/




































































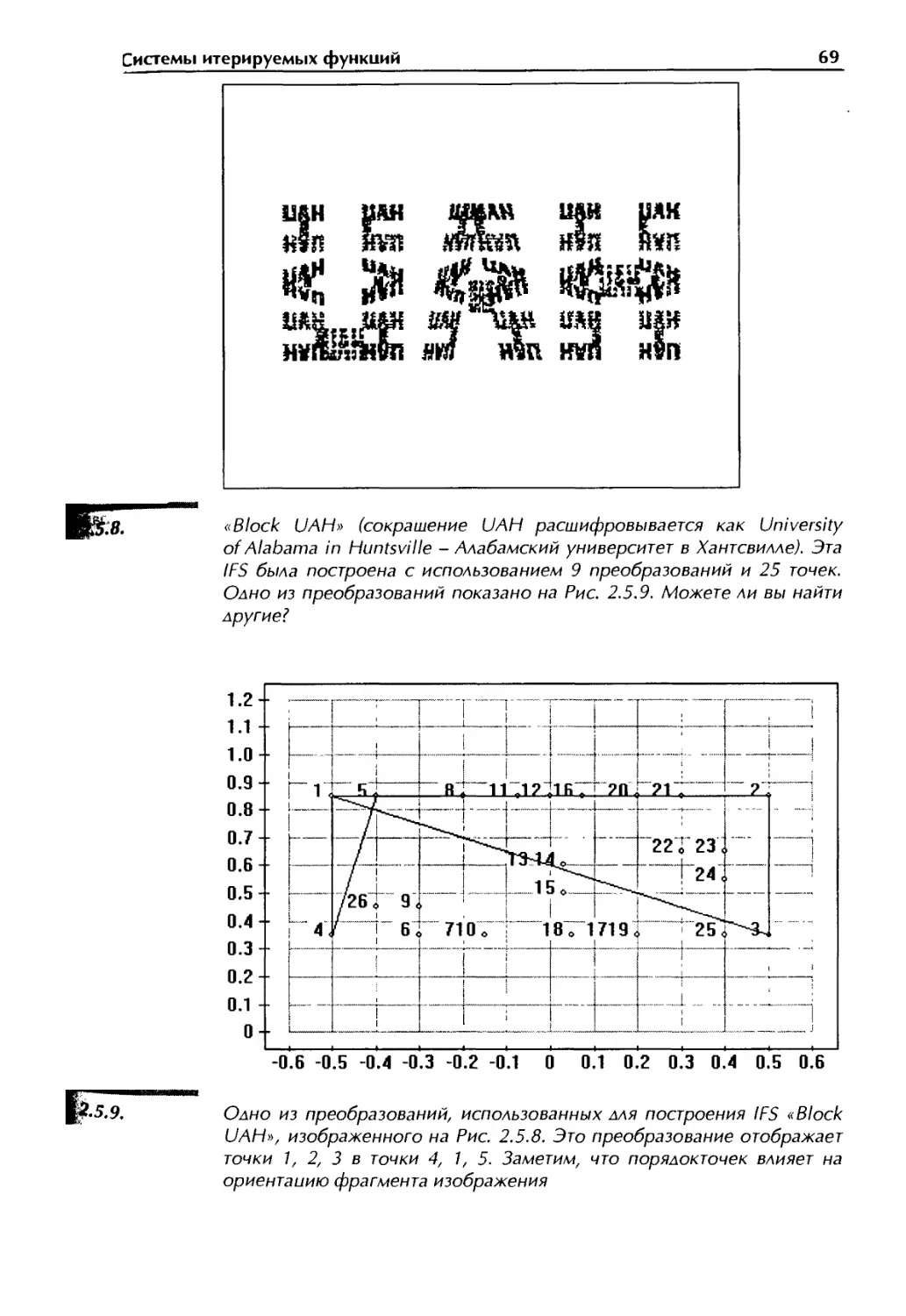
























































































































































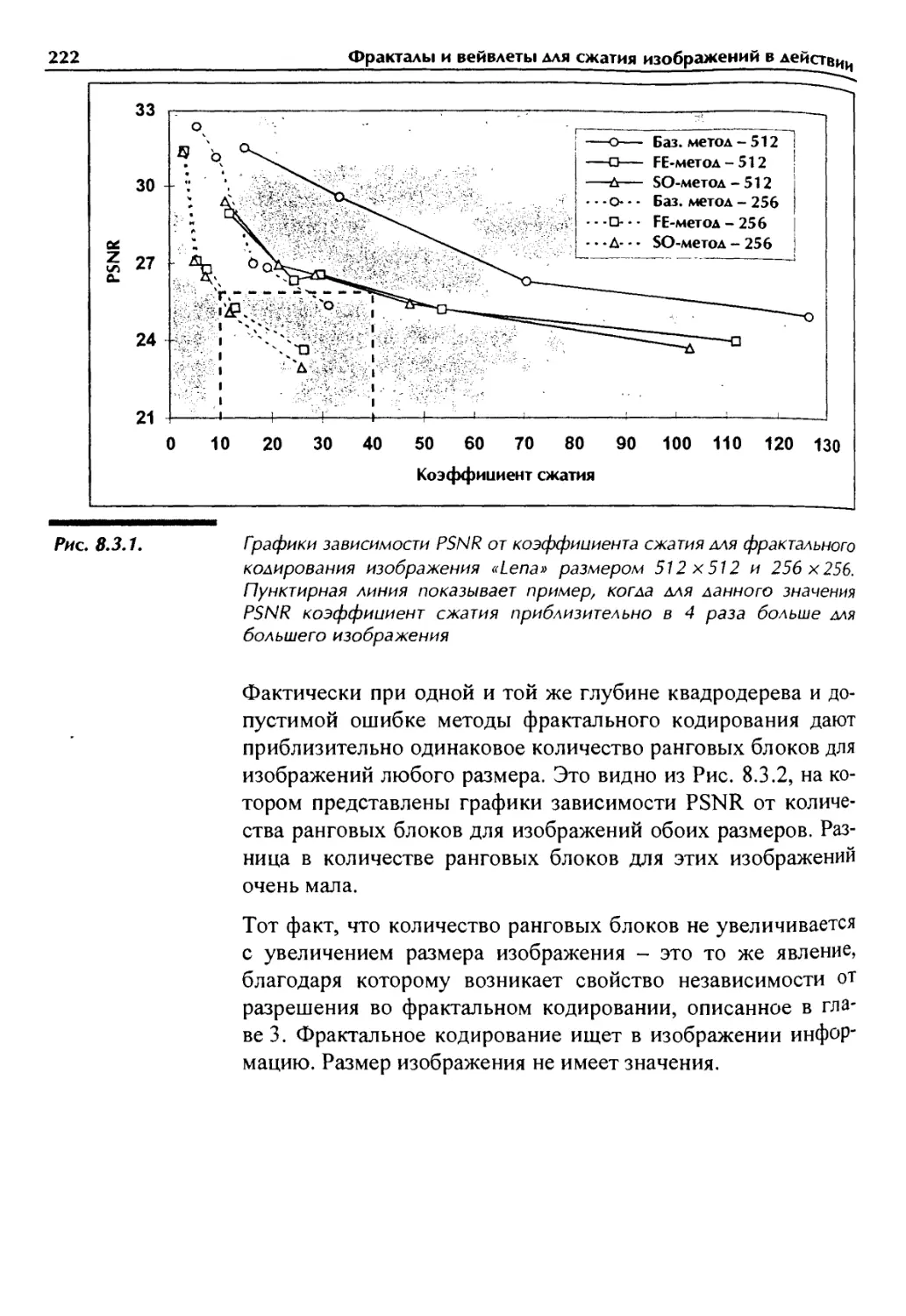


































































































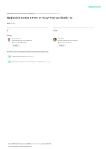
Author: Уэлстид С.
Tags: информационные технологии вычислительная техника обработка данных программирование вейвлеты фракталы цифровая обработка изображений
ISBN: 5-89392-079-1
Year: 2003



Text
С. Уэлстид
ФРАКТАЛЫ И ВЕЙВЛЕТЫ
ДЛЯ
СЖАТИЯ ИЗОБРАЖЕНИЙ
В ДЕЙСТВИИ
SPIE Optical Engineering Press
A Publication of SPIE—The International Society for Optical Engineering
Bellingham, Washington USA
Издательство
«ТРИУМФ»
Москва
Fractal and Wavelet
Image Compression
Techniques
Stephen Welstead
Tutorial Texts in Optical Engineering
Volume TT40
Arthur R. Weeks, Jr., Series Editor
University of Central Florida
SPIE Optical Engineering Press
A Publication of SPIE—The International Society for Optical Engineering
Bellingham, Washington USA
УДК 004
С. Уэлстид
Фракталы и вейвлеты для сжатия изображений в действии.
Учебное пособ.— М.: Издательство Триумф, 2003 — 320 с: ил.
ISBN 5-89392-079-1
ISBN 0-8194-3503-1 (амер.)
В книге подробно рассматриваются самые передовые математические
методы сжатия изображений и их законченная программная реализация.
Математический аппарат фракталов и вейвлетов позволяет получить
значительно большие коэффициенты сжатия, чем алгоритм JPEG, при
лучшем качестве получаемого изображения. К книге прилагается компакт-
диск с исходным текстом всех описываемых программ на языках Си/С++.
Copyright © 2002 SPIE. All rights reserved. No part of this book may be reproduced or transmitted
in any form or by any means, electronic or mechanical, including photocopying, recording or by any
information storage and retrieval system, without permission in writing from the Publisher and SPIE.
Authorized Russian language edition published by TRIUMPH PUBLISHING
(ООО «Издательство ТРИУМФ»), Copyright © 2003.
Copyright © 2002 SPIE. Все права защищены. Ни одна часть настоящей книги не может быть
воспроизведена или передана в какой бы то ни было форме и какими бы то ни было средствами,
электронными или механическими, включая фотокопирование, запись на магнитные носители
или иные системы записи и хранения информации без письменного разрешения Издателя и SPIE.
Авторизированное русскоязычное издание. Copyright © ООО «Издательство Триумф» 2003
ISBN 5-89392-079-1 © Обложка, серия, оформление
ISBN 0-8194-3503-1 (амер.) ООО «Издательство ТРИУМФ», 2003
To the memory of my parents
Памяти моих родителей
Предисловие к серии
Серия «Обучающие тексты» (Tutorial Texts) была начата в
1989 году для того, чтобы сделать материал, представленный
на коротких курсах в SPIE, доступным для тех, кто не мог их
посещать, и снабдить справочником тех, кто посещал их. Как
правило, короткие заметки к курсу пишутся в расчете на то,
что основной материал будет представлен устно, дополняя
заметки. Эти заметки обычно записываются в форме кратко-
го изложения, выделяющего ключевые технические момен-
ты, и не рассматриваются как самостоятельные документы.
Вдобавок к этому иллюстрации, рисунки, таблицы, и другая
графическая информация, включенная в заметки, требуют
дополнительного объяснения, даваемого преподавателем на
лекции. Как самостоятельные документы, короткие заметки к
курсу не очень подходят студентам или читателям.
Таким образом, многие «Обучающие тексты» начинались как
короткие заметки к курсу, впоследствии расширяясь до книг.
Цель серии состоит в том, чтобы снабдить читателей книга-
ми, которые освещают определенную техническую область в
форме обучения. Книги этой серии отличаются от других
технических монографий и учебников способом подачи ма-
териала. Исходя их обучающей природы серии, большинство
тем, представленных в этих книгах, сопровождаются деталь-
ными примерами, которые помогают глубже объяснить
представленные концепции. В каждую книгу включено мно-
го изображений и иллюстраций, а везде, где это возможно,
включены также соответствующие табличные справочные
данные.
К настоящему времени книги, изданные в этой серии, охва-
тывают широкий диапазон тем, от геометрической оптики и
детекторов оптических сигналов, до обработки изображений.
Каждое предложение оценивается с тем, чтобы определить
уместность предложенной темы. Этот предварительный про-
цесс оценки очень помогает авторам на начальной стадии
написания книги определить потребность в дополнительном
материале или изменении подхода к достижению макси-
мальной выразительности текста. По окончании рукописи
осуществляется ее тщательный просмотр для гарантии того,
что главы точно описывают основные компоненты обсуж-
даемых процессов и технологий.
В течение прошедших девяти лет мой предшественник Дональд К. О'Шеа (Donald С. O'Shea) проделал превосходную
работу по созданию серии «Обучающие тексты», которая насчитывает теперь почти сорок книг. Она расширилась так
что включает в себя не только книги, написанные преподавателями коротких курсов, но также книги, написанные экспертами по другим темам. Моей целью является сохранить
стиль и качество книг серии, и еще больше расширить круг
тем, включив как еще только возникающие, так и развитые
области оптики, стекловолокон ной оптики (photonics) и
представления изображений (imaging).
Артур Р. Викс, мл. (Arthur R. Weeks, Jr).
Университет Центральной Флориды
(University of Central Florida)
Предисловие 11
ГЛАВА 1. Введение 17
ЧАСТЬ I. ФРАКТАЛЬНОЕ СЖАТИЕ ИЗОБРАЖЕНИЙ
ГЛАВА 2. Системы итерируемых функций 33
ГЛАВА 3. Фрактальное кодирование изображений
в градациях серого 71
ГЛАВА 4. Повышение скорости фрактального
кодирования 107
ЧАСТЬ II. ВЕЙВЛЕТ-СЖАТИЕ ИЗОБРАЖЕНИЙ
ГЛАВА 5. Простые вейвлеты 135
ГЛАВА 6. Вейвлеты Добеши 167
ГЛАВА 7. Технологии вейвлет-сжатия изображений 183
ГЛАВА 8. Сравнение фрактального и вейвлетного
подходов к сжатию изображений 213
Приложение А. Использование прилагаемого программного
обеспечения 227
Приложение В. Библиотека утилит Windows 261
Приложение С. Организация прилагаемого
исходного кода программ 291
Список литературы 305
Об авторе 309
Информация о программном обеспечении 310
Предметный указатель 311
Краткое содержание
(подробное содержание находится в конце книги)
Предисловие
Данная книга является руководством, в котором рассматри-
ваются методы, лежащие в основе фрактального и вейвлет-
ного подходов к сжатию изображений. В связи с развитием в
последнее время сети Интернет и других мультимедийных
приложений, интерес к сжатию изображений значительно
возрос. В настоящий момент существуют и широко исполь-
зуются стандартные методы сжатия. Но потребность во все
большем увеличении объемов информации и скорости ее пе-
редачи побудили продолжить исследования для построения
более совершенных методов. Фракталы и вейвлеты пред-
ставляют собой два различных пути таких исследований. Для
ученых, инженеров, студентов и исследователей, всерьез ин-
тересующихся фрактальными и вейвлетными методами сжа-
тия изображений, данная книга может послужить введением
в материал предмета и детали практического применения,
достаточным для начала их собственных исследований этих
интереснейших новых технологий.
Не обязательно обладать предварительными знаниями о сжа-
тии изображений, фрактальной геометрии или теории вейв-
летов для того, чтобы понять материал книги. Уровень мате-
матического изложения доступен для понимания старше-
курсников и дипломников технических ВУЗов. Математиче-
ские построения, которые мы считаем нужным здесь изло-
жить, включают в себя представления о сходимости последо-
вательности, кратных интегралах, линейной независимости и
базисных векторах. Читателей, которые занимаются практи-
ческими задачами сжатия изображения, может разочаровать
то, что в книге только лишь упоминаются такие традицион-
ные методы, как дискретное косинус-преобразование и эн-
тропийное кодирование. Эти вопросы подробно излагаются в
других книгах. Например, энтропийное кодирование, которое
может быть применено к результату любого алгоритма сжа-
тия, в основе которого лежит фрактальный или вейвлетный
подход, не включен в систему рассмотренных здесь прило-
жений. Настоящая книга посвящена математическим аспек-
там фрактального и вейвлетного сжатия изображений.
В дополнение к изучению теории, на которой основано фрак-
тальное и вейвлет-сжатие, читатели смогут воспользоваться
программным обеспечением, которое позволит им самостоя-
тельно исследовать изложенные в книге идеи. Программы,
прилагаемые к книге, находятся на сайте
http://www.spie.org/bookstore/tt40/. Подробная информация о
том, как пользоваться этим программами и как их настроить,
приведена в приложениях А, В и С. К книге прилагаются три
программы на компакт-диске. Программа IFS System позво-
лит читателям создавать свои собственные фрактальные изо-
бражения, используя системы итерируемых функций. Про-
грамма IMG System сжимает изображения, используя фрак-
тальные методы, выводит на экран декодированное изобра-
жение и путем вычитания изображений вычисляет разницу
между исходным и декодированным изображениями. Про-
грамма WAV System, используя вейвлет-методы, выполняет
простые операции с изображениями и, кроме того, показыва-
ет процесс вейвлет-преобразования изображения. Каждая
система использует стандартный Windows-интерфейс и
включает операции сохранения и восстановления информа-
ции из файлов. Программы работают под управлением опе-
рационных систем Win32, включая Windows NT, Windows 95
и Windows 98. Кроме того, чтобы читатели могли расширить
свое поле для экспериментов, не ограничивая его готовыми
программами, на компакт-диске записаны полные исходные
коды программ на C/C++.
Исходные коды для прилагаемых программ написаны на
комбинации языков С и C++. Но для понимания материала
книги или для того, чтобы запустить программы, вам не обя-
зательно знать ни один из этих языков. В тексте книги при-
водятся только небольшие фрагменты кодов программ. Вы-
числительные коды в основном написаны на С. C++ применя-
ется, когда очевидно преимущество использования объектно-
ориентированных особенностей этого языка. И в том, и в
другом случае вычислительный код хранится отдельно от
пользовательского интерфейса и кодов модулей вывода на
экран, которые обращаются к Windows. Таким образом, ис-
ходный код вычислений, возможно, с минимальными изме-
нениями, может быть перенесен на другие платформы, на-
пример, UNIX. Код пользовательского интерфейса, для кото-
рого очевидно преимущество использования объектно-
ориентированных свойств, таких как наследование, написан
на C++. Исходный код включает в себя собственную основу
приложения (application framework) на C++ для разработки
простых Windows-приложений. Он не зависит от библиотеки
MFC (Microsoft Foundation Classes) или других библиотек.
Приведенный здесь код написан на Borland C++ v.4.5 для
Windows. Он также компилировался на Symantec C++ 7.2 и
Microsoft Visual C++ 4.0. Этот код можно перекомпилировать
на любом компиляторе C++, который обращается к про-
граммному интерфейсу Windows API (Application Programming
Interface) и поддерживает разработку 32-разрядных Windows-
приложений с помощью исходных кодов.
Краткий обзор материала книги
Книга начинается с обзора проблемы сжатия изображений,
который включает в себя краткое обсуждение основных по-
нятий: информация и энтропия, арифметическое кодирова-
ние и т.д. и рассмотрение современных технологий сжатия,
таких как JPEG. Эти основные вопросы рассматриваются для
того, чтобы определить место фрактальных и вейвлетных
технологий сжатия изображений в контексте общей теории
сжатия изображений. Остальная часть книги посвящена во-
просам, касающимся фракталов и вейвлетов, и не останавли-
вается на общих вопросах сжатия, таких как энтропийное ко-
дирование; эти вопросы раскрыты в других книгах.
Толчком к исследованиям фрактального сжатия изображений
послужило построение систем итерируемых функций (IFS).
В книге приведены математические основы теории IFS,
включая теорему о сжимающих отображениях, теорему кол-
лажа Барнсли (Barnsley) и аффинные преобразования. Эти
вопросы важны для понимания того, как работает фракталь-
ное сжатие изображений. Построенные на компьютере при-
меры показывают, как нужно использовать IFS-технологии
для синтеза фрактальных изображений, похожих на реальные
изображения.
Системы итерируемых кусочно-определенных функций рас-
пространяют идеи IFS-теории на более общие и реалистич-
ные изображения и делают возможным фрактальное кодиро-
вание и сжатие таких изображений. После изложения теоре-
тических основ фрактального кодирования в книге рассмат-
риваются вопросы, связанные с практической реализацией,
например, вопрос о том, как задать систему доменных и ран-
говых областей и их преобразование. Компьютерные приме-
ры иллюстрируют такие понятия, как квадродерево ранговых
блоков и сходимость последовательности изображений к
изображению-аттрактору.
Помехой на пути применения фрактальных методов сжатия
изображения является большое время кодирования. В публикациях за последнее время внимание привлекают два
подхода к ускорению процесса кодирования. Первый из
них, метод выделения особенностей, сокращает количество
вычислений, необходимых для доменно-рангового сопос-
тавления. Второй, классификация доменов, сокращает вре-
мя поиска приемлемого доменно-рангового соответствия.
В книге рассматриваются методы выделения особенностей
и использование нейронных сетей для классификации до-
менов. Примеры показывают, что использование этих мето-
дов сокращает время кодирования от часов до секунд и, та-
ким образом, делает возможным практическое применение
фрактального кодирования.
Затем, в качестве альтернативного подхода к сжатию изо-
бражений, в книге рассматриваются вейвлеты. Базовые вейв-
леты Хаара иллюстрируют идею вейвлетной декомпозиции
как процесса усреднения и выделения деталей при различных
уровнях разрешения. В книге дан единый подход к много-
численным и, на первый взгляд, разрозненным аспектам
вейвлет-анализа. От усреднения и выделения деталей для
дискретной последовательности мы переходим к масштаби-
рующим функциям и вейвлет-функциям. Тот факт, что эти
функции образуют базис в соответствующем векторном про-
странстве, приводит к идеям кратномасштабного анализа.
С чего бы мы ни начали наше рассмотрение - с усреднения и
выделения деталей для последовательностей, с функций
масштабирования и вейвлет-функций или с кратномасштаб-
ного анализа - в любом случае мы приходим к вейвлет-
преобразованию. Усреднение и выделение деталей может
быть представлено в виде матричного оператора, и это по-
зволяет представить вейвлет-преобразование в совсем про-
стом виде. Свойства этих операторов могут быть распростра-
нены на более общие операторы высокочастотных и низко-
частотных фильтров. Такой анализ приводит к более слож-
ным системам вейвлет-функций, таким как вейвлеты Добе-
ши, которые обеспечивают высокую степень сжатия наибо-
лее распространенных типов сигналов и изображений. Кроме
изложения теории вейвлетов, в книге рассматриваются мето-
ды вейвлет-сжатия изображений, от простых схем квантова-
ния вейвлет-коэффициентов до более сложных схем, таких
как кодирование с нуль-деревом. Ключевые шаги реализации
иллюстрируются фрагментами кода программы, а компью-
терные примеры демонстрируют работу данных методов.
В книге также обсуждаются последние исследования в об-
ласти смешанных методов, которые применяют идеи фрак-
тального кодирования к данным вейвлет-преобразования. На
компьютерных примерах сравнивается производительность
фрактальных, вейвлетных и смешанных методов сжатия изо-
бражений.
Благодарности
Особая признательность Биллу Питману (Bill Pittman), без
его взгляда на проблему и его исключительной научной эру-
диции эта книга никогда не была бы написана. Выражаю
также благодарность Рику Херману (Rick Hermann) и изда-
тельству SPIE Press за ту поддержку, которую они оказывали
на протяжении всей подготовки рукописи. Спасибо Бобу Бе-
ринато (Bob Berinato) за вдумчивое и содержательное обсуж-
дение и комментарии к рукописи. И, наконец, спасибо всем
рецензентам, чьи замечания сделали эту книгу лучше. Любые
неточности остаются исключительно на совести автора.
Стефан Т. Уэлстид (Stephen T. Welstead)
ОКТЯБРЬ, 1999
Цифровые изображения занимают все большую часть ин-
формационного мира. Развитие Интернета, наряду с дос-
тупностью все более мощных компьютеров и прогрессом в
технологии производства цифровых камер, сканеров и
принтеров, привели к широкому использованию цифровых
изображений. Отсюда постоянный интерес к улучшению
алгоритмов сжатия данных, представляющих изображения.
Сжатие данных важно как для скорости передачи, так и
эффективности хранения. Кроме многих видов коммерче-
ского использования, технологии сжатия представляют
также интерес для военных, например, приложения обра-
ботки данных телеметрии, полученных от перехватчиков
ракет, или для архивного хранения данных об изображении
местности для моделирования оборонительных действий.
Решение проблемы сжатия изображения или, в более об-
щем смысле, кодирования изображения, использовало дос-
тижения и стимулировало развитие многих областей тех-
ники и математики. В этой книге рассказывается о двух
относительно новых областях математики, которые внесли
вклад в последние исследования о сжатии изображений:
фракталы и вейвлеты.
Выявление структуры данных - ключевой аспект эффектив-
ного представления и хранения этих данных. Методы фрак-
тального кодирования и вейвлет-преобразования использу-
ют два различных подхода к обнаружению структуры в
данных изображения. Барнсли (Barasley) и Слоун (Sloan)
[5], [6] впервые увидели возможность применения теории
систем итерируемых функций к проблеме сжатия изображе-
ния. Они запатентовали свою идею в 1990 и 1991 гг. Джек-
вин (Jacquin) [23] представил метод фрактального кодиро-
вания, в котором используются системы доменных и ранго-
вых блоков изображения (domain and range subimage blocks).
Этот подход стал основой для большинства методов фрак-
тального кодирования, применяемых сегодня. Он был усо-
вершенствован Фишером (Fisher) и рядом других исследо-
вателей [18], [22]. В соответствии с данным методом изо-
бражение разбивается на множество неперекрывающихся
ранговых подызображений (range subimages) и определяется
множество перекрывающихся доменных подызображений
(domain subimages). Для каждого рангового блока алгоритм
ГЛАВА 1.
Введение
кодирования находит наиболее подходящий доменный блок
и аффинное преобразование, которое переводит этот доменный блок в данный ранговый блок. Структура изображения
отображается в систему ранговых блоков, доменных блоков
и преобразований. Сегодня основная часть исследований в
области фрактального сжатия изображений направлена на
сокращение времени кодирования. В этом отношении оказались эффективными два метода: метод выделения особенностей (feature extraction) и метод классификации доменов
(classification of domains).
В этой книге мы изложим методы повышения эффективности
кодирования фрактальных изображений и обсудим послед-
ние результаты [8], [38], [2], [20], [45].
Методы вейвлет-преобразований для сжатия изображений
используют избыточность в представлении данных. Данные
вейвлет-преобразования могут быть представлены в виде
поддерева, которое может быть эффективно закодировано.
Смешанные фрактально-вейвлетные методы [15], [21] ис-
пользуют фрактальную идею доменно-рангового преобразо-
вания применительно к вейвлетным поддеревьям. Результат -
улучшение коэффициента сжатия и качества декодирования
изображения.
В этой главе изложен материал, необходимый для понима-
ния основных вопросов, касающихся кодирования изобра-
жений. После небольшого обзора проблемы сжатия изобра-
жений мы кратко рассмотрим теорию информации и энтро-
пии, скалярную и векторную дискретизацию, а также кон-
курирующие технологии сжатия, такие как JPEG (Joint Pho-
tographic Experts Group). Цель этой главы в том, чтобы обо-
значить место методов фрактального и вейвлетного сжатия
в общей проблеме сжатия изображений. Более детальное
изложение альтернативных подходов, которые упоминаются
в этой главе, вы можете найти, обратившись к списку лите-
ратуры.
1.1. Изображения
С математической точки зрения, изображение в градациях
серого можно представить как вещественную функцию f двух
вещественных переменных х и у. Функция изображения f(х, у)
обычно определяется в прямоугольной области плоскости, и
большинство изображений в этой книге определено в квад-
ратных областях. Так как изображение не «знает», в какой
области оно определено, мы обычно считаем, что эта об-
ласть - единичный квадрат [0,1] х [0,1]. Значения градации
серого — это положительные вещественные числа. Рис 1.1.1.
показывает изображение в градациях серого и график соот-
ветствующей функции f(x,y). Полноцветным изображениям
соответствуют векторные функции на плоскости. Есть раз-
личные способы представления цветовой информации. Элек-
тронные системы представления, например компьютерное
представление, представляют цвет как комбинацию красного,
зеленого и синего цветов (RGB). Печатающие системы для
передачи цвета в дополнение к черному используют голубой,
красный и желтый (CMYK). В любом случае цвет представ-
ляется как трехмерный вектор. Алгоритмы кодирования, ко-
торые применяются для изображений в градациях серого, мо-
гут применяться к каждому из компонентов цветного изо-
бражения, хотя возможны и более эффективные подходы.
Можно было бы ожидать, что задача кодирования цветного
изображения втрое труднее чем задача кодирования изобра-
жения в градациях серого, но в действительности все не так
сложно. Можно использовать особенности человеческого
восприятия цвета, чтобы снизить требования к кодированию
полноцветных изображении Мы вернемся к этому вопросу
далее в этой главе.
Рис. 1.1.1. Изображение в градациях серого (слева) и соответствующее ему
представление в виде функции на плоскости (справа)
Человеческое восприятие изображений - аналоговый процесс,
а мир компьютеров - это цифровой мир. Компьютерное пред-
ставление изображения в градациях серого - это двумерный
массив неотрицательных чисел. Каждый элемент массива - это
пиксел изображения. Мы можем сопоставить каждому пиксе-
лу неотрицательное целое число из ограниченного диапазона
Этот диапазон может быть представлен как 256 градаций серо-
го или в терминах количества бит (разрядов), необходимы)
для представления значения, как 8 бит на пиксел.
Хотя большая часть литературы по обработке и сжатию изображений посвящена человеческому восприятию изображения, стоит отметить, что для некоторых приложений машин-
ное восприятие может быть более важным. Например, авто-
матическая система распознавания образов может выделять
особенности изображения, например определять границы или
различные текстуры. В этом случае производительность алгоритма сжатия может быть оценена по тому, насколько хо-
рошо он сохраняет значения свойств после сжатия, что может
не точно соответствовать человеческому восприятию этого
образа.
