/




































































































































































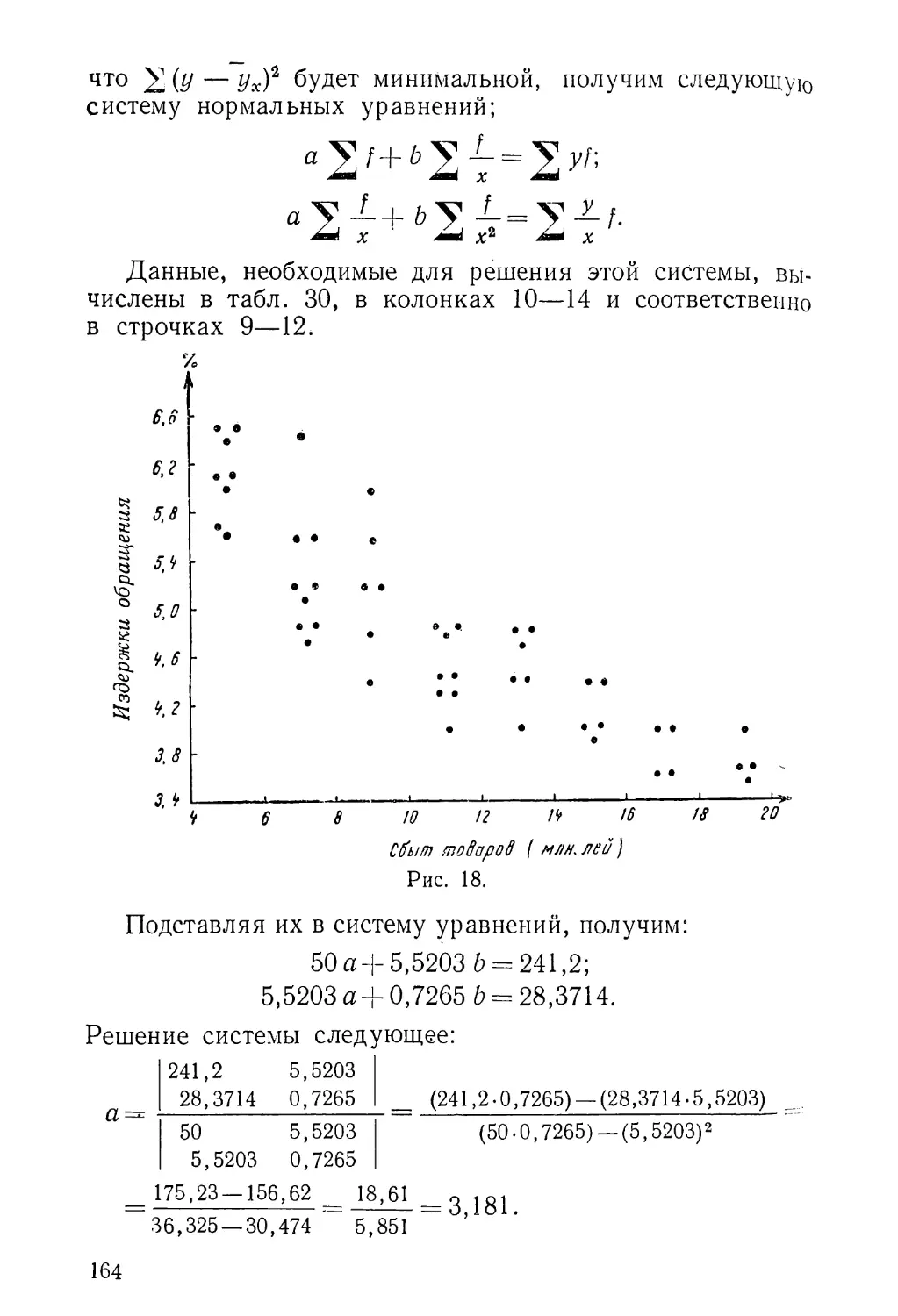
































































Text
Основы
математическое
статистики
и ее применение
И. МАРИНЕСКУ, Ч. МОЙНЯГУ, Р. НИКУЛЕСКУ,
Н. РАНКУ, В. УРСЯНУ
ОСНОВЫ
МАТЕМАТИЧЕСКОЙ
СТАТИСТИНИ
И ЕЕ ПРИМЕНЕНИЕ
Под редакцией В. У PC Я НУ
Перевод с румынского
Л. С. КУЧАЕВА
Статистика
Москва 1970
1. MARINESCU, C. MOINEAGU, R. NICULESCU,
N. RANCU, V. URSEANU
ELEMENTE DE STATIST1CA
MATEMATICA SI APLICAT1ILE El
9 У
sub redac|ia lui
V. URSEANU
1-8-3
42—70
Editura StiiriUfica
ПРЕДИСЛОВИЕ
В условиях большого расширения границ применения
методов современной математики во всех областях науч¬
ного исследования, фундаментальных и прикладных, и в
разрешении практических проблем данного высшего эта¬
па процесса завершения строительства социализма в нашей
стране, первоочередное внимание уделяется математиче¬
ской статистике и ее применению в социально-экономиче¬
ской жизни. Это легко понять, если учитывать тот факт, что
статистическими методами преимущественно пользуются
в подготовке официальных материалов, в разработке основ¬
ных показателей текущего планирования и перспектив
развития экономики и культуры.
Поэтому круг лиц, заинтересованных в знании основ¬
ных идет! математической статистики и ее методов, которые
находят эффективные применения в практической произ¬
водственной деятельности, все более расширяется, охваты¬
вая инженеров, экономистов, техников, работающих в об¬
ласти контроля качества продукции, статистиков и т. д.
Для того чтобы помочь тем категориям исследователей,
которые заинтересованы в знании прикладных сторон ма¬
тематической статистики, авторы стремились в данной ра¬
боте, в пределах сравнительно ограниченного объема, из¬
ложить наиболее общеупотребительные разделы матема¬
тической статистики, делая акцент на экономической ин¬
терпретации результатов, которые можно получить в прак¬
тическом применении.
С этой целью в первую очередь обращено внимание на
проблемы, которые возникают при изучении одномерных
статистических распределений, в тесной связи с соответ¬
ствующими теоретическими распределениями (главы II,
III и IV). Для облегчения понимания аналогии между
этими двумя категориями распределений и для образования
запаса наиболее необходимых знаний для подхода к проб¬
лемам определения теоретических законов распределения
на основе эмпирических данных наблюдения изложение
начинается с определения понятия случайной переменной.
3
Таким образом, сначала излагаются основы теории ве¬
роятностей, на которых базируются методы математической
статистики и их применение. В последующем анализиру¬
ются статистические ряды распределения, а затем анали¬
тические методы их разработки и некоторые критерии со¬
гласия.
Во вторую очередь изучается в нескольких теорети¬
ческих и практических аспектах метод корреляции (главы V,
VIII), имеющий фундаментальное значение для исследо¬
вания статистических связей, проводящихся в широкой
области социально-экономических явлений и процессов.
Затрагивая теоретический и прикладной аспекты этого
метода, мы сосредоточиваемся на проблемах исследования
статистических многомерных распределений. Поэтому оп¬
ределены теоретические понятия векторной случайной
переменной и формулы ее распределения и даны, таким
образом, вводные логические элементы вероятности, не¬
обходимые для общего понимания теоретической области
излагаемых проблем.
Всем перечисленным главам предшествует вводная гла¬
ва, посвященная проблемам общей методологии матема¬
тической статистики, уточнению целей этой дисциплины,
ее основным разделам в классическом и современном по¬
нимании, а также ее отношению к другим областям науки.
Читатели заметят, что в рамках данной работы нет важ¬
ного раздела математической статистики, объектом которого
является выборочный метод. Это «упущение» сделано впол¬
не сознательно, принимая во внимание, с одной стороны,
что такой особенно важный раздел нуждается в обширном
рассмотрении, а с другой стороны, что этот метод в общем
достаточно известен и с успехом применяется в практике,
особенно в контроле качества продукции. Интересующиеся
этим читатели должны обратиться для консультации к спе¬
циальным монографиям, посвященным методу выборки1,
а также к соответствующим разделам специальных работ,
появившихся в последнее время2.
1 См. М. В i j i, I. St oi ch i {• a. «Metoda selectiva in ce-
rcetarea statistic?», Editura Stiintifica, Bucuresti. 1957.
2 Cm. Cih. M i li о с, V. Ursc anu. Matematici aplicatc
in statistic?. Editura Acaderriioi, Bucuresti, 1962; N. R a n c u si
L. T о v i s s i. Analiza statistico-niatematica a calita^ii produse-
lor industrialc. Editura $tiin|ifica, Bucurctsi, 1964.
Глава i
ПРЕДМЕТ И ОСНОВНЫЕ ЗАДАЧИ
МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
§ 1. ПРЕДМЕТ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
И ЕЕ ОТНОШЕНИЕ К ДРУГИМ
СТАТИСТИЧЕСКИМ ДИСЦИПЛИНАМ
Как и теория вероятностей, математическая статистика
является отраслью математических знаний. Она разраба¬
тывает рациональные способы систематизации и анализа
эмпирических данных, предоставляемых наблюдением мас¬
совых явлений, для установления статистических зако¬
номерностей, которые свойственны этим явлениям.
Статистические закономерности охватывают не всю
объективную реальность, однако они существуют и дей¬
ствуют в определенных областях природы и общества. Стро¬
го научное изучение этих закономерностей предполагает
подход на основе метода материалистической диалектики,
с помощью которого получено абстрактное понятие ста¬
тистического коллектива, представляющего собой основ¬
ную категорию теории статистики.
Статистический коллектив и статистическая закономер¬
ность неразрывно связаны друг с другом, отражая явления
и законы, существующие в действительном мире, объек¬
тивно.
Под статистическим коллективом, пли «популяцией»
(последний термин напоминает, что первоначально стати¬
стические приемы применялись в изучении народонасе¬
ления), понимают множество качественно однородных
предметов или явлений1, формирующих на этой основе ан¬
самбль или систему данного типа.
1 Термин явление понимается в его наиболее широком смысле
по отношению не только к единичным элементам коллектива, а и к
многочисленным повторным испытаниям (каким служат, например,
классические схемы Бернулли извлечения шаров из урны или под¬
брасывания монеты), когда каждый результат может быть обуслов¬
лен случайными факторами.
5
Качественная однородность коллектива находит выра¬
жение в том, что его элементарные единицы связаны об¬
щими внутренними свойствами, характеризующими изуча¬
емый тип, несмотря на то что внешне, в аспекте изучаемых
признаков, определенных количественно, эти единицы раз¬
личны, представляют собой, таким образом, кажущуюся
независимость.
Внутреннее, общее и существенное свойство каждого
статистического коллектива обнаруживается как его устой¬
чивая постоянная величина (среднее значение), определя¬
ющая основные закономерности, содержащиеся в движении
его элементов. В общей теории статистики именно эта
устойчивость (закономерность) носит название статисти¬
ческой закономерности (закона) и проявляется, становясь
таким образом познанной, когда число наблюдаемых слу¬
чаев непрерывно возрастает.
Следовательно, не всякое множество предметов или яв¬
лений представляет собой коллектив, или популяцию, в об¬
щем, статистическом смысле этого понятия.
Строгое определение (понятие) статистического коллек¬
тива характеризуется: существованием множества (ан¬
самбля) предметов или явлений того же типа качественно
однородных; проявлением — только в ансамбле коллектива
и только при наблюдении большого числа случаев — оп¬
ределенной устойчивости признаков, подвергнутых изу¬
чению; относительной неустойчивостью (большей или мень¬
шей колеблемостью) изучаемых признаков различных еди¬
ниц коллектива по сравнению с закономерностью ансамбля.
Примеры статистического коллектива могут быть при¬
ведены из многих областей действительности, начиная от
уровня микрокосмоса и кончая человеческим обществом.
Можно видеть, таким образом, статистический коллектив
в ансамбле элементарных частиц со свойствами вполне оп¬
ределенными, в ансамбле клеток живой ткани, в ансамбле
одинакового типа элементов из социально-экономической
жизни (сельскохозяйственные производственные коопе¬
ративы, государственные, сельскохозяйственные предприя¬
тия и т. д.), в ансамбле продуктов промышленности и т. д.
Во всех этих случаях можно говорить о статистическом
коллективе, только если в его пределах проявляется устой¬
чивость, которая была характеризована выше и в отношении
которой индивидуальные вариации изучаемого признака
оказываются случайными.
6
Таким образом, в характеристике статистического кол¬
лектива главное составляет тот факт, что он подчиняется
действию специфических закономерностей особого типа,
объективно существующих в природе и обществе (стати¬
стических закономерностей); все другие свойства стати¬
стического коллектива вытекают из этой его сущности и не
могут быть поняты без отношения к ней.
Изучение статистических коллективов и специфических
закономерностей, которые ими управляют, как раз и об¬
разует содержание общей теории статистического знания.
Какую же роль играет математическая статистика в об¬
щей теории статистического знания?
Математическая статистика, самостоятельная научная
дисциплина, основанная полностью на теории вероятностей,
является по отношению к статистической науке вообще
составным и необходимым элементом, ее специфическим
методом исследования. Как метод она гармонически со¬
четается с общей научной методологией, с интерпретацией
явлений философией диалектического материализма и с
особенными методами специальных отраслей статистиче¬
ской науки, предлагая особую математическую технику
применительно к вероятностному характеру, свойственному
природе исследуемых явлений.
В современном научном исследовании характерно вза¬
имопроникновение различных наук, а также развитие так
называемых пересекающихся и пограничных наук. Это яв¬
ление становится особенно частым и привлекает внимание
в случае, который нас интересует: математическая стати¬
стика, научная дисциплина высокой степени обобщения,
становится методом по отношению к специальным наукам,
в которых она применяется.
Область применения методов математической стати¬
стики обширна и разнообразна, но она не обладает такими
качествами, которые позволяют изучать ее одинаковым
методом, пригодным для исследования всех явлений, не¬
зависимо от того, природное это явление или социальное.
Математическая статистика требует дифференцированного
применения в соответствии со специфическим качеством
изучаемых явлений, применительно к цели открытия кон¬
кретной научной истины, как ее понимает философия диа¬
лектического материализма.
Для статистической методологии, включая математиче¬
скую статистику как ее составную часть, следовательно,
7
имеет большое значение изучение статистических закономер¬
ностей (объективные закономерности с большой степенью
обобщения), онтологический фундамент которых образует
диалектика необходимости и случайности.
Практическая деятельность людей демонстрирует объ¬
ективное существование в природе и обществе как необ¬
ходимости, так и случайности. Вследствие того что общее
проявляется в единичном явлении, а необходимость также
проявляется в неисчислимых случайностях, задачей наук,
в частности статистики, является, посредством широкого
применения теории вероятностей и математической ста¬
тистики, открытие скрытой необходимости, внутренней за¬
кономерности в хаосе кажущихся случайностей.
Ф. Энгельс указывал, впрочем, что случайность не толь¬
ко форма проявления закономерности, но и ее дополне¬
ние: «То, что утверждается как необходимость, слагается
из чистых случайностей, а то, что считается случайным,
представляет собой форму, за которой скрывается необ¬
ходимость, и т. д.»1.
Из материала, составляющего предмет данной работы
и изложенного в ее тесных рамках, явствует специфич¬
ность этих законов и вероятностный характер выводов,
основанных на статистических исследованиях.
Равным образом следует, что всякая статистическая
закономерность проявляется одновременно с действием дру¬
гого объективного закона материального мира, а именно
закона больших чисел. Этот закон, таким образом, является
своего рода «сателлитом» каждой статистической закономер¬
ности, образуя и выражая устойчивость изучаемых яв¬
лений.
Очевидно, что материалистическая диалектика, глубоко
и многосторонне развивая взаимосвязь между необходи¬
мостью и случайностью, переходящими одна в другую, в
процессе развития материи объясняет в свете научного
детерминизма содержание и специфический характер стати¬
стических законов.
Мы видим, что проблема предмета математической ста¬
тистики ведет в сердцевину проблем общей методологии ста¬
тистической науки.
Опыт современных научных исследований в самых раз¬
личных областях науки показывает, что математическая
1 К.Мар кс и Ф. Энгельс. Соч., т. 21, стр. 303.
8
статистика со всей ее вероятностной методологией приме¬
няется непосредственно в изучении разнообразных форм
движения материи, порождая некоторые специальные ста¬
тистики, даже некоторые отрасли теоретических знаний,
обособленные от соответствующих наук.
В некоторых областях физики и механики, особенно в
количественном исследовании вещества, математическая
статистика и статистические методы вообще оказываются
единственным инструментом для изучения законов, которые
управляют движением соответствующих видов материи.
Подобным же образом математико-статистический метод
оказывается плодотворным и в изучении общественных яв¬
лений, образуя вспомогательный математический аппарат
социально-экономической статистики, в тех областях,
в которых специфическое качество изучаемых процессов
и явлений делает возможным и рациональным его при¬
менение.
§ 2. ОСНОВНЫЕ ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Основные задачи математической статистики, вернее
ее типичные задачи, которые встречаются в практике, могут
быть сгруппированы в три большие категории:
а) В первую очередь математическая статистика зани¬
мается решением многочисленных вопросов, которые вы¬
двигаются практической необходимостью установления за¬
конов распределения различных случайных переменных
(или системы случайных переменных) на основе данных,
предоставляемых статистическим наблюдением.
Естественно, что закономерности массовых случайных
явлений выражаются тем более отчетливо, чем больше объем
статистического материала.
В данной работе, как это сказано в предыдущем парагра¬
фе, затрагивается наряду с другими проблемами действие
закона больших чисел как элемента, являющегося компонен¬
том каждой статистической закономерности. Однако на
практике обычно располагают сокращенным объемом дан¬
ных, так что результаты, полученные на их основе, в большей
или меньшей мере находятся под влиянием случайных эле¬
ментов. Следовательно, нужно знать, какие именно черты
наблюдаемых явлений действительно устойчивы, постоян¬
ны и какие из них являются случайными, проявляющимися
благодаря тому, что эмпирические данные наблюдения бе¬
9
рутся не в полном объеме. Для решения этой задачи, есте¬
ственно, необходимо выбрать метод, которым следует поль¬
зоваться в обработке данных. Нужно, чтобы с помощью
этих методов можно было отметить и сохранить типичные
и характерные черты изучаемого явления, элиминировать
второстепенные и несущественные, которые появляются,
как указано, вследствие малого объема отобранных данных.
Набор соответствующих методов, относящихся к технике
систематизации и преобразованию статистических данных,
содержит первую категорию типичных задач, которые ре¬
шает математическая статистика.
б) Во вторую очередь математическая статистика за¬
нимается решением вопросов, которые выдвигает проверка
статистических гипотез.
Эта категория задач тесно связана с предшествующей.
Действительно, поскольку исследователь не располагает
обычно большим объемом данных, он обязан принять оп¬
ределенную гипотезу о характере статистической законо¬
мерности, которая проявляется в исследуемом явлении,
и он ее должен проверить с помощью имеющегося материа¬
ла. Например, он может спросить, подтверждают ли данные;
находящиеся в его распоряжении, гипотезу о том, что ис¬
следуемое явление подчинено закону нормального распре¬
деления и существует ли отношение зависимости между дву¬
мя исследуемыми случайными переменными, а также может
задать другие подобные вопросы.
Методология проверки статистической гипотезы строго
разработана в математической статистике.
в) Наконец, к третьей категории типичных задач, ко¬
торыми занимается математическая статистика, относится
оценка неизвестных параметров различных распределений.
В статистических исследованиях часто существуют до¬
статочные основания для принятия точной гипотезы о ха¬
рактере закона распределения, но из-за того, что данные
наблюдения берутся в ограниченном объеме, уровень ти¬
пичных величин неизвестен.
В этой ситуации применяется специфический метод,
выработанный математической статистикой для оценки сред¬
ней, рассеяния и других типичных величин исследуемого
коллектива, полученных на основе имеющихся данных
сокращенного наблюдения.
Конечно, одновременно с оценкой неизвестных парамет¬
ров ставится и задача определения точности, с которой она
10
делается. Математическая статистика в настоящее время
располагает целым рядом тщательно разработанных ме¬
тодов для решения как общей проблемы оценки, так и точ¬
ности этой оценки.
В этой работе рассматривается также группа некоторых
проблем, которые решаются методами математический ста¬
тистики, и отдельные основные проблемы, относящиеся к
аналитической характеристике одномерных статистических
распределений согласно модели теоретических распреде¬
лений этого типа1.
1 См главу III.
Глава II
СЛУЧАЙНЫЕ ПЕРЕМЕННЫЕ И ЗАКОНЫ
ИХ РАСПРЕДЕЛЕНИЯ
§ 1. ВВОДНЫЕ ПОНЯТИЯ, ОПРЕДЕЛЕНИЯ
Одним из фундаментальных понятий теории вероятно¬
стей, которое находит большое применение также в ста¬
тистике, является понятие случайной переменной.
В этой главе будут даны некоторые уточнения и объяс¬
нения, относящиеся к этому понятию, указаны наиболее
удобные методы, с помощью которых случайные перемен¬
ные могут быть определены в практике, проанализированы
и многосторонне характеризованы.
Случайной переменной называется величина, которая
как результат опыта может принимать некоторые значения,
которые заранее не могут быть предсказаны точно.
Условимся различать случайные переменные дискрет¬
ного типа и непрерывного типа. Возможные значения ди¬
скретной случайной переменной могут быть перечислены
заранее, в отличие от непрерывной случайной переменной,
которая может принимать любые значения в данном ин¬
тервале.
Условимся также в последующем обозначать случайные
переменные большими буквами, а их возможные значения
маленькими буквами.
Например, если обозначить буквой X число попаданий
в мишень в трех испытаниях по стрельбе из какого-либо
оружия, то очевидно, что наша случайная переменная ди¬
скретного типа и может принять значения: — 0 (ни од¬
ного попадания в цель); х2 = 1 (одно-единственное попа¬
дание); х3 = 2 (два попадания); х4 = 3 (три попадания).
Каждое из значений: xif х2, хп случайной переменной X
(число попаданий) является возможным, однако не досто¬
верным. Таким образом, в случае одного испытания из трех
выстрелов, случайная переменная примет одно из этих зна¬
чений с определенной вероятностью, которая обозначается
12
символом Р. Следовательно, будет иметь место одно собы¬
тие из полной системы несовместимых событий
Х = хх
Х = х2 (И.1.1)
Х = хп
каждое с соответствующей вероятностью
Р(Х = х1) = р1; Р (X = х2) = р2; ... Р(Х = хп) = р„.
Ввиду того что несовместимые события (II. 1.1) фор¬
мируют полную систему событий, имеем
п
i=\
т. е. сумма всех возможных значений случайной переменной
равна 1.
Если систему событий обозначить символами Аь А2,
..., Ап, то более строго понятие случайной переменной
можно определить так: величина X, которая, изменяясь
случайно, может принимать с известной вероятностью pt (i =
= 1, 2, ..., п) одно из значений xt(i = 1, 2, ..., п), реали¬
зующих одно из событий А} (I = 1, 2, ..., и) и формирую¬
щих полную систему событий, называется случайной пе¬
ременной.
В практике для случайной переменной пользуются
также терминами случайная вариация или случайный
признак.
Можно привести многочисленные примеры случайных
переменных: число дней в течение недели (при 6 рабочих
днях), когда потребление воды является нормальным (под
нормальным потреблением понимается определенное коли¬
чество литров, расходуемое в24часа); возможные величины
х = 0, 1, 2, 3, 4, 5, 6;
— число вызовов, получаемых центральной автомати¬
ческой телефонной станцией за одну минуту: возможные
величины х = 0, 1, 2, 3, ..., п\
— длительность горения одной электролампы: если га¬
рантируемая минимальная длительность — 500 часов, то
переменная может принимать любое значение, превосходя¬
щее 500;
— вес одного зерна пшеницы, взятого наугад.
13
Первые два примера относятся к переменным дискрет-
ным, а следующие два — к переменным непрерывным.
Понятие случайной переменной играет особенно важ¬
ную роль в математической статистике (полностью обосно¬
ванную теорией вероятностей), а также в ее применении.
В данном случае уместно подчеркнуть, что если в «класси¬
ческой» теории вероятностей основным понятием, которое
служило инструментом научного исследования, было со¬
бытие, то в новейшей теории вероятностей, так же как в
математической статистике, оперируют всегда, когда это
возможно, случайной переменной. Между событиями и
случайными переменными существует, следовательно, ор¬
ганическая связь. В отличие от «схемы возможностей» схе¬
ма случайных переменных более эластична и представляет
собой более универсальное орудие для решения различных
проблем, возникающих в практической производственной
деятельности. Тот факт, что сумма вероятностей всех воз¬
можных значений случайной переменной равна 1, означает,
что эта сумма распределяется каким-либо способом между
этими значениями. С вероятностной точки зрения случай^
ная переменная полностью характеризована, если можно
дать такое распределение, которое указывает с точно¬
стью вероятность каждого из событий (II. 1.1).
Для этого установлен так называемый закон распре¬
деления случайной переменной1.
Итак, под законом распределения понимается соотно¬
шение между возможными значениями случайной перемен¬
ной и корреспондирующими вероятностями. Обычно го¬
ворят, что случайная переменная подчиняется определен¬
ному закону распределения.
§ 2. РАСПРЕДЕЛЕНИЕ ДИСКРЕТНОЙ
СЛУЧАЙНОЙ ПЕРЕМЕННОЙ.
ПОЛИГОН РАСПРЕДЕЛЕНИЯ
Из наиболее простых форм, в которых можно предста¬
вить закон распределения множества значений х2, ..., хп
случайной переменной X и соответствующих, корреспон¬
дирующих им вероятностей р2, ..., рп, одной является
1 Некоторые авторы пользуются термином «закон вероятно¬
сти». Иногда этот закон неточно называют дистрибутивным законом,
14
таблица, которая называется рядом распределения:
хг | хг | х2 | ... | хп .
Pi I Pl I Р2 | ... I Рп
Другой формой выражения закона распределения яв¬
ляется график. На оси абсцисс обозначаются возможные
значения случайной переменной, а на оси ординат — соот¬
ветствующие вероятности; для большей выразительности
полученные точки соединяются посредством отрезков пря¬
мых линий и получается график, называемый полигоном
распределения (рис. 1)
Как ряд распределения, так и полигон распределения
характеризует полный комплект значений дискретной слу
чайной переменной.
Возьмем пример. Предположим, что проведен следую¬
щий опыт: из множества деталей, которые производятся
серийно на машиностроительном заводе, взята наугад одна
Деталь.
Предполагается, что имеет место событие Д, если деталь
окажется бракованной, с вероятностью 0,1. Случайная
переменная X, тесно связанная с этим событием, является
возможным значением А в производимом испытании. Эта
переменная является бивалентной. Если событие А имеет
15
место, то случайная переменная принимает значение 1,
а если оно не имеет места, то случайная переменная при¬
нимает значение 0.
Требуется построить ряд распределения и полигон рас¬
пределения случайной переменной X.
Решение.
Случайная переменная X является бивалентной, ряд
распределения имеет следующий вид:
| 0 I I
Pi | 0,9 I 0,1
Полигон распределения показан на рис. 2.
Если иметь в виду, что pt = Р(Х = xt) при Z = 1,2,..., п,
то тогда можно сказать с аналитической точки зрения, что
закон распределения случай-
/7 ной переменной X, выражаю¬
Рис. 2.
щий вероятность того, что
случайная переменная примет
определенное значение х,
является функцией этого зна¬
чения.
Р (Х = х) = f (х) при
х = х1, х2, ..., хп. (II.2.1)
Функция f(x)y будучи ве¬
роятностью, имеет неотрица¬
тельное значение
f(x)>0 (II.2.2)
Вследствие того, что при осуществлении одного из собы¬
тий Ль А2, Ап (которые образуют полную систему со¬
бытий) случайная переменная X принимает одно из зна¬
чений хь х2, хПу следует равенство
f Ui) + f (*г) + ... + / (хп) = 2 f (*г) = 1 • (П.2.3)
X
В целом выполняется условие (II.2.2) и (П.2.3).
16
С з. РАСПРЕДЕЛЕНИЕ непрерывной
СЛУЧАЙНОЙ ПЕРЕМЕННОЙ.
ФУНКЦИЯ РАСПРЕДЕЛЕНИЯ
Мы могли легко убедиться, что для дискретной случай¬
ной переменной закон распределения служит средством
полной характеристики.
Этого нельзя сказать о непрерывной случайной перемен¬
ной. Очевидно, что подобную переменную нельзя харак¬
теризовать законом распределения, представленным в фор¬
ме ряда или полигона распределения. Действительно, не¬
прерывная случайная переменная имеет бесконечное мно¬
жество значений и как таковая представляет собой ряд рас¬
пределения, в котором невозможно выделить каждое от¬
дельное значение с соответствующей вероятностью. Впро¬
чем, как увидим позднее, вероятность каждого значения
непрерывной переменной равна нулю.
Все же определенные области вариаций возможных зна¬
чений случайной переменной не являются равновероят¬
ными. Следовательно, и в случае непрерывной случайной
переменной существует определенное распределение ве¬
роятностей. Однако это понятие в данном случае приобре¬
тает иной смысл. Для количественной характеристики этого
распределения вероятностей пользуются не вероятностью
события X = х,а вероятностью события X <Д х, где X —
некоторая непрерывная переменная.
Вероятность этого события, зависящая от х, является
функцией х. Эта функция называется функцией распреде¬
ления случайной переменной X и обозначается F (х):
F(x) = P(X<x) (П.3.1)
С вероятностной точки зрения функция распределения
полностью характеризует случайную переменную, без¬
различно, идет ли речь о дискретной или непрерывной
случайной переменной. Она, следовательно, является также
формой закона распределения.
Функция распределения обладает некоторыми важными
свойствами:
1. Функция распределения является функцией неубы¬
вающей; если х2 > Xi, то тогда F(x2) > ^(xi). Тот же
результат следует из факта, что вероятность является не¬
отрицательной, т. е.
ТДх2) —F(xx)>0 (II.3.2)
2 Зак. 1050
17
или
F (x'2) > F (xj при x2 > л\.
2. Для наименьшего возможного значения случайной
переменной (—оо ) функция распределения равна нулю;
F(—оо) = 0. (II.3.3)
На самом деле получить событие X < — оо невозмож¬
но и, следовательно,
F(—oo) = F(X< — оо) = 0.
3. Для наибольшего возможного значения случайной
переменной! (+ оо) функция распределения равна 1.
Действительно, достоверным событием является то,
что случайная переменная при одном испытании принимает
одно из значений, только чуть меньше, чем наибольшее
из них.
F (+оо)-Р(Х < оо)= 1. (П.3.4)
4. Функция распределения, являющаяся вероятностью,
удовлетворяет двойному неравенству
0<F(x)<l. (II.3.5)
5. Вероятность, что случайная переменная X содержит¬
ся между Xi и х2 (хг х2), равна разности значений функ¬
ций распределения на концах интервала, т. е. приращению
функции в рассматриваемом интервале:
Р (хх < X < х2) - F (x2) — F (хх). (П.3.6)
Это отношение легко доказывается.
Если символом Ai обозначить событие X х2, симво¬
лами А2 — событие X <Z Xi, а символами А3 — событие
Xi < X <Д х2, то на основе того, что известно из теории ве¬
роятностей, и ввиду того, что А[ = А2 U Л3, а события
Л 2 и А3 несовместимы, можно написать:
р (лх) = Р (Л2 и лз) = Р (Л2) + р (А3),
или
Р(Х<х2)- Р(Х<х1) + Р(х1 Х<х2),
или
F (х9) = F (х,) + Р (хх < X < хе),
(Я
показывающий функцию чер-
утверждение, что вероятность
1—ЗН
1 1
1
1
1
1
1
1
Г"' >1 1
1
1
1—I 1
—1 1 1 1—
1
—1
откуда следует:
P(xl<X<x2)-F(^2)-F(%1).
функция распределения дискретной случайной перемен¬
ной представляет график,
точками. В каждой из то¬
чек на горизонтальной
оси, представляющих воз¬
можные значения случай
ной переменной, функцией
распределения допускает¬
ся точка прерывности, как
на рис. 3.
График
пределения
ременной
типа показан на рис. 4, на
котором функция имеет в
качестве асимптоты пря¬
мые F(x) = 0 и F(x) = 1.
Выше антиципировано
определенных индивидуальных значений непрерывной слу¬
чайной переменной равна нулю.
функции рас-
случайной пе¬
непрерывного
Действительно, воспользуемся отношением Р (а
С X < Р) ~ F (Р)—F (а) и, полагая, что р стремится к а,
получим
Р (X == а) = lim Р (а < X < Р) = lim [F (а) —F (Р)] -0.
p-а я-* а
2*
19
При случайной переменной непрерывного типа, следо¬
вательно, имеет смысл определение вероятности того, что
переменная содержится в данном интервале1.
§ 4. ПЛОТНОСТЬ РАСПРЕДЕЛЕНИЯ
Рассмотрим случайную переменную X с непрерывной
и дифференцируемой функцией распределения F(x) и вы¬
числим вероятность того, что эта переменная заключена в
интервале (х, х + Дх), т. е.
P(x<z X < х + Дх) = F (х-]- &х) — F(x).
Относя эту вероятность к длине интервала, получим
среднюю вероятность длины интервала, а если интер¬
вал Дх будет все больше уменьшаться, стремясь к нулю, то
получим предел, производную функции распределения:
lim WM-fOO = F'(x). (И.4.1)
А^О Дх
Введем отношение
/(x) = F'(x). (II.4.2)
Функция Дх), первая производная функции распре¬
деления, является значением некоторой характеристики
плотности, с которой распределятся значения случайной
переменной в данной точке; она называется плотностью
распределения (или плотностью вероятности) непрерывной
случайной переменной X.
1 Факт, что индивидуальное значение непрерывной случайной
переменной возможно, хотя вероятность его равна нулю, не следует
рассматривать как парадокс, а нужно интерпретировать в опре¬
деленном смысле. Если производится эксперимент, в продолжение
которого теоретически непрерывная случайная переменная прини¬
мает одно из своих возможных значений, то тогда до проведения
эксперимента следует рассматривать как нулевую вероятность осу¬
ществления каждого из этих значений; однако согласно эксперимен¬
ту наша случайная переменная необходимым образом принимает
одно из своих возможных значений, что означает, что имело место
событие, вероятность которого рассматривалась как равная нулю.
Следовательно, утверждение, что вероятность события Х = а равна
нулю нужно понимать в том смысле, что при неограниченном числе
экспериментов осуществление этого события будет крайне редким
(одним из бесконечно малого числа случаев). Действительно, это
выражается одной из знаменитых теорем, излагающих объективный
закон больших чисел (теорема Бернулли) в том смысле, что частота
событий при большом числе испытаний не равна вероятности, а
приближается к этой теоретической величине вероятности.
20
Понятие плотности распределения становится более яс¬
ным, если интерпретируется с помощью терминов механики;
в этой интерпретации функция /(х) точно характеризует
плотность по оси абсцисс (так называемая линейная плот¬
ность). Кривая, которая иллюстрирует плотность рас¬
пределения, называется кривой распределения.
Как и функция распределения, плотность распределения
является одной из форм закона распределения. Очевидно,
что плотность распределения не является общим законом;
никакая непрерывная случайная переменная с ней не сов¬
падает.
Из дифференциального исчисления известно, что если
элементарный интервала dx достаточно мал, то имеет место
приблизительное равенство
F (х + Ах) — F (х)^ f (х) dx.
Интерпретируя пробабилистически, будем говорить, что
вероятность как случайная переменная, значение которой
принадлежит интервалу (х, х + Ах), приблизительно равна
произведению плотности распределения в точке х на дли¬
ну Ах элементарного интервала.
Очевидно, что плотность распределения может быть вы¬
ражена через функцию распределения (11.4.2), но можно
поставить и обратную задачу, а именно: выразить функцию
распределения через плотность распределения.
Из определения функции распределения следует, что
X
F(x) = ^f(x) dx + С, где С является константой. Также
—ос
можно показать, что С = 0, полагая что X стремится
к —оо и учитывая свойство 3 функции распределения. Сле¬
довательно,
F(x) = f(x)dx. (II.4.3)
— оо
Из отношения (11.4.3) следует такая теорема: вероят¬
ность того, что непрерывная случайная переменная X при¬
нимает значение, находящееся в интервале (а, Р), равна
интегралу плотности распределения в интервале (а, Р).
Таким образом,
3
Р(а < X < Р) = JJ / (х) dx. (II.4.4)
а
21
Эта теорема может быть доказана, если написать прежде
всего равенство
Р (а < X < Р) - Р (а < X <|3) - р (а < X < Р) =
= Р(а<Х<0),
(II.4.5)
которое следует из того, что вероятность как определенное
значение, принимаемое непрерывной случайной перемен¬
ной, равна нулю.
Итак, из (И.4.3), а также из (11.4.5) следует:
P(a<X<P) = F (0)-F(a);
сообразно с отношением (11.4.3) получим:
0 а 0
F(p)— F(a)^ f(x)dx— f (х) dx (х) dx.
—оо —оо а
Тем самым теорема (11.4.4) доказана.
Эта теорема может быть интерпретирована и геомет¬
рически.
Вероятность того, что непрерывная случайная перемен¬
ная X примет значение, находящееся в интервале (а, Р),
равна площади криволинейной трапеции, ограниченной
осью х, кривой плотности распределения /(%) и прямыми
х = а и х = р (см. рис. 5).
Резюмируя, можно сказать, что характерными свой¬
ствами плотности распределения являются следующие:
1. f(x) > О
22
(плотность распределения неотрицательна, что следует
из того свойства функции распределения, что она неубыва¬
ющая);
-j-oo
2. f (х) dx = 1
—оо
(интеграл плотности распределения в границах области
бесконечных вариаций непрерывной случайной переменной
равен единице). Это свойство плотности распределения
следует непосредственно из свойства функции распределе¬
ния F(x = + оо) = 1 и из формулы (II.4.3).
Пример. Средняя продолжительность жизни определеи-
ного типа радиоламп в часах
имеет следующую плотность
распределения:
f(x) =.
' 100
если х > 100;
■ х2 ’
. о,
если х < 100.
Вычислить:
а) вероятность того, что лампа не будет заменена в пер¬
вые 150 часов функционирования;
б) вероятность того, что из трех ламп одного радиоприем¬
ника не будет заменена ни одна лампа в течение 150 часов
функционирования и
в) определить вероятность того, что лампа не будет функ¬
ционировать более 300 часов, если известно, что в большин¬
стве случаев лампа функционирует 200 часов.
Решение1.
а) Вероятность того, что лампа должна функционировать
более 150 часов, равна:
оо оо
m>150)= (' — =
,) Ji" L х Jibo ISO 3
150 150 Л’т
б) Пусть символы Л, В, С обозначают события, соответ¬
ствующие тому, что 3 лампы функционируют более 150 ча¬
сов. Вероятностью их будет
Р(Л) = Р(В) = Р(С) = |.
1 Здесь предполагается, что читатель знает классические тео¬
ремы вычисления вероятностей.
23
События Д, В, С являются независимыми, а вероят
костью их одновременного осуществления будет:
Р(А ПВПС) = Р(Д)-Р(В)-Р(С)=:А.
в) Пусть символ А означает, что лампа функционируй]
более 200 часов, а символ В, что она функционирует не¬
сколько менее 300 часов. Событие А является условие*
события В. Получим:
Рв (Л)-= Рх<зоо (X > 200)
Р (200 < X < 3
Р (X < 300)
300
г 100
) ~dx Г-100 poo
100 100
200 L х J200
300 200
§ 5. ДЕЙСТВИЯ С ДИСКРЕТНЫМИ
СЛУЧАЙНЫМИ ПЕРЕМЕННЫМИ.
ПОНЯТИЕ НЕЗАВИСИМОСТИ
а) Степень k порядка случайной переменной X являет¬
ся случайной переменной Xk с распределением
/у k yk yk
%k. Л1 Л2 * • ’ ’ Лп
'\Р1 Р2 •••• Рп
Если а является действительным числом, то произве¬
дение а и X является случайной переменной аХ с распре¬
делением
ахг ах2 ... ахп\
Р1 Р2- Рп/
б) Сум$а двух случайных переменных. Когда рассматри¬
ваются две или несколько совместных случайных перемен¬
ных, мы имеем дело с системой случайных переменных.
Пусть X и Y — случайные переменные, которые распре¬
деляются следующим образом:
у . /-^1 -^2 • • * \ pj Y • / У1 ’ У11 \
\Р1 Р2 ••• Рт / W1 Чп/
24
откуда
т п
ZPt=l и 2^=1.
1 = 1 i = 1
Сумма этих двух случайных переменных является слу¬
чайной переменной, которая имеет следующее распре¬
деление:
х + у. М14-У1, *1 + У1, •••> XiVh
\ Р11> Р12> •••’ РИ> Ртп /
в котором Pij представляет собой вероятность события,
что переменная X принимает значение xt, а переменная Y
принимает значение yjt т. е.
Pij = P(X = xi) Y = yj).
Из определения распределения суммы случайных пере¬
менных следует:
Pll + P12+--- + Pij+ ••• + Рштг = 5 PiJ=l-
i = 1 / = 1
п
Исследуем случай 2 Рц\ это выражение представляет
/= 1
собой сумму вероятностей всех событий формы (Х = хь
Y = yj), в которой показатель i является одинаковым,
а 1, 2, п.
События
(X = xt1 Y = y])- (X = xh Y = y^...(X = xi. Y = yn)
несовместимы два по два, а сумма
2 РЦ = Pzl + Pz2 ••• + Pin
/= 1
представляет собой вероятность, полученную из числа п
событий.
Каждое из полученных чисел, обозначающих осущест¬
вление одного из событий X = xt, соединяется с одним
из событий Y = y1, Y = y2, Y = yn.
Таким образом, вероятность осуществления одног© из
событий
(X--=xt, Y = yj), у—1,2, ...,/г
25
равна вероятности события X — xh т. е.
Pu = Pn + Piz + ••• +Pin -^ Pi' (11.5.1)
/ = 1
Аналогичным образом можно показать, что
2 Р и ' Ри + Рм -I- • • • + Pmj = Pi- (II -5.2)
i = \
в) Произведение двух случайных переменных. Произве¬
дением двух дискретных случайных переменных является
случайная переменная, которая имеет следующее рас¬
пределение:
xi7i> %i р2> •••» У ь •••> щ 5 д)
Р11> Р12» •••> Pij, •••> Ртп /
откуда
tn п
5 2^=1, a /^ = Р(Х = х{) У = ь).
i=l /-1
Естественно, можно спросить, существует ли какая-
либо связь между вероятностями р2, ..., рт и вероят¬
ностями qlt q2, qn.
Ответ в общем является положительным, но связь между
|этими вероятностями не всегда простая. Случай, когда
существует очень простая связь, это тот, в котором пере-
I менные X и Y независимы.
i Переменные X и Y называются независимыми, если
I при любом i и / 1 < i m, 1 < / < n, события (X=--Xi) и
| (У = уi) являются независимыми и, таким образом,
P(X = xit У = у,) = Р (Х = х;)-Р (У = у>);
следовательно,
PiJ = Pi Qj*
! Таким же образом можно определить сумму и произве¬
дение нескольких случайных переменных. Понятие неза-
I висимости может быть определено точно так же для любого
числа случайных переменных.
26
6 ТИПИЧНЫЕ ВЕЛИЧИНЫ ДИСКРЕТНОЙ
СЛУЧАЙНОЙ ПЕРЕМЕННОЙ
Средняя величина дискретной случайной переменной.
Случайная переменная может характеризоваться, как
указано, посредством ее распределения. Часто, однако,
распределение переменной неизвестно. В этих случаях для
характеристики случайной переменной можно использо¬
вать некоторые показатели, которые называют типичными
величинами, ассоциированными со случайной переменной.
Пользование типичными величинами иногда очень по¬
лезно, если даже распределение переменных не известно.
Среди наиболее полезных типичных- величин важное место
занимает средняя величина (математическое ожидание).
По определению средняя величина (кратко — средняя)
случайной переменной X с распределением
х/Х1Х2...Хп\
\ Р1 рг ••• Pj
равна сумме произведений ее возможных значений и коррес¬
пондирующих вероятностей. Следовательно, если обозна¬
чить среднюю X символом т =- 7И(Х), то по определению
имеем
m = M(X')^=x1p1 + x2p„+... + хпрп= У,х1Р1. (II.6.1)
i= 1
Например, если существует распределение X
х./3 5 2 \
’ ^0,1 0,4 0,5/
то тогда,
М (X)- 3-0,1 + 5-0,4-1-2-0,5 = 3,3
Пример. Рассмотрим бивалентную случайную перемен¬
ную X, а именно: число появлений события А в одном эк¬
сперименте. Если событие А имеет место, то случайная пе¬
ременная принимает величину лц = 1 с вероятностью р.
Если событие А не имеет места, то случайная переменная
принимает величину х2 = 0 с вероятностью q = 1 — р.
В этом случае средняя величина случайной переменной
следующая:
М(Х)= 1 -p + 0-q^-p.
27
Следовательно, средняя числа появлений некоторого со.
бытия в эксперименте равна вероятности этого события,
В дальнейшем будем исходить из этого положения.
Теперь, предвосхищая материалы, излагаемые в главе
III, посвященной эмпирическому распределению, уместно
уточнить связь, которая существует между средней ве-
личиной некоторой случайной переменной X (категория,
с которой мы встречаемся в теории вероятностей) и средней
арифметической наблюдаемых величин X в т эксперимен¬
тах, с которой мы встречаемся в математической статистике
и в различных областях науки.
Предположим, что в т экспериментах переменная X
принимает mi раз значение хр, т2 раз — значение х2, ...; тп
раз значение хп, так что mi + т2 + ... + тп = т. Сумма
всех значений, принимаемых X, равна:
х1т1 + х2т2 + ... +хп тп.
Для того чтобы получить среднюю арифметическую
величину значений х, принимаемых X, нужно полученную
сумму разделить на общее число испытаний.
Получим таким образом:
%1 Ш1 4~ *2 т2 • Ч~ *71 тП
т
или
Х = х1 —Ч-х2 --2 + ... +хп^- (П.6.2)
т т т
Можно заметить, что — является относительной часто-
т
„ по о
той значения х<\ — является относительной частотой зна-
чения х2 и т. д. Если число испытаний т велико, то отно¬
сительная частота сближается с вероятностью (к этому мы
еще возвратимся, когда будем заниматься теоремой закона
больших чисел).
т1
т
Р1>
т
Рп
Заменяя в (11.6.2) относительную частоту корреспон¬
дирующими вероятностями, получим приближенное ра¬
венство:
X « Ху рх + х2 р2 + ... + хп рп,
т. е.
ХжМ(Х).
28
Следовательно, среднее значение случайной перемен¬
ной X приближенно равно средней арифметической наблю¬
даемых значении X.
Свойства средних.
1. Средняя некоторой константы а равна а
М (а) = а.
