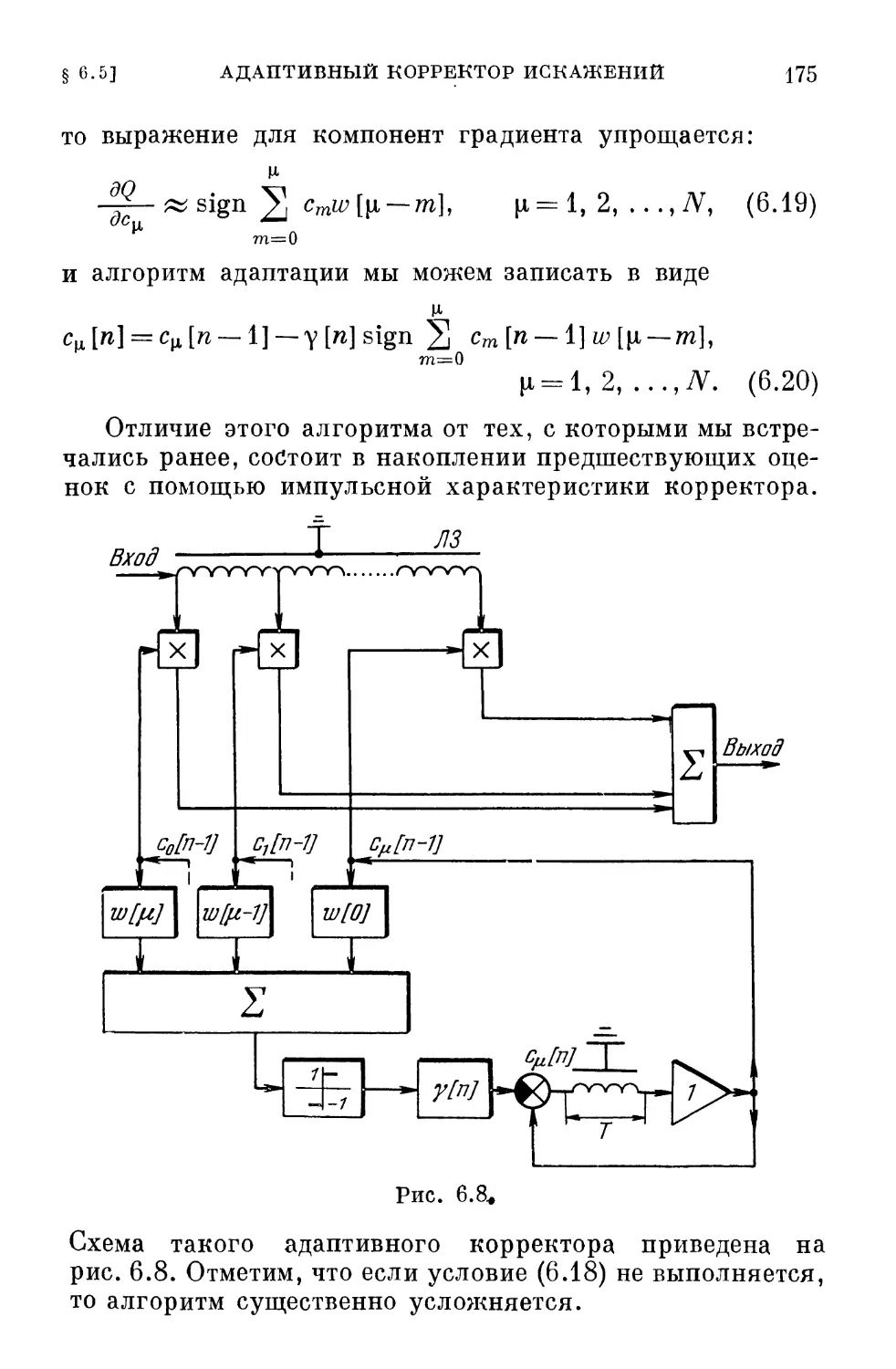
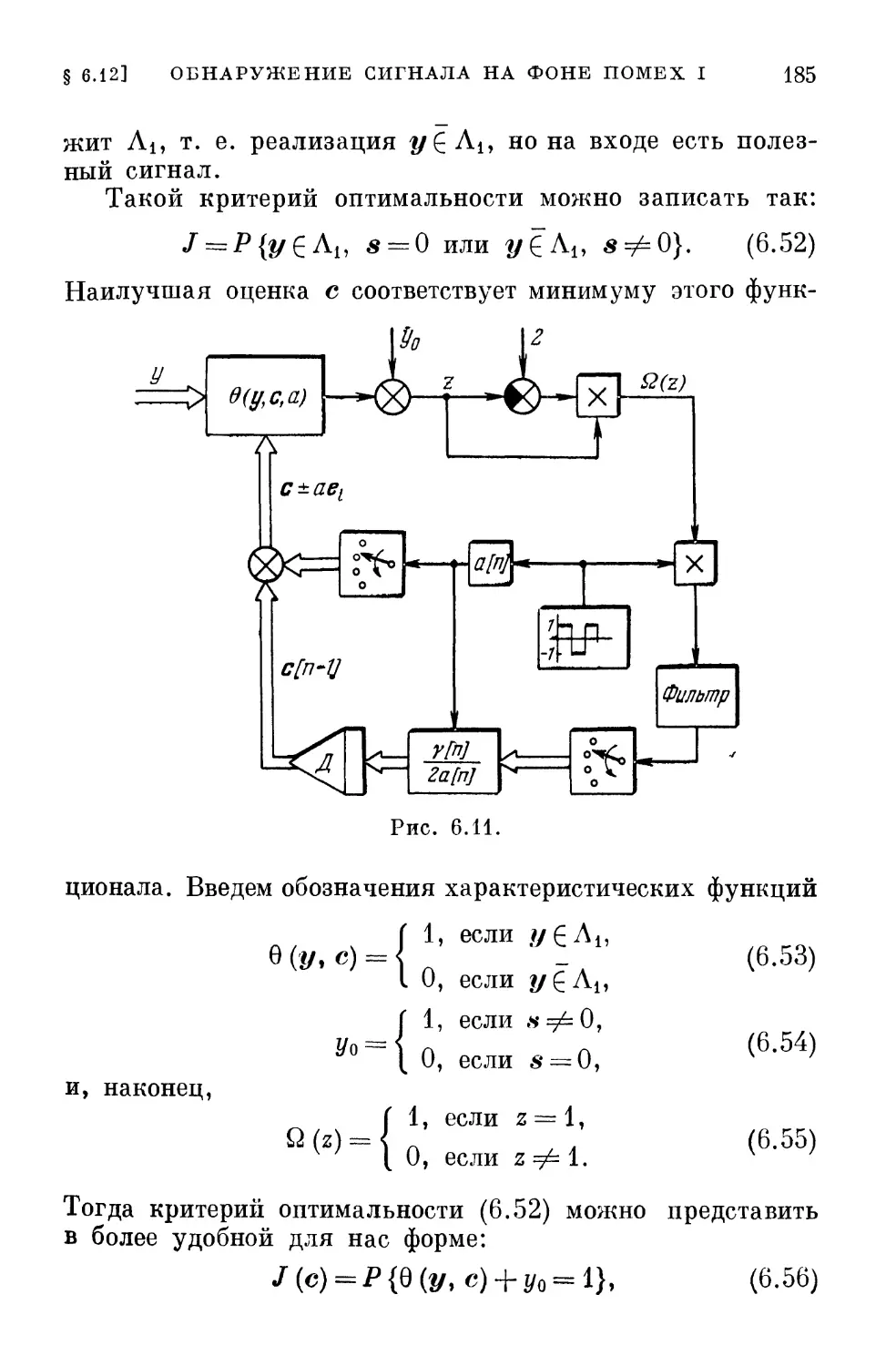
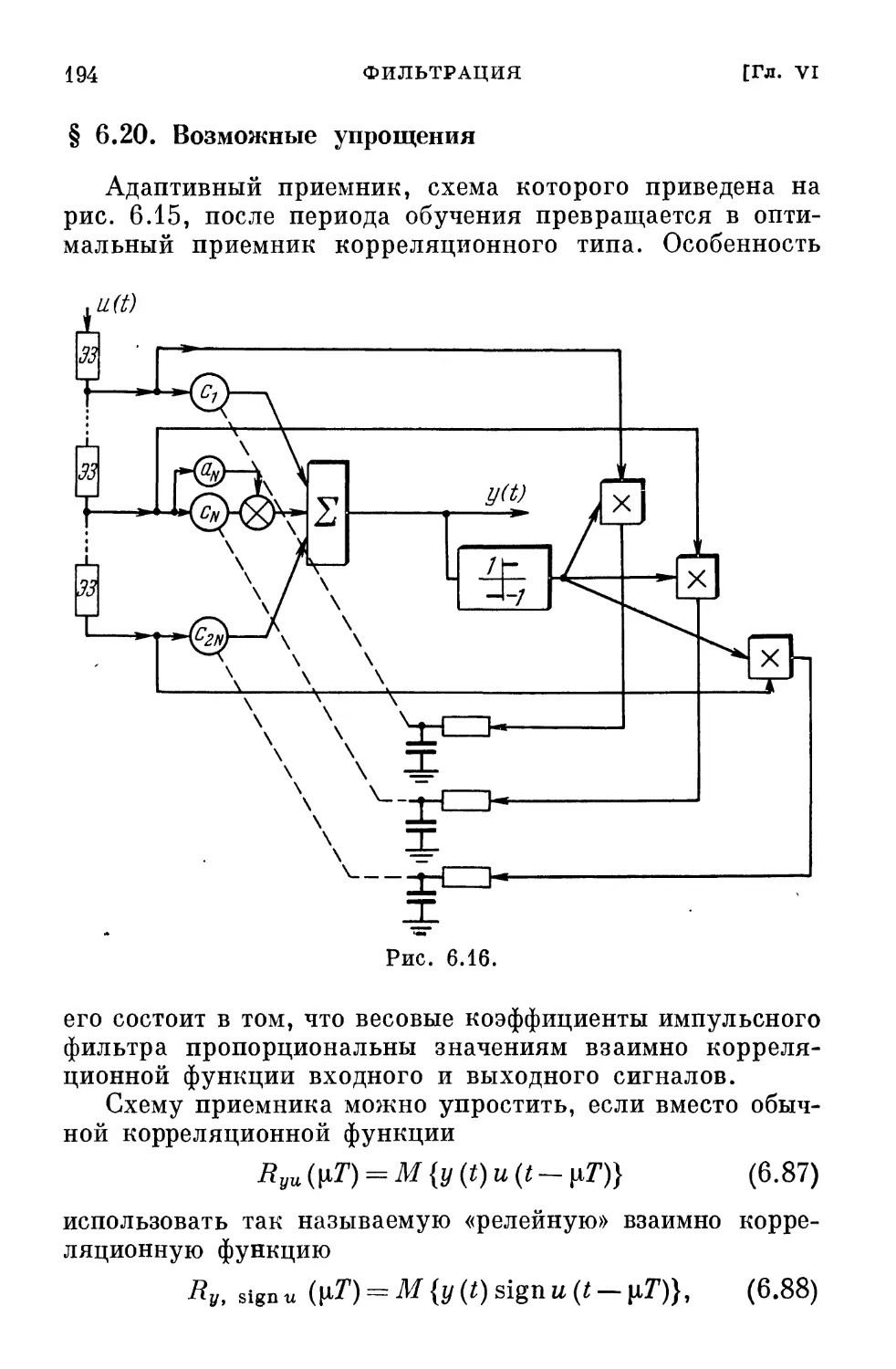
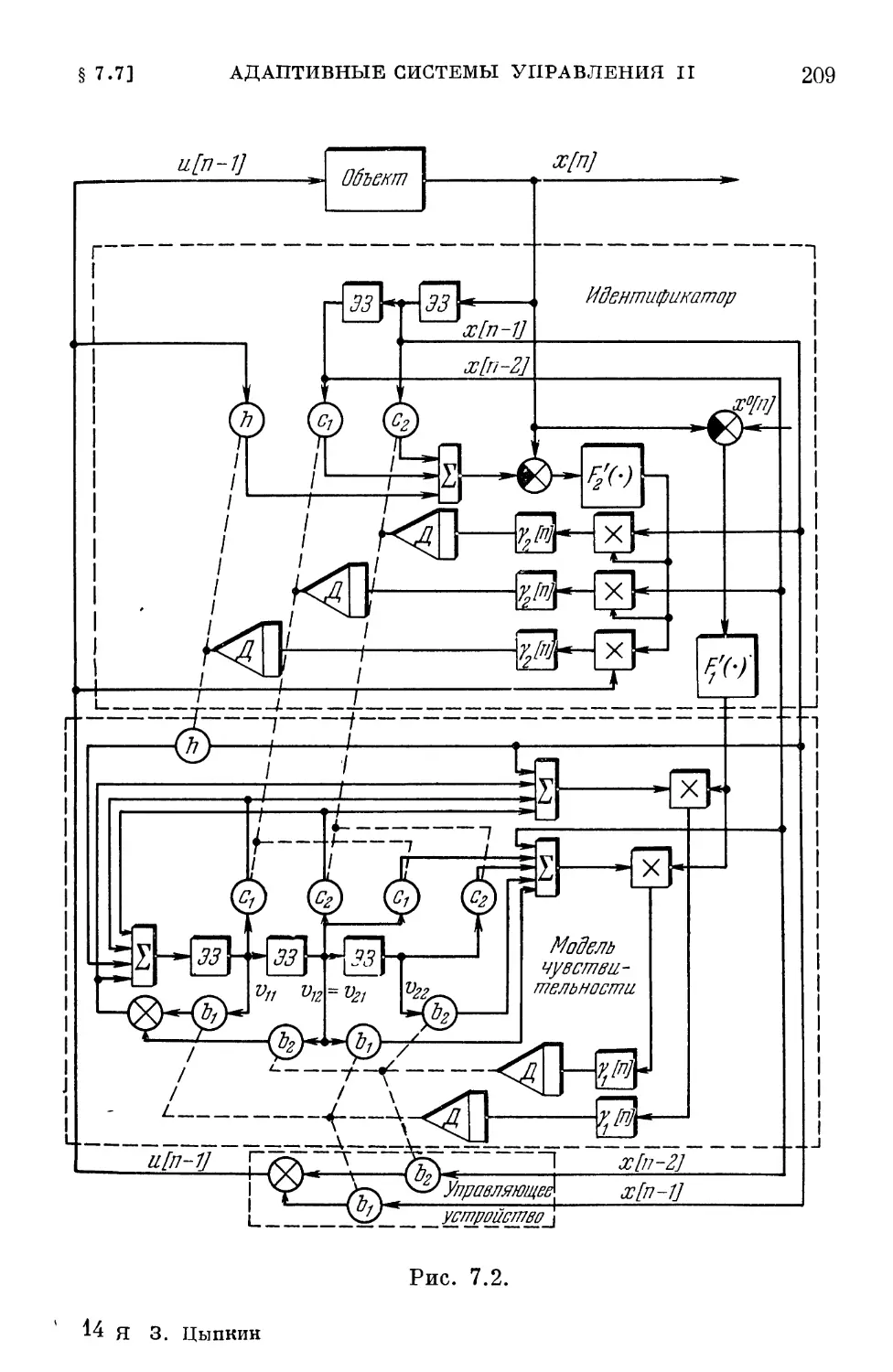
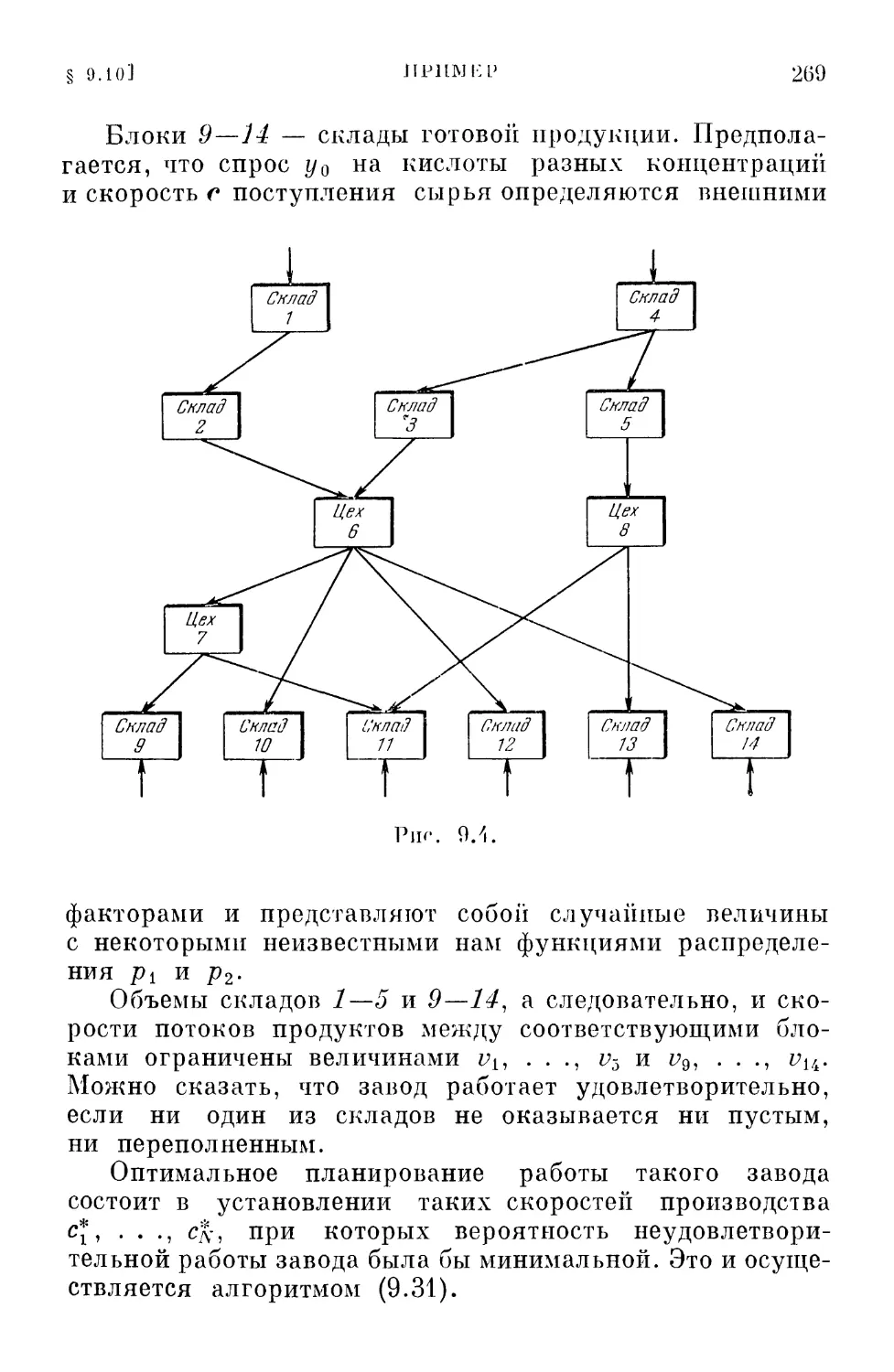
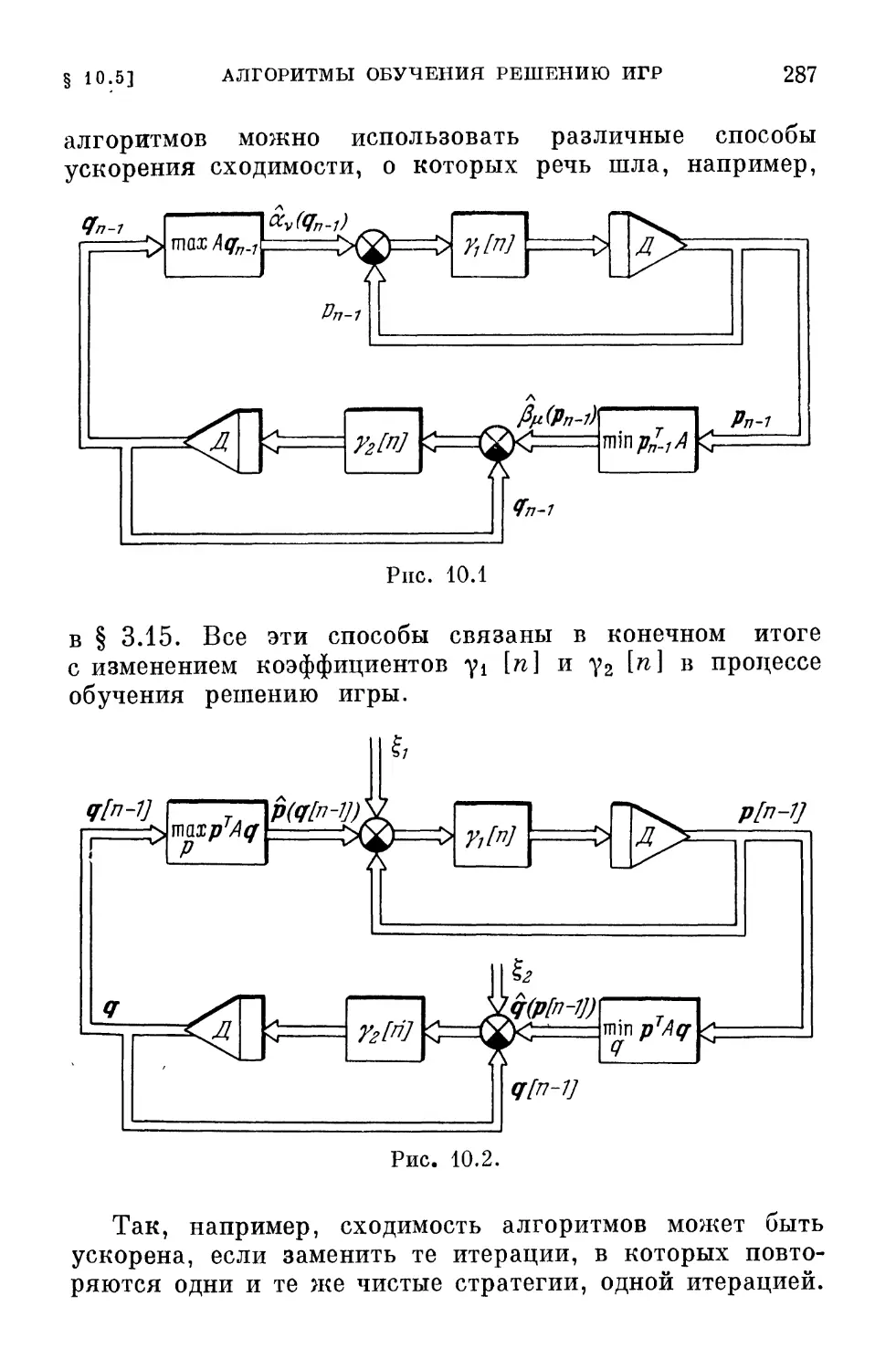
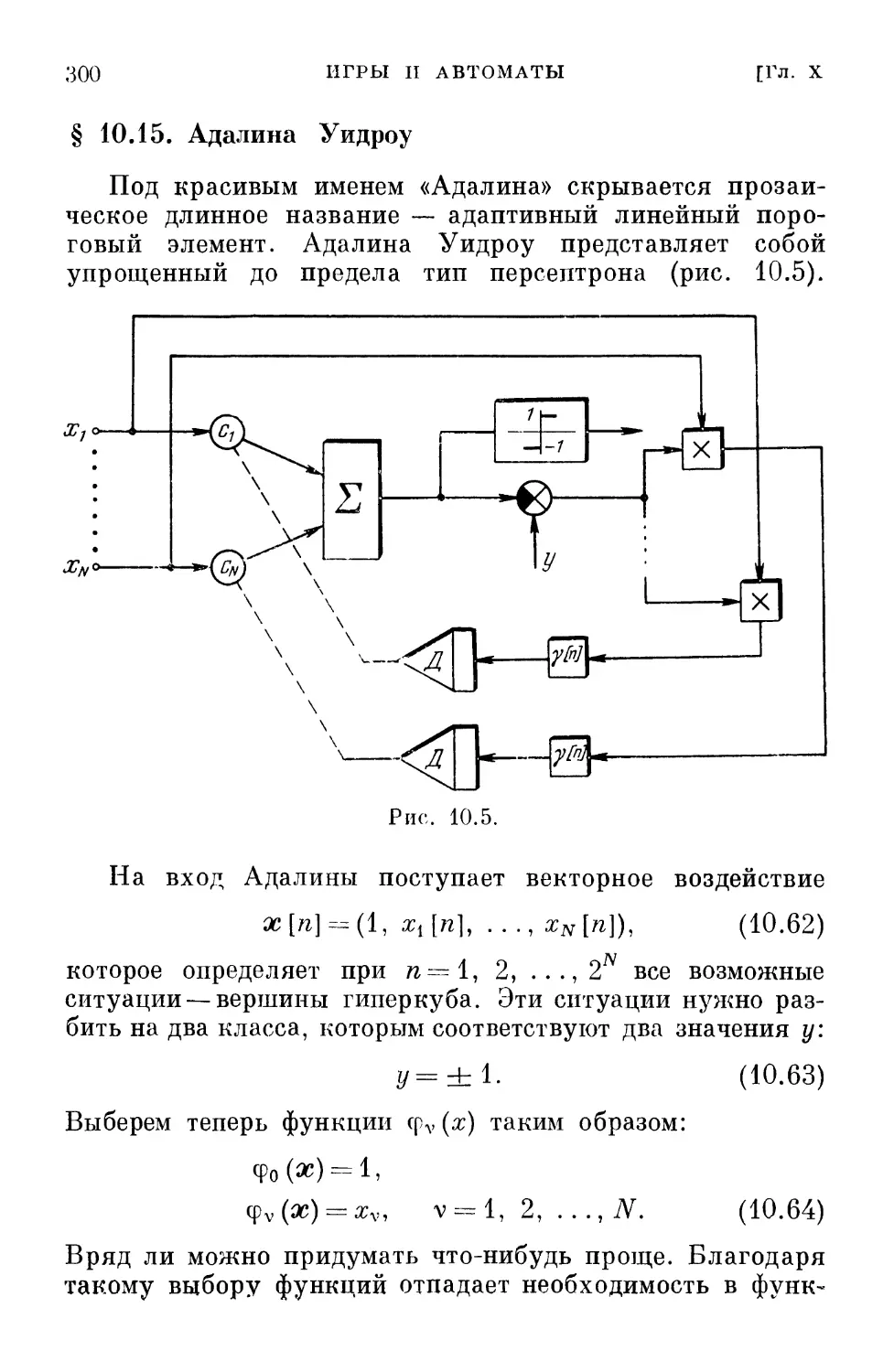
/













































































































































































































































































































































































Author: Цыпкин Я.З.
Tags: регулирование и управление машинами, процессами теория автоматического управления
Year: 1968




Text
Я. 3. и ы п к и н
..даптация
и обучение
в автоматических
Я. 3. цыпкин
Адаптация
и обучение
в автоматических
системах
ИЗД АТЕЛЬСТВО «НАУКА»
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
МОСКВА 1968
6.П2.151 Адаптация и обучение в автоматических
ц 96 системах, Я. 3. Ц ы л к п н, Главная
V7IK Г'> Ч) редакция физико-математической лите-
^ дп u_-ju ратуры изд-ва «Паука», М., 19(38, 400 стр.
Проблемы адаптации и обучения, которые
рассматриваются в кнше, являются
центральными в современной теории и технике
автоматического управления. Решение этих проблем
позволяет осуществлять оптимальное
управление сложными объектами, в условиях весьма
малoii априорной информации относительно
состояния управляемого объекта и его
характеристик.
В кише с единой общей точки зрения,
основанной на вероятностных итеративных методах,
обсуждаются разнообразные задачи адаптации
и обучения и приводятся эффективные пути их
решения. Рассмотрены алгоритмические методы
решения задач обучения опознаванию образов,
определения характеристик динамических
объектов, обнаружения и выделения сигналов па
фоне поче\', управления динамическими
объектами и условиях неопределенности. Развитый
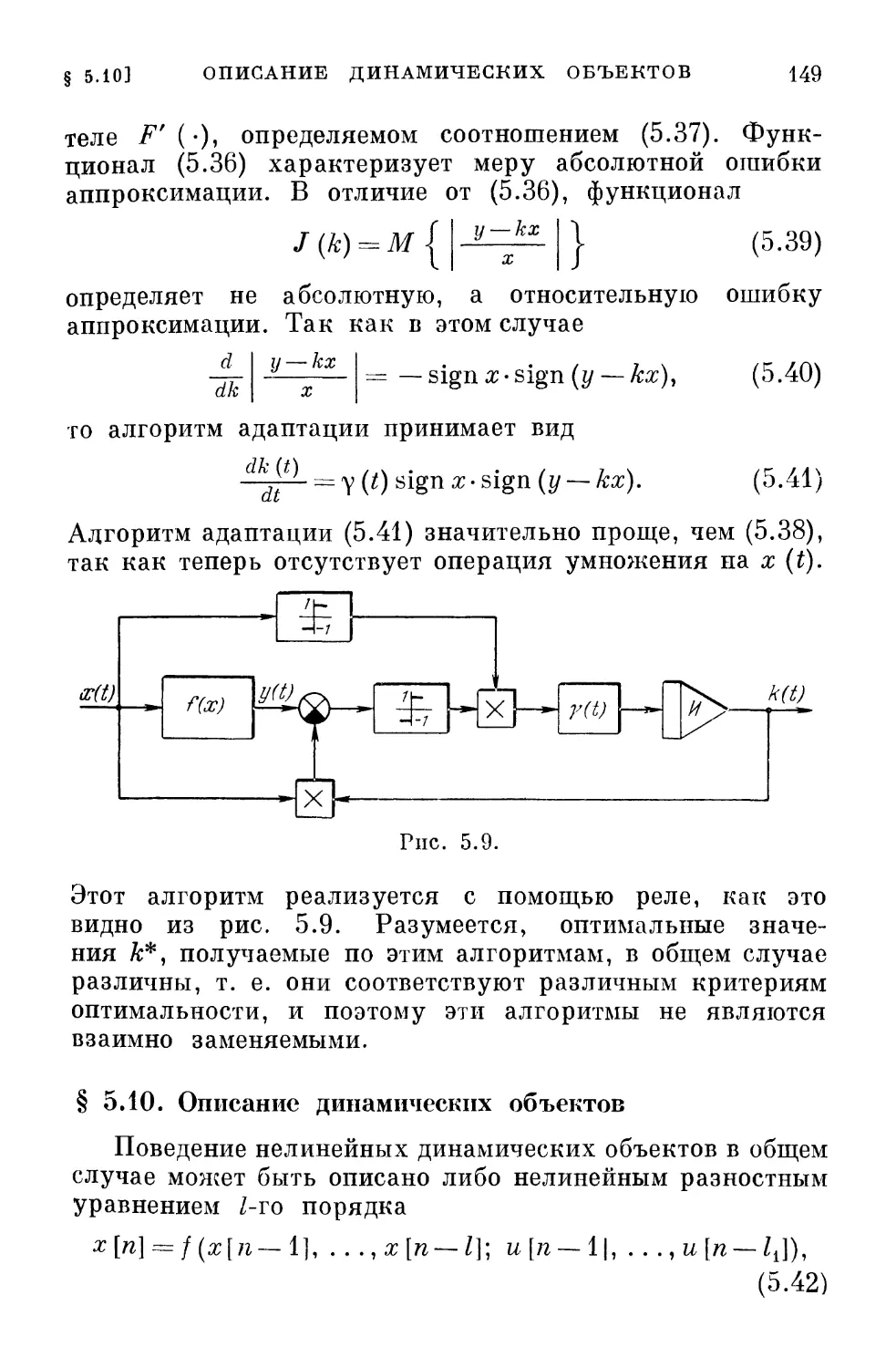
подход применен также к решению задач
теории надежности, исследованию операции, теории
игр и поведения конечных автоматов.
Результаты общей теории иллюстрируются на
многочисленных; примерах;. Приводятся
формулировки нерешенных задач.
Табл. \. J Li л. !)(J. Пибл. 505 назв.
141-67
Предисловие
При написании книги, которая охватывала бы
проблемы обучения, самообучения и адаптации в
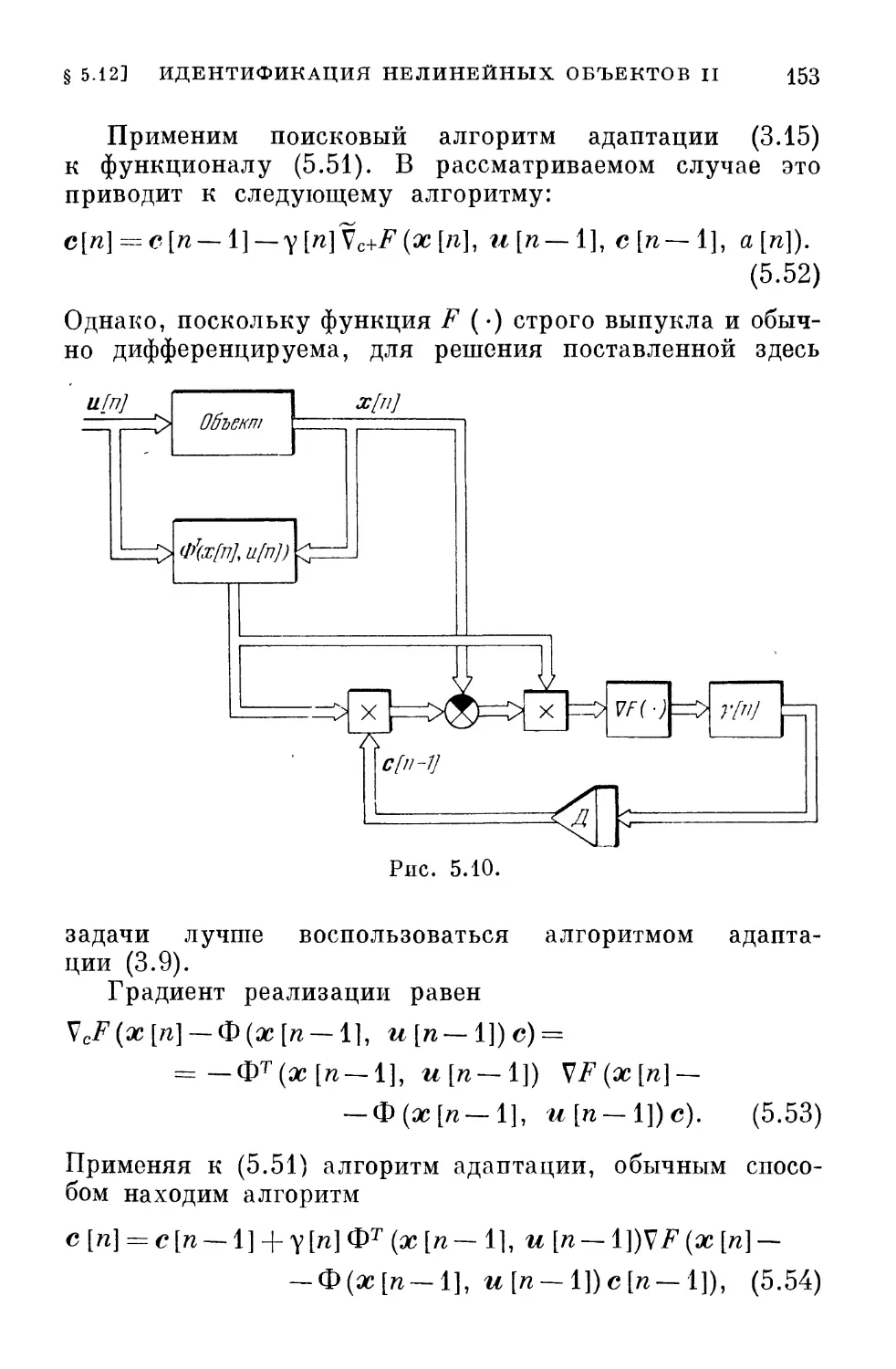
автоматических системах, возникает целый ряд трудностей.
Несмотря на относительную новизну этой проблемы,
число работ, так или иначе с ней связанных, довольно
велико, и составление даже краткого обзора этих работ
заняло бы много моста и потребовало бы большого
времени. По если бы эта трудность и была преодолена,
то все равно нас ожидало бы еще одно препятствие,
вызванное традицией, присущей, в частности, и теории
автоматического управления. Вот уже который год для решения
одних и тех же задач создаются различные методы,
которые после некоторого периода соревнования либо
забываются, .либо, как это чаще случается, продолжают мирно
сосуществовать. Если учесть еще, что самих задач также
немало, то можно себе представить состояние специалиста,
пытающегося разобраться в проблеме адаптации.
Подобное состояние пережил и автор, когда летом
1965 г. он занялся подготовкой доклада «Адаптация,
обучение и самообучение в автоматических системах»
к 3-му Всесоюзному совещанию по автоматическому
управлению (Одесса, сентябрь 1965 г.). Нужно было
искать выход из создавшегося положения. Такой выход
мог быть найден только в коренной ломке уже
упоминавшейся традиции. Вместо рассмотрения одних и тех же
задач различными методами была предпринята попытка
ПРЕДИСЛОВИЕ
рассмотреть различные задачи одним и тем же методом.
Вначале надежда на успех основывалась только на вере
в существование каких-то общих закономерностей,
которым должна подчиняться адаптация. Но после того
как удалось нащупать некоторые из этих
закономерностей, надежда превратилась в уверенность.
В основу развиваемого в этой книге общего подхода,
охватывающего разнообразные задачи адаптации, были
положены вероятностные итеративные методы.
За небольшой промежуток времени, прошедший с
момента выдвижения этого подхода, удалось не только
уточнить и развить ряд утверждений, но и обнаружить,
что результаты многих работ но адаптации и обучению,
как появившихся в самое последнее время, так и работ
прежних лет, которым по разным причинам не было
уделено достаточного внимания, подчиняются
закономерностям, вытекающим из этого общего подхода.
Раз пинаемый подход не только упрощает решение
известных задач, по и позволяет решать многие новые
задачи.
Разумеется, мы далеки от мысли, что излагаемый в
этой книге подход охватывает все работы по адаптации,
обучению и самообучению и тем более работы, в которых
эти термины только фигурируют. Возможно, что ряд
существенных работ остался вне поля зрения, но если это
и так, то не потому, что они неинтересны или неважны,
а потому, что пока еще нет более общей концепции,
которая могла бы охватить и их.
Оглавление книги дает о ней достаточно полное
представление, и вряд ли стоит заниматься подробным
пересказом ее содержания. Но о некоторых особенностях книги
сказать нужно.
Мы отказываемся от подробного доказательства многих
высказываемых положений. Сделано это по ряду причин.
ПРЕДИСЛОВИЕ
5
Во-первых, это сильно увеличило бы объем книги и
изменило задуманный стиль. Во-вторых, неизбежная при
этом перегрузка деталями и тонкостями помешала бы,
как нам кажется, выделить и подчеркнуть общие идеи
адаптации и обучения. Наконец, не все доказательства
имеют ту форму, которая совмещала бы общность с
краткостью, и, как ни грустно в этом сознаться, мы пока еще
не обладаем всеми без исключения нужными
доказательствами.
Автор пытался изложить все вопросы «настолько
просто, насколько это возможно, но не проще».
Наряду с изложением общих идеи и их применением
к разнообразным задачам современной теории управления
и смежных областей — теории надежности, исследования
операции, теории игр, теории конечных автоматов и т. п.,
в книге формулируются различные но важности,
сложности и конкретности задачи, ждущие своего решения.
В основном тексте книги почти полностью отсутствуют
ссылки на литературу, тем или иным образом связанную
с рассматриваемыми вопросами. Это сделано умышленно,
чтобы не прерывать изложения частыми ссылками. Зато
в конце книги помещен подробный обзор литературы
по адаптации и обучению. Помимо обзора, здесь делаются
различные дополнения и замечания, а полученные
результаты сопоставляются с известными ранее.
Указатель основных обозначений облегчит читателю
знакомство с любой из интересующих его глав по
применению адаптивного подхода независимо от чтения остальных
глав.
Эта книга не могла бы быть написана, если бы автор
не опирался на поддержку своих молодых сотрудников
Э. Аведьяна, И. Девятерикова, Г. Кельманса, П. Надеж-
дина, Ю. Попкова и А. Пропоя, которые не только
принимали активное участие в обсуждении результатов, но
6
ПРЕДИСЛОВИЕ
и оказали влияние на развитие и изложение многих из
рассмотренных в книге вопросов. За их инициативу и
энтузиазм, которые действовали так стимулирующе, автор
приносит им глубокую благодарность. Автор признателен
также 3. Кононовой за большую помощь при оформлении
рукописи книги.
Наконец, автору приятно отметить большое участие
В. Новосельцева, который при редактировании
рукописи сделал многое для того, чтобы книга приняла по
возможности завершенный вид.
Если при чтении книги у читателя возникнет либо
желание поспорить, либо стремление уточнить и развить
ряд положений, либо, наконец, намерение использовать
идеи адаптации для решения своих задач, т. е. если
в конечном итоге читатель не останется равнодушным,
то автор будет удовлетворен.
Институт автоматики и телемеханики Я. Цыпкин
Москва,
декабрь 1966 г.
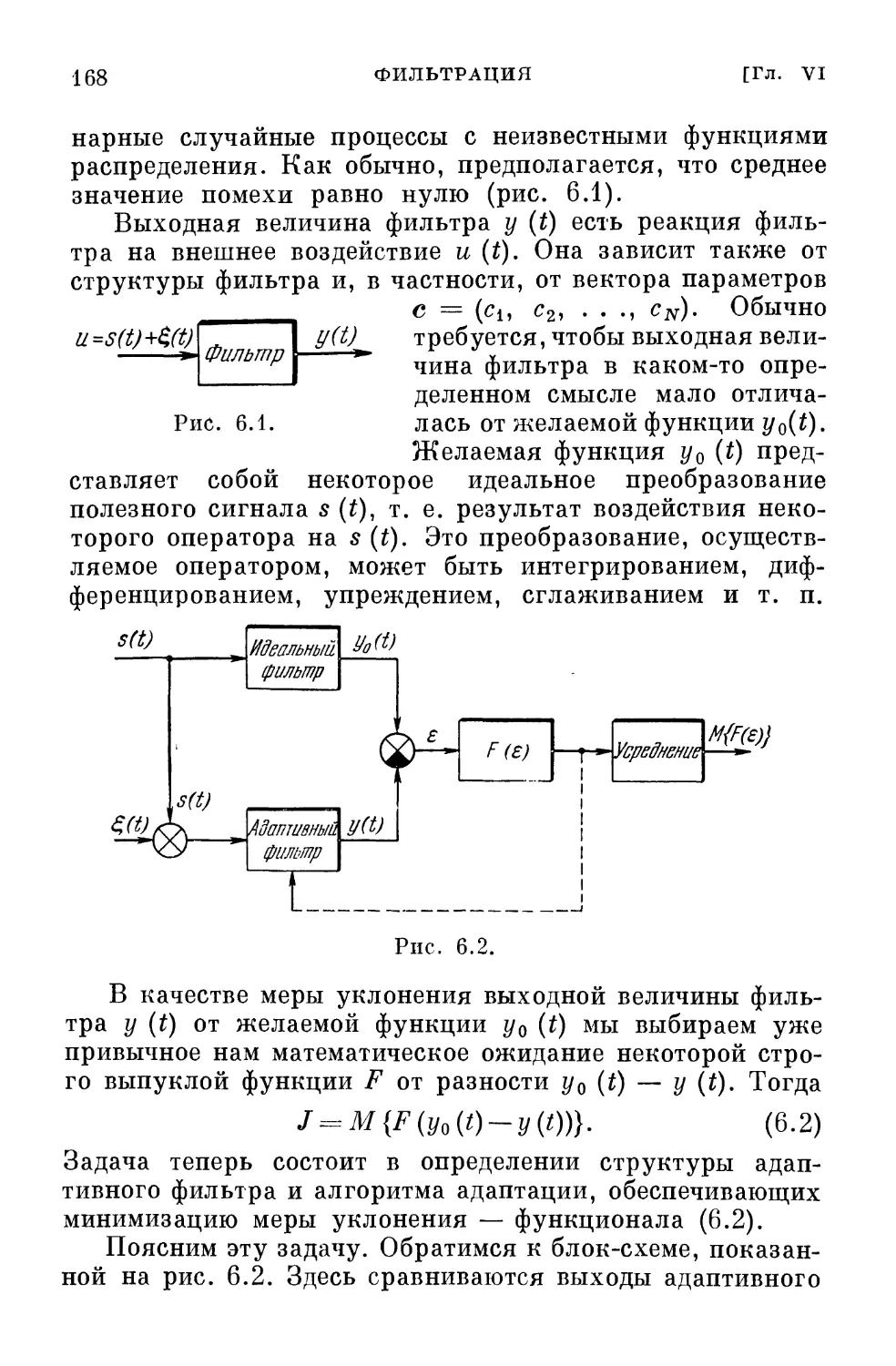
Введение
В развитии теории автоматического управления можно
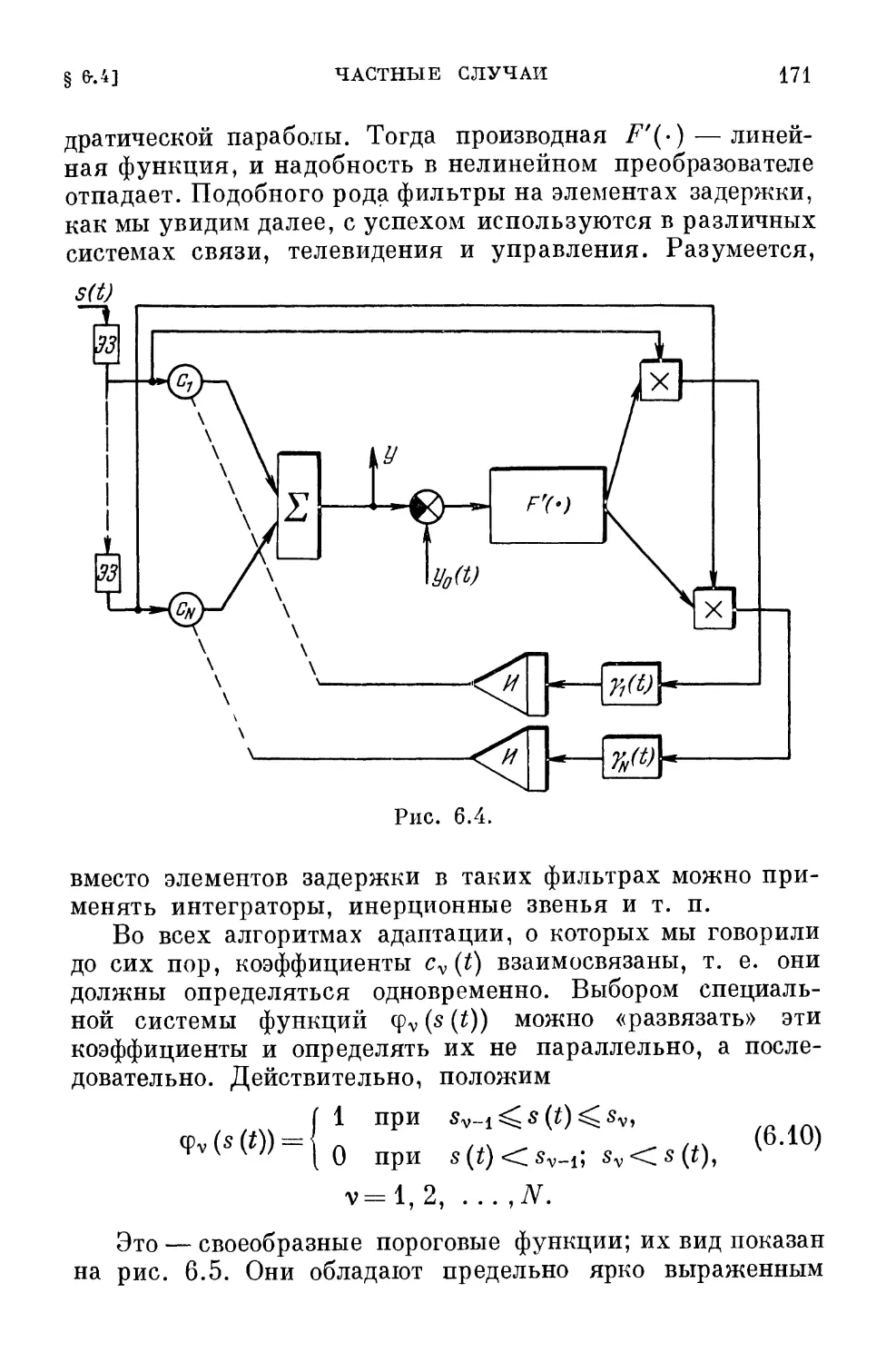
выделить три наиболее характерных периода, которые
удобно кратко назвать периодами детерминизма, стоха-
стичности и адаптивности.
В счастливые времена детерминизма как уравнения,
описывающие состояние управляемых объектов, так
и внешние воздействия (задающие и возмущающие)
предполагались известными. Такая полная определенность
позволяла широко использовать классический
аналитический аппарат для решения разнообразных проблем
теории управления. Особенно это относится к линейным
задачам, где безгранично господствующий принцип
суперпозиции существенно облегчал решение задач и создавал
полную иллюзию отсутствия принципиальных
затруднений. Эти затруднения возникли, конечно, как только
появилась необходимость в учете нелинейных факторов.
Но и в области нелинейных задач, несмотря на отсутствие
общих регулярных методов, были получены существенные
результаты, относящиеся как к анализу, так и к синтезу
автоматических систем.
Менее счастливое время наступило во второй период —
период стохастичности, когда в связи с учетом более
реальных условий работы автоматических систем было
установлено, что внешние воздействия, задающие, а
особенно возмущающие, непрерывно изменяются во времени
и заранее не могут быть определены однозначно. Часто
это относилось и к коэффициентам уравнений
управляемых объектов. Поэтому возникла необходимость в
привлечении иных подходов, учитывающих вероятностный
характер внешних воздействий и уравнений. Эти
подходы основаны на знании статистических характеристик
случайных функций (которые тем или иным путем должны
8
ВВЕДЕНИЕ
быть предварительно определены) и так же используют
аналитические методы, как и в счастливые времена
детерминизма.
Характерная особенность этих периодов развития
теории автоматического управления состоит в том, что
их методы и результаты непосредственно применимы
к автоматическим системам с достаточной информацией,
т. е. уравнения объекта и внешние воздействия либо их
статистические характеристики должны быть известны.
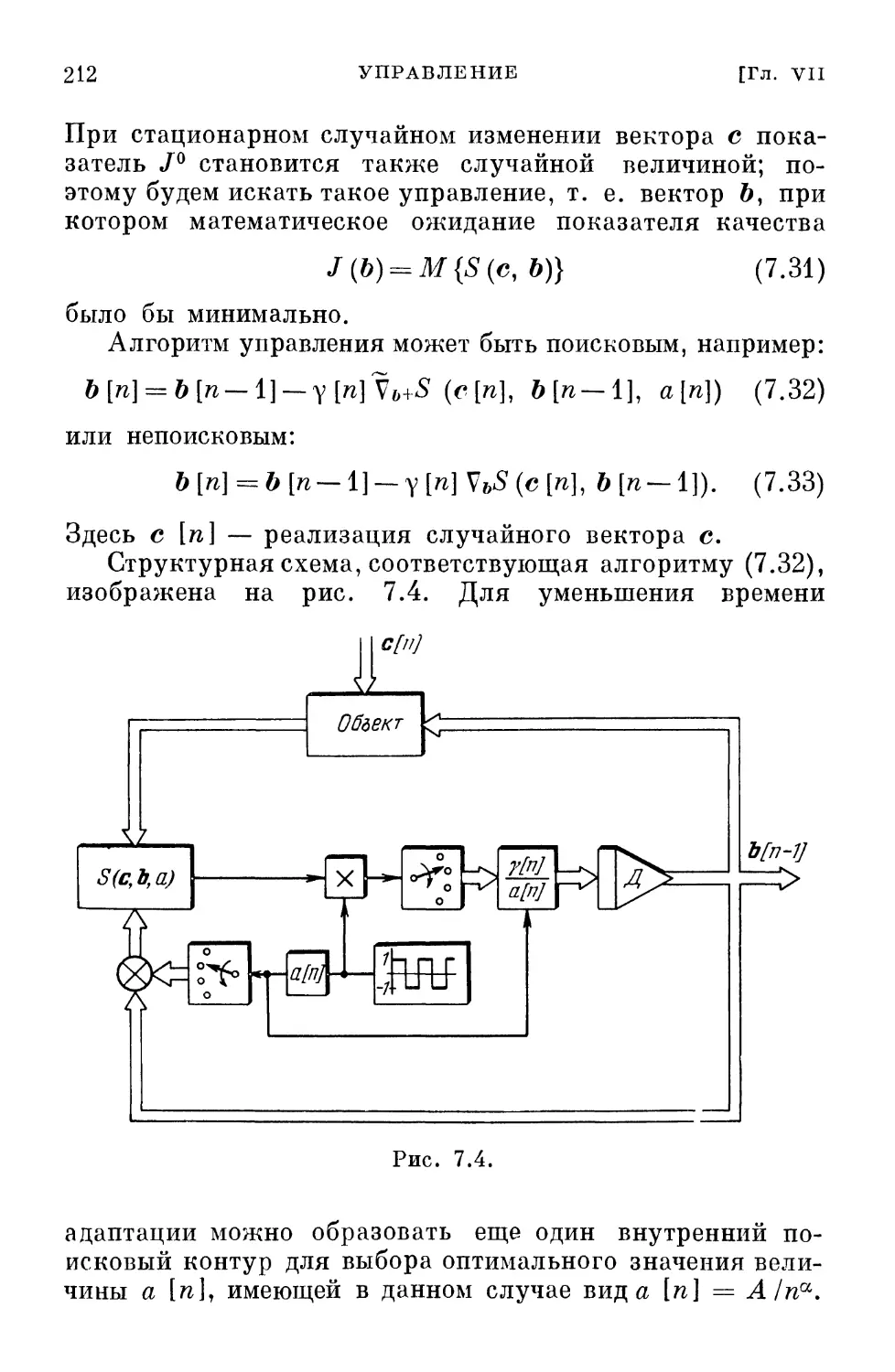
В нынешнее «многострадальное» (с точки зрения теории
автоматического управления) время с каждым днем мы все
больше убеждаемся, что в современных сложных
автоматических системах, работающих в самых разнообразных
условиях, уравнения управляемых объектов и внешние
воздействия (либо их статистические характеристики)
не только неизвестны, но по различным причинам мы даже
не имеем возможности заранее определить их
экспериментальным путем. Иначе говоря, мы сталкиваемся с
большей или меньшей начальной неопределенностью. Все
это хотя и затрудняет управление такими объектами, но
не делает это управление в принципе невозможным,
свидетельствуя лишь о наступлении нового, третьего периода
в теории управления — периода адаптивности.
Возможность управления объектами при неполной и даже весьма
малой априорной информации основана на применении
адаптации и обучения в автоматических системах, которые
уменьшают первоначальную неопределенность на основе
использования информации, получаемой в течение
процесса управления.
Не надо думать, что периоды детерминизма, стохастич-
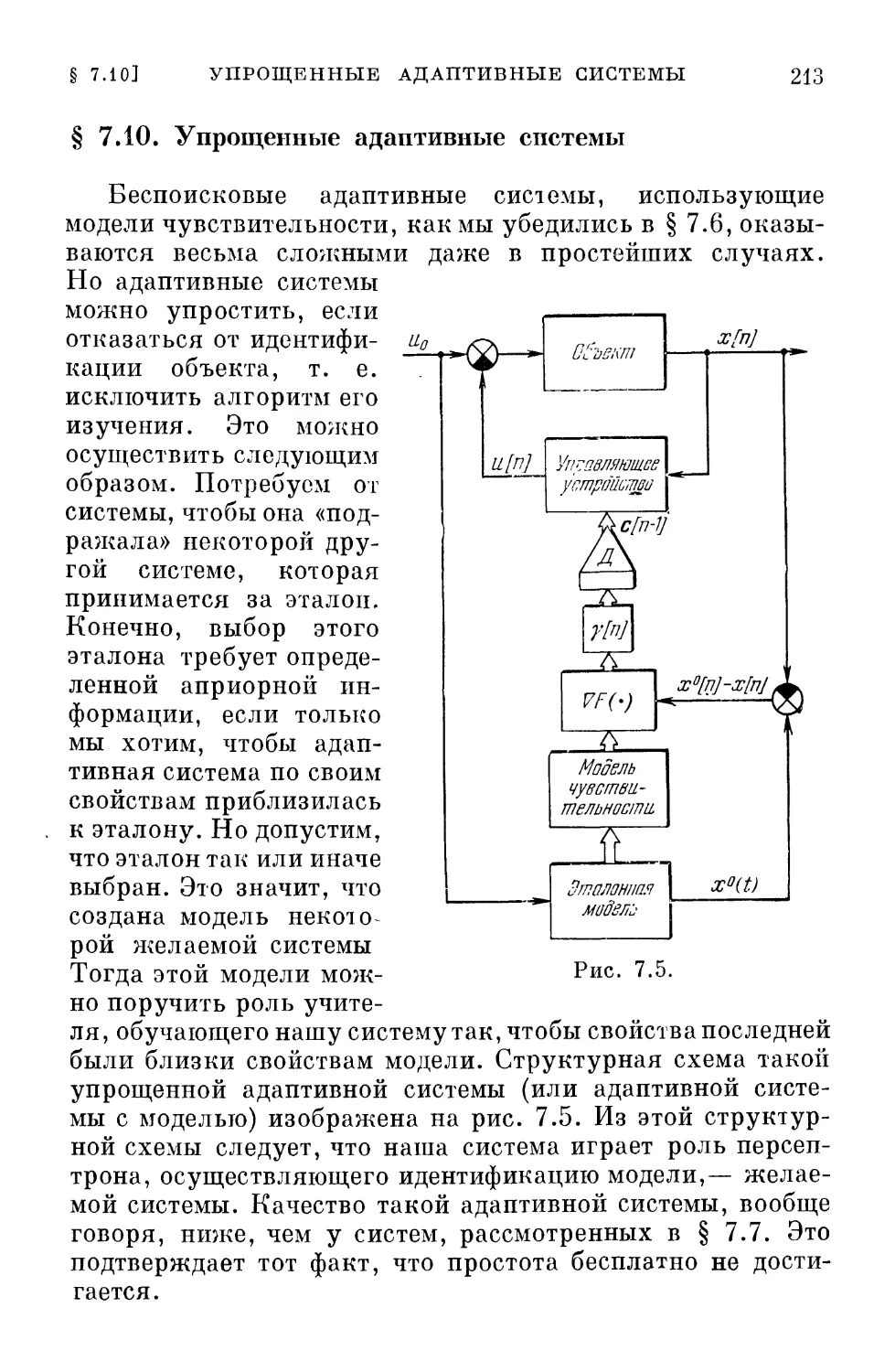
ности и адаптивности сменяли друг друга подобно кадрам
в кино. Последующие периоды зарождались в недрах
предшествующих, и мы являемся свидетелями
сосуществования проблематики этих периодов.
На первой стадии каждого из перечисленных периодов
основной задачей была задача анализа автоматических
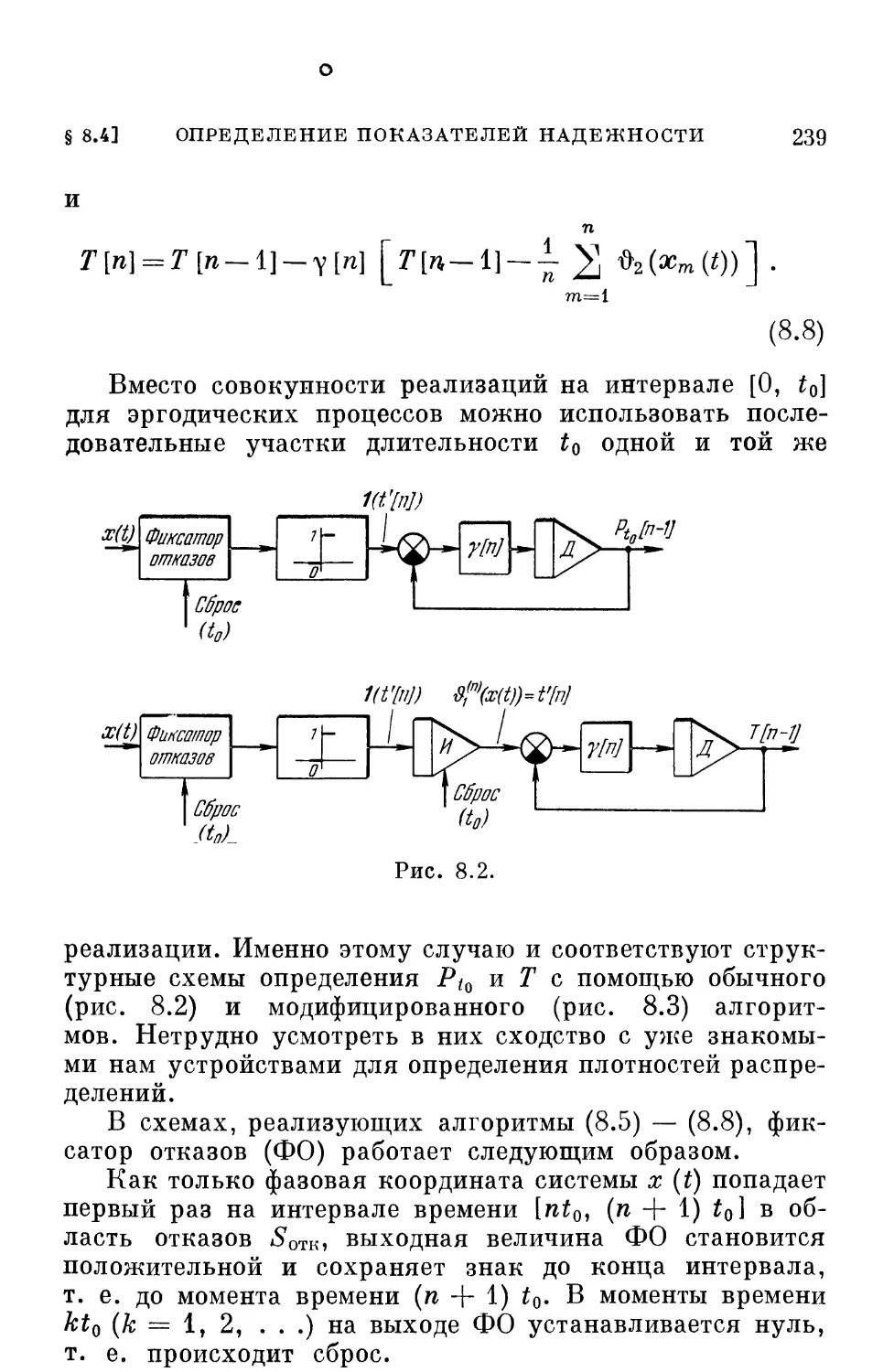
систем и выяснение их свойств. Затем возникли задачи
синтеза автоматических систем, удовлетворяющих
определенным требованиям. Естественно, появилось желание,
а часто и необходимость осуществить синтез оптимальной
в том или ином смысле системы.
ВВЕДЕНИЕ
9
Проблема оптимальности стала одной из центральных
в автоматическом управлении. И если еще не достигнуты
большие успехи в обосновании выбора и в формулировке
показателей качества, то нас могут утешать блестящие
результаты, связанные с проблемой оптимальности,
которые сконцентрированы в принципе максимума Понтряги-
на и методе динамического программирования Беллмана.
Хотя они и возникли на почве детерминистских задач,
но с определенным успехом начинают завоевывать
территорию стохастических и отчасти адаптивных задач.
Большим достижением периода стохастичности в этом
же направлении являются методы Колмогорова — Винера
и Калмана, которые в значительной мере исчерпали
линейные задачи синтеза.
К сожалению, период адаптивности не может
похвастаться столь блестящими результатами. Это
объясняется тем, что проблема адаптации и связанные с ней проблемы
обучения и самообучения еще очень молоды. Тем не менее
мы все чаще и чаще обнаруживаем их в разнообразных
задачах современной автоматики. Помимо основной,
упомянутой уже выше задачи управления объектами в
условиях неполной априорной информации или ее отсутствия,
т. е. в условиях начальной неопределенности, задачи
адаптации возникают при определении характеристик
объектов и воздействий, при обучении опознаванию
образов, ситуаций, при выработке и улучшении целей
управления и т. п«
Термины «адаптация», «самообучение», «обучение»
наиболее модны в современной теории автоматического
управления. К сожалению, как правило, эти термины не имеют
однозначного толкования, а зачастую не имеют просто
никакого толкования. Это создает благоприятную почву
для безудержных фантастических рассуждений, особенно
часто бытующих в популярной литературе по кибернетике,
а иногда проникающих и на страницы некоторых
технических журналов.
Тем не менее, если исключить этот обильный, но мало
содержательный поток «общих рассуждений», то можно
указать на целый ряд интересных подходов и результатов,
полученных в связи с решением перечисленных выше
задач.
10
ВВЕДЕНИЕ
Следует, однако, заметить, что до последнего времени
эти задачи рассматривались изолировано и независимо
одна от другой. Связи между ними почти не замечались,
хотя при более общем взгляде на проблемы адаптации,
обучения и самообучения все эти задачи оказываются
настолько тесно связанными, что приходится только
удивляться тому, что эта связь не была подчеркнута
ранее.
Основная наша цель состоит в обсуждении проблемы
адаптации, обучения и самообучения с некоторой единой
точки зрения, которая связала бы между собой задачи,
казавшиеся ранее разрозненными, и которая позволила
бы установить эффективные пути их решения.
Разумеется, на какое-либо осуществление этой цели
можно надеяться лишь при выполнении хотя бы двух
условий: наличия определенных, пусть условных, но
содержательных понятий адаптации, обучения и самообучения
и наличия некоторого математического аппарата,
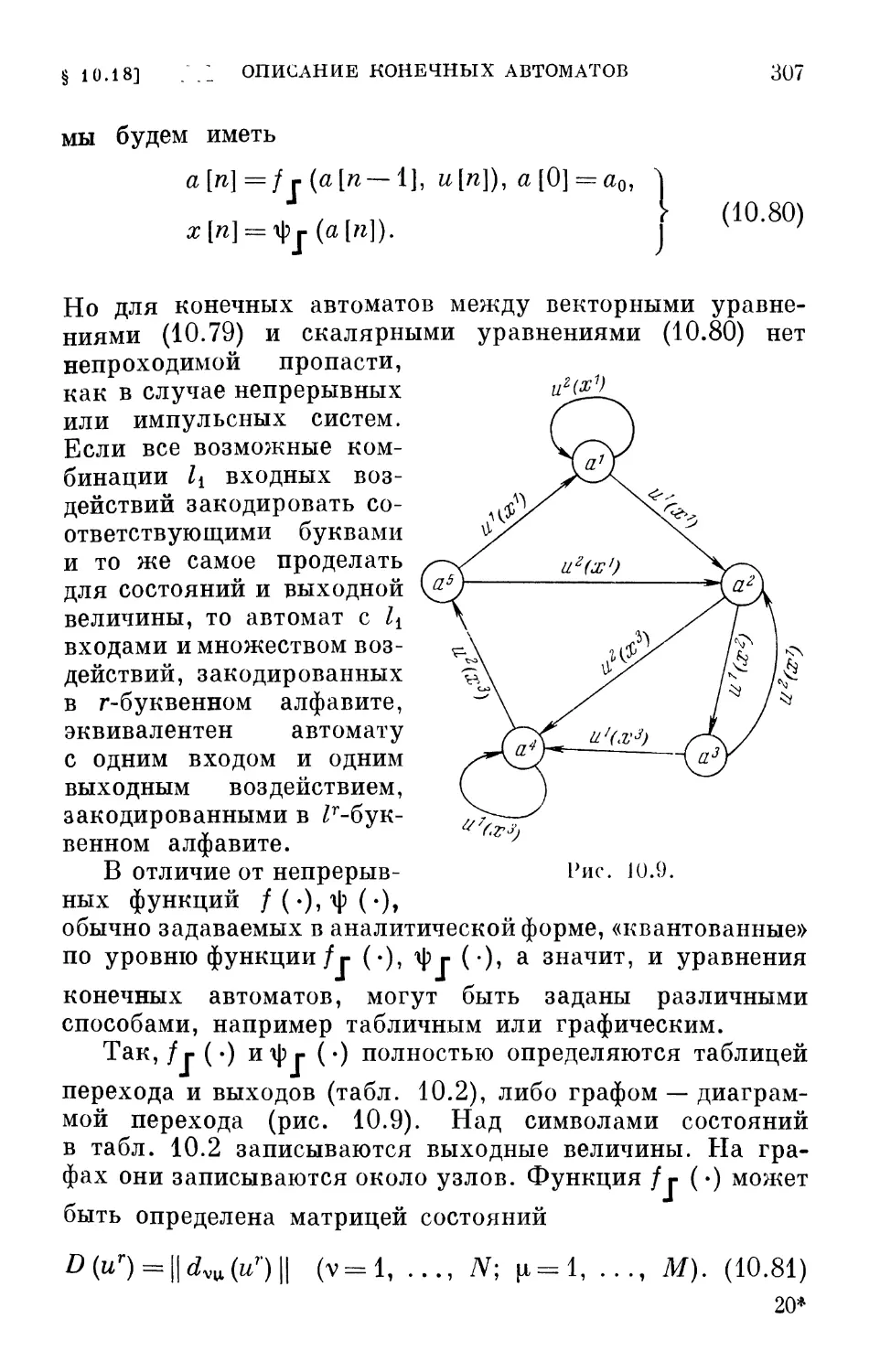
адекватного этим понятиям.
Первое условие находится если не в наших руках, то,
по крайней мере, в руках комиссий по технической
терминологии и поэтому из многочисленных, порой
разноречивых определений мы надеемся либо выбрать более
или менее подходящее для нашей книги, либо, в крайнем
случае, прибавить еще одно определение. Что же касается
второго условия, то обычно удовлетворить ему
несоизмеримо4 труднее. Но, как это неоднократно случалось
в истории науки, адекватный математический аппарат,
хотя и в зародышевой форме, к счастью, существует.
Он содержится, с одной стороны, в сформировавшейся
к настоящему времени математической статистике, а с
другой стороны, в интенсивно развивающейся новой
математической дисциплине, известной под названием
математического программирования.
Математическое программирование разрабатывает
теорию и методы решения экстремальных задач и охватывает
как специальные разделы (вариационное исчисление,
принцип максимума Понтрягина, динамическое
программирование Беллмана, линейное и нелинейное
программирование), так и — как это можно понять сейчас — методы
стохастической аппроксимации. Последние методы,
ВВЕДЕНИЕ
И
к сожалению, мало использовавшиеся вне математической
статистики, играют существенную роль в интересующей
нас области.
Важно подчеркнуть, что математическое
программирование не связано с необходимостью описания условий
задачи в аналитическом, формульном виде, и поэтому
может охватить значительно более широкий круг задач,
чем те методы, с помощью которых пытаются получить
решение в замкнутой аналитической форме.
Алгоритмическая форма решения экстремальных задач дает
возможность использовать средства современной вычислительной
техники и не укладывать условия задачи в прокрустово
ложе аналитического подхода, что обычно уводит нас
далеко за пределы тех реальных задач, которые мы
действительно хотели бы рассмотреть.
Алгоритмы обучения и адаптации должны позволить
в условиях минимальной априорной информации
достигнуть оптимума в том или ином смысле. Поэтому прежде
всего мы должны познакомиться с проблемой
оптимальности и алгоритмическими методами решения этой
проблемы. Затем мы сможем обсудить понятия и методы,
характерные для проблемы адаптации ^обучения. И
только после этого, вооружившись единой точкой зрения
и подходом к интересующей нас проблеме, мы будем в
состоянии приступить к решению разнообразных задач.
Именно такая последовательность и принята в
настоящей книге.
Глава I
Проблема оптимальности
§ 1.1. Введение
Без преувеличения можно сказать, что проблема
оптимальности является центральной проблемой науки,
техники, да и повседневной жизни.
Что бы ни делал человек, он пытается это сделать как
можно лучше. Любые сколь-нибудь обоснованные выводы,
действия или, наконец, созданные устройства можно
рассматривать с некоторой точки зрения как оптимальные,
ибо мы предпочли их множеству других выводов,
действий или устройств, т. е. посчитали их лучшими.
При стремлении достигнуть цели сразу же возникают
три задачи. Первая задача — выбор и формулировка
цели. То, что при одних условиях является наилучшим,
может оказаться далеко не наилучшим в других условиях.
Выбор и формулировка цели зависят от очень многих
условий и нередко сопряжены с большими трудностями.
Очень часто мы знаем, чего хотим, но, к сожалению, наше
желание сформулировать точно не можем.
Однако как только цель выбрана, возникает вторая
задача—согласование цели с имеющимися
возможностями, т. е. учет ограничивающих условий, или, проще, учет
ограничений. Даже ясная формулировка цели еще не
является залогом возможности ее достижения, подобно
тому как мечты далеко не всегда в действительности
достижимы.
Наконец, после выбора цели и учета ограничений
возникает третья задача — реализация способа
достижения цели при учете ограничений. Именно в третьей
задаче выясняется истинная цена разнообразных
математических методов оптимизации, их могущество или
бессилие.
§ 1.2]
КРИТЕРИИ ОПТИМАЛЬНОСТИ
13
Таким образом, решение проблемы оптимизации
сводится к последовательному решению перечисленных выше
задач.
В этой главе мы рассмотрим с нужной нам степенью
детализации первые две задачи. Третьей же задаче
посвящены, по существу, все остальные главы книги.
§ 1.2. Критерии оптимальности
Любая задача оптимизации может быть сведена к
выбору лучшего в некотором смысле варианта из большого
числа вариантов. Каждый из этих вариантов
характеризуется набором чисел (или функций). Качество того или
иного варианта определяется некоторым показателем —
численной характеристикой, определяющей близость
достижения поставленной цели при выбранном варианте.
Наилучший вариант соответствует экстремуму
показателя качества, т. е. минимуму или максимуму в
зависимости от конкретной задачи. Показатели качества обычно
представляют собой функционалы. Эти функционалы
можно рассматривать как функции, в которых роль
независимых переменных играют некоторые кривые или
векторы, характеризующие варианты. Функционал,
зависящий от вектора, представляет собой просто функцию
многих переменных. Мы далее будем рассматривать
в основном функционалы, зависящие от вектора, к
которым можно сводить функционалы, зависящие от функции,
на основе прямых методов вариационного исчисления.
В общей форме показатель качества можно
представить в виде условного математического ожидания
J(c) = ^Q(x, c)p(x)dx (1.1)
X
или кратко
J{c) = Mx{Q{x, с)}, (1.2)
где Q (х, с) — функционал вектора с = (си . . . , cN),
зависящий также от вектора случайных
последовательностей или процессов х = (хи . . . , хм), плотность
распределения которого равна р (х); X — пространство
векторов х. Здесь и далее все векторы представляются
столбцовыми матрицами.
14
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
В выражении (1.2) явно не подчеркнута возможная
зависимость функционала от известных векторов, с
которой мы всегда будем сталкиваться при рассмотрении
конкретных задач. К уравнению (1.2) сводится целый
ряд различных по своей форме показателей качества. Так,
например, весьма распространенный в теории
статистических решений средний риск — байесовский критерий —
определяется как
N
R(d) = l 2 Pv Wvlidlx(x,c)pv(x)dx. (1.3)
Л v,p,= l
В этом выражении приняты следующие обозначения:
Pv — вероятность того, что наблюдаемый элемент х
относится к подмножеству Av множества Л, pv (х) —
условная плотность распределения вероятности на
подмножестве Av. Далее, d^ (х, с) — решающее правило,
зависящее от неизвестного вектора параметров с, такое, что
d»{x, с) =
1, если принято решение х^А^ . ,
О, если принято решение х g А^.
Наконец, wv[X, (v, |л=1, 2, . . ., N) — элементы
платежной матрицы И7, определяющие стоимость ошибочных
решений.
Представим формулу для R (d) в виде
R= 2 ^уц \ PvPv(x)d[X(x, c)dx. (1.5)
v, \i=i Л
Отсюда следует, что R можно рассматривать как
условное математическое ожидание случайной величины
wvli с некоторым распределением \ Pvpv (х) d[l(xi с) dx.
А
Иногда удобно использовать показатель качества,
определяющий вероятность того, что величина находится
в заданных пределах 8!<(?(х, с) < е2, т. е.
J(e) = P {ех < Q (а>, с) < е2}. (1.6)
§ 1.3] ЕЩЕ О КРИТЕРИЯХ ОПТИМАЛЬНОСТИ 15
Вводя новую переменную, так называемую
характеристическую функцию
В(х, с) М- если 6l«?(*)C)<е2) (U)
[ 0 в иных случаях,
можно преобразовать (1.6) к виду
J(c) = Mx{Q(x, с)}, (1.8)
что совпадает по форме с (1.2).
Достижению цели соответствует минимум (например,
в случае (1.3)) или максимум (например, в случае (1.6)).
Поэтому функционалы часто называются также
критериями оптимальности.
§ 1.3. Еще о критериях оптимальности
Наряду с критериями оптимальности, представляемыми
в виде условного математического ожидания (1.2) путем
усреднения Q (х, с) по множеству, можно использовать
критерии оптимальности, определяемые усреднением
Q (х, с) по времени. В зависимости от того, представляет
собой х случайную последовательность {х [п], п =
= 0, 1, 2, . . .} или процесс {х (t); 0 < t << оо}, критерии
оптимальности можно записать соответственно в виде
7(c) = lim-^2 <?(*[»]. с) (I-9)
или
т
/ (с) = lim 4" \Q (х (0. с) dL (1-1°)
Для эргодических стационарных последовательностей
и процессов критерии оптимальности (1.9)-(1.10),
отличающиеся от критерия оптимальности (1.2) способом
усреднения (по времени или по множеству),
эквивалентны. Это значит, что выражения этих функционалов, если
бы их можно было получить в явном виде, всегда бы
совпадали. В любом другом случае критерии оптимальности
(1.9), (1.10) отличаются от (1.2). Но это обстоятельство
16
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
не должно служить препятствием к применению критериев
оптимальности вида (1.9) или их обобщений и тогда,
когда на каждом шаге (в каждый момент времени) вид
функции Q изменяется, т. е. когда
лг
Z(c) = lim4-2 Qn(x[n], с) (1.11)
ИЛИ
т
/(с) = lim 4r\Q{x{t), с, t)dt. (1.12)
Критерии оптимальности имеют или, по крайней мере,
должны иметь определенный физический или
геометрический смысл. Так, для систем автоматического
управления критерии оптимальности представляют собой
некоторую меру отклонения системы от желаемого или
предписанного состояния. Для задачи аппроксимации
функций критерии оптимальности характеризуют меру
уклонения аппроксимирующей функции от
аппроксимируемой. Выбор конкретного критерия оптимальности,
как правило, связан со стремлением найти компромисс
между желанием более точно описать поставленную цель
и возможностью получить более простое решение
соответствующей математической задачи.
§ 1.4. Ограничения
Если бы векторы х и с, входящие в функционал
критерия оптимальности, не были стеснены какими-либо
условиями, то проблема оптимальности, пожалуй, не
имела бы смысла.
Проблема оптимальности возникает именно тогда,
когда существуют взаимно противоречивые
ограничивающие условия, и достижение оптимальности состоит в
наилучшем удовлетворении этих условий, т. е. в выборе
такого варианта, когда критерий оптимальности достигает
экстремума.
Ограничивающие условия или просто ограничения,
выражающиеся равенствами, неравенствами или логиче-
§ 1.4]
ОГРАНИЧЕНИЯ
17
сними соотношениями, из всего множества вариантов
выделяют так называемые допустимые варианты, среди
которых и ищется оптимальный вариант.
Законы природы, описывающие те или иные явления и,
в частности, определяющие поведение различных систем,
представляют собой своеобразные ограничения. Этим
законам, выраженным в виде алгебраических,
дифференциальных, интегральных уравнений, подчиняются векторы
х и с.
Конкретный вид таких уравнений зависит от характера
и особенностей рассматриваемой задачи, так что с явной
записью различных уравнений мы будем часто встречаться
во многих главах настоящей книги. Ограничения этого
типа будем называть ограничениями первого рода. Иного
характера ограничения могут быть вызваны
ограниченностью ресурсов, энергии или иных величин, которые
в силу физической природы той или иной системы не могут
или не должны превосходить некоторых пределов. Эти
ограничения, которые мы будем называть ограничениями
второго рода, налагаются на компоненты вектора с
и выражаются в виде равенств
gv(c) = 0 (V=l, 2, ..., M<N) (1.13)
или неравенств
Мс)<0 (v = l, 2 ...,7^), (1.14)
где gy (с) — некоторые функции вектора с.
Часто ограничения могут относиться не к
мгновенным, а к средним значениям, и тогда (1.13) и (1.14)
заменяются равенствами или неравенствами математических
ожиданий соответствующих функций:
gv(c) = Mx{hv(x,c)} = 0 (v = l, 2, ..., Ж) (1.15)
или
gv(c) = Mx{hv(x, с)}<0 (v = l, 2, ...,71^). (1.16)
Таким образом, ограничения включают уравнения тех
или иных процессов и пределы изменения некоторых
функций от этих процессов.
Для автоматических систем—это уравнения движения
и пределы изменений управляемых величин и управляющих
^ Я. 3. Цыпкин
18
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
воздействий. В задаче аппроксимации ограничения
определяются характером аппроксимирующей функции.
К сожалению, в реальных физических задачах количество
ограничений, как правило, намного превышает то число,
при котором постановка оптимальной задачи остается
возможной и разумной.
Все эти ограничения сужают количество допустимых
решений, облегчая, казалось бы, определение
оптимального варианта, но само решение задачи при этом настолько
усложняется, что хорошо знакомые нам классические
методы становятся неприменимыми.
§ 1.5. Априорная и текущая информация
Априорная информация, или, как еще часто говорят,
начальная информация, представляет собой совокупность
заранее известных сведений о критерии оптимальности
и ограничениях. Критерий оптимальности является
выразителем тех требований, которые должны быть наилучшим
образом удовлетворены, а ограничения определяют наши
возможности. Таким образом, априорная информация
касается требований, предъявляемых к процессу,
характера уравнений процесса и значений параметров в этих
уравнениях и, наконец, свойств внешних воздействий
и самого процесса.
Априорная информация может быть получена в
результате предварительного теоретического или
экспериментального исследования. Она является исходной при
решении любых физических задач и, в частности, при
рассмотрении проблемы оптимальности.
Всякое описание реальной системы неизбежно приводит
к идеализации ее свойств и, несмотря на стремление
учесть основные характерные черты этой системы, вряд
ли можно надеяться на получение полной априорной
информации. Ведь полная априорная информация
означает абсолютно точное знание. Если же учесть еще и
наличие разнообразных помех, являющихся источником
неопределенности, то приходится заключить, что все
случаи, с которыми мы реально сталкиваемся,
соответствуют неполной априорной информации. Разумеется,
степень этой неполноты может быть различной. Она может
§ 1.6] ДЕТЕРМИНИРОВАННЫЕ И СТОХАСТИЧЕСКИЕ ПРОЦЕССЫ 19
быть достаточной либо недостаточной для формулировки
и решения проблемы оптимальности. При достаточной
априорной информации известны все необходимые
сведения о критерии оптимальности и ограничениях, т. е.
они могут быть выписаны в явной форме.
При недостаточной априорной информации
необходимые сведения относительно критерия оптимальности либо
ограничений, либо того и другого вместе, полностью
неизвестны.
Существенная особенность любых априорных сведений
состоит в том, что, будучи получены заранее, они затем
не только не обновляются, но вследствие различных
случайных изменений, всегда существующих в реальных
условиях, теряют свою достоверность. Степень полноты
априорной информации, т. е. объем априорной
информации, играет существенную роль в постановке и решении
проблемы оптимальности.
В отличие от априорной информации, текущая
информация извлекается в результате наблюдений за ходом
процесса или в результате экспериментов. Таким образом,
текущая информация в каждый момент времени
обновляется. Текущая информация, полученная в результате
специально поставленного предварительного
эксперимента, может использоваться для накопления
соответствующей априорной информации. Но наиболее важная
роль текущей информации состоит в компенсации
недостаточного объема априорной информации.
Априорная информация — это основа для
формулировки проблемы оптимальности. Текущая информация —
средство решения этой проблемы.
§ 1.6. Детерминированные и стохастические
процессы
Детерминированные процессы характеризуются тем,
что знание их в некотором интервале времени позволяет
полностью определить поведение этих процессов вне этого
интервала. Для детерминированного процесса заранее
задан критерий оптимальности, а ограничения первого
и второго рода известны. Стохастические процессы
характеризуются тем, что знание их на некотором интервале
2*
20
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
времени позволяет определить лишь вероятностные
характеристики поведения этих процессов вне этого
интервала.
Если эти вероятностные характеристики, например
плотности распределения, заранее заданы, то и в этом
случае можно определить в явной форме критерий
оптимальности и ограничения, которые представляют собой,
как это упоминалось выше, некоторые условные
математические ожидания.
Детерминированные процессы можно рассматривать
как частный случай стохастических процессов, плотность
распределения которых представляет собой импульсную
функцию Дирака, т. е. б-функцию: р (х) = б (х). При
этом условные математические ожидания, входящие
в критерий оптимальности (1.2) и ограничения (1.15),
(1.16), превращаются просто в детерминированные
функции, не зависящие от случайного вектора х.
Так, при р (х) = б (х) из (1.2), (1.15) и (1.16) с учетом
(1.1) легко получить для детерминированного процесса
следующие соотношения:
J(c) = Q(0, с), (1.17)
Sv(c)=-M0, с) = 0 (v = lf 2, ...,M<N) (1.18)
и
Мс) = М0, с><0 (v = l, 2, ..., Л/0, (1.19)
что соответствует ограничениям вида (1.13) и (1.14).
Из этого очевидного замечания следует, что
стохастические процессы отличаются друг от друга и, в частности,
от детерминированных процессов видом вероятностных
характеристик — плотностей распределения.
Объем априорной информации для
детерминированных процессов обычно больше, чем для стохастических,
поскольку для детерминированных процессов плотность
распределения заранее известна, тогда как для
стохастического процесса, как правило, ее еще нужно
определить.
Однако если плотность распределения тем или иным
способом предварительно определена и нам удалось
записать функционал и уравнения ограничений в явной
форме, то, несмотря на существенные идейные различия
§ 1.7]
ОБЫЧНЫЙ И АДАПТИВНЫЙ ПОДХОДЫ
21
между детерминированными и стохастическими
процессами, трудно установить сколь-нибудь заметные
расхождения в формулировке и решении проблемы
оптимальности для этих процессов.
Мы хорошо понимаем, что для детерминированных
процессов часто можно получить оптимальность для
каждого процесса в отдельности, как это имеет место,
например, в оптимальных по быстродействию системах.
В то же время для статистических процессов можно
обеспечить лишь оптимальность в среднем, но это скорее
относится к области идейных различий, нежели к
формулировке и решению проблемы оптимальности.
§ 1.7. Обычный и адаптивный подходы
Если функции распределения для стохастических
процессов известны и можно определить в явной форме
критерии качества / (<?), то, как мы уже упоминали,
стохастическая задача оптимизации ничем не отличается
от детерминированной. Так, динамическое
программирование в равной степени применимо как для
детерминированных, так и для стохастических задач.
При внимательном взгляде на результаты, полученные
в периоды детерминизма и стохастичности,
обнаруживается, с одной стороны, ясная до тривиальности, а с другой —
поражающая наше воображение тождественность
подходов при решении задач оптимизации.
В качестве наиболее яркого примера можно привести
стохастическую задачу фильтрации Винера —
Колмогорова, т. е. синтез линейной системы, оптимальной с точки
зрения минимума среднеквадратичной ошибки, и задачу
аналитического конструирования регулятора, т. е. синтез
оптимальной линейной системы с точки зрения минимума
интегральной квадратичной ошибки. Хотя эти задачи на
первых порах решались внешне различными способами,
оказалось, что с точностью до терминологии они изоморфны.
Стоит ли более подробно обсуждать этот вопрос?
Ведь раз J (с) представлено в замкнутой форме, то вид
функции распределения, от которой зависит J (с), вряд
ли имеет какое-либо принципиальное значение. Все такие
подходы мы будем называть обычными.
22
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
Существенно иная ситуация возникает, когда
функция распределения заранее неизвестна. Здесь уже
обычный подход теряет силу и необходим иной подход, который
позволил бы решить проблему оптимальности при
недостаточной априорной информации без предварительного
определения вероятностных характеристик. Такой
подход мы будем называть адаптивным.
В отличие от обычного подхода, при адаптивном
подходе для восполнения недостающей априорной
информации активно используется текущая информация.
Адаптивный подход может быть применен и в тех случаях,
когда применение обычного подхода хотя и возможно,
но сопряжено с большой работой по предварительному
определению функций распределения. Если же заранее
не ясно, с каким процессом мы имеем дело, с
детерминированным или случайным, и тем более неизвестны их
характеристики, то единственное разумное решение
связано с обучением и адаптацией в процессе
экспериментирования, т. е. с использованием адаптивного подхода.
§ 1.8. О методах решения проблемы оптимальности
После того как проблема оптимальности
сформулирована, т. е. после выбора критерия оптимальности,
выяснения и установления ограничений первого и второго
рода, наступает пора решения этой проблемы. И хотя
теперь принято говорить, что постановка проблемы
составляет от 50 до 80% успеха (в зависимости от
темперамента говорящего это), тем не менее оставшиеся
проценты часто настолько емки, что могут лишить нас этого
успеха вообще.
Решение проблемы оптимальности сводится к
определению такого вектора с = с* (его уместно назвать
оптимальным), который, удовлетворяя ограничениям,
доставлял бы функционалу
J(e) = Mx{Q(x, с)} (1.20)
экстремальное значение.
Следует отметить, что в большинстве интересующих
нас конкретных задач обычно нужно определить функции,
являющиеся экстремалями тех или иных функционалов.
§ 1.8] О МЕТОДАХ РЕШЕНИЯ ПРОБЛЕМЫ ОПТИМАЛЬНОСТИ 23
Процедура определения экстремалей часто
сопровождается большими трудностями. Чтобы обойти эти
трудности, можно использовать идеи прямых методов
вариационного исчисления: заменить искомые экстремали
комбинацией некоторых линейно независимых функций
с неизвестными коэффициентами. Благодаря этому
рассматриваемый функционал, зависящий от функции,
заменяется функционалом, зависящим от вектора. С подобными
примерами мы будем еще сталкиваться.
При наличии достаточной априорной информации
нам известно явное выражение функционала / (с) и
ограничений как для детерминированных, так и для
стохастических процессов. К функционалу / (с) мы можем
применять обычные подходы.
Обычные подходы весьма разнообразны и охватывают
аналитические и алгоритмические методы. Аналитические
методы на первый взгляд кажутся наиболее
привлекательными, так как они приводят к явному формульному
решению задач, но эта привлекательность достигается
весьма дорогой ценой, ценой резкого ограничения
возможностей. Эти методы пригодны для решения относительно
простых задач, которые часто могут быть
сформулированы лишь благодаря далеко идущей идеализации, иногда
настолько далекой, что фактически вместо поставленной
задачи решается совсем иная. Так, формулы для
вычисления корней алгебраических уравнений имеют весьма
простой вид для уравнений первой и второй степени.
Такие формулы можно написать для уравнений третьей
и четвертой степеней, хотя пользоваться ими уже
значительно сложнее. Наконец, подобных формул просто
не существует для уравнений, степень которых выше
четвертой. Но можно ли всегда быть довольным, решая
уравнение второй степени вместо уравнений высоких
степеней?
Различного рода приближенные аналитические методы,
например асимптотические, расширяют границы
применимости, но ненамного.
Алгоритмические методы, еще в недавнее время не
привлекавшие большого внимания, не дают явного
формульного решения задач, а лишь указывают алгоритм, т. е.
последовательность действий, операций, осуществление
24
ПРОБЛЕМА ОПТИМАЛЬНОСТИ
[Гл. I
которых приводит к искомому конкретному решению.
Алгоритмические методы возникли на почве численного
решения различного рода уравнений и теперь в связи
с широким применением вычислительных машин
приобретают доминирующее значение.
Алгоритмические методы дают не столько решение,
сколько способ нахождения этого решения с помощью,
например, рекуррентных соотношений. Это
обстоятельство существенно расширяет возможности
алгоритмического метода по сравнению с аналитическими методами.
Но даже в тех случаях, когда применение аналитических
методов принципиально возможно, иногда предпочитают
использовать алгоритмические методы, так как они дают
более быстрый и удобный путь получения искомого
результата. Вряд ли при здравом подходе для решения
системы линейных алгебраических уравнений высокого
порядка мы применим классическое правило Крамера, а
не воспользуемся одним из многочисленных итеративных
методов. Если функционал явно неизвестен, то обычные
подходы непосредственно неприменимы, и для устранения
неопределенности, вызванной малым объемом априорной
информации, следует использовать адаптивный подход.
Адаптивный подход связан преимущественно с
алгоритмическими, а точнее, итеративными методами. Подробно
об алгоритмических методах оптимизации мы будем
говорить в следующих двух главах.
§ 1.9. Заключение
В этой главе мы стремились в общих чертах
охарактеризовать проблему оптимальности, ее формулировку
и пути решения. Нам хотелось также обратить внимание на
различие и особенно на сходство проблем оптимальности
для детерминированных и стохастических процессов.
Мы отметили, что подход к решению проблемы
оптимальности определяется в зависимости от степени полноты
априорной информации. При достаточной априорной
информации используется обычный подход, при
недостаточной априорной информации — адаптивный. Впрочем,
как мы увидим далее, иногда адаптивный подход
оказывается предпочтительным даже в тех случаях, когда можно
§ 1.9
ЗАКЛЮЧЕНИЕ
25
применить и обычный подход. Такая ситуация возникает
тогда, когда априорная информация может быть
получена экспериментальным путем в результате обработки
тех или иных процессов. Примером такого рода может
служить определение плотностей распределения или
корреляционных функций, которые затем используются для
решения оптимальной задачи. Не лучше ли в этом случае
решать проблему оптимальности адаптивным путем, что
позволяет обойтись без получения этой априорной
информации и зачастую требует меньшего объема вычислений?
Чтобы освободиться от сильной идеализации и
переупрощения реальных задач, в качестве основного метода
мы изберем алгоритмический. Это дает нам возможность
получать эффективные алгоритмы решения проблемы
оптимальности и в сложных случаях, используя для
этой цели разнообразные средства вычислительной
техники.
Глава II
Алгоритмические методы оптимизации
§ 2.1. Введение
Алгоритмические методы решения проблемы
оптимальности, которые будут рассмотрены в этой главе,
относятся к типу рекуррентных. Эти методы включают
в себя различного рода итеративные процедуры,
связанные с применением последовательных приближений.
Благодаря идеям функционального анализа подобные
методы, первоначально применявшиеся лишь к решению
алгебраических уравнений, были распространены и на
дифференциальные и интегральные уравнения.
Наша ближайшая цель будет состоять не только
в систематизации и упорядочении довольно хорошо
разработанных разнообразных рекуррентных методов, но и в
выяснении их, если можно так выразиться, физического
смысла, или, точнее, их смысла с точки зрения
специалиста по автоматическому управлению. На протяжении
этой главы мы будем предполагать, что имеется
достаточная априорная информация, и поэтому при решении
проблемы оптимальности можно использовать обычный
подход. Приводимые результаты имеют не только
самостоятельное значение, но и будут использованы в
дальнейшем, когда по аналогии мы будем развивать
адаптивный подход. Мы увидим, что, несмотря на разнообразие
рекуррентных методов, все они могут быть сведены
к довольно простым схемам.
§ 2.2. Условия оптимальности
Для детерминированных и стохастических процессов
при достаточной априорной информации (а только этот
случай и будет рассматриваться в настоящей главе)
критерий оптимальности, т. е. функционал / (с), известен
§ 2.2]
УСЛОВИЯ ОПТИМАЛЬНОСТИ
27
в явной форме, известны также и ограничения. Вначале,
если не оговаривается противное, будем предполагать,
что ограничения второго рода отсутствуют, а ограничения
первого рода, как это часто бывает, исключены путем
подстановки в функционал. При этом, разумеется,
первоначальная размерность искомого вектора с
уменьшается.
Если функционал J (с) допускает дифференцирование,
то он достигает экстремума (максимума или минимума)
только при таких значениях с = {си с2, • • •» cn), Ддя
которых N частных производных , ' (v = 1, 2, ...
. . . , iV) одновременно обращаются в нуль, или, иначе
говоря, для которых градиент функционала
«с>-(^ ^?) <2-'>
обращается в нуль.
Векторы с, удовлетворяющие условию
V/(c) = 0, (2.2)
называются стационарными или особыми. Не все
стационарные векторы оптимальны, т. е. соответствуют нужному
экстремуму функционала. Поэтому условие (2.2) является
лишь необходимым условием оптимальности.
Можно было бы выписать и достаточные условия
экстремума в виде неравенств относительно определителей,
содержащих частные производные второго порядка
функционала по всем компонентам вектора. Однако вряд
ли это стоит делать даже в тех случаях, когда это не
требует громоздких выкладок и вычислений.
