данных
long ru_maxisrss Размер неразделяемой области стеков
long ru_minflt Количество запросов на страницы
1ong ru_maj f11 Количество ошибок из-за отсутствия страниц
long ru_nswap Количество перекачек страниц
long ru_inblock Блочные операции по вводу данных
long ru_oublock Блочные операции операций по выводу данных
long ru_msgsnd Количество отправленных сообщений
long rujnsgrcv Количество полученных сообщений
long ru_nsignaIs Количество полученных сигналов
long ru_nvcsw Количество преднамеренных переключений контекста
long ru_nivcsw Количество принудительных переключений контекста
3.9. Асинхронные и синхронные процессы
Асинхронные процессы выполняются независимо один от другого. Это означает,
что процесс А будет выполняться до конца безотносительно к процессу В. Между
асинхронными процессами могут быть прямые родственные (“родитель-сын”) отно-
шения, а могут и не быть. Если процесс А создает процесс В, они оба могут выпол-
няться независимо, но в некоторый момент родитель должен получить статус завер-
шения сыновнего процесса. Если между процессами нет прямых родственных отно-
шений, у них может быть общий родитель.
Асинхронные процессы могут выполняться последовательно, параллельно или с пе-
рекрытием. Эти сценарии изображены на рис. 3.12. В ситуации 1 до самого конца вы-
полняется процесс А, затем процесс В и процесс С выполняются до самого конца. Это
и есть последовательное выполнение процессов. В ситуации 2 процессы выполняются
одновременно. Процессы А и В — активные процессы. Во время выполнения процесса А
процесс В находится в состоянии ожидания. В течение некоторого интервала времени
а процесса пребывают в ждущем режиме. Затем процесс В “просыпается”, причем
раньше процесса А, а через некоторое время “просыпается” и процесс А, и теперь оба
процесса выполняются одновременно. Эта ситуация показывает, что асинхронные
процессы могут выполняться одновременно только в течение определенных интерва-
ле времени. В ситуации 3 выполнение процессов А и В перекрывается.
дя Глава 3. Разбиение С++-программ на множество задач
{^Ситуация 1 Г}
АСИНХРОННЫЕ ПРОЦЕССЫ
ПРОЦЕСС А
выполняется
ПРОЦЕСС В
ПРОЦЕСС С
выполняется ,
I
выполняется
ПРОЦЕСС А
ПРОЦЕСС В
выполняется ожидает выполняется
ожидает выполняется
яш* мм*» «ли* >м(^^^^ИМВИИИНВМВНИНИВ1
ПРОЦЕСС А
ПРОЦЕСС В
выполняется
ожидает выполняется
jwwssa жжк
ПРОЦЕСС А
СИНХРОННЫЕ ПРОЦЕССЫ
выполняется
ожидает
л»
выполняется
ПРОЦЕСС В
fork() '
у выполняется
• возвращает код выхода
Рис. 3.12. Возможные сценарии асинхронных и синхронных процессов
Асинхронные процессы могут совместно использовать такие ресурсы, как файлы
или память. Это может потребовать (или не потребовать) синхронизации или взаи-
модействия при разделении ресурсов. Если процессы выполняются последовательно
(ситуация 1), то они не потребуют никакой синхронизации. Например, все три про-
цесса, А, В и С, могут разделять некоторую глобальную переменную. Процесс А (перед
тем как завершиться) записывает значение в эту переменную, затем процесс В во вре-
мя своего выполнения считывает данные, хранимые в этой переменной и (перед тем
как завершиться) записывает в нее “свое” значение. Затем во время своего выполне-
ния процесс С считывает данные из этой переменной. Но в ситуациях 2 и 3 процессы
могут попытаться одновременно модифицировать эту переменную, поэтому здесь не
обойтись без синхронизации доступа к ней.
Мы определяем синхронные процессы как процессы с перемежающимся выпол-
нением, когда один процесс приостанавливает свое выполнение до тех пор, пока не
3.9. Асинхронные и синхронные процессы 99
завершится ДРУГОЙ- Например, процесс А, родительский, при выполнении создает
оцесс В, сыновний. Процесс А приостанавливает свое выполнение до тех пор,
пока не завершится процесс В. После завершения процесса В его выходной код по-
мещается в таблицу процессов. Тем самым процесс А уведомляется о завершении
процесса В. Процесс А может продолжить выполнение, а затем завершиться или за-
вершиться немедленно. В этом случае выполнение процессов А и В является син-
хронизированным. Сценарий синхронного выполнения процессов А и В (для срав-
нения с асинхронным) также показан на рис. 3.12.
3.9.1. Создание синхронных и асинхронных процессов
с помощью функций fork (), ехес (), system ()
и posix_spawn()
Функции fork (), fork-exec и posix_spawn () позволяют создавать асинхронные
процессы. При использовании функции fork() дублируется образ родительского
процесса. После создания сыновнего процесса эта функция возвращает родителю
(через параметр) идентификатор (PID) процесса-потомка и (обычным путем) число
О, означающее, что создание процесса прошло успешно. При этом родительский про-
цесс не приостанавливается; оба процесса продолжают выполняться независимо от
инструкции, следующей непосредственно за вызовом функции fork (). При создании
сыновнего процесса посредством f ork-exec-комбинации его образ инициализирует-
ся с помощью образа нового процесса. Если функция ехес () выполнилась успешно
(т.е. успешно прошла инициализация), она не возвращает родительскому процессу
никакого значения. Функции posix_spawn () создают образы сыновних процессов
и инициализируют их. Помимо идентификатора (PID), возвращаемого (через пара-
метр) функцией posix_spawn() родительскому процессу, обычным путем возвраща-
ется значение, служащее индикатором успешного порождения процесса. После вы-
полнения функции posix_spawn() оба процесса выполняются одновременно. Функ-
ция system О позволяет создавать синхронные процессы. При этом создается
оболочка, которая выполняет системную команду или запускает выполняемый файл.
В этом случае родительский процесс приостанавливается до тех пор, пока не завер-
шится сыновний процесс и функция system () не возвратит значение.
3.9.2. Функция wait ()
Асинхронный процесс, вызвав функцию wait (), может приостановить выполне-
ние до тех пор, пока не завершится сыновний процесс. После завершения сыновнего
пР°Цесса ожидающий родительский процесс считывает статус завершения своего по-
томка, чтобы не допустить создания процесса-“зомби”. Функция wait () получает ста-
тус завершения из таблицы процессов. Параметр status указывает на ту область, ко-
торая содержит статус завершения сыновнего процесса. Если родительский процесс
имеет не один, а несколько сыновних процессов и некоторые из них уже заверши-
ЛИсь’ функция wait () считывает из таблицы процессов статус завершения только для
°Дного сыновнего процесса. Если информация о статусе окажется доступной еще до
выполнения функции wait (), эта функция завершится немедленно. Если родитель-
СКий процесс не имеет ни одного потомка, эта функция возвратит код ошибки.
100 Глава 3. Разбиение С++-программ на множество задач
Функцию wait () можно использовать также в том случае, когда вызывающий про-
цесс должен ожидать до тех пор, пока не получит сигнал, чтобы затем выполнить оц.
ределенные действия по его обработке.
Синопсис
#include <sys/wait.h>
pid_t wait(int *status);
pid t waitpid(pid t pid, int *status, int options);
Функция waitpidO аналогична функции wait () за исключением того, что она
принимает дополнительные параметры pid и options. Параметр pid задает множе-
ство сыновних процессов, для которых считывается статус завершения. Другими сло-
вами, значение параметра pid определяет, какие процессы попадают в это множество.
pid > 0 Единственный сыновний процесс.
pid = 0 Любой сыновний процесс, групповой идентификатор которого совпа-
дает с идентификатором вызывающего процесса.
pid < -1 Любые сыновние процессы, групповой идентификатор которых равен
абсолютному значению pid.
pid = -1 Любые сыновние процессы.
Параметр options определяет, как должно происходить ожидание процесса,
и может принимать одно из значений следующих констант, определенных в заголовке
<sys/wait . h>:
WCONTINUED Сообщает статус завершения любого продолженного сыновнего про-
цесса (заданного параметром pid), о статусе которого не было доло-
жено с момента продолжения его выполнения.
WUNTRACED Сообщает статус завершения любого остановленного сыновнего про-
цесса (заданного параметром pid), о статусе которого не было доло-
жено с момента его останова.
WN0HANG Вызывающий процесс не приостанавливается, если статус завершения
заданного сыновнего процесса недоступен.
Эти константы могут быть объединены с помощью логической операции ИЛИ
и переданы в качестве параметра options (например, WCONTINUED | | WUNTRACED).
Обе эти функции возвращают идентификатор (PID) сыновнего процесса, для кото-
рого получен статус завершения. Если значение, содержащееся в параметре status,
равно числу 0, это означает, что сыновний процесс завершился при таких условиях:
• процесс вернул значение 0 из функции main ();
• процесс вызвал некоторую версию функции exit () с аргументом 0;
• процесс был завершен, поскольку завершился последний поток процесса.
В табл. 3.8 перечислены макросы, которые позволяют вычислить значение ста-
туса завершения.
3.10. Разбиение программы на задачи 101
Таблица 3.8. Макросы, которые позволяют вычислить значение статуса завершения
Макрос Описание
"wifexited Приводится к ненулевому значению, если статус был возвращен нормально завершенным сыновним процессом
WEXITSTATUS Если значение WIFEXITED оказывается ненулевым, то оцениваются младшие 8 бит аргумента status, переданного завершенным сынов- ним процессом функции _exit () или exit (), либо значения, воз- вращенного функцией main ()
WIFSIGNALED Приводится к ненулевому значению, если статус был возвращен от сыновнего процесса, который завершился, поскольку ему был послан сигнал, но этот сигнал не был перехвачен
WTERMSIG Если значение WIFSIGNALED оказывается ненулевым, то оценивает- ся номер сигнала, который послужил причиной завершения сынов- него процесса
WIFSTOPPED Приводится к ненулевому значению, если статус был возвращен от сыновнего процесса, который в данный момент остановлен
WSTOPSIG Если значение WIFSTOPPED оказывается ненулевым, то оценивается номер сигнала, который послужил причиной останова сыновнего процесса
WIFCONTINUED Приводится к ненулевому значению, если статус был возвращен от сыновнего процесса, который продолжил выполнение после сигнала останова, принятого от блока управления заданиями
3.10. Разбиение программы на задачи
Рассматривая разбиение программы на несколько задач, вы делаете первый шаг
к внесению параллелизма в свою программу. В однопроцессорной среде параллелизм
реализуется посредством многозадачности. Это достигается путем переключения про-
цессов. Каждый процесс выполняется в течение некоторого короткого интервала
времени, после чего процессор “передается” другому процессу. Это происходит на-
столько быстро, что создается иллюзия одновременного выполнения процессов,
многопроцессорной среде процессы, принадлежащие одной программе, могут быть
назначены одному или различным процессорам. Процессы, назначенные различным
процессорам, выполняются параллельно.
Различают два уровня параллельной обработки в приложении или системе:
, Ровень процессов и уровень потоков. Параллельная обработка на уровне пото-
ков носит название многопоточности (она рассматривается в следующей главе).
°оы разумно разделить программу на параллельные задачи, необходимо опре-
делить, где “гнездится” параллелизм и где можно воспользоваться преимуществами от
ег° реализации. Иногда в параллелизме нет насущной необходимости. Программа
Может интерпретироваться с учетом параллелизма, но и при последовательном
102 Глава 3. Разбиение С++-программ на множество задач
выполнении действий она прекрасно работает. Безусловно, внесение паралле-
лизма может повысить ее быстродействие и понизить уровень сложности. Одни
программы обладают естественным параллелизмом, а другим больше подходит
последовательное выполнение действий. Программы также могут иметь двойст-
венную интерпретацию.
При декомпозиции программы на функции обычно используется нисходящий
принцип, а при разделении на объекты — восходящий. При этом необходимо опреде-
лить, какие функции или объекты лучше реализовать в виде отдельных программ или
подпрограмм, а какие — в виде потоков. Подпрограммы должны выполняться опера-
ционной системой как процессы. Отдельные подпрограммы, или процессы, выпол-
няют задачи, порученные проектировщиком ПО.
Задачи, на которые будет разделена программа, могут выполняться параллельно,
причем здесь можно выделить следующие три способа реализации параллелизма.
1. Выделение в программе одной основной задачи, которая создает некоторое
количество подзадач.
2. Разделение программы на множество отдельных выполняемых файлов.
3. Разделение программы на несколько задач разного типа, отвечающих за созда-
ние других подзадач только определенного типа.
Эти способы реализации параллелизма отображены на рис. 3.13.
Например, эти методы реализации параллелизма можно применить к программе
визуализации. Под визуализацией будем понимать процесс перехода от представле-
ния трехмерного объекта в форме записей базы данных в двухмерную теневую гра-
фическую проекцию на поверхность отображения (экран дисплея). Изображение
представляется в виде теневых многоугольников, повторяющих форму объекта.
Этапы визуализации показаны на рис. 3.14. Визуализацию можно разбить на ряд от-
дельных задач.
1. Установить структуру данных для сеточных моделей многоугольников.
2. Применить линейные преобразования.
3. Отбраковать многоугольники, относящиеся к невидимой поверхности.
4. Выполнить растеризацию.
5. Применить алгоритм удаления скрытых поверхностей.
6. Затушевать отдельные пиксели.
Первая задача состоит в представлении объекта в виде массива многоугольни-
ков, в котором каждая вершина многоугольника описывается в трехмерной миро-
вой системе координат. Вторая задача — применить линейные преобразования к се-
точной модели многоугольников. Эти преобразования используются для позицио-
нирования объектов на сцене и создания точки обзора или поверхности
отображения (области, которая видима наблюдателю с его точки обзора). Третья
задача — отбраковать невидимые поверхности объектов на сцене. Это означает уда'
ление линий, принадлежащих тем частям объектов, которые невидимы с точки об-
зора. Четвертая задача — преобразовать модель вершин в набор координат пиксе-
лей. Пятая задача — удалить любые скрытые поверхности. Если сцена содержит
3.10. Разбиение программы на задачи 103
иМОДействУющие °бъекты» например, когда одни объекты заслоняют другие, то
в ь1Тые (передними объектами) поверхности должны быть удалены. Шестая зада-
наложить на поверхности изображения тень.
СПОСОБ 1
Представление программы в виде
родительского процесса, который
создает некоторое количество
сыновних процессов
ПРОГРАММА
СПОСОБ 2
Разделение программы на
множество отдельных
выполняемых файлов
ПРОГРАММА
СПОСОБ 3
Разделение программы на
несколько процессов, отвечающих
за создание других процессов
только определенного типа
рис. 3.13. Способы разбиения программы на отдельные задачи
104 Глава 3. Разбиение С++-программ на множество задач
ЭТАПЫ ВИЗУАЛИЗАЦИИ
№ вершины х у z
1 1,40000 0,00000 2,30000
2 1,40000 -0,78400 2,30000
3 0,78400 -1,40000 2,30000
4 0,00000 -1,40000 2,30000
5 1,33750 0,00000 2,53125
6 1,33750 -0,75000 2,53125
7 0,74900 -1,33700 2,53125
8 0,00000 -1,33700 2,53125
9 1,43750 0,00000 2,53125
10 1,43750 -0,90500 2,53125
306 1,42500 -0,79800 0,00000
1. Представление трехмерного
объекта в виде записей
базы данных.
2. Построение многоугольной 3. Наложение тени на
сеточной модели трехмерный объект,
трехмерного объекта.
Рис. 3.14. Этапы визуализации
Решение каждой задачи представляется в виде отдельного выполняемого файла.
Первые три задачи (Taskl, Task2 и Task3) выполняются последовательно, а осталь-
ные три (Task4, Task5 и Task6) — параллельно. Реализация первого способа созда-
ния программы визуализации приведена в листинге 3.5.
// Листинг 3.5. Использование способа 1
// для создания процессов
#include <spawn.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/wait.h>
#include <errno.h>
#include <unistd.h>
int main(void)
{
posix_spawnattr_t Attr;
posix_spawn—file_actions—t FileActions;
char *const argv4[] = {"Task4",...,NULL};
char *const argv5[] = {"Task5NULL};
char *const argv6[] = {"Task6NULL};
pid_t Pid;
int stat;
//. . .
// Выполняем первые три задачи синхронно,
system("Taskl ...");
system("Task2 ...");
system(”Task3 ...");
3.10. Разбиение программы на задачи 105
/ инициализируем структуры.
z/ ix__spawnattr_init(&Attr) ;
^osix spawn_file_actions—init (&FileActions)
. выполняем последние три задачи асинхронно.
ix spawn(&Pid,"Task4",&FileActions,&Attr,argv4,NULL)
^°^x""spawn (&Pid, "Task5", &FileActions, &Attr, argv5, NULL)
P°sixZspawn(&Pid, "Taske”,&FileActions,&Attr,argv6,NULL)
// Подобно хорошему родителю, ожидаем возвращения
// своих "детей".
wait (&stat);
wait (fcstat);
wait (fcstat);
return(0);
}
В листинге 3.5 из функции main () с помощью функции system () вызываются на
выполнение задачи Taskl, Task2 и Task3. Каждая из них выполняется синхронно
с родительским процессом. Задачи Task4, Task5 и Task6 выполняются асинхронно
родительскому процессу благодаря использованию функций posix—spawn(). Много-
точие (...) используется для обозначения файлов, требуемых задачам. Родительский
процесс вызывает три функции wait (), и каждая из них ожидает завершения одной
из задач (Task4, Task5 или Task6).
Используя второй способ, программу визуализации можно запустить из сценария
командной оболочки. Преимущество этого сценария состоит в том, что он позволяет
использовать все команды и операторы оболочки. В нашей программе визуализации
для управления выполнением задач используются метасимволы & и &&.
Taskl . . . && Task2 . . . && Task3
Task4 ... & Task5 ... & Task6
Здесь благодаря использованию метасимвола && задачи Taskl, Task2 и Task3 вы-
полняются последовательно при условии успешного выполнения предыдущей задачи.
Задачи же Task4, Task5 и Task6 выполняются одновременно, поскольку использо-
ван метасимвол &. Приведем некоторые метасимволы, применяемые при разделении
команд в средах UNIX/Linux, и способы выполнения этих команд.
&& Каждая следующая команда будет выполняться только в случае успешного вы-
полнения предыдущей команды.
। । Каждая следующая команда будет выполняться только в случае неудачного
выполнения предыдущей команды.
Команды должны выполняться последовательно.
Все команды должны выполняться одновременно.
При использовании третьего способа задачи делятся по категориям. При декомпо-
зиции программы следует разобраться, можно ли в ней выделить различные катего-
рии задач. Например, одни задачи могут “отвечать” за интерфейс пользователя, т.е.
ци Создание» ввод Данных, вывод данных и пр. Другим задачам поручаются вычисле-
’ Управление данными и пр. Такой подход весьма полезен не только при проекти-
ании программы, но и при ее реализации. В нашей программе визуализации мы
Жем Разделить задачи по следующим категориям:
106 Глава 3. Разбиение С++-программ на множество задач
• задачи, которые выполняют линейные преобразованиям
преобразования изображения на экране при изменении точки обзора;
преобразования сцены;
• задачи, которые выполняют растеризацию.
вычерчивание линий;
заливка участков сплошного фона;
растеризация многоугольников;
• задачи, которые выполняют удаление поверхностей:
удаление скрытых поверхностей;
удаление невидимых поверхностей;
• задачи, которые выполняют наложение теней:
затенение отдельных пикселей;
затенение изображения в целом.
Разбиение задач по категориям позволяет нашей программе приобрести более
общий характер. Процессы при необходимости создают другие процессы, предназна-
ченные для выполнения действий только определенной категории. Например, если
нашей программе предстоит визуализировать лишь один объект, а не всю сцену, то
нет никакой необходимости порождать процесс, который выполняет удаление скры-
тых поверхностей; вполне достаточно будет удаления невидимых поверхностей
(одного объекта). Если объект не нужно затенять, то нет необходимости порождать
задачу, выполняющую наложение тени; обязательным остается лишь линейное пре-
образование при решении задачи растеризации. Для запуска программы с использо-
ванием третьего способа можно использовать родительский процесс или сценарий
оболочки. Родительский процесс может определить, какой нужен тип визуализации,
и передать соответствующую информацию каждому из специализированных процес-
сов, чтобы они “знали”, какие процессы им следует порождать. Эта информация мо-
жет быть также перенаправлена каждому из специализированных процессов из сце-
нария оболочки. Реализация третьего способа представлена в листинге 3.6.
// Листинг 3.6. Использование третьего метода для
// создания процессов. Задачи запускаются из
// родительского процесса
#include <spawn.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/wait.h>
#include <errno.h>
#include <unistd.h>
int main(void)
{
posix_spawnattr_t Attr;
posix_spawn_file_actions_t FileActions;
pid_t Pid;
int stat;
3.10. Разбиение программы на задачи 107
system("Taskl ...");
// Выполняется безотносительно к
// типу используемой визуализации.
Определяем, какой нужен тип визуализации. Это можно
. сделать, получив информацию от пользователя или
// выполнив специальный анализ.
// затем сообщаем о результате другим задачам с помощью
// аргУментов•
char *const argv4[] = {"TaskType4NULL};
char *const argv5[] = {"TaskType5NULL};
char *const argv6[] = {”TaskType6NULL};
system("TaskType2 ...");
system("TaskType3
11 Инициализируем структуры.
posix_spawnattr_init (&Attr) ;
posix_spawn_f ile_actions_init (&FileActions) ;
posix_spawn (&Pid, " TaskType4", &FileActions, &Attr, argv4,
NULL);
posix_spawn (&Pid, "TaskType5", &FileActions, &Attr, argv5,
NULL);
if(Y){
posix—spawn(&Pid,"TaskType6",&FileActions,&Attr,
argv6,NULL);
}
// Подобно хорошему родителю, ожидаем возвращения
// своих "детей".
wait(&stat);
wait(&stat);
wait(&stat);
return(0) ;
}
// Bee TaskType-задачи должны быть аналогичными.
И. . .
int main(int argc, char *argv[])
int Rt;
//. . .
if(argv[l] == X){
/I Инициализируем структуры.
//. . .
posix_spawn(&Pid,"TaskTypeX",&FileActions,&Attr,...,
j NULL);
else{
// Инициализируем структуры.
108 Глава 3. Разбиение С++-программ на множество задач
//.. •
posix_spawn(&Pid,"TaskTypeY",&FileActions,&Attr,
...,NULL);
}
wait(&stat);
exi t(0);
}
В листинге 3.6 тип каждой задачи (а следовательно, и тип порождаемого процесса)
определяется на основе информации, передаваемой от родительского процесса или
сценария оболочки.
3.10.1. Линии видимого контура
Порождение процессов, как показано в листинге 3.7, возможно с помощью функ-
ций, вызываемых из функции main ().
// Листинг 3.7. Стержневая ветвь программы, из которой
// вызывается функция, порождающая процесс
int main(int argc, char *argv[])
{
Rt = funcl(X, Y, Z);
//. . .
}
// Определение функции.
int fund (char *M, char *N, char *V)
{
//. . .
char ‘const args[] = {"TaskX",M,N,V,NULL};
Pid - fork();
if(Pid == 0)
{
exec("TaskX",args);
}
if(Pid > 0)
{
//. . .
}
wait(&stat);
)
В листинге 3.7 функция fund () вызывается с тремя аргументами. Эти аргументы пе-
редаются порожденному процессу.
Процессы также могут порождаться из методов, принадлежащих объектам. Как
показано в листинге 3.8, объекты можно объявить в любом процессе.
3.11. Резюме 109
11 листинг 3.8.
Объявление объекта в процессе
//•••
my_object MyObject;
//-••
// объявление и определение класса.
class my_object
(
public:
//• • •
int spawnProcess(int X) ;
//...
};
int my_object:: spawnProcess (int X)
{
//. . .
// posix_spawn() или systemf)
//. . .
}
Как показано в листинге 3.8, объект может создавать любое количество процессов из
любого метода.
3.11. Резюме
Параллелизм в С++-программе достигается за счет ее разложения на несколько
процессов или несколько потоков. Процесс— это “единица работы”, создаваемая
операционной системой. Если программа— это артефакт (продукт деятельности)
разработчика, то процесс — это артефакт операционной системы. Приложение может
состоять из нескольких процессов, которые могут быть не связаны с какой-то кон-
кретной программой. Операционные системы способны управлять сотнями и даже
тысячами параллельно загруженных процессов.
Некоторые данные и атрибуты процесса хранятся в блоке управления процессами
(process control block — РСВ), или БУП, используемом операционной системой для
Идентификации процесса. С помощью этой информации операционная система
Управляет процессами. Многозадачность (выполнение одновременно нескольких
Процессов) реализуется путем переключения контекста. Текущее состояние выпол-
няемого процесса и его контекст сохраняются в БУП-блоке, что позволяет успешно
возобновить этот процесс в следующий раз, когда он будет назначен центральному
Процессору. Занимая процессор, процесс пребывает в состоянии выполнения, а когда
ожидает использования ЦП, — то в состоянии готовности (ожидания). Получить
формацию о процессах, выполняющихся в системе, можно с помощью утилиты ps.
1 процессы, которые создают другие процессы, вступают с ними в “родственные”
Цььи-дети) отношения. Создатель процесса называется родительским, а создан-
110 Глава 3. Разбиение С++-программ на множество задач
ный процесс — сыновним. Сыновние процессы наследуют от родительских множе-
ство атрибутов. “Святая обязанность” родительского процесса-- подождать, пока
сыновний не покинет систему. Для создания процессов предусмотрены различные
системные функции: fork (), fork-exec (), system () и posit_spawn (). Функции
forkO, fork-exec О и posix__spawn () создают процессы, которые являются
асинхронными, в то время как функция system () создает сыновний процесс, ко-
торый является синхронным по отношению к родительскому. Асинхронные роди-
тельские процессы могут вызвать функцию wait (), после чего “синхронно” ожи-
дать, пока сыновние процессы не завершатся или пока не будут считаны коды за-
вершения для уже завершившихся сыновних процессов.
Программу можно разбить на несколько процессов. Эти процессы может породить
родительский процесс, либо они могут быть запущены из сценария оболочки как от-
дельные выполняемые программы. Специализированные процессы могут при необ-
ходимости порождать другие процессы, предназначенные для выполнения действий
только определенного типа. Порождение процессов может быть осуществлено как из
функций, так и из методов.
РАЗБИЕНИЕ С++-
ПРОГРАММ
НА МНОЖЕСТВО
ПОТОКОВ
В этой главе...
4.1. Определение потока
4.2. Анатомия потока
4.3. Планирование потоков
4.4. Ресурсы потоков
4.5. Модели создания и функционирования потоков
4.6. Введение в библиотеку Pthread
4.7. Анатомия простой многопоточной программы
4.8. Создание потоков
4.9. Управление потоками
4.10. Безопасность использования потоков и библиотек
4.11. Разбиение программы на несколько потоков
4.12. Резюме
Непрерывное усложнение компьютерных систем вселяет в нас надежду, что
мы и в дальнейшем сможем успешно управлять этим видом абстракции.
— Эндрю Кёниг и Барбара Му (Andrew Koening and Barbara Moo), Ruminations on C++
Работу любой последовательной программы можно разделить между нескольки-
ми подпрограммами. Каждой подпрограмме назначается конкретная задача,
и все эти задачи выполняются одна за другой. Вторая задача не может начаться
до тех пор, пока не завершится первая, а третья — пока не закончится вторая и т.д.
Описанная схема прекрасно работает до тех пор, пока не будут достигнуты границы
производительности и сложности. В одних случаях единственное решение проблемы
производительности — найти возможность выполнять одновременно более одной за-
дачи. В других ситуациях работа подпрограмм в программе настолько сложна, что
имеет смысл представить эти подпрограммы в виде мини-программ, которые выпол-
няются параллельно внутри основной программы. В главе 3 были представлены мето-
ды разбиения одной программы на несколько процессов, каждый из которых выпол-
няет отдельную задачу. Такие методы позволяют приложению в каждый момент вре-
мени выполнять сразу несколько действий. Однако в этом случае каждый процесс
имеет собственные адресное пространство и ресурсы. Поскольку каждый процесс за-
нимает отдельное адресное пространство, то взаимодействие между процессами пре-
вращается в настоящую проблему. Для обеспечения связи между раздельно выпол-
няемыми частями общей программы нужно реализовать такие средства межпроцесс-
ного взаимодействия, как каналы, FIFO-очереди (с дисциплиной обслуживания по
принципу “первым пришел — первым обслужен”) и переменные среды. Иногда нужно
иметь одну программу (которая выполняет несколько задач одновременно), не разби-
вая ее на множество мини-программ. В таких обстоятельствах можно использовать
4.1. Определение потока 113
потоки. Потоки позволяют одной программе состоять из параллельно выполняемых
частей, причем все части имеют доступ к одним и тем же переменным, константам и ад-
еному пространству в целом. Потоки можно рассматривать как мини-программы в ос-
новной программе. Если программа разделена на несколько процессов, как было пока-
зано в главе 3, то с выполнением каждого отдельного процесса связаны определенные
затраты системных ресурсов. Для потоков требуется меньший объем затрат системных
песурсов. Поэтому потоки можно рассматривать как облегченные процессы, т.е. они позво-
ляют воспользоваться многими преимуществами процессов без больших затрат на орга-
низацию взаимодействия между ними. Потоки обеспечивают средства разделения ос-
новного “русла” программы на несколько параллельно выполняемых “ручейков”.
4.1. Определение потока
Под потоком подразумевается часть выполняемого кода в UNIX- или Linux-процессе,
которая может быть регламентирована определенным образом. Затраты вычислитель-
ных ресурсов, связанные с созданием потока, его поддержкой и управлением, у опера-
ционной системы значительно ниже по сравнению с аналогичными затратами для про-
цессов, поскольку объем информации отдельного потока гораздо меньше, чем у процес-
са. Каждый процесс имеет основной, или первичный, поток. Под основным потоком
процесса понимается программный поток управления или поток выполнения. Процесс
может иметь несколько потоков выполнения и, соответственно, столько же потоков
управления. Каждый поток, имея собственную последовательность инструкций, выпол-
няется независимо от других, а все они — параллельно друг другу. Процесс с нескольки-
ми потоками, называется многопоточным. Многопоточный процесс, состоящий из не-
скольких потоков, показан на рис. 4.1.
ПОТОКИ ВЫПОЛНЕНИЯ ПРОЦЕССА
Рис. 4.1. Потоки выполнения многопоточного процесса
114 Глава 4. Разбиение С++-программ на множество потоков
4.1.1. Контекстные требования потока
Все потоки одного процесса существуют в одном и том же адресном пространстве.
Все ресурсы, принадлежащие процессу, разделяются между потоками. Потоки не вла-
деют никакими ресурсами. Ресурсы, которыми владеет процесс, совместно использу-
ются всеми потоками этого процесса. Потоки разделяют дескрипторы файлов и фай-
ловые указатели, но каждый поток имеет собственные программный указатель, набор
регистров, состояние и стек. Все стеки потоков находятся в стековом разделе своего
процесса. Раздел данных процесса совместно используется потоками процесса. Поток
может считывать (и записывать) информацию из области памяти своего процесса. Ко-
гда основной поток записывает данные в память, то любые сыновние потоки могут по-
лучить к ним доступ. Потоки могут создавать другие потоки в пределах того же про-
цесса. Все потоки в одном процессе считаются равноправными. Потоки также могут
приостановить, возобновить или завершить другие потоки в своем процессе.
Потоки — это выполняемые части программы, которые соревнуются за использо-
вание процессора с потоками того же самого или других процессов. В многопроцес-
сорной системе потоки одного процесса могут выполняться одновременно на раз-
личных процессорах. Однако потоки конкретного процесса выполняются только на
процессоре, который назначен этому процессу. Если, например, процессоры 1, 2 и 3
назначены процессу А, а процесс А имеет три потока, то любой из них может быть на-
значен любому процессору. В среде с одним процессором потоки конкурируют за его
использование. Параллельность же достигается за счет переключения контекста. Кон-
текст переключается, если операционная система поддерживает многозадачность при
наличии единственного процессора. Многозадачность позволяет на одном процессоре
одновременно выполнять несколько задач. Каждая задача выполняется в течение выде-
ленного интервала времени. По истечении заданного интервала или после наступления
некоторого события текущая задача снимается с процессора, а ему назначается другая
задача. Когда потоки выполняются параллельно в одном процессе, то о таком процессе
говорят, что он — многопоточный. Каждый поток выполняет свою подзадачу таким обра-
зом, что подзадачи процесса могут выполняться независимо от основного потока управ-
ления процесса. При многозадачности потоки могут конкурировать за использование
одного процессора или назначаться другим процессорам. Но в любом случае переклю-
чение контекста между7 потоками одного и того же процесса требует меньше ресурсов,
чем переключение контекста между потоками различных процессов. Процесс использу-
ет много систехмных ресурсов для отслеживания соответствующей информации, а на
управление этой информацией при переключении контекста между процессами требу-
ется значительное время. Большая часть информации, содержащейся в контексте про-
цесса, описывает адресное пространство процесса и ресурсы, которыми он владеет.
Переключаясь между потоками, определенными в различных адресных пространствах,
контекст переключается и между процессами. Поскольку потоки в рамках одного про-
цесса не имеют собственного адресного пространства (или ресурсов), то операционной
системе приходится отслеживать меньший объем информации. Контекст потока со-
стоит только из идентификационного номера (id), стека, набора регистров и приори-
тета. В регистрах содержится програмхмный указатель и указатель стека. Текст
(программный код) потока содержится в текстовом разделе соответствующего про-
цесса. Поэтому переключение контекста между потоками одного процесса займет
меньше времени и потребует меньшего объема системных ресурсов.
4.1. Определение потока 115
4.1.2. Сравнение потоков и процессов
У потоков и процессов есть много общего. Они имеют идентификационный но-
мер (id), состояние, набор регистров, приоритет и привязку к определенной стра-
тегии планирования. Подобно процессам, потоки имеют атрибуты, которые опи-
сывают их для операционной системы. Эта информация содержится в информаци-
онном блоке потока, подобном информационному блоку процесса. Потоки
и сыновние процессы разделяют ресурсы родительского процесса. Ресурсы, откры-
тые родительским процессом (в его основном потоке), немедленно становятся дос-
тупными всем потокам и сыновним процессам. При этом никакой дополнительной
инициализации или подготовки не требуется. Потоки и сыновние процессы неза-
висимы от родителя (создателя) и конкурируют за использование процессора. Соз-
датель процесса или потока управляет своим потомком, т.е. он может отменить,
приостановить или возобновить его выполнение либо изменить его приоритет.
Поток или процесс может изменить свои атрибуты и создать новые ресурсы, но не
может получить доступ к ресурсам, принадлежащим другим процессам. Однако ме-
жду потоками и процессами есть множество различий.
4.1.2.1. Различия между потоками и процессами
Основное различие между потоками и процессами состоит в том, что каждый про-
цесс имеет собственное адресное пространство, а потоки — нет. Если процесс создает
множество потоков, то все они будут содержаться в его адресном пространстве. Вот
почему они так легко разделяют общие ресурсы, и так просто обеспечивается взаимо-
действие между ними. Сыновние процессы имеют собственные адресные простран-
ства и копии разделов данных. Следовательно, когда процесс-потомок изменяет свои
переменные или данные, это не влияет на данные родительского процесса. Если не-
обходимо, чтобы родительский и сыновний процессы совместно использовали дан-
ные, нужно создать общую область памяти. Для передачи данных между родителем
и потомком используются такие механизмы межпроцессного взаимодействия, как ка-
налы и FIFO-очереди. Потоки одного процесса могут передавать информацию и свя-
зываться друг с другом путем непосредственного считывания и записи общих данных,
которые доступны родительскому процессу.
4.1.2.2. Потоки, управляющие другими потоками
В то время как процессы могут управлять другими процессами, если между ними
установлены отношения типа “родитель-потомок”, потоки одного процесса счита-
ются равноправными и находятся на одном уровне, независимо от того, кто кого
создал. Любой поток, имеющий доступ к идентификационному7 номеру (id) некото-
рого другого потока, может отменить, приостановить, возобновить выполнение
этого потока либо изменить его приоритет. Отмена основного потока приведет
к завершению всех потоков процесса, т.е. к ликвидации процесса. Любые измене-
ния, внесенные в основной поток, могут повлиять на все потоки процесса. При из-
менении приоритета процесса все его потоки, которые унаследовали этот приори-
тет, должны также изменить свои приоритеты. Сходства и различия между потока-
ми и процессами сведены в табл. 4.1.
116 Глава 4. Разбиение С++-программ на множество потоков
Таблица 4.1. Сходства и различия между потоками и процессами
Сходства Различия
Оба имеют идентификационный
номер (id), состояние, набор реги-
стров, приоритет и привязку
к определенной стратегии плани-
рования
И поток, и процесс имеют атрибу-
ты, которые описывают их особенно-
сти для операционной системы
Как поток, так и процесс имеют
информационные блоки
Оба разделяют ресурсы с роди-
тельским процессом
Оба функционируют независимо от
родительского процесса
Их создатель может управлять по-
током или процессом
И поток, и процесс могут изменять
свои атрибуты
Оба могут создавать новые ресурсы
Как поток, так и процесс не имеют
доступа к ресурсам другого процесса
Потоки разделяют адресное пространство
процесса, который их создал; процессы имеют
собственное адресное пространство
Потоки имеют прямой доступ к разделу данных
своего процесса; процессы имеют собственную
копию раздела данных родительского процесса
Потоки могут напрямую взаимодействовать
с другими потоками своего процесса; процессы
должны использовать специальный механизм
межпроцессного взаимодействия для связи с
“братскими” процессами
Потоки почти не требуют системных затрат-
на поддержку процессов требуются значитель-
ные затраты системных ресурсов
Новые потоки создаются легко; новые процессы
требуют дублирования родительского процесса
Потоки могут в значительной степени управ-
лять потоками того же процесса; процессы
управляют только сыновними процессами
Изменения, вносимые в основной поток
(отмена, изменение приоритета и т.д.), могут
влиять на поведение других потоков процесса;
изменения, вносимые в родительский про-
цесс, не влияют на сыновние процессы
4.1.3. Преимущества использования потоков
При управлении подзадачами приложения использование потоков имеет ряд
преимуществ.
• Для переключения контекста требуется меньше системных ресурсов.
• Достигается более высокая производительность приложения.
• Для обеспечения взаимодействия между задачами не требуется никакого спе-
циального механизма.
• Программа имеет более простую структуру.
4.1.3.1. Переключение контекста при низкой (ограниченной)
доступности процессора
При организации процесса для выполнения возложенной на него функции может
оказаться вполне достаточно одного основного потока. Если же процесс имеет множе-
ство параллельных подзадач, то их асинхронное выполнение можно обеспечить с по-
мощью нескольких потоков, на переключение контекста которых потребуются незна-
чительные затраты системных ресурсов. При ограниченной доступности процессора
4.1. Определение потока 117
или при наличии в системе только одного процессора параллельное выполнение про-
цессов потребует существенных затрат системных ресурсов в связи с необходимостью
обеспечить переключение контекста. В некоторых ситуациях контекст процессов пере-
ключается только тогда, когда процессору последовательно назначаются потоки из разных
процессов. Под системными затратами подразумеваются не только системные ресурсы, но
и время, требуемое на переключение контекста. Но если система содержит достаточное
количество процессоров, то переключение контекста не является проблемой.
4.1.3.2. Возможности повышения производительности приложения
Создание нескольких потоков повышает производительность приложения. При
использовании одного потока запрос к устройствам ввода-вывода может остановить
весь процесс. Если же в приложении организовано несколько потоков, то пока один
из них будет ожидать удовлетворения запроса ввода-вывода, другие потоки, которые
не зависят от заблокированного, смогут продолжать выполнение. Тот факт, что не
все потоки ожидают завершения операции ввода-вывода, означает, что приложение
в целом не заблокировано ожиданием, а продолжает работать.
4.1.3.3. Простая схема взаимодействия между параллельно
выполняющимися потоками
Потоки не требуют специального механизма взаимодействия между7 подзадачами. По-
токи могут напрямую передавать данные другим потокам и получать данные от них, что
также способствует экономии системных ресурсов, которые при использовании несколь-
ких процессов пришлось бы направлять на настройку и поддержку специальных механиз-
мов взаимодействия. Потоки же используют общую память, выделяемую в адресном про-
странстве процесса. Процессы также могут взаимодействовать через общую память, но
они имеют раздельные адресные пространства, и поэтому такая общая память должна
быть вне адресных пространств обоих взаимодействующих процессов. Этот подход уве-
личит временные и пространственные расходы системы на поддержку и доступ к общей
памяти. Схема взаимодействия между потоками и процессами показана на рис. 4.2.
4.1.3.4. Упрощение структуры программы
Потоки можно использовать, чтобы упростить структуру приложения. Каждому
потоку назначается подзадача или подпрограмма, за выполнение которой он отвеча-
ет. Поток должен независимо управлять выполнением своей подзадачи. Каждому по-
току можно присвоить приоритет, отражающий важность выполняемой им задачи
Для приложения. Такой подход позволяет упростить поддержку программного кода.
4.1.4. Недостатки использования потоков
Простота доступности потоков к памяти процесса имеет свои недостатки.
• Потоки могут легко разрушить адресное пространство процесса.
• Потоки необходимо синхронизировать при параллельном доступе (для чтения
или записи) к памяти.
• Один поток может ликвидировать целый процесс или программу7.
• Потоки существуют только в рамках единого процесса и, следовательно, не яв-
ляются многократно используемыми.
118 Глава 4. Разбиение С++-программ на множество потоков
адресное пространство процесса а
Рис. 4.2. Взаимодействие между потоками одного процесса и взаимодействие между
несколькими процессами
4.1.4.1. Потоки могут легко разрушить адресное пространство
процесса
Потоки могут легко разрушить информацию процесса во время “гонки” данных,
если сразу несколько потоков получат доступ для записи одних и тех же данных. При
использовании процессов это невозможно. Каждый процесс имеет собственные дан-
ные, и другие процессы не в состоянии получить к ним доступ, если не сделать это
специально. Защита информации обусловлена наличием у процессов отдельных ад-
ресных пространств. Тот факт, что потоки совместно используют одно и то же адресное
пространство, делает данные незащищенными от искажения. Например, процесс имеет
три потока — А, В и С. Потоки А и В записывают информацию в некоторую область па-
мяти, а поток С считывает из нее значение и использует его для вычислений. Потоки А
и В могут попытаться одновременно записать информацию в эту область памяти. Поток
В может перезаписать данные, записанные потоком А, еще до того, как поток С получит
возможность считать их. Поведение этих потоков должно быть синхронизировано та-
ким образом, чтобы поток С мог считать данные, записанные потоком А, до того, как
поток В их перезапишет. Синхронизация защищает данные от перезаписи до их ис-
пользования. Тема синхронизации потоков рассматривается в главе 5.
4.2. Анатомия потока 119
4.1.4.2. Один поток может ликвидировать целую программу
Поскольку потоки не имеют собственного адресного пространства, они не изоли-
оованы. Если поток стал причиной фатального нарушения доступа, это может при-
вести к завершению всего процесса. Процессы изолированы друг от друга. Если про-
цесс разрушит свое адресное пространство, проблемы ограничатся этим процессом.
Процесс может допустить нарушение доступа, которое приведет к его завершению,
но все остальные процессы будут продолжать выполнение. Это нарушение не окажет-
ся фатальным для всего приложения. Ошибки, связанные с некорректностью данных,
могут не выйти за рамки одного процесса. Но ошибки, вызванные некорректным по-
ведением потока, как правило, гораздо серьезнее ошибок, допущенных процессом.
Потоки могут стать причиной ошибок, которые повлияют на все адресное простран-
ство всех потоков. Процессы защищают свои ресурсы от беспорядочного доступа со
стороны других процессов. Потоки же совместно используют ресурсы со всеми ос-
тальными потоками процесса. Поэтому поток, разрушающий ресурсы, оказывает не-
гативное влияние на процесс или программу в целом.
4.1.4.3. Потоки не могут многократно использоваться другими
программами
Потоки зависят от процесса, в котором они существуют, и их невозможно от него
отделить. Процессы отличаются большей степенью независимости, чем потоки. При-
ложение можно так разделить на задачи, порученные процессам, что эти процессы
можно оформить в виде модулей, которые возможно использовать в других приложе-
ниях. Потоки не могут существовать вне процессов, в которых они были созданы и,
следовательно, они не являются повторно используемыми. Преимущества и недос-
татки потоков сведены в табл. 4.2.
4.2. Анатомия потока
Образ потока встраивается в образ процесса. Как было описано в главе 3, процесс
имеет разделы программного кода, данных и стеков. Поток разделяет разделы кода
и данных с остальными потоками процесса. Каждый поток имеет собственный стек,
выделенный ему в стековом разделе адресного пространства процесса. Размер пото-
кового стека устанавливается при создании потока. Если создатель потока не опреде-
ляет размер его стека, то система назначает размер по умолчанию. Размер, устанавли-
ваемый по умолчанию, зависит от конкретной системы, максимально возможного ко-
личества потоков в процессе, размера адресного пространства, выделяемого
процессу, и пространства, используемого системными ресурсами. Размер потокового
стека должен быть достаточно большим для любых функций, вызываемых потоком,
любого кода, который является внешним по отношению к процессу (например, это
Может быть библиотечный код), и хранения локальных переменных. Процесс с не-
сколькими потоками должен иметь стековый раздел, который будет вмещать все сте-
ки его потоков. Адресное пространство, выделенное для процесса, ограничивает раз-
мер стека, ограничивая тем самым размер, который может иметь каждый поток. На
рис. 4.3 показана схема процесса, который содержит два потока.
Как показано на рис. 4.3. процесс содержит два потока А и В, и их стеки располо-
жены в стековом разделе процесса. Потоки выполняют различные функции: поток А
выполняет функцию fund (), а поток В — функцию func2 ().
120 Глава 4. Разбиение С++-программ на множество потоков
1 Атрибуты
И 345 priority = 2 size ...
[AttrObjB^^Hl । ThreadA
scope = process stack size = 1000 priority = 2 joinable //...
Атрибуты priority - 2
Регистры
Регистры
SPi<
ФО
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА
РАЗДЕЛ СТЕКОВ
Стек потока ThreadB
func2()
Count - 100
PC
size ...
main()
AttrObj
РАЗДЕЛ КОДА
pthread_attrJnit(&AttrObj);
pthread_create(&ThreadA?&AttrObj.func1.
pthread_create(&ThreadB,&AttrObj;func2,.
Стек потока ThreadA
fund ()
Count = 10
РАЗДЕЛ ДАННЫХ
ThreadA
ThreadB
X
pthreadj ThreadA;
pthreadj ThreadB;
int X;
' int Y;
pthreacjattrJ AttrObj;
main()
void funci (...)
Count- 10:
void func2(.,.)
Count ~ 100:
Рис. 4.3. Схема процесса, содержащего два потока (SP — указатель стека, PC — счетчик команд)
4.2. Анатомия потока 121
[таблица 4.2. Преимущества и недостатки потоков
Преимущества потоков Недостатки потоков
• Для переключения контекста требу- • Для параллельного доступа к памяти
ется меньше системных ресурсов (чтения или записи данных) требуется
• Потоки способны повысить произ- синхронизация
водительность приложения • Потоки могут разрушить адресное про-
• Для обеспечения взаимодействия странство своего процесса
между потоками никакого специаль- • Потоки существуют в рамках только од-
ного механизма не требуется ного процесса, поэтому их нельзя по-
• Благодаря потокам структуру про- граммы можно упростить вторно использовать
4.2.1. Атрибуты потока
Атрибуты процесса содержат информацию, которая описывает процесс для опе-
рационной системы. Операционная система использует эту информацию для управ-
ления процессами, а также для того, чтобы отличать один процесс от другого. Про-
цесс совместно использует со своими потоками практически все, включая ресурсы
и переменные среды. Разделы данных, раздел программного кода и все ресурсы свя-
заны с процессом, а не с потоками. Все, что нужно для функционирования потока,
определяется и предоставляется процессом. Потоки же отличаются один от другого
идентификационным номером (id), набором регистров, определяющих состояние
потока, его приоритетом и стеком. Именно эти атрибуты формируют уникальность
каждого потока. Как и при использовании процессов, информация о потоках хранит-
ся в структурах данных и возвращается функциями, поддерживаемыми операционной
системой. Например, часть информации о потоке содержится в структуре, именуемой
информационным блоком потока, который создается вместе с потоком.
Идентификационный номер (id) потока — это уникальное значение, которое иден-
тифицирует каждый поток во время его существования в процессе. Приоритет потока
определяет, каки^м потокам предоставлен привилегированный доступ к процессору
в выделенное время. Под состоянием потока понимаются условия, в которых он пребы-
вает в любой момент времени. Набор регистров для потока включает программный
счетчик и указатель стека. Программный счетчик содержит адрес инструкции, которую
поток должен выполнить, а указатель стека ссылается на вершину стека потока.
Библиотека потоков POSIX определяет объект атрибутов потока, инкапсулирую-
щим свойства потока, к которым его создатель может получить доступ и модифици-
ровать их. Объект атрибутов потока определяет следующие компоненты:
• область видимости;
• размер стека;
• адрес стека;
• приоритет;
• состояние;
стратегия планирования и параметры.
122 Глава 4. Разбиение С++-программ на множество потоков
Объект атрибутов потока может быть связан с одним или несколькими потоками.
При использовании этого объекта поведение потока или группы потоков определяется
профилем. Все потоки, которые используют объект атрибутов, приобретают все свой-
ства, определенные этим объектом. На рис. 4.3 показаны атрибуты, связанные с каждым
потоком. Как видите, оба потока (А и В) разделяют объект атрибутов, но они поддержи-
вают свои отдельные идентификационные номера и наборы регистров. После того как
объект атрибутов создан и инициализирован, его можно использовать в любых обраще-
ниях к функциям создания потоков. Следовательно, можно создать группу потоков, ко-
торые будут иметь “малый стек и низкий приоритет” или “большой стек, высокий при-
оритет и состояние открепления”. Открепленный (detached) поток — это поток, кото-
рый не синхронизирован с другими потоками в процессе. Иначе говоря, не существует
потоков, которые бы ожидали до тех пор, пока завершит выполнение открепленный
поток. Следовательно, если уж такой поток существует, то его ресурсы (а именно id
потока) немедленно принимаются на повторное использование. Для установки и счи-
тывания значений этих атрибутов предусмотрены специальные методы. После созда-
ния потока его атрибуты нельзя изменить до тех пор, пока он существует.
Атрибут области видимости описывает, с какими потоками конкретный поток кон-
курирует за обладание системными ресурсами. Потоки соперничают за ресурсы в рам-
ках двух областей видимости: процесса (потоки одного процесса) и системы (все потоки
в системе). Конкуренция потоков в пределах одного и того же процесса происходит за
дескрипторы файлов, а конкуренция потоков в масштабе всей системы — за ресурсы, ко-
торые выделяются системой (например, реальная память). Потоки соперничают с по-
токами, которые имеют область видимости процесса, и потоками из других процессов
за использование процессора в зависимости от состязательного режима и областей вы-
деления ресурсов (набора процессоров). Поток, обладающий системной областью ви-
димости, будет обслуживаться с учетом его приоритета и стратегии планирования, ко-
торая действует для всех потоков в масштабе всей системы. Члены POSIX-объекта атри-
бутов потока перечислены в табл. 4.3.
Таблица 4.3. Члены объекта атрибутов потока
Атрибуты Функции Описание
detachstate int pthread_attr_ setdetachstate (pthread_attr_t *attr, int detachstate); Атрибут' detachstate определяет, является ли новый поток откреплен- ным. Если это соответствует истине, то его нельзя объединить ни с каким другим потоком
guardsize int pthread_attr_ setguardsize (pthread_attr_t *attr, size_t guardsize); Атрибут guardsize позволяет управлять размером защитной облас- ти стека нового потока. Он создает буферную зону размером guardsize на переполненяемом конце стека
inheritsched int pthread_attr_ setinheritsched (pthread_attr_t *attr, int inheritsched); Атрибут inheritsched определяет, как будут установлены атрибуты пла- нирования для нового потока, т.е. бу- дут' ли они унаследованы от потока- создателя или установлены атрибут- ным объектом
4.3. Планирование потоков 123
Окончание табл. 4.3
Атрибуты Функции Описание
param int pthread_attr_ setschedparam (pthread—attr_t *restrict attr, const struct sched_param *restrict param); Атрибут param— это структура, ко- торую можно использовать для уста- новки приоритета нового потока
schedpolicy int pthread—attr_ setschedpolicy (pthread—attr_t *attr, int policy); Атрибут schedpolicy определяет стратегию планирования создаваемо- го потока
contentionscope int pthread—attr_ setscope (pthread—attr_t *attr, int contentionscope); Атрибут contentionscope опреде- ляет, с каким множеством потоков будет соперничать создаваемый по- ток за использование процессорного времени. Область видимости процес- са означает, что поток будет состя- заться со множеством потоков одно- го процесса, а область видимости системы означает, что поток будет состязаться с потоками в масштабе всей системы (т.е. сюда входят пото- ки других процессов)
stackaddr int pthread—attr_ Атрибуты stackaddr и stacksize
stacksize setstack (pthread—attr_t *attr, void *stackaddr, size_t stacksize); определяют базовый адрес и мини- мальный размер (в байтах) стека, вы- деляемого для создаваемого потока, соответственно
stackaddr int pthread—attr_ setstackaddr (pthread—attr_t *attr, void *stackaddr); Атрибут stackaddr определяет ба- зовый адрес стека, выделяемого для создаваемого потока
stacksize int pthread—attr_ setstacksize (pthread—attr_t *attr, size_t stacksize); Атрибут stacksize определяет ми- нимальный размер стека в байтах, вы- деляемого для создаваемого потока
4.3. Планирование потоков
Когда подходит время для выполнения процесса, процессор занимает один из его
оков. Если процесс имеет только один поток, то именно он (т.е. основной поток) на-
ается процессору. Если процесс содержит несколько потоков и в системе есть доста-
Ое количество процессоров, то процессорам назначаются все потоки. Потоки сопер-
акэт за процессор либо со всеми потоками из активного процесса системы, либо только
124 Глава 4. Разбиение С++-программ на множество потоков
с потоками из одного процесса. Потоки помещаются в очереди готовых потоков, отсор-
тированные по значению их приоритета. Потоки с одинаковым приоритетом назначают-
ся процессорам в соответствии с некоторой стратегией планирования. Если система не
содержит достаточного количества процессоров, поток с более высоким приоритетом
может выгрузить поток, выполняющийся в данный момент. Если новый активный поток
принадлежит тому же процессу, что и выгруженный, возникает переключение контек-
ста потоков. Если же новый активный поток “родом” из другого процесса, то сначала
происходит переключение контекста процессов, а затем — контекста потоков.
4.3.1. Состояния потоков
Потоки имеют такие же состояния и переходы между ними (см. главу 3), как и про-
цессы. Диаграмма состояний, показанная на рис. 4.4, — это копия диаграммы, изобра-
женной на рис. 3.4 из главы 3. (Вспомним, что процесс может пребывать в одном из че-
тырех состояний: готовности, выполнения, останова и ожидания, или блокирования.)
Состояние потока — это режим или условия, в которых поток существует в данный мо-
мент. Поток находится в состоянии готовности (работоспособности), когда он готов
к выполнению. Все готовые к работе потоки помещаются в очереди готовности, причем
в каждой такой очереди содержатся потоки с одинаковым приоритетом. Когда поток вы-
бирается из очереди готовности и назначается процессору, он (поток) переходит в со-
стояние выполнения. Поток снимается с процессора, если его квант времени истек, или
если перешел в состояние готовности поток с более высоким приоритетом. Выгру-
женный поток снова помещается в очередь готовых потоков. Поток пребывает в со-
стоянии ожидания, если он ожидает наступления некоторого события или заверше-
ния операции ввода-вывода. Поток прекращает выполнение, получив сигнал остано-
ва, и остается в этом состоянии до тех пор, пока не получит сигнал продолжить работу.
Рис. 4.4. Состояния потоков и переходы между ними
4.3. Планирование потоков 125
При получении этого сигнала поток переходит из состояния останова в состояние го-
товности. Переход потока из одного состояния в другое является своего рода сигналом
о наступлении некоторого события. Переход конкретного потока из состояния готовности
в состояние выполнения происходит потому, что система выбрала именно его для выпол-
нения, т.е. поток отправляется (dispatched) на процессор. Поток снимается, или выгружа-
ется (preempted), с процессора, если он делает запрос на ввод-вывод данных (или какой-
либо иной запрос к ядру), или если существуют какие-то причины внешнего характера.
Один поток может определить состояние всего процесса. Состояние процесса с од-
ним потоком синонимично состоянию его основного потока. Если его основной поток
находится в состоянии ожидания, значит, и весь процесс находится в состоянии ожида-
ния. Если основной поток выполняется, значит, и процесс выполняется. Что касается
процесса с несколькими потоками, то для того, чтобы утверждать, что весь процесс на-
ходится в состоянии ожидания или останова, необходимо, чтобы все его потоки пребы-
вали в состоянии ожидания или останова. Но если хотя бы один из его потоков активен
(т.е. готов к выполнению или выполняется), процесс считается активным.
4.3.2. Планирование потоков и область конкуренции
Область конкуренции потоков определяет, с каким множеством потоков будет со-
перничать рассматриваемый поток за использование процессорного времени. Если
поток имеет область конкуренции уровня процесса, он будет соперничать за ресурсы
с потоками того же самого процесса. Если же поток имеет системную область конку-
ренции, он будет соперничать за процессорный ресурс с равными ему по правам по-
токами (из одного с ним процесса) и с потоками других процессов. Пусть, например,
как показано на рис. 4.5, существуют два процесса в мультипроцессорной среде, кото-
рая включает три процессора. Процесс А имеет четыре потока, а процесс В — три. Для
процесса А “расстановка сил” такова: три (из четырех его потоков) имеют область
конкуренции уровня процесса, а один— уровня системы. Для процесса В такая
“картина”: два (из трех его потоков) имеют область конкуренции уровня процесса,
а один — уровня системы. Потоки процесса А с процессной областью конкуренции
соперничают за процессор А, а потоки процесса В с такой же (процессной) областью
конкуренции соперничают за процессор С. Потоки процессов А и В с системной об-
ластью конкуренции соперничают за процессор В.
ПРИМЕЧАНИЕ: потоки при моделировании их реального поведения в приложении
Должны иметь системную область конкуренции.
4.3.3. Стратегия планирования и приоритет
Стратегия планирования и приоритет процесса принадлежат основному потоку.
Каждый поток (независимо от основного) может иметь собственную стратегию плани-
рования и приоритет. Потокам присваиваются целочисленные значения приоритета,
Которые лежат в диапазоне между заданными минимальным и максимальным значения-
ми. Схема приоритетов используется при определении, какой поток следует назначить
Процессору: поток с более высоким приоритетом выполняется раньше потока с более
Низким приоритетом. После назначения потокам приоритетов задачам, которые тре-
У*°т немедленного выполнения или ответа от системы, предоставляется необходимое
126 Глава 4. Разбиение С++-программ на множество потоков
процессорное время. В операционной системе с приоритетами выполняющийся поток
снимается с процессора, если в состояние готовности переходит поток с более высоким
приоритетом, обладающий при этом тем же уровнем области конкуренции. Например,
как показано на рис. 4.5, потоки с процессной областью конкуренции соревнуются за
процессор с потоками того же процесса, имеющими такой же уровень области конку-
ренции. Процесс А имеет два потока с приоритетом 3, и один из них назначен процес-
сору. Как только поток с приоритетом 2 заявит о своей готовности, активный поток бу-
дет вытеснен, а процессор займет поток с более высоким приоритетом. Кроме того,
в процессе В есть два потока (процессной области конкуренции) с приоритетом 1
(приоритет 1 выше приоритета 2). Один из этих потоков назначается процессору. И хо-
тя другой поток с приоритетом 1 готов к выполнению, он не вытеснит поток с приори-
тетом 2 из процесса А, поскольку эти потоки соперничают за процессор в рамках своих
процессов. Потоки с системной областью конкуренции и более низким приоритетом
не вытесняются ни одним из потоков из процессов А или В. Они соперничают за про-
цессорное время только с потоками, имеющими системную область конкуренции.
Рис. 4.5. Планирование потоков (с процессной и системной
областями конкуренции) в мультипроцессорной среде
Как упоминалось в главе 3, очереди готовности организованы в виде отсортированных
списков, в которых каждый элемент представляет собой уровень приоритета. Под уров-
нем приоритета понимается очередь потоков с одинаковым значением приоритета. Все
потоки одного уровня приоритета назначаются процессору с использованием стратегии
планирования: FIFO (сокр. от First In First Out, т.е. первым прибыл, первым обслужен),
RR (сокр. от round-robin, т.е. циклическая) или какой-либо другой. При использовании
4.3. Планирование потоков 127
гии планирования FIFO поток, квант процессорного времени которого истек, по-
мещается в головную часть очереди соответствующего приоритетного уровня, а процес-
М назначается следующему потоку из очереди. Следовательно, поток будет выполняться
С°^тех пор, пока он не завершит выполнение, не перейдет в состояние ожидания
Гзаснет”) или не получит сигнал остановиться. Когда “спящий” поток “просыпается”, он
помещается в конец очереди соответствующего приоритетного уровня. Стратегия плани-
ования RR аналогична FIFO-стратегии, за исключением того, что по истечении кванта
п оцессорного времени поток помещается не в начало, а в конец “своей” очереди.
Циклическая стратегия планирования (RR) считает все потоки обладающими оди-
наковыми приоритетами и каждому потоку предоставляет процессор только в тече-
ние некоторого кванта времени. Поэтому выполнение задач получается поперемен-
ным. Например, программа, которая выполняет поиск файлов по заданным ключе-
вым словам, разбивается на два потока. Один поток (1) находит все файлы с заданным
расширением и помещает их пути в контейнер. Второй поток (2) выбирает имена
файлов из контейнера, просматривает каждый файл на предмет наличия в нем задан-
ных ключевых слов, а затем записывает имена файлов, которые содержат такие слова.
Если к этим потокам применить циклическую стратегию планирования с единствен-
ным процессором, то поток 1 использовал бы свой квант времени для поиска файлов
и вставки их путей в контейнер. Поток 2 использовал бы свой квант времени для вы-
деления имен файлов и поиска заданных ключевых слов. В идеальном мире потоки 1
и 2 должны выполняться попеременно. Но в действительности все может быть иначе.
Например, поток 2 может выполниться до потока 1, когда в контейнере еще нет ни
одного файла, или поток 1 может так долго искать файл, что до истечения кванта
времени не успеет записать его путь в контейнер. Такая ситуация требует синхрони-
зации, краткое рассмотрение которой приводится ниже в этой главе и в главе 5. Стра-
тегия планирования FIFO позволяет каждому потоку выполняться до завершения. Ес-
ли рассмотреть тот же пример с использованием FIFO-стратегии, то поток 1 будет
иметь достаточно времени, чтобы отыскать все нужные файлы и вставить их пути
в контейнер. Поток 2 затем выделит имена файлов и выполнит поиск заданных клю-
чевых слов. В идеальном мире завершение выполнения потока 2 будет означать за-
вершение программы в целом. Но в реальном мире поток 2 может быть назначен
процессору до потока 1, когда контейнер еще не будет содержать файлов для поиска
в них ключевых слов. После “холостого” выполнения потока 2 процессору будет на-
значен поток 1, который может успешно отыскать нужные файлы и поместить в кон-
тейнер их пути. Однако поиск ключевых слов выполнять уже будет некому. Поэтому
программа в целом потерпит фиаско. При использовании FIFO-стратегии не преду-
сматривается перемешивания задач. Поток, назначенный процессору, занимает его
До полного выполнения своей задачи. Такую стратегию планирования можно исполь-
зовать для приложений, в которых потоки необходимо выполнить как можно скорее,
од другими” стратегиями планирования подразумеваются уже рассмотренные, но
с небольшими вариациями. Например, FIFO-стратегия может быть изменена таким
разом, чтобы позволить разблокировать потоки, выбранные случайно.
4.3.3.1. Изменение приоритета потоков
Приоритеты потоков следует менять, чтобы ускорить выполнение потоков, от кото-
рых зависит выполнение других потоков. И, наоборот, этого не следует делать ради того,
Ы какой-то конкретный поток получил больше процессорного времени. Это может
128 Глава 4. Разбиение С++-программ на множество потоков
изменить общую производительность системы. Потоки с более высоким классом приорц.
тета получают больше процессорного времени, чем потоки с более низким классом при-
оритета, поскольку7 они выполняются чаще. Потоки с более высоким приоритетом прак-
тически монополизируют процессор, не выделяя потокам с более низким приоритетом
такое ценное процессорное время. Эта ситуация получила название информационного голода
(starvation). Системы, в которых используются механизмы динамического назначения
приоритетов, реагируют на подобную ситуацию путем назначения приоритетов, которые
бы действовали в течение коротких периодов времени. Система регулирует приоритет
потоков таким образом, чтобы потоки с более низким приоритетом увеличили время вы-
полнения. Такой подход должен повысить общую производительность системы.
Гарантировать, что конкретный процесс или поток будет выполняться до его
полного завершения, — все равно что присвоить ему самый высокий приоритет.
Однако реализация такой стратегии может повлиять на общую производительность
системы. Такие привилегированные потоки могут нарушить взаимодействие про-
граммных компонентов через сетевые средства коммуникации, вызвав потерю дан-
ных. На потоки, которые управляют интерфейсом пользователя, может быть ока-
зано чрезмерно большое влияние, выраженное в замедлении реакции на использо-
вание клавиатуры, мыши или экрана. В некоторых системах пользовательским
процессам или потокам не назначается более высокий приоритет, чем системным
процессам. В противном случае системные процессы или потоки не смогли бы реа-
гировать на критические изменения в системе. Поэтому большинство пользова-
тельских процессов и потоков попадают в категорию программных компонентов
с нормальным (средним) приоритетом.
4.4. Ресурсы потоков
Потоки используют большую часть своих ресурсов вместе с другими потоками из
того же процесса. Собственные ресурсы потока определяют его контекст. Так, в кон-
текст потока входят его идентификационный номер, набор регистров (включающих
указатель стека и программный счетчик) и стек. Остальные ресурсы (процессор, па-
мять и файловые дескрипторы), необходимые потоку для выполнения его задачи, он
должен разделять с другими потоками. Дескрипторы файлов выделяются каждому
процессу в отдельности, и потоки одного процесса соревнуются за доступ к этим де-
скрипторам. Что касается памяти, процессора и других глобально распределяемых
ресурсов, то за доступ к ним потоки конкурируют с другими потоками своего процес-
са, а также с потоками других процессов.
Поток при выполнении может запрашивать дополнительные ресурсы, например,
файлы или мьютексы, но они становятся доступными для всех потоков процесса. Су-
ществуют ограничения на ресурсы, которые может использовать один процесс. Та-
ким образом, все потоки в общей сложности не должны превышать предельный объ-
ем ресурсов, выделяемых процессу. Если поток попытается расходовать больше ре-
сурсов, чем предусмотрено предельным объемом, формируется сигнал о том, что
достигнут предельный объем ресурсов для данного процесса. Потоки, которые ис-
пользуют ресурсы, должны следить за тем, чтобы эти ресурсы не оставались в неста-
бильном состоянии после их аннулирования. Поток, который открыл файл или соз-
дал мьютекс, может завершиться, оставив этот файл открытым или мьютекс заблоки-
рованным. Если приложение завершилось, а файл не был закрыт надлежащим
4.5. Модели создания и функционирования потоков 129
зом, это может привести к его разрушению или потере данных. Завершение по-
° Р после блокировки мьютекса надежно запирает доступ к критическому разделу,
который находится под контролем этого мьютекса. Перед завершением поток должен
выполнить некоторые действия очистительно-восстановительного характера, чтобы
Не допустить возникновения нежелательных ситуаций.
4.5. Модели создания и функционирования
потоков
Цель потока— выполнить некоторую работу от имени процесса. Если процесс содер-
жит несколько потоков, каждый поток выполняет некоторые подзадачи как части общей
задачи, выполняемой процессом. Потокам делегируется работа в соответствии с конкрет-
ной стратегией, которая определяет, каким образом реализуется делегирование работы.
Если приложение моделирует некоторую процедуру или объект, то выбранная страте-
гия должна отражать эту модель. Используются следующие распространенные модели:
• делегирование (“управляющий-рабочий”);
• сеть с равноправными узлами;
• конвейер;
• “изготовитель-потребитель”.
Каждая модель характеризуется собственной декомпозицией работ (Work Breakdown
Structure — WBS), которая определяет, кто отвечает за создание потоков и при каких
условиях они создаются. Например, существует централизованный подход, при кото-
ром один поток создает другие потоки и каждому из них делегирует некоторую рабо-
ту. Существует также конвейерный (assembly-line) подход, при котором на различных
этапах потоки выполняют различную работу. Созданные потоки могут выполнять од-
ну и ту же задачу на различных наборах данных, различные задачи на одном и том же
наборе данных или различные задачи на различных наборах данных. Потоки подраз-
деляются на категории по выполнению задач только определенного типа. Например,
можно создать группы потоков, которые будут выполнять только вычисления, только
ввод или только вывод данных.
Возможны задачи, для успешного решения которых следует комбинировать пе-
речисленные выше модели. В главе 3 мы рассматривали процесс визуализации. За-
дачи 1, 2 и 3 выполнялись последовательно, а задачи 4, 5 и 6 могли выполняться па-
раллельно. Все задачи можно выполнить различными потоками. Если необходимо
визуализировать несколько изображений, потоки 1, 2 и 3 могут сформировать кон-
вейер. По завершении потока 1 изображение передается потоку 2, в то время
как поток 1 может выполнять свою работу над следующим изображением. После
Уферизации изображений потоки 4, 5 и 6 могут реализовать параллельную обра-
зку. Модель функционирования потоков представляет собой часть структуриро-
вания параллелизма в приложении, в котором каждый поток может выполняться на
отдельном процессоре. Модели функционирования потоков (и их краткое описа-
Ние) приведены в табл. 4.4.
130 Глава 4. Разбиение С++-программ на множество потоков
Таблица 4.4. Модели функционирования потоков
Модель Описание
Модель делегирования Центральный поток (“управляющий”) создает потоки (“рабочие”), на- значая каждому из них задачу. Управляющий поток может ожидать до тех пор, пока все потоки не завершат выполнение своих задач
Модель с равно- правными узлами Все потоки имеют одинаковый рабочий статус. Такие потоки называют- ся равноправными. Поток создает все потоки, необходимые для выполне- ния задач, но не осуществляет никакого делегирования ответственно- сти. Равноправные потоки могут обрабатывать запросы от одного вход- ного потока данных, разделяемого всеми потоками, или каждый поток может иметь собственный входной поток данных
Конвейер Конвейерный подход применяется для поэтапной обработки потока входных данных. Каждый этап — это поток, который выполняет работу на некоторой совокупности входных данных. Когда эта совокупность пройдет все этапы, обработка всего потока данных будет завершена
Модель “изготовитель- потребитель ” Поток-“изготовитель” готовит данные, потребляемые потоком- “потребителем”. Данные сохраняются в блоке памяти, разделяемом потоками — “изготовителем” и “потребителем”
4.5.1. Модель делегирования
В модели делегирования один поток (“управляющий”) создает потоки (“рабочие”)
и назначает каждому из них задачу. Управляющему потоку нужно ожидать до тех пор,
пока все потоки не завершат выполнение своих задач. Управляющий поток делегиру-
ет задачу, которую каждый рабочий поток должен выполнить, путем задания некото-
рой функции. Вместе с задачей на рабочий поток возлагается и ответственность за ее
выполнение и получение результатов. Кроме того, на этапе получения результатов
возможна синхронизация действий с управляющим (или другим) потоком.
Управляющий поток может создавать рабочие потоки в результате запросов, об-
ращенных к системе. При этом обработка запроса каждого типа может быть деле-
гирована рабочему потоку. В этом случае управляющий поток выполняет некото-
рый цикл событий. По мере возникновения событий рабочие потоки создаются
и на них тут же возлагаются определенные обязанности. Для каждого нового запро-
са, обращенного к системе, создается новый поток. При использовании такого под-
хода процесс может превысить предельный объем выделенных ему ресурсов или
предельное количество потоков. В качестве альтернативного варианта управляю-
щий поток может создать пул потоков, которым будут переназначаться новые за-
просы. Управляющий поток создает во время инициализации некоторое количест-
во потоков, а затем каждый поток приостанавливается до тех пор, пока не будет до-
бавлен запрос в их очередь. По мере размещения запросов в очереди управляющий
поток сигнализирует рабочему о необходимости обработки запроса. Как только по-
ток справится со своей задачей, он извлекает из очереди следующий запрос. Если
в очереди больше нет доступных запросов, поток приостанавливается до тех пор.
пока управляющий поток не просигналит ему о появлении очередного задания
в очереди. Если все рабочие потоки должны разделять одну очередь, то их можно
4.5. Модели создания и функционирования потоков 131
ограммировать на обработку запросов только определенного типа. Если тип
3 оса в очереди не совпадает с типом запросов, на обработку которых ориенти-
33 ан данный поток, то он может снова приостановиться. Главная цель управляю-
Р еГО потока — создать все потоки, поместить задания в очередь и “разбудить” рабо-
потоки, когда эти задания станут доступными. Рабочие потоки справляются
наличии запроса в очереди, выполняют назначенную задачу и приостанавливают-
ся сами, если для них больше нет работы. Все рабочие и управляющий потоки вы-
полняются параллельно. Описанные два подхода к построению модели делегиро-
вания представлены для сравнения на рис. 4.6.
Модель делегирования 1
Управляющий поток создает новый поток для каждого нового запроса.
ПРОГРАММА А
Модель делегирования 2
Управляющий поток создает пул потоков, которые обрабатывают все запросы.
ПРОГРАММА В
Ис- 4.6. Два подхода к реализации модели делегирования
132 Глава 4. Разбиение С++-программ на множество потоков
4.5.2. Модель с равноправными узлами
Если в модели делегирования есть управляющий поток, который делегирует зада-
чи рабочим потокам, то в модели с равноправными узлами все потоки имеют одинаковый
рабочий статус. Несмотря на существование одного потока, который изначально созда-
ет все потоки, необходимые для выполнения всех задач, этот поток считается рабочим
потоком, но он не выполняет никаких функций по делегированию задач. В этой модели
нет никакого централизованного потока, но на рабочие потоки возлагается большая от-
ветственность. Все равноправные потоки могут обрабатывать запросы из одного вход-
ного потока данных, либо каждый рабочий поток может иметь собственный входной
поток данных, за который он отвечает. Входной поток данных может также хранить-
ся в файле или базе данных. Рабочие потоки могут нуждаться во взаимодействии
и разделении ресурсов. Модель равноправных потоков представлена на рис. 4.7.
ПРОГРАММА А
Поток входных данных,
разделяемый
потоками выполнения
Рис. 4.7. Модель равноправных потоков (или модель с равноправными узлами)
4.5.3. Модель конвейера
Модель конвейера подобна ленте сборочного конвейера в том, что она предполагает
наличие потока элементов, которые обрабатываются поэтапно. На каждом этапе отдель-
ный поток выполняет некоторые операции над определенной совокупностью входных
данных. Когда эта совокупность данных пройдет все этапы, обработка всего входного
4.5. Модели создания и функционирования потоков 133
а данных будет завершена. Этот подход позволяет обрабатывать несколько вход-
П° потоков одновременно. Каждый поток отвечает за получение промежуточных ре-
НЫХтатов, делая их доступными для следующего этапа (или следующего потока) конвей-
* Последний этап (или поток) генерирует результаты работы конвейера в целом.
еРа^о мере того как входные данные проходят по конвейеру, не исключено, что неко-
ie их порции придется буферизировать на определенных этапах, пока потоки еще
занимаются обработкой предыдущих порций. Это может вызвать торможение конвейе-
если окажется, что обработка данных на каком-то этапе происходит медленнее, чем
на других. При этом образуется отставание в работе. Чтобы предотвратить отставание,
можно для “слабого” этапа создать дополнительные потоки. Все этапы конвейера долж-
ны быть уравновешены по времени, чтобы ни один этап не занимал больше времени,
чем другие Для этого необходимо всю работу распределить по конвейеру равномерно.
Чем больше этапов в конвейере, тем больше должно быть создано потоков обработки.
Увеличение количества потоков также может способствовать предотвращению отста-
ваний в работе. Модель конвейера представлена на рис. 4.8.
ПРОГРАММА
ЭТАП 1
Рис. 4.8. Модель конвейера
ЭТАП 2
БУФЕР
[входные данные 5
Поток 1
обрабатывает
входные данные 2
Поток 3
обрабатывает^
ЭТАПЗ
Обработка
входных
данных 1
завершена
4.5.4. Модель “изготовитель-потребитель”
В модели “изготовитель-потребитель” существует поток-“изготовитель”, который
готовит данные, потребляемые потоком-“потребителем”. Данные сохраняются в блоке
памяти, разделяемом между потоками “изготовителем” и “потребителем”. Поток-
изготовитель” должен сначала приготовить данные, которые затем поток-
потребитель” получит. Такому процессу необходима синхронизация. Если поток-
изготовитель” будет поставлять данные гораздо быстрее, чем поток-“потребитель”
сможет их потреблять, поток-“изготовитель” несколько раз перезапишет результаты,
полученные им ранее, прежде чем поток-“потребитель” успеет их обработать. Но если
поток-“потребитель” будет принимать данные гораздо быстрее, чем поток-
изготовитель” сможет их поставлять, поток-“потребитель” будет либо снова обраба-
тывать уже обработанные им данные, либо попытается принять еще не подготовлен-
ные данные. Модель “изготовитель-потребитель” представлена на рис. 4.9.
4.5.5. Модели SPMD и MPMD для потоков
° кажДой из описанных выше моделей потоки вновь и вновь выполняют одну и ту
задачу на различных наборах данных или им назначаются различные задачи для
-р ОЛНения на различных наборах данных. Эти потоковые модели используют схемы
(Single-Program, Multiple-Data — одна программа, несколько потоков данных)
134 Глава 4. Разбиение С++-программ на множество потоков
и MPMD (Multiple-Programs, Multiple-Data — множество программ, множество потоков
данных). Эти схемы представляют собой модели параллелизма, которые делят про-
граммы на потоки инструкций и данных. Их можно использовать для описания типа ра-
боты, которую реализуют потоковые модели с использованием параллелизма. В контек-
сте нашего изложения материала модель MPMD лучше представить как модель M7MD
(Multiples-Threads, Multiple-Data— множество потоков выполнения, множество потоков
данных). Эта модель описывает систему с различными потоками выполнения (thread),
которые обрабатывают различные наборы данных, или потоки данных (stream). Анало-
гично модель SPMD нам лучше рассматривать как модель STMD (Single- Thread, Multiple-
Data— один поток выполнения, несколько потоков данных). Эта модель описывает систе-
му с одним потоком выполнения, который обрабатывает различные наборы, или пото-
ки, данных. Это означает, что различные наборы данных обрабатываются несколькими
идентичными потоками выполнения (вызывающими одну и ту же подпрограмму).
ПРОГРАММА
БУФЕР
Данные
Потребитель
использует
Изготовитель
создает
Рис. 4.9. Модель конвейера
Как модель делегирования, так и модель равноправных потоков могут использовать
модели параллелизма STMD и MTMD. Как было описано выше, пул потоков может вы-
полнять различные подпрограммы для обработки различных наборов данных. Такое
поведение соответствует модели MTMD. Пул потоков может быть также настроен на
выполнение одной и той же подпрограммы. Запросы (или задания), отсылаемые системе,
могут представлять собой различные наборы данных, а не различные задачи. И в этом слу-
чае поведение множества потоков, реализующих одни и те же инструкции, но на различ-
ных наборах данных, соответствует модели STMD. Модель равноправных потоков может
быть реализована в виде потоков, выполняющих одинаковые или различные задачи. Каж-
дый поток выполнения может иметь собственный поток данных или несколько файлов
сданными, предназначенных для обработки каждым потоком. В модели конвейера ис-
пользуется MTMD-модель параллелизма. На разных этапах выполняются различные виды
обработки, поэтому в любой момент времени различные совокупности входных данных
будут находиться на различных этапах выполнения. Модельное представление конвей-
ера было бы бесполезным, если бы на каждом этапе выполнялась одна и та же обработ-
ка. Модели параллелизма STMD и MTMD представлены на рис. 4.10.
4.6. Введение в библиотеку Pthread
Библиотека Pthread предоставляет API-интерфейс для создания и управления пото-
ками в приложении. Библиотека Pthread основана на стандартизированном интерфейсе
программирования, который был определен комитетом по вытеку стандартов IEEE
в стандарте POSIX 1003.1с. Сторонние фирмы-изготовители придерживаются стандарта
POSIX в реализациях, которые именуются библиотеками потоков Pthread или POSIX.
4.6. Введение в библиотеку Pthread 135
Рис. 4.10. Модели параллелизма STMD и MTMD
Библиотека Pthread содержит более 60 функций, которые можно разделить на
следующие категории.
1. Функции управления потоками.
1.1. Конфигурирование потоков.
1.2. Отмена потоков.
1.3. Стратегии планирования потоков.
1.4. Доступ к данным потоков.
1.5. Обработка сигналов.
1.6. Функции доступа к атрибутам потоков.
1.6.1. Конфигурирование атрибутов потоков.
1.6.2. Конфигурирование атрибутов, относящихся к стекам потоков.
1.6.3. Конфигурирование атрибутов, относящихся к стратегиям планирова-
ния потоков.
2. Функции управления мьютексами.
2.1. Конфигурирование мьютексов.
2.2. Управление приоритетами.
2.3. Функции доступа к атрибутам мьютексов.
2.3.1. Конфигурирование атрибутов мьютексов.*
2.3.2. Конфигурирование атрибутов, относящихся к протоколам мьютексов.
2.3.3. Конфигурирование атрибутов, относящихся к управлению приорите-
тами мьютексов.
3. Функции управления условными переменными.
3.1. Конфигурирование условных переменных.
3.2. Функции доступа к атрибутам условных переменных.
3.2.1. Конфигурирование атрибутов условных переменных.
3.2.2. Функции совместного использования условных переменных.
с библиотека Pthread может быть реализована на любом языке, но для соответствия
Дарту POSIX она должна быть согласована со стандартизированным интерфей-
136 Глава 4. Разбиение С++-программ на множество потоков
сом. Библиотека Pthread— не единственная реализация потокового API-интерфейса
Существуют другие реализации, созданные сторонними фирмами-производителями ац.
паратных и программных средств. Например, среда Sun поддерживает библиотеку
Pthread и собственный вариант библиотеки потоков Solaris. В этой главе мы рассмотрим
некоторые функции библиотеки Pthread, которые реализуют управление потоками.
4.7. Анатомия простой многопоточной программы
Любая простая многопоточная программа должна состоять из основного потока
и функций, которые будут выполнять другие потоки. Выбранная для реализации модель соз-
дания и функционирования потоков определяет, каким образом в программе будут созда-
ваться потоки и как будет осуществляться управление ими. Потоки создаются по прин-
ципу “все и сразу” или при определенных условиях. Пример простой многопоточной
программы, в которой реализована модель делегирования, представлен в листинге 4.1.
// Листинг 4.1. Использование модели делегирования в
// простой многопоточной программе
#include <iostream>
#include <pthread.h>
void *taskl(void *X) // Определяем задачу для выполнения
// потоком ThreadA.
{
//. . .
cout « "Поток А завершен." « endl;
}
void *task2(void *X) // Определяем задачу для выполнения
// потоком ThreadB.
{
//. . .
cout « "Поток В завершен." « endl;
}
int main(int argc, char *argv[])
{
pthread_t ThreadA,ThreadB; // Объявляем потоки.
pthread—create(&ThreadA,NULL,taskl,NULL); // Создаем
// потоки.
pthread—create(&ThreadB,NULL,task2,NULL);
// Дополнительная обработка.
pthread—join(ThreadA,NULL); // Ожидание завершения
pthread—join(ThreadB,NULL); // потоков.
return (0);
}
В листинге 4.1 делается акцент на определении набора инструкций для основно-
го потока. Основным в данном случае является управляющий поток, который объ-
являет два рабочих потока ThreadA и ThreadB. С помощью функции
pthread—create () эти два потока связываются с задачами, которые они должны
выполнить (taskl и task2). Здесь (ради простоты примера) эти задачи всего лишь
4.7. Анатомия простой многопоточной программы 137
авляют сообщение в стандартный выходной поток, но понятно, что они могли
°ТП^быть запрограммированы на нечто более полезное. При вызове функции
^^read create () потоки немедленно приступают к выполнению назначенных
Р задач. Работа функции pthread_join() аналогична работе функции wait ()
И>я проЧессов' Основн°й поток ожидает до тех пор, пока не завершатся оба рабо-
потока. Диаграмма последовательностей, соответствующая листингу 4.1, пока-
зана на рис. 4.11. Обратите внимание на то, что происходит с потоками выполне-
ния при вызове функций pthread_create () и pthread_j oin ().
На рис. 4.11 показано, что вызов функции pthread_create () является причи-
ной разветвления, или образования “вилки” в основном потоке выполнения, в ре-
зультате чего образуются два дополнительных “ручейка” (по одному для каждой за-
дачи), которые выполняются параллельно. Функция pthread_create () заверша-
ется сразу же после создания потоков. Эта функция предназначена для создания
асинхронных потоков. Это означает, что, как рабочие, так и основной поток, вы-
полняют свои инструкции независимо друг от друга. Функция pthread_join () за-
ставляет основной поток ожидать до тех пор, пока все рабочие потоки завершатся
и “присоединятся” к основному.
Рис. 4.11. Диаграмма последовательностей, соответствующая листингу 4.1
^•7.1. Компиляция и компоновка многопоточных
программ
u &Се многопоточные программы, использующие библиотеку потоков POSIX, долж-
ны Включать заголовок:
'Pthread. h>
138 Глава 4. Разбиение С++-программ на множество потоков
Для компиляции многопоточного приложения в средах UNIX или Linux с помо-
щью компиляторов командной строки д++ или дсс необходимо скомпоновать его
с библиотекой Pthreads. Для задания библиотеки используйте опцию -1. Так, команда
-Ipthread
обеспечит компоновку вашего приложения с библиотекой, которая согласуется
с многопоточным интерфейсом, определенным стандартом POSIX 1003.1с. Библио-
теку Pthread, libpthread. so, следует поместить в каталог, в котором хранится сис-
темная стандартная библиотека, обычно это /usr/lib. Если она будет находиться не
в стандартном каталоге, то для того, чтобы обеспечить поиск компилятора в заданном
каталоге до поиска в стандартных, используйте опцию -L. По команде
д++ -о blackboard -L /src/local/lib blackboard.cpp -Ipthread
компилятор выполнит поиск библиотеки Pthread сначала в каталоге
/ src / local /1 ib, а затем в стандартных каталогах.
Законченные программы, представленные в этой книге, сопровождаются профи-
лем. Профиль программы содержит такие специальные сведения по ее реализации, как
необходимые заголовки и библиотеки, а также инструкции по компиляции и компо-
новке. Профиль программы также включает раздел примечаний, содержащий специ-
альную информацию, которую необходимо учитывать при выполнении программы.
4.8. Создание потоков
Библиотека Pthreads используется для создания, поддержки и управления потока-
ми многопоточных программ и приложений. При создании многопоточной програм-
мы потоки могут создаваться на любом этапе выполнения процесса, поскольку это —
динамические образования. Функция pthread_create () создает новый поток в ад-
ресном пространстве процесса. Параметр thread указывает на дескриптор, или
идентификатор (id), создаваемого потока. Новый поток будет иметь атрибуты, задан-
ные объектом attr. Созданный поток немедленно приступит к выполнению инст-
рукций, заданных параметром start_routine с использованием аргументов, задан-
ных параметром arg. При успешном создании потока функция возвращает его иден-
тификатор (id), значение которого сохраняется в параметре thread.
Синопсис
#include <pthread.h>
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void*),
void *restrict arg) ;
Если параметр attr содержит значение NULL, новый поток будет использовать
атрибуты, действующие по умолчанию. В противном случае новый поток использует
атрибуты, заданные параметром attr при его создании. Если же значение параметра
attr изменится после того, как поток был создан, это никак не отразится на его ат-
рибутах. При завершении параметра-функции start_routine завершается и поток,
причем так, как будто была вызвана функция pthread_exit () с использованием
в качестве статуса завершения значения, возвращаемого функцией start_routine.
4.8. Создание потоков 139
При успешном завершении функция возвращает число 0. В противном случае по-
не создается, и функция возвращает код ошибки. Если в системе отсутствуют ре-
ы для создания потока или в процессе достигнут предел по количеству возмож-
ных потоков, выполнение функции считается неудачным. Неудачным оно также будет
в случае, если атрибут потока задан некорректно или если инициатор вызова потока
не имеет разрешения на установку необходимых атрибутов потока.
Приведем примеры создания двух потоков с заданными по умолчанию атрибутами:
thread—create (&threadA, NULL, taskl,NULL) ;
pthread_create (&threads, NULL, task2,NULL) ;
Это — два вызова функции pthread—create () из листинга 4.1. Оба потока создаются
с атрибутами, действующими по умолчанию.
В программе 4.1 отображен основной поток, который передает аргумент из ко-
мандной строки в функции, выполняемые потоками.
/ / Программа 4.1
#include <iostream>
#include <pthread.h>
tfinclude <stdlib.h>
int main(int argc, char *argv[])
{
pthread—t ThreadA,ThreadB;
int N;
if(argc 1= 2) {
cout « "error" << endl;
exit (1) ;
}
N = atoi(argv[l] ) ;
pthread—create(&ThreadA,NULL,taskl,&N);
pthread—create(&ThreadB,NULL,task2,&N);
cout « "Ожидание присоединения потоков." << endl;
pthread—join(ThreadA,NULL);
Pthread—join(ThreadB,NULL);
} return ( 0 ) ;
В программе 4.1 показано, как основной поток может передать аргументы из ко-
мандной строки в каждую из потоковых функций. Число в командной строке имеет
строковый тип. Поэтому в основном потоке аргумент сначала преобразуется в цело-
численное значение, и только после этого результат преобразования передается при
каждом вызове функции pthread—create () посредством ее последнего аргумента,
программе 4.2 представлена каждая из потоковых функций.
11 Программа 4.2
v°id *taskl(void *Х)
int *Temp;
Temp = static-cast<int *>(X);
f°r(int Count = l;Count < *Temp;Count++){
cout « "В потоке A: " << Count << " * 2 = "
140 Глава 4. Разбиение С++-программ на множество потоков
<< Count * 2 « endl;
}
cout « "Поток А завершен." « endl;
}
void *task2(void *X)
{
int *Temp;
Temp = static_cast<int *>(X);
for(int Count = 1;Count < *Temp;Count++){
cout « "В потоке В: " « Count << " + 2
<< Count + 2 « endl;
}
cout « "Поток В завершен." « endl;
В программе 4.2 функции taskl и task2 выполняют цикл, количество итераций ко-
торого равно числу, переданному каждой функции в качестве параметра. Одна функция
увеличивает переменную цикла на два, вторая — умножает ее на два, а затем каждая из
них отправляет результат в стандартный поток вывода данных. По выходу из цикла ка-
ждая функция выводит сообщение о завершении выполнения потока. Инструкции по
компиляции и выполнению программ 4.1 и 4.2 содержатся в профиле программы 4.1.
J Профиль программы 4.1
Имя программы
,program4-12.сс
г
Описание
Принимает целочисленное значение из командной строки и передает функциям;
потоков. Каждая функция выполняет цикл, в котором переменная цикла
увеличивается (в одной функции на два, а в другой в два раза), а затем результат
отсылается в стандартный поток вывода данных. Код основного потока выполнения
приведен в программе 4.1, а код функций — в программе 4.2.
Требуемая библиотека
libpthread
Требуемые заголовки
<pthread.h> <iostream> <stdlib.h>
Инструкции по компиляции и компоновке программ
C++ -о program4-12 program4-12.сс -Ipthread
Среда для тестирования
. SuSE Linux 7.1, gcc 2.95.2,
Инструкции по выполнению
./program4~12 34
, Примечания
Эта программа требует задания аргумента командной строки.
4.8. Создание потоков 141
мента. Если необходим<
структуру (struct) или
дайте функции потока ук
3 этом разделе был приведен пример передачи функции потока лишь одного аргу-
передать функции потока несколько аргументов, создайте
контейнер, содержащий все требуемые аргументы, и пере-
азатель на эту структуру.
4.8.1- Получение идентификатора потока
Как упоминалось выше, процесс разделяет все свои ресурсы с потоками, используя
лишь собственное адресное пространство. Потокам в собственное пользование выде-
ляются весьма небольшие их объемы. Идентификатор потока (id) — это один из ре-
сурсов, уникальных для каждого потока. Чтобы узнать свой идентификатор, потоку
необходимо вызвать функцию pthread—self ().
Синопсис
#include <pthread.h>
pthread t pthread self(void);
Эта функция аналогична функции getpid () для процессов. При создании потока
его идентификатор возвращается его создателю или вызывающему потоку. Однако
идентификатор потока не становится известным созданному потоку автоматически.
Но если уж поток обладает собственным идентификатором, он может передать его
(предварительно узнав его сам) другим потокам процесса. Функция pthread—self ()
возвращает идентификатор потока, не определяя никаких кодов ошибок.
Вот пример вызова этой функции:
//. . .
pthread—t Threadld;
Threadld = pthread—self();
Поток вызывает функцию pthread—self (), а значение, возвращаемое ею
(идентификатор потока), сохраняет в переменной Threadld типа pthread— t.
4.8.2. Присоединение потоков
Функция pthread—join() используется для присоединения или воссоединения по-
токов выполнения в одном процессе. Эта функция обеспечивает приостановку выпол-
нения вызывающего потока до тех пор, пока не завершится заданный поток. По своему
Действию эта функция аналогична функции wait (), используемой процессами. Эту
функцию может вызвать создатель потока, после чего он будет ожидать до тех пор, пока
завершится новый (созданный им) поток, что, образно говоря, можно назвать воссо-
единением потоков выполнения. Функцию pthread—j oin () могут также вызывать
равноправные потоки, если потоковый дескриптор является глобальным. Это позволя-
любому потоку соединиться с любым другим потоком выполнения в процессе. Если
ка Ва1°щий поток аннулируется до завершения заданного (для присоединения) пото-
’ ЭТот 3аДанный поток не станет открепленным (detached) потоком (см. следующий
ел'* Если различные равноправные потоки одновременно вызовут функцию
аjoin () для одного и того же потока, его дальнейшее поведение не определено.
142 Глава 4. Разбиение С++-программ на множество потоков
Синопсис
#include <pthread.h>
int pthread—join(pthread—t thread, void **value ptr);
Параметр thread представляет поток, завершения которого ожидает вызывающий
поток. При успешном выполнении этой функции в параметре value_ptr будет записан
статус завершения потока. Статус завершения — это аргумент, передаваемый при вызове
функции pthread_exit () завершаемым потоком. При неудачном выполнении эта функ-
ция возвратит код ошибки. Функция не будет выполнена успешно, если заданный поток не
является присоединяемым, т.е. создан как открепленный. Об успешном выполнении
этой функции не может быть и речи, если заданный поток попросту не существует.
Функцию pthread_join () необходимо вызывать для всех присоединяемых пото-
ков. После присоединения потока операционная система сможет снова использовать
память, которую он занимал. Если присоединяемый поток не был присоединен ни
к одному потоку или если поток, который вызывает функцию присоединения, аннули-
руется, то заданный поток будет продолжать использовать свою память. Это состоя-
ние аналогично зомбированному процессу, в которое переходит сыновний процесс,
когда его родитель не принимает статус завершения потомка, и этот “беспризорный”
сыновний процесс продолжает занимать структуру в таблице процессов.
4.8.3. Создание открепленных потоков
Открепленным называется завершаемый поток, который не присоединился или за-
вершения которого не дождался другой поток. При завершении потока ограничен-
ные ресурсы, которые он использовал, включая его идентификатор, освобождаются
и возвращаются системе. Потокам нет необходимости получать статус завершения.
Попытка со стороны любого потока вызвать функцию pthread—join () для откреп-
ленного потока обречена на неудачу. Существует функция pthread—detach (), кото-
рая открепляет поток, заданный параметром thread. По умолчанию все потоки соз-
даются как присоединяемые, если атрибутным объектом не обусловлено иное. Эта
функция позволяет открепить уже существующие присоединяемые потоки. Если по-
ток не завершен, обращение к этой функции не обеспечит его завершения.
Синопсис
#include <pthread.h>
int pthread—detach(pthread—t thread thread);
При успешном выполнении эта функция возвращает число 0, в противном слу-
чае— код ошибки. Функция pthread—detach () не будет успешной, если заданный
поток уже откреплен или поток, заданный параметром thread, не был обнаружен.
Вот пример открепления уже существующего присоединяемого потока:
//. . .
pthread—create(&threadA,NULL,taskl,NULL);
pthread—detach(threadA);
//. . .
4.8. Создание потоков 143
Пои выполнении этих строк кода поток threadA станет открепленным. Чтобы соз-
дать открепленный поток (в противоположность динамическому откреплению пото-
ка) необходимо установить атрибут detachstate в объекте атрибутов потока и ис-
пользовать этот объект при создании потока.
4.8.4. Использование объекта атрибутов
Объект атрибутов инкапсулирует атрибуты потока или группы потоков. Он ис-
пользуется для установки атрибутов потоков при их создании. Атрибутный объект по-
тока имеет тип pthread—attr_t. Он представляет собой структуру, позволяющую
хранить следующие атрибуты:
• размер стека потока;
• местоположение стека потока;
• стратегия планирования, наследование и параметры;
• тип потока: открепленный или присоединяемый;
• область конкуренции потока.
Для типа pthread—attr_t предусмотрен ряд методов, которые могут быть вы-
званы для установки или считывания каждого из перечисленных выше атрибутов
(см. табл. 4.3).
Для инициализации и разрушения атрибутного объекта потока используются
функции pthread_attr_init () и pthread_at trades troy () соответственно.
Синопсис
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy (pthread_attr_t *attr) ;________________
Функция pthread_attr_init () инициализирует атрибутный объект потока
С помощью стандартных значений, действующих для всех этих атрибутов. Параметр
attr представляет собой указатель на объект типа pthread_attr_t. После инициа-
лизации attr-объекта значения его атрибутов можно изменить с помощью функций,
перечисленных в табл. 4.3. После соответствующей модификации атрибутов значение
attr используется в качестве параметра при вызове функции создания потока
Pthread—create (). При успешном выполнении эта функция возвращает число О,
в противном случае — код ошибки. Функция pthread_attr_init () завершится не-
успешно, если для создания объекта в системе недостаточно памяти.
Функцию pthread—attr_destroy () можно использовать для разрушения объ-
екта типа pthread—attr_t, заданного параметром attr. При обращении к этой
функции будут удалены любые скрытые данные, связанные с этим атрибутным объ-
м потока. При успешном выполнении эта функция возвращает число 0, в про-
ивном случае — код ошибки.
144 Глава 4. Разбиение С++-программ на множество потоков
4.8.4.1. Создание открепленных потоков с помощью
объекта атрибутов
После инициализации объекта потока его атрибуты можно модифицировать. Ддя
установки атрибута detachstate атрибутного объекта используется функция
pthread__attr_setdetachstate (). Параметр detachstate описывает поток как
открепленный или присоединяемый.
Синопсис
#include <pthread.h>
int pthread—attr_setdetachstate(
pthread_attr_t *attr,
int *detachstate);
int pthread—attr_getdetachstate(
const pthread—attr_t *attr,
int *detachstate);
Параметр detachstate может принимать одно из следующих значений:
PTHREAD—CREATE—DETACHED
PTHREAD—CREATE—JOINABLE
Значение PTHREAD—CREATE—DETACHED “превращает” все потоки, которые используют
этот атрибутный объект, в открепленные, а значение PTHREAD—CREATE—JOINABLE — в при-
соединяемые. Значение PTHREAD—CREATE—JOINABLE атрибут de tachstate принимает по
умолчанию. При успешном выполнении функция pthread—attr_setdetachstate () воз-
вращает число 0, в противном случае — код ошибки. Эта функция выполнится неуспешно,
если значение параметра detachstate окажется недействительным.
Функция pthread—attr_getdetachstate () возвращает значение атрибута
detachstate атрибутного объекта потока. При успешном выполнении эта функция
возвращает значение атрибута detachstate в параметре detachstate и число О
обычным способом. При неудаче функция возвращает код ошибки. В листинге 4.2 по-
казано, как открепляются потоки, созданные в программе 4.1. В этом примере при
создании одного из потоков используется объект атрибутов.
// Листинг 4.2. Использование атрибутного объекта для
// создания открепленного потока
//. . .
int main(int argc, char *argv[])
{
pthread—t ThreadA,ThreadB;
pthread—attr_t DetachedAttr;
int N;
if(argc != 2){
cout << "Ошибка” << endl;
exit (1);
}
N = atoi(argv[l]) ;
pthread—attr_init(&DetachedAttr);
4.9. Управление потоками 145
pthread—attr—setdetachstate(&DetachedAttr,
PTHREAD—CREATE—DETACHED);
pthread—create(&ThreadA,NULL,taskl,&N);
pthread—create(&ThreadB,&DetachedAttr,task2, &N);
1 cout « "Ожидание присоединения потока A.” « endl;
1 pthread—join(ThreadA,NULL);
return (0) ;
}
В листинге 4.2 объявляется атрибутный объект DetachedAttr, для инициализации ко-
торого используется функция pthread—attr_init (). После инициализации этого объ-
екта вызывается функция pthread—attr—detachstate (), которая изменяет свойство
detachstate (“присоединяемость”), установив значение PTHREAD—CREATE—DETACHED
(“открепленность”). При создании потока Threads с помощью функции
pthread-Create () в качестве ее второго аргумента используется модифицированный
объект DetachedAttr. Для потока Threads вызов функции pthread— j oin () не ис-
пользуется, поскольку открепленные потоки присоединить невозможно.
4.9. Управление потоками
Создавая приложение с несколькими потоками, можно по-разному организовать их
выполнение, использование ими ресурсов и состязание за ресурсы. Управление потоками
по большей части осуществляется путем установки стратегий планирования и значений
приоритета. Эти факторы влияют на эффективность потока. Кроме них, эффективность
потока также определяется тем, как потоки состязаются за ресурсы: в рамках одного про-
цесса либо в масштабе всей системы. Стратегию планирования, приоритет и область кон-
куренции потока можно установить с помощью объекта атрибутов потока. Поскольку по-
токи совместно используют ресурсы, доступ к ним необходимо синхронизировать. Эту те-
му мы кратко затронем в этой главе и более подробно— в главе5. К вопросам
синхронизации также относятся и такие: где и как завершаются и аннулируются потоки.
4.9.1. Завершение потоков
Выполнение потока может быть прервано по разным причинам:
• в результате выхода из процесса с возвращаемым им статусом завершения
(или без него);
• в результате собственного завершения и предоставления статуса завершения;
• в результате аннулирования другим потоком в том же адресном пространстве.
Завершаясь, функция присоединения потока pthread—join() возвращает вызы-
вающему потоку статус завершения, передаваемый функции pthread—exit (), кото-
рая была вызвана завершающимся потоком. Если завершающийся поток не обращал-
я к функции pthread—exit (), то в качестве статуса завершения будет использовано
чение, возвращаемое этой функцией, если оно существует; в противном случае
завершения равен значению NULL.
в °зможна ситуация, когда одному потоку необходимо завершить другой поток
eJ°M Же процессе. Например, приложение может иметь поток, который контролиру-
работу других потоков. Если окажется, что некоторый поток “плохо себя ведет”
146 Глава 4. Разбиение С++-программ на множество потоков
или больше не нужен, то ради экономии системных ресурсов, возможно, его нужцо
завершить. Завершающийся поток может окончиться немедленно или отложить за-
вершение до тех пор, пока не достигнет в своем выполнении некоторой логической
точки. При этом вполне вероятно, что такой поток (прежде чем завершиться) должен
выполнить некоторые действия очистительно-восстановительного характера. Поток
имеет также возможность отказаться от завершения.
Для завершения вызывающего потока используется функция pthread_exit ()
Значение value_.pt г передается потоку, который вызывает функцию
pthread—join() для этого потока. Еще не выполненные процедуры, связанные
с “уборкой”, будут выполнены вместе с деструкторами, предусмотренными для потоко-
вых данных. Никакие ресурсы, используемые потоками, при этом не освобождаются.
Синопсис
#include <pthread.h>
int pthread—exit(void *value ptr);
При завершении последнего потока в процессе завершается сам процесс со статусом
завершения, равным 0. Эта функция не может вернуться к вызывающему потоку и не
определяет никаких кодов ошибок.
Для отмены выполнения некоторого потока по инициативе потока из того же ад-
ресного пространства используется функция pthread—cancel (). Отменяемый поток
задается параметром thread.
Синопсис
#include <pthread.h>
int pthread—cancel(pthread—t thread thread);
Обращение к функции pthread—cancel () представляет собой запрос аннулировать по-
ток. Этот запрос может быть удовлетворен немедленно, с отсрочкой или проигнорирован.
Когда произойдет аннулирование (и произойдет ли оно вообще), зависит от типа аннули-
рования и состояния потока, подлежащего этой кардинальной операции. Для удовлетво-
рения запроса на отмену потока предусмотрен процесс аннулирования, который происхо-
дит асинхронно (т.е. не совпадает по времени) по отношению к выходу из функции
pthread—cancel () и ее возврату в вызывающий поток. Если потоку нужно выполнить
“уборочные” задачи, они обязательно выполняются. После выполнения последней та-
кой задачи-обработчика вызываются деструкторы потоковых объектов, если таковые
предусмотрены, и только после этого поток завершается. В этом и состоит процесс ан-
нулирования потока. При успешном выполнении функция pthread—cancel () возвра-
щает число 0, в противном случае — код ошибки. Эта функция не выполнится успешно,
если параметр thread не соответствует ни одному из существующих потоков.
Некоторые потоки могут потребовать принять меры безопасности против преж-
девременного их аннулирования. Внесение в потоковую функцию средств безопасно-
сти может предотвратить возникновение некоторых нежелательных ситуаций. Пото-
ки разделяют общие данные, и (в зависимости от используемой потоковой модели)
один поток может обрабатывать данные, которые должны быть переданы другому’ по-
току для последующей обработки. Пока поток обрабатывает данные, он является их
4.9. Управление потоками 147
единственным обладателем благодаря блокированию мьютекса, связанного с этими
данными. Если поток, имеющий заблокированный мьютекс, аннулируется до его ос-
вобождения, возникает взаимоблокировка. Для того чтобы снова использовать дан-
ные, их следует привести в определенное состояние. Если поток отменяется до освобо-
ждения мьютекса, могут возникнуть нежелательные условия. Другими словами, в зави-
симости от типа обработки, которую выполняет поток, его аннулирование должно
происходить тогда, когда это безопасно. Об опасных и безопасных периодах “знает”
только сам поток, и поэтому только он может предотвратить свое аннулирование в
опасные периоды. Следовательно, круг потоков, которые можно аннулировать, должен
быть ограничен потоками, которые не относятся к числу “жизненно важных” или ко-
торые не имеют блокировок ресурсов. Кроме того, аннулирование может быть отсро-
чено до тех пор, пока не будут выполнены “жизненно важные” действия.
Состояние готовности к аннулированию (cancelability state) описывает условия, при
которых поток может (или не может) быть аннулирован. Тип аннулирования
(cancelabilty type) потока определяет способность потока продолжать выполнение
после получения запросов на аннулирование. Поток может отреагировать на аннули-
рующий запрос немедленно или отложить аннулирование до определенной (более
поздней) точки в его выполнении. Состояние готовности к аннулированию и тип ан-
нулирования устанавливаются динамически самим потоком.
Для определения состояния готовности к аннулированию и типа аннулирова-
ния вызывающего потока используются функции pthread—setcancelstate ()
и pthread_setcanceltype (). Функция pthread—setcancelstate () устанавлива-
ет вызывающий поток в состояние, заданное параметром state, и возвращает пре-
дыдущее состояние в параметре olds tat е.
Синопсис
♦include <pthread.h>
int pthread—setcancelstate(int state, int *oldstate);
int pthread—setcanceltype(int type, int *oldtype);
Параметры state и oldstate могут принимать такие значения:
^THREAD—CANCEL—DI SABLE
^THREAD—CANCEL—ENABLE
начение PTHREAD—CANCEL—DISABLE определяет состояние, в котором поток будет
игнорировать запрос на аннулирование, а значение PTHREAD—CANCEL—ENABLE — со-
стояние, в котором поток “согласится” выполнить соответствующий запрос (это со-
стояние по умолчанию устанавливается для каждого нового потока). При успешном
циП°ЛНеНИИ Фуикцпя возвращает число 0, в противном случае — код ошибки. Функ-
ей* Pthread_ setcancel state () не может выполниться успешно, если переданное
значение параметра state окажется недействительным.
ед ' нкция pthread—setcanceltype () устанавливает для вызывающего потока тип
в п ' ЛИРОВания’ заданный параметром type, и возвращает предыдущее значение типа
раметре oldtype. Параметры type и oldtype могут принимать такие значения:
₽ThrfAD~CANCEL-DEFFERED
kead_cancel_asynchronous
148 Глава 4. Разбиение С++-программ на множество потоков
Значение PTHREAD—CANCEL—DEFFERED определяет тип аннулирования, при котором
поток откладывает завершение до тех пор, пока он не достигнет точки, в котором его
аннулирование возможно (этот тип по умолчанию устанавливается для каждого ново-
го потока). Значение PTHREAD—CANCEL—ASYNCHRONOUS определяет тип аннулирова-
ния, при котором поток завершается немедленно. При успешном выполнении функ-
ция возвращает число 0, в противном случае— код ошибки. Функция
pthread—setcanceltype () не может выполниться успешно, если переданное ей
значение параметра type окажется недействительным.
Функции pthread— setcancelstate () и pthread—setcanceltype () использу-
ются вместе для установки отношения вызывающего потока к потенциальному запро-
су на аннулирование. Возможные комбинации значений состояния и типа аннулиро-
вания перечислены и описаны в табл. 4.5.
Таблица 4.5. Комбинации значений состояния и типа аннулирования
Состояние Тип Описание
PTHREAD—CANCEL— PTHREAD—CANCEL— Отсроченное аннулирование. Эти состояние
ENABLE DEFERRED и тип аннулирования потока устанавлива- ются по умолчанию. Аннулирование пото- ка происходит, когда он достигает соот- ветствующей точки в своем выполнении или когда программист определяет точку аннулирования с помощью функции pthread—testcancel()
PTHREAD—CANCEL— PTHREAD—CANCEL- Асинхронное аннулирование. Аннулирование
ENABLE ASYNCHRONOUS потока происходит немедленно
PTHREAD—CANCEL- Игнорируется Аннулирование запрещено. Оно вообще не вы-
DISABLE полняется
4.9.1.1. Точки аннулирования потоков
Если удовлетворение запроса на аннулирование потока откладывается, значит,
оно произойдет позже, когда это делать “безопасно”, т.е. когда оно не попадает на пе-
риод выполнения некоторого критического кода, блокирования мьютекса или пре-
бывания данных в некотором “промежуточном” состоянии. Вне этих “опасных” ра3'
делов кода потоков вполне можно устанавливать точки аннулирования. Точка анну-
лирования — это контрольная точка, в которой поток проверяет факт существования
каких-либо ждущих (отложенных) запросов на аннулирование и, если таковые имеют-
ся, разрешает завершение.
Точки аннулирования можно пометить с помощью функции pthread—test cancel () •
Эта функция проверяет наличие необработанных запросов на аннулирование. Если
они есть, она активизирует процесс аннулирования в точке своего вызова. В против-
ном случае функция продолжает выполнение потока без каких-либо последствий. Вы-
зов этой функции можно разместить в любом месте кода потока, которое считается
безопасным для его завершения.
4.9. Управление потоками 149
Синопсис
^include <pthread.h>
void pthread—testcancel(void);
ПрогРамма 4-3 содержит функции, которые вызывают функции
pthread—set cancel state (), pthread—setcanceltype () и pthread—testcancel (),
связанные с установкой типа аннулирования потока и состояния готовности
к аннулированию.
// Программа 4.3
#include <iostream>
#include <pthread.h>
void *taskl(void *X)
{
int OldState;
// Запрет на аннулирование.
pthread—setcancelstate(PTHREAD—CANCEL—DISABLE,
&OldState);
for(int Count = 1;Count < 100;Count++)
{
cout << "В потоке A: " << Count << endl;
}
void *task2 (void *X)
{
int OldState,OldType;
11 Разрешено аннулирование асинхронного типа.
pthread-setcancelstate (PTHREAD—CANCEL—ENABLE,
&OldState);
pthread.setcancel type (PTHREAD—CANCEL—ASYNCHRONOUS,
&OldType);
for(int Count = 1;Count < 100;Count++)
cout << "В потоке В: " << Count « endl;
void *task3(void *X)
int OldState,OldType;
/^₽аз^ешено аннулирование отложенного типа.
Pthread-setcancelstate (PTHREAD—CANCEL—ENABLE,
&OldState);
ptnread—setcanceltype(PTHREAD—CANCEL—DEFERRED,
f &OldType);
Count = 1;Count < 1000;Count++)
cout << "в потоке C: " « Count « endl;
lf((Count%100) == 0){
Pthread—testcancel();
150 Глава 4. Разбиение С++-программ на множество потоков
}
}
}
В программе 4.3 каждая задача устанавливает свое условие аннулирования. В задаче
taskl аннулирование потока запрещено, поскольку вся она состоит из критического
кода, который должен быть выполнен до конца. В задаче task2 аннулирование потока
разрешено. Обращение к функции pthread—setcancelstate () является необязатель-
ным, поскольку все новые потоки имеют статус разрешения аннулирования. Тип аннули-
рования здесь устанавливается равным значению PTHREAD—CANCEL—ASYNCHRONOUS
Это означает, что после поступления запроса на аннулирование поток немедленно
запустит соответствующую процедуру, независимо от того, на какой этап его выпол-
нения придется этот запрос. А поскольку этот поток установил для себя именно такой
тип аннулирования, значит, он не выполняет никакого “жизненно важного” кода. На-
пример, вызовы системных функций должны попадать под категорию опасных для
аннулирования, но в задаче task2 таких нет. Там выполняется лишь цикл, который
будет работать до тех пор, пока не поступит запрос на аннулирование. В задаче task3
аннулирование потока также разрешено, а тип аннулирования устанавливается рав-
ным значению PTHREAD—CANCEL—DEFFERED. Эти состояние и тип аннулирования дей-
ствуют по умолчанию для новых потоков, следовательно, обращения к функциям
pthread—setcancelstate () и pthread— setcanceltype () здесь необязательны.
Критический код этого потока здесь может спокойно выполняться после установки со-
стояния и типа аннулирования, поскольку процедура завершения не стартует до вызова
функции pthread—testcancel (). Если не будут обнаружены ждущие запросы, поток
продолжит свое выполнение до тех пор, пока не встретит очередные обращения
к функции pthread— testcancel () (если таковые предусмотрены). В задаче task3
функция pthread—cancel () вызывается только после того, как переменная Count
без остатка разделится на число 100. Код, расположенный между точками аннулиро-
вания потока, не должен быть критическим, поскольку он может не выполниться.
Программа 4.4 содержит управляющий поток, который делает запрос на аннули-
рование каждого рабочего потока.
// Программа 4.4
int main(int argc, char *argv[])
{
pthread—t Threads[3];
void *Status;
pthread—create(&(Threads[0]),NULL,taskl,NULL);
pthread—create(&(Threads[1]), NULL,task2,NULL);
pthread—create(&(Threads[2]),NULL,task3,NULL);
pthread—cancel(Threads[ 0 ] ) ;
pthread—cancel(Threads[1]);
pthread—cancel(Threads[2] ) ;
for(int Count = 0;Count < 3;Count++)
{
pthread—join(Threads[Count],&Status);
if(Status == PTHREAD—CANCELED){
cout « "Поток" << Count « " аннулирован."
« endl;
}
4.9. Управление потоками 151
else{
cout « "Поток" « Count
« " продолжает выполнение." « endl;
}
}
return (0) ;
}
Управляющий поток в программе 4.4 сначала создает три рабочих потока, затем
делает запрос на аннулирование каждого из них. Управляющий поток для каждого ра-
бочего потока вызывает функцию pthread—j oin (). Эта функция завершается ус-
пешно даже тогда, когда она пытается присоединить поток, который уже завершен,
функция присоединения в этом случае просто считывает статус завершения завер-
шенного потока. И такое поведение весьма кстати, поскольку поток, который сделал
запрос на аннулирование, и поток, вызвавший функцию pthread—join (), могут ока-
заться совсем разными потоками. Мониторинг функционирования всех рабочих по-
токов может оказаться единственной задачей того потока, который “по совмести-
тельству” и аннулирует потоки. Опрашивать же статус завершения потоков с помо-
щью функции pthread—join () может совершенно другой поток. Этот тип
информации используется для получения статистической оценки того, какой из по-
токов наиболее эффективен. В рассматриваемой нами программе все это делает один
управляющий поток: в цикле он и присоединяет рабочие потоки, и проверяет их ста-
тус завершения. Поток Thread [0] не аннулирован, поскольку он имеет запрет на ан-
нулирование, в то время как два остальных потока были аннулированы. Статус завер-
шения аннулируемого потока может иметь, например, значение PTHREAD—CANCELED.
Профили программ 4.3 и 4.4 представлены в разделе “Профиль программы 4.2”.
; Профиль программы 4.2
Имя программы
j Program4-3 4.сс
; Описание
;Демонстрирует аннулирование потоков. Три потока имеют различные типы
; и состояния аннулирования. Каждый поток выполняет цикл. Состояние и тип
аннулирования определяет количество итераций цикла и то, будет ли цикл
выполняться вообще. Основной поток определяет статус завершения каждого
, рабочего потока.
Требуемая библиотека
libpthread
Требуемые заголовки
<Pthread.h> <iostream>
Инструкции по компиляции и компоновке программ
+ -° program4-34 program4-34.сс -lpthread
Рада для тестирования
; USE Linux 7.1, gcc 2.95.2.
|Инструкции по выполнению
^/^rogram4 - 3 4
152 Глава 4. Разбиение С++-программ на множество потоков
В функциях, определенных пользователем, используются точки аннулирования
отмеченные обращением к функции pthread—testcancel (). Библиотека Pthread
определяет в качестве точек аннулирования выполнение других функций. Эти функ-
ции блокируют вызывающий поток, а заблокированному потоку аннулирование не
грозит. Вот эти функции библиотеки Pthread:
pthread—testcancel()
pthread_cond_wait()
pthread—timedwait
pthread—join()
Если поток, пребывающий в состоянии отсроченного аннулирования, имеет ждущий
запрос на аннулирование, то при вызове одной из перечисленных выше функций биб-
лиотеки Pthread будет инициирована процедура аннулирования. Некоторые из систем-
ных функций, претендующих на роль точек аннулирования, перечислены в табл. 4.6.
Таблица 4.6. Системные POSIX-функции, претендующие на роль точек
аннулирования
accept() nanosleep() sem_wait()
aio__suspend () open() send()
clock—nanosleep() pause() sendmsg()
close() pollO sendto()
connect() pread() sigpause()
creat() pthread—cond_timedwait() sigsuspend()
fcntl() pthread—cond_wait() sigtimedwait()
fsync() pthread—j oin() sigwait()
getmsg() putmsg() sigwaitinfo()
lockf() putpmsg() sleep()
mq_receive() pwrite() system()
mq_send() read() usleep()
mq_timedreceive() readv() wait()
mq_timedsend () recvfrom() waitpid()
msgrcv() recvmsg() write()
msgsnd() select() writev()
msync() sem timedwait()
Несмотря на то что эти функции безопасны для отсроченного аннулирования по-
токов, они могут не быть таковыми для асинхронного аннулирования. Асинхронное
аннулирование во время вызова библиотечной функции, которая не является асин-
хронно-безопасной, может привести к тому, что библиотечные данные останутся не
в надлежащем состоянии. Библиотека выделит память от имени потока, и, когда по-
ток будет аннулирован, продолжит удерживать “за собой” эту память. Для других биб-
лиотечных и системных функций, которые не являются безопасными для аннулир0'
вания (асинхронного или отсроченного), возможно, имеет смысл написать код, пре'
4.9. Управление потоками 153
пятствующий завершению потока путем установки категорического запрета на анну-
лирование или использования отсроченного аннулирования до тех пор, пока эти
функции не будут выполнены.
4.9.1-2- Очистка перед завершением
Поток, “позволивший” себя аннулировать, прежде чем завершиться, обычно дол-
жен выполнить некоторые заключительные действия. Так, нужно закрыть файлы,
привести разделяемые данные в надлежащее состояние, снять блокировки или осво-
бодить занимаемые ресурсы. Библиотека Pthread определяет механизм поведения
каждого потока “в последние минуты своей жизни”. С каждым потоком связывается
стек очистительно-восстановительных операций (cleanup stack), который содержит
указатели на процедуры (или функции), предназначенные для выполнения во время
аннулирования потока. Для того чтобы поместить в этот стек указатель на процедуру,
предусмотрена функция pthread—сleanup_push ().
Синопсис
#include <pthread.h>
void pthread—сleanup_push(void (*routine)(void *),
void *arg);
void pthread—cl eanup pop (int execute);
Параметр routine представляет собой указатель на функцию, помещаемый в стек
завершающих процедур. Параметр arg содержит аргумент, передаваемый этой
routine-функции, которая вызывается при завершении потока с помощью функции
pthread—exit (), когда поток “покоряется” запросу на аннулирование или явным обра-
зом вызывает функцию pthread—сleanup_pop () с ненулевым значением параметра
execute. Функция, заданная параметром routine, не возвращает никакого значения.
Функция pthread—cleanup—pop () удаляет указатель routine-функции из вер-
шины стека завершающих процедур вызывающего потока. Параметр execute может
принимать значение 1 или 0. Если его значение равно 1, поток выполняет routine-
функцию, даже если он при этом и не завершается. Поток продолжает свое выполне-
ние с инструкции, расположенной за вызовом функции pthread—cleanup—pop ().
Если значение параметра execute равно 0, указатель извлекается из вершины стека
потока без выполнения routine-функции.
Необходимо позаботиться о том, чтобы для каждой функции занесения в стек
tpush) существовала функция извлечения из стека (pop) в пределах одной и той же
лексической области видимости. Например, для функции f uncA () обязательно вы-
полнение cleanup-обработчика при ее нормальном завершении или аннулировании:
(Oid *funcA(void *Х)
int *Tid;
Tid = new int;
// Выполнение некоторых действий.
//^pead-cleanuP-Push(cleanup—funcA,Tid);
Выполнение некоторых действий.
} pthread_c 1 eanup—pop (0) ;
154 Глава 4. Разбиение С++-программ на множество потоков
Здесь функция funcAf) помещает указатель на обработчик cleanup—funcА() в стек
завершающих процедур путем вызова функции pthread_cleanup—push (). Каждому
обращению к этой функции должно соответствовать обращение к функции
pthread—cleanup—pop(). Если функции извлечения указателя из стека (pop.
функции) передается значение 0, то извлечение из стека состоится, но без выполне-
ния обработчика. Обработчик будет выполнен лишь при аннулировании потока, вы-
полняющего функцию funcA().
Для функции funcB () также требуется cleanup-обработчик:
void *funcB(void *Х)
{
int *Tid;
Tid = new int;
// Выполнение некоторых действий.
//. . .
pthread—cleanup—push(cleanup—funcB,Tid);
// Выполнение некоторых действий.
//. . .
pthread—cleanup_pop(1);
}
Здесь функция funcB () помещает указатель на обработчик cleanup—funcB () в стек
завершающих процедур. Отличие этого примера от предыдущего состоит в том, что
функции pthread—cleanup—pop () передается параметр со значением 1, т.е. после из-
влечения из стека указателя на обработчик этот обработчик будет туг же выполнен. Необ-
ходимо отметить, что выполнение обработчика в данном случае состоится “при любой по-
годе”, т.е. и при аннулировании потока, который обеспечивает выполнение функции
funcB (), и при обычном его завершении. Обработчики-“уборщики”, cleanup—funcA ()
и cleanup—funcB (), — это обычные функции, которые можно использовать для закры-
тия файлов, освобождения ресурсов, разблокирования мьютексов и пр.
4.9.2. Управление стеком потока
Адресное пространство процесса делится на раздел кода, раздел статических дан-
ных, свободную память и раздел стеков. Стекам потоков выделяется область из стеко-
вого раздела процесса. Стек потока предназначен для хранения стекового фрейма, свя-
занного с каждой процедурой (функцией), которая была вызвана, но еще не заверше-
на. Стековый фрейм содержит временные переменные, локальные переменные,
адреса точек возврата и любую другую дополнительную информацию, которая необ-
ходима потоку, чтобы найти “обратную дорогу” к ранее вызванным процедурам. При
выходе из процедуры (функции) ее стековый фрейм извлекается из стека. Располо-
жение фреймов в стеке схематично показано на рис. 4.12.
Предположим, что поток А (см. рис. 4.12) выполняет функцию taskl () , кото-
рая создает некоторые локальные переменные, выполняет заданную обработку,
а затем вызывает функцию taskX (). При этом для функции taskl () создается сте-
ковый фрейм, который помещается в стек потока. Функция taskX () выполняет
“свои” действия, создает локальные переменные, а затем вызывает функцию
taskC (). Нетрудно догадаться, что стековый фрейм, созданный для функции
taskX () , также помещается в стек. Функция taskC () вызывает функцию taskY ()
и т.д. Каждый стек должен иметь достаточно большой размер, чтобы поместить всю
4.9. Управление потоками 155
информацию, необходимую для выполнения всех функций потока я
других подпрограмм, которые будут вызваны „ХО»Ы„„ Jy„KnL’?'pU"”'‘“
„ местопотожением стека поток, управляет о„ерац„„„„ая cnS™. “о L “Р°М
ки и считывания этой информации предусмотрим ДЛЯ Устад°в-
в объекте атрибутов потока. ды’ которые определены
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА
Рис. 4.12. Стековые фреймы, сгенерированные потоками
Функция pthread_attr_getstacksize () возвращает минимальный размер стека,
устанавливаемый по умолчанию. Параметр attr определяет объект атри утов пото
из которого считывается стандартный размер стека. При успешном выполнении срунк
ция возвращает значение 0, а стандартный размер стека, выраженный в байтах, сохра
няется в параметре stacksize. В случае неудачи функция возвращает код ошибки.
Функция pthread_attr_setstacksize() устанавливает минимальный размер
стека. Параметр attr определяет объект атрибутов потока, для которого устанав
ливается размер стека. Параметр stacksize содержит минимальный размер стека,
выраженный в байтах. При успешном выполнении функция возвращает значение ,
в противном случае — код ошибки. Функция завершается неудачно, если значени
параметра stacksize оказывается меньше значения PTHREAD_MIN_STACK или
превышает системный минимум. Вероятно, значение PTHREAD_STACK_MIN удет
меньше минимального размера стека, возвращаемого функцией
Pthread_attr_getstacksize(). Прежде чем увеличивать минимальный размер
стека потока, следует поинтересоваться значением, возвращаемым функцией
Pthread_attr_getstacksize() размер СТека фиксируется, чтобы его расшире-
ние во время выполнения программы ограничивалось рамками фиксированного
Пространства стека, установленного во время компиляции.
156 Глава 4. Разбиение С++-программ на множество потоков
Синопсис
#include <pthread.h>
void pthread—attr_getstacksize(
const pthread_attr_t *restrict attr,
void **restrict stacksize);
void pthread—attr_setstacksize(pthread—attr_t *attr,
void *stacksize);
Местоположение стека потока можно установить и прочитать с помощью функций
pthread—attr—setstackaddr() и pthread—attr_getstackaddr(). Функция
pthread—attr_setstackaddr () для потока, создаваемого с помощью атрибутного
объекта, заданного параметром attr, устанавливает базовый адрес стека равным ад-
ресу, заданному параметром stackaddr. Этот адрес stackaddr должен находиться
в пределах виртуального адресного пространства процесса. Размер стека должен быть
не меньше минимального размера стека, задаваемого значением
PTHREAD—STACK—MIN. При успешном выполнении функция возвращает значение О,
в противном случае — код ошибки.
Функция pthread—attr_getstackaddr () считывает базовый адрес стека для по-
тока, создаваемого с помощью атрибутного объекта потока, заданного параметром
attr. Считанный адрес сохраняется в параметре stackaddr. При успешном выпол-
нении функция возвращает значение 0, в противном случае — код ошибки.
Синопсис
#include <pthread.h>
void pthread—attr_setstackaddr(pthread—attr_t *attr,
void *stackaddr);
void pthread—attr_getstackaddr(
const pthread—attr—t *restrict attr,
void** res trict st ackaddr) ;
Атрибуты стека (размер и местоположение) можно установить с помощью одной
функции. Функция pthread—attr_setstack () устанавливает как размер, так
и адрес стека для потока, создаваемого с помощью атрибутного объекта, заданного
параметром attr. Базовый адрес стека устанавливается равным адресу, заданному
параметром stackaddr, а размер стека — равным значению параметра stacksize.
Функция pthread—attr_getstack () считывает размер и адрес стека для потока,
создаваемого с помощью атрибутного объекта, заданного параметром attr. Пр*1
успешном выполнении функция возвращает значение 0, в противном случае — коД
ошибки. Если считывание атрибутов стека прошло успешно, адрес будет записан
в параметр stackaddr, а размер— в параметр stacksize. Функция
pthread—setstack () выполнится неудачно, если значение параметра stacksize
окажется меньше значения PTHREAD—STACK—MIN или превысит некоторый преДсЛ’
определяемый реализацией.
4.9. Управление потоками 157
Синопсис
^include <pthread.h>
•Я nthread_attr_setstack(pthread_attr_ t *attr,
VO1 void *stackaddr,
size_t stacksize) ;
void pthread_attr_getstack(
const pthread_attr_t *restrict attr,
void **restrict stackaddr,
size_t stacksize) ;
В листинге 4.3 показан пример установки размера стека для потока, создаваемого
С помощью атрибутного объекта.
// Листинг 4.3. Изменение размера стека для потока
/ / с использованием смещения
//. . •
pthread—attr_getstacksize (&SchedAttr, &DefaultSize) ;
if (Defaultsize < Min_Stack_Req) {
Sizeoffset = Min_Stack—Req - Defaultsize;
NewSize = Defaultsize + Sizeoffset;
pthread_attr_setstacksize(&Attrl,(size_t)NewSize);
}
В листинге 4.3 сначала из атрибутного объекта потока считывается размер стека, дей-
ствующий по умолчанию. Затем, если окажется, что этот размер меньше желаемого
минимального размера стека, вычисляется разность между сравниваемыми размера-
ми, после чего значение этой разности (смещение) суммируется с размером стека, ис-
пользуемым по умолчанию. Результат суммирования становится новым минимальным
размером стека для этого потока.
ПРИМЕЧАНИЕ: установка размера и местоположения стека может сделать вашу
программу непереносимой. Размер и местоположение стека, устанавливаемые на од-
ной платформе, могут оказаться неподходящими для использования в качестве раз-
МсРа и местоположения стека для другой платформы.
4-9.3. Установка атрибутов планирования
и свойств потоков
Tok^0,zio®ho процессам, потоки выполняются независимо один от другого. Каждый по-
етсяНаЗНаЧаеТСЯ пР°ЦессоРУ Для выполнения его задачи. Для каждого потока определя-
сь - стРатегия планирования и приоритет, которые предписывают, как и когда именно
Пы п Назначен процессору. Стратегия планирования и приоритет потока (или груп-
Dt-ъ К°В }станавливаются с помощью объекта атрибутов и следующих функций:
pthreaH~’attr~Set^n^er^tsc^e<^ (
PthrGZd"attr~Setschedpolicy (}
—attr__setschedparam()
158 Глава 4. Разбиение С++-программ на множество потоков
Для получения информации о характере выполнения потока используются СЛе
дующие функции:
pthread_attr_getinheritsched()
pthread_attr_getschedpolicy()
pthread_attr_getschedparam()
Синопсис
#include <pthread.h>
#include <sched.h>
void pthread_attr_setinheritsched(
pthread_attr_t *attr,
int inheritsched);
void pthread_attr_setschedpolicy(
pthread_attr_t *attr,
int policy);
void pthread_attr_setschedparam(
pthread_attr_t *restrict attr,
const struct sched param *restrict param);
Функции pthread_attr_setinheritsched(), pthread_attr_setschedpolicy ()
и pthread_attr_setschedparam () используются для установки стратегии плани-
рования и приоритета потока. Функция pthread_attr_setinheritsched () позво-
ляет определить, как будут устанавливаться атрибуты планирования потока: путем на-
следования от потока-создателя или в соответствии с содержимым объекта атрибутов.
Параметр inheritsched может принимать одно из следующих значений.
PTHREAD_INHERIT_SCHED Атрибуты планирования потока должны быть унас-
ледованы от потока-создателя, при этом любые ат-
рибуты планирования, определяемые параметром
attr, будут игнорироваться.
PTHREAD_EXPLICIT_SCHED Атрибуты планирования потока должны быть уста-
новлены в соответствии с атрибутами планирования,
хранимыми в объекте, заданном параметром attr.
Если параметр inheritsched получает значение PTHREAD_EXPLICIT_SCHED, то
функция pthread_attr_setschedpolicy() используется для установки стратегии
планирования, а функция pthread_attr_setschedparam () — установки приоритета.
Функция pthread_attr_setschedpolicy () устанавливает член объекта атрибу-
тов потока (заданного параметром attr), “отвечающий” за стратегию планирования
потока. Параметр policy может принимать одно из следующих значений, опреде-
ленных в заголовке <sched. h>.
SCHED_FIFO
SCHED_RR
SCHED_OTHER
Стратегия планирования типа FIFO (первым прибыл, первым об-
служен), при которой поток выполняется до конца.
Стратегия циклического планирования, при которой каждый поток
назначается процессору только в течение некоторого кванта времени-
Стратегия планирования другого типа (определяемая реализацией)-
Для любого нового потока эта стратегия планирования принимается
по умолчанию.
4.9. Управление потоками 159
кция pthread_attr_setschedparam() используется для установки членов
1 тНОго объекта (заданного параметром attr), связанных со стратегией плани-
аТР ыя Параметр param представляет собой структуру, которая содержит эти чле-
СтрУкТУРа sched_param включает по крайней мере такой член данных:
struct sched_param {
int sched_priority;
};
Возможно, эта структура содержит и другие члены данных, а также ряд функций,
елназначенных для установки и считывания минимального и максимального зна-
чений приоритета, атрибутов планировщика и пр. Но если для задания стратегии
планирования используется либо значение SCHED_FIFO, либо значение SCHEDJRR, то
в структуре sched_param достаточно определить только член sched_priority.
Чтобы получить минимальное и максимальное значения приоритета, используйте
функции sched_get_priority_min () и sched_get_priority_max ().
Синопсис
#include <sched.h>
int sched_get_priority_max(int policy);
int sched—get priority min(int policy);
Обеим функциям в качестве параметра policy передается значение, определяю-
щее выбранную стратегию планирования, для которой нужно установить значения
приоритета, и обе функции возвращают соответствующее значение приоритета
(минимальное и максимальное) для заданной стратегии планирования.
Как установить стратегию планирования и приоритет потока с помощью атрибут-
ного объекта, показано в листинге 4.4.
// Листинг 4.4. Использование атрибутного объекта потока
II для установки стратегии планирования и
II приоритета потока
define Min_Stack_Req 3000000
Pthread-1 ThreadA;
Pthread_attr_t SchedAttr;
int^^ Defaultsize, Sizeoffset, NewSize;
Scb lnPri°rity, MaxPriority, MidPriority ;
e -Param SchedParam;
{ t rna^n(int argc, char *argv[])
₽1Нг₽И!аИаЛИЗИР‘>,ем объект атрибутов.
a -attr-init(&SchedAttr);
// минимальное и максимальное значения
Р^тета для стратегии планирования.
= sched—get_priority_max(SCHED_RR);
rity = sched_get_priority_inin (SCHED_RR) ;
160 Глава 4. Разбиение С++-программ на множество потоков
// Вычисляем значение приоритета.
MidPriority = (MaxPriority + MinPriority)/2;
// Записываем значение приоритета в структуру sched_param.
SchedParam.sched_priority = MidPriority;
// Устанавливаем объект атрибутов.
pthread—attr_setschedparam(&Attrl,&SchedParam);
// Обеспечиваем установку атрибутов планирования
// с помощью объекта атрибутов.
pthread_attr_setinheritsched(SAttrl,
PTHREAD_EXPLICIT_SCHED);
// Устанавливаем стратегию планирования.
pthread_attr_setschedpolicy(&Attrl, SCHEDJRR);
// Создаем поток с помощью объекта атрибутов.
pthread_create(&ThreadA,&Attrl, task2,Value);
}
В листинге 4.4 стратегия планирования и приоритет потока ThreadA устанавливаются
с использованием атрибутного объекта SchedAttr. Выполним следующие действия.
1. Инициализируем атрибутный объект.
2. Считаем минимальное и максимальное значения приоритета для стратегии
планирования.
3. Вычислим значение приоритета.
4. Запишем значение приоритета в структуру sched_param.
5. Установим атрибутный объект.
6. Обеспечим установку атрибутов планирования с помощью атрибутного объекта.
7. Установим стратегию планирования.
8. Создадим поток с помощью атрибутного объекта.
Последовательное выполнение этих действий позволяет установить стратегию
планирования и приоритет потока до его создания. Для динамического измене-
ния стратегии планирования и приоритета используйте функции
pthread—setschedparam() и pthread—setschedprio().
Синопсис
#include <pthread.h>
int pthread—setschedparam(
pthread—t thread, int policy,
const struct sched—param *param);
int pthread—getschedparam(
pthread—t thread,
int Restrict policy,
struct sched—param *restrict param);
int pthread—setschedprio(pthread—t thread, int prio);
4.9. Управление потоками 161
Лекция pthread—set schedparamf) устанавливает как стратегию планирова-
так и приоритет потока без использования атрибутного объекта. Параметр
НИЯ ad содержит идентификатор потока, параметр policy— новую стратегию пла-
L вания и параметр param— значения, связанные с приоритетом. Функция
thread-getschedparam () сохраняет значения стратегии планирования и приори-
Р а в параметрах policy и param соответственно. При успешном выполнении обе
ии возвращают число 0, в противном случае — код ошибки. Условия, при кото-
ых эти функции могут завершиться неудачно, перечислены в табл. 4.7.
Таблица 4.7. Условия потенциального неудачного завершения функций
установки стратегии планирования и приоритета
Функции Условия отказа
int pthread—getschedparam
(pthread-t thread,
int *restrict policy,
struct sched—param *restrict
param) ;
Параметр thread не ссылается на сущест-
вующий поток
int pthread—setschedparam
(pthread—t thread,
int *policy,
const struct sched—param
*param);
lnt pthread—setschedprio
(pthread—t thread,
int prio);
Некорректен параметр policy или один
из членов структуры, на которую указыва-
ет параметр param
Параметр policy или один из членов
структуры, на которую указывает пара-
метр param, содержит значение, которое
не поддерживается в данной среде
Вызывающий поток не имеет соответст-
вующего разрешения на установку значе-
ний приоритета или стратегии планиро-
вания для заданного потока
Параметр thread не ссылается на сущест-
вующий поток
Данная реализация не позволяет прило-
жению заменить один из параметров пла-
нирования заданным значением
Параметр prio не подходит к стратегии
планирования заданного потока
Параметр prio имеет значение, которое
не поддерживается в данной среде
Вызывающий поток не имеет соответст-
вующего разрешения на установку при-
оритета для заданного потока
Параметр thread не ссылается на сущест-
вующий поток
Данная реализация не позволяет прило-
жению заменить значение приоритета
заданным_____________________________
162 Глава 4. Разбиение С++-программ на множество потоков
Функция pthread—setschedprio () используется для установки значения
оритета выполняемого потока, идентификатор которого задан параметром threap
В результате выполнения этой функции текущее значение приоритета будет заменено
значением параметра prio. При успешном выполнении функция возвращает число о
в противном случае — код ошибки. При неуспешном выполнении функции приоритет
потока изменен не будет. Условия, при которых эта функция может завершиться не-
успешно, также перечислены в табл. 4.7.
ПРИМЕЧАНИЕ: к изменению стратегии планирования или приоритета выпол-
няемого потока необходимо отнестись очень осторожно. Это может непредсказуе-
мым образом повлиять на общую эффективность приложения. Потоки с более вы-
соким приоритетом будут вытеснять потоки с более низким, что приведет к зависа-
нию либо к тому, что поток будет постоянно выгружаться с процессора и поэтому
не сможет завершить выполнение.
4.9.3.1. Установка области конкуренции потока
Область конкуренции потока определяет, какое множество потоков с одинаковы-
ми стратегиями планирования и приоритетами будут состязаться за использование
процессора. Область конкуренции потока устанавливается его атрибутным объектом.
Синопсис
#include <pthread.h>
int pthread—attr_setscope(pthread—attr_t *attr,
int contentionscope);
int pthread—attr_getscope(
const pthread—attr_t *restrict attr,
int * restrict contentionscope) ; •
Функция pthread—attr_setscope () устанавливает член объекта атрибутов по-
тока (заданного параметром attr), связанный с областью конкуренции. Область кон-
куренции потока будет установлена равной значению параметра contentionscope,
который может принимать следующие значения.
PTHREAD—SCOPE—SYSTEM Область конкуренции системного уровня
PTHREAD—SCOPE—PROCESS Область конкуренции уровня процесса
Функция pthread—attr_getscope () возвращает атрибут области конкуренции и3
объекта атрибутов потока, заданного параметром attr. При успешном выполнении
значение области конкуренции сохраняется в параметре contentionscope. Обе фунК'
ции при успешном выполнении возвращают число 0, в противном случае — код ошибки-
4.9.4. Использование функции sysconf ()
Знание пределов, устанавливаемых системой на использование ресурсов, позволит на
шему приложению эффективно управлять ресурсами. Например, максимальное коли^ест
во потоков, приходящихся на один процесс, составляет верхнюю границу числа раб°
чих потоков, которое может быть создано процессом. Функция sysconf () используеТ'
ся для получения текущего значения конфигурируемых системных пределов или опЦ*114'
4.9. Управление потоками 163
cn»°aCSiC
#include
#include
<unistd.h>
<limits.h>
^sysconftint name);_________________________________________________
П аметр name — это запрашиваемая системная переменная. Функция возвращает
ения, соответствующие стандарту POSIX IEEE Std. 1003.1-2001 для заданных сис-
3 ных переменных. Эти значения можно сравнить с константами, определенными
вашей реализацией стандарта, чтобы узнать, насколько они согласуются между собой,
л я ояда системных переменных существуют константы-аналоги, относящиеся к по-
токам, процессам и семафорам (см. табл. 4.8).
Если параметр name не действителен, функция sysconf () возвращает число -1 и ус-
танавливает переменную errno, свидетельствующую об ошибке. Однако для заданного
параметра name предел может быть не определен, и функция может возвращать число -1
как действительное значение. В этом случае переменная errno не устанавливается. Не-
обходимо отметить, что неопределенный предел не означает безграничность ресурса.
Это просто означает, что не определен максимальный предел и (при условии доступно-
сти системных ресурсов) могут поддерживаться более высокие предельные значения.
Рассмотрим пример вызова функции sysconf ():
if (PTHREAD_STACK_MIN == (sysconf (_SC_THREAD_STACK_MIN) ) ) {
//...
}
Значение константы PTHREAD_STACK_MIN сравнивается co значением, возвра-
щаемым функцией sysconf (), вызванной с параметром _SC_THREAD_STACK_MIN.