Действительно, константу а можно рассматривать как
дискретную случайную переменную, которая принимает
единственное значение с вероятностью 1.
Следовательно,
М (а) = а -1 = а.
2. Средняя произведения константы а и случайной пере¬
менной X равна произведению а и средней из X.
/И(аХ) = шИ(Х).
Оказывается, что случайная переменная аХ имеет рас¬
пределение
ах± ах2 ... ахп
Pi Р2 ••• Рп
Следовательно,
М (аХ) = ах± рг 4- ах2 р2 + ••• + ахп Рп =
= а(х1р1 + х2р2+„. + хп рп) = аМ (X).
3. Среднее значение сумм двух случайных переменных
в системе равно сумме средних этих случайных перемен¬
ных.
В § 5 показано, что сумма двух случайных переменных
в системе имеет распределение
X-\-Y • + + •••Л4г+Уп\
\ Pll Р12 PiJ Ртп /
Средней величиной согласно определению является
(X 4-У) — (хх4- yj Рп 4- (*i + У2) Рп + • • • + (%i + Уп) Pin +
+ (Х2 4' У1) Р21 + (х2 + У2) Р22 + • • • + (х2 + Уп) Р2П +
29
4 ■ -1- У1) Р„ч 4- (xnl + у.,) plll2-\-... I - (x,n -I - yn) pmn =
= [X1 (Pll "1“ P12 + • • • + Pin) + X2 (P21 + P22 + • • ■ + Pin) 4~ •••
4" Xm (Pml 4" Pin2 4“ •• • "i_ Pmn)l 4“ lУ1 (Pll 4“ P21 4* • • • 4” Pml) 4
4-Уг (РхгЧ-РггЧ- ••• 4-pm2)4- ••• 4~ Уп (Pin + Ptn 4~ ••• 4"Pmn)] =
tn n tn n n m
= 22 2 2 2 2 p.>+2 у>2^
i=l f=\ i=\ j=l i=\ j = l /=1 i=l
Принимая во внимание, что
2^- = p< и 2pm = <7>>
/=1 1=1
получим
tn n
м (X+Y) = 2 xi Pi + 2 = M W + M (y)-
i=\ i=\
Вообще средняя величина сумм некоторого конечного
числа случайных переменных равна сумме средних величин
каждой переменной:
м (X. -I- х2 +... + Хп) = М (XJ+м (Х2) + ...+М (X J.
Пример. Найти среднее число очков, полученных при
выбрасывании двух игральных костей. Обозначим симво¬
лом X число очков, полученных выбрасыванием первой
кости, а символом Y — число очков, полученных при вы¬
брасывании второй кости.
Поскольку X и Y являются случайными переменными,
которые могут принимать значения 1, 2, 3, 4, 5 и 6 каждое
с вероятностью 1/6, если кости гомогенны, то значения Л
и Y имеют каждое следующее распределение:
1 2 3
4 5 6
11 ч
6 6 6 /
/111
\ 6 6 6
Следовательно,
7И(Х)-Л1(У)-
12... 2 ’- |
G 6
4 14-45 4 <4 1
6 6 С) 6 2
■М (Х)4-Л1(И-^ + ^- = 7.
' зо
4. Средняя величина произведения двух независимых
случайных переменных в системе равна произведению сред¬
них величин.
Известно,что распределением произведения двух слу¬
чайных переменных является
MiVi ЧУ2 ••• •••
\ Р11 Р12 ••• PiJ Рпп /
и что если переменные независимы, то pij = piqi и сред¬
ней величиной их произведения является
M(XY) = Xjy2p12+ ..■ + х1упр1п +
+ Х2 У1 Р21 + Х2 У 2 Р22 Н' • • • + Х2 Уп р2п +
+ Хт У1 Рт1 + Хт У2 Рп2 + ’ • • + Хт Уп Ртп =
= Х1 У1 Р1Р1 + Х1 У2 Р1 Ч2+ • • • + Х1 Уп Pl Рп +
+ Х2 УХ Р2Р1 + Х2 У2 Р2 73 + • - + Х2 Уп Р2 Рп
х»г У1 Pm Pl + Хт У2 Рт <?2 + • • • + хт Уп РтРп =
= xiPi<yiPi+ У2Р2 + - + Уп<7п) +
+ Х2 р2 (У1 Pl + У2Р2 + "- + Уп7п) +
+ XmPm(yiPl-\- У2Р2 + - + УпЯп) =
= +1 У1 + хгРг + ■■■~УХт Ут) (У1 71 + Уг 7г+ ••• + Уп Рп) —
— М (X)M(Y).
Вообще, для любого числа независимых случайных пе-
ременных получим
М (X. Х2... Хп) =М (XJ, М (Х2)... М (Хп),
что является доказательством через индукцию.
Дисперсия дискретной случайной переменной
Часто в практике мы встречаемся со случайными пере¬
менными, которые, имея равные средние, отличаются рас¬
пределением. Например, случайные переменные X и Y
Со следующими распределениями:
х./~ 0,1 о,1\ к / —1000 1000\
’ 0,5 0,5/ ’ 0,5 0,5/
31
имеют равные средние
М(х)-—0,1-0,5-|-0,1-0,5-0;
7И (у) — — 1 000-0,5-|- 1 000-0,5 — 0.
Однако заметно, что величины X немного отличаются от их
средней, тогда как величины у очень сильно отличаются от
их средней.
Из этого примера видно, что средняя не является доста¬
точной для характеристики рассеяния значений случайной
переменной.
Другая типичная величина, называемая дисперсией,
предназначена для характеристики этого рассеяния.
Пусть X случайная переменная, а М (X) ее средняя.
Рассмотрим случайную переменную X — М(Х), которая
носит название отклонение от средней (кратко — откло¬
нение). Отклонения имеют распределение
х_м (Х): р-М (X) х2-М (X). . . хп-М (Х)\
’ \ Pl Pi Рп ' ’
и можно видеть, что
М[Х-М(Х)] = [х1-М(Х)]р1 + ... + [хп-Л4(Х)]рп =
= х1р1 + х2р2+ ... + хп рп — М (X) (р1 + р2 + ... -I-рп) =
= Л4 (X) —М (X) = 0.
Этот результат указывает, что средняя величина откло¬
нений, являющаяся нулевой, не может быть использована
для измерения рассеяния величин случайной переменной.
По этой причине как мерой рассеяния случайной перемен¬
ной по отношению к средней пользуются дисперсией, ко¬
торую мы будем обозначать символом D2(X) и которая по
определению является средним квадратом отклонений
(X - М(Х)):
О2(Х) = Л1[Х —М(Х)]2.
Следовательно,
£)2(Х) = [хг —7W(X)]2pj + (X)]2pn. (II.6.3)
Учитывая свойства средней получим:
D2 (X) = М [X2 —2ХМ (X) + Л42 (X)] ==
= М (X2) — 2М (X) М (X) + М2 (X) =
= 7И (X2) — 2/И(Х) + Л12(Х) = М(Х2)—М2(Х). (II.6.4)
32
Другими словами', дисперсии некоторой случайной пере¬
менной представляет собой разность между средним квад¬
ратом случайной переменной и квадратом средней случай¬
ной переменной.
В начале этого параграфа при вычислении средней слу¬
чайной переменной X с распределением
'3 5 2 \
0,1 0,4 0,5/
МЫ получили Л4(Х) = 3,3.
Для вычисления дисперсии X отметим, что X2 имеет
следующее распределение:
X2:f 9 25 4 ;
^0,1 0,4 0,5/
следовательно,
Л4(Х2) = 9-0,Ц- 25-0,44-4-0,5= 12,9;
D2 (X) = Л4(Х2) — М2(Х) = 12,9 — 3,32 = 2,01
Свойства дисперсии
1. Дисперсия константы а равна нулю:
D2 (а) = 0.
Это свойство интуитивно очевидно, потому что констант¬
ная величина не имеет рассеяния.
2. Дисперсия произведения константы и случайной
переменной X равна произведению квадрата константы на
Дисперсию X:
О2 (aX) = a2D2 (X).
3. Дисперсия суммы двух случайных независимых пе¬
ременных равна сумме дисперсий этих двух случайных пе¬
ременных:
D2 (X + Y) = D2 (X) + D2 (Y).
Из этих двух свойств следуют два следствия:
Следствие 1. Дисперсия суммы независимых случайных
переменных равна сумме дисперсий случайных переменных:
(X, + Х2 + ... + Х„) = D2 (Хх) + D2 (Х2) 4-... + £)2 (Хп).
3
Зак. 1050
33
Следствие 2. Дисперсия суммы константы а и случайно^
переменной X равна дисперсии X:
D2 (a + X) = D2 (X).
Среднее квадратическое отклонение
Корень квадратный из дисперсии случайной перемен,
ной X называется средним квадратическим отклонением
случайной переменной:
Из следствия 1 третьего свойства дисперсии вытекает,
что среднее квадратическое отклонение суммы независимых
переменных равно корню квадратному из суммы квадратов
средних квадратических отклонений случайной перемен¬
ной.
В отличие от дисперсии среднее квадратическое откло¬
нение выражается в таких же единицах измерения, как и
случайная переменная.
Типичные величины высшего порядка дискретной случайной
переменной (моменты)
Знание типичных величин высшего порядка случайной
переменной часто полезно в разрешении практических за¬
дач. Мы имеем в виду моменты случайной переменной.
Существует три вида моментов: моменты начальные, мо¬
менты центральные и моменты условные.
Моментом начальным k порядка случайной перемен¬
ной X является средняя случайной переменной Xk
в частности,
С4 = Л4(Х);
а2 = /И(Х2).
Пользуясь этим моментом, формулу вычисления диспер*
сии можно написать так:
D2 (X) = М (Х2)—М2 (X) = «. — а,. (II.6.5)
Центральный момент случайной переменной X полу¬
чается, если принять во внимание отклонение X — М(Х)>
34
Моментом центральным k порядка случайной пере¬
менной X является средняя случайной переменной [Х =
= Л4(Х)Г
= М [X-М(Х)]«.
В частности, известно, что
Р! = М[Х — М(Х)]==0
[iz=M [Х-М(Х)]2 = D2(X). (П.6.6)
Отношение между этими двумя видами моментов легко
вывести. Например, сравнивая (II.6.5) с (П.6.6), получим
р,-а, — а2.
Подобным образом, используя свойства средней и учи¬
тывая определения моментов, находим формулы:
Нз = аз —3ctiGt2 + 2(x3;
р4 = а4 — 4а3а1 + 6а2а^ — За*.
Если рассматривать отклонение от выбранной произволь¬
ной величины, то мы получим непосредственно условный
момент по формуле
\k = M[X — a\k,
полезность которой станет ясной при изложении эмпири¬
ческих распределений.
§ 7. ОПРЕДЕЛЕНИЕ ТИПИЧНЫХ ВЕЛИЧИН
НЕПРЕРЫВНОЙ СЛУЧАЙНОЙ ПЕРЕМЕННОЙ.
ТИПИЧНЫЕ ВЕЛИЧИНЫ ПОЛОЖЕНИЯ
1. Рассмотрим случайную переменную X непрерыв¬
ного типа, которая принимает значения в интервале (а, Ь)
и имеет плотность распределения /(х). Что нужно сделать
Д^я определения средней X?
Разделим интервал (а, Ь) на п частичных интервалов,
Длину которых обозначим Дхц, Дх2, Дхп. Выделим в каж¬
дом частичном интервале по одной точке и абсциссы выбран¬
ных точек обозначим хц, х2, ..., хп. Способ определения
средней дискретной случайной переменной приводит к
рассмотрению суммы:
х4 f (xj Дхд 4- х2 f (х2) Д х2 + ... 4- xn f (хп) Дхп.
3*
35
Напомним, что произведение f(x)Ax приближенно равно
вероятности случайной переменной X как ее значению,
принадлежащему интервалу (х, х + Ах). Переходя к пре¬
делу, когда длина отрезков стремится к нулю, получим
определенный интеграл:
ь
[ xf(x)dx. (II.7.1)
и
а
Умозаключая из вышеизложенного, мы приходим к
следующему определению: средней непрерывной случайной
переменной, которая принимает значения в интервале (а, Ь)
и имеет плотность распределения f(x), является определен¬
ный интеграл от а до b произведения xf(x):
ь
М(Х) = {xf(x)dx.
а
По аналогии с определением дисперсии дискретной слу¬
чайной переменной дисперсия непрерывной случайной
переменной X является средним квадратом отклонения X.
ь
D2(X) = (* [x—M(X)]2f(x)dx. (11.7.2)
а
Подобным образом начальный момент k порядка дается
выражением
ь
ak = j xk f (x) dx. (II.7.3)
a
Центральный момент fe-порядка будет выражаться фор¬
мулой:
ь
Hil-=^(x—M(X)]kf(x)dx. (11.7.4)
а
Таким образом свойства средней и дисперсии (и вообще
свойства моментов) дискретных случайных переменных со¬
храняются в непрерывных случайных переменных.
2. Кроме средней оценки, которая характеризует по¬
ложение случайной переменной на ее оси, показывая ориен¬
тировочно центральную величину, около которой группи¬
руются все возможные значения переменной, в статистике
36
пользуются еще двумя типичными величинами положения:
модой и медианой.
Под модой (/Ио) понимается наиболее вероятное (для
дискретных переменных) значение случайной переменной,
или значение, плотность распределения которого максималь¬
на (для непрерывных величин).
Если полигон распределения (кривая распределения)
имеет два или несколько максимумов, то распределение
называется многомодальным.
Существуют распределения, которые регистрируют так¬
же величины с минимальной вероятностью этих двух край¬
ностей; эти распределения называются антимодальными.
Медиана также является типичной случайной перемен¬
ной, которая вычисляется преимущественно для непрерыв¬
ных случайных переменных, хотя формально она может быть
вычислена и для дискретной переменной.
Медиана Me случайной переменной X является тем ее
значением, для которого имеем равенство
Р(Х<Ме) = Р(Х>Ме).
С точки зрения геометрической медиана является аб¬
сциссой точки, в которой площадь, ограниченная кривой
распределения, делится на две равные части. В случаях
симметричного распределения имеет место равенство
М (X) = Мо = Me.
§ 8. КЛАССИЧЕСКИЕ ЗАКОНЫ ДИСКРЕТНОГО
И НЕПРЕРЫВНОГО РАСПРЕДЕЛЕНИЯ
Биномиальное распределение
Предположим, что производится п независимых испы¬
таний согласно схеме Бернулли извлечения шаров из урны1.
В каждом из испытаний вероятность осуществления не¬
которого события А является константой и равна р (сле¬
довательно, вероятность, что А не осуществится, равна
122 ~рУ
Под урной Бернулли понимается урна, которая содержит
шары нескольких цветов. Извлекая из этой урны п шаров, каждый
ШаР кладут обратно в урну (схема возвращенного шара). Вероят¬
ность того, что будет извлечен шар данной окраски, постоянна.
37
Очевидно, что число осуществлений события А в п испы¬
таниях образует случайную переменную Х(п). Значения,
которые может принять эта случайная переменная, равны
О, 1,2, ..., п. Действительно, событие А может никогда не
осуществиться или может осуществиться один раз, два
раза, ..., п раз в п испытаниях.
В определении вероятных значений Хп находит при¬
менение формула Бернулли, которая дает вероятное осу¬
ществление k раз события А в п независимых испытаниях:
Pn(k)--=C*pkqn~k. (II.8.1)
Таким образом, видно, что выражение (II.8.1) можно рас¬
сматривать как общий член развития бинома Ньютона:
/ I ~\п Л1 X* I 1 tl— 1 п— (п— 1) |
(p+q) ~Спр q +Сп р 7 -|-...
I I I Л'0 О 0
+ Спр q -\-...-\~Спр q
Первый член этого развития указывает возможность-
того, что Хп примет значение п (событие А осуществится п
раз в и независимых испытаниях), второй член С^~Х рп~{ q
указывает вероятность того, что Хп примет значение
п— 1, ... и последний член qtl показывает вероятность
того, что Хп примет значение 0.
Следовательно, распределение Хп следующее:
п ... и— 1 ... k ... 0
р пр q Сп р q q
Этот закон распределения называется биномиальным.
Справедливость этого названия объяснена выше.
Для биномиального распределения средняя величина
и дисперсия даются отношением:
т М (X) = 2 kC*p,lqn-,e = пр (II.8.2)
1<=0
D2 (X) = npq. (П.8.3)
Теоремы (II.8.2) и (П.8.3) демонстрируют полезность
третьего свойства средних величин случайной переменной,
а также первого следствия третьего свойства дисперсии,
формулированных выше.
38
Пример. Решим следующую задачу.
Число рабочих дней с нормальным потреблением воды
на промышленном предприятии является случайной пе¬
ременной X. Известно, что вероятность события А, когда
отмечается нормальное потребление воды, составляет р =
=3/4, а вероятность противоположного события q = 1/4,
очевидно, что р + q = 1 •
а) показать закон распределения переменной X;
б) вычислить вероятность того, что потребление воды
будет нормальным по крайней мере 3 дня;
в) вычислить вероятность того, что это потребление бу¬
дет продолжаться от 1 до 5 дней включительно;
г) вычислить среднюю арифметическую, дисперсию и
среднее квадратическое отклонение случайной переменной.
Решение
а) Пользуясь формулой Бернулли, получим искомое
биномиальное распределение.
Принимая во внимание, что случайная переменная X
в 6 дней недели (п = 6) может принять значение = О
(ни в один день недели не зарегистрировано нормальное
потребление воды) с вероятностью CgP°76; х2 = 1 (только
за один день зарегистрировано нормальное потребление)
с вероятностью C\p'q*', ...; х7 = 6 (во все дни недели за¬
регистрировано нормальное потребление воды) с вероят¬
ностью Сер67°, можно написать следующее распределение:
Зная распределение числа дней недели, в которые по¬
требление воды нормально, можно разрешить остальные
аспекты задачи.
39
б) На основе правила сложения вероятностей получим;
Р (X > 3) = Р (X = 3) Ч- р (X - 4) 4- р (X = 5) ч- Р (X = 6) =
— 540 I 1215 | 22L •
~ 4 096 ' 4 096 ' 4 096 Г 4 096 ’
в) Вероятностью того, что нормальное потребление будет
продолжаться от 1 до 5 дней в неделю, является:
Р (1 <X<5) = Р (X = 1)4- Р (X = 2)4-Р (X = 3)4-
4- Р (X = 4) 4- Р (X = 5) = — 4- — 4~ — 4-
V V 7 4 096 4 096 4 096
, 1 215 ; 1 458 _ 3 366 .
' 4 096 1 4 096 “ 4 096 ’
г) Средняя случайной переменной X дается отношением
2 /гС£рУ‘-* = пр = 6-- = 4,5,
/г = 0 4
а дисперсия и среднее квадратическое отклонение следую¬
щим отношением:
D2 (X) = npq = 6 - . Т = 1,125;
4 4
D (X) - УТ^/ - |ZTJ25 - 1,06.
Биномиальное распределение является дискретным ти¬
пом распределения.
Распределение гипергеометрическое (по урновой схеме не-
возвращенного шара Бернулли)
Из коллектива, состоящего из N элементов, из которых а
обладают качеством А, а остальные N — а им не обладают,
извлекается последовательно п элементов без возврата в
коллектив изучаемого элемента или извлекаются все п
элементов сразу.
Вероятность того, что число k из этих п извлеченных
элементов характеризуется свойством Л, можно вычислить
с помощью следующей формулы:
— k
Pr2k)(П.8.4)
где /е = 0, 1,2,..., п.
40
Можно доказать, что средняя величина и дисперсия
случайной переменной, которая следует гипергеометриче¬
скому закону распределения, являются следующими:
М(Х) = 2 k
k = Q
/->k — k
LN-a
(II.8.5)
М~п
N — 1
N — fi
N — 1
(II.8.6)
Из сравнения распределения случайных переменных,
которые следуют законам биномиального и гипергеомет¬
рического распределения, видно, что на практике более
удобно действовать по схеме невозвращенного шара, по¬
тому что дисперсия в этом случае будет наименьшей.
Пример. Из партии в 200 деталей, среди которых 26
с дефектами, извлекается последовательно наугад 10 де¬
талей без возврата каждой извлеченной детали в партию.
Необходимо:
а) проанализировать возможность появления k деталей
с дефектами после эксперимента;
б) вычислить среднюю арифметическую и дисперсию числа
дефектных деталей.
Имеется:
— полный коллектив деталей N = 200
— дефектные детали а = 26
— случайная переменная X — число дефектных дета¬
лей— может принять следующие значения: ki — 0;
^2 — 1, ..., fen = 10.
Решение.
а) Соответствующие вероятности определяются на ос¬
нове общей формулы
Ло (^) —
n — k
N — а
pk p\ 0 —k
g26 g174
rn
10
200
6 = 0, 1, 10;
c
6) M(X) = np=10— =1,3;
D2 (X) = npq
N—n
N — 1
10- —
200
41
Распределение Пуассона
Предположим, согласно биномиальному распределен
нию, что при проведении п независимых испытаний (шар
возвращается в урну) вероятность события А константна
и равна р.
Для определения вероятности того, что в п испытаниях
событие А осуществится k раз, воспользуемся формулой
(II.8.1) Бернулли.
Однако, если величина п очень большая, можно приме¬
нить асимптотическую формулу Лапласа:
J_ Цг-пр)2
2 npq
Все же применение этой формулы не ведет к достаточ¬
ному приближению, если вероятность р мала (р <: 0,1).
В этих случаях (величина п большая, а р маленькая), т. е.
в случаях, когда мы сталкиваемся с событиями редкими,
применяется асимптотическая формула Пуассона для вы¬
ражения закона распределения соответствующей случай¬
ной переменной.
Для получения этой формулы требуется допустить, что
произведение пр сохраняет константную величину X,
т. е. (пр = Х), а это означает, что средняя величина числа
случаев осуществления события А в различных сериях
испытаний (для различных величин /г) остается неизменной.
На основе формулы Бернулли запишем:
Рп (/г) = Cknpk qn~k = n(*-l)(n-2)...[n_(fe-l)] pk (l_q)n-k.
k\
поскольку пр = к, то имеем Р = ~ и, следовательно,
pn(k)
_ п(п—1) (п — 2) ... [п (k—1)]
~ kl
Заметим, что lim Рп (k) = Р (k, X);
гг->оо
п / \ п '
получим:
42
оо оо
У Р(£;Х) = v
/г —О /г — О
Однако
lim 1 = е_л и lim 1 =1
п->оо \ П /г ->оо \ П J
следовательно, согласно этому получим:
Р(/г; %) = (11.8.7)
/1—>оо /Л
Этим выражением мы определили закон распределения
Пуассона, в котором целым величинам х = О, 1, /г со¬
ответствуют вероятности Р(/г; X).
В форме таблицы закон Пуассона можно написать
так:
О 1 2 ... т
е~к... хе~к... — е~'-... —
2! т\
Очевидно, что
— е~А^е~А > — — е~АеА—1.
/г! k\
/г = 0
Распределение Пуассона применяется тогда, когда
большое число объектов распределено однообразно на
большой площади. Условия однообразия важны для полу¬
чения ценных результатов. Если, например, изучается рас¬
пределение личинок насекомого на культивируемой пло¬
щади, то нельзя применить распределение Пуассона, по¬
тому что распределение личинок не однообразно. Действи¬
тельно, известно, что насекомые откладывают яички не на
всей площади, а только в определенных благоприятных
местах.
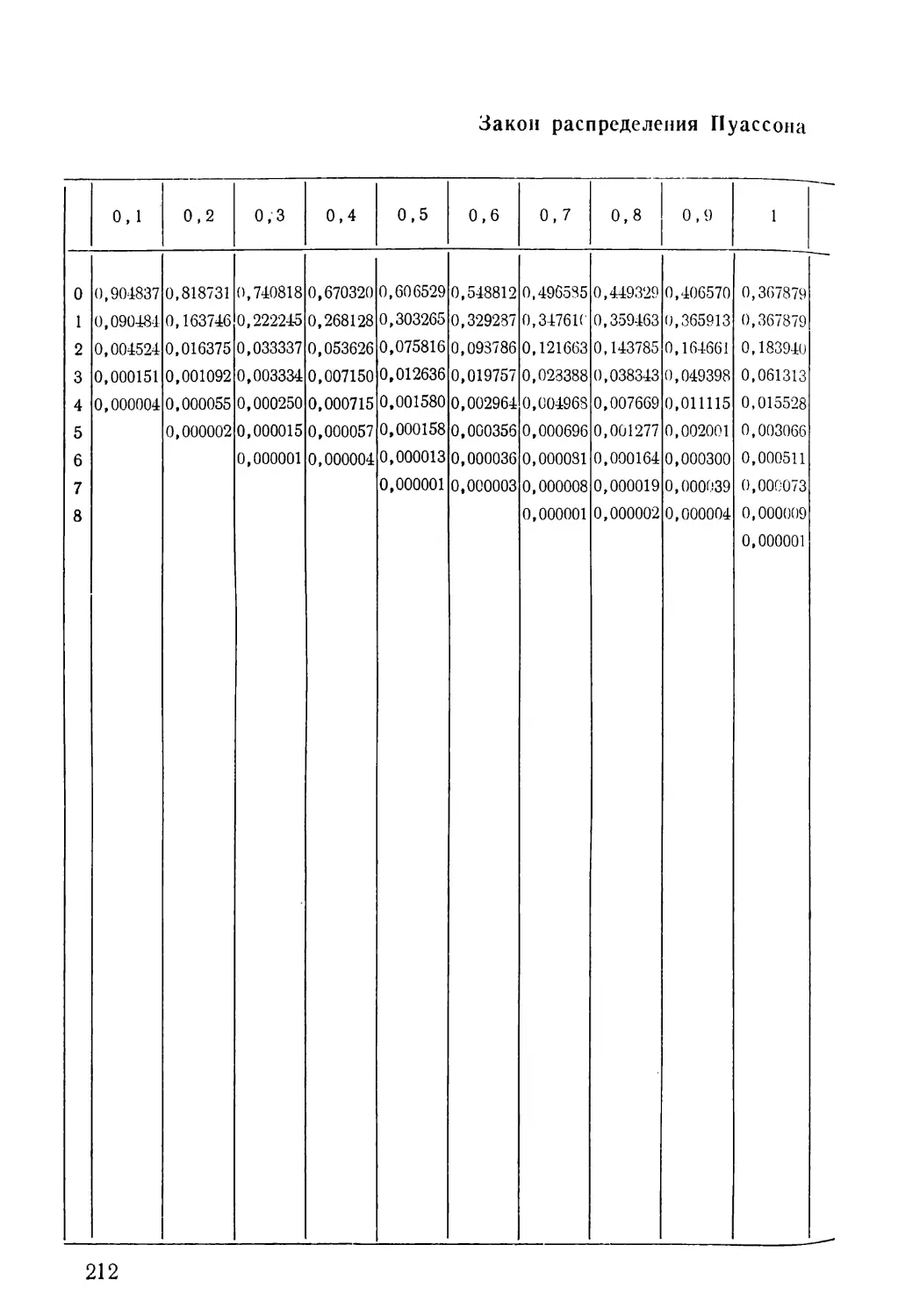
Для вычисления вероятности Р(&; X) составляется таб¬
лица значений параметров X, заключенных между О, 1
и 20. Другая таблица дает величины вероятности того, что
событие осуществится по крайней мере k раз; следовательно,
Р(Х>/г)= V 4
/г-0
Для тех же величин параметра.
43
Средняя величина и дисперсия переменной, которая
следует этому распределению, определяются по формула^
W) = =
k = 0
Они констатируют, что средняя и дисперсия распре-
деления Пуассона действительно равны параметрам рас¬
пределения.
Пример. В периоды «пик» центральная телефонная стаи-
ция принимает в среднем 900 вызовов в час. Зная, что стан¬
ция может сделать 25 соединений в минуту, вычислить ве¬
роятность того, что станция может не сделать соединения
в течение минуты.
Среднее число вызовов, которое принимает централь¬
ная станция в течение одной минуты, следующее:
Х= — = 15.
60
Закон распределения случайной переменной, которая пред¬
ставляет число вызовов, является, таким образом, следую¬
щим:
Р(к;К) = ^ е~'5; 6 = 0,1, 2
Для того чтобы на центральной телефонной станции было
невозможно сделать соединение в течение одной минуты,
нужно, чтобы нагрузка была больше 25 случаев. Следо¬
вательно, вероятность того, что центральная телефонная
станция не может сделать соединения, будет следующей:
°° 1
P(k>26)--= У — е-15 = 0,006.
Л^26 fel
Нормальное распределение
Закон нормального распределения, называемый обычно
законом Гаусса, является фундаментальным в теории ве¬
роятностей и в ее применении. Это распределение наиболее
часто встречается в изучении природных и социально-эко¬
номических явлений. Принципиальная особенность этого
закона в отношении к другим законам распределения со-
44
гоит в том, что он является законом предела, к которому
стремятся все другие законы распределения в определен¬
ных типичных условиях.
Закон нормального распределения является типом не¬
прерывного распределения и имеет следующую плотность
распределения:
Z(%)Z7Z>a>_± с • (II.8.8)
с (■ 2л
График функции f(x, т, о) называется нормальной кри¬
вой (кривая Гаусса) с параметрами пг и о.
Рис. 6.
Нормальные кривые имеют несколько общих свойств:
а) всякая нормальная кривая достигает точки максимума
(х = tri) и убывает непрерывно вправо и влево от него,
постепенно приближаясь к оси абсцисс;
б) всякая нормальная кривая симметрична по отноше¬
нию к прямой, параллельной оси ординат, проходящей че¬
рез точку максимума х = т; максимальная ордината рав¬
на —!_:-
2л’
в) всякая нормальная кривая имеет форму колокола,
обладает выпуклостью, направленной вверх, около точки
максимума. В точках т — о и гп + а она изменяет выпук¬
лость и, чем меньше о, тем острее колокол, а чем больше о,
тем больше колокол сплющивается.
Изменение т (величина о остается неизменной) не вы¬
зывает модификации формы кривой.
45
Рис. 7 иллюстрирует три нормальные кривые (I, р
и III), имеющие величину т = 0 и различные дисперсии
Кривая I соответствует большей величине о, а кривая
III—малой величине дисперсии.
Чтобы выяснить смысл параметров т и ст из выражение
11.8.8 нормального закона, докажем, что параметр т я в.
ляется не чем другим, как средней величиной, а пара¬
метр о — средним квадратическим отклонением случайной
переменной X.
Предположим, что случайная переменная X имеет плот¬
ность вероятности т; о)1; вычислим среднюю и диспер¬
сию:
+ OG -1-эо _ (х-ш)2
М (X) = 1 xf (x) dx = х —е 2°2 dx =
J J ар 2л
— оо — оо
1 (-V-»г)г
= —хе 2°2 dx.
а"|/2я J
— оо
Подставим переменную у=Х Q m , откуда x-=C)yXnt\
dx = o dy.
1 Можно сказать, что величина X является нормальной с па¬
раметрами т, о или что она принадлежит к классу N(m, о).
46
Оставим пределы интегрирования теми же самыми
и получим:
+ °о
— оо
__ Z1
т) е 2 dy =
--со — оо
(II.8.9)
Первый интеграл в правой части равенства является
нулевым, поскольку интегрируемая функция нечетная,
а пределы интегрирования симметричны по отношению к
началу; второй интеграл является известным интегралом
Эйлера — Пуассона и может быть доказан так:
V0 _ У2
J е 2 dy = V2л.
— сю
Следовательно,
М (X) = т,
т. е. параметр т представляет собой среднюю величину
случайной переменной X (в некоторых случаях применения
его можно назвать центром рассеяния).
Дисперсия случайной переменной X дается следующим
выражением:
D2(X) = J [х— Л4 (Х)]2/(х, т, о) dx =
— сю
_ (v~
~ j (х— т)2 е 2j2 dx.
— оо
(II.8.10)
Подставим опять переменную у = -——
dx = Gdy, получим
х = оу 4- т;
ста2
а У 2 л
-|- оо
— оо
-1-00
а2 f
■ж J у-уе
— оо
D2 (Х) =
47
и, интегрируя по частям, имея в виду, что и — у)
__ 21
уе 2 dy = dv, находим:
D-(X)-(J2, D(X)-a.
Таким образом, параметры т, о нормального закона
имеют простую вероятностную интерпретацию.
Из этого следует, что функция распределения нормаль»
ной переменной совершенно детерминирована средней и
дисперсией переменной.
Можно показать, что вероятность нормальной перемен¬
ной X с параметрами пг и ст, принимающими в интервале
значения (лд, х2), дается выражением
Р (лд < X < х2) =
X 2
Хх
(х — т)2
dx.
(II.8.11)
Если подставить переменную у = х т х = (5 у-\-т-
v х-.—т
и помнить, что для X~xr, имеем: у~--^—, а для
Х = х2 имеем у = --^, то получим
Р (х, < X < х2) =
а
а У2л
х2 — т
а у2
У е 2 dy=
xt —т
а
/ Л'о — т
А'!—/72 \
1 г Т -
)/ 2л 1 i 6
\ —сю
2 dy —
- 5 е 2 dy ■
— оо /
Если принять во внимание функцию нормального
распределения, называемую функцией Лапласа, с пара¬
метрами 0 и 1, и обозначить ее Ф(х),
X
ф(х)= | f(y, o,l)dy
— оо
48
тогда можно написать в другой форме вероятность как
случайную переменную X, заключенную в некотором ин¬
тервале:
Р(х1<Х<^) = Ф(^)-Ф^т) ■ (П-8.12)
Из этой формулы можно вывести и вероятность как от¬
клонение случайной переменной X — т, которая удов¬
летворяет неравенству |Х — т\ < а, потому что она эк¬
вивалентна двойному неравенству
— а < X— т < а
или
Итак, применяя формулу (II.8.12), получим
Р(\Х — m | < а) = Р (—а + т<Х<а + /п) =
Легко убедиться, что
ф(_%) = 1—ф(х)
и что, следовательно,
Р(|Х—/7г|<а) = 2Ф( — V1. (II.8.13)
\ а /
Из этой формулы следует очень важное правило, извест¬
ное под названием правила трех сигм. Если случайная пе¬
ременная X распределена нормально, то тогда, практи¬
чески говоря, ее отклонения по абсолютной величине не
превосходят тройной величины среднего квадратического
отклонения.
Действительно, если примем, например, что а = 36,
и применим формулу (11.8.13), то получим
Р (| X—т | < Зо) = 2Ф (3) — 1
и при значении функции Лапласа Ф(3)=0,9987 (см. прило¬
жение 1) находим
Р (| X — т | < Зо) = 2 • 0,9987 —1 =0,9974.
Зак. 1050
49
Это значит, другими словами, что можно утверждать
с вероятностью очень малой (1—0,9974—0,0026), что аб¬
солютная величина отклонения рассматриваемой случайной
переменной превзойдет интервал, равный Зо.
Пример. Отклонение диаметра деталей, изготовленных
на автоматическом токарном станке, от стандартного диа-
метра следует закону нормального распределения со сред¬
ней 15 мм и средним квадратическим отклонением 5 мм.
Определить вероятность того, что диаметр деталей ^удет
иметь отклонение между 5 и 25 мм.
Распределение переменной X следующее:
25 _ ±
f (х; 15; 5) = —fe 2 v 5 / dx-(— оо <дх < оо).
5 V 2л J
5
Искомой вероятностью будет:
Р (5<Х<25)
1
5 У 2 л
25 1_ /х — 1 5\ 2
е 2 5 ' dx = Ф
5
25—15
5
2Ф(2) находим по таблице (см. приложение 1).
Другие классические законы непрерывного распределения
Закон распределения х2
В решении многих практических задач встречается сум¬
ма квадратов нормированной независимой случайной пе¬
ременной со средней 0 и средним квадратическим откло¬
нением о. Пусть X2 + Х% + ... +Х2 — сумма подобных
переменных, которую обозначим символом у — х2 (читает¬
ся «хи-квадрат»).
В теории вероятностей доказывается, что эта сумма,
рассматриваемая как случайная переменная, характеризует-
50
ся следующей плотностью распределения:
1 А_!
— у 2 е 2°2 при
при
У >0;
у<0.
О
Эта плотноть распределения определяется функци¬
ей распределения %2 с параметрами s, о и обозначается сим¬
волом #($, о).
Параметр s называется числом степеней свободы, под
которым понимается число независимых переменных, ва¬
риации которых не подвергаются никаким ограничениям.
Например, если рассматривать переменную X, которая
может принимать значения xif х2, х3, ..., xs с вероятностя¬
ми pit р2, •••> ps» составляющими полную систему событий,
то мы будем иметь распределения с числом s значений ком¬
понентов и если знаем вероятность s — 1, то можем найти
и последнюю. Это случай одной переменной с s — 1 степенями
свободы.
Для законов распределения H(s, о) с определенным чис¬
лом степеней свободы построена таблица чисел.
На приведенном графике (рис. 8) представлены законы
распределения H(s, о) при s = 2, s = 4, s = 6, s = 15.
Замечено, что в тех случаях, когда величина s возрастает,
закон вероятности /7(s, о) имеет тенденцию приближения
к нормальному закону.
Средняя величина и дисперсия переменной %2 следующие:
M(X2) = m = so2;
D (X2) - 2so4.
1 В этом выражении появляется функция Г(х), где величина
+оо
х>0 и определяется отношением Г (х) = е~z tx~l dt. Функция
о
удовлетворяет функциональному равенству Г (х + 1) ~х Г (х).
п — целое число, то Г (/г + 1) = n I Можно доказать, что
4*
51
Таблица, построенная К. Пирсоном для этого распреде.
ления, дает вероятность
оо
Р(Х2>Х2) = J f(y)dy = q.
Эта вероятность геометрически представляет собой предел
площади, ограниченной кривой вправо от ординаты по аб¬
сциссе (см. рис. 9).
Для q = 0,95 и s — 20 (степени свободы) находим в
приложении 3 х2о,95 =10,851. Следовательно, вправо от
ординаты точки х2о,95 = 10,851 площадь под кривой рас¬
пределения равна 0,95.
Примечание. Функцию распределения %2 можно получить
следующим обр азом.
Пусть дискретная случайная переменная X с распре¬
делением
*1*2, *п
Р1Ръ> •••> Рп
является результатом т независимых экспериментов.
Предположим, что в этих т экспериментах рассматри¬
ваемая случайная переменная принимает раз значе¬
ние хг, т2 раз — значение х2, тп раз — значения
так что m2+ тп = т.
52
Это указывает, что функция распределения случайной
переменной
(mx — mpi)2 . (т2 — тр2)2 (тп — трп)2
трг тр2 ‘ трп
стремится к функции распределения %2 с параметрами
s п — 1 и о = 1, когда т ->■ оо. Это свойство имеет очень
широкое применение. Закон распределения %2 был открыт
астрономом Гельмертом (F. R. Helmert) в 1876 г. и был
надлежащим образом оценен только спустя 30 лет К. Пир¬
соном.
Распределение Стьюдента1
Если имеются две независимые случайные переменные X
и Y (первая нормальная с параметрами 0, о, а вторая яв¬
ляется функцией распределения %2 с параметрами s, о),
то функция распределения случайной переменной
ЕЕ
S
называется функцией распределения Стьюдента с s степе¬
нями свободы.
Плотность ее распределения выражается формулой
1 Ст моде нт — псевдоним английского математика У. Госсета.
Заметим, что этот закон распределения не зависит от 0
В математической статистике функция распределен^
Стьюдента имеет особенно важное значение для теории
выборки.
Средняя и дисперсия случайной переменной X, которая
является функцией распределения Стьюдента с s степенями
свободы, следующие:
М (X) = 0;
D2 (X) = •
Когда s -> оо, то функция распределения переменной
X
стремится к функции Лапласа Ф (х).
График f(t) является симметричным по отношению к
оси ординат и асимптотическим с осью абсцисс. Кривая
подобна нормальной, по мере того как величина (/) возрД'
стает, кривая приближается к оси абсцисс, однако более
медленно, чем в случае нормального распределения.
Функция распределения Стьюдента следующая:
t
§ f(x,s)dx.
— оо
54
Примечание. Для сравнения различных распределений
с нормальным пользуются двумя типичными величинами,
которые называются: асимметрия и эксцесс.
Асимметрия определяется отношением:
(М2
а эксцесс у2 определяется из равенства
Т2 = ^_3.
р2
§ 9. ЗАКОН БОЛЬШИХ ЧИСЕЛ
Общие замечания
Вероятность — это не теоретическая величина, оторван¬
ная от реальности, а действительная связь относительной
частоты явлений, так как установлено, что при повторении
испытаний в идентичных условиях частоты группируются
около вероятности р, которая является объективной кон¬
стантой, зависящей от природы рассматриваемых явле¬
ний и идентичных условий, в которых имеют место испы¬
тания.
Многие массовые явления, природные и социально-
экономические, происходят с определенной правильностью,
с так называемой статистической устойчивостью, которая
обнаруживается с очевидностью с тем большей силой,
чем больше число элементов, составляющих изучаемое
явление.
Например, выбрасывая игральную кость, мы наблю¬
даем, что между числом случаев появления определенных
сторон кости и общим числом выбрасываний существует
правильное отношение, составляющее приблизительно 1/6
и представляющее величину теоретически константную,
объективную, оправдывающую вероятность р появления
одной из граней кости.
Основу этой вероятности составляет как раз регуляр¬
ность, статистическая устойчивость или статистическая
55
закономерность. Статистическая закономерность не может
быть доказана; она представляет собой факт, установленный
экспериментально, постулат, которым пользуются как в
практическом применении, так и в экспериментальных
следованиях.
«Законы» теоретической вероятности формулируются
посредством абстрагирования этих реальных статистиче¬
ских закономерностей, свойственных массовым случайным
явлениям. Независимо от области действительности, в ко¬
торой проявляются статистические закономерности, сущ¬
ность их сводится к следующему: конкретные особенности
каждого случайного явления почти не влияют на средний
уровень массы явлений этого вида; случайные отклонения
от средней, свойственные индивидуальным элементам мас¬
сового явления, взаимно компенсируются, нивелируются.
Именно эта устойчивость средних представляет собой ма¬
териальное содержание всякой статистической закономер¬
ности и проявляется в форме так называемого закона боль¬
ших чисел в наиболее общем значении этого понятия.
При большом числе индивидуальных стохастических
событий их средний результат, практически говоря, почти’
не является случайным и может быть предусмотрен с боль¬
шой степенью статистической определенности.
В смысле более узком понятие закона больших чисел
относится к группе теорем теории вероятностей, каждая из
которых в определенных условиях устанавливает стрем¬
ление средних величин в испытаниях «к вероятности'», к
некоторой вполне определенной константе (и которая более
не является случайной).
Закон больших чисел играет важную роль в практиче¬
ском применении теории вероятностей. Отдельные случай¬
ные переменные в определенных условиях становятся как
бы неслучайными, делая возможным предвидение их раз¬
вития практически с полной определенностью. В этом на¬
ходит выражение интересный аспект диалектико-материа¬
листического детерминизма — детерминизм статистический.
Неравенство Чебышева. Теорема Чебышева. Теорема Бер¬
нулли. Теорема Пуассона
Изложим перечисленные теоремы без строгого дока¬
зательства с точки зрения математической.
Неравенство Чебышева позволяет оценить вероятность
56
отклонения на заранее данную величину а при условии,
что известна дисперсия случайной переменной X.
Неравенство Чебышева выражается одной из следующих
формул:
Р (IX-М (х) I >а) < ^-) (II.9.1)
а2
ИЛИ
Р(\Х— М(Х)\>а) > I— Ш . (II.9.2)
а2
Вторая форма неравенства Чебышева дает возможность
определить вероятность того, что абсолютная величина
ошибки средней будет меньше числа а, определяющего
нижний предел.
Поскольку неравенство |Х — 7И(Х) | <а эквивалент¬
но двойному неравенству М(Х) —а < X < /И(Х) + а,
это неравенство дает низшую границу вероятности того, что
переменная X заключается в интервале
[М(Х) —а, М(Х) + а].
Вычисление результатов этого неравенства является
иногда грубым, но оно все же может быть непосредственно
использовано в практике.
Обычно а выражается в единицах, одинаковых с О(Х),
т. е. принимается, что а = KD(X)-, тогда неравенство Чебы¬
шева становится следующим:
Pf|X-M(X)|<W(X)]>l-l-. (II.9.3)
Например, для k = 3 получим
P(|X — M(X)|<3D(X)]> 1—1 = 0,888.
Этот результат говорит, что если произвести большое
число серий испытаний по 100 испытаний каждая, напри¬
мер Ю00 серий, то по крайней мере в 888 из них событие А
(Осуществится в границах
М (X) — 3D (X) и M(X)-\-3D (X).
Пример 1. Рассмотрим как случайную переменную X
внутренний диаметр стальных колец, производимых ма¬
шиной.
-57
Установлено, что /14(X) = 10 см и £)(Х) = 0,2 см. Ве¬
роятность того, что величина диаметра (X) будет находить¬
ся между 9,5 см и 10,5 см, будет следующей:
Р(| X—101 <0,5) > 1-^> 1-2124 0>84.
1 0,52 0,25
Следовательно, с вероятностью по крайней мере 0,84
переменная X заключается между 9,5 и 10,5.
В действительности эта вероятность (предполагаем, что
диаметр колец следует нормальному распределению) равна:
Р (9,5 < X < 10,5) = Ф
/10,5 —10 \ ф/9,5 —10\
к 0,2 / 0,2 /
2. Вычислить вероятность того, что отклонение перемен¬
ной X, которое имеет распределение
/5%
15%
25%
35%
45%
у. U
6
4
2
1
\ 20
20
20
20
20
будет меньше, чем а
= 15.
Так как т = 17% и о2 *= D2(X) ц2 = 107,5, то полу¬
чим
Р(| Х-17|)<15> 1 -12L2 = O,54.
Следовательно, можно утверждать с вероятностю 0,54,
что отклонение от средней будет меньше чем 15.
Вероятность того, что отклонение будет меньше чем 15,
эквивалентна вероятности того, что расхождение с нормой
заключается в границах между 2% и 32%.
Теорема Чебышева. Рассмотрим ряд п случайных пере¬
менных (дискретных или непрерывных) Х4, Х2, ... Хп, ди¬
сперсия которых менее константы С. Теорема Чебышева
утверждает, что при любом позитивном числе е вероятность
неравенства
I Хг + X. + ...+Xn _ М(Х1)+М(Х2) + ..-+М(Хп) I < &
I п п \
58
а < в
стремится к 1, если число п случайных переменных стре¬
мится к бесконечности.
Примечание. Часто в практике, если независимые слу¬
чайные переменные Х2, Хп имеют среднюю а и
дисперсию меньшую, чем константа С, то вероятность не¬
равенства
I п
стремится к 1, если число п случайных переменных стре¬
мится к бесконечности. Это частный случай теоремы Чебы¬
шева.
В сущности теорема Чебышева выражает следующую
научную истину: несмотря на то что случайные переменные
могут принимать различные значения, отличающиеся от
средних, средняя арифметическая некоторого достаточно
большого числа этих случайных переменных принимает
с большой вероятностью значение, свойственное некоторому
константному числу, а именно:
M(X1)+M(zX2) + ...+M(Xn)
и
(или а в частном случае, когда все переменные имеют эту
среднюю а).
В результате этого в исследованиях различных случай¬
ных явлений мы не можем предвидеть значения, которые
примет каждое из них, однако с вероятностью очень боль¬
шой можно предвидеть значение, которое примет средняя
арифметическая.