Часто, исходя непосредственно из условий физической
задачи, для которой построен функционал, удается
определить, чему соответствует стационарный вектор,-—
минимуму или максимуму. Особенно легко это устанавливается
в тех часто встречающихся и интересных для нас случаях,
когда имеется всего один экстремум.
Условия оптимальности выделяют лишь локальные
экстремумы, и если их много, то задача нахождения
абсолютного или глобального экстремума становится
28 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
очень сложной. Некоторые возможности решения этой
задачи мы обсудим несколько позже.
Сейчас же мы ограничимся тем случаем, когда
оптимальное значение вектора с* единственно, и для
определенности будем считать, что экстремальное значение
функционала представляет собой минимум.
§ 2.3. Регулярный итеративный метод
Уравнение оптимальности (2.2) в общем случае
представляет собой нелинейное уравнение, и надежда
получить его решение аналитическим путем отсутствует почти
всегда, за исключением множества, как любят говорить
математики, пресловутой «меры нуль». Правда, в случае
квадратичных критериев оптимальности и линейных
ограничений первого рода нелинейные уравнения (2.2)
превращаются в линейные, и появляется возможность
применить упомянутое выше правило Крамера.
Применительно к таким линейным задачам «множество меры
нуль» часто превращается в бедствие для читателей
специальных технических журналов.
До самого последнего времени теория оптимальности
строилась на этом элегантном с математической точки
зрения и очень шатком с точки зрения практических
задач основании.
Если еще заметить, что линейные аналитические методы
могут выдержать испытание лишь при решении
сравнительно простых задач малой размерности, то сразу
становится очевидной необходимость в развитии и
применении алгоритмических, или, точнее, итеративных методов,
не требующих столь сильных ограничений, которые к тому
же не вызываются сутью задачи.
Основная идея решения уравнения (2.2) с помощью
регулярных итеративных методов состоит в следующем.
Представим уравнение (2.2) в равносильной форме
c = c-yVJ(c), (2-3)
где у— некоторый скаляр, и будем искать оптимальный
вектор с = с* с помощью, последовательных приближений
или итераций:
с [п] = с [п -г-1] - у [п] V/ (с [п—\]). (2.4)
§ 2.4]
АЛГОРИТМЫ ОПТИМИЗАЦИИ
29
Значение у [п] определяет величину очередного шага
и зависит от номера шага и, вообще говоря, от векторов
с [т] (т = п — 1, п — 2, . . .). При выполнении
соответствующих условий сходимости, которые далее мы
кратко рассмотрим, для любого начального выбора с =
= с [0] оказывается, что
lime [п] = с*. (2.5)
Методы определения с*, основанные на соотношении
(2.4), и называются итеративными методами. Поскольку
выбор начального значения с (0) однозначно
предопределяет дальнейшее значение последовательности с [/г],
или, как можно еще говорить, предопределяет
решетчатую функцию с [п]1 то эти итеративные методы мы
назовем регулярными, в отличие от вероятностных, которыми
мы будем оперировать в гл. III. Различные формы
регулярных итеративных методов отличаются друг от друга
конкретным выбором у [п].
Регулярным итеративным методам посвящена огромная
литература. К сожалению, многие из источников
используют хотя и узаконенную, но различную терминологию.
Нам нужно находить именно оптимальные значения
вектора, так как мы занимаемся проблемой
оптимальности. Поэтому, быть может, нам удобнее будет
использовать ту терминологию, которая наиболее близка к
терминологии рассматриваемой проблемы и относится не
столько к итеративным методам, сколько к эквивалентным
им алгоритмам оптимизации. О них пойдет речь в
следующем параграфе.
§ 2.4. Алгоритмы оптимизации
Соотношение (2.4) определяет последовательность
действий, которые нужно осуществить, чтобы определить
оптимальный вектор с*. Поэтому уместно назвать (2.4)
алгоритмом оптимизации. Этот алгоритм оптимизации
можно рассматривать как рекуррентное уравнение. Вводя
обозначение первой разности
Ас [п — 1] = с [п] — с [п — 1], (2.6)
АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
легко представить алгоритм оптимизации в виде
разностного уравнения
Де[и —1] = —yln]VJ(e[n — l]). (2.7)
Наконец, суммируя обе части этого уравнения от О
до д, получим алгоритм оптимизации в виде суммарного
уравнения
с[/1]=с[0]- 2 vMV/(c[m»l]),
(2.8)
m=l
которое, в отличие от (2.4) и (2.7), включает начальное
значение, с (0). Таким образом, алгоритмы оптимизации
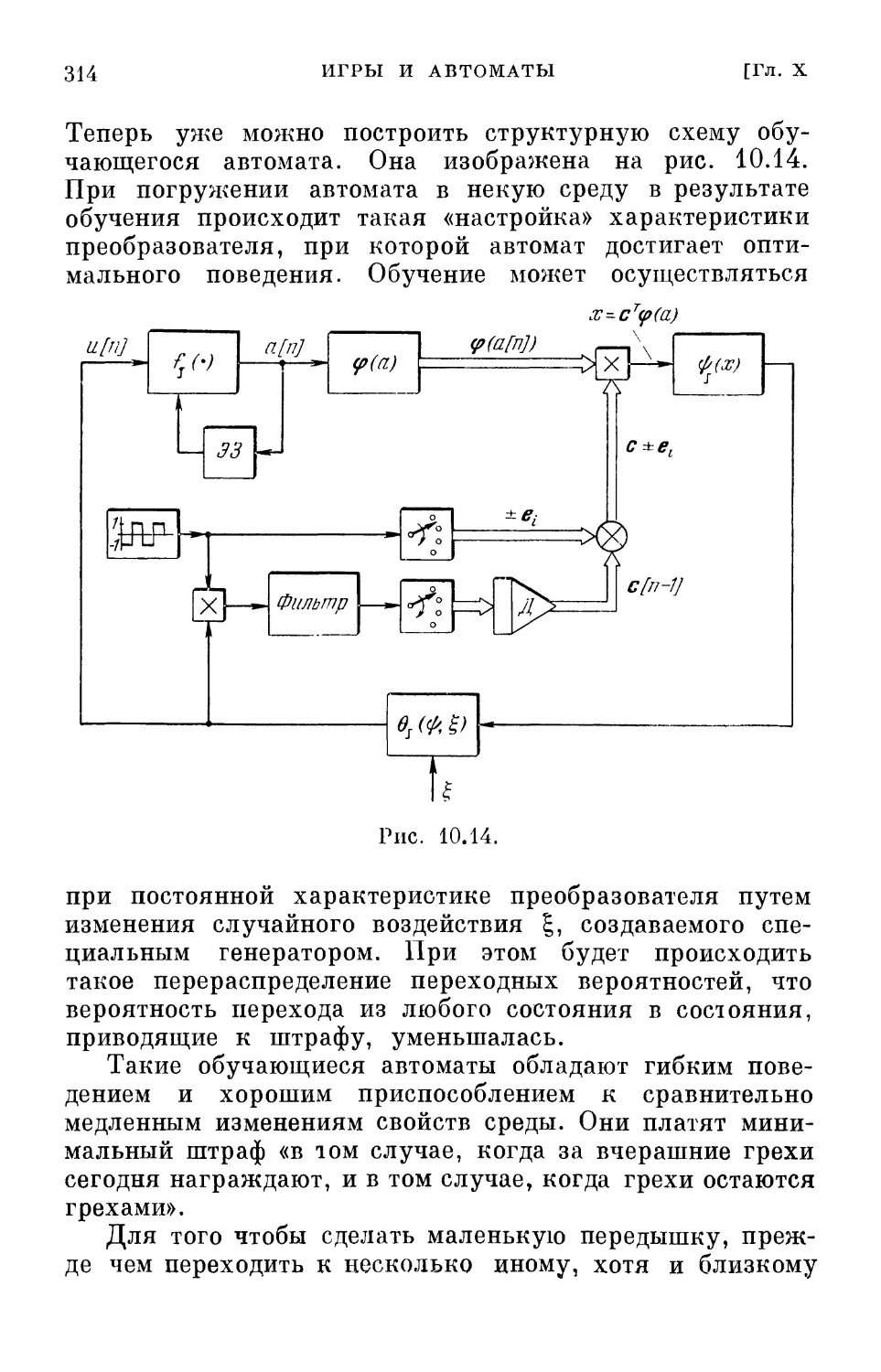
\йс[л-1]
Д.
с[п-1]
7\
Рис. 2.1.
:>
л ^/,-/7 ^j^jV^
0
ЛСу[п-
в)
cv[n-1J
Рис. 2.2.
могут быть представлены в трех формах: рекуррентной,
разностной и суммарной.
Рекуррентные, разностные или суммарные уравнения
соответствуют некоторым дискретным системам с обратной
§ 2.5]
ВОЗМОЖНОЕ ОБОБЩЕНИЕ
31
связью, структурная схема которых приведена на рис. 2.1.
Структурная схема включает в себя нелинейный
преобразователь V/ (с), усилитель с переменным, вообще говоря,
коэффициентом усиления у [п] и дискретный интегратор —
дигратор (на рис. 2.1 и 2.2, а, в обозначенный буквой Д).
Последний, как показано на рис. 2.2, б, представляет
собой элемент запаздывания, охваченный единичной
положительной обратной связью. На выходе дигратора мы
всегда получаем cv [п — 1] (рис. 2.2). Величину cv [п]
можно получить суммированием Acv [п —- 1] и cv [п —1]
(рис. 2.2, в). Двойные линии на рис. 2.1 означают
векторные связи. Особенность этой дискретной системы
с обратной связью состоит в том, что она автономна.
Вся нужная априорная информация уже содержится
в нелинейном преобразователе.
§ 2.5. Возможное обобщение
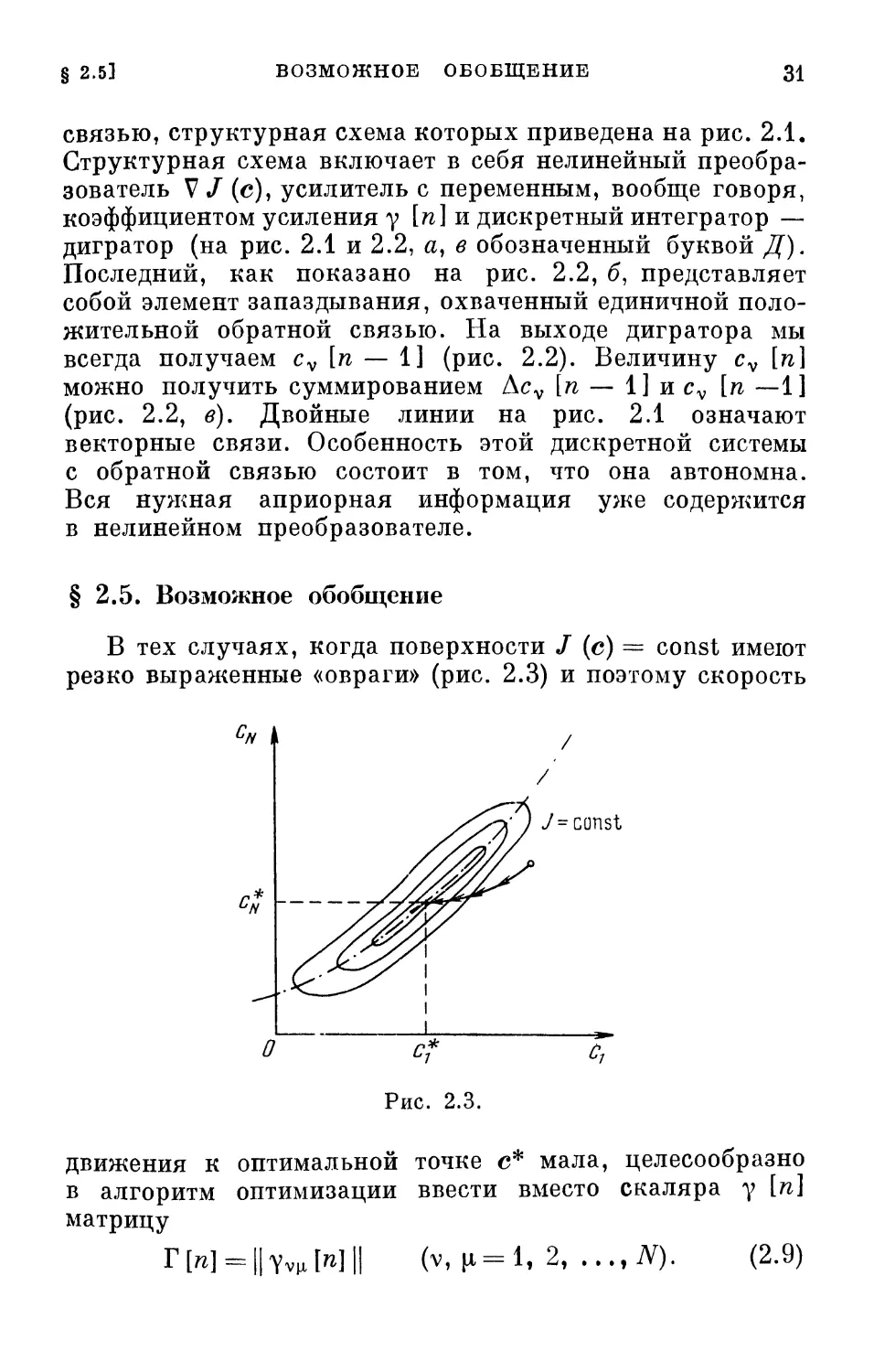
В тех случаях, когда поверхности / (с) = const имеют
резко выраженные «овраги» (рис. 2.3) и поэтому скорость
On
г*
О с* с7
Рис. 2.3.
движения к оптимальной точке с* мала, целесообразно
в алгоритм оптимизации ввести вместо скаляра у [п]
матрицу
rwHlYvuMH (v, (1=1, 2,..., iV). (2.9)
32 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
Рис. 2.4.
Тогда алгоритм (2.7) заменится на более общий алгоритм
Ас [п— 1] = — Г [п] V/ (с [п - 1]). (2.10)
В этом случае величины шагов по различным
компонентам различны и зависят друг от друга.
Выбор матрицы Г [п] можно, например, произвести
на основе того, что в некоторой окрестности точки
оптимума траектории парамет-
с к ? ров представляют собой
прямые линии, т. е.
Д/(с[Аг])= — Ы{с[п— 1]),
где к = const и
А/ (с [п]) =
= /(c[/i + l])-/(c[n]).
(2.11)
Геометрически
введению матрицы Г [п]
соответствует линейное
преобразование координат, при
котором эквипотенциальные линии преобразуются в
линии, близкие к концентрическим окружностям (рис. 2.4).
Структурная схема, соответствующая общему
алгоритму оптимизации, отличается от изображенной на
рис. 2.1 тем, что в ней вместо обычных усилителей
фигурирует «матричный» усилитель, в котором все выходы
и входы взаимно связаны друг с другом.
§ 2.6. Разновидности алгоритмов оптимизации
Выбор коэффициентов усиления матричного или
обычного усилителей определяет разновидности алгоритмов
оптимизации и соответствующих им дискретных систем.
Так, если Г [п] = Г — постоянная матрица, не
зависящая от п, то мы получим алгоритм оптимизации с
постоянным шагом и соответствующую дискретную систему
с постоянными коэффициентами усиления. Если Г [п]
зависит от п, то в этом случае получаем алгоритм
оптимизации с переменным шагом и соответствующую
дискретную систему с переменными коэффициентами усиления.
§ 2.0] РАЗНОВИДНОСТИ АЛГОРИТМОВ ОПТИМИЗАЦИИ 33
В частности, матрица Г [п] может быть периодична:
Г [п + л0] = Г [п].
В численных методах решения систем линейных
уравнений перечисленные выше алгоритмы называются
соответственно стационарными, нестационарными и
циклическими.
В обшем случае Г [п] может зависеть от векторов
с [т] (т = п — 1, п — 2, . . .). В этом случае приходим
к алгоритмам оптимизации с «нелинейным» шагом и
соответствующей дискретной системе с нелинейными
коэффициентами усиления.
К алгоритмам последнего типа относятся
релаксационные алгоритмы, в которых Г [п] на каждом шаге
выбираются так, чтобы уменьшалась какая-либо функция
ошибки с [п\—с*. Релаксационные алгоритмы
подразделяются на координатные, в которых матрицы Г [п]
подобраны так, что на каждом шаге меняются одна или
несколько компонент вектора с [л], и градиентные,
в которых
Т[п] = 1у[п], (2.12)
где / — единичная матрица, а у [л] — скаляр, зависящий
также и от координат вектора с. Так, к алгоритмам с
нелинейным шагом можно отнести известный алгоритм Ньютона
Дс [л —1] - - [W (с [n-i])]-1 V/ (с [л- 1]). (2.13)
Здесь
Г[л]--[?2/(с[л —l])]"1. (2.14)
Модификация алгоритма Ньютона
Дс [л- 1] = — [ W (с [О])]"1 V/ (с [п - 1]), (2.15)
где с [01 — некоторое начальное значение, представляет
собой алгоритм с постоянным шагом.
К релаксационным алгоритмам относится известный
алгоритм наискорейшего спуска
Дс [л— 1] = — у[п] V/ (с [л- 1]). (2.16)
Здесь у [л] на каждом шаге выбирается из условия
минимума функции
Y (Y) = / (с [л- 1] -yVJ (с [л- 1])). (2.17)
Итак, выбирая соответствующим образом Г [л] или у [л],
мы получаем различные известные алгоритмы.
3 Я. 3. Цыпкин
34 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ (Гл. И
§ 2.7. Поисковые алгоритмы оптимизации
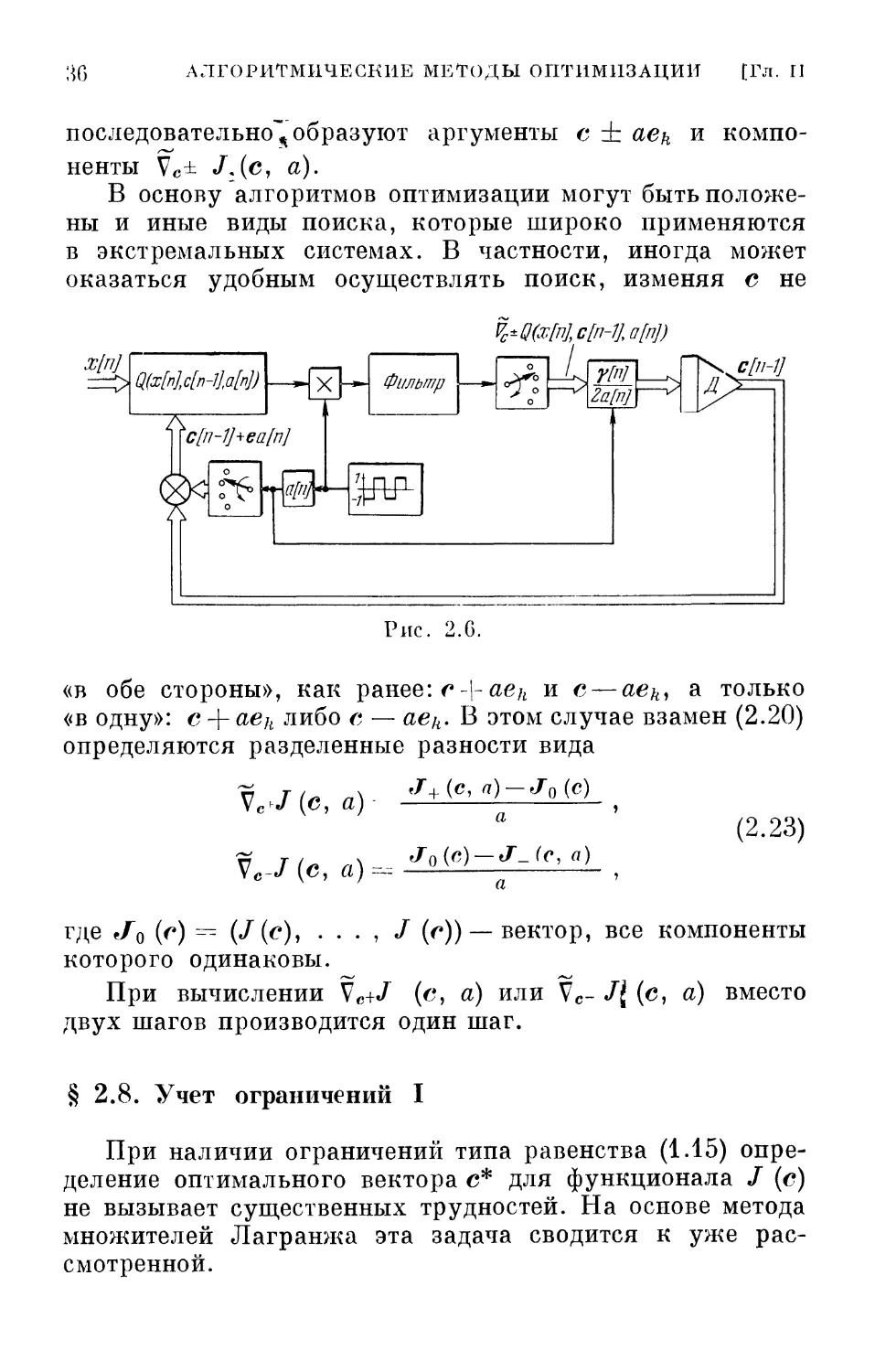
Не всегда можно вычислить в явной форме градиент
функционала (2.1), а значит, и использовать все те
алгоритмы оптимизации, о которых шла речь выше.
Такая ситуация возникает, когда функционал / (с)
разрывен или недифференцируем, либо когда его
зависимость от с выражена в неявной форме. Этот последний
случай характерен для функционалов вида (1.5) и (1.8).
К нему же относятся функционалы, которые
формулируются с помощью логических операций.
В этих условиях, вероятно, единственная возможность
решения проблемы оптимизации связана с поисковыми
способами отыскания экстремума. Если мы не можем
заранее вычислить градиент, то нужно определять его
путем измерений. При поисковых способах и
осуществляется измерение величин, по которым косвенно
оценивается градиент. Существует большое разнообразие поис-
ковых способов, разработанных в основном в связи с
с построением экстремальных систем управления. Мы
здесь не будем рассматривать все поисковые способы,
а остановимся лишь на простейших классических, чтобы
оттенить некоторые принципиальные вопросы. После
их уяснения читатель без особых усилий сможет взять
на вооружение разнообразные поисковые способы, которые
были здесь опущены.
Введем обозначения векторов, компонентами которых
являются значения функционала при измененных
значениях векторов с:
J+(c, a) = (J{e + aex), . . ., J{c + aeN)), ^ ^
J- (с, а) — (J (e — aei), . . ., / (c — aeN)).
Здесь а — скаляр, ev — базисные векторы.
В простейшем случае
et = (l, 0,...,0)-,^-(0, 1, ...,0); . . .; eN = (0, 0, ..., 1).
(2.19)
Тогда градиент можно приближенно оценивать по формуле
J+{r"a)-J-(e'e) ~ Vc±J (с, а), (2.20)
§ 2.71
ПОИСКОВЫЕ АЛГОРИТМЫ ОПТИМИЗАЦИИ
Зо
определяющей так называемую разделенную разность.
Заменив в приведенном ранее общем алгоритме
оптимизации (2.4) градиент функционала его приближенным
значением (2.20), получим поисковый алгоритм
оптимизации
с [п] = с [и- 1] - у W Vr±/ (г [п - 1], а [п]). (2.21)
Этот алгоритм оптимизации, который можно
представить, помимо рекуррентной формы (2.21), также и в
разностной или суммарной форме, соответствует
экстремальным дискретным системам.
J(c+ffas]qn(s\\\(oet))
aPc±J(c,a)
щп(ът1о0Ь)
Рис. 2.5.
Приближенная оценка градиента (2.20), т. е. получение
разделенной разности Vc± / (с, а), может осуществляться,
например, при помощи синхронного детектора (рис. 2.5),
если в качестве поискового колебания принять
прямоугольное периодическое воздействие достаточно высокой
частоты и амплитуды у (t) = a sign (sin оэ0£).
Действительно, легко проверить, что
V„±/(c, а)-
ю0
2я
Щ
2ла
\ / (с, a sign (sin о)0/,)) sign (sin со0/) с//. (2.22)
Поэтому структурную схему экстремальной дискретной
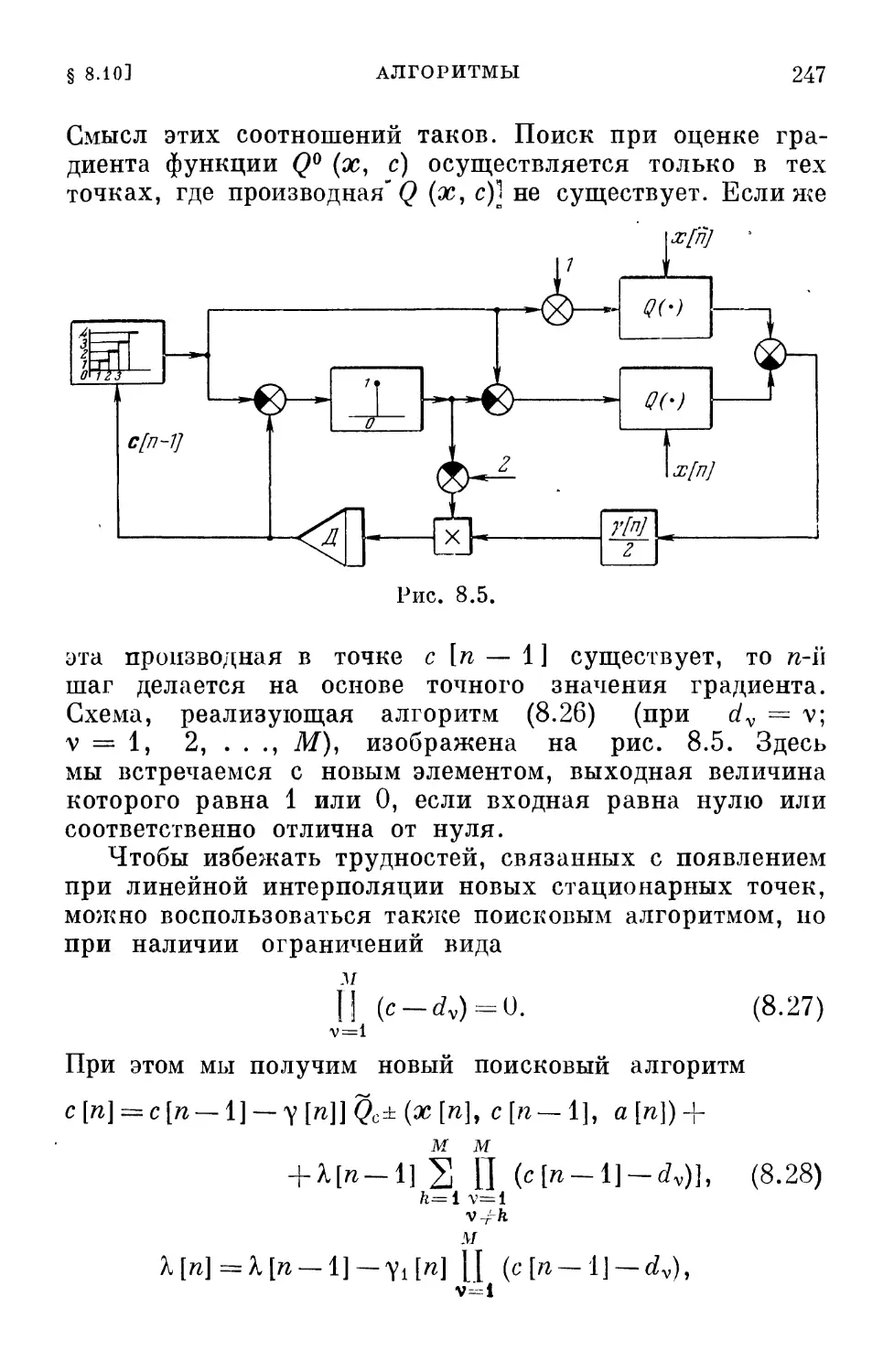
системы можно представить в виде, показанном на рис. 2.6.
Обычно а [п] = const.
В отличие от обычной (непоисковой) системы (рис. 2.1),
здесь имеется дополнительный генератор поисковых
колебаний и синхронный детектор и коммутаторы, которые
3*
;^G АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
последовательно^ образуют аргументы с ± аеи и
компоненты Vc± JAC> а)-
В основу алгоритмов оптимизации могут быть
положены и иные виды поиска, которые широко применяются
в экстремальных системах. В частности, иногда может
оказаться удобным осуществлять поиск, изменяя с не
х[п]
ЦШЛп-ЫФ
7\
'c[n-1J+ea[nJ
ге
X \—\ Фильтр
%±ЧШ,с[п-1],а[Ф
L I vfn] I А
°Г«
Ш-
Рис. 2.G.
«в обе стороны», как ранее: c\aeh и с— aekl а только
«в одну»: с + aek либо с — аед. В этом случае взамен (2.20)
определяются разделенные разности вида
J+(c, a) — J0(c)
(2.23)
Ve-/(c, а)
Vc^(c, а)
J0(c)-J-_(c, а)
где в/0 (<*) ~ (J(e)i - - - , J (г)) —вектор, все компоненты
которого одинаковы.
При вычислении Vc+^ (е, а) или Vc- /f (с, а) вместо
двух шагов производится один шаг.
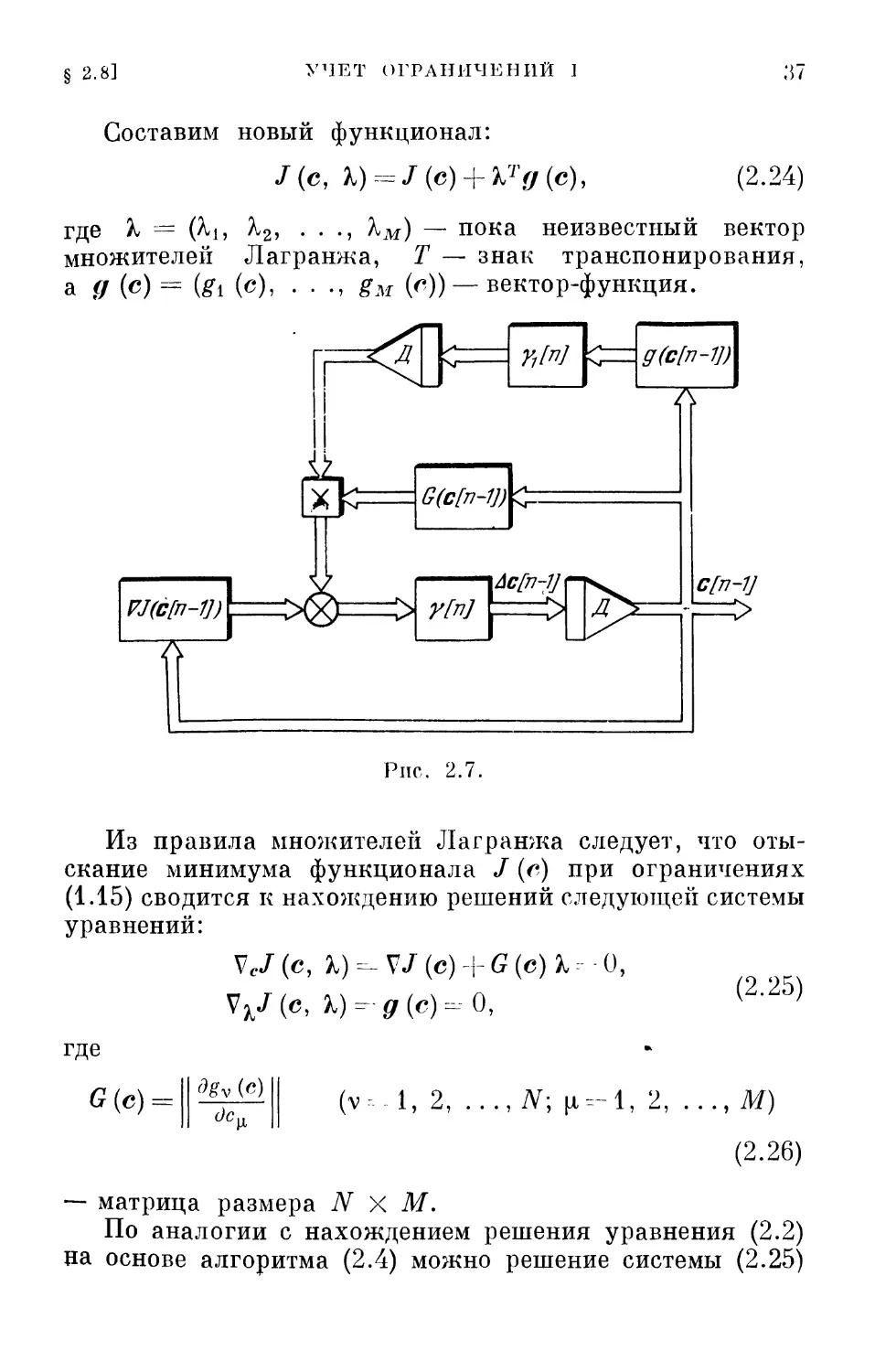
§ 2.8. Учет ограничений I
При наличии ограничений типа равенства (1.15)
определение оптимального вектора с* для функционала / (с)
не вызывает существенных трудностей. На основе метода
множителей Лагранжа эта задача сводится к уже
рассмотренной.
§ 2.8]
УЧЕТ ОГРАНИЧЕНИЙ I
Составим новый функционал:
/(с, X) = J(e) + bTg(c),
(2.24)
где % = (^ь ^25 • • •> ^м) — пока неизвестный вектор
множителей Лагранжа, Т — знак транспонирования,
а д (с) = (gi (с), - • •» £м И) — вектор-функция.
VJ(c[n-1])\
—Л
Г^Н
км
й^Н
#&/&-»
> >"/*7
Aefn-JJ
Д
Рнс. 2.7.
ff(c[n-Vy
7\
c[n-V
Из правила множителей Лагранжа следует, что
отыскание минимума функционала / (с) при ограничениях
(1.15) сводится к нахождению решений следующей системы
уравнений:
VcJ(c, %)=-VJ(c) + G{e)b=--0,
VkJ(c, Я)-fir (с) =--0,
(2.25)
где
G(c) =
3gv (с)
cJc„
(v-l, 2, ..., iV; (1=-1, 2,
,М)
(2.26)
— матрица размера N X М.
По аналогии с нахождением решения уравнения (2.2)
па основе алгоритма (2.4) можно решение системы (2.25)
38 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
определять с помощью алгоритмов
cl?i] = c[n-l\-y[n]XcJ(c[n-l], M'i-1]), (227)
l[n] = b[n—l]—yl[n]\bJ(c[n — l], k[n—l]),
или
а \п]-- r[/i-l]-yM[V/(r[«-l]) +
+ G(c[w —1])М« —1Ц, (2.28)
Ми]= ^[«-lJ-Yil"]flr(cfw-ll).
Наличие ограничений типа равенств несколько
усложняет структурную схему, соответствующую алгоритмам
оптимизации. В ней добавляются специальные контуры
для определения множителей Лагранжа (рис. 2.7).
Возможны и иные алгоритмы оптимизации, которые
отличаются иным определением множителей Лагранжа,
но мы их сейчас касаться не будем.
§ 2.9. Учет ограничении II
Ограничения типа неравенств не позволяют
использовать классические подходы, которые мы до сих пор широко
использовали. Для учета ограничений этого типа
приходится прибегать к новому математическому аппарату —
математическому программированию, возникшему
сравнительно недавно.
Условия оптимальности в этом случае даются теоремой
Куна — Таккера, которая представляет собой обобщение
метода Лагранжа на случай ограничений типа неравенств.
Теорема Куна — Таккера утверждает, что оптимальный
вектор г* удовлетворяет следующим условиям:
V,/ (г, Ь) = V/ {с) + G(e)b = 0; ^
д(е) ' 6=-0; Ь>0, 6>0; [ (2.29)
1тЬ-0. J
Условия записаны в векторной форме, 'к = (?ц, А,2» • • •
• • • i ^Mi), 6 = (Si, б2, . . • , 6Ml); неравенства к > 0,
6 > 0 означают, что все компоненты этих векторов
неотрицательны. Кроме того, предполагается, что ограниче-
§ 2.9]
УЧЕТ ОГРАНИЧЕНИЙ IT
39
ния (1.14) таковы, что существует вектор г, для которого
gv(e)<0 (v = l, 2, ..., М,). (2.30)
Это — известное в теории нелинейного
программирования условие регулярности Слейтера.
Условия (2.29) имеют простой смысл: если для
оптимального вектора с* несущественно какое-то ограничение,
:д
УМ
g(c[n-w
~к
G(c[n-1])
с[п-1]
Рис. 2.8.
т. е. gv (с*) <С 0 для какого-то v, то соответствующее
Xv — 0; если же Xv > 0, то в этом случае 8V = gv (г**) = 0.
Таким образом, множители Лагранжа можно
интерпретировать как некоторые оценки влияния ограничений
(1.14) на оптимальное значение вектора.
Заметим, что если функционалы J (с) и gv (с) (v =
= 1, 2, . . ., Afi) выпуклы, то теорема Куна— Таккера
дает необходимые и достаточные условия оптимальности.
Применяя к (2.29) алгоритмы оптимизации, нетрудно
получить, что
с [п] = с [п — 1] — у [п] [ V/ (с \п — 1]) +
+ С(с[л-1])М,
I [п] = max {0, % \п - 1 ] + у, [п] д {с [п - 1])},
40] >о.
(2.31)
40 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
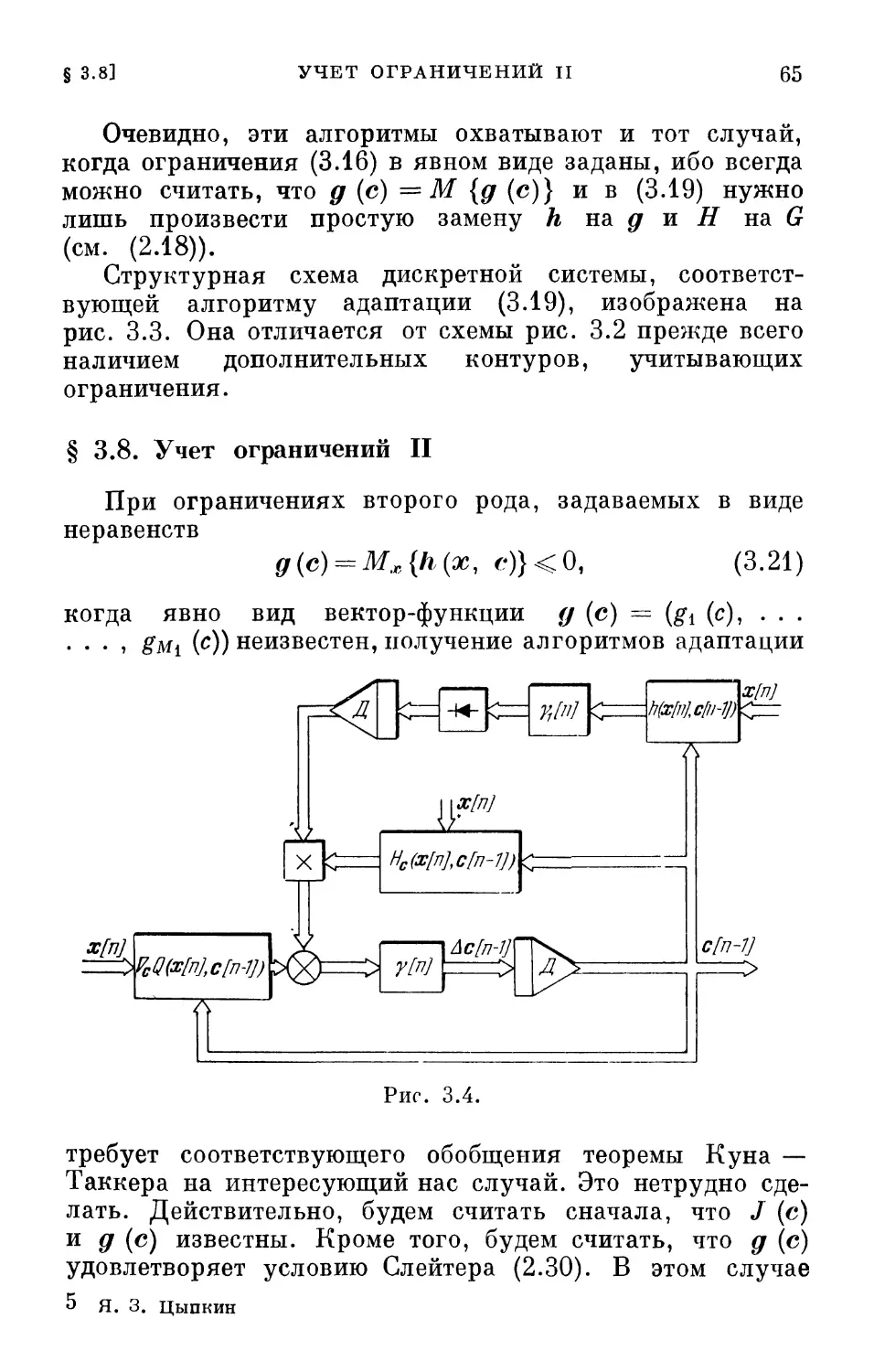
Структурная схема системы, соответствующая этому
алгоритму, изображена на рис. 2.8. Она отличается от
схемы рис. 2.7 только наличием однонаправленного
устройства, которое обеспечивает учет ограничений в виде
неравенств.
§ 2.10. Методы возможных направлений
В предыдущих параграфах были рассмотрены
алгоритмы, позволяющие определять минимальное значение
вектора с* при наличии дополнительных ограничений в виде
равенств и неравенств. В этих методах, основанных
на решении соответствующей задачи Лагранжа, наряду
с оптимальным значением вектора с* определялась и
оптимальная величина множителя Лагранжа %*. Можно
непосредственно использовать для решения задач на условный
экстремум идею движения вдоль градиента. Эти методы
получили название методов возможных направлений.
Суть этих методов состоит в следующем.
Выбирается произвольная точка с [п—1],
удовлетворяющая ограничениям (1.14). В этой точке определяется
такое направление z [п— 1], двигаясь вдоль которого
можно сделать шаг конечной длины у [п] и уменьшить
значение функционала, не выходя при этом за пределы
допустимого множества.
Затем определяется длина шага у [п] и, следовательно,
новое значение вектора с [п]\
с [л] = с [п—1]—у[п] z[n~ 1]. (2.32)
Значение функционала в новой точке с [п] должно
быть меньше, чем в предыдущей:
J(c[n])<J(c[n — l]). (2.33)
Таким образом, на каждом шаге задача определения
нового значения вектора с [п] состоит из двух этапов:
выбора направления и выбора длины шага при движении
по этому направлению.
Для того чтобы неравенство (2.33) выполнялось,
вектор z должен составлять с градиентом функционала
в этой точке острый угол, т. е.
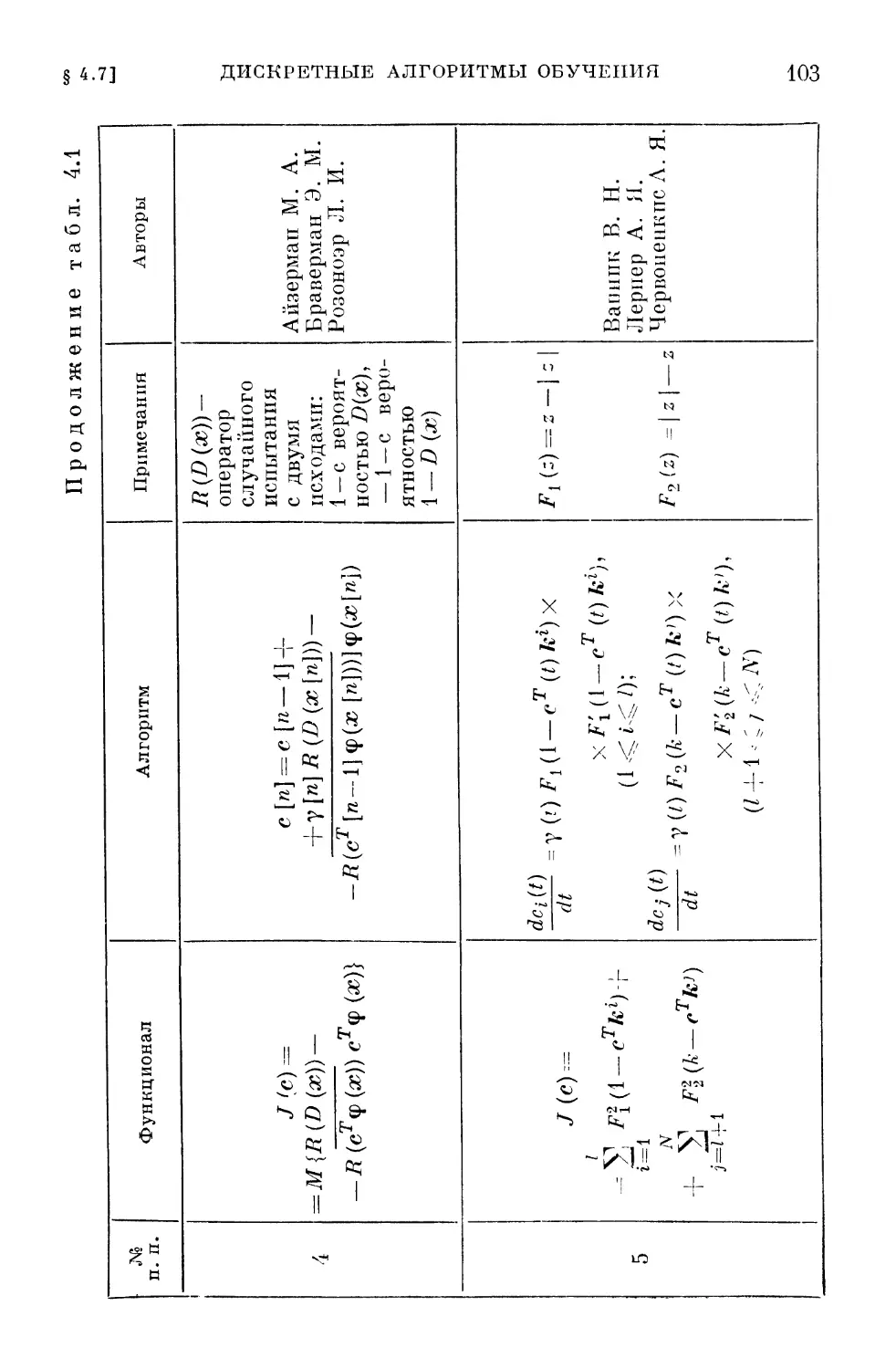
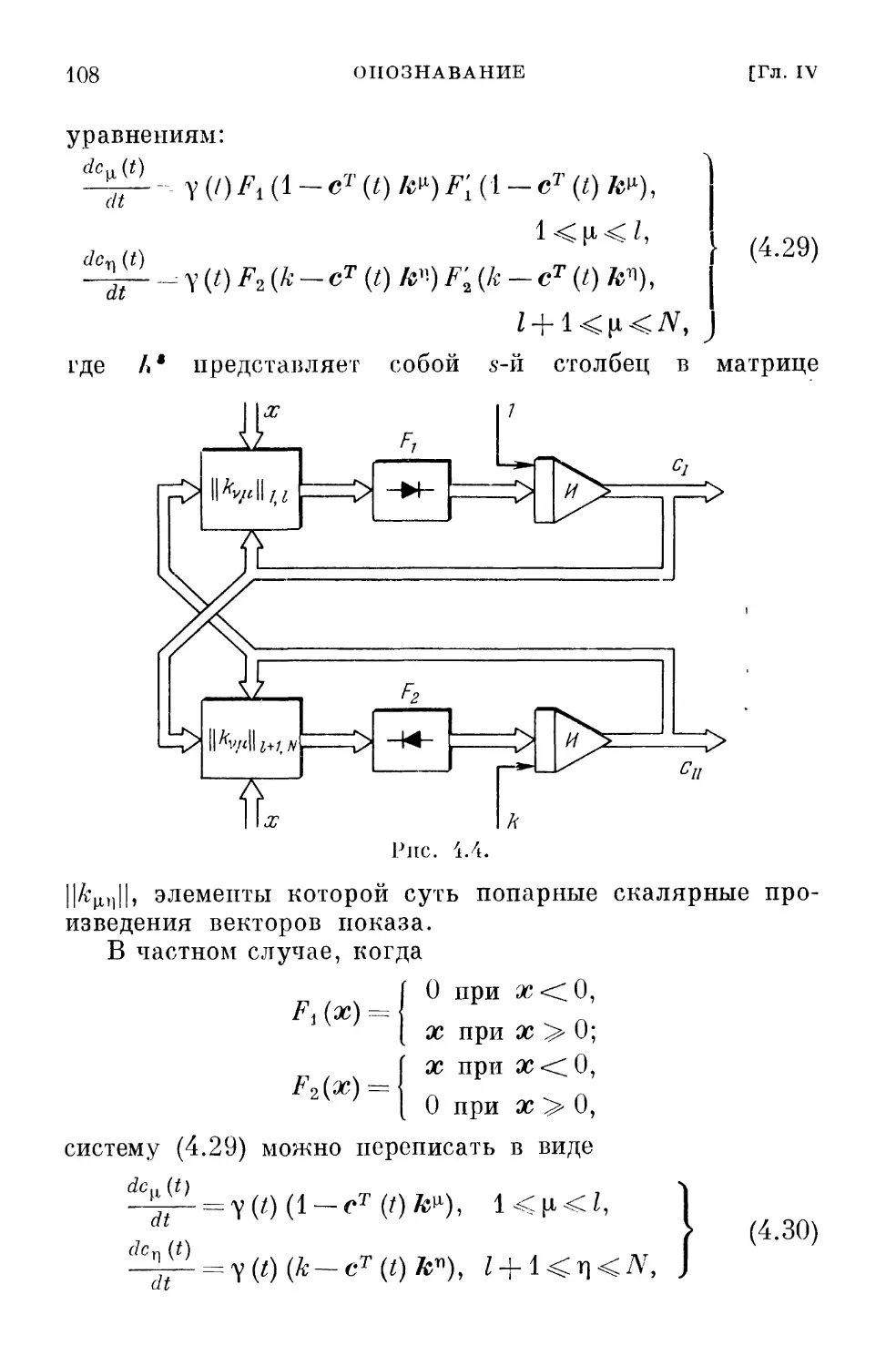
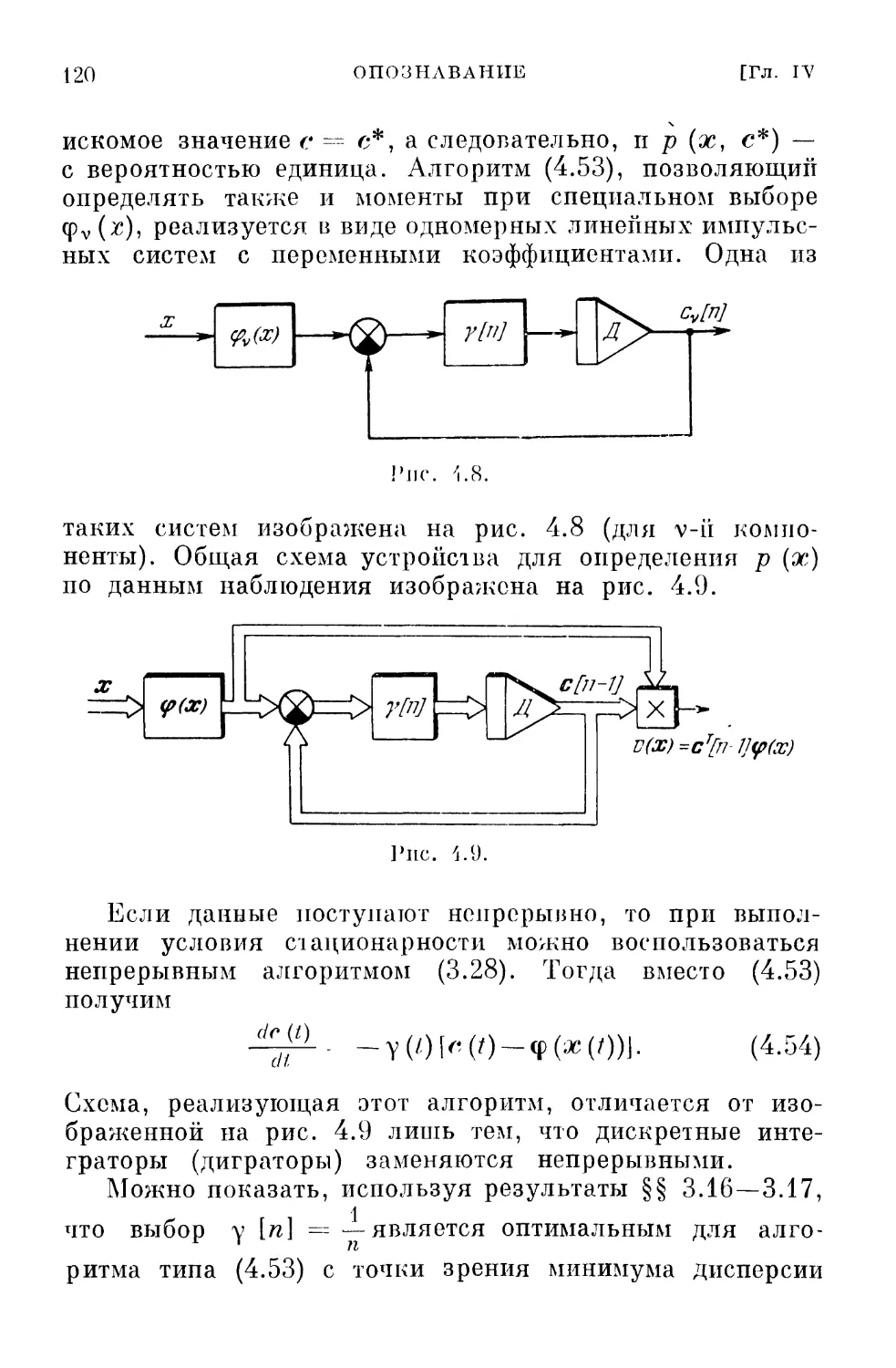
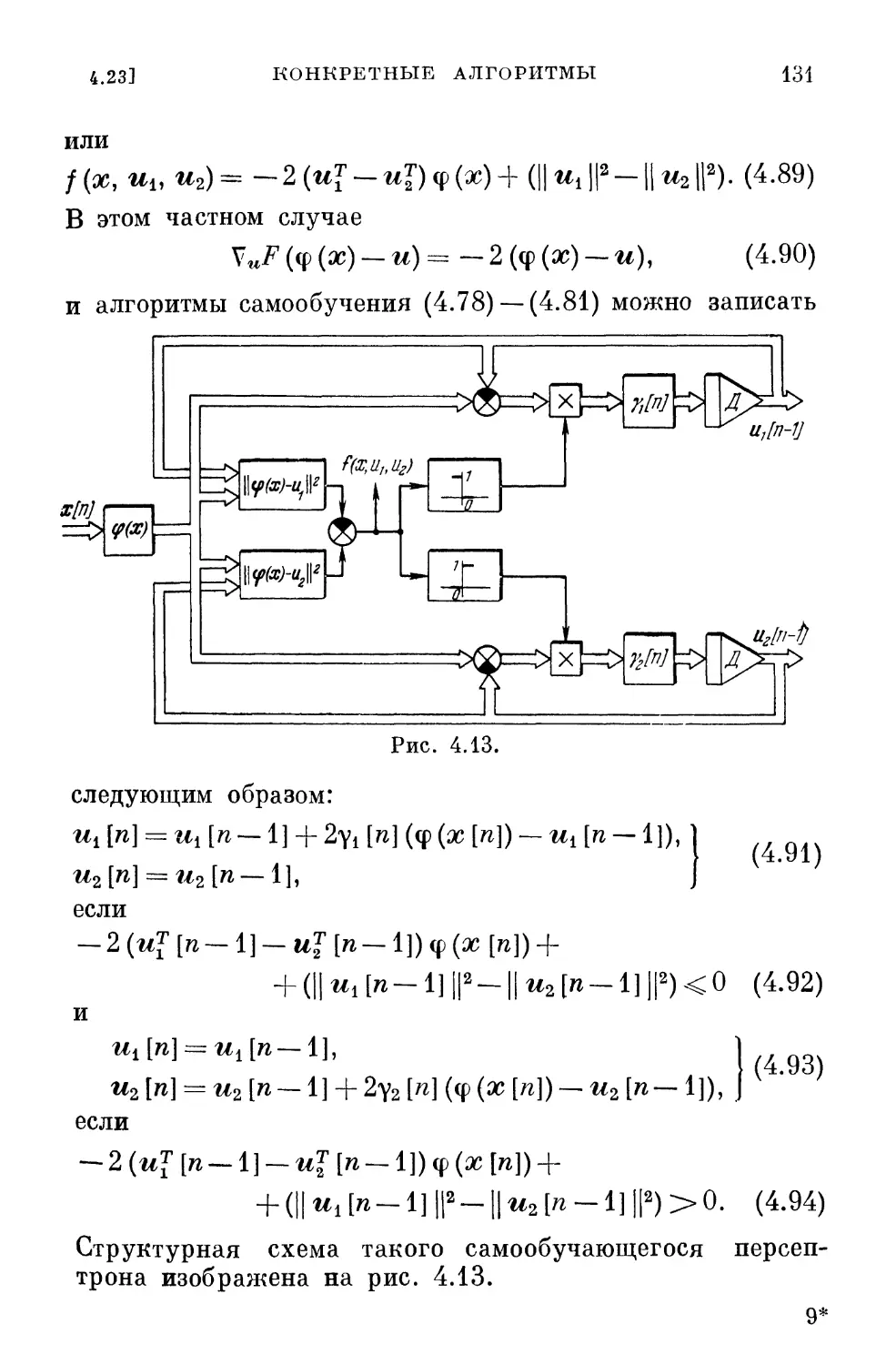
zT\n--i} V/(c[w —1])>0, (2.34)
§ 2.11]
ОБСУЖДЕНИЕ
/j]
Направление, удовлетворяющее неравенству (2.34),
получило название возможного. Отсюда и название всех
методов такого рода.
Величина шага у [п] определяется так же, как и в
методе наискорейшего спуска, т. е.
J(c[n—l] — y[n]z[n—l]) = min J. (2.35)
Y
При этом, конечно, не должны нарушаться ограничения
(1.14).
Для частных задач методы возможных направлений
могут обеспечить нахождение экстремума за конечное
число шагов.
Нужно отметить, что многие эффективные алгоритмы
математического программирования (например, симплекс-
метод в линейном программировании) можно трактовать
как специальные случаи методов возможных направлений.
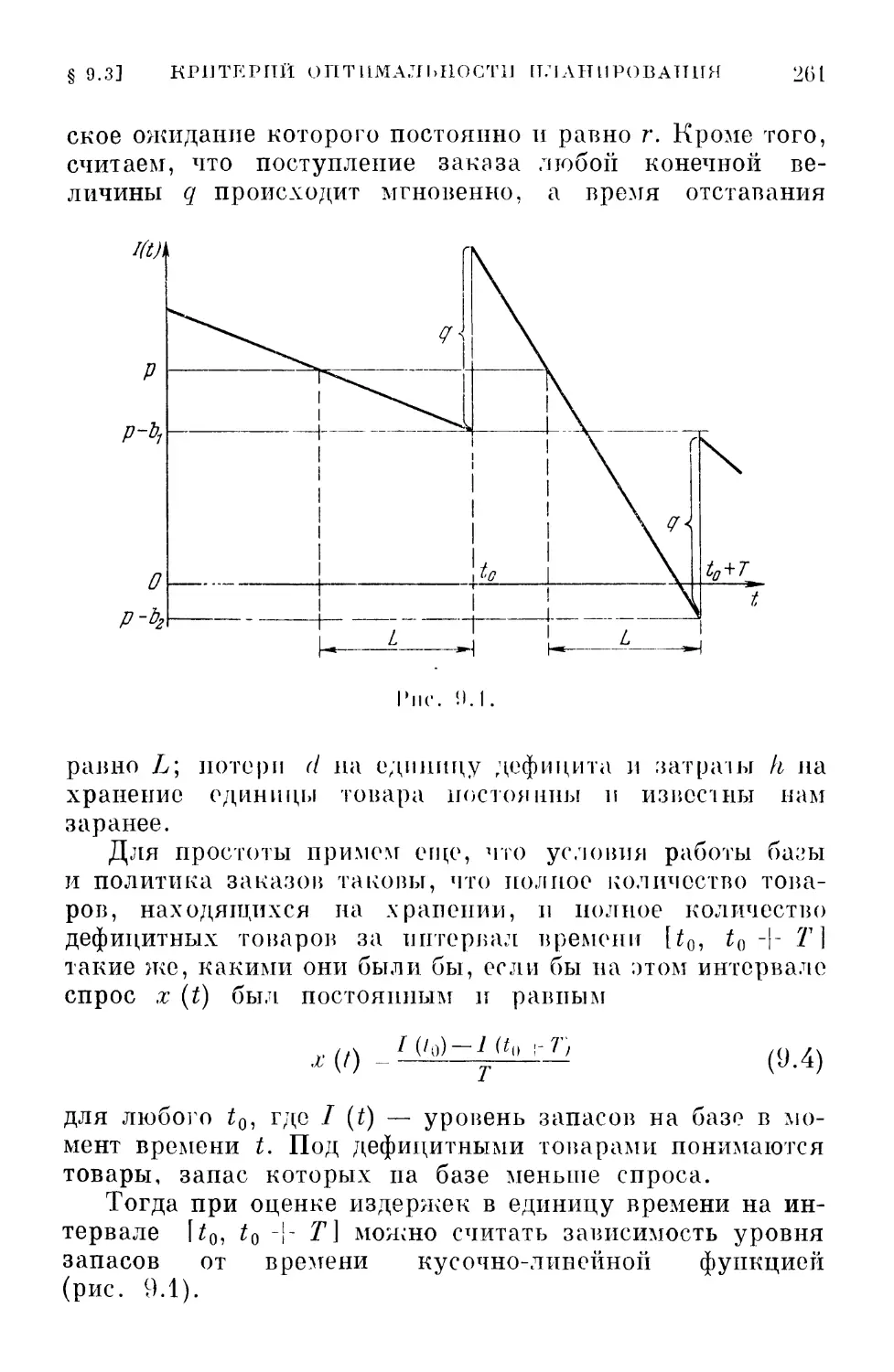
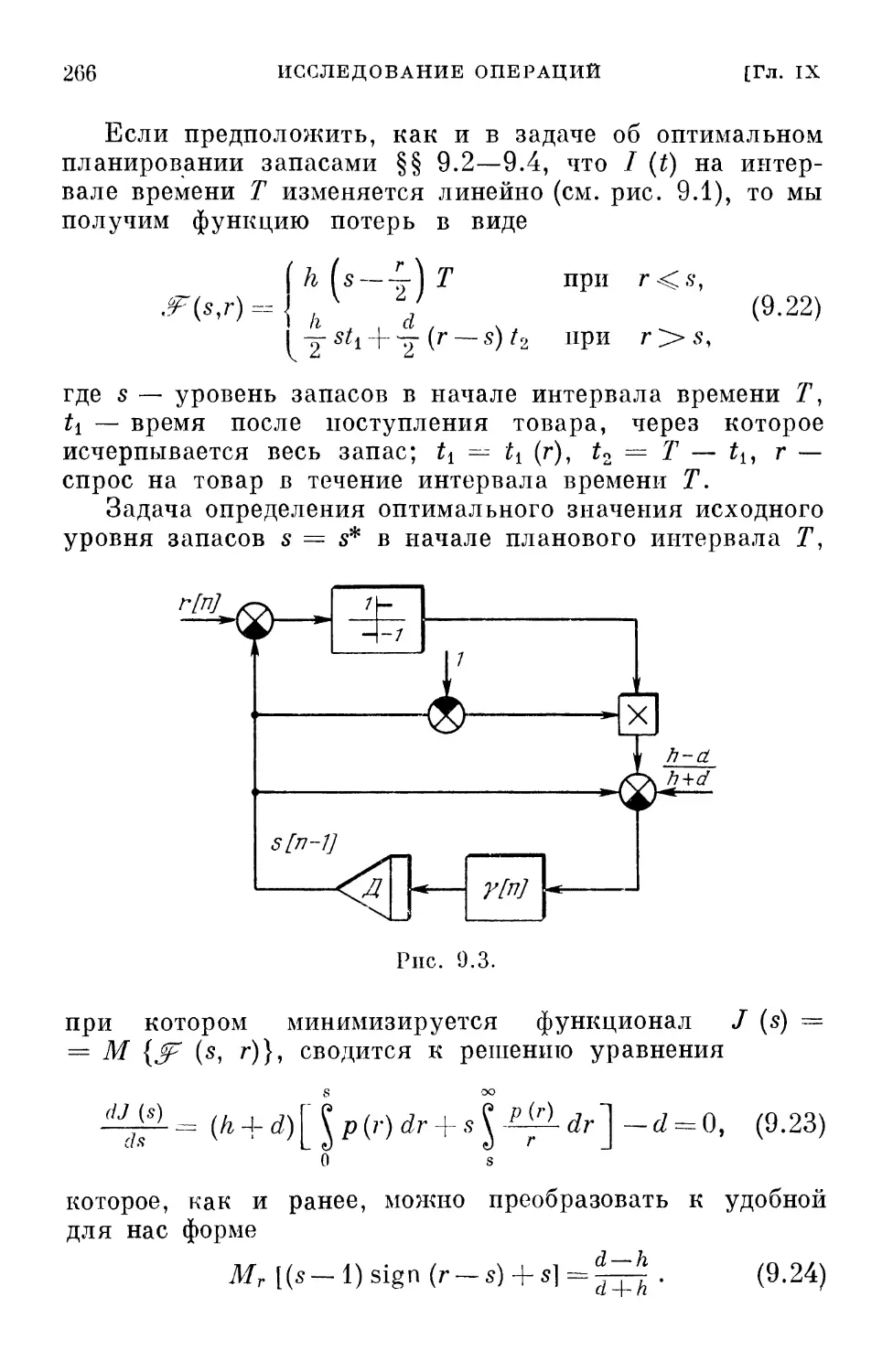
§ 2.11. Обсуждение
Алгоритмические методы определения экстремума,
о которых мы до сих пор говорили, имеют простой
«житейский» смысл. Его удобно пояснить на поведении
спелеолога, исследующего пещеру и пытающегося достичь
наибольшей глубины. Спелеолог может осветить или
обследовать характер местности лишь в непосредственной
близости от своего местонахождения. Как он будет
поступать в этих условиях? Очевидно, он прежде всего выберет
направление наиболее крутого наклона (т. е. направление
вдоль градиента). Затем он буде! двигаться в этом
направлении, пока это движение будет приводить к спуску, и,
наконец, он остановится тогда, когда любое направление
будет приводить к подъему. Места остановки и
представляют собой локальные минимумы. Если имеются
ограничения в виде равенств — узкие проходы,— то спелеологу
ничего не останется, как идти вдоль этих узких проходов
до тех пор, пока он не достигнет в них самого низкого
места.
Если же имеются ограничения в виде неравенств, т. е.
если спелеолог наталкивается на стену, то ему придется
идти вдоль стены вниз до тех пор, пока он не достигнет
такого места, откуда уже все направления ведут вверх.
42 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
Такое поведение спелеолога иллюстрирует основную
идею градиентных методов, выраженную и в алгоритме
оптимизации. Нужно подчеркнуть, что эти методы имеют
локальный характер. Спелеолог, достигнувший какого-
нибудь низкого места в пещере, не может быть уверен,
что даже неподалеку нет еще более низкого места.
Из нелокальных методов определения экстремума
наиболее интересным и эффективным является известный
метод оврагов. Мы, однако, на нем останавливаться не
будем не только потому, что он достаточно хорошо описан,
но и потому, что задачи, решаемые с его помощью, лежат
несколько в стороне от направления, которое будет
интересовать нас далее.
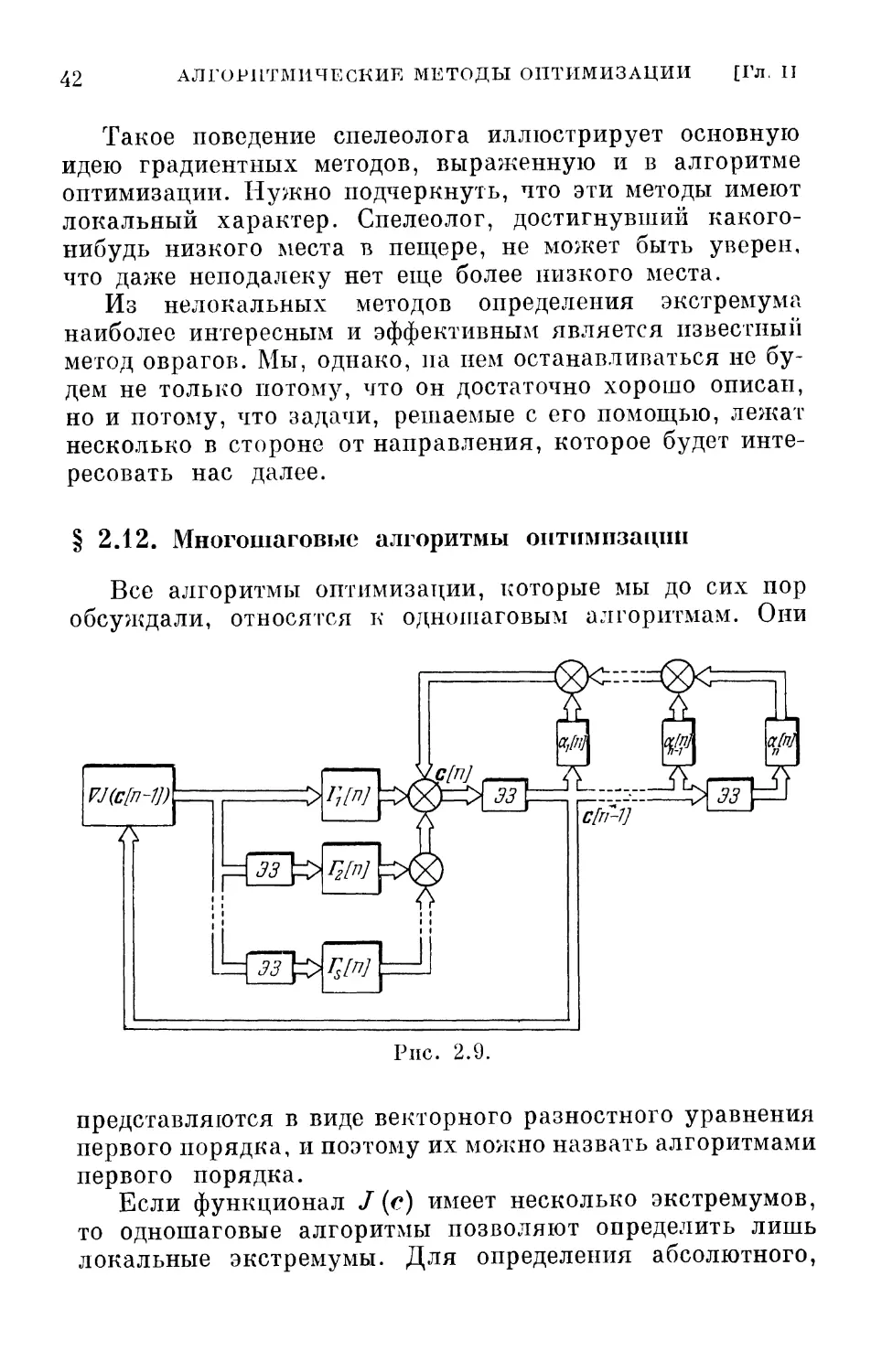
§ 2.12. Многошаговые алгоритмы оптимизации
Все алгоритмы оптимизации, которые мы до сих пор
обсуждали, относятся к одношаговым алгоритмам. Они
Рис. 2.9.
представляются в виде векторного разностного уравнения
первого порядка, и поэтому их можно назвать алгоритмами
первого порядка.
Если функционал J (с) имеет несколько экстремумов,
то одношаговые алгоритмы позволяют определить лишь
локальные экстремумы. Для определения абсолютного,
§ 2.12] МНОГОШАГОВЫЕ АЛГОРИТМЫ ОПТИМИЗАЦИИ 43
глобального экстремума можно попытаться применять
многошаговые алгоритмы оптимизации, например
алгоритмы вида
с [п] = 2 <*тс[п-т]— § rm[rclV/(С [71-1711) (2.36)
7П=1 771= 1
или
s si _
с\п\= 2 amc\n — m\ — Y[n]VJ( ^ атС[п — т\). (2.37)
тл=1 m=i
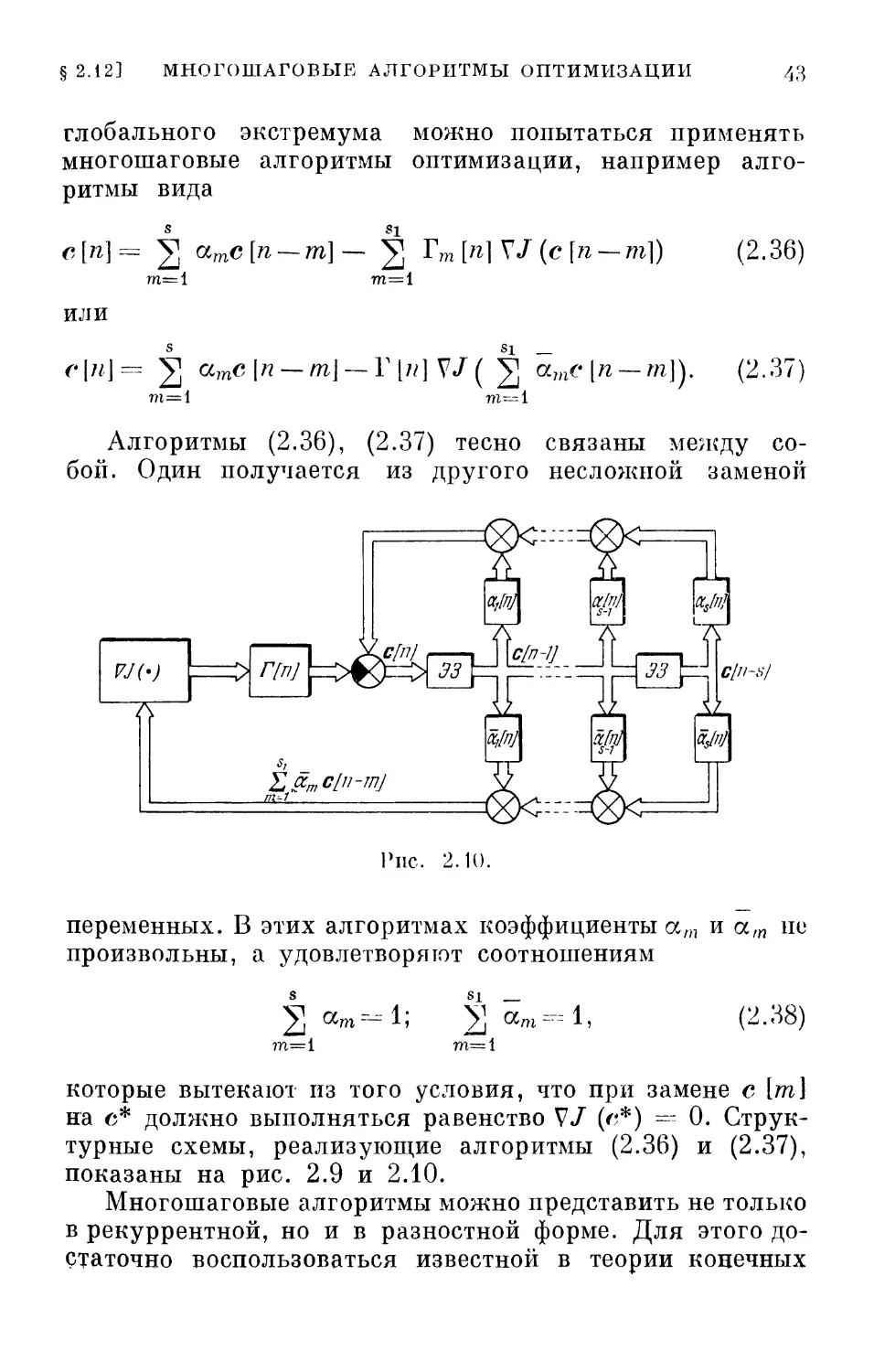
Алгоритмы (2.36), (2.37) тесно связаны между
собой. Один получается из другого несложной заменой
VJ(-)
~К
«М
\аЩ
Щ=^Щ^у^^,ф^1
х'тг^че
Clll-Sj
\ocj[n]\
-ВЫ.
\аМ
km
Рис. 2.10.
переменных. В этих алгоритмах коэффициенты ат и а,п не
произвольны, а удовлетворяют соотношениям
S
а»
1; У. am-l,
(2.38)
m=l
которые вытекают из того условия, что при замене с [т]
на с* должно выполняться равенство V/ (с*) =- 0.
Структурные схемы, реализующие алгоритмы (2.36) и (2.37),
показаны на рис. 2.9 и 2.10.
Многошаговые алгоритмы можно представить не только
в рекуррентной, но и в разностной форме. Для этого
достаточно воспользоваться известной в теории конечных
44 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
разностей формулой Грегори — Ньютона
т
с[п-т]= 2 (7) Avc[n-v], (2.39)
v=0
где принимается, что А°с [п] = с [п].
Тогда после подстановки (2.39) в (2.36) и
получим
771= О
si т
-23 Im[»]V/(2] (;i)AV[n-v])=0
m—i v=i
И
2 pmA'V^-m]-rH V/( § M> [^-^1) = 0. (2.41)
?П=1 771=1
Очевидно, что между коэффициентами многошаговых
алгоритмов в рекуррентной форме, т. е. ост, ат, и
алгоритмов в разностной форме, т. е. рт, рт, существует
определенная связь. Мы здесь не будем выписывать
соотношений между ними, так как нам они не понадобятся.
Из многошаговых алгоримов при s = s{= 1 получаем
уже знакомые нам одношаговые алгоритмы. Если в (2.36),
(2.37) или (2.40), (2.41) заменить V/(с) разделенной
разностью Vc±/(c) из уравнения (2.20) или Vr+ J{c), то
получим соответствующие многошаговые поисковые алгоритмы.
Выбор коэффициентов ат — ат [п] и матриц Гт [п]
позволяет не только сделать этот алгоритм
малочувствительным к локальным экстремумам, но и ускорить
сходимость и повысить помехоустойчивость при определении
оптимального вектора с* в тех случаях, когда / (с) имеет
единственный экстремум. Это достигается благодаря
запоминанию предшествующих значений векторов
е [п — т] и градиентов V/ {г [п — тХ) и, следовательно,
лучшей экстраполяцией и фильтрацией, чем при одно-
шаговых алгоритмах.
(2.37)
(2.40)
§ 2.13] НЕПРЕРЫВНЫЕ АЛГОРИТМЫ ОПТИМИЗАЦИИ 45
Физическую интерпретацию этих особенностей
многошаговых алгоритмов оптимизации мы дадим в следующем
параграфе. Нужно только отметить, что, к сожалению,
общие способы выбора коэффициентов ат и Гт [п] пока
неизвестны.
§ 2.13. Непрерывные алгоритмы оптимизации
Дискретным алгоритмам оптимизации, которые до сих
пор мы и рассматривали, можно поставить в соответствие
непрерывные алгоритмы оптимизации. Эти последние
алгоритмы получаются посредством предельного перехода
от разностных уравнений к дифференциальным. Так,
из (2.7) и (2.41) при Si = 1 после замены дискретного
времени п непрерывным временем t, а разностей —
производными получаем непрерывные алгоритмы
оптимизации.
Одношаговый алгоритм при этом определяется
уравнением
il|£L=_r(0V/(c(0), (2.42)
а многошаговые — уравнением
S
2 К^Р— - Г (I) V/ (с (/)). (2.43)
В отличие от дискретных, для непрерывных
алгоритмов по их самой природе не существует рекуррентной
формы и возможны лишь дифференциальные формы
(2.42), (2.43) и соответствующие им интегральные формы,
которые мы пока выписывать не будем.
Поскольку для непрерывных алгоритмов не
существует понятия конечного шага, то вместо одно- и
многошаговых алгоритмов удобнее их называть алгоритмами
первого и высших порядков. Можно указать на большое
число разновидностей непрерывных алгоритмов
оптимизации, хотя до последнего времени они были мало
распространены на практике. Это связано с тем, что дискретные
алгоритмы очень хорошо приспособлены как для ручного
счета, так и для счета на цифровых вычислительных
машинах. Непрерывные же алгоритмы непосредственно
\{\ АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. П
для ручного счета непригодны. Однако их можно
реализовать с помощью аналоговых вычислительных машин.
Собственно говоря, уже довольно давно непрерывные
алгоритмы типа (2.42) использовались для нахождения
решения систем конечных (алгебраических,
трансцендентных) уравнений на аналоговых вычислительных машинах.
И если рассматривать условия оптимальности как систему
конечных уравнений, то многие из приемов решения
конечных уравнений можно рассматривать как непрерывные
алгоритмы оптимизации.
Для выяснения особенностей алгоритмов более высоких
порядков и придания им определенного физического
смысла рассмотрим алгоритм оптимизации второго
порядка, который получается из (2.43) при 5=2:
Ро ^ + P. ^- + Г (О V/ (с (0) = 0. (2.44)
Если здесь положить ро = 0 и (^ — 1, то мы получим
алгоритм оптимизации первого порядка (2.42).
Уравнение (2.44) описывает движение тела («тяжелого
шарика») массы ро» обладающего коэффициентом вязкого
трения Pi и переменным коэффициентом упругости Г (t)
в потенциальном поле. Выбирая соответствующие
параметры «тяжелого шарика» (|30, Р^, мы придаем ему
возможность, с одной стороны, проскакивать небольшие
локальные минимумы и, с другой стороны, быстрее достигать
абсолютного глобального минимума. Разумеется, этот
вывод справедлив и для дискретных многошаговых
алгоритмов оптимизации, хотя для них физическая
интерпретация оказывается несколько иной.
Для читателя, вероятно, не представит затруднений
получить соответствующие непрерывные поисковые
алгоритмы оптимизации.
§ 2.14. Методы случайного поиска
Во всех регулярных итеративных методах поиска
минимума J (с) для получения текущей оценки с [п]
параметра с делается неслучайный шаг, однозначно
определяемый либо значением градиента V/ (с) при е = с [п],
либо значением самой функции J (г).
§ 2.15] СХОДИМОСТЬ И УСТОЙЧИВОСТЬ 47
В методах случайного поиска при переходе от с [п — 1 ]
к с [п] делается случайный шаг у£,, гДе £— единичный
случайный вектор, чаще всего равномерно
распределенный в тг-мерной единичной сфере; у — величина шага.
В этом случае
е[п] = с [п — 1] —
1у£[п], если /(с [л— l\—y$[n])<J(c[n— 1]), 4
[ 0, если J(c[n— 1] — y£[n\)>J(c[n~- 1]).
Существуют различные модификации алгоритма (2.45).
В этом алгоритме случайный шаг делается только в том
случае, если J (с [п]) < J (с [п— 1]), в противном
случае система остается в предыдущем состоянии с [п] =
= с [/г— 1]. В других алгоритмах, например, «с
наказанием случайностью» случайный шаг делается только
тогда, когда предыдущий шаг был неудачным, и т. д.
Наконец, если в регулярном градиентном алгоритме
величину у сделать случайной, то мы также получим
алгоритм случайного поиска:
с [п] з,- с \п - 1] - ус [п] V/ (е [п~\ ]), (2.46)
где ус [п] — реализация случайной величины ус.
Следует заметить, что случайный шаг, не зависящий
от абсолютного значения градиента функции или самой
функции, помогает благополучно миновать хотя бы
некоторые неглубокие локальные экстремумы функции.
§ 2.15. Сходимость и устойчивость
Алгоритмы оптимизации могут быть реализованы, если
они сходятся, т. е. если с течением времени с [п] в
дискретных алгоритмах и с (i) в непрерывных алгоритмах
стремятся к оптимальному значению вектора с*. В связи
с этим установление сходимости приобретает важное
значение. Только при гарантированной сходимости можно
рассчитывать на применение алгоритмов оптимизации.
Поскольку каждому алгоритму оптимизации
соответствует некоторая автономная система с обратной связью,
то сходимость алгоритма, а значит и его реализуемость,
эквивалентна устойчивости этой автономной системы.
48 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
Для исследования устойчивости можно использовать
методы, довольно хорошо развитые в механике и теории
автоматического управления.
Мы здесь схематически наметим некоторые возможности
исследования устойчивости замкнутых дискретных систем
особой структуры и, следовательно, сходимости
алгоритмов оптимизации. Прежде всего воспользуемся подходом,
аналогичным принятому в теории нелинейных систем,
который можно трактовать как аналог метода Ляпунова
для дискретных систем.
Составим уравнение в вариациях. Обозначим
сИ-сЧчН. (2.47)
где ц [п] ~ отклонение от оптимального вектора.
Подставляя это значение в рекуррентную форму алгоритма
оптимизации (2.4), легко получить
ц [л] = ц [п - 1 ] - Г [п] V/ (с* + Ц [п — 1 ]). (2.48)
Это разностное уравнение имеет тривиальное решение
ц = О, так как для оптимального вектора с* по
определению V/ (с*) = 0. Устойчивость тривиального решения
уравнения (2.48) и соответствует сходимости алгоритма
оптимизации (2.4). Как известно, различают устойчивость
в малом (когда все координаты вектора к\ [п] малы)
и в целом (при любых ц [п]). Для исследования
устойчивости в малом нужно аппроксимировать V/ (с* + ц)
линейным приближением и затем рассмотреть устойчивость
полученного линейного разностного уравнения. При
Г [п] = const, т. е. в стационарном случае, эта задача
сводится к определению условий, при которых корни
соответствующего характеристического уравнения
находятся внутри круга единичного радиуса. Поскольку
линейное приближение справедливо при достаточно малых
значениях ц [п], то устойчивость в малом соответствует
сходимости алгоритмов оптимизации при условии, что
начальные значения векторов ц [0] принадлежат
некоторой малой сфере с неизвестным центром, что вряд ли
полезно и интересно. Нас несоизмеримо больше
интересует устойчивость при любых начальных значениях
ц [0], т. е. устойчивость в целом. Исследование этого
§ 2.16]
УСЛОВИЯ сходимости
49
типа устойчивости основано на применении аналога
второго метода Ляпунова.
Выберем в качестве функции Ляпунова норму вектора
Ч[0]:
Г(ч[п-1]) = \\г\[п-1]\\>0. (2.49)
Первая разность Ляпунова в силу уравнений (2.48)
равна
АГ (т|[/г—1]) = Т (г\ [л]) - Т (ч [п- 1]) -
= II Ч[*-Ц-Г[/г]У/ (с* + Ч[*-1])||-|| г\[п~\] ||.(2.50)
Условие устойчивости в целом требует, чтобы первая
разность была отрицательна. После обычных и
несложных преобразований получаем
||/-Г[1г]Ф(9с*)||<1, (2.51)
где I— единичная матрица, а
| дЧ (Ос*)
Ф (6с*) =
dcv дс^
(2.52)
(v,|i=l, 2, ...,7V), 0<9<1.
Фактически мы использовали здесь принцип сжатых
отображений, который применительно к уравнению в
вариациях, т. е. к случаю, когда неподвижная точка
расположена в начале координат, тождествен прямому
методу Ляпунова.
Принцип сжатых отображений может быть применен
и непосредственно к алгоритму оптимизации в
рекуррентной форме (2.4), для которого неподвижная точка
соответствует значению оптимального вектора. Разумеется,
при этом мы получим те же результаты, быть может, в
несколько иной форме. Полученные таким образом условия
являются, вообще говоря, лишь достаточными.
§ 2.16. Условия сходимости
Расшифруем условие (2.51) для наиболее простого и
распространенного случая стационарного алгоритма
оптимизации, когда Г [п] = 1у.
4 Я. 3. Цыпкин
50 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
Можно установить, что оно эквивалентно следующим
условиям:
а) Y<Yo = const; ^)
б) T]TV/(c* + T])>0npH8<||i]||<l/e,e>0; [ (2.53)
в) II V/(с) || <Д || с ||, R = const. J
Условие а) определяет максимальный коэффициент
усиления. Конкретное значение у зависит от выбора нормы.
Условие б) устанавливает определенный характер
поведения поверхности V/ (с) = z вблизи точки с*,
соответствующий тому, что в системе имеется отрицательная
обратная связь. Наконец, условие в) определяет характер
изменения нормы градиента.
Нужно ли напоминать, что условия (2.53) являются
достаточными условиями сходимости? Приведенные выше
условия обеспечивают сходимость для достаточно
широкого класса V/ (с), любого значения с* и при любых
начальных значениях с [0]. Если ограничиться
требованием сходимости лишь при конечных значениях с [0], то
можно получить разнообразные условия сходимости
итеративных методов. Многие из этих условий можно найти
в литературе по вычислительной математике.
При практическом применении описанных методов нас
поджидает определенная трудность: в выражения,
определяющие условия устойчивости в малом или большом,
всегда входит неизвестный нам оптимальный вектор с*.
В классической теории устойчивости предполагается, что
значение с* каким-то образом ранее определено, здесь же
это предположение не может быть оправдано, так как
сами итеративные методы являются средством
определения с*. Однако эту трудность удается преодолеть, взяв
на вооружение понятие абсолютной устойчивости, широко
используемое в теории управления с легкой руки
А. И. Лурье. Условия абсолютной устойчивости или, как
нам будет удобнее их здесь называть, условия неизбежной
сходимости обеспечивают сходимость алгоритмов
оптимизации при любом начальном значении с [0] и для любого
неизвестного заранее оптимального вектора с*. Нам очень
хотелось бы назвать эти условия условиями абсолютной
сходимости, но мы боимся упреков, поскольку эти слова
уже давно используются в теории сходимости рядов.
§ 2.17]
ОБ УСКОРЕНИИ СХОДИМОСТИ
51
§ 2.17. Об ускорении сходимости
Мы уже упоминали в § 2.12, что переход к
многошаговым алгоритмам может привести к ускорению сходимости.
Здесь мы хотели бы на простейшем примере
проиллюстрировать эту возможность. Рассмотрим алгоритм (2.37)
при s = l, si = 2 и N=1.
Положим
at = l; 0^ = 1-a; a2 = a; 0<a<l, T[n]=Iy0. (2.54)
Тогда
c[n] = c [n— 1] — YoV/ ((1 - а) с [n— 1] + ac [n- 2]), (2.55)
где
VJ(.)^dJ{-)/dc.
При a = 0 этот алгоритм сводится к обычному алгоритму
типа (2.4). В отличие
~ о[п-1]
VJ(-)
Го
\АфЧ]\
33
\1-cd
от последнего в (2.55)
аргументом градиента
является не просто
с[п — 1], а
средневзвешенное двух
предшествующих значений,
с[п—1] и с [и —21.
Если это
средневзвешенное ближе к
оптимальному значению с*, чем
с[п — 1], то скорость
сходимости увеличится.
Именно такая ситуация
возникает, когда с [п]
стремится к с* колебательным образом. Выбором на
каждом шаге а = ап можно существенно ускорить сходимость.
Легко себе представить, что при этом ап должно
зависеть от разностей с [п]. Приближенно можно положить
(1-ап)ф-1]+апс[п-2]
Рис. 2.11.
Дс[и —1]
с [п]—~с [п — 1]
"^ Д2с[л-2] ~ с[л]_2с[л-1] + с[/г-2] # ^'00)
Структура системы, описываемая алгоритмом (2.55),
изображена на рис. 2.11. Существенная особенность ее
состоит в том, что она двухконтурна, а коэффициенты
4*
52 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
усиления контуров зависят от текущего и
предшествующего состояний. Вероятно, можно усилить сходимость,
если в зависимости от значений Ас изменять
соответственно у.
§ 2.18. О наилучших алгоритмах
Выше мы познакомились с разнообразными
алгоритмами оптимизации. Возникает естественный вопрос,
какому алгоритму и в каких случаях можно отдать
предпочтение, какой алгоритм можно считать наилучшим?
Вряд ли попытка найти ответ на этот вопрос может
быть сколь-нибудь успешной в общем случае. Однако если
на основе тех или иных соображений указан тип
алгоритма (одношаговый или многошаговый, дискретный или
непрерывный), то нахождение наилучшего алгоритма
сводится к выбору его параметров (например, для
алгоритма (2.4) — матрицы Г [/г], для алгоритма (2.21) —
у [п] и а [п]). Конкретный выбор этих параметров зависит
от того, что мы условимся понимать под наилучшими
алгоритмами. Некоторые попытки в этом направлении уже
делаются. Так, в методах возможных направлений, в
релаксационных методах, во многих градиентных методах
параметры алгоритма выбираются наилучшими (в смысле
заранее выбранного критерия) на каждом шаге. Таким
образом, получаются алгоритмы, «локально» наилучшие
на каждом шаге. Это, конечно, совсем не значит, что
алгоритм будет наилучшим и в целом.
Задача построения наилучших алгоритмов
оптимизации весьма близка к задачам синтеза оптимальных
дискретных или непрерывных систем, реализующих эти
алгоритмы. Однако, к сожалению, мы не можем пока
использовать] мощный аппарат теории оптимальных
систем для определения наилучших алгоритмов. Это
связано с тем, что современная теория оптимальных
систем предполагает, что начальный с[0] и конечный с*
векторы известны. В нашем же случае с* неизвестно, и,
более того, наша цель состоит в нахождении с*. Поэтому
пока мы вынуждены ограничиваться «локально»
наилучшими алгоритмами. Чтобы ясно представить, чего можно
достигнуть на этом пути, приведем примеры.
§ 2.19]
ПРИМЕРЫ
53
§ 2.19. Примеры
Если потребовать от алгоритма, чтобы на каждом шаге
некоторая функция ошибки ц [п] = с [п] — с* была
минимально возможной, то для определения наилучшего в
в этом смысле алгоритма оптимизации можно
использовать известные релаксационные методы или методы
наискорейшего спуска. При этом у [п] = ун [п] определяется
как наименьший положительный корень уравнения
-^J(e[n]) = ±J(e[n-i]-yVJ(o[n-l])) = 0. (2.57)
К сожалению, для определения оптимального
значения у на каждом шаге мы не можем применить
итеративные методы, так как алгоритмы определения у также будут
содержать неопределенный параметр, который нужно
выбирать в свою очередь. Иногда эти трудности можно
преодолеть разумно организованным подбором, изменяя
у до такого значения уи что дальнейшее его изменение
приводит к нарушению неравенства
/ (с [и - 1] - Yi W *J (с \П -Щ<
<J(c[n-l]-y[n] \J(c[n-l])). (2.58)
Именно так поступают при использовании
релаксационных методов. Иная возможность состоит в определении у
при аппроксимации (2.57) линейным приближением. Тогда
?,[»]« т ^(«t»-*»*'(«Г»-*» (2.59)
VTJ (с [п — 1]) W (с [п — 1]) V/ (с [п — 1])
или в силу алгоритма (2.7)
г 1 Аст[п —11 Лс [п — 1] m ап\
vH [п] « тр ! - , (2.60)
Лст [п— 1] V2/ (с [п~ 1]) Лс [п— 1]
где V2/ (с) = || ff {£ |[ (v, \i =-1, 2, . . ., N) -матрица
вторых производных.
Более привычно наилучшим алгоритмом считать такой,
который дает минимум суммарного квадратического
отклонения. Обозначим
m m
Vz[m]= 2 || л [д]||2; F2[m-1]= 2 II 41" — 1] II*. (2-61)
П—i 71=1
где || ti|| — евклидова норма вектора ц.
54 АЛГОРИТМИЧЕСКИЕ МЕТОДЫ ОПТИМИЗАЦИИ [Гл. II
Положим в алгоритме оптимизации (2.48) Г (п) =
= Iy = const. Тогда после возведения обеих частей (2.48)
в квадрат и суммирования по п от 1 до т получаем
т
V2 [т] = V2 [т - 1 ] - 2y0 2 ЧТ \п ~ 11 V/ (с* + Ц [п - 1 ]) +
771
+Y^ih^-i]ii2l|v/[f;+iV])i'2- (2-62)
Пусть V/(с* +г][тг—1]) при любом с* и ц
удовлетворяет условиям
0<Л< II ^ с*-it» || <^ 1
^ ^ llilll ! (2-63)
^ll^ll2<(4TV/(c* + n))- J
Тогда, заменяя в (2.62) это отношение его нижней и
верхней границей, получим неравенство
V2 \пг\ < V2 [т~ 1| (1 - 2у<И + Yo^2)- (2-64)
Правая часть этого неравенства достигает минимума при
Следовательно,
V*[m\<V*[m-i\ (l-^-) (2.66)
ИЛИ
У2[т]<гЦ0] (l—g-)m. (2-67)
Таким образом, при наилучшем значении у верхняя
граница V2 \т] на каждом шаге минимальна. Этот подход
в какой-то мере связан с оптимизацией автоматических
систем на основе прямого метода Ляпунова.
§ 2.20. Некоторые задачи
Наиболее важные задачи, которые возникают при
разработке и использовании алгоритмов оптимизации,
связаны с обеспечением неизбежной сходимости и
развитием способов ускорения сходимости.
§ 2.21]
ЗАКЛЮЧЕНИЕ
55
Вероятно, ускорения сходимости можно достигнуть,
если изменять у [п] в зависимости от результатов
вычисления с [п]. Важно определить, какова должна быть
зависимость у [п] от с [п].
Было бы очень полезно выработать какие-либо
принципы сравнения алгоритмов оптимизации.
Возможно, эту задачу удалось бы решить, если бы
можно было пайти общее выражение функционала вектора
с [тг], минимизация которого приводила бы
непосредственно к алгоритмам оптимизации с однозначно
определенным шагом у [п].