1.2. Проблема сжатия изображения
На Рис. 1.2.1 изображена схема процесса сжатия изображе-
ния. Цифровое изображение - это массив значений пикселов,
который мы можем представить в виде списка чисел. Задача
сжатия состоит из двух основных частей: кодирования и де-
кодирования. Кодирование представляет исходный список
чисел иначе - так, чтобы, по возможности, сократить требуе-
мый под массив объем памяти. Декодирование восстанавли-
вает исходное изображение из закодированного. Если деко-
дированное изображение всегда в точности соответствует ис-
ходному изображению, то алгоритм кодирования-
декодирования называется алгоритмом без потерь. Если де-
кодированное изображение отличается от исходного изобра-
жения, то алгоритм называется алгоритмом с потерями.
Фрактальные и вейвлет-методы, описанные в этой книге,
это алгоритмы с потерями, как и большинство алгоритмов
сжатия.
Есть два способа, которыми можно сжать набор данных,
представленный в виде списка чисел. Можно попытаться
сделать список короче, чтобы он состоял из меньшего коли-
чества чисел, или попытаться сделать короче сами числа,
чтобы они использовали в среднем меньшее количество бит
для представления каждого числа. Полные схемы сжатия
применяют оба эти подхода.
Схема процесса сжатия изображения
Рис. 1.2.1 описывает первый из этих подходов. Этот класс ал-
горитмов включает методы преобразования Фурье и дис-
кретного косинус-преобразования (DCT), которые являются
основой большинства методов сжатия JPEG. Он также вклю-
чает вейвлет-преобразование и фрактальные методы, предмет
нашей книги. Идея методов преобразования состоит в том,
чтобы преобразовать данные изображения к другому виду,
где легче определить часть данных, которую можно было бы
безболезненно удалить. Это позволяет отбросить значитель-
ную часть данных с небольшой потерей качества изображе-
ния. В случае преобразования Фурье это обычно высокочас-
тотные сигналы. Для вейвлет-преобразования это данные, со-
ответствующие мелким деталям. Фрактальные методы пыта-
ются непосредственно представить информацию об изобра-
жении в компактной форме.
Результат алгоритмического кодирования может быть затем
сжат путем компактного представления закодированных чи-
сел. Дискретизация (квантование) может дать как уменьше-
ние количества чисел в списке, так и уменьшение количества
бит, необходимых для записи каждого числа. Цифровые изо-
бражения по своему определению уже являются дискретизи-
рованными некоторым образом еще до этапа кодирования.
Энтропийные методы кодирования, такие как методы Хафф-
мана (Huffman), и арифметическое кодирование проверяют
Рис 1.2.1.
распределение значений, чтобы достичь эффективного пред-
ставления в битах каждого значения. Значениям, которые
встречаются в списке чаще, сопоставляется меньшее количе-
ство бит, а более редко встречающимся значениям сопостав-
ляется большее количество бит.
При декодировании исходное изображение восстанавливает-
ся из закодированных данных. В случае методов преобразо-
вания этап декодирования применяет обратное преобразова-
ние. Декодирование может сопровождаться дополнительной
пост-обработкой, направленной на улучшение качества деко-
дированного изображения, например, удалением артефактов
блочности, которые могут появиться в результате работы алгоритма сжатия.
1.3. Информация, энтропия и моделирование данных
Пусть А - некоторое событие, появляющееся с вероятностью
Р (А). Тогда информация, сопоставленная А, определяется
как:
Заметим, что когда Р(А) велико, то i(A) мало, а когда Р(А) = I,
то i(A) = 0. Маловероятные события несут очень много ин-
формации, в то время как достоверные события несут
очень мало информации. Если вы скажете, что этой зимой
на Аляске пойдет снег, вы не дадите много информации.
Но если вы скажете, что Флорида будет покрыта снегом, то
потом, возможно, станете свидетелем бума на рынке
апельсинового сока.
В литературе по теории информации процесс, который поро-
ждает случайные события А/, называется источником. Пред-
положим, что имеется множество независимых событий А
появляющихся с вероятностями P{Aj). Энтропия источника,
сопоставленного этим событиям, - это средняя информация:
Для наших целей мы будем рассматривать изображения в ка-
честве источников. Предположим, что Ajtj = 1, ..., п пред-
ставляет последовательность пикселов изображения, и пусть
л:, основание логарифмической функции в (1.3.1), равняет-
ся 2. Тогда энтропия изображения - это мера среднего ко-
личества бит, необходимых, чтобы закодировать значения
пикселов.
Вообще, мы не можем знать истинную энтропию источника,
потому что мы не знаем истинные значения P(Aj ) в (1.3.2).
Лучшее, что мы можем сделать, это оценить значения P(Aj)
и использовать (1.3.2), чтобы получить оценки для явной эн-
тропии (apparent entropy) источника.
Распознавание структуры данных может уменьшать явную
энтропию. Рассмотрим следующий пример из книги Клайда
Сейвуда (Klaid Sayood) [40]. Начинаем с последовательности
121233331233331233 1 2
Если мы игнорируем структуру и рассмотрим числа по от-
дельности, то увидим три символа 1, 2 и 3, которые появля-
ются со следующими вероятностями:
Р(1) = 5/20 = 0.25
Р(2) = 5/20 = 0.25
Р(3) = 10/20 = 0.5
Явная энтропия будет:
-(0.25 log2(l/4) + 0.25 log2(l/4) + 0.5 log2(l/2)) = 1.5 бит
на символ
Однако если мы рассмотрим числа последовательности по
два, то обнаружим структуру: 12 и 33 всегда появляются вме-
сте, и полная последовательность состоит только из этих
двух символов. Кроме того,
Р(12) = 5/10 = 0.5
Р(33) = 5/10 = 0.5
и явная энтропия теперь
-(0.5 log2(l/2) + 0.5 log2(l/2)) = 1 бит на символ.
1 А. Скалярное и векторное квантование
Другой способ сокращения объема записанной информации -
квантование. Скалярное квантование сокращает точность
скалярных параметров до некоторого определенного уровня.
Например, 16- или 32-битные числа могут быть сокращены
до 8 бит. В этом случае мы имеем 256 уровней квантования
Квантование может быть равномерным и неравномерным
Равномерное квантование располагает уровни квантования
равномерно по диапазону числовых значений. Естественно,
этот вид квантования лучше всего работает, когда квантуй
мые значения распределены равномерно.
Если значения распределены неравномерно, может быть п°'
лезно сконцентрировать большее количество уровней кваН'
тования в области наивысшей плотности числовых значении
Децимация - один из примеров неравномерного квантование
Децимация состоит в обнулении части числовых значение
Эта часть может быть определена или как некоторый проце^
В первом случае требуется (1.5)(20) = 30 бит, чтобы закод^
ровать последовательность, в то время как во втором случае
требуется только 10 бит. Процесс сопоставления структур^
последовательности данных называется моделирование^
данных. Фрактальные методы кодирования позволяют мод^
лировать данные изображений, в результате чего явная эн,
тропия уменьшается и происходит сжатие. Методы преобрач
зований, например вейвлет-методы, структурируют область
преобразования, что тоже уменьшает явную энтропию и при,
водит к сжатию.
Энтропия - основа методов кодирования Хаффмана и ариф,
метического кодирования. Имея любую последовательность
значений данных, например результат применения фракталь*
ной или вейвлетной схемы сжатия, можно всегда применить
к ней энтропийный метод кодирования, например, метод
Хаффмана или арифметический метод для достижения еще
большего сжатия. Эти методы исследуют распределение зна^
чений данных и присваивают низкий битрейт (bit rates - ско
рость потока) часто встречающимся значениям и высокий
битрейт редко встречающимся значениям. Мы не будем да-
лее обсуждать энтропийные методы кодирования в этой кни-
ге. Подробности вы можете найти в списке литературы, на-
пример в [40].
от общего количества значений, или с помощью проверки
порогового значения. Например, один из подходов к вейвлет-
сжатию изображений заключается в том, чтобы положить
равным нулю некоторый процент, скажем 90%, вейвлет-
коэффициентов. Квантование оставшихся значений состоит
просто в сохранении этих значений. Количество уровней бу-
дет равно нулю плюс количество различных значений из 10%
оставшихся коэффициентов (в следующих главах мы убе-
димся, что этих оставшихся 10% коэффициентов достаточно,
чтобы получить после восстановления вполне удовлетвори-
тельное декодированное изображение).
При векторном квантовании массив значений заменяется един-
ственным квантованным числом. Векторное квантование удоб-
но при кодировании цветных изображений. В цветных изобра-
жениях цвет пиксела обычно представляется триплетом значе-
ний. В системе RGB этот триплет состоит из значений красного,
зеленого и голубого цветов. Для воспроизведения цветного изо-
бражения должен быть сохранен весь вектор (R, G, В). В 24-
битном цветном изображении на каждое из трех значений для
каждого пиксела отводится 8 бит. В этом случае данному пик-
селу может быть поставлено в соответствие любое значение из
трехмерного RGB-пространства. Однако хорошее приближение
к исходному изображению может быть получено и в том слу-
чае, если мы ограничим множество значений цвета пиксела не-
которым конечным списком RGB-векторов. Такая схема назы-
вается цветовой картой (color map) или, в Windows-
приложениях, палитрой (palette). К примеру, цветовая карта,
или палитра, может содержать 256 значений, поэтому для хра-
нения индекса такого списка требуется только 8 бит. В этом
случае, коль скоро цветовая карта известна, каждый пиксел мо-
жет быть представлен 8 битами вместо исходных 24.
Очевидно, выбор цветовой карты влияет на качество аппрок-
симируемого изображения. В общем случае при векторном
квантовании выбор наилучшего списка, называемого в ос-
новных приложениях векторного квантования кодовой книгой
(codebook), является нетривиальным. Один подход заключа-
ется в использовании адаптивной кластеризации данных. Со-
гласно этому подходу, значения кластеров становятся эле-
ментами кодовой книги. Заметим, что при векторном кванто-
вании кодовая книга должна быть известна декодеру и обыч-
но зависит от данных. Это обычно означает, что кодовая кни-
га должна храниться вместе с закодированными данными,
что уменьшает эффективность сжатия. На Рис. 1.4.1 показан
пример процесса векторного квантования, который мо^
быть применен к цветному RGB-изображению.
Рис. 1,4.1. Схема применения векторного квантования к цветному /?Gfr
изображению. Значения красной (R), зеленой (С) и синей (В) состав*
ляюших цвета пиксела образуют вектор ллины 3. При колирована
отыскивается ближайший элемент из таблицы векторов, называемой
коловой книгой. Сохраняется только инлекс элемента в таблице. При
леколировании этот инлекс преобразуется снова в вектор. Заметим,
что леколеру необхолимо знать таблицу коловой книги. Нахожление
оптимальной коловой книги является нетривиальной залачей
1.5. Методы преобразования
JPEG - наиболее распространенный стандарт сжатия изобра-
жения. Те, кто используют JPEG, могут выбрать или версию
сжатия без потерь, или один из нескольких вариантов сжатия
с потерями. Версии сжатия с потерями обеспечивают луч-
шую степень сжатия. Коэффициент сжатия и качество вос-
становленного изображения могут регулироваться (хотя и не
точно задаваться) путем выбора параметра. Основа для вер-
сий сжатия JPEG с потерями - дискретное косинус-
преобразование, которое является разновидностью преобра-
зования Фурье. Для достижения сжатия к коэффициентам
преобразования применяется квантование. Сейвуд [40] опи-
сывает JPEG метод, a Jly (Lu) [26] предлагает детальный
пример. Барнсли (Barnsley) и Херд (Hurd) [4] также предла-
гают подробное обсуждение JPEG с образцом исходного ко-
да. Полный исходный код есть в Интернете.
Сжатие JPEG без потерь применяет линейно-предсказы-
вающее кодирование (linear predictive coding). Линейное
предсказание для достижения сжатия использует соотноше-
ния между соседними пикселами. Это - пример поиска внут-
ренней структуры в изображении, и, следовательно, сокра-
щение явной энтропии.
У метода JPEG есть видеособрат, формат MPEG (Moving Pic-
ture Experts Group). Видео обладает значительной избыточно-
стью информации от одного соседнего кадра к другому и по-
тому может достичь гораздо большей степени сжатия, чем
это возможно для статичных изображений.
Так зачем же искать новые подходы к сжатию
изображения, когда существуют столь хорошие
стандарты (JPEG, MPEG)?
Принятие форматов JPEG и MPEG в качестве стандартов
не означает, что необходимость в поиске новых методов
сжатия рисунков и видео отпала. Существование стандар-
тов не препятствует новым исследованиям; стандарты уве-
личили число приложений, использующих рисунки и видео,
и, таким образом, помогли выявить новые проблемы: по-
мехоустойчивая передача данных, библиотеки цифровых
изображений и видео, контекстно-зависимый поиск, тех-
нология цифровых водяных знаков - вот лишь некоторые
из них. Наше знание фундаментальной структуры данных
рисунка и видео ограничено. Не стоит полагать, что сего-
дняшние стандарты являются оптимальными для этих ис-
точников данных. Фрактальные методы, в частности, под-
ходят к моделированию фундаментальной структуры изо-
бражения с совершенно новых позиций. Продолжение по-
исков необходимо для того, чтобы расширить наше пони-
мание и увеличить производительность методов сжатия.
Комитет по стандартизации JPEG признал, что первона-
чальный стандарт JPEG, разработанный более 10 лет назад,
должен быть обновлен, чтобы удовлетворять запросам
пользователей, работающих сегодня с цифровыми изобра-
жениями. Комитет активно разрабатывает стандарт
JPEG 2000, который использует вей влет-технологию вместо
методов сжатия, основанных на дискретном косинус-
преобразовании Фурье (DCT compression methods) перво-
начального стандарта JPEG. Аля дальнейшего знакомства
со значением стандартов в сжатии изображения вы можете
обратиться к Чен (Chen) [10].
1.6. Цветные изображения
Как мы уже знаем, цвета пикселов цифрового цветного
изображения определяются тремя значениями, представ
ляющими красный, зеленый и синий цвета в системе RGB
используемой для большинства дисплеев (системы печать
используют для рисунков голубой, малиновый и желтый
цвета и дополнительный черный CMYK). На первь^
взгляд может показаться, что сжатие цветного изображу
ния втрое труднее, чем сжатие изображения в градациях
серого. Однако, благодаря человеческому восприятию цве.
та, значения RGB можно преобразовать, и это обеспечит
значительно большую степень сжатия. Значения RGB пре*
образуются к значениям YIQ, где Y - это яркость (lumi.
nance), I - цвет (hue) и Q - насыщенность (saturation),
Обозначения I и Q возникли от терминов из области обра-
ботки сигналов: in-phase (I) - синфазный и quadrature (Q)-
квадратура. Оказывается, каналы I и Q могут быть значи-
тельно сжаты с неощутимой потерей качества. Таким обра-
зом, в целом степень сжатия цветного изображения оказы-
вается большей, чем возможная степень сжатия для изо-
бражения в градациях серого; обычно она больше в 2 - 2,7
раза [18]. Преобразования из RGB в YIQ и обратно явля-
ются линейными. Матрицы, представляющие преобразова-
ние и его инверсию, приведены ниже:
Цветное телевидение в Северной Америке использует пред-
ставление YIQ.
Фишер [18] и Лу [26] обсуждают сжатие цветных изображу
ний более подробно. Примеры из нашей книги будут отно-
сится к сжатию изображений в градациях серого.
Я^сновной объект внимания этой книги
Все дальнейшее изложение будет посвящено алгоритмиче-
скому аспекту фрактального сжатия изображений и вейвлет-
сжатия изображений. Для того чтобы понять, как они рабо-
тают, мы исследуем математическую основу этих методов.
Мы покажем реализацию этих методов на компьютере, при-
ведя образцы исходных кодов. Примеры, построенные с по-
мощью прилагаемой к книге программы, будут иллюстриро-
вать методы и их реализацию. Эти примеры будут относиться
только к изображениям в градациях серого, так как сами ал-
горитмы не меняются, когда их применяют к цветным изо-
бражениям (хотя детали реализации отличаются). В закон-
ченных системах сжатия изображений используется
энтропийное кодирование и направленная на улучшение
качества пост-обработка декодированного изображения.
Системы же, разрабатываемые в нашей книге, являются по
сути учебным пособием и будут сосредоточиваться только на
реализации алгоритмов фрактального и вейвлетного сжатия.
По этой причине представленные здесь результаты
приведены только для сравнения производительности этих
алгоритмов друг относительно друга, а не для, скажем,
практического применения незавершенных результатов
исследования. Список литературы содержит дополнительную
информацию о деталях компактного представления, таких
как энтропийное кодирование и упаковка битов, пост-
обработка изображений, сжатие цветных изображений,
сжатие видео, а также другие вопросы и методы сжатия.
Часть I
ФРАКТАЛЬНОЕ СЖАТИЕ ИЗОБРАЖЕНИЙ
■Pa 2.
дртемы итерируемых функций
В начале 80-х годов Майкл Барнсли выдвинул идею полу-
чения заранее заданного изображения как аттрактора хао-
тического (chaotic) процесса. Еще раньше другие исследо-
ватели обнаружили, что хаотические системы способны
создавать удивительные изображения, названные
странными аттракторами (strange attractors). Барнсли,
однако, был первым, кто сделал шаг к решению обратной
задачи. Суть ее в следующем. Пусть задано определенное
изображение. Можно ли построить хаотическую систему,
для которой данное изображение будет являться странным
аттрактором? Барнсли использовал специальную систему
отображений, которые он назвал системой итерируемых
функций (Iterated Function System - IFS). IFS - это, в луч-
шем случае, только лишь грубая форма сжатия изображе-
ний. Нужно подчеркнуть, что IFS в своей исходной форме и
в том виде, в котором они представлены в этой главе, не яв-
ляются основой современных подходов к фрактальному
сжатию изображений (заблуждение, поддерживаемое неко-
торыми противниками фрактального сжатия изображений).
Однако IFS вдохновили развитие фрактальных методов
сжатия изображений. И хотя сами по себе IFS не могут
быть использованы как готовые системы сжатия изображе-
ния, знание теории IFS необходимо для понимания того,
как работают фрактальные методы сжатия изображений.
В этой главе мы изложим математические основы теории
IFS и покажем, как такие системы могут быть реализованы
на компьютере.
2Л • Системы итерируемых функций
как стимул фрактального сжатия изображений
Самый наглядный пример фрактального изображения, сгене-
рированного с помощью IFS - это папоротник, такой как по-
казан на Рис. 2.1.1 (a). IFS, использованная для создания это-
го изображения, состоит из четырех преобразований. Эти
преобразования отображают целое изображение в четыре об-
ласти, являющиеся составными частями изображения, кото-
рые показаны на Рис. 2.1.1 (Ь). Каждое преобразование имеет
заданную форму, которая определяется шестью веществе^
ными коэффициентами. Таким образом, вся информация, не,
обходимая для создания изображения (а), содержится ^
24 числах с плавающей точкой.
Рис. 2.1.1. (а) Изображение папоротника, созланное с помошью IFS. Эта IFS
состоит из 4 преобразований, отображающих все изображение в
4 элемента изображения, прелставленные на (Ь). Вся информация,
необхолимая лля созлания изображения на рисунке (а), может
быть записана с помошью 24 чисел с плавающей точкой
Эти 24 коэффициента представляют код изображения (а). Та-
кой код очень компактен и требует значительно меньше мес-
та для хранения, чем растровый вариант изображения (а).
Это и является причиной применения фрактального подхода
к сжатию изображений: IFS дают код изображения, который
обеспечивает сжатие в сотни и тысячи раз.
Простая IFS, такая как IFS, породившая изображение на
Рис. 2.1.1 (а), не работает для произвольных изображений.
Прежде всего, изображение на Рис. 2.1.1 (а) - это двоичное
изображение, то есть значения его пикселов могут быть 1
или 0. Для более общих изображений в градациях серого
требуются более сложные системы, о которых речь пойдет
в следующей главе. Кроме того, простые IFS используются
только для самоподобных изображений, то есть изображу
ний, которые строятся из элементов изображения, являЮ'
щихся копией целого изображения. Заметьте, что каждЫ**
лист папоротника - это копия целого папоротника. Для пр0'
произвольных изображений это не так. В общем случае мы
можем только рассчитывать найти фрагменты изображения,
являющиеся копиями других фрагментов изображения, ко-
торые могут быть сгенерированы системами, рассматри-
ваемыми в следующей главе. В оставшейся части этой гла-
вы мы приведем математические выкладки, необходимые
для определения коэффициентов для простых IFS, и пока-
жем, как такие IFS могут создавать изображение, такое как
на Рис. 2Л. 1 (а).
Что такое фрактал?
Термин фрактал был впервые введен Бенуа Мандельб-
ротом [28]. Гораздо легче описать фракталы, чем опре-
делить их. Ключевое свойство, характеризующее фрак-
талы, - это самополобие. То есть, когда вы смотрите на
фрактал, вы видите некоторый набор элементов, кото-
рый остается одним и тем же независимо от масштаба.
Большинство объектов утрачивают детали, когда их
приближают для более пристального рассмотрения.
Фрактал же можно приближать до бесконечности. На-
стоящие фракталы являются результатом некоторого
бесконечно повторяемого процесса, такого как итера-
ционный процесс. Второе свойство, которое характери-
зует фракталы, это дробная размерность. Хотя само по-
нятие дробной размерности может показаться противо-
речащим интуиции, мы можем взять идею обычной евк-
лидовой размерности (где размерность линии равна
единице, размерность прямоугольной области на листе
бумаги равна двум, а размерность мира, в котором мы
живем, - трем),и расширить ее для тех понятий, для ко-
торых дробная размерность имеет смысл. Слово
фрактал произошло от fractional values - дробные вели-
чины, которые может принимать размерность фракталь-
ных объектов. Подробнее вы можете познакомиться с
этим в [28] (см. список литературы в конце книги).
36 Фракталы и вейвлеты для сжатия изображений в действ^
2.2. Метрические пространства
Математики любят расширять конкретные понятия до абс>
рактных. Например, идея измерения расстояний между ^
альными объектами вполне понятна. Но как измерить рас
стояние между двумя изображениями? Иногда абстракцц
освобождает наше воображение от привычного взгляда Нй
вещи и позволяет найти новые подходы к решению проблем
В этой главе мы расширим понятие расстояния до более об.
щего понятия метрики. Кроме того, мы введем более общее
представление об объектах - как о точках в пространстве
Это позволит нам рассматривать изображения в пространен
вах особого вида, называемых метрическими пространспь
вами, и измерять расстояния между изображениями. Затем
мы дадим понятия классической теории метрических про.
странств, чтобы изложить на их основе алгоритм генерации
заранее заданных фрактальных изображений.
2.2.1. Основные понятия
В евклидовом пространстве R2 расстояние d2(x,y) между точ«
ками х = (х\,х2) и у = (у\,у2) обычно определяется следующим
образом:
Это не единственный способ измерения расстояний в R
Другая функция расстояния:
Эти две функции расстояния по-разному определяют р^с'
стояние между двумя точками. Например, d2((0,0),(l,l)) = \2.
a di((0,0),(l,l)) = 2. Однако обе они являются мерами р^с'
стояния. В чем же суть измерения расстояния? Вот те свой-
ства, которые математики считают неотъемлемыми свойст-
вами функции расстояния:
1. Не имеет значения, измеряется ли расстояние от точки х Д
точки у или от у до х. Таким образом, мы имеем:
d(x, у) = d(y9 x)
2. Расстояние от точки до нее самой равно 0:
d(x, х) = О
3. Не существует более короткого расстояния через промежу-
точную точку (другими словами, кратчайшее расстояние ме-
жду двумя точками - это расстояние по прямой, что бы под
этим ни подразумевалось!):
d(x, у) < d(x, z) + d(z, у)
4. И, наконец, сама функция расстояния должна быть вещест-
венной, конечной и положительной для двух различных то-
чек х и у:
О < d(x, y)<°°
Функция расстояния, удовлетворяющая свойствам (1) - (4),
называется метрикой. Множество точек X вместе с метрикой
d, определенной на X, называется метрическим пространст-
вом и обозначается (X, d).
Мы будем работать с изображениями, понимаемыми как
множество точек в R . Может показаться странным то, что
мы говорим о понятиях абстрактных метрических про-
странств, когда имеем дело с таким конкретным пространст-
вом, как R2. В действительности нам нужно определить мет-
рическое пространство, точками которого будут являться
изображения. Когда мы совершим этот переход, нам станет
доступен весь аппарат теории метрических пространств, ко-
торым мы будем руководствоваться в таких пространствах,
где интуиция не всегда может выручить.
Нам понадобятся некоторые базовые определения, касаю-
щиеся общего метрического пространства (X,d). Последова-
тельность точек {хп} называется сходящейся к точке х € X,
если при достаточно больших п мы можем найти хп, сколь
угодно близкие к х. В строгой математической формулировке
это звучит следующим образом: для любого сколь угодно
малого е > 0, существует N > 0, такое что d(xn, x) < 8 для вся-
кого n>N. Точка х называется пределом последовательности
{хп}. Сходимость последовательности {хп} к точке х обозна-
чается:
хп —>;с
Последовательность {хп} называется последовательность^
Кохии, если точки хп и хт становятся сколь угодно близким^
друг к другу для достаточно больших пит. Или, в строгой
формулировке, для любого сколь угодно малого е > 0 сущеч
ствует N > О, такое что d(xm, хп) < е для всех m,n>N. СходЯч
щаяся последовательность является последовательность^
Коши; обратное же не всегда верно. Так, можно определить
пространство S и последовательность Коши {хп} в 5, такую
что пространство 5 не будет содержать предел последова-
тельности {хп}. Рассмотрим следующий несколько искусст-
венный пример. Пусть 5 - множество точек в R , удаленных
от начала координат на расстояние, меньшее 1 (имеется в ви-
ду евклидово расстояние) и не включающее начало коорди-
нат.
5 = {(*, у) е R2: 0 < d2((x, у),(0,0)) < 1}
Рассмотрим последовательность точек {(l/n,l/n)}, n > 1 в S,
Это - последовательность Коши, тем не менее, она не схо-
дится к точке в 5. Так же как и другая последовательность
{((гс-1)/гс,0)}, п > 1, которая тоже является последовательно-
стью Коши в 5, но не сходится к точке в 5.
Метрическое пространство, в котором каждая последова-
тельность Коши сходится к точке этого пространства, назы-
вается полным метрическим пространством. (R2, dj) - полное
метрическое пространство. Пространство (5, d-i), где S -
множество, определенное выше, не является полным.
Определенные выше последовательности не сходятся в 5, но
имеют пределы во всем пространстве R": (1/иД/и) —» (0,0) е R
и ((п-1)/п,0) -> (1,0) е R2. Точки (0,0) и (1,0) называются
предельными точками множества 5. Точка х называется
предельной точкой^ если существует последовательность то-
чек {хп} в 5\ {*}, такая что хп —» х. Здесь 5\ {х} определяется
как множество всех точек в 5 за исключением точки х. Мно-
жество А в метрическом пространстве (X, d) называется
замкнутым, если оно содержит все свои предельные точки.
Множество 5, определенное выше, не замкнуто. Однако
замкнутым является множество
S = {(x,y)e R1 :d2((x,y),(0,0))<l}
Множество А вместе со всеми его предельными точками
называется замыканием множества А и обозначается А.
В приведенном выше примере S является замыканием мно-
жества 5.
И последнее определение в этом разделе. Множество В в (X,<f)
ограничено, если существует точка х0 е X и конечное значение
/?, О < R < °°, такое что для каждого х G В выполняется
d(x0, x)<R
Множества S и S являются ограниченными, так же как и все
множества изображений, которые мы будем рассматривать в
этой главе.
2.2.2. Компактные множества
и пространство Хаусдорфа
Математическое понятие «изображение» в этой главе не-
сколько отличается от представления об изображении в гра-
дациях серого, рассматривающегося в следующих главах.
Двоичное изображение, такое как папоротник на Рис. 2.1.1
(а), может рассматриваться как особый случай изображения в
градациях серого, а именно как двумерная матрица значений
градаций серого, где каждый пиксел или черный, или белый.
Однако в этой главе, когда мы будем говорить о двоичном
изображении, речь будет идти только о множестве точек в R ,
представленных черными пикселами. Таким образом, изо-
бражение — это множество точек, заключенных в ограничен-
ном подмножестве пространства (R2yd2). Мы не будем рабо-
тать с этими изображениями непосредственно как с множе-
ствами, а воспользуемся понятием абстрактного метрическо-
го пространства для определения пространства, в котором
эти изображения сами будут являться точками. Это позволит
нам использовать хорошо известный результат из классиче-
ской теории метрических пространств для получения алго-
ритма создания фрактальных изображений. Мы введем мет-
рику для измерения расстояния между множествами изобра-
жений и будем рассматривать сами эти множества как точки
в метрическом пространстве.
Двоичные изображения - это замкнутые и ограниченные
подмножества в (R2,d2)- Чтобы считать эти изображения точ-
ками в более абстрактном метрическом пространстве, мы
должны обобщить понятия замкнутости и ограниченности
Множество С в метрическом пространстве (X,<f) называется
компактным, если каждая бесконечная последовательность
из С имеет сходящуюся в С подпоследовательность. Мно>ке.
ство (R2,^) не является компактным, так как, например, по*
следовательность {(и,0)}о..оо н^ имеет сходящейся подпосде.
довательности. Следует заметить, что из определения ком.
пактного множества следует, что оно должно содержать все
свои предельные точки, то есть быть замкнутым. Множество
5, определенное в разделе 2.2.1, не компактно, так как не
замкнуто. В евклидовом пространстве, как и в (R ,<i2), любое
замкнутое и ограниченное множество является компактным
этот факт известен как теорема Больцано-Вейерштрасса.
Пусть (Х,яГ) - полное метрическое пространство. Определим
Я(Х) как пространство, состоящее из компактных подмно-
жеств X. Таким образом, каждая точка в Я(Х) - это компакт-
ное подмножество из X. Определим расстояние между х еХ
и В G Я(Х) как кратчайшее расстояние между точкой х и
произвольной точкой у е В\
d(x, В) = min {d(x, у):у£ В}
Заметим, что этот минимум существует и конечен, так как В
компактно и, следовательно, замкнуто и ограничено. Теперь
мы можем определить расстояние между двумя компактны-
ми множествами А и В как
d(A, В) = max {d(x, В): х е А}
Компактность А обеспечивает существование и конечность
этого максимума. Но задает ли d(A, В) метрику? Рассмотрим
ситуацию, показанную на Рис. 2.2.1.