Таблица 4.8. Системные переменные и соответствующие им символьные
‘ Г \ константы
Переменная Значение Описание
-SC_THREADS _POSIX_THREADS Поддерживает потоки
_SC_THREAD_ATTR_ STACKADDR _POS IX_THREAD_ATTR_ STACKADDR Поддерживает атрибут адреса стека потока
—SC__THREAD_ATTR STACKSIZE _POSIX_THREAD_ATTR_ STACKSIZE Поддерживает атрибут размера стека потока
--SC_THREAD_STACK MIN ~ PTHREAD—STACK_MIN Минимальный размер стека потока в байтах
-SC_JTHREAD_THREADS MAX ~ -SC-THREAD_KEYS_MAX PTHREAD—THREADS—MAX Максимальное количество по- токов на процесс
PTHREAD—KEYS—MAX Максимальное количество
twS«THREAD~priO inherit ” -S<THREAD^PRi0 __POSIX_THREAD_PRIO_ INHERIT _POSIX_THREAD—PRIO_ ключей на процесс Поддерживает опцию наследо- вания приоритета Поддерживает опцию приори-
тета потока
164 Глава 4. Разбиение С++-программ на множество потоков
Окончание табл. 4, $
Переменная Значение - Описание
_SC—THREAD-PRIORIТY_ -POSIX—THREAD—PRIORITY— Поддерживает опцию плани-
SCHEDULING SCHEDULING рования приоритета потока
_SC_THREAD_PROCESS— -POSIX—THREAD—PROCESS. Поддерживает синхронизацию
SHARED SHARED на уровне процесса
_SC_THREAD—SAFE— -POSIX—THREAD—SAFE— Поддерживает функции безо-
functions FUNCTIONS пасности потока
_SC_THREAD— -PTHREAD-THREAD- Определяет количество попы-
DESTRUCTOR- ITERATIONS DESTRUCTOR-ITERATIONS ток, направленных на разру- шение потоковых данных при завершении потока
_SC_CHILD—MAX CHILD_MAX Максимальное количество процессов, разрешенных для UID
_SC—PRIORITY— —POSIX—PRIORITY- Поддерживает планирование
SCHEDULING SCHEDULING процессов
_SC_REALTIME-. _POSIX—REALTIME— Поддерживает сигналы реаль-
SIGNALS SIGNALS ного времени
—SC—XOPEN—REALTIME- -XOPEN-REALTIME- Поддерживает группу потоко-
THREADS THREADS вых средств реального времени X/Open POSIX
-SC-STREAM-MAX STREAM-MAX Определяет количество потоков данных, которые один процесс может открыть одновременно
-SC.SEMAPHORES —POSIX—SEMAPHORES Поддерживает семафоры
_SC—SEM—NSEMS—MAX SEM—NSEMS—MAX Определяет максимальное ко- личество семафоров, которое может иметь процесс
_SC_SEM_VALUE—MAX SEM—VALUE—MAX Определяет максимальное зна- чение, которое может иметь се- мафор
—SC—SHARED—MEMORY- _POSIX—SHARED—MEMORY- Поддерживает объекты общей
OBJECTS OBJECTS памяти
4.9.5. Управление критическими разделами
Параллельно выполняемые процессы (или потоки в одном процессе) могут совме-
стно использовать структуры данных, переменные или отдельные данные. Разделе-
ние глобальной памяти позволяет процессам или потокам взаимодействовать ДрУг
с другом и получать доступ к общим данным. При использовании нескольких процес-
сов разделяемая глобальная память является внешней по отношению к ним. Внеш*
нюю структуру данных можно использовать для передачи данных или команд межДУ
процессами. Если же необходимо организовать взаимодействие потоков, то они могу’1'
4.9. Управление потоками 165
ть доступ к структурам данных или переменным, являющимся частью одного
получ прОцесса, которому они принадлежат.
И Т<Если существуют процессы или потоки, которые получают доступ к разделяемым
(Ьицируемым данным, структурам данных или переменным, то все эти данные
М ятся в критической области (или разделе) кода процессов или потоков. Крити-
Н а тзлел кода — это та его часть, в которой обеспечивается доступ потока или
ческии м
песса к разделяемому блоку модифицируемой памяти и обработка соответствую-
IX данных. Отнесение раздела кода к критическому можно использовать для управ-
ления состоянием “гонок”. Например, создаваемые в программе два потока, поток А
и поток В, используются для поиска нескольких ключевых слов во всех файлах системы.
Поток А просматривает текстовые файлы в каждом каталоге и записывает нужные пу-
ти в списочную структуру данных TextFiles, а затем инкрементирует переменную
FileCount. ПотокВ выделяет имена файлов из списка TextFiles, декрементирует
переменную FileCount, после чего просматривает файл на предмет поиска в нем за-
данных ключевых слов. Файл, который их содержит, переписывается в другой файл,
и инкрементируется еще одна переменная FoundCount. К переменной FoundCount
поток А доступа не имеет. Потоки А и В могут выполняться одновременно на отдель-
ных процессорах. Поток А выполняется до тех пор, пока не будут просмотрены все
каталоги, в то время как поток В просматривает каждый файл, путь к которому выде-
лен из переменной TextFiles. Упомянутый список поддерживается в отсортирован-
ном порядке, и в любой момент его содержимое можно отобразить на экране.
Здесь возможна масса проблем. Например, поток В может попытаться выделить
имя файла из списка TextFiles до того, как потокА его туда поместит. Поток В мо-
жет попытаться декрементировать переменную Searchcount до того, как поток А ее
инкрементирует, или же оба потока могут попытаться модифицировать эту перемен-
ную одновременно. Кроме того, во время сортировки элементов списка TextFiles
поток А может попытаться записать в него имя файла, или поток В будет в это время
пытаться выделить из него имя файла для выполнения своей задачи. Описанные про-
блемы— это примеры условий “гонок”, при которых несколько потоков (или процес-
сов) пытаются одновременно модифицировать один и тот же блок общей памяти.
Если потоки или процессы одновременно лишь читают один и тот же блок памяти,
условия “гонок” не возникают. Они возникают в случае, когда несколько процессов
или потоков одновременно получают доступ к одному и тому же блоку памяти, и по
крайней мере один из этих процессов или потоков делает попытку модифицировать
Данные. Раздел кода становится критическим, когда он делает возможными одновре-
менные попытки изменить один и тот же блок памяти. Один из способов защитить
критический раздел — разрешить только монопольный доступ к блоку памяти. Моно-
польный доступ означает, что к разделяемому блоку памяти будет иметь доступ один
НЬ1^ сс Или поток в течение короткого промежутка времени, при этом всем Осталь-
ские ПР°Цессам ИЛИ потокам запрещено (путем блокировки) входить в свои критиче-
^разделы, которые обеспечивают доступ к тому же самому блоку памяти.
Ровки ^71Равления условиями “гонок” можно использовать такой механизм блоки-
“mutual КаК В?аимно исключающий семафор, или мьютекс (mutex— сокращение от
критрГ ~ взаимное исключение). Мьютекс используется для блокирования
Него — Кого РазДела: он блокируется до входа в критический раздел, а при выходе из
Деблокируется:
166 Глава 4. Разбиение С++-лрограмм на множество потоков
Блокирование мьютекса
// Вход в критический раздел.
// Доступ к разделяемой модифицируемой памяти.
// Выход из критического раздела.
Деблокирование мьютекса
Класс pthread—mutex_t позволяет смоделировать мьютексный объект. Прежде
чем объект типа pthread—mutex_t можно будет использовать, его необходимо
инициализировать. Для инициализации мьютекса используется функция
pthread_mutex_init (). Инициализированный мьютекс можно заблокировать
деблокировать и разрушить с помощью функций pthread_mutex_lock () ’
pthread_mutex_unlock () и pthread—mutex_destroy () соответственно. В про-
грамме 4.5 содержится функция, которая выполняет поиск текстовых файлов
а в программе 4.6 — функция, которая просматривает каждый текстовый файл на
предмет содержания в нем заданных ключевых слов. Каждая функция выполняется
потоком. Основной поток реализован в программе 4.7. Эти программы реализуют мо-
дель “изготовитель-потребитель” для делегирования задач потокам. Программа 4.5
содержит поток-“изготовитель”, а программа 4.6 — поток-“потребитель”. Критические
разделы выделены в них полужирным шрифтом.
// Программа 4.5
1 int isDirectory(string FileName)
2 {
3 struct stat StatBuffer;
4
5 Istat(FileName.c_str(),&StatBuffer);
6 if((StatBuffer.st_mode & S_IFDIR) == -1)
7 {
8 cout « "Невозможно получить статистику по файлу."
« endl;
9 return (0);
Ю }
11 else{
12 if(StatBuffer.st_mode & S—IFDIR){
13 return (1);
14 }
15 }
16 return (0);
17 }
18
19
20 int isRegular(string FileName)
21 {
22 struct stat StatBuffer;
23
24 Istat(FileName.c_str(),&StatBuffer);
25 if((StatBuffer.st_mode & S_IFDIR) == -1)
26 {
27 cout « "Невозможно получить статистику по файлу."
« endl;
28 return (0);
29 }
30 else{
31 if(StatBuffer.st_mode & S_IFREG){
32 return (1);
33 }
4.9. Управление потоками 167
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
return (0);
void depthFirstTraversal(const char *CurrentDir)
{ DIR *DirP;
string Temp;
string FileName;
struct dirent *EntryP;
chdir(CurrentDir);
cout « "Просмотр каталога: " « CurrentDir « endl;
DirP = opendir(CurrentDir);
if(DirP == NULL){
cout « "He удается открыть файл." « endl;
return;
}
EntryP = readdir(DirP);
while(EntryP != NULL)
{
Temp.erase();
FileName.erase();
Temp = EntryP->d_name;
if((Temp != ".") && (Temp != "..")){
FileName.assign(CurrentDir);
FileName.append(1,'/');
FileName.append(EntryP->d_name);
if(isDirectory(FileName)){
string NewDirectory;
NewDirectory = FileName;
depthFirstTraversal(NewDirectory.c_str());
}
else{
if(isRegular(FileName)){
int Flag;
Flag = FileName.find(".cpp");
if(Flag > 0){
pthread_mutex_lock(&CountMutex);
Fi1eCount++;
pthread_mutex__unlock (&CountMutex) ;
pthread_mutex_lock(&QueueMutex) ;
TextFiles.push(FileName);
pthread_mutex_unlock(&QueueMutex);
}
}
}
}
Entry? = readdir(DirP);
closedir(DirP);
v°id *task(void *X)
168 Глава 4. Разбиение С++-программ на множество потоков
92 {
93 char *Directory;
94 Directory = static—cast<char *>(X);
95 depthFirstTraversal(Directory);
96 re turn(NULL);
97
98 }
Программа 4.6 содержит поток-“потребитель”, который выполнж
ных ключевых слов.
// Программа 4.6
1 void *keySearch(void *X)
2 {
3 string Temp, Filename;
4 less<string> Comp;
5
6 while(!Keyfile.eof() && Keyfile.good())
7 {
8 Keyfile » Temp;
9 if(’Keyfile.eof()){
10 Keywords.insert(Temp);
11 }
12 }
13 Keyfile.close();
14
15 while(TextFiles.empty () )
16 { }
17
18 while (! TextFiles. empty () )
19 {
20 pthread—mutex_lock(&QueueMutex);
21 Filename = TextFiles.front();
22 TextFiles.pop();
23 pthread_mutex—unlock(&QueueMutex);
24 Infile.open(Filename.C—str());
2 5 Searchwords.erase(Searchwords.begin(),
2 6 Searchwords.end());
27 while(’Infile.eof() && Infile.good())
28 {
29 Infile » Temp;
3 0 Searchwords.insert(Temp);
31 }
32
33 Infile.close();
34 i f(includes(Searchwords.begin(),Searchwords.end(),
Keywords.begin(),Keywords.end(),Comp)){
35 Outfile « Filename « endl;
3 6 pthread—mutex—lock(fcCountMutex);
37 FileCount—;
38 pthread—mutex—unlock(&CountMutex);
39 FoundCount++;
40 }
41 )
42 return(NULL);
43
44 }
4.9. Управление потоками 169
Программа
потребитель”,
4.7 содержит основной поток для потоков модели “изготовитель-
реализованных в программах 4.5 и 4.6.
// программа 4.7
1 ^include <sys/stat.h>
2 #include <fstream>
3 #include <queue>
4 #include <algorithm>
5 #include <pthread.h>
6 #include <iostream>
7 #include <set>
9 pthread—mu tex_t QueueMutex = PTHREAD—MUTEX—INITIALIZER;
10 pthread—mu tex_t CountMutex = PTHREAD—MUTEX_INITIALIZER;
11
12 int FileCount = 0;
13 int FoundCount = 0;
14
15 int keySearch (void) ;
16 queue<string> TextFiles;
17 set <string,less<string> >KeyWords;
18 set <string,less<string> >SearchWords;
19 ifstream Infile;
20 of stream Outfile;
21 ifstream Keyfile;
22 string KeywordFile;
23 string OutFilename;
24 pthread_t Threadl;
25 pthread-t Thread2;
26
27 void depthFirstTraversal(const char *CurrentDir);
28 int isDirectory(string FileName);
29 int isRegular(string FileName);
30
32 <nt ma^n^nt arUc, char *argv[])
33 if(argc != 4) {
34 cerr << "Нужна дополнительная информация." « endl;
35 exit (1);
36 }
37
38 Outfile.open(argv[3],ios::app||ios:rate);
40 Keyfile-open(argv[2]);
Pthread—create(&Threadl,NULL,task,argv[1]);
42 Pthread—create (&Thread2, NULL, keySearch, argv [ 1 ] ) ;
4з Pthread_join(Threadl,NULL);
44 Pthread-join(Thread2,NULL);
45 pt^read-mutex_destroy (&CountMutex) ;
4g Pthread—mutex—des troy (&Queu eMutex) ;
47
cout « argv[l] << " содержит " << FoundCount
40 <<: " файлов co всеми ключевыми словами." « endl;
49 } return(ОЬ-
170 Глава 4. Разбиение С++-программ на множество потоков
С помощью мьютексов доступ к разделяемой памяти для чтения или записи дац.
ных разрешается получить только одному потоку. Для гарантии безопасности работы
функций, определенных пользователем, можно использовать и другие механизмы
и методы, которые реализуют одну из моделей PRAM:
EREW (монопольное чтение и монопольная запись)
CREW (параллельное чтение и монопольная запись)
ERCW (монопольное чтение и параллельная запись)
CRCW (параллельное чтение и параллельная запись)
Мьютексы используются для реализации EREW-алгоритмов, которые рассматри-
ваются в главе 5.
4.10. Безопасность использования потоков
и библиотек
Климан (Klieman), Шах (Shah) и Смаалдерс (Smaalders) утверждали: “Функция или на-
бор функций могут сделать поток безопасным или реентерабельным (повторно входимым), если
эти функции могут вызываться не одним, а несколькими потоками без предъявления каких бы то ни
было требований к вызывающей части выполнить определенные действия” (1996). При разработ-
ке многопоточного приложения программист должен обеспечить безопасность парал-
лельно выполняемых функций. Мы уже обсуждали безопасность функций, определенных
пользователем, но без учета того, что приложение часто вызывает функции из систем-
ных библиотек или библиотек, созданных сторонними производителями. Одни такие
функции и/или библиотеки безопасны для потоков, а другие — нет. Если функция не-
безопасна, это означает, что в ней используется хотя бы одна статическая переменная,
осуществляется доступ к глобальным данным и/или она не является реентерабельной.
Известно, что статические переменные поддерживают свои значения между вызо-
вами функции. Если некоторая функция содержит статические переменные, то для ее
корректного функционирования требуется считывать (и/или изменять) их значения.
Если же к такой функции будут обращаться несколько параллельно выполняемых пото-
ков, возникнут условия “гонок”. Если функция модифицирует глобальную переменную,
то каждый из нескольких потоков, вызывающих функцию, может попытаться модифи-
цировать эту глобальную переменную. Возникновения условий “гонок” также не мино-
вать, если не синхронизировать множество параллельных доступов к глобальной пере-
менной. Например, несколько параллельных потоков могут выполнять функции, кото-
рые устанавливают переменную errno. Для некоторых потоков, предположим, эта
функция не может выполниться успешно, и переменная errno устанавливается равной
сообщению об ошибке, в то время как другие потоки выполняются успешно. Если реа-
лизация компилятора не обеспечивает потоковую безопасность поддержки переменной
errno, то какое сообщение получит поток при проверке состояния переменной errno?
Блок кода считается реентерабельным, если его невозможно изменить при выпол-
нении. Реентерабельный код исключает возникновение условий “гонок” благодаря
отсутствию ссылок на глобальные переменные и модифицируемые статические дан-
ные. Следовательно, такой код могут совместно использовать несколько параллель-
ных потоков или процессов без риска создать условия “гонок”. Стандарт POSIX опре'
деляет ряд реентерабельных функций. Их легко узнать по наличию “суффикса” —г’
присоединяемого к имени функции. Перечислим некоторые из них:
4.10. Безопасность использования потоков и библиотек 171
getgrgid_r()
getgrnanur
getpwuid_r<
sterror_r<)
strt°k-r(\.
readdir-r()
rand_r0
^tyTiciiTie—' *
Если функция получает доступ к незащищенным глобальным переменным, содер-
статические модифицируемые переменные или нереентерабельна, то такая
ия считается небезопасной для потока. Системные библиотеки или библиоте-
ки созданные сторонними производителями, могут иметь различные версии своих
стандартных библиотек. Одна версия предназначена для однопоточных приложений,
а другая — для многопоточных. Если предполагается разрабатывать многопоточное
приложение, программист должен использовать многопоточные версии нужной ему
библиотеки. Некоторые среды требуют не компоновки многопоточных приложений
с многопоточной версией библиотеки, а лишь определения макросов, что позволяет
объявить реентерабельные версии функций. Такое приложение будет затем компи-
лироваться как безопасное для выполнения потоков.
Во всех ситуациях использовать многопоточные версии функций попросту невоз-
можно. В отдельных случаях многопоточные версии конкретных функций недоступ-
ны для данного компилятора или среды. Иногда один интерфейс функции не в со-
стоянии сделать ее безопасной. Кроме того, программист может столкнуться с увели-
чением числа потоков в среде, которая изначально использовала функции,
предназначенные для функционирования в однопоточной среде. В таких условиях
обычно используются мьютексы. Например, программа имеет три параллельно вы-
полняемых потока. Два из них, threadl и thread2, параллельно выполняют функ-
цию f uncA (), которая не является безопасной для одновременной работы потоков.
Третий поток, thread3, выполняет функцию funcB (). Для решения проблемы, свя-
занной с функцией f uncA (), возможно, достаточно заключить в защитную оболочку
мьютекса доступ к ней со стороны потоков threadl и thread2:
threadl
{
lock()
funcA()
unlock()
thread3
{
funcB()
}
thread2
{
lock()
funcA()
unlock()
}
При реализации таких защитных мер к функции funcA () в любой момент времени
обе Г ПОЛ^ЧИТЬ Д°СТУП только один поток. Но проблемы на этом не исчерпываются. Если
исции funcA () и funcB () небезопасны для выполнения потоками, они могут обе
ифицировать глобальные или статические переменные. И хотя потоки threadl и
ead2 используют мьютексы для функции funcA (), поток thread3 может выполнять
Не ЧИЮ uncB (одновременно с любым из остальных потоков. В такой ситуации впол-
o6><WrrHO возникновение условий “гонок”, поскольку функции funcA () и funcB () мо-
модифицировать одну и ту же глобальную или статическую переменную.
нИи Р°ИЛЛЮстРиРУем euJc °дин тип условий “гонок”, возникающих при использова-
в°дятИбЛИОТеки i°streain- Предположим, у нас есть два потока, А и В, которые вы-
°бъе Данные в станДартный выходной поток, cout, который представляет собой
типа ostream. При использовании операторов “>>” и “<<” вызываются мето-
172 Глава 4. Разбиение С++-программ на множество потоков
ды объекта cout. Вопрос: являются ли эти методы безопасными? Если потока от
правляет сообщение “Мы существа разумные” объекту stdout, а поток В отправляет
сообщение “Люди алогичные существа”, то не произойдет ли “перемешивание” ВЬ1
ходных данных, в результате которого может получиться сообщение вроде такого- “
Мы Люди существа алогичные разумные существа”? В некоторых случаях безопасные
для потоков функции реализуются как атомные. Атомные функции — это функции, ко-
торые, если их выполнение началось, не могут быть прерваны. Если операция
для объекта cout реализована как атомная, то подобное “перемешивание” не про-
изойдет. Если есть несколько обращений к оператору “»”, то они будут выполнены
последовательно. Сначала отобразится сообщение потока А, а затем сообщение пото-
ка В или наоборот, хотя они вызвали функцию вывода одновременно. Это — пример
преобразования параллельных действий в последовательные, которое обеспечит
безопасность выполнения потоков. Но это не единственный способ обезопасить
функцию. Если функция не оказывает неблагоприятного эффекта, она может смеши-
вать свои операции. Например, если метод добавляет или удаляет элементы из струк-
туры, которая не отсортирована, и этот метод вызывают два различных потока, то
перемешивание их операций не даст неблагоприятного эффекта.
Если неизвестно, какие функции из библиотеки являются безопасными, а какие -
нет, программист может воспользоваться одним из следующих вариантов действий.
• Ограничить использование всех опасных функций одним потоком.
• Не использовать безопасные функции вообще.
• Собрать все потенциально опасные функции в один набор механизмов синхро-
низации.
Еще один вариант — создать интерфейсные классы для всех опасных функций, ко-
торые должны использоваться в многопоточном приложении, т.е. опасные функции
инкапсулируются в одном интерфейсном классе. Такой интерфейсный класс может
быть скомбинирован с соответствующими объектами синхронизации с помощью на-
следования или композиции и использован специализированным классом. Такой
подход устраняет возможность возникновения условий “гонок”.
4.11. Разбиение программы на несколько потоков
Выше в этой главе мы рассматривали делегирование работы в соответствии с кон-
кретной стратегией или потоковой моделью. Итак, используются следующие распро-
страненные модели:
• делегирование (“управляющий-рабочий”);
• сеть с равноправными узлами;
• конвейер;
• “изготовитель-потребитель”.
Каждая модель характеризуется собственной декомпозъщией работ (Work Breakdown
Structure — WBS), которая определяет, кто отвечает за создание потоков и при каких
условиях они создаются. В этом разделе мы рассмотрим пример программы для ка*
дой модели, использующей функции библиотеки Pthread.
4.11. Разбиение программы на несколько потоков 173
4.11.1. Использование модели делегирования
Мы рассмотрели два подхода к реализации модели делегирования при разделении
программы на потоки. Вспомним: в модели делегирования один поток (управляющий) соз
дает другие потоки (Р^очие) и назначает каждому из них задачу. Управляющий поток
делегирует каждому рабочему потоку задачу, которую он должен выполнить путем зала
ния некоторой функции. При одном подходе управляющий поток создает рабочие по
токи как результат запросов, обращенных к системе. Управляющий поток обрабатывает
запрос каждого типа в цикле событий. Как только событие произойдет будет создан па
бочий поток и ему будет назначена задача. Функционирование цикла событий в vnnaa
ляющем потоке и создание рабочих потоков продемонстрировано в листинге 4.5.
// Листинг 4.5. Подход 1: скелет программы реализации
// модели управляющего и рабочих потоков
// (псевдокод)
/ / • • •
pthread—mutex.t Mutex = PTHREAD_MUTEX_INITIALIZER
int AvailableThreads
pthread.t Thread [Max_Threads ]
void dec remen tThr eadAva i 1 abi 1 i ty (void)
void incrementThreadAvailability (void)
int threadAvailability (void) ;
// Управляющий поток.
{
//. . .
if (sysconf (_SC_THREAD_THREADS_MAX) > 0) {
AvailableThreads = sysconf (_SC_THREAD_THREADS_MAX)
)
else{
AvailableThreads = Default
}
int Count = 1;
Цикл while(Очередь запросов не пуста)
if(threadAvailability()){
Count++
decrementThreadAvailability()
Классификация запроса
switch(Тип запроса)
{
case X :
pthread_create(&(Thread[Count])...taskX...)
case Y :
pthread—create(&(Thread[Count])...taskY...)
case Z :
pthread—create(&(Thread[Count])...taskZ...)
//. . .
}
}
else{
// Освобождаем ресурсы потоков.
Конец цикла
174 Глава 4. Разбиение С++-программ на множество потоков
}
void *taskX(void *Х)
{
// Обрабатываем запрос типа X.
incrementThreadAvaliability()
return(NULL)
}
void *taskY(void *Y)
{
// Обрабатываем запрос типа Y.
incrementThreadAvailability()
return(NULL)
}
void *taskZ(void *Z)
{
// Обрабатываем запрос типа Z.
decrementThreadAvailability()
return(NULL)
}
//. . .
В листинге 4.5 управляющий поток динамически создает поток для обработки ка-
ждого нового запроса, который поступает в систему. Однако существует ограничение
на количество потоков (максимальное число потоков), которое можно создать в про-
цессе. Для обработки п типов запросов существует п задач. Чтобы гарантировать, что
максимальное число потоков на процесс не будет превышено, определяются следую-
щие дополнительные функции:
threadAvaliability()
incrementThreadAvailability()
decrementThreadAvailability()
В листинге 4.6 содержится псевдокод реализации этих функций.
// Листинг 4.6. Функции, которые управляют возможностью
// создания потоков
void incrementThreadAvailability(void)
{
//. . .
pthread—mutex_lock(&Mutex)
AvailableThreads++
pthread__mutex—unlock (&Mutex)
}
void decrementThreadAvailability(void)
{
//. . .
pthread—mutex—lock(&Mutex)
Ava i1ableThreads —
pthread—mutex—unlock(&Mutex)
}
int threadAvailability(void)
{
4.11. Разбиение программы на несколько потоков 175
yiread_mutex_lock (&Mutex)
(AvailableThreads > 1)
return 1
else
return 0
pthread_mutex_unlock(&Mutex)
}
функция threadAvaliability () возвратит число 1, если максимально допусти-
мое количество потоков для процесса еще не достигнуто. Эта функция опрашивает
глобальную переменную ThreadAvailability, в которой хранится число потоков,
еще доступных для процесса. Управляющий поток вызывает функцию
decrementThreadAvailability (), которая декрементирует эту глобальную пере-
менную до создания им рабочего потока. Каждый рабочий поток вызывает функцию
incrementThreadAvaliability (), которая инкрементирует глобальную перемен-
ную ThreadAvaliability до начала его выполнения. Обе функции содержат обра-
щение к функции pthread_mutex_lock () до получения доступа к этой глобальной
переменной и обращение к функции pthread—mutex_unlock () после него. Если
максимально допустимое количество потоков превышено, управляющий поток может
отменить создание потока, если это возможно, или породить другой процесс, если
это необходимо. Функции taskX (), taskY () и taskZ () выполняют код, предназна-
ченный для обработки запроса соответствующего типа.
Другой подход к реализации модели делегирования состоит в создании управляю-
щим потоком пула потоков, которым (вместо создания под каждый новый запрос ново-
го потока) переназначаются новые запросы. Управляющий поток во время инициали-
зации создает некоторое количество потоков, а затем каждый созданный поток приос-
танавливается до тех пор, пока в очередь не будет добавлен новый запрос.
Управляющий поток для выделения запросов из очереди по-прежнему использует цикл
событий. Но вместо создания нового потока для обслуживания очередного запроса,
управляющий поток уведомляет уже существующий поток о необходимости обработки
запроса. Этот подход к реализации модели делегирования представлен в листинге 4.7.
// Листинг 4.7. Подход 2: скелет программы реализации
модели управляющего и рабочих потоков
' (псевдокод)
Pthread-t Thread [N]
Управляющий поток.
nbkread“Create(&(Thread[1]...taskX...);
пьь a<^—creace (& (Thread[2 ] . . .taskY. . . ) ;
Pthread-create(&(Thread[3]...taskZ...);
Цикл while(Очередь запросов не пуста)
Получение запроса
Классификация запроса
switch(Тип запроса)
case X :
Ставим запрос в очередь XQueue
176 Глава 4. Разбиение С++-программ на множество потоков
Посылаем сигнал потоку Thread[l]
case Y :
Ставим запрос в очередь YQueue
Посылаем сигнал потоку Thread[2]
case Z :
Ставим запрос в очередь ZQueue
Посылаем сигнал потоку Thread[3]
//. . .
Конец цикла
}
void *taskX(void *Х)
{
Цикл
Приостанавливаем поток до получения сигнала
Цикл while (Очередь XQueue не пуста)
Извлекаем запрос из очереди
Обрабатываем запрос
Конец цикла while
Конец цикла
}
void *taskY(void *Y)
{
Цикл
Приостанавливаем поток до получения сигнала
Цикл while (Очередь YQueue не пуста)
Извлекаем запрос из очереди
Обрабатываем запрос
Конец цикла while
Конец цикла
}
void *taskZ(void *Z)
{
Цикл
Приостанавливаем поток до получения сигнала
Цикл while (Очередь ZQueue не пуста)
Извлекаем запрос из очереди
Обрабатываем запрос
Конец цикла while
Конец цикла
} В * * * * * * * *
В листинге 4.7 управляющий поток создает N рабочих потоков (по одному для
дого типа задачи). Каждая задача связана с обработкой запросов некоторого
В цикле событий управляющий поток извлекает запрос из очереди запросов, опре^
ляет его тип, ставит его в очередь запросов, соответствующую типу, а затем оправ-71
сигнал потоку, который обрабатывает запросы из этой очереди. Функции пото
также содержат циклы событий. Поток приостанавливается до тех пор, пока не п j •
чит сигнал от управляющего потока о существовании запроса в его очереди.
“пробуждения” (уже во внутреннем цикле) поток обрабатывает все запросы Д°
пор, пока его очередь не опустеет.
4.11. Разбиение программы на несколько потоков 177
4.11
Использование модели сети с равноправными
узлами
В модели равноправных узлов один поток сначала создает все потоки, необходимые
выполнения всех задач. Каждый из равноправных потоков обрабатывает запро-
поступающие из собственного входного потока данных. В листинге 4.8 представ-
СЫ келет программы, реализующий при разделении программы на потоки метод
лен
равноправных узлов.
/ / Листинг 4.8.
//
Скелет программы реализации модели
равноправных потоков
//...
pthread—t Thread [N]
// initial thread
pthread—create (& (Thread [ 1 ] . . . taskX ...);
pthread—create (& (Thread[2 ]...taskY...);
pthread_create(&(Thread[3]...taskZ...);
//...
void *taskX(void *X)
{
Цикл while (Доступны запросы типа XRequests)
Выделяем запрос
Обрабатываем запрос
Конец цикла
} return (NULL)
//...
В модели равноправных потоков каждый поток отвечает за собственный входной
поток данных. Входные данные могут быть выделены из базы данных, файла и т.п.
4-11.3. Использование модели конвейера
этап М°Дели конвейера поток входных данных обрабатывается поэтапно. На каждом
ним НеКотоРая порция работы (часть входного потока данных) обрабатывается од-
п°рцПиОТОКОМ выполнения’ а затем передается для обработки следующему. Каждая
будет ВХодных Данных переходит на очередной этап обработки до тех пор, пока не
ВХо 3авеРШена вся обработка. Такой подход позволяет обрабатывать несколько
тижени П°ТОКов Данных одновременно. Каждый поток выполнения отвечает за дос-
(т,е Промежуточного результата, делая его доступным для следующего этапа
РаПп Д^1О1Дего потока конвейера). Скелет программы реализации модели конвейе-
Редставлен в листинге 4.9.
178 Глава 4. Разбиение С++-программ на множество потоков
// Листинг 4.9. Скелет программы реализации модели
/ / конвейера
//. . .
pthread—t Thread[N]
Queues[N]
// Начальный поток.
{
Помещаем все входные потоки данных в очередь этапа
stagel.
pthread—create(&(Thread[1]...stagel...);
pthread—create(&(Thread[2]...stage2...);
pthread—create(&(Thread[3]...stage3...);
//. . .
}
void *stageX(void *X)
{
Цикл
Приостанавливаем выполнение до появления в очереди
порции входных данных.
Цикл while (Очередь XQueue не пуста)
Извлекаем порцию входных данных.
Обрабатываем порцию входных данных.
Помещаем результат в очередь следующего этапа.
Конец цикла
Конец цикла
return(NULL)
}
//. . .
В листинге 4.9 объявляется N очередей для N этапов. Начальный поток помещает
все порции входных потоков в очередь первого этапа, а затем создает все потоки,
необходимые для выполнения всех этапов. Каждый этап содержит свой цикл собы-
тий. Поток выполнения находится в состоянии ожидания до тех пор, пока в его
очереди не появится порция входных данных. Внутренний цикл продолжается до
опустения соответствующей очереди. Порция входных данных извлекается из оче-
реди, обрабатывается, а затем помещается в очередь следующего этапа обработки
(следующего потока выполнения).
4.11.4. Использование модели “изготовитель-
потребитель”
В модели “изготовитель-потребитель” поток-“изготовитель” готовит да^нь,е’
“потребляемые” потоком-“потребителем” (причем таких потоков-“потребителеи 1
жет быть несколько). Данные хранятся в блоке памяти, разделяемом всеми потока*
как изготовителем, так и потребителями. В листинге 4.10 представлен скелет пр
граммы реализации модели “изготовитель-потребитель” (эта модель также исполь
валась в программах 4.5, 4.6 и 4.7).
4.11. Разбиение программы на несколько потоков 179
ТИНГ 4.10. Скелет программы реализации модели
// "изготовитель-потребитель*
и
я mutex_t Mutex = PTHREAD_MUTEX_INITIALIZER
jjJreadZt Thread[2]
Queue
// Ha4aJIbHbI^ поток*
< thread_create(&(Thread[1]...producer...);
pthread—create (& (Thread [2 ] . . .consumer. . .) ;
//..•
}
void *producer(void *X) // Поток-"изготовитель*
(
Цикл
Выполняем действия
pthread—mutex_lock(&Mutex)
Помещаем данные в очередь
pthread—mutex_unlock(&Mutex)
Уведомляем потребителя
//. . .
Конец цикла
void * consumer(void *Х) // Поток-"потребитель*
{
Цикл
Приостанавливаем до получения сигнала
Цикл while(Очередь данных не пуста)
pthread—mutex—lock(&Mutex)
Извлекаем данные из очереди
pthread—mutex—unlock(&Mutex)
Выполняем действия
Конец цикла
Конец цикла
В листинге 4.9 начальный поток создает оба потока: “изготовителя” и “потребителя”,
^^-“изготовитель” содержит цикл, в котором после выполнения некоторых дейст-
Вий блокируется мьютекс для совместно используемой очереди, чтобы поместить в нее
подготовленные для потребителя данные. После этого “изготовитель” деблокирует
текс и посылает сигнал потоку-“потребителю” о том, что ожидаемые им данные уже
Не 6^ЯТСЯ В ОЧеРеди- Поток-“изготовитель” выполняет итерации цикла до тех пор, пока
0 выполнена вся работа. Поток-“потребитель” также выполняет цикл, в котором
“ПоПрИостанавливается до тех пор, пока не получит сигнал. Во внутреннем цикле поток-
Khdv’ ЬИТСЛЬ Срабатывает все данные до тех пор, пока не опустеет очередь. Он бло-
РУет Мьютекс Для разделяемой очереди перед извлечением из нее данных и деблоки-
^ЬЮТеКС после этого- Затем он выполняет обработку извлеченных данных. В про-
быть 6 б Поток’“потребитель” помещает свои результаты в файл. Вместо файла может
р0ли.11СПользована Другая структура данных. Зачастую потоки-“потребители” играют две
так и изготовителя. Сначала возможно “исполнение” роли по-
ПотОкТеЛя необработанных данных, подготовленных потоком-“изготовителем”, а затем
г°#соИГрает Р°ль иизготовителя”> когда он обрабатывает данные, сохраняемые в дру-
естно используемой очереди, “потребляемой” другим потоком.
180 Г лава 4. Разбиение С++-программ на множество потоков
4.11.5. Создание многопоточных объектов
Модели делегирования, равноправных потоков, конвейера и типа “изготовит
потребитель” предлагают деление программы на несколько потоков с помощьЬ
функций. При использовании объектов функции-члены могут создавать потоки
выполнения нескольких задач. Потоки используются для выполнения кода от имени
объекта: посредством отдельных функций и функций-членов.
В любом случае потоки объявляются в рамках объекта и создаются одной из функ
ций-членов (например, конструктором). Потоки могут затем выполнять некоторые
независимые функции (функции, определенные вне объекта), которые вызывают
функции-члены глобальных объектов. Это — один из способов создания многопоточ-
ного объекта. Пример многопоточного объекта представлен в листинге 4.10.
// Листинг 4.10. Объявление и определение многопоточного
// объекта
#include <pthread.h>
#include <iostream>
#include <unistd.h>
void *taskl(void *);
void *task2(void *);
class multithreaded—object
{
pthread_t Threadl, Thread2;
public:
multithreaded—object(void);
int cl(void);
int c2(void);
//. . .
multithreaded—object::multithreaded—object(void)
{
//. . .
pthread—create(&Threadl,NULL, taskl,NULL);
pthread—create(&Thread2,NULL, task2,NULL);
pthread—j oin(Threadl,NULL);
pthread—j oin(Thread2,NULL);
//. . .
int multithreaded—object::cl(void)
{
// Выполнение действий.
return(1);
int multithreaded—object::c2(void)
{
// Выполнение действий.
return(1);
Резюме 181
}
• threaded_obj ect MObj ;
mult1
„И .£а»И1™»1 •>
}
void *task2(void *)
{
MObj•c2();
return (NULL) ;
}
В листинге 4.10 в классе multithread_object объявляются два потока. Они соз-
даются и присоединяются к основному потоку в конструкторе этого класса. Поток
Threadl выполняет функцию taskl (), а поток Thread2 — функцию task2 (). Функ-
ции taskl () и task2 () затем вызывают функции-члены глобального объекта MObj.
4.12. Резюме
В последовательной программе всю нагрузку можно разделить между отдельными
подпрограммами таким образом, чтобы выполнение очередной подпрограммы было
возможно только после завершения предыдущей. Существует и другая организация
программ, когда, например, вся работа выполняется в виде мини-программ в рамках
основной программы, причем эти мини-программы выполняются параллельно ос-
новной. Такие мини-программы могут быть реализованы как процессы или потоки.
Если в реализации используются процессы, то каждый процесс должен иметь собст-
венное адресное пространство, а если процессы должны взаимодействовать между
собой, то такая реализация требует обеспечения механизма межпроцессного взаимо-
действия. Для потоков, разделяющих адресное пространство одного процесса, не
иркны специальные методы взаимодействия. Но для защиты совместно используемой
памяти (чтобы не допустить возникновения условий “гонок”) необходимо использо-
такие механизмы синхронизации, как мьютексы.
Существует ряд моделей, которые можно использовать для делегирования работы
^0ROKaM И ^пРавления их созданием и аннулированием. В модели делегирования один по-
^рввляющий) создает другие потоки (рабочие) и назначает им задачи. Управляю-
Поток ожидает до тех пор, пока каждый рабочий поток не завершит свою задачу,
дает Использовании модели равноправных узлов есть один поток, который изначально соз-
Pa6QBCe Потоки’ необходимые для выполнения всех задач, причем этот поток считается
в «ИМ Пот°ком, поскольку он не осуществляет никакого делегирования. Все потоки
Модели имеют одинаковый статус. Применяя модель конвейера, программу можно
ць^актеРизовать как сборочную линию, в которой входной поток (поток входных дан-
°^Ра^атывается поэтапно. На каждом этапе поток обрабатывает некоторую пор-
Ьцц Вх°ДНых элементов. Порция входных элементов перемещается от одного потока
°лпения к следующему до тех пор, пока не завершится вся предусмотренная обра-
182 Глава 4. Разбиение С++-программ на множество потоков
ботка. На последнем этапе работы конвейера формируются его результаты, т.е. Поел
ний поток отвечает за формирование конечных результатов программы. В мои
“изготовитель-потребитель” поток-“изготовитель” готовит данные, “потребляемые” И
током-“потребителем”. Данные хранятся в блоке памяти, разделяемом всеми Поток
ми: как изготовителем, так и потребителями. При использовании объектов функции
члены могут создавать потоки для выполнения нескольких задач. Объекты Можц
создавать с многопоточной направленностью. В этом случае потоки объявляются
в самом объекте. Функция-член может создать поток, который выполняет независи
мую функцию, а она (в свою очередь) вызывает одну из функций-членов объекта.
Для создания и управления потоками многопоточного приложения можно ис-
пользовать библиотеку Pthread. Библиотека Pthread опирается на стандартизирован-
ный программный интерфейс, предназначенный для создания и поддержки потоков
Этот интерфейс определен комитетом стандартов IEEE в стандарте POSIX 1003.1с
Сторонние производители при создании своих продуктов должны придерживаться
этого стандарта POSIX.
СИНХРОНИЗАЦИЯ
ПАРАЛЛЕЛЬНО
ВЫПОЛНЯЕМЫХ
ЗАДАЧ
В этой главе...
5.1. Координирование порядка выполнения потоков
5.2. Синхронизация доступа к данным
5.3. Что такое семафоры
5.4. Объектно-ориентированный подход к синхронизации
5.5. Резюме
Отношение этих механизмов ко времени требует тщательного изучения. <...>
Нас почти не интересовала производительность вычислительной машины
для одного входного сигнала. Чтобы адекватно функционировать, она
должна показывать удовлетворительную производительность для целого
класса входных сигналов, а это будет означать удовлетворительную
производительность для класса входных сигналов, получение которого
ожидается статистически...
— Ноберт Винер (Norbert Wiener), Кибернетика
Во всех компьютерных системах ресурсы ограничены. Ведь любой объем памя-
ти конечен, как и количество устройств ввода-вывода, портов, аппаратных
прерываний и процессоров. Если в среде ограниченных аппаратных ресурсов
приложение состоит из нескольких процессов и потоков, то эти составляющие долж-
ны конкурировать за память, периферийные устройства и процессорное время. Когда
и как долго процесс или поток будет использовать системные ресурсы, определяет
операционная система. При использовании приоритетного планирования операнд
онная система может прерывать выполняющийся процесс или поток, чтобы удовле
творить все остальные процессы и потоки, соревнующиеся за системные ресурсЬ1,
Процессам и потокам приходится также соперничать за программные ресурсы и р
сурсы данных. Примерами программных ресурсов служат разделяемые библиотеки
(которые предоставляют в общее пользование набор процедур или функций для пр
цессов и потоков), а также приложения, программы и утилиты. При совместном Пс
пользовании программных ресурсов в памяти содержится только одна копия пр
граммного кода. Под ресурсами данных подразумеваются объекты, системные даннЫе
5.1. Координация порядка выполнения потоков 185
мер переменные среды), файлы, глобально определенные переменные и струк-
1ДаНныХ- Что касается ресурсов данных, то процессы и потоки могут иметь собст-
ТУРЬ1 копии данных. В других случаях желательно и, возможно, даже необходимо,
бы данные были разделяемыми. Одни процессы и потоки, работая вместе, исполь-
4 т ограниченные системные ресурсы в определенном порядке, в то время как другие
ЗУЙствуют независимо и асинхронно, соревнуясь за использование разделяемых ресур-
Дов Для управления процессами и потоками, конкурирующими за использование дан-
bix программист может задействовать ряд специальных методов и механизмов.
Синхронизация также необходима для координации порядка выполнения парал-
лельных задач. Примером может служить модель “изготовитель-потребитель”, кото-
ая рассмотрена в главе 4. “Изготовитель” обязательно начинает выполняться до
“потребителя”, но не обязательно завершается до него. Подобные задачи нуждаются
в синхронизации. Синхронизация данных (синхронизация доступа к данным) и задач
(синхронизация последовательностей инструкций) — два типа синхронизации, которые
необходимо обеспечить при выполнении нескольких параллельных задач.
5.1. Координация порядка выполнения потоков
Предположим, у нас есть три параллельно выполняющихся потока — А, В и С.
Все они участвуют в обработке списка. Список необходимо отсортировать, выпол-
нить в нем операции поиска и вывода результатов. Каждому потоку назначается от-
дельная задача. Так, поток А должен отобразить результаты поиска, В — отсортиро-
вать список, а С — провести поиск. Сначала список необходимо отсортировать, за-
тем выполнить несколько параллельных операций поиска, а уж потом отобразить
результаты. Если задачи, выполняемые потоками, не синхронизировать надлежа-
щим образом, то поток А может попытаться отобразить еще не сгенерированные
результаты, что нарушит постусловие, или выходное условие (postcondition), про-
цесса. Предусловием, или входным условием (precondition), здесь является необхо-
димость получения отсортированного списка до выполнения в нем поиска. Поиск
в неотсортированном списке может дать неверные результаты. Поэтому для этих
трех потоков необходимо обеспечить синхронизацию задач, которая приводит
в исполнение постусловия и предусловия логических процессов. UML-диаграмма
видов деятельности для этого процесса представлена на рис. 5.1.
Сначала поток В должен отсортировать список, затем эстафета управления переда-
ется многоканальному” поиску, порождаемому потоком С. И только после завершения
Поисковых работ по всем направлениям поток А отображает результаты поиска.
5-1-1. Взаимоотношения между синхронизируемыми
задачами
Cv
ДвугМя1^еСТВ'еТ четыРе основных типа отношений синхронизации между любыми
Ло п°токами в одном процессе или между любыми двумя процессами в одном при-
(фф) и*11 стаРт’стаРт (СС), финиш-старт (ФС), старт-финиш (СФ) и финиш-финиш
Нацию П°МО1ЦЬЮ этих основных типов отношений можно охарактеризовать коорди-
Ка>кдо За^ач межДУ потоками и процессами. UML-диаграмма видов деятельности для
г° типа отношений синхронизации показана на рис. 5.2.
186 Глава 5. Синхронизация параллельно выполняемых задач
Рис. 5.1. Диаграмма видов деятельности для задач сортировки списка, поиска и отображения
результатов поиска
5.1.2. Отношения типа старт-старт (СС)
В отношениях синхронизации типа старт-старт одна задача не может начаться Д^
тех пор, пока не начнется другая. Одна задача может начаться раньше другой, &°
позже. Предположим, у нас есть программа, которая реализует инкарна
(воплощение). Инкарнация “материализуется” в виде говорящей головы, создай
разумеется, компьютерной программой. Инкарнация обеспечивает своего Р
“одушевление” программ. Программа, которая реализует “одушевление”, имеет
сколько потоков. Здесь нас в первую очередь интересует поток А, который “отвечает
5.1. Координация порядка выполнения потоков 187
цию результата, и поток В, который управляет звуком, или голосом, говорящей
аНИМ Мы хотим создать иллюзию синхронизации звука и движений рта. В идеале они
головы- исходить абсолютно одновременно. При наличии нескольких процессоров
&оЛ потока могут начинаться одновременно. Эти потоки связаны отношением типа
°^а П°гарт. В соответствии с условиями временной синхронизации допускается, чтобы
Сп>к А начинался немного раньше потока В (именно немного — иначе будет нарушена
П° мя одновременности), но потокВ не может начаться раньше потока А. Голос
иллюзия /а г
ен ожидать анимацию, а не наоборот. Совершенно нежелательно услышать голос
до того как зашевелятся губы (если это не синхронное озвучивание).
СТАРТ-СТАРТ
ФИНИШ-ФИНИШ
ФИНИШ-СТАРТ
СТАРТ-ФИНИШ
₽Ис- 5.2. Возможные отношения синхронизации между задачами А и В
^•1 -3. Отношения типа финиш-старт (ФС)
до Тех ТН°Шениях синхронизации типа финиш-старт задача А не может завершиться
^новних** Пока не начнется задача В. Этот тип отношений типичен для родительско-
т°РЫх о пР°Нсссов. Родительский процесс не может завершить выполнение неко-
Не будет РаЦИй до тех пор, пока не будет сгенерирован сыновний процесс или пока
Ние. СынП°ЛУ ~еНа °братная связь от сыновнего процесса, который начал выполне-
*°ДИМую °ВНи” процесс, “просигналивший” родителю или предоставивший ему необ-
может ИНф°РМаВДю* продолжает выполняться, а родительский процесс после это-
Заверщ иться.
188 Глава 5. Синхронизация параллельно выполняемых задач
5.1.4. Отношения типа старт-финиш (СФ)
Отношения типа старт-финиш можно считать обратным вариантом отношеци^
типа финиш-старт. В отношениях синхронизации типа старт-финиш одна задача це
может начаться до тех пор, пока не завершится другая. Задача А не может начать вы
полнение до тех пор, пока задача В не финиширует или не завершит выполнение оц
ределенной операции. Если процесс А считывает данные из канала, связанного
с процессом В, то процесс В должен записать данные в канал, прежде чем процесс Д
начнет считывать из него данные. Процесс В должен завершить по крайней мере одну
операцию, записав в канал один элемент, прежде чем начнет действовать процесс Д
Потоки, действующие по принципу “производитель-потребитель”, — это еще один
пример взаимоотношений типа финиш-старт. Потоки, обслуживающие сортировку
и поиск элементов в списке (см. рис. 5.1), также демонстрируют этот тип отношений
Прежде чем начнут действовать потоки, реализующие поиск, должен завершить свою
работу поток сортировки. Во всех этих случаях один поток или процесс должен за-
вершить свою операцию, прежде чем другой попытается выполнить свою задачу. Ес-
ли работа потоков не будет скоординирована, глобальная цель потока, процесса или
приложения достигнута не будет или же будут получены ошибочные результаты.
Отношения типа старт-финиш обычно предполагают существование информаци-
онной зависимости между задачами. При информационной зависимости для кор-
ректной работы потоков или процессов необходимо обеспечить межпоточное или
межпроцессное взаимодействие. Например, поток поиска данных в списке сгенери-
рует некорректные результаты, если не будет выполнена сортировка списка. И поток-
потребитель” не получит файлы для обработки, если поток-“производитель” не под-
готовит их для потребителя.
5.1.5. Отношения типа финиш-финиш (ФФ)
В отношениях синхронизации типа финиш-финиш одна задача не может завер-
шиться до тех пор, пока не завершится другая, т.е. задача А не может финишировать
до задачи В. Этот тип отношений можно применить к описанию отношений между
родительскими и сыновними процессами, которые рассматривались в главе 3. Роди-
тельский процесс должен ожидать до тех пор, пока не завершатся все сыновние про-
цессы, и только потом сможет завершиться сам. Если описанная последовательность
нарушится, и родительский процесс финиширует раньше своих потомков, то эти за
вершенные сыновние процессы перейдут в зомбированное состояние. Родительские
процессы не должны завершаться (выходить из системы в данном случае) до тех пор,
пока не выполнятся до конца их сыновние процессы. Для родительских процессов
это достигается за счет вызова функции wait () для каждого из своих сыновних пр
цессов либо ожидания деблокировки (освобождения) мьютекса или условной пеР^
менной, что может быть осуществлено сыновними потоками. Еще одним пример^^
отношений типа финиш-финиш может служить модель “управляющий-рабочии •
дача управляющего потока — делегировать работу рабочим потокам. Для управляю
го крайне нежелательно завершить работу раньше рабочих. В этом случае не были
обработаны новые запросы к системе, не имели работы существующие потоки и
создавались новые. Если управляющий поток является основным потоком проН
и он завершается, то процесс должен завершиться вместе со всеми рабочими по
5.2. Синхронизация доступа к данным 189
модели равноправных потоков поток А динамически создает объект, пере-
мц. поТОКуВ, и потокА затем завершается, то вместе с ним разрушается и соз-
даваем мм объект. Если это произойдет до того, как поток В получит возможность
данный • этот объект> возникнет ошибка сегментации или нарушится доступ
исПО м Чтобы предотвратить возникновение этого типа ошибок, завершение по-
КДаН синхронизируется с помощью функции pthread.join(). Обращение к этой
токов заставляет вызывающий поток ожидать до тех пор, пока не финиширует за-
Ф^ный поток. Таким образом и создается синхронизация типа финиш-финиш.
5.2. Синхронизация доступа к данным
Существует разница между данными, разделяемыми между процессами, и данны-
ми разделяемыми между потоками. Потоки совместно используют одно и то же ад-
ресное пространство, в то время как процессы имеют отдельные адресные простран-
ства. Если существуют два процесса А и В, то данные, объявленные в процессе А, не-
доступны процессу В, и наоборот. Следовательно, один из методов, используемых
процессами для разделения данных, состоит в создании блока памяти, отображаемого
затем на адресное пространство процессов, которые должны разделять память. Дру-
гой подход предполагает создание блока памяти, существующего вне адресного про-
странства обоих процессов. К типам механизмов межпроцессного взаимодействия
(МПВ) относятся каналы, файлы и передача сообщений.
Именно блок памяти, разделяемый между потоками внутри одного и того же ад-
ресного пространства, и блок памяти, разделяемый между процессами вне обоих ад-
ресных пространств, требует синхронизации данных. Память, разделяемая между по-
токами и процессами, показана на рис. 5.3.
Синхронизация данных необходима для управления состоянием “гонок”, а также
для того, чтобы позволить параллельным потокам или процессам безопасно получить
доступ к блоку памяти. Синхронизация данных позволяет управлять считыванием
и модификацией данных в блоке памяти. В многопоточной среде параллельный дос-
туп к общей памяти, глобальным переменным и файлам обязательно должен быть
синхронизирован. Что касается программного кода задачи, то синхронизация данных
необходима в тех его блоках, где делается попытка получить доступ к блоку памяти,
глобальным переменным или файлам, разделяемым с другими параллельно выпол-
няемыми процессами или потоками. Такие блоки кода называются критическими раз-
ыами. В качестве критического раздела может выступать любой блок кода, который
‘ яет позицию файлового указателя, записывает данные в файл, закрывает файл
Делени^а^ ИЛИ Устанавливает глобальные переменные либо структуры данных. Вы-
Изэтап ТаКИХ задач* которые выполняют чтение или запись данных, является одним
управления параллельным доступом к совместно используемой памяти.
5-2-1. Модель PRAM
-льньГ (Parallel Random-Access Machine — машина с параллельным произ-
в., Р Д°ступом) — это упрощенная модель с А процессорами, обозначаемыми Рр
Меццо n п КотоРые разделяют одну глобальную память. Все процессоры одновре-
лучают доступ для чтения и записи к совместно используемой глобальной
190 Глава 5. Синхронизация параллельно выполняемых задач
памяти. Каждый из этих теоретических процессоров может получить доступ к п
ляемой глобальной памяти в течение одного непрерываемого интервала времени
дель PRAM включает алгоритмы параллельного, а также исключающего чтения и °
писи. Алгоритмы параллельного чтения позволяют нескольким процессорам одц*
временно использовать одну и ту же область памяти без какого бы то ни бы^
искажения данных. Алгоритмы параллельной записи позволяют нескольким проце
сорам записывать данные в разделяемую область памяти. Алгоритмы исключающег
чтения используются для получения гарантии того, что никакие два процессора нико
гда не будут считывать информацию из одной и той же области памяти одновремен
но. Алгоритмы исключающей записи гарантируют, что никакие два процессора нико
гда не будут записывать данные в одну и ту же область памяти одновременно. Модель
PRAM можно использовать для определения характера параллельного доступа к об-
щей памяти со стороны нескольких задач.
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА А
РАЗДЕЛ ДАННЫХ РАЗДЕЛ КОДА
РАЗДЕЛ СТЕКОВ
СВОБОДНАЯ
ПАМЯТЬ
Локальные переменные Локальные переменные Глобальные । структуры данных Глобальные I переменные
Глобальные I Константы
переменные j Статические , переменные
МЕХАНИЗМЫ
МПВ
Сообщения
Разделяемая
память
Файлы | FIFO-очереди/каналы |
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА В
РАЗДЕЛ СТЕКОВ I Локальные | переменные । СВОБОДНАЯ ПАМЯТЬ Г , । Локальные ! переменные I г » Глобальные I переменные j РАЗДЕЛ ДАННЫХ | Глобальные i структуры данных ; Глобальные i переменные Константы | Статические переменные РАЗДЕЛ КОДА : I
Стек потока А Стек потока В Деревья • Графы * Очереди ♦ Стеки Код потока А | ммв»»'
Рис. 5.3. Память, разделяемая между потоками и процессами
5.2. Синхронизация доступа к данным 191
и исключающая запись (concurrent read and exclusive
и параллельная запись (exclusive read and concurrent
и параллельная запись (concurrent read and concurrent
1 1 Параллельный и исключающий доступ к памяти
5*2* ’ параллельного и исключающего чтения и записи можно скомбиниро-
АлГОР лучить следующие типы объединенных алгоритмов, которые можно реали-
для организации доступа к данным:
сключающее чтение и исключающая запись (exclusive read and exclusive
write — EREW);
• параллельное чтение
„rite-CREW);
• исключающее чтение
write -ERCW);
• параллельное чтение
write — CRCW).
Эти алгоритмы можно рассматривать как стратегии доступа, реализуемые задача-
ми, которые совместно используют данные (рис. 5.4). Алгоритм EREW подразумевает
последовательный доступ к разделяемой памяти, т.е. к общей памяти в любой момент
времени может получить доступ только одна задача. Примером стратегии доступа
EREW может служить вариант реализации модели потоков “производитель-
потребитель”, рассмотренный в главе 4. Доступ к очереди, содержащей имена фай-
лов, может быть ограничен исключающей записью “изготовителя” и исключающим
чтением “потребителя”. В любой момент времени доступ к очереди может быть раз-
решен только для одной задачи. Стратегия CREW позволяет множественный доступ
для чтения общей памяти и исключающий доступ для записи в нее данных. Это озна-
чает отсутствие ограничений на количество задач, которые могут одновременно чи-
тать разделяемую память, но записывать в нее данные может только одна задача. При
этом параллельное чтение может происходить одновременно с записью данных в об-
щую память. При использовании этой стратегии доступа все читающие задачи могут
прочитать различные значения, поскольку во время чтения значения из общей памя-
ти записывающая задача может его модифицировать. Стратегия доступа ERCW — это
прямая противоположность стратегии CREW. При использовании стратегии ERCW
разрешены параллельные записи в общую память, но лишь одна задача может читать
в любой момент времени. Стратегия доступа CRCW позволяет множеству задач вы-
°лнять параллельное чтение и запись.
ни *ЦЛЯ ЭТИХ четыРех типов алгоритмов требуются различные уровни и типы синхро-
ации. Их диапазон довольно широк: от стратегии доступа, реализация которой
требу МИНИМальной синхронизации, до стратегии доступа, реализация которой
ПоДДе максимальной синхронизации. Наша задача— реализовать эти стратегии,
мы. Е^£ууВаЯ Целостность данных и удовлетворительную производительность систе-
сутн толыГ СаМаЯ пРостая Для реализации стратегия, поскольку она предполагает, по
Показаться ° П°СЛедовательнУю обработку. На первый взгляд самой простой может
Кажется CRCW, но она таит в себе массу трудностей. А ведь это только
Не Идет о"0 е<-ЛИ К памяти можно получить доступ без ограничений, то в ней и речь
Пая Для п КаК°Й то ни было стратегии. Все как раз наоборот: CRCW — самая труд-
нзации стратегия, которая требует максимальной синхронизации.
192 Глава 5. Синхронизация параллельно выполняемых задач
EREW (исключающее чтение и исключающая запись)
ERCW (исключающее чтение и параллельная запись)
CREW (параллельное чтение и исключающая запись)
CRCW (параллельное чтение и параллельная запись)
Рис. 5.4. Стратегии доступа EREW, CREW, ERCW и CRCW
5.3. Что такое семафоры 193
5.3. Что такое семафоры
Семафор — это механизм синхронизации, который можно использовать для управ-
ления отношениями между параллельно выполняющимися программными компо-
нентами и реализации стратегий доступа к данным. Семафор — это переменная спе-
циального вида, которая может быть доступна только для выполнения узкого диапа-
зона операций. Семафор используется для синхронизации доступа процессов
и потоков к разделяемой модифицируемой памяти или для управления доступом
к устройствам или другим ресурсам. Семафор можно рассматривать как ключ к ресур-
сам. Этим ключом может владеть в любой момент времени только один процесс или
поток. Какая бы задача ни владела этим ключом, он надежно запирает (блокирует)
нужные ей ресурсы для ее монопольного использования. Блокирование ресурсов за-
ставляет другие задачи, которые желают воспользоваться этими ресурсами, ожидать
до тех пор, пока они не будут разблокированы и снова станут доступными. После раз-
блокирования ресурсов следующая задача, ожидающая семафор, получает его и дос-
туп к ресурсам. Какая задача будет следующей, определяется стратегией планирова-
ния, действующей для данного потока или процесса.
5.3.1. Операции по управлению семафором
Как упоминалось выше, к семафору можно получить доступ только с помощью спе-
циальных операций, подобных тем, которые выполняются с объектами. Это операции
декремента, Р (), и инкремента, V (). Если объект Mutex представляет собой семафор,
то логика реализации операций Р (Mutex) и V (Mutex) может выглядеть таким образом:
Р (Mutex)
if (Mutex > 0) {
Mutex--;
}
else {
Блокирование по объекту Mutex;
У (Mutex)
xf (Очередь доступа к объекту Mutex не пуста){
} Передача объекта Мьютекс следующей задаче;
else{
Mutex++;
от конкретной системы. Эти операции неделимы, т.е. их не-
Реализация зависит от конкретной системы. Эти операции неделимы, т.е. их не-
м°жно прервать. Если операцию Р () попытаются выполнить сразу несколько за-
бы Т° ЛИШЬ одна из них получит разрешение продолжить работу. Если объект Mutex
0^ У Же декрементирован, то задача будет заблокирована и займет место в очереди.
ерация V () вызывается задачей, которая имеет доступ к объекту Mutex. Если полу-
Ия доступа к объекту Мьютекс ожидают другие задачи, он “передается” следующей
из очереди. Если очередь задач пуста, объект Mutex инкрементируется.
Перации с семафором могут иметь другие имена:
Перация Р (): Операция V ():
unlock ()
194 Глава 5. Синхронизация параллельно выполняемых задач
Значение семафора зависит от его типа. Двоичный семафор будет иметь значение о
1. Вычислительный семафор (определяющий лимиты ресурсов для процессов, получающ^
доступ к ним) может иметь некоторое неотрицательное целочисленное значение Х
Стандарт POSIX определяет несколько типов семафоров. Эти семафоры исподь
зуются процессами или потоками. Типы семафоров (а также их некоторые основные
операции) перечислены в табл. 5.1.
Таблица 5.1. Типы семафоров, определенные стандартом POSIX
Тип семафора Пользователь Описание
Мьютексный семафор Процессы или потоки Механизм, используемый для реализации вза- имного исключения в критическом разделе кода
Блокировка для обеспе- чения чтения и записи Процессы или потоки Механизм, используемый для реализации страте- гии доступа для чтения и записи среди потоков
Условная переменная Процессы или потоки Механизм, используемый для уведомления по- токов о том, что произошло событие.
Событийный мьютекс остается заблокирован- ным потоком до тех пор, пока не будет получен соответствующий сигнал
Несколько условных переменных Процессы или потоки Аналогичен событийному мьютексу, но включа- ет несколько событий или условий
Операционные системы, которые не противоречат спецификации Single UNIX
Specification или стандарту POSIX Standard, поддерживают реализацию семафоров,
которые являются частью библиотеки libpthread (соответствующие функции объ-
явлены в заголовке pthread. h).
5.3.2. Мьютексные семафоры
Стандарт POSIX определяет мьютексный семафор, используемый потоками и про-
цессами, как объект типа pthread_mutex_t. Этот мьютекс обеспечивает базовые опе-
рации, необходимые для функционирования практического механизма синхронизации.
• инициализация;
• запрос на монопольное использование;
• отказ от монопольного использования;
• тестирование монопольного использования;
• разрушение.
Функции класса pthread_mutex_t, которые используются для выполнения этих
базовых операций, перечислены в табл. 5.2. Во время инигшализации выделяется
мять, необходимая для функционирования мьютексного семафора, и объекту сеМа
фора присваивается некоторое начальное значение. Для двоичного семафора
чальным может быть значение 0 или 1. Начальным значением вычислительного
мафора может быть неотрицательное число, которое представляет количес
5.3. Что такое семафоры 195
IX ресурсных единиц. Семафорное значение можно использовать для представ-
доступ льНОГО количества запросов, которое способна обработать программа в одном
денИЯ р отличие от обычных переменных, в инициализации которых сомневаться не
сеансе. ^ся факт инициализации мьютекса с помощью вызова соответствующей функции
ИР*** иоовать невозможно. Чтобы убедиться в том, что мьютекс проинициализирован,
дИмо после вызова операции инициализации принять некоторые меры предос-
Не жности (например, проверить значение, возвращаемое соответствующей мьютекс-
^•чьункцией, или значение переменной ептю). Системе не удастся создать мьютекс, если
ока^тся, что занята память, предусмотренная ранее для мьютексов, или превышено
устимое количество семафоров, или семафор с данным именем уже существует,
или же имеет место какая-то другая проблема, связанная с выделением памяти.
Таблица 5.2. Функции класса pthread—mutex—t
Мъютексные операции Прототипы функций (макросы)
ftinclude <pthread.h>
Инициализация int pthread—mutex—init( pthread—mutex—t *restrict mutex, const pthread—mutexattr_t *restrict attr); pthread—mutex_t mutex = PTHREAD—MUTEX.INITIALIZER;
Запрос на монопольное использование <time .h> int pthread—mutex—lock( pthread—mutex—t *mutex); int pthread—mutex—timedlock( pthread—mutex—t *restrict mutex, const struct tiemspec *restrict abs_timeout);
Отказ от монопольного использования Тестирование монопольного использования Разрушение int pthread—mutex—unlock( pthread—mutex—t *mutex); int pthread—mutex—trylock( pthread—mutex—t *mutex); int pthread—mutex—destroy( pthread—mutex—t *mutex);
Подобно потокам, мьютекс библиотеки Pthread имеет атрибутный объект
рассматривается ниже), который инкапсулирует все атрибуты мьютекса. Этот
дет ПНЫЙ °^ъект можно передать функции инициализации, в результате чего бу-
создан мьютекс с атрибутами, заданными с помощью этого объекта. Если при
*ализации атрибутный объект не используется, мьютекс будет инициализирован
лиз еНИЯМи’ Действующими по умолчанию. Объект типа pthread_mutex_t инициа-
ПотокаСТСЯ КаК ДеблокиР°ванный и закрытый. Закрытый мьютекс разделяется между
Иесколь” °ДНОГО пР°Цесса. Разделяемый мьютекс совместно используется потоками
МьютекКИХ ПРоцессов* При использовании атрибутов, действующих по умолчанию,
объект ° М°Жет быть инициализирован статически для статических мьютексных
Pth °В С ПОМО1ЦЬЮ следующего макроса:
ea<<_mutext Mutex = PTHREAD-MUTEX_INITIALIZER;
196 Глава 5. Синхронизация параллельно выполняемых задач
Этот метод менее затратный, но в нем не предусмотрено проверки ошибок.
Мьютекс может иметь или не иметь владельца. Операция запроса на монопольное
пользование предоставляет право владения мьютексом вызывающему потоку или пв
цессу. После того как мьютекс обрел владельца, поток (или процесс) получает моц0
польный доступ к запрашиваемому ресурсу. При попытке завладеть “уже занятым”
мьютексом (путем вызова этой операции), совершенной любыми другими потоками
или процессами, они будут заблокированы до тех пор, пока мьютекс не станет доступ
ным. При освобождении мьютекса следующий (по очереди) поток или процесс
(который был заблокирован) деблокируется и получает право собственности на этот
мьютекс. И освободить его может только поток, получивший данный мьютекс во вла-
дение с помощью функции pthread_mutex_lock(). Можно также использовать
синхронизированную версию этой функции. В этом случае, если мьютекс несвободен
то процесс или поток будет ожидать в течение заданного промежутка времени. Если
мьютекс за это время не освободится, то процесс или поток продолжит выполнение.
Операция тестирования монопольного использования предназначена для проверки дос-
тупности мьютекса. Если он занят, функция возвращает соответствующее значение.
Достоинство этой операции состоит в том, что поток или процесс (в случае недоступ-
ности мьютекса) не блокируется и может продолжать выполнение. Если же мьютекс
свободен, вызывающему потоку или процессу предоставляется право владения за-
прашиваемым мьютексом.
При выполнении операции разрушения освобождается память, связанная с мьютек-
сом. Память не освобождается, если у мьютекса есть владелец или если поток (или
процесс) ожидают права на владение им.
5.3.2.1. Использование мьютексного атрибутного объекта
Мьютексный объект типа pthread—mutex_t можно использовать вместе с атрибут-
ным объектом подобно атрибутному объекту потока. Мьютексный атрибутный объект
инкапсулирует все атрибуты объекта мьютекса. После инициализации его могут исполь-
зовать несколько мьютексных объектов, передавая в качестве параметра функции
pthread—mutex_init (). Мьютексный атрибутный объект определяет ряд функций,
используемых для установки таких атрибутов, как предельный приоритет, протокол
и тип. Эти и другие функции мьютексного атрибутного объекта перечислены в табл. 5.3.
Таблица 5.3. Функции доступа к мьютексному атрибутному объекту
Прототипы функций
Описание
#include <pthread.h>
int pthread—mutexattr_init
(pthread_mutexattr_t * attr);
int pthread—mutexattr_destroy
(pthread—mutexattr_t * attr);
Инициализирует мьютексный атрибутный объ-
ект, заданный параметром attr, значениями,
действующими по умолчанию для всех атрибу-
тов, определяемых реализацией
Разрушает мьютексный атрибутный объект, за-
данный параметром attr, в результате чего он
становится неинициализированным. Его мож-
но инициализировать повторно с помощью
функции pthread-mutexattr init ()_______
5.3. Что такое семафоры 197
Продолжение табл. 5.3
— Прототипы функций Описание
iJ1hread_mutexattr_setprioceiling Р (pthread_mutexattr_t * attr, int prioceiling); Устанавливает и возвращает атрибут предель- ного приоритета мьютекса, заданного парамет- ром attr. Параметр prioceiling содержит значение предельного приоритета мьютекса.
othread_mutexattr_getprioceiling (const pthread_mutexattr_t * restrict attr, Атрибут prioceiling определяет минималь- ный уровень приоритета, при котором еще вы- полняется критический раздел, защищаемый
int *restrict prioceiling); мьютексом. Значения, которые попадают в этот диапазон приоритетов, определяются страте- гией планирования SCHED_FIFO
int pthread_mutexattr_setprotocol (pthread_mutexattr_t * attr, protocol int protocol); int p thr ead_mutexattr__get protocol (const pthread_mutexattr_t * restrict attr, int *restrict protocol); Устанавливает и возвращает атрибут протокола мьютекса, заданного параметром attr. Параметр protocol может содержать следующие значения: PTHREAD_PRIO_NONE (на приоритет и стратегию планирования пото- ка владение мьютексом не оказывает влияния); PTHREAD_PRIO_INHERIT (при таком протоколе поток, блокирующий другие потоки с более высокими приоритета- ми, благодаря владению таким мьютексом бу- дет выполняться с самым высоким приорите- том из приоритетов потоков, ожидающих ос- вобождения любого из мьютексов, которыми владеет данный поток); PTHREAD_PRIO_PROTECT (при таком протоколе потоки, владеющие та- ким мьютексом, будут выполняться при наи- высших предельных значениях приоритетов всех мьютексов, которыми владеют эти пото- ки, независимо оттого, заблокированы ли дру-
int Pthr ead_mu t exa 11 r_s e tpshared <pthread_jnutexattr_t * attr, int pshared); int Pthread-jniitexattr—getpshared °nst pthread_mutexattr_t * . restrict attr, restrict pshared); гие потоки по каким-то из этих мьютексов) Устанавливает и возвращает атрибут process- shared мьютексного атрибутного объекта, за- данного параметром attr. Параметр pshared может содержать следующие значения: PTHREAD_PROCESS_SHARED (разрешает разделять мьютекс с любыми по- токами, которые имеют доступ к выделенной для этого мьютекса памяти, даже если эти по- токи принадлежат различным процессам); PTHREAD_PROCESS_PRIVATE (мьютекс разделяется между потоками одного
_ и того же процесса)
198 Глава 5. Синхронизация параллельно выполняемых задач
Прототипы функций
int
р thread—mutеха 11r_s et type
(pthread-mutexattr_t * attr,
int type);
int
pthread—mutexattr_gettype
(const pthread_mutexattr—t *
restrict attr,
int *restrict type);
__________________________Рычание табл, 5 3
Описание
Устанавливает и возвращает атрибут мьютекса^
type мьютексного атрибутного объекта, за-
данного параметром attr. Атрибут мьютекса
type позволяет определить, будет ли мьютекс
распознавать взаимоблокировку, проверять
ошибки и т.д. Параметр type может содер-
жать такие значения:
PTHREAD—MUTEX—DEFAULT
PTHREAD—MUTEX—RECURS IVE
PTHREAD—MUTEX—ERRORCHECK
PTHREAD—MUTEX—NORMAL
Самый большой интерес представляет установка атрибута, связанного с тем, каким
должен быть мьютекс: закрытым или разделяемым. Закрытые мьютексы разделяются
между потоками одного процесса. Можно либо объявить мьютекс глобальным, либо
организовать передачу дескриптора между потоками. Разделяемые мьютексы исполь-
зуются потоками, имеющими доступ к памяти, в которой размещен данный мьютекс.
Такой мьютекс могут разделять потоки различных процессов. Принцип действия за-
крытого и разделяемого мьютексов показан на рис. 5.5. Если разделять мьютекс при-
ходится потокам различных процессов, его необходимо разместить в памяти, которая
является общей для этих процессов. В библиотеке POSIX определено несколько
функций, предназначенных для распределения памяти между объектами с помощью
отображаемых в памяти файлов и объектов разделяемой памяти. В процессах мью-
тексы можно использовать для защиты критических разделов, которые получают дос-
туп к файлам, каналам, общей памяти и внешним устройствам.
5.3.2.2. Использование мьютексных семафоров для управления
критическими разделами
Мьютексы используются для управления критическими разделами процессов и по-
токов, чтобы предотвратить возникновение условий “гонок”. Мьютексы позволяют
избежать условий “гонок”, реализуя последовательный доступ к критическому разде-
лу. Рассмотрим код листинга 5.1. В нем демонстрируется выполнение двух потоков.
Для защиты их критических разделов и используются мьютексы.
// Листинг 5.1. Использование мьютексов для защиты
// критических разделов потоков
// . . .
pthread_t ThreadA,ThreadB;
pthread—mutex—t Mutex;
pthread—mutexattr_t MutexAttr;
void *taskl(void *X)
{
pthread—mutex_lock(&Mutex);
// Критический раздел кода.
pthread—mutex—unlock(&Mutex);
5.3. Что такое семафоры 199
return(0) ;
void *task2(void *Х)
{ thread_mutex_lock(&Mutex) ;
// критический раздел кода.
thread-mutex-unlockf&Mutex) ;
return(0);
int main (void)
{
pthread_mutexattr_init (&MutexAttr) ;
pthread_mutex_init (&Mutex, &MutexAttr) ;
//Устанавливаем атрибуты мьютекса.
pthread_create (&ThreadA,NULL, taskl,NULL) ;
pthread_create (&ThreadB, NULL,task2, NULL) ;
//. • •
return(0) ;
В листинге 5.1 потоки ThreadA и ThreadB содержат критические разделы, защи-
щаемые с помощью объекта Mutex.
В листинге 5.2 демонстрируется, как можно использовать мьютексы для защиты
критических разделов процессов.
// Листинг 5.2. Использование мьютексов для зашиты
// критических разделов процессов
//...
int Rt;
рthread_mu tex_t Mutexl;
Pthread_mutexattr_t MutexAttr;
int main (void)
//. . .
Pthread_mutexattr_init (&MutexAttr) ;
₽thread__xnutexattr_setpshared (&MutexAttr ,
PTHREAD_PROCESS_SHARED);
if (iead-mutex-init (&Mutexl, &MutexAttr) ;
((Rt = fork()) == 0){ // Сыновний процесс.
Pthread_jnutex—lock (&Mutexl) ;
// Критический раздел.
j pt“hread_mutex_unlock (&Mutexl) ;
// Родительский процесс.
Pthread_mutex_lock(&Mutexl) ;
J. Литический раздел.
hread_mutex_unlосk (&Mutexl) ;
}
//. . .
retUrn(0);
200 Глава 5. Синхронизация параллельно выполняемых задач
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА А
АДРЕСНОЕ ПРОСТРАНСТВО ПРОЦЕССА В
АДРЕСНОЕ ПРОСТРАНСТВО
ПРОЦЕССА А
АДРЕСНОЕ ПРОСТРАНСТВО
ПРОЦЕССА В
Рис. 5.5. Закрытые и разделяемые мьютексы
Важно отметить, что в листинге 5.2 при вызове следующей функции мьютекс инй
циализируется как разделяемый:
pthread_mutexattr_setpshared(&MutexAttr,
PTHREAD_PROCESS_SHARED);
5.3. Что такое семафоры 201
вка этого атрибута равным значению PTHREAD_PROCESS_SHARED позволяет
Уста rv Mutex стать разделяемым между потоками различных процессов. После вы-
Жункции fork () сыновний и родительский процессы могут защищать свои кри-
3°ВаХие разделы с помощью объекта Mutex. Критические разделы этих процессов
™ т содержать некоторые ресурсы, разделяемые обоими процессами.
5 3.3. Блокировки для чтения и записи
Мьютексные семафоры позволяют управлять критическими разделами, обеспе-
чивая последовательный вход в эти разделы. В любой момент времени вход в кри-
тический раздел разрешается только одному потоку или процессу. Реализуя блоки-
овки для чтения и записи, можно разрешить вход в критический раздел сразу не-
скольким потокам, если они намерены лишь считывать данные из разделяемой
памяти. Следовательно, блокировкой для чтения может владеть любое количество
потоков. Но если сразу несколько потоков должны записывать или модифициро-
вать данные общей памяти, то доступ для этого будет предоставлен только одному
потоку. Другими словами, никаким другим потокам не будет разрешено входить
в критический раздел, если одному потоку предоставлен монопольный доступ для
записи в разделяемую память. Такой подход может оказаться полезным, если при-
ложения чаще считывают данные, чем записывают их. Если в приложении создает-
ся множество потоков, организация взаимно исключающего доступа может ока-
заться излишней предосторожностью. Производительность такого приложения
может значительно увеличиться, если в нем разрешить одновременное считывание
данных несколькими потоками. Стандарт POSIX определяет механизм блокировки
для чтения и записи посредством типа pthread_rwlock_t.
Блокировки для чтения и записи имеют такие же операции, как и мьютексные се-
мафоры. Они перечислены в табл. 5.4.
Различие между обычными мьютексами и мьютексами, обеспечивающими чтение
и запись, заключается в операциях запроса на блокирование. Вместо одной операции
блокирования здесь предусмотрено две:
pthread_rwlock_rdlock ()
pthread_rwlock_wrlock ()
Функция pthread_rwlock_rdlock () предоставляет вызывающему потоку блоки-
блок^ ЧТеНИЯ' а ФУнкЦия pthread_rwlock_wrlock () — блокировку записи. Запросив
блок Р°ВКУ чтения> поток получит ее в том случае, если нет потоков, удерживающих
потокР°ВК> Записи‘ Ес™ же таковые имеются, вызывающий поток блокируется. Если
Уде 3аПР°СИТ блокировку записи, он ее получит в том случае, если нет потоков,
юЩих блокировку чтения или блокировку записи. Если же таковые имеются,
БлоюЩИЙП°ТОКбЛОКИруеТСЯ-
PthreadP°BKa чтения-записи реализуется с помощью объектов типа
РУет ат t. Этот же тип имеет атрибутный объект, который инкапсули-
числены в "ТЫ °^ъекта блокировки. Функции установки и чтения атрибутов пере-
Объект *
Потоками ™Па rwlock_t может быть закрытым (для разделения между
ЛИчнЫх процНОГ° пр°Цесса) или разделяемым (для разделения между потоками раз-
202 Глава 5. Синхронизация параллельно выполняемых задач
Таблица 5.4. Операции, используемые для блокировки чтения-записи ' '
Операции Прототипы функций
#include <pthread.h>
Инициализация int pthread—rwlock—init( pthread—rwlock—t *restrict rwlock, const pthread—rwlockattr_t *restrict attr);
Запрос на блокировку #include <time.h> int pthread—rwlock—rdlock( pthread—rwlock—t *rwlock);
int pthread—rwlock—wrlock( pthread—rwlock—t *rwlock);
int pthread—rwlock—timedrdlock( pthread—rwlock—t *restrict rwlock, const struct timespec *restrict abs—timeout);
int pthread—rwlock—timedwrlock ( pthread—rwlock—t | *restrict rwlock, const struct timespec *restrict abs_timeout);
Освобождение блокировки int pthread—rwlock—unlock( pthread—rwlock—t *rwlock);
Тестирование блокировки int pthread—rwlock—tryrdlock( pthread—rwlock—t *rwlock); int pthread—rwlock—trywrlock( pthread—rwlock—t *rwlock);
Разрушение int pthread—rwlock—destroy( pthread—rwlock_t *rwlock);
Таблица 5.5. Функции доступа к атрибутному объекту типа pthread rwlock t
Прототипы функций
Описание
#include <pthread.h>
int pthread_rwlockattr_init
(pthread—rwlockattr_t * attr);
int pthread—rwlockattr_destroy
(pthread—rwlockattr_t * attr);
Инициализирует атрибутный объект блоки-
ровки чтения-записи, заданный параметром
attr, значениями, действующими по умолча-
нию для всех атрибутов, определенных реа-
лизацией
Разрушает атрибутный объект блокировки
чтения-записи, заданный параметром attr-
Его можно инициализировать повторно, вы-
звав функцию
pthread—rwlockattr init()
5.3. Что такое семафоры 203
Окончание табл. 5.5
Прототипы функций
inS,read_rwlockattr_setpshared
P!pthread_rwlockattr_t * attr,
int pshared);
othread_rwlockattr_getpshared
(const pthread_rwlockattr_t *
restrict attr,
int *restrict pshared);
Описание
Устанавливает или возвращает атрибут
process-shared атрибутного объекта бло-
кировки чтения-записи, заданного парамет-
ром attr. Параметр pshared может содер-
жать следующие значения:
PTHREAD_PROCESS_SHARED
(разрешает блокировку чтения-записи, разде-
ляемую любыми потоками, которые имеют дос-
туп к памяти, выделенной для этого объекта
блокировки, даже если потоки принадлежат
различным процессам);
PTHREAD_PROCESS_PRIVATE
(блокировка чтения-записи разделяется меж-
ду потоками одного процесса)
5.3.3.1. Использование блокировок чтения-записи
для реализации стратегии доступа
Блокировки чтения-записи можно использовать для реализации стратегии доступа
CREW (параллельное чтение и исключающая запись). Согласно этой стратегии воз-
можность параллельно считывать данные может быть предоставлена сразу несколь-
ким задачам, но только одна задача получит право доступа для записи. При выполне-
нии монопольной записи в этом случае не будет дано разрешение на параллельное
чтение данных. Использование блокировок чтения-записи для защиты критических
разделов продемонстрировано в листинге 5.3.
// Листинг 5.3. Пример использования потоками блокировок
'' чтения-записи
//.. .
Pthread-t ThreadA,ThreadB,ThreadC,ThreadD;
₽thread_rwlock_t RWLock;
void *producerl (void *X)
Pthread_rwlock_wrlock(&RWLock) ;
''Критический раздел.
r_bread-rwlock_unl°ck(&RWLock);
} return(0);
(°id ’producer2 (void *X)
//h»^ad~rwlock-wrlock(&RWLock) ;
РГЬге^ИЧеСКИЙ Ра3«ел‘
} aa—rwlock_unlock(&RWLock);
204 Глава 5. Синхронизация параллельно выполняемых задач
void *consumerl(void *Х)
{
pthread—rwlосk_rdlоск(&RWLock);
// Критический раздел.
pthread—rwlock—unlock(&RWLock);
return(0) ;
}
void *consumer2(void *X)
{
pthread—rwlock—rdlock(&RWLock);
// Критический раздел.
pthread—rwlock—unlock(&RWLock);
return(0);
int main(void)
{
pthread—rwlock—init(&RWLock,NULL);
// Устанавливаем атрибуты мьютекса.
pthread—create(&ThreadA,NULL,producer1,NULL);
pthread—create(&ThreadB,NULL, consumer1,NULL);
pthread—create(&ThreadC,NULL,producer2,NULL);
pthread—create(&ThreadD,NULL,consumed,NULL);
//. . .
return(0) ;
}
В листинге 5.3 создаются четыре потока. Два потока, ThreadA и ThreadC, выпол-
няют роль изготовителей, а остальные два (ThreadB и ThreadD) — потребителей. Все
потоки имеют критический раздел, который защищается объектом блокировки чте-
ния-записи RWLock. Потоки ThreadB и ThreadD могут входить в свои критические
разделы параллельно или последовательно, но это исключено, если поток ThreadA
или ThreadC пребывает в своем критическом разделе. Потоки ThreadA и ThreadC не
могут входить в свои критические разделы параллельно. Частичная таблица решении
для листинга 5.3 показана в табл. 5.6.
Таблица 5.6. Частичная таблица решений для листинга 5.3
Поток А (выполняет запись) ПотокВ (выполняет чтение) Поток С (выполняет запись) Поток D (выполняет чтение^.
Нет Нет Нет Да
Нет Нет Да Нет
Нет Да Нет Нет
Нет Да Нет Да
Да Нет Нет Нет
5.3. Что такое семафоры 205
534. Условные переменные
Условная переменная представляет собой семафор, используемый для сигнализации
тии которое произошло. Сигнала о том, что произошло некоторое событие,
° ожидать один или несколько процессов (или потоков) от других процессов или
М ов Следует понимать различие между условными переменными и рассмотрен-
П выше мьютексными семафорами. Назначение мьютексного семафора и блоки-
HbIMIR чтения-записи — синхронизировать доступ к данным, в то время как условные
Р еменные обычно используются для синхронизации последовательности опера-
ций По этому поводу в своей книге UNIX Network Programming прекрасно высказался
Ричард Стивенс (W. Richard Stevens): “Мьютексы нужно использовать для блокирова-
ния, а не для ожидания”.
В листинге 4.6 поток-“потребитель” содержал цикл:
15 while(TextFiles.empty() )
16 {}
Поток-“потребитель” выполнял итерации цикла до тех пор, пока в очереди
TextFiles были элементы. Этот цикл можно заменить условной переменной. Поток-
изготовитель” сигналом уведомляет потребителя о том, что в очередь помещены
элементы. Поток-“потребитель” может ожидать до тех пор, пока не получит сигнал,
азатем перейдет к обработке очереди.
Условная переменная имеет тип pthread—с ond_t. Ниже перечислены типы опе-
раций, которые может она выполнять:
• инициализация;
• разрушение;
• ожидание;
• ожидание с ограничением по времени;
• адресная сигнализация;
• всеобщая сигнализация;
Операции инициализации и разрушения выполняются условными переменными
подобно аналогичным операциям других мьютексов. Функции класса
Pthread—с ond_t, которые реализуют эти операции, перечислены в табл. 5.7.
Таблица 5.7. Функции класса pthread_cond_t, которые реализуют
— операции условных переменных
О^раиии Прототипы функций (макросы)
Инициализация #include <pthread.h> int pthread—cond_init( pthread—cond_t *restrict cond, const pthread—condattr_t *restrict attr);
pthread—сond_t cond =
PTHREAD_COND_INITIALIZER;
206 Глава 5. Синхронизация параллельно выполняемых задач
Окончание табл. 5 •>
Операции Прототипы функций (макросы)
Ожидание int pthread—сond_wait( ' ' pthread—сond—t * restrict cond, pthread—mutex—t *restrict mutex); int pthread—cond_timedwait( pthread—cond—t * restrict cond, pthread—mutex—t *restrict mutex, const struct timespec *restrict abstime);
Сигнализация int pthread—cond_signal( pthread—cond—t *cond); int pthread—cond_broadcast( pthread—cond_t *cond);
Разрушение int pthread—cond_destroy( pthread—cond—t *cond);
Условные переменные используются совместно с мьютексами. При попытке за-
блокировать мьютекс поток или процесс будет заблокирован до тех пор, пока мью-
текс не освободится. После разблокирования поток или процесс получит мьютекс
и продолжит свою работу. При использовании условной переменной ее необходи-
мо связать с мьютексом.
/Л . .
pthread—mutex_lock (&Mutex) ;
pthread_.cond—wait (&EventMutex, &Mutex) ;
//. . .
pthread_mutex_unlock (&Mutex) ;
Итак, некоторая задача делает попытку заблокировать мьютекс. Если мьютекс уже
заблокирован, то эта задача блокируется. После разблокирования задача освободит
мьютекс Мьютекс и при этом будет ожидать сигнала для условной переменной
EventMutex. Если мьютекс не заблокирован, задача будет ожидать сигнала неограни-
ченно долго. При ожидании с ограничением по времени задача будет ожидать сигнала
в течение заданного интервала времени. Если это время истечет до получения зада-
чей сигнала, функция возвратит код ошибки. Затем задача вновь затребует мьютекс.
Выполняя адресную сигнализацию, задача уведомляет другой поток или процесс
о том, что произошло некоторое событие. Если задача ожидает сигнала для заданной
условной переменной, эта задача будет разблокирована и получит мьютекс. Если сраз)
несколько задач ожидают сигнала для заданной условной переменной, то разблоки
рована будет только одна из них. Остальные задачи будут ожидать в очереди, и их
разблокирование будет происходить в соответствии с используемой стратегией ила
нирования. При выполнении операции всеобщей сигнализации уведомление получат
все задачи, ожидающие сигнала для заданной условной переменной. При разблокир0'
вании нескольких задач они будут состязаться за право владения мьютексом в соот
ветствии с используемой стратегией планирования. В отличие от
ния, задача, выполняющая операцию сигнализации, не предъявляет
мьютексом, хотя это и следовало бы сделать.
Условная переменная также имеет атрибутный объект, функции которого пер
числены в табл. 5.8.
операции
прав на владений
5.3. Что такое семафоры 207
TfiXnia 5.8. Функции доступа к атрибутному объекту для условной
*а ’ переменной типа pthread_cond_t
Прототипы функций Описание
<pthread.h>
•nt pthread—condatt r_in it (
1 pthread_condattr_t * attr);
Инициализирует атрибутный объект условной
переменной, заданный параметром attr, зна-
чениями, действующими по умолчанию для
всех атрибутов, определенных реализацией
int pthread—с ondattr.destroy (
pthread_condattr_t * attr) ;
int
pthread_condattr_setpshared (
pthread—condattr_t *
attr,
int pshared) ;
int
pthread_condattr_getpshared (
const pthread_condattr_t *
restrict attr,
int *restrict pshared);
int pthread—condattr_setclock (
pthread_condattr_t * attr,
clockid-t clock_id);
int pthread—condattr_getclock (
const pthread—condattr_t *
restrict attr,
clockid-t *
clock—id);
restrict
Разрушает атрибутный объект условной пере-
менной, заданный параметром attr. Этот объ-
ект можно инициализировать повторно, вы-
звав функцию pthread—condattr_init ()
Устанавливает или возвращает атрибут
process - shared атрибутного объекта условной
переменной, заданного параметром attr. Па-
раметр pshared может содержать следующие
значения:
PTHREAD.PROCESS—SHARED
(разрешает блокировку чтения-записи, разде-
ляемую любыми потоками, которые имеют дос-
туп к памяти, выделенной для этой условной пе-
ременной, даже если потоки принадлежат раз-
личным процессам);
PTHREAD—PROCESS—PRIVATE
(условная переменная разделяется между пото-
ками одного процесса)
Устанавливает или возвращает атрибут clock
атрибутного объекта условной переменной, за-
данного параметром attr. Атрибут clock
представляет собой идентификатор часов, ис-
пользуемых для измерения лимита времени
в функции pthread—cond_timedwait ().
По умолчанию для атрибута clock использует-
ся идентификатор системных часов
^•3.4.1. Использование условных переменных для управления
Усл Отношениями синхронизации
зацИи ВНУЮ Переменную можно использовать для реализации отношений синхрони-
финищ ГГсЪТОРЬ1Х Упоминалось выше: старт-старт (СС), финиш-старт (ФС), старт-
Ками ол И ФИНИШ‘ФИНИШ (ФФ). Эти отношения могут существовать между пото-
Реализации° ИЛИ Различных процессов. В листингах 5.4 и 5.5 представлены примеры
Мьютекса о и <^<^>*отношений синхронизации. В каждом примере определено два
а Другой-1 ДИН МЬЮтекс используется для синхронизации доступа к общим данным,
’^Ля синхронизации выполнения кода.
208 Глава 5. Синхронизация параллельно выполняемых задач
// Листинг 5.4. ФС-отношения синхронизации между
// двумя потоками
//. . .
float Number;
pthread_t ThreadA,ThreadB;
pthread—mutex—t Mutex,EventMutex;
pthread_cond_t Event;
void *workerl(void *X)
{
for(int Count = l;Count < 100;Count++){
pthread_mutex—lock(&Mutex);
Number++;
pthread_mutex_unlock(&Mutex);
cout << "workerl: число равно " « Number « endl;
if(Number == 50){
pthread_cond_signal(&Event);
}
}
cout « "Выполнение функции workerl завершено." « endl;
return(0);
}
void *worker2(void *X)
{
pthread_mutex—lock(&EventMutex);
pthread_cond—wait(&Event,&EventMutex);
pthread_mutex_unlock(&EventMutex);
for(int Count = l;Count < 50;Count++){
pthread_mutex_lock(&Mutex);
Number = Number + 20;
pthread_mutex—unlock(&Mutex);
cout << "worker2: число равно " « Number « endl;
}
cout << "Выполнение функции worker2 завершено." « endl;
return(0);
int main(int argc, char *argv[])
{
pthread_mutex_init(&Mutex,NULL);
pthread_mutex_init(&EventMutex,NULL);
pthread_cond_init(&Event,NULL);
pthread_create(&ThreadA,NULL,workerl,NULL);
pthread_create(&ThreadB,NULL,worker2,NULL);
//. . .
return (0);
)
В листинге 5.4 показан пример реализации ФС-отношений синхронизации. ГТот°к
ThreadA не может завершиться до тех пор, пока не стартует поток ThreadB.
значение переменной Number станет равным 50, поток ThreadA сигнализирует о
этом потоку ThreadB. Теперь он может продолжать выполнение до самого к°нН^
Поток ThreadB не может начать выполнение до тех пор, пока не получит сигнал
потока ThreadA. Поток ThreadB использует объект EventMutex вместе с условН
переменной Event. Объект Mutex используется для синхронизации доступа для за
си значения разделяемой переменной Number. Для синхронизации различных событ
и доступа к критическим разделам задача может использовать несколько мьютексов-
5.3. Что такое семафоры 209
ер реализации ФФ-отношений синхронизации показан в листинге 5.5.
R 5. ФФ-отношения синхронизации между
// Лис'ГИНх - • дВуМя потоками
fthreadUtt>ThreadA, ThreadB;
Prhread'mutex_t Mutex, EventMutex;
pthreadZcond_t Event;
void *workerl (void *X)
{ fOr(int Count = l;Count < 10;Count++){
pthread—mu tex_lock (&Mu tex) ;
Number++;
pthread—mu tex_unlock (&Mut ex) ;
cout « "worker1: число равно " « Number « endl;
pthread—mutex—lock (&EventMutex) ;
cout « "Функция worker1 в состоянии ожидания. "
« endl;
pthread—cond_wait (&Event , &EventMutex) ;
pthread-inutex—unlock (&EventMutex) ;
return(0);
void *worker2 (void *X)
{
for(int Count = l;Count < 100;Count++){
pthread—mutex—lock (&Mutex) ;
Number = Number * 2 ;
pthread—mutex-unlock (&Mutex) ;
cout « "worker2: число равно " << Number << endl;
Pthread_cond_signal (&Event) ;
cout « "Функция worker2 послала сигнал " « endl;
return(0);
int main(int argc, char *argv[])
Pthread__mutex_init (&Mutex,NULL) ;
Pthread_mutex_init (&EventMutex, NULL) ;
Ptnread_cond_init (&Event z NULL) ;
пьъ ad-Create<&ThreadA,NULL,worker1,NULL);
Pthread_create (&ThreadB, NULL, worker2. NULL) ;
return (0);
Шится1ИСТИНГе 5'5 поток ThreadA не может завершиться до тех пор, пока не завер-
Пот°ТОК TllreadB‘ Поток ThreadA должен выполнить цикл 10 раз, a ThreadB —
°Жидат °К Т^геас^ завершит выполнение своих итераций раньше ThreadB, но будет
СС Де° ТеХ П°Р’ пока поток ThreadB не просигналит о своем завершении.
Эти м ф’отношения синхронизации невозможно реализовать подобным образом.
ДЬ1 используются для синхронизации порядка выполнения процессов.
210 Глава 5. Синхронизация параллельно выполняемых задач
5.4. Объектно-ориентированный подход
к синхронизации
Одно из преимуществ объектно-ориентированного программирования состои
в защите, которую обеспечивает инкапсуляция компонентов данных объекта. Инка^
суляция может обеспечить для пользователя объектов “стратегии доступа к объектам
и принципы их применения” [24]. В примерах, представленных в этой главе, за при
меняемые стратегии доступа вся ответственность возлагалась на пользователя дан
ных. С помощью объектов и инкапсуляции ответственность можно переложить
с пользователя данных на сами данные. При таком подходе создаются данные, кото-
рые, в отличие от функций, являются безопасными для потоков.
Для реализации такого подхода данные многопоточного приложения (по возмож-
ности) необходимо инкапсулировать с помощью С++-конструкций class или struct
Затем инкапсулируйте такие механизмы синхронизации, как семафоры, блокировки
для обеспечения чтения-записи и мьютексы событий. Если данные или механизмы
синхронизации представляют собой объекты, создайте для них интерфейсный класс.
Наконец, объедините объект данных с объектами синхронизации посредством насле-
дования или композиции, чтобы создать объекты данных, которые будут безопасны
для потоков. Этот подход подробно рассматривается в главе 11.
5.5. Резюме
Для координации порядка выполнения процессов и потоков (синхронизация задач),
а также доступа к разделяемым данным (синхронизация данных) можно использовать
различные механизмы синхронизации. Существует четыре основных вида отношений
синхронизации задач. Отношение вида “старт-старт” (СС) означает, что задача А не
может начаться до тех пор, пока не начнется задача В. Отношение вида “финиш-
старт” (ФС) означает, что задача А не может завершиться до тех пор, пока не начнет-
ся задача В. Отношение вида “старт-финиш” (СФ) означает, что задача А не может на-
чаться до тех пор, пока не завершится задача В. Отношение вида “финиш-финиш
(ФФ) означает, что задача А не может завершиться до тех пор, пока не завершится за-
дача В. Для реализации этих отношений синхронизации задач можно использовать
условную переменную THnapthread_cond_t, которая определена стандартом POSIX-
Для описания синхронизации данных используются некоторые типы алгоритмов
модели PRAM. Стратегию доступа EREW (исключающее чтение и исключающая за
пись) можно реализовать с помощью мьютексного семафора. Мьютексный семаф°Р
защищает критический раздел, обеспечивая последовательный вход в него. Эта стра
тегия разрешает либо доступ для чтения, либо доступ для записи. Стандарт POSIX оП
ределяет мьютексный семафор типа pthread_mutex_t, который можно использо
вать для реализации стратегии доступа EREW. Чтобы реализовать стратегию Д°сТ^па
CREW (параллельное чтение и исключающая запись), можно использовать блокир0^
ки чтения-записи. Стратегия доступа CREW описывает возможность удовлетвори
множества запросов на чтение, но при монопольной записи данных. Стандарт РО '
определяет объект блокировки для обеспечения чтения-записи т
pthread_rwlock_t, а объектно-ориентированный подход к синхронизации
позволяет встроить механизм синхронизации в объект данных.
ОБЪЕДИНЕНИЕ
ВОЗМОЖНОСТЕЙ
ПАРАЛЛЕЛЬНОГО
ПРОГРАММИРОВАНИЯ
И С++-СРЕДСТВ
НА ОСНОВЕPVM
В этой главе...
6.1. Классические модели параллелизма, поддерживаемые
системой PVM
6.2. Библиотека PVM для языка C++
6.3. Базовые механизмы PVM
6.4. Доступ к стандартному входному потоку (stdin)
и стандартному выходному потоку (stdout) со стороны
PVM-задач
6.5. Резюме
Мы разделили нашу проблему на две части: сгенерированную программу
и процесс обучения. Эти две части остаются тесно связанными. Нельзя
ожидать, что сгенерированная машина окажется удачной с первой же
попытки. Необходимо поэкспериментировать с обучением одной такой
машины и посмотреть, как пойдет этот процесс обучения...
— Алан Тьюринг (Alan Turing), Может ли машина думать?
Система программного обеспечения PVM (Parallel Virtual Machine — параллель-
ная виртуальная машина) предоставляет разработчику ПО средства для напи-
сания и выполнения программ, использующих параллелизм. Система PVM по-
зволяет разработчику представить коллекцию сетевых компьютеров в виде единой
логической машины с возможностями параллелизма. Компьютеры этой коллекции
могут иметь одинаковые или различные архитектуры. В PVM-систему связываются
даже компьютеры, которые попадают в категорию МРР (Massively Parallel Processor -
процессор с массовым параллелизмом). Несмотря на то что PVM-программы могут
разрабатываться для одного компьютера, реальные преимущества этой системы пр°
являются при связывании двух и более компьютеров.
Система PVM в качестве средства связи между параллельно выполняющимися за
дачами поддерживает модель передачи сообщений. Приложение взаимодействует
с PVM посредством библиотеки, которая состоит из API-интерфейсов, предназначе1<
ных для управления процессами, отправки и получения сообщений, сигнализаН
процессов и т.д. С++-программа взаимодействует с PVM-библиотекой точно так
как с любыми другими библиотеками функций. С++-программе для получения досту
к функциям PVM-библиотеки не нужно создавать специальную форму или архитектур, ’
даосические модели параллелизма, поддерживаемые системой PVM 213
пемя как программам, написанным на других языках, необходимо вызывать оп-
в Т° ленные функции для инициализации среды. Это означает, что С++-програм-мист
РеДС сочетать PVM-возможности с другими стилями С++-программирования
* имер, объектно-ориентированным, параметризованным, агентно-ориенти-
ванным и структурированным программированием). Благодаря использованию та-
Р° библиотек, как PVM, MPI или Linda, С++-разработчик может реализовать различ-
кИХ модели параллелизма, тогда как другие языки ограничены примитивами парал-
лелизма, которые встроены в сами языки. Библиотека PVM предлагает, пожалуй, са-
мый простой способ расширения средств языка C++ за счет возможностей
параллельного программирования.
6.1. Классические модели параллелизма,
поддерживаемые системой PVM
Система PVM поддерживает модели MIMD (Multiple-Instruction, Multiple-
Data— множество потоков команд, множество потоков данных) и SPMD (Single-
Program, Multiple-Data — одна программа, множество потоков данных) паралле-
лизма. В действительности SPMD — это вариант модели SIMD (Single-Instruction,
Multiple-Data — один поток команд, множество потоков данных). Эти модели раз-
бивают программы на потоки команд и данных. В модели MIMD программа со-
стоит из нескольких параллельно выполняющихся потоков команд, причем каж-
дому из них соответствует собственный локальный поток данных. По сути, каж-
дый процессор здесь имеет собственную память. В PVM-среде модель MIMD
считается моделью с распределенной памятью (в отличие от модели с общей па-
мятью). В моделях с общей памятью все процессоры “видят” одни и те же ячейки
памяти. В модели с распределенной памятью связь между хранимыми в ней зна-
чениями обеспечивается посредством механизма передачи сообщений. Однако
модель SPMD подразумевает наличие одной программы (одного набора команд),
которая параллельно выполняется на нескольких компьютерах, причем эти оди-
наковые на всех машинах программы обрабатывают различные потоки данных.
VM-среда поддерживает как MIMD-, так и SIMD-модели или их сочетание. Четы-
ре классические модели параллелизма показаны на рис. 6.1.
Обратите внимание на то, что модели SISD и MISD (см. рис. 6.1) неприменимы
MlSD^eMe PVM* Модель SISD описывает однопроцессорную машину, а для модели
вообще трудно найти практическое применение. Две остальные модели, кото-
Действ°ЖН° использовать с системой PVM, определяют, как С++-программа взаимо-
ный ° КомпьютеРами- Разработчик ПО представляет один логический виртуаль-
дач К°МпьютеР как среду для выполнения нескольких различных параллельных за-
Bbinojn^^351 КОТОРЫХ п°лучает доступ к собственным данным, либо одной задачи,
нымобЯЮЩеЙСЯ В виде на^ора параллельных клонов, получающих доступ к различ-
али п ЯМ данных* Таким образом, с PVM-задачами мы будет связывать только мо-
F слагающие наличие множества потоков команд и одной программы.
214 Глава 6. Объединение возможностей параллельного программирования
Рис. 6.1. Четыре классические модели параллелизма
6.2. Библиотека PVM для языка C++
К функциональным возможностям PVM из С++-программы можно получить доступ
с помощью коллекции библиотечных процедур, предоставляемых средой PVM. Эти
функции и процедуры PVM обычно делят на семь категорий.
• Управление процессами.
• Упаковка сообщений и их отправка.
• Распаковка сообщений и их прием.
• Обмен задач сигналами.
• Управление буфером сообщений.
• Функции обработки информации и служебные процедуры.
• Групповые операции.
Эти библиотечные функции легко интегрировать в С++-среду. Префикс pvm_ в и>*е
ни каждой функции позволяет не забыть о ее принадлежности соответствующему ПР°
странству имен. Для использования PVM-функций необходимо включить в программ?
заголовочный файл pvm3 . h и скомпоновать ее с библиотекой libpvm. В программах
и 6.2 демонстрируется, как работает простая PVM-программа. Инструкции по компи-71*
ции и выполнению программы 6.1 приведены в разделе “Профиль программы 6.1 •
6.2. Библиотека PVM для языка C++ 215
I/ программа 6.1
«include "pvm3.h"
«include <iostream>
Jinclude <string.h>
int main(int argc,char *argv[])
< int RetCode, Messageld;
int PTid, Tid;
char Message[100] ;
float Result[1] ;
PTid = pvm__mytid() ;
RetCode = pvm_spawn ("program6-2 ", NULL, 0, "", 1, &Tid) ;
if(RetCode == 1) {
Messageld = 1;
strcpy(Message,"22");
pvm_initsend(PvmDataDefault);
pvm_pkstr(Message);
pvm_send(Tid,Messageld);
pvm_recv(Tid,Messageld);
pvm_upkfloat(Result,1,1);
cout « Result[0] « endl;
pvm_exit();
return(0) ;
}
else{
cerr « "Задачу породить невозможно. " « endl;
pvm_exit();
return(1);
}
}
Крфиль программы 6.1
|ймяпрограммы
Fprogram6-1.сс
{Описание
«Использует функцию pvm_send () для пересылки числа в другую PVM-задачу, кото-
рая выполняется параллельно с данной (программа 6.2), и функцию pvm_recv()
|ДЛя получения числа от этой задачи.
>Требуемая библиотека
p-ibpvm3
.* Требуемые заголовки
Pvm3.h> <iostream> <string.h>
|С^ТРУКЦИИ По компиляции и компоновке программ
$PVM ^ogram6-l -I $PVM_ROOT/include -L $PVM_ROOT/lib/
Г . «-ARCH -1 Pvm3
> ДЛЯ ТбСТИПппдиыо
.1, gcc 2.95.2.
216 Глава 6. Объединение возможностей параллельного программирования
Инструкции по выполнению
. /ргодгашб-1
Примечания
Необходимо запустить на выполнение программу pvmd.
В программе 6.1 использовано восемь самых распространенных PVM-функций-
pvm_mytid(), pvm_spawn (), pvm_initsend(), pvm_pkstr(), pvm__send()
pvmrecvO, pvm_upkfloat() и pvm_exit(). Функция pvm_mytid() возвращает
идентификатор вызывающего процесса (задачи). PVM-система связывает идентифи-
катор задачи с каждым процессом, который ее создает. Идентификатор задачи ис-
пользуется для отправки сообщений задачам, получения сообщений от других задач
сигнализации, прерывания задач и т.п. Любая PVM-задача может связываться с любой
другой PVM-задачей до тех пор, пока не получит доступ к ее идентификатору. Функ-
ция pvm_spawn() предназначена для запуска нового PVM-процесса. В программе 6.1
функция pvm_spawn () используется для запуска на выполнение программы 6.2.
Идентификатор новой задачи возвращается в параметре &Tid вызова функции
pvm_spawn (). В PVM-среде для передачи данных между задачами используются буфе-
ры сообщений. Каждая задача может иметь один или несколько таких буферов. При
этом только один из них считается активным. Перед отправкой каждого сообщения
вызывается функция pvm_initsend(), которая позволяет подготовить или инициали-
зировать активный буфер сообщений. Функция pvm_pkstr () используется для упаков-
ки строки, содержащейся в параметре Message. При упаковке строка шифруется для
передачи другой задаче (в другой процесс), выполняемой, возможно, на другом компь-
ютере с другой архитектурой. PVM-среда обрабатывает элементы, связанные с преобра-
зованием из одной архитектуры в другую. Среда PVM требует применять процедуру упа-
ковки сообщения до его отправки и процедуру распаковки при его получении, чтобы
сделать сообщение читабельным для получателя. Однако из этого правила существует
исключение, которое мы обсудим ниже. Функции pvm_send() и pvm_recv() исполь-
зуются для отправки и приема сообщений соответственно. Параметр Messageld про-
сто определяет, с каким сообщением работает отправитель. Обратите внимание на
то, что в программе 6.1 функции pvm_send() и pvm_recv() содержат идентифика-
тор задачи, получающей данные, и идентификатор задачи, отправляющей данные,
соответственно. Функция pvm_upkf loat () извлекает полученное сообщение из ак-
тивного буфера сообщений и распаковывает его, сохраняя в массиве типа float.
Программа 6.1 порождает PVM-задачу для выполнения программы 6.2.
Обратите внимание на то, что обе программы 6.1 и 6.2 содержат обращение к функ
ции pvm_exit (). Эту функцию необходимо вызывать при завершении PVM-обработки
задачи. Несмотря на то что функция pvm_exit () не разрушает процесс и не прекраШа
ет его выполнение, она позволяет PVM-среде освободиться от задачи и отсоединить за
дачу от PVM-среды. Обратите внимание на то, что программы 6.1 и 6.2 — вполне авто"
номные и независимые программные модули, которые содержат функцию main () • Д
тали реализации программы 6.2 приведены в разделе “Профиль программы 6.2”.
// Программа 6.2
# include "pvm3.h”
#include "stdlib.h"
int main(int argc, char *argv[])
6.2. Библиотека PVM для языка C++ 217
< int Messageld, Ptid;
char Message[100] ;
float Num,Result;
Ptid = pvm_parent();
Messageld =1;
pvm_recv(Ptid,Messageld);
pvm_upkstr(Message);
Num = atof(Message);
Result = Num / 7.0001;
pvm_initsend(PvmDataDefault);
pvm_pkfloat(^Result,1,1);
Pvm_send(Ptid,Messageld);
pvm_exit();
return(0);
Профиль программы 6.2
||мя программы
pr6gram6-2. сс
Описание
^Эта программа принимает число от родительского процесса и делит его на 7. Затем
«она отправляет результат своему родительскому процессу
^Требуемая библиотека
iibpvm3
Требуемые заголовки
jcpvm3.h> <stdlib.h>
Инструкции по компиляции и компоновке программы
?t+<:-O’program6-2 -I $PVM_ROOT/include program6-2. cc -L
• .’^PVM_ROOT/lib/PVM_ARCH -lpvm3
:Среда для тестирования
ME Unux 7.1 gnu C++ 2.95.2, Solaris 8 Workshop 6, PVM 3.4.3.
Инструкции по выполнению
^та программа порождается программой 6.1.
Примечания
[Й^бходимо запустить на выполнение программу pvmd.
6-2-1. Компиляция и компоновка С++/Р\/М-программ
бы скРСИЯ 3 4*Х Р^М’сРеДЬ1 представлена в виде единой библиотеки libpvm3 . а. Что-
Файл pvin31JIHPOBaTb Р^М'пРогРаммУ’ необходимо включить в ее код заголовочный
$ с++ * k и ск°мпоновать ее вместе с библиотекой libpvm3 . а:
TOypvln-pro^rain “I $PVM_ROOT/include
°aram.cc -I$PVM_ROOT/lib -lpvm3
218 Глава 6. Объединение возможностей параллельного программирования
Переменная среды $PVM_ROOT указывает на каталог, в котором инсталлирована бцб
лиотека PVM. При выполнении этой команды создается двоичный фа^
mypvm_program.
Для выполнения программ 6.1 и 6.2 сначала необходимо инсталлировать PVM-cne
Выполнить PVM-программу можно одним из трех основных способов: запустить автсу
номный выполняемый (двоичный) файл, использовать PVM-консоль или среду XPVM
6.2.2. Выполнение PVM-программы в виде
двоичного файла
Во-первых, необходимо запустить программу pvmd; во-вторых, на каждом компью-
тере, включенном в PVM-среду, корректно скомпилированные программы-участницы
должны находиться в соответствующих каталогах. По умолчанию для скомпилиро-
ванных программ (выполняемых файлов) используется такой каталог:
$H0ME/pvm3/bin/$PVM_ARCH
Здесь PVM_ARCH содержит имя архитектуры компьютера (см. табл. 6.1 и параграфы 1
и 2 из раздела 6.2.5). Для выполняемых программ должны быть установлены соответ-
ствующие разрешения на доступ и использование. Программу pvmd можно запустить так:
pvmd &
или так:
pvmd hostfile &
Здесь host file — это файл конфигурации, содержащий специальные параметры для
передачи программе pvmd (см. табл. 6.2 и параграфы 1, 2 из раздела 6.2.3). После за-
пуска программы pvmd на одном из компьютеров, включенных в среду PVM, можно
запустить PVM-программу, используя следующую простую команду:
$MyPvmProgram
Если эта программа порождает другие задачи, то они запустятся автоматически.
6.2.2.1. Запуск PVM-программ с помощью PVM-консоли
Для выполнения программ с помощью PVM-консоли необходимо сначала запус-
тить PVM-консоль, введя следующую команду:
$pvm
Получив приглашение на ввод команд pvm>, введите имя программы, которую нужно
выполнить:
pvm> spawn -> MyPvmProgram
6.2.2.2. Запуск PVM-программ с помощью XPVM
Кроме PVM-консоли, можно использовать графический интерфейс XPVM ДлЯ
Windows. На рис. 6.2 показано диалоговое окно сеанса работы с XPVM-интерфейсО^о
Библиотека PVM не требует, чтобы С++-программа придерживалась какой
конкретной структуры. Первая PVM-функция, вызываемая программой, “помеШ
ее в PVM-среду. Для каждой программы, которая является частью PVM-среды, слеД}
всегда вызывать функцию pvm_exit (). Если этого не сделать, система завис
6.2. Библиотека PVM для языка C++ 219
тиКа показывает, что функции pvm_mytid() и pvm_parent () необходимо вы-
J вать в начале обработки задачи. Наиболее популярные категории функций PVM
^числены в табл. 6.1.
Рис. 6.2. Диалоговое окно графического интерфейса XPVM
^Таблица 6.1. Семь категорий функций библиотеки PVM
Категории PVM-функций
Управление процессами
Упаковка сообщений
и их отправка
Распаковка сообщений
и их прием
°6мен задач сигналами
Деление буфером, сообщений
обработки информа-
^UU^бные процедуры
операции
Описание
Используются для управления PVM-процессами
Применяются для упаковки сообщений в пересылочном
буфере и отправки их от одного PVM-процесса другому
Используются для получения сообщений и распаковки
данных из активного буфера
Применяются для сигнализации и уведомления PVM-
процессов о возникновении события
Используются для инициализации, очистки и размещения
буферов, предназначенных для приема и отправки сооб-
щений, которыми обмениваются PVM-процессы
Применяются для получения информации о PVM-
процессах и выполнения других важных задач
Используются для объединения процессов в группы
и выполнения других групповых операций
220 Глава 6. Объединение возможностей параллельного программирования
6.2.3. Требования к PVM-программам
Если PVM-среда реализуется в виде сети компьютеров, то, прежде чем ваша C++
программа начнет взаимодействовать с ней, необходимо обработать следующие элементы
Параграф 1
Следует установить переменные среды PVM_ROOT и PVM_ARCH. Переменная среды
PVM—ROOT должна указывать на каталог, в котором инсталлирована PVM-библиотека
Использование оболочки Войте (BASH)_Использование С-оболочки__
$ PVM_ROOT=/usr/lib/pvm3 setenv PVM_ROOT /usr/lib/pvm3
$ export PVM—ROOT
Переменная среды PVM_ARCH идентифицирует архитектуру компьютера. Каждый
компьютер, включенный в среду PVM, должен быть идентифицирован архитектурой.
Например, Ultrasparcs-компьютеры имеют обозначение SUN4SOL2, a Linux-
компьютеры — обозначение LINUX. В табл. 6.2 перечислены самые распространен-
ные архитектуры для PVM-среды.
Эта таблица содержит имя и тип компьютера, соответствующий этому имени. Ус-
тановите свою переменную среды PVM_ARCH равной одному из имен, приведенных
в табл. 6.2. Например:
Использование оболочки Войте (BASH)_Использование С-оболочки___________
$PVM_ARCH=LINUX setenv PVM_ARCH LINUX
$export PVM—ARCH
Таблица 6.2. Самые распространенные архитектуры для PVM-среды
PVM_ARCH Компьютер PVM_ARCH Компьютер
AFX8 Alliance LINUX 80386/486 PC (UNIX)
ALPHA DEC Alpha MASPAR Maspar
BAL Sequent Balance MIPS MIPS 4680
BFLY BBN Butterfly TC2000 NEXT NeXT
BSD386 80386/486 PC (UNIX) PGON Intel Paragon
СМ2 “Мыслящая машина” СМ2 PMAX DECstation 3100,5100
CM5 “Мыслящая машина” СМ5 RS6K IBM/RS6000
CNVX Convex С-серии RT IBMRT
CNVXN Convex С-серии SGI Silicon Graphics IRIS
CRAY С-90, YMP,T3D (доступный порт) SGI5 Silicon Graphics IRIS
CRAY2 Сгау-2 SGIMP SGI Multiprocessor
CRAYSIMP Cray S-MP SUN3 Sun 3 —
6.2. Библиотека PVM для языка C++ 221
Окончание табл. 6.2
Компьютер PVM_ARCH Компьютер
"dgav Data General Aviion SUN4 Sun 4, SPARCstation
Е88К Encore 88000 SUN2SOL2 Sun 4, SPARCstation
нрзоо HP-9000 Model 300 SUNMP SPARC Multiprocessor
НРРА HP-9000 PA-RISC SYMM Sequent Symmetry
I860 Intel iPSC/860 TITN Stardent Titan
IPSC2 Intel iPSC/2 386 Host U370 IBM 370
KSRI Kendall Square KSR-1 UVAX DEC LicroVAX
Параграф 2
Выполняемые файлы любых программ, участвующих в среде PVM, должны быть
размещены на всех компьютерах, включенных в среду PVM, или доступны всем ком-
пьютерам, включенным в среду PVM. При этом каждая программа должна быть ском-
пилирована для работы с учетом конкретной архитектуры. Это означает, что, если
вереду PVM включены процессоры UltraSparcs, PowerPCs и Intel, то мы должны иметь
версию программы, скомпилированную для каждой архитектуры. Эту версию про-
граммы следует разместить в известном для PVM месте. Таким местом часто служит
каталог $H0ME/pvm3 /bin. Этот каталог может быть также задан в файле конфигура-
ции PVM, который обычно имеет имя host file или .xpvm_hosts (если использует-
ся среда XPVM). Файл host file должен содержать такую запись:
ep=/usr/local/pvm3/bin
Эта запись означает, что любые пользовательские выполняемые файлы, необходи-
мые для среды PVM, можно найти в каталоге /usr/ local/pvm3 /bin.
Параграф 3
Пользователь, запускающий PVM-программу, должен иметь сетевой доступ (rsh
или ssh) к каждому компьютеру, включенному в среду PVM. По умолчанию PVM полу-
чает доступ к каждому компьютеру, используя зарегистрированное имя пользователя,
запускающего PVM-программу, или учетную запись компьютера, на котором она за-
У ается. Если потребуется другая учетная запись (помимо зарегистрированного
ПОЛЬЗОВателя‘инициатоРа)’ то в файл конфигурации PVM host file или
vnt-hosts необходимо добавить соответствующую запись, например:
io=flashgordon
Параграф 4
Со °
пьютеп*аИТе На каждом компьютере файл .rhosts, в котором перечислите все ком-
Можность ПОДЛежа1цие использованию. Эти компьютеры имеют потенциальную воз-
,xPvm host^n Включения в сРеДУ PVM. В зависимости от содержимого файла
Ны в PVM S ИЛИ Файда Pvni-hosts, эти компьютеры автоматически будут добавле-
Файлах СРедУ ПРИ запУске программы pvmd. Компьютеры, перечисленные в этих
е м°гут динамически включаться в PVM-среду во время работы.
222 Глава 6. Объединение возможностей параллельного программирования
Параграф 5
Создайте файл $НОМЕ/.xpvm_hosts и/или файл $HOME/pvm__hosts, в кото
перечислите все подлежащие использованию компьютеры с приставкой Нали^
приставки означает неавтоматическое включение компьютера. Без этой Приста С
ки компьютер будет включен в PVM-среду автоматически. Файл pvm_hosts создае В
пользователем и может иметь произвольное имя. Но в среде XPVM необходимо ис
пользовать только имя .xpvm_hosts. Пример такого файла показан на рис. 6.3. ДНа
логичный формат следует использовать для pvm_hosts- или . xpvm_ho st s-файла
Главное внимание необходимо уделить сетевому доступу пользователя, запускаю
щего PVM-программу. Владелец PVM-программы должен иметь доступ к каждому ком-
пьютеру, включенному в пул процессоров. Этот доступ будет использовать либо ко-
манду rsh, либо г login, либо ssh. Выполняемая программа должна быть доступна на
каждом компьютере, а PVM-среда должна быть “в курсе” того, какие компьютеры
имеются в наличии и где будут инсталлированы выполняемые файлы.
# Строки комментариев начинаются с символа
# (пустые строки игнорируются).
# Строки, начинающиеся с символа позволя-
ют
# включить компьютеры в среду PVM позднее. Ес-
ли
# имя компьютера не предваряется символом
# этот компьютер включается в среду PVM
# автоматически.
flavius
marcus
&cambius lo=romulus
&karsius
# Символ “*” означает стандартные опции для
# следующих компьютеров
* dx=/export/home/fred/pvm3/lib/pvmd
&octavius
# Если компьютеры являются частью типичного
# linux-кластера, то их имена можно использовать
# для включения узлов кластера в среду PVM
# вместе с другими узлами.
Рис. 6.3. Примерpvrnjiosts-файла
6.2.4. Объединение динамической С++-библиотеки
с библиотекой PVM
Поскольку доступ к PVM-средствам обеспечивается через коллекцию библи°те^
ных функций, С++-программа использует PVM как любую другую библиотеку. СлеД)
6.2. Библиотека PVM для языка C++ 223
в виду» что каждая PVM-программа представляет собой автономную С++-
ИмеТЬ mv с собственной функцией main(). Это означает, что все PVM-программы
ПрогР сОбственное адресное пространство. При порождении каждой PVM-задачи
ется ее собственный процесс с новым адресным пространством и, соответст-
С° о идентификационный номер процесса. PVM-процессы видимы для утилиты ps.
и отря на то что несколько PVM-задач могут выполняться вместе для решения не-
орой проблемы, они будут иметь собственные копии динамической С++-
библиотеки. Каждая программа имеет собственный поток iostr earn, библиотеку
шаблонов, алгоритмы и пр. В область видимости глобальных С++-переменных адрес-
ное пространство не попадает. Это означает, что глобальные переменные одной
pVM-задачи невидимы для других PVM-задач. Для взаимодействия отдельных задач
используется механизм передачи сообщений. Этим они отличаются от многопоточ-
ных программ, в которых потоки разделяют одно адресное пространство и могут
взаимодействовать посредством глобальных переменных и передачи параметров. Ес-
ли PVM-программы выполняются на одном компьютере с несколькими процессорами,
то как дополнительные средства коммуникации программы могут совместно исполь-
зовать файловую систему, каналы, FIFO-очереди и общую память. Несмотря на то что
передача сообщений — основной метод взаимодействия между PVM-задачами, ничто
не мешает им в качестве дополнительных средств использовать файловую систему,
буфер обмена или даже аргументы командной строки. PVM-библиотека не ограничи-
вает, а расширяет возможности динамической С++-библиотеки.
6.2.5. Методы использования PVM-задач
Работу, которую выполняет С++-программа, можно распределить между функциями,
объектами или их сочетаниями. Действия, выполняемые программой, обычно делятся
на такие логические категории: операции ввода-вывода, интерфейс пользователя, обра-
ботка базы данных, обработка сигналов и ошибок, числовые вычисления и т.д. Отделяя
код интерфейса пользователя от кода обработки файлов, а также код процедур печати
от кода числовых вычислений, мы не только распределяем работу программы между’
функциями или объектами, но и стараемся выделять категории действий в соответствии
с их характером. Логические группы организуются в библиотеки, модули, объектные
шаблоны, компоненты и оболочки. Такой тип организации мы поддерживаем и при
внесении PVM-задач в С++-программу. Мы можем подойти к декомпозиции работ
wor breakdown structure), используя метод либо восходящего, либо нисходящего
боту КТИРования* любом случае параллелизм должен естественно вписываться в ра-
pj которая намечена для выполнения функцией, модулем или объектом.
ИскуСсСаМаЯ Удачная идея — попытаться директивно навязать параллелизм программе,
кой ССТВенно насаждаемый параллелизм является причиной формирования громозд-
C4oXXHTeK WbI’ котоРая’ как правило, трудна для понимания и поддержки и создает
Подьзуе^р ПРИ ОПРеделении корректности программы. Поэтому, если программа ис-
граммы К ^-задачи, они должны быть результатом естественного разбиения про-
НацпИМегч кдую PVM-задачу следует отнести к одной из функциональных категорий.
На естеств ССЛИ МЫ РазРа^атываем приложение, которое содержит обработку данных
пР<>Изве еННОМ ЯЗЬ1ке (Natural Language Processing — NLP), механизм речевого вос-
^вателд X** Текста (text-to-speech engine — TTS-engine) как часть интерфейса поль-
Ф°рмирование логических выводов как часть выборки данных, то парал-
224 Глава 6. Объединение возможностей параллельного программирования
лелизм (естественный для NLP-компонента) должен быть представлен в виде
внутри NLP-модуля или объекта, который отвечает за NLP-обработку. Аналогично^^
раллелизм внутри компонента формирования логических выводов следует пре
вить в виде задач, составляющих модуль (объект или оболочку) выборки данных
вечающий за выборку данных. Другими словами, мы идентифицируем PVM-зал °Т
там, где они логически вписываются в работу, выполняемую программой, а не просу11
разбиваем работу программы на набор некоторых общих PVM-задач. 0
Соблюдение первичности логики и вторичности параллелизма имеет нескольк
последствий для С++-программ. Это означает, что мы могли бы порождать PVM
задачи из функции main () или из функций, вызываемых из функции main () (и даже
из других функций). Мы могли бы порождать PVM-задачи из методов, принадлежащих
объектам. Место порождения задач зависит от требований к параллельности, выдви-
гаемых соответствующей функцией, модулем или объектом. В общем случае PVM-
задачи можно разделить на две категории: SPMD (производная от SIMD) и MPMD
(производная от MIMD). В модели SPMD все задачи будут выполнять одинаковый на-
бор инструкций, но на различных наборах данных. В модели MPMD все задачи будут
выполнять различные наборы инструкций на различных наборах данных. Но какую
бы модель мы не использовали (SPMD или MPMD), создание задач должно происхо-
дить в соответствующих областях программы. Некоторые возможные конфигурации
для порождения PVM-задач показаны на рис. 6.4.
6.2.5.1. Реализация модели SPMD (SIMD) с помощью PVM-
и С++-средств
Вариант 1 на рис. 6.4 представляет ситуацию, при которой функция main () поро-
ждает от 1 до N задач, причем каждая задача выполняет один и тот же набор инструк-
ций, но на различных наборах данных. Существует несколько вариантов реализации
этого сценария. В листинге 6.1 показана функция main (), которая вызывает функцию
pvm_spawn ().
// Листинг 6.1. Вызов функции pvm_spawn() из
/ / функции main()
int main(int argc, char *argv[])
{
int TaskId[10];
int Taskld2[5);
// 1-е порождение:
pvm_spawn("set_combination",NULL,0,"",10,Taskld);
// 2-е порождение:
pvm_spawn("set_combination",argv,0,"",5,Taskld2);
//. . .
}
В листинге 6.1 при первом порождении создается 10 задач. Каждая задача ^УдеТ^е
поднять один и тот же набор инструкций, содержащихся в прогр^-^^
set_combination. При успешном выполнении функции pvm_spawn () массив Tas
будет содержать идентификаторы PVM-задач. Если программа в листинге 6.1
идентификатор Tasklds, то она может использовать функции pvm_send() для оТ^а.
ки данных, подготовленных для обработки каждой программой. Это возможно бляг
ря тому, что функция pvm_send () содержит идентификатор задачи-получателя-
6.2. Библиотека PVM для языка C++ 225
Р*10* 6.4. Некоторые возможные конфигурации для порождения PVM-задач
226 Глава 6. Объединение возможностей параллельного программирования
При втором порождении (см. листинг 6.1) создается пять задач, но в этом сл
каждой задаче с помощью параметра argv передается необходимая информа
Это __ дополнительный способ передачи информации задачам при их запуске. Тем **
мым сыновние задачи получают еще одну возможность уникальным образом Идец^
фицировать себя с помощью значений, получаемых в параметре argv. В листинге 6 2
чтобы создать N задач, функция main () несколько раз (вместо одного) обращается
к функции pvm_spawn ().
// Листинг 6.2. Использование нескольких вызовов
// функции pvm_spawn() из функции main{)
int main(int argc, char *argv[])
{
int Taskl;
int Task2;
int Task3;
//. . .
pvm_spawn("set_combination", NULL,1, "hostl",1,&Taskl);
pvm_spawn("set_combination",argv,1,"host2",1,&Task2);
pvm_spawn("set_combination",argv++,1,"host3",1,&Task3);
//. . .
}
Подход к созданию задач, продемонстрированный в листинге 6.2, можно исполь-
зовать в том случае, когда нужно, чтобы задачи выполнялись на конкретных компью-
терах. В этом состоит одно из достоинств PVM-среды. Ведь программе иногда стоит
воспользоваться преимуществами некоторых конкретных ресурсов конкретного ком-
пьютера, например, специальным математическим спецпроцессором, процессором
графического устройства вывода или какими-то другими возможностями. В листин-
ге 6.2 обратите внимание на то, что каждый компьютер выполняет один и тот же на-
бор инструкций, но все они получили при этом разные аргументы командной строки.
Вариант 2 (см. рис. 6.4) представляет сценарий, в котором функция main() не поро-
ждает PVM-задачи. В этом сценарии PVM-задачи логически связаны с функцией
f uncB (), и поэтому здесь именно функция f uncB () порождает PVM-задачи. Функци-
ям main() и funcA() нет необходимости знать что-либо о PVM-задачах, поэтому7 им
и не нужно иметь соответствующий PVM-код. Вариант 3 (см. рис. 6.4) представляет
сценарий, в котором функции main () и другим функциям в программе присущ естест-
венный параллелизм. В этом случае роль “других” функций играет функция funcA () •
PVM-задачи, порождаемые функциями main () и f uncA (), выполняют различный код-
Несмотря на то что задачи, порожденные функцией main (), выполняют идентичный
код, и задачи, порожденные функцией funcA (), выполняют идентичный код, эти Два
набора задач совершенно различны. Этот вариант иллюстрирует возможность С+
программы использовать коллекции задач для одновременного решения различны*
проблем. Ведь не существует причины, по которой на программу бы налагалось ОГР^4)
чение решать в любой момент времени только одну проблему. Вариант 4 (см. рис-
представляет случай, когда параллелизм заключен внутри объекта, поэтому порождс
PVM-задач реализует один из методов этого объекта. Этот вариант показывает, что г
необходимости параллелизм может исходить из класса, а не из “свободной” функции-
Как и в других вариантах, все PVM-задачи, порожденные в варианте 4, выпол
одинаковый набор инструкций, но с различными данными. Этот SPMD-метод (S10»
6.2. Библиотека PVM для языка C++ 227
Multiple-Data — одна программа, множество потоков данных) часто исполь-
progra111»^ реаЛИЗации параллельного решения проблем некоторого типа. И то, что
3УсТС* ^ЯобЛадает поддержкой объектов и средств обобщенного программирования
язык шаблонов, делает его основным инструментом при решении подобных за-
НаО<Объекты и шаблоны позволяют С++-программисту представлять обобщенные
даЧ бкие решения для различных проблем с помощью одной-единственной про-
И ГИ ой единицы. Наличие единой программной единицы прекрасно вписывается
ель параллелизма SPMD. Понятие класса расширяет модель SPMD, позволяя ре-
в м целЫй класс проблем. Шаблоны дают возможность решать определенный класс
ШаТблем для практически любого типа данных. Поэтому, хотя все задачи в модели SPMD
выполняют один и тот же код (программную единицу), он может быть предназначен для
любого объекта или любого из его потомков и рассчитан на различные типы данных
(азначит, и на различные объекты!). Например, в листинге 6.3 используется четыре
PVM-задачи для генерирования четырех множеств, в каждом из которых имеется С(п,г)
элементов: С(24,9), С(24,12), С(7,4) и С(7,3). В частности, в листинге 6.3 перечисляются
возможные сочетания из 24 цветов, взятые по 9 и по 12. Здесь также перечисляются
возможные сочетания из 7 чисел с плавающей точкой, взятые по 4 и по 3. Пояснения
по обозначению С(п,г) приведены в разделе $ 6.1 (“Обозначение сочетаний”).
/ / Листинг 6.3. Создание сочетаний из заданных множеств
int main(int argc,char *argv[])
{
int RetCode,Taskld[4];
RetCode = pvm_spawn ("pvm_generic_combination", NULL, 0,
4,Taskld);
if(RetCode == 4) {
colorCombinations (TaskId[0] ,9);
colorCombinations (Taskld [ 1 ] ,12) ;
numericCombinations (Taskld [2 ] , 4) ;
numericCombinations(Taskld[3],3);
saveResult(Taskld[0]);
saveResult(Taskld[1]);
saveResult(Taskld[2]);
saveResult(Taskld[3]);
j pvxn._exit
else{
cerr «
"Ошибка при порождении сыновнего процесса."
endl ;
Pvm_exit();
} return(о);
Истинге 6.3 обратите внимание на порождение четырех PVM-задач:
.spawn (" глт
v Pv^generic-confoination" ,NULL, О, и" ,4,Taskld) ;
Каждая п
pvm gener. Рожденная задача должна выполнять программу с именем
Чает, что С~coinbination. Аргумент NULL в вызове функции pvm_spawn() озна-
Функциц ЧеРез ПаРаметр argv [ ] не передаются никакие опции. Значение 0 в вызове
Pvin^spawn () свидетельствует, что нас не беспокоит, на каком компьютере
228 Глава 6. Объединение возможностей параллельного программирования
будет выполняться наша задача. Аргумент Taskld представляет массив, предцаз
ченный для хранения четырех целочисленных значений, который при условии усп^
ного выполнения функции pvm_spawn () будет содержать идентификаторы каждой по
рожденной PVM-задачи. В листинге 6.3 обратите также внимание на вызов функци-
colorCombinations () и numericCombinations (). Они “дают работу” PVM-задачам
Определение функции colorCombinations () представлено в листинге 6.4.
// Листинг 6.4. Определение функции colorCombinations()
void colorCombinations(int Taskld,int Choices)
{
int Messageld =1;
char *Buffer;
int Size;
int N;
string Source("blue purple green red yellow orange
silver gray ");
Source.append("pink black white brown light—green
aqua beige cyan ");
Source.append("olive azure magenta plum orchid violet
maroon lavender");
Source.append("\n");
Buffer = new char[(Source.size() + 100)];
strcpy(Buffer,Source.c_str());
N = pvm_initsend(PvmDataDefault);
pvm_pkint(&Choices,1,1);
pvm_send(Taskld,Messageld);
N = pvm_initsend(PvmDataDefault);
pvm_pkbyte(Buffer,strlen(Buffer),1);
pvm_send(Taskld,Messageld);
delete Buffer;
}
В листинге 6.3 отметьте два обращения к функции colorCombinations О. Каж-
дое из них велит PVM-задаче перечислить различное количество сочетаний цветов:
С(24,9) и С(24,12). Первая PVM-задача должна сгенерировать 1 307 504 цветовых со-
четаний, а вторая — 2 704 156. Эту работу выполняет программа, заданная в вызове
функции pvm_spawn (). Каждый цвет представляется строкой. Следовательно, про-
грамма pvm_generic_combination (с помощью функции colorCombinations О)
генерирует сочетания цветов, используя в качестве входных данных набор строк. Но
когда она орудует “руками” функции numericCombinations (), показанной в листин
ге 6.5, в качестве входных данных используется набор чисел с плавающей точкой. КоД
листинга 6.3 также содержит два вызова функции numericCombinations () . Первый
генерирует С(7,4) сочетаний, а второй — С(7,3).
// Листинг 6.5. Использование PVM-задач для генерирования
// сочетаний чисел
void numericCombinations(int Taskld,int Choices)
{
int Messageld = 2;
int re-
double ImportantNumbers[7] =
{3.00e+8,6.67e-ll,1.99e+30,
6.2. Библиотека PVM для языка C++ 229
1.67е-27,6.023е+23,6.63e-34,
3.14159265359};
nvm initsend(PvmDataDefault);
N = nkint(^Choices,1,1);
₽'*HLnd(TaskId,Messageld) ;
₽ ."pvm initsend(PvmDataDefault);
N ™ okdouble(ImportantNumbers,5,1);
pvmZsend(TaskId, Messageld) ;
}
В функции numericCombinations () из листинга 6.4 PVM-задача использует мас-
чисел с плавающей точкой, а не массив байтов, представляющих строки. Поэтому
А-нкция colorCombinations() отправляет свои данные PVM-задачам с помощью
вызовов таких функций:
pvm_send(Task!d,Messageld) ;
А функция numericCombination() отправляет свои данные PVM-задачам таким
образом:
pvm_pkdouble (ImportantNumbers ,5,1);
pvm_send(Taskld,Messageld) ;
Функция colorCombinations () в листинге 6.4 создает строку названий цветов,
азатем копирует ее в массив Buffer типа char. Этот массив затем упаковывается и от-
правляется PVM-задаче с помощью функций pvm__pkby te () и pvm_send (). Функция
numericCombinations () в листинге 6.5 создает массив типа double и отсылает
его PVM-задаче с помощью функций pvm__pkdouble () и pvm_send(). Одна функ-
ция отправляет символьный массив, а другая — массив типа double. В обоих случаях
PVM-задачи выполняют одну и туже программу pvm_generic_combination. Именно
здесь нас выручает преимущество использования С++-шаблонов. Одинаковые задачи бла-
годаря этому могут работать не только с различными данными, но и с различными типами
данных без изменения самого кода. Использование шаблонов в C++ позволяет сделать мо-
-Дель SPMD более гибкой и эффективной. Программе pvm_geneгic_combination
практически безразлично, с какими типами данных ей придется работать. Использо-
вание контейнерных С++-классов позволяет генерировать любые комбинации векто-
ров (vector<T>) объектов. Программа pvm_geneгic_combination “не знает”, что
°на будет работать с двумя типами данных. В листинге 6.6 представлен раздел кода из
программы pvm_generic_combination.
II Листинг 6.6. Использование тега Messageld для
распознания типов данных
if &NumBytes, &MessageId, &Ptid) ;
'messageld == i){
BuftOr<String> S°urce;
pvm char[NumBytes];
st^strobYte(Buf-NumBYtes,1) ;
ream Buffer;
S-SV" Buf « ^ds;
{ (Buffer.good())
Buffer » color;
230 Глава 6. Объединение возможностей параллельного программирования
if(!Buffer.eof()){
Source.push_back(Color);
}
}
generateCombinations<string>(Source,Ptid,Value);
delete Buf;
}
if(Messageld == 2){
vector<double> Source;
double *ImportantNumber;
NumBytes = NumBytes I sizeof(double);
ImportantNumber = new double[NumBytes];
pvm_upkdouble(ImportantNumber,NumBytes, 1) ;
copy(ImportantNumber,ImportantNumber +(NumBytes + 1),
inserter(Source, Source.begin()));
generateCombinations<double>(Source,Ptid,Value);
delete ImportantNumber;
}
Здесь используется тег Messageld, позволяющий распознать, с каким типом данных
мы работаем. Но в C++ возможно более удачное решение. Если тег Messageld содер-
жит число 1, значит, мы работаем со строками. Следовательно, можно сделать сле-
дующее объявление:
vector<string> Source;
Если тег Messageld содержит число 2, то мы знаем, что должны работать с числа-
ми с плавающей точкой, и поэтому делаем такое объявление:
vector<double> Source;
Объявив, какого типа данные будет содержать вектор Source, остальную часть
функции в программе рvm_geneгic_combination можно легко обобщить. В листин-
ге 6.6 обратите внимание на то, что каждая инструкция if () вызывает функцию
generateCombinations (), которая является шаблонной. Эта шаблонная архитекту-
ра позволяет достичь такой степени универсальности, которая распространяет сце-
нарии SPMD и MPMD на наши PVM-программы. Мы вернемся к обсуждению нашей
программы pvm_geneгic_combination после рассмотрения базовых механизмов
PVM-среды. Важно отметить, что контейнерные С++-классы, потоковые классы
и шаблонные алгоритмы значительно усиливают гибкость PVM-программирования,
которую невозможно было бы так просто реализовать в других PVM-средах. Именно
такая гибкость создает возможности для построения высокоорганизованных и эле
гантных параллельных архитектур.
6.2.5.2. Реализация модели MPMD (MIMD) с помощью PVM-
и С++-средств
В то время как модель SPMD использует функцию pvm_spawn () для создания
которого числа задач, выполняющих одну и ту же программу, но на потенции
различных наборах данных или ресурсов, модель MPMD использует фУнК
pvm_spawn () для создания задач, которые выполняют различные программы на р
личных наборах данных. Как с помощью одной С++-программы реализовать М°
MPMD (на основе PVM-функций), показано в листинге 6.7.
6.2. Библиотека PVM для языка C++ 231
6.7. Использование PVM для реализации
у/ дистии MPMD-модели вычисления
Task2[50]
int mainfint argc, char *argv[])
( int Taskl[20] ;
•„t Task2[50];
int Task3[30] ;
' awn("pvm_generic_combination", NULL,1,
P™- p “hostl", 20,Taskl);
nvm spawn("generate_plans",argv,050,Task2);
pvm spawn(“agent_filters”,argv++,l,"host 3",30,&Task3);
}
При выполнении кода, представленного в листинге 6.7, создается 100 задач. Пер-
вые 20 задач генерируют сочетания. Следующие 50 по мере создания сочетаний гене-
рируют планы на их основе. Последние 30 задач отфильтровывают самые удачные
планы из набора планов, сгенерированного предыдущими 50 задачами. Уже только
это краткое описание позволяет ощутить отличие модели MPMD от модели SPMD,
в которой все программы, порожденные функцией pvm_spawn (), были одинаковы.
Здесь же за работу, назначаемую PVM-задачам, “отвечают” программы
pvm_generic—combination, generate_plans и agent—fiIters. Все эти задачи
выполняются параллельно и работают с собственными наборами данных, несмотря
на то что одни наборы являются результатом преобразования других. Программа
pvm_generic_combination преобразует свой входной набор данных в набор, кото-
рый затем может использовать программа generate—plans. Программа
generate—plans, в свою очередь, преобразует входной набор данных в набор, кото-
рый может затем использовать программа agent_f ilters. Очевидно, что эти задачи
должны обмениваться сообщениями. Эти сообщения представляют собой входную
и управляющую информацию, которая передается между процессами. Необходимо
также отметить, что в листинге 6.7 функция pvm_spawn () используется для размеще-
ния 20 задач pvm—generic—combination на компьютере с именем hostl. Задача
generate-plans была размещена на 50 безымянных процессорах, но каждая из этих
задач получила при этом один и тот же аргумент командной строки с помощью па-
раметра argv. Задачи agent_f ilters также были направлены на конкретный ком-
HoftTeP ИМенем h°st 3), и каждая задача получила один и тот же аргумент команд-
ние СТР°КИ ПосРедств°м параметра argv. Этот пример — лишь еще одно подтвержде-
МРМп^КОСТИ И мощи библиотеки PVM. Некоторые варианты реализации модели
ц с использованием среды PVM показаны на рис. 6.5.
конк И Желании МЬ1 можем воспользоваться преимуществами конкретных ресурсов
них безНЫХ КомпьютеРов или же “положиться на судьбу” в виде “заказа” произволь-
Разли лянных компьютеров. Мы можем также назначить различные виды работ
Пьюте задачам одновременно. На рис. 6.5 компьютер А представляет собой ком-
РЫм ко Массовым параллелизмом (МП-компьютер), а компьютер В оснащен некото-
Те, что Р\тлСТВОМ специализиРованных математических процессоров. Также отметь-
Sparcs Сга\ С^еДа в данном случае состоит из таких компьютеров, как PowerPCs,
стях компь S И Т одних случаях можно не беспокоиться о конкретных возможно-
теров в PVM-среде, а в других требуется иной подход. Использование
232 Глава 6. Объединение возможностей параллельного программирования
функции pvm_spawn () позволяет С++-программисту не указывать конкретный
пьютер для решения задачи, когда это не важно. Но если вам известно, что компь^
тер оснащен специализированными средствами, то их можно эффективно исполь
вать, определив соответствующий параметр при вызове функции pvm_spawn (). 3°
Программа 1
Задача С
ОДНА ЛОГИЧЕСКАЯ ПАРАЛЛЕЛЬНАЯ
ВИРТУАЛЬНАЯ МАШИНА (КЛАСТЕР)!