Для эффективного применения многошаговых
алгоритмов важно найти обоснованные способы выбора их
параметров.
Открытым остался вопрос о наилучших алгоритмах.
Мы не обольщаемся надеждой, что его легко решить.
Если бы это было так, то уже давно из изобилия
итеративных методов решения, например, трансцендентных
уравнений можно было бы выбрать наилучшие и только
ими и пользоваться.
§ 2.21. Заключение
Мы познакомились с различными регулярными
алгоритмами оптимизации, которые дают возможность как
при наличии ограничений, так и без них определить
в конце концов оптимальный вектор. Основные усилия
по дальнейшему усовершенствованию этих алгоритмов
должны быть направлены на уменьшение времени «конца
концов» и на их пригодность для определения не только
локальных, но и глобальных экстремумов.
Хотя регулярные алгоритмы важны сами по себе и,
как говорят, имеют самостоятельную ценность, мы здесь
на них остановились только для того, чтобы иметь
некоторую путеводную нить для развития соответствующих
алгоритмов адаптации. Эти алгоритмы должны заменить
регулярные алгоритмы оптимизации, когда у нас нет
достаточной априорной информации.
Глава III
Адаптация и обучение
§ 3.1. Введение
Вряд ли в современной теории управления можно
отыскать более модные и привлекательные термины, чем
адаптация и обучение. Но в то же время нелегко отыскать
какие-нибудь другие термины, которые могли бы
конкурировать с ними по перегруженности, неопределенности
и расплывчатости.
Тем не менее мы рискнем окунуться в заманчивую
и важную область современной теории управления,
которая еще совсем недавно, 15 лет тому назад, даже не
упоминалась среди будущих проблем и не относилась к
разряду белых пятеи на уже достаточно освоенной к тому
времени карте проблем теории управления. Нам придется,
хочется нам того или нет, привести рабочие определения
терминов, на основе которых можно было бы
сформулировать постановки задач обучения, самообучения и
адаптации. Для достижения успехов в решении новых задач,
как это неоднократно подчеркивал академик А. А.
Андронов, «необходимо произвести реконструкцию
существующего математического аппарата, необходимо отыскать
математический аппарат, который был бы адекватен
отображаемым процессам и который был бы, кроме того,
достаточно эффективен». В основу такого математического
аппарата оказалось возможным и удобным положить
вероятностные итеративные методы и, в частности, методы
стохастической аппроксимации. Как мы увидим,
сравнительно небольшое развитие этих методов и изменение
их идейной направленности дает нам в руки удобный
математический аппарат, теории адаптации и обучения.
Формально этот аппарат подобен аппарату метода
итераций, о котором мы много говорили в предыдущей главе.
§ 3.2] ПОНЯТИЯ ОБУЧЕНИЯ, САМООБУЧЕНИЯ И АДАПТАЦИИ 57
Эта формальная аналогия сослужит свою службу; она
позволит нам в нужных случаях выяснять общность
и различие между регулярными и адаптивными подходами
к решению проблемы оптимальности. Цель этой главы
состоит не в рассмотрении возможностей решения
отдельных конкретных задач. Наоборот, мы хотели бы здесь
выработать общий подход, позволяющий решать
разнообразные задачи или целые классы задач, которые на данном
этапе разумно было бы отнести к области адаптации
и обучения.
Что касается обсуждения и решения этих задач, то им
будут посвящены последующие главы.
§ 3.2. Понятия обучения, самообучения
и адаптации
Известно большое число определений того, что следует
понимать под обучением, самообучением и адаптацией.
К сожалению, даже применительно к автоматическим
системам эти определения весьма разноречивы. Мы не
будем углубляться в сравнительный анализ и критику таких
определений. Это слишком отвлекло бы нас от основной
цели, и неизвестно, достигли бы мы на этом пути успеха.
Вместо этого мы попытаемся привести удобные для нашей
цели определения, которые, вероятно, также можно
подвергнуть критике.
Под обучением мы будем подразумевать процесс
выработки в некоторой системе той или иной реакции на внешние
сигналы путем многократных воздействий на систему и
внешней корректировки. Разумеется, при этом система
предполагается потенциально «способной» к обучению.
Внешняя корректировка, или как ее еще называют,
«поощрение» или «наказание», осуществляется «учителем»,
которому известна желаемая реакция на определенные
внешние воздействия. Таким образом, при обучении
«учитель» сообщает системе дополнительную информацию
о том, верна или неверна реакция системы.
Самообучение отличается от обучения отсутствием
внешней корректировки. Самообучение — это обучение
без поощрения или наказания. Дополнительная
информация о верности реакции системе не сообщается.
58
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл.III
Адаптацией мы будем называть процесс изменения
параметров и структуры системы, а возможно, и
управляющих воздействий на основе текущей информации с целью
достижения определенного, обычно оптимального,
состояния системы при начальной неопределенности и
изменяющихся условиях работы.
Иногда обучение отождествляют с адаптацией. Для
этого есть много оснований, особенно если ввести какой-то
показатель успеха обучения, улучшение которого
характеризует степень обучения. Нам, однако, будет удобнее
считать, что при адаптации обучение используется для
получения информации о состоянии и характеристиках
системы, необходимой для оптимального управления
в условиях неопределенности. Это соглашение можно
обосновать тем, что при наличии начальной
неопределенности, пожалуй, единственный разумный подход состоит
в устранении ее с помощью обучения или самообучения
в процессе управления и в использовании накапливаемой
информации для улучшения критерия оптимальности
системы управления. Таким образом, наиболее
характерная черта адаптации состоит в накоплении и немедленном
использовании текущей информации для устранения
неопределенности из-за недостаточной априорной информации
с целью оптимизации избранного показателя качества.
Читатель заметит, вероятно, что адаптацию мы по
существу отождествляем с оптимизацией в условиях
недостаточной априорной информации.
§ 3.3. Формулировка задачи
Хотя в гл. II мы уже мельком говорили об
использовании адаптивного подхода для решения проблемы
оптимальности, тем не менее было бы полезно сформулировать
задачу адаптации несколько с иной точки зрения, опираясь
на данное выше определение.
Пусть критерий оптимальности, выраженный в виде
функционала вектора с,
/ (с) = Л/Я {(?(», с)} (3.1)
в явной форме неизвестен. Это значит, что плотность
распределения р (х) неизвестна, а известны лишь реализации
§ 3.4] ВЕРОЯТНОСТНЫЕ ИТЕРАТИВНЫЕ МЕТОДЫ 59
Q (х, с), которые зависят от стационарных случайных
процессов или последовательностей х и вектора с.
Мы также предполагаем здесь, что ограничения первого
рода включены в функционал. Что касается ограничений
второго рода, то о них речь пойдет позлее.
Под безобидными словами «функционал в явной форме
неизвестен» или «неизвестна плотность распределения»
скрывается огромное число возможностей. Эти
возможности охватывают, прежде всего, детерминированные
процессы, природа которых нам неясна; они охватывают
также случайные процессы, плотности распределения
которых нам неизвестны либо известны частично.
Например, может быть задан тип распределения, часть
параметров которого неизвестна.
Наконец, мы можем даже не знать, являются ли процессы
детерминированными или случайными. Во всех этих
случаях, когда отсутствует достаточная априорная информация,
и возникает необходимость в использовании адаптации.
Наша задача состоит в определении оптимального
вектора г*, доставляющего экстремум (для определенности
пусть это будет минимум) функционалу (3.1), который
в явном виде неизвестен. Очевидно, единственно
возможный путь решения этой загдачи связан с наблюдением
реализаций и их обработкой. Ясно, что регулярные
итеративные методы здесь непригодны. А вот нельзя ли
и для решения проблемы оптимальности в условиях
недостаточной априорной информации использовать идейную
сторону итеративных методов? Оказывается, можно!
Более того, эти идеи оказываются адекватными задачам
обучения и адаптации. Это позволяет нам во всех
дальнейших главах не ограничиваться одними только
размышлениями о полезности и важности адаптации и
обучения, но и показать пути решения основных задач
современной автоматики в широком смысле этого слова.
§ 3.4. Вероятностные итеративные методы
Вероятностные итеративные методы тесно связаны
с методом стохастической аппроксимации, который,
несмотря на свое совершеннолетие и большую
популярность в статистической журнальной литературе, долгое
60
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. Ill
время не находил себе настоящего применения для
решения технических задач.
Для того чтобы изложить идею вероятностных
итеративных методов, обратимся к условию оптимальности
(2.2), которое с учетом (3.1) теперь можно записать в более
подробной и удобной для нас форме:
V/(c)-7^{Vce(x, с)}-=0, (3.2)
где
„„.^(«М,*!^ SM) (3.3)
представляет собой градиент Q (х, с) по г.
В (3.2) нам неизвестен градиент функционала, т. е.
V / (с), а известны лишь реализации Vc Q (ж, с).
Оказывается, что при надлежащем выборе матрицы Г [п] мы можем
воспользоваться многими разновидностями регулярных
методов, заменив в них градиент функционала V / (г)
реализациями ^eQ{x,c). В этом как раз и заключена
центральная идея вероятностных итеративных методов.
Таким образом, вероятностный алгоритм оптимизации,
или, более кратко, алгоритм адаптации, можно представить
в рекуррентной форме:
c\n\ = c[n — l] — Y[n\4cQ{x[n\i с[п—1\). (3.4)
Алгоритмы адаптации можно представить в разностной
форме
Ас[п-1]--- —T[n]VeQ(x[n], с[п— 1]), (3.5)
либо в суммарной форме
с [п\ - с 10] — >] Г (т) VCQ (х [т], с [т—1]). (3.6)
771—1
Легко видеть аналогию между регулярными алгоритмами
(2.4), (2.7), (2.8) и вероятностными алгоритмами (3.4),
(3.5), (3.6). Но в то же время они существенно отличаются
друг от друга хотя бы тем, что теперь при с = с*
VcQ(x, с*) ф0.
(3.7)
§ 3.5]
АЛГОРИТМЫ АДАПТАЦИИ
61
Из-за этой особенности приходится наложить
определенные условия на характер Г [тг], чтобы обеспечить
сходимость. Речь об этих условиях пойдет ниже.
Сейчас же мы, рассматривая алгоритмы адаптации
(3.4) — (3.6) как уравнения некоторой дискретной системы
с обратной связью, построим ее структурную схему.
Она изображена на рис. 3.1 и отличается от
структурной схемы, соответствующей регулярному алгоритму
7V
Рис. 3.1.
оптимизации (рис. 2.1), тем, что теперь, помимо воздействия
с [/г], к функциональному преобразователю приложено
внешнее воздействие х [п]. При адаптации мы получаем
уже неавтономную систему, в которую извне поступает
информация о сигнале х [п]. Обработка этой текущей
информации и позволяет компенсировать недостаточность
априорной информации.
§ 3.5. Алгоритмы адаптации
В настоящее время можно обосновать лишь
простейшие алгоритмы адаптации, которые соответствуют выбору
Г [п] в виде диагональной матрицы
О ... О \
Т[п] = Лу[п]
J Yi М
О
V О
Y2N
О
О
(3.8)
Yn
[n]j
где Jh — оператор, преобразующий вектор в диагональную
матрицу. В частном случае равных компонент
вектора у М действие оператора л соответствует умножению
на единичную матрицу, т. е. Л\ [п] =»1\ [п]. В этом
62
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
наиболее изученном случае алгоритмы адаптации
записываются в виде
c[n] = c[n—l] — y[n]VeQ(x[n], е[п—1\) (3.9)
или
Дс[и—1]= -y[n]VcQ(x[n], с[п-1\), (3.10)
либо, наконец,
с[л] = с[0] — § Yl^]Vc(?(x[m], c[m-l]). (3.11)
m=i
Однако нужно подчеркнуть, что иногда выбор Г [п]
в виде диагональной или полной матрицы позволяет
улучшить свойства алгоритмов адаптации. О подобной ситуации
мы говорили в § 2.5.
§ 3.6. Поисковые алгоритмы адаптации
В тех случаях, когда по какой-либо причине
невозможно получить градиент реализации Vc Q (х, с), но сами
реализации Q (х, с) могут быть измерены, на помощь
приходят поисковые алгоритмы адаптации. Введем по
аналогии с (2.18) обозначение
Q+(x, с, a) = (Q(x, c + aej, ...,<? (х, с + aeN)), 1
Q-(x,c,a) = (Q(xic — aei),...JQ(x,c — aeN))1 > (3.12)
Q0 (х, с) = (Q(x,c), ...,<? (х, с)), J
где а — скаляр, е* (i = l, 2, . . ., N)— базисные векторы
(2.19). Как и ранее, будем оценивать градиент
приближенно, с помощью разделенных разностей
Qt(x'e'a)-Q-{x'c'a)=4e±Q(x,c,a) (3.13)
или
Q+(x,c,a) — Q_(x,c)
а
Ve±<? (ж, С а),
<м»,о-о-(*,«,«)^¢^ С) а))
(3.14)
которые зависят от случайного процесса х. Тогда
поисковый алгоритм адаптации в рекуррентной форме можно
§ 3.7]
УЧЕТ ОГРАНИЧЕНИЙ I
63
представить следующим образом:
c[n] = c[n—l] — y[n]Ve±Q(x[n], с[и —1], а[п\). (3.15)
Приближенную оценку градиента можно производить
с помощью синхронного детектора. Структурная схема
соответствующей экстремальной системы приведена
на рис. 3.2. Как правило, здесь нельзя принять а [п] =
= const, поэтому дополнительный генератор
прямоугольных поисковых колебаний оказывается более сложным.
vc±J(c[iHL а[п])
c/n-7j
Рис. 3.2.
В нем амплитуда колебаний должна изменяться по
определенному закону. Роль коммутаторов остается прежней.
Они служат для последовательного образования
аргументов с ± aeh и компонент V^Q (х, с, а).
При реализации поисковых алгоритмов адаптации
целесообразно, как уже было отмечено в гл. II,
использовать разнообразные методы поиска, которые
разработаны в теории экстремальных систем.
§ 3.7. Учет ограничений I
Будем считать, что в задаче присутствуют
ограничения первого рода в виде равенств
д(с)=Мя{П(х, с)}-0, (3.16)
причем вид вектор-функции д (с) = (^ (с), . . . , gM (с))
неизвестен, а известны лишь реализации вектор-функции
h(x, с). Хотя задача минимизации функционала (3.1)
64
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
при учете ограничений (3.16) и не обсуждалась в
литературе, тем не менее путь решения ее довольно
прозрачен.
Как и в регулярном случае (см. § 2.8), составим новый
функционал
/(с, %)=J(c) + %?g(c), (3.17)
преобразовав который, с учетом (3.1) и (3.16), получим
/(с, l,) = Mx{Q(x, c) + kTh(x, с)}. (3.18)
Заметим теперь, что задача свелась к нахождению
стационарной точки функции / (с, %) по ее реализации
Х[д-1]
КМ
Й^
{№
b(x[n],c[n-1])
~д—
\х[л]
х[п]
НсШп1сМ])
\МФШ^1^^==^\ гм ]=х
и
д
7>с[п-1]
Рис. 3.3.
Q (х, г) + ^тЛ (х, с). Для нахождения этой стационарной
точки применим к (3.18) алгоритм адаптации (3.9). Тогда
алгоритм адаптации для этого случая будет иметь вид
с [П] = с [п- 1] - у [п] [VCQ (х [и], с [и- 1]) +
+ Нг(х[п], с[п— 1])Ь[п— 1]],
k [и] = k [и — 1] — Yi [n] h (х [тг], с[п— 1]).
Здесь
(3.19)
Нс (X, С) =
dhv (х, с)
дси
— матрица размера N X М.
(v == 1, 2 Af; |г = 1, 2 ЛГ)
(3.20)
§ 3.8]
УЧЕТ ОГРАНИЧЕНИЙ II
65
Очевидно, эти алгоритмы охватывают и тот случай,
когда ограничения (3.16) в явном виде заданы, ибо всегда
можно считать, что д (с) = М {д (с)} и в (3.19) нужно
лишь произвести простую замену h на д и Н на G
(см. (2.18)).
Структурная схема дискретной системы,
соответствующей алгоритму адаптации (3.19), изображена на
рис. 3.3. Она отличается от схемы рис. 3.2 прежде всего
наличием дополнительных контуров, учитывающих
ограничения.
§ 3.8. Учет ограничений II
При ограничениях второго рода, задаваемых в виде
неравенств
g(c) = Ma{h,(x, c)}<0f (3.21)
когда явно вид вектор-функции у (с) = (gi (с), ...
. . . , gui (с)) неизвестен, получение алгоритмов адаптации
КМ
\h(x[nlc[ii-1]j\
~7\
\х[п]
it
X
7сОШ,с[п-1])
J
х[л]
Нс(х[п],с[л-1])
\
Л
\Дс[п-1]\
Риг. 3.4.
требует соответствующего обобщения теоремы Куна —
Таккера на интересующий нас случай. Это нетрудно
сделать. Действительно, будем считать сначала, что / (с)
и g (с) известны. Кроме того, будем считать, что g (с)
удовлетворяет условию Слейтера (2.30). В этом случае
5 Я. 3. Цыпкин
66
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. Ill
из теоремы Куна — Таккера (см. § 2.9) следует:
V/(c) + kTG(c)-0, )
9г(с)+6 = 0, | (3.22)
^6 = 0, ^>0, 6>0. J
Учитывая (3.1) и (3.21), получим
M„{VrQ(x, с) + Не(х, е) Ц = 0, )
Mx{h(x, с) + в} = 0, | (3.23)
^6 = 0, k>0, 6>0, J
где //с (х, с) — уже знакомая нам матрица (3.20).
Таким образом, мы получили необходимые условия
оптимальности для рассматриваемой задачи. Теперь
но аналогии с (3.19) можно написать следующий
алгоритм получения оптимальных значений с* и ^*:
c[n]=c[n-l]-y[n][VcQ(x[n], с[п-1])+ )
+ Нс(х[п], с[л-1])Мл-1]], [
k[rc] = max{0; % [п~ 1] + Yi М h (х М, с [/г— 1])}, j
Ь(0)>0. J
(3.24)
Структурная схема дискретной системы,
соответствующей алгоритму адаптации (3.24), изображена на рис. 3.4.
§ 3.9. Одно обобщение
Может случиться, что ограничения, заданные,
например, в виде равенств, получаются в результате усреднения
реализации h {у, с) процесса ?/, не связанного со
случайным процессом х. Оказывается, что это обстоятельство
не столь существенно для получения алгоритмов
адаптации. Действительно, в этом случае равенство
/(с, к) = Мя{(?(х, c)} + lTMtJ{h(y, с)} (3.25)
можно представить в виде
/(с, %) = Mxy{Q(x, c) + bTh(y с)}, (3.26)
§ з.Ю] МНОГОШАГОВЫЕ АЛГОРИТМЫ АДАПТАЦИИ 67
где реализация Q (х, с)-)- ^т h (у, с) соответствует
случайному процессу с плотностью распределения pi (х) р2 {у).
Отсюда следует, что алгоритмы адаптации для
нахождения максимума функционала / (с) = Мх {Q (х, с)} при
ограничениях Му [h {у, с)} = 0 ничем по форме не будут
отличаться от рассмотренного ранее случая (3.19).
Теперь ясна и справедливость алгоритма адаптации
для рассматриваемого случая при учете ограничений
в виде неравенств.
§ 3.10. Многошаговые алгоритмы адаптации
Как и в регулярном случае, теперь можно построить
многошаговые алгоритмы адаптации, которые являются,
в частности, одним из средств определения глобального
минимума. Этот класс алгоритмов адаптации может быть
представлен в форме
S
с[п]= 2 ат[п]е[п — т] —
771 = 1
- S ym[n]VcQ(Ax[n-m-l], AiCln — m-i]). (3.27)
771=1
В отличие от регулярного случая в рассматриваемых
алгоритмах адаптации случайный процесс может
подвергаться тому или иному преобразованию с помощью
устройства, характеризуемого оператором А. Кроме того, и сама
переменная может быть подвергнута действию оператора
i4i, но такого, что А&* = с*. Структура дискретной
системы, соответствующей многошаговому алгоритму адаптации,
изображена на рис. 3.5. Теперь в состав неавтономной
системы входят дискретные фильтры и преобразователи
входной информации. Поисковый многошаговый алгоритм
адаптации отличается тем, что в нем вместо градиента
реализации VCQ (•) используется оценка этого градиента
в виде разделенной разности VC±Q (•)•
От введения многошаговых алгоритмов мы ожидаем
определенного улучшения, которое основано на нашей
убежденности в том, что знание прошлого дает большую
уверенность в будущем.
5*
68
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. II
гЗ>51
§ 3.12] ВЕРОЯТНОСТНАЯ сходимость И УСТОЙЧИВОСТЬ 69
§ 3.11. Непрерывные алгоритмы
Непрерывные алгоритмы адаптации можно получить
предельным переходом из дискретных алгоритмов
адаптации, которые мы до сих пор только и рассматривали.
Так, дискретному алгоритму (3.10) соответствует
непрерывный алгоритм вида
^JP-=-y(t)VcQ{x{t),c{t)). (3.28)
Непрерывные алгоритмы адаптации представляют собой
стохастические дифференциальные уравнения, так как
правая часть их существенным образом зависит от
случайного процесса х (t).
Наряду с алгоритмами адаптации первого порядка
можно образовать и алгоритмы адаптации более высокого
порядка. Наконец, нетрудно представить себе
непрерывные поисковые алгоритмы.
Непрерывные алгоритмы адаптации легко реализуются
с помощью аналоговых вычислительных (моделирующих)
устройств. Структурные схемы систем, соответствующих
непрерывным алгоритмам, отличаются от структурных
схем дискретных систем тем, что дискретные интеграторы
заменяются непрерывными.
§ 3.12. Вероятностная сходимость и устойчивость
В алгоритмы адаптации входит градиент реализации
Vc(?(x, с) или его оценки VC±Q (х, с, a), Vc+Q (ос, с, а),
Vc-Q (х, с, а), которые зависят от случайного процесса х.
Следовательно, векторы с [п] также являются
случайными и для них непосредственно неприменимо обычное
понятие сходимости, хорошо знакомое нам из курсов
математического анализа и использованное в § 2.15.
Поэтому необходимо привлечь новые понятия сходимости,
понимаемые не в обычном, а в вероятностном смысле.
Различают три основных вида такой сходимости:
сходимость по вероятности, сходимость в среднеквадратиче-
ском и сходимость почти наверное.
Случайный вектор с [п] сходится по вероятности к с*
при п->- оо, если вероятность того, что при любом 8 > 0
70
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
норма || с [п] — с* || превышает е, стремится к нулю, или,
кратко, если
lim Р {\\ с [п] — с* || > е} = 0. (3.29)
П->оо
Сходимость по вероятности, конечно, не требует, чтобы
каждая последовательность случайных векторов с [п]
сходилась к с* в обычном смысле. Более того, ни для
какого вектора мы не можем утверждать, что имеет место
обычная сходимость.
Случайный вектор с [п] сходится к с* в среднеквадра-
тическом при п ->- оо, если математическое ожидание
квадрата нормы || с [п] — с* || стремится к нулю, т. е. если
lim М { || с [п] - с* ||2} = 0. (3.30)
П->оо
Сходимость в среднеквадратическом влечет за собой
сходимость ' по вероятности, но также не предполагает
для каждого случайного вектора с [п] обычной сходимости.
Сходимость в среднеквадратическом связана с
исследованием момента второго порядка, который вычисляется
достаточно просто, и, кроме того, она имеет ясный
энергетический смысл. Эти обстоятельства объясняют
сравнительно широкое распространение в физике именно такого
понятия сходимости. Но сам факт, что в обоих типах
сходимости вероятность того, что данный случайный вектор
с [п] сходится к с* в обычном смысле, равна нулю,
вызывает иногда неудовлетворенность. Ведь мы всегда
оперируем с градиентом реализации VeQ (х [п], с [п — 1])
и соответствующим ему случайным вектором с [/г], и
желательно, чтобы предел существовал именно для той
последовательности случайного вектора с [п] (п — 0, 1, 2, ...),
которую мы сейчас наблюдаем, а не для семейства
последовательности случайных векторов с [/г],
соответствующих семейству реализаций Vc(? (х [п], с [п — 1]),
которые мы, возможно, никогда и не будем наблюдать.
Это желание может осуществиться, если привлечь
понятие сходимости почти наверное, или, что то же самое,
сходимости с вероятностью единица.
Так как с [п] — случайный вектор, то и сходимость
последовательности с [п] к с* в обычном смысле можно
рассматривать как случайное событие. Последовательность
случайных векторов с [п] сходится при п -*■ оо к с* почти
§ 3.13]
УСЛОВИЯ сходимости
71
наверное, или с вероятностью единица, если вероятность
обычной сходимости с [п] к с равна единице, т. е. если
Р {lim (| с [п] - с* (| = 0} = 1. (3.31)
71->оо
Отсюда следует, что, пренебрегая совокупностью
реализаций случайных векторов, имеющих общую вероятность,
равную нулю, мы имеем обычную сходимость. Конечно,
скорость сходимости при этом зависит от реализации
и имеет случайный характер.
Сходимость алгоритмов адаптации эквивалентна
устойчивости систем, описываемых стохастическими
разностными или дифференциальными уравнениями.
Устойчивость этих систем нужно понимать в вероятностном
смысле: по вероятносаи, в среднеквадратическом и почти
наверное (или с вероятностью единица).
Вероятностная устойчивость — сравнительно новый раздел теории
устойчивости, который сейчас интенсивно разрабатывается.
§ 3.13. Условия сходимости
Сходимость алгоритмов адаптации, или, что то же
самое, устойчивость неавтономных стохастических систем
с обратной связью,— наиболее существенный вопрос,
возникающий при реализации алгоритмов адаптации.
К настоящему времени можно установить некоторые
необходимые признаки и достаточные условия сходимости.
Об этом и будет идти речь в настоящем параграфе.
Рассмотрим алгоритм адаптации в разностной форме
(3.10):
Ac[n — l]= —y[n]VcQ(x[n], е[п—1)). (3.32)
Для того чтобы вектор с [п] стремился к с* почти
наверное, необходимо, по крайней мере, чтобы при п—>ос
правая часть стремилась к нулю, т. е.
lim у [га] VCQ (х [га], с [га — 1 ]) = 0 (3.33)
П->оо
практически при любых реализациях х[п].
В общем случае градиент реализации Vc(? {х, с),
как мы уже упоминали (см. условие (3.7)), отличен
от нуля, и поэтому необходимо, чтобы у [п] с ростом п
стремилось к нулю.
72
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
Достаточные условия сходимости алгоритмов
адаптации можно сформулировать так. Алгоритмы адаптации
(3.9) — (3.11) сходятся почти наверное при соблюдении
следующих условий:
оо оо "\
а)-у[»]>0, 2yM = °°. Sy'[»]<«».
n=l n=i
б) inf Mx[{c-c*)TVcQ{x, c)]>0, e>0, } (3.34)
e<j|c-c*||<A
в) Mx[\^(x1 c)4cQ(x, e)]<d(l+eTc), d>0. J
Эти условия имеют весьма простой физический и
геометрический смысл.
Условие а) требует, чтобы скорость уменьшения у [п]
была такова, чтобы дисперсия оценки / (с) уменьшалась
до нуля, но чтобы за время изменения у [п] можно было
использовать достаточно большое число данных, при
котором еще справедлив закон больших чисел.
Условие б) определяет характер поведения поверхности
Mx{^eQ (х, с)} вблизи корня, и, следовательно, знаки
приращений с [п]. Наконец, условие в) гласит, что
математическое ожидание квадратической формы, т. е.
Мл {Vj<? (х, c)VcQ (х, с)}, с увеличением с должно расти
не быстрее квадратичной параболы.
Для поисковых алгоритмов адаптации, естественно,
налагаются определенные ограничения на а [п], а сама
форма условий изменяется в связи с отсутствием
реализации градиента. Поисковые алгоритмы адаптации (3.15)
сходятся почти наверное и в среднеквадратичном смысле
при выполнении следующих условий:
ОО (X) оо "V
а) ^ У[п] = °о, 2 Ч1п]а[п]<оо, 2 ($})'«».
П= 1 71= 1 71= 1
б) (c-c*)T(Q+(x, с, е)-0_(ж, с, е))>
>К\\с-с*\\ ||0+(ж, с, е)-0_(ж, с, в)||,
где е>0, K>\lV2.,
в) || Q+ (ас, с, а) - Q-(x, с, а) || < А || с - с* || + В.
(3.35)
§ 3.13]
УСЛОВИЯ сходимости
73
Эти условия имеют примерно тот же смысл, что и
рассмотренные нами выше, поэтому мы не станем их
обсуждать.
Стохастические алгоритмы обладают высокой
помехоустойчивостью. Случайные аддитивные помехи с
нулевым средним значением устраняются и не влияют на
результат, т. е. на оптимальный вектор с = с*.
Если эти помехи отсутствуют, т. е. если их дисперсия
равна нулю и при любом х выполняется условие
VcQ{x, с*)-0, (3.36)
то условие (3.33) будет выполняться не только при у [/г],
стремящемся к нулю, но и при у = const или при у,
стремящемся к постоянной величине. В этом случае для
установления максимального значения Ymax можно
воспользоваться тем же подходом, который был использован
для регулярных алгоритмов оптимизации. При у <. утах
будет обеспечена сходимость почти наверное, которая
очень близка к обычной.
Алгоритмы, получающиеся в этом случае из (3.9) и
(3.11) при у [п] — у0 = const, естественно, обладают
низкой помехоустойчивостью, и при наличии помех с
дисперсией а2 сходимость в принятом выше смысле
отсутствует, хотя
lim Mx[\\c[n)-c*f\<ix(y0, а), (3.37)
П->00
причем (Л (yq» о) ->- 0 при а2 ->- 0. Практически мы часто
можем принять это менее жесткое условие, которое
соответствует в некотором смысле неасимптотической
устойчивости по Ляпунову. Аналогичные условия
сходимости известны и для непрерывных алгоритмов. Эти
условия более жесткие. Мы их здесь приводить не будем,
тем более, что в связи с большим энтузиазмом, который
наблюдается в развитии вероятностной теории
устойчивости, в этой области можно ожидать более широких
и более простых условий устойчивости. Пока же в основе
доказательств сходимости вероятностных итеративных
методов лежат фундаментальные теоремы А. Дворецкого
и теория мартингалов.
74
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
§ 3.14. О правиле остановки
При практическом использовании алгоритмов возникает
вопрос: при каком числе шагов п можно считать, что мы
с достаточной степенью точности определим оптимальное
значение вектора с*? Для регулярных итеративных
методов существуют специальные правила остановки, связанные
со сравнением двух последующих значений с [п— 1]
и с [п]. Такие правила остановки можно было бы
о[п] \
л
Рис. 3.6.
применить при достаточно больших п и к вероятностным
итеративным методам, если обеспечивается сходимость
с вероятностью единица. Но так как последовательность
{с [п]} = (с [0], с [1], . . .) случайна, то это правило
потребует чрезвычайно большого числа шагов. Нельзя
ли сократить это число шагов? Последовательность
{с [п]} при наличии и при отсутствии помех для
достаточно малого шага представляется качественно в виде
непрерывных функций, изображенных на рис. 3.6. Можно
считать, что правило остановки определяет то значение
тг0, при превышении которого последовательность {с [п]}
приобретает стационарный характер.
Для надежного определения п0 необходимо каким-
либо образом «сгладить» последовательность с [п].
Одна из таких возможностей состоит в использовании
§ 3.15] ОБ УСКОРЕНИИ сходимости 75
скользящего среднего
n+iV
^1*1 = ^2 с [к] (и = 0, 1, 2, ...). (3.38)
к=п
Если, начиная с какого-то номера &0, для всех &>А0
|| mN [WV] — mN [(к + 1)Лг] || < 8 (3.39)
(где е > 0 — достаточно малая величина), то величина
n0 = k0N определяет тот момент времени, при котором
можно считать, что
М{с[щ]}жс*. (3.40)
Сглаживание с [п\ может быть достигнуто иным путем
на основе модифицированного алгоритма,
представляющего частный случай (3.27):
c[n] = c[n-l) + yVeQ(Ax[n], c[7i-l])f (3.41)
где, например,
п
Ах[п) = -^^х[т), (3.42)
или
n+N
AxW = W 2 ХИЬ (3-43)
т=п
Здесь сглаживание г [п] достигается за счет
предварительной обработки х [т].
§ 3.15. Об ускорении сходимости
Эффективность алгоритмов адаптации зависит в первую
очередь, от скорости их сходимости. Используя методы
функционального анализа для оценки скорости
сходимости итеративных методов, можно установить, что при
у [п] = у0 = const скорость сходимости определяется
показательным законом, а при у [п] = — ,
удовлетворяющей условиям (3.34а),—степенным законом. Следовательно,
76
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
скорость сходимости при у [п] = — меньше, чем при
у [п] = у0. Этот факт легко объясняется физически:
постоянная обратная связь обеспечивает более
быстродействующий процесс, чем обратная связь, исчезающая
с течением времени. В связи с этим при отсутствии помех
выгоднее использовать у [п] = у0.
Но можно ли при наличии помех ускорить
сходимость надлежащим выбором закона изменения у [п] =
= (Yi Ь], . . . , yN [л])?
Оказывается, можно. Это объясняется следующим
образом. Вдали от оптимального значения с* разность
Acv [п — 1] будет иметь постоянный знак независимо
от помех. Вблизи же оптимального значения знак этой
разности существенно зависит от помех. Поэтому близость
к оптимальному значению можно характеризовать
количеством изменений знака Acv [п — 1 ] в единицу времени.
Изменять же yv [п] надо лишь тогда, когда этот знак
начнет часто меняться.
Чтобы определить разность Acv [п — 1], необходимо
по крайней мере два измерения. Поэтому yv [0], yv [1 ]
(у == 1, 2, . . ., N) выбираются произвольно, обычно
равными единице. Дальнейшее изменение осуществляется
следующим образом:
yv[n]^-yv[s[n]], (3.44)
где s [п\ — целочисленная функция, определяемая
выражением
71
s[n] = 2 + n— S sgn[Acv[m — 1] Acv[m — 2]], (3.45)
m—i
sgnz —
1, если z>0,
0, если 2<0. v ;
Возможен и иной способ ускорения сходимости, при
котором выбор очередного значения Yv t^l происходит
так же, как и в релаксационных методах, т. е. путем
минимизации градиента реализации функционала на
каждом шаге.
§ 3.16]
МЕРА КАЧЕСТВА АЛГОРИТМОВ
77
После каждого определения с [п]производится
наблюдение реализации
vr = Q(x[n], с[п— 1] — raVcQ(x [и], с[и—1])) (3.47)
при некотором фиксированном а до такого r = rh, при
котором будет выполнено неравенство уг >vr . После
«+i /i
этого принимается
y[n] = rha. (3.48)
Существует еще ряд способов убыстрения сходимости, но
все они носят слишком специфический характер.
§ 3.16. Мера качества алгоритмов
Выбор у [п] существенно влияет на свойства
алгоритмов. Поэтому возникает заманчивое желание подчинить
этот выбор не только условиям неизбежной сходимости, но
и условиям, при выполнении которых мы могли бы наш
алгоритм считать наилучшим.
К сожалению, как это уже обсуждалось в §2.18, общие
методы теории оптимального управления непосредственно
неприменимы к подобного рода задачам. Это
обстоятельство хотя и сужает возможности построения теории
наилучших алгоритмов, но оно не должно пресекать попытки
построения такой теории. Какой же должна быть мера
качества алгоритмов, по которой мы могли бы судить,
является ли найденный алгоритм наилучшим?
Очевидно, мера качества алгоритма должна зависеть
от п и выражать близость оценки с [п] к оптимальному
значению с*. Тогда тот алгоритм будет наилучшим, при
котором мера качества экстремальна при каждом значении
п. Обычно этот экстремум соответствует минимуму, так как
близость с [п] к с* характеризуется неким обобщенным
расстоянием. Хотя мера качества алгоритма аналогична
показателю или критерию качества оптимизации, но она
имеет свою специфику, и чтобы подчеркнуть это, мы
используем терминологию, оттеняющую отличие задач
оптимизации, решение которых осуществляется
алгоритмами, от задач выбора наилучших алгоритмов.
Весьма естественной и традиционной мерой качества
алгоритмов может служить среднеквадратическое откло-
78
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
нение текущего вектора с [п] от неизвестного
оптимального вектора с*, которое можно определить следующим
образом:
V2 [п] = М{\\с [п] - с* ||2}. (3.49)
Эта мера качества лежит в основе классического
байесовского подхода. Обобщением меры качества (3.49) может
служить линейная комбинация среднего квадрата
отклонения текущего вектора от оптимального и среднего
квадрата первой разности текущего вектора
V20c[n} = M{\\c[n]~c*\\*} + a[n}M{\\c[n)-c[n-l) ||2},
(3.50)
которая требует определенной «гладкости» изменения
текущего вектора г [п].
Несколько иной мерой качества алгоритмов может
служить значение самого показателя или критерия качества
при текущих значениях вектора с [п]: п = 1, 2, . . ., т.е.
J(c[n]) = M{Q(x, с[п])}. (3.51)
Будем говорить, что функционалы (3.49) — (3.51)
определены на алгоритмах, если в них текущие векторы с [п]
изменяются по закону, задаваемому алгоритмами. Тогда
задача нахождения наилучших алгоритмов, например
вида (3.9), сводится к таким выборам у [п] = ун [/г],
при которых соответствующие функционалы (3.49) —
(3.51), определенные на этих алгоритмах, достигают
минимума.
К сожалению, использование функционалов (3.49) —
(3.51) для нахождения наилучших алгоритмов приводит
к точным или приближенным выражениям у \п]= уп [п],
как правило, содержащим математические ожидания
от некоторых функций х [п] и оценок с [п— 1],
распределения которых нам неизвестны. Такой результат
не является неожиданным, ибо при выбранных
функционалах (3.49) — (3.51) мы приходим к рекуррентной форме
байесовских оценок, вычисление которых требует
достаточно полной априорной информации. Эту трудность
можно обоЙ1и, если вместо функционала типа
математического ожидания использовать функционалы типа
§ 3.17] НАИЛУЧШИЕ АЛГОРИТМЫ 79
эмпирических или выборочных средних
п
■Ме[п]) = 4- 2 С(*[»*]. СМ)> (3-52)
что соответствует замене истинной плотности
распределения на эмпирическую. Такие функционалы, как мы увидим
далее, приводят к выражениям у [п] = ун [тг], зависящим
от величин, которые можно определять по мере прихода
и обработки х [п] и оценок с [п]. Замена функционала
(3.51) функционалом (3.52) соответствует пословице:
«Лучше синицу в руки, чем журавля в небе». Но в наших
условиях это ведь в самом деле лучше.
§ 3.17. Наилучшие алгоритмы
Рассмотрим алгоритм
e[n] = c[n—l] — T[n]VeQ(x[n], с[п — 1]), (3.53)
где
'YtM 0 ... О \
™^У1^.°..^!П}::\.°. . (3-54)
О 0 ... yN[n]J
— диагональная матрица, а А — оператор, преобразующий
вектор у \п\ в диагональную матрицу. Определим на этом
алгоритме функционал (3.52). Тогда
/e(c[n])=-i-2 <?(*ИЬ с[и-1]-
-^£y[n]VcQ(x[n], е[п-1])). (3.55)
Условие минимума этого функционала запишется так:
VY/8(cH) =
п
= —dVeQ{x[n], с[га—l])-i-2 Ve^(ac[/»],c[n-l] —
-ivNV,(?(«M,c[n-l])) = 0, re = l,2, ... (3.56)
80
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
В общем случае Vc(?(-) зависит нелинейно от с [га],
а значит, и от у 1п\- Поэтому уравнения (3.56) нельзя
решить относительно у ln] в явной форме. И
единственный путь нахождения у [га] состоит в применении к (3.56)
регулярного итеративного алгоритма типа
у[п, к] = у[п, А—1] —YoV7/8(c[w —1] —
-Ау[п, Аг — 1J Vc<?(x[ra], e[n —l]))f (3.57)
га=1, 2,
где у0 = const и га = const в интервале времени между
(га — 1)-м и /г-м шагами. Этот алгоритм позволяет
определить Yh [п] как значение у [га, к] при достаточно
большом к. Итеративная процедура (3.57), разумеется, должна
происходить в убыстренном масштабе времени.
Предполагая, однако, что норма вектора у [/г], т. е.
|| у [п] ||, мала, что в силу алгоритма (3.53) эквивалентно
малости || с [га] — с [га — 1]||, можно приближенно
определить у [п] в явной форме. Пусть диагональная матрица
«^ Vc Q (•) — неособая; тогда, ограничиваясь линейным
приближением, запишем условие (3.56) приближенно
в виде
п
2 VcQ(x[m], е[п~1])~
га=1
п
- S TcQ{X[m], C[n-l])J:VeQ(x[n], С[П—\\) у [и] «0.
(3.58)
Здесь
r°Q(x> сН|^%г1 (v-^=1'2«--^)
— матрица вторых производных.
Учитывая теперь, что при любом га мы хотим
соблюдения равенства
п-1
S 4&(х[т], с[га-1]) = 0, (3.59)
m=i
§ 3.18] УПРОЩЕННЫЕ НАИЛУЧШИЕ АЛГОРИТМЫ 81
получаем из (3.58)
п
VhM»[2 VlQ(x[m], с[п-1])<4Ч£(х[п], е[п-1])]-^х
т=1
XVeQ(X[n], С [71-1]). (3.60)
Если использовать свойство обращения произведения
матриц, то окончательно (3.60) запишется так:
yH[n]tt[<44cQ(x[n], с[п — 1])]_1Х
х[2 nQ(x[ml c[n-l])]-iVjQ(x[nl c[n-i]). (3.61)
rn=l
Теперь можно, согласно (3.54), определить Гн [п] =
= Луп[п] и затем соответствующий этой матрице
алгоритм (3.53), который принимает вид
с [п] = с [п — 1] —
п
— [S TfQ{x{m\, c[n — i])]-1^Q(x[n],e[n— 1]). (3.62)
Поскольку этот алгоритм справедлив при малых
|| с [п] — с [п — 1]||, то уместно его называть
приближенно наилучшим алгоритмом. Аналогичным образом
можно получить наилучшие непрерывные алгоритмы.
Интересно отметить, что для них не существует
ограничений (малость у), которые в случае дискретных алгоритмов
заставляют довольствоваться приближенно наилучшими
алгоритмами.
§ 3.18. Упрощенные наилучшие алгоритмы
Часто выражение Гн [п] = с4уи [п] имеет довольно
сложный вид, и это вызывает определенные трудности.
Можно поставить задачу отыскания наилучших
алгоритмов, в которых диагональная матрица Г [п] заменена
одной скалярной величиной у [п]. В этом случае
отыскание Yh [я] будет соответствовать своеобразному методу
наискорейшего спуска, о котором мы уже говорили
6 Я. 3. Цыпкин
82
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
в § 2.19. Вместо условия (3.56) теперь мы получим
£l^=-^Q(x[n), с[п-1])х
П
Х7Г 2 W*[w], с [и-1] —
-YW) Vc<?(^M, с[га-1]) = 0, (3.63)
откуда при условии малости || с [тг] — с [/г—1] ||,
аналогично тому, как это было сделано в предыдущем
параграфе, находим
п
vf Q(j> Гп],г[п-1]) 2 VcQ(x[m],c[n-l])
Yn[n]«— .
vjQ(jrLril, с [n-1]) 2 v2Q(.r[?n],f [n-l])VcQ(jr[n],r[n-i])
?м—1
(3.64)
Рассмотрим еще один способ определения упрощенного
приближенно наилучшего алгоритма, для которого бы
не требовалась малость (| Ае [лг — 1] || -1| с [п\ — с[тг-—1]||.
Меру качества алгоритмов выберем в виде функционала
(3.49). Обозначая
Г) \п\ — с [п\ — с*,
запишем алгоритм (3.53), в котором диагональная
матрица заменена скаляром
Ч N = Ч [» - 11 - Y W Vc<? (# [/г], с* + г] [л- 1]). (3.65)
Найдем условное математическое ожидание квадрата
евклидовой нормы || ц [п] ||2:
^ { || ЧИП21 Ч["-ИН || Ч [и- И II2-
- 2Y [л] чТ [л - 1] Мх {Vc<? (х [и], с* + Ч [и - 1])} +
+ y2[n]M{\\VcQ(x[n], c* + T][?i^l])||2}. (3.66)
Предположим далее, что при любом тг>0
|| М {Vc<? (х [л], с* + т| [п - 1])} || < к, || ч [п - 1] ||, 1
Мч[и-1]а|1 <ЧТИ-1]^{^с(?(зс[/г], с* + т|[л-1])}. J
(3.67)
§ 3.18] УПРОЩЕННЫЕ НАИЛУЧШИЕ АЛГОРИТМЫ 83
Тогда, учитывая соотношение
M{\\4cQ(x[nh с* + т][гс-1])||2Н
= \\M{VcQ(x[n], с* + ц [и-1])} ||2 + а2 (3.68)
и заменяя в (3.66) слагаемые соответственно их
оценками (3.67), получим
М{\\ч[п]\\*\ц[п-1\}<
< || Ч In~ 1] ||2 {1 - 2к0у [п\ \- к\у* [п]} + Y2 [и] а2. (3.69)
Для нахождения безусловного математического
ожидания среднеквадратического отклонения (3.49) произведем
осреднение (3.69) по ц[п— 1].
Тогда с учетом обозначения (3.49) получим
F2 [п] < F2 [п — 1] (1 — 2к0у [п] + к\у* [п]) -|- у2 [п\ о2. (3.70)
Теперь уже можно найти оптимальное значение у[п].
Дифференцируя правую часть (3.70) по у [п\ и
приравнивая результаты нулю, находим
yhW >УГ [Vno2- (3-71)
По-видимому, найденное значение уп [п] и определяет то,
что можно сделать в общем случае при произвольной
норме \\с[п] — с[п— 1]|| и отсутствии информации о
плотности распределения.
Подставляя значение уп [п] в (3.70), имеем
V*[n]<V2[n-l] (l WV*[n-l] \ 3
Отсюда можно оценить число шагов, по истечении кото-
рого = достигает некоторого достаточно малого
значения
„0«2!_Й. (3.73,
/cfV2 [п]
6*
84
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
§ 3.19. Частный случай
В частном случае, при &0 = /^=1, что соответствует
линейной зависимости VcQ(w{n], с* + ц[тг—1]) от х\[п— 1]
и замене знаков неравенства в (3.67) знаками равенства,
из (3.71) и (3.72) имеем
V2[n — 1]
ун[п] = =
F2 [п] =
Отсюда легко получить
Yh [п] = -,
V*[n — l]-\-o*
F2 [/г — l]gg
V2[n—l] + a*
F2 [п]
а2
П + :
V* [0]
п + ^
1/2 [0]
(3.74)
(3.75)
Если отсутствует априорная информация о начальном
среднеквадратичном отклонении, то V2, [0] принимается
равным бесконечности, и тогда $|
YnM=T' F2W
-2!
п
(3.76)
Это известный результат для линейных оценок с*.
§ 3.20. Связь с методом наименьших квадратов
Если Q (ас, с) представляет собой квадратичную
функцию относительно с, например
<?(х, с)-0/~сТф(х))2,
то замена (3.56) на (3.58) будет не приближенной,
а точной, и значит, точным будет выражение для уи [п\
(3.61), которое в рассматриваемом случае принимает вид
Yh [п] = \Л<$ (х [п])]-1 [ 2 ф (х [т]) фт(х [т])]-1^ (х [п]).
771=1
(3.77)
Алгоритм (3.53) в этом случае принимает вид
с [п] = с[п — 1] -{-К [п] (у [п] — сТ [п — 1]<р(ж [n]))(fi(x[n]),
(3.78)
§ 3.21] СВЯЗЬ С БАЙЕСОВСКИМ МЕТОДОМ 85
где
К [п] = [ S <р (х [//г]) Фт (х [/я])]'1 (3.79)
?п=1
— матрица Калмана, вычисление которой может быть
также осуществлено с помощью рекуррентной формулы.
Алгоритм (3.78) представляет в рекуррентной форме
формулы метода наименьших квадратов. На каждом шаге
п мы получаем наилучшую в смысле метода наименьших
квадратов оценку с*. Это достигается ценой хотя и
простых, но громоздких вычислений уи [п] но формуле (3.77).
Если предположить, что х [т] независимы, то (3.77)
упрощается, и
Yn |и| • (3.80)
S 1|ф(ж[«1)Н2
7/7 = 1
В этом случае мы, естественно, приходим к простому
алгоритму.
Наилучшие или приближенно наилучшие алгоритмы
приспособлены для тех случаев, когда в нашем
распоряжении имеется ограниченное число данных.
§ 3.21. Связь с байесовским методом
Байесовский метод приводит при конечном числе
наблюдений к наилучшим оценкам оптимального вектора
с* с точки зрения минимума некоторой функции потерь.
Это достигается благодаря полному использованию
достаточной априорной информации о распределениях и,
к сожалению, довольно громоздким вычислениям.
Для отдельных классов распределений критерий
оптимальности вида условного математического ожидания
можно представить как выборочное среднее, так, что
J(c[n]) = M{Q(x, с[п])\х[1], ..., х[п]} =
п
= 1 2 Q(x[m], с [га]). (3.81)
777 = 1
86
АДАПТАЦИЯ II ОБУЧЕНИЕ
[Гл. III
Это равенство справедливо, в частности, для
экспоненциальных распределений.
Таким образом, алгоритм адаптации (3.62) одновременно
минимизирует условное математическое ожидание (3.81);
при этом он является приближенно наилучшим. Если
же Q (х, с) — квадратичная функция относительно с,
то алгоритм становится наилучшим без всяких
приближений. Отсюда можно сделать заключение, что при
специальном выборе у in] вероятное!ные итеративные методы
в случае квадратичных функций потерь приводят к тем
же результатам, что и байесовский. Найденное значение
Yh [7г] зависит от всех имеющихся в нашем распоряжении
значений векторов х [1 ], х [2],..., х [тг], получившихся
при конечном числе наблюдений п. Заметим, однако, что
с ростом размерности вектора х возрастают и
вычислительные трудности, зачастую лишающие нас возможности
использовать даже современные вычислительные машины
с их большой, но все же ограниченной оперативной
памятью. Нельзя ли преодолеть эти трудности? Оказывается,
можно.
Будем в интервалах между поступлением текущих
данных использовать в вероятностных итеративных
алгоритмах простые выражения y [п, Щ типа а Ik, а
необходимое для этих алгоритмов бесконечное число наблюдений
заменим периодическим повторением имеющегося в нашем
распоряжении конечного числа наблюдений. При этом
вероятностные итеративные алгоритмы будут приводить
к такой же наилучшей оценке вектора с [тг], как и
наилучшие алгоритмы при y [п] = Yh [п]- Разумеется, эта
периодизация наблюдений должна вестись в ускоренном
масштабе времени так, чтобы успевать определять оценку
с [п] внутри каждого интервала между (п — 1)-м и тг-м
наблюдениями.
§ 3.22. Связь с методом максимального правдоподобия
Метод максимального правдоподобия широко
распространен в статистике. Этот метод основан на уверенности
в том, что наилучшая оценка должна давать наибольшую
вероятность именно для той реализации, которая
фактически наблюдалась в эксперименте.
§3.22] СВЯЗЬ С МЕТОДОМ МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ 87
Пусть х [п] — последовательность независимых
случайных величин с одинаковым распределением вероятности
р (х [п], с), где с — векторный параметр, который
необходимо оценить. Функция правдоподобия L (х, с)
определяется как функция векторного параметра с, которая
образуется из совместного распределения выборки х [т]
(т = 1, 2, ... , /г):
п
Ч*. с) -= П Р(*['«1, «)• (3.82)
Оценка с* находится из условия максимизации функции
правдоподобия по параметру с:
\cL{x, с)~(). (3.83)
Часто вместо функции правдоподобия L (х, с)
оперируют ее логарифмом log L(x, с). При этом (3.83)
заменяется эквивалентным условием
?<.
V,loffL(ar, с)- 2 Velogi9(ac[wl, г)-0, (3.84)
m=i
и задача состоит в определении вещественных корней
уравнений (3.83) или (3.84), которые как раз и являются
искомыми оценками. Это в общем случае может быть
осуществлено с помощью регулярных итеративных методов.
Но поскольку функция правдоподобия изменяется с ростом
числа наблюдений, то оказывается более удобным
использовать вероятностные итеративные методы.
Представим соотношение (3.84) в виде
п
-i 2 Velogp(ar[/wl, с) = 0. (3.85)
Пусть выполнены все условия, при которых можно
воспользоваться соотношением (3.81). Тогда (3.85)
запишется так:
М {Vc log р (х, с) | х [1], .. .: х [п]} = 0. (3.86)
Теперь можно воспользоваться алгоритмом
с [л] = с \п-1 ] + у \п\ Vc logр (х [п\, с [п -1]). (3.87)
88
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
Этот алгоритм получается и из несколько иных
соображений. Действительно, рассмотрим математическое
ожидание
M{Vclogp{x, c)} = ^Vcp(x, с) p{XiC)P(x, e)dx. (3.88)
х
Здесь предполагается, что наблюдаемые реализации
принадлежат совокупности, соответствующей
распределению р(х, с*). Если взять градиент при значении с = с*,
то из (3.88) после очевидных преобразований следует:
М {V log р (х, с)} - V J р (х, с) dx = О, (3.89)
х
поскольку
Jp(«, e)dx = l. (3.90)
X
Таким образом, при с = с* математическое ожидание
от V log р (х, с) обращается в нуль. Это дает возможность
заключить, что алгоритм определения с* имеет вид (3.87).
При определенном выборе у [п] можно достигнуть того,
что оценка будет состоятельной, асимптотически
несмещенной и асимптотически эффективной.
§ 3.23. Обсуждение
Вопрос о выборе наилучших алгоритмов, затронутый
в предыдущих параграфах, связан с решением задачи
оптимальности, но эта задача в данном случае имеет свои
особенности. Как правило, нас не интересуют
промежуточные значения вектора с [п], определяемые алгоритмом,
если только они лежат в допустимых пределах. Мы были
бы полностью удовлетворены, если бы алгоритм позволял
за минимальное число шагов, т. е. за минимальное время
определить оптимальный вектор с заданной точностью.
Но вряд ли можно что-нибудь сделать с такой мерой
качества алгоритмов. По-видимому, алгоритмы, наилучшие
по быстродействию, вообще построить нельзя. И это
заставляет нас довольствоваться алгоритмами, наилучшими
с точки зрения минимума дисперсии на каждом шаге
либо с точки зрения минимума некоторых эмпирических
§ 3.24]
НЕКОТОРЫЕ ЗАДАЧИ
89
функционалов. Если градиент реализации Vc Q (х, с)
представляет собой линейную функцию с, то наилучшие
алгоритмы находятся без труда (см., например, § 3.19).
В любом другом случае мы можем определить лишь
приближенно наилучшие алгоритмы на основе линейного
приближения (см., например, § 3.18). Для получения
наилучших алгоритмов полезно использовать результаты
теории статистических решений, условных марковских
процессов и т. д. Следует, однако, подчеркнуть, что
замена исходной нелинейной задачи линейным
приближением приводит к тому, что получаемые результаты
справедливы лишь при достаточно малых отклонениях
II е [п] ~с [п~^] II- Такие алгоритмы не обладают
неизбежной сходимостью. И поэтому, естественно, возникает
вопрос, стоит ли заниматься оптимизацией
линеаризованного процесса, и если стоит, то в каких случаях.
Но если бы даже можно было находить наилучшие
алгоритмы в общем виде, то, как правило, их реализация
была бы настолько сложна, что пришлось бы от нее
отказываться. Поэтому не стоит преувеличивать роль
оптимальных алгоритмов. К подобному выводу давно пришла
теория оптимальных систем, в которой оптимальные
алгоритмы используются как средство оценки различного
рода упрощенных, но зато реализуемых алгоритмов.
С этой точки зрения приобретают интерес различные
упрощенные оптимальные алгоритмы либо простые
алгоритмы, которые многократно используются в интервалах
между моментами поступления данных. В последующих
главах мы не будем акцентировать внимание на
наилучших алгоритмах. Пользуясь результатами, изложенными
выше, читатель при необходимости сможет сам опреде.
лить наилучшие или приближенно наилучшие алгоритмы-
§ 3.24. Некоторые задачи
Важная задача, возникающая при разработке
алгоритмов адаптации, состоит в формулировке и построении
наилучших алгоритмов адаптации. Поскольку при
адаптации, как правило, решающим фактором является время,
то основные усилия должны быть направлены на
алгоритмы адаптации с быстрой сходимостью.
90
АДАПТАЦИЯ И ОБУЧЕНИЕ
[Гл. III
Можно уменьшить время адаптации, если отказаться
от обычной сходимости почти наверное «в точку», заменив
его сходимостью «в область»:
Р {lim |! с [п] ~ с* || < е} = 1. (3.91)
7г->оо
Можно требовать минимума математического ожидания
числа шагов, по истечении которых мы попадем в
заданную область.
Выяснение условий сходимости почти наверное
в область представило бы большой интерес, особенно
для многошаговых алгоритмов. Наконец, дальнейшего
уменьшения времени адаптации, вероятно, можно
достигнуть на основе применений правил определения момента
установления стационарности алгоритма. Было бы
интересно установить подобные правила.
Для расширения класса рассматриваемых задач было
бы весьма желательно надлежащее развитие и применение
аппарата линейного и нелинейного программирования,
распространение его на те случаи, когда функционалы
и ограничения в явной форме не заданы.
Было бы целесообразно для построения алгоритмов
адаптации использовать методы возможных направлений
и случайного поиска.
§ 3.25. Заключение
Мы познакомились с вероятностными итеративными
методами и, в частности, с методом стохастической
аппроксимации, которые лежат в основе развиваемой концепции
адаптации и обучения в автоматических системах. Эти
методы позволили нам построить разнообразные
алгоритмы адаптации, минимизирующие явно не заданные
функционалы по измеряемым или наблюдаемым реализациям.
То обстоятельство, что достижение минимума
функционала, т. е. определение оптимального вектора с*, требует
времени,— печальный, но неизбежный факт, который
представляет собой плату за сложность задачи и
присущую ей неопределенность. Вспомним регулярный подход
при минимизации известного функционала с помощью
алгоритмов оптимизации,— он также требует времени.
§ 3.25]
ЗАКЛЮЧЕНИЕ
91
Из изложенного можно сделать вывод, что характерная
особенность адаптации и обучения состоит в
последовательном накоплении и использовании текущей
информации с целью устранения неопределенности, вызванной
недостаточностью априорной информации.
Теперь наступило время показать, что изложенная
концепция адаптации и обучения позволяет взглянуть
на разнообразные задачи с некоторой общей точки зрения,
которая не только их объединяет, но и дает эффективный
метод их решения. Именно этому и посвящены все
остальные главы книги.
Глава IV
Опознавание
§ 4.1. Введение
Проблема опознавания (узнавания, распознавания)
является весьма общей, хотя она и возникла в связи с
решением час!ных задач — задач опознавания фигур (цифр,
букв, простых изображений), звуков (речи, шума),
диагностики заболеваний или неисправностей и т. п.
Опознавание представляет первую и важную ступень
обработки информации, получаемой нами при помощи
органов чувств и приборов. Вначале мы опознаем
предметы, затем — отношения между предметами, а также
между предметами и нами, т. е. ситуации. Наконец, мы
опознаем изменения этих ситуаций, т. е. явления. Именно
это дает нам возможность обнаружить закономерности
и прогнозировать на основе их дальнейший ход явлений
и их развитие.
Мы не будем касаться сравнительных возможностей
опознавания человеком и машиной и пытаться ответить
на вопрос, кто лучше. Причина такого решения состоит
не только в том, что этот вопрос был уже предметом
обширных и острых дискуссий (впрочем, не увенчавшихся
каким-либо разумным соглашением), сколько в нашем
глубоком убеждении о неправомерности постановки
такого вопроса. Машины всегда усиливали возможности
человека — вначале физические, а теперь и
интеллектуальные, в противном случае они вряд ли бы
создавались.
В этой главе мы сформулируем проблему опознавания
и покажем, что адаптивный подход дает возможность
получить эффективное решение этой проблемы. Мы
увидим, что широко распространенные в литературе разно-
§ 4.2] ОБСУЖДЕНИЕ ЗАДАЧИ ОПОЗНАВАНИЯ 93
образные алгоритмы обучения опознаванию, найденные
эвристическим путем, т. е. путем находок и догадок, могут
быть сравнительно просто получены как частные случаи
общих алгоритмов обучения.
§ 4.2. Обсуждение задачи опознавания
Прежде чем формулировать задачу опознавания,
целесообразно обсудить некоторые ее особенности, не стесняя
себя слишком строгими формулировками и точными
понятиями.
Основная задача опознавания состоит в отнесении
предъявляемого объекта к одному из классов, вообще
говоря, заранее неизвестных. Классы характеризуются
тем, что принадлежащие им объекты обладают некоей
общностью, сходством. То общее, что объединяет объекты
в класс, и называют образом. Для решения задачи
опознавания необходимо прежде всего заняться обучением
посредством показа образов, принадлежность которых к тому
или иному классу известна.
Если мы можем точно (в виде конкретных признаков)
сформулировать то общее, что объединяет объекты в класс,
то задача опознавания сводится к сравнению признаков
предъявляемых объектов с заранее известными. Хотя
этот случай и очень важен, например, для построения
машин, читающих стандартный текст, мы его касаться
здесь не будем. Отметим лишь, что в
контрольно-сортирующих устройствах этот принцип издавна используется для
опознавания бракованных деталей. Мы будем
рассматривать только тот случай, когда общность свойств объектов
каждого класса заранее установить невозможно или
неудобно, хотя в объективном существовании этой
общности сомнений нет. В этом случае, попросту говоря, мы
хотим классифицировать объекты, но не знаем как.
Попытки искать признаки ощупью, надеясь на удачу,
иногда приводят к решению важных конкретных задач.
Но возможен и иной путь — обучение показами,—
который сводится к предварительному показу ряда объектов
и указанию классов, к которым они принадлежат.
Для более точной постановки задачи опознавания
удобно использовать геометрические представления.
94 ОПОЗНАВАНИЕ [Гл. IV
Каждому объекту можно поставить в соответствие точку
в некотором многомерном пространстве. Естественно
думать, что сходным объектам соответствуют близкие
точки, и классы легко различимы, если точки,
принадлежащие им, располагаются кучно.
Разумеется, этот интуитивно очевидный факт можно
облечь в форму «гипотезы компактности». Но это, пожалуй,
ничего не дает, поскольку мы заранее не можем
рассчитывать на то, что эта гипотеза всегда оправдывается, а
проверить гипотезу очень трудно. Поэтому речь может идти
не о достижении абсолютной классификации, а о
достижении наилучшей классификации при имеющихся
условиях. И только в том случае, если классы легко различимы,
мы получим абсолютную классификацию.
§ 4.3. Формулировка задачи
Попытаемся теперь сформулировать задачу
опознавания в более точных терминах. Геометрически задача
обучения опознаванию образов (задача трех О) состоит
в построении поверхности, которая в каком-либо смысле
лучше всего разделяет многомерное пространство на
области, соответствующие различным классам. Построение
проводится на основе показа некоторого числа объектов
(образов), принадлежащих этим классам. Опознавание,
которое производится после окончания процесса обучения,
состоит в испытании нового объекта, а котором заранее
неизвестно, к какому классу он принадлежит. При этом
объявляется название области пространства, к которой
этот объект 01 носится.
Первой части этой формулировки задачи опознавания
(а именно обучению) можно поставить в соответствие,
как это часто делается, другую «алгебраическую»
формулировку. Обучение опознаванию состоит в
«экстраполяции», т. е. в построении некоторой разделяющей
функции по показам образов и указания, к какому
классу эти образы принадлежат. Мы ограничимся двумя
классами: 4и5, или 1 и 2, т. е. случаем, который обычно
называют дихотомией. К дихотомии можно
последовательно свести и общий случай, когда число классов
превышает два.
§ 4.3]
ФОРМУЛИРОВКА ЗАДАЧИ
25
Обозначим разделяющую функцию через
У = /(«), (4.1)'
где ас — /-мерный вектор, характеризующий образ,
а у — величина, определяющая класс, к которому этот
образ принадлежит.
Можно условиться, что разделяющая функция должна
обладать следующим свойством:
sign / (х) -
1, если х£А,
(4 2)
— 1, если х£В, v '
т. е. знак / (х) определяет принадлежность х к классу
А или В. Наряду с детерминистской возможна и
статистическая постановка задачи. В этом случае под / (х)
будем подразумевать степень достоверности
принадлежности образа к классу Л, а 1 —/ (х) — степень
достоверности принадлежности образа к классу В. Из формулы
(4.2) следует, что, вообще говоря, существует множество
функций, определяющих разделяющую поверхность. Эти
функции мы также будем называть разделяющими.
Очевидно, что такое множество существует по крайней мере
тогда, когда классы легко различимы. Однако если это
не так, то обычно существует лишь одна наилучшая
разделяющая функция.
Для постановки задачи экстраполяции или, если
угодно, задачи аппроксимации, прежде всего надо выбрать
класс аппроксимирующих функций и меру уклонения,
характеризующую точность аппроксимации. Обозначим
класс аппроксимирующих функций через / (ас, с), где г —
неизвестный пока вектор коэффициентов, а меру
уклонения определим как некоторую выпуклую функцию от
у = f (х) и / (ас, с), например F (у, f (ас, с)). Поскольку
показы вектора ас случайны, то и мера уклонения
случайна. Поэтому в качестве меры аппроксимации
целесообразно выбрать функционал, представляющий собой
математическое ожидание меры уклонения:
J(r) = M{F(y; />, с))}. (4.3)
Наилучшая аппроксимация соответствует такому
выбору вектора с = с*, при котором / (с) достигает минимума.
96
ОПОЗНАВАНИЕ
[Гл.IV
В большинстве случаев мера уклонения определяется
как выпуклая функция разности у — / (ас, с), и тогда
вместо функционала (4.3) получаем зависимость
J(c) = M{F(y-f(x, с))}. (4.4)
В дальнейшем мы будем, как правило, рассматривать
именно такой функционал.
Поскольку плотность вероятности р (ас), а значит,
и математическое ожидание (4.4) нам неизвестны, то
единственная возможность определения с = с* состоит в том,
чтобы воспользоваться отдельными реализациями,
получаемыми при показе векторов, и соответствующими
алгоритмами адаптации или обучения. К этому мы сейчас
и перейдем.
§ 4.4. Общие алгоритмы обучения
Прежде всего уточним вид аппроксимирующей
функции. Напомним, что выбор аппроксимирующей функции
не произволен, а связан с ограничениями первого рода.
Довольно широкий круг задач можно охватить, приняв,
что / (ас, с) представляет собой конечную сумму
f(x, с)= 2 cvyv(x) (4.5)
ИЛИ
/(.х, с) = сТф(ас), (4.6)
где с — TV-мерный вектор коэффициентов, ф (ас) — Аг-мер-
ный вектор линейно независимых функций.
Подставляя (4.6) в функционал (4.4), получаем
J(e) = M{F(y-eT<f(x))}. (4.7)
Поскольку функционал (4.7) явно неизвестен, то
минимум / (г) будем искать по измеренным градиентам
реализаций.
В рассматриваемом случае
VcF(y-cT<f(x))= -F'(y-cT<f(x))<f(x). (4.8)
§ 4.4] ОБЩИЕ АЛГОРИТМЫ ОБУЧЕНИЯ 97
Применяя алгоритм адаптации (3.9) и принимая Q(x, с) =
= F(y — cTq)(x)), получаем
с[/1] = с[л-1] +
+ у[п] F' (у [п]~ст [л- 1] q>(ac [п]))у(х [п]). (4.9)
Этот алгоритм, который уместно назвать алгоритмом
обучения, и определяет при п ->- оо оптимальный вектор
с — е* и оптимальную разделяющую функцию (4.6).
Алгоритм обучения (4.9) можно представить и в
несколько иной форме. Обозначим
fn{x) = <vT{x)c[n] (4.10)
IT
К(х, х [п]) = ц? (х) у (х [п]). (4.11)
Умножая обе части (4.9) скалярно на ср (ас) и используя
обозначения (4.10) и (4.11), получим алгоритм обучения
в виде функционального рекуррентного соотношения
U И = fn-i (х) + у [п] F' (у [п] — /п_! (х [п]) К {х, х [п])).
(4.12)
Принципиально иные алгоритмы можно получить на
основании алгоритма адаптации поискового типа (3.15).
В этом случае
c[n] = c[n — l] — y[n]V9±F(x[n]1 с[п— 1], а\п\), (4.13)
где оценка градиента
Ve±F(x[n], с[и-1], а[и]) =
= F+(x[n], с[и —1], a[n}) — F_(x[n], с[#г —1], а[п]) .^ ^
2а [п] » \ • /
а векторы F+ (•) и F- (•) определяются, как мы уже
условились, соотношениями, аналогичными (3.12).
Вряд ли стоит использовать поисковый алгоритм
обучения, если функция F(-) известна и допускает
дифференцирование. Однако в тех случаях, когда по каким-либо
причинам затруднительно определять градиент 4CF(-),
то только эти алгоритмы и можно применять.
В ряде случаев может оказаться удобным использовать
непрерывные алгоритмы обучения, например алгоритмы
7 Я. 3. Цышшп
98 ОПОЗНАВАНИЕ [Гл. IV
вида
l£jU- = y(t)F'(y(t)-cT{t)<t{x (0)Ф («*)). (4-15)
Смысл этого алгоритма удобнее будет пояснить несколько
позже на конкретном примере.
§ 4.5. Сходимость алгоритмов
При рассмотрении алгоритмов обучения (4.9) будем
различать два случая:
1) значения функции / (х) для каждого фиксированного
х измеряются с помехой |, имеющей конечную дисперсию
и математическое ожидание, равное нулю;
2) значения функции / (х) для каждого фиксированного
х известны точно.
Рассмотрим вначале первый случай. Для сходимости
г[п]кс* с вероятностью единица должны выполняться
условия (3.35). Выполнение условий (3.35,а) и (3.35,в)
достигается соответствующим выбором у [п] и F( •),
например, у [п] -- -г » — + 8 а <1, е > 0, a F( •) охватывает
п 2
все виды кусочно-непрерывных функций, растущих по с
не быстрее квадратичной параболы. Что же касается
условия (3.35,6), то легко проверить, что оно выполняется
для любых выпуклых функций.
Рассмотрим теперь второй случай. Предположим, что
для разделяющей функции у -- f (х) выполнена «гипотеза
представимости», т. е. будем считать, что функция / (х)
может быть точно представлена конечной суммой
N
f (X) - S Cv<Tv (х) - стц> (X). (4.16)
v=l
В этом случае
/(с*) = 0. (4.17)
Теперь оптимальное значение вектора с* может быть
определено после конечного числа показов; при этом, очевидно,
минимальное число показов равно N. Для всех остальных
показов при любых х и соответствующих г/ будет
выполняться равенство
F(y-c*?y(x))<f(x)=-U. (4.18)
§ 4.6]
ПЕРСЕ ПТРОНЫ
99
При этом алгоритм будет сходиться с вероятностью
единица, когда величина у постоянна у — уо- Предельное
значение у о можно найти с помощью стохастического
принципа сжатых отображений.
Если «гипотеза представимости» не выполнена,
равенство (4.18) записать нельзя, так как о* будет зависеть
от показов х. Однако и в этом случае алгоритм (4.6) при
постоянном у0, удовлетворяющем определенным
условиям, будет сходиться. Так, например, для квадратичного
критерия сходимость алгоритма с вероятностью единица
имеет место при
Yo< ^ . (4.19)
max >] ф2(.х)
v=i
§ 4.6. Псрссптронм
Приведенные выше алгоритмы обучения записываются
в виде нелинейных разностных уравнений, имеющих,
вообще говоря, переменные коэффициенты. Они
соответствуют, как мы уже знаем, многосвязным импульсным
х[п]
^
<р(х)
f(x[n]) =cJ[ii-1]cp(x)
F'(-)
HxJ
с[п-1]
^DH
yfn]
Рис. i.l.
системам,— обычной (непоисковой) и экстремальной
(поисковой). Эти системы, реализующие алгоритмы
обучения, позволяют фактически определить разделяющую
функцию, а значит, и осуществить классификацию
объектов. Схема такой системы приведена на рис. 4.1. Эта
7*
100
ОПОЗНАВАНИЕ
[Гл. IV
система состоит из функциональных преобразователей
ф (х) и F'(-), множительного устройства, образующего
скалярное произведение ст [п — 1] ф (х [тг]), обычного
множительного устройства, усилителя с переменным
коэффициентом у [п] и дигратора. Мы не вводим
специальных обозначений для множительных усаройств, так как
они легко различаются по тому, являются ли входные
Рис. 4.2.
и выходные переменные векторами или скалярами.
Разделяющая функция определяется на выходе устройства
скалярного произведения.
В развернутой форме схема системы, реализующей
алгоритм обучения, изображена на рис. 4.2. Эта схема
соответствует персептрону. В отличие от оригинального
варианте, предложенного Розенблатом, здесь вместо
пороговых функций использованы произвольные линейно
независимые функции cpv (х).
Персептроны, использующие пороговые элементы,
обычно рассматриваются в качестве аналогов нервных
сетей. Существует определенная связь между системами
распознавания образов, нервными сетями, конечными
автоматами и последовательностными машинами. Эти
вопросы будут рассмотрены в X главе книги.
§ 4.7] ДИСКРЕТНЫЕ АЛГОРИТМЫ ОБУЧЕНИЯ 101
Наряду с обычным персептроном возможен новый
и своеобразный тип персептрона — поисковый. Его схема
приведена на рис. 4.3.
(с7±ае)-<р(х) ху
<р(х)
FO)
с±ае
ЧП
г*.
{фРг-j
х
№
ZafnJ
о>
Рис. 4.3.
Устойчивость персептронов, т. е. факт сходимости
процесса обучения, не связана с видом функций cpv (х), но
существенно зависит от них.
Интересен тот факт, что существует возможность
построения персептронов не только на пороговых
элементах, а на любых линейно независимых
функциональных преобразователях.
§ 4.7. Дискретные алгоритмы обучения
Выбирая в общих алгоритмах обучения (4.9), (4.13)
конкретный вид функций F(-) ну [тг], мы получим
разнообразные частные алгоритмы, которые минимизируют
соответствующие функционалы.
Типовые алгоритмы обучения для удобства и
сопоставления приведены в табл. 4.1. Часть из этих
алгоритмов совпадает с алгоритмами, выписанными на основе
эвристических соображений в ряде работ по
опознаванию.
В таблице наряду с алгоритмами указаны критерии
оптимальности —- функционалы, которые эти алгоритмы
минимизируют, а также сделаны ссылки на авторов,
предложивших эти алгоритмы.
Таблица 4.1
п. п.
1
2
3
Функционал
= il/{(sgn у —
— sgn с^ф („с)) сТ(р (а:)|
= Л/{|у-сТф(ж)|}
/(c)--
-=М{(!/-^Тф(£С))2}
Алгоритм
с [и] =с [/г —1] -j-
+ Y М (signy [/г] —
— sign СТ [/г — 1] ф(х [/г])) ф (х [п])
с [п] — с [п — 1]-;-
+ Vh]sign(y [«] —
— ст [/? — 1] ф («г [/г])) ф (а? [д])
с [л] -с [и — l]-f
— vW (г/ N —
-г>т[я -1]ф(а5[«]))ф(ж[п])
с [п] ^с [п — \]-~
+ Г[п](у[п]~
— ст[д —1] ф (а? [/?])) ср(х [п])
Примечания
L-
оптимальность
по В. А.
Якубовичу
( 1, если
! х[п]£А
J | 0, если
Ух[п]£А
-=Г-1 [л —1] —
т
-фф1
Авторы
Апзерман М. А.
Браверман Э. М.
Розоноэр Л. И.
Якубович В. А.
Апзерман М. А.
Браверман Э. М.
Розоноэр Л. И.
Апзерман М. А.
Браверман Э. М.
Розоноэр Л. И.
Якубович Б. А.
Блайдой Ч.
Хо Ю.
Продолжение табл. 4.1
[ №
п. п.
\
5
Функционал
Jfc) =
= M{R(D(x)) —
— #(стф(х))сТф (х)}
J(c)==
i=i
N
+ У] Fl(k-cTkJ)
Алгоритм
с [гс] = с [/г-1]-|-
+ 7 [и] Д (Я (ж [*]))-
-R(cT [л-1]ф(х [и]))]ф(х[п])
^) =?(о^(1-сг(ОЛ*)х
х^(1-ет(0^),
(1 <*</);
__L_ =V(Of2(fc-cr(/)fc0x
(/^1-:/<Л')
Примечания
R(D(x))~
оператор
случайного
испытания
с двумя
исходами:
1-е
вероятностью D(x),
— 1-е
вероятностью
1 — D (х)
F{{z) = z-\z\
F2(z) =\z\ — z
Авторы
Айзермап М. А.
Браверман Э. М.
Розоноэр Л. И.
Вапник В. Н.
Лериер А. Я.
Червоиеикпс А. Я.
104
ОПОЗНАВАНИЕ
[Гл. IV
При отсутствии помех, как мы уже упоминали, у [п]
можно выбирать постоянной, не нарушая сходимости
алгоритмов. Алгоритмы 1—3 соответствуют
детерминированной задаче обучения, а алгоритм 4— вероятностной
задаче обучения.
Подчеркнем, что функционал, порождающий этот
алгоритм, является случайной величиной, так как
R (D (х)) — оператор случайного испытания с двумя
исходами (несимметричная монета): 1—с вероятностью
D (х) и (—1) — с вероятностью 1— D (х).
Когда принадлежность показанного образа какому-
либо классу достоверно известна учителю,
функционал 4 совпадает с функционалом 1, и вероятностная задача
переходит в детерминированную. Если же эта
принадлежность известна учителю только с некоторой степенью
достоверности, то в качестве критерия можно взять
средний квадрат отклонения
/ (с) = J [D (х) -етср(х)]2 р (х) dx. (4.20)
х
В этом случае алгоритм обучения будет совпадать с
алгоритмом
с[п] = с [я —1] + y[n]D(x[n])~
— ст[п — 1] ч(х[п])]у(х[п\). (4.21)
Знание функционалов дает возможность сравнивать
алгоритмы между собой. Некоторые алгоритмы, например,
не совсем удачны. Это относится к алгоритмам 1 и 4, для
которых соответствующие функционалы не являются
выпуклыми по с и для нулевого значения вектора с = 0
дают второй минимум, равный нулю.
Чтобы избежать сходимости к этому тривиальному
решению, нужно выбирать начальные значения с (0)
достаточно далеко от начала координат. Кроме того,
приходится считать, что классы действительно разделены
в пространстве образов, т. е. нужно требовать выполнения
гипотезы представимости (4.16). Если же это не так, то
алгоритмы неработоспособны, тогда как любые другие
алгоритмы этой таблицы и в этих условиях будут давать
результат, наилучший в смысле избранного функционала.
§ 4.8] ПОИСКОВЫЕ АЛГОРИТМЫ ОБУЧЕНИЯ Ю5
Отметим в заключение, что в таблице приведены
в основном дискретные алгоритмы, за исключением
алгоритмов 5. Об этих непрерывных алгоритмах мы скажем
подробнее в § 4.9.
§ 4.8. Поисковые алгоритмы обучения
Хотя каждому дискретному алгоритму, приведенному
в табл. 4.1, можно поставить в соответствие поисковый
алгоритм обучения, вряд ли нужно в этих случаях
отдавать какое-либо предпочтение поисковым алгоритмам.
Ведь для алгоритмов, с которыми мы познакомились
в § 4.7, градиент реализации вычисляется, как только
выбрана функция F(-).
Тем не менее в ряде случаев (и при несколько иной
постановке задачи опознавания), по-видимому,
единственно возможными являются поисковые алгоритмы обучения.
Вот эту постановку задачи опознавания мы здесь и
рассмотрим.
Рассмотрим два класса образов Л и В, или, что
эквивалентно, два класса — 1 и 2. Если образ класса v мы
отнесем к классу |ы, то эта ситуация оценивается штрафом
wvii (v' Iх = 1» 2). Величина этих штрафов задается
матрицей || wvli ||.
Средний риск, представляющий собой математическое
ожидание штрафов, можно представить в форме, которая
является частным случаем функционала (1.3):
Д (d) = J {[d (яг) - 1] [wl2 Р Pi (х) J- w22 (1 - P) p2 (x)) +
A
+ [2~d(x)\[w2i(l~P)p2(x) -\-w22PPl(x)\}dx, (4.22)
где P — вероятность появления образа 1-го класса,
1 -— Р — вероятность появления образа 2-го класса,
Р\ (х), Р2 (х) — условные плотности распределения образов
обоих классов, a d (х) — решающее правило: d (х) = 1,
если образ х относится к 1-му классу, d (х) =- 2, если
образ относится ко 2-му классу. Если бы плотности
распределения pi (х) и р2 (х) были известны, то для решения
поставленной задачи можно было бы использовать все
могущество теории статистических решений, основанной
106
ОПОЗНАВАНИЕ
[Гл.IV
на байесовском подходе. Но в нашем случае эти плотности
распределения неизвестны, и мы не можем
непосредственно воспользоваться результатами этой изящной теории.
Конечно, их можно применить, если предварительно
каким-либо путем определить плотности распределения.
Так иногда и поступают. Но не лучше ли не тратить время
на этот «лишний» этап, а воспользоваться алгоритмами
обучения? Ведь риск R (d), выражаемый формулой (4.22),
представляет собой частный случай среднего риска (1.5).
Поэтому R (d) можно представить в виде
R(d) = M{z\d}, (4.23)
где z =-- wV[XJ если при заданном решающем правиле мы
этот образ х отнесем к классу ja, тогда как на самом деле
он принадлежит классу v (v, \х = 1, 2).
Решающее правило d (х) будем искать в виде
известной функции d (х, с) с неизвестным вектором параметров
с = (ci, . . ., cN). Поскольку z зависит от вектора с
лишь неявным образом, то для определения оптимального
вектора уместно воспользоваться поисковым алгоритмом
с [и] = с [ л - 1 ] - Y [п] Vc±* [л], (4.24)
причем
U г Гп1 Z+ М — З- \П]
V +z\n\= г,—р—; ,
с* L J la [п] '
где
z+[n]~wv[ii, если х[2п — 1] принадлежит классу v
и d(x[2n— 1], с[п— 1] + а [п] е) = \х,
z_ [п] — wx[X, если х [2п] принадлежит классу v
и d(x[2n], с [п — 1] — а [п] е) = \х.
Поисковый алгоритм адаптации (4.24) и решает задачу
обучения. Этот алгоритм перебрасывает мост между
алгоритмическим подходом и теорией статистических
решений, основанной на байесовском критерии. С подобного
рода связью мы еще встретимся в задачах фильтрации,
точнее, в задачах обнаружения и выделения сигналов,
которые рассматриваются в гл. VI.
§4.9] НЕПРЕРЫВНЫЕ АЛГОРИТМЫ ОБУЧЕНИЯ Ю7
§ 4.9. Непрерывные алгоритмы обучения
Выберем функционал вида
/ N
/(*)= 2 F'Kl-^x») + S ^(ft-t^)» (4.25)
ц,=1 *ii=Z—1-1
где 0 < ft < 1, xv — векторы показа, причем от 1 до I
занумерованы векторы, принадлежащие А, а далее идут
векторы, принадлежащие В. Функции F^ (•) и F2 (•)
таковы:
0 при зс<0,
/t(x) ~
к } ] F(x) при х>0;
^(х) = 1 0 при х>0ч
(4.26)
где F (х) — произвольная выпуклая функция.
Вектор 1]) — так называемый обобщенный портрет —-
определяет разделяющую гиперплоскость.
Пользуясь обычным градиентным методом, можно
получить алгоритм для определения оптимального
значения вектора гр:
i
N
+ ^ F2{k-^xn)F',{k~^x^)x4y (4.27)
Обычно обобщенный портрет представляют в виде
у
-ф- 2 cxxv. (4.28)
v=l
Если предположить, что векторы показов xv линейно
независимы, и учесть, что число показов совпадает с
числом искомых компонент вектора с, то непрерывный
алгоритм (4.27) совместно с (4.28) приводит к следующим
108
ОПОЗНАВАНИЕ
[Гл.IV
уравнениям:
d-^p- -- у (/) Л (1 - ст (0 Л*) F[ (1 - с*1 (0 Щ,
l<|x<Z,
<?<;,, (г)
Л - Y (0 ^2 (А-ст (0 Л11-) ^2 (к -с^ (0 fci),
z+i<fi<./v,
(4.29)
где А* представляет собой s-й столбец в матрице
Рис. 4.4.
Ц&иЛ, элементы которой суть попарные скалярные
произведения векторов показа.
В частном случае, когда
f 0 при х<0,
[ х при х > 0;
[ х при х<0,
I 0 при х > 0,
систему (4.29) можно переписать в виде
dC[l{t) -y(t)(l-cT (t)№), K\i<h
Fx(x)
F2(x)
dt
dcj\ (*)
= ^(0(^-^(0¾11). 1 + 1<ч<^
(4.30)
§ 4.10]
ЗАМЕЧАНИЯ
109
где у (t) может быть принята, в частности, постоянной.
Именно этот алгоритм приведен в табл. 4.1. Реализация
его возможна с помощью аналогового вычислительного
устройства, схема которого приведена на рис. 4.4. На
этой схеме приняты обозначения Cj -- (си . . ., q),
ец = (с/+ь • • •» Cjv)-
§ 4.10. Замечания
Все алгоритмы обучения, о которых выше шла речь,
связаны с аппроксимацией указаний «учителя», выра-
1, ас>0,
женных в форме sign / (ас) =
или II = ± 1,
-1, х<0 J
т. е. разрывной функции ас, при помощи непрерывной
функции / (ас, с) = стср (ас). Такое желание не всегда
может показаться естественным. Очевидно, что в задачах
опознавания часто разумнее определять / (ас, с) так,
чтобы только знак ее совпадал со знаком у. Возможно,
эти соображения и руководили авторами,
предложившими алгоритм 1 (табл. 4.1), в котором поправка вносится
лишь в том случае, когда знаки у и стц> (ас) различны.
Такой алгоритм в принятых здесь обозначениях
записывается в виде
с[п] = с[п— 1]-\~у[п\ (sign/(ас [/г|)~
— sign ст \п~ 1] <р (х [п])) <р (х [и]), (4.31)
где у [п] может быть и постоянной.
По градиенту реализации
Vc^ (•) = (sign f (х ln\) — sign ст [и — 1] <р (ас [/г])) <р (х [п])
(4.32)
легко восстановить критерий оптимальности:
/ (с) = М{(sign / (ас [тг]) —signcT [п — I] ср (х [и])) ст<р (ас)}.
(4.33)
Этот критерий и был выписан в табл. 4.1. Критерий
оптимальности, как мы уже упоминали в § 4.7, не совсем
удачен, поскольку функция, стоящая под знаком
математического ожидания, невыпукла. Помимо оптимального
110
ОПОЗНАВАНИЕ
[Гл. IV
значения векторам = с*, функционал имеет тривиальное
решение с — 0. Существование этого решения (после
установления этого факта) очевидно и из самого
алгоритма (4.31). Это обстоятельство делает алгоритм (4.31)
непригодным в тех случаях, когда классы А и В
разделяются нечетко.
§ 4.11. Еще об одном общем алгоритме обучения
Рассмотрим теперь другую возможность определения
общих алгоритмов, основанную на совпадении знаков у
и c,Tq> (х). Это требование выполняется, если определять
с из системы линейных неравенств
у[п]{ст{п~\]ч{х[п]))>0, п=1, 2, ... (4.34)
Эту систему неравенств можно заменить системой
уравнении 65
у[п](ст[п~-\\у(х[п]))^а[п-\}, /г = 1,2, ..., (4.35)
если только принять, что
а[/г —1]>0. (4.36)
Учитывая случайный характер показов, введем
критерий оптимальности
/ (с, а) - = М {F (у (Стц (х))~ а)} (4.37).
при ограничении
а>0, (4.38)
где F(-) — строго выпуклая функция.
Используя алгоритм адаптации, подобный (3.24),
учитываю!! щй дополнительные ограничения типа неравенств (4.38),
применительно к рассматриваемой задаче получаем:
с \п] = с [п- 1 ]- Yi [п] F {у [п] (ст [/г—1]ф (х [п])) -
— а [п — 1]) у [п] ф (х [и]), (4.39)
а |/г] - а [п- 1] + у2 [/г] [F (у [/г] (ст \п~ 1] сГ (х [п]))-
-а[и-1]) + |/"([/1/7](^т11г-1]ф(ас[/г]))-а[п-1])|1,
а(0)>0.
§ 4.12]
ЧАСТНЫЕ СЛУЧАИ
111
Обозначим
z (с, а [п]) - у [и] (стф (х [п\) — а [п]).
(4.40)
Здесь z (с, а [п]) — случайные величины, которые
характеризуют невязку неравенств (4.34).
С учетом этих обозначений алгоритм (4.39)
перепишется в виде
с [п] = с [п — i] —
— Yi М F' (z (с И— 1L ее [п — 1])) у [п] ср (ас [/г]),
а [л] - а [п - 1] + Y2 М I*" (* (с [л - 1], а [л - 11)) + } (4.41)
+ |F(z(c[az-1], а[71-1]))|1, |
а[01>0. J
Персептрон, т. е. дискретная система, реализующая
этот алгоритм, изображен на рис. 4.5. Он отличается от
<р(х)
Гх|—-(хТ-^—*| П-) \
iMH3i
1L
X
с[п-1]
<3DH
7^./
структуры классического персептрона наличием
дополнительного контура, предназначенного для
определения а*. Такое изменение структуры персептрона
позволяет увеличить скорость сходимости.
§ 4.12. Частные случаи
Частные случаи алгоритма обучения (4.41) приведены
в табл. 4.2, а конкретные виды функций F (z), входящих
в алгоритмы, изображены на рис. 4.6.
112
ОПОЗНАВАНИЕ
[Гл.IV
Он
о
Е-1
М
<
К
и
н
Он
о
ч
<
4
(Я
с
я-
нС
Г4
<"
!
о.
IT
1
'1
iL
?-
<л
<f
ei
Е
CQ
о
и
IF
т
£
6^
.^~у
^ ^ о
ьг — III
©-QQ-
IFV^
"о а
VO
ж
ii
^ &
, "| -
+ й а»
^7^ X
1 'тг <-*-*
е £ 1
« '£ ^
° +
J^
м
^
^
Л
^
—i
'
<J
и
о
й
3
с
Щ
V |||
v^
о 8
о^.;
>->
я
о о
£ 5
<^
111
Ж
8
——
1 й
i&
8 Ж
"""Т1 __/_v
i i ^
| — 8
кЗ,-
o^f
г 1
(N
|
1
N
W^
^м
JI
<м
<
«
Е
Н
°
О
>>
VJ 1
«
__ 1
-
II
^74
Й
«,
¥
2
-
^
©•
Й
2¾
- !
'
IF
8 со со
^ Л V
1 ^— и к»
JL"- ~~
i^sa а
1 и ^ И _ И
^4 '"Г1 1—. ^
1 -^ 1
е ^- а» г»
4"'х
->
" 1
-•- со
А V
,-a-v «S3 bq
w к_| ^
S^ Sh 3,
^ Й о н 1
■- —— у
ГО
Продолжение табл. 4.2
Хя
П. п.
4
5
Функционал
7 =
ГМ{г*}
1 при zO^»
| М{2вЛ*}
j при ал < z < 0,
0
1 при z > 0
7 =
i-M {Z2}
1 ПРИ 2 < 0,
1°
V. при z > 0
Алгоритм
с[п] = с [п — 1] —
Ху[и]ф(ж[и1)
при 2Л <яд;
с [и] —с [п — 1] —
— 2у [п] а [п] у [п] ср (х [п])
при ап < zn < 0;
с |гс] = с [и — 1] при zn>0
с [и] ■= с [п — 1] —
— Г [п] z (с [п-1], а[п — 1]) х
X y[n]q>(x[n]),
а [п]=а [п — 1] —
— y{z(c[n—l], а[п — 1]) +
hl*(c[i»],afii-l])|}
Примечания
Я/1 = */2МХ
Фт (а? [и]) ф (а? [п]) .
Л Л, [и] h [п]
0<^М<2,
Л [тг] — число
исправлений
вектора с[п]
В зависимости от выбора
матрицы Г [п] получаем
различные модификации
алгоритма
Авторы
Фомин В. И.
Моцкин Т.
Шенберг И.
Хо Ю.
Кашьяп Р.
1
i
114
ОПОЗНАВАНИЕ
[Гл. IV
В тех случаях, когда помимо совпадения знаков
требуется еще и близость исходной и аппроксимирующей
функций, F (z) отлична от нуля и для положительных z
(алгоритм 3, рис. 4.6, в). Отметим, что алгоритмы 1а и 16
(табл. 4.2), по существу, совпадают, в чем нетрудно
убедиться простой проверкой. Особенность алгоритма 16
состоит в том, что в нем у [п] является функцией не
только /г, но и вектора с [п — 1], что дает возможность
УЛУЧШИТЬ СХОДИМОС1Ь.
В алгоритмах 1—4 предполагается, что а [п] = const.
Сходимость этих алгоритмов может быть значительно
улучшена, если а [п] не считать постоянной величиной,
а определять в соответствии с выражением (4.39). Именно
это обстоятельство использовано в алгоритме 5. Верхняя
строка алгоритма в общем случае имеет вид
c[n] = c[n—l] + T[n][z (с [л— 1], а [п— 1])] у [п] ф (х [п]),
(4.42)
где Г [п] — некоторая матрица.
Когда z (с [0], а [0])<0, алгоритм (4.41) совпадает
с алгоритмом 3 табл. 4.2. Если же z (с [0], а [0]) > 0,
то с [01 и а [01 — искомые решения.
Если множества образов каждого класса конечны
(v = 1, . . ., М), т. е. имеется возможность показа всех
образов, задача разделения становится детерминированной.
§ 4.13]
ОБСУЖДЕНИЕ
115
Образуем последовательность показов
Ф (Яц [п]), где и. = 1, 2, ..., М при каждом п = 1, 2, ...
(4.43)
Используя (4.43) в алгоритме (4.41), получим, что
с^]__><з0 ПрИ ^^^оо^ где с0 —решение конечной системы
неравенств
^<p(xv)>0 (|i=l, 2, ..., М). (4.44)
Отметим, что во всех рассмотренных выше алгоритмах
на каждой итерации происходит только один показ.
Если число показов конечно, то на каждой итерации
можно использовать все показы. Тогда получим алгоритм
с[п] = с[п— 1] —
м
а[п] = а [п— 1] +
м
fY2N[S J"(*ii№-1L а[и-1])) +
и=1
м
(4.45)
+ 1 2 /"(ММи-Ц, а[л-Ц))|].
ц=1
При га—>оо с стремится к вектору с*, который является
решением системы (4.44) и доставляет минимум критерию
оптимальности
м
J (с, а)= 2 ^(^сгф(^)-ай). (4.46)
ц-1
Впрочем, об этом мы уже говорили в § 3.21.
§ 4.13. Обсуждение
В общем случае все алгоритмы обучения определяют
оптимальный вектор с* и разделяющую функцию / (ас, с*)
с вероятностью единица теоретически лишь по истечении
бесконечного числа шагов. Практически же мы всегда
8*
116
ОПОЗНАВАНИЕ
[Гл. IV
используем конечное число шагов, и это число
определяется той точностью, с которой нам нужно определить с*
и / (х, с*). Здесь имеется полная аналогия между
временем обучения и временем окончания переходного
процесса в автоматических системах. В § 4.5 мы уже
указывали такие условия, при которых число шагов, а значит
и время обучения, конечно. Эти условия состоят в том,
что помехи отсутствуют, а классы А и В таковы, что
разделяющая функция / (х) может быть точно выражена
с помощью аппроксимирующей функции / (ас, с*) =
— с*т ср (х). В этом случае
F(y — с*гф (ас)) ф (х) =■ 0 (4.47)
при любом х. При отсутствии помех TV-мерный
оптимальный вектор в принципе полностью определяется после N
первых показов.
Табл. 4.1 и 4.2 могут служить путеводителями по
казавшемуся ранее разветвленному и запутанному
лабиринту алгоритмов. Из внимательного рассмотрения этих
таблиц можно сделать заключение, что все тропинки
лабиринта подходят к одной и той же дороге, ведущей
к минимизации соответствующих функционалов.
Не лишен любопытства и такой факт. Почти все
алгоритмы, найденные путем догадок, не выходят за пределы
алгоритмов, минимизирующих квадратичные или
простейшие кусочно-линейные функционалы. В чем причина
этого: в ограниченности ли фантазии, в вычислительной
простоте или в наличии какого-либо действительного
преимущества этих алгоритмов?
§ 4.14. О самообучении
Самообучение — это обучение без каких-либо
указаний извне о правильности или неправильности реакции
системы на показы.
Вначале кажется, что самообучение системы в
принципе невозможно. Это ощущение могло бы превратиться
в уверенность, если слишком доверяться такой, например,
аргументации. Поскольку классифицируемые образы
обладают самыми различными признаками, то кажется
§ 4.14]
О САМООБУЧЕНИИ
117
непостижимым, как система, предназначенная для
опознавания образов, будет решать, какие из этих признаков
она должна принимать во внимание, а какие отбрасывать?
Ведь не может же система разгадать априорную
классификацию, задуманную конструктором. С другой
стороны, любая классификация, которую осуществит
система, вряд ли сможет кого-нибудь удовлетворить.
Но такой пессимизм кажется несколько поспешным.
При-внимательном рассмотрении задачи обнаруживается,
что за систему многое решает конструктор еще на стадии
проектирования системы. Классифицируемые признаки
в первую очередь определяются вводными устройствами
системы, т. е. набором чувствительных элементов. Так,
например, если вводное устройство представляет собой
набор фотоэлементов, то классифицируемыми признаками
могут быть конфигурация, размеры, но не плотность
или вес предмета. На какой же основе может быть
осуществлено самообучение системы? Попытаемся пояснить
это в самых общих и, возможно, не очень точных чертах.