Следовательно, в силу теоремы Чебышева можно сде¬
лать следующее заключение: средняя арифметическая не¬
которого достаточно большого числа случайных перемен¬
ных (имеющих ограниченную дисперсию) теряет характер
случайной переменной.
В решении практических вопросов теорема Чебышева
имеет большое значение, например, если известно, что для
определения некоторой физической величины делается
много измерений и затем вычисляется их средняя арифме¬
тическая, которая берется в качестве приближенной оцен¬
ки измеряемых величин.
Таким образом, если результат различных измерений
Дает k независимых случайных переменных Х2, ..., Хп
59
(подписные значки показывают порядковые номера изме-
рения) с распределением
/ У1 У 2 ••• Ут^
\р'\ р2 ... Рт>
(поскольку измерения сделаны по той же самой методике
и теми же средствами), то их средняя арифметическая
будет следующей:
+ ■.• + *П
П
Рассмотрим проблему нахождения средней и диспер¬
сии случайной переменной X.
Если принять во внимание, что
tn
а= X yiPf,
/=1
О2= a)2 p'i,
/=1
то очевидно, что
M(X1)^M(X2)^... = M(Xn) = a;
D2(X1)^D2(X2)^...D2(An)^d2.
Пользуясь свойствами средней и дисперсии, получим:
М (X) = м ( х1+^+---+хп ) =
= — [М (Х,) + М(Х2)+ ••• + Л4 (*„)] = — = <г,
п п
Vn •
Как можно видеть, дисперсия средней арифметической
нескольких измерений в п раз меньше дисперсии одного
единственного измерения,
60
Теорема Чебышева, как и остальные теоремы закона
больших чисел, выражает в абстрактной математической
форме диалектические связи между категориями случай¬
ности и необходимости.
Теорема Бернулли, Теорема Бернулли утверждает, что
относительная частота некоторого события с константной
вероятностью р в каждом испытании стремится к вероят¬
ности константы р\ значит
limPdfn—р | < а) = 1.
П->оо
Следовательно, разность между относительной частотой
события, которую можно оценить на основе сделанных ис¬
пытаний, и вероятностью события, которая является чис¬
лом неизвестным, может быть сделана сколь угодно малой
с вероятностью, близкой к 1, если число испытаний воз¬
растает.
Теорема Пуассона, Пусть символы
-^1» ^2» •••>
представляют собой ряд событий, вероятность осуществ¬
ления которых имеет последовательные величины:
Pi, р2,
Обозначив символом fn относительную частоту, которая
указывает, сколько раз реализуются события Alf Д2, ...,
Дп, ... и символом р выражение
p=lim Pi + P2+--+Pn ,
п—>ОО Т1
Пуассон доказал, что если существует высшая граница, то
fn стремится к р «вероятности».
Очевидно, что эта теорема по существу является обоб¬
щением теоремы Бернулли.
Теорема Чебышева, теорема Бернулли и теорема Пуас¬
сона совместно образуют закон больших чисел.
В смысле более общем под названием закона больших
чисел понимается нечто большее, чем изложенные теоремы,
а именно: это объективный закон материальных пределов,
в основе которых действует большое число случайных фак¬
торов, ведущих в условиях достаточно общих к результату,
почти не зависящему от случайности.
61
§ 10. ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
Когда трактуется закон нормального распределения, то
подчеркивается его фундаментальное значение в теории
вероятностей. Теория случайных ошибок полностью ошь
рается на этот закон.
Вообще ошибки наблюдения могут быть двоякого рода:
ошибки систематические и ошибки случайные. Под ошиб¬
ками систематическими понимаются ошибки, обязанные
несовершенству измерительного инструментария или тех¬
ники наблюдения; эти ошибки могут быть корректированы.
Это нельзя сказать об ошибках случайных, которые яв¬
ляются прямым результатом некоторого комплекса об¬
стоятельств и, следовательно, не могут быть уловлены ни во
время процесса наблюдения, ни после того, как последний
имел место. Каждое из упомянутых обстоятельств имеет ре¬
зультатом частичную ошибку, а ошибка случайная, которая
нас интересует, является результатом глобального дей¬
ствия всех частичных ошибок.
Стремясь изучить случайную ошибку, теория вероят¬
ностей формулировала знаменитую теорему, известную под
названием центральной предельной теоремы.
В сущности эта теорема утверждает, что если случайная
переменная X является суммой некоторого большого числа
независимых1 случайных переменных и если каждая перемен¬
ная имеет малый удельный вес в сумме, то тогда закон рас¬
пределения случайной переменной очень близок к нормаль¬
ному.
В варианте А. М. Ляпунова эта теорема выражается
следующим образом.
Пусть Xlf Х2, ...,Хп— независимые случайные пере¬
менные.
Примем во внимание, что
ah = M(Xh)-, ul = D2(Xky, pA3 = M(|Xft-mk|3)
o^n) = i + 02 + ... + ;
3 3 I 3 I I 3
P(n) = Pl + P2 + ••• + Pn*
Если
lim—= 0,
rt->oo d(n)
1 Независимость, однако, не является существенным условием.
62
то функция распределения переменных
^1 + + ■ • • + (а1 4~Д2 + - « • 4~gn)
стремится к функции Ф(х) Лапласа, когда п->оо.
Эта теорема, известная в математической статистике
как и теорема Ляпунова и теорема закона больших чисел,
завершает группу фундаментальных теорем в теории ве¬
роятностей, делая очевидной эффективность методов этой
теории при различном практическом применении.
Глава IH
ЭМПИРИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ
ПО ОДНОМУ ПРИЗНАКУ (ОДНОМЕРНЫЕ)
§ 1. ВВОДНЫЕ ЭЛЕМЕНТЫ
Рассмотрим статистический коллектив, состоящий из
п элементарных единиц, у которых зарегистрировано не¬
которое число k признаков1 количественных и качествен¬
ных.
Для характеристики X какого-либо социально-эконо¬
мического явления может существовать несколько xi9 х2,
х3, ..., xs наблюдаемых значений признака, после¬
довательность которых можно рассматривать в порядке их
появления, в порядке их величины или в случайном по¬
рядке, т. е. без хорошо определенного критерия.
Очевидно, что для необходимого статистико-экономи¬
ческого анализа нужно, чтобы наблюдаемые оценки были
расположены либо в порядке восходящем, либо в нисходя¬
щем порядке величин. Для осуществления этого и для ог¬
раничения числа членов ряда, элементарные единицы ко¬
торого образуют статистический коллектив, их группируют
по размерам наблюдаемых величин.
Таким образом, формируются два отчетливых ряда чи¬
сел:
Наблюдаемые значения
признака X хг х2 х3 ... xt ... xs
Число соответствующих
наблюдений nT п2 п3 ... tit ... ns
1 При этом будем следовать введенному понятию признака для
определения специфического общего свойства или особенности всех
единиц данного статистического коллектива, подвергнутых наблюде¬
нию. Признак варьирует от одной единицы статистического коллек¬
тива к другой. Если значения, которые он принимает, можно вы¬
разить численно, то между конкретным признаком, принятым для
изучения, и случайной переменной существует полная аналогия
с тем отличием, что соответствующим значениям случайного при¬
знака корреспондируют относительные частоты, а не вероятность.
Как известно, при наблюдении большого числа элементов кол¬
лектива относительные частоты приближаются к вероятностям-
64
Группа наблюдаемых элементов, соответствующая не¬
которым эквивалентным значениям или классу значений,
называется абсолютной частотой. В некоторых случаях
вместо абсолютных частот пользуются их удельным весом
по всей совокупности , ..., ^..., называемым от¬
носительной частотой.
Эта форма, удобная для выражения данных, которые
дают возможность описания коллективов на основе наблю¬
даемых величин и соответствующих частот, известна в ма¬
тематической статистике под названием эмпирического ряда
распределения.
В экономической статистике встречаются многочислен¬
ные примеры эмпирических распределений: распределение
работников по номинальной заработной плате, распре¬
деление предприятий по числу рабочих или по стоимости
основных фондов, распределение промышленных предприя¬
тий по величине оборотных средств либо по товарной про¬
дукции и т. д.
В случаях признака с дискретной вариацией эмпири¬
ческое распределение устанавливает прямое соответствие
между наблюдаемыми значениями признака и соответству¬
ющими частотами.
Примеры 1. Распределение рабочих в промышленном
предприятии по тарифным разрядам следующее:
Таблица 1
Тарифный
разряд
Всего
2
3
4
5
6
7
8
Число ра¬
бочих
275
5
10
40
80
100
30
10
Единицы, из которых состоит статистический коллектив,
в Данном случае распределены по тарифным разрядам.
Можно оценить на базе этих числовых характеристик,
каков состав рабочих по степени их квалификации. Несом¬
ненно, что для более точного знания квалификации рабочих
На предприятии нужно прибегнуть к обычным способам
прямых характеристик, касающихся профессиональной под-
готовки и опыта рабочих в данном предприятии. Если,
следовательно, иметь в виду, что одним из основных кри¬
Зак. 1050
65
териев включения рабочих в тарифную категорию являет^
квалификация и опыт по данной специальности, то сведен и?
о распределении рабочих по тарифным разрядам достаток
ны для умозаключения в этом отношении.
Когда численная характеристика является непрерывной
вариацией, то ее значения располагаются обычно по к л ас-
сам величин или по интервалам вариации.
2. Распределение группы из 59 предприятий легкой
промышленности по размерам оборотных средств следую-
щее:
Таблица 2
Оборотные средства
Всего
Менее
5
5—10
10—20
20—30
30—40
4 0 и
1 выше
1
Число предприя¬
тий
59
13
11
11
11
6
7
Размер интервала вариации, зависящий от числа интер¬
валов, представляет важную особенность в выражении су¬
щественных типов эмпирических распределений.
Для облегчения сравнений в процессе анализа данных
установилось правило делать равные и не очень многочисле-
ные интервалы. В некоторых работах максимальным пре¬
делом считается 15—20 интервалов.
Следует подчеркнуть, что в этом отношении не существует
бесспорного критерия. Проблема решается применительно
к целям исследования с учетом природы явления и особен¬
но характерных вариаций группировки.
Опыт исследования и знание строения статистических
коллективов играют существенную роль в выборе числа
и размеров интервалов группировки.
Если наблюдаемые частоты не распределены примерно
единообразно между максимальными и минимальными вс-
личинами числовых характеристик, а амплитуда вариаций
очень большая, то можно образовывать неравные по вели-
чине интервалы и на концах открытые интервалы.
С точки зрения формы выражение эмпирических рас¬
пределений в интервалах значений имеет много возмоЖ'
ностей. Обычной формой, за исключением случаев открытых
крайних интервалов, является та, при которой в таблице
указываются низшая и высшая границы интервалов. Когда
66
вЬ1сшая граница интервала соответствует низшей границе
слеДУЮШ'его интервала, то это указывается таблицей сле¬
ду юшего вида:
J Т а б л п ц а 3
Средний месячный
оборот по заработ¬
ной плате в мил¬
лионах лей
Всего
До 5
5—10
10-20
20—30
30-40
Выше
40
Число предприя¬
тий
59
13
11
11
И
6
7
В этом случае частота, корреспондирующая интерва¬
лам значений, пишется в границах соответствующих ин¬
тервалов.
В некоторых мало обычных ситуациях вместо интервалов
указываются центры интервалов. Если символами xk
обозначить низшую границу интервалов, a — высшую
границу, то центром интервала будет
х __ xk~\~ xh~\~
2
Эта форма наиболее удобна для развития последовательных
вычислений, касающихся типичных величин эмпирических
распределений (средних, дисперсий и т. д.).
§ 2. ГРАФИЧЕСКОЕ ИЗОБРАЖЕНИЕ
ЭМПИРИЧЕСКИХ РАСПРЕДЕЛЕНИЙ
Графическое изображение распределений дает много
гибких приемов, делая более очевидными пропорции раз¬
ных частот коллектива и корреляцию между ними.
С помощью графических изображений легче установить
математические формулы, описывающие распределения,
определить форму их конкретизации.
Графическое выражение распределения по одному при¬
знаку просто и легко осуществимо. Формы графических изо¬
бражений разнообразны; мы остановимся только на тех,
которые наиболее часто применяются.
Распределение по качественным признакам может быть
выражено в различных геометрических формах (линиями,
квадратами, кругами и т. д.), которые воспроизводят струк¬
туру коллективов.
5*
67
Структурные диаграммы, вообще, достаточно известны
благодаря статистическим публикациям, и мы не будем оста*
навливаться в этой работе на технике их изображения.
Распределение по количественным признакам изобра*
жается диаграммами в виде полосок или линий, гистограм*
мой, полигоном частот и кривой частот. Диаграммами в виде
полосок или линий изображаются распределения количест¬
венных признаков с дискретной вариацией.
Так, можно графически представить число рабочих
промышленного предприятия по тарифным разрядам.
Рис. 11.
На оси абсцисс обозначаются значения признаков, в дан¬
ном случае число рабочих по тарифным разрядам, а на оси
ординат — относительная частота.
Если основой распределения является непрерывный
численный признак, то для его изображения может больше
подходить форма гистограммы или, в соответствующем
случае, можно воспользоваться кривой частоты.
В случае гистограммы на оси абсцисс наносятся основ-
ные интервалы значений признака, а на оси ординат — аб¬
солютная или относительная частота.
Затем из границ каждого интервала восстанавливаются
перпендикуляры к оси абсцисс, концы которых соединяются
линиями, образуя таким образом несколько прямоуголь¬
ников, площадь которых пропорциональна частоте соот¬
ветствующих интервалов.
68
Например, распределение 59 предприятий легкой про¬
мышленности по товарной продукции (рис. 12), реализован¬
ной в 1964 г., может быть выражено либо в форме гисто¬
граммы (А), либо в форме полигона частоты (В).
Изображение посредством гистограммы особенно под¬
ходит к распределениям непрерывных численных признаков
с неравными интервалами для устранения зрительного
влияния неравных групп.
Рис. 12.
я
в
Полигон частот получается в результате соединения
отрезками линий концов перпендикуляров, восстановлен¬
ных из центров интервалов, конечные точки которых рас¬
положены на расстоянии, пропорциональном частоте интер¬
валов.
Если интервалы малы и многочисленны, то гистограмма
может быть замещена кривой частоты. Кривая проводится
свободно, таким образом, что часть площади прямоуголь¬
ников гистограммы, остающаяся над кривой, компенси¬
руется площадями под кривой, находящимися вне гисто¬
граммы.
§ 3. ПЛОТНОСТЬ ЭМПИРИЧЕСКИХ РАСПРЕДЕЛЕНИЙ
Частота абсолютная и частота относительная указывают
число и соответствующий удельный вес единиц статисти¬
ческого коллектива, корреспондирующих некоторым на¬
блюдаемым величинам или элементарным интервалам ва¬
риаций распределения.
69
Если для распределений по количественному признаку
с дискретной вариацией определение наиболее частого ва.
рианта является относительно простым, то в случае харак.
теристики непрерывной вариации проблема является ие.
сколько более сложной.
Сравнение относительной частоты элементарных иптер.
валов не является достаточным, особенно если размер ин.
тервалов меняется в рамках распределения. В некоторых
случаях возникает проблема определения в пределах ка¬
кого-либо интервала величины или уровня, характеризу-
ющихся наибольшей частотой.
Предположим, например, что желательно знать, каково
наибольшее число промышленных предприятий прибли¬
зительно с 500 рабочих или с 1000 рабочих. С этой целью
проанализируем промышленные предприятия по числу ра¬
бочих на конец 1964 г.1:
Таблица 4
Размер предприя¬
тий по числу
рабочих
Число
предприятий
Распределение
предприятий
в процентах
Плотность
распределения
в процентах .
Всего
1 573
100,0
До 50
9
0,6
1,5*
51 — 100
72
4,6
9,2
101—200
205
13,0
13,0
201—500
510
32,4
10,8
501 — 1 000
397
25,2
5,0
1 001—2 000
242
15,4
1,5
2 001—3 000
79
5,0
0,5
3 001—5 000
37
2,4
0,1
Больше 5 000
22
1 Д
0,03**
* Считая нижней границей интервала 10 рабочих.
** Считая максимальной границей интервала 10 000 рабочих.
Данные, приведенные в таблице, показывают, что су¬
ществует 510 предприятий с числом рабочих от 201 до 500
и 397 предприятий с числом рабочих от 501 до 1000. Число
предприятий первой группы (201—500 рабочих) гораздо
больше по сравнению с группой от 500 до 1000 рабочих,
1 Без кустарных некооперированных мастерских (см. АгпЫ'
nil statistic al R. P. R. 1965, p. 142).
70
несмотря на то что интервал вариации последней группы
почти вдвое больше.
На основе этого соображения можно сделать заключе¬
ние, что имеется гораздо больше предприятий с 500 рабо¬
чих, чем предприятий, которые имеют 1000 рабочих.
Таким образом, из краткого анализа этого примера
следует, что для характеристики интенсивности вариаций
некоторого явления необходимо иметь в виду частоту и раз¬
мер интервала соответствующих вариаций.
Показателем, который выражает частоту характеризу¬
емого значения какой-либо вариации в непрерывном интер¬
вале, т. е. интенсивность вариации, является плотность рас¬
пределения.
Из сравнения плотности по интервалам вариации (по¬
следняя колонка в табл. 4) следует, что интервал 201 —
500 рабочих имеет плотность в два раза большую, чем ин¬
тервал 501—1000 рабочих, что подтверждает формулиро¬
ванный прежде вывод, сделанный на основе данных первых
трех колонок.
Очевидно, что для точного ответа на наш вопрос нужно
уменьшить наибольшие интервалы вариации для сопостав¬
ления плотности соответствующих интервалов, сближая
предприятия с числом рабочих от 500 до 1000.
Если обозначить рх~^^х относительную частоту интер¬
вала х, % + Ах, то плотность распределения в данном
интервале будет
pv-1-Дх
. (Ш.3.1)
При стремлении к пределу, когда Ах-->0, плотность
распределения можно рассматривать как плотность «в дан¬
ной точке».
рх-\-&х
/(x)-lim — . (III.3.2)
Дх->0 Ах
Для наиболее простого объяснения формулы плотности
распределения введем понятие «кумулированная (накоплен¬
ная) частота», или «огива», аналогичное понятию функции
Распределения F(x), с которой мы встречались в предше¬
ствующей главе. Кумулированная частота значений х,
Которую мы обозначим F*(x), является частью статисти¬
ческого коллектива, характерная величина которой мень¬
ше чем х.
71
Б случае количественных характеристик непрерывной
вариации можем написать формулу
^+Дх = Г’(х+Дх) —F*(x) (Ш.З.З)
и, заменяя обозначения в формуле (III.3.2), получим
е, х r F* (х + Дх) — F* (х) /ТТТ О
/ (х) = 1 ini, —-—! — , (III.3.4)
Дх->0 Дх
производную накопленных относительных частот.
f (Х) = _dF* <*> . (III.3.5)
dx
Из этого отношения следует:
f (х) dx = dF* (х);
А'Ц-ДЛ'
J f (x) dx = Fx+Ax. (III.3.6)
X
Следовательно, относительная частота интервала х,
х + Ах является определенным интегралом плотности
распределения в границах соответствующего интервала.
Накопленная частота получается посредством последо¬
вательного суммирования частот соответствующих интер¬
валов вариаций.
Обращаясь к предшествующему примеру, относящемуся
к распределению промышленных предприятий по числу
рабочих, для того чтобы вычислить абсолютные и относи¬
тельные частоты, будем действовать следующим образом:
Таблица 5
1
Размер пред¬
приятий по
числу рабочих
Число
предприятий
Распределе¬
ние пред¬
приятий
в процентах
Накопленная частот:!
абсолютная
относительная
Всего
1 573
100,0
До 50
9
0,6
9
0,6
51—100
72
4,6
81
5,2
101—200
205
13,0
286
18,2
201—500
510
32,4
796
50,6
501 — 1 000
397
25,2
1 193
75,8
1001—2 000
242
15,4
1 435
91,2
2001—3 000
79
5,0
1 514
96,2
3001—5 000
37
2,4
1 551
98,6
Выше 5 000
22
1,4
1 573
100,0
72
Из 1573 промышленных предприятий, действовавших
к концу 1964 г., 796 предприятий, составлявших 50,6%
общего числа, имели до 500 рабочих каждое.
Несомненно, что операция по кумулированию может
иметь место и в обратном направлении, т. е. начинаться от
высшей границы последнего интервала распределения.
В этой ситуации значение данных совсем иное, накоплен¬
ная частота указывает общее число единиц из исследуемого
коллектива, которое имеет уровень значений, превосходя¬
щий х, например:
Таблица 6
Размер предприятий
по числу рабочих
Число
предприятий
Абсолютная кумулированная
частота
от нижней
границы перво¬
го интервала
от высшей гра¬
ницы последне¬
го интервала
Всего
1 573
До 50
9
9
1 573
51—100
72
81
1 564
101—200
205
286
1 492
201—500
510
796
1 287
501—1 000
397
1 193
777
1 001—2 000
242
1 435
380
2 001—3 000
79
1 514
138
3 001—5 000
37
1 551
59
Свыше 5 000
22
1 573
22
Эта форма выражения накопленных частот намного
облегчает объяснение и анализ данных. Из табл. 6 следует,
что существует 1435 предприятий с числом рабочих менее
2000 каждое и 380 предприятий с числом рабочих больше
2000 каждое.
§ 4. РАЗЛОЖЕНИЕ ИНТЕРВАЛА И ОПРЕДЕЛЕНИЕ
СООТВЕТСТВУЮЩИХ ЧАСТОТ
Понятие плотности распределения и установленные
ранее отношения дают возможность решать некоторые про¬
блемы большого практического значения, как, например,
Разложение интервала на части и определение соответству¬
ющих долей частот.
73
Для разложения интервала на части пользуются отно¬
сительной частотой соответствующего интервала и относи¬
тельной частотой соседних интервалов.
Техническая операция разложения основана на гипо¬
тезе вариаций плотности распределения в границах этих
интервалов согласно некоторой теоретической функции.
При характеристике плотности распределения можно
спросить, какие предприятия чаще встречаются в нашей
промышленности, например с числом рабочих 500 или
1000. Установлено, что для ответа на этот вопрос необхо¬
димы меньшие интервалы вариации, близкие к этим двум
величинам.
Предположим, что интервалы 480—500 и 980—1000
достаточно малы для приблизительных частот, которые
должны быть вычислены. По гипотезе, согласно которой
плотность распределения в границах интервалов 101—200,
201—500, 501—1000 варьирует по параболе
f (х) = aQ + a1x + а2 х2
и при применении для упрощения операций по вычислению
границы интервалов — (—0,33; 0), (0; 1) и (1; 2,67) относи¬
тельные частоты даются интегралом плотности распределе¬
ния в области границ, соответствующих каждому интер¬
валу.
Для интервала (—0,33—0) относительная частота дана
интегралом
о о
[ f(x)dx~ j (a0 + a1x + a2x2)dx = W-\==
— 0,33 —0,33
о
— 0,33
= 0,333^ — 0,05545^ + 0,011979^- 13,0.
Подобным же образом для интервала (0,1) получим
1 1
J f (х) dx — J (а0 + х + а2 х2) dx —
о о
1
о
W - а0 + 0,5ах + О,333а2 = 32,4;
74
так же Для интервала (1, 2, 67)
2,67 2,67
J f (х) dx = j (а0 + + х + а2 x-)dx = w± =
— (2,67а0 + 3,5644а3 -|-6,344 472 la2) — (III.4.3)
— (а0 -|- 0,5 а± + 0,333 а2) =
= 1,67 а0 + 3,064 4ах + 6,0111а2
w = 1,67а0 + 3,064 4ах + 6,0117а2 = 25,27.
Итак, мы получили систему уравнений с тремя неиз¬
вестными:
+ 0,333 а0 — 0,05545 а± + 0,011979 а2 = 13,0
6Zq—0,5 + 0,333 6Z2 =32,4
1,67 aQ +3,0644^ +6,0117а2 =25,2,
решение которых дает величины параметров а0 =37,549;
= —9,292 3; а2 =—1,494 5. Относительная частота, кор¬
респондирующая интервалу вариации 480—500, соответ¬
ствует интегралу плотности распределения в пределах ин¬
тервала от 0,993 до 1.
Низшая граница нового интервала вычисляется как
отношение между величиной начального интервала (300)
и исключенной частью интервала (280):
1 1
1^0,933 — J f(x)dx= j (а0 + а± х + а2 х2) dx =
0,933 0,933
1
0,933
292
1
0,933
1,82%.
Следовательно, 1,82% из общего числа промышленных
предприятий нашей страны (примерно 29 предприятий)
имеют от 480 до 500 рабочих.
Подобным же образом для сравнения вычисляется от¬
носительная частота интервала 980—1000 рабочих.
75
§ 5. ТИПИЧНЫЕ ВЕЛИЧИНЫ ПОЛОЖЕНИЯ
Мода
Сравнение числа промышленных предприятий по иц.
тервалам вариации не вполне решает проблему прибли¬
зительного определения размеров промышленных пред¬
приятий (по числу рабочих), наиболее часто встречающихся
в нашей промышленности.
Подобные проблемы приходится решать в телефонной
связи для определения часов, когда центральная телефон¬
ная станция наиболее загружена; в городском пассажирском
транспорте для часов максимального скопления на опре¬
деленных линиях или участках линий; в демографии для
определения возраста вступления женщин в брак и т. д.
Для решения всех этих проблем пользуются модой
или доминантой1. Мода Мо является, по определению,
значением признака, которое встречается наиболее часто
в рамках коллективов. Моду можно определить как зна¬
чение признака, которое корреспондирует максимальной
плотности распределения.
Минимум плотности распределения, встречающийся в
распределениях формы / или и называется антимодой.
В практике встречаются эмпирические распределения
с двумя или несколькими вершинами. Эти многомодальные
распределения имеют одну главную моду и один или не¬
сколько вторичных модальных признаков.
Мода эмпирических распределений непрерывного при¬
знака графически выражается вершиной кривой распре¬
деления. Все же обычно мода — это показатель эмпири¬
ческих распределений с дискретной вариацией значения
признака (вариант, характеризующийся наибольшей ча¬
стотой). Очевидно, что для этих распределений определение
моды простая формальная операция, которая не нуждается
в обсуждении.
С большой приблизительностью моду можно опреде¬
лить в распределениях с непрерывной вариацией. Рассмот¬
рим модальную величину признака, которая корреспон¬
дирует середине интервала с максимальной частотой. Этот
метод определения моды основан на гипотезе прямолиней¬
1 Название мода наиболее распространенное. Термин, доминан¬
та взят из французской литературы.
76
ной вариации плотности распределения в границах модаль¬
ного интервала. Операции, которые проводятся для на¬
хождения моды с наибольшей точностью, основываются на
знании особенностей законов плотности распределения.
Предположим, что плотность распределения варьирует
по параболе (полином II степени)
f(x) = aQ + a1x + а2 х2.
(III.5.1)
Предположим, что (—1,0), (0,1) и (1,2) — последовательные
интервалы распределения с корреспондирующими относи¬
тельными частотами w_\, w и
Поскольку относительная частота w заключена в гра¬
ницах w-\ < w > Wt и корреспондирует с модальным
интервалом, моду следует искать в интервале (0,1).
Для определения моды необходимо вычислить распре¬
деление в интервале (—1,2) с помощью параболической
кривой таким образом, чтобы относительная частота этих
трех интервалов соответствовала вычисленным теоретиче¬
ским частотам.
Поскольку мода соответствует максимуму кривой ча¬
стоты, приравниваем первую производную функции нулю:
/' (х) = а1 + 2а2х = 0,
откуда получим величину х: 2а2х ——а±
(III.5.2)
которая указывает абсциссу вершины параболы.
Параметры и а2 определяются интегрированием, от¬
носительные частоты w_i, w и находятся соответственно
посредством интеграла плотности распределения в границах
корреспондирующих интервалов:
следовательно, для w_\ получим
Подобным же способом определяется и интеграл плотно,
сти распределения для w
1 1
w ~ J f (х) dx = [ (а0 - |- х -| - а2 х2) dx -----
о о
аох+-ix2 + ^x3W (III.5.4)
2 3 11 о ’
• | a2
+T + T.
а также для
2 2
~ \ f (x) dx = i (a0 + ai X + a2x2) d-x =
i i
= x +-^ x2 + -^-x3^=(2a0 + 2n1 + ya2J —
- («о+ f + у) = «о+ |«i+ a2; (III.5.5)
заметим, что
w— w_ i = ax,
— cu = (71 + 2a2,
откуда
2a2 = — w) — (w— i^_i) = — 2^ + W-i.
Следовательно, величина, которая указывает точку на
абсциссе, корреспондирующую с максимальной частотой
(х), может быть написана в следующей форме:
(III.5.6)
Производя последовательные вычисления, можно легко
найти моду нашего распределения:
W \ —W
Mo = x0 + d у—7- , (III.5.7)
где x0 — вариант, характеризующий низшую границу мо¬
дального интервала;
d — размер интервала..
78
к. Пирсон, вычисляя распределения с помощью их
кривых, построил формулу, которая дает величину моды,
свойственную всем одномодальным распределениям:
Мо = х + 3(Ме—х).
(III.5.8)
Пример. Предположим следующее распределение груп¬
пы 49 промышленных предприятий по скорости обращения
оборотных средств:
Таблица 7
Скорость обраще¬
ния в днях, X
Число
предприятий
20—30
8
30—40
11
40—50
16
50—60
9
60—70
5
Всего
49
В этом случае получим:
хо = 4О; d=10; /i_i = ll; /1=16; /i+i=9
(символами zi_i, п и п.±\ обозначим абсолютную частоту, со¬
ответствующую модальному интервалу и двум смежным
с ним интервалам).
Для определения моды распределения, соответствую¬
щей скорости обращения, наиболее частой у изучаемых пред¬
приятий, используем формулу (II 1.5.7), в которой относи¬
тельные частоты заменены частотами абсолютными:
Мо = 40-|-10 -<16~п) =44,17 дня.
9—(2Х16) + И
Вычисляя моду для распределений с неравными интер¬
валами вариаций, основываются на тех же самых принципах,
во производят арифметические операции в большем объеме
Для вычисления параметров.
Мода вычисляется, как правило, для распределений, со¬
стоящих из большого числа наблюдений, и имеет следую¬
щие особенности:
1. Величина моды зависит только от части наблюдений,
ив которых состоит статистический коллектив, а именно
79
из наблюдений, которые группируются вокруг интервала
с вариантом наиболее многочисленным.
2. Мода не может быть использована в вычислениях при
таком анализе распределений, которые включают сложные
алгебраические операции.
При всем этом помимо ее конкретного значения в ана¬
лизе экономических и социальных явлений мода может с
успехом заменить собственно среднюю величину в случаях
симметричного распределения с открытыми крайними ин¬
тервалами. Равным образом мода применяется для синте¬
тической характеристики структуры коллектива.
Медиана
Медиана Me по определению — это значение признака,
которое разделяет ряд на две равные части, когда единицы
коллектива расположены в порядке возрастания или убы¬
вания размеров величин наблюдаемых признаков.
С аналитической точки зрения медиана корреспондирует
с величиной абсциссы, ордината которой разделяет пло¬
щадь, ограниченную кривой распределения, на две равные
части.
Медиана, как и мода, определяется интерполированием
при предположении, что в границах медианного интервала
значение признака варьирует линейно.
Теоретическое вычисление медианы просто и не вызывает
трудностей, особенно в случаях дискретного распределения
признаков.
Единицы коллектива располагаются в восходящем или
нисходящем порядке наблюдаемых значений признаков.
Если коллектив состоит из нечетного числа наблюдений
2п + 1, то медиана представляет порядковую величину
п 4“ 1 •
В случае распределения, состоящего из четного числа
наблюдений 2 п, медиана располагается посредине между
двумя величинами (п и п + 1).
Вообще, условлено рассматривать как медиану среднюю
арифметическую этих двух серединных величин.
Определение медианы несколько более трудно в случае
распределения признака с непрерывной вариацией.
Возьмем тот же пример относительно распределения
49 промышленных предприятий по скорости обращения
оборотных средств:
80
Таблица 8
Скорость обраще¬
ния в днях, X
Число предпри¬
ятий п*
Середина интер¬
вала X}
Накопленные
частоты F* (х)
20—30
8
25
8
30—40
11
35
19
40—50
16
45
35
50—60
9
55
44
60—70
5
65
49
Всего . . .
49
X
X
Для определения медианного интервала необходимы на¬
копленные частоты для установления числа тех предприя¬
тий, которые имеют скорость обращения средств, равную
или превышающую каждую границу интервалов. Напри¬
мер, можно видеть, что сороковое предприятие находится
в интервале 50—60.
Медиана расположена в интервале, который корреспон¬
дирует с частотой , в нашем примере у = 24,5, сле¬
довательно, в интервале 40—50. Значение признака,
которое точно соответствует полусумме абсолютных или
относительных частот, определяется, таким образом, как
отмечено ранее, посредством линейной интерполяции ча¬
стоты в границах медианного интервала.
Если обозначить символами:
Fk(x) — накопленную частоту, корреспондирующую ме¬
дианному интервалу;
Fk-\(x) — накопленную частоту интервала, предшествую¬
щего медианному;
d—величину медианного интервала;
xh> Xk_\—высшую и низшую границы медианного интер¬
вала,
то можно написать следующую пропорцию:
xk~xk-i
Me~xk-1
(III.5.9)
6
Зак. 1050
81
Перемножая между собой средние и крайние члены
и выделяя затем неизвестную величину Me
(Fk(x)-Fk-t(x)) (Л4е-%,_!) =
Me = xk_1 + (xh—Xk — \)— ; (III.5.10)
(x)
заметим, что
xk— Xk-\ = d (величина интервала)
F*k(x)— Fk-i (x) = rth (абсолютная частота, соответствую’
щая медианному интервалу)
Итак, формулу вычисления медианы можно написать
наиболее просто следующим образом:
Me = Xk_\ + d
В нашем
примере
Ме~40-{- 10 19,0 = 43,44 дня,
16
что означает, что приблизительно 24 предприятия имеют
скорость обращения оборотных средств ниже 43,4 дня, а
24 предприятия выше 43,4 дня.
Медиана может быть определена графически с помощью
полигона накопленных частот. Она является точкой на абс¬
циссе полигона, которая соответствует ординате, представ¬
ляющей 1/2 частот
Действия при графическом определении медианы идут
в следующем порядке:
а) проводят линию, параллельную абсциссе через точку
ординаты, соответствующую частоте —d-d (точка!), рис. 13);
б) через точку D опускается перпендикуляр на абс¬
циссу. Точка в которой этот перпендикуляр касается абс¬
циссы, указывает медиану (Me).
Несомненно, что оценка медианы на основе полигона
кумулированных частот имеет преимущественно характер
демонстр ативный.
82
Пересечением линий,
проведенных из точек
Me и л^_1, с орди¬
натами , соответствую-
щими F*(x), и
(х), образуются
два подобных треуголь¬
ника АВС и AED. На
основе пропорциональ¬
ности сторон этих двух
треугольников полу¬
чают формулу медианы,
установленную ранее
прямым путем.
Хотя медиану опре¬
деляют, оперируя в об¬
щем всеми величинами
распределения, ее раз¬
меры зависят только от
центральных величин.
По этой причине данная
форма синтетической ха¬
рактеристики статисти¬
ческого р аспр еделен и я
является предпочтитель¬
ной, когда ряд представляет собой вариации крайне боль¬
шие или ненормально малые, обусловленные определен¬
ными пертурбирующими факторами. Такими вариациями
следует пренебречь.
§ 6. ЭМПИРИЧЕСКИЕ МОМЕНТЫ.
СрЕДНИЕ ВЕЛИЧИНЫ
В анализе эмпирических распределений важную роль
Играет вычисление моментов.
Если мы рассмотрим переменную X, распределение ко¬
брой обозначим схематически
-^Т > ’ ’ ’’
/?1, /12> • • •,
6*
83
то, по определению, моментом порядка k распределения \
является средняя арифметическая степень k отклонений
(%i — а), где а есть произвольно избранная константа:
У (Xi — a)kni
; -■ (Ш.6.1.)
/=1
Следовательно, момент k порядка характеризует рас¬
пределение с точки зрения способа, которым характеризует¬
ся распределение наблюдаемых значений признака.
По отношению к величине, принятой за начало, разли¬
чают моменты начальные (когда а = 0), моменты централь¬
ные (когда а =х) и моменты условные (когда а 0 х).
Моменты начальные и моменты центральные являются
частными случаями моментов формы Ш.6.1.
Моменты начальные характеризуют распределение по
отношению к величинам моментов центральных.
Таким образом, начальный момент первого порядка
(& = 1) является средней арифметической эмпирического
распределения
2 Л». VX;rai
i=0 _ t = l
Z=1 Z=1
(III.6.2)
Следующие начальные моменты используются для вы*
числения средних высшего порядка.
С этой целью формула (Ш.6.1) приводится к более удоб¬
ной форме.
Предположим, что существует функция
W ~ xk
в форме
V W V xkn-
/1 7; I
k i = 1 i = 1
W - X(k} = —— - — ,
i=l /=1
84
йТкуда следует тождество
S
V
i = 1
w = x[k} = Qm{k}
П.
i
V
Z = 1
Очевидно, что
X{k) =/
1
k
(III.6.3)
Если в выражении (III.6.3) k придаются различные зна¬
чения, большие единицы, то получают степенную среднюю.
Например, для k = 2
*(2) = КоШ(2)
(III.6.4)
получим формулу вычисления средней, известной под на¬
званием средней квадратической.
Не будем останавливаться на остальных степенных
средних, потому что они редко применяются в анализе эм¬
пирических распределений.
Одной из форм средней, довольно часто применяемой
Для характеристики и описания распределений, является
средняя гармоническая.
Средняя гармоническая является начальным моментом
Порядка (—1):
- — 1 — 1 1
*( -1) = от( -1) =
s
Z=1
(III.6.5)
85
Средняя геометрическая хар актер метика р аспределе.'
ния является начальным моментом нулевого порядка:
_i_
*(0) = от(°о)
2
i= 1
О
= 1°°.
s
Z=1
(Ш.6,6);
Следовательно, когда величина k = 0, она стремится к
неопределенности и решается дифференциальным исчис¬
лением.
В заключение следует вывод
S
(111.6.7)1
который дает формулу средней геометрической.
Из произведенных вычислений следует:
а) средняя арифметическая, средняя гармоническая,
средняя геометрическая и средняя квадратическая явля¬
ются особыми формами начальных моментов различного
порядка;
б) средние величины возрастают с порядком моментов,
так что отношение между ними дается неравенством
Х( _1) Х(0) *(1 ) "С *(2) < ... С *(&)•
Моменты центральные применяются в анализе эмпи¬
рических распределений для характеристики дисперсии
(рассеяния), асимметрии и эксцесса.
Общей формулой вычисления центральных моментов,
для обозначения которых примем символ является сле¬
дующая:
£(хг-Л^
j=l
Z= 1
(III.6.8)
86
В соответствии со значением, придаваемым k, получим:
i = \
при k = 0, поскольку всякое число степени 0 равно 1.
Центральный момент первого порядка (6=1):
S S S
2 (xi—x)ni y\xin.i х 2 ni
= - = -^ ^-==0. (III.6.10)
2 s nt 2
Z=1 Z = 1 Z=1
Центральный момент второго порядка (k = 2)\
2 (xi—x)2nt
^=^—s = 1. (111.6.11)
Z=1
Обычно центральный момент второго порядка обозна¬
чают символом о2, который представляет собой дисперсию
распределения.
Условные моменты не имеют конкретного значения в
анализе эмпирических распределений, однако использо¬
вание их свойств существенным образом упрощает операции
по вычислению средних и дисперсии.
Вычисление условных моментов довольно просто в срав¬
нении с вычислением центральных моментов, потому что
нет необходимости в предварительных математических опе¬
рациях для определения величины (а).
2 (xt — a)kni
vh = -^—s . (IIL6.12)
2 nt
i= 1
Поэтому в практике вычисляются сначала условные
Моменты, а затем делают переход к моментам центральным
и начальным.
87
Формулы перехода от условных моментов к центральным
моментам, установленные математически, исходят из от¬
ношения (III.6.8). I
С этой целью в числитель формулы введем со знаком -р !
и — произвольную величину (а):
2 l(*i — а) + (а—x)]knt
— j (Ш.6.13)
2 ni
i = 1
Заменяя в этой формуле (а—х) символом а, получим
2 [(Xi — a) + a]kn.i
i= 1
14 =
Развивая числитель
тона, получим:
2 (xi~а)кщ
2
i = 1
формулы, согласно биному Ныо-
4 =
ka
s
у
X
i= 1
(Х1— ' X
s
2 ni
i = 1
1-2
k (k—\) (k—2)
nt
1.2.3
s
E ni
i = 1
Заметим, что первым^’членом развития бинома являет¬
ся vft, вторым членом kaVk-\ и т. д.
Таким образом, получаем
+ ka.Vk-1 + а2vA_2 +
1.2
(III.6.14)
Выражение (111.6.14) представляет собой формулу связи
между условными и центральными моментами.
88
Для вычисления центральных моментов порядка 0,1,2
0 3 на основе условных моментов применяется формула
(III.6.14):
Но = v0 = 1,
Hi = vi + av0 = v1 —у1 = 0.
Очевидно, что
Иг = v2 + 2avi + «2 v0 = v2 — (vj2 = o2;
Из = vs + 3av2 + 3а'Ч + a3v0 = v3—3v, v2 + 2 (vj3.
Аналогичным образом поступают для установления пе¬
рехода от начальных моментов к центральным моментам.
Числитель общей формулы вычисления центральных
моментов вычисляется, согласно биному Ньютона, следу¬
ющим образом:
2 (^—mdkni
Hh = 1=1 s = tnk — km1 mk _ 1 -|-
У
+ (m1)2/n,_2-^iZ^T2)(m1)3m,_3+... (Ш.6.15)
откуда следует:
Но = mo =1;
p.1 = m1(l—mo) = O;
p2 = m2 —(m1)2 = o2;
,us = m3 — Зт^г» - 2 (m^3.
Для практической работы по вычислению средних по-
лезно знать отношение между начальным и условным момен¬
тами первого порядка.
Предположим, что произвольная величина а> на
некоторое количество а.
Следовательно,
a = m1 + a.
Заменим а эквивалентной величиной —v:
а = т1 — v,
°ткуда
т1 = v+ а. (III.6.16)
89
Выражение (III.6.16) используется в вычислении сред,
них упрощенным способом условных моментов.
Для иллюстрации этого показателя в дальнейшем (цри
вычислении моментов и при переходе от моментов началу
ных и моментов условных к моментам центральным) вос¬
пользуемся примером распределения по выработке на
одного рабочего в 1960 г.:
Таблица 9
Выработка на 1 рабо¬
чего в га
Число МТС
Удельный вес числа
рабочих в процентах
До 251
21
7,8
251—300
39
13,6
301—350
43
17,3
351—400
50
21,2
401—450
33
14,8
451—500
34
15,5
Выше 500
23
9,8
Всего ...
243
100,0
Данные взяты из сборника «Развитие сельского хозяйства в
Народной Республике Румынии». Центральное статистическое уп¬
равление, Бухарест, 1967, стр. 347.
Хотя не все моменты имеют конкретное значение в ана¬
лизе распределений, для иллюстрации метода вычислений
мы остановимся на первых трех моментах.
При вычислении эмпирических моментов распределения
в интервалах предполагается, что частоты распределяются
однообразно в границах интервалов вариаций. В этих ус¬
ловиях моменты являются приближенно достаточно точ¬
ными, если при вычислении пользуются центрами
интервалов1.
Для вычисления начальных моментов операции произ¬
водятся следующим образом:
1 Ошибки, которые могут быть допущены при этой гипотезе
в исчислении моментов, можно устранить на основе поправки, уста¬
новленной Шеппардом (Sheppard) еще в 1898 г. и потом уточненной
шведским статистиком Волдом (Н. Wold) в 1934 г.
90
Таблица К)
J
wi
xiwi
'4
225
50 625
11 390 625
7,8
1 755
394 875
88 846 875
275
75 625
20 796 875
13 6
3 740
1 028 500
282 837 500
325
105 625
34 328 125
17,3
5 623
1 827 313
593 876 563
375
140 625
52 734 375
21,2
7 950
2 981 250
1 117 968 750
425
180 625
76 765 625
14,8
6 290
2 673 250
1 136 131 250
475
225 625
107 171 875
15,5
7 363
3 497 188
1 661 164 063
525
275 625
144 703 125
9,8
5 145
2701 125
1 418 090 625
s
—
—
100,0
37 866
15 103 501
6 298 915 620
Низшая граница первого интервала и высшая граница
последнего интервала устанавливаются исходя из размера
интервала в 50 га, т.е. интервалами равными другим интер¬
валам распределения.
Пользуясь формулой, установленной для вычисления
начальных моментов, в нашем примере получим:
2 wi
/=J
т0
2
i = 1
100,0 _
100,0 ~
2 Xi Wi
i=\
2
i= 1
37 866
100
378,66;
m2
2
i=\
15 103-501
100
151 035;
i= 1
s
i= 1
s
m3
6 298 915 620 = g2 9g9 j 56
100
i = 1
91
Начальный момент первого порядка указывает средний
уровень выработки на одного рабочего в МТС, являясь
средней взвешенной арифметической величиной признака.
Затем пользуемся вторым начальным моментом для вы¬
числения среднего квадратического отклонения и диспер¬
сии методом начальных моментов.
Согласно формуле,
И2 = а2 = т2 —(mJ2.
Следовательно,
а2 = 151 035 — 378,662 7658,68.
Отметим трудности этого метода в случаях распределе¬
ний с большими величинами вариантов признака.
Поэтому вычисление дисперсии методом начальных мо¬
ментов рекомендуется только тогда, когда т2 и вычис¬
лены в других целях.
Для упрощения вычислений предпочтительней услов¬
ные моменты:
Таблица 11
X
х±—а
(хх—а)2
(*г~а)3
(хх—а) t<y.
(xi—a)2wi
(хг-а)»а>г-
1
225
1
—150
22 500
—3 375 000
7,8
—1 170
175 500
—26 325 000
275
—100
10 000
—1 000 000
13,6
—1 360
136 000
—13 600 000
325
— 50
2 500
— 125 000
17,3
— 865
43 250
— 2 162 500
375
0
0
0
21,2
—3 395
0
—42 087 500
425
50
2 500
125 000
14,8
740
37 000
1 850 000
475
100
10 000
1 000 000
15,5
1 550
155 000
15 500 000
525
150
22 500
3 375 000
9,8
1 470
220 500
33 075 000
S
—
—
—
100,0
+3 760
+365
767 250
+50 425 000
+8 337 500
Значения признака уменьшаются на произвольную ве¬
личину (а), чтобы обеспечить рациональное упрощение
вычислений. В нашем примере выбрана величина а = 375,
центр медианного интервала, так что операции упрощаются
на один член ряда.
Несомненно, что можно сделать и другие упрощения
для облегчения вычислений.
92
Так, например, отклонения от произвольной величины
(а) могут быть сокращены в данном числовом примере на
50 пропорционально размеру интервала.
Таблица 12
Х1
хГ~а
d
т’
■ wi
Ы"'
(xi-а \3
( __ ) w.