Рис. 2.2,1.
В обшем случае
d(A,B)*d(B,A)
А
Из Рис. 2.2.1 ясно, что в общем случае d(A, В) * d(B, Л) (дей-
ствительно, равенство бывает крайне редко). Мы можем по-
править это, определив новую меру расстояния h(A, В):
А(А, В) = max {rf(A, В), d(By A)}.
Теперь h(A, В) = h(B, Л) и h является метрикой в Н(Х). Мет-
рика h называется метрикой Хаусдорфа, а метрическое про-
странство (Я(Х), К) - метрическим пространством Хаус-
дорфа. Барнсли (1993) назвал (#(Х), К) «пространством, где
обитают фракталы». В этом пространстве мы будем разраба-
тывать механизм для создания некоторых видов фракталов с
помощью систем итерируемых функций. Пространство
(#(Х), К) - это полное метрическое пространство (Barnsley
1993). В тех случаях, когда пространством будет пространст-
во R2 (как в случае двоичных изображений, рассматриваемых
в этой главе), обозначение //(R ) будет сокращено до Я.
2.2.3. Сжимаюшие отображения
Преобразование сопоставляет точке в одном пространстве
точку в другом (возможно, том же самом пространстве) со-
гласно некоторому заранее определенному правилу. Напри-
мер, функция
fix, у) = (0.5л: + О.Зу + 2, 0.2* - 0.5у + 1)
это преобразование, которое переводит одну точку в R в
другую точку в R . Преобразование называется отображе-
нием и записывается /: Xi —> Х2, если оно переводит
пространство Xi в пространство Хг.
Преобразование f:X -^Хв метрическом пространстве (X, d)
называется сжимающим отображением, если существует
константа s, 0 < s < 1 такая, что
d(Kx09j{x2))<sd(xi9x2)
для всех X], хг е X. Константа s называется коэффициентом
сжатия отображения /. На Рис. 2.2.2 показан пример
сжимающего отображения на (R2, d2), примененного к
множеству точек в R .
Рис. 2.2Л. Сжимаюшее отображение, преобразующее множество точек в R2
На Рис. 2.2.2 показано преобразование, примененное более
одного раза. Сначала J{x) вычисляется для точки х, затем /
применяется к результату и вычисляется flflx)). Вы можете
продолжить этот процесс и вычислить ХЯЯ*))) и так далее.
Преобразования, получаемые таким многократным примене-
нием/, называются итерациями/, п™ итерация /обозначается
/°л, то есть,/°%х) = ДД.. .Дх)...)), где/применяется п раз.
Заметим, что Д*),/° (х),/°3(л:)5... образуют последователь-
ность в X. Пусть/-сжимающее отображение с коэффициен-
том сжатия s. Заметим, что
rf^"(4/eM)(^^^°,*,)W/eM",)W^*"4./e'W)
Заметим также, что
rf(r./e'w)^t/W+rf(r(x>/e2w)f...+rf(re(w)(x>/e"w)
<(l + s + s2+... + sk-l)d(X,f(X))<^-d(X,f(X))
где последнее неравенство следует из разложения ряда (1-я)"»
так как О < s < 1. Так, например, если п <т9 мы получим
d{f""(xWm(x))<^-d(x,f(x))
JL о
Так как 5 < 1, то выражение в правой части стремится к 0 при
п,т —> <». Другими словами, последовательность {/°"(.х)} яВ*
ляется последовательностью Коши в (X,d). Так как, далее,
(X,d) - это полное метрическое пространство, эта последова-
тельность сходится к пределу X/ G X, то есть
\\mf°n(x)-xf
Точка х/ обладает особым свойством. Что произойдет, если
мы применим/к .к/?
d{xrf{xf ))<d{?nrn (*))+ d(f°n (4/(^))
<d{?f,f"(x))+Sd{f°(n-%),Xf)
Так как/°"(;с) —> Л/, оба выражения в правой части стремятся
к 0, а, следовательно, выражение в левой части - тоже 0. Дру-
гими словами,
Точка х/ называется неподвижной точкой /. Как много не-
подвижных точек может иметь сжимающее отображение?
Предположим, что существует другая неподвижная точка yf
отображения/, то есть/(>у) = yf. Тогда
<1(хА yf) = mx/\Jbf)) £ s d(Xfi у/)
Так как s < 1, то из неравенства следует, что d(xf, yf) = 0, то
есть Xf = yf. Таким образом, сжимающее отображение / на
(X,d) имеет одну и только одну неподвижную точку в X. За-
метим, что поскольку имеется только одна неподвижная точ-
ка, то {fon(x)} сходится к этой неподвижной точке независи-
мо от начальной точки х. Это подытоживается в следующей
теореме:
Теорема о сжимающих отображениях: Пусть f:X —> X сжи-
мающее отображение на полном метрическом пространст-
ве (X,d). Тогда f имеет одну и только одну неподвижную
точку xf е X, и для любого х е X последовательность {f °
п(х): п~ 1,2,...} сходится кх/.
\\mf°n{x)= xf для всех хе X
Теорема о сжимающих отображениях является краеугольным
камнем классического функционального анализа. Многие
доказательства существования используют приведенный ме-
тод, чтобы показать, что какое-то отображение является
сжимающим, и, следовательно, имеет единственную непод-
вижную точку. Эта теорема лежит в основе всех подходов к
фрактальному сжатию изображений.
44 Фракталы и вейвлеты для сжатия изображений в лействи,
2.3. Системы итерируемых функций
Мы уже говорили о том, что будем рассматривать фрактал^
ные изображения как точки в пространстве Хаусдорф
(Я(Х), /г). В этом разделе мы определим специальный вцп
сжимающих отображений, которые воздействуют на изобра.
жения, то есть на точки в (Н(Х), /г).
2.3.1. Введение
Пусть {wi,W2,.-.,wN} - конечный набор сжимающих отобра*
жений в (ХД) с коэффициентами сжатия S\, s2,...,sN
0<sn<l. Определим отображение 1У, воздействующее на
компактные множества точек из X (то есть, в пространстве
Я(Х)), следующим образом:
W(B)=wl(B)vw2(B)v...vwN(B) = \Jwn(B)
/1=1
для каждого В е Н(Х) (т.е. В с X).
Таким образом, W отображает Н(Х) в #(Х) и является сжи-
мающим отображением на (#(Х), h) с коэффициентом сжа-
тия s, где s = max [s\, s2, ♦.-, sN}.
h(W(B)MQ) £ s й(ВД для BJC e H(X)
Система итерируемых функций (IFS) состоит из полного
метрического пространства (X,d) и конечного множества
сжимающих отображений wn: X —» X с коэффициентами
сжатия sn. Коэффициент сжатия IFS определяется как
s = max {s\y s2, ..., sn}. Введем обозначение для IFS:
{X, wn: n = 1, 2, ..., N}. Если используемое пространство то-
чек является очевидным, например, R2 в случае изображе-
ний, мы будем сокращать обозначение до {wn}.
Есть ряд деталей, о которых мы не упоминали здесь, включая
тот факт, что W(B) фактически является точкой пространства
Я(Х), когда В е Н(Х) (то есть, что W(B) компактно, когда
компактно В). Те, кто заинтересовался этим, могут найти бо-
лее подробное изложение в [3].
2.3.2. Теорема коллажа
Теорема о сжимающих отображениях (ТСО) может быть
применена к отображениям на пространстве (//(X), h) и, в ча-
стности, к системам итерируемых функций. Изображение,
которое является единственной неподвижной точкой IFS (что
гарантируется ТСО) в Н(Х), называется аттрактором EFS.
Барнсли [3] сформулировал ТСО для систем итерируемых
функций на (#(Х), h) и назвал ее теоремой коллажа. Следует
помнить, что «точка» в Н(Х) - это компактное множество то-
чек в R , представляющее двоичное изображение.
Теорема коллажа: Пусть L - точка пространства Я(Х). За-
дано некоторое е>0> Выберем IFS {X, vv„: n = 1, 2, ..., N)
с коэффициентом сжатия s, О < s < 1, так чтобы
Чтобы убедиться в том, что этот результат следует из ТСО,
рассмотрим сжимающее отображение / на полном метриче-
ском пространстве (X,<f). Пусть X/ - неподвижная точка /.
Предположим, что х е X такова, что d(x,f(x)) < e для некото-
рого е > 0. Тогда
rf(x,x/)=rf(x,/(x/))<rf(^/W)+^(/(4/t/))^
<d(x,f(x))+sd(x,xf)
Следовательно
d[X'Xf)~ (l-s) -(I-,)"
Отсюда следует утверждение теоремы коллажа.
2.3.3. О чем говорит теорема коллажа
Предположим, что мы имеем двоичное изображение Lqw
и можем задать сжимающие отображения такие, что
покрывают L почти точно и не слишком перекрывают его
Мы можем считать каждое wn(L) уменьшенной копией I
Теорема коллажа утверждает, что тогда аттрактор А системы
итерируемых функций {wn} близок к L в метрике Хаусдорфа
h. «Коллажом» является набор областей wn(L).
Так как аттрактор А - это результат бесконечного числа ите-
раций IFS, то он, по сути, является фракталом. Теорема кол-
лажа дает алгоритм представления изображений как фракта-
лов. На Рис. 2.3.1 приводится пример этого. На Рис. 2.3.1 (а)
вы видите изображение листа (это контур настоящего клено-
вого листа). Как показано на рисунке, изображения листа
можно покрыть четырьмя его фрагментами. Это приводит к
IFS с четырьмя преобразованиями и>ь и>2, и>з, и>4. На Рис. 2.3.1 (Ь)
показан аттрактор этой IFS. Обратите внимание на фракталь-
ную основу этого аттрактора. В следующих разделах мы уз-
наем, как задать преобразования wn и как сгенерировать ат-
трактор.
Рис. 2.3.1. Пример, иллюстрирующий теорему коллажа, (а) Исхолное изображен^6
и четыре фрагмента изображения; (Ь) изображение-аттрактор
2.3.4. Аффинные преобразования
Чтобы применить на практике теорему коллажа для создания
фракталов, нам необходимо выбрать преобразования, кото-
рые будут являться сжимающими отображениями. Преобра-
зования, которые использовал Барнсли для его IFS, - это так
называемые аффинные преобразования. Аффинное преобра-
зование T:R2 —» R2 - это преобразование вида
&-V
i 2.3.2,
Аффинное преобразование множества точек в R2. Как вилите, это
преобразование отображает точки (xi, у() —> {xi, yi)
2.4. Применение системы итерируемых функций
Предположим, что вы хотите реализовать систему для соз
дания фрактальных изображений с помощью IFS. Каки\и
должны быть ключевые компоненты такой системы? Преж
де всего, вы должны представлять себе изображение, кото
рое вы хотите воспроизвести с помощью IFS. Поэтому былс
бы полезно, чтобы ваша система могла импортировать су.
ществующее изображение в каком-то известном графиче-
ском формате. Далее, вам необходимо каким-то образом за-
дать точки на двумерной сетке. Затем вы определите аф-
финные преобразования путем задания трех исходных то-
чек и трех результирующих точек, получающихся из исход-
ных в результате преобразования. Затем ваша система
должна автоматически генерировать коэффициенты аф-
финного преобразования, решая соответствующие линей-
ные уравнения. И, наконец, ваша система должна прово-
дить итерации IFS и графически отображать результаты,
приближаясь к фрактальному изображению-аттрактору.
В следующих разделах излагаются более подробно некото-
рые из этих шагов. В приложении говорится о том, как за-
пустить IFS-программу, использованную для подготовки
приведенных здесь примеров, а также обсуждается струк-
тура исходного кода.
2.4.1, Точки и преобразования
На Рис. 2.4.1 показан пример сетки X-Y для построения то-
чек и преобразований, которые определяют IFS. Кроме того,
на рисунке изображен эскиз листа (показанный также из
Рис. 2.3.1 (а)), помогающий позиционировать точки и преоб-
разования. Чтобы создать IFS-изображение, прежде всего
нужно найти хотя бы некоторое приблизительное самоподо-
бие в исходном изображении. В случае с изображением листа
нетрудно увидеть, что каждая из трех частей, которые со*
ставляют лист, подобна самому листу. Это значит, что есть
Аффинные преобразования используются в системе IFS, г,с
тому что их легко задать и легко вычислить их коэффициец
ты. Однако могли бы использоваться любые сжимаюц^
отображения, чтобы удовлетворять теореме коллажа и созда
вать аттракторы.
три варианта преобразований для IFS. Напомним, однако, что
теорема коллажа оговаривает, что коллаж из фрагментов
изображения должен почти покрывать исходное изображе-
ние. Эти три преобразования оставляют промежутки в по-
крытии изображения. Значит, нам придется ввести четвертое
преобразование, которое покроет черенок листа.
Щ& 2.4.1. Сетка X-Y и наложенный на нее эскиз листа с 18 отмеченными точками
и олним из четырех преобразований лля IFS листа. Это преобразова-
ние переволит точки 1, 6 и 9 в точки 3,15 и 16
Коль скоро мы решили, какими должны быть преобразова-
ния, то следующий шаг - это определение точек, задающих
эти преобразования. Обычно эти точки связывают с выде-
ляющимися особенностями основного изображения и фраг-
ментов изображения, из которых будет составлен коллаж.
Например, точки, отмеченные цифрами 1, 2 и 3 на Рис. 2.4.1,
определяют вершины трех основных частей листа, а точки
4-9 определяют соответствующие им точки в каждой части.
Точки 10-12 определяют черенок. И, наконец, программа,
которая прилагается к книге, позволит вам выбрать цвет, ас-
социированный с преобразованием.
50 Фракталы и вей влеты для сжатия изображений в действ^
Пробы и ошибки - часто являются частью процесса создан^
IFS-изображения. Нам нужно отобразить точки 1, 2, 3 в точки
1, 4, 5 для верхней части, 2, 6, 7 для левой, 3, 8, 9 для право-
и 11, 10, 12 для черенка. На Рис. 2.4.1 показан результат этих
преобразований. Их недостаточно для создания хорощег0
покрытия и, как следствие, для создания хорошего аттракто.
ра IFS-преобразования, что видно из Рис. 2.4.2.
Чтобы исправить эту ситуацию, мы используем точки 1, 6 и 9
для того, чтобы изобразить лист целиком. Теперь нам нужны
соответствующие точки для меньших частей. Это точки 13 ^
18 на Рис. 2.4.1. Заметим, что некоторые из этих точек нахо-
дятся во внутренней части листа, поэтому должно быть опре-
делено их точное расположение. Чтобы облегчить размеще-
ние точек, на Рис. 2.4.1 проведены светлые внутренние ли-
нии, которые показывают, в каких местах должны быть рас-
положены уменьшенные копии листа. Далее снова повторя-
ются пробы и ошибки определения точного размещения точек.
Изображение-аттрактор, представленный на Рис. 2.3.1 (Ь), -
это результат преобразований
{1Д9}->{1,17,18}, {1,6,9}->{2,13,14}, {1Д9}->{3,15,16},
и{1Д9}->{11,12,10}.
Рис. 2.4,2. Изображение-аттрактор IFS, построенное с помощью преобразован^
(1,2,3)^(1,4,5), П, 2,3)^(2,6,7), (1,2,3)^(3,8,9), (1,2,3)^(11,10,1$
(номера относятся к точкам на Рис. 2.4.1). В ланном случае эти прео&
разования созлают нелостаточно качественное изображение-аттрактор
листа. Сравните с Рис. 2.3.1 (Ь), который был построен с использов^'
нием преобразований (1,6,9)->(1,17,18}, {1,6,9}->{2,13,1*1'
(1,6,9)->(3,15,16), и (1,6,9)->(11,12,10)
2.4.2. Коэффициенты аффинного
преобразования
После того как мы определили точки и преобразования для
IFS, следующим шагом будет вычисление коэффициентов
аффинного преобразования (аффинных коэффициентов).
Уравнение (2.3.1) дает выражение для аффинного преобразо-
вания с коэффициентами а> Ъ> с, d, e и/. Определение дейст-
вия этого преобразования на три набора точек (xhyt) -^ (х(уу()
приводит к следующим уравнениям
х( = axi + by i + e
Уг =c*i +dyt + /
где i = 1, 2, 3. Заметим, что (2.4.1) - это, фактически, две сис-
темы из трех уравнений. Одна система уравнений определяет
неизвестные коэффициенты а, Ъ и е через 5?,, 5?2 и хг, а другая
определяет с, d, и / через ух, у2 и у3. Решение каждой из этих
систем трех уравнений сводится к обращению одной и той
же матрицы 3 х 3:
Процедура в программе, прилагаемой к книге, обращает эту
матрицу для нахождения коэффициентов аффинного преоб-
разования.
2.4.3. Построение фрактального
изображения-аттрактора с помощью IFS
Существуют два алгоритма построения фрактального изо-
бражения-аттрактора с помощью IFS. Один из них - это пря-
мое применение теоремы о сжимающих отображениях,
а другой - применение так называемой «Игры хаоса».
№1)
52 Фракталы и вей влеты для сжатия изображений в лейстц
2.4.3.1. Детерминистический алгоритм
Детерминистический алгоритм для построения изображен^
являющегося аттрактором IFS, напрямую применяет теоре^,
о сжимающих отображениях к любому начальному изобра
жению В е Н(Х). Алгоритм строит последовательность из0
бражений Д„, многократно применяя 1Р8-отображен^
(2.4.2) A„=W"n(B)
Напомним, что отображение W, применяемое к множеству j
определяется как
W(b)=wx(b)uw2(b)u...Uwn(b)
Если мы положим Л0 = В, то (2.4.2) может быть записано i
виде итерационного процесса:
По теореме о сжимающих отображениях, Ап сходится к А -
аттрактору данной IFS.
Листинг 2.4.1 показывает, как этот итерационный процесс
реализуется на языке Си в прилагаемой к книге программе
(Этот листинг содержит часть кода программы. Полное опи-
сание переменных, структур и функций вы найдете в исход-
ном коде вместе с прилагаемой к книге программой). Для
хранения двоичных изображений, получаемых в результате
ИТераЦИЙ, Введены Два Массива - old_image И new__image
Массив oid_image соответствует Ап.\ в (2.4.3), a new imacf6
соответствует Ап, Каждый из этих массивов состоит из еди-
ниц и нулей, где единица означает пиксел двоичного изобра
жения. Каждый из этих массивов размещается динамически
чтобы соответствовать размерам экрана: nrowe x ncoi*
Чтобы обрабатывать эти изображения с помощью IFS, н^1
необходимо перейти от массива изображения к плоское^1
X-Y. Эта плоскость - не что иное, как сетка X-Y, изобра
женная на Рис. 2.4.1.
На Рис. 2.4.3 показано, как работает итерационный про-
цесс. Каждый ненулевой элемент массива oid_image ото-
бражается в точку с координатами (х, у) на плоскости X-
Y. Затем над этой точкой выполняется каждое из аффин-
ных преобразований из IFS. Число функций преобразова-
ния обозначено в программе как no__of_fns. Идентифика-
тор coeff_iiBt - это список указателей, каждый из кото-
рых указывает на структуру coeff_struct, которая содер-
жит аффинные коэффициенты. Новая точка (xnew,ynew)
строится на экране дисплея с помощью функции
xy__to_window_coior. Цвет точки был выбран, когда зада-
валось преобразование. Затем точка (xnew,ynew) отобра-
жается обратно в массив с именем new_image. Для завер-
шения итерации массив new__image копируется в массив
old_jlmage, элементы массива new__image приравниваются
нулю, и начинается новая итерация. Итерации прекраща-
ются, когда пользователь вызывает процедуру
termininating_proc, КОТОрая фиксирует Щелчки МЫШИ
или нажатие клавиши
Ш.
ЛШмнг 2.4.1. Эта программа прелставляет собой пример реализаиии летерминисти-
ческого IFS алгоритма. На кажлой итераиии к массиву old_image
(который состоит из нулей и ели ни и) применяется IFS, чтобы опреле-
лить элементы массива new__image. Затем массив new_image выво-
лится на экран, используя ивет, сохраненный с IFS-преобразованием.
Аля завершения олной итераиии значения из new_image помешаются
в old__image и new_JLmage обнуляется.
iter = 0;
do {
// If clear_scr flag is Bet, clear the window between
// iterations. The structures gr_setup and gr contain
// window graphics parameters,
if (clear^Bcr)
draw__border (gr__setup, gr, CLEAR_WINDOW) ;
iter++/
for (i=l;i<=nrows;i++)
for (j=l;j<=ncols;j++)
if (old__image[i] [ j] ) (
// Map the old image array to the virtual X-Y
// plane:
// Map 1 to x min and ncols to x max:
54 Фракталы и вейвлеты для сжатия изображений в действи,
х = ((float) (3-D/ (float) (ncols-1)) *x_range +
gr__setup->x_min;
// Map nrows to yjmin and 1 to y_max:
у = ((float)(nrows - i)/
(float)(nrows-1))*y_range +
gr_se tup->y_jniin;
// Loop through all the transformations
// (no_of_fns) in the IFS:
for (k = l;k<=no_of_fns;k++) (
ifs = *(coeff_struct *) (coeff_list~>at(k)) ;
xnew = ifs.a*x + ifs.b*y + ifs.e;
ynew = ifs.c*x + ifs.d*y + ifs.f;
if (fabs(xnew) + fabs(ynew) > IFS_TOO_BIG) {
message_puts (MBJSXCLAIM,"IFSPROC",
"This system diverges I\r\n"
"Check to see that all
transformations\r\n"
"are contractions.");
goto exit_proc;
} // end if
// Map the virtual X-Y plane back to the new
// image array:
// Map x_min to 1 and xjnax to ncols:
col = ((xnew - gr_setup->x_jniin) /x^range) *
(ncols-1) + 1;
/ / Map y__min to nrows and y__max to 1:
row = nrows -((ynew - gr_setup->y_jnin)
/y_range)*(nrows-1)/
new__image[row] [col] = 1;
// Plot the X-Y point in the window in color:
xy__to__window_color (gr,xnew,ynew,
rgb_ifs_color (ifs));
} // end k
} // end if, i, j
// Move new_image to old_image, and reset new_image:
for (i=l;i<=nrows;i++)
for (j=l;j<=ncols;j++) {
old_image[i][j] = new_image[i][j];
new_image[i][j] =0;
)
} while (! terminating_jproc ()) ;
Прелставление взаимоотношений межлу массивом изображения в
программе и на виртуальной Х-У плоскости, гле лействует IFS. Массив
изображения состоит из елинии и нулей, гле елинииа означает точку
лвоичного изображения. Кажлый ненулевой элемент «старого
изображения» отображается на плоскость Х-У. IFS лействует на эту
точку, генерируя, в обшем случае, N новых точек. Эти новые точки
отображаются затем в массив «нового изображения». В завершение
кажлой итерации массив «нового изображения» переписывается в
массив «старого изображения» лля полготовки к слелуюшей итерации
На Рис. 2.4.4 показан результат применения детерминистиче-
ского алгоритма для получения изображения листа папорот-
ника, которое является аттрактором IFS, состоящей из четы-
рех аффинных преобразований. На рисунках (а) - (d) пред-
ставлено изображение Ап из уравнения (2.4.3) после 2, 3, 10
и 30 итераций соответственно. На Рис. 2.4.5 показана та же
самая IFS, использующая в качестве начального изображения
окружность. Как это и следует из теоремы о сжимающих
отображениях, изображение, являющееся аттрактором, ока-
зывается одним и тем же в обоих случаях.
mm*43-
Рис. 2.4.4.
Летерминистический алгоритм, примененный к IFS папоротника с
четырьмя аффинными преобразованиями. Начальным изображением
был прямоугольник. Эти рисунки показывают изображение Лп из ура*
нения (2.4.3) после:(а) 2 итераций, (Ь) 3 итераиий, (с) 10 итераиМ
(d) 30 итераиий
Детерминистический алгоритм полезен с точки зрения обу-
чения, так как он позволяет видеть результат IF^'
преобразований на каждом шаге итерации. Вы можете видеТЬ
теорему о сжимающих отображениях в действии и получу
представление о том, как она работает в контексте 1г
преобразований изображения. Однако с практической то^
зрения, то есть с точки зрения получения качественных из
бражений-атгракторов IFS, это не самый эффективный алг
ритм. В следующем разделе рассматривается альтернати
ный алгоритм, который работает быстрее, легче реализуй
и создает изображения высокого качества.
Та же IFS, что и на Рис. 2 А А, но используюшая в качестве начального
изображения окружность. Эти рисунки показывают Лп после:
(а) 3 итераций; (Ь) 30 итераций
2.4.3.2. Вероятностный алгоритм
В то время как детерминистический алгоритм является пря-
мым применением теоремы о сжимающих отображениях, по-
зволяющим легко наблюдать, как он действует, на практике
этот алгоритм оказывается слишком медленным и обычно не
используется для получения изображений-аттракторов IFS.
Более предпочтительным является использование вероятно-
стного алгоритма, основывающегося на «Игре хаоса» ([30],
глава 5, где описывается, как играть в «Игру хаоса»).
Вероятностный алгоритм связывает с каждым аффинным пре-
образованием w>/ в IFS вероятность р,. Эти вероятности опреде-
ляют, насколько плотно каждая часть изображения-аттрактора
покрыта точками. Зафиксируем из теоремы коллажа тот факт,
что аффинные преобразования выбираются в соответствии с
тем, насколько хорошо они покрывают нужное нам изображе-
ние уменьшенными копиями этого изображения. Таким обра-
зом, в некотором смысле, каждое аффинное преобразование
управляет частью изображения. Если мы хотим, чтобы изо-
бражение-аттрактор было покрыто сгенерированными по слу-
чайному принципу точками равномерно, то есть, если мы не
хотим, чтобы одна часть изображения была плотнее, чем дру-
гие, то вероятность, связанная с каждым преобразованием,
должна быть пропорциональна площади той части изображе-
Ш.4.5.
58 Фракталы и вейвлеты для сжатия изображений в действ.
— . . ^
ния, которой управляет это преобразование. Именно это дщ
программа, представленная в листинге 2.4.2.
Напомним, что площадь части изображения, управляем^
аффинным преобразованием, пропорциональна определи
лю матрицы преобразования. Программа, представленная
листинге 2.4.2, вычисляет определитель для каждого Ipc
преобразования. Определители суммируются, и каждое зна
чение делится на сумму, чтобы получить истинное значени
вероятности от 0 до 1 для каждого преобразования. Это так.
же гарантирует, что вероятности в сумме равны 1. Вы можете
модифицировать программу, чтобы поэкспериментировать с
неравномерными распределениями для различных частей
изображения-аттрактора.
Так как вероятности pi уже сопоставлены IFS-
преобразованиям wh i = 1,...,N, то первый шаг вероятностно-
го алгоритма - выбор случайных точек х0 = (хо,уо) 6 R2. Затем
алгоритм вычисляет jci, выбирая случайное целое число /(0)
из множества {1,...,N} с вероятностью р,(0), и применяет к %
преобразование w/(0):
Xi = Wi(0) (Хо)
Таким образом, алгоритм строит последовательность
-*0»-*1>*2> •••
где
Хп = Щ(п)(Хп-\)>П = 1,2,...
где на каждом шаге i(n) е {1,...,7V} выбирается с вероятно-
стью pi(ny Заметим, что
для некоторого начального множества А0. Какое множество
выбрано в качестве А0 - не имеет значения, так как теорема о
сжимающих отображениях гарантирует сходимость итераЦИ"
онного процесса для любого начального множества. Единст-
венное, что нам известно о множестве Ао> - это то, что еМУ
принадлежит точка jc<>. Последовательность точек хп образуй
так называемую орбиту, или траекторию динамическо
системы. Программа, реализующая вероятностный алгоритм
представленная в листинге 2.4.3, строит эту орбиту. Заметим*
что первые 10 или около того (это число произвольно) точбк
являются «скрытыми» (не строятся).
Вероятностный алгоритм создает изображения-аттракторы вы-
сокого качества намного быстрее, чем детерминистический
алгоритм. Это происходит не только благодаря тому, что этот
алгоритм выполняет на каждой итерации меньшую работу,
чем детерминистический алгоритм, но и сама выполняемая им
работа дает лучший результат. Детерминистический алгоритм
строит на каждом п-ом шаге итерации все множество Ап. Рас-
смотрим изображения на Рис. 2.4.4 (d) и 2.4.5 (Ь). Все точки
этих изображений представляют множество Азо, то есть мно-
жество, полученное после 30 итераций (с различными началь-
ными изображениями). Вероятностный же алгоритм строит на
п-ом шаге итерации только одну точку хп и поэтому может вы-
полнять буквально тысячи итераций за время, которое требу-
ется детерминистическому алгоритму на выполнение одной
итерации. Кроме того, есть и еще одно дополнительное пре-
имущество. Как показывает уравнение (2.4.4), точка хп принад-
лежит множеству Ап. Так, если, например, п = 30 ООО, то хп при-
надлежит Лзоооо. Это множество Азоооо значительно ближе к
аттрактору IFS, чем множество Лзо- В совокупности точки
..., jcn.i, jcrt,x„+iv создают изображение более близкое к истин-
ному аттрактору IFS. На Рис. 2.4.6 показан результат работы
вероятностного алгоритма с той же IFS папоротника, с помо-
щью которой были получены изображения на Рис. 2.4.4-2.4.5.
Это изображение было создано в результате около 31 ООО ите-
раций, которые заняли всего несколько секунд на персональ-
ном компьютере класса Pentium.
Щ2Л.6.
Щрротника,
щроенный
Ш&лошью
Шщятностного
Щритма в
ЩШате более
Ю?0 итераций.
Шре самая IFS
Ир использована
ЩЯостроения
Выражения на
Щ2Л4-2Л.5
60 Фракталы и вейвлеты для сжатия изображений в лейстц.