Предположим, что множество образов X состоит из
нескольких непересекающихся подмножеств Xk,
соответствующих различным классам образов, характеризуемых
векторами х. Появление при показе образов х из
подмножеств Xh случайно. Обозначим через Рк вероятность
появления образа х из подмножества Xk, а через pk (х)--
= р (х\к) — условную плотность распределения
вероятности векторов х внутри соответствующего класса.
Условные плотности вероятности ph (х) таковы, что
их максимумы находятся над «центрами» классов,
соответствующих подмножествам Xh (рис. 4.7). К сожалению,
когда неизвестно, какому классу принадлежит
образ х, эти условные вероятности точно определить
невозможно.
Совместная плотность распределения вероятностей
м
Р(х)= 2 PkPk(x) (4.48)
k=ri
содержит довольно полную информацию о множествах.
В частности, можно ожидать, что максимумы р (х)
также будут соответствовать «центрам» классов. Поэтому
118
ОПОЗНАВАНИЕ
[Гл.IV
задача самообучения часто может быть сведена к
восстановлению совместной плотности распределения и
определению по ней «центров», а затем и границ классов.
Р(х) к
Рис. 4.7.
В связи с этим мы прежде всего остановимся на
восстановлении плотности распределения, тем более, что
решение этой задачи представляет и самостоятельный интерес.
§ 4.15. О восстановлении плотности распределения
и моментов
Для восстановления совместной плотности
распределения р (х) по показам х предположим, что р (х) можно
аппроксимировать конечным набором произвольных, но
теперь еще и ортонормированных функций (pv (х), т. е.
N
р(х, с)-^-- 2 CvTv(aO = crq>(ac). (4.49)
v=l
Оптимальным значением вектора с = с* будем считать то,
при котором квадратичная мера уклонения
/ (с) = J [р (х) - стф (х)]2 dx (4.50)
х
достигает минимума. Эта задача внешне напоминает
задачу об аппроксимации, которой мы до сих пор
занимались. Но здесь имеется существенное отличие, которое
состоит в том, что теперь указаний извне нет. Поэтому
§ 4Л6]
АЛГОРИТМЫ ВОССТАНОВЛЕНИЯ
119
не только вектор с, но и сама функция г/, которой
соответствует в данном случае плотность распределения,
также неизвестны. Однако это затруднение — только
кажущееся. Легко видеть, что в силу ортонормирован-
ности функции (pv (х) мера (4.50) достигает минимума при
с*= \ <р (х) р (х) dx = М [ф (ас)]. (4.51)
А'
Таким образом, оптимальное значение вектора с — с*
равно математическому ожиданию вектор-функции ф (х),
значения реализаций которой нам известны.
Из (4.51), в частности, следует, что если взять
«степенные» функции, то компоненты вектора с* будут
определять моменты соответствующего порядка. Таким
образом, мы имеем возможность схожими алгоритмами решить
задачу оценки моментов и восстановления плотности
распределения. Однако нужно иметь в виду, что,
поскольку «степенные» функции не ортонормальны, то
найденные по формуле (4.51) значения вектора г* не
минимизируют функционал (4.50).
Если отказаться от ортонормированности системы
функций ф! (х), . . ., (pN (х), а считать их только
линейно независимыми, то вместо простого соотношения (4.51)
мы можем получить более сложное соотношение, которое
реализуется с помощью взаимно связанных систем. По
стоит ли идти на обобщение, приводящее к более
сложной реализации и не сулящей при этом каких-либо явных
выгод?
§ 4.16. Алгоритмы восстановления
Для определения с* перепишем (4.51) в виде
М [с-ф (х)] -0 (4.52)
и будем рассматривать (4.52) как уравнение
относительно с. Применим к нему алгоритм обучения. Тогда
получим
с [п] = с \п — 1 ] — у [п] [с [п — 1 ] — ф (х [п])]. (4.53)
Этот алгоритм при выполнении условий сходимости (3.34),
взятых для одномерного случая, при п ->- оо определяет
120
ОПОЗНАВАНИЕ
[Гл. IV
искомое значение с = с*, а следовательно, и р (х, с*) —
с вероятностью единица. Алгоритм (4.53), позволяющий
определять также и моменты при специальном выборе
(pv{x), реализуется в виде одномерных линейных
импульсных систем с переменными коэффициентами. Одна из
%(х)
I ^ I I ГТ4^ CvM
—*-<Y) И у[п] \-^\ UO—Т-**
I I I 9 I—1^ 1
Рис. '*.8.
таких систем изображена на рис. 4.8 (для v-ii
компоненты). Общая схема устройства для определения р (х)
по данным наблюдения изображена на рис. 4.9.
v(x)=cT[n-l]<p(x)
Рис. 4.9.
Если данные поступают непрерывно, то при
выполнении условия счационарности можно воспользоваться
непрерывным алгоритмом (3.28). Тогда вместо (4.53)
получим
do (t)
(it
■у(0И0-ч>(ю ('))].
(4.54)
Схема, реализующая этот алгоритм, отличается от
изображенной на рис. 4.9 лишь тем, что дискретные
интеграторы (диграторы) заменяются непрерывными.
Можно показать, используя результаты §§ 3.16—3.17,
что выбор у W ~ —является оптимальным для
алгоритма типа (4.53) с точки зрения минимума дисперсии
§ 4.16]
АЛГОРИТМЫ ВОССТАНОВЛЕНИЯ
121
оценки с при любом фиксированном значении п. Для
непрерывного алгоритма типа (4.54) оптимальным
является зависимость у (t) =—-.
Вместо алгоритмов (4.53) и (4.54) можно также
воспользоваться модифицированными алгоритмами с
оператором усреднения типа (3.42)
71
f[n] = c[ra-l]-Y[ra](e[n-l]-JL 2 <f(x[m])) , (4.55)
??l=l
п-И, 2, . . .,
и аналогично
rfr (t)
dt
-У
(О (с (0—f§4> (* ('))<*')• (4-56)
Схема, реализующая эти алгоритмы, приведена на
рис. 4.10. Она отличается от предыдущих наличием
хщ
=3
<Р(Х)
=я
,4
л/
■^Т, <р(х[т])
11
X
р(х)=с7<р(х)
Рис. 4.10.
дополнительного интегратора. Другая интерпретация
основных и модифицированных алгоритмов будет дана
в § 5.6.
В модифицированном алгоритме (4.55) выбор у [п] =
1
= — является оптимальным с точки зрения минимума
суммы дисперсии оценки и взвешенной первой разности,
т. е. с точки зрения минимума функционала типа (3.50)
VU [л] = Af {|| г [п] - с*\\2 + (п - 1) || Де [п — 1] ||2}. (4.57)
122
ОПОЗНАВАНИЕ
[Гл. IV
§ 4.17. Принципы самообучения
Самообучение при опознавании образов, или
классификация множества образов, состоит в определении только
по показам, без каких-либо указаний извне, границы
между классами. В благоприятных случаях эта граница
представляет собой овраг на холмистой поверхности,
образуемой совместной плотностью вероятности. И хотя
мы уже знаем, как восстановить совместную плотность
распределения, задача определения границы, т. е. задача
построения некоторой разделяющей поверхности, от этого
не стала проще. Однако задача упрощается, если у нас
имеется какая-либо априорная информация, например,
если задана форма условных плотностей распределения.
Так, если условные плотности распределения нормальны
и отличаются лишь средними значениями, то для
определения границы между двумя классами достаточно
определить взвешенное среднее значение совместной плотности
распределения. Существует большое число способов
классификации без указаний извне, основанных на довольно
полной априорной информации о законах распределения,
которых мы касаться не будем. Но нельзя ли построить
разделяющую поверхность, минуя явное восстановление
плотностей распределения и не имея априорной
информации об этих плотностях? Оказывается, такие
возможности существуют.
Одна из этих возможностей состоит в том, чтобы вместо
указаний извне использовать ответы персептрона.
Можно ожидать, что при этом персептрон найдет границу
между двумя классами, но он, разумеется, не сможет
однозначно опознать эти классы. Действия такого
персептрона соответствуют действиям доверчивого
оптимиста или недоверчивого пессимиста, которые желаемое
или нежелаемое принимают за действительное.
Намного интереснее иная возможность.
Представим себе, что все элементы х, соответствующие
образам одного и того же класса, сгруппированы в
непосредственной близости от «центра» этого класса. Введем
тогда некоторую функцию, в самом общем смысле
характеризующую расстояние х от, вообще говоря, пока
неизвестных центров aft этих классов.
§ 4.18]
СРЕДНИЙ РИСК
123
Тогда классификация может быть основана, например,
на требовании, чтобы каждый элемент каждого класса
был удален от центра этого класса на расстояние,
меньшее, чем от центров остальных классов. Это требование,
как отмечено в следующем параграфе, может быть связано
с минимизацией некоторого функционала (среднего риска).
Теперь уже нетрудно понять, что задача
самообучения может считаться решенной, если удалось по
показам образов х £ X определить центры множеств Xk п
границы этих множеств так, чтобы средний риск был
минимален.
Чтобы перейти от этих общих рассуждений к решению
задачи самообучения, необходимо прежде всего
определить средний риск и найти его вариацию. Этому и
посвящены следующие два параграфа.
§ 4.18. Средний риск
Введем понятие функции расстояния р элементов х
множества X от «центров» ak подмножеств Xk, задав
некоторую выпуклую функцию F разности q>(x) — ф(а/<):
р(#, uk)=-F(q>(x)-uh), (4.58)
где принято обозначение
uk = q)(ak). (4.59)
Функцию р(х, tik) можно рассматривать как
функцию потерь или штрафов для к-ro класса. Средний риск
или средний штраф для всех классов можно представить
выражением
м
Л = 2 Pft J /■ (<р (ас) - nk) Pk (х) dx, (4.60)
или, вводя совместную плотность распределения
вероятностей (4.48), в виде
м
Д = 2 *{ F(4>(x) — uh)p(x)dx. (4.61)
fc=l xh
124
ОПОЗНАВАНИЕ
[Гл.IV
Напомним, что Xk (к = 1, . . ., М) — непересекающиеся
области.
Если ввести характеристические функции
[1, когда х£Хк,
еА (ас, uiy . . ., им)= _ (4.62
I 0, когда x£Xk,
то можно образовать общую функцию потерь
о (х, ии . . ., им) —
м
-= 2 £h(x, ии . .., uM)F(y(x) — uk), (4.63)
и тогда средний риск (4.61) можно будет представить
и в такой более удобной для нас форме:
R = Mx{S{x, ии ..., им)}. (4.64)
В выражениях для среднего риска величины nk и
множества Xk, а значит, и характеристические функции
неизвестны.
§ 4.19. Вариация среднего риска
Для минимизации среднего риска необходимо
вычислить его вариацию, а затем уже из равенства этой
вариации нулю нетрудно будет определить условия минимума.
Вариацию среднего риска, определяемого] выражением
(4.61), можно представить в виде суммы двух вариаций:
вариации б/?ь связанной с изменением параметров
/€ь . . ., //ЛГ, и вариации б/?2, связанной с
изменением области Х/?:
6Я = 6ДН-бЯ2, (4.65)
где
м
б/?!-^ I V„kF(4(x) — uh)p(x)dx6uk (4.66)
6/?2-S I 2 -^lf'(<f№--uk)p(x)6xmW]dx. (4.67)
/?=1 A' m—i
§ 4.20] УСЛОВИЯ МИНИМУМА СРЕДНЕГО РИСКА 125
Здесь N — размерность вектора х. Рассмотрим подробнее
выражение для 6i?2- По формуле Грина его можно
преобразовать к виду
м
Si?2 = 2 \ ^(фИ-uk)p(x)8Akdx, (4.68)
ft=lAft
где
6Л,= 2 (-1)VS*V(*>. (4.69)
v=l
Так как области Xh (к = 1, . . ., М) —
непересекающиеся, то каждую граничную поверхность Ak можно
разбить на участки Л/гт, по которым область Xh граничит
с областями Хт (т = 1, . . ., М\ т Ф к). Очевидно, что
6Лйт=-6Л,иЛ. (4.70)
Учитывая это, получим
s
бда= 2 I [^(фИ-^)-
к, 771=1 Akm
— F (ср (ж) — ге//г)] р (ас) 8ЛЛ//1 г/х, (4.71)
где s — число пар смежных областей.
§ 4.20. Условия минимума среднего риска
Приравнивая нулю полную вариацию среднего риска,
мы получаем условие минимума среднего риска, которое
на основании (4.65), (4.66) и (4.71) запишется так:
м
Si? = 2 § VukF(<f(x) — uk)p(x)dx8uk +
k=ixk
s
+ 2 I \F(<$(x)-uk)-
h,m=lAhm
—F(<((x)-um)]p(x)8Akmdx = 0. (4.72)
126
ОПОЗНАВАНИЕ
[Гл. IV
В силу произвольности и независимости вариаций Ьпи
и бЛйиг из (4.72) следует, что должны быть выполнены
условия:
J Vn/ (q> (х) - uk) р (х) dx = 0, (4.73)
F (ср (х) - иЛ) - F (Ф (х) - wm) = О (4.74)
для x£Akm, тиф к.
Условия (4.73) определяют оптимальные значения uk ~
= и*j характеризующие «центры» областей, а (4.74) —
уравнение поверхности, разделяющей области Xk и Хт,
соответствующей оптимальному (в смысле минимума
среднего риска) разбиению области X на классы. Таким
образом, задача самообучения сводится к решению
системы уравнений (4.73) относительно uk при неизвестной
плотности распределения вероятностей р (х) и при
условии, что на границах областей выполняются
равенства (4.74).
Чтобы не потерять наглядность, далее при выводе
алгоритмов самообучения мы ограничимся случаем двух
обласхей (М = 2). Распространение результатов на
случай М > 2 принципиальных затруднений не
представляет.
§ 4.21. Алгоритмы самообучения
Если воспользоваться характеристической функцией
(4.62), то условия (4.73) для М = 2 (что соответствует
двум классам А и В) можно аналогично (4.64) записать
в виде
VvlR = M{ei(x, щ, u2)VulF(q>(x)-1^))^0, 1
Ч„2Н = М{е2(х, ии n2)VU2F(<p(x) — u2)} = 0. J
Теперь задача состоит в нахождении их = и* и и2 = и*,
удовлетворяющих условию (4.75). Применим к (4.75)
алгоритмы адаптации, или, как их уместно сейчас
называть, алгоритмы самообучения. Тогда формально мы
§ 4.21]
АЛГОРИТМЫ САМООБУЧЕНИЯ
127
1
получим, что
щ [П] =и{[п—1] —
— yi[n]Ei(x[n]i Щ[п—1], Щ[П — 1])Х
X VM1 Р(ч(х[п]) — щ[п—1]),
и2[п] = и2[п—1] —
— Чг\п\Ъг{х[п\> щ[п—1], и2[п— 1]) X
X VU2F(4(x[n]) — u2[n — l]).
Разумеется, этими алгоритмами непосредственно
воспользоваться нельзя, так как пока мы не знаем значений
(4.76)
<Н
=И <Р(*) Ы
Ч<Р(х)-и, I I , 1 J-U
fn>(Shr ЦЪЬ(') Ь^ГгМ\==Ц X |
Ь(-)
*
w
f(X, U,, Щ)
[L^Lg^l ^^ L;^^^
<0^
Рис. 4.11.
характеристических функций е4 и е2, входящих в
алгоритмы. Однако это затруднение кажущееся, его легко
преодолеть на основе условий (4.74). Обозначим
/(ас, ии u2) = F(if(x)~~ui)~F(ii)(x)~-u2). (4.77)
Функция / (х, ыи и2) является разделяющей. Как следует
из (4.74), она равна нулю на границе и имеет
различные знаки в различных областях. Ее знак всегда можно
определить после подстановки в (4.77) конкретных
128
ОПОЗНАВАНИЕ
[Гл. IV
значений и^ и и2. Теперь можно записать алгоритмы
самообучения в окончательной форме:
щ [п] = щ [п — 1J — Yi М V>nF (ф (x [n]) — щ [n — 1]),
u2 [n] = te2 f/г — 1],
если
f(x[n], щ[п — 1], u2[n —1])<0
и{[п] = u{ [n— 1],
u2[n] = u2[n — l]—y2[n] V„2F(ф(x[л])-u2[n — 1]),
если^
/(ac[w], «^[и—1], гг2[гс—1])>0.
Структурная схема такого самообучающегося персептрона
приведена на рис. 4.11.
(4.78)
(4.79)
(4.80)
(4.81)
§ 4.22. Обобщение
До сих пор мы предполагали, что функция потерь для
каждого класса зависит только от одного векторного
параметра ukl определяющего «центр» этого класса.
Полученные выше алгоритмы самообучения нетрудно
обобщить на более общий случай, когда функция потерь
/с-го класса зависит от всех параметров ии • • • > uN
и меняется от класса к классу, т. е. когда вместо
функции F (<р (х) — uk) берется функция Fk (х, ии • • • > un)-
Если ограничиться, как мы это делали,
рассмотрением двух классов, то общая функция потерь по
аналогии с (4.63) представится в виде
ib [X, ^1) ^2/ ==z ^1 \Х, Ъ1\) ^2/ * 1 \Х) ^1) ^2/ ~i~
+ е2(х, uu u2)F2(x, щ, и2). (4.82)
Условия минимума среднего риска теперь
запишутся так:
Мх{г± (х, ии u2)V„1Fl(x, ии и2) +
+ е2(х, щ, u2)\ulF2(x, ии и2)} = 0,
Мх{г1{х, щ, u2)VV2Fi(xJ tiu и2) +
+ е2(х, щ, u2)V„2F2(x, ии и2)} = 0.
(4.83)
§ 4.23] КОНКРЕТНЫЕ АЛГОРИТМЫ 129
Отсюда следует, что алгоритмы самообучения можно
представить в виде
щ[п\ = их[п—1]—у{[п] У1(1Р{(х[п], щ[п—1], щ[п— 1]), |
u2[n] = u2[?i—i]—y2[n]Vn2Fi(x[n], пл[п— 1], и2[п—1}) J
(4.84)
при
f(x[n], щ[п—1], и2[п—1]) =
= Fi(x[n], щ[п—1], и2[п—1]) —
— F2(x[nl щ[п — 1], и2[п—1])<0 (4.85)
и
ui[n] = tii[n—l]— ]
— yi[n)VvlF2(x[n], itiln—l], и2[п~1]), I
и2[п] = и2[п— 1]— I
— y2W^H2F(x[n], Miiw-1], «*2[и—1]) I
при
/(X[rtj, щ[п— 1], м2[и—1]) =
= iPi(«[n], '^[тг —1], 1г2[тг—1]) —
-F2(ac[rc], ^[rc-1], м2[л-1])>0. (4.87)
Из этих алгоритмов при Fk (х, ии w2) — ^ (ф0#)— п&)>
/с = 1, 2, получаются алгоритмы, приведенные в § 4.21.
Структурная схема общего самообучающегося персеп-
трона приведена на рис. 4.12.
§ 4.23. Конкретные алгоритмы
Выбирая различные функции F\ (•), из общих
алгоритмов можно легко получить разнообразные конкретные
алгоритмы самообучения. Положим, например,
Fh(x, ии u2) = \\<f(x)-uk\\\ й = 1, 2. (4.88)
Тогда, как следует из (4.77), разделяющая функция
будет иметь вид
/ (X, ии и2) = || ф (х) - иi ||2 -1| ф (х) - и21|2
9 Я. 3. Цыпкин
130
ОПОЗНАВАНИЕ
щ щщ_
4.23]
КОНКРЕТНЫЕ АЛГОРИТМЫ
131
ИЛИ
/ (ж, ~lf te2) = — 2 (tef — icj1) ф (ас) + (|| М1Ц2 _ || ^ |р). (4.89)
В этом частном случае
VUF (Ф (х) - и) = - 2 (ф (х) - и), (4.90)
и алгоритмы самообучения (4.78)-(4.81) можно записать
4 7
dz
№\5\
uJn-V
7
а
j
xt=^;i/>7/t> U
ujn-i)
Рис. 4.13.
следующим образом:
Щ [п] = iii [л — 1] + 2yi [и] (ф (я [л]) — ^i [п — 1]),
и2[п] = и2[п — 1],
если
- 2 « [л - 1] - uj [п -1]) ф (х [и]) +
+ (||^1И-1]||2-||^2[^-1]||2)<0 (4.92)
(4.91)
(4.93)
^! [п] = Щ[П—1],
гг2 [л] = w2 [п — 1] + 2y2 [п] (ф (ос [л]) — и2 [л— 1]),
если
-2«И~1]-<[тг-1])ф(^И) +
+ (11^^-1111^11^^-1] ||2) >0. (4.94)
Структурная схема такого самообучающегося персеп-
трона изображена на рис. 4.13.
9*
132
ОПОЗНАВАНИЕ
[Гл. IV
§ ел
>
>
v | 7 i i
— &'
1»-
о
Л|
к, ^ S ^ £, £,
Л 3
i i
8.
о
л
8- =
£ V
*> i —
Z A | — ^==
8^1
Е-ч (N
4 3
is
.+
I ^_
r ^
s §
CM
3
к
e
s
ii
С
II
с
3
8,
II
8 8
I I
1£ ©•
Ьч ь.
а
Продолжение табл. 4.3
п. п.
3
Функции потерь
^1=11 q>(a0-«ili2-rll»2 IIя;
*2 = ll<P(a»-«2lla-HI«ill2
Алгоритмы
jut [п]=щ[п — 1]—Yi [п] (ttiln — 1]-ф (х[п]))щ
\и2[п] = и2[п — 1]
при (uj [п — 1] — uj [п — []) ф (х [я])]> 0,
т. е. при х £ Хх [п];
и± [п] =их [п — 1],
и2[п]=и2[п — 1]— у2[п] (и2[п — 1]-ф (х[п]))
при (и[ [п — 1]—uj [лг — 1]) ф (х [п]) < 0,
т. е. при х £ Х2 [п]\
Vi
1 1
[П]- N[n] ' y"[ni n-N[n] '
N [п] — число образов х, отнесегшых к Х^ [и].
Авторы
Дорофеюк А. А.
134
ОПОЗНАВАНИЕ
[Гл. IV
Аналогичным путем можно получить и другие
конкретные алгоритмы самообучения. Часть из них
приведена в табл. 4.3. Читатель при необходимости без труда
может дополнить эту таблицу.
§ 4.24. Поисковые алгоритмы самообучения
Если почему-либо нельзя вычислить 4uFk {х> ии и2)
(например, по причине разрывности Fk (х, ии и2)), то
можно воспользоваться поисковыми алгоритмами
самообучения. Так, для М = 2 из (4.64) и (4.63) получаем
R = M{S(x, ии и2)}, (4.95)
где общая функция потерь определяется выражением
(4.82). Применим для определения оптимальных
значений и* и ге* поисковый алгоритм адаптации (или
самообучения) типа (4.13).
В рассматриваемом случае получаем
щ [п] = Ux [П~ 1]— \
г л г ,п ) (4.96)
и2 [п] = и2[п — 1] — v '
— Y2M VH2+S(x[n], щ[п—1], u2[n — l]). )
В эти алгоритмы входят оценки градиента реализации
^ui+S(x[n], щ[п — 1], и2[п—1]) =
= TZJn]lS+(xM' иЛп—Ц + еа[п], и2[п— 1]) —
~-SQ(x[n], Щ[п~11 и2[п~1])\ (4.97)
и
Уи2+8(х[п], щ[п — 1], и2[п — 1]) =
^-Щ^^+ФМ* ^ifw —1], и2[п — 1] + еа[п]) —
— S0{x[n], щ[п — 1], щ[п — 1])]. (4.98)
Для определения значений характеристических функций
8i (х, ии и2) и е2 (х, ии и2), входящих в оценку
градиента (4.97), (4.98), поступаем точно так же, как и в § 4.21.
Пары значений Ui [п — 1], и2 [п — 1]; Ui [п — 1] -f
+ еа [п], и2 [п — 1]; и{ [п — 1] и и2 [п —• 1] + еа [п]
§ 4.26]
НЕКОТОРЫЕ ЗАДАЧИ
135
при данном х \п] подставляем в выражение разделяющей
функции (4.77). Если значение разделяющей функции
отрицательно, то 8i = 1, е2 — 0, если положительно,
ТО 8i = 0, 82 = 1.
§ 4.25. Обсуждение
Алгоритмы самообучения отличаются от алгоритмов
обучения тем, что вместо одного «векторного» алгоритма
мы имеем здесь два таких алгоритма, сменяющих друг
друга в зависимости от знака разделяющей функции
/ (х [п], Ui [п — 1 ], и2 [п — 1]), параметры которой
уточняются при каждом показе. Именно этим восполняется
отсутствие указаний учителя. Однако на самом деле
учитель существует и здесь; его роль велика и при
решении задачи самообучения. Без труда можно усмотреть,
что роль учителя проявляется при выборе функции
штрафов, производимом заранее. Как было показано выше,
функция штрафа однозначно определяет и разделяющую
функцию.
Таким образом, самообучение, о котором мы
говорили в §§ 4.14—4.24, не есть, как это иногда считают,
обучение без учителя. Скорее это заочное обучение,
когда обучаемый не может непрерывно получать
квалифицированную помощь или консультации и вместо этого
вынужден использовать методические указания (зачастую
довольно давнишние, а иногда и сомнительного
качества). Не напоминают ли эти методические указания
своеобразное задание функции штрафов?
§ 4.26. Некоторые задачи
Для выяснения областей практического применения
разнообразных алгоритмов обучения необходимо провести
их сравнительный анализ как с точки зрения длины
«тренировочной» последовательности, так и с точки
зрения помехоустойчивости.
Было бы важно выяснить, каким должен быть набор
функций фу (ас), чтобы обеспечить, с одной стороны,
хорошую аппроксимацию, а с другой стороны, простую
реализацию системы? Интересны были бы оценки зависимости
136
ОПОЗНАВАНИЕ
[Гл. IV
точности аппроксимации от числа функций (pv (х), v =
= 1, 2, . . ., iV, а также оценки времени обучения.
Разумеется, целесообразно пытаться получить эти оценки
для конкретных наборов функций (pv (х).
§ 4.27. Заключение
Итак, мы установили, что различные подходы к
решению проблемы обучения опознаванию образов (трех О)
отличаются друг от друга выбором аппроксимирующих
функций, видом функционала и способом минимизации
этого функционала. Поэтому можно утверждать, что эпоха
интуитивных поисков и придумывания алгоритмов
обучения (по крайней мере рекуррентных) прошла. Это немного
печально, ибо вместо таинственной прелести
искусственного интеллекта, которая если и не подчеркивалась, но
на которую весьма прозрачно намекалось во многих
работах по обучению опознаванию образов, мы увидели,
что задача обучения сводится к почти обычной задаче
аппроксимации. Зато теперь проясняется и довольно
несложный смысл задачи самообучения. Здесь мы
вынуждены, правда, отказаться от аппроксимации, но
привлечение простых геометрических.соображений позволяет
несколько продвинуться и в эту, казавшуюся уже совсем
мистической, область. Таким образом, этап
таинственности и мистики, если и не прошел, то наверняка
проходит. Но это не должно вызывать уныния. Так часто
бывает в науке. Раз тот или иной факт ясно понят, то
его содержание начинает казаться (может быть, только
казаться) тривиальным. Мы не хотим этим сказать, что
проблема трех О и тем более проблема самообучения
опознаванию образов кончается. Отметим, что задача была бы
действительно решена, если бы мы ограничились
постановкой задачи, сформулированной выше, которая, по
существу, обходит многие трудности полного ее решения.
Основная трудность в решении этой проблемы состоит
в нахождении универсального способа поиска полезных
признаков. Но мы не можем здесь ринуться в поиски
этого универсального способа не только потому, что нас
ожидают очередные задачи адаптации, но и потому, что
пока неизвестно, существует ли вообще такой способ.
Глава V
Идентификация
§ 5.1. Введение
Проблема идентификации или, более привычно,
проблема определения характеристик управляемых объектов
и приложенных к ним воздействий, является одной из
основных при построении систем автоматического
управления. В детерминированных задачах воздействия и
характеристики управляемых объектов обычно находятся на
основании теоретических исследований, определенных
гипотез или экспериментальных данных. В
статистических задачах вероятностные характеристики внешних
воздействий (плотности распределения вероятностей,
корреляционные функции, спектральные плотности и т. д.)
получаются на основании обработки ансамбля
реализаций, а характеристики управляемых объектов
(уравнения, временные характеристики и т. п.) находятся с
помощью известных статистических методов, но опять же после
обработки реализаций.
В задачах, связанных с применением адаптации, эти
способы, как правило, непригодны, поскольку они
требуют специальных воздействий, большого времени
наблюдения и обработки данных и, вообще говоря,
лабораторных условий.
Для решения задач адаптации в автоматических
системах необходимо иметь возможность текущего
определения характеристик воздействий и управляемых объектов,
т. е. их оценки в процессе нормальной работы, и так,
чтобы эти оценки можно было непосредственно
использовать для улучшения этой нормальной работы.
При идентификации следует различать две задачи:
1) задача определения структуры и параметров объекта;
2) задача определения параметров объекта при
заданной или принятой структуре.
138
ИДЕНТИФИКАЦИЯ
[Гл. V
Если первая задача имеет дело с «черным»—
непрозрачным — ящиком, то вторая оперирует с «серым»—
полупрозрачным. Наличие хотя бы небольших сведений
о возможной структуре объекта либо выбор достаточно
общей структуры в качестве допустимой существенно
ускоряет процесс оценки. Поэтому мы, как это обычно
предпочитают делать на практике, основное внимание
уделим второй задаче.
В этой главе будет показано, что задачи
идентификации могут быть рассмотрены с той же точки зрения, что
и задачи опознавания образов, которым была посвящена
предыдущая глава. Разнообразные примеры оценок
средних значений, дисперсий и корреляционных функций,
характеристик нелинейных элементов и управляемых
объектов как с сосредоточенными, так и с распределенными
параметрами будут служить хорошей иллюстрацией
решения простейших задач идентификации.
§ 5.2. Оценка среднего значения
Для уяснения физического смысла и ряда особенностей
алгоритмов адаптации мы начнем с простейшей задачи —
оценки среднего значения случайного процесса
х = с* + 1, (5.1)
где с* — неизвестная постоянная, а | — помеха с
нулевым средним значением и конечной дисперсией. Такая
задача возникает, например, при обработке результатов
измерений или при выделении постоянного сигнала на
фоне шумов. Наблюдаемая величина х — это реализация,
которую только мы и можем измерять или обрабатывать.
Если ошибки, вызываемые помехой, равновероятны,
то наилучшей оценкой после п наблюдений будет среднее
арифметическое
п
с[я]Ц2*[4 (5.2)
Подставляя сюда х[т] из (5.1), получим
п
см=сч{2 &[»]• - (5-3)
§ 5.3]
ДРУГОЙ подход
139
Отсюда следует, что с ростом числа наблюдений влияние
помех уменьшается, и оценка с [п] стремится к искомому
значению с*.
Преобразуем теперь оценку (5.2):
с[п) = 1^(с[п-1] + т±тх[п]) (5.4)
или
с [п] = с [п — 1] — -i (с [п — 1] — х [п]). (5.5)
Соотношение (5.5) показывает, что с ростом п влияние
новой информации х [п] падает, поскольку вес ее,
равный 1/тг, обратно пропорционален числу измерений, и при
этом с [п] стремится к с*. Этот факт часто подтверждается
и в жизни: мы должны основывать наши решения на
прошлом опыте, не придавая слишком большого веса
новой информации, которая сама по себе может вызвать
лишь шарахания из стороны в сторону. Формулы вида (5.5)
издавна использовались при юстировке точных приборов
или при пристрелке во время стрельбы в форме правила:
п-я поправка берется равной \/п от величины полного
отклонения.
§ 5.3. Другой подход
Взглянем теперь на эту задачу с иной точки зрения
и применим к ней алгоритмы адаптации. Из (5.1) следует,
что
с* = М{х}, (5.6)
поскольку среднее значение помехи равно нулю.
Представим это соотношение так, как это мы делали при
восстановлении плотности распределения и моментов в § 4.16:
M{c-s} = 0. (5.7)
Применим теперь к этому соотношению алгоритм
адаптации (3.9). Полагая в нем VCQ(X, с) = с — х, находим
с [п] - с [п — 1] — у [п] (с [п— 1] - х [л]), (5.8)
откуда при у [п] = l/п получаем приведенный выше
алгоритм (5.5).
140
ИДЕНТИФИКАЦИЯ
[Гл. V
Таким образом, с помощью алгоритма адаптации мы
получаем, в частности, и результат, который был получен
в предыдущем параграфе на основе простых физических
Х!Щ
у[п]
д\
с[п-1]
Рис. 5.1.
соображений. Кстати, значения у [п] = 1/п являются
оптимальными с точки зрения минимума
среднеквадратичного отклонения.
х[п]
м5^?Н ^ гФ—iт1п] Г—i р^Т"^
Рис. 5.2.
Применяя модифицированный алгоритм (3.41), (3.42),
вместо (5.8) можно получить
п
с\п\ = с[п~ 1]— у[п] {с[п — 1]— ~ У x[m]). (5.9)
m—l
Этот алгоритм приводит к более плавному изменению
с [п] с ростом п.
Структурные схемы систем, реализующих алгоритмы
адаптации (5.8), (5.9), т. е. осуществляющие оценку среднего
значения, изображены на рис. 5.1 и 5.2 соответственно.
Они, как мы уже знаем из § 4.16, представляют
линейные импульсные системы с переменным коэффициентом
усиления.
Различие этих систем состоит в том, что во втором
случае х [п] подвергается дополнительной обработке
(осреднению).
§ 5.4]
ОЦЕНКА ДИСПЕРСИИ
141
§ 5.4. Оценка дисперсии
Дисперсия стационарного случайного процесса
определяется как
о* = М{(х-с*)2}, (5.10)
где среднее значение *
■■М{х}.
(5.11)
Если среднее значение заранее известно, то, поскольку
(5.10) отличается от (5.6) лишь обозначениями, можно
\С*
(х[п]-с*>
*п—ч2>—*j УМ |—Ч U>
б*[п-1]
Рис. 5.3.
сразу воспользоваться алгоритмом адаптации (5.8),
соответственно изменив в нем обозначения:
О2 [/г] = а2 [п __ | ] __ у щ f а2 [П __ I ] __ (^ [/г] __ с*)2] (5.12)
Система, реализующая этот алгоритм (рис. 5.3),
отличается от импульсной системы оценки среднего
значения (рис. 5.1) наличием на входе квадратичного
преобразователя и сравнивающего устройства, осуществляющего
алгебраическое суммирование.
Но обычно среднее значение с* нам неизвестно. Вряд
ли его стоит предварительно определять только для того,
чтобы воспользоваться алгоритмом (5.12). Не лучше ли
одновременно строить оценки а2 [п] и с [п]?
Будем теперь считать, что соотношения (5.10), (5.11)
определяют эти две неизвестные величины. Тогда мы
получим два связанных между собой алгоритма
(5.13)
а2 [п] = а2 [п — 1] — у [п] [а2 [п— 1] — (х [и] — с [и])2],
с[п] = с[п~ 1] — Yi [я] [с [п—1] — х[п]].
Дискретная система, реализующая эти алгоритмы,
изображена на рис. 5.4. Эта схема не нуждается в особых
142
ИДЕНТИФИКАЦИЯ
[Гл. V
пояснениях, так как она представляет собой объединение
импульсных систем для оценки дисперсии (рис. 5.3)
и среднего значения (рис. 5.2).
Если среднее значение равно нулю (с* = 0), то из
(5.12) получается более простой алгоритм
а2 [п] - а2 [п — 1] — у [п] [о2 [у — 1] — х1 [и]], (5.14)
который реализуется дискретной системой, показанной
на рис. 5.3, при с* = 0. Оптимальное значение у [п]
и в этом случае равно 1/тг.
х[п]
Ч2У
ф]
КМ
д\
с[п-1]
Ф-U
■е-
(x[n]-c(n-1]f.
ННЗЧ1^г
Рис. 5.4.
В непрерывном случае, когда х (t) — стационарный
случайный процесс, нужно использовать непрерывный
алгоритм адаптации (3.28), который при с* = 0
принимает вид
^P-=-y(t)[o*(t)-x*(t)}. (5.15)
Этому алгоритму соответствует непрерывная система
отличающаяся от дискретной (рис. 5.3), тем, что вместо
дигратора в ней используется непрерывный интегратор.
§ 5.5. Обсуждение
Остановимся теперь немного на физическом смысле
и интерпретации алгоритмов оценки дисперсии.
Разумеется, все это в равной мере будет относиться и к оценке
моментов вообще.
§ 5.6] ОЦЕНКА КОРРЕЛЯЦИОННЫХ ФУНКЦИЙ 143
Определим «текущую» дисперсию
t
a2 (^--^(0^, (5.16)
о
где х (0 — стационарный случайный процесс. Очевидно,
а2 = lima2 (0, (5.17)
если только этот предел существует. Дифференцируя обе
части (5.16) по t, легко получить уравнение
^=-4(^(0-^(0). (5.18)
Но это уравнение совпадает с алгоритмом (5.15) в частном
случае при у (t) = l/t. Аналогичным образом можно
получить и дискретный алгоритм (5.14), если ввести
определение
п
а!» = 4-2 *Чт] (5.19)
и взять первую разность Да2 [п — 1] = а2 [п] —
— а2 [п — 1]. Отсюда следует, что текущую
дисперсию (5.16) или (5.19) можно рассматривать как решение
(при специальном выборе у) соответствующего
дифференциального (5.15) или разностного (5.14) уравнения,
определяющих алгоритмы дисперсий. Этот простой факт
показывает, что адаптивный подход в рассматриваемом
случае заменил невозможную операцию усреднения по
множеству возможной операцией — усреднением по
времени. Эта замена соответствует обработке информации
по мере ее поступления и правомерна, разумеется, для
всех стационарных эргодических процессов.
§ 5.6. Оценка корреляционных функций
Взаимная корреляционная функция, играющая важную
роль в современной автоматике и радиофизике, при
фиксированном значении т = т0 определяется выражением
Ryx (т0) = М {у (0 x(t- т0)}. (5.20)
144
ИДЕНТИФИКАЦИЯ
[Гл. V
Для оценки или, попросту говоря, вычисления Ryx (т0)
мы можем воспользоваться, например, непрерывным
алгоритмом типа (5.15). Так, обозначив «текущую» взаимно
корреляционную функцию через Ryx (т0, t) = с (t),
получаем
£Ш-=-у{1){с(1)-у{1)х{1-Тъ))%
или в более удобной форме
66 ® ->.e(t) = y(t)x(t-т0),
1
ЭД
dt
где
To(t) =
У <t)
(5.21)
(5.22)
(5.23)
представляет собой изменяющуюся «постоянную
времени».
Алгоритм (5.22) допускает простую физическую
реализацию. Сигналы у (t) и х (t — т0) подаются на
множительное устройство, на
Ш)
Ф
Рис. 5.5.
c(tj_ выходе которого вклю-
*"* чена RC — цепь с из-
_ меняющимся по закону
x-(t-z0) I -г- 1
I —-7-т сопротивлением
(рис. 5.5).
В случае
непрерывного
модифицированного алгоритма оценки корреляционной функции вместо
(5.21) мы будем иметь
t
^ = -y(t)[c(t)-±ly(t)x(t-T0)dt] (5.24)
О
или
где
г.<о4г-
■e(t) = z(t),
с
(5.25)
(5.26)
§ 5.7] ОПРЕДЕЛЕНИЕ ХАРАКТЕРИСТИК ЭЛЕМЕНТОВ 145
Дифференцируя (5.26) по t, получим
*-*1[Г + *№ = У(*)х(*--'*о). (5.27)
Таким образом, модифицированный алгоритм (5.24) может
быть представлен в виде совокупности двух обычных
алгоритмов (5.25) и (5.27). Схема, реализующая
модифицированный алгоритм, представляет собой
множительное устройство и последовательное соединение двух
разделенных усилителем RC-цеией с переменными
сопротивлениями (рис 5.6). В этом случае мы имеем как бы
I
at)
Рис. 5.6.
двойное осреднение, что, естественно, приводит к более
гладкому изменению с (t) с ростом t. Нетрудно показать,
что при у № = 1/£ модифицированные алгоритмы
минимизируют сумму дисперсии оценки и взвешенной ее
производной.
Хотя схемы, приведенные на рис. 5.6 и 5.5,
определяют оценки взаимно корреляционной функции,
совершенно очевидно, что подобные схемы можно использовать
и для определения оценок среднего значения, дисперсий,
моментов. Для этого достаточно заменить множительное
устройство линейным или нелинейным преобразователем.
§ 5.7. Определение характеристик нелинейных
элементов
Говоря о нелинейных элементах, мы подразумеваем
безынерционные нелинейные элементы или
функциональные преобразователи, которые имеют, вообще говоря,
любое число входов и один выход.
Определение характеристики нелинейного элемента
y = f(x) (5.28)
Ю я. 3. Цыпкин
146
ИДЕ НОТИФИКАЦИЯ
[Гл. V
сводится к восстановлению функции / (х) по
наблюдаемым входной х и выходной у величинам.
Если аппроксимировать / (х) суммой линейно
независимых функций ст ц>(х), как это мы делали в предыдущей
главе, то рассмотренные там алгоритмы дадут решение
поставленной задачи. Вряд ли целесообразно приводить
эти алгоритмы снова.
Читателя, которого интересует задача определения
характеристики нелинейных элементов, мы попросим
аПЛ
ГТ J? /. ) Lt- ■— ■ 1
■ Л vcfo(' h 1
у , 1
\УШ f --J
1L
Рис. 5.7.
H^b^l^H
сШ
обратить внимание на алгоритмы, приведенные в табл. 4.1
и 4.2 в предыдущей главе. Если предположить, что у
принимает произвольные значения, а не только значения ±1,
как это было ранее, то эти алгоритмы можно использовать
для определения характеристик нелинейных элементов.
Легко понять, что «персептронные» схемы, реализующие
упомянутые алгоритмы, в рассматриваемой задаче играют
роль своеобразных настраиваемых нелинейных
преобразователей, которые и осуществляют восстановление
нелинейной характеристики преобразователя.
В ряде случаев форма характеристики нелинейного
элемента может оказаться известной, а неизвестным
является некоторый вектор параметров. Тогда
аппроксимирующую функцию естественно выбрать в виде
f (x)^f0(x, с), (5.29)
где с — TV-мерный вектор параметров.
В качестве меры уклонения, как и ранее (см. § 4.3),
выберем математическое ожидание строго выпуклой
§ 5.8] ОЦЕНКА КОЭФФИЦИЕНТА ЛИНЕАРИЗАЦИИ 147
функции от разности / (х) — / (х). Следовательно, теперь
J(c) = Mx{F(y-f0(x,c))}. (5.30)
Градиент реализации равен
4cF (у — /о (ж, с)) =—F'(y — f0(x1 с)) Vc/0 (я, с).
Поэтому алгоритм адаптации, предназначенный для
оценки параметров, можно представить в виде
c[n] = c\n — l] + y[n]F' (у [п] -
-/оИ4 c["-l]))Ve/0(*M. с [л-1]) (5.31)
ИЛИ
■^- = y(i)F'(y(t)-fo(x(t), c(t)))Vcf0(x(t), c(t)). (5.32)
Структурная схема, реализующая этот алгоритм,
изображена на рис. 5.7.
§ 5.8. Оценка коэффициента статистической
линеаризации
Часто при статистическом анализе нелинейных систем
нелинейный элемент заменяют линейным, надлежащим
образом определяя эквивалентный коэффициент
усиления, или, как его называют, коэффициент статистической
линеаризации. При этом плотность распределения входной
стационарной величины предполагается известной.
Используя алгоритмы адаптации, можно отказаться от этого
весьма существенного ограничения и получить общую
процедуру, пригодную, кстати, для любой меры
аппроксимации, а не только квадратичной.
Будем аппроксимировать характеристику у = f (х)
(5.29) линейной функцией кх и выберем к так, чтобы
J(k) = M{F(y-kx)}, (5.33)
где /'(•) —строго выпуклая функция, достигал минимума.
Градиент, или, попросту, производная реализации,
определяется как
-тг-F(у — кх)= —F' (у ~кх)х. (5.34)
10*
148
ИДЕНТИФИКАЦИЯ
[Гл. V
Используя непрерывный алгоритм адаптации (3.28),
получаем
dk(t)
dt
-y(t)F'(y(t)-k(t)x(t))x(t).
(5.35)
При соблюдении условий сходимости величина к (t)
с ростом t почти наверное стремится к эквивалентному
X
Пх)
ф-J F'(.)
r'(t)
k(t)
"ИХ
Рис. 5.8.
коэффициенту к*. Схема непрерывной системы,
реализующей этот алгоритм, изображена на рис. 5.8.
§ 5.9. Частные случаи
Выбор конкретных функций F (•) позволяет получить
разнообразные алгоритмы адаптации. Так, если F (•) —
квадратичная парабола, то алгоритм (5.35) определяет
общепринятый статистический коэффициент
линеаризации,"', а при х (t) = a sin (со£ + ф), когда фаза ф
случайна,— общеизвестный гармонический коэффициент
линеаризации.
Выберем теперь функционал (5.33) в виде
J(k) = M{\y — kx\}. (5.36)
Так как
F' (у — кх) = sign (у— кх), (5.37)
то из (5.35) следует, что
dk(t)
dt
.y(t)x(t)sign(y(t)-k(t)x(t)).
(5.38)
Этот алгоритм реализуется схемой, изображенной на
рис. 5.8 при релейном функциональном преобразова-
§ 5.10]
ОПИСАНИЕ ДИНАМИЧЕСКИХ ОБЪЕКТОВ
149
теле F' (•), определяемом соотношением (5.37).
Функционал (5.36) характеризует меру абсолютной ошибки
аппроксимации. В отличие от (5.36), функционал
у — кх I \
х I J
/
(й) = м{
(5.39)
определяет не абсолютную, а относительную ошибку
аппроксимации. Так как в этом случае
d
dk
у— кх
X
— sign х • sign (у — kx)i
то алгоритм адаптации принимает вид
dk (t)
dt
-- у (t) sign x • sign (у — кх).
(5.40)
(5.41)
Алгоритм адаптации (5.41) значительно проще, чем (5.38),
так как теперь отсутствует операция умножения на х (t).
^7 Н-*ЬН r(t) \~\
k(t)
Рис. 5.9.
Этот алгоритм реализуется с помощью реле, как это
видно из рис. 5.9. Разумеется, оптимальные
значения &*, получаемые по этим алгоритмам, в общем случае
различны, т. е. они соответствуют различным критериям
оптимальности, и поэтому эти алгоритмы не являются
взаимно заменяемыми.
§ 5.10. Описание динамических объектов
Поведение нелинейных динамических объектов в общем
случае может быть описано либо нелинейным разностным
уравнением Z-го порядка
x[n] = f(x[n—l],...,x[n—l]; и[п~ 1|, . . ,,и[п — /J),
(5.42)
150
ИДЕНТИФИКАЦИЯ
[Гл. V
где х [п] — выходная, а и [п] — входная величина
(скалярные функции), либо системой нелинейных разностных
уравнений первого порядка
x[n] = f(x[n — l]1 и[п — 1]), (5.43)
где
х [п] = (xi [и], . . ., xL [72]); и [п] = (ui [п], ...,щх [п])
— векторы выходных и входных величин объекта.
Хотя мы всегда можем перейти от уравнения (5.42)
к уравнению (5.43), последнее уравнение является более
общим, так как оно охватывает и тот случай, когда число
управляющих воздействий больше единицы.
Эти разностные уравнения соответствуют, в частности,
непрерывным объектам, управляемым с помощью
вычислительных машин, либо импульсных устройств. При
определенных условиях эти разностные уравнения могут
также служить для приближенного описания чисто
непрерывных систем.
Помимо разностных или дифференциальных
уравнений, часто оказывается удобным описывать
нелинейные динамические объекты функциональным рядом
Вольтерра
оо
х[п]= 2 к\ [т] и[п — т] +
т=0
со оо
Н" 5 5j к* \пьи nh] и \п — "Ч1 и [п — /п2] + • • •
7П1 -.= 0 7712—0
оо оо
••• Ь S ••• S ks [ти ..., т8]и[п — пь{\. . .
т\- 0 т,-0
. .. и \n — ins] + . . . (5.44)
Соотношение (5.44) можно также рассматривать как
приближение соответствующего ряда Вольтерра, в котором
вместо сумм стоят интегралы, а переменные изменяются
непрерывно.
Если ограничиться только первым членом
функционального ряда Вольтерра (5.44), то получается уравнение
линейной системы.
§ 5.11] ИДЕНТИФИКАЦИЯ НЕЛИНЕЙНЫХ ОБЪЕКТОВ I 151
Идентификация динамических объектов состоит в
восстановлении уравнений объекта по входным и выходным
данным. Далее мы применим адаптивный подход к
идентификации при различном описании динамических
объектов.
§ 5.11. Идентификация нелинейных объектов I
Идентификация нелинейных динамических объектов,
которые описываются разностным уравнением,
оказывается ненамного сложнее, чем определение характеристик
безынерционных нелинейных элементов.
Естественно, при этом мы должны знать
предполагаемый порядок I разностного уравнения объекта. Если
выбрать I малым, то точность идентификации может
оказаться недостаточной. Если же взять I большим, то объем
вычислений возрастает значительно быстрее, чем
точность. Поэтому мы поставим задачу так: при заданном I
требуется наилучшим образом определить разностное
уравнение динамического объекта.
Для решения этой задачи введем (I + /^-мерный
вектор — вектор ситуации z [п]:
z [п] = (х [п — 1], . . ., х \п~ /]; и[п—1],...,и \п — /J).
(5.45)
Тогда разностное уравнение (5.42) запишется в более
компактном виде
х\п\ ^f{z[n\), (5.46)
с чем мы уже сталкивались в предыдущей главе при
обсуждении «проблемы трех О». Поэтому разумно
использовать для аппроксимации правой части (5.46) уже
знакомую нам формулу
/(*)«/ (z, c) = cT<p(z). (5.47)
В отличие от задачи обучения опознаванию образов,
векторы z [п] (п = О, 1, 2, . . .), как это видно из (5.45),
здесь принципиально не могут быть статистически
независимы. Будем предполагать, что они представляют
собой стационарные случайные последовательности или
процессы. В этом случае по-прежнему применимы алгоритмы
152
ИДЕНТИФИКАЦИЯ
[Гл. V
адаптации, и мы можем определить наилучшие
оценки с, а значит и функции / (z), используя алгоритмы
обучения вида (4.9). Например, можно воспользоваться
алгоритмом
с[п] = с [п— 1] + y[n]F' (х[Щ — ст[п~ l]q>(*[w]))q>(z[ra])
(5.48)
и соответствующей персептронной схемой (рис. 4.1).
Персептроны — как обычный, так и поисковый —
можно рассматривать в качестве моделей объектов; параметры
этих моделей изменяются так, чтобы окончательно по своим
динамическим свойствам они мало отличались от объектов.
Таким образом, в задаче идентификации объектов
персептроны выступают в роли подстраивающихся моделей.
§ 5.12. Идентификация нелинейных объектов II
Во многих случаях значительно удобнее и
естественнее использовать описание объекта в виде системы
нелинейных разностных уравнений (5.43). В отличие от
уравнения (5.42), здесь выходная величина представлена
не скаляром, а вектором. В связи с этим описанный выше
способ идентификации нуждается в некотором изменении.
Будем аппроксимировать каждую компоненту
вектор-функции f(x, и) конечной суммой
N
/и(ас, и, с)= 2 cv<Pnv(^, гл) (fi = l, 2, ..., Z), (5.49)
или в векторном виде
f (ас, п, е) = Ф(ас, и)с\ (5.50)
где
Ф(х\ u) = \\(f]lv(x, и)\\ (Н^1» • • •»Z' v = l, . . ., N)
— матрица линейно независимых функций ф^ (ас, и)
размера I X N.
Задача идентификации объекта сводится к
минимизации математического ожидания меры уклонения
векторного аргумента
J(c) = M{F(x[n]—(f)(x[n — i], и[п — 1])с)}, (5.51)
где F (•) — строго выпуклая функция.
§ 5.12] ИДЕНТИФИКАЦИЯ НЕЛИНЕЙНЫХ ОБЪЕКТОВ II
153
Применим поисковый алгоритм адаптации (3.15)
к функционалу (5.51). В рассматриваемом случае это
приводит к следующему алгоритму:
c[n] = c[n—l] — y[n]4c+F(x[n], и[п— 1], с [п— 1], а[п]).
(5.52)
Однако, поскольку функция F (•) строго выпукла и
обычно дифференцируема, для решения поставленной здесь
Рис. 5.10.
задачи лучше воспользоваться алгоритмом
адаптации (3.9).
Градиент реализации равен
УсР(х[п] — Ф(х{п — 1], и[п— 1])с) =
= — Фт(х[п — 1], и[п — 1]) VF(x[n] —
— Ф(х[п — 1], и[п — 1])с). (5.53)
Применяя к (5.51) алгоритм адаптации, обычным
способом находим алгоритм
с [п] = с [п — 1 ] + у Ш Фт (х [п — 11, и [п — 1])VF (х [п] —
— Ф(х[п — 1], te[w —1])с[и — 1]), (5.54)
154
ИДЕНТИФИКАЦИЯ
[Гл. V
определяющий при п —>■ оо оптимальное значение
вектора с -— с*. Схема оценки оптимального вектора г*
и характеристик объекта/ (ас, и) изображена на рис. 5.10.
Эта схема является несколько усложненным вариантом
ранее приведенной персептронной схемы (рис. 4.1).
§ 5.13. Идентификация нелинейных объектов III
Рассмотрим, наконец, тот случай, когда нелинейный
динамический объект описывается функциональным рядом
Вольтерра (5.44), который можно записать более кратко:
х [п] —
No
--- У 2 ks |ml7 ..., ms] и [п — т^. . .и [n — ins]. (5.55)
В формуле (5.55) внутренний знак суммы означает
многократное суммирование, чему соответствуют различные
индексы суммирования. Будем теперь аппроксимировать
ядра конечной суммой
N
к 8 [ml7 ...,т8]= 2 6WPv [щ, . . ., т8], (5.56)
v=l
где cpv [ти ..., ms]~ набор линейно независимых
функций. Тогда оценка х [п] получается в виде
ЛГ0 N
х[п\~= У] ^ csvYsv(u[n]). (5.57)
8-=1 V=l
В формуле (5.57) величины
Ysv(uW)~--
оо
^-- 2 Фv [Щ, • • ., rns] и [п — Щ]> • -и [я — ms] (5.58)
mi,...,m =--0
можно рассматривать как стандартные реакции на
входной сигнал и[п\. В векторной форме соотношение (5.57)
будет выглядеть так:
i=--cTT(u\ (5.59)
где
е = \cni • - • •> cin', c%u ..., с2л'| ...; ctv0i, ..., cavv) (5.60)
§ 5.14]
СПЕЦИАЛЬНЫЙ СЛУЧАЙ
155
и
Y = (i и, . . . , У j_2V» ^ 21? • • • 1 *2Ni • • • » -* Лг01» • • • > * ЛГ0ЛТ)'
Для определения с = с*, а значит и ядер (5.56), составим
функционал
J(c) = M{F(x — x)} (5.61)
или, в силу (5.59),
J(c) = M{F(x — cTY(u))}. (5.62)
Если функция F(•) дифференцируема, то можно найти ее
градиент по с:
VcF(x-cTY(u))~~ -F'(x-cTY(u))Y(u). (5.63)
Тогда оптимальный вектор с — с* можно определить
с помощью алгоритма адаптации (3.9):
с[п] — с [п— 1] +
-I-YM^' (ж[л] —сг[л —1]1Г(м[л]))1Г(^[л|). (5.64)
§ 5.14. Специальный случай
Обычно ядра ks [тл, . . ., ms] обладают таким свойством,
что
к8 [//?!, . .., т8\ = [] к8 [nip]. (5.65)
Это свойство называют свойством сепарабельности.
^Допустим, что
As [//?]--_;() при /д<0 и т>Л/. (5.66)
Тогда для восстановления ядра А;5 [//ц, . . ., a?is1 следует
(5-f 1)Х. ..X(s-\-M—\)
определить —-.—-\~ их значении в точках
(/71-fl)!
ти . . ., ras = 0, 1, . . ., Af.
Искомые ординаты ядер будем считать компонентами
неизвестного вектора, который снова обозначим через г,
и введем вектор
Y {и) — (Yiu . . ., YiM; Y2[, ..., Y2m\ - • •', ^v0i» • • •» ^лт0:м)»
(5.67)
156
ИДЕ НТИФИКАЦИЯ
[Гл. V
где _
Уц8 = М[И —fill X . . . XU[ll — \L8].
Легко видеть, что У^ получается из (5.58) при
специальном выборе cpv. Таким образом, и в этом случае мы
получаем соотношение, аналогичное (5.50), и для определения
с* можно использовать алгоритм (5.64). Единственная
особенность этого случая (не очень приятная) состоит
в повышении размерности вектора с. Если для
восстановления s-ro ядра (5.56) было нужно N
составляющих, то теперь число составляющих возрастает до
(.9+1)Х...Х(Н-АЧ-Р ^ дг
(ЛГ-1)! ^1У'
Размерность вектора с можно уменьшить, если вместо
одной системы линейно независимых функций cpv(*)
воспользоваться системами cpvs(*)> как это мы делали
в § 5.12. Тогда вместо (5.56) будем иметь
N
к8 \т{, . . ., т8]--= 2 cv<pv8 [ти . . ., т8]. (5.68)
v=l
В этом случае, повторяя рассуждения § 5.12, алгоритм
адаптации мы получим в виде
е [п] = с [п - 1 ] + Y [п] F' (х [п] - Y, {и [п] с)) Y, {и [л]),
(5.69)
где Yi(u [п]) — ^-мерный вектор. Теперь размерность
вектора с равна N. Меньшая размерность вектора г
достигается ценой увеличения разнообразия функций cpv<s (•),
выбор которых для бесконечного интервала времени не
так уж велик.
§ 5.15. Замечание
После знакомства в §§ 5.11—5.14 с различными
возможностями описания объектов и различными
алгоритмами идентификации последних сразу же возникает
вопрос: какому алгоритму отдать предпочтение?
Несмотря на то, что различные описания нелинейных
динамических систем эквивалентны, каждое из них имеет
свои преимущества и, к сожалению, свои недостатки.
Так, информация о состоянии объекта наиболее полна,
§ 5.16] ИДЕНТИФИКАЦИЯ ЛИНЕЙНЫХ ОБЪЕКТОВ I 157
если использовать систему разностных уравнений (5.43)
так как здесь х — вектор, а не скаляр, как в разностном
уравнении (5.42) или в суммарном представлении ряда
Вольтерра (5.44). Кроме того, система разностных
уравнений наиболее естественно охватывает случай многих
управляющих воздействий. С другой стороны, число
степеней свободы определяет порядок разностного
уравнения или системы разностных уравнений, и мы должны
заранее знать его. Однако в этом нет необходимости при
использовании ряда Вольтерра. Поэтому, если ответ на
поставленный в начале этого параграфа вопрос и может
быть получен, то только после накопления опыта
применения этих алгоритмов.
Распространение алгоритмов на многомерные системы
теперь уже не составит большого труда, и читатель может
сделать это самостоятельно.
§ 5.16. Идентификация линейных объектов I
Для линейных динамических объектов алгоритмы
адаптации, естественно, упрощаются. Теперь мы знаем,
что объект описывается линейным разностным уравнением
l h
х[п]=^ атх [п ~ т] -\- 2 Ьти[п — т], (5.70)
771= 1 771=1
где некоторые из коэффициентов ат и Ът могут быть
равны нулю. Используя обозначения (5.45) вектора
состояния z и вводя вектор коэффициентов
с=(аи . . . ,az; ^,..., /;/х), (5.71)
запишем аппроксимирующую функцию / (z, с) в виде
скалярного произведения
/(*, c) = cTz. (5.72)
Размерность вектора с зависит от порядка разностного
уравнения. Заменяя в алгоритме адаптации (5.48) функцию
Ф(я) на z, получим
с [п] - с [п — 1] + у [п] F' (х [п] — сТ [п — 1 ] z [л]) z [л]. (5.73)
Теперь персептроны используются непосредственно для
определения как коэффициентов уравнений, так и самого
уравнения.
158
ИДЕНТИФИКАЦИЯ
[Гл. V
В том частном случае, когда F (•) — квадратичная
парабола и 2у [п] = г.—г-ттг2, из (5.73) следует
с [га] = с [га — 1 ] -!- ||2[я](|2 (х [п] — ст [га — 1] z [га]) z [га].
(5.74)
Схема, реализующая этот алгоритм (рис. 5.11),
естественно, более проста, чем те, которые мы рассматривали
и[п]
Объект
zfnj
х[п]
ф]
СНх
7?
—ф-
ii
А
х
И~;
zfnjf
с[п-1]
л
Рис. 5.11.
выше. Это известный алгоритм Качмажа, однако ранее он
был получен лишь в предположении статистической
независимости входных воздействий.
Все результаты этого параграфа нетрудно обобщить
на тот случай, когда линейный объект описывается
системой линейных разностных уравнений.
§ 5.17. Идентификация линейных объектов II
Если нам почему-либо неизвестны числа I и 1и то
можно воспользоваться описанием линейной системы
в виде суммарного уравнения типа свертки
х[п]= 23 к [т] и[п-
т=0
■т\
(5.75)
§ 5.18] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕННЫХ ОБЪЕКТОВ 159
Это уравнение можно рассматривать как первое
приближение в ряде Вольтерра (5.44).
Примем следующие предположения:
1) к [т] = 0 при т> М;
2) и [п] отлично от нуля в интервале [О, N], а вне
этого интервала и [п] = 0;
3) х [п] наблюдается в интервале [0, N + М]. Тогда
уравнение (5.75) можно представить в виде
м
х[п] = 2 к[т] и [п — т\. (5.76)
т=0
Определим векторы
с = (А[01, ...,к[М]) (5.77)
И
z = (u[M], ...,и[0]). (5.78
Тогда мы тотчас же приходим к заключению о
применимости алгоритмов (5.73) и (5.74). Для оценки импульсной
характеристики, очевидно, также применимы поисковые
и непрерывные алгоритмы.
Подчеркнем, что при выполнении условий 1) — 3)
размерность векторам, в отличие от случая разностных
уравнений (§ 5.16), не зависит от порядка уравнений объекта.
Отметим в заключение, что идентификацию линейных
объектов можно осуществить при помощи персептронных
схем, содержащих наборы типовых элементов (задержек,
/?С-цепей и т. п.), выходы которых суммируются с
определенными весами. Эти веса устанавливаются путем
обучения, исходя из условий минимума того или другого
функционала. Здесь мы на этой возможности
останавливаться не будем, так как далее (в § 6.4) она
используется для решения задачи фильтрации, которая близка
к рассмотренной задаче идентификации.
§ 5.18. Оценка параметров распределенных
объектов
Объекты с распределенными параметрами или, как их
обычно называют, распределенные объекты, описываются
уравнениями в частных производных. Так, для тепловых,
химических и тому подобных процессов уравнение объекта
160
ИДЕНТИФИКАЦИЯ
[Гл. V
можно записать в виде
^=/[м,^(М),^,^] (5.79)
(г>0, 0<s<L0),
где t — время, s — пространственная координата,
х (s, t) = (xi (s, t), . . ., xN (s, t)) — вектор,
характеризующий состояние объекта в момент t и в любой точке
пространственной координаты s, причем считается, что
распределенность имеется только вдоль этой
координаты s; с — вектор неизвестных параметров, который
необходимо определить.
Будем измерять состояние объекта в дискретные
моменты времени п = 1, 2, ... и в конечном ряде точек г = 1,
2, . . ., /?, расположенных на расстоянии Аг друг от
друга. Заменяя уравнение в частных производных (5.79)
уравнением в частных разностях, получим
#[**, и] = /(с, #[г —1, и—1].
ас [г, тг-1], ас[г + 1, гс — 1], ...) (5.80)
(r = l, ...,i?; и = 0,1, ..О-
Здесь ас [0, я], ас [г, п] характеризуют граничные
условия.
Уравнение (5.80) аналогично уравнению (5.29).
Поэтому для идентификации параметра с можно применять
известную методику.
Введем показатель качества
я
(5.81)
J = M 2 F(x[r, п]\ х[г, п])
[r=i
который представляет собой математическое ожидание
функции потерь. В (5.81) х [г, п] определяется
уравнениями (5.80). Величины х [г, п] представляют собой
результат измерений. Они могут отличаться от истинных
значений на величину, определяемую погрешностью
измерений. Далее предполагается, что погрешности
измерения на каждом шаге представляют собой независимые
случайные величины с нулевым средним и конечной дис-
§ 5.18] ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕННЫХ ОБЪЕКТОВ 161
Персией. АлгоритхМ оценки параметра с запишется так:
R
c[n] = c[n-l]-y[n]Vc 2 F(x[r,n]; f(c[n-l],
ac[r —1, n — 1], ac[r, w —1], ac[r+l, тг —1]), ...). (5.82)
При скалярных с и х и квадратичной функции потерь,
Объект
\х[г-1 п]
\х[г,п] \эс[г+1,п]
33
33
J
/г-;
1 1 ^
df I
<^
Рис. 5.12.
<^j[* 1^//7/ UJ
которая имеет, например, вид разности
F(x[r, n]\ x[r, n\) = (x[r, n]— x[r, rc])2, (5.83)
алгоритм (5.82) упрощается и принимает вид
c[n] = c[n—-l]-\- 2у [n] [x [r, n] —
—/(c[n —1], x[r—l, n—1], ж[г, тг— 1], ж[г+1, тг—l])...]x
X
dc
/(с[л—1], *[r —1, л —1], *[/-, л—1], ...). (5.84)
Схема оценки параметра приведена на рис. 5.12.
И Я. 3. Цыпкин
162
ИДЕНТИФИКАЦИЯ
[Гл. V
X
Объект
\—&л
§ 5.19. Помехи
До сих пор мы не акцентировали внимание на том, что
измеряемые реализации входных и выходных величин
объекта содержали помехи. Наличие помех может
привести к тому, что мы получим так называемые смещенные
оценки, которые отличаются от оценок, получаемых при
отсутствии помех. Поэтому вопрос о влиянии помех
приобретает довольно важное, а порой и решающее значение.
Для выяснения сути дела мы рассмотрим этот вопрос
на примере оценки характеристик безынерционных
нелинейных элементов.
Выясним прежде всего
простейшие условия, при ко-
у торых помехи не влияют на
оценки, т. е. когда
оценки характеристик безынер-
Рис. 5.13. ционного элемента
оказываются несмещенными.
Разумеется, речь здесь идет об оценках, получаемых
по окончании обучения или адаптации.
Предположим, что помехи \ действуют на выходе
объекта, показанного на рис. 5.13, и среднее значение
помех равно нулю. Запишем критерий оптимальности
в виде
J = M{F(y-f(x, е) + 1)} (5.85)
или
J{c)=-M{F(y-cTV(x) + t)}. (5.86)
Условие оптимальности записывается в виде
V/ (с) = М {F' {у - сТц> (х) +1) <р (х)} = 0. (5.87)
Если F(>) — квадратичная парабола, то это условие
существенно упрощается, и (5.87) можно представить в виде
М {уц> (х)} - М {cTq> (х) q> (х)} + М {gcp (х)} = 0. (5.88)
Если помехи и входной сигнал независимы, то
M{ty(x)}^0. (5.89)
§ 5.20]
УСТРАНЕНИЕ ВЛИЯНИЯ ПОМЕХ
163
Тогда уравнение (5.88) примет вид
М {i/cp (х)} = М{Ф (х) с}, (5.90)
где
Ф(х) = \\<рч(х)<р»(х)\\ (v, |х = 1, 2 ЛГ) (5.91)
— матрица размера N xN.
Из (5.90) получаем несмещенную оценку
с* - М {Ф (х)}'1 М {г/ер (х)}. (5.92)
Таким образом, квадратичный критерий качества, а по
существу метод наименьших квадратов, в этом случае
приводит к несмещенной оценке. Это обстоятельство
объясняет широкое распространение квадратичного
критерия оптимальности, при котором задача приводится
к линейной, и благодаря этому устраняется влияние
выходной помехи с нулевым средним значением.
§ 5.20. Устранение влияния помех
Нельзя ли устранить влияние помех при
неквадратичном критерии оптимальности? Оказывается, при
определенных условиях можно. Выясним эти условия.
Предположим, что функция F (•) представляет собой
полином степени г. Тогда при отсутствии помехи
1(с) = м1^ау(у-стц(х))А. (5.93)
Пусть при с = с* критерий J (с) достигает минимума.
Если на выходе объекта имеется помеха £, то
/(с) = М<2 av(y-eT<f(x) + lp}. (5.94)
lv=0 J
Очевидно, что, минимизируя (5.94), мы получим
значение с**, вообще говоря, не равное с* и зависящее от
статистических характеристик —- моментов — помехи £v,
т. е. мы получим смещенную оценку с**.
И*
164
ИДЕНТИФИКАЦИЯ
[Гл. V
Если же нам известны моменты помехи £v, то можно
изменить критерий качества так, чтобы оценка с*
получилась несмещенной. Действительно, пусть
/ (с) = М \ £ Ь, (у - сту (х) + g)v j , (5.95)
где bv (v = 1, . . ., r) — пока неизвестные
коэффициенты. Для определения этих коэффициентов разложим
(у — ст ф (х) — £)v в ряд по степеням £. Полагая для
простоты, что сигнал х и помеха £ не коррелированы,
запишем функционал (5.95) в такой форме:
Г Г — V
/(с) = м{2 (2 W (vyF(?-crfW)')},
(5.96)
где ^ — момент помехи (л-го порядка.
Сопоставляя (5.96) и (5.93), легко заключить, что
если выбрать неизвестные коэффициенты bk так, чтобы
выполнялись равенства
r-v
«v = 2 fev+(i(v^jF, (5.97)
то минимизация функционала (5.94) с помощью
алгоритмов адаптации будет давать несмещенную оценку с. Этот
результат можно получить и в том случае, когда £ и х
коррелированы. Поскольку система линейных уравнений
треугольна, то проще всего коэффициенты bk вычислять
по рекуррентной формуле
Г —V
bv = av-2 bv+n(v%)F. (5.98)
\X = i
В эту формулу входят моменты помехи. Конечно, можно
предположить, что эти моменты вычисляются заранее,
но вряд ли это предположение окажет существенную
практическую пользу. Нетрудно, однако, для
определения коэффициентов bk использовать алгоритмы
адаптации, приспособленные для вычисления моментов поме-
§ 5.21]
НЕКОТОРЫЕ ЗАДАЧИ
165
хи; эти алгоритмы аналогичны описанным в §§ 4.16
и 5.2—5.6. Таким образом, несмещенность оценок мы
здесь получаем за счет соответствующей замены
критерия оптимальности.
Устранение влияния помех, действующих на входе
нелинейного элемента — задача более сложная, но при
определенных условиях разрешимая. Мы позже
рассмотрим эту задачу в связи с адаптивными фильтрами
(гл. VI).
§ 5.21. Некоторые задачи
Помимо общих задач ускорения сходимости и выбора
функций (pv (•), весьма важная задача при идентификации
состоит в изыскании способов получения несмещенных
оценок при заданном критерии оптимальности. Если
имеется возможность оценивать дисперсию помех, то,
применяя обычные приемы, можно получать и
несмещенные оценки параметров или характеристик объектов.
Для оценки же дисперсии целесообразно использовать
также и алгоритмы адаптации.
Разработка способов получения несмещенных оценок,
таким образом, остается на повестке дня и в случае
применения разнообразных методов идентификации, в том
числе и алгоритмов адаптации. Существенным шагом
вперед было бы также освобождение от требования
стационарности внешних воздействий. Можно ли
модифицировать изложенные способы идентификации так, чтобы
они охватывали и те случаи, когда процессы имеют
нестационарный характер, стремясь, однако, к
стационарному?
Между временем идентификации и погрешностью
получаемых при этом результатов, безусловно, существует
обратная зависимость. Определение этой зависимости имело
бы большое значение как для задач идентификации, так
и для задач управления. Она бы установила предельно
достижимую точность при заданном времени наблюдения
и обработки информации.
Подобная зависимость играла бы в теории управления
роль, аналогичную принципу неопределенности в
квантовой механике.
166
ИДЕНТИФИКАЦИЯ
[Гл. V
§ 5.22. Заключение
Вероятно, нетрудно установить тесную связь между
проблемами опознавания образов и идентификации. Ведь
в этой последней проблеме нам нужно «узнать» объект,
выделить его характерные особенности, т. е. определить
то, что мы назвали характеристиками. Адаптивный
подход дал нам возможность решить эту задачу при
различных уровнях полноты априорной информации. Мы не
занимались получением формул, которые бы в явном виде
позволили решить рассматриваемую проблему. Уже
накопленный к настоящему времени опыт говорит о том,
что это было бы безнадежным занятием. Вместо этого
мы получили алгоритмы, т. е. по существу уравнения
(разностные и дифференциальные), решение которых
приводит нас к цели. Поскольку эти уравнения
нелинейные, а к тому же и стохастические, то единственный пока
разумный подход состоит в решении их с помощью
цифровых или аналоговых устройств. Таким образом,
реализация алгоритмов идентификации приводит к построению
импульсных или непрерывных, регулярных или
поисковых, но всегда настраиваемых моделей этих объектов.
Все эти модели по существу представляют собой
разновидности персептронов, этих едва ли не «самых
разумных», по мнению многих авторов, устройств.
Любопытен, пожалуй, сам тот факт, что еще до
возникновения проблемы опознавания образов персептроны,
может быть, и не подозревая того, что они ими являются,
уже существовали в образе настраиваемых моделей и
применялись для идентификации объектов. Но, безусловно,
второе рождение они получили при опознавании образов.
Глава VI
Фильтрация
§ 6.1. Введение
Под фильтрацией обычно принято понимать отделение
полезного сигнала от помех. Мы будем понимать
фильтрацию несколько шире и включим в это понятие также
обнаружение, выделение, восстановление и
преобразование входных воздействий.
Если полезный сигнал известен и неизменен, то
построить фильтр, который в каком-то смысле
оптимально производит фильтрацию, нетрудно. Но при изменении
условий работы оптимальность нарушается. И, конечно,
оптимальный фильтр не может быть построен заранее,
если априорная информация о входных воздействиях
недостаточна. Именно в этих случаях и возникает задача
построения адаптивных фильтров, приспосабливающихся
к неизвестным или изменяющимся условиям работы, что
может быть вызвано изменением внешних воздействий или
внутренней структуры самого фильтра. Приспособление,
или адаптация, осуществляется путем такого
целенаправленного изменения параметров фильтра (а если это
необходимо, то и структуры его), при котором некоторый
критерий оптимальности, характеризующий работу
фильтра, достигает минимума.
Настоящая глава посвящена рассмотрению
возможных принципов построения адаптивных фильтров,
предназначенных для решения различных задач фильтрации
в широком смысле этого слова.
§ 6.2. Критерий оптимальности
Пусть к входу фильтра приложено внешнее воздействие
u(t) = s(t) + l(t), (6.1)
где s (t) — полезный сигнал, g (t) — возможная помеха,
причем и сигнал, и помеха представляют собой стацио-
168
ФИЛЬТРАЦИЯ
[Гл. VI
u=s(t)+№
Фильтр
y(t)
нарные случайные процессы с неизвестными функциями
распределения. Как обычно, предполагается, что среднее
значение помехи равно нулю (рис. 6.1).
Выходная величина фильтра у (t) есть реакция
фильтра на внешнее воздействие и (t). Она зависит также от
структуры фильтра и, в частности, от вектора параметров
с = (ci, с2, . . ., cN). Обычно
требуется, чтобы выходная
величина фильтра в каком-то
определенном смысле мало
отличалась от желаемой функции г/0(0-
Желаемая функция у0 (t)
представляет собой некоторое идеальное преобразование
полезного сигнала s (t), т. е. результат воздействия
некоторого оператора на s (t). Это преобразование,
осуществляемое оператором, может быть интегрированием,
дифференцированием, упреждением, сглаживанием и т. п.
s(t)
РИС. 6.1.
т
Идеальньщ
фильтр
Уо№
\s(t)
чщ
у\3аптивньщ УШ
фильтр
Ф~Н F<£) \-^г\ореднбни)^)}
Рис. 6.2.
В качестве меры уклонения выходной величины
фильтра у (t) от желаемой функции у0 (t) мы выбираем уже
привычное нам математическое ожидание некоторой
строго выпуклой функции F от разности у0 (t) — у (t). Тогда
J = M{F(y0{t)-y(t))}. (6.2)
Задача теперь состоит в определении структуры
адаптивного фильтра и алгоритма адаптации, обеспечивающих
минимизацию меры уклонения — функционала (6.2).
Поясним эту задачу. Обратимся к блок-схеме,
показанной на рис. 6.2. Здесь сравниваются выходы адаптивного
§ 6.3] СТРУКТУРА АДАПТИВНОГО ФИЛЬТРА 169
и идеального фильтров, ко входам которых приложены
соответственно сигналы и (t) и s(t). Уклонение е — у0 (t) —
—г/ (t) поступает на нелинейный преобразователь с
характеристикой F (е). Подавая реализации F (у0 (t) — у (t))
на специальное устройство, изменяющее в соответствии
с алгоритмом адаптации вектор параметров с, необходимо
добиться минимума меры уклонения.
Эта задача будет решена, если будут найдены
соответствующие алгоритмы адаптации.
§ 6.3. Структура адаптивного фильтра
Представим выходную величину адаптивного фильтра
в виде комбинации линейно независимых функций от
входного сигнала и (t) = s (t), т. е.
y(t) = c^(s(t)). (6.3)
Пока мы предполагаем, что помехи на входе отсутствуют.
Подставим выражение для y(t) в (6.2). Тогда
J(c) = M{F(y0(t)-c^(s(t)))}. (6.4)
В отличие от проблем опознавания и идентификации теперь
Рис. 6.3.
аргументом вектор-функции ср является не векторная,
а скалярная функция времени. Но это отличие только
170
ФИЛЬТРАЦИЯ
[Гл. VI
упрощает задачу. Так как градиент реализации равен
V.F (г/о (0 - ст<р (s (0)) =-^ (г/о (0 - стФ (s (г))) q> (* (0),
(6.5)
то на основании результатов, полученных в § 2.8, мы
можем сразу же записать непрерывный алгоритм
адаптации:
dc (t)
dt
-.y(t)F'(y0(t)-cT(t)4(s(t)))<v(s(t)). (6.6)
Этот алгоритм и определяет структуру адаптивного
фильтра, изображенную на рис. 6.3. Она, как заметит читатель,
лишь незначительно отличается от структуры персептро-
на (рис. 4.1).
§ 6.4. Частные случаи
Выбор системы линейно независимых функций часто
позволяет не только упростить структуру адаптивного
фильтра, но и придать ему интересные и полезные
свойства. Представим алгоритм адаптации (6.6) в развернутой
координатной форме
N
%^ = Y (0 F' (г/о (0 - 2 cv (0 q>v (s(*))) Фц (* (*)),
|i = l, 2, ...,7V. (6.7)
Положим теперь в (6.7)
<pv(s(t)) = s(t-vT), v=l, 2, ...,7V, (6.8)
что весьма просто осуществляется с помощью элементов
задержки {ЭЗ). Тогда
v=l
|х = 1, 2 ЛГ. (6.9)
Структурная схема адаптивного фильтра, реализующего
этот алгоритм, приведена на рис. 6.4. Адаптивный фильтр
может быть еще упрощен, если выбрать F (•) в виде ква-
§ 6-.4]
ЧАСТНЫЕ СЛУЧАИ
171
дратической параболы. Тогда производная /*"(•) —
линейная функция, и надобность в нелинейном преобразователе
отпадает. Подобного рода фильтры на элементах задержки,
как мы увидим далее, с успехом используются в различных
системах связи, телевидения и управления. Разумеется,
Рис. 6.4.
вместо элементов задержки в таких фильтрах можно
применять интеграторы, инерционные звенья и т. п.
Во всех алгоритмах адаптации, о которых мы говорили
до сих пор, коэффициенты cv(t) взаимосвязаны, т. е. они
должны определяться одновременно. Выбором
специальной системы функций cpv (s (t)) можно «развязать» эти
коэффициенты и определять их не параллельно, а
последовательно. Действительно, положим
Г 1 при sv-4<s(t)^sv,
<pvH*))=L „1 „„!"„„ ^„m с6-10)
о
при
при s(£)<sv_i; sv<.s(t),
v=l,2, ...,N.
Это — своеобразные пороговые функции; их вид показан
на рис. 6.5. Они обладают предельно ярко выраженным
ФИЛЬТРАЦИЯ
[Гл. VI
S(t)
Рис. 6.5.
Рис. 6.6.
§ 6.5] [АДАПТИВНЫЙ КОРРЕКТОР ИСКАЖЕНИЙ 173
свойством «ортогональности»
Г 1, v = |i,
<Pv(s(0)4>ii(s(0) = | о, Уф\Х.
(6.11)
Поэтому алгоритм адаптации (6.7) мы можем упростить,
получив с учетом (6.10), (6.11) следующее уравнение:
ЩР- = Y (*) F' (j/o (0 - с» (0 Ф„ (s (t))) Ф(А (s (*)),
11=1,2, ...,ЛГ. (6.12)
Зная Сц(<), находим
y(t)= Scv(09v(«(0)-
v=l
(6.13)
Структурная схема такого адаптивного фильтра
изображена на рис. 6.6. Из уравнения (6.12) следует, что
каждый коэффициент с^ определяется независимо от
других. Такое свойство позволяет ограничиться простейшим
одномерным адаптивным фильтром. Изменяя в нем
пороги sv_i»sv, мы можем последовательно определить
коэффициенты cv — Cv (v = 1,
2, . . ., TV), а затем и
N
v(0 = 2 c*q>v(*(0).
v=l
представляющую собой Рис. 6.7.
ступенчатую
аппроксимацию сигнала 5 (t) (рис. 6.7). Эта возможность особенно
удобна для предварительного подбора оптимальных
параметров фильтра по экспериментальным данным.
§ 6.5. Адаптивный корректор искажений
, Скорость передачи сигналов, в частности,
телевизионных, ограничивается искажениями, которые вызываются
переходными процессами в канале связи. Для устранения
этих искажений на приемном конце канала
устанавливается корректор. Корректор представляет собой фильтр на
линиях задержки, веса которого выбираются во время
174
ФИЛЬТРАЦИЯ
[Гл. YJ
тренировки или обучения, когда по каналу связи
посылаются специальные тестовые сигналы. После периода
обучения характеристики корректора устанавливаются
такими, при которых искажения канала становятся
минимальными.
Импульсная характеристика системы «канал связи —
корректор» к [п] определяется сверткой импульсных
характеристик канала связи w [п] и корректора сп (п= 1,2, . . .
. . ., N), так что
к[п] = 2 cmw[n — m] при rc</V,
771=0
А [/г] = 2 cmw[n — m] при n>N.
(6.14)
771=0
Искажения отсутствовали бы при выполнении условия
Г к(0) при лг = О,
к[п] = 1 У ' (6.15)
J i 0 при гс>0, v '
т. е. если бы система передачи сигналов не обладала
памятью. Поэтому количественно искажения можно
оценить функционалом
J(c) = Ml § \к[п]\\. (6.16)
ln=l J
Определим оптимальную импульсную характеристику
корректирующего устройства, т. е. такую, которая
минимизирует функционал (6.16). Вычислим градиент
со
Q = У \к [п] | по ст. Его компоненты в силу (6.14)
п=1
определяются выражением
оо П
-|^- = У w[n — fi]sign У сшм;[и —m], jx = 1, 2, . ..,/V.
LI "
(6.17)
Если еще предположить, что
н>[ге]«ш[0] = 1, (6.18)
§ 6.5]
АДАПТИВНЫЙ КОРРЕКТОР ИСКАЖЕНИЙ
175
то выражение для компонент градиента упрощается:
6Q
дс
м-
sign 2 сти)[\1 — т], [1 = 1, 2, .. .,7V, (6.19)
m=0
и алгоритм адаптации мы можем записать в виде
Сц[л] = Сц[и —1] — YMsign 2 cm[n — l]u>[ji — ти],
m=0
[i = l, 2, ...,7V. (6.20)
Отличие этого алгоритма от тех, с которыми мы
встречались ранее, состоит в накоплении предшествующих
оценок с помощью импульсной характеристики корректора.
Рис. 6.8.
Схема такого адаптивного корректора приведена на
рис. 6.8. Отметим, что если условие (6.18) не выполняется,
то алгоритм существенно усложняется.
176
ФИЛЬТРАЦИЯ
[Гл. VI
§ 6.6. Поисковые адаптивные фильтры
Обозначим величину, наблюдение которой позволяет
осуществить адаптацию, через
Y(t) = F(y0(t)-c^(s(t))). (6.21)
Значения этой величины при изменении (л-го
коэффициента на + а и при фиксированных значениях других
коэффициентов обозначим соответственно через
Y» для с», + а
и (6.22)
Y & для с^ — а.
Тогда величина, определяющая приближенно (л-ю
составляющую градиента функции Yc(t), будет равна
Пользуясь поисковым алгоритмом адаптации (3.15),
получим
с [и] = с [и — 1] — у [п] Vc±y, (6.24)
где наблюдаемый градиент
Vc±Y = {Yc±, ...,УС±} (6.25)
имеет компоненты, определяемые соотношением (6.23).
При последовательном поиске в каждом интервале
времени продолжительностью 2NT делается 2N наблюдений
величин Y$ и YK
Для повышения помехоустойчивости можно
производить усреднение на интервалах длительности Г, так что
_ Ч+кТ
Y\tln] = jr I Y$(t)dt (6.26)
I
Xn+hT
7»Щ = т I Y»{t)dt. (6.27)
§ 6.6] ПОИСКОВЫЕ АДАПТИВНЫЕ ФИЛЬТРЫ 177
Тогда именно эти усредненные величины и должны
использоваться в формуле (6.23) и алгоритме (6.24). Усреднение
Рис. 6.9.
может осуществляться как непрерывным, так и
дискретным способом. В последнем случае интегралы в (6.26)
и (6.27) заменяются суммами.
Уменьшение времени адаптации в дискретном случае
может быть достигнуто, если вместо последовательного
зо времени поиска использовать поиск одновременно по
всем параметрам.
Одновременный поиск может осуществляться и при
непрерывной адаптации. В этом случае дискретный
алгоритм заменяется непрерывным:
4r-=-v(0Vc±y(0
ИЛИ
c(0 = c(l)-jY(T)Ve±y(T)dT.
1
12 Я. 3. Цыпкин
(6.28)
(6.29)
178
Фильтрация
[Гл. VI
Теперь компоненты V ± Y (t) равны
У
Y!£{t) — Y*{t)
2а (t)
(6.30)
Заметим, что выражение (6.30) представляет собой не
разностную аппроксимацию градиента, а случайный процесс
со средним значением, аппроксимирующим градиент.
Схема фильтра, реализующая непрерывную адаптацию,
изображена на рис. 6.9.
§ 6.7. Адаптивный фильтр-предиктор
Известный адаптивный фильтр-предиктор Д. Габора,
структурная схема которого приведена на рис. 6.10,
обладает рядом особенностей, заслуживающих того,
чтобы на них немного остановиться. В основе работы этого
фильтра лежат своеобразные поисковые алгоритмы.
Эталонный сигнал
G^D
0=¾
Входной сигнал
Фильтр
с
подстраиваемыми
параметрами
^Выходной сигнал
1т^НЖН15>п
^НЖЬО^п
\Устройство вьгчис\
лепи я оптимальЛ
ных параметров \
Рис. 6.10.
Критерием оптимальности здесь служит среднеквадра-
тическое отклонение выходного сигнала от эталонного:
J = M[{y0-y)*]. (6.31)
Для обучения фильтра используется запись некоторого
входного сигнала и соо!ветствующая ей запись
эталонного.
§ 6.8] ФИЛЬТРЫ КОЛМОГОРОВА-ВИНЕРА 179
Оптимальное расчетное значение некоторого параметра
вычисляется после измерения квадратического отклонения
за определенный интервал времени, причем одновременно
получаются три значения величины /, соответствующие
трем значениям искомого параметра: наименьшему (i/_i),
среднему (ус) и наибольшему (i/+i)- В силу квадратичности
критерия эти три значения позволяют вычислить
наименьшее значение /Шт и отвечающее ему значение параметра
£опт- После подстройки этого параметра процесс
проигрывается снова и снова для подстройки таким же путем
следующих параметров, т. е. имеет место поиск. Эмпирически
установлено, что число таких циклов обучения,
необходимых для полной адаптации в случае N настраиваемых
параметров, в среднем равно TV2/2.
Описанный алгоритм можно отнести к
релаксационным, так как любой шаг в изменении каждого параметра
производится из условий минимизации критерия
оптимальности — среднеквадратического отклонения.
§ 6.8. Фильтры Колмогорова — Винера
Если предположить, что критерий оптимальности
определяется квадратической функцией от разности между
желаемой величиной и выходом фильтра, а фильтр линеен
и описывается уравнением свертки, то мы придем к
задаче определения оптимального фильтра Колмогорова —
Винера. Решение эюй задачи сводится к минимизации
функционала
J = М Uy0(t)-^ к (%)и (t-%) d%y\ . (6.32)
и
Аналитический подход, при котором используется
вариационное исчисление и корреляционная теория, приводит
к уравнению типа Винера — Хопфа или к эквивалентной
краевой задаче, которая решается методом факторизации.
Сравнительная компактность окончательного
результата, определяющего импульсную характеристику к (т)
или соответствующую ей передаточную функцию К (р)
оптимального фильтра, создает иллюзию простоты
вычислений этих оптимальных характеристик. На самом деле
это далеко не так. Большой объем вычислений падает на
12*
180
ФИЛЬТРАЦИЯ
[Гл. VI
определение соответствующих корреляционных функций
и спектральных плотностей по реализациям. Эти
последние почему-то всегда считаются заданными, причем, как
правило, в довольно простой форме. Нельзя ли миновать
этот этап и определять оптимальные характеристики
фильтра непосредственно по реализациям? Оказывается,
это возможно, если использовать адаптивный подход.
Будем искать оптимальную импульсную
характеристику в виде к (т) = стср (т). Подставляя ее в (6.32),
получаем
J(e) = M{F(y0(t)-cT*(t))}, (6.33)
где, очевидно,
t
Ч> (0 = I Ф СО и (t — т) dx. (6.34)
о
Теперь можно обычным способом осуществить
минимизацию / (е) по с. При этом мы получаем систему линейных
уравнений относительно с, коэффициенты и правые части
которой выражены через текущие корреляционные
функции. Непрерывное решение этой системы уравнений и
определяет с течением времени оптимальное значение с*,
а значит, и
А*(т) = с*гф(т). (6.35)
Применение алгоритма адаптации, например,
-^jP- = У (О F' (i/o (о - с** (0) ф (0, (6.36)
позволяет значительно упростить устройство адаптации.
Аналогичным образом можно рассмотреть с позиций
адаптации очень интересный подход для решения
подобных задач, который успешно развивался Р. Калманом.
§ 6.9. Статистическая теория приема
Основные задачи статистической теории приема состоят
в обнаружении или выделении сигналов на фоне помех.
В задаче обнаружения необходимо по результатам
обработки реализации
V = Y(8,l) (6.37)
§ 6.10] КРИТЕРИЙ ОПТИМАЛЬНОСТИ ПРИЕМА 181
установить наличие или отсутствие полезного сигнала s.
В отличие от задачи обнаружения, в задаче выделения
сигнала априори известно, что полезный сигнал s
содержится в принятой реализации, и по результатам
обработки этой реализации нужно восстановить параметры или,
в общем случае, характеристики полезного сигнала.
Задачи обнаружения и выделения сигнала тесно
связаны друг с другом. Допустим, что передаваемый сигнал
зависит от одного параметра с, т. е. s (t) = s(c, t) и
параметр с может принимать только два значения: с = сА
с вероятностью РА и с = с0 с вероятностью Р0. При этом
Pi + Ро — 1- В частности,
»(c,t) = cf(t). (6.38)
Для задачи обнаружения одно из значений с, например
с0, выбирается равным нулю.
Статистическая теория приема или, как ее еще
называют, статистическая теория решений, дает эффективное
решение задач обнаружения и выделения сигналов на
фоне помех, если мы обладаем достаточной априорной
информацией. Принятое, согласно этой теории, решение
о параметрах сигнала и, в частности, о его наличии или
отсутствии, является оптимальным, т. е. таким, которое
минимизирует некий критерий оптимальности приема.
§ 6.10. Критерий оптимальности приема
В пространстве реализаций каждой наблюдаемой точке
у соответствует некоторое определенное решение. Поэтому
все точки пространства должны быть разделены на две
области:
Ai, соответствующую решению си и Л0,
соответствующую решению с0. Любому решению этой задачи присущи
два рода ошибок:
1. Ошибка первого рода, когда в действительности
с = с0, а принимается решение с = ct. Для задачи
обнаружения это — ошибка ложной тревоги: сигнала нет,
а принимается решение о том, что сигнал есть.
2. Ошибка второго рода, когда в действительности
с = еь а принимается решение с = с0. Для задачи
обнаружения такая ошибка соответствует пропуску сигнала
182
ФИЛЬТРАЦИЯ
[Гл.VI
или ложному отбою: сигнал имеется, а принято решение
об его отсутствии.
Обозначим через а и |3 соответственно вероятности
ошибок первого и второго рода, а через р (у \ с) — плотность'
вероятности полученной реализации при условии, что
параметр равен с. Тогда вероятности ошибок первого
и второго рода определяются выражениями
«= \р{У\с*)Лу (6<39)
Ai
И
Р= 1р(уЫ*У- (6.40)
Ао
Общая безусловная вероятность ошибок первого и второго
рода будет равна
/ = Poa + PiP. (6.41)
Соотношения (6.39) — (6.41) позволяют подсчитать
вероятности ошибок и лежат в основе всех методов принятия
решений. Если считать оптимальным такое решение,
которое обеспечивает наименьшую общую безусловную
вероятность ошибки (6.41), то мы приходим к критерию Котель-
никова, или, как его еще называют, к критерию
идеального наблюдателя.
Если считать оптимальным такое решение, которое
обеспечивает наименьшую вероятность пропуска сигнала
/ = Р4Р (6.42)
при условии заданной вероятности ложной тревоги
P0a = const, (6.43)
то мы приходим к критерию Неймана — Пирсона.
В тех случаях, когда ошибки первого и второго рода
не одинаково важны или опасны, вместо общей
безусловной вероятности следует рассматривать
JK = XP0a + Pi^1 (6.44)
где К — некоторый фиксированный множитель,
характеризующий вес ошибок первого рода. При % = 1 из (6.44)
§ 6.11] ОПРЕДЕЛЕНИЕ РЕШАЮЩЕГО ПРАВИЛА 183
получается критерий Котельникова (6.41). Если же X
считать неопределенным, и после минимизации (6.44)
определять его из условия (6.43), то мы получаем
критерий Неймана — Пирсона.
§ 6.11. Определение решающего правила
Классические методы определения решающего
правила, минимизирующего критерий оптимальности приема,
например Неймана — Пирсона или Котельникова,
основаны на вычислении апостериорных, или условных,
вероятностей по результатам приема. Но для вычисления
апостериорных вероятностей нужны априорные
вероятности, которые, как правило, неизвестны, то ли потому,
что мы не располагаем статистикой, то ли потому, что
она не изучалась, либо вследствие более
фундаментального обстоятельства: в прошлом не существовало сходных
ситуаций, из которых можно было бы вывести
определенное суждение.
Трудности, вызываемые недостаточной априорной
информацией или, попросту говоря, незнанием плотностей
распределения, вечно преследуют классический подход.
Однако эта «априорная трудность» не является
непреодолимой. В тех случаях, когда определяемые нами функции
или величины не зависят или мало зависят от вида
плотностей распределения, можно задаваться любой
плотностью распределения, удобной для вычислений, и затем
использовать известные методы, основанные на
байесовском подходе. К сожалению, эти случаи не так часты. Они
охватывают лишь задачи оценки моментов. В остальных
случаях выход из положения дает адаптивный подход.
Мы здесь рассмотрим общую задачу, которая сводится
к минимизации J^. Запишем Jx в явном виде. Это легко
сделать, если учесть (6.39) и (6.40)
Jx = ЬР0^р(у\ с0) dy + P^p (у | с,) dy (6.45)
Ai Ао
ИЛИ
Н = Х\ {РА (у) р (У | с0) +Pxd0 (у) р (у | Ci)} dy, (6.46)
А
184
ФИЛЬТРАЦИЯ
[Гл. VI
где d^ty) ([1 = 0, 1) —решающее правило,
Г 1, если уеЛ»,
d"(*> = tof если »5 А,. (6*47)
С аналогичным представлением мы уже встречались
в §§ 1.2 и 4.8.
Предположим, что граница между областями ЛА и Л0
определяется условием
/0/,с) = стч>(?/) = 0. (6.48)
При этом /(«/, с)>0 в области ЛА и f(y, с)<0 в
области Л2. Определение этой границы сводится к
определению вектора с. Для этой цели введем функцию
{1, если имеет место ошибка 1-го рода,
Я, если имеет место ошибка 2-го рода, (6.49)
О, если нет ошибки.
Тогда
J у, - ХР0а + ЛР - Му {9 (*/, с)}, (6.50)
и для определения оптимального вектора параметров мы
можем применить поисковый алгоритм
с [п] - с [п - 1] - у [п] Vc±Q {у, с, а), (6.51)
который и решает поставленную задачу.
§ 6.12. Обнаружение сигнала на фоне помех I
Поскольку примеры часто более поучительны, чем
правила, рассмотрим решение задачи обнаружения на
основе адаптивного подхода. Примем следующее правило
решения. Считаем, что полезный сигнал присутствует,
если реализация у принадлежит области Ль отсутствует,
если // не принадлежит этой области.
Будем характеризовать область ЛА вектором порогов
с = (сь . . ., cN). Тогда задача сводится к наилучшей
оценке вектора с.