225
—3
9
—27
7,8
—23,4
70,2
—210,6
275
—2
4
— 8
13,6
—27,2
54 4
—108,8
325
—1
1
— 1
17,3
—17,3
17,3
— 17,3
375
0
0
0
21,2
—67,9
0
—336,7
425
1
1
1
14,8
14,8
14,8
14,8
475
2
4
8
15,5
31,0
62,0
124,0
525
3
9
27
9,8
29,4
88,2
264,6
S
—
—
—
100,0
+75,2
+7,3
306,9
+403,4
+66,7
В этой ситуации для стабильности конечных резуль¬
татов необходимо соблюдать дополнительные условия уп¬
рощения, например для вычисления условного момента
первого порядка имеем:
2
i=l
1 s
—- 2 (xi-a)Wi
а i= 1
2
i= 1
Этим методом условный момент первого порядка был
Уменьшен в d раз, так что
i= 1
с/= Ы 50 = 3,65.
100
93
При вычислении момента второго порядка упрощение
на d вело к уменьшению итога на d2;
2
1 = 1
2 (xi — a)2^t
& Z = 1
2
i = 1
Пользуясь данными нашего примера, получим:
2^
i = 1
-502 = 7672,5
100
Подобным образом условный момент третьего порядка вы¬
числяется по формуле
z = 1
^11.508 = 83 375.
100
Для вычисления центральных моментов очень удобно
пользоваться формулами перехода к ним от условных мо¬
ментов:
Pi = vx— = 3,65 — 3,65 = 0;
р2 = v2 —(Vi)2 = 7672,5 —3,652 = 7658,375;
Из == v3—3viv2 + 2 (vi)3 = 83 375 —
— (3 x 3,65 x 7672,5) + (2 x 3,653) = — 612.
Таким образом, вычисления существенно упростились.
Из изложенного следует, что средние величины являются
частной формой начальных моментов. Моменты условные
практически применяются в статистике только для упро¬
щения операции по вычислению средних, дисперсии и т. п.
Средняя имеет конкретное значение: средняя заработ¬
ная плата рабочих, среднее число экономически активных
лиц, приходящихся на семью, средняя скорость обращения
оборотных средств и т. д.
94
Анализируя большое число эмпирических распреде¬
лений, заметили, в общем, что единицы статистических
коллективов имеют тенденцию концентрироваться около
одного варианта какого-либо группового признака, вокруг
некоторой средней величины.
Следовательно, средняя имеет смысл только для ка¬
чественно однородного, гомогенного статистического кол¬
лектива.
Не имеет смысла вычислять средние для неоднородных
гетерогенных и рассеянных популяций, где не существует
тенденции сосредоточения единиц коллектива вокруг ка¬
кого-либо одного значения признака. Функцией средней
является количественная характеристика, которая типич¬
на в границах коллективов.
Для коллективов рассеянных, гетерогенных средняя
лишена смысла. Статистическая средняя отображает объ¬
ективное существование определенного уровня, к которому
стремятся индивидуальные признаки коллективов.
Несмотря на то что понятие средней и ее смысл достаточ¬
но ясны, все-таки в различных практических ситуациях
возникает вопрос выбора формулы ее вычислений, требуется,
таким образом, чтобы средняя наиболее верно отражала
объективную реальность.
В соотношениях величин, зависящих от k, было пока¬
зано, что с помощью формул начальных моментов можно
получить различные средние: среднюю арифметическую,
среднюю гармоническую, среднюю геометрическую и т. д.
Естественно, возникает вопрос: какая средняя наиболее
верно характеризует эмпирическое распределение в кон¬
кретных, хорошо определенных случаях? Каков критерий,
который нужно иметь для выбора средней.
Ответ на этот вопрос был дан в 1929 г. одновременно
Кизини (Италия) и Боярским (СССР).
В определении, данном этими авторами, устанавливает-
ся, что для любого статистического коллектива, состоящего
кз п значений xif х2, ..., хп, существует детерминированное
свойство, которое должно оставаться неизменным при лю¬
бых возможных вариантах xt.
Средняя определена этими авторами как значение х
временной X, которое при подстановке xt = х не изменяет
Терминированного свойства коллектива.
На основании этого определения следует, что детерми¬
нированным свойством X является функция f(x) и что сред-
95
няя х согласно этому детерминированному свойству па-
ходится с помощью равенства
f (х, х, x) = f(xlt х2, ..., хп).
На основе определения Боярского — Кизини решим
задачу по вычислению средних.
Например, возьмем распределение машинно-трактор¬
ных станций по выработке на одного рабочего.
Табл иц а 13
Выработка
на одного
рабочего,
и,.
Число
МТС
Ni
Число
рабочих
на одну
МТС
Ni ti
[wi~a\
kh"
Ниже 251
21
135,24
2 840
—3
—8 520
251—300
39
126,66
4 940
—2
—9 880
301—350
43
146,28
6 290
—1
—6 290
351—400
50
154,60
7 730
0
—24 690
401—450
33
163,94
5410
1
5 410
451—500
34
166,47
5 660
2
11 320
Более 500
23
155,43
3 575
3
10 725
243
—
36 445
X
+27 455
+ 2 765
Нужно вычислить среднюю выработку одного рабочего
в этих 243 МТС.
Характеристика выработки одного рабочего (оу) может
принять любое значение •••> wn-
В таблице приведено еще два ряда данных: число МТС
и среднее число рабочих, которое приходится на одну МТС
в каждом интервале вариации выработки.
Спрашивается, какие из этих данных использовать в
качестве удельного веса и какую среднюю нужно применить
в данном случае. Ответ на этот вопрос дается детермини¬
рованным свойством.
Для установления детерминированного свойства тре¬
буется сначала узнать функциональную зависимость между
признаками, приведенными в таблице.
Детерминированное свойство устанавливается по от¬
ношению к общей продукции МТС в гектарах.
96
Для этой цели нужно установить функциональные от¬
ношен1151 между коррелированными признаками, которые
детерминируют общую продукцию МТС.
Обозначив символом N число МТС, а / — среднее число
рабочих, приходящихся на одну МТС, можно установить
отношение
t-N-w = Q, (III.6.18)
где Q — общая продукция в гектарах.
Детерминированное свойство, которое определяется сред¬
ней, в данном случае имеет следующую форму:
w1t1N1 + wit2N2-\-... + wntnNn= w S iiNi’ (HI.6.19)
из которой следует форма средней арифметической с двой¬
ным весом:
S Mitill
£ tiNi
i = 1
Пользуясь методом условных моментов, получим
/ wi — а \
— : 1 \ d J 2765
w = : d + а = ■ 50 + 375 « 378,65 га.
" 36442
S tiNi
i = 1
Другой пример: объем продажи, средний запас и ско¬
рость обращения товаров в розничных торговых предприя¬
тиях характеризуются следующими данными:
Таблица 14
Объем
продажи
в тысячах
лей
Удельный
вес пред¬
приятий
в про¬
центах
Средний
запас на
пред¬
приятие
(si)
Скорость
обраще¬
ния
в днях
(zi)
wisi
1 Q
—wisi
Zi
Ниже 250
14,2
34
78
482,8
6,2
251—500
18,9
53
52
1001,7
19,3
501—750
14,3
77
44
1101,1
25,0
751—1 000
10,7
102
42
1091,4
26,0
7
Зак. 1050
97
Продолжение
Объем
продажи
в тысячах
лей
Удельный
вес пред¬
приятий
в процен¬
тах
<wi)
Средний
запас на
пред¬
приятие
(si)
Скорость
обраще¬
ния
в днях
(z,)
1 „
■z7wi si
1 001—1 500
13,9
142
42
1973,8
47,0
1 501—2 500
12,8
242
46
3097,6
67,3
2 501—5 000
9,3
490
51
4557,0
98,4
Выше 5 000
5,9
1 321
48
7793,9
162,4
Всего
100,0
—
—
| 21099,3
442,6
Для вычисления средней скорости обращения в роз¬
ничной торговле нужно установить детерминированное
свойство функции объема продажи в розничном предприя¬
тии.
Главным признаком, средний уровень которого вычис¬
ляется, является скорость обращения (Z). Общий объем роз¬
ничной продажи можно выразить в функции скорости об¬
ращения следующим уравнением:
T^ = v, (Ш.6.20)
в котором обозначим символами:
Т — число календарных дней в рассматриваемом периоде;
wt — удельный вес числа торговых предприятий;
— средний запас на торговую единицу;
V — объем розничной продажи.
Детерминированное свойство в этом случае дается урав¬
нением
и 1 j п
Т ^TwiS‘=TT^w‘S‘- (III.6.21)
/=1 1 7=1
Упрощая обе части уравнения на Т и выделяя неиз¬
вестную величину, получим
П J
2 — Si
1 _ i=\
z n
S wiSi
i=l
98
откуда следует выражение
2 ^s*'i
z = -^-
п !
2 7" Wi Si
i= 1
(III.6.22)
которое представляет собой формулу средней гармони¬
ческой с двойным весом.
В нашем примере
2 _ 21099,3 _
~~ 442,6 ~
47,6 дня.
Из приведенных двух последних примеров можно из¬
влечь следующее заключение:
а) хотя детерминированное свойство (в отношении ко¬
торого определяется средняя) может рассматриваться
абстрактно, как некоторая математическая функция
ф(%1, х2, ...» хп), не нужно терять из виду конкретное зна¬
чение элементарной переменной, которая представляет
собой численное выражение некоторого признака, общего
для всех единиц статистического коллектива, а не корреля¬
цию между различными признаками. Детерминированное
свойство, на основе которого делается вывод о форме сред¬
ней, служит, таким образом, детерминированным свойством
каждого статистического коллектива; оно остается неизмен¬
ным в синтезировании значений признака xt единой типич¬
ной величиной.
Следовательно, средняя может рассматриваться как
синтетическая характеристика, которая описывает рас¬
пределение посредством единой величины вместо ряда зна¬
чений xt, когда изучаемое детерминированное свойство
Коллектива остается неизменным;
б) детерминированное свойство коллектива, которое
Понимается как функция, зависит от числа признаков кол¬
лектива, от его непрерывности и структуры (в случаях,
Когда значения выражены комплексными показателями)
и от отношения между первичными компонентами и ком¬
плексным показателем.
7*
99
Детерминированным свойством средней арифметической
является данная сумма значений хг:
п _ п
f(xly х2, ...,хп) = 2 Щх^х 2
i = 1 i = 1
где n = У nt.
В случае средней гармонической детерминированным
свойством является форма
п п
Средняя гармоническая оказывается, таким образом,
средней из обратных величин рассматриваемых признаков
и применяется, как правило, тогда, когда переменная
является показателем производным, со сложной структу¬
рой.
Детерминированным свойством степенной средней яв¬
ляется отношение
2 xi ni = xk 2 ni> (Ш.6.23)
i = 1 i = 1
а для средней геометрической —
2 logxf = logz 2 ni> (III.6.24)
i = 1 i = 1
в) проблема выбора системы удельных весов и формулы
средней не решается механически. К ее разрешению ведет
анализ существенных свойств анализируемого явления и
определение на этой основе детерминированных свойств
коллектива.
§ 7. ПОКАЗАТЕЛИ ВАРИАЦИИ
В анализе эмпирических распределений характеристика
вариаций значений изучаемого признака около средней
имеет особенную важность.
Чем менее рассеяны наблюдаемые величины, тем более
репрезентативными будут средние.
Применяемые для характеристики вариации показатели
достаточно многочисленны, а их репрезентативность за¬
висит, очевидно, от форм и методов вычисления.
100
В общем эти показатели основываются на вычислении
отдельных отклонений.
Амплитуда или размах вариаций в границах эмпири¬
ческого распределения вычисляется как разность между
наибольшим и наименьшим значением признака.
Если этот показатель обозначить символами R, то по¬
лучим
R — ^тах Л-m in*
Например, для распределения величин 12,8, 6,5 и 1 ам¬
плитуда вариации равна 11, т. е.
/?= 12— 1 = 11.
Следовательно, вычисление этого показателя крайне
просто; он используется, как правило, в качестве вспомо¬
гательного показателя при анализе, особенно в статисти¬
ческом контроле качества продукции.
Интерквартильная вариация. Для того чтобы избежать
недостатков, связанных с использованием крайних зна¬
чений, для характеристики вариации пользуются разно¬
стями между двумя значениями переменной, выбираемыми
таким образом, чтобы число наблюдаемых случаев распре¬
делялось пропорционально по интервалам (продвигаясь
от низшего значения признака к высшему значению).
С этой целью пользуются квартилями ряда распре¬
деления.
Квартили это значения признака в распределении (Qi,
Q2 и Q3), выбранные так, что, после того как наблюдаемые
величины расположены в восходящем порядке, 25% из
числа единиц совокупности будут ниже 25% будут за¬
ключены между Qi и Q2, 25% между Q2 и Фз’> остальные 25%
превосходят Q3.
Когда величины квартилей приближаются к медиане,
эмпирическое распределение характеризуется малым рас¬
сеянием. Следовательно, в качестве показателя вариации
Можно взять отклонение квартилей от медианы.
Квартили ряда распределения определяются методом
подобным тому, который применяется для медианы. Сна¬
чала устанавливается основной интервал, в котором на¬
ходятся ранг * для Qi, З/г/4 для Q3,a затем линейным ин¬
терполированием в пределах этого интервала определяются
соответствующие значения признака. Этот способ осуществ¬
101
ляется посредством следующих формул вычисления квар.
тилей:
Qi = %k — 1 Н р ъ d', (III. 7.1 ]
rh~~rk-\ '
Q2 = Me; (III.7.2)
3 p p
Q3 = %k — i d p ^^pk ’ (HI • 7.3)
(сохранены обозначения, которыми пользовались для вы¬
числения медианы).
Согласно примеру, приведенному на стр. 79—81 (распре¬
деление группы 49 промышленных предприятий по ско¬
рости обращения оборотных средств), в котором вычислена
49
медиана, имеем для Qi — = 12,25.
Следовательно, квартиль Qi попадает в интервал, соот¬
ветствующий скорости обращения 30—40 дней.
Применяя формулу (III.7.1), находим величину квар¬
тиля Qi = 33,86 дня:
QT = 30+12,25 - 8 -10 = 33,86 дня.
Квартиль Q3, соответствующий накопленной частоте
з
49^ равен 36,75, заключен в интервале 50—60 дней.
Поэтому получим:
Q3 = 50+ 36,75-35 х 10 = 51,94 дня.
Для Q2 = Me вычисленная величина равна 43,44 дня.
Квартили могут быть определены приближенно графи¬
ческим методом с помощью полигона накопленных частот
(огива) согласно технике, описанной при нахождении ме¬
дианы.
Квартили согласно графику (рис. 14) являются абсцис¬
сами точек пересечения огивы с линиями ординат:
1 9 3
F-— , F — и F —.
4 4 4
J02
Исследуем кратко полученный результат. Ясно, что
между первым квартилем и медианой расположены 1/4
общего числа значений признака в коллективе, а также что
между первым и третьим квартилем находится половина
всего числа значений и
признаков.
Если р асп р едел ен и е
симметрично, то оправ¬
дывается с л ед у ющее
равенство:
х = Ме\
х— Qx = Q3 — х.
Можно вычислить
среднее отклонение, ко¬
торое условно обозна¬
чим Q и будем назы¬
вать интерквартильной
вариацией:
+ Q3-x) =
(III.7.4)
Интерквартильная
вариация в примере
распределения промыш¬
ленных предприятий по
средств равна 9,04 для
Рис. 14.
скорости обращения оборотных
Если Q 0, то это означает, что вариация в этом ин¬
тервале мала.
Этот относительно простой показатель особенно удобен
Для характеристики распределения вариации с небольшим
Числом интервалов. Очевидно, что он имеет и некоторые не¬
достатки, вытекающие из того факта, что он относится к
Вариации, соответствующей значениям признака, группиру¬
103
ющимся около медианы, а остальные 50% значений игц0.
рируются.
Для сравнительного изучения вариаций вычисляется
коэффициент интерквартильной вариации.
Коэффициент интерквартильной вариации, который обо.
значается символом q, представляет собой отношение между
интерквартильной вариацией и медианой:
Q3—Qi
Q _ 2
~ Me ~ ~Ме '
или приблизительно
9з—Qi
д __ _ Q3 Q1
Q3 + O1
2
В нашем примере
(III.7.5)
_ 51,94 — 33,86 _ 18,08
~ 51,94 + 33,86 ”"85,80
= 0,21.
Коэффициент интерквартильной вариации колеблется
между —1 и +1.
Он приближается к нулю в случаях симметричного рас¬
пределения с очень малой вариацией.
Среднее линейное отклонение, или среднее абсолютное
отклонение, представляет собой среднюю из отклонений от
средней, взятых в абсолютных значениях:
п _
2 I X | Щ
0 = ^-^ . (III.7.6)
i= 1
Несмотря на легкость вычисления показателя 0, он не¬
удобен с точки зрения точности результатов.
Самым выразительным показателем, характеризующим
вариацию, является дисперсия.
Понятие дисперсии, которое мы еще не рассматривали,
выражает центральный момент второго порядка (р2).
Среднее квадратическое отклонение, или стандартно?
отклонение, является квадратным корнем из дисперсии
(/^), а коэффициент вариации процентным отношением
104
между средним квадратическим отклонением и средней рас¬
пределения:
tr100)-
Вычисление дисперсии имеет важное практическое зна¬
чение в статистико-экономическом анализе. Например, про¬
изводительность труда рабочего за одну смену в двух
угольных шахтах одинакова — 2,6 т. Однако дисперсия
производительности труда в них сильно различается
(3,6125 в шахте А и 1,01787 в шахте В). Можно спросить,
почему так велика дисперсия в шахте А. Анализируя при¬
чины, которые определяют производительность труда ра¬
бочих в этих двух шахтах (толщина угольного пласта, объем
тектонической формации и степень механизации работ),
заключаем, что условия работы в шахте А отличаются от
условий работы в шахте В, и что это имеет влияние на рит¬
мичное развитие процессов вырубки угля в шахте. Шахта А
характеризуется тонкими слоями, с пропорцией тектони¬
ческих формаций 15—30%. Степень механизации подзем¬
ных работ много ниже, чем в шахте В.
Все эти условия приводят к тому, что производитель¬
ность труда рабочего в смену очень сильно варьирует в шах¬
те А по сравнению с производительностью труда в шахте В.
§ 8. АСИММЕТРИЯ, ЭКСЦЕСС
Воспользуемся теперь конкретно моментами третьего
(Рз) и четвертого (р4) порядка.
В случае симметричного распределения нечетные цент¬
ральные моменты равны нулю. Поэтому если третий цент¬
ральный момент не равен нулю, то это свидетельствует об
асимметрии распределения.
Для распределения нормированной переменной (сред¬
няя Х(о) = 0, дисперсия или момент второго порядка р2 =1)
момент третьего порядка, который условно обозначим сим¬
волом р3, используется для построения показателя асим¬
метрии:
Размер Sk характеризует асимметрию распределения.
105
В практике Sk вычисляется с применением показать
о
Из
ля ₽! = —, а асимметрия вычисляется по формуле ра«
И 2
венства
(ш.8.1)
Когда Sk>0, асимметрия положительна, т. е. |шЛ1о<х
и, наоборот, асимметрия негативна, когда Sh <0.
Асимметрия распределения является характеристикой
формы, полезной для различения распределений.
Последний, четвертый момент согласно нормальному
распределению равен
И4 = 3Н2;
следовательно, при нормальном распределении
р2=4 = з.
|12
Предполагая, что имеются два симметричных распре¬
деления, в которых
Н ‘2 И 2?
И 4
р2 и являются соответственно моментами второго и
четвертого порядка нормального распределения.
Когда р2 == > 3, то это означает, что дисперсия
Н2
распределения несколько отличается от нормальной,
вследствие чего кривая является заостренной сверху по
сравнению с нормальной кривой.
Если ₽2<3, то это указывает на вогнутость по срав¬
нению с нормальной кривой.
Разность ₽2 — 3 = Е называется эксцессом распреде¬
ления.
Когда Е ~ 0, кривая приближается к нормальной кри¬
вой, т. е, является показателем нормальности распреде¬
ления.
Глава IV
определение НОРМАЛЬНОСТИ
ЭМПИРИЧЕСКИХ РАСПРЕДЕЛЕНИЙ.
КРИТЕРИЙ СОГЛАСИЯ
§ 1. ОБЩИЕ ЗАМЕЧАНИЯ
Часто в практике ставится задача анализа статисти¬
ческих рядов с пониженным числом наблюдений, так что
закон больших чисел не действует. В этих случаях нужно
уточнить, насколько в существующих данных проявляются
свойства случайных событий, если их статистическая
закономерность затушевана. Статистические данные по¬
этому должны быть переработаны соответствующим образом
посредством подбора для данной цели подходящей кривой
теоретического распределения, с тем чтобы сделать очевид¬
ными существенные черты исследуемого явления. Решение
подобной задачи означает осуществление серии операций
по переработке данных. Эти операции известны под назва¬
нием подбора статистических рядов.
Проблема «оптимального» и в то же время строго науч¬
ного подбора не является однако вопросом чисто матема¬
тической техники. Прежде всего подбор оптимальной тео¬
ретической кривой, в том смысле, что подобная кривая
Должна давать наилучшую характеристику эмпирической
функции, является задачей неопределенной, а ее решение
зависит от критериев, которые определяют выбор.
Например, в подборе теоретических данных для харак¬
теристики эмпирических отношений зависимости применяет¬
ся обычно метод наименьших квадратов. При этом делается
предположение, что будет реализовано наибольшее прибли¬
жение к эмпирической зависимости в данном классе функ¬
ций, если сумма квадратов отклонений от избранной теоре¬
тической функции окажется наименьшей. Итак, для того
Чтобы решить, какую именно функцию нужно выбрать, ис¬
ходят не из чисто математических соображений, а из изуче¬
ния материальной сущности исследуемого явления, осо¬
107
бенностей полученных эмпирических кривых и точности
наблюдаемых данных. Но нужно подчеркнуть тот факт
что часто основные особенности функции, выражающее
корреляцию между явлениями, не известны заранее из
предшествующих теоретических исследований; в этом случае
только эмпирические данные служат для определения код
кретных числовых параметров, которые входят в матема¬
тические выражения функции при использовании метода
наименьших квадратов.
Аналогичным способом ставится задача теоретического
подбора рядов к эмпирическим распределениям. Принци¬
пиальная форма кривой выбирается на основе соображений,
вытекающих из сущности исследуемых явлений или просто
из наблюдаемых особенностей статистических рядов1.
Поскольку аналитическое выражение теоретической
кривой распределения зависит от определенных параметров,
задача подбора теоретических рядов распределения сводится
к рациональному выбору их численных значений.
Считается, что выбор был рациональным, если между
двумя распределениями: теоретическим и эмпирическим —
существует согласие наиболее полное.
Например, пусть случайный признак X представляет
собой погрешность измерений, возникновение которой яв¬
ляется результатом суммирования множества независимых
элементарных частных ошибок. Очевидно, что на основе
теоретических соображений, изложенных еще в главе II,
можно утверждать, что величина X подчиняется закону
нормального распределения, имея известную плотность
распределения (11.8.8).
1
G У 2л
f (*)
(Х-7И)2
2а2
Задача подбора теоретического ряда к эмпирическому
распределению состоит, следовательно, в рациональном
выборе параметров т и о для указанного выражения.
Несомненно, для других категорий признаков могут
быть выбраны другие законы распределения, согласно yi<a'
занным критериям. Однако независимо от типа аналитиче-
ской функции, которая выбрана для интерполяции эМ'
1 Это зависит в значительной мере от опыта исследователя.
108
лирических данных, нужно знать фундаментальные свой¬
ства плотности каждого распределения:
f (*) > 0;
ос
j f (х) dx = 1.
— оо
(IV. 1.1)
Принятие данной теоретической функции /(%) в качестве
инструмента подбора порождает другую весьма важную
проблему, а именно проблему определения параметров а,
b ... этой функции таким образом, чтобы получить наилуч¬
шее описание изучаемого эмпирического распределения.
Одним из методов, применяемых для решения этой задачи,
является так называемый метод моментов.
Суть этого метода состоит в том, что параметры а, Ь...
выбираются так, чтобы наиболее важные моменты теоре¬
тического распределения были бы равными соответствую¬
щим эмпирическим моментам.
Так, например, когда теоретическая кривая f(x) зависит
только от двух параметров а и Ь, параметры выбираются
таким образом, чтобы средняя величина М (X) и дисперсия
О2(Х) теоретического распределения были идентичными со
средней величиной и дисперсией изучаемого эмпирического
распределения.
§ 2. НОРМАЛЬНАЯ КРИВАЯ КАК ИНСТРУМЕНТ ПОДБОРА
При анализе рядов распределения, характеризующих
многочисленные явления в природе и обществе, часто при¬
бегают к аналитической кривой нормального распределения
Гаусса.
Ниже приводится пример, иллюстрирующий технику
подбора на основе этой кривой.
Предположим, что результаты некоторого числа изме¬
рений характеризуются следующим статистическим рядом
Распределения:
Таблица 15
X
—4; -3
-3; -2
—2; —1
-1; о
0; 1
1; 2
2; 3
3; 4
fn
0,011
0,051
0,140
0,270
0,244
0,172
0,090
0,022
109
Существуют мотивы, оправдывающие подбор этого ра<\
пределения с помощью закона нормального распределения.
Поскольку плотность распределений по этому закону
(II.8.8) зависит от двух параметров тио, выберем рас.
пределение в этом случае так, чтобы первые два момента
(средняя и дисперсия) сохранились.
Вычисление этих типичных величин дает следующие ре.
зультаты:
т*~М(Х) = —3,5 • 0,011 — 2,5-0,051 — 1,5-0,140 —
-0,5-0,270 + 0,5’0,244 + 1,5-0,172 +
+ 2,5-0,090 + 3,5 -0,022 ~ 0,171;
о*а = £»2(Х)= а2 — а? = 2 х? Pi — [M (x)]z= 2,216-
i= 1
— 0,029241 = 2,186759.
Выберем параметры нормальной кривой согласно урав¬
нениям
т* = М*(Х);
о* = ]/Др* (X),
т. е.
т* = 0,171,
о* = ]Л 2,186759~ 1,465.
Закон нормального распределения будет дан, таким об-
разом, следующим выражением:
(х — 0,171)2
2-1.4652
Пользуясь специальной таблицей значений функции
нормального распределения /(%), получим теоретическое
распределение, ограниченное интервалами:
Таблица 16
X
— 4
-3
— 2
-1
0
1
2
3
4
f(x)
0,004
0,025
0,090
0,199
0,274
0,234
0,124
0,041
0,008
110
На рис. 15 приводится гистограмма статистического
ряда, а также подобранная теоретическая кривая.
Можно видеть, что теоретическая кривая /(х) находится
в границах, очень существенно отличающихся от эмпири-
ческого распределения, будучи, однако, свободной от слу¬
чайных неправильностей, проявляющихся в этой гисто¬
грамме.
§ 3. СТАТИСТИЧЕСКАЯ ГИПОТЕЗА. КРИТЕРИЙ СОГЛАСИЯ
Знание теоретических законов распределений различного
типа, с одной стороны, и особенностей эмпирических рас¬
пределений, с другой стороны, делает возможной разработ¬
ку гипотез относительно теоретического закона, которому
следует эмпирическое распределение при данной средней
и Дисперсии генеральной совокупности.
В последующем изучаются критерии оценки достовер¬
ности гипотезы, принятой в связи с законом распределения
н параметрами распределения.
Критерий %2 оценки соответствия между
^еретическим и эмпирическим распределением
Определенные величины, характеризующие соответ¬
ствующие исследуемые единицы, составляющие эмпири-
111
ческое распределение, обрабатываются путем операций
группировки. Предположим, что исследуемые п единиц
наблюдаемых значений группируются в k групп и
что /it, /г2, ...} n.f представляют собой объемы этих
групп.
Подчеркиваем, что критерий %2 применяется в условиях
при которых объем групп больше 5. Если это условие не
выполнено вначале, то группы переделываются посредством
слияния интервалов таким образом, чтобы полученные
группы каждая имели объем больше 5.
По определению случайная переменная %2 равна сумме
квадратов некоторой стохастической независимой перемен¬
ной со средней 0 и дисперсией 1. Переменная %2 характе¬
ризуется известным числом степеней свободы, представля¬
ющих собой число квадратов данной переменной, из кото¬
рого вычтено число линейных отношений, существующих
между переменными, квадраты которых суммируются.
Следовательно, необходимо использовать объем групп
ni(i = 1,2, k) для получения ряда независимых перемен¬
ных со свойствами, указанными выше.
Если дело идет об определенной группе, то исследуемые
единицы могут быть разделены на единицы, которые имеют
свойства, принадлежащие данной группе, и единицы, ко¬
торые не принадлежат к данной группе. Если обозначим
символом pt(i = 1,2, ..., k) вероятность того, что взятая
наугад единица принадлежит группе объема и-, то тогда
среднее число единиц, которые принадлежат к этой группе,
равно пр..
Было показано, что нормированная переменная пред¬
ставляет собой отношение отклонения от средней к сред¬
нему квадратическому отклонению и что она имеет сред¬
нюю О и дисперсию 1. Равным образом известно, что число
единиц Пх9 которые имеют определенные свойства х, сле¬
дует закону биномиального распределения со средней пр
и средним квадратическим отклонением Yпр(\—р),гд£Р
является вероятностью того, что выбранная случайно еди¬
ница имеет свойства х.
Из этого следует, что объем некоторой данной группы т
может ассоциироваться с нормированной переменной
nj — npi
у npi (У—piY
112
Следовательно, числа пх, п2, nk могут находиться
в соответствии с переменными
п1 — пр1 rij—npi nk — npk
У nPi(l-Pi) / npi (1 — pi) ’ ” у npk(\—ph) ’
которые являются стохастически независимыми (т. е. ве¬
роятность некоторой группы, имеющей объем ni9 индиффе¬
рентна к объему других групп), имея среднюю 0 и дис¬
персию 1. Суммируя их квадраты, получим переменную %2:
2_ (^1 —^Р1)2 | | (nj—npi)2
Х “ / пр1(\— Р1) У npi(i —Pi)
(nh — npk)2
Vnph(l — pk)
Доказано, что эту сумму можно заменить суммой
Следовательно, зная: а) объем групп, полученных на
основе некоторого исследования, и б) вероятность того,
что единицы коллектива принадлежит к этой группе, можно
получить переменную %2.
Эта переменная, полученная суммированием квадратов,
переменных (£ = 1, 2, ..., &), связанных линейным
V "Pi
отношением
(«1—npt) + (па—пр2) + ... + (пг — npt) + ... + (tlh — nph) = О
имеет k — 1 степеней свободы.
Предполагается, что вероятность pt известна, но в дей¬
ствительности она не известна. Если, однако, эмпирическое
Распределение известной переменной х следует определен¬
ному закону распределения известной F(x), то тогда вероят¬
ность р. можно определить с помощью отношения
Pi = F (xj —F(xz_i),
гДе, как известно, F(Xi) — значение функции распреде¬
ления, соответствующее высшей границе интервала /,
Так же как —значение функции распределения,
Зак. 1050
113
соответствующее высшей границе предшествующего иц.
тервала i — 1.
Если параметры распределения не известны, а это бы.
вает очень часто, тогда они оцениваются на основе изучав
мых данных. В этих обстоятельствах случайная перемен,
ная х1 2 имеет число степеней свободы, уменьшенное на число
параметров распределения.
Заметим, что при I параметров распределения число
степеней свободы переменной х2 равно k — I — 1.
Если эмпирические распределения следуют закону тео¬
ретического распределения ^(х), то тогда переменная
будет иметь величину, меньшую чем полученная по фор-
муле (IV.3.1). Эти величины определяются, таким образом,
тем, что вероятность, которая ее превосходит, меньше чем !
0,05х; эту вероятность обозначим символом q\. Значение
переменной х2, соответствующее вероятности q\ установ¬
ленной исследователем, обозначается символом х?ь
Следовательно, можно написать отношение
q = (IV.3.2)
Поскольку для вероятности qi выбирается величина,
меньшая чем 0,05, считается, что результат, которым мы
интересуемся x2>X?i практически невозможен. Это форму¬
лируется следующим правилом: величина, полученная вы¬
числением с применением формулы IV.3.1, переменной %2
большей, чем x?i> отвергает гипотезу, что эмпирическое
распределение следует теоретическому закону функции
распределения F(x). Все же можно получить величины пе¬
ременной х2 большие, чем величины х?ь также в случаях,
когда гипотеза верна. Это в соответствии с правилом ведет
к необходимости отвергнуть гипотезу.
Следовательно, в 100^1 случаях из 100 существует воз¬
можность отвергнуть правильную гипотезу как следствие
того факта, что полученные величины переменной х2 боль¬
ше, чем х^ь В этом случае говорят, что совершают ошибку
типа /, а риск совершить подобную ошибку измеряют веь
роятностью ^i, которая называется риском типа I,
В сущности проверка гипотезы, что эмпирическое рас¬
пределение следует определенному закону распределения
1 Если вероятность результата меньше чем 0,05, то предпола¬
гают, что практически такой результат невозможен.
114
с функцией распределения F(x), означает вычисление ве-
дичины переменной х1 2 с помощью формулы (IV.3.1); эта
величина сравнивается с величиной соответствующей
риску типа It/i. Гипотеза принимается, если величина х2,
полученная вычислением, меньше или равна величине х?ь
и отвергается, если получен противоположный результат.
находят в таблице, разработанной для распределения
переменной х2 в функции риска и числа степеней сво¬
боды k — I — 1.
В специальных таблицах1 даются значения функции рас¬
пределения х2, т. е.
F(%2) = P(x2<x^)>
(IV.3.3)
если результаты %2 < и %2 > противоположны вы¬
воду, что соответствует вероятности F (%2) = 1—qi.
Применение критерия х2 для проверки
нормальности распределения
Предположим, что при анализе эмпирического распре¬
деления допускается гипотеза, что эмпирическое распре¬
деление следует закону нормального распределения с функ¬
цией распределения
1 р (х — т)2
I е~
— оо
Для определения вероятности pt необходимо вычислить
значение переменной х2» пользуясь таблицей значений
приведенной выше функции2.
1 N. R а п с u, L. Т б v i s s i. Statistics matematica cu apli-
£4ii in produc|ie, Editura Academiei, tabel VII, Bucuresti, pp. 824 —
827. (Таблицы, на которые ссылается автор, приложены к многим
Учебникам математической статистики. См., например: Н. К. Д р у-
^Инин. Основные математико-статистические методы в эконо¬
мических исследованиях М., «Статистика», 1968; И. Г. Венец-
к и й, Г. С. К и л ь д и ш е в. Основы теории вероятностей и мате¬
матической статистики, М., «Статистика», 1968. См. также прило¬
жения к этой книге, стр. 205—221. — Прим, перев.)
2 Т а м же, стр. 808—819.
8*
115
В этой таблице находим формулу
в которой
— оо
х— т
Следовательно,
Z
Вычисляя среднюю арифметическую и среднее квадра¬
тическое отклонение, получим т* =5,4% и о = 1,01%,
Вычисление величин переменной х2 производится по
схеме, данной в табл. 17 (см. стр. 117). Получаем х2 =
= 1,1107 (последняя колонка).
Выбирая для риска типа I величину q\ = 0,025 и учи¬
тывая, что число степеней свободы вытекает из числа ин¬
тервалов минус 3(5—3=2), в таблице значений переменной
X2 находим соответствующую вероятность Е(х2) = 0,975
и f = 2, величину x^i = 7,38.
Поскольку величина 1,1107, полученная вычислением
переменной х2, меньше, чем найденная по таблице величина
7,38, заключаем, что гипотеза относительно нормальности
распределения влажности высушенных опилок верна (см.
пример 1 на стр. 118).
Применение критерия х2 в случае, когда эмпирическое
распределение следует закону Пуассона
Если анализ распределения и условия, в которых полу*
чено это распределение, позволяют выдвинуть гипотезу,
что исследуемые характеристики следуют закону Пуас¬
сона, то вероятность pt определяется посредством приме¬
нения формулы, в которой функция распределения имее'Г
известное выражение:
X
А=0
116
Т а б л и и, а VI
сх
*1
сГ
е
-
0,0158
0,1356
6660‘0
0,1517
0,7077
1,1107
г-
о
о
о
о
о
о
оз
о
о
о
ю
00
04
о
г-
е
г-
СО
04
1
о
04
LQ
О1
о
С1
о"
04
СО
СО"
со
ф
СО
Ф
Ф
Г--
о>
Ю
О
со
04
ф
ю
LO
ь-
1
о
1
О
~-<
04
04
1
1
е
1
1
СО
СО
Ф
СО
СО
04
оз
LO
03
СО
Q
СО
ф
Ю
Ф
04
С
ф"
со"
LO
со"
ф
'
04
,
Ю
со
00
СО
г-
£
ОЗ
04
ю
04
04
п н
со
Ф
Ф
со
о, о
о-
Г--
о
04
СО
04
О
й К
о
о"
О*
О
o'
ю
,
О>
ю
04
о
04
О-
о
СО
о
00
со
Оз
О
о
СО
СО
ф
Ф
к.
о
о
о"
о
o'
£
1
to
00
оз
03
00
г-
Ф
ф
ф
ф
ф
ю
II
7
о
1
о
’-"ч
04
ц
1
1
о
о
о
о
О
1
Ю
ю
ю
ю
ю
1
ф
т—<
о
о"
,—(
оГ
1
1
Н (
2 «
-
Ч Ф
ь
ш
ю
со
03
СО
00
8 2
со
04
СО
\О J
Q
< К
л *
М
ь 2 - о
и ± 5-
о
о
03
оз
03
со"
ф
LO
со"
X А- $ 23 1
OI
1
о>
1
оз
1
оз
1
О)
1
03
И
ЧЕ-
CQ
М
< £
О1
со
ф
Ю
со
—
udэнон
04
СО
к cloj [
-
ф
ю
1
ЗГ-—
117
Значения этой функции даны в таблице 1 как функцИи
переменной величины х и параметра % в формуле Пуассона
Этот параметр является средней арифметической изучав
мого признака.
При установлении числа степеней свободы учитывает,
ся, что распределение имеет два параметра, так что число
степеней свободы составляет k = 3 (число интервалов с
абсолютной частотой, большей чем 5 минус 3).
Примеры'. 1. В процессе изготовления прессованных пла¬
стинок из древесных опилок влажность высушенных опи¬
лок является одним из признаков, которые определяют ка¬
чество этого изделия. Для характеристики процесса про-
изводства с точки зрения влажности высушенных опилок
необходимо проверить, является ли распределение значений
этого признака нормальным. С этой целью сделано 68 проб
влажности в процентах с точностью 0,1%. Поскольку по¬
лучено более 20 различных величин, данные сгруппированы
в пять групп соответственно условию, что число случаев
в каждой группе будет не меньше чем 5. Полученное таким
образом эмпирическое распределение приведено в колон¬
ках 2 и 3 табл. 17.
Имея в виду, что для применения закона Пуассона имеет¬
ся только один параметр, число степеней свободы перемен¬
ной х2 равно k — I — 1 = & — 2, т. е. числу значений
минус 2.
2. Вследствие механизации технологического процесса
в угольной шахте достигнуто увеличение скорости продви¬
жения фронта работ. Однако с возрастанием скорости про¬
движения за определенный период увеличивается поверх¬
ность пласта и в то же время поступает больше метана п
угольной мелочи, что сдерживает рост производительности
труда. По этой причине проблема изучения эрупций ме¬
тана и поступления угольной мелочи особенно важна.
В первую очередь нужно установить закон распре
деления числа эрупций метана. Изучение эрупций газа и
шахте дало возможность получить сведения, приводимы6
в колонках 1 и 2 табл. 18.
Для вычисления значений функции распределения соот;
ветствующих величин, характеризующих число эрупШ*11
метана, прежде всего вычисляется величина параметра
1 См. примечание 1 иа стр. 115.
118
Таблица 18
—г*-
С Л
р.сз
“S
ч2
№ 5
1
Число лет,
в которые
имели
место
эрупции
ni
о?
сГ
е
nl-npi
(rtz-np.)2
4Pi
2
3
4
5
6
7
8
0
42
0,640
0,640
38
4
16
0,42
1
10
0,922
0,282
16
—6
36
2,25
2
4
0,989
0,067
4
0
0
0,00
3
3
0,999
0,010
1
2
4
4,00
| 59 |
1
| | 6,67
которая, как было указано, является средней изучаемого
признака. На основе данных таблицы получаем
FQ.424-1.104-2.4 + 3-3
42+10 + 4 + 3
27
- = 0,458.
59
В таблице значений функции распределения Пуассона
находим путем интерполяции для X = 0,458 значения
функции распределения, приведенные в колонке 3 табл. 18.
По этой таблице мы можем затем сделать вычисления, не¬
обходимые для нахождения величины переменной %2, полу¬
чаемой суммированием данных последней колонки и рав¬
ной 6,67.
При риске типа I qi = 0,025 и числе степеней свободы,
равном числу значений признака минус 2 (4 | 2 = 2)
в таблице значений переменной %2, находим = 7,38.
Вычисленная величина 6,67 меньше, чем величина, получен¬
ная по таблице (7,38), и поэтому принимается гипотеза, что
число эрупций метана распределяется по закону Пуассона.
Критерий Колмогорова определения соответствия между
Теоретическим и эмпирическим распределением
Критерий Колмогорова основан на максимальной раз¬
ности между значениями функции теоретического распре¬
деления F (х) и значениями функции F* (х) эмпирического
Распределения.
Колмогоров установил, что, когда п неограниченно
Нозрастает, вероятность того, что максимальная разность
119
между значениями функции теоретического и эмпирического
распределения станет меньше величины —будет приблгь
у п
жаться к значениям функции
+°°
К (А.) = 5 (— l)fee-2*2O
— оо
что выражается формулой
-j-°o
lim Р [ dn < —— = 2 (“ О* е_2/гХ2,
\ У П J -оо
(IV.3.4)
(IV.3.5)
где символом dn обозначается абсолютная величина макси-
мальной разности между значениями теоретического и эм¬
пирического распределений, т. е.
dn = max \F (х) = F* (х) |. (IV.3.6)
Функция Колмогорова сведена в таблицу (см. прило¬
жение 2), и если только известно значение этой функции,
то по таблице можно определить величину X.
Если на основе анализа эмпирического распределения
приходят к заключению, что можно принять гипотезу,
что это распределение следует закону нормального теоре¬
тического распределения согласно функции распределения
F(x), и если эта гипотеза верна, то тогда накопленные от¬
носительные частоты (значения функции эмпирического
распределения) имеют величины, близкие к значениям
функции теоретического распределения, а разности
F(x)-F*(*i); F(x2)-F*(x2); ...; F(xJ - F* (xj; ...;
F (xk) — F* (х/г) являются наименьшими, так что они
тем больше по абсолютной величине, чем меньше величина
%
У п
Величина переменной X выбирается так, чтобы вероят-
%
ность результата dn > — была малой, (ниже 0,05) в силу
у п
того соображения, что невозможно получить такой резуль¬
тат тогда, когда между функцией теоретического и эмпири¬
ческого распределения существует соответствие (т. е. когда
принятая гипотеза верна). Эту вероятность, измеряемую
риском типа I, таким образом, можно выразить так:
Однако результат dn>
X
Vn
противоположен
результату
так что можно написать:
(IV.3.7)
Следовательно, если выбрать величину меньше чем 0,05
для риска типа I qlf тогда из отношения (IV.3.7) опреде¬
ляется та величина К(Х), которая ей соответствует в таб¬
лице величин переменной X; подобным образом, если вели¬
чина н известна и является объемом выборки, то тогда и ве-
X
личина , известна, при данных риске типа I и объеме
У/г
выборки.
Вообще, на основе вычислений устанавливается dn,
разность по абсолютной величине между значениями функ¬
ций теоретического и эмпирического распределения; эта
о X
разность сравнивается с величиной —, которую находят
у п
по таблице.
Если dn меньше, чем то считается правильной ги-
У п
потеза, что между теоретическим и эмпирическим распре¬
делением существует соответствие или что изучаемая пере¬
менная следует закону теоретического распределения
с функцией распределения F (х).
Если dn больше, чем то отвергается гипотеза, что
У п
изучаемая переменная следует закону с функцией распре¬
деления F (х).
Применение критерия Колмогорова в оценке
эмпирического распределения
Предположим, что существует эмпирическое распреде¬
ление, в связи с которым выдвигается гипотеза, что оно сле¬
дует закону нормального распределения с функцией рас-
пРеделения F (х).
121
На основе абсолютных частот nt вычисляются локалы
fli
ные относительные частоты = — и кумулированные от-
носительные частоты
i
F* (х;) = да1 + да2 + +... w.= 2 ws,
s= 1
так как иногда более удобно вычислять накопленные отно¬
сительные частоты делением абсолютных накопленных час¬
тот
i
S=1
на /г, общее число единиц, т. е.
По таблице со значениями функции распределения F (х)
нормального распределения устанавливаются величины,
соответствующие высшим границам интервалов, т. е. оты¬
скиваются значения функции распределения, которые кор¬
респондируют величинам г, вычисленным для высших
границ интервалов.
В табл. 19 приведена схема вычисления при применении
критерия Колмогоровым в оценке нормальности распре¬
деления влажности высушенных опилок. В колонке 6
приведены значения функции распределения, соответ¬
ствующие величинам г, вычисленным в колонке 5 для
границ 3,9; 4,9 и 6,9. Отметим, что вместо 7,9 берется
высшая граница интервала х = + оо и, следователь¬
но, z = + oo, так что для последнего интервала значе¬
ние функции распределения Г(4- оо) = 1,0. В ко¬
лонке 7 приводятся абсолютные накопленные частоты,
а в колонке 8 приводятся относительные накопленные час¬
тоты, полученные делением данных колонки 7 на 68 (общее
число изучаемых единиц). В колонке 9 приводятся раз¬
ности между значениями теоретической функции распре¬
деления (колонка 6) и значениями функции эмпирического
распределения (колонка 8). Можно видеть, что наибольшую
по абсолютной величине разность представляет dn = 0,06,
что соответствует интервалу с порядковым числом 3. Эта
величина, полученная вычислением по гипотезе, согласно
которой распределение влажности следует нормальному
122
л
закону, сопоставляется с —== Для риска типа I q\ = 0,05,
У п
следовательно, при значении функции Колмогорова
К (X) = 1 — q\ = 0,95, находим X = 1,36, так что для
а = 68 имеем -^=0,168.
У п
Таблица 19
№ п/п
Влаж¬
ность в
процентах
Частоты
абсолютные
п1
1^
£
1
1
г
ь
1
■Г"
u.
Частота
абсолют¬
ная накоп¬
ленная
i
3=1
Частота от¬
носительная
накопленная
F* (х)
jh
N
*
1
2
3
4
5
6
7
8
9
1
2,9—3,9
5
— 1,50
— 1,
.48
0,0695
5
0,07
0,00
2
3,9—4,9
15
—0,50
—0,49
0,3121
20
0,29
0,02
3
4,9—5,9
23
0,50
0,49
0,6879
43
0,63
0,06
4
5,9—6,9
19
1,50
1,
.48
0,9305
62
0,91
0,02
5
6,9—7,9
6
2,50
2,47
1,0000
68
1,00
0,00
S
68
—
—
—
—
—
Поскольку величина, полученная вычислением, dn =
= 0,06, меньше, чем величина, определенная по таблице,
— = 0,168, принимается гипотеза, что влажность сухих
У п
опилок подчиняется закону нормального распределения.