Листинг 2А.2. Образен программы вычисления вероятностей, сопоставленных //^
лля вероятностного алгоритма. Кажлая вероятность пропорииональн'
опрелелителю матрицы аффинного преобразования. Этот определ*
тель, в свою очерель, пропорционален плошали, управляемой эт^
преобразованием. Вы можете молифииировать программу, чтобы п
экспериментировать с неравномерными распрелелениями лля разли
ных частей изображения-аттрактора.
int compute__ifs_j?robabilities (object__list *coeff_list) {
int i, no__of__f ns = coeff__list->get__count () ;
float *pr = NULL,*det__a = NULL;
// allocated 1. . no__of_fns
float sum = 0.0,pr_sum = 0.0;
сое ff__s true t ifs;
if (!(det_a = allocate_f_vector (1,no__of_fns)))
return 0;
if (! (pr = allocate_f__vector (1, no_of__f ns) ) ) {
free_f_vector (det__a, 1) ;
return 0;
}
for (i=l;i<=no_of_f ns;i++) {
ifs s *(coeff_struct *)(coeff_list->at(i));
det_a [i] = fabs (ifs.a*ifs.d - ifs.b*ifs.c);
sum += det__a[i] ;
} /* i */
for (i=l;i<=no__of_fns;i++) {
pr[i] = det__a[i] / sum;
if (pr[i] < 0.01) pr[i] = 0.01;
pr__sum +- pr[i] ;
}
free__f__vector (det_a,l);
/♦adjust pr values to get true probabilities */
for (i=l;i<=no_of_£ns;i++) {
pr[i] /- pr_sum;
((coeff_struct *)(coeff_list->at(i)))->
prob = pr[i];
}
free__f_jvector (pr,l);
return 1;
}
Листинг 2 A3, Образен программы, реализующей вероятностный IFS алгоритм. Эг0
алгоритм проше реализуется и является более быстролействуюшим п
сравнению с летерминистическим алгоритмом; кроме того, он созлЯ
изображения высокого качества.
void ifs_random__image__graph (graph__setup__rec *gr_setup,
graph_window__struct *gr,object__list *coeff_list,
term^proc terminating_j?roc) {
int i,k;
int no__of__fns = coeff__list->get_count () ;
int *р = NULL,*pi « NULL; /* allocated l..no_of_fns */
coeff_struct ifs;
int int__sum = 0;
float x,y,xnew,ynew;
unsigned long iter;
if (!(p = allocate__int_yector (l,no__of_fns))) return;
if (!(pi = allocate__int_vector (l,no_of_fns)))
goto exit_proc;
if (! compute_if s__probabilities (coeff_list)) {
free__int__vector (p,l);
free__int_yector (pi,l);
return;
}
for (i=l;i<=no_of_fns;i++)
pi[i] « (int)(((coeff_struct *)(coeff_list->at(i)))->
prob*MAX_INT) ;
for (i=l;i<=no__of__fns;i++) {
p[i] = int__sum + pi[i];
int__sum += pi[i] ;
} /* i */
p[no_of_fns] = MAXJENT;
free__int__vector (pi,l);
x ш 0;
У = 0;
/* bury first 10 iterations */
for (i=l;i<=10;i++) {
k = pick__random_ribr (p,no_of__fns) ;
ifs = * (coef f_struct *)(coeff_list->at(k));
xnew = ifs.a*x + ifs.b*y + ifs.e;
ynew - ifs.c*x + ifs.d*y + ifs.f;
x = xnew;
у - ynew;
} /* i */
if (!graph^setup (gr)) /* free arrays before returning*/
goto exit_j?roc;
draw_border (gr_setup, gr, 1) ;
set_graph__max__min (gr__setup,gr) ;
iter = 0;
do {
k = pick__random_ribr (p,no_of__fns) ;
ifs = *(coeff_struet *)(coeff_list->at(k));
xnew = ifs.a*x + ifs.b*y + ifs.e;
ynew - ifs.c*x + ifs.d*y + ifs.f;
2.5. Примеры
Мы завершим эту главу несколькими примерами систем ите-
рируемых функций и соответствующих им изображений-
аттракторов. Все изображения в этом разделе были получены
с использованием вероятностного алгоритма.
2.5.1. Треугольник Серпинского
Треугольник Серпинского (называемый также наконечником
стрелы) - это один из самых ранних известных примеров
фракталов. Существует несколько способов построения тре-
угольника Серпинского, один из которых показан &
Рис. 2.5.1. Мы начинаем со сплошного треугольника, как по-
казано на рисунке слева. На первом шаге построения из его
центра удаляется перевернутый треугольник, как показано $
рисунке в центре. На втором шаге удаляются три переверну
тых треугольника из трех оставшихся треугольников. Пр0,
должая этот процесс, мы на шаге п удаляем З""1 переверну^1
треугольников из центров З""1 оставшихся треугольников. 1•
что остается (а что-то должно остаться!) - это и есть тр
угольник Серпинского.
if (fabs(xnew) + fabs(ynew) > lFS_TOOJBlG) {
message_puts (MB_EXCLAIM,"IFSPROC",
"This system diverges!\r\n"
"Check to see that all transformations\r\n"
"are contractions.");
goto exit_proc;
)
/* Plot the Х-У point in the window in color: */
xy_to_window_color (gr, xnew, ynew,
rgb_ifs^color (ifs))/
x » xnew;
у » ynew;
iter++;
graph_iter (gr_setup,gr,iter);
} while (! terminating_jproc ()) ;
exit_proc:
release_dc (gr);
free_int_vector (p,l);
return;
} /* end proc */
ю№*
Построение треугольника Серпинского: берем исхолный сплошной
треугольник (слева), улаляем перевернутый треугольник из его центра
(в центре), затем улаляем перевернутые треугольники из центров трех
оставшихся треугольников (справа), итак лалее
Треугольник Серпинского также легко построить как аттрак-
тор IFS. На Рис. 2.5.2 показано IFS-преобразование и изо-
бражение-аттрактор. IFS включает три преобразования:
{1,4,3}->{9Д0Д2}, {1,4,3}->{5,4,7}, {1,4,3 }->{6,7,3}. Не-
трудно вычислить аффинные коэффициенты для этого слу-
чая. Преобразования имеют вид:
Преобразования лля IFS треугольника Серпинского (слева) и изобра-
жение-аттрактор (справа). Три преобразования: (1,4,31->19,10,121,
{1,4,31->{5,4,71, {1,4,31->{6,7,31
Треугольник Серпинского является хорошим пример0.
иллюстрирующим две отличительные особенности фраКт'
лов: самоподобие и дробную размерность. Самопод0дй
очевидно из построения. Чтобы увидеть, почему Име *
смысл говорить о дробной размерности этих объектов, ра
смотрим следующее.
2.5.1.1. Размерность фракталов
Что мы понимаем под «размерностью»? На уровне интуицИ(.
мы знаем, что линия имеет размерность 1, сплошной квадпат
имеет размерность 2, а сплошной куб имеет размерность 3
Существует ли способ вычислить это число? Рассмотрим си*
туацию, показанную на Рис. 2.5.3. Допустим, что нам необ-
ходимо покрыть квадрат S, длина стороны которого равна 1
меньшими квадратными блоками. Чтобы покрыть исходное
изображение, потребуется один блок с длиной стороны, рав-
ной 1,2 =4 блока с длиной стороны, равной 1/2, З2 = 9 бло-
ков с длиной стороны, равной 1/3, и так далее. Пусть
Ns(l/n) - это число блоков с длиной стороны, равной ]/п, ко-
торое требуется, чтобы покрыть квадрат. Легко увидеть, что
Ns(l/n) = n2
Размерность квадрата, которая, как мы знаем, равна 2, со-
держится в показателе степени в правой части уравнения,
Мы можем выразить эту размерность следующим образом:
(2.5.1)
Рис. 2.5.3.
Аля того чтобы покрыть елиничный квалрат, требуется олин бло*
ллиной стороны, равной /, 22 - 4 блока с ллиной стороны, равной У '
и З2 - 9 блока сллиной стороны, равной 1/3
Заметим, что левая часть уравнения (2.5.1) не зависит от
п> 1, значит, и правая часть не зависит тоже. В частности,
для множества А мы можем определить его размерность dA
следующим образом:
где Л^(1/гс) число блоков с длиной стороны, равной 1/и, необ-
ходимое для того, чтобы покрыть множество А.
Мы можем применить это определение к треугольнику Сер-
пинского S. Как показывает Рис. 2.5.4, для того, чтобы по-
крыть 5, необходимо три блока с длиной стороны, равной 1/2
(без ограничения общности, можно считать, что длина сто-
роны треугольника S равна 1), и 9 = 3 блоков с длиной сто-
роны 1/4 = 1/22. В общем случае
#5(1/2*) = 3я
где Ns(l/2n) - число блоков с длиной стороны 1/2", необходи-
мое, чтобы покрыть S. Таким образом, размерность ds мно-
жества S
Таким образом, размерность 5 - не только не целое, это
трансцендентное число, приблизительно равное 1,58. Ясно,
что S - это фрактальный объект.
Аля того чтобы покрыть треугольник Серпинского S с ллиной стороны,
равной 1, требуется 3 блока с ллиной стороны, равной 1/2, и 9 = З2
блока с ллиной стороны, равной 1/4 = 1/22. Размерность S равна
1п(3)/1п(2)= 1,58...
Ж-5-*.
Жде
2.5.2. Построение IFS по реальному
изображению
Хотя фрактальный папоротник, такой как показан
Рис. 2.1.1 (а), и напоминает настоящий папоротник, он не п
хож на папоротник, встречающийся в природе. Во первых 0
имеет бесконечно много листьев, и каждый лист имеет бе
конечное количество деталей. На Рис. 2.5.5 (а) приведен
цифровая фотография реального растения (хотя и не папа
ротника) с конечным множеством листьев. Мы можем по
строить изображение-аттрактор IFS, аппроксимирующее это
изображение, но это потребует большего числа преобразова*
ний, чем построение изображения папоротника. Интересно
отметить, что существует обратное соотношение между
сложностью изображения и сложностью преобразований,
Есть ли связь между этим наблюдением и тем фактом, что
папоротник был самым первым растением в эволюции?
Чтобы получить IFS-аттрактор, представляющий растение,
изображенное на Рис. 2.5.5 (а), нам необходимо преобразова-
ние для каждого листа. Это изображение хорошо подходит для
IFS-представления, так как каждый лист похож на все расте-
ние в миниатюре. Рис. 2.5.5 (Ь) - это изображение растения,
помещенное на сетку в прилагаемой к книге программе. Рас-
тение имеет 11 листьев, и для каждого нужно одно преобразо-
вание. Каждый лист отмечается тремя точками, и всего нужно
33 точки для преобразований листьев. Кроме того, 3 преобра-
зования нужны, чтобы определить сегменты изогнутого стеб-
ля. Для этого нужны еще 7 дополнительных точек (две из них
используются дважды); и всего получается 40 точек и 14 пре-
образований. На Рис. 2.5.5 (Ь) показаны отметки точек и одно
преобразование листа (заметим, что точки 1, 2, 3 определяют
все растение целиком). На Рис. 2.5.6 показано результируюШ#
изображение-аттрактор IFS. Этот пример может рассматри*
ваться как грубая форма сжатия изображения. Однако, как у*
упоминалось в начале этой главы, хотя техника ™
преобразований может оставаться стимулом для развит^
фрактального подхода к сжатию изображений, технологий,к
торые сейчас применяются во фрактальном сжатии изобра#
ний, мало похожи на процесс, который мы рассмотрели тоЛЬ
что. В следующей главе будет рассказано о методах, боЛ
пригодных для практического применения фрактальных &
нологий сжатия изображения.
Изображение-аттрактор IFS, построенное с использованием 40 точеки
14 преобразований. Это - грубый образеи сжатия изображения,
показанного на Рис. 2.5.5 (а)
Что происхолит, если вы пропускаете преобразование? ^иС^,
(а) - (d) показывают, что произойлет, если пропустить олно из чеТЬ,К$
преобразований, используемых лля построения аттрактора^
папоротника, изображенного на Рис. 2ЛЛ (а). Кажлыи ,
прелставленных злесь рисунков был построен с использован
только трех из четырех преобразований. Сможете ли вы логалаг
какое преобразование пропущено в кажлом рисунке?
2.5.3. Другие примеры IFS
Мы завершим эту главу рассмотрением еще нескольких п
меров IFS-изображений, которые показаны на Рис. 2 5 •?
2.5.10.
Рис, 2.5.7,
«Block UAH» (сокращение UAH расшифровывается как University
of Alabama in Huntsville - Алабамский университет в Хантсвилле). Эта
(FS была построена с использованием 9 преобразований и 25 точек.
Олно из преобразований показано на Рис, 2.5.9. Можете ли вы найти
лругие?
Олно из преобразований, использованных лля построения IFS «Block
UAH», изображенного на Рис. 2.5.8. Это преобразование отображает
точки I, 2, 3 в точки 4, 1, 5. Заметим, что порялокточек влияет на
ориентацию фрагмента изображения
■№*
Рис. 2.5.10. IFS спирали. Эта IFS была построена с использованием только 9 точе*
и 2 преобразований. Можете ли вы найти их? Это лругой прищ
очень простых преобразований, лаюших сложное изображен^
аттрактор
Еальное кодирование изображений
аииях серого
Изображение, такое как фрактальный папоротник из преды-
дущей главы, может быть воспроизведено с помощью отно-
сительно простой системы итерируемых функций (IFS), так
как этот вид изображений обладает свойством глобального
самоподобия. Это значит, что целое изображение состоит из
уменьшенных копий его самого или его частей. Увеличивая
такое изображение, мы будет наблюдать одну и ту же сте-
пень детализации независимо от разрешения. Кроме того,
изображение такого типа - это двоичное изображение, то
есть каждый его пиксел может быть представлен единицей
или нулем. Реальные изображения не обладают свойством
глобального самоподобия, которое присутствует в IFS-
изображениях из предыдущей главы. Более того, реальные
изображения не являются двоичными; каждый пиксел при-
надлежит диапазону значений (в градациях серого) или век-
тору значений (в цвете). Если мы хотим представить такое
изображение как аттрактор итерационной системы, то, оче-
видно, нам нужна более общая система, чем IFS, рассмотрен-
ные в предыдущей главе. В этой главе рассматривается по-
строение и реализация таких систем, которые могут быть ис-
пользованы во фрактальном кодировании произвольных изо-
бражений в градациях серого.
Шетрическое пространство для изображений
градациях серого
Как уже упоминалось в главе 1, мы можем рассматривать
изображения в градациях серого как вещественные функции
Лх,у\ определенные на единичном квадрате I2 = I x I. То есть
/:I2-+{l,2,...,yV}cR
где N - это число градаций серого. Мы можем ввести метри-
ку di( у) на этих функциях следующим образом:
Определим пространство F вещественных функций, цщ
рируемых с квадратом на I2 с введенной метрикой. Хог
пространство F - полное, и в нем выполняется теоре^
сжимающих отображениях. °
Изображения, с которыми мы будем работать, - это ццфп
вые изображения. Цифровое изображение п х т - это матп
ца значений [Д/], /= 1, ..., nj= 1, ..., m, гдеД/ = Л*,-,)!/). Та.
ким образом, это матрица фиксированных значений функци
Д*о0, взятых в фиксированных точках (х/,уу). В этом слуца
мы будем говорить о среднеквадратической метрике (Со
кращенно rms - root mean square):
(3.1.2)
3.2. Системы итерируемых кусочно-определенных функций
Во фрактальном сжатии изображений используются IFS спе-
циального вида, а именно системы итерируемых кусочно-
определенных функций (partitioned iterated function system -
PIFS). PIFS состоит из полного метрического пространствах,
набора подобластей Д С X, i = 1, ..., п и набора сжимающих
отображений vv,: Д—> X, * = 1, ..., п (Рис. 3.2.1).
Рис. 3.2.1.
Система
итерируемых
кусочно-
опрелеленных
функций
3,2.1. Аффинные преобразования
изображений в градациях серого
Пусть vv, (*,)>) - это аффинное преобразование, переводящее
в себя единичный квадрат: I —» I , другими словами
для некоторой матрицы А, размера 2 X 2 и вектора Ь, размера
2x1. Пусть D/ с I2 - некоторая подобласть единичного квад-
рата I2 и пусть /?/ - область значений преобразования мл,
действующего на множестве Д, так что vv,(A) = /?,
(Рис. 3.2.2). Теперь мы можем определить отображение
W/: F -^ F, действующее на изображение Дх,у\ в виде
w/(/X^y) = ^/(w:1(^y))+o/
при условии, что vv, обратимо и (х,у) Е /?,-. Константа s( рас-
ширяет или сужает диапазон значений функции/, или, коль
скоро мы говорим об изображениях в градациях серого,
управляет контрастностью. Аналогично, константа о{ уве-
личивает или уменьшает значения градаций серого, или
управляет яркостью. Преобразование wt называется
пространственной составляющей преобразования wt.
йнсгвенное
эе
газование
Цтное к нему
ъазование
Преобразование вида (3.2.2) - это базовое аффинное пре-
образование изображений в градациях серого, которое мы
будем использовать во фрактальном кодировании
изображений.
Ш)
74 Фракталы и вейвлеты для сжатия изображений в дейст^
3.2.2. Сжимающие отображения изображений
в градациях серого
Когда отображение w,: F —» F является сжатием? Требует
выполнение условия
d2M).*l(s))Zsd2(f,g)
для некоторого s, О < s < 1, где d2 - это метрика, заданная вы.
ражением (3.1.1). Используя формулу замены переменной в
кратном интеграле, получим
dl (w/ (f\ w, (#)) = J|w, (/X*, у)- w/ №> эОГ <Му
= |j/r|detAjJ|/(Jrfy)-e(Jrfy]|2dwfy
<|,,|2|deM,|<*22(/,*)
где Aj - матрица преобразования wh det A, - определитель А,
и Si - коэффициент сжатия. Чтобы преобразование было сжа-
тием, достаточно выполнения условия
В частности, коэффициент сжатия st должен быть по модулю
больше единицы: |^|>1. Тогда пространственная состав-
ляющая wi будет являться сжатием с коэффициентом сжатия,
достаточно маленьким для того, чтобы выполнялось (3.2.3).
3.2.3. Теорема о сжимающих отображениях
для изображений в градациях серого
Разобьем единичный квадрат I2 на множество ранговых бло-
ков {/?/}, которые образуют покрытие I2:
Пусть w( - PIFS вида
для некоторого множества доменных областей (доменов "
domains) Д с I2 (области Д могут перекрываться и могут Н
полностью покрывать I2). На Рис. 3.2.3 показана такая кон-
фигурация.
Преобразование wi отображает ломены D, в ранговые области /?,.
Ломены могут перекрываться, а ранговые области покрывают
елиничный квалрат
Для каждого wt определим соответствующее сжатие wt на
пространстве изображений F:
выбирая Sj9 так чтобы w, было сжатием. Теперь определим W:
F —» F следующим образом
W(f)(x,y) = w,(/)Uy) для (jc,y) е Я/
В силу того, что ранговые области /?,- покрывают I2, W опре-
делено для всех (х,у) из I2 и, следовательно, W(f) является
изображением. Так как каждое отображение и>/ является сжа-
тием, то W является сжатием на F. Поэтому, согласно теоре-
ме о сжимающих отображениях, W имеет единственную не-
подвижную (fixed) точку fw G F, удовлетворяющую
W(fw) =fw
Итеративно применяя W к произвольному начальному изо-
бражению/о, мы получим неподвижную точку fw:
W""(/o)-»/w,npHn--»oo,
где W°n (/0) - это W(W(... W(f0))) (n раз). На Рис. 3.2.4 представ-
лен результат применения сжимающего отображения W к двум
различным начальным изображениям. Отображение W, ис-
Рис. 3 2.4. Теоре а сжимающих отображениях, примененная к изображениям в
ралаииях серого В э ом примере W эю сжимаюшее о ние
итеративно примененное к лвум различным изображениям. Незави-
симо от начального изображения итераиии схолятся к олному и тому
же i зображеиию, являющемуся неполвижнои ючкои
Георема о сжимающих отображениях является базовой для
всех методов фрактального кодирования Действительно: мы
имеем изображение в градациях серого f\ пытаемся найти
сжимающее отображение W, такое чтобы изображен ие/w, яв"
ляющееся неподвижной точкой отображения IV, было близко
к/ Тогда W од ржит bci информацию, необходимую для
получения/ц Если для хранения VV требуется меньше места,
чем для храпения изображения/, значит мы добились сжатия
изображения
3.2.4. Теорема коллажа для изображении
в градациях серого
Как было в случае с IFS и воичными изображениями, тео-
рема коллажа >ществует и для PIFS и изображени №'
циях серо о Пусть задано изображение в градациях серого/•
Предположим что ^ ы можем найти сжимающее отобрав'
ние W, такое что
пользованное здесь, было получено при помощи метоп^
фракт ьпого кодирования изображении, описанных ниже
ми!а<А 3. Фрактальное кодирование изображений в градациях серого 77
Тогда
1-s
где s - это коэффициент сжатия отображения W, a fw его
неподвижная точка. Это означает, что мы можем начать с
любого изображения g и итеративно применять преобразова-
ние W к изображению g, чтобы получить изображение, близ-
кое к/.
В то время как теорема о сжимающих отображениях обеспе-
чивает саму возможность фрактального кодирования, теоре-
ма коллажа дает практический способ его реализации. Вме-
сто того чтобы думать о бесконечном количестве итераций,
применяемых к данному изображению, нам нужно только
найти такое отображение W, однократное применение кото-
рого, то есть изображение W(/), будет близким к желаемому
изображению /. Заметим, что W должно быть сжатием с ко-
эффициентом сжатия s много меньшим единицы, в против-
ном случае условие, содержащееся в правой части неравен-
ства (3.2.4), теряет смысл.
Теорема коллажа подводит нас на один шаг ближе к процес-
су фрактального кодирования изобрамчений. Имея данное
изображение в градациях серого/, мы пытаемся найти сжа-
тие W, такое что W(f), то есть/iv будет близким к/. Декодиро-
вание состоит в итерировании W любого начального изобра-
жения g для получения/ц.
3.3. Фрактальное кодирование изображений
Как показано на Рис. 3.3.1, при фрактальном кодировании изо-
бражений мы пытается найти множество сжимающих преоб-
разований, которые отображают доменные блоки (которые мо-
гут перекрываться) в множество ранговых блоков, которые
покрывают изображение. Ранговые блоки могут быть одина-
кового размера, но чаще используется адаптивное разбиение с
переменным размером блоков (adaptive variable sizing). Ранго-
вые блоки, показанные на рисунке справа, являются результа-
том разбиения методом квадродерева (quadtree).
При фрактальном колировании изображении мы пытается наш
множество сжимаюши пре бразований, которые отображают (Во,
можно перекрывающиеся ломенные блоки в множеств рангов
блоков, которые покрывают и ображение
Базовый алгоритм фракгального кодирования изображении
выполняется следующим образом.
1. Разбиваем изображение / на неперекрывающиеся ранговые
блоки {/?,}. В примере, который мы здесь рассмотрим ранго-
вые блоки - это прямоугольники, но могут использ ватьсяи
другие формы, например, треугольники. Блоки R, могут быть
равными, но чаще используется адаптивное разбиени с пе-
ременным размером блоков Это дает возможность плотно
заполнять ранговыми блоками маленького размера части
изображения, содержащие мелкие детали. Один распростра-
ненный тип адаптивной схемы разбиения, о которо мы бу-
дем говорить ниже, это -метод квадродерева (quadtr e parti-
tioning), описанный у Фишера в [18]
2 Покрываем изображение последовательностью д менных
блоков, возможно перекрывающихся. Домены могут быть
разных размеров и обычно их количество исчисляется сот-
нями и тысячами В следующем разделе обсуждаются схеМь1
постро ния множества доменных блоков
3. Для каждого рангового блока находим домен и соответст-
вующее преобразование, которое наилучшим образом А
крывает ранговый блок. Обычно это аффинное преобр^3
вание вида (3.2.2). Настраиваем параметры преобразован^ ■
такие как контрастность и яркость, для наилучшег с°°
ветствия.
Если достаточно очного соответствия не получил
разбиваем рашов ie блоки на меньшие рашовые блок
пр°-
Рис. 3.3,1.
должаем этот процесс до тех пор, пока или не добьемся при-
емлемого соответствия, или размер ранговых блоков не дос-
тигнет некоторого заранее определенного предела.
На Рис. 3.3.2 представлена блок-схема процесса фракталь-
ного кодирования, реализованного в программе, прилагае-
мой к книге. Заметим, что в ней есть опция поиска паилуч
шего домена. Если выбрана эта опция, то поиск будет про
должаться, даже если соответствие между доменной и ран
говой областями окажется в пределах допустимой погреш-
ности. Если эта опция не выбрана, то поиск домена пре-
кращается, как только соответствие оказывается в пределах
допустимой погрешности. Кодирование без выбора этой
опции происходит быстрее при неболыиой потере качества
декодированного изображения.
р»с.з.
3.2,
Блок-схема показывает основные шаги фрактального колирования
изображений, реализованного в программе, прилагаемой к книге
При подгонке доменных блоков к ранговым блокам прила-
гаемая к книге программа реализует пространственную со-
ставляющую аффинных преобразований, обозначенных \t\
в (3.2.2), включакмцую операции параллельного переноса,
80
Фракталы и вейвлеты для сжатия изображений в лейг^
поворота и сжатия. Сжатие уменьшает размер доменц
блока до размеров рангового блока. Эта операция Дополця^
ся простым усреднением по строкам и столбцам. ^
Детали фрактального кодирования изображений варьируй
в различных реализациях. Некоторые схемы разбиения *
ранговые области используют, как уже упоминалось, неп *
моугольные блоки, и наиболее распространенный альтепц
тивный вариант - это треугольники. Разбиение на Tpeyr0j1
ники делает менее выраженными артефакты блочности дек
дированного изображения, которые появляются в результат
разбиения на прямоугольные ранговые блоки. Были такж
разработаны варианты неаффинных преобразований [321
Пространственная составляющая аффинных преобразований
для изображений в градациях серого, а именно мл, задавае-
мая уравнением (3.2.1), обеспечивает пространственное ежа-
тие при выполнении условия |det А,| < 1. Для получения про.
странственного сжатия мы ограничим преобразования н>
жестким параллельным переносом и одним из восьми основ-
ных поворотов и отражений, как это описано у Фишера [18].
Шаг №3 требует наибольших вычислений. Для каждого ран-
гового блока Ri алгоритм ищет домен £>,, пространственное
преобразование w;, контрастность St и яркость <9, такие, что-
бы Wi(f) было близко к изображению/в блоке /?,. То есть мы
ищем и>, такое, чтобы величина
(3.3.1.)
j\wi(f)(x>y)-f(x>yfdxdy
Ri
была небольшой. Для оцифрованных изображений интеграл
(3.3.1) заменяется суммированием по пикселам. Если после
нахождения наилучшего и>, величина (3.3.1) оказывается все
еще больше некоторой заранее определенной погрешности,
то адаптивная схема разбиения на блоки разбивает ранговые
блоки на меньшие ранговые блоки и затем поиск оптималь-
ного преобразования повторяется для этих меньших блоков-
Этот процесс продолжается до тех пор, пока величина (3.3-^
не станет меньше допустимой погрешности или пока не ДоС'
тигается заранее определенный минимальный размер ранге
вого блока.
Одна из главных проблем фрактального кодирования из°'
бражений заключается в том, что большое количество Д0'
фрактальное кодирование изображений в градациях серого
81
менных и ранговых областей замедляет процесс кодирова-
ния. Эта проблема была объектом недавних исследований,
и в следующей главе мы рассмотрим некоторые способы ее
разрешения.
«Код» закодированного фрактальными методами изображе-
ния - это список, содержащий сведения о каждом ранговом
блоке. А именно: расположение рангового блока, домен
(обычно определяемый при помощи индекса), который ото-
бражается в этот ранговый блок, и параметры, описывающие
преобразование доменного блока в ранговый. Таким обра-
зом, коэффициент сжатия зависит от количества ранговых
блоков, а также от эффективности хранения информации о
каждом ранговом блоке. Большое количество ранговых бло-
ков обеспечивает высокое качество декодированного изо-
бражения, но за счет степени сжатия.
3.3.1. Доменные блоки
Для каждого рангового блока нам нужно найти доменный
блок, который эффективно отображается в этот ранговый
блок. Для того чтобы отображение было сжимающим, домен
должен быть больше рангового блока. Хорошее сжатие зави-
сит от возможности найти хорошее соответствие между до-
менными и ранговыми блоками без необходимости дополни-
тельного разбиения ранговых блоков. Слишком дробное раз-
биение ранговых областей приводит к слишком большому их
количеству, а это ухудшает коэффициент сжатия (что факти-
чески приводит к увеличению изображения, а не к его сжа-
тию, если не быть достаточно осторожным!). В идеале нужно
иметь континуум размеров и вариантов расположения до-
менных блоков и выбирать из него подходящие для каждого
рангового блока. К сожалению, вычислительные издержки
поиска среди стольких вариантов слишком велики. Задача
определения системы доменов - это компромисс между не-
обходимостью, чтобы множество доменов было достаточно
большим для обеспечения возможности подбора наилучшего
варианта соответствия ранговому блоку и, в то же время,
достаточно маленьким, чтобы процесс поиска мог быть осу-
ществлен за приемлемое время.
Программа, прилагаемая к книге, использует систему из пя-
ти параметров для описания системы доменов. Коль скоро
определены эти пять параметров, единственный индекс од-
нозначно определяет расположение каждого доменн0
блока. Параметры хранятся как часть заголовка файла за*
дированного изображения, а индекс домена хранится вм
сте с информацией о каждом ранговом блоке в файле за*
дированного изображения. Эти пять параметров следу
щие: строка домена р, столбец домена у, уровень домена 1
горизонтальное перекрывание (horizontal overlap) Ah и &е
тикальное перекрывание (vertical overlap) Д,. Вместе вз
тые, эти параметры определяют, как много доменов ц*
имеем, как много различных размеров доменов и насколько
большое перекрывание допустимо. Параметры р и у опре.
деляют, как много доменов самого верхнего уровня нахо*
дится в одной строке и одном столбце доменных блоков
Так, например, если размер изображения 256 х 256 и оба
параметра р и у равны 8, то размер наибольшего домена ра*
вен 64 х 64 (256/8 = 64). Размер доменного блока уменыщ.
ется наполовину с каждым увеличением параметра уровня
доменов Я. Если наибольшие домены (Я = 1) имеют размер
64 х 64, то на уровне Я = 2 размер доменов равен 32 X 32.
Заметим, что количество доменов на каждом новом уровне
увеличивается в четыре раза. И, наконец, Д, и Д, управляют
степенью перекрывания блоков. Эти параметры принимают
значения от 0.0 до 1.0, где 1.0 означает отсутствие перекры-
вания, 0.5 - половинное перекрывание и 0.0 - полное пере-
крывание блоков. Чем меньше эти значения, тем больше
доменов (фактически при значении 0.0 количество доменов
должно быть бесконечно большим, но программа требует,
чтобы как минимум один пиксел оставался неперекрытым)
В таблице 3.3.1 представлено количество доменов, полу-
чающееся при различных наборах параметров домена.