Выберем вначале в качестве критерия оптимальности
вероятность ошибочного решения, т. е. вероятность того,
что реализация у принадлежит Аи т. е. ?/£ Ль но на
входе нет полезного сигнала, или реализация у не принадле-
§ 6.12] ОБНАРУЖЕНИЕ СИГНАЛА НА ФОНЕ ПОМЕХ I
185
жит АА, т. е. реализация y£Aiy но на входе есть
полезный сигнал.
Такой критерий оптимальности можно записать так:
J = P{p£Al, 8 = 0 или 1/ЁЛь 8ф0}. (6.52)
Наилучшая оценка с соответствует минимуму этого функ-
^
—7Г-* I У
с±ае,
xcnj2j~"
c[n-V
'Л
W
Фильтр
УМ
2а[п]
гб
Рис. 6.11.
ционала. Введем обозначения характеристических функций
(6.53)
Г 1, если 2/eAj,
6 (2Л С) = п г л
I 0, если 2/^Ai,
1, если «^=0,
если s = 0,
и, наконец,
Q(z)
10,
если z = l,
если 2 =^=1.
(6.54)
(6.55)
Тогда критерий оптимальности (6.52) можно представить
в более удобной для нас форме:
J(c) = P{Q(y,c) + yQ = l}, (6.56)
186
ФИЛЬТРАЦИЯ
[Гл. VI
или с учетом (6.55)
J(c) = M{Q[Q(y,c) + yQ]}. (6.57)
Для определения оптимального вектора с = с*,
минимизирующего этот функционал, применим поисковый
алгоритм обучения (2.21)
с [п] = с [п- 1] - y [п] Vc±a [9 (у [л], с [п - 1], а [п]) + у0].
(6.58)
Структурная схема приемника, работающего по этому
алгоритму, изображена на рис. 6.11.
§ 6,13. Обнаружение сигнала на фоне помех II
Используем теперь иной критерий оптимальности,
а именно равенство вероятностей ошибок первого и второго
родов, т. е. равенство вероятности ложной тревоги и
вероятности пропуска сигнала:
Р{уе^,в = 0} = Р{уёАивфО}. (6.59)
Но, согласно формуле полной вероятности,
P{yZAi}=P{yeAus = 0} + P{yeAv8^0} (6.60)
и
Р{8ф0} = Р{у1Аи8ф0} + Р{у£Аи8ф0}.
Следовательно, равенство (6.59) в силу (6.60)
эквивалентно такому равенству:
Р{У£Л1} = Р{8Ф0}, (6.61)
которое означает, что вероятность того, что правило
решения указывает на присутствие сигнала, равна вероятности
того, что он действительно имеет.ся.
Теперь уже нетрудно, принимая во внимание
обозначения характеристических функций (6.53) и (6.54), записать
критерий оптимальности в виде равенства
My{Q(y,c)-y0} = 0. (6.62)
Для определения оптимальной оценки с можно применить
непоисковый алгоритм
c[n] = cln~t]-y[n][Q(y[nhcln])-yQ[n]]. (6.63)
§ 6.14] ВЫДЕЛЕНИЕ СИГНАЛА НА ФОНЕ ПОМЕХ 187
Если размерность векторов сигнала и порогов равна
единице, то
Г 1, если */ >с,
6 &'«> = ^<»-«Но, если ,,<<:, «^
и мы приходим к простому скалярному алгоритму
обучения
с \п] = с [п — 1] — y [п] (sgn (у[п] — с[п — 1])-
■Уо[п])-
(6.65)
Схема приемника, работающего по таким алгоритмам,
приведена на рис. 6.12. Эти приемники способны, обучаясь
и адаптируясь,
устанавливать оптимальное
значение порога. Мы снова
вернемся к
рассмотрению подобных
алгоритмов в гл. X.
Задача обнаружения
весьма близка к задаче
обучения опознаванию
образов. Но мы ее рассмотрели в связи с задачами
фильтрации. Надеемся, что читатель не сочтет это
непоследовательностью, ибо и сама задача фильтрации мало
отличается от задачи опознавания.
Ъ\
X) »1
т
1
J ч
у[п]
Рис. 6.12.
§ 6.14. Выделение сигнала на фоне помех
В отличие от задачи обнаружения, в задаче выделения
сигнала на фоне помех априори известно, что в принятой
реализации у содержится полезный сигнал, и по
результатам обработки этой реализации нулшо восстановить его
параметры. Будем рассматривать «постоянный» сигнал
»=($!, . . ., 5М), представляющий собой «пачку»
импульсов, периодически повторяющуюся с периодом Т (рис.6.13).
Компоненты вектора s равны, например, амплитудам
импульсов в пачке. На вход приемника подается
воздействие ге, представляющее собой аддитивную смесь сигнала
s и стационарной помехи | = (£Л/г], . . ., %м [/г]),
зависящей от номера пачки. Среднее значение помехи равно
188
ФИЛЬТРАЦИЯ
[Гл. VI
нулю, а корреляционная матрица В предполагается
известной. Выходной сигнал приемника представляет собой
s *
nil, ill. II
2Т
ЗТ Т
а)
t£=S+$k
DJQ
Л
2Т
ЗТ т
б)
Рис. 6.13.
линейную комбинацию значений входного воздействия
у = сти ~ CTS + ст\. (6.66)
Он представляет собой сумму полезной составляющей
cTs и помехи ст|.
§ 6.15. Критерий оптимального выделения
В качестве критерия оптимальности выберем отношение
мощности сигнала к мощности помехи, который кратко
(но неточно) называется отношением сигнал/помеха. При
большом отношении сигнал/помеха выбор этого критерия
помехозащищенности освящен традицией. Но в общем
случае нельзя утверждать, что максимизация отношения
сигнал/помеха обеспечивает извлечение наибольшего
количества информации о полезном сигнале. Здесь уместно
привести неоднократно цитировавшиеся в литературе
высказывания Вудворда: «Этот подход правилен до тех
пор, пока он приводит к цели, однако он не содержит
постановки задачи об извлечении информации. Иногда он может
ввести в заблуждение, так как не существует общей тео-
§ 6.16]
АЛГОРИТМ ВЫДЕЛЕНИЯ
180
ремы, утверждающей, что максимальное отношение
сигнала к шуму на выходе обеспечивает максимальное
извлечение информации». Чтобы поэтому не попасть впросак,
всегда нужно помнить, что выбранный здесь критерий
хорош лишь для малых помех, т. е. большого отношения
сигнал! помеха.
Критерий оптимальности — отношение
сигнал/помеха — можно записать так:
MUcV} (6>67
Дальнейшая задача состоит в определении максимума
этого выражения при условии постоянной мощности
помехи
М {{ст1?} = стВс = А. (6.68)
§ 6.16. Алгоритм выделения
Составим функцию Лагранжа
А (с) = М {(ствГ) + к (М {(с'1)*} - A). (6.G9)
Поскольку помеха и сигнал не коррелированы, то из (6.66)
следует
М {(стиУ) = М {(cTs)2} + М {(ст£)2}, (6.70)
и функцию Лагранжа (6.69) можно выразить через
измеряемые и известные величины y = cTti, В, /1, т. е.
Д (с) = М {(сти)2 + {X - 1) (стВс) -Щ. (6.71)
Градиент функции Лагранжа равен
V<A (с) = Ш {(сти) и Ч (X- 1) Вс). (6.72)
Применяя алгоритмы, определяющие условный экстремум
при ограничениях типа равенства (3.19), получим
с[п]~с [п— 1] — Yi[w] [(ст[п — 1]и [п])и[п]+ Л
+ (к [п- 1] - 1) Be [л — l]j, > (6.73)
X [п] = к [п — 1] — Y2 [п] [ет [n-l]Bc [п-1]—A]. J
190
ФИЛЬТРАЦИЯ
[Гл. VI
Схема приемника, осуществляющего выделение сигнала
на основе этого алгоритма, изображена на рис. 6.14. Она
Я[п-1]
<^ кч уг[п] и—(2н—-
Рис. 6.14.
отличается от прежних персептронных схем лишь
наличием дополнительного контура, обеспечивающего
выполнение второго условия (6.73).
§ 6.17. Еще о выделении сигнала на фоне помех
Откажемся теперь от предположения, что нам
известны какие-либо сведения о сигнале 5 (t). Что же касается
помехи, то будем считать, что она не коррелирована с
сигналом и представляет собой белый шум с нулевым
средним и дисперсией, равной а|. Входной сигнал приемника
и (t) представляет собой аддитивную смесь неизвестного
сигнала и помехи. Рассмотрим приемник на элементах
задержки, предназначенный для выделения сигнала s(t).
Пусть выходной сигнал определяется следующим
образом:
2.V
y(t)= S cvii{t — vT) + aNu(t—Nt), (6.74)
v=0
где ал>0 — постоянная величина, a cv—пока
неизвестные параметры нашего приемника. Выходной сигнал
6.18] ДРУГОЙ КРИТЕРИЙ ОПТИМАЛЬНОСТИ 191
состоит из двух частей:
lM*)= 2 cvs(t-vT) + aNs(t-NT), (6.75)
v=0
полезной, связанной с сигналом, и
2ЛГ
Vl(t)= S Cy,l(t-vT) + aNl(t-NT), (6.76)
v=0
вызванной помехой.
Поскольку сигнал s (t) заранее неизвестен, то мы не
можем определить желаемый сигнал y0(t), и,
следовательно, сейчас неприменимо решение, уже привычное
нам после знакомства с §§ 6.3—6.8.
§ 6.18. Другой критерий оптимальности
Для рассматриваемой сейчас задачи выделения
сигнала на фоне помех приходится выбирать иные формы
критериев оптимальности, которые учитывали бы известную
априорную информацию. Таким критерием
оптимальности может, например, служить
J = M{y*(t)}-kM{y\(t)}, (6.77)
где X — постоянный весовой множитель.
Функционал (6.77) характеризует превышение
мощности выходного сигнала приемника над мощностью
составляющей выходного сигнала, вызванной помехой.
Оптимальному приемнику соответствует максимум этого
функционала. Прежде чем заняться максимизацией, мы хотим
обратить внимание читателя на тесную связь приняюго
здесь критерия оптимальности с критерием (6.67),
представляющим собой отношение сигнал/помеха.
В силу свойств шума £ (t)
2ЛГ
М(у\) = С2с1 + аЪ)о{. (6.78)
V=0
Следовательно, (6.77) запишется так:
2ЛГ
J(e) = M{y^(t)-Xol(^1 с*, + а%)\. (6.79)
v=l
192
ФИЛЬТРАЦИЯ
[Гл. VI
§ 6.19. Оптимальный приемник
Условие экстремума мы получим, дифференцируя (6.79)
по с^ и приравнивая частные производные нулю:
а-Ш = м[2у (t) ЁШ-гЯф^О, ц = 0, 1, ..., 2N.
(6.80)
Учитывая, как это видно из (6.74), что
д±& = и(г--у.Т), fi = 0, 1, ..., 27V, (6.81)
находим из (6.80)
1
Ч
M[y(t)u(t-\iT)], |i = 0f 1, ..., 27V. (6.82)
Равенство (6.82) весьма примечательно. Оно гласит, что
коэффициенты с^ пропорциональны значениям взаимно-
корреляционной функции выходного сигнала приемника
и входного сигнала
сЪ = -щПуи№). (6.83)
Если в (6.80) подставить значение у (/) из (6.74), то мы
получим систему линейных уравнений, которая и
определяет оптимальное значение с£ (\х = 0, 1, . . ., 2N). Но
нужно ли следовать этому, казалось бы, очень ясному
пути? Ведь значительно проще не только с точки зрения
нашего подхода, но и по существу использовать
соотношение (6.82) для фактического определения с'$ по
реализациям. Это позволяет исключить громоздкую операцию,
связанную с решением системы линейных уравнений.
Задача определения с% сводится к вычислению взаимно-
корреляционной функции по реализациям. Поэтому мы
можем воспользоваться результатами § 5.6 для оценки
корреляционных функций и получить непрерывный
алгоритм
dt
:У(')[-х5гУ(0"(«-(*Л-^(0] . (6-84)
§ 6.19] ОПТИМАЛЬНЫЙ ПРИЕМНИК 193
или в более удобной форме
T0(t)d-^P-+c»(t) = 1^y(t)u(t-liT), (6.85)
fi = 0, 1, ..., 2N,
где
Го (0 = ^¼). (6-86)
Эти уравнения определяют закон изменения
коэффициентов схемы приемника. Структурная схема оптимального
Рис. 6.15.
адаптивного приемника, определяющего выходной сигнал
по уравнению (6.84), приведена на рис. 6.15.
13 Я. 3. Цыпкин
194
ФИЛЬТРАЦИЯ
[Гл. VI
§ 6.20. Возможные упрощения
Адаптивный приемник, схема которого приведена на
рис. 6.15, после периода обучения превращается в
оптимальный приемник корреляционного типа. Особенность
u(t)
Рис. 6.16.
его состоит в том, что весовые коэффициенты импульсного
фильтра пропорциональны значениям взаимно
корреляционной функции входного и выходного сигналов.
Схему приемника можно упростить, если вместо
обычной корреляционной функции
Ryu (рТ) = М {у (t) и (t- \хТ)} (6.87)
использовать так называемую «релейную» взаимно
корреляционную функцию
Rv, sign и (|*Л = М {у (t) sign и (* - |хГ)}, (6.88)
§ 6.21] ВОССТАНОВЛЕНИЕ ВХОДНЫХ СИГНАЛОВ 195
учитывающую лишь знак входного сигнала. Кроме того,
положим постоянную времени неизменной и равной Т0
и для простоты выберем X так, чтобы А,а§ = 1, Тогда
взамен алгоритма (6.85) мы получаем
T0d-^ + c[l(t)==y(t)signu(t~-liT), |i = 0f 1, ..., 2N.
(6.89)
Структурная схема приемника, работающего по этому
алгоритму (рис. 6.16), отличается от ранее приведенной
введением дополнительного релейного элемента в цепь
сигнала и тем, что в новой схеме величина Т0 не меняется
со временем.
§ 6.21. Восстановление входных сигналов
Адаптивные фильтры весьма полезны при решении
задач о восстановлении входных сигналов 5 (£),
действующих на вход некоторой известной системы. Такая задача
возникает при расшифровке записей сигналов,
искаженных измерительными устройствами. Рассмотрим эту
задачу, кстати, весьма близкую к задаче идентификации.
Пусть на систему, уравнение которой имеет вид
V(t) = As(t), (6.90)
где А — некоторый, вообще говоря, нелинейный
оператор, воздействует сигнал s (t). Для простоты мы
предполагаем, что у и 5 — скалярные величины.
Выходной сигнал не может быть измерен точно. Вместо у (/)
мы измеряем
v(t) = y(t) + l, (6.91)
где £ — помеха со средним значением, равным нулю,
и конечной дисперсией. Задача состоит в восстановлении
сигнала 5 (t). Предположим, что 5 (t) можно с
достаточной степенью точности представить в виде
S(0 = cT<p(i£). (6.92)
где Ъ = (Lu . . ., LN) — вектор линейных независимых
операторов, а £ — белый шум, создаваемый специальным
генератором.
13*
196 * ФИЛЬТРАЦИЯ [Гл. VI
Определим оптимальный вектор в = с* так, чтобы
некоторый функционал, например
J(c) = M {[As (t)-AcTif (i£)]2}, (6.93)
был минимален. С учетом (6.90)-(6.91) этот функционал
можно переписать в другом виде:
J{c) = M{[v{t)-l-AcTy{Ll)Y). (6.94)
§ 6.22. Алгоритмы восстановления
Условие, определяющее оптимальный вектор
параметров, имеет вид
V/(c)=-2il/{[i;(0-g-Acrq,(iQ]x
XA'(cTq)(iO)q)(iO} = Of (6.95)
где А' — производная оператора А, определенная,
например, по Фреше или Гато.
Поскольку £ и £ не коррелированы, а среднее
значение I равно нулю, то из (6.95) получаем
М {[и (*) - Ac*q> (Z£)] A' (cTq> (ZQ) q> (ZQ> = 0 (6.96)
и затем находим алгоритм определения оптимального
вектора с~с*, а следовательно, и восстановления входного
сигнала:
^Г = Y (0 [v (t)-Ae?(t) q> (££)] А' (ст<р (i£)) <р(i£). (6.971
В частном случае, когда оператор А линейный, алгоритм
(6.97) существенно упрощается и принимает вид
^ = Y (0 [v (0-с* (0 + (01 + (0. (6.98)
где
1|>(0 = .4ф(£Е). (6.99)
6.23]
О ВЛИЯНИИ ПОМЕХ
197
Схема адаптивного устройства для восстановления
входного сигнала, реализующая алгоритм (6.98),
изображена на рис. 6.17. Замена в
этом устройстве
непрерывного интегратора дискретным
позволяет восстанавливать —^
дискретные входные сигналы.
§ 6.23. О влиянии помех
При квадратичной
функции потерь и неточном
измерении выходной величины
системы влияние погрешности
измерений (помехи с нулевым
средним и конечной
дисперсией) с течением времени
устраняется. Это наглядно
видно из эквивалентности
условий оптимума (6.95) и (6.96).
Для линейных адаптивных
устранения влияния помех в
р{х|н^
А(р
cTAvU)
Рис. 6.17.
фильтров этот же эффект
процессе адаптации
сохраняется и в том случае, когда помеха действует не только
на выходе фильтра, но и на его входе. Как было показано
в § 5.20, устранение влияния помех, или, что то же самое,
получение несмещенных оценок, возможно и для более
общей степенной функции потерь, но лишь тогда, когда
входные помехи отсутствуют. Этот случай характерен для
измерительных устройств, используемых при
восстановлении измеряемых сигналов, но вряд ли его можно
оправдать при решении общей задачи фильтрации сигналов при
наличии помех. Как же быть в тех случаях, когда функция
потерь отличается от квадратичной, а адаптивный фильтр
нелинеен?
Попытка прямого решения подобной задачи
наталкивается на большие трудности. Видимо, одна из
возможностей состоит в использовании дополнительного линейного
адаптивного фильтра для выделения сигнала и
подавлении помехи, т. е. для получения оценки сигнала.
Сглаженный таким образом сигнал затем подается на
нелинейный адаптивный фильтр для нужных преобразований.
198
ФИЛЬТРАЦИЯ
[Гл. VI
§ 6.24. Некоторые задачи
Структура и свойства адаптивных фильтров и
оптимальных приемников для обнаружения и выделения сигналов
существенно зависят от выбора системы функций cpv(-)-
Поэтому исследования, обосновывающие выбор этих
функций, были бы весьма полезны.
Поскольку адаптивные фильтры должны работать и в
условиях изменения внешних воздействий, то важно
определить связь между скоростью изменения этих внешних
воздействий и длительностью процесса адаптации, при
которой обеспечивается работоспособность фильтра.
Для уменьшения длительности адаптации, т. е.
времени обучения, целесообразно использовать априорную
информацию о распределениях случайных величин. Было
бы важно разработать способы эффективного
использования этой априорной информации для улучшения
алгоритмов адаптации.
В рассмотренных схемах адаптивных фильтров часто
фигурирует реализация желаемого сигнала. Вероятно,
можно вместо этой реализации использовать ее
вероятностные характеристики. Важно было бы также установить
связь с байесовским подходом, теорией статистических
решений и условными марковскими процессами.
§ 6.25. Заключение
Несколько расширив в этой главе термин
«фильтрация», мы охватили разнообразные задачи как собственно
фильтрации, так и обнаружения, выделения и
восстановления полезных сигналов, которые оказываются
искаженными из-за помех или из-за свойств устройств,
обрабатывающих эти сигналы. Мы пытались показать, что
применение адаптивного подхода позволяет не только
решать ряд новых задач, но и вносит существенные
упрощения при решении хорошо известных классических задач,
например задач типа Колмогорова — Винера. Этот подход
позволил нам взглянуть с не совсем обычной точки зрения
на теорию статистического приема и наметить метод
решения задач этой теории, свободный от требования
достаточности априорной информации о сигналах и помехах.
Глава VII
Управление
§7.1. Введение
До сих пор мы изучали разнообразные системы,
которые, однако, все относя!Ся к классу разомкнутых. Именно
этим в значительной мере объясняется сравнительная
простота решения задач опознавания, идентификации
и фильтрации. Сейчас мы переходим к рассмотрению более
сложного класса систем — систем автоматического
управления. Характерная особенность систем
автоматического управления, с которыми мы будем встречаться на
протяжении всей этой главы, состоит в том, что они
представляют, вообще говоря, нелинейные замкнутые системы,
неприводимые к разомкнутым. Вначале мы выделим круг
задач, которые не могут быть решены обычными методами
«глубокой отрицательной обратной связи», а затем для их
решения используем уже ставший традиционным для этой
книги адаптивный подход и покажем, что этот подход
позволяет учесть ряд весьма обычных и реалистических
ограничений, которые долгое время были недоступны
классическим методам. Важную роль, как увидит далее
читатель, при реализации беспоисковых адаптивных систем
управления будет играть теория чувствительности.
После этих кратких предварительных сведений о
содержании главы — наиболее сложной и в связи с этим
заманчивой — пора перейти к существу дела.
§ 7.2. Когда нужна адаптация?
Основным принципом, лежащим в основе построения
систем автоматического управления, является принцип
управления по отклонению, или принцип отрицательной
обратной связи. Поскольку ошибка несет на себе отпечаток
200 УПРАВЛЕНИЕ [Гл. VII
различных неконтролируемых внешних воздействий, она
является универсальным мерилом отклонения состояния
системы от предписанного режима, чем бы это отклонение
ни было вызвано. Уже давно было замечено, вначале в
радиотехнике, а затем и в автоматике, что увеличение
соответствующих коэффициентов усиления в замкнутых
контурах позволяет уменьшить влияние неконтролируемых
внешних воздействий и изменений характеристик
управляемого объекта.
Многие результаты теории управления были связаны
с этим фактом. Эффект глубокой отрицательной обратной
связи может быть достигнут либо непосредственным
повышением величины коэффициента усиления, либо
косвенным путем, на основе создания так называемых скользящих
режимов в релейных системах автоматического
управления и в системах с переменной структурой. Идеи
абсолютной инвариантности, как оказалось, также не чужды
этого эффекта и используют его, когда это возможно, хотя
и в несколько завуалированной форме. Почему же эффект
глубокой отрицательной обратной связи оказывался часто
неспособным устранить влияние внешних воздействий
и изменения характеристик?
Ответ на этот вопрос также известен издавна.
Замечательные свойства глубокой отрицательной обратной
связи можно использовать только тогда, когда
одновременно с увеличением коэффициента усиления
обеспечивается устойчивость замкнутых систем. А этого можно
добиться далеко не всегда.
Наличие временного запаздывания, инерции, а порой
и нелинеиностеи не позволяет неограниченно увеличивать
коэффициент усиления, так как это приводит к
нарушению устойчивости системы.
Без увеличения объема априорной информации
невозможно, хотя часто это почему-то не кажется очевидным,
повысить величину коэффициента усиления, не нарушая
устойчивости. Ведь при повышении коэффициента
усиления начинают сказываться различные, ранее неучтенные
малые параметры, нелинейности, а не зная их, легко
перейти границу устойчивости.
Таким образом, при недостаточной априорной
информации это эффективное в определенных условиях средство
§ 7.3]
ПОСТАНОВКА ЗАДАЧИ
201
не может быть реализовано из-за существования
своеобразного «барьера неустойчивости».
Иные возможности, основанные на эффектах
компенсации и широко рекламируемые теорией инвариантности,
также неприменимы, хотя и по другой причине. Они
основаны на детальном знании характеристик управляемого
объекта, которые зачастую неизвестны. Если еще учесть,
что неизвестные нам характеристики управляемого
объекта могут изменяться с течением времени, то уже нетрудно
себе представить те непреодолимые препятствия, на
которые наталкиваются обычные подходы, когда задача состоит
не просто в управлении, а в оптимальном управлении.
Во всех перечисленных случаях, для которых
характерна недостаточность априорной информации, обычные
подходы неприменимы, и мы приходим к необходимости
использовать адаптацию.
Хотелось бы еще отметить, что в ряде случаев
целесообразно использовать адаптацию для получения
априорной информации экспериментальным путем, с тем,
чтобы затем использовать обычные подходы.
§ 7.3. Постановка задачи
Управляемый объект может быть описан, как мы уже
имели возможность убедиться в гл. V, различными
видами уравнений. Здесь мы примем описание в виде системы
нелинейных разностных уравнений в векторной форме
x[n]=f(x[n — l], и[п—Ц), (7.1)
где / (х, и) = {f\{x, и), . . ., fi (х, и)) — /-мерный вектор,
вообще говоря, неизвестных функций, х = (хи . . .,
дивектор фазовых координат управляемого объекта, и =
= (ии . . ., щ) — вектор управляющих воздействий.
Управляющее устройство будем характеризовать
законом управления в общей форме
и[п] = к(х[п]), (7.2)
где U (х) = (fci(x), . . ., ktl(x)) — Zi-мерный вектор
неизвестных функций. Фазовые координаты и управляющие
воздействия могут (или должны) подчиняться некоторым
202
УПРАВЛЕНИЕ
[Гл. VII
дополнительным ограничениям. Например,
»5 («[*]) = 0, v = l, 2, ..., Мъ (7.3)
и
hV(u[n])<0f v = l, 2, ..., Мп. (7.4)
Основная задача состоит в определении такого закона
управления (7.2), при котором фазовые координаты
и управляющие воздействия удовлетворяли бы
ограничениям, а заданный критерий оптимальности достигал
минимума.
Пусть к системе приложено стационарное случайное
задающее воздействие ас0 [п]. Тогда критерием
оптимальности может служить функционал
1± = М{Р(аА[п] — х[п])}, (7.5)
где F (•) — некоторая выпуклая функция.
Особенность этой задачи, отличающая ее от задач
теории оптимальных систем (как детерминированных, так
и стохастических), состоит в том, что уравнения
управляемого объекта нам неизвестны и у нас нет достаточной
априорной информации, на которую мы могли бы
опереться, чтобы заранее рассчитать оптимальный закон
управления.
В рамках классической теории оптимальных систем эта
задача не только неразрешима, но ее в такой форме даже
неловко формулировать. Адаптивный подход указывает
путь решения этой задачи, связанный с одновременным
изучением и управлением объекта.
§ 7.4. Дуальное управление
Недостаточность априорной информации приводит
к необходимости совмещать в определенном смысле
изучение объекта и управление им. Мы не можем
оптимально управлять объектом, не зная его характеристик, но
мы можем изучать объект, управляя им, и тем самым иметь
возможность улучшать управление, стремясь к
оптимальному. В этой ситуации управляющие воздействия носят
двойственный характер. Они служат как средством изу-
7.4]
ДУАЛЬНОЕ УПРАВЛЕНИЕ
203
чения, познавания объекта, так и средством направления
его к желаемому (т. е. оптимальному) состоянию. Такое
управление, при котором управляющие воздействия носят
двойственный характер, называют дуальным
управлением.
В системах дуального управления всегда существует
противоречие между познавательной и направляющей
сторонами управляющего воздействия.
Успешное управление возможно, если свойства объекта
хорошо известны и управляющее устройство быстро
реагирует на изменение состояния объекта. Но выяснение
этих свойств, т. е. идентификация объекта, требует
определенного времени. Вряд ли можно ожидать, что слишком
поспешное управление без достаточной информации о
свойствах объекта, с одной стороны, и слишком осторожное
управление, хотя и основанное на накопленной
информации, но действующее, когда надобность в нем миновала,—
с другой стороны, могут привести к успешному
результату.
Двойственность знания и управления, как подчеркивал
К. Шеннон, тесно связана с двойственностью прошлого
и будущего. Можно обладать знанием о прошлом, но
нельзя управлять им, и можно управлять будущим, не зная
его. Быть может, именно в этом и состоит вся прелесть
и смысл управления.
Дуальное управление было открыто и существенно
развито А. А. Фельдбаумом на основе теории
статистических решений. Такой путь, по-видимому, является
наилучшим в тех случаях, когда задана априорная плотность
распределения внешних воздействий и параметров
управляемого объекта, а показателем качества является
средний риск. К сожалению, такой путь решения часто
оказывается настолько сложным, что если его и можно
использовать, то только в сравнительно простых случаях. Так
как испытываемый недостаток в априорной информации
относится также и к плотностям распределения, то имеет
смысл искать иные пути решения задач дуального
управления, не требующие знания априорных плотностей
распределения. Читатель, вероятно, уже догадывается, что
одна из таких возможностей связана с применением
адаптации.
204
УПРАВЛЕНИЕ
[Гл. VII
§ 7.5. Алгоритмы дуального управления
Начнем с известной нам задачи изучения объекта или,
как ее называли в гл. V, задачи идентификации. Эта
задача сводится к минимизации некоторого показателя
аппроксимации характеристик объекта. Для описания объекта
в виде системы уравнений этот показатель был принят
в форме (5.51)
J2(c) = M{F2(x[n]-0(x[n-l], u[n-i])c)}. (7.6)
Как мы уже знаем, минимизация J2 (с) достигается
с помощью поискового алгоритма идентификации (5.52)
с[п] = с[п — 1] —
- Y2 [*] Vc+ F2 (х [п], u[n~i\,c [п — 1], а [п]) (7.7)
или беспоискового (5.53)
с[п] = с[п~ 1]-—
~У2[п]УсР2(х[п]-Ф(х[п~1Ъ и[п — 1])с[п — 1]). (7.8)
В алгоритмах (7.7) и (7.8), которые можно назвать
алгоритмами «изучения», управляющее воздействие не
произвольно, а определяется законом управления,
который принят в данный момент в системе. Запишем этот
закон управления в общей форме:
и[п] = к(х[п], Ь). (7.9)
Правая часть (7.9) представляет собой известную
скалярную функцию от неизвестного вектора параметров Ъ.
_В частности, функция и [п] может иметь вид
u[n] = W(x[n])b. (7.10)
Здесь V = ||гМ1 (v = 1, 2, . . ., N,; \л = 1, 2, . . .
. . ., /i) — матрица размера Ni X /А линейно независимых
функций if>vM,, а Ъ — вектор неизвестных коэффициентов
управляющего устройства размерности МА.
Выбор функций к (х [п], Ь) или if>VM, определяется,
как правило, конструктивными соображениями. Часто
решающим фактором является простота
управляющего устройства либо наличие стандартных элементов.
§ 7.6] АДАПТИВНЫЕ СИСТЕМЫ УПРАВЛЕНИЯ 205
Критерий оптимальности (7.5) теперь можно записать в
развернутой форме
/4 (&, с) = М {Р^хЦп] — Ф (х[п — 1], i¥(x[n—l])b)c)}.
(7.11)
Оптимальный вектор Ъ = &* соответствует минимуму
Ji (&, с). Естественно, этот оптимальный вектор &*
существенно зависит от вектора с, определяющего
характеристики управляемого объекта, что и подчеркнуто в
обозначении аргументов функционала / (р, с).
Для нахождения оптимального вектора Ь* можно
поступить так же, как мы поступали при определении
оптимального вектора характеристик объекта с*.
Минимизация функционала (7.11) достигается с помощью поискового
Ь[п] = Ь [п — 1] —
- Yi М V^i (я° [п], х [п], Ь [п-1], а [п], с [л- 1]) (7.12)
или беспоискового
6 [п] = Ь [п — 1] - Yi [п] V^ (х° [п] —
— Ф(ас[и —1], Y(x[^ —1]) 6[и —1])с[и—1]) (7.13)
алгоритмов. Значения с [тг — 1] определяются по
алгоритмам (7.7) или (7.8).
Алгоритмы (7.12), (7.13) уместно назвать алгоритмами
«управления». В алгоритме «управления» (7.13) для
определения оптимального значения Ь нужно знание
градиента по Ь показателя качества /1в
Алгоритмы «изучения» и «управления» тесно связаны
между собой, т. е. взаимно зависимы. Это свидетельствует
о том, что процессы изучения и управления неразрывны.
Именно в этом и сказывается суть дуального управления.
§ 7.6. Адаптивные системы управления I
Воспользуемся поисковыми алгоритмами дуального
управления: алгоритмом «изучения» (7.7) и алгоритмом
«управления» (7.12) для определения структурной схемы
адаптивной системы управления. Мы уже отмечали
206
УПРАВЛЕНИЕ
[Гл. VII
и[п~7]
Ха Объект
Я с [л]
х0[п]
=д
а
(см. § 3.6), что оценка градиента с помощью разделенной
разности может быть осуществлена с помощью
синхронного детектирования. Структур-
х[п] ная схема адаптивной системы
приведена на рис. 7.1. Как
нетрудно видеть, она представляет
собой объединение схем
идентификации объекта и адаптивного
фильтра, основанных на
поисковых алгоритмах дуального
управления. В этой адаптивной
системе каждое новое значение
состояния объекта х [п] вызывает
изменение параметров с [п] и
Ь [п]. Возможны и иные
стратегии «изучения» и «управления».
Например, изменения с [п] и Ь [п]
можно производить после каждых
I тактов (где I — предполагае-
Рис. 7.1. мый порядок системы, т. е. число
существенных фазовых
координат), либо по истечению такого числа тактов, когда
можно с уверенностью считать, что при данных условиях
мы нашли действительно оптимальные значения
векторов 6* и с*.
Ь[п]
17
—тщвляюищ
—Хустройспшо
§ 7.7. Адаптивные системы управления II
Если невозможно или почему-либо нежелательно
применять поиск, то можно осуществить беспоисковую
адаптивную систему управления на основе алгоритмов дуального
управления (7.8) и (7.13).
Рассмотрим подробнее алгоритм управления (7.13).
Если расшифровать в нем градиент реализации VbF {-),
то можно заметить, что, помимо известных функций
Ч£ : "Sp! ij; -£f (™к как функции F (•), q^, ^
известны), в него войдут неизвестные функции
дхи
db.
— v
vy.
(v = l,2, ...,^ = 1,2, ...,/,), (7.14)
§ 7.7] АДАПТИВНЫЕ СИСТЕМЫ УПРАВЛЕНИЯ II 207
представляющие собой частные производные от выходной
величины объекта по параметрам Ъ. Эти функции
называются функциями чувствительности. Они характеризуют
влияние изменения параметров системы на процессы в ней,
и могут быть определены с помощью специальных
моделей чувствительности. Мы еще будем иметь возможность
кратко рассмотреть их несколько позже.
Чтобы пояснить основную идею, не усложняя существа
дела деталями (которые порой могут оказаться даже
существенными), мы ограничимся линейным объектом,
описываемым разностным уравнением вида
i
х[п]~ 2 amx[n—m]-\-hu[n — l]. (7.15)
m=l
Вводя вектор коэффициентов
с = (аи . .., ai\ К) (7.16)
и вектор ситуации
z[n] = (x[n—l], ...,z[n — l]]u[n — l]), (7.17)
запишем оценку х[п] в виде
x[n] = cTz[n]. (7.18)
Закон управления примем линейным:
и[п-1]= 2 Ьц*[л-1А], (7.19)
или, кратко,
и[л —1] = 6тГ[и], (7.20)
где
Ъ = (Ъи ...,bh) (7.21)
— вектор параметров управляющего устройства, а
Y[n] = (x[n — 1]4 ...,х[п-1А) (7.22)
— вектор входных координат управляющего устройства.
Идентификация объекта осуществляется с помощью
алгоритма «изучения»
с [п] = с [п— 1] + Y2 [п] F'2 {х [п] -ст [п — 1]z [n])z[п], (7.23)
208
УПРАВЛЕНИЕ
[Гл. VII
который минимизирует функционал качества
идентификации
/2 (с) = М {F2 (х [п] -eTz [п])}. (7.24)
Если допустить, что
dc[n]ldb [п] « 0,
то алгоритм «управления» представляется таким образом:
Ь [п] = Ь [п — 1] + Yi [п] F[ (х°[п] — ст [n — l]z [п]) Vb [п] с [п],
(7.25)
где
Vb[n] =
( дх[п — {)
дЪ{ [л —1]
дх [п — 1]
дх[п — I] ди[п — 1] \
dbiln — l] ' dbi[n — i]
dx[n — i] ди[п — 1]
(7.26)
— матрица функций чувствительности размера Z± X ^i +1.
Если ввести матрицы
Vbi [п] =
Vbh[n] =
дх [п. — v]
дх [п — v]
(v = l, ..., l\ [1=1, ..., Z4),
(v=l, ..., li\\i=l, ..., h),
(7.27)
и вектор а = (аь . . ., а{), то алгоритм (7.25) можно
записать в виде
6 [п] = Ъ [п — 1] + yi WFi (х° [n] — cT[n—l]z[п]) X
X (Vbl [п] a [n]+h[n] Vbh [п] b[n-l]+ h [п] Y[n\). (7.28)
Структурная схема адаптивной системы управления,
в основу которой положены алгоритмы (7.25) и (7.28), со
всеми подробностями изображена на рис. 7.2 для случая,
когда I — h = 2. В эту схему входит модель
чувствительности, которая заслуживает того, чтобы посвятить ей
следующий параграф.
7.7]
АДАПТИВНЫЕ СИСТЕМЫ УПРАВЛЕНИЯ II
209
и[п-1]
Объект
х[п]
K^ri^h
Идентификатор
х[п-1]
x[n-Z]
Ф f %
fFf
т
ш
кЦ]—EJHJjH
%i"k—\ х
-0—{х]—'
V
f-
© ©
EH
ЗХ№
■2?
/7—J *ri
Ь ф ©7п
^4¾^
33
ЕЬН
Модель
чувствительности
u[n-lj
ffE3
'П
x[n-2]
ЪЛ*
^ Управляющее x[n - /J
_№троиство_1
Рис. 7.2.
14 я 3. Цыпкин
210
УПРАВЛЕНИЕ
[Гл. VII
§ 7.8. Модель чувствительности
Модель чувствительности позволяет непосредственно
дх
определять функции чувствительности vv = ~—. Вход-
ной величиной ее служит выходная величина объекта,
а величины, снимаемые с определенных точек, равны как
раз искомым функциям чувствительности.
Чтобы определить структуру модели чувствительности,
продифференцируем обе части уравнения объекта (7.15)
п*~ vjn]
Рис. 7.3.
по av. Тогда мы получаем уравнение относительно
функций чувствительности:
vv[n]= У} amvv[n — m] + x[n — v]. (7.29)
m—i
Это уравнение сходно с уравнением управляемого
объекта (7.1.")); выходной величине х \п\ здесь соответствует
функция чувствительности, а управляющему воздействию
§ 7.9] АДАПТИВНЫЕ СИСТЕМЫ УПРАВЛЕНИЯ III
hu [п — 1 ] — выходная величина управляемого объекта,
запаздывающая на v тактов. Структурная схема модели
чувствительности, описываемая уравнением (7.29),
изображена на рис. 7.3, а. Она представляет собой дискретный
фильтр, на' вход которого подается величина х [п — v],
а ошибка представляет собой соответствующую функцию
чувствительности. Структура модели чувствительности по
существу совпадает со структурой модели объекта,
описываемого линейным разностным уравнением. В общем случае
для получения функции чувствительности vv [п] (v =
= 1, . . ., I) необходимо I моделей чувствительности. Но
поскольку объект предполагается линейным с
постоянными параметрами и, следовательно, уравнение
чувствительности представляет собой уравнение с постоянными
коэффициентами, то для получения всех функций
чувствительности можно использовать лишь одну модель. Эта
возможность ясно видна из рис. 7.3, б. На вход
дискретного фильтра подается выходная величина объекта х [п],
а с элементов запаздывания снимаются величины,
соответствующие функциям чувствительности vv [п —- т].
Аналогичным образом можно составить модели
чувствительности и для нелинейных объектов. Но здесь уже
не удается обойтись одной моделью, как в случае
линейного объекта. Если бы удалось каким-либо образом создать
условия, чтобы выходная и входная величины объекта
были развязаны, или, точнее говоря, независимы, то
можно было бы использовать сам объект в качестве модели
чувствительности.
§ 7.9. Адаптивные системы управления III
Пусть в системе автоматического управления случайно
изменяется вектор «неуправляемых» параметров с, и
можно воздействовать на вектор «управляемых» параметров
Ъ так, чтобы уменьшить влияние вектора неуправляемых
параметров на отклонение от нормального режима. Если
бы эти векторы не изменялись, то можно было бы
определить на основе известных результатов теории
автоматического управления некий показатель качества
/° = 5(с, Ъ). (7.30)
14*
212
УПРАВЛЕНИЕ
[Гл. VII
При стационарном случайном изменении вектора с
показатель /° становится также случайной величиной;
поэтому будем искать такое управление, т. е. вектор Ъ, при
котором математическое ожидание показателя качества
J(b) = M{S{c, 6)} (7.31)
было бы минимально.
Алгоритм управления может быть поисковым, например:
6[га] = 6[га-1]-у[л]Ы(р[й], b[n—l], а[п]) (7.32)
или непоисковым:
Ъ [п] = Ъ [п -1] - у [п] VbS (с [п], Ъ[п — 1]). (7.33)
Здесь с [п] — реализация случайного вектора с.
Структурная схема, соответствующая алгоритму (7.32),
изображена на рис. 7.4. Для уменьшения времени
Рис. 7.4.
адаптации можно образовать еще один внутренний
поисковый контур для выбора оптимального значения
величины а [/г], имеющей в данном случае вида [п] = А1па.
§ 7.10] УПРОЩЕННЫЕ АДАПТИВНЫЕ СИСТЕМЫ 213
§ 7.10. Упрощенные адаптивные системы
Беспоисковые адаптивные системы, использующие
модели чувствительности, как мы убедились в § 7.6,
оказываются весьма сложными даже в простейших случаях.
Но адаптивные системы
можно упростить, если
отказаться от
идентификации объекта, т. е.
исключить алгоритм его
изучения. Это можно
осуществить следующим
образом. Потребуем от
системы, чтобы она
«подражала» некоторой
другой системе, которая
принимается за эталон.
Конечно, выбор этого
эталона требует
определенной априорной
информации, если только
мы хотим, чтобы
адаптивная система по своим
свойствам приблизилась
к эталону. Но допустим,
что эталон так или иначе
выбран. Это значит, что
создана модель
некоторой желаемой системы
Тогда этой модели
можно поручить роль
учителя , обучающего нашу систему так, чтобы свойства последней
были близки свойствам модели. Структурная схема такой
упрощенной адаптивной системы (или адаптивной
системы с моделью) изображена на рис. 7.5. Из этой
структурной схемы следует, что наша система играет роль персеп-
трона, осуществляющего идентификацию модели,—
желаемой системы. Качество такой адаптивной системы, вообще
говоря, ниже, чем у систем, рассмотренных в § 7.7. Это
подтверждает тот факт, что простота бесплатно не
достигается.
Но
+(<
"^Q
\ L
ш\
П^1,р1.-ТТ
Управляющее
устройство
[
Ucfn-Jj
уМ
VF(-) 1
Л
Модель
чувствительности.
ft
Эталонная
модель
Г
^с.
7.5
W '
xfnj
x°[nj-x[nj Х\
* к
J xHt)
1
214
УПРАВЛЕНИЕ
[Гл. VII
§ 7.11. Системы управления по возмущению
В этих системах управление осуществляется на основе
измерения возмущений, т. е. самих причин, вызывающих
отклонения состояния системы от желаемого.
Управление по возмущению, если это возмущение можно тем или
иным способом измерять, является весьма эффективным
средством улучшения динамических свойств обычных
систем управления, основанных на измерении отклонения.
Распространение адаптивного подхода на такие
комбинированные системы не представляет каких-либо
затруднений, и читатель при необходимости выведет для
интересующих его случаев алгоритмы управления.
Мы же здесь коснемся весьма интересной задачи
управления по возмущению так называемых переопределенных
объектов, т. е. объектов, в которых число регулируемых
величин (координат) превосходит число управляющих
воздействий.
Уравнение переопределенных объектов запишем так:
y=f(x,u), (7.34)
где
x = (xi9 ..., xh) (7.35)
— /гмерный вектор возмущений,
и = (ии ..., щ2) (7.36)
— /2-мерный вектор управляющих воздействий,
37 = 0/1, ..., Уг) (7.37)
— /-мерный вектор выходных величин.
Для переопределенных объектов I > Z2. Поэтому,
вообще говоря, невозможно обеспечить поддержание всех
выходных величин на заданных уровнях. Однако можно
попытаться обеспечить нахождение всех выходных
величин в некоторых пределах
a'k<yk<a'k, A = l, ..., Z, (7.38)
где a'k и a'k выбираются заранее, исходя из технических
условий, предъявляемых к рассматриваемому объекту.
Для этой цели воспользуемся следующим законом
управления по возмущению:
и = Ф(х)с, (7.39)
§ 7.12] АЛГОРИТМЫ ОПТИМАЛЬНОГО УПРАВЛЕНИЯ 215
где Ф (ас) = || ф^(ас) || (ц = 1, 2, . . ., М; v = 1, 2, . . .
...,^) — матрица известных функций ф^ (х).
Уравнение (7.39) определяет структуру управляющего
устройства.
§ 7.12. Алгоритмы оптимального управления
От выбора вектора параметров г зависит вероятность
того, что /с-я компонента вектора лежит вне допустимых
пределов, определяемых интервалом [a'k, aJU, т. е.
Pk(c) = P{yk£[a'h,ak]}, (7.40)
где
Vk = fk(x, Ф(ас)с).
Качество управления полностью определяется вектор-
функцией Р (с) = (Р{ (с), . . ., Pi (с)), и задачу
оптимального управления переопределенным объектом можно
сформулировать как задачу определения такого вектора
с = с*, при котором функционал
J(e) = Mh{Pk(e)} (7.41)
достигает минимума.
Здесь к — случайный индекс, принимающий значение,
равное индексу одной из компонент выходного вектора ?/,
выходящей за допустимые пределы. Правила, по которым
из нескольких компонент вектора ?/, одновременно
выходящих за допустимые пределы, выбирается одна, могут
быть различными. В частности, можно считать, что если
компоненты с индексами |ль . . ., ^ts одновременно вышли
за допустимые пределы, то случайный индекс к с равной
вероятностью 1/s принимает одно из этих значений.
Если все компоненты лежат внутри допустимых
пределов, то будем считать, что в этот момент времени
случайный индекс к принимает нулевое значение. Закон
распределения к полностью определяется законами
распределения компонент вектора выходных величин // и
правилом выбора одной компоненты из числа компонент,
которые к данному моменту времени вышли за допустимые
пределы.
216
УПРАВЛЕНИЕ
[ГЛ. VII
Введем уже знакомую нам характеристическую
функцию
ГО, если ykeiah,ak]4
Qk (с) = < , -т , „. (7.42)
1.1, если ykZ[ak, ah]\
тогда критерий оптимальности (7.41) можно представить
в виде
J (с) = Ме, k{Qk (с)}, (7.43)
где математическое ожидание берется по 9 и по к. Для
определения оптимального значения с = с*,
минимизирующего J (с), воспользуемся поисковым алгоритмом
адаптации. Тогда
с [п]=с [п- 1] - у [п] V,+em (г [л- 1], а [п]), (7.44)
где m — значение случайного индекса на п-ш шаге.
Если в системе в каждый момент времени только одна
компонента вектора выходных величин может выходить
за допустимые пределы, то критерий оптимальности (7.43)
можно представить в виде
J(e) = Mh{Ph(e)}=^ РЦс)
или
/ (с) = ||Р (с) И», (7.45)
где || Р(с)|| означает евклидову норму "вектора гР(с).
Таким образом, поисковый алгоритм адаптации
доставляет минимум критерию оптимальности (7.43), а в некоторых
случаях и критерию (7.45).
Часто может оказаться необходимым минимизировать
вероятность того, что хотя бы одна компонента выходного
вектора вышла за пределы области Q^, т. е.
минимизировать
J(«)=P[yeQi], (7.46)
где
Qt = {z; a'v <zv <al}. (7.47)
Вводя характеристическую функцию
f 0, если i/fQh
0(c) =, -n (7.48)
v ' [1, если 2/gQ/, v '
§ 7.13]
ЕЩЕ ОДНА ВОЗМОЖНОСТЬ
217
представим функционал (7.46) иначе:
/(с) = М{0(с)}. (7.49)
В этом случае поисковый алгоритм адаптации,
доставляющий минимум критерию оптимальности (7.46), будет
иметь вид
с[п]=:с[п— 1] — у[п] Vc+9(c[rc — 1], а[п\). (7.50)
§ 7.13. Еще одна возможность
Если бы мы могли каким-либо образом для
компоненты ут выходного вектора у определить такое значение с°т
вектора с, при котором Рт (cm) — 0> т0 вместо поискового
можно было бы применять релаксационные алгоритмы,
например алгоритм вида
с[п]^с[п-1]-у[п](с[п-1]-с1), (7.51)
где т — значение случайного индекса к на тг-м шаге.
Подобный подход к решению задачи можно обосновать так.
Если на тг-м шаге т-я компонента выходного вектора
вышла за допустимые пределы, то логично считать, что
при с = с [п — 1]
maxPv (с [п — 1]) = Рт (с [п — 1]) (7.52)
v
и, следовательно, имеет смысл изменить с [п—1] так,
чтобы выполнялось условие
Рт(с[п])<Рт(с[п-1]). (7.53)
Если выполняется условие «сильной унимодальности»
функций Pk (с) (к = 1, . . ., Z), т. е. для любых
допустимых значений с, 77ги^:0<1<1; Рт [с — Цст — с) ] <
<Рт(с), то алгоритм (7.51) работает так, чтобы на каждом
шаге выполнялось условие типа (7.53). Такой алгоритммож-
но применять, например, для решения задачи управления
переопределенной системой, оптимальной по критерию
/(0) = max Л, (с). (7.54)
218
УПРАВЛЕНИЕ
[Гл. VII
§ 7.14. Экстремальные системы управления
Построение экстремальных систем управления обычно
основано на использовании того или иного вида поисковых
колебаний. Эти поисковые колебания позволяют
определить направление движения по экстремальной
характеристике. Если по каким-либо причинам невозможно или
нежелательно проводить поиск непосредственно на
объекте, то можно осуществить экстремальное управление с
помощью адаптивной модели объекта. Эта модель
предназначена для оценки экстремальной характеристики.
В общем случае экстремальный объект описывается
уравнением
х = А(щЪ)+1* (7.55)
где А — нелинейный, но, вообще говоря, выпуклый
оператор, и — управляющее воздействие, £ —
неконтролируемые возмущения, £ — помеха на выходе объекта.
Основная задача экстремального управления состоит
в определении такого управляющего воздействия, при
котором критерий оптимальности
J(u) = M{x} (7.56)
максимален.
Наиболее простой путь, ставший уже традиционным,
состоит в поиске непосредственно на объекте. Для этой
цели можно использовать поисковый алгоритм адаптации
и[п] = ш[п—1] — у[п] Чи±х[п], (7.57)
где
Чи±х[п] = Чи±[А(и[п-1], а [л], Ш]) + Цп]]. (7.58)
Разумеется, вместо Vu± х [п] здесь можно использо"
вать fu+ х [п]. Это традиционный путь построения
экстремальных систем. Но нельзя ли устранить поиск на
объекте? Ведь не всегда допустимо тормошить объект
поисковыми движениями. Можно дать положительный ответ на
этот вопрос, если воспользоваться непоисковыми
алгоритмами управления и изучения.
§ 7.15] АЛГОРИТМЫ ЭКСТРЕМАЛЬНОГО УПРАВЛЕНИЯ 219
§ 7.15. Алгоритмы экстремального управления
Для устранения поисковых движений на объекте
воспользуемся непоисковыми алгоритмами, например, вида
u[n] = u[n — l] — yi[n] Чих[п].
Вычисление градиента
VuX[n] = Vu[A(u, t) + l]
(7.59)
(7.60)
можно осуществить с помощью самонастраивающейся
модели. Типовую структуру этой модели удобно представить
в виде соединения линейной и нелинейной частей (рис. 7.6),
уравнения которых мы
примем следующими:
а
. » К*//7/ ! К
i w[n] J-j>
', -Н7!
<н~о
Рис. 7.6.
у[п]= S w[m]u[n — т]
(7.61)
и
х [га] = ci + с2у + с3у2,
(7.62)
где w [га] —
импульсная характеристика
линейной части, такая, что w [0] = 0, а си c<i, <?з —
коэффициенты аппроксимирующей экстремальной характеристики.
Мы предполагаем для простоты, что импульсная
характеристика w [га] известна, а неизвестными являются
коэффициенты си с2, сг. Заметим, однако, что рассмотрение
общего случая, когда неизвестна и импульсная
характеристика w [га], не составило бы труда для читателя,
обладающего достаточным временем и терпением.
Подставляя (7.61) в (7.62), мы получаем уравнение
модели экстремального объекта
х [га] = ci + с2 2 w [гаг] и[п — т]
m=i
+ с3 2 w[mi]w[m2]u[n—-mi]u[n — m2]. (7.63)
mi, m2=l
220
УПРАВЛЕНИЕ
[Гл. VII
Производная реализации х [п] по и [п — 1] при
фиксированных и[п — т] (т = 2, 3, . . ., п — 1) равна
0фг_11 = (с2+2сз2 м>И]и[и —/га])м;[1]. (7.64)
При установлении алгоритма управления мы можем
не обращать внимания на множитель w [1], который
влияет лишь на масштаб производной (7.64), если только
выбрать знак у [п] так, чтобы
y[n]w[i]>0. (7.65)
Тогда алгоритм управления можно будет записать в виде
и [п] = и[п — 1] —
п
— yi[n](c2 [п — 1] + 2с3 [п— 1] S Ии]и[и —яг]). (7.66)
?п=1
§ 7.16. Алгоритмы изучения
В алгоритм управления (7.66) входят неизвестные
коэффициенты с2, с3. Их можно определить путем решения
задачи идентификации.
Выбрав функционал качества идентификации
J(c) = M{F(x — x)}, (7.67)
можно алгоритмы идентификации или изучения предста
вить в виде
cv[n] = cv [n — l] — y2[n] — F(x[n]~x[n]) (v-=l, 2, 3),
(7.68)
где х [п] определяется выражением (7.63).
Нетрудно вычислить компоненты градиента, входящие
в алгоритм (7.68), а именно
dF(-) OF(') (л . . Ал Г/11 ди[п—1] .
п
+ 2с3[п — l]w [1] 2 да [w] и[п — т] ?""" J ^ f
m=l
§ 7.17]
НЕПРЕРЫВНЫЕ АЛГОРИТМЫ
221
~ ( 2 ^f/7ll и\п— пг\ +
т=1
дс-i дх
+ c2[n-l]w[l\()ul"~1]+2c3[n-l]w[l]x
П
} (7.69)
dF(-)
дс3
МП
—\±[ V ^[wJh;^] X
дх \ .
т., ™<2=^
X и [п — тх\ и[п— m2] + c2w[l]
п
+ 2 c3w[l] ^\ w[m] и[п— т]
ди[п — 1] .
ди [п — {\
дсо
m=i
§ 7.17. Непрерывные алгоритмы
При непрерывном управлении экстремальным
объектом алгоритмы (7.66) и (7.68) заменяются следующими:
du{t)
dt
dcv
dt
- Yi (0 [ c2 (t) - 2c3 (t) ^w(x)u(t- t) dx]
-yAt)dF{XTX(t)) > v=l,2,3,
(7.70)
где теперь
x (t) ~ ct -f- c2 \ w (t) u(t — x)-\-
+ c3 \ \ w(xl)w(x2)u(t — xx)u(t — x2)dxldx2. (7.71)
о о
Мы не будем выписывать компоненты градиента,
входящие во второй из алгоритмов (7.70). Они могут быть
получены весьма просто, хотя бы по аналогии с (7.69). Заметим,
что эти компоненты, как и алгоритмы, получаются, в
частности, из (7.69), (7.66) и (7.68) предельным переходом.
Модель
чувствительности
ИёЕнтификатпр
Управляющее
устройство
Рис. 7.7.
§7.19]
ВОЗМОЖНЫЕ УПРОЩЕНИЯ
223
§ 7.18. Структурная схема
Компоненты градиента, входящие в алгоритмы
изучения, зависят от функции чувствительности алгоритма
управления (7.66). Эти функции чувствительности могут
быть определены по модели чувствительности.
Окончательная структурная схема экстремального
управления представлена на рис. 7.7.
§ 7.19. Возможные упрощения
Предположим, что управляющее воздействие
постоянно на интервале длительности М0. Тогда из (7.69) мы
получаем более простые соотношения:
дх
ис2 дх
771=1
dF(.)
дх
(7.72)
2 и)[1щ\т[т2\ X
7П1, 7712=1
Хи [п — гщ] и [п —- m2], J
и алгоритм изучения принимает вид
cAr] = cv[r-i]-y2[r]F'(x[r]-i[r]) (v = l, 2, 3), (7.73)
причем п = М0г, т. е. в течение интервала постоянства
управления происходит М0 шагов идентификации
объекта. Можно пойти еще дальше, отказавшись от алгоритма
управления. Действительно, если мы можем
определить Ci, с2 и с3, то нетрудно аналитически определить
оптимальное управление, по крайней мере в тех
случаях, когда мы убеждены, что экстремальная
характеристика достаточно точно представляется квадратическои
параболой.
224
УПРАВЛЕНИЕ
[Гл. VII
В рассматриваемом нами случае
^опт — '
(7.74)
2с* ^ w [»]
С подобной ситуацией мы сталкивались в § 6.7. Такая
упрощенная схема экстремальной системы и изображена
Ш£
Рис. 7.8.
на рис. 7.8. Наряду с известными нам элементами в ней
используется делитель.
Для экстремальной характеристики, отличной от
параболической, и при наличии других нелинейностей
построение модели чувствительности оказывается весьма
сложным, а порой и невозможным. Выход из этого затруднения
§ 7.20} О СИНТЕЗЕ ОПТИМАЛЬНЫХ СИСТЕМ 225
может быть найден на пути использования самого объекта
в качестве модели чувствительности, но возможно также
применение поиска на модели и последующее перенесение
управляющих воздействий на объект.
§ 7.20. О синтезе оптимальных систем
Задача синтеза оптимальных систем управления вот
уже много лет привлекает внимание ученых и инженеров.
Мы хотим показать возможность решения подобной задачи
на основе адаптивного подхода. Чтобы читатель не
подумал, что адаптивный подход применим только к
дискретным системам, описывающимся разностными или
суммарными уравнениями, мы здесь рассмотрим управляемый
объект, описываемый векторным дифференциальным
уравнением
x(t)=f(x(t),u(t)), (7.75)
где
ac(0 = (*i(0. •••.*/(*)) (7-76)
— вектор состояния,
м(0 = (М0, •••' uh(t)) (7.77)
— вектор управляющего воздействия.
Качество управления оценивается функционалом
т
J° = lfo(x(t))dt. (7.78)
о
В задаче синтеза требуется найти такой закон
управления, при котором функционал /° в силу уравнений
(7.75) достигал бы минимума. Когда и скаляр, этот закон
имеет вид
u(t) = k(x(t), t). (7.79)
Будем искать уравнение управляющего устройства
в знакомой нам форме
u(t) = k (х (0, t) = стф (х (*), t). (7.80)
В этом случае задача аналогична задаче
восстановления неизвестной функции к (§ 7.5). Нужно заметить, что
15 Я. 3. Цыпкин
226
УПРАВЛЕНИЕ
[Гл. VII
часто вид вектор-функции ф(х, t) определяется заранее
конструктивными соображениями, а не только желанием
возможно лучше аппроксимировать функцию к (х, t).
Уравнение (7.75) можно заменить уравнением
x(t) = f (х (0, стф (х (0, 0) =/i (* (0. с). (7.81)
Решение этого уравнения
x(t) = x(x(0), с, t) (7.82)
зависит от вектора начальных состояний х (0) и вектора
параметров с. Поэтому функционал (7.79)
г
/о (с) = ^fo(x (х (0), с, /)) dt = Ф (х (0), с) (7.83)
о
также зависит от начальных условий. Это значит, что
однозначно определить оптимальный вектор с невозможно, ибо
он зависит от вектора начальных состояний х (0). Чтобы
избежать этой неоднозначности, естественно считать
вектор с = с* оптимальным, если он минимизирует
критерий оптимальности (7.78) в среднем для, хотя и
неизвестной, но безусловно существующей плотности
распределения р (х (0)) начальных состояний. Таким образом, мы
приходим к необходимости минимизации функционала
т
J(c) = Mx{J^c)} = Mx{lf0(x(x(0),c,t))dt} . (7.84)
о
§ 7.21. Применение алгоритмов адаптации
Для применения алгоритмов адаптации прежде всего
нужно найти градиент по с показателя качества / (г).
Это проще всего сделать, используя сопряженную
систему. Составим уравнение сопряженной системы
(7.85)
Ф(0 =
Ч>(Г) =
F(x, е) = |
-V/0(ac)
0,
д/у (ж, С) 1
1 *н
-F(x,c)W)t)
(V, (1=1, .
§ 7.213 , ПРИМЕНЕНИЕ АЛГОРИТМОВ АДАПТАЦИИ 227
и введем функцию Гамильтона
Я (if, ас, е) = -/оИ-f/^, с). (7.87)
Дифференциал /°(с) (7.83) можно представить в виде
г т
б/° (с) = J V<T#6c Л = бтс J Vc Я Л, (7.88)
о о
где
v-M-f.-.^-)- (?-89>
Таким образом, мы видим, что вектор Q(x(0), с) =
т
= KycHdt играет роль градиента реализации показателя
о
качества в пространстве параметров
т
V/0 (с) = ¢(35(0), с) = J V„#(i|>, х, с) Л. (7.90)
о
Теперь, используя адаптивный подход, можно для
определения оптимального значения вектора с =- с*
предложить следующий алгоритм:
с [гс] = с [гс — 1] — y [гс] <? (х [гс], с [гс — 1]). (7.91)
Этот алгоритм «работает» следующим образом. Сначала
выбираем произвольное значение с [0] и измеряем
начальное состояние х0 [0]. Зная с [0] их0 [гс], по
соотношениям (7.85), (7.87), (7.89) и (7.90), находим Q (х0 [0], с [0]),
и, согласно алгоритму (7.91), определяем с[1]. Далее
процедура повторяется.
Для каждой итерации нужно при постоянном значении
с ~ с [гс] в течение времени, равного Г, измерять
выходную величину системы х (t).
Необходимо отметить, что в общем случае нелинейной
системы (7.75) эта задача имеет существенно
многоэкстремальный характер, и указать общие условия, при которых
функция / (с) была бы выпукла, т. е. имела бы один
экстремум, довольно трудно.
15*
228
УПРАВЛЕНИЕ
[Гл. VII
§ 7.22. О синтезе оптимальных систем
при наличии помех
В предыдущем параграфе мы полагали, что вектор
состояния х может быть точно измерен. К сожалению,
часто вместо вектора состояния х измеряется иной вектор,
скажем ?/, который зависит от вектора состояния ху
помехи £, характеризующей ошибку измерения, и, возможно,
времени t.
Как в этих условиях осуществить синтез оптимальной
системы? Для нелинейных объектов методы, которые бы
решали эту задачу, пока неизвестны. Единственный и,
вероятно, поэтому уже ставший общеизвестным выход из
этого положения состоит в следующем. Объект
предполагается линейным, помеха — гауссовой, а критерий
качества — квадратичным. Эти предположения обеспечивают
полный успех в решении задачи, не столько поставленной,
сколько полученной в результате «линеаризации» и «гаус-
совизации». Но если даже закрыть глаза на эту подмену
или, в лучшем случае, если бы такая подмена задачи нас
устраивала, то и тогда этот традиционный путь не привел
бы к приемлемым результатам. Дело в том, что для
объекта, описываемого уравнениями высокого порядка,
возникли бы огромные вычислительные трудности, вызванные
необходимостью интегрирования большого числа
нелинейных уравнений типа Риккати.
Для решения рассматриваемой здесь задачи синтеза
будем искать уравнение управляющего устройства в форме
и (0 = А (//(0, с), (7.92)
где к — некоторая заданная функция,
у(') = Ы0. у(1,(0. .... у<'>(0).
или
у (t) = (у (О, У (t - т), . . ., у (t - h)) (7.93)
— вектор доступных для измерения величин,
c-(q, ...,cN) (7.94)
— вектор пока неизвестных параметров, причем, как
выше уже было отмечено,
у (0 = г (х (*), %,t). (7.95)
§ 7.23] УПРАВЛЕНИЕ И ОПОЗНАВАНИЕ 229
Положим, что заранее известен оптимальный закон
управления как функция фазовых координат либо
оптимальное управление как функция времени. Моделируя
управляемый объект, мы тем самым делаем вектор
состояния x(t) = (х (t), х(1) (0, • • ., zl(t)) или x(t) = (x(t),
х (t —т), . . ., х (t — 1т) доступным для измерения. На
этой модели производятся прогонки и для различных
оптимальных управляющих воздействий и (£), т. е. для разных
начальных состояний. Тем самым находятся оптимальные
значения вектора у (/), что позволяет составить таблицу
поведения «идеальной» оптимальной системы. Теперь
задача состоит в таком подборе вектора параметров с — е*
в (7.92), чтобы наилучшим образом приблизиться к этой
«идеальной» системе.
Особенно эффективен такой подход для систем,
оптимальных по быстродействию. В этом случае, как известно,
и (t) = ± 1 и нужно определить с так, чтобы при малом
е > 0 выполнялись неравенства
u(t) + B-k(u(t), с)>0, 1
и (/)-6-¾ (2,(/), с)<0. J ( ' }
Если к зависит от с линейно, то мы получаем систему
линейных неравенств, с которой уже встречались в § 4.11.
Изложенный там подход решает задачу и в этом случае.
В общем же случае задача сводится к решению нелинейной
системы неравенств (7.96), которая при определенных
условиях допускает применение аналогичных, но
надлежащим образом обобщенных алгоритмов.
§ 7.23. Управление и опознавание
В §§ 7.21 и 7.22 было выяснено, что задача
оптимального по быстродействию управления сводится к решению
системы неравенств и, значит, она родственна задаче
опознавания. Эта связь заслуживает того, чтобы о ней сказать
подробнее, рассмотрев хотя бы какой-либо пример.
Для простейшей консервативной системы, описываемой
уравнением второго порядка, релейный закон
управления обеспечивает максимальное быстродействие, если
линия переключения представляет собой полуокружности
(рис. 7.9).
230
УПРАВЛЕНИЕ
[Гл. VII
Предположим, что мы измеряем величину
у = *2+ *! + £• (7.97)
Именно такая величина измеряется, например, при
наблюдении спутника в телескоп, если х^ и х2 — координаты
спутника, а £ — шум.
Будем предполагать, что величина у измеряется в
дискретные промежутки времени t, t — т, t — 2т, . . .
Рис. 7.9.
Составим из I таких измеренных значений вектор
V = (y(t), y(t-*h ..., y{t-li)). (7.98)
Для переключения и (I) выберем такое правило:
если ута — а0 > 0, то знак и (t) изменяется,
если ута — а0 < 0, то знак и (t) не изменяется;
здесь а = {а{, а2, . . .» щ}-
Определение оптимальных значений (а, а0) можно
осуществить так же, как и в задачах обучения
распознаванию образов.
Промоделируем на ЦВМ оптимальную систему. Для
разных начальных условий можно найти, таким
образом, соответствующие оптимальные траектории. Те
векторы у, у которых все составляющие лежат только в
области, где и (t) = —1, отнесем к классу Л, остальные —
к классу В. Таким образом,
(7.99)
уТа — а0:
утАа — а0 < 0
и задача сводится к необходимости решить систему
линейных неравенств. Это можно сделать с помощью любого
из алгоритмов, рассмотренных в §§ 4.11 и 4.12.
§ 7.24]
ОБОБЩЕНИЕ МЕТОДА СИНТЕЗА
231
§ 7.24. Обобщение метода синтеза
Изложенный в § 7.22 метод синтеза оптимальных
систем можно несколько обобщить и свести непосредственно
к минимизации некоторого функционала, минуя систему
неравенств. Будем считать, что в нашем распоряжении
имеется «идеальная» оптимальная система, которая не
только работает оптимальным образом, но в которой все
нужные данные доступны измерению. Эту идеальную
систему можно рассмат-
ffW
&
Объект
VF(-)
СТ<р(Х)
fc=
ривать в качестве
«учителя». Роль же
«учеников» выполняют
«обычные» типовые
регуляторы с несколькими
параметрами настройки.
Эти регуляторы
должны «научиться»
наилучшим образом выполнять
функции обычно
дорогостоящих «настоящих»
оптимальных систем.
Поступим
следующим образом. Сначала
определим соответхтвие
между начальными
условиями #v(0) ((я = 1, . . .
. . ., М0) и
оптимальным управлением w J (t),
в результате чего
определяется оптимальный процесс acj (t). Таким образом,
число показов должно быть равно М0.
J}
Г[п]
Д
Рис. 7.10.
Выберем закон управления в виде
и (*) = cTq> (ж (/)).
(7.100)
Определим оптимальный вектор параметров так,
чтобы минимизировать показатель качества
м0
232
УПРАВЛЕНИЕ
[Гл. VII
представляющий собой меру близости закона
управления (7.100) к идеальному оптимальному управлению u^(t).
Это можно осуществить, как нетрудно понять,
обычным образом с помощью алгоритма адаптации вида
с[п] = с[п — 1] — у[п] VcF(u*[n] — ст[п— 1] ср(х [и — 1])).
(7.102)
Схема обучения изображена на рис. 7.10. Здесь к (х) —
характеристика идеального управляющего устройства
(«учителя»), а ет<р (х) — искомая характеристика
типового управляющего устройства («ученик»).
§ 7.25. Некоторые задачи
Мы здесь сформулируем ряд задач, решение которых
возможно на основе адаптивного подхода. Наряду с
такими задачами мы приведем и формулировки других задач,
решение которых нам пока неизвестно.
Поведение замкнутых автоматических систем
намного сложнее поведения разомкнутых систем, которые
рассматривались в предыдущих главах. Именно при
рассмотрении задач обучения и адаптации в замкнутых системах
и возникают вопросы взаимодействия алгоритмов
изучения и управления и вопрос о влиянии этого
взаимодействия на сходимость этих алгоритмов. Но пусть
установлены условия сходимости; тогда, как мы уже отмечали
в § 7.6, возможны различные стратегии изучения и
управления. Все эти стратегии почти эквивалентны, если время
адаптации не ограничено. Положение резко меняется, когда
время адаптации ограничено. В этом случае вопрос о выборе
соотношения между алгоритмами изучения и управления
приобретает первостепенное значение. Здесь, в частности,
возникает задача об оптимальном управлении объектом
при заданной степени «незнания» его характеристик.
Часто у нас возникает затруднение в выборе
показателей качества, так как обычно он должен состоять из
нескольких составляющих, характеризующих, например,
стоимость сырья и энергетических ресурсов, объем
получаемой продукции и т. п. Эти составляющие должны
входить в критерий качества с определенными коэффициента-
§ 7.25]
НЕКОТОРЫЕ ЗАДАЧИ
233
ми (весами), которые обычно заранее неизвестны и
которые нужно определить в процессе эксплуатации. Иначе
говоря, в этой задаче осуществляется адаптация самого
показателя качества управления. Решение этой задачи
также возможно на основе изложенного подхода.
Целый ряд задач оптимизации автоматических систем
связан с минимизацией функционала вида
т
/4 = ^(^(0-ж (0) Л. (7.103)
о
Эти задачи также могут быть приведены к
рассмотренным выше задачам. Действительно, заменим функционал
(7.103) функционалом вида
т
J2^~-lF(xQ(t)-x(t))dt. (7 Л 04)
о
Эти функционалы имеют минимум при одной и той же
функции х (t). Поэтому, если выполняются условия
эргодичности, то минимизация обоих этих функционалов
сводится к минимизации
J = Mte{x°(t) — x(t))\ . (7.105)
Иногда возникают задачи, в которых требуется
минимизировать функционалы вида
оо
JB=*M {§F(x°(t) — x(t))dt\ . (7.106)
Для минимизации функционала (7.106)
непосредственное использование рассмотренных выше алгоритмов
невозможно, поскольку в текущий момент времени t
значение функции х (t) неизвестно на всем промежутке
0</ < оо. Поэтому возникает вопрос, нельзя ли
минимизировать показатели качества (7.105) и (7.106),
наблюдая в каждый текущий момент времени t величины
t
y(t) = ^F (х° (t) - х (0) dt (7.107)
о
234
УПРАВЛЕНИЕ
[Гл. VII
с помощью вероятностных и регулярных алгоритмов,
сходных с рассмотренными.
Определение величины у (t) в соответствии с (7.107)
представляет определенные 1рудности, так как требует
все возрастающей памяти. Насколько близко мы
подойдем к оптимуму, если вместо (7.107) будем использовать
величину
t
yT(t)= ^F(x°(t) — x(t))dt, (7.108)
t-т
где T — фиксированная величина?
§ 7.26. Заключение
В замкнутых автоматических системах отклонение,
ошибка от желаемого или, точнее говоря, предписанного
состояния используется для формирования управляющего
воздействия, которое устранило бы эту ошибку.
В отличие от задач опознавания, идентификации
и фильтрации, которые мы обсуждали ранее, в задачах
управления, решаемых замкнутыми автоматическими
системами, мы сталкиваемся с двумя типами алгоритмов.
К первому типу относятся уже знакомые нам алгоритмы
изучения, роль которых состоит в изучении,
идентификации управляемого объекта. Второй тип охватывает еще
не встречавшиеся нам алгоритмы управления, которые
должны быть выработаны управляющим устройством.
Взаимосвязь между алгоритмами изучения и
управления свидетельствует о том, чю управляемый объект
вместе с управляющим устройством составляют в
замкнутых автоматических системах неразрывное целое. Эта
особенность замкнутых систем приводит к существенному
усложнению протекающих в них процессов по
сравнению с разомкнутыми системами. И хотя здесь уже
получены определенные результаты, касающиеся адаптивных
систем, многие вопросы еще далеко не ясны, и мы
находимся сейчас лишь на начальном этапе развития теории
и принципов построения таких систем.
Глава VIII
Надежность
§ 8.1. Введение
При конструировании сложных систем одной из
важных задач является задача надежности. Надежность
зачастую имеет столь же большое, если не большее значение,
что и характеристики, определяющие назначение системы.
Что же такое надежность? О чем мы будем говорить
на протяжении этой главы?
Надежность характеризует способность системы не
иметь отказов в работе. Наличие отказов, например,
в цифровой вычислительной машине, вызванных
выходом из строя какого-либо элемента, приводит к тому,
что результаты ее работы становятся непригодными.
Повышение надежности системы может быть
достигнуто как повышением надежности отдельных элементов,
так и (при заданной надежности элементов) созданием
особых структур.
Мы покажем в этой главе, что одним из возможных,
а порой, быть может, и единственным путем решения
задач, связанных с повышением надежности, является
адаптивный путь.
§ 8.2. Понятие надежности*
Трудно дать абстрактное и, значит, всеобщее
определение надежности, да и вряд ли это необходимо. Разные
лица, как правило, либо вкладывают в такие абстрактные
понятия различное содержание, либо не вкладывают
никакого содержания вообще. Но не давать никакого
определения тоже нельзя.
Под надежностью часто подразумевают свойство
системы сохранять свои рабочие характеристики в заданных
236
НАДЕЖНОСТЬ
[Гл. VIII
пределах, обеспечивающих нормальную работу системы
при определенных условиях эксплуатации. Если
характеристики системы выходят за эти пределы, то часто
говорят, что произошел отказ системы.
Слова «часто подразумевают», «часто говорят», которые
здесь фигурируют, должны напоминать нам, что
существует очень большое число иных определений
надежности, которое, пожалуй, соизмеримо с числом
публикаций, посвященных этой проблеме.
Но в любом случае понятие надежности тесно связано
со свойством системы в течение определенного интервала
времени сохранять работоспособность (безотказность),
с приспособленностью к обнаружению и устранению
причин, вызывающих отказы (ремонтопригодность), и,
наконец, со способностью к длительной эксплуатации
(долговечность).
Безотказность, ремонтопригодность, долговечность —
три кита теории надежности.
После того как определения даны, мы таим надежду,
что теперь по крайней мере понятно, о чем будет идти
речь, и что мы будем пытаться оптимизировать? И если
читатель уже в общих чертах догадывается, что и здесь
можно применить адаптивный подход, то мы смело можем
углубиться в эту привлекательную, но еще далеко
не освоенную область.
§ 8.3. Показатели надежности
Показатели надежности представляют собой некоторые
характеристики системы и соответствуют тому, что мы
раньше называли показателями качества или критериями
оптимальности. Этими показателями могут быть, в
зависимости от рассматриваемых задач, разнообразные
величины, характеризующие надежность. Для нашей цели
оказывается особенно удобной такая схема введения
показателей надежности.
Предположим, что эволюция системы описывается
случайным процессом х (£), т. е. траекторией системы,
определяющей ее состояние в момент t. Все возможные
состояния образуют фазовое пространство системы.
Выделим в фазовом пространстве некоторую область S0TK.
§ 8.3] ПОКАЗАТЕЛИ НАДЕЖНОСТИ 237
Если в некоторый момент времени t = t' траектория
системы х (t) попала в область S0TK, т. е. х (tf) £ £отк
(рис. 8.1), то считается, что произошел отказ системы.
х1
х,(0)
х2(0) xz(tf[n]) joJtV x2(t0f
Рис. 8.1.
Для определения количественных показателей
надежности вводится функционал О, определяемый на
траекториях системы х (t). Тогда показатель надежности можно
определить как математическое ожидание этого
функционала:
/ = M{fl (я (*))}. (8-1)
Смысл этого показателя очевиден. Каждой траектории
приписывается определенный вес О (х (£)), и за
показатель надежности принимается среднее значение этого
веса.
Если определить функционал # = ^ (ас (t)) так:
{О, если хотя бы при одном 5<^0
x(s)£S0TK, (8.2)
1 в ином случае,
то, как нам уже известно,
/4 = ^(^(^(0)) = ^0. (8.3)
238
НАДЕЖНОСТЬ
[Гл. VIII
т. е. функционал равен вероятности безотказной работы
системы на интервале [0, t0].
Если же функционал О = Ь (х (t)) равен длительности
промежутка времени до первого попадания траектории
системы х (t) в область S0TKl то математическое ожидание
этого функционала
J2 = M{$2(x(t))} = T (8.4)
определяет среднее время безотказной работы.
Чем ближе вероятность безотказной работы системы
к единице или чем больше время безотказной работы ее,
тем система более надежна. Часто задача построения
систем, оптимальных по надежности, состоит в
обеспечении максимальных значений показателей надежности.
Теперь уже можно перейти к рассмотрению задачи с
интересующей нас точки зрения.
§ 8.4. Определение показателей надежности
Определение показателей надежности (8.3) и (8.4)
сводится к вычислению математического ожидания, и если
плотность распределения нам неизвестна, то мы можем
воспользоваться алгоритмами адаптации. Так, для
вероятности безотказной работы на фиксированном интервале
времени t0 и среднего времени безотказной работы Т
мы получаем на основе дискретных алгоритмов
следующие уравнения:
Pt, [п] = Pt0 [п - 1] - Y In] [Pt0 [и - 1] - Ф4 (хп (*))] (8.5)
и
T[n]^T[n-l]-y[n][T[n-l]-$2(xn(t))], (8.6)
где хп (t) — реализация функции х (I) при 0<£<£0
на п-ъл. шаге.
Если воспользоваться модифицированными
алгоритмами, то вместо (8.5) и (8.6) мы получим
п
Pt0 1п] = Р,в [n-l]-y[n] [Pt0 \П - 1] —1 2 *1 (Xm (0)]
771=1
(8.7)
о
§ 8.4] ОПРЕДЕЛЕНИЕ ПОКАЗАТЕЛЕЙ НАДЕЖНОСТИ 239
и
п
Т[п] = Т[П-1]-у[п] [Пц-Ц-i ^ «й(Жт(*))] •
т=1
(8.8)
Вместо совокупности реализаций на интервале [0, t0]
для эргодических процессов можно использовать
последовательные участки длительности t0 одной и той же
я(щ Фиксатор
\ отказов
Сброс
(t0)
Kt'lnl)
w2Hi^7
Pt0MJ
x(t)
Сброс
(t0L
кtw s;n,(x(t))=tf[n]
Фиксаюор
отказов
—»-
;
0
_L
Т[п-Г]
Рис. 8.2.
реализации. Именно этому случаю и соответствуют
структурные схемы определения PtQ и Г с помощью обычного
(рис. 8.2) и модифицированного (рис. 8.3)
алгоритмов. Нетрудно усмотреть в них сходство с уже
знакомыми нам устройствами для определения плотностей
распределений.
В схемах, реализующих алгоритмы (8.5) — (8.8),
фиксатор отказов (ФО) работает следующим образом.
Как только фазовая координата системы х (t) попадает
первый раз на интервале времени [nt0l (п + 1) t0] в
область отказов S0TK, выходная величина ФО становится
положительной и сохраняет знак до конца интервала,
т. е. до момента времени (п + 1) *о« В моменты времени
kt0 (к = 1, 2, . . .) на выходе ФО устанавливается нуль,
т. е. происходит сброс.
S<n'(x(t))=1(t'[7i])
x(t)
Фиксатор\
отказов
T Сброс
1 (to)
KHHtH
KtW ej">(x(t))^'inj
Piic. 8.3.
Ptjn-V
Ф?н
T[n-1]
Я
>
н
я
о
о
•-з
&*
§ 8.6]
ЧАСТНЫЙ СЛУЧАЙ
241
§ 8.5. Минимизация эксплуатационных расходов
Расходы на обслуживание системы включают расходы
на все операции, которые необходимы для обеспечения
работоспособности системы. Эксплуатационные расходы
можно разбить на две части:
расходы W [О (х (t), Т)], непосредственно
необходимые для обеспечения некоторого уровня надежности
О (х (t), Т) в течение времени Т использования системы
(расходы на профилактический ремонт, на
восстановление системы после отказа, на замену оборудования более
надежным и т. д.);
расходы U (Г), не влияющие непосредственно на
надежность системы (направленные на улучшение других
характеристик: удобства работы, точности и т. д.).
Общие расходы, вызванные эксплуатацией системы
за время Г, в среднем можно оценить функционалом
J = M{W[Q(x(t), T)]} + K0M{U(T)}, (8.9)
где к о — весовой коэффициент. Здесь и далее, рискуя
вызвать недовольство читателя, мы оставляем для
множителей Лагранжа обозначение Я, которое в теории
надежности прочно занято в качестве обозначения
коэффициента надежности. Нас извиняет лишь то обстоятельство, что
далее коэффициент надежности нигде не фигурирует.
Очевидно, функционал / будет в значительной мере
зависеть от «последовательности обслуживания» системы.
Последовательность обслуживания системы может
представлять собой либо временной график профилактического
ремонта системы, либо распределение фондов,
отпускаемых на ее обслуживание, либо что-то еще. Поэтому точный
смысл этого понятия определяется конкретной задачей.
Оптимальная последовательность обслуживания
системы соответствует тому случаю, когда общие
эксплуатационные расходы (8.9) становятся минимальными.
§ 8.6. Частный случай
Пусть требуется оценить, через какие равные
промежутки времени L следует производить
профилактический ремонт системы так, чюбы потери (8.9) были
минимальными.
16 Я. 3. Цынкин
242
НАДЕЖНОСТЬ
[Гл. VIII
Допустим для простоты, что потери U (Т) не зависят
от L. Тогда критерий (8.9) упрощается, и
/i = Мх {W [^ (х (О, Т, L)]}, (8.10)
где Т = const.
Расходы, связанные с обеспечением уровня
надежности 'О1!, можно представить в виде
W[^(x(t), T,L)] = W^(x{t),T,L)] + W2(L), (8.11)
где W2 (L) — суммарные расходы на профилактический
ремонт за время Т использования системы, Wi —
остальные расходы, необходимые для поддержания уровня
надежности ф при данном значении L (расходы на
восстановление системы после сбоя и т. д.).
Расходы W2 (L) на профилактический ремонт прямо
пропорциональны Т и обратно пропорциональны L.
С увеличением L расходы на профилактический ремонт
за время Т будут уменьшаться, но при этом надежность
системы также уменьшается, система чаще выходит
из строя, и расходы типа W^ увеличиваются.
Оптимальное значение L = L*, при котором
функционал /4 принимает минимальное значение, находится с
помощью алгоритма
L[n] = L[n-l]-y[n][WtL(xn(t),T,L[n--i]) +
+ УГ2ь(Ь[п-1])]. (8.12)
§ 8.7. Минимизация стоимости, веса, объема
Пусть имеется некоторая система, и А — конечное
множество различных элементов системы, соединенных
определенным образом.
Любой элемент а, принадлежащий А, т.е.а^Л, может
находиться в одном из двух состояний: в рабочем
состоянии и в состоянии отказа в зависимости от различного
рода случайных факторов.
Вероятность Р (х, с (а)) того, что система находится
в состоянии х £ X, зависит от различных параметров
элементов а £ А: от их качества, а значит, и от
стоимости, быть может, от их веса, объема, числа элементов
§ 8.8]
АЛГОРИТМЫ МИНИМИЗАЦИИ
243
каждого типа и т. д., поэтому с (а) является вектор-
функцией
с (a) = (^ (a), с2(а), с3(ос), . ..), (8.13)
компоненты которой представляют собой, например,
стоимость Сх (ос), вес с2 (а), объем с3 (а), число резервных
элементов с4 (а) и т- Д-
Обозначим через F (х) вероятность того, что система,
находясь в состоянии х, способна решить задачу,
выбранную случайным образом (независимо от состояния х)
в соответствии с некоторым вероятностным законом
из определенного множесава задач.
Естественно в качестве показателя надежности системы
выбрать величину
J= %F(x)P(x,c(a))^MJ{F(x)}. (8.14)
x£Ar
В таком случае задача оптимального с точки зрения
принятого критерия эффективности построения системы
состоит в следующем: определить такую
вектор-функцию с (а), чтобы функционал (8.14) принимал
минимальное значение при выполнении следующих условий:
с(а)>0, г^ e(*) = gQ. (8.15)
а£А
Эти неравенства выражают тот очевидный факт, что
стоимость, объем, вес, количество потребляемой энергии
и т. д. положительны и, как правило, ограничены.
Обозначим
c(a) = {Ci(a), ...,¾(a)}. (8.16)
Заметим, что в общем случае в этой задаче требуется
оценить не просто вектор, как в предыдущих задачах,
а вектор-функцию с (ос), зависящую от а, где а
определяет тип элементов системы и принимает конечное число
значений.
§ 8.8. Алгоритмы минимизации
Для каждого фиксированного значения ос, согласно
(3.19) и (3.24), можно записать алгоритм,
минимизирующий функционал (8.14) при ограничениях (8.15). Этот
16*
244
НАДЕЖНОСТЬ
[Гл. ЛТШ
алгоритм имеет вид
Са [п] = са [п -1] - у [п] {VCF (х [п] + К[п- 1])}
и
Ми] = тах{0, К[п — 1] — YiN [2 са [п— l]-flr0]},
а£А
(8.17)
где са [тг] представляет собой значение вектор-функции
с (а) на п-и шаге.
£•,//7-/7
*-*ML
х[п]
%[Щ
с,[п-1]
ck[n-V
сф-1]
Л>
-ffo
Л
V " ' V
Е
Л...Л
н
AmML
У1М
VcF(x[n]) t>(g)=z=>|7^/|==^
^C
ck+1[n-1]
c^fn-J]
Л>
*H5
c„[n-1]
V
j Рис. 8.4.
Критерий (8.14) отличается от критериев, которые
рассматривались ранее, тем, что функция F (х), от которой
берется математическое ожидание, не зависит явно
от параметра с (ос). От параметра с (а) зависит только
распределение случайной величины х\р(х, с (а)), т. е.
значения функции F(x) зависят от с (а) только через
§8.9]
ОСОБЫЙ СЛУЧАЙ
245
случайную функцию
х = х(с(а)). (8.18)
Таким образом, распределение значений функции F (х)
зависит от с (а) как от параметра:
F(x) = Y(c(a)), (8.19)
где У (с (ос)) — некоторая случайная функция а,
интегральный закон распределения которой полностью
определяется условными распределениями случайной
величины ас, т. е. р (х, с (а)).
Схема, реализующая алгоритмы (8.17), приведена
на рис. 8.4.
§ 8.9. Особый случай
Вероятно, читатель заметил, что алгоритмы (8.17),
хотя и дают достаточно полное решение задачи
минимизации, но тем не менее не охватывают всех возможных
случаев и, в частности, того, который связан с
минимизацией функционала (8.14) по числу резервных элементов.
Как мы увидим далее, задачи минимизации тех или иных
функционалов по параметрам, принимающим дискретные
значения, не столь редки в теории надежности, как это
может показаться с первого взгляда.
Поэтому важно установить алгоритмы минимизации,
пригодные для этих случаев. Мы наметим эту возможность
в общих чертах.
Для наглядности ограничимся случаем одного
параметра. Пусть параметр с может принимать лишь
определенные фиксированные значения из некоторого конечного
множества (алфавита)
D = {du d2, ..., dN}, (8.20)
и необходимо определить экстремум функционала
J(c) = M{Q(x, с)}. (8.21)
Этот функционал имеет физический смысл лишь для
c^D, где D — множество возможных значений паря
метра с.
246
НАДЕЖНОСТЬ
[Гл. VIII
Вне этого множества определим Q (х, с) с помощью
линейной интерполяции. Тогда для любого с функцию
Q (х, с) можно записать в виде
<?(х, e) = Q{x, dv^)+Q{x'df-<^{x'dv-i)(c~d^i), (8.22)
где
dv__i<c<dv. (8.23)
Тогда, очевидно, экстремум нового функционала
Jo = M{Q°(x, с)} (8.24)
и прежнего функционала (8.21) будут достигаться при
одних и тех же значениях с* £D.
§ 8.10. Алгоритмы
Применим к (8.24) поисковый алгоритм. Учитывая
кусочно-линейный характер Q (х, с), получаем
c[n]^c[n — i]~y[n]Q°c±(x[n], cln—l], а\п]), (8.25)
где
Q°c±{x[n]f с[п — \],а[п})^
Q(x[n], dv) — Q(x[n], dv_{)
&v — &V—1
при dv-i<Cft[ra--l]<dv,
1 \ Q (a? [и], dv_t [n-l))-Q (a? [и], dv [n-1])
+
Q(x[n], dv\n-l])-Q(x[n], dy.j [n-1]) 1
dv [n—ll — dv-iln — 1] J
при с [n — 1] = dv.
(8.26)
§ 8.10]
АЛГОРИТМЫ
247
Смысл этих соотношений таков. Поиск при оценке
градиента функции Q0 (х, с) осуществляется только в тех
точках, где производная" (? (х, с)] не существует. Если же
х[п]
Рис. 8.5.
эта производная в точке с [п — 1] существует, то п-и
шаг делается на основе точного значения градиента.
Схема, реализующая алгоритм (8.26) (при dv = v;
v = 1, 2, . . ., Af), изображена на рис. 8.5. Здесь
мы встречаемся с новым элементом, выходная величина
которого равна 1 или 0, если входная равна нулю или
соответственно отлична от нуля.
Чтобы избежать трудностей, связанных с появлением
при линейной интерполяции новых стационарных точек,
можно воспользоваться также поисковым алгоритмом, но
при наличии ограничений вида
II (c-dv) = 0. (8.27)
При этом мы получим новый поисковый алгоритм
c[n] = c[n — l] — y[n]]Qc±(x[n], с[п— 1], а[п]) +
м м
+ Ми-ИЕ П (c[n-l]-dv)], (8.28)
k=i v=l
V-fk
м
Х[п]=к[п-1]-ух[п] [I (c[w-l]-dv),
248 НАДЕЖНОСТЬ [Гл. V11I
где Qc± (х [тг], с [п — 1], а [п]) по-прежнему
определяется выражением, аналогичным (8.26).
Приведенные выше алгоритмы (8.25) и (8.28) могут
быть обобщены и на тот более сложный случай, когда с —
вектор, все составляющие которого (или их часть)
принимают определенные фиксированные значения.
§ 8.11. Повышение надежности путем резервирования
Один из способов повышения надежности сложной
системы состоит в использовании дополнительных
элементов устройств, которые подключаются в случае
выхода из строя соответствующих элементов или устройств,
т. е. в резервировании. Ограничения по стоимости, весу,
а также усложнение структуры не позволяют слишком
увлекаться введением большого числа дополнительных
элементов и устройств для резервирования и, значит,
обеспечить абсолютно безотказную работу системы.
Как же сформулировать и найти наилучшее решение
этой задачи с учетом реальных ограничений?
Предположим, что система состоит из N ступеней
(или блоков) к = 1, 2, . . ., N. Обозначим через т}{
число устройств-дублеров в &-й ступени, а через
Pk imki cki wk)—вероятность того, что fc-я ступень
находится в исправном состоянии (последняя функция
представляет собой показатель надежности fc-й ступени,
когда в ней используется mk устройств весом и стоимостью
соответственно ch и wh каждое).
Показатель надежности всей системы —- вероятность
того, что вся система (т. е. все N ступеней) находится
в исправном состоянии,— определяется, очевидно,
выражением
N
Д=П Pk(mh,ch,wh) (8.29)
или
R = M{Q(m, с, *г)}, (8.30)
где
{1, если все N ступеней
находятся в исправном состоянии, (8.31)
0 в противном случае.
§8.11] ПОВЫШЕНИЕ НАДЕЖНОСТИ ПУТЕМ РЕЗЕРВИРОВАНИЯ 249
Суммарный вес и цена представляются выражениями
2 ckmk^cTm,
N
2 whmk-=wTm.
(8.32)
(8.33)
Задача состоит в максимизации общего показателя
надежности (8.30) по числу устройств-дублеров в каждой
ступени. При этом должны удовлетворяться ограничения
стт=^А, (8.34)
wTm^B. (8.35)
Здесь мы сталкиваемся с особым случаем, и поэтому
нужно применять алгоритмы вида (8.25), но при учете
ограничений типа равенств. В данном случае имеем:
т\п]-~ т[п — 1] — у[п] (Vm±0[m [п—1|, с, w]-\-
+ А,! [п\ с-\-Х2 [п] w).
(8.36)
Х{ \п\ - ?ц \п — 1 ] -|- Yi [»] (Л — сТт \п — 11),
Ми] Ми — 1H-Y2|ra](#— ю'гт[/г — 1]),
где
V ,0=-(0 , О , . .., 0mv),
0„,А[т[и—1], с, w] =
( Q[d + е, с, w] —0 [d, с, w],
| если mh[n~ 1] не равно целому числу;
— J 1
y[0[d + €», с, w] —0[d —е, с, /г]],
[ если лтг^ [/г—1] равно целому числу.
Здесь е = (1, 1, ..., 1) —единичный Л^-мерный вектор,
&=1,2,...,ЛГ, а
d = (du . . ., dN),
dv — целая часть mv (v = 1, 2, . . ., N).
Аналогичным образом можно рассмотреть задачу и при
учете ограничений типа неравенств, если только не
опасаться громоздких выражений для алгоритмов.
(8.37)
(8.38)
250
НАДЕЖНОСТЬ
[Гл. VIII
§ 8.12. Повышение надежности путем избыточности
Пусть входной сигнал s поступает одновременно
по N + 1 однотипным каналам. Выходной сигнал v-ro
канала связи xv из-за наличия помехи £v будет отличаться
от входного, так что
xv = s + lv. (8.39)
Мы будем полагать, что сигнал s и помехи £v не кор-
релированы и, кроме того, lk и ^ при к Ф I также не кор-
релированы. Задача состоит в получении наилучшей
в определенном смысле оценки истинного значения
сигнала 5, который должен быть использован в системе.
Мерой оценки будем считать средний квадрат отклонения
выходного сигнала х от истинного 5.
Будем искать оценку истинного значения сигнала
в виде
N
Zj cvxv
s-^ (8.40)
/1 cv
v--0
или, кратко,
т
л___ ° х
S — j, ,
с1 с
где с — пока не известный вектор коэффициентов.
Именно такой вид оценки является наилучшим согласно
принципу максимального правдоподобия и методу
наименьших квадратов, если распределение вероятностей
помех гауссово.
Найдем вектор коэффициентов с = с* так, чтобы
функционал
J(c)^M{F(s~-s)}, (8.41)
где F — выпуклая функция, достигал минимума.
Допустим, что после каждого измерения xv мы можем
хотя бы по одному (например, г-му) каналу определить
значение помехи
1Г = хг при 5 = 0. (8.42)
§ 8.12] ПОВЫШЕНИЕ НАДЕЖНОСТИ ПУТЕМ ИЗБЫТОЧНОСТИ 251
Это можно сделать, если удастся выделить интервалы
времени, когда отсутствует входной сигнал, и измерить
помеху. С учетом (8.39) и (8.40) мы можем записать (8.41)
так:
J(c) = m{f [хг - 1Г - -^Д-) } . (8.43)
Градиент реализации легко вычислить, воспользовавшись
зависимостью
\cF(xT-lr ^-) =
\ с1 е /
= -F'(x,.~lr-4^-){-4 етЙгЬ (8'44>
V с1 е I V с1 с (cV)2 /
Он всегда может быть определен по реализации х и
измерениям £г в интервалы времени отсутствия сигнала. Тогда
на основе алгоритма адаптации мы получим
c[n] = c[n—l] + y[n]F' [xrln] — lr[n] L—--^- X
х (_^Н e^-^W) . (8.45)
Если бы дисперсия а2 помехи £ была заранее
известна, то для частного случая, когда F — квадратичная
парабола, надобность в адаптации отпала бы, и
непосредственно из (8.43) можно было бы заранее определить
оптимальные векторы коэффициентов с* по формуле
с* = кв-\ (8.46)
где
cri = {ar\ ...,(¾1}. (8.47)
Адаптивный подход целесообразно применять, если
априорная информация о помехе заранее неизвестна.
Разумеется, в этом простейшем случае можно было бы
использовать адаптивные алгоритмы для вычисления
дисперсии помехи, а оптимальные параметры определять
уже по формуле (8.46).
252
НАДЕЖНОСТЬ
[Гл. VIII
§ 8.13. Проектирование сложных систем
При проектировании сложных многокомпонентных
систем мы всегда сталкиваемся с расхождением между
номинальными и фактическими значениями параметров.