Программа 2
Задача В
Программа 3
Задача А
Задача D
Рис. 6.5. Некоторые варианты модели MPMD доступны для реализации благодаря
использованию среды PVM
§ 6.1. Обозначение сочетаний
Предположим, мы хотели бы набрать команду программистов (в количестве восьми
человек) из 24 кандидатов. Сколько различных команд из восьми программистов
можно было бы составить из этого числа кандидатов? Один из результатов, коТ°т
рый следует из основного закона комбинаторики, говорит о том, что существ)
735 471 различных команд, состоящих из восьми программистов, которые мо
быть выбраны из 24 кандидатов. Обозначение С(п,г) читается как сочетание
элементов по г (и означает количество комбинаций из п элементов по г). Сочет
С(п,г) вычисляется по формуле:
6.3. Базовые механизмы PVM 233
п\
г\(п - г)!
нас есть множество, которое представляет сочетания, например {а,Ь,с}, то счи-
ЕслИ' что оно совпадает с множеством {Ь,а,с} или {с,Ь,а}. Другими словами, нас ин-
тастся. ПОрЯДОК членов в этом множестве, а сами члены. Многие параллельные
теРе ' ммЫ а именно программы, использующие алгоритмы поиска, эвристические
ПР°о ы и средства искусственного интеллекта, обрабатывают огромные множества
сочетаний и их близких родственников перестановок.
6.3. Базовые механизмы PVM
Среда PVM состоит из двух компонентов: PVM-демона (pvmd) и библиотеки pvmd.
Один PVM-демон pvmd выполняется на каждом компьютере в виртуальной машине.
Этот демон служит в качестве маршрутизатора сообщений и контроллера. Каждый
демон pvmd управляет списком PVM-задач на своем компьютере. Демон управляет
процессами, выполняет минимальную аутентификацию и отвечает за отказоустойчи-
вость. Обычно первый демон запускается вручную. Затем он запускает другие демоны.
Только исходный демон может запускать дополнительные демоны. И только исход-
ный демон может безусловно остановить другой демон.
Библиотека pvmd состоит из функций, которые позволяют одной PVM-задаче
взаимодействовать с другими. Эта библиотека также включает функции, которые по-
зволяют PVM-задаче связываться со своим демоном pvmd. Базовая архитектура PVM-
среды показана на рис. 6.6.
PVM-среда состоит из нескольких PVM-задач. Каждая задача должна содержать один
или несколько буферов отправки сообщений, но в каждый момент времени активным
может быть только один буфер (он называется активным буфером отправки сообщений).
Каждая задача имеет активный буфер приема сообщений. Обратите внимание
(см. рис. 6.6) на то, что взаимодействие между PVM-задачами реально выполняется с ис-
пользованием TCP-сокетов. Функции pvm_send () делают доступ к сокетам прозрачным,
рограммист не получает доступа к функциям TCP-сокетов напрямую. На рис. 6.6 также
показано взаимодействие PVM-задач со своими демонами pvmd с помощью ТСР-
сокетов и взаимодействие между самими демонами с помощью UDP-сокетов. И снова-
ло И °бРаи1ения к сокетам выполняются посредством PVM-функций. Программист не
топ еН заниматься программированием сокетов на низком уровне. PVM-функции, ко-
используются в этой книге, делятся на четыре следующие категории:
Управление процессами;
упаковка сообщений и их отправка;
Распаковка сообщений и их получение;
Управление буфером сообщений.
°нные и0^ На сУ1цествование Других категорий PVM-функций (например, информаци-
Внимание на 1СНЫе ФУ11КЦИИ 147114 функции групповой обработки), рекомендуем обратить
Же Функции б^ЪКции обработки сообщений и функции управления процессами. Другие
' ДУТ рассмотрены в контексте программ, в которых они используются.
234 Глава 6. Объединение возможностей параллельного программирования
Упрощенная архитектура PVM-программы
PVM-ЗАДАЧА PVM-ЗАДАЧА
Среда UNIX/Linux
Рис. 6.6. Базовая архитектура PVM-среды
6.3.1. Функции управления процессами
Библиотека PVM содержит шесть часто используемых функций.
Функция pvm_spawn () используется для создания новых PVM-задач. При вызове
этой функции можно указать количество создаваемых задач, место их создания и ар
гументы, передаваемые каждой задаче, например:
pvni—Spawn ("agent—filters", ar gv+f-, 1, "host 3 ", 30, &Task3) ;
6.3. Базовые механизмы PVM 235
СИИОПСИС 7 И"
„include "pvm3.h
spawn(char *task, char **argv, int flag,
int P - char *location,int ntask,int *taskids);
pvm kill<int taskid);
pvm_exit(void);
ovm addhosts(char **hosts,int nhosts,int *status);
pvm^delhosts(char **hosts,int nhosts,int *status);
pvmZhalt(void) ;
int
int
int
int
int
Параметр task содержит имя программы, которую должна выполнить функция
spawn(). Поскольку программа, которая запускается посредством функции
pvrrTspawn (), является автономной, ей могут потребоваться аргументы командной
строки. Поэтому для их передачи используется параметр argv. Параметр location по-
зволяет указать, на каком компьютере должна быть выполнена задача. Параметр
taskids содержит либо идентификаторы порождаемых задач, либо коды состояния,
представляющие любые ситуации сбоя, которые могут возникнуть во время порождения
процесса. Параметр ntasks определяет, сколько экземпляров задачи требуется создать.
Функция pvm_kill() используется для аннулирования задачи, указанной с помощью
параметра taskid. С помощью этой функции можно аннулировать любую задачу, опре-
деленную пользователем в среде PVM, за исключением вызывающей. Эта функция от-
правляет сигнал SIGTERM PVM-задаче, подлежащей уничтожению. Функция
pvm_exit () используется для выхода вызывающей задачи из среды PVM. Несмотря на
возможность вывода задачи из среды PVM, процесс, которому принадлежит эта задача,
может продолжать выполнение. Следует иметь в виду, что задача, выполняющая вызовы
PVM-функций, может выполнять и другую работу, которая не связана со средой PVM.
Функцию pvm_exit () должна вызывать любая задача, которая больше не имеет от-
ношения к специфике PVM-обработки. Функция pvm_addhosts () позволяет динами-
чески вносить дополнительные компьютеры в среду PVM. Обычно при вызове функции
pvm_addhosts () передается список имен добавляемых компьютеров, например:
int Status[3];
char *Hosts[] = {"porthos", "dartagnan","athos;
Pvm_addhosts ("porthose", 1, ^Status) ;
Pvm^addhosts (Hosts,3, Status) ;
Параметр Hosts обычно содержит измена компьютеров (одно или несколько), пере-
ко нных в файле .rhosts или .xpvm_hosts. Параметр nhost содержит количество
Ное ТеРов’ подлежащих добавлению в среду7 PVM, а параметр status — значение, рав-
Ес1иЗНаЧеПИЮ паРаметРа nhosts при успешном выполнении функции pvm_addhosts ().
функПРИ~ее ВЬ13ове не удалось добавить ни одного компьютера, значение, возвращаемое
УсПещ11еИ будет меньше числа 1. Если выполнение этой функции было лишь частично
ЛенньГМ’ ЗНачение’ возвращаемое функцией, будет равно количеству реально добав-
среды рЛ°МпьютеРов- Функция pvm_delhosts () позволяет динамически извлечь из
спцсок один или несколько заданных компьютеров. Параметр hosts содержит их
’а ПаРаметр nhosts — количество выводимых компьютеров, например:
-delhosts ("dartagnan", 1) ;
236 Глава 6. Объединение возможностей параллельного программирования
При выполнении этой функции компьютер с именем dartagnan будет извлечен
среды PVM. Функции pvm_addhosts () и pvm_delhosts () можно вызывать во вр И3
выполнения приложения. Это позволяет программисту динамически изменять *
меры среды PVM. Любая PVM-задача, выполняемая на компьютере, который удаляе
ся из PVM-среды, будет аннулирована. Демоны, выполняющиеся на удаляемых ком
пьютерах (pvmd), будут остановлены. В случае возникновения аварийной ситуации на
каком-либо компьютере PVM-среда автоматически удалит его. Значения, возвращае
мые функцией pvm_delhosts, совпадают со значениями, возвращаемыми функцией
pvm_addhosts (). Функция pvm_halt () прекращает работу всей системы PVM. При
этом все задачи и демоны (pvmd) останавливаются.
6.3.2. Упаковка и отправка сообщений
Гейст Бигулин (Geist Beguelin) и его коллеги так описывают модель сообщений
PVM-среды:
PVM-демоны и задачи могут формировать и отправлять произвольной длины сооб-
щения, содержащие типизированные данные. Если содержащиеся в сообщениях
данные имеют несовместимые форматы, то при передаче между компьютерами их
можно преобразовать, используя стандарт XDR1. Сообщения помечаются во время
отправки с помощью определенного пользователем целочисленного кода и могут
быть отобраны для приема посредством адреса источника, или тега. Отправитель
сообщения не ожидает от получателя подтверждения приема (квитирования),
а продолжает работу сразу после отправки сообщения в сеть. Затем буфер сообще-
ний может быть очищен или вновь использован по назначению. Сообщения буфери-
зируются до тех пор, пока не будут приняты получателем. PVM-система надежно дос-
тавляет сообщения адресатам, если таковые существуют. При оправке сообщений от
каждого отправителя каждому получателю их порядок сохраняется. Это означает,
что если отправителем было послано несколько сообщений, они будут получены ад-
ресатом в том же порядке, в котором были отправлены.
Библиотека PVM содержит семейство функций, используемых для упаковки дан-
ных различных типов в буфер оправки. В это семейство входят функции упаковки,
предназначенные для символьных массивов, значений типа double, float, int,
long, byte и т.д. Список pvm—pk-функций представлен в табл. 6.3.
Таблица 6.3. Функции упаковки
Байты:
int pvm_pkbyte(char *ср, int count, int std) ;
Комплексные числа (комплексные числа типа double):
int pvm_pkcplx(float *xp, int count, int std) ;
int pvm_pkdcplx(double *zp, int count, int std) ;
Значения типа double:
int pvm_pkdouble(double *dp, int count, int std) ;
1 XDR (eXtemal Data Representation) - стандарт для аппаратно-независимых структур данных, Р
работанный фирмой Sun Microsystems.
6.3. Базовые механизмы PVM 237
Окончание табл. 6.3
Значения типа float.
‘nt pvm_Pkfl°at(float *fp, int count, int std);
Значения типа int.
int pvm_pkint(int *np, int
Значения типа long.
int pvm_pklong(long *np, int count, int std);
Значения типа short:
count, int
std) ;
Строки:
int pvm pkstr(char *cp) ;
Все функции упаковки, перечисленные в табл. 6.3, используются для сохранения
массива данных в буфере отправки. Обратите внимание на то, что каждая PVM-задача
(см. рис. 6.6) должна иметь по крайней мере один буфер отправки и один буфер
приема. Каждая функция упаковки принимает указатель на массив соответствующего
типа данных. Все функции упаковки, за исключением функции pvm_pkstr (), прини-
мают общее количество элементов, подлежащих сохранению в массиве (а не количе-
ство байтов!). Для функции pvm_pkstr() предполагается, что символьный массив,
с которым она работает, завершается значением NULL. Каждая функция упаковки, за
исключением функции pvm_pkstr (), в качестве последнего параметра принимает
значение, которое представляет способ обхода элементов исходного массива при их
упаковке в буфер отправки. Этот параметр часто называют шагом по индексу (stride).
Например, если этот шаг равен четырем, то в буфер упаковки будет помещен каждый
четвертый элемент исходного массива. Важно отметить, что до отправки каждого со-
общения необходимо использовать функцию pvm_initsend (), которая очищает буфер
и готовит его к пересылке следующего сообщения. Функция pvm_initsend () готовит
буфер к пересылке сообщения в одном из трех форматов: XDR, Raw или In Place.
Формат XDR (External Data .Representation) — это стандарт, используемый для опи-
сания и шифрования данных. Следует иметь в виду, что компьютеры, включенные
среду PVM, могут быть совершенно разными, т.е. среда PVM, например, может со-
стоять из Sun-, Macintosh-, Crays- и AMD-компьютеров. Эти компьютеры могут отли-
В ся размерами машинных слов и по-разному сохранять различные типы данных.
ДаНе1уп°РЬ1Х слУчаях компьютеры могут различаться и битовой организацией. Стан-
а £ К позволяет компьютерам обмениваться данными вне зависимости от типа их
комп еКТУРы< Формат Raw используется для отправки данных в собственном формате
стся фоеРа’отпРавителя- При этом никакое специальное кодирование не применя-
правки °РМаТ 1п Р1асе в действительности не требует упаковки данных в буфере от-
случае * И ^Р^и^У отправляются лишь указатели на данные и размер данных. В этом
кодип 3аДача’ПолУчатель напрямую копирует данные. В библиотеке PVM эти три типа
ия данных представляются соответствующими тремя константами:
XDR
₽W)ataRaw к
Ьез специального кодирования
асе В буфер отправки копируются лишь указатели и размер данных
238 Глава 6. Объединение возможностей параллельного программирования
Вот пример:
int Bufferld;
Bufferld = pvm_initsend(PvmDataRaw);
//. . .
Здесь константа PvmDataRaw, переданная функции pvm_initsend () в качестве ца
раметра, означает, что данные упаковываются в буфер как есть, т.е. без специального
кодирования. При успешном выполнении функция возвращает номер буфера отправ
ки (в данном случае он будет записан в переменную Bufferld). Важно помнить, что
хотя в каждый момент времени активным может быть только один буфер отправки
любая PVM-задача может иметь несколько таких буферов, и с каждым из них связыва-
ется некоторый идентификационный номер.
В библиотеке PVM предусмотрено несколько функций, имеющих отношение
к процедуре отправки.
Синопсис
# include "pvm3.h"
int pvm_send(int taskid, int messageid);
int pvm psendCint taskid, int messageid,
char *buffer,int len, int datatype);
int pvm mcast(int *taskid,int ntask,int messageid);
В каждой из этих функций параметр taskid представляет собой идентификатор
PVM-задачи, которая принимает сообщение. При вызове функции pvm_mcast () па-
раметр taskid означает коллекцию задач, представляемых идентификаторами, ко-
торые передаются в массиве *taskid. Параметр messageid указывает идентифика-
тор посылаемого сообщения. Идентификаторы сообщений представляют собой це-
лочисленные значения, определенные пользователем. Они используются
отправителем и получателем для идентификации сообщения, например:
pvm_buf inf о (N, &NumBytes, &MessageId, &Ptid) ;
//. . .
switch(Messageld)
{
case 1 : // Некоторые действия,
break;
case 2 : // Другие действия,
break
//. . .
}
В данном случае функция pvm_buf inf о () используется для получения информа
ции о последнем сообщении, принятом в буфер приема N. Мы можем получить коли
чество байтов, идентификатор сообщения (messageid) и узнать, кто его отправил
Зная значение messageid, мы можем выполнить соответствующие логические дейст-
вия. Функция pvm_send () посылает заданной задаче команду псевдоблокирования,
после приема которой задача блокируется до тех пор, пока отправитель не убеди
в том, что сообщение было послано правильно. Задача-отправитель не ожидает р
ального получения сообщения. Функция pvm_psend () отправляет сообше
6.3. Базовые механизмы PVM 239
лственно указанной задаче. Обратите внимание на то, что функция
непоср > имеет параметр buffer, используемый в качестве буфера для хранения
₽Л^ылаемого сообщения. Функция pvm_mcast () используется для отправки сообще-
П°С нескольким задачам одновременно. Аргументы, передаваемые функции
нИЯ mcaSt (), включают массив идентификаторов задач-получателей сообщения
pVTn"^i J), количество задач — участников “широковещания” (ntask) и идентифика-
сообщения (messageid) для идентификации отправляемого сообщения. На
Т°Р показано, что у каждой PVM-задачи есть собственный буфер отправки, кото-
рый существует в течение промежутка времени, длительности которого было бы дос-
таточно, чтобы сообщение гарантированно дошло до адресата.
За исключением управляющих сообщений, значение сообщений, которыми обмени-
ваются любые две PVM-задачи, заранее определено логикой конкретного приложения,
т е назначение каждого сообщения должно быть заранее известно для задачи-
отправителя и задачи-получателя. Эти сообщения передаются асинхронно, могут иметь
любой тип данных и произвольную длину. Тем самым для приложения обеспечивается
максимальная гибкость. Аналогами отправляемых PVM-сообщений являются прини-
маемые PVM-сообщения. Так, за прием сообщений “отвечают” пять основных функций.
Синопсис
# inc lude ” pvm3 . h"
int pvm_recv(int taskid, int messageid) ;
int pvm_nrecv(int taskid, int messageid) ;
int pvm_precv(int taskid, int messageid, char *buffer,
int size, int type, int sender,
int messagetag, int messagelength);
int pvm_trecv(int taskid,int messageid,
struct timeval *timeout);
int pvm probe (int taskid , int messageid);
Функция pvm_recv () используется одними PVM-задачами для получения сообще-
нии от других. Эта функция создает новый активный буфер, предназначенный для
хранения полученного сообщения. Параметр taskid определяет идентификатор за-
дачи-отправителя. Параметр messageid идентифицирует сообщение, которое по-
слано отправителем. Следует иметь в виду, что задача может отправить несколько
сообщений, имеющих различные или одинаковые идентификаторы (messageid).
и taskid = -1, то функция pvm_recv () примет сообщение от любой задачи. Ес-
HM:eSSS9eid = Т° ФУНКЦИЯ пРимет любое сообщение. При успешном выполне-
нии функция pvm_recv() возвращает идентификатор нового активного буфера,
Противном случае — отрицательное значение. После вызова функции pvm_recv ()
лух^н 'Дет сблокирована и станет ожидать до тех пор, пока сообщение не будет по-
одн^0 П°СЛе нолучения сообщение считывается из активного буфера с помощью
°и из функций распаковки, например:
Value [1°1 ;
^uSr°002'2);
cout vaiat(4°0002' Value'1);
240 Глава 6. Объединение возможностей параллельного программирования
Здесь функция pvm_recv() обеспечивает ожидание сообщения от задачи, идентигЬ
катор которой равен 400002. Идентификатор сообщения (messageid), получецц И
от задачи с номером 400002, должен быть равен значению 2. Затем использу °Г°
функция распаковки для считывания массива чисел с плавающей точкой типа f 1О
Тогда как функция pvm_recv () вынуждает задачу ожидать до тех пор, пока она не По
лучит сообщение, функция pvm_nrecv () обеспечивает прием сообщений без блоки
рования. Если соответствующее сообщение не поступает адресату, функция
pvm_nrecv () немедленно завершается. По прибытии сообщения по месту назначе
ния функция pvm_nrecv () сразу же завершается, а активный буфер будет содержать
полученное сообщение. Если произойдет сбой, функция pvm_nrecv() возвратит от-
рицательное значение. Если сообщение не поступит адресату, функция возвратит
число 0. Если сообщение благополучно прибудет по месту назначения, функция воз-
вратит номер нового активного буфера. Параметр taskid содержит идентификатор
задачи-отправителя. Параметр messageid содержит идентификатор сообщения, оп-
ределенный пользователем. Если taskid = -1, функция pvm_nrecv() примет со-
общение от любой задачи. Если messageid = -1, эта функция примет любое сооб-
щение. При приеме сообщений с помощью функций pvm_recv () или pvm_nrecv ()
создается новый активный буфер, а текущий буфер приема очищается.
Тогда как функции pvm_recv (), pvm_nrecv () и pvm_trecv () принимают со-
общения в новый активный буфер, функция pvm_precv () принимает сообщение
непосредственно в буфер, определенный пользователем. Параметр taskid содер-
жит идентификатор задачи-отправителя. Параметр messageid идентифицирует
получаемые сообщения. Параметр buffer должен содержать реально принятое со-
общение. Поэтому вместо получения сообщения из активного буфера с помощью
одной из функций распаковки, сообщение считывается напрямую из параметра
buffer. Параметр size содержит длину сообщения в байтах. Параметр type опре-
деляет тип данных, содержащихся в сообщении. Параметр type может иметь сле-
дующие значения:
PVM_STR
PVM_SHORT
PVM_FLOAT
PVM_LONG
PVM-CPLX
PVMJJINT
Функция pvm_trecv() позволяет программисту организовать процедуру по
лучения сообщений с ограничением по времени. Эта функция заставляет вызы
вающую задачу перейти в заблокированное состояние и ожидать прихода соо
щения, но лишь в течение промежутка времени, заданного параметром timeout-
Этот параметр представляет собой структуру типа timeval, определенную в за
головке time.h, например:
#include "pvm3.h"
PVM_BYTE
PVM_INT
PVM_DOUBLE
PVM-USHORT
PVM_DCPLX
PVM-ULONG
struct timeval TimeOut;
TimeOut.tv_sec = 1000;
int Taskid;
int Messageld;
6.3. Базовые механизмы PVM 241
, тя = pvm_parent();
Task eld = 2;
^esS^eCv(Taskld, Messageld, &TimeOut) ;
pVflL-tr
//••*
сь переменная TimeOut содержит член tv_sec, установленный равным 1000 с.
timeval можно использовать для установки временных значений в секун-
микросекундах. Структура timeval имеет следующий вид:
struct timeval{
long tv_sec; // секунды
long tv_usec; // микросекунды
};
Этот пример означает, что функция pvm_trecv () заблокирует вызывающую задачу
максимум на 1000 с. Если сообщение будет получено до истечения заданных 1000 с,
функция сразу завершится. Функцию pvm_trecv () можно использовать для предот-
вращения бесконечных задержек и взаимоблокировок. При успешном выполнении
функция pvm_trecv() возвращает номер нового активного буфера, в противном слу-
чае (при возникновении ошибки) — отрицательное значение. Если taskid = -1,
функция примет сообщение от любого отправителя. Если messageid = -1, функция
примет любое сообщение.
Функция pvm_probe () определяет, поступило ли сообщение, заданное парамет-
ром messageid, от отправителя, заданного параметром taskid. Если функция
pvm_probe () “видит” указанное сообщение, она возвращает номер нового активного
буфера. Если заданное сообщение не прибыло, функция возвращает число 0. При
возникновении сбоя функция возвращает отрицательное значение.
Синопсис
# inc lude " pvm3 . h"
int pvm_getsbuf (void) ;
int pvm_getrbuf (void) ;
int pvm__setsbuf (int bufferid);
int pvm_setrbuf (int bufferid);
int pvm_mkbuf (int Code) ;
Jgt pvm_freebuf (int buf f erid) ;
В библиотеке PVM предусмотрено шесть полезных функций управления буфе-
рами, которые можно использовать для установки, идентификации и динамическо-
ДляСОЗДаНИЯ буферОВ отпРавки и приема. Функция pvm_getsbuf () используется
н Получения номера активного буфера отправки. Если текущего буфера отправки
существует, функция возвращает число 0. Функция pvm_getrbuf () использует-
иМеть П°Л^чения идентификационного номера активного буфера приема. Следует
фер ВиДУ» что при каждом получении сообщения создается новый активный бу-
Функ Тек^’1Ци^ буфер очищается. Если текущего буфера приема не существует,
. Возвращает число 0. Функция pvm_setsbuf () устанавливает параметр
-лькеоГ1а Равным номеру активного буфера отправки. Обычно PVM-задача имеет
КИх ^°ДИН буФеР отправки. Но иногда возникает необходимость в нескольких та-
<Рерах. Хотя в любой момент времени активным может быть только один
242 Глава 6. Объединение возможностей параллельного программирования
буфер отправки, PVM-задача может создавать дополнительные буфера отпп
с помощью функции pvm_mkbuf (). Функцию pvm_setsbuf () можно использо И
для установки в качестве активного буфера одного из буферов отправки, кото^^
были созданы во время работы приложения. Эта функция возвращает идентифик С
тор предыдущего активного буфера отправки. Функция pvm_setrbuf () устанавл^
вает активный буфер приема равным значению bufferid. Помните, что PVM
функции распаковки работают с активным буфером приема. Если существует Не
сколько буферов, функция pvm_setrbuf () позволит применить текущий буфер Для
использования функциями распаковки. При успешном выполнении функци
pvm_setrbuf () возвращает идентификатор предыдущего активного буфера. Если
идентификатора буфера, переданного функции pmv_setrbuf (), не существует или
он оказался недействительным, функция возвратит одно из следующих сообщений
об ошибке: PvmBadParam или PvmNoSuchbuf. Функция pvm_mkbuf () используется
для создания нового буфера сообщений. Параметр Code определяет формат дан-
ных, которые будут содержаться в этом буфере: XDR, собственный формат компью-
тера или формат, использующий указатели и размеры. Поэтому параметр Code мо-
жет содержать одно из трех значений:
PvmDataDefault XDR
PvmDataRaw В зависимости от марки компьютера (без кодирования)
PvmDatalnPlace Используются только указатели на данные и их размер
При успешном выполнении функция pvm_mkbuf () возвращает идентифика-
тор нового активного буфера, в противном случае — отрицательное значение. Для
каждого обращения к функции pvm_mkbuf () , если буфер отправки больше не бу-
дет нужен, необходимо вызвать функцию pvm_f reebuf () , которая освободит
память, выделенную функцией pvm_mkbuf (). Функцию pvm_f reebuf () следует
использовать только в случае, когда сообщение уже отправлено и в буфере нет
никакой необходимости.
6.4. Доступ к стандартному входному потоку
(stdin) и стандартному выходному потоку
(stdout) со стороны PVM-задач
Среда PVM связывает воедино коллекцию компьютеров и представляет их
программы в виде одной логической машины с несколькими процессорами. При этом
возникают следующие вопросы. Какой компьютер в PVM-среде должен действовать
как консоль? Где будут отображаться данные, выводимые PVM-задачей в объект cout
типа ostream? Если PVM-задача попытается принять данные с клавиатуры, то с како!
именно клавиатуры она должна их считывать? Выходной поток stdout для кажДоГ
сыновнего процесса перехватывается и отправляется назначенной PVM-задаче в в
PVM-сообщения. Каждый сыновний процесс наследует информацию, которая о
деляет, какая задача должна принять данные, записанные в поток stdout, и как
данные должны быть идентифицированы. Входной поток каждого сыновнего ПР^
цесса связан с устройством /dev/null. Все, что записано в устройство /dev/пи
6.5. Резюме 243
Если устройство /dev/null открыто для чтения, возвращается эквивалент
теряется. конца файла. Это означает, что код сыновних процессов не должен созда-
призНа^ расчете на считывание входных данных из стандартного потока stdin (cin)
ваться выходных данных в стандартный поток stdout (cout). При этом пото-
илИ и stdout для родительской задачи ведут себя вполне ожидаемым образом.
кИ алачи для взаимодействия между собой должны использовать сообщения. Это
* что входные данные можно принимать из сообщений, каналов, общей
зН еляемой) памяти, переменных среды, аргументов командной строки или фай-
лов И точно так же выходные данные можно записывать в сообщения, каналы, об-
щую память и файлы.
6.4.1 • Получение доступа к стандартному выходному
потоку (cout) из сыновней задачи
Поведение выходных данных, записанных в выходной поток stdout или поме-
щенных в объект cout, отличается для различных порожденных PVM-задач. Именно
родительский процесс решает, что в конце концов с ними должно произойти. Когда
выходные данные из порожденного потомка помещаются в объект cout или сегг,
они перехватываются демоном pvmd и упаковываются в стандартные PVM-
сообщения, которые отправляются задаче с идентификатором Taskld, заданным ро-
дителем. Родительский процесс может связать пару (Taskld, Code) с объектами cout
и сегг своего сыновнего процесса. Это реализуется с помощью функции
pvm_setopt (), которая вызывается перед порождением потомка. Если значение
Taskld равно 0, сообщения попадут ведущему демону pvmd и будут записаны в его
журнал регистрации ошибок. Порожденный процесс может установить значение пе-
ременной Taskld равным 0 или значению, унаследованному от его родителя, или
собственному значению идентификатора Taskld. Это означает, что именно роди-
тельский процесс управляет тем, куда будет записано содержимое объектов cout или
сегг. Порожденная PVM-задача может назначить другие PVM-задачи для получения
Данных, помещенных в объекты cout или сегг. Обычно записью любых важных
Данных в потоки stdout или stdin управляет порождающая задача, а всем осталь-
ным ведает ведущий демон pvmd.
6.5. Резюме
больщ6ЛПОТека PVM, отличающаяся большой гибкостью средств, поддерживает
сРеды П,СТВ° м°Делей параллельного программирования. К достоинствам PVM-
Теров °ТНОСИТСЯ ее способность работать с гетерогенными коллекциями компью-
быст К°!ОрЬ1е МОГУТ состоять из процессоров, отличающихся характеристиками
бибч^°Де,1СТВИЯ’ РазмеРами и архитектурой. Помимо аппаратной совместимости,
библг °ТеКа прекрасно работает со стандартной С++-библиотекой и системной
Шаблоно К°И U^X/Linux. В результате объединения с возможностями С++-
алгоп! ’ сРедств объектно-ориентированного программирования и коллекций
ВаюТся В Мо1ць PVM-среды значительно возрастает. Шаблоны прекрасно вписы-
В ^^^‘Программирование. А для расширения возможностей PVM-среды
244 Глава 6. Объединение возможностей параллельного программирован^
при использовании моделей MIMD (MPMD) можно успешно использовать q
контейнеры и алгоритмы. В главе 13 мы подробнее познакомимся со средСт
PVM-библиотеки и покажем, как ее можно использовать для С++-реализации ВаМи
тегии “классной доски”. Эта стратегия — один из основных способов решения*”^
блем параллельного программирования. ПР°*
ОБРАБОТКА ОШИБОК,
ИСКЛЮЧИТЕЛЬНЫХ
СИТУАЦИЙ
И НАДЕЖНОСТЬ
ПРОГРАММНОГО
ОБЕСПЕЧЕНИЯ
В этой главе...
7.1. Надежность программного обеспечения
7.2. Отказы в программных и аппаратных компонентах
7.3. Определение дефектов в зависимости от спецификаций ПО
7.4. Обработка ошибок или обработка исключительных
ситуаций?
7.5. Надежность ПО: простой план
7.6. Использование объектов отображения для
обработки ошибок
7.7. Механизмы обработки исключительных ситуаций в C++
7.8. Диаграммы событий, логические выражения
и логические схемы
7.9. Резюме
Всегда можно изобрести суперсложные модели, чтобы объяснить множество
исследуемых фактов, но ученый, если он не философ, скорее примет самую
простую теорию, которая согласуется со всеми имеющимися у него данными.
— Алястер Ри (Alastair Rae), Quantum Physics Illusion or Reality
Одна из главных целей разработки и проектирования программного обеспече-
ния — создать программу, которая бы отвечала требованиям пользователя
и работала корректно и надежно. Пользователи требуют от ПО корректно-
сти и надежности, независимо от его конкретного назначения. Использование нена-
дежных программ в любой сфере — финансовой, промышленной, медицинской, науч
ной или военной— может иметь разрушительные последствия. Зависимость людей
и механизмов от ПО на всех уровнях нашего общества вынуждает его создателей еде
лать все возможное, чтобы их детище было надежным, робастным и отказоустойчивым-
Эти требования налагают дополнительную ответственность на разработчиков и пр°еК
тировщиков ПО, которые создают системы, содержащие параллелизм. Программу
с параллелизмом или компоненты, которые выполняются в распределенных средах^^^
держат больше (по сравнению с ПО без параллелизма) программных уровнен-
больше уровней, тем сложнее управлять таким ПО. Чем выше сложность системы,
больше изъянов может остаться в ней невыявленными. А чем больше изъянов в ПО, т
выше вероятность того, что оно откажет, причем в самый неподходящий момент.
Для программ, разбиваемых на параллельно выполняемые или распределение
задачи, характерны дополнительные сложности, которые проявляются в ПР° п
поиска правильного решения, связанного с декомпозицией работ (work brea
structure — WBS). Кроме того, здесь необходимо учитывать проблемы, которые являю
7.1. Надежность программного обеспечения 247
емлемой частью именно сетевых коммуникаций. Помимо проблем коммуника-
йС0Г^ деКомпозиции, не следует забывать о таких “прелестях” синхронизации, как
данных и взаимоблокировка. Параллельное программирование “по определе-
Практически всегда сложнее последовательного, а следовательно, обработка
ЙИ1°б к и исключительных ситуаций для параллельных программ требует больше
° илий (и умственных, и физических, и временных), т.е. “больше” программирова-
УС Интересно отметить, что разработка ПО развивается в направлении приложе-
НИЯ которые требуют параллельного и распределенного программирования. В про-
ектироваНИИ современного ПО распространены Internet- и Intranet-модели. Нынче
становятся нормой (а не исключением) многопроцессорные компьютеры общего на-
значения. Встроенные и промышленные вычислительные устройства становятся все
более высокоорганизованными и мощными. Для серверного развертывания “де-
Лакто” становится стандартом понятие кластера. Мы считаем, что нынешним разра-
ботчикам и проектировщикам ПО не остается ничего другого, как разрабатывать
и проектировать надежные приложения для многопроцессорных и распределенных
сред. И, безусловно, излишне повторять, что требования, предъявляемы к ПО такого
рода, постоянно возрастают как по сложности, так и организации.
Во многих примерах программ этой книги мы не приводим кода обработки оши-
бок и исключительных ситуаций, чтобы не отвлекать внимание читателя от основ-
ной идеи или концепции. Однако важно иметь в виду, что использованные здесь
примеры имеют вводный характер. В действительности объем кода, посвященного
обработке ошибок и исключительных ситуаций в программах, включающих парал-
лелизм или рассчитанных на распределенную среду, довольно значителен. Обра-
ботка ошибок и исключительных ситуаций должна быть составной частью проекта
ПО на каждом этапе его разработки. Мы — сторонники моделирования на основе
раскрытия параллелизма в области проблемы и ее решения. И именно на этапе мо-
делирования следует заниматься разработкой моделей подсистем обработки оши-
бок и исключительных ситуаций. В главе 10 показано, как можно использовать язык
LML (Unified Modeling Language — унифицированный язык моделирования) для
визуализации проектирования систем, требующих параллельных или распределен-
ных методов программирования. Разработка подсистем обработки ошибок и ис-
ключительных ситуаций лишь выиграет от применения средств UML и самого про-
цесса визуализации, который ничем другим заменить нельзя. Следовательно, в ка-
честве исходной цели вам необходимо представить надежность разрабатываемого
с помощью таких инструментов, как UML, диаграммы событий, событийные
им ’ ения’ Диаграммы синхронизации и пр. В этой главе рассматриваются пре-
проектТВЛ РЯДа методов проектирования, которые способствуют визуализации
вкач п°Дсистемы обработки ошибок и исключительных ситуаций. Кроме того,
СЯ вст ОСНОВЫ для РазРа^отки надежного и отказоустойчивого ПО используют-
1ные средства языка C++, содержащие иерархию классов исключений.
^•L Надежность программного обеспечения
Р°ВацИя ь пРограмлшого обеспечения— это вероятность безотказного фут1кциони-
Ь Идеале ^^1ПЬ1°теРн°й программы в течение заданного времени в заданной среде.
Кот0 ВеР°ятность приближается к 100%. Если разработчики хотят создать сис-
Рая будет отличаться безотказной работой, ее ПО должно разрабатываться
248 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
с использованием методов отказоустойчивого программирования. Отказоустойчи
система — это система, которая сохраняет работоспособность в результате устранен****
последствий ошибок ПО. Под ошибкой (fault) понимается программный дефект
рый может привести к отказу в работе некоторой части ПО. В понятие “сбоя в сист
ме программного обеспечения” (failure) мы вкладываем выполнение некоторого кОм
понента ПО, который отклоняется от системных спецификаций. Мы согласнь
с трактовкой ошибок и сбоев, которую предложили Муса (Musa), Панино (lannin
и Окумото (Okumoto) в своей книге Software Reliability'. '
Ошибка — это дефект в программе, который при некоторых условиях приводит
к ее отказу. К отказу могут привести различные совокупности условий, причем эти
условия могут повторяться. Следовательно, ошибка может быть источником не
одного, а нескольких отказов. Ошибка (дефект) — это свойство программы, а не
результат (свойство) ее выполнения или поведения. Именно этот смысл мы вкла-
дываем в понятие термина “bug”. Ошибка ПО — это следствие оплошности, или
недоработки (error), программиста.
Ошибки, которые допускает программист или разработчик ПО, могут возникнуть
из-за неверной интерпретации требований к ПО или некачественного, некорректно-
го или недостаточно полного перевода этих требований в код. Если программист со-
вершает оплошности такого рода, он вносит в программу ошибки, или дефекты. При
выполнении дефектного кода может произойти сбой программы. Ошибки ПО можно
обнаружить только при выполнении кода. Очистить программу от ошибок, а следова-
тельно, и не допустить возможность отказа, позволяет процесс тестирования и отлад-
ки ПО. Обратите внимание на то, что мы используем термины “дефект” и “ошибка”
взаимозаменяемо. Термин “оплошность” мы относим к допускаемым программистом
промахам, которые являются причиной дефектов ПО. Отказоустойчивость — это свой-
ство, которое позволяет некоторой части ПО оставаться в исправном состоянии или
восстанавливать работоспособность после программных сбоев, вызванных ошибка-
ми, внесенными в ПО в результате недоработки программистов.
Одни отказы ПО являются результатом наличия дефектов в программах, другие
же— результатом исключительных условий (необязательно созданными оплошно-
стью программиста), которые могут создаться в оборудовании или используемых про-
граммных продуктах. Например, сетевая карта, поврежденная в результате всплеска
напряжения, может привести соответствующую часть ПО к сбою. Вирус может нару-
шить процесс передачи данных, в результате чего может отказать программа, которая
зависит от этого процесса. Пользователь может нечаянно удалить критические ком
поненты из системы, что неминуемо приведет к ее отказу. Перечисленные выше не
приятности вызываются не из-за дефектов в программе, а создаются в результате ус
ловий, которые мы называем исключительными ситуациями. Исключительная сит)а
ция, или исключение, — это ненормальные условия, или исключительные
обстоятельства, или экстраординарные явления (события), с которыми сталкивае
ПО, в результате чего оно (или некоторая его часть) отказывает. И хотя как дефекть
так и исключения приводят к отказам ПО, важно понимать различие между ними,
скольку для “борьбы” с ними применяются, как правило, различные методы. Нес* ?
ря на то что конечным результатом применения этих методов является надеж
и отказоустойчивое ПО, для обработки исключений и обработки ошибок (дефект0
используются различные способы проектирования и программные конструкции.
7.2. Отказы в программных и аппаратных компонентах 249
7 2 Отказы в программных и аппаратных
компонентах
и проектировании надежного и отказоустойчивого ПО мы должны поставить
создать такое ПО, которое бы продолжало функционировать даже после отказа
ЦеЛЬ пых его компонентов (аппаратных или программных). Если наше ПО претен-
Не на то, чтобы называться отказоустойчивым, оно должно обладать средствами,
ЛУеТ могли бы предусматривать последствия аппаратных или программных оши-
бок По крайней мере наши отказоустойчивые проекты должны обеспечивать не
мгновенное прекращение работы системы, а постепенное сокращение ее возможно-
стей Если наше ПО является отказоустойчивым, то в случае отказа отдельного его
компонента (компонентов) оно должно продолжать функционирование, но на более
низком уровне. Ошибки, которые наше ПО должно обрабатывать, можно разделить
на две категории: программные и аппаратные. На рис. 7.1 показана схема некоторых
аппаратных компонентов, а также уровни ПО, которые могут включать ошибки.
Уровень ошибок пользователя
'Программные сбои на уровне приложения
сбои на уровне библиотеки
..’“'ёЖЙмятй
Сбои'Устройств
ввбда-вывода,т.еЛ
дисководов, карт
специального
.назначения, .
видеоустройств
Специальные случаи
сбоев устройств
ввода-вывода (особенно
для распределенных
приложений),
сбои других устройств
СВЯЗИ '
7,1 * Схема аппаратных компонентов, а также уровней ПО, которые могут
^Держать ошибки
тодь^ ? ! Мы отДелили аппаратные компоненты от программных, поскольку ме-
гРаммньГа6°ТКИ аппаРатных сбоев часто отличаются от методов обработки про-
исходят °Ши^ок‘ Здесь также выделены различные уровни ПО. Некоторые из них
Мую) и ВНе Досягаемости” разработчика (т.е. он не может ими управлять напря-
бок. НаТРеб''ЮТ специального рассмотрения процесса обработки исключений и оши-
прИнцматьПаХ ПРоектиРования» разработки и тестирования ПО обязательно следует
ИЫх “слоях”ВПВНИМаНИе возможность аппаратных сбоев и наличия ошибок в различ-
^Ределенны ^ля пРогРамм’ к°торым присущ параллелизм или состоящих из рас-
компонентов, следует учитывать дополнительные обстоятельства, весьма
250 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
“благоприятные” для возникновения аппаратных сбоев. Например, в распределе
программах используется взаимодействие аппаратных и программных cnHHbIX
Ошибка, “закравшаяся” в компонент, отвечающий за это взаимодействие, может
вести к отказу всей системы. Программы, разработанные для параллельной n
процессоров, могут сбоить, если ожидаемое количество процессоров окажется н TbI
тупным. Даже если средства связи и процессоры прекрасно отработали при загрД°С'
системы, ее отказ возможен в любой момент после начала функционирования^ И е
ключительная ситуация может возникнуть в любом из компонентов оборудов С
и на любом уровне ПО. Кроме того, каждый программный уровень может содержат
дефекты, которые необходимо каким-то образом обрабатывать. На этапе проекти
вания ПО следует рассматривать возможные исключительные ситуации и ошибки
в программах, присущие каждому уровню ПО в отдельности. Ведь варианты восста
новления приложения после возникновения исключительных ситуаций и исправле-
ния ошибок, которые возможны на уровне 2, отличаются от вариантов, применимых
к уровню 3. К сбоям, которые возможны на различных уровнях ПО и в аппаратных
компонентах, следует добавить сбои, характеризующиеся архитектурной областью
локализации, специфической для каждого приложения. Например, на рис. 7.2 пока-
зано, как по мере увеличения дистанции между задачами возрастает уровень сложно-
сти обработки ошибок и исключительных ситуаций.
X
ш
со
о
СЧ
ш
со
О
CL
Ошибки и исключений; возникающие взаимодействии
вьюолняюшихся на .разню 1ных компыст ерах. относящихся
к различным сетям‘(с различными протоколами).
Ошибки и исключения, возникающие при взаимодейсгви» процессов,
выполняющихся на различны* компьютерах, но относадикзя к одной сети
Ошибки и исключения, возникающие при взаимодействии процессов,
выполняющихся на одном компьютере
Ошибки и исключения, возникающиё.при взаимодействии функций
одного процесса (одного адресного пространства)
Ошибки в одном 'потоке -Ошибки в разных потоках
... —.... ..-..—..... ... ...
।
| йедр возникающие в инструкциях одной функции
$
Рис. 7.2. Зависимость увеличения уровня сложности обработки исключительных ситуации
и ошибок от увеличения дистанции между логическим местоположением задач
7.3. Определение дефектов в зависимости от спецификаций ПО 251
Чем больше в программных или аппаратных компонентах дистанция между па-
А о выполняющимися задачами, тем более высокий уровень организации тре-
Р371 для проектирования компонентов обработки исключительных ситуаций
бСбок. Изучив рис. 7.1 и 7.2, можно понять: для того, чтобы спроектировать и раз-
И фотать надежное ПО, необходимо предусмотреть не только, какие возможны ис-
^ючительные ситуации и ошибки, но и где они могут возникнуть.
7.3. Определение дефектов в зависимости
от спецификаций ПО
Спецификация ПО — это своего рода “эталон”, позволяющий определить, имеет ли
данная часть ПО дефекты. Мы не можем оценить корректность программных компо-
нентов без доступа к программным спецификациям. Спецификация ПО содержит опи-
сание и требования, из которых должно быть ясно, что должен делать данный про-
граммный компонент и чего он делать не должен. Общеизвестно, что довольно трудно
написать полные, исчерпывающие и точные спецификации. Спецификации могут
представлять собой формальные документы и требования, составленные конечными
пользователями, аналитиками, специалистами по созданию пользовательского интер-
фейса, специалистами в предметной области и др. Спецификации могут также выглядеть
как множество целей и не жестко определенных задач, устно излагаемых пользователями
проектировщикам и разработчикам ПО. Любое отклонение компонента ПО от его спе-
цификации является дефектом. Чем выше качество спецификации, тем проще выявить
дефекты и понять, где программист сделал ошибки. Если спецификация проекта расплыв-
чата, с плохо определенными элементами и нечетко описанными требованиями, то опре-
деление программных дефектов для такого проекта представляет собой движущуюся
мишень. Если спецификации неоднозначны, то трудно сказать, что дефектно, а что нет.
Точно так же невозможно утверждать, прав ли был разработчик. Туманно определен-
ные спецификации являются причиной так же туманно определяемых ошибок. В таких
условиях создание отказоустойчивого и надежного ПО попросту невозможно.
7.4. Обработка ошибок или обработка
исключительных ситуаций?
Доп^й°^ЩеМ слУчае ошибки ПО (которые являются результатом оплошности или не-
п^г, КИ пРогРаммиста) должны быть обнаружены и исправлены на этапах тести-
РОВаНИЯ- перечисленных в табл. 7.1.
7.1. Типы тестирования, используемые в процессе разработки ПО
Описание
ПО тестируется поэлементно. Под элементом может подра-
зумеваться отдельный программный модуль, коллекция мо-
дулей, функция, процедура, алгоритм, объект, программа
или компонент
^пирования
Б^т°еП1еСПировпние-
МентС1?ировпние Me-
°® (unit testing)
252 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
Тип тестирования
Проверка взаимодейст-
вия и функционирова-
ния компонентов систе-
мы (integration testing)
Регрессивное тестирова-
ние (regression testing)
Испытания в утяже-
ленном режиме
(stress testing)
Эксплуатационные ис-
пытания
(operational testing)
Тестирование специфи-
кации
(specification testing)
Приемочные испытания
(acceptance testing)
Описание
Око^аниета^
Тестируется некоторая совокупность элементов. Элементы ""
объединяются в логические группы, и каждая группа тестир ет
ся как единый блок (элемент). Эти группы могут подвергатьс
одинаковым проверкам. Если группа элементов проходит тест
ее присоединяют к тестируемой совокупности, которая в свою
очередь должна быть протестирована с новым дополнением
Увеличение количества элементов, подлежащих тестированию
должно подчиняться формулам комбинаторики
Программные модули должны повторно тестироваться, если
в них были внесены изменения. Регрессивное тестирование
дает гарантию, что изменение любого компонента не приве-
дет к потере функциональности
Тестирование, которое проводится для компонента или всей
системы при предельных и “запредельных” значениях входных
параметров. Использование граничных условий позволяет опре-
делить, что может произойти с компонентом или системой в не-
штатных ситуациях
Тестирование системы с полной нагрузкой. Для этого исполь-
зуется реальная среда, создающая реальную нагрузку. Этот тип
тестирования также применяется для определения произво-
дительности системы в совершенно незнакомой среде
Компонент проверяется при сравнении с исходными специ-
фикациями. Именно спецификация устанавливает, какие
компоненты включены в систему и какие взаимоотношения
должны быть между ними. Этот этап является частью про-
цесса верификации ПО
Тестирование этого типа выполняется конечным пользовате-
лем модуля, компонента или системы для определения его
(ее) производительности. Этот этап является частью процесса
аттестации ПО
Во время процесса тестирования и отладки программные дефекты должны быть
обнаружены и ликвидированы. Однако исключительные ситуации (исключения) об-
рабатываются во время выполнения программы. Следует различать исключительные
и нежелательные условия. Например, если мы спроектировали программу, которая
будет добавлять в список числа, вводимые пользователем, а пользователь будет вво
дить и числа, и символы, которые не являются числами, то такая ситуация относится
к нежелательной, а не к исключительной. Мы должны проектировать программы, к°
торые были бы робастными, т.е. устойчивыми к ошибкам, предусматривая проверь
корректности входных данных. Ввод данных в программу должен быть организован
таким образом, чтобы пользователь был вынужден вводить данные, которые требую7*
ся нашей программе для надлежащего выполнения. Если, например, спроектирован
ный нами компонент программы сохраняет информацию на внешнем устройстве,
и программа попадает в ситуацию отсутствия свободного пространства на эт
7 4. Обработка ошибок или обработка исключительных ситуаций? 253
ойстве то такие условия работы программы также можно назвать нежелательными,
усг? ^ючительными, или экстраординарными. Исключительные ситуации мы связы-
а не с необычными условиями, а не с нежелательными. Методы обработки исключи-
вшем ситуаций предназначены для непредвиденных обстоятельств. Ситуации же,
ые являются нежелательными, но вполне возможными и потому предсказуемыми,
К°лжны обрабатываться с применением обычной программной логики, например:
•F <входные данные неприемлемы, то>
1Г <повторно запрашиваем входные данные>
е15е<выполняем нужную операцию>
end if
Такая проверка условий — одна из основополагающих граней искусства програм-
мирования. Продемонстрированный стиль программирования позволяет не допус-
тить возникновения многих проблем, но эта модель ситуации не “дотягивает” до оп-
ределения исключительной. Существуют различия между дефектами и исключитель-
ными ситуациями, а также между исключительными ситуациями и нежелательными
условиями. С дефектами справляются путем тестирования и отладки. Нежелательные
условия обрабатываются в рамках обычной программной логики, а исключительные
ситуации — методами обработки исключений. Различия между характеристиками об-
работки ошибок, исключений и нежелательных условий сведены в табл. 7.2.
Таблица 7.2. Различия между характеристиками обработки ошибок, исключений и нежелательных условий
Обработка ошибок Обработка исключительных ситуаций Обработка нежелательных условий
• Логические ошибки об- наруживаются на этапе тестирования и отладки • Корректно работаю- щие программы не со- держат ошибок • Для предупреждения и исправления ошибок используется про- граммная логика Поддерживается нор- Мальный ход выполне- ния программы • Описывает непредвиден- ные условия во время выпол- нения • Корректно написанные программы могут попадать в исключительные ситуации • Для восстановления ра- ботоспособности про- граммы после возникнове- ния исключительных си- туаций используются методы обработки исклю- чений • Нормальный ход выпол- нения программы наруша- ется • Описывает нежела- тельные условия, кото- рые весьма вероятны во время выполнения • Корректно написанные программы могут попадать в нежелательные ситуации • Для исправления неже- лательных условий ис- пользуется программная логика • Делается попытка под- держать нормальный ход выполнения программы
Нащц цель»
**Ий, чтобь ТаК ПОСТРОИТЬ компоненты обработки ошибок и обработки исключе-
ЩйМи п ИХ можно было объединить с другими компонентами, составляю-
г Дельные или распределенные приложения. Эти компоненты должны об-
254 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
ладать средствами идентификации проблем и уведомления о них, а также возмож
стями их корректировки или восстановления работоспособности приложения
восстановлением и корректировкой подразумеваются самые различные способ^
достижения поставленной цели: от предложения пользователю еще раз ввести
ные (с подсказкой, например, их правильного формата) до перезагрузки подсистем
в рамках ПО. Действия по восстановлению и корректировке могут включать обработ
ку файлов, возврат из базы данных, изменение сетевого маршрута, маскирование
процессоров, повторную инициализацию устройств, а для некоторых систем даже за
мену элементов оборудования. Компоненты обработки ошибок и исключительных
ситуаций могут быть выполнены в различных формах: от простых предписаний до
интеллектуальных агентов, единственное назначение которых состоит в предвиде-
нии ситуаций сбоя и их предотвращении. Компонентам обработки ошибок и исклю-
чений в ответственных участках ПО уделяется значительное внимание. Архитектура
упрощенного компонента обработки ошибок представлена на рис. 7.3.
УПРОЩЕННЫЙ КОМПОНЕНТ ОБРАБОТКИ ОШИБОК
Рис. 7.3. Архитектура упрощенного компонента обработки ошибок
Компонент 1 на рис. 7.3— это простой компонент отображения (шар), который
содержит список номеров ошибок и их описания. Компонент 2 содержит объект, ко-
торый преобразует номера ошибок в адреса переходов, функций или подсистем. По
номеру ошибки компонент 2 определяет направление перехода. Компонент 3 преоб-
разует номера ошибок в иерархическую структуру отчетов и логику отчетов. Иерар
хическая структура отчетов содержит данные о том, кого (или что) необходимо уве
домить об ошибке. Логика отчетов определяет, что должно включать это уведомлю
ние. Компонент 4 содержит два объекта отображения. Первый преобразует номер3
ошибок в объекты, назначение которых — скорректировать некоторые ситуации сбоя
(условия). Второй преобразует номера ошибок в объекты, которые возвращают сис
тему7 в стабильное или хотя бы частично стабильное состояние. Упрощенный комп°
нент обработки ошибок, показанный на рис. 7.3, можно применить к ПО любого ра
мера и формы. Характер использования компонентов обработки ошибок и исклЮ
тельных ситуаций определяется требуемой степенью надежности ПО.
7.5. Надежность ПО: простой план 255
7 5 Надежность ПО: простой план
мним, ЧТО мы различаем ошибочные и неудобные (нежелательные) условия.
^а. * или нежелательные условия должны обрабатываться обычной программ-
«Хгикой. Ошибки (дефекты) требуют специального программирования. В книге
ноИ ' па Язык программирования C++ (1997) автор приводит четыре основных аль-
С^нативных действия, которые может предпринять программа при обнаружении
теР А ' По мнению Страуструпа, программа, выявив проблему, которую невозможно
°б аботать логически, должна реализовать один из следующих вариантов поведения.
Вариант 1.
Вариант 2.
Вариант 3.
Вариант 4.
Завершить программу.
Возвратить значение, обозначающее “ошибку”.
Возвратить значение, обозначающее нормальное завершение, и оста-
вить программу в состоянии с необработанной ошибкой.
Вызвать функцию, предназначенную для вызова в случае ошибки.
Эти четыре альтернативы можно “примерить” к отношениям типа “изготовитель-
потребитель”. Изготовитель — это обычно некоторый участок программного кода,
который реализует библиотечную функцию, класс, библиотеку классов или оболочку
приложения. В качестве потребителя можно представить участок программного кода,
который вызывает библиотечную функцию, класс, библиотеку классов или оболочку
приложения. Потребитель делает запрос. Изготовитель при попытке выполнить за-
прос обнаруживает ошибку, и его дальнейшее поведение должно быть направлено на
реализацию одного из перечисленных выше четырех альтернативных вариантов.
Однако проблема состоит в том, что ни один из них не универсален.
Очевидно, что завершать программу при каждом обнаружении ошибки попросту
неприемлемо. Здесь мы согласны со Страуструпом. В таких случаях следует поступать
более изобретательно. Что касается варианта 2, то примитивный возврат значения
ошибки действительно может помочь в некоторых ситуациях, но далеко не во всех.
Не каждое возвращаемое значение может интерпретироваться как успешное или не-
удачное. Например, если значение, возвращаемое некоторой функцией, имеет веще-
ственный тип, и область определения функции включает как отрицательные, так и
положительные значения, то какое тогда значение функции можно использовать для
представления ошибки? Другими словами, это не всегда возможно. С нашей точки
обознЯ ВаРиант также неприемлем. Ведь если “изготовитель” возвращает значение,
Жив ак>щее нормальное завершение, “потребитель” продолжит работу, предполо-
талось70 СГО 3апРос был выполнен, а это может вызвать еще большие проблемы. Ос-
Дении расс*1ОТРеть вариант 4. Он требует более внимательного подхода при обсуж-
°оработки как ошибок, так и исключительных ситуаций.
•5.1. План А: модель возобновления, план Б:
модель завершения
HbIx плана На^ЖеНИИ оши^ки или исключительной ситуации существует два основ-
Вать Условия РеаЛИЗации варианта 4. Первый план состоит в попытке скорректиро-
^рой была ^°ТОРЬ1е вызвали сбой, а затем возобновить выполнение с точки, в ко-
аружена ошибка или исключительная ситуация. Этот подход называ-
256 Глава 7. Обработка ошибок, исключительных ситуаций и надежность.
ется возобновлением. Второй план состоит в признании (подтверждении) ошибки
исключительной ситуации и постепенном выходе из подсистемы или подпрограм^**
в которой возникла проблема. Постепенный выход реализуется путем закрытия coq*
ветствующих файлов, разрушения требуемых объектов, регистрации (если это
можно) ошибки, освобождения соответствующей памяти и обработки устройст
которые этого требуют. Такой подход называется завершением, и его не следует путат^
с понятием резкого выхода из программы. Оба плана вполне действенны и в различ
ных ситуациях оказываются весьма полезными. Прежде чем обсуждать способы реа
лизации моделей возобновления и завершения, имеет смысл рассмотреть средств
обработки ошибок и исключительных ситуаций, которые предусмотрены в языке C++
7.6. Использование объектов отображения
для обработки ошибок
Компонент отображения (шар) можно использовать как составную часть страте-
гии обработки ошибок или обработки исключений. Назначение отображения — свя-
зать один элемент с другим. Например, отображение можно использовать для связи
номеров ошибок с их описаниями:
//. . .
mapcint, string> ErrorTable;
ErrorTable[123] = "Деление на нуль";
ErrorTable[4556] = "Отсутствие тонального вызова";
//. . .
Здесь число 123 связано с описанием "Деление на нуль". Тогда при выполнении
инструкции
cout « ErrorTable[123] « endl;
в объект выходного потока cout будет записана строка " Деление на нуль".
Помимо отображения встроенных типов данных, можно также отображать
(т.е. находить соответствие) определенные пользователем объекты, содержащие
данные встроенных типов. Вместо того, чтобы некоторое отображение просто воз-
вращало описательное сообщение для каждого номера ошибки, можно позаботиться
о том, чтобы оно возвращало объект с соответствующим номером ошибки. Этот объект
может иметь методы, предназначенные для коррекции ошибок, составления отчетов
об ошибках и их регистрации (записи ошибок в системный журнал). Например, пРеД
положим, что у нас есть следующий определенный пользователем объект:
defect_response:
class defect_response{
protected:
//. . .
int DefectNo;
string Explanation;
public:
bool operator<(defect_response &X);
virtual int doSomething(void);
string explanation(void);
7.6. Использование объектов отображения для обработки ошибок 257
};
Теперь мы можем внести в отображение объекты типа def ect_response:
*<int,defect_reponse *> ErrorTable;
j3fect_response * Response;
npsponse = new defect_response;
ErrorTable [123] = Response;
//•••
Этот код связывает объект отклика (на ошибку) с номером ошибки 123. Благодаря
полиморфизму7 объект отображения может содержать указатели на любой объект ти-
па defect—response или любой объект, который выведен из него. Предположим,
что у нас есть следующий класс:
class exception—response : public defect—response{
//. . -
public:
int doSomething (void)
//. . .
};
Этот класс exception—response является потомком класса defect—response, по-
этому7 мы можем внести в объект ErrorTable указатели на тип
exception_response.
mapcint,defect—reponse *> ErrorTable;
defect—response * Response;
exception-response *Response2;
Response = new defect_response;
Respone2 = new exception—response;
ErrorTable[123] = Response; // Хранит объект типа
// defect_response.
ErrorTable[456] = Response2; // Хранит объект типа
// exception_response.
то определение означает, что объект типа ErrorTable может связывать с соот-
ветствующим номером ошибки различные объекты (с различными описаниями и ха-
Г^тиками). Следовательно, при вызове метода doSomething () объект
^Solver будет выполнять различные наборы инструкций:
defect гоо
?Toblp’‘response *₽roblemSolver;
Probl^o°Yler = ErrorTable[123] ;
ProblGT^°lver“>doSomething () •
Рг°Ь1Лс ler = ErrorTable [456] ;
//... IUS°vler->doSomething () ;
^eCMOTpo
defectr на To что переменная ProblemSolver представляет собой указатель на объект
Па е "resPonse, полиморфизм позволяет этой переменной указывать на объект ти-
^tlOn—response или любой другой объект, выведенный из класса
3efect'~resPonse. Поскольку метод doSomething () объявлен виртуальным в классе
—response, компилятор может выполнить динамическое связывание. Это дает
258 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
гарантию корректного вызова метода doSomething () при выполнении приложе
Именно динамическое связывание позволяет каждому потомку |0.НИя’
def ect_response определить собственный метод doSomething (). Нам нужно Чт J*
вызов метода doSomething () зависел от того, ссылка на какой именно потомок клас 1
def ect_response используется при этом. Рассматриваемый метод позволяет связыват^
номера ошибок с объектами, имеющими отношение к обработке определенных сбойн
ситуаций. С помощью этого метода можно значительно упростить код обработки ошибок
В листинге 7.1, например, показано, как значение, возвращаемое некоторой функции
можно использовать для выбора соответствующего объекта обработки ошибок.
// Листинг 7.1. Использование значений, возвращаемых
// функцией, для определения корректного
// объекта типа ErrorHandler
void importantOperation(void)
{
//. . .
Result = reliableoperation();
if(Result != Success){
defect.response *Solver;
Solver = ErrorTable[Result];
Solver->doSomething();
}
else{
// Продолжение обработки.
}
// . . .
}
В листинге 7.1 обратите внимание на то, что мы не используем последователь-
ность if- или case-инструкций. Объект отображения позволяет получить непосред-
ственный доступ к желаемому объекту обработки ошибок по индексу. Конкретный
метод doSomething (), вызываемый в листинге 7.1, зависит от значения переменной
Result. Безусловно, данный пример демонстрирует упрощенную схему обработки
ошибочных ситуаций. Так, например, в листинге 7.1 не показано, кто (или что) отве-
чает за управление динамически выделяемой памятью для объектов, хранимых в ото-
бражении ErrorTable. Кроме того, здесь не учтено, что функции
reliableOperation () и doSomething () могут выполниться неудачно. Поэтому ре‘
альный код будет, конечно же, несколько сложнее, чем тот, что приведен в листин-
ге 7.1. Но все же этот пример ясно показывает, как одним “ударом” обработать мно
жество ситуаций сбоя. Мы можем пойти еще дальше. В листинге 7.1 предполагается,
что все возможные ошибки будут охвачены объектами типа ErrorTable. Все
ErrorTable-объекты представляют собой либо объекты типа def ect_response, ли
бо объекты, выведенные из класса defect_response. А что, если у нас будет не
сколько семейств классов обработки ошибок? В листинге 7.2 показано, как с помоШь1°
шаблонов сделать функцию importantOperation () более общей.
// Листинг 7.2. Использование шаблона в функции
// importantOperation()
template<class Т,class U> int importantOperation(void)
{
T ErrorTable;
7.7. Механизмы обработки исключительных ситуаций в C++ 259
ц solver;
/ZTver = ErrorTable[Result];
Solver->doSornething (} 1
//•••
};
В листинге 7.2 тип ErrorTable не ограничен объектами класса
t resp°nse- Этот метод позволяет упростить код обработки ошибок и повы-
Й его гибкость. Здесь демонстрируется использование полиморфизма как по вер-
тикали так и по горизонтали, что чрезвычайно важно для SPMD- и MPMD-программ.
Как упростить программы, реализующие параллелизм с помощью шаблонов и поли-
Аизма, описано в главе 9. Использование объектов отображения и объектов об-
ботки ошибок — это важная составляющая повышения надежности ПО. Помимо
методов обработки ошибок, мы можем также воспользоваться преимуществами меха-
низма обработки исключительных ситуаций и классов исключений, предусмотренных
в C++ (этому посвящен следующий раздел).
7.7. Механизмы обработки исключительных
ситуаций в C++
В идеале во время тестирования и отладки должны быть ликвидированы все дефек-
ты программы или по крайней мере максимально возможное их количество. Кроме то-
го, следует обработать нежелательные и неудобные условия с использованием обычной
программной логики. После устранения всех (или почти всех) дефектов и обработки
нежелательных и неудобных условий все остальные “неприятности” попадают в разряд
исключительных ситуаций. Обработка исключительных ситуаций в C++ поддерживает-
ся с помощью трех ключевых слов: try, throw и catch. Любой код, сталкивающийся
с исключительной ситуацией, с которой он не в силах справиться самостоятельно, гене-
рирует исключение “в надежде” на то, что с ней совладает некоторый другой обработчик
(расположенный где-то в другом месте программы) (Б. Страуструп, Язык программиро-
вания C++, 1997). Для генерирования объекта некоторого специального типа (типа
исключения) используется ключевое слово throw. При этом происходит передача
Управления обработчику исключения, который предназначен для обработки объектов
пого типа. Для идентификации обработчиков, предназначенных для перехвата
ектов исключений, используется ключевое слово catch. Рассмотрим пример.
importantOperation
// ®XecuteIlnPortCode ()
i °зникает исключительная ситуация.
t1P°ssikle_condition Impossiblecondition;
II °w Impossiblecondition;
{ h (imPossible—condition &E)
Выполнение действий, связанный с объектом Е.
260 Глава 7. Обработка ошибок, исключительных ситуаций и надежность.
Функция importantOperation () пытается выполнить свою работу и сталкива
ся с необычными условиями, с которыми она не в состоянии справиться. В нащем
примере она создает объект типа impossible_condition и использует ключевое
слово throw для генерирования этого объекта. Блок кода, в котором используется
ключевое слово catch, предназначен для перехвата объектов типа
impossible_condition. Этот блок кода называется обработчиком исключений. Обра
ботчики исключений связаны с блоками кода, помещенными в try-выражения. На
значение try-блоков — обозначить область, в которой возможно возникновение ис-
ключительной ситуации. Блок catch должен сразу же следовать за соответствующим
try-блоком или другим catch-блоком. Вот пример:
try{
//...
importantOperation()
//. . .
}
catch(impossible_condition &E)
{
// Выполнение действий, связанных с объектом Е.
// . . .
}
Здесь при выполнении функции importantOperation () возможно возникновение
условий, с которыми она не в состоянии справиться. В этом случае функция сгенери-
рует исключение, в результате чего управление будет передано первому обработчику,
который принимает объект исключений типа impossible_condition. Этот обра-
ботчик либо сам справится с этой исключительной ситуацией, либо сгенерирует ис-
ключение, с которым придется иметь дело другому обработчику исключений. Объекты,
генерируемые при исключительных ситуациях, могут быть определены пользователем,
причем они могут просто содержать коды ошибок или сообщения об ошибках, которые
способны помочь обработчику исключений выполнить его работу. Если бы мы исполь-
зовали объекты, подобные объектам типа except ion_response из листингов 7.1
и 7.2, то обработчик исключений мог бы применить их для решения проблемы либо
для восстановления работоспособного состояния программы. Для создания объектов
исключений можно также использовать встроенные С++-классы исключений.
7.7.1. Классы исключений
Стандартная библиотека классов C++ содержит девять классов исключений, разДе
ленных на две основные группы (группа динамических ошибок и группа логических
ошибок), которые приведены в табл. 7.3. Группа динамических ошибок представл
ошибки, которые трудно предотвратить. В группу логических ошибок входят оши
которые “теоретически предотвратимы”.
7.7. Механизмы обработки исключительных ситуаций в C++ 261
7.3. Классы динамических и логических ошибок
Классы динамических ошибок
Классы логических ошибок
range_error
underflow_error
overflow—error
domain_error
invalid_argument
length—error
out_of_range
7 7.1.1. Классы runtime_error
На рис. 7.4 показана схема отношений между классами для семейства классов
runtime error. Это семейство выведено из класса exception. Из класса
runtime_error выведено три класса: range_error, overf low_error
и underflow^error, которые сообщают об ошибках промежуточных вычислений
(об ошибках выхода за границы диапазона, переполнения и потери значимости). По-
томки класса runtime_error наследуют основное поведение от своего предка, класса
exception (имеется в виду метод what (), оператор присваивания operator= ()
и конструкторы класса обработки исключений).
Рис. 7.4. Схема отношений между классами для
семейства классов runtime_error
Каждый класс обеспечивает определенный диапазон наследуемых функций, кото-
рыми программист может воспользоваться для конкретной программы. Например,
классы defect_response и exception_response, созданные в листингах 7.1 и 7.2,
можно вывести как из класса runtime—error, так и из класса logic_error. Но сначала
ге Тз Н° РассмотРеть Работу базовых классов исключений без специализации. В листин-
показано, как можно сгенерировать объекты классов exception и logic_error.
// Листинг 7.3. Генерирование объекта класса exception и
объекта класса logic_error
exception X;
| ^ГОУГ(Х) ;
{ h(c°nst exception &X)
> C°Ut X.whatf) « endl;
262 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
try{
logic—error Logic("Логическая ошибка");
throw(Logic);
}
catch(const exception &X)
{
cout « X.whatO « endl;
}
Объекты базового класса exception обладают лишь конструкторами, Деструктора
ми, средствами присваивания, копирования и простейшего вывода отчетной информа
ции. При сбое они не способны его скорректировать. Здесь можно рассчитывать лишь
на вывод сообщения об ошибке, возвращаемого методом what () классов исключений. Это
сообщение будет определяться строкой, переданной конструктору для объекта класса
logic_error. В листинге 7.3 переданная конструктору строка "Логическая ошибка"
будет возвращена методом what () в catch-блоке и выведена в виде сообщения.
7.7.1.2. Классы logic_error
Семейство классов logic_error выведено из класса exception. И в самом деле,
большинство функций классов этого семейства также унаследовано от класса
exception. Класс exception содержит метод what (), используемый для уведомле-
ния пользователя о возникшей ошибочной ситуации. Каждый класс logic_error-
семейства содержит конструктор, используемый для привязки сообщения, специфи-
ческого для данного конкретного класса. Схема отношений между классами для се-
мейства logic_error показана на рис. 7.5.
Рис. 7.5. Схема отношений между классами для семейства классов
logic—error
Подобно классам семейства runtime_error эти классы также предназначены для
последующей специализации. Если пользователь не расширит их функциональность,
они не смогут сделать ничего, кроме как уведомить об ошибке и ее типе. Упомянуты^
выше девять классов исключений общего назначения не обеспечивают никаких ДеИ
ствий по корректировке ситуации или обработке ошибок.
7.7.1.3. Выведение новых классов исключений
Классы исключений можно использовать как есть, т.е. просто для вывода coO^IIfI
ний с описанием происшедших ошибок. Но в качестве метода обработки исключ^^
такой подход практически бесполезен. Просто знать о возникновении исключу '
ной ситуации — не слишком большой шаг на пути повышения надежности ПО-
ная польза иерархии классов исключений состоит в обеспечении ими архитектур
7.7. Механизмы обработки исключительных ситуаций в C++ 263
пог для проектировщика и разработчика. Классы исключений предусматри-
картЫ сНоВНь1е типы ошибок, которые разработчик может уточнить. Многие исклю-
ва.к>т ° ситуации, которые возникают в среде выполнения, можно было бы отне-
ЧИТе категориям, “охватываемым” семействами классов logic_error или
стИ . error. В качестве примера возьмем класс runtime—error и продемонст-
можно “сузить” его специализацию. Класс runtime—error является по-
рируем, кдасса exception. Специализацию класса можно определить с помощью
механизма наследования. Вот пример:
file access—exception : public runtime—error{
class —
protected:
//...
int ErrorNumber ;
string DetailedExplanation;
string FileName;
//...
public:
virtual int takeCorrectiveAction(void)
string detailedExplanation(void);
};
Здесь класс file_access_exception наследует класс runtime—error и получает
специализацию путем добавления нескольких членов данных и функций-членов. В ча-
стности, добавляется метод takeCorrectiveAction (). Этот метод можно использо-
вать в качестве вспомогательного средства, с помощью которого обработчик исклю-
чений мог бы выполнять работу по коррекции ситуации и восстановлению работо-
способности программы. Объект класса file_access_exception “знает”, как
идентифицировать взаимоблокировку и как ее прекратить. Кроме того, он содержит
специализированную логику, предназначенную для борьбы с вирусами, которые могут
разрушить файлы, а также специальные средства на случай неожиданного прерыва-
ния процесса передачи файлов. Мы можем использовать объекты класса
file—access—exception вместе со средствами генерирования, перехвата и обра-
ботки исключений, предусмотренными в языке C++. Рассмотрим пример.
try{
//. . .
fileProcessingOperation() ;
}
catch(file__aCcess_exception &E)
cerr « E.whatO « endl;
E fr,<< E• detailedExplanation () « endl;
// 0 C°rreCtiveActi°n();
/Работник выполняет дополнительные действия
по корректировке ситуации.
Это
°б‘ьектаАМеТ°Д позволяет создать объекты отображения ExceptionTable, подобные
^Ключ М °т°бражения ErrorTable из листингов 7.1 и 7.2. При этом код обработчика
НогополиИИ М°ЖНО УпР°стить за счет использования вертикального и горизонталь-
264 Глава 7. Обработка ошибок, исключительных ситуаций и надежность.
7.7.1.4. Защита классов исключений от исключительных ситуаций
Объекты исключений генерируются в случае, когда некоторый программный
понент сталкивается с аномалией программного или аппаратного характера. Одц
следует отметить, что объекты исключений сами не должны генерировать исклк^ч °
ний. Ведь если окажется, что обработка одной исключительной ситуации слищк
сложна и потенциально может вызвать возникновение другой исключительн °
ситуации, то схему такой обработки необходимо пересмотреть, упростив ее везде где
только это возможно. Механизм обработки исключительных ситуаций неоправдан
усложняется именно тогда, когда код обработчика может генерировать исключения
Именно поэтому большинство методов в классах исключений содержат пустые спе-
цификации throw-инструкций.
// Объявление класса исключения.
class exception {
public:
exception() throw() {}
exception(const exception^) throw() {}
exception^ operator=(const exception&) throw()
{return *this;}
virtual -exception() throw() {}
virtual const char* what () const throwO;
};
Обратите внимание на отсутствие аргументов в объявлениях throw () -методов. Пус-
тые аргументы означают, что данный метод не может сгенерировать исключение. Ес-
ли он попытается это сделать, во время компиляции будет выдано сообщение об
ошибке. Если базовый класс не может сгенерировать исключение, то соответствую-
щий метод в любом производном классе также не сделает этого.
7.8. Диаграммы событий, логические выражения
и логические схемы
S = (АС + FBH + DE)
S = Успешное завершение программы
Рис. 7.6. Простая диаграмма событий
Обработку исключительных ситуаций необходимо использовать в качестве
“последней линии обороны”, поскольку ее механизм в корне меняет естественную пере-
дачу управления в программе. Существуют схемы, которые пытаются замаскировать
этот факт, но эти схемы обычно не характеризуются гибкостью, достаточной для про
грамм, реализующих методы параллелизма или раС
пределения. В подавляющем большинстве ситуа
ций, в которых есть соблазн использовать обработ
чики, перехватывающие абсолютно все исключе
ния, программную логику7 можно сделать более
ошибкоустойчивой с помощью ее усовершенство-
вания или жесткой обработки ошибок. Для облег
чения идентификации компонентов системы, ^от
рые критичны для приемлемого завершения
часто используются диаграммы событий. Диагр^
событий помогают понять, какие компоненты
7 8 Диаграммы событий, логические выражения и логические схемы 265
не опасны (и их можно не принимать во внимание), а какие могут привести
’ системы. В некоторых приложениях отказ одного компонента необязательно
к отказу тказу Всей системы. Для обеспечения безотказной работы системы в тех
ппиводит к 7
пг* когда отказ одного компонента таки приводит к отказу системы в целом, мето-
^^Т^аботки исключений можно использовать в сочетании с методами обработки
дЫ бок Пример простой диаграммы событий показан на рис. 7.6.
°Ш Мы используем диаграммы событий для построения схемы действия обработчика ис-
читечьных ситуаций. На рис. 7.6 схематично изображена система, состоящая из
10110 задач, помеченных буквами А, В, С, D, Е, F и Н. Обратите внимание на то, что
каждая метка (обозначающая задачу) расположена над переключателем. Если пере-
ключатели закрыты, компонент функционирует, в противном случае — нет. Крайняя
точка слева представляет начало, а крайняя точка справа — конец выполнения. Для
успешного завершения программы необходимо найти путь через действующие компо-
ненты. Попробуем продемонстрировать, как применить эту диаграмму к нашему случаю
обработки исключений. Предположим, что мы начинаем программу с выполнения за-
дачи А. Чтобы успешно завершить программу, необходимо корректно решить обе зада-
чи А и С. На языке диаграммы это означает, что переключатели А и С должны быть за-
крыты. На нашей диаграмме событий переключатели А и С находятся на одной ветви,
что свидетельствует об их параллельном выполнении. Если произойдет отказ в любой
из этих задач (А или С), будет сгенерировано исключение. Обработчик исключений мог
бы снова начать выполнение задач А и С. Однако анализ нашей диаграммы событий по-
казывает, что завершение всей программы будет успешным, если успешным будет вы-
полнение либо ветви АС, либо ветви DE, либо ветви FBH. Поэтому мы проектируем наш
обработчик исключений таким образом, чтобы он выполнял один из альтернативных
наборов компонентов (например, DE или FBH). Наборы компонентов (AC, DE и FBH)
связаны между собой отношением ИЛИ. Это значит, что к успешному завершению
программы приведет успешное выполнение любого набора параллельно выполняе-
мых компонентов. Таким образом, простая диаграмма событий (см. рис. 7.6) позволя-
ет понять, как следует построить обработчик исключений. Выражение
S = (АС + DE + FBH)
часто называют логическим выражением, или булевым. Это выражение означает, что
Для пребывания системы в устойчивом состоянии (т.е. ее надежной работы) необхо-
димо успешное выполнение одной из следующих групп задач: (А и С) или (D и Е) или
и В и Н). По диаграмме событий нетрудно также понять, какие комбинации отка-
компонентов могут привести к отказу системы. Например, если откажут только
поненты Е и F, то система успешно отработает, если при этом “не подведут” ком-
. НТЫ И С' Н° если бы дали сбой компоненты A, D и Н, то систему в этом случае
очень1ЧеГ° бЫ Не спасло от отказа. Диаграмма событий и логическое выражение — это
Понент107163^16 сРедства для описания параллельных зависимых и независимых ком-
туаций Н 3 ТаКЖе для построения схемы действия обработчика исключительных си-
следпп апРимер, используя диаграмму событий (см. рис. 7.6), мы можем наметить
ш подход к обработке исключений для нашего примера:
try{
j start<task A and В)
erious_condition &Е){
266 Глава 7. Обработка ошибок, исключительных ситуаций и надежность
try{
if(!(А && В)){
start(F and В and Н)
}
}
catch(mysterious_condition &Е){
start(D and E)
}
};
Этот вид стратегии призван улучшить надежность системы. Следует также отме
тить, что параллельно выполняемые программные компоненты и альтернативные
варианты для планирования безотказной работы системы можно отобразить с помо-
щью традиционной логической схемы, показанной на рис. 7.7.
Успешное
функционирование
системы
Рис. 7.7. Логическая диаграмма, отображающая три И-схемы, объединяемые
с помощью ИЛИ-схемы, для успешного завершения работы системы
Итак, на рис. 7.7 показано три И-схемы, объединяемые на основе ИЛИ-отношений
для получения результата S (который означает успешное завершение работы систе-
мы). Диаграмма событий (см. рис. 7.6) и логическая схема (см. рис. 7.7) — это примеры
простых методов, которые можно использовать для визуализации критических путей
(ветвей) и критических компонентов в некоторой части ПО. После идентификации
критических путей и компонентов разработчик должен предусмотреть ответные дей-
ствия, которые должна выполнить система в случае, если откажет любой из критиче-
ских компонентов. Если при этом используется модель завершения, то обработчик
исключений не делает попытку возобновить выполнение ПО с точки, в которой воз-
никла исключительная ситуация. Вместо этого осуществляется выход из функции или
процедуры, в которой произошло исключение, и предпринимаются действия по пе-
реводу системы в стабильное (насколько это возможно) состояние. Но если использу
ется модель возобновления, то корректируются условия, создавшие аномалию, и про
грамма возобновляется с точки, в которой возникла исключительная ситуация. Важно
отметить, что при реализации модели возобновления возможны определенные труД
ности. Например, предположим, что наш код содержит следующую последователь
ность вложенных вызовов процедур:
try{
А вызывает В
В вызывает С
С вызывает D
D вызывает Е
Е сталкивается с аномалией, с которой
не может справиться
7 8 Диаграммы событий, логические выражения и логические схемы 267
catch (exception Q)
{
)
Если в процедуре Е возникла аномалия и было сгенерировано исключение, то воз-
ожна проблема со стеком вызовов. Нужно также решить вопрос с разрушением объ-
ктов и проблему “подвешенных” значений, возвращаемых процедурами. Подумайте,
что произойдет, если процедуры С и D являются рекурсивными? Даже если мы от-
оектируем условие, вызвавшее исключение в процедуре Е, то как вернуть про-
амму в состояние, в котором она пребывала непосредственно перед выбросом ис-
ключения? А ведь мы должны сохранить информацию в стеке, таблицы создания
и разрушения объектов, таблицы прерываний и пр. Это потребует больших затрат
и обеспечения сложного взаимодействия между вызывающими и вызываемыми сто-
ронами. Все вышесказанное обозначило лишь поверхностный слой трудностей. Из-за
сложности реализации модели возобновления и благодаря тому факту, что разработка
больших систем может обойтись без нее, для C++ была выбрана модель завершения.
В книге [44] Страуструп дает полное обоснование того, почему комитет ANSI в конце
концов выбрал для механизма обработки исключений модель завершения. Но если,
несмотря на то что модель возобновления действительно сопряжена с большими
трудностями, надежность и бесперебойность ПО являются критичными факторами,
то для реализации этой модели все же имеет смысл приложить соответствующие уси-
лия. При этом стоит иметь в виду, что С++-средства обработки исключений можно ис-
пользовать и для реализации модели возобновления.
7.9. Резюме
Создание надежного ПО — серьезное занятие. К вопросам обработки исключи-
тельных ситуаций и исправления ошибок следует подходить с особой ответственно-
стью. Тщательное тестирование и отладка каждого компонента ПО должны быть ос-
новными средствами защиты от программных дефектов. Обработку исключений не-
обходимо внести в систему или подсистему ПО после того, как оно прошло этап
строжайшего тестирования. Механизм генерирования исключений не следует ис-
пользовать в качестве общего правила для обработки ошибок, поскольку он нарушает
1чныи ход выполнения программы. К средствам генерирования исключений сле-
^ет прибегать только после того, как будут исчерпаны все остальные меры. Про-
Е ♦ * ист, который планирует проектировать более полные и полезные (с его точки
я) классы исключений, должен использовать стандартные классы обработки ис-
Циали ИИ В Качестве архитектурных “дорожных карт”. Стандартные классы, не спе-
Можно Р°Ваннь1е с помощью наследования, могут лишь уведомлять об ошибках.
Рующим"^ б°лее полезные классы исключений, которые бы обладали корректи-
ВерШещИ ФУНКЦИЯМИ и большей информативностью. В общем случае, как модель за-
мы Обе^ ТаК И модель возобновления позволяют продолжать выполнение програм-
обнапх ЭТИ Модели предлагают альтернативу простому прерыванию программы при
сИтуап ° ИИ ОШи^ки- Более полное рассмотрение темы обработки исключительных
и Можно найти в работе [44].
РАСПРЕДЕЛЕННОЕ
ОБЪЕКТНО-
ОРИЕНТИРОВАННОЕ
ПРОГРАММИРОВАНИЕ
В C++
В этой главе...
8.1. Декомпозиция задачи и инкапсуляция ее решения
8.2. Доступ к объектам из других адресных пространств
8.3. Анатомия базовой CORBA-программы потребителя
8.4. Анатомия базовой CORBA-программы изготовителя
8.5. Базовый проект CORBA-приложения
8.6. Служба имен
8.7. Подробнее об объектных адаптерах
8.8. Хранилища реализаций и интерфейсов
8.9. Простые распределенные Web-службы, использующие
CORBA-спецификацию
8.10. Маклерская служба
8.11. Парадигма “клиент-сервер”
8.12. Резюме
\3J_EJ3J
Итак, основное различие между человеком и андроидом состоит в том, что
человек приходит со своим собственным “я”, чего нельзя сказать о роботе.
— Кэри де Бессонет(Сагу G deBessonet), Towards A Sentential ‘Reality’ for the
Android
Распределенные объекты — это объекты, которые являются частью одного прило-
жения, но размещены в различных адресных пространствах. Адресные простран-
ства могут относиться к одному или различным компьютерам, связанным сетью
другими средствами коммуникации. Объекты, включенные в приложение, могли
ггь изначально нацелены на совместную работу или разрабатываться различными от-
делами, подразделениями, компаниями или организациями в различное время и с раз-
ными целями. В категорию распределенных объектно-ориентированных приложений
Могут попадать приложения из большого диапазона: от одноразовой собранной совме-
стными усилиями коллекции несвязанных объектов до мульти-приложения,
0бъе °ВозРастные” объекты которого разбросаны по сети Internet. Местоположение
п ов м°жет быть самым разнообразным: intranet (корпоративная локальная сеть
и енной надежности с ограниченным доступом, использующая сетевые стандарты
(ЭКсСеТеВые программно-аппаратные средства, аналогичные Internet), extranet
вРоцщ}^еТЬ^ объединение корпоративных сетей различных компаний, взаимодейст-
предел ДР'Т С ДРУГОМ через Internet) и Internet. Согласно большинству описаний рас-
НапримННЫХ °^ъектов» °ни (объекты) могут быть реализованы в различных языках,
ролей^В^ С++’ Java’ Eiffel и Smalltalk. Распределенные объекты могут играть множество
• одних ситуациях такой объект (или коллекция объектов) используется в каче-
еРВера, который способен обеспечить услуги, например, по доступу к базе данных,
270 Глава 8. Распределенное объектно-ориентированное программирование
по обработке данных или их передаче. В других ситуациях объекты играют роль кли
тов. Распределенные объекты можно использовать в таких объединенных моделях
шения проблем, как “классная доска” и мультиагентные системы. Помимо объедин^
ных моделей, распределенные объекты могут быть полезны для реализации таких па
дигм параллельного программирования, как SPMD и MPMD. Объектам однор0
приложения не требуется специального протокола для связи между собой. КоммуниКа
ция достигается за счет обычного вызова методов, передачи параметров и использова
ния глобальных переменных. Но, поскольку распределенные объекты расположены
в различных адресных пространствах, здесь не обойтись без методов межпроцессного
взаимодействия и во многих случаях необходимо сетевое программирование.
Необходимость создания распределенных приложений обусловлена разны-
ми причинами.
• Необходимые ресурсы (например, базы данных, специализированные процес-
соры, модемы, принтеры и т.п.) расположены на различных компьютерах.
Клиентские объекты (объекты, формирующие запрос на обслуживание) взаи-
модействуют с серверными объектами (объектами, реагирующими на запрос
обслуживания) для получения доступа к этим ресурсам.
• Для выполнения некоторой важной работы или решения насущной проблемы
необходимо скооперировать объекты, различающиеся временем разработки,
разработчиками и местоположением.
• Агенты, реализованные как объекты, отличающиеся узкой специализацией,
требуют собственных адресных пространств, поскольку они запускаются как
отдельные процессы.
• Объекты используются в качестве базовых модулей, которые реализованы как от-
дельные программы, каждая из которых имеет собственное адресное пространство.
• Объекты реализованы в SPMD- или MPMD-архитектуре, рассчитанной на ис-
пользование параллельного программирования, причем эти объекты располо-
жены в различных процессах и на различных компьютерах.
В объектно-ориентированном приложении выполняемая программой работа де-
лится между несколькими объектами. Эти объекты представляют собой модели опре-
деленной реальной личности, реального места, предмета или идеи. Выполнение объ-
ектно-ориентированной программы вынуждает ее объекты взаимодействовать между
собой в соответствии с правилами, заложенными в этой модели. В распределенном
объектно-ориентированном приложении некоторые взаимодействующие объекты
будут создаваться различными программами, которые, возможно, выполняются на
различных компьютерах. В главе 3 упоминалось о том, что каждая выполняемая пр°
грамма включает один или несколько процессов. Каждый процесс обладает собствен
ными ресурсами. Например, любой процесс имеет собственную память, дескрипторы
файлов, стековое пространство, идентификатор и т.п. Задачи, выполняемые в одном
процессе, не имеют прямого доступа к ресурсам, принадлежащим другому процессу-
Если задачам, выполняемым в одном процессе, необходима информация, хранимая
в памяти другого процесса, то эти два процесса должны явно обменяться информаН1*
ей с помощью файлов, каналов, общей памяти, переменных среды или сокетов. Объек
ты, которые принадлежат различным процессам и нуждаются во взаимодействии >
жду собой, также должны использовать один из перечисленных выше способов явног°
8.1. Декомпозиция задачи и инкапсуляция ее решения 271
а информацией. Как правило, С++-разработчик при разработке распределенно-
обме^*^кТНО-ориентированного приложения сталкивается с необходимостью реше-
ния°с^дуюШихпРоблем-
• Декомпозиция задачи и ее решения на множество объектов, причем некоторые
из них будут принадлежать различным процессам и размещаться на разных
компьютерах.
Обеспечение связи между объектами, принадлежащими различным процессам
(адресным пространствам).
Синхронизация взаимодействия между локальными и удаленными объектами.
Обработка ошибок и исключений в распределенной среде.
8.1. Декомпозиция задачи и инкапсуляция
ее решения
Проектирование объектно-ориентированного программного обеспечения — это
процесс перевода требований к ПО в проект, в котором с помощью объектов модели-
руется каждый аспект разрабатываемой системы и выполняемой ею работы. Цен-
тральное место в этом проекте отводится структуре и иерархии коллекций объектов,
а также их взаимоотношениям и взаимодействиям. Для поддержки понятия модели
ПО в C++ используется ключевое слово class. Существует два базовых типа моделей.
Первый тип модели — масштабированное представление некоторого процесса, кон-
цепции или идеи. Этот тип модели используется для анализа или экспериментирова-
ния. Например, класс применяется для разработки модели молекулы, т.е. с помощью
концепции С++-класса можно смоделировать гипотетическую структуру некоторого
химического процесса, происходящего в молекулах. Программным путем можно за-
тем изучить поведение молекулы при внедрении новых групп атомов. Второй тип мо-
дели ПО — воспроизведение некоторой реальной задачи, процесса или идеи. Цель
этой модели — заставить некоторую часть системы ПО или приложения функциони-
ровать подобно ее “прототипу”. В этом случае ПО занимает место некоторого компо-
нента или некоторого физического предмета в неавтоматизированной системе. На-
пример, мы можем использовать концепцию класса для моделирования калькулятора.
Р корректном моделировании всех его характеристик и поведения можно создать
экземпляр этого класса и использовать в качестве настоящего калькулятора. Про-
граммный калькулятор здесь будет играть роль реального калькулятора. Таким обра-
Нек^МОДеЛИРованнЬ1Й нами класс может служить в качестве виртуального дублера
ли ____ Р°го реального лица, места, предмета или идеи. Главное в программной моде-
Дек ВаТИТЬ СУТЬ Реального предмета.
Ряд п МП0зиг^ия (decomposition) — это процесс разделения задачи и ее решения на
ектами ЗЭДаЧ КОЛЛекций °бъектов и принципов взаимоотношений между этими объ-
стик И 7^Налогично инкапсуляция (encapsulation) — это моделирование характери-
С++’ атРибутов и поведения некоторого лица, места, предмета или идеи с помощью
Яяютея Р'КЦИИ class. Такое моделирование (инкапсуляция) и декомпозиция яв-
°РИентиЧаСТЬЮ ЭТапа проектирования объектно-ориентированного ПО. Объектно-
Р°ванные приложения, которые содержат распределенные объекты, вносят
272 Глава 8. Распределенное объектно-ориентированное программирование
в процесс проектирования дополнительный уровень сложности. С точки зп
“чистого” проектирования местоположение объектов в приложении не должно
ять на разработку атрибутов и характеристик этих объектов. Класс — это модель
ли местоположение не является частью этой модели, то даже самое “крайнее” еС
z ч г распо-
ложение объектов (экземпляров этого класса) не должно иметь значение. Одн
объекты существуют не в вакууме. Они взаимодействуют и обмениваются информаци
ей с другими объектами. Если объекты (участники взаимодействия) расположены на
разных компьютерах, и, возможно, даже в различных сетях, то оказывается, что фак
тор местоположения объектов необходимо с самого начала включать в процесс про
ектирования ПО. И хотя насчет того, на каком именно этапе проектирования следует
рассматривать этот фактор, специалисты существенно расходятся во мнениях, тем не
менее все единодушны в том, что его необходимо рассматривать. Дело в том, что об-
работка ошибок и исключений при взаимодействии объектов, расположенных в раз-
личных процессах или на различных компьютерах, отличается от обработки ошибок
и исключений при взаимодействии объектов одного и того же процесса. Кроме того
связи и взаимодействия между объектами одного процесса реализуются совершенно
не так, как при расположении объектов в различных процессах, которые могут вы-
полняться на разных компьютерах. Это нужно иметь в виду еще на раннем этапе про-
ектирования. В распределенном объектно-ориентированном приложении вся его ра-
бота делится между объектами и реализуется в виде функций-членов различных объ-
ектов. Объекты должны быть логически разделены согласно определенной модели
декомпозиции работ (Work Breakdown Model — WBM). Они могут быть разделены со-
гласно моделям типа “клиент-сервер”, “изготовитель-потребитель”, равноправных узлов,
“классной доски” или мультиагентной системы. Логическая структура каждой такой
модели (с особенностями распределения объектов) показана на рис. 8.1.
Во всех моделях, показанных на рис. 8.1, предполагается, что объекты могут быть
на одном и том же или на разных компьютерах (главное — они принадлежат разным
процессам). Уже сам факт принадлежности различным процессам делает объекты
распределенными.1 Все модели представляют различные подходы к распределению
работы приложения между объектами.
8.1.1. Взаимодействие между распределенными
объектами
Если объекты относятся к одному и тому же процессу, то в качестве средств ме
жобъектного “общения” можно использовать механизм передачи параметров, вызовы
обычных методов и использование глобальных переменных. Если объекты принаД
лежат различным процессам, выполняемым на одном компьютере, то средствам11
коммуникации между объектами могут служить файлы, каналы, очереди с дисципли
ной обслуживания “первым пришел — первым обслужен”, разделяемая память, оуФ
ры обмена или переменные среды. Если же объекты “прописаны” на различных ком
пьютерах, то в качестве средств связи придется использовать сокеты, вызовы уда
ных процедур и другие типы средств сетевого программирования. При этом 1
должны подумать не только о том, как будут общаться объекты в распределен *
приложении, но и о том, посредством чего будет реализовано это общение. Объектно
Мы не включаем многопоточные программы в категорию распределенных
8.1. Декомпозиция задачи и инкапсуляция ее решения 273
МОДЕЛЬ ’ИЗГОТОВИТЕЛЬ-ПОТРЕБИТЕЛЬ'
КОМПЬЮТЕР^
Объект А
КОМПЬЮТЕР 2
Сетевая или другая связь
Клиент (потребитель)
Объект В
МОДЕЛЬ РАВНОПРАВНЫХ УЗЛОВ _
КОМПЬЮТЕР 1
Узел
КОМПЬЮТЕР 2
Узел
Объект А
КОМПЬЮТЕР 3
Узел
Объект С
Объект В
Объекты могут играть К
роль потребителя,
МОДЕЛЬ ^^с^й^о^и’Тмультиагенпюйсистемь!
КОМПЬЮТЕР 1
Источники знаний
КОМПЬЮТЕР 3
'КЛАССНАЯ ДОСКА1
АГЕНТ 1
УРОВЕНЬ А
Объект А
Частные решения
УРОВЕНЬ В
изготовителя или обоих
участников одновременно.
Они взаимодействуют и
сотрудничают при решении
определенной проблемы
Частные решения
АГЕНТ 2
ОПРЕДЕЛЕНИЕ ПРОБЛЕМЫ
Объект В
специальные данные
информация
знания
Агенты или источники L
знаний взаимодействуют
посредством "классной доски'
целевая установка
(директивы)
КОМПЬЮТЕР 4
Источники знаний
АГЕНТ 3
Источники знаний
АГЕНТ 4
Объект D
Объект С
8.1.
п°треб*ите ^,огическая структура и распределение объектов в моделях “изготовитель-
ь . Равноправных узлов, “классной доски” и мультиагентной системы
274 Глава 8. Распределенное объектно-ориентированное программирование
ориентированные приложения могут включать как простые типы данных, так
вольно сложные, а именно классы, определенные пользователем. Такие классы ч
используются для связи между объектами. Поэтому связь между распределений^0
объектами будет обеспечиваться не только с помощью простых встроенных ти И
данных (например int, float или double), но и посредством классовых типов В
ределенных пользователем, без которых некоторые объекты не смогут выполнит
свою работу. Кроме того, необходимо позаботиться о том, чтобы у одних объектов
была возможность вызывать методы других объектов, расположенных в других ад
ресных пространствах. Более того, необходимо предусмотреть возможность для од
ного объекта “знать” о методах удаленных объектов. В то время как язык C++ поддеп
живает средства объектно-ориентированного программирования, в нем не преду-
смотрено никаких встроенных средств по обеспечению связи между
распределенными объектами. Он не содержит никаких встроенных методов для ло-
кализации удаленных объектов и формирования к ним запросов.
Для реализации связи между распределенными объектами разработан ряд прото-
колов. Двумя наиболее важными из них являются ПОР (Internet Inter-ORB Protocol -
протокол, определяющий передачу сообщений между сетевыми объектами по
TCP/IP) и RMI (Remote Method Invocation — вызов удаленных методов). С помощью
этих протоколов могут общаться объекты, расположенные практически в любом мес-
ти сети. В этой главе мы рассмотрим методы реализации распределенных объектно-
ориентированных программ с использованием упомянутых протоколов и специфи-
кации CORBA (Common Object Request Broker Architecture). Спецификация CORBA
представляет собой промышленный стандарт для определения отношений, взаимо-
действий и связей между распределенными объектами. ПОР и GIOP — два основных
протокола, с которыми работает спецификация CORBA. Эти протоколы хорошо со-
гласуются с протоколом TCP/IP. CORBA — самый простой и наиболее гибкий способ
добавления средств распределенного программирования в среду C++. Средства, пре-
доставляемые спецификацией CORBA, реализуют поддержку двух основных моделей
объектно-ориентированного параллелизма, которые мы используем в этой книге:
“классная доска” и мультиагентные системы. Поскольку спецификация CORBA отра-
жает принципы объектно-ориентированного программирования, с ее помощью мож-
но реализовать приложения довольного широкого диапазона: от миниатюрных до
очень больших. В этой книге мы используем MICO2 — открытую реализацию специ-
фикации CORBA. MICO-реализация поддерживает основные CORBA-компоненты
и службы. C++ взаимодействует с MICO посредством коллекции классов и библиотек
классов. Спецификация CORBA поддерживает распределенное объектно
ориентированное моделирование на каждом его уровне.
8.1.2. Синхронизация взаимодействия локальных
и удаленных объектов
Для синхронизации доступа к данным и ресурсам со стороны нескольких °^ъе^
тов, принадлежащих различным процессам, но расположенных на одном компь
ре, можно использовать мьютексы и семафоры, поскольку каждый процесс,
2 Все примеры использования CORBA-компонентов в этой книге реализованы с исполъзо
нием версии MICO 233 в операционной системе SuSE Linux и версии MICO 23.7 в опера „
ной системе Solans 8.
8.2. Доступ к объектам из других адресных пространств 275
ленный от других, все же получает доступ к системной памяти компьютера. Эту
И°тде mvio память функционально можно рассматривать как разновидность памяти,
СИСТе яемой между процессами. Но если процессы распределены между различными
ра^ьютерами, то следует помнить, что разные компьютеры не имеют никакой об-
К°*“Ппамяти, и поэтому схемы синхронизации в этом случае должны быть реализова-
^Ндо-другому. Синхронизация доступа (в зависимости от используемой WBM-
НЫ и) может потребовать интенсивного взаимодействия между распределенными
Мбъектами. Поэтому мы расширим традиционные методы синхронизации с помощью
коммуникационных возможностей спецификации CORBA.
8.1.3. Обработка ошибок и исключений
в распределенной среде
Возможно, одной из самых сложных областей обработки исключительных ситуа-
ций или ошибок в распределенной среде считается область частичных отказов.
В распределенной системе могут отказать один или несколько компонентов, в то вре-
мя как другие компоненты будут функционировать в “предположении”, что в системе
все в полном порядке. Если такая ситуация (например, отказ одной функции) возни-
кает в локальном приложении, т.е. когда все компоненты принадлежат одному и тому
же процессу, об этом нетрудно уведомить все приложение в целом. Но для распреде-
ленных приложений все обстоит иначе. На одном компьютере может отказать сете-
вая карта, а объекты, выполняемые на других компьютерах, могут вообще не “узнать”
о том, что где-то в системе произошел отказ. Что случится, если один из объектов по-
пытается связаться с другим объектом и вдруг окажется, что сетевые связи с ним
оборвались? Если при использовании модели равноправных узлов (в которой мы
формируем различные группы объектов по принципу решения различных аспектов
проблемы) одна из групп откажет, то как об этом отказе “узнают” другие группы? Бо-
лее того, какое поведение мы должны “навязать” системе в такой ситуации? Должен
ли отказ одного компонента приводить к отказу всей системы? Если даст сбой один
клиент, то должны ли мы прекратить работу сервера? А если откажет сервер, то нуж-
но ли останавливать клиент? А что, если сервер или клиенты продемонстрируют
лишь частичные отказы? Поэтому в распределенной системе, помимо “гонок” данных
и взаимоблокировок, мы должны также найти способы справляться с частичными от-
иизами компонентов. И снова-таки подчеркиваем, важно найти распределенный под-
код к С++-механизму обработки исключительных ситуаций. Для начала нас удовлетво-
«т возможности, предоставляемые спецификацией CORBA.
8-2- Доступ к объектам из других адресных
пространств
бЪекты, Разделяющие одну область действия (видимости), могут взаимодейство-
Объект Л^ЧаЯ ДОСТУП Друг к другу по именам, псевдонимам или с помощью указателей.
Мость Д°стУПен только в случае, если “видимо” его имя или указатель на него. Види-
мых ИМен объектов определяется областью действия. C++ различает четыре основ-
х УРОВНЯ областей действия:
276 Глава 8. Распределенное объектно-ориентированное программирование
• блока;
• функции;
• файла;
• класса.
Вспомните, что блок в C++ определяется фигурными скобками { }, поэтому цп
сваивание значения Y переменной X в листинге 8.1 недопустимо, так как перемени
у видима только внутри блока. Функции main () неизвестно имя переменной у За
пределами блока, конец которого обозначен закрывающейся фигурной скобкой.
// Листинг 8.1. Простой пример области действия блока
int main(int argc, char argv[])
{
int X;
int Z;
{
int Y;
Z = Y; // Вполне правомочное присваивание.
//. . .
}
X = Y ; // Неверно, поскольку имя Y уже не определено.
}
Однако имя Y видимо для любого другого кода из того же блока, в котором опреде-
лена переменная Y. Имя, объявляемое внутри функции или ее объявления, получает
область видимости этой функции. В листинге 8.1 переменные X и Z видимы только
для функции main (), и к ним нельзя получить доступ из других функций. Понятие об-
ласти видимости файла относится к исходным файлам. Поскольку С++-программа может
состоять из нескольких файлов, мы можем создавать объекты, которые видимы в одном
файле и невидимы в другом. Имена, обладающие областью видимости файла, видимы,
начиная с местоположения их объявления и заканчивай! концом исходного файла. Име-
на с областью видимости файла не должны объявляться ни в одной из функций. Обычно
их называют глобальными переменными. Имена, которые характеризуются областью ви-
димости объекта, видимы для любой функции-члена, объявленной как часть этого объ-
екта. Мы используем область видимости объекта в качестве первого уровня доступа
к членам объекта. Закрытый, защищенный и открытый интерфейсы объекта определи
ют второй уровень. И хотя само имя объекта может быть видимым, закрытые и заши
щенные его члены тем не менее имеют ограниченный доступ. Область действия просТ°
сообщает нам, видимо ли имя объекта. В нераспределенной программе область деист
вия ассоциируется с единым адресным пространством. Два объекта в одном и том
адресном пространстве могут получать доступ друг к другу по имени или указателю
и взаимодействовать, просто вызывая методы друг друга.
// Листинг 8.2. Использование объектов, которые вызывают
// методы других объектов из того же
// адресного пространства
//. . .
some_object А;
another_object В;
8.2. Доступ к объектам из других адресных пространств 277
ic object *С;
пе^Упа1п1 с-оЬ3 ес е •
//jAsomething (A.doSomething О ) ;
doSomething(B.doSomething() ) ;
г’>doMore (A. doSomething () ) ;
В листинге 8.2 объекты А и В находятся в одной области видимости, т.е. объект
видим для объекта А, а объект А видим для объекта В. Объект А может вызывать
. ,нкции-члены объекта В, и наоборот. А что можно сказать об областях видимости,
^ли два объекта находятся на различных компьютерах? Что происходит, когда объ-
ект В создается другой программой и “получает прописку” совершенно в другом адрес-
ном пространстве? Как объект А узнает о существовании объекта В и как (что особенно
важно) объект А узнает имя и интерфейс объекта В? Каким образом объект А сможет вы-
зывать функции-члены, принадлежащие объекту В, если В — часть другой программы?
В листинге 8.2 объекты А и В создаются во время компиляции, а объект С — во время вы-
полнения. Все они являются частями одной и той же программы, обладают одной обла-
стью видимости, а их адреса принадлежат адресному пространству одного и того же
процесса. Чтобы процесс мог выполнить инструкцию, ему нужно знать ее адрес. При
компиляции программы, представленной в листинге 8.2, адреса объектов А и В хранятся
в выполняемом файле. Следовательно, процесс, который выполняет программу из лис-
тинга 8.2, будет знать местоположение объектов А и В. Адрес объекту С присваивается во
время выполнения программы, т.е. его точный адрес станет известен только тогда, ко-
гда будет вызвана функция new (). Однако указатель на объект С будет содержать адрес
в пределах того же пространства, в котором размещаются объекты А и В, и, следова-
тельно, процесс для получения доступа к объекту С воспользуется этим указателем. Та-
ким образом, доступ к каждому объекту осуществляется на основе доступа к их адресам
(прямого или косвенного). Имя переменной объекта — это просто псевдоним для его
адреса. Если имя объекта попадает в рамки нашей области видимости, то мы можем по-
лучить к нему доступ. Проблема в том, как связать удаленный объект с нашей локальной
областью видимости. Для того чтобы получить доступ к объекту D, который находится
в Другом адресном пространстве, нам необходим некоторый способ ввода адреса удален-
ного объекта в наш выполняющийся процесс, т.е. нужно научиться связывать уда-
ленный объект с нашей локальной областью видимости. Нам требуется видимое имя,
которое бы служило псевдонимом для адреса в другом процессе, причем этот процесс
Может выполняться даже на другом компьютере. В некоторых случаях этот самый
Другой компьютер может быть подключен к другой сети! Было бы весьма удобно за-
г ггь удаленный объект с помощью некоторого согласованного описания и получить
с эти\У ДЛЯ адРеса УДаленного объекта. Имея ссылку, мы могли бы взаимодействовать
им объектом из нашей локальной области действия. Именно для таких нужд распре-
°го программирования и можно использовать CORBA-реализацию.
8 ? 1
lOR-доступ к удаленным объектам
станл^ЪеКТН^Я ссылка специального типа IOR (Interoperable Object Reference) — это
СОЯвд ЫИ Ф°Рмат объектной ссылки для распределенных объектов. Каждый
объект имеет IOR-ссылку. IOR-ссылка— это дескриптор, который уникально
278 Глава 8. Распределенное объектно-ориентированное программирование
идентифицирует объект. В то время как обычный указатель содержит простой м
ный адрес для объекта, IOR-ссылка может содержать номер порта, имя хоста (имя ИН
пьютера в сети), объектный ключ и пр. В C++ для доступа к динамически создавае^°М
объектам используется указатель. Указатель содержит информацию о том, где в памя
компьютера расположен объект. При разыменовании указателя на объект использу И
полученный адрес для доступа к членам этого объекта. Однако процесс разыменова *
указателя на объект (с целью получения доступа к нему) требует больших усилий, когда
этот объект находится в другом адресном пространстве и, возможно, на другом компьк>
тере. Указатель в этом случае должен содержать достаточно информации, чтобы сооб
щить точное местоположение объекта. Если объект расположен в другой сети, указатеи
должен содержать (прямо или косвенно) сетевой адрес, сетевой протокол, имя хоста
адрес порта, объектный ключ и физический адрес. Стандартная IOR-ссылка действует
как разновидность распределенного указателя на удаленный объект. Набор компо-
нентов, содержащихся в IOR-ссылке под протоколом ПОР, показан на рис. 8.2.
Понятие переносимой (portable) объектной ссылки — это важный этап на пути к дос-
тижению распределенной обработки данных. Оно позволяет использовать локальные
ссылки на удаленные объекты практически везде (в Internet или intranet) и имеет
важные последствия для мультиагентных систем, в которых агентам приходится пе-
ремещаться между системами и по всему пространству Internet. Стандарт IOR создает
основу для мобильных объектов и распределенных агентов. После того как ваша про-
грамма получит доступ к IOR-ссылке объекта, можно использовать брокер объектных
запросов (Object Request Broker — ORB) для взаимодействия с удаленным объектом по-
средством вызова методов, механизма передачи параметров, возврата значений и т.п.
Логические компоненты IOR-ссылки:
Хост Порт Объектный ключ Другие компоненты
Идентифицирует Internet-хост Содержит но- мер порта TCP/IP, в котором целе- вой объект при- нимает запросы Значение, которое однозначно преоб- разуется в конкрет- ный объект Дополнительная инфор- мация, которую можно использовать при обра- щениях, например для безопасности
Рис. 8.2. Набор компонентов, содержащихся в IOR-ссылке под протоколом ПОР
8.2.2. Брокеры объектных запросов (ORB)
ORB-брокер действует от имени программы. Он посылает сообщения удаленно
му объекту’ и возвращает сообщения от него. Поведение ORB-брокера можно срав
нить с посредником между локальными и удаленными объектами. ORB-брокер Ре
шает все вопросы, связанные с маршрутизацией запроса от программы к удалеН
ному объекту и с маршрутизацией ответа программе, принятого от удаленного
объекта. Такое посредничество делает коммуникации между системами практике
ски прозрачными. ORB-брокер избавляет программиста от необходимости пр
граммирования сокетов между процессами, выполняющимися на различных кО>1
пьютерах. И точно так же он устраняет необходимость в программировании кана
лов и очередей с FIFO-дисциплиной между процессами, выполняющимися
8.2. Доступ к объектам из других адресных пространств 279
компьютере. Он берет на себя немалый объем сетевого программирования,
второго не обойтись при создании распределенных программ. Более того, он
бе3 разЛичия между операционными системами, языками программирования
сТИР атными средствами. При программировании локальных объектов програм-
и annaP^bHje не НуЖНО беспокоиться о том, на каком языке реализованы удален-
МИСТ^объекты, на какой платформе они выполняются и к какой сети они
-^писаны”: Internet или локальной intranet. ORB-брокер использует IOR-
сылкп чт°бы упростить взаимодействие между компьютерами, сетями и объек-
тами Обратите внимание на то, что IOR-ссылка (см. рис. 8.2) содержит инфор-
мацию которая может быть использована для TCP/IP-соединений. Мы представи-
ли лишь частичное описание IOR-компонентов, поскольку IOR-дескриптор должен
быть “черным ящиком” для разработчика. ORB-брокер использует IOR-ссылки, что-
бы найти объект назначения. Обнаружив объект, ORB-брокер активизирует его
и передает аргументы, необходимые для вызова этого объекта. ORB-брокер ожида-
ет завершения обслуживания запроса и возвращает вызывающему объекту ожидае-
мую информацию или исключение, если вызов метода оказался неудачным. Упро-
щенная последовательность действий, выполняемых ORB-брокером от имени ло-
кального объекта, показана на рис. 8.3.
Действия, перечисленные на рис. 8.3, представляют упрощенную схему того, что
делает ORB-брокер, взаимодействуя с удаленным объектом. Эти действия практиче-
ски незаметны для локального объекта. Локальный объект вызывает один из мето-
дов удаленного объекта, а ORB-брокер делает “свою работу” от имени локального
объекта. ORB-брокер выполняет большой объем обработки, заключенный всего
лишь в нескольких строках кода. Обычно распределенное объектно-ориенти-
рованное приложение состоит по крайней мере из двух программ. Каждая про-
грамма имеет один или несколько объектов, которые взаимодействуют друг с дру-
гом, “пересекая” адресные пространства. Характер взаимодействия объектов опре-
деляется отношениями “клиент-сервер”, “изготовитель-потребитель” или базирует-
ся на принципе равноправия (модель равноправных узлов). Следовательно, если
У нас есть две программы, то одна будет действовать как клиент, а другая — как сер-
вер, или одна — как изготовитель, а другая — как потребитель, либо обе они будут
равноправными. В программе 8.1 реализован потребитель, который вызывает про-
стои удаленный объект калькулятора. На примере этой программы демонстрирует-
ся, как можно получить доступ к удаленному объекту, а также как инициализируется
И используется ORB-брокер.
УПРОЩЕННАЯ последовательность действий orb-брокера при
YggOBE МЕТОДА УДАЛЕННОГО ОБЪЕКТА
^Ц^ити удаленный объект.________
Актив!
-^£ивизирован.
визировать модуль, содержащий искомый объект, если таковой еще не
•-р-^Рредать аргументы удаленному объекту.________________________________________
*5*ъ—Иать ответа после вызова метода удаленного объекта.__________________________
Е уть локальному объекту информацию или исключение, если вызов удаленного
оказался неуспешным.______________
Лока^ Л* ^пР01Денная последовательность действий, выполняемых ORB-брокером от имени
пог° объекта
280
Глава 8. Распределенное объектно-ориентированное программирова
НИое
// Программа 8.1
1 using namespace std;
2 #include "adding_machine_impl.h"
3 tfinclude <iostream>
4 #include <fstream>
5 #include <string>
6
7
8 int main(int argc, char *argv[])
9 {
10 CORBA::ORB_var Orb = CORBA::ORB_init(
argc,argv,
"mico-local-orb");
11 CORBA::BOA_var Boa = Orb->BOA_init(
argc,argv,"mico-local-boa");
12 ifstrearn In("adding_machine.objid");
13 string Ref;
14 if('In.eof()){
15 In » Ref;
16 }
17 In.close();
18 CORBA::0bject_var Obj = Orb->string__to_object (
Ref.data());
19 adding_machine_var Machine =
adding_machine::„narrow(Obj);
20 Machine->add(700) ;
21 Machine->subtract(250) ;
22 cout « "Результат равен " « Machine->result()
« endl;
23 return(0);
24 }
25
26
При выполнении строки 10 ORB-брокер инициализируется. Строка 15 обеспечи-
вает считывание из файла IOR-ссылки на объект adding_machine. Одно из прекрас-
ных свойств IOR-ссылки состоит в том, что ее можно хранить как простую строку’
и передавать другим программам. Передачу IOR-ссылки проще всего реализовать
с помощью аргументов командной строки, переменных среды или файлов. IOR'
ссылку можно отправить по электронной почте или с помощью протокола передачи
файлов (Tile Tiansfer Protocol — FTP). IOR-ссылки совместно используют файловые
системы, и их можно загружать с Web-страниц. Если некоторая программа имеет IOR*
ссылку на удаленный объект, то для доступа к нему можно использовать ORB-брокер-
Другие методы связи между объектами с помощью IOR-ссылок будут рассмотрены
ниже в этой главе. Но для начала вполне достаточно использования файловых систем-
так, в программе 8.1 IOR-ссылка была получена путем преобразования объектной
ссылки в “строковую” форму (с использованием ORB-брокера удаленного калькулятО'
ра) и записана в файл. При выполнении строки 18 локальный объект Orb преобразуй
строковую” IOR-ссылку обратно в объектную. В строке 19 эта объектная ссылка ис
пользуется для реализации объекта adding_machine. Обратите внимание на то,
при вызове методов этого объекта adding_machine выполняется соответству^шИ»1
код удаленного калькулятора (см. строки 20, 21 и 22).
8.2. Доступ к объектам из других адресных пространств 281
M»cbyn®'>sStract(250);
machine зультат равен " « Machine->result() « endl;
cout
вЫ этих методов сделаны в нашей локальной области видимости, они от-
Ихотя вызов
к выполняемому коду в другом адресном пространстве (в данном случае — да-
носятся компьютеру). Для разработчика местоположение объекта Machine как
*е К оестает иметь значение. После создания (в строке 19) этот объект использу-
будто^ лЮбой другой объект C++. И хотя существуют весьма значительные различия
еТСЯ вЫЗОвами локальных и удаленных объектов1 * *, объектно-ориентированное пред-
Мтавл^Ние тем не менее, поддерживается, и с точки зрения объектно-ориентирован-
ного программирования удаленные объекты ведут себя как локальные. Код, представ-
ленный в программе 8.1, является кодом клиентской части приложения (или кодом
“потребителя”), поскольку в нем используются возможности объекта adding__machine.
Поэтому теперь (для получения завершенного приложения калькулятора) нам нужен
код “ответной части”, который реализует объект adding_machine. Код этого второго
компонента представлен в программе 8.2.
Программа 8.2
//
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <iostream>
#include <fstream>
#include ”adding_machine_impl .h"
int main(int argc, char *argv[])
{
CORBA::ORB_var Orb = CORBA::ORB_init
(argc,argv,"mico-local-orb");
CORBA: : BOA—var Boa = Orb->BOA_init (argc , argv,
"mico-local-boa") ;
adding_machine_impl *AddingMachine =
new adding_machine—impl;
CORBA: .-String—var Ref = Orb->object_to_string(
AddingMachine);
of stream Out("adding_machine.obj id");
Out « Ref << endl;
Out.close();
®°ла~>^тР1_is_ready (CORBA: : ImplementationDef : :_nil () ) ;
Orb->run();
CORBA::release(AddingMachine);
return(0);
3ировать^И^е ВНимание на то» что программа-“изготовитель” также должна инициали-
МЫх к СОРНдеКТ °rk (В стРоке Ю)- Это — одно из важных требований, предъявляе-
_____ ориентированным программам, поскольку каждая программа реализует
1
^Пасностпии^1еННЫХ °^ъектов вносят задержку во времени, необходимость выполнять требования
возможность возникновения частичных отказов.
282 Глава 8. Распределенное объектно-ориентированное программирование
взаимодействие с удаленными объектами с помощью ORB-брокера. Именно поэт
инициализация ORB-объекта— первое действие, которое должна выполнить CORr
программа. В строке 12 объявляется реальный объект adding_machine. Это им
тот объект, с которым в действительности связывается программа 8.1. В строке °
объектная ссылка на реальный объект adding_machine преобразуется в "строков *
форму, а затем записывается в обычный текстовый файл, чтобы ее можно было бе
труда прочитать. После того как IOR-ссылка записана в файл, объект Orb ожидает
проса. При каждом вызове одного из его методов этот объект выполняет соответст
вующее арифметическое действие (сложение или вычитание). Значение результата
передается посредством вызова метода result () объекта adding_machine. Про
граммы 8.1 и 8.2 демонстрируют базовую структуру, которую должны иметь CORBA-
программы. Код, создающий объект adding_machine, начинается с объявления его
CORBA-класса. Каждый CORBA-объект начинается как IDL-проект (Interface
Definition Language — язык описания интерфейсов).
8.2.3. Язык описания интерфейсов (IDL):
более “пристальный” взгляд на CORBA-объекты
Язык описания интерфейсов (IDL) — стандартный язык объектно-
ориентированного проектирования, который используется для разработки классов,
предназначенных для распределенного программирования. Он применяется для ото-
бражения интерфейса класса и отношений между классами, а также для определения
прототипов функций-членов, типов параметров и типов значений, возвращаемых
функциями. Одно из основных назначений языка IDL — отделить интерфейс класса от
его реализации. Но для определения самих функций-членов и членов данных IDL не
используется. Язык IDL определяет только интерфейс функции. Основные ключевые
слова IDL перечислены в табл. 8.1.
Таблица 8.1. Ключевые слова IDL
abstract enum native struct
any factory Object supports
attribute FALSE octet typedef
boolean fixed oneway unsigned
case float out union
char in raises ValueBase
const inout readonly valuetype
cell interface sequence void
double long short wchar
exception module string
Ключевые слова, перечисленные в табл. 8.1, представляют собой зарезервировав
ные слова, используемые в CORBA-программах. Помимо определения интерфе11са
функций для класса, язык IDL используется для определения отношений между клаС
сами. IDL поддерживает:
8.2. Доступ к объектам из других адресных пространств 283
ТИПЫ, определенные пользователем;
последовательности, определенные пользователем;
типы массивов;
реверсивные
типы;
семантику исключений;
модули (по аналогии с пространствами имен);
единичное и множественное наследование;
поразрядные арифметические операторы.
Приведем IDL-определение для класса adding—machine из листинга 8.2:
interface adding_machine{
void addfin unsigned long X);
void subtract(in unsigned long X);
long result!);
Это определение начинается с ключевого слова CORBA interface. Обратите
внимание на то, что данное объявление интерфейса класса adding_machine не
включает ни одной переменной, которая бы могла хранить результат выполнения
операций сложения и вычитания. Методы add () и subtract () принимают в качест-
ве параметра одно значение типа unsigned long. Объявление типа параметра со-
провождается ключевым словом CORBA in, который говорит о том, что данный пара-
метр является входным (mput). Это объявление класса хранится в отдельном исходном
файле adding_machine. idl. Исходные файлы, содержащие IDL-определения, долж-
ны иметь . idl-расширения. Прежде чем такой файл можно будет использовать, его не-
обходимо преобразовать к С++-формату. Это преобразование можно выполнить с по-
мощью препроцессора или отдельной программы. Все CORBA-реализации включают
IDL-компиляторы. Существуют IDL-компиляторы для языков С, Smalltalk, C++, Java и др.
IDL-компилятор преобразует IDL-определения в код соответствующего языка. В дан-
ном случае IDL-компилятор преобразует объявление интерфейса в легитимный С++-
код. В зависимости от конкретной CORBA-реализации IDL-компилятор вызывается
с использованием синтаксиса, который будет подобен следующему:
adding__machine. idl
При выполнении этой команды создается файл, содержащий С++-код. Поскольку
наше IDL-определение хранится в файле adding_machine. idl, MICO IDL-компилятор
здаст файл adding_machine. h, который будет содержать несколько каркасных С++-
ссов и CORBA-типов данных. Базовые IDL-типы данных приведены в табл. 8.2.
2^блица 8.2. Базовые IDL-типы данных
данных
long "
short
long
Диапазон
-2'-2” - 1
_215 _ ।
0-2,2-1
Размер
> 32 бит
> 16 бит
> 32 бит
284 Глава 8. Распределенное объектно-ориентированное программирование
8 2
IDL-типы данных Диапазон Размер
unsigned short 0-2'6- 1 ^16 бит ~
float IEEE с обычной точностью 32 бит
double IEEE с двойной точностью 64 бит
char ISO латинский-1 8 бит
string ISO латинский-1, за исключением ASCII NULL Переменный
boolean TRUE ИЛИ FALSE Не определен
octet 0-255 > 8 бит
any Произвольный тип, идентифицируемый динами- чески Переменный
Даже после того как IDL-компилятор создаст из определения интерфейса С++-код
реализация методов интерфейсного класса остается все еще неопределенной. IDL-
компилятор создает несколько С++-конструкций, которые предназначены для ис-
пользования в качестве базовых классов. В листинге 8.3 показано два класса, сгенери-
рованных MICO IDL-компилятором на основе файла adding.machine . idl.
// Листинг 8.3. Два класса, сгенерированные
// MICO IDL-компилятором из файла
/ / adding_machine.idl
class adding_machine : virtual public CORBA::Object{
public:
virtual -adding.machine();
#ifdef HAVE.TYPEDEF—OVERLOAD
typedef adding_machine_ptr _ptr_type;
typedef adding.machine.var _var_type;
#endif
static adding_machine_ptr _narrow(
CORBA::Object_ptr obj );
static adding.machine.ptr _narrow(
CORBA::AbstractBase_ptr obj );
static adding_machine—ptr —duplicate(
adding_machine_ptr _obj ) ;
{
CORBA::Object::_duplicate (_obj);
return _obj;
}
static adding_machine_ptr _nil()
{
return 0;
}
virtual void *_narrow.helper( const char *repoid );
static vector<CORBA::Narrow.proto *_narrow.helpers;
static bool _narrow_helper2( CORBA::Object_ptr obj );
virtual void add( CORBA::ULong X ) =0;
8.2. Доступ к объектам из других адресных пространств 285
1 void subtract( CORBA::ULong X ) = 0;
virtual CORBA::Long resultO = 0;
₽r°addingimachine() O;
prlVdding-machine ( const adding_machine& );
void operator=( const adding_machine& );
class adding_machine_stub
virtual public adding_machine{
₽Ubvirtual ~adding_machine_stub() ;
void add( CORBA::ULong X );
void subtract( CORBA::ULong X );
CORBA::Long result() ;
private:
void operator=( const adding_machine_stub& );
};
Файл adding—machine. idl — это входные данные для компилятора, а файл
adding-machine.h вместе с каркасными классами— результат его работы. Чтобы
реализовать интерфейсы функций, объявленные в исходном IDL-файле, разработчик
использует наследование. Например, в листинге 8.4 представлен определенный поль-
зователем класс, который обеспечивает реализацию для одного из каркасных классов,
созданных IDL-компилятором.
// Листинг 8.4. Класс реализации структурных классов,
// созданных IDL-компилятором
class adding—machine—imp 1 : virtual public
adding_machine—skel{
private:
CORBA::Long Result;
public:
adding_machine_impl (void)
Result = 0;
};
void add(CORBA::ULong X)
Result = Result + X;
void subtract (CORBA: :ULong X)
p Result = Result - X;
CORBA: ;Long result (void)
return(Result);
ca
Один
a<idin
из каркасных файлов, созданных IDL-компилятором из интерфейсного клас-
Machine, называется adding_machine—skel. Обратите внимание на то,
286 Глава 8. Распределенное объектно-ориентированное программирование
что при выведении новых классов IDL-компилятор берет имя из определения ицт
фейса. Наш класс adding_machine_impl обеспечивает реализацию интерф
функций, объявленного с использованием языка IDL. Во-первых, в 1<Ла
adding_machine_impl объявляется член данных Result. Во-вторых, здесь ппе Се
гается реализация методов add(), subtract () и result (). В то время как инте*
фейсный класс adding_machine включает объявление этих методов, iOl
adding_machine_impl обеспечивает их реализацию. Определяемый пользовател^
класс adding_machine_impl должен наследовать из базового класса множество фуцк
ций, полезных для распределенного программирования. В этом и состоит основНая
схема работы, связанной с CORBA-программированием. Интерфейсный класс предНа
значен для представления используемых интерфейсов. Назначение IDL-компилятора -
сгенерировать реальные каркасные С++-классы, исходя из определения интерфейса
Разработчик выводит класс из одного каркасных и обеспечивает реализацию методов
определенных в интерфейсном классе, и членов данных, которые должны использо-
ваться для хранения атрибутов объекта. Итак, создание реальных С++-классов из IDL-
определения представляет собой процесс, состоящий из трех действий.
1. Проектирование интерфейсов классов, отношений и иерархии с использова-
нием языка IDL.
2. Использование IDL-компилятора для генерирования реальных каркасных С++-
классов на основе IDL-классов.
3. Использование наследования для создания потомков из одного из нескольких
каркасных классов и реализация методов интерфейса, унаследованных от кар-
касных классов.
Мы рассмотрим этот процесс более детально ниже в этой главе. Но сначала позна-
комимся с базовой структурой программы потребителя.
8.3. Анатомия базовой CORBA-программы
потребителя
Одной из самых распространенных моделей для применения распределенного
программирования является модель “изготовитель-потребитель”. В этой модели одна
программа играет роль “изготовителя”, а другая — “потребителя”. Изготовитель соз-
дает некоторые данные или предлагает ряд услуг, которыми пользуется потребитель
(например, наша программа могла бы по требованию генерировать уникальные но-
мерные знаки). Предположим, потребитель — это программа, которая создает запро
сы на новые номерные знаки, а изготовитель — это программа, которая их генериру
ет. Обычно потребитель и изготовитель размещаются в различных адресных про-
странствах. Компоненты такой программы и действия, которые должно содержать
большинство CORBA-программ потребителей, представлены на рис. 8.4.
Для взаимодействия с объектами, выполняемыми на других компьютерах или раС
положенными в других адресных пространствах, каждая программа— участниц
взаимодействия должна объявить ORB-объект. После этого программа-потребите
может получить доступ к его функциям-членам. Как показано на рис. 8.4, ORB-объ
инициализируется путем следующего вызова:
CORBA::ORB_var Orb = CORBA::ORB_init{argc,argv,
"mico-local-orb");
8.3. Анатомия базовой CORBA-программы потребителя 287
Включение объявления для
include ”adding_machinejmpl.hn
//...
int main (int argc, char *argvfl)
{ CORBA.:ORB_varOrb = CORBA::ORB initfar^^ .
- It(ar9c.argv,"mico-local-orb");
реализации используемого
объекта изготовителя
Инициализация
ORB-объекта
ifstream ln("adding_machine.ior”);
string lor;
getline(ln,lor);
In.cioseQ;_________________
CORBA: :Object_var Obj = Orb->string_to_object(lor.c_str());
Machine = adding_machine::narrow(Obj);
adding_machine_var
Machine->add(500)
Machine->subtract( 125),
cout«"Result is " « Machine->result() « endl;
retum(O);
A Получение
QJ IOR-ссылки для
удаленного объекта
Приведение
0 IOR-ссылки к типу
удаленного объекта
Вызов методов
"V удаленного объекта
}
Рис. 8.4. Компоненты CORBA-программ потребителей и действия, которые они должны содержать
При выполнении этой инструкции ORB-объект инициализируется. Для ORB-
объектов используется тип CORBA: :ORB_var. В CORBA-реализациях объекты, тип ко-
торых помечается суффиксом _var, берут на себя заботу об освобождении базовой
ссылки (в отличие от объектов, тип которых помечается суффиксом __ptr). Аргументы
командной строки передаются конструктору ORB-объекта вместе с идентификатором
orb_id. В данном случае идентификатором orb__id служит строка "mico-local-orb .
Строка, передаваемая функции инициализации ORB_init (), зависит от конкретной
CORBA-реализации. Полученный объект называют обслуживающим, (servant object).
После инициализации ORB-объекта и объектного адаптера разработчику CORBA-
приложения необходимо позаботиться об IOR-ссылке для удаленного объекта
(объектов). Как показано на рис. 8.4, IOR-ссылка считывается из файла
adding_machine. ior. IOR-ссылка была записана в этот файл в строковой форме.
ORB-объект используется для преобразования IOR-ссылки из строки снова в объект-
НУК) форму с помощью метода string_to_object (). Как показано на рис. 8.4, это
реализуется с помощью следующего вызова:
CORBA: :Object_var Obj = Orb->string—to_object(lor.c_str());
Здесь функция lor. c_str () возвращает IOR-ссылку в строковой форме, а объект
Obj будет содержать IOR-ссылку в объектной форме. Объектная форма IOR-ссылки
претерпевает процесс “сужения”, который подобен операции приведения типа
+’ результате этого процесса объектная ссылка приводится к соответствующему
пу объекта. В данном случае “соответствующим” является тип adding_machine. Про-
фамма-потребитель (см. рис. 8.4) сужает IOR-объект, используя следующий вызов:
№achine_var Machine = adding_machine: :_narrow (Obj ) ;
288 Глава 8. Распределенное объектно-ориентированное программирование
При выполнении этой инструкции создается ссылка на объект
adding—machine. Программа-потребитель может теперь вызывать методы о ТИПа
ленные в IDL-интерфейсе для класса adding_machine, например:
Machine->add(500);
Machine->subtract(125);
При выполнении этих инструкций вызываются методы add() и subtract ()
ленного объекта. Несмотря на то что рассматриваемая программа-потребитель силь
но упрощена, она дает представление о базовых компонентах типичных CORBA
программ потребителя или клиента. Однако программа-потребитель должна работать
совместно с программой-изготовителем. Поэтому мы рассмотрим упрощенную
CORBA-программу, которая действует как изготовитель для программы-потребителя
показанной на рис. 8.4.
8.4. Анатомия базовой CORBA-программы
изготовителя
Изготовитель отвечает за обеспечение программ-потребителей данными, функ-
циями или другими услугами. Изготовитель вместе с потребителем и составляют рас-
пределенное приложение. Каждая CORBA-программа изготовителя проектируется
в расчете на существование программ-потребителей, которые будут нуждаться в пре-
доставляемых ею услугах. Следовательно, каждая программа-изготовитель должна
создавать обслуживающие объекты и IOR-ссылки, посредством которых к этим объ-
ектам можно получить доступ. На рис. 8.5 представлена простая программа-
изготовитель, используемая “в содружестве” с программой-потребителем, отобра-
женной на рис. 8.4. На рис. 8.5 также перечислены основные компоненты, которые
должна содержать любая CORBA-программа изготовителя.
Обратите внимание на то, что части А обеих программ по сути одинаковы. Как по-
требителю, так и изготовителю требуется ORB-объект для связи друг с другом. Этот
ORB-объект используется для получения ссылки на объектный адаптер. На рис. 8.5
приведен следующий вызов:
CORBA::BOA_var Boa = Orb->BOA_init(argc,argv,
"mico-local-boa");
Итак, вызов этой функции используется для получения ссылки на объектный адап
тер, который служит посредником между ORB-брокером и объектом, реализуюШ^м
запрашиваемые методы. Следует иметь в виду, что CORBA-объекты должны начи
наться только как объявления интерфейсов. На некотором этапе процесса разработ
ки производный класс обеспечит реализацию CORBA-интерфейса. Объектный адап
тер действует как посредник между интерфейсом, с которым связан ORB-брокер-
и реальными методами, реализованными производным классом. Объектные адаптер
используются для доступа к обслуживающим объектам и объектам реализации. Изг°тО
витель (см. рис. 8.5) создает объект реализации в части В, используя следующий вызов-
adding_machine_iinpl *AddingMachine = new
adding_machine_impl;
8.5. Базовый проект CORBA-приложения 289
Включение объявления для реализации
используемого объекта adding_machine
int main (int argc. char *argvO)
—var Orb = CORBA: :ORB_init(argc,argv,"mico-local-orb"); A
^QPRA^BOA^r Boa = ОгЬ->ВОА 1П11(агдс,агду,"т1СО-1оса1-Ьоа,>); w
adding machinejmpl ‘AddingMachine = new adding machine impl; •«-ф
Инициализация
ORB-объекта
и объектного
адаптера
Создание
экземпляра объекта
CORBA: :String_var lor = Orb->object_to_string(AddingMachine);
ofstreamOut("adding_machine.ior");
Out«lor;
OutdoseQ;
Boa->implJsj'eady(CORBA::lmplementationDef::_nil());
Orb->run(); *----------------------------------------
CORBA::release(AddingMachine);
retum(O);
Получение строковой
G формы объектной
IOR-ссылки и запись
ее в файл
л Ожидание запросов
ф от объектов-
потребителей
}
Рис. 8.5. Основные компоненты, которые должна содержать CORBA-программа изготовителя
При выполнении этой инструкции создается объект, который обеспечит реализа-
цию услуг, потенциально запрашиваемых клиентскими объектами (или потребителя-
ми). Обратите также внимание на то, что в части С (см. рис. 8.5) программа-
изготовитель использует объект Orb для преобразования IOR-ссылки в строку и запи-
сывает ее в файл add ing_ma chine. ior. Этот файл можно передать с помощью FTP-
протокола, по электронной почте, посредством протокола передачи гипертекстовых
файлов (HTTP) вместе с Web-страницами, с помощью сетевой файловой системы NFS
и т.д. Существуют и другие способы передачи IOR-ссылок, но файловый метод — са-
мый простой. После записи IOR-ссылки программа-изготовитель просто ожидает за-
просы от программ-клиентов (потребителей). Программа-изготовитель, представ-
ленная на рис. 8.5, также представляет собой упрощенный вариант CORBA-
программы изготовителя (программы-сервера), тем не менее, она содержит все ос-
новные компоненты, которые должна иметь типичная программа-изготовитель.
8-5. Базовый проект CORBA-приложения
п JTaK’ И3 пРогРамм> представленных на рис. 8.4 и 8.5, видно, что для CORBA-
СсЬ1лки еНИЯ потРе^Уются два ORB-объекта, объектный адаптер, метод передачи IOR-
CORra И П° кРа^ней мере один обслуживающий объект. Логическая структура
приложения показана на рис. 8.6.
290
Глава 8. Распределенное объектно-ориентированное программиров
ание.
После получения IOR-ссылки и приведения ее к соответствующему типу выз
ленного метода в программе клиента (потребителя) подобен вызову обычного °В
в любой С++-программе. В CORBA-примерах этой книги предполагается исп МеТода
ние протокола ПОР (Internet Inter ORB Protocol). Поэтому ORB-брокеры (см °ЛЬЗ°Ва*
связываются с помощью протокола TCP/IP. IOR-ссылка должна содержать
цию о местоположении удаленного объекта, достаточную для реализации ТСР^*
связи. В качестве объектного адаптера обычно используется переносимый объект
адаптер. Но для некоторых программ (более старых и простых) можно использо^^
базовый объектный адаптер. Различие между этими двумя адаптерами мы рассмо ВВТЬ
ниже в этой главе. Каждое CORBA-приложение имеет один или несколько обслг^
вающих объектов, которые реализуют интерфейс, разработанный в IDL-классе
стейшие программы потребителя и изготовителя, показанные на рис. 8.4 и 8.5 могут
выполняться на одном компьютере в различных процессах или на различных компь
ютерах. Если эти программы выполняются на одном компьютере, файл
adding_machine. ior должен быть доступен из обеих программ. Если они выполня-
ются на различных компьютерах, этот файл должен быть послан клиентскому компь-
ютеру по FTP-протоколу, электронной почте, HTTP-протоколу и т.д. Детали компи-
ляции и выполнения этих программ описаны в разделах “Профиль программы 8.1”
и “Профиль программы 8.2”.
Рис. 8.6. Логическая структура CORBA-приложения
8.5. Базовый проект CORBA-приложения 291
программы 8.1
•«мяп^граммы
Inachine_client_intpl. сс
|оци<?зйи®
; rt)OfpaMMa представляет собой простой вариант программы-потребителя. Она связы-
^^сСОЯВА-программой изготовителя, представленной на рис. 8.5. Она вы-
^няет сложение с числом 500 с помощью калькулятора, а затем вычитает из
^^ипЬтата число 125. Результат выполнения операций отправляется в выходной
^TOKCOUt с помощью метода results().
Требуемые библиотеки
mico2.3.7.
^Требуемые заголовки
Нет.
Инструкции по компиляции и компоновке программ
adding_machine. idl
“Я -с adding_machine.cc -о adding_machine. о
а —гт _г« яЯгЧтпгг mprhinp ттпт>1 г1 г* -о ndrH пгт тпагУипр imnl _п
-д -с adding_machine_impl.cc -о adding_machine_impl. о
-д -с adding_machine_client_impl. сс -о
addiiig_machine_client_impl. о
-д -о adding_machine_client adding_machine_client_impl.о
Laddingllinachine_impl. о adding_machine. о - lmico2.3.3
Средадля тестирования
.8и5Ё^Йизих 7.1 дли C++ 2.95.2, Solaris 8 Workshop 7, MICO 2.3.3, MICO 2.3.7.
[Инструкции по выполнению
Выполняемый файл adding_machine_client (например,
b/adqrtKLjnacihine-client). CORBA-программа изготовителя с именем
! a’~^XJ®achine_server (представленная на рис. 8.5) должна быть запущена первой.
^Примечания
’'лоогпУ В*Эемени’ когда будет вызвана программа adding_machine_client, CORBA-
^£22®!**?? изготовителя должна уже выполняться.
: РрФиль программы 8.2
;^^программы
I n9rjnachine_server_impl. сс
’Икание
представляет собой простой вариант программы-сервера, пред-
^55ипол°И На Рис* 8’5*Она пРинимает запросы на выполнение сложения и вычита-
*^^?°Етавляет результаты этих операций.
292
Глава 8. Распределенное объектно-ориентированное программиров
ание.
Требуемые библиотеки
i mico2.3.3 или mico2.3.7.
. Требуемые заголовки
‘Нет.
। Инструкции по компиляции и компоновке программ
|idl —роа adding.jnachine.idl
|mico-c++ -g -с adding_machine.cc -о adding_machine.о
|mico-c++ -g -с adding_machine_impl.cc -о adding_machine_impl.о
*mico~c++ -g -с adding_machine_server_impl.cc -о
। adding_machine_server_impl. о
jmico-ld -g -о adding_machine_server adding_machine_server_impl. о
? adding_machine_impl. о adding_machine. о - lmico2.3.3
*
I Среда для тестирования
jSuSE Linux 7.1 gnu C++ 2.95.2, Solaris 8 Workshop 7, MICO 2.3.3, MICO 2.3.7
> Инструкции по выполнению
; Запустить выполняемый файл adding_machine_server (например,
! . /adding_jnachine_server).
j Примечания
|Нет.
8.5.1. IDL-компилятор
IDL-компилятор представляет собой инструмент, предназначенный для перевода
IDL-определений класса в С++-код. Этот код состоит из коллекции “каркасных” опре-
делений классов, перечислимых типов и шаблонных классов. Для CORBA-программ,
приведенных в этой книге, в качестве IDL-компилятора используется MICO IDL-
компилятор. В табл. 8.3 перечислены опции командной строки, которые чаще всего
применяются при вызове этого IDL-компилятора.
Таблица 8.3. Самые распространенные опции командной строки,
применяемые при вызове IDL-компилятора
Опции командной строки Описание
--boa Генерирует “каркасные” конструкции, которые используют базовый объектный адаптер (basic object adapter — BOA). Эта опция используется по умолчанию
--no-boa Отключает генерирование кода “каркасных” конструкций ДЛЯ
--роа Генерирует “каркасные” конструкции, которые используют пер носимый объектный адаптер (portable object adapter — РО*
--по-роа Отключает генерирование кода “каркасных” конструкции Д' РОА. Эта опция используется по умолчанию
8.5. Базовый проект CORBA-приложения 293
Окончание табл. 8.3
«---^^g^ded-def s "
Описание
Генерирует код, который был включен с помощью директив
#include
,-version
_0<define>
-I<path>
Выводит версию спецификации MICO
Определяет макрос препроцессора. Эта опция эквивалентна
ключу -D у большинства UNIX С-компиляторов
Определяет путь поиска для директив # include. Эта опция
эквивалентна ключу -1 у большинства UNIX С-компиляторов
будут ориентированы
нении следующей ком
Ключи -boa и -роа (см. табл. 8.3) позволяют определить, на какой тип адаптера
создаваемые “каркасные” конструкции. Например, при выпол-
анды
idl -роа -no-boa adding_machine.idl
будет получен файл adding_machine. h, который содержит “каркасные” конструк-
ции для РОА-адаптера (portable object adapter), и будет отключено генерирование
“каркасных” конструкций для ВОА-адаптера (basic object adapter).
При вводе команды
idl -h
будет сгенерирован полный список ключей IDL-компилятора. Если в поставке MICO
надлежащим образом инсталлированы man-страницы, то ввод команды
man idl
обеспечит полное описание доступных IDL-ключей. Проектирование IDL-классов —
первый шаг в CORBA-программировании. На следующем этапе необходимо опреде-
лить способ хранения и считывания IOR-ссылок на удаленные объекты.
^^ктронная почта
^•протокол
^аплетЫ/сервде1
^ляемая память
ПеР«меИные среды
8.5.2. Получение IOR-ссылки для удаленных объектов
ORB-класс содержит две функции-члена (string_to_object() Hobject_to_
string ()), которые можно использовать для преобразования IOR-объектов из строк
в объекты типа Objectjtrs и обратно. Функция-член string_to_object() при-
ает параметр типа const char * и преобразует его в объект типа Objectjptr.
’ТНкция-члсн object_to_string() принимает параметр типа Object_ptr и преоб-
ORB еГ° В Указатель типа char *. Эти методы являются составной частью интерфейса
ССЫЛ^ Метод object„to_string() используется для получения объектной IOR-
пРог И СТР0КОВ°й формы. IOR-ссылку, представленную в виде строки, можно передать
Риммам клиентов (потребителей) различными способами, например:
Разделяемые файловые системы (NFS-оборудование)
Встраивание в HTML-документы
Аргументы командной строки
Традиционные средства межпроцесной связи (IPC), т.е. кана-
лы, FIFO-очереди и пр.