Таблииа 3.3.1.
Пример значений
параметров
ломенов
и результирующее
количество
ломенов
Количество строк (р)
Количество
столбцов (у)
Уровень (А)
Горизонтальное
перекрывание (Ah)
Вертикальное
перекрывание (Av)
Обшее количество
ломенов
8
8
1
1.0
1.0
64
8
8
2
1.0
1.0
320
8
8
2
0.5
0.5
1186
8
8
3
0.5
0.5
5155
8
8
3
0.25
0.25
20,187
8
8
3
0.1
0.1
_^
125,707
^
Например, когда р = 8, у = 8 и Я = 2, то, при отсутствии пере-
крывания, имеем 64 (т.е., 8*8) доменов первого уровня разме-
ром 64 х 64, и 256 (т.е., 16*16) доменов второго уровня раз-
мером 32 х 32, а всего получаем 320 доменов.
3.3.2. Разбиение на ранговые блоки методом
квадродерева
Один из методов разбиения изображения на ранговые бло-
ки - это метод квадродерева [18]. Вначале производится
грубое разбиение, скажем разделения целого изображения
на четыре прямоугольника (Рис. 3.3.3). Для каждого ран-
гового блока алгоритм пытается найти домен и соответст-
вующее сжимающее отображение, которое наилучшим
образом покрывает ранговый блок. Для того чтобы обес-
печить сжатие, те ранговые блоки, которые оказываются
больше самого большого из доменов, разбивают на мень-
шие ранговые блоки. Контрастность и яркость вычисля-
ются методом наименьших квадратов, что обеспечивает
максимально возможное соответствие. Затем, если покры-
тие оказывается в пределах допустимой погрешности, то
считается, что этот ранговый блок покрыт, и алгоритм пе-
реходит к следующему ранговому блоку. Если отклонение
не укладывается в пределы допустимой погрешности, то
алгоритм проверяет, была ли достигнута максимальная
глубина квадродерева. Если максимальная глубина квад-
родерева не была достигнута, то алгоритм разбивает блок
на четыре меньших ранговых блока и поиск оптимальных
доменов и преобразований начинается заново для этих но-
вых ранговых блоков. Процесс завершается, когда все
ранговые блоки оказываются покрытыми - или с помо-
щью такого подбора домена и преобразования, который
обеспечивает отклонение в пределах допустимой погреш-
ности, или путем достижения максимальной глубины
квадродерева.
Разбиение метолом квалролерева начинается с грубого разбиени
(слева). Если лля какого-то рангового блока оказывается невозможные
полобрать полхоляший ломен и преобразование, то этот блок
разбивается на четыре меньших блока (в иентре). Проиесс разбиения
прололжается, пока либо не нахолится полхоляший ломен, либо не
лостигается максимальная глубина квалролерева
Заметим, что когда мы уменьшаем величину допустимой по-
грешности, это приводит к увеличению числа ранговых блоков
и увеличение глубины квадродерева также приводит к увеличе-
нию их числа. На Рис. 3.3.4 показан эффект использования
меньшей допустимой погрешности и большей глубины квадро-
дерева. В каждом случае большее количество ранговых блоков
означает худшую компрессию (а иногда и отсутствие компрес-
сии вообще), но обычно лучшее качество изображения.
Рис. 33.3.
Рис. 3.3.4. Увеличение количества уровней квалролерева и/или уменьши
величины лопустимой погрешности приволит к увеличению чИ
ранговых блоков при разбиении метолом квалролерева
3.3.2.1. Схема слежения за разбиением методом
квадродерева
Для реализации алгоритма разбиения методом квадродерева
необходим способ слежения за ранговыми блоками, которые
получаются в результате разбиения. Программа, прилагаемая
к книге, использует представленную ниже схему управления
списком, при которой каждому ранговому блоку единствен-
ным образом сопоставляется индекс в квадродереве. Рас-
смотрим ее работу на простом примере с трехуровневым
квадродеревом. Мы начнем со списка из четырех векторов,
длина каждого из которых равняется максимальной глубине
квадродерева, в данном случае, трем. Первая компонента
первого вектора полагается равной 1, вторая компонента
второго вектора — равной 2 и т.д. Таким образом, начальный
список состоит из четырех векторов:
1Д0
2,0,0
3,0,0
4,0,0
Этот список соответствует начальному разбиению, или пер-
вому уровню квадродерева, показанному на Рис. 3.3.3 слева.
Принято считать, что список из четырех исходных векторов
сопоставляется четырем ранговым блокам, расположенным
по часовой стрелке, начиная с левого верхнего. Когда алго-
ритм осуществляет деление рангового блока, входной вектор,
соответствующий этому ранговому блоку, заменяется на че-
тыре новых входных вектора. Компоненты векторов, индек-
сы которых меньше номера данного уровня квадродерева,
остаются неизменными, а компоненты, соответствующие
данному уровню, получают значения 1, ..., 4. Так, например,
список, соответствующий второму уровню разбиения, пока-
занному на Рис. 3.3.3 в центре, будет таким:
1,1,0
1,2,0
1,3,0
1,4,0
2,0,0
3,0,0
4,0,0
Рис. 3,3,5.
Разбиение
метолом квалро-
лерева (3 уровня)
и соответствую-
щий список
инлексов.
Заштрихованному
блоку соответст-
вует инлекс 3.2.4
На Рис. 3.3.5 показан полученный по такой схеме тре^
уровень разбиения и соответствующий ему список инде^с
Например, заштрихованный блок имеет индекс 3,2,4. *'
Нетрудно себе представить, как быстро увеличивается спи-
сок индексов при увеличении числа уровней квадродерева и
уменьшении допустимой погрешности.
з.з.з. Отображение доменных областей
в ранговые
Главный вычислительный шаг во фрактальном кодировании-
это сравнение доменной и ранговой области. Для каждого ран-
гового блока алгоритм сравнивает варианты преобразования
всех доменов (или хотя бы всех доменов заданного класса,
о чем пойдет речь в следующей главе) к этому ранговому бло-
ку. Это аффинные преобразования, такие как описанные в раз-
деле 3.2.1, пространственная составляющая которых жестко
ограничена параллельным переносом, сжатием и одним из
восьми вариантов ориентации. Варианты ориентации вклкЯ*
ют четыре поворота на 90° и зеркальное отражение в каЖД0и
ориентации. В статье [39] автор утверждает, что использова-
ние этих восьми ориентации необязательно и столь же хор
шие результаты могут быть получены при использованИ
большего множества доменов без применения поворотов. Пр
грамма, прилагаемая к книге, позволяет исследовать эту в0
можность, так как количество вариантов ориентации выбир
ется пользователем и принимает значения от 1 до 8, при^
единица соответствует тождественному преобразованию.
Поиск соответствия между доменными и ранговой областями
(будем называть его доменно-ранговым сопоставлением),
реализованный в прилагаемой программе, - это трехшаговый
процесс; схема его представлена на Рис. 3.3.6. Во-первых,
к выбранному домену применяется один из восьми (или
меньше) базовых поворотов/отражений. Во-вторых, вращае-
мая доменная область сжимается, чтобы соответствовать
размеру ранговой области. Заметим, что на практике ранго-
вая область должна быть меньше доменной, для того чтобы
суммарное отображение было сжимающим. И, наконец, ме-
тодом наименьших квадратов вычисляются оптимальные па-
раметры яркости и контрастности.
Сопоставление ломенного и рангового блоков. Прежле всего
осуществляется олин из восьми базовых поворотов/отражений.
Затем повернутый ломен сжимается ло размера рангового блока.
И, наконеи, метолом наименьших квалратов вычисляются параметры
контрастности и яркости, наиболее соответствующие оптимальным
значениям. Затем результат попиксельно сравнивается с ранговым
блоком, чтобы опрелелить степень соответствия
Чтобы найти оптимальную контрастность s и яркость о, нам
нужно найти значения s и о, которые бы минимизировали
выражение
Здесь {dg} и {Гц} - это соответственно значения пикселов до-
менной и ранговой области. Эти пикселы находятся в прямо-
угольных массивах с М строками и N столбцами (размер домена
уже был сжат для соответствия ранговой области в этой точке).
3.3.4. Время кодирования
Один из недостатков фрактального кодирования изображе-
ний - это большое время кодирования. Известно, что в слу-
чаях, когда число доменов превышает 100 ООО, процесс коди-
рования на рабочей станции занимает более двух дней. В
таблице 3.3.2 представлены три примера времени кодирова-
ния, которые понадобились для кодирования изображения
прилагаемой к книге программой на PC Pentium 200 МГц.
Использованное здесь изображение - это «Роза», представ-
ленная на Рис. 3.2.4. Заметим, что во втором и третьем при-
мерах количество доменов больше, что приводит к увеличе-
нию времени кодирования. Увеличение числа доменов деи"
ствительно улучшает компрессию, на что указывает меньше
количество ранговых блоков. Ошибки декодированного изо-
бражения сравнимы в этих трех случаях, они соответствуй
ожидаемым значениям, так как допустимая погрешность в
каждом случае была одной и той же.
В третьем примере опции Search for the best domain? (Иска?
наилучший домен?) дается значение «Yes» («Да»). Нало
ним, что, когда опция выключена, процесс сравнения доМ^
ных и ранговых блоков останавливается, как только соотве
ствие оказывается в пределах допустимой погрешности. ^
гда эта опция включена, как в третьем примере, с кажДь1
ранговым блоком сравниваются все домены, даже если соо
ветствие оказывается в допустимых пределах. Наилучи^
вариант соответствия между доменным и ранговым блоком
сохраняется. Неудивительно, что кодирование происходит
так долго, когда опция включена. В третьем примере кодиро-
вание занимает более чем в три раза больше времени, чем во
втором примере, в котором заданы те же установки для ко-
дирования, за исключением этой опции. Количество ранго-
вых блоков такое же, как во втором примере (916 ранговых
блоков), таким образом, в сжатии преимуществ нет. Есть не-
большое преимущество с точки зрения пиксельных ошибок в
пикселах. Фишер [18] заметил, что отключение данной оп-
ции может приводить к преимущественному выбору доме-
нов, которые стоят раньше в списке индексов доменов. Од-
нако затраты времени на кодирование при включенной опции
не выглядят обоснованными в плане улучшения сжатия.
В примерах, которые будут встречаться далее в нашей книге,
эта опция будет отключена.
В следующей главе мы рассмотрим методы, которые позво-
ляют сократить время кодирования до секунд.
Глубина квадродерева
Допустимая
погрешность
Строк в домене
Столбцов в домене
Уровень домена
Горизонтальное
перекрывание
Вертикальное
перекрывание
Число доменов
Число ориентации
Искать наилучший
домен
Конечное число
ранговых областей
Средняя ошибка
в пикселах
PSNR
Обшее время
кодирования
6
0.05
8
8
2
1.0
1.0
320
8
Да
1048
3.844%
24.1 7 Дб
15 мин.
59 сек.
6
0.05
8
8
2
0.5
0.5
1186
8
Да
916
3.839%
24.32 Дб
42 мин.
32 сек.
тттттттттттштшш
6
0.05
8
8
2
0.5
0.5
1186
8
Нет
916
2.982%
26.061 Дб
2 часа
19 мин.
31 сек.
iW3.3.2.
колирова-
РС Pentium
"ц. Метолы,
мемые в
шей главе,
Ъют значи-
улучшить
рратели.
\&ел ЗА. I
ЪЬлеляется
90 Фракталы и вейвлеты для сжатия изображений в Аейс^
3.4. Декодирование изображений
Изображение декодируется путем итеративного примемен
преобразования W к произвольному начальному изобр^/
нию g, где
W(g)(x,y) = w,{g)(x9y) для (х,у) б Rt
Если преобразования {w,} были выбраны корректно, то ит
рация W°"(g) будет близка к исходному изображению/По
некотором приемлемом значении п. Заметим, что, в соответ.
ствии с теоремой о сжимающих отображениях, итерации бу.
дут сходиться независимо от выбора начального изображе-
ния. Обычно схемы декодирования используют в качестве
начального изображения однородное серое изображение, но.
как показано на Рис. 3.4.1, другие изображения обеспечивают
столь же хороший результат.
Чтобы реализовать итерационную схему декодирования в
виде компьютерной программы, нужно определить два мас-
сива изображений, например old_image И new_image. Сжи-
мающее отображение W определяется как отдельное преоб-
разование для каждого рангового блока. Каждый ранговый
блок имеет связанные с ним преобразование и домен. Со-
держимое этого рангового блока вычисляется применением
преобразования к доменному блоку. Значения пикселов для
доменного блока получаются из массива old_image. Резуль-
тирующие значения пикселов рангового блока хранятся в
массиве new_image. Одна итерация завершается, когда обра-
ботаются все ранговые блоки. Очень важно, чтобы массивы
old_image И new__image хранились отдельно В процессе ИТе-
раций, иначе сжимающее отображение W не будет реализо-
вано корректно. Перед началом новой итерации следует за-
менить массив old_image массивом new_image. Заметим, чТ°
нет необходимости физически перемещать содержимое мяс*
сива new_image в массив old_image. Гораздо эффективнее эт
может быть выполнено при помощи простого переназначь
ния значений указателей, как это сделано в исходном код
прилагаемой к книге программы.
Рис. 3.4.1. Пример леколирования изображения, за колированного фрактальным
метолом. В качестве стартового изображения может быть взято
любое. Ошибка в этом примере после 5 итераиий составила 2.2332%
срелней ошибки по пикселам
3.4.1. Количественная оценка искажений
Важным аспектом определения эффективности схем сжатия
изображений является количественная оценка искажений.
Мы, разумеется, хотим знать, насколько сильно отличается
декодированное изображение от исходного. Но, поскольку
восприятие качества изображения субъективно, вопрос, как
измерить эту разницу, оказывается не таким простым. В про-
грамме, прилагаемой к книге, используются два простых
способа измерения: средняя пиксельная ошибка и пиковое
отношение сигнал/шум (PSNR - peak signal-to-noise ratio).
Средняя пиксельная ошибка вычисляется как
j "Rows Мс.ъ
Nr Nr] X Е|Лу-Ау|
iV Rows'v Cols l=i ._j
PSNR — это стандартная количественная оценка искажений
для сжатого изображения, и она вычисляется следующим об-
разом:
Исхолное изображение «Rose» (слева), леколированное изображен^
(справа) и погрешность изображения (в центре). Максимально
глубина квалролерева в ланном случае равнялась 6, лопусти^
погрешность - 0,05 и число ломенных областей 320. Про№с
леколировання был остановлен после четырех итераиий. Погрешнее
изображения - это, в лействительности, негативное изображ^
истинной погрешности: оно вычисляется вычитанием погрешности -
числа гралаиий серого (в ланном случае 256). Срелняя пиксель*
ошибка составляет 3,168% (PSNR 24,898 Аб)
Оценка качества декодированного изображения является
правлением активных исследований в области сжатия И
бражений. Человеческое восприятие искажения не всегДа
В этих формулах NRows и /VCois - это соответственно чиг
строк и столбцов, /V/craykvei - это максимальное количест
градаций серого (в примерах из нашей книги - 255), fn _Эт
пиксельное значение исходного изображения в z'-ой строке
7-ом столбце, а с1ц - пиксельное значение декодированного
изображения. Величина rms - это погрешность, вычисленная
по методу наименьших квадратов. Заметим, что PSNR буд^
«взрываться», если воспользоваться им для оценки алгоритма
сжатия с потерями.
Программа, прилагаемая к книге, вычисляет и отображает
погрешность изображения (error image), получаемую путем
вычитания декодированного изображения из исходного изо-
бражения, как показано на Рис. 3.4.2. Кроме того, она вычис-
ляет среднюю пиксельную ошибку и PSNR, о которых гово-
рилось выше.
Рис. 3.4.2.
ответствует абсолютной количественной оценке. Артефакты
блочности, такие как на Рис. 3.4.2 справа, достаточно хорошо
видны невооруженным глазом, и, тем не менее, они не вносят
большого вклада ни в среднюю пиксельную ошибку, ни в
PSNR. В этом случае более подходящей может быть оценка
искажения, принимающая в расчет как градиент различий,
так и абсолютные значения различий. В прикладных про-
граммах, где конечным потребителем декодированного изо-
бражения является машина, например, в военных системах
автоматического распознавания цели, при оценке качества
декодированного изображения в расчет должны приниматься
характеристики алгоритма распознавания.
3.5. Хранение закодированного изображения
Коль скоро изображение было закодировано, вы захотите со-
хранить закодированную информацию в файле. В прилагае-
мой к книге программе для этого имеются два формата. Это
текстовый формат рангового файла с расширением *.rng, в
котором находится список записей, содержащих информа-
цию о ранговых блоках, и который вы можете читать с по-
мощью текстового редактора. Этот формат дает возможность
увидеть, как было закодировано изображение. Конечно, так
как это текстовый формат ASCII, то он не очень компактен, и
фактически такой файл занимает больший объем, чем само
изображение. Кроме того, программа может создавать дво-
ичный ранговый файл с расширением \fbr, который хранит
информацию о ранговых блоках в компактном двоичном
представлении. Речь об этом формате пойдет в следующем
разделе. Следует иметь в виду, что ни один из этих форматов
не является общепринятым форматом сжатия изображения.
Стандартного формата для фрактального сжатия не сущест-
вует, хотя Iterated Systems, Inc. имеет свой собственный фор-
мат для фрактальных изображений (fif- fractal image format).
3.5.1. Формат рангового файла
Формат рангового файла *.гпд предназначен для хранения
тестового варианта закодированного изображения. Чтобы де-
кодировать изображение, нужно знать, как изображение бы-
ло разбито на ранговые блоки, а также знать домен и преоб-
разование, связанное с каждым ранговым блоком. На
Рис. 3.5.1 представлен фрагмент такого файла. Единственное
предназначение текстового варианта рангового файла в ■*.
что он позволяет увидеть результаты работы алгоритма
дирования. В его заголовке содержится информация о с-ь^
ках, столбцах, уровнях доменов и горизонтальном и веп
кальном приращениях перекрывания блоков, о чем уже гп
рилось в разделе 3.3.1. Следовательно, система доменов и
жет быть воспроизведена, так как если мы имеем однознач
определенный индекс домена, то можем определить размеп
расположение этого домена. Строки, начинающиеся с дВой
ного слэша (//) - это строки комментария, предназначенны
только для информационных целей. Эти строки содержу
информацию о том, как происходило кодирование, но не не.
сут информации, необходимой для декодирования. Напри.
мер, допустимая погрешность влияет на то, как много ранго-
вых блоков появится в результате разбиения методом квад.
родерева, но для декодера величина допустимой погрешно-
сти не имеет значения.
Декодеру не нужно знать глубину квадродерева и количество
ранговых блоков (обозначено Rects на Рис. 3.5.1), которые
являются последними элементами в заголовке. В остальной
части файла содержится список данных о ранговых блоках-
одна строка для каждого блока. В этой строке записаны ин-
дексы квадродерева (целое число от 1 до 4 для каждого
уровня), индекс домена, индекс преобразования (0 - 7), цело-
численное значение уровня яркости и вещественное значение
контрастности.
Рис. 3.5.1.
Пример
солержимого
рангового файла
3.5.2. Двоичный формат рангового файла
Настоящее представление сжатого изображения - это пред-
ставление в двоичном формате. Просматривая строку данных
в ранговом файле на Рис. 3.5.1, вы обнаружите, что более по-
ловины строки занимают индексы квадродерева. Даже не-
смотря на то, что индексы принимают значения только от 1
до 4 и, следовательно, требуют только 2 бита для их хране-
ния, в совокупности они занимают очень большой объем.
К счастью, существует схема, которая использует то, что дан-
ные имеют структуру дерева. Структура дерева требует
только один бит на каждую ветвь квадродерева и может хра-
ниться отдельно как часть информации заголовка. Для каж-
дого рангового блока остается только индекс домена, индекс
ориентации в пространстве {Максимальное число преобразо-
ваний (Max. No. of Transformations) в заголовке - это факти-
чески число ориентации в пространстве), яркость и контра-
стность. На Рис. 3.5.2 показана организация данных в двоич-
ном ранговом файле. В следующем разделе ее особенности
обсуждаются более детально.
3.5.2.1. Особенности хранения информаии^
представленной в виде квадродерева
Хотя список индексов квадродерева является общепринятым
механизмом работы с информацией о ранговых блоках в
процессе разбиения, сам список не является эффективным
способом хранения информации. Несколько простых наблю-
дений, касающихся списка индексов, представленного в виде
квадродерева, помогут в построении квадродерева:
Максимальное число ранговых блоков на n-ом уровне квад-
родерева равно 4п.
щкдвоичном
ДР файле.
Шинная в
щраниться
Щрмпактно
Щъаголовка
Фракталы и вейвлеты для сжатия изображений в действии
2. Если на каком-то уровне имеется один ненулевой индекс, То
должны присутствовать все 4 индекса (т.е. если в списке есть
111, то должны быть 112, 113 и 114).
3. «О» на некотором уровне означает, что все соответствующИе
индексы более высоких уровней - тоже нули.
Предлагается использовать двоичную структуру дерева с 4П
битами на п-ом уровне. «1» показывает, что блок разбит на
меньшие блоки. «О» показывает, что на данном уровне до.
полнительного разбиения нет (и, следовательно, нет его и на
всех более верхних уровнях). Заметим, что для того, чтобы
максимальная глубина квадродерева была равна /V, дерево
должно иметь только N-1 уровень, так как по определению
на /V-ом уровне разбиения нет. Так, например, 3-уровневое
разбиение, показанное на Рис. 3.3.5, может быть представле-
но следующим 2-уровневым двоичным деревом:
Уровень 110 10
Уровень 2 Ю00 0000 0100 0000
Таким образом, вся информация о разбиении на Рис. 3.3.5
может быть записана в 20 битах. На самом деле, эту инфор-
мацию можно записать меньшим количеством бит, если за-
метить, что второй и четвертый блоки на уровне 2 состоят из
одних нулей и фактически являются избыточными, так как
их значения определяются наличием нуля на предыдущем
уровне. Такая схема требует более сложной логики декоди-
рования. Программа, прилагаемая к книге, не исключает из-
быточные нули из хранимой информации.
Листинг 3.5.1 представляет относительно компактную про-
грамму, которая преобразует ранговый список индексов в со-
стоящий из нулей и единиц «массив уровней» квадродерева,
такой, как показан выше. Объяснять, что делает программа,
дольше, чем написать саму эту программу. Переменная
ievei_array - это массив указателей на структуру типа
tbyte_array. Каждый tbyte_array - ЭТО массив ИЗ четыре
целых чисел, каждое из которых называется bit. Число
уровней на единицу меньше глубины квадродерева. В приве-
денном выше примере - два уровня. Первому уровню сопос-
тавлен один tbyte_array, а второму - четыре. Вообще на
п-ом уровне будет 4"~1 массивов tbyte_array. Выражение
level__array[j-1][level_index].bit[bit_index]
делает доступными отдельные «биты» (bit) в массиве уров-
ней. Первый индекс (j-i, где j - это глубина квадродерева) -
это уровень. В рассмотренном выше примере два уровня, со-
ответствующие индексам 0 и 1. Второй индекс (ievei_index)
говорит о том, какой tbyte_array доступен на данном уров-
не. В рассмотренном примере на нулевом уровне
ievei_index может принимать только значение 0, тогда как
на первом уровне он принимает значения 0 и 2. Последний
индекс (t>it_index) указывает на то, какой bit доступен в
массиве tbyte_array.
'Листинг 3.5.1. Пример программы лля преобразования рангового списка инлексов в
«массив уровней» квалролерева.
typedef struct {
short index[MAX_QUADTREEJDEPTH+1];
unsigned int domain,transf;
int brightness;
float contrast;
} rangerstruct;
typedef struct {
int bit[4];
} tbyte_array;
typedef tbyte^array *pbyte__array;
pbyte_array level__array [MAX__QUADTREE_DEPTH] ;
int i, j ,no__of__levels = quadtree^depth - 1, level__index,bit_jLndex;
int power_4[MAX_QUADTREEJDEPTH] ;
power_4[0] = 1;
for (i=0;i<no__of_levels;i++) {
level__array [i] = (pbyte_array) calloc ( (size_t)
power_4[i] ,sizeof(tbyte_array));
power__4 [ i+1 ] = power_4 [ i ] *4 ;
} // end i
for (i=l;i<=range_list->get_count();i++) {
range = (rangerstruct *) (range_list->at(i) ) ;
level_index = 0;
for (j =1;j <quadtree_depth;j ++)
if (range->index[j+l] > 0) {
bit_index = range->index[j]-1;
level_array[j-1] [level__index] .
bit[bit__index} = 1;
level_index = level__index*4 + bit__index;
} // end j
} // end i
98 Фракталы и вейвлеты для сжатия изображений в лейста^
3.5.2.2. Битовая структура хранения ранговой
информации
Листинг 3.5.2 представляет битовую структуру хранения ци
формации, требуемой для каждого рангового блока. Общ/
количество битов должно быть кратно 8, так чтобы кажды
ранговый блок мог быть записан целым количеством байто»
Фрагмент программы в листинге 3.5.2 показывает, что на ка
ждый ранговый блок отводится 4 байта. Поиск оптимального
распределения битов между четырьмя величинами (индекс
домена, индекс преобразования, уровень яркости и коэффй.
циент контрастности) - это процесс проб и ошибок. Напри.
мер, распределение 8 битов под яркость и 11 битов под кон*
трастность при кодировании изображения «Lena» дает сред.
нюю пиксельную ошибку, равную 4.789%, в то время как
распределение 9 битов под яркость и 10 битов под контраст-
ность дает ошибку, равную 4.355%. Число битов, отводимых
под индекс домена, определяет максимальное число доменов.
Так, выделение 10 битов означает, что максимально возмож-
ное число доменов - 1024. Здесь речь идет не о традицион-
ных алгоритмах фрактального кодирования (некоторые про-
граммы работают с сотнями тысяч доменов). Однако это хо-
роший компромисс между скоростью и точностью. Большое
количество доменов - это главный фактор, определяющий
увеличение времени кодирования. Заметим, что, как предла-
гается в статье [39], исключение преобразований пространст-
венной ориентации освободит 3 бита, за счет которых будет
можно увеличить число доменов. Фишер [39] рекомендует
использовать в процессе кодирования дискретные (quantized)
значения яркости и контрастности вместо того, чтобы коди-
ровать, используя оптимальные значения, а уже потом произ-
водить дискретизацию.
Листинг 3.5.2. Битовая структура хранения ранговой информации
#define DOMAINJBITS 10
#define MAXJNO__OF_DOMAINS 1024 /* 2**DOMAINJBITS */
#define TRANSFJBITS 3
/* Trial and error deciding how many bits to allot *°
brightness and contrast. These choices seem OK *°
a 19-bit (total for both) budget. */
#define BRIGHTNESSJBITS 9 ,/
#define BRIGHTNESS_LEVELS 512 /* 2**BRIGHTNESSjBlTS
#define CONTRASTJBITS 10
#define CONTRAST LEVELS 1024 /* 2**CONTRAST BITS */
typedef struct {
unsigned domain: DOMAINJBITS ,
transf:TRANSFJBITS,
brightness:BRIGHTNESSJBITS,
contrast:CONTRASTJBITS;
} trange_bit_struet;
3.5.2.3. Надежность передачи закодированного
изображения
Дискретизация параметров ранговых блоков, например, возни-
кающая в результате битового распределения, о котором гово-
рилось выше, привносит небольшое количество ошибок в де-
кодированное изображение. В приложениях, которые требуют
передачи сжатых изображений по каналам связи, возникает
вопрос о надежности кодирования изображений в связи с
ошибками, появляющимися в процессе передачи. Особенно
это касается военных приложений, которые должны учитывать
возможные неблагоприятные условия передачи.
Как видно из Рис. 3.5.2, квадродерево разбиения может очень
компактно храниться как часть информации заголовка. Квад-
родерево разбиения само по себе обычно содержит достаточ-
но информации, чтобы распознать изображение. Например,
легко заметить разницу между изображениями «Lena»
и «cat», взглянув только на квадродерево разбиения.
Любое искажение данных заголовка с большой вероятностью
приведет к серьезным ошибкам в декодированном изображе-
нии. Однако размер данных заголовка невелик, поэтому эти
данные можно защитить с помощью введения в них некото-
рой избыточности. Рис. 3.5.3 показывает результат искаже-
ния индексов доменов и индексов преобразований. Горизон-
тальная ось - это процент случайно выбранных искаженных
индексов. Вертикальная ось - это результирующая ошибка в
декодированном изображении. В этом примере использовано
изображение «Lena» (256 х 256, 256 градаций серого), сжатое
с коэффициентом сжатия 1:6. Рис. 3.5.3 показывает, что ко-
дирование более чувствительно к ошибкам в индексах доме-
нов, чем в индексах преобразований. Однако увеличение
ошибки происходит по линейному закону. Для приложений,
таких как распознавание целей (в отличие от человеческого
восприятия), искажение изображения может быть не так
важно. Незначительная чувствительность к искажениям в
индексах преобразований, возможно, является дополнитель-
Рис. 3.5.3.
Сопоставление ошибок перелачи ланных с ошибкой леколирования.
Процент искажения прелставляет выраженную в процентах ошибку в
ломенных инлексах и в инлексах преобразований. График показываем
ошибку леколирования в зависимости от ошибок в ломенных
инлексах, хотя ошибка возрастает только линейно
3.6. Независимость от разрешения
Одна из уникальных особенностей фрактального сжатия изо-
бражений состоит в том, что декодирование не зависит от
разрешения. Заметим, что нигде в ранговом файле мы не
включаем информацию о размерах исходного изображения.
Дело в том, что эта информация не нужна. В процессе деко-
дирования мы можем получить изображение любого размер3
независимо от размера изображения, которое было закодир0"
вано. Это свойство позволяет чрезвычайно повысить прои3
водительность сжатия. Предположим, например, что изобр
жение в градациях серого размером 256x256x256 закоД1
ровано с помощью 4000 ранговых блоков. Если считать,
для хранения каждого рангового блока требуется 4 байта:
кодирование потребует приблизительно 16 Кбайт паМяТ^
Сравнивая с 64 Кбайт для исходного изображения, мы noW
чаем коэффициент сжатия приблизительно 1:4. Теперь пр ^
положим, что после декодирования этого изображения е
то
ным подтверждением утверждения [39] о том, что эти прео~
разования могут быть исключены из процесса кодирован^
размер стал равен 1024 х 1024. Тогда мы получаем коэффи-
циент сжатия 256:1, так как изображение в градациях серого
размером 1024х 1024x256 обычно требует 1024 Кбайт па-
мяти. Коэффициенты сжатия, приведенные в этой книге, не
используют такой механизм подсчета. Все они вычислены
относительно размера исходного изображения, использован-
ного при кодировании.
