/
























































































































































































































































































































Text
В. Н. Лебедев
ВВЕДЕНИЕ
СИСТЕМЫ
РОГРАММИ
РОВАН ИЯ
В. Н. ЛЕБЕДЕВ
ВВЕДЕНИЕ В СИСТЕМЫ ПРОГРАММИРОВАНИЯ
МОСКВА СТАТИСТИКА 1975
Лебедев В. Н.
Л 33 Введение в системы программирования. М.» «Стати* стика», 1975.
312 с. с ил.
Книга представляет собой монографию по системному программированию! После краткой характеристики основных элементов современных систем про* граммирования: библиотек, языков программирования и трансляторов — изло* жены принципы построения трансляторов для языков символического кодирования, макроязыков и процедурно-ориентированных языков высокого уровня.. Описаны наиболее распространенные прямые и синтаксические методы трак* сляции, а также некоторые способы автоматизации разработки трансляторов^
Книга предназначена для студентов старших курсов, аспирантов и про* граммистов, специализирующихся в области разработки системного математи* ческого обеспечения и в смежных областях.
„ 30502-014 „
Л 008(01)-75 64 75
© Издательство «Статистика», 1975,
ВВЕДЕНИЕ
Современные вычислительные и информационно-вычислительные системы, применяемые для решения научно-технических и учетно-плановых задач в интересах предприятий, учреждений и органов административного управления, включают две взаимосвязанные, но качественно различные компоненты: комплекс средств вычислительной техники и математическое (программное) обеспечение.
Математическое обеспечение в свою очередь можно разделить на две части: системное математическое обеспечение и прикладное математическое обеспечение.
Системное математическое обеспечение представляет собой комплекс управляющих и обрабатывающих программ, описаний и инструкций, которые обеспечивают техническое функционирование вычислительной системы, а также разработку, отладку и выполнение программ пользователей. Набор программ системного математического обеспечения мало зависит от характера решаемых задач пользователей.
Прикладное математическое обеспечение представляет собой совокупность программ решения конкретных задач, которые систематически используются в интересах данного предприятия, учреждения или органа управления для обеспечения его повседневной производственной, научной или административной деятельности.
Специализированные комплекты программ решения конкретных задач называют пакетами прикладных программ. При создании прикладных программ применяют методы специальных научных, инженерных и экономических дисциплин, а также общие методы вычислительной математики, теории оптимизации, теории информационного поиска и программирования для вычислительных машин.
Разработкой системного математического обеспечения занимается особая дисциплина — системное программирование. Предмет системного программирования—теория и методы разработки
1*
а
и эксплуатации программ системного математического обеспечения.
По функциональному назначению и применяемым методам внутри системного математического обеспечения можно выделить две системы программ: операционную систему и систему программирования.
Операционная система есть комплекс управляющих программ, которые обеспечивают техническое функционирование вычислительной системы, включая диагностику неисправностей, планирование использования ресурсов системы и решение задач по заданиям пользователей. Кроме того, на операционную систему часто возлагают управление вводом — выводом и обменом данными между различными компонентами системы (например, между оперативной и внешней памятью), а также ведение архива, т. е. размещение данных во внешней памяти и обеспечение доступа к ним.
Операционную систему можно рассматривать как программное продолжение и расширение аппаратурной части вычислительной системы.
Основной задачей операционной системы является управление выполнением программ пользователей с целью максимального повышения производительности машины.
Система программирования есть комплекс средств, обеспечивающих автоматизацию программирования и отладки программ.
К системе программирования относят библиотеку стандартных подпрограмм, языки программирования и трансляторы, а также отладочные программы. Эти элементы предназначены для облегчения и повышения производительности труда программистов.
Программные компоненты системы программирования выполняются под управлением операционной системы наравне с прикладными программами пользователей.
В развитых вычислительных системах объем программ системного математического обеспечения достигает многих сотен тысяч машинных слов. Например, системное математическое обеспечение отечественной машины БЭСМ-6, разработанное в Институте прикладной математики АН СССР, имеет объем 224 тыс. машинных слов, из них около 160 тыс. машинных слов приходится на долю системы программирования, а объем системных программ ЕС ЭВМ превышает 1,5 млн. команд.
Доля стоимости системного математического обеспечения в общей стоимости вычислительной системы сейчас достигает 50% и выше.
В этой книге рассматриваются методы, применяемые при разработке элементов системы программирования, главным образом методы трансляции с языков программирования разных уровней*
ГЛАВА 1
ЭЛЕМЕНТЫ
СИСТЕМЫ ПРОГРАММИРОВАНИЯ
1.1. БИБЛИОТЕКА СТАНДАРТНЫХ ПОДПРОГРАММ
1.1.1. НАЗНАЧЕНИЕ И СТРУКТУРА БИБЛИОТЕЧНЫХ ПОДПРОГРАММ
Последовательность команд на языке машины, которую используют в нескольких программах или нескольких местах одной программы для выполнения определенных действий, называют подпрограммой.
Подпрограммы, часто применяемые в разных программах, оформляют по единым правилам и называют стандартными подпрограммами. Стандартизация обычно предусматривает единую форму идентификации и обращения к подпрограммам, фиксированный формализованный способ задания информации об аргументах и результатах, а также единые правила составления самих подпрограмм, обеспечивающие возможность автоматизации включения подпрограмм в основную программу.
Совокупность стандартных подпрограмм, постоянно хранящихся в запоминающих устройствах машины, образует библиотеку стандартных подпрограмм. В состав библиотеки обычно входит от нескольких десятков до нескольких сотен подпрограмм.
Библиотека стандартных подпрограмм, по существу, представляет собой программное расширение набора операций, выполняемых машиной. Большинство этих операций можно было бы реализовать аппаратурным путем, однако это усложнило бы конструкцию машины. Фактически библиотеку стандартных подпрограмм можно считать компромиссным разрешением конфликта между удобством программирования и стоимостью необходимого оборудования.
Возможны два способа использования подпрограмм:
подпрограмма вставляется в основную программу в тех точках, где необходимо' ею воспользоваться (открытая подпрограмма);
подпрограмма записывается, в отведенном для нее месте оперативной памяти, а в тех точках основной программы, где необходимо ее использовать, вставляются команды обращения к этой подпрограмме (замкнутая подпрограмма).
Оба способа применяются на практике. Открытые подпрограммы обычно используют в ассемблерах при трансляции макро
5
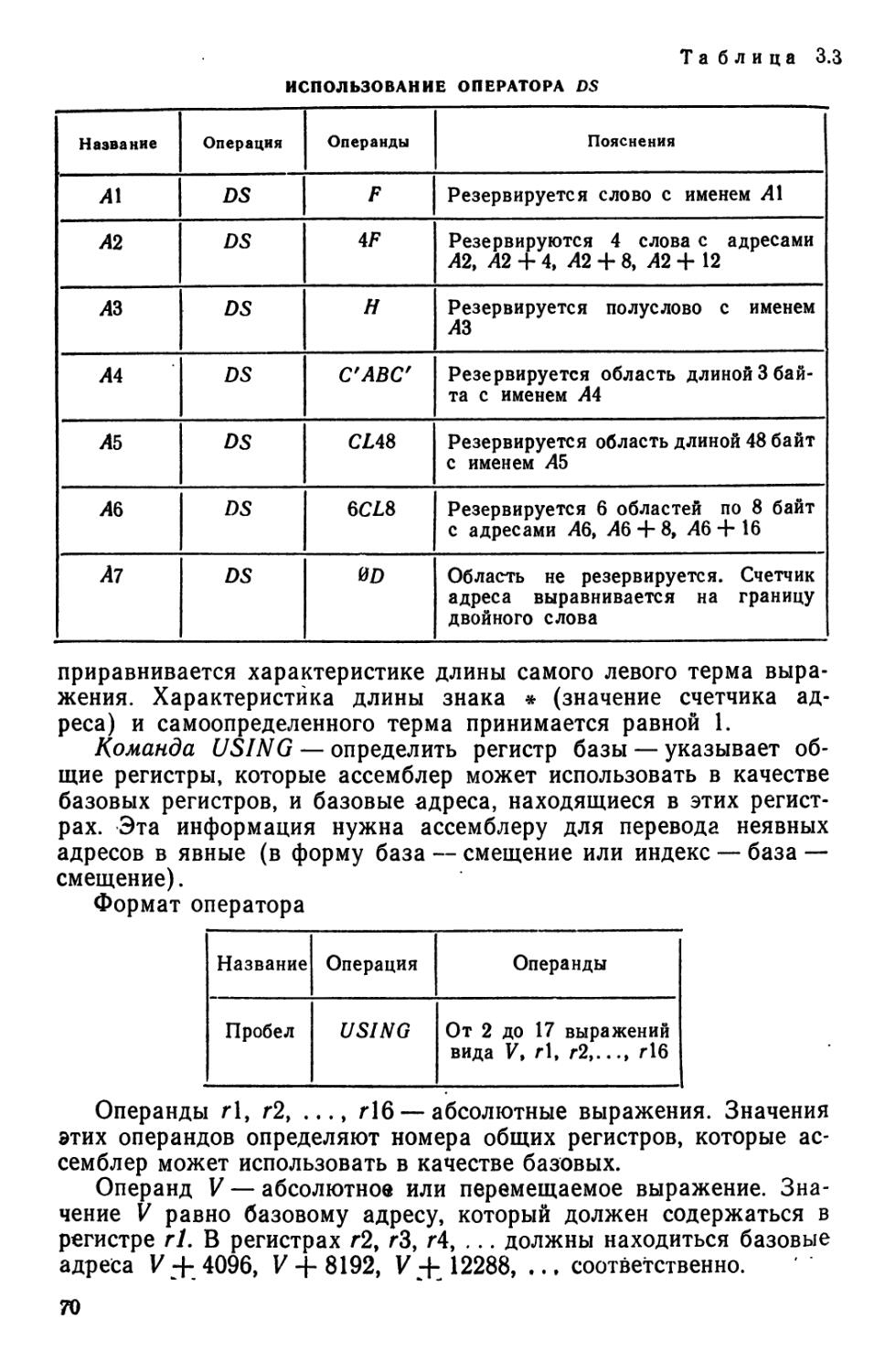
команд (см. 3.3). В качестве библиотечных подпрограмм чаще при* меняют закрытые подпрограммы. Закрытые библиотечные подпрограммы должны быть оформлены в виде модулей загрузки, т. е. должны допускать настройку по месту при любом расположении в оперативной памяти и установление связи с другими подпрограммами. По этой причине в тексте модуля загрузки приходится различать три типа адресов: -
абсолютные, значения которых не зависят от места расположения модуля;
внутренние, значения которых зависят от места расположения модуля;
внешние, значения которых зависят от места расположения других модулей.
Абсолютные адреса — это адреса постоянных рабочих ячеек или регистров машины, адресные части некоторых специфичных команд машины (например, константа сдвига в команде сдвига), а также адресные части числовых констант, записанных в формате команд машины.
Внутренние адреса встречаются в командах перехода, передающих управление внутри подпрограммы, и в командах, использующих константы, записанные в самой подпрограмме, а внешние адреса— в командах перехода к другим подпрограммам (модулям), с которыми взаимодействует данная подпрограмма.
При записи подпрограммы в оперативную память внутренние адреса должны быть скорректированы с учетом места расположения (адреса загрузки) подпрограммы. Внутренние адреса могут корректироваться аппаратными или программными средствами. На современных машинах третьего поколения, в частности на машинах ЕС ЭВМ, для этого предусмотрены специальные регистры (см. 3.1), позволяющие формировать исполнительные адреса с учетом расположения подпрограммы. При отсутствии аппаратных средств корректировка производится программно.
Внешние адреса также должны быть скорректированы. На практике для этой цели применяют разные способы. Наиболее простой из них состоит в перечислении внешних адресов в специальной таблице, прилагаемой к подпрограмме — модулю загрузки (см. 3.2).
1.1.2. КОМПИЛИРУЮЩИЕ
И ИНТЕРПРЕТИРУЮЩИЕ СИСТЕМЫ
Для вызова библиотечных стандартных подпрограмм в оперативную память и настройки в соответствии с их размещением применяют один из двух методов: метод компиляции или метод интерпретации. Использование обоих методов предусматривает выделение в оперативной памяти рабочего поля, на котором размещаются требующиеся подпрограммы. При применении метода компиляции вызов и размещение подпрограмм выполняет компи-
6
дарующая система, а при использовании метода интерпретации — интерпретирующая система. Как компилирующая, так и интерпре-тИрующая системы включают библиотеку стандартных подпрограмм, каталог библиотечных подпрограмм и управляющую программу (загрузчик).
Библиотека стандартных подпрограмм хранится во внешней памяти на магнитных барабанах, дисках или лентах. Каталог и управляющая программа обычно находятся в наиболее быстрой внешней памяти, например на магнитном барабане.
В методе компиляции все подпрограммы, требующиеся в основной программе, вызываются па рабочее поле в оперативной памяти до выполнения основной программы, а в методе интерпретации подпрограммы вызываются на рабочее поле в ходе выполнения основной программы. Основное преимущество метода компиляции заключается в относительно небольшом времени, затрачиваемом на служебные операции настройки стандартных подпрограмм по месту, которые выполняются лишь один раз для каждой подпрограммы. Недостаток метода компиляции состоит в сравнительно большом объеме требующегося рабочего поля, который должен быть равен сумме длин всех используемых в основной программе стандартных подпрограмм. Если все подпрограммы не умещаются на рабочем поле, компилирующая система выдает отказ: без расширения рабочего поля выполнение программы невозможно.
Интерпретирующая система может обеспечить выполнение основной программы при минимально возможном размере рабочего поля, достаточно, чтобы на рабочем поле умещалась лишь одна, но самая большая подпрограмма из тех, которые используются в основной программе. В чистом виде метод интерпретации предусматривает вызов подпрограммы на рабочее поле при каждом новом обращении к ней. В таком режиме настройка подпрограммы по месту выполняется каждый раз. Однако интерпретирующие системы, применяемые на практике, обычно сочетают черты как метода интерпретации, так и метода компиляции. Это означает, что при малом размере рабочего поля система работает в режиме интерпретации, а в тех случаях, когда на рабочем поле достаточно места для размещения всех требующих подпрограмм, по существу, применяется, режим компиляции, поскольку все однажды вызванные подпрограммы сохраняются на рабочем поле. В частности, так работает система ИС-2 для машин М-220 [20].
1.1.3. СОВРЕМЕННЫЕ ТЕНДЕНЦИИ В ОРГАНИЗАЦИИ БИБЛИОТЕКИ
Описанная выше организация библиотеки была характерна Для машин первого и некоторых машин второго поколения: БЭСМ-2, БЭСМ-4, М-20, М-220 и некоторых других. Однако уже на многих машинах второго поколения и на машинах третьего
7
поколения организация библиотеки усложнилась. Возросшее число компонент системного математического обеспечения потребовало создания отдельной системной библиотеки для хранения программ операционной системы и системы программирования. Увеличилась общая библиотека подпрограмм, доступная всем пользователям. Кроме подпрограмм на машинном языке (языке загрузки), в библиотеку стали включать процедуры и другие тексты на входных языках трансляторов. Регулярно применяемые программы прикладных задач и отдельные сегменты таких программ, оформленные в виде модулей загрузки и подготовленные для непосредственного исполнения, также стали хранить в особой библиотеке на магнитных дисках и лентах. В системах обработки данных начали создавать библиотеки для хранения часто используемых информационных массивов.
Увеличение емкости внешней памяти и повышение ее надежности позволило создавать на современных машинах личные библиотеки пользователей. Это привело к изменению организации работы на машине. Если прежде программы пользователей, как правило, хранились на перфокартах (перфолентах) и вводились в машину непосредственно перед исполнением, то теперь на некоторых машинах функцию хранения программ и массивов данных стали возлагать на библиотеки, постоянно размещенные во внешней памяти.
Каждая библиотека хранится во внешней памяти машины в библиотечном файле. Файлом в современных системах обработки данных принято называть набор данных, объединенных общим назначением, которому присвоено имя. Иногда под файлом понимают область памяти, предназначенную для хранения упомянутого набора данных. Обычно файл постоянно или временно, в период его существования, находится во внешней памяти. Для обработки содержимое файла полностью или частично переписывается в оперативную память машины.
В качестве примера кратко рассмотрим организацию и функционирование библиотек в дисковой операционной системе ЕС ЭВМ (ДОС/ЕС). Библиотеки ДОС/ЕС постоянно хранятся на дисках. Каждая библиотека состоит из набора модулей, являющихся единицами хранения. Перечень имен модулей, адресов их хранения и размеров содержится в оглавлении библиотеки. Каждому модулю соответствует одна запись оглавления.
Библиотеки ДОС/ЕС делятся на системные и личные.
К системным библиотекам относятся: библиотека абсолютных модулей, содержащая тексты на машинном языке; библиотека объектных модулей, содержащая тексты на языке загрузки; библиотека исходных модулей, содержащая тексты на входных языках трансляторов.
Собственно ДОС/ЕС представляет собой совокупность этих трех библиотек, причем обязательной библиотекой является только библиотека абсолютных модулей. Системные библиотеки постоян-
8
йО хранятся в резидентном файле, который обычно целиком занимает один дисковый пакет.
В состав личных библиотек могут входить личные библиотеки объектных модулей и личные библиотеки исходных модулей. Личные библиотеки не включаются в резидентный файл. Структурно эти библиотеки аналогичны системным, поэтому ниже рассматриваются только системные библиотеки.
Обслуживание всех библиотек в ДОС/ЕС возлагается на специальную системную программу — библиотекарь, которая создает, копирует и корректирует системные и личные библиотеки, а также печатает или перфорирует содержание библиотек и их оглавлений. Некоторые виды редактирования библиотечных модулей выполняет другая системная программа — редактор связей.
Библиотека абсолютных модулей содержит все системные программы ДОС/ЕС, включая трансляторы, а также хранит готовые к выполнению программы пользователей. Системные программы хранятся в этой библиотеке постоянно, а программы пользователей — либо постоянно, либо временно до их выполнения.
Модуль, хранящийся в библиотеке абсолютных модулей, называют фазой. Фаза представляет собой готовую к выполнению программу в абсолютных адресах или часть (сегмент) многофазной программы. Фазу формирует и включает в библиотеку редактор связей.
Оглавление библиотеки абсолютных модулей помимо имени каждой фазы, адреса ее хранения и размера содержит также адрес основной памяти, начиная с которого нужно загрузить данную фазу для выполнения, и точку входа в фазу.
Любая программа перед выполнением должна быть включена в библиотеку абсолютных модулей (в виде одной или нескольких: фаз). Загрузку фаз в основную память выполняет системный загрузчик, являющийся частью супервизора ДОС/ЕС, управляющего выполнением всех системных и прикладных программ. Фазы, помещенные в библиотеку для временного хранения, после очередного выполнения программы редактора связей теряются, поскольку редактор помещает на их место другие сформированные им фазы.
Библиотека объектных модулей хранит модули, сформированные трансляторами ДОС/ЕС. Каждый модуль представляет собой программу, часть программы или подпрограмму. Текст программы в объектном модуле не содержит внешних адресов. Однако в модуле имеется информация о внешних адресах для редактора связей. По этой причине текст объектного модуля непосредственно непригоден для выполнения на машине. Предварительно этот текст должен быть отредактирован редактором связей. Отметим, что объектные модули, формируемые разными трансляторами ДОС/ЕС, однотипны, это позволяет редактору связей формировать фазу из объектных модулей, подготовленных разными трансляторами. Структура объектных модулей описана
9
в п. 3.2.6. Объектные модули, формируемые трансляторами, помещает в библиотеку библиотекарь.
Заметим, что библиотека объектных модулей представляет собой естественное обобщение прежней библиотеки стандартных подпрограмм, применявшейся на машинах первого поколения. Подпрограммы, оформленные в виде объектных модулей, являются закрытыми подпрограммами.
Библиотека исходных модулей предназначена для хранения текстов на входных языках трансляторов ДОС/ЕС. Каждый такой текст образует книгу, являющуюся единицей хранения. Книгу помещает в библиотеку библиотекарь. Все книги на входном языке одного транслятора образуют подбиблиотеку этого транслятора. Часто книга представляет собой открытую подпрограмму, которая в ходе трансляции включается непосредственно в текст транслируемой программы. Однако в библиотеке исходных модулей могут храниться также законченные программы, процедуры или произвольные части программ.
Тексты открытых подпрограмм образуют макробиблиотеку соответствующего транслятора (см. 3.3).
Редактор связей формирует из объектных модулей готовую к выполнению программу, оформляет ее в виде фазы или нескольких фаз и помещает в библиотеку абсолютных модулей (см. п. 3.2.6).
Схема взаимодействия трансляторов, библиотекаря, редактора связей и системного загрузчика с системными библиотеками ДОС/ЕС показана на рис. 1.1.
Организация библиотек ДОС/ЕС типична для машин третьего поколения. Она отражает современные взгляды на структуру и способы выполнения на машине системных и прикладных программ, а также на использование подпрограмм. Можно отметить следующие характерные черты.
1. В структуре всех программ последовательно реализуется принцип модульного программирования, который требует, чтобы функционально независимые части программ и все замкнутые подпрограммы общего пользования оформлялись в виде стандартных модулей загрузки (в ДОС/ЕС — объектные модули), допускающих объединение с другими модулями и загрузку в любое место памяти. Отметим, что это требование относится не только к стандартным библиотечным подпрограммам, но и ко всем без исключения системным и прикладным программам.
2. Модули загрузки, полученные после трансляции- с разных' входных языков, однотипны. Это позволяет объединять их редактором связей в единую программу.
3. Помимо автоматизации использования закрытых подпрограмм (это обеспечивалось уже на машинах первого поколения) обеспечено также автоматизированное применение открытых подпрограмм, хранящихся в библиотеке исходных модулей.
10
4. При формировании готовых к исполнению прикладных программ используется принцип компиляции, в то время как большинство системных программ выполняется в режиме интерпретации (роль интерпретирующей системы возложена на супервизор, который вызывает необходимые системные программы в тот момент, когда их нужно выполнять). Это экономит машинное время
Ёыпопнение
программы
Рис. 1.1. Взаимодействие библиотек и системных программ в ДОС/ЕС
для выполнения прикладных программ и, с другой стороны, экономит память, выделяемую для системных программ, обеспечивая выделение возможно большей памяти прикладным программам.
Отметим еще одну характерную черту ДОС/ЕС — разделение функций трансляции, редактирования и загрузки между разными системными программами с одновременным обеспечением сохранения результатов трансляции и редактирования в соответствующих библиотеках.
На машинах первого поколения и некоторых машинах второго поколения для основной программы все три функции обычно
И
выполнял транслятор, а редактирование и загрузка библиотечных подпрограмм возлагались на компилирующую или интерпретирующую систему. Вследствие этого изменение любой части основной программы требовало повторной трансляции, редактирования и загрузки.
Уже на многих машинах второго поколения загрузчик был отделен от транслятора. Это позволило устранить повторную трансляцию для модулей, помещенных после трансляции в библиотеку, и дало возможность составлять части программы на разных языках, поскольку объединение модулей происходило на этапе загрузки. Загрузчик выполнял редактирование и собственно загрузку для всех частей программы, включая библиотечные подпрограммы, поэтому каждое повторное выполнение программы требовало повторного редактирования. Дополнительное отделение редактирования от загрузки в ДОС/ЕС позволило устранить повторное редактирование для программ, постоянно хранящихся в библиотеке абсолютных модулей.
1.1.4. ОСОБЕННОСТИ СТАНДАРТНЫХ ПОДПРОГРАММ В МУЛЬТИПРОГРАММНЫХ СИСТЕМАХ
Вычислительную систему, в которой за счет совмещения во времени работы разных устройств одновременно выполняется несколько программ, называют мультипрограммной. В такой системе различные программы могут одновременно использовать одни и те же подпрограммы. Поэтому
Рис. 1.2. Структура самовосстана-вливающегося модуля
для экономии числа обращений к внешней памяти и машинного времени, расходуемого на загрузку, все модули загрузки, в том числе библиотечные подпрограммы, делят на три вида: невосстанавливающиеся, самовос-станавливающиеся и инвариантные.
Невосстанавливающийся модуль портится в процессе использования, поэтому его приходится загружать в оперативную память каждый раз, когда он требуется. Самовосстанавливающиеся и инвариантные модули можно в принт ципе загрузить только один раз.
Самовосстанавливающийся модуль можно поочередно использовать в разных задачах. Если задача прервана во время выполнения этого модуля, то другая задача не может воспользоваться им до момента освобождения его первой задачей. Это объясняется особенностями структуры самовосстанавливающегося модуля (рис. 1.2). Рабочая область такого модуля размещена в нем самом. Поэтому прерывание во время выполнения модуля и переключение модуля на выполнение в составе другой задачи безвоз<
вратно портит данные, хранящиеся в рабочей области и относящиеся к первой задаче.
Инвариантные модули вообще не изменяются в процессе исполнения. За счет прерываний эти модули могут одновременно использоваться в нескольких разных задачах. Это достигается назначением в разных задачах разных рабочих областей, с которыми работает инвариантный модуль (рис. 1.3). Естественно, при этом расходуется дополнитель- z г
пая память.
Если памяти достаточно, то нужно стремиться к тому, чтобы как можно больше стандартных подпрограмм было инвариантно. Свойство инвариантности особенно желательно для часто применяемых
обращение к подпрограмме
^рабдчая^ ^область^ подпрограмм
Инвариантный модуль ^осстоноРление тело модуля ' воз1рат~~
Обращение к подпрограмме
лбласть^ подпрограмм
Рис. 1.3. Структура инвариантного мо-
стандартных подпрограмм, на- дуля
пример, перевода из одной си-
стемы счисления в другую, вычисления элементарных функций. Заметим, что инвариантность, ускоряющая решение задач, помимо
дополнительного расхода памяти несколько усложняет также механизм обработки обращений к стандартным подпрограммам, который должен обеспечить выделение рабочей области в том модуле, откуда произошло обращение к подпрограмме.
1.2. ЯЗЫКИ ПРОГРАММИРОВАНИЯ
1.2.1. КЛАССИФИКАЦИЯ
В системном программировании языком, называют определенный набор символов и правил (соглашений), устанавливающих способы комбинации этих символов для записи осмысленных сообщений (текстов).
Различают, вообще говоря нестрого, естественные языки, на которых говорят и пишут люди в повседневной жизни, и искусственные языки, создаваемые для некоторых частных целей.
Искусственные языки, предназначенные для записи программ, называют языками программирования. Каждая машина имеет свой собственный язык программирования — язык команд или машинный язык — и может исполнять программы, записанные только на этом языке. В машинном языке каждой команде соответствует определенная операция, которую может выполнять машина. Однако на машинном языке программировать трудно из-за чрезмерной детализации программы. Поэтому уже на машинах первого и второго поколения для повышения производительности тРУДа программистов начали применять языки программирования, Не совпадающие с машинными языками. На машинах третьего
13
поколения машинный язык практически не применяется для программирования задач, за ним сохранилась лишь роль внутреннего языка машины.
В настоящее время насчитывается несколько сотен различных языков программирования, которые классифицируют по различным признакам. Наиболее общей является классификация по степени зависимости языка от машины. По этому признаку языки делят на две большие группы: машинно-зависимые и машиннонезависимые.
Машинно-зависимые языки, в свою очередь, делят на машинные и машинно-ориентированные.
Машинно-ориентированные языки иногда называют автокодами. Различают два уровня машинно-ориентированных языков. К первому уровню относят языки символического кодирования, иначе называемые мнемокодами, а ко второму — макроязыки.
Мнемокод отличается от машинного языка соответствующей машины заменой цифровых кодов операций буквенными (мнемоническими), а цифровых адресов операндов — буквенными или буквенно-цифровыми. При переводе на язык машины каждая команда мнемокода заменяется соответствующей командой машинного языка («один в один»).
Применение мнемокода позволяет автоматизировать работу программиста по распределению памяти, точнее, по присваиванию истинных адресов. Это особенно полезно при программировании для машин с переменным форматом команд. Кроме того, мнемокод существенно облегчает работу по составлению больших программ, когда отдельные сегменты (модули) программы составляются разными программистами и объединяются в единую программу на этапе загрузки.
Язык второго уровня — макроязык — наряду с символическими аналогами машинных команд, из которых состоит мнемокод, допускает также использование макрокоманд, не имеющих прямых аналогов в машинном языке. При трансляции каждая макрокоманда заменяется группой команд машинного языка («один в несколько»). Применение макрокоманд сокращает программу, которую пишет программист, и, расширяя набор средств языка, повышает производительность труда программиста. Программист, использующий машинно-ориентированный язык, должен быть хорошо знаком с особенностями устройства машины, для которой составляется программа.
Машинно-независимые языки также делят на две группы по степени детализации программы. К первой группе относят процедурно-ориентированные языки, а ко второй — проблемно-ориентированные.
Процедурно-ориентированные языки предназначены для описания алгоритмов (процедур) решения задач, поэтому их иногда называют также алгоритмическими, хотя понятие алгоритмического языка не совпадает с понятием языка программирования. 14
Если запись алгоритма на алгоритмическом языке непосредственно пригодна для ввода в машину и преобразования в готовую рабочую программу, то такой алгоритмический язык является одновременно языком программирования. Некоторые алгоритмические языки, строго говоря, не являются языками программирования, если не добавить к ним специальных средств. В частности, широко известный алгоритмический язык Алгол-60 становится языком программирования только после включения в него операторов ввода и вывода и конкретизации способов выполнения некоторых других операций управления оборудованием машины.
Алгоритмы решения задач различных классов отличаются значительно, поэтому до последнего времени процедурно-ориентированные языки разрабатывались применительно к отдельным классам задач. Известны языки для решения задач вычислительной математики (Алгол-60, Фортран), языки для решения экономических задач и обработки данных (Кобол, Алгэк, Алгэм), языки для обработки строк (Снобол), языки для обработки списков (Лисп)! и др. По этой причине раньше эти языки называли также проблемно-ориентированными, т. е. ориентированными на задачи {problem (англ.)—задача). Однако в последнее время в литературе термин «проблемно-ориентированный язык» получил несколько иное значение: язык для описания задач, что более точно отвечает буквальному значению этого термина. Особенности проблемно-ориентированных языков рассматриваются в этом параграфе ниже.
Программа на процедурно-ориентированном языке почти не зависит от конкретной машины, на которой будет решаться задача. Слово «почти» следует понимать в том смысле, что в большинстве случаев программы решения одной и той же задачи для разных машин отличаются лишь некоторыми непринципиальными деталями внешнего оформления, которые при переходе от машины к машине заменяются почти механически.
Структура процедурно-ориентированных языков ближе к естественному языку, например русскому или английскому, чем к машинному. Поэтому перевод с процедурно-ориентированного языка на машинный осуществляется по принципу «несколько в несколько». Иными словами, в большинстве случаев здесь можно установить соответствие лишь между группой элементарных конструкций языка и группой команд машины, подобно тому как при переводе с английского языка на русский группу слов или даже группу предложений заменяют группой слов на другом языке. Пословный перевод здесь невозможен.
Если считать уровень машинного языка нулевым, то по степени независимости от машины процедурно-ориентированные языки следует отнести к третьему уровню, поскольку первый и второй уровни соответственно составляют языки символического кодирования и макроязыки.
15
Приведенная классификация в известных пределах отвечает квалификации лиц, составляющих программы. На машинно-ориентированных языках работают люди, профессионально владеющие программированием и знакомые с устройством машин. В частности, к этой категории лиц относятся системные программисты, применяющие мнемокоды и макроязыки при составлении программ системного математического обеспечения.
Процедурно-ориентированными языками пользуются специалисты, знакомые с математическими формулировками решаемых задач, методами (алгоритмами) их решения и приемами программирования. Это могут быть как профессиональные программисты,
Рис. 1.4. Классификация языков программирования
Занимающиеся прикладным программированием, так и специалисты в различных областях, хорошо владеющие программированием и методами решения задач в своей области. Важно подчеркнуть, что при программировании на процедурно-ориентированных языках детального знания устройства машины не требуется.
Существует еще одна категория пользователей машин, которая всё более расширяется в связи с внедрением машин во все сферы деятельности и особенно в связи с распространением систем с разделением времени. Пользователи этой категории, являясь специалистами в своей области и хорошо зная свои задачи, нуждаются в оперативном использовании машины для решения более или менее стереотипных задач, но не знакомы с методами решения задач на машинах и приемами программирования или не имеют возможности составлять программы на машинно-ориентированных и про-16
1
цедурно-ориентированных языках по причине недостаточной оперативности этого пути. К этой категории лиц относятся, в частности, работники производственных и административных органов управления, конструкторы, технологи и экономисты. Для таких пользователей разрабатывают специальные проблемно-ориентированные языки (непроцедурные языки), которые не требуют подробной записи алгоритма решения задачи. Пользователь должен
1956 119511 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 11968 11969 1970
Вычислительные задачи • « , 1 1 ФОРТРАН—ФОРТРЯН П О1Д | Д | q ЮРТРЯ о и пу Стандарт " и \ФОРТРЯН I । 1
1ЛГ0Л-ДО — ялгямс
1 1 I 1 г- 60 {nt I 1 о I
। АЛГОЛ-58-/ ! । °!д Я лгол-lo ресмо тренное сообщение) । ; !
Символьные . преобразования I 1 । 1 ! i_J г I I ФОРМЛК ОД1 I । । । 1 ! ।
Обработка , данных 1 | I ( КОБОЛ-КОБОЛ-61 - I ( |од| ОД| I i |" — л — 'ОБОЛ-\б5 — — \^-ялгэк l_2_i — К0Б0Л-68-К0Б0Л-70 - 1 1 1° ЯЛСЗМ 1 1 ° 1 д| 1
Обработка списков | I !ж/7- I I Iд о \лисп I '1,5 1° |_ I 1 1 ! । !
.обработка строк • 'иПАИМГ 1 1 мпмит I ГТ 1л^пглл,
I О 1 । 1 J 1 i д । nurini I I ° I I и Х/Ъпииил О \1>пииил 1 СНОВОЛ^0 1 1 0 I 1 °| 1 1 1 ..
Многоцелевые языки 1 ДЖОВИЯЛ-ДЖОВИЯЛ 2 1 1 ° 1 А1 I ! 1 I I I I 1 ДЖОВЙЯЛЗ 1 i j . 1 °, 1 ЯЛГОЛ-68 I \пп/'\ 1 О 1 1 1 ° 1 Д । 1 1
Диалоговые языки 1 1 1 I I ! джосс I |Д \БЭЙСЙК 1 I 1 Л 1 I !
Системное программирование 1 1 |_1 1 1 I I I I I I I I 1 1 1 1 ЯЛМО 1 |д 1 1 1 | ЭПСИЛОН 1 1 1 д 0 1
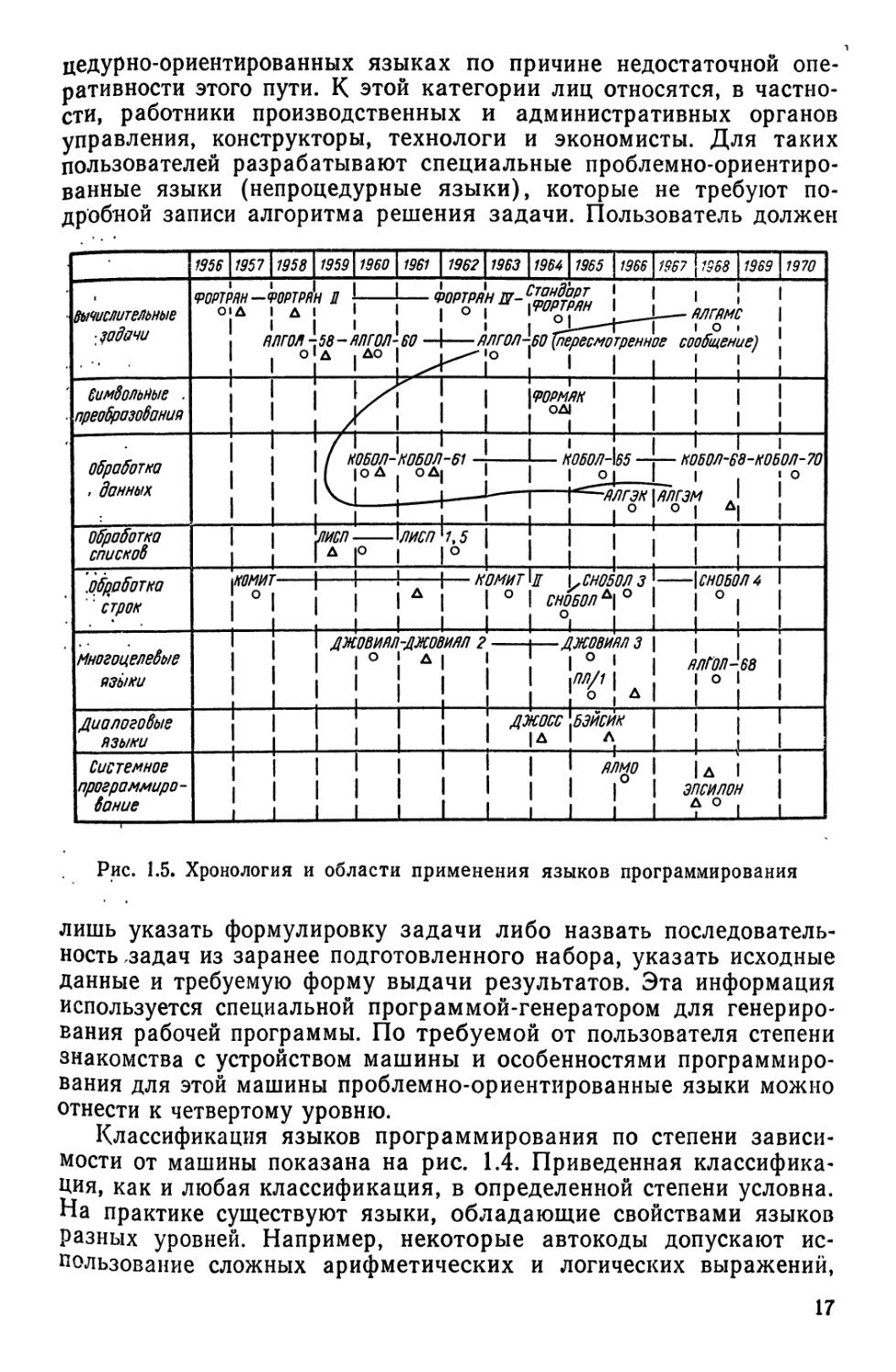
Рис. 1.5. Хронология и области применения языков программирования
лишь указать формулировку задачи либо назвать последовательность задач из заранее подготовленного набора, указать исходные данные и требуемую форму выдачи результатов. Эта информация используется специальной программой-генератором для генерирования рабочей программы. По требуемой от пользователя степени знакомства с устройством машины и особенностями программирования для этой машины проблемно-ориентированные языки можно отнести к четвертому уровню.
Классификация языков программирования по степени зависимости от машины показана на рис. 1.4. Приведенная классификация, как и любая классификация, в определенной степени условна. На практике существуют языки, обладающие свойствами языков разных уровней. Например, некоторые автокоды допускают использование сложных арифметических и логических выражений,
17
характерных для языков высокого уровня. Отдельные процедурноориентированные языки весьма специализированы, что приближает их к проблемно-ориентированным языкам. Наконец, существуют многоцелевые (универсальные) языки.
В приведенной классификации не нашли отражения диалоговые языки, применяемые в системах с разделением времени. Эти языки обеспечивают работу программиста с машиной в режиме непосредственного взаимодействия с дистанционного терминала.
Следует отметить, что, несмотря на очень большое число опубликованных языков программирования, на практике широко применяют только немногие из них. На рис. 1.5, составленном с использованием материалов обзора [53], показаны характерные области применения языков программирования и в хронологическом порядке указаны наиболее распространенные в нашей стране и за рубежом языки высокого уровня, применяемые в каждой области. Кружком отмечено время первой публикации, а треугольником — время первой реализации (появление транслятора).
По отношению к транслятору все упоминавшиеся выше языки, кроме машинных, являются входными. В процессе трансляции программа на входном языке переводится на некоторый внутренний язык, более удобный для дальнейшей работы транслятора, а затем последовательно проходит несколько стадий обработки. На каждой стадии транслируемая программа представляется на некотором промежуточном языке. Наконец, после обработки транслятором получается программа на выходном или объектном языке.
1.2.2. СРАВНИТЕЛЬНАЯ ХАРАКТЕРИСТИКА ЯЗЫКОВ
Машинно-ориентированные языки первого и второго уровней универсальны в той же степени, в которой универсален машинный язык, поскольку в них содержатся средства для программирования и решения на машине любых задач, с которыми машина может справиться по своим техническим возможностям. При программировании на этих языках можно учесть особенности системы команд и устройства машины, что в принципе позволяет создавать высококачественные программы. Однако машинно-ориентированные языки довольно трудны для изучения, а программировать на них сложно.
Каждый язык третьего и тем более четвертого уровня эффективен лишь для определенного класса задач. Вне этого класса большинство языков высокого уровня малоэффективно или вообще непригодно. Эти языки сравнительно легко изучать. Программирование на них значительно проще, чем на машинно-ориентированных языках.
Сейчас наибольшее практическое применение (по числу пользователей) получили процедурно-ориентированные языки третьего уровня. Данные об эффективности и применении языков разного 18
Таблица 1.1 СРАВНИТЕЛЬНАЯ ХАРАКТЕРИСТИКА ЯЗЫКОВ ПРОГРАММИРОВАНИЯ
ч Уровни языка
первый (мне* мо код) второй (макроязык) третий (Алгол-60, Фортран и Др.) четвертый (проблем-но-ориен-тирован-ный язык)
Хороший программист Эффективность программы, % 95 90 60—85 45—65
Стоимость программы, % 100 90 40-60 20-40
Плохой программист Эффективность программы, % 70 75 50-70 40-60
Стоимость программы, % ПО 100 50—70 30—50
Применение в 1962 г. ♦, % 20 65 0 20 75 5 5 10
Применение в 1972 г. *, % 10 25 0 15 80 40 10 20
Время обучения, % 100 110 40-50 10-20
* В числителе—научные и инженерные задачи; в знаменателе —задачи обработки данных.
уровня во всем мире приведены в табл. 1.1, заимствованной из литературы [7] и дополненной сведениями о времени обучения.
Данные, приведенные в табл. 1.1, конечно, весьма условны. Что понимать под эффективностью программы — время исполнения, длину или какую-либо обобщенную характеристику? Какого программиста считать хорошим, а какого плохим? Эти вопросы остаются неясными. Однако данные табл. 1.1 все же отражают общую тенденцию, которая состоит в возрастании роли и удельного веса языков высокого уровня, превосходящих языки низкого уровня по основным показателям: стоимости программирования, тесно связанной с производительностью труда, и времени обучения программированию.
Следует заметить, что большая популярность языков типа Ал-гол-60 и Фортран объясняется не толькой простотой обучения и меньшей трудоемкостью программирования и не только широтой
19
области применения методов вычислительной математики, но и высокой степенью независимости от машины. Специалист, изучивший Алгол-60, в наше время может программировать и решать свои задачи практически на любой машине.
1.2.3. УНИВЕРСАЛЬНЫЕ ЯЗЫКИ
Обилие разработанных и вновь разрабатываемых языков программирования объясняется, с одной стороны, большим разнообразием типов машин, но в еще большей степени — разнообразием классов решаемых на машинах задач. Постоянное увеличение числа типов машин и расширение сферы их применения приводит к столь же постоянному умножению числа машинно-ориентированных, процедурно-ориентированных и проблемно-ориентированных языков, а также соответствующих трансляторов.
Чрезмерное «многоязычие» программирования порождает серьезные трудности.
1. Различные языки часто строятся на разных методических принципах. Это затрудняет накопление опыта, обучение и профессиональное взаимопонимание программистов.
2. На одной машине приходится иметь несколько совершенно различных трансляторов, что усложняет, а также удорожает создание и эксплуатацию системного математического обеспечения, но, самое главное, отнюдь не останавливает появления все новых языков с их трансляторами.
3. При замене старых машин новыми необходимо перерабатывать или создавать заново все системные и прикладные программы. Это весьма трудоемкая работа, если учесть, что объем математического обеспечения современных вычислительных систем достигает многих сотен тысяч машинных слов. Частично переход к новой машине облегчается применением на некоторых машинах эмуляторов, позволяющих моделировать систему команд старой машины на уровне микропрограмм, т. е. на аппаратурном уровне. Однако эмуляция обычно значительно снижает эффективное быстродействие машины (в 3—4 раза).
Перечисленные трудности можно преодолеть созданием серий машин, совместимых на программном уровне, и разработкой универсальных языков программирования.
Работы ведутся в обоих направлениях в международном масштабе. Уже сейчас серии машин ИБМ/360, Система 4, Сименс 4004, разработанные за рубежом, и серии отечественных машин ЕС ЭВМ и АСВТ имеют, по существу, одинаковые системы команд и одинаковые принципы представления данных. С другой стороны, созданы языки программирования, которые в широком классе задач можно считать универсальными.
Проекты универсальных языков программирования начали разрабатываться еще в первой половине 60-х годов. Можно выделить два направления работ. К первому относятся проекты уни
20
версального машинно-ориентированного языка, а ко второму —• проекты универсального языка программирования.
Универсальный машинно-ориентированный язык представляет собой язык обобщенной абстрактной машины, сочетающей в своем устройстве характерные черты большинства современных машин. Этот язык используется для создания универсальной системы программирования, в которую входят трансляторы для перевода с процедурно-ориентированных языков на универсальный, а также некоторые вспомогательные программы. Все программы универсальной системы программирования записаны на универсальном языке. Для использования универсальной системы программирования на конкретной машине достаточно иметь один транслятор, переводящий программы с универсального языка на язык данной машины. С помощью этого транслятора все программы универсальной системы программирования переводятся на машинный язык.
Трансляция программы решения задачи с конкретного процедурно-ориентированного языка на язык машины осуществляется в два этапа:
1) входная программа переводится транслятором процедурноориентированного языка па универсальный машинно-ориентированный язык;
2) полученная программа переводится транслятором универсального языка на язык машины.
Следовательно, при использовании универсального машинноориентированного языка и основанной на нем универсальной системы программирования для создания системы программирования новой машины достаточно разработать только один новый транслятор «универсальный язык» — «язык машины». С другой стороны, внедрение нового процедурно-ориентированного языка на все машины, где используется универсальная система программирования, требует создания лишь одного нового транслятора «новый язык» — «универсальный язык». Этот транслятор программируется, как и вся универсальная система программирования, на универсальном языке и включается в универсальную систему.
Система программирования, основанная на универсальном машинно-ориентированном языке, не является, конечно, самой эффективной из всех возможных для данной конкретной машины, но она создается относительно недорогой ценой и, кроме того, все машины, оснащенные универсальной системой программирования, программно совместимы на уровне входных языков универсальной системы программирования.
Примером универсального машинно-ориентированного языка может служить язык АЛМО, разработанный в 1966 г. в Институте прикладной математики АН СССР [19]. Основанная на этом языке универсальная система программирования практически реализована на машинах М-220, БЭСМ-4, БЭСМ-6, АСВТ, «Минск-32» и ЕС ЭВМ, а также на ряде других машин.
2t
Аналогичный проект обсуждался за рубежом в начале 60-х годов, речь идет о языке Юнкол, однако этот проект не был реалй-зован.
Универсальный язык программирования объединяет на единой методической основе наиболее существенные черты и специфичные средства современных машинно-ориентированных и процедурно-ориентированных языков с учетом возможности их практической реализации на существующих машинах и машинах ближайшего будущего, по крайней мере к этому стремятся авторы проектов таких языков.
Известны две концепции универсального языка программирования: язык-ядро и язык-оболочка.
Язык-ядро содержит набор тщательно отобранных средств. По замыслу из этих средств можно сконструировать процедурноориентированный язык для любого класса задач, причем каждый пользователь может формировать свою собственную версию языка, ориентированную на решаемые им задачи.
Язык-оболочка, напротив, представляет собой конгломерат самых различных средств, имеющихся в существующих процедурно-ориентированных и машинно-ориентированных языках. Разные подмножества языка-оболочки могут использоваться в качестве самостоятельных процедурно-ориентированных языков. При достаточно широком наборе средств разработка новых процедурноориентированных языков вне рамок языка-оболочки становится ненужной, во всяком случае таков замысел создания языка-обр-лочки.
Создание универсальных языков программирования, обладающих в достаточно полной мере свойствами языка-ядра и языка-оболочки, — дело будущего. Однако уже сейчас разработаны и внедряются языки программирования, имеющие некоторые свойства описанных универсальных языков. Наиболее близок к языку-ядру Алгол-68 [2]. Появились первые трансляторы для сокращенных версий этого языка. Приближением к языку-оболочке можно считать ПЛ/1. Некоторые версии этого языка реализованы на машинах серии ИБМ/360 и на других машинах, в частности на ЕС ЭВМ.
1.3. ТРАНСЛЯТОРЫ
1.3.1. КЛАССИФИКАЦИЯ
Любую программу, которая переводит произвольный текст на некотором входном языке в текст на другом языке называют транслятором. В частности, исходным текстом может быть входная программа. Транслятор переводит ее в выходную или объектную программу.
В смысле этого определения простейшим транслятором можно -считать загрузчик, который переводит программу в условных ад-22
ресах, оформленную в виде модуля загрузки, в объектную программу в абсолютных адресах. В этом случае входной язык (язык загрузчика) и объектный язык (язык машины) являются языками одного уровня. Однако чаще входной и объектный языки относятся к разным уровням. Обычно уровень входного языка выше уровня объектного языка.
По уровню входного языка трансляторы принято делить на ассемблеры, макроассемблеры,’ компиляторы, генераторы.
Входным языком ассемблера является мнемокод, макроассемблера — макроязык, компилятора — процедурно-ориентированный язык третьего уровня, а генератора — проблемно-ориентированный язык четвертого уровня. В связи с этим входной язык иногда называют по типу транслятора: язык ассемблера, язык макроассемблера и т. д.
Программа, полученная после обработки транслятором, либо непосредственно исполняется на машине, либо подвергается обработке другим транслятором.
1.3.2. КОМПИЛЯТОРЫ И ИНТЕРПРЕТАТОРЫ
Обычно процессы трансляции и исполнения программы разделены во времени. Сначала вся программа транслируется, а потом исполняется. Трансляторы, работающие в этом режиме, называют трансляторами компилирующего типа. Если входным языком такого транслятора является процедурно-ориентированный язык вы
сокого уровня, то транслятор называют компилятором.
Существуют трансляторы, в которых трансляция и исполнение совмещены во времени, их называют интерпретаторами. В состав; интерпретатора входит блок анализа, распознающий операторы
входного языка, набор подпрограмм, соответствующих различным операторам, и блок, управляющий порядком просмотра операторов и всей работой интерпретатора.
По указаниям управляющего блока блок анализа просматривает операторы входной программы, распознает их тип и определяет возможность немедленного выполнения. Информация о воз
можности выполнения оператора передается управляющему блоку,, который вызывает соответствующую подпрограмму, исполняющую-действия, предписанные оператором.
Интерпретаторы иногда применяют в качестве отладочных трансляторов и диалоговых трансляторов, обеспечивающих работу
пользователя с машиной в диалоговом режиме с дистанционного-терминала. Кроме того, интерпретаторы используют для исполнения (интерпретации) на машине программ, составленных для другой машины, а иногда в качестве последнего блока транслятора Компилирующего типа. В последнем случае транслятор состоит Из двух частей [26]: первой — компилятора, переводящего программу на промежуточный язык, являющийся входным языком
2J
интерпретатора; второй — интерпретатора, исполняющего программу на промежуточном языке.
В такой схеме компилятор можно сделать очень простым. Интерпретатор несколько проще компилятора, поскольку немедленное исполнение распознанных операторов входного языка делает ненужными действия, связанные с компоновкой объектной программы, оформлением ее в виде модуля загрузки или в виде нескольких модулей загрузки, если она велика;
Недостаток интерпретаторов заключается в неэффективном использовании машинного времени. Например, при выполнении циклических программ один и тот же оператор приходится интерпретировать многократно. При повторном выполнении программы интерпретацию приходится выполнять заново, в то время как транслятор компилирующего типа позволяет выполнить трансляцию только один раз, а затем хранить программу в машинных кодах. По указанной причине интерпретаторы применяют относительно редко.
1.3.3. ОБЩАЯ СХЕМА ТРАНСЛЯЦИИ
Основой любого естественного или искусственного языка является алфавит, определяющий набор допустимых элементарных знаков (букв, цифр и служебных знаков). Знаки могут объединяться в слова — элементарные конструкции языка, рассматриваемые в данном тексте (программе) как неделимые символы, имеющие определенный смысл. Иногда символ обозначают одним знаком, который тоже можно считать словом. Например, в языке Алгол-60 словами (символами) являются основные символы, идентификаторы, числа и некоторые ограничители, в частности знаки операций и скобки. Словарный состав языка — набор допустимых слов (символов) — вместе с описанием способов их представления составляет лексику языка.
Слова могут объединяться в более сложные конструкции — предложения. В языке Алгол-60, например, простейшим предложением является оператор. Предложения строятся из слов (символов) и более простых предложений по правилам синтаксиса. Синтаксис языка представляет собой описание правильных предложений. Каждому правильному предложению языка приписывается некоторый смысл. Описание смысла предложений составляет 'се-мантику языка. Практически семантика языка программирования есть описание того, как каждое предложение следует выполнять на машине.
Алфавит, лексика и синтаксис полностью определяют набор допустимых конструкций языка и внутренние взаимоотношения между конструкциями. Семантика выражает связь между конструкциями в разных языках. Перевод программы с одного языка на другой в общем случае состоит в изменении алфавита, лексики и синтаксиса языка программы с сохранением семантики. В част-
24
Рис. 1.6. Схема работы Альфа-транслятора
ных случаях могут меняться только некоторые элементы. Например, загрузчик изменяет лишь лексику, ассемблер — алфавит и лексику, а компилятор — алфавит, лексику и синтаксис языка программы.
Трансляция обычно происходит в несколько этапов, на каждом из которых выполняется вполне определенная работа.
Входная программа может быть подготовлена на разных внешних устройствах (телетайп, специальное клавишное устройство, стандартное устройство подготовки данных) и для удобочитаемости может иметь неполные строки и другие индивидуальные особенности. Кроме того, слова входного языка обычно имеют неодинаковый формат, например идентификаторы состоят из разного числа букв, числа —из разного числа цифр. Поэтому на первом этапе трансляции осуществляется лексический анализ, состоящий в приведении входной программы к стандартному виду — редактировании программы— и переводе ее на внутренний язык. Обычно во внутреннем языке все слова имеют одинаковый формат, что облегчает дальнейшую обработку. Одновременно с переводом на внутренний язык выполняется лексический контроль, выявляющий недопустимые слова.
На втором этапе трансляции выполняется синтаксический анализ, в задачу которого входит распознавание типа предложений
и выявление структуры программы, а также синтаксический контроль, выявляющий синтаксические ошибки.
На третьем этапе производится семантический анализ, в ходе которого проводится исследование каждого предложения и генерирование семантически эквивалентных предложений объектного языка. Иными словами, на третьем этапе выполняется собственно перевод.
Иногда вводят еще один этап, на котором проводится оптимизация программы с целью сокращения времени ее выполнения и минимизации используемого программой объема памяти.
В некоторых трансляторах каждому из описанных этапов /^ответствует определенная часть транслятора, В других
25
трансляторах отдельные блоки выполняют одновременно несколько этапов, например семантический анализ, оптимизацию и генерирование предложений выходного языка. Наконец, существуют трансляторы, в которых описанная общая схема повторяется несколько раз, например при переводе с выходного языка на внутренний, с внутреннего на промежуточный или выходной (объектный).
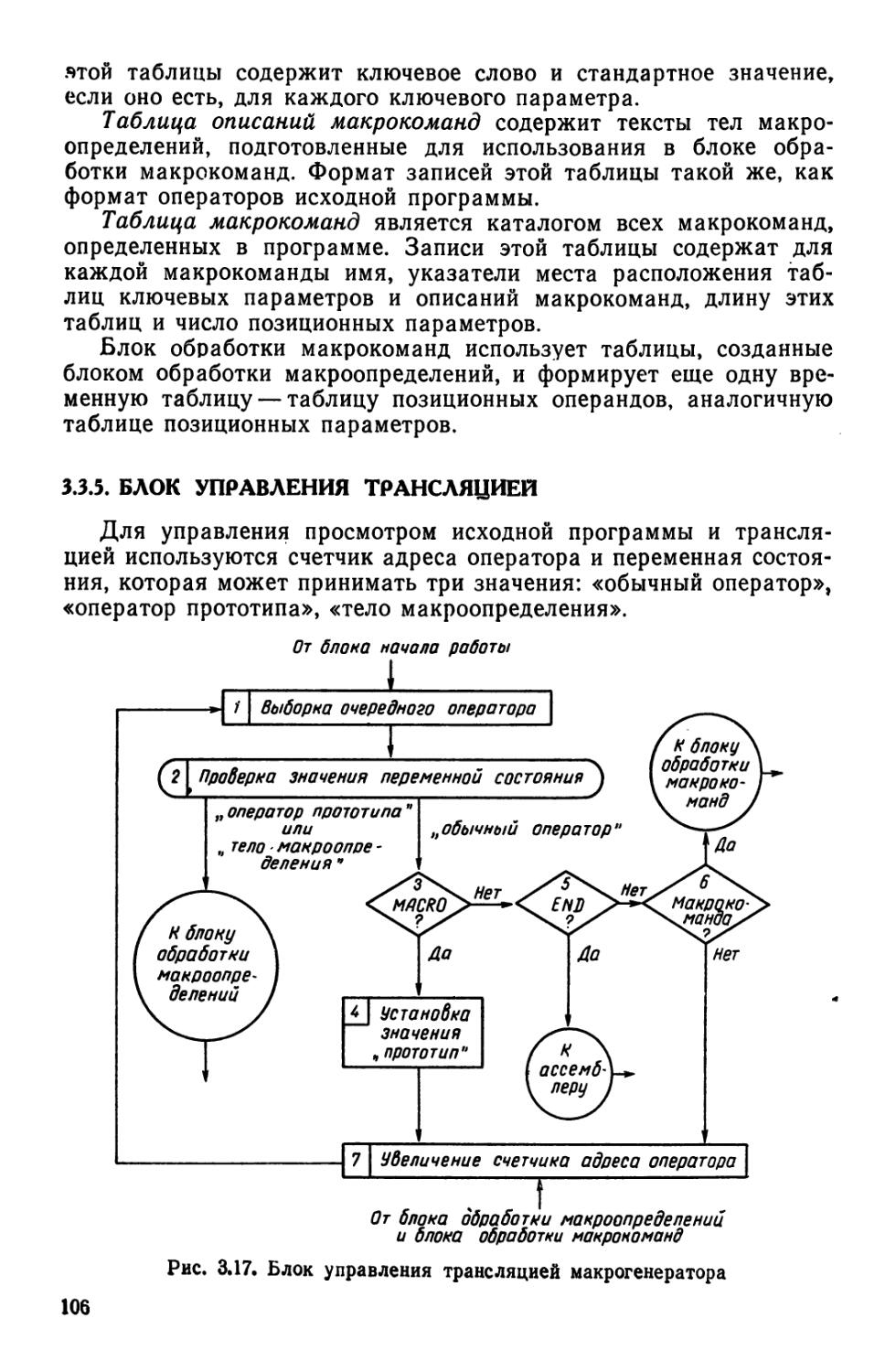
Альфа-транслятор, один из первых советских трансляторов, разработанный в 1961—1964 гг. в Вычислительном центре Сибирского отделения АН СССР под руководством А. П. Ершова, построен по схеме, показанной на рис. 1.6. Процесс трансляции разделен на две фазы: перевод на внутренний язык и перевод на язык машины. Каждая фаза состоит из трех функционально однотипных этапов. На первой фазе этап анализа совмещает лексический и синтаксический анализы. Третий этап на каждой фазе оптимизирует программу.
1.3.4. СТРУКТУРА ТРАНСЛЯТОРОВ
Под структурой транслятора будем понимать организацию программы трансляции. Структура конкретного транслятора зависит от уровня и свойств входного и выходного языков, требуемого качества объектной программы и принятого способа ее выполнения, метода трансляции, особенностей устройства машипьк в частности состава запоминающих устройств и объема оперативной памяти, а также принятого способа организации хранения и просмотра информации о транслируемой программе. Наиболее сложную структуру имеют компиляторы, т. е. трансляторы с языков высокого уровня.
На структуру трансляторов с языков типа Алгол-60 больше всего влияет метод трансляции и объем оперативной памяти. Методы трансляции, используемые в компиляторах, условно можно разделить на две группы: прямые и синтаксические. Следует отметить, что четкой границы между методами этих двух групп нет.
Прямые методы трансляции ориентированы на конкретные входные языки. Это преимущественно эвристические методы, в которых на основе некоторой общей руководящей идеи для каждой конструкции входного языка подбирается индивидуальный алгоритм трансляции. Этапы синтаксического и семантического анализов здесь обычно четко не разделены. Алгоритмы трансляции, применяемые в прямых методах, как правило, существенно зависят от входного языка.
Синтаксические методы трансляции отличаются прежде всего более или менее четко выраженным разделением этапов синтаксического и семантического анализов. Некоторые из ранних синтаксических методов, как и прямые методы, ориентированы на конкретные входные языки. Характерным примером является метод синтаксических подпрограмм, в котором каждой синтаксической единице входного языка соответствует отдельная подпрограмма.
26
Более поздние синтаксические методы основаны на теории формальных грамматик. Каждый из этих методов ориентирован не на конкретный входной язык, а на некоторый класс входных языков, точнее, на определенный способ описания синтаксиса входных языков. Поэтому эти методы называют синтаксически-ориентирован-ными.
Компилятор — это очень большая и сложная программа, содержащая от нескольких тысяч до нескольких десятков тысяч машинных слов. Разработку и программирование компилятора обычно выполняет группа системных программистов. Для организации параллельной работы членов группы и упрощения программирования компилятор делят на части, каждая из которых выполняет при трансляции определенную работу. Части компилятора могут быть блоками или подпрограммами, различие между которыми состоит в том, что блок выполняется всегда, когда приходит его очередь, а подпрограмма — только тогда, когда это требуется. Реальные трансляторы обычно состоят как из блоков, так и из подпрограмм. Однако некоторые трансляторы имеют преимущественно блочную структуру, а другие преимущественно состоят из подпрограмм. Применяются также комбинированные схемы, в которых при общей блочной структуре отдельные блоки состоят из подпрограмм.
В трансляторах с блочной структурой порядок выполнения блоков заранее определен и не зависит от особенностей входной программы. В трансляторах, состоящих из подпрограмм, порядок их вызова заранее не определен, он зависит от набора и взаимного расположения конструкций входной программы.
Решение вопроса о том, что взять за основу структуры транслятора— блоки или подпрограммы, во многом зависит от объема оперативной памяти машины.
В машинах с большой оперативной памятью обычно применяют двух-трехпросмотровые схемы трансляции, а иногда даже однопросмотровые. В таких схемах небольшая часть транслируемой программы просматривается и перерабатывается поочередно вызываемыми частями транслятора до получения готовой или почти готовой части объектной программы. Затем обрабатывается следующая часть программы и т. д. Малое число просмотров обеспечивает высокую скорость трансляции, если весь транслятор хранится в оперативной памяти машины. При расположении всех частей компилятора в оперативной памяти выгодно, чтобы он состоял преимущественно из подпрограмм. Это позволяет для обработки каждой части входной программы использовать только необходимые подпрограммы, причем любая подпрограмма может вызываться многократно. В виде блоков оформляют только те части транслятора, которые по необходимости должны обработать всю входную программу (например, блок лексического анализа).
При небольшой оперативной памяти части транслятора приходится хранить во внешней памяти машины. Применение
27
предыдущей схемы обработки приведет к большому числу обращений к внешней памяти для многократного и неупорядоченного вызова подпрограмм транслятора. Если подпрограммы записаны на носителе с последовательным доступом (магнитная лента), то время трансляции резко возрастет. Поэтому здесь используют другую, а именно многопросмотровую схему, а транслятор делают из блоков. Каждый блок вызывается в оперативную память только один раз, но просматривает всю программу. Блоки вызываются последовательно, поэтому число просмотров равно числу блоков. Некоторые трансляторы, имеющие блочную структуру, просматривают входную программу 10—20 и более раз.
Заметим, что многопросмотровая схема трансляции отличается от многоэтапной трансляции (упоминавшейся в п. 1.3.1), когда программа последовательно транслируется на промежуточные языки. Отличие состоит в том, что после каждого этапа многоэтапной трансляции получается готовая программа на промежуточном языке. Вся информация о промежуточной программе содержится в ней самой. В многопросмотровой схеме ни один из просмотров, кроме последнего, не формирует готовую программу. Часть информации, полученной при предыдущих просмотрах, заключена в частично переработанной программе, а часть — во вспомогательных таблицах.
1.3.5. СЕГМЕНТАЦИЯ ПРОГРАММЫ И ДАННЫХ
Большие программы приходится сегментировать, т. е. делить на части, называемые сегментами, которые хранятся во внешней памяти и вызываются в оперативную память для исполнения по мере необходимости. Иногда приходится делить на сегменты и обрабатываемые данные, прежде всего массивы. В задачах обработки данных, к которым относятся различные учетно-плановые задачи, данные, как правило, сегментируются.
Некоторые языки программирования, например АЛМО, Фортран, Комплекс Алгол, позволяют программисту разделить программу на сегменты. В языках АЛМО, Кобол и конкретных представлениях Алгола-60 для отдельных трансляторов имеются также средства для указания желаемого распределения массивов по видам памяти.
В эталонном Алголе-60 таких средств нет, однако существуют трансляторы, автоматически сегментирующие программу. Например, транслятор Жиер-Алгол [28], разработанный под руководством П. Наура в 1963 г. для машины Жиер с оперативной памятью всего в 1024 машинных слова, автоматически делил программу на равные по величине сегменты по 128 слов. В каждом сегменте помимо команд содержались также все требующиеся в нем константы. Сегменты хранились на магнитном барабане и в процессе исполнения программы по мере необходимости загружались в оперативную память специальной административной систе-
28
мои, которая при недостатке места удаляла тот сегмент, к которому дольше всего не было обращений.
В некоторых отечественных и зарубежных трансляторах предусмотрена автоматическая сегментация данных. Массивы, не умещающиеся в оперативной памяти, размещаются транслятором во внешней памяти, при этом учитываются рекомендации программиста, который может указать в описании массивов частоту их использования. Редко применяемые массивы размещаются в первую очередь во внешней памяти. Загрузку сегментов массивов во внутреннюю память по мере необходимости выполняет административная система. В частности, такая система имеется в отечественном трансляторе Алгола-60 ТА-2М.
В современных вычислительных системах для Ьблегчения сегментации программ и данных используется понятие математической памяти. Математическая память, иначе называемая виртуальной памятью, есть фиктивная память, диапазон адресов которой может превосходить объем физической оперативной памяти. Математическая память делится на страницы, являющиеся, по существу, сегментами в описанном выше смысле. Типичный объем страницы 128, 256, 512 или 1024 машинных слова. Физическая память, состоящая из оперативной памяти и внешней памяти разных уровней, разделена на такие же страницы. Обмен между оперативной и внешней памятью возможен только целыми страницами.
Программа составляется транслятором в математических адресах. Для исполнения части программы, записанной на определенной математической странице, или для использования данных, хранящихся на некоторой математической странице, эта математическая страница переписывается на физическую страницу оперативной памяти. Настройка по месту обычно производится аппаратными средствами с помощью базовых регистров, которые формируют исполнительные адреса динамически в процессе исполнения программы. При формировании исполнительных адресов учитывается разность номеров физической и математической страницы. Операционная система ведет учет математических страниц, находящихся в оперативной памяти, и при необходимости вызывает недостающие страницы из внешней памяти. При недостатке места неиспользуемые страницы переписываются во внешнюю память. Последнее требуется лишь в том случае, когда содержимое страницы подвергалось изменениям.
1.3.6. СТРУКТУРА ТРАНСЛЯТОРА ТА-2М
Транслятор ТА-2 для машины М-20 был разработан под руководством М. Р. Шура-Буры в 1961 —1963 гг. в Институте прикладной математики АН СССР. Это был один из первых отечественных трансляторов с языка Алгол-60. В 1967 г. транслятор был модернизирован для использования на машине М-220
29
с увеличенной оперативной памятью и получил название ТА-2М. Транслятор использует прямые методы трансляции, многопросмотровую схему и построен из блоков. Блоки транслятора записаны на магнитной ленте и вызываются подряд. Каждый блок работает
только один раз и просматривает информацию, относящуюся ко всей программе. Структура транслятора показана на рис. 1.7.
Рассмотрим кратко назначение блоков. Блок перекодировки входной информации (блок 1) вводит с перфокарт текст программы в 7-разрядном коде уст* ройства подготовки перфокарт, с помощью таблиц перекодирует его в 15-разрядный код внутреннего языка транслятора и записывает переработанный текст на магнитный барабан. На печать выдается информация о лексических ошибках.
Блок синтаксического контроля (блок 2) с помощью синтаксических таблиц проверяет корректность синтаксиса Алгол-программы. Информация об обнаруженных ошибках выдается на печать.
Блок выделения понятий (блок 3) переводит программу с внутреннего языка на промежуточный, в котором нетрекурсивно-сти, свойственной языку Алгол-60. Перевод выполняется с помощью таблиц. В процессе перевода из отдельных букв и цифр собираются идентификаторы, а числа переводятся в двоичную систему. Информация о неописанных идеи- тификаторах выдается на печать.
Следует заметить, что сборка идентификаторов и перевод чи-
программа но вводном языке^
блок перекодировки входной информации
| 2 I блок синтаксического контроля
J] блок выделения понятий
♦
|4 блок программирования выражений
блок служебных операторов |
блок операторов входа I ♦
Блок циклов ♦
блок переключателей
9 блок операторов присваивания |
ю
блок тел процедур
п блок операторов процедур |
12 блок распределения памяти |
13
16
16
блок процедур обмена
блок процедур - кодов
блок формирования
блок компоновки
I Программа на объектном (машинном) языке
Рис.
1.7. Структура транслятора ТА-2М
сел по смыслу относятся к лексическому анализу, поэтому во мно-гих трансляторах эти действия выполняются блоком лексического анализа (первым блоком транслятора).
Блоки с номерами 4—II, а также 13 и 14 переводят на машинный язык отдельные конструкции исходной программы.
Блок распределения памяти (блок 12) распределяет память для простых переменных и массивов. В трансляторе память распределяется статически (на этапе трансляции), поэтому для массивов
30
с переменными границами в исходной программе нужно указывать максимальные размеры. Если недостаточно места в оперативной памяти, то массивы размещаются во внешней памяти. Для обращения к элементам массивов, размещенных во внешней памяти (внешних массивов), в блоке 15 программируются команды обращения к специальной административной системе АС-2. Эта система постоянно находится в памяти во время исполнения рабочей программы и вводит требующиеся части массивов на рабочее поле в оперативной памяти. Рабочее поле разделено на страницы по 128 ячеек. Если требуется некоторый элемент внешнего массива, то вводится часть массива размером в страницу (128 ячеек). При последующих обращениях к этому же элементу или к соседним элементам, расположенным на той же странице, они выбираются из рабочего поля.
Если для записи в оперативную память требующейся страницы недостает свободного места, то место освобождается путем переписывания во внешнюю память той страницы, к которой дольше всего не было обращений.
Блок компоновки (блок 16) переводит программу, которая до этого записывалась отдельными фрагментами в условных адресах, в абсолютные адреса, т. е. компонует готовую программу.
Общий объем транслятора — около 20000 машинных слов, из них около 3000 машинных слов приходится на различные таблицы. При работе транслятора и в ходе исполнения рабочей программы используется библиотека стандартных подпрограмм с интерпретирующей системой ИС-2 [20]. Скорость трансляции при работе с одним кубом оперативной памяти 40—50 команд в минуту, а при работе с двумя кубами 140—150 команд в минуту.