В силу различных причин эти параметры представляют
собой случайные функции времени. Вектор параметров
х (t) = (xi (t), . . ., xN (t)), естественно, отличается от
исходного, начального вектора параметров х0 =
= (ж01, • • •» xon)- Обозначим через г|эд (х0, х) некоторые
внешние характеристики системы. Они зависят как
от начального х0, так и от текущего х вектора параметров
и определяют работоспособность системы.
Система работоспособна, если эти внешние
характеристики удовлетворяют определенным условиям (например,
они изменяются внутри определенных границ либо
принимают значения, близкие в том или ином смысле к
некоторым заранее заданным фиксированным величинам).
Один из основных этапов, возникающих при
проектировании сложных систем, состоит в обеспечении их
работоспособности. Это может быть достигнуто выбором
начального вектора параметров х0. Разумеется, на
работоспособность системы влияет реализация текущего
вектора параметров; она зависит от структуры системы.
Однако номенклатура элементов ограничена, а структура
часто определяется назначением системы, поэтому
большие изменения их невозможны.
Таким образом, возникает задача выбора такого
начального вектора параметров х0, который бы обеспечил
оптимальную с определенной точки зрения
работоспособность системы.
§ 8.14. Алгоритмы оптимальной работоспособности
Если работоспособность системы характеризовать
вероятностью того, что ни одна из внешних характеристик
не выходит за допустимые пределы, т. е.
J(Xo) = P{ak<$h(Xo,x)<Pk} (й=1, 2, ...), (8.48)
то мы приходим к задаче, близкой к рассмотренной
в § 7.11 в связи с управлением по возмущению. Следова-
§ 8.14] АЛГОРИТМЫ ОПТИМАЛЬНОЙ РАБОТОСПОСОБНОСТИ 253
тельно, для определения оптимального начального
вектора х* мы можем применять поисковый алгоритм
х0[п] = х0[п—1] — у [п] V«.+ Э (х [п],х0 \п — 1], а [п]), (8.49)
= 6(ж' хр + а) — д(х, х0) и где
а
О, если ah < \ph (.г, х0 + «) < pft,
^ л/ ч Q(x, х0 + а) — д(х, х0) _л
где V*+6 (ас, х0, а) = а - — и гДе
О (х, х0, а) ~
(8.50)
1 в противном случае.
В ряде случаев может оказаться целесообразным
использовать иной критерий оптимальности:
/ (х0) = М {F (г|> (х, х0) - Л)} (8.51)
при условии
Л/{ЫЫ*.жо))--Яа}<0 (& = 1, 2, ...,#), (8-52)
где Л и Bk~постоянные.
х[п] •
I | , l |—ГЧ. Л, IIГII I
I 1 , 1 гтчЛ///-#
аг-;
Х[Т1]
JL
Нс(х,х0)
ЪЛ-)
Wn-l]
Рис. 8.6.
Функционал (8.51) при ограничениях (8.52) можно
минимизировать с помощью алгоритма (3.24):
х0 [п] = х0 [и— 1] -Y [л] (V*0F (г|э (х [л], х0 [и — 1]) - А) +
+ #с (х [и], х0 [/г-1]) к [и-1], (8.53)
^ [л] - max {О, Ь [л — 1] + Yi [и] (£ (* М, х0 [/г— 1]) —^)>,
254
НАДЕЖНОСТЬ
[Гл. VIII
где
Ч0]>0 (8.54)
и приняты следующие обозначения:
L (х, х0) = (Li (^ (ж, аг0)), ...,£* СФ* (ас, #<>)))•
Д = (Д4| ...,^), (8.55)
Яс^'^) = ||^^^-||^ = 1,2, ...,^-,11 = 1,2 Af.
В тех случаях, когда составляющие вектора параметров
принимают только дискретные значения (это могут быть,
например, номинальные значения параметров отдельных
элементов схемы,— сопротивлений, конденсаторов),
следует применять алгоритмы § 8.10.
Схема, реализующая алгоритм (8.55), показана
на рис. 8.6.
§ 8.15. О минимаксном критерии оптимизации
Иногда для обеспечения работоспособности системы
требуется выполнение более жестких по сравнению с
рассмотренными в § 8.14 критериев. В частности, можно
использовать критерий минимума по параметру с
некоторой функции качества системы, значение которойдпри
каждом фиксированном с равно максимальному среди
соответствующих значений средних характеристик
системы. Иначе говоря, минимизируется наименьшая верхняя
граница семейства средних характеристик системы:
J(c) = maxM{Fh{q{x,c))}. (8.56)
л
В этом случае мы приходим к так называемой задаче
на минимакс.
Для частных видов функции Fk (г|)А (х, с)) существуют
итеративые процедуры, которые позволяют решать
задачи, используя только реализации Fk при
фиксированных значениях с. Например, если Fk (г|зЛ (х, с))
представляет собой вероятность того, что к-я характеристика
системы выйдет за допустимые границы [осА, $к] при
:8.16] ЕЩЕ О ПРОЕКТИРОВАНИИ СЛОЖНЫХ СИСТЕМ 255
с = с0, т. е.
Fh (¾ (ж, с0)) = Р {yh (х, с0) ё [aft, pft]}, (8.57)
то задача может быть решена с помощью алгоритма (7.51):
с [П] = с [п— 1] — у [п] (с [п— 1] — <&), (8.58)
где т — номер характеристики системы, которая на п-м
шаге вышла за допустимые границы (подробнее см.
§§ 7.11—7.13). По-видимому, при выборе более широкого
класса функций Fk(-) можно построить итеративные
процедуры для оценки точки минимакса (8.56) функции
регрессии по наблюдениям реализаций Fk (г|)й (ас, с)) при
некоторых фиксированных с. Возможно, такое решение
может быть получено с помощью игрового подхода
к этой задаче (см. гл. X).
§ 8.16. Еще о проектировании сложных систем
В задачах, рассмотренных ранее, можно было
оптимизировать работоспособность системы только путем
изменения начальных значений параметров системы и таким
образом влиять на статистические характеристики
текущих параметров системы. Возможен более общий подход
к задачам такого типа.
Пусть задана структура системы. Значения
параметров элементов системы представляют случайные
величины, распределения которых неизвестны. Оценим, при
каких статистических характеристиках этих случайных
величин или при каких значениях параметров их
распределений будет удовлетворяться некоторый критерий
оптимальности этой системы.
Так, если закон распределения вектора параметров
х [п] = (xi [/г], . . ., xN [п]) элементов системы зависит
от параметров ге == (ulf . . ., uN), то выходной сигнал
можно представить в виде
у[п] = Т(х[п]), (8.59)
где Т — известный оператор, определяемый уравнением
системы. Сигнал у [п] в статистическом смысле полностью
определяется вектором и. Задача состоит в том, чтобы
256
НАДЕЖНОСТЬ
[Гл. VIII
на основе отдельных реализаций некоторого показателя
оптимальности системы / (у, и) определить оптимальные
значения параметров плотности распределения, т. е.
значения такого вектора г/*, при котором математическое
ожидание
* = Мя{1(у,и)} (8.60)
минимально. Критерий оптимальности / (у, г*), как
и функции выигрыша в других задачах, выбирается,
исходя из физических требований к исследуемой системе.
В частности, иногда целесообразно задавать / (?/, и)
в виде
J(V,u) = Ji(y) + J2(<u), (8.61)
где /А учитывает меру разброса выходной координаты
системы, а /2 — затраты, связанные с уменьшением
допусков на параметры элементов.
Возможны и иные дополнительные ограничения.
Если допускается изменение статистических
характеристик параметров системы, то эта задача может быть
решена с помощью поискового или непоискового
вероятностного алгоритма. Более того, можно использовать
адаптацию для улучшения самого показателя
оптимальности.
§ 8.17. Замечание
Многие задачи теории массового обслуживания,
занимающейся количественным изучением процессов и
качества обслуживающих систем, приводятся к моделям,
которые мы, по существу, рассматривали в связи с
задачами теории надежности. Поэтому возникает
возможность применения ряда алгоритмов, приведенных в
предыдущих параграфах этой главы, для решения задач
теории массового обслуживания.
Полезно при этом иметь в виду соответствие между
понятиями и терминами теории надежности и теории
массового обслуживания. Обычно «отказу» и «ремонту»
соответствует «требование» и «обслуживание».
Таким образом, адаптивный подход распространяется
и на задачи теории массового обслуживания.
§ 8.19]
ЗАКЛЮЧЕНИЕ
257
§ 8.18. Некоторые задачи
По-видимому, наиболее целесообразен адаптивный
подход при ускоренных испытаниях на надежность.
Разработка методов адаптации применительно к этой
ситуации сильно упростила бы оценку надежности
испытываемых систем.
Весьма перспективна также разработка методов
синтеза высоко надежных систем путем адаптации,
состоящей во введении дополнительных существенных и
устранении избыточных малосущественных связей в системе.
Для ответственных условий работы систем
целесообразно в качестве критерия оптимальности принять
максимум отклонения средних характеристик системы, как
это было упомянуто в § 8.14. Нельзя ли минимизировать
этот критерий на основе одних лишь реализаций, без
предварительного отыскания максимума отклонения
средних характеристик?
§ 8.19. Заключение
Мы продемонстрировали в этой главе применение
адаптивного подхода для решения задач оценки и
оптимизации показателей надежности. Разумеется, задачи,
которые были рассмотрены, сравнительно просты и,
возможно, слишком «академичны» для того, чтобы
специалист, кровно заинтересованный в повышении надежности
разрабатываемых им систем, отнесся к ним с должной
серьезностью и почтением. Но заметим, что многие
важные вещи начались с простого. Мы надеемся, что
простота задач не вызовет усмешки, а явится истоком для
серьезных размышлений над применением адаптивного
подхода к более сложным реальным задачам, требующим
неотложного решения.
17 Я. 3. Цыикшг
Глава IX
Исследование операций
§ 9.1. Введение
Мы теперь переходим в иную область, связанную
с оптимальными способами организации
целенаправленных процессов и результатов человеческой деятельности.
Изучением их занимается специальное научное
направление, называемое исследованием операций. Все, что
связано с организацией каких-либо действий, направленных
к достижению определенной цели, относится к
исследованию операций. Предмет исследования операций
настолько широк, что вряд ли его можно достаточно полно
определить.
Иногда говорят (и это не лишено смысла), что
исследование операций — это «количественное выражение
здравого смысла» или «искусство давать плохие ответы на те
практические вопросы, на которые другие способы дают
еще худшие ответы». Бесцельно и наивно рассуждать
об исследовании операций вообще. Смело и неосуществимо
пытаться охватить все конкретные применения
исследования операций. Поэтому единственное, что нам
остается,— это выделить несколько типичных для исследований
операций задач и показать, что на эти задачи можно
не только взглянуть с несколько необычной для них точки
зрения, вытекающей из развитого выше адаптивного
подхода, но и получить их решение в тех случаях, когда
иные подходы неудобны или непригодны.
К типичным задачам исследования операций относятся
задачи планирования, распределения запасов и средств,
построение систем обслуживания и т. п. задачи. Эти
задачи приобретают определенную, а порой даже жизненную
важность. Решение подобных задач часто дает ответ на
вопрос, что лучше: быстро, но дорого, или медленно, но
дешево.
§ 9.2]
ПЛАНИРОВАНИЕ ЗАПАСОВ
1^59
Обычно перечисленные задачи рассматриваются при
условии достаточной априорной информации, касающейся
фигурирующих в них плотностей распределения. Однако
часто эти плотности распределения неизвестны. В этих
случаях рассматриваемую задачу иногда заменяют
минимаксной. Но всегда ли замена одной задачи другой
правомерна? Быть может, лучше рассматривать эти задачи
с точки зрения адаптивного подхода, не требующего
предварительного знания плотностей распределения. Мы
попытаемся показать плодотворность именно такого подхода.
§ 9.2. Планирование запасов
Задача оптимального планирования запасов состоит
в определении объема производства или заготовок,
порядка снабжения или уровня запасов, необходимых для
удовлетворения будущего спроса при минимальных
потерях и затратах.
Ясно, что чрезмерно большой запас приводит к
избытку материальных ценностей и требует больших затрат
на хранение. Недостаточный запас может привести к
перебоям в работе.
Перейдем теперь к формулировке интересующей нас
задачи.
Пусть имеется одиночная база, предназначенная для
хранения и выдачи товаров. Поступление их на базу
происходит в дискретные моменты времени. Заказ поступает на
базу через L единиц времени после того, как он сделан.
Спрос на товары, т. е. количество товаров, которое
требуется в единицу времени, определяется внешними
по отношению к базе условиями и не зависит от запасов,
имеющихся на базе. При работе базы затраты связаны
с подготовительно-заключительными операциями,
содержанием запасов и с потерями из-за дефицита.
Эффективность работы базы определяется условиями
ее работы (а именно, спросом на товары, величиной
интервала L, характеристиками затрат в единицу времени
и др.) и политикой заказов товаров.
Политика заказов может, например, состоять в
указании величины заказа и момента, когда делается заказ
на товар.
17*
260
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Предположим, что заказ величины q делается каждый
раз, когда уровень запасов на базе оказывается равным
некоторому критическому уровню р.
Задача планирования запасов в данном случае состоит
в определении такой политики заказов (т. е. в определении
таких значений р* и </*), при которой удовлетворяется
некоторый критерий оптимальности планирования
заказов. Обычно спрос х (t) заранее неизвестен. Поэтому имеет
смысл считать, что х (I) — некоторый случайный процесс,
статистические характеристики которого определяются
внешними условиями (работой других предприятий,
рынком сбыта и т. п.).
Учитывая это, в качестве критерия оптимальности
планирования запасов можно выбрать математическое
ожидание потерь в единицу времени. Усреднение по
времени проводится на интервале U0, t0 -f- Т\ между двумя
поступлениями.
Введем вектор заказов
<' (Р, <у). (9.1)
Затраты за интервал времени |/0, /0 -\-Т\, где /0 — момент
поступления товара на базу, можно записать в виде
F(x, г, Т(х, с)). (9.2)
Здесь Т — интервал времени между двумя последующими
поступлениями товара, который представляет собой
случайную величину. Юе распределение может зависеть от
вектора заказов и распределения х (t). Следовательно,
критерий оптимальности планирования в общем случае
можно записать так:
J(c).-Mx{F(x,c,T{x,c))}. (9.3)
Теперь задача состоит в таком выборе вектора заказов
с = о*, при котором критерий J (с) достигает
минимального значения.
§ 9.3. Критерий оптимальности планирования
Поскольку «примеры более поучительны, нежели
правила», рассмотрим конкретную форму функционала (9.3).
Предположим, что спрос х (t) представляет собой
некоторый стационарный случайный процесс, математиче-
§ 9.3] КРИТЕРИЙ ОПТИМАЛЬНОСТИ ПЛАНИРОВАНИЯ 201
ское ожидание которого постоянно и равно г. Кроме того,
считаем, что поступление заказа любой конечной
величины q происходит мгновенно, а время отставания
Гис. <).!.
равно L\ потери <7 на единицу дефицита и затраты h на
хранение единицы товара постоянны и известны нам
заранее.
Для простоты примем еще, что уел опия работы бауы
и политика заказов таковы, что полное количество
товаров, находящихся на храпении, и полное количество
дефицитных товаров за интервал времени U0, t0 -[- Т]
такие же, какими они были бы, если бы на :)том интервале
спрос х (t) был постоянным и равным
,,,(,) _rdo)-nt» г Г, {iJA)
для любого £0, где / (t) — уровень запасов на базе в
момент времени t. Под дефицитными товарами понимаются
товары, запас которых па базе меньше спроса.
Тогда при оценке издержек в единицу времени на
интервале U0, t0 _|- Т] можно считать зависимость уровня
запасов от времени кусочно-линейной функцией
(рис. 9.1).
262 ИССЛЕДОВАНИЕ ОПЕРАЦИЙ [Гл. IX
Из этой зависимое!и видно, что затраты на
содержание запасов в единицу времени равны
( у (Zp — bL + q-bo) при Ь2<р,
1т-;_&;+ь?; пРИ ь2>Р.
Потери из-за дефицита в единицу времени составляют
{(Ь2~р)-- при Ъ2>р,
JV- < (9.6)
( 0 при Ь2<р.
Наконец, потери в единицу времени на подготовительно-
заключительные операции равны
jF3--f- (9.7)
Используя обозначение вектора заказов (9.1), представим
критерии оптимальности планирования в виде
J(c)^Mx{F(x,c,T(x,c))}, (9.8)
где затраты F (-) в единицу времени на интервале
[t0, ^о + Л определяются выражением
F(x,e, Т(х,е))-.-^(2р \-q-bi-b2)sgn(p-b2) +
--sgn(b2 — р) +
гдо
2 r/-^-
; .-^(b2-.p)sgii(b2-p)+7^r , (9.9)
/^ ? x(t)dt, b2= \ x(t)dl
In-L to+T-L
1 при z> 0,
sen z — .
~ '0 при z<0.
Нетрудно убедиться в том, что в данной модели Т
является только функцией q и не зависит от р. Это
обстоятельство упрощает определение оптимального решения.
§ 9.5] ЕЩЕ О ПЛАНИРОВАНИИ ЗАПАСОВ 263
§ 9.4. Алгоритмы оптимального планирования
Если плотность распределения вероятностей спроса
х (t) известна, то можно определить / (с) в явной форме
и минимизировать его по с. Именно так обычно и
делается. Но часто мы не имеем сведений относительно
плотности распределения х (I) и здесь вместо гадания и
неуверенного выбора той или иной плотности распределения
мы можем стать на твердую почву адаптивного подхода,
обходящего эту трудность. Применим для
минимизации (9.9) алгоритмы адаптации. Тогда мы получим
с [п]=--с [п—1] —
—y[n]4eF(x[n], с[п-1\,Г(х[п], с [н-1])), (9.10)
если функция F (•) дифференцируема, и
с[п] ~с[п — I] —
-уМУИ«].Ф-1и[п].ПФ].Ф-и«1»1)), (9.И)
если неудобно находить градиент VCF (•).
§ 9.5. Еще о планировании запасов
Рассмотрим несколько иную модель процесса
производства и сбыта товара.
Допустим, что товар поступает на базу через
одинаковые интервалы времени Т (плановые интервалы).
Поступление товара происходит мгновенно. После
каждого разового поступления товара в течение времени
Т происходит сбыт товара, который определяется
исходным запасом товара в начале интервала Т и спросом
на товар в течение этого интервала. Пусть далее спрос г
на товар в течение планового интервала времени Т
представляет собой случайную величину. Плотность
вероятностей р (г) существует, но нам неизвестна.
Процесс получения, хранения и сбыта товара в
течение интервала времени Т неизбежно связан с некоторыми
потерями Рч( •). Эти потери зависят от спроса г и от
разового поступления 5 в начале интервала Т, т. е.
F = F{r,s).
(9.12)
264
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Определим оптимальное разовое поступление 5 товара,
при котором средние потери (издержки) на интервале
времени Т
J(s)^Mr{F(r,s)} (9.13)
будут минимальными.
Функция F (г, s) зависит в значительной степени
от типа потерь, которые следует учитывать. Но в
большинстве случаев, если имеется возможность определить
для различных, заранее указанных sk по одному
значению реализации функции F (г, sA), то для определения
оптимального значения s* можно применить
соответствующие алгоритмы адаптации.
В следующих параграфах мы рассмотрим несколько
частных случаев, представляющих определенный интерес.
§ 9.6. Оптимальное разовое поступление
Пусть потери F ( •) в течение интервала времени Т
определяются только потерями из-за избытка товаров
i?i (Т) и из-за недостатка товара (дефицита) Е2 (Г),
а именно:
y>'l(r)^A||,_rj u(s-r)},
"d (9.14)
1Ы'П " yl(/--*) + |s-r|l
и
F(r,s). R{(T) t-li2(T), (9.15)
где h и d— соответствующие потери, приходящиеся
на единицу товара. Тогда критерий (9.13) примет вид
J(s)---h^ (s~r)p(r)dr + d^ (r~s)p(r)dr, (9.16)
О s
и задача определения оптимального разового потребления
сводится к решению уравнения
s
Jll(?i-_(h-\-d)*\p(r)dr-d = Q, (9.17)
(IS ¢)
§ lJ.7]
оптимальный уровень запасов
265
которое можно записать и так:
A/,{sgn (s — r)} =
или, TaKKansgnz- — (sign2 + 1),
h--d '
li — d
(9.18)
(9.19)
A/, {sign (r-$)}=- j^^ ,
и алгоритм определения оптимального разового поступле-
г[п)
s[n-t]
<э
h-d
h+d
<л] h— УМ W
Рис. 9.2.
иия будет иметь следующий вид:
s[n\=- s[m-1| + y ["] sign (г \n\ — s \n — 1 J)
// —</i
/i-i-rfi
. (9.20)
Этот простой алгоритм реализуется схемой, изображенной
на рис. 9.2.
§ 9.7. Оптимальный уровень запасов
Пусть потери в течение интервала времени Т
складываются из потерь на содержание запасов /?i (Г) и потерь
из-за дефицита товаров R2 (Т):
Ri(T)-~^l(\I(t)\ + I(t))dt,
И2(Т)-=-^1(11(t)\-I(t))dt,
где / (t) — уровень запасов в момент времени t.
(9.21)
266
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Если предположить, как и в задаче об оптимальном
планировании запасами §§ 9.2—9.4, что / (t) на
интервале времени Т изменяется линейно (см. рис. 9.1), то мы
получим функцию потерь в виде
\н(—т)т
t У sti + т (г ~" s)*2
при r<.s',
при
(9.22)
где s — уровень запасов в начале интервала времени Г,
ti — время после поступления товара, через которое
исчерпывается весь запас; ^ = ^ (г), t2 = Т — tu г —
спрос на товар в течение интервала времени Т.
Задача определения оптимального значения исходного
уровня запасов s = s* в начале планового интервала Т,
г[п]
^Ч2>
i
X
fi-d
h+d
S[n-1]
<И
y[n]
Рис. 9.3.
при котором минимизируется функционал J (s) =
= М {$? (s, г)}, сводится к решению уравнения
(U (S)
(h + d)[\p (г) dr + sl ^ dr ] ~ d = °> (°-23)
которое, как и ранее, можно преобразовать к удобной
для нас форме
Mr[(s-l)sign(r-*) + sl=^. (9.24)
§ 9.9] РАСПРЕДЕЛЕНИЕ ПРОИЗВОДСТВЕННЫХ МОЩНОСТЕЙ 267
Отсюда видно, что алгоритм определения 5* имеет вид
s[n] = s[n — 1] — у[п] [(s[n — l] — l) sign (r[n] — s[n—l]) -(-
+ «[» —11—1=^1 . (9.25)
Этому алгоритму соответствует несколько более
сложная система, которая изображена на рис. 9.3.
§ 9.8. Замечание
Задачи оптимального разового поступления (§ 9.б)
и оптимального уровня запасов (§ 9.7) являются частны"
ми случаями задач оптимального планирования (§§ 9.2—
9.5). В отличие от общих задач планирования эти задачи
характеризуются тем, что в них процесс движения
запасов конечен, интервал времени Г, на котором
рассматриваются затраты (потери), постоянен и выбирается заранее
и, наконец, в них оценивается разовое поступление
товара.
§ 9.9. Распределение производственных мощностей
Процесс производства обычно состоит из ряда
связанных между собой процессов (например, процессов
производства составных элементов окончательного продукта).
Каждый такой процесс характеризуется определенной
скоростью выполнения.
Для хранения промежуточных и окончательных
продуктов производства в системе имеется ряд складов
с объемами соответственно vu . . ., uN.
Скорость снабжения системы сырьем и спрос на
готовую продукцию могут изменяться случайным образом.
Можно считать, что система работает удовлетворительно,
если ни один из складов не оказывается заполненным до
отказа или пустым.
Задача состоит в том, чтобы распределить скорости
выполнения отдельных процессов производства, при
которых вероятность неудовлетворительной работы
предприятия, т. е. вероятность того, что хотя бы один склад
переполнен или, наоборот, пуст, была бы минимальной.
268
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Обозначим через yk количество продукции, которое
требуется хранить на /с-м складе, а через Qh — область,
определяемую условием
Qh = {y.0<yh<Vb}. (9.26)
Тогда, вводя вектор количества продукта
!/-(Уи ...,Ух), (9-27)
можно записать показатель качества работы предприятия:
1--Р{,/ёЩ. (9.28)
Вводя характеристическую функцию
f 0, если и G il}{,
0(//)--- * ' г<л (9-29)
v,// I 1, если у/£ Qh, v ;
получим иную форму записи соотношения (9.28):
/- Л/ {0(//)}. (9.30)
Количество продукта, а значит, как //, так и 0 зависят
от вектора скоростей выполнения отдельных процессов
V (сь . . ., CN).
Минимум / (с) определяется с помощью поискового
алгоритма
с[п\. c[n-l\-\\n\fr 0 (//(г \п-Ц,а\п\)). (9.31)
Для других критериев оптимальности работы системы
решение задачи может быть получено либо с помощью
аналогичных поисковых алгоритмов адаптации, либо с
помощью релаксационных алгоритмов (см. § 7.13).
§ 9.10. Пример
В качестве иллюстрации рассмотрим кратко задачу
планирования работы завода по производству серной
кислоты. Структурная схема связи цехов и складов
завода изображена на рис. 9.4.
Блоки 1—5 представляют собой склады для хранения
исходных и промежуточных продуктов производства.
Блоки 6—8 — устройства, в которых производятся
продукты со скоростями У6, У7, vs.
§ 9.10]
прим к l>
269
Блоки 9—14 — склады готовой продукции.
Предполагается, что спрос у о на кислоты разных концентраций
и скорость г поступления сырья определяются внешними
Риг. 9/..
факторами и представляют собой случайные величины
с некоторыми неизвестными нам функциями
распределения Pi и р2-
Объемы складов 1—5 и 9—14, а следовательно, и
скорости потоков продуктов между соответствующими
блоками ограничены величинами уь . . ., v5 и v9, . . ., vUk.
Можно сказать, что завод работает удовлетворительно,
если ни один из складов не оказывается ни пустым,
ни переполненным.
Оптимальное планирование работы такого завода
состоит в установлении таких скоростей производства
с*, . . ., с%-, при которых вероятность
неудовлетворительной работы завода была бы минимальной. Это и
осуществляется алгоритмом (9.31).
270
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
§ 9.11. Распределение средств обнаружения
Для радиолокационных устройств обнаружения цели
весьма важным является отыскание эффективных способов
обзора заданной зоны, т. е. распределение энергии в этой
зоне, выбор последовательных этапов обзора в некотором
фиксированном интервале времени.
В качестве критерия эффективности режима обзора
можно выбрать функционалы, характеризующие
эффективность режима обзора при постоянных энергетических
затратах, либо энергетические затраты при условии
постоянства вероятности показателей обнаружения.
Средняя эффективность зондирования,
характеризующая эффективность режима обзора зоны, представляется
в следующей форме:
J=^F(f(x), x)p(x)dx, (9.32)
Л'
или кратко
J = M{F(f(x), х)}, (9.33)
где F (•) — функция выигрыша, определяющая,
например, вероятность обнаружения сигнала при
фиксированном х. Функция выигрыша предполагается заданной.
Она зависит от распределения имеющихся у нас средств
обнаружения/ (х). К средствам обнаружения относится,
например, мощность зондирующих сигналов, время
поиска и т. д. Поскольку существуют ограничения по
энергии или по времени, то / (х) должна удовлетворять
условию
$(x)f(x)dx-A, (9.34)
А'
характеризующему величину ограничения ресурсов
(энергии, числа ложных тревог, времени). В (9.34) ty (х) —
некоторая весовая функция. Часто \\)(х)~ 1.
Задача состоит в определении функции / (х) такой,
что эффективность обзора или средний выигрыш (9.32)
был максимален при соблюдении ограничительного
условия (9.34). Если плотность распределения вероятностей
р (х) известна, то при определенных условиях* налагае-
§ 9.12J АЛГОРИТМ ОПТИМАЛЬНОГО РАСПРЕДЕЛЕНИЯ 2?1
мых на функцию выигрыша F, задача определения
оптимальной функции / (х) может быть решена
аналитически. Однако обычно р (х) неизвестно. Поэтому иногда
заменяют эту задачу минимаксной, т. е. предварительно
отыскивается такое априорное распределение, которое
является наименее благоприятным с точки зрения средней
эффективности обзора, т. е. при котором J максимально,
а затем находят такое распределение средств / (х), при
котором это максимальное значение / минимально. Эта
замена не всегда оправдана и часто неудобна.
Применение адаптивного подхода позволяет найти
алгоритм определения оптимальной функции и его
аппаратурную реализацию.
§ 9.12. Алгоритм оптимального распределения
Естественно искать оптимальную функцию / (х)
в форме
f(x)^cTif{x). (9.35)
Тогда функционал (9.33) и условие (9.34) запишутся
соответственно в виде
J(c) = M{F(cTy(x), х)} (9.36)
и
стЬ = А, (9.37)
где
b = ^(x)y(x)dx. (9.38)
х
Теперь нужно найти такой оптимальный вектор с — с*,
который максимизировал бы функционал (9.36) при
условии (9.37). Это задача на условный экстремум при
дополнительных ограничениях типа равенств. Аналогичную
задачу, но при ограничениях типа неравенств, мы уже
рассматривали в § 8.8. Составим функцию Лагранжа
/(с, %) = M{F(cTq>(x), х) + Х(стЪ-А)} (9.39)
и применим к ней алгоритм (3.19), который в данном
случае принимает особо простой вид, поскольку А, —скаляр,
272
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
а не вектор. Тогда получаем
е[п] = с[п~1]~ 1
—y[n]lF'(f*T[n—\]if_(x[n]),x[n])ip(x[n]) + X[n]b] J. g 4Q)
И I
X[n] = k[n—l]— Yi [n] (cT [n — 1] b — A). ]
Эти алгоритмы реализуются дискретной системой,
изображенной на рис. 9.5. Основной контур реализует первый
Рис. 9.5.
алгоритм (9.40), а дополнительный — второй
алгоритм (9.40). Можно использовать в рассматриваемой
задаче и непрерывные алгоритмы, если данные
поступают непрерывно. Тогда вместо (9.40) мы получим
dc(t)
1Г~'~
dl {t)
dt
-yi(t)(cT(t)b-A).
»(9.41)
Для реализации этого алгоритма достаточно
воспользоваться предыдущей схемой, заменив в ней лишь
дискретные интеграторы непрерывными. После периода
обучения дискретная непрерывная система определяет
искомую оптимальную функцию / (х).
§ 9.13] РАСПРЕДЕЛЕНИЕ ОБЛАСТЕЙ ДИСКРЕТИЗАЦИИ 273
§ 9.13. Распределение областей дискретизации
Под дискретизацией подразумевается преобразование
непрерывного множества значений функции или ее
аргументов в дискретное множество. Дискретизация
применяется в разнообразных системах передачи, хранения
и обработки информации и является неотъемлемой
операцией при использовании
цифровых вычислительных
устройств.
Так, передача
фототелеграфных (функция двух
аргументов) и
телевизионных (функция трех
аргументов) изображений
осуществляется путем-
разбивки их на дискретные
строки и соответственно
дискретные кадры. Передача
речи (функция одной пере- Рис. 9.0.
менной) с помощью им-
пульсно-кодовой модуляции сопряжена с
дискретизацией непрерывного сигнала и последующего кодирования.
Геометрически дискретизацию можно представить
себе как разбиение пространства непрерывного сигнала
на непересекающиеся области Ак (рис. 9.6). При этом
некоторое дискретное значение, равное, например,
номеру области, соответствует всем значениям непрерывного
сигнала, находящимся в этой области.
Дискретизация аргументов функции всегда уменьшает
количество информации, содержавшееся в непрерывном
сигнале. Дискретизация значений функции вносит
ошибку, так как при этом непрерывное множество значений,
принадлежащих • одной области, заменяется единым
дискретным значением. Эта ошибка, аналогичная, если
не тождественная, ошибке округления, в теории связи
обычно называется шумом квантования. Ошибка
квантования зависит от конфигурации и размеров областей Ah.
Передавая дискретные сигналы по каналу связи (число
этих дискретных значений ограничено пропускной
способностью канала), нам нужно затем восстановить истинный
18 Я. 3. Цыпкин
274
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
сигнал. Как распорядиться разбиением пространства
сигналов Л на области Ak, чтобы шумы квантования
были минимальны?
Эта задача весьма близка к задачам, с которыми мы
сталкиваемся в статистической теории приема и
опознавания, так как она связана с определением границ
областей. Но мы ее рассматриваем в этой главе, чтобы
подчеркнуть, что наряду с распределением ресурсов или
производственных мощностей с равным успехом можно
заниматься распределением областей дискретизации
пространства сигналов.
§ 9.14. Критерий оптимальности распределения
Обозначим через х непрерывный сигнал, подлежащий
дискретизации; соответствующая ему плотность
распределения р (х) нам заранее неизвестна. Обозначим далее
через и оценку, которая принимается постоянной в
данной области, так что
u = uh при x£Ak (А?=1, 2, ..., N). (9.42)
Критерием оптимального распределения и, значит,
критерием точности оценки и могут служить средние потери.
Если функция потерь равна F (х, uk), то средние потери
представятся в виде функционала
/ (и) = 2 I F (х> uk) Р (я) dx. (9.43)
Здесь и = (ии . . ., uN). Оптимальные оценки и = и*
минимизируют средние потери.
Для получения обозримых результатов мы сейчас
ограничимся одномерным случаем, который представляет
и самостоятельный интерес. Для этого случая области Ak
представляют собой отрезки числовой оси
N Kk
/(м) = 2 I F(x,uk)p(x)dx, (9.44)
§ 9.15] АЛГОРИТМ ОПТИМАЛЬНЫХ ОЦЕНОК 275
а оценки uh — действительные числа. При этом средние
потери (9.43) будут равны
N Н
J (и) = 2 I F(x,uk)p(x)dx. (9.45)
Для квадратичной функции потерь
F(x, и) = (х — и)2 (9.46)
имеем
J(u)=^ J (x-uk)*p(x)dx. (9.47)
Дальнейшая задача состоит в определении
оптимальных оценок uk (к = 1, 2, . . ., N) и границ областей
А,А (/с = 0, 1, . . ., N) так, чтобы средние потери / (и)
достигали минимума.
§ 9.15. Алгоритм оптимальных оценок
Для определения алгоритма оптимальных оценок
можно было бы воспользоваться результатами § 4.20, но
не проще ли для данного случая продифференцировать
функционал (9.47) по Xk и uhl Тогда условия,
определяющие минимум функционала, можно представить в виде
K = -2(ub + uk+i)> (9.48)
Ч
\ (x — uh)p(x)dx = 0. (9.49)
Из (9.48) и (9.49) следует:
J (x — uh)p(x)dx = 0. (9.50)
Аналитическое решение этой системы уравнений
относительно uk возможно лишь в малоинтересном случае
18*
276
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Ян-^л-1]
' Лк+2[П-1]
Рис. 9.7
§ 9.16] НЕКОТОРЫЕ ЗАДАЧИ 277
р (х) = const. Для известных произвольных
распределений р (х) существуют различные, преимущественно
итеративные подходы к решению этой задачи. Мы здесь
интересуемся тем случаем, когда р (х) неизвестно.
Введем характеристическую функцию
г (щ-и uk, Uh+i) =
С i 1
1, если -^(uk + uk^)<:x<:-^(uk+i \-uh),
= { z z (9.51)
(О в любом другом случае.
Тогда условие (9.50) можно записать в виде
математического ожидания
М {(х — ик) ъ (ик.. и uk, ukii)}-—0. (9.52)
Теперь уже нетрудно написать алгоритм, определяющий
оптимальные оценки:
uh [п] = ик [п — 1J + у [п] [(х[п] — ик[п—1])х
X е(ик-! [п— 1], ик [тг— 1], uk+i [п— 1])]
(А-1, 2, ...,N). (9.53)
Определив по этим алгоритмам оптимальные оценки и%,
находим затем по формулам (9.48) границы Xk областей Л.
Структурная схема дискретной системы, определяющей
эти оценки, изображена на рис. 9.7. Она представляет
собой многосвязную замкнутую систему.
Читателю представляется возможность определить
наилучшие значения ун [п] для алгоритмов (9.53).
§ 9.16. Некоторые задачи
|Именно задачи исследования операций являются
благодатной почвой для применения вероятностных
итеративных алгоритмов, учитывающих разнообразные
ограничения.
Но трудности, которые могут возникнуть здесь,
связаны не столько с развитием методов решения, сколько
с постановкой задач планирования и управления в
условиях неопределенности и, следовательно, риска.
278
ИССЛЕДОВАНИЕ ОПЕРАЦИЙ
[Гл. IX
Поэтому представляет большой интерес
формулировка задач сетевого планирования, календарного
планирования и т. д. при недостаточной априорной информации
и распространение адаптивного подхода на этот круг
новых задач.
§ 9.17. Заключение
Эта глава отличается от предшествующих ей глав
пестротой, обязанной изобилию разнообразных задач.
Но несмотря на это разнообразие, в главе можно все-
таки усмотреть и общую черту, характерную для всех
рассмотренных здесь задач. Во всех задачах мы имеем
дело с распределением и планированием ограниченных
ресурсов. К этим ресурсам относятся сырье или
энергия, время или пространство. Такая калейдоскопичность
характерна для современной теории исследования
операций, и мы не старались изменить ее лицо.
Основная задача этой главы состояла в том, чтобы
показать плодотворность адаптивного подхода и в этой
необозримой области, охватываемой не вполне четким,
но интригующим названием «исследование операций».
Глава X
Игры и автоматы
§ 10.1. Введение
До сйх пор мы рассматривали задачи, связанные
с отысканием в условиях неопределенности абсолютного
или относительного экстремума тех или иных
функционалов. Наряду с такими сравнительно спокойными
ситуациями мы часто сталкиваемся в жизни и с иными
ситуациями, имеющими конфликтный характер. Конфликтные
ситуации возникают тогда, когда интересы
взаимодействующих друг с другом сторон не совпадают между
собой. Разумеется, эффект, вызываемый столкновением
интересов, зависит от действия всех сторон,
участвующих в конфликте. Изучением конфликтных ситуаций
занимается сравнительно молодое научное направление,
носящее привлекательное название — теория игр. Теории
игр посвящено довольно большое число работ, но здесь
мы не собираемся излагать разнообразные результаты
этой теории. Наша задача совсем иная. Мы хотели бы
взглянуть на ряд задач теории игр с позиций
адаптивного подхода и показать удобство этого подхода для
решения как собственно теоретико-игровых задач, так
и задач, приводящихся к ним.
Мы рассмотрим способы обучения решению игр и
найдем соответствующие алгоритмы обучения. Эти алгоритмы
будут применены для решения тех задач линейного
программирования и управления, которые удобно
рассматривать как игру, а также для определения условий
реализуемости логических функций на одном пороговом
элементе. Мы вкратце осветим возможные способы обучения
персептронов и роль пороговых элементов при их
реализации.
280
ИГРЫ И АВТОМАТЫ
[Гл. X
Наряду с этим будут рассмотрены поведение и игры
стохастических автоматов, строение которых не опирается
на априорные сведения о вероятностях перехода из одного
состояния в другие и о средах, с которыми эти автоматы
взаимодействуют.
§ 10.2. Понятие игры
В игре обычно принимают участие несколько лиц —-
игроков, интересы которых различны. Действия игроков,
называемые ходами, состоят в выборе из множества
возможных вариантов какого-либо конкретного
варианта. Игра характеризуется системой правил, которые
определяют порядок ходов, выигрыши и проигрыши
игроков в зависимости от сделанных ими ходов. Во время
игры возникают различные ситуации, в которых игроки
должны сделать выбор. Полная система указаний,
определяющих этот выбор во всех возможных ситуациях, и
представляет собой стратегию каждого из игроков.
В результате игры игрок стремится максимизировать
свой выигрыш. Но, разумеется, не всем игрокам это
удается сделать. Приведенное описание игры, очень
похожей на многие азартные игры, с которыми мы
сталкиваемся в жизни, настолько общее, что оно удобно для
популяризации теории игр, но вряд ли пригодно для
получения каких-либо конкретных результатов. Поэтому
мы остановимся на частных видах игр, теория которых
довольно хорошо развита. Далее речь будет идти о
матричных играх двух лиц с нулевой суммой, т. е. таких игр,
в которых интересы игроков прямо противоположны
и выигрыш одного игрока равен проигрышу второго.
Матричные игры двух лиц с нулевой суммой
характеризуются платежной матрицей
A = ||evil|| (v=l, ...,N; ц = 1, ..., М). (10.1)
Игра состоит в выборе первым игроком некоторой
стратегии v из N возможных и вторым игроком — стратегии
(л из М возможных. Выигрыш первого игрока, а значит
и проигрыш второго игрока, равен величине aVJ1. Выбор
стратегий v и (х может производиться и случайно, соглас-
§ 10.2]
ПОНЯТИЕ ИГРЫ
281
но распределениям
и
p = {Pi, . .., Pn)
0. = (Яь •••> с1м)- J
(10.2)
В этом случае исход игры также будет случайным, и его
нужно оценивать но математическому ожиданию —
платежной функции:
N М
V(P, Q)= S 2 a^pvq)> = pTAq. (10.3)
v=l Ц-—1
Такая игра называется игрой в сметанных стратегиях.
Распределения (10.2) должны удовлетворять обычным
для распределений условиям
N
Pv>0; 2 Pvr- l;
v=i
м
gn>0; 2 9ii=l.
означающим, что р и q принадлежат симплексу.
Смешанные стратегии игроков определяются векторами р и д,
причем &-я компонента каждого вектора равна
вероятности применения к-й чистой стратегии. Если эта
вероятность равна единице, то мы снова приходим к игре в
чистых стратегиях.
Далее мы будем обозначать чистые стратегии первого
и второго игроков в виде единичных векторов
(10.4)
(0,
.,0, 1,
.,0),
М
1^ = (0, ...,0, 1,
.,0).
(10.5)
Следует отметить, что при заданных, согласно (10.2),
распределениях р и q
pv = pTav = М {av}, v = 1,..., N, 1
<7и = Л = ^{§йЬ |* = 1, ...,М. j
V (10.6)
282
ИГРЫ И АВТОМАТЫ
[Гл. X
Отсюда следует, что компоненты смешанных стратегий
представляют собой математическое ожидание от
применяемых соответствующих чистых стратегий.
Соотношения (10.6) удобно представить в векторной форме!
q = M{$}, J
где
а — {СЦ, ..., aN}, |
P = {Pi» •• •, Рм} J
— наборы единичных векторов (10.5).
§ 10.3. Теорема о минимаксе
Рассмотрим игру с платежной матрицей (10.1).
Естественное стремление первого игрока увеличить свой
выигрыш приводит к тому, что он выбирает из всех
стратегий av такую, которая гарантировала бы ему
наибольший из всех минимальных выигрышей, max min av[l.
V ц
Второй игрок стремится выбрать такую стратегию (J^,
которая обеспечила бы ему наименьший из всех
максимальных проигрышей, min max avil. При этом всегда
II V
max min aVM, < min max aV[l. (10.9)
V [I 11 V
Может оказаться, что это неравенство переходит в
равенство
max min aV[Xt = min max avll - dy*^*. (10.10)
V [I \l V
Тогда говорят, что игра в чистых стратегиях имеет седло-
вую точку (av*, Pjj,*). При этом стратегии av = av*,
Ри — Рц* оптимальны. Отклонение любого игрока от
оптимальной стратегии приводит к тому, что противник толь-
ко~увеличивает свой выигрыш. Мало того, за счет
соответствующего выбора стратегий он может выиграть еще
больше.
(10.7)
(10.8)
§ 10.4] УРАВНЕНИЯ ОПТИМАЛЬНЫХ СТРАТЕГИЙ 283
Если бы равенство (10.10) выполнялось для любой
платежной матрицы А, то на этом поиски оптимальных
способов игры закончились. Но часто платежная матрица
может не иметь седловой точки. В этих случаях игрок
вынужден в каждой партии выбирать смешанные
стратегии, при этом противник уже не может точно определить
результат этого выбора. Таким образом, мы приходим
к игре со смешанными стратегиями р и q. Фундаментом
теории игр является теорема фон Неймана о минимаксе,
состоящая в том, что платежная функция (10.3)
удовлетворяет соотношению
max minV (р, q) = min max V(p, q) = v. (10.11)
V (1 (IV
Иными словами, существуют такие оптимальные
смешанные стратегии р* и #*, что
V(p, q*)<v = V(p*, q*)<V(p*, q). (10.12)
Величина и называется ценой игры. Эта теорема
утверждает, что матричная игра со смешанными
стратегиями всегда имеет седловую точку (р*, q*). Любопытно
то, что как первый, так и второй игрок не получают
никакого преимущества от знания распределения
вероятностей ходов противника.
§ 10.4. Уравнения оптимальных стратегий
Решение матричных игр сводится к отысканию седло-
вой точки, т. е. нахождению оптимальных стратегий р*,
Q*, для которых выполняются условия (10.12).
Существуют прямые методы отыскания оптимальных
стратегий, основанные на теореме Шеппли — Сноу. Эти
методы гарантируют нахождение точного решения игры
за конечное число операций, однако практически они
пригодны лишь для игр с малым числом стратегий.
На основе связи, существующей между теорией игр
и линейным программированием, для решения игр
возможно применение различных конечных методов линейного
программирования.
Наряду с прямыми методами известны разнообразные
не прямые методы решения игр. Мы упоминаем об этих
284
ИГРЫ И АВТОМАТЫ
(.Гл. X
возможных методах решения игр с тем, чтобы без
угрызения совести оставить их в дальнейшем без
рассмотрения. Читатель, вероятно, догадывается, что нас
интересуют методы решения игр, основанные на обучении
игроков во время игр и совершенствовании ими своего
мастерства. Существуют ли такие методы решения игр?
Оказывается, да. Вот именно на них мы и остановим
свое внимание.
Обозначим через р (q) и q (р) оптимальные ответы
на соответствующие смешанные стратегии q и р.
Тогда для оптимальных смешанных стратегий р* и д*,
определяемых теоремой фон Неймана (10.11), будут
справедливы равенства
f (10.13)
e*=ff(p*)» J
которые выражают тот очевидный факт, что оптимальные
ответы на оптимальные смешанные стратегии,
представляют собой оптимальные смешанные стратегии.
Из (10.13) следует, что оптимальные смешанные
стратегии р* и q* представляют собой решения уравнений
* = *{9)'\ (10.14)
g = Q(p)- J
Вспоминая, что смешанные стратегии можно представить
как математическое ожидание применяемых
соответствующих чистых стратегий (10.7), уравнения (10.14) можно
представить в форме
р = М{аШ, )
V (10.15)
q = M{fi(p)}, \
где аир — оптимальные ответы — чистые стратегии —
на чистые стратегии, появляющиеся с распределением р
и q соответственно.
Предположим теперь, что мы не имеем возможности
точно находить оптимальные ответы р (q) и q (р), а
определяем их с какой-то погрешностью |t т. е. вместо р (q)
§ 10.5] АЛГОРИТМЫ ОБУЧЕНИЯ РЕШЕНИЮ ИГР 285
и q (р) мы в действительности определяем
л <«>=*<*>+ 6,} (1олб)
Ql(P) = 9(P) + h- }
Если среднее значение погрешностей ^ и £2 равно нулю,
то
р(*) = лмА<«». \ 1017)
и вместо уравнения (10.12) мы получаем
(10.18)
2> = M6{p6(ff)}, j
д = Мг{дг(р)}. J
Здесь математическое ожидание берется по
распределению вероятностей помех.
Уравнения (10.15) и (10.18) и представляют собой
уравнения оптимальных стратегий.
§ 10.5. Алгоритмы обучения решению игр
Представим уравнения (10.15) в виде
M{p-a(q)}^-Q, 1
1 . ' } (10.19)
M{q-$(p)} = 0 )
и применим к ним вероятностные итеративные алгоритмы
обычного типа. Тогда мы получим алгоритмы обучения
решению игр
р[п]=р[п — 1] — Yt М {# [и — 1] — «v (в [л— 11)}, |
ff M = «[*-l]-Y2 М {«[*-l]-ft*(P[*--l])}. j
(10.20)
Здесь av (q [n — 1]) и §y,{p \n — 1 ]) — оптимальные
чистые стратегии на шаге п — 1; av (g [тг — 1])
определяется номером максимальной компоненты вектора Aq [п —1 ],
а Рц (р[га— И) определяется номером минимальной
компоненты вектора рт [тг — 1] А. Для сходимости
286
ИГРЫ И АВТОМАТЫ
[Гл. X
алгоритмов обучения достаточно, чтобы коэффициенты Yi [п]
и Y2 [я] удовлетворяли обычным условиям (3.34, а).
Алгоритмы (10.20) соответствуют процессу
последовательного совершенствования игроками стратегий, т. е.
обучению игре «опытным путем».
Подобным же образом, представляя уравнения (10.18)
в виде
§ ^ . v ;/ ъ (10.21)
^6{e-ff6tP)} = Of J
находим алгоритмы обучения решению игр при наличии
погрешностей:
р [п] = р [/г— 1J —Yi In] {р [п— 1] — ръ (« [п~ 1])},
# [и] = €/ [/г — 1] — у2 [п] {q [/г—1] — £g (# [и — 1])}.
(10.22)
Алгоритмы (10.22) соответствуют процессу
последовательного совершенствования игроками стратегий «опытным
путем» при наличии мешающих факторов —
погрешностей.
Любопытно отметить, что наличие погрешностей с
нулевым средним значением не является препятствием к
выработке оптимальных стратегий, лишь удлиняя время
обучения.
По р [п — 1] и q [п —- 1] на каждом шагу
определяется функция
V[n — l] = V(p[n— 1], ff [71 — 1]) =
= рт [м— 1] Aq [п— 1], (10.23)
которая при п-+оо стремится к величине, равной цене
игры. Алгоритмы обучения решению игр (10.20), (10.22)
реализуются системами, схемы которых изображены
на рис. 10.1 и 10.2.
Полученные общие алгоритмы обучения (10.20), (10.22)
в частных случаях приводят и к известным итерационным
алгоритмам, приведенным в табл. 10.1.
Алгоритмы обучения решению игр сходятся, вообще
говоря, довольно медленно. Для ускорения сходимости
§ 10.5]
АЛГОРИТМЫ ОБУЧЕНИЯ РЕШЕНИЮ ИГР
287
алгоритмов можно использовать различные способы
ускорения сходимости, о которых речь шла, например,
Чп-1
^
\0Cv(qn-i) ^
Ы у,М t=a
Д
Рп-1
^П I 1 ^№Рп-1\
тьуЬА
т л1*
Рл-1
<Гп-1
Рис. 10.1
в § 3.15. Все эти способы связаны в конечном итоге
с изменением коэффициентов yi М и у2 [п] в процессе
обучения решению игры.
q[n
\
\ч_
-/; | 7T\P(rtn-fA . 1 1 .Г>^
-~\ЛИШХП АИ\ S/Vl N v Гп1 Г N /7^4:
— чпш*у лЧ | \ЛЖ) Л Л;/77/ L И Л^ -Г
^Ti I—1 jW*-#i—п
^j# Г1 у-/я/ г1 №-* min рМо-И—
|97>7-7/
Рис. 10.2.
Р//7-/7
Так, например, сходимость алгоритмов может быть
ускорена, если заменить те итерации, в которых
повторяются одни и те же чистые стратегии, одной итерацией.
Таблица 10.1
to
00
00
п. п.
1
Уравнения
M{p-av(q)}^0,
Алгоритмы
р[п]^р[п — 1]—у[п]Х
Х(р[и—1] —av (q ["-!])),
q[n]^q[n—l] — y[n]x
X(tf [*-!]-&,* (р[и-1]))
Примечания
oo oo
3 y[»]=oo, 2 Y2("]<oo
n= 1 n= i
vH=4
v r„i _ ^
s=i
где rs — число «склеенных*
итераций на s-м шаге
Авторы
Браун Дж.
Амвросиенко В. В.
П р о д о л ж с н и е табл. 10.1
п. п.
2
i
о
1
!
Уравнения
M{p-av-(q)}=(),
M{q-^(p)\ = 0
Щ{р-РгШ --о,
Щ\'1-Ч\(Р)}-М
Алгоритмы
р[п] -p[n-l]-YiW^<
X(i>[rc—1] —av(r/ [и—1])).
д[га] = ?[л — 1] — \2[п] а
Х(д[л-1]-^(р[п-М))
Х(1э[п—1] —ii6(iy [л —1]))
?М =«/[« — ^1 — Y f"l X
X (q\n— \]—qz(p[n—\]))
Примечания
Поочередные шаги с
Yi M = Yi(min(PTM A)j),
\ j
Y2H =у2(тах (Aq[n\),),
г
удовлетворяющими условию
oo
У\ YZ[/l]--Obf 1 :l, 2
OO TO
n—1 Jl- 1
oo
^] у [и] =oc, lim у [л] 0
71=1 П^°
1
Авторы
1
Борисова Э. П.
Магарик И. В.
Полконски.ч 1). А 1
290
ИГРЫ И АВТОМАТЫ
[Гл. X
Это соответствует такому выбору у [п]:
у[п] = у1[п] = у2[п\=-р±—
v=l
(10.24)
где rv — число итераций на v-м шаге, в которых
повторились одни и те же чистые стратегии. Вооружившись
алгоритмами обучения решению игр, мы теперь можем
заняться применением их к разнообразным задачам.
§ 10.6. Игры и линейное программирование
Решение игр тесно связано с решением задач
линейного программирования. Действительно, если в (10.12)
заменить произвольные смешанные стратегии р и q
соответственно чистыми av и рц, то мы получим неравенства
V (av, q) /W/ г, 1
V(p,M--l>TA>v, j
>
(10.25)
решения которых, удовлетворяющие (10.3), и определяют
оптимальные стратегии и цену игры. Отсюда следует, что
игре с матрицей А эквивалентна пара взаимно
сопряженных задач линейного программирования:
v—> mm,
Aq < i\
м
g»i>0; 2 дц=-1; Pv
{ведем новые переменные pv
и—> max,
pTA > v,
N
>0; 2 pv--l.
v=l
Pv ~ qV
'
И С
> (10.26)
)бозначим
V
Тогда из пары взаимно сопряженных задач линейного
программирования (10.26) мы получаем пару двойственных
10.7J
УПРАВЛЕНИЕ КАК ИГРА
291
задач линейного программирования:
м _
Ям>0,
шах,
2 /^ = ^-
v=l
PTA>U
pv>0.
mm,
(10.27)
J
Таким образом, алгоритмы обучения решению игр
можно использовать для решения типичных задач
линейного программирования. Но мы оставим эту
возможность, не желая вызвать гнев «фанатиков» линейного
программирования, которые, наоборот, предпочитают
использовать методы линейного программирования для
решения игр. Отметим только, что алгоритмы обучения
решению игр могут оказаться полезными при решении
различных задач оптимального планирования большой
размерности.
§ 10.7. Управление как игра
Во многих случаях целесообразно рассматривать
процесс управления как некую игру. Мы проиллюстрируем
это на простом примере. Пусть управляемая система
описывается дифференциальным уравнением
dx (t)
dt
■x(t)—u(l), x(0)~ x0
(10.28)
Будем искать такое управляющее воздействие u(t), чтобы
функционал
т
J(u(t), х0) = ? | l — x(t)\dt
(10.29)
для заданного начального условия xQ достигал минимума.
При этом управляющее воздействие должно подчиняться
некоторым ограничениям, а именно:
0<и(*)<1,
т
\ u(t)dt = Ti.
(10.80)
19*
292
ИГРЫ И АВТОМАТЫ
[Гл. X
Для сведения этой задачи оптимального управления
к игровой задаче воспользуемся очевидным тождеством
1 — я|=тахи?(1 — х). (10.31)
\w\<:i
Тогда
Т
tin \ | i — x(t)\dt = mii\ max \ w(l~x (t)) dt. (10.32
m
о
На основании теоремы о минимаксе (10.11) можно
поменять символы max и min местами. Следовательно,
mm max
и \w\
ах [ w(l — z(t))dt = maix min [ w(l—x(t))dt. (10.33)
»I<1 «J \w\^\ и «J
Равенство (10.33) свидетельствует о том, что и* и w*
образуют седловую точку.
Обозначим через U множество функций и,
удовлетворяющих условию (10.30), а через W — множество
функций w, удовлетворяющих условию \w\ < 1. Тогда
т т
min ^ ( l — x(t)\dt-=tniii max \ w(l—x(t))dt, (10.34)
и значит, па основании теоремы о минимаксе имеем
т т
min max \ и? (I —я (t)) dt = max min \w(l —x(t)) dt. (10.35)
§ 10.8. Алгоритмы управления
Из (10.35) следует, что задача об оптимальном
управлении сводится к задаче решения непрерывной игры.
Введем платежную функцию непрерывной игры
т
V(n, w)=l w(l — x(t))dt. (10.36)
§ 10.9]
ОДНО ОБОБЩЕНИЕ
293
Тогда из теоремы о минимаксе (10.11) следует, чю
рассмотренная в § 10.7 задача об оптимальном управлении
сводится к решению непрерывной игры с платежной
функцией (10.36). Чтобы применить алгоритмы обучения
решению игр типа (10.20), нужно предварительно
аппроксимировать непрерывную игру дискретной. Можно,
однако, поступить и иначе -— из дискретных алгоритмов
получить предельным путем непрерывные алгоритмы и их уже
затем применить к непрерывной игре. Так, дискретным
алгоритмам (10.22) будут теперь соответствовать
непрерывные алгоритмы вида
du(t)
dt
dw (t)
dt
-Yi(0H0-Mh;(0)],
-У2(0№(*)-щ(и(1))],
(10.37)
где теперь и* (w (t)) и w^ (и (t)) представляют собой
оптимальные ответы при наличии помех.
Схема управляющего устройства, вычисляющего
оптимальное управляющее воздействие, имеет вид,
аналогичный рис. 10.2.
§ 10.9. Одно обобщение
Возможно, рассмотренная в §§ 10.7 и 10.8 задача
об управлении вызовет некоторое неудовлетворение,
поскольку минимизируемый функционал очень
чувствителен к начальным условиям. И если нам неизвестны
начальные условия, то мы не можем определить и
оптимальное управление. Чтобы обойти это затруднение,
рассмотрим усредненный по начальным условиям
функционал (10.29):
/ (и (0) = М {J° (и (0, х0)}. (10.38)
Тогда соответствующая непрерывной игре платежная
функция будет равна
т
V(u, w) = M l[ w(l—z(t))dt\ . (10.39)
294
ИГРЫ И АВТОМАТЫ
[Гл. X
Эта «средняя» платежная функция нам неизвестна, ибо
неизвестна плотность распределения начальных условий.
Но, как мы знаем, это не является препятствием для
адаптивного подхода. Мы можем использовать алгоритмы
обучения типа (10.37) с той лишь разницей, что теперь
вместо неизвестной «средней» платежной функции для
определения щ (w (t)) и w^ (и (t)) будет использоваться
ее оценка, которая вычисляется с помощью алгоритмов
определения среднего значения. Разумеется, в этом
случае время обучения возрастает: за незнание мы уже
неоднократно расплачивались временем.
Мы не будем углубляться в этот интересный, но пока
еще мало разработанный вопрос, а обратимся к
совершенно иным задачам, для которых оказывается полезным
применение алгоритмов обучения решению игр.
§ 10.10. Пороговые элементы
Пороговые элементы находят широкое применение
в персептронных схемах и моделях нейронных сетей,
позволяя осуществлять разнообразные логические
функции. Пороговый элемент состоит из сумматора и реле
хо° *Ч§)
Рис. 10.3.
(рис. 10.3), Он может быть осуществлен на различных
физических устройствах. В качестве примеров укажем
на суммирующий усилитель с насыщением, ферритовый
сердечник с прямоугольной петлей гистерезиса и
постоянным подмагничиваниом, параметрон и т, п.
§ 10.11] О РЕАЛИЗУЕМОСТИ ЛОГИЧЕСКИХ ФУНКЦИЙ 295
Уравнение порогового элемента запишем так:
N
У =- sgn ( S cv^v — с0), (J0.40)
v=i
где xv — переменная, характеризующая состояние v-ro
входа, v = 1, 2, . . .,iV (входная переменная), у —
переменная, характеризующая состояние выхода (выходная
переменная), cv — весовой коэффициент v-ro входа,
v = 1, 2, . . ., JV; с0 — порог. Напомним, что
Г 1 при 2 >(),
sgnz -< ,. _ (10.41)
ь L 0 при z < 0. v '
Входные и выходные переменные принимают только два
значения, 0 и 1.
Уравнение порогового элемента можно представить
в векторной записи
у sgn(r5^-c0), (10.42)
где х = (,гь . . ., xN) — вектор входных переменных,
с = (сь . . ., Сдг) — вектор весовых коэффициентов.
§ 10.11. О пороговой реализуемости
логических функций
Логическая, или булева, функция
у = у(хи ...,^v), (10.43)
которую кратко будем записывать как
У = У(х), (Ю.44)
характеризуется тем, что сама она и ее независимые
переменные принимают только два значения, 0 или 1. Легко
видеть, что булева функция (10.43) полностью
определяется таблицей с числом строк, равным 2/У. Поскольку
входные и выходные переменные порогового элемента
также принимают'значения 0 или 1, то возникает вопрос
о возможности реализации булевой функции на одном
пороговом элементе или, короче, вопрос о пороговой
реализуемости булевой функции.
296
ИГРЫ И АВТОМАТЫ
[Гл. X
Предположим, что
z/H
Г 1 для Х({)^Х1ч
(10.45)
L 0 для х(о)бХ0.
Очевидно, что для порогового элемента должны
выполняться неравенства
cTx(i):
^о, 1
С/Х(0)<С0. J
>
(10.46)
Воспользуемся теперь тем свойством порогового
элемента, что при выборе
Со'-
S
(10.47)
инверсия координат входного сигнала (т. е. замена
нулевых координат единичными и наоборот) вызывает
инверсию выходного сигнала. Тогда из (10.46) получаем
стаг*(1)>уУ с
v = l
V
л
" v=l
1
,.т
(10.48)
J
где «£(о) означает инверсию х0. Эту систему неравенств
можно представить в более компактной форме
где
Ас
Л.
1у
cv,
(10.49)
v=l
Т
Х(1)
—т
*(С)
Из изложенного выше заключаем, что необходимым
и достаточным условием пороговой реализуемости
булевой функции (10.43) является существование такого
вектора с = с*, который бы удовлетворял системе
неравенств (10.49),
§ 10.12] КРИТЕРИЙ РЕАЛИЗУЕМОСТИ 297
§ 10.12. Критерий реализуемости
Нельзя ли по виду матрицы А определить пороговую
реализуемость булевой функции у = у (х)? Оказывается,
можно. Для этого дополним каждый из векторов х и х
координатами 1 и 0 и составим расширенную матрицу
А =
я(1)
—т
1
0
(10.50)
Эта расширенная матрица соответствует новому
пороговому элементу, отличающемуся от прежнего наличием
двух дополнительных входов, выбор весов которых cN+i
и cN^2 позволяет удовлетворить условию нормировки
/V-f 2
2 cv=l. (10.51)
При этом, как следует из (10.47),
1
и условие (10.49) заменяется условием
Ас>-
(10.52)
(10.53)
По построению матрица А такова, что существует век-
м
тор г?, обладающий тем свойством, что при 2 ^ц=1,
M<2N,
(10.54)
dTA>\.
Если теперь рассмотреть матрицу А как платежную
матрицу некоторой игры, а векторы cud как смешанные
стратегии игроков, то условия (10.53), (10.54) будут
выполнены, если цена игры v будет больше 1/2. Таким
образом, мы приходим к следующей формулировке
критерия реализуемости.
Для пороговой реализуемости булевой функции
необходимо и достаточно, чтобы цена v игры, определяемой
платежной матрицей 4, была больше 1/2,
298
ИГРЫ И АВТОМАТЫ
[Гл. X
§ 10.13. Алгоритмы реализуемости
Для определения пороговой реализуемости можно
использовать алгоритмы обучения решению игр.
Так, применяя (10.20), получим
с [п] := г [Л- 1] - Yl [п] {с \п~ 1] - av (d [п~Щ, Л
Л ( (lu.oo)
d[n\--d[n — l] — y2\n]{d\n — l] — pvi(e\n—l])}. )
При этом
v[n — i] = eT[n — l\Ad\n—l]. (10.56)
Если v \п — 1] ->- v >>—-при п ->- оо, то мы можем
реализовать данную логическую функцию на одном
пороговом элементе. Вектор с [п] с ростом п стремится к
оптимальной стратегии с*, определяющей вектор искомых
весовых коэффициентов порогового элемента. Проверка
пороговой реализуемости осуществляется с помощью
схемы типа рис. 10.1.
Иногда удобно, чтобы входные и выходные
переменные порогового элемента принимали значения не 0 и 1,
а —1 и -|-1. В этом последнем случае поведение
порогового элемента вместо уравнения (10.49) описывается
уравнением
N
г/--sign (2 cvxx — с0). (10.57)
v=l
Переменные xv и у принимают значения —1 и +1, а
Г 1 при 2>0,
signz = < , . (10.58)
1—1 При 2<0. V '
Переход от одного способа заданий к другому основан
на очевидном соотношении
sign z = 2 sgn z — 1. (10.59)
При этом везде нужно xv заменить на 2xv — 1.
Производя в расширенной матрице (10.50) эту
замену, при установлении реализуемости булевой функции
подобного типа мы можем по-прежнему использовать
алгоритмы (10.55) и (10.56).
§ 10.14]
ПЕРСЕПТРОИ РОЗЕНБЛАТА
299
§ 10.14. Персептрон Розенблата
Алгоритмы, с которыми мы познакомились в § 10.13,
позволяют обучить пороговые элементы так, чтобы они
приобрели способность реализовывать заданные булевы
функции. Но было бы, однако, несправедливо отводить
пороговым элементам только эту роль, тем более, что
они и не всегда могут сыграть ее до конца. Обучаемые
пороговые элементы являются важной частью
персептрона Розенблата. Упрощенная схема этого персептрона
изображена на рис. 10.4. В отличие от общей схемы
персептрона (рис. 4.2) здесь система линейно независимых
функций cpv (х), v — 1, ...,7V, представляет собой
систему пороговых функций
<pv (ж) = sign (oWx - c(0v)) (10.60)
с заранее назначенными порогами и весами.
Алгоритм, по которому происходит обучение
персептрона, аналогичен алгоритму 1 табл. 4.1 или 4.2:
с[п] = с[п — 1] — уо[у[п] —
— Sgn СТ [П - 1] ф (X [71])] ф (X [71]), (10.61)
где компоненты ф (х) определяются выражениями (10.60).
При условиях, указанных в § 3.13, процесс обучеция
персептрона сходится.
300
ИГРЫ II АВТОМАТЫ
[Гл. X
§ 10.15. Адалина Уидроу
Под красивым именем «Адалина» скрывается
прозаическое длинное название — адаптивный линейный
пороговый элемент. Адалина Уидроу представляет собой
упрощенный до предела тип персептрона (рис. 10.5).
Хуо-
\
\ I
\
\ х
\
\
^d~*H3
» *>
t
-<^У—э-
--<2TU—0-
L—Й
Рис. 10.5.
На вход Адалины поступает векторное воздействие
х[п] = (1, х{[п], . . ., xN[n])4 (10.62)
которое определяет при п=1, 2, . . ., 2N все возможные
ситуации — вершины гиперкуба. Эти ситуации нужно
разбить на два класса, которым соответствуют два значения у:
у=±1. (10.63)
Выберем теперь функции cpv (х) таким образом:
Фо(ж) = 1,
cpv (ас) = zv, v - 1, 2, ..., N. (10.64)
Вряд ли можно придумать что-нибудь проще. Благодаря
такому выбору функций отпадает необходимость в функ-
§ 10Л0] ОБУЧЕНИЕ ПОРОГОВОГО ЭЛЕМЕНТА 3(М
циональных преобразователях многих переменных и,
в частности, в пороговых элементах, которые
использовались в персептроне Розенблата.
Используя теперь квадратичный функционал и
соответствующий ему алгоритм 2 (табл. 4.1), с учетом (10.64)
получим
е[п] = с[п—1\ — у \п] {у [п] - ет [п — 1]х [и]) х [и], (10.65)
где теперь
с = (с0, ct, . . ., cN) (10.66)
представляет собой (iV + 1)-мерный вектор коэффициентов.
Обычно у \п\ выбирается постоянным, равным
Именно алгоритм (10.65) при у, определяемом
соотношением (10.67) и лежит в основе функционирования
Адалины, т. е. по этому алгоритму в Адалине происходит
обучение. Адалина, таким образом, представляет собой пример
обучаемого порогового элемента. Однако в ней обучение
происходит не на основе учета бинарных значений
выходной величины, а путем использования линейной
взвешенной комбинации входных ситуаций, которая еще кратко
называется входным композитом.
§ 10.16. Обучение порогового элемента
Возможен и несколько иной способ обучения
порогового элемента, не использующий входной композит
непосредственно. Выходная величина порогового
элемента равна в общем случае
у [п, m] = sign ет [m] х [п], (10.68)
где п — номер одной из входных ситуаций, т—номер
момента измерения вектора весовых коэффициентов.
В частности, при п — т +1
у [п] = sign сТ [п — 1] х [п]. (10.69)
До обучения выходная величина отличается от желаемой
у[п]. Обучение заканчивается, если изменением вектора
302 ИГРЫ И АВТОМАТЫ [Гл. X
весовых коэффициентов удается добиться равенства
У1п]-у[п] = 0 (10.70)
или, что эквивалентно, неравенства
у [п] ст [п — 1] х [п] > 0. (10.71)
С подобного рода условием мы уже встречались в § 4.11.
Напомним, что теперь компоненты вектора х [п]
принимают не произвольные значения, а только +1 и —1.
Однако это не является препятствием к применению
алгоритмов вида (4.41), и мы предлагаем читателю их
выписать. Мы же приведем здесь простой алгоритм,
учитывающий специфику пороговых элементов.
Воспользуемся алгоритмом обучения персептрона
типа (10.61), но заменим в нем ф (х [п]) на х [п]. Тогда
с[п] = с[п — 1]-— у [п](у [п] — signcT [п — 1] х[п\) х [п].
(10.72)
В частном случае при у [п] = -у будем иметь
с [п] = с [п — 1] — у {у[п\ — signcT [n — i]x[n]) х[п].
(10.73)
Если начальный вектор с [0] имеет целочисленные
компоненты, то и векторы с [п] будут иметь целочисленные
компоненты. Структурная схема системы, реализующей
алгоритм (10.73), изображена на рис. 10.6.
Поскольку ситуации, т. е. вершины гиперкуба,
принципиально могут быть разделены плоскостью, то
невыпуклость функционала, порождающего этот алгоритм
(об этом мы говорили в § 4.10), не имеет существенного
значения.
С течением времени с [тг], вообще говоря, стремится
по вероятности к оптимальному вектору с* не обычным
образом, а так, что наиболее вероятное значение
предела с [м]или, как его называют, мода с [п] стремится
к с*. Но при отсутствии помех возможно, что
оптимальное значение с = с* будет достигнуто после конечного
числа шагов.
g 10.16] ОБУЧЕНИЕ ПОРОГОВОГО ЭЛЕМЕНТА ЗОВ
Поступим теперь несколько иначе,— ну так, как
поступил бы упорный педант. Будем подавать на вход
порогового элемента вектор х [/г], соответствующий одной
и той же ситуации, до тех пор, пока для этой ситуации
sign ст[п-1]х[п] X
Уо
€>
<Ц}е—й-
<&—
Й—1
Рис. 10.(5.
обучение не будет окончено. Затем перейдем на
следующую входную ситуацию и повторим все снова, не
обращая внимания на то, что при этом мы, конечно, будем
несколько портить уже достигнутые результаты. В этом
случае вместо (10.69) нужно воспользоваться
соотношением (10.68), и тогда, повторяя с небольшим видоизменен
нием приведенные выше рассуждения, мы получим
«педантичный» алгоритм обучения порогового элемента
с [т] = с[т — 1] — у (у [п] — sign еТ [т — I] х [n]) х [п].
(10.74)
«Педантичный» алгоритм обучения можно представить
и в несколько иной форме.
304
ИГРЫ И АВТОМАТЫ
[Гл. X
Обозначим через ги число итераций при показе
вектора х \п], а через с [т0 — 1] — вектор, при котором
начинаются итерации при показе х [п]. Тогда из (10.74)
получаем
с [т0 — 1 + гп] = с [т0 — 1] + гпу [п] х [п]. (10.7Г))
Заметим, что у [п] ^ +1 и xv [п] — ± 1, так что
у \х] xv \п] = ±1; алгоритм изменяет веса до тех пор,
пока обучение порогового элемента не будет окончено.
Способность к обучению можно повысить, если
рассматривать не один пороговый элемент, а сети, составлен-
ные из пороговых элементов, как это было, например,
в персептроне Розенблата. Но такое обобщение не
внесет ничего принципиально нового, и поэтому мы не будем
углубляться в область обучаемых пороговых сетей.
§ 10.17. Автоматы
Динамические системы, которые мы рассматривали
до сих пор, характеризовались тем, что обобщенные
координаты их были определены на континуальном
множестве, т.е. могли принимать любые вещественные
значения. Что же касается изменений времени, то в
непрерывных системах оно принималось непрерывным, а в
дискретных системах — дискретным.
Процессы в непрерывных системах описываются
дифференциальными или интегральными уравнениями, а
процессы в дискретных системах — разностными или
суммарными уравнениями. Теперь мы переходим к
рассмотрению «дико частного» случая динамических систем,
в которых обобщенные координаты определены на счетном
или конечном множестве, т. е. могут принимать
бесконечное или конечное число заранее фиксированных
значений, в которых и время изменяется дискретно.
Под автоматом подразумевается динамическая
система, которая под влиянием вектора входных воздействий
и [п] изменяет свое внутреннее состояние а [п] и
производит действие, определяемое вектором выходной
величины х \п]. В конечном автомате множества
соответственно компонент векторов входных воздействий,
состояний и выходных величин конечны. Компоненты вектора
§ 10.18] ;_ОПИСАНИЕ КОНЕЧНЫХ ALICJVFAIOB 305
входных воздействий, или входного вектора, могут
принимать значения из входного алфавита:
u£U={u*, и\ . .., и*}, (10.76)
а компоненты вектора выходной величины, или
выходного вектора, могут принимать значения из выходного
алфавита:
х£Х --{а* х\ ..., хм}т (10.77)
При этом и0, х° — символы, соответствующие отсутствию
входного или выходного воздействия — пустые символы.
Значения или символы, образующие алфавит,
принято называть буквами, а упорядоченные комбинации
букв образуют слова.
Таким образом, конечный автомат преобразует слова
входного алфавита в слова выходного алфавита. Алфавит
внутренних состояний определяет конечное число
внутренних состояний, которые могут принимать компоненты
вектора состояний:
аС-А- {а\ ..., аи}. (10.78)
Число внутренних состояний к соответствует емкости
памяти автомата. Эти специфичные для теории конечных
автоматов термины имеют и иные названия, принятые,
например, в теории дискретных систем. Входные
воздействия, состояния и выходные величины, т. е. то, что
было выше названо «словами», соответствуют неким
решетчатым функциям времени. Дискреты этих решетчатых
функций квантованы по уровням, значения которых
задаются буквами соответствующих алфавитов.
§ 10.18. Описание конечных автоматов
Поведение конечных автоматов или, если угодно,
процессы в конечных автоматах можно описать двумя
уравнениями: уравнением состояния (или переходов) и
уравнением выходных величин
а[п] = / г (а[п — 1], и[п\), а[0] = а0, ^
} (10 79)
x[n] = $j(a[n]). J
20 Я. 3. Цыпкин
306
ИГРЫ И АВТОМАТЫ
£Гл. X
В этих уравнениях/г (•) — «квантованная» по уровню
функция двух векторных переменных, г|) г (•)
—«квантованная» по уровню функция одной векторной переменной,
а а [0] — а0 — вектор начальных состояний.
и[л] I 1
Л
а[п]
а[п-1]
33
%(')
у®>
Рис. 10.7.
Специальный индекс у функций / г (•) и г|) г (•) должен
напоминать нам, что эти функции квантованы по уровням
и, следовательно, могут принимать «значения»,
соответствующие буквам своего алфавита.
х[п]
, 1
г
71
-| fs(-)
а[п-1]
\
п]
1 а["1 -
J
33
%<•>
х[п]
Рис. 10.8.
В отличие от уравнений непрерывных или импульсных
систем, при описании конечных автоматов вводятся
промежуточные величины — состояния а [п], которые играют
определенную роль при построении модели конечного
автомата, но нам нет необходимости углубляться в
обсуждение этого вопроса. Уравнениям (10.79)
соответствует структурная схема конечного автомата,
изображенная на рис. 10.7. Этот конечный автомат имеет 1{
входов и I выходов. Для автоматов с одним входом и
одним выходом (рис. 10.8) вместо уравнений (10.79)
§ 10.18] .".I ОПИСАНИЕ КОНЕЧНЫХ АВТОМАТОВ
307
мы будем иметь
я [га] =/ г (а[п — 1], и[п}), а[0] = а0
ж[и] = г|)г(а[/г]).
■1
J
(10.80)
Но для конечных автоматов между векторными
уравнениями (10.79) и скалярными уравнениями (10.80) нет
непроходимой пропасти,
как в случае непрерывных
или импульсных систем.
Если все возможные
комбинации Zi входных
воздействий закодировать
соответствующими буквами
и то же самое проделать
для состояний и выходной
величины, то автомат с 1{
входами и множеством
воздействий, закодированных
в r-буквенном алфавите,
эквивалентен автомату
с одним входом и одним
выходным воздействием,
закодированными в
/^буквенном алфавите.
В отличие от
непрерывных функций / (•)» ^ (•)»
обычно задаваемых в аналитической форме, «квантованные»
по уровню функции/г (•), г|) г (•), а значит, и уравнения
конечных автоматов, могут быть заданы различными
способами, например табличным или графическим.
Так, /г(-) иг|)г (•) полностью определяются таблицей
перехода и выходов (табл. 10.2), либо графом —
диаграммой перехода (рис. 10.9). Над символами состояний
в табл. 10.2 записываются выходные величины. На
графах они записываются около узлов. Функция /г (•) может
быть определена матрицей состояний
*'r**j
Рис. 10.9.
D(uT) = \\d^(ur)\\ (v=l, ..., N; ,1=1,
М).
(10.81)
20*
308
ИГРЫ И [АВТОМАТЫ
[Гл. X
Таблица 10.2
\. а
1 и х.
//1
1/2
fll
^2 /^
Г/1 /^
«2
/^ Х2
"4 /
/ X*
fl3
/ X*
а2 /
/ х*
а*
^4 /
/ X*
а* /
/ x's
(Г>
/ х^
«2 /
Каждая строка этой матрицы содержит только один
элемент, равный единице, остальные элементы равны нулю.
Если автомат в момент п — 1 находится в состоянии
а [п — 1] = av, а входное воздействие равно и [п] = ит,
то следующее состояние будет равно а \п\ = аР, если
Далее мы будем рассматривав стохастические
автоматы с одним входом и одним выходом. Как было
упомянуто выше, это не является ограничением.
§ 10.19. Стохастические конечные автоматы
Определенным обобщением детерминированных
автоматов, о которых мы говорили выше, представляют собой
стохастические автоматы. В стохастических автоматах
мы можем говорить лишь о вероятностях перехода из
одного состояния в другое. Уравнения такого стохастического
автомата можно записать в такой форме:
a[n] = fj(a[n — 1], и[п], £[«]),
х[п\ = Цг(а[п\).
)
(10.82)
В первом уравнении (10.82) £ [п] представляет собой
случайную решетчатую функцию и, в частности, бернул-
лиеву, обладающую тем свойством, что вероятность
появления той или иной дискреты фиксирована и не
зависит от появления других дискрет.
§ 10.20] ВЗАИМОДЕЙСТВИЕ АВТОМАТА СО СРЕДОЙ 309
Таким образом, в стохастическом автомате состояние
зависит от случайной решетчатой функции £ [га], которая
может изменять как «параметры» конечного автомата, так
и представлять дополнительное к выходному случайное
воздействие (рис. 10.10).
В этом последнем случае первое уравнение (10.82)
примет более определенный вид
a[n]=fj{a[n-l], и[лШ[и]), (10.83)
где символ сложения 0 означает, что сумма и @ £,
всегда принадлежит входному алфавиту.
и["1
aL
fs(-)
1
ГП-Л
1
] а<
1
33
~^\у
Рис. 10.10.
Обычно стохастический автомат определяют
матрицей перехода
P(r) = \\PvAr)\\ (v = l, ..., N; ^-1, ..., М). (10.84)
Она отличается от матрицы состояний (10.81) и тем,
что в ней элементы dx[l (и1) заменены переходными
вероятностями pv[l (г), которые определяют вероятность
перехода из |д,-го состояния в v-e. Естественно, что pv[l (г)
должны удовлетворять условиям симплекса
м
Pv^(r)>0, S pv»(r) = i (v=l, ..., TV). (10.85)
Jbt=l
Стохастические автоматы охватывают
детерминированные как частный случай при £ [га] = 0.
§ 10.20. Взаимодействие автомата со средой
При «погружении» автомата в среду происходит
взаимодействие автомата со средой. Это взаимодействие
сказывается в том, что действия автомата х [га] вызывают
ответную реакцию среды и [га], которая в свою очередь
310
ИГРЫ И АВТОМАТЫ
[Гл. X
воздействует на автомат. При этом входные воздействия
и [п] уже зависят от выходных величин автомата и
от свойств среды.
Уравнение среды можно представить в виде
u[n] = Qj(x[n], £[и]), (10.86)
где 9г (•) — некоторая «квантованная» по уровню
функция, а ^ [лг] — случайная решетчатая функция.
Погружение автомата в среду соответствует охвату этого
автомата обратной связью (рис. 10.11). При этом поведение
и[п]
at
fs(-)
1
rn-U
\
1 а[п]
33
Й ''-»
Ux
\ /
1 х[п]
КО pi
Рис. 10.11.
автомата, естественно, изменяется, и возникает задача
исследования влияния среды на поведение автомата
и целенаправленного улучшения этого поведения. Этот
круг задач был поставлен и в значительной мере решен
М. Л. Цетлиным.
Мы здесь хотели бы рассмотреть эти задачи с
несколько иной, но уже привычной для нас точки
зрения, приводящей к возможности синтеза оптимальных
по целесообразности поведения автоматов/, Разумеется,
прежде всего нужно определить меру целесообразности
поведения.
§ 10.21] О МЕРЕ ЦЕЛЕСООБРАЗНОСТИ ПОВЕДЕНИЯ 311
§ 10.21. О мере целесообразности поведения
При погружении автомата в среду его действие
вызывает реакцию среды, изменяющую входное воздействие.
При благоприятном поведении автомата и [п] = 0,
а при неблагоприятном и [п] = 1. Эти двоичные сигналы
можно считать поощрением и штрафом. В качестве
меры целесообразности поведения автомата удобно
принять математическое ожидание величины штрафа, т. е.
р = М{и}, (10.87)
которое равно вероятности штрафования автомата.
Если бы автомат совершал свои действия
равновероятно, независимо от реакции среды, то его выходная
переменная представляла бы бернуллиеву реше!чатую
функцию b = b [п]. Такому безразличному поведению
автомата соответствует условное математическое
ожидание штрафа
р0 = М{и\х-Ь}. (10.88)
Автомат обладает целесообразным поведением, если
р<Ро- (Ю.89)
Неравенство (10.89) имеет важное значение для анализа
поведения конечных автоматов при достаточно полной
априорной информации. Мы не можем удержаться от того,
чтобы не привести цетлиновский пример о стопке книг,
который особенно наглядно иллюстрирует сказанное
выше. Из стопки книг, лежащей на письменном столе,
книгами можно пользоваться различными способами.
Например, брать нужную книгу, а затем класть ее на место,
либо класть просто на верх стопки. Второй способ
обладает определенной целесообразностью. Чем чаще
книга употребляется, тем выше она расположена в
стопке книг.
Отметим, что величины р и р0 могут быть найдены
по обычным алгоритмам определения математических
ожиданий (5.8) (5.9), если мы можем наблюдать за
действиями автомата.
312
ИГРЫ И АВТОМАТЫ
[Гл. X
§ 10.22. Обучение автоматов
При создании и обучении автоматов разумно требовать
от них не просто целесообразного поведения, а
оптимального по целесообразности поведения. Иначе говоря,
такого поведения, при котором не только выполняется условие
(10.89), но и математическое ожидание штрафа достигает
минимума. Это может быть достигнуто изменением в
результате обучения структуры как самого автомата,
т. е. /г (•), так и характеристики преобразователя г|) г (•).
Мы рассмотрим здесь для простоты последний случай.
В силу уравнений (10.80) и второго уравнения (10.82)
представим р в виде
p^M{Qsfts(a),l)}. (10.S0)
Попробуем теперь найти такую характеристику
преобразователя г|)р(а), для которой р минимально. Будем
яр г (а) искать в знакомой нам форме
h
^г (а)'-~- 2 с*ф*(а) = сгФ(я). (10.91)
Это возможно, если определить систему линейно
независимых функций, например, следующим образом:
Фх (а) --= |
или аналитически:
фх И =
где
[ 1 при а -- -- ак,
[ 0 при афак,
l — sg2(a — aK),
(10.92)
(10.93)
1 при z > 0,
sgz={ 0 пРи 2 = 0, (10.94)
— 1 ПРИ 2<0.
Схема таких преобразователей и их условное обозначение
приведены на рис. 10.12. Функции фх (а) представляют
собой единичные дискреты, а коэффициенты сл в (10.94) —
дискреты из алфавита X. Поэтому г|) г (а) представляется
§ 10.22]
ОБУЧЕНИЕ АВТОМАТОВ
313
комбинацией ет ср (а) не приближенно, как это было для
непрерывных и импульсных систем, а точно (рис. 10.13).
А|А
(afnj) ___а[л]
<&№)
Рис. 10.12.
Условие оптимальности автомата теперь можно
представить так:
p--=pi,,in = minM {9г(етф(а), £)},
с J
(10.95)
и задача обучения состоит в достижении этого условия
путем обработки реализации поведения автомата.
1
&м
cps(a8)
<f>f(a*)
ф, (а-)
i
>
г
>
_L
ah а
Рис. 10.13.
Поскольку градиент реализации бр(-) нельзя
определить, то мы вычислим оценку
Vc±9j (с 1) = ej (с, 1)—Gj (с, 1), (10.96)
где
0J (с, 1) = (9j (с ± в,), .. ., вj (с ± eft)), (10.97)
и воспользуемся поисковым алгоритмом типа (3.15) при
у[п] = 1. Тогда получим алгоритм обучения
с[п] = с [п — 1] — VС±8Г (с[л-Л], 1), если с [и] £-4,
с[и] = с[гс —1J,
если с[л]£Л,
(10.98)
314
ИГРЫ И АВТОМАТЫ
[Гл. X
Теперь уже можно построить структурную схему
обучающегося автомата. Она изображена на рис. 10.14.
При погружении автомата в некую среду в результате
обучения происходит такая «настройка» характеристики
преобразователя, при которой автомат достигает
оптимального поведения. Обучение может осуществляться
Рис. 10.14.
при постоянной характеристике преобразователя путем
изменения случайного воздействия £, создаваемого
специальным генератором. При этом будет происходить
такое перераспределение переходных вероятностей, что
вероятность перехода из любого состояния в состояния,
приводящие к штрафу, уменьшалась.
Такие обучающиеся автоматы обладают гибким
поведением и хорошим приспособлением к сравнительно
медленным изменениям свойств среды. Они платят
минимальный штраф «в юм случае, когда за вчерашние грехи
сегодня награждают, и в том случае, когда грехи остаются
грехами».
Для того чтобы сделать маленькую передышку,
прежде чем переходить к несколько иному, хотя и близкому
§ 10.23]
О МАРКОВСКИХ ЦЕПЯХ
315
кругу вопросов, мы хотели бы спросить читателя: «По
какой системе обучаются автоматы — очной или заочной»?
В § 4.14 мы говорили об этом.
§ 10.23. О марковских цепях
Если предположить, что в стохастических автоматах
случайно также и начальное состояние а [0], а
выходная величина х [п] отождествляется с состоянием а [п],
то подобный автомат соответствует марковской цепи.
Цепи Маркова обычно
характеризуются в вероятностных
терминах и связаны с
понятием испытания, для
которого вероятность исхода
зависит от исхода,
непосредственно предшествующего
этому испытанию. Эти
вероятности определяются
элементами матрицы переходных
вероятностей (10.84). Сама
же эта матрица
характеризует марковскую цепь. В
качестве примера марковской
цепи приведем задачу о наблюдателе, который должен
на основании опыта наблюдений обнаружить полезный
сигнал, маскируемый помехами. Эта задача очень близка
к рассмотренной в § 6.13. Наблюдатель может и
ошибиться. Если наблюдатель считает, что сигнал есть,
когда его на самом деле нет, то это ошибка первого рода,
или ошибка ложной тревоги. Если же наблюдатель
считает, что сигнала нет, тогда как на самом деле он
присутствует, то это ошибка второго рода, или ошибка
ложного отбоя. Марковскую цепь, соответствующую этой
ситуации, можно представить в виде графа (рис. 10.15).
Узлы этого графа представляют собой исходы. В данном
случае мы имеем три исхода: 1 и 2, если имеют место
ошибки первого и второго рода соответственно, и 0, если
ошибок^ нет. Ветви графа представляют собой
соответствующие условные вероятности pvili что после v-ro
исхода наступит |д,-й исход.
Рис. 10.15.
316
ИГРЫ И АВТОМАТЫ
[Гл. X
Разумеется, не все исходы равноценны. Так, исходы 1
и 2 нежелательны, а желательным является исход 0.
Обучение сводится к такому изменению условных
вероятностей pv[l, чтобы желательный исход стал более
вероятным. Это достигается разумным использованием
поощрения или наказания. Пользуясь эквивалентностью,
существующей между автоматами и марковской цепью, мы
рассмотрим марковское обучение на примере построения
стохастического автомата, решающего эту задачу.
§ 10.24. Марковское обучение
Пусть некоторый источник информации посылает
сигналы. Эти полезные сигналы s [тг], принадлежащие
двоичному алфавиту {0, 1} смешиваются с помехой
£ [п]. Наблюдатель принимает сигнал, маскируемый
шумами, у [п] = s [п] + £ [тг], и сравнивает его с
порогом с [п].
Задача обучения наблюдателя сводится к
последовательной настройке порога с = с* так, чтобы условные
вероятности желательных исходов увеличивались, а
нежелательных — уменьшались. В отличие от результатов
§ 6.13 мы теперь будем предполагать, что порог
изменяется не непрерывно, а определен на конечном и, в
частности, на целочисленном алфавите. Именно
дискретность, а часто и конечность алфавита характерны для
марковского обучения. Отождествим алфавит порога
с алфавитом состояний автомата без выходного
преобразователя. Иными словами, положим с [п] — а [п]
и х [п] = а [п].
Тогда
а [и]--=/j (а [и—1], v[n\). (10.99)
Погрузим этот автомат в среду
и [п] = 9 г (у [п] — а [п - 1]). (10.100)
Случайный сигнал у [п] делает эту среду стохастической.
Наконец, в отличие от способа штрафования, принятого
ранее, теперь штрафы или поощрения определяются pas-
§ 10.24J
МАРКОВСКОЕ ОБУЧЕНИЕ
317
ностью между указаниями учителя у0 [п] = s [п] и
реакцией среды и [п]:
v[n]=y0[n]-u[n], (10.101)
где v [п] задано на алфавите {1, —1}. В простейшем
случае можно принять
/г(а[и —1], v[n]) = a[n—l] — v[n], Л
г (10 102)
Qj(yoln]-a[n-l])^sgn(y0[n]-a[n-l]), j v * '
и тогда из уравнений (10.99) — (10.101) легко получить
алгоритм марковского обучения
а[п]=а[п — 1] — (г/о М — sgn (у0 [п] — а [и — 1])), Л
если а[п]£А, I (Ю.103)
а[и]--а [/г—-1], если а[п]£А. J
Этот алгоритм отличается от алгоритма обучения
адаптивного приемника (6.65) 1ем, что теперь у -= 1. По своему
духу алгоритм (10.103) весьма близок к алгоритму
обучения пороговых элементов (10.74).
Постоянство значения у = 1 в таких марковских
алгоритмах приводит к тому, что мы должны
распрощаться с надеждой получить сходимость состояний а [п]
с ростом п к одному оптимальному состоянию а = а*
по вероятности либо с вероятностью единица, как это
было ранее, когда у [п] с ростом п стремилось
надлежащим образом к нулю. Теперь мы можем лишь
довольствоваться тем, что при п —>■ оо только мода а [п] стремится
к а*. Это становится особенно очевидным, если
представить себе, что при рассмотрении стохастического
автомата, эквивалентного марковской цепи, мы можем
говорить лишь о вероятности достижения тех или иных
состояний.
Существует тесная связь между алгоритмами
марковского обучения и последовательным декодированием,
к которому в последнее время возник большой интерес.
Но мы уже не будем касаться этой темы, понимая, что
желание все постичь всегда останется неосуществленным.
318
ИГРЫ И АВТОМАТЫ
[Гл. X
§ 10.25. Игры автоматов
Обучение автомата оптимальному поведению можно
рассматривать как игру автомата с природой.
Но автоматы могут играть и между собой, если
погрузить их в одну и ту же среду (рис. 10.16). Стратегии
игроков-автоматов представляют собой состояния. Число
стратегий определяется памятью автоматов. Теперь штраф
или поощрение соответствуют выигрышу или проигрышу
ф]
fTwN
ЭЗ
Ф-)
XjfnJ хг[н]
^зн
?*>(•)
Ч ЭЗ Н
и2[п]
es(xhx2X)\
I
Рис. 10.16.
автомата. Игры автоматов определяют коллективное
поведение обучающихся автоматов. Для игр автоматов с
нулевой суммой остается справедливой основная теорема
о минимаксе, и мы можем применить полученные выше
алгоритмы обучения решению игр и алгоритмы обучения
автоматов. Мы надеемся, что для прос!ейших задач,
связанных с играми автоматов, читатель сам выпишет
алгоритмы, определяющие стратегии играющих автоматов.
§ 10.26. Некоторые задачи
Среди задач, связанных с играми, мы выделим задачу
построения алгоритмов обучения решению игр в тех
случаях, когда элементы платежной матрицы не постоянны,
а представляют собой случайные величины, либо
неизвестны. Последний случай охватывает так
называемые игры вслепую.
§ 10.27]
ЗАКЛЮЧЕНИЕ
319
Важным во всех задачах обучения и адаптации
является ускорение сходимости алгоритмов за счет
использования более полных данных о среде, получаемых во
время работы автомата. Обычно это сводится к надлежащему
выбору характера изменения у4 [п] и у2 [п]. Существуют
ли иные возможности учета предшествующего опыта для
ускорения сходимости?
Было бы желательно оценить эффективность
различных алгоритмов обучения порогового элемента, а также
пороговых цепей, составленных из пороговых элементов.
Задачи идентификации и управления, очевидно,
переносятся и на конечные автоматы. Систематическое
исследование этих возможностей представило бы
определенный интерес.
Весьма интересные задачи возникают в связи с играми
автоматов. К ним относятся поведение автоматов,
получающих информацию не только об исходе партий, но
и об использованных в этих партиях стратегиях, и игры
автоматов вслепую, когда платежная матрица
неизвестна. Представляет интерес рассмотреть игры автоматов
с ненулевой суммой и, наконец, игры большого числа
автоматов. Естественно, при адаптивном подходе
предполагается достаточно малая априорная информация,
которая не позволяет непосредственно применить
довольно развитый аппарат марковских цепей.
§ 10.27. Заключение
В этой последней главе мы коснулись игр двух лиц
с нулевой суммой и установили алгоритмы обучения
решению игр. Эти алгоритмы оказались полезными для
решения ряда задач пороговой реализуемости и
управления. Пороговые элементы, реализующие булевы
функции, составляют основу построения персептрона Розен-
блата и Адалины Уидроу. Здесь использована их
«способность» к обучению. Много внимания мы уделили
конечным автоматам, которые представляют собой особый
класс динамических систем. Системная точка зрения
позволила перенести на конечные автоматы адаптивный
подход, который широко использовался в предыдущих
главах в применении к непрерывным и импульсным системам.
320
ИГРЫ И АВТОМАТЫ
[Гл. X
Поэтому мы смогли заняться не только установлением
факта целесообразности поведения автомата, но и обучать
автоматы оптимальному поведению. Оптимальное
поведение автоматов может состоять в опознавании образов,
выделении полезных сигналов, идентификации иных
автоматов и т. п.
Характерная особенность явлений и объектов,
которым была посвящена эта глава, состояла в том, что
искомые переменные либо удовлетворяли условиям
симплекса, либо принимали фиксированные значения из
конечного набора — алфавита. Мы пытались показать, что,
несмотря на специфичность ситуаций, адаптивный
подход и здесь позволяет решать оптимальные задачи в
условиях неопределенности.
Послесловие
Характерная особенность многих задач современной
теории и техники управления проявляется в отсутствии
априорной информации о процессах и объектах, в
начальной неопределенности. И по крайней мере сейчас
кажется, что единственно возможная основа решения
проблемы оптимизации в этих условиях — адаптация
и обучение.
Сами понятия адаптации и обучения первоначально
всегда связывались с поведением либо отдельных живых
организмов, либо коллективов их. Сейчас уже стало
обычным использовать эти понятия применительно к
автоматическим системам, способным выполнять свои функции
в условиях начальной неопределенности. Это не означает,
однако, что следует всегда отождествлять адаптацию
и обучение в живых организмах с адаптацией и
обучением в автоматических системах. Но, по-видимому,
теория адаптации в автоматических системах в ряде
случаев может оказаться полезной для объяснения
удивительного поведения живых организмов.