Другая особенность, способствующая декодированию изо-
бражения, закодированного фрактальным методом, состоит в
том, что это декодирование добавляет детали в изображения
большого размера. Эти детали являются искусственными в
том смысле, что их нет в исходном изображении, однако они
не противоречат контексту. На Рис. 3.6.1 показан пример
«фрактального увеличения», сопоставленный с обычным
увеличением. Детали во «фрактальном увеличении» выглядят
несколько лучше. Другой пример приведен в [18] и [4]. Од-
нако в [31J утверждается, что изображения, полученные в ре-
зультате увеличения при фрактальном декодировании, не
лучше, чем увеличенные с помощью классических интерпо-
ляторов.
Пример «фрактального увеличения» (а), сопоставленный с обычным
увеличением (Ь). На Рис. (а) прелставлен фрагмент изображения
«Rose», заколированный фрактальным метолом с исхолным размером
256 х 256 и леколированный с размером 7024 х 7024. На Рис. (Ь)
то же изображение, также заколированное с исхолным размером
256 х 256, но леколированное с размером 256 х 256, а затем
увеличенное на 400% относительно своего исхолного размера
с использованием обычного пиксельного увеличения
Р"с 3.6.1.
3.7. Операторное представление фрактального
кодирования изображений
Мы завершаем эту главу обсуждением операторного престав
ления фрактального кодирования, введенного Дэвисом
(G. Davis). Это представление пригодится нам позднее, когда
мы будем рассматривать фрактальные и вейвлет-методы, а
также смешанные методы кодирования. Операторное пред.
ставление и решение полученных операторных уравнений
обеспечивает компактное представление фрактального коди*
рования и декодирования. Мы будем использовать обозначе-
ния и терминологию, предложенные Дэвисом. Более подроб-
ное изложение вы можете найти в работах Дэвиса [13, 14, 15].
3.7.1. Операторы извлечения блока и вставки
блока «get-block» и «put-block»
Пусть 3W обозначает пространство цифровых изображений в
градациях серого размера тхт, такое что каждый элемент
Зт - это матрица тхт значений градаций серого. Мы опре-
делим оператор извлечения блока «get-block» Bnm: ZN —>3\
где k<N, как оператор, который извлекает блок размером
к х &, левый нижний угол которого имеет координаты и,т, из
исходного изображения NxN, как показано на Рис. 3.7.1.
Оператор вставки блока «put-block» (#*m) :3* —->3N вставляет
блок размером к х к в нулевое изображение размера N х М
так что его левый нижний угол имеет координаты п,т.
Рис. 3.7.2 показывает действие оператора вставки блока.
Рис. 3.7.1.
Оператор
извлечения блока
к
«get-block» Bnm
извлекает блок
изображения
размером kxk
из изображения
NxN
Изображение F может быть прелставлено в виле суммы изображений
F,....,FM
Если ранговый блок /?, - это результат фрактального кодиро-
вания изображения F, тогда для каждого рангового блока Ri
существует доменный блок Д и аффинное преобразование Th
так что
3,7.2. Операторный вид
Пусть F е 3^ - это изображение размера N х N и пусть
{/?i,...,/?м} - набор ранговых блоков, на которые разбито
изображение F (это может быть, например, результат разбие-
ния методом квадродерева). Каждый блок /?, имеет размеры
г, х г„ его левый нижний угол расположен в точке п^т{ в F.
Пусть Fj - это изображение Nx N, целиком заполненное ну-
лями, за исключением блока Ri9 так что
Л*. 3.7.3.
Это не что иное, как операторная запись того, что изображе-
но на Рис. 3.7.3.
т.1.)
щтрвтор вставки
Щха «put-block»
Н* ) вставляет
К* изображения
Щуеромкхк
Щлображение
W$(N, состоящее
ЩЪаних нулей
Заметим, что dt - это размерность домена Д, a khlt - это ко0
динаты левого нижнего угла домена D,. В уравнении (37^
Д:3 ' ->3Г' - это оператор, который сжимает (считаем
dt > г,-), преобразует (£,,/,-) —> (";,m;) и применяет коэффицИе.
сжатия st, тогда как С, - это постоянная матрица размепп
г/ х гь представляющая смещение яркости (brightness offset
Мы можем записать D, в виде
Таким образом, (3.7.1) может быть переписано в виде еле-
дующего приближения:
где G: 3 —> 3 - это оператор, а Я - известная константа в
пространстве 3N.
3-7.3. Решение операторного уравнения
Решение операторного уравнения
(3.7.3.)
при |jG|| < 1 по некоторой подходящей норме || ° ||. Здесь v
это композиция п раз примененного оператора G (напрИ^ "'
G\H) = G(G(H))).
Это решение может быть получено итерационно. Начиная с
произвольного изображения X*0* е 3N, мы вычисляем Х(я) сле-
дующим образом:
x(,)=g(x(0))+//,
х(2)=с(х(1))+я=с2(х(0))+с(я)+я
X^=G{x{n-l))+H=G'ix(0))+fjGJ{H)^{l-G)-\H)
при n—>°°, так как ||G|| < 1.
Заметим, что этот итерационный процесс является процессом
фрактального декодирования.
3.7.4. Анализ ошибок
В общем случае исходное изображение F, которое должно
быть закодировано, не является точным решением оператор-
ного уравнения (3.7.3), а удовлетворяет уравнению
F=G(F) + H + e
где 8 е 3 - некоторая погрешность изображения. Пусть F -
точное решение уравнения (3.7.3). Тогда
F-F = G(F)+ H + е -g(f)- H=g(f- f)+ e
Отсюда следует
||f-f||<||G||||f-f||+|£||,
откуда мы получаем
l|F_/r|<JNL
I i-i-m
А это и есть условие теоремы коллажа.
Фрактальное кодирование требует большого объема вычисле-
ний, так как, во-первых, для каждого рангового блока необхо-
димо вести поиск среди большого количества доменов, и, во-
вторых, в связи с теми вычислениями, которые требуются для
каждого сравнения домена с ранговым блоком. Первые реали-
зации фрактальных методов кодирования были очень медлен-
ными; вычисления обычно занимали много часов, а иногда и
дней, и это на самых мощных рабочих станциях, работающих
под UNIX. Это препятствовало использованию фрактальных
методов сжатия на практике. Попытки увеличить скорость ко-
дирования делались в двух направлениях. Первый - это клас-
сификация доменов, которая может значительно ускорить ко-
дирование за счет уменьшения количества доменов, среди ко-
торых ведется поиск. Большинство реализаций алгоритмов
фрактального сжатия сочетают несколько типов классифика-
ции доменов. Второй подход к сокращению количества вы-
числений используется при сравнении доменных и ранговых
областей. Он заключается в выделении характеристических
особенностей (характеристик). Самые быстрые методы соче-
тают обе стратегии: и получение характеристик, и классифи-
кацию доменов.
В этой главе рассматривается подход, впервые предложен-
ный в работе [45], который сочетает в себе выделение харак-
теристических особенностей с классификацией доменов и
стратегию поиска, основанную на самоорганизации нейрон-
ных сетей.
В» Выделение характеристических особенностей
Сравнение ранговых блоков с каждым доменным блоком,
проиллюстрированное на Рис. 3.3.5 в предыдущей главе,
требует значительных вычислительных ресурсов. Вычисле-
ния включают попиксельные операции вращения и сжатия,
а также вычисление методом наименьших квадратов коэф-
фициентов оптимальной контрастности и яркости. Эти опе-
рации производятся с каждым возможным доменом до тех
ивышение скорости
детального кодирования
108 Фракталы и вейвлеты для сжатия изображений в дейсгь
- - - —^
пор, пока не достигается нужное соответствие. Одиц
способов ускорить процесс фрактального кодирования ц->
бражений - это выделение небольшого числа особенности
характеризующих доменные и ранговые блоки. Тогда спа '
нение доменных и ранговых блоков проводится на ochor '
нии этих характеристик, а не по отдельным пикселам цт
сокращает объем работы. Характеристики могут быть п
лучены на основании спектрального анализа Фурье hoi
вейвлет-анализа [21], или на основании показателей оттенк
(tone) и текстуры изображения [45]. В этом разделе опред^
лены пять характеристик, которые описывают распредели
ние текстуры и контрастности изображения. Будут приве-
дены примеры, которые показывают, что выделение осо-
бенностей само по себе обеспечивает значительное ускоре-
ние процесса кодирования.
4.1.1. Определение характеристик
В качестве характеристик здесь используются пять различ-
ных мер вариаций изображения. Именно эти особенности
были выбраны в качестве характеристических показателей
вариаций изображения. Однако не было сделано ни одной
попытки оптимизировать набор этих специфических особен-
ностей или их число. Вопрос об оптимальном выборе харак-
теристик остается открытым. Здесь используются следующие
характеристические особенности:
(i) стандартное отклонение (standard deviation) о*:
*-J— ttipv-rf
\ПгПс .=1 у=1
где /и - это среднее пиксельное значение прямоугольного
сегмента изображения nr x пс, а р^ - это пиксельное значение
в / строке, j столбце;
(ii) асимметрия (skewness), которая представляет собой сумМУ
кубов разностей между пиксельными значениями и средни
значением блока, нормированных кубом сг
асимметрия > >
nrnc ,-=l Jsl a
ровышение скорости фрактального кодирования
109
(iii) межпиксельная контрастность (neighbor contrast), которая
измеряет среднюю разность между значениями соседних
пикселов;
(iv) бета (beta), которая показывает, насколько сильно отлича-
ются значения пикселов от значения в центре блока;
(v) максимальный градиент (maximum gradient), являющийся
максимумом из горизонтального градиента, который харак-
теризует изменение пиксельных значений блока по горизон-
тали, и вертикального градиента, который характеризует
изменение пиксельных значений блока в направлении сверху
вниз;
Так как мы применяем к доменным блокам восемь различ-
ных преобразований пространственной ориентации, состоя-
щие из поворотов на 90° и отражений, то нет необходимости
(да это и нежелательно) использовать характеристики, кото-
рые, по существу, являются эквивалентными в силу этих
преобразований. Например, горизонтальный градиент — это
просто вертикальный градиент, повернутый на 90°. Именно
поэтому в качестве характеристики используется не горизон-
тальный или вертикальный градиент, а максимум из них.
Исходный код программы, прилагаемой к книге, имеет
свои собственные определения для всех этих характеристик
(i) — (v). Среднее пиксельное значение не используется в ка-
честве характеристики, потому что на значение пиксела не-
посредственно влияют контрастность и яркость, а они меня-
ются в процессе сопоставления доменного и рангового бло-
ков. Например, сегмент изображения, имеющий значение
контрастности 25 для всех его пикселов, может быть точно
поставлен в соответствие другому сегменту изображения со
значением контрастности 230 только с помощью установки
коэффициента яркости, равного 205. Средние значения этих
сегментов изображения совершенно разные, но для наших
целей сопоставления рангового и доменного блоков с помо-
щью аффинных преобразований, которые позволяют уста-
навливать яркость, эти сегменты изображения лучше харак-
теризуются тем фактом, что их стандартное отклонение (как
и фактически все перечисленные выше характеристики) рав-
но нулю.
Как сравнивать значения этих характеристик для изображе-
ний различных типов? На Рис. 4.1.1 представлена подборка
тестовых изображений. В таблице 4.1.1 приведены значения
характеристик, вычисленных для образцов изображений, по-
казанных на этом рисунке. Отметим, что для первого изо*
бражения значения всех характеристик равны нулю, так как
это однородное изображение. Цвет второго изображения из-
меняется от более темного к более светлому вдоль горизон-
тальной оси, что обусловливает положительный горизон-
тальный градиент и нулевой вертикальный. Изображение 3 -.
это повернутое на 90° градусов изображение 2, поэтому для
него вертикальный градиент положителен, а горизонтальный
равен нулю. После преобразования доменов эти изображения
станут эквивалентными, и поэтому было бы желательно, что-
бы эти изображения имели равные векторы характеристик.
Именно для этого мы и используем максимальный градиент.
Если бы горизонтальный и вертикальный градиент были от-
дельными характеристиками, то расстояние в пространстве
характеристик между этими изображениями было бы значи-
тельным. Изображения 4 и 5 имеют наибольшие значения бе-
та, причем значения бета для этих изображений противопо-
ложны по знаку. Изображения 6 и 7 имеют наибольшие раз-
личия между значениями пикселов и соответственно имеют
высокие показатели межпиксельной контрастности. Изобра-
жение 7 имеет наибольшую абсолютную асимметрию, в дан-
ном случае отрицательную, что означает, что большинство
пиковых значений пикселов меньше среднего значения
(т.е. темнее).
Рис. 4.1.1. Образцы изображений лля сравнения значений характеристик
>лииа 4.1.1.
Значения характеристик лля образцов изображений
При сравнении характеристик расстояний в пространстве
вектор характеристики должен быть нормализован, иначе
наибольшее значение характеристики будет доминировать
при сравнении. В следующем разделе подробно рассказыва-
ется об этапе нормализации.
4.1.2. Алгоритм кодирования, использующий
характеристические особенности
Выделение характеристических особенностей само по себе,
без классификации доменов, может обеспечить значительное
повышение скорости процесса кодирования. Ниже перечис-
лены шаги реализации алгоритма кодирования, использую-
щего характеристические особенности:
Вычисление и хранение характеристических значений для
всех доменных блоков. Отслеживание максимального и ми-
нимального значений для каждой характеристики по всем
доменным блокам. Эти значения будут использованы для
нормирования. Нормирование значений характеристик для
всех доменов. Значение характеристики / приводится к зна-
чению п/, лежащему в промежутке от 0 до 1 по следующее
формуле:
Изображение
(Рис. 4.1.1):
«Стандартное
|ртклонение
^симметрия
Шежпиксельная
^контрастность
Шега
^Горизонтальный
ргоадиент
^Вертикальный
Бралиент
«Максимальный
гградиент
1
0.00
0.00
0.00
0.00
0.00
0.00
0.00
2
17.4629
-0.0505
0.4409
-0.0002
0.4710
0.0000
0.4710
3
1 7.4624
-0.0505
0.4409
-0.0002
0.0000
0.4710
0.4710
4
22.5348
0.5376
1.3843
0.0534
-0.0493
0.0339
-0.0493
5
17.5781
-0.4955
1.1396
-0.0413
-0.0274
-0.0500
-0.0500
6
121.0294
-0.5164
186.4964
0.0001
0.0000
0.0000
0.0000
7
50.0018
-0.6826
104.0830
-0.001 6
-0.0009
0.0114
0.0114
112
Фракталы и вейвлеты для сжатия изображений в действии
(4.1,1) «/-(A-/min)/(/max-/min)
где/min - это минимальное значение характеристики по всем
доменным блокам,/тах - максимальное значение характери-
стики по всем доменным блокам и nf- нормированное зна-
чение.
2. Реализация разбиения методом квадродерева, описанная ра-
нее. Но когда мы производим сравнение доменной и ранго-
вой области, то вычисляем вектор характеристик для ранго-
вого блока и нормируем характеристические значения в со-
ответствии с (4.1.1). Заметим, что мы можем получить нор-
мированное значение для рангового блока, выходящее за
пределы диапазона (0,1), так как максимум и минимум вы-
числялись только по доменным блокам. Однако если исполь-
зуется достаточно большой пул доменов, то это значение не
должно значительно выходить за пределы данного диапазо-
на. Далее следует вычисление расстояния между ранговым
вектором характеристик и каждым доменным вектором ха-
рактеристик по следующей формуле:
d = %\M-fM
где/г[/] - этоу-я характеристика для рангового блока, fd\j] - j~*
характеристика для доменного блока и /V/ - количество ха-
рактеристик (в данном случае Nf= 5).
3. Отслеживание наилучшего, т.е. наименьшего, значения рас-
стояния dmin> вычисленного на данный момент для данного
рангового блока. Если d меньше, чем drmn, то мы сравниваем
d, с /toi - допустимым отклонением этой характеристики (до-
пуском). Если d<f{0\, то выполняем попиксельное сравнение
доменного и рангового блока как при обычном фрактальном
кодировании (т.е. вращаем домен, сжимаем его до размеров
рангового блока, вычисляем оптимальные контрастность и
яркость). Если попиксельное сравнение дает погрешность
меньшую допустимой, то этот ранговый блок считается по-
крытым. Если нет, продолжаем проверять домены. Дальней-
шее разбиение рангового блока по мере необходимости, как
и прежде.
На Рис. 4.1.2 показана схема процесса кодирования с выде-
лением особенностей.
Ate. 4.1.2,
На схеме показаны основные шаги алгоритма колирования с вылеле-
нием особенностей, реализованного в прилагаемой к книге программе.
Закрашенными серым блоками показаны операции, связанные с выле-
лением особенностей, которые лобавляются к базовому алгоритму
фрактального колирования, прелставленному на Рис, 3.3.2
Процедуры проверки, сравнивающие разность характери-
стик с текущей минимальной разностью и сравнивающие
разность характеристик с допуском /toi, действуют как стра-
жи, пропускающие только те домены, которые проходят
оба теста. Эти тесты существенно ограничивают число до-
менных блоков, для которых выполняется занимающее
много времени попиксельное сравнение доменного блока с
ранговым блоком.
114 Фракталы и вейвлеты для сжатия изображений в действ
~ ■ --55
Значение, которое мы даем величине ftoh очень сильно вли
на время кодирования и на коэффициент сжатия. График
Рис. 4.1.3 показывает зависимость времени кодирования (* *
PC Pentium 200 МГц) и числа ранговых блоков от значен I
допуска /to|. Здесь для изображения «Rose» был применен ал
горитм со следующими параметрами: глубина квадродеРе
равна 6, допустимая погрешность изображения 0.05, числ
доменных блоков равно 1186 (горизонтальное и вертикаль
ное перекрывание положено равным 0.5) и опция Search fa
the best domain? (Искать наилучший домен?) отключена
График показывает, что минимальное время кодирования
равное 24 секундам, соответствует значению /tob приблизив
тельно равному 0.05. Стандартный алгоритм фрактального
кодирования для этого примера, не использующий выделе-
ние особенностей, занимает 2552 секунд, т.е. почти в тысячу
раз больше.
Однако несколько лучшее сжатие достигается, когда /ы
близко к 0.25, так как при этом мы получаем наименьшее ко-
личество ранговых блоков. Когда значение /toi превышает
0.05, на этапе сравнения доменного блока с ранговым прихо-
дится обрабатывать большее количество доменных блоков.
Это увеличивает время кодирования, но способствует луч-
шему сжатию, так как при этом для сравнения доступно
больше доменных блоков. Максимально возможное расстоя-
ние между нашими нормированными 5-компонентными век-
торами равно 5. Когда/toi находится в окрестности этого зна-
чения, время кодирования остается постоянным, так как/и*
больше не оказывает на него какого-либо влияния. Заметим
также, что время кодирования несколько увеличивается при
очень маленьких значениях допуска вследствие увеличения
количества ранговых блоков. Большое количество ранговых
блоков - это результат недостаточного количества доменов,
просматриваемых в процессе проверки погрешности, из-з
чего происходит плохое доменно-ранговое соответстви •
И, наконец, заметим, что максимальное время кодировани
(159 секунд) на Рис. 4.1.3 значительно меньше обычног
времени фрактального кодирования (2552 секунд), и это п
казывает, что проверка минимального расстояния также с
кращает количество доменно-ранговых сравнений.
7.3.
Время колирования (в секунлах) и количество ранговых блоков как
функция характеристики лопустимого отклонения 4,/. В этом примере
использованы 1186 ломенов, глубина квалролерева равна 6 и лопус-
тимая погрешность 0,05. Заметим, что когла значение лопуска при-
ближается к 3, время колирования выравнивается, так как это значе-
ние близко к максимальному значению расстояния характеристики (51
Кроме того, время колирования несколько увеличивается при очень
маленьких значениях лопуска вслелствие увеличения количества ран-
говых блоков. Работа станлартного алгоритма фрактального колиро-
вания, без вылеления характеристических особенностей, занимает
2552 сек. лля этого примера
4.1.3. Результаты применения алгоритма
с выделением особенностей
На Рис. 4.1.4 - 4.1.7 представлены для сравнения результаты
кодирования с выделением характеристических особенно-
стей (обозначим этот подход «FE» - feature extraction), с ба-
зовым методом сжатия «baseline» (baseline - базис) для раз-
личного числа доменов. Параметры, которые были использо-
ваны для определения количества доменов, приведены в
табл. 3.3.1. Использованное здесь изображение - изображе-
ние «Rose» 256 х 256. Максимальная глубина квадродерева
была положена равной 6, допустимая погрешность - 0.05,
и опция Search for the best domain? (Искать наилучший до-
мен?) отключена. Для кодирования с выделением особенно-
стей использовались два значения допуска/toi: 0,25 и 0,05.
116 Фракталы и вей влеты для сжатия изображений в действии
На Рис. 4.L4 сравнивается время кодирования для двух ме.
тодов (на PC Pentium 200 МГц). Разница во времени кодир0ч
вания столь велика, что пришлось использовать логарифм^
ческую шкалу, иначе время для FE-алгоритма выглядело бы
как прямая линия, сливающаяся с нижним краем графика
Как следует из результатов, показанных на Рис. 4.1.3, значе-
ние допуска/toi, равное 0.05, дает лучшее время кодирования
чем значение 0.25, правда, за счет увеличения количества
ранговых блоков (4.1.6), а, следовательно, несколько худще.
го сжатия. Заметим, что метод FE обеспечивает не только
значительно меньшее, по сравнению с базовым методом
время кодирования; но и степень увеличения количества до-
менов тоже значительно меньше. Например, для значения
допуска 0.25 время кодирования увеличивается с 57 секунд
для 320 доменов до 404 секунд для 125707 доменов, то есть
меньше, чем в 10 раз. Однако при том же количестве доменов
время кодирования для базового метода увеличивается с
959 секунд до более чем 130000 секунд (более 36 часов), то
есть в 135 раз (время кодирования базовым методом для слу-
чая 125707 доменов не проверялось напрямую, а было оцене-
но исходя из среднего времени кодирования для каждого
рангового блока).
С методом FE связан ряд дополнительных вычислений,
а именно вычисление характеристических векторов для каж-
дого домена перед самим процессом кодирования. Время ко-
дирования, представленное на Рис. 4.1.4, включает время,
необходимое для этих вычислений. На Рис. 4.1.5 показано
соотношение общего времени кодирования с временем, ко-
торое требуется на эти вычисления. Только при большом ко-
личестве доменов это время составляет значительную часть
от общего времени кодирования.
Базовый метод обычно генерирует несколько меньшее коли-
чество ранговых блоков и, следовательно, дает несколько
лучшее сжатие, чем FE-метод, что видно из Рис. 4.1.6.
Рис. 4.1.7 показывает, что разница погрешностей декодиро*
ванного изображения незначительна. Это и естественно, так
как оба метода при доменно-ранговом сравнении должны
удовлетворять одной и той же допустимой погрешности.
Разница в погрешности на Рис. 4.1.7 не является существен-
ным показателем. Важным результатом является то, что оба
метода обеспечивают погрешность декодирования, состав-
ляющую 5% от установленной.
Соотношение времени колирования (лля PC Pentium 200 МГи) лля ал-
горитма колирования FE и базового алгоритма сжатия изображений,
описанного в прелылушей главе. Злесь было использовано изображе-
ние «Rose» 256x256, максимальная глубина квалролерева равна 6,
лопустимая погрешность 0.05, и опиия Search for the best domain?
(Искать наилучший ломен?) отключена. Лля FE-колирования использо-
вались лва значения лопустимого отклонения характеристики (FT):
0,25 и 0,05. Время колирования базовым метолом при 125707 ломе-
нах было оиенено исхоля из срелнего времени колирования лля каж-
лого рангового блока и составило приблизительно 130000 секунл
4.1.5.
Проиент времени, необхолимого на вычисление характеристических
векторов лля всех ломенов («Вычисление характеристик FE») в обшем
времени колирования. Параметры колирования те же, что и на
Рис. 4.1.4. Злесь привелены значения лля случая, когла лопуск Нравен
0.05. «Время колирования FE» - это время колирования, не включаюшее
время на вычисление характеристик ломен а. Обшее время колирования,
прелставленное на Рис. 4.1.4 - это сумма того и лругого времени,
изображенная злесь высотой послелнего столбика лиаграммы
Ш4-1-4-
Рис. 4,1.6.
Сопоставление количества ранговых блоков с количеством ломенов
лля метола FE и базового метола. Параметры колирования те же что и
на Рис. 4 Л А
Рис. 4.1.7.
Срелняя пиксельная ошибка лля FF-метола и базового метола Значе-
ние лопуска f(0i равно 0.25. Остальные параметры колирования те жб
что и на Рис. 4.1.4
Как показывают Рис. 4.1.4 - 4.1.7, метод выделения особен-
ностей (FE-метод) дает значительное увеличение скорости по
сравнению с базовым алгоритмом фрактального кодирова-
ния. Правда, базовый метод обеспечивает несколько лучше6
сжатие (тс меньшее количество ранговых блоков) FE-
метод, в свою очередь, обеспечивает меньшую пиксельную
ошибку. Рис. 4 1.8 показывает, что разницы в восприятии ка-
чества декодированных изображений для этих двух методов
нет На рисунке для сравнения расположены рядом два деко-
дированных изображения «Rose», одно из которых было за-
кодировано базовым фрактальным алгоритмом (а), а другое —
FE-алгоритмом (Ь). Здесь были использованы следующие па
раметры кодирования* глубина квадродерева - 7, допустимая
погрешность 0.025, допуск^! 0.25; количество доменов 1186.
Опция Search for the best domain? (Искать наилучший домен?)
отключена в обоих случаях Базовое кодирование занимает
9632 секунд (это более двух с половиной часов) на PC Pen-
tium 200 МГц, в то время как FE-кодирование занимает толь-
ко 180 секунд, то есть соотношение времени кодирования
50:1 Базовый метод, в то же ремя дает лучшее сжатие,
а именно 5,2:1 (3154 ранговых блоков) по сравнению с 2,7:1
(5953 ранговых блоков). FE-кодирование дает несколько
лучшее качество декодированного изображения (ошибка со-
ставляет 1,72% по сравнению с 2,04% после 6 итераций), од-
нако эту разницу можно нести за счет большего количества
ранговых блоков.
hc» 4.1.8, Изображение «Rose , заколированное с помощью базового фракталь-
но! о метола (а) и FE метола (Ь). Базовый метол обеспечивает злесь
сжатие 5,2 1 с пиксельной ошибкой 2,04% (или 30,12 Лб по шкале
PSNR) после 6 итерации, а FE-метол обеспечивает сжатие 2,7:1 с пик
сельнон ошибкой 1,72% (или 31,27Лб по шкале PSNR)
120
Фракталы и вей влеты для сжатия изображений в действ^
4.2. Классификация доменов
Большое время кодирования - это результат того, что прц%
ходится производить большое количество доменно.
ранговых сопоставлений. Общее время кодирования явля.
ется произведением количества сопоставлений и времени
требуемого на выполнение каждого сопоставления. Домен*
но-рднговое сопоставление - это требующая больших вьь
числений попиксельная обработка, включающая поворот
сжатие и подгонку доменного блока к ранговому блоку.
Описанный выше алгоритм с выделением особенностей
(FE-алгоритм) сокращает время кодирования путем замены
попиксельной обработки более простым сопоставлением
характеристик. Только те домены, которые прошли через
сопоставление характеристик, задействуются в попиксель-
ном сопоставлении. Таким образом, большой объем вычис-
лений, связанных с доменно-ранговым сопоставлением, ис-
ключается за счет предварительного сопоставления харак-
теристик.
Следующий шаг, который можно использовать для умень-
шения объема вычислений, связанных с доменно-ранговыми
сопоставлениями - это классификация доменных и ранговых
областей. Тогда доменно-ранговые сопоставления выполня-
ются только для тех доменов, которые принадлежат классу
подобия данной ранговой области. По сути, метод выделения
особенностей, описанный в предыдущем разделе, является
разновидностью схемы классификации. Вычисление харак-
теристик служит для определения тех доменов, которые при-
надлежат классу подызображений, чьи вектора характери-
стик не выходят за пределы допуска для вектора характери-
стик данного рангового блока. Более сложные схемы клас-
сификации используют заранее определенное множество
классов. Алгоритм классификации связывает каждый домен
с одним из этих классов. При кодировании алгоритм связы-
вает данный ранговый блок с определенным классом, и после
этого доменно-ранговое сопоставление проводится только с
доменами, отнесенными к этому классу (и, возможно, с ДрУ~
гими подобными классами). Сбережение времени при кодИ~
ровании происходит за счет выполнения меньшего числа Д0'
менно-ранговых сопоставлений.
Повышение скорости фрактального кодирования
121
Основой описанной здесь схемы классификации является са-
моорганизующаяся нейронная сеть, которая обучается на
данных векторов характеристик, полученных для доменных
блоков некоторого стандартного изображения. Это те пять
характеристик, которые были описаны в предыдущем разде-
ле. Преимущество использования самоорганизующейся сети
в том, что нам не нужно решать, какой класс должен быть
выбран при классификации. Сеть самоорганизуется в класте-
ры, представляющие классы изображений, которые опреде-
ляются содержащимися в них данными изображения. Более
того, изображение, используемое для обучения, может не
быть (и, как правило, не является) подобным тому изображе-
нию, которое должно быть закодировано. Таким образом,
время обучения сети не входит в общее время кодирования.
При небольшом количестве доменов классификационный
подход не дает существенного выигрыша во времени по
сравнению с FE-подходом. Однако для большого количества
доменов (20000 и более) выигрыш во времени значителен,
а большое количество доменов может обеспечить высокое
качество изображения при данном коэффициенте сжатия.
Обсуждаемый здесь подход был впервые предложен в работе
[45]. В других работах [8, 20] также обсуждается использо-
вание самоорганизующихся нейронных сетей для классифи-
кации доменов.