Транслятор ТА-2М можно считать типичным представителем компиляторов, имеющих блочную структуру и использующих прямые методы трансляции. Блочная структура и многопросмотровая схема здесь являются вынужденными, поскольку оперативная память машины М-20, для которой первоначально создавался транс-«лятор, имела объем всего в 4096 машинных слов, что впятеро, меньше объема компилятора. Большинство первых отечественных и зарубежных компиляторов также использовали прямые методы, многопросмотровую схему и имели блочную структуру.
1.3.7. ХАРАКТЕРИСТИКИ НЕКОТОРЫХ ОТЕЧЕСТВЕННЫХ ТРАНСЛЯТОРОВ
Сейчас на всех отечественных машинах, выпускаемых серийно, имеются трансляторы для различных входных языков. Некоторые характеристики трансляторов Алгола-60 для машин типа М-220 приведены в табл. 1.2.
Первые три компилятора — TA-IM, ТА-2М и Альфа — были пер-ВЫми отечественными трансляторами с языка Алгол-60. Транслятор ТА-1М был разработан под руководством С. С. Лаврова,
31
Таблица 1.2
ХАРАКТЕРИСТИКИ ТРАНСЛЯТОРОВ АЛГОЛА-60 ДЛЯ МАШИН ТИПА М-220
Транслятор, год сдачи в эксплуатацию Объем транслятора, распределяемая память Скорость трансляции, команд в минуту Отношение характеристик транслированной и «ручной» программы
длина время выполнения
TA-IM, 1963 17000 слов, 1 куб МОЗУ 120—200 1,5-2,5 1,5—2,5
ТА-2М, 1963 20 000 слов, вся память 40—50 при 1 кубе МОЗУ, 140—150 при 2 кубах 1,3-2,0 1,3—2,0 при работе без процедур, до 10 раз при работе с процедурами
Альфа, 1964 45 000 слов, 1 куб МОЗУ 150 1,3 1.2
ТАУ-67 1967 4 500 слов, 1 куб МОЗУ 200—300 1,4—2,0 1.4-1,8
Комплекс Алгол, 1968 18 000 слов-1-12000 слов, вся память 90 1,5—3,0 1,5-1,6 >
транслятор ТА-2М создавался коллективом под руководством М. Р. Шура-Буры, а разработкой транслятора Альфа руководил А. П. Ершов. Все эти трансляторы используют прямые методы трансляции, м.ногопросмотровую схему и имеют блочную структуру.
Трансляторы Комплекс Алгол и ТАУ-67 основаны на метод ё синтаксических подпрограмм. Транслятор Комплекс Алгол, имеющий объем 18000 машинных слов, входит в универсальную систему программирования Института прикладной математики АН СССР. [14]. Этот транслятор переводит программу на универсальный машинно-ориентированный язык АЛМО, а затем компилятор АЛМО (его объем 12000 машинных слов) переводит АЛМО-программу на язык машины. Двухэтапная схема трансляции существенно увеличивает время трансляции, что отмечено в табл. 1.2. Следует отметить, что Комплекс Алгол — единственный из трансляторов, обеспечивающий полуавтоматическую сегментацию программы и автоматическое размещение сегментов программы и массивов данных во 32
внешней памяти машины. Дополнительная работа по сегментации программы и распределению внешней памяти также увеличивает время трансляции.
Все трансляторы, кроме ТАУ-67, во время трансляции хранятся во внешней памяти (на магнитной ленте). Транслятор ТАУ-67 имеет небольшой объем, это дает возможность целиком разместить его в быстрой памяти (в оперативной памяти и на магнитных барабанах), причем собственно трансляция выполняется за два просмотра, поэтому этот транслятор работает быстрее других. Однако небольшой объем транслятора ТАУ-67 достигнут за счет некоторого упрощения входного языка, отказа от сегментации программы и распределения внешней памяти, а также снижения уровня сервиса при трансляции (не выдается печатный документ о программе, информация об ошибках печатается в восьмеричной форме в т. п.).
Наиболее высококачественные программы, прежде всего повремени выполнения, дает компилятор Альфа. Это достигнуто применением в трансляторе специальных алгоритмов оптимизации, которые усложнили транслятор и увеличили его объем в два с лишним раза по сравнению с компиляторами ТА-1М и ТА-2М. Вместе с тем компилятор Альфа работает достаточно быстро. Некоторые средства, способствующие его быстродействию, рассматриваются в следующей главе.
1.3.8. СРЕДСТВА ОТЛАДКИ
Применение языков высокого уровня требует создания средств отладки на уровне входного языка. Опыт показывает, что от 20 до 40% рабочего времени программист расходует на отладку программ, поэтому отсутствие удобных средств отладки существенно сдерживает повышение производительности труда программистов. Опыт практической эксплуатации трансляторов показывает, что достаточно полный Набор средств отладки должен обеспечивать: л
1. Контроль лексических и синтаксических ошибок в процессе трансляции и выдачу информации об ошибках вместе с текстом программы с указанием характера и места ошибки.
2. Аварийную («авостную») выдачу информации об операторе, в котором произошел «авост», и о значениях переменных в этот момент. Аварийная выдача может быть стандартной, когда выдаются значения переменных, входящих в «авостный» оператор, или значения всех переменных, используемых в программе. В некоторых системах состав аварийной выдачи указывает програм-МИСТ.
3. Контроль зацикливания и выдачу информации об операто-Рах, входящих в цикл.
4- Прослеживание хода выполнения программы, например выдачу последовательности всех меток или определенного числа
2 бак. 221 оо
последних меток («трассировка»), печать числа выполнения циклов и т. п.
5. «Прокрутку» участка программы с выдачей текста исполняемых операторов и получаемых результатов.
6. Вставление в текст программы отладочных операторов или замену некоторых операторов отладочными.
Контроль лексических и синтаксических ошибок предусматривается во всех трансляторах. В некоторых трансляторах имеется также аварийная выдача.
Из первых отечественных трансляторов лучше всего был оснащен средствами отладки Альфа-транслятор. В Альфа-системе автоматизации программирования имеется специальный Альфа-отладчик, обеспечивающий программиста средствами отладки, выполняющими большинство из описанных выше действий. В задание для Альфа-отладчика программист может включить требующиеся ему отладочные операции. На основании этого задания перед трансляцией Альфа-отладчик вносит в исходную программу необходимые изменения, поэтому измененная программа выполняется в отладочном режиме. Недостатком первоначального варианта этой системы было отсутствие на машине М-20 алфавитно-цифрового печатающего устройства, что вынуждало выдавать всю отладочную информацию в цифровой форме и расшифровывать ее с помощью таблиц.
Наиболее совершенным набором средств отладки обладает' проект системы отладки для транслятора Комплекс Алгол. Собственно Комплекс есть совокупность транслятора с входного языка типа Алгол и системы отладки, позволяющей отлаживать объектную программу на уровне входного языка. Предусматриваемая система отладки содержит все перечисленные выше средства отладки. Для использования этих средств программист составляет задание для системы отладки, на основании которого система отладки вносит изменения в исходную программу так же, как в Альфа-отладчике. Информацию о ходе отладки предусмотрено выдавать в виде удобного цечатного документа. Однако к моменту написания этой книги этот проект еще не был реализован.
Средства отладки включаются во все современные системы программирования. Например, в ДОС/ЕС имеется специальная системная обслуживающая программа ОТЛАДКА, которую можно использовать для отладки объектных модулей, создаваемых ассемблером и трансляторами с языков РПГ, Фортран и ПЛ/1. Эта программа позволяет корректировать объектные модули путем замены, добавления или удаления отдельных команд без повторной трансляции, печатать указанную программистом информацию в определенных точках программы или при выполнении определенных условий.
Однако использование ОТЛАДКИ требует определенной квалификации и знания основ устройства ЕС ЭВМ.
ГЛАВА 2
ОРГАНИЗАЦИЯ, ХРАНЕНИЕ И ПОИСК ДАННЫХ
2.1. СТРУКТУРЫ И ХРАНЕНИЕ ДАННЫХ
2.1.1. СТРУКТУРЫ ДАННЫХ
Любой набор знаков, рассматриваемый безотносительно кегр содержательному смыслу, называют данными. Данные обычно изображают некоторую информацию, которую можно получить, если известен смысл, приписываемый данным. Однако в программировании, особенно в системном программировании, часто приходится иметь дело именно с данными. Например, разрабатывая систему хранения и поиска некоторых текстов, программист может не знать их содержания. Его задача — обеспечить экономное использование памяти, надежное хранение и быстрый поиск требуемых текстов по заданным признакам. Для решения этой задачи достаточно знать лишь количественные характеристики текстов, рассматриваемых как данные. Вообще вычислительные машины выполняют только обработку данных, которая заинтересованным лицам, приписывающим этим данным определенный смысл, представляется обработкой информации.
В языках программирования и в трансляторах часто используют различные совокупности данных, организованные определенным образом. Организованные совокупности данных называют структурами данных. Каждая структура состоит из элементов или „записей. Структура определяется правилами, устанавливающими отношения между элементами. В общем случае каждый элемент в свою очередь может быть некоторой структурой. Так образуются сложные иерархические структуры. Наименьшие элементы записи, имеющие определенный содержательный смысл, называют полями. Например, в машинной команде, рассматриваемой как отдельная запись, полями можно считать части, соответствующие коду операции, адресам и признакам.
Рассмотрим наиболее распространенные структуры данных.
Строка есть упорядоченный одномерный набор элементов, каждый из которых, кроме первого, имеет предшественника и последователя (последователя нет у последнего элемента). Получить Доступ к элементу строки можно лишь путем последовательного просмотра элементов с одного из концов строки. В частности, входная программа является для транслятора строкой.
2* 35
Массив — набор элементов, с каждым из которых связан упорядоченный набор целых чисел, называемых индексами. Индексы однозначно определяют позицию каждого элемента массива. Частный вид массивов — прямоугольные массивы, в которых каждый индекс изменяется с постоянным шагом от нижнего до верхнего значения. Примером прямоугольных массивов могут служить массивы в языке Алгол-60. Массив с п индексами называют п-мерным.
Очереди и стеки — одномерные динамически изменяемые упо-1овый элемент всегда добавляют к одному и тому же концу набора. Элемент удаляется из очереди всегда с другого конца по принципу «первым пришел, первым ушел». Удаление элемента в стеке производится с того же конца, с которого добавляются элементы, по принципу «последним при-
. шел, первым ушел». Стек называют также магазином, по аналогии с магазином пистолета, в котором патрон, вставленный последним, первым выходит из магазина. Конец стека, с которого добавляются и удаляются элементы, называют вершиной стека. Очередь и стек показаны на рис. 2.1.
Таблица — набор элементов, каждый из которых имеет отличительный признак, называемый ключом. Элементы выбираются из
рядоченные нао Очередь
элементов.
выход
Стен
вход
Входи выход (вершина стена)
Рис. 2.1. Очередь и стек
я?
ТАБЛИЦА ФУНКЦИИ sin (х)
Ключ (значение аргумента) Данные (значение функции)
0,00 0,0000
0,01 0,0100
0,02 0,0200
• • • • • •
ТАБЛИЦА ИМЕН
Ключ (идентификатор) Данные (тип и адрес)
XI real 0301
Х2 real 0302
Y real 0303
• • • • • •
Рис. 2.2. Примеры таблиц
таблицы и добавляются в таблицу по ключу. Помимо ключа элемент таблицы (табличная запись) обычно содержит также данные, несущие некоторую информацию. Примером таблицы может служить любая таблица значений функции. Ключом в такой таблице является значение аргумента, а информацию несет значение функции. Значение аргумента и функции вместе образуют таблич-
36
ную запись (рис. 2.2). В трансляторах часто применяют таблицу имен (см. рис. 2.2). Ключом такой таблицы является обычно идентификатор, а данные содержат указание о типе величины и адресе хранения ее значения.
Дерево состоит из набора узлов (или вершин), каждый из которых содержит помимо данных указатели на узлы нижнего уровня. Единственный узел самого верхнего уровня называют корнем, а узлы самого нижнего уровня называют листьями. На каждый узел, кроме корня, указывает лишь один узел верхнего уровня, поэтому имеется единственный путь от данного уз.ра до корня. Листья — это элементы внешние по отношению к дереву. С помощью деревьев удобно представлять иерархические отношения между данными.
Пример 1. Оператор присваивания языка Алгол-60
х: — а X b + eld.
можно представить деревом, показанным на рис. 2.3.
Рис. 2.3. Дерево, изображающее оператор присваивания
Рис. 2.4. Ориентированный граф, изображающий блок-схему
Ориентированный граф отличается от дерева тем, что на узел может указывать более чем один другой узел. Для отличия указывающих узлов от указываемых на: линиях, соединяющих узлы, ставят стрелки. В дереве стрелки не нужны, поскольку всегда верхние узлы указывают на нижние. В ориентированном графе возможен путь от узла к самому себе. Если такой путь не содержит других узлов, его называют петлей, а если содержит — циклом. Петля — частный случай цикла. Граф без циклов называют ациклическим. Блок-схемы программ обычно изображают в виде ориентированных графов.
Пример 2. Блок-схему, представляющую операторы Алго-ла-60
x: = ifx > у then х— 1 elsex-j- 1;
z: = z-|-x;
Можно изобразить ориентированным графом (рис. 2.4).
37
2.1.2. СТРУКТУРЫ ХРАНЕНИЯ
Различные структуры данных хранятся в памяти машины в разных структурах хранения. Набор структур хранения ограничен, поскольку память большинства машин состоит из упорядоченного набора непосредственно адресуемых машинных слов (ячеек) или слогов (байт). Структура хранения состоит из элементов хранения (записей). Запись могут образовывать несколько машинных слов (байт), если элемент данных не умещается в одном машинном слове или, наоборот, в одно машинное слово может быть упаковано несколько элементов данных. Минимальный элемент хранения — бит — один двоичный разряд.
Рассмотрим типичные структуры хранения.
Вектор — это набор соседних элементов хранения одинакового размера, которые расположены в памяти машины рядом. Вектор определяется базой, которой является адрес первого элемента вектора, размером элементов и длиной. Чаще всего каждый элемент вектора имеет размер стандартного машинного слова. В этом случае его можно описать как одномерный массив Алгола-60
array а [ 1: га].
Для получения адреса элемента a[i] нужно к базе вектора прибавить величину i— 1.
Список представляет собой набор элементов, каждый из которых состоит из двух полей. Одно поле содержит элемент данных или указатель на элемент данных, а другое — указатель на следующий элемент списка, который в свою очередь может быть списком. Например, строка букв КОРА может быть представлена списком в двух вариантах (рис. 2.5). Сймволом 0 в поле указателя
Рис. 2.5. Списки, отображающие строку Рис. 2.6. Включение b список но-букв вых элементов
на следующий элемент отмечен последний элемент списка.
Списковые структуры позволяют легко включать новые элементы между любыми двумя уже имеющимися, как это показано на рис. 2.6, где из строки КОРА образована строка КОРИЦА. Столь же просто из списка исключаются элементы путем простого изменения указателей. Заметим, что включение и исключение элементов происходит в списках без физического перемещения элементов. Это весьма полезное свойство часто используется в системном программировании.
38
Особенно полезны списковые структуры в тех случаях, когда памяти машины требуется разместить несколько динамически неизвестным заранее
^меняющихся массивов (строк, таблиц) с цислом элементов. Такая ситуация типична для трансляторов. На рис. 2.7, а показаны три динамических массива Д, В и С в отведенной для них области памяти. Каждый массив имеет фиксированное начало. Со временем массивы растут. На рис. 2.7, б показан момент, когда очередное пополнение массива А «уперлось» в массив В. Последний элемент массива А заменен указателем на продолжение этого массива за массивом В. На рис. 2.7, в такое же продолжение появилось у массива В, а у массива А появилось еще одно продолжение. В этот момент массив А представлен урех-элементным списком, а массив В — двухэлементным. Каждый элемент обоих спи-
Рис. 2.7. Применение списковых структур для хранения динамически изменяющихся массивов
сков состоит из части (сегмента) соответствующего массива и указателя на следующую часть (сегмент).
На рис. 2.8 показана ситуация, соответствующая рис. 2.7, в, но здесь списки со-
стоят только из указателей, а в начале каждого сегмента массива
указана его длина.
Списки полезны во всех тех случаях, когда требуется упорядочить элементы данных без их физического перемещения или свя-
Рис. 2.8. Список, состоящий из указателей
Рис. 2.9. Сеть, отображающая дерево оператора присваивания
Зать воедино элементы данных, размещенные в разных местах памяти. Особенно удобны списки для объединения динамических затеей переменной длины.
Сети отличаются от списков тем, что каждый элемент сети имеет несколько полей с указателями на другие элементы сети.
39
Кроме того, в одном из полей помещается элемент данных или указатель на элемент данных. Каждый элемент сети может содержать также информацию о формате поля данных и полей указателей и о их числе. Сети лучше приспособлены для отображения сложных структур данных, таких, как деревья и ориентированные графы, чем списки. На рис. 2.9 показана сеть, изображающая дерево, показанное на рис. 2.3.
2.1.3. ОТОБРАЖЕНИЕ СТРУКТУР ДАННЫХ В СТРУКТУРЫ ХРАНЕНИЯ
Строки, состоящие из элементов одинакового размера, обычно хранят в памяти машины в виде векторов. При небольшом размере элементов в одно машинное слово «упаковывают» несколько
Массив А
Д11 Й12
Дг1 дг2
.д31 дзг
Йн
Й23 Д24
А33 Й34.
Вектор В
Отображение массива А „строками"
Й11 д12 д13 д14 Д21 д22 д23 д24 Д31 д32 д33 д34
Отображение массива А „столбцами"
Вектор В
Д11 дг) Д31 Д12 д22 д32 д13 Д23 д33 д14 д24 Д34
Рис. 2.10. Способы отображения двумерного массива в вектор
элементов строки. Однако строку с крупными элементами переменной длины целесообразнее хранить в виде списка. Особенно выгодно списковое представление строк в тех случаях, когда приходится производить операции над строками: объединение двух строк, разделение строки на части и сравнение двух строк элемент за элементом.
Массив, как правило, хранят в виде вектора, однако возможны исключения. Например, в задачах линейного программирования большинство элементов матрицы условий обычно равно нулю. В таких случаях лучше хранить массив в виде таблицы, содержащей лишь ненулевые элементы. Ключом каждого элемента здесь является набор индексов элемента массива.
40
Рассмотрим хранение массива в виде вектора. Пусть массив с описанием
array A [zt: k{, in : /гп]
хранится в памяти машины в виде одномерного вектора, определяемого описанием
array В [1 : ЛГ],
где п
N = Г1(^-4т+ 1).
Элементы массива А можно отобразить в массив В двумя способами (рис. 2.10):
«строками», когда наиболее быстро меняется последний индекс; «столбцами», когда наиболее быстро меняется первый индекс. Выражения «строками» и «столбцами», естественно, имеют буквальный смысл только для двумерных массивов. В отечественных ..трансляторах обычно используется отображение «строками», а в зарубежных — «столбцами».
В обоих случаях можно построить функцию упорядочения, поз-воляющую по индексам элемента исходного массива Л[/ь ..., jn] вычислить соответствующий индекс I элемента массива В. Эта «функция, как нетрудно убедиться непосредственной проверкой, имеет вид
п
(2.1)
где при отображении «строками»
Dn =: 1 И Dm = (^/п+1 ^т+1 “Ь О ^т+1> т= !»•••> 1, (2.2)
-а при отображении «столбцами»
D\ == 1 и = zm__|1) Dm_x, т = 2, п, (2.3)
Для определения адреса хранения а элемента А[]\, ..., jn] в •случае, когда вектор В имеет базу Ь, формулу (2.1) целесообразно преобразовать к виду
п
a = b + c+ 2 jmDm, (2.4)
т=\
где
п
с = - (2.5)
Постоянная величина с, как и коэффициенты Dm, зависит толь-ко от значений граничных пар в описании массива А.
Для вычисления адреса элемента произвольного массива А по Формуле (2.4) нужно знать базу отображающего вектора Ь,
41
размерность массива п и п целых чисел. При отображении «стро ками» это коэффициенты
коэффициент Dn здесь всегда равен единице.
Некоторые трансляторы предусматривают контроль правиль-ности обращений к элементам массивов при выполнении транслированной программы. Чтобы осуществить контроль, нужно для
Указатель стеке
Рис. 2.11. Хранение стека в виде вектора с указателем
каждого массива хранить нижнюю и верхнюю границы каждого индекса.
В программе может быть несколько массивов. Для распределения памяти под массивы необходимо знать число элементов в каждом массиве А/. При отображении массива «строками» величину W можно вычислить по формуле (2.2) при пг = 0:
AZ = D0 = (£1 —Л + 1)
(2.6)
Заметим, что перечисленные величины: размерность массива и; коэффициенты c,Dq, Dh ..., значения граничных пар
ib k\. ..., in,kn — зависят только от описания массива. Все эти величины обычно хранят в виде так называемого определяющего
Указатель начала очереди
Указатель конца очереди
Рис. 2.12. Хранение очереди в виде циклического списка с двумя указателями
вектора массива. Для массивов с одинаковыми описаниями определяющие векторы равны. Итак, для вычисления адреса элемента массива достаточно знать базу отображающего вектора b и место хранения определяющего вектора.
Стек обычно хранят в памяти машины в виде вектора, длина которого должна быть равна максимальной ожидаемой длине стека. Кроме того, нужно иметь указатель, называемый указателем стека, постоянно указывающий на вершину стека (на последнюю занятую позицию стека или на первую свободную позицию). При добавлении в стек нового элемента указатель стека увеличивается на единицу, а при исключении элемента — уменьшается на единицу (рис. 2.11).
Очередь хранить в виде вектора неудобно, поскольку при исключении элемента (удалении элемента с выходного конца очере-42
ди) пришлось бы двигать все элементы вдоль вектора к выходному концу. Обычно очередь хранят в памяти машины в виде циклического списка с двумя указателями, один из которых указывает на начало, а другой — на конец очереди. При исключении из очереди ее первого элемента в первый указатель засылается ссылка на следующий элемент списка, содержащийся в поле указателя исключаемого элемента (рис. 2.12), а при включении в очередь нового элемента во второй указатель засылается ссылка на новый элемент.
Как уже упоминалось, деревья и ориентированные графы удобнее всего отображать сетями. Однако, как будет показано в дальнейшем, используя специальные формы записи, деревья можно хранить в виде векторов. Это широко используется в трансляторах.
2.2. ХРАНЕНИЕ И ПОИСК ДАННЫХ В ТАБЛИЦАХ
2.2.1. ТАБЛИЦЫ
Наиболее употребительной структурой данных в трансляторах являются таблицы. В частности, в таблицах хранят основные символы входного языка, используемые для распознавания синтаксических конструкций, а также коды операций машины или «заготовки» машинных команд, необходимые для генерирования команд объектной программы. Это постоянные таблицы, составляемые заблаговременно. Одной из основных таблиц при трансляции является таблица имен, иногда ее заменяют две таблицы: таблица переменных и таблица меток. Все это временные таблицы, составляемые в ходе трансляции.
Обычно таблицы отображаются в памяти машины вектором, но иногда используют также списки или комбинацию векторов со списками. Напомним, что записи включаются в таблицу и выбираются из таблицы по ключу. До половины всего времени работы транслятора, а иногда и больше, расходуется на поиск в таблицах. Достаточно вспомнить, что в трансляторе ТА-2М, структура которого рассматривалась в 1.3, только постоянные таблицы имеют объем 3000 машинных слов из общего объема транслятора 20000 слов. В некоторых трансляторах объем постоянных таблиц еЩе больше. Например, синтаксический транслятор СТ-2 для языка Алгэм на машине «Минск-22» имеет объем синтаксических таблиц 6000 слов при 4000 командах, составляющих программу транслятора.
Задача поиска состоит в определении по заданному ключу адреса хранения табличной записи, если имеется такая запись в таблице. Эта задача решается по-разному в различных таблицах в зависимости от способа организации таблицы. Основной характеристикой способа организации таблицы является среднее время
43
поиска одной записи. Это время пропорционально средней длине поиска, под которой понимают среднее количество записей, просматриваемых для отыскания требуемой записи.
2.2.2. НЕУПОРЯДОЧЕННЫЕ ТАБЛИЦЫ
В простейших неупорядоченных таблицах записи располагаются одна за другой без пропусков. Такие таблицы легко составлять. Новая запись просто добавляется к таблице. Для поиска применяется последовательный просмотр, при котором записи просматриваются подряд, начиная с первой. Средняя длина поиска при последовательном просмотре таблицы с п записями определяется формулой п
D = 2 iPi, (2.7)
1=1
где I — порядковый номер записи, a pi — вероятность того, что требуемая запись имеет номер i.
Если искомая запись с равной вероятностью находится на любом месте таблицы, то
1
средняя длина поиска равна
п
= = (2.8)
1 п п 2 2 '
i=l
Неупорядоченные таблицы неэкономичны по времени поиска,, поэтому в качестве постоянных таблиц транслятора их не используют. Однако на включение новой записи в таких таблицах расходуется минимальное время, поэтому неупорядоченные таблицы иногда применяют в трансляторах в качестве временных таблиц, заполняемых в ходе трансляции. Первые две позиции вектора, отображающего таблицу, часто используют для указания максимального допустимого номера записи и номера первой свободной строки таблицы.
Иногда в трансляторах в качестве временных таблиц применяют древовидные таблицы, организованные в виде двоичного дерева, которое в памяти машины отображается сетью. Каждая запись в такой таблице сопровождается двумя указателями: один указатель содержит адрес хранения записи с меньшим значением ключа, а другой — с большим. На рис. 2.13 левый указатель отвечает меньшему ключу, а правый — большему, причем предполагается, что запись занимает два машинных слова: первое занимает собственно запись, а второе — указатели. Нумерация машинных слов десятичная.
Новые записи добавляются в таблицу подряд, как в простейших неупорядоченных таблицах. После добавления в таблицу новой
44
записи значение ее ключа сравнивается со значением ключа первой табличной записи. По результату сравнения с помощью указателя определяется адрес хранения следующей записи, с ключом которой нужно сравнивать значение ключа новой записи. Этот процесс продолжается до тех пор, пока не будет найдена запись с пустым указателем нужного направления просмотра. В этот указатель записывают адрес хранения новой записи.
Древовидная таблица на рис. 2.13 заполнена для случая, когда записи имели следующие значения ключей (в порядке их поступления): 5, 3, 4, 7, 1 и SK Поиск в древовидной таблице по заданному
ключу происходит почти так же, как отыскание места, в которое записывается адрес хранения. Искомое значение ключа сравнивается со значением ключа первой записи. По результату сравнения с помощью указателей определяется направление дальнейшего поиска. Поиск прекращается либо при совпадении ключа очередной просматриваемой записи с искомым, либо при обнаружении пустого указателя. Последнее означает, что записи с требуемым значением ключа в таблице нет.
Средняя длина поиска в древовидной таблице зависит от порядка поступления записей при заполнении таблицы. В худшем случае, когда записи поступали в порядке возрастания (или в порядке убывания) значений ключа, дерево будет иметь всего одну ветвь, и средняя длина поиска останется равной п/2,
как в обычной неупорядоченной таблице. В лучшем случае, когда порядок поступления записей таков, что получается симметричное
дерево, длина поиска уменьшится до
£>2 = entier (log2 п + 2).
0100 0101
0102 0103 0104 0105 0106 0107 0108 0109 0110 0111
Рис. 2.13. Древовидная таблица.
(2.9)
Недостатком древовидных таблиц является большой расход памяти, поскольку дополнительно приходится хранить указатели, и несколько более сложный алгоритм заполнения таблицы и поиска записей, чем в обычных неупорядоченных таблицах.
2.2.3. УПОРЯДОЧЕННЫЕ ТАБЛИЦЫ
Таблица может быть упорядочена по возрастанию цифрового кода ключа или по частоте обращения к записям. В первом случае Для поиска записей обычно применяют двоичный поиск, а во втором — последовательный просмотр.
Двоичный поиск состоит в последовательном делении таблицы на две примерно равные части и определении, в какой из двух частей находится требуемое значение ключа. Последующему деле-Чию каждый раз подвергается часть, содержащая ключ. Поскольку
45
таблица упорядочена по возрастанию ключа, определить в какой части находится требуемое значение ключа нетрудно. Для этого достаточно сравнить значение ключа в точке деления с искомым.
Алгоритм двоичного поиска можно описать следующей процедурой на языке Алгол-60:
procedure bisearch (Г, п, К, I); value п. К; integer п, К, i; integer array Т;
comment Т [1: n] — массив, содержащий значения ключей,
К. — заданное значение ключа.
Результат выполнения процедуры:
IФ 0 — номер табличной записи, имеющей заданное значение ключа,
i — 0 — если в таблице нет записи с заданным значением ключа;
begin integer р; р: = 1;
for I: = (р 4- п) -е- 2 while р < п do
if Т[<] < К then р: = i + I else п: = i;
I: = if T [p] = К then p else 0 end
Длина двоичного поиска D2 определяется формулой (2.9), что при достаточно больших п почти равно теоретическому нижнему пределу для методов поиска, основанных только на сравнении признаков (значений ключа). Теоретический нижний предел равен
log2(n+ 1).
В общем случае двоичный поиск значительно эффективнее последовательного просмотра. Например, для таблицы из 1000 записей средняя длина последовательного просмотра равна 500, а длина двоичного поиска—только 11.
Средняя длина последовательного просмотра в таблице, упорядоченной по частоте обращения к записям, существенно зависит от распределения частот обращения и определяется по общей формуле (2.7). Если относительно небольшое число записей приходится отыскивать очень часто, то средняя длина поиска может оказаться значительно меньше, чем при двоичном поиске. Это иногда используют при составлении постоянных таблиц транслятора, например таблиц основных символов входного языка.
Упорядочивание таблиц требует дополнительного расхода машинного времени, поэтому упорядоченные таблицы применяют прежде всего как постоянные таблицы транслятора. Однако иногда упорядочивают и временные таблицы, хотя это связано с определенными трудностями. Дело в том, что временные таблицы, составляемые в ходе трансляции, в большинстве случаев тут же используются для поиска. Уже заполнение таких таблиц требует проверки: не включена ли данная запись в таблицу на предыдущих этапах
40
работы транслятора. Поэтому упорядочивание временных таблиц транслятора приходится проводить одновременно с их заполнением.
Для сокращения расхода машинного времени на упорядочивание временных таблиц иногда применяют способ разделителей, при котором таблица делится на разделы, соответствующие различным интервалам значений ключа. Разделы упорядочены, а внутри разделов записи не упорядочивают. Для поиска записей применяют комбинированный метод. Например, раздел отыскивается путем двоичного поиска, а внутри раздела используют последовательный просмотр.
23. ТАБЛИЦЫ С ВЫЧИСЛЯЕМЫМИ ВХОДАМИ
2.3.1. ТАБЛИЦЫ С ПРЯМЫМ ДОСТУПОМ
Пусть в таблице из т записей все записи имеют разные значения ключа kit ..., km и таблица отображается в вектор д[1], ..., а[п], причем
т^п.
Если определена функция f(k), такая, что для любого kj, 1=1, ...» tn, f(ki) имеет целое значение между 1 и п, причем
то табличная запись с ключом k взаимно-однозначно отображается в элемент а[f(k)].
Функцию f(k) называют функцией расстановки. Эта функция обеспечивает вычисление для каждой табличной записи номера соответствующего элемента вектора а. Доступ к записи по ключу k осуществляется в этом случае непосредственно путем вычисления значения f(k). Таблицы, для которых существует и известна описанная функция расстановки, называют таблицами с прямым доступом. Средняя длина поиска в таких таблицах минимальна и равна D3 = 1.
Подбор функции расстановки, обеспечивающей взаимную однозначность преобразования ключа записи в адрес ее хранения, в общем случае весьма трудная задача. На практике ее можно решить только для постоянных таблиц с заранее известным набором значений ключа. Такие таблицы широко используются в трансляторах. Например, все однолитерные с точки зрения устройства подготовки перфокарт (перфолент) символы входного языка транслятора обычно кодируют отрезком натурального ряда, поэтому номер строки таблицы символов равен цифровому коду символа. Иными словами, при использовании в качестве ключа цифрового кода символа таблица символов входного языка является таблицей с прямым доступом.
47
2.3.2. ТАБЛИЦЫ СО СЛУЧАЙНЫМ ПЕРЕМЕШИВАНИЕМ
Поскольку взаимную однозначность преобразования ключа в адрес хранения записи в общем случае обеспечить практически Невозможно, от требования взаимной однозначности отказываются. Это приводит иногда к наложению записей или, иначе говоря, к переполнению позиций отображающего вектора. Чтобы таких переполнений было меньше, функцию расстановки подбирают из условия случайного и возможно более равномерного отображения ключей в адреса хранения. Таблицы, построенные по такому принципу, называют таблицами со случайным перемешиванием.
Случайное перемешивание не, устраняет полностью возможности наложения записей. Поэтому приходится применять различные способы устранения переполнений. Отличие разных вариантов таблиц со случайным перемешиванием определяется используемым способом устранения переполнений.
В методе открытого перемешивания при отображении таблицы в вектор длины п применяется следующий алгоритм включения и выборки записей по заданному ключу k:
1. Вычислить i — f(k).
2. Если при включении в таблицу новой записи позиция I свободна, а при выборке записи эта позиция содержит заданный ключ k, то поиск завершен. В противном случае нужно перейти к следующему пункту.
3. Положить ;
I: = i + 1 (mod п)
и перейти к пункту 2. Здесь
х (mod п) =
' х, если х п,
1, если х > я.
Нетрудно видеть, что при включении новых записей алгоритм остается конечным до тех пор, пока вектор, в который отображается таблица, содержит хотя бы одну свободную позицию. При выборке записей алгоритм конечен, если таблица содержит запись с заданным ключом. При невыполнении этих условий возможно зацикливание, против которого нужно принимать специальные меры. Например, можно ввести счетчик числа просмотренных позиций, если это число станет больше я, то алгоритм «зациклился».
Пример. В таблице имен, имеющей 8 позиций, требуется разместить идентификаторы:
a, al, h, hl, b, a2.
Будем предполагать, что каждая запись таблицы имен состоит из поля идентификатора, который является ключом записи, и поля адреса машинного слова, выделенного для размещения соответ
48
ствующей переменной. Условимся также, что идентификатор может начинаться с одной из первых восьми букв латинского алфавита:
а, 6, с, d, 5, f, gf Л,
а значение функции расстановки равно порядковому номеру в алфавите первой буквы идентификатора.
Схема заполнения таблицы при поступлении идентификаторов в приведенной выше последовательности показана на рис. 2.14, из которого видно, почему метод назван «открытым»: для записи, отображаемой в позицию, уже занятую другой записью, в принципе «открыты» все свободные позиции.
Средняя длина поиска в методе открытого перемешивания исследовалась теоретически и экспериментально. Оказалось, что при случайном равномерном распределении значений функции расстановки в интервале (1,п) средняя длина поиска не зависит от размера таблицы, а зависит только от заполненности отображающего вектора
Рис. 2.14. Заполнение таблицы методом открытого перемешивания
где т — длина таблицы, ап — длина отображающего вектора. Это весьма важное свойство, особенно ценное для больших таблиц. Заметим, что
детерминированные таблицы как упорядоченные, так и неупорядоченные не обладают этим свойством. В детерминированных таблицах средняя длина поиска возрастает с ростом длины таблицы, что видно из формул (2.8) и (2.9).
Следующая приближенная формула [35] для средней длины поиска в методе открытого перемешивания дает удовлетворительное согласование с экспериментом при о 0,85:
D(a) =
2 — а
2 — 2а
(2.10)
Формула получена в предположении случайного равномерного распределения записей по позициям отображающего вектора. Значения средней длины поиска, вычисленные по формуле (2.10), приведены в табл. 2.4.
Эксперименты показывают, что при а = 1 средняя длина поиска не превосходит 20.
При неравномерном распределении записей по позициям отображающего вектора приведенные в табл. 2.4 числа, как показали эксперименты, возрастают в среднем в 1,5—2 раза. Даже с этой
49
Таблица 2.4
ТЕОРЕТИЧЕСКАЯ СРЕДНЯЯ ДЛИНА ПОИСКА В ТАБЛИЦЕ С ОТКРЫТЫМ ПЕРЕМЕШИВАНИЕМ
1 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9
О (а) 1,06 1,13 1,21 1,33 1,50 1,75 2,17 3,00 5,50
поправкой открытое перемешивание имеет меньшую среднюю длину поиска, чем другие методы. Например, для таблицы в 400 записей при длине отображающего вектора, равной 512, средняя длина поиска по таблице с открытым перемешиванием с учетом поправки на неравномерность распределения записей не превосходит 4,5—6. В этих же условиях длина двоичного поиска равна 10, а средняя длина последовательного просмотра — 200. Правда, в открытом перемешивании около 20% памяти, отведенной под таблицу, не используется.
2.3.3. ПЕРЕМЕШИВАНИЕ С ЦЕПОЧКАМИ ПЕРЕПОЛНЕНИЯ
В методе открытого перемешивания записи переполнения включаются в пустые позиции того же отображающего вектора. Однако
Рис. 2.15. Таблица перемешиванля с цепочками переполнения
для записей переполнения можно завести отдельную таблицу. В дополнительной таблице записи можно связать в цепочку, как в списке, чтобы облегчить их поиск.
Таблица перемешивания с цепочками переполнения для примера, показанного на рис. 2.14, изображена на рис. 2.15.
В таблице со случайным перемешиванием и цепочками переполнения средняя длина поиска для случайных равномерно распреде-
50
денных записей определяется по формуле
(2.11)
где и— длина отображающего вектора, а т — длина таблицы.
Существует модификация этого метода, называемая перемешиванием с внутренними цепочками. Здесь заполнение позиций отображающего вектора состоит из двух этапов. Первый этап ничем не отличается от предыдущего метода с цепочками переполнения, а второй этап выполняется после завершения формирования основной и дополнительной таблиц. Он состоит в переносе цепочек из
дополнительной таблицы переполнения в незанятые позиции основной таблицы.
Для рассмотренного выше примера таблицы, показанные на рис. 2.15, преобразуются в таблицу, изображенную на рис. 2.16. Преимущество этого метода по сравнению с предыдущим — экономия памяти, а недостаток — меньшая гибкость
и более сложный алгоритм Рис. 2.16. Таблица перемешивания заполнения таблицы. Сред- с внутренними цепочками переполнения
няя длина поиска здесь так-
же определяется формулой (2.11). Этот метод можно использовать для постоянных таблиц, а также для временных таблиц, за
полняемых на одном этапе трансляции, а применяемых на другом.
Для постоянных таблиц наиболее часто требующиеся записи целесообразно записывать первыми, тогда во внутренние цепочки переполнения попадут относительно редко требующиеся записи, что
сократит среднюю длину поиска.
Характерно, что при использовании внутренних цепочек переполнения все позиции отображающего вектора могут быть заполнены записями, т. е. т = п, а средняя длина поиска при равномерном случайном распределении записей не превзойдет 1,5. Это непосредственно следует из формулы (2.11).
Таблицы со случайным перемешиванием заполняются относительно просто, не требуют упорядочивания записей и обеспечивают Достаточно быстрый поиск, поэтому начиная с середины 50-х годов эти таблицы часто используют в трансляторах.
2.3.4. ФУНКЦИИ РАССТАНОВКИ
При выборе алгоритма, реализующего функцию расстановки, нужно исходить из того, что время вычисления значений функции расстановки f(k), по существу, входит в среднее время поиска.
51
Хорошая функция расстановки должна обеспечить равномерное распределение записей по позициям отображающего вектора, поскольку неравномерность распределения увеличивает среднее время поиска. Однако если вычисление значений функции расстановки требует выполнения большого числа действий, то это может уничтожить всю экономию во времени поиска. Поэтому алгоритм вычисления функции расстановки должен быть несложным.
В литературе [16, 35, 57] описано несколько методов получения функции расстановки. Одним из простых методов является выделение части цифрового кода ключа. Например, пусть максимальный ожидаемый размер таблицы имен не превосходит 512. Тогда функция расстановки может иметь в качестве значения 9-разряд-ное двоичное число, поскольку
512 = 29.
Можно просто выделить первые 9 разрядов двоичного кода идентификатора или взять какие-либо 9 разрядов из середины кода. Нужно лишь обеспечить возможно большую равномерность распределения значений функции f(k) в интервале (0, 511).
Для улучшения равномерности распределения иногда применяют «складывание» кода идентификатора: первая половина кода складывается со второй и из результата выделяются какие-либо 9 разрядов. Можно также разделить код ключа на куски по 9 разрядов, а затем сложить их по модулю 29.
Последняя модификация имеет некоторое теоретико-вероятностное обоснование: при предположении о статистической независимости складываемых кусков получается распределение, близкое к равномерному. В частности, именно этот вариант «складывания» использовался в Альфа-трансляторе для машины М-20 [16] при вычислении функции расстановки.
В Альфа-трансляторе таблица имен рассчитана на 512 идентификаторов. Функция расстановки вычисляется по формуле
HjCli, 1=0
где S— суммирование по модулю 29 с переносом единицы переполнения из старшего разряда в младший, I — длина идентификатора (число букв и цифр), я,-, 1=1, ..., I — девятиразрядные коды букв и цифр, а «о — номер блока Альфа-программы, отсчитываемый от начала программы и равный количеству слов begin, открывающих блоки и предшествующих данному идентификатору. Слагаемое я» введено, чтобы избежать одинаковых значений функции расстановки для одинаковых идентификаторов, описанных в разных блоках.
Другой способ получения функции расстановки — деление. Для отображающего вектора длиной п код ключа, рассматриваемый как целое число, делится на величину п—1. Эксперименты показы
52
вают, что остаток от деления распределен приблизительно равномерно в интервале (0, п 2) и может использоваться как значение функции расстановки.
Экспериментальная проверка описанных методов для таблиц с открытым перемешиванием показала, что простое «складывание» кода идентификатора с выделением средней части результата уве-личивает среднюю длину поиска по сравнению с теоретической вы-численной по формуле (2.10), в 4-5 и более раз, средняя длина поиска для метода, использованного в Альфа-трансляторе прибли-зительно вдвое больше теоретической, а при делении средняя длина, поиска практически совпадает с теоретической для о 0,85.
ГЛАВА 3
АССЕМБЛЕРЫ
3.1. ЯЗЫКИ СИМВОЛИЧЕСКОГО КОДИРОВАНИЯ
3.1.1. ОБЛАСТИ ПРИМЕНЕНИЯ
И СРЕДСТВА ЯЗЫКОВ СИМВОЛИЧЕСКОГО КОДИРОВАНИЯ
Язык символического кодирования, иначе называемый мнемокодом или языком ассемблера, в настоящее время является основным языком системного программирования. При разработке прикладного математического обеспечения и программирования текущих производственных задач в вычислительных центрах язык ассемблера применяют в тех случаях, когда требуются особо высококачественные программы по быстродействию и используемой памяти. В частности, на языке ассемблера часто программируют задачи обработки данных и задачи, решаемые в реальном времени. Большинство производственных задач обычно пишут на процедурно-ориентированных языках высокого уровня.
В некоторых системах программирования в нашей стране и за рубежом [33] мнемокоды используют в качестве промежуточных языков.
Применение мнемокода в качестве языка системного программирования и промежуточного языка позволяет сократить сроки и •снизить стоимость создания системного математического обеспечения. Дело в том, что для новой машины обычно в первую очередь разрабатывают простейший ассемблер мнемокода. Вместе с библиотекой стандартных подпрограмм и загрузчиком ассемблер образует минимальную систему программирования, которая используется для разработки всех других компонент системного математического обеспечения, включая трансляторы с языков высокого уровня.
Программировать на языке ассемблера легче, чем на языке машины, а трансляция с языка высокого уровня на язык ассемблера дает возможность упростить транслятор, поскольку, с одной стороны, язык ассемблера ближе к языку высокого уровня, чем машинный язык, и, с другой стороны, при переводе на язык ассемблера отпадает необходимость в оформлении объектной программы в виде модуля загрузки, упрощается распределение памяти (память можно распределять в символических адресах), а также сегментирование программы и данных. Для выполнения всех этих
«4
действий используется готовый аппарат, имеющийся в ассемблере.. Выгода от этих преимуществ умножается, когда одновременно разрабатывают два-три транслятора с разных языков. Применение мнемокода в качестве промежуточного языка позволяет составлять разные части программы на разных языках и объединять их с помощью ассемблера и загрузчика.
Использование мнемокода в качестве промежуточного языка имеет и теневую сторону: в конце первого этапа трансляции приходится дополнительно оформлять готовую программу на мнемокоде, при этом часть информации о транслируемой программе, накопленной в таблицах транслятора, теряется и ее приходится вновь собирать в процессе работы ассемблера. Это увеличивает общее-время трансляции.
Мнемокоды для разных машин имеют индивидуальные особенности. Однако принципы их построения одинаковы, поэтому для понимания основ устройства ассемблеров достаточно рассмотреть, средства одного какого-либо мнемокода. В качестве примера рас-\ смотрим кратко основные черты языка ассемблера ЕС ЭВМ.
Алфавит мнемокода обычно включает некоторое подмножество* набора знаков стандартного устройства подготовки перфокарт (или телетайпа). В алфавит языка ассемблера ЕС ЭВМ входят:
1. Прописные буквы латинского алфавита от А до Z и знаки:
рассматриваемые как буквы. < 2 Арабские цифры от 0 до 9.
3. Специальные знаки:
Поле Поле RSI Поле N Поле ’ назван ио ^операции ^операндов ^комментария :
Поле
Рис. 3.1. Структура оператора в языке ассемблера ЕС ЭВМ
Кроме того, при записи комментариев и некоторых констант можно использовать все прочие знаки кода ДКОИ, принятого в-ЕС ЭВМ.
Исходная программа на языке ассемблера состоит из последовательности операторов (предложений). Оператор может определять команду, константу, резервируемую область памяти или может содержать информацию, используемую при трансляции.
Оператор разделен на несколько полей. Структура ти-
пичного оператора показана на рис. 3.1. Поля оператора отделены одним или несколькими пробелами, которые на рис. 3.1 показаны штриховкой. Чтобы облегчить отыскание границ полей при трансляции, внутри каждого поля (кроме поля комментария и текста некоторых констант) пробелы не допускаются.
Поле названия может содержать символическое имя — имя оператора — или может быть пустым. Символическое имя есть идентификатор, т. е. последовательность букв и цифр, начинаю
щаяся с буквы. Длина символического имени в мнемокоде обычно ограничена сверху. В языке ассемблера ЕС ЭВМ символическое имя может иметь не более восьми знаков. Если оператор определяет команду, константу или область памяти, то имя оператора есть имя (метка) соответствующего объекта.
Поле операции содержит мнемонический код операции (мнемонику) команды, определяющей действия, которые нужно выполнить в объектной программе или в ходе трансляции. Наибольшая длина мнемоники фиксирована. В языке ассемблера ЕС ЭВМ мнемоника имеет не более пяти букв.
Среди команд мнемокода можно выделить машинные команды, имеющие прямые аналоги в машинном языке, а также команды ассемблера и макрокоманды, для которых в машинном языке нет непосредственных эквивалентов.
Поле операндов содержит один или несколько операндов, описывающих данные, с которыми оперирует команда. Если операндов несколько, их разделяют запятыми.
В поле комментария помещают текст, который не используется при трансляции и содержит описательную информацию. Этот текст переносится ассемблером в печатный документ о транслируемой программе — листинг — без всяких изменений.
Операторы мнемокода, как правило, записывают на специальном стандартном бланке. Для идентификации программы и нумерации операторов исходной программы на бланке выделяют еще одно поле — поле идентификации. Стандартный бланк языка ассемблера ЕС ЭВМ показан на рис. 3.2.
Каждая строка бланка используется для записи одного оператора или части оператора и перфорируется на одной перфокарте. Следовательно, длина строки бланка определяется числом знаков из алфавита мнемокода, которые можно разместить на одной перфокарте. Строка стандартного бланка языка ассемблера ЕС ЭВМ имеет 80 позиций, соответствующих 80 колонкам перфокарты. Позиции бланка, как и колонки перфокарты, нумеруются слева направо.
Для записи оператора обычно используют колонки с 1 по 71. Колонки 73—80 отводят под поле идентификации. Колонка 72 служит для записи указателя продолжения оператора на следующей карте.
Очередной оператор всегда записывают с новой строки (с новой перфокарты). Символическое имя в поле названия, если оно есть, всегда начинают с колонки 1 (ее называют начало). Остальные поля можно записывать с любой колонки между колонками 2 и 71 (колонку 71 называют конец), сохраняя последовательность полей (название, операция, операнды, комментарий) и разделяя их пробелами. Однако для получения удобного листинга рекомендуется придерживаться распределения полей, указанного на бланке: поле названия — колонки 1—8, поле операции — колонки 10—14, поле операндов — начиная с колонки 16.
56
Яссе мЯлер
Программа Указатель перфорации Задача » » » . 73 75 Страница . . . 76 77
Знак
Программист Дата Перфорация
Рис. 3.2. Стандартный бланк языка ассемблера ЕС ЭВМ
г
Если оператор не умещается на одной строке, то, записав в кокон ке 72 любой знак, можно продолжить оператор в следующей •строке, начиная с колонки 16 (ее называют продолжение). В языке ассемблера ЕС ЭВМ допускается одна строка продолжения. Поле названия и поле операции всегда записывают в первой строке.
Признаком окончания оператора является отсутствие знака в колонке 72. Заметим, что записав в колонке 1 знак *, можно всю строку использовать для комментария.
Жесткая фиксация колонок начала, конца, продолжения и указателя продолжения на каждой перфокарте, а также стандартизация последовательности полей облегчают выделение и анализ операторов в ходе трансляции.
3.1.2. МАШИННЫЕ КОМАНДЫ
Команды мнемокода, относящиеся к группе машинных команд, подобны соответствующим командам машинного языка, но в общем случае не тождественны им. Каждой машинной команде мне
Рис. 3.3. Логическая структура моделей ЕС ЭВМ
мокода соответствует одна команда машинного языка. Обратное, вообще говоря, неверно — одной команде машинного языка может соответствовать более чем одна машинная команда ассемблера.
Рассмотрим кратко особенности машинного языка ЕС ЭВМ. Все модели ЕС ЭВМ имеют логическую структуру, которая упрощенно показана на рис. 3.3. Команды машинного языка, кроме команд, управляющих вводом — выводом, выполняет центральный процессор. Команды ввода—вы-
вода исполняются каналами. Программа, выполняемая центральным процессором, как и программы каналов, размещаются в основной памяти.
Данные, с которыми оперирует центральный процессор, могут находиться в основной памяти, в общих регистрах, в регистрах с плавающей запятой или могут быть записаны непосредственно в команде (непосредственные операнды). Основная память состоит из байт (8 двоичных разрядов), каждому из которых приписан
адрес. Адреса записывают в виде шестиразрядных шестнадцатеричных чисел. Шестнадцатеричные цифры обозначают:
О, 1, 2, 3, 4, 5, 6, 7, 8, 9, А, В, С, D, Е, F.
Минимальный адрес основной памяти 000000. Максимальный адрес зависит от объема основной памяти. Например, в машине с памятью 64 Кбайт (К = 1024) максимальный адрес будет 0OFFFF.
Центральный процессор может оперировать с отдельными байтами или группами байт (до 256 байт). Два соседних байта, первый из которых имеет четный адрес, образуют полуслово. Четыре соседних байта, первый из которых имеет адрес, кратный четырем, образуют слово. Восемь соседних байт, первый из которых имеет адрес, кратный восьми, образуют двойное слово. Группу последовательных байт произвольной длины называют полем. Для указания в команде ЕС ЭВМ адреса полуслова, слова, двойного слова или поля достаточно записать адрес первого (левого) байта соответствующей группы байт.
Шестнадцать общих регистров центрального процессора, каждый из которых может хранить одно слово (4 байта), имеют номера от 0 до 15 (в шестнадцатеричной системе от 0 до F) и используются главным образом в операциях над числами с фиксированной запятой (целыми числами) и двоичными кодами.
Четыре регистра с плавающей запятой, каждый из которых может хранить одно двойное слово (8 байт), имеют номера 0, 2, 4, & и используются в операциях над числами с плавающей запятой.
Для указания адреса данных, размещенных в регистре, в команде ЕС ЭВМ записывают номер соответствующего регистра (одну шестнадцатеричную цифру). Заметим, что в одном байте' можно записать две шестнадцатеричные цифры.
Адреса данных в основной памяти записывают в одной из двух форм: BDDD или XBDDD. Здесь В, D и X — шестнадцатеричные-цифры. В и X обычно указывают номер одного из общих регистров (от 1 до F). Регистр В называют базовым регистром, а его содержимое — базой или базовым адресом. Регистр X называют индексным регистром, а его содержимое — индексом. Трехразрядное шестнадцатеричное число DDD называют смещением.
Очевидно, величина смещения не превосходит 4095ю = FFF^. Исполнительный адрес образуется сложением базового адреса и смещения (при использовании формы BDDD) или сложением индекса и базового адреса со смещением (при использовании формы-XBDDD). Если В = 0, то база равна нулю. Если X = 0, то индекс равен нулю.
” Команды ЕС ЭВМ имеют от одного до трех операндов, причем большинство команд двухоперандные. С другой стороны, адреса Данных, размещенных в регистрах и основной памяти, имеют разную длину, поэтому для записи команд, оперирующих с данными
5»
из разных видов памяти, используют разные форматы. Имеются следующие пять форматов команд:
/?/? — регистр — регистр — оба операнда находятся в регистрах;
RX— регистр — индексируемая память — один операнд в регистре, другой — в основной памяти, причем его адрес имеет форму XBDDD\
RS — регистр — память — один операнд в регистре, другой в основной памяти, причем его адрес имеет форму В DDD-,
SI — память — непосредственный операнд — один операнд в основной памяти, а другой — непосредственно записан в команде;
SS — память — память — оба операнда в основной памяти.
Отметим, что некоторые команды форматов RR и SI имеют •только один операнд, а команды формата RS могут иметь три операнда. Команды формата SS предназначены для оперирования с полями переменной длины, поэтому в поле операндов этих команд помимо адресов указывают также длину операндов.
Команды формата RR размещаются в одном полуслове (2 байта), команды форматов RX, RS и SI— в двух полусловах, а команды формата SS — в трех полусловах. Во всех форматах код операции занимает один (первый) байт команды.
Отличия машинных команд языка ассемблера ЕС ЭВМ от соответствующих команд машинного языка состоят в следующем:
вместо цифрового кода операции записывают мнемонику;
вместо цифрового обозначения адресов (значений) операндов записывают выражения, позволяющие вычислить значения адресов или непосредственных операндов;
структура поля операндов может отличаться от машинного 'формата.
Для записи операндов в языке ассемблера используют два типа выражений: абсолютные и перемещаемые. Значения абсолютных выражений не изменяются при перемещении программы, а значения перемещаемых выражений изменяются. Абсолютные выражения обычно применяют для записи номеров регистров и непосредственных операндов, а перемещаемые — для указания данных, размещенных в основной памяти.
Для данных в основной памяти язык ассемблера допускает две •формы адресации: явную и неявную. В явном адресе указывают регистр базы и смещение или индексный регистр, регистр базы и смещение. Неявный адрес не содержит в явном виде указания на регистр базы. Явный адрес всегда записывают с использованием абсолютных выражений, а в неявный адрес, как правило, входит перемещаемое выражение.
Форматы команд ЕС ЭВМ и соответствующие им варианты •структуры поля операндов языка ассемблера показаны на рис. 3.4. На этом рисунке цифрой 1 отмечены величины, относящиеся к пер-<60
Формат команд ЕС ЭВМ Структура поля операндов в языке ассемблера
Формат Первое полуслово Второе полуслово Третье полуслово Явная адресация Неявная адресация
RR \ — — Rl, R2 R1 1 11
КОП R1 R2
КОП R1
КОП I
RX КОП R1 Х2 В2 П2 R1, 82 (Х2, В?) R1,S2(X2)
RS КОП R1 R3 82 В2 R1, R3, 82 (82) R1, 82 (82) Rl, R3, S2 Rl, 82
КОП D2
SI 81 (81), 12 01(81) 31, 12 SI
КОП 12 В1 U1
коп Шк П1
!
S3 1 • 81(11, 81), 82(12,82) 81 (1,81),82(82) 81 (LI, B1),S2(12) или SI (LI), 82(12,82) или S1(11),S2(L2) 81(1,81), S2 или $1(1), 82(82) или $1 (1 ),$2
КОП L1 L2 у D1 В2 D2
I I I I
кол L В1 D1 82 D2
1 I I а
Рис. 3.4. Форматы команд ЕС ЭВМ и структура поля операндов в языке ассемблера
вому операнду, цифрой 2 — ко второму, а цифрой 3 — к третьему. Обозначения означают следующее:
Pl, R2, R3—абсолютные выражения, определяющие регистры;
DI, D2 — абсолютные выражения, не превышающие 4095, определяющие смещение;
Bl, В2— абсолютные выражения, определяющие базовые регистры;
61
/ Х2— абсолютное выражение, определяющее индексный ( регистр;
L, IA, L2— абсолютные выражения, определяющие длины полей;
7, 72 — абсолютные выражения, представляющие непосредственные данные со значениями от 0 до 255;
SI, S2 — абсолютные или перемещаемые выражения, определяющие адреса основной памяти.
Набор команд ЕС ЭВМ включает 143 команды. Все команды, кроме команды ДИАГНОСТИКА, имеют эквиваленты в языке ассемблера. Для упрощения записи команд условного перехода ВС и BCR в языке ассемблера ЕС ЭВМ предусмотрены расширенные мнемонические коды этих команд, которые определяют не только операцию, но и условие выполнения перехода. Например, вместо машинной команды
ВС 15, £>2 (Х2, В2), определяющей безусловный переход, расширенная мнемоника позволяет записать
В D2 (Х2, В2), а машинной команде
ВС 8, D2 (Х2, В2), определяющей «переход, если равно», соответствует расширенная мнемоника
BE D2 (Х2, В2).
Всего имеется 21 команда с расширенной мнемоникой, поэтому полный набор машинных команд ассемблера ЕС ЭВМ содержит 163 команды.
3.1.3. ВЫРАЖЕНИЯ
В общем случае, как следует из рис. 3.4, операнд в языке ассемблера ЕС ЭВМ может иметь одну из трех форм: выражение, выражение (выражение), выражение (выражение, выражение). При трансляции выражения используются ассемблером для вычисления значений адресов или значений непосредственных данных.
Структура выражений в языке ассемблера ЕС ЭВМ показана на рис. 3.5. Выражение состоит из термов. Терм — это общее название ряда понятий языка ассемблера, смысл которых разъясняется ниже.
Как и выражение, терм может быть абсолютным (АТ) и перемещаемым (ПТ). Выражение может состоять из одного терма или нескольких, соединенных знаками арифметических операций, +, —, * и/, а также круглыми скобками.
Символическое имя, как упоминалось в п. 3.1.1, обычно есть имя оператора, у которого оно появляется в поле названия. В объектной программе на машинном языке символическому 62
имени соответствует адрес первого (самого левого) байта области памяти, содержащей команду, константу или область, в которую транслируется оператор. Длина этой области памяти в байтах есть характеристика длины символического имени.
Имя определено в данном программном модуле, если оно появляется в поле названия одного из операторов этого модуля. В этом случае его называют внутренним. Внутренние имена, на которые имеются ссылки в других независимо транслированных программных модулях, называют входными именами. Кроме внутренних имен, в поле некоторых операндов могут быть записаны внешние имена, определенные в других программных модулях.
Рис. 3.5. Структура выражений языка ассемблера ЕС ЭВМ
Символические имена служат для ссылок на адреса команд, констант или областей памяти. Если нужно сослаться на адрес текущей команды (константы), то используют знак *, которому соответствует адрес первого байта команды (константы), в которой он употребляется. В частности, две записанные ниже машинные команды ассемблера эквивалентны:
Название Операция Операнды
АВ BAL 12, 4В4-10
BAL 12, *4-10
Знак *, употребляемый в качестве ссылки на текущий адрес, Можно записывать только в самой левой позиции выражения. Это позволяет отличить употребление того же знака в качестве знака Умножения,
63
Для хранения текущего адреса основной памяти в ходе трансляции используется счетчик адреса. Во время трансляции значение этого счетчика, обозначаемое в языке ассемблера знаком приписывается каждой машинной команде, константе или области памяти. После трансляции очередного оператора значение счетчика адреса увеличивается на длину транслированного элемента программы. Если следующий элемент программы должен адресоваться с определенной границы, например с границы слова или двойного слова, то перед назначением ему адреса счетчик адреса устанавливается на соответствующую границу. Программист может управлять установкой счетчика адреса с помощью команд ассемблера START и ORG, Эти команды рассматриваются в п. 3.1.4.
Самоопределенный терм — это абсолютный терм, значение которого заключено в нем самом. Обычно это число или набор знаков алфавита мнемокода. Самоопределенные термы используют для записи адресов и непосредственных данных. В языке ассемблера ЕС ЭВМ существует четыре типа самоолределенных термов: десятичный, шестнадцатеричный, двоичный, знаковый.
Десятичный самоопределенный терм записывается как целое десятичное число без знака, содержащее не более восьми цифр. Максимальная допустимая величина числа зависит от его использования. Например, десятичный терм, обозначающий общий регистр, может принимать значения от 0 до 15. В любом случае значение десятичного терма не может превосходить 224 — 1. При трансляции десятичный терм заменяется двоичным эквивалентом.
Шестнадцатеричный самоопределенный терм представляет собой букву X, за которой следует не более чем шестиразрядное шестнадцатеричное число без знака, заключенное в апострофы. Например,
Х'8', X'0A', X'FFFFFF'.
При трансляции каждая шестнадцатеричная цифра заменяется двоичным эквивалентом.
Двоичный самоопределенный терм представляет собой букву В, за которой записано не более чем 24-разрядное двоичное число без знака, заключенное в апострофы. Например,
В'1011', 5'00001111'.
Знаковый самоопределенный терм записывают в виде заключенной в апострофы последовательности не более чем трех любых знаков кода ДКОИ, перед которой стоит буква С. Например,
CM', С' + (', С'Л/В'.
Поскольку апостроф и знак амперсенда & в языке ассемблера ЕС ЭВМ используют как специальные символы, для задания этих символов в знаковой константе их нужно записать дважды. Например, последовательность А'В нужно записать в виде С'А"В'< 64
При трансляции каждый знак знакового терма заменяется восьмиразрядным двоичным эквивалентом.
Литерал — это перемещаемый терм, значением которого является адрес хранения определяемой им константы. В поле операндов литерал записывают в виде константы, перед которой стоит зНак =. Например,
=Х'00Л2'— литерал, определяющий шестнадцатеричное число 00Д2;
=5'1001'— литерал, определяющий двоичное число 1001.
При трансляции ассемблер обычно собирает все литералы в единую область литералов, «встраивает» эту область в конце транслируемого программного модуля и заменяет каждый литерал, встречающийся в поле операндов исходной программы, адресом его хранения. Например, машинная команда ассемблера формата RX
Операция Операнды
LH 5, = Х'0001'
предписывает загрузить в общий регистр 5 шестнадцатеричную константу 0001. При трансляции второй операнд будет заменен адресом полуслова из области литералов, содержащего двоичный эквивалент кода 000 he.
Обычно литерал можно применять всюду, где допустимо использовать в качестве операнда адрес основной памяти. Способы записи констант несколько подробнее рассматриваются в следующем пункте при описании команды ассемблера DC.
Характеристика длины имени — это абсолютный терм, значение которого равно длине в байтах области памяти, названной этим именем. Характеристику длины записывают в виде
L' имя
Например, если А — имя машинной команды формата RX, занимающей в памяти два полуслова, то L'A = 4.
3.1.4. КОМАНДЫ АССЕМБЛЕРА *
Эти команды предназначены для передачи ассемблеру информации, используемой при трансляции, определения констант и выделения областей памяти, а также для разделения программы на секции и объединения независимо транслированных программных модулей.
Команды ассемблера не имеют прямых аналогов в машинном языке и не всегда порождают элементы объектной программы, поэтому часто их называют псевдокомандами. Во всех мнемокодах применяют примерно одинаковый набор псевдокоманд.
3 Зак. 221 о5
В языке ассемблера ЕС ЭВМ имеется 25 команд ассемблера, которые делят на три группы: команды определения, команды секционирования и соединения программ, команды управления.
Ради краткости ниже с некоторыми упрощениями рассматриваются лишь те команды ассемблера ЕС ЭВМ, которые наиболее существенно влияют на работу ассемблера.
Команды определения запасают и определяют константы, резервируют области памяти, присваивают значения символическим именам, а также определяют базовые регистры. В языке ассемблера ЕС ЭВМ таких команд шесть.
Команда DC — определить константу — определяет одну или несколько констант и, быть может, дает им имя.
Формат оператора
Название Операция Операнды
Символическое имя или пробел DC кратность тип модификаторы константа или группа констант
Символическое имя, записанное в поле названия, именует константу или первую из констант, если их несколько.
Кратность указывает количество повторений создаваемой конг станты (группы констант). Кратность задают десятичным самоопре-деленным термом или абсолютным выражением в круглых скобках. Кратность можно не указывать, это эквивалентно кратности 1.
Тип константы задают однобуквенным кодом; обозначения некоторых типов констант приведены в табл. 3.1.
модификаторы описывают длину константы, ее масштаб и порядок. Модификаторы можно опускать. На работу ассемблера существенно влияет только модификатор длины. Этот модификатор записывают в форме Ln, где L — указатель модификатора длины, ап — десятичный самоопределенный терм без знака или положительное абсолютное выражение в круглых скобках. Величина п не должна превосходить 256 для констант типа С, X и В. Для числовых констант, перечисленных в табл. 3.1, п 8. Значение п указывает явную длину константы — количество байт памяти, отводимое для размещения константы. Если явная длина не определена, то ассемблер назначает неявную длину, зависящую от типа константы.
При несоответствии длины области памяти, выделенной для константы, фактической длине самой константы эта константа либо усекается, либо дополняется. Числовые константы дополняются нулями, а знаковые — пробелами. Знаковая константа и константы с плавающей запятой усекаются и дополняются справа, а остальные константы — слева.
В поле операндов команды DC можно записать одну или несколько констант (константа типа С, X и В может быть только
66.
Таблица 3.1
СВЕДЕНИЯ О НЕКОТОРЫХ КОНСТАНТАХ В ЯЗЫКЕ АССЕМБЛЕРА ЕС ЭВМ
Тип Константа Изображение Неявная длина в байтах Граница размещения в памяти
С Знаковая Знаки кода ДКОИ По потребности Байт
X Шестнадцатеричная Шестнадцатеричные цифры По потребности Байт
в Двоичная Двоичные цифры По потреб- ности Байт
F С фиксированной запятой Десятичные цифры 4 Слово
Н С фиксированной запятой Десятичные цифры 2 Полуслово
Е С плавающей запятой Десятичные цифры 4 Слово
D С плавающей запятой Десятичные цифры 8 Двойное , слово
А Адресная Любое выражение 4 Слово
одна). Если констант несколько, их разделяют запятыми. Любая константа (группа констант), кроме адресной, заключается в апострофы. Адресная константа (группа адресных констант) записывается в круглых скобках. Заметим, что правила записи литералов почти совпадают с правилами записи поля операндов команды DC. Основное отличие состоит в том, что литералу предшествует знак =. Кроме того, кратность и модификатор длины литерала можно указывать только десятичным самоопределенный термом. Практически любую константу из числа указанных в табл. 3.1 Можно задать либо в виде литерала, либо с помощью команды DC.
В ходе трансляции каждая константа переводится ассемблером в машинный формат. Константы типа С, X и В заменяются двоичными кодами, константы типа F и Н — числами с фиксированной запятой, а константы типа Е и D — двоичными числами с плавающей запятой. Адресная константа типа А — это адрес основной памяти, записанный в виде абсолютного или перемещаемого выражения. При трансляции адресная константа заменяется значением этого выражения.
Каждая константа размещается ассемблером в определенных границах (см. табл. 3.1), Напомним, что левый байт полуслова
67
3*
Таблица 3.2 ИСПОЛЬЗОВАНИЕ ОПЕРАТОРА DC И ЗАПИСЬ ЛИТЕРАЛОВ
Название 1 Операция Операнды Пояснения
ТЕХТ\ DC С'ЗАДАЧА— 1' Знак — — пробел
ТЕХТ2 DC 10САВС' Определено 10 расположенных подряд знаковых констант АВС АВС..., каждая из которых занимает 3 байта
ТЕХТЗ DC CIA'AB' Явная длина отменяет неявную. В памяти записывается константа АВ
к\ Ki L L 1, ТЕХТЗ \, = CL4'AB' Команды с именами К1 и К2 эквивалентны
W DC F'—15' Слово с именем W содержит целое число — 15, записанное в формате чисел с фиксированной запятой
н DC Zf'—15' Полуслово с именем Н содержит целое число — 15, записанное в формате чисел с фиксированной запятой
КЗ К4 L L 2, W 2, = F'-15' Команды КЗ и К4 эквивалентны
р DC E't, 2, 2, 1' В четырех последовательных словах запасены константы с плавающей запятой: 1, 2, 2, 1. Их адреса Р, Р + 4, Р + 8, Р + 12
А1 DC A(TEXT\) Слово с именем А\ содержит адрес слова с именем TEXT!
А2 DC A(TEXT1 +20) Слово с именем А2 содержит адрес слова с именем ТЕХТ\, увеличенный на 20
КЗ КЗ L L 3, Л1 3. = A(TEXT\) Команды с именами К5 и Кб эквивалентны
т DC D'l, 2' В двух последовательных двойных словах с адресами Г и Т + 8 запасены константы 1 и 2
68
должен иметь четный адрес, слова — адрес, кратный четырем, а двойного слова — адрес, кратный восьми. Перед размещением константы в памяти ассемблер выравнивает адрес на соответствующую границу путем увеличения значения счетчика адреса. Пропущенные байты заполняются нулями. Указание явной длины отменяет неявную длину. При указании явной длины выравнивание границы размещения константы в памяти не выполняется. Если кратность определена и равна нулю, то константа не создается, а при неявной длине и нулевой кратности происходит только выравнивание границы.
Примеры определения констант командой DC и записи литералов приведены в табл. 3.2.
Команда DS — определить память — резервирует область памяти и, быть может, дает ей имя.
Формат оператора
Название Операция Операнды
Символическое имя или пробел DS Один операнд, подобный операнду команды DC
Операнд команды DS отличается от операнда команды DC только тем, что в поле операнда можно не записывать константу, а максимальная явная длина для констант типа С и X равна 65535, а не 256, как в команде DC.
При трансляции ассемблер обрабатывает команду DS почти так же, как команду DC. Отличие состоит в том, что в выделенную область памяти константа не помещается. Кроме того, при выравнивании на границу пропущенные байты не очищаются, в то время как при трансляции команды DC пропущенные байты заполняются нулями. Примеры использования оператора DS приведены в табл. 3.3.
Команда EQU — присвоить значение — определяет символическое имя, присваивая ему значение, характеристику длины и характеристику переместимости выражения, записанного в поле операндов.
Формат оператора
Название Операция Операнды
Символическое имя EQU Выражение
Имена, появляющиеся в выражении, должны быть предварительно определены. Характеристика длины определяемого имени
09
Таблица 3.3
ИСПОЛЬЗОВАНИЕ ОПЕРАТОРА DS
Название Операция Операнды Пояснения
А1 DS F Резервируется слово с именем Л1
А2 DS 4F Резервируются 4 слова с адресами Л2, Л2 + 4, Л2 4- 8, Л2 + 12
АЗ DS Н Резервируется полуслово с именем АЗ
А4 DS С'АВС' Резервируется область длиной Збайта с именем А4
А5 DS CL48 Резервируется область длиной 48 байт с именем Л5
Л6 DS 6CL8 Резервируется 6 областей по 8 байт с адресами Л6, Л6 + 8, Л6 + 16
А7 DS 0D Область не резервируется. Счетчик адреса выравнивается на границу двойного слова
приравнивается характеристике длины самого левого терма выражения. Характеристика длины знака * (значение счетчика адреса) и самоопределенного терма принимается равной 1.
Команда USING — определить регистр базы — указывает общие регистры, которые ассемблер может использовать в качестве базовых регистров, и базовые адреса, находящиеся в этих регистрах. Эта информация нужна ассемблеру для перевода неявных адресов в явные (в форму база — смещение или индекс — база — смещение).
Формат оператора
Название Операция Операнды
Пробел USING От 2 до 17 выражений вида Vt rl, г2»..г16
Операнды rl, г2, г16 — абсолютные выражения. Значения
этих операндов определяют номера общих регистров, которые ассемблер может использовать в качестве базовых.
Операнд V — абсолютное или перемещаемое выражение. Значение V равно базовому адресу, который должен содержаться в регистре rl. В регистрах г2, гЗ, г4, ... должны находиться базовые адреса V-f-4096, V + 8192, V-f- 12288, ... соответственно.
70
Заметим, что команда USING не загружает базовые регистры, а лишь сообщает ассемблеру, что они загружены. Программист должен сам предусмотреть в программе команды для загрузки базовых регистров. Кроме того, оператор USING, как и оператор EQU, не порождает никаких элементов объектной программы, поэтому при трансляции этих операторов счетчик адреса не изменяется.