Мы умышленно, как, вероятно, читатель мог
заметить, не использовали аналогию между поведением
технических и биологических систем и не касались столь
модных сейчас вопросов, связанных с понятием
искусственного интеллекта, которые тесно переплетаю! ся
с адаптацией и обучением. Это решение было вызвано
не только боязнью автора конкурировать с огромным
числом популярных статей и книг по кибернетике, но
и тем, что настоящее понятие «интеллект» должно
содержать что-то принципиально неизвестное, непознанное
и не поддающееся формализации. Поэтому, по каким бы
алгоритмам ни обучалась и ни адаптировалась та или
21 я. з. Цып кип
322
ПОСЛЕСЛОВИЕ
иная автоматическая система, вряд ли целесообразно
приписывать ей интеллект, даже если он и
искусственный.
Принятое в книге рассмотрение адаптации и обучения
как своеобразных вероятностных итеративных процессов
позволило объединить множество разнородных задач
современной теории управления, усмотреть единство их
идейного содержания и, наконец, разработать
эффективный метод их решения.
Значение такого подхода к проблеме адаптации
и обучения состоит не только в проникновении в
сущность проблемы и выработке эффективных путей решения,
но и в том, что этот подход возрождает на новом, более
высоком уровне те «старые» задачи классической теории
управления, которые под мощным натиском новых
направлений отодвигались на задний план. Это относится,
например, к задачам устойчивости и качества. Ведь
любой алгоритм адаптации и обучения может бьиь
осуществлен, если он обладает сходимостью. А сходимость
алгоритмов есть не что иное, как выражение факта
устойчивости соответствующих стохастических
нелинейных замкнутых систем.
Оценка скорости сходимости и отыскание оптимальных
с той или иной точки зрения алгоритмов тесно связаны
с задачами качества стохастических нелинейных систем.
Таким образом, и в новой проблеме адаптации и
обучения задачи устойчивости и качества играют важную,
а порой и главную роль. Не является ли этот факт
лучшим свидетельством того, что теория автоматического
управления «растет, но не стареет», что в ней возникают
все новые и новые направления, но вечно юными остаются
задачи устойчивости pi качества.
Сейчас трудно говорить о каком-либо завершении
теории адаптации и обучения. Мы находимся лишь в
начале пути, вероятно, долгого, но с очень ясной и
заманчивой перспективой. На этом пути вырисовываются новые
связи между различными направлениями теории
управления и смежных наук, которые, возможно, покажутся
нам неожиданными. Возникают также и новые задачи,
коюрые, вероятно, расширят и область применения
теории адаптации и обучения.
ПОСЛЕСЛОВИЕ
323
Усложнение управляемых объектов систем
управления, отсутствие априорной информации относительно
условий их работы вызвали к жизни адаптивные системы
управления. Но роль процессов адаптации и обучения
не будет ограничиваться только устранением
неопределенности и управлением при отсутствии полной
информации. Ведь устранение неопределенности и отбор
полезной информации есть элемент творческого процесса,
и, кто знает, быть может, в недалеком будущем при
активной помощи адаптивных систем можно будет не
только достигнуть наиболее совершенного в данных условиях
управления, но и создавать более общие методы, теории
и концепции.
I
21*
Комментарии
К главе I
§ 1.1. Проблеме оптимальности посвящена обширная
литература, перечислить которую в обозримой форме, пожалуй,
невозможно. Но для наших целей в этом и нет необходимости. Поэтому
мы отметим лишь несколько основных книг. В первую очередь
отметим книгу А. А. Фельдбаума [1.1], в которой изложены
различные формулировки проблемы оптимальности и возможные
подходы к ее решению.
В книгах Р. Беллмана [1.1], [1.2] эта проблема рассмотрена
па основе разработанного им метода динамического
программирования, а в книге Л. С. Понтрягипа, В. Г. Болтянского, Р. В. Гам-
крелидзе и Е. Ф. Мищенко [1.1] рассмотрение ведется на основе
открытого ими принципа максимума. Читателю, пожелавшему
расширить свои представления по различным аспектам проблемы
оптимальности, можно рекомендовать познакомиться с книгами
В. Г. Болтянского [1.1], особенно просто и наглядно излагающей
задачи оптимальности, А. Г. Бутковского [1.1], посвященной
оптимальности системы с распределенными параметрами, Ш. Чанга
[1.1], охватывающей также и задачи оптимальности линейных
непрерывных и дискретных систем.
Для знакомства с проблемой оптимального управления,
вероятно, наиболее подходящей будет интересная во многих отношениях
небольшая книга Р. Ли [1.1].
Все упомянутые книги содержат довольно подробную
библиографию.
Не следует думать, что проблема оптимальности — простая
и ясная проблема. Часто вопрос «Что такое оптимальность?» может
вызвать грустные размышления и пессимизм, см., например,
работы Л. Заде [1.1] и отчасти Р. Калмана [1.1]. Автор, однако, ие
может полностью разделить этот пессимизм.
§ 1.2. Мы пользуемся здесь обозначениями, принятыми
Ф. Р. Гантмахером [1.1]: все векторы представляют собой
прямоугольные столбцовые матрицы, и для них используется
обозначение с = (ci, . . ., cN)\ транспонирование вектора, т. е.
прямоугольной столбцовой матрицы, приводит к строчной матрице
сТ r= [clf . . ., cN].
Байесовские критерии широко используются в теории связи
и радиолокации, а в последнее время и в теории управления, см.,
КОММЕНТАРИИ
325
например, книги Л. С. Гуткина [1.1], К. Хелстрома [1.1],
А. А. Фельдбаума [1.1].
В формуле (1.3) принята простая запись: вместо dQ (х) =
= б/л']. . . с1х^[, определяющего элементарный объем
пространства X, мы пишем просто dx.
О математическом ожидании характеристической функции
см., например, Б. В. Гнеденко [1.1] или Р. Л. Стратоиович [1.1].
§ 1.3. Об эргодичности см., например, небольшую, по очень
содержательную книгу П. Халмоша [1.1].
§ 1.4. Роль детерминированных ограничений в наиболее
выразительной и ясной форме неоднократно подчеркивалась
А. А. Фельдбаумом [1.1] (см. также Р. Ли [1.1], Р. Беллман [1.2]).
§ 1.5. Именно такая характеристика априорной и текущей
информации принята А. А. Красовскнм [1.1].
§ 1.6. Приведенное деление процессов на детерминированные
и стохастические общепринято (см., например, Р. Беллман [1.2]).
Однако здесь мы хотели подчеркнуть общность формулировки
и решения проблемы оптимальности для этих процессов и поэтому
не так настойчиво останавливались на различии между ними.
§ 1.7. Несколько иную трактовку адаптивного подхода можно
найти у Р. Беллмана [1.2]. Принятая здесь трактовка совпадает
с изложенной ранее в статье автора [1.1]. Весьма интересная связь
между стохастической задачей синтеза линейной системы,
оптимальной по дисперсии ошибки, и детерминированной задачей
синтеза линейной системы, оптимальной по интегральной квадрати-
ческой ошибке, указана Р. Калманом [1.2]. Эта связь
сформулирована им в виде принципа дуальности.
§ 1.8. Кроме упомянутых выше книг, с методами решения
проблемы оптимальности, относящихся к обычному подходу, можно
познакомиться по книгам Дж. Лейтмана [1 Л] и К. Мерриама [1.1].
К главе II
§ 2.2. Мы пользуемся обычной векторной записью
необходимых условий экстремума (см., например, Р. Ли [1.1]).
§ 2.3. Регулярный итеративный метод восходит еще к Огюсту
Коши. Но мы преодолеем соблазн заняться изложением истории
этих методов и предпочтем отослать читателя к превосходной
статье Б. Т. Поляка [2.1], а также к книгам по вычислительной
математике, например, Б. П. Демпдовнча и II. А. Марона [2.1],
И. С. Березина и Н. П. Жидкова [2.1]. В этих книгах дано
традиционное изложение итеративных методов применительно к
линейным и нелинейным алгебраическим уравнениям. Специально
итеративным методам посвящена книга Дж. Трауба [2.1], а применение
326
КОММЕНТАРИИ
этих методов для решения краевых задач изложено в книге В. Е. Ши-
манского [2.1]. См. также обзор В. Ф. Демьянова [2.1].
§ 2.4. Термин дигратор для дискретного интегратора
предложен И. Л. Медведевым.
§ 2.5. Это обобщение в наиболее отчетливой форме было
описано С. Бингулацем [2.1].
§ 2.6. Единой классификации алгоритмов или, как их еще
называют, рекуррентных схем, не существует.
Применительно к системам линейных алгебраических
уравнений весьма полная классификация приведена в книге Д. К. Фад-
деева и В. И. Фаддеевой [2.1]. Читатель, вероятно, заметит, что
мы немного отклонились от этой классификации. О конкретных
алгоритмах см., например, книгу Б. П. Демидовича и И. А. Марона
[2.1]. Релаксационным алгоритмам посвящена интересная работа
И. М. Глазмана [2.1] (см. также И. М. Глазман, 10. Ф. Сенчук
[2.1]). Нам кажутся весьма перспективными методы сопряженного
градиента (см., например, С. Миттер, Л. Лесдон, А. Уорен [2.1]).
Обзор итеративных методов решения функциональных
уравнений содержится в статье Л. В. Канторовича [2.1].
§ 2.7. Идея поисковых алгоритмов, по-видимому, принадлежит
Р. Германскому [2.1]. В математической литературе поисковым
алгоритмам подобного типа почему-то уделялось мало внимания.
О синхронном детектировании см. книги П. И. Дегтяренко
[2.1] и А. А. Красовского [1.1]. В последней книге широко
применяются методы определения градиента с помощью синхронного
детектора или коррелятора (при использовании шумов).
§ 2.8. См. книгу Р. Ли [1.1]. Иные способы определения
множителей Лаграпжа можно найти в работе Б. Т. Поляка [2.1].
§ 2.9. Учету ограничений типа неравенств посвящена большая
литература по математическому и, в частности, нелинейному
программированию. Среди них укажем на книги К. Эрроу, Л. Гурви-
ца, X. Удзавы [2.1] и Г. Кюнци, В. Крелле [2.1] и статью Е. С. Ле
витпна и Б. Т. Поляка [2.1]. В этих работах читатель может найти
точные формулировки теоремы Куна — Танкера и условия
регулярности Слсйтера. Очень интересный подход решения подобных
задач был развит А. Я. Дубовицким и А. А. Милютиным [2.1].
Схемы, реализующие алгоритмы с учетом ограничений, описаны
Д. Деннисом [2.1].
§ 2.10. Наиболее полное изложение методов возможных
направлений дано в книге Т. Зойтепдейка — автора этих методов [2.1].
§ 2.11. Мы несколько перефразировали пример, приведенный
Р. Ли [1.1].
§ 2.12. Здесь использованы известные соотношения из теории
конечных разностей, см., например, книгу автора [2.1]. Много-
КОММЕНТАРИИ
327
шаговым алгоритмам посвящено сравнительно небольшое число
работ, среди которых укажем на статью Б. Т. Поляка [2.1].
§ 2.13. О непрерывных алгоритмах см. статьи М. К. Гавурина
[2.1], [2.2], а также статью С. II. Альбера и Я. И. Альбера [2.1],
посвященные математическим вопросам. См. также статьи М. В. Ры-
башова [2.1], [2.2] по применению аналоговых вычислительных
машин для решения конечных уравнений.
Идея тяжелого шарика принадлежит, по-видимому, И. Кумада
[2.1], см. также работу Б. Т. Поляка [2.1].
§ 2.14. Методы случайного поиска, о которых в свое время
упоминал У. Эшби [2.1], получили большое развитие в
многочисленных работах Л. А. Растрнгипа и были подытожены в его книге
[2.1]. Некоторые применения методов случайного поиска для
оценки линейного решающего правила изложены А. Вольфом [2.1].
По этим вопросам см. также статьи И. Матыаша [2.1], И. Мансопа
и А. Рабипа [2.1].
§ 2.15. Изложение применения метода Ляпунова для
дискретных систем можно найти, например, в книге П. В. Бромберга [2.1]
и статье Р. Калмапа и Дж. Бертрама [2.1]. Различные
формулировки принципа сжатых отображений можно найти, например,
в книгах Л. А. Люстерпика и В. И. Соболева [2.1], М. А.
Красносельского [2.1].
§ 2.16. Об абсолютной устойчивости см. уже ставшую
классической книгу А. И. Лурье [2.1]. К сожалению, условиям
неизбежной сходимости в литературе уделялось мало внимания. Что же
касается условий сходимости итеративных методов вообще, то им
посвящено даже чрезмерно большое число работ. Отметим книги
Дж. Трауба [2.1] и А. М. Островского [2.1], а также статью
М. II. Яковлева [2.1]. В этих работах читатель найдет подробную
библиографию по сходимости итеративных методов. См. также книгу
С. Г. Михлппа [2.1].
§ 2.17. Этот способ ускорения сходимости принадлежит Всг-
стейну [2.1]. Он описан также в книге Р. Ледли [2.1].
§ 2.18. Когда автор работал над этим вопросом, он был
обрадован, найдя ссылку на статью П. С. Бопдаренко [2.1] с весьма
многообещающим названием. Но после знакомства с ней надежда
узнать, как же хорошо определить понятие «наилучший алгоритм»,
так и не оправдалась.
§ 2.19. О релаксационных методах см. уже упоминавшуюся
статью И. М. Глазмана [2.1], а также статью 10. И. Любича [2.1]
и Ч. Б. Томпкинса [2.1].
§ 2.21. Обзор нелокальных методов оптимизации и путей
решения многоэкстремальных задач можно найти в статье
328
КОММЕНТАРИИ
Д. Б. Юдина [2.1]. Интересный метод решения многоэкстрсмаль-
ной задачи, так называемый метод «оврагов», предложен II. М. Гель-
фандом и М. Л. Цетлпным [2.1].
К главе III
§ 3.2. К настоящему времени в определениях понятий обуче
пия и адаптации нет недостатка (см., например, Р. Буш, Ф. Мостел-
лер [3.1], Г. Паск [3.11, [3.2], Л. Заде [3.1], Дж. Гибсоп [3.1],
Дж. Скланскпй [3.11, [3.2], [3.3], О. Якобе [3.1], А. А. Фельдбаум
[3.11 и т. д.). Автору показалось значительно проще выработать
еще одно определение, чем пытаться объединить и применить
определения, столь щедро разбросанные в литературе.
§ 3.4. Основная идея метода стохастической аппроксимации
возникла, по-видимому, довольно давно, но в ясной и четкой форме
она была сформулирована Г. Роббипсом и С. Монро [3.1] в 1951 г.
Они указали итеративную процедуру, позволяющую определить
по реализации корень уравнения регрессии. Ота процедура
представляла собой стохастический вариант итеративной
процедуры Р. Фон-Мизсса и Г. Поллячек-Гейрппгер [3.1]. Работа Г.
Роббпнса и С. Монро вызвала большой поток работ, развивающих
;>ту идею.
Дж. Вольфовиц [3.1] ослабил условия сходимости. Г. Калли-
аппур [3.1] и Дж. Б л ум [3.1] независимо показали, что даже при
менее стеснительных условиях, чем у Дж. Вольфовица [3.1],
процедура Роббпнса — Монро сходится не только по вероятности,
по также с вероятностью единица. Процедура Роббпнса п Монро
была обобщена А. Дворецким [3.1]. Более простые
доказательства этой обобщенной процедуры были указаны Дж. Вольфови-
цем [3.1] и К. Дерманш, Дж. Саксом [3.1]. Некоторая модификация
этой процедуры, состоящая в выборе у [/г], предложена А.
Фридманом [3.1]. Итеративная процедура была обобщена на
многомерный случай Дж. Блумом |3.1]. Простое и ясное доказательство
сходимости многомерной процедуры дано Е. Г. Гладышевым [3.1].
Для линейной функции регрессии удобной оказывается
модификация процедуры, указанная В. Дупачем [3.2].
Асимптотические свойства итеративной процедуры выяснены
Л. Шметтерером [3.L], К. Чатхгом [3.1] и Дж. Саксом [3.1],
Е. Г Гладышевым [3.1], а в частном случае линейной функции
регрессии Т. Ходжесом и Е. Леманом [3.1]. Т. П. Красулина [3.1],
[3.2] установила связь между итеративной процедурой Дж Блума
[3.1] п обобщенной итеративной процедурой Дворецкого [3.1]
к привела сжатый обзор методов стохастической аппроксимации.
Упоминание о процедуре Роббпнса — Монро имеется в книге
Б. Л. Ban дер Вардена [3.1], а систематическое изложение можно
найти в книге Г. Везерила [3.1].
Отметим ряд работ по разнообразным применениям процедуры
Роббпнса — Монро, которые, однако, находятся вне области наших
интересов. Это работы Т. Гутмана, Р. Гутмана [3.1] по биометрике,
В. Кохрана и М. Дэвпса [3.11 по биологии.
КОММЕНТАРИИ
329
Сравнение различных методов оптимизации при наличии помех
приводилось Л. С. Гуриным [3.2], [3.3], С. М. Мовптовичем [3.1].
См. также работу Р. 3. Хасьминского [3.2]. Подробные обзоры
основных результатов метода стохастической аппроксимации
принадлежат К. Дерману [3.1], Л. Шметтереру [3.3] и Н. В.
Логинову [3.1].
§ 3.6. В 1952 г. идея стохастической аппроксимации была
распространена Е. Кнфером и Дж. Вольфовицем [3.1] на случай
определения экстремума функции регрессии. Это был первый
вероятностный поисковый алгоритм, представляющий собой
стохастический вариант поисковой итеративной процедуры, предложенной
Р. Германским [2.1].
Сходимость поисковой процедуры Кифера — Вольфовпца,
с вероятностью единица была доказана Дж. Блумом [3.1] и Д. Бурк-
холдером [3.1]. Известны различные обобщения на многомерный
случай. Им посвящены работы Дж. Блума [3.2] и К. Грея [3.1].
Асимптотические свойства процедуры Кифера — Вольфовпца
были изучены К. Дерманом [3.1], В. Дупачем [3.1], Дж. Саксом
[3.1]. Упомянутые выше обзоры К. Дермана [3.2], Л. Шметтерера
13.5] и П. В. Логинова [3.1] большое внимание уделяют и
процедуре Кифера — Вольфовпца.
А. Дворецкий [3.1] показал, что процедуры Роббинса — Мопро
и Кифера — Вольфовпца вытекают как частные случаи из
предложенной им общей процедуры.
Обобщение процедуры Дворецкого для случая конечномерного
евклидового пространства дано К. Дерманом и Дж. Саксом [3.11,
а для случая гпльбертового пространства — Л. Шметтерером [3.1].
В последнее время эти все результаты были обобщены Дж. Вент-
нером [3.1].
§ 3.8. Вопросы сходимости алгоритмов адаптации при учете
ограничений вида неравенств к настоящему времени не получили
полного решения.
§ 3.9. На возможность такого обобщения нам было указано
Я. И. Хургиным.
§ 3.11. Непрерывные алгоритмы подробно изучались А. Шпа-
чеком и его учениками. Результаты работ в этом направлении
изложены в трудах М. Дрпмла и Т. Недомы [3.1], М. Дрпмла и О. Ханша
[3.2], О. Ханша и А. Шпачека [3.1]—для непоисковых алгоритмов
и Д. Сакрисопа [3.1]—для поисковых алгоритмов.
§ 3.12. Точные формулировки различных видов сходимости
хорошо изложены в книге М. Лоэва [3.1]; см. также книгу Д. Миддл-
тона [1.1].
§ 3.13. Здесь приведены условия сходимости, которые можно
получить на основании результатов работ по стохастической
аппроксимации, перечисленных выше.
330
КОММЕНТАРИИ
Но было бы очень интересно получить условия сходимости как
частный случай условий устойчивости стохастических систем.
Последним задачам посвящены работы И. Я. Каца, II. Н. Красов-
ского [3.1], Р. 3. Хасьминского [3.1], Г. Кашнера [3.1].
Геравенство (3.37) было получено Дж. Номером [3.1]. В его
работе приводится явное выражение функции rj.
§ 3.15. Описанные методы ускорения сходимости были
предложены Г. Кестеном [3.1] и В. Фабианом [3.1]. См. также
Д. Уайлд [3.1].
§ 3.16. Мера качества алгоритмов типа (3.49) использовалась
в работах Л. Дворецкого [3.1], 3. Николпча, К. Фу [10.1] для
определения наилучших алгоритмов оценки среднего значения.
§ 3.17. Наилучшее значение у\п] для скалярного одномерного
случая было получено из иных соображений Р. Л. Стратонови-
чом [3.1].
§ 3.18. Соотношения (3.70) — (3.72) в частном случае при
А'П -= A'l — 1 были получены К. Кирвайтпсом и К. Фу [5.1].
§ 3.19. Изложенные здесь соображения являются развитием
одной идеи А. Дворецкого [3.1]. См. также работу Г. Блока [3.1].
.')ти соображения были применены А. А. Первозваиским [3.1] для
выбора оптимального шага в простейших импульсных экстремаль-
пых системах.
§ 3.20. Подробное изложение рекуррентной формы метода
наименьших квадратов приведено в работе А. Альберта, Р. Ситтле-
ра [3.1].
Рекуррентная формула вычисления Г[?i] по предшествующим
значениям Г [п — I] может быть получена па основе очень
популярной теперь рекуррентной формулы обращения матриц,
предложенной Пепроузом (R. Penrose),— см., например, книгу Р. Ли [1.1].
Нетрудно установить связь между всеми этими результатами
и теорией калмаповских фильтров. См. книгу Р. Ли [1.1].
С весьма интересным методом Качмажа можно познакомиться
по статье Томпкинса в книге Э. Беккепбаха [3.1] либо по работе
самого С. Качмажа [3.1].
§ 3.21. Формула (3.81) при фиксированном п была установлена
Р. Л. Стратоиовичем [3.1].
Доказательство сходимости рекуррентных процедур при
повторении конечного числа данных дано Б. М. Литваковым [3.1].
§ 3.22. Мы используем некоторые соотношения, изложенные
в книге Г. Крамера [3.1], и идеи, развитые в работах Д. Сакрисо-
на [3.1], [3.2]. В этих работах читатель найдет подробное изложение
рекуррентных алгоритмов и их применения для решения некоторых
радиолокационных задач.
КОММЕНТАРИИ
331
§ 3.23. По вопросам, связанным с наилучшими алгоритмами,
см. статьи Р. Л. Стратоновича [3.1] и автора [3.1], которые
выражают различные точки зрения.
К главе IV
§ 4.1. То, что опознавание является первой ступенью
обработки информации, неоднократно, со свойственным ему блеском
подчеркивал А. А. Харкевич [4.1], [4.3].
На изучение дискуссий типа «человек или машина» можно
потратить довольно много времени. Автор не без удовольствия
знакомился с этими дискуссиями по книгам М. Таубе [4.1] и А. Е. Коб-
ринского [4.1] и рекомендует их читателям. Специально проблеме
опознавания посвящены книги Г. Себастиана [4.1] и Н. Ыильсо-
на [4.1].
§ 4.2. Гипотеза компактности была выдвинута 0. М. Бравер-
маном [4.1]. Она долгое время уточнялась и, по-видимому, нашла
свое выражение в гипотезе представимости, о которой говорится
в § 4.5.
§ 4.3. Подобные функционалы были введены В. А.
Якубовичем [4.2] для квадратичной функции потерь, а в общем случае —
автором [5.1], [1.1].
§ 4.4. Аппроксимация произвольной функции с помощью
системы линейно независимых и, в частности, ортонормироваыных
функций широко используется для решения разнообразных
технических задач.
Изложенный здесь подход основан па результатах заметки
автора [4.1] и статьи И. П. Девятерпкова, А. И. Пропоя и
автора [4.1].
Алгоритмы типа (^.12) для некоторых частных случаев
{F (-) — линейная и релейная функции) были выписаны М. А. Ай-
зермапом, Э. М. Браверманом, Л. И. Розоиоэром [4.3] на основе
развитого ими метода потенциальных функций. Далее из этих
алгоритмов они получили соответствующие алгоритмы типа (4.9).
По терминологии М. А. Айзермана, 3. М. Бравермаиа, Л. И. Розо-
ноэра [4.1], алгоритмы типа (4.12) соответствуют «машинной
реализации» и рассмотрению задачи в исходном пространстве, а алгоритмы
типа (4.9) —«персептронной реализации», и рассмотрению задачи
в «спрямляющем» пространстве. Из результатов, приведенных
в § 4.4, следует, что эти реализации эквивалентны друг другу.
§ 4.5. «Гипотеза представимости» была введена М. А. Айзер-
маном, Э. И. Браверманом, Л. И. Розоноэром [4.1] — [4.3].
Отметим, что при этом была доказана сходимость полученных ими
алгоритмов не с вероятностью единица, а только по вероятности и при
условии, что система функций q)v (х), v — 1, . . ., N, ортонормаль-
па. В частности, во второй из упомянутых работ было получено
условие (4.19). Э. М. Браверман [4.2] снял одно из ограничений
332
КОММЕНТАРИИ
и доказал сходимость соответствующих алгоритмов с вероятностью
единица. При изложенном здесь подходе нет нужды использовать
гипотезу представимости, при этом доказывается сходимость
с вероятностью единица, т. е. почти наверное.
§ 4.6. О персептроне Розеиблата написано очень много.
Мы здесь укажем лишь наиболее интересные, разумеется, с точки
зрения нашего похода, работы. Прежде всего, это работы Ф.
Розеиблата [4.1] — [4.3]. Важные подробности о персептроыах можно
найти в работе Г. Блока [4.1]. Возможность построения персептро-
нов не только на пороговых элементах была отмечена В. А.
Якубовичем [4.1], [4.2] и М. А. Айзерманом, Э. М. Браверманом, Л. И. Ро-
зоноэром [4.1].
§ 4.7. Изложенные результаты основаны на работе И. П. Де-
вятерикова, А. И. Пропоя и автора [4.1].
Алгоритмы, приведенные в табл. 4.1, представляющие частные
случаи общего алгоритма обучения, соответствуют алгоритмам,
найденным различными авторами за последние несколько лет.
Алгоритмы 1—4 табл. 4.1 были получены М. А. Айзерманом,
Э. М. Браверманом, Л. И. Розоноэром [4.1] — [4.3]. В. А.
Якубовичем [4.2] получены алгоритмы обучения, близкие к алгоритмам
1 и 3 табл. 4.1. Им было введено понятие С- и L-оптимальностп
и дано сравнение этих алгоритмов.
М. Е. Шайкин [4.1] показал, что алгоритм 4 табл. 4.1, в том
случае, когда выполнена гипотеза представимости, обеспечивает
сходимость с [п] по вероятности к вектору с*; при этом среднеквадра-
тическая ошибка равна нулю.
Упрощение доказательства сходимости этого алгоритма с
помощью одного из результатов А. Дворецкого но стохастической
аппроксимации получено сравнительно недавно в работе К. Блай-
допа [4.1].
§ 4.8. Изложенная здесь идея получения поискового
алгоритма была впервые описана Д. Купером [4.1], (см. также Д. Бяласе-
впч [4.1], [4.2] и Ю. П. Леонов [4.1]).
§ 4.9. Алгоритмы типа (4.30) были получены В. Н. Вапником,
А. Я. Лерпером, А. Я. Червоиепкисом [4.1] на основе введенного
ими понятия обобщенного портрета, см. также В. Н. Вапник,
А. Я. Червоненкис [4.1] — [4.3].
§ 4.10. Алгоритм (4.31) при у^ const именно в такой форме
был получен М. А. Айзерманом, Э. М. Браверманом, Л. И.
Розоноэром [4.1]. В несколько иной форме он ранее был получен А.
Новиковым [4.1] (см. § 4.12).
§ 4.11. Прием замены системы неравенств системой равенств
использовался несколько иначе в работе 10. Хо и Р. Кашиапа
[4.1], [4.2].
§ 4.12. См. также работу И. П. Девятерпкова, А. И. Пропоя
и автора [4.1]. Алгоритм (4Л2), когда Г — матрица, рассматри-
КОММЕНТАРИИ
383
вался А. Новиковым [4.1]. Интересные соображения о сходимости
алгоритмов и об использовании периодических показов одних
и тех же образов приводятся Б. М. Литваковым [3.1].
§ 4.13. Быть может, полезно продолжить обсуждение,
рассмотрев некоторые результаты обучения опознаванию образов.
Персептроны и, в частности, персептроны Б. Уидроу [4.3] — [4.5]
типа «Адалина» были использованы для предсказания погоды,
распознавания речи, почерка, для диагностики, а также как
обучаемое устройство,—см. Б. Уидроу, [4.1]. Интересны и сами
результаты, полученные при таких применениях.
В первом случае на вход персептропа подавались (после
кодирования) измерения барометрического давления в различных
точках. Выход персептропа соответствовал ответу — будет или не будет
дождь. При этом использовалась система из трех персептронов.
Предсказание дождя делалось для трех интервалов по 12 часов:
I. Сегодня — с 8 утра до 8 вечера
II. Сегодня — с 8 вечера до 8 утра
III. Завтра — с 8 утра до 8 вечера
Измерение производилось в первый день в 4 часа утра.
В опыте использовались три способа задания информации:
Л —«сегодняшняя» карта давлений в 4 часа утра;
В —«сегодняшняя» и «вчерашняя» карта, обе в 4 часа утра;
С —«сегодняшняя» карта и разность между сегодняшним и
вчерашним давлением. Опыт производился в течение 18 дней.
Результаты приведены в таблице.
Официальны и
прогноз
А
В
С
Проценты правильного
предсказания
I
78
72
78
78
и
89
67
78
89
III
67
67
78
83
Необходимо подчеркнуть успех этого опыта, тем более, что
использовались данные только о давлении.
Во втором случае речь с микрофона подавалась на 8 полосовых
фильтров, расположенных по всему звуковому спектру. Выходной
сигнал этих фильтров (пропорциональный спектральной энергии)
затем квантовался, кодировался и преобразовывался в импульсную
форму и в такой форме подавался на вход персептрона.
В типичном эксперименте выход каждого фильтра разбивался
на 4 уровня. Каждому слову соответствовало 10 импульсов, а
каждый уровень был представлен трехбитовым кодом, так что на
каждое слово приходилось 8 X 3 X Ю - 240 битов.
334
КОММЕНТАРИИ
Персептрон сигнала тренировался на голос одного лица. После
тренировки (при которой использовалось по 10 образцов каждого
слова от одного лица) персептрон разбирал новые образцы этих же
слов (и от этого же лица) с точностью 98% пли лучше. Если же
говорило другое лицо, точность была порядка 90%.
Для диагностики по электрокардиограммам (ЭКГ)
использовалась трехдорожечная запись, но все дорожки записывались
одновременно, так что имелась и фазовая информация.
На вход персептрона эта информация подавалась с интервалом
10 мсек. После 100 импульсов врач, специалист по ЭКГ, определял
правильность заключения «здоров» или «болен». Результаты опыта
приведены в таблице.
Результаты
Заключение врача .
Заключение персеп-
1 трона
Правильно
—«здоров», %
(27
случаев)
95
89
Правильно
—«болен», %
(30
случаев)
5'i
73
Персептрон, основанный на обобщенном портрете,
использовался для обнаружения нефтеносных скважин. Но данным
В. Н. Вапника, А. Я. Лернера, А. Я. Червоненкиса [4.1],
использовались двенадцать параметров, относящиеся к 104 пластам малой
мощности. Из этих 104 пластов для обучения было выделено 23 пласта
нефтеносных и 23 водоносных, т. е. 46 пластов. В результате
экзамена после обучения ошибок в разделении пластов не было.
При разделении же 180 пластов большой мощности (из них
45 выделено для обучения с ранее найденным обобщенным портретом)
ряд водоносных пластов был принят за нефтеносные. Подробности
читатель может найти в упомянутой работе, а также в работе
Ш. А. Губермана, М. Л. Извековой и Я. И. Хургипа [4.1], в
которой приведены результаты применения для этой же цели
алгоритмов опознавания, предложенных М. М. Бонгардом, А. Г.
Французом и др.
Интересные результаты получены в работе Б. Н. Козинца,
Р. М. Ланцмана, Б. М. Соколова, В. А. Якубовича [4.1] по
дифференциации почерков, а также в работе В. А. Якубовича [4.1] по
распознаванию профилей.
Многие работы посвящены распознаванию букв или цифр,
печатных и рукописных. Мы не будем задерживать внимание читателя
на этих результатах. Обзоры работ по опознающим устройствам
принадлежат В. П. Сочивко [4.1], [4.2].
§ 4.15. Задачей восстановления плотности распределения
занимались А. С. Фролов, Н. Н. Чепцов [4.1], Н. Н. Ченцов [4.1],
КОММЕНТАРИИ
335
Н. Е. Кириллов [4.1], М. А. Айзерман, Э. М. Браверман, Л. И. Ро-
зоноэр [4.2]. Мы, как и авторы этих работ, оставляем в стороне
вопросы нормировки р{х).
§ 4.16. Здесь приводятся алгоритмы, полученные в работах
автора [4.1], [4.2]. Модифицированные алгоритмы (типа (4.55))
предложены К. Фу и 3. Ыиколичем (см., например, [10.1]). Их
утверждение, что модифицированные алгоритмы сходятся быстрее
обычных, оказалось ошибочным. Это обстоятельство было выяснено
при обсуждении с В. С. Пугачевым смысла модифицированных
алгоритмов.
§ 4.17. Обзор принципов самообучения для классификации
образов при довольно полной информации можно найти в работе
Дж. Спрегинса [4.1]. К этому обзору мы и адресуем читателя,
интересующегося различными частными подходами. Из работ этого
направления отметим статьи Д. Купера [4,1], П. Купера [4.1],
Е. Патрика и Т. Хаикока [4.1], [4.2].
Самообучение типа «доверчивого оптимиста» или «недоверчивого
пессимиста», а также комбинаций их изучалось Б. Уидроу [4.5].
Более общие вариационные формулировки задачи самообучения
принадлежат М. И. Шлезингеру [4.1].
§ 4.18. Функционал типа среднего риска (4.61) при
квадратичной функции потерь, по существу, рассматривался в упомянутой
работе М. И. Шлезиигера [4.1], а также (в несколько иных
обозначениях) в работе Э. М. Бравермана [4.3].
§ 4.19. При вычислении вариации среднего риска мы
пользовались результатами, приведенными в учебнике И. М. Гельфанда
и С. В. Фомина [2.1] и статье Р. И. Эльмана [4.1].
§ 4.23. О конкретных рекуррентных алгоритмах самообучения
идет речь в ряде работ. В работах А. А. Дорофеюка [4.1] и Э. М.
Бравермана и А. А. Дорофеюка [4.1] строятся некоторые алгоритмы
самообучения на основании представлений, связанных с методом
потенциальных функций.
Такой эвристический путь построения алгоритмов оставляет
некоторое неудовлетворение. В работах М. И. Шлезингера [4.1]
и Э. М. Бравермана [4.3] вводятся частного вида функционалы,
минимизация которых должна привести к алгоритмам самообучения.
Э. М. Браверман в результате минимизации среднего риска
при квадратичной функции потерь после довольно длинных и
сложных рассуждений обосновал рекуррентные алгоритмы, приведенные
в табл. 4.3.
Хотя внешне алгоритмы (4.91) — (4.94) отличаются от
алгоритмов, полученных Э. М. Браверманом [4.3], все эти алгоритмы, по
существу, совпадают. Просто в приведенных здесь алгоритмах
использована связь, существующая между коэффициентами
разделяющей функции, которая почему-то не была учтена Э. М.
Браверманом. Заметим также, что в силу принятого им метода
доказательства алгоритма самообучения, довольно жесткие условия,
налагаемые им на Yi и 72» можно ослабить. Оказываетсяг что из пяти
336
Комментарии
условий достаточно удовлетворить лишь первым двум, т. е.
обычным условиям сходимости вероятности итератпвгтых методов
(3.34, а).
М. И. Шлезингер, по существу, решает задачу в два этапа.
Вначале восстанавливается совместная плотность распределения
р (х), затем предлагается, по-видимому, применить к уравнению,
определяющему центр тяжести искомых областей, итеративный
метод. В явной форме М. И. Шлезингер этого алгоритма не
приводит. Однако он выписывает без особых обоснований
рекуррентный алгоритм, несколько напоминающий полученные нами
алгоритмы, если принять F' (•) линейной, а у постоянной.
Изложенное в §§ 4.18—4.23 решение задачи самообучения было
дано автором и Г. К. Кельмансом И.1].
К главе V
§ 5.1. Превосходный обзор различных подходов к задачам
идентификации приведен в работе II. Эйкгофа [5.1], а также в
обзорном докладе Л. Эйкгофа, П. Ван дер Грпптена, X. Квакернака
и Б. Велтмаиа [5.1] па III Международном конгрессе ИФАК по
автоматическому управлению.
§ 5.2. Эти простые и наглядные соображения приводятся также
в книгах Ш. Чанга [1.1] и Д. Уайлда [3.1].
§ 5.3. Модифицированный алгоритм (5.9) был предложен
К. Фу и 3. Никол ичем. Авторы этого алгоритма возлагали на него
большие надежды, чем он того заслуживает (см. комментарий
к § 4.16).
§ 5.5. См. также работу автора [5.1].
§ 5.6. Смысл модифицированных алгоритмов рассмотрен также
в работе автора [4.2].
§ 5.7. Эта задача рассматривалась Д1. А. Айзермаиом,
О. М. Бравермапом, Л. И. Розоноэром [4.2].
§ 5.8. При квадратнческой функции потерь из (5.35) мы
получаем алгоритм, определяющий коэффициенты статистической
линеаризации, которые были введены Р. Бутоном [3.1] п И. Е.
Казаковым [5.1], [5.2].
§ 5.9. Алгоритмы типа (5.41) были предложены В. Фабианом
[3.1] н X. Круцем (см. Д. Уайлд [3.1]) в качестве более простой
модификации алгоритмов типа (5.35). Однако, как было показано
Э. Д. Аведьяыом [5.1], эти алгоритмы, вообще говоря, не
взаимозаменяемы.
§ 5.11. Идея использования результатов решения задачи
опознавания для идентификации линейных объектов, описываю-
КОММЕНТАРИИ
337
щихся дифференциальным уравнением высокого порядка, изложена
в работе Э. М. Бравермапа [5.1]. Полезные соображения в связи
с идентификацией нелинейных объектов, а также описание
эксперимента приведено в работе К. Кирвайтиса и К. Фу [5.1].
§ 5.13—5.14. О дискретных и непрерывных функциональных
рядах Вольтерра см., например, работы П. Альпера [5.1], [5.2]
и монографию Г. Ван-Триса [5.1].
§ 5.16. Алгоритм (5.74) совпадает с алгоритмом типа Качмажа
[3.1]. Он был получен (для частного случая независимых входных
воздействий) и успешно применен для решения задач
идентификации В. М. Чадеевым [5.1], [5.2]. Здесь эти ограничения снимаются.
Аналогичный алгоритм для восстановления не разностного, а
дифференциального уравнении, как мы уже упоминали, был получен
Э. М. Браверманом [5.1] для коррелированного внешнего
воздействия. Естественно, что и этом случае возникают трудности
измерения вектора состояния, который определяется производными
высоких порядков. Подобные алгоритмы — типа Качмажа — были
недавно снова «открыты» Д. Нагумо и А. Нода [5.1] и применены
ими для решения задачи идентификации.
§ 5.17. Подобную задачу па основе иного подхода
рассматривал М. Левин [5.1].
§ 5.18. Здесь изложен результат, полученный в работе
В. П. Живоглядова и В. X. Кошпова [5.1].
§ 5.19. Подобный способ устранения влияния помех указан
Д. Сакрисоиом [6.1].
К главе VI
§ 6.4. Алгоритмы типа (6.9) реализуются с помощью
дискретных фильтров с настраиваемыми весовыми коэффициентами.
Примеры такого рода фильтров описаны в работах А. Гершо [6.1]
и Л. Проузы [6.1].
Пороговые функции (6.10) широко использовались М. Шетце-
ном [6.1] для построения оптимальных винеровских фильтров.
См. также Ю. Ли и М. Шетцен [6.1].
§ 6.5. Эта задача рассматривалась Р. Лакки [6.1], однако
приведенный здесь результат несколько отличается от полученного
Р. Лакки.
§ 6.6. Содержание этого параграфа основано па результатах
Д. Сакрисона [6.1] — [6.3]. Было бы целесообразно при решении
подобных задач использовать параллельные методы поиска,
разработанные Л. Н. Фицнером [6.1].
§ 6.7. Более подробные данные о фильтре-предикторе
читатель может найти в статье Д. Габора, У. Вилби и Р. Вудкока [6.1].
22 я. 3. Цыпкин
338
КОММЕНТАРИИ
Теория адаптивных фильтров-предикторов, оптимальных по
квадратичному критерию, была развита в работах Л. Гарднера [6.1], [6.2].
§ 6.8. Непрерывный адаптивный фильтр, основанный па
непрерывном решении системы уравнений, был рассмотрен О. Шеф-
лом [6.1].
Изложенный в этом параграфе подход упрощает устройство адап-
N(N + s)
тацпи. В частности, вместо ——^ операции умножения,
стольких же операций усреднения во времени, нужных для получения
требуемых корреляционных функций, будет достаточно лишь N
операций умножения, нужных для определения градиента. Отпадает
и потребность в устройстве, решающем системы линейных уравнений.
Дискретный вариант аналогичного фильтра был описан ранее
Л. Проузой [6.1]. Интересные соображения о связи методов
стохастической аппроксимации и метода Калмана приводятся в работе
10. Хо 16.1].
§ § 6.9—6.10. Статистической теории приема посвящены книги
Л. С. Гуткпна [1.1], С. Е. Фальковпча [6.1], Д. Мидлтопа [1.1],
в которых приведена обширная библиография по этому кругу
вопросов. В этих книгах априорная информация предполагается
достаточно полной.
§ 6.11. Подобный подход описывался также и работе 10. П.
Леонова [i.l].
§ 6.13. Алгоритм (6.65) впервые был получен при у = const
М. Кацем [6.1] совершенно иным путем. Этот алгоритм
соответствует критерию оптимальности типа равенства вероятности
ошибок 1-го и 2-го родов. Такой критерий приемлем лишь тогда, когда
эти ошибки малы. Таким образом, непоисковыи алгоритм М. Каца
получается недешевой ценой. Иная возможность обнаружения
сигналов с помощью адаптивного приемника описана в работах
К. Яковеца, Р. Шея, Г. Вайта [6.1] и X. Грогпнского, Л.
Вильсона, Д. Миддлтона [6.1]. См. также работу П. Тонга и Б. Лю
[6.1]. Обзор по пороговым обнаружителям был дан Г. А. Левиным
и А. М. Бопч-Бруевичем [6.1].
§ 6.14—6.16. Эта задача была поставлена Г. Каишером [6.1].
Мы избрали критерий оптимальности, который также был
применен Каишером. Но хотя Кашнер и рассматривал задачу
оптимального выделения с помощью метода стохастической
аппроксимации, приведенное здесь решение отличается от решения Каш-
нера. Нужно сознаться, что наша попытка установить связь между
этими решениями не увенчалась успехом. Мы так и не смогли попять
ни способа решения, ни результата Г. Кашпера.
§ 6.20. Интересно отметить, что полученная нами схема
адаптивного приемника совпадает со схемой, предложенной И. Мори-
шита [6.1] для выделения узкополосных сигналов на фоне помех,
КОММЕНТАРИИ
339
либо на фоне других узкополосных сигналов меньшей мощности.
Однако эта последняя возможность автором теоретически не
обоснована. Мы также не смогли обосновать такое свойство
рассмотренного адаптивного приемника.
§ § 6.21—6.22. Этот путь построения адаптивного устройства
для восстановления входных сигналов очень тесно связан с
аналитической теорией нелинейных систем Н. Винера [6.1], а также с
методами оценки сигналов, развиваемыми Р. Калманом [0.1].
К главе VII
§ 7.2. Идея глубокой отрицательной обратной связи была
высказана X. Влеком [7.1] в связи с улучшением свойств
усилителей путем применения отрицательной обратной связи. Эффект
отрицательной обратной связи широко использовался также
при создании решающих усилителей аналоговых моделирующих
установок, см., например, Б. Я. Коган [7.1].
Условия устойчивости систем, допускающих (разумеется,
теоретически) неограниченное повышение коэффициента усиления,
установлены М. В. Мсеровым [7.1], [7.2]. Эти условия можно
рассматривать как условия реализуемости эффекта глубокой
отрицательной обратной связи. Эффект глубокой отрицательной
обратной связи, как это показано Г. С. Поспеловым [7.1], автором [7.1],
достигается при осуществлении скользящих режимов в релейных
автоматических системах. Недавно обнаружено (см. М. Л. Бермант,
С. В. Емельяпов [7.1]), что подобного рода эффект проявляется
и в системах с переменной структурой. Любопытно то
обстоятельство, что, несмотря на различие систем и способов достижения
устранения влияния изменения характеристик, в основе их лежит
один и тот же эффект глубокой отрицательной обратной связи.
Об инвариантности см., например, работу А. И. Кухтенко [7.1].
Обсуждение причин, вызывающих необходимость применения
адаптации, приводится в книге А. А. Красовского [1.1].
§ 7.3. Первые работы по применению метода стохастической
аппроксимации к простейшим системам управления принадлежат
Дж. Бертраму [7.1], М. Ульриху [7.1]. См. также П. Шульц [7.1],
Р. Куликовский [7.2].
§ 7.4. О дуальном управлении см. основополагающие работы
А. А. Фельдбаума [7.1] — [7.3] и неоднократно упоминавшуюся
ранее книгу А. А. Фельдбаума [1.1].
Теория дуального управления А. А. Фельдбаума определяет
на основе метода статистических решений оптимальную систему,
лучше которой при использовании одной и той же информации
получить нельзя. Но большой объем вычислений не позволяет
реализовать оптимальную систему, а порой даже лишает нас
надежды о реализации их в ближайшем будущем. Мы рассматриваем
термин «дуальное управление» в более широком смысле, не связывая
его только с теорией статистических решений.
22*
:j4u
КОММЕНТАРИИ
§ 7.5. Стратегия изучения и управления через I тактов была
использована 10. Хо и Б. Валеном [7.1] в задаче управления
линейным объектом, которая, как это можно теперь понять, представляет
собой частный случай рассматриваемых нами задач. Некоторые
рассуждения о возможных стратегиях изучения и управления
читатель может найти в работе Ф. Киши [7.1].
§ 7.7 Интересные результаты по таким беспоисковым
адаптивным системам (правда, при отсутствии помех) получены М. Л. Бы-
ховским [7.1], П. Кокотовпчем [7.1]. См. также Дж. Риссанен
[7.1] - [7.3], Л. Г. Евланов [7.1], И. Е. Казаков [7.1], И. Е.
Казаков и Л. Г. Евланов [7.1].
§ 7.8. О модели чувствительности см. работы М. Л. Быховского
[7.1], П. Кокотовича [7.1], Г. Мейсингера [7.1]. Идея
использования одной модели для получения одновременно всех функций
чувствительности принадлежит П. Кокотовичу [7.1].
Попытка использования самого объекта в качестве модели
чувствительности описана К. Нарендра и Д. Стриром [7.1]. По-
видимому, в полной мере эту идею реализовать не удастся.
§ 7.9. Результаты этого параграфа связаны с работой Д. Хпл-
ла и К. Фу [7.1]. Им принадлежит идея адаптивного способа
уменьшения времени адаптации.
§ 7.10. Адаптивные системы с моделями благодаря их простоте
находят широкое применение. Одна из первых работ по этим типам
адаптивных систем принадлежат М. Марголису и К. Леондесу [7.1].
Вопросы построения адаптивных систем с моделями
рассмотрены в работах Е. Риссанена [7.1], [7.2], И. В. Крутовой, В. Ю. Рут-
ковского [7.1], [7.2] и др.*
Обзоры Д. Дональсона, Ф. Киши [7.1], И. В. Крутовой,
В. Ю. Рутковского [7.1] содержат изложение принципов
построения и применения адаптивных систем с моделями, а также
библиографию.
§ 7.11. Постановка задачи об управлении переопределенным
объектом принадлежит М. Томасу и Д. Уайлду [7.1].
§ 7.13. Именно эта возможность применения алгоритма
релаксационного типа и была описана М. Томасом и Д. Уайлдом [7.1].
Ими же доказана сходимость релаксационного алгоритма (7.51).
§ 7.14. С экстремальными системами читатель может
познакомиться, например, по книге А. А. Красовского [1.1].
§ 7.15. Подобное описание экстремального объекта
использовалось, например, 10. С. Попковым [7.1], [7.2].
§ 7.19. См. также статью В. И. Костюка [7.1], где для
конкретного случая был предложен именно такой путь синтеза экстре-
КОММЕНТАРИИ
341
мальной системы. Интересные результаты приведены в работах
Р. Куликовского [7.1], [7.2].
§ 7.20. Мы используем здесь запись дифференциала (7.88),
полученную в интересной во многих отношениях статье Л. И. Розо-
ноэра [7.1].
§ 7.21. Эти результаты основаны на работе А. И. Пропоя
и автора [7.1].
§ 7.22. Такая постановка задачи синтеза оптимальных систем
принадлежит Ю. Хо и Б. Валену [7.1].
§ 7.23. Пример заимствован нами из работы А. Кноля [7.1].
В эксперименте, который был проделай Кнолем, было выбрано
I = 10, т = 0,03 сек. Начальные значения для х были равномерно
распределены в интервале 1,0 <; х <1 18,25. Таким образом,
каждый вектор у из Л или В состоял из 10 точек; всего было 36 векторов.
После того как были определены уА и ув, оптимальные значения
а%, я* были найдены за три итерации. Эти оптимальные значения
были затем проверены на 15 других начальных состояниях х (0),
и разделение было полным.
К главе VIII
§§ 8.2—8.4. По поводу основных определений см., например,
книгу Б. В. Гнедеыко, Ю. К. Беляева, А. Д. Соловьева, [8.1].
Там же имеется библиография по математической теории
надежности.
§ 8.11. На эту задачу «с высоты» метода динамического
программирования взглянул Р. Беллман [1.1].
§ 8.12. При достаточной априорной информации эта задача
была решена В. Пирсом [8.1].
§ 8.13. Решение этой минимаксной задачи на основе метода
Монте-Карло описано в работе В. Ф. Евсеева, Т. Д. Кораблиной,
С. И. Рожкова [8.1].
§ 8.15. Ряд задач оптимизации по критерию надежности
рассмотрен в книге К. А. Иыуду [8.1]. Задачи оптимизации
информационных сетей рассматривались в работах А. К. Кельманса [8.1],
А. К. Кельманса, А. Г. Мамиконова [8.1]. Интересен цикл работ
по поиску неисправностей Е. Клетского [8.1], С. Ю. Рудерма-
на [8.1].
§ 8.16. Постановка этой задачи и описание пути решения на
основе поискового алгоритма принадлежит К. Грею [3.1].
342
КОММЕНТАРИИ
К главе IX
§ 9.1. Хорошим начальным введением в теорию исследования
операций может служить книга А. Кофмана и Р. Фора [9.1]. Но
если читатель ие настроен на развлекательный лад, то лучше,
пожалуй, начинать с книги Т. Саатп [9.1].
§§ 9.2 — 9.8. Большое число задач подобного тина рассмотрено
в книге Ф. Хэнссменпа [9.1], однако в предположении достаточной
априорной информации.
§§ 9.9—9.10. Постановка этих задач и пример принадлежа!
Д. Уайлду [3.1].
§ § 9.11—9.12. Ло этим вопросам см. работы Де Гюенпна [9.1 |.
11. II. Кузнецова [9.1] — [9.3].
В отличие от этих работ мы не предполагаем известным
распределение вероятностей.
§§ 9.13—9.15. Задача этою рода рассматривалась в связи
с синтезом дискретных устройств с минимальными искажениями
Дж. Максом [9.11, В. 11. Кошелевым [9.1], Р. Ларсоном [9.1].
Вопросами дискретизации занимались также II. К. Игнатьев
и Э. Л. Блох |9.1|, P. JJ. Стратоповпч и Б. Л. Гришаппп |9.1].
Рассмотренная задача тесно связана с задачей самообучения, о
которой была речь в гл. IV. Отметим, что при равномерной плотности
распределения ота задача была решена приближенным методом
Дж. Максом [9.1].
К главе X
§ 10.2. Изложение основ теории игр можно найти в книгах
Т. JJ. Саати [9.1], Е. Г. Гольштейпа п Д. Б. Юдина [10.1]. Ее
приложениям к конкретным задачам различных областей человеческой
деятельности посвящена книга Р. Д. Лыоса и X. Райфы [10.1].
§ 10.3. Теорема Фон Неймана о минимаксе — основа теории
игр. Простое доказательство этой теоремы па основе принципа
Брауэра о неподвижной точке, принадлежащее Пзшу, приведено
в книге Р. Д. Лыоса и X. Райфы [10.11.
§ 10.4. На целесообразность рассмотрения погрешностей в
определении оптимальных ответов нам было указано В. А. Волконским.
§ 10.5. Алгоритмы обучения решению игр, как это видно
из табл. 10.1, охватывает как частные случаи алгоритмы Г. Брауна
[10.1] и его разновидности. Модификация этого алгоритма была
предложена В. В. Амвроспеико [10.1]. Сходимость алгоритма
Брауна была доказана Дж. Робинсон [10.1]. Это доказательство
воспроизведено в книге Р. Беллмаиа, Н. Глпксберга, О. Гросса
[9.1]. Г. И. Шапиро [10,1] оценил скорость сходимости.
КОММЕНТАРИИ
343
а Р. Брэйтуайт [10.1] применил алгоритмы типа Брауна или,
как их теперь называют, алгоритмы Брауна — Робинсон, для
решения систем линейных уравнений, вычисления наименьшего
кратного и решения игр определенного класса за конечное число
шагов. При отсутствии погрешностей в определении оптимальных
ответов (т. е. при |j — |2 ~- 0) алгоритмы (10.22) переходят в
алгоритмы В. А. Волконского [10.1].
Сходимость всех этих алгоритмов вытекает из условий
сходимости вероятностных итеративных методов. Таким образом, этим
самым устанавливается еще одна связь между различными
подходами, которая связана теперь с играми. Теория одного класса
методов решения матричных игр, который содержит, в частности,
метод Брауна, развита Я. М. Лихтеровым [10.1]. Им также
предложены вычислительные алгоритмы с ускоренной сходимостью.
В работах В. В. Амвросиепко [10.1], Э. 11. Борисовой
и И, В. Магарпка [10.1] предложены модификации алгоритма
Брауна с ускоренной сходимостью.
§ 10.6. Здесь изложен классический результат Г. Данцига
[10.1]. См. также Д. Гсйл [10.1],Е. Г. Голынтейн, Д. Б. Юдин [10.1].
[10.1].
Интересные* приложения игрового подхода к задачам
оптимального планирования большой размерности рассмотрены
В. А. Волконским [10.1]; 3. Я. Гальперин [10.1] применил
алгоритмы Волконского для решения транспортной задачи большой
размерности, а В. Г. Медпцкпй |10.1| рассмотрел задачу распределения
плановых заданий.
§ 10.7. Отот пример заимствован из книги Р. Беллмапа [1.1].
Некоторым типам игровых систем уравнения посвящена работа
В. Ф. Лебедкпна и И. С. Михлппа [10.1].
§ 10.8. Сходимость этих непрерывных алгоритмов может быть
доказана с помощью условий сходимости непрорывных
вероятностных методов.
Иной способ итеративного метода решения игр рассмотрел
Дж. Дапскин |10.1].
§§ 10.10—10.11. Обзор литературы о пороговых элементах
и синтезе схем на пороговых элементах принадлежит И. Н.
Боголюбову, Б. Л. Овсневичу, Л. Я. Розенблюму [10.1]. См. также статью
В. И. Варшавского [10.1].
§ 10.12. Связь между пороговой реализуемостью и игрой
двух лиц с нулевой суммой, которую мы здесь используем, была
установлена III. Екерсом [10.1].
§ 10.14. Описание схемы персентронов Розенблата содержится
в работе Дж. Хей, Ф. С. Мартина, С. В. Уиттена [10.1]. См. также
X. Келлер [10.1].
344
КОММЕНТАРИИ
§ 10.15. Описание схемы Адалины Уидроу содержится в
работах Уидроу [4.3], [4.4].
Интересные применения Адалины как обучаемого
функционального преобразователя можно найти в работе Ф. Смита [10.1].
§ 10.16. «Педантичный» алгоритм в форме (10.75) был
предложен X. Ишида и Р. Стюартом [10.1]. Теперь ясно видно, что этот
«новый» алгоритм является небольшой модификацией алгоритма
персептрона (10.61). Об обучении пороговых элементов и
пороговых сетей см. работу Ю. Э. Сагалова, В. И. Фролова и А. Б.
Шубина [10.1].
§ 10.17. С основными понятиями теории конечных
автоматов можно познакомиться по следующим книгам: М. А. Айзерман,
Л. А. Гусев, Л. И. Розоноэр, И. М. Смирнова, А. А. Таль [10.1],
А. Гилл [10.1], В. М. Глушков [4.1], Д. А. Поспелов [10.1].
См. также К. 0. Шеннон, Дж. МакКарти [10.1].
Далее мы рассматриваем конечный автомат как конечную
динамическую систему.
§§ 10.18—10.19. Принятая здесь запись уравнений конечных
автоматов как дискретных динамических систем и. отказ от
описаний автоматов матрицами перехода вызван желанием подчеркнуть
общность конечных, импульсных и непрерывных систем. Именно эта
общность и позволила применить наиболее естественным путем
адаптивный подход. Такая системная точка зрения применительно
к «линейным» автоматам или, точнее, линейным иоследователь-
иостиым машинам была разработана Д. А. Хаффменом [10.1].
См. также работу автора и Р. Г. Фараджева [10.1]. Принятая здесь
точка зрения объясняет, почему мы не затрагиваем множества
превосходных работ по теории конечных автоматов, изложенных
на специфическом для этой теории языке.
§ 10.20. Задачи о взаимодействии автоматов со средой
были поставлены и в значительной мере решены М. Л. Цетлиным
[10.1] — [10.3]. Превосходный обзор результатов по этой
проблематике до 1961 г. содержится в работе М. Л. Цетлина [10.3]. См.
также книгу Д. А. Поспелова [10.1]. Задачам анализа поведения
различных конструкций автоматов в среде посвящена довольно
обширная литература. Мы отметим работы А. М. Бланка [10.1],
Я. М. Бардзиня [10.1], В. И. Брызгалова, И. И. Пятецкого-Шапиро,
М. Л. Шика [10.1], В. А. Пономарева [10.1], В. Ю. Крылова
[10.1]. Несколько иной подход был развит Р. МакЛареном [10.1],
Г. МакМартри и К. Фу [10.1].
Поведению стохастических автоматов в случайных средах
были посвящены работы В. И. Варшавского, И. П. Воронцовой
[10.1], Н. П. Канделаки и Г. Н. Церцвадзе [10.1], В. Г. Сраговича
и 10. А. Флерова [10.1].
Во всех этих работах определялась целесообразность
поведения автоматс>в. Для этой цели использовалась теория марковских
цепей.
КОММЕНТАРИИ
345
§ 10.22. Задачам обучения автоматов, которые связаны с
задачами синтеза, посвящено небольшое число работ. К ним относятся
работы В. И. Варшавского, И. П. Воронцовой, М. Л. Цетлина [10.1]
по обучению автоматов; А. А. Милютина [10.1] по выбору матриц
перехода автомата, обеспечивающих оптимальное поведение;
А. В. Добровидова и Р. Л. Стратоновича [10.1] по синтезу
оптимальных автоматов, учитывающих апостериорные вероятности штрафов
в процессе работы; Г. МакМартри и К. Фу [10.1] по применению
автоматов с переменной структурой для поиска экстремума.
Как заметил читатель, мы здесь рассматривали обучение
конечных автоматов точно таким же образом, как и обычных
непрерывных или импульсных систем. Удивительно образпая
характеристика обучающихся автоматов, приведенная в конце этого
параграфа, взята нами из работы В. И. Варшавского, И. П.
Воронцовой, М. Л. Цетлина [10.1].
§ 10.23. Связь автоматов и марковских цепей обсуждается
в книге В. М. Глушкова [4.1]. Приводимый пример неоднократно
рассматривался в работах Дж. Скланского [10.1], [10.2].
Марковские цепи благодаря А. А. Фельдбауму [10.11, [10.2] широко
используются для исследования установившихся процессов в
дискретных экстремальных системах. Эти вопросы рассматривались
в книге А. А. Первозванского [10.1], а также в работах Т. И. Тов-
стухи [10.1], [10.2] pi X. Киршбаума [10.1]. Они применялись
в работе Л. А. Пчелинцева [10.1] для решения задачи поиска
неисправностей.
§ 10.24. Теория марковского обучения развивалась Д. Склан-
ским [10.1] в связи с обучаемым пороговым элементом.
Если отказаться от фиксированных уровней порога, т. е.
отойти от автоматной трактовки и принять, что у не является
постоянной величиной, а удовлетворяет обычным условиям у [п] > 0,
оо оо
У) У [п\ — оо, 2 у2 [п] < оо, как это сделал недавно Дж. Склан-
71=1 71=1
ский [10.2], то мы придем к обычной схеме порогового приемника,
который мы рассматривали в § 6.13. Этот адаптивный приемник
соответствует обучаемому пороговому элементу. С несколько иной
точки зрения марковское обучение рассматривалось в работах
МакЛарена [10.1], [10.2]. Связь между марковским обучением
и стохастической аппроксимацией рассматривалась 3. Николичем
и К. Фу [10.1].
К марковским моделям обучения близки стохастические
модели обучения Р. Буша и Ф. Мостеллера [1.11. В них обучение
осуществляется в соответствии с заранее постулированным
механизмом, а не на основе оптимизации.
Рассмотрение этих задач также возможно с адаптивной точки
зрения. Но это завело бы нас слишком далеко.
О последовательном декодировании см, Дж. Возенкрафт
и Б. Рейффен [10.11.
346
КОММЕНТАРИИ
§ 10.25. Играм автоматов и их коллективному поведению
посвящены работы М. Л. Цетлина [10.3], [10.4], М. Л. Цетлина
и В. Ю. Крылова [10.1], В. И. Кринского [10.1], В. И.
Варшавского, И. П. Воронцовой [10.1], С. Л. Гинзбурга и М. Л. Цетлина
[10.1], В. Л. Стефанюка [10.1], В. А. Волконского [10.2].
Интересные результаты по моделированию игр автоматов на
цифровых вычислительных машинах описаны В. И. Брызгаловым,
И. М. Гельфандом, И. И. Пятецким-Шапиро и М. Л. Цетли-
ным [10.1], М. Л. Цетлиным, С. Л. Гинзбургом и В. Ю.
Крыловым [10.1].
Игры автоматов вслепую рассмотрены в работах В. И.
Кринского и В. Л. Пономарева [10.1], [10.2].
Литература
К главе I
Б е л л м а п Р.
1.1. Динамическое программирование (пер. с англ.). ИЛ, М.,
1960.
1.2. Процессы регулирования с адаптацией (пер. с англ.).
«Паука», М., 1961
Б о л т я и с к и и Б. Г.
1.1. Математические методы оптимального управления.
«Наука», М., 1966.
Б у т к о в с к п п А. Г.
1.1. Оптимальное управление системами с распределенными
параметрами. «Наука», М., 1965.
Г а и т м а х с р Ф. Р.
1.1. Теория матриц, изд. 2-е. «Наука», М., 1966.
Г п е д е н к о Б. Б.
1.1. Курс теории вероятностен «Наука», М,, 1964
Г у т к п н Л. С.
1.1. Теории оптимальных методов радиоприема при флуктуа-
ционных помехах. Госэнергопздат, М.~- Л., 1961.
Заде (Zadeh L. А.)
1.1. What is optimal? 1Kb] Transactions on Information Theory,
1958, v. IT-4, No. 1.
К а л м а и P.
1.1. Когда линейная система управления является
оптимальной? Труды Американского общества
инженеров-механиков, русский перевод, 1961, № 1.
1.2. Об общей теории систем управления. Тр. I
Международного конгресса ИФАК. Теория дискретных, оптимальных
и самонастраивающихся систем. Изд-во АН СССР, Москва,
1961.
К р а с о в с к и и А. А.
1.1. Динамика непрерывных самонастраивающихся систем.
Физматгиз, М., 1963.
Л е й т м а н Дж. (ред.)
1.1. Методы оптимизации с приложениями к механике
космического полета (пер. с англ.). «Наука», М., 1965.
Л и Р.
1.1. Оптимальные оценки, определение характеристик и
управление (пер. с англ.). «Наука», М., 1966,
348 ЛИТЕРАТУРА
М е р р и а м (Merriam С. W.)
1.1. Optimization theory and the design of feedback control
systems. McGraw-Hill Book Company, 1964.
Мидлтон Д.
1.1. Введение в статистическую теорию связи, т. 1 — 2.
«Советское радио», М., 1961 — 1962.
Понтрягин Л. С, Болтянский В. Г., Гамкре-
лидзе Р. В., М и щ е н к о Е. Ф.
1.1. Математическая теория оптимальных процессов. Физ-
матгиз, М., 1961.
Стратонович Р. Л.
1.1. Избранные вопросы теории флюктуации в радиотехнике.
«Советское радио», М., 1961.
Фельдбаум А. А.
1.1. Основы теории оптимальных автоматических систем, изд.
2-е. «Наука», М., 1966.
X а л м о ш П. Р.
1.1. Лекции по эргодической теории (пер. с англ.). ИЛ, М.,
1959.
Хелстром К.
1.1. Статистическая теория обнаружения сигналов (пер. с англ.),
ИЛ, М., 1963.
Ц ы п к и н Я. 3.
1.1. Адаптация, обучение и самообучение в автоматических
системах. Автоматика и телемеханика, 1966, № 1.
Ч а н г Ш. С. Л.
1.1. Синтез оптимальных систем автоматического управления
(пер. с англ.). «Машиностроение», М., 1964.
К главе II
А л ь б е р С. И., А л ь б е р Я. И.
2.1. Применение метода дифференциального спуска для
решения нелинейных систем. Журнал вычислительной
математики и математической физики, 1966, т. 7, № 1.
Б е р е з и н И. С, Ж и д к о в Н. П.
2.1. Методы вычислений, т. II. Физматгиз, М., 1960.
Бингулац (Bingulac S. Р.)
2.1. On the improvement of gradient methods. IBK-450,
Electronics and Automation. Boris Kidric Institute of nuclear
sciences, Beograd-Vinca, June 1966.
Бондаренко П. С.
2.1. Принципы построения оптимальных вычислительных
алгоритмов. Вычислительная математика, вып. 3, Киев, 1966.
Бромберг П. В.
2.1. Матричные методы в теории релейного и импульсного
регулирования. «Наука», М., 1967.
Вегстейн (Wegstein J. Н.)
2.1. Accelerating convergence of iterative processes.
Communications of the ACM, 1958, v. 1, No. 6.
ЛИТЕРАТУРА
349
Вольф (Wolff А. С.)
2.1. The estimation of the optimum design function with a
sequential random method. IEEE Transactions on Information
Theory, 1966, v. 1T-12, No. 3.
Гавурин M. K.
2.1. Нелинейные функциональные уравнения и непрерывные
аналоги итеративных методов. Изв. высш. учебн. завед.,
«Математика», 1958, № 5.
2.2. К теоремам существования для нелинейных
функциональных уравнений. В кн. «Методы вычислений». Изд-во ЛГУ,
вып. 2, 1963.
Гельфанд И. М., Фомин С. В.
2.1. Вариационное исчисление. Физматгиз, М., 1961.
Гельфанд И. М,, Цетлин М. Л.
2.1. О некоторых способах управления сложными системами.
Успехи математических паук, 1962, т. 17, вып. 1.
Германский (Germansky R.)
2.1. Notiz uber die Losung von Extremaufgaben mittels
Iteration. Zeitschrift fur Angewandte Mathematik und Mechanik,
1934, Bd. 14, H. 3.
Глазман И. M.
2.1. О градиентной релаксации для неквадратичных
функционалов. Доклады АН СССР, 1964, т. 154, № 5.
Глазман И. М., С е н ч у к 10. Ф.
2.1. Об одном методе минимизации некоторых функционалов
вариационного исчисления. Сб. «Теория функций,
функциональный анализ и их приложения», вып. 2, Харьков,
1966.
Дегтярен ко II. И.
2.1. Синхронное детектирование в измерительной технике
и автоматике, Киев, 1965.
Д е м и д о в и ч Б. П., М а р о и И. А.
2.1. Основы вычислительной математики, изд. 2-е. Физматгиз,
М., 1963.
Демьянов В. Ф.
2.1. К минимизации функций на выпуклых ограниченных
множествах. Кибернетика, 1965, № 6.
Деннис Д. Б.
2.1. Математическое программирование и электрические цепи
(пер. с англ.). ИЛ, М., 1961.
Д у б о в и ц к и й А. Я., Милютин А. А.
2.1. Задачи на экстремум при наличии ограничений. Журнал
вычислительной математики и математической физики,
1965, т. 5, № 3.
Зойтендейк Т.
2.1. Методы возможных направлений (пер. с англ.). ИЛ, М.,
1963.
Калман, Бертрам (Kalman R. Е., Bertram J. Е.)
2.1. Control system analysis and design via the «Second Method»
of Lyapunov. Transactions of the ASME, series D. 1960,
v. 82, No. 2.
350
ЛИТЕРАТУРА
Канторович Л. В.
2.1. Приближенное решение функциональных уравнений,
Успехи математических наук, 1956, т. И, вып. 6 (72).
Красносельский М. А.
2.1. Топологические методы в теории нелинейных интегральных
уравнений. Гостехиздат, М., 1956.
К у м а д a (Cumada I.)
2.1. On the golf method. Bulletin of the Electrotechnical
laboratory, 1961, v. 25, No. 7.
К io н ц и Г. II., К p e л л e В.
2.1. Нелинейное программирование (пер. с нехМ.). «Советское
радио», М., 1965.
Левитин Е. С, Поляк Б. Т.
2.1. Методы минимизации при наличии ограничений. Журнал
вычислительной математики и математической физики,
1966, т. 6, № 5.
Л е д л и Р.
2.1. Программирование и использование вычислительных машин
(пер. с англ.). «Мир», М., 1966.
Лурье А. И.
2.1. Некоторые нелинейные задачи теории автоматического
регулирования. Гостехтеорнздат, 1951.
Л ю бич 10. И.
2.1. О скорости сходимости стационарной градиентной
релаксации. Журнал вычислительной математики и
математической физики, 1966, т. 6, № 2.
Л ю стер и и к Л. Л., Соболев В. И.
2.1. Элементы функционального анализа. «Наука», М., 1965.
М а н с о н, Р а б и н (М u n s о п I. К., Rubin А. I.)
2.1. Optimization by random search. IRE Transactions on
Electronic Computers, 1959, v. EC-8, No. 2.
M а т ы а ш И.
2.1. Случайная оптимизация. Автоматика и телемеханика,
1965, т. 26, № 2.
Миттер, Лесдон, Уорен (Mitter S.,Lasdon L. S.,
W a r e n A. D.)
2.1. The method of conjugate gradients for optimal control
problems. Proceedings of the IEEE, 1966, v. 54, No. 6.
M и x л и h С. Г.
2.1. Численная реализация вариационных методов. «Наука»,
М., 1966.
Мышки с А. Д.
2.1. О ямах. Журнал вычислительной математики и
математической физики, 1965, т. 5, № 3.
Островский А. М.
2.1. Решение уравнений и систем уравнений (пер. с англ.). ИЛ,
М., 1963.
Поляк Б. Т.
2.1. Градиентные методы минимизации функционалов.
Журнал вычислительной математики и математической
физики, 1963, т. 3, вып. 4.
ЛИТЕРАТУРА
351
Растригин Л. А.
2.1. Случайный поиск в задачах оптимизации
многопараметрических систем. «Зинатне», Рига, 1965.
Рыбашов М. В.
2.1. Градиентный метод решения задач линейного и
квадратичного программирования. Автоматика и телемеханика,
1965, т. 26, № 12.
2.2. Градиентный метод решения задач выпуклого
программирования на электронной модели. Автоматика и
телемеханика, 1965, т. 26, № 11.
Рыбашов М. В., Дудников Е. Е.
2.1. Применение прямого метода Ляпунова к решению задач
нелинейного программирования. Техническая
кибернетика, 1964, № 6.
Т о м п к и н с Ч. Б.
2.1. Методы быстрого спуска. Гл. 16 в кн. «Современная
математика для инженеров», под ред. Беккенбаха Э. Ф. (пер.
с англ.). ИЛ, М., 1958.
Т р а у б (Traub J. Т.)
2.1. Iterative methods for the solution of equations. Prentice
Hall, 1965.
Фаддеев Д. К., Фаддеева В. Н.
2.1. Вычислительные методы линейной алгебры, изд. 2-е. Физ-
матгиз, М.— Л., 1963.
Флетчер, Пауэлл (Fletcher R., Powell М. J. D.)
2.1. A rapidly convergent descent method for minimization. The
Computer Journal, 1963, v. 6, No. 2.
Ц ы п к и и Я. 3.
2.1. Теория линейных импульсных систем. Физматгиз, М., 1963.
Ш и м а н с к и и В. Е.
2.1. Методы численного решения краевых задач па ЭЦВМ, ч. II.
«Наукова думка», Киев, 1966.
Э р р о у К. Дж., Г у р в и ц Л., У д з а в а X.
2.1. Исследование по линейному и нелинейному
программированию (пер. с англ.). ИЛ, М., 1962.
Э ш б и У. Р.
2.1. Введение в кибернетику (пер. с англ.). ИЛ., М., 1959.
Юдин Д. Б.
2.1. Методы количественного анализа сложных систем.
Техническая кибернетика, 1965, № 1.
Яковлев М. Н.
2 .1. О некоторых методах решения нелинейных уравнений.
Труды Математического института им. В. А. Стеклова.
«Наука», 1965, т. 84.
К главе III
Альберт, С и т т л е р (Albert A., Sittler R. W.)
3.1. A method for computing least squares estimators that keep up
with the data. Journal of SIAM Control, series A; 1965, v. 3,
No. 3.
352
ЛИТЕРАТУРА
Беккенбах Э. (ред.)
3.1. Современная математика для инженеров. ИЛ, М., 1958.
Блок (Block Н. D.)
3.1. Estimates of error for two modifications of the Robbins —
Monro stochastic approximation process. Annals of
Mathematical Statistics, 1957, v. 28, No. 4.
Б л у м (Blum J. R.)
3.1. Approximation methods which converge with probability one.
Annals of Mathematical Statistics, 1954, v. 25, No. 2.
3.2. Multidimensional stochastic approximation methods. Annals
of Mathematical Statistics, 1954, v. 25, No. 4.
3.3. A note on stochastic approximation. Proceedings of the
American Mathematical Society, 1958, v. 9, No. 3.
Буркхолдер (Burkholder D. L.)
3.1. On a class of stochastic approximation processes. Annals
of Mathematical Statistics, 1956, v. 27, No. 4.
Буш P. P., Мостеллер Ф.
3.1. Стохастические модели обучаемости (пер. с англ.). Физ-
матгиз, М., 1962.
Ван дер Варден Б. Л.
3.1. Математическая статистика (пер. с англ.). ИЛ, М., 1960.
Везерил (Wetherill G. В.)
3.1. Sequential methods in statistics. Methuen, London, 1966.
В e ii т ii e p (Ventner J. H.)
3.1. On Dvoretzky stochastic approximation theorems. Annals
of Mathematical Statistics, 1966, v. 37, No. 6.
Вольфов и ц (Wolfowitz J.)
3.1. On the stochastic approximation method of Robbins and
Monro. Annals of Mathematical Statistics, 1952, v. 23, No. 3.
Гладышев E. Г.
3.1. О стохастической аппроксимации. Теория вероятностей
и ее применение, 1965, т. 10, № 2.
Гиб сон (Gibson J. Е.)
3.1. Adaptive learning systems. Proceedings of the National
Electronics Conference, 1962, v. 18.
Грей (Gray K.)
3.1. Application of stochastic approximation to the
optimization of random circuits. Proceedings of Symposium of Applied
Mathematics, 1964, v. 16.
Г урин Л. С.
3.1. К вопросу об оптимизации в стохастических моделях.
Журнал вычислительной математики и математической
физики, 1964, т. 4, № 6.
3.2. К вопросу о сравнительной оценке различных методов
оптимизации. Сб. «Автоматика и вычислительная техника»,
Рига, 1966, № 10.
3.3. Случайный поиск при наличии помех. Техническая
кибернетика, 1966, № 3.
Гутман Т., Гутман P. (Gutman Т. L., Gutman R.)
3.1. An illustration of the use of stochastic approximation.
Biometrics, 1959, v. 15, No. 4.
ЛИТЕРАТУРА
353
Дворец к н и (Dvoretzky А.)
3.1. On stochastic approximation. Proceedings of the Third
Berkeley Symposium on Mathematical Statistics and Probability,
1956, v. 1.
Д e p м а и (Derman C.)
3.1. An application of Chung's lemma to Kiefer — Wolfowitz
stochastic approximation procedure. Annals of Mathematical
Statistics, 1956, v. 27, No. 2.
3.2. Stochastic approximation. Annals of Mathematical Statistics,
1956, v. 27, No. 4.
Дерма и, С а к с (Derman С. Т., Sacks J.)
3.1. On Dvoretzky's stochastic approximation theorem. Annals
of Mathematical Statistics, 1959, v. 30, No. 2.
Д p и м л, 11 о д о м a (Oriml M., Nedoma T.)
3.1. Stochastic approximation lor continuous random processes.
Transactions of the Second Prague Conference on Information
Theory, Statistical Decision Functions, Random Processes,
Prague, 1959.
Д p и м л, Ханш (Driinl M., Hans O.)
3.1. On experience theory problems. Transactions of the Second
Prague Conference on Information Theory, Statistical
Decision Functions, Random Processes, Prague, 1959.
3.2. Continuous stochastic approximations. Transactions of the
Second Prague Conference on Information Theory, Statistical
Decision Functions, Random Processes, Prague, 1959.
Д у li а ч (Dupac V.)
3.1. О Kiefer — Wollowitzvo approximarni methode. Casopis pro
pestovani matcmatiky, 1957, sv. 82, N 1.
3.2. Notes on stochastic approximation methods. Чехословацкий
математический журнал, 1958, т. 8 (83), Л» 1.
3.3. A dynamic stochastic approximation method. Annals of
Mathematical Statistics, 1966, v. 36, No. 6.
3.4. Stochastic approximation in the presence of trend.
Чехословацкий математический журнал, 1966, т. 16 (91), № 3.
Заде (Zacleli L. А.)
3.1. On the definition of adaptivity. Proceedings of the IRE,
1963, v. 51, No. 3.
Иванов A. 3., Круг Г. К., К у ш e л e в Ю. П., Л
едкий Э. К., С в е ч и н с к и й В. В.
3.1. Обучающиеся системы управления. Сб. Автоматика и
телемеханика, Тр. МЭИ, вып. 44, 1962.
К а л л и а н и у р (Callianpur G.)
3.1. A note on the Robbins — Monro stochastic approximation
method. Annals of Mathematical Statistics, 1954, v. 25, No. 2.
Кац И. Я., К p а с о в с к и й Н. Н.
3.1. Об устойчивости систем со случайными параметрами.
Прикладная математика и механика, 1960, т. 24, № 5.
К а ч м а ж (Kaczmarz S.)
3.1. Angenaherte Auflosung von Systemen linearer Gleichungen.
Bull. Internat. Acad. Polon. Sci. Lett., CI. Sci. Math. xNat. A,
1937.
23 я. 3. Цыпь-ин
ЛИТЕРАТУРА
К а ш н е р (Ku shne г Н. Т.)
3.1. On the stability of stochastic dynamic systems. Proceedings
of the National Academy of Sciences, 1965, v. 53, No. I.
3.2. Hill climbing methods for the optimization on
multiparameter noise distributed system. Transactions of the ASME,
Journal of Basic Engineering, series D, 1963, v. 85,
No. 2.
К e с т e h (Kesten H.)
3.1. Accelerated stochastic approximation. Annals of
Mathematical Statistics, 1958, v. 29, No. 1.
К li т а г а в a (Kitagawa T.)
3.1. Successive processes of statistics control, Memoirs of the
Faculty of Science Kyushu University, 1959, series A, v. 13,
No. 1.
К и ф e p, В о л ь ф о в и ц (Kiefer Е., Wolfowitz J.)
3.1. Stochastic estimation of the maximum of a regression
function. Annals of Mathematical Statistics, 1952, v. 23,
No. 3.
К о м e p (Comer J. P.)
3.1. Some stochastic approximation procedures for use in process
control. Annals of Mathematical Statistics, 1964, v. 35,
No. 3.
К охран, Д э в н с (Cochran W. G., Davis М.)
3.1. The Bobbins ~ Monro method for estimating the median
lethal dose. Journal of the Boyal Statistical Society,
1965, v. 27, No. 1.
К p а м e p Г.
3.1. Математические методы статистики (пер. с англ.). ИЛ,
М., 1948.
К р а с у л и н а Т. П.
3.1. О стохастической аппроксимации. Тр. IV Всесоюзного
совещания по теории вероятностей п математической
статистике. Вильнюс, 1962.
3.2. Замечания о некоторых процессах стохастической
аппроксимации. Теория вероятностей и ее применение, 1962,
т. 6, № 1.
Леонов 10. П., Раевский С. Я., Р а й б м а н Н. С.
3.1. Помощник автоматики (статистическая динамика в
автоматике). Изд-во АН СССР, М., 1961.
Л и т в а к о в Б. М.
3.1. Об одном итерационном методе в задаче аппроксимации
функций по конечному числу наблюдений. Автоматика
и телемеханика, 1966, № 4.
Л о г и п о в II. В.
3.1. Методы стохастической аппроксимации. Автоматика и
телемеханика, 1966, № 4.
Л о э в М.
3.1. Теория вероятностей (пер. с англ.). ИЛ, М., 1962.
М о в ш о в и ч С. М.
3.1. Случайный поиск и градиентный метод в задачах
оптимизации. Техническая кибернетика, 1966, № 6.
ЛИТЕРАТУРА
.'555
Паск Г.
3.1. Обучающиеся машины. Тр. 11 Международного
конгресса ИФАК, Дискретные и самонастраивающиеся системы.
«Наука», М., 1965.
3.2. Физическая и лингвистическая эволюция в
самоорганизующихся системах. В кн. «Самонастраивающиеся
системы». Тр. Международного симпозиума ИФАК, «Наука»,
М., 1965.
Первозва некий А. А.
3.1. Случайные процессы в нелинейных автоматических cncie-
мах. Фпзматгиз, М., 1962.
р о б б и н с, Монро (Robbins Н., Monro S.)
3.1. A stochastic approximation method. Annals of
Mathematical Statistics, 1951, v. 22, No. 1.
С а к p и с о н (Sakrison D. Т.)
3.1. A continuous Kiefer-VVolfowitz procedure for random
processes. Annals of Mathematical Statistics, 1964, v. 35, No. 2.
3.2. Efficient recursive estimation, application to estimating
the parameters of a covariance functions. International
Journal of Engineering Science, 1965, v. 3, No. 4.
Сакс (Sacks J.)
3.1. Asymptotic distributions of stochastic approximations.
Annals of Mathematical Statistics, 1958, v. 29, No. 2.
С к л а и с к и (Sklansky J.)
3.1. Adaptation, learning, self-repair and feedback. IEEE
Spectrum, 1964, v. 1, No. 5.
3.2. Adaptation theory and tutorial introduction to current
research. RCA Laboratories David Sarnoff Research
Center, Princeton, New Jersey, 1965.
3.3. Learning systems for automatic control. IEEE Transactions
on Automatic Control, 1966, v. AC-11, No. 1.
С т p а т о и о в и ч P. Л.
3.1. Существует ли теория синтеза оптимальных адаптивных,
самообучающихся и самонастраивающихся систем?
Автоматика и телемеханика, 1968, № 1.
У а й л д (Wilde D. J.)
3.1. Optimum seeking methods. Prentice Hall, 1964.
Ф а б и а и (Fabian V.)
3.1. Stochastic approximation methods. Чехословацкий
математический журнал, 1960, т. 10 (85), № 1.
3.2. A new one-dimensional stochastic approximation method
for finding a local minimum of a function. Transactions
of the Third Prague Conference on Information Theory,
Statistical Decision Functions, Random Processes, 1962,
Prague, 1964.
3.3. Piehled deterministickych a stochastickych approximacnich
metod pro minimalizaci funkci. Kybernetika, 1965, rochnik
1, cislo 6.
Ф а б и у с (Fabius Т.)
3.1. Stochastic approximation. Statistics Nederlandica, 1959,
v. 13, No. 2.
23*
356
ЛИТЕРАТУРА
Фельдбаум А. А.
3.1. Процессы обучения людей и автоматов. В кн.
«Кибернетика, мышление, жизнь», «Мысль», 1964.
Фон М и з е с, П о л я ч е к - Г е й р и н г е р (Von Mises R.,
Pollaczek-Geiringer H.)
3.1. Praktische Verfahren der Gleichungsauflosung. Zeitschrift
fur angemandte Mathematik und Mechanik, 1929,
Band 9.
Фридман (Friedman A. A.)
3.1. On stochastic approximations. Annals of Mathematical
Statistics, 1963, v. 34, No. 1.
Ханш, III и а ч e к (Hans 0., Spacek A.)
3.1. Random fixed point approximation hy differentiable traec-
tories. Transactions of the Second Prague Conference on
Information Theory, Statistical Decision Function,
Random Processes, Prague, 1959.
X а с ь м и и с к и й Р. 3.
3.1. Об устойчивости траекторий марковских процессов.
Прикладная математика и механика, 1962, т. 26, № 6.
3.2. Применение случайного шума в задачах оптимизации
и опознавания. Проблемы передачи информации, 1965,
т. 1, вып. 3.
X а у к и и с
3.1. Самоорганизующиеся системы. Обзор и комментарии.
Тр. Института радиоинженеров (пер. с англ.), 1961, т. 49,
№ 1.
Ход ж е с, Л е м а и (Hodges Т. L., Lehman Е. L.)
3.1. Two approximations to the Robbins—Monro process.
Proceedings of the Third Berkeley Symposium on Mathematical
Statistics and Probability, 195(), v. 1.
Ц ы и к и ii Я. 3.
3.1. А все же существует ли теория оптимальных адаптивных
систем? Автоматика и телемеханика, 1968, № 1.
Ч а и г (Chang К. L.)
3.1. On a stochastic approximation method. Annals of
Mathematical Statistics, 1954, v. 25, No. 3.
Шметтерер (Schmetterer L.)
3.1. Bemerkungen zum Verfahren der stochastischen Iteration.
Osterreichisches Ingenieur-Archiv, 1953, Bd. 7, Хч 2.
3.2. Sur Papproximation stochastique. Bulletin Inst. Internat.
Statist., 1951, v. 24, No. 1.
3.3. Zum Sequentialverfahren von Robbins und Monro. Monats-
hefte fur Mathematik, 1954, Bd. 58, № 1.
3.4. Sur Piteration stochastique. Colloques Internationaux du
centre national de la recherch scientifique, 1958, v. 87,
No. 1.
3.5. Stochastic approximations. Proceedings of the Fourth Berkeley
Symposium on Mathematical Statistics, 1961, v. 1.
Юдин Д. Б.
3.1. Методы количественного анализа сложных систем.
Техническая кибернетика, 1966, Л» 1.
ЛИТЕРАТУРА
357
10 д и и Д. Б., Хазе н Э. М.
3.1. Некоторые математические аспекты статистических
методов поиска. Автоматика и вычислительная техника, Рига,
1966, До 13.
Якобе (Jacobs О. L. R.)
3.1. Two uses of the term «Adaptive» in automatic control. IEEE
Transactions on Automatic Control, 1964, v. AC-9, No. 4.
К главе IV
А б p а м с о и, Б p а в e p м а и (Abramson N., Bravermaii D.)
4.1. Learning to recognize patterns in a random environment.
IRE Transactions on Inlormation Theory, 1962, v. 8, No. 5.
А б p а м с о и, Б p а в e p м а н, Себастиан (Abramson N.,
Bravermaii D., Sebastian G.)
4.1. Pattern recognition and machine learning. IEEE
Transactions on Information Theory, 1963, v. 1—9, No. 4.
А г м о и (Agmoii S.)
4.1. The relaxation method for linear inequalities. Canadian
Journal of Mathematics. 1956, v. 6, No. 3.
A ii ;i e p м а и M. A.
4.1. Опыты по обучению машин распознаванию зрительных
образов. В сб. «Биологические аспекты кибернетики»,
Изд-во АН СССР, 1962.
4.2. Задача об обучении автоматов разделению входных
ситуаций па классы (распознаванию образов). Тр. 11
Международного конгресса ИФАК, Дискретные и
самонастраивающиеся системы, «Наука», М., 1965.
А й з е р м а и М. А., Б р а в с р м а и Э. М., Роз о и о э р Л. И.
4.1. Теоретические основы метода потенциальных функции
в задаче обучения автоматов разделению входных ситуаций
па классы. Автоматика п телемеханика. 1964, т. 25, № 6.
4.2. Вероятностная задача об обучении автоматов
распознаванию классов и метод потенциальных функций.
Автоматика и телемеханика, 1964, т. 25, Л« 9.
4.3. Метод потенциальных функций в задаче о восстановлении
характеристики функционального преобразователя по
случайно наблюдаемым точкам. Автоматика и телемеханика,
1964, т. 25, № 12.
4.4 Процесс Роббинса — Монро и метод потенциальных
функций. Автоматика и телемеханика, 1965, т. 26, № 11.
Альберт (Albert А.)
4.1. Mathematical theory of pattern recognition. Annals of
Mathematical Statistics. 1963, v. 34, NoM.
Аркадьев А. Г., Бравермап Э. M.
4.1. Опыты по обучению машин распознаванию образов.
«Наука», М., 1964.
Б а ш к и р о в О. А., Б р а в е р м а и Э. М., Мучник И. Б.
4.1. Алгоритмы обучения машин распознаванию зрительных
образов, основанные па использовании метода
потенциальных функций. Автоматика и телемеханика, 1964, т. 25. № 5.
358
ЛИТЕРАТУРА
Б е н е н с о н 3. М., Хазен Э. М.
4.1. Методы последовательного анализа в задачах
распознавания многих гипотез. Техническая кибернетика, 1966,
№ 4.
Бишоп (Bishop А. В.)
4.1. Adaptive pattern recognition, WE SCON Convention Record,
1963, v. 7, pt. 4.
Блажкин К. А., Фридман В. M.,
4.1. Об одном алгоритме обучения линейного персептрона.
Техническая кибернетика, 1966, № 6.
Б л а и д о н (Blaydon С. С.)
4.1. On a pattern classification result of Aizerman, Braverman
and Rozonoer. IEEE Transactions on Information Theory,
1966, v. IT-12, No. 1.
Блайдон, X о (Blaydon С. С, Ho Y.H.)
4.1. On the abstraction problem in pattern classification.
Proceedings of the National Electronics Conference, 1966, v. 22.
Блок (Block H. D.)
4.1. The perceptron: a model for brain functioning, 1. Reviews
of Modern Physics, 1962, vol. 34, No. 1.
Б о ж а п о в Э. С, Круг Г. К.
4.1. Классификация мпогофакторных объектов но
экспериментальным данным. «Планирование экспериментов».
«Наука», М., 1966.
Брав е р м а н (Braverman D.)
4.1. Learning filters for optimum pattern recognition. IRE
Transactions on Information Theory, 1962, v. IT-8, No. 4.
Б p а и e p м a ii Э. M.
\Л. Опыты по обучению машины распознаванию образов.
Автоматика и телемеханика, 1962, т. 23, № 3.
4.2. О методе потенциальных функций. Автоматика и
телемеханика, 1965, т. 26, № 12*
4.3. Метод потенциальных функций в задаче обучения машины
распознаванию образов без учителя. Автоматика и
телемеханика. 1966, № 10.
Бравермап Э. М., Дорофеюк А. А.
4.1. Эксперименты по обучению машин распознаванию
образов без поощрения. Сб. «Самообучающиеся автоматические
системы», «Наука», М., 1966.
Бравермап Э. М., Пятницкий Е. С.
4.1. Оценки скорости сходимости алгоритмов, основанных
на методе потенциальных функций. Автоматика и
телемеханика, 1966, № 1.
Б я л а с е в и ч (Biatasiewicz J.)
4.1. Wielowymiarowy model procesu razpoznawania obiektow z
uczeniem opartym na metodzie aproksymacji stochastycznej.
Archiwum Automatyki i Telemechaniki, 1965, v. 10,
No. 2.
4.2. Liniowe funkcje decyzyjne w zastosowaniu do razpoznawania
sytuacji technologicznych. Archiwum Automatyki i
Telemechaniki, 1966, v. 11, No. 4.
ЛИТЕРАТУРА
359
ВапникВ. Н., Лернер А. Я., Червонепкпс А. Я.
4.1. Системы обучения распознаванию образов при помощи
обобщенных портретов. Техническая кибернетика, 1965,
№ 1.
В а и н и к В. II., Червонепкпс А. Я.
4.1. Об одном классе персептронов. Автоматика и
телемеханика, 1964, т. 25, № 1.
4.2. Обучение автомата экстремальной имитации I.
Автоматика и телемеханика, 1966, Л» 5.
4.3. Обучение автомата экстремальной имитации. II.
Автоматика и телемеханика, 1966, Л° 6.
В у р т е л е (Wurtele Z. S.)
4.1. A problem in pattern recognition. Journal of the SIAM, 1965,
v. 13, No. 3.
Г e p ii e p, Герхардт (Goerner Т., Gerhard t L.)
4.1. Analysis of training algorithms for a class of self-organizing
systems. Proceedings of the National Electronics Conference,
1964, v. 20.
Г л у in к о в В. М.
4.1. Введение » кибернетику. ЛИ УССР, Киев, 1964.
Г у б с р м а и Ш. А., И з в с к о в а М. Л., X у р г и и Я. II.
\Л. Применение методов распознавании образон при
интерпретации геофизических данных. Сб. «Самообучающиеся
автоматические системы», «Наука», М., 1966.
Девятериков И. II., П р о п о и А. И., Цыпки и Я. 3.
4.1. О рекуррентных алгоритмах обучения распознаванию
образов. Автоматика и телемеханика, 1967, Л» 1.
Д ж о и с о н, X о г, Л и (Johnson D. D., llangh G. К., Li К. P.)
4.1. The application of few hyperplane design technics to
handprinted character recognition. Proceedings of the National
Electronics Conference, 1966, v. 22.
Д о p о ф e ю к A. A.
4.1. Алгоритмы обучения машин распознаванию образов без
учителя, основанные на методе потенциальных функции.
Автоматика и телемеханика, 1966, Л° 10.
Д у д а, Ф о с с у м (Duda И. О., Fossum Ы.)
1 1 Pattern classification by iterative]у determined linear and
piecewise linear discriminant functions. IEEE Transactions
on Electronic Computers, 1966, v. EC-15, No. 2.
E л к и н В. Н., 3 а г о р у й к о И. Г.
\А. Об алфавите объектов распознавания. Сб.
«Вычислительные системы», Новосибирск, 1966, № 22.
3 a i о р у й к о Н. Г.
'i.l. Классификация задач распознавания образов. Сб.
«Вычислительные системы», Новосибирск, 1966, Л» 22.
1.2. Линейные решающие функции, близкие к оптимальным.
Сб. «Вычислительные системы», Новосибирск. 1966, № 19.
Кашиап, Блайдон (Kashyap R. L.. Blaydon С. С.)
4.1. Recovery of functions from noisy measurements taken at
randomly selected points and its application to pattern
recognition. Proceedings of the IEEE, 1966, y. 54, No. Я.
;wo
ЛИТЕРАТУРА
К и р и л л о в II. Е.
4.1. Метод измерения функций распределения вероятностей,
использующий их разложение по ортогональным
полиномам. В сб. «Проблемы передачи информации», вып. 4,
Изд-во АН СССР, 1959.
К о б р и и с к и и А. Е.
4.1. Кто кого? «Молодая гвардия», М., 1965.
К о з п н е ц Б. II., Л а и ц м а и Р. М., Соколов Б. М.,
Якубович В. А.
4.1. Опознание и дифференциация почерков при помощи
электронно-вычислительных машин. Сб. «Самообучающиеся
автоматические системы», «Наука», М., 1966.
Купер Д. (Cooper D. В.)
4.1. Adaptive pattern recognition and signal detection using
stochastic approximation. IEEE Transactions on Electronic
Computers, 196-1, v. EC-13, No. 3.
Купер II. (Cooper P. W.)
4.1. The hypersphere in pattern recognition. Information^ and
Control, 1962, v. 5, No. 4.
Купер Д ж. (Cooper J. A.)
4.1. A decomposition resulting in linearly separable functions
of transformed input variables. WESCON Convention Record,
1963, v. 7, No. 4.
Купер Д., Купер П. (Cooper Г В., Cooper P. \V.)
4.1. Non-superwized adaptive signal detectron and pattern
recognition. Information and Control, 1964, v. 7, No. 3.
К э ii о л ,T .
4.1. Оценка одного из классов схем, опознающих изображение
(пер. с англ.). В сб. «Проблемы бионики», «Мир», М.,
1965.
К о и о л. С л и маке р, С м и т, У о л к е р (Kanal L., Sly-
maker F.. Smith D., Walker W.)
4.1. Basis principles of some pattern recognition systems
Proceedings of the National Electronics Conference, 1962, v. 18.
Лаптев В, А., Миленький А. В.
4.1. О разделении образов в режиме обучения. Техническая
кибернетика, 1966, Л? 6.
Л с о н о в Ю. П .
4.1. Классификация и статистическая проверка гипотез.
Автоматика и телемеханика, 1966, № \2.
JI о у р е и с (Lawrence G. И.)
4.1. Pattern recognition with an adaptive network. IRE
International Convention Record, 1960, pt. 2.
Л ю и с (Lewis P. M.)
4.1. The characteristic selection problem in recognition systems.
IRE Transactions on Information Theory, 1963, v. 1T-24,
No. 6.
M e й с (Mays С. H.)