Можно видеть, что как критерий х2, так и критерий Кол¬
могорова ведут к одному и тому же заключению: эмпири¬
ческое распределение следует нормальному закону.
Применение критерия Колмогорова в оценке
соответствия между распределением Пуассона
и эрупциями газа метана и доли угольной мелочи
В табл. 20 приводится распределение эрупций газа ме¬
тана и доли угольной мелочи, так чтобы с помощью крите¬
рия х2 показать, что оно следует закону распределения
Пуассона. Покажем, что, пользуясь критерием Колмого¬
рова, можно прийти к такому же заключению относительно
соответствия между распределениегл Пуассона и эмпири¬
ческим распределением.
123
Таблица 20
X
п1
F U)
ni
F* (х)
F (х) —F* (х)
59
1
2
3
4
5
6
0
42
0,640
0,71
0,71
—0,07
1
10
0,922
0,17
0,88
0,04
2
4
0,989
0,07
0,95
0,04
3
3
0,999
0,05
1,00
0,00
S
59
—
1,00
- 1
1 -
С целью установления разности ^определим по таблице
значения функции распределения Пуассона, соответствую¬
щие числу эрупций (0; 1; 2; 3), имевших место за 59 лет,
учитывая, что среднее число эрупций составляет 0,458.
Путем интерполяции устанавливаем эти величины, приве¬
денные в колонке 3 табл. 20. Подобным же образом вычис¬
ляются и значения функции эмпирического распределения
(накопленные относительные частоты), которые приводятся
в колонке 5 табл. 19. В колонке 6 вычислены разности
F (х) — F* (х). Заметим, что наибольшей разностью абсо¬
лютных значений является та, которая соответствует зна¬
чению х = 0, т. е. dn = 0,07.
Если выбрать риск типа I q\ = 0,05, следовательно,
если функция Колмогорова имеет значение К (X) = 1 —
— qx = 0,95, то в таблице находим X = 1,36; для /г = 59
получаем = 0,18. Очевидно, что величина d = 0,07,
полученная вычислением, меньше, чем величина, установ-
ленная по таблице на основе = 0,18; так что приходим
У и
к заключению, что число эрупций метана и количество
добываемой угольной мелочи следует закону Пуассона.
Оценка нормальности на основе многих наблюдении
сокращенного объема
Часто на практике трудно получить большое число по¬
следовательных наблюдений, касающихся определенного
признака. В этих случаях пользуются несколькими после¬
довательными наблюдениями сокращенного объема, полу-
124
генными в различные моменты. Эти наблюдения не могут
быть объединены в одно эмпирическое распределение, по¬
тому что возможно, что средняя арифметическая и среднее
квадратическое отклонение каждого частичного наблюде¬
ния не будут оценками такой же средней и такой же диспер¬
сии генеральной совокупности. Поэтому для оценки соот¬
ветствия между теоретическим и эмпирическим распре¬
делением не может быть применен критерий, рассмотренный
выше, в данной форме. Следовательно, оценку нормаль¬
ности нужно сделать без принятия гипотезы о генеральной
средней и генеральной средней квадратической. С этой
целью пользуются нормированными отклонениями наблю¬
даемых данных от выборочных средних х:
st
где i указывает порядковый номер выборки, a v — поряд¬
ковый номер наблюдения в выборке. Переменная и имеет
функцию распределения F (и), которая не зависит от объема
выборки, но зато имеет недостаток, заключающийся в том,
что ее вычисление ввиду различных объемов выборок,
весьма громоздко. Поэтому целесообразно установить связь
между этой переменной и переменной Стьюдента.
Оказывается, что если изучаемый признак следует за¬
кону нормального распределения, то переменная
(IV.3.9)
у п — 1 — и1 2
следует закону распределения Стьюдента с п — 2 степенями
свободы при п объеме выборок.
При переменной t задача оценки нормальности эмпири¬
ческого распределения ограничивается проверкой факта,
Действительно ли переменная t следует закону распреде¬
ления Стьюдента.
С этой целью применяется критерий Колмогорова в фор¬
ме, представленной ниже. Применяя формулу IV.3.8, вы¬
числяют значения переменной ц, соответствующие одному
отдельному наблюдению из каждой выборки, с порядковым
заранее фиксированным номером v, который является од¬
ним и тем же для всех выборок. Если производят К выбо¬
1 Типичные величины каждого наблюдения сокращенного объ¬
ема могут рассматриваться как выборочные величины.
125
рок, то вычисляют К значений переменной и. На основе
этих /< значений переменной и с помощью формулы (IV.3.9)
вычисляется К значений переменной t, которые записы¬
ваются в таблицу в возрастающем порядке.
Поскольку значения переменной t записываются в воз¬
растающем порядке и каждое из них имеет частоту 1, зна¬
чения функции эмпирического распределения Fj опреде¬
ляются просто посредством формулы
1
(iv.3.10)
где / есть порядковый номер значений переменной Z, рас¬
положенных в возрастающем порядке (в отличие от 1, ко¬
торая представлена порядковым номером выборки), тогда
как К является числом выборок.
Значения функции распределения Стьюдента F(tj)
берутся из таблицы в зависимости от значений переменной t
и числа степеней свободы f = п — 2. В таблице 1 приведены
значения функции распределения, соответствующие по¬
ложительным величинам переменной /; если, однако, пе¬
ременная t имеет отрицательные значения, то для опреде¬
ления соответствующих значений функции распределения
пользуются отношением:
F(-t)=\-F(t). (IV.3.11)
Данные значения функции теоретического распределе¬
ния F (t ) и эмпирического распределения Fj* дают воз¬
можность установить, можно ли применять критерий Колмо¬
горова, который в этом случае состоит в сравнении макси¬
мальной разности (по абсолютному значению), между F(tj)
и F; с величиной полученной по таблице значений
V п
функций Колмогорова и по числу выборок К-
Пример. Прохладительные напитки, изготовляемые из
натуральных фруктовых соков или из ароматического эк¬
стракта лимонной кожуры, должны иметь ряд характери¬
стик, в частности необходимо содержание 9—10 г сахара на
каждые 100 г раствора. Предлагаемая задача заключается
в том, чтобы, пользуясь статистико-математическими мето¬
дами, управлять процессом изготовления прохладительных
1 См. примечание 1 на стр. 115.
126
напитков так, чтобы обеспечить получение напитка, который
имел бы содержание сахара, заключающееся между по¬
стоянными границами, следовательно так, чтобы напиток
содержал не больше сахара (что влечет повышение себесто¬
имости) и не меньше (что причиняет ущерб потребителю).
Для того чтобы знать вариации содержания сахара
в разных бутылках, в течение 5 часов извлекают каждый
час с закупорочной машины по 9 бутылок. Так, получено
было 5 выборок по 9 наблюдений каждая, результаты ана¬
лиза которых приведены в табл. 21.
Таблица 21
Порядковый
номер опро¬
бованных
бутылок
Порядковый номер выборки (часы) 1
9
10
11
1 2
13
1
2
3
4
5
6
1
9,2
9,2
9,3
9,3
9,2
2
9,0
8,9
8,9
9,2
9,0
3
9,3
9,1
9,3
9,3
9,3
4
9,5
9,3
9,0
8,9
9,2
5
9,4
9,2
9,3
9,4
9,3
6
9,4
8,9
9,3
8,9
9,2
7
9,4
8,8
9,2
9,2
8,9
8
8,8
9,2
9,2
9,2
9,0
9
9,3
9,3
9,3
9,3
9,3
Для каждой выборки вычислена средняя и дисперсия
S\, которые приведены в табл. 22 (колонки 3 и 4).
Условия, в которых происходит процесс изготовления,
не позволяют выдвинуть гипотезу, что распределение со¬
держания сахара в прохладительных напитках является
нормальным. Для проверки того, что эта гипотеза верна,
применим критерий, исследованный выше. С этой целью
выберем случайный порядковый номер наблюдения из
состава выборок, на основе которого вычислим значение
переменной и применим отношение (IV.3.8).
Условимся пользоваться наблюдением с порядковым
Номером 5 и, следовательно, значениями х15 = 9,40;
*25 = 9,20; х35 = 9,30; %45 = 9,40 и х55 = 9,30 (эти данные
записаны в колонке 2—6 табл. 21).
В колонке 6 табл. 22 вычисляется 5 значений перемен¬
ной и, а в колонках 6—11 производятся вычисления, не-
127
Таблица 22
[СЧ
I
е
СП
—<
СО
1--
г—
о
Tf
00
сч
СО
UO
(О
со
00
О
О
О
—Г
о
I
о
г-
со
ОО
см
СО
сч
о
ио
о
ю
СО
00
см
СП
LO
о-
СО
СО
СП
Г-
г-
С-
ю
со
см"
сч"
сч
см
см
LO
to
00
О
СО
00
00
о
г-
о
СП
tr¬
СП
00
LO
ee
Tf
сч
г-
г-
г-
со
г-
8
СО
LO
СО
сч
со
00
ю
см
о
оо
сч
00
о
ем
о
оо
’’ф
со
LO
ю
tr¬
о"
о"
о"
ee
II
1^
СО
СМ
г-
о
СО
|сч
’’t1
00
о
СП
сч
1
о
СП
СО
1
г—
tr¬
СП
г-
со
СО
1 е
ee
00
со
сч
II
_г
со"
сч"
к4
00
о
о
1
г-
00
сч
LO
1
СО
’ф
со
г-
о
>)
С-0
СО
о
СО
>г
со
ю
г-
сч
00
1
1
о
о
о
о
о
5
£
ю
о
о
I
to
1
сч
1
ю
0
о
о
о
о
о
со
Tt<
СО
tr-
СО
СО
со
г-
СО
с—
’’ф
СО
tr-
со
СМ
т“ч
1
*
1
о
о"
о
о
о
LO
сч
СП
О
со
СП
о
сч
оГ
СП
СП
«о
oq
О
’'ф
а?
о
см
СП
о
со
СП
о
СП
ю
СП
о
со
СП
7 мобормя
udawoH
oiqaoMtfKdou
сч
со
Ю
128
обхоДимые для определения значений переменной t со¬
образно отношению (IV.3.9). Значения переменной /, при¬
веденные в колонке 11, записываются в порядке возраста¬
ния в колонке 2 табл. 23.
Таблица 23
№ п/п
9
F (fj)
1
2
3
4
5
1
0,541
0,100
0 683
0,583
2
0,609
0,300
0,715
0,415
3
0,683
0,500
0,930
0,430
4
0,827
0,700
0,773
0,073
5
1,317
0,900
0,879
0,021
Из таблицы значений функции распределения Стьюдента
берут соответствующие величины приведенные в колонке
2 таблицы, и число степеней свободы f = п — 2 = 9 —
— 2 = 7; эти величины приведены в колонке 4 табл. 23.
Для вычисления значений функции эмпирического рас¬
пределения применяется отношение IV.3.8, и они записы¬
ваются в колонке 3 табл. 23.
В заключение вычисляются разности F(tj)— F*, ко¬
торые приводятся в колонке 5 табл. 23.
Наибольшей из этих разностей является dn~ 0,583.
Эта величина меньше, чем величина = 0,68,
У k у 5
определенная в зависимости от риска и числа
выборок К = 5 по отношению К(Х)=1—с результа¬
том 0,95, который соответствует Х= 1,36.
Так как величина, полученная вычислением на основе
эмпирического распределения, 0,538, меньше, чем ве¬
личина, полученная на основе таблицы (0,68), можно сде¬
лать заключение, что переменная t следует закону Стью-
Дента и что содержание сахара в прохладительных напит¬
ках следует закону нормального распределения.
Зак. 1050
9
Глава V
МНОГОМЕРНЫЕ РАСПРЕДЕЛЕНИЯ
(ПО НЕСКОЛЬКИМ ПРИЗНАКАМ)
§ 1. ОБЩИЕ ЗАМЕЧАНИЯ
В предшествующих главах были рассмотрены случайные
переменные (признаки), возможные значения которых яв¬
ляются числами, корреспондирующими вероятностям или
соответствующим частотам, определяемым одномерным
теоретическим или эмпирическим распределением.
В статистической практике встречаются, однако, много¬
численные случайные переменные, значения которых яв¬
ляются системой двух, трех, ..., п чисел. В этом случае не¬
которому значению первой переменной корреспондирует
целый ряд значений второй, третьей, ... переменных,
распределяющихся определенным образом. Вследствие это¬
го соответствие между значениями признаков проявляется
своеобразно: не в отношении одного значения к другому
значению, а в отношении ко всему распределению значений
признаков или по отношению ко многим распределениям.
Следовательно, то, что изменяется в соотношении с одной
из переменных, является соответствующей структурой
другой переменной. В плоскости строго теоретической, ве¬
роятностной, мы находимся в многомерной области случай¬
ных векторов.
В общем, для многомерного распределения можно уста¬
новить, так же как и для одномерного распределения,
столько же различных форм выражения законов распреде¬
лений (функций распределения, плотности распределения
и т. д.), сколько и типичных величин (средние, моменты), с
помощью которых их можно характеризовать. Определяют¬
ся также другие статистические категории и вычисляются
специфические показатели многомерных распределений с
целью характеристики многосторонних взаимных связей
между наблюдаемыми случайными переменными (признака¬
ми) рассматриваемой системы. В этом направлении установ¬
лены, например, понятия условное распределение, условные
130
средние величины, условия, необходимые и достаточные
для независимости двух или многих случайных перемен¬
ах, а также корреляция — показатели и понятия суще¬
ственные для понимания и научного применения в практи¬
ческой работе метода корреляции как множественного мето¬
дологического синтеза исследования комплекса взаимоза¬
висимых признаков, которым мы займемся в последних
главах.
§ 2. ДИСКРЕТНОЕ РАСПРЕДЕЛЕНИЕ ПО ДВуМ
ПРИЗНАКАМ (РАСПРЕДЕЛЕНИЕ СЛУЧАЙНОГО
ДИСКРЕТНОГО ВЕКТОРА)
Рассмотрим случайный дискретный двумерный вектор,
который обозначим символом V (х, у). Каждая из величин
х и у называется компонентом случайного вектора, пред¬
ставляющим одномерную случайную переменную. Напри¬
мер, если измерены длина (х) и ширина (у) стальной пла¬
стинки, которая штампуется автоматическим станком, то
мы имеем систему двух случайных переменных (признаков)
или двумерных векторов, распределение которых можно
изучить.
Под распределением некоторого случайного двумерного
(дискретного) вектора (теоретическое двумерное дискрет¬
ное распределение) понимается — подобно одномерной ди¬
скретной переменной — постоянное соответствие между
возможными величинами случайного вектора, т. е. между
парами реальных чисел (ху, yt) и корреспондирующими
вероятностями ptj 1 < i <; п; 1 < j т.
В форме таблицы с двойным входом распределение
случайного двумерного вектора можно представить очень
просто:
Таблица 24
\ А
У
х2
xi
хп
У1
Ри
Р21
Рн
Pni
У2
Р12
Р22
Pi2 '
Рп2
У/
РЧ
P2j
РП
Pnj
Ут
Р1т
р2т
Pirn
Рпт
9*
131
Заметим, что первая строчка таблицы содержит все воз,
можные значения х, а первая колонка — все возможные
значения у.
В пересечении колонок xt со строчками yt в соответ,
ствующих случаях находится вероятность Ptj того, что
случайный вектор V (х, у) принимает значение (xit у-).
Полагая, что события (x = xh y = yt) при 1<кпй
формируют полную систему событий, сумма всех
вероятностей из случаев системы равна 1.
Если известно распределение случайного двумерного
вектора, можно с легкостью найти распределение каждого
из его компонентов.
Действительно, представим следующие несовместимые
события:
(х = Ч. у==У1), (х = х1г у = у.2), ... , (х = х1( у = уп).
Это значит, что вероятность Pif когда х принимает значе¬
ние лц, согласно теореме сложения вероятностей равна
Л- —^11 + ^ 12+ ••• +
т. е. вероятность Р(х^=х1) равна сумме вероятностей ко¬
лонки ЛД.
Вообще, вероятность события E(x = xt) равна сумме
вероятностей колонки xt. Аналогичным образом находим
вероятность Ptj события Е (у = yt), суммируя вероятно¬
сти строчки yj.
Вероятности Pt и Pj называются предельными ве¬
роятностями.
Пример. Зная распределение случайного вектора V (х, у)
из табл. 25, найти распределение одномерных переменных
х и у.
Распределение случайного вектора V (м, у) следующее:
Таблица 25
х
у
лч
Л'о
Л'у
-
У1
0,10
0,30
0,20
0,60
У2
0,06
0,20
0,14
0,40
V
0,16
0,50
0,34
1,00
132
Заходим;
Pt. =0,10 + 0,06 = 0,16; Ро. =0,30 + 0,20 = 0,50;
Р3. =0,20 + 0,14 = 0,34;
Р.{ =0,10 + 0,30 + 0,20 = 0,60; Р.2 = 0,06+ 0,20 +
+ 0,14 = 0,40,
Следовательно, распределение этих двух случайных пе¬
ременных у таково:
. / х2 х3 \ / У1 У2 \
Х'\0,16 0,50 0,34/’ У'\0,60 0,40 Д
Функция распределения случайного двумерного вектора
Рассмотрим векторную случайную переменную V (х, у)
и пару реальных чисел а и Ь.
Вероятность события Е (х <z а, у <С Ь), которая состоит
в том, что х примет значение меньше а и у примет значе¬
ние меньше Ь, обозначим символом F (а, Ь).
Если а и b являются векторами переменной a (aif а2);
b (bi, b2), тогда, в общем, F (а, b) будет заменять функцию
вариаций случайных векторов а и Ь.
Функция F (а, Ь), определяющая вероятность события
(х <а, у < Ь),
F (а, Ь)^=Р (х <а, у< &), (V.2.1)
назыв ается фу н к ци е й двумерного расп р еде лен и я.
Эта функция отличается следующими свойствами:
0 < F (a, b) < 1;
F ( — оо, fc)-0, F (а,— оо) = 0;
F (4- °о,-г °°) = 1;
Р (a + h,b-\- k) — F (a, b + ty— F (a-\-h, b) + F (а, b) > 0;
(а, Ь) является неубывающей по отношению к каждой
Переменной а и Ь, взятой отдельно, и непрерывна вправо.
Свойства функции распределения F (а, Ь) аналогичны,
это можно видеть, таким же свойствам функции случай¬
ной переменной.
Для непрерывного двумерного распределения можно
°пределить плотность распределения.
133
Вторая смешанная частная производная (если она суще%
ствует) функции распределения F (а, Ь) называется плот,
ностью двумерного распределения:
д2 F (а, Ь)
да дЬ
(V.2.2)
Свойства плотности двумерного распределения анало¬
гичны свойствам плотности одномерного распределения.
§ 3. РАСПРЕДЕЛЕНИЕ ТРЕХМЕРНОЕ И /г-МЕРНОЕ
Вероятностное определение теоретических распреде¬
лений — это непосредственное расширение понятий, встре¬
чающихся в одномерном и двумерном распределениях.
Рассмотрим, например, вектор V (£, т], в), в котором
символами £, т], е обозначены компоненты случайной
переменной в Эвклидовом пространстве с тремя измерения¬
ми /?з, a Vi (аь Ьь V2 (а2, b2, c2)—два вектора,
данные их компонентами.
Рассмотрим вероятность неравенств
ai<£<fl2> Ci<£<£2>
которую обозначим
^(VX<V<V2). (V.3.1)
В заключение, если рассмотреть функцию F (х, у, г)
реальных переменных х, у, z, которые отличаются свой¬
ствами функции F (а, Ь), исследованными в § 2 этой главы,
то можно определить функцию трехмерного распределения-
Вероятность (V.3.1) выражается с помощью F (х, у, z)
следующим образом:
PiVj^cV <.V2) = F(a2,b2,c2) — F(a1,b2, с2) —
— F (а2, blt с2) — F (а2, b2, с,) + F (а1, bt, с,)-|- F (а±, b2, q) Т
+ F (а2, blt cJ — F (alt blt q).
Если существует смешанная частная производная
f (х, у, Z) =
д3 F (х, у, z)
дх ду dz
то в любой точке х, у, z функция / (х, у, z) непрерывна
134
по отношению к х, у, z, закон распределения является
непрерывным, a f (х, у, г) является плотностью трехмер¬
ного распределения.
В тех случаях, когда имеется п переменных, определе¬
ния, формулированные выше для двумерного и трехмерного
распределения, распространяются на многомерные распре¬
деления. Подобным образом распространяются так же, как
это очевидно, формулы регрессий и корреляций.
Проблема корреляции будет изложена после того, как
будет определено условное распределение и будут приведены
формулы относительно условных средних величин.
§ 4. УСЛОВНОЕ РАСПРЕДЕЛЕНИЕ
Напомним из теории вероятностей, что вероятность
события В, обусловленного событием Л, дается отношением
рА^=
P(AftB)
Р(А)
(V.4.I.)
Условная вероятность играет важную роль в исследова¬
нии и характеристике зависимости двух случайных пере¬
менных X и Y, компонентов двумерного распределения.
Предположим, что возможные значения X и Y —со¬
ответственно хг, х2, ..., хп и ylf Ут-
Во время некоторого эксперемента Y принимает зна¬
чения у;, 1 у < т; обозначим Р (^t/Уг) условную ве¬
роятность события (Y = уj) при событии' (X = xf), i =
= 1,2, ... ,п. Под теоретическим распределением X, обу¬
словленным Y = yjf понимается распределение
Аналогично можно представить распределение У,
обусловленное X = xt
У1 У2 Уп
Р(У1\*1) • • • Р(Уп\*1)
. Если известно двухмерное распределение, можно вы¬
числить вероятность p(Xt\yj) и p(yj\xi),
135
Сообразно отношению (V.4.1) можно записать форму,
лы
Р | yj)
Р(У=Уг)
P(X = xt, Y = yj)
Pii
Pi ’
Легко заметить, что
P (Y = yhX = Xi)
P(X = xt)
n m
Ър (хг1ь)-1, 2 р(К/Ц)= 1.
Z=1 i=\
Пример. На основе примера двумерного распределения,
приведенного в § 2 этой главы, определить распределение X,
обусловленное У = yi
Р (-11 У1)
__ Рц _ 0,10 _ 10
~ Р.\~ 0,60 ~ 60
Р (*2 I У1) =
p2i 0,30
Р. I ~ 0,60
30
60
Р (*3 | У1) =
Рз1 ^0,20
Р.1 0,60
P (Xj I =
6 ’
1
2 ’
20 _ J_
60 “ 3 *
По этим вероятностям можно написать закон распределе-
ия X, обусловленный Y = yL:
§ 5. УСЛОВНЫЕ СРЕДНИЕ ВЕЛИЧИНЫ
С условным распределением можно ассоциировать услов-
ные средние величины.
Например, для дискретной случайной величины услов¬
ная средняя X, обусловленная Y = у, дается отношением
М(Х|У = у)=2хгр(*г1у)
/= 1
и соответственно средняя У, обусловленная X = xif дается
отношением
т
М(Г|Х = х) = 2 У1Р(У;\х).
/=1
136
Условные средние непрерывных случайных переменных
имеют такие же формы, с тем отличием, что вместо суммар¬
ных признаков появляются признаки интегральные от
оо до + оо плотности условного распределения.
Пример. Рассмотрим двумерное распределение:
Таблица 26
X
у
•4 = 1
л-2=2
А'з » 4
Л'+
V
у,=3
0,15
0,06
0,25
0,04
0,50
у2=4
0,30
0,10
0,03
0,07
0,50
2
0,45
0,16
0,28
0,11
1,00
Нужно определить, что тО^Х-х^.
Заметим, что
Р! .= 0,15 + 0,30 = 0,45.
На этой основе можно вычислить вначале распределение
Yt обусловленное X = Х[.
Поскольку
3 ’
2_
з" ’
искомое распределение можно написать непосредственно
следовательно,
М(У|Х = х1) = 3.| + 4-|^-У-.
137
§ 6. УСЛОВИЯ, НЕОБХОДИМЫЕ И ДОСТАТОЧНЫЕ
ДЛЯ НЕЗАВИСИМОСТИ ДВУХ СЛУЧАЙНЫХ ПЕРЕМЕННЫХ.
КОРРЕЛЯЦИЯ И КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
В главе II было определено понятие независимости двух
дискретных переменных. Теперь можно определить более
общее понятие независимости, применимое к случайной
переменной любого типа (дискретной или непрерывной).
Две переменные X и Y являются независимыми, если со-
бытия £ (X < х и Е (Y <Zy) независимы при любых зна¬
чениях X и у.
Согласно сказанному выше имеем
Р(Х<%, Y<y) = P(X<x) • Р(Х<у)
%ля любого значения х и у.
Как можно видеть, с помощью функции распределения
можно выявить необходимые и достаточные условия неза¬
висимости двух случайных переменных.
В теории строгое доказательство этих условий форму¬
лируется следующей теоремой: &ля того чтобы случайные
переменные X и Y были независимыми, необходимо и доста¬
точно, чтобы функция распределения F (X, Y) случайного
двумерного распределения (X, У) была равна произведению
функции распределения (X) и F2 (У) случайных перемен¬
ных X и У:
F (X,Y) = F1(X)-F2 (Y).
Можно доказать, следовательно, что, для того чтобы не*
прерывные случайные переменные X и У были независи¬
мыми, необходимо и достаточно, чтобы плотность двумер¬
ного распределения f (х, у) и распределения (X, У) была
равна произведению плотностей распределений (х) и
f2(x) переменных X и У:
Для всестороннего изучения двумерных распределений
помимо средних и дисперсий их двух компонентов приме¬
няются и другие типичные показатели, среди которых
центральное место занимают корреляция и коэффициент
корреляции.
138
Назовем корреляцией случайных переменных X и Y
среднюю из произведений отклонений этих переменных и
обозначим символом
\х, у М [X - М (X) • Y- М (У)]. (V.6.1)
Из этого определения следует, что
2 2 [хг-м(Х)^-м(пь
Z=1 /=1
когда эти две переменные дискретны, и
kx,y= J j (х— М(Х)(у — M(Y)f(x, y)dxdy,
когда эти две переменные непрерывны.
Можно легко доказать, пользуясь свойствами средних,
что, если эти две переменные X и Y независимы, то корре¬
ляция равна нулю. Отсюда выводится следствие, что если
корреляция отличается от нуля, то эти две переменные за¬
висимы.
Следовательно, корреляция служит характеристикой
зависимости между двумя случайными переменными.
Очевидно, что показатели корреляции зависят от еди¬
ниц, в которых измеряются случайные переменные X и Y.
Этот недостаток можно устранить, если рассматривать
коэффициент корреляции оху, который не зависит от еди¬
ницы измерения:
РхУ —
^ху
D(X)D{Y)
(V.6.2)
Можно доказать, что всегда имеется двойное неравен¬
ство
- 1<Р,У<1. (V.6.3.)
Если рХу = ± 1, то между X и Y существует линей¬
ная зависимость.
Из (V.6.3) следует, что если X и Y являются независи¬
мыми случайными переменными, то тогда
Рху = 0;
139
а если
p.vy 7^ О,
то случайные переменные X и Y зависимы. Возникает во¬
прос, можно ли утверждать, что случайные переменные х
и Y независимы в тех случаях, когда рх = 0, а также
С помощью простого примера легко увидеть, что в не¬
которых случаях можно утверждать, что переменные неза¬
висимы, в то время как в других случаях этого сделать
нельзя. В данном случае при равенстве рху = 0 скорее
можно утверждать, что две случайные переменные не кор¬
релированны. Следовательно, если рху = 0, то тогда сле¬
дует, что случайные переменные X и Кис коррелированны.
Независимые переменные считаются некоррелированными,
однако обратное утверждение не всегда истинно. Только
в случаях двумерного нормального распределения понятие
независимости и некоррелированности эквивалентны.
В следующих главах, посвященных многомерным эмпи¬
рическим распределениям, будут более широко развиты
эти понятия, необходимые для вычисления конкретных по¬
казателей, характеризующих простую, частную и множе¬
ственную корреляцию.
Глава VI
ЭМПИРИЧЕСКИЕ МНОГОМЕРНЫЕ РАСПРЕДЕЛЕНИЯ.
МЕТОД КОРРЕЛЯЦИИ
§ 1. ОПРЕДЕЛЕНИЯ
Эмпирические (статистические) многомерные распре¬
деления устанавливаются таким же образом, как и законы
соответствующих теоретических распределений, с тем от¬
личием, что вместо рассмотрения вероятностей событий
обсуждаются частоты индивидуальных значений дискрет¬
ных переменных или интервалов с 2, 3, ..., п измерениями
при непрерывных случайных переменных.
Например, в случае статистического двумерного распре¬
деления вместо вероятности Р (а < V < Ь) соответствую¬
щего события Е (а < V < Ь) говорят об N (а < V <; Ь)
частоте, соответствующей интервалу с двумя измерениями1.
Функция накопленной частоты или огива F (х, у) опре¬
деляется отношением
F*(x,y) = N(X<x,Y<y) (VI. 1.1)
и имеет те же свойства, как и функция распределения. Она
определяется таким же образом, как и двумерное статисти¬
ческое распределение.
Если существует смешанная частная производная
Н*,У) =
д2 F* (х, у)
дх ду
в каждой точке (х, у), то функция f (х, у) непрерывна по
отношению к х и у, распределение непрерывно и f (х, у) но¬
сит название функции частоты.
Статистическое трехмерное распределение и вообще
статистическое многомерное распределение определяется
1 Множество точек па плоскости, удовлетворяющее условиям
ai < X < а2, Ьг < Y < Ь2 носит название интервала с двумя из¬
мерениями.
141
аналогичным образом, посредством распространения поня¬
тий, встречающихся выше. Особенное значение для харак¬
теристики многомерных статистических распределений
имеет определение моментов различного типа и порядка.
Техника их вычисления аналогична применяемой в опре¬
делении законов теоретического распределения. Она будет
показана по мере необходимости при изложении метода
корреляции.
Под методом корреляции понимается вся методология
исследования взаимозависимостей и связей, в которых на¬
ходятся явления природы и общества; речь идет о методо¬
логическом синтезе научных исследований, в котором гар¬
монически переплетается метод материалистической диа¬
лектики, метод, специфический для изучаемых объектов,
и метод статистико-математический.
§ 2. ВВОДНЫЕ ЭЛЕМЕНТЫ КОРРЕЛЯЦИОННОГО
АНАЛИЗА СТАТИСТИЧЕСКИХ РЯДОВ
В анализе многомерных рядов распределения часто не¬
обходимо, как было указано, чтобы связи между двумя или
многими переменными были выражены в форме синтети¬
ческого показателя. Эта задача решается посредством мето¬
да статистической корреляции. С помощью метода корре¬
ляции можно численно характеризовать как интенсивность
и направление связей, так и степень влияния различных
факторов.
Связь между статистическими переменными отражает
факт сложной зависимости, существующей между массо¬
выми явлениями и процессами. Она указывает численное
отношение между величинами, которое выражает тенден¬
цию возрастания или убывания одной переменной величины,
наблюдаемую при возрастании или убывании одной ппг
нескольких других величин.
Так, например, между производительностью труда и
квалификацией рабочих существует прямая зависимость
в том смысле, что по мере повышения квалификации рабо¬
чих, в общем, возрастает и производительность их труда-
Однако квалификация не определяет одинаковым образом
уровень производительности труда. Возрастание произ¬
водительности труда определяется также рядом други*
факторов, какими являются техническое оснащение труда,
142
механизация и автоматизация производственных процессов,
организация труда и т. д., которые действуют параллельно
с повышением квалификации. Влияние этих факторов
таково, что тенденция роста производительности труда
в отношении к росту квалификации проявляется только
как средняя тенденция, действительная для коллектива
рабочих.
Сложный характер статистической зависимости выдви¬
гает на первое место задачу идентификации причинных
связей между явлениями. Вычисление показателей кор¬
реляции допустимо при условии предварительного уста¬
новления существования реальной причинной связи между
изучаемыми явлениями. Простой параллелизм вариаций
двух или многих явлений не означает необходимым обра¬
зом того, что явления коррелированы. Часто одновремен¬
ная вариация двух явлений, происходящая с определен¬
ной регулярностью, может быть общим результатом измене¬
ний некоторого третьего явления, без того, чтобы между
первыми двумя явлениями существовала причинная
связь.
Статистические связи присущи и явлениям социально-
экономическим. В этой области в большинстве случаев
невозможно выявить все факторы, которые влияют на ис¬
следуемые явления. В немногих случаях, преимущественно
с целью проведения анализа, применяется корреляция
функционального типа. Например, для определения при¬
чин, которые объясняют вариации месячной производи¬
тельности труда, последнюю связывают с такими факто¬
рами, как почасовая производительность труда, средняя
продолжительность рабочего дня и средняя продолжитель¬
ность месячной работы. Месячная производительность тру¬
да представляет собой функцию отношения трех переменных.
Для того чтобы обеспечить научно обоснованные выводы
на основе корреляционных вычислений, необходимо вклю¬
чить в исследования, насколько возможно, все существен¬
ные систематически действующие факторы. В той мере,
в которой это условие не выполнено, уменьшается позна¬
вательная ценность показателей корреляции.
Статистические показатели корреляции могут быть
°Иределены для нескольких рядов двумерного распреде¬
ления (зависимой и независимой переменной). Соответ¬
ствующим образом различают корреляцию простую и кор¬
реляцию множественную.
143
По форме связей корреляция может быть прямолпней.
ной и криволинейной. Корреляция прямолинейная выра.
жается синтетически уравнением прямой линии, а корре.
ляция криволинейная — уравнениями параболы, гипер.
болы, экспоненциальной кривой и т. д.
§ 3. ПРОСТАЯ КОРРЕЛЯЦИЯ
Элементарный случай применения метода корреляции
представляет собой ряд распределения по отношению
к двум переменным.
Рассмотрим следующую таблицу рядов, относящихся
к распределению группы 40 предприятий машинострои¬
тельной промышленности по величине основных производ¬
ственных фондов и по числу рабочих х.
Таблица 27
X. Основные фон-
\ ды —перво-
X. начальная
х. стоимость
X. в млн. лей
Число X.
рабочих X.
Всего
Менее 20
20-40
40—60
60—100
| 1 00—1 4 0
Всего
40
6
8
11
10
5
3 001—3 500
2
2
2 501—3 000
4
1
3
2 001—2 500
5
1
4
1 501—2 000
14
2
7
5
1 001—1 500
9
1
5
3
501—1 000
4
3
1
Менее 500
2
2
Связь между числом рабочих и размером основных про¬
изводственных фондов, которые в физическом выражении
представляют собой средства производства, является обще¬
известной. В общем, при большем количестве средств труДа
необходимо больше рабочих. Однако вариации числа рабо¬
чих не зависят исключительно от объема основных фондов-
Наоборот, многочисленные другие факторы и в первую
1 Данные условные.
144
очередь степень концентрации производства, механизации
Л автоматизации процессов производства оказывают силь¬
фе влияние на потребность в рабочей силе. Этот факт
проявляется в данных, приведенных в таблице; при том же
объеме основных средств число рабочих варьирует в боль¬
ших пределах. Для определения размеров, в которых из¬
меняется число рабочих под влиянием изменения объема
основных фондов, необходимо абстрагировать его от влия¬
ния всех других факторов, чтобы стала очевидной связь
только с рассматриваемым фактором.
Корреляция между числом рабочих и объемом основных
фондов является очевидной в глобальном аспекте, если поль¬
зоваться способом группировки частот в таблицу, а именно
в такую, по диагонали которой показывается возрастание
основных фондов, сопровождаемое увеличением числа ра¬
бочих.
Сгруппированные таким способом факты дают возмож¬
ность оценить приблизительно направление и интенсивность
корреляции.
Более наглядна связь между этими двумя переменными
на приведенной диаграмме (рис. 16).
Заметно, что распространение точек не единообразно
и что основная масса располагается полосой на графике,
выражая тенденцию концентрироваться вдоль прямой ли¬
нии, наклоненной влево.
Конечно, простая констатация связи на основе группи¬
ровки и графического изображения не достаточна для на¬
учного анализа. Необходимо чтобы общая оценка, часто
смутная и субъективная, которая ведет одного исследова¬
теля к заключениям, отличным от заключений другого ис¬
следователя, была подтверждена объективным способом,
посредством синтетического числового выражения. Дру¬
гими словами, абсолютно необходимо построить численный
аналитический метод, приспособленный для этой цели.
Точнее сказать, статистическая связь состоит в том, что
На вариации одной из переменных другая переменная реа¬
гирует посредством изменения распределения. Из табл. 27
Можно видеть, что каждому значению основных фондов
(х) корреспондирует распределение числа рабочих (у).
Если для каждого распределения (у) мы вычислим зна¬
чения его средней, то получим ряд таких величин, которые,
Нак известно, являются ее условными средними величинами
По переменной х.
Ю
145
Зак. 1050
Таблица 27-бис
Основные фонды
в млн. лей х
оо
20—40
40—60
60—100
Ю0-140
Число рабочих ух
667
1 313
1 659
2 050
2 950
Каждая условная средняя вычисляется как средняя
арифметическая, взвешенная по формуле
2 yfyx
i=\
п ’
2 fyx
i= 1
в которой
ух—условная средняя;
у—средние величины интервалов ряда у;
fxy — частоты парных величин y-L и xt.
Например, условная средняя, корреспондирующая с
интервалом «менее 20 миллионов лей»,
ух < 20 миллионов лей
_ (250-2) + (750-3) + (1 250» 1)
2 + 3+1
_ 4000 ggg g ggy рабочих.
6 н
На приведенном графике в системе прямоугольных коорди¬
нат точки, изображающие парные величины соеди¬
нены полигональной линией, называемой линией регрессии1
переменной у по отношению к переменной х (рис. 17)-
В случаях, когда переменные х и у независимы, линия
регрессии переменной у по отношению к х является прямой,
1 Названа так Фрэнсисом Гальтоном на основе сделанных им
наблюдений. Гальтон заметил, что у родителей, рост которых больше
среднего группового, родятся дети пониженного роста и наоборот.
Он констатировал, следовательно, регрессию, выражаемую сред¬
ними величинами, откуда и название линия регрессии для связи
между условными средними распределений зависимых переменных*
Очевидно, что термин неточен в широком применении,
146
параллельной оси абсцисс, а линия регрессии переменной
х по отношению к у является прямой, параллельной оси
ординат.
Конкретно, таким образом, посредством вычисления
корреляции установлено увеличение числа рабочих, кор¬
респондирующее возрастанию основных фондов (на 1 млн.
3000
9
2 500
• •
i
2000
/ 500
••
•••
•••
• •
с »
«о
юоо
»о
в
500
О
| » I I I 1 1 1 Ча
?0 >t0 60 80 ЮО 120 №0
Основные фонды (млн леи)
Рис. 16.
лей). Если бы все точки парных величин yt и xt находились
на одной линии, например на прямой, то для определения
числа рабочих не требовалось бы специальных вычислений.
Мы имели бы функциональную зависимость и нам было бы
Достаточно знать координаты любой из двух точек. Зави¬
симость между данными двумя переменными, однако, не
является функциональной, и эти точки находятся на поли¬
гональной линии.
10*
147
Для решения задачи необходимо выбрать такую функ-
цию регрессии, которая выражает зависимость переменной
у по отношению к переменной х в некоторой чистой форме,
7.
?0 W 60 80 100 120
Основные ср он в к/ (ылн леи)
Рис. 17.
абстрагируя ее от влияния других факторов. Графическое
изображение функции, которое выражает математически
связь между переменными, является теоретической регрес¬
сией (см. рис. 17).
§ 4. ПРЯМОЛИНЕЙНАЯ РЕГРЕССИЯ.
КОЭФФИЦИЕНТ РЕГРЕССИИ
Линия теоретической регрессии двумерного ряда рас¬
пределения может иметь различные формы. Определение
формы линии регрессии, соответствующей реальной форме
зависимости, составляет принципиальный момент в изучении
корреляции. От хорошего выбора линии регрессии зависят
148
результат корреляционного анализа, оцененные значения
зависимой переменной. Глубокое знание исследуемых
явлений природы, зависимости между ними является суще¬
ственным элементом для правильного выбора линии ре¬
грессии. К этому нужно добавить накопленный опыт ана¬
лиза аналогичных примеров корреляции, графические изо¬
бражения поля корреляции, эмпирической линии регрес¬
сии и т. д. Так, относительно ряда распределения в табл. 26
допустим, что зависимость является линейной, т. е. что ко¬
нечные отрезки, которые представляют условные средние,
находятся на прямой линии. Уравнение этой линейной
функции в рассматриваемой системе координат имеет
форму
Ух^-a^-bx,
где ух является условной средней, вычисленной теорети¬
чески по соотношению у и %.
Для вычисления параметров а и b применяется метод
наименьших квадратов. Сущность этого метода состоит
в определении параметров а и Ь, как функции регрессии,
таким образом, что сумма квадратов отклонений действи¬
тельных значений у от соответствующих вычисленных
значений ух должна быть минимальной. Следовательно,
обозначая символом S сумму, о минимуме которой идет
речь, получим
S = У (у — ух)2 = минимум
или
S = У (a-f- Ьх— у)2 = минимум.
Величина S зависит от значений, принимаемых пара¬
метрами а и Ь.
нахождения минимума функции необходимо преж¬
де всего вычислить ее частные производные, дифференци¬
руя сначала в отношении а и затем Ь:
^ = 22(а + &х-у)-1;
да
^- = 2S(a+&x—у)-х.
дЬ
149
Опуская частные производные, упрощая на 2 и вводя х в
скобки во втором уравнении, получим:
2(а+ Ьх — у) = 0;
2 (ах + Ьх2 — ху) = 0.
Разлагая суммы почленно, находим:
Za + ^bx = %y;
Уах-\-^Ьх2 = ^ху.
а и Ь, являющиеся константными сомножителями, вы¬
деляют из указанных сумм и получают систему нормаль¬
ных уравнений:
па+Ь^х=^у\
а^х+ЬУ,х2==^ху;
Если принять во внимание частоты сгруппированного
ряда данных, то получают систему уравнений:
^f+b^xfx = ^yfy;
a^xfx+b^x^x=--^xyfxy,
в которой
[х и fy — частоты групп, образованных из значений
относительно у;
fxy— частоты парных значений х, у.
В табл. 28 вычислены суммы:
2/^ 40 (колонка 6);
2 xfx = 2 250 (колонка 9);
2У/у~ 68 000 (колонка 7);
^x2fx = 171 300 (колонка 10);
22хУ/*у=г 4 677 500 (колонка 11);
подставляя эти данные в систему нормальных уравнений,
получим:
40 а+ 2 250 Ь = 68 000;
2 250а+ 171 300 6 = 4 677 500.
150
Т а б л и lx a *2&
S
-
ОООООООО
ОООООООО
ооюююоою
uOl.ONNCNOON
ф 00 ,—ч СЧ г—< 00 О-
СО ф ОО СЧ b- CD
—< —< Ф
i
1
в
о
ОООООООО
ОООООООО
СЧ СЧ —• СО ₽-н СО СО СО
г-н СЧ ’—' 00 О 00 —и
г-^ сО(Мф СЧЬ
в
в
СЛ
ОООООООО
СЧ CD —< -—' Ь ФФШ
СО 00 СО ф СЧ СЧ
СЧ
00
ОООООООО
ОООООООО
ООЮОЮООО
Ю о СЧ Ю СЧ О LO о
СЧ ио со >- —< но СЧ о
^СЧОООСОСЧг-<о
СЧ Ф СЧ ю о —• о
ф СЧ СО СЧ СО
ОООООООО
ооюоюооо
LOOC4UOC40LOO
СО ф —< 1—■ со оо
_, СЧ —• со
СО
СЧФОфнОфСЧО
хф
о о о о о
lo о о о о
СЧ СО о О to
сч ч—< оо о ь-
Ь- СО о [ф
г-м о СО
СО Ф
со
120
ю
со СЧ но
о о о о о
О О to о о
со о О’ to о
СЧ -Ф СЧ О
О ,—1 ’—1 г-
00 О'¬
СО —И
ф
о
оо
ф
но Ф —< О
о о о о о
о о о о о
оо о но о о
Ф О to о
СО СЧ СЧ ф
г-н СО
СО Г-<
ф
о
ю
со
СО Г- —' т-н
о о о о о
но о,to о о
Ю to СЧ to но
Г- 00 СЧ
СЧ —' 00 —«
—• о
со
о
СО
CSI
-И Ю СЧ ОО
о о о о о
Ф о о о о
СЧ СЧ ю о о
О- О О to
— О <
Ю СО
ф
о
-
СЧ СО ' со
о о о о о
со о о о о
СО о О О
Ф to о
О ф
со
со
Ч s'
//
о
о о о о о о о
Ю но 1.0 Ю 1-0 LO НО
СЧ СЧ (Ф СЧ [ф СЧ
< СЧ СЧ Ф*4
'O-'ei ^(М
>■1
-КМСОФЮСС^ОО
О о СЧ СО
151
Решая эту систему с помощью определителей, найдем
I 68 000 2 250 |
14 077 500 171 300 | 468Ю00-171 300)-(4 677 500-2 250)
1 40 2250 р (40 - 171 300) —(2 250-2 250)
I 2 250 171 300 I
1 124 025 000
1 789 500
628,122;
| 40 68 000 i
I 2 250 4 677 500 | (40-4 677 500) — (2^250 • 68 000)
= I 40 2250 | = (40-171 300) —(2 250-2 250)
I 2 250 171 300 |
34 100 000
1 789 500
19,055.
Уравнением регрессии будет
р = 628,1224- 19,055%.
Параметры а и Ь уравнения регрессии дают возможность
вычислять среднюю величину у для данного значения х
при прочих равных условиях. Параметр Ь, который назы¬
вается коэффициентом регрессии, геометрически представ¬
ляет наклон прямой линии. В вычислении корреляции
этот параметр указывает меру, в которой изменяется у при
изменении х на единицу. В нашем примере, если основные
фонды увеличиваются на 1 млн. , число рабочих в среднем
увеличивается на 19. При объеме основных фондов в 50 млн.
лей можно ожидать, что число рабочих будет приблизи¬
тельно равным: ух = 628,122 4- 19,055 X 50 = 1 581.
Аналогичным образом можно оценить число рабочих для
другого объема основных фондов на основе гипотезы, что
сохраняются те же условия, которые имели место в основе
определения функции регрессии.
Уравнения регрессии, служащие для оценки уровней
исследуемых зависимых переменных, представляют боль¬
шой интерес, особенно в работе по планированию. В усло¬
виях, в которых синтезируются определенные действующие
факторы, сделанные оценки очень близки к линии эволю¬
ции реальных явлений. Оценки могут быть сделаны не
только в предела?; той массы случаев, по которой произве¬
дено вычисление уравнения регрессии, но и вне ее. Однако
152
ле рекомендуется слишком отдаляться от данных эмпири¬
ческих границ. Нужно иметь в виду тот факт, что экстра¬
поляция допускается только тогда, когда доказана полная
аналогия условий места и времени, а также однородность
явлений, к которым относятся оценки.
Коэффициент регрессии, который, как было указано,
является коэффициентом пропорциональности, получает
положительное значение в случае прямой корреляции и
отрицательное значение в случае обратной корреляции.
Таким образом, линия регрессии в случае прямой корреля¬
ции выражает тенденцию возрастания, поскольку b яв¬
ляется величиной положительной, а в случае корреляции
обратной — b величина отрицательная. Что касается пара¬
метра а, то он не имеет, как правило, никакого независимого
значения, а в некоторых вычислениях может быть отрица¬
тельной величиной х.