Если операнд rl в команде USING равен нулю, то независимо от значения операнда V назначаются базовые адреса 0, 4096, .8192, ..., причем программа становится непереместимой. Это объясняется тем, что при нулевом базовом регистре база всегда 0 (см. п. 3.1.2).
Команда USING нужна в тех и только тех случаях, когда в программе имеются неявные адреса. Для абсолютных и перемещаемых неявных адресов базовые регистры и базовые адреса нужно указывать в разных командах USING. Для изменения базового адреса записывают новую команду USING.
Ассемблер использует информацию, переданную ему командой USING, следующим образом. Когда в ходе трансляции встречается неявный адрес, ассемблер определяет доступный базовый регистр. Для неявных абсолютных адресов доступным считается базовый регистр, содержащий абсолютный базовый адрес, значение которого меньше или равно неявному адресу, причем разность между неявным и базовым адресом (смещение) не превосходит 4095. Для неявных перемещаемых адресов условия доступности те же, но базовый адрес должен быть перемещаемым. Определив доступный базовый регистр и вычислив смещение, ассемблер заменяет неявный адрес явным. Например, пусть команда USING определила, что регистры 2, 3, 4 содержат базовые адреса 10000», 14096» и 18192» соответственно. Тогда неявный адрес, имеющий значение 15000», будет заменен явным адресом с базовым регистром 3 и смещением 904». Для неявного адреса со значением 9000» допустимого базового регистра нет. В этом случае ассемблер сообщит об ошибке.
Команда DROP — отменить регистр базы — указывает общие регистры, которые не должны больше использоваться в качестве базовых.
Формат оператора
Название Операция Операнды
Пробел DROP До 16 абсолютных выражений вида rl, г2».. Н6
Ассемблер вычеркивает из списка базовых регистров, указан* ных ранее командой USING, те регистры, номера которых определены операндами rl, г2, ..,, г16 команды DROP.
71
Еще одна команда определения, имеющая мнемонику CCW, служит для записи программ каналов. Здесь она не рассматривается.
Команды секционирования и соединения программ предназначены для разделения больших программ на части, называемые программными секциями, и объединения отдельно транслируемых программ или программных секций. Здесь рассматриваются только три из шести команд этой группы.
Команда START — определить начало программы — исполь-ауется для присваивания имени первой (или единственной) программной секции и указания первоначального значения счетчика адреса.
Формат оператора
Название Операция Операнды
Символическое имя или пробел START Самоопределенный терм или пробел
Символическое имя в поле названия именует программную секцию. Это имя является перемещаемым и имеет характеристику длины, равную 1. Значение его равно адресу первого байта программной секции.
Самоопределенный терм в поле операнда определяет начальное значение счетчика адреса. Перед занесением в счетчик адреса это значение выравнивается на ближайшую границу двойного слова. Если операнд пуст, то начальное значение счетчика адреса приравнивается нулю. Обычно START первый оператор программы. В любом случае оператору START не должны предшествовать какие-либо операторы, изменяющие счетчик адреса.
Следующие две команды ассемблера предназначены для объединения в единую выполняемую программу независимо транслированных программных модулей, которые совместно загружаются в основную память.
Команда ENTRY — определить входное имя — объявляет символические имена, которые определены в данном программном модуле, но могут использоваться другими независимо транслированными модулями.
Формат оператора
Название Операция Операнды
Пробел ENTRY Одно или несколько перемещаемых символических имен, разделенных запятыми
Команда EXTRN— определить внешнее имя — объявляет символические имена, которые применяются в данном программном модуле, а определены в других независимо транслированных модулях.
Формат оператора
Название Операция Операнды
Пробел EXTRN Одно или несколько перемещаемых символических имен, разделенных запятыми
Команды управления служат для управления трансляцией, а также для редактирования листинга и управления вводом и выводом информации во время трансляции.
В языке ассемблера ЕС ЭВМ имеется тринадцать команд управления. Здесь рассматриваются только пять из них.
Команда ORG — установить счетчик адреса — присваивает счетчику адреса значение, которое задано в поле операндов.
Формат оператора
Название Операция Операнды
Пробел ORG Перемещаемое выражение или пробел
Новое значение счетчика адреса не должно быть меньше начального адреса программной секции и не должно превышать максимальное значение адреса основной памяти для данной модели ЭВМ. Если операнд пропущен, то в счетчике адреса восстанавливается максимальное значение, достигнутое в ходе трансляции. Например, оператор
Название Операция Операнды
ORG * -256
уменьшает текущее значение счетчика адреса на 256.
Команда LTORG — начать область литералов — определяет начало области литералов, в которую помещаются все литералы, встретившиеся после предыдущей команды LTORG или начала программы.
73
Формат оператора
Название Операция Операнды
Символическое имя или пробел LTORG Пробел
Символическому имени в поле названия соответствует адрес первого байта области литералов, а его характеристика длины— 1.
Началом области литералов является адрес первого двойного слова, следующего за оператором LTORG. Если до оператора LTORG литералов не было, то счетчик адреса выравнивается на границу ближайшего двойного слова. Пропущенные байты нулями
Двойное слово
Слово Слово
Полуслово Полуслово Полуслово Полуслово
Байт Байт Байт Байт Байт Байт Байт Байт
0,4 2,4 0,4 2,4 0,8 2,8 4,8 6,8
Рис. 3.6. Границы, соответствующие значениям операндов команды С МОР
не заполняются. Область литералов состоит из четырех разделов: в первый помещаются литералы с длиной, кратной восьми, во второй — с длиной, кратной четырем, в третий — с длиной, кратной двум, а в четвертый — с нечетной длиной.
Литералы, используемые в модуле после последнего оператора LTORG, помещаются в конце первой пограммной секции многосекционной программы (в конце модуля — для односекционной программы). Там же размещаются все литералы, если в программе нет операторов LTORG.
Команда CNOP — установить границу — выравнивает значение счетчика адреса на указанную границу полуслова, слова или двойного слова. Пропущенные байты заполняются командой НЕТ ОПЕРАЦИИ (ВС/?0,0).
Формат оператора
Название Операция Операнды
Пробел CNOP Два абсолютных выражения в форме Л, В
74
Символические имена, входящие в выражения А и В, должны быть предварительно определены. Операнд А указывает номер байта в слове или двойном слове (А == 0, 2 — для слова и А = = 0,2,4,6 — для двойного слова). Операнд В указывает, где находится байт: в слове (В = 4) или в двойном слове (В = 8). Счетчик адреса устанавливается на указанный байт. На рис. 3.6 показаны границы, соответствующие всем возможным парам А, В.
Перед обработкой команды CNOP, как и перед обработкой машинных команд, ассемблер выравнивает счетчик адреса на границу полуслова, если это необходимо, а затем происходит выравнивание на указанную границу. Например, если счетчик адреса находится на границе двойного слова, то оператор
CNOP 0,4 или оператор CNOP 0,8
не выполняет никакого действия, а операторы
CNOP 6,8 BALR 2,14 эквивалентны операторам
BCR 0,0 ВС R 0,0 BCR0J3 BALR 2,14
Команда END — закончить модуль — предписывает закончить трансляцию исходного модуля и сформировать область литералов. Формат оператора
Название Операция Операнды
Пробел END Перемещаемое выражение
Перемещаемое выражение в поле операнда указывает’точку, в которую передается управление после загрузки. Область литералов формируется по тем же правилам, что для команды LTORG, но для многосекционной программы она помещается в конце первой программной секции.
Команда COPY — копировать — предназначена для включения в исходную программу текста из системной библиотеки ассемблера. Имя текста записывают в поле операнда.
•75
3.2. АССЕМБЛЕР МНЕМОКОДА
3.2.1. СХЕМА ТРАНСЛЯЦИИ
Ассемблер получает на вход исходную программу на мнемокоде и перерабатывает ее в программу на языке машины. Объектная программа либо оформляется в виде объектного модуля (модуля загрузки), подлежащего дальнейшей обработке редактором связей (загрузчиком), либо составляется в абсолютных адресах. В последнем случае она непосредственно гртова к исполнению.
В ходе трансляции ассемблер должен:
распределить память, т. е. каждому имени и литералу сопоставить адрес основной памяти;
перевести на машинный язык команды мнемокода и константы с учетом распределения памяти;
выявить и выдать на печать ошибки в исходной программе;
сформировать объектный модуль (модуль загрузки) или готовую к исполнению объектную программу;
сформировать и выдать печатный документ о программе (листинг).
Эти задачи трудно решить за один просмотр исходной программы, поскольку при трансляции каждой команды нужно знать значения (адреса), сопоставленные именам и литералам, выступающим в качестве операндов, а для выявления всех имен и литералов и присваивания им значений (адресов) требуется предварительно просмотреть всю исходную программу. Правда, в ходе одного просмотра можно присваивать значение каждому новому имени в момент его появления, но тогда придется временно задерживать присваивание адресов именам, которые еще не появлялись в поле названия, потому что значение имени зависит от положения машинного эквивалента именованного оператора в объектной программе. Это усложняет алгоритм трансляции. Поэтому чаще используют двухпросмотровые ассемблеры. В частности, ассемблеры ЕС ЭВМ — двухпросмотровые.
При первом просмотре выявляются все имена и литералы и распределяется память. При втором просмотре генерируются машинные команды, оформляется объектная программа и формируется печатный документ.
3.2.2. СТРУКТУРА ДВУХПРОСМОТРОВОГО АССЕМБЛЕРА
Типичная блок-схема двухпросмотрового ассемблера показана на рис. 3.7.
1. Блок подготовки первого просмотра приводит в исходное состояние счетчики и таблицы ассемблера.
2. Блок выделения имен, просматривая каждый оператор исходной программы, выявляет имена и литералы, заносит их в таблицы
и присваивает именам значения (адреса), а также фиксирует ошибки.
3. Блок распределения памяти для литералов включается после завершения первого просмотра. Здесь распределяется память
для размещения тех литералов, адреса которым не назначены в ходе первого просмотра.
4. Блок подготовки второго просмотра приводит в исходное состояние счетчики и таблицы, используемые при втором просмотре, а также формирует и выдает часть выходной информации.
5. Блок генерирования машинных команд, формирования объектного модуля и печатного документа, используя таблицы, подготовленные при первом просмотре, переводит каждую команду на язык машины, одновременно формирует объектный модуль и выдает на печать соответствующие строки листинга. После завершения работы этого блока сформирован объектный модуль или готовая грамма.
Исходная программа на мнемокоде
1 Блок подготовки первого просмотра
Рис. 3.7. Структура двухпросмотрового ассемблера
к исполнению объектная про-
3.2.3. ТАБЛИЦЫ АССЕМБЛЕРА
В процессе трансляции ассемблер использует различные таблицы, которые можно разделить на постоянные, составляемые заблаговременно, при разработке ассемблера, и временные, создаваемые в ходе трансляции.
Обязательной постоянной таблицей является таблица операций, в которой перечислены все мнемонические коды машинных команд, команд ассемблера и некоторых макрокоманд. Для машинных команд таблица операций содержит машинные эквиваленты кодов операций, используемые при переводе команд на язык машины, а для команд ассемблера и макрокоманд — признаки, позволяющие перейти к соответствующим подпрограммам обработки. Могут быть и другие постоянные таблицы, например таблица стандартных текстов, выдаваемых на печать в качестве заголовков разделов печатного документа, а также идентифицирующих ошибки, выявленные ассемблером.
77
Обязательной временной таблицей в любом ассемблере является таблица имен, содержащая все имена, определенные в исходной программе. Для литералов создается отдельная таблица
ТАБЛИЦА ИМЕН
Имя Характеристика длины (байт) Значение (адрес) Номер оператора, где имя определено Перемести-мость
ТАБЛИЦА ЛИТЕРАЛОВ
Длина Адрес Количество знаков Литерал
ТАБЛИЦА ВНЕШНИХ ИМЕН
ТАБЛИЦА
ТАБЛИЦА
Внешнее имя
ВХОДНЫХ ИМЕН
Входное имя
БАЗОВЫХ РЕГИСТРОВ
Номер регистра Базовый адрес
ТАБЛИЦА ИСПОЛЬЗОВАНИЯ ИМЕН
Номер оператора Длина записи Ссылки на таблицу имен
ТАБЛИЦА 1 ПЕРЕМЕЩАЕМЫХ АДРЕСНЫХ КОНСТАНТ
Ссылка на таблицу внешних имен* Характеристики константы Адрес
длина знак перемещения
ТАБЛИЦА ОШИБОК
Номер оператора Признак ошибки (идентификатор сообщения об ошибке»
Рис. 3.8. Временные таблицы ассемблера
литералов. Другие временные таблицы имеют вспомогательное значение, их наличие или отсутствие определяется особенностями машины, семантикой команд мнемокода и структурой ассемблера.
В описываемом ниже ассемблере, входной язык которого подобен языку ассемблера ЕС ЭВМ, используются следующие времен
78
ные таблицы (рис. 3.8): таблица имен, таблица литералов, таблица внешних имен, таблица входных имен, таблица базовых регистров, таблица перемещаемых адресных констант, таблица использования имен, таблица ошибок.
Первые четыре таблицы создаются во время первого просмотра, таблица ошибок заполняется во время обоих просмотров, остальные таблицы создаются при втором просмотре.
Таблица имен содержит все имена, встречающиеся в поле названия операторов исходной программы, и их характеристики. Напомним, что характеристика длины имени есть длина идентифицируемой этим именем области памяти. Значение (адрес) назначается имени в момент его включения в таблицу. Адрес равен текущему значению счетчика адреса, быть может, скорректированному для выравнивания на соответствующую границу.
Характеристика переместимости позволяет отличить имена с абсолютными значениями от перемещаемых имен и обеспечивает контроль правильности употребления имен. Например, имя, идентифицирующее регистр или длину операнда, должно иметь абсолютное значение. Абсолютными считаются лишь имена, определенные оператором EQU, в поле операнда которого записано абсолютное выражение, все остальные имена являются перемещаемыми. В некоторых ассемблерах в таблицу имен включают дополнительную информацию. Например, иногда записывают характеристику типа идентифицируемого объекта (команда, константа, область памяти).
Таблица литералов хранит все литералы, встречающиеся в программе. Идентичные по написанию литералы включаются в таблицу только один раз. Адреса назначаются литералам после завершения первого просмотра исходной программы или по команде LTORG. Записи таблицы литералов имеют переменную длину, зависящую от количества знаков в литерале.
Таблица внешних имен содержит имена, объявленные операторами EXTRN, и имя, указанное в поле названия оператора START. Последнее имя, являющееся именем исходной программы (первой программной секции многосекционной программы), всегда есть первая запись таблицы, эта запись может, быть пустой.
Таблица входных имен накапливает имена, записанные в поле операндов onepaTopa,£W77?y.
Таблица базовых регистров содержит номера базовых регистров и базовые адреса, объявленные операторами USING. Эта таблица состоит из двух частей: в одной части хранятся номера базовых регистров и базовые адреса для перемещаемых неявных адресов, а в другой — для абсолютных. Каждая часть не может иметь больше 16 записей (по числу общих регистров).
Таблица перемещаемых адресных констант хранит адреса адресных констант, заданных перемещаемыми выражениями, зависящими от внутренних или внешних имен. Вычислить значение такой константы можно только после установления адресов загрузки
79
программных модулей (секций), в которых определены имена, входящие в выражение. Помимо адреса константы в таблицу заносят порядковый номер имени в таблице внешних имен (если константа зависит от внутреннего имени, то фиксируются номер имени исходной программы — секции), длина константы и знак (4-или —), с которым имя входит в выражение, определяющее значение адресной константы.
Эта информация нужна для формирования специальных карт объектного модуля, образующих словарь перемещений, исполь-ауемый для вычисления значений перемещаемых адресных констант в ходе обработки объектного модуля редактором связей (см. п. 3.2.6).
Таблица использованных имен фиксирует имена, встречающиеся в поле операндов каждого оператора исходной программы. Для сокращения длины записей вместо имен обычно записывают их порядковые номера в таблице имен (ссылки на таблицу имен). Поскольку число имен в поле операндов может быть разным, записи этой таблицы имеют переменную длину. Длина каждой записи указывается в таблице. Вообще говоря, для трансляции эта таблица не нужна, она применяется при формировании листинга.
Таблица ошибок содержит номера операторов, в которых ассемблер выявил ошибки, и признаки ошибок. В качестве признака используют порядковый номер или идентификатор текста сообщения об ошибке. В частности, в ассемблерах ЕС ЭВМ предусмотрено 109 различных текстов сообщений об ошибках.
3.2.4. ПЕРВЫЙ ПРОСМОТР. ВЫЯВЛЕНИЕ ИМЕН
Блок подготовки первого просмотра устанавливает в исходное состояние три счетчика ассемблера:
счетчик адреса, хранящий текущий адрес объектной программы (адрес первого свободного байта объектной программы);
счетчик операторов, фиксирующий порядковый номер очередного оператора исходной программы;
счетчик адреса оператора, содержимое которого есть адрес первого байта просматриваемого оператора исходной программы (шаг приращения этого счетчика равен длине исходного оператора в байтах — обычно 80 или, если есть строка продолжения, 160байт).
Исходное значение счетчика адреса равно нулю, счетчика операторов— единице. В счетчик адреса оператора заносится адрес начала рабочего поля, на котором хранится исходная программа во время трансляции.
Исходное значение счетчика адреса присваивается также двум переменным AMIN и АМАХ. Переменная AMIN хранит начальный адрес объектной программы, а переменная АМАХ— наибольшее значение счетчика адреса, достигнутое к моменту появления команды ORG.
Ви
Кроме установки счетчиков ассемблера, блок подготовки первого просмотра очищает временные таблицы (например, заполняя их нулями) и вызывает используемые при первом просмотре постоянные таблицы. Затем управление передается блоку выделения имен. Схема работы этого блока показана на рис. 3.9.
От блока 1
Рис. 3.9. Блок выделения имен
Блок выделения имен, имеющий на блок-схеме ассемблера (см. рис. 3.7) номер 2, последовательно просматривает все операторы исходной программы. После выборки очередного оператора (блок 1) проверяется содержимое его первого байта, соответствующего колонке «начало» перфокарты (в стандартном формате — Колонка 1). Если в этом байте находится знак *, то в строке запи« сан комментарий (блок 2). Обработка комментария (блок 3) состоит в проверке указателя продолжения (колонка 72 стандартного
81
бланка). Любой знак в этой колонке, отличный от пробела,— признак продолжения. Если указатель продолжения не пуст, счетчик адреса оператора увеличивается на 80 (число байт в строке исходной программы), чтобы пропустить строку продолжения комментария.
Если блок 2 не обнаружил комментария, то с помощью таблицы операций определяется тип команды (блок 4): машинная, макрокоманда или псевдокоманда. Отсутствие мнемонического кода операции в таблице означает, что оператор содержит запрещенную команду. Номер оператора, содержащего запрещенную команду, заносится в таблицу ошибок (блок 5) с соответствующим признаком, и обработка ее продолжается так же, как обработка машинной команды.
Обработка машинной команды (блок 6) начинается с выравнивания счетчика адреса на границу полуслова. Для этого к счетчику адреса добавляется единица, а затем последний двоичный разряд счетчика заменяется нулем. Вообще для выравнивания некоторого значения на границу, кратную 2\ нужно увеличить это значение на 2*—1, а затем заменить последние k разрядов нулями.
Имя из поля названия, если поле названия не пусто, вместе с содержимым счетчика адреса заносится в таблицу имен. Если в таблице имен это имя уже имеется, в таблице ошибок фиксируется признак ошибки: «имя было определено ранее». Вместе с именем фиксируются его характеристика длины, номер оператора и признак «переместимое имя» (см. рис. 3.8).
В ЕС, ЭВМ значение характеристики длины имени машинной команды определяется двумя первыми двоичными разрядами машинного кода операции. Для команд формата RR (длина 2 байта) эти разряды содержат код 00, для команд формата RX, RS и SI (длина 4 байта) —код 01 или 10, а для команд формата SS (длина 6 байт)—код 11.
Обработка машинной команды завершается просмотром поля операндов, включая строку продолжения, если она есть. Литералы, встретившиеся в поле операндов, заносятся в таблицу литералов вместе с характеристикой длины. После обработки машинной команды к счетчику адреса добавляется длина команды (блок 7).
На уровне ассемблера обрабатывается только фиксированное число макрокоманд ассемблера, обеспечивающих связь с операционной системой и выполнение операций ввода — вывода. Обработка других макрокоманд рассматривается в 3.3.
Обработка макрокоманды ассемблера (блок 9) при первом просмотре сводится к занесению имени из поля названия (если оно есть) в таблицу имен и увеличению счетчика адреса соответственно числу байт, требующихся для макрокоманды в объектной программе (блок 7). Как и при обработке машинной команды, предварительно счетчик адреса выравнивается на границу полуслова.
,82
Обработка псевдокоманд (команд ассемблера) выполняется по разным правилам для каждой псевдокоманды.
Псевдокоманды USING и DROP при первом просмотре не обрабатываются.
Появление псевдокоманды END прекращает первый просмотр (блок 10), управление передается блоку распределения памяти для литералов (см. рис. 3.7). Остальные псевдокоманды обрабатываются в блоке 11 следующим образом:
START устанавливает начальное значение счетчика адреса (для этого значение операнда вычисляется, выравнивается на границу двойного слова и заносится в счетчик адреса), записывает имя из поля названия (если оно не пусто) в таблицу имен и формирует первую запись таблицы внешних имен (в момент появления оператора START счетчик адреса должен быть равен нулю, в противном случае делается запись в таблице ошибок и описанные выше действия не выполняются);
EXTRN заносит имена из поля операндов в таблицу внешних имен;
ENTRY заносит имена из поля операндов в таблицу входных имен;
ORG устанавливает новое значение счетчика адреса и корректирует значение переменной АМАХ по правилу:
if операнд = пробел
then счетчик адреса: = шах {счетчик адреса, АМАХ)
else if операнд корректен = true
then begin АМАХ: = max {счетчик адреса, операнд, АМАХ); счетчик адреса: = операнд
end
else ОШИБКА;
LTORG выравнивает значение счетчика адреса на границу двойного слова, заносит имя из поля названия (если оно не пусто) в таблицу имен и формирует область литералов по правилам, изложенным в п. 3.1.4 (присваивание литералам адресов сопровождается увеличением счетчика адреса, а после присваивания адресов всем литералам в таблицу литералов заносится условная запись «конец области литералов», которая предписывает следующей команде LTORG присваивать адреса литералам, записанным после этой условной записи);
CNOP выравнивает значение счетчика адреса на указанную границу;
DC (или DS) определяет длину выделяемой области памяти (в случае неявной длины счетчик адреса выравнивается на соответствующую границу), заносит имя из поля названия (если оно не пусто) в таблицу имен и корректирует счетчик адреса с учетом выделенной памяти;
EQU после вычисления значения операнда и проверки его корректности заносит имя из поля названия и его характеристики в
83
таблицу имен (если операнд некорректен, то делается запись в таблице ошибок).
Обработка любого оператора, кроме оператора END, завершается увеличением счетчика операторов и счетчика адреса оператора. Последнее обеспечивает переход к обработке следующего оператора.
3.2.5. РАСПРЕДЕЛЕНИЕ ПАМЯТИ ДЛЯ ЛИТЕРАЛОВ
Получив управление от блока выделения имен, блок распределения памяти создает область литералов, в которую включаются все те литералы, которые встретились в исходной программе после последней команды LTORG. В таблице литералов эти литералы к моменту завершения первого просмотра не имеют адресов и записаны после условной записи, являющейся признаком конца последней области литералов, созданной командой LTORG. Если в исходной программе не было команд LTORG, то ни один литерал не имеет адреса.
Область литералов размещается вслед за программой и создается с соблюдением тех же правил, что и при выполнении команды LTORG. В этом блоке могут также контролироваться таблицы внешних и входных имен:
любое имя в таблице внешних имен не должно совпадать с каким-либо именем в той же таблице и таблице имен (последнее не относится к первой записи таблицы);
любое имя из таблицы входных имен непременно должно содержаться в таблице имен.
Обнаруженные в ходе контроля ошибки заносятся в таблицу ошибок.
3.2.6. ЛИСТИНГ И ОБЪЕКТНЫЙ МОДУЛЬ
Задачей второго просмотра помимо генерирования машинных команд является формирование листинга, обеспечивающего документирование и отладку программы. На современных машинах результат трансляции обычно оформляется в виде объектного модуля, который после редактирования можно загружать в любое место основной памяти, объединяя его (если нужно) с другими объектными модулями.
Ассемблеры, входящие в дисковую операционную систему ЕС ЭВМ (ДОС/ЕС), формируют листинг, состоящий из пяти частей: словарь внешних имен;
исходная и объектная программа;
словарь перемещаемых адресных констант;
таблица перекрестных ссылок;
диагностические сообщения об ошибках.
Для упрощения здесь предполагается, что исходная программа состоит из одной программной секции (особенности ассемблера «1
для многосекционных программ кратко рассматриваются в. п. 3.2.8), в связи с этим излагается несколько упрощенная структура частей листинга.
Словарь внешних имен включает имя из поля названия оператора START (название программы) и все имена, встречающиеся, в поле операндов операторов ENTRY и EXTRN.
Каждая строка словаря содержит пять полей: имя;
тип имени (название программы, входное имя, внешнее имя);, порядковый номер имени в таблице внешних имен (только для внешних имен и названия программы), называемый в ДОС/ЕС. идентифицирующим номером ESD;
значение (адрес) входного имени или названия программы, (только для внутренних имен);
длину объектного модуля (только для названия программы).
Строка словаря формируется из таблиц имен, внешних имен и входных имен, составленных при первом просмотре.
Исходная и объектная программа представлена в листинге последовательностью строк, каждая из которых состоит из символической части (оператор исходной программы) и объектной (машинной) части, представляющей собой соответствующую команду (константу) на машинном языке.
Объектная часть строки содержит адрес объектного кода (значение счетчика адреса) и объектный (машинный) код операции и операндов.
Для команд объектный код приводится полностью, а для констант и областей памяти — полностью или частично, в зависимости от указаний программиста.
Символическая часть строки включает номер оператора (значение счетчика операторов); оператор исходной программы или литералы, помещаемые ассемблером вслед за операторами LTORG и END\ поле идентификации исходного оператора.
Вслед за ошибочным оператором исходной программы в листинге помещается индикатор ошибки в виде
♦ ♦ ♦ ERROR ♦ • *
Для команд ассемблера, не порождающих объектного кода,, объектная часть строки пуста. Для макрокоманд, наоборот, может быть пуста символическая часть нескольких строк.
Образец этой части листинга показан на рис. 3.10.
Словарь перемещаемых адресных констант содержит строки таблицы перемещаемых адресных констант (см. рис. 3.8).
Таблица перекрестных ссылок содержит строки таблицы имен,, дополненные номерами операторов, в которых используется данное имя. Номера операторов извлекаются из таблицы использования имен (см. рис. 3.8).
Диагностические сообщения об ошибках печатаются в виде-последовательности строк, каждая из которых формируется на
85>
I
«сновании таблицы ошибок (см. рис. 3.8) и содержит номер ошибочного оператора, идентификатор сообщения об ошибке и текст сообщения об ошибке.
Объектный модуль оформляется по правилам, обеспечивающим его обработку редактором связей при формировании фаз програм-
ЮС ОВ^ЕС* CODE ADDR1 AD0R2 STMT source statement
1 PRINT NOGEN
402000 2 start ei»j
402000 0520 3 88 BALR 2,0
402002 4 USING ««2
402002 5890 20С2 020С4 5 L 9iCl CONSTANT OF MODIFICATION
6 open tout,blank
14 GET TlVLEl
19 PUT titleo
24 PUT BLANK
40203Е 5850 20С6 020С8 29 L 5,02
402042 S8A0 200А 020ВС 30 B0 L 18,ZERO OPERAND Д
402046 5880 20С< 02000 31 8J L 8<C256
00204Д 5800 208Й 020С0 >2 Bl L 11,B OPERAND в
002046 6870 20СА 020CQ >3 L 7,C128
402032 4140 2006 02008 34 lA 4,ARG
402056 1 ВС А 35 8C0 LR 12,10
002056 1АСВ 36 AR 12>H
40205А 50С0 2002 02004 37 ST 12(RES
002056 0200 4000 20D5 00000 02007 38 MVC 011.4),RES*3
002064 1 аВ4 39 AR Hi»
002066 16 4 9 40 ALR 4.9
002060 4670 2054 02056 41 BCT 7.BGC
40206С 007F 2006 221F 02008 02221 42 tr arc(i2b>(Field
002072 027F 2157 2006 02159 02006 43 MVC yut(120)(ARC
002070 1АА9 44 AR 10,9
45 рит уоит
002086 4680 2048 0204А 50 H2 BCT BiBl
40208Д 58С0 208Е 020С0 51 L 12,8
00208Е $АС0 20СА 020СС 52 A 12,0126
002092 50С0 2060 020С0 53 ST 12>B
54 PUT blank
0020А2 4650 2040 02042 59 BCT S<80
60 CLOSE yOUT<8LANK
66 EOJ
40200С 00000000 71 ZERO DC F'0'
4020С0 00000000 72 0 ОС F "0 •
4020С4 0000000 1 73 Ct DC F«1 •
Рис. 3.10. Фрагмент листинга ЕС ЭВМ
мы (п. 1.1.3). Обычно ассемблеры ДОС/ЕС формируют в составе объектного модуля карты четырех типов:
карты словаря внешних имен (External Symbol Dictionary—• сокращенно ESD)-
карты с текстом объектной программы (карты ТХТ)\
карты словаря перемещений (Relocation Dictionary — сокращенно RLD);
карту END.
Каждая карта содержит служебную информацию для редактора связей и основную информацию. К служебной информации
S6
относятся, в частности, признак типа карты и указатель количества байт основной информации. На картах ТХТ служебная информация содержит также адрес первого байта текста, помещенного на карте, назначенный при трансляции.
В качестве основной информации карты словаря внешних имен (ESD) и словаря перемещений (RLD) содержат ту же информацию, что соответствующие части листинга, а карта END служит для указания окончания объектного модуля и может содержать адрес, с которого нужно начать выполнение программы после загрузки.
Карты ESD и RLD используются редактором связей для объединения независимо транслированных модулей в единую программу. При генерировании машинных команд формируется таблица перемещаемых адресных констант (см. рис. 3.8), информация из этой таблицы переносится затем в словарь перемещений (RLD). Значения перемещаемых адресных констант формируются в объектном модуле при нулевых значениях внешних имен, а из значений перемещаемых констант, зависящих от внутренних имен, вычитается значение имени программы (программной секции), в которой определена константа.
После получения сведений о фазовой структуре программы, названиях Модулей, входящих в каждую фазу, и адресе загрузки первой фазы редактор связей приступает к редактированию объектных модулей и формированию фаз программы. Если не вдаваться в детали формирования фаз и особенности организации просмотра словарей внешних имен в разных режимах, а также предположить, что каждый объектный модуль состоит из одной программной секции, то упрощенно процесс редактирования в ДОС/ЕС можно описать так.
Для каждого модуля, начиная с первого, редактор выполняет следующее:
1. Вычисляет перемещение, равное разности адреса загрузки и начального адреса модуля, назначенного при трансляции.
2. Вычисляет абсолютные адреса всех входных имен модуля (абсолютный адрес равен сумме перемещения и адреса, назначенного при трансляции).
3. Определяет абсолютные адреса внешних имен, указанных в словаре внешних имен (ESD) данного модуля. Для этого среди входных имен ранее обработанных модулей отыскивается имя, совпадающее с рассматриваемым внешним именем. Адрес внешнего имени равен адресу этого входного имени. Внешние имена,, для которых не найдены соответствующие входные имена, остаются неопределенными. Если программист не даст других указаний, для поиска недостающих входных имен редактор связей может организовать автоматический просмотр оглавлений личных и системной библиотек объектных модулей (см. п. 1.1.3). Библиотечные модули, содержащие искомые входные имена, редактор включает в формируемую фазу.
87
Адрес загрузки каждого последующего модуля редактор определяет с учетом длин предыдущих модулей и фазовой структуры программы (программист может запланировать полное или частичное перекрытие отдельных фаз при выполнении программы).
Адрес загрузки модуля я
Перемещение ’ модуля я
Адрес \ ыгрузки модуля в
Словарь внешних имен (ESO) модуля А
Название модуля А Адрес длина
Словарь перемещении {RLD} модуля А
внешнее имя номер
приращений
константы
внешнего имени
номер ХдлинаХ Знак \ Адрес константы
Абсолютный адрес * внешнего -имени
значение
Исходное значение
Приращение перемещаемой адресной константы
Рис. 3.11. Схема корректирования редактором связей значений перемещаемой адресной константы
Перемещение модуля в
( Словарь ч внешних имен (ESD)) модуля в
название лЯпоп Пп,,„п модуля В ядрен Длина
Входное имя
Абсолютный адрес входного имени
Абсолютный адрес > константы
часть текста разы, соответствующая модулю А
Перемещаемая лесная константа
Закончив обработку всех модулей, редактор связей повторяет выполнение пункта 3 для внешних имен, оставшихся неопределенными. На этот раз просматриваются все модули программы (входящие во все фазы), после этого все внешние имена должны по
-88
лучить адреса. Наличие неопределенных имен свидетельствует об* ошибках.
При успешном завершении описанной процедуры начинается заключительный этап редактирования — корректирование перемещаемых адресных констант и формирование окончательных текстов фаз программы. Формируя окончательный текст фазы, редактор связей просматривает словари перемещений (RLD), определяет адрес каждой перемещаемой адресной константы и находит в тексте соответствующего модуля ее исходное значение. Кроме того, редактор определяет по словарю перемещений знак приращения и номер (идентифицирующий номер ESD) имени, использованного в константе. По этому номеру отыскивается имя и его* абсолютный адрес. Наконец, найденный адрес имени с учетом знака приращения алгебраически складывается с исходным значением константы. Эта сумма записывается в текст фазы в качестве скорректированного значения перемещаемой адресной константы.
Схема работы редактора связей при корректировании значения перемещаемой адресной константы, используемой в модуле А и ссылающейся на внешнее имя, определенное в модуле В, показана на рис. 3.11. Пунктиром показано вычисление перемещений и адреса входного имени, сплошными линиями — поиск адреса внешнего имени, а двойными — корректировка перемещаемой адресной константы.
3.2.7. ВТОРОЙ ПРОСМОТР. ГЕНЕРИРОВАНИЕ МАШИННЫХ КОМАНД.
Блок подготовки второго просмотра (блок 4 на рис. 3.7) запоминает длину объектного модуля, равную
max {счетчик адреса, АМАХ) — AMIN,
восстанавливает счетчик адреса, счетчик операторов и счетчик адреса оператора, а также значения переменных AMIN и АМАХ. Затем формируется и выдается на печать первая часть листинга — словарь внешних имен. Одновременно формируются и выдаются на перфокарты или записываются во внешнюю память карты словаря внешних имен (карты ESD). После этого включается блок генерирования машинных команд, формирования объектного модуля и печатного документа (блок 5 на рис. 3.7).
Схема генерирования машинных команд и формирования выходной информации показала на рис. 3.12. Для обеспечения параллельной печати исходной и объектной программы, а также формирования карт ТХТ объектного модуля формируются два массива:
массив «программа», содержащий программу на объектном языке в формате карт TXT;
массив «печать», содержащий строки листинга с текстом объектной и исходной программы.
Or блока i
Рис. 3.12. Блок генерирования машинных команд и формирования выходной информации
Работа ассемблера при втором просмотре начинается с выборки очередного оператора исходной программы и занесения его в символическую часть массива «печать» (блок 1) (см. рис. 3.12). Затем по коду, записанному в поле операции с помощью таблицы операций, определяется тип команды (блок 2). Команды разного
90
типа обрабатываются раздельно, при этом запрещенные команды обрабатываются как машинные.
Комментарии, содержащие в столбце «начало» знак *, пропускаются точно так же, как й при первом просмотре (для упрощения блок-схемы на рис. 3.12 это не показано).
Обработка машинной команды, как и при первом просмотре, начинается с выравнивания счетчика адреса на границу полуслова и формирования объектного кода операции, который уже определен в блоке 2 по таблице операций. Затем просматривается поле операндов (вместе с продолжением, если оно есть), выделяется операнд (блок 4), определяется его тип и формируется соответствующий машинный операнд (блоки 5, 6 и 7). Напомним, что границей между операндами является запятая, а признаком конца поля операндов служит пробел.
Десятичные еамоопределенные операнды переводятся в двоичную систему счисления (блок 5). Значения (адреса) символических имен и литералов отыскиваются в таблицах имен и литералов соответственно. При этом порядковые номера имен по таблице имен заносятся в таблицу использованных имен (см. рис. 3.8) вместе с номером оператора по счетчику операторов. Символ ♦ получает значение, равное текущему значению счетчика адреса. Если операнд является выражением, то вычисляется значение этого выражения. Способы вычисления выражений в ходе трансляции рассматриваются в 4.3.
Значение выражения не должно превосходить некоторого максимального допустимого значения, определяемого характером операнда (регистр, непосредственный операнд, адрес основной памяти), и некоторого минимального значения, например для основной памяти AMIN, если адрес перемещаемый. Нарушение этих условий фиксируется в таблице ошибок. Отсутствие символического имени в таблице имен или неправильное употребление имени (абсолютное значение вместо перемещаемого) также фиксируется в таблице ошибок.
В блоке 7 значение выражения, представляющее неявный адрес основной памяти, переводится в явный адрес. Для этого по таблице базовых регистров определяется доступный базовый регистр по правилам, изложенным в п. 3.1.4 при описании команды USING. Отсутствие допустимого базового регистра отмечается в таблице ошибок.
Описанный процесс перевода операндов повторяется циклически до тех пор, пока не будет определено (блок 8), что все операнды сформированы. Отсутствие нужного операнда фиксируется в таблице ошибок (блок 9).
Сформированная машинная команда заносится в массивы «программа» и «печать» (блок 10). При занесении готовой команды в массив «печать» в объектную часть строки этого массива переписывается также адрес первого байта сформированной команды, равный значению счетчика адреса. Одновременно просматривается
91
таблица ошибок. Входом в таблицу служит номер оператора. Если в данном операторе замечена ошибка, то в массив «печать» заносится текст индикатора ошибки (**♦ ERROR **»). Затем увеличивается счетчик адреса (блок 11).
Обработка макрокоманды (блок 12) сводится к формированию обращения к соответствующей стандартной подпрограмме, реализующей данную макрокоманду, или к замене макрокоманды стандартной группой команд прямо в .тексте программы. В обоих •случаях фактические параметры макрокоманды переводятся в машинные эквиваленты так же, как при трансляции машинных команд. Сформированная группа машинных команд заносится в массивы «программа» и «печать», причем в массив «печать» переносятся также значения счетчика адреса, отвечающие сформированным командам. Перед началом обработки макрокоманды счетчик адреса выравнивается на границу полуслова, а в ходе формирования машинных команд увеличивается соответственно длине каждого сформированного объектного кода.
Обработка псевдокоманд выполняется блоками 13, 14 и 20. Псевдокоманды EQU, ENTRY и EXTRN не обрабатываются, поскольку содержащаяся в них информация перенесена в соответствующие таблицы при первом просмотре. Остальные псевдокоманды, кроме команды END, обрабатывает блок 20. Каждая псевдокоманда обрабатывается в соответствии с ее семантикой:
START устанавливает начальное значение счетчика адреса точно так же, как при первом просмотре, но без занесения признака ошибки в таблицу ошибок;
USING заносит номера базовых регистров и базовые адреса в таблицу базовых регистров;
DROP вычеркивает из таблицы базовых регистров номера тех регистров, которые указаны в поле операндов;
ORG устанавливает новое значение счетчика адреса так же, как при первом просмотре;
LTORG выравнивает счетчик адреса на границу двойного слова, переводит литералы, входящие в формируемую область литералов, в машинную форму и заносит переведенные литералы в массив «программа», кроме того, переведенные и исходные литералы заносятся в массив «печать» с одновременным увеличением счетчика адреса;
CNOP выравнивает счетчик адреса на указанную границу и заполняет пропущенные байты командой НЕТ ОПЕРАЦИИ с занесением этих команд в массивы «программа» и «печать»;
DC заносит в программу константы, указанные в поле операндов, причем константы переводятся в машинную форму и записываются в массивы «программа» и «печать» с одновременным увеличением счетчика адреса;
DS резервирует область памяти путем увеличения счетчика адреса.
92
Обработка любого оператора, кроме оператора END, завершается переходом к блоку 21, который увеличивает счетчик операторов и счетчик адреса оператора. Команда END прекращает трансляцию (блок 13). Затем вычисляется операнд этой команды и формируется область литералов (блок 14) так же, как при обработке команды LTORG.
Блоки 15—18 выполняют заключительные операции, завершая выдачу на печать листинга и выдачу карт объектного модуля. Последний блок 19 по указанию программиста организует запись объектного модуля в библиотеку для последующего исполнения.
3.2.8. ОСОБЕННОСТИ АССЕМБЛЕРА ДЛЯ МНОГОСЕКЦИОННЫХ ПРОГРАММ
Описанный выше ассемблер подобен ассемблерам ЕС ЭВМ, но устроен несколько проще. Основные упрощения связаны с исключением из входного языка операторов CSECT, DSECT и СОМ [15].
Одератор CSECT определяет начало программной секции. Назначение этого оператора состоит в разделении больших программ на части (программные секции).
Оператор DSECT определяет фиктивную программную секцию (фиктивную область), которая используется для экономного описания структуры реальных областей памяти.
Оператор СОМ определяет общую область, к которой можно обращаться из совместно исполняемых независимых программных секций.
Операторы секционирования позволяют записывать многосекционную программу в виде одного исходного модуля, включающего части, относящиеся к разным секциям. Заметим, что части одной и той же секции могут находиться в разных местах исходного модуля. Этой возможности нет в описанном ассемблере, который может транслировать лишь односекционный модуль, хотя формируемая ассемблером объектная информация (карты ESD и RLD) обеспечивает объединение независимо транслированных односекционных модулей.
Для трансляции многосекционных программ ассемблер нужно усовершенствовать. Характер усовершенствований связан с двумя обстоятельствами:
1) редактор связей размещает в памяти каждую программную секцию независимо от остальных секций (обычно в порядке появления начала каждой секции в исходном модуле);
2) части одной и той же секции могут находиться в разных местах исходного модуля.
Первое обстоятельство требует использования в каждой программной секции своих базовых регистров. Это вынуждает создавать для каждой секции отдельную таблицу базовых регистров. Отсюда следует, что для вычисления явных адресов в таблице имен
93
необходимо фиксировать имя (номер) секции, в которой определено данное имя. Для входных имен эта информация переносится в словарь внешних имен, чтобы обеспечить работу редактора связей. Аналогично в таблице перемещаемых адресных констант нужно указывать секцию, в которой определена адресная константа. Кроме того, в словарь внешних имен включаются все имена программных секций.
Второе обстоятельство требует введения для каждой секции отдельного счетчика адреса.
Для упрощения объединения программных секций с помощью перемещаемых адресных констант в языке ассемблера ЕС ЭВМ предусмотрены специальные внешние адресные константы типа V. Такая константа резервирует в программе память для адреса внешнего имени (и только для внешнего имени, в отличие от константы типа Л). Символическое имя, записанное в поле операндов констант типа V, не нужно объявлять в операторе EXTRN. Иными словами, использование константы типа V эквивалентно использованию константы типа А с одновременным объявлением внешнего имени в операторе EXTRN.
3.2.9. ИСПОЛЬЗОВАНИЕ ПАМЯТИ РАЗНЫХ УРОВНЕЙ
ПРИ ТРАНСЛЯЦИИ
Современные машины обычно имеют переменную конфигурацию оборудования, в частности переменный комплект запоминающих устройств. Поскольку простейший ассемблер мнемокода входит в состав минимального математического обеспечения, он должен быть рассчитан на работу с минимальной оперативной памятью. На большинстве машин минимальный объем оперативной памяти равен 16—64 Кбайт.
При небольшом объеме оперативной памяти в ней не удается одновременно разместить блоки ассемблера, транслируемую программу и промежуточную информацию, поэтому приходится использовать внешнюю память. Исходная программа на мнемокоде переписывается во внешнюю память в процессе ввода с перфокарт. Для ее хранения обычно применяют магнитный барабан или диск.
Блоки ассемблера постоянно хранятся на диске или магнитной ленте. В ходе трансляции они последовательно вызываются в оперативную память. Двухпросмотровый ассемблер естественно разделить по крайней мере на две части: первая часть вызывается при первом просмотре, а вторая — при втором. Промежуточная информация от первого просмотра ко второму передается через рассмотренные выше временные таблицы, некоторые из которых могут временно переписываться во внешнюю память.
Минимальный объем ассемблеров на современных машинах — 15—30 тыс. байт, что в 4—5 раз меньше объема трансляторов с языков высокого уровня (см. табл. 1.2),
94
В процессе первого и второго просмотров исходная программа вызывается в оперативную память по частям и записывается на фиксированное рабочее поле. При втором просмотре объектная программа формируется на другом рабочем поле, а листинг — на третьем. При заполнении двух последних рабочих полей они освобождаются путем вывода информации во внешнюю память или на перфокарты (на печать). Чтобы устранить задержки трансляции на время освобождения рабочих полей с выходной информацией и на время заполнения рабочего поля новой частью входной программы, рабочие поля можно дублировать. Тогда, пока ассемблер работает с одним экземпляром рабочего поля, другой экземпляр участвует в операциях ввода — вывода.
Необходимо подчеркнуть, что время трансляции существенно зависит от распределения информации и способа организации обмена между разными видами памяти в процессе трансляции. Слишком большие или, наоборот, слишком малые блоки ассемблера и рабочие поля могут сильно замедлить трансляцию за счет увеличения числа обменов с внешней памятью. В связи с этим следует заметить, что ассемблер, рассчитанный на небольшую память, может оказаться недостаточно эффективным по быстродействию при работе с большой памятью. Именно по этой причине в состав математического обеспечения ЕС ЭВМ включены разные ассемблеры: в ДОС/ЕС — ассемблеры Е и F. Для работы ассемблера Е достаточно иметь 14 Кбайт памяти, а для ассемблера F— 44 Кбайт. Естественно, ассемблер F работает быстрее.
33. МАКРОАССЕМБЛЕР
* 3.3.1. МАКРОЯЗЫК
Помимо машинных команд мнемокода, имеющих прямые аналоги в языке машины, и команд ассемблера, предназначенных для управления трансляцией, определения констант и выделения областей памяти, в развитых машинно-ориентированных языках используют также макрокоманды. В частности, макрокоманды можно применять в языке ассемблера ЕС ЭВМ.
Макрокомандой называют команду машинно-ориентированного языка (автокода), которая не имеет прямого аналога в языке машины и порождает в объектной программе группу машинных команд. Макрокоманды предназначены для упрощения программирования. путем краткого описания повторяющихся последовательностей команд. По существу, макрокоманды — это специфичная форма использования подпрограмм в машинно-ориентированных языках.
Макрокоманда, указывающая имя и значения аргументов требуемой подпрограммы, записывается в том месте исходной программы, где требуется выполнить подпрограмму. При трансляции
95
макрокоманда заменяется текстом подпрограммы, скорректированным в соответствии с заданными макрокомандой значениями аргументов. Следовательно, макрокоманды — средство использования открытых подпрограмм (см. 1.1).
Прототип текста подпрограммы на языке ассемблера задают с помощью макроопределения. Совокупность средств и правил записи макрокоманд и соответствующих им макроопределений образует макроязык, являющийся расширением языка ассемблера, поскольку он включает все средства языка ассемблера и дополнительные средства для записи и определения макрокоманд.
В зависимости от места нахождения макроопределения различают библиотечные макрокоманды, макрокоманды ассемблера и макрокоманды, определенные в программе.
Макроопределения для библиотечных макрокоманд составляют заблаговременно и хранят в специальной макробиблиотеке во внешней памяти машины. Обычно макробиблиотека содержит макроопределения часто употребляемых алгоритмов вычислительной математики и обработки данных.
Заметим, что в некоторых машинно-ориентированных языках предусмотрена возможность включения в программу библиотечных текстов без использования описываемых здесь макрокоманд. Например, в языке ассемблера ЕС ЭВМ имеется команда COPY (см. п. 3.1.4). Текст, имя которого указано в поле операндов оператора COPY, во время трансляции включается в исходную программу. Оператор COPY можно считать специфичной формой библиотечной макрокоманды без параметров.
Макроопределения для макрокоманд ассемблера, как правило, соответствуют системным макрокомандам, обеспечивающим связь программы пользователя с компонентами операционной системы. В частности, системные макрокоманды выполняют операции ввода— вывода и редактирования данных. Системные макрокоманды используются практически в каждой программе, поэтому обычно они определены непосредственно в ассемблере.
Библиотечные и системные макрокоманды доступны любой программе. Для использования этих макрокоманд достаточно записать их в исходной программе.
Различие между макробиблиотекой и обычной библиотекой стандартных подпрограмм (1.1) состоит в том, что:
библиотечные макрокоманды определены в макробиблиотеке на языке ассемблера и заменяются текстами соответствующих подпрограмм на этапе трансляции, в то время как обычные библиотечные подпрограммы объединяются с объектной программой на этапе загрузки или на этапе выполнения программы;
макробиблиотека состоит из открытых подпрограмм, а обычная библиотека стандартных подпрограмм — из замкнутых (1.1).
Макроопределения для макрокоманд, определенных в программе, разрабатываются программистом при составлении программы на языке ассемблера и помещаются непосредственно в ис-96
ходной программе. По назначению и структуре эти макроопределения подобны описаниям процедур в языке Алгол-60. Макроопределение содержит имя макрокоманды, описание ее формата и операндов, выполняющих роль параметров процедуры, а также описание последовательности операторов языка ассемблера, которой заменяется каждое вхождение макрокоманды. Последовательность операторов языка ассемблера имеет то же назначение, что тело процедуры.
Продолжая аналогию с Алголом-60, можно сказать, что макрокоманда имеет то же назначение, что оператор процедуры: она называет имя требуемой подпрограммы и указывает значения ее аргументов (параметров).
Различают позиционные макрокоманды, в которых операнды записывают в заранее определенном фиксированном порядке, как фактические параметры в операторе процедуры Алгола-60; ключевые макрокоманды, в которых операнды можно записывать в произвольном порядке; смешанные макрокоманды, сочетающие свойства позиционных и ключевых макрокоманд.
Наиболее просты позиционные макрокоманды. Недостатком их является жесткая структура, вынуждающая каждый раз выписывать в макрокоманде все операнды. Этого недостатка лишены ключевые макрокоманды, в которых для параметров можно указать стандартные значения. Это позволяет записывать лишь нестандартные операнды.
3.3.2. МАКРООПРЕДЕЛЕНИЯ
Макроопределение служит для указания ассемблеру имени, формата и операндов макрокоманды, а также выполняемых ею-действий. Операнды макрокоманды представлены в макроопределении параметрами. При трансляции параметры заменяются значениями операндов, указанными в макрокоманде.
В разных макроязыках применяют различные правила записи макроопределений. Типовыми можно считать правила, установленные в макроязыке ЕС ЭВМ. Ниже с некоторыми упрощениями рассматриваются основные черты макроязыка ЕС ЭВМ в объеме, позволяющем изложить основы устройства макроассемблеров.
Макроопределение должно предшествовать в программе любому вхождению соответствующей макрокоманды. Начало и конец макроопределения обозначают специальными псевдокомандами. В макроязыке ЕС ЭВМ начало макроопределения задает оператор MACRO, который имеет формат
Название Операция Операнды
Пробел MACRO Пробел
4 Зак. 221
07
а конец макроопределения — оператор MEND с форматом
Название Операция Операнды
Пробел MEND Пробел
Макроопределение включает:
оператор MACRO, являющийся первым оператором макроопределения;
оператор прототипа, занимающий вторую и, быть может, несколько последующих строк макроопределения;
тело макроопределения (один или несколько операторов языка ассемблера), иначе модель;
оператор MEND, являющийся последним оператором макроопределения.
Соответственно типам макрокоманд различают позиционные, ключевые и смешанные макроопределения, отличающиеся только правилами записи оператора прототипа.
Оператор прототипа определяет имя макрокоманды, ее формат и параметры. Любая макрокоманда в программе, соответствующая данному макроопределению, должна иметь имя и формат, установленный оператором прототипа.
Оператор прототипа позиционного макроопределения имеет формат
Название Операция Операнды
Параметр или пробел Имя макрокоманды Список параметров
Имя макрокоманды есть идентификатор, содержащий не более восьми букв и цифр. Параметр состоит из знака амперсенда &, за которым следует начинающаяся с буквы последовательность не более семи букв и цифр. Список параметров в макроязыке ЕС ЭВМ может содержать от 0 до 100 параметров, разделенных запятыми. Естественно, такой список иногда приходится записывать в нескольких строках стандартного бланка. Признаком продолжения списка в следующей строке служит запятая, заканчивающая строку, и знак, отличный от пробела, в колонке указателя продолжения. Признаком окончания оператора прототипа является пробел после параметра и отсутствие указателя продолжения (только пробел после параметра означает окончание списка параметров, но еще в нескольких строках может продолжаться комментарий, относящийся к оператору прототипа). Комментарий можно записывать
98
в каждой строке оператора прототипа, отделяя его от элементов списка параметров хотя бы одним пробелом.
Заметим, что употребление особого начального знака (&) облегчает распознавание параметров, позволяет соединять несколько параметров в один и ускоряет трансляцию.
Имя макрокоманды не должно совпадать с мнемоникой машинной команды и псевдокоманды или именем другой макрокоманды.
• Тело макроопределения указывает действия, выполняемые макрокомандой, и представляет собой последовательность операторов языка ассемблера, которая определяет прототип текста, вставляемого в программу вместо макрокоманды при трансляции.
Параметры могут входить в поле названия, операции, операндов и комментария. При замене макрокоманды текстом тела макроопределения параметры заменяются значениями, указанными макрокомандой, всюду, кроме комментария. Текст комментария не изменяется.
Пример 1. Макрокоманда MOVE (табл. 3.4) порождает последовательность операторов языка ассемблера, выполняющую пересылку содержимого слова из одного места основной памяти в другое. Содержимое общего регистра 2, используемого при пересылке, вначале «спасается», а затем восстанавливается.
В порождаемом тексте параметры &NAME, &А, &В и &С заменены соответственно именами М, Л1, А2 и АЗ, указанными в макрокоманде, а комментарий остался без изменений.
Таблица 3.4
ПРИМЕР ТРАНСЛЯЦИИ МАКРОКОМАНДЫ MOVE
Пояснения Название Операция Операнды комментарий
начало MRCRO
Прототип &NHME Move &B,&B,&C
тело &NHME ST 2,&C &C :~(2)
L 2,&H (2):-&B
ST 2,&B &B : =
L 2,&C (2) : = &C
конец MEND
макрокоманда М MOVE яг,нз
Порождаемый текст М ST 2. ЯЗ &C ‘='(2)
L ' 2,01 (2) • = &/)
ST 2,Д2 SB
L 2,ДЗ (2) : = &C
4*
99
Если в макрокоманде позиция операнда пуста, то при трансляции соответствующий параметр заменяется пустым значением. Допускается также соединение нескольких параметров и соединение параметра с неизменяемой частью имени или мнемоники команды.
Пример 2. Макрокоманду MOVEI можно использовать для пересылки слов и двойных слов (табл. 3.5). Поскольку в макрокомандах имя в поле названия опущено, в порождаемых текстах позиция параметра & NAME пуста. Аналогично пропуск первого операнда в макрокоманде пересылки слов приводит к пустым позициям параметра & V.
Таблица 3.5
ПРИМЕР ТРАНСЛЯЦИИ МАКРОКОМАНДЫ MOVEI
Пояснение назЬоние Операция Операнды
начало мяско
прототип &НЯМЕ MOVE1 &в,
тело &NHME ST&V г^с
L&V 2,М
ST&V 2,&8
L&V 2^0
конец MEND
макрокоманда MOVE! ,Х7, Y1. К1
порождаемый текст (пересылка слаб) ST 2, К1
L 2, Х1
ST 2, Y1
L 2, К1
макрокоманда MOVE1 D, Х2, Y2, К2
порождаемый текст (пересылка двойных слов) STD 2, кг
• LD 2, Х2
STD 2, Y2
LD г, кг
Оператор прототипа позиционного макроопределения устанавливает жесткий порядок записи операндов макрокоманды. В ключевых макрокомандах, напротив, операнды можно записывать в произвольном порядке, а некоторые операнды вообще можно явно йе записывать. Это достигается введением стандартных значений параметров. Если в макрокоманде не указано значение параметра, то при трансляции этот параметр заменяется стандартным значе
100
нием (с этих позиций можно считать, что стандартным значением позиционного параметра является пустое значение). Следовательно, в ключевой макрокоманде нужно записывать только те операнды, которые задают нестандартные значения параметров.
В операторе прототипа ключевого макроопределения список параметров записывается иначе, чем в позиционном макроопределении: после каждого параметра (ключевого слова) в списке следует знак равенства и при необходимости стандартное значение.
В ключевой макрокоманде каждому выписываемому явно операнду должно предшествовать ключевое слово, за которым следует знак равенства. Ключевое слово в макроопределении и макрокоманде записывают так же, как позиционный параметр, начиная знаком амперсенда &.
Пример 3. В габл. 3.6 записано ключевое макроопределение для макрокоманды MOVE\ из примера 2. Параметр &С имеет стандартное значение, равное Л. Стандартные значения остальных параметров пусты. Кроме макроопределения, в табл. 3.6 приведена макрокоманда и порождаемый ею текст. Макрокоманда определяет только имена пересылаемых слов, остальные параметры получают стандартные значения. z
Таблица 36
ПРИМЕР КЛЮЧЕВОГО МАКРООПРЕДЕЛЕНИЯ И МАКРОКОМАНДЫ
Пояснение наздание Операция Операнды
начало MHCR0
Прототип &NRME MOVE1
тело &NHME ST&V 2. &C
L&V 2,&Я
ST&V 2. ZB
L&V 2. ZD
конец MENO
макрокоманда M0VE1 &H=X,g,B=Y
Порождаемый текст ( пересылка слов) st 2, К
L г.х
ST 2,Y
L 2, К
В операторе прототипа смешанного макроопределения используют как позиционные, так и, ключевые параметры. Все позиционные параметры должны предшествовать первому ключевому параметру. Аналогично записывается смешанная макрокоманда:
101
вначале выписываются все позиционные операнды, а затем — все ключевые.
Некоторые операторы в теле макроопределения могут быть макрокомандами, их называют внутренними. Макрокоманду, не содержащуюся в тексте макроопределения, называют внешней. При
Исходная программа
Программа после замены макрокоманд
Внутренняя макрокоманда
Внешняя макрокоманда
макроопределение внешней макрокоманды
Макроопределение внутренней макрокоманды
Текст, соответствующий
Текст, соответствующий внешней макрокоманде
Рис. 3.13. Замена внешних и внутренних макрокоманд
5 внутренней макрокоманде
замене внешней макрокоманды порождаемым ею текстом, прототип которого содержится в ее макроопределении (рис. 3.13), внутренняя макрокоманда заменяется текстом из своего макроопределения.
3.3.3. МАКРОГЕНЕРАТОР
Транслятор, предназначенный для перевода программ с макроязыка на язык машины или язык загрузки, называют макроассемблером. Обычно макроассемблер состоит из двух последовательно работающих частей (рис. 3.14): первая — макрогенератор — переводит программу с макроязыка на язык ассемблера (мнемокод), а вторая — ассемблер — переводит программу на язык машины. Двухступенчатая схема трансляции упрощает конструкцию макроассемблера и существенно облегчает его разработку. Как отмечалось в начале этой главы, при создании системы программирования для новой машины в первую очередь разрабатывают ассемблер для простейшего мнемокода. Это дает возможность программировать макрогенератор на мнемокоде. После отладки программу
102
макрогенератора на языке машины объединяют с ассемблером и получают макроассемблер.
Макроассемблер в свою очередь можно использовать при разработке трансляторов с языков более высокого уровня. Такой метод применения разработанных ранее относительно простых компонент математического обеспечения при создании более сложных
компонент значительно сокращает трудовые затраты на создание математического обеспечения. Иногда этот метод называют «раскруткой» [18].
Макрогенератор заменяет макрокоманды текстами на языке
ассемблера, прототипы которых содержатся в соответствующих
макроопределениях. Каждый текст редактируется применительно к конкретной макрокоманде с учетом значений ее операндов. Редактирование заключается в замене каждого параметра значением соответствующего операнда и в замене каждого внутреннего имени, определенного в теле макроопределения, перемещаемым выражением вида
* zt i.
Замена внутренних имен нужна для того, чтобы избежать переопределения внутренних имен при многократном использовании одной и той же
Рис. 3.14. Макроассемблер
макрокоманды в программе. Дело в
том, что при редактировании тела
макроопределения заменяются только параметры, остальные имена переносятся в отредактированный текст без изменения. Если внутренние имена не будут заменены, в разных частях программы на языке ассемблера, порожденных разными вхождениями одной и той же макрокоманды, будут определены одни и те же имена. Это будет истолковано ассемблером как ошибка.
По тем же причинам, по которым в ассемблере приходится применять двухпросмотровую схему трансляции, для замены внутренних имен требуется дважды просмотреть тело каждого макроопределения. Во время первого просмотра выявляются все внутренние имена и определяются их адреса относительно начала тела макроопределения. При втором просмотре внутренние имена в операндах заменяются относительными выражениями. Из поля названия внутренние имена удаляются. Эту работу для каждого макроопределения нужно выполнить только один раз, в то время как замену параметров значениями операндов макрокоманды приходится повторять вновь для каждого вхождения макрокоманды. В связи с этим в макрогенераторе обработку макроопределений и обработку макрокоманд выполняют два различных блока.
103
Заметим, что ассемблеры ЕС ЭВМ являются, по существу, макроассемблерами. Входящий в их состав макрогенератор наряду с заменой макрокоманд заменяет также операторы COPY текстами из библиотеки. Одна из возможных схем макрогенератора показана на рис. 3.15. Эта схема предполагает однократный просмотр исходной программы.
1. Блок начала работы приводит в исходное состояние счетчик адреса оператора, восстанавливает рабочие ячейки и очищает рабочее поле для таблиц макрогенератора.
2. Блок управления трансляцией последовательно просматривает операторы исходной программы и определяет, когда должен работать блок обработки макроопределений, когда — блок обработки макрокоманд, а когда нужно просто пропустить очередной
Рис. 3.15. Схема макрогенератора
оператор, поскольку он не входит в макроопределение и не является макрокомандой. Работа макрогенератора заканчивается при появлении псевдокоманды END.
3. Блок обработки макроопределений дважды просматривает каждое макроопределение, описанное в программе, и формирует временные таблицы макрогенератора.
4. Блок обработки макрокоманд, используя таблицы, подготовленные блоком обработки макроопределений, заменяет каждое вхождение макрокоманды соответствующим текстом на языке ассемблера.
Описываемый здесь макрогенератор предназначен для трансляции макрокоманд, определенных в программе, и библиотечных макрокоманд (оператор COPY можно считать частным случаем библиотечной макрокоманды). Макрокоманды ассемблера, обеспечивающие связь с операционной системой, определены в самом ассемблере и обычно транслируются непосредственно в команды машины на этапе генерирования машинных команд (3.2).
3.3.4. ТАБЛИЦЫ МАКРОГЕНЕРАТОРА
Макрогенератор использует две постоянные таблицы: таблицу операций, содержащую мнемонические обозначения всех операций мнемокода, включая обозначения макрокоманд ассемблера, и 104
каталог макробиблиотеки, в котором указаны имена и адреса хранения библиотечных макроопределений.
В ходе трансляции блок обработки макроопределений создает пять временных таблиц: таблицу позиционных параметров, таблицу внутренних имен, таблицу ключевых параметров, таблицу описаний макрокоманд и таблицу макрокоманд.
Две первые таблицы нужны только в процессе обработки макроопределения. В трех последних таблицах фиксируется результат работы блока обработки макроопределений. Эти таблицы используются затем блоком обработки макрокоманд.
ТАБЛИЦА ПОЗИЦИОННЫХ ПАРАМЕТРОВ
Позиционный параметр
ТАБЛИЦА ВНУТРЕННИХ ИМЕН
Имя Адрес
ТАБЛИЦА МАКРОКОМАНД
Имя макрокоманды Указатель таблицы ключевых параметров Указатель таблицы описаний макрокоманд Число позиционных параметров
адрес длина адрес длина
ТАБЛИЦА КЛЮЧЕВЫХ ПАРАМЕТРОВ
Ключевое слово Стандартное значение
ТАБЛИЦА ОПИСАНИИ МАКРОКОМАНД
Имя Операция Операнды Комментарий
Рис. 3.16. Временные таблицы макрогенератора
Структура и связи временных таблиц макрогенератора показаны на рис. 3.16.
Таблица позиционных параметров заполняется при обработке оператора прототипа. Это просто перечень всех позиционных параметров. Каждый параметр размещается в одной строке таблицы.
Таблица внутренних имен заполняется при первом просмотре тела макроопределения. Она содержит все имена, определенные в теле макроопределения, и их относительные адреса.
Таблица ключевых параметров, как и таблица позиционных параметров, заполняется при обработке оператора прототипа. Строка
105
этой таблицы содержит ключевое слово и стандартное значение, если оно есть, для каждого ключевого параметра.
Таблица описаний макрокоманд содержит тексты тел макроопределений, подготовленные для использования в блоке обработки макрокоманд. Формат записей этой таблицы такой же, как формат операторов исходной программы.
Таблица макрокоманд является каталогом всех макрокоманд, определенных в программе. Записи этой таблицы содержат для каждой макрокоманды имя, указатели места расположения таблиц ключевых параметров и описаний макрокоманд, длину этих таблиц и число позиционных параметров.
Блок обработки макрокоманд использует таблицы, созданные блоком обработки макроопределений, и формирует еще одну временную таблицу — таблицу позиционных операндов, аналогичную таблице позиционных параметров.
3.3.5. БЛОК УПРАВЛЕНИЯ ТРАНСЛЯЦИЕЙ
Для управления просмотром исходной программы и трансляцией используются счетчик адреса оператора и переменная состояния, которая может принимать три значения: «обычный оператор», «оператор прототипа», «тело макроопределения».
От блока начала работы
Рис. 3.17. Блок управления трансляцией макрогенератора
106
Перед началом трансляции блок начала работы очищает рабочие поля, устанавливает в исходное состояние счетчик адреса оператора, присваивает переменной состояния значение «обычный оператор» и передает управление блоку управления трансляцией (рис. 3.17).
Блок управления трансляцией обеспечивает: последовательный просмотр операторов исходной программы; установку значения переменной состояния «оператор прототипа» при появлении псевдокоманды MACRO;
передачу управления блоку обработки макрокоманд, если переменная состояния имеет значение «обычный оператор» и мнемоника в поле операции очередного оператора не совпадает с мнемоникой машинной команды, псевдокоманды или макрокоманды ассемблера;
передачу управления ассемблеру при появлении псевдокоманды END.
3.3.6. БЛОК ОБРАБОТКИ МАКРООПРЕДЕЛЕНИЙ
Этот блок (рис. 3.18) получает управление от блока управления трансляцией при обнаружении в программе макроопределения. Если переменная состояния имеет значение «прототип», то обрабатывается оператор прототипа (блок 2). Обработка начинается с занесения параметра из поля названия, если он есть, в таблицу позиционных параметров. Имя макрокоманды, следующее за полем названия, переносится в таблицу макрокоманд. Если в операторе прототипа имеются позиционные параметры, то они непосредственно следуют за именем макрокоманды. Эти параметры последовательно переносятся в таблицу позиционных параметров. Одновременно подсчитывается число позиционных параметров. Появление параметра, после которого следует знак равенства или пробел, служит сигналом окончания формирования таблицы позиционных параметров.
Если после параметра следует знак равенства, этот параметр заносится в таблицу ключевых параметров в качестве ключевого слова вместе со стандартным значением, если оно есть. Запятая после последнего в строке параметра и знак, отличный от пробела в колонке указателя продолжения, означают, что прототип макрокоманды продолжается в следующей строке. В этом случае управление возвращается блоку управления трансляцией, который выбирает очередную строку исходной программы, после чего трансляция оператора прототипа продолжается.
Пробел после последнего в строке параметра — признак окончания оператора прототипа. В этом случае переменная состояния получает значение «тело макроопределения» и управление передается блоку управления трансляцией (блок 4).
107
Результат обработки оператора прототипа — таблицы позиционных и ключевых параметров.
Если переменная состояния имеет значение «тело макроопределения», то происходит первый просмотр текста тела макроопределения, в ходе которого операторы последовательно накапливаются на рабочем поле для временного хранения (блок 6). Одновременно просматривается поле названия и имя из поля названия,
От блока
Рис. 3.18. Блок обработки макроопределений
если оно есть, заносится в таблицу внутренних имен вместе с относительным адресом, отсчитываемым от первого оператора тела Макроопределения.
Первый просмотр заканчивается, когда появляется псевдокоманда MEND (блок 5). В этот момент все операторы тела макроопределения находятся на рабочем поле, и сформирована таблица внутренних имен. Теперь переменная состояния получает значение «обычный оператор», и формируется строка таблицы макрокоманд (блок 7).
Второй просмотр (блок 8) происходит без обращения к блоку управления трансляцией. Операторы тела макроопределения последовательно извлекаются из рабочего поля, на которое они были записаны во время первого просмотра. В каждом операторе параметры заменяются ссылками на таблицы позиционных и ключевых параметров. Одновременно с помощью таблицы внутренних 108
имен каждое внутреннее имя в поле операндов заменяется пере* мещаемым выражением вида
* 4“ -^тви —
где Дтви —относительный адрес внутреннего имени, а А — текущее значение счетчика адреса, отвечающее рассматриваемому оператору.
Обработанные операторы переписываются в таблицу описаний макрокоманд, причем внутренние имена в поле названия уничтожаются. Второй просмотр заканчивается после обработки всех операторов тела макроопределения.
3.3.7. БЛОК ОБРАБОТКИ МАКРОКОМАНД
Обнаружив в поле операции очередного оператора код, которого нет в таблице операций, блок управления трансляцией считает этот код именем макрокоманды и передает управление блоку обработки макрокоманд (рис. 3.19).
При обработке макрокоманд используется переменная «уровень», равная нулю в начале обработки любой внешней макрокоманды. Появление каждой внутренней макрокоманды увеличивает значение этой переменной на единицу. После окончания обработки внутренней макрокоманды значение «уровня» уменьшается на единицу. Следовательно, переменная «уровень» фиксирует «глубину вложенности» обрабатываемой макрокоманды, обеспечивая тем самым обработку вложенных макрокоманд.
При входе в блок обработки макрокоманд переменной «уровень» присваивается значение нуль, одновременно восстанавливается начало рабочего поля (блок 1), на котором размещаются временные таблицы, используемые при обработке макрокоманды.
В исходной программе макроопределение всегда предшествует макрокоманде, поэтому в момент появления любой макрокоманды ее имя должно находиться в таблице макрокоманд или каталоге макробиблиотеки. Вначале просматривается таблица макрокоманд (блок 2). Если имя найдено, строка таблицы макрокоманд заносится на рабочее поле (блок 4). Имеющиеся в этой строке данные о числе позиционных параметров, а также о местоположении и длине таблицы ключевых параметров используются для выделения на рабочем поле места для размещения таблицы позиционных операндов и копии таблицы ключевых параметров, которая после заполнения становится таблицей ключевых операндов. Выделенные области и начало свободной части рабочего поля фиксируются в указателях рабочего поля (блок 5).
Далее просматривается макрокоманда. Позиционные операнды последовательно переносятся в таблицу позиционных операндов (блок 6) в те же позиции, в которых при обработке макроопределения помещались соответствующие параметры. Значения
109
От блока
Рис. 3.19. Блок обработки макрокоманд
ключевых операндов записываются в колонку «стандартное значение» копии таблицы ключевых параметров (см. рис. 3.16). Следовательно, имеющиеся в этой колонке стандартные значения сохраняются лишь для тех ключевых параметров, которые не указаны в макрокоманде.
Теперь начинается замена макрокоманды операторами из таблицы описаний макрокоманд, указатель начала которой имеется, в строке таблицы макрокоманд, записанной блоком 4 на рабочее поле. В каждом операторе описания макрокоманды ссылки па таблицы позиционных и ключевых параметров заменяются соответствующими значениями операндов макрокоманды (блок 13) из таблиц позиционных и ключевых операндов, сформированных блоком 6. Отредактированные операторы переносятся в объектную программу макрогенератора.