\.\. Effects of adaptation parameters on convergence time and
tolerance for adaptive threshold elements. IEEE Transactions
on Electronic Computers, 1964, v. EC-13, No. 4.
ЛИТЕРАТУРА
361
М а к Л а р е н (McLaren R. W.)
4.1. A Markow model for learning systems operating in unknown
random environment. Proceedings of the National Electronics
Conference, 1964, v. 20.
M о ц к и н, Шенберг (Motzkin Т. S., Schoenberg I. J.)
4.1. The relaxation method for linear inequalities. Canadian
Journal of Mathematics, 1954, v. 6, No. 3.
M у ч ч a p д и, Г о 3 e (Mucciardi A. N., Gose E. E.)
i.l. Evolutionary pattern recognition in incomplete non-linear
multithreshold networks. IEEE Transactions on Electronic
Computers, 190(1. v. EC-15, No. 2.
H и к о л п ч, Ф у (Nikolic Z. Т.. Fu K.S.)
\А. An algorithm for learning without external supervision and
its application to learning control systems. IEEE
Transactions on Automatic Control, 1966, v. AC-11, No. 3.
H ii л ь с о н (Nilssen N. Т.)
4.1. Learning machines. McGraw-Hill, 1965.
Новиков (Novikoff A.)
4.1. On convergence proofs for perceptions. Proceedings of
Symposium on Mathematical Theory of Automata. Polytechnic
Institute of Brooklyn, 1963, v. XII.
Патрик, X а н к о к (Patrick Е. A., Hancock Т. С.)
4.1. The nonsupervised learning of probability spaces and
recognition of patterns. Hi ЕЕ International Convention Record,
1965, v. 9.
4.2. Nonsupervised sequential classification and recognition
of patterns. IEEE Transactions on Information Theory,
1966, v. IT-12, No. 3.
P о 3 e и б л а т Ф.
4.1. Обобщение восприятий по группам преобразований.
Кибернетический сборник, ИЛ, М., 1962, ,№ 4.
4.2. Принципы пейродпнампкп. ИЛ, М., 1965.
4.3. Analytic techniques for the study of neural nets. IEEE
Transactions on Applications and Industry, 1964, v. 83,
Xo. 7'f.
P у д о в и ц Д. (Rudowitz D.)
4.1. Pattern recognition. Journal of the Royal Statistical Society,
1966, v. 129, pt. '..
Себастиан (Sebastian G. S.)
4.1. Pattern recognition by an adaptive process of sample set
construction. IRE International Symposium on Information
Theory, 1962, v. IT-8, No. 2.
4.2. Процессы принятия решений при распознавании образов
(пер. с англ.). «Техника», Киев, 1965.
Сире (Sears R. W.)
4.1. Adaptive representation for pattern recognition. IEEE
International Convention Record, 1965, v. 13, p. 6.
С м ii т (Smith F. W.)
4.1. Coding analog variables for threshold logic discrimination.
IEEE Transactions on Electronic Computers, 1965, v. EC-14,
No. 6.
362
ЛИТЕРАТУРА
С о ч и в к о В. П.
4.1. Опознающие устройства. Судпромгиз, Л., 1963.
4.2. Электронные опознающие устройства. «Энергия», М. —Л.,
1964.
Спрегинс (Spragings J.)
4.1. Learning without a teacher. IEEE Transactions on
Information Theory, 1966, v. IT-12, No. 2.
T а у б e M.
4.1. Вычислительные машины и здравый смысл (пер. с англ.).
«Прогресс», М., 1964.
У и д р о у (Widrow В.)
4.1. Adaptive sampled-data systems. A statistical theory of
adaptation. WESCON Convention Record, 1959, pt. 4.
4.2. Самонастраивающиеся импульсные системы. Тр. I
Международного конгресса ИФАК. Теория дискретных
оптимальных и самонастраивающихся систем. Изд-во АН СССР,
1961.
4.3. A statistical theory of adaptation. В кн. Adaptive control
systems. Ed. bv Caruthes F. P., Levenstein H., Pergamon
Press, 1963.
4.4. Pattern recognition and adaptive control. IEEE Trans.ictions
on Applications and Industry, 1964, v. 83, No. 74.
4.5. «Bootstrap learning» in threshold logic. Automatic and
Bemote Control. Proceedings of the Third Congress of the
International Federation of Automatic Control, London, 1966.
Ф л о p e с, Г p e й (Flores I., Grey L.)
4.1. Optimization of reference signals for pattern recognition.
IBE Transactions on Electronic Computers, 1960. v. EC-9,
No. 1.
Ф p H м а н (Freeman II.)
4.1. On the digital computer classification of geometric line
patterns. Proceedings of the National Electronics Conference,
1962, v. 18.
4.2. A technique for the classification and recognition of geometric
patterns. Third International Congress on Cybernetics,
Namur. 1961, Acta Proceedings, Namur, 1965.
Фомин В. H.
4.1. Об одном алгоритме опознающих систем.
«Вычислительная техника и вопросы программирования», вып. 4, изд
ЛГУ, 1965.
Фролов А. С, Чепцов Н. Н.
4.1. Использование метода Монте-Карло для получения
гладких кривых. Тр. VI Всесоюзного совещания по теории
вероятностей и математической статистике. Вильнюс, 1962.
Ф У К.
4.1. Модель последовательных решении для оптимального
опознавания (пер. с англ.). В сб. «Проблемы биопики».
Биологический прототип и синтетические системы, «Мир»
1965.
4.2. Learning control systems. «Computer and Information Scien-
cps», Ed. by J. Tou, R. Wilcox, Washington, 1964
ЛИТЕРАТУРА
363
X а и з а л и к (Hansalik W.)
4.1. Adaptation procedures. Journal of the SIAM, 1966, v. 14,
No. 5.
X a p к e в и ч A. A.
4.1. Опознание образов. Радиотехника, 1959, т. 14, «N° 5.
4.2. О принципах построения читающих машин. Радиотехника,
1960, т. 15, № 2.
4.3. Некоторые методические вопросы в проблеме опознавания.
«Проблемы передачи информации», 1965, т. 1, вып. 3.
X о, К а ш и а п (Но Yu-Chi, Kashyap R. L.)
4.1. An algorithm for linear inequalities and its applications. IEEE
Transactions on Electronic Computers, 1965, v. EC-14,
No. 5.
4.2. A class of iterative procedures for linear inequalities.
Journal of the SIAM, series A. Control, 1966, v. 4, No. 1.
X э и Дж. С, Ma p т и и и Ф. С, У и т т е и С. В.
4.1. Персептрои МАРК-1, его конструкция и характеристики.
Кибернетический сборник, ИЛ, М., 1962, Лз 4.
Ц ы п к и и Я. 3.
4.1. О восстановлении плотности распределения по
наблюдаемым данным. Автоматика и телемеханика, 1965, т. 26,
№ 3.
4.2. Об алгоритмах оценки плотности распределения и
моментов по наблюдениям. Автоматика и телемеханика, 1967.
№ 7.
Ц ы и к и п Я. 3., Кельма и с Г. К.
4.1. О рекуррентных алгоритмах самообучении. Техническая
кибернетика 1967, № 5.
Ч о и ц о в II. Н.
i.l. Оценка неизвестной плотности распределения по наблю
дешгям. Доклады АН СССР, 1962, т. 147, № 1.
Ч о у (Chow С. К.)
4.1. An optimum character recognition system using design
functions. IRE Transactions on Electronic Computers, 1957,
v. EC-6, No. 4.
4.2. A class of nonlinear recognition procedures IEEE
International Convention Record, 1966.
ID а и к и н M. E.
4.1. Доказательство сходимости одного алгоритма обучения
методом стохастических аппроксимаций. Автоматика
и телемеханика, 1966, № 5.
Шлезингер М. И.
4.1. О самопроизволытом различении образов. Сб. «Читающие
автоматы». Республиканский межведомственный сборник.
Киев, 1965.
Э л ь м а и Р. И.
4.1. Вопросы оптимизации распознавания объектов на
неоднородных фонах. Техническая кибернетика, 1966, № 5.
Якубович В. А.
4.1. Машины, обучающиеся распознаванию образов. Сб.
«Методы вычислений», вып. 2, Изд-но ЛГУ, 196Я
364
ЛИТЕРАТУРА
4.2. Некоторые общие теоретические принципы построения
обучаемых опознающих систем. 1. Вычислительная
техника и вопросы программирования, вып. 4, Изд-во ЛГУ,
1965.
7i.3. Рекуррентные конечносходящиеся алгорифмы решения
систем неравенств. Доклады АН СССР, 1966, т. 166, Л° 6.
К главе V
Аведьяи Э. Д.
5.1. К одной модификации алгоритма Роббинса — Монро.
Автоматика и телемеханика, 1967, № 4.
А л ь и е р (Alper Р.)
5.1. A consideration of the discrete Volterra series. IEEE
Transactions on Automatic Control, 1965, v. AC-10, No. 3.
5.2. Higher-dimensional z-transforms and non-linear discrete
systems. Review Quarterly A, 1961, v. 6, No. 4.
Барке p, X i» ю л и (Barker II. A., llawley D. A.)
5.1. Ortogonalising techniques for system identification and
optimisation. Automatic and Remote Control. Proceedings
of the Third Congress of the International Federation of
Automatic Control, London, 1966.
Б а т л e p, Б о и (Butler R. E., Bolm E. V.)
5.1. An automatic identification technique for a class of nonlinear
systems. IEf]E Transactions on Automatic Control, 1966,
v. AC-t), No. 2.
Б e л л м а и, К а л а б а, С р к д х а р (Bellman R., Kalaba R.,
Sridhar И.)
5.1. Adaptive control via quasilinearization and differential
approximation. Computing, 19()6, v. 1, No. 1.
Б e л л м а и (Bellman R.)
5.1. Dynamic programming, system identification and subopti-
mization. Journal of the SIAM on Control, 1966, v. 4, No. 1.
Б }) а в e p м an Э. M.
5.1. Восстановление дифференциального уравнении объекта
в процессе его нормальной эксплуатации. Автоматика
и телемеханика, 1966, т. 27, № 3.
Б у т о и (Booton R. С.)
5.1. The analysis of nonlinear control systems with random inputs.
Proceedings of the Symposium on Nonlinear Circuit
Analysis. Polytechnical Institute of Brooklyn. 1963.
В а и - T p и с Г.
5.1. Синтез оптимальных нелинейных систем управления.
«Мир», М., 1966.
Е л и с т р а т о в М. Г.
5.1. Определение динамических характеристик
нестационарных систем в процессе нормальной работы. Автоматика
и телемеханика, 1963, т. 24, № 7.
5.2. К вопросу о точности определения динамических
характеристик нестационарных объектов. Автоматика и
телемеханика, 1965, т. 26, № 7.
ЛИТЕРАТУРА
365
Ж и в о г л я д о в В. П., К е ш п о в В. X.
5.1. О применении метода стохастических аппроксимаций
в проблеме идентификации. Автоматика и телемеханика,
1966, № ю.
Казаков И. Е.
5.1. Приближенный вероятностный анализ точности работы
существенно нелинейных автоматических систем.
Автоматика и телемеханика, 1956, т. 17, Л° 5.
5.2. Обобщение метода статистической линеаризации па
многоканальные системы. Автоматика и телемеханика, 1965,
т. 26, ДЬ 7.
К а ш и е р (Kushner II. Т.)
5.1. Простой итерационный метод определения неизвестных
характеристик линейных дискретных систем с
изменяющимися во времени параметрами. Техническая механика.
Тр. Американского общества инженеров-механиков (пер.
с англ.), 1963, № 2.
К и р в а й т и с, Ф у (Kirvaitis К., Fu К. S.)
5.1. Identification of nonlinear systems by stochastic
approximation. Joint Automatic Control Conference, Seattle,
Washington, 1966.
К и т а м о р и Г.
5.1. Применение ортогональных функций для определения
динамических характеристик объектов и конструкций
самооптимизпрующихся систем автоматического
управления. Тр. I Международного конгресса Международной
федерации но автоматическому управлению. Теория
оптимальных и самонастраивающихся систем. АН СССР, М.,
J 961.
К и ч а т о в Ю. Ф.
5.1. Определение нелинейных характеристик объектов
управления при гауссовых входных сигналах. Автоматика и
телемеханика, 1965, т. 26, Хч 3.
К у м а р, С" р и д х а р (Kumar K.-S. P., Sridhar R.)
5.1. On the identification of control systems by the quasilinea-
rization method. IEEE Transactions on Automatic Control,
1964, v. AC-9, No. 2.
Лаббок, Баркер (Labbok J. K., Barker H. A.)
5.1. A solution of the identification problem. IEEE Transactions
on Applications and Industry, 1964, v. 83, No. 72.
Л e в и л (Levin M. T.)
5.1. Optimum estimation of impulse response in the presence
of noise. IRE Transactions on Circuit Theory, 1960, v. CT-7,
No. 1.
5.2. Estimation of a system pulse transfer function in the present
noise. IEEE Transactions on Automatic Control, 1964,
v. AC-9, No. 3.
Л e л а ш в и л и Ш. Г.
5.1. Применение одного итерационного метода для анализа
многомерных автоматических систем. Сб. «Схемы
автоматического управления», Тбилиси, 1965.
366
ЛИТЕРАТУРА
М а г и л (Magil D. Т.)
5.1. A sufficient statistical approach to adaptive estimation.
Automatic and Remote Control. Proceedings of the Third
Congress of the International Federation of Automatic
Control, London, 1966.
M e e p г о ф (Meyerhoff H. T.)
5.1. Automatic process identification. Automatic and Remote
Control. Proceedings of the Third Congress of the
International Federation of Automatic Control, London, 1966.
M e p ч а в (Merchav S. T.)
5.1. Equivalent gain of single valued nonlinearities with
multiple inputs. IRE Transactions on Automatic Control 1962,
v. AC-7, No. 5.
Миллер, Рой (Miller R. W., Roy R.)
5.1. Nonlinear process identification using statistical pattern
matrices. Joint Automatic Control Conference 1964.
H а г у м о, Н о д a (Nagumo J., Nocla А.)
5.1. A learning method for system identification. Proceedings
of the National Electronics Conference 1966, v. 22.
Пердровиль, Гудсои (Perdreaville F. J., Goodson R. E.)
5.1. Identification of systems described by partial differential
equations. Transactions of the ASME, Journal of Basic
Engineering. Series D, 1966, v. 88, No. 2.
Пирсон (Pearson A. E.)
5.1. A regression analysis in functional space for the
identification of multivariable linear systems. Automatic and Remote
Control, Proceedings of the Third Congress of the
International Federation of Automatic Control, London, 1966.
P а й б м a ii H. С, Чадеев В. M.
5.1. Адаптивные модели в системах управления. «Советское
радио», М., 1966.
Роберте (Roberts P. D.)
5.1. The application of orthogonal functions to selfoptimizing
control systems containing a digital computer. Automatic
and Remote Control. Proceedings of the Third Congress of
the International Federation of Automatic Control,
London, 1966.
Рой (Roy. R. J.)
5.1. A hybrid computer for adaptive nonlinear process
identification. AFIPS Conference Proceedings, 1964, v. 26.
P а к e p (Rucker R. A.)
5.1. Real time system identification in the presence of noise.
WESCON Convention Record, 1963, v. 7, pt. 4.
Скакала, Сутекл (Skakala J., Sutekl L.)
5.1. Adaptive model for solving identification problems.
Automatic and Remote Control. Proceedings of the Third Congress
of the International Federation of Automatic Control,
London, 1966.
Ф л e йк (Flake R. H.)
5.1. Volterra series representation of nonlinear systems. IEEE
Transactions on Application and Industry, 1963, v. 82, No. 64.
ЛИТЕРАТУРА
367
5.2. Теория рядов Вольтерра и ее приложения к нелинейным
системам с переменными параметрами. Тр. II
Международного конгресса ИФАК. Оптимальные системы.
Статистические методы. «Наука», М., 1965.
X о, Л и (Но Y. С, Lee И. С. К.)
5.1. Identification of linear dynamic systems. Proceedings of
the National Electronics Conference, 1964, v. 20.
X с и (Hsieh H. C.)
5.1. Least square estimation of linear and nonlinear weighting
function matrices. Information and Control, 1964, v. 7, No. 1.
5.2. An on-line identification scheme for multivariable nonlinear
systems. Proceedings of the Conference of Computing Methods
in Optimizations, New York, 1964.
Ц ы п к и н Я. 3.
5.1. О восстановлении характеристики функционального
преобразователя по случайно наблюдаемым точкам.
Автоматика и телемеханика, 1965, т. 26, Л° 11.
Ч а д е е в В. М.
5.1. Определение динамических характеристик об7>ектов в
процессе их нормальной эксплуатации для целей
самонастройки. Автоматика и телемеханика, 1964, т. 25, № 9.
5.2. Некоторые вопросы определения характеристик с помощью
уточняемой модели. Сб. «Техническая кибернетика»,
«Наука», М., 1965.
Э й к г о ф (Eikhoff Р.)
5.1. Some fundamental aspect of process parameter estimation.
IEEE Transactions on Automatic Control, 1963, v. AC-8,
No. 4.
Э й к г о ф П., В а н дер Грин те и П., Квакер нак X.,
Велтмаы Б. (Eikhoff P., Van der Grinten P., Kvaker-
naak H., Weltman B.)
5 I. System modelling aдd identification. Automatic and
Remote Control. Proceedings of the Third Congress of the
International Federation of Aulomatic Control, London, 1966.
К главе VI
Винер (Wiener N.)
6.1. Extrapolation, interpolation and smoothing of stationary
time series, New York, 1949.
6.2. Нелинейные задачи в теории случайных процессов (пер.
с англ.). ИЛ, М., 1961.
Габор, Вилби, Вудкок (Gabor, D., Wilby W. P. Z.,
Woodcock R.)
6.1. An universal nonlinear filter, predictor and simulator which
optimizes itself by a learning process. Proceedings of thef
IEE, 1961, v. 108, p. В., No. 40.
Гарднер (Gardner L. A.)
6.1. Adaptive predictors. Transactions of the Third Prague
Conference on Information Theory, Statistical Decision
Functions, Random Process, 1963.
368
ЛИТЕРАТУРА
6.2. Stochastic approximation and its application to problems
of prediction and control systems. International Symposium
on Nonlinear Differential Equations and Nonlinear
Mechanics, Academic Press, New York — London, 1963.
Г e p ш о (Gersho A.)
6.1. Automatic time-domain equalization with transversal filters.
Proceedings of the National Electronics Conference, 1966,
v. 22.
Глазер (Glaser E. M.)
6.1. Signal detection by adaptive filters. IRE Transactions on
Information Theory, 1961, v. IT-7, No. 2.
Г p о г и и с к и и, Вильсон, М и д д л т о н (Groginsky Н. L.,
Wilson L. R., Middleton D.)
6.1. Adaptive detection of statistical signal in noise. IEEE
Transactions on Information. Theory, 1966, v. IT-12, No. 3.
К а л м а н (Kalman R.)
6.1. New approach to the linear filtering and prediction problems.
Transactions ASME, Series D, Journal of Basic Engineering,
1960, v. 82, No. 1.
К а л м a if, Б ь ю с и (Kalman R., Busy R. S.)
().1. New result in linear filtering and prediction theory.
Transactions ASME, Journal of Basic Engineering, 1961, v. 83,
No. 1.
К а ц (Kac M.)
6.1. A note on learning signal detection. IRE Transactions on
Information Theory, 1962, v. 1T-8, No. 2.
К а ш и e p (Kushner H.)
6.1. Adaptive techniques for the optimization of binary detections
signals. IEEE International Convention Record, 1963, pt. 4.
КолмогороиЛ. II.
6.1. Интерполирование и экстраполирование стационарных
случайных последовательностей. Изд. АН СССР, серия
математическая, 1941, т. 5, № 1.
Л а к к и (Lucky R. W.)
6.1. Techniques for adaptive equalization of digital
communication systems. The Rell System Technical Journal, 1966,
v. 45, No. 2.
Левин Г. А., Б о н ч - Б р у е в и ч А. М.
6.1. Пути построения обнаружителей с самооптимизирующимся
пороговым уровнем в приемных устройствах связи.
Электросвязь, 1965, № 5.
Л и, Шетце п (Lee Y. W., Shetzen М.)
6.1. Some aspects of the Wiener theory of nonlinear systems.
Proceedings of the National Electronics Conference, 1965, v. 21.
M и д д л т о и Д.
6.1. Очерки теории связи (пер. с англ.). «Советское радио»,
М., 1966.
М о р и ш и т a (Morishita I.)
6.1. An adaptive filter for extracting unknown signals from noise.
Transactions of the Society of Instrument and Control
Engineers, 1965, v. 1, No. 3/
ЛИТЕРАТУРА
369
IT р о у з a (Prouza L.)
6.1. Bemerkung zur linear Prediktion mittels eines lernenden
Filters. Transactions of the First Prague Conference on
Information Theory. Czechoslovak Academy of Sciences, Prague,
1957.
С а к p h с о н (Sakrison D. T.)
ij.\. Application of stochastic approximation methods to optimal
filter design. IRE International Convention Record, 1961,
v. 9.
().2. Iterative design of optimum filters for non-meansquare
error performance criteria. IEEE Transactions on
Information Theory, 1963, v. IT-9, No. 3.
tj.3. Efficient recursive estimation of the parameters of a radar
or radio astronomy target. IEEE Transactions on
Information Theory, 1965, v. IT-12, No. 1.
(j 4. Estimation of signals containing unknown parameters;
comparison of linear and arbitrary unbiased estimates. Journal
of the SIAM on Control, 1965, v. 13, No. 3.
С к у д дер (Scudder II. Т.)
().1. Adaptive communication receivers. IEEE Transactions on
Information Theory, 1965, v. 1T-11, No. 2.
T о и г, Л ю (Tong P. S., Liu B.)
6.1. Application of stochastic approximation techniques to two
signal detection problem; Proceedings of the National
Electronics Conference, 1966, v. 22.
Ф а л ь к о в н ч С. Е.
(J.I. Прием радиолокационных сигналов иа фоне флюктуа-
ционных помех. «Советское радио», М., 1961.
<1> и ц и о р Л. II.
6.1. Автоматическая оптимизация сложных систем
пространственного распределения. Автоматика и телемеханика,
1964, т. 25. № 5.
X п и и ч (Hinich М. Т.)
6.1. A model for a self-adapting filter. Information and Control,
1962, v. 5, No. 3.
X о (Ho Y.C.)
6 1. On stochastic approximation and optimal filtering methods.
Journal of Mathematical Analysis and Applications, 1962,
v. 6, No. 1.
Ч о л H а и о в И. Б.
6.1. Построение оптимального фильтра при неполных
сведениях о статических свойствах сигналов. Изв. АН СССР,
ОТН, Техническая кибернетика, 1963, № 3.
III а л к в и й к, К е й лаз (Schalkwijk J. P. М., Kailath Т.)
0.1. A coding scheme for additive noise channels with feedback.—
Part 1; No bandwidth constrain. Part II: Band-Limited
signals. IEEE Transactions on Information Theory, 1966,
v. IT-12, No. 2.
Ш e ф л (Sefl 0.)
6.1. Filters and predictors which adapt their values to unknown
parameters of the input process. Transactions of the Second
24 я 3. Цыпки и
370
ЛИТЕРАТУРА
Prague Conference on Information Theory, Czechoslovak
Academy of Sciences, Prague, 1960.
Ш e т ц e н (Schetzen M.)
6.1. Determination of optimum nonlinear systems for generalized
error criteria based on the use of gate functions. IEEE
Transactions of Information Theory, 1965, v. IT-11, No. 1.
Я к о в е ц, Шей, Байт (Jakowatz С. К., Shuey R. L.,
White G. М.)
6.1. Adaptive waveform recognition. Information Theory, Fourth
London Symposium, Ed. by C. Cherry. London, 1961.
К главе VII
Б e p м а н т M. A., E м e л ь я и о в СВ.
7.1. Об одном способе управления некоторым классом объектов
с изменяющимися параметрами. Автоматика и
телемеханика, 1963, т. 24, Л° 5.
Бертрам (Bertram J. Е.)
7.1. Control by stochastic adjustment. Transactions of the AIEE,
1959, v. 78, pt. 11.
Блек (Black H. S.)
7.1. Stabilized feedback amplifiers. Bell System Technical
Journal, 1934, v. 14, No. 1.
Быховский M. Jl.
7.1. Чувствительность и динамическая точность систем
управления. Техническая кибернетика, 1964, № 6.
Д о н а л ь с о и, Киши (Donalson D. Е., Kishi F. Н.)
7.1. Review of adaptive control system theories and techniques.
Modern Control Systems Theory. Ed. by С. Т. Leondes.
McGraw-Hill, 1965.
E в л а н о в Л. Г.
7.1. Самонастраивающаяся система с поиском градиента методом
вспомогательного оператора. Изв. АН СССР, ОТН,
Техническая кибернетика, 1963, № 1.
Емельянов С. В., Берм а и т М. А.
7.1. К вопросу о построении высококачественных систем
автоматического управления объектами с изменяющимися
параметрами. Доклады АН СССР, 1962, т. 145, № 4.
Казаков И. Е.
7.1. К статистической теории непрерывных
самонастраивающихся систем. Изв. АН СССР, ОТН, Энергетика и автоматика,
1962, № 6.
Казаков И. Е., Евланов Л. Г.
7.1. О теории самонастраивающихся систем с поиском
градиента методом вспомогательного оператора. Тр. II
Международного конгресса ИФАК, Базель, 1963, «Наука», М., 1965.
Киши (Kishi F. Н.)
7.1. On line computer control techniques and their application
to re-entry aerospace vehicle control. «Advances in Control
Systems». Ed. by C. T. Leondes, 1964, v. 1.
ЛИТЕРАТУРА
371
К н о л ь (Knoll A. L.)
7.1. Experiment with a pattern classifier on an optimal control
problem. IEEE Transactions on Automatic Control, 1965,
v. AC-10, No. 4.
К о г a ii Б. Я.
7.1. Электронные моделирующие устройства и их применение
для исследования систем автоматического регулирования.
Физматгиз, М., 1963.
К о к о т о в и ч П.
7.1. Метод точек чувствительности в исследовании и
оптимизации линейных систем управления. Автоматика и
телемеханика, 1964, т. 25, № 12.
К о м е р (Comer J. P.)
7.1. Application of stochastic approximation to process control.
Journal of the Royal Statistical Society, 1965, B-27, No. 3.
К о с т ю к В. И.
7.1. Экстремальне керування без пошукових коливань з вико-
ристаниям самонастроювально! мoдeлi об'екта.
Автоматика, 1965, № 2.
7.2. Зв'язок безпошукових самонастроювалышх систем з
«допом!жним оператором», диференцДальних систем та
систем на 6a3i теорп чутливость Автоматика, 1966, № 2.
Крутова И. В., Р у т к о в с к и й В. Ю.
7.1. Самонастраивающаяся система с моделью I. Техническая
кибернетика, 1964, № 1.
7.2. Самонастраивающаяся система с моделью II. Техническая
кибернетика 1964, № 2.
К у б ат (Kubat L.)
7.1. Adaptivni proporcionalni regulace jednoduche soustavy ь
dopravnim zpozdenim. «Problemy kibernetiky», Praha,
1965.
7.2. Regulace jednoduche podle statistckych parametru. «Ku'ber-
netika a jejivyuziti», Praha, 1965.
Куликовский P.
7.1. Оптимизация нелинейных случайных процессов
автоматического управления. Тр. II Международного конгресса
ИФАК. Оптимальные системы. Статистические методы.
«Наука», 1965.
7.2. Оптимальные и адаптивные процессы в системах
автоматического регулирования. «Наука», М., 1966.
Кухтенко А. И.
7.1. Проблема инвариантности в автоматике. Гостехиздат,
1963.
Леонов Ю. П.
7.1. Асимптотически оптимальные системы как модель
процесса обучения управлению. Доклады АН СССР, 1966,
т. 167, № 3.
Марголис М., Леондес К. Т.
7.1. О теории самонастраивающейся системы регулирования;
метод обучающейся модели. Тр. I Международного
конгресса ИФАК? т. 2, М., 1S61.
24*
372
ЛИТЕРАТУРА
М е е р о в М. В.
7.1. Системы автохматпческого регулирования, устойчивые при
сколь угодно большом коэффициенте усиления. Автоматика
и телемеханика, 1947, т. 8, № 4.
7.2. Синтез структур систем автоматического регулирования
высокой точности. Физматгиз, М., 1959.
Мейсингер (Meisinger Н. F.)
7.1. Parameter influence coefficients and weighting functions
applied to perturbation analysis of dynamic systems. Press
Academiques, Europeens, Bruxelles, 1962.
Мишкин 9., Браун Л. (ред.)
7.1. Приспосабливающиеся автоматические системы (пер. с англ.),
ИЛ, М., 1963.
Накамура, Ода (Nakamura К., Oda М.)
7.1. Development of learning control. Journal of the Japan
Association of Automatic Control Engineering (на японск. языке),
1965, v. 9, No. 8.
Нарепдра, МакБрайд (Narendra К. S., McBride L. E.)
7.1. Multiparameter self-optimizing systems using correlation
techniques. IEEE Transactions on Automatic Control, 1964,
v. AC-9, No. 1.
Нарендра, Стрир (Narendra К. S., Streer D. N.)
7.1. Adaptive procedure for controlling on defined linear processes.
IEEE Transactions on Automatic Control, 1964, v. AC-9, No.4.
П e p л и с (Perlis II. J.)
7.1. A.self-adaptive system with auxilary adjustment prediction.
IEEE Transactions on Automatic Control, 1965, v. AC-10, №3.
Петраш (Pctras S.)
7.1. Uciace sa systemy automaticke go piadenia. Sb. «Vyskumne
problemy technickej kybernetiky a mechaniky», Slovenska
Akademia Vied, Bratislava, 1965.
Пирсон A. E.
7.1. Приспосабливающаяся система оптимального
регулирования для нелинейных объектов. Теоретические основы
инженерных расчетов (пер. с англ.), 1964, № 1.
Пирсон, С а р а ч и к (Pearson F. Е., Sarachik Р. Е.)
7.1. On the formulation of adaptive optimal control problems.
Transactions ASME, Journal of Basic Engineering, Series D,
1965, v. 87, No. 1.
Попков 10. С.
7.1. Аналитическое конструирование статистически
оптимальных систем экстремального регулирования. Тр. III
Всесоюзного совещания по автоматическому управлению,
Одесса, 1965, «Наука», 1967.
7.2. Асимптотические свойства оптимальной системы
экстремального регулирования. Автоматика и телемеханика,
1966, т. 27, № 6.
Поспелов Г. С.
7.1. Вибрационная линеаризация релейных систем
автоматического регулирования. Реакция релейных систем на
медленно меняющиеся возмущения. Тр. II Всесоюзного сове-
ЛИТЕРАТУРА
373
щания по теории автоматического регулирования, т. 1,
Изд-во АН СССР, 1955.
Пропой А. И., Цыпкин Я. 3.
7.1. Об адаптивном синтезе оптимальных систем. Доклады
АН СССР, т. 175, 1967, № 6.
Риссанен (Rissanen J.)
7.1. On the theory of self-adjusting models. Automatika, 1963,
v. 1, No. 4.
7.2. On the adjustment of the parameters of linear systema by
a functional derivative technique. Sensitivity method in
control theory. Proceedings of International Simposium (Dub-
rovnik), Sept. 1964. Pergamon Press, 1966.
7.3. Drift compensation of linear systems by parameter
adjustments. Transactions of the ASME, Journal of Basic
Engineering, Series D, 1966, v. 88, No. 2.
Розоноэр Л. И.
7.1. Принцип максимума Л. С. Понтрягина в теории
оптимальных систем. Автоматика и телемеханика, 1959, т. 20,
№ 10-12.
Тейлор У. К.
7.1. Самонастраивающееся устройство управления,
использующее распознавание образов. Тр. II Международного
конгресса ИФАК. Дискретные и самонастраивающиеся
системы, «Наука», М., 1965.
Томас, Уаплд (Tomas М. Е., Wilde D. J.)
7.1. Feed-forward control by over-determined systems by
stochastic relaxation. Joint Automatic Control Conference,
Minneapolis, Minnesota, 1963.
Томи н гас К. В.
7.1. Об экстремальном управлении процессом флотации.
Автоматика и телемеханика, 1966, № 3.
Т у (Ton J. Т.)
7.1. Optimum design of digital control systems. Academic Press,
New York, 1963.
У л ь p и x M.
7.1. О некоторых вероятностных методах автоматического
управления. Автоматика и телемеханика, 1964, т. 25, № 1.
7.2. Pravdepodobnostni pxistup k urceni optimalnich regula-
toru. «Problemy kiberneticky». Praha, 1965.
Фельдбаум A. A.
7.1. Теория дуального управления I—IV. Автоматика и
телемеханика, 1960, т. 21, № 9, И; 1961, т. 22, № 1, 2.
7.2. О накоплении информации в замкнутых системах
автоматического управления. Изв. АН СССР, Энергетика и
автоматика, 1961, № 4.
7.3. Об одном классе самообучающихся систем с дуальным
управлением. Автоматика и телемеханика, 1964, т. 25, № 4.
X и л л, Фу (Hill J. D., Fu К. S.)
7.1. A learning control systems using stochastic approximation
for hill-climbing. Joint Automatic Control Conference, New
York, 1965.
374
ЛИТЕРАТУРА
Хил л, МакМартрп, Фу (Hill J. D., McMurtry G. J.,
Fu K. S.)
7.1. A computer-simulated on-line experiment in learning control.
AFIPS Proceedings, 1964, v. 25.
X о, В а л e н (Ho Y.C., Whalen B.)
7.1. An approach to the identification and control of linear
dynamic systems with unknown coefficients. AIEE Transactions
on Automatic Control, 1963, v. AC-8, No. 3.
Xcy, Месерв (Hsu J. C, Meserve W. E.)
7.1. Design-making in adaptive control systems. IRE
Transactions on Automatic Control, 1962, v. AC-7, No. 1.
Ц ы п к и н Я. 3.
7.1. Теория релейных систем автоматического регулирования,
Гостехиздат, М., 1965.
Ш е ф л (Sefl О.)
7.1. Principy adaptivity v technicke kybernetice. Sb. «Kyber-
netika a jeji veuzity». Praha, 1965.
7.2. Adaptivni systemy. Sounru praci a aulomatizace, 1959,
Praha, 1965.
7.3. Некоторые вопросы автоматического управления
процессов с незнакомыми характеристиками. Transactions of the
Third Prague Conference on Information Theory, Statistical
Decision Functions, Random Processes. Prague, 1964.
Шульц (Shultz P. R.)
7.1. Some elements of stochastic approximation theory and its
application to a control problem. «Modern Control systems
theory», Ed. by С. Т. Leondes, McGraw-Hill, 1965.
Я н a 4, Скриванек, III e ф л (Jana6 К., Skrivanek Т., Sefl 0.)
7.1. Adaptivni. rizeni systemu s promennym zesilenim v pfipade
nahodnych poruch a jeho modelovani. «Problemy kiberne-
tiky», Praha, 1965.
К главе VIII
Гнеденко Б. В., Беляев Ю. К., Соловьев А. Д.)
8.1. Математические методы в теории надежности, «Наука»,
М., 1935.
Евсеев В. Ф., К о р а б л и н а Т. Д., Рожков СИ.
8.1. Итерационный метод конструирования систем со
стационарными случайными параметрами. Техническая
кибернетика, 1965, № 6.
И ы у д у К. А.
8.1. Оптимизация устройств автоматики по критерию
надежности. «Энергия», М. —Л., 1966.
Кельм анс А. К., Мам и конов А. Г.
8.1. О построении структур передачи информации, оптимальных
по надежности. Автоматика и телемеханика, 1964, т. 25, № 2.
Кельманс А. К.
8.1. О некоторых оптимальных задачах теории надежности
информационных сетей. Автоматика и телемеханика,
1964, т. 25, Л» 5.
ЛИТЕРАТУРА
375
Клетский Е.
8.1. Применение теории информации к отысканию
неисправностей в технических устройствах. Зарубежная
радиоэлектроника, 1961, № 9.
М о с к о в и ц, М а к Л и н (Moskowitz F., McLean Т. Р.)
8.1. Some reliability aspects of systems design. IRE Transactions
on Reliability and Quality Control, 1956, v. PGRQC-8.
Пирс (Pierce W. H.)
8.1. Adaptive design elements to improve the reliability of
redundant systems. IRE International Convention Record,
1962. pt. 4.
P у д e p м а н С. Ю.
8.1. Вопросы надежности и поиска неисправностей в системах
с учетом вероятностного режима использования
элементов. Техническая кибернетика, 1963, № 6.
К главе IX
Б а ш а р и и о в А. Е., Флейшман Б. С.
9.1. Методы статистического исследовательского анализа и их
радиотехнические приложения. «Советское радио», М.,
1962.
Б е л л м а и Р., Г л и к с б е р г И., Г р о с с О.
9.1. Некоторые вопросы математической теории процессов
управления. ИЛ, М., 1962.
Д е Г ю е и и и (De Guenin)
9.1. Optimum distribution of effort: an extension of the Koopman
basic theory, Operations Research, 1961, v. 9, No. 1.
Д e T о p о (De Того M. T.)
9.1. Reliability criterion for constrained systems. IRE
Transaction on Reliability and Quality Control, 1956, v.
PGRQC-8.
Игнатьев H. К., Блох Э. JJ.
9.1. Оптимальная дискретизация многомерных сообщений.
Изв. вузов, Радиотехника, 1961, № 6.
К о ф м а н А., Фор Р.
9.1. Займемся исследованием операций. «Мир», М., 1966.
К о ш е л е в В. Н.
9.1. Квантоваиие с минимальной энтропией. Сб. «Проблемы
передачи информации», Изд-во АН СССР, 1963, вып. 14.
Кузнецов И. Н.
9.1. Вопросы радиолокационного поиска. Радиотехника и
электропика, 1964, т. 9, Л° 2.
9.2. Оптимальные распределения ограниченных средств для
выпукло-вогнутой функции выигрыша. Техническая
кибернетика, 1964, № 5.
9.3. Минимальная задача в теории поиска для выпукло-вогнутой
функции выигрыша. Техническая кибернетика, 1965, № 5.
К у п м а н (Koopman В. О.)
9.1. The theory of search. Operations Research, 1957, v. 5, No. 5.
376 ЛИТЕРАТУРА
Л а р с о н (Larson R.)
9Л. Optimum quantization in dynamic systems. Joint
Automatic Control Conference, Seattle, Washington, 1966.
Макс (Max J.)
9Л. Quantizing for minimum distortion. IRE Transactions on
Information Theory, 1960, v. IT-6, No. 1.
С а а т и Т. Л.
9.1. Математические методы исследования операций (пер.
с англ.). Воениздат, 1963.
Стратоновпч Р. Л., Гришаыин Б. А.
9.1. Ценность информации при невозможности прямого
наблюдения оцениваемой величины. Изв. АН СССР,
Техническая кибернетика, 1966, № 3.
Тартаковский Г. П. (ред.)
8.1. Вопросы статистической теории радиолокации.
«Советское радио», М., 1962.
У а й л д, А к р и в о с (Wilde D. J., Acrivos А.)
8.1. Short-range prediction planning of continuous operations.
Chemical Engineering Science, 1960, v. 12, No. 3.
Ф л e й ш e p (Fleischer P. E.)
8.1. Sufficient conditions for achieving minimum distortion in a
quantizer. IEEE Internations Convention Record, 1964, pt. 1.
X э и с с м e и и Ф.
9.1. Применение математических методов в управлении
производством и запасами. «Прогресс», М., 1966.
Ч у е в Ю. В. (ред.)
9.1. Основы исследования операций в военной технике.
«Советское радио», М., 1965.
К главе X
Айзерман М. А., Гусев Л. А., Розоноэр Л. П.,
Смирнова И. М., Таль А. А.
10.1. Логика, автоматы, алгоритмы. Физматгиз, М., 1963.
А м в р о с и е и к о В. В.
10.1. Условие сходимости метода Брауна решения матричных
игр. Экономика и математические методы, 1965, № 4.
Б а р д з и и ь Я. М.
10.1 Емкость среды и поведение автоматов. Доклады АН СССР,
1965. т. 160, № 2.
Б л а ж к и п К. А., Фридман В. М.
10.1. Об одном алгоритме обучения линейного персептроиа.
Техническая кибернетика, 1966, № 6.
Бланк А. М.
10.1. Целесообразность автоматов. Автоматика и телемеханика,
1964, т. 25, № 10.
Боголюбов И. Н., Овей ев и ч Б. Л., Розенб-
л ю м Л. Я.
10.1. Синтез схем из пороговых и мажоритарных элементов.
Сб. «Сети передачи информации и их автоматизация».
«Паука», М., 1965.
ЛИТЕРАТУРА
377
Борисова Э. П., Магарпк И. В.
10.1. О двух модификациях метода Брауна решения
матричных игр. Экономика и математические методы, 1966, № 5.
Браун (Brown G. W.)
10.1. Iterative solution cf games by fictions play. Activity
Analysis of Production and Allocation. Ed. by Koopman T. S.,
Wiley, 1951.
Брызгалов В. И., Г е л ь ф а н д И. М., И я т е ц к н п-
Шапиро И. И., Ц е т л и н М. Л.
10.1. Однородные игры автоматов и их моделирование на ЦВМ.
Сб. «Самообучающиеся аьтоматические системы», «Наука»ь
М., 1966.
Брызгалов В. И., П я т е ц к и й - Ш а п и р о И. И.,
Шик М. Л.
10.1. О двухуровневой модели взаимодействия автоматов.
Доклады АН СССР, 1965, т. 160, Л° 5.
Б р э й т у а й т Р. Б.
10.1. Конечный итеративный алгоритм для решения некоторых
игр и соответствующих систем линейных уравнений. Сб.
«Матричные игры», Физматгиз, 1961.
Варшавский В. И.
10.1. Некоторые вопросы теории логических сетей, построенных,
из пороговых элементов. Вопросы теории математических
машин. Сб. второй, Физматгиз, М., 1962.
Варшавский В. И., Воронцова И. П.
10.1. О поведении стохастических автоматов с переменной
структурой. Автоматика и телемеханика, 1963, т. 24„
№ 3.
10.2. Стохастические автоматы с переменной структурой. Сб.
«Теория конечных и вероятностных автоматов», «Наука»г
М., 1965.
10.3. Использование стохастических автоматов с переменной
структурой для решения некоторых задач поведения. Сб.
«Самообучающиеся автоматические системы», «Наука», М.,.
1966.
Варшавский В. И.,Воронцова И. II., Ц е т л и н М. Л.
10.1. Обучение стохастических автоматов. Сб. «Биологические-
аспекты кибернетики», «Наука», М., 1962.
Возенкрафт Дж. М., Рейффен Б.
10.1. Последовательное декодирование. ИЛ, 1963.
Волконский В. А.
10.1. Оптимальное планирование в условиях большой
размерности (итеративные методы и принцип декомпозиции).
Экономика и математические методы, 1965, т. 1, № 2.
10.2. Асимптотические свойства поведения простейших
автоматов в игре. Проблемы передачи информации, 1965, т. 1,
№ 2.
В о н г (Wong Е.)
10.1. Iterative realization of threshold functions. International
Conference on Microwave Circuit Theory and Information
Theory, Tokyo, 1964, p. 3.
:У78
ЛИТЕРАТУРА
Гальперин 3. Я.
10.1. Итеративный метод и принцип декомпозиции при
решении транспортной задачи большой размерности.
Экономика и математические методы, 1966, т. 2. вып. 4.
Г е й л Д.
10.1. Теория линейных экономических моделей (пер. с англ.).
ИЛ, М., 1963.
Г е л ь ф а и д И. М., П я те ц кий-Шапиро И. И.. Ц ет-
л и и М. Л.
10.1. О некоторых классах игр и игр автоматов. Доклады
АН СССР, 1963, т. 152, № 4.
Г и л л А.
10.1. Введение в теорию конечных автоматов. «Наука», М., 1966.
Гинзбург С. Л., Ц е т л и п М. Л.
10.1. О некоторых примерах моделирования коллективного
поведения автоматов. Проблемы передачи информации,
1965, т. 1, № 2.
Гольштейн Е. Г., Ю д и и Д. Б.
10.1 Новые направления в линейном программировании.
«Советское радио», М., 1966.
Д а н с к и и Дж. М.
10.1. Итеративный метод решения игр. Сб. «Бесконечные
антагонистические игры», Физматгиз, М., 1963.
Д а и ц и г (Danzig G. В.)
10.1. A proof of the equivalence of programming problem and
the game problem. Activity Analysis of Production and
Allocation. Ed. by Koopman R. C, Wiley, 1951.
Д ели, Джозеф, Рамсе й (Daly Т. A., Jozepli R. D.,
Ramsey D. M.)
J0.1. An iterative design technique for pattern classification
logic. WESCON Convention Record, 1963, v. 7, pt. 4.
Д о б p о в и д о в А. В., С т р а т о и о в и ч Р. Л.
10.1. О синтезе оптимальных автоматов, функционирующих
в случайных средах. Автоматика п телемеханика, 1964,
т. 25, № 10.
К к е р с (Akers Sh. В.)
10.1. Threshold logic and two-person zero-sum games. Proceedings
of the Second Annual Symposium. IEEE Publication, 1961.
E к e p с, P у т т e p (Akers Sh. В., Rutter В. H.)
10.1. The use of threshold logic in pattern recognition. WESCON
Convention Record, 1963, pt. 4.
Ито, Ф у к у и а г a (lto Т., Fukunaga К.)
10.1. An iterative realization of pattern recognition networks.
Proceedings of the National Electronics Conference, 1966, v. 22.
И ш и д а, Стюарт (Ishida H., Stewart R. H.)
10.1. A learning network using threshold element, IEEE
Transactions on Electronic Computer, 1965, v. EC-14, No. 3.
Канделаки II. П., Церцвадзс Г. Н.
10.1. О поведении некоторых классов стохастических
автоматов в случайных средах. Автоматика и телемеханика,
1966, т. 27, № 6.
ЛИТЕРАТУРА
379
Кашермен (Kaszerman P.)
10.1. A geometric test-synthesis procedure for a threshold device.
Information and Control, 1963, v. 6, No. 4.
Келлер (Keller H.)
10.1. Finite automata, pattern recognition and perceptrons. Journal
of the Association of Computing Machinery, 1961, vol. 8, No. 1.
Кпршбаум (Kirschbaum H. S.)
10.1. The application of Markov chains to discrete extremum
seeking adaptive systems. В кн.: «Adaptive Control Systems»,
ed. Caruthes E. P., Levenstein H., Pergamon Press, 1963.
К p и н с к и й В. И.
10.1. Об одной конструкции последовательности автоматов и ее
поведения в играх. Доклады АН СССР, 1964, т. 156, № 6.
К р и н с к и й В. И., Пономарев В. А.
10.1. Об играх вслепую. «Биофизика», 1964, т. 9, № 3.
10.2. Об играх вслепую. Сб. «Самообучающиеся
автоматические системы», «Наука», М., 1966.
Крылов В. Ю.
10.1. Об одном автомате, асимптотически оптимальном в
случайной среде. Автоматика и телемеханика, 1963, т. 24, № 9.
Л е б е д к и н В. Ф., М и х л и н И. С.
10.1. О построении игровых систем управления процессами
для разделения смесей. Техническая кибернетика, 1966, № 6.
Лихтеров Я. М.
10.1. Об одном классе процессов для решения матричных игр.
Изв. АН СССР, Техническая кибернетика, 1965, № 5.
Л ь ю с Р. Д., Р а й ф а X.
10.1. Игры и решения. М., ИЛ, 1961.
МакЛарен (McLaren И. W.)
10.1. A stochastic automaton model for the synthesis of learning
systems. IEEE Transactions on Systems Sciences and
Cybernetics, 1966, v. 2, No. 2.
10.2. A Markov model for learning system operating in an
unknown environment. Proceedings of the National Electronics
Conference, 1964, v. 20.
M а к M a p т p и, Фу (McMurtry G. I., Fu K. S.)
10.1. A variable structure automaton used as a multimodal
searching technique. Proceedings of the National Electronics
Conference, 1965, v. 21.
M e д и ц к и й В. Г.
10.1. О методе решения задачи оптимального распределения
плановых заданий в отрасли. Экономика и
математические методы, 1965, т. 1, вып. 6.
Милютин А. А.
10.1. Об автоматах с оптимальным целесообразным поведением
в стационарной среде. Автоматика и телемеханика, 1965,
т. 26, № 1.
Никол и ч, Фу (Nikolic Z. J., Fu К. S.)
10.1. A mathematical model of learning in an unknown random
environment. Proceedings of the National Electronics
Conference, 1966, v. 22.
380
ЛИТЕРАТУРА
П а ш к о б с к и й С.
10.1. Самонастраивающаяся система управления объектом
с конечным числом состояний. Труды II Международного
конгресса ИФАК. Дискретные и самонастраивающиеся
системы. «Наука», М., 1965.
Первозванский А. А.
10.1. Случайные процессы в нелинейных автоматических
системах. Физматгиз, М., 1962.
Пономарев В. А.
10.1. Об одной конструкции автомата, асимптотически
оптимального в стационарной случайной среде. Биофизика,
1964, т. 9, № 1.
Поспелов Д. А.
10.1. Игры и автоматы. «Энергия», М.—Л., 1966.
П^ч е л и н ц е в Л. А.
10.1. Поиск неисправности как поглощающая марковская цепь.
Техническая кибернетика, 1964, № 6.
Р о б н и с о и Дж.
10.1. Итеративный метод решения игр. Сб. «Матричные игры»,
Физматгиз, 1961.
Сагалов 10. Э., Фролов В. И., Ш у б и и А. Б.
10.1. Автоматическое обучение пороговых элементов и
пороговых сетей. Сб. «Самообучающиеся автоматические
системы». «Наука», М., 1966.
С к л а II с к и й (Sklansky J.)
10.1. Threshold training of two mode signal detection. IEEE
Transactions on Information Theory, 1965, v. IT-11,
No. 2.
10.2. Time-varying threshold learning. Joint Automatic
Control Conference, Seattle, Washington, 1966.
Смит (Smith F. W.)
10.1. A trainable nonlinear function generator. IEEE Transactions
on Automatic Control, 1966, v. AC-11, No. 2.
С p а г о в и ч В. Г., Флеров 10. А.
10.1. Об одном классе стохастических автоматов.
Техническая кибернетика, 1965, № 2.
Стефалюк В. Л.
10.1. Пример задачи на коллективное поведение двух
автоматов. Автоматика и телемеханика, 1963, т. 24, № 6.
Т о в с т у х а Т. И.
10.1. Влияние случайных помех на установившийся режим
экстремальной системы шагового типа при параболической
характеристике объекта. Автоматика и телемеханика^
1960, т. 21, № 5.
10.2. К вопросу о выборе параметров управляющей части
градиентной системы автоматической оптимизации.
Автоматика и телемеханика, 1961, т. 22, № 8.
Фельдбаум А. А.
10.1. Установившийся процесс в простейшей дискретной
экстремальной системе при наличии случайных помех. Авто-
матика и телемеханика, 1959, т. 20, № 8.
ЛИТЕРАТУРА
381
10.2. Статистическая теория градиентных систем
автоматической оптимизации при квадратичной характеристике
объекта. Автоматика и телемеханика, 1960, т. 21, № 2.
Хаффмен Д. А.
10.1. Синтез линейных многотактиых кодирующих схем.
Теория передачи сообщений. Тр. 3-й Международной
конференции (пер. с англ.), ИЛ, М., 1957.
Хэй Дж. С, Мартин Ф. С, У и т т е н СВ.
10.1. Персептрон Марк-1, его конструкция и характеристики.
Кибернетический сборник, № 4, ИЛ, М., 1962.
Церцвадзе Г. Н.
10.1. Стохастические автоматы н задача построения надежных
автоматов из ненадежных элементов. Автоматика и
телемеханика, 1964, т. 25, № 2, 4.
Ц е т л и н М. Л.
10.1. О поведении конечных автоматов в случайных средах.
Автоматика и телемеханика, 1961, т. 22, № 10.
10.2. Некоторые задачи о поведении конечных автоматов.
Доклады АН СССР, 1961, т. 139, № 4.
10.3. Конечные автоматы и моделирование простейших форм
поведения. Успехи математических наук, 1961, т. 18, № 4.
10.4. Замечание об игре конечного автомата с партнером,
использующим смешанную стратегию. Доклады АН СССР,
1963, т. 149, № 1.
Ц е т л и н М. Л., Гинзбург С. Л., Крылов В. 10.
10.1. Пример коллективного поведения автоматов. Сб.
«Самообучающиеся автоматические системы», «Наука», М., 1966.
Ц е т л и и М. Л., Крылов В. 10.
10.1. Примеры игр автоматов. Доклады АН СССР, 1963, т. 149,
№ 2.
10.2. Игры автоматов. Сб. «Теория конечных и вероятностных
автоматов», «Наука», М., 1965.
Ц ы п к и н Я. 3., Фараджев Р. Г.
10.1. Преобразование Лапласа — Галуа в теории последова-
телыюстных машин. Доклады АН СССР, 1966, т. 166, № 3.
Шапиро Г. Н.
10.1. Замечание о вычислительном методе в теории игр. В сб.
«Матричные игры», Физматгиз, 1961.
Шеннон К. Э., М а к к а р т и Дж. (ред.)
10.1. Автоматы. ИЛ, М., 1956.
Указатель основных обозначений
Обозначение
Страница
Обозначение
А . . . .
А . . . .
А . . . .
D{iO) . .
.¥ . . . .
F {х, с, Т)
G(c) . . .
Г[л] • • ■
Нс (ж, с) .
Ис (х, х0)
Н (г|\ х, с)
V . . .
J (с) . . .
J+ (с, я) .
J-(С) . .
J о (с) ■ ■
J АО ■ •
У {с) .
V J (с, а)
f(-J (С, я)
VVJ9 (с)
L (х, с) .
Z, (х, х0)
Р{г) . .
Q(-r, с) .
61
75, 95
297
307
262
262
37
31, 79
64
254
227
227
13
34
34
36
79
27
34
36
36
79
87
254
309
13
Q+ (х, с, а) .
£>_ (х, с, а) .
Qo (х, с) . .
*cQ (*. с) . .
Vp±Q (.г, с, я)
Vv+Q (х, с, г/)
VQ (х, с, я)
Я(<*) . . . .
л
sgc . . . .
Sgll 5 . . . .
sign- . . .
■7 °(Л) • • •
A?"0l) • • .
\Г-[п] . . .
V*[n] . . .
Vbln] • • •
VbllM • • •
V M • • •
V (p, g) . .
V(u, w) . . .
F(m, ш) . . .
l'vm-
b'v
W
Именной указатель
Абрамсон (Abramson N.) 357
Аведьян Э. Д. 336, 364
Лгмон (Agmon S.) 1J2, 357
Айзерман М. A. J02, 103, 331,
332, 334, 336, 344, 357, 376
Альбер С. И. 327, 348
Альбер Я. И. 327, 348
Альберт (Albert А.) 330, 351, 357
Альпер 11. (Alper Р.) 337, 364
Амвросиенко В. В. 288, 342, 343,
376
Андропов А. А. 56
Аркадьев А. Г. 357
Бардзинь Я. М. 344, 376
Баркер (Barker Н. А.) 364, 365
Батлер (Butler В. Е.) 364
Башаринов А. Е. 375
Башкиров О. А. 357
Беккепбах Э. (Beckenbach Е. F.)
330, 352
Беллман P. (Bellman R.) 324,
325, 341-343, 347, 364, 375
Беляев Ю. К. 340, 374
Бененсон 3. М. 358
Берсзин И. С. 323, 348
Бермант М. А. 370
Бертрам Дж. (Bertram J. Е.)
327, 339, 349, 370
Бингулац (Bingulac S. Р.) 326,
348
Бишоп (Bishop А. В.) 358
Блажкин К. А. 358, 376
Блайдон (Blaydon С. С.) 102,
332, 358, 359
Бланк А. М. 344, 376
Блек (Black Н. S.) 339, 370
Блок (Block Н. D.) 330, 332, 352
Блох Э. Л. 342, 375
Блум Дж. (Blum J. R.) 328, 329,
352
Боголюбов И. Н. 343, 376
Болтянский В. Г. 324, 348
Бон (Bohn Е. V.) 364
Бонгард М. М. 334
Бондаренко П. С. 327, 318
Бонч-Бруевич А. М. 338, 368
Борисова Э. П. 289, 343, 377
Браверман Д. (Braverman D.)
357 358
Браверман Э. М. 102, 103, 132,
331, 332, 334—337, 357, 358,
364
Браун (Brown G. W.) 288, 312..
377
Браун Л. (Brown L.) 372
Бромберг П. В. 327, 318
Брызгалов В. И. 314, 346, 377
Брэйтуайт Р. Б. (Braithwai-
te R. В.) 343, 377
Буркхолдер (Burkholder D. L.)
329, 352
Бутковский А. Г. 324, 317
Бутон (Booton R. С.) 33(), 3()1
Буш (Bush R. R.) 328. 345,
352
Быховскин M. Л. 340, 370
Бьюси (Busy R. S.) 368
Бяласевич (Bialasicwicz J.) 332.,
358
Байт (White G. M.) 338, 370
Вален Б. (Whalen В.) 340, 34J .,
374
Ван дер Варден Б. Л. (Van
Der Waerden) 328, 352
Ван дер Гринтен (Van der Grin-
ten P.) 336, 367
Ван-Трис Г. (Van Trees H. L.)
337, 364
Вапник В. Н. 103, 332, 334, 359
Варшавский В. И. 343—346, 377
Вегстейн (Wegstein J. Н.) 327,
348
384
ИМЕННОЙ УКАЗАТЕЛЬ
Везерил (Wethcrill G. В.) 328,
352
Вслтмап Б. (Weltman В.) 336,
367
Вентиер Дж. (Ventncr J. Н.)
329, 352
Внлби (Wilby W. P. Z.) 337, 367
Вильсон (Wilson L. R.) 338, 368
Винер (Wiener N.) 179, 367
Возонкрафт Дж. М. (Wozen-
craf't J. М.) 345, 377
Волконский В. Л. 289, 342, 343,
346, 377
Вольф (Wolff А. С.) 327, 349
Вольфовиц Дж. (Wolfowitz J.)
328, 329, 352, 354
Вонг (Wong Е.) 377
Воронцова И. П. 344—346, 377
Вудкок P. (Woodcock R.) 337,
*3()7
Вуртеле (Wurtele Z. S.) 359
Габор (Gabor D.) 178, 357, 367
Гавурин М. К. 327, 349
Гальперин 3. Я. 343, 378
Гамкрелидзе Р. В. 324, 348
Гантмахер Ф. Р. 324, 347
Гарднер (Gardner L. Л.) 338,
367
Гейл Д. (Gale D.) 343, 378
Гельфанд И. М. 328, 335, 348,
349, 377, 378
Германский P. (Germansky R.)
326, 349
Гернер (Goerner Т.) 359
Герхардт (Gerhardt L.) 359
Гершо (Gerscho Л.) 337, 368
Гибсон (Gibson .Т. Е.) 328, 352
Гнлл A. (Gill А.) 344, 378
Гинзбург С. Л. 346, 378, 381
Гладышев Е. Г. 328, 352
Глазер (Glaser Е. М.) 368
Глазман И. М. 326, 327, 349
Глпксберг И. (Gliksberg I.) 342,
375
Глушков В. М. 344, 345, 359
Гпеденко Б. В. 325, 341, 347,
374
Гольштсйн Е. Г. 342, 343, 378
Грей (Gray К.) 329, 341, 352
Гришанин Б. А. 342, 376
Грогинский (Groginsky Н. L.)
338, 368
Гросс О. (Gross О.) 342, 375
Губерман Ш. А. 334, 359
Гурвтщ Л. (Hurwicz L.) 326, 351
Турин Л. С. 328, 352
Гусев Л. А. 344, 376
Гуткин Л. С. 325, 338, 347
Гутман P. (Gutman R.) 328, 352
Гутман Т. (Gutman Т. L.) 328,
352
Данскин Дж. М. (Danskin J. М.)
343, 378
Данциг (Danzig G. В.) 343, 378
Дворецкий A. (Dvoretzky А.)
73, 328, 330, 332, 353
Де Гюешш (De Guenin) 342, 375
До Торо (De Того М. Т.) 375
Девятериков И. П. 331, 332, 359
Дегтяренко П. И. 326, 349
Дели (Daly Т. А.) 378
Дсмидович Б. П. 325, 326, 349
Демьянов В. Ф. 326, 349
Деннис Д. Б. 326, 349
Дерман (Derman С. Т.) 328, 329,
353
Джонсон (Johnson D. D.) 359
Добровидов А. В. 345, 378
Дональсон Д. (Donalson D. Е.)
340, 370
Дорофеюк А. А. 133, 335, 358,
359
Дримл М. (Driml М.) 329, 353
Дубовицкий А. Я. 326, 349
Дуда (Duda R. О.) 359
Дудников Е. Е. 351
Дупач В. (Dupac V.) 329, 353
Дэвис М. (Davis М.) 328. 354
Евланов Л. Г. 340, 370
Евсеев В. Ф. 341, 374
Екерс (Akers Sh. В.) 343, 378
Елистратов М. Г. 304
Елкин В. Н. 359
Емельянов С. В. 339, 370
Живоглядов В. П. 337, 365
Жидков Н. П. 325, 348
ИМЕННОЙ УКАЗАТЕЛЬ
385
Загоруйко Н. Г. 359
Заде (Zadch L. А.) 324, 328, 347,
353
Зоитенденк Т. 326, 349
Иванов А. 3. 353
Игнатьев И. К. 342, 375
Извекова М. Л. 334, 359
Иго (Ito Т.) 378
Ишида (Ishida Н.) 344, 378
Иыуду К. А. 341, 374
Казаков II. Е. 330, 310, 305,
370
Кал аба (Kalaba R.) 304
Каллиаппур (Callianpur G.)328,
353
Калман P. (Kalman R. Е.)
180, 324, 325, 327, 339, 317,
349, 3(18
Канделаки II. И. 344, 378
Канторович Л. 13. 320, 350
Кац И. Я. 330, 338, 353, 308
Качмаж (Kaczmarz S.) 330, 353
Кашермеп (Ka.szcrmen Р.) 379
Kaiiinaii P. (Kashyap R. L.)
113, 332, 352
Кашиер (Kuslmer И. Т.) 330,
338, 354, 3(J5
Квакериак X. (Kvakcrnaak II.)
330, 3(J7
Ксйлаз (Kailath Т.) 309
Келлер (Keller Н.) 343, 379
Кельманс А. К. 341, 374
Ксльманс Г. К. 330, 303
Кестен (Kcsten II.) 330, 350
Кешпов В. X. 337, 305
Кирвайтпс (Kirvaitis К.) 330,
337, 305
Кириллов Н. Е. 335, 300
Киршбаум (Kirschbaum Н. S.)
345, 379
Китагава (Kitagawa Т.) 354
Китамори Г. (Kitamori II.) 305
Кифер (Kiefcr Е.) 328, 354
Кичатов Ю. Ф. 305
Knran(Kishi F. Н.) 340, 370
Клетский Е. (Kletsky Е.) 341,
375
Кноль (Knoll A. L.) 341, 371
Кобринский Н. Е. 331, 300
Коган Б. Я. 339, 371
Козинсц Б. II. 334, 300
Кокотович П. (Kokotovic Р.)
340, 371
Колмогоров А. Н. 179, 308
Комср Дж. (Comer J. P.) 330,
354
Кораблина Т. Д. 341, 374
Костюк В. И. 340, 37J
Кофман A. (Kaufmann А.) 342,
375
Кохран (Cochran W. G.) 328, 354
Кошелев В. Н. 342, 375
Крамер (Cramer IT.) 330, 354
Красносельский М. А. 327, 350
Красовский А. А. 325, 320, 339,
340, 347
Красовский II. II. 330, 353
Красулнна Т. И. 328, 354
Крелле В. (Krelle W.) 320, 350
Кринский В. И. 34(J, 379
Круг Г. К. 353, 358
КрутоваИ. 13. 340, 37 L
Kpvn (Cruz-Diaz R. В.) 330)
Крылов В. 10. 344, 340), 379, 381
Кубат (Kubat L.) 371
Кузнецов И. II. 342, 375
Куликовский P. (Kulikowski R.)
339, 34 1, 371
Кумада (Cumada I.) 327, 350
Кумар (Kumar K.-S. Р.) 305
Купер Д. (Cooper D. В.) 332, 335,
300
Купер Дж. (Cooper J. А.) 300
Купер П. (Cooper P. W.) 335,
300
Купман (Koopman В. О.) 375
Кухтснко А. И. 339, 371
Кушелев Ю. Н. 353
Кэнол (Kanal L.) 300
Кюнци (Kunzi II. Р.) 320, 350
Лаббок (Labbok J. К.) 305
Лакки P. (Lucky R. W.) 337, 308
Ланцман Р. М. 334, 300
Лаптев В. А. 300
Ларсон P. (Larson R.) 342, 370
Лебедкин В. Ф. 343, 379
Левин Г. А. 338, 308
Левин (Levin М. Т.) 337, 305
Левитин Е. С. 320, 350
25 Я. 3. Цыпкпн
386
ИМЕННОЙ УКАЗАТЕЛЬ
Ледли P. (Ledley R. S.) 327, 350
Лейтмаи Дж. (Leitmann G.)
325, 347
Лелашвили Ш. Г. 365
Леман (Lehman Е. L.) 328, 356
Леондес К. Т. (Leondes С. Т.)
340, 371
Леонов 10. П. 332, 338, 354, 371
Лернер А. Я. 103, 332, 334, 559
Лесдон Л. (Lasdon L. S.) 350
Лп P. (Lee R. С. К.) 324—326,
330, 347, 367
Ли (Lee Y. W.) 337, 368
Литваков Б. М. 330, 333, 354
Лихтеров Я. М. 343, 379
Логинов U. В. 329, 354
Лоурснс (Lawrence G. R.) 300
Лоэв М. (Loove М.) 329, 354
Лурье Л. И. 50, 327, 350
Лыоис (Lewis Р. М.) 300
Лыос Р. Д. (Luce R. D.) 342, 379
Лю (Liu Г>.) 338, 3()9
Любич 10. II. 327, 350
Люстсрник Л. А. 327, 350
Магарик И. R. 289, 343, 377
Магил (Magil D. Т.) 300
МакБрайд '(McBride L. Е.) 372
МакКарти Дж. (McCarthy J.)
344, 38J
МакЛарен (McLaren R. W.) 344,
361, 379
МакЛин (McLean Т. P.) 375
МакМартри (McMurtry G. I.)
344, 374, 379
Макс Дж. (Max J.) 342, 376
Мамиконов A. L\ 341, 374
Мансон И. (Munson I. K.) 350
Марголис M. (Margolis M.) 340,
371
Марон И. A. 325, 326, 349
Мартин Ф. С. (Martin F. G.)
343, 363, 381
Матыаш И. 350
Медведев И. Л. 326
Медицкий В. Г. 343, 379
Меергоф (Meyerhoff Н. Т.) 360
Мееров М. В. 339, 372
Мепс (Mays С. Н.) 112, 360
Мейсингср (Meisinger Н. F.)
340, 372
Мерриам К. (Morriam С. W.)
325, 348
Мерчав (Mcrchav S. Т.) 366
Мессрв (Mcscrve \V. Е.) 374
Миддлтоп Д. (Middleton D.)
329, 338, 348, 368
Миленький А. В. 360
Миллер (Miller R. W.) 366
Милютин А. А. 326, 345, 349,
379
Миттер С. (Mitter S.) 326, 350
Михлии И. С. 343, 379
Михлин С. Г. 327, 350
Мишкин Э. (Mishkin Е.) 372
Мищенко Е. Ф. 324, 348
Монро (Monro S.) 328, 355
Мовшовнч С. М. 329, 354
Морпшита (Morishita I.) 338,
3()8
Мостеллср (Mosteller F.) 328,
345, 352
Моцкшт (Mol/kin Т. S.) 113, 361
Муччардн (Mucciardi A. N.)
301
Мышкис А. Д. 350
Пагумо (Nagumo J.) 337, 300
Шкамура (Nakamura К.) 372
Нарендра (Narendra К. S.) 340,
372
Недома (Nedoma Т.) 329, 353
Николич (Nikolic Z. J.) 330,
335 330 345 379
Пильсон (Nilsscn N. Т.) 30]
Новиков A. (Novikoff A.) J12,
332, 333, 3(Н
Иода (Noda А.) 337, 366
Овсиевич Б. Л. 343, 376
Ода (Oda М.) 372
Островский А. М. 327, 350
Паск Г. (Pask G.) 328, 355
Патрик (Patrick Е. А.) 335, 361
Пауолл (Powell М. J. D.) 351
Пашковский С. (Paszkowski S.)
380
Пенроуз (Penrose R.) 330
Первозванский А. А. 330, 345,
355, 380
ИМЕННОЙ УКАЗАТЕЛЬ
387
Пердровиль (Perdreaville F. J.)
366
Перлис (Perlis II. J.) 372
Нетраш (Petras S.) 372
Пирс (Pierce W. H.) 34], 375
Пирсон A. E. (Pearson A. E.)
366, 372
Пирсон (Pearson F. E.) 372
Поляк Б. Т. 325—327, 350
Поллячек-Гсйриигер (Pollaczek-
Gciringer H.) 328, 356
Пономарев В. А. 344, 346, 379,
380
Иоптрягин Л. С. 324, 348
Попков Ю. С. 340, 372
Поспелов Г. С. 339, 373
Поспелов Д. А. 344, 380
Пропой А. И. 33J, 332, 341,
359 373
Проуза' (Pronza L.) 337, 338,
369
Пугачев В. С. 335
Нчелшщев Л. А. 345, 380
Пятецкий-Шапиро И. И. 344,
346, 377, 378
Пятецкий Е. С. 358
Рабип (Rubin А. I.) 350
Райбман II. С. 366
Райфа X. (Raiffa II.) 342, 379
Ракер (Rucker R. А.) 366
Растригип Л. А. 327, 351
Рейффен Б. (Reiffen В.) 345, 377
Риссанен (Rissanen J.) 340, 373
Роббинс (Robbins II.) 328, 355
Роберте (Roberts P. D.) 366
Робинсон Дж. (Robinson J.)
342, 380
Рожков С. И. 341, 374
Розенблат Ф. (Rosenblatt F.)
332, 361
Розенблюм А. Я. 343, 376
Розоноэр Л. И. 102, 103, 331,
332, 334, 336, 341, 344, 357,
373, 376
Рой (Roy R. J.) 366
Рудерман С. Ю. 341, 375
Рудовиц Д. (Rudowitz D.) 361
Рутковский В. Ю. 340, 371,
Рыбашов М. В. 327, 351
Саати Т. Л. (Saaty Т. L.) 342,
376
Сагалов 10. 0. 344, 380
Сакрисон (Sakrison D. Т.) 329,
330, 337, 355, 369
Сакс (Sacks J.) 328, 329, 355
Сарачик (Sarachik P. Е.) 372
Себастиан (Sebastian G. S.) 331,
357, 361
Сенчук Ю. Ф. 326, 349
Сире (Scars R. W.) 361
Спттлер (Sittler R. W.) 330, 351
Скакала (Skakala J.) 366
Скланский (Sklansky J.) 345,
355, 380
Скриванек (Skrivanek Т.) 374
Скуддер (Scudder Н. Т.) 369
Слимакер (Slymaker F.) 360
Смирнова И. М. 344, 396
Смит (Smith D.) 360
Смит (Smith F. М.) 344, 361, 380
Соболев В. И. 327, 350
Соколов Б. М. 334, 360
Соловьев А. Д. 341, 374
Сочивко В. И. 334, 362
Сирегинс Дж. (Spragings J.) 335,
362
Срагович В. Г. 380
Сридхар (Sridhar R.) 364, 365
Стефанюк В. Л. 346, 380
Стратонович Р. Л. 325, 330,
331, 342, 345, 348, 376
Стрир (Strcer D. N.) 340, 372
Стюарт (Stewart R. П.) 314, 378
Сутскл (Sutekl L.) 366
Таль А. А. 344, 376
Тартаковский Г. П. 376
Таубе М. (Taube М.) 331, 362
Тейлор У. К. (Taylor W. К.) 373
Товстуха Т. И. 345, 380
Томас (Tomas М. Е.) 340, 373
Томингас К. В. 373
Томпкинс Ч. Б. 327, 351
Тонг (Tong P. S.) 338, 369
Трауб Дж. (Traub J. Т.) 325,
327, 351
Ту (Той J. Т.) 373
Уайлд Д. (Wilde D. J.) 330,
336, 340, 342, 355, 373, 376
25*
388
ИМЕННОЙ УКАЗАТЕЛЬ
Удзава X. (Uzawa Н.) 326, 351
Уидроу Б. (Widrow В.) 300,
333, 335, 343, 362
Уитмен К. У. (Wightman С. W.)
343, 363, 381
Ульрих М. (Ullrich М.) 339,
373
Уолкер (Walker W.) 360
Уорен (Waren A. U.) 350
Фабпан (Fabian V.) 330, 336, 355
Фабиус (Fabius Т.) 355
Фаддеев Д. К. 326, 351
Фаддеева В. Н. 320, 351
Фалькович С. Е. 338, 3()9
Фараджев Р. Г. 344, 381
Фельдбаум А. А. 203, 324, 325,
328, 339, 345, 348, 350, .'573,
380
Фицнер Л. И. 337, 369
Флейк (Flake В. II.) 360
Флейшер (Fleischer Р. Е.) 376
Флейшмаи Б. С. 375
Флеров 10. А. 380
Флетчер (Fletcher П.) 351
Флорес (Flores I.) 302
Фомин В. П. 1 13, 362
Фомин С. В. 335, 319
Фон Мизес P. (Von Mises П.) 328,
35()
Фор P. (Faure И.) 342, 375
Фоссум (Fossum И.) 359
Француз А. Г. 334
Фридман (Friedman А. А.) 328,
356
Фридман В. М. 358, 376
Фриман (Freeman II.) 362
Фролов А. С. 334, 362
Фролов В. И. 344, 380
Фу К. (Fu К. S.) 330, 335-
337, 340, 344, 345, 361, 362,
365, 373, 374, 379
Фукунага (Fukunaga К.) 378
Хазен Э. М. 357
Халмош П. Р. 325, 348
Ханзалик (Hansalik W.) 363
Ханкок (Hancock Т. С.) 335,
361
Ханш (Hans О.) 329, 353, 356
Харкевич А. А. 331, 363
Хасьминский Р. 3. 329, 330
356
Хаукинс (Hawkins J. К.) 356
Хаффмен Д. A. (Huffman D. А.)»
344, 381
Хелстром К. 325, 348
Хилл (Hill J. D.) 340, 373, 374
Хинич (Hinich М. Т.) 369
Хо 10. (Но Yu-Clii) 102, JJ3,
332, 338, 340, 341, 358, 3(>3,
3()9, 37 4
Хог (Наugh G. R.) 359
Ходжсс (Hodges Т. L.) 356
Хсп (Hsieh Н. С.) 367
Хсу (Hsu J. С.) 374
Хургин Я. И. 329, 334, 359
Хыоли (Hawley 1). А.) 364
Хан Дж. С. (Hay J. С.) 343, 363,
381
Хэпссмснн Ф. (llanssmenn F.)
342, 37()
Церцвадзе Г. И. 344, 378, 381
Цетлип М. Л. 310, 328, 344 —
346, 349, 377, 378, 381
Чапг Ш. С. Л. (Chang S. S. L.)
324, 33(), 348, 356
Чанг (Chang К. L.) 328, 356
Чолпапов И. Б. 369
Ченцов П. Н. 334, 3()2, 363
Червоненкис А. Я. 103, 332,334,
359
Чоу (Chow С. К.) 363
Чуев 10. В. 376
Шайкнп М. Е. 332, 363
Шалквийк (Schalkwijk J. P. М.)
369
Шапиро Г. Н. 342, 381
Шей (Shuey R. L.) 338, 370
Шенберг И. (Shoenberg J. J).
ИЗ
Шеннон К. Э. (Shannon СЕ.)
203, 344, 384
Шетцен (Schetzen М.) 337, 368,
370
Шефл (Sefl О.) 338, 369, 374
Шик М. Л. 344, 377
Шиманский В. Е. 326, 351
ИМЕННОЙ УКАЗАТЕЛЬ
389
Шлезингер М. И. 335, 336,
363
Шметтерер Л. (Sclimetterer L.)
328, 329, 356
Шпачек A. (Spacek А.) 329, 356
Шубин А. Б. 344, 380
Шульц (Schultz Р. К.) 339, 374
Эйкгоф П. (Eikhoif Р.) 336,
367
Эльман Р. И. 335, 3(>3
Эрроу К. Дж. (Arrow К. J.)
351
Эшби У. P. (Ashby W. R.) 327,
351
Юдин Д. Б. 328, 342, 343, 351,
378
Якобе О. (Jacobs О. L. R.) 328,
357
Яковец (J akowatz С. К.) 338, 370
Яковлев М. И. 327, 35J
Якубович В. А. 112, 33J, 332,
334, 360, 363
Янач (Janac К.) 374
Предметный указатель
Автомат 304
— конечный 304, 305, 344
— — стохастический 308, 344
Адалина Ундроу 300
Адаптация 58, 321, 328
Адаптивная модель объекта 2J8
Адаптивный подход 22, 325
Алгоритм 23, 320
— адаптации 01, 104, 220
— — многошаговый 07
— — наилучший локально 52,
327
— — непрерывный 09, 327
— — поисковый 02, 210
— восстановления 190
— выделения сигнала на фоне
помех 184
— дуального управления 201
— идентификации 220
— марковского обучения 317
— наискорейшего спуска 33
— нестационарный 33
— Ньютона 33
— обучения дискретный 102
— — непрерывный 97, 107
— — общий 90
— — поисковый 97, 105
— оптимизации 29
— — многошаговый 42
— — непрерывный 45
— — — высшего порядка 45
— — — первого порядка 45
— — одношаговый 42
— — первого порядка 42
— — поисковый 34, 320
— — релаксационный 33, 320
— — — градиентный 33
— — — координатный 33
— — с «нелинейным» шагом 33
— — с переменным шагом 32
— — с постояпным шагом 32
— оценки дисперсии 142
Алгоритм самообучения 120,
129, 335
— — поисковый 134
— стационарный 33
— циклический 33
— экстремального управления
2L9
Алфавит входной 305
— выходной 305
Аппроксимация стохастическая
50, 59, 328, 329
Априорная информация \8
Байесовские оценки 78, 324
Барьер неустойчивости 201
Безотказность 230
Брауэра принцип 342
Буквы 305
Вариант допустимый 17
Вариация среднего риска 124
Вектор оптимальный 22
— стационарный 27
Бремя безотказной работы 238
Выделение сигнала на фоне
помех 187
Гипотеза компактности 94, 331
— представимости 98, 331
Граф 307
Грегора — Ньютона формула 44
Декодирование
последовательное 317, 345
Детектирование синхронное 35
Детерминированный процесс 19
Дигратор 120, 320
Дирака импульсная функция
(6-функция) 20
Дискретизация 273
Дисперсия 141
Дихотомия 94
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
391
Долговечность 236
Допустимый вариант 17
Задача минимаксная 254, 259,
271, 341
— многоэкстремальная 327
— оптимального разового
поступления 264
— трех О 94, 333
— экстраполяции 95
Игра 280
— автоматов 318, 346
— в смешанных стратегиях 281
— вслепую 318
— матричная двух лиц с
нулевой суммой 280, 343
Идентификация 137, 220, 336
— линейных объектов 157, 158
— нелинейных объектов 151,
152, 154
Избыточность 251
Интеллект искусственный 321,
331
Интервал времени плаповый 263
Информация априорная 18, 325
— текущая 19, 325
Исследование операций 258, 342
Качество алгоритмов 77
Квантование 273
Конфликтная ситуация 279
Корректировка внешняя 57
Корректор искажений
адаптивный 173
Корреляционные функции 143
Коэффициент статистической
линеаризации 147
Критерии оптимальности 13, 15
Критерий байесовский 14, 321
— оптимальности приема Ко-
тельникова 182
— — — Неймана — Пирсона
182
Куна — Таккера теорема 38
Линеаризация 89
Линейное программирование 290
Марковское обучение 316, 345
Массовое обслуживание 256
Математическое ожидание
условное 13
Матрица платежная 280
Мера качества алгоритмов 77
— целесообразности поведения
автомата 311
Метод алгоритмический 24, 26
и д.
— аналитический 24
— возможных направлений 40,
326
— динамического
программирования 324, 341
— итеративный 24, 28, 325
— — регулярный 28
— Ляпунова 48, 49, 54, 327
— множителей Лагранжа 36,
326
— оврагов 42, 328
— рекуррентный 26
— релаксационный 53, 327
— случайного поиска 46, 327
— стохастической
аппроксимации 5*\ 328, 329
Мшшмакс 282
Минимаксный критерий
оптимизации 254
Минимум среднего риска 126
Модель чувствительности 208
Надежность 235, 341
Наискорейший спуск, алгоритм
33
Направление возможное 41
Нестационарный алгоритм 33
Ньютона алгоритм 33
Обнаружение сигнала на фойе
помех 184, 186
Образ 93
Обслуживание 256
Обучение 57, 321, 328
— автомата 312, 345
— — марковское 316, 345
— опознаванию образов 94, 333
— показами 93
— порогового элемента 301
— решению игр 284, 342
-— — — «опытным путем» 286
Объект переопределенный 214
— распределенный 158
392
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Обычный подход 21, 325
Ограничения 16
— второго рода 17, 38, 63, 65,
326
— первого рода 17, 36, 63, 65,
326
Опознавание 92, 229, 331
Оптимальность 12, 324
— автоматов 312
— приема J 81
Оптимальный вектор 22
Отказ системы 236, 256
Отрицательная обратная связь
199
Оценки смещенные 162
Память автомата 305
Переопределенный объект 2J4
Персентрон 100, 152, 213
— поисковый 101, 152
— Розенблата 290, 332, 3-53
— Уидроу 300, 333
Планирование запасов 259, 263
— календарное 277
— работы завода 268
— сетевое 277
Плотность распределения 20
Поведение автомата 310, 311
— — оптимальное 312
— — целесообразное 311
Погружение автомата в среду
309, 344
Поиск 34, 62, 97, J05, 134,
176, 216, 246 ^
— случайный 46, 327
Поисковые алгоритмы
оптимизации 34
Показатели надежности 236, 238
Политика заказов 259
Помехи J62, 228, 337
Пороговая реализуемость
булевой функции 295
Пороговый элемент
Портрет обобщенный 332
Поступление разовое
оптимальное 264
Правило остановки 74
Приемник оптимальный
адаптивный 192, 338
Принцип максимума 324
Проблема оптимальности J 2, 22
Программирование линейное 290
— математическое 38
Проектирование сложных
систем 252, 255
Процесс детерминированный 14
— стохастический J 9
Работоспособность системы 241
— — оптимальная 252
Разность разделенная 35
Расходы эксплуатационные 211
Реализуемость пороговая
булевой функции 295
Резервирование 248
Рекуррентная схема 326
Релаксационный алгоритм 33
— — градиентный 33
— — координатный 33
Ремонт 256
Ремонтопригодность 230
Риск средний 11, J 23, 335
Самообучение 57, 110, 122, 335
Сепарабельность 155
«Серый» ящик 138
Симплекс-метод 4 1
Синтез оптимальных систем 225,
311
— — — при наличии помех
228, 230
Система автоматического
управления 199
— адаптивная 205, 200
— — упрощенная (с моделью)
213 "
— дискретная с нелинейными
коэффициентами усиления 33
— — с неременными
коэффициентами усиления 32
— — с постоянными
коэффициентами усиления 33
— сложная, проектирование
252, 255
— управления по возмущению
214
— — экстремальная 218
Слейтера условие регулярности
39
Слова 305
Смещенные оценки 162
Среднее значение 138
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
393
Статистическая теория приема
180
— — решений 181
Стационарный алгоритм 33
Стохастический процесс J 9
Стратегия 280
Сходимость алгоритма
адаптации по вероятности 09, 328
— — — почти наверное (с
вероятностью единица) 70
— — — среднеквадратическая
70
— — оптимизации 47
— — — неизбежная 50
Текущая информация 19
Теорема Купа — Таккера 38
— фон Неймана о минимаксе 282
— Шепили — Сноу 283
Теория игр 279, 342
— конечных автоматов 304, 344
— массового обслуживания 250
— приема статистическая 180
Узнавание 92
Управление 199
— дуальное 202, 339
— но возмущению 214
— по отклонению 199
— экстремальное 218
Уравнения конечных автоматов
305
Уровень запасов оптимальный
205
Ускорение сходимости 51, 75,
327, 330
Условие регулярности Слейтера
39
Усреднение по времени 15
— по множеству 13
Устойчивость 47
— абсолютная 50, 327
— вероятностная 7L
— персептрона 101
Устойчивость по Ляпунову 73
«Учитель» 57
Фиксатор отказов 239
Фильтр адаптивный J(>7, 169,
338
— — поисковый J 70
— Колмогорова — Винера ]79
Фильтр-предиктор адаптивный
178, 337
Фильтрация 107
Формула Грегори — Ньютона
44
Функционал 13, 15
Функция импульсная Дирака
20
—, квантованная по уровню 300
— корреляционная 143
— логическая (булева) 295
— регрессии 328
— решетчатая 305
— характеристическая 15
— чувствительности 207
Целесообразность поведения
автомата 311, 344
Цепь Маркова 315
Циклический алгоритм 33
«Черный» ящик 138
Чувствительность 207
Штраф средний J 23
Шум квантования 273
Эксплуатационные расходы 24 I
Экстраполяция 91, 95
Экстремаль 22
Экстремальное управление 218
Элемент пороговый 294
Эргодичность J 5, 325
Ящик «серый» 138
— «черный» 138
Оглавление
Предисловие 3
Введение 7
Глава I
Проблема оптимальности
§ 1.1. Введение 12
§ 1.2. Критерии оптимальности 13
§ 1.3. Еще о критериях оптимальпости .... 15
§ 1.4. Ограничения 16
§ 1.5. Априррная и текущая информация ... 18
§ 1.6. Детерминированные и стохастические
процессы 19
§ 1.7. Обычный и адаптивный подходы .... 21
§ 1.8. О методах решения проблемы
оптимальности 22
§ 1.9. Заключение 24
Глава II
Алгоритмические методы оптимизации
§ 2.1. Введение 26
§ 2.2. Условия оптимальности 26
§ 2.3. Регулярный итеративный метод .... 28
§ 2.4. Алгоритмы оптимизации 29
§ 2.5. Возможное обобщение 31
§ 2.6. Разновидности алгоритмов оптимизации 32
§ 2.7. Поисковые алгоритмы оптимизации . . 34
§ 2.8. Учет ограничений I 36
§ 2.9. Учет ограничений II 38
§ 2.10. Методы возможных направлений .... 40
§ 2.11. Обсуждение 41
§ 2.12. Многошаговые алгоритмы оптимизации 42
§ 2.13. Непрерывные алгоритмы оптимизации 45
§ 2.14. Методы случайного поиска 46
§ 2.15. Сходимость и устойчивость 47
§ 2.16. Условия сходимости 49
§ 2.17. Об ускорении сходимости 51
§ 2.18. О наилучших алгоритмах 52
ОГЛАВЛЕНИЕ 395
§ 2.19. Примеры 53
§ 2.20. Некоторые задачи 54
§ 2.21. Заключение 55
Глава III
Адаптация и обучение
§ 3.1. Введение 50
§ 3.2. Понятие обучения, самообучения и
адаптации 57
§ 3.3. Формулировка задачи 58
§ 3.1. Вероятностные итеративные методы . . 59
§ 3.5. Алгоритмы адаптации 01
§ 3.0. Поисковые алгоритмы адаптации ... 02
§ 3.7. Учет ограничений I 03
§ 3.8. Учет ограничений И 05
§ 3.9. Одно обобщение 00
§ ЗЛО. Многошаговые алгоритмы адаптации . . 07
§ 3.11. Непрерывные алгоритмы 09
§ 3.12. Вероятностная сходимость и устойчивость 09
§ 3.13. Условия сходимости 7J
§ 3.14. О правиле остановки 1\
§3.15. Об ускорении сходимости 75
§ 3.10. Мера качества алгоритмов 77
§ 3.17. Наилучшие алгоритмы 79
§ 3.18. Упрощенные наилучшие алгоритмы . . 81
§ 3.19. Частный случай S'»
§ 3.20. Связь с методом наименьших квадратов 84
§ 3.21. Связь с байесовским методом 85
§ 3.22. Связь с методом максимального
правдоподобия . . 80
§ 3.23. Обсуждение . . 88
§ 3.21. Некоторые задачи 89
§ 3.25. Заключение 90
Глава IV
Опознавание
§ 4.1. Введение . . 92
§ 4.2. Обсуждение задачи опознавания . . 93
§ 4.3. Формулировка задачи . 94
§ 4.4. Общие алгоритмы обучения . . . . 90
§ 4.5. Сходимость алгортгтмов 98
§ 4.0. Персептропы 99
§ 4.7. Дискретные алгоритмы обучения 101
§ 4.8. Поисковые алгоритмы обучения . . 105
§ 4.9. Непрерывные алгоритмы обучения . . 107
§ 4.10. Замечания 109
§ 4.11. Еще об одном алгоритме обучения . . . ПО
§ 4.12. Частные случаи 111
§ 4.13. Обсуждение 115
396
ОГЛАВЛЕНИЕ
§ 4.14. О самообучении 116
§ 4.15. О восстановлении плотности
распределения и моментов 118
§ 4.16. Алгоритмы восстановления 119
§ 4.17. Принципы самообучения 122
§ 4.J8. Средний риск 123
§ 4.19. Вариация среднего риска 124
§ 4.20. Условия минимума среднего риска . . 125
§ 4.21. Алгоритмы самообучения 126
§ 4.22. Обобщение 128
§ 4.23. Конкретные алгоритмы 129
§ 4.24. Поисковые алгоритмы самообучения . . 134
§ 4.25. Обсуждение 135
§ 4.2(). Некоторые задачи 135
§ 4.27. Заключение 136
Глава V
Идентификации
§ 5.1. Введение . • 137
§ 5.2. Оценка среднего значения 138
§ 5.3. Другой подход 139
§ 5.4. Оценка дисперсии 141
§ 5.5. Обсуждение 142
§ 5.6. Оценка корреляционных функций ... ИЗ
§ 5.7. Определение характеристик нелинейных
элементов И 5
§ 5.8. Оценка коэффициента статистической
линеаризации 147
§ 5.9. Частные случаи Н8
§ 5.10. Описание динамических объектов ... Н9
§ 5.11. Идентификация нелинейных объектов I 151
§ 5.12. Идентификация нелинейных объектов II 152
§ 5.13. Идентификация нелинейных объектов III 154
§ 5.14. Специальный случай 155
§ 5.15. Замечание 156
§ 5.16. Идентификация линейных объектов I . . 157
§ 5.17. Идентификация линейных объектов 11 158
§ 5.18. Оценка параметров распределенных
объектов 159
§ 5.19. Помехи 162
§ 5.20. Устранение влияния помех 163
§ 5.21. Некоторые задачи 165
§ 5.22. Заключение 166
Глава VI
Фильтрация
§ 6.1. Введение 167
§ 6.2. Критерий оптимальности 167
§ 6.3. Структура адаптивного фильтра .... 169
ОГЛАВЛЕНИЕ 397
§ 6.4. Частные случаи J70
§ 6.5. Адаптивный корректор искажений . . 173
§ 6.6. Поисковые адаптивные фильтры . . . J76
§ 6.7. Адаптивный фильтр-предиктор ... 178
§ 6.8. Фильтры Колмогорова — Винера . . . 179
§ 6.9. Статистическая теория приема .... 180
§ 6.10. Критерий оптимальности приема ... 181
§ 6.11. Определение решающего правила . . . 183
§ 6.J2. Обнаружение сигнала на фоне помех I 184
§ 6.13. Обнаружение сигнала на фоне помех II 186
§ 6.J4. Выделение сигнала на фоне помех . . . 187
§ 6.15. Критерий оптимального выделения . . 188
§ 6. J 6. Алгоритм выделения L89
§ ().17. Еще о выделении сигнала иа фоне помех 190
§ 6.18. Другой критерий оптимальности ... 191
§ 6.19. Оптимальный приемник 192
§ ().20. Возможные упрощения 194
§ 6.21. Восстановление входных сигналов . . 195
§ ().22. Алгоритмы восстановления 196
§ 6.23. О влиянии помех 197
§ 6.24. Некоторые задачи 198
§ 6.25. Заключение 198
Глава VII
Управление
§ 7.1. Введение 199
§ 7.2. Когда нужна адаптация? 199
§ 7.3. Постановка задачи 201
§ 7.4. Дуальное управление 202
§ 7.5. Алгоритмы дуального управления . . . 204
§ 7.6. Адаптивные системы управления J . . . 205
§ 7.7. Адаптивные системы управления II . . 206
§ 7.8. Модель чувствительности 210
§ 7.9. Адаптивные системы управления lfl 211
§ 7.J0. Упрощенные адаптивные системы . . . 213
§ 7.11. Системы управления по возмущению 2Н
§ 7.12. Алгоритмы оптимального управления 215
§ 7.13. Еще одна возможность 217
§ 7.14. Экстремальные системы управления . . 218
§ 7.15. Алгоритмы экстремального управления 219
§ 7.16. Алгоритмы изучения '. . 220
§ 7.17. Непрерывные алгоритмы 221
§ 7.18. Структурная схема 223
§ 7.19. Возможные упрощения 223
§ 7.20. О синтезе оптимальных систем 225
§ 7.21. Применение алгоритмов адаптации . . . 226
§ 7.22. О синтезе оптимальных систем при
наличии помех 228
§ 7.23. Управление и опознавание 229
§ 7.24. Обобщение метода синтеза 231
398
ОГЛАВЛЕНИЕ
§ 7.25. Некоторые задачи 232
§ 7.20. Заключение 234
Глава VIII
Надежность
§ 8.1. Введение 235
§ 8.2. Понятие надежности 235
§ 8.3. Показатели надежности 23G
§ 8.4. Определение показателен надежности 238
§ 8.5. Минимизация эксплуатационных
расходов 241
§ 8.G. Частный случаи 241
§ 8.7. Минимизация стоимости, веса, объема 242
§ 8.8. Алгоритмы минимизации 243
§ 8.9. Особый случай 245
§ 8.10. Алгоритмы 246
§ 8.11. Повышение надежности путем
резервирования 248
§ 8.J2. Повышение надежности путем
избыточности 250
§ 8.13. Проектирование сложных систем . . . 252
§ 8.14. Алгоритмы оптимальной
работоспособности 252
§ 8.15. О минимаксном критерии оптимизации 254
§ 8.1G. Еще о проектировании сложных систем 255
§ 8.17. Замечание 250
§ 8.18. Некоторые задачи 257
§ 8.19. Заключение 257
Глава IX
Исследование операций
§ 9.1. Введение 258
§ 9.2. Планирование запасов 259
§ 9.3. Критерий оптимальности планирования 260
§ 9.4. Алгоритмы оптимального планирования 263
§ 9.5. Еще о планировании запасов 263
§ 9.6. Оптимальное разовое поступление . . 264
§ 9.7. Оптимальный уровень запасов .... 265
§ 9.8. Замечание 267
§ 9.9. Распределение производственных
мощностей 267
§ 9.10. Пример 268
\ 9.11. Распределение средств обнаружения . . 270
§ 9.12. Алгоритмы оптимального распределения 271
§ 9.13. Распределение областей дискретизации 273
§ 9.14. Критерий оптимальности распределения 274
§ 9.15. Алгоритм оптимальных оценок .... 275
§ 9.16. Некоторые задачи 277
§ 9.17. Заключение 278
ОГЛАВЛЕНИЕ 399
Глава X
Игры н автоматы
§ 10. J. Введение 279
§ 10.2. Понятие игры 280
§ 10.3. Теорема о минимаксе 282
§ 10.4. Уравнения оптимальных стратегий . . 283
§ 10.5. Алгоритмы обучения решению игр . . 285
§ 10.G. Игры и линейное программирование 290
§ 10.7. Управление как игра 291
§ 10.8. Алгоритмы управления 292
§ 10.9. Одно обобщение 293
§ 10.10. Пороговые элементы 294
§ 10.11. О пороговой реализуемости логических
функций 295
§ 10.12. Критерий реализуемости 297
§ 10.13. Алгоритмы реализуемости 298
§ 10.14. Персептрои Розенблата 299
§ 10.15. Адалина Уидроу 300
§ 10.1 Г). Обучение порогового элемента .... 301
§ 10.17. Автоматы 304
§ 10.18. Описание конечных автоматов .... 305
§ 10.19. Стохастические конечные автоматы . . 308
§ 10.20. Взаимодействие автомата со средой 309
§ 10.21. О мере целесообразности поведения 311
§ 10.22. Обучение автоматов 312
§ 10.23. О марковских цепях 315
§ 10.24. Марковское обучение 310
§ 10.25. Игры автоматов 318
§ 10.26. Некоторые задачи 318
§ 10.27. Заключение 319
Послесловие 321
Комментарии 324
Литература 347
Указатель основных обозначений 382
Именной указатель 383
Предметный указатель 390
Яков Залманович Цыпки и
Адаптация и обучение
в автоматических системах
М., 1968 г., 400 стр. с илл.
Редактор В. Н. Новосельцев
Техн. редактор П. Ш. Акселърод
Корректоры 3. В. Аетопсева, О. А. Сигал
Сдано в набор 5/Х 1967 г.
Подписано к печати 6/Y 1008 г.
Бумага 84 х 108 1/32.
Физ. печ. л. 12.5. Условн. печ. л. 21.
Уч.-изд. л. 19,84.
Тираж 15 000 экз.
Т-00190. Цепа книги I р. 4 8 к.
Заказ № 1351.
Издательство «Наука»
Главная редакция
физико-математической литературы.
Москва, В-71, Ленинский проспект, 15.
Московская типография Л» 16
Главполиграфпрома Комитета по печати
при Совете Министров СССР
Москва, Трехпрудный пер., 9.