CGI-команды приема и отправки данных
294 Глава 8. Распределенное объектно-ориентированное программировав
Затем программа приема данных получает строковый вариант IOR-ссылки
пользует функцию-член string_to_object () ORB-объекта для преобразования1? ИС
ссылки в CORBA-объект pt г. Этот CORBA-объект pt г затем “сужается” (т.е
дится к соответствующему типу) и используется для инициализации локальног^*^0
екта. В программах 8.1 и 8.2 для передачи IOR-ссылки между программ^
потребителем и программой-изготовителем используются строковые формы об °И
тов и файл. Строковую форму IOR-ссылок можно использовать для обеспеч
очень гибкой связи с удаленными объектами, которые могут размещаться практич^
ски в любом месте Internet, intranet или extranet. Существует реализация MIWCQ
(Wireless Mico) — открытая реализация спецификации wCORBA1, стандарт бесп
водной спецификации CORBA, который можно использовать для улучшения мобиль
ности объектов. Эта беспроводная спецификация позволяет реализовать связь по
средством MIOR-ссылки (Mobile IOR). Она поддерживается для TCP-, UDP- и WAP
WDP-механизмов передачи (Wireless Application Protocol Wireless Datagram Protocol)
Мультиагентные и распределенные агентные системы также могут воспользоваться
преимуществами стандартов IOR-ссылок. IOR- и MIOR-ссылки являются частью
“строительных блоков” следующего поколения объектно-ориентированных Web-
служб. Важно отметить, что хотя строковые IOR-ссылки обеспечивают гибкость и пе-
реносимость, они не могут идеально подходить ко всем ситуациям и конфигурациям.
Передача файла, который содержит IOR-ссылку, — не слишком приемлемое требование
для многих систем. Трудно с точки зрения практичности требовать от приложений кли-
ента и сервера разделять одну и ту же файловую систему или сеть. А с точки зрения
безопасности строковый вариант IOR-ссылки вообще исключается как достойный рас-
смотрения. Если приложение типа “клиент-сервер” велико по объему и достаточно раз-
нотипно, то требование разделения строковой формы IOR-ссылки может оказаться
слишком ограничивающим. CORBA-спецификация включает еще два стандарта для по-
лучения или передачи объектных ссылок: службы имен и маклерские службы.
8.6. Служба имен
Стандарт службы имен обеспечивает механизм преобразования имен в объектные
ссылки. Автор запроса на IOR-ссылку предоставляет в службу имен имя, а она возвра-
щает ему объектную ссылку, соответствующую этому имени.
Служба имен действует как разновидность телефонного справочника, в котором
по имени ищется номер. Эта служба позволяет программам клиента (потребител
находить по имени объектные ссылки. Эту службу можно использовать не только для
получения IOR-ссылок, но и для других ресурсов приложения. Получение объектной
ссылки по имени называется связыванием по имени (name binding). Коллекция вариан.
тов связывания по имени соотносится с объектом именного контекста (па о
context). Чтобы проиллюстрировать понятие именного контекста, предположим,
у нас есть приложение, которое предназначено для планирования маршрутов
стоит из большого количества различных объектов. Мы можем организовать
объектов в соответствии с выполняемыми ими функциями. Одни объекты отН°р|аЦ1е
к группе файлового ввода-вывода данных, а другие — к группе безопасности.
1 wCorba - это стандарт CORBA для беспроводного взаимодействия удаленных объект
Материалы по стандарту wCORBA доступны по адресу: www. отд. огд.
8.6. Служба имен 295
использует также объекты, которые имеют отношение к видам транс-
0рИЛОжеНИ^ автобус, автомобиль и велосипед. Каждое такое группирование образует
пор^ п° „ коНТекст. Например, чтобы логически сгруппировать объекты, связанные
неКОтоРь1И нсПОрТа можно создать контекст транспорта и связать с ним все виды
с виДаМИ Р таКое группирование позволяет сформировать именной контекст. Снача-
транспорт^ наименование каждого вида транспорта с его IOR-ссылкой. Это и есть
ла свя имени. Затем соотносим это связывание по имени с контекстом транс-
свЯЗЫв используем контексты для логической организации групп связанных объ-
порта. коллекция связанных именных контекстов образует именной граф (naming
ектов. именные контексты представляются объектами. Поскольку именной контекст
Я™" уется как объект, он может участвовать в связывании по имени подобно любо-
Р -Тому’ объекту. Это означает, что именной контекст может потенциально содер-
жать другие именные контексты. Например, на рис. 8.7 показано несколько контек-
стов включающих логическое представление нашего контекста транспорта.
Обратите внимание на то, что последняя строка в контексте транспорта представ-
ляет собой имя airborne (воздушный вид транспорта). Для имени airborne сущест-
вует еще один контекст, именуемый flying_machines (летательные аппараты).
Контекст f lying_machines содержит связи с несколькими объектами (на основе
выполняемых функций). Контекст transportation (транспортные средства) вместе
с контекстом f lying_machines образуют именной граф. На рис. 8.7 обратите внимание на
то, что последний объект в контексте f lying_machines называется sonic (звуковые).
Имя sonic связано с контекстом f ast_f lying_machines. Имя sonic имеет объект-
ную ссылку 8888. Тем самым к именному графу добавляется еще один контекст. Это —
пример именного контекста, содержащего другой именной контекст. Именной граф
можно использовать для представления “многоплановой” структуры взаимосвязей
в распределенном объектно-ориентированном приложении. Можно сказать, что
именной граф фиксирует панораму распределенного приложения. Для мультиагент-
ных систем именной граф можно использовать в качестве разновидности семантиче-
ской сети (см. § 8.1). Несмотря на то что объекты могут быть разбросаны по различ-
ным аппаратным платформам, операционным системам, языкам программирования
и географически отдаленным компьютерам, именной граф может представлять еди-
ную логическую структуру взаимоотношений и связей между объектами. На рис. 8.8
показано альтернативное представление именного графа, приведенного на рис. 8.7.
иные контексты этих двух рисунков совпадают, и в обоих случаях отчетливо
°т°бражены взаимоотношения между именными контекстами. На рис. 8.8 также
fast3aH° ЧТ° сУществУет путь от контекста transportation к контексту
lyin<?__machines и обратно к контексту transportation.
Няют Я °^ХОДа именного графа в процессе решения распределенной задачи приме-
Ного известные алгоритмы обхода графов. При этом различные пути обхода имен-
ет гРаФа могут представлять различные решения задачи. Служба имен обеспечива-
к°нтек 3апРоса Д°ступом к именным контекстам и именным графам. К именным
контекСТаМ ДОСТУП осУШ^ствляется через именные графы, а к связям — через именные
ки. раТЫ Связывание обеспечивает прямое соответствие имени и объектной ссыл-
*Изгот СМотРим программу 8.3, в которой представлен простой вариант
сНеко°ВИТеЛЯ ’ созДаЮ1Пего связывание по имени и соотносящего это связывание
°рым именным контекстом.
296
Глава 8. Распределенное объектно-ориентированное программиров
ание.
КОНТЕКСТ
"ТРАНСПОРТНЫЕ СРЕДСТВА"
Имя объекта Объектная ссылка
boat 1234
саг 5678
train 9876
bicycle 2345
airborne 9999 —► wq
КОНТЕКСТ
"ЛЕТАТЕЛЬНЫЕ АППАРАТЫ"
Имя объекта Объектная ссылка
helicopter 9331
kite 9221
balloon 0911
sonic 8888
•
КОНТЕКСТ "СКОРОСТНЫЕ
ЛЕТАТЕЛЬНЫЕ АППАРАТЫ"
Имя объекта Объектная ссылка
jet 9898
shuttle 8899
starship 8869
Рис. 8.7. Несколько различных именных контекстов
Рис. 8.8. Альтернативное представление именного графа
8.6. Служба имен 297
//
1
2
3
4
5
6
7
8
9
Программа 8.3
. ^inde <iostream>
#1ПЙЙ <fstream>
include "permutation_impl.h"
# - MICO__CONF_IMR
<CORBA-SMALL.h>
<iostrearn.h>
<fstream.h>
^define
^include
#include
#include
«include <unistd.h>
Jinclude <mico/CosNaming.h>
10
int main(int argc, char *argv[])
13 {
14 CORBA: :ORB_var Orb = CORBA::ORB_init
1 (argc,argv,"mico-local-orb");
15 CORBA: :0bject_var PoaObj =
Orb->resolve_initial_references("RootPOA");
16 portableserver:: P0A_var Poa =
Portableserver::POA::„narrow(PoaObj);
17 Portableserver:: POAManager_var Mgr =
Poa->the_POAManager();
18 inversion Server;
19 Portableserver: :Objectld_var Oid =
Poa->activate_object(^Server);
20 Mgr->activate() ;
21 permutation_ptr Obj ectReference = Server.„this();
22 CORBA: :Object_var NameService =
Orb->resolve_initial_references ("NameService");
23 CosNaming: : NamingContext_var NamingContext =
CosNaming::NamingContext::„narrow (NameService);
24 CosNaming: :Name name;
25 name.length (1) ;
26 name[0].id = CORBA::string_dup ("Inflection");
27 name[0] .kind = CORBA::string_dup ("");
28 NamingContext->bind (name, ObjectReference);
29 Orb->run() ;
30 Poa->destroy (TRUE, TRUE) ;
31 return(Q) ;
32 }
33
34
® o.1. Семантические сети
Сем
‘ аНТИческая сеть (semantic network) — это одна из самых старых и простых схем
Нйе СТавления знаний. В основе семантической сети лежит графическое изображе-
Се^^еРаРхических взаимоотношений между объектами. На рис. 8.9 показана простая
Ио нческая сеть, которая отображает знания о транспортных средствах в целом
к°нкретных транспортных средствах в частности.
298 Глава 8. Распределенное объектно-ориентированное программирование
Рис. 8.9. Простая семантическая сеть транспорт-
ных средств
Овалы в семантической сети называются узлами, а линии — связями. Связи представ-
ляют существующие отношения между узлами. Узлы используются для представления
объектов и фактов (или описателей). Некоторые связи являются дефинициональны-
ми, а другие могут быть вычислены. Связи можно использовать для отображения на-
следования или подчиненности. Узлы и связи вместе выражают некоторые порции
знаний. Например, изучив семантическую сеть, представленную на рис. 8.9, мы пони-
маем, что F-15— это транспортное средство, а также летательный аппарат, который
имеет по крайней мере два крыла. Семантические сети используются для представле-
ния знаний, необходимых в ПО принятия решений.
8.6.1. Использование службы имен и создание именных
контекстов
При выполнении строки 22 серверная программа получает ссылку на службу имеИ
CORBA::Object_var NameService =
Orb->resolve_initial_references("NameService");
Помимо получения объектных ссылок на хранилище реализаций (Implementat^
Repository) и хранилище интерфейсов (Interface Repository), метод ORB-об'ьеь^
resolve—initial—references () используется для получения ссылки на
имен. Получив нужную ссылку’, программа-сервер создает на ее основе именной
текст (см. строку 23):
CosNaming::NamingContext_var NamingConrexr =
CosNaming::NamingContext::_narrow(NameService);
8.6. Служба имен 299
подходе мы получаем начальный именной контекст, который играет
При TaKO,L действующего по умолчанию. Обнаружив службу имен и создав на-
роль ^менН’ой контекст, серверная программа может добавлять в контекст пары
чальныи имеНи) “имя/объектная ссылка”. Имена могут представлять собой
(связывания или другие контексты. Чтобы добавить в контекст пару
объекты ссылка”, необходимо сначала создать имя. Имена реализуются
*цмя/0 CORBA посредством структуры NameComponent.
в станд г
truct NameComponent {
Istring__var id,
lstring__var kind;
В CORBA-реализации MICO структура NameComponent объявляется в файле
CosNaming. h. Структура NameComponent содержит два атрибута: id и kind. Первый
атрибут используется для хранения текста имени, а второй представляет собой иден-
тификатор, который можно использовать для классификации объекта, например так.
//...
CosNaming: : Name Obj ес tName ;
ObjectName. length (1) ;
ObjectName. id = Corba : : string_dup ( " train" ) ;
ObjectName. kind = Corba : : string_dup (" land—transportation") ;
NamingContext->bind(ObjectName, ObjectReference) ;
Здесь объявляется объект типа NameComponent. Атрибут' id устанавливается равным
значению "train", а атрибут kind — значению land_transportation. Очевидно, ат-
рибут id должен быть описателем (дескриптором) объекта. Атрибут kind можно ис-
пользовать для описания контекста или логической группы, к которой принадлежит этот
объект. В данном случае он классифицирует поезд (train) как объект
land-transportation (наземный вид транспорта). Метод bind () преобразует имя объ-
екта ObjectName в объектную ссылку ObjectReference и связывает ее с начальным
именным контекстом. Имя может состоять из нескольких объектов типа NameComponent.
Ьсли имя состоит только из одного объекта типа NameComponent, оно называется про-
а если из нескольких — составным. Если имя составное, то атрибут kind можно ис-
пользовать для описания отношения (этот метод рассматривается в главе 12). В програм-
•э объект связывается с объектной ссылкой, которая соотносится с именованным кон-
текстом. После связывания с именным контекстом объект клиента может получить доступ
контексту посредством службы имен. В программах 8.1 и 8.2 для связи (посредством
ли Л ?В°й Ссылки) между7 программами потребителя и изготовителя мы использова-
ния- А для связи клиента и сервера (см. программу 8.3) используется служба имен.
л Тали инсталляции и функционирования службы имен зависят от конкретной реа-
слул^ИИ СреДа MICO включает программу nsd, которая реализует COS-совместимую
Необх ИМеН* ПрежДе чем служба имен будет доступной для программы-потребителя,
реали°ДИМ° мстить демон mi cod и внести соответствующие элементы в хранилище
к сооГ^ Чтобы узнать, как пользоваться программами nsd, micod и imr, обратитесь
^Рим етствующей документации и руководству по MICO (оно содержит множество
фраг^а Использования программ imr, nsd, micod и ird). В листинге 8.5 приведен
е^Т И3 сЧенаРия’ используемого для настройки сервера в программе 8.3, позво-
еИ сделать службу имен доступной для программы-потребителя.
300 Глава 8. Распределенное объектно-ориентированное программирование
// Листинг 8.5. Сценарий внесения записи в хранилище
// реализаций и запуска службы имен
И
minnd -ORBIIOPAddr inet:hostname:рогtnumber —forward &
ixnr create NameService poa 'which nsd' IDL.-omg.org/CosNaming/
NamingContext:1.0#NameService \
-ORBImplRepoAddr inet:hostname:portnumber \
-ORBNamingAddr inet:hostname:hostname:portnumberportnumber
imr create permutation persistent "'pwd'/permutation—server \
-ORBImplRepoAddr inet:hostname:portnumber \
-ORBNamingAddr inet:hostname:portnumber" IDL:permutation:1.0 \
-ORBImplRepoAddr inet:hostname:portnumber \
-ORBNamingAddr inet:hos tname:portnumber
imr activate permutation
-ORBImplRepoAddr inet:hostname:portnumber \
-ORBNamingAddr inet:hostname:portnumber
Этот сценарий можно использовать в сочетании с кодом сервера, приведенным
в программе 8.3. Приведенный здесь сценарий реально позволяет автоматически за-
пустить программу-сервер permutation—server. Обратите внимание на то, что
имена hostname и рогtnumber в программе 8.5 необходимо заменить реальным име-
нем компьютера, на котором выполняется сервер, и номером порта соответственно.
8.6.2. Служба имен “потребитель-клиент”
Программа 8.3 связывает имя объекта с именным контекстом. Программа 8.4 со-
держит текст программы-потребителя, которая использует службу имен для доступа
к связкам “объект-ссылка”, которые были созданы в программе 8.3. Программа 8.3 ге-
нерирует перестановки любой строки символов, которую она получает. Для переста-
новки изменяется местоположение символов в строке. Например, эти строки
Objcte JbOetc tbOjec
Оjbeet JObetc
Оjbeet JtObec
представляют собой перестановки строки Object. Клиент передает серверу строку
и сервер генерирует 2V перестановок. Сервер связывает имя "Inflection" с имен-
ным контекстом. Именно это имя программа-клиент должна задать, чтобы получить
объектную ссылку из именного контекста.
// Программа 8.4
1 int main(int argc, char *argv[])
2 {
3
4 try{
5 CORBA::ORB_var Orb = CORBA::ORB_init
(argc,argv,"mico-local-orb");
6 object—reference Remote("NameService",Orb);
7 Remote.objectName("Inflection");
8 permutation—var Client =
permutation::_narrow(Remote.objectReference());
8.6. Служба имен 301
char Value[1000] ;
9 Ю 11 12 13 14 15 strcpy(Value, "Common Object Request Broker"); ciient->original(Value); int N; for(N = 0;N < 15;N++) cout << "Значение функции nextPermutation() " << Client->nextPermutation() « endl;
16 17 18 19 20 21 22 23 24 25 26 } } catch(CosNaming::NamingContext::NotFound_catch &exc) { cerr « " Исключение: объект не обнаружен." « endl; catch (CosNaming: :NamingContext: : InvalidName__catch &exc) { cerr « "Исключение: некорректное имя." « endl; } return(0);
Для доступа к соответствующему объекту именного контекста в программе-
потребителе необходимо выполнить следующие три действия.
1. Получить ссылку на службу имен.
2. С помощью службы имен получить ссылку на соответствующий именной контекст.
3. С помощью именного контекста получить ссылку на соответствующий объект.
Действие 1 реализуется путем вызова метода resolve_initial_ref erences () :
//. . .
CORBA: :Object_var NameService;
NameService = Orb->resolve_initial_references
("NameService") ;
//...
Функция resolve_initial_ref erences () возвратит объектную ссылку на служ-
бу имен. В действии 2 эта ссылка используется для получения объектной ссылки на
именной контекст:
CosNaming: :NamingContext,_var NameContext;
^©Context = CosNaming::NamingContext::_narrow
(NameService) ;
В Действии 3 значение объектной ссылки NameService “сужается”, т.е. приводит-
Ной С°ОТВетствУЮ1ЦемУ типу, в результате чего получается объектная ссылка на имен-
По к°нтекст NameContext. С помощью объекта NameContext программа-
Исп^е°ИТеЛЬ может вызвать его метод resolve(). Строки 24-27 из программы 8.3
}ются для построения имени, которое и будет передано методу resolve ().
и,.-
Name г ~“ C0RBA::string_dup ("Inflection");
try -kind = CORBA::string_dup ("");
} kjectReference = NameContext->resolve (Name);
302 Глава 8. Распределенное объектно-ориентированное программирование
Метод resolve () возвращает объектную ссылку, связанную с заданным и
объекта. В данном случае задано имя "Inflection". Обратите внимание на то
такое же имя связывается с именным контекстом в программе 8.3 (строка 28) £ЧТ°
программа-потребитель имеет объектную ссылку, она может ее “сузить”, а затем СЛИ
помощью получить доступ к удаленному объекту. Процесс получения объектной с
ки на удаленный объект вполне тривиален, и поэтому имеет смысл его упростить
тем инкапсуляции соответствующих компонентов в классе.
class object—reference{
//. . .
protected:
CORBA::Object—var NameService;
CosNaming::NamingContext—var NameContext;
CosNaming::Name Name;
CORBA::Object—var ObjectReference;
public:
object—reference(char *Service,CORBA::ORB_var Orb);
CORBA::Object—var objectReference(void);
void objectName(char *FileName,CORBA::ORB_var Orb);
void objectName(char *OName);
}
Программа 8.4 использует преимущества простого каркасного класса
obj ect_ref erence, который мы создали с этой целью.
В программе 8.4 (строка 6) обратите внимание на создание объекта Remote типа
obj ect_reference. В строке 8 этот объект используется для получения ссылки на
удаленный объект с помощью следующего вызова метода:
Remote.obj ectReference();
После этого программа-потребитель получает доступ к удаленному объекту.
Класс object—reference обеспечивает выполнение некоторых необходимых дей-
ствий и тем самым упрощает написание программы-потребителя. Конструктор
класса obj ect_ref erence (он вызывается в строке 6 программы 8.4) реализован
следующим образом.
object—reference::object—reference(char *Service,
CORBA::0RB_var Orb)
{
NameService = Orb->resolve_initial_references (Service);
NameContext = CosNaming::NamingContext::_narrow (
NameService);
}
Этот конструктор получает ссылку на службу имен и создает объект класса
NameContext. В строке 7 имя этого объекта передается методу obj ectName () • Затем
для получения объектной ссылки, связанной с именем объекта, используется именной
контекст. Метод obj ectName () реализован следующим образом.
void object_reference::objectName(char *OName)
{
Name.length (1);
Name[0].id = CORBA::string_dup (OName);
Name[0].kind = CORBA::string_dup ("");
try {
8.7. Подробнее об объектных адаптерах 303
Ob3 ectReference = NameContext->resolve (Name);
Catcerr « " Problem resolving Name " « endl;
throw;
}
)
После вызова метода obj ectName () программа-потребитель получает доступ
к ссылке на удаленный объект. Теперь остается лишь вызвать метод
ot>jectReference () (это реализуется в строке 8 программы 8.4). В методе
obj ectName () основную часть работы выполняет функция resolve (). Программы 8.3
и 84 образуют простое распределенное приложение “клиент-сервер”, которое для дос-
тупа к объектным ссылкам вместо строковой формы IOR-ссылок использует службу
имен. В сетях intranet или Internet можно использовать оба подхода. Эти же варианты
применяются в качестве опорных структурных компонентов в контексте новой модели
Web-служб.
8.7. Подробнее об объектных адаптерах
Помимо службы имен и объекта именованного контекста, сервер в программе 8.3
также использует переносимый объектный адаптер. Вспомните, что адаптер
(см. рис. 8.6) действует как своего рода посредник между ORB-брокером и обслужи-
вающим объектом, который в действительности выполняет работу CORBA-объекта.
Мы можем сравнить этот обслуживающий объект с “наемным” писателем, который
пишет книгу от имени “подуставшей” знаменитости. С этой знаменитостью напере-
бой общаются журналисты, литературные агенты и юристы. Знаменитость удостаи-
вается всех почестей, но реальную работу делает за него другой человек. CORBA-
объект “публикует” интерфейс с внешним миром и играет роль “знаменитости”
в CORBA-программе. Программа-клиент (или потребитель) взаимодействует с ин-
терфейсом, который обеспечивает CORBA-объект, но реальную работу выполняет
обслуживающий объект, играя роль “наемного” писателя. Обслуживающий объект
имеет собственный протокол, который может отличаться от используемого
WRBA-объектом. CORBA-объект может предоставить С++-интерфейс для связи
с клиентом. Обслуживающий объект может быть реализован на Java, Smalltalk,
пгап и других языках программирования. Объектный адаптер обеспечивает ин-
терфейс с обслуживающим объектом. Он адаптирует этот интерфейс, чтобы реали-
зация обслуживающего объекта была прозрачна для ORB-брокера и программы-
ента. CORBA-реализация должна нормально поддерживать два типа объектных
дааПТрРОВ: Basic Object Adapter (BOA) и Portable Object Adapter (РОА). Сначала стан-
т°чно был ориентирован на использование ВОА-адаптера, но он не был доста-
Кое ° ГИ^КИМ> Поэтому и был разработан РОА-адаптер, который нашел более широ-
Не пРИМенение. ВОА-адаптер обладает минимальным набором средств, но его впол-
Ко Но Использовать для активизации объектных реализаций на базе информации,
рая содержится в хранилище реализаций (табл. 8.4).
304 Глава 8. Распределенное объектно-ориентированное программирование
Таблица 8.4. Некоторые элементы, содержащиеся в хранилище реализаций]
Элементы Описание ** ’
Имя объекта Уникальный идентификатор для каждого объек^
Режим активизации Разделяемый, неразделяемый, постоянный, биб лиотека penne thod
Путь Список идентификаторов хранилища Имя или путь выполняемого файла
ВОА-адаптер, чтобы приступить к выполнению объекта изготовителя (сервера)
использует такие записи из хранилища реализаций, как режим активизации и путь
И хотя в ряде более простых примеров, приведенных в этой главе, используется ВОА-
адаптер, мы рекомендуем для серьезной CORBA-разработки применять РОА-адаптер
РОА-адаптер поддерживает:
• прозрачную активизацию объекта;
• транзитные объекты;
• неявную активизацию обслуживающих объектов;
• перманентные (постоянные) объекты за пределами сервера.
Возможно, наиболее важной функцией РОА-адаптера является взаимодействие
с обслуживающими объектами. CORBA-спецификация определяет обслуживающий
объект следующим образом.
Обслуживающий объект — объект языка программирования, который реализует
запросы к одному или нескольким объектам. Обслуживающие объекты в общем
случае существуют в контексте процесса сервера. Запросы на получение объект-
ных ссылок обслуживаются ORB-брокером, действующим в качестве связующего
звена, и трансформируются в вызовы конкретных обслуживающих объектов. Во
время своего жизненного цикла объект может быть связан с несколькими обслу-
живающими объектами.
Каждый обслуживающий объект должен иметь по крайней мере один РОА-
адаптер. Но возможны и другие конфигурации (рис. 8.10).
РОА-адаптерами управляют специальные объекты управления, или РОА
менеджеры. CORBA-спецификация определяет РОА-менеджер таким образом:
РОА-менеджер — это объект, который инкапсулирует состояние обработки одного
или нескольких РОА-адаптеров. С помощью РОА-менеджера разработчик может сде-
лать запросы к соответствующим РОА-адаптерам с организацией очереди. Разработ
чик также может использовать РОА-менеджер для дезактивизации РОА-адаптеров.
Сервер в программе 8.3 служит простым примером использования объектов
адаптеров и РОА-менеджеров. Более подробное рассмотрение РОА выходит за
нашей книги. За деталями обращайтесь к работе [20]. MICO-поставка также содер
ряд примеров использования мощных средств РОА.
8.8. Хранилища реализаций и интерфейсов 305
конфигурацияз
।___________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________:
Рис. 8.10. Возможные конфигурации отношений между РОА-агентами и обслуживающими
объектами
8.8. Хранилища реализаций и интерфейсов
ORB-брокер для определения местоположения объектов, когда строковые IOR-
ссылки недоступны, использует хранилище реализаций. Хранилища реализаций пред-
ставляют собой удобное место для хранения информации, связанной со спецификой
среды (например, данные о системе безопасности, детали отладки и т.д.). Хранилище
реализаций должно содержать информацию, достаточную для того, чтобы ORB-брокер
мог отыскать путь объекта и выполняемый файл. Утилита imr в поставке MICO исполь-
зуется для управления хранилищем реализаций. Она позволяет отображать записи хра-
нилища реализаций, вносить в него новые и удалять ненужные, например:
create permutation persistent "'pwd'/permutation_server \
-ORBImplRepoAddr inet:hostname:portnumber \
-ORBNamingAddr inet:hostname:portnumber” IDL:permutation:1.0 \
При выполнении этой команды в хранилище будет добавлена запись с перестанов
имени. Местоположение выполняемого файла определяется как
‘pwd’ /permutation_server. Эта запись также включает значения hostname
и Portnumber, которые сообщают, где должна выполняться программа. Хранилище
Реализаций — весьма подходящее место для хранения информации этого типа об объ-
екте. Эта запись также устанавливает режим активизации (persistent). ORB-брокер
ИсПользует эту информацию для надлежащей инициализации выполнения программы
Именем permutation_server. Полный список опций, доступных для программы
содержится в соответствующей документации. Помимо хранилища реализаций,
306 Глава 8. Распределенное объектно-ориентированное программирование
используется хранилище интерфейсов, которое предназначено для хранения ДИн
ческой информации о каждом объекте. Хранилище интерфейсов можно использо И
для динамического определения местоположения интерфейса с CORBA-объектами д*ТЬ
работы с хранилищем интерфейсов в MICO-реализациях CORBA-спецификации *
пользуется программа ird. И хотя CORBA-спецификация описывает логические Воз
можности хранилищ реализаций и интерфейсов, все же некоторые ее детали
(например, способы записи данных в хранилища и управления ими) зависят от кон
кретной среды, поставки и производителя.
8.9. Простые распределенные Web-службы,
использующие CORBA-спецификацию
Адреса для хранилищ реализаций и служб имен можно встроить в код HTML и ис-
пользовать как часть CGI-обращения к Web-серверу. Этот метод с помощью CORBA-
спецификации можно применить для реализации простых распределенных Web-
служб. В листинге 8.6 представлен простой HTML-код. При щелчке на гиперссылке
будет выполнен CORBA-клиент. Этот CORBA-клиент может затем получить доступ
к серверу, используя адрес хранилища реализаций и службы имен, который был пере-
дан в CGI-команде HTML-кода.
// Листинг 8.6. HTML-документ со встроенным обращением к
// CORBA-программе (клиенту)
<HTML>
<HEAD>
<TITLE> CORBA</TITLE>
</HEAD>
<BODY>
<a href="http: //ww. somewhere. org/cgi-bin/client?-
ORBImp1RepoAddr+inet:hostname:port+-
ORBNamingAddr+inet:hostname:port">Click</a>
<P>
</HTML>
Здесь клиент ссылается на программу, которая должна получить доступ к CORBA-
изготовителю (серверу). У клиента есть имя объекта, с которым ему необходимо свя-
заться, а для дальнейших действий он использует службу имен. Этот метод не требует
загрузки кода на компьютер пользователя. Совсем наоборот, код клиента, выполняясь
на Web-сервере, должен получить доступ к CORBA-ориентированной программе
серверу независимо от ее местоположения (или в intranet-сети, подключенной к we
серверу, или где-нибудь в другом месте Internet). Программа-клиент должна ответить
HTML-браузеру, используя соответствующий CGI-протокол. Простая конфигурация
Web-служб с CORBA-компонентами показана на рис. 8.11.
Помимо протокола http, для запуска CORBA-ориентированных клиентов и сер
веров можно использовать сетевой теледоступ telnet. Протоколы http и tel
можно использовать для поддержки глобального распределения СОК '
компонентов. При проектировании распределенных компонентов, ориентир
ванных на функционирование в сети Internet или intranet, важно не забыв
о системе безопасности (соответствующем ПО и данных). И хотя реализа
8.10. Маклерская служба 307
ия предъявляемые к безопасности, выходят за рамки этой книги, мы
йтребов важнуЮ роль в любом проекте распределенной системы. Для
подчер * иНформации, имеющей отношение к безопасности, можно использо-
хРанеНИ^нИЛИ1Це реализаций. Любую CORBA-реализацию можно использовать
вать ХР и с протоколом защищенных сокетов (Secure Socket Layer — SSL) и спе-
циальной оболочкой SSH (Secure Shell).
Простая архитектура Web-служб_____________________________________
КОМПЬЮТЕР А
компьютер в
Программа-сервер
Программа-клиент
Хранилище
реализаций
Хранилище
интерфейсов
TCP/IP
Служба
имен
| Доступ к IP-адресам;
। * хранилища реализаций
‘Хранилища интерфейсов
I >:'службыимен
TCP/IP
CGI
http
КОМПЬЮТЕР
ПОЛЬЗОВАТЕЛЯ Е
• использует протокол html/CGI
• вызывает программу-клиент
Рис. 8.11. Простая конфигурация Web-служб с CORBA-компонентами
8.10. Маклерская служба
Помимо строковых IOR-ссылок и службы имен, CORBA-спецификация включает
се прогрессивный и динамический метод получения объектных ссылок, име-
Ный ЫИ Макле1)ск°и службой (trading service). Эта служба предлагает более интерес-
ыи (по сравнению с рассмотренными выше) подход к взаимодействию с удален-
‘ и ооъектами. Вместо взаимодействия со службой имен, клиент общается
^МаклеР°м”, у которого доступ к объектным ссылкам организован практически так
> как и в службе имен. Однако “маклер” связывает с объектными ссылками не
Па «1е Имена’ а описания и интерфейсы. В то время как служба имен содержит
ссыд имя-ссылка”, маклерская служба содержит пары “описания (интерфейсы)-
Ка • Клиенты могут описать для “маклера” объект, который им нужен, и тот
308 Глава 8. Распределенное объектно-ориентированное программирование.
ответит им соответствующей объектной ссылкой, если искомое соответствие будет
обнаружено. Это — очень мощный поисковый метод. При этом клиент может це
знать не только местоположения объекта, но и даже его имени. Это позволяет кли-
енту делать запросы на основе списка услуг, которые ему нужны, а не искать кон-
кретный объект (запросы чего-то, которые не важно, где и кем будут
удовлетворены). CORBA-спецификация определяет “маклер” следующим образом.
Маклер — это объект, который поддерживает маклерскую службу в распределенной
среде. Его можно представить себе в виде объекта, посредством которого другие
объекты могут информировать о своих возможностях и сопоставлять свои потреб-
ности с объявленными (разрекламированными) возможностями. Рекламирование
возможностей или услуг называется “экспортом”. Совпадение с ними потребностей
или обнаружение нужных услуг называется “импортом”. Экспорт и импорт позволя-
ют динамически обнаружить необходимые услуги и реализовать позднее связывание.
И точно так же, как при связывании нескольких именных контекстов формиру-
ются именные графы, при связывании нескольких маклеров формируются маклер-
ские графы. Именные и маклерские графы — это мощные методы представления
знаний и функциональных возможностей. Именные и маклерские графы обеспечи-
вают функционирование глобальных Web- и telnet-служб. Обход именных и маклер-
ских графов может включать участки, которые потенциально имеют “ответвления”
в какую-нибудь локальную сеть, intranet, extranet или Internet. Подобно именным
контекстам маклеры обычно представляют определенные типы объектов. Напри-
мер, мы могли бы позаботиться о том, чтобы маклеры одного типа имели доступ
к объектам кредитных карточек, а маклеры другого — к объектам сжатия и шифро-
вания. Можно создать маклеры, которые бы занимались объектами погоды и гео-
графии. А еще мы могли бы “научить” маклеры интересоваться финансовой дея-
тельностью и страхованием. Объединив все эти маклеры, получим маклерский
граф. Если один маклер будет работать от имени других, мы получим то, что можно
назвать федерацией маклеров. Когда клиент описывает одному маклеру услуги, в кото-
рых он нуждается, а затем маклер общается со своими коллегами, чтобы найти эти
услуги, то клиент и этот маклер включаются в федерацию маклеров. Это — самая
мощная и гибкая форма “запроса, который не важно, где и кем будет удовлетворен’.
Когда федерация маклеров возвратит объектную ссылку, может оказаться, что она
“родом бог-знает-откуда” и может быть реализована обслуживающим объектом
(объектами), операционная система и язык программирования которого совер-
шенно чужд программе клиента. Федерация маклеров обеспечивает доступ к очень
большим и разнообразным коллекциям услуг. Следует иметь в виду, что CORBA-
стандарт включает беспроводную спецификацию wCORBA, используемую для раз-
работки мобильных агентных и мультиагентных систем. На рис. 8.12 показана базо-
вая архитектура CORBA-ориентированного приложения типа “клиент-сервер”, ко-
торое делает запросы к маклерам.
Программа-клиент может взаимодействовать с маклером (или маклерами) на-
прямую или косвенно через федерацию маклеров. На рис. 8.12 обратите внима-
ние на то, что после получения объектной ссылки осуществляется взаимодейст-
вие с ORB-брокером. Термины, связанные с темой программирования маклеров,
приведены в табл. 8.5.
8.11. Парадигма “клиент-сервер” 309
Приложение типа "клиент-сервер", использующее маклерские объекты
КОМПЬЮТЕР А КОМПЬЮТЕР С
КОМПЬЮТЕР D
Рис. 8.12. Базовая архитектура CORBA-ориентированного приложения типа “клиент-
сервер”, которое делает запросы к маклерам
^Таблица 8.5. Термины, связанные с темой программирования маклеров
Термин
Экспортер
Импортер
Предложение
услуги
Описание
Рекламирует услугу с помощью маклера. Экспортер может быть про-
вайдером услуг или анонсировать услугу от имени кого-то другого
Использует маклер для поиска услуг, соответствующих некоторому
критерию. Импортер может быть потенциальным клиентом услуг
или импортировать услугу от имени кого-то другого
Содержит описание анонсируемой услуги. Описание состоит из име-
ни типа услуги, объектной ссылки и свойств объекта
8.11. Парадигма “клиент-сервер”
Термины “клиент” и “сервер” часто применяются к различным видам программ-
ных приложений. Парадигма “клиент-сервер” состоит в разделении работы на две
Части, представляемые процессами или потоками. Одна часть, клиент, создает запро-
сы на получение данных либо действий. Другая часть, сервер, выполняет эти запросы.
°ли запрашивающей и отвечающей стороны в большинстве случаев определяются
Логикой самих приложений. Термины “клиент-сервер” используются на уровне
310 Глава 8. Распределенное объектно-ориентированное программирование
операционной системы для описания отношений типа “изготовитель-потребит
которые могут существовать между процессами. Например, если для взаимодей ’
двух процессов используется FIFO-очередь, один из процессов “играет” роль сеп ИЯ
а другой — роль клиента. Иногда клиент может “исполнить” роль сервера, если cabi
дет получать запросы. Аналогично сервер будет выступать в роли клиента, если^
потребуется обращаться с запросами к другим программам. Конфигурация “клиен^
сервер” — основная архитектура распределенного программирования. При этом
сервера обычно характеризует все приложение. Некоторые наиболее популярные
типы программных серверов перечислены в табл. 8.6.
Таблица 8.6. Основные типы программных серверов I
Типы программных серверов Описание
Сервер приложений Используется для обеспечения множества клиентов доступом к при- ложению. Вся работа приложения делится между клиентом и серве- ром, причем большая ее часть делается на сервере, а клиент (имея собственный процессор) выполняет только некоторую часть работы
Файловый сервер Действует как центральное хранилище для разделяемых документов, мультимедийных файлов, баз данных и т.д. Клиенты обычно пред- ставлены терминалами или рабочими станциями в сети. Клиент де- лает запрос на файлы или отдельные записи в этих файлах, затем файловый сервер передает запрос к клиенту. Файловый сервер под- держивает целостность данных и безопасность доступа к файлу
Сервер баз данных Разбивает работу приложения между различными компьютерами в сетевой среде. Клиент формирует запросы на получение некоторо- го элемента данных, затем сервер баз данных находит эти данные и передает запрос клиенту. Сервер баз данных может обрабатывать сложные информационные запросы, для удовлетворения которых могут понадобиться мощности нескольких баз данных
Серверы транзакций Используется для выполнения транзакций, которые происходят на компьютере или компьютерах, содержащих сервер транзак- ций. Каждое действие или обновление выполняется полностью без прерывания. При возникновении некоторых проблем все действия или обновления отменяются, и делается новая попытка выполнить транзакцию
Логические серверы Используется для решения задач, которые требуют интенсивных символьных вычислений. Логический сервер способен отыскать как неявно, так и явно заданную информацию в базе данных. Логи ческий сервер способен проследить некоторую информацию и сДе лать логический вывод об информации, которая не была явно ввеДе на в базу данных. Логический сервер состоит из базы данных с оДН или несколькими встроенными механизмами логического выво Этот механизм используется для получения заключений и вывод от сервера. База данных состоит из правил, теорем, аксиом и про дур. Чтобы удовлетворить запросы, логический сервер ДоЛ применять дедукцию, индукцию, силлогизмы и другие приемы —
8.12. Резюме 311
w г снаЯ доска” и мультиагентные системы — это две основные архитектуры, ис-
,еМЫе в данной книге для поддержки параллельного и распределенного про-
п°ль У _ ваНИя. Особое внимание мы уделяем логическим серверам (см. табл. 8.6).
ский сервер — это специальный тип сервера приложений, который использу-
^°я для решения задач, требующих интенсивных символьных и, возможно, парал-
еТСЯнЫХ вычислений. Процесс формирования некоторого вывода и дедукции часто
Ляжелым бременем ложится на процессор и может значительно выиграть от исполь-
зования параллельно работающих процессоров. Обычно чем больше процессоров
сТУпно логическим серверам, тем лучше. Мультиагентные архитектуры и архитек-
' “классной доски”, рассматриваемые в главах 12 и 13, опираются на понятие рас-
пределенных логических серверов, которые могут совместными усилиями решать
проблемы в сетевой среде, intranet или Internet. Несмотря на то что агентный подход
и стратегия “классной доски” формируют архитектуру с уклоном в сторону равно-
правных узлов, они являются клиентами логических серверов. Распределенные объ-
екты используются для реализации всех компонентов системы, а CORBA-
спецификация позволяет упростить сетевое программирование.
8.12. Резюме
Распределенное программирование включает программы, которые выполняются
в различных процессах. Все процессы потенциально размещаются на различных
компьютерах и, возможно, в различных сетях с различными сетевыми протоколами.
Методы распределенного программирования позволяют разработчику разделить
приложение на отдельно выполняемые модули, отношения между которыми можно
определить на основе равноправия или как “изготовитель-потребитель”. Каждый мо-
дуль имеет собственное адресное пространство и компьютерные ресурсы. Распреде-
ленное программирование позволяет использовать преимущества специальных про-
цессоров, периферийного оборудования и других компьютерных ресурсов
(например, серверов баз данных, приложений, почтовых серверов и т.д.). CORBA —
это стандарт, применяемый для распределенного объектно-ориентированного про-
граммирования. В этой главе рассматриваются только CORBA-спецификации и CORBA-
службы. Здесь вы должны были получить представление об этих базовых компонентах
и о том, как можно построить простую распределенную программу. CORBA-
спецификации для Web-служб, MAF, службы имен можно получить по адресу:
WWw-omg.org. За подробностями можно обратиться к книге [20]. Именные и маклер-
ские графы обеспечивают основу для мощного распределенного механизма представ-
ления знаний, который можно использовать в сочетании с мультиагентным програм-
Р ванием. Они создают основу для следующего уровня интеллектуальных Web-служб.
РЕАЛИЗАЦИЯ
МОДЕЛЕЙ SPMD
И MPMD С ПОМОЩЬЮ
ШАБЛОНОВ И MPI-
ПРОГРАММИРОВАНИЯ
В этой главе...
9.1. Декомпозиция работ для MPI-интерфейса
9.2. Использование шаблонных функций для представления
MPI-задач
9.3. Упрощение взаимодействия между MPI-задачами
9.4. Резюме
В сознательных действиях должен присутствовать существенный
неалгоритмический компонент.
— Роджер Пенроуз (Roger Penrose), The Emperor’s New Mind
Понятие параметризованного программирования поддерживается шаблонами.
Основная идея параметризованного программирования — обеспечить макси-
мально благоприятные условия для многократного использования ПО путем
реализации его проектов в максимально возможной общей форме. Шаблоны функций
поддерживают обобщенные абстракции процедур, а шаблоны классов — обобщенные
абстракции данных. Обычно компьютерные программы уже представляют собой
обобщенные решения некоторых конкретных проблем. Программа, которая сумми-
рует два числа, обычно рассчитана на сложение любых двух чисел. Но если программа
выполняет только операцию сложения, ее можно обобщить, “научив” выполнять
и другие операции над двумя любыми числами. Если мы хотим получить самую общую
рограмму, можем ли мы остановиться лишь на выполнении различных операций над
и УМя числами? А что если эти числа будут иметь различные типы, т.е. комплексные
© еШественные? Можно заложить в разработку программы выполнение различных
пов^нй НС только над любыми двумя числами, но и над значениями различных ти-
п Или Классов чисел (например, значениями типа int, float, double или ком-
бинаСНЫМИ)' Кроме того, мы хотели бы, чтобы наша программа выполняла любую
опеРаЧию на любой паре чисел — главное, чтобы эта операция была ле-
вПла Лля этих Двух чисел. Если мы реализуем такую программу, ее возможности
С++.п МНогокРатного использования будут просто грандиозными. Эту возможность
НИя Р°гРаммисту предоставляют шаблоны функций и классов. Такого вида обобще-
нно добиться с помощью параметризованного программирования.
314 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
Парадигма параметризованного программирования, поддерживаемая средст
C++, в сочетании с объектно-ориентированной парадигмой, также поддержива
средствами C++, обеспечивают уникальный подход к MPI-программированию. Ка^0**
миналось в главе 1, MPI (Message Passing Interface — интерфейс передачи сообщений?^
это стандарт средств коммуникации, используемых при реализации программ, треб
щих параллелизма. MPI-интерфейс реализуется как коллекция, состоящая более чем
300 функций. MPI-функции охватывают большой диапазон: от порождения задач И3
барьерной синхронизации операций установки. Существует также С++-представлени°
для MPI-функций, которые инкапсулируют функциональность MPI-интерфейса в набо
классов. Однако в библиотеке MPI не используются многие преимущества объектно-
ориентированной парадигмы. Преимуществ параметризованного программирования
в ней также нет. Поэтому, несмотря на то что MPI-интерфейс весьма важен как стан-
дарт, его “мощности” не позволяют упростить параллельное программирование. Да, он
действительно освобождает программиста от программирования сокетов и позволяет
избежать многих ловушек сетевого программирования. Но этого недостаточно. Здесь
может пригодиться кластерное программирование, а также программирование SMP-
и МРР-приложений. Шаблонные и объектно-ориентированные средства программиро-
вания C++ могут оказаться весьма полезными для достижения этой цели. В этой главе
для упрощения базовых SPMD- и MPMD-подходов'вместе с MPI-программированием
мы используем шаблоны и методы объектно-ориентированного программирования.
9.1. Декомпозиция работ для MPI-интерфейса
Одним из преимуществ использования MPI-интерфейса перед традиционными
UNIX/Linux-процессами и сокетами является способность MPI-среды запускать од-
новременно несколько выполняемых файлов. MPI-реализация может запустить не-
сколько выполняемых файлов, установить между ними базовые отношения и иденти-
фицировать каждый выполняемый файл. В этой книге мы используем MPICH-
реализацию MPI-интерфейса1. При выполнении команды
$ mpirun -пр 16 /tmp/mpi_examplel
будет запущено 16 процессов. Каждый процесс будет выполнять программу с именем
mpi—example 1. Все процессы могут использовать разные доступные процессоры.
Кроме того, каждый процесс может выполняться на отдельном компьютере, если MPI
работает в среде кластерного типа. Процессы при этом будут выполняться параллель-
но. Команда mpirun представляет собой основной сценарий, который отвечает за за-
пуск MPI-заданий на необходимом количестве процессоров. Этот сценарий изолирует
пользователя от подробностей запуска параллельных процессов на различных ком
пьютерах. Здесь будет запущено 16 копий программы mpi_examplel. Несмотря на то
что стандарт MPI-2 определяет функции порождения, которые можно использовать
для динамического добавления программ к выполняемому MPI-приложению, этот ме
тод не популярен. В общем случае необходимое количество процессов создается при
запуске MPI-приложения. Следовательно, во время старта этот код тиражируется
N раз. Описанная схема легко поддерживает модель параллелизма SPMD (SIMD), п°
скольку одна и та же программа запускается одновременно на нескольких процессе
рах. Данные, с которыми каждой программе нужно работать, определяются после
1 Все MPI-примеры в этой книге реализованы с использованием версий MPICH 1.1.2 и MPICH l-Z^
среде Linux.
9.1. Декомпозиция работ для MPI-интерфейса 315
ска программ. Этот метод старта одной и той же программы на нескольких про-
з*11 опах можно развить, если нужно реализовать модель MPMD. Вся работа MPI-
раммы делится между несколькими процессами, запускаемыми на старте про-
’Пмы. Информация о распределении “обязанностей” (т.е. кто что делает и какие
^оцессы работают с какими данными) содержится в самой выполняемой программе.
Компьютеры, задействованные в этой работе, перечисляются в файле
machines. arch (machines . Linux в данном случае) с использованием имени компь-
ютера. Местоположение этого файла зависит от конкретной реализации. В зависимо-
сти от инсталляции, взаимодействие компьютеров, перечисленных в этом файле, бу-
дет обеспечено либо командой ssh, либо UNIX/Linux-командой ' г'.
9.1.1. Дифференциация задач по рангу
Во время старта процессов, включенных в MPI-приложение, MPI-среда назначает
каждому процессу ранг и группу коммуникации. Ранг хранится как int-значение
и служит в качестве идентификатора процесса для каждой MPI-задачи. Группа комму-
никации определяет, какие процессы можно включить во взаимодействие типа
“точка-точка”. Сначала все MPI-процессы относят к группе, действующей по умолча-
нию. Заменить членов группы коммуникации можно, запустив приложения. После
старта каждого процесса необходимо определить его ранг с помощью функции
MPI_Conun_rank (). Функция MPI_Conun_rank () возвращает ранг вызывающего про-
цесса. В первом аргументе, передаваемом функции, вызывающий процесс определя-
ет, с каким коммуникатором он связывается, а его ранг возвращается во втором аргу-
менте. Пример использования функции MPI_Comm_rank () показан в листинге 9.1.
// Листинг 9.1. Использование функции MPI_Comm_rank()
//. . .
int Tag = 33;
int Worldsize;
int TaskRank;
MPI_Status Status;
MPI_init (&argc, &argv) ;
MPI_Coinm_rank (MPI_COMM_WORLD, &TaskRank) ;
MPl_Comm_size (MPI_COMM_WORLD, &WorldSize) ;
Коммуникатору MPI_COMM_WORLD по умолчанию при запуске назначаются все MPI-
задачи. MPI-задачи группируются по коммуникаторам, которые определяют группу
коммуникации. В листинге 9.1 ранг возвращается в переменной TaskRank. Каждый
процесс должен иметь уникальный ранг. После определения ранга задаче передаются
соответствующие данные либо определяется код, который ей надлежит выполнить,
ассмотрим следующие варианты.
Бриант 1. Простая MPMD-моделъ
lf(TaskRank == 1){
Il Некоторые действия.
(TaskRank == 2) {
} Другие действия.
Вариант 2. Простая SIMD-моделъ
if(TaskRank == 1){
// Используем одни данные.
}
if(TaskRank == 2){
// Используем другие данные.
316 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
В первом варианте ранг используется для разграничения между процессам
полняемой работы, а во втором — для разграничения данных, которые они л ВЬь
обрабатывать. Несмотря на то что каждый выполняемый MPI-файл стартует Hbl
ним и тем же кодом, модель MPMD (MIMD) можно реализовать с помощью п
и соответствующего ветвления программы. Аналогично после определения п °В
данным процесса можно назначить некоторый тип, тем самым определив конк &
ные данные, с которыми должен работать конкретный процесс. Ранг также исполь
зуется при передаче сообщений. MPI-задачи идентифицируют одна другую при об
мене сообщениями по рангам и коммуникаторам. Функции MPl_Send ()
HMPI_Recv() используют ранг в качестве указания пунктов назначения и отправ
ления соответственно. При выполнении вызова
MPI_Send (Buffer, Count, MPI_LONG, TaskRank, Tag, Comm) ;
будет отправлено Count значений типа long MPI-процессу с рангом, равным значе-
нию TaskRank. Параметр Buffer представляет собой указатель на данные, посылае-
мые процессу TaskRank. Параметр Count характеризует количество элементов в бу-
фере Buffer, а не его размер. Каждое сообщение имеет тег. Этот тег позволяет отли-
чить одно сообщение от другого, сгруппировать сообщения в классы, связать
определенные сообщения с определенными коммуникаторами и пр. Тег имеет тип
int, а его значение определяется пользователем. Параметр Comm представляет ком-
муникатор, которому назначается процесс. Если ранг и коммуникатор задачи извест-
ны, этой задаче можно посылать сообщения. При выполнении вызова
MPI_Recv (Buffer, Count, MPI__INT, TaskRank, Tag,
Comm,&Status);
будет получено Count значений типа int от процесса с рангом TaskRank. Инициатор
вызова будет заблокирован до тех пор, пока не получит сообщение от процесса с ран-
гом TaskRank и соответствующим значением тега (Тад). MPI-интерфейс для пара-
метров ранга и тега поддерживает групповые символы. Такими групповыми символа-
ми являются значения MPI_ANY_TAG и MPI,J\NY_SOURCE. При использовании этих
значений вызывающий процесс примет следующее полученное им сообщение незави-
симо от его источника и тега. Параметр Status имеет тип MPI_Status. Информа-
цию об операции приема можно получить из объекта Status. Параметр статуса со-
держит три поля: MPIJSOURCE, MPI-TAG и MPI_ERROR. Следовательно, объект
Status можно использовать для определения тега и источника процесса-
отправителя. При известном количестве процессов-участников можно точно опреде-
лить отправителей сообщений и их получателей. Обычно для этого используется кон-
кретное приложение. Распределение работы также зависит от приложения. Перед
началом работы каждый процесс сразу же определяет, сколько других процессов
включено в приложение. Это реализуется следующим вызовом:
MPI„Comm_size(MPI_CONM_WORLD,&WorldSize);
С помощью этой функции определяется размер группы процессов, связанных с кон
кретным коммуникатором. В данном используется стандартный коммуникат р
(MPI_COMM_WORLD). Количество процессов-участников возвращается в параметр
WorldSize. Этот параметр имеет тип int. Если каждому процессу известно значе
Worldsize, значит, он знает, сколько процессов связано его коммуникатором.
9.1. Декомпозиция работ для MPI-интерфейса 317
g 1.2. Группирование задач по коммуникаторам
Процессы связываются не только с рангами, но и с коммуникаторами. Коммуника-
определяет область коммуникации для некоторого множества процессов. Все
Т°Рцессы, связанные с одним и тем же коммуникатором, относятся к одной и той же
,ппе коммуникации. Работу, выполняемую MPI-программой, можно разделить меж-
группами коммуникаций. По умолчанию все процессы относятся к группе
СОММ—WORLD. Для создания новых коммуникаторов можно использовать функ-
fpuoMPI-Conwrucreate (). Список функций (с краткими описаниями), используемых
для работы с коммуникаторами, приведен в табл. 9.1.
Благодаря использованию рангов и коммуникаторов MPI-задачи легко идентифи-
цировать и различать. Ранг и коммуникатор позволяют структурировать программу
как SPMD- или MPMD-модель либо как некоторую их комбинацию. Для упрощения ко-
да MPI-программы мы используем ранг и коммуникатор в сочетании с параметризо-
ванным программированием и объектно-ориентированными методами. Шаблоны
можно использовать не только применительно к аспекту различных данных SIMD-
модели, но и к заданию различных типов данных. Это значительно упрощает структуру
многих приложений, требующих выполнения большого объема одинаковых вычис-
лений, но с различными типами данных. Для реализации модели MPMD (MIMD) мы
рекомендуем использовать динамический полиморфизм (поддерживаемый объекта-
ми), параметрический полиморфизм (поддерживаемый шаблонами), объекты-
функции и предикаты. Для разделения всего объема работы MPI-приложения эти ме-
тоды используются в сочетании с рангами и коммуникаторами MPI-процессов. При
использовании объектно-ориентированного подхода работа программы делится меж-
ду семействами объектов. Все семейства объектов связываются с различными комму-
никаторами. Соответствие семейств объектов различным коммуникаторам способст-
вует модульности проекта MPI-приложения. Такой способ разделения также помогает
понять, как следует применить параллелизм. Мы убедились, что объектно-
ориентированный подход делает MPl-программы более открытыми для расширения,
а также простыми для поддержки, отладки и тестирования.
^Таблица 9.1. Функции, используемые для работы с коммуникаторами
_____ Функции
#include "mpi.h"
int MPI_intercomm_create(
MPI—Comm LocalComm,
int LocalLeader,
MPI—Comm PeerComm,
int remote—leader,
int MessageTag,
MPI—Comm *CommOut) ;
int MPi_intercomm_.merge (
MPI__Comm Comm,
int High,
MPI—Comm *CommOut);
MPi-Cartdim_get (
MPI_Comm Comm,
—--------int *NDims ) ;______
Описание
Создает inter-коммуникатор из двух intra-
коммуникаторов
Создает intra-коммуникатор из inter-
коммуникатора
Возвращает декартову топологическую ин-
формацию, связанную с коммуникатором
318 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
Функции
int MPI_Cart_create(
MPI_Comm CommOld,
int NDims,
int *Dims,
int *Periods,
int Reorder,
MPI_Comm *CommCart);
int MPI_Cart_sub(
MPI_Comm Comm,
int *RemainDims,
MPI—Comm *CommNew) ;
int MPI_Cart—shift(
MPI—Comm Comm,
int Direction,
int Display,
int *Source,
int destination) ;
int MPI—Cart—map(
MPI—Comm CommOld,
int NDims,
int dims,
int *Periods,
int *Newrank) ;
int MPI—Cart—get(
MPI—Comm Comm,
int MaxDims,
int dims,
int *Periods,
int *Coords);
int MPI—Cart—coords(
MPI—Comm Comm,
int Rank,
int MaxDims,
int *Coords);
int MPI_Comm_create(
MPI—Comm Comm,
MPI—Group Group,
MPI_Comm *CommOut) ;
int MPI—Comm_rank(
MPI—Comm Comm,
int *Rank );
int MPI—Cart—rank(
MPI—Comm Comm,
int *Coords,
int *Rank );
int MPI—Comm_compare(
MPI—Comm Comml,
MPI—Comm Comm2,
int ^Result);
___________________^^^2?
Описание "
Создает новый коммуникатор, к котор^Г —
присоединяется топологическая инфорМаци
Делит коммуникатор на подгруппы, которые
образуют декартовы подсистемы более низкой
размерности
Считывает смещенные ранги источника
и приемника при заданном направлении
и величине смещения
Преобразует процесс в декартову топологи-
ческую информацию
Возвращает декартову топологическую
информацию, связанную с коммуникатором
Вычисляет координаты процесса в декарто-
вой топологии при заданном ранге в группе
Создает новый коммуникатор
Вычисляет и возвращает ранг вызывающего
процесса в коммуникаторе
Вычисляет и возвращает ранг процесса
в коммуникаторе при заданном декартовом
местоположении
Сравнивает два коммуникатора Comml
и Comm2
9.1. Декомпозиция работ для MPI-интерфейса 319
Окончание табл. 9.1
функции Описание
int "Tipi comm__dup( ~ Mpi_Comm Commin, эдР1_Comm *CommOut) ; Дублирует уже существующий коммуникатор со всей его кэшированной информацией
int ree ( MPI__Comm *Comm) ; Отмечает объект коммуникатора как освобо- жденный
int j4PI—Comm_group ( MPI—Comm Comm, MPI_.Group *Group) ; Получает доступ к группе, связанной с задан- ным коммуникатором
int MP I—C omm__s i z e ( MPI__Comm Comm, int *Size); Вычисляет и возвращает размер группы, свя- занной с заданным коммуникатором
int MPI_Comm_split( MPI_Comm Comm, int Color, int Key, MPI_Comm *CommOut) ; Создает новые коммуникаторы на основе цветов и ключей
int MPI_Comm_test_inter( MPI-Comm Comm, int *Flag); Определяет, является ли коммуникатор inter- коммуникатором
int MPI_Comm_remote_group ( MPI—Comm Comm, MPI—Group *Group); Получает доступ к удаленной группе, связан- ной с заданным inter-коммуникатором
int MPI_Comm_remote_size( MPI—Comm Comm, int *Size); Вычисляет и возвращает размер удаленной группы, связанной с заданным inter- коммуникатором
9.1.3. Анатомия MPI-задачи
На рис. 9.1 представлена каркасная MPI-программа. Задачи, выполняемые этой
программой, просто сообщают свои ранги MPI-задаче с нулевым рангом. Каждая
MPI-программа должна иметь по крайней мере функции MPI_Init ()
Finalize (). Функция MPI_Init() инициализирует MPI-среду для вызы-
вающей задачи, а функция MPI__Finalize () освобождает ресурсы этой МР1-задачи.
^кдая MPI-задача должна вызвать функцию MPI_Finalize() до своего заверше-
И №1 Обратите внимание на обращения к функциям MPI_COMM_rank ()
Ва -Size (). Они используются для получения значений ранга и количест-
во ^°Цессов’ которые принадлежат MPI-приложению. Эти функции вызываются
' инством MPI-приложений. Вызов же остальных MPI-функций зависит от кон-
(Ьо °ГО пРИложения- MPI-среда поддерживает более 300 функций (подробная ин-
г* ция представлена в соответствующей документации).
320 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
#include <mpi.h> <----- Заголовочный MPI-файл
int Dest;
int Tag = 50;
int Worldsize;
int TaskRank;
string M;
char Messagein[1000];
int N;
strstream Buffer;
MPI_Status Status;
MPI_Init(&argc,&argc); <----- Функция инициализации
MPI_Comm_rank(MPI_COMM_WORLD, TaskRank) ; <--- Получение ранга задачи
МР1_Со1Ш1—size(MPI—COMM—WORLD,&WorldSize); <---- Получение числа MPI-задач
Dest = 0; <---- Сообщает, кто получает сообщение.
N = 1;
if(TaskRank != 0)(
Buffer « "Ready To Work From Rank#" « TaskRank « ends;
getline(Buffer,M);
MPI_Send(const—char<char*>(M.data()),M.size 0+1,
MPI—CHAR,Dest,Tag,MPI—COMM—WORLD); <-------------- Отправка сообщения
}
else{
do{
cout « "From Supervisor" « endl;
MPI.Recv(Me s sagein,100,MPI.CHAR,N,
Tag,MPI—COMM—WORLD,^Status); <-------------------- Получение сообщения
cout « Messagein « endl;
cout « "Received From " « Messagein « endl;
N++;
} while(N < Worldsize);
}
MPI—Finalize();<----- Завершение MPI
}
Рис. 9.1. MPI-программа
9.2. Использование шаблонных функций для
представления MPI-задач
Шаблоны функции позволяют обобщать процедуры для любого типа данных. Рас-
смотрим процедуру умножения, которая работает для любого типа данных (точнее,
для типов данных, для которых операция умножения имеет смысл).
templatecclass Т> Т multiplies(Т X, Т Y)
{
return( X * Y) ;
}
Для такой шаблонной функции, как эта, используются необходимые параметра
для типа Т. Параметр Т означает некоторый тип данных, который будет реально
зан при реализации этого шаблона. Так, мы можем реализовать функн
multiplies () следующим образом.
//. . .
multiplies<double>(3.2,4.5);
9 2 Использование шаблонных функций для представления МР1-задач 321
"7/2","3/4");
аметр Т заменяется типом double, int и rational соответственно, опреде-
ЗДеСЬ самым точную реализацию операции умножения. Умножение для разных типов
ЛЯЯ определяется по-разному. Это означает, что для разных типов данных выполняет^
даН ^днчньШ код. Шаблонная функция позволяет написать одну операцию умножения
(в виде функции multiplies ()) и применить ее ко многим различным типам данных.
9.2.1. Реализация шаблонов и модель SPMD
(типы данных)
Параметризованные функции можно использовать с MPI-интерфейсом для обра-
ботки ситуаций, в которых все процессы выполняют одинаковый код, но работают
с различными типами данных. Так, определив значение TaskRank процесса, мы мо-
жем распознать, с какими данными и данными какого типа должен работать процесс.
В листинге 9.2 показано, как реализовать различные задачи для различных рангов.
//Листинг 9.2. Использование шаблонных функций для
// определения "фронта работ" МР1-задач
int main(int argc, char *argv[])
{
//. . .
int Tag = 2;
int Worldsize;
int TaskRank;
MPI_Status Status;
MPI_lnit(&argc,&argv) ;
MPI_Coiran_rank (MPI_COMM_WORLD, &TaskRank) ;
MPI_Comm_size (MPI_COMM__WORLD, &WorldSize) ;
//. . .
switch (TaskRank)
{
case 1: multiplies<double>(3.2,4.6);
break;
case 2: multiplies<complex>(X,Y)
break;
//case n:
//. . .
}
Поскольку' не существует двух задач с одинаковым рангом, все ветви в инструкции
Case листинга 9.2 будут выполнены различными MPI-задачами. Кроме того, такой тип
Параметризации можно распространить на контейнерные аргументы шаблонных
тункций. Это позволит передавать одной и той же шаблонной функции различные
г еинеры объектов, содержащие различные типы объектов. Например, в листин-
е -3 показана обобщенная шаблонная функция search ().
322 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
// Листинг 9.3. Использование контейнерных шаблонов в
// качестве аргументов шаблонных функций
template<T> bool search(Т Key, graph<T>)
{
//. . .
locate(Key)
//. . .
}
// . . .
MPI_Coiran_rank(MPI_COMM_WORLD,&TaskRank);
// . . .
switch(TaskRank)
{
case 1:
{
graph<string> bullion;
search<string> search("gold", bullion);
}
break;
case 2:
{
graph<complex> Coordinates;
search<complex>((X,Y),Coordinates);
}
break;
//. . .
В листинге 9.3 процесс, у которого TaskRank = 1, выполняет поиск в графе (graph)
с именем bullion, содержащем string-объекты, а процесс, у которого TaskRank = 2,
выполняет поиск в графе Coordinates, содержащем комплексные числа. Мы не должны
изменять функцию search (), чтобы приспособиться к другим данным или типам
данных, да и MPI-программа в этом случае имеет более простую структуру, поскольку
мы можем многократно использовать шаблонную функцию поиска (search) для про-
смотра контейнера graph, содержащего данные любого типа. Использование шабло-
нов значительно упрощает SPMD-программирование. Чем более общей мы делаем MPI-
задачу, тем более гибкой она становится. Кроме того, если некоторый шаблон прошел
этап отладки и тестирования, надежность всех построенных на его основе MPI-задач
можно считать довольно высокой, поскольку все они выполняют одинаковый код.
9.2.2. Использование полиморфизма для реализации
MPMD-модели
Полиморфизм— одна из основных характеристик объектно-ориентированного
программирования. Если язык претендует на поддержку объектно-ориентированного
программирования, он должен поддерживать инкапсуляцию, наследование и по^ли
морфизм. Полиморфизм — это способность объекта принимать множество форм- ,
лиморфизм поддерживает понятие “один интерфейс — множество реализации^
Пользователь использует одно имя, или интерфейс, реализованный различными
собами и различными объектами. Чтобы проиллюстрировать концепцию полиморфи
92.
Использование шаблонных функций для представления MPI-задач
323
им класс vehicle, его потомков и простую функцию travel (), которая
рассм г класс vehicle. На рис. 9.2 показана простая иерархия нашего семей-
используе.
сТВа класса vehicle.
Рис. 9.2. Иерархия семейства класса vehicle
Самолеты, вертолеты, автомобили и подводные лодки — все это потомки класса
vehicle (транспортные средства). Объект класса vehicle может заводить мотор,
перемещаться вперед, поворачивать вправо, поворачивать влево, останавливаться
и пр. В листинге 9.4 демонстрируется, как функция travel () использует объект клас-
са vehicle для совершения компьютеризованного путешествия.
// Листинг 9.4. Функция travel () , которая, в качестве
параметра использует объект класса vehicle
void travel(vehicle *Transport)
Transport->startEngine();
Transport->moveForward () ;
Transport->turnLeft () ;
Transports stop();
(Ht ^infint argc, char *argv[])
//. . .
car *Car;
Transportation = new VechicleO;
travel(Car);
о^^^ЦИя travel () принимает указатель на объект класса vehicle и вызывает методы
класса vehicle. Обратите внимание на то, что функция main() в листинге 9.4
324 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
объявляет объект типа саг, а не vehicle, а также на то, что функции travel ()
сто объекта типа vehicle передается объект типа саг. Это возможно благодаря то^
что в C++ указатель на класс может ссылаться на объект этого типа или на любой об
ект, который является потомком этого типа. Поскольку класс саг является прои
ным от класса vehicle, то указатель на тип vehicle может ссылаться на объект тип^
саг. Функция travel () написана без учета того, какими конкретно типами vehicl
объектов она будет манипулировать. Для функции travel () вполне достаточно что
бы ее vehicle-объекты могли запускать мотор, двигаться вперед, поворачивать вле
во, вправо и т.д. Если vehicle-объект способен выполнять эти действия, то функция
travel () сможет справиться со своей работой. Обратите внимание на то, что на
рис. 9.2 методы класса vehicle объявлены как виртуальные (virtual). Объявление
методов виртуальными в базовом классе является необходимым условием динамиче-
ского полиморфизма. В каждом из классов car, helicopter, submarine и airplane
будут определены следующие функции.
startEngine();
moveForward();
turnLeft();
turnRight();
stopO ;
//. . .
При этом объявление каждой функции будет соответствовать типу транспортного
средства. Несмотря на то что транспортное средство каждого типа способно двигать-
ся вперед, метод, в котором обеспечивается движение автомобиля, отличается от ме-
тода перемещения подводной лодки. Управление поворотом вправо у самолета отли-
чается от управления таким же поворотом у автомобиля. Следовательно, транспорт-
ное средство каждого типа должно реализовать необходимые операции для
получения законченного описания “своего” класса. Поскольку эти операции объяв-
ляются как виртуальные в базовом классе, они и являются кандидатами для реализа-
ции полиморфизма. Если vehicle-указатель, переданный функции travel (), в дей-
ствительности ссылается на объект типа саг, то методами, вызываемыми в этой
функции (startEngine (), moveForward () и пр.), реально окажутся те, которые оп-
ределены в классе саг. Если vehicle-указатель, переданный функции travel (),
в действительности ссылается на объект класса airplane, то методами, вызываемы-
ми в этой функции, реально окажутся те, которые определены в классе airplane. Это
и есть тот случай, когда много форм реализуется при одном интерфейсе. Несмотря на то
что функция travel () вызывает только один набор методов, поведение этих мето-
дов может радикально отличаться в зависимости от того, указатель на объект какого
vehicle-класса был назначен vehicle-указателю. Полиморфизм функции travel ()
состоит в том, что при каждом вызове она может выполнять совершенно разные деи
ствия. И в самом деле, поскольку функция travel () использует указатель на класс
vehicle, в будущем ее можно использовать для типов, производных от класса
vehicle, которые были неизвестны или не существовали во время разработки ф)нК
ции travel О. До тех пор пока будущие vehicle-классы будут наследовать класс
vehicle и определять необходимые методы, ими можно будет управлять с помощью
функции travel (). Этот тип полиморфизма называется динамическим (runtin^
polymorphism), поскольку функция travel () не знает точно, какие именно функ
startEngine (), moveForward () или turnLef t () она будет вызывать, до тех пор,
пока программа не начнет выполняться.
q 2 Использование шаблонных функций для представления МР1-задач 325
Этот тип полиморфизма полезен при реализации MPI-программ, которые исполь-
модель MPMD. Если MPI-задачи работают с указателями на базовые классы, то
3У1° ‘ физм позволяет MPI-классу также работать с любыми классами, производны-
П от пего. Предположим, что вместо объявления с указателем функция travel ()
мИ листинг 9.4) имела бы такое объявление:
oid travel(vehicle Transport);
В эТОМ случае при обращении к функциям startEngine (), moveForward () и про-
чим вызывались бы методы, принадлежащие только классу vehicle, и обращение
к производным классам было проблематичным. Использование же указателя на класс
vehicle и объявления методов в классе vehicle виртуальными (virtual) заставля-
ют работать механизм полиморфизма. MPI-задачи, которые манипулируют указателя-
ми на базовые классы, могут точно так же использовать преимущества полиморфиз-
ма как функции travel () удается работать с любым типом vehicle-объекта
(настоящим или будущим). Этот метод открывает большие перспективы для будущего
кластерных приложений, а также приложений SMP (Symmetrical Multi/jrocessing —
симметричная многопроцессорная обработка) и МРР (Massively Parallel Processing —
массовая параллельная обработка), в которых необходимо реализовать модели
MPMD. Чтобы понять, как модель MPMD работает в MPI-контексте, попробуем ис-
пользовать нашу функцию travel () в качестве MPI-задачи, которая является частью
подсистемы поиска. Все MPI-задачи отвечают за выполнение поисково-спасательных
операций применительно к vehicle-объектам различного типа. Очевидно, что каж-
дое транспортное средство (vehicle-объект) характеризуется различными способа-
ми движения. Несмотря на то что проблема, стоящая перед всеми MPI-задачами, за-
ключается в выполнении поиска, все они будут иметь различные коды, поскольку все
эти задачи используют различные виды vehicle-объектов, которые работают по-
разному и требуют различных данных. Код, который содержится в листинге 9.5, не-
обходимо запустить в нашей среде MPICH с помощью следующей команды.
$ npirun -пр 16 /txnp/search_n_rescue
// Листинг 9.5. Реализация MPI-задачами простого
поиска и имитации спасения поврежденных
объектов
template<T> bool travel(vehicle *Transport,
set<T> Location,
T Object)
{
-ransport->startEngine();
^ransport->moveForward(XDegrees);
^ransport->turnLeft(YDegrees);
(Location.find(Transport->location() == Object){
. rescue()
}
nt rcaindnt argc, char *argv[])
326 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
//...
int Tag = 2;
int Worldsize;
int TaskRank;
MPI_Status Status;
MPI—Init(&argc,fcargv);
MPI—Comm—rank(MPI_COMM_WORLD,&TaskRank);
MPI—Comm_size (MPI_COMM_WORLD, &WorldSize) ;
//. . .
switch(TaskRank)
{
case 1:
{
//. . .
car * Car;
set<streets> Searchspace
travel<streets>(Car, Searchspace,Street);
//. . .
}
break;
case 2:
{
//. . .
helicopter *BlueThunder;
set<air_space> NationalAirSpace;
travel<air_space>(BlueThunder,
NationalAirSpace,
AirSpace);
//. . .
}
//case n:
//. . .
}
Программа search_n_rescue будет запущена в 16 процессах, причем все процессы
потенциально могут выполняться на различных процессорах, а все процессоры — нахо-
диться на различных компьютерах. Несмотря на то что все процессы выполняют один
и тот же код, их действия могут радикально различаться (как и данные, с которыми они
работают). Шаблоны и полиморфизм позволяют отличать одну MPI-задачу от другом
(а значит, и данные, которые они будут использовать). Обратите внимание на то, что
в листинге 9.5 MPI-процесс, у которого TaskRank = 1, будет использовать объект клас-
са Саг и контейнер, содержащий streets-объекты. MPI-процесс, у которого TaskRank
- 2, будет использовать объект класса helicopter и а!г_зрасе-объекты. Обе задачи
вызывают шаблонную функцию travel (). Поскольку шаблонная функция travel ()
манипулирует указателями на класс vehicle, она может воспользоваться преимущест-
вами полиморфизма и выполнять операции с потомками класса vehicle. Это означает,
что, хотя все MPI-задачи вызывают одну и ту же функцию travel (), действия, вы
полняемые этой функцией, различны. Обратите внимание на то, что в функции
travel () нет инструкций case или if, которые бы пытались идентифицировать тип
vehicle-объекта, с которым она работает. Конкретный vehicle-объект определяет
ся типом, на который используется указатель. Это MPI-приложение может работать
g 2 Использование шаблонных функций для представления МР1-задач 327
нциально с 16 различными транспортными средствами, каждое из которых ха»
поте оИЗуется собственным типом мобильности и областью поиска. Существуют
Рак ие методы, которые можно использовать для реализации модели MPMD в среде
но полиморфический подход обычно требует меньшего объема кода.
Основные два типа полиморфизма, которые мы здесь демонстрируем, — это поли-
пывизм динамического связывания, поддерживаемый наследованием и виртуальными
методами, и параметрический полиморфизм, поддерживаемый шаблонами. Функция
travel () в листинге 9.5 использует оба типа полиморфизма. Полиморфизм, осно-
ранный на наследовании, характеризует параметр vehicle *Transport, а парамет-
рический полиморфизм - параметры set<T> и Т Object. Параметрический поли-
морфизм представляет собой механизм, благодаря которому один и тот же код ис-
пользуется для различных типов, передаваемых в качестве параметров. Различные
типы полиморфизма, которые позволяют упростить MPI-задачи и сократить код, не-
обходимый для реализации MPI-программы, перечислены в табл. 9.2.
Таблица 9.2. Различные типы полиморфизма, которые можно использовать
” для упрощения МР1-задач
Типы полиморфизма Механизмы Описание
Динамический
Параметрический
Наследование
и виртуальные
методы
Шаблоны
Вся информация, необходимая для определения
того, какие виртуальные методы будет вызывать
функция, неизвестна до выполнения программы
Механизм, в котором один и тот же код ис-
пользуется для различных типов, которые пе-
редаются как параметры
9.2.3. Введение MPMD-модели с помощью
фу н кци й - объе кто в
Функции-объекты используются в стандартных алгоритмах для реализации гори-
зонтального полиморфизма. Полиморфизм, реализованный с помощью передачи па-
раметра vehicle *Transport в листинге 9.5, является вертикальным, поскольку для
функционирования необходимо, чтобы классы были связаны наследованием. При го-
ризонтальном полиморфизме классы связаны не наследованием, а интерфейсом. Все
функции-объекты определяют операторную функцию operator (). Функции-объекты
позволяют разрабатывать MPI-задачи с использованием некоторой общей формы.
Функция-объект
Class some_class{
operator();
>;
{®nplate<class Т> Т mpiTask(T X)
//
328 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
Т Result;
Result = Х()
//. . .
}
Шаблонная функция mpiTask () будет работать с любым типом Т, который имеет
соответствующим образом определенную функцию operator ().
//. . .
MPI—Init(&argc,&argv);
MPI_Comm—rank(MPI_COMM_WORLD,&TaskRank);
MPI_Conuri—size (MPI_COMM_WORLD, &WorldSize) ;
//. . .
if(TaskRank == 0){
//. . .
user_defined—type M;
mpiTask(M);
//. . .
}
if(TaskRank == N){
//. . .
some_other_userdefined—type N;
mpiTask(N) ;
}
//....
Этот горизонтальный полиморфизм не имеет отношения к наследованию или
виртуальным функциям. Поэтому, если наша MPI-задача получит свой ранг, а затем
объявит тип объекта, в котором определена функция operator (), то при вызове
функции mpiTask () ее поведение будет продиктовано содержимым метода
operator (). Тогда, несмотря на идентичность всех процессов, запущенных посред-
ством сценария mpirun, полиморфизм шаблонов и функций-объектов позволит всем
MPI-задачам выполнять различную работу над различными данными.
9.3. Как упростить взаимодействие между
MPI-задачами
Помимо упрощения и сокращения размеров кода MPI-задачи с помощью поли-
морфизма и шаблонов, мы можем также упростить взаимодействие между MPI
задачами, воспользовавшись преимуществами перегрузки операторов. Функции
MPI_Send () и MPI_Recv () имеют следующий формат:
MPI_Send(Buffer,Count,MPI_LONG,TaskRank,Tag,Comm);
MPI_Recv(Buf fer, Count,MPI_INT,TaskRank,Tag,Comm,
&Status);
При вызове этих функций необходимо, чтобы пользователь указал тип применяемы*
здесь данных и буфер, предназначенный для хранения посылаемых или принимав
мых данных. Спецификация типа посылаемых или принимаемых данных м°ж
иметь довольно громоздкий вид и чревата последующими ошибками при передаче
верного типа. В табл. 9.3 приведены прототипы MPI-функций отправки и приеМа
данных и их краткое описание.
9.3. Как упростить взаимодействие между МРЬзадачами 329
П^^ица9-3- Прототипы MPI-функций отправки и приема данных
Функции Описание
int MPI—Send (void «Buffer,int Count, MPI_Datatype.Type, int Destination, int MessageTag, I4PI_Conun Comm) ; Выполняет базовую отправку данных
int MPI_Send_init (void *Buffer,int Count, MPI__Datatype Type, int Destination, int MessageTag, MPI_Comm Comm, MPI_Request *Request); Инициализирует дескриптор для стандарт- ной отправки данных
int MPI_Ssend (void *Buffer,int Count, MPI_Datatype Type, int Destination, int MessageTag, MPI—Comm Comm) ; Выполняет базовую отправку данных с син- хронизацией
int MPI—Ssend_init (void *Buffer,int Count, MPI—Datatype Type, int Destination, int MessageTag, MPI—Comm Comm, MPI-Request ‘Request); Инициализирует дескриптор для стандарт- ной отправки данных с синхронизацией
int MPI_Rsend (void *Buffer,int Count, I—Dat a type Type, int Destination, int MessageTag, MPI—Comm Comm) ; Выполняет базовую отправку данных с сиг- налом готовности
int MPl_Rsend_init (void *Buffer,int Count, MPI_Datatype Type, int Destination, int MessageTag, MPI—Comm Comm, M₽I_Request ‘Request); Инициализирует дескриптор для стандарт- ной отправки данных с сигналом готовно- сти
int MPi_isend (void *Buffer,int Count, MPI-Datatype Type, int Destination, Запускает отправку без блокировки
int MessageTag,
MpI—Comm Comm,
MpiJequest ‘Request ) ;
330 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов...
Продалженштп^ 9з
Функции Описание
int MPI-Issend (void *Buffer,int Count, MPI_Datatype Type, int Destination, int MessageTag, MPI_Comm Comm, MPI_Request *Request); Запускает синхронную отправку без блокировки
int MPI_Irsend (void *Buffer,int Count, MPI_Datatype Type, int Destination, int MessageTag, MPI—Comm Comm, MPI_Request *Request); Запускает неблокирующую отправку данных с сигналом готовности
int MPI_Recv (void *Buffer,int Count, MPI_Datatype Type, int source, int MessageTag, MPI_Comm Comm, MPI_Status *Status); Выполняет базовый прием данных
int MPI_Recv_init (void *Buffer,int Count, MPI_Datatype Type, int source, int MessageTag, MPI_Comm Comm, MPI_Request *Request); int MPI_Irecv (void *Buffer,int Count, MPI_Datatype Type, int source, int MessageTag, MPI_Comm Comm, MPI_Request *Request); Инициализирует дескриптор для приема данных Запускает прием данных* без блокировки
int MPI_Sendrecv (void *sendBuffer, int SendCount, MPI_Datatype SendType, int Destination, int SendTag, void *recvBuffer, int RecvCount, MPI_Datatype RecvYype, int Source, int RecvTag, MPI—Comm Comm, MPI—Status *Status); Отправляет и принимает сообщение
9.3. Как упростить взаимодействие между МР1-задачами 331
Окончание табл. 9.3
Функции Описание
-T^^pi__Sendrecv_replace in(void *Buffer,int Count, MPI__Datatype Type, int Destination, int SendTag, int Source,int RecvTag, j4PI__Comm Comm, MPI—Status *Status); Отправляет и принимает сообщение с ис- пользованием единого буфера
Наша цель — обеспечить отправку и получение MPI-данных с помощью пото-
кового представления iostream-классов. Данные удобно отправлять, используя
следующий синтаксис.
//...
int X;
float Y;
user_def ined_type Z;
cout « X « Y << Z;
//. . .
Здесь разработчик не должен указывать типы данных при вставке их в объект
cout. Для вывода этих данных трех типов достаточно определить оператор “«”.
Аналогично можно поступить при выделении данных из потокового объекта с in.
//. . .
int X;
float Y;
user_defined__type Z;
cin » X >> Y » Z;
//...
В инструкции ввода данных их типы не задаются. Перегрузка операторов позволяет
разработчику использовать этот метод для MPI-задач. Поток cout реализуется из
класса ©stream, а поток cin — из класса istream. В этих классах определены опера-
торы «” и “»” для встроенных С++-типов данных. Например, класс ostream со-
держит ряд перегруженных операторных функций “«”.
°stream&
°stream&
Ostream&
Ostream&
Ostream&
°stream&
Ostream&
Ostream&
Ostream&
°stream&
°stream&
operator« (char c);
operator« (unsigned char c) ;
operator« (signed char c) ;
operator« (const char *s) ;
operator« (const unsigned char *s) ;
operator« (const signed char *s) ;
operator« (const void *p) ;
operator« (int n) ;
operator« (unsigned int n) ;
operator« (long n) ;
operator« (unsigned long n) ;
332 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
С помощью этих определений пользователь классов ostream и istream прим^
ет объекты cout и с in, не указывая типы передаваемых данных. Этот метод п Я
грузки можно использовать для упрощения MPI-взаимодействия. Мы рассмотрел
идею PVM-потока в главе 6. Здесь мы применяем тот же подход к созданию Мр^
потока, используя структуру классов istream и ostream в качестве руководства ддя
разработки класса mpi_stream. Потоковые классы состоят из компонентов состоя
ния, буфера и преобразования. Компонент состояния представлен классом ios; ком
понент буфера — классами streambuf, stringbuf или filebuf. Компонент преоб
разования обслуживается классами istream, ostream, istringstream
os t ringstr earn, if stream и of stream. Компонент состояния отвечает за инкапсуля-
цию состояния потока. Класс ios включает формат потока, информацию о состоянии
(работоспособное или состояние отказа), факт достижения конца файла (eof). Компо-
нент буфера используется для хранения считываемых или записываемых данных. Клас-
сы преобразования предназначены для перевода данных встроенных типов в потоки
байтов и обратно. UML-диаграмма семейства классов iostream показана на рис. 9.3.
Рис. 9.3. UML-диаграмма семейства классов iostream
9.3.1. Перегрузка операторов “«” и “»” для организации
взаимодействия между MPI-задачами
Взаимоотношения и функциональность классов, показанных на рис. 9.3, можно
использовать как своего рода образец для проектирования класса mpi_strearns-
И хотя проектирование потоковых MPI-классов требует больше предварительной
9.3. Как упростить взаимодействие между MPI-задачами 333
боты по сравнению с непосредственным использованием функций MPI_Recv ()
mpI Send (), в целом оно делает MPI-разработку значительно проще. А если про-
И аммь*с параллельной обработкой можно упростить, это нужно сделать обязательно,
уменьшение сложности программ — весьма достойная цель для программиста. Здесь
Ы представляем лишь каркас класса mpi_s tream. Но этого вполне достаточно для
получения понятия о конструкции потокового MPI-класса. После разработки класса
/ stream можно приступать к упрощению организации взаимодействия между
дорр^адачами в большинстве MPI-программ. Листинг 9.6 содержит фрагмент из объяв-
ления класса mpi_s tream.
// Листинг 9.6. Фрагмент объявления
,, класса mpi_stream
class mpios{
protected:
int Rank;
int Tag;
MPI—Comm Comm;
MPI_.Status Status;
int Buffercount;
//• . .
public:
int tag(void) ;
//. . .
}
class mpi_stream public mpios{
protected:
mpi_buffer Buffer;
//. . .
public:
//. . .
mpi_stream (void) ;
mpi_stream(int R,int T,MPI_Comm C);
void rank(int R);
void tag(int T);
void comm(MPI—Comm C);
stream &operator« (int X) ;
stream &operator« (float X) ;
mPi__stream &operator« (string X) ;
mPi__stream &operator« (vector<long> &X) ;
stream &operator« (vector<int> &X) ;
mPi__stream &operator« (vector<f loat> &X) ;
stream &operator« (vector<string> &X) ;
tream ^operator» (int &X) ;
stream ^operator» (float &X) ;
tream ^operator» (string &X) ;
P^stream ^operator» (vector<long> &X) ;
-Stream ^operator» (vector<int> &X);
Pi_stream ^operator»(vector<float> &X);
// "stream ^operator»(vector<string> &X);
334 Глава 9. Реализация моделей SPMD и MPMD с помощью шаблонов
Для того чтобы сократить описание, мы объединили классы impi stre
и ompi-Stream в единый класс mpi_stream. И точно так же, как классы istre^
и ostream перегружают операторы “«” и мы обеспечим их перегрузку в
се mpi_stream. В листинге 9.7 показано, как можно определить эти перегруженны
операторы:
// Листинг 9.7. Определение операторов "«" и "»"
//. . .
mpi_stream &operator« (string X)
{
MPI_Send(const_cast<char*>(X.data()),X.size(),
MPI_CHAR,Rank,Tag,Comm);
return(*this);
}
// Упрощенное управление буфером.
mpi_stream &operator«(vector<long> &X)
{
long *Buffer;
Buffer = new long[X.size()];
copy(X.begin(),X.end(),Buffer);
MPI_Send(Buffer,X.size(),MPI_LONG,Rank,Tag,Comm);
delete Buffer;
return(*this);
}
// Упрощенное управление буфером.
mpi_stream &operator>>(string &X)
{
char Buffer[10000];
MPI_Recv(Buffer,10000,MPI_CHAR,Rank,Tag,Comm,&Status);
MPI_Get_count(&Status,MPI_CHAR,&BufferCount);
X.append(Buffer);
return(*this);
}
Назначение класса mpios в листинге 9.7 такое же, как у класса ios в семействе
классов iostream, а именно: поддерживать состояние класса mpi_stream. Все типы
данных, которые должны использоваться в ваших MPI-приложениях, должны иметь
операторы “«” и “>>”, перегруженные с учетом каждого типа данных. Здесь мы про-
демонстрируем несколько простых перегруженных операторов. В каждом случае мы
представляем упрощенный вариант управления буфером. На практике необходимо
предусмотреть обработку исключений (на базе шаблонных классов) и распределение
памяти (на базе классов-распределителей ресурсов). В листинге 9.7 обратите внима
ние на то, что класс mpios содержит коммуникатор, статус класса mpi_stream, номер
буфера и значение ранга или тега (это — лишь одна из возможных конфигураШ111
класса mpi_stream — существует множество других). После того как класс
mpi_stream определен, его можно использовать в любой MPI-программе. Взаимо
действие между MPI-задачами может быть организовано следующим образом.
//. . .
int X;
float Y;
vector<float> Z;
9.4. Резюме 335
• с г ream S tгearn(Rank,Tag,MPI_WORLD—COMM);
mP1-5 // y << z-
Stream « *« z-
Stream « Y'
и • * * 7
Stream >:>
Такой подход позволяет программисту, поддерживая потоковое представление,
vnoocTHTb MPI-код. Безусловно, в определение операторов “«” и “>>” необходимо
включить соответствующую проверку ошибок и обработку исключительных ситуаций.
9.4. Резюме
Реализация SPMD- и MPMD-моделей параллелизма во многом выигрывает от ис-
пользования шаблонов и механизма полиморфизма. Несмотря на то что MPI-
интерфейс включает средства динамического С++-связывания, в нем не используются
преимущества методов объектно-ориентированного программирования. Это создает
определенные трудности для разработчиков, использующих стандарт MPI. Для упро-
щения MPMD-программирования можно успешно использовать такие свойства объ-
ектно-ориентированного программирования, как наследование и полиморфизм. Па-
раметризованное программирование, которое поддерживается с помощью С++-
шаблонов, позволяет упростить SPMD-программирование MPI-задач. Разделение ра-
боты программы между объектами — это естественный способ реализовать паралле-
лизм в приложении. Для того чтобы облегчить взаимодействие между группами объ-
ектов, характеризующимися различной степенью ответственности за выполняемую
работу, семейства объектов в MPI-приложении можно связать с коммуникаторами.
Для поддержки потокового представления используется перегрузка операторов.
Применение методов объектно-ориентированного и параметризованного програм-
мирования в рамках одного и того же MPI-приложения является воплощением муль-
типарадигматического подхода, который упрощает код и во многих случаях уменьша-
ет его объем. Тем самым упрощается отладка программ, их тестирование и поддерж-
ка. MPI-задачи, реализованные с помощью шаблонных функций, характеризуются
более высокой надежностью при использовании различных типов данных, чем от-
дельно определенные функции с последующим обязательным выполнением операции
приведения типа.
ВИЗУАЛИЗАЦИЯ
ПРОЕКТОВ
ПАРАЛЛЕЛЬНЫХ
И РАСПРЕДЕЛЕННЫХ
СИСТЕМ
В этой главе...
10.1. Визуализация структур
10.2. Отображение параллельного поведения
10.3. Визуализация всей системы
10.4. Резюме
“Мысли, не оформленные в словесную оболочку, — это вполне обычное
явление. Наши идеи часто возникают на уровне ощущений. Мы вдруг
начинаем чувствовать правильность решения проблем, над которыми бились
долгое время, и только потом решаемся обозначить их на том или ином
языке... Очень много идей приходят нам в головы в бессловесной форме...”
— О. Коэхлер (О. Koehler), The Ability of Birds to Count
одель системы представляет собой своего рода информационное тело,
“собранное” с целью изучения системы и лучшего ее понимания разработ-
чиками и специалистами, которые должны ее поддерживать. При модели-
ровании системы должны быть идентифицированы отдельные ее части, атрибуты,
а также действия, выполняемые системой. Моделирование — важный инструмент
пРоЦессе проектирования любой системы, поэтому очень важно добиться того,
чтобы разработчики до конца понимали систему, которую разрабатывают. Модели-
рование помогает выявить заложенный в систему параллелизм и понять, как имен-
^еДует реализовать ее распределение.
инфицированный язык моделирования (Unifited Modeling Language — UML)
ржит графические средства, используемые для проектирования, визуализации,
нИя „ИР°Вания и Документирования артефактов системы программного обеспече-
Но-о 3bIK UML представляет собой фактический стандарт для моделирования объект-
ам РИентированных систем. Этот язык использует символы и условные знаки для обо-
лИчн аРтеФактов системы ПО, отображаемых с различных точек зрения и при раз-
НОГо°И ФОкусировке. Язык UML вобрал в себя методы объектно-ориентирован-
„ анализа и проектирования, предложенные Гради Бучем (Grady Booch),
‘ Сом Рамбау (James Rumbaugh) и Айваром Джекобсоном (Ivar Jacobson)
338 Глава 10. Визуализация проектов параллельных и распределенных систем
в 1980-х и 1990-х годах. Он был принят рабочей группой по развитию станл
объектного программирования (Object Management Group — OMG), междуц T°B
ной организацией, состоящей из разработчиков ПО и производителей инсЬоРОД
ционных систем и насчитывающей более 800 членов. Принятие UML дало п
ботчикам ПО не просто единый язык, а инструмент для анализа объектов, их
сания, визуализации и документирования. °Пи*
В этой главе мы покажем, как можно визуализировать и смоделировать параллел
ную и распределенную систему с помощью UML. Помимо помощи в разработке сис
темы, моделирование позволяет идентифицировать области параллелизма (где имен
но?), понять необходимость применения синхронизации и взаимодействия подсис
тем (когда именно?), а также продумать степень распределения объектов (как
именно?). Мы рассматриваем диаграммные методы визуализации и моделирования
параллельных систем со структурной и поведенческой точек зрения. Однако следует
отметить, что классы, объекты и системы, используемые в этой главе как примеры
служат целям демонстрации и необязательно отражают реальные классы, объекты
или структуры, используемые в действительно существующей системе.
10.1. Визуализация структур
При рассмотрении системы со структурной точки зрения акцент ставится на ее ста-
тических частях, т.е. нас интересует, как построены элементы системы. В этом случае
изучаются атрибуты, свойства и операции, выполняемые системой, а также ее органи-
зация, устройство (состав компонентов) и взаимоотношение элементов в системе.
В этом разделе рассматриваются диаграммные методы, используемые для моделирования:
• классов, объектов, шаблонов, процессов и потоков;
• организации объектов, работающих “в одной команде”.
Изображаемые при моделировании системы элементы могут быть концептуаль-
ными или физическими.
10.1.1. Классы и объекты
Класс — это модель некоторой конструкции, характеризующейся определенными
атрибутами и поведением. Это — описание множества понятий или объектов, кото
рые обладают общими атрибутами. Класс — это базовый компонент любой объектно
ориентированной системы. Классы можно использовать для представления реаль
ных, концептуальных, аппаратных и программных конструкций. Для представления
классов, объектов и взаимоотношений, которые существуют между ними в параллель
ной и/или распределенной системе, используется диаграмма класса (class diagiai /•
Диаграмма класса позволяет отобразить атрибуты и услуги, предоставляемые классом.
а также ограничения, налагаемые на способ связи этих классов/объектов.
Язык UML содержит средства для графического представления класса. Для ПР^
стейшего изображения класса достаточно начертить прямоугольник и написать
нем имя класса. При использовании только одного имени говорят, что это проС
имя. С помощью диаграммы класса можно также отобразить атрибуты и ),сЛ)с
предоставляемые пользователю этого класса (или операции, выполняемые э
10.1. Визуализация структур 339
сом) Чтобы включить в диаграмму атрибуты и операции, прямоугольник ото-
к7136 тсЯ с Тремя горизонтальными отделениями. В верхнем отделении записыва-
браж тое имя класса, в среднем — атрибуты, а в нижнем — операции. Разделы
сТСЯ в и операций можно пометить словами “атрибуты” и “операции” соответ-
аТР но Имя класса должно быть указано в любом случае, а раздел атрибутов или
СТ апий — по необходимости. Это значит, что если нужно указать один из разде-
ле (атрибутов или операций), то другой отображается пустым. Различные способы
представления класса показаны на рис. 10.1.
s tudent_s chedu1е
а)________
s tudent_schedu1е
Атрибуты
string : StudentNumber
string : Terra
map<string,vector<course> > : StudentSchedule
map<string,vector<course> >::iterator : Schedulelterator
Операции
student_schedule (void)
student_schedule(const student_schedule &Sched)
~student_schedule(void)
scheduleDayOfWeek(string DayOfWeek) : vector<course> &
student Schedule (void) : map<stnng, vector<course> > &
studentSchedule(raap<string,vector<course> > &X) : void
suudentNumber (string SN) : void
student Number (void) : string
term(string &X) : void
term(void) : string
operator=(const student_schedule ^Schedule) : student_schedule &
operator==(student—schedule &Sched) : bool
operaror«(ostream &Out, student_schedule &Sched) : ostream & {friend}
6)
student—schedule
Операции
student_schedule (void)
student_schedule(const student_schedule &Sched)
''Student_schedule (void)
scheduleDayOfWeek(string DayOfWeek) : vector<course> &
studentschedule(void) : map<string,vector<course> > &
studentschedule(map<string,vector<course> > &X) : void
StudentNumber (string SN) : void
studentNumber(void) : string
term(string &X) : void
^erm(void) : string
°Perator=(const student—schedule ^Schedule) : student_schedule &
°perator==(student_schedule &Sched) : bool
J3perator<<(ostream &Out, student—schedule &Sched) : ostream & {friend}
в)
Рис. 10.1. Различные способы представления класса
340 Глава 10. Визуализация проектов параллельных и распределенных систем
На рис. 10.1 представлен класс student_schedule. На рис. 10.1, а показано
простейшее представление, рис. 10.1, б содержит полную информацию о классе-
имя, атрибуты и операции, а рис. 10.1, в представляет имя класса и его опеп
(раздел, который должен содержать атрибуты, пуст). Если раздел атрибутов оставл^
пустым, это означает, что данный класс имеет атрибуты, но их показывать в лар еН
конкретном случае не нужно.
Иногда используется дополнительный раздел, который служит для описания обя
занностей класса. Он размещается под разделом операций и может быть опущен П
обязанностями класса подразумевают то, что ему надлежит выполнить. Обязанности
класса отображаются как “договорные” предложения, которые трансформируются
в операции и атрибуты. Атрибуты трансформируются в типы данных и структуры
данных, а операции — в методы (функции). Этот дополнительный раздел можно по-
метить словом “обязанности”. Обязанности класса student—schedule можно изло-
жить следующим образом: “возвращает расписание для студента на любой день неде-
ли при заданном номере студента, годе и периоде расписания”. Обязанности класса
отображаются в виде текста, причем каждая обязанность представляется в соответст-
вующем разделе как короткое предложение или абзац.
С помощью диаграммы класса можно отобразить объект, или экземпляр класса.
Как и при использовании класса, простейшее представление объекта состоит в изо-
бражении прямоугольника, который содержит подчеркнутое имя объекта. Тем самым
указывается именованный экземпляр класса. Именованный экземпляр класса можно
сопровождать именем класса или обойтись без него.
mySchedule именованный экземпляр
mySchedule: student—schedule именованный экземпляр с именем класса
Поскольку реальное имя объекта может быть известно только для программы, ко-
торая его объявляет, то в системной документации, возможно, имеет смысл указывать
анонимные экземпляры классов. Анонимный объект класса можно представить сле-
дующим образом.
:student—schedule
Такой тип обозначения может оказаться удобным в случае, когда в системе сущест-
вует несколько экземпляров класса. Несколько экземпляров класса можно предста-
вить двумя способами: в виде объектов и в виде классов.
Количество экземпляров, которое может иметь класс, называется множественно-
стью. Количество экземпляров класса (от нуля до бесконечности) можно указать на
диаграмме класса. Класс с нулевым количеством экземпляров является чистым абст-
рактным классом. Он не может иметь ни одного объекта, явно объявленного с исполь
зованием этого типа. Количество экземпляров может иметь нижнюю и верхнюю гра
ницы, которые также могут быть указаны на диаграмме класса. На рис. 10.2 показаны
возможные варианты обозначения нескольких экземпляров класса на диаграмме
класса (с помощью графических средств или значения множественности). 7
На рис. 10.2 множественность класса student—schedule указана как диапазон 1 •
а это означает, что наименьшее количество расписаний в нашей системе равно 1, а н
большее — 7. Приведем еще несколько примеров обозначения множественности класса
1 Один экземпляр
1. . п От одного до заданного числа п
1. . * От одного до бесконечности
0 . . 1 От нуля до единицы
10.1. Визуализация структур 341
о..
От нуля до бесконечности
Бесконечное количество экземпляров
Безусловно, бесконечное количество экземпляров будет ограничено объемом
^гл/иней или внешней памяти.
внутрен
student_schedule
student_schedule
Операции
student_schedule(void)
student_schedule(const student_schedule &
Sched)~student_schedule(void)
scheduleDayOfWeek(string DayOfWeek): vector<course> &
studentSchedule(void): map<string,vector<course> > &
studentSchedule(map<string,vector<course> > &X): void
studentNumber(string SN): void
studentNumber(void): string
term(string &X): void
term(void): string
operator=(const student_schedule &Schedule): student_schedule &
operator==(student_schedule &Sched): bool
operator«(ostream &Out, student_schedule &Sched): ostream & {friend}
Рис. 10.2. Обозначение нескольких экземпляров класса с помощью графических средств
и значения множественности
Ю.1.1.1. Отображение информации об атрибутах
и операциях класса
Диаграмма класса может содержать более подробную информацию об атрибутах
и операциях класса. В разделе атрибутов можно указать тип данных и/или значе-
ние по умолчанию (если оно предусмотрено) для класса и значения атрибутов для
объектов. Например, типы данных, содержащиеся в разделе атрибутов класса
student—schedule, могут иметь следующий вид.
StudentNumber : string
Term : string
udentSchedule : map <string,vector<course> >
cnedulelterator : map <string,
vector<course> >::iterator
Для объекта my Schedule эти атрибуты могут принимать такие значения.
Te^SntNuinber : strin9 = "Ю2933"
: string = "Spring"
ИМи^еТОДЬ1 мог)гг быть отображены с параметрами и с указанием типов возвращаемых
u^entSchedule (&Х : map <string,
Sbifl vector<course> >) : void
entNumber () : string
342 Глава 10. Визуализация проектов параллельных и распределенных систем
Функция student Schedule () принимает значение course для заданного ctv
(course - это класс, который моделирует один курс обучения). Курсы для каждого
недели хранятся в векторе. Контейнер шар устанавливает соответствие строки (ДНЯ
недели) и вектора курсов (для заданного дня недели). Функция studentschedu 1е?Я
возвращает void-значение, а функция StudentNumber () — значение типа string
На диаграмме класса можно также отобразить свойства атрибутов и операци-
(методов). Свойства атрибутов помогают описать характер использования того или
иного атрибута, что дает возможность судить о том, можно ли его изменять или пет
Так, для описания атрибутов используются три свойства: changeable, addOnl
и frozen. Краткое описание этих свойств приведено в табл. 10.1. Для определения
методов используются четыре свойства: isQuery, sequential, guarded
и concurrent. Они также описаны в табл. 10.1. Свойства sequential, guarded
и concurrent имеют отношение к параллельности выполнения методов. Свойство
sequential описывает операцию, ответственность за синхронизацию которой ле-
жит на инициаторе ее вызова. Такие операции не гарантируют целостности объекта.
Свойство guarded описывает параллельно выполняемую операцию с уже встроенной
синхронизацией. При этом guarded-операции означают, что в каждый момент вре-
мени возможен только один ее вызов. Свойство concurrent описывает операцию,
которая позволяет ее одновременное использование. Операции, описываемые с по-
мощью свойств guarded и concurrent, гарантируют целостность объекта. Гарантия
целостности объекта применима к операциям, которые изменяют состояние объекта.
Таблица 10.1. Свойства атрибутов и методов
Свойства атрибутов Описание
{changeable} {addOnly} {frozen} На значения этого типа атрибута никакие ограничения не налагаются Для атрибутов, у которых значение множественности >1, можно добавлять дополнительные значения. Созданное значение невозможно удалить или изменить После инициализации объекта значение атрибута изменить нельзя
Свойства методов
{isQuery} {sequential} {guarded} {concurrent} При выполнении метода этого типа состояние объекта остается неизменным. Этот метод возвращает значения Пользователи этого метода для обеспечения гарантии последо- вательного доступа к нему должны использовать синхронизацию- При множественном параллельном доступе к этому методу' цело стность объекта подвергается опасности Синхронизированный последовательный доступ к этому методу встроен в объект; целостность объекта гарантируется К этому методу7 разрешен множественный параллельный доступ, целостность объекта при этом гарантируется
10.1. Визуализация структур 343
Свойства guarded и concurrent можно использовать для отражения модели
RAM (Parallel Random-Access Machine — параллельная машина с произвольным дос-
,пОм). Если мет°Д считывает и/или записывает данные в память, доступную для дру-
ПОГО метода, который также считывает и/или записывает данные в ту же память, этот
метод может быть описан как PRAM-алгоритм. При этом можно использовать соот-
ветствующие свойства, например, такие.
PRAM-алгоритмы Свойства
CR (Concurrent Read — параллельное чтение) concurrent
C\V (Concurrent Write — параллельная запись) concurrent
CRCW (Concurrent Read Concurrent Write — параллельное чтение, параллельная запись) concurrent
EW (Exclusive Write — монопольная запись) guarded
ER (Exclusive Read — монопольное чтение) guarded
EREW (Exclusive Read Exclusive Write — монопольное чтение, монопольная запись) guarded
Описание класса student „schedule можно сделать еще более подробным, указав
с помощью свойств, как использовать его (класса) атрибуты и операции.
Атрибуты:
StudentNumber : string {frozen}
Term : string {changeable}
Student Schedule : map <s tring,
vector<course> > {changeable}
Операции:
scheduleDayOfWeek (&X : vector<course>, Day : string) :
void {guarded}
StudentNumber () : string {isQuery, concurrent}
Атрибут StudentNumber представляет собой константу типа string. После при-
своения значение константы изменить нельзя. Если объект student_schedule ис-
пользуется для того же студента, но для различных периодов времени, то атрибуты
Term и Studentschedule должны быть модифицируемыми. Метод
scheduleDayOfWeek () принимает вектор курсов (vector<course>) для конкретно-
Го дня недели, хранимого в строке Day. Это — защищенная (guarded) операция. Она
Помещает расписание студента, соответствующее конкретному дню недели, в шар-
ъект Studentschedule, изменяя тем самым его состояние. Синхронизация,
Утраиваемая в этот объект, обеспечивается за счет использования мьютексов. Метод
U entNumber () имеет два свойства: isQuery и concurrent. Этот метод возвра-
те Т КонстантУ StudentNumber и безопасен для одновременного доступа. Его вызов
Изменяет состояния объекта, поэтому здесь и использовано свойство isQuery.
а Диаграмме класса можно отобразить еще одно важное свойство атрибутов
^Раций ~ их видимость. Свойство видимости описывает, кто может получить дос-
/ атРибуту или вызвать операцию. Для представления этого свойства (уровня ви-
си СТИ Используется соответствующий символ. Уровни видимости соответствуют
Ификаторам доступа, определенным в C++.
Мвол видимости предваряет имя атрибута или операции (метода).
344 Глава 10. Визуализация проектов параллельных и распределенных систем
Спецификаторы доступа Символы видимости 1
public protected private (+) Общий доступ (#) Доступ имеет сам класс и его потомки (-) Доступ имеет только сам класс
10.1.1.2. Организация атрибутов и операций
От того, как будут организованы атрибуты и операции в соответствующих отделе
ниях диаграммы класса, зависит степень успешности использования этого класса дт
рибуты и операции можно упорядочить по алфавиту, уровню доступа или категориям
Как оказалось, алфавитный порядок вряд ли поможет узнать, как могут называться те
или иные атрибуты или операции (если документация находится в руках пользователя
системы), или какие из них еще не определены (если документация используется
в процессе разработки). Упорядочение по уровню доступа зарекомендовало себя го-
раздо лучше. В этом случае пользователь четко видит, какие атрибуты и операции яв-
ляются, например, общедоступными (public) или закрытыми (private). Знание пе-
речня защищенных (protected) членов поможет расширить возможности класса
или специализировать его, используя механизм наследования. Такое упорядочение
просто реализовать с помощью символов видимости (+, - и #) или С++-
спецификаторов доступа (public, private и protected,).
Существует несколько способов разбиения атрибутов и операций по категориям.
Минимальный стандартный интерфейс определяет категории для операций, которые
в свою очередь определяют атрибуты, поддерживающие эти операции. Составители
минимального стандартного интерфейса руководствовались тем, что все классы
должны определять такие операции и функции, которые делают его полезным. Вот
список этих операций:
• конструктор по умолчанию;
• деструктор;
• конструктор копии:
• операции присваивания;
• операции сопоставления на равенство;
• операции ввода-вывода;
• операции хеширования;
• операции запросов.
Этот список можно использовать в качестве основного перечня категорий для
фикации операций, определяемых в классе. В этот перечень можно внести категории,
торые позволяют указать дополнительные характеристики для атрибутов и операции-
Атрибуты:
static
const
Операции:
virtual
pure virtual
friend
10.1. Визуализация структур 345
Пой выборе категорий следует исходить из того, какая из них лучше всего описы- услуги. предоставляемые классом. Имя категории справа и слева заключается ^LftHbie угловые скобки («. . .»). На рис. 10.3 показано два возможных способа ганизации атрибутов и операций для класса student_schedule, использующих: символы видимости и спецификаторы доступа (рис. 10.3, а) и категории минимально- го стандартного интерфейса (рис. 10.3, б).
s tu dent_schedu1e
Атрибуты # string : StudentNumber # string : Term # map<string,vector<course> > : Studentschedule # map<string,vector<course> >::iterator : Schedulelterator
Операции « public >> student_schedule(void) student_schedule(const student_schedule &Sched) ~student_schedule(void) scheduleDayOfWeek(string DayOfWeek) : vector<course> &
а) символы видимости и спецификаторы доступа
student_schedule
Атрибуты « const » string : StudentNumber string : Term
Операции << конструктор >> student-schedule(void)
« конструктор копии » student_schedule(const student_schedule &Sched)
« деструктор >> -student_schedule(void)
« операции запросов >> studentSchedule(void) : map<stringzvector<course> > & term(void) : string StudentNumber(void) : string scheduleDayOfWeek(string DayOfWeek) : vector<course> &
« операции присваивания » studentschedule (map<stringzvector<course> > &X) : void StudentNumber(string SN) : void term (string &X) : void operator=(const student_schedule ^Schedule) : student_schedule &
<< операции ввода-вывода » °perator« (ostream &Outz student_schedule &Sched) : ostream & {friend}
<<: операции сопоставления на равенство » operator==(student_schedule &Sched) : bool
категории минимального стандартного интерфейса Рис- 10.3. Два способа организации атрибутов и операций в диаграмме класса
346 Глава 10. Визуализация проектов параллельных и распределенных систем
Ю.1.1.3. Шаблонные классы
Шаблонный класс представляет собой механизм, который позволяет в качест
параметра в определении класса использовать тип. Шаблон определяет действия
торые выполняются над переданным ему типом. В C++ параметризованный класс К°
дается с помощью ключевого слова template.
template <class Type > classname {...};
Параметр Type представляет любой тип, передаваемый шаблону. Это может быть
встроенный С++-тип или определенный пользователем класс. При объявлении пап
метра Туре шаблон связывается с элементом, переданным ему в качестве параметри
зованного типа. Например, класс student—schedule включает контейнер шар Ко.
торый содержит векторы объектов типа course для каждого дня недели. Как класс
тар, так и класс vector являются шаблонными.
map <stringzvector<course> > StudentSchedule;
Контейнер map использует для ключа тип string, а для значения — тип vector.
Контейнер vector содержит объекты определенного пользователем типа course.
Контейнер тар может отобразить соответствие между значениями двух любых типов
данных, а контейнер vector содержать значения любого типа данных.
map <int, vector <string> > Соответствие между числом и вектором строк
map <int, string> > Соответствие между числом и строкой
vector <student_schedule> Вектор объектов класса student—schedule
vector стар <int,string> > Вектор отображений, которые устанавливают
соответствие между числом и строкой
Шаблонные классы также представляются как прямоугольники. Параметризован-
ный тип представляется как прямоугольник (меньшего размера), начертанный штриховой
линией и расположенный в правом верхнем углу прямоугольника класса. Шаблонный
класс может быть связанным или несвязанным. При представлении несвязанного шаблонно-
го класса в штриховом прямоугольнике отображается прописная буква Т, означающая не-
связанный параметризованный тип. Для представления связанного шаблонного класса
существует два способа. Один из них состоит в использовании символа класса, содер-
жащего синтаксис C++ для объявления и связывания шаблонного класса, например:
vector <string>
Этот вариант называется неявным связыванием. В другом способе используется стерео
тип зависимости bind (связать). Этот стереотип задает источник, который реализу
ет шаблонный класс посредством использования реального параметризованного ти
па. Этот вариант называется явным связыванием. Шаблонный объект является реал и
зацией шаблонного класса. Он обладает отношением зависимости с шаблонный
классом. С помощью стереотипа связать указывается имя параметра-типа. В штр1*
ховом прямоугольнике отображаются соответствующие типы данных. Шаблон
объект можно также рассматривать как детализацию шаблонного класса. Детая
ция — это общий термин, означающий более высокий уровень представления ин<р
мации о том, что уже существует. Стереотипный индикатор «связать» детая
рует шаблонный класс посредством реализации параметризованного типа. Спосо
представления шаблонного класса для контейнера тар представлены на рис. 10.4-
10.1. Визуализация структур 347
I string .
] vector<courses> ’
map
। «bind» (реальные
параметры)
StudentSchedule
Рис. 10.4. Способы представления связанного и несвязанного шаблонного класса
10.1.2. Отношения между классами и объектами
Язык UML определяет три типа отношений между классами:
• зависимости;
• обобщения;
• ассоциации.
Зависимость определяет отношение между двумя классами. Если один класс зависит
от другого, это означает, что изменение, внесенное в независимый класс, может по-
влиять на зависимый от него класс. Обобщение — это отношение между некоторой об-
щей конструкцией и более конкретным типом этой конструкции. Под общей конст-
рукцией подразумевается родительский класс (или суперкласс), а под более конкретным
ее типом— сыновний класс (или подкласс). Потомок наследует свойства, атрибуты
и операции родителя и может при этом определять собственные атрибуты и опера-
ции. Сыновний класс выводится из родительского, и его можно использовать в каче-
стве заменителя родительского класса. Класс, не имеющий родителей (предков), на-
зывается корневым, или базовым классом. Ассоциация — это структурное отношение, ко-
торое означает, что объекты одного типа связаны с объектами другого типа,
ссоциации между объектами двунаправлены. Например, если объект 1 связан с объ-
ектом 2, то объект2 связан с объектом!. Ассоциация между двумя элементами
ример, классами) называется бинарной связью, а между п элементами — п-арной.
с А ависимость’ обобщение и ассоциацию можно рассматривать как различные клас-
Щеш ЛЦИИ отношений, поскольку существует множество типов зависимостей, обоб-
имеет И аСС°ЦИацИЙ’ котоРые можно определить. Каждая классификация отношений
(на^ С°бСТВенный символ представления. Таким символом является отрезок прямой
увенСРТаННЬ1й сплошн°й или пунктирной линией) между элементами, который может
ТЬся стрелкой некоторого типа. Для более детального определения отноше-
(“\т<ГеЗКИ ПРЯМЬ1Х мо^ Дополняться стереотипами и специальными обозначения-
сания ^теРеотип~ это метка, используемая для более подробного опи-
ки, и п ’ЭЛеМента. Он представляется в виде имени, заключенного в угловые скоб-
°Писани Ле1^аемого над элементом или рядом с ним. Например, на рис. 10.4 для
Я Щаолонного объекта стереотип
>:> ^<<связать>>)
348 Глава 10. Визуализация проектов параллельных и распределенных систем
размещен рядом со стрелкой, которая отображает зависимость используемых об
тов. Под “украшениями” понимаются текстовые или графические элементы л к К
ляемые к базовой интерпретации элемента и используемые для Документирован
сведений о спецификации элемента. Например, ассоциация отображается в виде **
резка сплошной линии между элементами. Агрегирование — это тип ассоциации ко-
торый выражает отношение “целое-часть”. Для отображения агрегирования исполь
зуется отрезок сплошной линии, у которого один конец (прилегающий к “целома
элементу) венчается полым ромбом.
Зависимость обозначается пунктирной направленной линией (со стрелкой), кото-
рая указывает на зависимую конструкцию. Отношение зависимости следует приме-
нять в случае, когда одна конструкция использует другую. Обобщение обозначается
сплошной направленной линией со стрелкой, указывающей на родительский класс
(суперкласс). Отношение обобщения следует применять в случае, когда одна конст-
рукция выведена из другой. Ассоциация обозначается сплошной линией, которая со-
единяет одинаковые или различные конструкции. Отношение ассоциации следует
применять в случае, когда одна конструкция структурно связана с другой. Некоторые
стереотипы и ограничивающие условия, которые применяются к зависимостям, при-
ведены в табл. 10.2. Эти стереотипы используются для отображения зависимостей
между классами, интерактивными объектами, состояниями и пакетами. Стереотипы
и ограничивающие условия, которые могут применяться к обобщениям и ассоциаци-
ям, приведены в табл. 10.3 и 10.4. Если стереотипы используют графические
“украшения”, они показаны в таблицах.
Таблица 10.2. Стереотипы, применяемые к зависимостям
Зависимость . Описание
| источник |- ->| ПРИЕМНИК
Стереотип Обусловливает, что:
« bind » источник реализует шаблонный приемник, используя ре-
(« связать ») альные параметры
<< friend » видимость источника распространяется на содержимое
(« друг ») приемника
« instanceOf » источник является экземпляром приемника; используется
(« экземпляр ») для определения отношений между классами и объектами
« instantiate » источник создает экземпляры приемника; используется для
(« создать экземпляр » ) определения отношений между классами и объектами
<< refine >> источник представляет более высокий уровень детализа-
(<< уточнить >>) ции, чем приемник; используется для определения отно- шений между’ производным и базовым классами
<< use » источник зависит от открытого (public) интерфейса
(« использовать ») приемника
« become » объект-приемник совпадает с объектом-источником, но
(« стать ») в более поздний период жизненного цикла объекта; при- емник может иметь другие значения, состояния и пр.
10.1. Визуализация структур 349
Окончание табл, 10.2
Зависимость
Описание
(« вызвать »)
« сору »
(« копировать »)
« access »
(« получить доступ
« extend »
(« расширить »)
« include »
(« включить »)
объект-источник вызывает метод приемника
объект-приемник является точной и независимой копией
объекта-источника
исходному пакету предоставляется право ссылаться на
элементы приемного пакета
данный прецедент приемника расширяет поведение ис-
точника
данный прецедент источника может включать прецедент
приемника
Ассоциации имеют еще один уровень детализации, который может быть применен
к стереотипам, перечисленным в табл. 10.4:
Имя Ассоциация может иметь имя (название), которое используется для описания природы отношений. К имени может быть добав- лен треугольник, указывающий направление, в котором должно читаться имя.
Роль Роль обозначает функцию, которую выполняет класс, представ- ленный на одном конце линии ассоциации, относительно клас- са, представленного на другом конце этой линии.
Множественность Обозначение множественности может использоваться для ука-
зания количества объектов, которые могут быть связаны с по-
мощью данной ассоциации. Множественность можно отобра-
жать на обоих концах линии ассоциации.
Передвижение Передвижение по ассоциации может быть однонаправленным, ес-
ли объект 1 связан с объектом 2, но объект 2 не связан с объектом 1.
^Таблица 10.3. Стереотипы и ограничивающие условия, которые могут
применяться к обобщениям
Обобщение
----Н>рОДИТЕЛЬ]
Описание
9Тереотип «
implementation »
Реализация >>)
Ограничение {complete}
\ПОЛНоТа})
Обусловливает, что:
потомок наследует реализацию родителя, но не делает от-
крытыми (public) его интерфейсы и не поддерживает их
все потомки в обобщении получили имена, и никаких до-
полнительных потомков больше не было выведено
350 Глава 10. Визуализация проектов параллельных и распределенных систем
________________________________________________________^^ние табл. 1() 3
Обобщение Описание
| потомок-]--о| родитель]
Ограничение {incomplete} ({неполнота}) Ограничение {disjoint} ({несовместимость}) не все потомки в обобщении получили имена, и дополи^ тельные потомки могут быть выведены объекты родителя не могут иметь больше одного потомка используемого в качестве типа
Ограничение {overlapping} объекты родителя могут иметь больше одного потомка
({перекрытие}) используемого в качестве типа
Таблица 10.4. Стереотипы и ограничивающие условия, которые могут
применяться к ассоциациям
Ассоциация Описание
| ОБЪЕКТ 1 ]—--] ОБЪЕКТ 2 "|
Тип navigation (передвижен ие) Описывает однонаправленную (нереверсивную) ас- социацию, при которой объект 1 связан с объектом 2,
| ОБЪЕКТ 1 (- ->| ОБЪЕКТ 2 | но объект 2 не связан с объектом 1
Тип aggregation (агрегирование) | ЧАСТЬ -ф| ЦЕЛОЕ | Описывает связь “целое-часть”, при которой “часть” во время своего существования связана не только с одним “целым”
Тип composition (композиция) | ЧАСТЬ —-»| ЦЕЛОЕ | Описывает связь “целое-часть”, при которой “часть” во время своего существования может быть связана только с одним “целым”
Ограничение {implicit} ({неявное}) Ограничение {ordered} ({упорядоченность}) Свойство {changeable} ({модифицируемость}) Свойство {addOnly} ({расширяемость}) Свойство {frozen} ({жесткость}) Обусловливает, что отношение является концепту- альным Обусловливает, что объекты на одном конце ассоциа- ции упорядочены Описывает, что может быть добавлено, удалено и из- менено между двумя объектами Описывает новые связи, которые могут быть добавле- ны к объекту на противоположном конце ассоциации Описывает связь, которая после добавления к объект) на противоположном конце ассоциации не может быть изменена или удалена
10.1.2.1. Интерфейсные классы
Интерфейсный класс используется для модификации интерфейса другого класс
или множества классов. Такая модификация упрощает использование класса, Де
его более функциональным, безопасным или семантически корректным. Примера
интерфейсных классов могут служить адаптеры контейнеров, которые являю
10.1. Визуализация структур 351
асТЬю стандартной библиотеки шаблонов (Standard Template Library — STL). Адаптеры
обеспечивают новый открытый (public) интерфейс для таких контейнеров, как deque
Z/fouble-nided queue — очередь с двусторонним доступом), vector (вектор) и list
/ писок). Рассмотрим пример. В листинге 10.1 представлено определение класса stack,
который используется в качестве интерфейсного для модификации класса vector.
Использование класса stack в качестве
интерфейсного класса
I / листинг 10.1.
template < class
class stack{
Container >
public:
typedef Container::value_type value_type;
typedef Container::size_type size_type;
protected:
Container c;
public:
bool empty(void) const {return c. empty ();}
size_type size (void) const {return c.sizeO; }
value_type& top (void) {return c.backO; }
const value_type& top const {return c.backO; }
void push(const value.type& x) {c.push.back(x); }
void pop(void) {c.pop.back(); }
};
Класс stack объявляется путем задания типа Container.
stack < vector< T > > Stack;
В данном случае типом Container является класс vector, но в качестве класса реа-
лизации для интерфейсного класса stack (вместо класса vector) можно использо-
вать любой контейнер, который определяет следующие методы:
empty ()
size ()
back()
Push.back()
Pop.back()
Класс stack поддерживает семантически корректный интерфейс, традиционно при-
нятый для стеков.
Существует несколько способов отображения интерфейса. Один из них — круг, ря-
дом с которым (чаще — под ним) записывается имя интерфейсного класса. Этот спо-
с°б показан на рис. 10.5, а. Для отображения операций класса stack можно также ис-
пользовать символическое обозначение класса (см. рис. 10.5, б). Здесь над именем
^асса отображается индикатор стереотипа <<interface>>, обозначающий, что
и " интерфейсный класс. Имя интерфейсного класса может начинаться с буквы “I”,
Тогда все операции этого класса будут заметнее отличаться от других классов.
вать Я °т°бражения отношений между классами stack и vector можно использо-
самиП°НЯТИе Реализации- Ремизация— это семантическое отношение между клас-
его * В КОтоРом один из них предлагает “контракт” (интерфейсный класс), а другой
ТраХЬ1ПОЛНЯСТ (класс реализации). В нашем примере класс stack определяет кон-
’ акласс vector его выполняет. Отношение реализации отображается отрез-
Пунктирной линии между двумя прямоугольниками классов с крупной полой
352 Глава 10. Визуализация проектов параллельных и распределенных систем
стрелкой, указывающей на интерфейсный класс, т.е. на класс, который определ
контракт (рис. 10.5, в). Это изображение читается так: “Класс stack реализу
классом vector”. Отношение между интерфейсным классом и его реализато *
(средством реализации) также можно отобразить в виде “леденца на палочк^
(рис. 10.5, г). Класс stack может быть реализован не только классом vector
и классами list или deque.
stack
а) класс stack в качестве интерфейсного класса
Рис. 10.5. Способы представления интерфейсного класса
10.1. Визуализация структур 353
10/1.3. Организация интерактивных объектов
Как видите, классы и интерфейсы можно использовать в качестве строительных
блоков (т.е. базовых элементов) при создании более сложных классов и интерфейсов,
распределенной или параллельной системе возможно существование больших
сложных структур, сотрудничающих с другими структурами, что создает объедине-
ние классов и интерфейсов, работающих вместе над достижением общих целей сис-
темы- В языке UML такое поведение называется сотрудничеством. Упомянутые выше
строительные блоки могут включать как структурные, так и поведенческие элементы
системы- Конкретная задача, которую запрашивает пользователь, может включать
множество выполняемых вместе объектов. При этом для выполнения разных задач
могут использоваться одни и те же объекты, взаимодействующие в разных случаях с
различными элементами. Такая коллекция элементов (с учетом взаимодействия меж-
ду ними) формирует сотрудничество. Понятие сотрудничества состоит из двух частей:
структурной части, в которой акцент делается на характере организации и построе-
нии сотрудничающих элементов, и поведенческой, в которой основное внимание уделя-
ется взаимодействию между элементами. (Об этом пойдет речь в следующем разделе.)
Сотрудничество отображается в виде эллипса (начертанного пунктирной линией),
содержащего название варианта сотрудничества. Имя сотрудничества должно быть
уникальным. Оно представляет собой существительное или короткую фразу, состоя-
щую из существительных, которые входят в словарный состав моделируемой системы.
Структурные и поведенческие части сотрудничества отображаются внутри эллипса
сотрудничества. Пример структурной части системы составления расписания показан
на рис. 10.6. Структурная часть сотрудничества представляет собой сочетание классов
ВАРИАНТЫ СОТРУДНИЧЕСТВА
' Интерфейс — —z Рассмотрение Тенерирование»
* запросов * 1 ч курсов * ‘ ч ответа •
Сотрудничество "Рассмотрение курсов"
^Ис. 10.6. Диаграмма сотрудничества для системы составления расписания
354 Глава 10. Визуализация проектов параллельных и распределенных систем
и интерфейсов, компонентов и узлов. Система, показанная на рис. 10.6, может с
жать множество вариантов сотрудничества. Каждый вариант сотрудничества ун
лен в системе, но его элементы — нет. Элементы одного варианта сотрудничества
гут быть использованы в другом варианте за счет иной организации. Мо
10.2. Отображение параллельного поведения
При отражении поведенческой характеристики системы акцент ставится на ее ди
намических аспектах. С этой точки зрения нас интересует, как ведут себя элементы
системы при взаимодействии с другими элементами той же системы. Именно во взаи-
модействии одних элементов с другими и проявляются особенности параллелизма
Диаграммы, используемые в этом разделе, позволяют смоделировать:
• поведение объекта в течение его периода существования;
• поведение объектов, которые совместно работают ради достижения конкрет-
ной цели;
• поток управления с акцентом на определенном действии или последовательно-
сти действий;
• синхронизацию действий элементов и взаимодействие между ними.
В этом разделе также описаны диаграммы, используемые для моделирования рас-
пределенных объектов.
10.2.1. Сотрудничество объектов
Сотрудничество объектов заключается в привлечении друг друга к работе с целью
выполнения некоторой конкретной задачи. Они не вступают в постоянные отноше-
ния. Одни и те же объекты могут привлекаться разными объектами для выполнения
различных задач. Сотрудничество объектов можно представить в виде диаграммы со-
трудничества. Диаграммы сотрудничества имеют структурную и интерактивную час-
ти. Структурную часть мы рассмотрели выше. Интерактивная часть отображается
в виде графа, вершинами которого являются объекты — участники рассматриваемого
сотрудничества. Связи между объектами представляются ребрами. Ребра могут со-
провождаться сообщениями, передаваемыми между объектами, вызовами методов
и индикаторами стереотипов, которые позволяют подробнее отобразить характер связи.
Связь между объектами имеет тип ассоциации. С двумя связанными объектами могут
выполняться действия. В результате действия может измениться состояние одного или
двух объектов. Приведем примеры различных типов действий, связанных с объектами.
create Объект может быть создан
destroy Объект может быть разрушен
call Операция, определенная в одном объекте, может быть вызвана дрУ
гим объектом или им самим
return Объекту7 возвращается значение
send Объекту может быть послан сигнал
10.2. Отображение параллельного поведения 355
гт и вызове и выполнении любого метода возможно наличие передаваемых пара-
в и возвращаемого значения (а также другие действия).
Ме этц действия могут иметь место, если принимающий объект видим для вызы-
го. Для объяснения причины видимости объекта можно использовать еле-
дующие стереотипы.
association
parain^ten
Объект видим по причине существования ассоциации (самый
общий случай)
Объект видим, поскольку он является параметром для вызы-
вающего объекта
local Объект видим, поскольку он имеет локальную область видимо- сти для вызывающего объекта
global Объект видим, поскольку он имеет глобальную область видимо- сти для вызывающего объекта
self Объект вызывает собственный метод
Помимо перечисленных, возможно применение и других стереотипов.
При вызове некоторого метода возможен вызов других методов иными объектами.
Последовательность выполнения операций можно отобразить с помощью комбина-
ции порядковых номеров и двоеточия, отделяющего имя метода от соответствующего
номера. Комбинация порядковых номеров выражает последовательность, в которой
выполняются операции. Например, на рис. 10.7 показана диаграмма сотрудничества,
в которой используются порядковые номера.
Рис. 10.7. Диаграмма сотрудничества, использующая порядковые номера для обозначения
оследовательности выполнения операций
Как показано на рис. 10.7, объект MainObject выполняет две операции в следую-
щей последовательности:
«create»
Value := performAction(ObjectF)
Ov вып°лнении операции 1 объект MainObj ect создает объект Obj ectA. Объект
B ctA локален по отношению к объекту MainObject (поскольку имеет место
*енн еНИе <*ъектов). Это инициирует первую последовательность операций во вло-
сти 1 Потоке управления. Для обозначения всех операций этой последовательно-
Пенц^Пт>ЛЬ3^ется число К за которым следует число, отражающее порядок их выпол-
• 1так, первая операция последовательности 1 такова:
*1: initialize()
356 Глава 10. Визуализация проектов параллельных и распределенных систем
Объект Obj ectA вызывает собственный метод. Выполнение объектом собственн
метода выражается соединительной линией, связывающей объект с самим собой и Г°
дикатором стереотипа {self} ({сам}). Операция ObjectA: :initialize() также***1
пускает другую последовательность действий: За'
1.1.1: initializes()
1.1.2: initializeC()
В этой последовательности два других объекта (которые локальны по отношению
к объекту Obj ectA) инициализируются посредством вызова соответствующих мето-
дов инициализации. Операция
2: performAction(ObjectD)
является началом еще одной вложенной последовательности действий. Объекту
Obj ectA передается объект ObjectD. Объект Obj ectA вызывает операцию, опреде-
ленную в объекте Obj ectD:
2.1: doAction()
Объект ObjectA имеет право вызвать эту операцию, поскольку объект ObjectD
является параметром (переданным объектом MainObject), как отмечено стереоти-
пом {parameter}. В результате выполнения этой последовательности действий объ-
екту ObjectA возвращается значение и объекту MainObject также возвращается зна-
чение. Помимо комбинаций порядковых номеров, обозначение этих вложенных по-
токов управления можно усилить с помощью линии с зачерненной стрелкой,
указывающей в направлении выполнения последовательности действий.
10.2.1.1. Процессы и потоки
Процесс — это часть работы (кода), создаваемая операционной системой. Он
включает один или несколько потоков, выполняемых в его адресном пространстве.
Если потоков несколько, то один из них является основным (main thread). Несколько
процессов могут выполняться параллельно. Потоки одного процесса могут выпол-
няться параллельно с потоками других процессов.
При использовании языка UML для отображения функционирования процессов
и потоков каждый независимый поток выполнения считается активным объектом. Актив-
ный объект — это объект, который является владельцем процесса или потока. Каждый
активный объект может активизировать то, чем он владеет. Активный класс — это класс,
объекты которого являются активными. Активные классы можно использовать для мо-
делирования группы процессов или потоков, которые разделяют одни и те же члены
данных и методы. Объекты конкретной системы могут не иметь однозначной взаимо-
связи с активными объектами. Как упоминалось в главах 3 и 4, при разделении програм-
мы на процессы и потоки следует учитывать, что методы объектов могут выполняться
в отдельном процессе или отдельных потоках. Следовательно, при моделировании од-
ного такого объекта его можно представить в виде нескольких активных объектов. От-
ношение между статическими и активными объектами можно изобразить с помощью
диаграммы взаимодействия. В системе может быть несколько PVM- или MPI-задач, или
процессов, и каждую из них можно представить непосредственно как активный объект.
Язык UML позволяет представить активный объект или класс таким же способом,
как статический объект, за исключением того, что периметр прямоугольника, о
значающего этот объект или класс, обводится более жирной линией. В этом случае
можно также использовать следующие два стереотипа:
process
thread
10.2. Отображение параллельного поведения 357
Индикаторы этих стереотипов позволяют отобразить различие между двумя типа-
аКТивных объектов. На рис. 10.8 показана PVM-задача в виде активного класса
М активного объекта. Диаграмма сотрудничества может состоять из активных объектов.
pvm_stream
mutex Mutex;
int Taskld;
mt Messageld;
pvm_stream
operator «(string X): pvm_stream &
operator «(Int X): pvm_stream &
operator «(float X): pvm_stream &
operator»(strlng X): pvm_stream &
Рис. 10.8. Активный объект и класс
10.2.1.2. Отображение нескольких потоков выполнения
и взаимодействия между ними
В параллельной и распределенной системе возможно существование нескольких
потоков выполнения, которые относятся к одному или нескольким процессам. Эти
процессы и потоки могут выполняться в одной компьютерной системе с несколькими
процессорами либо распределяться между несколькими различными компьютерами.
Для представления каждого потока выполнения используется активный объект или
класс. При создании активного объекта инициируется независимый поток выполне-
ния. При разрушении активного объекта этот поток прекращает свое существование.
Моделирование потоков в системе позволяет успешно осуществить управление, син-
хронизацию и взаимодействие между ними.
В диаграмме сотрудничества для идентификации потоков используются числа
и стрелки со сплошной заливкой наконечника. В диаграмме сотрудничества, которая
состоит из активных объектов параллельной системы, имя активного объекта пред-
ставляется порядковыми числами операций, выполняемых активным объектом. Ак-
тивный объект может вызвать метод, определенный в другом объекте, и приостано-
вить выполнение до тех пор, пока этот метод не завершится. Стрелки используются
только для отображения направления хода выполнения потока, но и природы его
дения. Стрелки со сплошной заливкой наконечника используются для представ-
я синхронного вызова, а стрелка с однореберным наконечником — для представ-
асинхронного вызова. Поскольку один и тот же метод может быть вызван сразу
Mo* - Лькими активными объектами, то для описания синхронизации этого метода
по использовать такие его свойства:
sequential
guarded
concurrent
Кото* Ю 9 представлена диаграмма сотрудники ства нескольких активных объектов,
РЬ1е совместными усилиями” создают расписание студента. Объект blackboard
358 Глава 10. Визуализация проектов параллельных и распределенных систем
MajorAgent 1:
X := currentDegreePlan()
MajorAgent 2:
Y := coursesTaken()
MinorAgent 2:
Y := coursesTaken()
MinorAgent 4:
suggestionsForMinor(B)
Blackboard
SuggestionForMajor
SuggestionForMinor
Schedule
DegreePlan
possibleSchedules(vector<ScheduleMap> &): void {guarded}
possibleSchedules(void): vector<ScheduleMap> & {guarded}
suggestionsForMajor(const courses &X): void {concurrent}
suggestionsForMinor(const courses &X): void {concurrent}
currentDegreePlan(void): ScheduleMap & {concurrent}
produceMasterList(void)
masterList(void): ScheduleMap & {guarded}
suggestedSchedules(void): vector<ScheduleMap &> {guarded}
suggestedSchedules(vector<ScheduleMap &>): void {guarded}
Рис. 10.9. Диаграмма сотрудничества статических и активных объектов в системе
составления расписаний
используется для регистрации результатов предварительной работы и ее координа
ции, а также представления итогового расписания, сгенерированного решателями
задач активных объектов, именуемых в данном случае агентами (agent).
MajorAgent
MinorAgent
FilterAgent
ScheduleAgent
Создает список имеющихся основных курсов
Создает список имеющихся непрофилирующих курсов
Фильтрует список курсов и генерирует список возможных курсоВ
Генерирует несколько вариантов расписаний на основе списка
возможных курсов
10.2. Отображение параллельного поведения 359
Объект schedule_of_courses содержит все имеющиеся курсы.
Объекты blackboard и schedule_of„courses доступны при параллельном
ним обращении со стороны нескольких агентов. В данном варианте сотрудничества
Кба эти объекта видимы для всех агентов. Агенты MajorAgent, MinorAgent,
‘ iterAgent и ScheduleAgent вызывают методы объекта blackboard. Агенты
'orAgent и MinorAgent вызывают методы объекта schedule_of_courses. При
этом агенты Maj orAgent и MinorAgent имеют аналогичную последовательность об-
ращений к объектам blackboard и schedule_of„courses.
Maj orAgent 1: currentDegreePlan ()
Maj orAgent2 : coursesTaken ()
MajorAgent3 : scheduleOfCourses ()
MajorAgent4 : suggestionsForMaj or ()
MinorAgent1:currentDegreePlan()
MinorAgent2:coursesTaken()
MinorAgent!:scheduleOfCourses()
MinorAgent4:suggestionsForMinor()
Как видите, к имени активного объекта, который вызывает эти методы, присоединяет-
ся порядковый номер. Оба объекта параллельно вызывают методы объектов blackboard
и schedule_pf_.courses. Все эти методы параллельно синхронизированы и защищены
от одновременного вызова. Методы masterList () и possiblecourses () имеют
свойство guarded. Одни объекты могут модифицировать содержимое курсов, а дру-
гие— считывать его. Поэтому методы masterList () и possiblecourses () защи-
щены разрешением только последовательного к ним доступа (EREW).
10.2.2 . Последовательность передачи сообщений
между объектами
В то время как в диаграмме сотрудничества основное внимание уделяется структур-
ной организации и взаимодействию объектов, совместно выполняющих некоторую за-
дачу или реализующих прецедент (вариант использования системы), в диаграмме по-
следовательностей акцент ставится на временном упорядочении вызовов методов или
процедур, составляющих данную задачу или прецедент. В диаграмме последовательно-
стей имя каждого объекта или конструкции отображается в собственном прямоугольни-
ке. Все прямоугольники размещаются в верхней части диаграммы, вдоль ее оси X. В диа-
грамму следует включать только основных исполнителей прецедента и наиболее важ-
ные функции, в противном случае диаграмма будет перенасыщена деталями и утратит
свою полезность. Объекты упорядочиваются слева направо, начиная с объекта или про-
цедуры, которая является инициатором действия для большинства второстепенных
°°ъектов или процедур. Вызовы функций отображаются вдоль оси Y сверху вниз в по-
рядке возрастания значения времени. Под каждым прямоугольником наносятся верти-
^ьные линии, представляющие “жизненные пути” (линии жизни) объектов. Стрелки
к С11Лошной заливкой наконечника, направленные от линии жизни одного объекта
^линии жизни другого, обозначают вызовы функций или методов (причем такая стрел-
имекуг^ напРавлена от инициатора вызова). Стрелки с “реберными” наконечниками
Или ОоРатное направление (т.е. к инициатору вызова), обозначая возврат из функции
х<эдим Т°Да* каждый вызов функции помечается ее именем. Помимо имени, при необ-
‘ СТи отображается информация об аргументах и условиях вызова, например:
360 Глава 10. Визуализация проектов параллельных и распределенных систем
Функция или метод не выполнится, если заданное условие не будет истинным Kf
тоды, которые должны быть вызваны несколько раз (например, при считывании зн^
чений из структуры), предваряются признаком итерации (*). а'
На рис. 10.10 показана диаграмма последовательностей для объектов системы состав
ления расписания. Чтобы не перегружать эту демонстрационную диаграмму, количеств
объектов в ней ограничено лишь тремя. В диаграммах последовательностей для парал
лельных объектов или процедур используются символы активизации. Символ активизации
представляет собой прямоугольник, отображаемый на линии жизни объекта. Наличие
символа активизации означает активность объекта или процедуры. Символы активизации
используются в случае, когда объект обращается к другому объекту без блокирования. Тем
самым становится понятно, что объект или процедура продолжает выполняться или быть
активной. На рис. 10.10 показано, что объект blackboard всегда активен. Он порождает
объект schedule-agent и не блокируется. Объект schedule„agent вызывает метод
blackboard, mas terList () и ожидает получения от него списка курсов. Как упомина-
лось выше, возвращение метода обозначается стрелкой с “реберным” наконечником. Ме-
тод schedule-agent затем вызывает один из собственных методов createSchedules ().
Для обозначения вызова объектом одного из собственных методов используется специ-
альный символ, состоящий из символа активизации и стрелки вызова. Символ активиза-
ции при этом накладывается на уже имеющийся символ активизации. Линия выходит из
исходного символа активизации, а ее стрелка указывает на дополнительный символ. После
передачи объектом schedule—agent результатов своей работы путем вызова метода
blackboard.possibleschedule () объект blackboard аннулирует его. Аннулирование
обозначается большим символом “X” в конце линии жизни объекта. Стрелка вызова ме-
тода, исходящая из объекта blackboard и указывающая на символ “X”, означает, что
инициатором аннулирования является объект blackboard. Объект blackboard затем
порождает объект filter—agent и опять-таки не блокируется. Объект filter-agent
вызывает метод blackboard.possibleschedules () и ожидает получения от него ва-
риантов расписаний. Объект filter—agent после этого вызывает один из собственных
методов filtercourses (). После передачи результатов объект filter—agent ликви-
дирует себя. Объект blackboard последовательно вызывает собственные методы
organizeSolution () и updateRecords (), а затем также ликвидируется.
10.2.3 . Деятельность объектов
Язык UML можно использовать для моделирования видов деятельности объек-
тов — участников конкретной операции или прецедента. В этом случае строится
грамма (видов) деятельности, которая представляет собой блок-схему, отражающую по
следовательные и параллельные действия (или виды деятельности) объектов, прини-
мающих участие в выполнении конкретной задачи. На этой диаграмме с помощью
стрелок указывается направление передачи управления для соответствующих видов
деятельности. В то время как в диаграммах сотрудничества основное внимание уДелЯ
ется передаче управления от объекта к объекту, в диаграммах последовательностей
временному упорядочению потоков выполнения, в диаграммах деятельности акцент
ставится на передаче управления от одного действия (или вида деятельности) к ДрУ
тому. В результате действия (или вида деятельности) изменяется состояние объекта
или возвращается некоторое значение. Содержимое действия (или вида деятельно
сти) называется состоянием действия (или вида деятельности). Состояние объекта
представляется в этом случае как конкретный момент в потоке выполнения.
10.2. Отображение параллельного поведения 361
^Ис* Ю-10. Диаграмма последовательностей некоторых объектов системы
оставления расписаний
362 Глава 10. Визуализация проектов параллельных и распределенных систем
Действие и деятельность имеют различия. Действия не могут быть логически п
вергнуты декомпозиции или прерваны другими действиями или событиями. Примеп
ми действий могут служить создание или разрушение объекта, вызов метода или функ
ции. Деятельность можно разложить на составные части (другие виды деятельности)
В качестве примеров деятельности можно назвать программу, прецедент или процеду
ру. Деятельность можно прервать событием, другим видом деятельности или действием
Диаграмма (видов) деятельности представляет собой граф, узлы которого обозна-
чают действия или виды деятельности, а ребра — безусловные переходы. Безуслов-
ность перехода состоит в том, что для того, чтобы он произошел, не требуется ника-
кого события. Переход происходит сразу же по завершении предыдущего действия
или вида деятельности. Эта диаграмма содержит ветви решений, символы начала, оста-
нова и синхронизации, которые объединяют несколько действий (или видов деятельно-
сти) или обеспечивают их разветвление. Состояния действий и видов деятельности
представляются аналогичным образом. Для представления состояния действия или дея-
тельности в языке UML используется стандартный символ блок-схемы, который обычно
служит для отображения точек входа и выхода. Этот символ применяется независимо от
типа действия или деятельности. Мы предпочитаем использовать стандартные символы
блок-схемы, которые позволяют отличить действия ввода-вывода (параллелограмм) от
действий обработки или преобразования (прямоугольник). Описание действия или ви-
да деятельности, т.е. имя функции, выражения, прецедента или программы, отобра-
жается в соответствующем элементе графа. Состояние деятельности может дополни-
тельно включать отображение действий входа и/или выхода. Действие входа— это
действие, которое происходит, когда имеет место вход в состояние деятельности,
а действие выхода — это действие, которое происходит непосредственно перед выхо-
дом из состояния деятельности. Эти действия являются первым и последним дейст-
виями соответственно, которые должны быть выполнены в состоянии активности.