Если очередной оператор описания макрокоманды оказывается внутренней макрокомандой (блок 8), то переменная «уровень» увеличивается на единицу (блок 9) и, начиная с блока 2, повторяется уже описанная процедура. Поскольку теперь используется новое начало рабочего поля, установленное в блоке 5, таблицы операндов внутренней макрокоманды формируются в блоке 6 на новом месте, а соответствующие таблицы внешней макрокоманды сохраняются. Иными словами, рабочее поле организовано по принципу стека. Это обеспечивает возврат к продолжению обработки внешней макрокоманды после завершения обработки внутренней. Возврат осуществляет блок 15, который не считает трансляцию макрокоманды завершенной до тех пор, пока «уровень» не станет равным нулю. Для продолжения трансляции внешней макрокоманды восстанавливаются указатели рабочего поля, одновременно переменная «уровень» уменьшается на единицу (блок 16).
Обработка библиотечных макрокоманд, по существу, не имеет особенностей, если считать, что библиотечные макроопределения перед записью в макробиблиотеку редактируются блоком обработки макроопределений так, как это описано в п. 3.3.6, с формированием соответствующих таблиц. В противном случае при первом появлении библиотечной макрокоманды нужно обработать ее макроопределение блоком обработки макроопределений с занесением имени библиотечной макрокоманды в таблицу макрокоманд и формированием остальных таблиц.
Если имя предполагаемой макрокоманды не найдено ни в таблице макрокоманд, ни в каталоге макробиблиотеки, этот факт фиксируется в таблице ошибок (блок 12). После окончания обработки самой внешней макрокоманды управление возвращается блоку управления трансляцией (блок 15, выход «да»).
Описанная схема макроассемблера не является единственно возможной. Например, на макрогенератор можно возложить только обработку макроопределений. В этом случае блок обработки макрокоманд нужно включить в ассемблер.
111
ГЛАВА 4
ПРЯМЫЕ МЕТОДЫ ТРАНСЛЯЦИИ
4.1. ПРОЦЕДУРНО-ОРИЕНТИРОВАННЫЕ ЯЗЫКИ
4.1.1. АЛГОЛ-60
Алгол-60 — наиболее распространенный в СССР и ряде других стран язык для решения задач вычислительной математики. Этот язык является .типичным представителем класса процедурно-ориентированных языков и достаточно хорошо известен читателю, поэтому методы трансляции с языков высокого уровня, излагаемые в этой главе, описываются применительно к этому языку. Ниже отмечаются некоторые особенности языка с точки зрения составителей трансляторов.
Важнейшим отличием языка Алгол-60 от предшествовавших ему языков, например Фортрана, является строго формальное определение синтаксиса. В официальном описании языка [1] для определения синтаксиса впервые были использованы металингвистические формулы, предложенные Дж. Бэкусом. Синтаксис доалго-ловских языков, как правило, не был точно определен. Фактически язык определялся предназначенным для него транслятором, действие которого при трансляции некоторых конструкций языка нельзя было заранее предсказать.
Точное определение синтаксиса способствовало единообразному пониманию правил языка различными пользователями и составителями трансляторов, сделало язык в значительной степени независимым от машины, облегчило обмен алгоритмами и создало основу для разработки формальных, машинно-независимых методов трансляции.
В противоположность синтаксису семантика языка Алгол-60 описана неформально. Это приводит в некоторых случаях к возможности неоднозначного истолкования отдельных конструкций языка и, самое главное, препятствует полной формализации процесса составления трансляторов.
Другой важной особенностью Алгола-60 является его рекурсив-ность. Большинство конструкций языка определено рекурсивно, т. е. конструкции языка могут включать в явном виде конструкции того же типа. Например, блок может содержать внутренние блоки, оператор—другие операторы того же или другого типа, элементы 112
арифметических выражений, такие, как индексы и параметры указателей функций, могут вновь быть арифметическими выражениями. Следует отметить, что рекурсивность отвечает самой природе алгоритмов вычислительной математики. Рекурсивные конструкции облегчают программирование вычислительных задач, способствуют наглядности и выразительности записи алгоритмов. Однако трансляция рекурсивных конструкций предъявляет специфичные требования к методам трансляции. Создатели первых трансляторов с языка Алгол-60 вынуждены были разработать специальные приемы обработки рекурсивных конструкций.
Наконец, еще одним характерным свойством языка Алгол-60 является блочная структура программы. Блок определяет область действия описаний переменных, массивов, процедур и меток. Это позволяет экономно использовать память при выполнении программы. Но для реализации этой возможности нужно предусмотреть динамическое перераспределение памяти в процессе исполнения программы при входе в каждый новый блок. Транслятор должен обеспечить программирование соответствующих действий в объектной программе.
Появление языка Алгол-60 явилось крупным шагом вперед в деле внедрения процедурно-ориентированных языков высокого уровня. Язык быстро завоевал широкое международное признание. В настоящее время практически все машины универсального назначения в СССР и большинство зарубежных машин имеют трансляторы с языка Алгол-60. На основе Алгола-60 создано несколько процедурно-ориентированных языков для решения экономических и экономико-математических задач (Алгэм, Алгэк), для решения задач моделирования (Симула) и для других специфичных применений.
Высокая степень независимости от машины является важным преимуществом Алгола-60. Однако эта независимость имеет и теневые стороны. Полная независимость от машины привела к тому, что эталонный Алгол-60 стал алгоритмическим языком, языком для записи алгоритмов, а не языком программирования. Непосредственно эталонный язык не может быть использован в качестве языка программирования для современных машин потому, что в нем отсутствуют некоторые необходимые средства, превращающие алгоритм в программу. В частности, в эталонном языке [1] не определены стандартные средства ввода — вывода данных и обмена между разными запоминающими устройствами, не установлены стандартные форматы вводимых и выводимых данных и средства описания форматов, отсутствуют средства сегментации программ и данных, а также средства отладки. Правда, в 1964 г. в качестве дополнения к эталонному языку были предложены стандартные процедуры и форматы ввода — вывода [28], но они появились со значительным опозданием, когда многие трансляторы уже были введены в эксплуатацию, поэтбму вновь предложенные средства не получили широкого распространения.
ИЗ
Отсутствие стандартов на перечисленные средства привело к тому, что в каждом трансляторе в качестве входного языка используется индивидуальный диалект Алгола-60. Входные языки для разных трансляторов не совпадают даже для одной и той же машины. Поэтому программу, составленную на входном языке одного транслятора, нельзя транслировать другим транслятором. Не случайно публикуемые в литературе алгоритмы на Алголе-60 всегда оформляются в виде процедур, а не в виде готовых программ.
С другой стороны, независимость Алгола-60 от машины в ряде случаев приводит к чрезмерному усложнению алгоритмов трансляции и к снижению качества рабочих программ. Стремление составителей трансляторов упростить транслятор и повысить качество объектных программ вынуждает их отказываться от реализации некоторых свойств Алгола-60 и, следовательно, порождает еще большее разнообразие диалектов языка. Для обеспечения совместимости различных диалектов Алгола-60 в 1964 г. было предложено «Подмножество Алгол-60» [28] — стандартный упрощенный вариант языка. В 1968 г. опубликован язык Алгамс [24], принятый в СССР и странах СЭВ в качестве стандартной версии Алгола-60. Алгамс является подмножеством Алгола-60, дополненным средствами ввода — вывода и обмена.
4.1.2. ФОРТРАН
Фортран — процедурно-ориентированный язык для записи алгоритмов и программ решения вычислительных задач. Первоначальный вариант Фортрана был разработан сотрудниками фирмы ИВМ в 1954 г. Это был первый процедурно-ориентированный язык высокого уровня, получивший широкое распространение. В 1957 г. появился первый компилятор Фортрана для машины ИБМ-704. Разработка его потребовала 18 человеко-лет. Фортран неоднократно совершенствовался, уже к 1964 г. было опубликовано несколько версий языка (Фортран I, Фортран II, Фортран IV) и множество диалектов. По существу, на каждой машине использовался свой диалект Фортрана, это создавало большие неудобства, поэтому в 1964 г. Американской ассоциацией стандартов был предложен «Стандарт языка Фортран» [23], который, впрочем, не прекратил использования других версий языка.
В настоящее время Фортран — широко распространенный язык программирования. Компиляторами Фортрана оснащены практически все машины универсального назначения, выпускаемые в США и Японии, а также большинство западноевропейских машин. По распространенности Алгол-60 занимает второе место после Фортрана.
В последние годы Фортран наряду с Алголом-60 начали применять также в СССР. Имеются системы программирования, основанные на Фортране, для машин «Минск-22», «Минск-32», М-220 и БЭСМ-6. Разработан транслятор Фортрана для универсальной си-114
стемы программирования Института прикладной математики АН СССР, который позволяет программировать и решать задачи на машине М-220 и некоторых других, где внедрена универсальная система программирования. Компиляторами Фортрана комплектуются также машины ЕС ЭВМ.
Широкое распространение Фортрана объясняется наличием в нем средств, позволяющих более полно, чем в Алголе-60, использовать возможности оборудования современных машин. В частности, Фортран имеет развитые средства описания форматов вводимых и выводимых данных как числовых, так и текстовых. Имеются средства управления магнитными лентами, а также удобный аппарат сегментирования больших программ. Системы программирования, основанные на Фортране, обеспечивают объединение сегментов после их независимой трансляции. Некоторые конструкции Фортрана проще соответствующих конструкций Алгола-60 и лучше приспособлены к особенностям современных машин. Это упрощает разработку компиляторов и, по мнению ряда специалистов, дает более высокую в среднем эффективность объектных программ, чем в языке Алгол-60. Наряду с этим имеются дополнительные по сравнению с Алголом-60 средства, облегчающие программирование некоторых вычислительных задач: комплексные переменные, удвоенная точность представления чисел и выполнения операций.
В Фортране хорошо развит аппарат функций и процедур, имеется более богатый, чем в Алголе-60, набор стандартных функций. Кроме того, на языке Фортран накоплена обширная библиотека стандартных алгоритмов, которая существенно повышает производительность труда программистов.
Фортран, являясь процедурно-ориентированным языком высокого уровня, в то же время имеет некоторые черты, свойственные машинно-ориентированным языкам (автокодам). Например, в Фортране стандартизован формат записи исходной программы. Для записи программы используются специальные бланки, подобные бланкам для автокода. Поля бланка жестко распределены для записи меток, операторов и вспомогательных символов. Стандартизовано также расположение входной программы на перфокартах. Это упрощает входной блок компилятора.
Наличие в Фортране средств управления вводом — выводом и обменом с внешними запоминающими устройствами позволяет непосредственно использовать Фортран (в отличие от Алгола-60) в качестве входного языка систем программирования современных машин. В то же время запись алгоритмов на Фортране менее выразительна, чем на Алголе-60, поэтому Алгол-60 чаще используют в качестве языка публикаций в литературе по программированию.
Наиболее существенный недостаток Фортрана заключается в неформальном, нестрогом определении синтаксиса. В этом отношении Фортран уступает Алголу-60. По этой причине конструкции Фортрана редко рассматриваются в теоретических работах по программированию. Следует также отметить, что первоначальные вер
115
сии Фортрана были довольно бедны выразительными средствами, и, несомненно, Фортран достиг современного достаточно совершенного уровня под влиянием Алгола-60 и некоторых других языков.
4.1.3. ПЛ/1
Название этого языка происходит от сокращения английских слов Programming Language!One (язык программирования/один). Язык предложен сотрудниками фирмы ИБМ. Первоначальный вариант языка опубликован в 1964 г., с тех пор разработано несколько версий. Язык продолжает развиваться, но основные его черты уже сложились [15, 30].
По замыслу авторов ПЛ/1 — язык-оболочка (см. п. 1.2.3). В нем собраны средства, типичные для решения задач обработки данных (в частности, обработки экономической информации, обработки строк и списков, характерных для информационных задач), научно-технических задач вычислительного характера, задач управления объектами в реальном времени и задач системного программирования. Это многоцелевой язык, позволяющий, кроме всего прочего, использовать важнейшие особенности современных машин: прерывания, наличие нескольких уровней памяти и нескольких процессоров. Следовательно, ПЛ/1 сочетает черты основных процедурно-ориентированных и машинно-ориентированных языков.
Для конкретного класса задач нет необходимости использовать все средства языка, поэтому язык построен по модулярному принципу. Модулярность состоит в возможности образовывать специализированные подмножества языка путем почти механического отбрасывания ненужных для данных приложений языковых средств. Это облегчает изучение и практическое освоение языка, а также разработку трансляторов.
В одном отношении ПЛ/1 приближен к естественному языку больше, чем другие языки программирования: в ПЛ/1 широко используется «интерпретация умолчания», которая состоит в том, что если применяемый в программе объект может иметь одно из нескольких свойств, но программист не указал, какое свойство имеется в виду, то автоматически будет выбрано свойство, наиболее вероятное в данном контексте. Принцип умолчания упрощает программу, хотя, естественно, усложняется транслятор. Принцип умолчания иногда применялся и в других языках. В качестве примеров можно сослаться на опускание знака «+» перед положительными константами, опускание описателя real перед словом array в Алголе-60. Однако в языке ПЛ/1 этот принцип применяется более широко и последовательно.
На выбор средств языка ПЛ/1 оказали влияние такие высокоразвитые языки, как Фортран, Алгол-60 и Кобол. Однако в ПЛ/1 имеются и специфичные средства.
1. Структура программы. Программа состоит из независимых программных единиц (так же устроена программа на Фортране).
116
Программные единицы называют в ПЛ/1 внешними процедурами. Внешние процедуры имеют имена (метки) и могут транслироваться независимо. Каждая внешняя процедура состоит из параллель-ных и вложенных друг в друга блоков, аналогичных по свойствам блокам Алгола-60: блок определяет область действия объявленных в нем имен. Различают обычные блоки и процедурные блоки. Процедурный блок — аналог процедуры Алгола-60. Внешняя процедура— процедурный блок, не входящий ни в какие другие блоки. Обратиться к процедурному блоку можно только по имени, в то . время как обычные блоки исполняются в естественном порядке.
2. Типы данных. Язык ПЛ/1 отличается большим разнообразием типов данных. Различают рабочие и управляющие данные.
Рабочие данные делятся на арифметические (вещественные и комплексные числа) и строковые (символьные и битовые строки). Битовые строки, в частности, заменяют логические величины, которые отдельно в ПЛ/1 не выделены.
К управляющим данным относят данные типа метка, ветвь (имя ветви распараллеливаемого вычислительного процесса), указатель (адрес хранения переменной), область (имя области памяти) и некоторые другие. Все эти типы данных могут быть переменными или константами, их называют элементами данных или скалярными данными.
3. Организация данных. Элементы данных могут объединяться в массивы и структуры. Массив аналогичен массиву Алгола-60 и обязательно состоит из однотипных скалярных данных одинакового класса и размера.
Понятие структуры в языке ПЛ/1 совпадает с общим понятием структуры в системном программировании (см. п. 2.1.1). Структура есть иерархически упорядоченная совокупность скалярных данных, массивов и структур, иными словами, элементы структуры могут быть разнотипны. К элементам структуры обращаются с помощью составных имен, которые образуются объединением имен всех иерархически старших элементов, содержащих данный элемент.
Структуры значительно облегчают программирование задач обработки данных. Например, с помощью структуры легко задать форму таблицы или ведомости с заголовками и подзаголовками. Вообще структуры полезны при обработке символьной информации.
Полезным нововведением языка ПЛ/1 для массивов является понятие сечения. Сечение получается, если заменить один или несколько индексов элемента массива знаком « * ». Этот знак означает, что индекс принимает все значения между граничными. Например, Л(3, *) — третья строка массива А; А(*9 *) —весь массив А; В(*, *, 2) — двумерное сечение массива В.
4. Действия с данными. Действия с данными выполняются с помощью выражений. Выражение — это алгоритм, используемый для получения значения. Операндами и значениями выражения
117
могут быть скалярные данные, массивы и структуры. Заметим, что в Алголе-60 и Фортране выражениями могут быть только алгоритмы со скалярными операндами. Правда, в некоторых входных языках систем программирования, основанных на Алголе-60, например в языке Альфа [16], допустимы выражения с матрицами в качестве операндов, кроме того, в языке Альфа и в некоторых версиях Фортрана разрешены комплексные операнды, но это исключения. Возможность оперирования с массивами и структурами существенно повышает выразительность программ на языке ПЛ/1 и снижает трудоемкость программирования.
5. Описания данных. Описания в ПЛ/1, как и в других языках высокого уровня, служат для указания типа данных и их характеристик (формата, разрядности, размерности, системы счисления и др.). Описания могут быть явными, как в Алголе-60, а также неявными и контекстуальными, когда свойства объектов опреде-, ляются по принципу умолчания. Область действия описания, как и в Алголе-60, — блок.
6. Процедуры. Аппарат процедур впервые стал широко использоваться в Алголе-60. Процедуры (подпрограммы) введены также в поздних версиях Фортрана. В языке ПЛ/1 процедуры делятся на процедуры-функции и процедуры-подпрограммы. В отличие от Фортрана допускаются рекурсивные процедуры, как в Ал-голе-60.
7. Динамика выполнения программы. Блочная структура программы требует в общем случае динамического распределения памяти для параллельных блоков, входящих во внешний блок. Для внешнего блока память распределяется статически (в период трансляции).
Средства ПЛ/1 позволяют программно организовать параллельную мультипроцессорную обработку за счет указания ветвей программы, которые могут выполняться параллельно. Кроме того, имеются средства использования программистом прерываний, а также средства отладки программ путем использования прерываний и специальных операторов периода компиляции, позволяющих включать в программу отладочные вставки и задавать отладочные режимы исполнения программы.
8. Ввод — вывод. Средства ввода — вывода, имеющиеся в Фортране, значительно пополнены в ПЛ/1 за счет средств управления файлами, находящимися во внешней памяти и в каналах, а также средств редактирования записей при вводе и выводе, используемых обычно в системах обработки данных и в языках типа -Кобол.
Трансляторы для различных версий языка ПЛ/1 имеются уже на многих вычислительных машинах. В частности, созданы компиляторы для двух версий языка на машинах серии ИБМ/360. Компиляторы ПЛ/1 входят в состав математического обеспечения ЕС ЭВМ, разрабатываются также новые системы программирования, где ПЛ/1 является одним из входных языков.
118
Машинно-ориентированное подмножество ПЛ/1 используется за рубежом в качестве базового языка некоторых систем программирования для написания трансляторов, а также некоторых компонент операционных систем.
4.1.4. АЛГОЛ-6»
Алгол-68 — типичный пример языка-ядра (см. п. 1.2.3), на базе которого могут создаваться новые языки. Создание новых языков происходит не путем выделения специализированных подмножеств, как в языке-оболочке, а путем конструирования новых средств из имеющихся элементов языка-ядра.
Алгол-68 — детище рабочей группы Международной федерации по обработке информации (ИФИП). Работа над языком происходила с 1963 по 1968 г. Алгол-68 получен не просто расширением Алгола-60, это совершенно новый язык, в котором все основные конструкции Алгола-60 подверглись коренному пересмотру. Язык описан в официальном «Сообщении об алгоритмическом языке Алгол-68» [2]. Неформальное описание опубликовано в литературе [22].
По набору средств Алгол-68 не имеет себе равных. Наряду со многими средствами, имеющимися в Алголе-60 и ПЛ/1, Алгол-68 имеет специальный аппарат для создания новых средств.
1. Структура программы. Программа имеет блочную структуру, как в Алголе-60. Однако понятие «блок» здесь значительно расширено. Например, блоком можно считать конструкции, подобные составным операторам Алгола-60, причем блок обычно имеет значение, равное значению его последнего выражения. Поэтому блок можно использовать как первичное выражение в арифметическом выражении. В частности, допускаются конструкции вида
, х : = 1 4- begin real у, read («/); х — у end,
где read (у) — процедура ввода переменной у.
Возможность использования таких конструкций создает большие удобства, например, при работе в режиме диалога.
2. Типы данных. Если пользоваться терминологией Алгола-60, то можно сказать, что наряду с переменными типа real, integer и boolean, применявшимися в Алголе-60, имеются также переменные типа комплексный, битовый, литерный (отдельные символы), строковый (строки символов переменной длины), слоговый (строки символов постоянной длины). Для переменной любого из перечисленных типов помимо идентификатора и значения существует еще имя (адрес хранения), аналогичное указателю в языке ПЛ/1. Кроме того, имеются форматные переменные, обеспечивающие изменение формата преобразований при вводе — выводе данных. Процедуры также могут рассматриваться как значения переменных особого типа. Наконец, имеются объединенные типы данных, когда один и тот же идентификатор выступает вначале как вещественная переменная, затем как целая и т. д.
119
Строго говоря, в Алголе-68 нет понятия типа в том смысле, в котором это понятие используется в Алголе-60. Здесь введено понятие вид, относящееся не к переменной, обозначающей некоторый объект, а к значению, приписываемому объекту. Множество видов в Алголе-68 бесконечно [9], [22]. Описания переменных могут появляться в любом месте программы. Это очень удобно для работы с машиной в диалоговом режиме.
3. Организация данных. Как и в языке ПЛ/1, имеются массивы и структуры данных. Массивы, называемые в Алголе-68 кратными значениями, состоят из однотипных элементов и подобны массивам в Алголе-60. Однако элементами массивов могут быть любые объекты, имеющие значения, например процедуры. Кроме того, границы значений индексов могут заранее не указываться, а значение массиву можно присвоить одним оператором присваивания. Для массивов введена специальная операция, позволяющая выделять любые связные подмассивы.
Структуры, называемые в Алголе-68 структурными значениями, в отличие от массивов могут иметь разнотипные элементы, включая простые переменные, массивы и структуры. Это, как и в ПЛ/1, дает возможность строить сложные иерархические структуры, например списковые структуры. К элементам структур обращаются по именам. Имена могут быть составными, как в языке ПЛ/1.
4. Операции. Помимо обычных арифметических, логических и других операций, имеющихся в языке, программист имеет возможность вводить любые нужные ему операции с помощью описания операций. Например, можно описать операцию сложения структур или массивов, тогда знак «+» для соответствующих операндов будет интерпретироваться так, как указано в описании операции. Это одно из средств, позволяющих создавать новые языки, поскольку вновь описанные операции можно накапливать в библиотеке, хранящейся в памяти машины. z,
5. Предложения. Конструкции, аналогичные Ьператорам Ал-гола-60, в Алголе-68 называют предложениями. Большинство предложений имеет значения. Это повышает гибкость языка и в ряде случаев позволяет экономить машинное время.
6. Ввод — вывод. Как и в ПЛ/1, в Алголе-68 имеются средства для обращения к файлам во внешней памяти. Принцип организации ввода — вывода и редактирования данных форматный, как в Фортране и ПЛ/1. Однако за счет переменных указателей формата и переменных указателей числа повторений аппарат процедур ввода — вывода приобрел большую гибкость.
Важным отличием Алгола-60 от других языков программирования является то, что в официальном сообщении об этом языке [2] сделана попытка строго определить семантику синтаксических конструкций. Этот шаг в сторону полной формализации описания языков программирования имеет большое значение для создания формальных методов разработки трансляторов. Однако формализация семантики сильно усложнила описание языка. Официальное описа-120
ние [2] содержит около 170 страниц сжатого высокоформализован-ного текста, поэтому изучать язык по его описанию чрезвычайно* трудно.
Алгол-68 еще не нашел широкого применения, пока появились первые экспериментальные трансляторы для упрощенных версий языка. Однако работы по созданию трансляторов Алгола-68 ведутся несколькими группами в нашей стране и за рубежом.
В заключение следует подчеркнуть, что Алгол-68 — это не просто еще один многоцелевой универсальный язык программирования. Понятия и идеи, введенные описанием языка (2], отражают современный уровень понимания сущности вычислительных процессов как процессов обработки любых числовых или символьных данных, а также способов их изображения и выполнения на вычислительных машинах.
Естественно, реализация Алгола-68 возможна только на мощных вычислительных системах, имеющих большую память, высокое быстродействие и обладающих достаточной надежностью.
4.1.5. ЗАДАЧИ ТРАНСЛЯЦИИ
Входную программу, записанную на процедурно-ориентированном языке высокого уровня, в объектную программу на языке машины переводит компилятор. Объектная программа либо составляется в абсолютных адресах, либо оформляется в виде одного или нескольких модулей загрузки.
В процессе трансляции компилятор в конечном итоге должен решить те же задачи, что и ассемблер (см. п. 3.2.1):
распределить память для программы и данных;
перевести на объектный язык предложения (операторы) входной программы;
выявить ошибки в программе;
оформить объектную программу в виде готовой программы или модулей загрузки;
сформировать и выдать печатный документ (листинг).
Однако вследствие того, что входная программа написана на машинно-независимом языке, который сильно отличается от объектного и не учитывает особенностей устройства конкретной машины, каждая из этих задач решается значительно сложнее, чем в ассемблере.
Для облегчения трансляции входная программа обычно вначале подвергается лексическому анализу (см. п. 1.3.3) и переводится на внутренний язык, в котором выделены операнды, знаки операций и служебные слова. Затем выполняется синтаксический анализ» выявляющий структуру программы и выделяющий отдельные конструкции (описания, операторы, выражения и т. д.). Результаты синтаксического анализа используются для перевода программы на промежуточный язь(к. Промежуточный язык подбирается так»
121
чтобы на него легко было перевести входную программу и чтобы из него легко можно было получить программу на объектном языке.
После перевода на внутренний и промежуточный язык часть информации о входной программе хранится в виде текста на промежуточном языке, а другая часть информации зафиксирована в различных таблицах. Вся эта информация используется на этапе семантического анализа для распределения памяти и генерирования машинных команд.
Перевод на внутренний и промежуточный языки может быть явным, когда в результате перевода вся программа явно записывается на каждом из этих языков, или неявным, когда перевод на внутренний язык совмещается с переводом на промежуточный язык, или перевод на промежуточный язык совмещается с генерированием машинных команд.
В компиляторах, как и в ассемблерах, при распределении памяти нужно назначить адреса всем именам (меткам, константам, переменным и т. п.). Однако все имена можно выявить только после просмотра всей программы, а адреса меток можно определить лишь после генерирования машинных команд. Поэтому обычно компилятор просматривает программу не менее двух-трех раз.
В последующих параграфах этой главы описаны прямые методы трансляции с процедурно-ориентированных языков типа Ал-гол-60. В этих методах на основе некоторой общей идеи для каждой конструкции конкретного входного языка подбирается индивидуальный алгоритм перевода.
4.2. ЛЕКСИЧЕСКИЙ АНАЛИЗ
4.2.1. ЗАДАЧИ ЛЕКСИЧЕСКОГО АНАЛИЗА
Исходная программа на входном языке одного и того же компилятора может быть подготовлена на разных внешних устройствах (стандартном устройстве подготовки перфокарт, телетайпе, специальном клавишном устройстве). В каждом из этих случаев двоичная кодировка входной программы может быть разной.
Цель лексического анализа состоит в переводе исходной программы на стандартный входной язык компилятора и преобразовании ее к виду, удобному для дальнейшей обработки на этапах синтаксического и семантического анализа.
В процессе лексического анализа обычно собираются из отдельных знаков (букв и цифр) простые синтаксические конструкции: идентификаторы, числа, а также служебные слова типа begin, end и др. При дальнейшей обработке такие простые конструкции рассматриваются как неделимые, поэтому оставлять их распознавание и сборку до этапа синтаксического анализа невыгодно прежде всего с точки зрения общего времени и сложности алгоритмов трансляции.
122
В общем случае в процессе лексического анализа необходимо выполнить следующее:
1) перекодировать исходную программу, рассматриваемую как входная строка, и привести ее к стандартному входному языку;
2) выделить и собрать из отдельных знаков в слова идентификаторы и служебные слова (основные символы языка);
3) выделить и собрать из цифр, а также перевести в машинную форму числовые константы.
В некоторых компиляторах лексический анализ составляет отдельный этап и выполняется специальными блоками за один-два просмотра входной программы. В других компиляторах отдельные задачи лексического анализа решаются на разных этапах трансляции. Однако перекодирование входной программы и приведение ее к стандартному входному языку всегда выполняет первый блок компилятора.
4.2.2. ПЕРЕКОДИРОВАНИЕ ВХОДНОЙ ПРОГРАММЫ
Символы входной программы, закодированные двоичными числами, обычно обрабатываются последовательно. Иногда обработка происходит в темпе ввода.
При байтовой организации памяти каждый байт содержит двоичный код символа входной программы. В этом случае символ доступен непосредственно. В остальных случаях в машинное слово упаковывают несколько символов. Например, в 45-разрядную ячейку памяти машины М-220 упаковывают шесть семиразрядных кодов, представляющих символы в коде устройства подготовки перфокарт или в коде специального клавишного устройства. Здесь обработке очередного символа предшествует распаковка.
Поскольку число разных символов входной программы обычно сравнимо с числом всех возможных кодовых комбинаций, для перекодировки в стандартный алфавит входного языка компилятора часто используют таблицы прямого доступа (см. п. 2.3.1). Допустимый код входного символа непосредственно указывает адрес эквивалентного символа в таблице, быть может, сдвинутый на константу. Недопустимый код, который может появиться из-за ошибки в пробивке или искажения при вводе, выходит из диапазона адресов таблицы. Информация о месте ошибки фиксируется в таблице ошибок.
Для символов, имеющих прямые аналоги во входном языке компилятора, таблица перекодировки содержит эквивалентные коды стандартного входного алфавита, а для символов, не имеющих прямых аналогов или имеющих разные значения в зависимости от контекста, таблица перекодировки указывает соответствующие им подпрограммы* анализа и обработки. Например, символ «:» в языке Алгол-60 может появиться в граничных парах описания массивов, следовать после метки или использоваться в разделителях формальных параметров процедур. Однако этот же символ в сочетании со знаком равейства = образует знак присваивания
123
«: = ». Внешнее устройство, на котором исходная программа готовится для ввода в машину, может не иметь специального символа «: = ». В этом случае при появлении во входной строке символа «:» нужно вызвать подпрограмму анализа и обработки. Эта подпрограмма задержит перекодировку до просмотра следующего символа.
Подпрограмма анализа и обработки может также снабжать перекодируемый символ признаком, характеризующим качество, в котором он используется. В частности, символ «:» можно сопроводить признаком использования в граничной паре описания массива, метке или списке формальных параметров процедуры.
При обработке входной программы, подготовленной на телетайпе или специальной пишущей машинке, за очередным символом может следовать символ вычеркивания или группа символов вычеркивания. Каждый такой символ «стирает» один из ранее выбранных символов. Следовательно, группа символов вычеркивания «стирает» предшествующую группу символов входной строки.
На пишущей машинке может также использоваться символ возврата каретки, означающий совмещение двух ранее набранных символов. Например, символы $=» и «/» могут совмещаться, образуя символ «=#». Здесь уже нельзя ограничиться простой перекодировкой и нужна реконструкция входной строки, которая осуществляется специальной подпрограммой реконструкции, обрабатывающей несколько предыдущих символов.
Окончание обработки обычно определяется по специальному признаку конца входной программы. (
4.2.3. ПЕРЕВОД СЛУЖЕБНЫХ СЛОВ, ИДЕНТИФИКАТОРОВ И КОНСТАНТ
Служебные слова — это основные символы языка, которые во внешнем представлении программы состоят из нескольких знаков (букв). Идентификаторы переменных, массивов, меток и других подобных объектов, а также константы тоже могут состоять из нескольких знаков (букв и цифр). Служебные слова, идентификаторы и константы приходится многократно распознавать в ходе трансляции, поэтому для сокращения времени трансляции целесообразно как можно раньше заменить их ссылками на соответствующие таблицы. В процессе сборки и замены ссылками основные символы языка, идентификаторы, метки и константы обычно получают одинаковый формат и снабжаются признаками, позволяющими отличить класс каждого объекта, что упрощает дальнейшую работу с ними.
Служебные слова языка заранее записаны в постоянную таблицу. При использовании для подготовки программы специального клавишного устройства, на котором основные символы представляются иероглифически (для каждого основного символа, ограничителя, буквы и цифры — отдельная клавиша), служебные слова 124
отличаются от букв и цифр по значению цифрового кода. Стан* дартное устройство подготовки перфокарт и телетайп не имеют отдельных клавиш для каждого служебного слова, поэтому их приходится распознавать с помощью таблицы. Однако в большинстве входных языков компиляторов Алгола-60 служебные слова маркируются, это облегчает их распознавание. Например, во входных языках некоторых компиляторов символ begin представляется в виде __b__е_g__i__п. Черта перед буквой означает, что буква
подчеркнута. Так подчеркиваются буквы, входящие во все служебные слова.
Иногда служебные слова выделяют специальными кавычками «‘» и «’» или апострофом «'». Например, 'begin'. Этот случай сводится к предыдущему, поскольку можно считать, что появление открывающей кавычки (апострофа) означает подчеркивание всех последующих символов, а появление закрывающей кавычки (второго апострофа) уничтожает признак подчеркивания.
Слово, состоящее из подчеркнутых букв, заменяется ссылкой на таблицу служебных слов. Если в таблице служебных слов рассматриваемого слова не оказалось, то это ошибка, которая должна быть зафиксирована в таблице ошибок. Обычно оператор, содержащий ошибку, при трансляции пропускается. Однако наряду с фиксацией в таблице ошибок можно попытаться заменить ошибочное служебное слово наиболее подходящим по написанию и контексту, выдав одновременно предупредительное сообщение программисту.
Неподчеркнутые символы могут быть основными символами языка, состоящими из одного знака, а также буквами и цифрами. Код однознакового основного символа также заменяется ссылкой на таблицу основных символов и приводится к принятому стандартному формату.
Буквы и цифры могут входить в состав идентификатора и константы, образуя слово. Слово обычно ограничено двумя основными символами. Это позволяет выделить слово. Характер слова определяется по составляющим его символам и контексту. Например, в большинстве языков высокого уровня идентификатор всегда начинается с буквы, в отличие от числовой константы. Метка либо появляется перед оператором на особой позиции (в Фортране), либо находится перед особым символом (двоеточие в Алголе-60), причем в Фортране метка всегда целое число. Кроме того, метка может входить в некоторые специфичные конструкции (именующие выражения и переключатели в Алголе-60, оператор цикла и условный оператор в Фортране).
Идентификаторы заносятся в таблицу имен и заменяются в программе ссылками на эту таблицу. Идентификаторы, опознанные как метки (в Алголе-60), могут заноситься в отдельную таблицу меток, а константы переводятся в машинную форму и заносятся в таблицу констант. Заметим, что допускаемые в эталонном Алголе-60 целые метки не так просто отличить от целых констант,
125
поэтому в большинстве входных языков компиляторов Алгола-60 целые метки не допускаются.
В результате описанной обработки входной программы формируется программа на внутреннем языке, в которой служебные слова, идентификаторы, метки и константы приведены к единому формату и заменены ссылками на соответствующие таблицы.
Программа на внутреннем языке не содержит комментариев. При переводе на внутренний язык комментарии исключают, поскольку они не нужны при дальнейшей трансляции. Исходная программа в первоначальном виде с комментариями переписывается во внешнюю память. Она затем используется только при формировании печатного документа (листинга) о транслируемой программе.
Если печатный документ выдается в виде двух параллельных текстов на входном и объектном языке, то в ходе перевода на внутренний язык составляется таблица соответствия исходного текста и текста на внутреннем языке. Каждая запись этой таблицы содержит координату начала (или конца) оператора (описания) входной программы и соответствующую координату в программе на внутреннем языке. В дальнейшем при генерировании машинных команд координаты программы на внутреннем языке будут заменены соответствующими координатами программы на объектном языке. Таблица соответствия текстов используется в ходе трансляции при занесении информации в таблицу ошибок, а затем применяется для формирования строк печатного документа.
4.2.4. АЛГОРИТМ ПЕРЕВОДА ЧИСЛОВЫХ КОНСТАНТ
Слово, распознанное в блоке перевода служебных слов, идентификаторов и констант как число, является числом без знака. Для определенности будем предполагать, что число заканчивается пробелом.
В общем случае число может содержать цифры от 0 до 9, десятичную точку «.», знак основания системы счисления (символ ю в Алголе-60, буква Е или буква D в Фортране), знак порядка (+ или —).
При переводе вещественного десятичного числа в машинную форму обычно требуется сформировать двоичное число с плавающей запятой в форме
г== т • 10р.
Целые числа (значения переменных типа целый), как правило, представляются в машине в виде условных двоичных чисел, например в виде единиц какого-либо адреса машинной команды. Это объ-. ясняется тем, что константы и переменные типа целый применяются главным образом в индексных выражениях элементов массивов, а в машинной программе значения индексных выражений преобразуются в адреса элементов массивов. Преобразование чисел из формы вещественный в форму целый выполняется на уровне ма-126
шинных команд с использованием специфичных для конкретной машины операций машинного языка. Преобразование выполняется специальной подпрограммой.
Признаком целого числа в Фортране и в некоторых конкретных представлениях Алгола-60 служит отсутствие в записи числа десятичной точки. Вещественные числа в этом случае непременно содержат десятичную точку или основание степени. Например, в Фортране 12 — целое число, а 12.0 — вещественное.
В эталонном Алголе-60 отличить целое число от вещественного можно лишь по контексту. Поскольку анализ контекста на этапе лексического анализа обычно не выполняется, выделить на этом этапе константы типа целый в эталонном Алголе-60 практически невозможно.
Рассмотрим алгоритм перевода вещественных чисел, записанных по правилам эталонного Алгола-60. Будем предполагать, что •символы числа поступают на вход алгоритма перевода по одному, начиная с самого левого. Тогда алгоритм перевода можно представить в виде таблицы с двумя входами (табл. 4.1), в которой строка соответствует некоторому состоянию процесса перевода, а столбец— рассматриваемому символу.
Таблица 4.1 ТАБЛИЧНЫЙ АЛГОРИТМ ПЕРЕВОДА ВЕЩЕСТВЕННЫХ ЧИСЕЛ
Символ Состояние^. Десятичная цифра Десятичная точка «.» Основание степени 10 Знак +, — Пробел
1 2, п 1 3 I 5, п4
2 2, п1 3 5 выход
3 4, п2
4 4, п2 5 выход
5 7, пЗ 6, п5
6 7, пЗ
7 7, пЗ выход
Процесс перевода начинается с состояния 1. В клетках табл. 4.1 записано следующее состояние и название подпрограммы, которую нужно выполнить. Незаполненные клетки таблицы соответствуют ошибкам в записи числа, причем каждая клетка отвечает определенному виду ошибки. Например, появление десятичной точки в записи числа при состояниях 3 или 4 означает, что число содержит две десятичные точки, а появление знака основания системы
127
счисления ю при состоянии 3 означает, что мантисса заканчивается десятичной точкой.
В подпрограммах используются следующие переменные:
т — текущее значение мантиссы;
р — текущее значение порядка;
п — счетчик числа десятичных цифр дробной части мантиссы;
s — знак порядка (+1 или —1);
г — результат перевода;
d — значение очередной цифры.
Перед началом перевода нужно положить
т = р = п = 0, s = + 1.
Подпрограммы:
п1: т : = 10 X т + d\
п2: п : = п + 1; т: = 10 X т + d\
пЗ: р: = 10 X Р + d\
п4: т : = 1;
п5: if “ then s: = — 1;
ВЫХОД: г: = т X 10 f (s X Р — п).
Пример. Пользуясь табл. 4.1, перевести число 1.02ю—1.
Решение. Решение показано в табл. 4.2.
Таблица 4.2 ПРИМЕР ПЕРЕВОДА ВЕЩЕСТВЕННОГО ЧИСЛА
Состояние Сим юл Новое состояние Подпрограмма, результат
1 1 2 nl, т = 1
2 • 3 —
3 0 4 п2, п = 1, т = 10
4 2 4 п2, п = 2, т = 102
4 19 5 —
5 —— 6 п5, s = —1
6 1 7 пЗ, р = 1
7 Пробел — ВЫХОД, г =0.102
Естественно, система счисления, в которой будет представлен результат, совпадает с той системой, в которой производятся арифметические действия, предписываемые подпрограммами. При вы
128
полнении всех действий в десятичной системе, как в нашем примере, результат также будет представлен в десятичной системе, а при выполнении действий в двоичной системе ( на машине) результатом будет двоичное число в машинной форме.
4.2.5. КОНТРОЛЬ ВХОДНОЙ ПРОГРАММЫ НА ЭТАПЕ ЛЕКСИЧЕСКОГО АНАЛИЗА
В ходе лексического анализа помимо чисто лексического контроля (выявление недопустимых символов и служебных слов, а также ошибок в записи идентификаторов и констант) иногда выполняют частичный синтаксический контроль. В частности, при лексическом анализе легко проверяется парность некоторых основных символов. Например, в Алголе-60 парными должны быть следующие символы: begin и end, if и then, for и do, (и), [и]. Отсутствие одного из символов пары при дальнейшей обработке программы помимо неправильной трансляции может приводить к появлению «ложных ошибок», когда выдаются сообщения об ошибках, которых в действительности нет.
Особенно неприятные последствия в Алголе-60 и других языках с блочной структурой (например, АЛМО, ПЛ/1, Алгол-68) может иметь непарность символов begin и end, которая нарушает правильную структуру блоков и приводит к многочисленным «ложным ошибкам» типа «неописанный идентификатор».
Непарные символы легко обнаружить. Например, при появлении первого символа пары к содержимому фиксированной ячейки памяти, где вначале находится нуль, добавляется единица, а при появлении второго символа пары единица вычитается. Ненулевая сумма в конце просмотра программы (блока, программной единицы, а иногда оператора) свидетельствует о непарности. По знаку суммы можно определить, каких символов пары недостает.
Труднее локализовать место, где должен быть отсутствующий символ, особенно такой, как begin или end. Для установления места, где должен быть отсутствующий символ, требуется анализировать контекст. Например, появление после символа if символа else указывает интервал, где должен находиться отсутствующий символ then. Однако анализ контекста — задача более свойственная этапу синтаксического анализа.
Другой вид контроля, иногда применяемый при лексическом анализе, — проверка сочетаемости стоящих рядом символов [16]. Например, пары символов begin х и else begin — сочетаемы (допустимы), но те же символы, стоящие в обратном порядке: х begin и begin else — несочетаемы. В то же время пары -|-end, +/, Х[ — несочетаемы ни в каком порядке.
Выявление несочетаемых пар символов выполняется с помощью матрицы сочетаемости. Это квадратная матрица II хц ||, порядок которой равен числу- основных символов языка (все буквы
5 Зак. 221
129
в матрице можно заменить одним символом «буква», а все цифры— одним символом «цифра»). Элемент Xij = 1, если символ с номером i и символ с номером / сочетаемы, в противном случае Хц = 0.
Способ получения матрицы сочетаемости для любого языка программирования, синтаксис которого подобно синтаксису Алгола?60 задан металингвистическими формулами, вытекает из более общего метода синтаксического анализа, описанного в 5.3.
Матрицу сочетаемости можно компактно записать в виде вектора, состоящего из нулей и единиц. Для записи компонент такого вектора используются двоичные разряды нескольких соседних ячеек памяти. Доступ к элементу х^ осуществляется с помощью функции упорядочения (2.1).
Пусть порядок матрицы сочетаемости т, элементы матрицы нумеруются с i = /= 1, а вектор, отображающий матрицу по строкам, расположен в нескольких соседних ячейках памяти, первая из которых имеет номер &. Тогда, как следует из формул (2.2), (2.4) и (2.5), элемент Хц расположен в ячейке с номером
& +
~(/-l)m + /-l 1
Л ]цел
на позиции
‘ — 1) т + / — 1 ‘
Х«4-1,
п
др
считая левый разряд ячейки первым. Здесь [у]Цел— целая часть числа у, а [«/]дР — его дробная часть, п — число двоичных разрядов в одной ячейке.
4.3. ТРАНСЛЯЦИЯ ВЫРАЖЕНИИ
4.3.1. ПОЛЬСКАЯ ЗАПИСЬ
Первые процедурно-ориентированные языки программирования высокого уровня предназначались для решения инженерных и научно-технических задач, в которых широко применяются методы вычислительной математики. Значительную часть программ решения таких задач составляют арифметические и логические выражения. Поэтому трансляцией выражений занимались очень многие исследователи и разработчики трансляторов. Начиная с 1952 г., когда была опубликована работа Г. Рутисхаузера [51], в которой впервые предлагался метод трансляции арифметических выражений, разработано много различных методов. Сейчас классическим стал метод трансляции выражений, основанный на использовании промежуточной обратной польской записи, названной так в честь польского математика Яна Лукашевича, который впервые использовал эту форму представления выражений в математической логике. Однако в существующих трансляторах используются и другие методы.
130
Рассмотрим сущность обратной польской записи на примере. Простое арифметическое выражение с вещественными переменными
а + b X с — d! (а 4-6)
рассматривались слева
Рис. 4.1. Порядок обхода дерева простого арифметического выражения для получения обратной польской записи
можно графически представить в виде дерева (рис. 4.1). Узлы дерева соответствуют операциям, а ветви — операндам. Левая ветвь, исходящая из узла, отвечает левому операнду, а правая— правому. В каждой ветви операциям, которые выполняются раньше, соответствуют нижележащие узлы. Верхний узел (корень дерева) отвечает операции, которая выполняется последней. С него начинается построение дерева.
Если, начав с нижнего листа самой левой ветви дерева, обойти все листья и узлы дерева так, чтобы веп направо, а узел рассматривался только после обхода всех исходящих из него ветвей, как показано стрелками на рис. 4.1, то последовательность просмотра листьев и узлов даст обратную польскую запись исходного выражения:
abc X Л-dab 4-/—.
Эту бесскобочную запись называют также постфиксной записью, потому что знак каждой операции записан после соответствующих операндов. Заметим, что в обратной польской записи операнды располагаются в том же порядке, что в исходном выражении, а знаки
операций при просмотре записи слева направо встречаются в том порядке, в котором нужно выполнять соответствующие действия. Отсюда вытекает основное преимущество обратной польской записи перед обычной записью выражений со скобками: выражение можно вычислить в процессе однократного просмотра слева направо.
Правило вычисления выражения в обратной польской записи состоит в следующем. Обратная польская запись просматривается слева направо. Если рассматриваемый элемент — операнд, то рассматривается следующий элемент. Если рассматриваемый элемент— знак операции, то выполняется эта операция над операндами, записанными левее знака операции. Результат операции записывается вместо первого (самого левого) операнда, участвовавшего в операции. Остальные элементы (операнды и знак операции), участвовавшие в операции, вычеркиваются из записи. Просмотр продолжается.
В результате последовательного выполнения этого правила будут выполнены все операции, имеющиеся в выражении, и запись
5*
131
сократится до одного элемента — результата вычисления выражения.
Выполнение правила для нашего примера приводит к последовательности строк, записанных во второй графе табл. 4.3. Рассматриваемый на каждом шаге процесса элемент строки отмечен кружком. В третьей графе таблицы записаны соответствующие действия, а в четвертой графе — эквивалентные команды трехадресной машины.
Таблица 4.3
ПРИМЕР ВЫЧИСЛЕНИЯ ВЫРАЖЕНИЯ В ОБРАТНОЙ ПОЛЬСКОЙ ЗАПИСИ
№ Состояние строки действие Машинная команда
1 2 4
1 (a) Bc^+daB^/- Просмотреть следующий элемент —
г а (В) cx+da8+/~ Просмотреть следующий элемент —
3 а 8 (с) х + da8 Просмотреть следующий элемент
4 аве (х) + Лаб *7- Г] В*с х Вег,
5 Г,—ат. + аг,г,
6 ту @ а В +/- Просмотреть следующий элемент
7 rf d (а) 6 +/- Просмотреть следующий элемент
8 ту d а (В) U- Просмотреть следующий элемент
9 т-f d а 8 0 /- Tg Q + 6 + авг2
10 0- Гг :^d/r2 /дгггг
11 № 0 Г1 ^г}-г2 ~^Г2Г1
12 «мт “““ I
Результат выполнения операции фиксируется в виде рабочей переменной вида г,. После очередной операции рабочая переменная П или г2 вычеркивается, освободившуюся рабочую переменную можно использовать вновь для записи результата операции. Использование каждый раз свободной рабочей переменной с минимальным номером экономит количество занятых рабочих переменных. Такой пример экономии рабочих ячеек приведен в табл. 4.3. Это же правило используют в трансляторах.
Аналогичным способом можно записывать и вычислять булевские выражения. Простое булевское выражение
а 4- д > - 5 А .2 — d = 1 +
132
представляется деревом (рис. 4.2), обход которого по пути, показанному стрелками, дает обратную польскую запись
ab + 5 ИЗ > zd—1^2| + = Л,
в которой знак минус перед числом 5 в исходной записи, обозначающий одноместную операцию, заменен знаком операции ИЗ (изменение знака). Вообще при трансляции во избежание ошибок
Рис. 4.2. Обход дерева простого булевского выражения для получения обратной польской записи
нужно отличать знак минус как знак одноместной операции от того же знака, обозначающего двухместную операцию. В реальных трансляторах выражения вида —а заменяются выражениями вида 0 — а или знак минус в обратной польской записи снабжается признаком одноместной операции. Впредь минус, являющийся знаком одноместной операции, будем обозначать знаком операции ИЗ.
Таблица 4.4
ВЫЧИСЛЕНИЕ БУЛЕВСКОГО ВЫРАЖЕНИЯ В ОБРАТНОЙ ПОЛЬСКОЙ ЗАПИСИ
№ пп Состояние строки Действие
1 а 6 (+) 5 ИЗ > z d - 1 0 2 ) + = Л r,: = a+B
2 т15 @ > zd - 1 q 2 !+ = Л rZ : = -5
3 Г1 r2 (Z) 2 & ~ 1 ? 2 1 + = Л rz : = Г;>Г2
4 rf zd Q 1 q 21 += Л r2 -=z-d
§ rf г г 1 q 2 (?) + == Л r3 - = qlZ
6 ri гг 1 r3 Q = Л . r3 :=1 + r3
7 ri Гг гз (=) л r2 :=-r2 = r3
8 Г, гг (Л) Ti := г., Л r2
133
Рис. 4.3. Порядок обхода дерева простого арифметического выражения для получения прямой польской записи
Рассматриваемое булевское выражение можно вычислить по общему правилу вычисления выражений в обратной польской записи. В табл. 4.4 выписаны только строки, отвечающие состояниям, в которых выполняются действия, и строка сокращается.
Существует еще одна форма бесскобочной-записи выражений, которая также иногда применяется в трансляторах. На рис. 4.3 изображено то же дерево, что и на рис. 4.1. Если, начав с верхнего узла, обойти все узлы и листья дерева так, чтобы верхний узел рассматривался раньше нижнего и сразу после рассмотрения очередного узла просматривались слева направо исходящие из него ветви, как показано стрелками на рис. 4.3, то получится следующая бесскобочная запись выражения
—Ь а X bc/d + ab.
Такую запись называют прямой польской записью. Как и в обратной польской записи, операнды расположены здесь в том же порядке, что в исходном выражении. Однако знаки операций теперь записаны перед операндами, поэтому такую запись называют также префиксной. Выражение, записанное в пря
мой польской записи, вычисляется справа налево. Поскольку общий порядок работы компилятора обычно слева направо, прямую польскую запись применяют относительно редко.
4.3.2. АЛГОРИТМ ПЕРЕВОДА ОБРАТНОЙ ПОЛЬСКОЙ ЗАПИСИ В МАШИННЫЕ КОМАНДЫ
Последовательность машинных команд в табл. 4.3 есть, по существу, результат трансляции выражения, записанного в обратной польской записи, в машинные команды. Если для каждого операнда, включая рабочие переменные г>, известен адрес, то для получения окончательных машинных команд остается лишь заменить знаки операций машинными кодами операций, а операнды — адресами. Пример показывает, что в данном частном случае трансляция выполняется достаточно просто. Однако правило вычисления значения выражения по обратной польской записи, которое можно считать одновременно правилом трансляции выражения в машинные команды, недостаточно детализировано и формализовано для непосредственной реализаций на машине, хотя бы потому, что в нем не определен способ записи выражения в памяти машины и порядок использования рабочих ячеек. Для машинной реализации требуется более формальное правило.
В двух рассмотренных примерах встречались двухместные операции и одноместная операция ИЗ. Каждая такая операция, как 134
правило, заменяется одной или двумя машинными командами (в зависимости от адресности машины). В общем случае операция /? может иметь k операндов (k& 1). На машине такая операция должна заменяться группой машинных команд. Будем считать, что к моменту генерирования машинных команд проведено распределение памяти и каждый операнд представлен соответствующим адресом или ссылкой на таблицу имен, содержащую адрес операнда. Аналогично, для каждой рабочей переменной известен ее адрес. Подробно распределение памяти рассматривается в 4.5.
Для трансляции выражения из обратной польской записи в машинные команды используется стек операндов (СО) с указателем i. В исходном состоянии стек операндов пуст, а указатель i = 1. Будем также считать, что в исходном состоянии номер первой свободной рабочей переменной / = 1.
Алгоритм трансляции состоит в следующем.
I. Взять очередной символ S из обратной польской записи выражения.
2. Если S — операнд, то занести S в CO[i], выполнить i := i -f- 1 и перейти к пункту 1, иначе перейти к пункту 3.
3. Если S — не знак операции, то перейти к пункту 4, иначе, если S — знак операции R, выполнить следующее:
ЗА. Среди элементов стека CO[i — Л], ... , СО(» — 1], где k —. число операндов операции R, найти рабочую переменную с минимальным номером I. Если в рассматриваемых элементах стека нет рабочих переменных, то положить I = j.
ЗБ. Записать машинные команды, реализующие оператор присваивания
rf. = R (СО [Z — Л], ..СО [Z — 1]).
Здесь R(xj, хл)—результат выполнения операции /? над операндами Xi, ..., Xk.
ЗВ. Занести символ и в СО [t — Л].
ЗГ. Выполнить i := i — k 1 и / := I 1.
Перейти к пункту 1.
4. Если запись выражения исчерпана, то трансляция закончена. Стек операндов должен содержать только переменную и, в противном случае нужно записать информацию об ошибке в таблицу ошибок.
Для реализации пункта ЗБ приведенного алгоритма используются заранее подготовленные «заготовки» групп машинных команд, в которые требуется лишь подставить адреса операндов (или значения самоонределенных операндов), взятые из стека операндов. Эту подстановку выполняет подпрограмма, соответствующая рассматриваемой операции /?.
Надо, однако, отметить, что используемая подпрограмма определяется не только знаком операции R, но и типом операндов.
135
Например, одна подпрограмма соответствует операции сложения вещественных чисел, а другая — операции сложения целых. Иногда в пункте ЗБ приходится выполнять несколько подпрограмм. В частности, если один операнд целый, а другой вещественный, то вначале нужно привести операнды к одному типу, а затем выполнить подпрограмму формирования команды сложения. При несовместности операндов, например в операции сложения один операнд
Вход
Рис. 4.4. Блок-схема перевода обратной польской записи в машинные команды
вещественный, а другой булевский, или при несоответствии операндов знаку операции выдается информация об ошибке.
Блок-схема алгоритма перевода обратной польской записи в машинные команды приведена на рис. 4.4.
Заметим, что описанный алгоритм пригоден для перевода в машинные команды не только арифметических и логических выражений, но и любых текстов, записанных в обратной польской записи с использованием произвольных операций, реализуемых машинными командами.
136
4.3.3. ПЕРЕВОД ПРОСТЫХ АРИФМЕТИЧЕСКИХ И ЛОГИЧЕСКИХ ВЫРАЖЕНИЙ В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ
Поскольку существует относительно несложный алгоритм перевода обратной польской записи в машинные команды, для полного решения задачи трансляции выражений в языках высокого уровня типа Алгол-60 и Фортран достаточно перевести выражение в обратную поль- Таблица 4.5
скую запись.
Известно несколько методов получения обратной польской записи. Обзор различных методов дан в книге Б. Ренделла и Л. Рассела «Реализация Алгола-60» [26]. Один из наиболее эффективных методов предложен в 1960 г. голландским ученым Е. В. Дикстрой.
Метод Е. В. Дикстры основан на использовании стека с приоритетами, позволяющего изменить порядок следования знаков операций в выражении так, что получается обратная польская запись. Простейший вариант этого метода применим только к простым арифметическим и логическим выражениям, содержащим простые переменные, знаки арифметических и логических операций, знаки операций отношения и круглые скобки.
ПРИОРИТЕТЫ ОГРАНИЧИТЕЛЕЙ
Ограничители Приоритеты
( С if 0
=) J, then etse; 1
г
V 3
A 4
1 5
>»=*<< 6
4“ — 7
X / -г ИЗ В
♦ 9
Каждому ограничителю, входящему в выражение, присваивается приоритет (табл. 4.5). Для знаков операций приоритеты возрастают в порядке, обратном старшинству операций. Скобки имеют низший приоритет.
Арифметическое или логическое выражение рассматривается как входная строка символов. Входная строка просматривается слева направо. Операнды переписываются в выходную строку, а знаки операций помещаются вначале в стек операций (рис. 4.5). Если приоритет входного знака равен нулю или больше приоритета знака, находящегося в вершине стека, то новый знак добав-
ляется к вершине стека. В противном случае из стека «выталкивается» и переписывается в выходную строку знак, находящийся в вершине, а также следующие за ним знаки с приоритетами,
выходная страна
Входная стропа
Операнды
Знак операции
Знан операции
Вершина
стена
Стек операций
Рис. 4.5. Использование стека раций для перевода выражений ратную польскую запись
опе-в об-
137
большими или равными приоритету входного знака. После этого входной знак добавляется к вершине стека.
Особенности имеет лишь обработка скобок. Открывающая круглая скобка, имеющая «особый» приоритет нуль, просто записывается в вершину стека и не выталкивает ни одного знака. В то же время ее не может вытолкнуть ни один знак, кроме закрывающей скобки.
Таблица 4.6
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ АРИФМЕТИЧЕСКОГО ВЫРАЖЕНИЯ
в а а а а а а а а а а а а а Q
bl с в в в в в в в в в в в в
т с с с с с с с с с с
X п у^ X X X X X X у^
0 н *4“ ц* •Ц- —|— "4*
а 0 d d d d d d d d
н я а а а а о
я в в в
я +
я •
—
с +
т ( ( (
Е X X
Я *4“
Q в X с — d ( О 6 )
входная строка
Закрывающая скобка имеет приоритет 1, не превосходящий приоритета любой операции. Поэтому появление закрывающей скобки вызывает выталкивание всех знаков до ближайшей открывающей скобки включительно. В стек закрывающая скобка не записывается. Открывающая и закрывающая скобки как бы взаимно уничтожаются и в выходную строку не переносятся.
После просмотра всех символов ‘входной строки происходит выталкивание всех оставшихся в стеке символов и дописывание их к выходной строке.
138
Пример 1. Перевести в обратную польскую запись выражение а + b X с — d/(a + Ь).
решение. Решение показано в табл. 4.6.
Окончательная выходная строка в табл. 4.6, как нетрудно убедиться, совпадает с обратной польской записью того же выражения, полученной обходом дерева, изображенного на рис. 4.1.
Таблица 4.7
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ ЛОГИЧЕСКОГО ВЫРАЖЕНИЯ
выходная стропа а а а а а а О а О а а а а а О а ° I
в 6 6 6 в 6 6 6 в в в в 6 в 6
-f- Ц- ч* Ч" 4м ч* 1
5 5 5 5 5 5 5 5 5 5 S 5
ИЗ ИЗ ИЗ из ИЗ ИЗ ИЗ ИЗ ИЗ из из
1
Z Z Z Z Z Z Z Z Z Z I
d d d d d d d d
— — — — — — 1
1 1 1 1 1 1
Ч Ч ч
2 2
♦
— 1
A 1
1 г ♦ ♦
ч*
из ИЗ —
А А А А А л А А А А
а 6 — 5 А Z — d —— 1 ч I г
Входная страна
Пример 2. Перевести в обратную польскую запись простое логическое выражение
а {!)> — 5 Д z — d = 1 -j-qf 2.
139
Решение. Решение приведено в табл. 4.7, подобной табл. 4.6.
Как и в примере 1, окончательная выходная строка совпадает с обратной польской записью, полученной обходом соответствующего дерева (рис. 4.2).
4.3.4. ПЕРЕМЕННЫЕ С ИНДЕКСАМИ
Пусть требуется вычислить выражение
(« + Мг’ + 1, /]) X с + d. (4.1)
Рис. 4.6. Дерево выражения, содержащего переменную с индексами
Для выполнения вычислений на машине необходимо сначала найти адрес переменной с индексами. Адрес этой переменной дает функция упорядочения (см. п. 2.1.3). Коэффициенты функции упорядочения хранятся в группе ячеек памяти, на начало которой указывает адрес, назначенный идентификатору массива в результате обработки описаний и распределения памяти (см. 4.5). Аргументами функции упорядочения являются значения индексов (индексных выражений) элемента массива.
Введем операцию АДРЕС ЭЛЕМЕНТА МАССИВА (АЭМ), результат выполнения которой — адрес элемента массива, а операнды— идентификатор массива (точнее, назначенный ему адрес) и значения индексных выражений. Тогда рассматриваемое выражение , (4.1) можно представить деревом, показанным на рис. 4.6.
Обратная польская запись, полученная обходом дерева, имеет вид
а6Л4-/АЭМ + сХ</+. (4.2)
Как обычно, в обратной польской записи левее операции АЭМ расположены операнды. Однако в отличие от логических и арифметических операций количество операндов опе-
рации АЭМ переменно. Оно зависит от размерности массива. Это вынуждает вместе со знаком операции АЭМ явным образом задавать количество операндов.
Будем обозначать операцию АЭМ парой символов Л],
где k — целое число, равное количеству операндов, а ]—'символ закрывающей индексной скобки, используемый в качестве знака операции АЭМ. Очевидно, если п — число индексов, то
k = n+ 1.
Используя новое обозначение операции АЭМ, обратную польскую запись (4.2) можно переписать в виде
abil + /3]4-сХ«/ + . (4.3)
140
Для перевода выражений, содержащих переменные с индексами, также применим стек с приоритетами. Индексные скобки [ и ] в некотором смысле играют ту же роль, что и круглые скобки. По этой причине им можно приписать те же приоритеты: 0 для [ и 1 для ]. Действие этих скобок на стек, как и действие круглых скобок, состоит прежде всего в следующем. Открывающая индексная скобка всегда записывается в вершину стека, а закрывающая индексная скобка выталкивает из стека все знаки до ближайшей открывающей индексной скобки включительно.
Однако в отличие от круглых скобок одновременно с записью в стек открывающей индексной скобки туда записывается также начальное (минимальное) значение счетчика операндов операции АЭМ, равное 2. Кроме того, после выталкивания из стека знаков закрывающей индексной скобкой и переписи их в выходную строку
Таблица 4.8
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ ВЫРАЖЕНИЯ. СОДЕРЖАЩЕГО ПЕРЕМЕННУЮ С ИНДЕКСАМИ
В ы с т 0 р д о НК А А Я а а а а а а а а а а а а а а а а
6 в в в в в в в в в в в в в
L L L L 1 L L 1 L L L L
1 1 1 1 / / / / / 1
*4* + *4*
/ £ у* / j
3 3 3 3 3 3 3
3 3 D ] D
"4* *4* *4* +
с с с с
X
d d
*4*
С т к — •
£2 [2 L2 С2 13 [з
*4* — + *4*
( (. ( ( ( ( ( ( ( ( X X *4*
( а 6 с 4 1 9 3 ) X с — d
входная строка
141
туда же переписывается значение счетчика операндов, а затем и сама закрывающая скобка.
Запятая, разделяющая индексные выражения, играет одновременно роль закрывающей скобки для предыдущего индексного выражения и роль открывающей скобки — для последующего. Поэтому запятой можно назначить приоритет 1, как закрывающей скобке, дополнив алгоритм условием, что запятая выталкивает из стека все знаки операций до ближайшей открывающей индексной скобки исключительно. Сама запятая, как и любая закрывающая скобка, в стек не записывается. Появление запятой равносильно появлению еще одного индекса, поэтому каждая запятая добавляет в счетчик операндов операции АЭМ единицу.
Пример. Перевести в обратную польскую запись выражение (4.1).
Решение. Решение показано в табл. 4.8.
В табл. 4.8 знак [ сопровождается значением счетчика операндов операции АЭМ. ^Напомним, что минимальное значение этого счетчика равно 2. Нетрудно видеть, что окончательная выходная строка в табл. 4.8 совпадает с записью (4.3), полученной обходом дерева на рис. 4.6.
4.3.5. УКАЗАТЕЛИ ФУНКЦИИ
Помимо простых переменных и переменных с индексами выражение может содержать также указатели функций. Рассмотрим вначале наиболее простой случай, когда параметры функции вызываются по значению. В частности, этот случай имеет место для стандартных функций Алгола-60. Более сложный случай, когда параметры могут вызываться также по наименованию, описан в разделе 4.6 при изложении методов трансляции процедур.
Выражение на Алголе-60
y — f(x, у+ l,z) (4.4)
содержит указатель функции с идентификатором f. Внешне указатель функции отличается от переменной с индексами лишь тем, что после идентификатора функции записана строка, заключенная в круглые скобки, а не в квадратные, как у элемента массива. Поэтому дерево для указателя функции и алгоритм перевода указателя функции в обратную польскую запись практически те же, что для переменных с индексами.
Введем операцию ФУНКЦИЯ, операнды которой — идентификатор функции и значения (или идентификаторы) ее аргументов, а результат — значение функции (точнее, адрес значения функции). Тогда выражение (4.4) можно представить в виде дерева, изображенного на рис. 4.7. Обход этого дерева дает обратную польскую запись выражения (4.4).
Очевидно, как и в случае переменных с индексами, в обратной польской записи целесообразно вместе со знаком операции ФУНК-
142
ЦИЯ указывать количество операндов. Это облегчает последующую трансляцию указателя функции в машинные команды и позволяет контролировать правильность обращения к функции (соответствие числа фактических и формальных параметров).
Будем обозначать операцию ФУНКЦИЯ парой символов
кФ,
где k — количество операндов, а Ф — знак операции ФУНКЦИЯ. Тогда обратная польская запись выражения (4.4) примет следующий вид:
yfxyl + г4Ф—.
Алгоритм перевода в обратную польскую запись функции, имеющей не менее одного параметра, тот же, что для переменной с индексами. Различие состоит лишь в том, что в момент прихода закрывающей круглой скобки в выходную строку записывается символ Ф. Чтобы отличить открывающую круглую скобку в начале списка фактических параметров от открывающей круглой скобки в начале выражения, можно использовать специальную
Таблица 4.9
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ ВЫРАЖЕНИЯ. СОДЕРЖАЩЕГО УКАЗАТЕЛЬ ФУНКЦИИ
Выходная строка У У У У У У У У У У У У У
£ i 1 у у
сс JC JC ОС
У У У У У У У
1 1 1 1 1
-Р +
Z Z Z
4 4
9 Ф
—
F 0 0 1 0 О 0 0 0 0 0 0 0 0
Стен 4* +
(г (2 (з (3 (3 (3 (4 (4
У — ( т ) У 1 9 г )
Входная страна
143
Рис. 4.7. Дерево выражения, содержащего указатель функции
переменную состояния F (признак функции). Эта переменная обычно имеет значение 0. В момент появления идентификатора функции она принимает значение 1, а после занесения в стек круглой скобки и начального значения счетчика операндов, равного 2 (см. п. 4.3.4), вновь принимает значение 0. Закрывающая скобка, встретив в стеке открывающую круглую скобку, записанную вместе со значением счетчика операндов, занесет это значение в выходную строку, запишет туда знак Ф и уничтожит в стеке круглую скобку и значение счетчика операндов.
Пример. Перевести в обратную польскую запись выражение (4.4).
Решение. Решение приведено в табл. 4.9.
Как видно из таблицы, окончательная выходная строка совпадает с обратной польской записью, полученной обходом дерева, показанного на рис. 4.7.
Особый случай, когда указатель функции употребляется без параметров, при переводе в обратную польскую запись можно не выделять, поскольку в этом случае указатель функции, как
и все идентификаторы, будет перенесен непосредственно в выходную строку. Одновременно переменная состояния F примет значение 1. Если следующий символ не круглая скобка, то признаку F присваивается значение 0, а в выходную строку заносится запись 1Ф в знак того, что операция ФУНКЦИЯ имеет всего один операнд— идентификатор функции.
4.3.6. УСЛОВНЫЕ ВЫРАЖЕНИЯ
До сих пор рассматривались выражения, в которых порядок действий определяется только старшинством операций и скобками и в ходе исполнения программы не изменяется. Каждое такое выражение графически изображается статическим деревом. Обход статического дерева дает обратную польскую запись выражения, которую, как было показано в п. 4.3.2, нетрудно транслировать в машинные команды. Однако в языках типа Алгол-60 имеются условные выражения с динамически изменяемым порядком действий. Условное выражение можно изобразить динамическим деревом. Об-, ход динамического дерева дает обратную польскую запись условного выражения.
Для изображения динамических деревьев введем метки, которыми могут помечаться листья и некоторые узлы динамических деревьев. Введем также две операции:
условный переход по значению «ложь» (УПЛ);
безусловный переход (БП).
Операция УПЛ имеет два операнда: первый — логическое выражение, а второй — метка. Если логическое выражение истинно, 144
то операция УПЛ пропускается, а если ложно, то происходит переход на метку. Ветвь динамического дерева с узлом УПЛ показана на рис. 4.8. В Алголе-60 такую конструкцию называют условием.
У операции БП имеется лишь один операнд — метка (рис. 4.9). Результат операции БП — переход на метку.
В деревьях, изображающих простые арифметические и логические выражения, которые рассматривались до сих пор, каждый узел соответствовал некоторой арифметической или логической операции, а каждая ветвь — операнду. Число ветвей, исходящих из узла, было равно числу операндов операции, изображаемой узлом. Это обеспечивало наглядность графического изображения выражений. Чтобы сохранить принцип соответствия числа ветвей числу операндов, в динамических деревьях приходится вводить пустые
метка
Рис. 4.8. Графическое изображение Рис. 4.9. Графическое изображение операции УСЛОВНЫЙ ПЕРЕХОД операции БЕЗУСЛОВНЫЙ ПЕРЕ-ПО ЗНАЧЕНИЮ ЛОЖЬ ХОД
узлы. Такому узлу не соответствует никакая операция, а количество исходящих из него ветвей произвольно.
При изображении условных выражений пустой узел отвечает разветвлению вычислительного процесса. Разветвление есть выбор в ходе вычислений одной из нескольких альтернатив, например выбор одного из нескольких возможных значений операнда.
В дальнейшем пустые узлы будут использоваться также для объединения нескольких последовательно выполняемых действий.
Используя операции УПЛ и БП, арифметическое выражение Алгола-60
у + (if а > b then х + 1 else 2) (4.5)
можно изобразить деревом, показанным на рис. 4.10. Обход этого Дерева дает следующую обратную польскую запись
I 4
yab > /П| УПЛ х 1 + пг2 БП /и.: 2пг2: + .
I 4
(4.6)
Здесь стрелками показаны возможные переходы.
Такая запись вполне пригодна для вычисления значения условного выражения путем интерпретации. Однако для транслятора компилирующего типа она неудобна, поскольку в записи не
145
указана явно переменная, которой присваивается значение условного выражения. Это затрудняет компиляцию машинных команд.
Для компилятора удобно иметь обратную польскую запись, в которой явно фигурирует переменная (одна и та же для всех ветвей), получающая значение условного выражения. Такую запись
Рис. 4.10. Дерево для интерпретации условного выражения
можно получить, если заменить выражения х +1 и 2 в исходной записи (4.5) операторами присваивания
г{: =%+1 и п: =2.
Тогда получается дерево, изображенное на рис. 4.11, а обратная польская запись получается в виде
yab > тх УПЛ гр;! +: = т2БТ1 т^г^: = т2: +. (4.7)
Изменения в обратную польскую запись вносит алгоритм перевода при обработке символов then и else. Этот алгоритм описан в п. 4.3.7.
Рис. 4.11. Дерево для компиляции условного выражения
Запись (4.7) легко транслируется в машинные команды. Процесс трансляции, выполняемый в соответствии с алгоритмом, описанным в п. 4.3.2, показан в табл. 4.10. Трансляция выполняется подпрограммами отдельных операций. Действия, программируе-146
Рис. 4.12. Дерево для компиляции условного выражения, содержащего условное булевское выражение
Таблица 4.10
ПЕРЕВОД УСЛОВНОГО ВЫРАЖЕНИЯ В МАШИННЫЕ КОМАНДЫ
пп Обрабатываемая часть стропи Программируемые и дополнительные действия Имя подпрограммы
1 уа в > rt := а >в
2 ут1тп1 УПЛ if “I r1 then goto тп} Здесь возможна оптимизация путем объединения формируемой команды с предыдущей. Удаление из строки rj УПЛ
3 yrf Х1 + 4*
4 УГ1 гг'-= rz: = r2 Возможна оптимизация путем объединения с предыдущей командой • —
5 у rf m2 6П go to тп2 Удаляется идентификатор rf БП
6 У.т1 : Занесение адреса метки т} в таблицу меток и удаление из строки тп z: • •
7 ул; 2: = Г/ ••=? • ~
8 ТП2-. Занесение адреса метки тп2 в таблицу меток и удаление из строки тп2 : • •
9 утч* Г/ :=У*Г/
10 т 1 Трансляция закончена
147
мне каждой подпрограммой, указаны в таблице. Генерируемые машинные команды не приводятся, поскольку они зависят от конкретной машины. Пояснений требует лишь подпрограмма операции БП, которая помимо формирования команды безусловного перехода на метку, являющуюся ее операндом, удаляет из обрабатываемой строки операнд, предшествующий этой метке, и уничтожает тем самым в обрабатываемой строке «след» первой ветви условного выражения.