§ 5. КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ
Определение уравнения регрессии служит описанию кор»
реляции между переменными величинами, знанию того,
как модифицируется одна переменная в соотношении с мо¬
дификациями другой переменной. Этого знания, несмотря
на его особенную важность, недостаточно для глубокого
изучения корреляции. Кроме изменчивости весьма необ¬
ходимо оценить и степень интенсивности корреляции.
Оценка, полученная с помощью уравнений регрессии,
имеет точность тем большую, чем более интенсивна корре¬
ляция.
Показателем интенсивности линейной корреляции слу¬
жит коэффициент корреляции (г), определяемый, как из¬
вестно, по формуле
г_= £(*—*) (у—у)
ПС>х °у
Коэффициент корреляции является величиной абстракт¬
ной, не связанной с единицей измерения переменных.
Формула вычисления это показывает; сравниваются не
Индивидуальные отклонения, а их величины, преобразо-
1 В динамических рядах при их выравнивании свободный член
Имеет всегда независимое значение, представляя начальный уро-
вень динамического ряда.
153
ванные соответственно в абстрактные числа — нормнр0ч
ванные отклонения, т. е. величины индивидуальных от¬
клонений от средней арифметической, измеренные в средних
квадратических отклонениях и
Среднее произведение нормированных отклонений дает
коэффициент корреляции. Из формулы вычисления яв¬
ствует общий логический смысл вычислительных операций.
Коэффициент корреляции варьирует в границах —1
-т-1 в зависимости от того, является ли корреляция нега¬
тивной (возрастанию одной из переменных корреспонди¬
рует убывание другой переменной) или позитивной (возра¬
станию одной из переменных корреспондирует возрастание
другой переменной). Знак коэффициента корреляции зави¬
сит от знака при У (х — х) (у — у).
В случаях, в которых преобладают пары отклонений
с одинаковым знаком (х — х) (у — у), будет иметь знак
плюс и, наоборот, если преобладают пары отклонений с раз¬
ными знаками, то знаком будет минус. Чем более коэффи¬
циент корреляции приближается к +1 или —1, тем более
интенсивной становится прямолинейная корреляция между
переменными. Если переменные у и х не коррелированы,
то тогда коэффициентом корреляции будет нуль. В случае
нелинейной корреляции коэффициент корреляции является
слабым показателем интенсивности корреляции. В этих
случаях интенсивность корреляции измеряется, как будет
показано, с помощью корреляционного отношения.
Коэффициент корреляции можно вычислить по разным
формулам, полученным простым преобразованием формулы
г = %(У~У) , КОТОрая очень громоздка, так как требует
пах о у
предварительного вычисления отклонений и их произве¬
дений. Если умножить величины (х—х) на (у — у) и за¬
тем сложить полученные члены, то тогда У (х—х) (у—у
= ^ХУ— пхУ> поскольку Ух = /гх; У у = /гу, Уху
^Уу7-=/гху и ^£ху = пхУ- Подставляя полученные
результаты в приведенную выше формулу, получим:
X ху — пху
пох (Уу
154
Можно также для вычисления пользоваться формулой
п^ху-дх) (2 у)
у-[п 2 х2 - (2 X)2] [п 2 у2 — (2 у)2] ’
В случае, когда применяется ряд распределения типа,
риведенного в табл. 27, вводятся веса и формула ста-
овится следующей:
- х у х =. (VI.5.1)
]/|2/p2Zx-[p7xj2]
Элементы вычисления для рассмотренного примера на-
эдим в табл. 27.
Вводя их в формулу, получим:
(40 • 4 677 500) — (2 250 • 68 000)
■К[(40П‘7Г300Р-’(2^УбрТЖсГГЗб ООО 000)" — (68 ооор]
34-100 000 _
38 212 982 ~
0,892.
олученный коэффициент указывает на положительную и
<ачительную связь между числом рабочих и объемом ос-
)вных фондов. Ценность знания полученного коэффициента
! может быть подвергнута сомнению, хотя объективно
'Шествуют некоторые условия, ограничивающие его при-
шение. Имеется в виду несовершенство ценностного пока¬
те л я основных фондов, малая степень однородности сово-
шности предприятий, невключение в вычисление неко¬
рых других факторов, имеющих существенное влияние,
т. п. В связи с этим интересно отметить факт, который
утверждает наше заключение, что вычисление дифферен-
фованных коэффициентов корреляции во всей промыш-
!нности дает следующие величины: 0,54—для промышлен-
>сти в целом, 0,64 — в группе мелких и средних пред-
>иятий и 0,13 — в группе крупных предприятий, что со-
ветствует действительности.
155
§ 6. УПРОЩЕННЫЙ МЕТОД ВЫЧИСЛЕНИЯ
КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ
В случае рядов распределения с равными интервалами
объем операций по вычислению коэффициента корреляции
может быть сокращен, если рассматривать уменьшенные
величины переменных х и у.
С этой целью по правилу для каждой переменной выби¬
рается из ряда данных одна величина в качестве начала вы¬
числений (произвольное начало), на которую уменьшаются
все величины ряда, а полученные разности делятся на ве¬
личину интервала.
Обозначая символами х' и у' уменьшенные величины
х и у, получим
, х—х0 , у—у0
X = - и у = -—-- ,
kx ky
где xQ и yQ — соответственно начала вычислений перемен¬
ной х и у;
kx, k, — величина интервала ряда х и у соответ¬
ственно.
Формула вычисления коэффициента корреляции при¬
нимает следующий вид:
V г V V х~ х° у~ Уо f
X у Х '
_ V х~~хо f v у — у° f
z kx tx' kv h
x ~ у
Для иллюстрации процесса упрощенного вычисления
коэффициента корреляции приведем в качестве примеря
ряд распределения из табл. 29, который выражает связь
между издержками производства (зависимая переменная)
и производительностью труда (независимая переменная)
машинно-тракторных станций.
156
Последовательность операций по вычислению, развер¬
нутых в таблице, следующая:
выбор начала вычислений х0 375 (колонка 9) для
переменной х и //0 = 85 (строчка 9) для переменной у\
вычисление отклонений значений ряда от избранного
начала вычислений в условной форме посредством умень-
х 375
щен и я на величину интервала —(колонка 10) и
(строчка 10);
□и
умножение отклонений по интервалам на частоты и
алгебраическое суммирование полученных произведений:
Х 703?5 fx= - 14 (колонка 11); =
= —122 (строчка 11);
вычисление квадратов отклонений (колонка 12 и
строчка 12), умножение на частоты (колонка 13 и
строчка 13) и суммирование полученных произведений
2(ЫТ-=764; 2(ТХХ=528;
• перемножение парных отклонений между собой, умноже¬
ние на соответствующие частоты и суммирование произве¬
дений каждой строчки, например:
—105 = (—3) (-1)-2 + (-3).(+1).5 + (-3).( + 2).7 +
+ (—3)-( + 3)-6 = 6—15-42 —54.
Сумма записывается в колонке 14. Для проверки вы¬
числений операция производится и по колонкам (смотрите
строчку 14):
V4 х—^75
ю
-V У
у —85
50
4у=—475.
На основе этих результатов находим
г [243.(—475)] —[(—14) Д—122)] =
V[(243.764’) — (— 14)2] [(243 • 528) — (— 122р]
= = _о,8О758.
145 040,9
Этот результат идентичен полученному посредством пря-
Мых вычислений.
157
7j
Издержки
X. производства
\ У
Производи- \
тельность "к
труда в га х х.
До GO
00 ‘02—10*09
70,01—80,00
80,01—90, 00
90, 01 — 100,00
о
о
о
о
о
о
А
0
1
2
3
4
5
Г
1
До 250
2
1
5
7
2
251—300
2
9
18
9
3
301—350
2
15
19
5
2
4
351—400
6
25
17
2
5
401—450
11
20
2
6
451—500
2
19
13
7
Выше 500
6
15
2
8
fy
8
53
79
48
30
18
9
Центр интервала
85
10
У—Уо
ky
—3
—2
— 1
0
+ 1
+2
11
У—Уо
йу 'У
—24
—106
—79
0
+30
+36
12
( У — Уо\2
1 ky )
9
4
1
0
1
4
13
72
212
79
0
30
72
14
V * —*о У — Уо
kx ‘ kv
—66
— 184
—27
0
—56
—82
Так, на основе вычислений по первичным данным
= 6991 125;
Л- у
У.х[х = 90 425;
к
= 19 435:
£ х2/х = 35 556 875;
X
У 1 601 075
У
158
Таблица 29
о
<У
а
3
PQ
<х
Центр интервала
x — Xq
kX
11^ ‘
и 1
га1
(v)
x—x0
2d. x
У — Уо
* fxy
7
8
9
10
11
1 2
13
1 4
6
1
21
39*
43
50
33
34
23
375
—2-
—1
0
+ 1
+2
+3
—63
—78
—43
0
+33
+68
+69
9
4
1
0
1
4
9
189
156
43
0
33
136
207
— 105
—74
+ Ю
0
—42
— 114
—150
7
243
■ |-14
1 764
—475
+з
+21
9
—122
х — представляет среднюю производительность
труда на одного работника занятого на МТС,
в гектарах
у — издержки производства на гектар
63
528
-60
—475
Источник: Dezvoltcirea agriculturil
R- Р. R. 1961, birectia Centrala
de Statistical.
и, применяя формулу (VI.5.1), получаем:
(243- 6 991 125)-(90 425-19 435)
У[(243-35 556 875) — (90 425)2] [(243-1 601 075)"—(19 4'35)2'
58 566 500 0,8076.
72 516 238
Установлено, таким образом, что существует сильная
связь между себестоимостью л производительностью труда.
Что касается вида корреляции, то он является негатив¬
ным: рост производительности труда корреспондирует
с понижением себестоимости. Размер, в котором умень-
159
шается в среднем себестоимость, если производительность
возрастает на 1 га пашни, выражается коэффициентом ре.
грессии, который можно вывести из отношения:
где ov — представляет собой среднее квадратическое от.
клонение переменной у\
— среднее квадратическое отклонение переменной х;
г — коэффициент корреляции.
В нашем примере crv и <зх можно получить с помощью
формулы упрощенного вычисления
•Ху-Щ-Уо)2 =
Ю2—(79,98 —85)2 = 1/217,28 — 25,2
= ]/192,08 = 13,86 леи,
764
243
• 502 — (372,12 — 375)2 = J/7860,08 —8,2944 = =
= 1/7851,786 =88,61 га,
при которых
У = Уо+ /гу
1 С/Х '>
^fy
= 85+ 10-
—122
243
= 85 — 5,02 = 79,98 леи;
= 375 + 50— =
243
= 375 — 2,88 = 372,12 га
160
0 коэффициент регрессии
/ 13,86 / пол-7 11,193 3 n 1fW
b ^- -( — 0,807 6)— ’ = —0,120 леи.
88,61 7 88,61
Если производительность труда возрастает на 1 га, то
издержки производства уменьшаются в среднем на 0,13 лен
(конечно, в предположении, что сохраняются условия, ко¬
торые имели место в основе определения функции регрес¬
сии).
§ 7. КРИВОЛИНЕЙНАЯ РЕГРЕССИЯ. ВЫЧИСЛЕНИЕ
ПАРАМЕТРОВ ЛИНИИ РЕГРЕССИИ
Прямолинейная корреляция, синтетически выраженная
уравнением прямой линии, предполагает однообразное из¬
менение зависимой переменной под влиянием изменения не¬
зависимой переменной. Каким бы ни был уровень незави¬
симой переменной, ее возрастание или убывание на единицу
рассматривается в каждом случае как причина возрастания
или убывания зависимой переменной в одинаковом размере
(в размере b — коэффициента регрессии).
Однако в действительности довольно часто встречаются
статистические связи, в которых интенсивность влияния
независимой переменной на зависимую переменную ме¬
няется при изменениях уровня, на котором находится не¬
зависимая переменная. Рассмотрим, например, корреляцию
между относительным уровнем издержек обращения и
объемо?л сбыта товаров на основе данных табл. 30.
Между этими двумя переменными существует обратная
корреляция: с возрастанием объема сбыта товаров «при про¬
чих равных условиях» в относительном уровне издержек
обращения проявляется тенденция к понижению.
Однако эта тенденция не имеет заметного единообраз¬
ного характера; она бывает более ускоренной в начальных
Числовых значениях ряда и становится более медленной
По мере увеличения объема сбыта. Этот факт объясняется
различными тенденциями в вариациях двух компонентов
Издержек обращения: издержки изменяемые (издержки
транспорта, заработная плата оперативного персонала,
издержки по хранению и подготовке товаров и т. д.) имеют
И Зак. 1050
161
\ Относительный
\ уровень издер-
\ жек обраще-
\ ния в про-
\ центах
\ У
3,4-3,8
3,6
3,8—4,2
4,0
4,2—4,6
4,4
4,6—5,0
4,8
5.0-5,4
5.2
Объем сбыта \
товаров \
в млн. лей х \
А
0
1
2
3
4
5 ~~
1
4—6 5
2
6—8 7
3
3
3
8—10 9
1
1
2
4
10—12 И
1
4
3
5
12—14 13
1
2
3
6
14—16 15
3
2
7
16—18 17
2
2
8
18—20 19
3
1
9
fy
5
8
9
10
5
10
yfy
18
32
39,6
48
26
11
y*fv
64,8
128
174,24
230,4
135,2
1 У
12
х
0,2755
> 0,5381
0,7619
i 1,0432
: 0,6505
13
1
х2 fxy
0,0152
! 0,0372
' 0,0661
0,1162
! 0,085?
)
14
^~yfxy
0,991S
i 2,1524
: 3,3523
i 5,0074
: 3,3841
)
* Данные условные.
тенденцию к увеличению пропорционально объему сбыта,
в то время как издержки условно-постоянные (заработная
плата административно-управленческого персонала, из¬
держки по содержанию основных средств, административ¬
но-управленческие расходы и т. д.) имеют тенденцию оста¬
ваться одинаковыми.
Особенности связи между относительным уровнем из¬
держек обращения и объемом сбыта товаров хорошо про¬
являются в приведенном ниже графике.
162
Таблица 30
5,4-5,8
5,6
5,8-6,2
6,0
6,2—6,6
6,4
fx
4-'*
yfyx
2 xyfyx
~~ 6
7
8
9
10
11
12
13
2
3
3
8
1,6000
0,3200
48,4
9,6800
2
1
9
1,2857
0,1837
47,6
6,8000
1
1
6
0,6667
0,0741
31,2
3,4667
8
0,7273
0,0661
36,0
3,2727
6
0,4615
0,0355
27,2
2,0923
5
0,3333
0,0222
20,8
1,3867
4
0,2353
0,0138
15,2
0,8941
4
0,2105
0,0111
14,8
0,7789
; 5
4
4
50
5,5203
0,7265
241,2
28,3714
28
24
25,6
241,2
156,8
144
163,84
1197,28
0,7968
0,7111
0,7429
5,5203
0,1332
0,1323
0,1404
0,7265
4,4621
4,2666
4,7546
28,3714
—
Точки на графике группируются около кривой типа
гиперболы, уравнением которой является:
Ух
Параметр а представляет собой издержки, пропорцио¬
нальные единице объема оборота, а параметр b — постоян¬
ные издержки. Величины параметров определяются
с помощью метода наименьших квадратов. При условии,
И*
163
что У (у — ух)* будет минимальной,
систему нормальных уравнений;
получим следующую
Данные, необходимые для решения этой системы, вы¬
числены в табл. 30, в колонках 10—14 и соответственно
в строчках 9—12.
Сбыт товаров ( млн.лей)
Рис. 18.
Подставляя их в систему уравнений, получим:
50 а-\- 5,5203 & = 241,2;
5,5203 а + 0,7265 b = 28,3714.
Решение системы следующее:
I 241,2 5,5203 I
__ | 28,3714 0,7265 I _ (241,2.0,7265) — (28,3714-5,5203)
I 50 5,5203 I (50-0,7265) —(5,5203)2
I 5,5203 0,7265 |
175,23 — 156,62 18,61 о 1О1
= = = 0,101.
36,325 — 30,474 5,851
164
I 50 241,2 I
b _ I 5,5203 28,3714 | _ (50-28,3714) — (5,5203-241,2) _
“I 50 5,5203| _ (50-0,7265) — (5,5203)2 ~
I 5,5203 0,7265|
_ 1418,57—1331,50 _ 87,07 _ j 4 gg j j
_ 36,325 — 30,474 ~ 5,851 ~ ’
Уравнением регрессии является у — 3,181 + 14,881 •—.
X
Это означает, что в условиях магазинов, подвергнутых
исследованию, на 100 лей сбыта товаров издерживается
3,18 лей зависимых расходов и сверх того определенная
часть из суммы 14,88 млн. лей, представляющей условно¬
постоянные издержки, часть которых является тем мень¬
шей, чем больше объем сбыта.
Например, если объем сбыта равен 5 млн. лей, уровень
относительных издержек обращения выражается в среднем
так:
ух = 3,181 + 14,881 ■ — = 3,181 + 2,976 = 6,16%,
а если рассмотреть максимальный объем сбыта, соответ¬
ствующий данным нашего ряда, т. е. 19 млн. лей, то относи¬
тельный уровень издержек обращения будет следующим:
ух = 3,181 + 14,881 • Т =3,181 + 0,783 = 3,96%.
Если полученные уравнения рассматривать абстрактно,
имея в виду неограниченное возрастание объема сбыта
товаров, то тогда часть, которая приходится на единицу
оборота из издержек условно-постоянных, будет стремиться
к очень малой величине и относительный уровень издержек
обращения сильно приблизится к 3,18 лей, т. е. к сумме
зависимых издержек, приходящихся на 100 лей объема
сбыта.
Уравнение
ух = 3,181+ 14,881 • у,
является описанием кривой, изображенной на рис. 19.
Часто криволинейная корреляция принимает форму па¬
раболы. Классический пример этого рода представляет кор¬
165
реляция между урожаем кукурузы и серией определяющих
его факторов, как-то: количество удобрений, ирригациою
ный режим, плотность посева. Накопленный опыт анализа
массовых статистических данных доказывает, что по мере
возрастания количества удобрений, количества воды цЛи
плотности посева возрастает и урожай, однако только д0
определенной границы. После этой критической точки удоб¬
рение, вода и уплотнение посева становятся излишними
и урожай снижается.
Исследуем зависимость между размером урожая ку.
курузы и режимом ирригации по данным, приведенным
в табл. 31.
Таблица 31
\ Номер
\ участка
Ре- \
жим \
ирри- \
гации в \
куб. м \
воды на \
1 га \
1
9
3
4
5
6
7
8
9
10
11
1 2
0
28,4
38,7
29,7
52,8 27,8 50,9
30,0,37,0
1
43,7'43,8:
37,5
53,7
800
35,1
40,7
59,9
39,2,66,6:65,4
59,9 62,2 63,9 59,3
52,9
,59,7
1 600
44,2
65,7
72,4
73,4,67,4 41,0
41,5*78,6’60,0)62,1
61,0^3,1
В отношении к режиму ирригации опыты по агротех¬
нике кукурузы на разных участках проводились в трех ва¬
риантах; без орошения, орошение в два полива (800 м3
воды на гектар), орошение в четыре полива (1600 м3 воды на
гектар). Сделано по 12 наблюдений каждого режима ирри-
гации.
Из ряда цифровых данных трудно сделать заключение
о форме связи. Поэтому прибегаем к графику корреляции.
Диаграмма рассеяния (рис. 20) подтверждает гипотезу
о криволинейной связи параболического типа. В этом слу¬
чае предполагаем, что функция
ух = а-\- Ьх + Ь'х2
является той параболой, которая достаточно хорошо выра¬
жает связь между изучаемыми переменными.
J66
Издержки обращения
О 800 1600
Режим ирригации
Рис. 20.
167
В определении функции регрессии, таким же образом
как в предыдущем примере, мы стремимся к тому, чтобы
величины yXi вычисленные с ее помощью, были наиболее
близкими к действительным величинам у.
Понимая в этом смысле условия метода наименьших
квадратов, находим а, Ь, Ь', так что сумма
S У (а 4~ + Ь'х2 — у)2
будет минимальной.
Дифференцируем последовательно это выражение в от¬
ношении а, Ь, Ь'.
Ь' х2— у)-х;
— = 2 У (а + Ьх -f
db ~v
= ^(а~г Ьх-)- Ь'х2-у)-х2.
дЬ'
Отбрасываем частные производные и упрощаем на 2:
2(# + Ьх-\- Ь'х2 — у) -1 =0;
У. (а ф- Ьх + Ь'х2 — у)-х = 0;
У (а4~ bx-j-b'x2— у)-х2 = 0.
Разложим суммы почленно
У а У Ьх 4- У Ь'х2 = У у;
У ах + У Ьх2 + УЬ'х3 = ^ху-
У ах2 4- 2 Ьх3 + 2 Ь'х^ = У х2у.
Вынесем параметры а, Ь, Ь' вперед, перед знаками сум-м>
и получим систему нормальных уравнений.
na-j-&2x + Ь' ^х2 = У у;
a х -f- Ь У х2 b' X х3 = У ху;
аУ.х2+ b^,x3+ Ь'^х4 = ^х2у.
168
Для получения сумм Ух, У^х2, Ух3, Ух4, У у, Уху
и Ух2у воспользуемся табл. 32.
Таблица 32
X
У
X2
Л'3
А1
А'У
х2у
0
39,5
0
0
0
0
0
8
55,4
64
512
4 096
443,2
3545,0
16
61,7
256
4 096
65 536
987,2
15795,2
S 24
156,6
320
4 608
69 632
1430,4
19340,8
vx = 24’12 = 288;
£у = 156,6-12= 1879,2;
Ух2 = 320’12 = 3840;
vx3 = 4608-12 = 55 296
Ух4 = 69 632-12 = 835 584;
Уху = 1430,4-12 = 17164,8;
V х2у = 19340,8 • 12 = 232089,6.
Подставим числовые значения сумм в соответствующие
уравнения:
36 а + 288 b + 3840 У = 1879,2;
288 а + 3840 b + 55296 У = 17164,8;
3840 а -у 55296 b 835584 У = 232089,6.
Для упрощения вычислений, необходимых для решения
этой системы нормальных уравнений, вместо наблюдаемых
величии переменной х и у будем рассматривать их откло¬
нение от средней арифметической х—х и у — у.
Элиминируем, таким образом, свободный член а из урав¬
нения регрессии и, следовательно, уменьшим число уравне¬
ний в системе на одно уравнение.
После преобразования система становится следующей:
b — х/ + У 2 (х—х)3 2 (х — х] (у— у);
Ь 2 — х)3у Ь' 2 (х — х)4 =--У^[х — х}2 (у— у).
169
На основе данных табл. 32 вычислим суммы:
2 (х-Г)2 = £х*- £41 = 3 840 - Ж = 1 536;
v 7 п 36
V(x — х)3 = 2х3— £££! = 55 296— 2^4840 = 24 5?б
п 36 ’
2 (х-х)4 - 2 х‘- -£421 = 835 584—= 425 984;
п 36
2(х—х) (у — у) = 2-^7 — £^£2 =
11
= 17164,8 — 288 1879,2 = 2131,2;
36
2 (х-х)2 (у-7) =2*2у- =
= 23 2 0 89,6 — 3 840'1 879>2 =31 641 д
36
С вычисленными величинами получим систему уравнений:
1 536 6 + 24 576 Ь' -2131,2;
24 576 b + 425 984 Ь' - 31641,6.
Решая систему уравнений, находим: а—39,5, 6 — 2,588
и 6' =—0,075, откуда корреляционное уравнение:
ух ==-. 39,5 + 2,588 х — 0,075 х2.
Если введем определенную величину переменной х, то
найдем теоретическую величину переменной у для данного х.
Например, когда х = 8,
ух - 39,5 + (2,588 • 8) — (0,075 • 82) = 55,4 квинтала.
С помощью уравнения легко определить, при каком
уровне переменной х переменная у достигает максимальной
величины.
С этой целью находим первую производную и приводим
уравнение к нулю. Первая производная параболы второго
порядка равна 6 + 2 Ь'х.
В данном примере
2,588+[2 ( — 0,075) х] — 0,
170
откуда х = 1725 лг3 воды на гектар. Следовательно, в рас¬
сматриваемом примере при режиме ирригации в четыре по¬
ливки получается наибольший урожай, в среднем 62 квин¬
тала на гектар.
§ 8. КОРРЕЛЯЦИОННОЕ ОТНОШЕНИЕ
Коэффициент корреляции является показателем интен¬
сивности корреляции только в случаях, когда она имеет
линейную форму. Для характеристики нелинейной корре¬
ляции применяется корреляционное отношение, известное
под названием «индекс корреляции», определяемое отно'
шением
которое можно написать так:
или
i/aiy»1
Л =
Из формулы можно видеть, что в основе корреляци¬
онного отношения лежит разложение общего рассеяния
коррелированной зависимой переменной Оу = ^-^у~~у^
п
на рассеяние ее эмпирических величин по отношению
к величинам теоретическим (вычисленным) = Оу у2х =--
%(у-ух)2
= х— и рассеяние теоретических величин около
средней = oy .
х п
Сопоставление рассеяния теоретических величин по
отношению к средней с рассеянием эмпирических величин
по отношению к средней дает корреляционное отношение.
В какой мере эмпирическое распределение приближается
к теоретическом)/ распределению и насколько больше удель¬
ный вес о| в Оу, в той же мере значение корреляционного
отношения приближается к единице и, следовательно, тем
171
большей будет интенсивность корреляции. Если все точки
эмпирического распределения будут располагаться на тео¬
ретической линии регрессии, эти две регрессии будут рав.
ны и корреляционное отношение будет иметь величину,
равную 1, указывая на функциональную зависимость.
Наоборот, в случае полной независимости, величины теоре¬
тического распределения не будут отличаться от средней,
дисперсия теоретического распределения по отношению
к средней будет равна нулю и корреляционное отношение
будет также равно нулю.
Вычислим корреляционное отношение, которое харак¬
теризует интенсивность связи между относительным уров¬
нем издержек обращения и объемом сбыта товаров. Эле¬
менты для вычисления находим в табл. 30 и 33.
1197,28
а^= ;
а- = 0,6746
ух
^^- = 0,6746 — 0,1566 = 0,518;
50
n = 1 / 0,518 = V0,767862 = 0,876.
1 Г 0,6746
Корреляционное отношение, равное 0,876, указывает
на тесную связь между этими двумя переменными.
Вычисление корреляционного отношения может быть
2 (у-TJ2 fxy
значительно упрощено, если определять
2 /
по формуле:
2 у,)2 /,у _ 2 у’ >у- ° 2 2 т
3/ 2/
Действительно, рассмотрим ряд индивидуальных ве¬
личин:
у— Ух = У—а — ь— .
X
172
/ср-
и
о
0,3904
’■Ф
о
со
хГ
О
0,1925
0,7814
0,5672
о
СО
оо
6,00
ь-
5,60
СО
5,20
ю
4,80
0,2209
3
0,6627
0,0729
3
0,2187
4,40
СО
0,0529
2
0,1058
0,0049
2
0,0098
0,0169
4
0,0676
4,00
О|
0,0016
1
0,0016
0,0036
2
0,0072
0,0289
3
0,0867
0,1089
1
0,1089
0,2809
1
0,2809
3,60
-
0,1296
3
0,3888
0,2116
2
0,4232
/
/ 1
СО
3,96
4,06
4,17
4,33
4,53
-
СЧ
СО
LO
173
Продолжение
Примечание: графа 1 строка (у —
174
Для каждого случая существует подобное уравнение,
умножая каждое уравнение на у — ух и суммируя,
получим:
2 (у—ух)2 = 2(у—Ух)у—а2(у—Ух) — ^2(у—ух) р
полагаем, что
2у—Ух = о и £у—Ух 7 = о
и, следовательно,
2(у—Ух)2 = 2(у—Ух)у-
Умножая каждое уравнение у — ух = у — а — Ь —
X
на величину у и суммируя результаты, получаем:
2 (у—Ух) у ^У*_аЪу-ь^У-
Подставляя — Ух)2 вместо 2 (у — Ух) У получаем
2 (у- Ух)2 = 2 У2—°2у~ 6 2
а в рядах, в которых фигурируют удельные веса,
2 (у —Ух)2/ху = 2у2^-
Применяя эту формулу в нашем примере, получим:
^(у~Ух)2 Су _ 1197,28—(3,181-241,2) — (14,881-28,3714) =
’ 2/ ~ 50
= 222=0,1566.
50
Корреляционное отношение может быть получено и
без вычисления промежуточной величины 2(у—Ух)2-
175
Так, пользуясь формулой
Пу-уУ
и принимая во внимание, что
2 (у—у )2 = 2у2—^У2,
подставим величину, эквивалентную 2 (у — Ух)2,
2 У2—а^У—S ~~ У> ПОЛУЧИМ
после упрощения находим:
v, у2— пу2
соответственно
С данными приведенного примера
(3,181-241,2)+ (14,881.28,3714)—(50-4,8242)
1197,28 —(50-4,8242)
2^ = 1/0,768= 0,876
33,78
результат идентичен полученному выше.
176
Степень влияния количества воды для орошения 1 га
на урожай кукурузы выражается корреляционным отно¬
шением (смотрите элементы вычисления в табл. 31 и 32)
= ■,/ _
1
(1879,2)2
105414,26 — —4179,93
36
105414,26 —
(1879,2)2
36
= 1/ 732О’°2 4179’93 — ]Д) 428972 =0,655.
|/ 7320,2
Тот же результат достигается и по формуле упрощенного
вычисления
а^у + b^xy — b' У^х2у — пу2
^у2-пу2
(3,95-1879,2)+(2588-17164,8)—(0,075-232089,6)—(36 - 52,22)
105414,24 —(36-52,22)
= 0,655.
Связь между изучаемыми переменными характеры*
зуется умеренной интенсивностью.
* 2 у — ух = S у2 — aS у — bS ху — b1 S х2у, следовательно,
105414,26 —39,5-1879,2 —2,588.17164,8 + 0,075-232089,6=4179,93.
12 Зак. 1050
177
Глава VII
МНОЖЕСТВЕННАЯ КОРРЕЛЯЦИЯ.
УРАВНЕНИЕ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
§ 1. ВВОДНЫЕ ЭЛЕМЕНТЫ
Обычно в процессе исследования причинных связей
между массовыми явлениями встречаются, как указывалось,
со слиянием действий множества причин, которые опреде¬
ляют последующие вариации явления.
В таких случаях вычисление корреляции не может огра¬
ничиться парой переменных и необходимо включить другие
независимые переменные, существенно влияющие на изу¬
чаемую зависимую переменную. Общее влияние этих пере¬
менных измеряется с помощью показателя множественной
корреляции.
Для иллюстрации процесса вычислений рассмотрим
корреляцию трех переменных: одной зависимой переменной
(у) и двух независимых переменных (хь х2), выраженную
линейной функцией типа
Ух', х* ~ "Ь сх%'
Параметры а, b и с определяются методом наименьших
квадратов. Предполагается условие:
У (а+ Ьх1-]-сх2— y)2 = min.
С этой целью приравниваются нулю частные производ¬
ные, выраженные в отношении к параметрам
—— 2 2 (а-f- Ьх1-\- сх2— у) -1=0;
оа
22(а+^1 + ^2—У)--«1 = 0;
—- = 2 2 у) ’ %2 =
178
Откуда в результате получаем следующую систему нор¬
мальных уравнений
na+ b 2 хг + с £ х2 = 2 у;
a S + & 2 +с S xi х2 = 2 xi у;
а 2 Х2 + Ь 2 Х1 Х2 + С *2 = Z *2 У-
Как пример конкретного применения приведем корре¬
ляцию между себестоимостью (у), производительностью
труда (%i) и оснащенностью основными фондами машинно-
тракторных станций (х2). Наблюдаемые значения этих трех
переменных по 48 МТС (20% общего числа) приведены
в табл. 34. Вводя в систему уравнений количества:
п = 48, - 18636, %х2 = 1 159, = 3771,6,
= 7637046, 2 Х1 х2 = 466721,5, %х22 = 29811,84
у = 1 413 078 и У х2 у = 88 494,18 и производя вы¬
числения на основе наблюдаемых величин, получаем:
48а+ 18 636 & + 1 159с = 3771,60;
18 636 а + 7 637 046 b + 466721,5 с = 1413078,00;
1 159 а + 466721,5 b + 29811,84 с = 88494,18.
Эта система нормальных уравнений может быть решена
с помощью симплексного метода, который нуждается в ма¬
лом объеме вычислений и в то же время позволяет опреде¬
лить суммы квадратов отклонений наблюдаемых значений
у от вычисленных с помощью уравнения регрессии z/X1,X2.
Последовательный порядок вычислений следующий.
а) Выписываются коэффициенты системы нормальных
Уравнений и свободные члены в форме таблицы
(см. табл. 35).
В последней рубрике табл. 34 фигурирует 2 У2 =
= 305283,06.
б) Каждый коэффициент первого уравнения (строка 1)
п . . /48 18 636 \
Делится на его коэффициент при а I —48 и т. д. I, затем
Из коэффициентов следующего уравнения вычитаются ве¬
личины, являющиеся результатом деления соответствующих
Коэффициентов первого уравнения на коэффициент при а,
12*
179
Таблица 34
СГ>
' Ю СО
СМООСОСМСОСООООЬ-ОСЭОЮСОЮООСЧСЧООСОтфЗС.^
Orf Q - X’t Ю COQ Crf ЮСО ЮС ХЬ (N ОЮ X (О <Л
—ib-TfCOOQOCMCOCOcOCMCO —'OOlOb^lCTTOO^^
coco—< сто сп сч сч ю —< со ю о ю ~ ь ю -< ow oi cr ь
Ь-ХЮСО^^Ю^ООСОЮ^ЮЮСОСОЮЮСОсОю^
£
ОО
юсоо-сосчоооооооососчососоюсчсооосоп
^O^^mq^O00(MO)O^(NO(£)00c000[>-hCIq^
С N X ОЮ О X ООт|< Ю UW CW СО N СО DW b- СО С\Гг<
Ь-'ЮО'^ЬЮСЧС^ОСП^ОО’^’^О^^СС’Н
rf СО О 1О 00 СО Ю О СЧ Ю О Ю N СО Tf< b- ОО GO -?
—< —< СЧ СЧ СЧ —< СЧ —< —< СЧ —< СЧ СЧ г-н —
Ь’
ЮМ-нО^оОХОХХ^ОООХООЮОСМ^^^
CW СО Ф Ю С0| rf О 0 М СО Tf< СО 00 О X О О
О Ю '«Ф СЧ —<Tfb-CO0CO'^COOO0^0COOOCMTf —< b- ю
ООООЬ-ОСОСП^-иОО^СПОЮ—^b- ONCO ОЮООСчО
—<b-<OOO0OOC4CMOO —(CCrfLQOOClO^NinOCOl
СЧСЧСЧСЧСЧСЧСОСОСОСОСОСМСОСОСЧСОСОСОСЧСМСЧСЧСО
*
>7
о
ЮоОСОСООООООЮСООО'-ОЮООЬ’^ООООООсО
—(Ь-О^’-чЮСГ)’—(b-^LQ^Tf—(Щ^СОСОО^СЧСМСТ?
— ЮСЧЮООСО—<Ь-СО—'СЧОО —<00—< СЧ 0 СО —< О0 Ь- —' 0
^b-CSCNOXCWCDXb-< XCOb-'CON OlOXO ) b
Tf СО —< rf Ь^ О Ь- 0 СО X СО 0 X СО X Ю Ь4* 00 Ь^ Ю b- b- b
сч сч
1О
QOTf — — ОЮ^ОЬО—« О О —< —<О00ОСОООСО<О
СЧ О О О X СЧ ТГ О 'М О О Э М СЧ С О О О N О О Х Ь
о СЧ CD М О сч' о О О LO rf 0 О; гн CC' CN со О Tt“ X М
0 0 О —'CDO’-i'^NCNClGO’-tiDxm^O^ObXCD
ОЬХОО^ЬСО^Х(£)СОЬ’-н(М'ФОД'^ХЮтГЮХО
сч —
’ф
Ю~^00СООЮ—< Ю СО —< Ю Ю Ю 0 —1 о Tf со
CMOOCMO—'ОСЧОСЧ—<ОООСЧСЧСЧСЧтф<СЧОООООСО—<
О СЧ —' X 0 —<0^'СМСОМ4ЮОСЧСЧ^СОЬ-ЮСЧЮ<0’-«
ЮСО00ОООО1ОСО0Ю—<Ь-ООСЧСЧО-СОСЧСЧЬ'-0-СООО
0гнСООФЮ^О’-'(МОООМЬЬ-’^О<ММО1Оа;
_ — сч СМ СО Г-t СО —< СО —< СЧ — —< — — сч
й)
СО
ЮЬ.Ь’Ь-^0ОЮФ(ЧСЧХ^МСОО-< Ю СЧ 0 СО СЧ 03
Ю-^^СЧСОО^СЧЬОО^СОтГ-нО^’-нЬ—<0X0
XXbCOCDb-XbXOXNXNMXXb’b'Ob-bX
4*
сч
СОХ-нОСОЮСЧОЮОООО^СМСООХ-нО^^
b-Г 0 o' —" оо" <О со" —Г 0 Tf" LO оо СО СО —1 00 о СП СЧ О ”Ф 00
—1—иСОСОСОСЧСОСЧСЧСЧСЧСЧСО —-< СЧ СЧ СЧ —1 СЧ СЧ СЧ —«СО
н
Юг-чсомхою —юч<оод1пююЬ"Фа)Оооххх
ю ’’f О- Tf —чСПЮСОЮ^СЧЮ^—(СЧМСОЮМСЧО'С
CMCOCOTf'rrTfTfTfLOCOtOcOLQTf'^fLOCO'^'COCMCOCObJ
о
—(СЧСО’^ЮСООООООО^СЧСОт^ЮСОЬ'ООООО’—' £} £3
—< —< .—< —1 г—< —< —< —11—«СЧСЧСЧС,^
180
—nO’FCHUO — СОСИ —< — F1 CH СИ О —< —< CO О CO CO CO CH —• CO F
(МС^СОСЧОССООС^ОСООСОФООСО^-н^СОЮтГ
г-иОООМО'5ЮО^^’фОШ’^ССЮС0^^0 10(М^СС-н
CDOCC'^iMOaiNQC^OlLOOOOCNOOOOO^COOO'-1 F CO F
Г-а)^’-|^-н^0сОО0СОООЮ^СС0Г-^^СОЮЮсОСМ
|П^ЬЮ^ЮФкО<£)0^-|(£)Ю«а)-|(£)(М^С^ЮО(0-|0
О
О
ooocOFuoFootooo4oocotoocncooooo40FooF04co
lQOGOO)CO — QOuOFOOOOC004C010F04t004- Ю — COCO
lO О —<0040— Ю — — — Ю00 —<--H(M^CCcOCDb(NOCC^
—ч to —ILOOOOO^CNNN-'OOCOOOGOCHCO — FCHLOO
—<OCOCHC004FOOCHCncOCOlOFCnFCOcOO)OOC4Cn— 00
040404 — — 040404 O) — 04 04 —4 —~< —~< —ч *-4 —^ —“< —~< —“< 04 —~<
О
о
О
СО
ю
F
00
LO
F
Ю
F
04
04
о
СО
Ю
о
О
00
СО
F
СО
—
СО
о
04
о
(О
О
со
00
СП
&
со
04
О)
LCD
оо
F
Ю
СО
F
F
СО
_Ч
00
00
О
со
О
04
00
ю
F
со
СО
F
Ю
F
00
О
04
СП
04
о
о
ю
04
F
ь-
00
04
со
сп
(О
СП
00
СО
00
04
F
СП
04
СП
СО
О
о
tO
о
г^-
00
04
СП
ь-
О
о
00
F
СО
04
со
F
F
СП
F
ю
to
СО
СО
СП
оо
со
СО
Ю
сп
со
о
co
СО
СО
СО
СО
со
04
СО
04
04
04
04
О)
04
04
04
04
04
04
04
04
04
со
со
со
ю
04
to
o
о
F
FCHCHF — COF — CHF — F^<—' — COFOCHO — COCOFF
00000000с00с00004004040ю04юс0000 — — ООО
04 О) 00 О О О GO CO О 00 О 00 1O —< OlO О) N -< СП О to Ю ОО CO
(ООО — COQOc00004FOtOOOF0040000CHcOOOcOOO —
О&ЗОЬЮООО^О^ QO F Ю О) СО 04 Ю СО — Ю 04 СО F СО
00
00
о
О)
о
СО
Ю
СО
о
ю
СО
ю
F
СО
СО
^_Ч
СО
ю
1-0
F
СП
_<
00
,—<
Ю
СО
о
04
00
F
СП
00
04
со
04
00
Г-
со
00
LQ
04
04
О
00
00
00
СО
00
04
F
F
о
04
со
F
о
00
о
СО
04
04
О)
п-
О
ь-
СО
04
(F
ОО
о
СО
'—<
04
СО
О
О
со
СО
ОО
о
СП
о
о
(^
СО
СП
СП
со
СО
00
о
ю
04
F
СО
о-
F
СО
Ю
F
со
to
ь-
F
F
04
СП
о
СП
СП
F
о
04
Ю
О’
о-
О
ю
СО
00
со
СО
00
О)
со
04
04
04
04
СО
со
to
о
-Н004ью00с00’-04^ь0^^00'^^,'^ь-0004
ООО—ч СО —OiOQtOOOOOOOOOCCOfM’tNlOOOOO
t^b’OOl^ONOObbOOI>>'OOOQOlOOObOOGOO-<
о
О
СО
00ЮСОО4— СО00СИС0О4СП00- СНСТ>СОООСОСОО — FCOCOOO
ЬОо'Ь'^ОООЮОООО-нСО'фЬОООСО^Ю’^ОГ-
04 04С00404С004010101 040)04—<—<—<0404 — 04 — 0)04—<
ООЮОООС0ЮОЮО4ОО — 00004Г-0 — о о — ю
С4СПООЮО-СОСОЮО — OIOIlQFCOOCOlO — 1.Q О О О О О
FFCOFFFCOFCnc004COC0040l04COlOF04 04COFOtCO
■^lOCONOOOO— (MCO’ti^OSOOOO — (NCO^LOOt^OO
04 04 О) 04 04 04 CO CO CO CO CO CO CO CO CO CO F F F1 F F F F F F
181
Таблица 35
а
ь
С
а
18 636
1 159
3771,6
b
18 636
7 637 046
466721,5
1 413 078
с
1 159
466721,5
29811,84
88494,18
3771,6
1 413078
88494,18
305283,06
и результат умножается на первый коэффициент соответ¬
ствующего уравнения (например, второе уравнение:
48 18 636 \
18636 — 48. 18636; 7 637 046 —-48~. 18 636 и т. д.\
В результате этих операций получаем:
Таблица 36
ь
С
а
388,25
24,14583
78,575
b
| 401 619 |
16739,8
—51 246
с
16739,8
—51 246
1826,82
—2574,424
—2574,24
8929,66 = 2 (у —у)2
Здесь элиминируется колонка а, поскольку ее элементы
равны нулю, за исключением первого элемента, равного
единице.
в) Элементы второй строки табл. 36 делятся на первый
/ 401 619 16 739,8 \
элемент этой строки i ; и т. д. , после
чего остальные элементы строки уменьшаются на кор¬
респондирующее частное, умноженное на первый элемент
соответствующей строки (например, строка первая:
388,25 — ^-^-388,25; 24,146— 1673М. 388,25 и т. д.) •
401 619 401 619
Таким образом, получим таблицу, в которую колония
b не вписывается, так как все ее элементы равны нулю,
за исключением второго элемента, равного единице.
18?
Табл и ц а 37
с
а
7,64
128,11
b
0,04168
—0,12759
с
| 1129,11 |
—438,41
—438,41
2390,76 = 2(у-yj2
г) Элементы третьей строки делятся на первый эле-
71129,11 —438.41 \
мент или —; — , а затем, поступая таким же
<1129,11 1129,11 ! J
образом, как в пунктах бив, получаем:
Таблица 38
а
131,2
b
—0,1114
с
—0,3882
2220,57=2 (у_~УХ1ХУ
Следовательно, множественное уравнение регрессии,
которое выражает зависимость себестоимости у от произ¬
водительности труда %i, как интенсивного фактора, и от
оснащенности основными средствами х2, как экстенсивного
фактора, можно написать так:
= 131,2 —0,111 4х1 — 0,3882х2.
Как и в случае простой корреляции, коэффициенты b и с
(коэффициенты множественной регрессии) указывают, на¬
сколько именно изменяется зависимая переменная, когда
соответствующая независимая переменная изменяется на
единицу, разумеется, при гипотезе, что другие независимые
переменные, включенные в вычисление, сохраняют по¬
стоянный уровень. Таким образом, коэффициент регрессии
Ь — —0,1114 показывает, что себестоимость на 1 га пашни
снижается в среднем на 0,11 лей, если производительность
труда увеличивается на 1 га, а оснащение основными
средствами сохраняется на постоянном уровне; коэффи¬
циент регрессии с = —0,3882 указывает, что себестоимость
183
уменьшается в среднем на 0,39 лей, когда оснащенность
основными фондами увеличивается на 1 млн. лей, а произ¬
водительность труда сохраняется на постоянном уровне.
Коэффициент множественной регрессии в нашем приме¬
ре отличается от коэффициента простой регрессии. На самом
деле, пользуясь тем же методом наименьших квадратов,
можно получить два уравнения простой регрессии:
128,1157 — 0,1276 лд
и
уХ2= 112,596— 1,409 ад.
В случае простой регрессии, пренебрегая влиянием дру¬
гих факторов и полагая, что себестоимость зависит только
от исследованного фактора, заключаем, что возрастание
производительности труда на 1 га уменьшает себестоимость
в среднем на 0,13 лей, а возрастание на 1 млн. оснащенности
основными фондами уменьшает в среднем себестоимость на
1,41 лей.
Независимые переменные в рассматриваемом примере
выражены в различных единицах измерения, и точно так же
различно отношение их дисперсий, указывающее на то,
что коэффициенты регрессии должны быть приведены
в сравнимую форму.
Этого можно достигнуть, если корректировать первич¬
ные коэффициенты регрессии по соотношению между
средним квадратическим отклонением независимой пере¬
менной и средним квадратическим отклонением зависимой
переменной, т. е.:
В, =-0,1114- — 0,0576;
1 13,63
В, = —0,3882 • —0,51 = —0,2993.
- 13,63
Коэффициенты Pj и Р?, которые являются нормирован¬
ными коэффициентами множественной регрессии, обозна¬
чаемые греческой буквой Р и называемые «коэффициентами
бэта», сравнимы между собой, потому что они выражены
в тех же единицах — в средних квадратических отклоне¬
ниях зависимой переменной. Эти коэффициенты нужно
понимать в том смысле, что если производительность труда
возрастает на величину ее среднего квадратического от¬
184
клонения аЛ1, то тогда себестоимость уменьшается прибли¬
зительно на 0,06 оу; при возрастании основных средств
в количестве, равном оу„, себестоимость уменьшается при¬
мерно на 0,3 (Уу при условии, что «другие переменные
константны».