По завершении одного действия происходит немедленный переход к началу сле-
дующего. Переход обозначается стрелкой с двухреберным наконечником, направлен-
ной от одного состояния к другому (следующему). Переход, который указывает на со-
стояние, называется входящим, а переход, обозначающий выход из состояния, — выхо-
дящим. Прежде чем произойдет выходящий переход, должно выполниться действие
выхода, если таковое предусмотрено. Действие входа, если таковое предусмотрено,
выполняется после того, как произойдет входной переход. Начало потока выполне-
ния представляется в виде крупной закрашенной точки. Первый переход ведет из за-
крашенной точки к первому состоянию диаграммы. Точка останова, или состояние
останова, диаграммы деятельности представляется крупной закрашенной точкой, за-
ключенной внутри окружности.
Диаграммы деятельности подобно блок-схемам имеют символ решения. Символ
решения имеет форму ромба с одним входящим переходом и двумя (или более) выхо-
дящими переходами. Выходящие переходы сопровождаются условиями, которые оп-
ределяют дальнейшее направление передачи управления. Это условие представляет
собой обычное булево выражение. Выходящие переходы должны охватывать все воз-
можные варианты ветвления. На рис. 10.11 показан символ решения, используемый
при определении необходимости построения источника знаний.
Иногда после завершения одного действия или вида деятельности начинается па
раллельное существование нескольких потоков, выполняющих различные последова
тельности действий или виды деятельности. В отличие от блок-схемы, язык UML
10.2. Отображение параллельного поведения 363
еделяет символ, который можно использовать для представления момента, на-
°иная с которого несколько потоков выполняются параллельно. Для отображения
этого момента используется символ синхронизации, который также служит для
бозначения соединения параллельных путей. Этот символ имеет форму жирной
пизонтальной линии с несколькими выходящими переходами (разветвление) или
несколькими входящими переходами (соединение). Переходы, выходящие из ли-
нии синхронизации, означают состояние действия или деятельности, которое при-
водит к выполнению нескольких потоков. Переходы, входящие в линию синхрони-
зации, означают необходимость синхронизации нескольких потоков, а линия син-
хронизации в этом случае используется для отображения ожидания до тех пор, пока
все ветви не соединятся в единую ветвь (поток). Пример разветвления потоков и их
соединения показан на рис. 10.12.
Рис. 10.11. Символ решения, используемый при
определении необходимости построения
источника знаний (ИЗ)
Пример разветвления потоков из линии синхронизации и их соединения
источник знаний)
364 Глава 10. Визуализация проектов параллельных и распределенных систем
При создании объекта MajorAgent вызывается его конструктор, которЬ1-
(см. рис. 10.12) инициирует три параллельных потока выполнения. После заверщенИя
этих трех действий потоки соединяются в единый поток, назначение которого состо
ит в выполнении действия по созданию списка основных курсов.
Эту диаграмму можно разбить на три отдельных раздела, именуемых
“плавательными дорожками”. В каждой такой дорожке происходят действия или виды
деятельности конкретного объекта, компонента или прецедента. “Плавательные до-
рожки” разделены на диаграмме вертикальными линиями. Одно действие (или вид
деятельности) может происходить только в одной дорожке. Линии переходов и ли-
нии синхронизации могут пересекать одну или несколько дорожек. Действия или ви-
ды деятельности, обозначенные в одной и той же или различных дорожках, но нахо-
дящиеся при этом на одном уровне, являются параллельными. Диаграмма деятельно-
сти с “плавательными дорожками” показана на рис. 10.13.
Назначение этой диаграммы деятельности — смоделировать последовательность
действий объекта blackboard, который генерирует сводный список курсов для сис-
темы составления расписаний. Объект blackboard (см. рис. 10.13) сначала принима-
ет решение о том, нужно ли создавать объект MajorAgent. Если нужно, то вызывает-
ся конструктор объектаMajorAgent. Это приводит к созданию трех ветвей передачи
управления. В двух из них действия выполняет объект blackboard (“получает теку-
щий план выдачи дипломов” и “считывает курсы обучения”), а в третьей — объект
ScheduleofCourses (“считывает расписание курсов”). Все эти действия — входные
(поэтому для их обозначения используются параллелограммы). Затем три ветви объе-
диняются в одну, и объект Maj orAgent выполняет действие, которое состоит в соз-
дании списка основных курсов. После того как объект blackboard выполнит “свое”
действие, а именно “получит список основных курсов”, происходит удаление объекта
MajorAgent. Объект blackboard “генерирует сводный список курсов”, и на этом
деятельность рассматриваемых объектов прекращается.
10.2.4 . Конечные автоматы
С помощью конечных автоматов отображается поведение единой логической кон-
струкции, определяющей последовательность ее преобразований в качестве ответов
на внутренние и внешние события в течение ее линии жизни. Такой единой логиче-
ской конструкцией может быть система, прецедент или объект. Конечные автоматы
используются для моделирования поведения одного элемента. Элемент может реаги-
ровать на такие события, как процедуры, функции, операции и сигналы. Элемент мо-
жет также отвечать на факт истечения времени. Когда происходит подобное собы-
тие, элемент реагирует на него определенным видом деятельности или путем выпол-
нения некоторого действия, которое приводит к изменению состояния этого
элемента или созданию некоторого артефакта. Выполняемое в этом случае действие
должно зависеть от текущего состояния элемента. Под состоянием понимается сит}»
ция, которая создается в результате выполнения элементом некоторого действия или
его ответа на некоторое событие в течение его линии жизни.
Конечный автомат можно представить в виде таблицы или ориентированного граф3,
именуемого диаграммой состояний. На рис. 10.14 изображена UML-диаграмма состоя
ний для конечного автомата некоторого процесса. На этом рисунке показаны состоя
ния, через которые проходит процесс в период своей активности. Рассматриваемый
10.2. Отображение параллельного поведения 365
пос*10*13’ ^иагРамма деятельности с "плавательными дорожками”, отображающая
ледовательность действий в системе составления расписаний
НияЦеСС Может иметь в системе четыре состояния: готовности, выполнения, ожида-
Вос И °СТанова- К наступлению этих четырех состояний процесса могут привести
ь событий. Три из них происходят только при выполнении определенного
366 Глава 10. Визуализация проектов параллельных и распределенных систем
шивает операцию ввода-вывода или ожидает наступления некоторого события. Собы
тие блокирования инициирует переход процесса из состояния выполнения
(“бодрствования”) в состояние ожидания (“сна”). “Пробуждение” процесса происхо-
дит или из-за события пробуждения или в результате завершения операции ввода-
вывода. Событие пробуждения заставляет процесс перейти из состояния ожидания
(исходного состояния) в состояние готовности (целевое состояние). Событие выхода
происходит только в случае, если процесс выполнит все свои инструкции. Событие
выхода заставляет процесс перейти из состояния выполнения в состояние ожидания
Остальные события относятся к категории внешних и не подвластны процессу. Они
возникают по некоторым внешним причинам, вынуждающим процесс перейти из не-
которого исходного в некоторое целевое состояние.
Рис. 10.14. Диаграмма состояний для процессов
Диаграммы состояний используются для моделирования динамических аспектов
объекта, прецедента или системы. Диаграммы последовательностей, видов деятель-
ности, сотрудничества и (добавленная) диаграмма состояний используются для моде-
лирования поведения системы (или объекта) в период ее (его) активности. Структур-
ная часть диаграммы сотрудничества и диаграмма классов позволяют смоделировать
структурную организацию объекта или системы. Диаграммы состояний прекрасно
подходят для описания поведения объекта вне зависимости от конкретного преце-
дента. Их следует использовать не для описания поведения нескольких взаимодейст-
вующих или сотрудничающих объектов, а для описания поведения объекта, системы
или прецедента, который претерпевает ряд преобразований, причем именно в сл>
чае, когда одно преобразование может быть вызвано несколькими событиями. Речь
идет о таких логических конструкциях, которые весьма активно реагируют на внут
ренние или внешние события.
10.2. Отображение параллельного поведения 367
В диаграмме состояний узлы представляют состояния, а ребра— переходы. Со-
тояния обозначаются прямоугольниками с закругленными углами, внутри которых
писываются названия состояний. Переходы изображаются линиями с двухребер-
ными стрелками, связывающими исходное и целевое состояния, причем острие
елки должно указывать на целевое состояние. Существуют также начальное и конеч-
ное состояния. Начальное состояние представляет собой начало работы конечного
автомата. Оно обозначается черной точкой с ребром перехода к первому состоянию ав-
томата. Конечное состояние, означающее, что система, прецедент или объект достигли
конца своей линии жизни, отображается черной точкой, встроенной в окружность.
Состояние имеет несколько частей (они перечислены в табл. 10.5). Состояние
можно представить простым отображением его названия в центре соответствующей
вершины диаграммы состояний (прямоугольника с закруглёнными углами). Если
внутри этого прямоугольника необходимо отобразить также некоторые действия, то
для названия состояния должен быть выделен отдельный раздел в верхней части
прямоугольника. Действия перечисляются под этим разделом и должны иметь сле-
дующий формат отображения:
метка [Условие] / действие или деятельность
Рассмотрим пример:
do / validate(data)
Здесь do — это метка, которая используется для обозначения выполнения указанного
действия до тех пор, пока объект находится в данном состоянии. Имя
validate (data) — это имя вызываемой функции, a data — имя аргумента, с которым
она вызывается. Если действие состоит в обращении к функции или методу, то аргу-
менты желательно указывать.
Таблица 10.5. Составные части состояния
Части состояния
Описание
Название
Действия входа-выхода
Подсостояния
Внутренние переходы
Самопереходы
Отсроченные события
Уникальное имя состояния, которое отличает его от других
состояний: состояние может не иметь имени
Действия, выполняемые при входе в состояние (состояние
входа) или при выходе из него (состояние выхода)
Вложенные состояния; подсостояния — это составные части со-
стояния, которые могут быть активизированы последовательно
или параллельно. Составное состояние, или суперсостояние,
— это состояние, которое содержит подсостояния
Переходы, которые совершаются внутри состояния, не вызы-
вая при этом изменения состояния
Переходы, которые совершаются внутри состояния, не вызы-
вая изменения состояния, но приводящие к выполнению
входного, а затем выходного действия
Список событий, которые происходят, пока объект находится
в данном состоянии, но помещаются в очередь и обрабатыва-
ются, когда объект пребывает уже в другом состоянии
368 Глава 10. Визуализация проектов параллельных и распределенных систем
Условие — это условное выражение, которое приводится к значению ЛОЖЬ
ИСТИНА. Если условие дает значение ИСТИНА, выполняется действие или осущ^с **
вляется деятельность, например: Т'
exit [data valid] / send(data)
Действие выхода (exit) send (data) защищено выражением data valid, koto
рое при вычислении может дать ложное или истинное значение. Если при выходе
данного состояния это выражение даст значение ИСТИНА, то будет вызвана функци
send (data). Использование выражения защиты необязательно.
Переходы из одного состояния (объекта, системы или прецедента) в другое про-
исходят при наступлении событий. Существует два вида переходов, которые могут
осуществляться без изменения состояния (объекта, системы или прецедента) — это
внутренние и самопереходы.
Самопереход имеет место, когда возникновение конкретного события вынуждает
объект выйти из текущего состояния. При выходе из него объект выполняет действие
выхода (если таковое предусмотрено), а затем — действие, связанное с самопереходом
(если таковое предусмотрено). Затем объект снова входит в прежнее состояние, вы-
полняя при этом действие входа (если таковое предусмотрено). При внутренних пере-
ходах объект вовсе не выходит из текущего состояния и, следовательно, никаких дей-
ствий (ни входного, ни выходного) не выполняет. На рис. 10.15 показана общая
структура состояния, включающая действия входа и выхода, осуществляемую дея-
тельность, а также внутренние и самопереходы. Самопереход обозначается линией,
направленной назад к тому же состоянию.
Название состояния
Действие входа-
Деятельность
Внутренний переход-
> entry / действие или функция
-> do / деятельность
-> поте / действие или функция
Действие выхода
exit / действие или функция
Рис. 10.15. Общая структура состояния
Переход между разными состояниями означает, что между ними существует неко-
торое отношение. В то время, как объект находится в одном (исходном) состоянии,
может произойти некоторое событие или могут создаться определенные условия, ко-
торые заставят этот объект перейти в другое (целевое) состояние. Таким образом,
переход объекта из состояния в состояние инициируется событием. Один переход
может иметь несколько параллельно существующих исходных состояний. В этом слу-
чае они соединяются перед осуществлением перехода. Один переход также может
иметь несколько параллельно существующих целевых состояний, и тогда имеет место
разветвление. Составные части перехода перечислены в табл. 10.6. Переход изобра-
жается линией, направленной от исходного состояния к целевому. Имя инициатора
события отображается рядом с переходом. Подобно действиям и видам деятельности,
события также могут быть защищены. Переход может быть безусловным, а это зна
чит, что для его осуществления не требуется никакого специального события. При
в’ (\mr исходного состояния объект немедленно переходит в целевое состояние.
10.2. Отображение параллельного поведения 369
|^блица 10.6. Составные части перехода
Части перехода
Исходное состояние
Описание
Первоначальное состояние объекта; при осуществлении перехода
объект выходит из исходного состояния
Целевое состояние
Событийный
инициатор
Защитное условие
Действие
Состояние, в которое объект входит после осуществления перехода
Событие, которое инициирует осуществление перехода. Переход
может быть безусловным (т.е. не иметь инициатора), в этом случае
переход происходит сразу же после того, как объект заверши г все
свои действия (виды деятельности) в исходном состоянии
Булево выражение, связанное С событийным инициатором, кото-
рое обеспечивает осуществление перехода только в • |учае, если
при вычислении дает значение ИСТИНА
Действие, выполняемое объектом при осуществлении перехода;
оно может быть связано с событийным инициатором и/или за-
щитным условием
10.2.4.1 . Параллельные подсостояния
Подсостояние позволяет еще больше упростить описание модели поведения сис-
темы с параллелизмом. Подсостояние— это состояние, которое является составной ча-
стью другого состояния, именуемого суперсостоянием или составным состоянием. Такое
представление означает, что состояние можно разбить на несколько подсостояний.
Эти подсостояния могут существовать последовательно или параллельно. Паралле-
лизм подсостояний означает, что один объект может быть занят в двух независимых
поведенческих множествах. Это справедливо для нашего объекта “классной доски”
(blackboard). При обработке каждого возможного расписания он должен обновлять
соответствующие структуры и выполнять другие обслуживающие процедуры. Каждое
подсостояние отображается в отдельном разделе. Подсостояния синхронизируются
и объединяются перед выходом из составного состояния. Когда одно подсостояние
подходит к концу, оно ожидает, пока другие состояния подойдут к концу, после чего
Подсостояния снова соединяются в одно. На рис. 10.16 показана диаграмма состояний
Для объекта blackboard, который генерирует расписание для студентов.
Состояние Генерирование расписания (см. рис. 10.16) является составным. Его парал-
лельные подсостояния называются Фильтрование и Обновление. Подсостояния отделя-
ется пунктирной линией и представляются собственными конечными автоматами,
причем каждый конечный автомат имеет свои начальное и конечное состояния.
Подсостоянии Фильтрование объект последовательно проходит через следующие со-
ния: Фильтрование временных конфликтов, Балансировка и Персонификация. В под-
ОЯИии Поддержка объект проходит только через одно состояние: Обновление. Когда
Подсостояния Фильтрование и Поддержка (вернее, соответствующие им конечные
Маты) достигают своих конечных состояний, то перед выходом из составного со-
НИя Генерирование расписания происходит их объединение.
370 Глава 10. Визуализация проектов параллельных и распределенных систем
10.3. Визуализация всей системы 371
10.2.5 . Распределенные объекты
Распределенные объекты — это объекты, выполняющиеся на различных процес-
о ах принадлежащих различным компьютерам. Диаграмма развертывания использу-
ется для построения такой модели системы, в которой отображаются физические от-
ношения между ее программным и аппаратным компонентами. Диаграмма разверты-
вания позволяет отобразить маршрутизацию компонентов и объектов в распреде-
ленной системе. Компоненты могут представлять собой выполняемые программы,
библиотеки или базы данных. Поэтому весьма полезно четко представлять, где имен-
но размещается в системе конкретный компонент или объект. Понять, как именно
стоит распределить параллельные компоненты системы — задача непростая. Поэтому
моделирование распределенных компонентов поможет в управлении конфигурацией,
функционированием и производительностью системы.
Диаграмма развертывания состоит из узлов и объектов или компонентов, которые
размещаются в этих узлах. Узел — это вычислительное устройство или блок оборудо-
вания, который оснащен средствами хранения и обработки данных (например, это
может быть отдельное периферийное устройство, компьютер, универсальная вычис-
лительная машина или кластер компьютеров). Узлы этой диаграммы связаны между
собой зависимостями. Эти зависимостями представляют, как компоненты взаимодей-
ствуют друг с другом. Направление зависимости означает, какой компонент осведом-
лен о существовании другого компонента. Даже если связь между узлами является
двунаправленной, один компонент может не “знать” о том, с кем он связан.
Существует два способа смоделировать местоположение компонентов или объек-
тов в UML-диаграмме развертывания: посредством вложения или использования те-
гированного значения.
Согласно первому способу компоненты, которые располагаются в узле, перечис-
ляются внутри символьного обозначения узла. Второй способ предлагает отображать
местоположение компонентов в символе компонента. Узлы являются частью диа-
граммы развертывания. В качестве символа узла используется куб. Куб может иметь
два отдельных раздела: один будет содержать индикатор стереотипа, описывающий
тип узла, а второй — список компонентов, относящихся к этому узлу (первый способ).
При использовании символа компонента (второй способ) тегу location
(местоположение) присваивается имя узла, в котором размещается данный компо-
нент. Тег location имеет следующий формат:
{location = имя узла}
Тег location может быть частью любой диаграммы, в которой местоположение
компонентов является существенным фактором (например, в диаграммах сотрудни-
чества. объектов или видов деятельности). На рис. 10.17 отображены два способа
обозначения местоположения компонентов в распределенной системе. В части а это-
рисунка показан символ узла, содержащий список компонентов, а в части б пред-
ставлен символ активного объекта, в котором используется тег location.
10.3. Визуализация всей системы
Система состоит из множества элементов, включая подсистемы, которые сотруд-
а1от между собой с целью выполнения конкретных задач. Сотрудничество — это
Г1,рование конструкций, соединяемых в процессе регулярного взаимодействия.
372 Глава 10. Визуализация проектов параллельных и распределенных систем
а)
б)
MajorAgent
{location = М5}
MinorAgent
{location = М5}
Рис. 10.17. Способы отображения местоположения
компонента в распределенной системе
Рассмотренные в этой главе диаграммные методы позволяют разработчику взглянуть
на систему с различных точек зрения, с различных уровней, как извне, так и изнутри.
В этом разделе мы обсудим моделирование системы в целом. Это означает, что на самом
высоком уровне моделирования следует отображать только основные компоненты или
функциональные элементы. Диаграммные методы, предлагаемые для рассмотрения
в этом разделе, используются для моделирования развертывания системы и ее архитек-
туры. И хотя этот раздел — последний в этой главе, моделирование и документирование
системы в целом должно быть первым этапом ее проектирования и разработки.
10.3.1. Визуализация развертывания систем
Развертывание системы — последний этап в ее разработке. При развертывании
системы имеет смысл смоделировать реальные физические компоненты исполняе-
мой версии системы. Диаграмма развертывания отображает конфигурацию элемен-
тов оборудования и программных компонентов. Программные компоненты пред-
ставляют собой такие реальные выполняемые модули, как активные объекты
(процессы), библиотеки, базы данных и пр. Диаграмма развертывания состоит из уз-
лов и компонентов. Компоненты — это экземпляры физической реализации логиче-
ских элементов. Например, класс— это логический элемент, который может быть
реализован в виде одного или нескольких компонентов. Класс можно разделить на
процессы или потоки, и каждый процесс или поток в диаграмме развертывания мо-
жет быть компонентом. Компоненты класса могут выполняться на различных узлах
одного компьютера (потоки/процессы) или различных компьютерах (процессы).
Узел обозначается в виде куба. Узлы соединяются связями. Компоненты и узлы
также могут соединяться связями. Как упоминалось выше, узел может содержать спи
сок компонентов, либо компонент может быть отображен отдельно от узла, но при
этом необходимо показать связь между ними. Компонент можно представить в виде
прямоугольника с указанием тегов в его левой части. Имя компонента указывается
внутри его символьного обозначения.
Для отображения более крупных частей системы компоненты можно сгруппи
вать в пакеты или подсистемы. Пример диаграммы развертывания показан на рис. 1 • ’
Здесь пользователи подключаются к системе через intranet. Узлы являются час &
кластера компьютеров. Они группируются в пакет. Пользователи подключаю
10.3. Визуализация всей системы 373
кластеру как к единому элементу. В каждом узле перечисляются программные ком-
поненты, которые на нем установлены. Взаимодействие между узлами обеспечивается
посредством сетевого узла.
INTRANET
КЛАСТЕР
Рис. 10.18. Диаграмма развертывания, использующая пакеты
Ю.3.2. Архитектура системы
Моделирование и документирование архитектуры системы — это ее описание па
сам°м высоком уровне. Гради Буч, Джеймс Рамбау и Айвар Джекобсон определяю!
архитектуру как
Набор важных решений по организации системы программного обеспечения, выбор
структурных элементов и их интерфейсов, посредством которых составляется сис-
тема, вместе с их поведением, определенным на периоды их сотру дничесп ва, обье-
Динение этих структурных и поведенческих элементов в более крупные под< и с юмы
И архитектурный стиль, который направляет эту opiанпзацию — эти элстешы и их
интерфейсы, их варианты взаимодействия и их композицию.
374 Глава 10. Визуализация проектов параллельных и распределенных систем
Процесс
Назначение
Реализация
Развертывание
Моделирование и документирование архитектуры системы должно охватывать
логические и физические элементы, а также структуру и поведение системы на самом
высоком уровне.
Архитектура системы — это ее описание с различных точек зрения, но с акцентом
на структуре и организации системы. Ниже представлены различные точки зрения
Прецедент Описывает поведение системы с точки зрения конечного
(вариант использования) пользователя
Описывает процессы и потоки, используемые в механизмах
обеспечения параллелизма и синхронизации
Описывает функции системы и услуги, предоставляемые
конечному пользователю
Описывает аппаратные компоненты, используемые для
создания физической системы
Описывает программные компоненты и узлы, на которых
они выполняются, в поставляемой системе
Очевидно, что эти “поля зрения” (представления о системе) частично перекры-
ваются и взаимодействуют между собой. Например, в описании назначения систе-
мы могут упоминаться прецеденты, а при описании ее реализации процессы часто
представляют в качестве компонентов. Программные компоненты используются
как в части реализации, так и части развертывания системы. При описании архи-
тектуры системы очень полезно строить диаграммы, которые отражают каждый из
перечисленных выше ее “портретов”.
Систему можно разложить на подсистемы и модули. Подсистемы и модули могут
быть подвергнуты дальнейшей декомпозиции и разложены на компоненты, узлы,
классы, объекты и интерфейсы. В языке UML подсистемы и модули, используемые на
архитектурном уровне документации, называются пакетами. Пакет можно использо-
вать для организации элементов в группу, которая описывает общую цель этих эле-
ментов. Пакет представляется в виде прямоугольника со вкладкой (ярлыком), распо-
ложенной над его верхним левым углом. Символ пакета должен содержать его назва-
ние. Пакеты в системе могут связывать отношения, построенные на основе
композиции, агрегирования, зависимости и наследования. Для того чтобы отличать
один тип пакета от другого, можно использовать индикаторы стереотипов. На
рис. 10.19 показаны пакеты, входящие в систему составления расписаний. Для сис-
темного пакета используется индикатор «system» («система»), а для пакета
уровня подсистемы — индикатор «subsystem» («подсистема»). Подсистемы
связаны с системой отношением агрегирования.
Одни пакеты могут содержать другие пакеты. В этом случае имя пакета указывает
ся во вкладке. На рис. 10.19 также показано содержимое каждой подсистемы.
10.4. Резюме
Модель системы представляет собой своего рода информационное тело,
“собранное” с целью изучения системы. При моделировании любой системы не обои
тись без документирования ее различных аспектов. Поскольку в создании системы
обычно занято множество людей, очень важно, чтобы все они пользовались одним
10.4. Резюме 375
Рис. 10.19. Пакеты, используемые в системе составления расписаний (NLI- естественно-
языковый интерфейс; NLP — обработка данных на естественном языке; NLG — генерация
словаря естественного языка)
языком. Таким языком стал унифицированный язык моделирования (United Modeling
Language — UML), который представляет собой совокупность графических средств,
используемых для проектирования, визуализации, моделирования и документирова-
ния артефактов системы программного обеспечения. Этот язык создан Гради Бучем,
Джеймсом Рамбау и Айваром Джекобсоном. Язык UML стал фактическим стандартом
для моделирования объектно-ориентированных систем. Его средства также успешно
можно использовать для моделирования параллельных и распределенных систем
в плане описания ее структурных и поведенческих аспектов.
Диаграммы UML можно использовать для моделирования основных модулей сис-
темы, отдельных объектов и системы в целом. Объект — это основная “единица” мо-
ДелироВания используемая во многих диаграммах UML. Композиция, агрегирование,
зависимость и наследование — это некоторые из отношений, который могут сущест-
вовать между объектами. Для отображения поведения объектов и идентификации па-
раллелизма в системе используются диаграммы взаимодействия. Диаграммы сотруд-
ества позволяют отобразить взаимодействие между объектами, совместно рабо-
чими над выполнением некоторой конкретной задачи. Для представления
‘ °Деиствия между объектами во времени используются диаграммы последова-
екта °СТеИ‘ С пом°Щью диаграмм состояний можно отобразить действия одного объ-
в течение всего периода его существования. Для распределенных объектов пре-
трена возможность указать их местоположение в системе.
376 Глава 10. Визуализация проектов параллельных и распределенных систем
Диаграммы развертывания используются для моделирования системы с точки
ния их поставки. Базовыми элементами диаграммы развертывания являются
и компоненты. Узлы представляют блоки оборудования, а компоненты — части ^ЛЬ1
граммного обеспечения. В символах узлов указывается, какие объекты или компонен^
установлены на них. При моделировании всей системы базовым элементом явля ТЫ
пакет. Пакеты можно использовать для представления систем и подсистем. Между паке
тами могут существовать отношения, которые также отражаются на диаграмме.
ПРОЕКТИРОВАНИЕ
КОМПОНЕНТОВ
ДЛЯ ПОДДЕРЖКИ
ПАРАЛЛЕЛИЗМА
В этой главе...
11.1. Как воспользоваться преимуществами интерфейсных
классов
11.2. Подробнее об объектно-ориентированном взаимном
исключении и интерфейсных классах
11.3. Поддержка потокового представления
11.4. Пользовательские классы, создаваемые для обработки
PVM-потоков данных
11.5. Объектно-ориентированные каналы и FIFO-очереди как
базовые элементы низкого уровня
11.6. Каркасные классы
11.7. Резюме
“Как только мы пересекаем черту, чтобы реализовать себя в компьютерной
технологии, наши успехи начинают зависеть от способности нашего ума
к эволюции. Мы становимся частью программного, а не аппаратного
обеспечения.”
— Рей Курзвейл (Ray Kurzweil), The Age of Spiritual Machines
При реализации параллелизма в программном обеспечении необходимо следовать
одному важному7 правилу: параллелизм нужно обнаружить, а не внести извне.
Иногда цель увеличения быстродействия программы не является достаточно оп-
равданной для насаждения параллелизма в логику программы, которая по своей природе
является последовательной. Параллелизм в проекте должен быть естественным следстви-
ем требований системы. Если параллельность определена в технических требованиях
к системе, то следует с самого начала рассматривать варианты архитектуры и алгорит-
мы, которые поддерживают параллелизм. В противном случае необходимость паралле
лизма “всплывет” в уже существующей системе, которая изначально была нацелена лишь
на выполнение последовательных действий. Такая у^часть часто постигает системы, ко
торые первоначально разрабатывались как однопользовательские, а затем постепенно
вырастали во многопользовательские, или системы, которые с функциональной точки
зрения слишком далеко отошли от исходных спецификаций. В таких системах намере
пне внести в систему' параллелизм можно сравнить с попыткой “махать ручками после
драки”, и в этом случае для поддержки параллельности остается лишь делать архитек
турные “пристройки”. В этой книге мы описываем методы реализации естественного
параллелизма. Другими словами, если мы знаем, что нам нужно обеспечить парал-
лизм, нас интересует, как это сделать, используя средства C++?
11.1. Как воспользоваться преимуществами интерфейсных классов 379
Мы представляем архитектурный подход к управлению параллелизмом в програм-
ме используя преимущества С++-поддержки объектно-ориентированного програм-
мирования и универсальности. В частности, С++-средства поддержки наследования,
полиморфизма и шаблонов успешно применяются для реализации архитектурных
ешений и программных компонентов, которые поддерживают параллельность. Ме-
тоды объектно-ориентированного программирования обеспечивают поддержку деся-
ти типов классов, перечисленных в табл. 11.1.
рГаблица 11.1. Типы объектно-ориентированных классов
Типы классов Описание
Шаблонный класс Обобщенный код, который может использовать любой тип; ре- альный тип является параметром для тела этого кода
Контейнерный класс Класс, используемый для хранения объектов во внутренней или внешней памяти
Виртуальный базовый Базовый класс, который служит прямой и/или косвенной осно-
класс вой для создания производных посредством множественного на- следования; только одна его копия разделяется всеми его произ- водными классами
Абстрактный класс Класс, который поддерживает интерфейс для производных классов и который может быть использован только в качестве базового; используется как макет для построения других классов
Интерфейсный класс Класс, который используется для установки интерфейса дру- гих классов
Узловой класс Класс, функции которого расширены за счет добавления новых членов к тем, которые были унаследованы от базового класса
Доменный класс Класс, созданный для имитации некоторого элемента в конкрет- ной предметной области; значение класса связано с этой пред- метной областью
Составной класс Класс, который содержит другие классы; имеет с этими классами отношения типа “целое-часть”
Конкретный класс Класс, реализация которого определена, что позволяет объяв- лять экземпляры этого класса; он не предполагается для исполь- зования в качестве базового класса и не предусматривает попы- ток создавать операции общего характера
Каркасный класс Класс (или коллекция классов), который имеет предопределен- ную структуру и представляет обобщенный характер функцио- нирования
Безусловно, эти типы классов особенно полезны для проектов, в которых предпо-
лагается реализовать параллельность. Дело в том, что они позволяют внедрить
принцип компоновки из стандартных блоков. Мы обычно начинаем с примитивных
Понентов, используя их для построения классов синхронизации. Классы син-
Hbi ИЗаЦИИ позволят нам создавать контейнерные и каркасные классы, рассчитан-
На безопасное внедрение параллелизма. Каркасные классы представляют собой
380 Глава 11. Проектирование компонентов для поддержки параллелизма
строительные блоки, предназначенные для таких параллельных архитектур более
высокого уровня, как мультиагентные системы и “доски объявлений”. На каждом
\ ровне сложность параллельного и распределенного программирования уменьшается
благодаря использованию различных типов классов, перечисленных в табл. 11.1.
Шак, начнем с интерфейсного класса. Интерфейсный (или адаптерный) класс ис-
нользхется для модификации или усовершенствования интерфейса другого класса
или множества классов. Интерфейсный класс может также выступать в качестве обо-
лочки, созданной вокруг одной ити нескольких функций, которые не являются чле-
нами конкретного класса Такая роль интерфейсного класса позволяет обеспечить
объектно-ориентированный интерфейс с программным обеспечением, которое не-
обяк1гет1ыю является объектно-ориентированным. Более того, интерфейсные
классы позволяют упростить интерфейсы таких библиотек функций, как POSIX
tin c ads, PVM и MPI. Мы можем “обернуть” необъектно-ориентированную функцию
в объектно-ориентированный интерфейс; либо мы можем “обернуть” в интерфейс-
ный класс некоторые данные, инкапсулировать их и предоставить им таким обра-
зом объектно-ориентированный интерфейс. Помимо упрощения сложности неко-
торых библиотек функций, интерфейсные классы используются для обеспечения
разработчиков ПО согласующимся интерфейсом API (Application Programmer
Intri lac с). Например, С++-программисты, которые привыкли работать с iostream-
классами, получат возможность выполнять операции ввода-вывода, оперируя катего-
риями обьек! но-ориентированных потоков данных. Кривая обучения существенно
минимизируется, если новые методы ввода-вывода описать в виде привычного
iosi 1 гаш-нредс! явления. Например, мы можем представить библиотеку средств пере-
дачи сообщений MPI как коллекцию потоков.
mpi_stream Streaml;
mpi_stream Stream2;
Streaml << Messagel « Message2 « Message3;
Stream2 >> Message4;
// . . .
При таком подходе программист может целиком сосредоточиться на логике про-
1 раммы и нс ломать голову над соблюдением требований к синтаксису библиотеки MPI.
11.1. Как воспользоваться преимуществами
интерфейсных классов
Зачастую полезно использовать инкапсуляцию, чтобы скрыть детали библиотек
функций и обеспечить создание самодостаточных компонентов, которые годятся для
многократного использования. Возьмем для примера мьютекс, который мы рассмат-
ривали в гтаве7. Вспомним, что мыогскс — это переменная специального типа, не
пользуемая для синхронизации. Мьютексы позволяют получать безопасный доступ
к критическому разделе данных или кода программы. Существует шесть основных
фхнкций. предназначенных для работы с переменной типа pthread_mutex__
(14 )SIX Till cads Mutex).
11.1. Как воспользоваться преимуществами интерфейсных классов 381
Синопсис
#include <pthread.h>
nthread_mutex_destroy (pthread_jnutex_t *mutex) ;
nthread_mutex_init(pthread_mutex_t *mutex,
P pthread—mutexattr_t *attr);
thread_mutex_lock(pthread^mutex_t *mutex);
pthread_mutex-timedlock (pthread—mutex_t *mutex) ;
pthread__mutex—trylock (pthread—inutex__t *mutex) ;
pthread mutex-unlock(pthread_mutex-t *mutex);
Все эти функции принимают в качестве параметра указатель на переменную типа
pthread_mutex-t. Для инкапсуляции доступа к переменной типа pthread_mutex-t
и упрощения вызовов функций, которые обращаются к мьютексным переменным,
можно использовать интерфейсный класс. Рассмотрим листинг 11.1, в котором объ-
является класс mutex.
// Листинг 11.1. Объявление класса mutex
class mutex{
protected:
pthread_mutex—t *Mutex;
pthread—mutexattr—t *Attr;
public:
mutex(void)
int lock(void);
int unlock(void);
int trylock(void);
int timedlock(void);
};
Объявив класс mutex, используем его для определения мьютексных переменных.
Мы можем объявлять массивы мьютексов и использовать эти переменные как члены
пользовательских классов. Инкапсулировав переменную типа -pthread—mutex—t
имьютексные функции, воспользуемся преимуществами методов объектно-
ориентированного программирования. Эти мьютексные переменные можно затем
применять в качестве аргументов функций и значений, возвращаемых функциями.
А поскольку мьютексные функции теперь связаны с переменной типа pthread—mutex_t,
то там, где мы используем мьютексную переменную, эти функции также будут доступны.
Функции-члены класса mutex определяются путем заключения в оболочку вызовов
соответствующих Pthread-функций, например, так.
II Листинг 11.2. Функции-члены класса mutex
™uteX::mutex(void)
try{
int Value;
Value = pthread_mutexattr_int(Attr);
Value = pthread_jnutex_init(Mutex,Attr);
г >
382 Глава 11. Проектирование компонентов для поддержки параллелизма
int mutex: : lock (void)
{
int RetValue;
RetValue = pthread_mutex_lock(Mutex);
return(Returnvalue);
}
Благодаря инкапсуляции мы также защищаем переменные типа
pthread_mutex_t * и pthread_mutexattr_t *. Другими словами, при вызове ме-
тодов lockO, unlockO, trylockO и других нам не нужно беспокоиться о том
к каким мьютексным переменным или переменным атрибутов будут применены эти
функции. Возможность скрывать информацию (посредством инкапсуляции) позволя-
ет программист}7 писать вполне безопасный код. С помощью свободно распростра-
няемых версий Pthread-функций этим функциям можно передать любую переменную
типа pthread—mutex_t. Однако при передаче одной из этих функций неверно за-
данного мьютекса может возникнуть взаимоблокировка или отсрочка бесконечной
длины. Инкапсуляция переменных типа pthread_mutex_t и pthread_mutexattr_t
в классе mutex предоставляет программисту полный контроль над тем, какие функ-
ции получат доступ к этим переменным.
Теперь мы можем использовать такой встроенный интерфейсный класс, как
mutex, в любых других пользовательских классах, предназначенных для безопасной
обработки потоков выполнения. Предположим, мы хотели бы создать очередь с мно-
гопоточной поддержкой и многопоточный класс pvm_stream. Очередь будем ис-
пользовать для хранения поступающих событий для множества потоков, образован-
ных в программе. На некоторые потоки возложена ответственность за отправку со-
общений различным PVM-задачам. PVM-задачи и потоки выполняются параллельно.
Несколько потоков выполнения разделяют единственный PVM-класс и единственную
очередь событий. Отношения между потоками, PVM-задачами, очередью событий
и классом pvm_stream показаны на рис. 11.1.
Очередь, показанная на рис. 11.1, представляет собой критический раздел, по-
скольку она совместно используется несколькими выполняемыми потоками. Класс
pvm_stream — это также критический раздел и по той же причине. Если эти критиче-
ские разделы не синхронизировать и не защитить, то данные в очереди и классе
pvm_stream могут разрушиться. Тот факт, что несколько потоков могут одновре-
менно обновлять либо очередь, либо код класса pvm_stream, открывает среду Для
“гонок”. Чтобы не допустить этого, мы должны обеспечить нашу очередь и класс
pvm_stream встроенными средствами блокировки и разблокировки. Эти средства
также поддерживаются классом mutex. На рис. 11.2 показана диаграмма классов для
наших пользовательских классов x_queue и pvm_stream.
Обратите внимание на то, что класс x_queue содержит класс мьютекс, т.е. меж
ду классами x_queue и мьютекс существует отношение агрегирования. Любая one
рация, которая изменяет состояние нашего класса x_queue, может привести
к “гонкам” данных, если, конечно, эту операцию не синхронизировать. Следова
тельно, операции, которые добавляют объект в очередь или удаляют его из нее, яв
ляются кандидатами для синхронизации. В листинге 11.3 приведено объявление
класса x_queue как шаблонного.
11.1. Как воспользоваться преимуществами интерфейсных классов
PVM-программа
Среда UNIX/Linux
// Листинг 11.3. Объявление класса x_queue
template <class Т> x_queue class{
Protected:
queue<T> EventQ;
Wtex Mutex;
//.. .
Public:
bool enqueue(T Object);
^dequeue (void) ;
384 Глава 11. Проектирование компонентов для поддержки параллелизма
Метод enqueue () используется для добавления элементов в очередь, а ме
dequeue () — для удаления их из очереди. Каждый из этих методов рассчитан на
пользование объекта Mutex. Определение этих методов приведено в листинге 11 4
// Листинг 11.4. Определение методов enqueue() и dequeue()
template<class Т> bool x_queue<T>::enqueue(Т Object)
(
Ииtex.lock();
EventQ.push(Object);
Mutex.unlock();
}
templetecclass T> T x_queue<T>::dequeue(void)
{
T Object;
// . . .
Mutex.lock();
Object = EventQ.front()
EventQ pop();
Mutex.unlock();
// . . .
return(Object);
}
Теперь очередь может функционировать (принимать новые элементы и избавляться
от пещжпых) в многопоточной среде. ПотокВ (см. рис. 11.1) добавляет элементы
в очередь а поток А удаляет их оттуда. Класс mutex является интерфейсным классом. Он
заключает в оболочку' функции pthread_mutex_lock (), pthread—mutex_unlock (),
pthread—mutex—init () и pthread_mutex_trylock (). Класс X—queue также явля-
ется интерфейсным, поскольку7 он адаптирует интерфейс для встроенного класса
queue<T>. Прежде всего, он заменяет интерфейсы методов push() и рор() метода-
ми enqueue () и dequeue (). При этом операции вставки и удаления элементов из
очереди заключаются между’ вызовами методов Mutex, lock () и Mutex.unlock О •
Поэтому’ в первом случае мы используем интерфейсный класс для инкапсуляции пе-
ременных типа pthread_mutex_t* и pthread_mutexattr_t*, а также заключаем
в интерфейсную оболочку несколько функций из библиотеки Pthread. А во втором
случае мы используем интерфейсный класс для адаптации интерфейса класса
queue<T>. Еще одно достоинство класса mutex состоит в том, что его легко исполь-
зовать в других классах, которые содержат критические разделы или области.
Класс p^mi—Stream (см. рис. 111) также является критическим разделом, посколь
ку оба потока выполнения (А и В) имеют доступ к потоку данных. Опасность возник
новения “гонок” данных здесь вполне реальна, поскольку потокА и поток В могут* по
лхчить достхп к потоку данных одновременно. Следовательно, мы используем класс
mutex в нашем классе pvm_stream для обеспечения необходимой синхронизации.
U Листинг 11.5. Объявление класса pvm—stream
class pvm_stream{
protected:
mutex Mutex;
int Taskld;
int Messageld;
/ / .
public:
j 1 2. Подробнее об объектно-ориентированном взаимном исключении... 385
ovm_stream & operator «(string X) ;
pvm stream & operator «(int X) ;
pvmZstream ^operator «(float X) ;
pvitL-Stream &operator>>(string X) ;
//••
Как и в классе х_queue, объект Mutex используется применительно к функциям,
которые могут изменить состояние объекта класса pvm_stream. Например, мы могли
определить один из операторов “«” следующим образом.
// Листинг 11.6.
//
Определение оператора « для
класса pvm_stream
pvm__s tream &pvm_stream:: operator« (string X)
{
//.. .
pvm_pkbyte(const_cast<char *>(X.data()),X.size(),1);
Mutex.lock();
pvm_send(Taskid,Messageld) ;
Mutex.unlock();
//. . .
return(*this) ;
}
Класс pvm_stream использует объекты Mutex для синхронизации доступа к его
критическому разделу точно так же, как это было сделано в классе х_queue. Важно
отметить, что в обоих случаях инкапсулируются pthread_mutex^yHKHHH. Програм-
мист не должен беспокоиться о правильном синтаксисе их вызова. Здесь также ис-
пользуется более простой интерфейс для вызова функций lock () и unlock (). Более
того, здесь нельзя перепутать, какую pthread—mutex_t*-переменную нужно исполь-
зовать с pthread_mutex-функциями. Наконец, программист может объявить не-
сколько экземпляров класса mutex, не обращаясь снова и снова к функциям библио-
теки Pthread. Раз мы сделали ссылку на Pthread-функции в определениях методов
класса mu tex, то теперь нам достаточно вызывать только эти методы.
11-2. Подробнее об объектно-ориентированном
взаимном исключении и интерфейсных
классах
Чтобы справиться со сложностью написания и поддержки программ с паралле-
лизмом, попробуем упростить API-интерфейс с соответствующими библиотеками.
Некоторых системах, возможно, имеет смысл создать библиотеки Pthreads, MPI,
а также стандартные функции использования семафоров и разделяемой памяти как
Часть единого решения. Все эти библиотеки и функции имеют собственные протоко-
^bI и синтаксис. Но у них есть много общего. Поэтому мы можем использовать интер-
т Исные классы, наследование и полиморфизм для создания упрощенного и непро-
тиворечивого интерфейса, с которым непосредственно будет работать программист.
1 Можем также скрыть от наших приложений детали реализации конкретной биб-
лиотеки. Если приложение опирается только на методы, используемые в наших
386 Глава 11. Проектирование компонентов для поддержки параллелизма
интерфейсных классах, то оно будет защищено от изменений, вносимых в реализацн
функций, обновлений библиотек и прочих “подводных” реструктуризаций. В кон
концов, работа над интерфейсом (интерфейсными классами) с компонентами пап
лелизма и библиотеками функций позволит существенно понизить уровень сложно
сти параллельного программирования. Итак, рассмотрим подробнее, какие методы
разработки интерфейсных классов можно реализовать для поддержки параллелизма
11.2.1. “Полуширокие” интерфейсы
Базовый POSIX-семафор используется для синхронизации доступа к критическому
раздел)’ нескольких процессов, а базовый POSIX-поток — для синхронизации доступа
к критическому разделу нескольких потоков. В обоих случаях используются переменные
синхронизации и ряд функций, работающих с этими переменными. Библиотеки MPI
и PVM содержат примитивы передачи сообщений и обладают средствами порождения
задач. Но интерфейсы этих библиотек различны. Нетрудно предположить, что работа
прикладного программиста была бы эффективней, если бы он сосредоточил свое вни-
мание на логике и структуре программы. Однако там, где семантика программы теряет
свою ясность из-за необходимости использовать библиотеки, в которых попадаются
аналогичные функции, а сами библиотеки отличаются синтаксисом и протоколами,
у программиста возникают немалые трудности. Отсюда вытекает потребность универ-
сализации интерфейса, который бы подходил для работы с разными библиотеками.
Существует по крайней мере два подхода к разработке общего интерфейса для се-
мейства, или коллекции классов. Объектно-ориентированный подход начинается с об-
щего и переходит к частностям посредством наследования. Другими словами, возьмем
минимальный набор характеристик и атрибутов, которыми должен обладать каждый
член рассматриваемого семейства классов, а затем посредством наследования будем
конкретизировать характеристики для каждого класса. При таком подходе по мере
“спуска” по иерархии классов интерфейс становится все более “узким”. Второй подход
часто используется в коллекциях шаблонов. Шаблонные методы начинаются с конкрет-
ного и переходят к более общему посредством “широких” интерфейсов. “Широкий” ин-
терфейс включает обобщение всех характеристик и атрибутов (см. книгу Страуструпа
Язык программирования C++, 1997). Если бы нам пришлось применить к библиотекам
средств параллелизма “узкий” и “широкий” интерфейсы, то согласно методу “узкого ин-
терфейса” мы бы взяли от каждой библиотеки общие, или пересекающиеся, части
(т.е. пересечение), обобщили их и поместили в базовый класс. И, наоборот, реализуя метод
“широкого интерфейса”, нужно было бы поместить в базовый класс все функциональ-
ные части каждой библиотеки (т.е. объединение), предварительно обобщив их. В ре-
зультате пересечения мы получили бы меньший по объему да и менее полезный класс.
А результат объединения, скорей всего, поразил бы каждого своей грохмоздкостью.
Решение, которое интересует нас в данном случае, находится где-то посередине, т.е.
нам нужны “полуширокие” интерфейсы. Начнем же мы с метода “узкого” интерфейса
и обобщим его настолько, насколько это можно сделать в пределах иерархии одного
класса. Затем используем этот “узкий” интерфейс в качестве основы для коллекции
классов, которые связаны не наследованием, а функциями. “Узкий” интерфейс ДоЛ
жен действовать в качестве стратегии сдерживания “ширины”, до которой может ра3
бухнуть “полуширокий” интерфейс. Друтими словами, нам не нужно объединять о)
вально все характеристики и атрибуты; мы хотим получить объединение только тех
11.2. Подробнее об объектно-ориентированном взаимном исключении... 387
частей, которые логически связаны с нашим “узким” интерфейсом. Проиллюстрируем
МЬ1СЛЬ на примере простого проекта интерфейсных классов для POSIX-семафора,
р^-еаЗ-мыотекса и Pthread-переменной блокировки.
Безотносительно к реализации деталей, операции блокировки, разблокировки
и “пробной” блокировки являются характеристиками переменных синхронизации. Поэтому
мы создадим базовый класс, который будет служить “трафаретом” для целого семейства
классов. Объявление класса synchronization—variable представлено в листинге 11.7.
// Листинг 11.7. Объявление класса synchronization—variable
class synchronization-variable{
protected:
runtime—error Exception;
//. - •
public:
int virtual lock(void) = 0;
int virtual unlock(void) = 0;
int virtual trylock(void) = 0;
//. . .
};
Обратите внимание на то, что методы синхронизации класса synchroniza-
tion—variable объявлены виртуальными и инициализированы значением 0. Это
означает, что они являются чисто виртуальными методами, что делает класс
synchronization—variable абстрактным. Из класса, который содержит одну или
несколько чисто виртуальных функций, объект прямым путем создать нельзя. Чтобы
использовать этот класс, необходимо вывести из него новый класс и определить в нем
все чисто виртуальные функции. Абстрактный класс — это своего рода трафарет с ука-
занием того, какие функции должны быть определены в производном классе. Он
предлагает интерфейсный проект для производных классов. Он отнюдь не диктует,
как нужно реализовать методы, он лишь отмечает, какие методы должны быть пред-
ставлены в выведенном классе, причем они не могут оставаться в нем чисто виртуаль-
ными. С помощью имен этих методов мы можем подсказать предполагаемое их пове-
дение. Таким образом, проектный интерфейсный класс предлагает проект без реали-
зации. Класс этого типа используется в качестве фундамента для будущих классов.
Проектный класс гарантирует, что интерфейс будет иметь определенный вид [9].
Класс synchronization—variable обеспечивает интерфейсный трафарет для се-
мейства переменных синхронизации. Для обеспечения различных вариантов реали-
зации интерфейса мы используем наследование. Pthread-мьютекс — прекрасный кан-
дидат для интерфейсного класса, поэтому мы определяем класс mutex как производ-
ный от класса synchronization—variable.
// Листинг 11.8. Объявление класса мьютекс, который
наследует класс synchronization—variable
class mutex : public synchronization—variable{
Protected:
Pthread—mutex—t *Mutex;
Pthread—mutexattr t *MutexAttr;
// . .
PubliC:
rnt lock(void);
388 Глава 11. Проектирование компонентов для поддержки параллелизма
int unlock(void);
int trylock(void);
//. . .
};
Класс mutex должен обеспечить реализации для всех чисто виртуальных функций
Если эти функции определены, значит, политика, предложенная абстрактным клас-
сом, выдержана. Класс mutex теперь не является абстрактным, поэтому из него и из
его потомков можно создавать объекты. Каждый из методов класса mutex заключает
в оболочку соответствующую Pthread-функцию. Например, код
int mutex: : trylock(void)
{
//. . .
return (pthread_mutex_ try lock (Mutex) ;
//. . .
}
обеспечивает интерфейс для функции pthread_mutex_trylock (). Интерфейсные
варианты функций lock (), unlock () и trylock () упрощают вызовы функций биб-
лиотеки Pthread. Наша цель — использовать инкапсуляцию и наследование для опреде-
ления всего семейства мьютексных классов. Процесс наследования — это процесс спе-
циализации. Производный класс включает дополнительные атрибуты или характери-
стики, которые отличают его от предков. Каждый атрибут или характеристика,
добавленная в производный класс, конкретизирует его. Теперь мы, используя наследова-
ние, можем спроектировать специализацию класса mutex путем введения понятия мыо-
тексного класса, способного обеспечить чтение и запись. Наш обобщенный класс mutex
предназначен для защиты доступа к критическому разделу. Если один поток заблокировал
мьютекс, он получает доступ к критическому разделу, защищаемому этим мьютексом. Ино-
гда такая мера предосторожности оказывается излишне суровой. Возможны ситуации, ко-
гда вполне можно разрешить доступ нескольких потоков к одним и тем же данным, если
ни один из этих потоков не модифицирует данные. Другими словами, в некоторых случа-
ях мы можем ослабить блокировку критического раздела и “намертво” запирать его
только для действий, которые стремятся модифицировать данные, разрешая при этом
доступ для действий, которые предполагают лишь считывание или копирование дан-
ных. Такой вид блокировки называется блокировкой считывания (read lock). Блокировка
считывания позволяет параллельный доступ к критическому разделу для чтения дан-
ных. Критический раздел может быть уже заблокированным одним потоком, но дру-
гой поток также может получить блокировку, если у него нет намерения изменять
данные. Критический раздел может быть заблокирован для записи одним потоком,
а другой поток может запросить блокировку для чтения этого критического раздела.
Архитектура “классной доски” служит прекрасным примером структуры, которая
может использовать преимущества “мьютексов считывания” и мьютексов более обще-
го назначения. Под “классной доской” понимается область памяти, разделяемая па-
раллельно выполняемыми задачами. “Классная доска” используется для хранения ре
шений некоторой проблемы, которую совместными усилиями решает целая группа
задач. По мере приближения задач к решению проблемы каждая из них записывает
результаты на “классную доску” и просматривает ее содержимое с целью поиска ре
зультатов, сгенерированных другими задачами, которые могут оказаться полезным11
для нее. Структура “классной доски” является критическим разделом. В действительно
сти мы хотим, чтобы одновременно только одна задача могла обновлять содержимое
1 2. Подробнее об объектно-ориентированном взаимном исключении... 389
“классной доски”. Однако ее одновременное считывание мы можем позволить любо-
количеству задач. Кроме того, если несколько задач уже считывает содержимое
«классной доски”, нам нужно, чтобы оно не начало обновляться до тех пор, пока все
эти задачи не завершат чтение. “Мьютекс считывания” как раз подходит для такой си-
апии, поскольку он может управлять доступом к “классной доске”, разрешая его
только считывающим задачам и запрещая его для записывающих задач. Но если ре-
шение проблемы будет найдено, содержимое “классной доски” необходимо обновить.
В процессе обновления нам нужно, чтобы ни одна считывающая задача не получила
доступ к критическому разделу. Мы хотим заблокировать доступ для чтения до тех
пор пока не завершит обновление записывающая задача. Следовательно, нам нужно
создать “мьютекс записи”. В любой момент времени удерживать этот “мьютекс запи-
си” может только одна задача. Поэтому мы делаем различие между мьютексом, кото-
рый блокируется для считывания, но не для записи, и мьютексом, который блокиру-
ется для записи, но не для считывания. С использованием мьютекса считывания у нас
может быть несколько параллельных считывающих задач, а с использованием мью-
текса записи — только одна записывающая задача. Описанная схема является частью
модели CREW (Concurrent Read Exclusive Write — параллельное чтение, монопольная
запись) параллельного программирования.
Для разработки спецификации нашего мьютексного класса нам нужно наделить
его способностью выполнять блокировки считывания и блокировки записи.
В библиотеке Pthreads предусмотрены мьютексные переменные блокировки чте-
ния-записи и атрибутов:
pthread—rwl о ck_t и pthread—rwlоckattr_t
Эти переменные используются совместно с 11 pthread—rwl оск ()-функциями.
Мы используем наш интерфейсный класс rw_mutex для инкапсуляции переменных
pthread—rwlock_t и pthread—rwlockattr_t, а также для заключения в оболочку
Pthread-функций мьютексной организации чтения-записи.
Синопсис
#include <ptrhead.h>
int pthread—rwlock—init(
pthread—rwlock_t *,
const pthread_rwlockattr_t *) ;
int pthread—rwlock_destroy (pthread_rwlock_t *) ;
int pthread—rwlock—rdlock(pthread—rwlock—t *);
int pthread—rwlock—tryrdlock(pthread—rwlock_t *);
int pthread—rwlock_wrlock(pthread_rwlock_t *) ;
int pthread—rwlock_trywrlock(pthread—rwlock_t *);
int pthread—rwlock_unlock(pthread—rwlock—t *) ;
int pthread—rwlockattr_init(pthread_rwlockattr_t *) ;
int pthread—rwlockattr_destroy(pthread—rwlockattr_t *);
xnt pthread—rwlockattr_getpshared(
const pthread—rwlockattr_t *,
int *);
pthread—rwlockattr_setpshared(
pthread—rwlockattr_t ★,
---— int);
390 Глава 11. Проектирование компонентов для поддержки параллелизма
// Листинг 11.9. Объявление класса rw_mutex, который
// содержит объекты типа pthread—rwlock_ t
// и pthread—rwlockattr_t
class rw__mutex : public mutex{
protected:
struct pthread—rwlock_t *RwLock;
struct pthread—rwlоckattr_t *RwLockAttr;
public:
//. . .
int read_lock(void);
int write_lock(void);
int try_readlock(void);
int try_writelock(void);
//. . -
Класс rw_mutex наследует класс mutex. На рис. 11.3 показаны отношения между
классами rw_mutex, mutex, synchronization—variable и runtime—error.
Пока мы создаем “узкий” интерфейс. На данном этапе мы заинтересованы в обес-
печении минимального набора атрибутов и характеристик, необходимых для обоб-
щения нашего класса mutex с использованием мьютексных типов и функций из биб-
лиотеки Pthread. Но после создания “узкого” интерфейса для
класса mutex мы воспользуемся им как основой для создания
“полуширокого” интерфейса. “Узкий” интерфейс обычно при-
меняется в отношении классов, которые связаны наследовани-
ем. “Широкие” интерфейсы, как правило, применяют к классам,
которые связаны функциями, а не наследованием. Нам нужен
интерфейсный класс для упрощения работы с классами или
функциями, которые принадлежат различным библиотекам, но
выполняют подобные действия. Интерфейсный класс должен
обеспечить программиста удобными рабочими инструментами.
Для этого мы берем все библиотеки или классы с подобными
функциями, отбираем все общие функции и переменные и после
некоторого обобщения помещаем их в большой класс, который
содержит все требуемые функции и атрибуты. Так определяется
класс с “широким” интерфейсом. Но если включить в него
(например, в класс rw_mutex) только интересующие нас функ-
ции и данные, мы получим “полуширокий” интерфейс. Его пре-
имущества перед “широким” интерфейсом заключаются в том,
что он позволяет нам получать доступ к объектам, которые свя-
заны лишь функционально, и ограничивает множество методов,
которыми может пользоваться программист, теми, которые со-
держатся в интерфейсном классе с узким “силуэтом”. Это может
быть очень важно при интеграции таких больших библиотек
функций, как MPI и PVM с POSIX-возможностями параллелизма.
Объединение MPI-, PVM- и POSIX-средств дает сотни функций
Рис. 11.3. Отношения между классами rw_mutex, mutex,
synchronization_variable и runtime_error
1 -j 2 Подробнее об объектно-ориентированном взаимном исключении... 391
алогичными целями. Затратив время на упрощение этой функциональности в ин-
С Жейсных классах, вы позволите программисту понизить уровень сложности, свя-
Танный с параллельным и распределенным программированием. Кроме того, эти ин-
Жейсные классы становятся компонентами, которые можно многократно исполь-
зовать в различных приложениях.
Чтобы понять, как подойти к созданию “полуширокого” интерфейса, построим
интерфейсный класс для POSIX-семафора. И хотя семафор не является частью биб-
лиотеки Pthread, он находит аналогичные применения в многопоточной среде. Его
можно использовать в среде, которая включает параллельно выполняемые процессы
и потоки. Поэтому в некоторых случаях требуется объект синхронизации более обще-
го характера, чем наш класс mutex.
Определение класса semaphore показано в листинге 11.10.
// Листинг 11.10. Объявление класса semaphore
class semaphore : public synchronization-variable{
protected:
sem_t *Semaphore;
public:
II...
int lock(void);
int unlock(void);
int trylock(void);
//. . .
};
Синопсис
<semaphore. h>
int sem_init(sem_t *, int, unsigned int);
int sem_destroy(sem_t *);
sem__t *sem_open(const char *, int, ...);
int sem_close(sem_t *);
int sem__u.nlink (const char *) ;
int sem__wait (sem_t *) ;
int sem_trywait (sem_t *) ;
int sem__post (sem_t *) ;
-int sem_getvalue (sem t *, int *);
Обратите внимание на то, что класс semaphore имеет такой же интерфейс, как
и наш класс mutex. Чем же они различаются? Хотя интерфейсы классов mutex
и semaphore одинаковы, реализация функций lock (), unlock (), trylock () и тому
подобных представляет собой вызовы семафорных функций библиотеки POSIX.
// Листинг 11.11. Определение методов lock(), unlock() и
trylock() для класса semaphore
|nt semaphore:: lock (void)
//. . .
return(sem_wait(Semaphore));
392 Глава 11. Проектирование компонентов для поддержки параллелизма
int semaphore::unlock(void)
{
//. . .
return(sem_post(Semaphore));
}
Итак, теперь функции lock (), unlock (), trylock () и тому подобные заклю-
чают в оболочку семафорные функции библиотеки POSIX, а не функции библио-
теки Pthread. Важно отметить, что семафор и мьютекс — не одно и то же. Но их
можно использовать в аналогичных ситуациях. Зачастую с точки зрения инструк-
ций, которые реализуют параллелизм, механизмы функций 1оск() и unlock ()
имеют одно и то же назначение. Некоторые основные различия между мьютексом
и семафором указаны в табл. 11.2.
Таблица 11.2. Основные различия между мьютексами и семафорами
Характеристики мьютексов Характеристики семафоров
Мьютексы и переменные условий разделяются между потоками Семафоры обычно разделяются между процессами, но их разделение возможно и между потоками
Мьютекс деблокируется теми же по- токами, которые его заблокировали Освобождать семафор должен необязательно тот процесс или поток, который его удерживал
Мьютекс либо блокируется, либо деблокируется Семафоры управляются количеством ссылок. Стан- дарт POSIX включает именованные семафоры
Несмотря на важность различий в семантике (см. табл. 11.2), часто их оказыва-
ется недостаточно для оправдания применения к семафорам и мьютексам совер-
шенно различных интерфейсов. Поэтому мы оставляем “полуширокий” интерфейс
для функций lock(), unlock() и trylock () с одним предостережением: про-
граммист должен знать различия между мьютексом и семафором. Это можно срав-
нить с ситуацией, которая возникает с такими “широкими” интерфейсами таких
контейнерных классов, как deque, queue, set, multiset и пр. Эти контейнерные
классы связаны общим интерфейсом, но их семантика в определенных областях
различна. Используя понятие интерфейсного класса, можно разработать соответ-
ствующие компоненты синхронизации для мьютексов, переменных условий, мью-
тексов чтения-записи и семафоров. Имея такие компоненты, мы можем спроекти-
ровать безопасные (с точки зрения параллелизма) контейнерные, доменные
и каркасные классы. Мы можем также применять интерфейсные классы для обес-
печения единого интерфейса с различными версиями одной и той же библиотеки
функций при необходимости использования обеих версий (по разным причинам)
в одном и том же приложении. Иногда интерфейсный класс может быть успешно
применен для безболезненного перехода от устарелых функций к новым. Если
мы хотим оградить программиста от различий, существующих между операцион
ными системами, то наша цель — обеспечить его соответствующим API-ин
терфейсом, независимо от того, какая библиотека семафорных функций использу
ется в среде: System V или POSIX.
11.3. Поддержка потокового представления 393
11.3. Поддержка потокового представления
Помимо использования интерфейсных классов для упрощения программирования
создания новых “широких” интерфейсов библиотек средств параллелизма и пере-
дачи сообщений, имеет смысл также расширить существующие интерфейсы. Напри-
мер объектно-ориентированное представление потоков данных можно расширить за
счет использования каналов, FIFO-очередей и таких библиотек передачи сообщений,
как PVM и MPI. Эти компоненты используются ради достижения межпроцессного
взаимодействия (Inter-Process Communication — IPC), межпотокового взаимодействия
(Inter-Thread Communication — ITC), а в некоторых случаях и взаимодействия между
объектами (Object-to-Object Communicaton — ОТОС). Если взаимодействие имеет ме-
сто между параллельно выполняемыми потоками или процессами, то канал связи мо-
жет представлять собой критический раздел. Другими словами, если несколько про-
цессов (потоков) попытаются одновременно обновить один и тот же канал, FIFO-
очередь или буфер сообщений, непременно возникнет “гонка” данных. Если мы со-
бираемся расширить объектно-ориентированный интерфейс потоков данных за счет
включения компонентов из библиотеки PVM или MPI, нам нужно быть уверенными
в том, что доступ к этим потокам данных будет безопасен с точки зрения параллелиз-
ма. Именно здесь могут пригодиться наши компоненты синхронизации, спроектиро-
ванные в виде интерфейсных классов. Рассмотрим простой класс pvm_stream.
// Листинг 11.12. Объявление класса pvm_stream, который
// наследует класс mios
class pvm_stream : public mios{
protected:
int Taskid;
int Messageld;
mutex Mutex;
//. . .
public:
void taskid(int Tid);
void messageld(int Mid);
pvm_stream(int Coding = PvmDataDefault);
void reset(int Coding = PvmDataDefault);
pvm_stream &operator«(string &Data);
pvm_stream &operator>>(string &Data);
pvm_stream &operator>>(int &Data);
pvm_stream &operator« (int &Data) ;
//. . .
Этот класс обработки потоков данных предназначен для инкапсуляции состоя-
ния активного буфера в PVM-задаче. Операторы вставки “<<” и извлечения “>>”
Можно использовать для отправки и приема сообщений между PVM-процессами.
Десь мы рассмотрим использование этих операторов только для обработки строк
и значений типа int. Интерфейс этого класса далек от совершенства. Поскольку этот
Класс предназначен для обработки данных любого типа, мы должны расширить опре-
деления операторов “«” и “»”. А так как мы планируем использовать класс
Pvin-Stream в многопоточной программе, мы должны быть уверены в том, что объ-
ект Класса pvm_stream безопасен для потоков. Поэтому мы включаем в качестве
394 Глава 11. Проектирование компонентов для поддержки параллелизма
члена нашего класса pvm_stream класс mutex. Поскольку сообщение может быть
направлено для конкретной PVM-задачи, класс pvm_stream инкапсулирует для нее
активный буфер. Наша цель — использовать классы ostream и istream в качестве
“путеводителя” по функциям, которые должен иметь класс pvm_stream. Вспомним
что классы ostream и istream являются классами трансляции. Они переводят ти-
пы данных в обобщенные потоки байтов при выводе и обобщенные потоки байтов
в конкретные типы данных при вводе. Используя классы istream и ostream, про-
граммисту не нужно погружаться в детали вставки в поток или выделения из потока
данных того или иного типа. Мы хотим, чтобы и поведение класса pvm_stream бы-
ло аналогичным. Библиотека PVM располагает различными функциями для каждого
типа данных, которые необходимо упаковать в буфер отправки или распаковать из
буфера приема. Например, функции
pvm_pkdouble ()
pvm_pkint()
pvm__pkf loat ()
используются для упаковки double-, int- и float-значений соответственно. Анало-
гичные функции существуют и для других типов данных, определенных в C++. Мы
бы хотели поддерживать наше потоковое представление, т.е. чтобы ввод и вывод
данных можно было представить как обобщенный поток байтов, который переме-
щается в программу или из нее. Следовательно, мы должны определить операторы
вставки (<<) и извлечения (>>) для каждого типа данных, который мы собираемся
использовать при обмене сообщениями между PVM-задачами. Мы также моделиру-
ем состояние потока данных в соответствии с классами istream и ostream, кото-
рые содержат компонент ios, предназначенный для хранения состояния этого по-
тока. Поток данных может находиться в состоянии ошибки либо в одном из раз-
личных состояний, которые выражаются восьмеричным, десятичным или
шестнадцатеричным числом. Поток также может пребывать в нормальном, забло-
кированном или состоянии конца файла. Класс pvm_stream должен не только со-
держать компонент, который поддерживает состояние потока данных, но и мето-
ды, которые устанавливают заданное или исходное состояние PVM-задачи, а также
считывают его. Наш класс pvm_stream для этих целей содержит компонент mios.
Этот компонент поддерживает состояние потока данных и активного буфера от-
правки и приема информации. На рис. 11.4 представлены две диаграммы классов:
одна отображает отношения между основными классами библиотеки iostream,
а вторая — отношения между классом pvm_stream и его компонентами.
Обратите внимание на то, что классы istream и ostream наследуют класс ios.
Класс ios поддерживает состояние потока данных и состояние буфера, используемо-
го классами istream и ostream. Наш класс mios исполняет ту же роль в отношении
класса pvm_stream. Классы istream и ostream содержат определения операторов
“«” и “>>”. Эти же операторы определены и в нашем классе pvm_stream. Поэтом},
хотя наш класс pvm_stream не связан с iostream-классами наследованием, между ними
существует интерфейсная связь. Мы используем интерфейс iostream-классов в качест
ве “полуширокого” интерфейса для классов pvm_stream и mios. Обратите внимание
на то, что класс mios (см. рис. 11.4) наследуется классом pvm_stream. Если мы хотим
поддерживать потоковое представление с помощью класса pvm_stream, то для этого
как раз подходит понятие интерфейсного класса.
11.3. Поддержка потокового представления 395
ИЕРАРХИЯ iostream-классов
J
ios base I
1 1 J
basic_filebun
~~~ I T .
basic_ —. J
stringbuf
basic_ios
J
' • J
basicjstream
1 ' J
basic_ostream
basic_ —। J
ifstream
............I Т
basic_ — ।J
istringstream
basic_ — । J
iostream
________
basic_ —। J
ostringstream
basic_ — J
ofstream
к . I т
basic_ — iJ
stringstream
— —I T ।
basic_ —।J
fstream
Рис. 11.4. Диаграмма классов, отображающая отношения между основными классами
библиотеки iostream, и диаграмма класса pvm_stream
11.3.1. Перегрузка операторов “«” и “»”
для PVM-потоков данных
Итак, рассмотрим определение операторов “<<” и “>> для класса pvm_stream.
Оператор вставки («) используется для заключения в оболочку функций
Pvm_Send () и pvm_pk. Вот как выглядит определение этого операторного метода.
// Листинг 11.13. Определение оператора "«" для класса
pvm_stream class
^Vrn— stream &pvm_stream::operator<<(int Data)
396 Глава 11. Проектирование компонентов для поддержки параллелизма
//...
reset();
pvm_pkint(&Data,1,1);
pvm_send(Taskld,Messageld);
//. . .
return(*this);
}
Подобное определение существует для каждого типа данных, которые будут обраба-
тываться с использованием класса pvm_streain. Метод reset () унаследован от клас-
са mios. Этот метод используется для инициализации буфера отправки данных
Taskld и Messageld — это члены данных класса pvm_ stream, которые устанавлива-
ются с помощью методов taskld () и messageld (). Определяемый здесь оператор
вставки позволяет отправлять данные PVM-задаче с помощью стандартной записи
операции вывода в поток.
int Value = 2004;
pvm_stream Mystream;
//. . .
MyStream « Value;
//. . .
Оператор извлечения данных (») используется подобным образом, но для получения
сообщений от PVM-задач. В действительности оператор “»” заключает в оболочку функ-
ции pvm_recv () и pvmupk (). Определение этого операторного метода выглядит так.
// Листинг 11.14. Определение оператора "»" для класса
// pvm_stream
pvm_stream &pvm_stream::operator»(int &Data)
{
int Bufld;
//. . .
Bufld = pvm_recv(Taskld,Messageld);
Streamstate = pvm_upkint(&Data,1,1);
//. . .
return(*this);
}
Этот тип определения позволяет получать сообщения от PVM-задач с помощью
оператора извлечения данных.
int Value;
pvm_stream MyStream;
MyStream » Value;
Поскольку каждый из рассмотренных операторных методов возвращает ссылку на
тип pvm_stream, операторы вставки и извлечения можно соединить в цепочку.
Mystream « Valuel « Value2;
Mystream » Value3 >> Value4;
Используя этот простой синтаксис, программист изолирован от более громоздко-
го синтаксиса функций pvm_send, pvm pk, pvm_upk и pvm_recv. При этом он рабо
тает с более знакомыми для него объектно-ориентированными потоками данных-
В данном случае поток данных представляет буфер сообщений, а элементы, которые
11.3. Поддержка потокового представления 397
помещаются в него или извлекаются оттуда, представляют сообщения, которыми об-
лениваются между собой PVM-процессы. Вспомните, что каждый PVM-процесс имеет
отдельное адресное пространство. Поэтому операторы “«” и “»” не только маски-
в них организацию связи. Поскольку класс pvm_stream можно использовать в много-
поточной среде, операторы вставки и извлечения данных должны обеспечивать
безопасность потоков выполнения.
Класс pvm_stream (см. рис. 11.4) содержит класс mutex. Класс mutex можно ис-
пользовать для защиты критических разделов, которые имеются в классе
pvm_stream. Класс pvm_stream инкапсулирует доступ к буферу отправки и буферу
приема данных. Взаимодействие потоков выполнения и класса pvm_stream с буфе-
рами pvm__send и pvm_receive показано на рис. 11.5.
PVM-ЗАДАЧА А
pvm_stream
Класс mutex
Оператор « : {pvm_send()}
Оператор » : {pvm_receive()}
J ’ Поток 1
вызывает
Поток 2
вызывает
операцию
Рис. 11.5. Взаимодействие потоков выполнения и класса pvnvstream с буферами pvnusend
иpvm_receive
Критическими разделами являются не только буферы отправки и приема данных.
Класс mi os, используемый для хранения состояния класса pvm_stream, также является
критическим разделом. Для защиты этого компонента можно использовать класс mutex.
При обращении к операторам вставки и извлечения данных можно использовать
объект Mutex.
// Листинг 11.15. Определение операторов "<<" и "»"
' для класса pvm_stream
Pvm__stream &pvm_stream: : operator<< (int Data)
//. . .
Mutex.lock();
reset();
Pvm-pkint(&Data,1,1);
^VIn—send (Taskld, Messageld);
Mutex.unlock();
//...
return(*this);
398 Глава 11. Проектирование компонентов для поддержки параллелизма
}
pvm_stream &pvm_stream::operator»(int &Data)
{
int BufId;
//. . .
Mutex.lock();
BufId = pvm_recv(Taskid,Messageld);
Streamstate = pvm_upkint(&Data,1,1);
Mutex.unlock();
//. . .
return(*this);
}
Этот вид защиты позволяет сделать класс pvm_stream безопасным. Здесь мы не
представили код обработки исключений или другой код, который бы позволил предот-
вратить бесконечные отсрочки или взаимную блокировку. Основная идея в данном слу-
чае — сделать акцент на компонентах и вариантах архитектуры, которые пригодны для
поддержки параллелизма. Интерфейсный класс mutex и класс pvm_stream можно ис-
пользовать многократно, и оба они поддерживают параллельное программирование.
Предполагается, что объекты класса pvm_stream должны использоваться PVM-
задачами при отправке и приеме сообщений. Но это не является жестким требованием.
Для того чтобы пользователь мог применить концепцию класса pvm_stream к своим
классам, для них необходимо определить операторы вставки («) и извлечения (»).
11.4. Пользовательские классы, создаваемые
для обработки PVM-потоков данных
Чтобы понять, как определенный пользователем класс можно использовать со-
вместно с классом pvm_stream, попробуем усовершенствовать возможности PVM-
палитры, представленной в главе 6. Класс палитры представляет простую коллекцию
цветов. Для удобства будем сохранять цвета в векторе строк (vector<string>)
с именем Colors.
Начнем с объявления класса spectral__palette, который содержит friend-
объявления для операторов вставки (<<) и извлечения (>>).
// Листинг 11.16. Объявление класса spectral_palette
class spectral_palette : public pvm_object{
protected:
//. . .
vector<string> Colors;
public:
spectral_palette(void);
//. . .
friend pvm_stream &operator»(pvm_stream &In,
spectral_palette &Obj);
friend pvm_stream &operator<<(pvm_stream &Out,
spectral_palette &Obj);
11.4. Пользовательские классы, создаваемые для обработки... 399
Обратите внимание на то, что класс spectral—palette в листинге 11.16 насле-
т класс pvm— object. Класс pvm_object тем самым обеспечивает своего наслед-
ника доступом к идентификатору задачи и идентификатору сообщения. Вспомните,
что идентификаторы задачи и сообщения используются во многих PVM-функциях.
С помощью определения операторов вставки («) и извлечения (») объекты клас-
са spectral__palette можно пересылать между параллельно выполняемыми PVM-
задачами. Метод, используемый для класса spectral_palette, очень прост, и его
можно так же успешно применить к любому пользовательскому классу. Поскольку
класс pvm_stream должен иметь эти операторы для встроенных типов данных
и контейнеров, которые содержат значения встроенных типов данных, в пользова-
тельском классе необходимо определить только операторы “«” и “»” для перево-
да их представления в любой встроенный тип данных или стандартный контейнер.
Вот как, например, определяется оператор “«” для класса spectral—palette
в листинге 11.17.
// Листинг 11.17.
//
Определение оператора "«" для
класса spectral—palette
pvm_stream &operator« (pvm_stream &Out,
spectral—palette &Obj)
{
int N;
string Source;
for(N = 0;N < Obj.Colors.size();N++)
{
Source.append(Obj.Colors[N]);
if( N <Obj.Colors.size() - 1){
Source.append(” ");
}
}
Out.reset();
Out.taskld(Obj.Taskld);
Out.messageld(Obj.Messageld);
Out << Source;
return(Out);
Рассмотрим подробнее определение этой операции вставки в листинге 11.17. По-
скольку класс pvm_stream работает только со встроенными типами данных, цель
пользовательского оператора “<<” — перевести пользовательский объект в последова-
тельность значений встроенных типов данных. Этот перевод является одной из ос-
новных обязанностей классов, “отвечающих” за потоковое представление данных.
Жданном случае объект класса spectral—palette должен быть переведен в строку
Цветов”, разделенных пробелами. Список цветовых значений сохраняется в строке
Source. Рассматриваемый процесс перевода позволяет применить к объекту этого
класса оператор “<<”, который был определен для строкового типа данных. Имея оп-
ределения этих операторов, API-интерфейс программиста становится более удоб-
ным, чем при использовании оригинальных версий функций библиотеки Pthread,
Ь1Х и MPI. Ведь теперь объект класса spectral—palette можно переслать из од-
Нои PVM-задачи в другую, используя такую привычную операцию вставки («).
400 Глава 11. Проектирование компонентов для поддержки параллелизма
// Листинг 11.18. Использование объектов классов
// pvm_stream и spectral_palette
pvm_stream Taskstream;
spectral_palette MyColors;
-
Taskstream.taskid(20001);
TaskStream.messageld(l);
//. . .
TaskStream « MyColors;
//. . •
Здесь объект MyColors пересылается в соответствующую PVM-задачу. На рис. Ц.6
показаны компоненты, используемые для поддержки объектов Taskstream
и MyColors. Каждый компонент на рис. 11.6 можно детализировать и оптимизиро-
вать в отдельности. Каждый представленный здесь уровень обеспечивает дополни-
тельный слой изоляции от сложности этих компонентов. В идеале на самом высоком
уровне программист должен заниматься только деталями, связанными с данной пред-
метной областью. Такой высокий уровень абстракции позволяет программисту самым
естественным образом представлять параллелизм, который вытекает из требований
предметной области, не углубляясь при этом в синтаксис и сложные последователь-
ности вызовов функций. Компоненты, представленные на рис. 11.6, следует рассмат-
ривать лишь как малую толику библиотеки классов, которую можно использовать для
PVM-программ и многопоточных PVM-программ. Те же методы можно применять для
взаимодействия между параллельно выполняемыми задачами, которые не являются
частью PVM-среды. Ведь существует множество приложений, которые требуют реали-
зации параллельности, но не нуждаются во всей полноте функционирования меха-
низма PVM-среды. Для таких приложений вполне достаточно использования функций
ехес (), fork () или pvm_spawn (). Примерами таких приложений могут служить
программы, которые требуют создания нескольких параллельно выполняемых про-
цессов, и приложения типа “клиент-сервер”. Для таких HePVM- или неМР1-
приложений также может потребоваться организация межпроцессного взаимодейст-
вия. Для параллельно выполняемых процессов, создаваемых посредством f ork-exec-
последовательности вызовов или функций pvm_spawn, имело бы смысл поддержи-
вать потоковое представление данных. Понятие объектно-ориентированного потока
данных можно также расширить с помощью каналов и FIFO-очередей.
Рис. 11.6. Компоненты, используемые для поддержки объектов
TaskStream и MyColors
11.5. Объектно-ориентированные каналы и FIFO-очереди... 401
11.5. Объектно-ориентированные каналы
и FIFO-очереди как базовые элементы
низкого уровня
Приступая к разработке объектно-ориентированных каналов, начнем с рассмот-
пения базовых характеристик и поведения каналов в целом. Канал представляет со-
бой средство взаимодействия между несколькими процессами. Для того чтобы про-
цессы могли взаимодействовать, необходимо обеспечить между ними передачу ин-
формации определенного вида. Эта информация может представлять данные или
команды, предназначенные для выполнения. Обычно такая информация преобразу-
ется в последовательность данных и помещается в канал, а затем считывается процес-
сом с другого конца канала. При считывании из канала данные снова преобразуются,
чтобы обрести смысл для считывающего процесса. В любом случае при передаче от
одного процесса другому эти данные должны где-то храниться. Мы называем область
хранения информации буфером данных. Для размещения данных в этом буфере и из-
влечения их оттуда необходимо выполнять соответствующие операции. Но прежде
чем говорить о выполнении таких операций, необходимо позаботиться о существо-
вании самого буфера данных. Объектно-ориентированный канал должен обладать
средствами, которые поддерживают операции создания и инициализации буфера дан-
ных. После завершения взаимодействия между процессами буфер данных, используе-
мый для хранения информации, становится ненужным. Это означает, что наш объект-
но-ориентированный канал должен “уметь” удалять буфер данных после его использо-
вания. Из этого “введения в каналы” вырисовываются по крайней мере пять основных
компонентов, которыми должен обладать объектно-ориентированный канал:
• буфер;
• операция вставки данных в буфер;
• операция извлечения данных из буфера;
• операция создания/инициализации буфера;
• операция ликвидации буфера.
Помимо этих пяти базовых компонентов, канал должен иметь два конца. Один ко-
нец предназначен для вставки данных, а другой — для их извлечения. К этим двум
концам могут получать доступ различные процессы. Чтобы наше описание канала бы-
ло полным, мы должны включить в него порт ввода и порт вывода, к которым могут
подключаться различные процессы. В результате мы получаем уже семь базовых ком-
понентов, составляющих описание нашего объектно-ориентированного канала:
• порт ввода;
• порт вывода;
• буфер;
• операция вставки данных в буфер;
• операция извлечения данных из буфера;
• операция создания/инициализации буфера;
• операция ликвидации буфера.
402 Глава 11. Проектирование компонентов для поддержки параллелизма
Эти компоненты образуют минимальный набор характеристик, составляющи
описание канала. Уточнив базовые компоненты, можно поразмыслить о том, как п *
разработке объектно-ориентированного канала лучше всего использовать суще^т
вующие системные API-интерфейсы или структуры данных. В разработке каналов по
пробуем для начала применить те же методы (инкапсуляцию и перегрузку операто-
ров), которые мы использовали при разработке класса pvm_stream.
Обратите внимание на то, что пять из семи выше перечисленных базовых компо-
нентов являются общими для многих основных структур данных и типов контейне-
ров, которые обычно используются для операций ввода-вывода. В большинстве слу-
чаев UNIX/Linux-средства работы с файлами поддерживают:
• буферы;
• операции вставки данных в буфер;
• операции извлечения данных из буфера;
• операции создания буфера;
• операции удаления буфера.
Для инкапсуляции функций, предоставляемых системными UNIX/Linux-
службами, мы используем понятие интерфейсных С++-классов и создаем объектно-
ориентированные версии сервисных функций ввода-вывода. Если в случае с классом
pvm_stream для библиотеки PVM нам приходилось начинать “с нуля”, то здесь мы
можем воспользоваться преимуществами существующей стандартной библиотеки C++
и библиотеки классов iostreams. Вспомните, что библиотека классов iostreams под-
держивает объектно-ориентированную модель потоков ввода и вывода. Более того,
эта объектно-ориентированная библиотека оснащена поддержкой буферизации дан-
ных и всех операций, связанных с использованием буфера. На рис. 11.7 показана про-
стая диаграмма класса basic_iostream.
Рис. 11.7. Диаграмма классов, отображающая основные
компоненты класса basic_iostream
Основные компоненты класса basic__iostream можно описать тремя видам0
классов: компонент буфера, компонент преобразования и компонент состояния
Компонент буфера используется в качестве области промежуточного хранения баи
тов информации. Компонент преобразования отвечает за перевод анонимных после
11.5. Объектно-ориентированные каналы и FIFO-очереди... 403
овательностей байтов в значения и структуры данных соответствующих типов,
а также за перевод структур данных и отдельных значений в анонимные последова-
тельности байтов. Компонент преобразования отвечает за обеспечение программи-
ст потоковым представлением байтов, в котором все операции ввода-вывода незави-
симо от источника и приемника обрабатываются как поток байтов. Компонент со-
стояния инкапсулирует состояние объектно-ориентированного потока и позволяет
определить, какой тип форматирования применим к байтам данных, которые содер-
жатся в компоненте буфера. Компонент состояния также содержит информацию
о том, в каком режиме был открыт поток: дозаписи, создания, монопольного чтения,
монопольной записи, а также о том, будут ли числа интерпретироваться как шестна-
дцатеричные, восьмеричные или двоичные. Компонент состояния также можно ис-
пользовать для определения состояния ошибки операций ввода-вывода, выполняе-
мых над компонентом буфера. Опросив этот компонент, программист может опреде-
лить, в каком состоянии находится буфер, условно говоря, в хорошем или плохом.
Эти три компонента представляют собой объекты, которые можно использовать со-
вместно (для формирования полнофункционального объектно-ориентированного
потока) или в отдельности (в качестве вспомогательных объектов в других задачах).
Пять из семи базовых компонентов нашего потока уже реализованы в библиотеке
классов iostreams. Поэтому нам остается лишь дополнить их компонентами портов
ввода и вывода. Для этого мы можем рассмотреть системные средства поддержки по-
токов. В среде UNIX/Linux создать канал можно с помощью вызовов системных
функций (листинг 11.19).
// Листинг 11.19. Использование системного вызова для
// создания канала
int main(int argc, char *argv[])
{
int Fd[2];
pipe(Fd);
//. . .
1
Функция pipe () предназначена для создания структуры данных канала, которую
можно использовать для взаимодействия между родительским и сыновним процесса-
ми. При успешном обращении к функции pipe () она возвращает два дескриптора
файла. (Дескрипторы файлов представляют собой целые значения, которые исполь-
зуются для идентификации успешно открытых файлов.) В этом случае дескрипторы
сохраняются в массиве Fd. Элемент Fd[0] используется при открытии файла для
чтения, а элемент Fd [ 1 ] — при открытии файла для записи. После создания эти два
Дескриптора файлов можно использовать при вызове функций read О и write().
}нкция write () обеспечивает вставку данных в канал посредством дескриптора
, а функция read() — извлечение данных из канала посредством дескриптора
. Поскольку функция pipe () возвращает дескрипторы файлов, доступ к каналу
Можно получить с помощью системных средств работы с файлами. Для определения
Максимально возможного количества доступных дескрипторов файлов, открытых од-
НиМ процессом, можно использовать системную функцию sysconf (_SC_OPEN_MAX),
Для определения размера канала — функцию pathconf (_РС_PIPE_BUF).
404 Глава 11. Проектирование компонентов для поддержки параллелизма
Эти два файловых дескриптора представляют наши логические порты ввода и вы
вода соответственно. Мы также используем их для связи с библиотекой классов
iostreams. В частности, они обеспечивают связь с классом буфера. Компонент буфе
iostreams-классов имеет три семейства классов. Эти три типа буферных классов пере
числены в табл. 11.3.
Таблица 11.3. Три типа буферных классов
Типы классов Описание
basic_streambuf Описывает поведение различных потоковых буферов с целью управ- ления входными и выходными последовательностями символов
basic_stringbuf Связывает входные и выходные последовательности с последова- тельностью произвольных символов, которая может быть использо- вана для инициализации или доступна в качестве строкового объекта
basic_filebuf Связывает входные и выходные последовательности символов с файлом
Рассмотрим подробнее класс basic_f ilebuf. Тогда как класс basic_streambuf
используется в качестве объектно-ориентированного буфера в операциях ввода-вывода
с применением стандартного потока, а класс basic_stringbuf — в качестве объектно-
ориентированного буфера для памяти, класс basic_f ilebuf применяется в качестве
объектно-ориентированного буфера для файлов. Рассмотрев интерфейс для класса
basic_.f ilebuf и интерфейс для классов преобразования (basic_if stream,
basic_of stream и basic_fstream), можно найти способ связать дескрипторы фай-
лов, возвращаемые системной функцией pipe (), с объектами класса basic_iostream.
На рис. 11.8 показаны диаграммы классов для семейства f stream-классов.
Рис. 11.8. Диаграммы классов для семейства f stream-классов
11.5. Объектно-ориентированные каналы и FIFO-очереди... 405
Обратите внимание на то, что все классы basic_ifstream, basic__ofstream
basic_f stream содержат класс basic_f ilebuf. Следовательно, чтобы упростить
со3дание объектно-ориентированного канала, мы можем использовать любой класс из
семейства f stream-классов. Мы можем связать дескрипторы файлов, возвращаемые
системной функцией pipe (), либо с помощью конструкторов, либо с помощью функ-
ции-члена attach().
Синопсис
tfinclude <fstream>
// UNIX-системы
ifstream(int fd)
fstream(int fd)
ofstream(int fd)
// gnu C++
void attach(int fd) ;
11.5.1. Связь каналов c iostream-объектами с помощью
дескрипторов файлов
Существует три iostream-класса (ifstream, of stream и f stream), которые мы
можем использовать для подключения к каналу. Объект класса ifstream использу-
ется для ввода данных, объект класса of stream — для их вывода, а объект класса
f st ream можно применять и в том и в другом случае. Несмотря на то что непо-
средственная поддержка дескрипторов файлов и потоков ввода-вывода не являет-
ся частью стандарта ISO, в большинстве UNIX- и Linux-сред поддерживается С++-
ориентированный iostream-доступ к дескрипторам файлов. В библиотеке GNU
C++ iostreams предусмотрена поддержка дескриптора файла в одном из конструк-
торов классов ifstream, of stream и f stream и в методе attach () , определен-
ном в классах ifstream и of stream. UNIX-компилятор языка C++ компании Sun
также поддерживает дескрипторы файлов с помощью одного из конструкторов
классов ifstream, of stream и f stream. Поэтому при выполнении следующего
фрагмента кода
//. . .
int Fd[2];
₽ipe(Fd);
ifstream IPipe(Fd[0]) ;
°fstream OPipe(Fd[l] ) ;
будут созданы объектно-ориентированные каналы. Объект IPipe будет играть
Р°ль входного потока, а объект OPipe— выходного. После создания эти потоки
^°жно применять для связи между параллельно выполняемыми процессами с ис-
ьзованием потокового представления и операторов вставки (<<) и извлечения
>)« Для С++-сред, которые поддерживают метод attach(), дескриптор файла
Но связать с объектами классов ifstream, of stream или f stream, используя
еДующий синтаксис.
406 Глава 11. Проектирование компонентов для поддержки параллелизма
// Листинг 11.20. Создание канала и использование
// функции attach()
int Fd[2];
ofstream OPipe;
//. . .
pipe(Fd);
//. . .
OPipe.attach(Fd[l]);
//. . .
OPipe « Value « endl;
Такой способ использования объектно-ориентированных каналов предполагает
существование сыновнего процесса, который может считывать из них информацию
В программе 11.1 для создания двух процессов используется fork-инструкция. Роди-
тельский процесс отправляет значение сыновнему процессу с помощью iostreams-
ориентированного канала.
// Программа 11.1
1 #include <unistd.h>
2 #include <iostream.h>
3 #include <fstream.h>
4 #include <math.h>
5 #include <sys/wait.h>
6
7
8
9
10 int main(int argc, char *argv[])
11 {
12
13 int Fd[2];
14 int Pid;
15 float Value;
16 int Status;
17 if(pipe(Fd) != 0){
18 cerr « "Ошибка при создании канала " « endl;
19 exit(1);
20 }
21 Pid = fork();
22 if(Pid == 0){
23 ifstream IPipe(Fd[0]);
24 IPipe » Value;
25 cout « "От процесса-родителя получено значение "
« Value << endl;
26 IPipe.close();
27 }
28 else{
29 ofstream OPipe(Fd[1]);
30 OPipe « M_PI « endl;
31 wait(&Status);
32 OPipe.close();
33
34 }
35
36 }
11.5. Объектно-ориентированные каналы и FIFO-очереди... 407
Вспомните, что значение 0, возвращаемое функцией fork(), принадлежит сы-
новнему процессу. В программе 11.1 канал создается при выполнении инструкции,
неположенной на строке 17. А при выполнении инструкции, расположенной на
строке 29, родительский процесс открывает канал для записи. Файловый дескриптор
Fd [ 11 означает “записывающий” конец канала. К этому концу канала (благодаря вы-
3OBV конструктора на строке 29) присоединяется объект класса of stream.
К “считывающему” концу канала присоединяется объект класса if stream (строка 23).
Сыновний процесс открывает канал для чтения и получает доступ к дескриптору
файла, поскольку он вместе со средой родителя наследует и дескрипторы файлов. Та-
ким образом, любые файлы, которые открыты в среде родителя, будут оставаться от-
крытыми и в среде наследника, если операционная система не получит явные инст-
рукции, основанные на системной функции f cntl. Помимо наследования открытых
файлов, маркеры внутрифайловых позиций остаются там, где они были в момент по-
рождения сыновнего процесса, чтобы сыновний процесс также получил доступ
к маркеру позиции. При изменении позиции в родительском процессе маркер сынов-
него также смещается. В этом случае мы могли бы реализовать потоковое представле-
ние данных, не создавая интерфейсный класс. Просто присоединив файловые деск-
рипторы канала к объектам классов of stream и if stream, мы сможем использовать
операторы вставки (<<) и извлечения (>>). Аналогично любой класс, в котором оп-
ределены операторы “»” и “<<”, может выполнять операции вставки данных в канал
и извлечения их оттуда без какого-либо дополнительного программирования. В про-
грамме 11.1 родительский процесс помещает значение М_Р1 в канал (строка 30), а сы-
новний процесс извлекает это значение из канала, используя оператор “>>”
(строка 24). Инструкции по выполнению и компиляции этой программы приведены
в разделе “Профиль программы 11.1”.
^Профиль программы 11.1
Имя программы
pprogramll-l.ee
| Описание
^Программа 11.1 демонстрирует использование объектно-ориентированного потока
| с использованием анонимных системных каналов. Для создания двух процессов,
^которые взаимодействуют между собой с помощью операторов вставки («) и из-
влечения (»), программа использует функцию fork().
| Требуемые заголовки
;<wait.h>, <unistd.h>, <iostream.h>, <fstream.h>, <math.h>.
^Инструкции по компиляции и компоновке программ
j C++ _о programll-1 programll-l.ee
Среда для тестирования
rSolaris 8, SuSE Linux 7.1.
I Инструкции по выполнению
* r/programll-l
408 Глава 11. Проектирование компонентов для поддержки параллелизма
Компилятор gnu C++ также поддерживает метод attach (). Этот метод можно
пользовать для связи файловых дескрипторов с объектами классов ifst Ис
и of stream (листинг 11.21).
// Листинг 11.21. Подключение файловых дескрипторов к
// объекту класса ofstream
int main (int argc, char *argv[])
{
int Fd[2];
ofstream Out;
pipe(Fd);
Out.attach(Fd[1]);
// - - *
// Межпроцессное взаимодействие.
// . . .
Out.close( );
}
При вызове функции Out. attach (Fd[l] ) объект класса of stream связывается
с файловым дескриптором канала. Теперь любая информация, которая будет поме-
щена в объект Out, в действительности запишется в канал. Использование операто-
ров извлечения и вставки для выполнения автоматического преобразования формата
является основным достоинством использования семейства f stream-классов в соче-
тании с канальной связью. Возможность применять пользовательские средства извле-
чения и вставки избавляет программиста от определенных трудностей, которые мо-
гут иметь место при программировании каналов связи. Поэтому вместо явного пере-
числения размеров данных, записываемых в канал и читаемых из него, при
управлении доступом для чтения-записи мы используем только количество переда-
ваемых через канал элементов, что существенно упрощает весь процесс. К тому же та-
кое “снижение себестоимости” немного упрощает параллельное программирование.
Рекомендуемый нами метод состоит в использовании архитектуры, в основе которой
лежит принцип “разделяй и властвуй”. Главное — правильно расставить компоненты
“по своим местам” — и программирование станет более простым. Например, посколь-
ку канал связывается с объектами классов of stream и if stream, мы можем исполь-
зовать информацию, хранимую компонентом ios, для определения состояния кана-
ла. Компоненты преобразования iostreams-классов можно использовать для выполне-
ния автоматического преобразования данных, помещаемых в один конец канала
и извлекаемых из его другого конца. Использование каналов вместе с iostream-классами
также позволяет программисту интегрировать стандартные контейнеры и алгоритмы
с использованием межпроцессного взаимодействия на основе канала. На рис. 11.9 по
казаны взаимоотношения между объектами классов if stream, of str earn, каналом
и средствами вставки и извлечения при организации межпроцессного взаимодействия.
Для чтения данных из канала и записи данных в канал можно также использовать
семейство классов f stream и функции-члены read () и write ().
11.5.2. Доступ к анонимным каналам с использованием
итератора ostream_iterator
Канал можно также использовать с итераторами ostream_iterator и istr®a
iterator, которые представляют собой обобщенные объектно-ориентироваjC
указатели. Итератор ostream_iterator позволяет передавать через канал Н
11.5. Объектно-ориентированные каналы и FIFO-очереди... 409
тейнеры (т.е. списки, векторы, множества, очереди и пр.). Без использования
К°И еат-объектов и итератора ostream_iterator передача контейнеров объектов бы-
i°6w очень громоздкой и подверженной ошибкам процедурой. Операции, которые дос-
ны для классов ostream_iterator и istream_iterator, перечислены в табл. 11.4.
Рис. 11.9. Взаимоотношения между объектами классов ifstream, of stream, каналом
и средствами вставки и извлечения при организации межпроцессного взаимодействия
ЙЙ^ЛИЦа.11.4. Операции, доступные для классов ostream_iterator и istream— iterator
Итераторы Операции Описание
istream_iterator a == b Отношение эквивалентности
a ! = b Отношение неэквивалентности
*a Разыменовывание
++ r Инкремент (префиксная форма)
r ++ Инкремент (постфиксная форма)
ostream_iterator ++ r Инкремент (префиксная форма)
r ++ Инкремент (постфиксная форма)
Обычно эти итераторы используются вместе с iostreams-классами и стандартными
алгоритмами. Итератор ostream_iterator предназначен только для последова-
тельно выполняемой записи. После доступа к некоторому элементу программист не
Ни ВерНГГЬСЯ К НеМу опять» не повторив всю итерацию сначала. При использова-
этих итераторов канал обрабатывается как последовательный контейнер. Это оз-
ет, что при связывании канала с iostreams-объектами посредством итератора
ean_iterator и файловых дескрипторов мы можем применить стандартный
Ри™ обработки данных для ввода их из канала и вывода их в канал. Причина того,
ЭТи итераторы можно использовать вместе с каналами, состоит в связи, которая
410 Глава 11. Проектирование компонентов для поддержки параллелизма
существует между итераторами и iostreams-классами. На рис. 11.10 предста
на диаграмма, отображающая отношения между итераторами ввода-вывода
iostreams-классами.
ц
Контейнер A j
юпировант
ofstream
Объектно-
ориентированный
КАНАЛ
j Объек
С
j ostream^
j Herator_ j
Рис. 11.10. Отношения между итераторами ввода-вывода и iostreams-классами
На рис. 11.10 также показано, как эти классы взаимодействуют с объектно-ориен-
тированным каналом. Рассмотрим подробнее, как итератор ostream_iterator ис-
пользуется с объектом класса ostream. Если инкрементируется указатель, мы ожидаем
что он будет указывать на следующую область памяти. Если же инкрементируется итера-
тор ostream_iterator, он перемещается на следующую позицию выходного потока.
Присваивая значение разыменованному указателю, мы тем самым помещаем это значе-
ние в область, на которую он указывает. Присваивая значение итератору
ostream_iterator, мы помещаем это значение в выходной поток. Если выходной по-
ток связан с объектом cout, это значение отобразится на стандартном устройстве вы-
вода. Мы можем объявить объект класса ostream_iterator следующим образом.
ostream_iterator<int> X(cout,"\n");
Тогда X является объектом типа ostream_iterator. При выполнении операции ин-
кремента
Х++;
итератор X перейдет к следующей позиции выходного потока. А при выполнении
этой инструкции присваивания
*Х = Y;
значение Y будет отображено на стандартном устройстве вывода. Дело в том, что
оператор присваивания “=” перегружен для использования объекта класса ostream.
В результате объявления
ostream_iterator<int> X(cout, "\n");
будет создан объект X с использованием аргумента cout. Второй аргумент в констр)Е
торе является разделителем, который автоматически будет размещаться после кажД°
го int-значения, вставляемого в поток данных. Объявление итератора
ostream_iterator выглядит следующим образом (листинг 11.22).
// Листинг 11.22. Объявление класса ostream_iterator
template <class _Тр>
class ostream_iterator {
protected:
ostream* _M_stream;
const char* _M_string;
public:
11.5. Объектно-ориентированные каналы и FIFO-очереди... 411
vnedef output-iterator_tag iterator_category;
tvpedef void value-type;
tvpedef void difference_type;
typedef void pointer;
typedef void reference;
stream-iterator (ostreamb _s) : _M_stream(&___s) ,
_M_string(O) {}
ostream_iterator(ostream& ___s, const char* ___c)
: _M_str earn (&_s) , _M_s tring (_c) {}
ostream_iterator<_Tp>& operator=(const _Tp& ____value) {
*JM_stream « value;
if (_M_string) *_M_stream « _M_string;
return *this;
ostream_iterator<_Tp>& operator*() { return *this; }
ostream_iterator<_Tp>& operator++() { return *this; }
ostream_iterator<_Tp>& operator++(int) { return *this; }
};
Конструктор класса ostream_iterator принимает ссылку на объект класса
ostream. Класс ostream_iterator находится с классом ostream в отношении агре-
гирования. Назначение класса istream_iterator прямо противоположно классу
ostream_iterator. Он используется с объектами класса istream (а не с объектами
класса ostream). Если объекты классов istream_iterator и ostream_iterator
связаны с iostream-объектами, которые в свою очередь связаны с файловыми деск-
рипторами канала, то при каждом инкрементировании итератора типа
istream_iterator из канала будут считываться данные, а при каждом инкременти-
ровании итератора типа ostream_iterator в канал будут записываться данные.
Чтобы продемонстрировать, как эти компоненты работают вместе, рассмотрим две
программы (11.2 и 11.2.1), в которых используются анонимные каналы связи. Про-
грамма 11.2 представляет родительский процесс, а программа 11.2.1 — сыновний.
В “родительской” части для создания сыновнего процесса используются системные
функции fork() и execl (). При том, что файловые дескрипторы наследуются сы-
новним процессом, их значения незамедлительно становятся достоянием програм-
мы 11.2.1 благодаря вызову функции execl ().
// Программа 11.2
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
int main(int argc, char *argv[])
int Size,Pid,Status,Fdl[2],Fd2[2];
Pipe(Fdl); pipe(Fd2);
strstream Buffer;
char Value[50];
float Data;
vector<float> X(5,2.1221), Y;
Buffer « Fdl[0] « ends;
Buffer » Value;
setenv("Fdin",Value,1);
Buffer.clear();
Buffer « Fd2[l] « ends;
Buffer » Value;
setenv(Fdout”,Value,1);
₽1<3 = fork() ;
412 Глава 11. Проектирование компонентов для поддержки параллелизма
27 if(Pid != 0){
28 ofstream OPipe;
29 OPipe.attach(Fdl[1]);
30 ostream__i terator< float > OPtr(OPipe," \n") ;
31 OPipe « X.sizeO « endl;
32 copy(X.begin(),X.end(),OPtr);
33 OPipe « flush;
34 ifstream IPipe;
35 IPipe.attach(Fd2[0]);
36 IPipe » Size;
37 for(int N = 0; N < Size;N++)
38 {
39 IPi pe >> Data;
40 Y.push—back(Data);
41 }
42 wait(&Status);
43 ostream_iterator<float> OPtr2(cout,”\n”);
44 copy (Y.begin () , Y.endO ,OPtr2) ;
45 OPipe.close() ;
46 IPipe.close() ;
47 }
48 else{
49 execl("./programi1-2b","programll-2b",NULL);
50 }
51
52 return(O);
53 }
В строках 21 и 25 системная функция setenv () используется для передачи значе-
ний файловых дескрипторов сыновнему процессу. Это возможно благодаря тому, что
сыновний процесс наследует среду родительского процесса. Мы можем устанавливать
переменные средъб в программе с помощью вызова функции setenv (). В данном слу-
чае мы устанавливаем их следующим образом.
Fdin=filedesc;
Fdout=filedesc;
Сыновний процесс затем использует системный вызов getenv() для считывания
значений переменных Fdin и Fdout. Значение переменной Fdin будет представлять
считывающий конец канала для сыновнего процесса, а значение переменной
Fdout — записывающий”. Использование системных функций setenv () и getenv ()
обеспечивает простую форму межпроцессного взаимодействия (interprocess
communication — IPC) между родительским и сыновним процессами. Каналы создают-
ся при выполнении инструкций, приведенных в строке 14. Родительский процесс
присоединяется к одному концу канала для операции записи с помощью метода
attach () (строка 29). После присоединения любые данные, помещенные в объект
OPipe типа of stream, будут записаны в канал. Итератор типа ostreairi— iterator
подключается к объекту OPipe при выполнении следующей инструкции (строка 30)-
ostream_iterator<float> OPtr(OPipe,"\n");
Теперь итератор OPtr ссылается на объект OPipe. После каждой порции помешае*
мых в канал данных будет вставляться разделитель "\n". С помощью итератора OPt*
мы можем поместить в канал любое количество float-значений. При этом мы мо*еМ
связать с каналом несколько итераторов различных типов. Но в этом случае необхоД**'
мо, чтобы на считывающем” конце канала данные извлекались с использованием ите-
11.5. Объектно-ориентированные каналы и FIFO-очереди... 413
в соответствующих типов. При выполнении следующей инструкции из програм-
PaTJ 1 2 в канал сначала помещается количество элементов, подлежащих передаче:
OPipe « X.size О « endl;
Сами элементы отправляются с использованием одного из стандартных С++-
алгоритмов:
copy (X.begin () . X. end () . OPtr) ;
Алгоритм copy () копирует содержимое одного контейнера в контейнер, связан-
ный с итератором приемника. Здесь итератором приемника является объект OPtr.
Объект OPtr связан с объектом OPipe, поэтому при выполнении алгоритма сору ()
/«уместившегося” в одной строке кода) в канал переписывается все содержимое кон-
тейнера. Этот пример демонстрирует возможность использования стандартных алго-
ритмов для организации взаимодействия между различными частями сред параллель-
ного или распределенного программирования. В данном случае алгоритм сору () пе-
ресылает информацию от одного процесса другому (из одного адресного
пространства в другое). Эти процессы выполняются параллельно, и алгоритм сору ()
значительно упрощает взаимодействие между ними. Мы подчеркиваем важность это-
го подхода, поскольку, если есть хоть какая-то возможность упростить логику парал-
лельной или распределенной программы, ею нужно непременно воспользоваться.
Ведь межпроцессное взаимодействие — это один из самых сложных разделов парал-
лельного или распределенного программирования. С++-алгоритмы, библиотека клас-
сов iostreamS и итератор типа ostream_iterator как раз и позволяют понизить уро-
вень сложности разработки таких программ. Использование манипулятора flush
(в строке 33) гарантирует прохождение данных по каналу. Инструкции по выполне-
нию и компиляции этой программы, а также заголовки, которые необходимо в нее
включить, приведены в разделе “Профиль программы 11.2”.
иль программы 11.2
... « программы
ami1-2.сс
. исание
эамма использует библиотеку классов iostreams и итератор типа
®am_iterator для пересылки содержимого векторного контейнера через ано-
дный канал.
ЙР^буемые заголовки
K®Js^ithin>, <fstream>, <vector>, <iterator>, <stdlib.h>, <string.h>,
-Л'йХ’ •. - -
р/^ГРУкции по компиляции и компоновке программ
и * ₽ro9ramll-2 programll-2. сс
для тестирования
7.1, 6.2.
1,0 выполнению
414 Глава 11. Проектирование компонентов для поддержки параллелизма
В программе 11.2.1 сыновний процесс сначала получает количество объ
принимаемых от канала (в строке 36), а затем для считывания самих объектов еКТ°в>
зует объект IPipe класса istream. °Ль
// Программа 11.2.1
11 class multiplier!
12 float X;
13 public:
14 multiplier(float Value) { X = Value;}
15 float &operator()(float Y) { X = (X * Y)/return(X);}
16 };
17
18
19 int main(int argc,char *argv[])
20 {
21 char Value[50];
22 int Fd[2];
23 float Data;
24 vector<float> X;
25 int NumElements;
26 multiplier N(12.2);
27 strcpy(Value,getenv("Fdin"));
28 Fd[0] = atoi(Value);
29 strcpy(Value,getenv("Fdout”));
30 Fd[l] = atoi(Value);
31 ifstream IPipe;
32 ofstream OPipe;
33 IPipe.attach(Fd[0]);
34 OPipe.attach(Fd[1]);
35 ostream_iterator<float> OPtr(OPipe,"\n");
36 IPipe » NumElements;
37 for(int N = 0;N < NumElements;N++)
38 {
39 IPipe » Data;
40 X.push-back(Data);
41 }
42 OPipe << X.sizeO << endl;
43 transform(X.begin () ,X.end() ,OPtr,N) ;
44 OPipe « flush;
45 return(0);
46
47 }
Сыновний процесс считывает элементы данных из канала, помещает их в вектор,
азатем выполняет математические преобразования над каждым элементом вектора,
после чего отправляет их назад родительскому процессу. Математические преобразо
вания (строка 43) выполняются с использованием стандартного С++-алгоритМа
transform и пользовательского класса multiplier. Алгоритм transform применя
ет к каждому элементу контейнера операцию, а затем результат этой операции п
щает в контейнер-приемник. В данном случае контейнером-приемником служит
ект Opt г, который связан с объектом OPipe. Заголовки, которые необходимо в
чить в программу 11.2.1, приведены в разделе “Профиль программы 11.2.1”.
11.5. Объектно-ориентированные каналы и FIFO-очереди... 415
Профиль программы 11.2.1
^Имя программы
|programll-2b.cc
‘ Описание
: огоамма представляет собой код сыновнего процесса, который запускается про-
s аммой 11-2- В этой программе для получения содержимого контейнера, отправ-
ленного из программы 11.2, используется объект класса ifstream. Для отправки че-
!оез канал обработанной информации родительскому процессу в программе исполь-
i^TCfl объект класса ostream_iterator и стандартный алгоритм transform.
(Требуемые заголовки
F<iostream>, algorithm», <fstream>, «vector», «iterator», «stdlib.h»,
i'<string.h>, «unistd.h».
(Инструкции по компиляции и компоновке программ
|с++ -o'programll-2b programll-2b.cc
6‘S
(Инструкции по выполнению
|Эта программа запускается программой 11.2.
Несмотря на то что классы библиотеки ios tream, итераторы типа
istream_iterator и ostream__iterator упрощают программирование канала, они
не изменяют его поведение. По-прежнему остаются в силе вопросы блокирования
и проблемы, связанные с корректным порядком открытия и закрытия каналов, рас-
смотренные в главе 5. Но использование основных механизмов тех же методов объектно-
ориентированного программирования все же позволяет понизить уровень сложности
параллельного и распределенного программирования.
11.5.3. FIFO-очереди (именованные каналы),
iostreams-классы и итераторы типа
ostream_iterator
Методы, которые мы использовали для реализации объектно-ориентированных
анонимных каналов, обладают двумя недостатками. Во-первых, любым процессам, ко-
торые взаимодействуют с другими процессами, нужен доступ к файловым дескрипто-
рам, возвращаемым при вызове системной функции pipe (). Поэтому существует
Эта ЛеМа полУчения этих файловых дескрипторов для всех процессов-участников,
проблема легко решается, если процессы связаны отношением “родитель-
Пп ?М°К (как в программах 11.1, 11.2 и 11.2.1), но в этом случае возникает другая
Лема. Выходит, во-вторых, что процессы, которые используют неименованные
щЬ1о ’ Д°лжны быть связаны отношениями. Это требование можно обойти с помо-
пеРеДачи дескриптора. Для решения этой проблемы используется струк-
достои ^irst In — First Out — первым прибыл, первым обслужен). Самое большое ее
СвЯзац НСТВ° как Раз и сост°ит в том, что к ней могут получить доступ процессы, не
НЬ1е никакими отношениями. Процессы должны выполняться на одном компь-
416 Глава 11. Проектирование компонентов для поддержки параллелизма
ютере — это единственное, что должно их связывать. При этом процессы могут з
каться программами, реализованными на разных языках программирования и с
пользованием различных парадигм программирования (например, обобщен
или объектно-ориентированной). При групповых вычислениях и при использов**
нии других конфигураций равноправных элементов можно воспользоваться п *
имуществами FIFO-очередей (иногда называемых именованными каналами) по
скольку в UNIX- и Linux-среде FIFO-структура имеет имя (определяемое пользова-
телем) и ее (в отличие от анонимных каналов) можно сравнить с “капитальным
сооружением”. FIFO — однонаправленная структура, а это значит, что пользователь
именованного канала в среде UNIX должен открыть его либо для чтения, либо для
записи, но не для того и другого одновременно. Именованные каналы, созданные
в среде UNIX, остаются в файловой системе до тех пор, пока они не будут явно уда-
лены с помощью вызова из программы функции unlink () или выполнения соот-
ветствующей команды из командной строки (например, команды rm). Именован-
ным каналам при их создании присваивается эквивалент имени файла. Любой про-
цесс, которому известно имя канала и который обладает необходимыми правами
доступа, может открыть его, прочитать из него данные и записать их туда.
Чтобы связать анонимные каналы с объектами классов if stream и of stream, мы
использовали нестандартное связывание с файловым дескриптором. Нестандарт-
ность ситуации вытекает из того, что “брак” между файловыми дескрипторами
и iostreams-объектами пока не “освящен” стандартом ISO C++. Поэтому безопаснее
использовать FIFO-структуры. К FIFO-файлу специального типа можно получить дос-
туп с помощью имени в файловой системе, в которой “официально” поддерживается
связывание с объектами С++-классов if stream и of stream. Поэтому точно так же,
как мы упрощали межпроцессное взаимодействие (IPC) с помощью iostream-классов
и анонимного канала, мы упрощаем доступ к FIFO-структуре. FIFO-структура, основ-
ные функции которой совпадают с функциями анонимного канала, позволяет распро-
странить возможности взаимодействия на классы, не связанные никакими родствен-
ными отношениями. Однако каждая программа — участник взаимодействия должна
при этом “знать” имена FIFO-структур. Это требование, казалось бы, напоминает ог-
раничение, с котороым мы встречались при использовании файловых дескрипторов.
Однако FIFO — это все же “шаг вперед”. Во-первых, при открытии анонимного канала
только система определяет, какие файловые дескрипторы доступны в данный мо-
мент. Это означает, что программист не в состоянии полностью контролировать си-
туацию. Во-вторых, существует ограничение на количество файловых дескрипторов»
котороми располагает система. В-третьих, поскольку FIFO-структурам имена присваи
ваются пользователем, то количество таких имен не ограничивается. Файловые доек
рипторы должны принадлежать файлам, открытым ранее (и причем успешн Л
а FIFO-имена — это всего лишь имена. FIFO-имя определяется пользователем, а <р
ловые дескрипторы— системой. Имена файлов связываются с объектами классов
if stream, f stream и of stream с помощью либо конструктора класса либо мет
ореп(). В программе 11.3.1 для связывания объектов классов of stream и if str
с FIFO-структурой используется конструктор.
// Программа 11.3.1
14 using namespace std;
15
11.5. Объектно-ориентированные каналы и FIFO-очереди... 417
16
17
18
19
20
21
22
25
26
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
const int FMode = S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH;
int main(int argc, char *argv[])
{
int Pid,Status,Size;
double Value;
mkfifо("Itmp/channel.1",FMode);
mkfifо("Itmp/channel.2",FMode);
vector<double> X(100,13.0);
vector<double> Y;
ofstream OPipe("/tmp/channel.1",ios::app);
ifstream IPipe("/tmp/channel.2");
OPipe « X.sizeO « endl;
ostream_iterator<double> Optr(OPipe,"\n");
copy(X.begin(),X.end(),Optr);
OPipe « flush;
IPipe » Size;
for (int N = 0;N < Size; N++)
{
IPipe » Value;
Y.push_back(Value);
}
IPipe.close();
OPipe.close();
unlink("/tmp/channel.1");
unlink("/tmp/channel.2");
cout « accumulate(Y.begin(),Y.end(),-13.0) « endl;
return(O);
В программе 11.3.1 используется две FIFO-структуры. Вспомните, что FIFO-
структуры являются однонаправленными компонентами. Поэтому, если процессы
Должны обмениваться данными, то необходимо использовать по крайней мере две
FIFO-структуры. В программе 11.3.1 они называются channel. 1 и channel. 2. Обра-
тите внимание на установку флагов полномочий для FIFO-структур (строка 16). Эти
полномочия означают, что владелец FIFO-структуры имеет право доступа для чтения
и записи, а все остальные — право доступа только для чтения. При выполнении стро-
ки 30 FIFO-структура channel. 1 будет открыта только для вывода данных. Тот же ре-
зультат можно было бы получить следующим образом:
0₽ipe. open (" / tmp/channel. 1", ios: : app) ;
Используемые здесь параметры алгоритма open () означают, что FIFO-структура
°ТКРЫта в Режиме дозаписи. В программе 11.3.1 алгоритм сору () используется
вставки объектов в объект OPipe типа f stream и косвенно в FIFO-структуру. Мы
гли бы также использовать здесь объект типа f stream:
st^eam OPipe ("/tmp/channel. 1 ”, ios: :out | ios: :app) ;
ТолькЭТ°М СЛуЧае взаимоде^ствие процессов было бы ограничено выводом данных
° В Режиме дозаписи. Если бы мы не использовали флаг ios: : app, попытка
КТа Типа of st ream создать FIFO-структуру (см. строку 30) была бы неудачной.
418 Глава 11. Проектирование компонентов для поддержки параллелизма
К сожалению, такой вариант работать не будет. Создание FIFO-структур находит
в компетенции функции mkfifo(). В строках 45 и 46 программы 11.3.1 FIFO
структуры удаляются из файловой системы. С этого момента любые процессы в
торых открыты FIFO-структуры, еще в состоянии получить к ним доступ. Однако
имен больше не существует. Поэтому такие процессы не смогут использовать алго
ритм open О или создать новые объекты типа of stream или if stream на основе
имени, которое было “отсоединено”. В строках 32-34, объекты типа ostream
iterator и ofstream используются для вставки элементов в FIFO-структуру. Обра
тите внимание на то, что программа 11.3.1 не образует никаких ветвлений и не созда-
ет сыновних процессов. Программа 11.3.1 зависит от другой программы, которая
должна считывать информацию из FIFO-структуры channel. 1 или записывать ин-
формацию в FIFO-структуру channel. 2. Если такая программа не будет работать од-
новременно с программой 11.3.1, последняя останется заблокированной. Детали реа-
лизации приведены в разделе “Профиль программы 11.3.1”.
: Профиль программы 11.3.1
Имя программы
programi1-За.сс
Описание
Для пересылки контейнерного объекта через FIFO-структуру используются объекты
типа ostream_iterator и ofstream. Для извлечения информации из FIFO-
структуры применяется объект типа ifstream.
Требуемые заголовки
<unistd.h>, <iomanip>, <algorithm>, <fstream.h>, <vector>, <iterator>
<strstream.h>, <stdlib.h>, <sys/wait ,h>, <sys/types.h>, <sys/stat .h>
<fcntl .h>, <numeric>.
Инструкции по компиляции и компоновке программ
C++ -о programll-3a programll-3a.сс
Среда для тестирования
SuSE Linux 7.1, gcc 2.95.2, Solaris 8, Sun Workshop 6.
Инструкции по выполнению
./programll-3a & programll-ЗЬ
Примечания
Сначала запускается программа 11.3.1. Программа 11.3.2 содержит инструкцию
sleep, которая восполняет собой отсутствие реальной синхронизации.
Программа 11.3.2 считывает данные из FIFO-структуры channel. 1 и записывает
информацию в FIFO-структуру channel. 2.
// Программа 11.3.2. Считывание данных из FIFO-структуры
// channel.1 и запись информации в
11.5. Объектно-ориентированные каналы и FIFO-очереди... 419
FIFO-структуру channel.2
^0 usincf namespace std;
11
12 class multiplier!
^3 double X;
14 public:
15 multiplier(double Value) { X = Value;}
16 double &operator()(double Y) { X = (X * Y);return(X);}
17 };
18
19
20 int main(int argc,char *argv[])
21 {
22
23 double Size;
24 double Data;
25 vector<double> X;
26 multiplier R(1.5);
27 sleep(15);
28 fstream IPipe("/tmp/channel.1");
29 ofstream OPipe("/tmp/channel.2", ios::app);
30 if(IPipe.is_open()){
31 IPipe » Size;
32 }
33 else{
34 exit(1);
35 }
36 cout « "Количество элементов " « Size « endl;
37 for(int N = 0;N < Size;N++)
38 {
39 IPipe » Data;
40 X.push_back(Data);
41 }
42 OPipe « X.sizeO << endl;
43 ostream__iterator<double> Optr(OPipe,"\n");
44 transform(X.begin() ,X.end() ,Optr,R) ;
45 OPipe << flush;
46 OPipe.close();
47 IPipe.close();
48 return(0);
49
50 }
Обратите внимание на то, что в программе 11.3.1 FIFO-структура channel. 1 от-
крывается для вывода данных, а в программе 11.3.2 та же FIFO-структура channel. 1 —
ввода данных. Следует иметь в виду, что FIFO-структуры действуют как однона-
правленные механизмы связи, поэтому не пытайтесь пересылать данные в обоих на-
правлениях! Достоинство использования iostreams-классов в сочетании с FIFO-
стРуктурами состоит в том, что мы можем использовать iostreams-методы примени-
тельно к FIFO-структурам. Например, в строке 30 мы используем метод is_open()
класса basic_f ilebuf, который позволяет определить, открыта ли FIFO-структура.
п она не открыта, то программа 11.3.2 завершается. Детали реализации програм-
bI 11.3.2 приведены в разделе “Профиль программы 11.3.2”.
420 Глава 11. Проектирование компонентов для поддержки параллелизма
Профиль программы 11.3.2
'Имя программы
;programll-ЗЬ.сс
‘ Описание
Программа считывает объекты из FIFO-структуры с помощью объекта типа
ifstream. Для пересылки данных через FIFO-структуру здесь используется итера-
, тор типа ostream_iterator и стандартный алгоритм transform.
’ Требуемые заголовки
> <unistd.h>, <iomanip>, <algorithm>, <f stream.h>, <vector>, <iterator>,
;<strstream.h>, <stdlib.h>,<sys/wait.h>,<sys/types.h>, <sys/stat.h>,
' <fcntl.h>, <numeric>.
Инструкции по компиляции и компоновке программ
C++ -о programll-3b programll-3b.cc
j Среда для тестирования
(SuSE Linux 7.1, gcc 2.95.2, Solaris 8, Sun Workshop 6.0.
i Инструкции по выполнению
Sprogramll.За & programll-3b
\ Примечания
:Сначала запускается программа 11.3.1. Программа 11.3.2 содержит инструкцию!
sleep, которая восполняет собой отсутствие реальной синхронизации.
11.5.3.1. Интерфейсные FIFO-классы
Упростить межпроцессное взаимодействие (IPC) можно не только с помощью
iostreams-классов или классов istream_iterator и ostream_iterator, но и по-
средством инкапсуляции FIFO-механизма в FIFO-классе (листинг 11.23).
// Листинг 11.23. Объявление FIFO-класса
class fifo{
mutex Mutex;
//. . .
protected:
string Name;
public:
fifo &operator<<(fifо &In, int X);
fifo &operator« (f if о &In, char X) ;
fifo &operator>>(fifо &0ut, float X);
//. . .
В этом случае мы можем легко создавать объекты класса fifo с помощью конструкта
ра, а также передавать их как параметры и принимать в качестве значений, возвра
щаемых функциями. Мы можем использовать их в сочетании с классами стандарт
11.6. Каркасные классы 421
нтейнеров. Применение такой конструкции значительно сокращает объем кода,
необходимого для функционирования FIFO-механизма. Более того, “классовый” под-
ход создает условия для обеспечения типовой безопасности и вообще позволяет про-
аммисту работать на более высоком уровне.
11.6. Каркасные классы
Под каркасным понимается класс (или целая коллекция классов), который имеет за-
панее определенную структуру и представляет обобщенную модель поведения. Точно
так же, как программы обеспечивают общие решения для конкретных задач, каркасные
классы предоставляют конкретные решения для классов задач. Другими словами, каркас
приложений содержит общую направленность выполнения кода для целого диапазона
программ, которые решают задачи подобным образом. Поскольку каркас приложений
представляет одно решение для семейства задач, то их можно назвать обощенными ав-
тономными мини-приложениями. Каркасный класс служит своего рода проектом для
мини-приложения. Он предлагает фундаментальную структуру (скелет), которую долж-
но иметь приложение, не навязывая никаких деталей. Каркасный класс определяет от-
ношения, распределяет обязанности, намечает порядок действий и протоколы между
частями ПО в объектно-ориентированной архитектуре. Например, мы можем спроек-
тировать класс языкового процессора, который должен содержать общую схему работы
для целого диапазона приложений. Эта схема должна определить действия, которые
необходимо выполнить для преобразования некоторого входного языка в заданный вы-
ходной формат. Такой каркас состоит из нескольких общих частей ПО:
• компоненты проверки достоверности;
• компоненты выделения лексем;
• компоненты грамматического разбора;
• компоненты синтаксического анализа;
• компоненты лексического анализа.
Эти части ПО можно объединить, чтобы сформировать уже знакомую нам про-
граммную конструкцию (листинг 11.24).
// Листинг 11.24. Объявление класса language—processor
' и определение метода process—input
cla^ language—processor {
Protected:
virtual
virtual
virtual
//. . .
Public.
j. bo°l Process—input(void);
getString(void) = 0;
validateString(void) = 0;
parseString(void) = 0;
bool
bool
bool
(°°1 language—processor::process—input(void)
422 Глава 11. Проектирование компонентов для поддержки параллелизма
getString();
validateString();
parseString();
//. . .
compareTokens();
//. . .
}
Во-первых, класс language—processor является абстрактным и базовым, по-
скольку он содержит чисто виртуальные функции:
virtual bool getString(void) = 0;
virtual bool validateString(void) = 0;
virtual bool parseString(void) = 0;
Это означает, что класс language—processor не предназначен для непосредст-
венного использования. Он служит в качестве проекта для производных классов.
Особенно стоит остановиться на методе process—input (). Этот метод представляет
собой план работы, которую предстоит обобщить классу language—processor. Во
многих отношениях именно это и отличает каркасные классы от классов других ти-
пов. Каркасный класс описывает не только обобщенную структуру и характер отно-
шений между компонентами, но содержит и заранее определенные последовательно-
сти выполняемых действий. Однако в таком своеобразном описании поведения не
указываются детали его реализации. В данном случае модель поведения задается на-
бором чисто виртуальных функций. Каркасный класс не определяет, как именно эти
действия должны быть выполнены, — важно то, что они должны быть выполнены,
причем в определенном порядке. А производный класс должен обеспечить реализа-
цию всех чисто виртуальных функций. При этом ответственность за корректность
выполняемых действий целиком возлагается на производный класс. Каркасные клас-
сы по определению — договорные классы. Для достижения успешного результата тре-
буется надлежащее выполнение обеих частей договора. Каркасный класс намечает
четкий план, а производный реализует этот план в виде конкретного определения
чисто виртуальных функций. Последовательность действий, “намеченная” методом
process—input (), соблюдается в таких приложениях.
Компиляторы Интерпретаторы команд
Обработчики естественных языков Программы шифрования-
дешифрирования
Упаковка-распаковка Протоколы пересылки файлов
Графические интерфейсы пользователей Контроллеры устройств
Корректная разработка каркасного класса language—processsor (при надлежа
щем его тестировании и отладке) позволяет ускорить разработку широкого диапазона
приложений.
Понятие каркасного класса также полезно использовать при разработке приложе
ний, к которым предъявляются требования параллелизма. Так, использование агент-
ных каркасов и каркасов “классной доски” фиксирует базовую структуру параллелизма
и схемы работы в этих структурах. Майкл Вулдридж в своей книге [51] предлагает
следующий обобщенный цикл управления агентами.
11.6. Каркасные классы 423
-^^ритм: цикл управления агентами
в = в0 .
while true do
aet next percept p
B = brf(B.p)
I = deliberate(B)
П= plan(B,I)
execute(П)
end while
Эта модель поведения реализуется широким диапазоном рациональных агентов.
Если вы разрабатываете программу, в которой используются рациональные агенты,
то скорее всего эта последовательность действий будет реализована в вашей про-
грамме. На фиксации последовательностей действий такого типа и “специализи-
руются” каркасные классы. Для цикла управления агентами функции brf(),
deliberate () и plan () должны быть объявлены чисто виртуальными функциями.
Цикл управления агентами определяет, в каком порядке и как должны вызываться эти
функции, а также сам факт того, что они должны быть вызваны. Однако конкретное
содержание функции определит производный класс. При надлежащем определении
цикла управления агентами будет решен целый класс проблем. Ведь системы, состоящие
из множества параллельно выполняющихся агентов, постепенно становятся стандартом
для реализации приложений параллельного программирования. Такие системы часто
называют мулътиагентными системами. Агентно-ориентированные системы мы рассмот-
рим в главе 12, а пока отметим, что агентные каркасные классы позволяют понизить
уровень сложности разработки мультиагентных систем, что очень ценно в свете того,
что мультиагентные системы становятся предпочтительным вариантом архитектуры
для реализации средне- и крупномасштабных приложений, которые требуют реали-
зации параллелизма или массового параллелизма.
Каркасные классы обеспечивают своих потомков не только планом действий (что
весьма полезно для параллельных или распределенных систем), но и такими компо-
нентами синхронизации, как объектно-ориентированные мьютексы, семафоры и по-
токи сообщений. Структура “классной доски” — полезное средство для взаимодейст-
вия множества агентов— представляет собой критический раздел, поскольку сразу
несколько агентов должны иметь возможность одновременно считывать из нее ин-
формацию и записывать ее туда. Следовательно, каркасный класс должен обеспечить
базовую структуру для отношений между агентами, компонентами синхронизации
и классной доской”. Например, листинг 11.25 содержит два метода, которые каркас-
ный класс мог бы использовать для доступа к “классной доске”.
// Листинг 11.25. Определение методов recordMessge() и
getMessageO для класса agent—framework
a9ent—framework::recordMessage(void)
Mutex, lock () ;
BlackBoardStream << Agent[N].message();
Mutex.unlock() ;
^nt agent—framework::getMessage(void)
424 Глава 11. Проектирование компонентов для поддержки параллелизма
Mutex.lock();
BlackBoardStream » Values;
Agent[N].perceive(Values);
Mutex.unlock();
Здесь каркасный класс должен защищать доступ к “классной доске” с помощью
объектов синхронизации. Поэтому, когда агенты считывают сообщения
с “классной доски” или записывают их туда, синхронизация уже будет обеспечена
каркасным классом. Программисту не нужно беспокоиться о синхронизации дос-
тупа к “классной доске”. Базовая структура агентно-ориентированного каркасного
класса a gen t_ framework показана на рис. 11.11.
МУЛЬТИ АГЕНТНАЯ СИСТЕМА
agent framework
содержит [X
ссылку на
объект Blackboard
agent framework
содержит |\
ссылку на
объект Blackboard
объектно-
ориентированные
условные переменные
Задача
объектно-
ориентированные
условные переменные
объектно-
ориентированные
мьютексы
ЦИКЛ УПРАВЛЕНИЯ
АГЕНТАМИ
МОДЕЛЬ/
" BDL '
Предложения,
данные,...
Частные
решения
объектно-
ориентированные
мьютексы
ЦИКЛ УПРАВЛЕНИЯ
АГЕНТАМИ
МОДЕЛЬ
Вр1 ‘
'1
MPI-поток сообщений, PVM-поток сообщений, FIFO-структуры
или каналы, используемые для взаимодействия агентов
Среда UNIX/Linux
Рис. 11.11. Базовая структура каркасного класса agent_f ramework
11.7. Резюме 425
Обратите внимание на то, что каркасный класс инкапсулирует объектно-
ентированные мьютексы и переменные условий. Агентно-ориентированный кар-
касный класс (см. рис. 11.11) для организации взаимодействия процессов в MPI- либо
pVM-ориентированной системе должен использовать MPI- либо PVM-потоки сообще-
ний Вспомните, что эти потоки сообщений были разработаны как интерфейсные
классы, что позволяет программисту для доступа к PVM- или MPI-классу использовать
iostreamS-представление. Если MPI- или PVM-классы не используются, агенты могут
взаимодействовать через сокеты, каналы или даже общую память. В любом случае мы
рекомендуем реализовать примитивы синхронизации с помощью интерфейсных
классов, которые упрощают их использование. Структура “классной доски”, показан-
ная на рис. 11.11, является объектно-ориентированной и использует преимущества
универсальности, обеспечиваемой шаблонными классами, что также упрощает реали-
зацию параллелизма. Агенты, выполняемые параллельно, представляют эффектив-
ную модель параллельного и распределенного программирования.
11.7. Резюме
Проблемы параллельного программирования, представленные в главе 2, можно
эффективно решить, используя “строительные блоки”, рассмотренные в этой главе.
Роль интерфейсного класса в упрощении использования библиотек функций трудно
преувеличить. Интерфейсный класс вносит логичность API-интерфейса путем заклю-
чения в оболочку вызовов функций из таких библиотек, как MPI или PVM. Интер-
фейсные классы обеспечивают типовую безопасность и возможность многократного
использования кода, а также позволяют программисту работать в привычной
“системе координат”, как с PVM- или MPI-потоками данных. Межпроцессное взаимо-
действие (IPC) упрощается путем связывания канала или потоков сообщений
с iostreams-объектами и перегрузки операторов вставки («) и извлечения (») для
пользовательских классов. Класс ostream_iterator доказывает свою полезность
в “оптовой” пересылке контейнерных объектов и их содержимого между процессами.
Итераторы типа ostream_iterator и istream_iterator также обеспечивают свя-
зующее звено между стандартными алгоритмами и IPC-компонентами и методами.
Поскольку модель передачи сообщений используется во многих параллельных и рас-
пределенных приложениях, то любой метод, который упрощает передачу различных
типов данных между процессами, упрощает программирование приложения в целом.
К таким способам упрощения относится использование iostreams-классов и итерато-
ров типа ostream_iterator и istream_iterator. Каркасный класс представлен
здесь как базовый строительный блок параллельных приложений. Мы рассматриваем
классы, подобные классам мьютексов, переменных условий и потоков, как компоненты
низкого уровня, которые должны быть скрыты от программиста в каркасном классе (где
ВТо возможно!). При создании средне- и крупномасштабных приложений, которые тре-
' т реализации параллелизма, программист не должен “застревать” на этих низко-
уровневых компонентах. В идеале для удовлетворения требований параллельной обра-
ки каркасный класс должен быть строительным блоком базового уровня и обеспечи-
Вать Нас “готовыми” схемами равноправных элементов и взаимодействия типа “клиент-
Сервер . Мы можем использовать различные типы каркасных классов: для обработки
Чисел, баз данных или применения агентов, технологии “классной доски”, GUI и т.д.
426 Глава 11. Проектирование компонентов для поддержки параллелизма
Метод, который мы предлагаем для реализации параллелизма, состоит в построении
приложений на базе коллекции каркасных классов, которые уже оснащены надлежащи
ми компонентами синхронизации, связанными соответствующими отношениями
В главах 12 и 13 мы подробнее остановимся на каркасных классах, которые поддерЖи
вают параллелизм. Мы также рассмотрим использование стандартных С++-алгоритмов
контейнеров и объектов-функций для управления процессом создания множества задач
или потоков в приложениях, требующих параллелизма.
РЕАЛИЗАЦИЯ
АГЕНТНО-
ОРИЕНТИРОВАННЫХ
АРХИТЕКТУР
В этой главе...
12.1. Что такое агенты
12.2. Понятие об агентно-ориентированном
программировании
12.3. Базовые компоненты агентов
12.4. Реализация агентов в C++
12.5. Мультиагентные системы
12.6. Резюме
Нам предстоит сделать еще немало, прежде чем мы поймем, как люди
описывают свои задачи и какую роль эти описания играют в решении задач.
Но мы уже знаем достаточно для того, чтобы предположить, что
используемые людьми описания, представленные как в виде высказываний,
так и в форме рисунков, могут быть сымитированы компьютерами.
— ГврбертА. Саймон (Herbert A. Simon), Machine as Mind (Android Epistemology)
Если бы последовательное (процедурное) программирование позволяло нахо-
дить решения в любых ситуациях, то не было бы необходимости для развития
технологий параллельного и распределенного программирования. Во многих
случаях методы последовательного программирования просто не отвечают требова-
ниям и опыту современных пользователей компьютеров. В процессе поиска разра-
ботчиками новых подходов к решению все возрастающих проблем и создаются аль-
тернативные модели программного обеспечения. Программисты находят более эф-
фективные способы организации ПО. Структурное программирование было шагом
вперед по сравнению с процедурным (изобиловавшим безусловными переходами),
объектно-ориентированное программирование сменило структурное. Во многих от-
ношениях агенты и агентно-ориентированное программирование можно рассматри-
вать как очередную (более высокую) ступень развития программирования. Агенты
представляют иной (более сложный) метод организации и представления распреде-
ленных/ параллельных программ.
12.1. Что такое агенты 429
12.1. Что такое агенты
Когда объектное программирование впервые заявило о себе, сама трактовка поня-
тия объекта вызвала большие споры. Подобные разногласия вызывает и трактовка по-
нятия агента. Одни определяют агенты как автономные постоянно выполняющиеся про-
граммы, которые действуют от имени пользователя. Однако это определение можно при-
менить и к UNIX-демонам или даже некоторым драйверам устройств. Другие дополняют
это определение тем, что агент должен обладать специальными знаниями пользователя,
должен выполняться в среде, “населенной” другими агентами, и обязан действовать толь-
ко в рамках заданной среды. Эти требования должны исключать другие программы, кото-
рые можно было бы до некоторой степени считать агентами. Например, многие агенты
электронной почты действуют автономно и могут работать по многих средах. Кроме того,
в различных кругах программистов для описания агентов появились такие термины, как
софтбот, т.е. программный робот (softbot), база знаний (knowbot), программный брокер
(software broker) и интеллектуальный объект (smart object). В этой главе мы многократно
будем определять термин агент. Начнем с простых согласованных частичных определе-
ний и построим определение, которое бы устраивало С++-программистов.
Существует определение, согласно которому агент определяется как некоторая
сущность, функционирующая постоянно и автономно в среде, в которой выполняются другие
агенты и процессы. Хотя весьма заманчиво принять это определение и развить его, мы
не будем этого делать, поскольку оно “с таким же успехом” описывает и другие виды
программных конструкций. Многие объектно-ориентированные компоненты функ-
ционируют постоянно и автономно в среде, в которой выполняются другие процессы
и существуют другие агенты. И в самом деле, многие CORBA-ориентированные сис-
темы типа “клиент-сервер” вполне соответствуют этому описанию! Поэтому, если мы
заменим в этом определении слово агент словом объект, оно в точности опишет мно-
гие объектно-ориентированные системы. Если заглянуть в более официальный ис-
точник, Foundation for Intelligent Physical Agents (FIPA), то в соответствии с ним тер-
мин агент определяется следующим образом:
Агент — это главный исполнитель в домене. Он обладает одной или несколькими сервис-
ными возможностями, образующими единую и комплексную модель выполнения, кото-
рая может включать доступ к внешнему ПО, пользователям (людям) и средствам связи.
Несмотря на то что это определение имеет более структурированную форму,
оно также нуждается в дальнейшем уточнении, поскольку под это определение по-
падают многие серверы (объектно-ориентированные и нет). Это определение в та-
ком виде включило бы слишком много типов программ и программных конструк-
ции. И хотя мы опираемся на FIPA-спецификацию, это базовое определение требу-
ет дальнейшей проработки.
12.1.1. Агенты: исходное определение
Одной из причин, по которой слово объект может заменить слово агент во многих
°пределениях и описаниях агента, состоит в том, что агенты по сути основаны на
объектах. И в самом деле, наше первое требование к определению агента заключается
в Том» что оно в первую очередь должно удовлетворять определению объекта1, т.е. мы
При использовании термина объект в определении агента мы включаем родственные для него поня-
из области искусственного интеллекта: исполнитель и фрейм.
430 Глава 12. Реализация агентно-ориентированных архитектур
имеем в виду, что агент — это объект определенного вида. В этой главе особый акцецт
делается на том, что отличает агента от других категорий объектов. Исходя из того
что C++ поддерживает интерфейсные, контейнерные и каркасные классы, мы можем
с таким же успехом ввести и агентные классы. Это приводит нас ко второму требова
нию, выдвигаемому к определению агентов в С++-среде. В C++ агент реализуется с ис-
пользованием понятия класса. Типы классов отличаются друг от друга тем, как они
функционируют, или тем, как они структурированы. Например, контейнерный класс
описывает объект, используемый для хранения других объектов. Интерфейсный
класс применяется для описания объекта, который преобразует или адаптирует ин-
терфейс другого объекта. Каркасный класс описывает объект, который содержит
шаблон, или образец поведения, являющегося общим для целого семейства других
объектов. Агентные классы предназначены для определения объектов, которые обла-
дают тем, что Иогав Шохам (Yohav Shoham) описывает как психическое
(интеллектуальное) состояние: “Психическое состояние должно включать такие ком-
поненты, как представления, возможности, варианты выбора и обязательства”. Это
психическое состояние зачастую описывается моделью убеждений, желаний и наме-
рений (Belief, Desires and Intentions — BDI). Мы расширяем модель BDI, чтобы вклю-
чить в нее действия. Теперь в нашем первом определении агент описывается как
часть ПО, отвечающая следующим требованиям.
1. Это определенный тип объекта (т.е. не все объекты являются агентами).
2. Его реализация использует понятие класса (для агентов весьма существенны
инкапсуляция, наследование и полиморфизм).
3. Он содержит набор поведенческих вариантов и атрибутов, которые должны
включать убеждения, желания, намерения и действия.
В рамках нашего изложения материала агенты по определению являются рацио-
нальными программными компонентами. Прежде чем мы перейдем к дельнейшему
определению агентов, рассмотрим типы агентов, которые реализуются чаще всего.
12.1.2. Типы агентов
Существует несколько категорий агентов. Несмотря на то что не все агенты можно
отнести к одной из них, с их помощью все же можно описать большинство агентов, ко-
торые уже нашли практическое применение. В табл. 12.1 перечислено пять основных
категорий агентов. Очевидно, существуют и агенты смешанного типа, которые можно
отнести к нескольким категориям одновременно, поскольку для распределения агентов
по категориям нет никаких жестких правил. Эти категории представлены для удобства
и используются в качестве отправной точки в попытке классифицировать агенты, кото-
рые, возможно, вам придется разрабатывать или использовать в своей работе.
В табл. 12.1 не указаны компоненты, которые должны иметь агенты. Здесь опреде-
лены лишь виды деятельности, которые характерны для агентов той или иной кате-
гории. При этом следует понимать, что эти категории не являются исключительном
сферой агентов. Подобным образом по категориям можно разделить и другие классы
ПО (например, экспертные и объектно-ориентированные системы). В нескольких
случаях единственным отличием может оказаться сам факт того, что мы говорим об
агентах, а не об объектах или экспертных системах.