Заметим, что при переводе в машинные команды операнды операций управления УПЛ и БП удаляются из обрабатываемой строки. Этим отличается их обработка от обработки арифметических и логических операций, а также операций присваивания, которые оставляют в обрабатываемой строке имя (адрес) рабочей переменной, содержащей результат.
Рис. 4.13. Дерево для компиляции условного выражения, содержащего условное арифметическое выражение
Операция «:» заносит в таблицу меток адрес очередной машинной команды, которая будет формироваться в объектной программе, а ее операнд (метка) удаляется из обрабатываемой строки.
Операции УПЛ и БП позволяют строить деревья и, следовательно, получать обратную польскую запись для сколь угодно сложных условных выражений. На рис. 4.12 показано дерево, соответствующее выражению
у + (if if а — 1 then и /\w else w V zthenx 4-1 elsex— 1) (4.8) и пригодное для последующей компиляции объектной программы, а на рис. 4.13 изображено дерево, отвечающее выражению
у + (if cl > b then x + 1 else if a = ftthenx else x— 1). (4.9)
Это дерево также порождает обратную польскую запись, приспособленную для последующей компиляции.
148
Читателю предлагается самостоятельно определить упрощения в деревьях для случая, когда предусматривается непосредственная интерпретация обратной польской записи.
4.3.7. ОСОБЕННОСТИ АЛГОРИТМА ПЕРЕВОДА УСЛОВНЫХ ВЫРАЖЕНИЙ В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ
Ограничители if, then и else играют в некотором смысле роль скобок. Как и обычные скобки, они выделяют подвыражения и порождают новые ветви дерева. В этом смысле символ if эквивалентен открывающей скобке, а символы then и else, подобно запятым в списках индексов и фактических параметров, являются закрывающими скобками для предшествующего выражения и открывающими для последующего.
Закрывающей скобкой для выражения, следующего за else, может служить либо символ then, как в выражении (4.8), либо другой знак конца условного выражения: закрывающая круглая скобка, закрывающая индексная скобка, запятая или знак конца оператора (точка с запятой или end).
По этим причинам символу if припишем приоритет 0, а символам then и else — приоритет 1.
При переводе условных выражений в обратную польскую запись особенности имеет только обработка символов if, then, else, а также обработка знака конца выражения.
Рассмотрим особенности обработки отдельных символов.
1. Символ if, имеющий приоритет 0, как и любая открывающая скобка, записывается в вершину стека. Этот символ используется в качестве «хранителя» и «переносчика» рабочих меток операций УПЛ и БП. При появлении символа then запись if превращается в if иг,, а появление символа else превращает запись ifm, в ifmj/ni+i. Здесь i — номер очередной рабочей метки. Как будет видно в дальнейшем, описанные действия дают возможность формировать метки операций УПЛ и БП в нужных местах выходной строки.
2. Символ then с приоритетом 1 выталкивает из стека все знаки до первого if исключительно. После этого анализируется запись в вершине стека. Она может иметь одну из двух форм:
a) if
б) if/nj-mi+i, где т, и mt+i — рабочие метки.
Появление какой-либо другой записи — признак ошибки.
Случай (а) означает, что между символами if и then нет другого условного логического выражения (примером случая (а) может служить выражение (4.5)). При этом в выходную строку заносится запись
mt УПЛ г}, (4.10)
где i — номер очередной нечетной рабочей метки, а / — номер очередной рабочей переменной (рабочей ячейки).
149
Затем метка mt заносится в таблицу меток, к символу if в вершине стека дописывается mt (получается запись ifm{, о которой шла речь в п. 1). На этом обработка символа then заканчивается.
Случай (б) означает, что закончилось условное логическое выражение, входящее в другое условное логическое выражение между символами if и then (пример случая (б) — выражение (4.8)).
Вообще говоря, условное логическое выражение может, в свою очередь, содержать условное логическое выражение после символа else, поэтому случай (б) может означать окончание не одного, а нескольких условных логических выражений, объединенных конструкцией вида
if A then В else if Л( then Вг else if Л2 then В2 else ... (4.11)
Каждое условное выражение, входящее в (4.11), оставляет в стеке «след» в виде записи
iimitni+i (4.12)
(см. ниже п. 3).
Следовательно, в общем случае конструкция вида (4.11) порождает в стеке последовательность записей
if
It (4.13)
if W(_2feWli—2fe+l>
первая из которых находится в вершине стека. При излагаемом здесь способе перевода условных выражений все записи, образующие последовательность (4.13), должны быть удалены из стека, а в выходную строку должна быть добавлена запись вида
: = mi+1: : — т{^: ... :=mt_2k+i:, (4.14)
где каждая метка помечает место выхода по операции БП.
После последовательности (4.13) непременно следует запись
являющаяся открывающей скобкой в конструкции вида if ... then. Эта запись соответствует случаю (а), поэтому нужно выполнить описанные выше действия, соответствующие случаю (а). Это означает, что процедура обработки случая (б) непременно завершается процедурой обработки случая (а).
3. Символ else с приоритетом 1 выталкивает из стека все знаки до первого if исключительно. После этого в вершине стека должна быть запись вида
if т{.
Появление другой записи — признак ошибки (напомним, что здесь речь идет только об обработке выражений).
150
В выходную строку добавляется запись
: =т/+1БПт1: гу, (4.15>
затем метка Шг+\ заносится в таблицу меток, а в вершину стека к записи if mi дописывается метка т^\ (получается запись if
4. Символ конца условного выражения, отличный от then (таким символом может быть точка с запятой, запятая, end, а также круглая или индексная скобка) вначале выталкивает из стека его содержимое до ближайшей записи вида
if
которая в общем случае может быть началом последовательности вида (4.13), когда одновременно заканчивается несколько условных выражений, объединенных конструкцией вида (4.11). Обработка такой последовательности выполняется точно так же, как в п. 2 (б), т.е. последовательность (4.13) удаляется из стека, а в выходную строку добавляется запись вида (4.14). На этом обработка условного выражения заканчивается.
Подчеркнем, что рабочая переменная в записях (4.10) и (4.15) одна и та же. Вообще при переводе в обратную польскую запись любого сколь угодно сложного условного выражения используется лишь одна рабочая переменная, которая в итоге содержит значение этого выражения. Конечно, это не означает, что во внутренних подвыражениях не могут использоваться другие рабочие переменные.
Таблица 4.11
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ УСЛОВНОГО ВЫРАЖЕНИЯ
Выходная стропа
у а 6 > т1 упл Tj х 1 +:= тг БП т1 : г1 2 т2 : +
Выход У а 6 X 1 4- 2 +
/77/ • = ГП2
УПЛ fTl2 • •
Г1 ВП
Г1
Стек 4-
4/ if if if if ™i if mi ifmi ifm1 1/10^2 ifr^mz
( ( ( ( ( ( ( ( ( ( (
ч* 4“ 4“ 4“ 4" +
У ( ч а 6 then X 4* 1 else 2
Входная стропа
151
Пример. Перевести в обратную польскую запись выражение у 4- (if а > b then х 4- 1 else 2).
Решение. Решение показано в табл. 4.11, которая устроена иначе, чем предыдущие таблицы. Для сокращения размеров таблицы в графе «Выход» показаны записи, заносимые в выходную строку, а в графе «Выходная строка» — окончательный вид выходной строки.
Таблица 4.12 ПРИОРИТЕТЫ ОГРАНИЧИТЕЛЕЙ. ПРИМЕНЯЕМЫХ В УСЛОВНЫХ ВЫРАЖЕНИЯХ
Ограничители Приоритеты
( 0
= ) 1
2
V 3
л 4
“1 5
V II •н /а 6
— 7
х / ИЗ 8
1 9
4.3.8. АЛГОРИТМ ТРАНСЛЯЦИИ ВЫРАЖЕНИЙ
Помимо арифметических и логических выражений в языках высокого уровня, например в Алголе-60, применяются именующие выражения, определяющие метку. Для перевода именующих выражений в обратную польскую запись можно использовать те же алгоритмы, что и для арифметических и логических, с небольшими коррективами. В частности, если описание переключателя рассматривать как описание массива меток, то указатель переключателя можно переводить почти по тем же правилам, что элемент одномерного массива. С другой стороны, используя понятие косвенной переменной, т. е. переменной, содержащей ссылку на другую переменную или метку (ссылкой является адрес переменной или метки), условное именующее выражение можно переводить в обратную польскую запись как условное арифметическое. Применение косвенных переменных для транстрансляции различных конструкций сокра-вается в следующем параграфе при описании перевода операторов перехода.
Применение общих алгоритмов для трансляции различных конструкций сокращает объем транслятора и повышает скорость трансляции. Однако при этом обычно ухудшается качество рабочей программы. Поэтому в оптимизирующих трансляторах, напротив, для перевода различных конструкций применяют разные алгоритмы.
Описанные в этом параграфе алгоритмы выражений обычно используют в быстрых трансляторах, где главное — скорость трансляции. Объединение алгоритмов перевода отдельных конструкций дает общий алгоритм перевода выражений (арифметических, логических и именующих) в обратную польскую запись. Этот алгоритм основан на применении стека с приоритетами.
Приоритеты всех символов, встречающихся в выражениях, приведены в табл. 4.12. В таблицу включен также символ «;», рас-* сматриваемый как символ конца выражения.
152
В трансляторах интерпретирующего типа обратная польская запись может использоваться непосредственно для вычисления (интерпретации) выражений. В компиляторах обратную польскую запись используют для получения машинных команд в соответствии с алгоритмом, описанным в п. 4.3.2. Алгоритмы перевода в обратную польскую запись и перевода в машинные команды, вообще говоря, можно объединить в единый алгоритм трансляции выражений, который программирует все выражения, встречающиеся во входной программе, за один просмотр. В таком алгоритме обратная польская запись обычно явно не выписывается. Каждый очередной символ, который должен записываться в обратную польскую запись, немедленно поступает на вход блока генерирования машинных команд (см. рис. 4.4).
В многопросмотровых трансляторах, имеющих блочную структуру (например, ТА-2М, Альфа), алгоритм трансляции выражений оформлен в виде блока трансляции выражений (см. п. 1.3.6). Однако существуют трансляторы, в которых выражения рассматриваются как составная часть более сложных конструкций — операторов— и отдельно не транслируются.
4.4. ТРАНСЛЯЦИЯ ОПЕРАТОРОВ
4.4.1. ПРОМЕЖУТОЧНАЯ ОБРАТНАЯ ПОЛЬСКАЯ ЗАПИСЬ ОПЕРАТОРОВ
Обратная польская запись выражений обладает двумя важными свойствами:
1) описываемые ею действия можно выполнять (или программировать) в процессе одностороннего безвозвратного просмотра слева направо, поскольку в момент появления знака операции известно местоположение и вычислены значения соответствующих операндов;
2) операнды расположены в том же порядке, как в исходной записи, поэтому перевод в обратную польскую запись сводится к изменению порядка следования знаков операций.
Именно на этих свойствах основано использование обратной польской записи в качестве промежуточного языка. Первое свойство сближает обратную польскую запись с записью программы на машинных языках, обладающих таким же свойством. Благодаря этому перевод в машинные команды выполняется достаточно просто. Второе свойство существенно облегчает перевод выражений в обратную польскую запись. Перевод оказывается возможным выполнить при помощи стека с приоритетами.
Однако одно переупорядочивание знаков операций позволяет переводить только простые выражения, содержащие простые переменные и константы Для перевода переменных с индексами, указателей функций и условных выражений потребовалось вводить
153.
в обратную польскую запись новые операции, которых в явном виде в исходной записи нет. Успешное применение этого приема привело составителей трансляторов к мысли о возможности использования промежуточной обратной польской записи при переводе всех конструкций, имеющихся в языках типа Алгол-60, включая операторы и описания.
Для реализации этой идеи нужно выбрать подходящий набор операций промежуточного языка. Набор операций должен быть таким, чтобы, с одной стороны, обратная польская запись получалась достаточно простой, а с другой стороны, чтобы при переводе на машинный язык возможно более полно использовались особенности устройства и команд конкретной машины.
В конце этой главы описана основная идея применения промежуточной обратной польской записи при трансляции операторов и описаний Алгола-60. Набор операций промежуточного языка выбран только из соображений простоты перевода в обратную польскую запись. Эффективность объектной программы во внимание не принималась, поскольку конкретная машина не рассматривается. Для конкретной машины набор операций промежуточного языка можно и нужно скорректировать, чтобы полнее использовать возможности машины.
4.4.2. ОПЕРАТОР ПРИСВАИВАНИЯ
Оператор присваивания Алгола-60
а: = &4-с
представляется деревом, изображенным на рис. 4.14. Обход дерева дает обратную польскую запись
abc.
В общем случае левая часть оператора присваивания может содержать несколько знаков присваивания и переменные с индексами, как в операторе
а [/+ 1]: = 6: =«: = 0.
Соответствующее дерево показано на рис. 4.15. Обход этого дерева дает следующую обратную польскую запись:
а I1 +2] Ь / 0: =: — : =.
Из рассмотрения этих двух примеров вытекают требования к величине приоритета знака «: = »:
приоритет знака присваивания должен быть меньше приоритета знака любой арифметической и логической операции, поскольку операция присваивания выполняется после вычисления выражения, записанного в правой части оператора присваивания;
приоритет знака присваивания должен быть больше приоритетов знаков конца оператора (точка с запятой, end и else), чтобы знак конца оператора очищал стек;-
154
знаки присваивания не должны выталкивать из стека друг друга, чтобы операция присваивания выполнялась справа налево, а индексные выражения в списке левой части вычислялись слева направо, как требует семантика Алгола-60.
Из табл. 4.12 видно, что первые два требования можно выполнить, приписав знаку присваивания приоритет 2 и увеличив одновременно приоритеты всех знаков арифметических и логических операций, приведенные в табл. 4.12, на 2.
Рис. 4.14. Графическое изображение оператора присваивания
Третье требование можно выполнить, если ввести для знака присваивания два приоритета:
стековый приоритет, соответствующий знаку присваивания, когда он находится в стеке;
сравнительный приоритет, который имеет знак присваивания до записи в стек.
Стековый приоритет уже выбран. Он равен 2. Сравнительный приоритет нужно положить большим приоритета любого другого
Рис. 4.-15. Дерево, изображающее оператор присваивания с несколькими знаками присваивания в списке левой части
знака, чтобы знак присваивания не выталкивал из стека никакого знака. В табл. 4.13, где приведены новые приоритеты, сравнительный приоритет знака присваивания принят равным 12.
Табл. 4.13 содержит также приоритеты операторных скобок begin и end, такие же, как у всех скобок, и приоритет знака оператора перехода go to, такой же, как стековый приоритет знака оператора присваивания. Это обеспечивает определение значения именующего выражения до выполнения оператора перехода.
155-
Таблица 4.13
ПРИОРИТЕТЫ ОГРАНИЧИТЕЛЕЙ, ПРИМЕНЯЕМЫХ В ОПЕРАТОРАХ
Ограничители Стековый приоритет Сравнительный приоритет
( С Begin 0 —
) J , then eBse ; end / /
• 2 12
go to 2 2
3 3
3 4 4
5 5
6 6
7 7
V/ II A 8 8
— 9 9
X / -Г ИЗ 10 10
f 11 11
4.4.3. ОПЕРАТОР ПЕРЕХОДА
Используя операцию БЕЗУСЛОВНЫЙ ПЕРЕХОД, оператор перехода
go tom
можно представить деревом (см. рис. 4.9). Его обратная польская запись имеет вид
m БП.
Дерево, которое можно использовать для интерпретации оператора перехода с условным именующим выражением
go to if а = b then M else Af, (4.16)
показано на рис. 4.16. Обход этого дерева дает обратную польскую запись
ab — тх УПЛ Мт2 БП/nf. Nm2: БП.
156
Однако, как и в случае условного арифметического и условного логического выражения, эта запись неудобна для компиляции. Чтобы получить простой алгоритм трансляции именующих выражений, пригодный для компиляции, целесообразно ввести косвенные переменные, допустив присваивание им значений меток. Кос-
Рис. 4.16. Дерево для интерпретации опера-тора перехода с условным именующим выражением
венной переменной может быть любая переменная, содержащая ссылку на метку.
Применение косвенных переменных позволяет использовать в качестве операнда операции БП любую рабочую переменную (при
Рис. 4.17. Дерево для компиляции оператора перехода с условным именующим выражением
условии, что значением этой переменной является ссылка на метку), а также дает возможность применять для перевода условных именующих выражений в обратную польскую запись общий алгоритм трансляции условных выражений, описанный в п. 4.3.7. В частности, оператор перехода (4.16) можно представить деревом, показанным на рис. 4.17. Обход этого дерева, или применение общего алгоритма трансляции выражений, дает следующую обратную польскую запись:
ab — т{ УПЛ rtM: = т2 БПлПр rPV: = т2: БП. (4.17)
157
При трансляции записи (4.17) в машинные команды сокращение этой записи приведет к операции
И БП.
При исполнении программы значением косвенной переменной Г1 будет ссылка на метку М или на метку N, в зависимости от значения истинности отношения а = Ь.
4.4.4. УСЛОВНЫЙ ОПЕРАТОР
Условный оператор вида if A then В else С;,
где А — логическое выражение;
В — безусловный оператор;
С — оператор, подобно условному выражению можно представить в виде динамического дерева (рис. 4.18). Заметим, что в изображении дерева
Рис. 4.18. Дерево, изображающее условный оператор
знак «;» не является знаком операции. Отвечающий ему узел играет роль пустого узла и служит для объединения отдельных ветвей. В обратную польскую запись знак «;» можно не переносить.
Обход дерева дает обратную польскую запись
Ат{ УПЛ Вт^ БП тх'. Ст?:.
Частным случаем условного оператора является оператор «если»:
if A then В;. (4.18)
Соответствующее дерево показано на рис. 4.19. Обратная польская запись оператора (4.18) имеет вид
Атх УПЛ Втх..
Сравнивая обратную польскую запись условного выражения и условного оператора, нетрудно видеть, что для полного условного оператора отличия состоят лишь в «обрамлении» знаков операций УПЛ и БП, а также в ином оформлении конца оператора.
158
Аналогии оператору «если» в условных выражениях нет. Однако оператор «если» можно рассматривать как особый частный случай полного условного оператора.
По этим причинам алгоритм перевода условных операторов в обратную польскую запись почти тот же, что для условных выражений. Это дает возможность использовать в обоих случаях один и тот же блок транслятора.
Рис. 4.19. Дерево, изображающее оператор «если»
Чтобы обеспечить специфичную обработку условного оператора, целесообразно при занесении в стек символа if фиксировать вместе с этим символом признак условного оператора, отличающий его от условного выражения. Обозначим этот признак знаком *. При
Таблица 4.14
РАЗЛИЧИЕ ОБРАОТКИ СИМВОЛОВ В УСЛОВНЫХ ОПЕРАТОРАХ И ВЫРАЖЕНИЯХ
Обраба-тываеиый символ Условное выражение Условный оператор
Запись в стек Запись в выходную строку Запись в стек Запись в выходную строку
if if — if * —
then a) if mi 6) - а)пц УПЛ г; б):=тс+1:- a) if ♦ mi б) - a) rnL УПЛ б) mi+1 :...
etse if Щ mL±1 •^тмБПт^ if*mi mi+t БП тп^ :
Конец Выражения (оператора) —— а) при owe встретилась за (конец оператор тке стека пись if * rof ta „если”) । ”4-
б) при очис встретилась заг (конец полного ротора) тке стека юсь if *mi условного one-
159
появлении условного оператора в стек будем заносить запись if*, а не просто if, как в условном выражении.
В соответствии с синтаксисом Алгола-60 символ if является началом условного оператора, если ему предшествует один из символов: ; : (в конце метки) begin do или символ else, к которому «парным» является if *.
Рис. 4.20. Пример дерева условного оператора
Алгоритм обработки условных выражений, описанный в п. 4.3.7, включает четыре пункта. В табл. 4.14 приведены изменения, которые нужно внести в этот алгоритм для обработки условных операторов.
Пример. Перевести в обратную польскую запись оператор if а = b then begin а: = 0; go to М end else a: = 1;.
Решение. Решение приведено в табл. 4.15, а также получено обходом дерева, изображенного на рис. 4.20. В обоих случаях получена следующая обратная польская запись:
аЬ=тх УПЛ а0: = М БП т2 БП гщ: al: = т2:.
Таблица 4.15
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ УСЛОВНОГО ОПЕРАТОРА
ВЫХОДНАЯ СТРОКА
а в = тj УПЛ а 0 : = МБП т2 БПтП] : а1' = тп2'
В Ы X 0 д а б — a 0 • — M БП m2 a 1 ! s
БП m2
УПП m. • •
•
с т Е К • «». до to goto
— бед beg beg beg Beg beg beg • —" ♦ —
if* if* 4/* if* mj if * 77?; If* if» if* if* if * Л7; if * Л7/ if* m. if* Tfl2 if* mi m2 if» ТП2 X ТП9
а — в then Begin a 0 7 goto M ела e&e a • “ 1 • 3
ВХОДНАЯ СТРОКА
160
Нетрудно видеть, что общий алгоритм в данном случае дает избыточную запись выполняемых действий: наличие М БП делает излишней следующую операцию т2 БП. Такого рода избыточность и оптимизирующих трансляторах устраняется специальными алго* ритмами оптимизации.
I 4.4.5. ОПЕРАТОР ЦИКЛА
Оператор цикла Алгола-60 в общем случае имеет вид for (переме! ная) : = (список цикла) do (оператор).
Как известно, список цикла состоит из элементов, разделенных запятыми. Элементы списка цикла могут быть трех типов: типа арифметического выражения, типа пересчета, типа арифметической прогрессии.
Алгоритм перевода оператора цикла в обратную польскую запись должен строиться с учетом того, что:
семантика элемента списка цикла зависит от его типа;
любой элемент списка цикла начинается арифметическим выражением, поэтому в начале перевода очередного элемента его тип неизвестен;
в списке цикла различные элементы могут встречаться в произвольной последовательности;
желательно, чтобы алгоритм перевода был безвозвратным, т. е. не требовал повторного просмотра уже рассмотренных символов входной строки.
Рис. 4.21. Графическое представление операции БЕЗУСЛОВНЫЙ ПЕРЕХОД С ВОЗВРАТОМ
Рис. 4.22. Графическое изображение операции ВОЗВРАТ
Выполнение последнего требования позволяет получить быстрый алгоритм, который, однако, не дает оптимальной объектной программы. В оптимизирующих трансляторах входная программа просматривается неоднократно (см. 4.7).
Для представления оператора цикла в виде дерева введем операцию БЕЗУСЛОВНЫЙ ПЕРЕХОД С ВОЗВРАТОМ (БПВ) с тремя операндами — метками (рис. 4.21) и вспомогательную операцию ВОЗВРАТ (В), обеспечивающую резервирование свободной ячейки с меткой тг для записи команды возврата (рис. 4.22).
Операция БПВ предписывает безусловный переход на метку mq и формирует в ячейке тГ9 резервированной операцией В, команду безусловного перехода на метку тр. Целые числа р, q и г интерпретируются как номера меток.
6 Зак. 221 161 •
А. ЭЛЕМЕНТ СПИСКА ЦИКЛА ТИПА АРИФМЕТИЧЕСКОГО ВЫРАЖЕНИЯ
Оператор цикла
for/: = at, а2, .... andoA;,
(4.19)
где Яь а2, .... ап — арифметические выражения, изображается деревом, показанным на рис. 4.23.
Заметим, что метка mt+2 на рис. 4.23, вообще говоря, не нужна. Эта метка, как будет видно в дальнейшем, необходима только для элемента списка цикла типа пересчета. Однако в момент начала просмотра оператора цикла неизвестно, каким окажется первый элемент списка цикла. Эта метка вводится, чтобы обеспечить общность алгоритма.
Рис. 4.23. Дерево оператора цикла с элементами списка цикла типа арифметического выражения
Структура дерева на рис. 4.23 обеспечивает последовательное присваивание параметру цикла / значений выражений at, а2,..., ап перед каждым исполнением оператора А и возврат к следующему элементу списка цикла после каждого исполнения этого оператора.
На рис. 4.23 / — номер первой свободной рабочей метки в момент начала перевода оператора цикла. Меткой mj помечена операция В, т. е. ячейка памяти, в которую записывается команда возврата к следующему элементу списка цикла после исполнения оператора А. Меткой nti+i помечен оператор А (тело цикла).
Обход дерева дает следующую обратную польскую запись:
/п<+2: lat: = т<+зт/+1т/БПВт<+1:1а2 for ,
: = т<+4/и(+1т,БПВ... mi+n+l: 1ап (4.20)
* II I —К.» — ~ I —i !>
: » т/+„+2т<+1т/БПВт<+1: Amt: Bmt+n+2:
I- . I ! > 14 —-——»
do :
162
В записи (4.20) фигурными скобками выделены части выходной строки, порождаемые специфичными для оператора цикла символами входной строки (4.19).
Операции БПВ и В и структура дерева, изображенного на рис. 4.23, специально выбраны так, чтобы получить возможно более простой алгоритм перевода в обратную польскую запись. Собственно в этом и состоит сущность прямых методов трансляции. Взяв за основу некоторую общую идею (здесь такой идеей является перевод в промежуточную обратную польскую запись), для каждой конструкции входного языка подбирают индивидуальный алгоритм перевода. Элементами, которые можно подбирать, в данном случае являются операции промежуточного языка и структура обратной польской записи.
Б. ЭЛЕМЕНТ СПИСКА ЦИКЛА ТИПА ПЕРЕСЧЕТА
Оператор цикла for/:—Й! while а2whileb2doA;, (4.21)
где Я1 и а2 — арифметические выражения, а Ь\ и Ь2 — логические выражения, изображается деревом, которое приведено на рис. 4.24.
Рис. 4.24. Дерево оператора цикла с элементами списка цикла типа пересчета
Обход дерева дает обратную польскую запись
mi+2: la{: = б^+зУПЛт^г/п^.нЦьБПВ/п^з:1а2 (4.22)
for while ,
: = b2mi+4yTl.nmi+3mi+imiBTIBmi+i: Ат{ :Bmt+4:
мЖГе ch 7
в которой также фигурными скобками выделены части выходной строки, порождаемые специфичными для оператора цикла символами входной строки (4.21).
Заметим, что в обоих рассмотренных случаях выходная строка намного длиннее входной и на первый взгляд кажется более
6*
1(53
громоздкой. Однако в обратной польской записи оператора цикла нет рекурсивности и из нее легко получить машинные команды, используя алгоритм, описанный в п. 4.3.2.
В. ЭЛЕМЕНТ СПИСКА ЦИКЛА ТИПА АРИФМЕТИЧЕСКОЙ ПРОГРЕССИИ
Это наиболее сложный для перевода в обратную польскую запись элемент списка цикла.
Рис. 4.25. Дерево оператора цикла с элементами списка цикла типа арифметической прогрессии
Оператор цикла
for /: = step until а2 step й2 until с2 do Л;, (4.23)
где Яь fti, Ci, а2, h2 и с2— арифметические выражения, представляется деревом, изображенным на рис. 4.25.
164
Обход дерева дает обратную польскую запись mz+2: /й! : == гр : = mi+3:
for step
: = г/0 = mi+iynjUlrl+i + : — ml+4 :rjO: = lc\ until
— r/+1 sign X 0 < /П(+5УПЛт(+зт/+1/п/БПВ/П(+5: la2
•, = r j\ : = mi+3: r)+ih2
*_-- _J
step
(4.24)
: = Г/0 — т/+7УПЛ//г;+1 + : — /П/+7 :r70 : = lc2 until
— rl+i sign X 0 < т7+8УПЛ/п7+6/П/+1т(БПВт(+1: A
--------------------d5---------------------
пц : Btnt+3 :.
'I—.
Здесь, как и в предыдущих случаях, фигурными скобками выделены части выходной строки, порождаемые отдельными символами входной строки (4.23). В строке (4.24) г, — очередная свободная рабочая переменная.
4.4.6. АЛГОРИТМ ПЕРЕВОДА ОПЕРАТОРА ЦИКЛА
В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ
При переводе оператора цикла в обратную польскую запись арифметические и логические выражения в заголовке и теле цикла переводятся по сформулированным раньше общим правилам. Особенности имеет только обработка символов, специфичных для заголовка цикла:
for: —, while step until do,
а также обработка символа, обозначающего конец оператора цикла («;» или end).
В описываемом ниже варианте алгоритма перевода оператора Цикла используются два признака:
признак «цикл» с двумя значениями 0 и 1;
признак «тип элемента» со значениями 0, 1, 2 и 3, где 0 соответствует элементу списка цикла типа арифметического выражения, 1 — элементу типа пересчета, а 2 и 3 — элементу типа арифметической прогрессии.
Кроме того, используется одна стандартная ячейка «параметр цикла» для хранения идентификатора параметра цикла, если
165
параметр цикла простая переменная, или группа стандартных ячеек для хранения символов, описывающих переменную с индексами, если параметр цикла — переменная с индексами. В большинстве трансляторов Алгола-60 входной язык не допускает использования в качестве параметра цикла переменных с индексами, поэтому для упрощения изложения будем предполагать, что параметр цикла — простая переменная, хотя усложнения алгоритма в случае, когда параметр цикла — переменная с индексами, непринципиальны.
1. Символ for в заголовке цикла играет роль открывающей скобки и имеет поэтому приоритет 0, как и любая открывающая скобка.
При появлении символа for в выходную строку записывается
mi+2:, (4.25)
а в вершину стека
for mi+3nii+imi = for tnpmqmr, (4.26)
где mi — рабочая метка операции В (метка ячейки возврата); т{+1 — рабочая метка тела цикла (метка начала оператора А в предыдущих примерах);
/П{+з — рабочая метка участка программы, который в случаях А и Б п. 4.4.5 вычисляет второй элемент списка цикла, а в случае В засылает в рабочую ячейку значение шага изменения параметра цикла.
Кроме того, символ for формирует признак «цикл» = 1 и признак «тип элемента» = 0. Последнее означает, что первый элемент списка цикла по предположению является элементом типа «арифметическое выражение».
Как уже говорилось, запись (4.25) выполняется «про запас» для обеспечения безвозвратности алгоритма перевода в случае, если первый элемент списка цикла окажется элементом типа пересчета. Для элементов списка цикла другого типа она не нужна и не используется.
2. Символ «: = ». Появление символа «: = » при ненулевом значении признака «цикл» означает, что последняя запись в выходной строке есть параметр цикла I. Символ «:=» в стек не заносится, а идентификатор параметра цикла I записывается в стандартную ячейку «параметр цикла», поскольку он необходим для дальнейшего перевода. Затем признак «цикл» делается равным нулю.
3. Символ «,». Запятая является закрывающей скобкой для предшествующего выражения и имеет поэтому приоритет 1, который обеспечивает выталкивание из стека всех знаков до записи
for mpmqmr
исключительно. Напомним, что эта запись занесена в стек при обработке символа for (запись 4.26).
166
Дальнейшие действия зависят от значения признака «тип элемента» и определяются табл. 4.16.
Таблица 4.16
ОБРАБОТКА СИМВОЛА «,»
Значение признана „ тип элемента ” Запись в выходную строку Запись в стек и дополнительные действия
0-„арифметическое Выражение ” :=тр тп тГ БПВ тр > В fOT* ГПр+1 ГПу Юр
1 пересчет ” тр УПЛ Шу тг ВПВгпр: е for три т^ тг
2- ошибка: после символа step нет символа until • Занесение 6 таблицу ошибок
3 - „арифметическая прогрессия ” -г,*, sign хо^ тр^2 УПЛ тр тп тг БПВ тр+г В for Юр+з nfy тр „счетчик рабочих ячеек „ счетчик рабочих ячеек"—2
В графе «Запись в стек» табл. 4.16 указана запись, которой заменяется запись for mpmqmr в вершине стека. Изменение значения счетчика рабочих ячеек /, когда признак «тип элемента» равен 3, обеспечивает правильное формирование номеров рабочих переменных вида г, в обратной польской записи оператора цикла.
После выполнения действий, определенных табл. 4.16, признаку «тип элемента» присваивается значение 0.
4. Символ do является закрывающей скобкой для предшествующего выражения и всего заголовка цикла, следовательно, он имеет приоритет 1. Поэтому все знаки до записи
for mptnqmr
исключительно выталкиваются из стека. Дальнейшие действия зависят от значения признака «тип элемента» и определяются табл. 4.17.
После занесения в выходную строку записи, определяемой табл. 4.17, запись for mpmgmr в вершине стека заменяется записью, указанной в графе «Запись в стек», а признаку «тип элемента присваивается значение 0.
5. Символ while, являясь закрывающей скобкой для предшествующего выражения в элементе списка цикла типа пересчета, имеет приоритет 1, поэтому все знаки до записи
for mpmqtnr
исключительно выталкиваются из стека. Затем в выходную строку заносится запись «: = », а признаку «тип элемента» присваивается
167
ОБРАБОТКА СИМВОЛА do
Таблица 4.17
Значение признана п тип элемента” Запись в Выходную строну Запись в стен и дополнительные действия
0 - „ арифметическое выражение” : = Шр ТПу тпг бПВ 7П^ : do ТПр mq тпг
/ - „ пересчет” 7Пр УЛЛтр.1 тпп тпг БПВ Шу: do ТПр тп^ ТПр
2 - ошибка' после символа step нет символа unite Занесение в таблицу ошибок
3 - „арифметическая прогрессия ” -Г;г1 Sign х mp+2 УМ mp mq тпг БПВ тп^ : do Шр+2 Пу тпг „счетчик рабочих ячеек” :« „счетчик рабочих, ячеек” -2
значение 1, соответствующее элементу списка цикла типа пересчета. До этого признак «тип элемента» должен иметь значение О, другое значение — ошибка.
6. Символ step является закрывающей скобкой для предшествующего арифметического выражения в элементе списка цикла типа арифметической прогрессии и имеет, следовательно, приоритет 1. Поэтому этот символ выталкивает из стека все знаки до записи
I" for трГПцШг
исключительно. Затем в выходную строку заносится запись : = Г;1 : = mp:r/+1,
а признаку «тип элемента» присваивается значение 2. До этого признак должен иметь значение 0. Иное значение признака — ошибка: неправильно записан предыдущий элемент списка цикла или вообще неправильно записан заголовок цикла, например нет символа for.
7. Символ until, как и символ step, является закрывающей скобкой, имеет приоритет 1 и действует подобно символу step, выталкивая из стека все знаки до записи
for mPmqmr
исключительно. Затем в выходную строку заносится запись : = гу0 = /пр+1УШШг/+1 + : = mp+i: ry0 : = Z,
а признаку «тип элемента» присваивается значение 3, соответствующее элементу списка типа арифметической прогрессии. До 168
этого признак должен иметь значение 2. Иное значение — ошибка: перед символом until нет символа step.
8. Конец оператора цикла (символы «;» или end). При появлении во входной строке символа «;» или символа end стек очищается в соответствии с правилами обработки каждого из этих символов.
X 8 г2
Рис. 4.26. Пример дерева оператора цикла
Если в процессе очистки стека встречается запись
do mpmqmr, (4.27)
то это означает окончание оператора цикла. В выходную строку заносится запись
тг:Втр:, (4.28)
после чего запись (4.27) удаляется из стека и очистка стека продолжается. Запись вида (4.27) может встречаться несколько раз подряд (вложенные циклы), тогда каждый раз в выходную строку заносится запись вида (4.28).
Пример. Перевести в обратную польскую запись оператор Цикла
for х: = у, 1 step 2 until 8 do у: = у + х
Решение показано в табл. 4.18, а на рис. 4.26 изображено соответствующее дерево, обход которого дает ту же самую обратную польскую запись.
169
Таблица 4 IS
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ ОПЕРАТОРА ЦИКЛА
ВЫХОДНАЯ СТРОНА
тп 2 : ту : = т3 т1 т0 БПВ тп3 : х 1 : = rf 1: = mA : r2 ? у> — ..... .1. - । , / Ч. . ✓
for , step
: = rlO = ms УПЛ ххгг + : = ms: r,O: = x 8 \----,----z.-------------------------/
unti.2
-гг sign х 0 ^ms УПЛтп^ mt m0 6nBmt: уу i+-. = m0:Bm6: --------------_--------------------/ \--------v--->
do }
В ы X 0 д тп2 зс У *= 1 • —— 2 • — 8 У У X +
• ™3 7*/ r2 • —
77?; 1 0 sign
7770 • — X • •
БПВ 777^ ^5 0 в
m3 • УПЛ m6
• • л2 X • •
X % ynn
r2 ТП
T^1
• TOq
^5 БЛВ
• ^1
Г1 • •
0
• —
X
/7// — — X X X X X X X X X X X X X X X
и 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ТЭ 0 0 0 0 0 0 2 2 3 3 0 0 0 0 0 0 0
С Т Е К 4“ +
• —» •— • • ——
for m3 mj ITlQ for m3 mj mo for m3 ГП] mo for 7773 m, m0 for 777 ; m0 for m^ mf mo for mo for mj mo for mj mo for m^. 777 7 mo do m6 mj mo do m6 mr mo do m6 Л7; mo do m6 mi mo do m6 777; mo do m6 mj mo
1 for X * zx. У > 1 step 2 untlE 8 do У У X >
входная строил
170
Табл. 4.18 имеет такую же структуру, как табл. 4.15. Однако между верхней частью таблицы, где показаны записи в выходную строку, и нижней ее частью, отображающей состояние стека, помещены три дополнительные строки, содержащие значения признаков (сверху вниз) «параметр цикла», «цикл» и «тип элемента».
Подчеркнем еще раз, что приведенные способы перевода в обратную польскую запись операторов Алгола-60 являются безвозвратными и поэтому обеспечивают быструю трансляцию. Однако эти способы не учитывают особенностей конкретной машины и, следовательно, не могут дать хорошей по качеству объектной программы, если не дополнить их специальными алгоритмами оптимизации, которые должны учитывать особенности данной машины.
4.5. БЛОКИ И ТРАНСЛЯЦИЯ ОПИСАНИЙ
4.5.1. БЛОЧНАЯ СТРУКТУРА ПРОГРАММЫ И СПОСОБЫ РАСПРЕДЕЛЕНИЯ ПАМЯТИ
Одной из важных функций транслятора является распределение памяти для размещения данных, используемых в программе.
Различают два способа распределения памяти: статический и динамический.
Статическое распределение памяти состоит в назначении адресов для размещения данных в процессе трансляции. Адреса могут затем корректироваться при загрузке программы, но в процессе исполнения объектной программы остаются неизменными.
Динамическое распределение памяти состоит в назначении адресов для размещения данных в процессе исполнения программы. С этой целью транслятор включает в объектную программу специальные команды, обеспечивающие перераспределение памяти в ходе исполнения программы.
На практике оба способа часто применяют совместно. Однако существуют трансляторы, в которых память распределяется только статически [3]. Известны также трансляторы, в которых память распределяется только динамически [26].
Динамическое распределение памяти связано с блочной структурой программы. Блоки определяют область действия описанных в них объектов и предназначены прежде всего для экономии памяти в процессе исполнения программы. Экономия достигается размещением величин, описанных в независимых блоках, в одних и тех же ячейках памяти. Однако сами по себе блоки не предопределяют необходимости динамического распределения памяти. Например, в программах на языке АЛМО, имеющих блочную структуру, память распределяется статически.
171
Пример 1. При выполнениия Алгол-программы
begin real at b\
d: = 0;
ml: begin real c, d\
d: = d+ 1;
m2 : ...
end ml;
nl: begin real f, a;
n2 : if b = 1 then go to ml; ...
end nl;
end
распределение памяти изменяется, как показано в табл. 4.19. Каждое новое состояние памяти отвечает моменту достижения указанной в таблице метки и указанному значению переменной Ь.
Таблица 4.19
РАСПРЕДЕЛЕНИЕ ПАМЯТИ С УЧЕТОМ БЛОЧНОЙ СТРУКТУРЫ
Ячейка т1 6=0 7П2 6=1 nl 8=1 7J2 8=1 т1 8=1 m2 8=2 nl 6=2 П2 6=2
к + 0 к + 1 К + 2 к+3 а в а в с d а 8 а В а а 6 а в с d а 6 а 6 а
Из таблицы видно, что переменные с, d и f, а последовательно сменяют друг друга в одних и тех же ячейках памяти. Заметим также, что внутри блока nl (когда достигнута метка п2) переменная а, описанная во внешнем блоке и размещенная в ячейке k + 0; недоступна для использования, поскольку переменная с тем же идентификатором описана во внутреннем блоке nl. Эта локальная переменная размещена в ячейке k + 3.
Блочную структуру программы наглядно можно представить в виде дерева. Дерево, изображенное на рис. 4.27, соответствует приведенному выше примеру. Узлы дерева отвечают блокам и Расположены на разных уровнях. Внешнему блоку приписан уро-в’ень 1. Блоки, содержащиеся во внешнем, отнесены к уровню 2. Вообще блоку, содержащемуся в блоке уровня i, будем приписывать уровень i + 1.
Перемещение из узла в узел соответствует переходу из блока в блок. Состояние памяти при выполнении блока определяется переменными, указанными в узлах, лежащих на пути от данного узла до корня дерева включительно. Корень всегда соответствует самому внешнему блоку. Это справедливо с одной оговоркой: при совпадении идентификаторов переменных, описанных во внешнем и внутреннем блоках, переменная внешнего блока становится недоступной, но не вычеркивается из памяти.
172
Следовательно, путь от данного узла до корня дерева дает текущее (статическое) состояние памяти, а переходы из узла в узел и связанное с ними изменение пути до корня наглядно представляют процесс динамического перераспределения памяти в ходе выполнения программы.
Поскольку от любого узла до корня дерева имеется единственный путь, а количество скалярных переменных, описанных в каждом блоке, не меняется при повторных входах в блок, скалярные переменные каждого блока (кроме переменных, описанных в теле рекурсивных процедур) можно разместить в ячейках памяти заблаговременно, на этапе трансляции. Это позволяет экономить память за счет совмещения адресов переменных в независимых блоках и в то же время избавляет от необходимости определять заново адреса переменных при каждом входе в блок во время исполнения программы.
Однако статическое распределение памяти возможно лишь в тех случаях, когда количество данных, описанных в блоке, не меняется при повторных входах в блок. В общем случае в трансляторах с языков типа Алгол-60 заблаговременное распределение памяти (статическое распределение) невозможно по крайней мере по двум причинам:
применение массивов с переменными границами, размеры которых можно определить лишь в момент входа в блок;
использование рекурсивных процедур (процедур, содержащих обращение к самим себе), поскольку исполнение таких процедур требует копирования области памяти, выделенной процедуре, причем до исполнения программы количество копий определить нельзя.
В некоторых трансляторах для массивов, скалярных переменных и процедур выделяют различные области памяти, а рекурсивные процедуры запрещают. Это позволяет ограничиться динамическим перераспределением памяти в ходе выполнения программы только для массивов с переменными границами. Чтобы избавиться от необходимости динамически перераспределять память для
173
массивов с переменными границами, входные языки некоторых трансляторов требуют указания максимальных размеров каждого массива, а в Фортране это обязательное требование. В Фортране, кроме того, запрещены рекурсивные процедуры.
4.5.2. СТАТИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ПАМЯТИ
Статическое распределение памяти целесообразно проводить в два этапа. На первом этапе выделяется секция памяти каждому блоку, а на втором — назначаются адреса переменным внутри блока.
Пусть программа имеет блочную структуру, изображенную деревом на рис. 4.28. В каждом узле дерева указан порядковый номер блока i и записано количество ячеек памяти П{, требующееся для размещения данных, описанных в блоке. Блоки занумерованы
Рис. 4.28. Пример блочной структуры программы
в том порядке, в котором они расположены в программе. Предполагается, что количество ячеек памяти tit не меняется при повторных входах в блок.
Для выполнения первого этапа распределения памяти в ходе трансляции составляется таблица блоков, каждая запись которой для блока с номером i содержит: УБ{ — уровень блока; — количество ячеек памяти (машинных слов) для размещения в блоке i данных.
Таблица блоков для программы, изображенной деревом на рис. 4.28, показана в левой части рис. 4.29. Заметим, что первая позиция этой таблицы оставлена свободной. После определения начала поля памяти, выделенного для размещения данных, в эту позицию записывают значение указателя Wi, которое равно адресу ячейки памяти, предшествующей первой ячейке поля для размещения данных. Следовательно, адрес ячейки, начиная с которой размещаются данные, равен Afj + 1.
Распределение памяти для блоков состоит в преобразовании таблицы блоков в таблицу указателей начала блоков. Эта таблица отличается от таблицы блоков лишь тем, что количество ячеек памяти для размещения описанных в блоке данных tii заме-174
няется указателем начала секции памяти, выделенной следующему блоку с номером i + 1.
Таблица указателей начала блоков, соответствующая рассматриваемому примеру, приведена на рис. 4.29. На этом же рисунке показано распределение памяти для блоков. Секция памяти, выделенная каждому блоку, изображена отрезком прямой.
таблица блоков
Рис. 4.29. Статическое распределение памяти для блоков
Указатели начала блоков JV, вычисляются, исходя из следующих соображений. Пусть блоки имеют номера 1........т. Для пер-
вого блока указатель /Vi задан. Для второго блока указатель
N2 — Nx-\-nx.
Очевидно, Л^2 — последняя ячейка памяти, занятая блоком 1. Вообще для произвольного блока с номером i в качестве указателя начала блока Nx нужно взять последнюю ячейку, занятую блоком, в котором непосредственно содержится блок i.
Формально
Ni = Ni + nl = Ni+x, (4.29)
где
Мх = max [N........
уб,>убй
k = 1, .... i — 1
175
Иными словами, для вычисления значения Nit i = 2, т нужно, последовательно просматривая записи с номерами i—1, i — 2, ..., 1, найти первую запись с номером I, такую, что УБ{ > УБ/. После этого значение Nt вычисляется по формуле .(4.29).
В ходе формирования таблицы указателей начала блоков нужно также определить адрес последней ячейки, занятой данными. Очевидно, этот адрес
ALax = =ПаХ {Ni + niV I
Величину Nma* записывают в последнюю позицию таблицы указателей начала блоков, которая в таблице блоков занята величиной пт.
Если предположить, что таблица блоков размещена в массиве с описанием
integer array Г [0 : 2 X т\
и что в этом же массиве затем помещается таблица указателей начала блоков, как это показано на рис. 4.29, то процесс статического распределения памяти для блоков можно описать приводимой ниже процедурой СРП (статическое распределение памяти).
procedure СРП (Г, /и, N1);
value m, .VI; integer tn, NV, integer array Г;
begin integer /, lt max',
T [0]: = Л1; max.: = T [2]: = T [2] + AH;
for i: = 4 step 2 until 2 X do
begin if T [Z —• 1] < T [i — 3] then
begin for I: = i — 5 step — 2 until 1 do if T [i — \]> T [Z] then
begin T [Z — 2]: = T [Z + 1]; go to Л4 end end;
M : T [Z]: = T [Z] + T [Z - 2];
if max < T [Z] then max : = T [Z] end;
T [2 X m] • = max
end СРП;
При статическом распределении памяти все данные, описанные в блоке, можно расположить в области памяти, выделенной Для этого блока. Однако на практике массивы обычно размещают в отдельном поле массивов. Это связано с тем, что массивы иногда приходится выносить во внешнюю память.
Будем считать, что массивы размещаются отдельно. В этом случае упоминавшаяся выше величина пг- есть количество скалярных переменных, описанных в блоке. Для назначения адресов скалярным переменным внутри блока используют таблицу идентификаторов, составляемую в ходе обработки описаний.
176
В общем случае каждая запись таблицы идентификаторов содержит:
идентификатор (или заменяющую его ссылку на таблицу имен, составленную в процессе лексического анализа и перевода на внутренний язык);
порядковый номер блока — i\
уровень блока — УБг-;
порядковый номер (или относительный адрес) идентификатора данного класса в блоке — /;
признак, определяющий класс и тип идентификатора.
Последнее требует пояснения. В Алголе-60 идентификаторы могут обозначать объекты одного из следующих классов: простая переменная, массив, метка, переключатель, процедура, процедура-функция. Для простых переменных используется понятие «тип»: вещественный, целый и булевский. Понятие типа распространяется также на массивы и процедуры-функции.
После составления таблицы указателей начала блоков относительные адреса (порядковые номера) простых переменных / пересчитываются в абсолютные адреса по формуле
АДРЕС = Nt + /.
Абсолютные адреса заносятся в таблицу идентификаторов вместо относительных.
Заметим, что вся информация, содержащаяся в описанной выше таблице блоков, содержится в таблице идентификаторов, поэтому в ходе трансляции можно составлять только таблицу идентификаторов. Тогда таблица блоков формируется при распределении памяти на основании таблицы идентификаторов.
Как уже говорилось, статическое распределение памяти для массивов в языках с блочной структурой программы возможно в двух случаях:
в языке используются только массивы с постоянными границами (например, язык АЛМО);
входной язык предусматривает обязательное указание максимальных размеров каждого массива (например, входной язык транслятора ТА-2М).
В этих двух случаях память для массивов можно распределять почти так же, как для простых переменных: на первом этапе выделяется секция памяти каждому блоку, а на втором — назначаются начальные адреса массивам внутри блока. Различие состоит в том, что для каждого массива нужно определить не только его начальный адрес, но и место хранения определяющего вектора, обеспечивающего вычисление адресов элементов массивов (см. п. 2.1.3). Поэтому в результате статического распределения памяти для массивов в таблицу идентификаторов для каждого Массива нужно занести его начальный адрес (базу вектора, отображающего массив) и адрес хранения первого элемента
177
определяющего вектора. Заметим, что определяющий вектор может быть одним и тем же для нескольких массивов.
Для массива с постоянными границами определяющий вектор можно хранить вместе со всеми константами программы. Для массивов с переменными границами значения компонент определяющего вектора могут изменяться в ходе выполнения программы, поэтому их нужно вычислять при каждом входе в блок (даже в том случае, когда максимальные размеры массива заданы).
Определяющие векторы массивов с переменными границами целесообразно хранить на поле данных вместе со скалярными переменными блока. Для этого, естественно, нужно несколько изменить описанный выше алгоритм статического распределения памяти для простых переменных, включив в него резервирование места для определяющих векторов массивов, а также занесение адреса хранения определяющего вектора, соответствующего каждому массиву, в таблицу идентификаторов.
После распределения памяти для скалярных переменных и определяющих векторов массивов статическое распределение памяти для массивов можно производить в следующем порядке:
определяется количество элементов каждого массива (максимальное количество);
формируется таблица блоков (такая же, как для скалярных переменных);
определяется указатель начала поля массивов (если поле массивов расположено вслед за полем скалярных данных, то указателем начала поля массивов является адрес последней ячейки, ЗаНЯТОЙ ДаННЫМИ, — NtnanY,
таблица блоков преобразуется в таблицу указателей начала блоков (такую же, как для скалярных переменных);
для всех блоков с номерами i= 1, ..., tn определяется адрес начала каждого массива по формулам:
^ = ^-1-1, (4.30)
b, — -|- Я/-1, / = 2,..., fe/,
где Ь/ — адрес первой ячейки, выделенной массиву с номером /; / = 1, .... kt (здесь ki — количество массивов в блоке i);
N{ — указатель начала секции памяти, выделенной блоку I;
П/ — количество элементов массива с номером / (максимальное количество).
В общем случае в языках с блочной структурой максимальные размеры массивов с переменными границами не указываются. В этом случае память для массивов приходится распределять динамически. Это означает, что начальные адреса всех массивов, описанных в блоках второго и высших уровней, и определяющие векторы массивов с переменными границами вычисляются при каждом входе в блок. В формулах (4.30) переменными являются величины Ni (для i > 2), bj и п,.
178
4.5.3. ИСПОЛЬЗОВАНИЕ СТЕКА ДЛЯ ДИНАМИЧЕСКОГО РАСПРЕДЕЛЕНИЯ ПАМЯТИ
Недостатком статического распределения памяти является неэкономное использование памяти, а преимуществом — экономия машинного времени при исполнении объектной программы. В случаях, когда данные не удается разместить в оперативной памяти, это преимущество сводится на нет дополнительными затратами времени на обмен с внешней памятью. В таких случаях динамическое распределение памяти может оказаться более выгодным с точки зрения общих затрат машинного времени.
Полностью динамическое распределение памяти юзволяет иметь единственную сплошную область памяти для всех описанных и рабочих переменных, массивов и процедур программы, а также обеспечивает относительно простой способ обработки рекурсивных процедур. С другой стороны, современные машины обычно имеют несколько индексных регистров, которые существенно облегчают динамическое перераспределение памяти при исполнении программы. По этим причинам на современных машинах часто используют именно динамическое распределение памяти.
Радикальным средством реализации динамического распределения памяти является стек. Рассмотрим пример. Пусть алгол-программа имеет следующую структуру:
begin real а, b;
real procedure pl (х, уУ
real х, у;
begin real и, v,...
end pl;...;
a: = pl (a, by, m\: begin real c, d;...; m2: begin real /;...;
d: — pl (c, f);
m3:...
end m2;
n2:...
end ml;
end
Тело процедуры, являющееся непомеченным блоком, будем рассматривать как помеченный блок, меткой которого является идентификатор процедуры. Программе припишем метку р.
На рис. 4.30 показано дерево, изображающее структуру программы. К процедуре pl происходят обращения из внешнего блока и блока m2. Это приводит к динамическим переходам из блока в блок. На рис. 4.30 этим переходам соответствуют перемещения
179
по дереву из узла в узел, показанные пунктирными стрелками. Перемещения по дереву связаны с динамическим перераспределением памяти. Все данные, используемые в программе, размещаются в стеке. Рассмотрим использование стека при исполнении программы.
В исходном состоянии (до входа во внешний блок р) стек свободен (рис. 4.31). Указатель стека, размещенный в ячейке с именем УС, всегда содержит адрес первой свободной ячейки стека. В исходном состоянии в УС записана ссылка на начало стека, помеченное меткой р. Ссылка на метку р обозначена [р].
При входе в блок р (начало программы) в вершине стека выделяется ячейка для размещения признака начала стека (в качестве такого признака использован знак 0), а затем выделяются
Рис. 4.30. Дерево, изображающее структуру программы
ячейки для всех описанных и рабочих величин, используемых в блоке (рис. 4.32). Количество ячеек, используемых в блоке р обозначено пр. Указатель стека увеличивается на величину np-j- 1. После этого в первую ячейку массива указателей начала блоков, имеющего имя УНБ, заносится адрес начала стека (здесь УНБ [1J : = [р]), а переменная /, которая постоянно содержит значение уровня текущего блока, получает значение 1.
Описанные действия по подготовке стека выполняет подпрограмма НАЧВХОД (НАЧальный ВХОД):
НАЧВХОД: СТЕК [1]: = 0;
f: = 1;
УНБ [1]: = [р];
УС: = [р] + пр+ 1;
При исполнении операторов, входящих во внешний блок, для переменных, помещенных в стек, используются адреса вида :
УНБ [1] + /,
180
где j — относительный адрес переменной в блоке, назначенный при трансляции. Очевидно, в качестве элементов массива УНБ удобно использовать индексные регистры.
Перед входом в блок ml во внешнем блоке выполняется оператор присваивания
а : = pi (а, Ь),
вызывающий обращение к процедуре-функции pl. Это приводит к перемещению по дереву (см. рис. 4.30) из узла р в узел pl и,.
Рис. 4.31. Исходное состояние стека
Рис. 4.32. Состояние стека после входа во» внешний блок
следовательно, к новому распределению памяти, которое фиксируется путем изменения состояния стека и связанных с ним переменных (рис. 4.33).
Рис. 4.33. Состояние стека после обращения к процедуре-функции pl из внешнего блока
При входе в блок, отвечающий процедуре-функции, в ячейке СТЕК[УС + 1] формируется вектор вида
(УНБ [УБ* — 1], УНБН, I),
где УБь — уровень блока, в который произошел вход (в данном случае УБй = УБР1 = 2). Первая компонента формируемого вектора есть значение указателя начала блока, в котором находится описание процедуры-функции, а вторая — значение указателя начала блока, из которого произошло обращение к процедуре-функции.
181
Обе эти ссылки составляют основную часть так называемой связующей информации [26], обеспечивающей возобновление нормального выполнения операторов после вычисления значения процедуры-функции с учетом блочной структуры программы. В данном случае обе ссылки имеют значение [р], т. е. указывают на начало секции стека, отведенной блоку р, поскольку процедура-функция р\ описана в этом блоке и обращение к ней произошло из этого же блока.
Третьей компонентой связующей информации является значение уровня блока, из которого произошло обращение к процедуре-функции, т. е. значение переменной i.
Оставшаяся свободной ячейка СТЕК[УС], расположенная в стеке выше связующей информации, выделяется только при обращении к процедуре-функции. Она предназначена для размещения результата вычисления функции pl.
После формирования связующей информации величина i получает значение уровня блока, в который произошел вход (в данном случае i: = УБР1 = 2). Затем формируется новый элемент массива указателей начала блоков УНБ[(] = УНБ [2], в который заносится ссылка на связующую информацию блока pl, т. е. на ячейку с меткой pl. Наконец, указатель стека (УС) увеличивается так, чтобы во вновь выделенной секции стека разместились формальные параметры процедуры-функции (здесь х и у), а также описанные (и и и) и рабочие переменные тела процедуры (в данном случае УС: = УНБ[1] + npl + 1, где nPi— количество ячеек, требующееся для выполнения процедуры-функции pl). Новое значение УС вновь указывает на первую свободную ячейку (вершину) отека.
Описанные действия можно представить в виде двух последовательно выполняемых подпрограмм ПФ (Процедура-Функция) и ВХОД (ВХОД в блок):
ПФ: УС: =УС+ 1;
ВХОД: СТЕК [УС]: = (УНБ [УБ* - 1], УНБ [Z], Z);
i: = УБ*;
УНБ [Z]: = УС;
УС: = УНБ [Z] + п. 4- 1;
В подпрограмме ВХОД индекс k — номер (метка) блока, в который происходит вход.
В результате выполнения описанных действий для всех переменных, локализованных в теле процедуры-функции pl и во внешнем блоке р, в стеке выделяется память. Обращение к переменным внешнего блока обеспечивается адресами вида УНБ[1] а к переменным в теле процедуры — адресами вида УНБ[2] -|- /, где ./ — относительный адрес переменной в соответствующем блоке, назначенный при трансляции. Заметим, что индекс элемента массива УНБ равен уровню соответствующего блока. Этот индекс
482
также определяется при трансляции. Вычисленное значение процедуры-функции помещается в ячейку УНБ[2]— 1.
После вычисления значения процедуры-функции р\ и выхода из блока pl переменные, локализованные в теле процедуры, становятся недоступными. Однако в общем случае возобновляется доступ к переменным, локализованным в блоке, из которого произошло обращение к процедуре. Следовательно, необходимо восстановить состояние стека, которое было до обращения к процедуре. Для этого используют связующую информацию, помещенную’ в начале участка стека, отведенного для процедуры-функции.
В общем случае связующая информация имеет вид
(др Z)
где а\—значение указателя начала блока, в котором описана процедура или содержится рассматриваемый блок;
а‘, — значение указателя начала блока, из которого произошло обращение к процедуре (вход в блок);
I — уровень блока, из которого произошло обращение к процедуре (вход в блок).
Первым шагом восстановления состояния стека является занесение в указатель начала блока УНБ [Z] значения ссылки а'2. Это делает доступными переменные, локализованные в блоке уровня I. В случае, если I >• 2, нужно сделать доступными и все-переменные, являющиеся глобальными «по отношению к блоку уровня /. Это можно сделать, построив цепочку первых ссылок связующей информации
и записав значения элементов этой цепочки, кроме последнего, в элементы массива указателей начала блоков с номерами /—1, / —2,..., 2.
В общем случае все описанные выше действия выполняет следующая подпрограмма:
ВЫХОД ИЗ ПРОЦЕДУРЫ: УС: = УНБ [Z] — 1;
Из СТЕК [УНБ [/]] извлечь а12, Z);
if / = 1 then go to М2;
УНБ [Z]: —
i: = j: = Z;
Ml: if j = 2 then go to М2;
Из СТЕК [УНБ [Д1 извлечь (а\, al2,1);
j: —1\
УНБ [/[ =а{;
go to Ml;
М2: ;
183;
В нашем случае при выходе из процедуры-функции pl связующая информация есть
( 1р1» 1р|, О,
поэтому восстанавливается состояние стека, показанное на рис. 4.32.
После входа в блок т\ стек изменяется в соответствии с приведенной выше подпрограммой ВХОД и принимает вид, показанный на рис. 4.34.
УС
СТЕК
УНБ
U1
Рис. 4.34. Состояние стека после входа в блок т\
При входе в блок m2 вновь включается подпрограмма ВХОД. Новое состояние стека показано на рис. 4.35.
УС СТЕК УНБ
L1] [г] [3]
Рис. 4.35. Состояние стека после входа в блок m2
В блоке m2 выполняется оператор присваивания d:=pl(c,f).
При выполнении этого оператора вновь происходит обращение к процедуре-функции р\. Стек изменяется в соответствии с подпрограммами ПФ и ВХОД, как показано на рис. 4.36. Здесь уже наглядно видна различная роль первой и второй ссылок в связующей информации. При выполнении операторов в теле проце
184
дуры-функпии pl переменные, локализованные в блоках ml и m2, становятся недоступными. Нет никакого способа обратиться к ним, поскольку массив указателей начала блоков УНБ не содержит ссылок на их связующую информацию. Вместе с тем цепочка вторых ссылок отражает динамику выполнения программы. В ней связаны все блоки, которые начали выполняться, но еще не закончены. Поэтому эту цепочку называют динамической. В то* же время цепочка первых ссылок соответствует пути по дереву (см. рис. 4.30) от узла pl до корня дерева р и связывает все доступные в данный момент переменные. Эта цепочка не зависит отхода выполнения программы, а определяется только структурой.
Рис. 4.36. Состояние стека после обращения к процедуре-функции из блока m2
программы, поэтому ее называют статической. Заметим, что обе цепочки совпадают, если не было обращений к процедурам, а также если процедура описана в том же блоке, из которого произошло обращение к ней.
При переходе к метке m3 рассматриваемой программы в результате действий, выполняемых подпрограммой ВЫХОД ИЗ ПРОЦЕДУРЫ, стек вновь принимает вид, показанный на рис. 4.35, т. е. восстанавливается доступ к переменным, локализованным в блоках ml и m2.
Затем при переходе к метке п2 происходит выход из блока m2 и восстановление состояния, показанного на рис. 4.34. Выход из блока осуществляется приводимой ниже подпрограммой:
ВЫХОД ИЗ БЛОКА: г. = УБ/:
УС: = УНБ [/+ 1].
185-
Здесь УБ( — уровень нового блока. При выходе через конец уровень нового блока на единицу меньше уровня старого блока, т. е. УБ; = i— 1. Однако возможен выход по метке, тогда информация об уровне нового блока должна содержаться в метке. Следовательно, при трансляции программы в языках с блочной структурой программы вместе с меткой нужно фиксировать уровень блока, в котором она находится. При динамическом распределении
Рис. 4.37. Состояние стека в случае, когда процедура-функция pl дважды обратилась к самой себе.
памяти выход из блока по метке должен сопровождаться выполнением подпрограммы ВЫХОД ИЗ БЛОКА.
При динамическом распределении памяти рекурсивные процедуры программируются и выполняются по правилам, общим для всех процедур. Каждое обращение к процедуре приводит к выделению в стеке памяти для этой процедуры независимо от того, является это обращение обычным или рекурсивным. В частности, если предположить, что в рассматриваемой программе процедура-486
функция pl является рекурсивной и что в состоянии, изображенном на рис. 4.36, эта процедура дважды обратилась к самой себе,, то в стеке будет дополнительно дважды выделена секция памяти для процедуры (рис. 4.37).
Для практической реализации описанного способа динамического распределения памяти нужно в ходе трансляции включить в объектную программу команды, обеспечивающие выполнение приведенных выше подпрограмм:
НАЧВХОД — при входе во внешний блок;
ВХОД — при входе в каждый новый блок, в том числе при: обращении к процедуре;
ПФ и ВХОД — при обращении к процедуре-функции;
ВЫХОД ИЗ БЛОКА —при выходе из блока через его конец; или по метке;
ВЫХОД ИЗ ПРОЦЕДУРЫ — при выходе из любой процедуры, включая процедуру-функцию.
Программирование этих подпрограмм (или обращений к ним) обеспечивает информация, содержащаяся в таблице блоков, описанной в п. 4.5.2. В отличие от статического распределения памяти записи этой таблицы, указывающие количество машинных слов tii для размещения данных блока i, приходится корректировать, (вычислять заново) в ходе исполнения программы при каждом входе в блок i. Для этого в объектную программу нужно включить команды, вычисляющие величину tii перед каждым исполнением подпрограммы ВХОД.
' Подчеркнем еще раз, что динамическое распределение памяти реализуется достаточно просто и без больших дополнительных затрат машинного времени, если в качестве элементов массива УНБ используются индексные регистры (регистры-модификаторы),, обеспечивающие автоматическое формирование исполнительных, адресов при выполнении каждой команды.
4.5.4. ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ БЛОКОВ И ОПИСАНИЙ ТИПА
Обработка описаний в компиляторах производится с целью: выявить описанные объекты, определить их класс и тип;
подготовить информацию для распределения памяти с учетом: блочной структуры программы;
перевести на объектный язык элементы описаний, требующие-перевода;
выявить ошибки в описаниях.
Результаты обработки описаний частично фиксируются в таблицах компилятора, частично — в объектной программе. В разных, компиляторах описания обрабатывают на различных этапах трансляции. Однако в любом случае обработка описаний должна предшествовать генерированию машинных команд (предложений объектного языка), соответствующих операторной части программы
18Г
(блока). Поэтому в большинстве компиляторов описания обрабатывают сразу после перевода программы на внутренний язык.
В языках с блочной структурой программы обработка описаний тесно связана с обработкой границ блоков, поскольку границы блоков определяют область действия описанных в блоке имен.
Рассмотрим вначале обработку описаний типа, основная задача которой — формирование таблицы идентификаторов. Формат записей этой таблицы для простых переменных показан в табл. 4.20. Для получения всей информации, помещаемой в этой таблице, необходимо одновремен-Таблица 4.20 но обрабатывать границы блоков. При динамическом распределении памяти в задачу обработки блоков помимо определения номеров и уровней блоков д^я таблицы идентификаторов входит формирование команд, обеспечивающих выполнение описанных в предыдущем пункте подпрограмм: НАЧВХОД, ВХОД и ВЫХОД ИЗ БЛОКА.
В качестве промежуточного языка воспользуемся обратной польской записью. Для этого введем следующие операции промежуточного языка:
операцию ТИП, обозначаемую k real k int или k bool, где k — число операндов (операндами являются идентификаторы простых переменных, перечисленные в списке типа);
операции НАЧАЛО БЛОКА (НБ) и КОНЕЦ ОПИСАНИЙ (КО), каждая из которых имеет два операнда — номер блока (i) и уровень блока (УБ);
операцию КОНЕЦ БЛОКА (КБ), не имеющую операндов.
ФОРМАТ ЗАПИСЕЙ ТАБЛИЦЫ ИДЕНТИФИКАТОРОВ ДЛЯ ПРОСТЫХ ПЕРЕМЕННЫХ
Идентификатор
Номер блока — i
Уровень блока — УБ
Относительный адрес (порядковый номер) в блоке — /
Признак (класс и тип)
Рис. 4.38. Графическое изображение описания типа
Семантику этих операций рассмотрим после определения их места в обратной польской записи.
При использовании операции ТИП описание типа reala, b, с
можно представить деревом (рис. 4.38), обход которого дает обратную польскую запись
аЬсЗгегй.
188
Операции НАЧАЛО БЛОКА, КОНЕЦ ОПИСАНИЙ и КОНЕЦ рЛОКА позволяют представить блок Алгола-60, схематически изображенный деревом (рис. 4.39), в виде дерева, показанного на рис. 4.40.
Алгол-программа
begin real а, 6; ...;
begin real с, d\ integer p;
end;
begin boolean f; ...;
begin real g, h\.. end end end
имеет структуру, изображенную на рис. 4.41. Ее можно предста-
Рис. 4.39. Структура блока Алгола-60 Рис. 4.40. Дерево блока на промежуточном языке
вить деревом (рис. 4.42), при обходе которого получаем обратную польскую запись
1 1 НБ а b 2 real 1 1 КО ...
begin знак конца
описаний
2 2 НБ с d 2 real р 1 int 2 2 КО ... КБ begin знак конца end
описаний
3 2 НБ f 1 boo! 3 2 КО ... *4‘3,)
---' -----------
v begin знак конца
описаний
4 3 НБ g h 2 real 4 3 КО ... КБ КБ КБ begin знак конца end end end
описаний
В записи (4.31) фигурными скобками выделены элементы выходной строки, порождаемые отдельными символами входной строки.
189
Семантика введенных операций состоит в следующем.
Операция НАЧАЛО БЛОКА (НБ) не порождает команд в объектной программе. В ходе трансляции эта операция присваивает значение номера блока переменной i (номер блока) и значение уровня блока — переменной УБ (уровень блока), а также устанавливает исходное (нулевое) значение переменной / (порядковый номер описанной переменной в блоке). Значения этих переменных используются затем операциями ТИП и «:» при формировании записей таблицы идентификаторов и таблицы меток со-
ответственно.
Рис. 4.41. Структура программы с описаниями типа
9 h 4 3
Рис. 4.42. Дерево программы с описаниями типа на промежуточном языке
Операция ТИП также не порождает команд в объектной программе. В ходе трансляции эта операция, используя значения переменных i, УБ и /, формирует для каждого идентификатора, являющегося ее операндом, запись таблицы идентификаторов, которая имеет формат, приведенный в табл. 4.20. Перед занесением в таблицу идентификаторов очередного идентификатора значение переменной / увеличивается на единицу.
Операция КОНЕЦ ОПИСАНИИ (КО) формирует в объектной программе подпрограмму НАЧВХОД, если i = 1, или подпрограмму ВХОД, если »=/= 1.
Операция КОНЕЦ БЛОКА (КБ) формирует в объектной программе подпрограмму ВЫХОД ИЗ БЛОКА.
При переводе входной строки в обратную польскую запись вида (4.31) помимо упоминавшихся переменных i, УБ и / используется также счетчик блоков (СЧБЛ). Кроме того, поскольку в
190
языке Алгол-60 символ begin, открывающий новый блок, и символ «;», отделяющий описания от операторов, можно выделить только путем рассмотрения пары символов: begin (описатель) и -(описатель) соответственно, приходится вводить специальный признак ЗАДЕРЖКА, предписывающий задержать окончание обработки очередного символа до рассмотрения следующего символа.
В исходном состоянии (до трансляции) переменные I, УБ, /, СЧБЛ и признак ЗАДЕРЖКА имеют значение 0.
Для получения обратной польской записи вида (4.31) нужно обрабатывать специальным образом символы begin, (описатель) «,», «;» и end.
Символ begin, имеющий приоритет 0, заносится в стек. Одновременно выполняется операция
ЗАДЕРЖКА: = I.
Если при этом значении признака ЗАДЕРЖКА очередной символ не описатель, то выполняется
ЗАДЕРЖКА: =0, а затем перевод в обратную польскую запись продолжается обычным образом.
Описатель вида real, integer или boolean может появиться только после символов begin или «;». Символ begin формирует значение ЗАДЕРЖКА = 1, а символ «;»— значение ЗАДЕРЖКА = 2. Если при появлении описателя ЗАДЕРЖКА = 0, то это ошибка, которая фиксируется в таблице ошибок. Если ЗАДЕРЖКА = 1, то выполняются следующие действия:
запись begin в вершине стека заменяется записью begin*-; означающей, что начинается новый блок;
ЗАДЕРЖКА: =0;
/: =СЧБЛ: = СЧБЛ 4-1;
УБ: = УБ 4-1;
в выходную строку заносится запись вида i УБ НБ;
в стек заносится запись вида «(описатель) 1», где 1—начальное значение счетчика операндов операции ТИП.
Если ЗАДЕРЖКА = 2, то выполняется
ЗАДЕРЖКА: =0,
а в стек заносится запись «(описатель) 1».
Символ «,», встретив в стеке запись вида «(описатель) &», где k — значение счетчика операндов операции ТИП, увеличивает значение k на единицу.
Символ «;» очищает стек обычным образом. Если при очистке стека встретится запись вида «(описатель) k», то в выходную строку заносится запись «£ (описатель)» и выполняется операция
ЗАДЕРЖКА: =2.
191
Если при этом значении признака ЗАДЕРЖКА очередной сим-вол не является описателем, то выполняется
ЗАДЕРЖКА: =0,
а в выходную строку заносится запись вида i УБ КО.