§ 2. КОЭФФИЦИЕНТ МНОЖЕСТВЕННОЙ КОРРЕЛЯЦИИ
Для измерения интенсивности корреляции между зави¬
симой переменной у и многими независимыми переменными
%1, х2, .хп применяется коэффициент множественной кор¬
реляции, выводимый по формуле:
Ry
1
S(y-y)2
Величина коэффициента множественной корреляции
зависит от отношения между рассеянием значений, опре¬
деленных на основе уравнения множественной регрессии,
и рассеянием наблюдаемых значений зависимой перемен¬
ной. Чем меньше наблюдаемые величины отклоняются от
линии множественной регрессии, тем большую величину
имеет коэффициент корреляции, следовательно, корреля¬
ция является более интенсивной.
Гипотеза, что У (у — уХг ... xj2 = 0 и, следователь¬
но, Ry.xx...xn = 1, показывает, что наблюдаемые зна¬
чения у совпадают со значениями, вычисленными на основе
уравнения множественной регрессии и по вариации перемен¬
ной у полностью объясняются вариациями независимых пе¬
ременных, включенных в вычисление корреляции.
Интенсивность корреляции между себестоимостью,
с одной стороны, и производительностью труда и оснащен¬
ностью основными средствами, с другой стороны, выра¬
жается коэффициентом:
= 0,866.
Элементы вычисления
Х(у-Ц2 = 8929,66 и £ (у-F.vi;J2 = 2220,57
получены применением симплексного метода в решении
системы нормальных уравнений (см. табл. 36 и 38).
185
Коэффициент множественной корреляции может быть
выведен из простого коэффициента корреляции. Если рас¬
смотреть:
.Xl J...
•" (1 ГУХп-х2хг ... хп_{ )>
то для случая трех переменных получим:
Оу-Х1 Х2
°У
1 —-- /"2 -— 7*2
yxt 'xtx2
О — 4J (1 — ryXl.x)=
Гух2 + 2гуХ1 ГХ]
х2ГУХ2
и, следовательно,
ГУХ1 Гух2 Гх± х2
2
Xi х2
величины:
В приведенном примере коэффициенты простой кор¬
реляции имеют следующие
г^. = 0,85572;
гух2 = 0,63736;
rXlx2 =0,61808,
откуда
RyX1 хг
0,855722+ 0.637362 —(0,85572.0,63736-0,61808)
1—0,618082
= КтШЙ = °’7512702 = °-866-
По отношению к коэффициентам простой корреляции
коэффициент множественной корреляции является большей
величиной, что вполне объяснимо, поскольку этот коэффи¬
циент выражает полное и одновременное влияние на себе¬
стоимость роста производительности труда и оснащен¬
ности основными фондами.
§ 3. ЧАСТНЫЕ КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
Коэффициент множественной корреляции измеряет одно¬
временное влияние независимых переменных xit ..., хп на
зависимую переменную у. Для научного анализа корреля-
186
ции представляет также интерес определение силы связи
между зависимой переменной и отдельной независимой
переменной при исключении влияния других независимых
переменных. Полезность таких коэффициентов, называе¬
мых частными коэффициентами корреляции, можно видеть
из их применения в приводимом ниже примере. Формулы
вычисления, по которым можно выделить значение, при¬
сущее этим коэффициентам, следующие:
Подставляя соответствующие величины в формулу1, на¬
ходим:
49,808 — 46,261
49,805
= 0,267.
Гух2 -А х
Первый коэффициент корреляции выражает зависимость
себестоимости от производительности труда при исключе¬
нии влияния оснащенности основными фондами, а второй —
зависимость себестоимости от объема основных фондов при
исключении влияния производительности труда. Инте¬
ресно отметить, что вычисление частной корреляции обна¬
руживает решающее влияние производительности труда
и пониженное влияние, оказываемое другими факторами,
что отражается в малых величинах их частных коэффициен¬
тов корреляции.
п2 _ 2 у2 — аЪу — ЬЪух2 _
yXi ~ п
305283,06—112,596 -3771,6 + 1,409-88494,18
5 = 110,506;
48
CF
2
*У 1
2390,76
48
49,808; а2 . .. =
J Л 1 Л 2
2220,57
48
= 46,261
(см. элементы вычислений в табл. 34,37 и 38).
187
Вычисление частных коэффициентов корреляции можно
сделать и на основе простых коэффициентов корреляции по
формуле:
ГуХ1 Гух 2ГХ1 Х2
и
„ ГУХ2~ ГУХ1 Гх1 х2
1 ух2'X, !
/(>-<,) 0-,’, .,)
таким
образом,
Г Ухг- х2
0,85572 — 0,63736-0,61808
у(1 — 0,637362) (1 — 0,618082)
-0,762;
Гух2 •
0,63736-0,85572-0,61808
V(1 —0,855722) (1—0,618082)
0,267.
Как можно видеть, результаты являются идентичными.
§ 4. РАЗЛОЖЕНИЕ ВЛИЯНИЯ ФАКТОРОВ.
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ
Статистический метод корреляции обладает ценными
познавательными преимуществами, заключающимися в воз¬
можности определять долю, вносимую каждым фактором
в модификацию явлений действительности. Показатели,
применяемые для этой цели, получили название коэффи¬
циентов детерминации.
Степень влияния каждого фактора, включенного в вы¬
числение корреляции, выражается той частью дисперсии
значений признака явлений, которая определяется вариа¬
цией значений соответствующего фактора. Другими сло¬
вами, разложение влияния факторов состоит, в сущности,
в разложении рассеяния зависимой переменной Оу на при¬
нятое во внимание рассеяние каждой независимой перемен¬
ной. При исчерпывающем знании факторов, влияющих на
исследуемое явление, ву разлагается полностью.
Единицей измерения одновременного влияния, оказы¬
ваемого вариациями всех исследуемых факторов, служит
квадрат множественного коэффициента корреляции, из¬
вестный под названием «коэффициент множественной де¬
терминации».
188
Таким образом, при корреляции трех переменных из
отношения
GV—Y Y
2 У У • xi x2
ГУ-Х1 x2 ~2
Gy
следует
_2 ,
ГУ-Х1 х2 4 ~2
°У
1.
у. xt -х2
Показатель Гу. Xl.X2 представляет собой часть рассея¬
ния Оу, объясняемую влиянием переменных и х2, т. е.
величину, на которую уменьшается ву под общим влия¬
нием двух переменных х± и х2. Если обозначить симво¬
лом dy.Xi.Xn коэффициент множественной детерминации,
то тогда
... Хп^Г
г2
...
2 2
Qv~ х х
У у-хг ... хп
В изучаемом примере множественная детерминация
равна
dy.x, х2
это означает, что дисперсия издержек производства опре¬
делена в пропорции 75,1 % к одновременному влиянию про¬
изводительности труда и объема основных фондов.
Отдельное влияние каждого из этих двух факторов
можно установить разложением всей дисперсии. Формула
вычисления коэффициента множественной детерминации
(случай двух независимых переменных), которую можно
написать так:
S yxL - - \ ух2
—
j 2
аУ -Xi Х2 ' У-Xi
У Х2 )
>
преобразуется в следующую:
189
й, после разделения правой части выражения, получают
частную детерминацию:
a_y-xix2 —
В рассматриваемом примере
^У'Хгх2
Коэффициенты частной детерминации показывают, что
63,9% из вариации издержек производства приходится на
вариации производительности труда и только 11,2% —
на вариации объема основных фондов. Сумма этих коэффи¬
циентов 75,1% равна общей детерминации, обусловленной
одновременным действием двух независимых переменных.
§ 5. ОЦЕНКА СУЩЕСТВЕННОСТИ ПОКАЗАТЕЛЕЙ
КОРРЕЛЯЦИИ
Статистическая корреляция часто вычисляется по вы¬
борочным наблюдениям, так что полученные показатели не
являются вполне точными оценками величины корреляции
в генеральной совокупности.
Поэтому абсолютно необходимо знать точность оценки
показателей корреляции, проверить их существенность и
определить границы доверительности, соответствующие
определенному уровню существенности.
а. Существенность коэффициента регрессии проверяется
с помощью критерия t, определяемого по формуле
190
В которой Sb —ошибка выборки коэффициента регрессии Ь.
Ошибка выборки Sb определяется по формуле
S = ^(У-Ух)2 f
Ъ (N — 2)Z(x—~x)2'
в которой 2 (У — Ух)2 — сумма квадратов отклонений зна¬
чений, вычисленных на основе уравнения регрессии (ух), по
отношению к эмпирическим значениям зависимой перемен¬
ной (у). Ее можно легко определить по формуле
£ у2_ ДГу2_ £2 V(%_-)2
и также
S (х — х)2 = 2 х2 .
Применим ее в примере, взятом из табл. 27 (стр. 144),
Ь= 19,055;
2 (у — Ух)2 = 4 160 106;
S(x —х)2 = 44 738;
Af —2 = 40 —2 = 38,
откуда t = 19,Q55~ = --19055 - = 7,78 с38 степенями свободы.
J 4 160 106 2,447
38-44738
Считается, что b существенно тогда, когда величина t,
вычисленная на основе изучаемых данных, является боль¬
шей, чем величина в таблице, соответствующая уровню
существенности qi9 т. е. вероятности Р = 1 — и числу
степеней свободы f = 2 f — 2 или N — 2.
Для Р = 0,05 с 38 степенями свободы t = 2,04, т. е.
| ниже величины, полученной вычислением. Таким образом,
возрастание числа рабочих примерно на 19 при возрастании
объема основных фондов на 1 млн. обязано не случаю и
является реальным. Границами доверительности коэффи¬
циента регрессии в генеральной совокупности с вероят¬
ностью превышения в 5 случаях из 100 будут
19,055 ± 2,04= 17,015 —21,095,
т. е. от 17 до 22 рабочих.
191
б. Существенность коэффициента корреляции. Коэф¬
фициент корреляции является величиной нормированной
поэтому функция частоты f(r) этой переменной зависит толь¬
ко от объема выборки (число пар наблюдений, Лг) и величи¬
ны коэффициента теоретической корреляции (<>). Действи¬
тельно, распределение г из выборки модифицируется с из¬
менением объема выборки (N) и величины коэффициента
корреляции генеральной совокупности (р). В выборках из
первичной нормальной совокупности распределение прибли¬
жается к нормальному по мере возрастания N.
Эта тенденция видна более ясно тогда, когда р прибли¬
жается к нулю, чем тогда, когда р сильно отличается от
нуля. В случаях, когда величина р близка к +1 или —1,
необходимо, чтобы N было достаточно большим для того,
чтобы распределение было симметричным и приближалось
к нормальному. По мере того как коэффициент корреляции
приближается к нулю и число пар наблюдений возрастает,
эмпирический коэффициент корреляции получает распре¬
деление, близкое к нормальному с М(г) = р и дисперсией
1 О2
(5Г = (оу — квадратическая ошибка г).
При применении этой формулы необходимо иметь в виду
в первую очередь, что она основана на р — величине обычно
неизвестной. Замена ее величиной г, полученной из выбор¬
ки, близкой к р, как это обычно в практике, может быть
совсем неудовлетворительной, особенно если величина N
мала.
В специальных случаях, когда проверяется гипотеза,
что выборка взята из генеральной совокупности, в которой
величина р равна нулю, формула сводится к оу = —
и для подобной проверки незнание коэффициента корре¬
ляции р служит только препятствием. Во-вторых, при вы¬
борке с малым объемом распределение г в выборке может
значительно отличаться от нормального, особенно при ма¬
лых величинах р. Если величина р близка к единице,
тогда необходимо, чтобы N было достаточно большим, для
того чтобы формула ог = была применена с наи¬
большей уверенностью в конкретном исследовании.
Проверим существенность коэффициента корреляция
0,892, полученного на основе данных табл. 28 (стр. 151)-
Прежде всего проверим возможность отвергнуть нулевую
192
гипотезу, т. е. возможность несовместимости с презумп¬
цией того, что реальная корреляция равна нулю.
Согласно гипотезе р=--0 величина квадратической
ошибки г будет следующей:
= =0,1601.
1/40 — 1 6,245
Коэффициент корреляции, вычисленный по соотноше-
нию квадратических отклонении — = Q 16Q1 = 5,57. Следо¬
вательно, нулевая гипотеза не подтвердилась.
Дальше вычислим Sr и доверительные границы коэф¬
фициента корреляции в генеральной совокупности. Полагая,
что величина г приблизительно равна р, находим
__ 1—г2 __ 1 —0,8922 ___ 0,204336
} N — i У40 — 1 6,245
с вероятностью 0,99, соответствующей t = 2,58, что грани¬
цами для р будут:
0,892+2,58 • 0,03271 - 0,808— 0,976.
Изложенный метод позволяет установить существен¬
ность коэффициента корреляции при условии, что N яв¬
ляется достаточно большим.
Для малого объема выборки с распределением г, далеким
от нормального, и достаточно явной асимметрией, нужно
применить другие методы. В этих случаях можно проверить
г по отношению к нулю, т. е. можно проверить нулевую
гипотезу с помощью критерия Z, полученного по формуле
t
Эта переменная следует приблизительно закону распре¬
деления Стьюдента с f = п — 2 степенями свободы. Если
вычисленная величина меньше, чем в таблице, то полагают,
Что теоретический коэффициент корреляции равен нулю и
соответственно эмпирический коэффициент корреляции не
'отличается существенно от нуля, т. е. является оценкой тео¬
ретического коэффициента корреляции р = 0. Если вы¬
числение величины t превосходит величину tp по таблице,
ho не существует основания для того, чтобы считать, что
(Величина эмпирического коэффициента корреляции г не
«отличается существенно от теоретической величины р = 0.
РЗ Зак. 1050
193
Применим это к исследованию корреляции между числом
рабочих и величиной основных фондов в машиностроитель¬
ной промышленности. При объеме выборки в 40 предприя¬
тий в условиях, что величина г равна 0,892,
> 0,892 z
]/Т— 67892* 40 — 2 = 12,165.
В таблице значений t находим, что величина t в строчке
N — 2 = 40, соответствующая вероятности в 1%, много
ниже вычисленной величины t (между 2, 57 и 2,75). Полу¬
ченная величина t является существенно большей, чем
величина по таблице, и вероятность того, что найденная
величина t выражает случайный момент выборки, крайне
мала.
В другом случае проверку на основе нулевой гипотезы
можно сделать без вычислений, пользуясь таблицей, со¬
ставленной Р. А. Фишером, которая показывает величину
коэффициента корреляции до определенной степени вероят¬
ности, признаваемой существенной. Если выборка содержит
40 парных значений, тогда граница г, на пороге 0,05 равна
примерно 0,31, а на пороге 0,01 —примерно 0,40, т. е.
величинам, меньшим вычисленной величины г (0,892). Сле¬
довательно, коэффициент корреляции 0,892 можно считать
значимым при критерии существенности Р = 0,01, т. е.
только один случай из 100 испытаний в выборке в 40 еди¬
ниц из генеральной совокупности даст величину г, равную
0,40.
При том же объеме выборки только 5 случаев из 100 ис¬
пытаний дадут величину г, равную 0,31, и т. д.
Третьим методом, применимым к относительно малой
выборке, в которой величина г очень близка к единице
(в условиях, когда распределение г существенно отличается
от нормального), является так называемый «метод преобра¬
зованной корреляции». Фишер указывает, что распреде¬
ление переменной
Z = argth г = — log—
& 2 1-г
(логарифмы Непера)
приближается к нормальному, какой бы ни была точная
величина р и значимость выборки. Вариация Z вира-
жается формулой !— .
н J z N-3
194
Существенность коэффициента корреляции, следова¬
тельно, может быть проверена посредством Z и использова¬
ния свойств нормального распределения.
Характеристику Sz можно рассматривать как среднее
квадратическое отклонение нормального распределения Z.
В нашем примере
Sz = J = J— — 0,164;
J 1V-3 J-40-3 6,0828
1,43 _ q yq
Sz~0,164 ’
По таблице соотношений Z = argthr, которая позволяет
избежать вычисления логарифмов, находят, что г = 0,892
■ соответствует Z = 1,43.
Умозаключаем: величина г = 0,892 существенна.
Границами Z, соответствующими вероятности 0,99,
являются 1,43 ± 2,58-0,164 = 1,01 — 1,85, а после ре¬
трансформации в шкалу г на основе таблицы «Отношение
между г и z для величин г от 0 до 5» будут:
0,7658—0,9518.
Проверка существенности корреляции между размерами
основных фондов и числом рабочих (техническим оснаще¬
нием и объемом рабочей силы) при применении или крите¬
рия t (Стьюдента — Фишера), или критерия z (Фишера)
приводит к заключению, что полученные показатели кор¬
реляции указывают на существенную положительную связь.
в. Существенность корреляционного отношения. Су¬
щественность корреляционного отношения проверяется
^(ух~ у)2
критерием F, т. е. отношением F = — между
^*(У Ух)2
п— k
объясняемой вариацией и вариацией остаточной с учетом
соответствующих степеней свободы.
Посредством простого преобразования получим F по
формуле
р = n~k п2
? k — 1 1—Т]2
13*
195
Корреляционное отношение существенно, если объяс¬
няемая регрессией вариация (межгрупповая вариация)
является существенной. Вычисления на основе данных
табл. 30 (стр. 162—163) дают
2Б-у)2/ = 0,5180;
= 0Л566;
2/ = 50;
т)2 = 0,767862;
Л = 0,876;
k = 8,
откуда
0,5180
’ я—Г 42 0,767 862
F= 0,1566'=20? ИЛИ 7 ’ Г=-~0,767 862 = 19,8 ~20,
50—ЛГ
Таблица Снедекора указывает, что при = 7 и п2 = 42
степенях свободы величина F равна 2,24 с вероятностью
95% и примерно 3,1 с вероятностью 99%. Вычисленная ве¬
личина F является гораздо большей, указывая на интен¬
сивную корреляцию между относительным уровнем из¬
держек обращения и объемом сбыта товаров, отражающую¬
ся в эмпирическом корреляционном отношении q = 0,876.
Другой пример. Предполагается влияние густоты посева
на урожай кукурузы на опытной станции (двойной гибрид
VIR 42)1
Число растений на
гектар (в тысячах)
Урожай зерна кукурузы
(квинталов на гектар)
X
У
20
42,7
30
48,5
40
51,3
50
54,7
60
54,1
70
51,7
1 Experience cu porumbul dublu hibrid. Editura Agro — Silvica,
Bucuresti, 1962, p. 107.
196
Примечание: урожай кукурузного зерна — средние ве¬
личины из 5 наблюдений; следовательно, п = 30 (условно).
Элементы вычисления
1315;
2 ух = 69805;
2(у —у)* = 668,12;
п = 30;
2 у2 = 77175,62;
S/x-3 638 250;
/е = 6;
668,12 — 252,68
668,12
т] = 0,788;
30 — 6
Так как при щ = 5 и п2 = 24 степеням свободы F равно
примерно 3,9 с вероятностью 0,99, то следует, что эмпири¬
ческое корреляционное отношение в этом примере является
существенным.
г. Существенность коэффициента множественной кор¬
реляции. Критерий существенности коэффициента множе¬
ственной корреляции состоит в доказательстве того, что
вариация, обусловленная зависимостью, не превосходит
остаточной вариации, т. е. что
n—k R2
k — \ * 1_7^2
существенно превышает единицу (критерий Снедекора
с rii = k — 1 и п2 = п — k степенями свободы).
Сошлемся на пример, приведенный в § 2 настоящей
главы.
Интенсивность корреляции между издержками произ¬
водства, с одной стороны, и производительностью труда и
197
оснащенностью основными фондами — с другой, по дан¬
ным, зарегистрированным в 48 МТС, выражается коэффц.
циентом Ry.Xix2 = 0,866. Следовательно, k = 7;
р — 0,8662 __ 41 0,7499 _ 30,7459 __ g
~ ’ 1 —0,8662 ~ 6 ”о?25О1'~ 1,5 ~ ’ ’
"1==6 | 3,28; Р = 0,99; 20,5 >3,28.
а?2-41 J
Коэффициент корреляции R = 0,866 является суще¬
ственным.
Глава VIII
КОРРЕЛЯЦИЯ РАНГОВ
В применении методов измерения связей между явле¬
ниями, рассмотренных в предыдущем параграфе, нужно
иметь в виду, что они ограничены распределениями только
нормального типа или приближающимися к нормальным
распределениям. Если распределение отличается от нор¬
мального, то применяются методы, которые не нуждаются
в каком-либо предположении относительно параметров со¬
вокупности и известны под названием непараметрических
методов х. Можно избежать параметрической презумпции,
упорядочив значения признаков по величине и оперируя
полученными рангами. Поскольку оперируют рангами,
а не значениями признаков, под непараметрическими по¬
нимают методы, позволяющие измерять интенсивность свя¬
зей как между количественными признаками, так и между
качественными признаками.
Из многочисленных непараметрических методов рас¬
смотрим коэффициенты корреляции рангов, разработанные
Спирмэном и Кендэлом, как имеющие наибольшее приме¬
нение в статистическом анализе корреляции.
Коэффициент Спирмэна определяется отношением:
9=1 ——6Srf2 ,
1)
в котором d — разность между числами порядков (рангов)
соответствующих х и у;
п — число членов ряда.
1 /Метод непараметрического анализа был разработан первона¬
чально К. Пирсоном и развит Хотеллингом, Пабстом, Спирмэном,
Кендэлом и другими.
199
Если обозначить ранги символами значений коррели¬
рованных признаков, то данная формула вычислений легко
выводится из выражения
А = S (х —х) (у —у)
V S(x —х)2 I7 2 (у — Д2 ’
аналогичного формуле линейного коэффициента корреля¬
ции.
/ Действительно, составляя два ряда х и у из последова¬
тельных простых целых чисел 1, 2, ..., /г, получим средние
и
2(х —x)2 = S(y—у)2=/1 ,
а также числитель’
S (х — х) (у—у) = у [2 (х — х)г + S (у — у)2] —
— у 2 [(х—х)— (у — У)]2 = « /г2~--. — у 2 <Р,
в котором
d =* (х — х)— (у — у) = х— у,
откуда
О
/г2— 1
12
•П
/г2 —1
12
/г
п
—Zd?
12 _ j 6 S d"
/г2 —1 ~ п(п2—1)'
П
12
Для двух рядов идентичных рангов х и у вся разность
d = х — у равна 0 и 0 = +1; в случае двух рядов рангов,
точно противоположных, например 1, 2, ..., п для х и /о
п — 1, ..., 1 для у, имеем:
d = 1 —п, 3 — п ...
-1, +1
или
— 2,0 +2
... , п — 3, п— 1,
200
если /г, является четным, п ^2 р;
S d2 = 2 [12 +32+... + (2 р—1)2| =р (2 р-|-1) (2р—1).
если /2 является нечетным, п = 2 р+1;
Sd2 = 2[22 + 42+ ... + (2р)2] = ур(р+1)(2р-|-1)
при п четном или нечетном 0 = —1.
В случаях, промежуточных между двумя отмеченными,
0 находится между — 1 и +1. Коэффициент корреляции
рангов интерпретируется, так же как коэффициент линей¬
ной корреляции.
Для иллюстрации процедуры вычисления коэффициента
Спирмэна измерим корреляцию между долей лиц, полу¬
чающих заработную плату, и долей городского населения,
пользуясь данными, полученными по областям страны
в 1963 г.:
Таблица 39
Область
Доля город¬
ского населе¬
ния во всем
населении в
процентах х
[ОЛЯ лиц,
олучающих
аработную
лату, на 100
сителей у
Ранги районов
Колонка
3 минус
колонка 4
6f2
по доле
город¬
ского
населения
по доле
лиц, полу¬
чающих
заработ¬
ную плату
С со С Ж
0
1
2
3
4
5
6
Аргеш
15,3
14,8
15
12
+з
9
Бакэу
27,3
18,4
9
7
+2
4
Банат
43,1
29,3
3
3
0
0
Брашов
49,7
31,6
2
1
+ 1
1
Бухарест ....
12,5
11,0
16
16
0
0
Клуж
30,5
18,0
6
9
—3
9
Кришана ....
30,2
15,9
7
11
—4
16
Добру джа ....
18,2
17,7
12
10
+ 2
4
Галац
29,3
19,5
8
5
+з
9
Хунедоара ....
56,3
30,5
1
2
— 1
1
Яссы
20,7
13,5
11
14
—3
9
Марамуреш . . .
Муреш—Вепгерск.
31,1
18,2
5
8
—3
9
автономи. обл. .
26,7
19,0
10
6
+4
16
Ольтения ....
17,6
13,6
13
13
0
0
Плоешти
34,9
20,9
4
4
0
0
Сучава
17,1
12,7
14
15
—1
1
Всего
—
—
—
—
0
88
Anuarul statistic al R. P. R., 1964.
201
В соответствии с размерами величин х (колонка 1) и у
(колонка 2), рассматриваемых в убывающем порядке, каж¬
дому району присваиваются ранги (колонки 3 и 4) и вы¬
числяются разности между парами рангов (колонка 5).
Алгебраическая сумма разностей между рангами равна
нулю, и поэтому разности возводятся в квадрат (колонка 6).
Введем элементы^вычисления^ У d2 = 88 и /г = 16 в фор¬
мулу и получим:
о — 1 6 S 6/2 — 1 _ 6-88 __ j ___ 528
~ п(п2 — 1) 16(162 —1) 4080 ~~
= 1 — 0,129 = 0,871.
Согласно полученному коэффициенту между призна¬
ками «доля городского населения» и «доля лиц, получаю¬
щих заработную плату», существует тесная связь, что есте¬
ственно, поскольку большинство городского населения —
это лица, получающие заработную плату.
Таблица 40
Область
Доля
городского
населения
во всем
населении
в процентах
X
Доля лиц,
получающих
заработную
плату, на
1 00 жителей
У
Ранги районов
по доле
город¬
ского
населения
по доле
лиц по¬
лучающих
заработ¬
ную плату
0
1
2
3
4
Хунедоара ....
56,3
30,5
1
2
Брашов
49,7
31,6
2
I
Банат
43,1
29,3
3
3
Плоешти ....
34,9
20,9
4
4
Марамуреш . .
31,1
18,2
5
8
Клуж
30,5
18,0
6
9
Кришана ....
30,2
15,9
7
11
Галац
29,3
19,5
8
5
Бакэу
27,3
18,4
9
7
Муреш—Венгерск.
автономн. обл. .
26,7
19,0
10
6
Яссы
20,7
13,5
11
14
Добруджа ....
18,2
17,7
12
10
Ольтения ....
17,6
13,6
13
13
Сучава
17,1
12,7
14
15
Аргеш
15,3
14,8
15
12
Бухарест ....
12,5
11,0
16
16
202
Коэффициент Кендэла вычисляется по формуле
п(п — 1)
или
2S
п (п, — 1) ’
S
в которой S представляет алгебраическую сумму числа
высших рангов по отношению к каждому низшему рангу,
взятому последовательно как значение у и сопоставлен¬
ному с рядом значений х в восходящем или нисходящем
порядке.
Возьмем опять предыдущий пример (см. табл. 40).
В табл. 40 области расположены в порядке возрастания
рангов доли городского населения (х). S определяется по
положению рангов у (колонка 4) относительно соответствую¬
щих порядков первого ряда (колонка 3).
Таким образом, область Хунедоара, которая занимает
первое место по доле городского населения, расположена на
втором месте по доле лиц, получающих заработную плату,
являясь в порядке последовательности на один ранг ниже
области Брашов (—1), на один ранг выше области Банат
(+1), на один ранг выше области Плоешти (+1) и т. д. Де¬
лая вычисления для всех рангов ряда, получим:
Хунедоара
— 1 + 14= + 13
Брашов
+ 14
= + 14
Банат
+ 13
= + 13
Плоешти
+ 12
= + 12
Марамуреш
— 3 + 8
= + 5
Клуж
-3 + 7 =
= +4
Кришана
— 45
= + 1
Галац
+ 8 =
= +8
Бакэу
-1 + 6 =
= +5
Муреш
-1- 6 =
= +6
Яссы
-3 + 2 =
= —1
Добруджа
+ 4 =
= +4
Ольтения
-1+2 =
= + 1
Сучава
- 1 •+ 1 =
= 0
Аргеш
+ 1 =
= +1
Бухарест
0 =
0
s =
= +86
203
Вставляя полученную величину в формулу коэффициен¬
та т, получим:
2S 2-86 172
т — = = = 0,716.
п(п — 1) 1615 240
Коэффициент Кендэла может принимать значение от —1
до +1. Если два ряда рангов идентичны, т = +1, а когда
они имеют обратное значение, то т = —1. Коэффициент т
равен нулю, когда не существует никакой связи между
рядами рангов. В промежуточных случаях—1 < т 1.
Из этих двух видов коэффициентов корреляции рангов
коэффициент Кендэла в большей мере удовлетворяет по-
требности анализа корреляции вследствие того, что су¬
ществует его известное распределение в выборке при
определенной величине п и существует возможность про¬
верки его существенности.
БИБЛИОГРАФИЯ
Ionescu Н. М., Elemente de statistica matematica, Editura
stiinjifica, Bucuresti, 1957.
Mihoc G h., Elemente de calculul probabilityilor, Editura tc-
hnica, Bucuresti, 1954.
Mihoc Gh., U r s e a n u V., Matematici aplicate in statistica,
Editura Academiei R. P. R., Bucuresti, 1962.
.Mi haila N., Introducere in teoria probability ilor si statistica
matematica, Editura didactica §i pedagogica, Bucuresti, 1965.
Mills F. C., Statistical methods... New York.
(Ф. Миллс. Статистические методы, M., Госстатиздат, 1958).
О n i с е s с и О., Mihoc, G h., Lec\ii de statistica matematica,
Editura tehnica, Bucuresti, 1956.
Rancu N., Tovissi L., Statistica matematica cu aplica(ii
in produc|ie, Editura Academiei R. P. R., Bucuresti 1963.
В e и т ц e л ь E. С., Теория вероятностей, M., изд-во «Наука»,
1964.
***Dialectica materialista — metodologia generala a stiiyelor
particulare, Editura Academiei R. P. R., — Bucuresti, 1963.
Приложение 1
Нормальное распределение. Функция Лапласа
г2
Z
Ф (г)
Z
Ф (2)
Z
Ф (2)
Z
Ф (г)
0,00
0,00000
0,52
0, 19847
1 ,04
0,35083
1 ,56
0,44062
0,01
0,00399
0,53
0,20194
1 ,05
0,35314
1 ,57
0,44179
0,02
0.00798
0,54
0,20540
1 , 06
0,35543
1 ,58
0,44295
0,03
0,01197
0,55
0,20884
1 ,07
0,35769
1 ,59
0,44408
0,04
0,01595
0,56
0,21226
1 , 08
0,35993
1 , 60
0,44520
0,05
0,01994
0,57
0,21566
1 , 09
0,36214
1,61
0,44630
0,06
0,02392
0,58
0,21904
1,10
0,36433
1 ,62
0,44738
0,07
0,02790
0,59
0,22240
1,11
0,36650
1 ,63
0,44845
0,08
0,03188
0,60
0,22575
1,12
0,36864
1 ,64
0,44950
0,09
0,03586
0,61
0,22907
1,13
0,37076
1 , 65
0,45053
0,10
0,03983
0,62
0,23237
1,14
0,37286
1 . 66
0,45154
0,11
0,04380
0,63
0,23565
1,15
0,37493
1 , 67
0,45254
0,12
0,04776
0,64
0,23891
1,16
0,37698
1 ,68
0,45352
0,13
0,05172
0,65
0,24215
1,17
0,37900
1 ,69
0,45449
0,14
0,05567
0,66
0,24537
1,18
0,38100
1 , 70
0,45543
0,15
0,05962
0,67
0,24857
1,19
0,38298
1 ,71
0,45637
о; 16
0,06356
0,68
0,25175
1 ,20
0,38493
1 , 72
0,45728
0,17
0,06749
0,69
0,25490
1,21
0,38686
1 ,73
0,45818
0, 18
0,07142
0,70
0,25804
1 ,22
0.38877
1 ,74
0,45907
0,19
0,07535
0,71
0,261 15
1 , 23
0,39065
1 , 75
0,45994
0, 20
0,07926
0,72
0,26424
1 , 24
0,39251
1 ,76
0,46080
0,21
0,08317
0,73
0,26730
1 ,25
0,39435
1 , 77
0,46164
0,22
0,08706
0,74
0,27035
1 , 26
0,39617
1 ,78
0,46246
0,23
0,09095
0,75
0,27337
1 , 27
0,39796
1 ,79
0,46327
0,24
0,09483'
0,76
0,27637
1 , 28
0,39973
1 ,80
0,46407
0,25
0,09871
0,77
0,27935
1 ,29
0,40147
1,81
0,46485
0,26
0,10257
0,78
0,28230
1 , 30
0,40320
1 ,82
0,46562
0,27
0,10642
0,79
0,28524
1,31
0,40490
1 ,83
0,46638
0,28
0,11026
0, 80
0,28814
1 ,32
0,40658
1 ,84
0,46712
0,29
0,11409
0,81
0,29103
1 , 33
0,40824
1 ,85
0,46784
0,30
0,11791
0,82
0,29389
1 ,34
0,40988
1 ,86
. 0,46856
0,31
0,12172
0,83
0,29673
1 , 35
0,41149
1 ,87
0,46926
0,32
0,12552
0,84
0,29955
1,36
0,41309
1 ,88
0,46995
0,33
0,12930
0,85
0,30234
1,37
0,41466
1 ,89
0,47062
0,34
0,13307
0,86
0,3051 1
1 ,38
0,41621
1 , 90
0,47128
0,35
0,13683
0,87
0,30785
1 , 39
0,41774
1,91
0,47193
0,36
0,14058
0,88
0,31057
1 ,40
0,41924
1 ,92
0,47257
0,37
0,14431
0,89
0,31327
1,41
0,42073
1 , 93
0,47320
0,38
0,14803
0,90
0,31594
1 ,42
0,42220
1 ,94
0,47381
0,39
0,15173
0,91
0,31859
1 , 43
0,42364
1,95
0,47441
0,40
0,15542
0,92
0,32121
1 ,44
0,42507
1 , 96
0,47500
0,41
0,15910
0,93
0,32381
1 ,45
0,42647
1 ,97
0,47558
0,42
0,16276
0,94
0,32639
1 ,46
0,42786
1 ,98
0,47615
0,43
0,16640
0,95
0,32894
1 ,47
0,42922
1 ,99
0,47670
0,44
0,17003
0,96
0,33147
1 ,48
0,43056
2,00
0,47725
0,45
0,17364
0,97
0,33398
1 ,49
0,43189
2,01
0,47778
0,46
0,17724
0,98
0,33646
1 ,50
0,43319
2,02
0,47831
0,47
0,18082
0,99
0,33891
1 ,51
0,43448
2,03
0,47882
0,48
0,18439
1 ,00
0,34134
1 ,52
0,43574
2,04
0,47932
0,49
0,1&793
1 ,01
0,34375
1 ,53
0,43699
2,05
0,47982
0,50
0,19146
1 , 02
0,34614
1 ,54
0,43822
2,06
0,48030
0,51
0,19497
1 ,03
0,34850
1,55
0,43943
2,07
0,48077
205
11 родолжение
z
Ф (z)
z
Ф (2)
z
Ф (Z)
z
Ф (Z)
2,08
0,48124
2,68
0,49632
3,27
0,49946
3,86
0,499943
2,09
0,48169
2,69
0,49643
3,28
0,49948
3,87
0,499946
2,10
0,48214
2,70
0,49653
3,29
0,49950
3,88
0,499948
2,11
0,48257
2,71
0,49664
3,30
0,49952
3,89
0,499950
2,12
0,48300
2,72
0,49674
3,31
0,49953
3,90
0,499952
2,13
0,48341
2,73
0,49688
3,32
0,49955
3,91
0,499954
2,14
0,48382
2,74
0,49693
3,33
0,49957
3,92
0,499956
2,15
0,48422
2,75
0,49702
3,34
0,49958
3,93
0,49995.3
2,16
6,48461
2,76
0,49711
3,35
0,49960
3,94
0,499959
2,17
0,48500
2,77
0,49720
3,36
0,49961
3,95
0,499961
2,18
0,48537
2,78
0,49728
3,37
0,49962
3,96
0,499963
2,19
0,48574
2,79
0,49736
3,38
0,49964
3,97
0,499964
2,20
0,48610
2,80
0,49744
3,39
0,49965
3,98
0,499966
2,21
0,48645
2,81
0,49752
3,40
0,49966
3,99
0,499967
2,22
0,48679
2,82
0,49760
3,41
0,49968
4,00
0,499968
2,23
0,48713
2,83
0,49767
3,42
0,49969
4,01
0,499970
2,24
0,48745
2,84
0,49774
3,43
0,49970
4,02
0,499971
2,25
0,48778
2,85
0,49781
3 44
0,49971
4,03
0,499972
2,26
0,48809
2,86
0,49788
3,’ 4 5
0,49972
4,04
0,499973
2,27
0,48840
2,87
0,49795
3,46
0,49973
4,05
0,499974
2,28
0,48870
2,88
0,49801
3,47
0,49974
4 , 06
0,499976
2,29
0,48899
2,89
0,49807
3,48
0,49975
4,07
0,499977
2,30
0,48928
2,90
0,49813
3,49
0,49976
4,08
0,499978
2,31
0,48956
2,91
0,49819
3,50
0,49977
4,09
0,499978
2,32
0,48983
2,92
0,49825
3,51
0,49978
4,10
0,499979
2,33
0,49010
2,93
0,49831
3,52
0,499784
4,11
0,499980
2,34
0,49036
2,94
0,49836
3,53
0,499792
4,12
0,499981
2,35
0,49061
2,95
0,49841
3,54
0,499799
4,13
0,499982
2,36
0,49106
2,96
0,49846
3,55
0,499807
4,14
0,499983
2,37
0,49111
2,97
0,49851
3,56
0,499814
4,15
0,499983
2,38
0,49134
2,98
0,49856
3,57
0,499821
4,16
0,499984
2,39
0,49158
2,99
0,49861
3,58
0,499828
4,17
0,499985
2,40
0,49180
3,00
0,49865
3,59
0,499834
4,18
0,499985
2,41
0,49202
3,01
0,49869
3,60
0,499841
4,19
0,499986
2,42
0,49224
3,02
0,49874
3,61
0,499847
4,20
0,499987
2,43
0,49245
3,03
0,49878
3,62
0,499853
4,21
0,499987
2,44
0,49266
3,04
0,49882
3,63
0,499858
4,22
0,499987
2,45
0,49286
3,05
0,49886
3,64
0,499864
4,23
0,499988
2,46
0,49305
3,06
0,49889
3,65
0,499869
4,24
0,499988
2,47
0,49324
3,07
0,49893
3,66
0,499874
4,25
0,499989
2,48
0,49343
3,08
0,49897
3,67
0,499879
4.26
4.27
0,499990
2,49
0,49361
3,09
0,49900
3,68
0,499883
0,499990
2,50
0,49379
3,10
0,49903
3,69
0,499888
4,28
0,499991
2,51
0,49396
3,11
0,49906
3,70
0,499892
4,29
0,499991
2,52
0,49413
3,12
0,49909
3,71
0,499896
4,30
0,499992
2,53
0,49430
3,13
0,49913
3,72
0,499900
4,31
0,499992
2,54
0,49446
3, 1 4
0,49916
3,73
0,499904
4,32
0,499992
2,55
0,49461
3,15
0,49918
3,74
0,499908
4,33
0,499993
2,56
0,49477
3,16
0,49921
3,75
0,499912
4,34
0,499993
2,57
0,49492
3,17
0,49924
3,76
0,499915
4,35
0,499993
2,58
0,49506
3,18
0,49926
3,77
0,499918
4,36
0,499994
2,59
0,49520
3,19
0,49929
3,78
0,499922
4,37
0,499994
2,60
0,49534
3,20
0,4994 1
3,79
0,499925
4,38
0,499994
2,61
0,49547
3,21
0,49934
3,80
0,499927
4,39
0,499994
2,62
0.49560
3,22
0,49936
3,81
0,499931
4,40
0,499995
2,63
0,49573
3,23
0,49938
3,82
0,499933
4,45
0,499996
2,64
0,49585
3,24
0,49940
3,83
0,499936
4,50
0,499997
2,65
0,49598
3,25
0,49942
3,84
0,499938
4,60
0,499998
2,66
2,67
0,49609
0,49621
3,26
0,49944
3,85
0,49994 1
5,00
0,4999997
206
Приложение 2
Значение функции К (/) Колмогорова
X
К (/)
* (А)
Л
К(')
А
*('•)
0,28
0,000001
0,86
0,549744
1 ,44
0,968382
2,02
0,999428
0,2 9
0,000004
0,87
0,564546
1 ,45
0,970158
2,03
0,999474
0,30
0,000009
0,88
0,579070
1 ,46
0,971846
2,04
0,999516
0,31
0,000021
0,89
0,593316
1 ,47
0,973448
2,05
0,999552
0,32
0,000046
0,90
0,602270
1 ,48
0,974970
2,06
0,999588
0,33
0,000091
0,91
0,62U928
1 ,49
0,956412
2,07
0,999620
0,34
0,000171
0,92
0,634286
1 ,50
1 ,51
0,977782
2,08
0,999650
0,35
0,000303
0,93
0,647338
0,979080
2,09
0,999680
0,36
0,000511
0,94
0,660082
1 ,52
0,980310
2,10
0,999705
0,37
0,000826
0,95
0,672516
1 ,53
0,981476
2,11
0,999728
0,3 8
0,001285
0,96
0,684636
1 ,54
0,982578
2,12
0,999750
0,39
0,001929
0,97
0,696444
1 ,55
0,983622
2,13
0,999770
0,40
0,002808
0,98
0,702814
1 ,56
0,984610
2, 14
0,999790
0,41
0,003972
0,99
0,719126
1 ,57
0,985544
2,15
0,999806
0,42
0,005476
1 ,00
0,730000
1 ,58
0,985426
2,16
0,999822
0,43
0,007377
1,01
0,740566
1 ,59
0,987260
2,17
0,999838
0,44
0,009730
1 , 02
0,750826
1 ,60
0,988048
2,18
0,999852
0,45
0,012590
1 ,03
0,760780
1 ,61
0,988791
2,19
0,999864
0,4 6
0,016005
I ,04
0,770434
1 ,62
0,989492
2,20
0,999874
0,47
0,020022
1 , 05
0,779794
1 ,63
0,990154
2,21
0,999886
0,48
0,024682
1 ,06
0,788860
1 ,64
0,990777
2,22
0,999896
0,49
0,030017
1 ,07
0,797636
1 ,65
0.991364
2,23
0,999904
0,50
0,036055
1 , 08
0,806128
1 ,66
0,991917
2,24
0,999912
0 ,-5 1
0,042814
1 ,09
0,814342
1 ,67
0,992438