12.1. Что такое агенты 431
Таблица 12.1. Пять основных категорий агентов
Категории агентов
Описание
~~ИНтерфейсные агенты Представляют следующее поколение взаимодействия между человеком и компьютером. Эти агенты обеспечивают новый пользовательский интерфейс с компьютером
Агенты поиска Агенты мониторинга/управления Выполняют различные виды поиска информации Патрулируют, наблюдают, отслеживают (выполняемые дейст- вия), управляют и контролируют устройства и условия, данные и процессы
Агенты сбора данных Уполномочены запросить некоторые данные или услуги от имени пользователя
Агенты поддержки принятия решений Обеспечивают анализ и синтез информации, интерпретацию условий и данных, планирование действий и оценку результата
12.1.3. В чем состоит разница между объектами
и агентами
Агент прежде всего должен отвечать условиям объектной ориентации. Это оз-
начает, что агенты и объекты имеют больше общего, чем многие специалисты хо-
тели бы это признать. Именно функциональная и конструктивная составляющие
объектов сближают их с агентами. Объекты по определению самодостаточны
и проявляют определенную автономность. Если степень автономности пересекает
определенный порог, и объекту предоставляются такие когнитивные
(познавательные) структуры данных, как те, что характерны для модели BDI, то та-
кой объект является агентом. Автономный рациональный объект является агентом.2
Объект считается рациональным в случае, если он обладает:
методами, которые реализуют некоторую форму дедукции, индукции или
абдукции;
• членами данных, которые представляют собой реализации когнитивных струк-
тур данных.
Следует иметь в виду, что в объектно-ориентированном программировании под-
программы, определенные для класса, называются методами, а в C++— функциями-
членами. Переменные или компоненты данных, определенные для класса, называются
апгрибутами, а в C++ — членами данных. Если некоторые функции-члены используются
Для реализации дедукции, индукции или абдукции с использованием членов данных,
которые представляют собой реализации когнитивных структур данных, то такой
объект является рациональным. Если рациональный объект при этом пересекает оп-
ределенный порог автономности, то это и есть агент.
Мы намеренно избегаем термина интеллектуальный. В настоящее время неизвестно, будем ли мы
a-либо создавать интеллектуальное программное обеспечение. Но бесспорно то, что мы можем созда-
ь рациональное ПО на основе хорошо понимаемого логического формализма.
432 Глава 12. Реализация агентно-ориентированных архитектур
Когнитивные структуры данных — это
таких интеллектуальных компонентов, к<
шения, настроения и знания. Например, мы могли бы обозначить структуру убежде
ний, используя С++-множество (set).
set<statements> Beliefs;
struct statement{
//. . .
float ArrivalTime;
float DepartureTime;
string Destination;
//. . .
};
Здесь инструкции связаны с составлением расписания для некоторого вида общест-
венного. транспорта. Коллекция этих инструкций хранится в С++-множесгве
set<statements> и представляет “убеждения” агента. Это именно то, что мы подра-
зумеваем под членами данных, которые являются реализациями когнитивных струк-
тур данных. Агент должен объявить член данных соответствующим образом.
class agent{
//. . .
set<statements> Beliefs;
//. . .
};
В классе agent для обработки множества Beliefs, чтобы сформировать намерения,
обязательства или планы, используется дедукция, индукция или абдукция. Из нашего
определения агентов следует, что, если мы имеем дело с рациональным автономным
объектом, то мы имеем дело с агентом. Если он не рациональный, то он не агент, он —
просто объект. А о степени автономности мы поговорим подробнее ниже в этой главе.
структуры, используемые для представления
1К убеждения, намерения, обязательства
12.2. Понятие об агентно-ориентированном
программировании
Агентно-ориентированное программирование — это процесс назначения работы,
порученной программе, одному или нескольким агентам. В декомпозиции работ
(Work Breakdown Structure — WBS) в этом случае участвуют только агенты. Если всю
работу, которую должна выполнить программа, можно назначить одному или не-
скольким агентам, мы имеем дело с чистой агентно-ориентированной программой,
в которой весь необходимый объем проектирования и разработки требует только
агентно-ориентированного программирования. Во многих ситуациях наряду с аген
тами в приложении будут задействованы и другие виды объектов и систем, которые
не являются агентно-ориентированными, и, следовательно, такое программирование
нельзя назвать агентно-ориентированным. Подобное сотрудничество часто имеет ме
сто, когда агенты участвуют в работе серверов баз данных, серверов приложений
и других типов объектно-ориентированных систем. При создании систем ПО — либо
полностью агентно-ориентированных, либо только частично — создаются рациональ
ные объектно-ориентированные программные компоненты.
12.2. Понятие об агентно-ориентированном программировании 433
Дедукция, индукция и абдукция
Дедукция, индукция и абдукция — это процессы, используемые для того, чтобы сде-
лать вывод на основании набора утверждений или коллекции данных. Процесс дедук-
ции позволяет механизму рассуждений прийти к заключению, оценив множество ут-
верждений. Если эти утверждения (посылки) истинны, и механизм рассуждений еле-
дуеТ соответствующим правилам генерирования вывода, то это дает основания
утверждать, что непременно истинны и следствия, например:
Все фигуры с тремя сторонами являются треугольниками.
Данная фигура имеет три стороны.
Эта фигура — треугольник. <— Вывод получен по дедукции.
Правила генерирования вывода — это руководящие принципы и ограничения, которые
определяют, как механизм рассуждений может переходить от одного утверждения
к другом}7. Правила генерирования вывода определяют, когда утверждения логически
эквивалентны, и условия, при которых одно утверждение может быть преобразовано
в другое. Основные правила генерирования вывода приведены в конце этого раздела.
Процесс индукции позволяет механизму рассуждений делать вывод на основании
множества утверждений, являющихся фактами, например:
Вчера шел дождь.
Позавчера шел дождь.
Дождь шел всю прошлую неделю.
Завтра будет идти дождь. <— Вывод получен по индукции.
Тогда как следствия, полученные в процессе дедукции объявляются непременно истин-
ными (если правила генерирования вывода были применены корректно), то заключе-
ния, к которым приходят в процессе индукции, имеют лишь некоторую вероятность
быть истинными. Насколько близко эта вероятность приближается к 100%, зависит от
характера и контекста утверждений, а также данных, на которые они опираются.
Процесс абдукции позволяет механизму рассуждений сделать наиболее правдоподоб-
ный вывод на основе набора утверждений или данных, например, так.
Предметы одежды обвиняемого были обнаружены на месте преступления.
Между обвиняемым и покойником недавно произошел бурный конфликт.
ДНК обвиняемого была обнаружена на месте преступления.
Обвиняемый виновен в свершении преступления. <— Вывод получен по абдукции.
Дедукция, индукция и абдукция — это три основных процесса логического мышления.
X роль в логике можно сравнить с ролью вычислений и арифметики в математике.
Пособность корректно переходить от посылок (утверждений, данных и фактов)
к заключениям является процессом, который мы называем рассуждением.
434 Глава 12. Реализация агентно-ориентированных архитектур
Основные правила генерирования вывода
1. Модус поненс (правило отделения)
p>q
Р
.-.q
3. Гипотетический силлогизм
p>q
q<r
Л р > г
5. Конструктивная дилемма
(p>q) • (r>s)
л q v s
7. Упрощение
p.q
лр
9. Сложение
Р
л pvq
2. Модус толленс
(принцип фальсификации)
p>q
л~р
4. Дизъюнктный силлогизм
p>q
~Р
лЧ
6. Поглощение
p>q
••• р > (р • q)
8. Конъюнкция
Р
Ч
лр • q
12.2.1. Роль агентов в распределенном
программировании
Возникновение распределенных программ было вызвано практической необхо-
димостью. Нетрудно представить, что существует некоторый ресурс, который нужен
программе, но этот ресурс размещен на другом компьютере или в сети. Под такими
ресурсами часто понимают базы данных, Web-серверы, серверы электронной почты,
серверы приложений, принтеры и крупные запоминающие устройства. Подобными
ресурсами обычно управляет часть ПО, именуемая сервером. Другая часть ПО, которой
необходимо получить доступ к ресурсам, называется клиентом. Тот факт, что ресурсы
и клиент расположены на различных компьютерах, приводит к необходимости ис-
пользования распределенных архитектур. В большинстве случаев не имеет смысла
объединять эти программы в одну большую и выполнять ее на одном компьютере
и в едином адресном пространстве. Более того, существует множество программ, ра3'
работанных в различное время, разными разработчиками и для разных целей, но которые
12.2. Понятие об агентно-ориентированном программировании 435
orvT успешно использовать преимущества друг друга. Приложение, которое исполь-
зовал0 эти программы, эволюционировало определенным образом и в итоге
“ ^служило звание” распределенного приложения. Поскольку эти программы отделе-
ны ДрУг от дРУга» каждая из них Должна иметь собственное адресное пространство
и “свои” ресурсы. Когда эти программы используются для совместного решения зада-
чи они образуют распределенное приложение. Оказывается, что архитектура рас-
’ деленной программы обнаружила высокую степень гибкости, что позволило при-
менить ее к крупномасштабным приложениям. Во многих приложениях необходи-
мость в распределенной архитектуре обнаруживается довольно поздно, “когда поезд
уже ушел”. Но если заранее идентифицировать такую необходимость, можно с успе-
хом использовать соответствующие методы проектирования программного обеспе-
чения. Если вы уже точно знаете, что вам нужно разрабатывать распределенное при-
ложение, то следующий вопрос должен прозвучать так: “как именно оно должно быть
распределено?”. От ответа на этот вопрос будет зависеть, какую модель следует ис-
пользовать в этом случае. Несмотря на существование множества различных моделей
(равноправных узлов и типа “клиент/сервер”), в этой книге мы остановимся только
на двух: мультиагентной архитектуре и архитектуре “классной доски”.
Оба эти вида архитектуры могут использовать преимущества агентов, поскольку
агенты представляют собой самодостаточные, автономные и рациональные про-
граммные структуры. Рациональность агентов заключается в том, что им известно их
назначение. И обычные объекты имеют цель, но агенты “знают”, какова эта цель.
Идентификация назначения каждого аспекта ПО — вполне естественный процесс. На
этапе проектирования нетрудно продумать цель отдельной части ПО, и поэтому про-
стейшая форма декомпозиции ПО состоит в том, чтобы назначить агенту его цель.
Затем приходит черед понять, агентов какого класса лучше всего уполномочивать на
выполнение той или иной работы. Поскольку агент— это единица модульности
в агентно-ориентированной программе (agent-oriented program — АОР), то проблема
распределения сводится к поиску средств взаимодействия множества агентов. Про-
цесс проектирования исходного класса агента вбирает в себя все то, что необходимо
Для идентификации отдельных составных частей распределенной программы. Спра-
вившись с созданием агентов как действительно рациональных объектов, мы сможем
воспользоваться преимуществами CORBA-спецификации для разработки действи-
тельно распределенных мультиагентных систем. CORBA скрадывает сложность рас-
пределенного программирования и взаимодействия посредством сетей (intranet
и Internet). Обзор средств распределенного программирования с использованием
CORBA-спецификации приведен в главе 8. Поскольку агенты являются объектами,
этот обзор CORBA-средств имеет силу и для агентов. В главе 6 рассмотрена система
М (Parallel Virtual Machine — параллельная виртуальная машина). Систему PVM
также можно использовать для значительного упрощения взаимодействия между
агентами, существующими в различных процессах или на разных компьютерах. Аген-
РхкМ°ЖНО Реализовать как CORBA-объекты, либо их можно назначить отдельным
1-процессам. В обоих случаях взаимодействие агентов упрощается в значительной
степени. Если в одном приложении задействовано несколько агентов, то такое при-
ложение представляет собой мультиагентную систему. Если агенты расположены на
Компыотере, то для взаимодействия между собой они могут использовать
КВА-, PVM- или MPI-средства (Message Passing Interface). Агенты в различных про-
сах также могут использовать такие традиционные методы межпроцессного взаи-
МоДействия (IPC) , как FIFO-структуры, разделяемую память и каналы. В распределен-
Программировании есть три основные проблемы.
436 Глава 12. Реализация агентно-ориентированных архитектур
1.
Идентификация декомпозиции ПО распределенного решения.
2. Реализация эффективного и рационального взаимодействия между распреде
ленными компонентами.
3. Обработка исключительных ситуаций, ошибок и частичных отказов.
Несмотря на то что для реализации п. 2 в понятии класса агента нет ничего такого
что было бы свойственно только агентам, смысл п. 1 и 3 почти подразумевается в са
мой сути агента. Рациональность каждого агента определяет его назначение, а следо-
вательно, и роль, которую он будет играть в решении ПО. Поскольку агенты самодос-
таточны и автономны, то хорошо продуманный класс агента должен включать необ-
ходимые меры по обеспечению их отказоустойчивости.
12.2.2. Агенты и параллельное программирование
При размещении агентов в среде с несколькими процессорами или параллельно
выполняющимися потоками вы получаете такие же преимущества, как и при распре-
деленном программировании, но с той лишь разницей, что сотрудничество между
агентами программировать в этом случае гораздо проще. Для передачи сообщений
между агентами, которые коллективно решают задачи некоторого вида, также можно
использовать PVM- и MPI-среды. И снова-таки, рациональность агентов облегчает по-
нимание, как следует провести декомпозицию работ для параллелизма. В параллель-
ном программировании, как правило, встречаются такие проблемы.
1. Эффективное и рациональное разделение работы между несколькими ком-
понентами.
2. Координация параллельно выполняющихся программных компонентов.
3. Разработка соответствующего взаимодействия (когда это необходимо) между
компонентами.
4. Обработка исключительных ситуаций, ошибок и частичных отказов (если аген-
ты функционируют на отдельных компьютерах).
Мультиагентные параллельные архитектуры часто характеризуются как слабосвя-
занные, т.е. им присущ минимум взаимодействия и взаимозависимости. Каждый агент
знает свою цель и обладает методами для ее достижения. В то время как п. 3 не под-
властен классу агента, п. 1, 2 и 4 можно легко управлять с помощью классов агентов.
Например, при использовании агентов влияние п. 2 уменьшается, поскольку каждый
агент рационален, имеет цель, а также способы и средства ее достижения. Поэтому
вся ответственность смещается с алгоритма координации и управления на действия
каждого агента. Влияние п. 4 также уменьшается, поскольку агенты самодостаточны,
рациональны и автономны, а кроме того, хорошо продуманный класс агента должен
включать необходимые меры по обеспечению отказоустойчивости агентов. Посколь
ку состояние агента инкапсулировано, ответственность за защиту критических разде*
лов в объекте агента целиком возлагается на класс агента. Агент должен приводить
в исполнение собственные стратегии доступа к данным. Возможные стратегии досту
па, из которых могут выбирать агенты, перечислены в табл. 12.2.
12.3. Базовые компоненты агентов 437
^Таблица 12.2. Стратегии доступа
Типы алгоритмов чтения-записи Значение
"erew Монопольное чтение, монопольная запись (Exclusive Read Exclusive Write)
CREW Параллельное чтение, монопольная запись (Concurrent Read Exclusive Write)
ERCW Монопольное чтение, параллельная запись (Exclusive Read Concurrent Write)
CRCW Параллельное чтение, параллельная запись (Concurrent Read Concurrent Write)
Класс каждого агента должен определить, какая именно стратегия доступа прием-
лема в мультиагентной среде. В ряде случаев реализуются не просто отдельные стра-
тегии доступа, перечисленные в табл. 12.2, а их комбинации. Это позволяет упростить
параллельное программирование, поскольку разработчик может работать на более
высоком уровне и не беспокоиться о построении мьютексов, семафоров и пр. Муль-
тиагентные решения позволяют разработчику не погружаться в детали координации
вызова каждой функции и организации доступа к данным. Каждый агент имеет цель.
Каждый агент рационален, а следовательно, обладает определенной логикой для дос-
тижения своей цели. Процесс программирования в этом случае больше напоминает
делегирование задач, а не координацию задач, которая характерна для традиционно-
го параллельного программирования. Поскольку агентно-ориентированное програм-
мирование — это объектно-ориентированное программирование специального вида,
применительно к агентам используется более декларативный вид параллельного про-
граммирования по сравнению с традиционным процедурно-ориентированным про-
граммированием, которое часто реализуется такими языками, как Fortran или С. Раз-
работчик лишь определяет, что нужно сделать и какие агенты должны это сделать, т.е.
выходит, что параллелизм практически сам заботится о себе. При этом всегда сущест-
вует некоторый объем программирования, связанного с координацией и организаци-
ей взаимодействия, но агентно-ориентированное программирование сводит этот не-
обходимый объем к минимуму. Однако обо всех этих “плюсах” можно говорить лишь
при условии существования классов агентов. Очевидно, кто-то должен спроектиро-
вать классы агентов и написать их код. Теперь самое время разобраться в том, что
Должен содержать класс агента.
12.3. Базовые компоненты агентов
Агент объявляется с использованием ключевого слова class. Компоненты агента
Должны состоять из С++-членов данных и функций-членов. Логическая структура
^асса агента показана на рис. 12.1.
Класс агента (см. рис. 12.1) определяет типичные методы инициализации, чтения
записи, которые должен иметь практически любой объект. В “джентльменский на-
Р входят конструкторы, деструкторы, операторы присваивания, обработчики ис-
ключений и т.д. Атрибуты этого класса включают переменные состояния, опреде-
ляющие объект. Если же ограничиться перечнем этих атрибутов и методов, мы полу-
438 Глава 12. Реализация агентно-ориентированных архитектур
чим только традиционный объект. Рациональный компонент создают когнитивные
структуры данных и методы рассуждений (логического вывода). А ведь именно г>
циональный компонент трансформирует “обычный” объект в агент.
Класс агента
Атрибуты класса
Методы класса
Традиционные объектно-
ориентированные компоненты
Когнитивные структуры данных
Рациональные компоненты
Методы рассуждений
Рис. 12.1. Логическая структура класса агента
12.3.1. Когнитивные структуры данных
Под структурой данных понимается набор правил, применяемых для логической
организации данных, а также правила доступа к этой логической организации. Имен-
но метод организации определяет, как данные должны быть концептуально структу-
рированы и какие операции доступа могут быть применены к этой структуре. Если для
типов данных вообще и абстрактных типов данных (abstract datatypes — ADT) в част-
ности важно, что хранить, то для структур данных важно, как хранить. Например, це-
лочисленный тип данных определяет некоторую “сущность”, которая характеризует-
ся наличием компонента данных и некоторого количества арифметических операций
(например, сложение, вычитание, умножение, деление и т.д.). Этот компонент дан-
ных не имеет дробной части и состоит из отрицательных и положительных чисел.
Спецификация типа данных ничего не “говорит” о том, как целые числа нужно ис-
пользовать или как к ним получить доступ. Однако спецификация структуры данных
(например, стека) определяет список элементов, сохраняемых по принципу
“последним прибыл — первым обслужен” (last-in-first-out — LIFO). Структура данных
стека также определяет, что элементы из нее можно извлекать только по одному за
раз и причем только из вершины стека. Другими словами, элемент, помещенный
в стек последним, должен быть извлечен из него раньше остальных элементов. Это
означает, что структура данных стека определяет не только характер организации
элементов, но и характер доступа к ним (т.е. как элементы можно помещать в структу-
ру, опрашивать, изменять, удалять и т.п.). Когнитивные структуры данных ограничи-
вают правила организации данных и доступа к ним такими, которые относятся к об-
ласти логики и эпистемологии. Особенности когнитивных структур данных опреДО'
ляются правилами логического вывода, методами рассуждений (т.е. дедукцией,
индукцией и абдукцией), понятиями эпистемологических данных, знания, обоснова-
ния, убеждений, посылок, высказываний, ошибочных доказательств и заключении.
1 Из нашего определения когнитивных структур данных намеренно исключены такие относящиеся *
психике человека понятия, как воображение, паранойя, беспокойство, счастье, грусть и т.п. Нас интерн
сует рациональное эпистемологическое, а не интеллектуальное ПО.
12.3. Базовые компоненты агентов 439
Тогда как для традиционных структур данных вполне обычными являются, например,
оритмы сортировки и поиска, то для когнитивных структур данных более прием-
лемы методы рассуждений. Абстрактные типы данных, используемые вместе с когни-
тивными структурами данных, часто включают следующие:
вопросы
факты
предположения
убеждения
утверждения
заключения
события
время
заблуждения
цель
обоснование
Безусловно, с когнитивными структурами данных можно сочетать и другие типы
данных, но приведенные выше являются характеристиками программ, которые ис-
пользуют такие рациональные программные компоненты, как агенты. Эти абстракт-
ные типы обычно реализуются как типы данных, объявленные с помощью ключевых
слов struct или class. Например, так.
struct question{
string Requiredlnformation;
target_object QuestionDomain;
string Tense;
string Mood;
//. . .
class justification{
//. . .
time EventTime;
bool Observed;
bool Present;
//. . .
Шаблонные и контейнерные С++-классы можно использовать для организации та-
ких когнитивных структур данных, как знания, например, так.
class preliminary_knowledge {
//. . .
map<question,belief> Opinion;
map<conclusion,justification> SimpleKnowledge;
set<propositions> Argument;
//. . .
};
"•2.3.1.2. Методы рассуждений
Под методами рассуждений (см. рис. 12.1) понимают дедукцию, индукцию и абдук-
цию. (Краткое описание этих методов приведено в параграфе 12.1.) Несмотря на то
1ТО в агентно-ориентированной архитектуре требуется их использование, не сущест-
в}ет конкретных ссылок на то, как они реализуются. Дедукция, индукция и абдукция
вносятся к процессам высокого уровня. Подробности реализации этих процессов —
’Hi iHoe дело разработчика ПО. Рассуждение — это процесс выведения логического за-
ения на основании посылок, истинность которых предполагается или точно ус-
рассВЛеНа С' ЩествУет единственно правильного способа реализации процесса
Это^'ЖДсний, иногда называемого машиной (или механизмом) логического вывода. При
На практике применяется несколько распространенных способов реализации
(рас ПР°цесса‘ Например, можно использовать методы прямого построения цепочки
ссркдений от исходных посылок к целевой гипотезе) или обратного построения
440 Глава 12. Реализация агентно-ориентированных архитектур
цепочки (рассуждений от целевой гипотезы к исходным посылкам). Нашли здесь при-
менение методы анализа целей и средств, а также такие алгоритмы обхода графов, как
“поиск вглубь” (Depth First Search — DFS) и “поиск в ширину” (Breadth First Search — BFS)
Существует также целая совокупность методов доказательства теорем, которые можно
использовать для реализации методов рассуждений и механизмов логического вывода
Здесь важно отметить, что класс агента может иметь один или несколько методов рас-
суждений. Описание самых основных способов их реализации приведено в табл. 12.3.
Таблица 12.3. Основные способы реализации методов рассуждений
Способы реализации методов рассуждений Описание
Обратное построение цепочки Управляемый целями метод, в котором процесс начи- нается с предположения, утверждения или гипотезы и стремится найти подтверждающие доказательства
Прямое построение цепочки Управляемый данными метод, который начинается с анализа имеющихся данных или фактов и приходит к определенным выводам
Анализ целей и средств Использует множество операторов для последова- тельного решения подзадач до тех пор, пока не будет решена вся задача в целом
Эти методы достаточно понятны и широко доступны во многих библиотеках, обо-
лочках и языках программирования. Эти методы являются “строительными блоками”
для базовых методов рассуждений. Чтобы понять, как происходит процесс рассужде-
ния, используем одно из правил генерирования вывода, а именно модус поненс
(правило отделения), и построим простой метод рассуждения. Возьмем следующее
утверждение. Если существует автобусный маршрут из Детройта в Нью-Йорк, то Джон
поедет в отпуск. Если мы выясним, что автобусный маршрут из Детройта в Нью-Йорк
действительно существует, то будем знать, что Джон поедет в отпуск. Правило модус
поненс имеет следующий формат.
Р —> Q
Р
Q
Здесь:
Р = Если существует автобусный маршрут из Детройта в Нью-Йорк,
Q = Джон поедет в отпуск.
Мы могли бы спроектировать простой агент обеспечения решения, который позволит
нам узнать, поедет Джон в отпуск или нет. Этому агенту нужно узнать все возможное об ав
тобусных маршрутах. Предположим, у нас есть список автобусных маршрутов:
Толедо-Кливленд Детройт-Чикаго Янгстаун-Ныо-Йорк
Кливленд-Колумбус Цинциннати-Детройт Детройт-Толедо
Колумбус-Нью-Йорк Цинциннати-Янгстаун
12.3. Базовые компоненты агентов 441
Каждый из этих маршрутов представляет обязательство, взятое на себя компанией
дВС Bus Company. Если наш агент получит доступ к расписанию автобусных маршру-
тов этой компании, то приведенный выше список маршрутов можно будет использо-
вать для представления некоторой части убеждений нашего агента. Возникает во-
поос: как перейти от списка маршрутов к убеждениям? Для начала попробуем разра-
ботать простую структуру утверждений.
Struct existing_trip{
//. • •
string From;
time Departure;
string To;
time Arrival;
Затем попытаемся использовать контейнерный класс для представления убежде-
ний нашего агента в отношении автобусных маршрутов.
set<existing_trips> BusTripKnowledge;
Если определенный автобусный маршрут содержится в множестве
BusTripKnowledge, то наш агент убежден в том, что в указанное время автобус не-
пременно отправится по этому маршруту из пункта отправления в пункт назначения.
Итак, мы можем зафиксировать любой маршрут в соответствии с заданной структурой.
//...
existing_trip Trip;
Trip. From. append (" Toledo " ) ;
Trip. To. append ("Cleveland") ;
Trip.Departure("4:30") ;
Trip.Arrival("5:45");
BusTripKnowledge. insert (Trip) ;
//...
Если мы поместим каждый маршрут в множество BusTripKnowledge, то убежде-
ния нашего агента об автобусных перевозках компании ABC Bus Company будут пол-
ностью описаны. Обратите внимание на то, что прямого маршрута из Детройта
в Нью-Йорк не существует. Но Джон может добраться в Нью-Йорк из Детройта более
сложным путем, осуществив следующие переезды автобусом:
из Детройта в Толедо;
из Толедо в Кливленд;
из Кливленда в Колумбус;
из Колумбуса Нью-Йорк.
Поэтому, несмотря на то что компания ABC Bus Company не предоставляет прямо-
Го маршрута (из пункта А в пункт Б), она позволяет совершить переезд с большим ко-
личеством промежуточных остановок. Задача состоит в следующем: как об этом мо-
ж^т узнать наш агент? Агент на основе своих знаний об автобусных маршрутах должен
адать некоторым алгоритмом генерирования вывода о том, существует ли мар-
ем И3 ДетРойт* в Нью-Йорк. Мы используем простой цепной метод. Просматрива-
элементы множества BusTripKnowledge и находим первый маршрут из Дет-
Та““ из Детройта в Чикаго. Опрашиваем атрибут То этого элемента. Если бы он
Равен значению "Нью-Йорк", процесс поиска был бы прекращен, поскольку мы
442 Глава 12. Реализация агентно-ориентированных архитектур
нашли нужный маршрут. В противном случае сохраняем найденный (промежуток
ный) маршрут в стеке. Затем ищем маршрут с атрибутом From, равным "Чикаго-
При этом может оказаться, что таких маршрутов не предусмотрено вообще. Посколь
ку далее хранить элемент множества, соответствующий маршруту “Детройт-Чикаго”
нет никакого смысла, мы удаляем его из стека, сделав пометку, что этот маршрут у^
был рассмотрен. Затем повторяем поиск маршрута с отправлением из Детройта. На-
ходим такой маршрут: “Детройт-Толедо”. Проверяем, не равен ли его атрибут То зна-
чению "Нью-Йорк", и поскольку наши надежды не оправдались, сохраняем этот эле-
мент в стеке. Затем ищем маршрут с атрибутом From, равным "Толедо". Находим
маршрут “Толедо-Кливленд” и также помещаем его на хранение в стек. После этого
просматриваем маршруты в надежде найти элемент, у которого атрибут From был бы
равен значению "Кливленд". Для каждого найденного маршрута проверяем значе-
ние атрибута То. Если он равен значению " Нью-Йорк", то промежуточные маршруты,
помещенные в стек, представляют в целом маршрут' из Детройта в Нью-Йорк, начало
которого находится на “дне” стека, а его конечный пункт — в вершине. Если мы прой-
дем по всему списку маршрутов и не найдем ни одного с атрибутом То, равным значе-
нию "Нью-Йорк", или иссякнут возможные варианты проверки атрибута То для
верхнего элемента стека, то мы, извлекая верхний элемент из стека, будем искать сле-
дующий элемент, значение атрибута From которого совпадает со значением атрибута
То элемента, расположенного в вершине стека. Этот процесс повторяется до тех пор,
пока стек не опустеет или мы все-таки не найдем нужный маршрут. Для определения,
существует ли маршрут из пункта А в пункт Б, используется в данном случае упрощен-
ный метод DFS (Depth First Search — “поиск вглубь”).
Наш простой агент будет использовать этот DFS-метод для выяснения, существует
ли маршрут из Детройта в Нью-Йорк. Выяснив этот факт, агент может обновить свои
убеждения насчет Джона. Теперь агент убежден, что Джон поедет в отпуск. Предпо-
ложим, мы внесли дополнительное предусловие относительно отпуска Джона.
Если Джон обслужит 15 или больше новых клиентов, его доходы превысят (>)
150000.
Если доходы Джона превысят 150000 и существует маршрут из Детройта в Нью-
Йорк, то Джон отправится в отпуск.
Теперь агент должен выяснить, превышают ли доходы Джона сумму 150000 и су-
ществует ли маршрут из Детройта в Нью-Йорк. Чтобы выяснить положение дел на-
счет доходов Джона, агент должен сначала узнать, обслужил ли Джон хотя бы 15 но-
вых клиентов. Предположим, мы уверяем программного агента в том, что Джон оо-
служил 23 новых клиента. Затем агент должен убедиться в том, что его доходы
превышают 150000. На основе содержимого множества BusTripKnowledge агент су-
мел прийти к выводу о существовании маршрута из Детройта в Нью-Йорк. На основа-
нии убеждений об автобусных маршрутах и 23 новых клиентах агент использует про-
цесс прямого построения цепочки (т.е. рассуждений от исходных посылок к целевой
гипотезе) и приходит к заключению, что Джон таки поедет в отпуск. Формат рассуж
дений этого процесса имеет такой вид.
А -> В
(В и С) -> D
А
С
D
12.3. Базовые компоненты агентов 443
Здесь:
д = Если Джон обслужит не менее 15 новых клиентов,
В = Доходы > 150000,
С == Существует автобусный маршрут из Детройта в Нью-Йорк,
D = Джон поедет в отпуск.
В этом примере агент убеждается, что элементы А и С истинны. С использованием
правил ведения рассуждений агент заключает, что элементы В и D равны значению
ИСТИНА. Следовательно, агент делает вывод о том, что Джон поедет в отпуск. По-
добный вид обработки имеющихся данных можно было бы применить к агенту в си-
туации, когда у директора фирмы в подчинении находятся сотни или даже тысячи
служащих, и он хотел бы, чтобы агент регулярно составлял почасовой график работы
для своих служащих. Директор намерен затем получать от агента справку о том, кто
работал, кто находился в отпуске по болезни, а кто — в очередном отпуске и т.д. Агент
должен обладать знаниями и полномочиями устанавливать график работы. Каждую не-
делю агент должен представлять ряд приемлемых графиков работы, очередных отпус-
ков и сведений о пропусках по болезни. Агент в этом случае для получения результата
использует простой метод прямого построения цепочки и метод DFS. Чтобы реализо-
вать этот вид рассуждений, мы использовали такие типы данных, как struct и классы
стеков и множеств. Эти классы используются для хранения знаний, предположений
и методов рассуждений. Они позволяют реализовать когнитивные структуры данных
(Cognitive Data Structures — CDS). Для поддержки процесса рассуждений, а именно при
опросе наших структур данных (стека и множества) мы использовали DFS-методы.
При сочетании метода прямого построения цепочки и метода DFS создается про-
цесс, в соответствии с которым одно предположение может быть подтверждено на
основе уже принятых предыдущих. Это очень важный момент, поскольку наш агент
при достижении цели должен знать, что в действительности следует считать кор-
ректным. Такой подход также влияет на отношение к вопросам параллельного про-
граммирования. Тот факт, что агент рационален и действует в соответствии с прави-
лами построения рассуждений, позволяет разработчику сосредоточиться на коррект-
ном моделировании задачи, выполняемой агентом, а не на стремлении явно
управлять параллелизмом в программе. Минимальные требования параллелизма, вы-
ражаемые тремя “китами” — декомпозицией, взаимодействием и синхронизацией
(decomposition, communication, synchronization — DCS), — по большей части относятся
к архитектуре агента. Каждый агент для своего поведения имеет логическое обосно-
вание. Это обоснование должно опираться на хорошо определенные и хорошо пони-
маемые правила ведения рассуждений. Декомпозиция зачастую выражается в простом
назначении агенту одного или нескольких основных указаний (директив). Декомпо-
зиция работ в этом случае должна иметь естественный характер и в конце концов вы-
разиться в параллельных или распределенных программах, которые нетрудно под-
держивать и развивать. Взаимодействие агентов проще представить, чем взаимодей-
ствие анонимных модулей, поскольку границы между агентами более четки
очевидны. Каждый агент имеет цель, которая лежит на поверхности. Знания, или
формация, необходимые каждому агенту для достижения его цели, в этом случае
Же^° определяются. Чтобы позволить агентам взаимодействовать, разработчик мо-
использовать простые MPI-функции или средства взаимодействия объектов, ко-
Pbie являются частью любой CORBA-реализации. При обеспечении взаимодействия
тов самыми сложными являются следующие моменты:
444 Глава 12. Реализация агентно-ориентированных архитектур
• посредством чего должно происходить взаимодействие;
• кому нужно взаимодействовать;
• когда должно происходить взаимодействие;
• какой формат должно иметь взаимодействие.
Ответы на эти вопросы должны быть изначально заложены в проект агентов. Теперь
осталось лишь определиться с физической реализацией взаимодействия агентов. Ддя
этого можно воспользоваться библиотеками, которые поддерживают параллелизм. На-
конец, что касается проблем синхронизации, то с ними можно легко справиться, по-
скольку именно логическое обоснование агента сообщает ему, когда он может и должен
выполнять действия. Следовательно, сложные вопросы синхронизации сводятся к про-
стым вопросам сотрудничества. Благодаря этому упрощается и задача разработчика в це-
лом. Теперь рассмотрим базовую структуру агента и возможности его реализации в C++.
12.4. Реализация агентов в C++
Рассмотрим упрощенный вариант предыдущего примера агента и продемонстри-
руем, как его можно реализовать в C++. Цель этого агента — составлять график отпус-
ков и выполнять подготовку к поездкам владельца компании ABC Auto Repair
Company. В компании работают десятки служащих, и поэтому у хозяина нет времени
заботиться о проведении своего очередного отпуска. Кроме того, если хозяин не по-
лучит определенного объема прибыли, об отпуске не может быть и речи. Поэтому
владельцу компании хотелось бы, чтобы агент распланировал его отпуска равномерно
по всему году при условии процветания фирмы. По мнению владельца компании,
главное, чтобы агент работал автоматически, т.е. после инсталляции на компьютере о
нем можно было не беспокоиться. Когда агент определит, что подошло время для от-
пуска, он должен предъявить план проведения отпуска, забронировать места в отеле
и проездные билеты, а затем по электронной почте представить хозяину маршрут. Вла-
делец должен побеспокоиться только о формировании задания для агента. Он должен
указать, куда желает отправиться и какой объем прибыли необходимо получить, что-
бы запланированная поездка состоялась. Теперь рассмотрим, как можно спроектиро-
вать такой агент. Вспомним, что рациональный компонент (см. рис. 12.1) класса аген-
та состоит из когнитивных структур данных и методов рассуждений (стратегий логи-
ческого вывода). Когнитивные структуры данных (CDS) позволяют хранить
убеждения, предположения, знания, заблуждения, факты и пр. Для доступа к этим
когнитивным структурам данных в процессе решения проблемы и выполнения задач
класс агента использует стратегии логического вывода. Для реализации CDS-структур
данных и методов построения рассуждений можно использовать ряд контейнерных
классов и алгоритмов, которые содержатся в стандартной библиотеке C++.
12.4.1. Типы данных предположений и структуры
убеждений
Этот агент обладает убеждениями о показателях авторемонтной мастерской.
ждения составляют информацию о том, сколько клиентов обслуживается в час, какова
загрузка ремонтных секций в день и общий объем продаж (запчастей и услуг) за неко
12.4. Реализация агентов в C++ 445
ый период времени. Кроме того, агент знает, что владелец фирмы любит путеше-
ствовать только автобусами. Поэтому агент хранит информацию об автобусных мар-
ах которые могут для отпускника оказаться привлекательными. В программе,
насыщенной математическими вычислениями, используются в основном целочис-
ленные значения и числа с плавающей точкой. В графических программах участвуют
пиксели, линии, цвета, геометрические фигуры и пр. В агентно-ориентированной
ппограмме основными типами данных являются предположения, правила, утвержде-
ния литералы и строки. Для построения типов данных, свойственных агентно-
ориентированному программированию, мы будем опираться на объектно-
ориентированную поддержку, предусмотренную в C++. Итак, рассмотрим объявление
класса предположения (листинг 12.1).
/ / Листинг 12.1. Объявление класса предположения
template<class С> class proposition {
//.. .
protected:
list<C> UniverseOfDiscourse;
bool Truthvalue;
public:
virtual bool operator()(void) = 0;
bool operator&&(proposition &X) ;
bool operator]|(proposition &X);
bool operator!|(bool X);
bool operator&&(bool X) ;
operator void*();
bool operator!(void);
bool possible(proposition &X);
bool necessary(proposition &X) ;
void universe(list<C> &X);
//. . .
Предположение представляет собой утверждение, тема (предмет) которого под-
тверждается или отрицается предикатом. Предположение может принять значение
ИСТИНА или ЛОЖЬ. Предположение можно использовать для фиксации одного
убеждения, которое есть у агента. Кроме того, в качестве предположения может быть
представлена некоторая другая информация, которая предлагается агенту и которую
агент необязательно воспринимает как убеждение. Для представления предположе-
ний используется когнитивный тип данных, который должен быть таким же функ-
циональным в агентно-ориентированной программе, как целочисленные и вещест-
венные типы данных в математических программах. Поэтому, чтобы обеспечить не-
которые основные операторы, применимые к предположениям, мы используем С++-
средства перегрузки операторов. В табл. 12.4 показано, как такие операторы преобра-
зуются в логические.
Класс proposition (см. листинг 12.1) представляет собой упрощенную версию
сокращённым набором функциональных возможностей). Назначение этого клас-
** сделать использование типа данных proposition таким же простым и естест-
венным, как использование любого другого С++-типа данных. Обратите внимание на
следующее объявление в классе proposition:
Vlrtual bool operator()(void) = 0;
446 Глава 12. Реализация агентно-ориентированных архитектур
Таблица 12.4. Преобразование операторов в логические ~~1
Пользовательские С++чтераторы Распространенные логические операторы
8с&
II ! V
possible ♦
necessary □
Это объявление чисто виртуального метода. Если в классе объявлен чисто вирту-
альный метод, это означает, что данный класс — абстрактный, и из него нельзя созда-
вать объекты, поскольку в нем отсутствует определение этого метода. Метод лишь
объявлен, но не определен. Абстрактные классы используются для определения стра-
тегий и являются своего рода проектами производных классов. Производный класс
должен определить все виртуальные функции, которые он наследует от абстрактного
класса. В данном случае класс proposition используется для определения мини-
мального набора возможностей, которыми может обладать класс-потомок. Необхо-
димо также отметить еще одну важную особенность класса proposition (см. лис-
тинг 12.1): это шаблонный класс. Он содержит такой член данных:
list<C> UniverseOfDiscourse;
Этот член данных предполагается использовать для хранения значения предмет-
ной области, к которой относится предположение. В логике область рассуждения со-
держит все легальные сущности, которые могут рассматриваться при обсуждении.
Здесь мы используем контейнер list. Поскольку в общем случае темы обсуждения
могут быть самыми разными, мы используем контейнерный класс. Список
UniverseOfDiscourse мы объявляем защищенным (protected), а не закрытым
(private), чтобы к нему могли получить доступ все потомки класса proposition.
Классу proposition также “знакомы” такие понятия модальной логики, как логиче-
ская необходимость и вероятность, которые весьма полезны в агентно-
ориентированном программировании. Модальная логика позволяет агенту различать
такие определения, как “вероятно, ИСТИНА” и “несомненно, ИСТИНА”. Основные
операторы, используемые для выражения логической необходимости и вероятности,
перечислены в табл. 12.4. Мы определяем эти методы только в описательных целях;
их реализация выходит за рамки рассмотрения в этой книге. Но они являются частью
классов предположений, которые мы успешно применяем на практике. Чтобы сде-
лать класс proposition “годным к употреблению”, выведем из него новый класс
и назовем его trip_announcement. Класс trip_announcement представляет собой
утверждение о существовании автобусного маршрута из некоторого исходного пункта
(отправления) в пункт назначения. Например, предположим, что существует автобус-
ный маршрут из Детройта в Толедо. Эта информация позволяет сформулировать вы-
сказывание, которое может быть либо истинным, либо ложным. Если бы нас интере-
совало, когда это высказывание истинно или ложно, мы бы воспользовались поня
тиями временной логики. Временная логика— это логика времени. Агенты также
применяют обоснования, зависящие от времени. Но в данном случае все предполо
жения относятся к текущему времени. Это утверждение декларирует, что в данное
12.4. Реализация агентов в C++ 447
пемя существует автобусный маршрут из Детройта в Толедо. Агент должен
“уметь” удостовериться в этом и либо “довериться” этому факту, либо отвергнуть
его как ложное высказывание. Теперь можно рассмотреть объявление класса
trip announcement, представленное в листинге 12.2.
// Листинг 12.2. Объявление класса tгip_announcement
class trip—announcement :
public propos i tion< trip_announcement>{
//• - •
protected:
string Origin;
string Destination;
stack<trip_announcement> Candidates;
public:
bool operator()(void);
bool operator==(const trip_announcement &X) const;
void origin(string X) ;
string origin(void);
void destination(string X);
string destination(void);
bool directTrip(void);
bool validTrip(1ist<trip_announcement::iterator I,
string TempOrigin);
stack<trip_announcement> candidates(void);
friend bool operator)|(bool X,trip_announcement &Y);
friend bool operator&&(bool X,trip_announcement &Y);
//. . .
Обратите внимание на то, что класс trip_announcement наследует класс
proposition. Вспомните, что класс proposition является шаблонным и требует за-
дания параметра, определяющего тип. Объявление
class trip_announcement :
public proposition<trip__announcement>
{...};
обеспечивает класс proposition требуемым типом. Кроме того, важно отметить, что
класс trip__announcement определяет операторный метод operator (). Следова-
тельно, наш класс trip_announcement — конкретный, а не абстрактный. Теперь мы
можем объявить и использовать предположение типа trip_announcement непо-
средственно в программе агента. В классе trip_announcement определены следую-
щие дополнительные члены данных:
Origin
Destination
Candidates
Эти члены данных используются для указания пунктов отправления и назначения
автобусного маршрута. Если автобусный маршрут требует пересадки с одного автобуса
На ДРУГОЙ и несколько остановок в пути, то член данных Candidates будет содержать
Полный путь следования. Следовательно, объект класса trip__announcement пред-
ставляет собой утверждение об автобусном маршруте и пути следования. В классе
announcement также определены некоторые дополнительные операторы. Эти
448 Глава 12. Реализация агентно-ориентированных архитектур
операторы позволяют уравнять класс trip_announcement “в правах” со встроенны-
ми типами данных языка C++. Помимо убеждений относительно автобусных марщру.
тов, агент также обладает убеждениями, связанными с показателями успешности
функционирования рассматриваемой компании. Эти убеждения отличаются по
структуре, но в основном содержат высказывания, которые могут быть истинными
либо ложными. Итак, мы снова используем класс proposition в качестве базового
В листинге 12.3 представлено объявление imaccapef ormance—statement.
// Листинг 12.3. Объявление класса performance—statement
class performance—statement :
public proposition<performance—statement>{
//. . .
int Bays;
float Sales;
float PerHour;
public:
bool operator() (void);
bool operator==(const performance—statement &X) const;
void bays(int X);
int bays(void);
float sales(void);
void sales(float X);
float perHour(void);
void perHour(float X) ;
friend bool operator]|(bool X,performance—statement &Y);
friend bool operator&&(bool X,performance—statement &Y);
//. . .
};
Обратите внимание на то, что этот класс также обеспечивает шаблонный класс
proposition параметром.
class performance—statement :
public proposition<performance—statement> {...}
Благодаря этому объявлению класс proposition теперь определен для объектов
типа performance—statement. Класс performance—statement используется для
представления убеждений об объеме продаж, количестве обслуженных клиентов
(в час) и загрузке ремонтных секций в день. Для каждого из перечисленных убежде-
ний о том, что агент имеет в соответствующей области, существует отдельное выска-
зывание. Эта информация хранится в таких членах данных:
Bays
Sales
PerHour
Такие высказывания, как “По секции 1 объем продаж составил 300 тыс. долл.,
обслужено 10 клиентов в час, а коэффициент загрузки равен 4”, можно представить
с помощью объекта класса performance—statement. Итак, наш класс агента имеет
две категории убеждений, реализованных в виде данных, тип которых выведен из
класса proposition. На рис. 12.2 представлена UML-диаграмма классов
trip_announcement и performance—statement. Эти классы предназначены ДЛЯ
хранения структуры убеждений агента.
12.4. Реализация агентов в C++ 449
performance-
1 statement
performance-
statement
proposition
Рис, 12,2, UML-диаграмма классов trip_announcement
и perf ormance_statement
12.4.2. Класс агента
Классы, представленные на рис. 12.2, образуют фундамент для когнитивных струк-
тур данных агента, которые делают агента рациональным. Именно рационализм клас-
са агента отличает его от других типов объектно-ориентированных классов. Рассмот
рим объявление класса агента, приведенное в листинге 12.4.
// Листинг 12.4. Объявление класса agent
class agent{
//. . .
private:
performance—statement Manager 1;
performance—statement Manager2;
performance—statement МападегЗ;
trip—announcement Tripl;
trip—announcement Trip2;
trip—announcement Trip3;
list<trip—announcement* TripBeliefs;
list<performance_statement> PerformanceBeliefs;
public:
agent(void);
bool determineVacationAppropriate (void) ;
bool schedulevacation(void);
void updateBeliefs(void);
void setGoals(void);
void displayTravelPlan(void);
//. . .
г .
450 Глава 12. Реализация агентно-ориентированных архитектур
Как и классы предположений, класс агента представляет собой упрощенную вер-
сию. Полный листинг объявления класса, который можно было бы использовать на
практике, занял бы три или четыре страницы. Но для описательных целей, которые
мы преследуем в этой книге, приведенного вполне достаточно. Итак, класс agent со-
держит два контейнера-списка.
1i s t< tг ip_announc ement > Tr ipBeliefs;
list<performance_statement> PerformanceBeliefs;
Контейнеры типа list — это стандартные С++-списки. Каждый список использу-
ется для хранения коллекции текущих убеждений агента. “Мировоззрение” нашего
простого агента ограничено знаниями об автобусных маршрутах и характеристиках
успешности его владельца. Содержимое этих двух контейнеров представляет полные
знания агента и набор его убеждений. Если в этих списках есть утверждения, в кото-
рые агент больше не верит, их следует удалить. Если в процессе рассуждений агент
обнаруживает новые утверждения, они добавляются в список уже существующих убе-
ждений. Агент имеет постоянный доступ к информации об автобусных маршрутах
и эффективности ведения бизнеса его владельца и при необходимости может обнов-
лять свои убеждения. Помимо убеждений, агент имеет цели, которые иногда пред-
ставляются как желания в модели убеждений, желаний и намерений (Beliefs, Desires,
Intentions — BDI). Цели поддерживают основные директивы, выдаваемые агенту кли-
ентом. В нашем случае цели сохраняются в высказываниях, приведенных ниже.
performance_statement Managerl;
performance_statement Manager2;
performance_statement Manager!;
trip_announcement Tripl;
trip_announcement Trip2;
trip_announcement Trip3;
Следует иметь в виду, что мы значительно упрощаем представление целей и ди-
ректив в классе агента. Но все же этого достаточно, чтобы понять, как построены эти
структуры. Три Manager-утверждения содержат цели, связанные с эффективностью
бизнеса, которые должны быть удовлетворены, прежде чем владелец фирмы сможет
хотя бы подумать об отпуске. Три Trip-утверждения содержат автобусные маршруты,
по которым владелец фирмы хотел бы прокатиться при условии успешности его биз-
неса. Убеждения вместе с директивами образуют базовые когнитивные типы данных,
которыми располагает агент. Используемые агентом стратегии логического вывода
вместе с этими когнитивными типами данных образуют когнитивную структуру дан-
ных агента (Cognitive Data Structure — CDS). На базе CDS-структуры формируются ра-
циональный компонент и характерные особенности класса агента. Помимо контей-
неров, в которых хранятся убеждения и структуры, которые в свою очередь хранят
директивы и цели, большинство классов агентов имеют контейнеры, предназначен-
ные для хранения намерений, обязательств или планов агента. Агент получает дирек-
тивы от своего клиента, а затем использует свою способность делать выводы и совер-
шать действия, направленные на выполнение этих директив. Результат рассуждении
и выполнения агентом действий часто сохраняется в контейнере с его намерениями,
обязательствами или планами. Что касается нашего простого агента, то для хранения
намерений или планов отдельного контейнера не ему требуется. Однако он должен
зафиксировать путь следования (с пересадками и остановками) предполагаемой отпу
скной поездки на автобусе. Эта информация хранится в контейнере Candidates.
12.4. Реализация агентов в C++ 451
Намерения или планы должны быть обработаны аналогичным образом. Если агент
может выполнить директивы, он распланирует поездку и по электронной почте под-
обно сообщит об этом своему владельцу7. Агент приступает к своим обязанностям
в момент создания объекта. Фрагмент конструктора агента представлен в листинге 12.5
// Листинг 12.5. Конструктор класса agent
agent: :agent (void)
setGoals();
updateBeliefs () ;
if(determineVacationAppropriate()){
displayTravelPlan();
schedulevacation();
cout « "Сообщение о возможности отпуска."
« endl;
}
else{
cout « "В данное время отпуск нецелесообразен."
« endl;
}
}
12.4.2.1. Цикл активизации агента
Многие определения агентов включают требования непрерывности и автономно-
сти. Идея состоит в том, что агент должен непрерывно выполнять поставленные пе-
ред ним задачи без вмешательства оператора. Агент обладает способностью взаимо-
действовать со своей средой и (до некоторой степени) контролировать ее благодаря
наличию цепи обратной связи. Непрерывность и автономность часто реализуются
в виде событийного цикла, при выполнении которого агент постоянно получает со-
общения и информацию о событиях. Эти сообщения и события агент использует для
обновления своей внутренней модели мира, намерений и предпринимаемых действий.
Однако непрерывность и автономность — понятия относительные. Одни агенты долж-
ны активизироваться каждую микросекунду, в то время как другие — лишь один раз в год.
А в случае программного обеспечения полетов в дальний космос агент может иметь
Цикл даже больше одного года. Поэтому мы не будем акцентировать внимание на физи-
ческих событийных циклах и постоянно активных очередях сообщений. Такая органи-
зация может подходить для одних агентов, но оказаться непригодной для других. Мы
пришли к выводу, что лучше всего здесь применить понятие логического цикла. Логи-
ческий цикл может (или не может) быть реализован как событийный. Логический цикл
может длиться от одной наносекунды до некоторого количества лет. Общий вид про-
стого логического цикла активизации агента показан на рис. 12.3.
Область рассуждения (см. рис. 12.3) представляет все, с чем наш агент может леги-
тимно взаимодействовать. Эта область может состоять из файлов, информации от
портов или устройств сбора данных. Получаемая информация должна быть представ-
Лена в виде предположений или утверждений (высказываний). Обратите внимание на
существование цепи обратной связи от выходных данных агента к входным. Наш
Нет^ (СМ ЛИСТинг 12.4) активизируется только несколько раз в год. Следовательно,
смысла помещать его в постоянно выполняющийся событийный цикл. Наш агент
Б ен периодически активизироваться в течение года для выполнения своих задач.
Листинге 12.5 представлен конструктор агента. При активизации агент устанавливает
452 Глава 12. Реализация агентно-ориентированных архитектур
цели, обновляет убеждения, а затем определяет уместность отпуска. Если отпуск воз-
можен, агент предпринимает некоторые действия и по электронной почте уведомля-
ет об этом владельца фирмы. Если же отпуск в данное время нецелесообразен, владе-
лец получает от агента сообщение другого содержания.
Активизировать
Дезактивизировать
Рис. 12.3. Общий вид простого логического цикла активизации агента
12.4.2.2. Стратегии логического вывода агента
Этот агент обладает способностями рассуждать, реализованными частично клас-
сом proposition и частично методом determineVacationAppropriate() •
Вспомните, что в классе proposition объявлен метод operator () = 0 в виде чисто
виртуальной функции. Поэтому в производном классе необходимо реализовать ме-
тод operator (). Мы используем этот оператор, чтобы объект предположения мог
самостоятельно определить свою “суть”, т.е. понять, истинно данное предположе-
ние или ложно. Это означает самодостаточность классов предположений. Именно
в самодостаточности и состоит фундаментальный принцип объектно-ориентирован-
ного программирования: класс представляет собой самостоятельную конструкцию,
12.4. Реализация агентов в C++ 453
инкапсулирующую его характеристики и поведение. Итак, одной из основных линий
поведения класса предположений и его потомков является способность определять,
истинно данное предположение или нет. Для реализации этого средства используется
перегрузка операторов и объекты-функции. Рассмотрим фрагменты определения
класса proposition и определений его потомков.
//Листинг 12.6. Фрагменты определений класса
II proposition и его потомков
template <class С> bool proposition<C>::operator&&(
proposition &X)
{ return ( (*this) О &&X0);
}
template cclass C> bool proposition<C>::operator||(
proposition &X)
{
return((*this)() || X());
}
template*:class C> proposition<C>::operator void*(void)
{
return((void*)(Truthvalue));
}
bool trip_announcement::operator()(void)
{
list<trip_announcement>::iterator I;
if(directTrip()){
return(true);
}
I = UniverseOfDiscourse.begin();
if(validTrip(I,Origin)){
return(true);
}
j return(false);
Операторы “ | | ” и используемые в классах предположений, позволяют опре-
делить, истинно данное предположение или ложно. В каждом из этих определений
операторов в конечном счете вызывается метод operator (), определенный в классе-
потомке. Обратите внимание на определение оператора “ | | ” (см. листинг 12.6). Этот
оператор определен следующим образом.
template <class С> bool proposition<C>::operator||
(proposition &Х)
} return((*this)() | | X () ) ;
Эго определение позволяет использовать следующий код.
announcement А;
Y®rf°rmance_statement В;
lf А || В){
'/ Какие-нибудь действия.
454 Глава 12. Реализация агентно-ориентированных архитектур
При вычислении выражений А или В будет вызван оператор operator (). Каждый
класс предположений определяет поведение оператора operator () по-своему. На-
пример, в классе trip_announcement оператор operator () определяется так.
bool trip_announcement::operator()(void)
{
list<trip_announcement>::iterator I;
if(directTrip()){
return(true);
}
I = UniverseOfDiscourse.beginO;
if(validTrip(I,Origin)){
return(true);
}
return(false);
}
При выполнении этого кода станет ясно, существует ли маршрут из заданного ис-
ходного пункта в некоторый пункт назаначения. Например, предположим, что нас
интересует переезд из Детройта в Колумбус, при этом область рассуждений содержит
следующие данные:
Детройт - Толедо
Толедо - Колумбус
Тогда объект класса trip_announcement “доложит” о том, что утверждение о су-
ществовании автобусного маршрута из Детройта в Колумбус истинно, несмотря на то,
что область рассуждений не содержит утверждения о прямом маршруте:
Детройт - Колумбус
Объект класса trip_announcement действительно проверит, существует ли пря-
мой маршрут из Детройта в Колумбус. Если он существует, объект возвратит значение
ИСТИНА. В противном случае он попытается найти обходной путь. Подобное пове-
дение реализуется так.
if(directTrip()){
return(true);
}
I = UniverseOfDiscourse.beginO;
if(validTrip(I,Origin)){
return(true);
}
“Самоопределением” истинности объект обязан оператору operator () класса
tгip_anouncement. Метод directTrip () довольно прост, и его работа заключается
в последовательном просмотре области рассуждений на предмет существования сле-
дующего утверждения:
Детройт - Колумбус
Метод validTrip (), чтобы узнать, существует ли обходной путь, использует тех-
нологию поиска вглубь (Depth First Search— DFS). Определения методов
validTrip () и directTrip () приведены в листинге 12.7.
12.4. Реализация агентов в C++ 455
/ листинг 12.7. Определения методов validTripO и
// directTripO
о1 trip_announcement::validTrip (list<trip_announcement::
iterator I, string TempOrigin)
if(I == UniverseOfDiscourse.end()){
if(Candidates.empty()){
Truthvalue = false;
return(false);
}
else{
trip_announcement Temp;
Temp = Candidates.top();
I = find(UniverseOfDiscourse.begin(),
UniverseOfDiscourse.end(),Temp);
UniverseOfDiscourse.erase(I);
Candidates.pop();
I = UniverseOfDiscourse.begin();
if(I != UniverseOfDiscourse.end()){
TempOrigin = Origin;
}
else{
Truthvalue = false;
return(false);
}
}
}
if ((*1).origin() == TempOrigin &&
(*1).destination() == Destination){
Candidates.push(*I);
Truthvalue = true;
return(true);
}
if((*I).origin() == TempOrigin){
TempOrigin = (*I).destination();
Candidates.push(*I);
}
} return(validTrip(I,TempOrigin));
bool trip_announcement: : directTrip (void)
list<trip_announcement>::iterator I;
I = find(UniverseOfDiscourse.begin(),
UniverseOfDiscourse.end(), *this);
if (I == UniverseOfDiscourse.end()){
Truthvalue = false;
j return(false);
Truthvalue = true;
J r®turn(true);
456 Глава 12. Реализация агентно-ориентированных архитектур
В обоих методах validTrip () и directTrip () используется алгоритм find () Из
стандартной библиотеки C++. UniverseOfDiscourse — это контейнер, который со
держит убеждения агента и подготовленные для него утверждения. Вспомните, что
одним из первых действий, предпринимаемых агентом, является вызов метода
updateBelief s (), который заполняет контейнер UniverseOfDiscourse. Опреде-
ление метода updateBelief s () приведено в листинге 12.8.
// Листинг 12.8. Обновление убеждений
void agent::updateBeliefs(void)
{
performance_statement TempP;
TempP.sales(203.0);
TempP.perHour(100.0) ;
TempP.bays(4);
PerformanceBeliefs.push—back(TempP);
trip_announcement Temp;
Temp.origin("Detroit") ;
Temp.destination("LA");
TripBeliefs.push—back(Temp);
Temp.origin("LA");
Temp.destination("NJ");
TripBeliefs.push—back(Temp);
Temp.origin("NJ");
Temp.destination("Windsor");
TripBeliefs.push—back(Temp);
)
На практике убеждения обычно поступают из среды выполнения агента (т.е. из
файлов, от датчиков, портов, устройств сбора данных и пр.). В листинге 12.8 инфор-
мация, поступающая в списки TripBeliefs и PerfоппапсеВеliefs, представляет
новые высказывания, которые агент получает о приемлемых маршрутах и эффектив-
ности авторемонтной мастерской. Эти высказывания оцениваются относительно ди-
ректив, выданных агенту. Установкой директив агента занимается метод
setGoals (). (Его определение приведено в листинге 12.9.)
// Листинг 12.9. Метод установки целей агента
void agent::setGoals(void)
{
Manager1.perHour(15.0) ;
Manager1.bays(8) ;
Manager1.sales(12 3.2 3 ) ;
Manager2.perHour(25.34) ;
Manager2.bays(4);
Manager2.sales(12.33);
Manager3.perHour(34.34) ;
МападегЗ.sales(100000.12);
Manager!.bays(10);
Tripl.origin("Detroit") ;
Tripl.destination("Chicago");
Trip2.origin("Detroit") ;
Trip2.destination("NY");
Trip3.origin("Detroit") ;
Trip3.destination("Windsor");
}
12.4. Реализация агентов в C++ 457
Эти директивы сообщают агенту о том, что его владелец хотел бы отправиться
в отпуск из Детройта в Чикаго, из Детройта в Нью-Йорк или из Детройта в Виндзор.
Помимо маршрутов, также устанавливаются финансовые цели. Чтобы отпуск состо-
ялся необходимо достижение одной или нескольких таких целей. После установки
целей агент обновляет свои убеждения, и его следующая задача будет определена в за-
висимости от целей и убеждений при условии возможности планирования отпуска.
И тогда вызывается второй компонент методов рассуждений агента:
determineVacationAppropriate ()
Этот метод передает контейнер Uni ver seOf Discourse каждому из объектов пред-
положений. После этого он использует утверждение, выраженное в следующей форме:
(A v В v С) Л (Q v R v S) --> W
Это выражение можно озвучить так: если хотя бы одно из утверждений каждой группы
истинно, то элемент W примет значение ИСТИНА. Для нашего агента это означает, что
если достигнута хотя бы одна из целей эффективности биснеса и существует хотя бы
один из приемлемых автобусных маршрутов, то отпуск можно планировать. Определе-
ние метода determineVacationAppropriate () представлено в листинге 12.10.
// Листинг 12.10. Второй метод рассуждений
bool agent::determineVacationAppropriate(void)
{
bool Truthvalue;
Managerl.universe(PerformanceBeliefs);
Manager2.universe(PerformanceBeliefs);
Manager?.universe(PerformanceBeliefs);
Tripl.universe(TripBeliefs);
Trip2.universe(TripBeliefs);
Trip3.universe(TripBeliefs);
Truthvalue = ((Managerl || Manager2 || Manager?) &&
(Tripl I I Trip2 I I Trip?));
return(Truthvalue);
1
Обратите внимание на то, что списки TripBeliefs и PerformanceBeliefs яв-
ляются аргументами метода universe () объектов Trip и Manager. Именно здесь
объекты предположений получают информацию из предметной области
(UniverseOf Discourse). Прежде чем объект класса proposition вызовет оператор
operator (), его контейнер UniverseOf Discourse должен заполниться имеющи-
мися у агента данными. В листинге 12.10 при вычислении выражения
((Managerl || Manager2 || Manager?) && (Tripl || Trip2 || Trip?));
оценивается шесть предположений (посредством выполнения оператора “| |”).
ператор “| | ” для каждого предположения выполняет оператор operator (),
определения истинности предположения использует список
scourse. Следует иметь в виду, что классы trip_announcement
^Performance__statement наследуют довольно много функций класса proposition.
листингах 12.6 и 12.7 было показано, как определяется оператор operator () для
ССа trip__announcement, а в листинге 12.11 приведено определение оператора
Perator () Для класса perf ormance_statement.
‘^юрыи для
UniverseOfDi
458 Глава 12. Реализация агентно-ориентированных архитектур
// Листинг 12.11. Класс performance_statement
bool performance_statement::operator()(void)
{
bool Satisfactory = false;
list<performance_statement>::iterator I;
I = UniverseOfDiscourse.begin();
whiled ’ = UniverseOfDiscourse.end() && ’Satisfactory)
{
if(((*1).bays() >= Bays) || ((*1).sales() >= Sales)
|| ((*1).perHour() >= PerHour)){
Satisfactory = true;
}
}
return(Satisfactory);
}
Оператор operator () для каждого класса proposition играет “свою” роль в спо-
собности класса агента делать логические выводы. В листинге 12.6 показано, как вы-
зывается оператор operator () при каждом вычислении оператора “ | | ” или “&&” для
класса proposition или для одного из его потомков. Именно такое сочетание мето-
дов operator (), определенных в proposition-классах, и методов класса agent об-
разует стратегии логического вывода для класса agent. В дополнение к операторам
“||” и определенным в классе proposition, классы trip_announcement
и perf ormance_statement содержат свои определения.
friend bool operator||(bool X,trip_announcement &Y);
friend bool operator&&(bool X,trip_announcement &Y);
Эти friend-объявления позволяют использовать предположения в более длинных
выражениях. Сделаем следующие объявления.
//. . .
trip_announcement А, В, С;
bool X;
X = А | | В | | С;
//. . .
При этом объекты А и В будут объединены с помощью операции ИЛИ, а результат
этой операции будет иметь тип bool. Затем мы попробуем с помощью той же опера-
ции ИЛИ получить значение типа bool и объект типа trip_announcement:
bool || trip_announcement
Без приведенных выше friend-объявлений такая операция была бы недопусти-
мой. Определение этих функций-"друзей” показано в листинге 12.12.
// Листинг 12.12. Перегрузка операторов "||" и
bool operator]|(bool X,trip_announcement &Y)
{
return(X || Y () ) ;
}
bool operator&&(bool X,trip_announcement &Y)
{
return(X && Y());
}
12.4. Реализация агентов в C++ 459
Обратите внимание на то, что в определении этих функций-“друзей” (благодаря
ссылке на элемент Y ()) также используется вызов функции operator (). Эти функции
определяются и в классе perf ormance_statement. Наша задача — сделать использова-
ние proposition-классов таким же простым, как использование встроенных типов
данных. В классе proposition также определен другой оператор, который позволя-
ет использовать предположение естественным образом. Рассмотрим следующий код.
//• • •
f-rip_announcement А;
if (А) {
II... Некоторые действия.
}
//. . •
Как в этом случае компилятор тестирует объект А? При выполнении инструкции
if () компилятор стремится найти в скобках значение целочисленного типа данных
или типа bool. Но тип объекта А совсем другой. Мы хотим, чтобы компилятор вос-
принимал объект А как высказывание, которое может быть либо истинным, либо
ложным. При таких обстоятельствах функция operator () не вызывается. Поэтому
для получения нужного эффекта мы определяем оператор void*. Эту функцию-
оператор можно определить следующим образом.
templatecclass С> proposition<C>::operator void*(void)
{
return((void*)(TruthValue));
}
Это определение позволяет предположение любого типа, представленное “в един-
ственном числе”, протестировать как значение истинности. Например, когда наш
класс agent собирается отправить по электронной почте владельцу фирмы сообще-
ние, содержащее путь следования, агенту нужно определить, какой маршрут отвечает
заданным требованиям. В листинге 12.13 представлен еще один фрагмент из методов
обработки автобусных маршрутов.
// Листинг 12.13. Метод displayTravelPlan()
void agent::displayTravelPlan(void)
stack<trip_announcement Route;
if(Tripl){
Route = Tripl.candidates();
if(Trip2){
Route = Trip2.candidates();
if(Trip3){
} Route = Trip3.candidates();
while(!Route.empty())
cout << Route.top().origin() << " TO "
<< Route.top().destination() « endl;
j Route.pop();
1
460 Глава 12. Реализация агентно-ориентированных архитектур
Обратите внимание на то, что объекты Tripl, Trip2 и Trip3 тестируются так
как будто они имеют тип bool. Метод candidates () просто возвращает путь следо-
вания, соответствующий заданному маршруту. Таким образом, разработка стратегий
логического вывода и когнитивных структур данных становится проще благодаря ис-
пользованию перегрузки операторов и С++-шаблонов. Именно стратегии логического
вывода и когнитивные структуры данных делают объект рациональным. С++-
программист для разработки агентов использует конструкцию класса, а для реализа-
ции когнитивных структур данных (CDS) — контейнерные объекты в сочетании со
встроенными алгоритмами. Класс, который содержит CDS-структуры, становится ра-
циональным, а рациональный класс — агентом.
12.4.3. Простая автономность
Поскольку наш простой класс агента не требует выполнения традиционного
“цикла активизации”, нам нужны другие средства, которые бы периодически активи-
зировали агент без вмешательства человека. Возможны ситуации, когда агент нужно
запускать на выполнение лишь иногда или только при определенных условиях. Среды
UNIX/Linux оснащены утилитой crontab, которая представляет собой пользова-
тельский интерфейс “хрон-системы” (хрон — это демон ОС UNIX, исполняющий
предписанные команды в соответствии со строго определенными значениями даты
и времени, указанными в специальном файле с именем crontab). Утилита crontab
позволяет организовать периодическое выполнение одной или нескольких программ.
Задания для утилиты с г on tab можно назначать с указанием месяца, дня недели, дня
(месяца), часов и минут. Для использования утилиты crontab в нашем случае необ-
ходимо создать текстовый файл, который будет содержать график активизации аген-
та. Записи этого файла должны иметь следующий формат:
минуты
часы
день
месяц
день недели
команда
Каждый элемент записи может принимать следующие значения:
минуты
часы
день
месяц
день недели
команда
0-59
0-23
1-31
1-12
1-7 (1 — понедельник, 7 — воскресенье)
может быть любой UNIX/Linux-командой, а также именем файла,
который содержит агенты
Созданный в таком формате текстовый файл передается “хрон-системе” с помо-
щью следующей команды:
$crontab NameOfCronFile
Например, предположим, у нас есть файл activate . agent, содержимое которого
имеет такой вид.
15 8 * * * agentl
0 21 * * 6 agent2
agent3
12
1
12.5. Мультиагентные системы 461
После выполнения с г on tab-команды
Jcrontab activate.agent
агент agent 1 будет активизироваться каждый день в 8:15, агент agent2 — каждое вос-
кресенье в 21:00, а агент agent3 — каждый раз при наступлении первого декабря.
Хрон-файлы можно при необходимости добавлять или удалять. Хрон-файлы могут со-
держать ссылки на другие хрон-задания, позволяя таким образом агенту “самому” пере-
планировать свою работу. Так, для обеспечения чрезвычайно гибкой, динамичной и на-
дежной процедуры активизации агентов можно использовать сценарии оболочки в со-
четании с утилитой crontab. Чтобы получить полное описание утилиты crontab,
обратитесь к оперативным страницам руководства {manpages — гипертекстовые страни-
цы консультативной информации, поясняющие действие конкретных команд):
$man crontab или $xnan at
Средства crontab и at представляют собой простейший способ автоматизации
или регулярного запуска агентов, который не требует постоянного выполнения цик-
лов активизации. Эти утилиты надежны и гибки. Однако для реализации автоматиче-
ской активизации агента также можно использовать хранилище, или репозиторий,
реализаций и брокер объектных запросов (object request brokers — ORB), который мы
рассматривали в главе 8. Стандартные CORBA-реализации также предоставляют
средства организации событийных циклов.
12.5. Мультиагентные системы
Мультиагентные системы— это системы, в которых задействовано несколько
агентов, обладающих способностью в процессе решения некоторой задачи взаимо-
действовать, сотрудничать, “договариваться” или соперничать. У С++-разработчика
программного обеспечения есть несколько вариантов для реализации мультиагент-
ных систем. Агенты можно реализовать в отдельных потоках выполнения с помощью
API-интерфейса POSIX thread. В этом случае одна программа разбивается на несколь-
ко потоков, каждый из которых содержит один или несколько агентов. Следователь-
но, агенты одного потока будут разделять одно и то же адресное пространство. Это
позволяет агентам легко взаимодействовать путем использования глобальных пере-
менных и простой передачи параметров. Если компьютер, на котором выполняется
программа, содержит несколько процессоров, то агенты могут выполняться парал-
лельно. В этом случае каждый агент должен быть оснащен объектами синхронизации
(см. главы 5 и 11) и компонентами обработки исключительных ситуаций (см. главу 7).
Мультиагентные системы, реализованные посредством многопоточности, представ-
ляют самое простое решение, но тем не менее ограничивающее агентов рамками од-
ного компьютера. Более гибкий подход к созданию мультиагентных систем предос-
тавляет CORBA-реализация. Стандарт CORBA (помимо ядра спецификации CORBA)
содержит спецификацию мультиагентного средства (multi-agent facility— MAF).
СО-реализацию, которую мы используем в CORBA-примерах этой книги, можно
применять для реализации агентов, которые способны взаимодействовать через сети
егпсС intranet и локальные сети. С++-привязка CORBA-стандарта имеет полную
ПоДДержку объектно-ориентированного представления и, следовательно, поддержку
тн©-ориентированного программирования. В главе 13 мы рассмотрим, как можно
ользовать библиотеки PVM и MPI для поддержки агентов в контексте параллель-
°11 Распределенного программирования.
462 Глава 12. Реализация агентно-ориентированных архитектур
12.6. Резюме
Агенты — это рациональные объекты. Агентно-ориентированное программирова-
ние _ это свежий взгляд на старые проблемы декомпозиции, взаимодействия и син-
хронизации, которые являются обязательной частью каждого проекта параллельного
или распределенного программирования. С++-поддержка перегрузки операторов
контейнеров и шаблонов обеспечивает эффективные средства реализации широкого
диапазона классов агентов. Будущие системы с массовым параллелизмом и большие
распределенные системы будут опираться на агентно-ориентированные реализации
поскольку практически не существует других путей построения таких систем. Не-
смотря на “вводный” характер примеров создания агентов, представленных в этой
главе, они вполне обеспечивают основу для понимания практических принципов по-
строения агентных систем. Для развертывания мультиагентных систем можно ис-
пользовать общедоступные и популярные библиотеки POSIX thread API, MICO, PVM
и MPI. Мультиагентные системы можно использовать для реализации решений, кото-
рые требуют параллельного или распределенного программирования. В этой книге
представлены два основных варианта архитектуры для параллельного и распределен-
ного программирования: первый представляют агенты, а второй — “классные доски”
(которые предполагают использование агентов). О том, как использовать “классные
доски” для реализации решений параллельного и распределенного программирова-
ния, мы поговорим в следующей главе.
РЕАЛИЗАЦИЯ
ТЕХНОЛОГИИ
“КЛАССНОЙ ДОСКИ”
С ИСПОЛЬЗОВАНИЕМ
PVM-СРЕДСТВ,
ПОТОКОВ и
КОМПОНЕНТОВ C++
В этой главе...
13.1. Модель “классной доски”
13.2. Методы структурирования "классной доски”
13.3. Анатомия источника знаний
13.4. Стратегии управления для “классной доски”
13.5. Реализация модели “классной доски” с помощью
CORBA-объектов
13.6. Реализация модели “классной доски” с помощью
глобальных объектов
13.7. Активизация источников знаний с помощью потоков
13.8. Резюме
“Человеческий разум гораздо сложнее, чем любой компьютер, но будущая
цель развития компьютерной техники — достичь уровня “мышления”
не отдельного индивидуума, а умственного потенциала целого общества..
— Тимоти Феррис (Timothy Ferris), The Universe and Eye
Одна из основных целей в параллельном программировании — разбить всю ра-
боту, предусмотренную для выполнения программой, на множество задач,
которые могут при необходимости выполняться с определенной степенью
параллелизма. Эта цель труднодостижима. Довольно сложно так провести декомпо-
зицию работ (Work Breakdown Structure— WBS), чтобы создать соответствующий
фундамент для параллелизма и обеспечить корректные и эффективные результаты
работы. Для достижения этой цели мы используем методы моделирования и специ-
альные архитектурные решения. На практике на этапе моделирования самой задачи
и ее решения стараются выявить естественный параллелизм. Не следует в решение
вносить параллелизм искусственно. Если задача и ее решение смоделированы надле-
жащим образом, то необходимый параллелизм обнаружится сам собой. Архитектура
“классной доски” облегчает такой процесс моделирования. В частности, модель
“классной доски” позволяет организовать и концептуализировать параллельность
и взаимодействие компонентов в системе, которая требует применения параллельно"
го или распределенного программирования.
13.1. Модель “классной доски” 465
13.1 • Модель “классной доски”
Модель “классной доски” — это технология совместного решения задач. “Классная
доска” используется для регистрации и координации действий, а также организации
взаимодействия между двумя или больше программными решателями задач. Таким
образом, в модели “классной доски” существует два основных типа компонентов:
“классная доска” и решатели задач.
“Классная доска” представляет собой централизованный объект, к которому имеет
доступ каждый из решателей задач. Решатели задач могут считывать содержимое
“классной доски” и изменять его. Содержимое “классной доски” в различные моменты
времени различно. Исходное содержимое “классной доски” включает задачу, которую
необходимо решить, а также информацию, представляющую начальное состояние за-
дачи, ее ограничения, цели и требования. По мере того как решатели задач продви-
гаются к получению решения, на “классной доске” фиксируются промежуточные ре-
зультаты, гипотезы и выводы. Промежуточные результаты, записанные одним ре-
шателем задач, могут действовать как катализатор для других решателей задач,
считывающих содержимое “классной доски”. На “классную доску” записываются
предварительные решения. Решения, признанные неудовлетворительными,
“стираются”, и процесс поиска новых решений продолжается. В отличие от сеансов
непосредственной связи, решатели задач используют “классную доску” не только для
передачи частичных результатов, но и поиска друг друга. В некоторых конфигураци-
ях “классная доска” действует как рефери, информируя решателей задач о факте дос-
тижения решения или выдавая сигнал начать либо завершить работу. “Классная дос-
ка”— это активный объект, а не просто область памяти. В некоторых случаях
“классная доска” определяет, каких решателей задач нужно привлечь и какое ее со-
держимое следует принять или отвергнуть. “Классная доска” может преобразовывать
или интерпретировать результаты, полученные от решателей задач одной группы,
чтобы ими могли воспользоваться решатели задач другой группы.
Решатель задач — это программное средство, которое обычно обладает специальны-
ми знаниями или возможностями обработки получаемой информации в пределах неко-
торой предметной области. Решатель задач может быть довольно простой функцией,
которая, например, переводит значение температуры по Цельсию в значение по Фа-
ренгейту, или достаточно сложным интеллектуальным агентом, который обрабатывает
медицинские диагнозы. В модели “классной доски” эти решатели задач называются ис-
точниками знаний. Чтобы решить задачу с использованием “классной доски”, необходи-
мо наличие двух или больше источников знаний, которые обычно обладают различной
специализацией. Модель “классной доски” более подходит для задач, разделяемых на
отдельные подзадачи, которые можно решать независимо (или почти независимо) от
Других. В базовой конфигурации архитектуры “классной доски” каждый решатель зани-
мается “своей” частью задачи, т.е. он “видит” только часть общей задачи, с которой ра-
стает. Если решение одной части задачи зависит от решения другой ее части, то
классная доска” используется для координации действий решателей задач и объедине-
ния частных решений. Решатели задач, задействованные в архитектуре “классной дос-
ки , не должны быть одинаковыми. Каждый из них может быть реализован по-своему.
пример, одни решатели задач могут быть реализованы с использованием объектно-
°риентированных технологий, а другие — как функции. Более того, решатели задач мо-
ГУТ использовать совершенно различные парадигмы решения. Например, решатель А
466 Глава 13. Реализация технологии “классной доски”...
для решения своей подзадачи может применять метод обратного построения цепоч
ки (т.е. ведения рассуждений от целевой гипотезы к исходным посылкам), а реша-
тель В — метод от противного. При этом также необязательно, чтобы решатели задач
были реализованы с помощью одного и того же языка программирования.
Модель “классной доски” не определяет никакой конкретной структуры ни для са-
мой “классной доски”, ни для источников знаний. Как правило, структура “классной
доски” зависит от конкретной задачи.1 Реализация источников знаний также зависит
от специфики решаемой задачи. “Классная доска” — это концептуальная модель, опи-
сывающая отношения без представления структуры самой “классной доски” и источ-
ников знаний. Модель “классной доски” не диктует количество используемых источ-
ников знаний или их назначение. “Классная доска” может быть единственным гло-
бальным или распределенным объектом, компоненты которого расположены на
нескольких компьютерах. Системы “классной доски” могут состоять из нескольких
“классных досок”, и каждая из них “занимается” решением определенной части ис-
ходной задачи. Это делает модель “классной доски” чрезвычайно гибкой. Модель
“классной доски” поддерживает параллельное и распределенное программирование.
Во-первых, источники знаний, работая над решением части общей задачи, могут вы-
полняться одновременно. Во-вторых, источники знаний могут быть реализованы
в различных потоках или отдельных процессах одного или нескольких компьютеров.
“Классная доска” может быть разделена на несколько отдельных частей, позво-
ляющих параллельный доступ со стороны нескольких источников знаний. “Классная
доска” легко поддерживает такие архитектурные варианты, как CREW (concurrent
read, exclusive write — параллельное чтение и монопольная запись), EREW (exclusive
read, exclusive write — монопольное чтение и монопольная запись) и MIMD (multiple-
instruction, multiple-data — множество потоков данных и множество потоков команд).
Мы реализуем “классную доску” как глобальный объект или коллекцию объектов, а ис-
точники знаний — как отдельные потоки. Поскольку потоки разделяют одно и то же
адресное пространство, к “классной доске”, реализованной как глобальный объект
или семейство объектов, будут получать доступ все потоковые источники знаний. Ес-
ли источники знаний реализовать как отдельные процессы, выполняющиеся на од-
ном или нескольких компьютерах, то “классную доску” имеет смысл реализовать как
CORBA-объект или как коллекцию CORBA-объектов. Вспомните, что CORBA-объекты
можно использовать для поддержки как параллельной, так и распределенной модели
вычислений. Здесь мы используем технологию CORBA для поддержки “классной дос-
ки” как разновидность распределенной памяти, совместно используемой задачами, выпол-
няющимися в различных адресных пространствах. Эти задачи могут быть PVM-типа
(Parallel Virtual Machine — параллельная виртуальная машина), задачами, порождае-
мыми традиционными f ork-exec-вызовами функций, или задачами, порождаемыми
библиотечными функциями posix_spawn (). Две конфигурации памяти для реализа-
ции технологии “классной доски” показаны на рис. 13.1.
В обоих случаях (см. рис. 13.1) все источники знаний имеют доступ к “классной
доске”. Источники знаний, размещенные в различных адресных пространствах,
1 Несмотря на то что “классную доску”можно использовать для решения для многих аналогичных за
дач, вряд ли это возможно для совершенно различных классов задач, т.е. многократное использование
“классной доски” обычно ограничено близкими по своей сути задачами. Дело в том, что пространстворе-
шений в этом случае тесно связано с конкретной задачей, а компонент правил тесно связан с пространств0*1
решений, что не позволяет использовать “классную доску ” для решения задач более широкого диапазона.
13.2. Методы структурирования “классной доски” 467
должны иметь сетевую связь с “классной доской”, реализованной как один или не-
сколько CORBA-объектов. Если источники знаний реализованы как PVM-задачи, то их
связь с “классной доской” можно построить на основе передачи сообщений. Такая
конфигурация обеспечивает чрезвычайно гибкую модель решения задач.
ПАМЯТЬ "КЛАССНОЙ ДОСКИ" (КОНФИГУРАЦИЯ 1)
Источники знаний расположены в различных адресных пространствах
ПАМЯТЬ "КЛАССНОЙ ДОСКИ" (КОНФИГУРАЦИЯ 2)
Источники знаний расположены в одном адресном пространстве
ПРОЦЕСС 1
Рис. 13.1. Две конфигурации памяти для реализации технологии “классной
доски” (ИЗ — источник знаний)
13.2. Методы структурирования “классной доски”
Методов структурирования “классной доски” не существует. Однако большинство
реализаций этой технологии имеют определенные характеристики и атрибуты. Ис-
ходное содержимое “классной доски” обычно включает часть пространства решения
468 Глава 13. Реализация технологии “классной доски”...
задачи. Пространство решений должно содержать все частные и полное решения за-
дачи. Например, предположим, что у нас есть механизм поиска изображений автомо-
билей в Internet. Этот механизм поиска может обрабатывать растровое или векторное
изображение, чтобы определить, содержит ли оно изображение автомобиля, и если
содержит, то отвечает ли оно параметрам поиска. Допустим, этот механизм поиска
разработан с использованием модели “классной доски”. Каждый источник знаний
имеет свою специфику: один — специалист в области идентификации изображений
покрышек, другой — идентифицирует зеркала задней обзорности, третий — эксперт
по дверным ручкам для автомобилей и т.д. Каждая деталь автомобиля представляет
малую часть пространства решений. Одни части пространства решений содержат
полное изображение автомобиля с различных точек зрения (т.е. сверху, снизу, под уг-
лом 45° и т.д.), а другие — только отдельные детали автомобилей, например, фронталь-
ную и заднюю части, крышу или багажник. На “классной доске” размещается растровое
или векторное изображение, и отдельные источники знаний пытаются идентифициро-
вать детали изображения, которые могут быть частями автомобиля. Если некоторая
часть пространства решений совпадает с какой-нибудь частью изображения, эта часть
изображения будет записана в другую часть “классной доски” как частное решение.
Один источник знаний может поместить на “классную доску” дверную ручку7 идентифи-
цируемого автомобиля, другой — дверцу. Если эти две части информации оказались на
“классной доске”, то какой-нибудь третий источник знаний может использовать эту ин-
формацию как вспомогательную при идентификации передней части автомобиля в ис-
следуемом изображении. После того как будет идентифицирована передняя часть,
она также размещается на “классной доске”. Каждый из этих различных способов
идентификации изображения автомобиля представляет часть пространства решений.
Пространство решений иногда организуется иерархически. В нашем примере
с автомобилем на вершине иерархии могут находиться полные изображения автомо-
биля, следующий уровень может состоять из различных видов передних и задних час-
тей, еще один уровень может содержать двери, багажники, капоты, ветровые стекла и
колеса. Каждый уровень описывает в этом случае меньшее, возможно, менее харак-
терное изображение некоторой части автомобиля. Источники знаний могут работать
одновременно на нескольких уровнях иерархии. Пространство решений также мож-
но организовать в виде графа, в котором каждый узел представляет некоторую часть
решения, а каждое ребро — отношения между двумя частными решениями. Простран-
ство решений может быть представлено в виде одной или нескольких матриц, а каж-
дый элемент матрицы будет содержать в этом случае полное или частное решение.
Представление пространства решений — это важный компонент архитектуры
“классной доски”. Именно характер задачи часто определяет, как должно быть рас-
пределено пространство решений. Помимо компонента пространства решении,
“классная доска” обычно имеет один или несколько компонентов (эвристических)
правил. Компонент правил используется для определения того, какие источники зна-
ний стоит использовать и какие решения принимать или отвергать. Компонент пра-
вил можно также применить для перевода частных решений с одного уровня иерар-
хии пространства решений на другой. Компонент правил позволяет назначать при-
оритеты источникам знаний. Некоторые источники знаний могут “зайти в тупик •
“Классная доска” может “снять отметку7” с одной группы источников знаний в пользу
друтой, а также использовать компонент правил, чтобы предложить источникам знании
более потенциально подходящие гипотезы на основе уже сгенерированных частных
13.2. Методы структурирования “классной доски” 469
гипотез. Помимо пространства решений и компонента правил, “классная доска”
часто содержит начальные значения, значения ограничений и вспомогательные
цели. В некоторых случаях “классная доска” может содержать одну или несколько
очередей событий, используемых для приема входных данных либо из пространст-
ва задачи, либо от источников знаний. Логическая схема базовой архитектуры
“классной доски” показана на рис. 13.2.
Архитектура "классной доски"
ВЗАИМОДЕЙСТВИЕ
* Если ИЗ (источник знаний) является процессом, взаимодействие может быть
реализовано через сеть или средства межпроцессного взаимодействия.
Если ИЗ — поток, связь можно осуществить посредством передачи параметров
Рис. 13.2. Логическая схема базовой архитектуры “классной доски”
“Классная доска” (см. рис. 13.2) имеет ряд сегментов, а каждый сегмент — различные
реализации. Это говорит о том, что “классная доска” — это нечто большее, чем просто
область глобальной памяти или традиционные базы данных. Хотя на рис. 13.2 показаны
только основные компоненты, которые имеют многие “классные доски”, этот вид архи-
тектуры не ограничивается таким составом. К числу дополнительных компонентов по-
тенциально можно отнести модели контекстов задачи и модели предметной области,
которые могут оказаться полезными для решателей задач при навигации по простран-
ству решений. С++-поддержка объектно-ориентированного проектирования и програм-
мирования прекрасно сочетается с требованиями гибкости, которые обычно предъяв-
ляются к модели “классной доски”. Большинство архитектур “классной доски” может
ыть смоделировано с использованием С++-классов. Вспомните, что классы можно ис-
пользовать для моделирования человека, местности, предмета или идеи, а “классные
Доски используются для решения задач, в которых часто участвуют люди, местности,
Предметы или идеи. Поэтом)7 весьма уместно применять С++-классы для моделирования
°бъектов, которые содержит “классная доска”. В своих реализациях модели “классной
470 Глава 13. Реализация технологии “классной доски”...
доски” мы используем преимущества контейнерных С++-классов и стандартных алго-
ритмов. Помимо встроенных классов, мы создаем интерфейсные классы для мьютексов
и других переменных синхронизации, используемых в реализации “классной доски”
Поскольку к “классной доске” могут получить доступ сразу несколько источников зна-
ний одновременно, это означает, что она является критическим разделом, доступ к
которому нуждается в синхронизации. Поэтому вместе с другими компонентами
“классной доски” мы будем использовать здесь и объекты синхронизации.
13.3. Анатомия источника знаний
Источники знаний представляются как объекты, процедуры, множества правил
логические утверждения, а в некоторых случаях и целые программы. Источники зна-
ний включают часть условий и часть действий. Если “классная доска” содержит ин-
формацию, которая удовлетворяет части условий некоторого источника знаний, то
его часть действий активизируется. Инглемор (Englemore) и Морган (Morgan) в своей
работе [14] четко описывают обязанности источника знаний.
Каждый источник знаний отвечает за знание условий, при которых он может внести
свой вклад в решение. Каждый источник знаний имеет предусловия, т.е. условия, ко-
торые должны быть записаны на “классной доске” и существовать до того, как будет
активизировано тело источника знаний. Источник знаний можно рассматривать как
большое правило. Главное, чем отличается правило от источника знаний, состоит
в степени детализации знаний. Часть условий этого большого правила называется
предусловием источника знаний, а часть действий — его телом.
Здесь Инглемор и Морган не определяют ни единой детали части условий или час-
ти действий источника знаний. Они представляют собой логические конструкции.
Часть условий может иметь форму простого значения булевого флага на “классной
доске” или сложной последовательности событий, поступающих в очередь событий
в пределах определенного периода времени. Аналогично часть действий источника
знаний может быть выражена простой инструкцией, выполняющей операцию при-
сваивания переменной некоторого выражения, или механизмом прямого построения
цепочки в экспертной системе. Это описание широты диапазона еще раз подчеркива-
ет гибкость модели “классной доски”. Для наших целей вполне достаточно конструк-
ции С++-класса и понятия объекта. Каждый источник знаний должен быть объектом.
Часть действий источника знаний должна быть реализована в виде методов объекта,
а часть условий — в виде его членов данных. Если объект находится в определенном
состоянии, то его часть действий должна быть активизирована. Проще говоря, мы
реализуем источники знаний в виде потоков или процессов. Следовательно, для каж-
дого потока и для каждого процесса должен существовать только один источник зна-
ний. Применяя к “классной доске” PVM-механизм, источник знаний будет эквивален-
том PVM-задачи. Логическая схема источника знаний показана на рис. 13.3.
Часть “Условия” каждого источника знаний обновляется “из закромов” “классной
доски”, а часть “Действия” источников знаний обновляет ее содержимое. Обратите
внимание на то (см. рис. 13.3), что между пространством процесса и источником зна
ний (или между пространством потока и источником знаний) существует взаимно оД
позначное отношение. Важным атрибутом источника знаний является его автоноМ
ность. Каждый источник знаний является специалистом в своей области и почти
13.4. Стратегии управления для “классной доски” 471
не зависит от других решателей задач. Это составляет одно из требуемых качеств для па-
раллельной программы. В идеале задачи в параллельной программе могут выполняться
одновременно, почти не нуждаясь во взаимодействии с другими задачами. Такое пове-
дение в точности описывает схему модели “классной доски”. Источники знаний дейст-
вуют независимо, и любое взаимодействие осуществляется посредством “классной дос-
ки”. Поэтому источник знаний (с его точки зрения) действует в одиночку, получая до-
полнительную информацию от “классной доски” и записывая на “классную доску” свои
изыскания. О деятельности других источников знаний и их стратегиях поведения ему
ничего не известно. В модели “классной доски” задача делится на ряд автономных или
полуавтономных решателей задач. В этом и состоит преимущество модели “классной
доски” перед другими моделями. В самой гибкой конфигурации источники знаний
должны быть интеллектуальными агентами. Агент должен быть совершенно самодос-
таточным и способным действовать самостоятельно при минимальной потребности
к взаимодействию с “классной доской”. Именно интеллектуальный агент представляет
самую грандиозную перспективу для реализации крупномасштабного параллелизма.
"<<процесс/потбк>>'
Источникзнаний
• директивы
* цели
• требования
• область поиска
• база знаний
• стратегии логического вывода
• методы поиска
• стратегии решения задачи
Рис. 13.3. Логическая схема источника знаний
13.4. Стратегии управления для “классной доски”
В реализации модели “классной доски” предусмотрено несколько уровней управ-
ления, обеспечивающих возможность параллельного функционирования источников
знаний. На самом нижнем уровне их схемы синхронизации должны защищать цело-
стность “классной доски”. “Классная доска” является критическим разделом, посколь-
ку она представляет собой совместно используемый модифицируемый ресурс. В па-
раллельной среде доступ со стороны источников знаний для чтения и записи должен
ыть скоординирован и синхронизирован. Координация и синхронизация может
включать блокировку файлов, семафоры, мьютексы и т.д. Этот уровень управления не
включается непосредственно в решение, над которым работают источники знаний.
° Можно назвать вспомогательным уровнем управления, и он не должен зависеть от
СПеЧифики задачи, решаемой с помощью “классной доски”. В нашем архитектурном
472 Глава 13. Реализация технологии “классной доски”...
подходе этот уровень управления реализуется интерфейсными классами (напримеп
классами мьютекса и семафора, использованными в главе 11). Вспомните, что дейст
вия, инкапсулированные в этих классах, не зависят от приложения, в котором они
используются. Для параллельных реализаций “классной доски” на этом уровне выби-
рается один (или больше) из четырех типов параллельного доступа, которыми долж-
ны обладать алгоритмы или эвристические правила источников знаний для физиче-
ской реализации “классной доски”. Другими словами, пользователи “классной доски”
могут использовать EREW-, CREW-, ERCW- или CRCW-доступ. Именно характер досту-
па определяет, как будут использованы примитивы синхронизации. Описание упомя-
нутых здесь типов доступа приведено в табл. 13.1.
Таблица 13.1. Четыре типа параллельного доступа, используемых в модели “классной доски”
PRAM-модели Описание
EREW Exclusive Read Exclusive Write (монопольное чтение и монопольная запись)
CREW Concurrent Read Exclusive Write (параллельное чтение и монопольная запись)
ERCW Exclusive Read Concurrent Write (монопольное чтение и параллельная запись)
CRCW Concurrent Read Concurrent Write (параллельное чтение и параллельная запись)
При разделении “классной доски” на части будет определено, какие из типов парал-
лельности (см. табл. 13.1) подходят больше всего. Самый гибкий тип (CRCW) доступа
может быть достигнут в зависимости от структуры “классной доски”. Например, если
используется 16 источников знаний, и каждый из них получает доступ к собственному
сегменту “классной доски”, то такие источники знаний могут параллельно считывать
данные с “классной доски” и записывать их туда, не испытывая проблем “гонки” данных.
Следующий уровень управления включает выбор источников знаний. При этом
определяется, какие из них следует включить в поиск решения и какие аспекты задачи
им поручить. На этом уровне управления принимается решение перенести центр
(фокус) внимания на ту или иную область задачи, что и определяет выбор соответст-
вующих источников знаний. При решении задач любого типа всегда ставятся сле-
дующие вопросы: “с чего начать?” и “что нужно для этого знать?”. Уровень центра
внимания отвечает за начальные условия задачи, а также определяет, какие источни-
ки знаний необходимо использовать и в какой момент они должны “вступить в игру •
“Классной доске” должно быть известно, какими источниками знаний она может рас-
полагать, и обычно источники знаний принимают сообщения или параметры, кото-
рые предписывают, как им действовать или в какой области пространства решении
следует начинать поиск. Для параллельных реализаций этот уровень управления оп-
ределяет базовую модель параллелизма (распределение решателей задачи). Обычно
для “классной доски” используется модель MPMD (Multiple Programs Multiple Data"
множество программ и множество потоков данных), известная также как MIMD
(multiple-instruction, multiple-data — множество потоков команд и множество потоков
данных), поскольку каждый источник знаний (решатель задачи) имеет собственную
область специализации. Однако сама природа задачи иногда может дать право на ис-
пользование такой популярной модели, как SPMD (Single Program Multiple Data"
13.4. Стратегии управления для “классной доски” 473
одна программа, несколько потоков данных). В этом случае уровень управления по-
родит ^одинаковых источников знаний, но передаст им различные параметры.
На следующем уровне управления определяется, что делать с решением или част-
ными решениями, записанными на “классной доске”. Этот уровень управления дол-
жен оценить, могут ли источники знаний остановить работу, и является ли сгенери-
рованное решение приемлемым, неприемлемым, частично приемлемым и т.д. Имен-
но этим уровнем управления завершается видимость “классной доски” и всех частных
или предварительных решений. Именно здесь осуществляется руководство общими
стратегиями решения задач коллективными усилиями. В соответствии со структурой
“классной доски” и источников знаний модель “классной доски” предполагает сущест-
вование компонента управления, но не определяет, как он должен быть структуриро-
ван. Иногда компонент управления является частью “классной доски”, а иногда он
реализуется источниками знаний. В некоторых случаях компонент управления реали-
зуется модулями, которые являются внешними по отношению к “классной доске”.
Компонент управления также может быть реализован любым сочетанием предыду-
щих вариантов. Источники знаний совместно ищут решение задачи. Следует отме-
тить, что некоторые задачи имеют несколько решений. Одни из них могут находиться
глубже в пространстве поиска, чем другие; поиск одних решений может быть более
затратным по сравнению с поиском других, а некоторые решения могут быть недос-
таточно хорошо продуманы. Компонент управления не только руководит коллектив-
ными стратегиями поиска, выполняемого источниками знаний, но и контролирует
частные или предварительные решения, чтобы убедиться, что источники знаний не
реализуют какую-нибудь непрактичную стратегию поиска. Компонент управления вы-
являет бесконечные циклы, тупики или рекурсивные регрессии. Более того, компо-
нент управления включается в выбор наилучших или наиболее подходящих источни-
ков знаний для данной задачи. По мере продвижения источников знаний к искомому
решению компонент управления может разгрузить одни источники знаний за счет
других. Стратегия управления должна быть тесно связана с со стратегиями поиска,
которыми руководствуются источники знаний. Важно помнить, что все источники
знаний могут использовать различные стратегии поиска и методы решения задачи.
И хотя они работают с общей “классной доской”, источники знаний по своей сути ав-
тономны и самодостаточны. Следовательно, этот уровень управления имеет двусто-
роннее взаимодействие с источниками знаний. Возможные конфигурации управле-
ния и их уровни в архитектуре “классной доски” показаны на рис. 13.4.
Обратите внимание на то, что в первой из представленных конфигураций
(см. рис. 13.4) механизм управления содержится в самой “классной доске”, а не в от-
дельном модуле и не в источниках знаний. В этой конфигурации блок управления
проектируется как часть класса “классной доски”. Поскольку на уровнях 2 и 3 необхо-
димо двустороннее взаимодействие, имеет смысл, чтобы “классная доска” порождала
процессы или потоки, которые будут содержать источники знаний. Если “классная
Доска порождает процессы или потоки, ей нетрудно получить доступ к идентифика-
ционном}’ номеру любого потока или процесса. Это позволяет “классной доске” легко
Передавать сообщения источникам знаний и осуществлять управление процессами
и потоками. Если “классной доске” по некоторой причине нужно прекратить деятель-
ность конкретного источника знаний, то доступ к идентификатору потока или про-
цесса делает эту задачу очень простой. Обратите внимание на то, что в одном из пред-
ставленных на рис. 13.4 вариантов блок управления является внешним по отношению
классной доске” и источникам знаний. В этом случае идентификационный номер
Потока или процесса должен быть явным образом связан с модулями управления.
474 Глава 13. Реализация технологии “классной доски"...
ВАРИАНТ 1
Компонент управления является частью "классной доски'
'КЛАССНАЯ ДОСКА'
Частные решения^---
Вровень 2
[УРОВЕНЬ 3
Начальные
значения
Включает:
эвристические
ограничения задачи,
метазнания об
источниках знаний
взаимодействие
« процесс/поток »
ИЗ-t
Программная
модель решения
I Контроль
?управленйе<
источниками,
знаний, :
« процесс/поток »
ИЗ1
ВАРИАНТ 2
Компонент управления является частью "классной доски" и источников знаний
'КЛАССНАЯ ДОСКА'
I Частные решения
Начальные
значения
Контроль и
управление
Источниками
I знаний J
ВАРИАНТ 3
Компонент управления является внешним по отношению к
"классной доске" и источникам знаний
Рис. 13.4. Конфигурации управления и их уровни в архитектуре
“классной доски”
13.5. Реализация модели “классной доски" с помощью CORBA-объектов 475
13.5. Реализация модели “классной доски”
с помощью CORBA-объектов
Вспомните, что CORBA-объект (см. главу 8) является независимым от платформы
распределенным объектом. К CORBA-объектам могут получать доступ процессы, вы-
полняющиеся на одном или на разных компьютерах, подключенных к сети. Это дела-
ет CORBA-объекты кандидатами для использования в PVM-средах, когда программа
делится на ряд процессов, которые могут (или не могут) выполняться на одном и том
ясе компьютере. Обычно PVM-среда используется для передачи сообщений при вто-
ричной роли общей памяти (если она вообще существует). Введение понятия разде-
ляемого и доступного по сети объекта существенно усиливает вычислительные мощ-
ности PVM-среды. Следует иметь в виду, что с помощью CORBA-объектов можно смо-
делировать все, что позволяют смоделировать нераспределенные объекты. Это
означает, что PVM-задачи, которые имеют совместный доступ к CORBA-объектам, мо-
гут получать доступ к контейнерным объектам, объектам оболочки, шаблонов, доме-
нов и другим видам вспомогательных объектов. В данном случае мы хотели бы, чтобы
PVM-задачи имели доступ к объектам “классной доски”. Поэтому модель передачи со-
общений мы дополняем совместным доступом к сложным объектам. Помимо PVM-
задач, получающих доступ к распределенным CORBA-объектам, к ним также могут об-
ращаться задачи, порожденные функциями posix_spawn () или fork-exec. Эти за-
дачи выполняются в отдельных адресных пространствах одного и того же компьюте-
ра, но могут, тем не менее, связываться с CORBA-объектами, которые расположены
либо на том же, либо на другом компьютере. Поэтому, несмотря на то что все задачи,
созданные с помощью функций posix_spawn() или fork-exec, должны размещать-
ся на одном компьютере, CORBA-объекты могут располагаться на любом компьютере.
13.5.1. Пример использования CORBA-объекта
“классной доски”
Чтобы продемонстрировать наше представление о CORBA-ориентированной
классной доске”, рассмотрим ее реализацию, предложенную разработчиками из ком-
пании Ctest Laboratories. И хотя полное описание этого варианта выходит за рамки
нашей книги, мы все же остановимся на самых важных аспектах “классной доски”
и источников знаний, имеющих отношение к нашему архитектурному подходу к па-
раллельному программированию. “Классная доска” реализует услуги программно-
ориентированного консультанта по составлению расписания учебных курсов.
Классная доска” решает задачи планирования учебных курсов для студента типично-
го колледжа. Студенты часто сталкиваются с проблемой “неудобного” расписания за-
нятий. Во время регистрации курсов всегда существует конкуренция за места в ауди-
ториях. В какой-то момент важные для студента курсы попросту “закрываются”. Ведь
Не зря существует печально известное правило, соответствующее дисциплине обслу-
живания очереди: “первым пришел — первым обслужен”. Поэтом}7 во время регистра-
ции. когда десятки тысяч студентов пытаются записаться на ограниченное количест-
курсов, важным фактором выступает своевременность. Студент желает пройти
Урсы, которые дают право на получение диплома. В идеале эти курсы должны быть
несены во времени. Кроме того, студент хотел бы поддерживать определенную
°Ную нагрузку и иметь свободное время для домашних и факультативных занятий.
476 Глава 13. Реализация технологии “классной доски”...
Проблема состоит в том, что, когда студент готов взять выбранный им курс, прием ца
него может уже оказаться закрытым, и вместо него ему предлагаются другие курсы ко-
торые его интересуют в меньшей степени. Курсы-заменители увеличивают стоимость
и продолжительность обучения студента в колледже, что с точки зрения студента явля-
ется негативным фактором. Но если курсы-заменители отвечают “посторонним” инте-
ресам студента (имеются в виду хобби или перспективные цели), то такие курсы-
заменители могут оказаться допустимыми. Кроме того, существует ряд факультативных
кусов, которые могут также давать право для “выхода на диплом”. Студент хотел бы по-
лучить оптимальный набор курсов, который бы позволил ему в запланированные сроки
(или досрочно) претендовать на диплом, оставаясь при этом в рамках намеченного
бюджета с максимальной гибкостью участвуя в учебном процессе. Для решения этой
задачи студент использует работающую в реальном масштабе времени программу со-
ставления расписания учебных курсов, основанную на технологии “классной доски”.
Важно отметить, что “классная доска” имеет доступ реального времени к академи-
ческой характеристике студента и текущим курсам (с открытым или закрытым прие-
мом) в любой момент периода регистрации. Кроме того, “классная доска” имеет дос-
туп к дипломному плану студента, академическим требованиям для реализации этого
плана, расписанию “готовности” студента посещать занятия, данным о его целях
и предпочтениях и т.д. Все эти элементы моделируются с помощью C++- и CORBA-
классов и образуют компоненты “классной доски”. Для упрощения нашего примера
мы рассмотрим только следующие четыре источника знаний:
• консультант по общеобразовательным курсам;
• консультант по основным курсам;
• консультант по факультативным курсам;
• консультант по непрофилирующим курсам.
Итак, рассмотрим фрагмент CORBA-интерфейса “классной доски”.
// Листинг 13.1. CORBA-объявления, необходимые для нашего
// класса "классной доски"
typedef sequence<long> courses;
interface black—board{
//. . .
void suggestionsForMajor(in courses Major);
void suggestionsForMinor(in courses Minor);
void suggestionsForGeneral(in courses General);
void suggestionsForElectives(in courses Electives);
courses currentDegreePlan();
courses suggestedSchedule();
//. . .
};
Главная цель интерфейса black-board — обеспечить доступ для чтения и за-
писи со стороны источников знаний. В данном случае при разделении “классной
доски” необходимо предусмотреть сегменты для каждого источника знаний. Это
7 На практике каждый сегмент источника знаний должен содержать один или несколько стандарт
ных контейнерных С++-классов, используемых в качестве очередей данных и очередей событий. Безопас
ность каждого контейнера обеспечивается за счет компонентов синхронизации.
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 477
позволяет источникам знаний получать доступ к “классной доске” посредством
CRCW-стратегии. Другими словами, несколько типов источников знаний могут по-
лучить доступ к “классной доске” одновременно, но источники знаний одинакового
типа должны быть ограничены применением CREW-стратегии. Любой метод или
функция-член, с помощью которого источники знаний будут получать доступ
к “классной доске”, должен быть определен в интерфейсном классе blackboard.
Класс courses объявляется с использованием типа CORBA, и поэтому его можно
применять в качестве параметра и значений, возвращаемых методами при взаимо-
действии между источниками знаний и “классной доской”. Поэтому эти объявления
класса blackboard
courses Minor;
courses Major;
будут использованы для представления информации, которая либо записывается на
“классную доску”, либо считывается с нее. Тип courses — это синоним для CORBA-
типа sequence<long>, полученный в результате использования typedef-
объявления. Тип sequence<long> в CORBA представляет собой вектор (массив) пе-
ременной длины. Это означает, что переменные типа courses используются для
хранения массива элементов типа long. Каждый long-элемент предназначен для
хранения кода курса. Каждый код курса представляет курс обучения, предлагаемый
в колледже. Поскольку C++ не имеет типа sequence, то объявление sequence<long>
преобразуется в С++-класс. Этот класс имеет такое же имя, как sequence<long>
typedef: courses. Процесс преобразования из CORBA-типов в типы C++ происхо-
дит во время IDL-компиляции при построении CORBA-приложения. IDL-компилятор
должен перевести объявление sequencedong> в С++-код. С++-класс courses должен
автоматически включать перечисленные ниже функции.
allocbuf()
freebuf()
get—buffer()
length()
operator[]
release()
replace()
maximum()
Источники знаний будут взаимодействовать с “классной доской” с помощью этих
методов. Объявление sequence<long> “невидимо” для источников знаний; они
видят” только класс courses. Поскольку CORBA поддерживает такие типы данных,
как структуры (struct), классы, массивы и последовательности, источники знаний
могут обмениваться с “классной доской” высокоорганизованными объектами. Это по-
зволяет программист}^ поддерживать объектно-ориентированное представление при
°°мене данными с “классной доской”. Поддержка объектно-ориентированного пред-
ставления (где это необходимо) является важным фактором понижения уровня слож-
ности параллельного программирования. Способность просто считывать с “классной
Доски и записывать на нее сложные объекты или даже иерархии объектов упрощает
программирование в параллельных приложениях. Нет необходимости выполнять
Преооразование из примитивных типов данных в сложные объекты: можно совер-
шать обмен сложными объектами напрямую.
478 Глава 13. Реализация технологии “классной доски”...
13.5.2. Реализация интерфейсного класса black_board
Обратите внимание на то, что в интерфейсном классе (см. листинг 13.1) нет объ-
явлений переменных. Вспомните, что интерфейсный класс в CORBA-реализации ог-
раничивается только объявлением методов. В интерфейсном классе не существует
компонентов, предназначенных для хранения информации. CORBA-классы должны
тесно контактировать с С++-реализациями до конца работы приложения. Реальные
реализации методов и необходимых переменных вносятся в производный класс
(выведенный из этого интерфейсного класса). Производный класс, выведенный из
интерфейсного класса black_board, представлен в листинге 13.2.
// Листинг 13.2. Фрагмент класса реализации для
// интерфейсного класса black_board
#include "black—board.h"
^include <set.h>
class blackboard : virtual public POA_black—board{
protected:
set<long> SuggestionForMajor;
set<long> SuggestionForMinor;
set<long> SuggestionForGeneral;
set<long> SuggestionForElective;
courses Schedule;
courses Degreeplan;
public:
blackboard(void);
-blackboard(void);
void suggestionsForMajor(const courses &X);
void suggestionsForMinor(const courses &X);
void suggestionsForGeneral(const courses &X);
void suggestionsForElectives(const courses &X);
courses *currentDegreePlan(void);
courses *suggestedSchedule(void);
//. . .
Этот класс реализации используется для предоставления реальных определении
методов, объявленных в интерфейсном классе. Помимо реализации методов, произ-
водный класс может содержать компоненты данных, поскольку они не объявлены
в качестве интерфейса. Обратите внимание на то, что класс реализации
black_board, представленный в листинге 13.2, наследует непосредственно не ин-
терфейсный класс black_board, а класс РОА_black—board, который является од-
ним из тех классов, которые создает IDL-компилятор от имени интерфейсного класса
black-board. Объявление класса РОА_black—board приведено в листинге 13.3.
// Листинг 13.3. Фрагмент объявления класса РОА_black_board,
// созданного idl-компилятором для
// интерфейсного класса black—board
class РОА—black—board : virtual public Portableserver:
:Staticlmplementation
{
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 479
public:
virtual ~POA_black_board ();
black—board—ptr _this ();
bool dispatch (CORBA::StaticServerRequest_ptr);
virtual void invoke (CORBA::StaticServerRequest—ptr);
virtual CORBA: :Boolean _is_a (const char *);
virtual CORBA::InterfaceDef—ptr _get_interface ();
virtual CORBA::RepositoryId _primary_interface
(const Portableserver::0bjectld &,
Portableserver::POA__ptr);
virtual void * _narrow_helper (const char *);
static POA—black-board * .narrow (
Portableserver::Servant);
virtual CORBA::Object_ptr __make_stub (Portableserver::
POA_ptr,
CORBA::Object —ptr) ;
//. • •
virtual void suggestionsForMajor (const courses^ Major)
= 0;
virtual void suggestionsForMinor (const courses^ Minor)
= 0;
virtual void suggestionsForGeneral (
const courses& General) = 0;
virtual void suggestionsForElectives (
const courses& Electives) = 0;
virtual courses* currentDegreePlan() = 0;
virtual courses* suggestedSchedule() = 0;
//. . .
protected:
POA_black—board () {};
private:
POA—black-board (const POA_black_board &);
void operator= (const POA_black-board &);
};
Обратите внимание на то, что класс в листинге 13.3 является абстрактным, по-
скольку он содержит чисто виртуальные функции-члены, например:
virtual courses* suggestedSchedule() = 0;
Это означает, что данный класс нельзя использовать напрямую. Из него необхо-
димо вывести производный класс, в котором будут определены реальные функции-
члены для всех объявлений чисто виртуальных функций. Класс POA_black_board,
представленный в листинге 13.2, содержит требуемые определения для всех чисто
виртуальных функций-членов. Что касается нашего класса “классной доски”, то для
реализации действий самой “доски” и источников знаний используются С++-методы.
Днако источники знаний реализованы частично в языке C++ и частично в языке ло-
гического программирования Prolog.2 Но поскольку C++ поддерживает мультиязыковую
•-------------
$тп конфигурация обусловлена тем, что Prolog имеет множество таких встроенных средств, как
^рация унификации, возврат к предыдущему состоянию и поддержка логики предикатов, которые
&^?тибиом случае (без использования языка Prolog) пришлось бы реализовать в C++ “с нуля”. В этой кни-
• примеров, в которых мы “смешиваем” C++ с языком Prolog, используется версия SWI-Prolog
Р отка университета в Амстердаме) и ее С++-библиотека интерфейсов.
480 Глава 13. Реализация технологии “классной доски”...
и мультипарадигматическую разработку, к средствам C++ можно вполне добавить дос-
тоинства языка Prolog. В C++ мы можем либо породить Prolog-задачи (с помощью
posix..spawn ()- или f ork-exec-функций), либо получить доступ к среде Prolog че-
рез ее интерфейс с незнакомыми языками программирования, который позволяет
Prolog-среде общаться непосредственно с C++ и наоборот. Независимо от того, на ка-
ком языке создана реализация источников знаний — C++ или Prolog, объект “классной
доски” должен взаимодействовать только с С++-методами.
13.5.3. Порождение источников знаний в конструкторе
“классной доски”
“Классная доска” реализуется как распределенный объект, использующий CORBA-
протокол. В данном случае одной из основных целей “классной доски” является по-
рождение источников знаний. Это важный момент, поскольку “классная доска” долж-
на иметь доступ к идентификационным номерам задач. Начальное состояние
“классной доски” (оно устанавливается в конструкторе) включает информацию о сту-
денте, его академической характеристике, текущем семестре, требованиях для полу-
чения диплома и т.д. С помощью “классной доски”, исходя из начального состояния,
определяется, какие источники знаний следует запустить в работу. Иначе говоря,
оценив начальную задачу и исходное состояние системы, “классная доска” составляет
список запускаемых на выполнение источников знаний. Каждый источник знаний
имеет соответствующий двоичный файл, а для хранения имен этих файлов “классная
доска” использует контейнер Solvers. Позже, при функционировании конструктора,
с помощью функционального объекта (или объекта-функции) и алгоритма
for_each() порождаются источники знаний. Вспомните, что любой класс, в кото-
ром определена операторная функция operator (), можно использовать как функ-
циональный объект. Объекты-функции, как правило применяют совместно со стан-
дартными алгоритмами вместо функций или в дополнение к ним. Обычно везде, где
можно использовать обычную функцию, ее можно заменить объектом-функцией.
Чтобы определить собственный функциональный объект, необходимо определить
операторный метод operator (), придав ему соответствующий смысл, указав список
параметров и тип возвращаемого им значения. Наша CORBA-реализация “классной
доски” может поддерживать источники знаний, реализованные с помощью PVM-
задач, традиционных UNIX/Linux-задач или отдельных потоков, использующих биб-
лиотеки POSIX thread. По типу задач, порождаемых в конструкторе, можно опреде-
лить, с какими именно задачами будет работать “классная доска”: с POSIX-потоками,
традиционными UNIX/Linux-процессами или PVM-задачами.
13.5.3.1. Порождение источников знаний с помощью PVM-задач
Конструктор “классной доски” содержит следующий вызов алгоритма.
for_each(Solve.begin()z Solve.end(),Task);
Алгоритм f or_each () применяет операторный метод объекта-функции (созданного
для класса задачи) к каждому элементу контейнера Solve. Этот метод используется Д71*1
порождения источников знаний в соответствии с моделью MIMD, при реализации ко-
торой все источники знаний имеют различную специализацию и работают с различ
ными наборами данных. Объявление этого класса задач приведено в листинге 13-4.
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 481
// Листинг 13.4. Объявление класса задачи
class task{
int Tid[4J;
int N;
//. - •
publici
//. . •
task(void) { N = 0; }
void operator()(string X) ;
};
void task::operator()(string X)
{
int cc;
pvm_mytid();
cc = pvm_spawn(const—cast<char *>(X.data()),NULL,0, ""z1,
&Tid[N]);N++;
blackboard: blackboard(void)
{
task Task;
vector<string> Solve;
//. . .
// Determine which KS to invoke
//. . .
Solve.push-back(KS1);
Solve.push—back(KS2);
Solve.push-back(KS3);
Solve.push_back(KS4);
for-each(Solve.begin(), Solve.end(),Task);
}
Этот класс task инкапсулирует порожденный процесс. Он содержит идентифика-
ционный номер задачи (поскольку у нас используется PVM-задача). В случае примене-
ния стандартных UNIX/Linux-процессов или Pthread-потоков, он должен содержать
идентификационный номер процесса или потока. Этот класс действует как интер-
фейс между создаваемым процессом или потоком и “классной доской”. “Классная дос-
ка здесь является основным компонентом управления. Она может управлять PVM-
задачами с помощью их идентификационных номеров. Кроме того, “классная доска”
может использовать групповые PVM-операции для синхронизации PVM-задач с ис-
пользованием барьеров, организации PVM-задач в логические группы, которые
Должны отрабатывать определенные аспекты решаемой задачи, и сигнализации чле-
нов группы с помощью соответствующих тегов сообщений. Групповые PVM-операции
перечислены и описаны в табл. 13.2.
Особый интерес для нашей “классной доски” представляют операции
barrier () и pvm_joingroup (), поскольку существуют ситуации, в которых
классная доска” не запускает новые источники знаний до тех пор, пока определенная
группа источников знаний не завершит свою работу. Для блокирования вызывающего
процесса до нужного момента (до окончания обработки данных соответствующими
Источниками знаний) можно использовать операцию pvm_barrier (). Например,
482 Глава 13. Реализация технологии “классной доски”...
“классная доска” в качестве консультанта по выбору курсов обучения не будет активи-
зировать источник знаний, отвечающий за составление расписания, до тех пор, пока
не представят свои предложения источники знаний, которые специализируются на
основных, общеобразовательных, второстепенных и факультативных курсах. Поэто-
му “классная доска” будет использовать операцию pvm_barrier () для ожидания за-
вершения работы этой группы PVM-задач. На рис. 13.5 представлена UML-диаграмма
видов деятельности, которая позволяет понять, как синхронизируются источники
знаний и “классная доска”.
Барьер синхронизации здесь реализуется с помощью операций pvm_barrier ()
и pvm_ jo ingroup (). Реализация операторной функции для объекта задачи приведе-
на в листинге 13.5.
Таблица 13.2. Групповые PVM-операции
Операции Описание
int pvm_j оingroup( char *groupname); Вносит вызывающий процесс в группу groupname, а затем возвращает int-значение, которое пред- ставляет собой номер процесса в этой группе
int pvm_Ivgroup( char *groupname); Удаляет вызывающий процесс из группы groupname
int pvm_gsive( char *groupname); Возвращает int-значение, которое представляет собой количество членов в группе groupname
int pvm_gettid( char *groupname, int inum); Возвращает int-значение, равное идентификаци- онному номеру задачи, выполняемой процессом, который идентифицируется именем группы groupname и номером экземпляра inum
int pvm_getinst( char *groupname, int taskid); Возвращает int-значение, которое представляет собой номер экземпляра, связанный с именем группы groupname и процессом, выполняющим задачу с идентификационным номером taskid
int pvm_barrier( char *groupname, int count); Блокирует вызывающий процесс до тех пор, пока count членов в группе groupname не вызовут эту функцию
int pvm_bcast( char *groupname, int messageid); Передает всем членам группы groupname сооб- щение, хранимое в активном буфере отправки, связанном с номером messageid
int pvm_reduce( void *operation, void *buffer, int count, int datatype, int messageid, cha r * groupname, int root); Выполняет глобальную операцию operation во всех процессах группы groupname
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 483
Рис. 13.5. UML-диаграмма видов деятельности, отображающая синхронизацию “классной
Доски” и источников знаний
484 Глава 13. Реализация технологии “классной доски"...
// Листинг 13.5. Определение функции operator()
II в классе task
void task::operator()(string X)
{
int cc;
pvm_mytid();
cc = pvm_spawn(const_cast<char *>(X.data()),NULL,0, "”,1,
&Tid[N]);N++;
}
Функция-оператор operator () используется для порождения PVM-задач. Имя за-
дачи содержится в элементе X. data (). При обращении к функции pvm_spawn ()
(см. листинг 13.5) создается одна задача, а ее идентификационный номер сохраняется
в элементе Tid[N]. (Подробнее о функции pvm_spawn () и вызове PVM-задач см. гла-
ву 6.) Класс task используется для создания функциональных объектов (объектов-
функций). При выполнении алгоритма
fог_each(Solve.begin(), Solve.end(),Task);
вызывается функция operator (), которая выполняет объект Task. Эта операция за-
ставляет активизироваться источники знаний, содержащиеся в контейнере Solve.
Алгоритм for_each() гарантирует активизацию всех источников знаний. Если ис-
пользуется модель SIMD, то в алгоритме for_each() нет никакой необходимости.
Вместо него прямо в конструкторе “классной доски” мы используем вызов функции
pvm_spawn (). В листинге 13.6 как раз и показано, как при использовании модели
SIMD можно запустить множество PVM-задач из конструктора “классной доски”.
// Листинг 13.6. Запуск PVM-задач из конструктора
// класса task
void task::operator()(string X)
{
int cc;
pvm_inytid () ;
cc = pvm_spawn(const_cast<char *>(X.data()),NULL,0,1,
&Tid[N]);N++;
1
13.5.3.2. Связь “классной доски” и источников знаний
Согласно коду, приведенному в листинге 13.6, порождается 20 источников знании.
Сначала все они выполняют одинаковый код. После их порождения “классная доска
должна отправить сообщения с указанием, какую роль они будут играть в процессе
решения задачи. При использовании данной конфигурации источники знании
и “классная доска” являются частью PVM-среды. После создания источники знании
будут взаимодействовать с “классной доской” путем соединения с портом, на котором
она размещается, или по ее адресу в сети intranet или Internet. Для этого источникам
знаний понадобится объектная ссылка на “классную доску”. Эти ссылки можно
“зашить” в код источников знаний, или они могут прочитать их из файла конфигура'
ции либо получить из службы имен. Имея ссылку, источник знаний взаимодействует
с ORB-брокером (Object Request Broker — брокер объектных запросов), чтобы наити
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 485
удаленный объект, содержащий реальные данные (знания) и активизировать его. Для
нашего примера мы назначаем “классной доске” конкретный порт и запускаем
CORBA-объект “классной доски” с помощью следующей команды.
blackboard -ORBIIOPAddr inet:porthos:12458
По этой команде запускается наша программа “классной доски” с подключением к
порту 12458 хоста porthos. Запуск CORBA-объекта зависит от используемой CORBA-
реализации. В данном случае мы используем “открытую” CORBA-реализацию Mico’.
При выполнении программы blackboard реализуется экземпляр “классной доски”,
который в свою очередь порождает источники знаний. В созданных источниках зна-
ний жестко закодирован номер порта, по которому они будут связываться с “классной
доской”. Фрагмент кода реализации источника знаний, который связывается
с CORBA-ориентированным объектом “классной доски”, представлен в листинге 13.7.
// Листинг 13.7. Код источника знаний, который связывается
II с CORBA-ориентированной "классной доской"
1 #include "pvm3.h"
2 using namespace std;
3 #include <iostream>
4 #include <fstream>
5 #include <string.h>
6 #include <strstream>
7 #include "black—board_impl.h"
8
9 int main(int argc, char *argv[])
10 {
11 CORBA::ORB—var Orb = CORBA::ORB_init(argc,argv,
"mico-local-orb");
12 CORBA::Object_var Obj =Orb->bind("IDL:black-board:1.0",
"inet:porthos:12458");
13 courses Courses;
14 //...
15 //...
16 black—board—var BlackBoard = black—board::_narrow(Obj);
17
18 int Pid;
19 //..,
20 //...
21
22 cout << "Источник знаний создан." « endl;
23 Courses.length(2);
24 Courses[0] = 255551;
25 Courses[1] = 253212;
26 string FileName;
27 strstream Buffer;
on Pid = Pvm-mytid();
9 Buffer « "Результат." « Pid « ends;
30 Buffer » FileName;
32 °^stream Fout(FileName.data());
2 BlackBoard->suggestionsForMajor(Courses);
Для всех CORBA-примеров этой книги мы использовали реализацию Mico 2.3.3 в среде Linux
и Mico 2.3.7 в ОС Solans 8.
486 Глава 13. Реализация технологии “классной доски”...
33 Font.close();
34 pvm_exitO;
35 return(0);
36 1
37
В строке 11 (см. листинг 13.7) инициализируется ORB-брокер. При выполнении
строки 12 осуществляется связывание имени объекта black_board с портом 12458
и возвращается ссылка на CORBA-объект в переменной Obj. Строку 16 можно расце-
нивать как разновидность операции приведения типа, чтобы переменная
Blackboard ссылалась на объект “правильного размера”. После того как источник
знаний реализовал объект Blackboard, он может вызывать любой метод, объявлен-
ный в интерфейсе black_board, код которого приведен в листинге 13.1. Обратите
внимание на создание в строке 13 объекта Courses. Вспомните, что тип courses из-
начально был определен как CORBA-тип sequence. Здесь источник знаний использу-
ет класс courses, созданный во время IDL-компиляции. Добавление элементов в этот
класс можно представить как добавление элементов в любой массив. При выполнении
строк 24 и 25 в объект Courses добавляются два элемента, а в строке 32 содержится
вызов метода, которому в качестве параметра передается объект Courses:
BlackBoard->suggestionsForMajor(Courses)
При выполнении этого вызова информация о курсах обучения записывается на
“классную доску”. Аналогично следующие методы
courses currentDegreePlan();
courses suggestedSchedule();
можно использовать для считывания информации с “классной доски”. Поэтому для
общения с “классной доской” источнику знаний достаточно иметь ссылку на объект
Black_board. Объект Black_board может располагаться в любом месте сети intranet
или Internet. Найти реальное местоположение удаленного объекта — забота исключи-
тельно ORB-боркера. (Процесс отыскания и активизации CORBA-объектов рассмат-
ривается в главе 8.) Поскольку объект Black—board имеет идентификационные но-
мера PVM-задач, он может управлять этими задачами и обмениваться сообщениями
(отправлять и получать их) непосредственно с источниками знаний. Аналогично ис-
точники знаний могут напрямую взаимодействовать друг с другом, используя тради-
ционный обмен PVM-сообщениями. Важно отметить следующее: после того как ока-
жется, что не существует больше никаких системных PVM-вызовов, деструктор объек-
та Black_board должен вызвать метод pvrn_exit(), а каждый источник знаний —
метод pvrn_exit (). Тем самым из PVM-среды будут удалены ненужные больше объек-
ты, но обработка данных, не связанная с этими объектами, может продолжаться.
13.5.3.3. Активизация источников знаний с помощью
POSIX-функции spawn ()
Реализация источников знаний в рамках PVM-задач особенно полезна в ситуации,
если задачи должны выполняться на разных компьютерах. Каждый источник знании
в этом случае может воспользоваться преимуществами любого специализированного р^
сурса, которым может быть оснащен конкретный компьютер. К таким ресурсам можно
отнести быстродействующий процессор, базу данных, специальное периферийное обо-
рудование и наличие нескольких процессоров. PVM-задачи можно также использовать
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 487
на одном компьютере с несколькими процессорами. Но поскольку взаимодействие
с нашей “классной доской” легко реализовать путем подключения к порту, для реализа-
ции источников знаний, не мудрствуя лукаво, мы можем также использовать традици-
онные UNIX/Linux-процессы. Если источники знаний создаются в стандартных
UNIX/Linux-процессах, а компьютер содержит несколько процессоров, то источни-
ки знаний могут выполняться параллельно на этих процессорах. Но если источников
знаний больше, чем процессоров, возникает необходимость в многозадачности. На
рис. 13.6 показаны два простых архитектурных варианта, которые можно использо-
вать с CORBA-ориентированной “классной доской” и UNIX/Linux-процессами.
ВАРИАНТ 1
"Классная доска" и источники знаний (ИЗ)
находятся на одном компьютере.
Все ИЗ реализованы в различных процессах.
ВАРИАНТ 2
"Классная доска" находится на одном компьютере,
а все источники знаний (ИЗ) на другом.
Все ИЗ реализованы в различных процессах.
КОМПЬЮТЕР С
КОМПЬЮТЕР А
« CORBA-объект »
"Классная доска"
КОМПЬЮТЕР В
« CORBA-объеьл » j
"Классная доска” j
АДРЕСНОЕ
ПРОСТРАНСТВО 1
АДРЕСНОЕ
ПРОСТРАНСТВО 2
АДРЕСНОЕ
ПРОСТРАНСТВО 1
АДРЕСНОЕ
ПРОСТРАНСТВО 2
«процесс »
И31
« процесс »
И32
« процесс »
И31
« процесс »
И32
АДРЕСНОЕ
ПРОСТРАНСТВО 3
« процесс »
И33
АДРЕСНОЕ
ПРОСТРАНСТВО 4
« процесс »
И34
АДРЕСНОЕ
ПРОСТРАНСТВО 3
« процесс »
И33
АДРЕСНОЕ
ПРОСТРАНСТВО 4
« процесс »
И34
Источники знаний порождаются
Функциями posix_spawn() или fork-exec().
Источники знаний порождаются функциями
posix__spawn() или fork-exec().
Рис. 13.6. Два архитектурных варианта использования CORBA-ориентированной “классной
Доски” и UNIX/Linux-процессов
В варианте 1 CORBA-объект и источники знаний размещаются на одном компью-
тере, и каждый источник знаний имеет собственное адресное пространство. Другими
словами, каждый источник знаний порожден с помощью функции posix_spawn ()
или семейств а функций fork-ехес. В варианте 2 CORBA-объект размещается на од-
ном компьютере, а все источники знаний — на другом, но в различных адресных про-
странствах. В обоих вариантах CORBA-объект действует как разновидность общей
Памяти для источников знаний, поскольку все они получают доступ к нему и могут об-
лениваться информацией через “классную доску”. При этом важно помнить о сущест-
вовании основного преимущества CORBA-объекта — он имеет более высокую органи-
зацию, чем простой блок памяти. “Классная доска” — это объект, который может
488 Глава 13. Реализация технологии “классной доски”...
состоять из структур данных любого типа, объектов и даже других “классных досок”
Такой вид организации не может быть реализован простым использованием базовых
функций доступа к общей памяти. Поэтому CORBA-реализация обеспечивает идеаль-
ный способ разделения сложных объектов между процессами. В подразделе 13.5.3.1
описано создание PVM-задач, которые реализуют источники знаний. Здесь мы изме-
няем конструктор, включая в него вызовы функции posix_spawn () (с той же целью
можно использовать алгоритм f or_each () и функциональный объект задачи для вы-
зова функции posix—spawn ()). В варианте 1 (см. рис. 13.6) “классная доска” может
порождать источники знаний при реализации конструктора. Но в варианте 2 это не-
возможно, поскольку “классная доска” расположена на отдельном компьютере. По-
этому в варианте 2 “классной доске” для вызова функции posix_spawn () приходится
прибегать к услугам посредника. Посредничество можно организовать разными спо-
собами, например, “классная доска” может вызвать другой CORBA-объект, располо-
женный на одном компьютере с источниками знаний. С той же целью можно исполь-
зовать удаленный вызов процедуры (Remote Procedure Call — RPC) или MPI- либо
PVM-задачу, которая должна вызвать программу, содержащую обращение к функции
posix_spawn (). (Описание вызовов функции posix_spawn () приведено в главе 3.)
Как можно использовать функцию posix—spawn() для активизации одного из ис-
точников знаний, показано в листинге 13.8.
// Листинг 13.8. Использование функции posix_spawn() для
// запуска источников знаний
#include <spawn.h>
blackboard::blackboard(void)
{
//. . .
pid_t Pid;
posix—spawnattr_t M;
posix—spawn_file_actions—t N;
posix_spawn_attr_init(&M);
posix_spawn_file_actions—init(&N);
char *const argv[] = {"knowledge—sourcel", NULL};
posix_spawn(&Pid,"knowledge—sourcel",&N,&M,argv,NULL);
//. . .
}
В листинге 13.8 инициализируются атрибуты и действия, необходимые для поро-
ждения задач, после чего с помощью функции posix_spawn () создается отдельный
процесс, который предназначен для выполнения источника знании
knowledge—sour cel. После создания этого процесса “классная доска” получает к не-
му доступ через его идентификационный номер, сохраняемый в параметре Pid. Кро-
ме “классной доски”, используемой в качестве средства связи, возможно и стандарт-
ное межпроцессное взаимодействие (IPC), если “классная доска” расположена на од-
ном компьютере с источниками знаний. “Классная доска” — самый простой способ
взаимодействия между источниками знаний, хотя в конфигурации размещения
“классной доски” на отдельном компьютере можно использовать с этой целью сокеты.
В этом случае управление, осуществляемое “классной доской” над источниками зна-
ний, будет более жестким и обусловленным в любой момент времени содержимым
“классной доски”, а не сообщениями, передаваемыми непосредственно источникам
знаний. Прямую пересылку сообщений легче реализовать при использовании
13.5. Реализация модели “классной доски” с помощью CORBA-объектов 489
“классной доски” в сочетании с PVM-задачами. В этом случае источники знаний сами
настраивают себя на основе содержимого “классной доски”. Но “классная доска” все же
имеет определенный “рычаг” управления источниками знаний, поскольку ей “известны”
идентификационные номера всех процессов, содержащих источники знаний. Как мо-
дель MPMD (MIMD), так и модель SPMD (SIMD), также поддерживаются использовани-
ем функции posix—spawn (). В листинге 13.9 представлен класс, который можно ис-
пользовать в качестве объекта-функции при выполнении алгоритма for_each ().
// Листинг 13.9. Использование класса child_process как
11 объекта-функции при запуске источников
11 знаний
class child—process{
string Command;
posix_spawnattr_t M;
posix—spawn_file_actions—t N;
pid-t Pid;
//. . .
public:
child—process(void);
void operator()(string X);
void spawn(string X) ;
};
void child_process::operator()(string X)
{
//. . .
posix—spawnattr_init(&M);
posix_spawn_file_actions—init (&N) ;
Command.append("/tmp/");
Command.append(X);
char *const argv[] = {const—cast<char*>(Command.data())
,NULL};
posix—spawn(&PidzCommand.data(),&N,argv,NULL);
Command. erase (Command. begin () , Command. end () ) ;
//. . .
}
Мы инкапсулируем атрибуты, необходимые для функции posix_spawn (), в классе
child-process. Инкапсуляция всех данных, требуемых для вызова этой функции
в классе, упрощает ее использование и обеспечивает естественный интерфейс с атрибу-
тами процесса, который создается с ее помощью. Обратите внимание на то, что в классе
child_process мы определили функцию operator () (см. листинг 13.9). Это означает,
что класс child—process можно использовать в качестве функционального объекта
при выполнении алгоритма f or_each (). По мере того как “классная доска” решает, ка-
кие источники знаний необходимо активизировать для решения задачи, она сохраняет
их имена в контейнере Solve. Позже при выполнении конструктора “классной дос-
ки нужные источники знаний активизируются с помощью алгоритма for_each ().
// Конструктор.
child—process Task;
Or—each(Solve.begin(), Solve.end(),Task);
При выполнении этого конструктора для каждого элемента контейнера Solve вызы-
вается метод operator (), код которого приведен в листинге 13.9. После активизации
490 Глава 13. Реализация технологии “классной доски”...
источники знаний получают доступ к ссылке на объект “классной доски” и могут при-
ступать к решению свой части задачи. И хотя источники знаний здесь не являются
PVM-задачами, они связываются с “классной доской” таким же способом (см. подраз-
дел 13.5.3.2) и так же выполняют свою работу. Дело в том, что межпроцессное взаи-
модействие между стандартными UNIX/Linux-процессами отличается от межпро-
цессного взаимодействия, которое возможно с использованием PVM-среды. Кроме
того, PVM-задачи могут располагаться на разных компьютерах, в то время как процес-
сы, созданные с помощью функции posix_spawn(), могут существовать только на
одном и том же компьютере. Если процессы, созданные функцией posix_spawn()
(либо семейством функций fork-exec), необходимо использовать в сочетании с мо-
делью SIMD, то в дополнение к объекту “классной доски” для назначения источникам
знаний конкретных областей задачи, которые они должны решать, можно использовать
параметры argc и argv. В случае, когда “классная доска” находится на одном компью-
тере с источниками знаний, и она активизирует источники знаний в своем конструкто-
ре, то формально “классная доска” является для них родителем, а потомки наследуют от
родителя переменные среды. Переменные среды “классной доски” можно использовать
в качестве еще одного способа передачи информации источникам знаний. Этими пере-
менными среды можно легко управлять, используя следующие функции.
#include <stdlib.h>
//. . .
setenv();
unsetenv();
putenvf);
Если источники знаний реализуются в процессах, которые созданы с помощью функ-
ции posix_spawn () (или fork-ехес), то их программирование не выходит за рамки
обычного CORBA-программирования с доступом ко всех средствам, предлагаемым
CORBA-протоколом.
13.6. Реализация модели “классной доски”
с помощью глобальных объектов
Выбор CORBA-ориентированной “классной доски” вполне естествен в условиях,
когда источники знаний должны быть реализованы в среде intranet или Internet,
или когда в целях соблюдения модульного принципа организации, инкапсуляции
и так далее каждый источник знаний реализуется в отдельном процессе. Однако
в распределении “классной доски” необходимость возникает не всегда. Если источ-
ники знаний можно реализовать в рамках одного процесса или на одном компьюте-
ре, то лучше всего в этом случае организовать несколько потоков, поскольку при
таком варианте быстродействие выше, расходы системных ресурсов меньше, а сама
работа (настройка) — проще. Взаимодействие между потоками легче организовать,
поскольку потоки разделяют одно адресное пространство и могут использовать
глобальные переменные. Ведь тогда “классную доску” можно реализовать как гло-
бальный объект, доступный всем потокам в процессе. При реализации источников
знаний в виде потоков в рамках одной программы отпадает необходимость в меж-
процессном взаимодействии, использовании сокетов или какого-либо другого типа
сетевой связи. Кроме того, в этом случае оказывается ненужным дополнительным
13.6. Реализация модели “классной доски” с помощью глобальных объектов 491
уровень CORBA-протокола, поскольку можно обойтись разработкой обычных С++-
классов. Если многопоточная программа рассчитана на использование одного ком-
пьютера с несколькими процессорами, то потоки могут выполняться параллельно
на доступных процессорах. В SMP- и МРР-системах потоковая конфигурация
“классной доски” весьма привлекательна. В общем случае при использовании пото-
ков достигается самая высокая производительность. Потоки часто называют облег-
ченными процессами, поскольку они не требуют таких же расходов системных ресур-
сов, как традиционные UNIX/Linux-процессы. В библиотеке POSIX threads
(Pthreads) предусмотрено практически все, что нужно для создания источников
знаний и управления ими. На рис. 13.7.1-13.7.3 представлены три базовые конфи-
гурации распределения процессов для “классной доски” и источников знаний.
РАСПРЕДЕЛЕНИЕ ПРОЦЕССОВ 1
Источники знаний реализованы как потоки одного процесса,
которые разделяют "классную доску" как глобальный объект.
ЕДИНСТВЕННЫЙ ПРОЦЕСС
Адресное пространство
« глобальный объект »
blackboard
поток 1 потока
« поток» « поток» |
ИЗ. j И32 |
ПОТОК3
« поток »
И33
Рис. 13.7.1. Базовая конфигурация распределения процес-
сов для “классной доски” и источников знаний (вариант 1)
Поскольку “классная доска” реализована в многопоточной среде, то для синхрони-
зации доступа к “классной доске” можно использовать Pthread-мьютексы и перемен-
ные условий, которые необходимо инкапсулировать в интерфейсных классах, как
описано в главе 11. Кроме того, для координации и синхронизации работы, выполняе-
мой источниками знаний, можно использовать функции pthread_cond_signal ()
и Pthread-cond—broadcast (). Поскольку “классная доска” сама создает потоки, ей бу-
дет нетрудно получить доступ к идентификационным номерам всех источников знаний,
то означает, что “классная доска” может при необходимости аннулировать поток, ис-
пользуя функцию pthread—cancel (). Кроме того, “классная доска” способна синхро-
низировать выполнение источников знаний с помощью функции pthread j oin ().
°Мимо уже перечисленных достоинств многопоточной реализации (высокое быст-
родействие и простота использования потоков и глобального объекта “классной дос-
Ки ), существует также проблема обработки ошибок и исключительных ситуаций.
492 Глава 13. Реализация технологии “классной доски”...
В общем случае эта проблема решается проще в рамках одного процесса и одного
компьютера, чем при использовании нескольких процессов и нескольких компьюте-
ров. На рис. 13.8 показаны уровни сложности, связанные с обработкой ошибок и ис-
ключительных ситуаций при использовании различных конфигураций.
РАСПРЕДЕЛЕНИЕ ПРОЦЕССОВ 2
Источники знаний, реализованные как процессы, и CORBA-объект "классной доски"
выполняются на одном компьютере, а для связи друг с другом используют
механизм межпроцессного взаимодействия.
ОДИН КОМПЬЮТЕР С НЕСКОЛЬКИМИ ПРОЦЕССАМИ
Рис. 13.7.2. Базовая конфигурация распределения процессов для “классной доски”
и источников знаний (вариант 2)
РАСПРЕДЕЛЕНИЕ ПРОЦЕССОВ 3
Источники знаний реализованы как процессы, выполняющиеся на разных компьютерах,
и используют для связи с CORBA-объектом "классной доски" НОР-протокол.
НЕСКОЛЬКО ПРОЦЕССОВ НА НЕСКОЛЬКИХ КОМПЬЮТЕРАХ
КОМПЬЮТЕР 1
Рис. 13.7.3. Базовая конфигурация распределения процессов для “классной доски"
и источников знаний (вариант 3)
13.6. Реализация модели “классной доски” с помощью глобальных объектов 493
и
О
Обработка ошибок и исключительных ситуаций, возникающих при выполнении
нескольких процессов на различных компьютерах, расположенных в различных
сетях (при использовании разных протоколов).
Обработка ошибок и исключительных ситуаций,
возникающих при выполнении нескольких процессов на
различных компьютерах, но расположенных в одной сети,.
Обработка ошибок и исключительных ситуаций, возникающих
при выполнении нескольких процессов на одном компьютере.
Обработка ошибок и исключительных ситуаций, возникающих при выполнений
функций одного процесс^ (в одном адресном пространстве). _
Обработка, ошибок,: ' Обработка ошибок, возникающих
возникающих в одном потоке. ;в различных потоках,.
Рис. 13.8. Уровни сложности при обработке ошибок и исключений
Если источники знаний реализованы в отдельных потоках одного и того же процесса,
то обработка возможных ошибок или исключительных ситуаций в этом случае относится
к уровню сложности 2. Эту степень сложности необходимо учитывать еще на этапах про-
ектирования и разработки программы, особенно в случае, если она требует параллельного
программирования. Простейшее архитектурное решение, использующее модель
‘классной доски”, состоит в реализации “классной доски” в виде глобального объекта, а ис-
точников знаний — в виде потоков. Рассмотрим фрагмент объявления класса blackboard.
// Листинг 13.10. Фрагмент объявления класса blackboard,
разработанного для многопоточной среды
class blackboard{
Protected:
//. . .
set<long> SuggestionForMajor;
set<long> SuggestionForMinor;
set<long> SuggestionForGeneral;
set<long> SuggestionForElective;
set<long> Schedule;
set<long> Degreeplan;
mutex Mutex[10];
//. . .
Public:
blackboard (void) ;
"•blackboard (void) ;
494 Глава 13. Реализация технологии “классной доски”...
void suggestionsForMajor(set<long> &Х) ;
void suggestionsForMinor(set<long> &X) ;
void suggestionsForGeneral(set<long> &X) ;
void suggestionsForElectives(set<long> &X);
set<long> currentDegreePlan(void);
set<long> suggestedSchedule(void);
//. . .
};
Класс blackboard предназначен для реализации в качестве глобального объекта, к ко-
торому смогут получать доступ все потоки в программе. Обратите внимание на то, что
класс blackboard в листинге 13.10 включает массив мьютексов. Эти мьютексы использу-
ются для защиты критических разделов “классной доски”. При реализации источников
знаний практически нет необходимости беспокоиться о синхронизации доступа к крити-
ческим разделам, поскольку код синхронизации инкапсулирован в классе blackboard.