Символ end очищает стек обычным образом. Если при очистке стека встретилась запись begin *, то эта запись удаляется из стека, в выходную строку записывается знак операции КБ и выполняется
Z: = / — 1;
УБ: = УБ — I.
Операции НБ и ТИП целесообразно выполнять немедленно, не занося их в выходную строку, поскольку они не порождают команд в объектной программе.
4.5.5. ТРАНСЛЯЦИЯ ОПИСАНИЙ МАССИВОВ
Для перевода описаний массивов в обратную польскую запись введем операцию МАССИВ, обозначаемую тп ВМ (вещественный массив), тп ЦМ (целый массив) или тп БМ (булевский массив), где т — число массивов, п — число граничных пар в каждом массиве, ВМ соответствует описателям real array или array, ЦМ — integer array, а БМ — boolean array.
Операндами операции МАССИВ являются идентификаторы массивов и арифметические выражения, определяющие значения граничных пар.
С помощью операции МАССИВ описание массивов вида
array 41, ..., Ami pi: k\. .... ln^: £ftl], (4.32)
Pi. ..., Bm pi . k\, ..., in . kn 1,
содержащее два сегмента массивов, можно представить деревом (рис. 4.43), каждая ветвь которого отвечает одному сегменту массивов.
Обход этого дерева дает обратную польскую запись описания (4.32):
Ai, .... Amtiik....1П|Ц/П|П|ВМ (4.33)
Bi, .... Bmi'ik'i, ..., W & &
Операция МАССИВ выполняет следующие действия:
заносит запись о каждом массиве в таблицу идентификаторов;
выделяет для каждого массива две ячейки, одна из которых предназначена для хранения адреса начала массива (адреса базы отображающего вектора), а другая — для хранения адреса места хранения определяющего вектора (см. п. 2.1.3);
формирует в объектной программе команды, обеспечивающие перед входом в блок вычисление компонент определяющего век
192
тора, а также вычисление адреса хранения каждого массива и адреса хранения определяющего’ вектора и занесение этих адресов в соответствующие ячейки.
Заметим, что для массивов с постоянными границами компоненты определяющего вектора можно вычислить в ходе трансля-ции только один раз и поместить их среди констант программы. Отличить переменные граничные пары от постоянных можно, путем анализа операндов операции МАССИВ, являющихся граничными парами.
Запись о массиве в таблице идентификаторов может иметь тот же формат, что и для простых переменных (см. табл. 4.20). Однако, чтобы обеспечить выделение для каждого массива двух ячеек, операция МАССИВ после занесения записи о массиве в таблицу
идентификаторов увеличивает относительный адрес / не на одну единицу, как для простых переменных, а на две. Вследствие этого в области памяти, выделенной блоку, для массива будет отведено две ячейки: ячейка / для хранения адреса начала массива и ячейка / + 1 для адреса места хранения определяющего вектора.
Компоненты определяющих векторов могут располагаться вслед за парой ячеек, выделенной последнему массиву блока, или храниться среди констант программы (для массивов с постоянными границами).
При статическом распределении памяти для простых переменных массивы, как уже отмечалось, размещаются в отдельной области памяти, а при динамическом распределении памяти — в той же области памяти, где простые переменные. На рис. 4.44 показан фрагмент таблицы идентификаторов и возможный вариант распределения секции стека для массивов.
Для получения из исходной записи вида (4.32) обратной польской записи (4.33) нужно обрабатывать особым образом символы: array, «,», [, «:» и], а также «;».
Символ array может появиться в исходной записи только после символов begin, «,» или (описатель типа). Первые два символа
7 Зак. 221
.193
формируют ненулевое значение признака ЗАДЕРЖКА (см. п. 4.5.4). При ненулевом значении признака ЗАДЕРЖКА обработка описателя array производится почти так же, как обработка
Таблица идентифика торов
СТЕК
А, I
Номер блока- I
Уровень блока - УБ Относительный адрес -j_________
real ar ay
Адрес о . начала массива Z7Z
Адрес определяющего вектора
Нгпч
Номер блока-I
Уровень блока-уб
Относительный адрес-J + 2(m1-i) real аг ау
*/
Номер блока- i
Уровень блока - УБ
Относи те ль ный адрес j+ZJjfy-ij+e real аг ау
Адрес ' начала массива Ат1
Адрес определяющего вектора
Адрес . начала массива Bf
Адрес определяющего вектора
Адрес . начала массива
Адрес определяющего вектора
Определяющий вектор массивов Af... Amj
Определяющий вектор массивов Bf... Bm2 •*-
Номер блока- I Уровень блока- УБ Относительный адрес ^2(104-1)^2^1}-real аг ау
Массив Ai
Массив Ami
Массив Bj
массив
Рис. 4.44. Распределение памяти для массивов
описателя типа (см. п. 4.5.4), с тем отличием, что в стек заносится запись
вм 1 о
вместо записи «(описатель типа) 1».
194
I
Если при появлении символа array признак ЗАДЕРЖКА = О, то в вершине стека должна быть запись «(описатель типа) 1» (дру* гая запись — ошибка). Запись «(описатель типа) 1» заменяется записью
ВМ 1 О, ЦМ 1 О или БМ 1 О
а зависимости от конкретного значения символа «описатель типа» (напомним, что (описатель типа) может- иметь значение real, integer или boolean).
Символ [, являясь открывающей скобкой для индексного выражения, как известно (см. п. 4.3.4), всегда заносится в стек. Однако если в вершине стека находится запись вида
ВМ т О, ЦМ т 0 или БМ т 0, (4.34)
то символ [ в стек не заносится, а к имеющейся в вершине стека записи добавляется значение счетчика числа граничных пар п = 1, т. е. запись в вершине стека вида (4.34) заменяется одной из записей
ВМ т 1, ЦМ т 1 или БМ т 1
соответственно.
Символ «,», как обычно, очищает стек. Однако если в вершине стека находится одна из записей вида (4.34), где пг имеет любое значение, включая 0, то стек не очищается, а к значению счетчика числа массивов т добавляется единица, т. е. значение т заменяется на т + 1.
Если при очистке стека встретится запись вида
ВМ т п, ЦМ т п или БМ т п.
(4.35)
где п ф 0, то на единицу увеличивается значение счетчика граничных пар, т. е. значение п заменяется на и + 1.
Символ «:», расположенный между индексными скобками [и], является закрывающей скобкой для предшествующего индексного выражения (нижней границы). Этот символ очищает стек до записи вида (4.35) исключительно. Чтобы отличить символ «:», используемый в граничных парах, от того же символа, записанного после метки, на этапе лексического анализа целесообразно заменять символ «:», встречающийся между индексными скобками, каким-либо другим специальным символом.
Символ ] является закрывающей скобкой для списка граничных пар. Этот символ очищает стек до записи вида (4.35) исключительно. Затем в выходную строку заносится запись
т п ВМ, т п ЦМ или т п БМ
соответственно, а запись вида (4.35) в вершине стека заменяется записью
ВМ О О, ЦМ О О или БМ О О (4.36)
соответственно, означающей окончание сегмента массивов.
195
Символ «;» обрабатывается почти так же, как в п. 4.5.4, с тем отличием, что запись вида (4.36) не переносится в выходную строку, а просто удаляется из стека.
4.5.6. ОБРАБОТКА МЕТОК
И ОПИСАНИЙ ПЕРЕКЛЮЧАТЕЛЕЙ
Описанием метки служит ее появление перед оператором со знаком «:» в конце. Метки заносятся в таблицу меток, записи которой имеют вид:
метка (или ссылка на таблицу имен, которой заменена метка на этапе лексического анализа);
номер блока (i);
уровень блока (УБ);
адрес.
Естественно, адрес метки можно получить только в ходе генерирования машинных команд.
Если ввести операцию промежуточного языка switch, то описание переключателя также можно перевести в обратную польскую запись. Техника перевода принципиально не отличается от перевода описаний типа, поэтому подробно не рассматривается. Основное отличие состоит в том, что именующие выражения, состоящие более чем из одной метки, должны быть вынесены из переключательного списка и оформлены в виде отдельных подпрограмм.
При генерировании машинных команд операция switch формирует таблицу переходов, каждая запись которой соответствует одному элементу переключательного списка и представляет собой команду безусловного перехода на метку, указанную в переключательном списке, или на подпрограмму, вычисляющую соответствующее именующее выражение.
4.6. ТРАНСЛЯЦИЯ ПРОЦЕДУР
4.6.1. СПОСОБЫ ТРАНСЛЯЦИИ ПРОЦЕДУР
Способ перевода в обратную польскую запись указателей функций, описанный в п. 4.3.5, можно использовать лишь в простейших частных случаях, когда формальные параметры функции заменяются значениями фактических параметров. Этот способ применим, например, при трансляции стандартных функций, рекомендованных в описании эталонного языка Алгол-60 [1].
В общем случае проблема трансляции процедур, частным случаем которых являются функции, не решается столь просто. Если буквально следовать способу выполнения операторов процедур, предусмотренному в эталонном языке [1], то каждый оператор процедуры нужно заменить телом процедуры, в котором формальные параметры заменены соответствующими фактическими пара
196
метрами (при вызове по наименованию) или значениями фактических параметров (при вызове по значению).
Такой способ требует совместной обработки операторов процедур и описаний процедур, что существенно увеличивает время трансляции. Возрастает также объем объектной программы. Для рекурсивных процедур этот способ можно реализовать только динамически (в режиме интерпретации). Интерпретация связана с большими затратами машинного времени. По этим причинам непосредственная замена операторов процедур как средство трансляции процедур на практике не применяется.
Чаще всего составители трансляторов стремятся транслировать операторы процедур независимо от их описаний. Это существенно упрощает алгоритм трансляции, хотя и ухудшает качество объектной программы, поскольку приходится использовать самые общие (и самые неэкономичные) алгоритмы трансляции. Для получения достаточно эффективной объектной программы при независимой трансляции описаний процедур требуется, чтобы все формальные параметры были специфицированы. Независимая трансляция требует также проверки соответствия фактических и формальных параметров в ходе исполнения объектной программы.
Ниже описан один из возможных вариантов раздельной трансляции описаний и операторов процедур. Сущность этого способа, который является наиболее общим способом раздельной трансляции операторов и описаний процедур, состоит в следующем. Тело процедуры программируется как подпрограмма и обычно оформляется в виде модуля загрузки, подобно стандартной библиотечной подпрограмме. Это позволяет использовать для загрузки и исполнения процедур тот же аппарат, что для библиотечных подпрограмм (см. 1.1). В ходе трансляции оператор процедуры заменяется обращением к телу процедуры, а каждый фактический параметр в операторе процедуры заменяется подпрограммой, которая либо вычисляет значение этого параметра, либо фиксирует его имя (адрес), либо, наконец, делает то и другое. Во всех случаях подпрограмма фактического параметра фиксирует также его класс и тип.
Подпрограмму фактического параметра иногда называют «санк», поскольку такое название использовалось в статье П. Ин-германа [49], впервые описавшего этот метод. При трансляции описания (тела) процедуры перед использованием каждого формального параметра формируются команды обращения к подпрограмме соответствующего фактического параметра («санку»). Передача значений или имен (адресов) фактических параметров происходит через специально выделенные стандартные ячейки памяти. В ходе исполнения объектной программы сформированный аппарат подпрограмм обеспечивает как бы подстановку тела процедуры на место оператора процедуры и замену формальных параметров фактическими.
197
Описанный способ реализуется достаточно просто. Основной его недостаток — относительно низкая эффективность, поскольку во многих случаях подстановку фактических параметров можно выполнить более простыми способами.
4.6.2. ОБРАТНАЯ ПОЛЬСКАЯ ЗАПИСЬ
ОПЕРАТОРА ПРОЦЕДУРЫ
При переводе оператора процедуры в обратную польскую запись приходится обрабатывать особым образом идентификатор процедуры; круглую скобку, открывающую список фактических параметров; запятую, разделяющую фактические параметры; круглую скобку, закрывающую список фактических параметров; знак конца оператора процедуры: «;», end или else.
В частности, при применении метода «санков» (подпрограмм фактических параметров) оператор процедуры вида
<ИП) (Л, А2, ...,/„);,
где (ИП)— идентификатор процедуры, Ait Л2, •••> — фактиче-
ские параметры, переводится в следующую обратную польскую запись:
(ИП) /И/ОПВ tni+l: Bmi+2: НПФПг/Ai
идентификатор (
процедуры
КПФПт<+1БП/П/+3: Вт1+4: НПФПг,Д2
КПФПт/+3БП/П/+5: Bmt+6: НПФП/7... (4.37)
КПФП/п/+2п 3БПтг+2п 1: В mt+2n: НПФПгуЛ
КПФП/П/+2п 1БПг//п/+2т/+4.. .тг+2„пИФПт<:
)
В обратной польской записи (4.37) фигурными скобками выделены части записи, порождаемые различными символами входной строки. Принципы образования отдельных частей выходной строки поясняются ниже.
Идентификатор процедуры порождает запись
<ИП) т;ОПВ, (4.38)
где (ИП) — собственно идентификатор процедуры, mi — метка ячейки возврата, в которую нужно перейти после выполнения процедуры, а ОПВ — мнемоническое обозначение операции промежуточного языка ОБРАЩЕНИЕ К ПРОЦЕДУРЕ С ВОЗВРАТОМ.
198
В дальнейшем при генерировании машинных команд операция опв, имеющая два операнда (ИП) и /п,, заменяется командами обращения к процедуре с именем (ИП). Команды обращения к процедуре должны обеспечить также возврат к метке пи после исполнения процедуры.
Для обеспечения специфичной обработки открывающей круглой скобки, которая может следовать за оператором процедуры, используется признак ОПЕРАТОР ПРОЦЕДУРЫ. Обычно этот признак равен нулю. При появлении идентификатора процедуры в операторной части программы он становится равным единице, а после обработки открывающей круглой скобки, за которой следует список фактических параметров, снова становится равным нулю.
При ненулевом значении признака ОПЕРАТОР ПРОЦЕДУРЫ открывающая круглая скобка заносит в выходную строку запись
nti+l: Bmi+2 : НПФПгу. (4.39)
Здесь меткой tnt+i помечена свободная ячейка, резервируемая операцией В (ВОЗВРАТ) для команды возврата. При обращении к подпрограмме первого фактического параметра из тела процедуры в эту ячейку заносится команда возврата к телу процедуры. Меткой mi+2 помечено начало подпрограммы первого фактического параметра. Эта подпрограмма начинается операцией НАЧАЛО ПОДПРОГРАММЫ ФАКТИЧЕСКОГО ПАРАМЕТРА (НПФП), которая при переводе обратной польской записи в машинные команды предписывает программировать все адреса в подпрограмме специальным образом, обеспечивающим эффективное выполнение подпрограммы при динамическом распределении памяти.
Необходимость специального программирования адресов в подпрограммах фактических параметров объясняется следующим. При динамическом распределении памяти (см. п. 4.5.3) адреса переменных в блоке уровня k программируются в виде
УНБ [Л] + /, (4.40)
где / — относительный адрес переменной в блоке.
При обращении к процедуре из блока, уровень которого не меньше уровня процедуры, секция памяти, выделенная в стеке Для этого блока, сохраняется в памяти, но становится недоступной, потому что из массива указателей начало блоков (УНБ) Удаляется указатель начала этого блока. Между тем для вычисления фактических параметров в ходе выполнения тела процедуры приходится переходить из тела процедуры в блок, где находится оператор процедуры, поскольку именно на месте этого оператора находится подпрограмма каждого фактического параметра. После выполнения подпрограммы фактического параметра нужно вновь возвратиться в тело процедуры. Такие переходы приходится
199
делать при появлении в теле процедуры каждого формального параметра, вызываемого по наименованию.
В принципе при каждом входе в блок, где. находится оператор процедуры, нужно восстанавливать статическую цепочку связующей информации (цепочку первых ссылок связующей информации) и отображающий ее массив указателей начала блоков (УНБ). Однако это явно неэкономично. Более целесообразно в ходе трансляции каждой подпрограммы фактического параметра формировать адреса переменных, не доступных в теле процедуры в силу блочной структуры Алгол-программы, не в виде (4.40), а в виде
УНБ[1] + р, (4.41)
где указатель УНБ [1] содержит ссылку на начало стека, ар — адрес переменной относительно начала стека.
Адрес р можно определить по формуле
P = j + S(k).
В этой формуле /, как и прежде, — относительный адрес переменной в блоке, a S(k) — адрес начала секции стека, выделенной блоку уровня k.
Величина S(k) определяется путем просмотра динамической цепочки (цепочки вторых ссылок связующей информации). Этот просмотр как раз и выполняет операция НПФП. Действие операции НПФП распространяется на адреса только тех переменных, которые локализованы в блоках с уровнем, не меньшим, чем уровень тела процедуры. Область действия операции НПФП — подпрограмма, которой она предшествует.
В записи (4.39) за операцией НПФП следует рабочая переменная г,. В ячейку г, заносится значение фактического параметра, а в следующую ячейку rj+i всегда записывается имя (адрес) фактического параметра, а также его класс и тип. Одна из записей (имя или значение), очевидно, излишняя. Однако при раздельной трансляции операторов и описаний процедур приходится фиксировать как значения фактических параметров, так я их имена, поскольку в момент трансляции оператора процедуры не известно, какие параметры вызываются по значению, а какие — по наименованию. Класс и тип фактического параметра фиксируется для проверки соответствия фактических и формальных параметров, которая осуществляется при исполнении оператора процедуры.
Символ «запятая», который является ограничителем фактического параметра Ль порождает (4.37) запись
КПФП/и/+1БПт,+3: В/п{+4: НПФПг/. (4.42)
Начальная часть этой записи
КПФП/п/+1БП (4.43)
200
служит для выполнения действий, завершающих оформление подпрограммы фактического параметра.
Операция КПФП (КОНЕЦ ПОДПРОГРАММЫ ФАКТИЧЕ СКОГО ПАРАМЕТРА) записывает значение фактического параметра, его имя, класс и тип в рабочие ячейки rj и о которые шла речь выше. Кроме того, эта операция выключает специфичный механизм формирования адресов в подпрограмме, включенный операцией НПФП.
Операция БП (БЕЗУСЛОВНЫЙ ПЕРЕХОД) обеспечивает переход на метку т. е. на ячейку, в которую при обращении к подпрограмме фактического параметра заносится команда возврата к телу процедуры.
Вторая часть записи (4.42) подобна записи (4.39), порождаемой открывающей круглой скобкой, и для второго фактического параметра А2 играет ту же роль, что запись (4.39) для первого фактического параметра Ар
Запись
КПФПг7г/+2п-1БПг/т/+2т(+4... /и/+2ппИФП, (4.44)
порождаемая закрывающей круглой скобкой, также состоит из двух частей:
начальная часть
КП ФП 1БП
подобна записи (4.43) и играет ту же роль для последнего фактического параметра Ап;
вторая часть
r/Wi+jiBi+i. • .т1+2„пИФП
служит для передачи в тело процедуры информации о местонахождении подпрограмм фактических параметров. Операция ИФП (ИНФОРМАЦИЯ О ФАКТИЧЕСКИХ ПАРАМЕТРАХ) обеспечивает при генерировании машинных команд занесение в текст объектной программы адреса рабочей ячейки г>, содержащей значение вычисляемого фактического параметра, и меток подпрограмм фактических параметров
Wj+2> • • •» f^‘t+2n>
а также указания о числе фактических параметров п.
Эта информация используется при формировании в теле процедуры команд обращения к подпрограммам фактических параметров и для передачи значений и имен (адресов) фактических параметров в тело процедуры при ее исполнении.
Наконец, символ конца оператора процедуры (в данном случае символ «;») формирует метку, на которую нужно передать Управление после выполнения процедуры.
201
4.6.3. АЛГОРИТМ ТРАНСЛЯЦИИ
ОПЕРАТОРОВ ПРОЦЕДУР
Обработку специфичных символов в операторе процедуры, обеспечивающих формирование обратной польской записи вида (4.37), можно выполнять следующим образом.
1. Идентификатор процедуры ((ИП)) присваивает признаку ОПЕРАТОР ПРОЦЕДУРЫ значение 1, заносит в выходную строку запись
(ИП) т^ПВ, а в стек операций —
НПт{,
где НП — специальный символ НАЧАЛО ПРОЦЕДУРЫ, ат,— первая свободная рабочая метка.
2. Открывающая круглая скобка при наличии ненулевого признака ОПЕРАТОР ПРОЦЕДУРЫ присваивает этому признаку значение 0, затем, используя имеющуюся в вершине стека запись НП mi, формирует в выходной строке запись
tni+l: Bnii+2: НПФПг/ и заносит в стек запись
(1т<+1Г/.
В общем случае последняя запись имеет вид
(nmprlt
где п — значение счетчика фактических параметров;
тр— метка ячейки возврата последней обрабатываемой подпрограммы фактического параметра;
Г/ — рабочая переменная, предназначенная для . записи значения фактического параметра (эта переменная одна и та же для всех фактических параметров в данном операторе процедуры).
Напомним, что в ячейку r3+i заносится имя (адрес), класс и тип фактического параметра.
3. Символ «запятая» является ограничителем предшествующего фактического параметра и в этом качестве играет для него роль закрывающей скобки, поэтому стек очищается до записи вида
(ПГПрГ/,
исключительно. Информация, содержащаяся в этой записи, используется для формирования записи в выходную строку
КПФП тр БП тР+2: Втр+3 .* НПФПг/а
После этого запись в вершине стека корректируется и приводится к виду
(« 4- Imp+Zy.
202
4. Закрывающая круглая скобка, с одной стороны, играет ту роль, что запятая для последнего фактического параметра, а с другой стороны, обозначает конец списка фактических параметров. Поэтому стек вначале очищается до записи
(п/ПрГр
исключительно. Затем формируется запись в выходную строку
КПФП БПГу/Пр.гп+з/Пр^.д ... тр+1ПИФП, после чего запись
(П/ПрГу удаляется из стека.
5. Символ конца оператора процедуры, которым может быть end или else, очищает стек до записи НП mt включительно, а затем заносит в выходную строку метку продолжения про-граммы
тг.
и присваивает значение 0 признаку ОПЕРАТОР ПРОЦЕДУРЫ. Последнее действие для процедур с параметрами излишне, поскольку его еще раньше выполняет открывающая круглая скобка. Однако в операторе процедуры без параметров круглых скобок нет, поэтому для таких процедур это действие необходимо.
4.6.4. ОСОБЕННОСТИ ТРАНСЛЯЦИИ
ОПИСАНИЙ ПРОЦЕДУР
Обработка заголовка процедуры имеет целью определить тип процедуры, а также выявить формальные параметры, их класс и тип. Информация о формальных параметрах помещается в таблицу формальных параметров, которая должна быть доступна в ходе выполнения объектной программы. Следовательно, эта таблица должна быть «встроена» в объектную программу.
Перед трансляцией тела процедуры необходимо предусмотреть выполнение действий, обеспечивающих при каждом обращении к процедуре:
установление места, где размещена информация о метках подпрограмм фактических параметров (для этого в описываемом здесь варианте трансляции процедур используется метка ячейки возврата т,-, поскольку информация о метках подпрограмм фактических параметров записывается, как условлено, в объектной программе непосредственно перед ячейкой с меткой /п<) ;
формирование обращений к подпрограммам фактических параметров, вызываемых по значению;
исполнение этих подпрограмм до входа в тело процедуры и занесение значений вычисленных фактических параметров из ячейки Г) в секцию памяти, выделенную для процедуры;
проверку соответствия класса и типа фактических параметров, вызываемых по значению, классу и типу соответствующих
203
формальных параметров (обнаруженные несоответствия должны быть зафиксированы, а сообщения о них выдаются на печать, после чего выполнение программы прекращается).
Эти действия либо выполняются непосредственно в начале подпрограммы, в которую превращается тело процедуры, либо выполнение их возлагается на специальную служебную подпрограмму, которая вызывается интерпретирующей системой использования библиотечных подпрограмм (см. 1.1) или загрузчиком и исполняется при каждом обращении к процедуре. Использование служебной подпрограммы упрощает и ускоряет трансляцию, а также сокращает объем объектной программы, но замедляет ее исполнение.
Заметим, что занесение значений и проверка соответствия параметров упрощаются, если ячейки г,- и r,+i имеют постоянные стандартные адреса.
Выполнение описанных действий позволяет при трансляции операторов в теле процедуры заменять все формальные параметры, перечисленные в списке значений, просто адресами ячеек памяти, выделенных для этих формальных параметров в секции памяти, отведенной процедуре.
Способ обработки формального параметра в теле процедуры определяется не только тем, находится он в списке значений или нет, но и существенно зависит от характера использования этого формального параметра.
Рассмотрим простой пример. Пусть в операторе присваивания
А’ — В-^-С
А и В — формальные параметры, вызываемые по наименованию, а С — параметр, вызываемый значением. Тогда для вычисления правой части этого оператора достаточно иметь значения соответствующих фактических параметров в момент выполнения вычислений, хотя один из формальных параметров вызывается по наименованию, а другой — вызывается по значению. В то же время программирование операции присваивания невозможно, если неизвестен адрес фактического параметра, соответствующего формальному параметру А.
Еще более наглядно эта особенность проявляется в том случае, когда фактический параметр является нетривиальным выражением, которое, естественно, характеризуется прежде всего значением. Однако столь же очевидно, что формальный параметр в левой части оператора присваивания всегда должен заменяться адресом фактического параметра. Эта особенность использования формальных параметров используется для оптимизации объектной программы (см. 4.7).
По указанным причинам при независимой трансляции описании процедур целесообразно (хотя и не обязательно) для каждого формального параметра выделять две ячейки памяти в секции, отведенной процедуре. В одну из этих ячеек всегда заносится зна-204
чение соответствующего фактического параметра, если это зна-1 чение существует, а в другую — его адрес. Значение пересылается йз упоминавшейся ячейки г,-, а адрес — из ячейки rj+ь Кстати, содержимое ячейки гн-1 всегда требуется для определения соответствия формального и фактического параметров.
Если для каждого формального параметра выделять две ячейки, то трансляция тела процедуры упрощается.
Обработка формального параметра, вызываемого по наименованию, состоит в следующем:
формируется обращение к подпрограмме соответствующего фактического параметра;
после обращения программируются команды пересылки содержимого ячеек г,- и rj+i в ячейки памяти, отведенные формальному параметру,
программируется проверка соответствия фактических и формальных параметров (для этого используются содержимое ячейки г3+1 и таблица формальных параметров);
программируется требуемая операция, причем если для выполнения этой операции требуется значение, то его берут из ячейки, в которую занесено содержимое г3-, а если требуется адрес, то его можно найти в ячейке, в которую помещено содержимое ячейки гз+ь
В оптимизирующих трансляторах описанный общий способ трансляции процедур дополняется набором частных алгоритмов, приспособленных для более эффективной, с точки зрения качества объектной программы, обработки специфичных частных случаев.
4.7. ОПТИМИЗАЦИЯ ОБЪЕКТНОЙ ПРОГРАММЫ И ТРАНСЛЯТОРА
4.7.1. ЗАДАЧИ ОПТИМИЗАЦИЙ
Под оптимизацией объектной программы понимают улучшение ее характеристик в процессе трансляции с целью уменьшения времени исполнения, сокращения длины программы, сокращения объема памяти, используемого программой при исполнении.
Эти задачи противоречивы. Длину программы иногда можно сократить заменой линейных участков циклическими, которые, естественно, исполняются дольше, поскольку требуется выполнять дополнительные команды управления циклами. Аналогично объем используемой памяти в некоторых случаях можно сократить за счет применения более сложных и, следовательно, дольше исполняемых алгоритмов. Однако бывают случаи, когда программа содержит избыточные команды, устранение которых сокращает й ее длину, и время исполнения.
Под оптимизацией транслятора понимают улучшение его характеристик с целью уменьшения времени трансляции, уменьшения
205
объема транслятора, увеличения перечня и повышения качества услуг, обеспечиваемых транслятором: выдача удобного печатного документа, возможность разнообразного редактирования печатного документа, полный контроль ошибок и точная локализация их места и т. п.
Нетрудно видеть, что первые две цели взаимосвязаны: небольшой транслятор чаще работает быстрее. Однако бывают отклонения от этого правила, поскольку время трансляции существенно зависит от конструкции транслятора и применяемых в нем алгоритмов. В то же время третья из перечисленных целей явно противоречит первым двум, потому что выполнение любой дополнительной услуги во время трансляции, несомненно, требует увеличения объема транслятора и дополнительного времени.
Сравнивая задачи оптимизации объектной программы и задачи оптимизации транслятора, можно заметить, что эти задачи также противоречивы. В частности, для получения объектной программы высокого качества (например, по быстродействию) обычно требуется предусматривать выполнение транслятором дополнительных оптимизирующих операций. Это, естественно, приводит к увеличению времени трансляции и объема транслятора. Поэтому при оптимизации либо ограничиваются какой-либо одной целью (например, стремятся построить быстродействующий транслятор), либо стараются достичь некоторой компромиссной цели (например, обеспечить минимальное время исполнения объектной программы при возможно меньшей ее длине и приемлемом времени трансляции).
Так или иначе составители транслятора всегда стремятся сделать его возможно лучше (быстрее, короче, с хорошим качеством рабочей программы и наибольшими удобствами для пользователя) в рамках времени, отведенного для выполнения работы. Однако, •поскольку все эти цели одновременно недостижимы, особо выделяют оптимизирующие трансляторы, в которых предусмотрены дополнительные меры для повышения качества рабочей программы (обычно прежде всего стремятся сократить время ее исполнения), и быстрые трансляторы, в которых приняты специальные меры для ускорения трансляции.
В общем случае на разных этапах разработки и эксплуатации программы к ее качеству и времени, расходуемому на ее трансляцию, предъявляются разные требования. Пока программа находится в стадии отладки, требования к ее качеству невысоки. С другой стороны, цель отладки — выявление ошибок в программе. Для достижения этой цели программу приходится многократно транслировать, поэтому естественно требовать, чтобы на этапе отладки транслятор обеспечивал возможно более полный контроль ошибок и работал возможно быстрее.
Когда программа отлажена и регулярно используется для решения производственных задач, столь же целесообразно требовать, чтобы она выполнялась возможно быстрее. Поэтому иде-206
адьной можно считать систему программирования, которая для каждого входного языка содержит два транслятора. Один транслятор (отладочный) должен быть возможно более быстродействующим и должен обеспечивать хороший контроль ошибок, а также удобную форму выдачи информации об ошибках, выявленных при трансляции и исполнении программ. Другой транслятор должен быть оптимизирующим. Этот транслятор применяется только для трансляции уже отлаженных программ, к которым предъявляются высокие требования по быстродействию.
Такие «идеальные» системы программирования эксплуатировались на некоторых машинах [26], но в большинстве существующих систем программирования для каждого входного языка имеется лишь один транслятор.
Заметим, что в принципе транслятор можно сделать параметрическим так, чтобы в зависимости от заданного режима он мог работать либо как отладочный (отключены блоки оптимизации и включены блоки контроля), либо как оптимизирующий (включены блоки оптимизации и выключены блоки контроля).
4.7.2. ОПТИМИЗИРУЮЩИЕ ТРАНСЛЯТОРЫ
Как уже отмечалось, основное требование к оптимизирующему транслятору — высокое качество объектной программы (прежде всего, по быстродействию). Такие трансляторы нужны для трансляции программ многократного использования, когда время трансляции в среднем меньше общего времени решения задач по транслированной программе, а также для трансляции программ, работающих в реальном времени.
Обычно оптимизирующие трансляторы являются многопросмотровыми. Типичным примером оптимизирующего транслятора может служить Альфа-транслятор [16]. Он просматривает транслируемую программу (точнее, информацию, относящуюся к транслируемой программе) 24 раза. Правда, такое большое число просмотров связано не только с задачами оптимизации. В значительной степени «многопросмотровость» транслятора обусловлена небольшим объемом оперативной памяти машины М-20, для которой первоначально создавался Альфа-транслятор. Схема работы Альфа-транслятора очень кратко описана в п. 1.3.3.
Можно выделить три основных направления оптимизации транслируемых программ:
улучшение качества исходной программы;
применение различных алгоритмов трансляции в разных частных случаях;
использование в алгоритмах трансляции особенностей конкретной машины.
Улучшение качества исходной программы состоит в преобразовании ее с целью обеспечить наиболее быстрое выполнение на любой машине. Иными словами, оптимизирующие преобразования
207
этого вида не зависят от конкретной машины. Здесь транслятор частично исправляет нерациональные решения программиста.
Опыт показывает, что главный резерв увеличения быстродействия объектной программы состоит в рациональном программировании обращений к процедурам и операторов цикла, а также в экономном использовании переменных с индексами. В связи с этим основные оптимизирующие преобразования обычно состоят в следующем.
1. Выражения или подвыражения для фактических параметров, которые остаются постоянными при выполнении тела процедуры, выносятся из тела процедуры и вычисляются перед входом в тело процедуры. Это обеспечивает устранение дублирования одних и тех же вычислений.
2. Выражения и подвыражения, остающиеся постоянными внутри оператора цикла, выносятся из цикла и вычисляются перед входом в оператор цикла. Назначение этого преобразования — то же, что и в первом случае.
3. Адрес одной и той же переменной с индексами, встречающейся в выражении, операторе или теле цикла, вычисляется только один раз. Вариантом этого преобразования является присваивание значения переменной с индексами простой переменной с последующей заменой этой простой переменной всех других вхождений той же переменной с индексами.
Первые два преобразования называют соответственно «чисткой процедур» и «чисткой циклов».
Подробно методы оптимизации этого вида описаны в [16] и [54].
Применение различных алгоритмов трансляции для частных случаев конструкций входного языка частично связано с Особенностями конкретной машины. Например, в машине, имеющей индексные регистры (регистры-модификаторы) и специальные команды для построения циклов, целесообразно выделять частный случай, когда в элементе списка цикла типа арифметической прогрессии параметр цикла принимает лишь целые значения и меняется линейно. В этом случае можно эффективно использовать индексные регистры.
Использование особенностей машины должно обеспечить применение наиболее эффективных команд, а также рациональное распределение различных видов памяти: сверхбыстрых регистров, быстрой оперативной памяти, основной оперативной памяти и различных уровней внешней памяти для хранения программы, данных и промежуточных результатов, а также массивов.
Следует отметить, что особо важное значение имеет рациональная система обмена между основной и внешней памятью, используемая в процессе исполнения программы. Неудачная система обмена может свести на нет всю экономию машинного времени, полученную за счет применения оптимизирующих алгоритмов.
208
4.7.3. БЫСТРЫЕ ТРАНСЛЯТОРЫ
Основное требование к быстрому транслятору — минимальное время трансляции. Выполнение этого требования достигается применением наиболее общих алгоритмов для обработки каждой конструкции входного языка и использованием специальной схемы трансляции, обеспечивающей минимальное число просмотров транслируемой программы.
Чтобы получить минимальное время трансляции, прежде всего стремятся сделать быстрый транслятор возможно меньшим по объему. Транслятор небольшого объема можно хранить во время трансляции в оперативной памяти или, в крайнем случае, частично в оперативной памяти, а частично в быстрой промежуточной памяти (например, на магнитном барабане). Это позволяет избежать больших потерь машинного времени во время трансляции на обращение к медленной внешней памяти..
В общем случае для трансляции программы с языка высокого уровня требуется по крайней мере два просмотра входной программы и один дополнительный просмотр объектной программы. Во время первого просмотра выполняется лексический анализ, обрабатываются описания и составляются таблицы идентификаторов, меток и т. п. Во время второго просмотра выполняется собственно трансляция — генерирование машинных команд. Дополнительный просмотр нужен для замены адресами меток, отсылающих вперед.
Однако в некоторых случаях число просмотров можно уменьшить. Минимальное число просмотров обеспечивает строго последовательный алгоритм трансляции, когда каждая конструкция входной программы просматривается только один раз. Такой алгоритм можно получить, объединяя описанные в этой главе алгоритмы лексического анализа, преобразования в обратную польскую запись и генерирования машинных команд в единый алгоритм трансляции, в котором машинные команды генерируются сразу в действительных адресах. Необходимые для трансляции выражений и операторов таблицы идентификаторов, меток, формальных параметров процедур и другие составляются в этом случае в ходе просмотра. Однако такая схема требует, чтобы описание любого объекта всегда предшествовало его употреблению. Например, описания переменных должны предшествовать описанию процедур, в которых используются эти переменные. Если наложить такое требование на входной язык, то транслятор можно сделать двухпросмотровым. Второй просмотр нужен только для замены меток, отсылающих вперед.
При использовании быстрого транслятора в качестве отладочного предусматривают особые меры для возможно более полного синтаксического и семантического контроля программы. Детально синтаксический контроль рассматривается в следующей главе. Семантический контроль выполняется в ходе исполнения объектной
209
программы. Этот вид контроля включает, в частности, проверку соответствия фактических и формальных параметров, контроль нарушения границ индексов в массивах и контроль использования неопределенных значений.
Способ проверки соответствия фактических и формальных параметров кратко описан в п. 4.6.4.
Нарушение границ индексов можно выявить сравнением значения каждого индексного выражения в момент вычисления адреса элемента массива с границами этого индекса, хранящимися в определяющем векторе массива.
Для контроля использования неопределенных значений, т. е. использования переменной, которой не присвоено значение, при каждом входе в блок в ячейки секции памяти, выделенной для блока, засылается специальный признак НЕОПРЕДЕЛЕННОЕ ЗНАЧЕНИЕ. Занесение в ячейку любого значения уничтожает этот признак. Появление среди операндов любой операции величины из ячейки с признаком НЕОПРЕДЕЛЕННОЕ ЗНАЧЕНИЕ фиксируется как ошибка. Эта проверка может выполняться достаточно экономно лишь при наличии на машине специальных аппаратных средств, автоматически реагирующих на появление признака НЕОПРЕДЕЛЕННОЕ. ЗНАЧЕНИЕ при выборке значения из ячейки. В некоторых трансляторах для машин, не имеющих аппаратных средств контроля неопределенных значений, наличие признака НЕОПРЕДЕЛЕННОЕ ЗНАЧЕНИЕ контролируется только при обращении к подпрограммам.
ГЛАВА 5
СИНТАКСИЧЕСКИЕ МЕТОДЫ ТРАНСЛЯЦИИ
5.1. СУЩНОСТЬ СИНТАКСИЧЕСКИХ МЕТОДОВ
5.1.1. МЕТОД СИНТАКСИЧЕСКИХ ПОДПРОГРАММ
Ранние методы трансляции базировались на особенностях кон' кретного входного языка и особенностях конкретной машины, для которой создавался транслятор. Поэтому при разработке транслятора с нового языка или для новой машины почти вся работа выполнялась заново. Большая трудоемкость разработки трансляторов (от 4 до 30 и более человеко-лет) вынудила искать методы трансляции, не зависимые от конкретной машины.
Полностью не зависимые от машины методы трансляции до сих пор найти не удалось. Однако использование в процессе трансляции машинно-независимого промежуточного языка позволило сделать значительную часть алгоритма трансляции с конкретного входного языка не зависимой от машины. В частности, в рассмотренном методе трансляции с Алгола-60 (глава 4), основанном на стеке с приоритетами, алгоритм перевода на промежуточный язык (в обратную польскую запись) не зависит от конкретной машины. С машиной связана лишь вторая часть алгоритма трансляции — генерирование машинных команд. Еще дальше пошли авторы языка АЛМО. Стандартизация промежуточного языка и придание ему свойств языка программирования трансляторов позволили сделать не зависимыми от машины не только алгоритмы, но и программы перевода на промежуточный язык (АЛМО). Благодаря этому программы всех трансляторов, входящих в универсальную систему программирования ИПМ АН СССР, не зависят от конкретной машины. Все особенности машины учитываются в компиляторе АЛМО [3, 19].
Общая схема трансляции для методов, использующих промежуточный язык, показана на рис. 5.1. Алгоритм перевода на промежуточный язык выполняет синтаксический анализ и ту часть семантического анализа, которая связана с переводом на промежуточный язык. Генерирование машинных команд, завершающее семантический анализ, сводится к распознаванию операций промежуточного языка и выполнению для каждой операции
211
подпрограммы, которая формирует соответствующую этой операции группу машинных команд. Такие подпрограммы называют семантическими, поскольку в них выражена семантика операций промежуточного языка.
Прямые методы перевода на промежуточный язык, будучи не зависимыми от машины, тем не менее существенно используют особенности входного языка. Этот недостаток прямых методов препятствует созданию на их основе общих алгоритмов трансляции, применимых к существенно разным входным языкам. Между тем создание общих алгоритмов позволило бы значительно снизить трудоемкость разработки трансляторов за счет полной, или
Входная программа
йлгоритм перевода на промежуточный язык |
^Программа на промежуточном языке
Генерирование машинных команд
Объектная программа на языке машины или на языке загрузки
Рис. 5.1. Схема трансляции с использованием
промежуточного языка
по крайней мере частичной, автоматизации процесса составления трансляторов.
Для создания достаточно общих алгоритмов трансляции нужно прежде всего разделить этапы синтаксического и семантического анализа. Дело в том, что синтаксис входного языка никак не связан с конкретной машиной, поэтому алгоритм синтаксического анализа нетрудно сделать не зависимым от машины. Если сверх того использовать какую-либо стандартную форму описания синтаксиса входного языка, то можно разработать алгоритм синтаксического анализа, который будет не зависим и от конкретного входного языка.
Уже в первых компиляторах Фортрана применялся метод трансляции, в котором синтаксический анализ в определенной степени был отделен от семантического анализа. Этот метод называют методом синтаксических подпрограмм. Его часто используют и в современных трансляторах. В частности, на нем основан транслятор Комплекс Алгол, входящий в универсальную систему программирования ИПМ АН СССР [14].
212
Общая идея метода синтаксических подпрограмм состоит в разделении программы транслятора на две части (рис. 5.2). Одна часть состоит из набора синтаксических подпрограмм. Каждая подпрограмма соответствует определенной синтаксической конструкции входного языка и предназначена для обработки именно этой конструкции. Например, подпрограмма оператора цикла обрабатывает только операторы цикла, а подпрограмма оператора присваивания обрабатывает только операторы присваивания. Другая часть транслятора — управляющая программа — выделяет и
распознает отдельные конструкции каждый раз нужную синтаксическую подпрограмму. Следовательно, управляющая программа выполняет только синтаксический анализ.
Каждая синтаксическая подпрограмма либо непосредственно генерирует машинные команды (в этом случае она выступает и как семантическая подпрограмма), либо выделяет более мелкие конструкции и вызывает для их обработки соответствующие под
входнои программы и вызывает
Рис. 5.2. Структура транслятора, основанного на методе синтаксических подпрограмм
программы.
Существуют трансляторы, в которых используется модификация этой основной идеи: управляющая программа отсутствует, подпрограммы вызывают друг друга по мере необходимости, причем первой работает всегда подпрограмма, соответствующая наиболее общей конструкции, например блоку в Алголе-60 [27].
Метод синтаксических подпрограмм ориентирован на описание синтаксиса конкретного входного языка. Отсюда вытекает основной недостаток этого метода, такой же, как и у прямых мего-дов, — сильная зависимость транслятора от конкретного входного1 языка, поскольку набор синтаксических конструкций и семантика входного языка определяют как набор синтаксических подпрограмм, так и алгоритм трансляции, используемый в каждой подпрограмме. Заметим, что привязанность к конкретному языку имеет и определенное преимущество: транслятор можно сделать более эффективным.
5.1.2. СИНТАКСИЧЕСКИЕ МЕТОДЫ И УНИВЕРСАЛЬНЫЙ КОМПИЛЯТОР
Стремление создать методы трансляции, не зависимые от конкретного входного языка, привело к разработке методов, ориентированных на определенный способ описания синтаксиса входного языка. Иногда эти методы называют методами синтаксической информации [26], а основанные на них трансляторы
213
называют синтаксически ориентированными или синтаксически управляемыми [18]. Каждый метод этой группы синтаксических методов трансляции применим к некоторому классу входных языков. Этапы синтаксического и семантического анализа здесь можно всегда четко разделить, причем в алгоритме каждого этапа можно выделить часть, не зависящую от конкретного входного языка. В принципе это позволяет создать компилятор, универсальный в некотором классе входных языков. В таком компиляторе синтаксис и семантику входного языка можно рассматривать как параметры.
Гипотетический универсальный компилятор состоит из трех частей (рис. 5.3):
Рис. 5.3. Универсальный компилятор
синтаксический загрузчик — получает на вход описание синтаксиса входного языка L в некоторой стандартной форме и перерабатывает его в синтаксическую таблицу;
семантический загрузчик — аналогичным путем перерабатывает в семантическую таблицу описание семантики входного языка;
ядро компилятора — содержит программы синтаксического и семантического анализа, не зависящие от входного языка. Эти программы, используя табличное представление синтаксиса и семантики данного входного языка L, перерабатывают входную программу на этом языке в выходную программу.
Основу такой методики трансляции составляет формальное описание синтаксиса и семантики входного языка.
Сейчас созданы практически работающие синтаксические загрузчики, называемые конструкторами, которые по описанию синтаксиса входного языка автоматически генерируют синтаксический анализатор, способный выполнять синтаксический анализ входной программы.
214
Работа над семантическими загрузчиками пока не вышла из стадии экспериментов. Причина этого — трудности формального описания семантики. Однако исследования способов формализации семантики ведутся весьма интенсивно. Успехи в этом направлении обещают превратить искусство разработки трансляторов в точную науку.
5.2. ФОРМАЛЬНЫЕ ГРАММАТИКИ И ЯЗЫКИ
5.2.1. ФОРМАЛЬНЫЕ ГРАММАТИКИ
Методы синтаксического анализа основаны на теории формальных грамматик и языков, разрабатываемой математической лингвистикой. Эта теория тесно связана с теорией конечных автоматов и автоматов с памятью [11].
Сначала напомним неформальные определения, введенные в п. 1.3.3.
Язык есть множество предложений. Каждое предложение состоит из слов или символов. Предложения составляются из слов (символов) согласно правилам синтаксиса. По существу, синтаксис— это описание правильных предложений языка.
Для описания синтаксиса какого-либо языка, в свою очередь,, нужен некоторый язык. Язык, предназначенный для описания другого языка, называют метаязыком. Язык, используемый для описания синтаксиса языка, называют синтаксическим метаязыком. или метасинтаксическим языком.
Набор правил синтаксиса образует грамматику языка. Правила синтаксиса могут описывать либо процедуру получения правильных предложений, либо процедуру распознавания «правильности» предложения, т. е. процедуру распознавания принадлежности предложений языку. В первом случае грамматику называют порождающей, а во втором — распознающей.
Пример 1. Грамматика Go задана следующим набором правил:
(предложение) -> (подлежащее) (сказуемое)
(подлежащее) -> (имя существительное)
(подлежащее) -> (местоимение)
(имя существительное) -> КОТ
(имя существительное) -> ПЕС
(местоимение) -> ОН
(сказуемое) -> (глагольная форма)
(глагольная форма) -> ИДЕТ
(глагольная форма)-> ЛЕЖИТ
Знак -► читается «это есть». Он делит каждое правило на две части: правую и левую.
215
Используя очевидные сокращения, грамматику Go можно записать короче:
<Пр)->(П) (С) (П)->(ИС) (П)->(М)
(ИС)->КОТ
(ИС) -+ ПЕС
(М)->ОН
(С)->(ГФ)
(ГФ)-» ИДЕТ (ГФ)-> ЛЕЖИТ
Множество правил произвольной грамматики будем обозначать Р.
Символы, входящие в правила, образуют словарь V.
Для грамматики Go словарь
У = {(Пр), (П), (С), (ИС), (М), (ГФ), КОТ, ПЕС, ОН, ИДЕТ, ЛЕЖИТ}.
В теории формальных грамматик элементы словаря V обычно обозначают прописными (большими) буквами латинского алфавита.
Множество всех конечных последовательностей символов (строк) из словаря V, включая пустую строку, обозначим V*. Элементы множества V* обычно обозначают строчными (малыми) буквами латинского алфавита.
Множество V делят на два подмножества:
1. Подмножество Т символов, которые входят только в правые части правил Р. Для грамматики Go
Т = {КОТ, ПЕС, ОН, ИДЕТ, ЛЕЖИТ).
Эти символы называют основными или терминальными (конечными). Например, в Алголе-60 множество Т состоит из основных символов языка: begin, end, for, do и т. п., а также из букв, цифр и специальных знаков +, —, X и др. Всего в Алголе-60 имеется 116 терминальных символов.
2. Подмножество N = V — Т неосновных или нетерминальных символов. Для грамматики Go
У={{Пр), (П), (С), (ИС), (М), <ГФ».
В Алголе-60 неосновными символами являются металингвистические переменные — названия конструкций языка: (блок), (оператор), (переменная) и т. д. Всего в Алголе-60 имеется ПО нетерминальных символов. Множество строк из элементов множества N обозначим N* = (V—Г)*.
В грамматике Go среди нетерминальных символов есть один символ, который входит только в левую часть правил Р. Этот
216
символ обычно обозначают А (аксиома) или S и называют начале-ныя символом грамматики.
В грамматике Go начальный символ А = (Пр), а в Алголе-60 — (программа).
Грамматику G, определяемую четверкой G={V, Т, Р, А), где элементы множества правил Р имеют вид х-*у, (х у, х е (V - ТУ, у е V*), называют порождающей, причем правила вида х—*у называют порождающими правилами или правилами подстановки.
В дальнейшем, если не оговорено иное, рассматриваются порождающие грамматики с правилами вида U-*u, где Ge е (V — Г). В частности, грамматика Go является порождающей.. Пример 2. Порождающая грамматика
0, = !^, Тр Рр А,) описывает арифметические выражения, использующие операции: типа сложения и типа умножения, скобки и идентификаторы. Выражение, ограниченнее концевыми знаками ±, образует программу.
Множество Р\ есть П->± В ± В->Т В->В4-Т Т->М (5-2).
Т->Т хм М->И М->(В)
Здесь буквы являются очевидными сокращениями: П — (программа), В —(выражение), Т—(терм), М—(множитель), И — (идентификатор).
Грамматику называют прямо леворекурсивной, если в ней: имеются правила вида U-^Uu, и прямо праворекурсивной при наличии правил вида U—>uU, где U — нетерминальный символ.
Нетрудно видеть, что правила В—>В-|-;Т и Т—►ТХМ делают грамматику Gi прямо леворекурсивной.
217
5.2.2. НОТАЦИЯ
В работах по теории формальных грамматик для записи порождающих правил обычно используют уже описанную нами нотацию (совокупность условных знаков). Однако для описания синсаксиса языков программирования применяют также другие системы обозначений.
Язык Алгол-60, как известно, описан при помощи нотации Бэ-куса, которую часто сокращенно обозначают БНФ — бэкусова нормальная форма или бэкусово-науровская форма. В этой нотации вместо знака «-» (это есть) пишут знак «::=», а правила с одинаковыми левыми частями собирают в одно, используя в качестве разделителя знак «|» (или). Нетерминальные символы всегда заключают в угловые скобки «(» и «)».
В БНФ грамматику Go, определенную правилами (5.1), можно записать в виде
(Пр):: = (П) (С)
(П):: = (ИС) | (М)
(ИС):: = КОТ|ПЕС
(М):: = ОН
(С):: = (ГФ)
(ГФ) :: = ИДЕТ | ЛЕЖИТ,
а грамматику Gi, определенную правилами (5.2), — в виде
(П)::=1(В)1
(В):: = (Т) | (В) + (Т)
(Т):: = (М)|(Т)Х(М)
(М):: = И|((В))
На практике применяют также различные модификации БНФ, сокращенно МБНФ. В одной из модификаций знаки «::=» и «|» имеют те же значения, что в БНФ. Нетерминальные символы записываются малыми буквами, а терминальные символы выделяются большими буквами или полужирным шрифтом. Кроме того, введены:
фигурные скобки «{» и «}», обозначающие, что в правило входит один из ряда символов, стоящих в скобках и разделенных знаками «|», например
в:: = {т | в + т};
квадратные скобки «[» и «]», означающие, что заключенный в них символ (или конструкция) может входить, а может и не входить в правило, например
в:: = [в+]т;
многоточие «...», означающее, что предшествующий символ или предшествующая конструкция может повторяться, например
идентификатор :; = буква [буква | цифра] ....
218
Для наглядного представления взаимосвязи между различными правилами и символами грамматику можно изобразить в виде ориентированного графа.
Символ левой части правила изображают выше символа правой части и соединяют их стрелкой. Например, правило Т— изображают графически в виде, изображенном на рис. 5.4, а. Если
Рис. 5.4. Графическое изображение порождающих правил
в правую часть правила входят несколько символов, то их объединяют узлом, отмеченным знаком +. Например, правило т-тхм можно изобразить, как показано на рис. 5.4,6. Чтобы не иметь в графе разных узлов с одинаковыми названиями, удалим нижний узел Т, заменив его стрелкой от верхнего узла Г (рис. 5.4,в).
Для изображения правил с одинаковыми левыми частями используют узел, отмеченный знаком V, означающим «или». Этот узел указывает, что для определения правой части нужно взять
кот
Рис. 5.5. Граф грамматики Go
какую-либо одну из входящих в него дуг. Применяя такой узел,, правила Т-*М и Т—*ТХМ можно изобразить в виде, показанном на рис. 5.4,г. На рис. 5.5 показан ориентированный граф, изображающий грамматику Go, а на рис. 5.6 — граф грамматики Gt.
Нетрудно видеть, что все терминальные символы грамматики образуют концевые (буквально — терминальные, отсюда и название) узлы каждого графа. В них не входят никакие дуги графа., В узел, отвечающий нетерминальному символу, наоборот, непре-’ Менно входит хотя бы одна дуга. Среди нетерминальных символов
219-
имеется лишь один, из которого не выходит никакая дуга. Это начальный символ грамматики.
Сравнивая рисунки, можно заметить, что граф грамматики Go ацикличен, а граф грамматики Gi содержит циклы. Наличие цик-
лов— следствие рекурсивности грамматики. Цикличность графа отражает существенные для синтаксического анализа свойства грамматики.
5.2.3. ФОРМАЛЬНЫЕ ЯЗЫКИ
Порождающая грамматика G порождает язык L (G). Чтобы показать, как это происходит, введем дополнительные определения.
Строка xg V* прямо порождает строку у е V* (символически это обозначают х => у), если:
x = pUq,
y = pzq, где р е V* и q е V* (строки р и q могут быть пустыми), и существует правило
U z. (5.3)
220
Иными словами, у — прямое порождение х, если у можно/получить заменой в х нетерминального символа U строкой z в соответствии с правилом (5.3).
Пример 1. В грамматике Go строка ОН ИДЕТ — прямое порождение строки (М) ИДЕТ, полученное применением правила
<М> -> ОН.
Строка х е V* порождает у е V* (символически х* у), если существует последовательность строк
х — Хо> Xi) • • •, Хд — у, (5.4)
таких, что
xz=^x/+1, i = 0, 1, .... п — 1.
Последовательность (5.4) называют выводом.
Иными словами, у — порождение х, если существует последовательность прямых порождений (вывод), переводящая х в у.
Пример 2. В грамматике Go строка КОТ ЛЕЖИТ — порождение строки (Пр):
(Пр)=ф(П) (С)=^(ИС) (С)=>кот (С)=>кот (ГФ)=ф.КОТ ЛЕЖИТ (5.5) Любое порождение начального символа А грамматики G называют сентенциальной формой. Язык L(G), порождаемый грамматикой G, есть множество всех сентенциальных форм, состоящих только из терминальных символов. Такие сентенциальные формы называют предложениями языка L(G).
Пример 3. Грамматика Go порождает шесть сентенциальных форм, состоящих только из терминальных символов (шесть предложений) : КОТ ИДЕТ КОТ ЛЕЖИТ ПЕС ИДЕТ ПЕС ЛЕЖИТ ОН ИДЕТ ОН ЛЕЖИТ
Следовательно, в языке L(G0) только шесть правильных предложений. Отметим, что в языке, порождаемом Грамматикой Gi, число правильных предложений бесконечно. Это — следствие ре-курсивности грамматики Gi.
Если две различные грамматики порождают один и тот же язык, то эти грамматики называют эквивалентными. Эквивалентные грамматики могут обладать разными свойствами, облегчающими или, наоборот, затрудняющими разработку алгоритма трансляции. Этим широко пользуются при создании синтаксически ориентированных трансляторов.
Каждой сентенциальной форме по определению соответствует по крайней мере один вывод. Однако одной и той же сентенциальной форме может соответствовать более чем один вывод.
221
Пример 4. Сентенциальной форме КОТ ЛЕЖИТ в примере 2 отвечает вывод (5.5), но можно построить другой вывод:
(Пр)=>(П) (С)=>(П) (ГФ)=>(П) ЛЕЖИТ=£.(ИС) ЛЕЖИТ=£>КОТ ЛЕЖИТ*
Вывод можно наглядно представить синтаксическим деревом, которое иначе называют деревом вывода (или деревом разбора). На рис. 5.7,о показано синтаксическое дерево, отвечающее всем возможным выводам сентенциальной формы КОТ ЛЕЖИТ грамматики Go, на рис. 5.7,6 изображено синтаксическое дерево для сентенциальной формы ± М + Т X М ± грамматики Gi.
Рис. 5.7. Синтаксические деревья
Если хотя бы одна сентенциальная форма имеет более одного синтаксического дерева, то грамматику называют неоднозначной.
5.2.4. ЗАДАЧА РАЗБОРА < '
Эта задача обратна задаче вывода. Преобразование строки, обратное порождению, называют приведением (или сведением, или редукцией) строки.
Строка у е V* прямо приводима (прямо редуцируема) к строке х е V*, если х => у (х прямо порождает у).
Пример 1. В грамматике Go строка КОТ ЛЕЖИТ прямо приводима к строке (ИС) ЛЕЖИТ. Строка у е V* приводима (сводима, редуцируема) к строке х е V*, если х у (х порождает у).
Пример 2. «В грамматике Go строка КОТ ЛЕЖИТ приводима к начальному символу (Пр).
Выводу
X —~ Хо —Х| -7 • • • —т' Х„ у,
который соответствует порождению х=^у, отвечает обратное преобразование — разбор с элементами
У—• ••» Х\, Xq —-X
показывающее, как реализуется приведение у к х.
Пример 3. Редукция
J. М4-ТХМ 1 кП
222
(см. рис. 5.7,6) осуществляется разбором с элементами!
J.M + TXM1, 1Т + ТХМ1,
1В + ТХМ1, 1В + Т1, 1В1, П (5.6)
или разбором с элементами:
J.M + TXMJL, 1М4-Т1, ±Т + Т±, 1В + Т±, J.BJL, П.
Каноническим называют такой разбор, который проводится слева направо и редуцирует самую левую часть сентенциальной формы, пока это возможно. Редуцируемую в каноническом разборе часть сентенциальной формы называют основой (иногда связкой). В примере 3 первый разбор (5.6) является каноническим. Основами в нем последовательно являются: М, Т, Т X М, В -f- Т,
Итак, разбор — это тот же вывод, но прослеженный в обратном порядке.
Основная задача синтаксического анализа состоит в отыскании разбора (вывода) для заданного предложения входного языка. Если разбор (вывод) существует, то предложение синтаксически правильное (является сентенциальной формой). Разбор дает его структуру (синтаксическое дерево).
По существу, термины «синтаксический анализ», «задача разбора» и «задача распознавания входной строки» — синонимы. Алгоритм, решающий задачу разбора, называют анализатором или распознавателем.
Существуют две основные стратегии синтаксического анализа: нисходящая (сверху вниз), когда для данного предложения, исходя из начального символа грамматики, строят вывод;
восходящая (снизу вверх), когда для данного предложения, исходя из символов самого предложения, строят разбор.
Соответственно различают нисходящие и восходящие синтаксические распознаватели (анализаторы).
5.2.5. КЛАССИФИКАЦИЯ ЯЗЫКОВ ПО ХОМСКОМУ
В 1959 г. американский ученый-лингвивт Н. Хомский предложил классифицировать формальные языки по типу правил порождающей грамматики [34].
Класс 0. Правила имеют форму
а—>Ь
без каких-либо ограничений на строки а и Ь. Языки этого класса могут служить моделью естественных языков.
Класс 1. Все правила имеют вид
pUq-^puq, где строки р и q могут быть пустыми, и — непустая строка, а U — нетерминальный символ.
223
Порождающая грамматика с такими правилами называется грамматикой непосредственно составляющих. Языки, порождаемые грамматиками этого класса, называют контекстно-чувствительными или контекстно-зависимыми, поскольку подстановка U —-и допустима только в контексте р, q.
Класс 2. Все порождающие правила имеют вид
U-+U,
т. е. слева имеется единственный нетерминальный символ U.
Такие грамматики и порождаемые ими языки называют контекстно-свободными, поскольку подстановка U-+u возможна независимо от контекста.
Грамматики класса 2 являются хорошей моделью для языков программирования. Даже если грамматика конкретного языка программирования не относится к классу 2, то, как правило, для нее можно построить эквивалентную грамматику второго класса. Разбор предложения языка класса 2 можно выполнить, используя автомат с магазинной (стековой) памятью.
Класс 3. Все правила относятся к одной из двух форм:
U-*a,
U-+aU',
где U и U' — нетерминальные символы, а — терминальный символ.
Языки класса 3 называют языками с конечным числом состояний или автоматными языками.
Рассматривавшуюся выше грамматику Go можно заменить эквивалентной грамматикой класса 3:
(Пр) КОТ (С) (Пр) + ПЕС (С) (Пр)^ОН (С)
(С)->ИДЕТ (С) -> ЛЕЖИТ
В реальных языках программирования отдельные подмножества также можно отнести к третьему классу. Например, подмножество правил Алгола-60, определяющее (число без знака), можно представить эквивалентным набором правил, образующих грамматику третьего класса. Распознавание сентенциальной формы в таком языке можно выполнить алгоритмом, который реализуется конечным автоматом (автоматом с конечным числом состояний)., Именно такой алгоритм был описан в п. 4.2.4 для перевода чисел.
Вообще распознаватель для языка с конечным числом состояний всегда можно представить в виде таблицы с двумя входами, которая представляет собой специфичную запись набора поро-
224
jkдающих правил. В частности, распознаватель для грамматики Go можно записать в виде следующей таблицы:
Входной символ Состояние кот ПЕС * он ИДЕТ ЛЕЖИТ
(Пр) (С) (С) (С) •
(С) • Разбор получен Разбор получен
Число строк (состояний) таблицы равно числу нетерминальных символов, а число столбцов — числу терминальных символов грамматики. Исходное состояние—начальный символ грамматики. В клетках таблицы записано следующее состояние для данной пары входов. Пустые клетки соответствуют ошибочным предложениям языка.
Читателю предлагается сравнить эту таблицу с табл. 4.1 в п. 4.2.4.
Заметим, что грамматику Gb определенную правилами (5.2), нельзя заменить эквивалентной грамматикой третьего класса. Это грамматика второго класса. Отсюда можно заключить, что существуют языки ьго класса, не сводимые к классу /4-1, i = О, 1, 2, поэтому класс языка является некоторым показателем его мощности. Установление классов языков дает теоретический фундамент для разработки теории и методов анализа языков программирования.
5.2.6. НИСХОДЯЩИЙ АНАЛИЗ
Отличительная черта нисходящего анализа — целенаправленность. На каждом шаге анализа нисходящий распознаватель формирует цель — найти вывод, начинающийся с некоторого нетерминального символа и порождающий часть входной строки. Распознаватель пытается достичь этой цели путем направленного перебора различных возможностей.
Предположим, что входной язык относится к классу 2 по Хомскому, а его грамматика контекстно-свободная.
Основная идея нисходящего анализа состоит в следующем. Начиная процесс анализа входной строки
SA ... Sn, (5.7)
Распознаватель исходит из предположения, что эта строка является предложением входного языка. Отсюда вытекает главная
8 Зак. 221 225
цель анализа — найти вывод
А • • • Sn, (5-8)
где А — начальный символ грамматики.
Если существует вывод (5.8), то имеется порождающее правило
UtU2 ... Um, Ui е V, i = 1...т, (5.9)
и вывод
ад •.. ит й> . S„. (5.10)
Среди символов Ui могут быть терминальные Ur и нетерминальные Un. Поскольку входная строка (5.7) по определению состоит только из терминальных символов и в левую часть любого порождающего правила терминальные символы не входят, каждый терминальный символ UT должен совпадать с одним из символов входной строки Sj, а для каждого нетерминального символа Un должен существовать вывод
Un^SniSn2 ••• (5.11)
Здесь в правой части записана часть входной строки (5.7).
Вывод (5.8) можно найти, если известны выводы (5.11). Следовательно, возникают вспомогательные цели — найти все выводы (5.11). При отыскании этих выводов в свою очередь появляются новые вспомогательные цели и т. д.
Заметим, что для каждого нетерминального символа UN, включая начальный символ А, в грамматике может быть несколько правил с различными правыми частями. Какое именно правило следует применять, заранее неизвестно. При неудачном выборе правила вспомогательная цель может оказаться недостижимой. Тогда нужно попытаться применить другое правило. Возможен случай, когда для данного нетерминального символа UN, являющегося вспомогательной целью, все правила приводят к неудаче. Это означает, что неправильно выбрано правило более высокого уровня, которое определило вспомогательную цель Un. В этом случае нужно вернуться и взять другое правило.
Описанный процесс завершается, когда найден вывод (5.8) или когда установлено, что этого вывода не существует (входная строка не является предложением входного языка).
Обычно нисходящий распознаватель просматривает символы входной строки и символы правой части применяемого правила слева направо. Такие распознаватели называют левосторонними.
Программа нисходящего распознавателя может иметь разную структуру. В частности, ее можно построить в виде набора рекурсивных процедур, каждая из которых распознает нетерминальный символ грамматики входного языка, формирует вспомогательную цель и вызывает процедуру более низкого уровня. Такая 226
структура лежит в основе метода синтаксических подпрограмм (п. 5.1.1). Как отмечалось, этот метод может быть достаточно эффективен для конкретного языка, но его недостатком является сильная зависимость алгоритма трансляции от входного языка. Чтобы избавиться от этого недостатка, нужно отделить описание синтаксиса от алгоритма синтаксического анализа. Это приводит к различным вариантам нисходящих распознавателей [18, 21], использующих табличное представление синтаксиса входного языка. Изменение грамматики входного языка (в определенных пределах) не затрагивает алгоритма анализа в таком распознавателе, изменяются лишь синтаксические таблицы.
В качестве примера рассмотрим схему нисходящего анализа предложений языка, порождаемого грамматикой Go.
Порождающие правила этой грамматики запишем в БНФ
(Пр) = (П) (С) (П):: = (ИС)|(М) (ИС):: =» КОТ | ПЕС
(М):: = ОН
(С):: = (ГФ)
(ГФ) = ИДЕТ | ЛЕЖИТ
В памяти машины эти правила могут храниться в виде синтаксической таблицы, подобной табл. 5.1.
Пусть требуется найти вывод для предложения
ОН ИДЕТ.
В качестве главной цели выбираем символ (Пр) — начальный символ грамматики Go. Первая вспомогательная цель—(П) (первый символ правой части правила для (Пр)), вторая вспомога« тельная цель — (ИС) (правая часть первого правила для (П)).
<п>
<ио
I I
ОН ИДЕТ
<П> <с>
<м> <га»
он идет
Рис. 5.8. Вспомогательная цель (ИС) недостижима
Рис. 5.9. Дерево вывода предложения ОН ИДЕТ
Непосредственная проверка показывает, что вспомогательная цель (ИС) недостижима, поскольку правые части обоих правил для (ЙС) состоят только из терминальных символов (КОТ и ПЕС) и ни один из них не совпадает с первым символом анализируемой строки (рис. 5.8), поэтому вместо (ИС) выбираем новую вспомогательную цель—(М) (правую часть второго правила для (П)). Теперь вспомогательная цель (П) достигнута. В результате получена левая ветвь синтаксического дерева (рис. 5.9).
8*
227
Таблица 5.1 ТАБЛИЦА ПРАВИЛ ГРАММАТИКИ
1 (Пр)
2 (П>
3 (С)
4 Признак конца правила
5 (П)
6 (ИС)
7 Признак конца правой части
8 (М)
9 Признак конца правила
10 (ИС)
11 кот
12 Признак конца правой части
13 ПЕС
14 Признак конца правила
15 (М)
16 он
17 Признак конца правила
18 (С)
19 (ГФ)
20 Признак конца правила
21 (ГФ)
22 ИДЕТ
23 Признак конца правой части
24 ЛЕЖИТ
25 • Признак конца таблицы
223
После этого рассматриваем нераспознанную часть анализируемой строки и формируем новую вспомогательную цель—(С) (второй символ правой части правила для (Пр)). Для распознавания (С) формируется еще одна вспомогательная цель — (ГФ), которая приводит к достижению главной цели — построению вывода, порождающего анализируемое предложение (см. рис. 5.9).
Описанный левосторонний распознаватель неприменим, если грамматика леворекурсивна. Например, правило грамматики Gi
в^-в + Т
требует, чтобы для отыскания цели В формировалась вспомогательная цель В, которая в свою очередь требует формирования вспомогательной цели В, и т. д. Следовательно, алгоритм левостороннего распознавателя будет бесконечно генерировать вспомогательные цели В, и программа зациклится.
Для применения левостороннего нисходящего распознавателя в данном случае нужно заменить грамматику G] эквивалентной грамматикой, в которой нет левой рекурсии.
Приведенное выше сильно упрощенное описание процесса нисходящего анализа, конечно, не дает • полного представления о всех трудностях, которые приходится преодолевать, когда вспомогательная цель оказывается недостижимой, и анализ заходит в «тупик». Для выхода из «тупика» приходится возвращаться к исходной точке и делать новые попытки, что сильно усложняет алгоритм и замедляет процесс трансляции. По этой причине нисходящие распознаватели в чистом виде применяют относительно редко.
Практическое применение нашли различные модифицированные нисходящие распознаватели, в которых используются дополнительные таблицы, показывающие, может ли порождение испытываемого нетерминального символа начинаться с данного терминального символа входной строки. Такое «заглядывание вперед» существенно сокращает количество неудачных попыток. Нисходящие модифицированные распознаватели использованы в трансляторах с языков Алгэм и Алгамс для машины «Минск-22».
Креме того, в производственных трансляторах широко применяют комбинацию нисходящих и восходящих методов синтаксического анализа. Например, нисходящий анализ выделяет относительно крупные синтаксические конструкции (описание, оператор), каждая из которых затем аналйзируется методами восходящего анализа.
, В целом стратегия нисходящего анализа дает лишь руководящую идею для разработки эвристических методов трансляции.
5.2.7. ВОСХОДЯЩИЙ АНАЛИЗ
Методы восходящего анализа нашли широкое применение в действующих трансляторах. Обшая идея восходящего анализа состоит в следующем. Входная программа рассматривается как
229
строка символов S]$2 •. . Sn. Распознаватель отыскивает часть строки, которую можно привести к нетерминальному символу. Такую часть строки называют фразой. Фразу, которая прямо приводима к нетерминальному символу, называют непосредственно приводимой. В большинстве восходящих распознавателей отыскивается самая левая непосредственно приводимая фраза, называемая основой. Основа заменяется нетерминальным символом. Во вновь полученной строке опять отыскивается основа, которая
также заменяется нетерминальным символом, и т. д.
Процесс продолжается либо до получения начального сим-
вола, либо до установления
Рис. 5.10. Дерево вывода
невозможности приведения строки к начальному символу. Последовательность промежуточных строк, которая заканчивается начальным символом, образует разбор. Если строка
Т X И
Рис. 5.11. Частично редуцированное дерево
неприводима к начальному символу, то разбора не существует, и входная программа синтаксически некорректна
Пример 1. Сентенциальная форма
± a + bXc1
грамматики дополненной определением индентификатора как буквы латинского алфавита:
И —* о |ft |... | г, порождается выводом, дерево которого изображено на рис. 5.10. Фразами являются символы a, b, с, b X с, а -f- b X с, J_a + ft X C-J— Непосредственно приводимые фразы: а, b и с. Основа — а.
После приведения а к В, ft к Т и с к М дерево приобретает вид, показанный на рис. 5.11. Здесь уже фразами являются ТХМ, В + Т X М и 1В + Т X М±.
Непосредственно приводимая фраза (она же основа) лишь одна —
ТХМ.
Дальнейшее приведение строки происходит так:
1 В + ТХМ 1, 1 В + Т1, ±В 1, П.
230
Начальный символ получен, следовательно, входная строка синтаксически правильна.
Пример 2. Для строки
ОН КОТ
в грамматике Go фразами являются ОН и КОТ. Основа — ОН. Приведение ОН к (М) дает строку
(М) кот с двумя фразами (М) и КОТ. Основа — (М). Далее (М) КОТ. (П) КОТ, <П) (ИС>, (И) (П).
Дальнейшее приведение невозможно. Разбора нет, следовательно, эта строка синтаксически некорректна.
Рассмотренный в примерах процесс приведения исходной строки к начальному символу происходит слева направо, т. е. выполняется левосторонним распознавателем. В общем случае восходящий распознаватель, как и нисходящий, может делать «ошибочные» редукции, которые приводят в «тупик».