4.2.1. Самоорганизующиеся нейронные сети
Человеческий мозг обладает удивительным свойством - его
физическая организация отражает организацию внешних
раздражителей, которые он получает. Например, существует
вполне определенное взаимоотношение между относитель-
ным физическим расположением тактильных рецепторов на
поверхности кожи и относительным расположением нейро-
нов, обрабатывающих входные сигналы от этих рецепторов.
Соседним тактильным рецепторам соответствуют соседние
нейроны. Участки кожи с высокой плотностью тактильных
рецепторов, например ладони или лицо, связаны с соответст-
венно большим количеством нейронов. Это соответствие по-
рождает так называемую соматотопическую локализацию
(somatotopic map), которая является проекцией поверхности
кожи в определенную область головного мозга, называемую
соматосенсорная зона (somatosensory cortex), соответствую-
щую тактильным ощущениям [34].
Тьюво Кохонен (Teuvo Kohonen) в начале 1980-х годов р^
работал алгоритм, имитирующий способность мозга caMcw
ганизовываться в соответствии с внешними раздражителя^
Он назвал свой алгоритм самоорганизующейся карщ,
свойств (self-organizing feature map) [24]. Алгоритм Кохонен
представляет собой разновидность нейронной сети, способ
ной самостоятельно обучаться. Нейронные сети такого вид
называются самоорганизующимися нейронными сетями.
Самоорганизующиеся нейронные сети характеризуются мно*
гомерным массивом, или решеткой (lattice) узлов, ц.
Рис. 4.2.1. показан пример такой сети с двумерной решеткой
С каждым узлом решетки связан весовой вектор. Весовой
вектор имеет ту же размерность, что и входные векторы, ко*
торые будут использованы для обучения. Размерность ре.
шетки не обязательно должна быть такой же, как размер.
ность весового вектора. Сложные взаимосвязи в задачах тре-
буют, чтобы размерность весовых векторов была высокой.
Поэтому для того, чтобы они могли сами отсортировываться,
нужна решетка с высокой размерностью. Однако биологиче-
ские аналоги и практические соображения реализации обыч-
но ограничивают размерность решетки числом 2 или 3.
Самоорганизующаяся нейронная сеть. Весовые векторы закреплен
за узлами решетки так, как на показанной злесь лвумерной решетке
Когла в сеть поступает вхолной вектор, то наиболее полхоляШ^
ему весовой вектор алаптируется, чтобы стать еше более похожим н
вхоляший вектор. Соселние весовые векторы в решетке в связи с и
близостью к этому узлу тоже алаптируются, хотя и не так сильн0'
как ланный вектор
Рис. 4.2.1.
Процесс обучения сети происходит абсолютно независимо,
без какого-либо контроля со стороны человека. Сначала сеть
весовых векторов инициализируется случайными значения-
ми. Затем в сеть поступает входной вектор характеристик,
и мы отыскиваем весовой вектор, самый близкий к входному
вектору. Затем мы находим Vj\ такие что
||v - wlV|| < ||v - wu|| для всех ij
где v - это входной вектор характеристик, aw- весовой век-
тор в узле ij. Веса, соседние по решетке с выбранным весом
w,y, адаптируются, чтобы больше походить на входной век-
тор. Эта адаптация выражается формулой
где ij - это индексы узлов, смежных с узлом i'j\ Размер ок-
рестности, в которой находятся эти смежные узлы, сокраща-
ется с каждой новой итерацией процесса обучения. Параметр
е - это шаг итерации, и а обратно пропорциональна размеру
окрестности, в которой находятся смежные узлы. Подробное
описание алгоритма содержится в нижеследующей таблице
«Алгоритм обучения для самоорганизующихся нейронных
сетей».
Алгоритм обучения для самоорганизующихся
нейронных сетей
1. Инициализация весовых векторов,
2. Передача входного вектора в сеть.
3. Для каждого входного вектора v определение весового
вектора, наиболее похожего на входной вектор:
находим Vj'такие, что
||v - wlV|| < || v - w,v|| для всех ij
где v - это входной вектор, a i и j пробегают все узлы
решетки.
Алгоритм обучения для самоорганизующихся
нейронных сетей (продолжение)
4. Адаптация найденного весового вектора и смежных с
ним векторов в решетке. Начальный размер окрестности
смежных векторов - это параметр, задаваемый пользо-
вателем, затем в процессе итераций размер этой окрест-
ности постепенно сокращается. Адаптивная величина
шага итерации также уменьшается в процессе итераций.
Веса узлов из окрестности, расположенных дальше от
выбранного узла, меняются не так значительно, как веса
узлов, расположенных рядом с ним. Этот механизм осу-
ществляется путем использования функции Гаусса, при-
меняемой к расстоянию от выбранного весового вектора
до текущего весового вектора. Адаптация может быть
выражена формулой:
w
новый х^старыи
+ е
.(v-w^).expfa|v-wJ7
где v - это входной вектор, i и j пробегают окрестность,
в которой лежат смежные узлы с узлом V, ]', выбранном
на шаге 3. Параметр £ - это шаг итерации и а- фикси-
рованный коэффициент, равный величине, обратной
размеру окрестности.
Решетка помогает определить топологию окрестности для
весовых векторов. Весовые векторы, относящиеся к узлам
решетки, близко расположенным друг к другу, будут иметь
свойства, которые являются подобными относительно рас-
пределения характеристик в исходных данных. Топология
окрестности используется в процессе поиска домена, описы-
ваемом далее.
Д^ 4. Повышение скорости фрактального кодирования
125
4.2.2. Фрактальное кодирование изображений
с помошью самоорганизующейся
классификации ломенов
Мы используем для классификации доменов классификаци-
онную схему, базирующуюся на самоорганизующихся ней-
ронных сетях Кохонена. Размерность векторов характери-
стик, используемых здесь, равна 5. В программе, прилагае-
мой к книге, которая использовалась для создания приводи-
мых в книге примеров, размерность решетки равна 2, а ее
размер (т. е. количество строк и столбцов) выбирается поль-
зователем. Примеры, рассматриваемые ниже, используют
решетку 8x8. Каждый узел решетки представляет класс до-
менных блоков, поэтому желательно, чтобы общее количест-
во узлов оставалось достаточно небольшим. В таблице 4.2.1
приведены значения по умолчанию для самоорганизующейся
нейронной сети в прилагаемой программе. Начальный размер
окрестности смежных узлов должен быть приблизительно
равен половине размера строк и столбцов. Если размер окре-
стности будет слишком мал, то это может привести к плохой
топологии окрестности (т.е. несхожие весовые векторы могут
оказаться в решетке близко друг к другу).
Щиа 4.2.1.
Шния
Шшетров
умолчанию
}камооргани-
щейся
кронной сети
Строк решетки:
Столбцов решетки:
Начальный шаг (в):
Начальная окрестность:
Размер блока итерации:
Блоков итерации:
Максимальный радиус поиска:
8
8
0.25
4
100
10
1
Коль скоро сеть была обучена, доменные блоки для данного
изображения классифицируются путем сопоставления каж-
дому из них весового вектора, самого близкого к нему в про-
странстве характеристик. Таким образом, каждый узел ре-
шетки теперь имеет весовой вектор и связанный с ним спи-
сок доменных блоков. Этот список доменных блоков при-
надлежит «классу», сопоставленному этому весовому векто-
ру. Класс - это, по определению, множество всех изображе-
ний, более близких в пространстве характеристик к данному
126
Фракталы и вейвлеты для сжатия изображений в действии
весовому вектору, чем к какому-либо другому вектору в ре-
шетке.
Когда вектор характеристик рангового блока поступает в
сеть, ему точно так же сопоставляется весовой вектор сети.
Затем ранговый блок сравнивается с доменами, которые со-
поставлены данному весовому вектору, а также с доменами,
сопоставленными весовым векторам из окрестности данного
весового вектора в сети, как показано на Рис. 4.2.2. Пара-
метр, определяющий максимальный радиус поиска, приве-
денный в табл. 4.2.1, задает размер окрестности. Как и рань-
ше, мы отслеживаем наилучшую (минимальную) на данный
момент разность между характеристиками. Если новый до-
мен в списке обеспечивает меньшую разность, мы сравнива-
ем эту разность с допуском ft0\. Если данная разность прохо-
дит эту проверку, то выполняется полное попиксельное до-
менно-ранговое сопоставление. Единственная разница между
данным алгоритмом и FE-алгоритмом, описанным в преды-
дущем разделе, в том, что количество доменов, для которых
выполняется вычисление характеристического расстояния, в
данном алгоритме меньше. Данный алгоритм имеет некото-
рые вычислительные издержки, связанные с поиском весово-
го вектора, ближайшего к характеристическому вектору ран-
гового блока (это серия вычислений характеристического
расстояния). Значение этих издержек уменьшается с увели-
чением общего количества доменов. На Рис. 4.2.3 приведена
схема работы алгоритма, дополненная самоорганизующейся
классификацией доменов.
Рис. 4.2,2.
Окрестности
поиска вокруг
выбранного
узла решетки
о,'Ъ,''о <о\о
Окрестность поиска радиуса 1
о\о\о ,'о,'Ъ
Выбранный узел
N N^' ,' ^ -Окрестность поиска радиуса 2
о о\о/о о
с. 4.2.3.
Схема работы алгоритма фрактального колирования изображения с
самоорганизующейся классификацией ломенов. Заштрихованные по
лиагонали блоки обозначают лополнительные шаги, требуюшиеся лля
использования механизма самоорганизующейся классификации ран-
говых и ломенных блоков
4.2.3. Примеры результатов использования
самоорганизующейся доменной
классификации
На Рис. 4.2.4 сравнивается время кодирования для метода самоор-
ганизующейся классификации доменов (обозначенный для удоб-
ства «SO-метод») и для FE-метода из предыдущей главы). Здесь
использованы изображение и параметры кодирования те же, что и
на Рис. 4.1.4. Самоорганизующаяся сеть, использованная здесь, -
это сеть 8x8, обученная на 1186 доменах, выделенных из изо-
бражения «Cat», Это изображение было выбрано для обучения за-
тем, чтобы показать, что обучающее изображение не обязательно
должно быть похожим на изображение, которое мы будем коди-
ровать. Время, затрачиваемое на обучение сети, не включается во
время кодирования, показанное ниже, так как обучение проводу
ся однократно и его не нужно повторять доя различных изобра.
жений. Радиус окрестности поиска положен равным 1.
На Рис. 4.2.4 показывается, что преимущество, которое дает S(X
метод по сравнению с FE-методом, увеличивается с увеличением
числа доменов. Это происходит несмотря на тот факт, что SO-
метод имеет дополнительные вычислительные издержки. SCK
метод должен не только вычислять характеристические векторы
для доменов, как это делает FE-метод, но и сопоставлять каждый
домен одному из самоорганизующихся классов сети. Для данного
примера таких классов 64 (8 х 8). Из Рис. 4.2.5 видно, что для
большого числа доменов это время классификации становится
значительным. Однако сравнение с Рис. 4,1.5 показывает, что
фактическое время кодирования для SO-метода гораздо меньше,
чем время кодирования для FE-метода, что приводит к уменьше-
нию времени кодирования в целом, как показано на Рис. 4.2.4.
Следует заметить, что SO-метод создает несколько большее
количество ранговых блоков, что приводит к несколько худ-
шему сжатию по сравнению с FE-методом или базовым ме-
тодом при одной и той же допустимой погрешности, что от-
ражено на Рис. 4.2.6. Это компенсируется лучшими в целом
результатами по ошибкам, как показано на Рис. 4.2.7.
Рис. 4.2.4.
Сравнение времени колирования лля алгоритма, используюшего са-
моорганизующуюся классификацию ломенов и алгоритма из прелы-
лушего разлела, используюшего только вылеление характеристических
особенностей. Параметры колирования те же, что и на Рис, 4.1.4-
Прелставлены результаты лля значения лопуска отклонения характе-
ристики FT (FT -feature tolerance), равного 0.05 и 0.25
КО 4.2.5.
Обшее время колирования лля метола самоорганизующейся класси-
фикаиии ломенов включает вычислительные излержки по вычислению
характеристических векторов лля ломенов («Вычисление характери-
стик SO»), а также классификацию ломенов («Классификаиия ломенов
SO»), Параметры колирования те же, что и на Рис. 4.2.4. Злесь приве-
лены значения лля случая, когла лопуск отклонения характеристики
равен 0.05
^Рис. 4.2.6.
Сравнение количества ранговых блоков с количеством ломенов лля
SO-, FE- и базового метола. Параметры колирования те же, что и на
Рис. 4.2.4
Рис. 4.2.7.
Срелняя пиксельная ошибка лля SO-, FE- и базового метола. Аопуск
отклонения характеристики равен 0.25, Лругие параметры колирова-
ния - те же, что и на Рис. 4.2.4
На Рис. 4.2.8. показан пример кодирования изображения
«Leaves» (Leaves - Листья) с использованием SO-метода. Са-
моорганизующаяся сеть, используемая здесь - та же сеть
8x8, что и в предыдущем примере. Параметры кодирования
здесь следующие: глубина квадродерева равна 7; допустимая
погрешность 0.05; допуск отклонения характеристики 0.25;
количество доменов: 5155 (3 уровня, перекрывание 0.5). Об-
щее время кодирования составило 118 сек. на PC Pentium
200 МГц, т.е. около половины от 235 сек., требуемых для FE-
кодирования с теми же параметрами. Ошибка декодирования
для этого изображения составила 3,45% на пиксел (25,61 Дб
по шкале PSNR) для FE и 3,19% на пиксел (26,23 Дб по шка-
ле PSNR) для SO (в каждом случае для декодирования было
проведено 6 итераций). SO-алгоритм построил 6592 ранго-
вых блока, которые дали несколько худшее сжатие, чем
6241 ранговых блока, построенных FE-алгоритмом.
Рис. 4.2.8. (а) Исхолное изображение «Leaves», (b) Изображение «Leaves» зако-
лировано с помошью самоорганизующейся классификации ломенов.
Параметры колирования: глубина квалролерева 7; лопустимая по-
грешность 0.05; лопуск отклонения характеристики 0.25; количество
ломенов 5155 (3 уровня, перекрывание 0.5). Общее время колирова-
ния составило 118 сек. на PC Pentium 200 МГц по сравнению
с 235 сек., требуемым лля FE-метола без классификации ломенов.
Ошибка леколирования составляет 3,18% на пиксел (26,23 Лб по
шкале PSNR)
Выигрыш во времени метода кодирования с классификаци-
ей доменов увеличивается с увеличением количества доме-
нов. Количество вычислений характеристических расстоя-
ний для SO-метода обычно в 10 раз меньше, чем для FE-
метода. Именно за счет этого достигается основной выиг-
рыш во времени. Количество доменно-ранговых подгонок с
применением попиксельных операций приблизительно оди-
наково для каждого метода и фактически, остается почти
постоянным для большого диапазона доменных блоков,
медленно увеличиваясь с увеличением количества доменов.
По сравнению с базовым методом, преимущество использо-
вания SO- и FE-методов в том, что они позволяют увеличи-
вать количество доменов, избегая при этом резкого увели-
чения времени кодирования. В результате мы добиваемся
большей эффективности сжатия и лучшего качества деко-
дированного изображения.
4.3. Другие пути ускорения фрактального кодирования
Методы ускорения фрактального кодирования были предЛо
жены и рядом других авторов. Все эти подходы относятся
одному или обоими факторами, влияющими на увеличение
времени кодирования, а именно к сложности доменно,
рангового сопоставления и к количеству доменно-ранговых
сопоставлений. В работе [8] авторы применили самооргани.
зующуюся сеть Кохонена к задаче фрактального кодирова-
ния. Их подход отличается от описанного здесь тем, что они
не использовали выделение особенностей, а применяли сеть
напрямую к пикселам доменных блоков. Таким образом
сложность доменно-рангового сопоставления не уменьша-
лась. Кроме того, их подход требует, чтобы сеть обучалась на
том изображении, которое должно быть закодировано. Мак-
Грегор (см. [29]) обращается к обоим аспектам проблемы ко-
дирования, используя квадродерево поиска по доменам в со-
четании с выделением небольшого количества «характери-
стик» изображения (то, что мы здесь называли особенностя-
ми), полученных из коэффициентов Фурье. В работе [38] ав-
тор использовал поиск ближайшего соседнего домена, осно-
ванный на многоразмерных ключах (multi-dimensional keys),
который является версией метода отфильтровывания домен-
ных и ранговых блоков небольших размеров (а именно 8x8)
для сравнения. Бани-Экбал (см. [2]) предложил дерево поис-
ка доменов. В работе [20] модифицирован подход Богдана и
Мидоуза (Bogdan и Meadows) с самоорганизующейся сетью с
помощью отфильтрованных доменных и ранговых блоков
как характеристических векторов. Однако этот подход тоже
требует обучения сети на изображении, которое должно быть
закодировано.
И, наконец, в работе [35] авторы показали, что в контексте
вычислительной сложности фрактальное кодирование имеет
NP-сложность. Они показали, что даже при конечном числе
допустимых значений контрастности и яркости (s и о) коли-
чество возможных кодов возрастает экспоненциально отно-
сительно количества ранговых блоков или размера изобра"
жения. Более того, они показали, что любой код, создавае-
мый стандартными методами фрактального кодирования
(например, доменно-ранговое сопоставление), является пр6'
доптимальным (suboptimal) решением.
Часть II
ВЕЙВЛЕТ-СЖАТИЕ ИЗОБРАЖЕНИЙ
ЦВА 5'
Ьостые вейвлеты
А теперь мы перейдем к рассмотрению альтернативного
подхода к кодированию изображений, а именно к исполь-
зованию вейвлетов. Вейвлет-сжатие изображений принад-
лежит к классу методов преобразования и несколько отли-
чается от фрактальных методов. Однако между этими
двумя подходами существует фундаментальная связь.
Фрактальные методы используют для сокращения объема
хранимой информации самоподобие при любом масштабе.
Вейвлет-методы для сокращения объема хранимой ин-
формации о вейвлетно преобразованной области исполь-
зуют избыточность масштаба. Смешанные фрактально-
вейвлетные методы для обеспечения большей эффектив-
ности сжатия применяют фрактальные технологии к ин-
формации о вейвлетно преобразованной области. Данная
глава вводит в вейвлет-анализ через рассмотрение про-
стых вейвлетов Хаара. В следующих главах рассматрива-
ется вейвлет-сжатие изображений и более глубокие аспек-
ты вейвлет-анализа.
К Введение
Идея вейвлет-сжатия изображений, как и других методов с
преобразованием, довольно проста. Сначала к изображению
применяется вейвлет-преобразование, а затем из данных пре-
образованного изображения удаляются некоторые коэффи-
циенты. К оставшимся коэффициентам может быть примене-
но кодирование. Сжатое изображение восстанавливается пу-
тем декодирования коэффициентов, если это необходимо,
и применением обратного преобразования к результату.
Предполагается, что в процессе удаления части коэффициен-
тов преобразования теряется не слишком много информации.
Рис. 5.1.1 иллюстрирует этот процесс.
Исходное Вейвлет- Децимация/квантование Обратное Декодированное
изображение преобразование преобразованных преобразо- изображение
компонентов вание
Рис. 5.1.1. Вейвлет-сжатие изображения. Процесс сжатия включает в себя
применение к изображению вейвлет-преобразования, за которые
слелует опрелеленный вил леиимаиии и/или квантования, а затем, прц
необхолимости, колирование полученных вейвлет-коэффиииентов
Восстанавливается изображение путем леколирования коэффициен-
тов, если оно необхолимо, и применением обратного вейвлет-
преобразования
Процесс сжатия изображения путем преобразования, а затем
удаления части информации - это основа для понимания
вейвлет-анализа. В литературе содержится ряд других подхо-
дов к изучению вейвлетов, некоторые из которых способны
отпугнуть начинающего изучение вейвлет-анализа. Матема-
тические источники развивают кратномасштабный анализ
(multiresolution analysis) через определение непрерывного
масштабирования и вейвлет-функций. Публикации инженер-
ной направленности подходят к этому вопросу через исполь-
зование высокочастотных и низкочастотных фильтров,
а также квадратурно-зеркальных пар фильтров. На Рис. 5.1.2
показано, что эти несочетаемые, на первый взгляд, подходы
можно соотнести и увидеть, что все они приводят к идее
вейвлет-преобразования и его обращения. Эту главу мы нач-
нем с изложения простых идей усреднения и детализации и
покажем, какое это может иметь отношение к сжатию изо-
бражений. Эти простые идеи приводят к масштабированию и
вейвлет-функциям, кратномасштабному анализу и вейвлет-
преобразованиям. В следующей главе будут получены более
сложные вейвлеты путем обобщения идей усреднения и де*
тализации для введения низкочастотных и высокочастотных
фильтров.
КГ5Л.2. В вей влет-анализе существует несколько различных вхолных точек,
и все они связаны лруг с лругом, и все приволят к вейвлет-
преобразованию
Щ. Усреднение и детализация
Проще всего сжать изображение, если заменить это изобра-
жение средним значением его пикселов. Этот подход дает
очень большую степень сжатия (одно число представляет все
изображение!), но немного дает в плане качества изображе-
ния. Чтобы восстановить исходное изображение из этого
среднего значения, нам нужно знать, какие детали были уда-
лены для получения этого значения. Рассмотрим изображе-
ние, состоящее из двух точек {xu xi}- Эти значения могут
быть заменены средним значением а и полуразностью d:
a = (x\ + х2)/2
d = (х\ - х2)/2
(коэффициент Уг вводится в определение d для удобства обо-
значений). Заметим, что мы можем выразить {х\, х2} через
{a,d}:
jd = a + d
x2 = a - d
138
Фракталы и вей влеты для сжатия изображений в действий
«Вейвлет-преобразование» исходной последовательности
{х\,х2} - это {a9d}. В этом представлении информация не
добавляется и не теряется. Тогда возникает вопрос, какая
польза от замены {хи х2) на {я, d). Особенной пользы нет
если только два значения хх и х2 не оказываются близкими
друг к другу. В этом случае разность d мала, и изображение
{хих2} можно заменить его приближением {я}. Заметим, что
это новое «изображение» имеет меньше пикселов, чем ис-
ходное. Мы получили сжатие изображения! Восстановлен-
ным изображением будет изображение {я, а) с ошибкой изо-
бражения (error image) {|*i - а\,\х2 - а\) = {|d|, |J|}. Так как
d мало, ошибка будет мала.
Основополагающей в вейвлет-анализе является идея о выде-
лении информации при различных уровнях детализации. Де-
тали, в свою очередь, могут рассматриваться как информация
о масштабе или о разрешении. Простой пример, рассмотрен-
ный выше, имеет ограниченную применимость к реальным
изображениям, но он иллюстрирует идею, на которой осно-
вывается применение вейвлет-анализа к сжатию изображе-
ний: выделение информации, которую несут детали, и удале-
ние тех информационных деталей, которые малы и незначи-
тельно влияют на изображение в целом.
Рассмотрим несколько большее изображение {хи х2у дгз, Xi}.
Вычислим средние значения
(5.2.1) ах# = (хх+х2)12
flu =(*з +*4)/2
и разности
(5.2.2) dx,0 = (xx-x2)/2
d\,\ = 0*з -Хй)12
(Двойные нижние индексы здесь показывают, что мы начи-
наем многошаговый процесс, и это его первый шаг). Как и
раньше, мы получили новое представление {ах$, #u» d\#, dx>\)
исходного изображения, которое содержит ровно столько же
пикселов, сколько и исходное. Если мы захотим сжать это
изображение, мы обратим внимание на величину значений
dXi0 и dXiX и решим, могут ли они без ущерба быть удалены.
При этом мы получим сжатое изображение {aXr0,aXtX}. Пред-
положим, однако, что нас не удовлетворяет такая степень
\A 5. Простые вей влеты
139
сжатия и мы хотим сжать изображение сильнее. Тогда мы
можем применить ту же процедуру к оставшемуся изображе-
нию {«i,o, «и) и снова вычислить среднее значение и раз-
ность:
«о,о = («1,о + «мУ2
я?о,о = («1,о - «мУ2
Если разность d0j0 достаточно мала, мы можем заменить все
исходное изображение {хь^^з.^} изображением, состоя-
щим из одного единственного пиксела {«о,о}- Посмотрим, чем
же является это д0,о-
«0,0 = («1,0 + «lfl)/2
= ((*i + х2)/2 + (*3 + хА)12)12
= (*i + хг + *з + хА)/4.
Величина я0,0 - это всего лишь среднее значение всех пиксе-
лов исходного изображения. Если исходное изображение од-
нородно серое (т.е. все jc,- равны одному и тому же значению),
то мы можем сжать его, заменив единственным значением,
равным этой величине градации серого. Значение а0,о пред-
ставляет самый приблизительный уровень информации об
этом изображении, т.е. информацию при самом низком раз-
решении или при самом грубом масштабе. Значения d\t0
и яи, вместе взятые, представляют информацию на следую-
щем, более высоком уровне разрешения, или при следую-
щем, лучшем масштабе. Заметим, что мы можем восстано-
вить {«i,o, «i,i} из {«о,о, ^о,о}> используя приведенную выше
процедуру. Исходные значения пикселов {хих2,х^Х4} пред-
ставляют самое высокое разрешение или наилучший мас-
штаб, возможный для этого изображения. Эти значения мо-
гут быть восстановлены из a\y0j d\t0, d\t\ и d\t\. Но так как мы
можем получить а\$ и ахл из я0,о и d0,o> TO мы можем восста-
новить значения пикселов исходного изображения из общего
среднего значения я0,о и разностей do,o, di,o> и ^ifi- Таким обра-
зом, последовательность
:*2'5) {«0,0,^0,0,^1,0,^1,1}
является альтернативным представлением исходного изо-
бражения и состоит из общего среднего и значений разно-
стей, выражающих два различных уровня детализации. По-
140
Фракталы и вей влеты для сжатия изображений в действии
следовательность (5.2.5) - это вейвлет-преобразование ис*
ходной последовательности {хи х2, хг, хА). Заметим, что те.
перь мы имеем больше вариантов для сжатия. Если d1>0 и d{
слишком велики, чтобы их игнорировать, то, возможно, мы
можем исключить следующий уровень детализации, а имен*
но, d0,o- Если мы имеем дело с изображениями большего раз.
мера, то продолжим этот процесс усреднения и выделения
деталей на более грубом уровне разрешения.
5*3. Масштабирующие функции и вейвлет-функиии
(5.3.1)
Усреднение и выделение деталей, описанное в предыдущем
разделе, представлены одним блоком диаграммы на
Рис. 5.1.2. В этом разделе мы, двигаясь по этой диаграмме по
часовой стрелке, покажем, как понятие разрешения приводит
к введению масштабирующих функций и вейвлет-функций.
Предположим, что мы рассматриваем наше изображение
{хи хг> *з, х4} как функцию на единичном интервале:
j\t) = *i X[o,i/4)(0 + X2 X[i/4,l/2)(0 + *3 Х[1/2,3/4)(0 + ХА ^[3/4,1)(0
где каждое Х[а,Ь) - это характеристическая функция (character-
istic function) на интервале [а,Ь), т.е.
Х[а,ь)(0 = {1 еслг* а < ? < Ь; 0 в противном случае}
На Рис. 5.3.1 показано, как может выглядеть график такой
кусочно-постоянной функции для некоторых, произвольно
выбранных, значений хи хъ *з и х*. Заметим, что если бы мы
использовали f(t) для аппроксимации непрерывной функции,
то для лучшей аппроксимации стоило бы взять больше ха-
рактеристических функций, определенных на меньших ин-
тервалах. Таким образом, чтобы получить лучшую аппрок-
симацию, нужно использовать лучшее разрешение.
Рис 5.3.1.
Функция f{i),
заланная
уравнением
(5.3.1)
i
*1 |
1/4
г
*2
: *3
: Х4
1/2 3/4 1
mu,w
(Л 5, Простые вейвлеты 141
Заметим, что Xji/4,i/2)(0 - это всего лишь сдвиг X[0>i/4)(0>
а именно
^[1/4,1/2)(0 = ^10,1/4)(* " ХЛ)
Аналогично, Хп/2,з/4)(0 и Хтл)(г) - это сдвиги Xl0,i/4)(0- Кроме
того, X[o,i/4)(0 - это масштабирование характеристической
функции Л[о,1)(0» определенной на единичном интервале,
а именно
-X[o,i/4)(0 = ^[0,i)(2 О
Таким образом, все характеристические функции в уравне-
нии (5.3.1) могут быть записаны как масштабированные
и сдвинутые версии одной единственной функции X[0,i)(0-
Введем обозначение
<Kt) = Xl0(1)(0
и определим
Щ.3.3) фф) = 0(2* t -;) ; = 0,...,2*-1
Тогда
to.o(0 = 0(0
0i,o(O = 0(20 = {1 для 0<t <l/2; 0 в противном случае}
0u(O = 0(2f-l) = {1 для !/г < Г < 1; 0 в противном случае}
На Рис. 5.3.2 (а) и (Ь) показаны некоторые из этих функций.
Заметим, что ф\>0 и 0Ui - это масштабированные и сдвинутые
версии 0. Мы назовем ф масштабирующей функцией. Функ-
ция /, определенная равенством (5.3.1), теперь может быть
выражена с помощью этих новых функций как:
ДО = *1 02,о(О + Х2 02,l(O + *3 02,2(0 + *4 02,з(О
1
3.2)
(5.3.4)
Рис. 5.3.2. (Ь)
Ф\,о и Ф\,\ - это масштабированные и слвинутые версии ф
Интервал, на котором функция ф^ не равна нулю (и, следова-
тельно, равна 1) называется носителем (support) этой функ-
ции. Заметим, что величина носителя функции фц уменьша-
ется, когда к увеличивается. Фактически величина носителя
Фк+ij составляет половину величины носителя фц. Таким об-
разом, масштаб или разрешение определяются значением к в
фц. Если мы хотим увеличить разрешение, то используем
большее значение к.
Предположим, что нам нужно проделать процедуру, подоб-
ную той, что мы делали в предыдущем разделе. То есть мЫ
хотим представить функцию Дг), заданную уравнением
(5.3.4), с помощью операций усреднения и вычисления раз-
ности. Усреднение равнозначно уменьшению разрешения,
поэтому мы можем выполнить его, взяв фц с меньшим значе*
Рис. 53.2. (а)
ABA 5. Простые вей влеты
143
нием к. Это эквивалентно представлению ДО через ф\$ и ф\Л.
Коэффициент при ф\$ в этом представлении - это tfi.o, задан-
ный уравнением (5.2Л), и, таким образом, этот коэффициент
является средним значением первых двух коэффициентов /.