2,25
0,999920
0,52
0,050306
1,10
0,822282
1 ,68
0,992928
2,26
0,999926
0,53
0,058534
1,11
0,829950
1 ,69
0,993389
2,27
0,999934
0,54
0,067497
1,12
1,13
0,837356
1 ,70
0,993823
2,28
0,999940
0,55
0,077183
0,844502
1,71
0,994230
2,29
0,999944
0,56
0,087577
1 , 14
0,851394
1 ,72
0,994612
2,30
0,099949
0,57
0,098656
1,15
0,858038
1 ,73
0,994972
2,31
0,999954
0,58
0,110395
1,16
0,864442
1 ,74
0,995309
2,32
0,999958
0,59
0,122760
1,17
0,870612
1 ,75
0,995625
2,33
0,999962
0,60
0,135718
1,18
0,876548
1 ,76
0,995922
2,34
0,999965
0,61
0 , 149229
1,19
0,882258
1 ,77
0,996200
2,35
0,999968
0,62
0, 163225
1 , 20
0,887750
1,78
0,996460
2,36
0,999970
0,63
0, 177753
1 ,21
0,893030
1,79
1 ,80
0,996704
2,37
0,999973
0,64
0,192677
1 ,22
0,898104
0,996932
2,38
0,999976
0,65
0,207987
1 ,23
0,902972
1 ,81
0,997146
2,39
0,999978
0,66
0,223637
1 , 24
0,907648
1 ,82
0,997346
2,40
0,999980
0,67
0,239582
1 ,25
0,912132
1 ,83
0,997533
2,41
0,999982
0,68
0,255780
1 ,26
0,916432
I ,84
0,997707
2,42
0,999984
0,69
0,272189
1 , 27
0,920556
1 ,85
0,997870
2,43
0,999986
0,70
0,288765
1 ,28
0,924505
1 ,86
0,998023
2,44
0,999987
0,71
0,305471
1 ,29
0,928288
1 ,87
0,998145
2,45
0,999988
0,72
0,322265
1 ,30
0,931908
1 ,88
0,998297
2,46
0,999988
0,73
0,339113
1,31
0,935370
1 ,89
0,998421
2,47
0,999990
0,74
0,355981
1 ,32
0,938682
1 ,90
0,998536
2,48
0,999991
0,75
0,372833
1 ,33
0,941848
1 ,91
0,998644
2,49
0,999992
0,76
0,389640
1 ,34
0,944872
1 ,92
0,998745
2,50
0,9999925
0,77
0,406472
1 ,35
0,947756
1 ,93
0,998837
2,55
0,9999956
0,78
0,423002
1 ,36
0,950512
1 ,94
0,998924
2,60
0,9999974
0,79
0,439505
1 ,37
0,952142
1 ,95
0,999004
2,65
0,9099984
0,80
0,455857
1 , 38
0,955650
1 ,96
0,999079
2,70
0,9999990
0,81
0,472041
1 ,39
0,958040
1 ,97
0,999149
2,75
0,9999994
0,82
0,488030
1 ,40
0,960318
1 ,98
0,999213
2,80
0,9999997
0,83
0,503808
1 ,41
0,962486
1 ,99
0,999273
2,85
0,99999982
0,84
0,519366
1 ,42
0,964552
2,00
0,999329
2,90
0,99999990
0,85
0,534682
1 ,43
0,966516
2,01
0,999380
2,95
3,00
0,99999994
0,99999997
207
Распределение /2. Значения /“ в функции верояг
\
f '
D
0,0
5 0,1
0,5
i
| 1 ,о
2,5
5,0
10,С
> 20,0
1 30,0
I 40,0
5 0,0
1
0,000000
393
0,00000
157
0,0000
393
0,000
157
0, 000
382
0,00
393
0,158
0,0642
0,148
0,275
0,455
2
0,00100
0,00200
0,0100
0,201
0*0506
0,103
0,211
0,446
0,713
1 ,02
1,39
3
0,0153
0,0'243
0,0717
0,115
0,216
0,352
0,548
1 ,00
1 ,42
1 ,87
2,37
4
0,0639
0,0908
0,207
0,297
0,484
0,711
1 , 06
1 ,65
2,19
2,75
3,36
5
0,158
0,210
0,412
0,554
0,831
1,15
1 ,64
1,61
2,34
3,00
3,66
4,35
6
0,299
0,381
0,676
0,827
1 ,24
2,20
3,07
3,83
4,57
5,35
7
0,485
0,598
0,989
1 ,24
1 ,69
2,17
2,83
3,82
4,67
5,49
6,35
8
0,710
0,857
1 ,34
1 ,65
2,18
2,73
3,49
4,59
5,53
6,42
7,34
9
0,972
1,15
1 ,73
2,09
2,70
3,33
4,17
5,38
6,39
7,36
8,3 4
10
1,26
1 ,48
2,16
2,56
3,25
3,94
4,87
6,18
7,27
8,30
9,34
1 1
1 , 59
1 ,83
2,60
3,05
3,82
4,57
5,58
6,99
8,15
9,24
10,3
12
1,93
2,21
3,07
3,57
4,40
5,23
6,30
7,81
9,03
10,2
11,3
13
2,31
2,62
3,57
4,11
5,01
5,89
7,04
8,63
9,93
11,1
12,3
1 4
2,70
3,04
4,07
4,66
5,63
6,57
7,79
9,47
10,8
12, 1
13,3
15
3,11
3,48
4,60
5,23
6,26
7,26
8,55
10,3
11,7
13,0
14,3
16
3,54
3,94
5,14
5,81
6,91
7,96
9,31
И,2
12,6
14,0
15,3
17
3,98
4,42
5,70
6,41
7,56
8,67
10,1
12,0
13,5
14,9
16,3
18
4,44
4,90
6,26
7,01
8,23
9,39
10,9
12,9
14,4
15,9
17,3
19
4,91
5,41
6,48
7,63
8,91
10,1
11,7
13,7
15,4
16,9
18,3
20
5,40
5,92
7,43
8,26
9,59
10,9
12,4
14,6
16,3
17,8
19,3
21
5,90
6,45
8,03
8,90
10,3
11,6
13,2
15,4
17,2
18,8
20,3
22
6,40
6,98
8,64
9,54
11,0
12,3
14,0
16,3
18,1
18,7
2 1,3
23
6,92
7,53
9,26
10,2
11,7
13, 1
14,8
17,2
19,0
20,7
22,3
24
7,45
8,08
9,89
10,9
12,4
13,8
15,7
18,1
19,9
21 ,7
23,3
25
7,99
8,65
10,5
11,5
13,1
14,6
16,5
18,9
20,9
22,6
24‘3
26
8,54
9,22
11,2
12,2
13,8
15,4
17,3
19,8
21,8
23,6
25,3
27
9,09
9,80
11,8
12,9
14,6
16,2
18, 1
20,7
22,7
24,5
26,3
28
9,66
10,4
12,5
13,6
15,3
16,9
18,9
21 ,6
23,6
25,5
27,3
29
10,2
11,0
13, 1
14,3
16,0
17,7
19,8
22,5
24,6
26,5
28,3
30
10,8
11,6
13,8
15,8
16,8
18,5
20,6
23,4
25,5
27,4
29,3
31
И,4
12,2
14,5
15,7
17,5
19,3
21 ,4
24,3
26,4
28,4
30,3
32
12,0
12,8
15, 1
16,4
18,3
20, 1
22, 3
25,1
27,4
29,4
31,3
33
12,6
13,4
15,8
17,1
19,0
20,9
23 , 1
26,0
28,3
30,3
32,3
34
13,2
14,1
16,5
17,8
19,8
21,7
24,0
26,9
29,2
31 ,3
33,3
35
13,8
14,7
17,2
18,5
20,6
22,5
24,8
27,8
30,2
32,3
34,3
36
14,4
15,3
17,9
19,2
21 ,3
23,3
25,6
28,7
31,1
33,3
35,3
37
15,0
16,0
18,6
20,0
22, 1
24, 1
26,5
29,6
32, 1
34,2
36,3
38
15,6
16,6
19,3
20,7
22,9
24,9
27,3
30,5
33,0
35,2
37,3
39
16,3
17,3
20,0
21,4
23,7
25,2
28,2
31,4
33,9
36,2
38,3
40
16,9
17,9
20,7
22,2
24,4
26,5
29 , 1
32,3
34,9
37, 1
39,3
41
17,5
18,6
21,4
22,9
25,2
27,3
29,9
33,3
35,8
38, 1
40,3
42
18,2
19,2
22, 1
23,7
26,0
28, 1
30,8
34,2
36,8
39, 1
40,0
4 1,3
43
18,8
19,9
22,9
24,4
26,8
29,0
31,6
35,1
37,7
42,3
44
19,5
20,6
23,6
25,1
27,6
29,8
32,5
36,0
38,6
4 1,0
43,3
45
20, 1
21 ,3
24,3
25,9
28,4
30,6
33,4
36,9
39,6
42,0
44,3
46
20,8
21,9
25,0
26,7
29,2
31,4
34,2
37,8
40,5
43,0
4 5,3
47
21,5
22,6
25,8
27,4
30,0
32,3
35, 1
38,7
41,5
43,9
46,3
48
22, 1
23,3
26,5
28,2
30,8
33 , 1
3 5,9
39,6
42,4
44,9
47,3
49
22,8
24,0
27,2
28,9
31,6
33,9
36,8
40,5
43,4
45,9
48,3
208
Приложение 3
ости Р = Р(у? С x^i) и числа степеней свободы/
60,0
70,0
80,0
90,0
95,0
97,5
99,0
99,5
99,9 1
99,95
р/
/ f
), 708
1,07
1,64
2,71
3,84
5,02
6,63
7,88
10,8
12,1
1
,83
2,41
3,22
4,61
5,99
7,38
9,21
10,6
13,8
15,2
2
2,95
3,67
4,64
6,25
7,81
9,35
1 1 ,3
12,8
16,3
17,7
3
1,04
4,88
5,99
7,78
9,49
11,1
13,3
14,9
18,5
20,0
4
5,13
6,06
7,29
9,24
11,1
12,8
15,1
16,7
20,5
22 , 1
5
6,21
7,23
8,56
10,6
2,6
.4,4
16,8
18,5
22,5
24,1
6
7,28
8,38
9,80
12,0
14,1
[6,0
18,5
20,3
24,3
26,0
7
8,35
9,52
11,0
13,4
15,5
17,5
20,1
22,0
26, 1
27,9
8
9,41
10,7
12,2
14,7
16,9
19,0
21 ,7
23,6
27,9
29,7
g
10,5
11,8
13,4
16,0
18,3
20:5
23,2
25,2
29,6
31,4
10
1 1,5
12,9
14,6
17,3
19,7
21 ,9
24,7
26,8
31 ,3
33,3
1 1
12,6
14,0
15,8
18,5
21 ,0
23,3
26,2
28,3
32,9
34,8
12
13,6
15,1
17,0
19,8
22,4
24,7
27,7
29,8
34,5
36,5
13
14,7
16,2
18,2
21 ,1
23,7
26,1
29,1
31,3
36, 1
38, 1
14
15,7
17,3
19,3
22,3
25,0
27,5
30,6
32,8
37,7
39,7
15
16,8
18,4
20,5
23,5
26,3
28,8
32,0
34,3
39,3
41,3
16
17,8
19,5
21,6
24,8
27,6
30,2
33,4
35,7
40,8
42,9
17
18,9
20,6
22,8
26,0
28,9
31,5
34,8
37,8
42,3
44,4
18
19,9
21 ,7
23,9
27,2
30,1
32,9
36,2
38,6
43,8
46,0
19
21,0
22,8
25,0
28,4
31,4
34,2
37,6
40,0
45,3
47,5
20
22,0
23,9
26,2
29,6
32,7
35,5
38,9
41,4
46,8
49,0
21
23,0
24,9
27,3
30,8
33,9
36,9
40,3
42,8
48,3
50,5
22
24, 1
26,0
28,4
32,0
35,0
38,1
41,6
44,2
49,7
52,0
23
25,1
27,1
29,6
33,2
36,4
39,4
43,0
45,6
51,2
53,5
24
26,1
28,2
30,7
34,4
37,7
40,6
44,3
46,9
52,6
54,9
25
27,2
29,2
31,8
35,6
38,9
41,9
45,6
48,3
54,1
56,4
26
28,2
30,3
32,9
36,7
40,1
43,2
47,0
49,6
55,5
57,9
27
29,2
31,4
34,0
37,9
41 ,3
44,5
48,3
51,0
56,9
59,3
28
30,3
32,5
35,1
39,1
42,6
45,7
49,6
52,3
58,3
60,7
29
31 ,3
33,5
36,3
40,3
43,8
47,0
50,9
53,7
59,7
62,2
30
32,3
34,6
37,4
41 ,4
45,0
48,2
52,2
55,0
61 , 1
63,6
31
33,4
35,7
38,5
42,6
46,2
49,5
53,5
56,3
62,5
65,0 ,
32
34,4
36,7
39,6
43,7
47,4
50,7
54,8
57,6
63,9
66,4
33
35,4
37,8
40,7
44,9
48,6
52,0
56, 1
59,0
65, 2
67,8
34
36,5
38,9
41,8
46,1
49,8
53,2
57,3
60,3
66,6
69,2
35
37,5
39,9
42,9
47,2
51,0
54,4
58,6
61,6
68,0
70,6
36
38,5
41,0
44,0
48,4
52,2
55,7
59,9
62,9
69,3
72,0
37
39,6
42,0
45,1
49,5
53,4
56,9
61 ,2
64,2
70,7
73,4
38
40.6
43,1
46,2
50,7
54,6
58,1
62,4
65,5
72,1
74,7
39
41,6
44,2
47,3
51,8
55,8
59,3
63,7
66,8
73,4
76,1
40
42,7
45,2
48,4
52,9
56,9
60,6
65,0
68, 1
74,7
77,5
41
43,7
46,3
49,5
54, 1
58,1
61 ,8
66,2
69,3
76,1
78,8
42
44,7
47,3
50,5
55,2
59,3
63,0
67,5
70,6
77,4
80,2
43
45,7
48,4
51,6
56,4
60,5
64,2
68,7
71,9
78,7
81,5
44
46,8
49,5
52,7
57,5
61,7
65,4
70,0
73,2
80, 1
82,9
45
47,8
50,5
53,8
58,6
62,8
66,6
71,2
74,4
81,4
84,2
46
48,8
51,6
54,9
59,8
64,0
67,8
72,4
75,7
82,7
85,6
47
49,8
52,6
56,0
60,9
65,2
69,0
73,7
77,0
84,0
86,9
48
50,9
53,7
57,1
62,0
66,3
70,2
74,9
78,2
85,4
88,2
49
14 Зак. 1050
209
\ р
f\
0,05
0,1
0,5
1 ,о
2,5
5,0
10,0
20,0
30,0
4 0,0
5О,о
50
23,5
24,7
28,0
29,7
32,4
34,8
37,7
41,4
44,3
46,9
49,з
51
24,1
25,4
28,7
30,5
33,2
35,6
38,6
42,4
45,3
47,8
5 (j, з
52
24,8
26,1
29,5
31,2
34,0
36,4
39,4
43,3
46,2
48,8
51,3
53
25,5
26,8
30,2
32,0
34,8
37,3
40,3
44,2
47,2
49,8
52,3
54
26,2
27,5
31 ,0
32,8
35,6
38,1
41,2
45,1
48,1
50,8
53,3
55
26,9
28,2
31,7
33,6
36,4
39,0
42,1
46,0
49,1
51,7
54,3
56
27.6
28,9
32,5
34,3
37,2
39,8
42,9
47,0
50,0
52,7
55,3
57
28,2
29,6
33,2
35, 1
38,0
40,6
43,8
47,9
51,0
53,7
56,4
58
28,9
30,3
34,0
35,9
38,8
41 ,5
44,7
48,8
51,9
54,7
5 7,3
59
29,6
31,0
34,8
36,7
39,7
42,3
45,6
49,7
52,9
55,6
58,3
60
30,3
31,7
35,5
37,5
40,5
43,2
46,5
50,6
53,8
56,6
59,3
61
31,0
32,5
36,3
78,3
41,3
44,0
47,3
51 ,6
54,8
57,6
60,3
62
31,7
33,2
37,1
39,1
42,1
44,9
48,2
52,5
55,7
58,6
61,3
63
32,5
33,9
37,8
39,9
43,0
45,7
49,1
53,4
56,7
59,6
62,3
64
33,2
34,6
38,6
40,6
43,8
46,6
50,0
54,3
57,6
60,5
63,3
65
33,9
35,4
39,4
41,4
44,6
47,4
50,9
55,3
58,6
61 ,5
64,3
66
34,6
36,1
40,2
42,2
45,4
48,3
51,8
56,2
59,5
62,5
65,3
67
35,3
36,8
40,9
43,0
46,3
49,2
52,7
57,1
60,5
63,5
66,3
68
36,0
37,6
41,7
43,8
47, 1
50,0
53,5
58,0
61 ,4
64,4
67,3
69
36,7
38,3
42,5
44,6
47,9
50,9
54,4
59,0
62,4
65,4
68,3
70
37,5
39,0
43,3
45,4
48,8
51 ,7
55,3
59,9
63,3
66,4
69,3
71
38,2
39,8
44,1
46,2
49,6
52,6
56,2
60,8
64,3
67,4
70,3
72
38,9
40,5
44,8
47,1
50,4
53,5
57,1
61 ,8
65,3
68,4
71 ,3
73
39,6
41,3
45,6
47,9
51,3
54,3
58,0
62,7
66,2
69,2
72,3
74
40,4
42,0
46,4
48,7
52, 1
55,2
58,0
63,6
67,2
70,3
73,3
75
41 , 1
42,8
47,2
49,5
52,9
56,1
59,8
64,5
68,1
71 ,3
74,3
76 ~
41,8
43,5
48,0
50,3
53,8
56,9
60,7
65,5
69,1
72,3
75,3
77
42,6
44,3
48,8
51,1
54,6
57,8
61,6
66,4
70,0
73,2
77,3
78
43,3
45,0
49,6
51,9
55,5
58,7
62,5
67,3
71 ,0
74,2
77,3
79
44, 1
45,8
50,4
52,7
56,3
59,5
63,4
68,3
72,0
75,2
78,3
80
44,8
46,5
51,2
53,5
57,2
60,4
64,3
69,9
72,9
76,2
79,3
81
45,5
47,3
52,0
54,4
58,0
61 ,3
65,2
70,1
73,9
77,2
80,3
82
46,3
48,0
52,8
55,2
58,8
62,2
66,1
71 ,1
74,8
78,1
81,3
83
47,0
48,8
53,6
56,0
59,7
63,0
67,0
72,0
75,8
79,1
82,3
84
47,8
49,6
54,4
56,8
60,5
63,9
67,9
72,9
76,8
80,1
83,3
85
48,5
50,3
55,2
57,6
61,4
64,7
68,8
73,9
77,7
81 , 1
84,3
86
49,3
51,1
56,0
58,5
62,2
65,6
69,7
74,8
78,7
82,1
85,3
87
50,0
51,9
56,8
59,3
63,1
66,5
70,6
75,7
79,6
83,0
86,3
88
50,8
52,6
57,6
60,1
63,9
67,4
71 ,5
76,7
80,6
84,0
87,3
89
51,5
53,4
58,4
60,9
64,8
68,2
72,4
77,6
81,6
85,0
88,3
90
52,3
54,2
59,2
61,8
65,6
69,1
73,3
78,6
82,5
86,0
89,3
91
53,0
54,9
60,0
62,6
66,5
70,0
74,2
79,5
83,5
87,0
90,3
92
53,8
55,7
60,8
63,4
67,4
70,9
75,1
80,4
84,4
88,0
91 ,3
93
54,5
56,5
61,6
64,2
68,2
71 ,8
76,0
81,4
85,4
88,9
92,3
94
55,3
57,2
62,4
65,1
69,1
72,6
76,9
82,3
86,4
89,9
93,3
95
56,1
58,0
63,2
65,9
69,9
73,5
77,8
83,2
87,3
90,9
94,3
96
56,8
58,8
64,1
66,7
70,8
74,4
78,7
84,2
88,3
91,9
95,3
97
57,6
59,6
64,9
67,6
71,6
75,3
79,6
85,1
89,2
92,9
96,3
98
59,4
60,4
65,7
68,4
72,5
76,2
80,5
86,1
90,2
93,8
97,3
99
59,1
61,1
66,5
69,2
73,4
77,0
81 ,4
87,0
91,2
94,8
98,3
100
59,9
61,9
67,3
70,1
74,2
77,9
82,4
87,9
92,1
95,8
99,3
210
Продолжение прилож. .9
60,0
70,0
80,0
90,0
95,0
97,5
99,0
99,5
99,9
99,95
X
i
51 ,9
54,7
58,2
63,2
67,5
71 ,4
76,2
79,5
86,7
89,6
50
52,9
55,8
59,2
64,3
68,7
72,6
77,4
80,7
88,7
90,9
51
53,9
56,8
60,3
65,4
69,8
73,8
78,6
82,0
89,3
92,2
52
55,0
57,9
61 ,4
66,5
71 ,0
75,0
79,8
83,3
90,6
93,5
53
56,0
58,9
62,5
67,7
72,2
76,2
81,1
84,5
91,9
94,8
54
57,0
60,0
63,6
68,8
73,3
77,4
82,3
85,7
93,9
96,2
55
58,0
61 ,0
64,7
69,9
74,5
78,6
83,5
87,0
94,5
97,5
56
59,1
62,1
65,7
71,0
75,6
79,8
84,7
88,2
95,8
98,8
57
60,1
63,1
66,8
72,2
76,8
80,9
86,0
89,5
97,0
100, 1
58
61 , 1
64,2
67,9
73,3
77,9
82,1
87,2
90,7
98,3
101,4
59
62,1
65,2
69,0
74,4
79,1
83,3
88,4
92,0
99,6
102,7
60
63,2
66,3
70,0
75,5
80,2
84,5
89,6
93,2
1 00,9
104,0
61
64,2
67,3
71,1
76,6
81 ,4
85,7
90,8
94.4
102,2
105,3
62
65,2
68,4
72,2
77,7
82,5
86,8
92,0
95,6
103,4
106,6
63
66,2
69,4
73,3
78,9
83,7
88,0
93,2
96,9
104,7
107,9
64
67,2
70,5
74,4
80,0
84,8
89,2
94,4
98,1
106,0
109,2
65
68,3
71 ,5
75,4
81,1
86,0
90,3
95,6
99,3
107,3
110,5
66
69,3
72,6
76,5
82,2
87,1
91,5
96,8
100,6
108,5
111.7
67
70,3
73,6
77,6
83,3
88,3
92,7
98,0
101,8
109,8
113,0
68
71 ,3
74,6
78,6
84,4
89,4
93,9
99,2
103,0
111,1
114,3
69
72,4
75,7
79,7
85,5
90,5
95,0
100,4
104,2
112,3
115,6
70
73,4
76,7
80,8
86,6
91,7
96,2
101 ,6
105,4
113,6
116,9
71
74,4
77,8
81,9
87,7
92,8
97,4
102,8
106,6
114,8
118,1
72
75,4
78,8
82,9
88,8
93.9
98,5
104,0
107,9
116,1
119,4
73
76,4
79,9
84,0
90,0
95, 1
99,7
105,2
109,1
117,3
120,7
74
■77,5
80,9
85,1
91,1
96,2
100,8
106,4
110,3
1 18,6
121,9
75
78,5
82,0
86,1
92,2
97,4
102,0
107,6
111,5
119,9
123,2
76
79,5
83,0
87,2
93,3
98,5
103,2
108,8
112,7
121,1
124,5
77
80,5
84,0
88,3
94,4
99,6
104,3
110,0
113,9
122,3
125,7
78
81 ,5
85,1
89,3
95,5
100,7
105,5
111,1
115,1
123,6
127,0
79
82,6
86,1
90,4
96,6
101,9
106,6
112,3
116,3
124,8
128,3
80
83,6
87,2
91,5
97,7
103,0
107,8
1 13,5
117,5
126,1
129,5
81
84,6
88,2
92,5
98,8
104,1
108,9
114,7
118,7
127,3
130,8
82
85, 6
89,2
93,6
99,9
105,3
110,1
115,9
119,9
128,6
132,0
83
86,6
90,3
94,7
101,0
1 Об, 4
111,2
117,1
121,1
129,6
133,3
84
87,7
91,3
95,7
102,1
107,5
112,4
118,2
122,3
131,5
134,5
85
88,7
92,4
96,8
103,2
108,6
113,5
119,4
123,5
132,3
135,8
86
89,7
93,4
97,9
104,3
109,8
114,7
1 20,6
124,7
133,5
137,0
87
90,7
94,4
98,9
105,4
110,9
115,8
121,8
125,9
134,7
138,3
88
91,7
95,5
100,0
106,5
112,0
117,0
122,0
127,1
136,0
139,5
89
92,8
96,5
101,1
107,6
113,1
118,1
124,1
128,3
137,2
140,8
90
93,8
97,6
102,1
108,7
114,3
119,3
125,3
129,5
138,4
142,0
91
94,8
98,6
103,2
109,8
115,4
120,4
1 26,5
130,7
139,7
143,3
92
95,8
99,6
104,2
110,9
116,5
121 ,6
127,6
131,9
140,9
144,5
93
96,8
100,7
105,3
111,9
117,6
122,7
128,8
133,1
142,1
145,8
94
97,9
101,7
106,4
113,0
118,8
123,9
130,0
134,2
143,3
147,0
95
98,9
102,8
107,4
114,1
119,9
125,0
131,1
135,4
144,6
148,2
96
99,9
103,8
108,5
115,2
121,0
126,1
132,3
136,6
145,8
149,5
97
100,9
104,8
109,5
116,3
122,1
127,3
133,5
137,8
147,0
1 50,7
98
101,9
105,9
1 10,6
117,4
123,2
128,4
134,6
139,0
148,2
151,9
99
102,9
106,9
111,7
118,5
124,3
129,5
135,8
140,2
149,4
153,2
100
14*
211
Закон распределения Пуассона
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
0
0,904837
0,818731
0,740818
0,670320
0,606529
0,548812
0,496585
0,449329
0,406570
0,367879
1
0,090484
0,163746
0,222245
0,268128
0,303265
0,329287
0,347610
0,359463
0,365913
0,367879
2
0,004524
0,016375
0,033337
0,053626
0,075816
0,098786
0,121663
0,143785
0,164661
0,183940
3
0,000151
0,001092
0,003334
0,007150
0,012636
0,019757
0,028388
0,038343
0,049398
0,061313
4
0,000004
0,000055
0,000250
0,000715
0,001580
0,002964
0,004968
0,007669
0,011115
0,015528
5
0,000002
0,000015
0,000057
0,000158
0,000356
0,000696
0,001277
0,002001
0,003066
6
0,000001
0,000004
0,000013
0,000036
0,000081
0,000164
0,000300
0,000511
7
0,000001
0,000003
0,000008
0,000019
0,000039
0,000073
8
0,000001
0,000002
0,000004
0,000009
0,000001
212
Приложение 4
1
2
3
4
5
6
7
8
9
10
11
1
0,135335
0,49787
0,018316
0,006738
0,002479
0,000912
0,000335
0,000123
0,000045
0,000017
1
0,270671
0,149361
0,073263
0,033690
0,014873
0,006388
0,002684
0,001111
0,000454
0,000184
1
0,270671
0,224042
0,146525
0,084224
0,044618
0,022341
0,010735
0,004998
0,002270
0,001010
f
0,180447
0,224042
0,195367
0,140374
0,089235
0,052129
0,028626
0,014994
0,007567
0,003705
0,090224
0,168031
0,195367
0,175467
0,133853
0,091226
0,057252
0,033737
0,018917
0,010189
0,036089
0,100819
0,156293
0,175457
0,160623
0,127717
0,091604
0,060727
0,037833
0,022415
0,012030
0,050409
0,104196
0,146223
0,160623
0,149003
0,122138
0,091090
0,063055
0,041095
0,003437
0,021604
0,059540
0,104445
0,137677
0,149003
0,139587
0,117116
0,090079
0,064577
0,000859
0,008102
0,029770
0,065278
0,103258
0,130377
0,139587
0,131756
0,112599
0,088794
0,000191
0,002701
0,013231
0,036266
0,068838
0,101405
0,124077
0,131756
0,125110
0,103526
0,000038
0,000810
0,005292
0,018133
0,041303
0,070983
0,099262
0,118580
0,125110
0,119371
0,000007
0,000221
0,001925
0,008242
0,022529
0,045171
0,072190
0,097020
0,113736
0,119378
0,000001
0,000055
0,000642
0,003434
0,011264
0,026350
0,048127
0,072765
0,094780
0,109430
0,000013
0,000197
0,001321
0,005199
0,014188
0,029616
0,050376
0,072908
0,092595
1
0,000003
0,000056
0,000472
0,002228
0,007094
0,016924
0,032384
0,052077
0,072735
0,000001
0,000015
0,000157
0,000891
0,003311
0,009026
0,019431
0,034718
0,053352
0,000004
0,000049
0,000334
0,001448
0,004513
0,010930
0,021699
0,036680
0,000001
0,000014
0,000118
0,000596
0,002124
0,005786
0,012764
0,023734
0,000004
0,000039
0,000232
0,000944
0,002893
0,007091
0,014504
0,000001
0,000012
0,000085
0,000397
0,001370
0,003732
0,008397
0,000004
0,000030
0,000159
0,000617
0,001866
0,004618
0,000001
0,000010
0,000061
0,000264
0,000889
0,002419
0,000003
0,000022
0,000108
0,000494
0,001210
0,000001
0,000008
0.0C0042
0,000176
0,000578
0,000003
0,000016
0,000073
0,000265
0,000001
O,OoOOO6
0,000029
0,000117
0,000002
0,000011
0,000049
0,000001
0,000004
0,000020
0,000001
0,000008
1
1
0,000001
0,000003
0,000001
r-
213
Закон распределения Пуассона. Функция
а \
0
1
2
3
4
5
6
7
8
9
10
11
12
13
0,02
980
1000
0,04
961
999
1000
0,06
942
998
1000
0,08
923
997
1000
0, 10
9 05
995
1000
0,15
861
990
999
1000
0,20
819
982
999
1000
0,25
779
974
998
1000
0,30
741
963
996
1000
0,35
705
951
994
1000
0,40
670
938
992
999
1000
0,45
638
925
989
999
1000
0,50
607
910
986
998
1000
0,55
577
894
982
998
1000
0,60
549
878
977
997
1000
0,65
522
861
972
996
999
1000
0,70
497
844
966
994
999
1000
0,75
472
827
959
993
999
1000
0,80
449
809
953
991
999
1000
0,85
427
791
945
989
998
1000
0,90
407
772
917
987
998
1000
0,95
387
754
929
984
997
1000
1,00
368
736
920
981
996
999
1000
1 , 1
333
699
900
974
995
999
1000
1 ,2
301
663
879
966
992
998
1000
1 ,з
273
627
857
957
989
998
1000
1 ,4
247
592
833
946
986
997
999
1000
1 ,5
223
558
809
934
981
995
999
1000
1 ,6
202
525
783
921
976
994
999
1000
1 ,7
183
493
757
907
970
992
998
1000
1 ,8
165
4G3
731
891
964
990
997
999
1000
1 ,9
150
434
706
875
956
987
997
999
1000
2,0
135
406
677
857
947
983
995
999
1000
2,2
1 1 1
355
623
819
928
975
993
998
1000
2,4
091
308
570
779
904
964
988
997
999
1000
2,6
074
267
518
736
877
951
983
995
999
1000
214
Приложение 5
“ ап
распределения Р (х < k)— 2j —Г е
л=0
Г
15
16
17
18
19
20
2!
22
23
24
25
26
27
28
29
215
\ k
а \
0
1
2
3
4
5
6
7
8
9
10
1 1
12
13
2,8
061
231
469
692
848
935
976
992
998
999
1000
3,0
050
199
423
647
815
916
966
988
996
999
1000
3,2
041
171
380
603
781
895
955
983
994
998
1000
3,4
033
147
340
558
744
871
942
977
992
997
999
1000
3,6
027
1 26
303
515
706
844
927
969
988
996
999
1000
3,8
022
107
269
473
668
816
909
960
984
994
998
999
1000
4,0
018
092
238
433
629
785
889
949
979
992
997
999
1000
4,2
015
078
210
395
590
753
867
936
972
989
993
999
1000
4,4
012
066
185
359
551
720
844
921
964
985
994
998
999
1 000
4,6
010
056
163
326
513
686
818
905
955
980
992
997
999
10001
4,8
008
048
143
294
476
651
791
887
944
975
990
996
999
1 000
5,0
007
04 0
125
265
440
616
762
867
932
968
986
995
998
9 99
5,2
006
034
109
238
406
581
732
845
918
960
982
993
997
999
5,4
005
029
095
213
373
546
702
822
903
951
977
990
996
999
5,6
004
024
082
191
342
512
670
797
886
941
972
988
995
998
5,8
003
021
072
170
313
478
638
771
867
929
965
984
993
997
6,0
002
017
062
151
285
446
606
744
847
916
957
980
991
996
6,2
002
015
054
134
259
414
574
716
826
902
949
975
989
995
6,4
002
012
046
119
235
384
542
687
803
886
939
969
986
994
6,6
001
010
040
105
213
355
511
658
780
869
927
963
982
992
6,8
001
009
034
093
1 92
327
480
628
755
850
915
955
978
990
7,0
001
007
030
082
173
301
450
599
729
830
901
947
973
987
7,2
001
006
025
072
156
276
420
569
703
810
887
937
967
984
7,4
001
005
022
063
140
253
392
539
676
788
871
926
961
980
7,6
001
004
019
055
125
231
365
510
648
765
854
915
954
976
7,8
ООО
004
016
048
112
210
338
481
620
741
835
902
945
971
8, 0
ООО
003
014
042
100
191
313
453
593
717
816
888
936
966
8,5
ООО
002
009
030
074
150
256
386
523
653
763
849
909
949
9,0
ООО
001
006
021
055
116
207
324
456
587
706
803
876
926
9,5
ООО
001
004
015
040
089
165
269
392
522
645
752
836
898
10,0
ООО
ООО
003
010
029
067
130
220
333
458
583
697
792
8^4
10,5
ООО
ООО
002
007
021
050
102
179
279
397
521
639
742
8 25
11,0
ООО
ООО
001
005
015
038
079
143
232
341-
460
579
689
781
1 1 ,5
ООО
ООО
001
003
011
028
060
114
191
289
402
520
633
733
12,0
ООО
ООО
001
002
008
020
046
090
155
242
347
462
576
682
12,5
ООО
ООО
ООО
002
005
015
035
070
125
201
297
406
519
628
13,0
ООО
ООО
ООО
001
004
011
026
054
100
166
252
353
463
573
13,5
ООО
ООО
ООО
001
003
008
019
041
079
135
211
304
409
5 1 8
14,0
ООО
ООО
ООО
ООО
002
006
014
032
062
109
176
260
358
464
14,5
ООО
ООО
ООО
ООО
001
004
010
024
048
088
1 45
220
31 1
4 13
15,0
ООО
ООО
ООО
ООО
001
003
008
018
037
070
118
185
268
363
216
Продолжение прилож. 5
f
14
15
16
17
18
19
20
21
22
23
24
1 2£
1 2С
) 21
7 2£
1 29
1000
1000
1000
999
1000
999
1000
999
999
1000
998
999
1000
997
999
1000
997
999
999
1 000
996
998
999
1000
994
998
999
1000
993
997
999
999
1000
991
996
998
999
1000
989
995
998
999
1 000
986
993
997
999
1000
983
992
996
998
999
1 000
973
986
993
997
999
999
1000
959
978
989
995
998
999
1000
940
967
982
991
996
998
999
1000
917
951
973
986
993
997
998
999
1000
888
932
960
978
988
994
997
999
999
1000
854
907
944
968
982
991
995
998
999
1000
815
878
924
954
974
986
992
996
998
999
1000
772
884
899
937
963
979
988
994
997
999
999
1000
725
806
869
916
948
969
983
991
995
998 1
999
999
1000
675
764
835
890
930
957
975
986
992
996 I
998 '
999
1000
623
718
798
861
908
942
965
980
989
994 ’
997 !
998 !
999 :
1000
570
669
756
827
883
923
952
971
983
991 !
995 !
997 I
999 !
999
1000
518
619
71 1
790
853
901
936
960
976
986 <
992 !
996 !
998 !
999 I
999 1
ЮОО
466
568
664
749
819
875
917
947
967
981 <
989 !
994 !
997 !
998 1
999 1
1000
217
Распределение Стыодента. Значение функции распре
\ f
t
2
3
4
5
6
7
8
9
10
0,0
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,5 00
0,1
532
535
537
537
538
538
538
539
539
0,2
563
570
573
574
575
576
576
577
577
0,3
593
604
608
610
612
613
614
614
614
0,4
621
636
642
645
647
648
650
650
6 5 1
0,5
648
667
674
678
681
683
684
685
68G
0,6
672
695
705
710
713
715
716
717
718
0,7
694
722
733
739
742
745
747
74 8
749
0,8
715
746
759
766
770
773
775
777
778
0,9
733
768
783
790
795
799
801
803
804
1 ,0
750
789
804
813
818
822
825
827
828
1 , 1
765
807
824
834
839
843
84 6
848
850
1 ,2
779
824
842
852
858
862
865
868
870
1,3
791
839
858
868
875
879
883
885
887
1 ,4
803
852
872
883
890
894
898
900
902
1 ,5
813
864
885
896
903
908
911
914
916
1 ,6
822
875
896
908
915
920
923
926
928
1,7
831
884
906
918
925
930
934
936
938
1 ,8
839
893
915
927
934
939
943
945
947
1,9
846
901
923
935
942
947
950
953
955
2,0
0,852
908
930
942
949
954
957
960
962
2,2
864
921
942
954
960
965
968
970
972
2,4
874
931
952
963
969
973
976
978
980
2,6
883
938
960
97 0
976
980
982
984
986
2,8
891
946
966
976
981
984
987
988
990
3,0
898
952
971
980
985
988
990'
992
992
3,2
904
957
975
984
988
991
992
994
995
3,4
909
962
979
986
990
993
994
995
996
3,6
914
965
982
989
992
994
996
996
997
3,8
918
969
984
990
994
996
997
99 7
998
4,0
922
971
986
992
995
996
997
998
998
4,2
926
974
988
993
996
997
998
998
999
4,4
929
976
989
994
996
998
998
999
999
4,6
932
978
990
995
997
998
999
999
999
4,8
935
980
991
996
998
998
999
999
1 ,000
5,0
937
981
992
996
998
999
999
1 ,000
5,2
940
982
993
997
998
999
999
5,4
942
984
994
997
998
999
1 , ООО
5,6
944
985
994
998
999
999
5,8
946
986
995
998
999
999
6,0
947
987
995
998
999
1,000
218
Приложение 6
деления в функции t и числа степеней свободы f
11
12
13
14
15
16
17
18
1 9
20
00
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,500
0,50000
539
539
539
539
539
539
539
539
539
539
53983
577
577
578
578
578
578
578
578
578
578
57926•
615
615
615
616
616
616
616
6 1 6
616
616
61791
651
652
652
652
652
653
653
653
653
653
65542
686
686
687
687
688
688
688
688
688
689
69146
719
720
720
721
721
721
722
722
722
722
72575
750
751
751
752
752
753
753
753
754
754
75804
779
780
780
781
782
782
782
783
783
783
78814
805
806
807
808
808
809
809
810
810
810
81594
830
831
832
832
833
833
834
834
835
835
84 134
851
853
854
854
855
856
856
857
857
858
86433
871
872
873
874
875
876
876
877
877
878
88493
889
890
891
892
893
893
894
894
895
895
90320
904
906
907
908
908
909
910
910
911
911
91924
918
919
920
921
922
923
924
924
924
925
93319
930
931
932
933
934
935
935
936
936
937
94520
940
941
943
944
945
945
946
946
947
947
95543
949
950
952
952
953
954
955
955
956
956
96407
957
958
959
960
961
962
962
963
963
964
97128
963
965
967
967
967
968
969
969
970
970
97725
974
975
976
977
977
978
979
979
979
980
98610
981
982
983
984
985
985
986
986
986’
! 987
99180
987
988
988
989
990
990
990
991
991
991
99534
991
991
992
992
993
993
994
994
994
994
99744
993
994
994
995
995
996
996
996
996
996
99865
995
996
996
996
997
997
997
997
998
' 998
99931
997
997
997
998
998
998
998
998
998
998
99966
998
998
998
998
999
999
999
999
999
999
99984
998
998
999
999
999
999
999
999
999
999
99993
999
999
999
1 ,000
999
999
1 ,000
999
999
1 ,000
999
1,000
999
1,000
999
1 ,000
1 ,000
1 ,000
1 ,000
1 ,000
99997
99999
99999
219
Приложение 7
Распределение Стьюдента. Значение t в функции вероятности q = Р (\t\ > tg) и числа степеней свободы
о
о
о
ст>оо-остстзсп — — >-г^оо — осоштсчсооооомг-ттг^ох^осо — осо —
— G’f^ifliOO'foOCOcO-. 04 -ф — <OO)00iO-0)C0TrC-IOCDNW^W(ONQ
<OLOO<OOOGM,0(^l^TtcOC4->OOcnO)OOOOCOSNNNSC£>0<D<Oin^cOC'|
СО — 01сО<ОтиОЮ-<,'Ф’ф-^'М<'Ф'^,'ФСОСОСОСОсОСОсОСОСОСОСОСОСОСОсОСОСОсО
СО СО —•
СО
о
о
t'-L.O — -^-СЧ^ОЮСООСОЮСЧГ^Ь.-^00 00—*m^OSb-SO)-'CO(OO^OSo
oci-rccooainincooio — NM'wascO’tco — oooosNcoiciooco-t^
СО О. СС ’О О Tf СО Ol — — CDOOOOOOOOQOOOOOOOOOb~t^t^.r^t^-t^-r^t>.<OCOLO
COCTI-O^^COCOCOCOCOCOCOCOOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOI
0,02
—. LO —• lO СО 00 CD — 00 —■0^01cOS<MO)KOOCOOCSirjO)CONWScOOCOO
СЧ-О-^^ГСО’ФООСЧСО—'ООПСЧОООСОПС001~ОООСО>>ФОЮ01аЮС'1
oocii^Nn^ooocosNcocococoni^iflmninioio^-^^^’c^Tj-Tfncoco
—■ О CO CO CO Ol 04 Ol 04 04 04 Ol 04 04 Ol Ol 04 04 Ol Ol 04 C l Ol 04 O l 04 Ol Ol Ol Ol Ol Ol C l
CO
0,05
CD CO 04 CD — >-10(00100 — oom — О О — СОСОО^ОтГОСОСЧООЮС^ — coo
OOCCN>cf<OOCO<MO>(£>Tt-cOci- OOOOoOXOOOlOlO^^’fOQCCC
> n->io xf COCOO) Cl Cl - ^-OOOOQOOOO OOOOOOC)
OI^COOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOIOI — —
о
TFOCOOlL-QCOinOcOOlCOOl — — COCDOTfCntn — Ь-хГ — OOCOCO—•Ot'-Tt'—-coin
— oimco — rococo — cnoor-coin'^'^cooioioi — —. — ссоооосо>ю-г
COOiCO — О CT>COcOCOOOt^>-t'->-t'^t'^t^t'-t''-t-^t^>-l'- t^t^<OCO<OCD<OCD
oi
о
oococococooint^cooicocoom — > co о cc ю co - ст oo <d m <- co — о co со ст oi
>0Сс0СО>^-П00><ОЮЮ^^СОСОсОС1СЧО1(М-<-------OOOOOO
OOOCOLQ'^'^M’COCOCOCOCOCOCOCOCOCOCOCO&OCOCOCOCOCOCOCOCOCOCOCOOIOIOI
СО
о
COCDOOtD'fCTCOOCOOOCOCTCD'^' — CT >- (D ’cf CO — OOOOOOb-cOinmO'O — CD
cOCOLQOincO — OOOOOOOt"-t'->-t^cOCDCDCOCDCOCDinininiOLDiOinin''fTrcO
степ oi — — — — — —.0000000000000000000000000
о
CD — 00 — OCOCOCncOOCDCOCDoOcOincoO) — O<CT00 00>-CD(Dmin’^’^' — 00 >n oi
>со>т-(мотоооо>>ь>сооосо(осо<ою1л1люю1оююююю^^^
cOOCTCTCTCTOOOOCOCOCOOOoOOOOOOOOOOOOQOOOOCOOCCOCOoCOOoOOOOOOOoOCOOO
— — oooooooooooooooooooooooooooooooo
Ш
о
О CD iD — t^OO — СОСООГ^ШМ'О) — ОСПООООГ^СОСОШШ'Ф'Ф^СОСОСО — CT t"-- ■'f
О — CD 04 — — OOOQOlODCnOOCMOOOOoOOOOOCOOOCOCZjCOMoOCOSN
OOOt^.>-t^-t^->->-t^-t^COCOCDCOCOCOCOCOCOCOCOCO<OCOCDCDCOCOCOC41<OCOCDCO
— ooooooooooooooooooooooooooooooooo
со
о
> s G Q CO О О CO oi О О CO SO Ю CO CO Cl CM Cl - - - - О О О О N о
C4 — ОООЮЮ^^^^^СОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСООШОШ
^■coininininmininininininmininmmininininminininininminmininin
oooooooooooooooooooooooooooooooooo
t-
о
0i0'4<'t,00'^r040^o0>-c0in’=t,c0c0010401 — — — ooooacncncnooob-couo
— -ctC4 — OOOCTCTCT<CTCTCTCTCT>CDCTCTCTCT)CT>0>CT>0>CT>CTOOOOOOOOOOOOOOCO
Ш'^,'^,'Ф'^''Ф’^СОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСОСО
oooooooooooooooooooooooooooooooooo
00
о
lOQN-SiDCOCM-OOOQOOCOOOSSSt^XDCOtD'DCDCOcOCDCOLO't'tCO
oicot^r^cococococococDininininmLDiomminmmininininLQioininininin
cnC4C4<DlC4C4C4mC4C4C4C4mC4 04 01C4C4C4C4C4C4C4C4C4C4C4C4C4C4C4C4C4Cl
oooooooooooooooooooooooooooooooooo
о
о
00041^^04 — OOCTCT>CTOOOOOOOCOOOOh-t^>-t^->->-t--b->->-b.r^t--CDCD<DCD
Ю^СПСОСПСПСПСОС4С4СМС4С4С4С4С4С4С4С4С4С4С4 04СЧС4СЧС4С4С4С4С4С4С4СЧ
oooooooooooooooooooooooooooooooooo
о /
— Ol co '-M IQ CO t'- 00 СТ) о — Ol CO Tf IO co I'- 00 СТ О — Ol CO Ш <D >- 00 Ci О О О О Q
— — — « — — — — — — C401010104C4 010lC'4 04 a?’^C001 О
I
220
ОО
Распределение Стьюдента. Значение t в функции вероятности Р=Р (МР) и числа степеней свободы
221
ОГЛАВЛЕНИЕ
Стр.
Предисловие 3
Г л а в а I. Предмет и основные задачи математической ста¬
тистики 5
§ 1. Предмет математической статистики и ее отношение к
другим статистическим дисциплинам 5
§ 2. Основные задачи математической статистики 9
Глава II. Случайные переменные и законы их распреде¬
ления 12
§1. Вводные понятия, определения 12
§ 2. Распределение дискретной случайной переменной. По¬
лигон распределения 14
§ 3. Распределение непрерывной случайной переменной.
Функция распределения 17
§ 4. Плотность распределения 20
§ 5. Действия с дискретными случайными переменными.
Понятие независимости . 24
§ 6. Типичные величины дискретной случайной перемен¬
ной 27
Средняя величина дискретной случайной переменной 27
Дисперсия дискретной случайной переменной ... 31
Среднее квадратическое отклонение 34
Типичные величины высшего порядка дискретной
случайной переменной (моменты) ' 34
§ 7. Определение типичных величин непрерывной слу¬
чайной переменной. Типичные величины положения . . 35
§ 8. Классические законы дискретного и непрерывного
распределения 37
Биномиальное распределение 37
Распределение гипергеометрическое (по урновой схеме
невозвращенного шара Бернулли) 40
Распределение Пуассона 42
Нормальное распределение 44
Другие классические законы непрерывного распре¬
деления 50
§ 9. Закон больших чисел 55
Общие замечания 55
Неравенство Чебышева. Теорема Чебышева. Теорема
Бернулли. Теорема Пуассона 56
§ 10. Центральная предельная теорема 62
222
Стр.
Глава III. Эмпирические распределения по одному призна¬
ку (одномерные) 64
§ 1. Вводные элементы 64
§ 2. Графическое изображение эмпирических распределе¬
ний 67
§ 3. Плотность эмпирических распределений 69
§ 4. Разложение интервала и определение соответст¬
вующих частот 73
§ 5. Типичные величины положения 76
§ 6. Эмпирические моменты. Средние величины 83
§ 7. Показатели вариации 100
§ 8. Асимметрия, эксцесс 105
Глава IV. Определение нормальности эмпирических рас¬
пределений. Критерий согласия 107
§ 1. Общие замечания 107
§ 2. Нормальная кривая как инструмент подбора .... 109
§3. Статистическая гипотеза. Критерий согласия . . .111
Критерий х2 оценки соответствия между теоретиче¬
ским и эмпирическим распределением 111
Применение критерия %2 для проверки нормальности
распределения 115
Применение критерия %2 в случае, когда эмпири¬
ческое распределение следует закону Пуассона . 116
Критерий Колмогорова определения соответствия меж¬
ду теоретическим и эмпирическим распределением 119
Применение критерия Колмогорова в оценке эмпири¬
ческого распределения 121
Применение критерия Колмогорова в оценке соот¬
ветствия между распределением Пуассона и эруп-
циями газа метана и доли угольной мелочи . . . 123
Оценка нормальности на основе многих наблюдений
сокращенного объема 124
Глава V. Многомерные распределения (по нескольким
признакам) 130
§ 1. Общие замечания 130
§ 2. Дискретное распределение по двум признакам (рас¬
пределение случайного дискретного вектора) 131
Функция распределения случайного двумерного век¬
тора 133
§ 3. Распределение трехмерное и п-мерное 134
§ 4. Условное распределение 135
§ 5. Условные средние величины 136
§ 6. Условия, необходимые и достаточные для независи¬
мости двух случайных переменных. Корреляция и коэф¬
фициент корреляции 138
Глава VI. Эмпирические многомерные распределения. Ме¬
тод корреляции 141
§ 1. Определения 141
223
Стр.
§ 2. Вводные элементы корреляционного анализа стати¬
стических рядов 142
§ 3. Простая корреляция 144
§ 4., Прямолинейная регрессия. Коэффициент регрессии 148
§ 5. Коэффициент корреляции 153
§ 6. Упрощенный метод вычисления коэффициента корре¬
ляции 156
§ 7. Криволинейная регрессия. Вычисление параметров
линии регрессии 161
§ 8. Корреляционное отношение 171
Глава VII. Множественная корреляция. Уравнение мно¬
жественной регрессии 178
§ 1. Вводные элементы 178
§ 2. Коэффициент множественной корреляции 185
§ 3. Частные коэффициенты корреляции 186
§ 4. Разложение влияния факторов. Коэффициент де¬
терминации 188
§ 5. Оценка существенности показателей корреляции . . 190
Глава VIII. Корреляция рангов . 199
Библиография ... 204
Приложения ... 205
Основы математической статистики
и ее применение
Редактор 3. А. Сумник Технический редактор К. К- Сенчило
Корректор В. А. Жудов Худ. редактор Т. В. Стихно
Обложка художника Л. С. Эрмана
Сдано в набор 17/Ш 1970 г. Подписано к печати 1/VII 1970 г.
Формат бумаги 84 х Юв^зг. Бумага № 2 Объем 7 печ. л.
Уч.-изд." л. 11,15. Тираж 9:750 экз. (Тематич. план 1970 г. № 42)
Зак. 1050 Цена 1 р. 12 к.
Издательство «Статистика-», Москва, ул. Кирова, 39.
Московская типография № 4 Главполиграфпрома Комитета по печати
при Совете Министров СССР. Б. Переяславская, 4 6
1 р. 12
к.