Пример 3. Для строки, порожденной грамматикой Gt,
1 Т ХМ 1
редукция Т к В приводит к неприводимой строке
1ВХМ1.
Здесь нужно вернуться к исходной строке и выполнить редукцию Т X М к Т, которая дает строку
±Т±,
приводимую к начальному символу:
J.T ±, ± В±. П.
Для того чтобы при применении конкретного метода синтаксического анализа распознаватель работал в одном направлении (слева направо) без «тупиков» и возвратов, грамматика должна обладать определенными свойствами. Различные методы анализа предъявляют разные требования к грамматикам. Иногда применение конкретного метода возможно лишь после существенного изменения грамматики. При этом нужно следить, чтобы исходная и измененная грамматики были эквивалентны, т. е. порождали один и тот же язык.
На каждом шаге процесса задачей левостороннего восходящего анализа является определение основы. Разные методы восходящего анализа как раз и отличаются способом отыскания-осно-вы- или другой непосредственно приводимой фразы, выполняющей ту же роль, что основа.
В последующих параграфах рассматриваются наиболее распространенные методы восходящего анализа.
231
5.3. МЕТОД ПРЕДШЕСТВОВАНИЯ
5.3.1. ОТНОШЕНИЯ ПРЕДШЕСТВОВАНИЯ
Обобщая ранние работы по синтаксическому анализу, в 1966 г. Н. Вирт и Г. Вебер предложили метод предшествования [56], основанный на том факте, что между любыми двумя соседними символами Si и Si+i приводимой строки могут существовать лишь три отношения;
Si < Si+i, если символ Si+i— самый левый символ некоторой основы (рис. 5.12);
Si > Si+i, если символ Si — самый правый символ основы (рис. 5.13) ;
Si = Si+i, если символы Si и Si+i принадлежат одной основе (рис. 5.14).
основа
Рис. 5.12. Отношение
••• Si+1 *---v—•
основа
Рис. 5.13. Отношение
основа
Рис. 5.14. Отношение
Отношения <, > и == называют отношениями предшествова ния (precedence). Заметим, что отношения предшествования завиг сят от порядка, в котором стоят символы, и из
Si < Sj отнюдь не следует
Sy > Si, а из
$/ = $/ вовсе не вытекает
Sz = 5i.
Если для каждой упорядоченной пары символов грамматики существует не более чем одно отношение предшествования, то на каждом шаге синтаксического анализа можно легко выделить основу. Основой является самая левая группа символов приводимой строки Si ... Sj, связанная отношениями предшествования вида
основа
Пример. Пусть для любой упорядоченной пары терминальных и нетерминальных символов некоторой грамматики известны отношения предшествования. Дана входная строка с отношениями предшествования:
(5.12)
232
Тогда символы S2S3S4 образуют основу. Следовательно, по определению (основа — самая левая непосредственно приводимая фраза), должно существовать правило вида
£/] -» S2S3S4.
Пусть прямая редукции строки (5.12), выполненная в соответствии с этим правилом, приводит к строке с отношениями предшествования
1 <S1 = t/1>S5 = S6> ±. (5.13)
Следовательно, существует правило вида
с/2-*ЗД-
Пусть применение этого правила дает строку с отношениями предшествования
1 <t/2=S5=S6.> 1. (5.14)
Из (5.14) следует, что существует правило
^3 ~* ^2^5*^6>
поэтому строка (5.14) прямо приводится, к строке
±U3±.
Если существует правило
(начальный символ) -> ± U3 ±, то пряхмая редукция
±{/3 ± к (начальный символ)
завершает анализ. Разбор получен.
5.3.2. ГРАММАТИКА ПРЕДШЕСТВОВАНИЯ
Пусть U, С и D — нетерминальные символы, х, у, г и w — любые строки, возможно, пустые.
Грамматикой предшествования (precedence grammar) называют такую грамматику класса 2 по Хомскому, в которой:
1) для каждой упорядоченной пары терминальных и нетерминальных символов выполняется не более чем одно из трех отношений предшествования, определяемых следующим образом:
A. Si = Sj, если и только если существует правило
U -> xSiSjg.
Б. St < Sj, если и только если существует правило U-+xSjDy и вывод D=^SjZ.
В. 5г > Sj, если и только если существует правило U—*-xCSty и вывод С => zSt, или — правило U xCDy и выводы С => zSit
SjW,
233
2) разные порождающие правила имеют различные правые части.
Первое условие обеспечивает единственность отношения предшествования для каждой упорядоченной пары соседних символов в приводимой строке. Если между какими-либо двумя символами нет отношения предшествования, то это означает, что они не могут находиться рядом ни в одном элементе разбора синтаксически правильной сентенциальной формы.
Второе условие обеспечивает однозначность редукций.
5.3.3. РАСПОЗНАВАТЕЛЬ
Основную идею алгоритма разбора, основанного на отношениях предшествования, можно описать так.
Символы входной строки поочередно переписываются в стек до тех пор. пока между символом в вершине стека (обозначим
Вершина
необработанная часть Входной стропи
Ч fyi ...
стен
стен
необработанная часть Входной стропа
Рис. 5.16. Стек и входная строка после редукции
Рис. 5.15. Стек и входная строка до редукции
его Sz) и очередным символом входной строки (обозначим его Si) не появится отношение > , т. е. окажется, что Sz > S<. Тогда стек просматривается в направлении от вершины к началу до тех пор, пока между двумя очередными символами S&-1 и Sa не появится отношение <, т. е. S^-i < S&. Часть стека от символа S& до символа в вершине Sz — основа. Теперь среди порождающих правил отыскивается правило вида
U-+Sk ... Sz (5.15)
и, если нужно, вызывается семантическая подпрограмма, которая обрабатывает строку Sh ... Sz, переводя ее на промежуточный или выходной язык. После этого в стеке строка Sa ... Sz заменяется символом 17, и описанный выше процесс заполнения стека символами входной строки продолжается.
234
На рис. 5.15 и 5.16 показано состояние стека и входной строки до и после редукции соответственно.
Если на некотором шаге процесса обнаружится, что между соседними символами SP и SQ не существует отношения предшествования, то это свидетельствует об ошибке типа «символы Sp и не могут находиться рядом». Соответствующая информация заносится в таблицу ошибок.
Описанный алгоритм прост и обеспечивает полный синтаксический контроль транслируемой программы.
5.3.4. МАТРИЦА ПРЕДШЕСТВОВАНИЯ
Отношения предшествования. можно найти непосредственно, пользуясь определениями, приведенными в 5.3.2. Однако удобнее ввести дополнительные определения.
Обозначим L(U) множество самых левых символов относительно нетерминального символа U. Формально множество L(U) определяется формулой
£(£/)=($ IB (t/4Sz)|, (5.16)
где z — любая строка, быть может, пустая.
В формуле (5.16) фигурные скобки — обозначение множества, вертикальная черта «|» отделяет обозначение элементов определяемого множества (элементы обозначены S) от условия, которому они должны удовлетворять. Запись ЗА — квантор существования— означает «существует А». Формула (5.16) читается так: «Множество L(U) состоит из элементов S, таких, что существует вывод U=$Sz>.
Используя знаки дизъюнкции V и конъюнкции Д, множество L(U) можно определить рекурсивно:
L(U) = [S\B(U-»Sz) V 3 (С/AS е £(£/'))}. (5.17)
Аналогично обозначим R(U) множество самых правых символов относительно нетерминального символа U. Формально
/?({/) = {S|3(6/4zS)| (5.18)
или
7?(t7)={S|3(C/->*S)V3(C/->z'C/'A 5еЯ(С/'))). (5.19)
Определения (5.17) и (5.19) удобнее для практического отыскания множеств L(U) и /?([/), которые используются для выявления отношений предшествования по следующим правилам (знак •*-*• читается «если и только если»):
1. S< = S,«-* 3 (U -> xStSjy). (5.20)
2. St <Sl^3(U-^xSiDy) /\SteL(D). (5.21)
3. S, > S, ++ 3 (U -> xCS/y) A S, e /? (C)
V 3 (U -> xCDy) (D). (5.22)
235
Здесь С и D — нетермйнальные символы, ахи у — любые строки, быть может, пустые.
‘ Пример 1. Найти.множества L(U) и R(U) для грамматики Gi, определяемой правилами:
П~>± В± в -> т в -> в + т Т -> М . (5.23)
Т -> ТХМ М-> И М-> (В)
* Решение. Нетерминальные символы грамматики Gi: П, В, Т, М. Множества L(U) и R(U) нужно построить только для этих символов. Это можно сделать так.
1. Для каждого нетерминального символа U отыскиваются все правила, содержащие U в левой части. В L(U) включается самый левый символ правой части каждого такого правила, а в R(U)—; самый правый символ. В результате получается табл. 5.2.
Таблица 5.2
МНОЖЕСТВА L(U) И R(U) ИА ШАГЕ 1
и L(U) в (и)
п 1 1»
в Т, В т- :
т М, 7 И
м и, ( и, )
Таблица 5.3
МНОЖЕСТВА L(U) И R (U) НА ШАГЕ 2
и L(U) ff (и)
п 1 1
в Г, 8, М г, м
т М, т, и, .( . М, И, )
м И, ( И, )
2. Просматривается каждое полученное множество. Если множество L(U) содержит нетерминальные символы (/', [/", ..., то это множество дополняется символами, входящими в L(U')„ L(U"), ... и не входящими в L(U). Аналогичным образом дополняется множество R(U). В результате получается табл. 5.3.
•’ 3. Выполнение пункта 2 повторяется до тех пор, пока множества L(U) и R(U) не перестанут изменяться. В результате получается таблица, содержащая искомые множества.
Таблица 5.4
МНОЖЕСТВА L(U) И R(U) (ОКОНЧАТЕЛЬНАЯ ТАБЛИЦА)
и L (If) Ш '
п 1 1
в т, В, М, И, ( 7, М, И, )
т И, 7, И, ( М, И, )
м И, ( И, )
236
Грамматика Gi не является грамматикой' предшествования, поскольку из (5.20) и (5.23) следует:
(—В и + = Т,
а, с другой стороны, из (5.21), (5.23) и табл. 5.4 вытекает, что «Ви + <• Т, *
т. е. отношения предшествования для пар символов [(, В] и [+, Т] неоднозначны.
Вообше говоря, неоднозначность отношений предшествования, встречающаяся в грамматиках языков программирования, следствие того, что для выделения основы в методе предшествования используется минимальный контекст: Сравниваются лишь пары символов. Для устранения нёоднозначности, если’ она появляется, нужно либо изменить грамматику (подробнее об этом будет сказано ниже), либо использовать более далекий контекст. Так, оче-вйдно, в контексте
(В) и В + Т + ...
справедливо соответственно
(=В и + = Т,
поскольку возможны прямые редукции В к М и B -J-T к В, а в контексте
(В + Т) и ... +тхм,
напротив, справедливо
«Ви + <Т соответственно, ввиду того что здесь нужно выполнить прямые редукции В + ТкВиТХМкТ.
В данном конкретном случае формально неоднозначность отношений предшествования вытекает из того, что, с одной стороны, символы (и В, а также + и Т встречаются в правых частях правил (5.23) рядом, а с другой стороны, BeL(B) ri TeL(T). Если устранить рекурсивность множеств L(B) и £(Т) относительно В и Т соответственно, то рассматриваемая грамматика станет грамматикой предшествования.
Для преобразования грамматики Gi в грамматику предшествования заменим в (5.23) правила
В->Т
В->В + Т
В ->В' В'->Т В' -> В' + т,
Т->М
т->тхм
правилами
а правила
правилами
Т'->М Т'-»Т'ХМ.
237
Новая грамматика G{ определяется правилами П ->1В1 В -*В' В'-*Т В'-*В'+Т Т -*Т' Т'->М Т'->Т'ХМ м-*и М->(В)
(5.24)
1
и, как будет показано, является грамматикой предшествования.
Отношения предшествования удобно записывать. в.виде матрицы предшествования, представляющей собой таблицу с двумя входами. Входами в таблицу являются предшествующий ($<) и последующий (Sj) символы приводимой строки, а в ее клетках записываются отношения предшествования.
Пример 2. Составить матрицу предшествования для грамматики G{.
Решение.
1. По методике, описанной в примере I, для всех нетерминальных символов грамматики G[ находим множества L(U) и R(U).
Таблица 5.5
МНОЖЕСТВА L(t/) И Я(У) ДЛЯ ГРАММАТИКИ О[
2. Составляем матрицу предшествования:
А. Отношения = отыскиваем по правилу (5.20) непосредственным просмотром правых частей порождающих правил (5.24). Символы, стоящие в правой части рядом, связаны отношением =ь.
Б. Отношения < отыскиваем по правилу (5.21) путем просмотра правых частей порождающих правил (5.24) с использованием табл. 5.5, содержащей описания множеств L(D). Например, из правил Т'-*Т'ХМ и L(M) = {И, (} следует Х<И и Х< (•
В. Отношения •> отыскиваем по правилу (5.22) путем просмотра правых частей порождающих правил с использованием табл. 5.5, содержащей описания множеств L(D) и R(C).
238
В результате выполнения этого алгоритма получается матрица предшествования, приведенная в табл. 5.6. Назначение первого столбца и первой строки этой таблицы разъясняется в следующем пункте. Напомним, что пустые клетки в табл. 5.6 соответствуют парам символов, которые не могут стоять рядом ни в одной синтаксически правильной сентенциальной форме.
Таблица 5.6 МАТРИЦА ПРЕДШЕСТВОВАНИЯ И ФУНКЦИИ ПРЕДШЕСТВОВАНИЯ ДЛЯ ГРАММАТИКИ в'
4 4 3 3 3 2 2 2 1 / 7
( И м X т1 Т В' ) в 1
4 ) •> •> •>
4 И > ’>
4 и
3 X ♦
3 т' •
3 т •>
2 <• •
2 в' •
1 В ♦ •
1 ( * <• <• <• •
/ 1 <• <• <• <• •
5.3.5. ФУНКЦИИ ПРЕДШЕСТВОВАНИЯ
В реальных языках программирования число символов грамматики бывает довольно велико. В таких языках, как Алгол-60, Фортран, ПЛ/1, Кобол, общее число символов 200—500. Среди них 50—300 терминальных символов. Например, в Алголе-60 всего 226 символов, из них 116 — терминальные. Некоторые символы можно исключить, если на этапе лексического анализа собрать идентификаторы и числа (см. 4.2), а также отбросить неиспользуемые правила. Даже после таких упрощений в Алголе-60 остается не менее 70 символов. Поэтому матрица предшествования на практике может быть велика (для Алгола-60 не менее 70 X 70 = 4900).
Обычно матрицу предшествования хранят в «упакованном» виде: по 2 бита на элемент матрицы. Но и в упакованном виде матрица предшествования занимает достаточно много места. Например, при 45-разрядной ячейке машины М-220 для хранения
239
упакованной, матрицы размером 70X70 потребуется 223 ячейки. Кроме того, работа с упакованной матрицей требует выполнения дополнительных операций «распаковки», увеличивающих время трансляции.
Чтобы устранить эти недостатки, Р. В. Флойд уже в ранней работе по методам предшествования [45] предложил ввести две целочисленные функции предшествования f(Si) и g(Sj), такие, что:
f(5i) = g(S/)^Si = S/;
f(Si)<g(S/)^SJ<.S/; (5.25)
Такие функции существуют не всегда, но существование их гарантировано, если путем перестановки строк и столбцов матрицу предшествования можно представить так, чтобы она разделялась на три области, каждая из которых содержит отношения только одного типа (рис. 5.17).
Рис. 5.17. Структура матрицы предшествования, гарантирующая существование функций предшествования
Найдены также более сложные необходимые и достаточные условия существования функций предшествования [50].
Матрица предшествования в табл. 5.6 представлена именно так, как показано на рис. 5.17. В первом столбце и первой строке этой матрицы выписаны значения функций предшествования. Эти значения вычислены в приводимом ниже примере.
Для отыскания значений функций предшествования предложено несколько алгоритмов [45, 50, 55]. Наиболее прост самый ранний из «их — итеративный алгоритм Р. В., Флойда [45]. Этот алгоритм либо находит функции предшествования, либо устанавливает, что они не существуют. Рассмотрим его на примере.
Пример. Найти функции предшествования для грамматики Gf.
Решение. При решении используется вычисленная заранее матрица предшествования (табл. 5.6). Ход решения показан в табл. 5.7. Алгоритм состоит в следующем.
1. Положить f (S,) = g(Sj) = 1, i, / = 1, ..., m.
2. Просмотреть каждую строку матрицы предшествования, начиная с первой. Если S,-> Sj, a f(Si) g(Sj), то положить
f(Si) = g(S/)4-l.
240
3. Просмотреть каждый столбец матрицы предшествования, начиная с первого. Если Si <Sj, a f(S<) ^g(Sj)f то положить .,
g (Sj) == f (S<) +1.
4. Просмотреть все позиции матрицы предшествования. Если Si = Sj, a f(Si) g(Sj)f то положить
f(Sf) = g(Sy) = max{f(Sa, £(SZ)|,
т. е. сделать значения обеих функций равными большему из них.
5. Повторять выполнение пунктов 2, 3 и 4 до тех пор, пока не будут найдены функции, удовлетворяющие (5.25) (значения функций f и g перестанут изменяться), или пока значение одной из функций не превзойдет величину 2m.
В первом случае задача решена, а во втором — установлено, что для данной грамматики функции предшествования не существуют.
Таблица 5.7
ВЫЧИСЛЕНИЕ ФУНКЦИЙ ПРЕДШЕСТВОВАНИЯ ДЛЯ ГРАММАТИКИ
Номер итерации $1 или SJ ( И M X T' T + B' ) В 1 9 Пояснения t
0 W ./ 1 1 1 1 1 1 1 1 1 1 Пункт 1
9 (SP 1 1 1 1 1 i 1 1 1 1 1 1
1 1 2 2 1 • 2 2 1 2 2 1 1 Пункт 2 Пункт 3
g(sj) 2 2 2 1 2 2 1 2 1 1 1
W 1 2 2 2 2 2 2 2 2 1 1 Пункт 4
2 2 2 2 2 2 2 2 1 1 1
2 f(Si) 1 3 3 2 3 3 2 2 3 1 1 Пункт 2 Пункт 3
g(Sj-) 3 3 3 2 3 2 2 2 1 1 1
1 3 3 3 3 3 2 2 3 1 1 Пункт 4
9(Sj) 3 3 3 3 3 2 2 2 i • 1 9
3 fW 1 4 4 3 3 3 2 2 4 Пункт 2 Пункт 3
9 (sj> 4 4 3 3 3 2 2 2 4 r 1 1
1 4 4 3 3 3 2 2 4 1 1 Пункт 4
9(Sj) 4 4 3 3 3 2 2 2 7 1 1
4 /(V 1 4 4 3 3 3 2 2 4 1 1 Значения Функций 9 ч h не изменяются — задача решена
9W 4 4 3 3 3 2 2 2 7 1 1
1 4 4 3 3 3 2 2 4 1 1
9(Sj) 4 4 3 3 3 2' 2 2 1 1 1
241
Использование функций предшествования сокращает потребность в памяти с т2 до 2т величин. Правда, для хранения значений функций предшествования недостаточно двух бит, но доступ к значениям функций предшествования значительно проще, чем к элементам матрицы предшествования. Надо отметить, что использование функций предшествования приводит к «исчезновению» пустых позиций матрицы предшествования, позволяющих осуществлять контроль несовместности символов. Поэтому при использовании функций предшествования нужно либо проводить предварительный синтаксический контроль, либо пользоваться дополнительной матрицей сочетаемости (см. п. 4.2.5), элемент которой равен 1, если пара символов сочетаема, и равен 0 — в противном случае. При хранении в упакованном виде матрица сочетаемости вдвое меньше матрицы предшествования.
5.3.6. ТРАНСЛЯТОР
' Транслятор для входного языка, порождаемого грамматикой предшествования, можно построить по классической схеме (рис. 5.18), в которой четко выделяются три части:
лексический анализатор;
распознаватель (синтаксический анализатор); генератор (семантический анализатор).
Лексический анализатор переводит программу на стандартный входной язык распознавателя (см. 4.2). В частности, здесь обычно идентификаторы и числа собираются из отдельных знаков (букв, цифр).
Распознаватель решает задачу разбора. Алгоритм распознавателя для грамматики предшествования был описан в п. 5.3.3. В процессе синтаксического анализа распознаватель использует матрицу предшествования (или функции предшествования) и таблицу порождающих правил грамматики входного языка. Каждая запись этой таблицы содержит одно из порождающих правил и (для некоторых правил) имя семантической подпрограммы, которую нужно выполнить, когда это правило применяется для редукции. Результат работы распознавателя — разбор входной программы.
Генератор получает на вход разбор и, используя семантические подпрограммы, отвечающие примененным при разборе правилам, генерирует машинные команды или предложения другого выходного языка.
Возможны две схемы работы транслятора. Первая схема использует блочный принцип, при котором части транслятора вызываются в последовательности: лексический анализатор, распознаватель, генератор. Каждая часть обрабатывает всю программу от начала до конца и только после этого работает следующая часть.
Во второй схеме используется принцип подпрограмм, когда все части транслятора работают совместно, каждый очередной выходной символ лексического анализатора немедленно обрабатывается 242
распознавателем, а каждый элемент разбора, если нужно, тут же вызывает требуемую семантическую подпрограмму генератора.
Первую, схему применяют, когда все части транслятора одновременно не умещаются в быстрой памяти машины, а вторую — когда весь транслятор можно разместить в быстрой памяти. На практике обе схемы часто комбинируют. Например, вначале работает только блок лексического анализа, а затем — блок, объединяющий распознаватель и генератор и построенный по схеме подпрограмм.
Описываемый транслятор можно использовать для перевода с любого входного языка, грамматика которого является грамма-
Рис. 5.18. Схема транслятора, основанного на методе предшествования
тикой предшествования. Для этого нужно прежде всего стандартизировать лексику входных языков, т. е. правила записи служебных слов, идентификаторов и констант, а также алфавит. Тогда алгоритм лексического анализатора будет определяться только особенностями устройств, применяемых для подготовки и ввода программ, и принятым стандартным входным языком распознавателя. Алгоритм распознавателя универсален в классе грамматик предшествования. Алгоритм генератора предельно прост — генератор вызывает требуемую семантическую подпрограмму и передает ей аргументы, определяемые элементом разбора.
Синтаксис входного языка задается таблицей порождающих правил. Используя эту таблицу, матрицу предшествования можно построить автоматически по правилам, описанным в 5.3.4. Семантика входного языка в терминах выходного языка отражена в семантических подпрограммах, которые составляются вручную. Если
243
изменяется только входной язык, то нужно изменить лишь эти подпрограммы. Если изменяется входной язык, то нужно изменить таблицу порождающих правил, матрицу предшествования и семантические подпрограммы.
В принципе описываемый транслятор пригоден для перевода с нескольких входных языков, грамматики которых — грамматики прёдшествования, на несколько выходных языков. Транслятор, переводящий с М входных языкбв на N выходных, должен иметь М экземпляров таблиц порождающих правил и матриц предшествования* и Л4ХЛ/ наборов семантических подпрограмм. Однако за универсальность транслятора в классе грамматик предшествования приходится платить сравнительно невысокой эффективностью алгоритмов трансляции. В этом можно убедиться на рассматриваемом ниже примере.
Рассмотрим применение метода предшествования при переводе в обратную польскую запись предложений языка, порождаемого грамматикой G{; которая определена правилами (5.24). Чтобы язык был более реалистичным, будем считать, что в качестве идентификатора в языке может использоваться любая строчная буква латинского алфавита. Каждая’ такая буква воспринимается распознавателем как идентификатор И.
Составим таблицу порождающих правил, дополнив ее семантическими подпрограммами для перевода в обратную польскую запись (табл. 5.8).
Таблица 5.8
ТАБЛИЦА ПОРОЖДАЮЩИХ ПРАВИЛ ГРАММАТИКИ
Номер правила Порождающее * правило ^Сем штическая подпрограмма для перевода в обратную польскую запись
1 п ->1В1
2 в- ->В'
3 Bz ->т
4 В' ->В' +т Занести символ «+» в выходную строку
5 т- ->Т'
6 Г ->м
7 Т' ->Т'ХМ Занести символ «X» в выходную строку
8 м ->и Занести идентификатор в выходную строку
9 м ->(В)
244
Пример. Иёпользуя распознаватель предшествования, таблицу порождающих' правил и семантических * подпрограмм (табл. 5.8), а такэйе Матрицу предшествования (табл. 5.6), перевести в обратную польскую запись выражение
а + АХ^- (5.26}
Решение показано в табл. 5.9. В соответствии с алгоритмом распознавателя для грамматики предшествования (п. 5.3.3) символы входной строки переписываются в стек распознавателя до тех пор, пока между верхним символом в стеке и очередным символом входной строки не появится отношение >. Тогда выделяется основа, заключенная между < и >, выполняется редукция и, если нужно, семантическая подпрограмма.
Процесс синтаксического анализа прекращается при появлении во входной строке концевого символа _L. Выписав элементы из столбца «Запись в выходную строку» в порядке их появления, получим требуемую обратную польскую запись
айсХ+. (5.27)
Таблица 5.9
ТРАНСЛЯЦИЯ ВЫРАЖЕНИЯ МЕТОДОМ ПРЕДШЕСТВОВАНИЯ
Запись 6 выходную строку Стек распознава теля Отношение пр ед шест -Сования Входная строка номер правила Семантическая подпрограмма
ь 1 а+в*с1. — _1 Ш
ь * + 6хС 1 8 выходная строка
. а 6хС J. 6 —
т' + в*с 1 5
’ я т +6*с 1 3 в»
1<.в' • 1 — II
1 в'± в*с JL
хс 1 8 И^выходная строка
6 в[+м хС J. 6 II
1 . 1 в'+ Г < =<• • xf jl —• —-
1< С Л —• мм.
1 в'* г'х с < == < = <• 1 8 Исходная строка
с 1 в'_+т\х 1 7 ^выходная строка
X 1 в'^т' 1 5
1 1 4 +^выходная строка
+ • 1 в' 2 II
1 в • "« 1 1
п •
245
Объединение в каждой строке табл. 5.9 содержимого стека и необработанной части входной строки дает элемент разбора. Последовательность таких элементов образует разбор:
I а 4- &Х с X 1М + *Хс± ±Т' + &Хс± J.T + &XC1 X В' + 6Хс1 X B' + MXcJ-X B' + T'Xd X В' 4-Т'ХМ
(5.28)
П
Если последовательно выписать символы, записываемые в ходе анализа в стек распознавателя, и при успешном разборе дополнить полученную строку парой символов X П, то получится строка (запятые используются как разделители)
1, а, М, Г, Т, В', +, b, М, Г, X, с, М, Г, Т, В', В, X, П, (5.29) которая представляет собой обратную польскую запись разбора, полученную обходом дерева разбора (рис. 5.19). Строку (5.29) можно записать короче, если заменить в ней нетерминальные символы номерами правил, применяемых для их получения. При этом целесообразно сохранить лишь номера тех правил, которым соответствуют семантические подпрограммы:
1, а, 8, +, Ь, 8, X» с, 8, 7, 4.
Запись разбора в таком виде поступает на вход генератора (см. рис. 5.18).
Заметим, что распознаватель для грамматики предшествования дает канонический разбор. Всего полный разбор (5.28) содержит 13 элементов, считая исходное выражение и начальный символ грамматики П.
Выражение (5.26) является частью выражения
а 4- b X с — d/(a 4- b),
перевод которого в обратную польскую запись с использованием стека с приоритетами показан в табл. 4.6 (п. 4.3.3, пример 1). Это дает возможность приближенно оценить сравнительную эффективность метода предшествования и метода стека с приоритетами. При использовании стека с приоритетами обратная польская запись
246
(5.27) получается за 6 шагов, а в методе предшествования —за 15 (кроме того, еще два шага завершают разбор). Правда, в методе предшествования три шага выполняются только для выделения идентификаторов (а, Ь, с). При использовании стека с приоритетами тоже приходится выделять идентификаторы (операнды), но
эти действия не выделены в отдельные шаги. Однако и после исключения шагов, выделяющих идентификаторы, в методе предшествования остается 12 шагов — вдвое больше, чем в методе стека с приоритетами. Большая часть шагов в методе предшествования требует выполнения редукций. Перед каждой редукцией нужно найти правило, правая часть которого совпадает с основой. Это требует выполнения дополнительных операций поиска правила.
Из сказанного можно сделать предварительный вывод, что для языков типа Алгол-60 метод предшествования работает
Рис. 5.19. Дерево раэбора
медленнее метода, основанного на стеке
с приоритетами. Это — плата за универсальность и простоту алго
ритма.
5.3.7. РАСШИРЕННОЕ ПРЕДШЕСТВОВАНИЕ
Практическое применение метода предшествования затрудняется неоднозначностью отношений предшествования, которая часто встречается в грамматиках реальных языков программирования. Даже в очень простой грамматике арифметических выра-“жетий*б1 (п. 5:3.4,- пример 1) отношения предшествования неоднозначны;
Общего алгоритма приведения грамматики к грамматике предшествования нет, однако существуют алгоритмы, позволяющие в большинстве случаев устранить конфликты предшествования [39, 10]. Недостаток этих алгоритмов состоит в том, что они обычно не гарантируют сохранения единственности правых частей порождающих правил модифицированной грамматики. Кроме того, после модификации грамматика, как правило, сильно расширяется и становится непригодной для использования программистом.
По этим причинам метод предшествования в чистом виде не нашел применения в трансляторах. На практике иногда используют расширенное предшествование, сущность которого состоит в использовании контекста для устранения неоднозначности отношений предшествования. Об этой возможности упоминалось в п. 5.3.4.
Основная идея расширенного предшествования состоит в следующем. Пусть между символами S, и Sz+i существуют отношения
S/<Sy+1 и SZ = S/+I
247
и требуется определить, какое именно отношение нужно взять в контексте
• • • + +2 • • •
Если справедливо первое отношение (<) и грамматика однозначна, то должно существовать порождающее правило, правая , часть которого начинается символами Sj+iSj+2- Если такого правила нет, то нужно взять второе отношение (==).
Аналогичные рассуждения можно провести и в других случаях неоднозначности.
В соответствии с этой общей идеей для устранения неоднозначности отношений предшествования между парами символов используют тройки символов. На рис. 5.20 показан случай, когда на обоих концах предполагаемой основы имеются конфликты предшествования, причем символы Sk-.i ... S/ находятся в стеке распознавателя, a St — очередной символ входной строки.
... = = •> $£..•
... — ' V * 1
Стек распознавателя I
Рис.. 5.20., Конфликты предшествования на концах предпо- • лагаемой основы .. .
Для выделения правого конца основы заранее заготавливают тройки S1S2S3, такие, что S1S2 — символы, которыми заканчивается правая часть какого-либо порождающего правила, а S3—.символ, образующий с S2 конфликтную пару S2^S3 или S2^S3. Если S(-iSjSj = S1S2S3, то справедливо отношение >, иначе справедливо отношение = или <5.
Для выделения левого конца основы заготавливают тройки S1S2S3, такие, что S2S3 — символы, которыми начинается правая часть какого-либо порождающего правила, a SJ — символ, образующий с S2 конфликтную пару S{ S2. Если Sfe_iSkSk+i = SJS2$3, то справедливо отношение <, иначе справедливо отношение =’
Естественно, этот метод применим, если использование троек устраняет неоднозначность отношений предшествования. В противном случае нужно привлечь еще более далекий, контекст.
Если конфликты предшествования становятся нормой, то для записи элемента матрицы предшествования уже недостаточно двух бит. Здесь нужно либо записывать каждый элемент матрицы предшествования тремя битами, либо использовать две матрицы с двухбитовыми элементами, одну для выделения правого конца основы, а другую — для левого. В обоих случаях нужно заготовить также две таблицы троек: таблицу правых троек для устранения неоднозначности на правом конце предполагаемой основы и таблицу левых троек для устранения неоднозначности на левом конце.
248
Если N — число нетерминальных символов грамматики, а Т — число терминальных символов, то объем матрицы предшествования для левого конца основы равен (W 4- T)X(N. + Г), а для правого— (N + Г)ХЛ поскольку входная строка состоит только из терминальных символов.
Следовательно, общий объем двух двухбитовых матриц равен
2(N + T)X(N + 2Т) бит, в
а объем одной трехбитовой матрицы —
3(М+Т)Х (М + Т)бит.
Отсюда можно заключить, что при N > Т выгоднее иметь две двухбитовые матрицы, а при N <ZT — одну трехбитовую.
Метод расширенного предшествования с двумя матрицами объемом 90 X 45 и 90 X 90 применялся В. Н. Маккиманом в компиляторе для диалекта языка ПЛ/1 на одной из машин серии ИБМ/360 [10, 31]. Дополнительно использовались таблицы, содержащие 450 троек.
г Пример. Составить матрицу предшествования и таблицы правых и левых троек для грамматики Gi, определенной правилами (5.23).
Решение!. По методике, описанной в примере 1, п. 5.3.4, составить множества L(U) и R(U) (см. табл. 5.4).
2. По методике, описанной в примере 2, п. 5.3.4, составить матрицу предшествования (табл. 5.10).
3. Составить таблицу правых троек:
а) просмотреть матрицу предшествования и найти пары символов S2S3, для которых существует отношение >, причем отношения предшествования неоднозначны;
б) для каждой пары, выделенной в пункте (а), просмотреть столбец S2 матрицы предшествования и найти все символы Si, связанные с символом S2 отношением Si = S2;
в) просмотреть порождающие правила. Если существует npzr вило, правая часть которого заканчивается парой 515г, то тройка S1S2S3 должна быть включена в таблицу правых троек.
Однако если одновременно существует правило, в правой части которого символы Si, S2 и S3 стоят рядом, то применение троек не устраняет неоднозначности. Для такой грамматики метод расширенного предшествования неприменим. . .
В рассматриваемом примере матрица предшествования не содержит конфликтов предшествования с отношением •>, поэтому таблицу правых троек составлять не нужно.
4. Составить таблицу левых троек:
а) просмотреть матрицу предшествования и найти пары символов S1S2, для которых существует отношение S[ <5 S2, причем отношения предшествования неоднозначны;
249
Таблица 5.10
МАТРИЦА ПРЕДШЕСТВОВАНИЯ ДЛЯ ГРАММАТИКИ G(
в т м 1 4- X и ( )
в • • •
т •> • •>
м •> •> >
1
к •
и •> •> •>
(
) •>
б) для каждой пары, выделенной в пункте (а), просмотреть строку S£ и найти все символы S3, связанные с символом S£ отношением S2 = S3;
в) просмотреть порождающие правила. Если существует правило, правая часть которого начинается символами S2S3, то тройка S-S>S.; должна быть включена в таблицу левых троек.
Однако если одновременно существует правило, в правой части которого символы S(, S2 и S3 стоят рядом, то применение троек не устраняет неоднозначности. Метод расширенного предшествования в этом случае неприменим.
В нашем примере в пункте (а) выявляются три конфликта предшествования:
1 В, + “ Т и (“ В.
В пункте (б) находим:
В=±, В = + и В =), а также
Т=Х-
Наконец, в пункте (в) обнаруживаем порождающие правила, начинающиеся символами В-|- и ТХ> поэтому получаем следующую таблицу левых троек:
±в +
(В +
4-ТХ
Задача решена.
5.3.8. РАСПОЗНАВАТЕЛЬ РАСШИРЕННОГО ПРЕДШЕСТВОВАНИЯ
Распознаватель расширенного предшествования работает почти по той же схеме, что распознаватель предшествования, описанный в п. 5.3.3. Однако ввиду возможных конфликтов предшествования дополнительно используются таблицы правых и левых троек.
250
Блок-схема распознавателя показана на рис. 5.21. На блок-схеме использованы следующие обозначения:
S — идентификатор массива, являющегося стеком распознавателя;
I — указатель стека распознавателя (номер последней записи в стек),
/—номер символа внутри стекла (при обратном просмотре).
Р—идентификатор массива, содержащего входную строку;
i — номер очередного символа входной строки;
С — вспомогательная простая переменная, используемая для хранения очередного символа входной строки;
R — вспомогательная переменная, используемая для хранения значений отношений предшествования;
— какая-либо тройка символов из таблицы правых троек;
S1S2S3—какая-либо тройка символов из таблицы левых троек;
U — левая часть порождающего правила.
Предполагается, что приводимая входная строка начинается и заканчивается концевыми знаками ±. Первый элемент входной строки, отличный от ±, находится в Р [1].
Дополнительное условие / < / проверяется в блоке 12 потому, что при j = I стек не содержит элемента S [j + 1]. В этом случае заведомо не существует левая тройка.
Пример. Используя распознаватель расширенного предшествования, матрицу предшествования (табл. 5.10) и таблицу левых троек (5.29). привести к начальному символу строку
а + ЬХс.
Решение показано в табл. 5.11.
Таблица 5.11
ПРИМЕР РЕШЕНИЯ ЗАДАЧИ РАЗБОРА МЕТОДОМ РАСШИРЕННОГО ПРЕДШЕСТВОВАНИЯ
Раэбор Примечание
1 <•£•>+ В к с 1 буква Воспринимается как идентификатор-~И
!<•«•> + 6 х cl
1 <• т > + 8 х с 1
1 «5=+<0>х С 1
1 J « =+<•«•> х с 1
1<. e=+jr = x<c>l -
1^Я = +^г=х=и>-1 Существует тройка + Т *
1. В стене неполная тройка (У-б), поэтому нужно принять + ±Т 2. Существует тройка -1-5 +
* Концевой символ ± прекращает анализ, поскольку существует правило Л-~1В1. - разбор получен.
251
Метод расширенного предшествования позволяет обойтись без существенного изменения исходной грамматики. Недостатком является большой объем постоянных таблиц.
Возможен вариант метода расширенного предшествования, в котором определяется только правый конец основы. Для этого ис-
Рис. 5.21. Блок-схема распознавателя расширенного предшествования
пользуется одна двухбитовая матрица размером (АГ + Т)\Т и дополнительная таблица правых троек. После появления отношения > между верхним символом стека и очередным символом входной строки для выделения основы правые части всех порождающих правил непосредственно сравниваются с верхними символами стека. Сначала сравниваются более длинные правые части. Этот
252
вариант метода расширенного предшествования позволяет обходиться таблицами меньшего объема, однако возрастает время поиска в таблице порождающих правил..
5.4. ОПЕРАТОРНОЕ ПРЕДШЕСТВОВАНИЕ
5.4.1. ГРАММАТИКА С ОПЕРАТОРНЫМ ПРЕДШЕСТВОВАНИЕМ
В компиляторах часто применяют ранний вариант метода предшествования — метод операторного предшествования, предложенный в 1963 г. Р. В. Флойдом [45]. Этот метод применим только к грамматикам с операторным предшествованием.
Пусть а и b — терминальные символы, U, С и D — нетерминальные символы, х, у и z — любые строки, в том числе пустые.
Грамматикой с операторным предшествованием (operator precedence grammar) называют грамматику класса 2 по Хомскому, в которой:
1. Правые части порождающих правил не содержат рядом •стоящих нетерминальных символов, т. е. в грамматике нет правил вида
U-+xCDy.
Грамматику, обладающую таким свойством, называют операторной грамматикой.
2. Для каждой упорядоченной пары терминальных символов а я b выполняется не более чем одно из трех отношений, предшествования, определяемых так:
А. а ~ Ь, если и только если существует правило
U —► xaby или правило
U хаСЬу.
Б. а < Ь, если и только если существует правило
U ->хаСу
и вывод С bz или вывод С =ф Dbz.
В. а > &, если и только если существует правило
U -► хСЬу
й вывод C=$za или вывод C=$zaD.
3. Различные порождающие правила имеют разные правые части.
Первое из приведенных требований позволяет ограничиться установлением отношений предшествования только для терминальных символов. Это значительно сокращает размер матрицы предшествования и повышает эффективность алгоритма разбора по сравнению с методом предшествования.
253
В то же время класс грамматик, для которых существует операторное предшествование или которые можно привести к грамматике с операторным предшествованием, достаточно широк. В частности, грамматики реальных языков программирования, или по крайней мере их части, почти всегда можно привести к грамматике с операторным предшествованием.
Второе и третье требования, как и аналогичные требования к грамматике предшествования, обеспечивают «беступиковость» алгоритма разбора. Строго говоря, перечисленные требования не гарантируют однозначности алгоритма разбора. Это будет видно из дальнейшего. Однако характер возможных неоднозначностей таков, что они без особого труда устраняются семантическими подпрограммами.
5.4.2. РАСПОЗНАВАТЕЛЬ
Алгоритм разбора использует только отношения терминальных символов и отыскивает для редукции не основу, а так называемую первичную фразу.
Первичная фраза — это фраза, не содержащая никакой другой фразы, кроме самой себя, и содержащая по крайней мере один терминальный символ.
Пример. Сентенциальная форма грамматики Gi
1 Т4-ТХМ1
имеет дерево раэбора, показанное на рис. 5.22.
- Рис.-&22.-гДерево, разбора
Первичная фраза здесь ТХМ, в то время как основой является самый левый символ Т. Очевидно, выделение вместо основы первичной фразы приводит к неканоническому разбору. Из свойств грамматики с операторным предшествованием следует, что если х — первичная фраза, то либо существует порождающее правило
U-+X,
либо существует порождающее правило
U-*x'
и вывод х =$х, в котором применяются только порождающие правила вида где U{ и Uj— нетерминальные символы.
254
Алгоритм разбора отыскивает самую левую первичную фразу и состоит в следующем. Символы входной строки поочередно переписываются в стек до тех пор, пока между верхним терминальным символом стека ti и очередным терминальным символом входной строки ti не появится отношение > (именно ti > ti). Тогда стек просматривается в направлении от вершины к началу до тех пор, пока между двумя очередными терминальными символами стека /л-i и h не появится отношение < (именно tk-i<tk). Часть стека от символа tk-i, исключительно, до вершины стека, включительно, есть первичная фраза.
Входная строка
Входная строка
Ч *1+1 999
Вершина
-стена
Пербичнао ураза
б) После редукции
Ц-1
а) До редукции
Рис. 5.23. Стек и входная строка до и после редукции
Среди порождающих правил отыскивается правило £/->х,
(5.30)
правая часть которого (х) есть либо найденная первичная фраза, либо отличается от нее только нетерминальными символами. Именно в этом отличии заключена возможность неоднозначного разбора, отмеченная в предыдущем пункте.
Если нужно, вызывается семантическая подпрограмма, соответствующая правилу (5.30), которая обрабатывает строку х, переводя ее на выходной язык. Семантическая подпрограмма учитывает как терминальные, так и нетерминальные символы первичной фразы, поэтому в ней можно предусмотреть возможность устранения неоднозначности разбора.
Затем в стеке -строка х заменяется- символом* I/, и описанный выше процесс продолжается. Состояние стека и входной строки может быть, например, таким, как показано на рис. 5.23. Буквами
255
S обозначены нетерминальные символы, а буквами / — терминальные.
Если на некотором шаге процесса синтаксического анализа обнаружится, что между двумя последовательными терминальными символами tp и tq (которые могут быть разделены нетерминальным символом) не существует отношения предшествования, то это свидетельствует об ошибке типа: «конструкция tp ... tq недопустима».
Описанный алгоритм реализуется в трансляторе почти так же, как общий алгоритм метода предшествования (п. 5.3.6), но матрица предшествования получается гораздо меньших размеров (для Алгола-60 почти вчетверо).
5.4.3. МАТРИЦА И ФУНКЦИИ
ОПЕРАТОРНОГО ПРЕДШЕСТВОВАНИЯ
Для отыскания отношений операторного предшествования удобно ввести множество самых левых терминальных символов Lt(U) и множество самых правых терминальных символов Rt(U) относительно нетерминального символа U.
Пусть t — терминальный символ, х, у и z — любые строки, быть может, пустые, С — нетерминальный символ, L(U')—множество самых левых, a R(U')—множество самых правых символов относительно нетерминального символа U' (см. определения 5.16 и 5.18 в п. 5 3.4), тогда
Lt(U) = {t\3(U^tz) V 3 (U^Ctz)] (5.31)
или
Lt (U) = {/| 3 (U -> tz) V 3 (U -> Ctz) V (U' ^L(U) At Lt ([/'))}.
(5.32)
. Rt(U)= |/| 3(u4zt) V 3(U^ztC)} (5.33)
или
Rt (U) = {/1 3 (U->zt) V 3 (U-> ztC) V (U' g= R(U) A t g= Rt ((/'))}.
(5.34)
Формулы (5.31) и (5.33) являются определениями множеств Lt и Rt, а эквивалентные формулы (5.32) и (5.34) фактически определяют алгоритм отыскания множеств Lt и Rt.
Определения отношений операторного предшествования, введенные в п. 5.3.1, теперь можно записать так:
1. э (и -> хЩу) V 3 (U -> xtiCtjy). (5.35)
2. ti<ti^3(U^xtiCy) Atf^Lt(C). (5.36)
3. ti > tf 3 (U -> xCtfy) Ati<==Rt (C). (5.37)
Эти формулы удобнее для практического применения.
256
Пример. Найти матрицу и функции операторного предшествования для грамматики Gi:
П->± в± в->т В->В + т т->м Т->ТХМ м->и М->(В)
Решение. Нетерминальные символы грамматики G\: П, В, Т, М,
а терминальные —
1, +, X, и, (,).
Матрицу операторного предшествования можно найти в следующем порядке.
1. Для каждого нетерминального символа U грамматики G\ отыскиваются множества Lt(U) и Rt(JU). Для этого:
1.1. Отыскиваются множества L(U) и /?((7) (для грамматики Gi эти множества найдены в примере 1, п. 5.3.4 и приведены з табл. 5.4).
1.2. Для каждого нетерминального символа 1к
а) отыскиваются правила грамматики G\ с правыми частями вида tz и Ctz. Терминальные символы t фиксируются в качестве элементов множества Lt(U)\
б) отыскиваются правила с правыми частями вида zt и ztC. Терминальные символы t фиксируются в качестве элементов множества Rt(U).
В результате получается табл. 5.12.
Таблица 5.12
МНОЖЕСТВА Lt(U) И Rt(U) ПОСЛЕ ВЫПОЛНЕНИЯ ПЕРВОГО ШАГА АЛГОРИТМА
и Kt(V)
п 1 1
в +
J X X
м и,( )
1.3. Для каждого нетерминального символа U:
а) просматривается множество L(U) и отыскиваются входящие в него нетерминальные символы U', U", ... Затем множество дополняется символами, входящими в ...
и не входящими в Lt(U);
V2 9 Зак. 221 257
б) просматривается множество R(U) и отыскиваются входя-щие в него нетерминальные символы U', U" > ... Затем множество /?/({/) дополняется символами, входящими в Rt(U'}> Rt(U"), ... и не входящими в Rt(U)-
В результате получается табл. 5.13.
Таблица 5.13
МНОЖЕСТВА LAU) И R AU) (ОКОНЧАТЕЛЬНАЯ ТАБЛИЦА) ( I
и Lt{U)
п 1 1
в +» х > И,( +, X , И, )
т х ,И, ( и* )
и ( , и ), И
2. Составляется матрица операторного предшествования. Для этого просматриваются правые части порождающих правил грамматики Gj.
2.1. По правилу (5.35) определяются отношения—.
2.2. По правилу (5.36) с использованием табл. 5.13 определяются отношения <•.
2.3. По правилу (5.37) с использованием табл. 5.13 определяются отношения >.
Полученная матрица отношений операторного предшествования приведена в табл. 5.14.
Таблица 5.14
МАТРИЦА ОПЕРАТОРНОГО ПРЕДШЕСТВОВАНИЯ ДЛЯ ГРАММАТИКИ Gk
6 6 4 2 / 7
f(tl) ( и X 4 ) 1
5 ) •> •>
5 и •> •> •>
5 X
3 <• <• •> •>
1 ( <• <• <• •
1 1 <• <• <• _ •
Поскольку матрица операторного предшествования в данном случае имеет вид, показанный на рис. 5.17, существуют функции операторного предшествования f(ti) и определяемые, как и для грамматики предшествования, формулами (5.25). Значения этих функций, полученные по методике, изложенной в н. 5.3.5, также приведены в табл. 5.1ч.
258
5.4.4 ОСОБЕННОСТИ ТРАНСЛЯТОРА
Общая структура транслятора для языка, порожденного грамматикой с операторным предшествованием, не отличается от структуры транслятора для грамматики предшествования (см. рис. 5.18). Лексический анализатор тот же. Распознаватель также использует таблицу порождающих правил, а вместо матрицы предшествования —матрицу операторного предшествования или функции операторного предшествования. Генератор содержит набор семантических подпрограмм.
Небольшие отличия имеет алгоритм распознавателя и таблица порождающих правил. Дело в том, что, как отмечалось в п. 5.4.2, распознаватель для грамматики с операторным предшествованием редуцирует не основу, а самую левую первичную фразу, которая по определению содержит хотя бы один терминальный символ. Отыскивая эту фразу и выполняя редукцию, распознаватель не обращает внимания на нетерминальные символы приводимой первичной фразы. Нетерминальные символы учитываются только семантическими подпрограммами, если это необходимо. Поэтому порождающие правила, в правых частях которых имеются лишь нетерминальные символы, вообще никогда не используются распознавателем, и их можно не включать в таблицу порождающих правил распознавателя. В правых частях остальных порождающих правил все различные нетерминальные символы часто можно заменить одним символом, например символом У, обозначающим произвольный нетерминальный символ.
Фактически распознаватель для грамматики с операторным предшествованием без помощи семантических подпрограмм не может найти полный разбор входной строки. Он отыскивает лишь «сокращенный» разбор, в котором отсутствуют элементы, отличающиеся только нетерминальными символами. Следовательно,, этот распознаватель без привлечения семантических подпрограмм неспособен выполнить полный синтаксический контроль. Это делает метод операторного предшествования менее надежным, чем метод предшествования. Однако неполнота разбора имеет определенное преимущество: сокращаются объем таблицы порождающих пра* вил и число шагов трансляции, поскольку из разбора исключены шаги, редуцирующие части строки, состоящие только из нетерминальных символов.
В качестве примера в табл. 5.15 представлена таблица порождающих правил распознавателя применительно к грамматике G\. В таблицу не включены правила грамматики содержащие в правых частях только нетерминальные символы (правила В->Т и Т—>М), а в правых частях всех остальных правил нетерминальные символы заменены символами N. Кроме того, таблица дополнена семантическими подпрограммами для перевода арифметиче ских выражений в обратную польскую запись.
i/29*
259.
Таблица 5.15 ТАБЛИЦА ПОРОЖДАЮЩИХ ПРАВИЛ ГРАММАТИКИ
Номер правила Порождающее правило Семантическая подпрограмма для перевода в обратную польскую запись
1 П->1 N 1
2 B->W + W Занести символ «+» в выходную строку
3 T-*WXW Занести символ «X» в выходную строку
4 м->и Занести идентификатор в выходную строку
5
В приводимом ниже примере будем считать, что в качестве идентификатора в языке, порожденном грамматикой G\, может использоваться любая строчная буква латинского алфавита. Каждая такая буква воспринимается распознавателем как идентификатор (И).
Пример. Используя распознаватель для грамматики с операторным предшествованием, таблицу порождающих правил и семантических подпрограмм (табл. 5.15), а также матрицу операторного предшествования (табл. 5.14), перевести в обратную польскую запись выражение
а 4- b X с-
Решение показано в табл. 5.16. В соответствии с алгоритмом распознавателя для грамматики с операторным предшествованием, описанным в п. 5.4.2, символы входной строки переписываются в стек распознавателя до тех пор, пока между верхним терминальным символом в стеке и очередным терминальным символом входной строки не появится отношение >. В этот момент в стеке выделяется первичная фраза, заключенная между отношениями <• и •>, по таблице порождающих правил отыскивается правило, правая часть которого совпадает с первичной фразой с точностью до нетерминальных символов, затем выполняется редукция и, если нужно, семантическая подпрограмма.
Требуемая обратная польская запись исходного выражения получается, если прочитать записи в выходную строку сверху вниз:
abc X +.
Объединяя в каждой строке табл. 5.16 содержимое стека распознавателя и необработанную часть входной строки, получим эле-
200
Таблица 5.16
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ МЕТОДОМ ОПЕРАТОРНОГО ПРЕДШЕСТВОВАНИЯ
Запись в выходную строку Стек распознавателя Отношение предшествования Входная строка Номер правила Семантическая подрограмма
J а+вхсА. — —
а + вхс 1 4 #=» вых. строка
а 1 м + вхс А.
1 м + вхс А. ——
1 м +^в х с 1 4 И'Ф вых. строка
6 1 м + м х с 1 —
1 М + М х с 1
1 М + МХ^С 1 4 //=> вых. строка
с 1 М +(.м X м 1 3 х => вых. строка
X 1 <. М + т 1 2 + вых. строка
«Ц- 1 в • 1
1 А « = 1 1 _ ь
п — >»
менты «сокращенного» разбора:
(5.38)
Заметим, что «сокращенный» разбор содержит 7 элементов, считая исходное выражение и начальный символ грамматики П, в то время как полный разбор содержал бы еще три дополнительных элемента за счет применения правил вида Т->М и В—>Т.
Обратная польская запись в этом примере получается за 10 шагов, но, если исключить 3 шага, которые служат только для выделения идентификаторов, останется лишь 7 шагов. Напомним, что метод предшествования решает эту задачу за 12 шагов (если не считать шагов, выделяющих идентификаторы), а метод стека с приоритетами — за 6 шагов (см. п. 5.3.6). Следовательно^ по числу
Зак. 221 261
шагов метод операторного предшествования эффективнее общего метода предшествования и почти столь же эффективен, как и метод, основанный на стеке с приоритетами.
Если в методе операторного предшествования вместо матрицы предшествования использовать функции операторного предшествования, то обнаружится, что алгоритм этого метода при переводе в обратную польскую запись практически такой же, как в методе стека с приоритетами. Стек распознавателя играет здесь роль стека операций, функция f (ti), по существу, задает стековый приоритет ограничителей (терминальных символов), а функция задает сравнительный приоритет. Для полной аналогии можно ввести процедуру выделения операндов (идентификаторов и констант) до записи их в стек и особую процедуру обработки скобок, как это сделано в методе стека с приоритетами.
Следовательно, можно считать, что метод операторного предшествования есть обобщение метода стека с приоритетами для языков, порождаемых грамматиками с операторным предшествованием, а общий метод предшествования-—обобщение этих двух методов для языков, порождаемых грамматиками предшествования. Надо, однако, отметить, что грамматики с операторным предшествованием в общем случае не являются подмножеством грамматик предшествования. В самом деле, грамматика G\ является грамматикой с операторным предшествованием, но не грамматикой предшествования, хотя ее можно привести к эквивалентной грамматике предшествования G[.
Заметим, что отмеченные выше обобщения нетривиальны, поскольку, например, метод стека с приоритетами в чистом виде применим лишь в том случае, когда существуют функции операторного предшествования / (Л) и в то время как метод операторного предшествования применим в более общем случае, когда существует лишь матрица операторного предшествования, что не гарантирует, вообще говоря, существования функций операторного предшествования.
. Необходимо также заметить, что в чистом виде метод стека с приоритетами неприменим к языкам типа Алгол-60. Чтобы «подогнать» этот метод для трансляции условных операторов и операторов цикла, приходится вводить дополнительные переменные состояния и другие уточнения общего алгоритма (см. 4.4). Аналогичные замечания можно сделать и в отношении всех методов предшествования: некоторые особенности реального входного языка почти всегда приходится учитывать в семантических подпрограммах.
5.4.5. СРАВНИТЕЛЬНАЯ ОЦЕНКА МЕТОДОВ, ОСНОВАННЫХ НА ПРЕДШЕСТВОВАНИИ
Основное достоинство методов, основанных на предшествовании, простота алгоритмов распознавателя. Другое важное преимущество — наличие общих алгоритмов, позволяющих;
262
проверить, является ли грамматика грамматикой предшествования (или расширенного предшествования, или операторного предшествования);
отыскать отношения предшествования (операторного предшествования);
вычислить значения функций предшествования (операторного предшествования), если они существуют;
построить таблицы правых и левых троек для метода расширенного предшествования.
Существование таких алгоритмов дает возможность создать конструктор, автоматически составляющий распознаватель для любой грамматики предшествования (или расширенного предшествования, или операторного предшествования).
Однако при практическом построении и эксплуатации транслятора большое значение имеет не только простота алгоритма распознавателя, но также общий объем распознавателя, его быстродействие, простота приведения грамматики реального языка к грамматике со стандартными свойствами и возможность учета в распознавателе неформализованных особенностей языка.
В языках типа Алгол-60, Фортран, Кобол, ПЛ/1 число порождающих правил колеблется от 200 до 1000. Например, в эталонном Алголе-60 насчитывается 369 правил. Даже после исключения правил, которые не используются в реальных входных языках, в Алголе-60 остается 200—300 правил. Следовательно, таблица порождающих правил реального языка высокого уровня может быть достаточно велика. Таблица большого объема, с одной стороны, занимает много места в памяти, а с другой стороны, замедляет трансляцию за счет дополнительных операций поиска правила для редукции. Например, даже при двоичном поиске правила в таблице для Алгола-60 требуется не менее 9 сравнений (20—30 машинных операций). Относительно большой объем таблиц — недостаток всех методов, основанных на предшествовании.
Рассмотренные примеры показывают, что по быстродействию (числу шагов) метод предшествования значительно уступает методу операторного предшествования, хотя и в этом методе тратится много времени на поиск в таблицах. По этой причине оба метода работают сравнительно медленно. Метод расширенного предшествования при прочих равных условиях еще медленнее за счет дополнительного поиска в таблицах троек.
Здесь нужно сделать одно важное замечание. Реальное быстродействие транслятора в значительной степени зависит от того, удается ли разместить в оперативной памяти всю работающую в данный момент часть транслятора. По этой причине окончательно судить о быстродействии того или иного метода синтаксического анализа можно лишь применительно к конкретному транслятору для конкретной машины.
Большие неприятности при применении методов, основанных на предшествовании, причиняет неоднозначность отношений
9* 263
предшествования, поскольку надежных стандартных методов приведения грамматики к грамматике предшествования или к грамматике с операторным предшествованием пока нет. В этом отношен нии несомненное преимущество имеет метод расширенного предшествования, применимый к более широкому классу грамматик.
Неудобства возникают также из-за существования в реальных грамматиках порождающих правил с одинаковыми правыми частями. Например, в описании Алгола-60 [1] имеются правила:
(идентификатор переменной):: = (идентификатор), (идентификатор массива):: = (идентификатор), (идентификатор процедуры):: = (идентификатор).
Для устранения таких неоднозначностей приходится усложнять блок лексического анализа, что делает его зависимым от входного языка.
Чтобы учесть неформализованные особенности языка, целесообразно иметь возможность вызова семантических подпрограмм не только при выделении основы (или первичной фразы), но и при появлении некоторых символов. Такой возможности в методах, основанных на предшествовании, нет.
По этим причинам метод предшествования в чистом виде в реальных трансляторах не применяется, но он может найти применение в экспериментальных системах, используемых для отработки новых языков, а также в трансляторах для языков, специально приспособленных для анализа методом предшествования.
Метод расширенного предшествования, как упоминалось в п. 5.3.7, использовался на практике и, возможно, найдет дальнейшее применение благодаря меньшим, чем в других методах, требованиям к грамматике входного языка.
Метод операторного предшествования проще для реализации, чем другие методы, и имеет большее быстродействие, поэтому он часто применяется в компиляторах. Однако чаще всего его применяют в сочетании с другими методами для анализа отдельных конструкций языка (например, для арифметических и логических выражений).
Следует также упомянуть об одной модификации метода предшествования. Методы предшествования и операторного предшествования можно рассматривать как крайние случаи: в одном методе отношения предшествования устанавливаются между всеми символами грамматики, а в другом — только между терминальными символами. Теоретически разработан также «промежуточный» метод, в котором отношения предшествования устанавливаются между всеми терминальными символами и частью нетерминальных [36]. Это увеличивает гибкость метода, позволяя создавать распознаватель, использующий минимальное количество отношений предшествования, необходимых для эффективного анализа,
264
5.5. МАТРИЦА ПЕРЕХОДОВ
5.5.1. РАСШИРЕНИЕ ОПЕРАТОРНОЙ ГРАММАТИКИ
В 1959 г. К. Замельзон и Ф. Л. Бауэр предложили метод трансляции с языков высокого уровня [52], который вскоре нашел широкое применение в трансляторах Алгола-60 группы АЛКОР (группа западноевропейских и американских пользователей, принявшая в качестве входного языка единое подмножество Алгола-60). Появившийся позже метод стека с приоритетами Е. В. Дикстры (см. 4.3 и 4.4), по существу, был упрощенной модификацией этого метода.
Как и в методе стека с приоритетами, трансляция происходила слева направо. Операнды записывались в стек операндов, а ограничители (знаки операций) —в стек ограничителей (стек операций). Однако для управления стеком ограничителей вместо приоритетов использовалась матрица имен подпрограмм, которую назвали матрицей переходов. Каждый элемент этой матрицы M(S<, Tj) — имя подпрограммы, которую нужно выполнить, если — верхний элемент стека ограничителей, а Г,- — очередной символ входной строки.
Позже метод матрицы переходов был усовершенствован Д. Грисом [31, 48], который за счет некоторого изменения распознавателя расширил класс грамматик, пригодных для обработки, и предложил алгоритм конструктора, автоматически составляющего распознаватель.
Как было установлено в предыдущем параграфе, метод Е. В. Дикстры применим только к грамматикам с операторным предшествованием, причем лишь к таким грамматикам, для которых существуют функции операторного предшествования. Усовершенствованный Д. Грисом метод матрицы переходов пригоден для более широкого класса операторных грамматик, подмножеством которого являются грамматики с операторным предшествованием. Более точно класс грамматик, для которых применим метод Д. Гриса, будет установлен при описании конструктора. Здесь излагается метод Д. Гриса, описанный в [48], с некоторым усовершенствованием, сокращающим матрицу переходов и число шагов разбора.
Напомним, что операторной грамматикой называют грамматику, в которой правая часть любого порождающего правила не содержит двух рядом стоящих нетерминальных символов. Р. В. Флойд доказал, что это свойство сохраняется в любой сентенциальной форме операторной грамматики [45].
Путем включения дополнительных правил операторную грамматику можно преобразовать в эквивалентную расширенную грамматику, в которой правая часть каждого порождающего правила содержит не более трех символов и. имеет специфичную структуру.
265
Обозначим:
Т — терминальный символ (набор терминальных символов исходной и расширенной грамматики один и тот же);
U — нетерминальный символ исходной операторной грамматики;
V — дополнительный специальный нетерминальный символ расширенной грамматики;
z— любая строка, быть может, пустая.
Исходная операторная грамматика может иметь правила только трех типов:
1. их-+и2
2. U -+Tz
3. U{-+U2Tz
При переходе к расширенной грамматике преобразованию подвергаются лишь правила второго и третьего типа, причем только те, в которых z не пусто (последнее как раз и составляет сущность модификации метода Д. Гриса, позволяющей уменьшить матрицу переходов). Каждое правило второго и третьего типа заменяется последовательностью правил вида
п Vп_ jXn
U п%п+1
где любая из строк хг, ..., хп содержит один и только один терминальный символ и заканчивается этим символом, т. е. имеет форму либо Г, либо U'T, а строка xn+i имеет форму либо Т, либо U', либо U'T.
При замене надо следить, чтобы не появлялись порождающие правила с одинаковыми правыми частями и различными левыми частями.
Пример 1. Заменить правило операторной грамматики
(условное выражение) -> if (логическое выражение) then (безусловное выражение) else (выражение)
последовательностью правил расширенной грамматики.
Решение. Специальные нетерминальные символы расширенной грамматики будем заключать в кавычки, чтобы отличить их от исходных нетерминальных символов, заключенных в угловые скобки. Решение дает следующая последовательность правил:
“если" -► If
“если — то"-► “если" (логическое выражение) then
“если — то — инйче" -> “если — то“ (безусловное выражение) else (условное выражение) -> “если — то — иначе" (выражение).
266
В этом примере
И1 = “если**, Xi = if V2 = “если — то“, х2 = (логическое выражение) then У3 = “если — то — иначе**, х3 = (безусловное выражение) else х4 = (выражение).
Из примера видно, что расширенная грамматика уже не является операторной грамматикой, поскольку в правилах встречаются соседствующие нетерминальные символы.
Пример 2. Для грамматики Gi:
П->± В 1 в->т в->в + т т->м т-»тхм м->и М->(В)
построить расширенную грамматику.
Решение. В грамматике Gi терминальные символы — JL, +» X, (,), И, остальные символы — нетерминальные. Как и в примере 1, специальные нетерминальные символы будем заключать в кавычки, исходные нетерминальные символы оставим без изменения. Расширенная грамматика определяется правилами:
м | а _у ।
В 1 в ->т “В+“->В + В -> “В +“ т т-»м “Т Х“ -> т х Т -+ “Т х“ м м->и “(“ -► ( М->“(“ В).
Из описания процедуры построения расширенной грамматики и примеров можно заключить, что расширенная грамматика содержит только правила вида
V->T, V-+UT, V"-*V'T, V"-*V'UT, UТ, UiU2T, -> VU2, U -> VT, U(VU2T (5.39)
и правила вида
С/, -* и2.
(5.40)
Правая часть каждого из этих правил содержит не более трех символов, причем в правой части любого правила специальный нетерминальный символ V может находиться только в самой левой позиции (в «голове»), а терминальный символ Т — только в
2(57
самой правой позиции (в «хвосте»). Следовательно, каждый специальный нетерминальный символ есть представление «головы» правой части некоторого порождающего правила. Заметим также, что правая часть правила для V всегда заканчивается терминальным символом Т.
5.5.2. РАСПОЗНАВАТЕЛЬ И ТРАНСЛЯТОР
Стандартная ячейка U!
Необработанная часть входной строки (массйб'Р)
Рис.
СТЕК S
5.24. Входная строка, стек и стандартная ячейка распознавателя
Специальная форма правил расширенной грамматики позволяет построить достаточно простой и эффективный левосторонний распознаватель, который на каждом шаге анализа распознает и редуцирует самую левую первичную фразу исходной грамматики, т. е. фразу, которая не содержит никакой другой фразы и имеет по крайней мере один терминальный символ. Каждая такая фраза х либо совпадает с правой частью х' одного из правил (5.39), либо отличается от х' нетерминальным символом U исходной грамматики, причем существует вывод х'=$х, в котором применяются только правила вида U\ -> С72.
Исходная входная строка, подлежащая приведению, состоит только из терминальных символов
ЛГ2... Tk. (5.41)
Алгоритм распознавателя построен так, что после некоторого числа шагов строка (5.41) приводится к виду
V,Vx...Vi^VlTlTl+x...Tk (5.42)
или к виду
VQV{...Vt_xViUTjTi+x...Tk. (5.43)
Последовательность VqVi ••• Vi хранится в стеке распознавателя, причем Vi — верхний элемент стека (рис. 5.24). Последовательность TjTj+l ... Tk — необработанная часть входной строки. Символ U хранится в стандартной ячейке распознавателя. Эту ячейку будем обозначать 1/1.
Рассмотрим действия, выполняемые на очередном шаге синтаксического анализа.
Из структуры правил расширенной грамматики (5.39) видно, что в случае, когда приводимая строка имеет вид (5.42), самой левой первичной фразой может быть либо символ Tj, либо пара соседних символов ViTj, причем возможны лишь четыре вида ре
2ЬЬ
дукции, показанные в табл. 5.17. В этой таблице приведены также описания очевидных действий, отвечающих каждому виду редукции (в скобках записаны операторы Алгола-60, выполняющие эта действия), и результат выполнения редукции.
В случае, когда'приводимая строка имеет вид (5.43), самой левой первичной фразой может быть либо пара символов ViU, либо пара UTj, либо тройка ViUTj. Читателю предлагается самостоятельно убедиться, что другие комбинации символов не могут образовать самую левую первичную фразу. Здесь возможны пять видов редукций (табл. 5.18). В табл. 5.18 номера вариантов редукций продолжают нумерацию табл. 5.17.
Таблица <5.17
ВИДЫ РЕДУКЦИЙ для ПАР СИМВОЛОВ VtTj
№ применяемое пробило Дейстбия, выполняющие редукцию Результат выполнения редукции
Стек распознавателя Ячейка U1 Выходная строка
1 i‘.~i*1tS[l]:-Vj*i; Vi-tl Vi Vi-1 • я • „Пусто” Tj+i •••T/f
2 U-^Tj U1 Vi vi-1 • 4 • Vg u Tj*1 '“Ту
3 v'i~*~vj Tj J : Vi Vi-1 < я • Vg „Пусто" Tj+i • • • Ъ<
4 и —4 Tj I : »i — 1 > U1 : = U; j Vi-1 • • • Vg и Tj^ ...Tft
Если для каждой пары символов Vi и Tj расширенной грамматики существует не более чем одна из редукций, перечисленных в табл. 5.17, а для каждой тройки ViUTj существует не более чем одна из редукций, указанных в табл. 5.18, то можно построить матрицу переходов, каждая строка которой соответствует одному из символов Vi, а каждый столбец — символу Tj (рис. 5.25).
Элемент матрицы переходов
M4 = M(Vt, Т^
269
содержит имя (номер) подпрограммы, которую нужно выполнить, если верхний символ стека есть Vi, а очередной символ входной строки — Tj.
Если для данной пары ViTj или тройки ViUTj существует единственная редукция, то подпрограмма с именем выполняет действия, указанные в табл. 5.17 или 5.18. Если редукция не существует, то подпрограмма формирует сообщение об ошибке типа:
В случае, когда для какой-либо пары ViTj (или тройки ViUTj) существует более чем одна редукция, описываемый здесь распознаватель неприменим. Это означает, что расширенная грамматика неоднозначна, хотя исходная грамматика может быть однозначной. Следовательно, условие единственности редукции есть достаточное условие применимости этого метода (и однозначности исходной грамматики).
Итак, алгоритм распознавателя состоит в следующем. На каждом шаге разбора выделяются символы Vi и Tj, по матрице переходов определяется имя требуемой подпрограммы, и эта подпрограмма выполняется.
Для генерирования предложений выходного языка в любую подпрограмму распознавателя можно включить семантическую подпрограмму или обращение к семантической подпрограмме, если это нужно.
Вариант структуры транслятора, использующего распознаватель с матрицей переходов, показан на рис. 5.26. Подобно транслятору для грамматики предшествования, описанному в п. 5.3.6, транслятор состоит из трех частей:
лексический анализатор переводит входную программу на стандартный язык распознавателя;
распознаватель, используя матрицу переходов и подпрограммы, выполняет синтаксический анализ;
генератор, состоящий из набора семантических подпрограмм, переводит программу на выходной язык.
270
Таблица 5.13
ВИДЫ РЕДУКЦИИ ДЛЯ ТРОЕК СИМВОЛОВ VtUTf
Применяемое правило Действия, выполняющие редукцию Результат выполнения редукции
Стек Ячейка vt Выходная строка
5 и' If U'= UvUf = Vy...yUn =Uthen begin 4 .’=4-/; Vf • = !/" end; n-1 Vo V" Tj т^1-тк
6 if V'^VvUj =UV... vUn^vthen begin I:=/ ♦/; s[(.]• = Vt+f; V]- = v пусто ";j = =/ * / end; Vi+! Vi Vi-1 • • • Vp .пусто" т/.1-тк f
7 U"-~U'Ti if U'=Uv Uj = Uv...vUn=uthen begin end; vi Vl4 • • • V0 U" Tk
8 yf-V^'Tj if V'=Uv U^Uv.. .vUn =U then begin I: = i-f j Ui:=„ngcTo”i j:=j+iend; vl • • • Vo „пусто" Tj^i-Tk > •
9 V*-ViV'Tj if u,=Ut'U1=Ui'. vUns‘ Uthen begin 11-1+1-, U1:=U"; j:=j+1end; Vi-f • • Vo v" TJ + 1...TK
271
На рис. 5.26 предполагается, что стек распознавателя представ лен массивом S[0: Q], где Q + 1 — максимальный ожидаемый раз мер стека, а входная строка записана в массиве Р [0: К + 1].
Рис. 5.26. Вариант структуры транслятора, использующего распознаватель с матрицей переходов “
Распознаватель состоит из двух блоков. Блок НАЧАЛО устанавливает в исходное состояние указатель стека i и указатель входной строки /, а также заносит в начало стека специальный не» терминальный символ расширенной грамматики соот
272
ветствующий начальному символу ± программы, и заносит в стандартную ячейку U\ исходное значение «пусто».
Блок ВЫЗОВ выполняет основной алгоритм синтаксического анализа, любая подпрограмма распознавателя после исполнения переходит на метку ВЫЗОВ.
В описываемой схеме основным процессом трансляции управляет распознаватель, который не только выполняет синтаксический анализ, но и через свои подпрограммы вызывает требуемые семантические подпрограммы генератора. Это, естественно, не означает невозможности использования схемы, подобной рис. 5.18, когда генератор включается только после получения разбора.