13.7. Активизация источников знаний с помощью
потоков
В этом разделе рассматривается реализация источников знаний в отдельных пото-
ках. Потоки создаются здесь при выполнении конструктора класса “классной доски”
(blackboard), и каждому потоку назначается конкретный источник знаний. Тем са-
мым реализуется модель MIMD. Фрагмент кода конструктора класса blackboard
приведен в листинге 13.11.
// Листинг 13.11. Конструктор класса blackboard,
// используемый для создания потоков,
// содержащих источники знаний
blackboard::blackboard(void)
{
pthread_t Tid[4];
//. . .
try{
pthread—create(&Tid[0],NULL,suggestionForMajor,
NULL);
pthread—create(&Tid[l],NULL,suggestionForMinor,
NULL);
pthread—create(&Tid[2],NULL,suggestionForGeneral,
NULL);
pthread_create(&Tid[3],NULL,suggestionForElective,
NULL);
pthread_join(Tid[0],NULL);
pthread_join(Tid[l],NULL);
pthread_join(Tid[2],NULL);
pthread—join(Tid[3],NULL);
}
//. . .
}
Обратите внимание на то, что конструктор вызывает функцию pthread—join() •
Этот вызов заставляет конструктор ожидать завершения работы всех четырех пото-
ков. Эти потоки могут активизироваться и с помощью других функций-членов класса
13.8. Резюме 495
blackboard. Но те действия, которые выполняют источники знаний “в рамках” конст-
поэтому весьма уместно не продолжать работу по созданию объекта “классной дос-
ки” Д° тех ПОР» пока эти потоки не доведут до конца свою работу. Такой подход
к созданию потоков в конструкторе заставляет задуматься об обработке ошибок и ис-
ключительных ситуаций. Что произойдет, если по какой-то причине при выполнении
потоков случится сбой? Поскольку конструкторы не возвращают никаких значений,
то здесь просто необходимо позаботиться об обработке исключительных ситуаций.
Каждый поток связывается со “своей” функцией.
void *suggestionForMajor(void *Х);
void *suggestionForMinor(void *X) ;
void *suggestionForGeneral(void *X);
void *suggestionForElective(void *X);
Эти четыре функции используются потоками для реализации действий соответст-
вующих источников знаний. Поскольку “классная доска” является глобальным объек-
том, каждая из этих функций имеет непосредственный доступ к функциям-членам
класса blackboard. Поэтому источники знаний могут вызывать функции-члены
“классной доски” напрямую.
//. . .
Combination.generateCombinations(1,9,Courses);
Result = Combination.element(9) ;
//. . .
Blackboard.suggestionsForMinor(Value);
//. . .
Поскольку некоторые разделы “классной доски” имеют ограниченный доступ для
отдельных источников знаний, то к этим разделам можно применить CRCW-
стратегию доступа (рис. 13.9).
Тип параллелизма, представленный на рис. 13.9, вполне естествен для систем,
реализующих модель “классной доски”, поскольку “классная доска” часто делится на
разделы, относящиеся к определенным частям задачи или подзадачи. Обычно одной
проблемной области соответствует один источник знаний, поэтому параллельный
доступ к этим разделам вполне уместен.
13.8. Резюме
Модель “классной доски” поддерживает параллелизм, который присутствует как
в структуре “классной доски”, так и в отношениях между “классной доской” и источни-
ками знаний, а также между самими источниками знаний. Модель “классной доски” —
это модель решения некоторой задачи. Общая задача делится на части, соответст-
вующие конкретным областям знаний. Каждой области назначается источник знаний,
или решатель задач. Источники знаний обычно отличаются самодостаточностью
(автономностью) и не требуют интенсивного общения с другими источниками зна-
нии. Необходимое взаимодействие осуществляется через “классную доску”. Следова-
тельно, источники знаний позволяют организовать обработку данных в рамках про-
траммы по модульному принципу. Такие своеобразные модули могут работать отдельно
и параллельно, не требуя сложной синхронизации. “Классную доску” можно реали-
зовать в виде CORBA-объектов. В этом случае источники знаний могут быть распре-
496 Глава 13. Реализация технологии “классной доски”...
Рис. 13.9. Четыре источника знаний могут параллельно считывать информацию из соответст-
вующих разделов “классной доски” и записывать ее туда
делены в сетях intranet или Internet. “Классная доска” действует как разновидность
общей распределенной памяти для задач, выполняемых в среде PVM-типа. В модель
“классной доски” легко вписываются модели MPMD (MIMD) и SPMD (SIMD). Концеп-
ция “классной доски” побуждает разработчика разделить работу, которую должна вы-
полнить программа, на области знаний. После проведения декомпозиции работ
“классная доска” должна содержать модели ПО предметной области и пространства
решений. Эти модели ПО позволяют проектировщику и разработчику вскрыть парал-
лелизм, который необходимо реализовать в программе. После классической модели
распределенного программирования “клиент-сервер” модель “классной доски” явля-
ется одной из мощных моделей, доступных как для распределенного, так и для парал-
лельного программирования. Источники знаний, или решатели задач, в модели
“классной доски” зачастую реализуются как агенты.
Приложение
Зто приложение представляет собой краткий справочник UML-диаграмм, ис-
пользуемых в этой книге. Универсальный язык моделирования (Unified
Modeling Language — UML) предлагает графические обозначения, исполь-
зуемые для проектирования, визуализации, моделирования и документирования
артефактов системы программного обеспечения. Этот язык является стандартом
“де-факто” для моделирования объектно-ориентированных систем. В нем исполь-
зуются символы и обозначения для представления артефактов системы ПО с раз-
личных точек зрения. И хотя в книге используются и другие обозначения, это при-
ложение позволит читателю быстро ознакомиться с основными элементами и сим-
волами языка UML, которые могут понадобиться ему при составлении
Документации на разрабатываемые системы ПО.
А-1. Диаграммы классов и объектов
Диаграммы классов и объектов — самые распространенные диаграммы, исполь-
зуемые в моделировании объектно-ориентированных систем. Диаграммы классов
используются для представления классов любого типа, в том числе шаблонных
и интерфейсных классов. Эти диаграммы могут содержать члены класса (атрибуты
°перации). В диаграммах классов и объектов отображаются типы данных, значе-
ния переменных и типы значений, возвращаемых функциями. В диаграммах объек-
т°в можно отобразить имя объекта. В диаграммах обоих типов можно указать коли-
чество классов или объектов, используемых в системе, а также отношения между
Яссами и объектами.
498 Приложение А
ПРЕДСТАВЛЕНИЕ КЛАССА
Имя класса
Имя класса
Атрибуты
- private
# protected
+ public
Имя активного
класса
Имя класса
атрибут:
тип = начальное значение
Операции
- private
# protected
+ public
Имя активного класса
Атрибут:
тип = начальное значение
операция
(список аргументов):
тип возвращаемого
значения
Обязанности
класса
Операция (список аргументов):
тип возвращаемого
значения
ПРЕДСТАВЛЕНИЕ ОБЪЕКТА
Имя объекта: имя класса
Имя активного объекта:
имя класса
Рис.А.1. Различные способы представления класса или объекта. Для классов можно
отобразить атрибуты, операции и их область видимости. При обозначении активных
классов или объектов используется более жирная линия
ПРЕДСТАВЛЕНИЕ МНОЖЕСТВА ЭКЗЕМПЛЯРОВ
1 ..7 Обозначение
множественности
Рис. А.2. Различные способы представления множества классов или
объектов. Множество экземпляров можно отобразить графически или
с помощью обозначения множественности
А.2. Диаграммы взаимодействия 499
а) несвязанный класс
б) связанный класс
. параметризованные ।
I ТИПЫ I
Шаблонный класс
Шаблонный класс
<параметризованные типы >
Шаблонный класс
Шаблонный класс
_________I «^параметризованные'
। типы > |
Шаблонный класс
тк--------
I «связать»
(реальные параметры)
Шаблонный объект
I т
Рис. А.З. Способы представления связанных и несвязанных шаблонов или параметризован-
ных классов
А.2. Диаграммы взаимодействия
Диаграммы взаимодействия предназначены для отображения взаимодействия ме-
жду объектами. Такие диаграммы состоят из множества объектов, отношений и со-
общений, которыми обмениваются объекты. Диаграммы взаимодействия включают
диаграммы сотрудничества, последовательностей и видов деятельности.
А.2.1. Диаграммы сотрудничества
Диаграммы сотрудничества используются для отображения объектов, работающих
вместе с целью выполнения некоторой общей работы. Под сотрудничеством в систе-
ме понимается временная кооперация множества объектов. Диаграммы этого типа
могут отображать организацию или структуру сотрудничества. Это подразумевает
отображение всех объектов данного множества, связей между ними, а также отправ-
ляемых и получаемых ими сообщений.
А.2.2. Диаграммы последовательностей
Диаграммы последовательностей предназначены для отображения временного
упорядочения сообщений, отправляемых и получаемых объектами в системе.
500 Приложение А
ПРЕДСТАВЛЕНИЕ ИНТЕРФЕЙСНОГО КЛАССА
А. Использование символа "леденец на палочке"
Интерфейсный класс
Рис. А.4. Способы представления интерфейсного класса. Интерфейсный
класс можно отобразить с помощью символа “леденец на палочке” или
стереотипа «интерфейс». Можно также отобразить отношения между
интерфейсным классом и классом реализации
А.2. Диаграммы взаимодействия 501
ЕДИНИЧНОЕ НАСЛЕДОВАНИЕ
МНОЖЕСТВЕННОЕ НАСЛЕДОВАНИЕ
Рис. А.5. Способы представления единичного и множественного наследования. Существует два
стиля, которые можно использовать при участии нескольких классов в отношении: объединенный
и разъединенный. При использовании объединенного стиля несколько классов привязываются к
единому символу наследования, который указывает на целевой класс. При использовании
разъединенного стиля каждый класс имеет собственный символ наследования
А.2.3. Диаграммы видов деятельности
Диаграммы видов деятельности отображают передачу управления от одного вида
Деятельности другому. Под деятельностью подразумеваются действия, выполняемые
«объектами. Действия включают обработку операций ввода-вывода, создание или раз-
рушение объектов либо выполнение вычислений. Диаграммы видов деятельности по-
добны блок-схемам.
502 Приложение А
Агрегирование
Включение
Зависимость:
класс В зависит от класса А.
Способность к переходу
Отношения множественности
Класс В 1 Класс А Класс А всегда связан с одним классом В.
Класс В : * Класс А Класс А всегда связан с некоторым количеством классов В, которое больше или равно нулю.
Класс В 0..1 Класс А Класс А всегда связан с некоторым количеством классов В, которое может быть равно нулю или единице.
Класс В т..п Класс А Класс А всегда связан с некоторым количеством классов В, которое может лежать в диапазоне от m до п.
Рис. А.6. Примеры различных отношений, которые можно отобразить на диаграммах
классов. Для отображения количества экземпляров, участвующих в отношениях, можно
использовать обозначение множественности
А.2. Диаграммы взаимодействия 503
ОРГАНИЗАЦИЯ ВАРИАНТОВ СОТРУДНИЧЕСТВА
•Сотрудничество^------.Сотрудничество'--->. Сотрудничество'
А 4 . в . . С
СТРУЮуРНЬ1ЕАСПЕ1дЫ_СрТРУДНИЧ_ЕСТВА
Рис. А.7. Диаграмма сотрудничества, отображающая организа-
цию сотрудничества в системе и структурные отношения объек-
тов в этом сотрудничестве
:объект А
Вызов собственного метода
(Синхронная связь) |
Возвращение значения ।
Разрушение объекта
Саморазрушение объекта
Рис. А.8. Диаграмма последовательностей ис-
пользуется для отображения временного упоря-
дочения сообщений, передаваемых между объ-
ектами. Активные объекты размещаются в верх-
ней части диаграммы (по оси х). Сообщения,
передаваемые между объектами, располагают-
ся по оси у. На диаграмме можно отображать
синхронные и асинхронные сообщения. Времен-
ное упорядочение сообщений демонстрируется
путем чтения сообщений сверху вниз вдоль оси у
504 Приложение А
"ПЛАВАТЕЛЬНАЯ ДОРОЖКА Г
Объект А
НАЧАЛЬНОЕ
СОСТОЯНИЕ
"ПЛАВАТЕЛЬНАЯ ДОРОЖКА 2"
Объект В
ПРИНЯТИЕ РЕШЕНИЯ.
[Условие
истинно]
Этап
обработки 1
[Условие ложно]
РАЗВЕТВЛЕНИЕ^
БЕЗУСЛОВНЫЙ
ПЕРЕХОД
Ввод
данных 1
ПОЛОСА
СИНХРОНИЗАЦИИ
Рис. А.9. Диаграммы видов деятельности отображают действия объектов с точки зрения
передачи управления от одного объекта другому. Диаграмма этого типа с помощью полосы
синхронизации позволяет отобразить разветвление программы на несколько потоков
управления (параллельность) и их слияние. Чтобы было понятно, какой объект выполняет
соответствующее действие, здесь используется принцип “плавательных дорожек”. Эти
“плавательные дорожки” могут пересекаться переходами. “Плавательные дорожки” также
могут пересекаться полосами синхронизации, что означает, что несколько потоков
управления, распределенные по различным объектам, выполняют действия параллельно
А.З. Диаграммы состояний 505
А.З. Диаграммы состояний
Диаграмма состояний используется для отображения последовательности измене-
ния состояния объектов. Состояние — это условие, при котором объект занимает ту
или иную позицию на своей “линии жизни”. Объект за время своего существования
может многократно изменять свое состояние. Объекты переходят в новое состояние,
если создаются определенные условия, выполняется некоторое действие или проис-
ходит соответствующее событие.
РАСШИРЕННЫЕ СОСТОЯНИЯ И ПЕРЕХОДЫ
Действие входа
Деятельность
Внутренний переход
Действие выхода
entry / действие или функция
Название состояния
> do / деятельность
name / действие или функция
exit / действие или функция
СЛОЖНОЕ СОСТОЯНИЕ
Рис. А. 10. Диаграммы состояний отображают состояния объектов и их переходы из
одного состояния в другое за время их существования. Диаграмма этого вида
содержит начальное и конечное состояние объекта. Состояние может включать
несколько стадий (частей). Оно может также быть представлено совокупностью других
состояний или даже других диаграмм состояний. Подсостояния, которые существуют
параллельно в рамках одного объекта, называются параллельными подсостояниями
506 Приложение А
А.4. Диаграммы пакетов
Диаграммы пакетов используются для организации элементов системы по группам
ОТНОШЕНИЯ МЕЖДУ СИСТЕМАМИ
Система 2 включает подсистему А,
подсистема А содержит подсистему А1
Система 1 зависит от подсистемы А
Рис. А.11. Диаграммы пакетов могут служить для отображения организации
элементов системы. При этом можно использовать стереотипы «система» или
«подсистема». Если пакет содержит другие элементы, во вкладке
(расположенной слева) можно указать имя пакета
Приложение
Имя
posix_spawn, posix_spawnp— функции порождения
REALTIME)
процессов (ADVANCED
Синопсис
SPN #include <spawn.h>
int posix_spawn (
pid_t *restrict pid,
const char *restrict path,
const posix_spawn_file_actions—t *file_actions,
const posix—spawnattr_t *restrict attrp,
char *const argv[restrict],
char *const envp[restrict]);
int posix_spawnp (
pid_t *restrict pid,
const char *restrict file,
const posix—spawn_file_actions—t *file_actions,
const posix.spawnattr_t *restrict attrp,
char *const argv[restrict] ,
char * const envp[restrict]);
508 Приложение Б
Описание
Функции posix__spawn () и posix_spawnp () предназначены для создания нового
(сыновнего) процесса из заданного образа процесса. Новый образ процесса создается
на основе обычного выполняемого файла, именуемого файлом образа нового процесса.
Если в качестве результата этого вызова выполняется С-программа, то она должна
быть представлена как функция языка С следующим образом:
int main (int argc, char *argv[]) ;
Здесь argc — количество аргументов, a argv— массив символьных указателей на ар-
гументы функции. Кроме того, следующая переменная
extern char **environ;
должна быть инициализирована как указатель на массив символьных указателей на
строки описания конфигурации среды.
Аргумент argv представляет собой массив символьных указателей на строки с за-
вершающим нулем. Последний член этого массива (он не учитывается аргументом
argc) должен быть нулевым указателем. Эти строки составляют список аргументов,
доступных для образа нового процесса. Значение элемента argrvfO] должно указы-
вать на имя файла, который связан с образом процесса, запускаемого функцией
posix_spawn() или posix—spawnp ().
Аргумент envp представляет собой массив символьных указателей на строки с за-
вершающим нулем. Эти строки составляют среду для образа нового процесса. Массив
среды завершается нулевым указателем.
Количество байтов, допустимых для обобщенного аргумента сыновнего процесса
и списков строк описания конфигурации среды, составляет {ARG_MAX}. В системной до-
кументации конкретной реализации (см. том Base Definitions стандарта IEEE Std 1003.1-
2001, Chapter 2, Conformance) должно быть указано, включаются ли в это значение та-
кие служебные данные, как символы конца строки, указатели или байты выравнивания.
Аргумент path, передаваемый функции posix__spawn (), содержит путевое имя,
которое идентифицирует файл образа нового процесса.
Параметр file, передаваемый функции posix_spawnp (), используется для фор-
мирования путевого имени, которое идентифицирует файл образа нового процесса.
Если параметр file содержит символ “косая черта”, то параметр file следует рас-
сматривать как путевое имя файла образа нового процесса. В противном случае пре-
фикс пути для этого файла должен быть получен путем поиска в каталогах, указанных
с помощью переменной среды PATH (см. том Base Definitions стандарта IEEE Std
1003.1-2001, Chapter 8, Environment Variables). Если эта переменная среды не опреде-
лена, результаты поиска определяются конкретной реализацией.
Если параметр file_actions является нулевым указателем, то файловые деск-
рипторы, открытые в вызывающем процессе, останутся открытыми и в сыновнем, за
исключением тех из них, для которых установлен флаг “закрытия после выполнения
FD_CLOEXEC (см. описание функции fcntlO). Для оставшихся открытыми файле**
вых дескрипторов все атрибуты соответствующих описаний открытых файлов, вклю*
чая блокировки файлов (см. описание функции f cntl ()), останутся без изменений.
Если параметр file_actions не содержит значение NULL, то файловые ДеС^’
рипторы, открытые в сыновнем процессе, должны соответствовать открытым фаИ
ловым дескрипторам вызывающего процесса, но с учетом модификации, проведен-
ной в соответствии с содержимым объекта действий, адресуемого параметров
Приложение Б 509
file_actions, и флагом FD_CLOEXEC каждого из оставшихся открытыми (после вы-
полнения действий над файлами) файловых дескрипторов. Порядок выполнения
действий над файлами должен быть таким.
1. Множество открытых файловых дескрипторов для сыновнего процесса
должно сначала совпадать со множеством открытых файловых дескрипторов
для вызывающего процесса. Все атрибуты соответствующих описаний откры-
тых файлов, включая блокировки файлов (см. описание функции f cntl ()),
останутся без изменений.
2. Маска сигнала, стандартные действия сигналов, а также идентификационные
номера эффективного пользователя и группы для сыновнего процесса должны
измениться в соответствии со значениями, заданными в объекте атрибутов, ад-
ресуемом параметром a t trp.
3. Действия над файлами, заданные объектом действий для порождаемого про-
цесса, должны быть выполнены в порядке их добавления в этот объект.
4. Любой файловый дескриптор, у которого установлен флаг FD_CLOEXEC
(см. описание функции f cntl ()), должен быть закрыт.
Тип объекта атрибутов posix_spawnattr_t определяется в заголовке
<spawn. h>. По меньшей мере он должен содержать атрибуты, определенные ниже.
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, установлен
флаг POSIX_SPAWN_SETPGROUP, а атрибут spawn-pgroup того же объекта не равен нулю,
то группа сыновних процессов должна быть задана этим (ненулевым) атрибутом объекта.
В качестве специального случая, если в атрибуте spawn-flags объекта, адресуе-
мого параметром attrp, установлен флаг POSIX_SPAWN_SETPGROUP, а атрибут
spawn-рдгоир того же объекта равен нулю, то порождаемый сыновний процесс бу-
дет входить в новую группу процессов, идентификатор (ID) которой будет равен зна-
чению ID его процесса. Если в атрибуте spawn-flags объекта, адресуемого парамет-
ром attrp, флаг POSIX—SPAWN—SETPGROUP не установлен, то новый сыновний про-
цесс наследует группу родительского процесса.
PS Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, установ-
лен флаг POSIX—SPAWN—SETSCHEDPARAM, но флаг POSIX_SPAWN_SETSCHEDULER
не установлен, то образ нового процесса будет изначально обладать стратегией
планирования вызывающего процесса с параметрами планирования, заданными
в атрибуте spawn-schedparamобъекта, адресуемого параметром attrp.
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, уста-
новлен флаг POSIX—SPAWN—SETSCHEDULER (независимо от установки флага
POSIX_SPAWN—SETSCHEDPARAM), то образ нового процесса будет изначально
обладать стратегией планирования, заданной атрибутом spawn-schedpolicy
объекта, адресуемого параметром attrp, и параметрами планирования, за-
данными в атрибуте spawn-schedparamтого же объекта.
Флаг POSIX—SPAWN.RESETIDS в атрибуте spawn-flags объекта, адресуемого па-
раметром a t trp, обусловливает значение ID эффективного пользователя сыновнего
процесса. Если этот флаг не установлен, сыновний процесс наследует ID эффективно-
го пользователя родительского процесса. Если этот флаг установлен, ID эффективно-
го пользователя сыновнего процесса должен быть установлен равным значению ID
реального пользователя родительского процесса. В любом случае, если установлен
510 Приложение Б
бит режима “set-user-ID” для файла образа нового процесса, ID эффективного пользо-
вателя сыновнего процесса примет значение, равное значению ID владельца этого
файла до того, как начнет выполняться образ нового процесса.
Флаг POSIX__SPAWN_RESETIDS в атрибуте spawn-flags объекта, адресуемого пара-
метром attrp, также обусловливает значение ID эффективной группы сыновнего процесса.
Если этот флаг не установлен, сыновний процесс наследует ID эффективной группы роди-
тельского процесса. Если этот флаг установлен, ID эффективной группы сыновнего про-
цесса должен быть установлен равным значению ID реальной группы родительского
процесса. В любом случае, если установлен бит режима “set-group-ID” для файла образа но-
вого процесса, ID эффективной группы сыновнего процесса примет значение, равное
значению ID группы этого файла до того, как начнет выполняться образ нового процесса.
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, установлен
флаг POSIX—SPAWN_SETSIGMASK, то сыновний процесс изначально будет иметь маску
сигнала, заданную в атрибуте spawn-sigmaskобъекта, адресуемого параметром attrp.
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, установ-
лен флаг POSIX—SPAWN—SETSIGDEF, то сигналы, заданные в атрибуте spawn-
si gdefaul t того же объекта, будут установлены равными их действиям по умолчанию в сы-
новнем процессе. Сигналы, установленные равными действиям по умолчанию
в родительском процессе, должны быть установлены равными действиям по умолча-
нию в сыновнем процессе.
Сигналы, установленные для перехвата вызывающим процессом, должны быть ус-
тановлены равными действиям по умолчанию в сыновнем процессе.
За исключением сигнала SIGCHLD, сигналы, которые должны игнорироваться об-
разом вызывающего процесса, должны игнорироваться сыновним процессом, если не
определено иное посредством флага POSIX_SPAWN—SETSIGDEF, установленного в ат-
рибуте spawn-flags объекта, адресуемого параметром attrp, и сигнала SIGCHLD,
обозначенного в атрибуте spawn-sigdefaul t того же объекта.
Если сигнал SIGCHLD установлен как игнорируемый вызывающим процессом, точ-
но не установлено, должен ли сигнал SIGCHLD игнорироваться сыновним процессом
или он будет установлен равным действию по умолчанию в сыновнем процессе, если
не определено иное посредством флага POSIX—SPAWN—SETSIGDEF, установленного
в атрибуте spawn-flags объекта, адресуемого параметром attrp, и сигнала
SIGCHLD, обозначенного в атрибуте spawn_sigdefaul t того же объекта.
Если указатель a t trp содержит значение NULL, используются значения по умолчанию.
Все атрибуты процесса, на которые не было оказано влияния со стороны атрибутов,
установленных в объекте, адресуемом параметром attrp (как было описано выше), или
вследствие манипуляций с файловыми дескрипторами, заданных в параметре
file_actions, должны присутствовать в образе нового процесса в таком виде, как будто
была вызвана функция fork() для создания сыновнего процесса, а затем член семейства
функций ехесбыл вызван сыновним процессом для выполнения образа нового процесса.
THR Запускаются ли обработчики разветвлений при вызове функций posix_spawn ()
или posix— spawnp (), определяется конкретной реализацией.
Возвращаемые значения
При успешном выполнении функция posix_spawn () (и функция
posix— spawnp ()) должна возвратить родительскому процессу идентификационный
Приложение Б 511
номер (ID) сыновнего процесса в переменной, адресуемой аргументом pid (если его
значение не равно NULL), и нуль в качестве значения, возвращаемого функцией.
В противном случае сыновний процесс не создается, значение, сохраненное в пере-
менной, адресуемой аргументом pid (если его значение не равно NULL), не определя-
ется, а в качестве значения, возвращаемого функцией, передается код ошибки, обо-
значающий ее характер. Если аргумент pid содержит нулевой указатель, значение ID
сыновнего процесса инициатору вызова не возвращается.
Ошибки
Вызовы функций posix_spawn () и posix_spawnp () могут оказаться неудачны-
ми, если:
[EINVAL] значение, заданное параметром file_actions или параметром attrp,
недействительно.
Если ошибка возникла после того, как вызывающий процесс успешно вернулся из
функции posix_spawn() или posix_spawnp(), то сыновний процесс может завер-
шиться со статусом выхода (exit status), равным значению 127.
Если неудачный исход функции posix_spawn () или posix_spawnp () вызван од-
ной из причин, которые бы привели к отказу функции fork () или одной из функций
семейства ехес, то возвращаемое значение ошибки будет соответствовать описанию
для функций fork () и ехес соответственно (или, если ошибка возникнет после того,
как вызывающий процесс успешно вернется, сыновний процесс завершится со стату-
сом выхода, равным значению 127).
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp, установлен
флаг POSIX_SPAWN_SETPGROUP, а функция posix_spawn () или posix_spawnp () по-
терпела неудачу при изменении группы сыновнего процесса, то возвращаемое значение
ошибки будет соответствовать описанию для функции setpgid () (или, если ошибка
возникнет после того, как вызывающий процесс успешно вернется, сыновний процесс
завершится со статусом выхода, равным значению 127).
PS Если в атрибуте spawn-flags объекта, адресуемого параметром
attrp, установлен флаг POS IX_SPAWN_SET SCHEDPARAM, а флаг
POSIX_SPAWN_SETSCHEDULER не установлен, то, если неудачный исход
функции posix_spawn () или posix_spawnp () вызван одной из при-
чин, которые бы привели к отказу функции sched_setparam(), возвра-
щаемое значение ошибки будет соответствовать описанию для функции
sched_setparam() (или, если ошибка возникнет после того, как вызы-
вающий процесс успешно вернется, сыновний процесс завершится со
статусом выхода, равным значению 127).
Если в атрибуте spawn-flags объекта, адресуемого параметром attrp,
установлен флаг POSIX_SPAWN_SETSCHEDULER, и если неудачный исход
функции posix_spawn() или posix_spawnp() вызван одной из при-
чин, которые бы привели к отказу функции sched_setscheduler (),
возвращаемое значение ошибки будет соответствовать описанию для
функции sched_setscheduler () (или, если ошибка возникнет после
того, как вызывающий процесс успешно вернется, сыновний процесс за-
вершится со статусом выхода, равным значению 127).
512 Приложение Б
Если аргумент file_actions не равен значению NULL и определяет для выпол-
нения любое из действий close, dup2 или open, и если неудачный исход функции
posix_spawn () или posix_spawnp() вызван одной из причин, которые бы при-
вели к отказу функций close(), dup2() или ореп(), возвращаемое значение
ошибки будет соответствовать описанию для функций close (), dup2 () и open ()
соответственно (или, если ошибка возникнет после того, как вызывающий процесс
успешно вернется, сыновний процесс завершится со статусом выхода, равным зна-
чению 127). Действие, связанное с открытием файла, может само по себе выразить-
ся в любой из ошибок, описанных для функций close () или dup2 (), помимо тех,
что описаны для функции open ().
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Функция posix_spawn О и ее “близкая родственница” функция posix_spawnp ()
были введены для преодоления следующих ощутимых трудностей использования
функции fork (): функцию fork () сложно (или невозможно) реализовать без обмена
(подкачки) или динамической трансляции адреса.
• Обмен (механизм подкачки в оперативную память недостающей страницы вир-
туальной памяти, затребованной программой) — в общем случае слишком мед-
ленный механизм для среды реального времени.
• Осуществление динамической трансляции адреса возможно не везде, где может
использоваться библиотека POSIX.
• Создание процессов с помощью библиотеки POSIX не требует трансляции ад-
ресов или иных услуг, связанных с MMU (memory management unit — блок
управления памятью).
Таким образом, библиотека POSIX использует примитивы создания процессов
и выполнения файлов, которые могут быть эффективно реализованы без трансляции
адресов или иных MMU-процедур.
Функция posix_spawn() реализуется как библиотечная программа, но обе функ-
ции posix_spawn() и posix_spawnp () задуманы как операции ядра операционной
системы. Несмотря на то что они могут представлять эффективную замену для многих
пар функций fork () /ехес, их цель — обеспечить возможность создания процессов
для систем, в которых возникают сложности с применением функции fork О , а не
полностью вытеснить функции fork () /ехес.
Такая роль функций posix_spawn () и posix_spawnp () оказала влияние на их
API-интерфейс. Здесь не было попытки обеспечить полную функциональность пар
fork ()/ехес, при использовании которых между созданием сыновнего процесса
Приложение Б 513
и выполнением образа нового процесса разрешаются любые определенные пользова-
телем операции; ведь любая попытка достичь такого уровня потребовала бы парамет-
рического задания используемого языка программирования. Поэтому функции
posix_spawn () и posix_spawnp () представляют собой базовые операции создания
процессов, подобные процедурам Start_Process и Start_Process_Search из па-
кета POSIX_Process_Primifives в языке программирования Ada, а также другим
операциям, предусмотренным во многих операционных системах (но не UNIX), ос-
нащенных POSIX-расширениями.
Функции posix_spawn () и posix_spawnp() обеспечивают управление шестью
типами наследования: файловыми дескрипторами, идентификационным номером
(ID) группы процессов, ID пользователя и группы, маской сигналов, стратегией пла-
нирования, а также управление сигналами (будет ли каждый сигнал, игнорируемый
в родительском процессе, игнорироваться и в сыновнем, или же он будет установлен
равным действию по умолчанию).
Возможность управления файловыми дескрипторами позволяет независимо запи-
санному образу сыновнего процесса получить доступ к потокам данных, открытым
(или даже сгенерированным) либо читаемым родительским процессом, без специаль-
ного программирования средств, с помощью которых можно было бы определить,
какие файлы (файловые дескрипторы) используются в родительском процессе. Воз-
можность управления идентификационным номером группы процессов позволяет ус-
тановить, как механизм управления заданиями в сыновнем процессе связан с анало-
гичным механизмом в родительском процессе.
Управления маской сигналов и установкой сигналов по умолчанию вполне достаточ-
но для поддержки реализации функции system(). Несмотря на то что поддержка
функции system () не является одной из явных целей для функций posix_spawn ()
и posix_spawnp (), все же эта поддержка составляет не менее 50% от общей “суммы целей”.
Намерение состоит в том, что обычное наследование файлового дескриптора че-
рез функцию fork (), последующий результат заданных действий над файлами
и обычное наследование файлового дескриптора через одну из функций семейства
ехес должно полностью определять наследование открытых файлов. Реализации не
нужно принимать никаких решений относительно набора открытых дескрипторов
файлов в начале выполнения образа сыновнего процесса, эти решения уже были при-
няты инициатором вызова функции и выражены в виде набора открытых дескрипторов
файлов и их флагов FD_CLOEXEC в момент вызова, а также объекта действий над файла-
ми, заданного в этом вызове. Мы убеждены, что в случаях, когда POSIX-примитивы язы-
ка Ada (Start_Process) реализованы в библиотеке, этот метод управления наследова-
нием файловых дескрипторов может быть реализован очень легко.
Мы можем идентифицировать ряд проблем, связанных с использованием функций
PosiX—spawn () и posix_spawnp (), но нам неизвестно решение с меньшим количе-
ством проблем. Модификация среды для атрибутов сыновнего процесса, которая не
определяется с помощью аргументов attrp или file_actions, должна быть выпол-
нена в родительском процессе, а поскольку’ родительский процесс обычно стремится
сохранить свой контекст, это более затратно, чем аналогичное поведение, достигае-
мое с помощью функций fork () /ехес. Кроме того, сложно модифицировать на вре-
мя среду многопоточного процесса, поскольку7 для безопасного изменения среды все
Потоки должны быть согласованы. Однако на эти затраты еще можно было бы пойти,
применяя вызовы тех функций posix_spawn () и posix_spawnp (), которые исполь-
зуют дополнительные возможности. А поскольку расширенные модификации— это
514 Приложение Б
исключение, а не правило, и они особенно непригодны в критическом ко времени
полнения коде, сохранение большинства “рычагов управления” средой вне функций
posix_spawn () и posix_spawnp () возлагается на соответствующее проектирование
функции posix_spawn() и posix_spawnp () не обладают всей полнотой власти ко-
торая характерна для функций fork () /ехес. И такой эффект вполне ожидаем. Функция
fork () — чрезвычайно мощная. Мы и не надеялись скопировать все ее возможности
в простой и быстрой функции, не предъявляя специальных требований к оборудованию
Важно то, что функции posix_spawn () и posix_spawnp () очень близки к средствам
создания процессов во многих операционных системах, отличных от UNIX.
Требования
К реализации функций posix_spawn () и posix_spawnp () предъявляются сле-
дующие требования.
• Они должны быть реализованы без использования MMU (memory management
unit — блок управления памятью) или какого-то иного специального оборудования.
• Они должны быть совместимы с существующими POSIX-стандартами.
Дополнительные требования таковы.
• Они должны быть эффективными.
• Их способность по замещению функции fork () (в обычных условиях) должна
составлять не меньше 50%.
• Система, в которой реализованы функции posix_spawn () и posix_spawnp (),
но не реализована функция fork(), должна иметь достаточную эффектив-
ность, по крайней мере для приложений реального времени.
• Система, в которой реализована функция fork() и семейство функций ехес,
должна обладать способностью к реализации функций posix_spawn ()
и posix_.spawnp () как библиотечных программ.
Двухвариантный синтаксис
POSIX-функция ехес имеет несколько последовательностей вызовов с приблизитель-
но одинаковой результативностью. Это вызвано практическими реалиями. Поскольку ус-
тановившаяся практика использования функций posix_spawn () существенно отли-
чается от POSIX-варианта, мы посчитали, что простота важнее полной совместимо-
сти. Поэтому мы представили только две модификации для функции posix_spawn () •
Различий в списках параметров между функциями posix_spawn () и posix_spawnp (>
практически нет; при использовании функции posix_spawnp() второй параметр
интерпретируется более сложно, чем при использовании функции posix_spawn () •
Совместимость с POSIX.5 (Ada)
Процедуры Start_Process и Start_Process_Search из пакета привязки языка
Ada POSIX-ProcesS-Primitives к POSIX. 1 инкапсулируют действия функций fork^
и ехес практически так же, как это делают функции posix_spawn
и posix_spawnp (). Первоначально, придерживаясь цели более простого подх
разработчики стандарта ограничили возможности функций posix_spaWn^
иposix_spawnp() подмножеством возможностей, присущих процеДУР4
Приложение Б 515
Start—Process и Start—Process—Search, отказавшись от поддержки конкретных
нестандартных средств. Но на основе пожеланий группы приема стандарта усовер-
шенствовать отображение дескрипторов файлов или совсем отказаться от них, а так-
же до рекомендации членов рабочей группы Ada Language Bindings разработчики
стандарта решили, что функции posix_spawn() и posix_spawnp() должны быть
достаточной степени эффективными для реализации возможностей процедур
Start—Process и Start_Process_Search. Мы исходили из того, что если привязка
языка Ada к такому базовому варианту уже была одобрена в качестве стандарта IEEE,
то вряд ли не будут одобрены эквивалентные части С-привязки. Среди возможностей,
реализованных функциями posix_spawn () и posix_spawnp(), можно насчитать
только следующие три пункта, которые не обеспечивались процедурами
Start—Process и Start_Process_Search: необязательное задание идентификаци-
онного номера группы сыновних процессов, набор сигналов, подлежащих стандартной
обработке в сыновнем процессе, а также стратегия планирования (и ее параметры).
Для того чтобы привязку языка Ada в виде процедуры Start_Process можно бы-
ло реализовать с помощью функции posix_spawn (), функции posix_spawn () при-
шлось бы явно передавать пустую маску сигналов и среду родительского процесса вез-
де, где инициатор вызова процедуры Start_Process позволял установку этих аргу-
ментов по умолчанию, поскольку в функции posix_spawn () такой установки
аргументов по умолчанию не предусмотрено. Способность процедуры
Start_Process маскировать определенные пользователем сигналы во время ее вы-
полнения является уникальной для привязки языка Ada и должна быть обработана
в самой привязке отдельно от вызова функции posix_spawn ().
Группа процессов
Поле наследования группы процессов можно использовать для присоединения
сыновнего процесса к существующей группе процессов. Если атрибуту spawn-рдгоир
объекта, адресуемого параметром attrp, присвоить нулевое значение, то механизм
выполнения функции setpgidO обеспечит присоединение сыновнего процесса
к группе нового процесса.
Потоки
В системах, в которых отсутствует трансляция адресов, для представления абст-
ракции параллелизма можно использовать потоки, так сказать, “в обход” функций
P°six__spawn () и posix_spawnp (). Во многих случаях создания потоков для дости-
жения параллельности вполне достаточно, но это не всегда является достойной заме-
ной. Использование функций posix_spawn() и posix_spawnp() считается более
серьезным” вариантом, чем создание потоков. Процессы имеют ряд важных атрибу-
те, которые отсутствуют у потоков. Даже без трансляции адресов процесс может об-
ладать определенной защитой памяти. Каждый процесс имеет среду, включающую
атрибуты защиты и характеристики файлов, а также атрибуты планирования. Про-
HofCbI абстрагируют поведение множества процессоров с архитектурой неоднород-
памяти лучше, чем потоки, и их удобнее использовать для отражения слабо свя-
bix (в функциональном смысле) ветвей параллелизма.
ункции posix_spawn() и posix_spawnp () могут оказаться полезными не для
ДОИ конфигурации. Ведь для поддержки функционирования множества процессов
си СТаточно ограничиться только их созданием. В некоторых условиях общие затраты
Мных ресурсов на поддержку “боеспособности” нескольких процессов могут быть
516 Приложение Б
довольно высокими. Существующая практика показывает, что необходимость в под-
держке множества процессов для систем с “малым ядром” скорее является исключе-
нием, чем правилом, а “правило” как раз образуют потоки. Поэтому для операцион-
ных систем с одним процессом рассматриваемые функции не представляют интерес.
Асинхронное уведомление об ошибках
Библиотечная реализация функций posix_spawn () или posix_spawnp () не по-
зволяет выявить все возможные ошибки до создания сыновнего процесса. Стандарт
IEEE Std 1003.1-2001 обеспечивает возможность индикации ошибок, возвращаемых из
сыновнего процесса, которому не удалось успешно завершить операцию создания,
с помощью специального статуса выхода, который можно обнаружить, используя зна-
чение статуса, возвращаемое функциями wait () и waitpid ().
Интерфейс stat_val и макрос, используемый для его интерпретации, не совсем
подходят для цели возврата API-ошибок, но они являются единственным способом,
доступным для библиотечной реализации. Таким образом, реализация может заста-
вить сыновний процесс завершиться со статусом выхода 127 в случае любой ошибки,
выявленной во время порождения процесса после успешного завершения функции
posix_spawn () или posix_spawnp ().
Разработчики стандарта для интерпретации значения stat_val предложили ис-
пользовать два дополнительных макроса. Первый, WIFSPAWNFAIL, предназначен для
выявления статуса, который свидетельствует о завершении сыновнего процесса по
причине ошибки, обнаруженной во время выполнения операции posix_spawn()
или posix_spawnp (), а не во время реального выполнения образа сыновнего про-
цесса; второй макрос, WSPAWNERRNO, должен выделить значение ошибки, если макрос
WIFSPAWNFAIL обнаружит сбой. К сожалению, группа приема стандарта резко возра-
жала против этого дополнения, поскольку оно поставило бы библиотечную реализа-
цию функции posix_spawn () или posix_spawnp () в зависимость от модификации
функции waitpidO, способной встраивать специальную информацию в значение
stat—Val для индикации сбоя при порождении процесса.
Восьми бит статуса выхода сыновнего процесса, доступность которых для ожи-
дающего родительского процесса гарантирована стандартом IEEE Std 1003.1-2001, не-
достаточно для устранения неоднозначности ошибок порождения процесса, которые
может возвратить образ любого процесса. Требуется, чтобы в значении stat_val
никакие другие биты статуса выхода не были видимы, поэтому упомянутые выше мак-
росы не поддаются строгой реализации на библиотечном уровне. Резервирование
значения статуса выхода 127 для таких ошибок порождения процессов согласуется
с использованием этого значения функциями system () и рореп() при пропадании
сигналов в этих операциях, которые возникают после завершения функции, но перед
тем, как системная оболочка сможет их отработать. Статус выхода 127 уникальным
образом не идентифицирует этот класс ошибок и не предоставляет никакой деталь-
ной информации о природе сбоя. Обратите внимание на то, что разрешается (и даже
поощряется) “ядерная” реализация функций posix_spawn() и posix_spawnp()
с обеспечением возврата любых возможных ошибок в виде значений, возвращаемых
этой функцией, тем самым предоставляя для родительского процесса более деталь-
ную информацию о происшедших сбоях.
Таким образом, для выделения асинхронных ошибок при выполнении функции
posix_spawn () или posix_spawnp () упомянутые выше макросы не используются.
О возможных ошибках, обнаруженных в контексте сыновнего процесса до того, как
выполнится образ нового процесса, уведомление происходит путем установки статуса
Приложение Б 517
выхода сыновнего процесса равным значению 127. Вызывающий процесс для выяв-
ления сбоев при порождении процессов может использовать макросы WIFEXITED
HWEXITSTATUS и значение stat_val, сохраненное функциями wait () или
waitpidO, в тех случаях, когда другие значения статуса, с которыми может завер-
шиться образ сыновнего процесса (до того, как родительский процесс сможет окон-
чательно определить, что образ сыновнего процесса начал выполняться), отличаются
от статуса выхода, равного числу 127.
Будущие направления
Отсутствуют.
Смотри также
alarm(), chmod(), close(), dup(),exec, exit(), fcntl(),fork(),kill (),
open (), posix_spawn_file_actions_addclose (),
posix_spawn_f ile_actions_adddup2 (),
posix_spawn_f ile_actions_addopen (),
posix_spawn_f ile_actions_destroy (), <REFERENCE
UNDEFINED> (posix_spawn_f ile_actions_init), posix_spawnattr_destroy (),
posix_spawnattr_init(), posix_spawnattr_getsigdefault(),
posix_spawnattr_getflags(), posix_spawnattr_getpgroup(),
posix_spawnattr_getschedparam(), posix_spawnattr_getschedpolicy (),
posix_spawnattr_getsigmask (), posix_spawnattr_setsigdefault (),
posix_spawnattr_setflags(), posix_spawnattr_setpgroup(),
po six_spawnattr_set schedparam (), posix_spawnattr_setschedpolicy (),
posix_spawnattr_setsigmask (), sched_setparam (), sched_setscheduler (),
setpgid (), setuid (), stat (), times (), wait (), том Base Definitions стандарта
IEEEStd 1003.1-2001, <spawn.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #103, которая указы-
вает, что в пункте 2 действия, соответствующие установкам сигналов по умолчанию,
изменены так же, как маска сигналов.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #132.
518 Приложение Б
Имя
posix_spawn_file_actions—addclose,
posix_spawn_file_actions—addopen — функции внесения в объект действий над
файлами действия “закрыть файл” (или “открыть файл”) (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
int posix_spawn_file_actions—addclose (
posiX—spawn_fi1e_actions_t *file_actions,
int fildes};
int posix—spawn_file_actions_addopen (
posix_spawn—file_actions—t *restrict file_actions,
int fildes,
const char *restrict path,
int о flag, mode_t mode} ;
Описание
Эти функции добавляют в объект действий над файлами действие “закрыть файл”
(или “открыть файл”) или удаляют соответствующее действие из этого объекта.
Объект действий над файлами имеет тип posix_spawn_file_actions_t
(который определен в заголовке <spawn.h>) и используется для задания последова-
тельности действий, подлежащих выполнению функциями posix— spawn () или
posix_spawnp () с целью получения для сыновнего процесса множества открытых
файловых дескрипторов в соответствии с множеством открытых файловых дескрип-
торов родительского процесса. Стандарт IEEE Std 1003.1-2001 не определяет для типа
posix—spawn_file_actions—t операторы сравнения или присваивания.
Объект действий над файлами, передаваемый функции posix— spawn () или
posix_spawnp (), определяет, как множество открытых файловых дескрипторов вы-
зывающего процесса должно быть трансформировано во множество потенциально
открытых файловых дескрипторов для порождаемого процесса. Эта трансформация
должна выглядеть так, как если бы однократно была выполнена заданная последова-
тельность действий в контексте порожденного процесса (до выполнения образа но-
вого процесса), причем в порядке, в котором эти действия были добавлены в объект.
Кроме того, при выполнении образа нового процесса любой файловый дескриптор
(из этого нового множества), у которого установлен флаг FD_CLOEXEC, должен быть
закрыт (см. описание функции posix_spawn ()).
Функция posix_spawn_file_асtions_addclose () добавляет в объект, адре-
суемый параметром file_actions, действие по закрытию файлов close, в результа-
те чего при порождении нового процесса с использованием объекта действий файло-
вый дескриптор, заданный параметром fildes, будет закрыт (как если бы была вы-
звана функция close (fildes}).
Функция posix— spawn_f ile_actions_addopen () добавляет в объект, адресуемый
параметром file_actions, действие по открытию файлов open, в результате чего при
Приложение Б 519
порождении нового процесса с использованием объекта действий файл, имя которого
задано параметром path, будет открыт (как если бы была вызвана функция open (path,
оflag, mode), и возвращенному ею файловому дескриптору, если он не равен значе-
нию fildes, будет присвоено значение fildes). Если дескриптор fildes относится к
уже открытому файлу, этот файл будет закрыт перед открытием нового файла.
Строка, адресуемая параметром pa th, копируется функцией
posix_spawn_file_actions_addopen().
Возвращаемые значения
При успешном завершении эти функции возвращают нулевое значение; в против-
ном случае — код ошибки, обозначающий ее характер.
Ошибки
Эти функции завершатся неудачно, если:
[EBADF] значение, заданное параметром fildes, отрицательно либо больше
или равно значению {OPEN_MAX}.
Выполнение этих функций может завершиться неудачно, если:
[EINVAL] значение, заданное параметром file_actions, недопустимо;
[ENOMEM] для расширения содержимого объекта действий над файлами недоста-
точно существующей памяти.
Не считается ошибкой, если в качестве значения аргумента fildes, передаваемо-
го этим функциям, указан файловый дескриптор, для которого заданная операция не
может быть выполнена во время вызова. Любая подобная ошибка будет обнаружена,
когда соответствующий объект действий над файлами позже будет использован при
выполнении функции posix_spawn () или posix_spawnp ().
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Объект действий над файлами можно инициализировать с помощью упорядочен-
ной последовательности операций close (), dup2 () и open (), предназначенной для
использования функциями posix_spawn () или posix_spawnp () с целью получения
множества открытых файловых дескрипторов, унаследованных порожденным про-
цессом от своего родителя, имеющего собственное множество открытых файловых
Дескрипторов в момент вызова функции posix_spawn () или posix_spawnp (). Для
Реорганизации файловых дескрипторов было предложено ограничиться только опе-
рациями close () и dup2 (), а для того, чтобы порожденный процесс получил “в на-
следство” открытые файлы, можно поступить двумя способами: либо заставить вызы-
520 Приложение Б
вающий процесс открывать их перед вызовом функции posix_spawn () или
posix_spawnp () (и закрывать их потом), либо передавать имена нужных файлов
в порожденный процесс (в аргументе argv), чтобы он мог их открыть самостоятель-
но. Разработчики стандарта рекомендовали использовать на практике один из этих
двух способов, поскольку детализированный статус ошибки в случае сбоя при выпол-
нении операции открытия файла всегда доступен для приложения. Но разработчики
стандарта по следующим причинам все же считают возможным разрешить включение
в объект действий над файлами операцию open.
1. Это согласуется с эквивалентной функциональностью библиотеки POSIX.5 (Ada).
2. Это поддерживает парадигму перенаправления потоков ввода-вывода, часто
применяемую POSIX-программами, предназначенными для вызова из оболоч-
ки. Если такая программа является сыновним процессом, ее можно сориенти-
ровать на самостоятельное открытие файлов.
3. Это позволяет сыновнему процессу открывать файлы, которые не должен откры-
вать родительский процесс, поскольку операция по открытию файлов в этом слу-
чае может оказаться неудачной или нарушить права доступа к файлам (или пра-
ва собственности).
Относительно приведенного выше п. 2 заметим, что действие “открыть файл” соз-
дает для функций posix_spawn () и posix_spawnp () те же возможности, что и опе-
раторы перенаправления для функции system (), но только без промежуточного вы-
полнения оболочки. Например, так:
system ("myprog <filel 3<file2");
Относительно приведенного выше п. 3 заметим, что если вызывающему процессу
нужно открыть один или несколько файлов для доступа к ним порожденного процес-
са, но он обладает недостаточными запасами файловых дескрипторов, то выполнение
действия open () необходимо позволить в контексте сыновнего процесса после того,
как другие файловые дескрипторы (которые должны оставаться открытыми в роди-
тельском процессе) будут закрыты.
Кроме того, если родительский процесс выполняется из файла, для которого уста-
новлен бит режима “set-user-id” (идентификационный номер пользователя установлен)
и в атрибутах порожденного процесса установлен флаг POSIX_SPAWN_RESETIDS, то
файл, созданный в родительском процессе, получит (возможно, некорректно) в качест-
ве владельца родительский ID эффективного пользователя, в то время как файл, соз-
данный действием ореп() при выполнении функции posix_spawn () или
posix—spawnp (), получит в качестве владельца реальный ID родительского процесса;
при этом операция open, выполненная родительским процессом, может успешно открыть
файл, к которому реальный пользователь не должен иметь доступ, или неудачно от-
крыть (т.е. не открыть) файл, к которому реальный пользователь должен иметь доступ.
Преобразование файловых дескрипторов
Разработчики стандарта первоначально предлагали использовать массив, который
бы определял преобразование файловых дескрипторов сыновнего процесса в обрат-
ном направлении, т.е. при переходе к родительскому процессу. Группа приема стан-
дарта обратила внимание на то, что невозможно произвольно перетасовывать файловые
дескрипторы в библиотечной реализации функции posix_spawn() или
Приложение Б 521
posix__spawnp (), не имея запаса файловых дескрипторов (которого попросту может
не быть). Такой массив требует, чтобы реализация обладала сложной стратегией дос-
тижения нужного преобразования, которая бы исключала случайное закрытие “не то-
го” файлового дескриптора в самое неподходящее время.
Одним из членов рабочей группы Ada Language Bindings было отмечено, что при-
нятое в языке Ada семейство POSIX-примитивов Start__Process использует множе-
ство действий (задаваемое инициатором вызова функции), чтобы изменить обще-
принятую семантику функций fork ()/ехес с целью наследования файловых деск-
рипторов довольно гибким способом, и пока никаких проблем не возникало,
поскольку все бремя определения, как достичь конечного преобразования файловых
дескрипторов, полностью лежит на приложении. Более того, хотя интерфейс, свя-
занный с действиями над файлами, выглядит устрашающе сложным, в действительно-
сти он довольно прост для реализации либо в библиотеке, либо в ядре.
Будущие направления
Отсутствуют.
Смотри также
close (), dup (), open (), posix—spawn (),
posix—spawn_file__actions_adddup2 (),
posix_spawn_f ile_actions_destroy (), posix_spawnp (), том Base Definitions
стандарта IEEE Std 1003.1-2001, < spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #105, согласно кото-
рой в раздел “Описание” было внесено дополнение о том, что строка, адресуемая па-
раметром path, копируется функцией posix_spawn— f ile_actions—addopen ().
522 Приложение Б
Имя
posix_spawn_f ile_actions—adddup2 — функция внесения в объект действий
над файлами действия dup2 (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
int posix_spawn_file_actions—adddup2 (
posix_spawn_file_actions—t *file_actions,
int fildes, int newfildes);
Описание
Функция posix—spawn_file_actions_adddup2 () добавляет в объект, адресуе-
мый параметром file_actions, действие dup2 (), в результате чего при порожде-
нии нового процесса с использованием объекта действий файловый дескриптор
fildes дублируется в параметр newfildes (как если бы была вызвана функция
dup2 (fildes, newfildes)).
Объект действий над файлами порожденного процесса определяется в описании
функции posix—spawn_file_actions—addclose ().
Возвращаемое значение
При успешном завершении функция posix_spawn_f ile_actions—adddup2 ()
возвращает нулевое значение; в противном случае — код ошибки, обозначающий ее
характер.
Ошибки
Функция posix_spawn_f ile_actions—adddup2 () завершится неудачно, если:
[EBADF] значение, заданное параметром fildes или newfildes, отрицательно
либо больше или равно значению {OPEN_МАХ};
[ENOMEM] для расширения содержимого объекта действий над файлами недоста-
точно существующей памяти.
Выполнение функции posix_spawn_f ile_actions—adddup2 () может завер-
шиться неудачно, если:
[EINVAL] значение, заданное параметром file_actions, недопустимо.
Не считается ошибкой, если в качестве значения аргумента fildes, передавае-
мого функции posix— spawn_file_асtions_adddup2 (), указан файловый деск-
риптор, для которого заданная операция не может быть выполнена во время вызо-
ва. Любая подобная ошибка будет обнаружена, когда соответствующий объект дей-
ствий над файлами позже будет использован при выполнении функции
posix_spawn () или posix_spawnp ().
Приложение Б 523
Примеры
Отсутствуют.
Замечания по использованию
Эта функция является частью опции Spawn и может быть не представлена во всех
реализациях.
Логическое обоснование
Смотрите раздел “Логическое обоснование” в описании функции
posix_spawn_file_actions_addclose().
Будущие направления
Отсутствуют.
Смотри также
dup (), posix_spawn (), posix_spawn_f ile_actions—addclose (),
posix— spawn_f ile_actions_destroy (), posix_spawnp (), том Base Definitions
стандарта IEEE Std 1003.1-2001, <spawn. h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #104, в которой ука-
зывается, что ошибка [EBADF], помимо аргумента fildes, может быть применима
к аргументу newfildes.
524 Приложение Б
Имя
posix_spawn_f ile_actions—destroy, posix_spawn_file_actions—init ~~
функции разрушения и инициализации объекта действий над файлами для порож-
денного процесса (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
int posix_spawn_file_actions—destroy (
posix—spawn_file_actions—t *file_actions);
int posix_spawn_file_actions_init (
posix_spawn_fi1e_actions_t *filenactions);
Описание
Функция posix—spawn_file_actions—destroy () предназначена для разруше-
ния объекта, адресуемого параметром file_actions; после ее применения объект
становится неинициализированным. В конкретной реализации функция
posix—spawn_f ile_actions—destroy () может устанавливать объект, адресуемый
параметром file_actions, равным недействительному значению. Разрушенный
объект действий над файлами можно снова инициализировать с помощью функции
posix_spawn_f ile—actions—init (); результаты ссылки на этот объект после его
разрушения не определены.
Функция posix_spawn_file_actions—init () используется для инициализации
объекта, адресуемого параметром file_actions; после ее применения объект не бу-
дет содержать никаких действий, предназначенных для выполнения над файлами при
вызове функций posix_spawn () или posix_spawnp ().
Объект действий над файлами порожденного процесса определяется в описании
функции posix_spawn_file_actions—addclose (). Результат инициализации уже
инициализированного объекта действий над файлами не определен.
Возвращаемые значения
При успешном завершении эти функции возвращают нулевое значение; в против-
ном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция posix_spawn_f ile_actions—init () завершится неудачно, если:
[ENOMEM] для инициализации объекта действий над файлами недоста-
точно существующей памяти.
Функция posix_spawn_file_асtions_destroy () может завершиться неудач-
но, если:
[EINVAL]
значение, заданное параметром file_actions, недопустимо.
Приложение Б 525
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Смотрите раздел “Логическое обоснование” в описании функции
posix—spawn_file_actions—addclose().
Будущие направления
Отсутствуют.
Смотри также
posix— spawn (), posix—spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001,
< spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
В разделе “Синопсис” включение заголовка <sys/ types . h> больше не требуется.
526 Приложение Б
Имя
posix_spawnattr_destroy, posix_spawnattr_init— функции разрушения
и инициализации объекта атрибутов порожденного процесса (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
int posix—spawnattr_destroy (posix_spawnattr_t *attr);
int posix_spawnattr_init (posix_spawnattr_t *attr);
Описание
Функция posix—spawnattr_destroy () предназначена для разрушения объекта
атрибутов порожденного процесса. Разрушенный объект атрибутов, адресуемый па-
раметром a t tr, можно снова инициализировать с помощью функции
posix_spawnattr_init (); результаты ссылки на этот объект после его разрушения
не определены. В конкретной реализации функция posix_spawnattr_destroy()
может устанавливать объект, адресуемый параметром attr, равным некоторому не-
действительному значению.
Функция posix—spawnattr_init () служит для инициализации объекта атрибу-
тов порожденного процесса, адресуемого параметром attr, значениями, действую-
щими по умолчанию для всех отдельных атрибутов, используемых конкретной реали-
зацией. Результат вызова функции posix_spawnattr_init () не определен, если за-
данный параметром a t tr объект атрибутов уже инициализирован.
Объект атрибутов порожденного процесса имеет тип posix_spawnattr_t
(определен в заголовке <spawn.h>) и используется для задания наследования атри-
бутов процесса при выполнении операции порождения процесса. Для типа
posix__spawnattr_t операторы сравнения и присваивания стандарт IEEE Std
1003.1-2001 не определяет.
Для каждой реализации должны быть описаны отдельные атрибуты, которые она
использует, и их стандартные значения, если они не определены стандартом IEEE Std
1003.1-2001. Атрибуты, не определенные стандартом IEEE Std 1003.1-2001, их стан-
дартные значения и имена соответствующих функций чтения и записи этих атрибу-
тов определяются конкретной реализацией.
Результирующий объект атрибутов порожденного процесса (возможно, модифициро-
ванный путем установки значений отдельных атрибутов) используется для модификации
поведения функций posix_spawn () или posix_spawnp (). После того как объект атри-
бутов был использован для порождения процесса путем вызова функции posix_spawn ()
или posix_spawnp (), любая функция, способная изменить объект атрибутов (включая
функцию разрушения), не может повлиять на процесс, созданный таким способом.
Возвращаемые значения
При успешном завершении функции posix_spawnattr_destroy()
иposix_spawnattr_init() возвращают нулевое значение; в противном случае —
код ошибки, обозначающий ее характер.
Приложение Б 527
Ошибки
функция posix_spawnattr_init () завершится неудачно, если:
[ ENOMEM ] для инициализации объекта атрибутов недостаточно существующей памяти,
функция posix_spawnattr_destroy () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром a t tr, недопустимо.
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Исходный интерфейс, предложенный в стандарте IEEE Std 1003.1-2001, определял
атрибуты, наследуемые при выполнении операции порождения процесса, в виде струк-
туры. Чтобы иметь возможность выделить некоторые необязательные атрибуты в от-
дельные опции (например, атрибуты spawn-schedparam и spawn-schedpolicy отно-
сятся к опции Process Scheduling), а также с целью расширяемости и совместимости
с более новыми POSIX-интерфейсами, для интерфейса атрибутов был изменен тип дан-
ных. Этот интерфейс в настоящее время состоит из типа posix_spawnattr_t, пред-
ставляющего объект атрибутов порожденного процесса, и соответствующих функций,
которые позволяют инициализировать или разрушить этот объект атрибутов, а также
установить или получить значение каждого отдельного атрибута. Несмотря на то что
новый объектно-ориентированный интерфейс более сложен, чем исходная структура,
его проще использовать, легче наращивать и реализовывать.
Будущие направления
Отсутствуют.
Смотри также
posix—spawn (), posix—spawnat t r_get sigdefault (),
posix—spawnattr_getflags(),posix_spawnattr_getpgroup(),
posix—spawnattr_getschedparam (), posix_spawnattr_getschedpolicy (),
posix__spawnattr_getsigmask (), posix_spawnattr_setsigdef ault (),
posix_spawnattr_setflags(),posix_spawnattr_setpgroup(),
Posix_spawnattr_setsigmask(), posix_spawnattr_setschedpolicy(),
Posix_spawnattr_setschedparam (), posix_spawnp (), том Base Definitions стан-
дарта IEEEStd 1003.1-2001, <spawn.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
КЕЕ Std 1003.1d-1999.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #106, в которой отмечается,
4110 результат инициализации уже инициализированного объекта атрибутов не определен.
528 Приложение Б
Имя
posix_spawnattr_getflags, posix_spawnattr_setflags — функции считы-
вания и установки атрибута spawn-flags из объекта атрибутов порожденного про-
цесса (ADVANCED REALTIME).
Синопсис
SPN # include < spawn.h>
int posix—spawnattr_getflags (
const posix—spawnattr_t *restrict attr,
short *restrict flags);
int posix_spawnattr_setflags (posix_spawnattr_t *attr,
short flags);
Описание
Функция posix—spawnatt r_get flags () предназначена для получения значения
атрибута spawn -flags из объекта атрибутов, адресуемого параметром a t tr.
Функция posix—spawnat tr_set flags () предназначена для установки значения
атрибута spawn-flags в инициализированном объекте атрибутов, адресуемом пара-
метром a t tr.
Атрибут spawn-flags используется для обозначения того, какие атрибуты про-
цесса должны быть изменены в образе нового процесса при вызове функции
posix—spawn () или posix_spawnp (). Этот атрибут представляет собой результат
применения поразрядной операции включающего ИЛИ к некоторому числу (которое
может быть нулевым) следующих флагов:
POSIX_SPAWN_RESETIDS
POSIX_SPAWN_SETPGROUP
POSIX_SPAWN_SETSIGDEF
POSIX_SPAWN_SETSIGMASK
PS POSIX_SPAWN_SETSCHEDPARAM
POSIX_SPAWN_SETSCHEDULER
Эти флаги определены в заголовке <spawn.h>. Значение, действующее по умол-
чанию для этого атрибута, должно соответствовать ситуации, при которой ни один
флаг не установлен.
Возвращаемые значения
При успешном выполнении функция pos ix_spawnattr_get flags () возвращает
нулевое значение и сохраняет значение атрибута spawn-flags из объекта атрибутов,
адресуемого параметром attr, в объекте, адресуемом параметром flags; в против-
ном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция pos ix_spawnattr_set flags () возвращает
нулевое значение, в противном случае — код ошибки, обозначающий ее характер.
Приложение Б 529
Ошибки
Эти функции могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром a t tr, недопустимо.
функция posix_spawnattr_set flags () может завершиться неудачно, если:
[ EINVAL ] устанавливаемое значение атрибута недопустимо.
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix_spawn (), posix_spawnattr_destroy (), posix_spawnattr__init (),
posix—spawnattr_getsigdef ault (), posix_spawnattr_getpgroup (),
posix—spawnattr_getschedparam(), posix_spawnattr_getschedpolicy (),
posix_spawnattr_getsigmask (), posix_spawnattr_setsigdef ault (),
posix—spawnattr_setpgroup (), posix_spawnattr_setschedparam(),
posix—spawnattr_setschedpolicy (), posix_spawnattr_setsigmask (),
posix—spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
530 Приложение Б
Имя
posix—spawnattr_getpgroup, posix_spawnattr_setpgroup — функции счи-
тывания и установки атрибута spawn -pgroup из объекта атрибутов порожденного
процесса (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
int posix_spawnattr_getpgroup (
const posix_spawnattr_t *restrict attr,
pid—t *restrict pgroup);
int posix_spawnattr_setpgroup (posix_spawnattr_t ★attr,
pid_t pgroup) ;
Описание
Функция posix—spawnattГ—getpgroup () предназначена для получения значе-
ния атрибута spawn-pgroup из объекта атрибутов, адресуемого параметром a ttr.
Функция posiX—spawnattГ—setpgroup () позволяет установить атрибут spawn-
pgroup в инициализированном объекте атрибутов, адресуемом параметром attr.
Атрибут spawn-pgroup представляет группу процессов, к которой при выполне-
нии операции порождения процесса присоединяется новый процесс (если в атрибуте
spawn-flags установлен флаг POSIX—SPAWN—SETPGROUP). По умолчанию значение
этого атрибута равно нулю.
Возвращаемые значения
При успешном выполнении функция posix_spawnattr_getpgroup () возвраща-
ет нулевое значение и сохраняет значение атрибута spawn-pgroup из объекта атри-
бутов, адресуемого параметром attr, в объекте, адресуемом параметром pgroup;
в противном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция posix_spawnattr_set group () возвращает
нулевое значение, в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Выполнение этих функций может завершиться неудачно, если:
[EINVAL] значение, заданное параметром a t tr, недопустимо.
Функция posix_ spawnatt г_set group () может завершиться неудачно, если:
[ EINVAL ] устанавливаемое значение атрибута недопустимо.
Примеры
Отсутствуют.
Приложение Б 531
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix_spawn(),posix_spawnattr_destroy(),posix_spawnattr_init(),
posix_spawnattr_getsigdefault(), posix_spawnattr_getflags(),
posix_spawnattr_getschedparam(), posix_spawnattr_getschedpolicy(),
posix_spawnattr_getsigmask(), posix_spawnattr_setsigdefault(),
posix_spawnattr_setflags(), posix_spawnattr_setschedparam(),
posix—spawnattr_setschedpolicy(), posix_spawnattr_setsigmask(),
posix_spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
532 Приложение Б
Имя
pos ix_spawna11r_get schedparam, pos ix_spawnat1 rjset schedparam —
функции считывания и установки атрибута spawn-schedparam из объекта атрибутов
порожденного процесса (ADVANCED REALTIME).
Синопсис
SPN PS #include <spawn.h>
#include <sched.h>
int posix_spawnattr_getschedparam (
const posix—spawnattr_t *restrict attr,
struct sched_param *restrict schedparam);
int posix_spawnattr_setschedparam (
posix—spawnattr_t *restrict attr,
const struct sched_param *restrict schedparam);
Описание
Функция posix—spawnattr_getschedparam() предназначена для получения значе-
ния атрибута spawn-schedparamиз объекта атрибутов, адресуемого параметром attr.
Функция posix_spawnattr_setschedparam() позволяет установить атрибут
spawn-schedparam в инициализированном объекте атрибутов, адресуемом пара-
метром a t tr.
Атрибут spawn-schedparam представляет параметры стратегии планирования, при-
сваиваемые образу нового процесса при выполнении операции порождения процесса
(если в атрибуте spawn-flags установлен флаг POSIX_SPAWN—SETSCHEDULER или флаг
POSIX_SPAWN—SETSCHEDPARAM). По умолчанию значение этого атрибута не задано.
Возвращаемые значения
При успешном выполнении функция posix_spawnattr_getschedparam () воз-
вращает нулевое значение и сохраняет значение атрибута spawn-schedparam из объекта
атрибутов, адресуемого параметром attr, в объекте, адресуемом параметром
schedparam, в противном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция posix_spawnattr_setschedparam() возвра-
щает нулевое значение, в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Выполнение этих функций может завершиться неудачно, если:
[ EINVAL] значение, заданное параметром a t tr, недопустимо.
Функция posix_spawnattr_setschedparam () может завершиться неудачно, если:
[ ЕINVAL ] устанавливаемое значение атрибута недопустимо.
Приложение Б 533
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опций Spawn и Process Scheduling и могут быть не
представлены во всех реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix—spawn (), pos ix_spawnattr_des troy (), posix_spawnattr_init (),
posix_spawnattr_getsigdefault(), posix_spawnattr_getflags(),
posix—spawnattr_getpgroup(), posix_spawnattr_getschedpolicy(),
posix—spawnattr_getsigmask(), posix_spawnattr_setsigdefault(),
posix_spawnattr_setflags(), posix_spawnattr_setpgroup(),
posix_spawnattr_setschedpolicy(), posix_spawnattr_setsigmask(),
posix—spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <sched.h>,
< spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
534 Приложение Б
Имя
posix_spawnattr_getschedpolicy, posix_spawnattr_setschedpolicy—
функции считывания и установки атрибута spawn-schedpolicy из объекта атрибу-
тов порожденного процесса (ADVANCED REALTIME).
Синопсис
SPN #include <spawn.h>
#include <sched.h>
int posix_spawnattr_getschedpolicy (
const posix—spawnattr_t *restrict attr,
int *restrict schedpolicy);
int posix—spawnattr_setschedpolicy (
posix_spawnattr_t *attr,
int schedpolicy);
Описание
Функция posix—spawnattr_getschedpolicy () предназначена для получения
значения атрибута spawn-schedpolicy из объекта атрибутов, адресуемого пара-
метром a t tr.
Функция posix—spawnattr_setschedpolicy () позволяет установить атрибут
spawn-schedpolicy в инициализированном объекте атрибутов, адресуемом пара-
метром a t tr.
Атрибут spawn-schedpoliсу представляет стратегию планирования, назначае-
мую образу нового процесса при выполнении операции порождения процесса (если
в атрибуте spawn-flags установлен флаг POSIX_SPAWN_SETSCHEDULER). По умол-
чанию значение этого атрибута не задано.
Возвращаемые значения
При успешном выполнении функция posix_spawnattr_getschedpolicy () возвра-
щает нулевое значение и сохраняет значение атрибута spawn-schedpolicy из объекта
атрибутов, адресуемого параметром attr, в объекте, адресуемом параметром
schedpolicy в противном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция posix_spawnattr_setschedpolicy () возвра-
щает нулевое значение, в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Выполнение этих функций может завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, недопустимо.
Функция posix—spawnattr_setschedpolicy () может завершиться неудачно, если:
[ EINVAL] устанавливаемое значение атрибута недопустимо.
Приложение Б 535
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опций Spawn и Process Scheduling и могут быть не
представлены во всех реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix—spawn (), posix_spawnattr_destroy (), posix_spawnattr_init (),
posix_spawnattr_getsigdefault(), posix_spawnattr_getflags(),
posix_spawnattr_getpgroup(),posix_spawnattr_getschedparam(),
posix_spawnattr_get sigmask (), posix_spawnattr_set sigdefault (),
posix—spawnattr_setflags(), posix_spawnattr_setpgroup(),
posix—spawnattr_setschedparam (), posix_spawnattr_setsigmask (),
posix_spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <sched.h>,
<spawn.h>
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std I003.1d-1999.
536 Приложение Б
Имя
posix_spawnattr_getsigdefault, posix_spawnattr_setsigdefault —
функции считывания и установки атрибута spawn-sigdefault из объекта атрибутов
порожденного процесса (ADVANCED REALTIME).
Синопсис
SPN #include <signal.h>
#include <spawn.h>
int posix_spawnattr_getsigdefault (
const posix_spawnattr_t *restrict attr,
sigset—t *restrict sigdefault};
int posix—spawnattr_setsigdefault (
posix—spawnattr_t *restrict attr,
const sigset—t *restrict sigdefault};
Описание
Функция posix— spawnattr_getsigdefault () предназначена для получения
значения атрибута spawn-sigdefaul t из объекта атрибутов, адресуемого пара-
метром attr.
Функция posix—spawnattr—setsigdefault () позволяет установить атрибут
spawn-sigdefaul t в инициализированном объекте атрибутов, адресуемом пара-
метром a t tr.
Атрибут spawn-sigdefaul t представляет множество сигналов, которые должны
быть подвергнуты обработке по умолчанию в образе нового процесса (если в атрибуте
spawn-flags установлен флаг POSIX_SPAWN— SETSIGDEF) при выполнении опера-
ции порождения процесса. По умолчанию значение этого атрибута представляет со-
бой пустое множество сигналов.
Возвращаемые значения
При успешном выполнении функция posix_spawnattr_getsigdefault () возвра-
щает нулевое значение и сохраняет значение атрибута spawn-sigdefaul t из объекта ат-
рибутов, адресуемого параметром attr, в объекте, адресуемом параметром sigdefault’,
в противном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция posix_spawnattr_setsigdef ault ()
возвращает нулевое значение, в противном случае — код ошибки, обозначающий
ее характер.
Ошибки
Выполнение этих функций может завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, недопустимо.
Приложение Б 537
Функция posix_spawnattr_setsigdef ault () может завершиться неудачно, если:
[ ЕINVAL ] устанавливаемое значение атрибута недопустимо.
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix_spawn (), posix_spawnattr_destroy (), posix_spawnattr_init (),
posix_spawnattr_get flags (), posix_spawnattr_getpgroup (),
posix—spawnattr_getschedparam (), posix_spawnattr_getschedpolicy (),
pos ix_spawna ttr_get sigmask (), pos ix_spawnattr_set flags (),
posix—spawnattr_setpgroup (), posix_spawnattr_setschedparam (),
posix_spawnattr_setschedpolicy (), posix_spawnattr_setsigmask (),
posix_spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <signal. h>,
< spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.18-1999.
538 Приложение Б
Имя
pos ix_spawnattr_get sigmask, posix_spawnattr_setsigmask — функции
считывания и установки атрибута spawn-sigmask из объекта атрибутов порожденно-
го процесса (ADVANCED REALTIME).
Синопсис
SPN #include <signal.h>
#include <spawn.h>
int posix—spawnattr_getsigmask (
const posix—spawnattr_t *restrict attr,
sigset—t *restrict sigmask);
int posix—spawnattr_setsigmask (
posix—spawnattr_t *restrict attr,
const sigset—t *restrict sigmask);
Описание
Функция posix— spawnattr_getsigmask () предназначена для получения значе-
ния атрибута spawn-sigmaskиз объекта атрибутов, адресуемого параметром attr.
Функция posix— spawnat t r_ set sigmask () позволяет установить атрибут spawn-
si gmaskв инициализированном объекте атрибутов, адресуемом параметром attr.
Атрибут spawn-sigmask представляет маску сигналов, предназначенную для ис-
пользования в образе нового процесса при выполнении операции порождения про-
цесса (если в атрибуте spawn-flags установлен флаг POSIX_SPAWN— SETSIGMASK).
По умолчанию значение этого атрибута не определено.
Возвращаемые значения
При успешном выполнении функция posix_spawnattr_getsigmask () возвра-
щает нулевое значение и сохраняет значение атрибута spawn-sigmask из объекта
атрибутов, адресуемого параметром attr, в объекте, адресуемом параметром
sigmask; в противном случае возвращается код ошибки, обозначающий ее характер.
При успешном выполнении функция posix_spawnattr_setsigmask () возвраща-
ет нулевое значение, в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Выполнение этих функций может завершиться неудачно, если:
[EINVAL] значение, заданное параметром at tr, недопустимо.
Функция posix— spawnattr_setsigmask () может завершиться неудачно, если:
[EINVAL] устанавливаемое значение атрибута недопустимо.
Приложение Б 539
Примеры
Отсутствуют.
Замечания по использованию
Эти функции являются частью опции Spawn и могут быть не представлены во всех
реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
posix_spawn(), posix—spawnattг_destroy(), posix_spawnattr_init(),
posix_spawnattr_getsigdef ault (), pos ix_spawnattr_get flags (),
posix_spawnattr_getpgroup (), posix_spawnattr_getschedparam (),
posix_spawnattr_getschedpolicy(), posix_spawnattr_setsigdefault(),
pos ix_spawnattr_set flags (), posix_spawnattr_setpgroup (),
posix—spawnattr_setschedparam (), posix_spawnattr_setschedpolicy (),
posix_spawnp (), том Base Definitions стандарта IEEE Std 1003.1-2001, <signal. h>,
< spawn. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
540 Приложение Б
Имя
pthread_attг_destroy, pthread—attr_init — функции разрушения и инициа-
лизации объекта атрибутов потока.
Синопсис
THR #include <рthread.h>
int pthread—attr_destroy (pthread—attr—t *attr);
int pthread—at tr_in it (pthread—at tr_t ★attr)
Описание
Функция pthread— attr_destroy () предназначена для разрушения объекта
атрибутов потока. В конкретной реализации функция pthread—attr_destroy ()
может устанавливать параметр attr равным некоторому недействительному зна-
чению, определяемому реализацией. Разрушенный объект атрибутов, адресуемый
параметром attr, можно инициализировать повторно с помощью функции
pthread—attr_init (); результаты ссылки на этот объект после его разрушения
не определены.
Функция pthread—attr_init () позволяет инициализировать объект атрибутов
потока, адресуемый параметром attr, значением, действующим по умолчанию для
всех отдельных атрибутов, используемых в данной реализации.
Результирующий объект атрибутов (возможно, модифицированный путем уста-
новки значений отдельных атрибутов) при выполнении функции pthread—create ()
определяет атрибуты создаваемого потока. В нескольких одновременных вызовах
функции pthread—create () можно использовать один объект атрибутов. Результат
вызова функции pthread—attr_init () не определен, если заданный параметром
attr объект атрибутов уже инициализирован.
Возвращаемые значения
При успешном завершении эти функции возвращают нулевое значение; в против-
ном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—attr_init () завершится неудачно, если:
[ENOMEM] для инициализации объекта атрибутов потока недостаточно сущест-
вующей памяти.
Эти функции не возвращают код ошибки в виде значения [EINTR].
Примеры
Отсутствуют.
Приложение Б 541
Замечания по использованию
Отсутствует.
Логическое обоснование
Объекты атрибутов используются для потоков, мьютексов и условных переменных
в качестве будущего механизма поддержки стандартизации в этих областях, не тре-
бующего изменения самих функций.
Объекты атрибутов обеспечивают четкую автономность реконфигурируемых ас-
пектов потоков. Например, важным атрибутом потока является “размер стека”, кото-
рый при переносе многопоточной программы с одного компьютера на другой часто
приходится корректировать. Использование объектов атрибутов позволит вносить
необходимые изменения в одном месте программы, а не в разных местах,
“разбросанных” по всем экземплярам потоков.
Объекты атрибутов можно использовать для создания классов потоков с анало-
гичными атрибутами; например, “потоков с большими стеками и высоким приорите-
том” или “потоков с минимальными стеками”. Эти классы можно определить в одном
месте программы, а затем их использовать, когда понадобится создать поток. В ре-
зультате значительно упростится процесс изменения “классовых” решений потоков,
и не придется подробно анализировать каждый вызов функции pthread_create ().
Объекты атрибутов с целью потенциальной расширяемости определяются как
“закрытые” типы. Если бы они были определены как “прозрачные” структуры, то при
добавлении новых атрибутов (т.е. при расширении объектов атрибутов) пришлось бы
перекомпилировать все многопоточные программы, что не всегда возможно, например,
если различные программные компоненты приобретены у различных изготовителей.
Кроме того, “непрозрачные” объекты атрибутов предоставляют возможность для
повышения быстродействия. Достоверность атрибутов можно проверить один раз при их
установке, а не при каждом создании потока. Ведь реализации зачастую требуют кэширо-
вания объектов ядра, создание которых считается “дорогим удовольствием”. Именно
“непрозрачные” объекты атрибутов позволяют вовремя определить, в какой момент
кэшированные объекты становятся недействительными из-за изменения атрибутов.
Поскольку оператор присваивания необязательно должен быть определен для ка-
ждого “непрозрачного” типа, значения, определяемые конкретной реализацией по
умолчанию, невозможно назначать без ущерба для переносимости. Для решения этой
проблемы можно позволить динамическую инициализацию объектов атрибутов с по-
мощью соответствующих функций инициализации, и тогда значения, действующие по
умолчанию, реализация сможет назначать автоматически.
В качестве предполагаемой альтернативы поддержки атрибутов были представле-
ны следующие предложения.
1. Поддерживается стиль передачи функциям инициализации (pthread_create (),
pthread_mutex_init (), pthread_cond_init ()) параметра, формируемого пу-
тем применения поразрядной операции включающего ИЛИ к флагам. Содержащий
эти флаги параметр (в расчете на расширяемость в будущем) должен иметь
“непрозрачный” тип. Если в этом параметре флаги не установлены, то объекты соз-
даются с использованием характеристик, действующих по умолчанию. Реализация
самостоятельно может задавать значения флагов и соответствующее им поведение.
542 Приложение Б
2. Если необходима дальнейшая специализация мьютексов и условных перемен-
ных, в реализациях могут быть определены дополнительные процедуры, пред-
назначенные для выполнения действий над объектами типа pthread_mutex__t
и pthread_cond_t (а не над объектами атрибутов).
При внедрении этого решения возможны следующие трудности.
1. Побитовая маска не будет считаться “закрытой”, если биты должны быть уста-
новлены в векторных объектах атрибутов с использованием явно закодирован-
ных поразрядных операций включающего ИЛИ. Если количество опций пре-
вышает размер типа int, прикладные программисты должны знать местопо-
ложение каждого бита. Если биты устанавливаются или считываются путем
средств инкапсуляции (т.е. с помощью функций считывания и установки), то
побитовая маска будет представлять собой всего лишь реализацию объектов
атрибутов без свободного доступа для программиста.
2. Многие атрибуты имеют тип, отличный от булевого, или представляют собой ма-
лые целые значения. Например, для задания стратегии планирования можно вы-
делить 3 или 4 бит, но для приоритета потребуется 5 или больше бит, следова-
тельно по меньшей мере 8 из 16 возможных бит (для компьютеров с 16-разряд-
ными целочисленными значениями) уже “занято”. Поэтому побитовая маска
может корректно управлять только атрибутами булевого типа (“установлен”
или нет) и не может служить в качестве хранилища для значений иного типа.
Такие значения необходимо задавать или в качестве параметров функций
(которые не относятся к числу наращиваемых), или путем установки полей
структуры (которые не являются “закрытыми”), или с помощью функций дос-
тупа, т.е. функций считывания и записи (которые делают побитовую маску из-
лишним дополнением к объектам атрибутов).
Размер стека определяется как необязательный атрибут, поскольку само понятие
стека зависит от конкретного компьютера. Например, в одних реализациях невозможно
изменить размер стека, а в других в этом вообще нет необходимости, поскольку стра-
ницы стека могут быть несмежными и выделяться (и освобождаться) по требованию.
Механизм атрибутов разработан по большей мере ради расширяемости. Будущие
дополнения к механизму атрибутов или любому объекту атрибутов, определенному
в этом томе (разделе) стандарта IEEE Std 1003.1-2001, необходимо вносить с чрез-
вычайной тщательностью, чтобы они не отразились на совместимости на уровне
машинных кодов.
Объекты атрибутов, даже создаваемые с помощью таких функций динамического
распределения памяти, как mallocO, во время компиляции могут иметь фиксиро-
ванный размер. Это означает, например, что функция pthread_create () в реализа-
ции с дополнениями для использования типа pthread_attr_t не сможет “видеть” за
пределами области, которую двоичное приложение считает допустимой. Это говорит
о том, что реализации должны поддерживать в объекте атрибутов поле размера,
а также информацию о версии, если дополнения приходится использовать в различ-
ных направлениях (или объединять продукты различных изготовителей).
Приложение Б 543
Будущие направления
Отсутствуют.
Смотри также
pthread_attr_getstackaddr(), pthread_attr_getstacksize(),
pthread_attr_getdetachstate (), thread—create (), том Base Definitions стандарта
lEEEStd 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread_attr_destroy () и pthread—attr_init () отмечены как
часть опции Threads.
Применяется интерпретация IEEE PASC Interpretation 1003.1 #107, в которой ука
зывается, что результат инициализации уже инициализированного объекта атрибутоЕ
потока не определен.
544 Приложение Б
Имя
pthread_attr_getdetachstate, pthread—attr_setdetachstate — функции
считывания и записи атрибута detachstate.
Синопсис
THR #include <pthread.h>
int pthread_attr_getdetachstate (
const pthread—attr_t ★attr,
int *detachstate);
int pthread—attr_setdetachstate (pthread—attr_t ★attr,
int detachstate);
Описание
Атрибут de tachstate управляет тем, создается ли поток в открепленном
(отсоединенном) состоянии. Если поток создается открепленным, то использование
его идентификационного номера (ID) функциями pthread_detach () или
pthread_j oin () является ошибкой.
Функции pthread_attr_getdetachstate() и pthread—attr_setde-
tachstateO считывают и устанавливают соответственно атрибут de tachs ta te
в объекте атрибутов, адресуемом параметром a t tr.
С помощью функции pthread—attr—setdetachstate () приложение может ус-
тановить атрибут detachstate равным либо значению PTHREAD—CREATE—DETACHED,
либо значению PTHREAD—CREATE—JOINABLE.
С помощью функции pthread_attr_getdetachstate () считывается значение
атрибута de tachstate, которое может быть равным либо PTHREAD—
CREATE—DETACHED, либо PTHREAD—CREATE—JOINABLE.
Значение PTHREAD—CREATE—DETACHED используется для перевода всех потоков,
создаваемых с помощью объекта, адресуемого параметром attr, в открепленное со-
стояние, в то время как значение PTHREAD—CREATE—JOINABLE применяется для пе-
ревода всех потоков, создаваемых с помощью объекта, адресуемого параметром attr,
в присоединенное состояние. По умолчанию атрибут detachstate устанавливается
равным значению PTHREAD_CREATE_JOINABLE.
Возвращаемые значения
При успешном завершении функции pthread_attr_getdetachstate ()
и pthread—attr_setdetachstate () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Функция pthread—attr_getdetachstate () при успешном выполнении сохра-
няет значение атрибута detachstate в параметре detachstate.
Приложение Б 545
Ошибки
функция pthread—attr_setdetachstate () завершится неудачно, если:
[EINVAL] значение, заданное параметром detachstate, недействительно.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствует.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
рthread_attг_destroy(), pthread—attr_getstackaddr(),
pthread—attr_getstacksize (), pthread_create (), том Base Definitions стандарта
IEEEStd 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—attr_getdetachstate () и pthread— attr_setdetachs-
tate () отмечены как часть опции Threads.
Раздел “Описание” был отредактирован с целью исключить из него слово “must”
(“должен”).
546 Приложение Б
Имя
pthread_attr_getguardsize, pthread—attr_setguardsize— функции счи-
тывания и установки значения потокового атрибута guardsize.
Синопсис
XSI #include <pthread.h>
int pthread—attr_getguardsize (
const pthread—attr—t *restrict attr,
size—t *restrict guardsize);
int pthread—attr_setguardsize (pthread—attr—t *attr,
size_t guardsize);
Описание
Функция pthread—attr_getguardsize () используется для считывания атрибута
guardsize из объекта атрибутов, адресуемого параметром attr. Этот атрибут воз-
вращается в параметре guardsize.
Функция pthread—attr_setguardsize () позволяет установить атрибут guardsize
в объекте атрибутов, адресуемом параметром a t tr. Новое значение этого атрибута за-
писывается из параметра guardsize. Если значение параметра guardsize равно ну-
лю, то для потоков, создаваемых с использованием атрибута attr, защищенная об-
ласть не предоставляется. Если значение параметра guardsize больше нуля, то для
каждого потока, создаваемого с использованием атрибута attr, предоставляется за-
щищенная область, размер которой составляет не менее guardsize байтов.
Атрибут guardsize позволяет управлять размером защищенной области, выделяе-
мой для стека создаваемого потока. Атрибут guardsize обеспечивает защиту от адрес-
ного переполнения указателя стека. Если стек создается с использованием такой защиты,
реализация выделяет дополнительную память в конце области переполнения стека, кото-
рая служит специальным буфером. Если приложение переполняет стек, входя в этот бу-
фер, формируется сигнал ошибки (возможно, в сигнале SIGSEGV, передаваемом потоку).
Реализация может округлить значение, содержащееся в атрибуте guardsize, до
числа, кратного значению реконфигурируемой системной переменной {PAGESIZE}
(см. заголовок <sys/mman.h>). Если реализация округлит значение атрибута
guardsize до числа, кратного значению переменной {PAGESIZE}, то при вызове
функции pthread—attr_getguardsize () с заданным параметром attr в параметре
guardsize сохранится размер защитной области, установленный в результате пред-
варительного вызова функции pthread—at tr_ set guard size ().
По умолчанию значение атрибута guardsize равно {PAGESIZE} байтам. Реальное
значение переменной {PAGESIZE} определяется реализацией.
Если предварительно был установлен атрибут stackaddr или stack (т.е. инициа-
тор вызова самостоятельно выделяет память для стеков потока и управляет этой па-
мятью), то атрибут guardsize игнорируется, и никакая защита от переполнения сте-
ка потока реализацией не обеспечивается. Вся ответственность в этом случае за
управление памятью стека лежит на приложении.
Приложение Б 547
Возвращаемые значения
При успешном завершении функции р thr ead_attr_get guards i ze ()
npthread—attr_setguardsize () возвращают нулевое значение; в противном слу-
чае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread_attr_getguardsize () завершится неудачно, если:
[EINVAL] значение, заданное параметром guardsize, недействительно;
[ ЕINVAL ] значение параметра a t tr недействительно.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствует.
Логическое обоснование
Атрибут guardsize предлагается для использования приложением по двум причинам.
1. На защиту от переполнения могут потенциально затрачиваться существенные
системные ресурсы. Для приложения, в котором создается большое количество
потоков и существует уверенность в том, что при выполнении потоков их стеки
никогда не будут переполнены, можно сэкономить системные ресурсы, отклю-
чив выделение областей защиты.
2. Если потоки размещают в стеке большие структуры данных, то для обнаружения
факта переполнения стека могут понадобиться области защиты большого объема.
Будущие направления
Отсутствуют.
Смотри также
Том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h> , <sys/mman.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Из раздела “Ошибки” было удалено третье условие возникновения ошибки
[EINVAL], поскольку оно включается во второе условие.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread_attr_getguardsize () было добавлено ключевое слово restrict.
548 Приложение Б
Имя
pthread—attr_getinheritsched, pthread—attr_setinheritsched— функ-
ции считывания и установки атрибута inheri tsched (REALTIME THREADS).
Синопсис
THR TPS # include <pthread.h>
int pthread_attr_getinheritsched (
const pthread—attr_t *restrict attr,
int *restrict inheritsched);
int pthread—attr—setinheritsched (pthread_attr_t ★attr,
int inheritsched) ;
Описание
Функции pthread_attr_getinheritsched() и pthread_attr_setinhe-
ri tsched () используются для считывания и установки соответственно атрибута
inheri tsched в объекте, заданном параметром a t tr.
Если при вызове функции pthread__create () используются объекты атрибутов,
то атрибут inheritsched определяет, как будут устанавливаться другие атрибуты
планирования создаваемого потока.
Значение PTHREAD—INHERIT—SCHED говорит о том, что атрибуты планирования
потоков наследуются от создающего потока, а атрибуты планирования, содержащие-
ся в объекте, заданном параметром attr, игнорируются.
Значение PTHREAD—EXPLICIT—SCHED подразумевает, что атрибуты планирования
потоков устанавливаются равными соответствующим значениям, содержащимся
в объекте атрибутов, заданном параметром a t tr.
Значения PTHREAD—INHERIT—SCHED и PTHREAD—EXPLICIT—SCHED определяются
в заголовке <pthread. h>.
От значения атрибута inheri tsched зависят следующие атрибуты планирования
потоков, определенные стандартом IEEE Std 1003.1-2001: стратегия планирования
(schedpolicy), параметры планирования (schedparam) и область конкуренции
(con tentionscope).
Возвращаемые значения
При успешном завершении функции pthread_attr_get inheritsched ()
и pthread—attr_setinheritsched () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—attr_setinheritsched () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром inheri tsched, недействительно;
Приложение Б 549
[ENOTSUP] была сделана попытка установить атрибут равным значению, кото-
рое не поддерживается реализацией.
Эти функции не возвращают код ошибки [ EINTR].
Примеры
Отсутствуют.
Замечания по использованию
После установки этих атрибутов поток можно создать путем вызова функции
pthread—create () с заданными атрибутами. Использование этих функций не ока-
зывает влияния на поток, выполняемый в данный момент.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread_attr_destroy (), pthread—attr_getscope (),
pthread—attr_getschedpolicy(), pthread_attr_getschedparam(),
pthread_create (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>, <sched.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—attr_getinheritsched() и pthread—attr_setinheri-
t sched () отмечены как часть опций Threads и Thread Execution Scheduling.
Условие ошибки [ENOSYS] было удалено, поскольку в заглушках нет необходимо-
сти, если реализация не поддерживает опцию Thread Execution Scheduling.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
Pthread—attr_getinheritsched () было добавлено ключевое слово restrict.
550 Приложение Б
Имя
pthread—attr_getschedparam, pthread—attr_setschedparam— функции
считывания и установки атрибута schedparam.
Синопсис
THR #include <pthread.h>
int pthread—attr_getschedparam (
const pthread—attr_t *restrict attr,
struct sched—param *restrict param);
int pthread—attr_setschedparam (
pthread—attr_t *restrict attr,
const struct sched—param *restrict param);
Описание
Функции pthread—attr_getschedparam () и pthread—attr_setschedparam ()
используются для считывания и установки соответственно атрибутов параметров плани-
рования в объекте, заданном параметром a t tr. Содержимое структуры param определено
в заголовке <sched.h>. Для установки стратегий планирования SCHED_FIFO и SCHED_RR
единственным обязательным членом структуры param является sched_priori ty.
таР Для установки стратегии планирования SCHED—SPORADIC необходимо
установить следующие члены структуры param: sched-priority,
sched—ss_low-priority, sched__ss_repl-period, sched_ss_init_budget
и sched_ss_max_repl. Для успешного выполнения функции установки
необходимо, чтобы заданное значение члена sched_ss_repl_period
было больше или равно значению заданного члена sched_ss_ini t_
budget; в противном случае функция завершится неудачно. Для ус-
пешного выполнения функции установки также необходимо, чтобы
значение члена sched— ss_max_repl находилось в пределах вклю-
чающего диапазона [1. {SS_REPL_MAX} ]; в противном случае
функция завершится неудачно.
Возвращаемые значения
При успешном завершении функции pthread—attr_getschedparamf)
и pthread—attr_setschedparam () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—attr_setschedparam () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром param, недействительно;
Приложение Б 551
[ ENOTSUP ] была сделана попытка установить атрибут равным значению, которое
не поддерживается реализацией.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
После установки этих атрибутов поток можно создать путем вызова функции
pthread—create () с использованием объекта атрибутов. Применение этих функций
не оказывает влияния на поток, выполняемый в данный момент.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—at t г_destroy (), pthread—at tr_get scope (),
pthread—attr_getinheritsched (), pthread—attr_getschedpolicy (),
pthread—create (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>, <sched.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—attr_getschedparam () и pthread—attr_setschedparam ()
отмечены как часть опции Threads.
В целях согласования со стандартом IEEE Std 1003. Id-1999 была добавлена страте-
гия планирования SCHED_SPORADIC.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототипы функций
pthread—attr_getschedparam () и pthread—attr_setschedparam () было добав-
лено ключевое слово restrict.
552 Приложение Б
Имя
pthread_attr_getschedpolicy, pthread—attr_setschedpolicy— функции
считывания и установки атрибута schedpoliсу (REALTIME THREADS).
Синопсис
THRTPS #include <pthread.h>
int pthread—attr_getschedpolicy (
const pthread—attr—t *restrict attr,
int *restrict policy);
int pthread—attr—setschedpolicy (
pthread—attr—t *attr,
int policy) ;
Описание
Функции pthread—attr_getschedpolicy () и pthread—attr_setschedpolicy ()
используются для считывания и установки соответственно атрибута schedpolicy
в объекте атрибутов, адресуемом параметром a t tr.
Для обозначения стратегии планирования поддерживаются значения
SCHED—FIFO, SCHED—RR и SCHED_OTHER, которые определены в заго-
ловке <sched. h>.
TSP Когда потоки, выполняющиеся с использованием стратегий планиро-
вания SCHED—FIFO, SCHED—RR или SCHED_SPORADIC, ожидают освобо-
ждения мьютекса, то его получение (после разблокировки) происходит
согласно приоритетам.
Возвращаемые значения
При успешном завершении функции pthread— attr_getschedpolicy ()
и pthread—attr_setschedpolicy () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread_attr_setschedpolicy () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром policy, недействительно;
[ENOTSUP] была сделана попытка установить атрибут равным значению, которое
не поддерживается реализацией.
Эти функции не возвращают код ошибки [EINTR].
Приложение Б 553
Примеры
Отсутствуют.
Замечания по использованию
После установки этих атрибутов поток можно создать путем вызова функции
pthread—create () с использованием объекта атрибутов. Применение этих функций
не оказывает влияния на поток, выполняемый в данный момент.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—attr_destroy(), pthread—attr_getscope(),
pthread—attr—getinheritsched (), pthread—attr_getschedparam(),
pthread—create (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>, <sched.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—attr_getschedpolicy() и pthread—attr_setsched-
policy () отмечены как часть опций Threads и Thread Execution Scheduling.
Условие ошибки [ENOSYS] было удалено, поскольку в заглушках нет необходимо-
сти, если реализация не поддерживает опцию Thread Execution Scheduling.
В целях согласования со стандартом IEEE Std 1003.1d-1999 была добавлена страте-
гия планирования SCHED_SPORADIC.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—attr_getschedpolicy () было добавлено ключевое слово restrict.
554 Приложение Б
Имя
pthread—cancel — функция отмены выполнения потока.
Синопсис
THR # include <ptbread.h>
int pthread_cancel (pthread—t thread);
Описание
Функция pthread—cancel () создает запрос на отмену потока. Когда именно от-
мена вступит в силу, зависит от текущего состояния потока, заданного параметром
thread, и его типа. При отмене потока должны быть вызваны обработчики, выпол-
няющие подготовительные действия, связанные с отменой потока. По завершении
последнего обработчика должны быть вызваны деструкторы объектных данных, ис-
пользуемых отменяемым потоком. По завершении последнего деструктора поток, за-
данный параметром thread, должен завершиться.
Действия, связанные с отменой заданного потока, выполняются асинхронно по
отношению к потоку, вызывающему функцию pthread—cancel ().
Возвращаемое значение
При успешном завершении функция pthread—cancel () возвращает нулевое зна-
чение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—cancel () может завершиться неудачно, если:
[ESRCH] не удалось найти поток, идентификационный номер (ID) которого соот-
ветствовал бы заданному.
Функция pthread—cancel () не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Для отправки потоку уведомления об отмене рассматривалось два альтернативных
варианта. Для одного предполагалось определить новый сигнал SIGCANCEL с соот-
Приложение Б 555
ветствующей семантикой отмены, а для другого— новую функцию
pthread—cancel (), которая бы приводила в действие процедуру отмены потока.
Преимущество варианта, предусматривающего создание нового сигнала, состояло
в том, что критерии его выдачи были бы во многом идентичны тем, которые исполь-
зовались при попытке выдать любой другой сигнал, поэтому сигнальный механизм
уведомления об отмене казался унифицированным. И в самом деле, во многих реали-
зациях отмена потоков осуществляется посредством специального сигнала. Однако до
сих пор не существовало ни одной сигнальной функции (за исключением функции
pthread—kill ()), которую можно было бы использовать совместно с этим новым
сигналом, поскольку поведение выдаваемого сигнала отмены должно было отличать-
ся от поведения любого из уже определенных сигналов.
К достоинству варианта создания специальной функции можно отнести осознание
того, что уведомление об отмене потока было бы в этом случае четко определенным.
Кроме того, механизм выдачи уведомления об отмене не требует реализации в виде сиг-
нала. Ведь если такой механизм заметно ближе к сигналам, то ему свойственны аналогии
с языковым механизмом исключительных ситуаций, которые потенциально не видны.
В конечном счете, поскольку необходимость обеспечивать обработку большого
числа исключительных ситуаций при использовании нового сигнала с существующи-
ми сигнальными функциями может неоправданно усложнить (даже запутать) процесс
отмены потока, было решено сделать выбор в пользу специальной функции, которая
устраняет эту проблему. Такая функция была тщательно разработана, причем так, что
любая реализация могла бы обеспечить “безоговорочное” выполнение процедуры
отмены “поверх” каких бы то ни было сигналов. Наличие специальной функции от-
мены потока также означает, что реализации не обязаны обеспечивать процедуру от-
мены с помощью сигналов.
Будущие направления
Отсутствуют.
Смотри также
pthread—exit(), pthread—сond_timedwait(), pthread—join(),
pthread—setcancelstate (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с расширением POSIX Threads Extension.
Issue 6
Функция pthread—cancel () отмечена как часть опции Threads.
556 Приложение Б
Имя
pthread_cleanup_pop, pthread—cleanup—push — функции создания обработ-
чиков запроса об отмене потоков.
Синопсис
THR #include <pthread.h>
void pthread—cleanup—pop (int execute);
void pthread—cleanup—push (void (* routine) (void*),
void *arg);
Описание
Функция pthread—cleanup—pop () используется для извлечения функции, распо-
ложенной в вершине стека вызывающего потока, предназначенного для выполнения
подготовительных действий по аннулированию потока, и ее вызова (если параметр
execute не равен нулю).
Функция pthread—cleanup—push () позволяет поместить в стек вызывающего по-
тока заданную функцию обработчика гои tine, предназначенного для выполнения под-
готовительных действий по аннулированию потока. Этот обработчик будет извлечен из
соответствующего стека и вызван с аргументом агд при наличии следующих условий:
• поток существует (т.е. он вызывает функцию pthread—exit ());
• поток действует в соответствии с запросом отмены;
• поток вызывает функцию pthread—cleanup—pop () с ненулевым значением
аргумента execute.
Эти функции можно реализовать как макросы. Приложение должно гарантировать,
что они имеют форму инструкций и используются попарно в пределах одного и того же
лексического контекста (чтобы макрос pthread—cleanup—push () раскрывался в спи-
сок лексем, начинающийся лексемой ‘{\ а макрос pthread—cleanup—pop () раскры-
вался в список лексем, завершающийся соответствующей лексемой ’} ’)•
Результат вызова функции longjmp() или siglongjmp () не определен, ес-
ли имели место обращения к функции pthread—cleanup—push () или
pthread—cleanup—pop () без соответствующего “парного” вызова по причине за-
полнения буфера переходов. Результат вызова функции long jmp () или
siglongjmp () из обработчика, предназначенного для выполнения подготовитель-
ных действий по аннулированию потока, также не определен.
Возвращаемые значения
Функции pthread—cleanup—push () и hread_cleanup—pop () не возвращают
никакого значения.
Приложение Б 557
Ошибки
Ошибки не определены.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Следующий код представляет собой пример использования примитивов потока
для реализации блокировки чтения-записи (с приоритетом для записи) с возможно-
стью отмены.
typedef struct {
pthread—mutex_t lock;
pthread—cond—t rcond,
wcond;
int lock_count;
/* lock—count < 0 .. Удерживается записывающим потоком. */
/* lock—count > 0 .. Удерживается lock_count считывающими
* потоками. */
/* lock_count = 0 .. Ничем не удерживается. */
int waiting—writers; /* Счетчик ожидающих записывающих
* потоков. */
} rwlock;
void
waiting—reader—cleanup (void. *arg)
{
rwlock *1;
1 = (rwlock *) arg;
pthread—mutex—unlock (&l->lock);
}
void
lock_for_read (rwlock *1)
{
pthread—mutex—lock (&l->lock);
pthread—cleanup—push (waiting—reader_cleanup, 1);
while ((l->lock_count < 0) && (l->waiting_writers ! = 0))
pthread—cond_wait (&l->rcond, &l->lock);
l->lock_count++;
/*
* Обратите внимание на то, что функция pthread—cleanup—pop()
* выполняет здесь функцию waiting—reader—cleanup().
*/
pthread—cleanup—pop(1);
void
release—read_lock (rwlock *1)
pthread—mutex—lock (&l->lock);
if (--l->lock_count == 0)
pthread—cond_signal (&l->wcond);
pthread—mutex—unlock (1);
558 Приложение Б
void
Waiting_writer_cleanup (void *arg)
{
rwlock *1;
1 = (rwlock *) arg;
if ((--l->waiting_writers == 0) && (l->lock—count >= 0)) {
/*
* Это происходит только в случае отмены потока.
*/
pthread_cond_broadcast (&l->wcond);
}
pthread—mutex—unlock (&l->lock) ;
}
void
lock—for—write (rwlock *1)
{
pthread—mutex—lock (&l->lock) ;
l->waiting_writers++;
pthread—cleanup_push (waiting_writer_cleanup, 1);
while (l->lock_count ! = 0)
pthread_cond—wait (&l->wcond, &l->lock);
l->lock_count = -1;
/*
* Обратите внимание на то, что функция pthread—сleanup_pop()
* выполняет здесь функцию waiting—writer—cleanup().
*/
pthread—cleanup—pop (1) ;
}
void
release—write_lock (rwlock *1)
{
pthread—mutex—lock (&l->lock);
l->lock_count = 0;
if (l->waiting_writers == 0)
pthread—cond_broadcast (&l->rcond)
else
pthread—cond_signal (&l->wcond);
pthread—mutex—unlock (&l->lock);
}
/*
* Эта функция вызывается для инициализации блокировки
* чтения-записи.
*/
void
initialize—rwlock (rwlock *1)
{
pthread—mutex—init (&l->lock, pthread-mutexattr_default);
pthread—cond_init (&l->wcond, pthread—condattr_default);
pthread—cond_init (&l->rcond, pthread—condattr_default);
l->lock—count = 0;
l->waiting_writers = 0;
Приложение Б 559
reader_thread()
lock—for_read (block);
pthread—cleanup-push (release—read—lock, block);
/*
* Поток устанавливает блокировку для чтения.
*/
pthread—cleanup_pop (1) ;
}
writer_thread()
{
lock—for_write (block);
pthread_cleanup-push (release—write_lock, block);
/*
* Поток устанавливает блокировку для записи.
*/
pthread—cleanup—pop (1) ;
}
Замечания по использованию
Две описываемые здесь функции, pthread_cleanup—push () и pthread—clea-
nup—pop (), которые помещают и извлекают из стека обработчики запроса на отмену
потока, можно сравнить с левой и правой круглыми скобками. Их нужно всегда ис-
пользовать “в паре”.
Логическое обоснование
Ограничение, налагаемое на две функции, pthread—cleanup—push ()
и pthread—cleanup—pop (), которые помещают и извлекают из стека обработчики
запроса на отмену потока, и состоящее в том, что они должны использоваться попарно
в пределах одного и того же лексического контекста, позволяет создавать эффективные
макросы (или компиляторные реализации) и эффективно управлять памятью. Вариант
реализации этих функций в виде макросов может выглядеть следующим образом.
#define pthread—cleanup—push (rtn, arg) { \
struct —pthread—handler—rec cleanup_handler, ** head; \
—cleanup-handler.rtn = rtn; \
—cleanup—handler.arg = arg; \
(void) pthread_getspecific (_pthread-handler—key, &__head);
—cleanup_handler.next = *___head; \
*—head = &__cleanup—handler;
^define pthread—cleanup—pop (ex) \
*—head = cleanup—handler.next; \
if (ex) (*__cleanup_handler.rtn) (_cleanup—handler.arg); \
Возможна даже более “смелая” реализация этих функций, которая позволит компи-
лятору “считать” обработчик запроса на отмену константой, значение которой можно
560 Приложение Б
“встраивать” в код. В данном томе стандарта IEEE Std 1003.1-2001 пока оставлен неопре-
деленным результат вызова функции longjmp () из обработчика сигнала, выполняемо-
го в функции библиотеки POSIX System Interfaces. Если в какой-то реализации потребу-
ется разрешить этот вызов и придать ему надлежащее поведение, функция longjmp ()
должна в этом случае вызвать все обработчики запроса на отмену, которые были поме-
щены в стек (но еще не извлечены из него) с момента вызова функции set jmp ().
Рассмотрим многопоточную функцию, вызываемую одним потоком, который ис-
пользует сигналы. Если бы сигнал был выдан обработчику сигналов во время опера-
ции qsort (), и этому обработчику пришлось бы вызвать функцию longjmp ()
(которая в свою очередь не вызывала бы обработчики запроса на отмену), то вспомо-
гательные потоки, создаваемые функцией qsort (), не были бы аннулированы. Они
бы продолжали выполняться и осуществляли запись в массив аргументов даже в том
случае, если этот массив был к тому времени извлечен из стека.
Обратите внимание на то, что такой механизм обработки запросов на отмену осо-
бенно тесно связан с языком С, и, несмотря на требование независимости языка,
предъявляемое к любому унифицированному механизму выполнения “очистительно-
восстановительных работ”, подобный механизм, выраженный в других языках, может
быть совершенно иным. Кроме того, необходимость этого механизма в действитель-
ности связана только с отсутствием реального механизма обработки исключительных
ситуаций в языке С, который был бы идеальным решением.
Здесь отсутствуют замечания о функции безопасной отмены потока. Если прило-
жение в своих обработчиках сигналов не имеет точек отмены, блокирует любой сиг-
нал, обработчик которого может иметь точки отмены (несмотря на вызов асинхрон-
но-опасных функций), или запрещает отмену (несмотря на вызов асинхронно-
опасных функций), все функции можно безопасно вызывать из функций обработки
запросов на отмену потоков.
Будущие направления
Отсутствуют.
Смотри также
pthread_cancel (), pthread_setcancelstate (), том Base Definitions стандарта
IEEEStd 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—cleanup—pop() и pthread—cleanup—push () отмечены как
часть опции Threads.
Добавлен раздел “Замечания по использованию” (APPLICATION USAGE).
Раздел “Описание” был отредактирован с целью исключить из него слово
“must” (“должен”).
Приложение Б 561
Имя
pthread-Cond—broadcast, pthread—cond—signal — функции разблокировки
потоков, заблокированных с помощью переменной условия.
Синопсис
THR # include <рthread.h>
int pthread—cond_broadcast (pthread—cond_t *cond);
int pthread_cond_signal (pthread—cond_t *cond);
Описание
Эти функции используются для разблокировки потоков, заблокированных с по-
мощью переменной условия.
Функция pthread—сond_broadcast () позволяет разблокировать все потоки, за-
блокированные в данный момент с использованием переменной условия, заданной
параметром cond.
Функция pthread—cond—signal () используется для разблокировки по крайней
мере одного из потоков, заблокированных с использованием условной переменной,
заданной параметром cond (если таковые существуют). Если с использованием этой
переменной условия заблокировано несколько потоков, то порядок разблокировки
будет определен в соответствии с их стратегией планирования. Когда каждый по-
ток, разблокированный в результате вызова функции pthread—cond—broadcast ()
или pthread—cond_signal (), вернется из вызванной им функции
pthread—cond_wait () или pthread—cond—timedwait (), этот поток получит мью-
текс, с которым была вызвана функция pthread—cond—wait () или
pthread—cond—timedwait (). Разблокированные потоки будут состязаться за мью-
текс в соответствии с их стратегией планирования (если это имеет смысл), как будто
каждый из них вызвал функцию pthread—mutex—lock ().
Функции pthread—cond_broadcast () и pthread—cond—signal () могут быть вы-
званы потоком, владеющим (или нет) в данный момент мьютексом. При этом потоки, вы-
звавшие функцию pthread—cond—wait () или pthread—cond—timedwait (), связали во
время ожидания этот мьютекс с условной переменной. Однако, если необходимо обес-
печить прогнозируемое поведение, этот мьютекс может быть заблокирован потоком,
вызвавшим функцию pthread—cond_broadcast () или pthread—cond_signal ().
Функции pthread—cond—broadcast() и pthread—cond_signal() не будут
иметь результата, если в данный момент не существует потоков, заблокированных
с использованием условной переменной, заданной параметром cond.
Возвращаемые значения
При успешном завершении функции pthread—cond—broadcast () и pthread—
cond—signal () возвращают нулевое значение; в противном случае — код ошибки,
обозначающий ее характер.
562 Приложение Б
Ошибки
Функции pthread—cond_broadcast () и pthread—cond_signal () могут завер-
шиться неудачно, если:
[EINVAL] значение, заданное параметром cond, не ссылается на инициализиро-
ванную условную переменную.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Функция pthread—cond—broadcast () используется при изменении состояния общей
переменной в ситуации, когда выполняется сразу несколько потоков. Рассмотрим задачу с
участием одного “изготовителя” и нескольких “потребителей”, в которой “изготовитель”
может вставить в список несколько элементов, к которым могут получать доступ
“потребители” (по одному элементу за раз). Путем вызова функции
pthread—cond_broadcast () “изготовитель” уведомляет о своем действии всех
“потребителей”, которые, возможно, находятся в состоянии ожидания, и, таким образом,
при использовании мультипроцессора приложение может достичь более высокой пропу-
скной способности. Кроме того, функция pthread—cond—broadcast () позволяет упро-
стить реализацию блокировки чтения-записи. Функция pthread—cond—broadcast ()
весьма полезна, когда записывающий поток освобождает блокировку, и нужно
“запустить” все “читающие” потоки, находящиеся в состоянии ожидания. Наконец,
эту широковещательную функцию можно использовать в двухфазном алгоритме
фиксации для уведомления всех клиентов о предстоящей фиксации транзакции.
Функцию pthread—cond—signal () небезопасно использовать в обработчике
сигналов, который вызывается асинхронно. Даже если это было бы безопасно, имела
бы место “гонка” данных между проверками булевой функции pthread—cond—
wait (), которую невозможно эффективно устранить.
Следовательно, мьютексы и переменные условий не подходят для освобождения
ожидающего потока путем сигнализации из кода обработчика сигналов.
Логическое обоснование
Несколько запусков по условному сигналу
Для мультипроцессора, скорее всего, невозможно применить функцию
pthread—cond—signal (), чтобы избежать разблокировки нескольких потоков, за-
блокированных с использованием условной переменной. Рассмотрим, например, сле-
дующую частичную реализацию функций pthread—сond_wait () и pthread—cond_
signal (), выполняемых потоками в заданном порядке. Один поток пытается
“дождаться” нужного значения условной переменной, другой при этом выполняет
функцию pthread—cond_signal (), в то время как третий поток уже находится
в состоянии ожидания.
Приложение Б 563
pthread—cond_wait (mutex, cond) :
value = cond->value; /* 1 */
pthread_mutex_unlock (mutex); /* 2 */
pthread—mutex—lock (cond->mutex); /* 10 */
if (value == cond->value) { /* 11 */
me->next—cond = cond->waiter;
cond->waiter = me;
pthread—mutex_unlock (cond->mutex);
unable_to—run (me);
} else
pthread—mutex_unlock (cond->mutex); /* 12 */
pthread—mutex__lock (mutex) ; /* 13 * /
pthread_cond-Signal (cond) :
pthread_mutex_lock (cond->mutex); /* 3 */
cond->value++; /* 4 */
if (cond->waiter) { /* 5 */
sleeper = cond->waiter; /* 6 */
cond->waiter = sleeper->next—cond; /*7 */
able_to_run (sleeper); /* 8 */
}
pthread—inutex—unlock (cond->mutex) ; /* 9 */
Итак, в результате одного обращения к функции pthread—cond—signal () сразу
несколько потоков могут вернуться из вызова функции pthread—сond_wait () или
pthread—cond—timedwait (). Такой эффект называется “фиктивным запуском”. Об-
ратите внимание на то, что подобная ситуация является самокорректирующейся бла-
годаря тому, что количество потоков, “пробуждающихся” таким путем, ограничено;
например, следующий поток, который вызывает функцию pthread—cond_wait (),
после определенной последовательности событий блокируется.
Несмотря на то что эту проблему можно было бы решить, потеря эффективности
ради обработки дополнительного условия, которое возникает лишь иногда, неприем-
лема, особенно в случае, когда нужно протестировать предикат, связанный с условной
переменной. Корректировка этой проблемы слишком уж понизила бы уровень парал-
лелизма в этом базовом стандартном блоке при выполнении всех высокоуровневых
операций синхронизации.
В разрешении “фиктивных запусков” есть одно дополнительное преимущество:
зная о них, разработчикам приложений придется предусмотреть цикл тестирования
предиката при ожидании наступления нужного условия. Это также вынудит приложе-
ние “терпеливо” отнестись к распространению “лишних” условных сигналов, связан-
ных с одной и той же условной переменной, формирование которых может быть за-
кодировано в какой-то другой части приложения. В результате приложения станут
более устойчивыми. Поэтому в стандарте IEEE Std 1003.1-2001 в прямой форме отме-
чена возможность возникновения “фиктивных запусков”.
Будущие направления
Отсутствуют.
564 Приложение Б
Смотри также
pthread—сond_destroy (), pthread—cond_timedwait (), том Base Definitions
стандарта IEEE Std 1003.1-2001, <pthread. h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—cond—broadcast() и pthread—cond—signal() отмечены
как часть опции Threads.
Добавлен раздел “Замечания по использованию” (APPLICATION USAGE).
Приложение Б 565
Имя
pthread—cond—destroy, pthread_cond_init — функции разрушения и инициа-
лизации условных переменных.
Синопсис
THR #include <pthread.h>
int pthread—cond—destroy (pthread—cond—t ★cond);
int pthread—cond_init (
pthread—cond_t *restrict cond,
const pthread—condattr_t *restrict attr);
pthread—cond_t cond = PTHREAD-COND-INITIALIZER;
Описание
Функция pthread—cond—destroy () используется для разрушения условной пе-
ременной, заданной параметром cond, в результате чего объект становится неини-
циализированным. В конкретной реализации функция pthread—cond_destroy ()
может устанавливать объект, адресуемый параметром cond, равным недействитель-
ному значению. Разрушенный объект условной переменной можно снова инициали-
зировать с помощью функции pthread—cond_init (); результаты ссылки на этот
объект после его разрушения не определены.
Нет никакой опасности в разрушении инициализированной условной перемен-
ной, по которой не заблокирован в данный момент ни один поток. Попытка же раз-
рушить условную переменную, по которой заблокированы в данный момент другие
потоки, может привести к неопределенному поведению.
Функция pthread—cond_init () используется для инициализации условной пе-
ременной, адресуемой параметром cond, объектом атрибутов, адресуемым парамет-
ром attr. Если параметр attr содержит значение NULL, для инициализации приме-
няются атрибуты условной переменной, действующие по умолчанию, т.е. результат
в этом случае равносилен передаче адреса объекта, содержащего стандартные атри-
буты условной переменной. После успешной инициализации условная переменная
становится инициализированной.
Для осуществления синхронизации используется только сама условная переменная
cond. Результат ссылки на копии переменной cond в обращениях к функциям
pthread—cond—wait(), pthread—cond_timedwait(), pthread—cond—signal(),
Pthread—cond—broadcast () и pthread—cond_des troy () не определен. Попытка
инициализировать уже инициализированную условную переменную приведет к неоп-
ределенному поведению.
Если атрибуты условной переменной, действующие по умолчанию, заранее опре-
делены, для инициализации условных переменных, которые создаются статически,
можно использовать макрос PTHREAD-COND-INITIALIZER. Результат в этом случае
эквивалентен динамической инициализации путем вызова функции
Pthread—cond—init () с параметром attr, равным значению NULL, но без проверки
На наличие ошибок.
566 Приложение Б
Возвращаемые значения
При успешном завершении функции pthread—cond—destroy ()
иpthread—cond—init () возвращают нулевое значение; в противном случае— код
ошибки, обозначающий ее характер.
Проверка на наличие ошибок с кодами [EBUSY] и [EINVAL] реализована так
(если реализована вообще), как будто она выполняется в самом начале работы каждой
функции, и код ошибки в случае ее обнаружения возвращается до модификации со-
стояния условной переменной, заданной параметром cond.
Ошибки
Функция pthread—cond_destroy () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку разрушить объект, адресуемый па-
раметром cond, который относится к другому потоку (например,
при использовании в функциях pthread—cond—wait () или
pthread—cond_timedwait ());
[EINVAL] значение, заданное параметром cond, недействительно.
Функция pthread—cond—init () завершится неудачно, если:
[EAGAIN] система испытывает недостаток в ресурсах (не имеется в виду память),
необходимых для инициализации еще одной условной переменной;
[ENOMEM] для инициализации условной переменной недостаточно существую-
щей памяти.
Функция pthread—cond_init () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку повторно инициализировать объект
условной переменной, адресуемый параметром cond, которой был ра-
нее инициализирован, но еще не разрушен;
[ ЕINVAL ] значение, заданное параметром a t tr, недействительно.
Примеры
Условную переменную можно разрушить сразу после того, как будут запущены все
потоки, заблокированные по ней. Рассмотрим, например, следующий код.
struct list {
pthread—mutex—t Im;
}
struct elt {
key k;
int busy;
pthread_cond_t notbusy;
}
/* Находим элемент списка и сохраняем его. */
struct elt *
list_find (struct list *lp, key k)
{
struct elt *ep;
pthread—mutex—lock (&lp->lm);
Приложение Б 567
while ((ер = find—elt (1, к) ! = NULL) && ep->busy)
pthread—cond—wait (&ep->notbusy, &lp->lm);
if (ep ! = NULL)
ep->busy = 1;
pthread—mutex-unlock (&lp->lm);
return (ep);
delete_elt (struct list *lp, struct elt *ep)
pthread—mutex—lock (&lp->lm);
assert (ep->busy);
... удаляем элемент ер из списка ...
ep->busy = 0; /* Paranoid. */
(A) pthread_cond—broadcast (&ep->notbusy);
pthread—mutex—unlock (&lp->lm);
(B) pthread_cond—destroy (&rp->notbusy);
free (ep);
}
В этом примере условную переменную и ее элемент списка можно освободить
(строка В) сразу после того, как все потоки, ожидающие соответствующего значения
условной переменной, будут “разбужены” (строка А), поскольку мьютекс и этот код
гарантируют, что никакой другой поток не сможет ссылаться на удаляемый элемент.
Замечания по использованию
Отсутствуют.
Логическое обоснование
См. раздел “Логическое обоснование” в описании функции pthread—mutex_init ().
Будущие направления
Отсутствуют.
Смотри также
pthread—cond—broadcast (), pthread—cond_signal (), pthread—cond_timedwait (),
том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с Расширением POSIX Threads Extension.
Issue 6
Функции pthread_cond—destroy() и pthread—cond_init() отмечены как
Часть опции Threads.
Раздел “Описание” был отредактирован путем применения интерпретации IEEE
PASC Interpretation 1003.1с #34.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
Pthread—cond—init () было добавлено ключевое слово restrict.
568 Приложение Б
Имя
pthread—cond—timedwait, pthread—cond_wait — функции ожидания условия.
Синопсис
THR #include <pthread.h>
int pthread—cond—timedwait (
pthread—cond—t *restrict cond,
pthread—mutex—t *restrict mutex,
const struct timespec *restrict abstime);
int pthread—cond—wait (pthread—cond_t *restrict cond,
pthread—mutex—t *restrict mutex);
Описание
Функции pthread—cond—timedwait () и pthread—cond_wait () используются
для блокирования потоков по условной переменной. Они вызываются с использова-
нием мьютекса mutex, блокируемого вызывающим потоком; в противном случае ре-
зультирующее поведение не определено.
Эти функции автоматически освобождают мьютекс mutex и обеспечивают
блокирование вызывающего потока по условной переменной cond;
“автоматически” здесь означает “автоматический доступ к мьютексу со стороны
другого потока с последующим доступом к условной переменной”. Другими сло-
вами, если какой-то другой поток может получить мьютекс после его освобожде-
ния вызывающим потоком, то результат последующего вызова функции
pthread—cond_broadcast () или pthread— cond_signal () в этом (другом) пото-
ке будет таким, как если бы он имел место после блокирования вызывающего потока.
При успешном выполнении мьютекс будет заблокирован, а владеть им будет вызы-
вающий поток.
При использовании условных переменных всегда существует булев предикат, со-
вместно используемый этими переменными, которые связаны с каждым ожидаемым
условием. Это условие становится истинным, если поток должен продолжать выпол-
нение. При использовании функций pthread—cond_timedwait () или
pthread—cond_wait () возможны фиктивные запуски. Поскольку возврат из этих
функций не подразумевает ничего, кроме оценки значения упомянутого выше преди-
ката, он должен вычисляться после каждого такого выхода из функции.
Результат использования нескольких мьютексов для параллельно выполняемых опе-
раций pthread—cond_timedwait () или pthread—cond_wait () по одной и той же ус-
ловной переменной не определен; другими словами, условная переменная связывается с
уникальным мьютексом, когда поток ожидает заданного значения условной перемен-
ной, и это (динамическое) связывание завершится вместе с завершением ожидания.
Ожидание условия (синхронизированное или нет) представляет собой “точку от-
мены”. Если статус возможности анулирования для потока соответствует значению
PTHREAD—CANCEL—DEFERRED, побочным эффектом действий, выполняемых по за-
просу на аннулирование во время ожидания условия будет повторный захват мьютек-
Приложение Б 569
са перед вызовом первого обработчика запроса на отмену. Другими словами, резуль-
тат будет выглядеть так, как если бы поток был разблокирован и получил возможность
выполниться до точки выхода из вызова функции pthread—cond—timedwait () или
pthread_cond_wait (), но в этой точке “обнаружил” запрос на отмену и вместо воз-
врата к инициатору вызова функции pthread_cond_timedwait () или
pthread_cond_wait () приступил к выполнению действий по аннулированию, кото-
рые включают вызов обработчиков этого запроса.
Поток, который был разблокирован по причине отмены в то время, пока он был
заблокирован в вызове функции pthread—cond—timedwait () или
pthread_cond—wait (), не будет использовать условный сигнал, который можно на-
править параллельно на условную переменную, если существуют другие потоки, за-
блокированные по этой условной переменной.
Функция pthread—cond—timedwait () эквивалентна функции pthre-
ad_cond_wait (), за исключением того, что она возвращает код ошибки, если абсо-
лютное время, заданное параметром abstime, наступит (т.е. системное время станет
равным или превысит значение abstime) до того, как будет передано (с помощью
сигнала) условие cond, или если абсолютное время, заданное параметром abstime,
уже наступило в момент вызова.
CS Если поддерживается опция Clock Selection, условная переменная будет иметь
атрибут часов, определяющий механизм, который предназначен для измерения
времени, заданного параметром abstime. По истечении заданного времени
функция pthread_cond_timedwait () освободит и снова захватит мьютекс,
адресуемый параметром mutex. Функция pthread—сond_timedwait () также
представляет собой точку отмены.
Если потоку, ожидающему значения условной переменной, передается сигнал, то
при возврате из обработчика сигнала поток возобновит ожидание этой условной пе-
ременной (как будто не было никакого прерывания на обработку сигнала) или воз-
вратит нуль вследствие фиктивного запуска.
Возвращаемые значения
За исключением кода ошибки [ETIMEDOUT], все проверки на наличие ошибок
реализованы так, как если бы они были выполнены в самом начале работы каждой
функции, и код ошибки в случае ее обнаружения возвращается до модификации со-
стояния мьютекса, заданного параметром mutex, или условной переменной, заданной
параметром cond.
При успешном завершении возвращается нулевое значение; в противном случае —
код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—cond_timedwait () завершится неудачно, если:
[ETIMEDOUT] время, заданное параметром abstime, наступило.
Функции pthread—cond_timedwait () и pthread—сond_wait () могут завер-
шиться неудачно, если:
570 Приложение Б
[EINVAL] значение, заданное хотя бы одним из параметров cond, mutex или
abstime, недействительно;
[EINVAL] для выполнения параллельных операций pthread—cond_timedwait()
или pthread—cond—wait () по одной и той же условной переменной бы-
ли задействованы различные мьютексы;
[ EPERM ] во время вызова любой из функций мьютексом не владел текущий поток.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Семантика ожидания по условию
Важно отметить, что, когда функции pthread—cond—wait () и
pthread—cond_timedwait () завершаются без ошибки, соответствующий предикат
может все еще иметь ложное значение. Аналогично, когда функция
pthread—cond_timedwait () возвращается с ошибкой истечения времени ожида-
ния, соответствующий предикат может иметь истинное значение из-за неизбежной
“гонки” между истечением периода ожидания и изменением состояния предиката.
В некоторых реализациях, в частности мультипроцессорных, иногда возможно
пробуждение сразу нескольких потоков, если сигнал об изменении состояния услов-
ной переменной генерируется одновременно на различных процессорах.
В общем случае при каждом завершении ожидания по условию поток должен оце-
нивать значение предиката, связанного с ожиданием по условию, чтобы узнать, мо-
жет ли он безопасно продолжать выполнение, ожидать или объявить тайм-аут. Воз-
врат из состояния ожидания не означает, что соответствующий предикат имеет кон-
кретное значение (ЛОЖЬ или ИСТИНА).
Поэтому рекомендуется ожидание по условию выражать в коде, эквивалентном
циклу “while”, который выполняет проверку предиката.
Семантика ожидания по времени
Абсолютное время было выбрано для задания параметра лимита времени по двум
причинам. Во-первых, несмотря на то, что измерение относительного времени нетруД"
но реализовать в начале функции, для которой задается абсолютное время, с заданием
абсолютного времени в начале функции, которая определяет относительное время,
связано условие “гонок”. Предположим, например, что функция clock—get time ()
возвращает текущее время, а функция cond_relative—timed—wait () использует
относительное время.
Приложение Б 571
clOck_gettime (CLOCK—REALTIME, &now)
reltime = sleep_til_this_absolute—time -now;
cond—relative—timed—wait (c, m, &reltime) ;
Если поток выгружается между первой и последней инструкциями, поток блокиру-
ется слишком надолго. Однако блокирование несущественно, если используется абсо-
лютное время. Кроме того, абсолютное время не нужно пересчитывать, если оно ис-
пользуется в цикле несколько раз.
Для случаев, когда системные часы работают дискретно, можно предполагать, что
реализации обработают любые ожидания по времени, истекающие в промежутке ме-
жду дискретными состояниями, так, как если бы нужное время уже наступило.
Аннулирование потока и ожидание по условию
Ожидание по условию, синхронизированное или нет, является точкой отмены
(аннулирования) потока. Другими словами, функции pthread—cond_wait () или
pthread—cond_timedwait () представляют собой точки, в которых обнаружен необ-
работанный запрос на отмену. Дело в том, что в этих точках возможно бесконечное
ожидание, т.е. какое бы событие ни ожидалось, даже при совершенно корректной про-
грамме оно может никогда не произойти; например, входные данные, получения кото-
рых ожидает программа, могут быть никогда не отправлены. Сделав же ожидание по ус-
ловию точкой отмены, поток можно безопасно аннулировать и выполнить соответст-
вующие обработчики даже в случае, если программа “увязнет” в бесконечном ожидании.
Побочный эффект обработки запроса на отмену потока в случае, когда он забло-
кирован по условной переменной, состоит в повторном захвате мьютекса до вызова
любого из обработчиков. Это позволяет гарантировать, что обработчик запроса на
отмену выполняется в таком же статусе, который имеет критический код, располо-
женный до и после вызова функции ожидания по условию. Это правило также требу-
ется соблюдать при взаимодействии с POSIX-потоками, написанными на таких языках
программирования, как Ada или C++, причем здесь можно организовать отмену пото-
ков с использованием встроенного в язык механизма исключительных ситуаций. Это
правило гарантирует, что каждый обработчик исключения, защищающий критиче-
ский раздел, всегда может безопасно отталкиваться от следующего факта: связанный
мьютекс уже заблокирован, независимо от того, в каком именно месте критического
раздела было сгенерировано исключение. Без этого правила обработчики исключи-
тельных ситуаций не могли бы единообразно выполнять свою работу в отношении
блокировки, и поэтому кодирование стало бы весьма громоздким.
Следовательно, поскольку в случае, когда запрос на отмену приходит во время
ожидания, в отношении состояния блокировки должна быть выполнена определен-
ная инструкция, при этом должно быть выбрано такое определение, которое сделает
кодирование приложения наиболее удобным и свободным от ошибок.
При выполнении действий, связанных с получением запроса на отмену потока в то
время, когда он заблокирован по условной переменной, реализация требует гарантии,
что поток не будет использовать ни один из условных сигналов, направленных на услов-
ную переменную, если существуют другие потоки, ожидающие сигнала по этой условной
переменной. Соблюдение этого правила позволяет избежать условий взаимоблокиров-
ки, которые могут возникнуть в случае, если два независимых запроса (один действует
в потоке, а другой связан с условной переменной) не были обработаны независимо.
572 Приложение Б
Быстродействие мьютексов и условных переменных
Предполагается, что мьютексы должны блокироваться только для нескольких ин-
струкций. Такая практика почти автоматически вытекает из желания программистов
избегать длинных последовательностей программных инструкций (которые способ-
ны снизить общую эффективность параллелизма).
При использовании мьютексов и условных переменных всегда пытаются обес-
печить последовательность, которая считается обычным случаем: заблокировать
мьютекс, получить доступ к общим данным и разблокировать мьютекс. Ожидание
по условной переменной — относительно редкая ситуация. Например, при реализа-
ции блокировки чтения-записи коду, который получает блокировку чтения, обычно
нужно лишь инкрементировать счетчик считывающих потоков (при взаимном ис-
ключении доступа). Вызывающий поток будет реально ожидать по условной пере-
менной только тогда, когда уже существует активный записывающий поток. Поэто-
му эффективность операции синхронизации связана с “ценой” блокировки-
разблокировки мьютекса, а не с ожиданием по условию. Обратите внимание на то,
что в обычном случае переключения контекста не происходит.
Из вышесказанного отнюдь не следует, что эффективность ожидания по условию
не важна. Поскольку существует потребность по крайней мере в одном переключении
контекста на рандеву (взаимодействие между параллельными процессами), то эффек-
тивность ожидания по условию также важна. Цена ожидания по условной перемен-
ной должна быть намного меньше минимальной цены одного переключения контек-
ста и времени, затрачиваемого на разблокировку и блокировку мьютекса.
Особенности мьютексов и условных переменных
Было предложено отделить захват и освобождение мьютекса от ожидания по ус-
ловию. Но это предложение было отклонено, по причине “сборной природы” этой
операции, которая в действительности упрощает реализации реального времени.
Такие реализации могут незаметно перемещать высокоприоритетный поток между
условной переменной и мьютексом, тем самым предотвращая излишние переклю-
чения контекстов и обеспечивая более детерминированное владение мьютексом
при получении сигнала ожидающим потоком. Таким образом, вопросы равнодос-
тупности и приоритетности могут быть решены непосредственно самой дисципли-
ной планирования. К тому же, широко распространенная операция ожидания по
условию соответствует существующей практике.
Планирование поведения мьютексов и условных переменных
Примитивы (базовые элементы) синхронизации, которые могут противоречить
используемой стратегии планирования путем установки “своего” правила упорядоче-
ния, считаются нежелательными. Выбор среди потоков, ожидающих освобождения
мьютексов и условных переменных, происходит в порядке, который зависит именно
от стратегии планирования, а не от какой-то другой дисциплины, устанавливающей
некий фиксированный порядок (имеется в виду, например, FIFO-дисциплина или
учет приоритетов). Таким образом, только стратегия планирования определяет, ка-
кой поток (потоки) будет запущен для продолжения работы.
Приложение Б 573
Синхронизированное ожидание по условию
функция pthread—cond_timedwait () позволяет приложению прервать ожида-
ние наступления конкретного условия после истечения заданного интервала времени.
Рассмотрим следующий пример.
(void) pthread—mutex—lock (&t. mn) ;
t,waiters++;
clock—gettime (CLOCK—REALTIME, &ts);
ts.tv_sec += 5;
rc = 0 ;
while (! mypredicate (&t) && rc == 0)
rc = pthread—cond_timedwait (&t.cond, St.mn, &ts);
t.waiters-- ;
if (rc == 0) setmystate (&t);
(void) pthread—mutex—unlock (&t.mn);
Абсолютный параметр времени ожидания позволяет не пересчитывать его значение
каждый раз, когда программа проверяет значение предиката блокирования. Если бы
время ожидания было задано относительной величиной, соответствующий пересчет
пришлось бы делать перед каждым вызовом функции. Это было бы особенно трудно
сделать, поскольку такому коду пришлось бы учитывать возможность дополнительных
запусков вследствие дополнительной сигнализации по условной переменной, которые
могут происходить до того, как предикат станет истинным или истечет время ожидания.
Будущие направления
Отсутствуют.
Смотри также
pthread—cond_signal (), pthread—cond_.broadcast (), том Base Definitions стан-
дарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—cond—timedwait () и pthread—cond_wait () отмечены как
часть опции Threads.
К описанию прототипа функции pthread—сond_wait () был приложен список
опечаток Open Group Corrigendum U021/9.
Для согласования со стандартом IEEE Std 1003.1j-2000 раздел “Описание” был от-
редактирован путем добавления семантики для опции Clock Selection.
В раздел “Ошибки” внесен еще один код ошибки [EPERM] в ответ на включение
Интерпретации IEEE PASC Interpretation 1003.1с #28.
В Целях согласования со стандартом ISO/IEC 9899: 1999 в прототипы функций
Pthread__cond_timedwait () и pthread_cond_wait () было добавлено ключевое
Слово restrict.
574 Приложение Б
Имя
pthread—condattr_destroy, pthread—condattr_init — функции разрушения
и инициализации объекта атрибутов условной переменной.
Синопсис
THR #include <pthread.h>
int pthread—condattr_destroy (pthread_condattr_t *attr)•
int pthread_condattr_init (pthread_condattr_t *attr);
Описание
Функция pthread_condattr_destroy () используется для разрушения объекта
атрибутов условной переменной, в результате чего он становится неинициализиро-
ванным. В конкретной реализации функция pthread—condatt r_des troy () может
устанавливать объект, адресуемый параметром a t tr, равным недействительному зна-
чению. Разрушенный объект атрибутов attr можно снова инициализировать с по-
мощью функции pthread—condattг_init (); результаты ссылки на этот объект по-
сле его разрушения не определены.
Функция pthread—condattг_init () предназначена для инициализации объекта
атрибутов условной переменной attr значением, действующим по умолчанию для
всех атрибутов, определенных конкретной реализацией.
Если функция pthread—condattг_init () вызывается для уже инициализиро-
ванного объекта атрибутов attr, то результаты вызова этой функции не определены.
После того как объект атрибутов условной переменной уже был использован для
инициализации одной или нескольких условных переменных, любая функция, кото-
рая оказывает влияние на объект атрибутов (включая деструктор), никак не отразится
на ранее инициализированных условных переменных.
Этот том стандарта IEEE Std 1003.1-2001 требует наличия двух атрибутов: clock
и process-shared.
Дополнительные атрибуты, их значения по умолчанию и имена соответствующих
функций доступа, которые считывают и устанавливают эти значения атрибутов, оп-
ределяются конкретной реализацией.
Возвращаемые значения
При успешном завершении функции pthread_condattr_destroy()
иpthread_condattr_init() возвращают нулевое значение; в противном случае —
код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—сondattГ—destroy () может завершиться неудачно, если:
[ EINVAL] значение, заданное параметром a t tr, недействительно.
Приложение Б 575
функция pthread—condattr_init () завершится неудачно, если:
[ENOMEM] для инициализации объекта атрибутов условной переменной недос-
таточно существующей памяти.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
См. описание функций pthread_attr_init () и pthread—mutex_init ().
Атрибут process-shared был определен для условных переменных по той же
причине, что и для мьютексов.
Будущие направления
Отсутствуют.
Смотри также
pthread_attr_destroy (), pthread—cond_destroy (),
pthread—condattr_getpshared(), pthread—create(),
pthread—mutex—destroy (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—condattr_destroy () и pthread—condattr_init () отмече-
ны как часть опции Threads.
576 Приложение Б
Имя
pthread_condattr_getpshared, pthread—condattr_setpshared — функции
считывания и установки атрибута условной переменной process-shared.
Синопсис
THRTSH #include <pthread.h>
int pthread—condattr—getpshared (
const pthread—condattr—t *restrict attr,
int *restrict pshared);
int pthread—condattr_setpshared (
p thread—c onda 11 r_t * a 11r,
int pshared);
Описание
Функция pthread— condattr_getpshared () используется для получения значения
атрибута process-shared из объекта атрибутов, адресуемого параметром attr. Функция
pthread—condattr_setpshared () позволяет установить атрибут process-shared
в инициализированном объекте атрибутов, адресуемом параметром attr.
Атрибут process-shared устанавливается равным значению PTHREAD—PROCESS-
SHARED, чтобы разрешить использование условной переменной любым потоком,
имеющим доступ к области памяти, в которой она размещена, даже если эта область па-
мяти разделяется несколькими процессами. Если же атрибут process-shared равен
значению PTHREAD—PROCESS—PRIVATE, условная переменная должна использоваться
только потоками, созданными в одном процессе с потоком, который ее инициализиро-
вал; если с этой условной переменной попытаются работать потоки из различных про-
цессов, поведение такой программы не определено. По умолчанию для этого атрибута
устанавливается значение PTHREAD—PROCESS—PRIVATE.
Возвращаемые значения
При успешном завершении функция pthread—condattr_setpshared () возвра-
щает нулевое значение; в противном случае — код ошибки, обозначающий ее характер.
При успешном завершении функция pthread—condattr_getpshared () возвра-
щает нулевое значение и сохраняет считанное значение атрибута process-shared
объекта attr в объекте, адресуемом параметром pshared; в противном случае воз-
вращается код ошибки, обозначающий ее характер.
Ошибки
Функции pthread_condattr_getpshared () и pthread_condattr_setpshared ()
могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, недействительно.
Приложение Б 577
функция pthread—condattr_setpshared () может завершиться неудачно, если:
[EINVAL] новое значение, заданное для атрибута, не попадает в диапа-
зон значений, действительных для этого атрибута.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—create (), pthread_cond_destroy (), pthread—condattr—destroy (),
pthread—mutex_destroy (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—condattr_getpshared () и pthread_condattr_setpshared ()
отмечены как часть опций Threads и Thread Process-Shared Synchronization.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
Pthread—condattr_getpshared () было добавлено ключевое слово restrict.
578 Приложение Б
Имя
pthread_create — функция создания потока.
Синопсис
THR #include <рthread.h>
int pthread—create (pthread_t *restrict thread,
const pthread—attr_t *restrict attr,
void * (*start_routine) (void*),
void *restrict arg);
Описание
Функция pthread—create () используется для создания в процессе нового потока
с атрибутами, заданными параметром attr. Если значение параметра attr равно NULL,
используются атрибуты, действующие по умолчанию. Если атрибуты, заданные пара-
метром attr, будут модифицироваться позже, то на атрибуты уже созданного потока
это не повлияет. При успешном завершении функция pthread_create () сохраняет ID-
значение созданного потока в области памяти, адресуемой параметром thread.
При создании потока выполняется функция start_routine, которая вызывается
с единственным аргументом агд. Если функция start_routine выполнится до кон-
ца, то результат будет таким, как если бы было сделано явное обращение к функции
pthread—exit (), использующей в качестве состояния выхода (exit status) значение,
возвращаемое функцией start_routine. Обратите внимание на то, что поток, в ко-
тором изначально вызывалась функция main(), отличается от функции
start—routine. При выходе из функции main () результат будет таким, как если бы
было сделано явное обращение к функции exit (), использующей в качестве состоя-
ния выхода значение, возвращаемое функцией main ().
Статус сигналов для нового потока будет инициализирован следующим образом:
• маска сигналов будет унаследована от создающего потока;
• множество необработанных сигналов для нового потока будет пустым.
Среда обработки данных с плавающей точкой будет унаследована от создаю-
щего потока.
При неудачном выполнении функции pthread—create () поток не создается,
а содержимое области, адресуемое параметром thread, остается неопределенным.
ТСТ Если определено значение _POSIX_THREAD—CPUTIME, новый поток по-
лучит доступ к таймеру центрального процессора (CPU-time clock),
и начальное значение для этих часов будет установлено равным нулю.
Возвращаемое значение
При успешном завершении функция pthread—create () возвращает нулевое зна-
чение; в противном случае — код ошибки, обозначающий ее характер.
Приложение Б 579
Ошибки
функция pthread_create () завершится неудачно, если:
[EAGAIN] в системе недостаточно ресурсов, необходимых для создания еще одно-
го потока, или был превышен предел ((PTHREAD_THREADS_MAX)), ус-
тановленный в системе для общего количества потоков в процессе;
[EINVAL] значение, заданное параметром at tr, недействительно;
[EPERM] инициатор вызова не имеет соответствующего разрешения на установку
требуемых параметров планирования или стратегии планирования.