Трансляторы, использующие матрицу переходов, имеют три основных преимущества:
семантические подпрограммы можно включать на каждом шаге разбора, а не только после выделения основы (или первичной фразы), как в методах, основанных на предшествовании. Это обеспечивает возможность учета неформализованных свойств входного языка в подпрограммах распознавателя и позволяет обойтись без существенного изменения исходной грамматики;
если распознаватель и генератор удается разместить в быстрой памяти, то процесс трансляции идет очень быстро, поскольку для выполнения редукций не требуется просматривать таблицу порождающих правил;
распознаватель обеспечивает полный синтаксический контроль.
Недостатком является сравнительно большой объем матрицы переходов и большое число подпрограмм. В существующих трансляторах для подмножества Алгола-60 матрица переходов имеет размер порядка 50\40 и содержит имена примерно 500 подпрограмм.
Заметим, что распознаватель с матрицей переходов, по существу, определяет распознающую грамматику (распознающий синтаксис) входного языка, поскольку таблицы порождающих правил здесь нет.
5.5.3. КОНСТРУКТОР
В распознавателе, изображенном на рис. 5.26, алгоритмы блоков НАЧАЛО и ВЫЗОВ не зависят от конкретного входного языка и конкретной машины. С изменением входного языка меняется лишь матрица переходов и подпрограммы распознавателя. Существует алгоритм, позволяющий автоматически построить матрицу переходов и подпрограммы по заданной операторной грамматике или установить, что распознаватель с матрицей переходов к данной грамматике неприменим. Следовательно, можно создать конструктор, генерирующий распознаватель с матрицей переходов, если он существует.
Исходная грамматика должна быть задана в БНФ. Матрица переходов и подпрограммы распознавателя формируются конструктором по следующей методике.
273
1. Выявляются все правила исходной операторной грамматики вида
и^и2
и строятся все выводы вида
После этого формируется таблица выводов, содержащая для каждого вывода цепочку входящих в него элементов.
t/p U2, ип.
2. По правилам, изложенным в п. 5.5.1, строится расширенная грамматика.
3. По методике, описанной в п. 5.3.4, для символов расширенной грамматики строится матрица предшествования.
4. Для всех символов W расширенной грамматики формируются вспомогательные множества
Н (W) = {S|3 ((начальный символ грамматики)=^xSWy)}9 где W и S — любые символы расширенной грамматики, а х и у — любые строки, быть может, пустые.
Иными словами, множество H(W) состоит из тех и только тех символов S, которые могут находиться рядом и слева от символа W в какой-либо сентенциальной форме расширенной грамматики.
Для практического построения множеств H(W) удобнее использовать эквивалентное определение
H(W) = [S\S=W VS<W V S> IF), (5.44)
которое означает, что для каждого символа W множество Н образуют все те символы, позиции которых в столбце матрицы предшествования, соответствующем символу IF, содержат какое-либо отношение предшествования.
5. Для каждой возможной пары ViTj расширенной грамматики, т. е. для каждой такой пары, что определяется тип
редукции по следующему правилу (номер типа редукции соответствует табл. 5.17):
1) Л VteH(VM),
3)
4) а^-ед.
Затем для каждой возможной тройки ViUTj расширенной грамматики, т. е. для каждой такой тройки, что и
274
U^H(Tj), определяется тип редукции по следующему правилу (номер типа редукции соответствует табл. 5.18):
б) Л (U" — VtU') Л ((/" е Н (Г,)) Л (U' = U V Я (U' 4 U)),
6) а(и<+1 ->u'Tf) (v1+I)) Л (U'=и v я (uf 4{/)),
7) a([/"-t/'Ty)A(VyeH(t7"))A(t/, = £/Vfl(t/,4f/)), (5.46)
8) Я (VI -► ViU'Tj) A ((/' = t/ V Я (£/' 4£/)),
9) a (t/" — VfU'T,) k{u'=u\j^u'^ u)).
Для проверки существования вывода U'=^U используется таблица выводов, составленная в п. 1 этой методики.
Если для каждой пары ViTj существует не более чем одна редукция вида (5.45) и для каждой тройки ViUTj существует не более чем одна редукция вида (5.46), то формируется подпрограмма, выполняющая действия, указанные для этого типа редукции в табл. 5.17 или 5.18.
«Каркас» подпрограммы каждого типа (всего 9 вариантов-«каркаса») заготавливается заранее. Для формирования подпро-граммы достаточно лишь поставить в определенные позиции «каркаса» символы V и U, соответствующие конкретной паре ViTj или тройке ViUTj и, может быть, объединить два «каркаса» (один для ViTb а другой для ViUTj). Подпрограмме присваивается имя (номер), которое заносится в позицию матрицы переходов, отвечающую строке Vi и столбцу Tj.
Если редукция не существует, то формируется подпрограмма выдачи стандартного текста об ошибке, а ее имя заносится в матрицу переходов. Наконец, если редукция неединственна, то создание распознавателя невозможно.
Описанный алгоритм конструктора был реализован в виде программы для машины М-220. Программа содержит около 3500 машинных слов и строит матрицу переходов для операторной грамматики со скоростью примерно 1,25 операторных правила в минуту. Малая скорость объясняется использованием внешней памяти для хранения исходной грамматики и таблиц.
Порождающим правилам исходной грамматики можно заранее поставить в соответствие имена семантических подпрограмм, выполняющих перевод на объектный язык. Тогда конструктор может включить в подпрограммы распознавателя обращения к семантическим подпрограммам. В этом случае в результате работы конструктора получается готовый распознаватель. Объединение его с лексическим анализатором и генератором дает основную часть транслятора.
Пример 1. Построить матрицу переходов и сформировать подпрограммы распознавателя для грамматики Gi, включив в них семантические подпрограммы для перевода выражений в обратную польскую запись.
275
Таблица 519
ТАБЛИЦА ПОРОЖДАЮЩИХ ПРАВИЛ РАСШИРЕННОЙ ГРАММАТИКИ
правила Порождающее продало Семантическая подпрограмма для перевода В обратную польскую запись
1 1 ” 1
2 /7—„1 "В 1
3 В + Т
4 „В+* — В+
5 в—„в+” т Занести символ „+* 8 Выходную строну
6 т+м
7 „т*"+ т*
8 т—„т*”м Занести симВол „х” В Выходную строну
9 М—И Занести символ Tj в Выходную строну
10 (
11
Решение. Действуем по описанной выше методике.
1. В грамматике Gi лишь два правила вида U\ —► U2: В -* Т и Т —► М. Они образуют два вывода: В Т => М и Т => М.
2. Расширенная грамматика для грамматики Gi была построена в примере 1, п. 5.5.1. Семантические подпрограммы для перевода в обратную польскую запись приведены в табл. 5.19 вместе с правилами грамматики.
Таблица 5.20
МНОЖЕСТВА L(U) И R(C/) РАСШИРЕННОЙ ГРАММАТИКИ
и Ци) в(и)
1 ” »»•х> £ 1
п 1 ” 1 1
в Г, „В+”, М, „Тх", в. И, ( Г, М,^И, )
,л+” в, т, „в*”, м, „тх”, И, ( + 1
т М, „Тх", И, Т, ( М, И, )
„Г*” т, М, „тх ”, И, ( X
И И, ( И, )
(” ( (
27й
3. Чтобы построить матрицу предшествования по методике, описанной в п. 5.3.4, вначале формируем множества L(U) и R(U) для всех нетерминальных символов расширенной грамматики (табл. 5.20), а затем отыскиваем отношения предшествования и строим матрицу предшествования (табл. 5.21).
Таблица 5.21
МАТРИЦА ПРЕДШЕСТВОВАНИЯ РАСШИРЕННОЙ ГРАММАТИКИ
1” п в ,,в+” т „ТХ” и (” JL 4* X и ( )
1" • <• ^9
п
в • «
„В+" <• <• ^9
т *> • 9^
X • s= ^9 ^9
м 9^
»»1 ^9 <• ^9 ^9 ^9
1
4* •> 9^ •>
X 9^ •>
И •> •> •>
( •> •> 9^ •> •>
) •> 9^
4. По матрице предшествования в соответствии с формулой (5.44) строим таблицу вспомогательных множеств H(W) (табл. 5.22). Заметим, что для построения множества Н для данного символа № нужен лишь один столбец матрицы предшествования, поэтому на практике для экономии памяти целесообразно объединить построение столбцов матрицы предшествования с формированием соответствующих множеств H(W). После построения множества H(W) столбец W матрицы предшествования не нужен. Занимаемое им место в памяти можно использовать для следующего столбца.
5. Используя табл. 5.22, определяем возможные пары V{Tj. Заметим, что в нашем примере возможны только пары вида и Vi(. Для каждой возможной пары ViTj по правилу (5.45) определяем вариант редукции, а по табл. 5.19 — применяемое правило.
Аналогично по табл. 5.22 определяем возможные тройки ViUTj. Для каждой возможной тройки по правилу (5.46) определяем
277
Т я б и и u a 5.22
МНОЖЕСТВА РАСШИРЕННОЙ ГРАММАТИКИ
W H(W)
1 ”
/7
В 1” (” ( м -Ь , „1 , 1
„г;
т „г, (
„Г* ” „Г, „в+”, (
и „1”, „в+", „тх”, +,Х, (
(” >» ' » 1 , » п? * 1 ( 9+9*9 (
1 в, г, и, и, )
в, т, м, и, )
X Г, и, и, )
и „1”, „гх”, х, г
( „±”, „В+”, ,,гх’; +, х, (
) в, Г, м, и, )
вариант редукции и по табл. 5.19 — применяемое правило расширенной грамматики.
Результаты приведены в табл. 5.23. Различные комбинации входов в эту таблицу, соответствуют всем мыслимым комбинациям пар ViTj и троек ViUTj, а в ее клетках указаны номера вариантов редукций (первое число) и номера применяемых правил расширенной грамматики (второе число). Если редукция невозможна, то клетка оставлена пустой.
Как видно из табл. 5.23, для каждой пары ViTj и тройки ViUTj существует не более чем одна редукция, поэтому, используя табл. 5.17 и 5.18, строим подпрограммы распознавателя и матрицу переходов (табл. 5.24).
В матрице переходов указаны номера подпрограмм распознавателя. В подпрограммах меткой ОШИБКА помечена подпрограмма выдачи сообщения об ошибке, меткой ВЫЗОВ — блок ВЫЗОВ распознавателя (см. рис. 5.26), а меткой ВЫХОД — выход при успешном окончании разбора. На месте семантической подпрограммы (или обращения к семантической подпрограмме) записан текст, описывающий действия, выполняемые семантической подпрограммой.
278
Таблица 5.23
ТАБЛИЦА НОМЕРОВ РЕДУКЦИЙ И НОМЕРОВ ПРИМЕНЯЕМЫХ ПРАВИЛ РАСШИРЕННОЙ ГРАММАТИКИ
и >ч. 1 —|— X в И (
„пусто’1 „1 ’ 2,9 т.то
„в + ' 2,9 Т.ю
„ Г-х " 2.9 т.то
Л" * 2.9 7,10
в „1 ” 9,2 6.4
„ В +”
„тх"
(” »» 4 6,4 9.П
г „1" 9.2 б.ь 6,7
„а+" 5,5 5,5 6,7 45
ТХ ”
(’’ »/ х 6,4 6,7 9.11
н „1 ” 9.2 6,4 6,7
„В+” 5.5 5,5 6,7
„Тх ’’ 5,8 5,8 5,8 5,8
»» х 6.4- 6,7 9,11
Таблица 5.24 МАТРИЦА ПЕРЕХОДОВ
J *4* X И ( )
1 " ft х 3 4 7 1 2
„5+ " 6 6 7 1 2 6
„Тх ' 8 8 8 1 2 8
(° 4 7 1 2 5
279
Подпрограммы распознавателя:
1: if Ul = «пусто» then begin Ul: = M;
занести символ Tj в выходную строку;
/: = / + 1; go to ВЫЗОВ end else go to ОШИБКА;
2: if J71 = «пусто» then begin i: = i + 1;
S[f] j: = j 1; go to ВЫЗОВ end
else go to ОШИБКА;
3: if Ul = В V Ul = T V Ul = M then go to ВЫХОД else go to ОШИБКА;
4: if (71 = BV(71 = TVl/l =M then begin =
S[i]: =“B + * = «пусто»; /: = / + 1; go to ВЫЗОВ end
else go to ОШИБКА;
5: if Ul = В V Ul = T V Ul = M then begin i: = i- 1; Ul : = M; /: = / + 1; go to ВЫЗОВ end else go to ОШИБКА;
6: if Ul = T V Ul = M then begin i; = i — 1; Ul : = В; занести знак «+» в выходную строку; go to ВЫЗОВ end else go to ОШИБКА;
7: if Ul = T V Ul = M then begin Z: = Z-f- 1; Ul : = «пусто»;
S[i]: = “T X /: = /+!; &° t° ВЫЗОВ end else go to ОШИБКА;'
8;if[/l=M then begin i: = i—l\ (71: = T; занести знак «X» в выходную строку; go to ВЫЗОВ end else go to ОШИБКА;
Таблица 5.25
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ С ИСПОЛЬЗОВАНИЕМ МАТРИЦЫ ПЕРЕХОДОВ
Выходная страна под пр о -граммы Стен распознавателя U1 Входная строка Р ( P[j] - 7 )
L J
0 2 1 2 3 4 5 6
1 „1” „пусто" а В X С 1
а 4 ..1” м 4- 6 X с 1
1 ] ” я X „ Пусто” В X с 1
6 7 „1” „в* ” И X с 1
1 1 ” „Пусто ” с 1
с 8 1 ” >♦ W „я* м i
X 6 1” »> •*- _ »» т 1
3 1” И X в 1
Выход
280
Пример 2. Используя распознаватель с матрицей переходов, перевести в обратную польскую запись выражение
а + b Хс.
Решение показано в табл. 5.25.
Из этого примера можно заключить, что метод матрицы переходов по числу шагов столь же эффективен, как метод операторного предшествования (см. п. 5.4.4), однако быстродействие его выше, поскольку здесь не нужно просматривать таблицу порождающих правил.
5.6. ПРАВИЛА ПОДСТАНОВКИ ФЛОЙДА
5.6.1. РАСПОЗНАВАТЕЛЬ
Для выделения основы (или первичной фазы) левосторонний восходящий распознаватель обычно использует некоторый контекст. Если для однозначного определения основы на любом шаге синтаксического анализа достаточно рассмотреть не более т символов слева от основы и не более п символов справа, то говорят, что эта грамматика с (т, п) ограниченным контекстом. Все рассмотренные выше распознаватели применимы только к грамматикам с (1,1) ограниченным контекстом. В принципе почти каждый из распознавателей можно изменить так, чтобы он стал пригодным для обработки грамматик с (т, п) ограниченным контекстом при т>1 и п > 1. Например, в методе предшествования для этого нужно определить отношения предшествования между всеми возможными строками х и у, длина которых не превосходит пг и п соответственно. На практике этого не делают из-за чрезвычайно большого объема памяти, требующегося для хранения ма-трицы предшествования строк, а также резкого увеличения машинного времени.
Д. Е. Кнут показал (ссылки на его работы можно найти в обзоре [31]), что грамматика с (tn, п) ограниченным контекстом является частным случаем LR(k) грамматики, в которой основа однозначно определяется всей находящейся слева от нее частью приводимой строки и не более чем k расположенными справа терминальными символами. Д. Е. Кнут показал также, что можно создать конструктор, способный автоматически строить левосторонние распознаватели для любой LR(k) грамматики. Сейчас LR(k) грамматики — наиболее общий класс грамматик, для которых доказана возможность создания конструкторов. Интересно заметить, что для любой LR(k) грамматики существует эквива-. лентная LR(1) грамматика.
Алгоритмы распознавателей для языков, порождаемых LR(k) грамматиками, удобно описывать на языке, идея которого была предложена Р. В. Флойдом [44]. Этот язык называют языком правил подстановки (production language) Флойда. По существу,
ю Зак, 221
281
язык Флойда — это метаязык для описания распознающих грамматик. Известно несколько модификаций правил подстановки.
Будем записывать правила подстановки Флойда в формате, показанном на рис. 5.27 [40].
mix х,хг...х/г Im *
Рис. 5.27. Формат правил подстановки Флойда
Поля правила подстановки имеют следующий смысл: ЛИ — метка правила (может отсутствовать);
XtX2 ... Хп — образец для сравнения с частью приводимой строки;
YxY2 ... Ym—строка, которой заменяется часть приводимой строки Х1Л2 ... Хп (может отсутствовать);
СП — имя семантической подпрограммы (может отсутствовать) ;
* — знак, предписывающий прочитать следующий символ входной строки (может отсутствовать);
М2—метка правила, к которому нужно перейти после успешного применения данного правила (может отсутствовать) .
Распознаватель использует таблицу правил подстановки, записанных в формате рис. 5.27, и стек, содержащий уже рассмотренную и быть может частично редуцированную часть приводимой строки. Как и все ранее рассмотренные распознаватели, распознаватель работает слева направо. Применение очередного правила подстановки начинается сопоставлением h верхних символов стека с образцом Х1Х2 • • • Хп- При несовпадении хотя бы одного символа применяется следующее по порядку правило. Если п верхних символов стека совпали с образцом, то:
строка Х1Х2 Хп в стеке заменяется строкой У1У2 ... Ym (строка YiY2 ... Ym не должна быть пустой, если она пуста, то замена не производится);
исполняется семантическая подпрограмма (если СП не пусто);
если правило содержит знак *, то в вершину стека добавляется очередной символ входной строки;
происходит переход к правилу с меткой М2, а если М2 пусто, то к следующему по порядку правилу.
Блок-схема распознавателя показана на рис. 5.28. На блок-схеме использованы следующие обозначения:
S — идентификатор массива, являющегося стеком распознавателя;
/ — указатель стека распознавателя (S[ZJ — последняя запись в стек);
Р—идентификатор массива, содержащего входную строку;
i — номер очередного символа входной строки;
t — номер правила в таблице правил подстановки.
282
Предполагается, что приводимая входная строка начинается и заканчивается концевыми символами ±.
Вход
Рис. 5.28. Блок-схема распознавателя, основанного на правилах подстановки Флойда
После получения разбора или установления, что разбора нет, работу распознавателя прекращает одна из семантических подпрограмм.
Заметим, что в общем случае порождение
к,г2... ут=^ад... Хп
может быть представлено в виде xUy^xuy,
10*
283
где U — нетерминальный символ, х и у — любые строки, быть может, пустые, а и — порождаемая символом U часть строки (основа).
Если во всех правилах подстановки длина строки х не более т, а длина строки у не более п, то распознаватель анализирует грамматику с (/и, п) ограниченным контекстом. С другой стороны, ничто не препятствует тому, чтобы строка хиу, являющаяся образцом, при необходимости совпадала со всем содержимым стека. Это означает, что описываемый распознаватель способен анализировать LR(k) грамматику (здесь k — наибольшая длина стро-ки у).
Подводя итог, можно сказать, что строки х и у представляют тот контекст, который необходим для однозначного определения основы. В каждом правиле можно использовать ровно столько контекста, сколько необходимо, не ограничивая заранее его длину, как в рассмотренных ранее распознавателях. Это, а также возможность использования семантических подпрограмм на каждом шаге анализа, делает язык правил подстановки очень гибким. В принципе, используя язык Флойда, можно строить распознаватели для любых контекстно-чувствительных языков, порождаемых грамматиками непосредственно составляющих, относящихся к классу 1 по Хомскому (см. п. 5.2.5).
5.6.2. КОНСТРУКТОР
Описываемый ниже конструктор [40] строит распознаватель на языке правил подстановки Флойда для LR(l) грамматики. Исходная контекстно-свободная грамматика должна быть задана порождающими правилами в БНФ. Предъявляемые к ней требования описаны в следующем пункте.
Для символа S конструктор может генерировать правила подстановки двух видов:
0-правила, в которых образцом является терминальный символ, находящийся в вершине стека распознавателя; эти правила получают метку S0;
1-правила, в которых образец содержит символ S, находящийся в следующей за вершиной позиции стека; эти правила получают метку S1.
В процессе построения распознавателя конструктор создает четыре множества:
L0 — множество символов S, образующих метки вида S0;
LI—множество символов S, образующих метки вида S1;
L0* — множество символов S, для которых уже построены 0-правила;
L1*— множество символов S, для которых уже построен^ 1-правила.
При описании алгоритма конструктора используются операции над множествами:
284
4UB — множество, состоящее из элементов, каждый из которых входит в А или в В (объединение множеств А и В);
А — В — множество, состоящее из элементов, каждый из которых входит в Л и не входит в В (разность множеств Л и В).
При описании алгоритма конструктора будем обозначать:
{Ki» Кг...Кг\ — множество, состоящее из элементов Ki, Кг, ...
• • • , Кт,
0 — пустое множество;
о—произвольный символ исходной грамматики;
а, Ь, с, d—терминальные символы;
G, Н, К — нетерминальные символы;
X, Y — любые определенные символы (терминальные или нетерминальные);
u, v, w, х, у, г—любые строки, быть может, пустые.
Алгоритм конструктора состоит в следующем.
ПОДГОТОВИТЕЛЬНЫЕ ДЕЙСТВИЯ
0.0.L0: = {Л}, где А — начальный символ грамматики.
Ll: = £1*: = £0*: = 0.
ОБРАЗОВАНИЕ О-ПРАВИЛ
0.1. Если £0— £0* — 0, то перейти к пункту 1.1, иначе — к следующему пункту.
0.2. Для символа Н е £0 — £0* построить множество
£'(Я)={а|а«= Т /\а<=ЦН)\,
где £'(Я)—множество терминальных символов, которыми может начинаться порождение нетерминального символа Н; Т — множество терминальных символов грамматики; L(H)—множество самых левых символов относительно Н, определяемое формулой (5.16) или формулой (5.17).
0.3. Для каждого яе£'(Я) найти множество
\К\ К-*аг\ = \К\, Кг---, Кг}, может быть Ki = Kj,
и выполнить следующие действия:
0.3.1. Если r> 1, то сформировать правило подстановки
но а
а выполнить £1: = LI U {а}.
285
0.3.2. Если г = 1 и К —► az, то:
в случае, когда z = пусто, построить правило
но а к * К1
и выполнить LI : = LI U {Л};
в случае, когда z = bw, построить правило
но а * af
и выполнить L1 : = LI U {а};
в случае, когда z — Gw построить правило
но а
* 60
и выполнить L0: = L0 U {G}.
0.4. Уничтожить метку НО во всех правилах подстановки, кроме одного (первого). Добавить правило
б Ошибка к
и выполнить L0*: = L0* U {Н}.
Перейти к пункту 0.1.
ОБРАЗОВАНИЕ 1-ПРАВИЛ
1.1. Если L1 —L1* = 0, то перейти к пункту 1.8, иначе — к следующему пункту.
1.2. Для символа X&L1-—L1* выделить все порождающие правила исходной грамматики, правые части которых содержат символ X.
1.3. Для каждого выделенного правила G-+uXv образовать правила подстановки следующим образом:
если v = пусто, то
Х1 \иХб Ge 61 1
если v = Hw, то для каждого c^L'(H) построить правило
X/ их с но
если v = с, то
х; ихс 6 * 61
286
если v = cdw, то
XI iUXC * с/
если v = cHw, то
XI ихс * но
1.4. Объединить каждые два правила подстановки с образцами вида ус и хус в одно правило, имеющее форм>'
XI ус * С1
1.5. Упорядочить правила подстановки следующим образом.
1.5.1. Правила с символом о в конце образца поместить после остальных, кроме случая, когда имеются два образца вида ус и хус, причем х =/= «пусто» и существует сентенциальная форма хус, т. е. существует вывод А=^хус. В этом специальном случае правило с образцом хус должно быть впереди правила с образцом ус.
1.5.2. Внутри последовательности правил с символом о в конце образца вначале идут правила с более «длинными» образцами.
1.6. Выполнить:
LI; = LI U {У| У1 находится в поле метки перехода);
L0: = LO U {G|G0 находится в поле метки перехода);
LI*: = LI* U {X}.
1.7. Уничтожить метку XI во всех полученных правилах подстановки, кроме одного (первого). Добавить правило
У
Ошибка
Перейти к пункту 0.1.
1.8. Алгоритм завершен.
5.6.3. ПОДГОТОВКА ГРАММАТИКИ ДЛЯ КОНСТРУКТОРА
Дж. К. Эрли, предложивший в 1965 г. алгоритм описанного выше конструктора (ссылка на его работу приведена в обзоре [31]), показал, что распознающая грамматика, представленная распознавателем, эквивалентна исходной порождающей грамматике, если в исходной контекстно-свободной грамматике:
1) нет порождающих правил с пустыми правыми частями вида G -> у,
где у — пустая строка;
287
2) нет пар порождающих правил с одинаковыми правыми и разными левыми частями вида
Н^-у,
3) нет пар порождающих правил вида
Н ->ху,
таких, что существует сентенциальная форма uxGv;
4) нет пар порождающих правил вида
Н -» xyz, таких, что существуют сентенциальные формы uxGv и u\Gbv\, где be (с| z=>cw};
5) нет пар порождающих правил вида
G -» у г Н->ху,
таких, что существуют сентенциальные формы uxGv и UiHbvi, где fts {с| z=>cw}.
Грамматика, содержащая правила с пустыми правыми частями или пары порождающих правил со свойствами, указанными в условиях (2) — (5) (такие пары правил будем называть конфликтными), не является £/?(!) грамматикой, поскольку при содержимом стека
... хуо
нельзя решить, какое из правил конфликтной пары следует применять для редукции (первое или второе).
Для приведения исходной грамматики к LR(\) грамматике нужно выделить и удалить все правила вида G—*у, отвечающие условиям (1) — (5). Чтобы полученная таким путем грамматика была эквивалентна исходной грамматике, при удалении каждого правила G—*y нужно заменить в правых частях всех остающихся порождающих правил нетерминальный символ G строкой у и добавить полученные таким путем правила к остальным. Например, если из набора правил
Н-> Н; Р
Н->вК
К^К; гТ
нужно удалить правило выглядеть так:
Н-»вК, то новый набор правил будет
Н-+Н; Р К-*К; гТ Н -> вК; Р.
Правила с пустыми и одинаковыми правыми частями отыскиваются простым просмотром исходной грамматики. Сложнее най
288
ти правила, образующие конфликтные пары вида (3) — (5). Конфликтные пары можно найти прямым перебором с использованием множеств самых левых и самых правых символов и матрицы предшествования (см. п. 5.3.4).
5.6.4. ПРИМЕРЫ
Пример 1. Для грамматики Gi
п-> ± В ± в->т В-> В + Т т->м Т->ТХМ м->и М-*(В)
построить распознаватель с правилами подстановки Флойда, включив в них семантические подпрограммы для перевода в обратную польскую запись.
Решение.
1. Непосредственной проверкой убеждаемся, что в грамматике <?i нет правил с пустыми правыми частями и нет конфликтных пар правил.
2. Выполняем алгоритм конструктора.
ПОДГОТОВИТЕЛЬНЫЕ ДЕЙСТВИЯ
0.0. £0 = {П), LI = LI* = L0* = 0.
ОБРАЗОВАНИЕ О-ПРАВИЛ
0.1. L0 — L0* = {П} — 0 — {П} Ф 0, поэтому выполняем пункт 0.2.
0.2. Для символа П, используя таблицу множеств L(U) грамматики Gi (табл. 5.4, в п. 5.3.4), находим
L'(n)-ub
0.3. Имеется единственное правило вида К -*• az:
П-1В1,
т. е. здесь К = П, а = J., z = B.L, г = 1.
0.3.2. Поскольку г = 1 и г = В1, строим правило
ПО 1 * во
и выполняем L0: = L0 U (В). После этого LQ = {П, В}.
289
0.4. Добавляем правило
6 Ошибка 1
и выполняем L0*: = L0* U {П}. Теперь L0* = {П}.
Итак, построены первые два правила подстановки:
по 1 * во
в Ошибка 1
(5.47)
Переходим к пункту 0.1.
При втором выполнении того же цикла последовательно выполняется следующее.
0.1. L0 — L0* = {П, В} — {П} = {В} = 0, поэтому переходим к пункту 0.2.
0.2. Для символа В по табл. 5.4 находим
£'(В)={И, (К
0.3. Для а = И получаем
{Я| Д’-* Из} = {М| М-> И) = {М},
т. е. К = М, z = пусто, г = 1.
0.3.2.
во И м СП1 * М1
£1 = {М}.
Здесь СП 1 — имя семантической подпрограммы: «занести идентификатор в выходную строку».
Для а = ( получаем
{/С|>(з} = (М| М->(В)} = (М.},
т. е. К = М, z = В), r= 1.
0.3.2.
во ВО
£0 = {П,
В}.
0.4. Уничтожаем метку в правиле с образцом (. Добавляем правило
Ошибка г
и выполняем L0* : = L0* U {В} = (П, В}. 290
При втором выполнении цикла построены следующие три правила
ВО и м СП1 * М1
( * во
6 Ошибка 2
(5.48)
Вновь переходим к пункту 0.1.
Теперь в 0.1 получаем L0— 10* = {П, В}—{П, В} = 0, поэтому переходим к пункту 1.1.
ОБРАЗОВАНИЕ. 1-ПРАВИЛ
1.1 11 —11* = {М} — 0 = (М) 4= 0, поэтому переходим к пункту 1.2.
1.2. Символ М содержится в правых частях двух порождающих правил:
Т->М
Т^ТХМ.
1.3. Формируем два правила подстановки:
М1 Мб Тб Т1
М1 Тх Мб Тб СП2 Tt
Здесь СП 2 — имя семантической подпрограммы: «занести символ «X» в выходную строку».
1.4. Здесь не выполняется.
1.5. Упорядочение полученных правил подстановки:
1.5.2. Второе из полученных правил нужно поставить впереди первого, поскольку у него «длиннее» образец.
1.6. 11 = {М,Т), £1* = {М}.
1.7. Получены правд
М1 ТХ Мб Тб СП2 Т1
Мб Тб Г1
Ошибка 3
(5.49)
Перейти к пункту 0.1.
0.1. Поскольку 10— 10* = 0, переходим к пункту 1.1.
291
1.1 LI — LI* = {M, T} — {M} = {T} = 0, поэтому переходим к пункту 1.2.
1.2. Символ Т содержат правые части трех правил:
В->Т В->В + Т Т->ТХМ.
1.3. Образуем три правила подстановки:
Здесь СПЗ — имя семантической подпрограммы: «занести символ «4~» в выходную строку».
1.4. Здесь не выполняется.
1.5. Упорядочение полученных правил подстановки:
1.5.1. Третье из полученных в пункте 1.3 правил поставить на первое место.
1.5.2. Второе из полученных в пункте 1.3 правил поставить впереди правила, полученного первым.
1.6. LI = {М, Т, В},
L0 = (П, В, М}, Ll* = {М,Т}.
1.7. Получены правила
Т1 Гх * МО
я + га Вв спз В1
га Вб Bi
б ошибка 4. I
(5.50)
Перейти к пункту 0.1.
Продолжая выполнять алгоритм, последовательно получаем следующие правила подстановки:
МО И м СП1 * М
( * во
б Ошибка 2
(5.51)
.292
В! 1 а 1 п Выход
в + * то
(8) м * М1
б Ошибка 5
(5.52)
то И м СП1 * М1
( * ВО
б Ошибка 2
(5.53)
В первом правиле (5.52) ВЫХОД — имя семантической подпрограммы: «разбор получен». В этом правиле знак * и метка перехода не записываются, поскольку алгоритм распознавателя выполнен.
Заметим, что правила (5.48), (5.51) и (5.53) отличаются только входными метками, поэтому их можно объединить.
Объединяя все полученные правила, получаем алгоритм распознавателя.
Таблица 5.26
РАСПОЗНАВАТЕЛЬ С ПРАВИЛАМИ ПОДСТАНОВКИ ФЛОЙДА
по 1 * ВО
6 Ошибка 1
ВО, МО, то И м см * М1
( * во
- б Ошибка 2
М1 Т X Мб Тб СП2 Т1
Мб Тб Т1
б Ошибка 3
Т1 Т * * МО
В + Тб Вб СПЗ 81
Тб Вб В1
1 . б ошибка а
В1 101 п Выход
в+ * то
(Я) И * М1
б Ошибка 5
Семантические подпрограммы, указанные в табл. 5.26, выполняют следующие действия:
СП1 —заносит в выходную строку идентификатор;
СП2 — заносит в выходную строку символ «X»;
293
СПЗ — заносит в выходную строку символ «+»;
ВЫХОД — прекращает процесс разбора.
Подпрограмма ОШИБКА 1 в соответствии с алгоритмом распознавателя (см. блок-схему на рис. 5.28) может быть вызвана лишь в случае сбоя (в начало стека не занесен символ J_). Эта подпрограмма должна возобновить выполнение алгоритма распознавателя с блока 1 (рис. 5.28). Остальные подпрограммы обработки ошибок печатают текст «конструкция S[/ — /V] ... S'[/] недопустима» с указанием места ошибочной конструкции в исходной программе. Здесь S[l — Af] ... S[/] — верхние символы стека (/ — номер последней записи в стек). Если L — длина наибольшего образца в правилах подстановки, отвечающих данной входной метке, то
если
если
I — L>0,
/ —£<0.
После формирования и печати текста сообщения об ошибке подпрограмма обработки ошибки обычно удаляет ошибочную конструкцию (оператор, описание), а затем процесс синтаксического анализа продолжается без формирования выходной программы.
Пример 2. Используя распознаватель с правилами подстановки Флойда, перевести в обратную польскую запись выражение
а + & Х^-
Решение показано в табл. 5.27.
Таблица 5.27
ПЕРЕВОД В ОБРАТНУЮ ПОЛЬСКУЮ ЗАПИСЬ С ИСПОЛЬЗОВАНИЕМ ПРАВИЛ ПОДСТАНОВКИ ФЛОЙДА
Выходная строка Метка правила метка Выхода Семантическая подпрограмма Стек распознавателя Входная строка
ПО ВО 1 а + в*с1
ВО Ml СП1 10 +B*cL
а М1 Т1 1 м + BxcL
Т1 В1 1 г + в* Cl
В1 ТО 15 + 6 X fl
то Ml СП1 1 в + 6 Xfl '
6 М1 Т1 1 В + М х fl
Т1 МО 1 8+ Т * c 1
МО Ml СП1 1 В + Т х с 1
с Ml Т1 СП2 1 В + Т х М 1
X 7" j В1 СОЗ 15+71
4- 81 ВЫХОД 15 1
П
294
5.6.5. ВЗАИМОСВЯЗЬ МЕТОДОВ СИНТАКСИЧЕСКОГО АНАЛИЗА
Каждый из рассмотренных методов восходящего анализа применим к определенной грамматике. Поскольку между формальными грамматиками существуют иерархические отношения, можно построить также иерархию методов синтаксического анализа.
Взаимосвязь и подчиненность формальных грамматик и методов их анализа показана на рис. 5.29. Наверху иерархии находится грамматика непосредственно составляющих. Метода, пригодного для синтаксического анализа произвольной грамматики этого класса, пока нет.
LR(k) грамматики можно анализировать распознавателями, основанными на правилах подстановки Флойда. На рис. 5.29 это показано двойной стрелкой, соединяющей название метода с названием грамматики. Однако конкретный конструктор Д. Эрли может автоматически строить распознаватели только для LR(1) грамматик.
Грамматики с (m,k) ограниченным контекстом образуют подмножество LR(k) грамматик, поэтому к ним также применимы распознаватели, основанные на правилах подстановки Флойда. Вообще метод, пригодный для анализа грамматик определенного типа, применим также ко всем грамматикам, расположенным на нижних уровнях иерархии.
Метод (т, k) предшествования, в котором отношения предшествования устанавливаются между строками символов длиной не более т и k соответственно, применим, вообще говоря, лишь к некоторому подмножеству (т, k) грамматик. Поэтому на рис. 5.29 двойная стрелка соединяет название этого метода с линией, указывающей на грамматику низшего ранга. Аналогично матрица переходов, которую строит конструктор Д. Гриса, применима только к подмножеству операторных грамматик, что показано соответствующей стрелкой. Соответствие между остальными методами и грамматиками наглядно видно на рис. 5.29 и особых пояснений не требует.
Заметим, что на рис. 5.29 все методы синтаксического анализа соотнесены подмножествам LR(k) грамматик или грамматик с (т, k) ограниченным контекстом, которые относятся к контекстночувствительным грамматикам. На первый взгляд это может показаться странным, поскольку при описании способов построения конкретных распознавателей всегда требовалось, чтобы исходная грамматика была контекстно-саободной. Однако на самом • деле ничего удивительного здесь нет. По существу, процесс построения распознавателя как раз заключается в. превращении исходной порождающей контекстно-свободной грамматики в распознающую контекстно-чувствительную грамматику путем добавления в каждое исходное порождающее правило необходимого левого и правого контекста. Разные методы отличаются длиной и способом внесения контекста.
295
Грамматика непосредственно составляющих
LH(k) грамматика
L П(1) грамматика
Грамматика с (т, к) ограниченным контекстом
Грамматика ( метод А
предшествования Ч-----\ предшествованияJ
Операторная грамматика
Грамматика с (1, 1) ограниченным контекстом
Правила подстановки
Флойда с конструктором Эрли
Грамматика с функциями предшествования
Рис. 5.29. Иерархия формальных грамматик и методов синтаксического анализа
В методах предшествования и операторного предшествования контекст вносится матрицей или функциями предшествования, которые определяют отношения между символами внутри и вне основы (первичной фазы), т. е. отношения между правой частью порождающего правила и контекстом. В методе матрицы переходов необходимый контекст вносят подпрограммы распознавателя. Во всех этих методах контекст добавлен в порождающие правила неявно и учитывается в момент выделения основы (первичной фразы).
В правилах подстановки Флойда контекст учитывается установлением определенного порядка просмотра правил, который зависит от контекста. Кроме того, контекст может непосредственно вноситься в образец правила подстановки.
В заключение отметим, что все описанные методы, кроме правил подстановки Флойда, являются типичными методами восходящего анализа. Распознаватель с правилами подстановки, формируемый конструктором Д. Эрли, сочетает черты как восходящего, так и нисходящего анализа. С одной стороны, образцы в правилах подстановки служат для опознания основы. После распознавания основы немедленно выполняется редукция. Это характерно для восходящих распознавателей. С другой стороны, с самого начала ставится цель — найти вывод, порождаемый начальным символом. В процессе достижения этой цели ставятся и анализируются подцели, указываемые метками перехода правил подстановки. Анализ и выбор подцелей выполняется при помощи образцов. Такая целенаправленность характерна для нисходящих распознавателей.
Распознаватель, описанный правилами подстановки, нетрудно переписать в виде набора синтаксических подпрограмм. Например, алгоритм распознавателя (транслятора для перевода в обратную польскую запись), заданный таблицей 5.26, можно записать в виде пяти подпрограмм с именами ПО, ВО—МО—ТО, Ml, Т1 и В1, в которые включены соответствующие семантические подпрограммы ОШИБКА 1, СП1, СП2, СПЗ и ВЫХОД. К этому набору нужно добавить одну общую подпрограмму ОШИБКА, выполняющую функции подпрограмм ОШИБКА 2, ОШИБКА 3, ОШИБКА 4 и ОШИБКА 5. В результате получится типичный нисходящий транслятор, основанный на методе синтаксических подпрограмм.
ЗАКЛЮЧЕНИЕ
Первые системы программирования создавались для машин, которые проектировались без учета специфичных требований трансляции с языков высокого уровня. На этих машинах не было некоторых нужных операций, неудовлетворительна была организация данных, отсутствовали аппаратные средства, обеспечивающие переместимость программ. Это вынуждало составителей трансляторов широко применять подпрограммы и служебные системные программы, снижающие эффективность использования машинного времени.
Машины третьего поколения лучше приспособлены для решения задач системного программирования. Байтовая организация памяти и широкий набор операций существенно облегчают решение любых задач символьной обработки. Наличие базовых регистров упрощает перемещение программ. Некоторые новые машины имеют стековую память и даже могут непосредственно выполнять программы в обратной польской записи. Тенденция аппаратного исполнения операций, характерных для системного программирования, несомненно, получит дальнейшее развитие в машинах четвертого поколения.
Практические потребности разработки языков высокого уровня и эффективных трансляторов привели в последние годы к интенсивным работам в области теории формальных грамматик и методов синтаксического анализа. Некоторые из этих методов уже нашли применение в действующих трансляторах. Однако значение этих исследований шире.
Исследования синтаксиса помогли понять природу трудностей, которые приходится преодолевать при разработке трансляторов. Причиной некоторых из этих трудностей является неудачное описание синтаксиса реальных языков программирования. Описание языка грамматикой определенного типа, для которой можно автоматически создать распознаватель, существенно облегчает разработку транслятора. Это очень важно для специализированных проблемно-ориентированных языков, которые неизбежно придется
298
разрабатывать в интересах узких групп пользователей в связи с распространением информационно-вычислительных систем коллективного пользования. Успешное внедрение таких систем в значительной степени зависит от того, насколько близок и понятен язык общения с системой пользователю, не являющемуся профессиональным программистом. Этот язык не должен сильно отличаться от обычного профессионального языка пользователя.
Если создание транслятора перестанет быть проблемой, решение которой каждый раз требует больших трудозатрат, то для каждой группы пользователей можно будет создавать собственный язык.
Однако блоки синтаксического анализа составляют не более 20—30% компилятора, поэтому для полного решения проблемы автоматического создания трансляторов необходимо разработать практичный стандартный способ описания семантики языков программирования, допускающий формальное преобразование в язык машины.
Существует принципиально иной путь реализации новых языков и, в частности, проблемно-ориентированных непроцедурных языков пользователей, который не требует разработки транслятора для каждого нового языка. Этот путь основан на использовании расширяемых языков.
Простейшим расширяемым языком является макрорасширение языка ассемблера. Однако ничто не препятствует созданию макроязыков на базе языков высокого уровня, например Фортрана или Алгола-60. Для создания нового проблемно-ориентированного языка на базе макроязыка достаточно разработать библиотечные макроопределения, описывающие макрокоманды нового языка.
К достоинствам такого пути можно отнести простоту реализации, обучения пользователей и дальнейшего расширения или изменения языка. Последнее особенно важно, потому что язык пользователя по своей природе должен быть динамичным. По мере освоения работы с системой у пользователя неизбежно появятся новые задачи, для решения которых придется вводить новые макрокоманды. Недостатком такого языка является бедность выразительных средств, определяемая относительно жестким форматом макрокоманд.
Значительно большие возможности дает применение расширяемых языков высокого уровня. Примером может служить Алгол-68, в котором предусмотрены средства для описания новых языков, в частности, новых операций и новых типов данных. Однако реализация полного Алгола-68 возможна только на достаточно мощных машинах.
Появление систем с разделением времени поставило задачу создания диалоговых трансляторов, допускающих оперативное взаимодействие программиста с машиной в процессе трансляции, отладки и решения задач. Методы трансляции отдельных операторов в диалоговых трансляторах те же, что и в обычных
299
компиляторах. Иначе организовано управление трансляцией и хранение информации о входной и объектной программах. Диалоговый транслятор обычно сочетает черты интерпретатора и компилятора. Каждый оператор при первом исполнении интерпретируется, а его машинный эквивалент, полученный в ходе интерпретации, сохраняется и при последующих исполнениях используется в режиме компиляции. Для обеспечения простой замены любого оператора входной программы без повторной трансляции всей программы исходные операторы и их машинные эквиваленты хранятся в виде списковой структуры.
Системное программирование еще очень молодо, поэтому неудивительно, что большую часть его технологического арсенала составляют эвристические приемы, не допускающие автоматизации технологии. Однако результаты теоретических исследований уже начинают использоваться при создании трансляторов. От успехов в этом направлении существенно зависит повышение производительности труда системных программистов.
ЛИТЕРАТУРА
1. Алгоритмический язык Алгол-60. Пересмотренное сообщение. «Мир», 1965.
2. Алгоритмический язык Алгол-68. — «Кибернетика», 1969, № 6; 1970, № 1.
3. Баркова И. С., Богданов В. В. и др. Компилятор с языка АЛМО для машины БЭСМ-4. ИПМ АН СССР. М., 1968.
4. Белявский Е. И., Иванов Е. К. и др. Сравнительная характеристика алгольных трансляторов TA-IM, ТА-2М, АЛЬФА. ИПМ АН СССР. М., 1969.
5. Бертен Ж., Р у ж и е Ж., Риту М. Работа ЭВМ с разделением времени. «Наука», 1970.
6. Болье Л. Методы построения компиляторов. — В сб. под ред. Ф. Женюи «Языки программирования». «Мир», 1972.
7. Брандон Д. X. Организация работ на вычислительном центре. «Статистика», 1970.
8. Б у х ш т а б Ю. А., Ермаков Е. А. и др. Система программирования Фортран-АЛ МО. — В сб.: [25].
9. Васильев В. А. Язык Алгол-68. Основные понятия. «Наука», 1972.
10. Виленкин С. Я-, Трахтенгерц Э. А. Математическое обеспечение управляющих вычислительных машин. «Энергия», 1972.
11. Гинзбург С. Математическая теория контекстно-свободных языков. «Мир», 1970.
12. Глушков В. М., Гладун В. П. и др. Обработка информационных массивов в автоматизированных системах управления. Киев, «Наукова думка», 1970.
13. Глушков В. М. и др. Человек и вычислительная техника. Киев, «Наукова думка», 1971.
14. Г о р е л ы ш е в а И. В., Кац Э. X., Луховицкая Э. С. Комплекс Алгол — В сб.: [25].
15. Джермейн К. Программирование на ИБМ/360. «Мир», 1971.
16. Ершов А. П. и др. АЛЬФА-система автоматизации программирования. Новосибирск, «Наука», 1967.
17. Ж о г о л е в Е. А., Трифонов Н. П. Курс программирования. «Наука», 1970.
18. Ингерман П. Синтаксически ориентированный транслятор. «Мир», 1969.
19. Камынин С. С., Любимский Э. 3 Алгоритмический машинно-ориентированный язык — АЛМО. «Алгоритмы и алгоритмические языки», вып. 1, ВЦ АН СССР. М., 1967.
301
20. Ла в р о в С. С., Гончарова Л. И. Автоматическая обработка данных. Хранение информации в памяти ЭВМ. «Наука», 1971.
21. Ледли В. С. Программирование и использование цифровых вычислительных машин. «/Мир», 1966.
22. Линдси Ч., С. ван дер Мюйлен. Неформальное введение в Алгол-68. «Мир», 1973.
23. Математическое обеспечение БЭСМ-6. Фортран (описание языка), 8, ИПМ АН СССР. М.. 1970.
24. Описание языка АЛГАМС. «Алгоритмы и алгоритмические языки», вып. 3 ВЦ АН СССР. М., 1968.
25. Первая всесоюзная конференция по программированию. Заседание «К», новые работы по трансляторам. Киев, 1968.
26. Рен дел л Б., Рассел Л. Реализация Алгола-60. «Мир», 1967.
*'27. Савинков В. М., Сидоренко Л. А. Синтаксический транслятор анализирующего типа «Статистика», 1972.
28. Современное программирование. Вып. 1. Сб. статей под ред. Любимского Э. 3. «Сов. радио», 1966.
29. Современное программирование. Вып. 2. Сб. статей под ред. Задыхайло И. Б., «Сов. радио», 1967.
30. Универсальный язык программирования PL/1. «Мир», 1968.
31. Фельдман Дж., Грис Д. Системы построения трансляторов. «Алгоритмы и алгоритмические языки», вып. 5, ВЦ АН СССР. М., 1971.
ч 32. Фишер Ф. П., С у и н д л Д. Ф. Системы программирования. «Статистика», 1971.
33. Флорес А. Программное обеспечение. «Мир», 1971.
34. Хомский Н. О некоторых формальных свойствах грамматик. «Кибернетический сборник», вып. 5, ИЛ, 1962, 279—312.
35. Хопгуд Ф. Методы компиляции. «Мир», 1972.
36. Ш у м е й А. С. Синтаксический анализ входного текста по определяющим символам. — «Автоматика и телемеханика», 1971, № 12, 114—122.
37. Ш у р а - Б у р а М. Р Некоторые вопросы математического обеспечения ЭВМ. ВЦ АН СССР. М., 1971.
38. Ш у р а к о в В. В. Математическое обеспечение ЭВМ. Киевский институт народного хозяйства им. Д. С. Коротченко. Киев, 1971.
39. A f е е J. Me. and Presser L. An algorithm for the Design of Simple Precedence Grammars, Journal of the ACM, 19, 3 (July 1972), 385—395.
40. Backes S. Automatische Erzeugung von Syntax — Analise — Programmen. Elektronische Rechenanlagen, 12, 2(1970), 80—86.
41. Dijkstra E. W. Recursive Programming. Numerische Mathematik, 2, 5(1960), 312—318.
42. F e r 1 i n g H. D., Schmitt H., S t r e 1 e n Chr., T h i e 1 m a n n H. und Wald-schmidt H. Ein Testlaufcompiler fur Algol 60. Angewandte Informatik, 1(1971), 17—21.
43. F e r 1 i n g H. D., Schmitt H., S t r e 1 e n Chr., Thielmann H. und Waldschmidt H. Objektzeitfehlerprufung bei einem Testlaufcompiler fйг Algol 60. Angewandte Informatik, 4(1971), 165—168.
44. F1 о у d R. W. A descriptive language for symbol manipulation. Journal of the ACM, 8 (Oct. 1961), 579—584.
45. F1 о у d R. W. Syntactic analysis and operator precedence. Journal of the ACM, 10(July 1963), 316—333.
46. Goos G., Einige Eigenschaften von Algol-68. Elektronische Datenverarbeitung, 9(1969), 437—442.
47. Gould I. H. (ed). IFIP Guide to Concepts and Terms in Data Processing. North — Holland Publishing company, Amsterdam — London, 1971.
302
48. G г i e s D. Use of Transition Matrices in Compiling. Communication of the ACM, 11, l(Jan. 1968).
49. Ingerman P. Z. Thunks — A way of Compiling Procedure Statements with some Comments on Procedure Declarations. Commucation of the ACM, 4, 1(1961), 55—58.
50. M a r t i n D. F. A Boolean Matrix Method for the Computation of Linear Precedence Functions. Communication of the ACM, 15, 6(June 1972).
51. Rutishauser H. Automatische Rechenplanfertigung bei Programmsteuerten Rechenmaschinen. Mitt. Inst. Angew. Math., ETH, Zurich, 3(1952).
52. S a m e 1 s о n K-, Bauer E. L. Sequential Formula Translation. Communication of the ACM, 3, 2(1959), 76—83.
53. S a m m e t J. E. Programming Languages: History and Future. Communication of the ACM, 15, 7 (July 1972).
54. Strobel R. Ein Verfahren zur Optimierung von Laufverweisungen und Prozeduraufrufen bei der Algol — Obersetzung. Elektronische Informations-verarbeitung und Kybernetik, 6, 4(1970), 255—276.
55. Wirth N. Algorithm 265: Find Precedence Functions. Communication of the ACM, 8, 10(1965), 604—605.
56. Wirth N. and Weber H. EULER — a generalisation of ALGOL, and its formal definition. Part I, Part II, Communication of the ACM, 9, (Jan., Feb, 1966), 13—25, 89—99.
57. Wirth N. Lecture notes on course systems programming by Alan C. Shaw, Stanford University, «Technical Report», 9, 52, 1966.
58. Z i m m e r R. Zusammenhange zwichen formalen Sprachen und Syntax — Erkennung. Angewandte Informatik, 1, (1971), 2—11.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Абсолютное выражение — 60
Абсолютный адрес — 6
Аварийная выдача — 33
Автокод — 14
Автоматный язык — 224
Административная система — 28
Адресная константа — 67
Алгамс— 114
Алгол-60 — 112
Алгол-68 — 119
Алгоритмический язык—14
Алгэк —15
Алгэм — 15
АЛКОР — 265
АЛМО —21
Алфавит — 24
Алфавит мнемокода — 55
Альфа-отладчик — 34
Альфа-транслятор — 26, 31, 207
Анализатор — 223
Ассемблер — 23. 76
База — 59, 70
База вектора — 38
Базовый адрес — 59, 70
Базовый регистр — 59, 70
Байт — 38, 58, 123
Библиотекарь — 9
Библиотека абсолютных модулей —8
Библиотека исходных модулей — 8
Библиотека объектных модулей — 8
Библиотека стандартных подпро-
грамм — 5
Библиотечная макрокоманда — 96
Блок —27, 113
БНФ (бэкусова нормальная форма)— 218
Быстрый транслятор — 209
Ввод — вывод — 58, 96, ИЗ
Вектор — 38
Вид — 120
304
Виртуальная память — 29
Внешнее имя — 63, 73
Внешний адрес — 6
Внешняя адресная константа — 94
Внешняя процедура — 117
Внутреннее имя—63, 103
Внутренний адрес — 6
Внутренний язык — 18, 121
Восходящий анализ — 223
Восходящий распознаватель — 223
Входная программа — 22
Входное имя — 63, 72
Входной язык— 18, 23
Вывод — 221
Выражение — 62
Выходная программа — 22
Выходной язык — 18
Генератор — 23, 242
Генерирование машинных команд —
77, 89, 135
Грамматика —215
Грамматика непосредственно составляющих — 224
Грамматика предшествования — 233
Грамматика с операторным предшествованием — 253
Грамматика LR(k) —281
Грамматика LR(l) —281
Грамматика с (tn, п) ограниченным контекстом — 281
Грамматика с (1,1) ограниченным контекстом — 281
Данные — 35
Двоичный поиск — 45
Двойное слово — 59
Дерево — 37
Дерево вывода — 222
Дерево разбора — 222
Диалоговый транслятор — 23, 299
Диалоговый язык — 18
Динамическое дерево — 144
Динамическое распределение памяти — 171
Длина поиска — 44
ДОС/ЕС — 8
Древовидная таблица — 44
Естественный язык— 13
ЕС ЭВМ — 58
Загрузчик — 7, 12
Замкнутая подпрограмма — 5
Запись — 35
Запрещенная команда — 82
Идентификатор — 55
Индекс — 36, 59
Индексный регистр — 59
Инвариантный модуль —12
Интерпретатор — 23
Интерпретирующая система — 6
Искусственный язык— 13
Исполнительный адрес — 6, 59
Исходный модуль — 10, 75
Канал — 58, 72
Канонический разбор — 223
Каталог макробиблиотеки —105
Ключ — 36
Ключевая макрокоманда — 97, 100
Ключевое слово—101
Книга — 10
Кобол — 15
Команда ассемблера — 65
Компилирующая система — 6
Компилятор — 23
Комплекс Алгол — 32, 34
Константа — 66, 124
Конструктор — 214
Контекст — 224, 284
Контекстно-зависимый язык — 224
Контекстно-свободная грамматика — 224
Контекстно-чу вствител ьна я гр а м м ати-ка — 224
Контекстно-чувствительный язык — 224
Конфликтные пары правил — 288
Конфликты предшествования — 248
Концевой знак — 217
Корень дерева — 37
Косвенная переменная —152
Кратность — 66
Левосторонний распознаватель — 226
Лексика — 24
Лексический анализ — 25, 122
Лексический анализатор — 242
Лексический контроль — 25, 129
Лист — 37
Листинг — 56, 84
Литерал — 65
Личная библиотека — 8
Магазин — 36
Макроассемблер —102
Макробиблиотека — 10, 96
Макрогенератор — 102
Макрокоманда — 14, 92
Макрокоманда ассемблера -— 96
Макрокоманда, определенная в про-
грамме — 96
Макроопределение — 96, 97
Макроязык —14, 96
Массив —- 36
Математическая память — 29
Математическое обеспечение — 3
Матрица операторного предшествования — 257
Матрица переходов — 265
Матрица предшествования — 238
Матрица сочетаемости—129
Машинная команда — 56, 58
Машинно-зависимый язык — 14
Машинно-независимый язык — 14
Машинно-ориентированный язык —14
Машинный язык— 13
МБНФ (модифицированная бэкусова нормальная форма) —218
Металингвистическая переменная -* 216
Метасинтаксический язык — 215
Метаязык — 215
Метод операторного предшествования — 253
Метод предшествования — 232
Метод расширенного предшествования — 252
Метод синтаксических подпро-
грамм — 212
Метод синтаксической информации — 213
Метод (т, п) предшествования — 295
Методы трансляции — 26
Мнемокод— 14, 54
Мнемоника — 56
Многопросмотровая схема трансляции — 28
Многоэтапная трансляция — 28
Многоцелевой язык— 116, 121
Модификатор — 66
Модифицированный нисходящий распознаватель — 229
Модуль загрузки — 6
Модульное программирование— 10
Мультипрограммная вычислительная система —12
Начальный символ грамматики — 217
Невосстанавливающийся модуль 12
305
Неоднозначная грамматика — 222
Неосновной символ — 216
Непосредственно приводимая фра-
за — 230
Непосредственный операнд — 58
Непроцедурный язык — 17
Нетерминальный символ — 216
Неупорядоченная таблица — 44
Неявная длина — 66
Неявный адрес — 60
Нисходящий анализ — 223
Нисходящий распознаватель — 223
Нотация — 218
Область литералов — 65
Образец — 282
Обратная польская запись — 130
Обратная польская запись разбора — 246
Общая обласгь — 93
Общий регистр — 59
Объектная программа — 22
Объектный модуль — 9, 86
Объектный язык— 18
Оглавление библиотеки — 8
Операнд — 56, 131
Оператор — 24, 55
Операторная грамматика — 253
Оператор прототипа — 98
Операторное предшествование — 253
Операционная система — 4
Описание данных— 118
Описания — 187
Определяющий вектор массива — 42
Оптимизация программы — 205
Оптимизация транслятора — 205
Оптимизирующий транслятор — 207
Ориентированный граф — 37
Основа — 223, 230, 232
Основная память ЕС ЭВМ — 58
Основной символ — 216
Открытая подпрограмма — 5
Открытое перемешивание — 48
Отладка — 33
Отношения операторного предшествования — 256
Отношения предшествования — 232
Очередь — 36
Пакет прикладных программ — 3
Параметры макроопределения — 97
Первичная фраза — 254
Переключатель — 196
Перемешивание с внутренними цепочками— 51
Перемешивание с цепочками переполнения — 50
Перемещаемое выражение — 60
Перемещение — 87
ПЛ/1 — 116
Подбиблиотека — 10
Подпрограмма — 5
Позиционная макрокоманда — 97
Поле — 35, 59
Поле идентификации — 56
Поле комментария — 56
Поле массивов — 176
Поле названия — 55
Поле операндов — 56
Поле операции — 56
Полуслово — 59
Польская запись — 130
Порождающая грамматика — 215, 217
Порождающие правила — 217
Порождение — 221
Постфиксная запись— 131
Правила подстановки — 217
Правила подстановки Флойда — 281
Предложение — 24, 55, 221
Префиксная запись — 134
Приведение строки — 222
Прикладное математическое обеспечение — 3
Приоритет— 137
Проблемно-ориентированный язык — 17
Программная секция — 93
Программное обеспечение — 3
Программный модуль — 65
Прокрутка — 34
Промежуточный язык— 121
Процедура — 97, 196
Процедурно-ориентированный язык — 14
Процедурный блок — 117
Прямая польская запись— 134
Прямое порождение — 221
Прямо леворекурсивная грамматика—217
Прямо праворекурсивная грамматика — 217
Прямые методы трансляции — 26
Псевдокоманда — 65
Разбор — 222
Раскрутка —103
Распознаватель — 223
Распознаватель операторного предшествования — 254
Распознаватель предшествования — 234
Распознаватель расширенного предшествования — 250
Распознающая грамматика — 215, 273
Расширенная операторная грамматика — 265
Расширенное предшествование — 247
Расширенный мнемонический код
команды — 62
<306
Расширяемый язык — 299
Регистр с плавающей запятой — 59
Редактор связей — 10, 87
Редукция строки — 222
Резидентный файл — 9
Рекурсивная процедура —173
Рекурсивность — 112
Самовосстанавливающийся модуль — 12
Самоопределенный терм — 64
Санк — 197
Сведение строки — 222
Связка — 223
Связующая информация —182
Сегмент — 28
Сегментация данных — 28
Сегментация программы — 28
Сегмент массивов — 192
Семантика — 24
Семантическая подпрограмма — 212
Семантический анализ — 25
Семантический анализатор — 242
Семантический загрузчик — 214
Семантический контроль — 209
Сентенциальная форма — 221
Сеть — 39
Сечение— 117
Символическое имя — 55
Синтаксис — 24, 215
Синтаксическая подпрограмма — 213
Синтаксические методы трансляции — 26
Синтаксический анализ — 25
Синтаксический анализатор — 214
Синтаксический загрузчик — 214
Синтаксически-ориентированный транслятор — 214
Синтаксически-управляемый транслятор — 214
Синтаксический контроль — 25
Синтаксически-ориентированные методы — 27
Синтаксическое дерево — 222
Система программирования — 4
Системная библиотека — 8
Системная макрокоманда — 96
Системное математическое обеспечение — 3
Системное программирование — 3
Системный загрузчик — 9
Словарь внешних мен — 85
Словарь грамматики — 216
Словарь перемещаемых адресных констант — 85
Словарь перемещений — 86
Слово — 24, 59
Служебное слово— 124
Смешанная макрокоманда — 97
Смещение — 59
Специальный нетерминальный символ — 266
Списковая структура — 38
Список — 38
Сравнительный приоритет—155
Средства отладки — 33
Стандартная подпрограмма — 5
Статическое дерево— 144
Статическое распределение памяти — 171
Стек — 36
Стековый приоритет — 155
Стек операндов— 135
Стек операций — 137
Стек с приоритетами — 137
Страница — 29
Строка — 35
Структура — 117, 120
Структура транслятора — 26
Структуры данных — 35
Структуры хранения — 38
Супервизор —9
Счетчик адреса — 64
Счетчик адреса оператора — 80
Счетчик операторов — 80
Таблица — 36
Таблица базовых регистров — 79
Таблица блоков— 174
Таблица внешних имен — 79
Таблица внутренних имен— 105
Таблица входных имен — 78
Таблица выводов — 274
Таблица идентификаторов — 176
Таблица имен — 79, 125
Таблица использования имен — 80
Таблица ключевых операндов— 109
Таблица ключевых параметров— 105
Таблица левых троек — 248
Таблица литералов — 79
Таблица макрокоманд— 106
Таблица меток— 125
Таблица операций — 77
Таблица описаний макрокоманд —
106
Таблица ошибок —80
Таблица перекрестных ссылок — 85
Таблица перемещаемых адресных констант — 79
Таблица позиционных операндов — 106
Таблица позиционных параметров — 105
Таблица порождающих правил — 244
Таблица правых троек — 248
Таблица указателей начала блоков —
174
Таблицы ассемблера — 77
Таблицы макрогенератора— 104
307
Таблицы с вычисляемыми входами — 47
Таблицы с прямым доступом — 47
Таблицы со случайным перемешиванием — 48
Тело макроопределения — 98
Терм — 62
Терминальный символ — 216
Тип константы — 66
Тип переменной — 119
Транслятор — 22, 242, 270
Транслятор ТА-1М — 31
Транслятор ТА-2М — 29
Транслятор ТАУ-67 — 32
Трассировка — 34
Узел — 37
Указатель стека — 42
Универсальная система программирования — 21, 32, 211
Универсальный компилятор — 213
Универсальный машинно-ориентированный язык — 21
Универсальный язык — 20
Универсальный язык программирования — 21
Упорядоченная таблица — 45
Уровень блока — 172
Фаза — 9
Файл — 8
Формализация семантики — 215
Формат команды — 59
Формальная грамматика — 215
Формальный язык — 220
Фортран — 114
Фраза — 230
Функции операторного предшествования — 256
Функции предшествования — 240
Функция расстановки — 47, 51
Функция упорядочения — 41
Характеристика длины имени — 63
Характеристика переместимости — 69 79
Центральный процессор — 58
Циклический список — 42
Эквивалентные грамматики — 221
Эмулятор — 20
Юнкол — 22
Явная длина — 66
Явный адрес — 60
Язык — 13
Язык ассемблера — 23
Язык высокого уровня — 19
Язык загрузчика — 8
Язык макроассемблера — 23
Язык-оболочка — 22
Язык правил подстановки — 281
Язык программирования —13
Язык символического кодирования —
14, 54
Язык с конечным числом состояний — 224
Язык-ядро — 22
СОДЕРЖАНИЕ
Введение..............................................................3
Глава 1. Элементы системы программирования . 5
1.1. Библиотека стандартных подпрограмм......5
1.1.1. Назначение и структура библиотечных подпрограмм . . 5
1.1.2. Компилирующие и интерпретирующие системы .... 6
1.1.3. Современные тенденции в организации библиотеки ... 7
1.1.4. Особенности стандартных подпрограмм в мультипрограммных системах.............................................12
1.2. Языки программирования..................................13
1.2.1. Классификация ....................................13
1.2.2. Сравнительная характеристика языков...............18
1.2.3. Универсальные языки...............................20
1.3. Трансляторы ............................................22
1.3.1. Классификация ....................................22
1.3.2. Компиляторы и интерпретаторы .... ................23
1.3.3. Общая схема трансляции.......................... 24
1.3.4. Структура трансляторов............................26
1.3.5. Сегментация программы и данных....................28
1.3.6. Структура транслятора ТА-2М.......................29
1.3.7. Характеристики некоторых отечественных трансляторов 31
1.3.8. Средства отладки..................................33
Глава 2. Организация, хранение и поиск данных.......................* 35
2.1. Структуры и хранение данных.............................35
2.1.1. Структуры данных..................................35
2.1.2. Структуры хранения................................38
2.1.3. Отображение структур данных в структуры хранения . . 40
2.2. Хранение и поиск данных в таблицах......................43
2.2.1. Таблицы . . 43
2.2.2. Неупорядоченные таблицы...........................44
2.2.3. Упорядоченные таблицы.............................4э
2.3. Таблицы с вычисляемыми входами..........................47
2.3.1. Таблицы с прямым доступом....................... 47
2.3.2. Таблицы со случайным перемешиванием...............48
2.3.3. Перемешивание с цепочками переполнения............30
2.3.4. Функции расстановки...............................31
Глава 3. Ассемблеры..................................................54
3.1. Языки символического кодирования........................34
3.1.1. Области применения и средства языков символического кодирования ...............................................34
309
3.1.2. Машинные команды.....................................58
3.1.3. Выражения ...........................................62
3.1.4. Команды ассемблера........................... ..... 65
3.2. Ассемблер мнемокода........................................76
3.2.1. Схема трансляции..................................76
3.2.2. Структура двухпросмотрового ассемблера............76
3.2.3. Таблицы ассемблера................................77
3.2.4. Первый просмотр. Выявление имен...................80
3.2.5. Распределение памяти для литералов................84
3.2.6. Листинг и объектный модуль........................84
3.2.7. Второй просмотр. Генерирование машинных команд . . 89
3.2.8. Особенности ассемблера для многосекционных программ 93
3.2.9. Использование памяти разных уровней при трансляции . 94
3.3. Макроассемблер.............................................95
3.3.1. Макроязык.........................................95
3.3.2. Макроопределения..................................97
3.3.3. Макрогенератор...................................102
3.3.4. Таблицы макрогенератора..........................101
3.3.5. Блок управления трансляцией......................106
3.3.6. Блок обработки макроопределений..................107
3.3.7. Блок обработки макрокоманд.......................109
Глава 4. Прямые методы трансляции .....................................112
4.1. Процедурно-ориентированные языки..........................112
4.1.1. Алгол-60............................................112
4.1.2. Фортран.............................................114
4.1.3. ПЛ/1 ...............................................116
4.1.4. Алгол-68............................................119
4.1.5. Задачи трансляции...................................121
4.2. Лексический анализ........................................122
4.2.1. Задачи лексического анализа.........................122
4.2.2. Перекодирование входной программы....123
4.2.3. Перевод служебных слов, идентификаторов и констант . 124
4.2.4. Алгоритм перевода числовых констант................126
4.2.5. Контроль входной программы на этапе лексического анализа .....................................................129
4.3. Трансляция выражений......................................130
4.3.1. Польская запись.....................................130
4.3.2. Алгоритм перевода обратной польской записи в машинные команды...................................................134
4.3.3. Перевод простых арифметических и логических выражений в обратную польскую запись.........................137
4.3.4. Переменные с индексами..............................140
4.3.5. Указатели функций...................................142
4.3.6. Условные выражения..................................144
4.3.7. Особенности алгоритма перевода условных выражений в обратную польскую запись.........................149
4.3.8. Алгоритм трансляции выражений.......................152
4.4. Трансляция операторов.....................................153
4.4.1. Промежуточная обратная польская запись операторов . 153
4.4.2. Оператор присваивания...............................154
4.4.3. Оператор перехода...................................156
4.4.4. Условный оператор...................................158
4.4.5. Оператор цикла.................................... 161
4.4.6. Алгоритм перевода оператора цикла в обратную польскую
запись ...............................................165
4.5. Блоки и трансляция описаний...............................171
4.5.1. Блочная структура программы и способы распределения памяти ...................................................171
4.5.2. Статическое распределение памяти....................174
810
4.5.3. Использование стека для динамического распределения памяти .......................................................179
4.5.4. Перевод в обратную польскую запись блоков и описаний типа .........................................................187
4.5.5. Трансляция описаний массивов.....................192
4.5.6. Обработка меток и описаний переключателей........196
4.6. Трансляция процедур....................................196
4.6.1. Способы трансляции процедур......................196
4.6.2. Обратная польская запись оператора процедуры .... 198
4.6.3. Алгоритм трансляции операторов процедур..........202
4.6.4. Особенности трансляции описаний процедур ..... 203
4.7. Оптимизация объектной программы и транслятора..........205
4.7.1. Задачи оптимизации...............................205
4.7.2. Оптимизирующие трансляторы.......................207
4.7.3. Быстрые трансляторы..............................209
Глава 5. Синтаксические методы трансляции................................211
5.1. Сущность синтаксических методов.............................211
5.1.1. Метод синтаксических подпрограмм.................211
5.1.2. Синтаксические методы и универсальный компилятор . . 213
5.2. Формальные грамматики и языки..........................215
5.2.1. Формальные грамматики.................................215
5.2.2. Нотация...............................................218
5.2.3. Формальные языки......................................220
5.2.4. Задача разбора........................................222
5.2.5. Классификация языков по Хомскому......................223
5.2.6. Нисходящий анализ . ..................................225
5.2.7. Восходящий анализ............................. ... 229
5.3. Метод предшествования....................................232
5.3.1. Отношения предшествования.............................232
5.3.2. Грамматика предшествования............................233
5.3.3. Распознаватель........................................234
5.3.4. Матрица предшествования...............................235
5.3.5. Функции предшествования...............................239
5.3.6. Транслятор............................................242
5.3.7. Расширенное предшествование...........................247
5.3.8. Распознаватель расширенного предшествования .... 250
5.4. Операторное предшествование..............................253
5.4.1. Грамматика с операторным предшествованием .... 253
5.4.2. Распознаватель .......................................254
5.4.3. Матрица и функции операторного предшествования . . 256
5.4.4. Особенности транслятора............................259
5.4.5. Сравнительная оценка методов, основанных на предшествовании .............................................262
5.5. Матрица переходов...........................................265
5.5.1. Расширение операторной грамматики................... 265
5.5.2. Распознаватель и транслятор...........................268
5.5.3. Конструктор ..........................................273
5.6. Правила подстановки Флойда..................................281
5.6 1. Распознаватель .......................................281
5.6.2. Конструктор .............................. . . . 284
5.6.3. Подготовка грамматики для конструктора................287
5.6.4. Примеры ..............................................289
5.6.5. Взаимосвязь методов синтаксического анализа . . . • 295
Заключение.............................................................. 298
Литература . ......................................................... 301
Предметный указатель...................................................309
Владлен
Николаевич
Лебедев
ВВЕДЕНИЕ В СИСТЕМЫ ПРОГРАММИРОВАНИЯ
Редактор Г. 77. Яшина
Техн, редактор Л. Г. Челышева Корректор Я. Б. Островский
Худ. редактор Т. В. Стихно
Переплет художника Г. Н. Погореловой
Сдано в набор 10/IX 1974 г. Подписано к печати 16/XII 1974 г.
Формат бумаги 60 X ЭО1/^- Бумага № 2 Объем 19,5 печ. л. Уч.-изд. л. 20,12 Тираж 40000 экз. А12840 (Тематич. план 1975 г. № 64)
Издательство «Статистика», Москва, ул. Кирова, 39 Заказ № 321
Отпечатано в тип. им. Котлякова издательства <Финансы» Государственного Комитета Совета Министров СССР по делам издательств, полиграфии и книжной торговли.
191023. Ленинград Д*23, Садовая, 21 с матриц ордена Трудового Красного Знамени Ленинградской типографии № 2 имени Евгении Соколовой Союзполиграфпрома при Государственном комитете Совета Министров СССР по делам издательств, полиграфии и книжной торговли.
198052, Ленинград, Л-52, Измайловский проспект, 29
Заказ № 221
Цена 1 р. 37 к.