Эта функция не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
В качестве альтернативного решения для функции pthread_create () предлага-
лось определить две отдельные операции: “создать” и “запустить”. Для некоторых
приложений такое поведение было бы более естественным. В среде Ada, в частности,
отделено “создание” задачи от ее “активизации”.
Разбиение этой операции на две части разработчиками стандарта было отклонено
по нескольким причинам.
• Количество вызовов, требуемых для запуска потока, в этом случае возросло бы от
одного до двух, что, таким образом, возложило бы излишние расходы на прило-
жения, которым не нужна дополнительная синхронизация. Однако второго вы-
зова можно было бы избежать за счет усложнения атрибута состояния запуска.
• Для потока пришлось бы вводить дополнительное состояние, которое можно
определить как “созданный, но не активизированный”. Это потребовало бы
введения стандарта для определения поведения операций потока в случае, ко-
гда поток еще не начал выполняться.
• Для приложений, которым подходит именно такое поведение, можно сымитиро-
вать два отдельных действия с использованием существующих средств. Функцию
start_routine () можно синхронизировать путем организации ожидания по
условной переменной, сигнализируемой операцией активизации потока.
При реализации Ada-приложений можно создавать потоки в любой из двух точек
Ada-программы: при создании объекта задачи или при ее активизации. В случае при-
нятия первого варианта функции start_routine () пришлось бы ожидать по услов-
ной переменной получения “приказа” начать активизацию. Второй вариант не требу-
ет использования условной переменной или дополнительной синхронизации. В лю-
580 Приложение Б
бом случае при создании объекта задачи потребовалось бы создание отдельного блока
управления Ada-задачей, чтобы поддерживать рандеву-очереди.
Расширение упомянутой модели позволило бы модифицировать состояние потока
между созданием и активизацией, и, следовательно, удалить объект атрибутов потока.
Это предложение было отвергнуто по таким причинам.
• Должна существовать возможность установки любого состояния в объекте ат-
рибутов потока. Это потребовало бы определения функций для модификации
атрибутов потока, что не уменьшило бы количество вызовов, необходимых для
установки потока. На самом деле для приложения, которое создает все потоки
с использованием идентичных атрибутов, количество вызовов функций, необ-
ходимых для установки потоков, резко бы возросло. Использование объектов
атрибутов потока позволяет приложению создать один набор вызовов функций
установки атрибутов. В противном случае набор вызовов функций установки
атрибутов пришлось бы делать для создания каждого потока.
• В зависимости от архитектурного решения функции установки состояния по-
тока потребовали бы вызовов функций ядра системы или (по каким-то иным
причинам) не могли быть реализованы как макросы, что увеличило бы расходы
ресурсов на создание потока.
• Была бы утеряна возможность “классовой” организации потоков для приложений.
Предлагалась еще одна альтернатива, в которой рассматривалось использование
модели, аналогичной созданию процессов, — “разветвление потока”. Семантика раз-
ветвления обеспечивала бы большую гибкость, и функцию создания можно было реа-
лизовать в виде простого разветвления потока, за которым немедленно следовал вы-
зов требуемой “запускающей” функции. Этот вариант имел такие недостатки.
• Для многих реализаций внутренний стек вызывающего потока пришлось бы
дублировать, поскольку во многих архитектурах нет возможности определить
размер вызывающего фрейма.
• Эффективность снизилась бы, поскольку пришлось бы копировать по крайней мере
некоторую часть стека, несмотря на то, что в большинстве случаев после вызова
нужной “запускающей” функции потоку уже не требуется скопированный контекст.
Будущие направления
Отсутствуют.
Смотри также
fork(), pthread_exit() , pthread_join(), том Base Definitions стандарта IEEE
Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с расширением POSIX Threads Extension.
Приложение Б 581
Issue 6
Функция pthread_create () отмечена как часть опции Threads.
В результате согласования со спецификацией Single UNIX Specification был добав-
лен обязательный код ошибки [EPERM].
С целью согласования со стандартом IEEE Std 1003.1d-1999 для потока была добав-
лена семантика таймера центрального процессора.
Для согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—create () было добавлено ключевое слово restrict.
В раздел “Описание” внесено явное утверждение о том, что среда обработки дан-
ных с плавающей точкой наследуется от создающего потока.
582 Приложение Б
Имя
pthread_detach — функция отсоединения потока.
Синопсис
THR #include <pthread.h>
int pthread—detach (pthread_t thread};
Описание
Функция pthread_detach () уведомляет реализацию о том, что область памяти
для потока thread может быть восстановлена, когда он завершит выполнение. Если
поток не завершается, функция pthread_detach () не служит причиной для его за-
вершения. Результат нескольких вызовов функции pthread_detach () для одного
и того же потока не определен.
Возвращаемое значение
При успешном завершении функция pthread_detach () возвращает нулевое зна-
чение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread_detach () завершится неудачно, если:
[EINVAL] реализация обнаружила, что значение, заданное параметром thread,
не относится к присоединенному потоку;
[ESRCH] не был найден ни один поток, соответствующий заданному идентифи-
кационному номеру потока ID.
Эта функция не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Функции pthread—join () или pthread_detach () должны вызываться для каж-
дого потока, который создается, чтобы можно было снова использовать область па-
мяти, связанную с потоком.
Приложение Б 583
Высказывалось мнение о необязательности использования функции
pthread—detach (): поскольку поток никогда динамически не отсоединяется, то дос-
таточно использовать атрибут создания потока detachstate. Однако необходимость
в этой функции возникает по крайней мере в двух случаях.
1. В обработчике запроса на отмену для функции присоединения потока
(pthread—join()) важно иметь функцию pthread_detach (), чтобы отсо-
единить поток. Без нее обработчик вынужден был бы выполнить еще раз функ-
цию pthread_j oin (), чтобы попытаться отсоединить поток, который не
только задерживает процедуру отмены в течение неограниченного времени, но
и вносит новый вызов функции pthread—j oin (). В этом случае есть смысл го-
ворить о динамическом отсоединении.
2. Чтобы отсоединить “исходный поток” (это может понадобиться в процессах,
которые создают потоки сервера).
Будущие направления
Отсутствуют.
Смотри также
pthread—j oin (), том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread. h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с расширением POSIX Threads Extension.
Issue 6
Функция pthread—detach () отмечена как часть опции Threads.
584 Приложение Б
Имя
pthread_exit — функция завершения потока.
Синопсис
THR #include <рthread.h>
void pthread_exit (void *value_ptr) ;
Описание
Функция pthread_exit () завершает вызывающий поток и делает значение
value__ptr доступным для успешного присоединения к завершающему потоку. Лю-
бые обработчики отмены, которые были помещены в стек, но еще не извлечены из
него, будут извлечены в порядке, обратном тому, в котором они помещались туда,
азатем выполнены. Если потоку принадлежат данные, то после выполнения всех об-
работчиков отмены будут вызваны соответствующие функции деструкторов (в неоп-
ределенном порядке). При завершении потока ресурсы процесса, включая мьютексы
и дескрипторы файлов, не освобождаются, и не выполняются какие бы то ни было
“восстановительные” действия уровня процесса, включая вызовы любых функций
at exit (), какие только могут существовать.
Когда из функции запуска возвращается поток, отличный от того, в котором была
изначально вызвана функция main (), делается неявное обращение к функции
pthread_exit (). Значение, возвращаемое этой функцией, служит в качестве со-
стояния выхода этого потока.
Поведение функции pthread_exit () не определено, если она вызвана из обра-
ботчика запроса на отмену потока или функции деструктора, к которой было сделано
обращение в результате явного или неявного вызова функции pthread_exit ().
После завершения потока результат доступа к локальным переменным потока не
определен. Таким образом, ссылки на локальные переменные существующего пото-
ка не следует использовать для функции pthread_exit () в качестве значения па-
раметра value_ptr.
После завершения процесс будет иметь состояние выхода, равное нулю, после то-
го, как завершится его последний поток. Поведение при этом будет таким, как если
бы во время завершения потока была вызвана функция exit () с нулевым аргументом.
Возвращаемое значение
Функция pthread_exit () не возвращается к инициатору ее вызова.
Ошибки
Ошибки не определены.
Приложение Б 585
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Нормальный механизм завершения потока состоит в возвращении из функции, ко-
торая была задана в вызове функции pthread_create (). Функция pthread_exit ()
обеспечивает возможность завершения потока без обязательного выхода из стартовой
функции этого потока и, следовательно, служит аналогом функции exit ().
Независимо от метода завершения потока любые обработчики отмены, которые
были помещены в стек, но еще не извлечены из него, будут выполнены, а также вы-
званы деструкторы для любых существующих данных потока. Этот том стандарта
IEEE Std 1003.1-2001 требует, чтобы обработчики отмены извлекались из стека и вы-
полнялись по порядку. После выполнения всех обработчиков отмены для каждого
элемента потоковых данных вызываются соответствующие функции деструкторов
(в неопределенном порядке). Такая последовательность действий обязательна, по-
скольку обработчики отмены могут использовать данные потока.
Поскольку значение состояния выхода определяется приложением (за исключе-
нием случаев, когда поток был отменен, т.е. в случаях отмены используется значение
PTHREAD_CANCELED), реализации не известно, что следует понимать под недействи-
тельным значением состояния, поэтому проверка на наличие ошибок не выполняется.
Будущие направления
Отсутствуют.
Смотри также
exit (), pthread_create (), pthread_j oin (), том Base Definitions стандарта IEEE
Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с Расширением POSIX Threads Extension.
Issue 6
Функция pthread_exit () отмечена как часть опции Threads.
586 Приложение Б
Имя
pthread_getconcurrency, pthread_setconcurrency — функции считывания
и установки уровня параллелизма.
Синопсис
XSI #include <pthread.h>
int pthread—getconcurrency (void);
int pthread—setconcurrency (int new_level);
Описание
Несвязанные потоки в процессе выполняются (или не выполняются) одновремен-
но. По умолчанию реализация потоков гарантирует активность достаточного количе-
ства потоков для того, чтобы процесс мог успешно продолжать выполнение. И хотя
такой подход сохраняет системные ресурсы, он может не обеспечить наиболее эф-
фективный уровень параллелизма.
Функция pthread_setconcurrency () позволяет приложению с помощью пара-
метра new_level информировать реализацию потоков о желаемом уровне паралле-
лизма. Реальный же уровень параллелизма, обеспечиваемый реализацией в результа-
те вызова этой функции, не определен. Если значение параметра new_level равно
нулю, это означает, что реализация должна поддерживать уровень параллелизма та-
ким, как если бы функция pthread—setconcurrency () никогда не вызывалась.
Функция pthread—getconcurrency () возвращает значение, установленное в ре-
зультате предыдущего обращения к функции pthread—setconcurrency (). Если
“предыдущего” вызова этой функции не было, функция pthread_getconcurrency ()
возвращает нуль, который означает, что реализация поддерживает заданный уровень
параллелизма.
Обращение к функции pthread_setconcurrency () информирует реализацию
о желаемом уровне параллелизма, а реализация использует его как совет, а не требование.
Если реализация не поддерживает мультиплексирование пользовательских пото-
ков, то функции pthread—setconcurrency() и pthread_getconcurrency() ис-
пользуются ради совместимости исходного кода, но не дают никакого эффекта при
вызове. Для поддержки семантики функций параметр new_level сохраняется при
вызове функции pthread—setconcurrency (), чтобы последующее обращение
к функции pthread—getconcurrency () могло вернуть то же значение.
Возвращаемые значения
При успешном выполнении функция pthread—setconcurrency () возвращает
нулевое значение; в противном случае — код ошибки, обозначающий ее характер.
Функция pthread—getconcurrency () всегда возвращает уровень параллелизма,
установленный в результате предыдущего обращения к функции
pthread—setconcurrency (). Если “предыдущего” вызова этой функции не был°,
функция pthread—getconcurrency () возвращает нуль.
Приложение Б 587
Ошибки
Функция pthread—setconcurrency () завершится неудачно, если:
[EINVAL] значение, заданное параметром new_level, отрицательно;
[EAGAIN] значение, заданное параметром new_level, приводит к перерасходу
системных ресурсов.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Использование этих функций изменяет состояние базового уровня параллелизма, от
которого зависит работа приложения. Разработчикам библиотек рекомендуется не ис-
пользовать функции pthread—getconcurrency() и pthread—setconcurrency(),
поскольку это может привести к конфликту с их использованием в приложении.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
Том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
588 Приложение Б
Имя
pthread—getschedparam, pthread—setschedparam — функции динамического
доступа к параметрам стратегии планирования потока (REALTIME THREADS).
Синопсис
THRTPS tfinclude <pthread.h>
int pthread—getschedparam (
pthread—t thread,
int *restrict policy,
struct sched—param *restrict param) ;
int pthread—setschedparam (
pthread—t thread,
int policy,
const struct sched__param ★ param) ;
Описание
Функции pthread—getschedparam () и pthread—setschedparam () использу-
ются для считывания и установки соответственно значений стратегии планирования
и параметров отдельных потоков многопоточного процесса. Для значений стратегии
планирования SCHED_FIFO и SCHED_RR в структуре sched_param должен быть уста-
новлен только один ее член sched-priority (уровень приоритета). Для значения
SCHED—OTHER параметры планирования определяются реализацией.
Функция pthread—getschedparam () предназначена для считывания значения
стратегии планирования и параметров планирования для потока, идентификацион-
ный номер (ID) которого задан параметром thread. Считанные значения сохраня-
ются в параметрах policy и param. Функция pthread—getschedparam () возвраща-
ет значение приоритета, установленное в результате самого последнего вызова функ-
ций pthread—setschedparam (), pthread—setschedprio () или
pthread—create () для данного потока. Она не отражает никаких временных кор-
ректировок, вносимых в значение приоритета в результате выполнения других функ-
ций. Функция pthread—set schedparam () устанавливает для потока, ID которого за-
дан параметром thread, стратегию планирования и соответствующие параметры
планирования равными значениям параметров policy и param соответственно.
Параметр policy может иметь значения SCHED_OTHER, SCHED_FIFO или SCHED—RR-
Параметры планирования для стратегии планирования, заданной значением
SCHED—OTHER, определяются реализацией. Для стратегии планирования, задаваемой
значениями SCHED_FIFO и SCHED_RR, используется только один параметр priori ty.
TSP Если определено значение _POSIX_THREAD— SPORADIC—SERVER, аргумент
policy может иметь значение SCHED_SPORADIC (за исключением функции
pthread—setschedparam()). Если стратегия планирования в момент вы-
зова этой функции не соответствовала значению SCHED_SPORADIC, то под-
держка этого значения определяется реализацией, т.е. реализация может не
Приложение Б 589
позволить приложению динамически изменять стратегию планирования,
устанавливая ее равной значению SCHED_SPORADIC. Для стратегии плани-
рования, определяемой значением SCHED_SPORADIC, устанавливаются та-
кие параметры: sched_ss_low_priority, sched_ss_repl_period,
sched_ss_init_budget, sched_priority и sched_ss_max_repl. Для ус-
пешного выполнения функции установки параметров значение параметра
sched—ss_repl_period должно быть больше или равно значению
sched— ss_init_budget; в противном случае функция завершится неудач-
но. Кроме того, для успешного выполнения этой функции значение пара-
метра sched— ss_max_repl должно попадать во включающий диапазон
[ 1 / SS_REPL—МАХ]; в противном случае функция завершится неудачно.
При неудачном завершении функции pthread—setschedparam () параметры
планирования для заданного потока изменены не будут.
Возвращаемые значения
При успешном завершении функции pthread—getschedparam ()
и pthread_setschedparam () возвращают нулевое значение; в противном случае —
кодошибки, обозначающий ее характер.
Ошибки
Функция pthread—getschedparam () может завершиться неудачно, если:
[ESRCH] значение, заданное параметром thread, не относится ни к од- ному из существующих потоков.
Функция pthread—set schedparam () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром policy, или значение одного из параметров планирования, связанных со значением страте- гии планирования policy, недействительно;
[ENOTSUP] была сделана попытка установить для стратегии планирования
TSP [ENOTSUP] или ее параметров неподдерживаемые значения; была сделана попытка динамически изменить стратегию пла- нирования, установив для нее значение SCHED_SPORADIC, при
[EPERM] том, что реализация не поддерживает такое изменение; инициатор вызова не имеет соответствующего разрешения ус- танавливать параметры планирования или стратегию планиро- вания для заданного потока;
[EPERM] реализация не позволяет приложению модифицировать один
[ESRCH] из параметров в соответствии с заданным значением; значение, заданное параметром thread, не относится ни к од- ному из существующих потоков.
Эти функции не возвращают код ошибки [EINTR].
590 Приложение Б
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—setschedprio (), sched_getparam(), sched_get scheduler (), том Base
Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>, <sched.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—getschedparam () и pthread—setschedparam() отмечены
как часть опций Threads и Thread Execution Scheduling.
Код ошибки [ENOSYS] был исключен, поскольку его нет смысла учитывать, если
реализация не поддерживает опцию Thread Execution Scheduling.
К описанию прототипа функции pthread—setschedparam () был приложен спи-
сок опечаток Open Group Corrigendum U026/2, чтобы второй аргумент этой функ-
ции имел тип int.
Для согласования со стандартом IEEE Std 1003.1d-1999 было добавлено значение
стратегии планирования SCHED_SPORADIC.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—getschedparam () было добавлено ключевое слово restrict.
Был добавлен список опечаток Open Group Corrigendum U047/1.
Была добавлена интерпретация IEEE PASC Interpretation 1003.1 #96, отмечающая»
что значения приоритета также можно установить путем вызова функции
pthread—setschedprio().
Приложение Б 591
Имя
pthread—j oin — функция ожидания завершения потока.
Синопсис
THR #include <pthread.h>
int pthread—join (pthread—t thread, void **value_ptr) ;
Описание
Функция pthread—join() приостанавливает выполнение вызывающего потока
до тех пор, пока не завершится заданный поток (если он еще не завершился). Если
после удачного возвращения из функции pthread—j oin () параметр value__ptr не
равен значению NULL, значение, передаваемое функции pthread—exit () завер-
шающимся потоком, будет доступным в области памяти, адресуемой параметром
value__ptr. Успешное выполнение функции pthread—join () означает, что задан-
ный поток завершился. Результаты нескольких одновременных обращений к функ-
ции pthread—join (), в параметрах которых задается один и тот же поток, не оп-
ределены. Если поток, вызывающий функцию pthread—join(), отменен, то за-
данный поток не будет выгружен.
Не определено, учитывается ли в значении {PTHREAD—THREADS—МАХ} поток, ко-
торый завершился, но остался отсоединенным.
Возвращаемые значения
При успешном завершении функция pthread—join () возвращает нулевое значе-
ние; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—j oin () завершится неудачно, если:
[EINVAL] реализация обнаружила, что значение, заданное параметром
thread, не относится ни к одному из присоединенных потоков;
[ESRCH] не найден ни один поток, идентификационный номер которого (ID)
соответствовал бы заданному потоку.
Функция pthread—j oin () может завершиться неудачно, если:
[EDEADLK] была обнаружена взаимоблокировка или значение параметра
thread соответствует вызывающему потоку.
Функция pthread—j oin () не возвращает код ошибки [EINTR].
Примеры
Ниже приведен пример создания потока и его удаления.
592 Приложение Б
typedef struct {
int *ar;
long n;
} subarray;
void *
incer (void *arg)
{
long i;
for (i =0; i < ((subarray *)arg)
((subarray *) arg) ->ar[i]++;
}
int main (void)
{
int ar[1000000];
pthread—t thl, th2;
subarray sbl, sb2;
sbl.ar = &ar[0];
sbl.n = 500000;
(void) pthread—create(&thl, NULL,
sb2.ar = &ar[500000];
sb2.n = 500000;
(void) pthread—create(&th2, NULL,
(void) pthread—join(thl, NULL);
(void) pthread—join(th2, NULL);
return 0;
}
->n; i++)
incer, &sbl);
incer, &sb2);
Замечания по использованию
Отсутствуют.
Логическое обоснование
Функция pthread_join () представляет собой удобное и полезное средство для
использования в многопоточных приложениях. Конечно, программист мог бы сыми-
тировать эту функцию, если бы она не существовала, другими средствами, например,
путем передачи функции start—routine () дополнительного состояния как части
аргумента. Завершающийся поток в этом случае установил бы флаг, означающий за-
вершение, и отправил бы условную переменную, которая является частью этого со-
стояния, а присоединяющий поток ожидал бы получения этой условной переменной.
Несмотря на то что такой метод позволил бы организовать ожидание наступления
более сложных условий (например, завершения сразу нескольких потоков), ожидание
завершения одного потока— весьма распространенная ситуация, и поэтому
“заслуживает” отдельной функции. Кроме того, включение в библиотеку функции
pthread_join () никоим образом не мешает программисту самому кодировать такие
сложные ожидания. Таким образом, включение функции pthread—j oin () в этот том
стандарта IEEE Std 1003.1-2001 считается весьма полезным.
Функция pthread—join () обеспечивает простой механизм, позволяющий при-
ложению ожидать завершения потока. После того как поток завершится, приложение
может приступать к освобождению ресурсов, которые использовались этим потоком.
Приложение Б 593
Например, после возвращения функции pthread_j oin () может быть восстановлена
любая область памяти, предоставленная приложением под стек.
функции pthread join () или pthread_detach() должны в конце концов быть
вызваны для каждого потока, который создается с атрибутом detachstate, равным
значению PTHREAD_CREATE_JOINABLE, чтобы можно было восстановить память,
связанную с потоком.
Взаимодействие между функцией pthread_j oin () и механизмом отмены потока
хорошо определено по следующим причинам:
• функция pthread_j oin (), как и все остальные неасинхронные функции безо-
пасной отмены потоков, можно вызывать только при возможности отложенно-
го типа отмены.
• отмена потока не может происходить в состоянии запрещения отмены.
Таким образом, имеет смысл рассматривать только стандартное состояние воз-
можности отмены. Итак, вызов функции pthread_join() либо отменяется, либо ус-
пешно завершается. Для приложения это различие очевидно, поскольку либо выпол-
няется обработчик запроса на отмену, либо возвращается функция рthread_join ().
В этом случае условия “гонок” не возникают, поскольку функция pthread_j oin ()
вызывается в состоянии отложенного запроса на отмену.
Будущие направления
Отсутствуют.
Смотри также
pthread_create (), wait (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с расширением POSIX Threads Extension.
Issue 6
Функция pthread_j oin () отмечена как часть опции Threads.
594 Приложение Б
Имя
pthread_mutex_destroy, pthread_mutex_init — функции разрушения и ини-
цианизации мьютекса.
Синопсис
THR #include <pthread.h>
int pthread—mutex_destroy (pthread—mutex—t *mutex);
int pthread—mutex—init (
pthread—mutex—t *restrict mutex,
const pthread—mutexattr_t *restrict attr);
pthread—mutex—t mutex = PTHREAD-MUTEX_INITIALIZER;
Описание
Функция pthread—mutex—destroy () используется для разрушения объекта мью-
текса, адресуемого параметром mutex, в результате чего этот объект мьютекса стано-
вится неинициализированным. В конкретной реализации функция
pthread—mutex—destroy () может устанавливать объект, адресуемый параметром
mutex, равным недействительному значению. Разрушенный объект мьютекса можно
снова инициализировать с помощью функции pthread—mutex_init (); результаты
ссылки на этот объект после его разрушения не определены.
Нет никакой опасности в разрушении инициализированного объекта мьютекса, по
которому не заблокирован в данный момент ни один поток. Попытка же разрушить
заблокированный мьютекс может привести к неопределенному поведению.
Функция pthread—mutex—init () используется для инициализации мьютекса, адре-
суемого параметром mutex, объектом атрибутов, адресуемым параметром attr. Если
параметр attr содержит значение NULL, для инициализации применяются атрибуты
мьютекса, действующие по умолчанию, т.е. результат в этом случае равносилен передаче
адреса объекта, содержащего стандартные атрибуты мьютекса. После успешной ини-
циализации мьютекс становится инициализированным и разблокированным.
Для осуществления синхронизации используется только сам объект, адресуемый па-
раметром mutex. Результат ссылки на копии объекта mutex в обращениях к функциям
pthread—mutex—lock(), pthread—mutex_trylock(), pthread—mutex_uniock()
и pthread—mutex—destroy () не определен.
Попытка инициализировать уже инициализированный объект мьютекса приведет
к неопределенному поведению.
В случаях, когда атрибуты мьютекса, действующие по умолчанию, заранее определены,
для инициализации мьютексов, которые создаются статически, можно использовать мак-
рос PTHREAD—MUTEX—INITIALIZER. Результат в этом случае эквивалентен динамиче-
ской инициализации путем вызова функции pthread—mutex_init () с параметром
attr, равным значению NULL, но без выполнения проверки на наличие ошибок.
Приложение Б 595
Возвращаемые значения
При успешном завершении функции pthread_mutex_destroy() Hpthread_
mutex— init () возвращают нулевое значение; в противном случае — код ошибки, обо-
значающий ее характер.
Проверка на наличие ошибок с кодами [EBUSY] и [EINVAL] реализована так
(если реализована вообще), как будто она выполняется в самом начале работы каждой
функции, и код ошибки в случае ее обнаружения возвращается до модификации со-
стояния мьютекса, заданного параметром mu tex.
Ошибки
Функция pthread_mutex_destroy () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку разрушить объект, адресуемый пара-
метром mutex, который относится к другому потоку (например, при
использовании в функциях pthread_mutex_wait () или
pthread_mutex_timedwait ()), или указанный объект заблокирован;
[ EINVAL] значение, заданное параметром mu tex, недействительно.
Функция pthread_mutex_init () завершится неудачно, если:
[EAGAIN] система испытывает недостаток ресурсов (не имеется в виду память),
необходимых для инициализации еще одного мьютекса;
[ENOMEM] для инициализации мьютекса недостаточно существующей памяти;
[EPERM] инициатор вызова функции не имеет привилегий для выполнения
этой операции.
Функция pthread_mutex_init () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку повторно инициализировать объект
мьютекса, адресуемый параметром mutex, которой был ранее ини-
циализирован, но еще не разрушен;
[EINVAL] значение, заданное параметром at tr, недействительно.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Логическое обоснование
Возможность альтернативных реализаций
Данный том стандарта IEEE Std 1003.1-2001 поддерживает несколько альтернатив-
ных реализаций мьютексов. Реализация может сохранять блокировку непосредствен-
596 Приложение Б
но в объекте типа pthread_mutex_t. Возможно также хранение блокировки в “куче”
а указателя, дескриптора или уникального ID — в объекте мьютекса. Каждая реализа-
ция обладает различными достоинствами в зависимости от определенных конфигу-
раций оборудования. Поэтому, чтобы написать код, который не нужно будет изменять
в зависимости от выбранной реализации, в данном томе стандарта IEEE Std 1003.1-
2001 жестко не определяется тип хранения блокировки и термин “инициализировать”
используется для усиления утверждения о том, что блокировка может в действительно-
сти располагаться в самом объекте мьютекса.
Обратите внимание на то, что это устраняет избыточность определения типа
мьютекса или условной переменной.
В реализации разрешается, чтобы при выполнении функции pthread_mutex_
destroy () в мьютексе хранилось недействительное значение. Это позволит выявить
ошибочные программы, которые пытаются заблокировать уже разрушенный мьютекс
(или по крайней мере сослаться на него).
Компромисс между контролем за ошибками и производительностью
Существует множество случаев, когда можно обойтись без проверки на наличие
ошибок ради достижения более высокой производительности. Полнота применения
контроля за ошибками должна соответствовать нуждам конкретных приложений
и возможностям сред выполнения. В общем случае об ошибках или ошибочных усло-
виях, вызванных системными причинами (например, недостаточностью памяти), не-
обходимо уведомлять всегда, но необязательно сообщать об ошибках, связанных с не-
корректностью кода приложения (например, при неудачной попытке обеспечить
адекватную синхронизацию, используемую при защите мьютекса от удаления).
Таким образом, возможен широкий диапазон реализаций. Например, реализация,
предназначенная для отладки приложений, может включать все возможные проверки
ошибок, в то время как реализация, выполняющая на встроенном компьютере одно-
единственное уже отлаженное приложение при очень строгих требованиях к произ-
водительности, может содержать лишь минимальный набор проверок на наличие
ошибок. Более того, реализация может быть представлена даже в двух версиях подоб-
но опциям, предоставляемым компиляторами: в версии с полным объемом проверок
ошибок (но более медленной) и в версии с ограниченным объемом проверок ошибок
(но более быстрой). Запретить возможность необязательности контроля за ошибками
значило бы оказать пользователю медвежью услугу.
Предусмотрительно ограничивая использование понятия “неопределенное поведе-
ние” только случаями ошибочных действий самого приложения (по причине недоста-
точно продуманного кода) и обязательно определяя ошибки, связанные с недоступно-
стью системных ресурсов, данный том стандарта IEEE Std 1003.1-2001 гарантирует, что
любое корректно написанное приложение переносимо в полном диапазоне реализа-
ций, но не обязывает все реализации нести дополнительные затраты на проверку мно-
гочисленных условий, которые корректно написанная программа никогда не создаст.
Почему не определяются предельные значения
Определение символьных значений для использования в качестве максимального
числа мьютексов и условных переменных рассматривалось, но было отвергнуто, по-
скольку количество этих объектов может изменяться динамически. Более того, мно-
Приложение Б 597
гие реализации размещают эти объекты в памяти приложения, следовательно, гово-
рить о необходимости явного определения максимума нет никакого смысла.
Статические инициализаторы для мьютексов и условных переменных
Обеспечение статической инициализации статически размещаемых в памяти объектов
синхронизации позволяет в модулях, содержащих закрытые статические переменные
синхронизации, избежать тестирования и соответствующих затрат, связанных с динами-
ческой инициализацией. Более того, это упрощает кодирование модулей самоинициа-
лизации. Такие модули широко используются в С-библиотеках, в которых по различным
причинам вместо явного вызова функций инициализации используется самоинициали-
зация. Ниже приводится пример использования статической инициализации.
Без применения статической инициализации функция самоинициализации f оо ()
может иметь следующий вид.
static pthread—once__t foo_once = PTHREAD—ONCE_INIT;
static pthread—mutex_t foo_mutex;
void foo-init ()
{
pthread—mutex_init (&foo_mutex, NULL);
}
void foo()
{
pthread—once (&foo_once, foo_init);
pthread—mutex—lock (&foo_mutex) ;
/* Выполнение действий. */
pthread—mutex—unlock (&foo_mutex);
}
С применением статической инициализации ту же функцию самоинициализации
f оо () можно было бы закодировать таким образом.
static pthread—mutex—t foo—mutex = PTHREAD—MUTEX_INITIALIZER;
void foo()
{
pthread—mutex—lock (&foo_mutex) ;
/* Выполнение действий. */
pthread—mutex—unlock(&foo_mutex);
}
Обратите внимание на то, что статическая инициализация устраняет необходи-
мость в тестировании, проводимом в функции pthread—once (), и получении значе-
ния адреса &foo_mutex, передаваемого функции pthread—mutex_1 ock () или
Pthread—mutex_unlock ().
Таким образом, С-код, написанный для инициализации статических объектов,
проще во всех системах и работает быстрее на большом классе систем, в которых
объект (внутренней) синхронизации можно хранить в памяти приложения.
До сих пор вопрос о быстродействии блокировок поднимался для машин, которые
тРебовали, чтобы для мьютексов выделялась специальная память. В действительности
в таких машинах мьютексы и, возможно, условные переменные должны были содержать
Указатели на реальные аппаратные средства защиты. Для того чтобы на таких машинах
работала статическая инициализация, функция pthread—mutex_lock () также должна
проверять, выделена ли память для указателя на реальный объект блокировки. Если не
вЬ1делена, функция рthread—mutex_1 ock (), прежде чем его использовать, должна его
598 Приложение Б
инициализировать. Резервирование таких ресурсов можно выполнить при загрузке
программы, и поэтому для мьютексов и условных переменных не были введены допол-
нительные коды ошибок, означающие неудачное выполнение инициализации.
Такое динамическое тестирование в функции pthread_mutex_lock(), которое
позволяет узнать, был ли инициализирован указатель, могло показаться на первый
взгляд лишним. На большинстве компьютеров это было бы реализовано в виде счи-
тывания его значения, сравнения с нулем и использования по назначению при усло-
вии получения нужного результата сравнения. Несмотря на то что это тестирование
кажется лишним, дополнительные затраты (на тестирование содержимого регистра)
обычно незначительны, поскольку в действительности никакие дополнительные
ссылки на память не делаются. Так как все больше и больше компьютеров оснащаются
кэш-памятью (быстродействующей буферной памятью большой емкости), то реаль-
ные издержки представляют собой отработку ссылок, а не выполнение инструкций.
В качестве альтернативного варианта (в зависимости от архитектуры компьютера)
можно в наиболее важных случаях ликвидировать все расходы системных ресурсов на
операции блокировки, которые выполняются после инициализации средств блокировки.
Это можно сделать путем перехода от более затратных к редко выполняемым операци-
ям, т.е. перенести весь “груз расходов” на однократно выполняемую инициализацию.
Поскольку “внешняя” (т.е. выполняемая вне основной программы) инициализация
мьютекса также означает, что для получения реальной блокировки адрес должен быть
разыменовывай, один из широко применяемых методов при статической инициализа-
ции состоит в сохранении фиктивного значения для этого адреса; в частности, адреса,
который вызывает сбой в работе компьютера. При возникновении такого сбоя во время
первой попытки заблокировать мьютекс можно сделать проверку достоверности, а за-
тем для реальной блокировки использовать корректный адрес. Последующие опера-
ции, связанные с блокировкой, не будут сопряжены с дополнительными расходами,
поскольку они уже не являются “сбойными”. Это — всего лишь метод, который можно
использовать для поддержки статической инициализации, несмотря на то, что он не-
благоприятно отражается на скорости захвата блокировки. Безусловно, существуют
и другие методы, которые в высокой степени зависят от архитектуры компьютера.
Расходы на блокировку для компьютеров, выполняющих “внешнюю” инициализа-
цию мьютекса, сравнимы с расходами для модулей, инициализируемых неявным об-
разом (имеются в виду те из них, где достигнута “внутренняя” инициализация мью-
тексов). Безусловно, “внутренняя” инициализация выполняется гораздо быстрее, но
“внешняя” ненамного хуже.
Помимо вопроса быстродействия блокировки, нас беспокоит то, что потоки мог}7!'
соперничать за блокировки при попытке завершить инициализацию статически разме-
щаемых в памяти мьютексов. (Такое завершение обычно включает захват внутренней
блокировки, выделение памяти для структуры, сохранение указателя на эту структуру
в мьютексе и освобождение внутуренней блокировки.) Во-первых, многие реализации
могут сократить эту последовательность действий путем хэширования по адресу мью-
текса. Во-вторых, количество таких “сериалов” может быть весьма ограниченным. В ча-
стности, их может быть столько, сколько создается статически размещаемых объектов
синхронизации. Динамически же создаваемые объекты по-прежнему инициализирую^'
ся с помощью функций pthread_mutex_init () или pthread_cond_init ().
Наконец, если ни один из описанных выше методов оптимизации для “внешнего
размещения объектов синхронизации не позволяет достичь нужной производительно
Приложение Б 599
сти приложения при использовании определенной реализации, приложение может из-
бежать статической инициализации, явным образом инициализируя все объекты син-
хронизации с помощью соответствующих функций pthread—★_ini t (), которые под-
держиваются всеми реализациями. В документации на реализацию также могут быть
описаны компромиссные решения и рекомендации относительно того, какие методы
инициализации являются наиболее эффективными для данной конкретной реализации.
Разрушение мьютексов
Мьютекс можно разрушить сразу после разблокировки. Например, рассмотрим
следующий код.
struct obj {
рthread_mutex_t om;
int refent;
};
obj_done (struct obj *op)
{
pthread_mutex_lock (&op- >om) ;
if (--op- >refcnt == 0) {
pthread_mutex_unlock (&op- >om);
(A) pthread_mutex_destroy (&op- >om);
(B) free(op);
} else
(C) pthread_mutex_unlock (&op->om);
}
В данном случае структура obj служит для учета количества ссылок, а функция
obj_done() вызывается всякий раз, когда удаляется ссылка на объект. Реализации
должны позволить разрушение объекта и освобождение занимаемых им ресурсов
(см. строки А и В) сразу после его разблокировки (строка С).
Будущие направления
Отсутствуют.
Смотри также
pthread_mutex_getprioceiling (), pthread_mutex_lock (),
pthread_mutex_timedlock (), pthread_mutexattr_getpshared (), том Base
Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread_mutex_destroy() и pthread_mutex_init () отмечены как
часть опции Threads.
В целях согласования со стандартом IEEE Std 1003.1d-1999 в раздел “Смотри также”
была добавлена функция pthread_mutex_t imedlock ().
600 Приложение Б
Раздел “Описание” был отредактирован путем применения интерпретации IEEE
PASC Interpretation 1003.1с #34.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread_mutex_init () было добавлено ключевое слово restrict.
Приложение Б 601
Имя
pthread—mutex—getprioceiling, pthread—mutex_setprioceiling — функ-
ции считывания и установки предельного значения приоритета мьютекса
(REALTIME THREADS).
Синопсис
THR #include <рthread.h>
TPP int pthread—mutex—getprioceiling (
const pthread—mutex—t *restrict mutex,
int *restrict prioceiling) ;
int pthread—mutex—setprioceiling (
pthread—mutex—t *restrict mutex,
int prioceiling,
int *restrict old_ceiling);
Описание
Функция pthread—mutex—getprioceiling () используется для считывания
текущего значения предельного приоритета мьютекса. Функция
pthread—mutex—setprioceiling () сначала блокирует мьютекс, если он раз-
блокирован, или надежно удерживает его в заблокированном состоянии, а затем из-
меняет значение предельного приоритета мьютекса и после этого освобождает его.
При успешном изменении приоритета его предыдущее значение возвращается с по-
мощью параметра old__ceiling. В процессе блокирования мьютекса нет необходи-
мости привязываться к протоколу защиты приоритета.
При неудачном выполнении функции pthread—mutex_setprioceiling () пре-
дельное значение приоритета мьютекса не будет изменено.
Возвращаемые значения
При успешном завершении функции pthread_mutex_getprioceiling ()
и pthread—mutex_setprioceiling () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Ошибки
Функции pthread—mutex—getprioceiling() и
Pthread—mutex—setprioceiling () могут завершиться неудачно, если:
[EINVAL] приоритет, заданный параметром prioceiling, не попадает в нуж-
ный диапазон:
[EINVAL] значение, заданное параметром mutex, не относится ни к одному из
существующих мьютексов;
[ EPERM] инициатор вызова не имеет привилегий для выполнения этой операции.
602 Приложение Б
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—mutex—destroy(),pthread—mutex_1ock(),
pthread—mutex—timedlock (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—mutex—getprioceiling () и pthread—mutex_setprioceiling()
отмечены как часть опций Threads и Thread Execution Scheduling.
Код ошибки [ENOSYS] был исключен, поскольку его нет смысла учитывать, если
реализация не поддерживает опцию Thread Priority Protection.
Код ошибки [ENOSYS], обозначающий отсутствие поддержки протокола учета
приоритета для мьютексов, был исключен. Дело в том, что если реализация предос-
тавляет эти функции (независимо от того, определено ли значение
—POSIX—PTHREAD—PRIO—PROTECT), они должны работать так, как отмечено в разделе
“Описание”, т.е. протокол учета приоритета для мьютексов должен поддерживаться.
В целях согласования со стандартом IEEE Std 1003.1d-1999 в раздел “Смотри также
была добавлена функция pthread—mu tex_ timed lock ().
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототипы функции
pthread—mutex—getprioceiling() и pthread—mutexjsetprioceiling() было
добавлено ключевое слово restrict.
Приложение Б 603
Имя
pthread_mutex—lock, pthread—mutex—trylock, pthread—mutex—unlock —
функции блокировки и разблокировки мьютекса.
Синопсис
THR #include <pthread.h>
int
int
int
pthread—mutex—lock (pthread—mutex_t ★mutex);
pthread—mutex—trylock (pthread—mutex_t * mutex);
pthread—mutex—unlock (pthread—mutex_t *mutex);
Описание
Объект мьютекса, адресуемый параметром mutex, блокируется путем вызова
функции pthread—mutex—lock (). Если мьютекс уже заблокирован, вызывающий
поток блокируется до тех пор, пока мьютекс не станет доступным. При завершении
этой операции объект мьютекса, адресуемый параметром mutex, находится в состоя-
нии блокировки, а вызывающий поток является его владельцем.
XSI Если мьютекс имеет тип PTHREAD—MUTEX_NORMAL, обнаружение взаимо-
блокировок не обеспечивается. К взаимоблокировке может привести по-
пытка заблокировать мьютекс повторно. Если поток попытается разбло-
кировать мьютекс, который не заблокирован, дальнейшее его поведение
не определено.
Для мьютексов типа PTHREAD—MUTEX_ERRORCHECK предусмотрена про-
верка на наличие ошибок. Если поток попытается заблокировать мьютекс,
который уже заблокирован, возвращается ошибка. Если поток попытается
разблокировать мьютекс, который не заблокирован, возвращается ошибка.
Если мьютекс имеет тип PTHREAD—MUTEX_RECURSIVE, мьютекс должен под-
держивать концепцию подсчета блокировок. При первом успешном блоки-
ровании мьютекса счетчик блокировок устанавливается равным единице.
При каждом очередном блокировании этого мьютекса счетчик блокировок
инкрементируется, а при каждом разблокировании — декрементируется. Ко-
гда счетчик блокировок достигает нулевого значения, мьютекс становится
доступным для других потоков. Если поток попытается разблокировать мью-
текс, который не заблокирован, возвращается ошибка.
Если мьютекс имеет тип PTHREAD—MUTEX_DEF AULT, попытка рекурсивно
заблокировать мьютекс приводит к неопределенному поведению. Попытка
разблокировать мьютекс, который не был заблокирован (любым потоком,
включая вызывающий), приводит к неопределенному поведению.
Функция pthread._mutex_trylock () эквивалентна функции
Pthread—mutex— lock (), за исключением того, что если объект мьютекса, адресуемый
Параметром mutex, в данный момент заблокирован (любым потоком, включая теку-
щий), эта функция немедленно завершится. Если мьютекс имеет тип
604 Приложение Б
PTHREAD—MUTEX_RECURSIVE, и в данный момент мьютексом владеет вызывающий поток
счетчик блокировок этого мьютекса инкрементируется, а функция
pthread—mutex—trylock () немедленно возвращает признак успешного завершения.
Функция pthread—mutex__unlock () освобождает объект мьютекса
адресуемый параметром mutex.
XSI Способ освобождения зависит от атрибута типа мьютекса.
Если при вызове функции pthread—mutex_unlock (), в результате ко-
торого мьютекс стал доступным, существуют потоки, заблокированные
по объекту мьютекса, адресуемому параметром мьютекс, то поток-
владелец этого мьютекса будет установлен стратегией планирования.
XSI (Для мьютексов типа PTHREAD—MUTEX—RECURSIVE: мьютекс становится
доступным, когда счетчик блокировок достигает нуля, и вызывающий
поток больше не имеет никаких блокировок по этому мьютексу.)
Если к потоку, ожидающему освобождения мьютекса, поступает сигнал, то после
выполнения обработчика этого сигнала поток снова перейдет в состояние ожидания,
как если бы он и не прерывался на обработку сигнала.
Возвращаемые значения
При успешном завершении функции pthread—mutex— lock ()
и pthread—mutex—unlock () возвращают нулевое значение; в противном случае —
код ошибки, обозначающий ее характер.
Функция pthread—mutex—trylock () возвращает нулевое значение, если выпол-
нена блокировка по объекту мьютекса, адресуемому параметром mutex. В противном
случае возвращается код ошибки, обозначающий ее характер.
Ошибки
Функции pthread—mutex—lock () и pthread—mutex_trylock () завершатся не-
удачно, если:
[EINVAL] мьютекс был создан с использованием атрибута protocol, имеющего
значение PTHREAD— PRIO_PROTECT, а приоритет вызывающего потока
выше текущего значения предельного приоритета мьютекса.
Функция pthread—mutex—trylock () завершится неудачно, если:
[ EBUSY] мьютекс остался недоступным, поскольку он был уже заблокирован.
Функции pthread—mutex—lock() , pthread—mutex_trylock()
и pthread—mutex—unlock () могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром mutex, не относится к инициа-
лизированному объекту мьютекса;
XSI [EAGAIN] мьютекс остался недоступным, поскольку было превышено
максимальное количество рекурсивных блокировок для мью-
текса, заданного параметром mutex.
Приложение Б 605
функция pthread—mutex_lock () может завершиться неудачно, если:
[ EDEADLK ] текущий поток уже владеет мьютексом.
функция pthread—mutex_unlock () может завершиться неудачно, если:
[ EPERM ] текущий поток не владеет мьютексом.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Объекты мьютексов служат в качестве базовых элементов низкого уровня, на ос-
нове которых можно построить другие функции синхронизации потоков. Поэтому
реализация мьютексов должна быть максимально эффективной.
Функции управления мьютексами и, в частности, устанавливаемые по умолчанию
значения атрибутов мьютексов позволяют по желанию организовать быстродейст-
вующие встроенные реализации блокировок и разблокировок мьютексов.
Например, тупиковая ситуация при двойной блокировке— это явным образом
разрешенное поведение, которое позволяет избежать внесения в базовый механизм
больших затрат. (Более “дружественные” мьютексы, которые обнаруживают взаимо-
блокировку или позволяют множественное блокирование одним и тем же потоком,
пользователь может легко создать с помощью других механизмов. Например, для ре-
гистрации владельцев мьютекса можно использовать функцию pthread—self О.)
Реализации путем использования специальных атрибутов мьютексов также могут
предоставлять дополнительные возможности в виде опций.
Поскольку большинство атрибутов проверяется перед тем, как поток должен быть
заблокирован, их использование не замедляет процесс блокирования мьютекса.
Более того, несмотря на возможность выделить идентификационный номер (ID)
владельца мьютекса, это потребовало бы сохранения текущего ID потока при каждом
блокировании мьютекса, что связано с неприемлемым уровнем затрат. Аналогичные
аргументы применимы и к операции mutex_tryunlock.
Будущие направления
Отсутствуют.
Смотри также
Pthread—mutex—destroy (), pthread—mutex_timedlock (), том Base Definitions
стандарта IEEE Std 1003.1-2001, <pthread.h>.
606 Приложение Б
Последовательность внесения изменений
функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—mutex_lock (), pthread_mutex_trylock () и pthread—mutex__
unlock () отмечены как часть опции Threads.
В результате согласования со спецификацией Single UNIX Specification было опре-
делено поведение при попытке повторно заблокировать мьютекс.
В целях согласования со стандартом IEEE Std 1003.1d-1999 в раздел “Смотри также”
была добавлена функция pthread_mutex_t imedlock ().
Приложение Б 607
Имя
pthread—mutex_timedlock — функция блокировки мьютекса (ADVANCED
REALTIME).
Синопсис
THR #include <рthread.h>
ТМО #include <time.h>
int pthread_mutex_timedlock (
pthread—mutex_t *restrict mutex,
const struct timespec *restrict abs_timeout);
Описание
Функция pthread—mutex—timedlock () используется для блокирования
объекта мьютекса, адресуемого параметром mutex. Если этот мьютекс уже заблокиро-
ван, блокируется вызывающий поток до тех пор, пока мьютекс не станет доступным
(как при использовании функции pthread—mutex_1 ock ()). Если мьютекс нельзя за-
блокировать без ожидания, пока другой поток его разблокирует, это ожидание будет
прервано, когда истечет заданный интервал времени.
Заданный интервал времени истекает, когда наступит абсолютное время, заданное
параметром abs_timeout (т.е. когда значение системных часов станет равным или
превысит значение abs_timeout) или если в момент вызова функции абсолютное
время, заданное параметром abs__timeout, уже наступило.
TMR Если поддерживается опция Timers, отсчет интервала времени проис-
ходит с использованием часов CLOCK—REALTIME; в противном случае —
с использованием системных часов, значение которых возвращает
функция time ().
Разрешение для интервала времени определяется разрешением часов, которые ис-
пользуются для его отсчета. Тип данных timespec определяется в заголовке <time. h>.
Ни при каких условиях эта функция не завершится неудачно, если мьютекс может
быть заблокирован немедленно. В проверке достоверности параметра abs_timeout
Нет никакой необходимости, если мьютекс может быть заблокирован немедленно.
У правил наследования приоритета (для мьютексов, инициализированных с ис-
пользованием протокола PRIO—INHERIT) есть следствие: если ожидание мьютекса,
Действующего с ограничением по времени, завершается по причине исчерпания за-
данного интервала времени, то приоритет владельца мьютекса будет откорректиро-
ван таким образом, чтобы отражать факт того, что данный поток больше не относит-
ся к числу потоков, ожидающих заданный мьютекс.
Возвращаемое значение
При успешном завершении функция pthread—mutex_timedlock () возвращает
^Девое значение; в противном случае — код ошибки, обозначающий ее характер.
608 Приложение Б
Ошибки
Функция pthread—mutex_timedlock () завершится неудачно, если:
[EINVAL] мьютекс был создан с использованием атрибута protocol, имеюще- го значение PTHREAD— PRIO_PROTECT, а приоритет вызывающего потока выше текущего значения предельного приоритета мьютекса;
[EINVAL] процесс или поток заблокирован, а параметр abs_timeout в поле наносекунд имеет значение, которое меньше нуля либо больше или равно 1000 млн;
[ETIMEDOUT] мьютекс не удалось заблокировать до истечения заданного интер- вала времени.
Функция pthread—mutex—timedlock () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром mutex, не относится к ини- циализированному объекту мьютекса;
XSI [EAGAIN] мьютекс остался недоступным, поскольку было превышено максимальное количество рекурсивных блокировок для мью- текса, заданного параметром mutex,
[ EDEADLK] текущий поток уже владеет мьютексом.
Эта функция не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Функция pthread_mutex_timedlock() является частью опций Threads
и Timeouts и может быть не представлена во всех реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—mutex_destroy (), pthread—mutex_lock (), pthread—mutex_trylock ()»
time (), том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread. h>, <time. h>-
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003.1d-1999.
Приложение Б 609
Имя
pthread_mutexattr_destroy, pthread_mutexattr_init — функции разруше-
ния и инициализации объекта атрибутов мьютекса.
Синопсис
THR #include <pthread.h>
int pthread—mutexattr_destroy (
pthread—mutexattr_t *attr) ;
int pthread—mutexattr_init (pthread—mutexattr_t *attr) ;
Описание
Функция pthread—mutexattr_destroy () используется для разрушения объекта
атрибутов мьютекса, в результате чего этот объект становится неинициализирован-
ным. В конкретной реализации функция pthread—mutexattr_destroy() может ус-
танавливать объект, адресуемый параметром attr, равным недействительному зна-
чению. Разрушенный объект атрибутов можно снова инициализировать с помощью
функции pthread—mutexattr_init (); результаты ссылки на этот объект после его
разрушения не определены.
Результаты не определены, если функция pthread—mutexattr—init () вызыва-
ется, ссылаясь на уже инициализированный объект атрибутов attr.
После того как объект атрибутов мьютекса был использован для инициализации
одного или нескольких мьютексов, любая функция, которая оказывает влияние на
объект атрибутов (включая деструктор), никак не отразится на ранее инициализиро-
ванных мьютексах.
Возвращаемые значения
При успешном завершении функции pthread—mutexattr—destroy ()
и pthread—mutexattr_init () возвращают нулевое значение; в противном случае —
код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—mutexattr—destroy () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром a t tr, недействительно.
Функция pthread—mutexattr—init () завершится неудачно, если:
IENOMEM] для инициализации объекта атрибутов мьютекса недостаточно су-
ществующей памяти.
Эти функции не возвращают код ошибки [EINTR].
610 Приложение Б
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Для получения общих разъяснений назначения атрибутов см. описание функции
pthread—attr_init (). Объекты атрибутов позволяют реализациям эксперименти-
ровать с полезными расширениями и разрешают использовать расширение этого то-
ма стандарта IEEE Std 1003.1-2001, не изменяя существующих функций. Таким обра-
зом, они обеспечивают возможности для будущего расширения этого тома стандарта
IEEE Std 1003.1-2001 и уменьшают соблазн преждевременно стандартизировать се-
мантику, которая еще широко не реализована или не до конца понята.
Рассматривалась возможность использования таких дополнительных атрибутов
мьютексов, как spin_only, limited spin, no_spin, recursive и metered.
(Считаем необходимым разъяснить назначение таких атрибутов, как recursive
и metered: рекурсивные мьютексы позволяют выполнение нескольких повторных
блокировок со стороны текущего владельца; мьютексы с регистрирацией фиксируют
длину очереди, время ожидания и т.д.) Поскольку еще нет достаточных данных о том,
насколько полезны эти атрибуты, в данном томе стандарта IEEE Std 1003.1-2001 они
не определены. Однако объекты атрибутов мьютексов позволяют проверить эти идеи
на предмет возможной их стандартизации в будущем.
Атрибуты мьютекса и производительность
Необходимо позаботиться о том, чтобы действующие по умолчанию значения ат-
рибутов мьютекса были определены таким образом, чтобы мьютексы, инициализиро-
ванные этими значениями, имели достаточно простую семантику, согласно которой
блокирование и разблокирование можно было бы выполнить с помощью инструкций,
эквивалентных операциям тестирования и установки значений (и, возможно, еще не-
которых других базовых инструкций).
Существует по крайней мере один метод реализации, который можно использо-
вать для сокращения расходов в период блокирования на проверку того, имеет ли
мьютекс нестандартные атрибуты. Один такой метод заключается в том, чтобы пред-
варительно заблокировать любые мьютексы, которые инициализированы нестан-
дартными атрибутами. Любая попытка позже заблокировать такой мьютекс заставит
реализацию перейти на “медленный путь”, как если бы мьютекс был недоступен; затем
реализация могла бы “по-настоящему” заблокировать “нестандартный” мьютекс. Ба-
зовая операция разблокировки более сложна, поскольку реализация никогда в дейст-
вительности не желает освобождать мьютекс, который был предварительно заблоки-
рован. Это показывает, что (в зависимости от оборудования) существует необходи-
мость применения оптимизаций для более эффективной обработки часто
используемых атрибутов мьютекса.
Приложение Б 611
Использование общей памяти и синхронизация процессов
Существование функций распределения памяти в этом томе стандарта IEEE Std
1003.1-2001 дает приложению возможность выделять память объектам синхрониза-
ции из того раздела, который доступен многим процессам (а следовательно, и пото-
кам многих процессов).
Чтобы реализовать такую возможность при эффективной поддержке обычного
(т.е. однопроцессорного) случая, был определен атрибут process-shared.
Если реализация поддерживает опцию _POSIX_THREAD_PROCESS—SHARED, то ат-
рибут process-shared можно использовать для индикации того, что к мьютексам или
условным переменным могут получать доступ потоки сразу нескольких процессов.
Для того чтобы объекты синхронизации по умолчанию создавались в самой эф-
фективной форме, для атрибута process-shared в качестве стандартного было вы-
брано значение PTHREAD—PROCESS—PRIVATE. Переменные синхронизации, которые
инициализированы значением PTHREAD—PROCESS—PRIVATE атрибута process-
shared, могут обрабатываться потоками только в том процессе, в котором была вы-
полнена инициализации этих переменных. Переменные синхронизации, которые
инициализированы значением PTHREAD—PROCESS—SHARED атрибута process-
shared, могут обрабатываться любым потоком в любом процессе, который имеет
к ним доступ. В частности, эти процессы могут существовать независимо от процесса
инициализации. Например, следующий код реализует простой семафор-счетчик
в общедоступном файле, который может быть использован многими процессами.
/* sem.h */
struct semaphore {
pthread—mutex—t lock;
pthread—cond—t nonzero;
unsigned count;
};
typedef struct semaphore semaphore—t;
semaphore—t *semaphore—create (char *semaphore—name);
semaphore—t *semaphore—open (char *semaphore—name);
void semaphore—post (semaphore—t *semap);
void semaphore—wait (semaphore—t *semap);
void semaphore—close (semaphore—t *semap);
/* sem.c
^include
^include
^include
#include
^include
^include
*/
<sys/types.h>
<sys/stat.h>
<sys/mman.h>
<fcntl.h>
<pthread.h>
"sem.h"
semaphore—t *
semaphore—create (char *semaphore—name)
int fd;
semaphore—t * semap;
pthread—mutexattr_t psharedm;
612 Приложение Б
pthread—condattr_t psharedc;
fd = open(semaphore—name, O_RDWR | 0_CREAT | 0—EXCL, 0666);
if (fd <0)
return (NULL);
(void) ftruncate (fd, sizeof (semaphore—t));
(void) pthread—mutexattr_init (&psharedm);
(void) pthread_mutexattr_setpshared(&psharedm,
PTHREAD—PROCESS—SHARED);
(void) pthread_condattr_init (&psharedc);
(void) pthread—condattr—setpshared (&psharedc,
PTHREAD_PROCESS_SHARED);
semap = (semaphore—t *) mmap (NULL, sizeof (semaphore—t),
PROT—READ | PROT—WRITE,
MAP_SHARED, fd, 0);
close (fd);
(void) pthread—mutex—init (&semap->lock, &psharedm);
(void) pthread—cond_init (&semap->nonzero, &psharedc);
semap->count = 0;
return (semap);
}
semaphore—t *
semaphore—open (char *semaphore—name)
{
int fd;
semaphore—t *semap;
fd = open (semaphore—name, O_RDWR, 0666);
if (fd <0)
return (NULL);
semap = (semaphore—t *) mmap (NULL, sizeof (semaphore—t),
PROT-READ | PROT—WRITE,
MAP-SHARED, fd, 0);
close (fd);
return (semap);
}
void
semaphore—post (semaphore—t *semap)
{
pthread—mutex—lock (&semap->lock);
if (semap->count == 0)
pthread—cond_signal (&semapx->nonzero);
semap->count++;
pthread—mutex—unlock (&semap->lock);
}
void
semaphore—wai t (semaphore—t * semap)
{
Приложение Б 613
pthread—mutex_lock (&semap->lock);
while (semap->count == 0)
pthread—cond_wait (&semap->nonzero, &semap->lock);
semap->count— ;
pthread—mutex_unlock (&semap->lock);
}
void
semaphore_close (semaphore—t *semap)
{
munmap ((void *) semap, sizeof (semaphore—t));
}
Следующий код обеспечивает выполнение трех отдельных процессов, которые
создают семафор в файле /tmp/semaphore, отправляют сигналы и ожидают его ос-
вобождения. После того как семафор создан, программы сигнализации и ожидания
инкрементируют и декрементируют счетчик семафора, несмотря на то, что они сами
не инициализировали семафор.
/* create.с */
#include "pthread.h"
# include "sem.h"
int
main ()
{
semaphore—t * semap;
semap = semaphore—create("/tmp/semaphore");
if (semap == NULL)
exit(1);
semaphore—close (semap);
return (0);
}
/* post */
#include "pthread.h"
#include "sem.h"
int
main()
{
semaphore_t * semap;
semap = semaphore—open ("/tmp/semaphore");
if (semap == NULL)
exit (1);
semaphore—post (semap);
semaphore—close (semap);
} return (0);
z* wait */
^include "pthread.h"
614 Приложение Б
#include "sem.h”
int
main ()
{
semaphore_t * semap;
semap = semaphore_open ("/tmp/semaphore");
if (semap == NULL)
exit (1) ;
semaphore—wait (semap);
semaphore_close (semap);
return (0);
}
Будущие направления
Отсутствуют.
Смотри также
pthread—cond_destroy (), pthread—create (), pthread—mu tex_des troy (),
pthread—mutexattr_destroy (), том Base Definitions стандарта IEEE Std 1003.1-
2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread—mutexattr_destroy () и pthread—mutexattr—init () отме-
чены как часть опции Threads.
Раздел “Ошибки” был отредактирован путем применения интерпретации IEEE
PASC Interpretation 1003.1с #27.
Приложение Б 615
Имя
pthread—mutexattr_getprioceiling, pthread—mutexattr_setprioceiling —
функции считывания и установки атрибута prioceiling в объекте атрибутов мью-
текса (REALTIME THREADS).
Синопсис
THR #include <рthread.h>
TPP int pthread_mutexattr_getprioceiling (
const pthread_mutexattr_t *restrict attr,
int *restrict prioceiling);
int pthread_mutexattr_setprioceiling (
pthread—mutexat tr_t * a t tr,
int prioceiling);
Описание
Функции pthread—mutexattr_getprioceiling() и pthread—mute-
xattr—setpr ioceil ing () используются для считывания и установки соответст-
венно атрибута prioceiling в объекте атрибутов мьютекса, адресуемого пара-
метром attr, который был ранее создан с помощью функции
pthread—mutexattr_init ().
Атрибут prioceiling содержит предельное значение приоритета инициализи-
рованных мьютексов. Значения атрибута prioceiling ограничены границами диа-
пазона приоритетов, определенного для стратегии планирования, соответствующей
значению SCHED_FIFO.
Значение атрибута prioceiling — это минимальный уровень приоритета, на ко-
тором еще выполняется критический раздел, защищаемый мьютексом. Чтобы избе-
жать инверсии приоритетов, предельное значение приоритета мьютекса устанавли-
вается выше самого высокого приоритета всех потоков, которые могут блокировать
этот мьютекс, или равным ему.
Возвращаемые значения
При успешном завершении функции pthread—mutexattr—getprioceiling()
иpthread—mutexattr_setprioceiling () возвращают нулевое значение; в про-
тивном случае — код ошибки, обозначающий ее характер.
Ошибки
Функции pthread_mutexattr_getprioceiling() и pthread_mutexattr_setp-
rioceiling () могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, или параметром prioceiling,
недействительно;
[EPERM] инициатор вызова не обладает привелегиями для выполнения этой
операции.
Эти функции не возвращают код ошибки [ EINTR].
616 Приложение Б
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—cond_destroy (), pthread—create (), pthread—mutex_destroy (), том
Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—mutexattr_getprioceiling () и pthread—mutexattr_setp-
rioceiling () отмечены как часть опций Threads и Thread Priority Protection.
Код ошибки [ENOSYS] был исключен, поскольку его нет смысла учитывать, если
реализация не поддерживает опцию Thread Priority Protection.
Код ошибки [ENOTSUP] был исключен, поскольку эти функции не имеют аргумен-
та protocol.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—mutexattr_getprioceiling () было добавлено ключевое слово
restrict.
Приложение Б 617
Имя
pthread—mutexattr_getprotocol, pthread—mutexattr_setprotocol —
функции считывания и установки атрибута protocol в объекте атрибутов мьютекса
(REALTIME THREADS).
Синопсис
THR TPPITPI #include <pthread.h> int pthread—mutexattr_getprotocol ( const pthread—mutexattr—t *restrict attr, int *restrict protocol); int pthread—mutexattr_setprotocol ( pthread—mutexattr_t * attr,
int protocol) ;
Описание
Функции pthread—mutexattr_getprotocol() и pthread—mutexattr_setp-
rotocol () используются для считывания и установки соответственно атрибута
protocol в объекте атрибутов мьютекса, адресуемого параметром attr, который
был ранее создан с помощью функции pthread—mutexattr_init ().
Атрибут protocol определяет протокол, которому необходимо следовать при ис-
пользовании мьютексов. Этот атрибут может иметь следующие значения (которые
определены в заголовке <рthread. h>):
TPI
ТРР
PTHREAD—PRIO—NONE
PTHREAD—PRIO—INHERIT
PTHREAD—PRIO—PROTECT
Если поток владеет мьютексом с использованием значения PTHREAD— PRIO_NONE
Для атрибута protocol, то факт обладания мьютексом не отражается на значении его
приоритета и стратегии планирования.
TPI Если поток блокирует потоки с более высоким приоритетом благодаря
тому, что он владеет одним или несколькими мьютексами, у которых
атрибут protocol имеет значение PTHREAD—PRIO_INHERIT, то он бу-
дет выполняться с наивысшим из приоритетов потоков, ожидающих
освобождения любого из мьютексов.
ТРР Если поток владеет одним или несколькими мьютексами, у которых ат-
рибут protocol имеет значение PTHREAD—PRIO_PROTECT, то он будет
выполняться с самым высоким из предельных приоритетов всех мью-
тексов, принадлежащих этому потоку и инициализированных с этим
атрибутом, независимо от того, заблокированы другие потоки по лю-
бому из этих мьютексов или нет.
618 Приложение Б
Пока поток удерживает мьютекс, у которого атрибут protocol был инициализи-
рован значением PTHREAD—PRIO—INHERIT или PTHREAD—PRIO_PROTECT, он не будет
претендентом для перемещения в конец очереди планируемых заданий в результате
изменения его исходного приоритета, например, после вызова функции
sched_setparam (). Аналогично, если поток разблокирует мьютекс, у которого ат-
рибут protocol был инициализирован значением PTHREAD—PRIO—INHERIT или
PTHREAD—PRIO_PROTECT, он не будет претендентом для перемещения в конец очере-
ди планируемых заданий в результате изменения его исходного приоритета.
Если поток одновременно владеет несколькими мьютексами, инициализирован-
ными в соответствии с различными протоколами, он будет выполняться с самым вы-
соким из приоритетов, полученных по каждому из протоколов.
TPI Если поток обращается к функции pthread_mutex_lock (), а атрибут
protocol задаваемого мьютекса был инициализирован значением
PTHREAD_PRIO_INHERIT, и если вызывающий поток блокируется из-за
того, что мьютекс принадлежит другому потоку, то этот поток — владе-
лец мьютекса — наследует уровень приоритета вызывающего потока,
причем до тех пор, пока он продолжает удерживать мьютекс. Реализа-
ция устанавливает приоритет выполнения согласно максимальному
значению (выбранного из заданного и всех унаследованных приорите-
тов). Более того, если этот поток — владелец мьютекса сам блокируется
по другому мьютексу, такой же эффект наследования приоритетов ре-
курсивно распространяется и на этого владельца.
Возвращаемые значения
При успешном завершении функции pthread—mutexattr_getprotocol () и
pthread—mutexattr_setprotocol () возвращают нулевое значение; в противном
случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—mutexattr—setprotocol () завершится неудачно, если:
[ ENOTSUP ] значение, заданное параметром pro tocol, не поддерживается.
Функции pthread—mutexattr_getprotocol() и pthread—mutexattr_setp-
rotocol () могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, или параметром protocol, не-
действительно;
[EPERM] инициатор вызова не обладает привилегиями для выполнения этой
операции.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Приложение Б 619
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—cond—destroy(), pthread—create(), pthread_mutex_destroy(),том
Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Отмечены как часть группы Realtime Threads Feature Group.
Issue 6
Функции pthread—mutexattr_getprotocol() и pthread—mutexattr—setp-
rotocol () отмечены как часть опции Threads и одной из опций Thread Priority
Protection или Thread Priority Inheritance.
Код ошибки [ENOSYS] был исключен, поскольку его нет смысла учитывать, если
реализация не поддерживает опции Thread Priority Protection или Thread Priority
Inheritance.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—mutexattr—getprotocol () было добавлено ключевое слово restrict.
620 Приложение Б
Имя
pthread—mutexattr_getpshared, pthread_mutexattr_setpshared — функ-
ции считывания и установки атрибута process-shared.
Синопсис
THR #include <рthread.h>
TSH
int pthread_mutexattr_getpshared (
const pthread_mutexattr_t *restrict attr,
int *restrict pshared);
int pthread—mutexattr_setpshared(
pthread—mutexattr_t ★attr,
int pshared);
Описание
Функция pthread—mutexattr_getpshared () используется для получения значения
атрибута process-shared из объекта атрибутов, адресуемого параметром attr. Функция
pthread—mutexattr_setpshared () позволяет установить атрибут process-
shared в инициализированном объекте атрибутов, адресуемом параметром a t tr.
Атрибут process-shared устанавливается равным значению
PTHREAD—PROCESS—SHARED, чтобы позволить обработку мьютекса любым другим по-
током, который имеет доступ к памяти, в которой размещен этот мьютекс, даже если
он размещен в памяти, совместно используемой несколькими процессами. Если атри-
бут process-shared установлен равным значению PTHREAD—PROCESS-PRIVATE,
мьютекс будет обрабатываться только теми потоками, созданными в одном процессе
с потоком, который инициализировал этот мьютекс; если потоки из различных про-
цессов попытаются работать с таким мьютексом, то дальнейшее их поведение не оп-
ределено. По умолчанию этот атрибут устанавливается равным значению
PTHREAD—PROC ES S_PRI VATE.
Возвращаемые значения
При успешном завершении функция pthread—mutexattr_setpshared() возвра-
щает нулевое значение; в противном случае — код ошибки, обозначающий ее характер.
При успешном завершении функция pthread—mutexattr_getpshared () воз-
вращает нулевое значение и сохраняет считанное значение атрибута process-
shared объекта a t tr в объекте, адресуемом параметром pshared; в противном слу-
чае возвращается код ошибки, обозначающий ее характер.
Ошибки
Функции pthread_mutexattr_getpshared() и pthread_mutexattr_setp"
shared () могут завершиться неудачно, если:
Приложение Б 621
[ EINVAL] значение, заданное параметром a t tr, недействительно.
Функция pthread__mutexat tr_.se tpshared () может завершиться неудачно, если:
[EINVAL] новое значение, заданное для атрибута, попадает вне диапазона зна-
чений, действительных для этого атрибута.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread_cond_.destroy (), pthread_create (), pthread__mutex__destroy (),
pthread_mutexattr_destroy (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread_mutexattr_getpshared() и pthread_mutexattr_setp-
shared () отмечены как часть опций Threads и Thread Process-Shared Synchronization.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread_mutexattr_getpshared () было добавлено ключевое слово restrict.
622 Приложение Б
Имя
pthread—mutexattr_gettype, pthread—mutexattr—settype — функции счи-
тывания и установки атрибута type.
Синопсис
XSI tfinclude <pthread.h>
int pthread—mutexattr_gettype (
const pthread—mutexattr_t *restrict attr,
int *restrict type);
int pthread—mutexattr_settype (
pthread—mutexattr_t *attr,
int type);
Описание
Функции pthread—mutexattr_gettype() и pthread_mutexattr_settype()
используются для считывания и установки соответственно атрибута суре. Этот атри-
бут задается при вызове этих функций в параметре type. По умолчанию атрибут type
устанавливается равным значению PTHREAD—MUTEX_DEFAULT.
Атрибут type содержит тип мьютекса. Допустимыми значениями атрибута type
могут быть следующие:
PTHREAD—MUTEX—NORMAL
Мьютекс этого типа не обнаруживает взаимоблокировки. Поток, пытаясь переза-
блокировать такой мьютекс без первоначального его разблокирования, попадает во
взаимоблокировку. Попытка разблокировать мьютекс, заблокированный другим по-
током, приводит к неопределенному поведению. Попытка разблокировать незабло-
кированный мьютекс также приводит к неопределенному поведению.
PTHREAD—MUTEX.ERRORCHECK
Мьютекс этого типа выполняет проверку на наличие ошибок. Поток, пытаясь пе-
резаблокировать такой мьютекс без первоначального его разблокирования, генери-
рует код ошибки. При попытке разблокировать мьютекс, заблокированный другим
потоком, генерируется код ошибки. При попытке разблокировать незаблокирован-
ный мьютекс также генерируется код ошибки.
PTHREAD—MUTEX—RECURSIVE
Поток, пытаясь перезаблокировать такой мьютекс без первоначального его раз-
блокирования, успешно его блокирует. Взаимоблокировка, возникающая в результате
переблокирования мьютексов типа PTHREAD—MUTEX_NORMAL, не может произойти
с мьютексами этого типа. Множественное блокирование такого мьютекса потребует
такого же количества раблокировок, которые полностью освободят мьютекс, прежде
чем другой поток сможет его захватить. При попытке разблокировать мьютекс, за-
блокированный другим потоком, генерируется код ошибки. При попытке разблоки-
ровать незаблокированный мьютекс также генерируется код ошибки.
Приложение Б 623
PTHREAD_MUTEX_DEFAULT
Попытка рекурсивного блокирования мьютекса этого типа приводит к неопреде-
ленному поведению. Попытка разблокировать мьютекс, не заблокированный вызы-
вающим потоком, приводит к неопределенному поведению. Попытка разблокировать
^заблокированный мьютекс также приводит к неопределенному поведению. Реали-
зация может преобразовать мьютекс этого типа в один из других типов мьютексов.
Возвращаемые значения
При успешном завершении функция pthread—mutexattr_gettype() возвраща-
ет нулевое значение и сохраняет значение атрибута type, считанное из объекта attr,
в объекте, адресуемом параметром type; в противном случае она возвращает код
ошибки, обозначающий ее характер.
При успешном завершении функция pthread—mutexattr_settype () возвраща-
ет нулевое значение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—mutexattr_ set type () завершится неудачно, если:
[EINVAL] значение, заданное параметром type, недействительно.
Функции pthread—mutexattr_gettype() и pthread—mutexattr_settype()
могут завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, недействительно.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
В приложениях предлагалось не использовать мьютекс типа PTHREAD—MU-
TEX—RECURSIVE с условными переменными, поскольку неявная блокировка, выпол-
ненная для функций pthread—cond_timedwait () или pthread—сond_wait (), мо-
жет в действительности не освободить мьютекс (если он был заблокирован много-
кратно). Если это произойдет, никакой другой поток не сможет удовлетворить усло-
вию предиката.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
624 Приложение Б
Смотри также
pthread—cond_timedwait (), том Base Definitions стандарта IEEE Std 1003.1-2001
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Приложен список опечаток Open Group Corrigendum U033/3. Был отредактиро-
ван раздел “Синопсис” для функции pthread—mutexattr_gettype (), в результате
чего первый аргумент получил тип const pthread—mut exatt r_t *.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—mutexattг_gettype было добавлено ключевое слово restrict.
Приложение Б 625
Имя
pthread_once — функция динамической инициализации пакетов.
Синопсис
THR #include <pthread.h>
int pthread—once (pthread_once_t *once_control,
void (*init_routine) (void));
pthread—once_t once_control = PTHREAD—ONCE_INIT;
Описание
При первом обращении к функции pthread—once () любым потоком процесса
с заданным параметром опсе__control будет вызвана функция ini t_routine без ар-
гументов. Последующие обращения к функции pthread—once () с тем же параметром
once_control не вызывают функцию init_routine. Возвращение из функции
pthread—once () означает, что функция init__routine выполнена. Параметр
опсе_control определяет, вызывалась ли соответствующая функция инициализации.
Функция pthread—once () не является точкой отмены. Но если функция
init_routine является точкой отмены, и отмена таки происходит, то ее воздейст-
вие на параметр опсе_control будет таким, как если бы функция pthread—once ()
никогда не вызывалась.
Константа PTHREAD—ONCE_INIT определяется в заголовке <pthread. h>.
Поведение функции pthread—once () будет неопределенным, если параметр
once_control имеет автоматический класс памяти (объекты этого класса размеща-
ются в стеке и инициализируются всякий раз при входе в блок, где они объявлены,
и разрушаются при выходе из этого блока) или не инициализирован константой
PTHREAD—ONCE.INIT.
Возвращаемое значение
При успешном завершении функция pthread—once () возвращает нулевое зна-
чение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—once () может завершиться неудачно, если:
tEINVAL] значения, заданные параметрами опсе_control или ini t_routine,
недействительны.
Функция pthread—once () не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
626 Приложение Б
Замечания по использованию
Отсутствуют.
Логическое обоснование
Некоторые библиотеки С разработаны для динамической инициализации. Это оз-
начает, что глобальная инициализация для такой библиотеки выполняется при вызо-
ве первой библиотечной процедуры. В однопоточной программе это обычно реали-
зуется с использованием статической переменной, значение которой проверяется
при входе в функцию, например:
static int random—is_initialized = 0;
extern int initialize—random ();
int random_function ()
{
if (random—is—initialized == 0) {
initialize—random ();
random—is—initialized = 1;
}
... /* Операции, выполняемые после инициализации. */
}
Чтобы хранить такую же структуру в многопоточной программе, нужно использо-
вать новый примитив. В противном случае инициализация библиотеки должна быть
выполнена путем явного вызова экспортированной функции инициализации до како-
го бы то ни было использования этой библиотеки.
Для динамической инициализации в многопоточном процессе недостаточно про-
стого флага инициализации; этот флаг необходимо защищать от модификации дан-
ных со стороны нескольких потоков, одновременно обращающихся к библиотеке.
Защита флага требует использования мьютекса, однако мьютексы должны быть ини-
циализированы до их использования. Для гарантии того, что мьютекс инициализиру-
ется только единожды, требуется рекурсивное решение этой проблемы.
Использование функции pthread—once () не только предоставляет гарантиро-
ванные реализацией средства динамической инициализации, но и способствует на-
дежному функционированию многопоточных систем реального времени. Предыду-
щий пример с учетом вышесказанного принимает следующий вид.
tfinclude <pthread.h>
static pthread—once—t random—is_initialized =
PTHREAD—ONCE—INIT;
extern int initialize—random();
int random_function()
{
(void) pthread—once (&random_is_initialized,
initialize—random);
... /* Операции, выполняемые после инициализации. */
}
Обратите внимание на то, что тип pthread—once_t не может быть массивом, по-
скольку для некоторых компиляторов конструкция &<array_name> неприемлема.
Приложение Б 627
Будущие направления
Отсутствуют.
Смотри также
Том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функция pthread_once () отмечена как часть опции Threads.
Был добавлен код ошибки [EINVAL], возвращаемый при неудачном завершении
функции в случае, если хотя бы один из аргументов недействителен.
628 Приложение Б
Имя
pthread—rwlock—destroy, pthread—rwlock—init — функции разрушения
и инициализации объекта блокировки для чтения и записи.
Синопсис
THR tfinclude <pthread.h>
int pthread—rwlock_destroy(pthread—rwlock_t ★rwlock) ;
int pthread—rwlock—init(
pthread—rwlock—t *restrict rwlock,
const pthread—rwlоckattr—t *restrict attr);
Описание
Функция pthread—rwlock—destroy () используется для разрушения объекта бло-
кировки чтения и записи, адресуемого параметром rwlock, и освобождения любых ре-
сурсов, задействованных этой блокировкой. Результат последующего использования
этой блокировки не определен до тех пор, пока объект не будет инициализирован по-
вторно посредством еще одного обращения к функции pthread—rwlock_init ().
В конкретной реализации функция pthread— rwlock_des troy () может устанавливать
объект, адресуемый параметром rwlock, равным недействительному значению. Резуль-
таты не определены, если функция pthread—rwlock_des troy () вызывается в то вре-
мя, когда какой-нибудь поток удерживает объект блокировки, адресуемый параметром
rwlock. Попытка разрушить неинициализированный объект блокировки для чтения
и записи приводит к неопределенному поведению.
Функция pthread—rwlock—init () выделяет любые ресурсы, необходимые для
использования объекта блокировки для чтения и записи, адресуемого параметром
rwlock, и инициализирует его (он переходит в незаблокированное состояние) с ис-
пользованием объекта атрибутов, адресуемого параметром attr. Если параметр attr
содержит значение NULL, для блокировки чтения и записи будут использованы атри-
буты, действующие по умолчанию; т.е. результат в этом случае равносилен передаче
адреса объекта, содержащего стандартные атрибуты блокировки для чтения и записи.
После первой инициализации объект блокировки можно использовать любое число
раз без повторной инициализации. Результаты не определены, если функция
pthread—rwlock—init () вызвана с заданием уже инициализированного объекта
блокировки. Результаты не определены, если объект блокировки для чтения и записи
используется без предварительной инициализации.
При неудачном выполнении функции pthread—rwlock_init () объект, адресуе-
мый параметром rwlock, остается неинициализированным, а содержимое параметра
rwl ock — неопределенным.
Для выполнения синхронизации можно использовать только объект, адресуемый
параметром rwlock. Результат ссылки на копии этого объекта в вызовах функЦИи
pthread—rwlock—destroy (), pthread—rwlock_rdlock (), pthread—rwlock__ti
medrdlock(), pthread—rwlock_timedwrlock(), pthread—rwlock—tryrdlock() >
pthread—rwlock—trywrlock (), pthread—rwlock_uniock () или pthread—rwlock^
wrlock () не определен.
Приложение Б 629
Возвращаемые значения
При успешном завершении функции рthread_rwlock_destroy ()
и pthread—rwlock—init () возвращают нулевое значение; в противном случае — код
ошибки, обозначающий ее характер.
Проверка на наличие ошибок с кодами [EBUSY] и [EINVAL] реализована (если
реализована вообще) так, как будто она выполняется в самом начале работы каждой
функции, и код ошибки в случае ее обнаружения возвращается до модификации со-
стояния объекта блокировки чтения и записи, заданного параметром rwlock.
Ошибки
Функция pthread_rwlock_destroy () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку разрушить заблокированный объ-
ект, адресуемый параметром rwlock;
[EINVAL] значение, заданное параметром rwlock, недействительно.
Функция pthread—rwlock_init () завершится неудачно, если:
[EAGAIN] система испытывает недостаток в ресурсах (не имеется в виду па-
мять), необходимых для инициализации еще одного объекта блоки-
ровки для чтения и записи;
[ENOMEM] для инициализации объекта блокировки для чтения и записи недос-
таточно существующей памяти;
[EPERM] инициатор вызова не обладает привилегиями для выполнения этой
операции.
Функция pthread—rwlock—init () может завершиться неудачно, если:
[EBUSY] реализация обнаружила попытку повторно инициализировать объ-
ект блокировки, адресуемый параметром rwlock, которой был ра-
нее инициализирован, но еще не разрушен;
[EINVAL] значение, заданное параметром a t tr, недействительно.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
630 Приложение Б
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock_rdlock (), pthread—rwlock_timedrdlock (),
pthread_rwlock_timedwrlock (), pthread—rwlock_tryrdlock (),
pthread—rwlock—trywrlock(), pthread—rwlock_unlock(),
pthread—rwlock—wrlock (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003.1J-2000 были внесены следующие
изменения.
• В разделе “Синопсис” изменена метка. Новая метка THR обозначает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они от-
носились к опции Read-Write Locks стандарта IEEE Std 1003.1j-2000, а также
считались частью дополнения XSI). В раздел “Синопсис” также не входит мак-
рос инициализации.
• Раздел “Описание” отредактирован следующим образом:
— явно отмечено выделение ресурсов при инициализации объекта блокировки
для чтения и записи;
— добавлен абзац, в котором указывается, что копии объекта блокировки для
чтения и записи использовать нельзя.
• В раздел “Ошибки” добавлен код ошибки [EINVAL], означающий, что при вы-
зове функции pthread—rwlock—init () значение, заданное параметром attr,
было недействительно.
• Отредактирован раздел “Смотри также”.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread—rwlock—init () было добавлено ключевое слово restrict.
Приложение Б 631
Имя
pthread_rwlock_rdlock, pthread—rwlock—tryrdlock — функции блокирова-
ния объекта блокировки чтения-записи для обеспечения чтения.
Синопсис
THR #include <pthread.h>
int pthread—rwlock_rdlock (pthread_rwlock_t ★rwlock) ;
int pthread_rwlock_tryrdlock (pthread—rwlock_t ★rwlock) ;
Описание
Функция pthread_rwlock_rdlock () применяет блокировку для обеспечения
чтения к объекту блокировки чтения-записи, адресуемому параметром rwlock. Вызы-
вающий поток получает блокировку для чтения, если никакой записывающий поток
не удерживает этот объект блокировки и не существует никаких других записываю-
щих потоков, заблокированных по этому объекту.
Если поддерживается опция Thread Execution Scheduling и потоки, уча-
ствующие в данной блокировке, выполняются с использованием стра-
тегий планирования SCHED—FIFO или SCHED_RR, то вызывающий поток
не получит эту блокировку, если ее удерживает записывающий поток
или если по этому объекту блокировки заблокированы записывающие
потоки такого же или более высокого приоритета; в противном случае
вызывающий поток получит блокировку.
TSP TSP Если поддерживается опция Thread Execution Scheduling и потоки, уча-
ствующие в данной блокировке, выполняются с использованием стра-
тегии планирования SCHED_SPORADIC, то вызывающий поток не полу-
чит эту блокировку, если ее удерживает записывающий поток или если
по этому объекту блокировки заблокированы записывающие потоки та-
кого же или более высокого приоритета; в противном случае вызываю-
щий поток получит блокировку.
Если опция Thread Execution Scheduling не поддерживается, то только
конкретная реализация определяет, получит ли вызывающий поток эту
блокировку, если никакой записывающий поток не удерживает этот
объект блокировки и существуют другие записывающие потоки, забло-
кированные по этому объекту. Если записывающий поток удерживает
этот объект блокировки, вызывающий поток не получит блокировку для
чтения. Если блокировка для чтения не предоставлена, вызывающий
поток блокируется до тех пор, пока он не получит блокировку. Вызы-
вающий поток может попасть в ловушку взаимоблокировки, если во
время вызова он удерживает блокировку для обеспечения записи.
Поток может удерживать несколько параллельных блокировок для чтения по объ-
екту rwlock (т.е. функция pthread—rwlock_rdlock () может быть успешно вызвана
632 Приложение Б
п раз). В этом случае приложение должно гарантировать, что поток выполнит соот-
ветствующие действия по разблокировке объекта rwlock (т.е. он п раз вызовет
функцию pthread—rwlock_unlock ()).
Максимальное количество одновременных (и гарантированно успешных) блоки-
ровок для чтения, которое может быть применено к объекту блокировки чтения-
записи, определяется конкретной реализацией. В случае превышения этого максиму-
ма функция pthread—rwlock_rdlock () может завершиться неудачно.
Функция pthread—rwlock_tryrdlock() применяет блокировку для обеспе-
чения чтения подобно функции pthread—rwlock_rdlock (), за исключением
того, что эта функция завершится неудачно, если эквивалентный вызов функции
pthread—rwlock—rdlock () заблокировал вызывающий поток. Ни в каких случаях
функция pthread—rwlock—tryrdlock () не блокирует потоки; она всегда либо до-
бивается блокировки, либо немедленно завершается с неудачным результатом.
Результаты выполнения этих функций не определены, если любая из них вызыва-
ется с неинициализированным объектом блокировки чтения-записи. Если потоку,
ожидающему освобождения блокировки чтения-записи для обеспечения блокировки
чтения передается сигнал, то после его обработки поток возобновит ожидание осво-
бождения блокировки, как если бы оно и не прерывалось.
Возвращаемые значения
При успешном завершении функция pthread—rwlock_rdlock () возвращает ну-
левое значение; в противном случае — код ошибки, обозначающий ее характер.
Функция pthread—rwlock—tryrdlock () возвращает нулевое значение, если
блокировка для чтения по объекту блокировки чтения-записи, адресуемому парамет-
ром rwloc, предоставлена. В противном случае возвращается код ошибки, обозна-
чающий ее характер.
Ошибки
Функция pthread—rwlock—tryrdlock () завершится неудачно, если:
[ EBUSY ] блокировка чтения-записи не могла быть предоставлена для чтения, по-
скольку удерживает блокировку записывающий поток, или по этому объек-
ту заблокирован записывающий поток с соответствующим приоритетом.
Функции pthread—rwlock—rdlock() и pthread—rwlock_tryrdlock() могут
завершиться неудачно, если:
[EINVAL] значение, заданное параметром rwlock, не относится к инициализи-
рованному объекту блокировки чтения-записи;
[EAGAIN] блокировка не могла быть предоставлена для чтения, поскольку пре"
вышено максимальное число блокировок чтения по объекту, адресуй"
мому параметром rwlock.
Функция pthread—rwlock—rdlock () может завершиться неудачно, если:
[EDEADLK] текущий поток уже удерживает объект блокировки чтения-записи ДлЯ
обеспечения записи.
Эти функции не возвращают код ошибки [EINTR].
Приложение Б 633
Примеры
Отсутствуют.
Замечания по использованию
Как упоминалось в томе Base Definitions стандарта IEEE Std 1003.1-2001 (Section
3.285, Priority Inversion), приложения, которые используют эти функции, могут под-
вергнуться инверсии приоритетов.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock_destroy (), pthread—rwlock_timedrdlock (),
pthread—rwl ock_timedwr lock (), pthread—rwlock—trywrlock (),
pthread—rwlock_unlock (), pthread—rwlock—wrlock (), том Base Definitions
стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003. lj-2000 были внесены следующие
изменения.
• В разделе “Синопсис” была изменена метка. Новая метка THR означает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они от-
носились к опции Read-Write Locks стандарта IEEE Std 1003. lj-2000, а также
считались частью дополнения XSI).
• Раздел “Описание” был отредактирован следующим образом:
~ заданы условия, при которых записывающие потоки имеют преимущество
перед считывающими;
- разъяснена возможная причина неудачного завершения функции
pthread—rwlock—tryгdlock();
“ добавлен абзац, в котором говорится о применении максимального количе-
ство блокировок для обеспечения чтения.
• Был модифицирован раздел “Ошибки”, посвященный описанию кода ошибки
[EBUSY]: теперь предлагается принять во внимание приоритет записывающих
потоков. Удален абзац, посвященный описанию кода ошибки [EDEADLK], воз-
вращаемому функцией pthread—rwlock—tryrdlock ().
• Был отредактирован раздел “Смотри также”.
634 Приложение Б
Имя
pthread—rwlock_timedrdlock— функция, блокирующая объект блокировки
чтения-записи для обеспечения чтения.
Синопсис
THR #include <pthread.h>
ТМО #include <time.h>
int pthread—rwlock—timedrdlock (
pthread—rwlock—t *restrict rwlock,
const struct timespec *restrict abs_timeout);
Описание
Функция pthread—rwlock—timedrdlock () применяет блокировку для обеспече-
ния чтения к объекту блокировки чтения-записи, адресуемому параметром rwlock,
подобно функции pthread_rwlock_rdlock (). Однако, если блокировка не может
быть предоставлена без ожидания, пока другие потоки не освободят ее, это ожидание
будет прервано, когда истечет заданный интервал времени. Интервал времени исте-
кает, когда наступит абсолютное время, заданное параметром abs_timeout (т.е. ко-
гда показания времени на используемых в системе часах станут равными или превы-
сят значение abs_timeout), или если абсолютное время, заданное параметром
abs_ timeou t, уже наступило в момент вызова.
TMR Если поддерживается опция Timers, отсчет интервала времени происхо-
дит с использованием часов CLOCK—REALTIME.
Если опция Timers не поддерживается, отсчет интервала времени происхо-
дит с использованием системных часов, значение которых возвращает функ-
ция time (). Разрешение для интервала времени определяется разрешением
часов, которые используются для его отсчета. Тип данных timespec опре-
деляется в заголовке <time .h>. Ни при каких условиях эта функция не за-
вершится неудачно, если блокировка может быть предоставлена немед-
ленно. В проверке достоверности параметра abs_timeout нет никакой
необходимости, если блокировка может быть предоставлена немедленно.
Если потоку, заблокированному по объекту блокировки чтения-записи при вы-
зове функции pthread_rwlock_timedrdlock (), передается сигнал, то после его
обработки поток возобновит ожидание освобождения блокировки, как если бы оно
и не прерывалось.
Вызывающий поток может попасть в ловушку взаимоблокировки, если во время
вызова он удерживает блокировку для обеспечения записи по объекту, адресуемом)'
параметром rwlock Результаты не определены, если эта функция вызывается с не-
инициализированным объектом блокировки чтения-записи.
Приложение Б 635
Возвращаемое значение
Функция pthread—rwlосk_timedrdlock () возвращает нулевое значение, если
блокировка для чтения по объекту блокировки чтения-записи, адресуемому парамет-
ром rwloc, предоставлена. В противном случае возвращается код ошибки, обозна-
чающий ее характер.
Ошибки
Функция pthread—rwlock—timedrdlock () завершится неудачно, если:
[ETIMEDOUT] блокировка не могла быть предоставлена до истечения заданного
интервала времени.
Функция pthread—rwlock—timedrdlock () может завершиться неудачно, если:
[EAGAIN] блокировка для чтения не могла быть предоставлена, поскольку
превышено максимальное число блокировок чтения по объекту, ад-
ресуемому параметром rwlock,
[EDEADLK] вызывающий поток уже удерживает объект блокировки для обеспе-
чения записи по объекту, адресуемому параметром rwlock,
[EINVAL] значение, заданное параметром rwlock, не относится к инициали-
зированному объекту блокировки чтения-записи, или значение
abs_timeout, выраженное в наносекундах, меньше нуля либо
больше или равно 1000 миллионам.
Эта функция не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Как упоминалось в томе Base Definitions стандарта IEEE Std 1003.1-2001
(Section 3.285, Priority Inversion), приложения, которые используют эту функцию,
могут подвергнуться инверсии приоритетов.
Функция pthread—rwlock—timedrdlock() является частью опций Threads
и Timeouts и может быть не предоставлена во всех реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
636 Приложение Б
Смотри также
pthread—rwlock_destroy (), pthread—rwlосk_rdlock (),
pthread—rwlock—timedwr lock (), pthread—rwlock—tryrdlock (),
pthread—rwlock_trywrlock (), pthread—rwlock—unlock (),
pthread—rwlock—wrlock (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>, <time.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003. lj-2000.
Приложение Б 637
Имя
pthread—rwlock—timedwrlock — функция, блокирующая объект блокировки
чтения-записи для обеспечения записи.
Синопсис
THRTMO #include <pthread.h>
#include <time.h>
int pthread—rwlock_timedwrlock (
pthread—rwlock—t *restrict rwlock,
const struct timespec *restrict abs_timeout) ;
Описание
Функция pthread_rwlock—timedwrlock () применяет блокировку для обеспече-
ния записи к объекту блокировки чтения-записи, адресуемому параметром rwlock,
подобно функции pthread—rwlock—wrlock (). Однако, если блокировка не может
быть предоставлена без ожидания, пока другие потоки не освободят ее, это ожидание
будет прервано, когда истечет заданный интервал времени. Интервал времени исте-
кает, когда наступит абсолютное время, заданное параметром abs_timeout (т.е. ко-
гда показания времени на используемых в системе часах станут равными или превы-
сят значение abs_timeout), или если абсолютное время, заданное параметром
abs_timeout, уже наступило в момент вызова.
TMR Если поддерживается опция Timers, отсчет интервала времени происхо-
дит с использованием часов CLOCK—REALTIME.
Если опция Timers не поддерживается, отсчет интервала времени про-
исходит с использованием системных часов, значение которых возвра-
щает функция time (). Разрешение для интервала времени определяется
разрешением часов, которые используются для его отсчета. Тип данных
timespec определяется в заголовке <time.h>. Ни при каких условиях
эта функция не завершится неудачно, если блокировка может быть пре-
доставлена немедленно. В проверке достоверности параметра
abs_timeout нет никакой необходимости, если блокировка может быть
предоставлена немедленно.
Если потоку, заблокированному по объекту блокировки чтения-записи при вы-
зове функции pthread_rwlock_timedwrlock (), передается сигнал, то после его
обработки поток возобновит ожидание освобождения блокировки, как если бы оно
и не прерывалось.
Вызывающий поток может попасть в ловушку взаимоблокировки, если во время
вызова он удерживает блокировку чтения-записи по объекту, адресуемому параметром
rwlock. Результаты не определены, если эта функция вызывается с неинициализиро-
ванным объектом блокировки чтения-записи.
638 Приложение Б
Возвращаемое значение
Функция pthread—rwlock_timedwrlock () возвращает нулевое значение, если
блокировка для записи по объекту блокировки чтения-записи, адресуемому пара-
метром rwloc, предоставлена. В противном случае возвращается код ошибки, обо-
значающий ее характер.
Ошибки
Функция pthread—rwlock_timedwrlock () завершится неудачно, если:
[ETIMEDOUT] блокировка не могла быть предоставлена до истечения заданного
интервала времени.
Функция pthread_rwlock_timedwrlock () может завершиться неудачно, если:
[EDEADLK] вызывающий поток уже удерживает объект блокировки по объекту,
адресуемому параметром rwlock:,
[EINVAL] значение, заданное параметром rwlock, не относится к инициали-
зированному объекту блокировки чтения-записи, или значение
abs_timeout, выраженное в наносекундах, меньше нуля либо
больше или равно 1000 миллионам.
Эта функция не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Как упоминалось в томе Base Definitions стандарта IEEE Std 1003.1-2001 (Section 3.285,
Priority Inversion), приложения, которые используют эту функцию, могут подвергнуть-
ся инверсии приоритетов.
Функция pthread—rwlock—timedwrlock () является частью опций Threads
и Timeouts и может быть не предоставлена во всех реализациях.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock—destroy(),pthread—rwlock_rdlock(),
pthread—rwlock—timedrdlock (), pthread—rwlock_tryrdlock (),
Приложение Б 639
pthread—rwlock—trywrlock (), pthread—rwlock_unlock (),
pthread—rwlock—wrlock (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread. h>, <t ime. h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 6, основанием послужил стандарт
IEEE Std 1003. lj-2000.
640 Приложение Б
Имя
pthread—rwlock—trywrlock, pthread—rwlock—wrlock — функции, блокирую-
щие объект блокировки чтения-записи для обеспечения записи.
Синопсис
THR #include <pthread.h>
int pthread—rwlock—trywrlock (pthread—rwlock_t *rwlock) ;
int pthread—rwlock—wrlock (pthread—rwlock—t ★rwlock) ;
Описание
Функция pthread—rwlock_trywrlock () применяет блокировку для обеспечения
записи подобно функции pthread—rwlock—wrlock (), за исключением того, что эта
функция завершится неудачно, если какой-нибудь поток в данный момент удерживает
блокировку по объекту, адресуемому параметром rwlock (для чтения или записи).
Функция pthread—rwlock—wrlock () применяет блокировку для обеспечения за-
писи к объекту блокировки чтения-записи, адресуемому параметром rwlock. Вызы-
вающий поток получает блокировку для записи, если никакой другой поток
(записывающий или считывающий) не удерживает этот объект блокировки. В про-
тивном случае этот поток будет заблокирован до тех пор, пока он не сможет получить
блокировку. Вызывающий поток может попасть в ловушку взаимоблокировки, если во
время вызова он удерживает блокировку чтения-записи (либо для записи, либо для
чтения) по объекту, адресуемому параметром rwlock.
Реализации могут благоприятствовать записывающим потокам перед считываю-
щими, чтобы избежать зависания записывающего потока. Результаты не определены,
если любая из этих функций вызывается с неинициализированным объектом блоки-
ровки чтения-записи. Если потоку, ожидающему блокировки для обеспечения записи,
передается сигнал, то после его обработки поток возобновит ожидание освобожде-
ния блокировки, как если бы оно и не прерывалось.
Возвращаемые значения
Функция pthread—rwlock—trywrlock () возвращает нулевое значение, если
блокировка для записи по объекту блокировки чтения-записи, адресуемому парамет-
ром rwloc, предоставлена. В противном случае возвращается код ошибки, обозна-
чающий ее характер.
При успешном завершении функция pthread—rwlock_wrlock () возвращает ну-
левое значение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—rwlock—trywrlock () завершится неудачно, если:
[EBUSY] блокировка чтения-записи не могла быть предоставлена для записи,
поскольку заданный объект блокировки уже заблокирован для чтения
или записи.
Приложение Б 641
Функции pthread—rwlock—wrlock () и pthread— rwlock.trywrlock () могут
завершиться неудачно, если:
[EINVAL] значение, заданное параметром rwlock, не относится к инициализи-
рованному объекту блокировки чтения-записи.
Функция pthread—rwlock—wr lock () может завершиться неудачно, если:
[EDEADLK] текущий поток уже удерживает объект блокировки чтения-записи для
обеспечения записи или чтения.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Как упоминалось в томе Base Definitions стандарта IEEE Std 1003.1-2001 (Section 3.285,
Priority Inversion), приложения, которые используют эти функции, могут подверг-
нуться инверсии приоритетов.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock—destroy(),pthread—rwlock_rdlock(),
pthread—rwlock—timedrdlock (), pthread—rwlock—timedwrlock (),
Pthread— rwlock_tryrdlock (), pthread— rwlock_uniock (),
том Base Definitions стандарта IEEE Std 1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003. lj-2000 были внесены следующие
изменения:
• В разделе “Синопсис” была изменена метка. Новая метка THR означает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они от-
642 Приложение Б
носились к опции Read-Write Locks стандарта IEEE Std 1003.1j-2000, а также
считались частью дополнения XSI).
• Из раздела “Ошибки” удален абзац, посвященный описанию кода ошибки
[EDEADLK], возвращаемому функцией pthread—rwlock—trywrlock ().
• Был отредактирован раздел “Смотри также”.
Приложение Б 643
Имя
pthread—rwlock—unlock— функция разблокирования объекта блокировки чте-
ния-записи.
Синопсис
THR # include <рthread.h>
int pthread—rwlock—unlock(pthread—rwlock—t * rwlock);
Описание
Функция pthread—rwlock—unlock () используется для освобождения блокиров-
ки, удерживаемой с помощью объекта блокировки чтения-записи, адресуемого пара-
метром rwlock. Результаты не определены, если объект блокировки чтения-записи,
адресуемый параметром rwlock, не удерживается вызывающим потоком.
Если эта функция вызывается, чтобы освободить блокировку для обеспечения чте-
ния, и существуют другие блокировки чтения, удерживаемые в данный момент по этому
объекту блокировки чтения-записи, то он (объект) останется в состоянии блокирования
для обеспечения чтения. Если с помощью этой функции освобождается последняя бло-
кировка для чтения по заданному объекту блокировки чтения-записи, то этот объект пе-
рейдет в разблокированное состояние и, соответственно, не будет иметь владельцев.
Если эта функция вызывается, чтобы освободить блокировку для обеспечения за-
писи по заданному объекту блокировки чтения-записи, то этот объект перейдет в раз-
блокированное состояние.
Если существуют потоки, заблокированные по этому объекту блокиров-
ки, то при его освобождении именно стратегия планирования опреде-
ляет, какой поток (потоки) получит блокировку.
TPS Если потоки, ожидающие освобождения блокировки, выполняются
в соответствии со стратегиями планирования SCHED—FIFO, SCHED_RR
или SCHED—SPORADIC, то при поддержке опции Thread Execution
Scheduling после освобождения этой блокировки потоки получат бло-
кировку в порядке следования их приоритетов. Для потоков с одинако-
выми приоритетами блокировки для записи имеют преимущество пе-
ред блокировками для чтения.
Если опция Thread Execution Scheduling не поддерживается, то будут
ли блокировки для записи иметь преимущество перед блокировками
для чтения, определяется конкретной реализацией.
Результаты не определены, если эта функция вызывается с неинициализирован-
ным объектом блокировки чтения-записи.
644 Приложение Б
Возвращаемое значение
При успешном завершении функция pthread—rwlock_unlock () возвращает ну-
левое значение; в противном случае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread_rwlock_unlock () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром rwlock, не относится к инициализи-
рованному объекту блокировки чтения-записи
[EPERM] текущий поток не удерживает объект блокировки чтения-записи для
обеспечения записи или чтения.
Функция pthread_rwlock_unlock () не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock—destroy(), pthread—rwlock_rdlock(),
pthread—rwlock—timedrdlock (), pthread—rwlock_timedwrlock (),
pthread—rwlock—tryrdlock(), pthread—rwlock—trywrlock(),
pthread—rwlock—wrlock (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003.1j-2000 были внесены следующие
изменения.
• В разделе “Синопсис” была изменена метка. Новая метка THR означает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они
Приложение Б 645
относились к опции Read-Write Locks стандарта IEEE Std 1003. lj-2000, а также
считались частью дополнения XSI).
Раздел “Описание” был отредактирован следующим образом:
— заданы условия, при которых записывающие потоки имеют пре-
имущество перед считывающими;
— удалена концепция владельца блокировки чтения-записи.
Был отредактирован раздел “Смотри также”.
646 Приложение Б
Имя
pthread—rwlockattr_destroy, pthread—rwlockattr_init — функции разру-
шения и инициализации объекта атрибутов для блокировки чтения-записи.
Синопсис
THR #include <pthread.h>
int pthread—rwlockattr_destroy(
pthread—rwlockattr—t *attr);
int pthread—rwlockattr—init (pthread—rwlockattr—t *attr);
Описание
Функция pthread_rwlockattr_destroy () используется для разрушения объек-
та атрибутов для блокировки чтения-записи. Разрушенный объект атрибутов, адре-
суемый параметром attr, можно инициализировать повторно с помощью функции
pthread—rwl ockattr_init (); результаты ссылки на этот объект после его разрушения
не определены. В конкретной реализации функция pthread—rwlockattr_destroy ()
может устанавливать объект, адресуемый параметром attr, равным недействи-
тельному значению.
Функция pthread—rwlockattr_init () предназначена для инициализации объ-
екта атрибутов блокировки чтения-записи attr значением, действующим по умолча-
нию для всех атрибутов, определенных конкретной реализацией.
Если функция pthread—rwlockattr_init () вызывается для уже инициализиро-
ванного объекта атрибутов attr, то результаты вызова этой функции не определены.
После того как объект атрибутов блокировки чтения-записи уже был использован
для инициализации одной или нескольких блокировок чтения-записи, любая функ-
ция, которая оказывает влияние на объект атрибутов (включая деструктор), никак не
отразится на ранее инициализированных блокировках чтения-записи.
Возвращаемые значения
При успешном завершении функции pthread— rwlockattr_destroy ()
и pthread—rwlockattr—init () возвращают нулевое значение; в противном слу-
чае — код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—rwlockattr_destroy () может завершиться неудачно, если:
[EINVAL] значение, заданное параметром attr, недействительно.
Функция pthread—rwlockattr—init () завершится неудачно, если:
[ENOMEM] для инициализации объекта атрибутов блокировки чтения-записи
недостаточно существующей памяти.
Эти функции не возвращают код ошибки [EINTR].
Приложение Б 647
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread_rwlock_destroy (), pthread_rwlockattr_getpshared (),
pthread_rwlockattr_setpshared (), том Base Definitions стандарта IEEE Std
1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003.1j-2000 были внесены следующие
изменения.
• В разделе “Синопсис” была изменена метка. Новая метка THR означает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они от-
носились к опции Read-Write Locks стандарта IEEE Std 1003.1j-2000, а также
считались частью дополнения XSI).
• Был отредактирован раздел “Смотри также”.
648 Приложение Б
Имя
pthread—rwlockattr—getpshared, pthread_rwlockattr_setpshared —
функции считывания и установки атрибута process-shared в объекте атрибутов
блокировки чтения-записи.
Синопсис
THRTSH #include <рthread.h>
int pthread_rwlockattr_getpshared(
const pthread—rwlockattr_t *restrict attr,
int *restrict pshared);
int pthread—rwlockattr—setpshared(
pthread—rwlockattr_t * a t tr,
int pshared);
Описание
Функция pthread—rwlockattr_getpshared () используется для получения зна-
чения атрибута process-shared из инициализированного объекта атрибутов, адре-
суемого параметром attr. Функция pthread—rwlockattr_setpshared () позволяет
установить атрибут process-shared в инициализированном объекте атрибутов, ад-
ресуемом параметром a t tr.
Атрибут pro cess-shared устанавливается равным значению PTHREAD—PROCESS-
SHARED, чтобы разрешить использование объекта блокировки чтения-записи любым
потоком, имеющим доступ к области памяти, в которой он размещен, даже если эта
область памяти разделяется несколькими процессами. Если же атрибут process-
shared равен значению PTHREAD—PROCESS—PRIVATE, объект блокировки чтения-
записи должен использоваться только потоками, созданными в одном процессе с по-
током, который его инициализировал; если с этим объектом блокировки чтения-
записи попытаются работать потоки из различных процессов, поведение такой про-
граммы не определено. По умолчанию для этого атрибута устанавливается значение
PTHREAD—PROCESS—PRIVATE.
Дополнительные атрибуты, их значения по умолчанию и имена соответствующих
функций считывания и установки значений этих атрибутов определяются конкретной
реализацией.
Возвращаемые значения
При успешном завершении функция pthread—rwlockattr_getpshared () воз-
вращает нулевое значение и сохраняет считанное значение атрибута process -
shared объекта attr ь объекте, адресуемом параметром pshared; в противном слу-
чае возвращается код ошибки, обозначающий ее характер.
При успешном завершении функция pthread—rwlockattr_setpshared() возвра-
щает нулевое значение; в противном случае — код ошибки, обозначающий ее характер.
Приложение Б 649
Ошибки
Функции pthread—rwlockattr_getpshared() и pthread_rwlockattr__
setpshared () могут завершиться неудачно, если:
[ EINVAL ] значение, заданное параметром a t tr, недействительно.
Функция pthread—rwlockattr_setpshared () может завершиться неудачно, если:
[EINVAL] новое значение, заданное для атрибута, попадает вне диапазона значе-
ний, действительных для этого атрибута.
Эти функции не возвращают код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Отсутствует.
Будущие направления
Отсутствуют.
Смотри также
pthread—rwlock_destroy (), pthread— rwlockattr_destroy (),
pthread—rwlockattr_init (), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5.
Issue 6
Для согласования со стандартом IEEE Std 1003.1j-2000 были внесены следующие
изменения.
• В разделе “Синопсис” была изменена метка. Новая метка THR означает, что рас-
сматриваемые функции теперь являются частью опции Threads (ранее они от-
носились к опции Read-Write Locks стандарта IEEE Std 1003. lj-2000, а также
считались частью дополнения XSI).
650 Приложение Б
• В разделе “Описание” отмечено, что дополнительные атрибуты определяются
конкретной реализацией.
• Был отредактирован раздел “Смотри также”.
В целях согласования со стандартом ISO/IEC 9899: 1999 в прототип функции
pthread_rwlockattr_getpshared () было добавлено ключевое слово restrict.
Приложение Б 651
Имя
pthread_self — функция получения идентификационного номера (ID) вызы-
вающего потока*
Синопсис
THR #include <pthread.h>
pthread—t pthread—self (void);
Описание
Функция pthread_self () возвращает идентификационный номер (ID) вызы-
вающего потока.
Возвращаемое значение
См. раздел “Описание”.
Ошибки
Коды ошибок не определены.
Функция pthread_self () не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Функция pthread—self () обеспечивает возможность, аналогичную функции
getpid () для процессов, поэтому и логическое обоснование у нее такое же: при вы-
зове функции создания потока идентификационный номер (ID) созданному потоку
автоматически не предоставляется.
Будущие направления
Отсутствуют.
652 Приложение Б
Смотри также
pthread—create (), pthread—equal (), том Base Definitions стандарта IEEE Std
1003.1-2001, <pthread.h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 5. Включена для согласования
с расширением POSIX Threads Extension.
Issue 6
Функция pthread—self () отмечена как часть опции Threads.
Приложение Б 653
Имя
pthread—setcancelstate, pthread—setcanceltype, pthread—testcancel —
функции установки состояния отмены (аннулирования) потока.
Синопсис
THR #include <pthread.h>
int pthread—setcancelstate(int state, int *oldstate);
int pthread—setcanceltype(int type, int *oldtype);
void pthread—testcancel(void);
Описание
Функция pthread—setcancelstate () одновременно устанавливает состояние
отмены вызывающего потока равным значению, заданному параметром state, и воз-
вращает значение предыдущего состояния отмены в переменной, адресуемой пара-
метром oldstate. Допустимыми значениями для параметра state являются
PTHREAD—CANCEL—ENABLE и PTHREAD_CANCEL-DISABLE.
Функция pthread—setcanceltype () одновременно устанавливает тип отмены
вызывающего потока равным значению, заданному параметром type, и возвращает
значение предыдущего типа отмены в переменной, адресуемой параметром oldtype.
Допустимыми значениями для параметра type являются PTHREAD—CANCEL-
DEFERRED и PTHREAD—CANCEL—ASYNCHRONOUS.
Состояние и тип отмены любых создаваемых потоков, включая поток, в котором
впервые вызывается функция main(), устанавливаются равными значениям
PTHREAD—CANCEL—ENABLE и PTHREAD—CANCEL—DEFERRED соответственно.
Функция pthread—testcancel () предназначена для создания точки отмены
в вызывающем потоке. Функция pthread—testcancel () не имеет эффекта, если от-
мена потока запрещена.
Возвращаемые значения
При успешном завершении функции pthread—setcancelstate () и pthread—
setcanceltype () возвращают нулевое значение; в противном случае возвращается
код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—setcancel state () может завершиться неудачно, если:
[EINVAL] заданный параметр state не содержит ни значения PTHREAD—
CANCEL_ENABLE, ни значения PTHREAD—CANCEL—DI SABLE.
Функция pthread—setcancel type () может завершиться неудачно, если:
[EINVAL] заданный параметр type не содержит ни значения PTHREAD—
CANCEL-DEFERRED, ни значения PTHREAD—CANCEL-ASYNCHRONOUS.
Эти функции не возвращают код ошибки [EINTR].
654 Приложение Б
Примеры
Отсутствуют.
Замечания по использованию
Отсутствуют.
Логическое обоснование
Функции pthread_setcancelstate () и pthread_setcanceltype () позволяют
управлять точками, в которых поток можно асинхронно отменить. Для того чтобы
управление отменой потоков можно было осуществлять в соответствии с модульными
принципами, необходимо следовать следующим правилам.
Объект можно рассматривать как обобщение некоторой процедуры. Вернее, он
представляет собой множество процедур и глобальных переменных, организованных
в виде одного модуля, вызываемого клиентами, не известными для этого объекта,
причем одни объекты могут зависеть от других.
Во-первых, на входе в объект возможность отмены должна быть запрещена
(никогда явно не разрешена). На выходе из объекта состояние отмены должно быть
всегда восстановлено до значения, которое оно имело на входе в этот объект.
Это следует из принципа модульности: если клиент объекта (или клиент объекта,
использующего данный объект) запретил возможность отмены, это означает, что
клиент не желает проведения очистительно-восстановительных операций в случае,
если поток будет отменен во время выполнения некоторой важной последовательно-
сти действий. Если объект вызывается в таком состоянии и предоставляет возмож-
ность отмены, а запрос на отмену задерживается для этого потока, то такой поток от-
меняется вопреки желанию клиента (т.е. вопреки запрету на отмену).
Во-вторых, на входе в объект тип отмены можно установить явным образом
(равным либо “отложенному”, либо “асинхронному” значению). Но, как и для состоя-
ния отмены, на выходе из объекта тип отмены должен быть всегда восстановлен до
значения, которое он имел на входе в этот объект.
Наконец, из потока, который позволяет асинхронную отмену, можно вызывать
только безопасные (с точки зрения отмены) функции.
Будущие направления
Отсутствуют.
Смотри также
pthread_cancel(), том Base Definitions стандарта IEEE Std 1003.1-2001,
<pthread.h>.
Последовательность внесения изменений
Функции впервые реализованы в выпуске Issue 5. Включены для согласования
с расширением POSIX Threads Extension.
Issue 6
Функции pthread_set cancel state (), pthread_set cancel type () и pthread—
testcancel () отмечены как часть опции Threads.
Приложение Б 655
Имя
pthread—setschedprio— функция динамического доступа к параметрам плани-
рования потока (REALTIME THREADS).
Синопсис
THRTPS #include <pthread.h>
int pthread_setschedprio(pthread_t thread, int prio);
Описание
Функция pthread—setschedprio () используется для установки приоритета пла-
нирования равным значению, заданному параметром prio, для потока, идентифика-
ционный номер (ID) которого задан параметром thread.
В случае неудачного завершения функции pthread_setschedprio () приоритет
планирования заданного потока останется без изменения.
Возвращаемое значение
При успешном завершении функция pthread_setschedprio () возвращает нуле-
вое значение; в противном случае возвращается код ошибки, обозначающий ее характер.
Ошибки
Функция pthread—setschedprio () может завершиться неудачно, если:
[EINVAL] значение параметра prio не действительно для стратегии планирова-
ния заданного потока;
[ENOTSUP] была сделана попытка установить приоритет равным значению, кото-
рое не поддерживается;
[EPERM] инициатор вызова не имеет соответствующего разрешения на установ-
ку параметров стратегии планирования заданного потока;
[EPERM] реализация не позволяет приложению модифицировать приоритет, ус-
танавливая его равным заданному значению;
[ESRCH] значение, заданное параметром thread, не относится к существую-
щему потоку.
Функция pthread—setschedprio () не возвращает код ошибки [EINTR].
Примеры
Отсутствуют.
656 Приложение Б
Замечания по использованию
Отсутствуют.
Логическое обоснование
Функция pthread—setschedprio () обеспечивает для приложения возможность
временного увеличения приоритета с последующим его понижением без нежелатель-
ного побочного эффекта, выражаемого в установке другими потоками такого же при-
оритета. Это нужно, если приложение должно реализовать такие собственные стра-
тегии для ограничения инверсии приоритетов, как наследование приоритетов или
использование предельных значений приоритетов. Эта возможность особенно важ-
на, если реализация не поддерживает опции Thread Priority Protection или Thread
Priority Inheritance, но даже в случае их поддержки эту возможность необходимо ис-
пользовать, если приложение обязано привязывать наследование приоритетов к ис-
пользованию таких ресурсов, как семафоры.
Несмотря на то что, возможно, предпочтительнее было бы решить эту проблему,
модифицируя спецификацию функции pthread—setschedparam (), было слишком
поздно вносить такое изменение, поскольку уже существовали реализации, которые
пришлось бы в этом случае изменять. Поэтому данная функция и была введена.
Будущие направления
Отсутствуют.
Смотри также
pthread_getschedparam(), том Base Definitions стандарта IEEE Std 1003.1-2001,
<р thread. h>.
Последовательность внесения изменений
Функция впервые реализована в выпуске Issue 6. Включена в качестве реакции на
интерпретацию IEEE PASC Interpretation 1003.1 #96.
СПИСОК ЛИТЕРАТУРЫ
1. Audi, Robert. Action, Intention, and Reason. Ithaca, N. Y.: Cornell University Press, 1993.
2. Axford, Tom. Concurrent Programming: Fundamental Techniques for Real-Time and
Parallel Software Design. Chichester, U. K.: John Wiley, 1989.
3. Baase, Sarah. Computer Algorithms: Introduction to Design and Analysis. 2nd ed. Reading,
Mass.: Addison-Wesley, 1988.
4. Barfield, Woodrow, and Thomas A. Furnell III. Virtual Environments and Advanced
Interface Design. New York: Oxford University Press, 1995.
5. Binkley, Robert, Bronaugh, Richard, and Ausonio Marras. Agent, Action, and Reason.
Toronto: University of Toronto Press, 1971.
6. Booch, Grady, James Rumbaugh, and Ivar Jacobson. The Unified Modeling Language
User Guide. Boston: Addison-Wesley, 1999.
7. Bowan, Howard, and John Derrick. Formal Methods for Distributed Processing: A Survey of
Object-Oriented Approaches. New York: Cambridge University Press, 2001.
8. Brewka, Gerhard, Jurgen Diz, and Kurt Konolige. Nonmonotonic Reasoning. Stanford,
Calif.: CSLI Publications, 1997.
9. Carroll, Martin D., and Margaret A. Ellis. Designing and Coding Reusable C++. Reading,
Mass.: Addison-Wesley, 1995.
10. Cassell, Justine, Joseph Sullivan, Scott Prevost, and Elizabeth Churchill. Embodied
Conversational Agents. Cambridge, Mass.: MIT Press, 2000.
11. Chellas, Brian F. Modal Logic: An Introduction. New York: Cambridge University
Press, 1980.
12. Coplien, James O. Multi-Paradigm Design for C++. Reading, Mass.: Addison-Wesley, 1999.
13. Cormen, Thomas, Charles Leiserson, and Ronald Rivet. Introduction to Algorithms.
Cambridge, Mass.: MIT Press, 1995.
14. Englemore, Robert, and Tony Morgan. Blackboard Systems. Wokingham, England:
Addison-Wesley, 1988.
15. Garg, Vijay K. Principles of Distributed Systems. Norwell, Mass.: Kluwer Academic, 1996.
658 Список литературы
16. Geist, Al, Adam Beguelin, Jack Dongarra, Weicheng Jiang, Robert Manchek, and
Vaidy Sinderman. PVM: Parallel Virtual Machine. London, England: MIT Press, 1994.
17. Goodheart, Bemy, and James Cox. The Magic Garden Explained: The Internals of Unix
System VRelease 4. New York: Prentice Hall, 1994.
18. Gropp, William, Steven Huss-Lederman, Andrew Lumsdaine, Ewing Lusk, Bill
Nitzberg, William Saphir, and Marc Snir. MPI: The Complete Reference. Vol. 2.
Cambridge, Mass.: MIT Press, 1998.
19. Heath, Michael T. Scientific Computing: An Introduction Survey. New York: McGraw-Hill.
20. Henning, Michi, and Steve Vinoski. Advanced COBRA Programming with C++.
Reading, Mass.: Addison-Wesley, 1999.
21. Hintikka, Jakko, and Merrill Hintikka. The Logic of Epistemology and the Epistemology of
Logic. Amsterdam: Kluwer Academic, 1989.
22. Horty, John F. Agency and Deontic Logic. New York: Oxford University Press, 2001.
23. Hughes, Cameron, and Tracey Hughes. Mastering the Standard C++ Classes. New York:
John Wiley, 1990.
24. Hughes, Cameron, and Tracey Hughes. Object-Oriented Multithreading Using C++. New
York: John Wiley, 1997.
25. Hughes, Cameron, and Tracey Hughes. Linux Rapid Application Development. Foster
City, Calif.: M & T Books, 2000.
26. International Standard Organization. Information Technology: Portable Operating System
Interface. Pt. 1 System Application Program Interface. 2nd ed. Std 1003.1
ANSI/IEEE. 1996.
27. Josuttis, Nicolai M. The C++ Standard. Boston: Addison-Wesley, 1999.
28. Koeing, Andrew, and Barbara Moo. Ruminations on C++. Reading, Mass.: Addison-
Wesley, 1997.
29. Krishnamoorthy, C. S., and S. Raj ееv. Artificial Intelligence and Expert Systems for
Engineers. Boca Raton, Fla.: CRC Press, 1996.
30. Lewis, Ted, Glenn Andert, Paul Calder, Erich Gamma, Wolfgang Press, Larry
Rosenstein, and Kraus, Sarit. Strategic Negotiation in Multitangent Environments.
London: МГГ Press, 2001.
31. Luger, George F. Artificial Intelligence 4th ed. England: Addison-Wesley, 2002.
32. Mandrioli Dino, and Carlo Ghezzi. Theoretical Foundations of Computer Science. New
York: John Wiley, 1987.
33. Nielsen, Michael A., and Isaac L. Chuang. Quantum Computation and Quantum
Information. New York: Cambridge University Press, 2000.
34. Patel, Mukesh J., Vasant Honavar, and Karthik Balakrishnan. Advances in the
Evolutionary Synthesis of Intelligent Agents. Cambridge, Mass.: МГГ Press, 2001.
35. Picard, Rosalind. Affective Computing. London: MIT Press, 1997.
36. Rescher, Nicholas, and Alasdir Urquhart. Temporal Logic. New York: Springer-
Verlag, 1971.
Список литературы 659
37. Robbins, Kay A., and Steven Robbins. Practical Unix Programming, Upper Saddle
River, N. J.: Prentice Hall, 1996.
38. Schmucker, Kurt, Ander Weinand, and John M. Vlissides. Object-Oriented Application
Frameworks. Greenwich, Conn.: Manning Publications, 1995.
39. Singh, Harry. Progressing to Distributed Multiprocessing. Upper Saddle River, N.J.:
Prentice Hall, 1999.
40. Skillicorn, David. Foundations of Parallel Programming. New York: Cambridge
University Press, 1994.
41. Soukup, Jiri. Taming C++: Pattern Classes and Persistence for Large Projects. Reading,
Mass.: Addison-Wesley, 1994.
42. Sterling, Thomas L., John Salmon, Donald J. Becker, and Daniel F. Savarese. How
to Build a Bewoulf: A Guide to Implementation and Application of PC Clusters. London:
MIT Press, 1999.
43. Stevens, Richard W. UNIX Network Programming: Interprocess Communications. Vol. 2,
2nd ed. Upper Saddle River: Prentice Hall, 1999.
44. Stroustrup, Bjame. The Design and Evolution of C++. Reading, Mass.: Addison-Wesley, 1994.
45. Subrahmanian, V.S., Piero Bonatti, Jurgen Dix, Thomas Eiter, Sarit Kraus, Fatma Ozcan,
and Robert Ross. Heterogeneous Agent Systems. Cambridge, Mass.: МГГ Press, 2000.
46. Tel, Gerard. Introduction to Distributed Algorithms. 2nd ed. New York: Cambridge
University Press, 2000.
47. Thompson, William J. Computing for Scientists and Engineers. New York: John Wiley, 1992.
48. Tomas, Gerald, and Christoph W. Uebeerhuber. Visualization of Scientific Parallel
Programming. New York: Springer-Verlag, 1994.
49. Tracy, Kim W. and Peter Bouthoom. Object-Oriented: Artificial Intelligence Using C++.
New York: Computer Science Press, 1997.
50. Weiss, Gerhard. Multitagent Systems. Cambridge, Mass.: МГГ Press, 1999.
51. Wooldridge, Michael. Reasoning About Rational Agents. London: MIT Press, 2000.
ПРЕДМЕТНЫЙ
УКАЗАТЕЛЬ
А
Ada, 573; 574; 520
ADT, 438
AI, 77
American National Standards Institute, 18
ANSI, 18
AOP, 435
API, 19
Artificial intelligence, 7 7
в
Basic object adapter, 293
BDI, 430; 450
BFS, 440
BOA, 292; 303
ВОА-адаптер, 293
Breadth First Search, 440
Bug, 248
c
catch, 259
CDS, 443; 444; 450
class, 271
Class diagram, 338
Clipboard, 35
Cognitive Data Structures, 443
Common Object Request Broker
Architecture, 77
CORBA, 77; 35; 37; 38; 274; 435; 466
CR (Concurrent Read), 343
CRCW, 29, 170, 343; 437
CREW, 29, 170, 203; 437’, 466
crontab, 460
CW (Concurrent Write), 343
D
Daemon, 74
Data race, 47
DCS, 443
Decomposition, 271
Depth First Search, 440
deque, 357
DFS, 440, 442; 454
E
Eiffel, 269
Encapsulation, 271
ER (Exclusive Read), 343
ERCW, 29, 170, 437
EREW, 29, 170, 343; 437; 466
Error, 248
EW (Exclusive Write), 343
Extranet, 269
Предметный указатель 661
F M
Failure, 248 Fault, 248 FIFO, 19, 67; 415; 435 FIPA, 429 FTP, протокол, 280 MAF, 461 Main thread, 356 Man pages, 461 Massively Parallel Processing, 325 Massively Parallel Processors, 28 Message Passing Interface, 17; 26; 314
H MICO, 17; 39,274 MIMD, 30, 213; 466
HTTP, 289, 306 MIOR-ссылка, 294 MIWCO, 294
I MMU, 512; 514 Mobile IOR, 294
IDL, 282 IDL-компилятор, 292 IEEE, 19 HOP, 39 ПОР, протокол, 274 Implementation Repository, 298 imr, утилита, 305 Indefinite postponement, 48 interface, 283 Interface Definition Language, 282 Interface Repository, 298 International Organization for Standardization, 18 Internet Protocol, 17 Interoperable Object Reference, 277 Inter-Process Communication, 50, 393 Inter-Thread Communication, 393 Intranet, 269 IOR, 277 IPC, 50, 60, 393; 412; 420, 435; 488 ird, 306 ISO, 36 ITC, 393 MPI, 17; 26; 37; 314; 435 MPICH, 19, 37 MPMD, 30,134 MPP, 28; 38; 212; 325 MTMD, 134 Multi-agent facility, 461 Multiple-Instruction, Multiple-Data, 30 Multiple-Programs, Multiple-Data, 30 Mutex, 165 N Name binding, 294 Naming context, 294 Naming graph, 295 NFS, 289 Nice value, 71 NLG, 375 NLI, 375 NLP, 223; 375 о Object Management Group, 338
J Object-to-Object Communicaton, 393 OMG, 338
Java, 269 ORB, 51; 278; 461 ORB-брокер, 484
L OTOC, 393
LIFO, 438 list, 351 p Parallel Random Access Machine, 29 Parallel Virtual Machine, 26 PCB, 59 Peer-to-peer, 32
662 Предметный указатель
PID, 60
РОА, 303
РОА-адаптер, 293
РОА-менеджер, 304
Portable object adapter, 293
POSIX, 19,36
Postcondition, 185
PPID, 60
PRAM, 29 39 189
Precondition, 185
Process, 26; 58
Prolog, 480
ps, утилита, 69
pstree, утилита, 77
Pthread, 134
Pthreads, 19
PVM, 27; 26; 37; 222J 435
PVM-демон, 233
R
Race condition, 47
Read lock, 388
RMI, протокол, 274
RPC, 488
RR, 67
Runtime polymorphism, 324
s
Secure Shell, 307
Secure Socket Layer, 307
Semantic network, 297
SIMD, 39 213
Single UNIX Specifications Standard, 19
Single-Instruction, Multiple-Data, 30
Single-Program, Multiple-Data, 30
Smalltalk, 269
SMP, 38; 325
SPMD, 39 133; 213
SSH, 307
SSL, 307
stack, класс, 351
Standard Template Library, 351
STL, 351
STMD, 134
Symmetrical Multiprocessing, 325
T
TCP/IP, 17
telnet, 306
template, 346
Thread, 26
main, 356
throw, 259
Trading service, 307
Transmission Control Protocol, 17
try, 260
TTS-engine, 223
и
UML, 20, 55\ 337\ 497
Unified Modeling Language, 29 337; 497
V
vector, 351
virtual, 324
w
WAPWDP, 294
WBM, 272
WBR, 53
WBS, 33; 129 432; 464
WCORBA, 294
Wireless Mico, 294
X
XDR, стандарт, 236
XPVM, 218
A
Абдукция, 433
Агент, 32; 429
реализация в C++, 444
стратегии логического вывода, 452
цикл активизации, 451
Агентно-ориентированная система, 423
Агрегирование, 348
Адаптер, 350
базовый объектный, 292
переносимый объектный, 303
Предметный указатель 663
Алгоритм
сору(), 413; 417
CRCW, 191
CREW, 191
ERCW, 191
EREW, 191
find(), 456
open(), 417
transform(), 414
Архитектура:, 388
системы, 373
Ассоциация, 347
Б
Бесконечная отсрочка, 48
Библиотека
iostream, 171
lib pthread, 194
libpvm, 214
libpvmS.a, 217
MPICH, 37
POSIX, 36
POSIX Threads, 36
Pthread, 134
Pthreads, 37
pvmd, 233
шаблонов, 351
Бинарная связь, 347
Блокировка считывания, 388
Брокер объектных запросов, 278
БУП, 59
в
Взаимоблокировка, 48
г
Гонка данных, 47
д
Дедукция, 433
Декомпозиция, 271
работ, 33
Дефект, 248
Диаграмма
видов деятельности, 360, 501
взаимодействия, 499
класса, 338
классов, 497
объектов, 497
пакетов, 506
последовательностей, 359, 499
развертывания, 371
событий, 265
состояний, 364; 505
сотрудничества, 354; 499
ДСС, 33
3
Зависимость, 347
и
Именной
граф, 295
контекст, 294
Индукция, 433
Инкапсуляция, 271
Интерфейс
передачи сообщений, 314
Информационный голод, 128
Исключение, 248
Исключительная ситуация, 248
Источник знаний, 465; 470
Итератор
istream_iterator, 408
ostream_iterator, 408
к
Канал, 401
именованный, 416
Квант времени, 64
Класс, 338
agent_framework, 424
basiC-filebuf, 404
basic_streambuf, 404
basic_stringbuf, 404
domain-error, 261
exception, 261
invalid_argument, 261
ios, 394
istream, 394
istream_iterator, 409
length_error, 261
logic_error, 261; 262
664 Предметный указатель
map, 346
mutex, 381; 397
ostream, 394
ostream_iterator, 409
out_of_range, 261
overflow_error, 261
pthread_cond_t, 205
pthrcad_mutex_t, 166; 194; 381
pvm_stream, 397
range_error, 261
runtime_error, 261
stack, 351
underflow error, 261
vector, 346
абстрактный, 379
адаптерный, 380
активный, 356
базовый, 347; 379
доменный, 379
интерфейсный, 350, 379
каркасный, 379, 421
конкретный, 379
контейнерный, 379
синхронизации, 379
составной, 379
сыновний, 347
узловой, 379
шаблонный, 346; 379
Классная доска, 388
Классы исключений, 260
Кластер, 40
Коммуникатор, 317
Конечные автоматы, 364
Контейнер
deque, 351
list, 351
vector, 351
м
Маклер, 308
Маклерская служба, 307
Методология, 16
Механизмы обработки исключений, 259
Многозадачность, 101
Многопоточность, 101
Множественность, 340
Моделирование, 337
Модель
BDI, 430, 450
CRCW, 170
CREW, 170, 389
ERCW, 170
EREW, 170
MIMD, 213; 472
MPMD, 134; 315; 322; 327; 472
MTMD, 134
PRAM, 189, 343
SIMD, 213; 314; 484
SPMD, 134; 213; 314; 321; 472
STMD, 134
декомпозиции работ, 272
делегирования, 130, 173
конвейер, 130
конвейера, 132; 177
равноправных узлов, 32; 130, 132; 177
системы, 337
Модель:, 32; 130, 133; 178; 286; 465
ПО, 271
МПВ-технология, 50
Мультиагентная система, 423; 461
Мультиагентные распределенные
системы, 32
Мьютекс, 165; 380, 392
н
Надежность ПО, 247
о
Обобщение, 347
Обработчик исключений, 260
Образ процесса, 61
Объект
активный, 356
распределенный, 371
Объектная ссылка, 277
Оператор
вставки («), 395
извлечения данных (»), 396
Оплошность, 248
Отказоустойчивая система, 248
Отказоустойчивость, 248
Отношения
между классами, 347
Отношения синхронизации
старт-старт, 186
Предметный указатель 665
старт-финиш, 188
финиш-старт, 187
финиш-финиш, 188
Ошибка, 248
п
Пакет, 374
Перегрузка операторов, 395
Подкласс, 347
Подсостояние, 369
Поиск
в ширину, 440
вглубь, 440
Полиморфизм, 257; 3J7; 322
вертикальный, 327
горизонтальный, 327
динамического связывания, 327
параметрический, 327
Постусловие, 185
Поток, 26
определение, 113
Предусловие, 185
Прецедент, 359
Протокол
FTP, 280
HTTP, 28% 306
ПОР, 3% 274
RMI, 274
TCP/IP, 274; 290
telnet, 306
защищенных сокетов, 307
передачи файлов, 280
Процесс, 26; 58; 356
init, 74
образ, 61
создание, 74
р
Ранг, 315
Распределенные объекты, 269
Реализатор, 352
Реализация, 351
Решатель задач, 465
с
Сбой, 248
Связывание по имени, 294
Семантическая сеть, 297
Семафор, 193; 392
мьютексный, 194
условная переменная, 205
Сервер
баз данных, 310
логический, 310
приложений, 310
транзакций, 310
файловый, 310
Синхронизация, 185
доступа к данным, 189
потоков, 185
Служба имен, 294
Состояние
гонок, 47
действия, 360
деятельности, 362
подсостояние, 369
составное, 369
элемента, 364
Сотрудничество, 353
объектов, 354
Стековый фрейм, 154
Стереотип, 347
Стратегия планирования, 67
FIFO, 67; 126
RR, 67; 126
Суперкласс, 347
Суперсостояние, 369
У
Условная переменная, 205
Утилита
crontab, 460
imr, 305
ird, 306
ф
Фактор уступчивости, 71
Формат
In Place, 237
Raw, 237
XDR, 237
Функция
abort(), 90
exec, 78
execl(), 79
666 Предметный указатель
execleQ, 79
execlpQ, 79
execv(), 80, 81
execve(), 80, 81
execvp(), 80, 81
exit(), 90
fclose(), 90
fork(), 78
getenv(), 82; 412
getpid(), 89, 141
getppidQ, 89
getpriority(), 72
getrlimit(), 96
getrusage(), 96
kill(), 91
pathconf(), 403
pipe(), 403
posix_spawn, 507
posix_spawn(), 83
posix_spawn_file_actions_addclose(), 518
posix_spawn_file_aciions_adddup2(), 522
posix_spawn_file_actions_addopen, 518
posix_spawn_file_actions_destroy(), 524
posix_spawn_file_actions_init (), 524
posix_spawnattr_destroy(), 526
posix_spawnattr__getflags(), 528
posix_spawnattr_getpgroup(), 530
posix_spawnattr_getschedparam (), 532
posix_spawnattr_getschedpolicy(), 534
posix_spawnattr_getsigdefault(), 536
posix_spawnattr_getsigmask(), 538
posix_spawnattr_init(), 526
posix_spawnattr_setflags(), 528
posix_spawnattr_setpgroup(), 530
posix_spawnattr_setschedparam (), 532
posix_spawnattr_setschedpolicy(), 534
posix_spawnattr_setsigdefault(), 536
posix_spawnattr_setsigmask(), 538
posix_spawnp, 507
pth read_attr_destroy (), 143
pth read_attr_getde tachstate (), 144
pthread_attr_getscope(), 162
pthread_attr_getstack(), 156
pthread_attr_getstackaddr(), 156
pthread_attr_getstacksize (), 155
pthread_attr_init(), 143
pthread_attr_setd etachstate (), 144
pthread_attr_setinheritsched (), 158
pthread_attr_setschedparam(), 159
pthread_attr_setschedpolicy (), 158
pthread_attr_setscope(), 162
pthread_attr_setstack(), 156
pthread_attr_setstackaddr(), 156
pthread_attr_setstacksize(), 155
pthread_cancel(), 146
pthread_cleanup_pop(), 153
pthread_cleanup_push(), 153
pthread_cond_destroy(), 565
pthread_cond_init, 565
pthread_cond__timedwait(), 568
pthread_cond_wait(), 568
pthread_condattr_destroy(), 574
Pthread_condattr_getpshared(), 576
pthread_condattr_init(), 574
pthread_condattr_setpshared(), 576
pthread_create, 578
pthread_create(), 139
pthread_detach(), 142; 582
pthread_exit(), 146; 584
pthread__getconcurrency(), 586
pthread_getschedparam(), 161; 588
pthreadjoin(), 141; 189, 591
pthread_mutex_destroy(), 166; 381; 594
pthread_mutex__getprioceiling(), 601
pthread_mutex_init(), 196; 381; 594
pthread_mutex_lock(), 166; 381; 603
pthread_mutex_setprioceiling(), 601
pthread_mutex_timedlock(), 381; 607
pthread_mutex_trylock(), 381; 603
pthread_mutex_unlock(), 166; 381; 603
pthread_mutexattr_destroy(), 609
pthread_mutexattr_getprioceiling(), 615
pthread_mutexattr__getprotocol (), 617
pthread_mutexattr_getpshared (), 620
pthread_mutexattr_gettype(), 622
pthread_mutexattr_mit(), 609
pthread_mutexattr_setprioceiling(), 615
pthread_mutexattr_setprotocol(), 617
pthread_mutexattr_setpshared(), 620
pthread_mutexattr_settype (), 622
pthread_once, 625
pthread_rwlock_destroy(), 628
pthread_rwlock_init(), 628
pthread_rwlock_rdlock(), 631
pthread_rwlock_timedrdlock(), 634
pthread_rwlock_timedwrlock(), 637
Функция
pthread^-wlock^tiyrdlockO, 631
pthread_rwlock_trywrlock(), 640
pthread_rwlock_unlock(), 643
Предметный указатель 667
pthread_rwlock_wrlock(), 640
pthread_rwlockattr_destroy(), 646
pthread_rwlockattr__getpshared(), 648
pthread_rwlockattr_init(), 646
pth read_rwlockattr_setpsh ared (), 648
pthread_self(), 141; 651
pthread_setcancelstate(), 147; 653
pthread_setcanceltype(), 147; 653
pthread_setconcurrency(), 586
pthread_setschedparam(), 161; 588
pthread-setschedprio, 655
pthread_setschedprio(), 162
pthread_testcancel(), 148; 653
pvm_addhosts(), 235
pvm_barrier(), 481
pvm_delhosts(), 235
pvm_exit(), 216; 235
pvm_freebuf(), 242
pvm__getrbuf(), 241
pvm__getsbuf(), 241
pvm_halt(), 236
pvm_mitsend(), 216; 237
pvm_joingroup(), 481
pvm_kill(), 235
pvm_mcast(), 238
pvm_mkbuf(), 242
pvm_mytid(), 216
pvm_nrecv(), 240
pvm_pkbyte, 236
pvm_pkcplx, 236
pvm_pkdcplx, 236
pvm_pkdouble, 236
pvm_pkdouble(), 394
pvm_pkfloat, 237
pvm_pkfloat(), 394
pvm_pkinc, 237
pvm_pkint(), 394
pvm_pklong, 237
pvm_pkshort, 237
pvm_pkstr, 237
pvm_pkstr(), 216
pvm_precv(), 240
pvm_probe(), 241
pvm_psend(), 238
pvm_recv(), 216; 239
pvm_send(), 216; 238
pvm_setopt(), 243
pvm_setrbuf(), 242
pvm_setsbuf(), 241
pvm_spawn(), 216; 232; 235
pvm_trecv(), 240
pvm_upkfloat(), 216
sched_gei_priority_max(), 159
sched_get_priority_min(), 159
sem_close(), 391
sem_destroy(), 391
sem_getvalue(), 391
sem_init(), 391
sem_open(), 391
sem_post(), 391
sem_trywait(), 391
sem_unlink(), 391
sem_wait(), 391
setenv(), 83; 412
setpriorityO, 72
sysconf(), 81; 162; 403
system(), 83; 513
unsetenv(), 83
wait(), 99,188
waitpid(), 100
X
Хранилище
интерфейсов, 298; 306
реализаций, 298; 305
Хрон, 460
ш
Шаблон, 346
э
Экстрасеть, 269
я
ЯзыкиМЬ, 337
C++
Параллельное и распределенное г*
программирование с использованием V*
В книге Параллельное и распределенное программирование с использованием C++ отражен свежий
взгляд на построение программ, ориентированных на использование преимуществ мультипроцессорных
компьютеров. Здесь представлены простые методы программирования параллельных виртуальных машин
и основы разработки кластерных приложений Эта книга не только научит создавать программные
компоненты, предназначенные для совместной работы в сетевой среде, но и послужит надежным
“путеводителем” по стандартам для программистов которые занимаются многозадачными
и многопоточными приложениями.
Данная книга, представляющая архитектурный подход к параллельному программированию, адресована
программистам, проектировщикам и разработчикам программных продуктов, а также научным работникам
преподавателям и студентам, которых интересует введение в параллельное и распределенное
программирование с использованием языка C++.
• Возможность использования агентов и технологии “классной доски ’ для уг
программирования
• Объектно-ориентированные подходы к многозадачности и многопоточное!
• Использование средств языка UML в разработке проектов, требующих при
распределенного программирования.
• Новый стандарт POSIX/UNIX IEEE для библиотеки Pthreads.
Об авторах
КАМЕРОН ХЬЮЗ — старший инженер-программист компании CTEST Laboratories и штатный программист-
аналитик государственного университета в г. Янгстаун (Youngstown State University) Он участвовал
в разработках программных продуктов различного уровня, а в настоящее время занимается кластерным
программированием для системы PROTEUS V, в которой используется обработка данных на естественном
языке (NLP) и моделирование представления знаний.
ТРЕЙСИ ХЬЮЗ — инженер-программист компании CTEST Laboratories. Она занимается программированием
машинной графики и имитационным моделированием на C++, успешно разрабатывает библиотеки классов
для обработки изображений и создает виртуальные миры
КАМЕРОН и ТРЕЙСИ ХЬЮЗ — соавторы многочисленных книг, включая Linux Rapid Application Development
и Object-Oriented Multithreading Using C++.
ISBN 5 8459-0686-5
Посетите Издательский дом "Вильямс”
в Internet по адресу:
http://www.williamspublishing.com
/▼Addison-Wesley
Pearson Education
www. awprofessional. com
Данный файл был взят с сайта:
-FVQHBook.IlGfe
Данный файл представлен исключительно в ознакомительных
целях. Уважаемый читатель! Если вы скопируете его, Вы должны
незамедлительно удалить его сразу после ознакомления с
содержанием. Копируя и сохраняя его Вы принимаете на себя всю
ответственность, согласно действующему международному
законодательству.
Все авторские права на данный файл сохраняются за
правообладателем. Любое коммерческое и иное использование
кроме предварительного ознакомления запрещено. Публикация
данного документа не преследует за собой никакой коммерческой
выгоды. Но такие документы способствуют быстрейшему
профессиональному и духовному росту читателей и являются
рекламой бумажных изданий таких документов.
Все авторские права сохраняются за правообладателем. Если
Вы являетесь автором данного документа и хотите дополнить его
или изменить, уточнить реквизиты автора или опубликовать
другие документы, пожалуйста, свяжитесь с нами по e-mail - мы
будем рады услышать ваши пожелания.
ProgBook.net - библиотека программиста.
В нашей библиотеке Вы найдете книги и статьи практически по
любому языку программирования.