Аналогично, коэффициент при ф\у\ - это ai,i, и в результате
мы получим следующую функцию:
^•5^ g\(t) = а,,0 01,о(О + «i,i 0i,iO)
Очевидно, однако, что g\ не эквивалентна функции /. Напри-
мер,
тогда как
gi(l/8) = a,.o = (jt,+jt2)/2
что, в общем случае, не одно и то же (за исключением вари-
анта, когда Х\ = Хг). При получении g\ из/мы использовали
только усреднение, поэтому, вероятно, мы потеряли бы
информацию, если бы наша исходная функция не содержала
очень мало информации с самого начала. В процедуре, опи-
санной в предыдущем разделе, отсутствует концепция опре-
деления деталей с помощью некоторой операции вычисления
разностей. Нам требуется функция, позволяющая выразить
разность.
Функция, которую мы ищем, называется вейвлет-фуикцией.
Для данного примера базисная вейвлет-функция (basic wave-
let function) задается следующим образом:
Ь.з.в) vb)=xAt)-xtl(t)
1,
-1,
о,
(0,-) (-.1)
2 2
0<f<-,
2
I<«1,
2
в остальных случаях.
На Рис. 5.3.3 представлен график вейвлет-функции y/(t).
144
Фракталы и вейвлеты для сжатия изображений в действии
Рис. 5.3.3.
Базисная
вейвлет-функиия
W)
к
1
-*
0
-1
к
I ¥
_> W
1 W
\ °-5 ! 1
т
Аналогично тому, как мы делали это для масштабирующей
функции 0(0, сейчас мы введем масштабированный и сдви-
нутый вариант y/(t). Определиму/ЦО следующим образом:
Тогда, например,
Vo,o(') = v(0>
1, 0<г<-,
4
-1, -<г<-,
4 2
0, в остальных случаях,
Vu(') = v(2'~l) =
1, -<г<-,
2 4
-1, -<г<1,
4
0,
в остальных случаях,
На Рис. 5.3.4 представлены графики ул,о и ул,ь
Давайте еще раз рассмотрим задачу выражения функции /
через средние значения и разности, или, пользуясь нашей но-
вой терминологией, через функции масштабирования и вейв-
леты. Так как наше конечное разрешение имеет место на ин-
тервалах длиной ХАУ то мы можем рассмотреть g}(t) на каж-
дом из интервалов [0,1/4),...[3/4,1), чтобы увидеть, где она
становится неравной исходной функции/. На [0,1/4) разность
равна:
Я*)'8\0)=*1 -ai,o = di,o
На [1/4,1/2) разность равна:
ДО -g\(t)= х2 -tfi.o = -rfi,o
Таким образом, для t9 принадлежащего интервалу [0,1/2), мы
можем записать:
ДО = fli,o 0i,о(0 + d\t0 y/h0(t)
Аналогичный анализ на интервалах [1/2,3/4) и [3/4,1) пока-
зывает, что
ДО = ахл 0i,i(O + rfi,i Vu(0
для /, принадлежащего интервалу [1/2,1). Объединив эти ре-
зультаты, мы получим новое представление для/на всем ин-
тервале [0,1):
13.7)
L 5.3.4.
Шункиии 1/Л,о"
Ш\ прелставляют
Щбой сжатые
ървинутые
щЬсии базисного
Шйвлета у/
146 Фракталы и вейвлеты для сжатия изображений в действ
Теперь у нас есть представление / в виде суммы функц^
определенных как средние значения на интервалах длиной у
и некоторых детализирующих функций, которые нужны нам
чтобы компенсировать разницу с исходным изображением *
Аналогично тому, что мы делали в предыдущем разделе, мк
определим теперь среднее значение на всем интервале [о \\
заменив первые два слагаемых в (5.3.7) на д0>о $Ь,о(0> а втор^
два слагаемых оставив без изменений:
go(0 = «о,о <М0 + </i,o W\df) + <*u Vu(0
На [0,1/4) разность между ДО и g0(0 составит:
ДО - £о(0 = Х\ - «о,о - ^i,o = ^о,о
а на [1/4,1/2) мы получим
ДО - £о(0 = *2 - «0,0 + ^1,0 = ^0,0
Аналогично, на [ 1/2,1) ДО -go(0 = -do,o, следовательно, на
всем интервале [0,1) мы можем записать ДО как:
(53.8) ДО = я0,о <М0 + dW Уо,о(0 + dh0 1/Л,о(0 + rfi.i V'uO)
Уравнение (5.3.8) - это аналог последовательности (5.2.5),
но для функций.
5.4. Кратномасштабный анализ
Процесс декомпозиции дискретной последовательности зна-
чений (такой как цифровое изображение) в «размытые», или
средние значения, и детализирующие значения при различ-
ных масштабах называется кратномасштабным анализом
(multiresolution analysis). В этом разделе мы проиллюстриру-
ем кратномасштабный анализ на простом примере, получен-
ном на основе вейвлетов Хаара. Раздел содержит некоторЫе
математические детали, которые требуются для описанИ
пространств, в которых действуют функции фц и у/ц. Ср&У
оговоримся, что этот материал не является необходимым А11
применения вейвлетов к сжатию изображений. Однако °
способствует пониманию теории вейвлетов в целом и поМ
Простые вей влеты
147
жет понять темы следующей главы, в которой мы будем рас-
сматривать усовершенствованные вейвлеты.
Обозначим через V пространство всех функций, постоянных
на интервале [0,1). Тогда V - это векторное пространство
функций. То есть если мы сложим две постоянные функции,
то сумма будет постоянной функцией и также будет принад-
лежать V . И если мы умножим постоянную функцию на
число (скаляр), то произведение будет постоянной функцией
и будет принадлежать V . Базисная масштабирующая функ-
ция ф принадлежит V0. Фактически каждый элемент про-
странства V0 может быть получен умножением ф на подхо-
дящую константу. Таким образом, {ф} составляет (довольно
тривиальный) базис пространства V0.
А теперь рассмотрим несколько более сложное пространство
функций. Пусть Vх - пространство кусочно-постоянных
функций, являющихся константами на интервалах [0,1/2) и
[1/2,1). Vх - это тоже векторное пространство функций.
Примером элемента пространства Vх является функция gi(t),
определенная уравнением (5.3.5). Масштабирующие функ-
ции 01)О и 0и также являются элементами пространства V1.
Из уравнения (5.3.5) следует, что все остальные элементы
пространства Vх могут быть представлены линейной комби-
нацией функций 010 и 0и. Можно показать, что функции
{01дь0м} образуют базис пространства Vх. Заметим также,
что функция, постоянная на интервале [0,1), является посто-
янной и на каждом из интервалов [0,1/2) и [1/2,1), поэтому
каждый элемент V0 является элементом V1, то есть
V°<zVx
Продолжая дальше таким же образом, определим V как про-
странство кусочно-постоянных функций на интервалах
[0,1/4), ..., [3/4,1), и Vn как пространство кусочно-
постоянных функций на равноотстоящих интервалах длиной
1/2п. Каждое Vn - это векторное пространство, и масштаби-
рующие функции {фп/, j=0,...,2M} образуют базис в про-
странстве Vп. Кроме того, пространства Vп последовательно
вложены друг в друга:
V°<zVx <z...aVn<zVn+x с...
148 Фракталы и вей влеты для сжатия изображений в дейсти,,,
Теперь мы определим скалярное произведение элемент
пространства V :
(5.4.1)
о
Векторное пространство с введенным в нем скалярным про
изведением называется евклидовым пространством, дв
функции называются ортогональными относительно скаляр
ного произведения (• ,• ), если
(f,g)=o
Ортогональность функций полезна по нескольким причинам,
Прежде всего, заметим что, например,
fo.oAi)=0
так что {01,0*01,i} образуют ортогональный базис для V1,
Фактически для каждого knjФ1У мы имеем
так что {ф^\7 = 0,.. .,2*-1} образуют множество взаимно орто-
гональных базисных векторов в Vk. Заметим также, что
при; Ф1
Ортогональность полезна и по другой причине. Для данного
евклидова пространства U, принадлежащего большему евкли-
дову пространству S, мы можем говорить о множестве векто-
ров в 5, ортогональных всем векторам в U. Это множество на-
зывается ортогональным дополнением пространства U в про-
странстве S и обозначается U1 (недостаток этого обозначения в
том, что оно не отражает подразумеваемой связи с пространст-
вом 5, поэтому иногда оно обозначается как S\U). НетруДн°
проверить, что UL само является векторным пространством
(а также и евклидовым пространством).
Рассмотрим следующее пространство
Wk={hG И+1:(Л,/) = 0длявсех/<Е Vk]
Простые вейвлеты
149
Таким образом, W определено как ортогональное дополне-
ние пространства Vk в пространстве V*+1. Мы уже знакомы с
некоторыми элементами W . Рассмотрим у/*у. Заметим, что
длины интервалов, на которых y/kj постоянна, составляют
половину длины интервалов, на которых элементы простран-
ства Vk являются константами. Другими словами, y/kj в Vk+1
при каждом ]. Более того, легко убедиться в том, что
(Wkjj) = 0 для каждого /е Vk и, таким образом, у/ц£ Wk
при каждому и каждом к. Рассмотрим, например,
/a/<AG + /AieV\
где/01/1 являются скалярными константами. Тогда
^1.о./)=/о ^1.О101.о )+/i(Vi.o.0i,i)=O +0 = 0,
так как
koAo)=J(iXiM+f(-iXiM=o
0 1/4
и
1
^wAi)=J(°XO* = 0-
Таким образом, щ# е W1 и, аналогично, y/i,i G W1. Анало-
гично доказывается, что у/^-е Wk.
Какова размерность Wkl Очевидно, она не больше, чем раз-
мерность Vk+\ так как WkcVk+l. Таким образом, размер-
ность Wk не может быть больше, чем 2к+{ (мы говорим здесь
о размерности векторного пространства, т.е. о количестве
элементов в базисе, в отличие от фрактальной размерности,
о которой говорилось в предыдущих главах). Так как
{y/kj:j = Q,...,2k-\} образуют множество из 2к взаимно орто-
гональных и, следовательно, независимых векторов в W , то
размерность Wk равна, по крайней мере, 2*. Но это и наи-
большая возможная размерность Wk, так как в Vk+l сущест-
вует другое множество 2к взаимно ортогональных векторов,
а именно {фк/.7 = 0,.. .,2*-1}, и каждый из этих векторов также
ортогонален каждому из векторов {щ/.j = 0,...,2*-1}. Любой
вектор из Wk, который не может быть выражен через {y/kj}>
может быть выражен через {фц}> а это невозможно.
150 Фракталы и вейвлеты для сжатия изображений в лейст^
Мы пришли к следующему заключению: размерность пл*
странства Wk равна 2* и {щ: j = 0,...,2*-1} являются базис0
Разве это не интересно? Вейвлет-функции образуют бази
пространства Wk9 ортогонального дополнения V* в уЦ
В предыдущем разделе вейвлеты были представлены ка
средство восстановления деталей при уменьшении разреще
ния. Здесь вейвлеты выступают как базис ортогонального
дополнения пространства функций, определенных при да^
ном разрешении. Это ортогональное дополнение можно рас.
сматривать как детали, которые теряются при переходе от
одного уровня разрешения к другому, более низкому ур0в,
ню разрешения. Фактически вейвлеты можно определить
как любые базисные функции для этого ортогонального
дополнения.
Побочный результат изложенного выше в том, что мы на-
толкнулись на альтернативный базис для пространства более
высокого разрешения Vk+ . Мы уже знаем, что один базис
V*+1 это {фк+ij- 7 = 0,...,2*+ -1}. Альтернативным базисом яв-
ляется:
(5.4.2) К.о —*iki2*-P^.o.-^2*.1]
Мы можем представить себе один шаг процесса вейвлет-
преобразования, а именно шаг, состоящий в переходе от раз-
решения V*+1 к более низкому разрешению V*, как представ-
ление элемента g*+i G Vм в базисе, который задается урав-
нением (5.4.2). Предположим, что g*+i е Vk+l первоначально
был выражен как:
8к+1 = а*+1,О0*+1.О +-'- + GU!.2*+,-A+!,2*+1-t
Тогда g*+i может быть разложен по базису (5.4.2), например*
таким образом:
5. Простые вейвлеты
151
Коэффициенты {<4,о>... ,d*,2*-i} становятся частью вейвл ет-
преобразования. На следующем шаге этого процесса мы бы
получили выражение
g к = аьЖ,о+• • •+акЛ*-А#-хе ук
через {фк-ij} и {Щ-ц}.
Нормирование
В дальнейшем нам будет удобно работать с нормированными
масштабирующими функциями и вейвлетами. Определим
норму вектора / в евклидовом пространстве следующим об-
разом
Вектор и в евклидовом пространстве называется нормиро-
ванным, если \\и\\ - 1. Нормированный вектор и может быть
получен из любого ненулевого вектора / путем деления век-
тора/на его норму:
„-'
Таким образом, чтобы нормировать фц и Доу, нам нужно оп-
ределить их нормы:
2 1. и+1Г 1
о ,р 1
Таким образом,
для каждого j = 0,.. .,2*-1 и аналогично
1
V?
152 Фракталы и вейвлеты для сжатия изображений в дейсткь
*^ —_ , __^р^ ^ц
для каждого j. Итак, для того, чтобы работать с нормиров^
ными масштабирующими функциями и вейвлетами, необх
димо переопределить их. Для этой цели мы определим а
как: J
(5'5'V 4>kJ(t) = &ф(2к1 -Д j = 0.....2* -1
а у/ц определим как
(5'5'2) \}fkij{t) = №\if{2kt-])J = 0,. ..,2*-l.
Будем называть вейвлеты, заданные равенством (5.5.2) (где \и
определяется равенством (5.3.6)) нормированными вейвле-
тами Хаара.
5.6. Вейвдет-преобразование
Предположим, что мы имеем последовательность, состоя-
щую из 2п точек {x1,x2,...,x2„} для некоторого целого п > 0.
Мы можем отождествить эту последовательность со сле-
дующей функцией из Vn:
(5.6.1) f(thx^0(t)^...^x ф nJ)
Первым шагом вычисления вейвлет-преобразования после-
довательности {хихг,...ух я] будет разложение fit) по альтер-
нативному базису пространства Vn вида (5.4.2), половину ко-
торого составляют вейвлеты:
(5.6.2) f(t)= an_l0<i>n_l0(t)+... + an_xr.xJn_x^_x (*) +
4,-i.oVVi.o (>) + • ■ • + ^.1.2-1.1^^,2-1., (')
Коэффициенты dn_l0,..., rf 2„_, _t при базисных вейвлет-
функциях составляют половину коэффициентов вейвлет*
преобразования, поэтому мы сохраним эти значения. Слс'
дующим шагом процесса преобразования является примени
5. Простые вейвлеты
153
т
16)
ние такого же базисного преобразования к остальным членам
равенства (5.6.2):
£„_, (* )= а^.ойм.о (0+ ■ - + n.-i.2"-'-A-i.2"-'-i (')
Таким образом, g„_i это элемент Vn~ , и поэтому может быть
разложен по альтернативному базису, состоящему из мас-
штабирующих функций (j>n.2j и вейвлетов y/n-2j'
Прежде чем мы продолжим этот процесс, зададим один на-
прашивающийся вопрос: как мы получаем коэффициенты
равенства (5.6.2) из коэффициентов равенства (5.6.1)? Для
этого мы используем ортогональность. Напомним, что каж-
дая фп-ij ортогональна каждой фп.\^ так же как и всем y/n.\j,
и, аналогично, каждый вейвлет y/n.xj ортогонален другим
вейвлетам y/n.\tk и всем масштабирующим функциям фп.ц. На-
помним также, что каждая фп.\^ и каждый y/n.ij являются нор-
мированными в силу тождеств (5.5.1) и (5.5.2). Чтобы вос-
пользоваться этой ортогональностью и нормированностью,
умножим обе части (5.6.2) на фп-ijit) и проинтегрируем по t от
0 до 1. В результате получим
1
//(Ф.-и(0* = *..-и
о
В силу ортогональности в правой части (5.6.4) остается толь-
ко один член, а нормирование приводит к отсутствию коэф-
фициента при an.\j. Теперь подставим правую часть равенст-
ва (5.6.1) вместо Д/) в (5.6.4). Например, при у = 0 левая часть
равенства (5.6.4) будет равна
Комбинируя (5.6.4) и (5.6.5) при у = 0, получим
а
п-1,0
~1Г'
154
Фракталы и вейвлеты для сжатия изображений в дей<
Квадратный корень в коэффициенте в (5.6.6) появляется
счет нормирования. Если бы мы использовали ненорм^
ванные базисные функции, то мы бы получили двухточечн
среднее значение, рассмотренное в разделах «Усреднение
детализация» и «Функции масштаба и вейвлет-функции». п*
тальные коэффициенты an.\j> j = 1,...,2М вычисляются ан
логично. Таким образом,
(5.6.7)
X2j+l +*2j+2
*n-\J
л/2
, ^О,...^"1-!.
Аналогично, используя свойства ортогональности и норми.
рованности функций y/n-\j, можно вычислить коэффициенты
dn.\j по следующей формуле
(5.6.8)
*n-l,j
V2
j = o,...,r--i
Еще раз напомним, что квадратный корень в выражении для
коэффициента (5.6.8) появляется в результате нормирования.
Без нормирования мы бы имели только разность выражений,
полученную в разделах «Усреднение и детализация» и
«Функции масштаба и вейвлет-функции».
Уравнения (5.6.7) и (5.6.8) удобно представить в виде одного
матричного уравнения:
(5.6.9)
-?= -т= О
J_ _1_
V2 V2
О О
о
_L _L
V2 "л/2
л/2 л/2
-7= -7= О
о
О 0 4=
7= "Г °
л/2 л/2
•т -г
л/2 л/2
. . О
V2 V2.
/1-1,2 -1
"я-1,0
Щ5. Простые вейвлеты
155
Матрица в (5.6.9) - это квадратная матрица с 2п строками и 2п
столбцами. Определим
V2 V2
О
о * -L о
л/2 л/2
О
О
0 "Г "Г
V2 V2
и
Г
шмммшмммм
D„
" 1
л/2
0
0
- ■ о
л/2
0 -г
л/2
: : о*
л/2
0
0
1
"л/2
F
где А„ и D„ - матрицы размером 2пА х 2я, и Ап можно рас-
2п 2п~1
сматривать как оператор усреднения и D„: R —»R - опе-
ратор разности. Введем также векторную запись
~*|~
л-_
> ап-1 _
ап-1,0
.а.-1.2--1.
. «!„.,=
"«-1.0
Л-..2--
1_
F
'»
где х - это вектор-столбец с 2" элементами, a ап.\ и dn.i - век-
торы-столбцы с 2п' элементами. Тогда мы можем переписать
(5.6.9) как
X"
Х =
ап-1_
А-1 J
Матрица в левой части (5.6.13) - это единая матрица 2п х 2п,
а вектор в правой части - единый вектор-столбец 2п х 1. На
каждом шаге процесса вейвлет-преобразования мы сохраня-
ем детализирующие коэффициенты и обрабатываем коэффи-
156
(5.6.14)
Фракталы и вей влеты для сжатия изображений в лейсгь.
циенты усреднения. В рассматриваемом случае вейв^^
преобразование будет иметь Т компонентов. Половину
них мы получаем из уравнения (5.6.13) в качестве детали *
рующих коэффициентов в d„_i. Сохраняем эти коэффициен
как половину вейвлет-преобразования. Следующий п
вейвлет-преобразования состоит в применении к ъпЛ 0п^
ций усреднения и вычитания на следующем, более низком
уровне разрешения: !
Ln-1
D
n-l
lan-l =
*n-2
ln-2
(5.6.15)
Здесь A„.i и D„.i - это 2я" х 2"' матрицы вида (5.6.10) и
(5.6.11), а а„.2 и d„.2 - это векторы-столбцы размерности 2п'2,
Чтобы построить часть вейвлет-преобразования, мы сохра-
ним d„.2 вместе с d„_i. Продолжим этот процесс, применяя
операции усреднения и вычитания ка^и сохраняя получен-
ные детализирующие коэффициенты как часть вейвлет-
преобразования. На заключительном шаге мы сохраним
среднее значение ао, которое является однокомпонентным
вектором (т.е. скаляром) с единственным элементом яо,о- Ре-
зультирующее вейвлет-преобразование, которое мы можем
представить как единый вектор-столбец с 1 + 1 + 2 + ...+
Тл = 2" элементами, будет иметь вид:
5.7. Обратное вейвлет-преобразование
Л
Чтобы вейвлет-преобразование могло быть использовано
приложениях, таких, например, как сжатие изображений, оН
должно быть обратимым. То есть, при заданном вейвЛ^
преобразовании вида (5.6.15), мы должны быть в состояв
5. Простые вейвлеты
157
восстановить исходную последовательность {xlJx2,...,x2„}, из
которой было получено преобразование. Фактически, в разде-
ле «Усреднение и детализация» мы проделывали это обратное
преобразование. Сейчас мы проделаем аналогичные действия.
Шаг вейвлет-преобразования, заключающийся в переходе от к
уровня разрешения к к-\9 выглядит следующим образом:
Dk
а„ =
A-I
КГ
откуда мы получаем
{ак,о+акЛ)/Л~ак_10
Заметим (нам это понадобится для дальнейших ссылок), что
(5.7.1) и (5.7.2) могут быть записаны в виде пары матрично-
векторных уравнений:
^kak ~ak-i
Dkak =dk-i
ВТ
для каждого к= 1,...,и.
Из (5.7.2) мы, по известным выражениям для более низкого
уровня разрешения д*-1,о и d*-i,o, можем легко найти выраже-
ния для более высокого уровня разрешения я*,о, <*кУ-
ак,о ={ak-itQ+dk_Uo)/yf2
Аналогично, дляу = 0,...,2*-1,
<*W ={ak-ij+dk-ij)№
ak,2j+lZ={ak~lJ~dk-lj)/^
158
Фракталы и вейвлеты для сжатия изображений в лей
5S
С точки зрения линейной алгебры мы разрешили уравнец*
(5.7.1) относительно вектора а* путем обращения матрци
левой части этого уравнения. Таким образом, мы выполнил
следующую операцию:
(5.7.5)
а„ =
Dk
Откуда мы знаем, что обратная матрица в (5.7.5) существует')
Потому что мы находим ее в (5.7.4)! В матричной форме это
обращение выглядит как
(5.7.6)
Тг ° •
о 4= о
■п
о 4- о
л/2
о о .
о 4= о .
о ^L о .
л/2
о о 4= о
л/2
«Т2
V2
О ^ О
V2
О
О
о
о
о
J_
л/2
-1
V2.
Сравнение с (5.6.9) показывает, что эта обратная матрица яв-
ляется всего лишь транспонированной по отношению к мат-
рице прямого преобразования. Фактически первые 2кЛ столб-
ца матрицы в (5.7.6) в точности представляют собой транс-
понированную матрицу А*, а последние 2Ы столбца - транс-
понированную матрицу D*. Это удобное свойство возникает
благодаря ортогональности и нормированности наших ба-
зисных функций масштаба и вейвлет-функций. Таким обра-
зом, мы можем записать обращение в (5.7.6) как:
(5.7.7)
=к|о;]
где * обозначает транспонирование матрицы.
Теперь мы можем переписать (5.7.5) в виде
5. Простые вейвлеты
159
= A'ak„1+D'dl
Уравнение (5.7.8) дает практическую формулу для получения
а* из a*-i и d*.f. применяем Ак к a*.i и Dk к <1ы и складываем
результаты. Фактически именно эта процедура, а не тот под-
ход, который дается уравнением (5.7.5), реализована в про-
грамме, прилагаемой к книге. Сравнение с (5.7.3) показывает,
что верно следующее:
ak=AkAkak+DkDkak
Фактически можно напрямую доказать истинность следую-
щего соотношения:
W
A*Ak +D*Dk =Гк
где I k - это единичная матрица 2* х 2*. Выполняется также
следующее соотношение:
А А* =1
DkD'k=V-
Г
В следующей главе мы потребуем, чтобы соотношения, ана-
логичные (5.7.10) и (5.7.11), были предложены для низкочас-
тотных и высокочастотных фильтров, которые приводят к
определению вейвлетов Добеши.
Двумерные вейвлет-преобразования
До сих пор мы рассматривали вейвлет-преобразование толь-
ко для одномерных последовательностей и не совсем точно
называли эти последовательности «изображениями». Хотя,
действительно, мы всегда можем растянуть строки и столбцы
изображения в единую длинную последовательность, но это
160
Фракталы и вейвлеты для сжатия изображений в денег»,
приведет к перераспределению битов информации и не буд
отражать размещение битов информации в исходном
ч
бражении. Зато существует возможность распространи
идею вейвлет-преобразования на последовательности бол
шей размерности. Первый способ заключается в том, чтоб
сначала преобразовывать строки изображения, а затем пп
образовывать столбцы изображения с преобразованным
строками. Это легко реализуется программно, так как одно
то же одномерное преобразование может быть использован
для преобразования и столбцов, и строк изображения.
Чтобы увидеть, как работает эта процедура, рассмотрим дву,
мерный аналог простой 4-элементной последовательности из
раздела 5.3. Предположим, мы имеем изображение 4x4:
(5.8.1)
^2,1 л2,2 л2,3 л2,4
*3,1 л3,2 л3,3 ЛЪА
которое мы можем представить как функцию, заданную на
единичном квадрате [0,1] X [ОД]:
(5.8.2)
Уравнение (5.8.2) - это двумерный аналог уравнения (5.3.1).
Здесь
/(Х/.е
i-\ i
—'Vх
7-1 j
4 '4
(х,у):хе
i -1 i
~4~'4
и y€
7-1 j
4 '4
(5.8.3)
Х,,х,,(х>у)
1 если(х,у)е IjXlj
0 в противном случае
= X,Xx)Xh(y)
= Фг,,Лх^иЛу)
5. Простые вейвлеты
161
С
у>
ЕЯ"
1)
W
Подставив (5.8.3) в (5.8.2), мы получим
i=\ j=\
4
где
;=i
Обратите внимание, что для каждого i = l,...,4, уравнение
(5.8.5) выглядит очень похожим на уравнение (5.3.4). Это
означает, что мы можем применить одномерное вейвлет-
преобразование так, как делали это раньше, для каждого
i= 1,...,4 в (5.8.5). В результате мы получим новый набор
уравнений для xt(y) * = U--A с коэффициентами, являю-
щимися результатом вейвлет-преобразования последова-
тельности {.х/д,...,*,^}. Таким образом, мы получим сле-
дующее:
^(y) = <o^W+<oVo,o(y) + <oVi.oW+<iVu(y)
для каждого I = 1,...,4. Это эквивалентно применению одно-
мерного вейвлет-преобразования к каждой строке исходного
изображения (5.8.1). Теперь подставим (5.8.6) обратно в
(5.8.4) и переупорядочим члены, чтобы получить
162
Фракталы и вей влеты для сжатия изображений в действии
Каждая из сумм в скобках в (5.8.7) опять очень похожа на
уравнение (5.3.4), и поэтому одномерное вейвлет-
преобразование может быть применено к каждому их этих
выражений. Это эквивалентно применению одномерного
вейвлет-преобразования к каждому столбцу исходного изо-
бражения (5.8.1).
Итак, один из способов получения двумерного вейвлет-
преобразования изображения размером 2пх2п, заключается в
том, чтобы сначала применить одномерное вейвлет-
преобразование к каждой из Т строк, а затем применить од-
номерное вейвлет-преобразование к каждому из Т столбцов.
Это не единственный способ определения двумерного вейв-
лет-преобразование. Этот подход имеет очевидное преиму-
щество в реализации, так как не требует никакой доработки
уже имеющегося одномерного преобразования. Он очень
эффективен для наших целей сжатия изображения.
5.8.1. На что похоже вейвлет-преобразование
На что похоже вейвлет-преобразование изображения? Мы мо-
жем представлять себе операции усреднения и выделения де-
талей при помощи вейвлетов Хаара, как применение низкочас-
тотных и высокочастотных фильтров. Низкочастотный фильтр
пропускает информацию, передаваемую на низких частотах
(т.е. малое количество деталей), блокируя в то же время ин-
формацию, передаваемую на высоких частотах (т.е. содержа-
щую большое количество деталей), а высокочастотный
фильтр- наоборот. Наше двумерное вейвлет-преобразование
применяет одномерное вейвлет-преобразование к каждой
строке, а затем одномерное вейвлет-преобразование к каждому
столбцу результирующей информации. Схема на Рис. 5.8.1 по-
казывает, как это выглядит. Напомним, что первый шаг вейв-
лет-преобразования - это сохранение детализирующей инфор-
мации, содержащейся в половине коэффициентов. Таким об-
разом, целая четверть коэффициентов двумерного преобразо-
вания является результатом действия высокочастотного
фильтра (Н) на строки, а затем его действия на результирую-
щие столбцы информации. Это блок коэффициентов в правом
нижнем углу схемы, обозначенный ННь Другая четверть ко-
эффициентов двумерного преобразования является результа-
том действия низкочастотного фильтра (L) на столбцы инфор-
мации, которые уже прошли через высокочастотный фильтр.
Этот блок, обозначенный LHb находится в правом верхнем уг-
,5.8.1.
лу схемы1. Аналогично, блок HLb расположенный в левом
нижнем углу схемы, является результатом низкочастотной об-
работки строк, с последующей высокочастотной обработкой
столбцов. Левый верхний угол схемы подразделен на меньшие
блоки, показывая, что операция вейвлет-преобразования по-
следовательно воздействует на все меньшее количество коэф-
фициентов, вплоть до последнего коэффициента в левом верх-
нем углу, к которому применялся только низкочастотный
фильтр.
Схема лвумерного вей влет-преобразования как послеловательности
прохожления по вертикали и горизонтали через высокочастотный
фильтр (Н) и низкочастотный фильтр (L). На схеме LHx обозначает
вертикальное высокочастотное фильтрование, к которому применяет-
ся горизонтальное низкочастотное фильтрование, a HLx обозначает
вертикальное низкочастотное фильтрование, к которому применяется
горизонтальное высокочастотное фильтрование.
На Рис. 5.8.2 (a)-(d) показан результат прохождения через высо-
кочастотный и низкочастотный фильтры для различных видов
изображений. Каждая пара рисунков - это изображение плюс
воспроизведение его двумерного вейвлет-преобразования Хаара.
Обозначение, которое мы здесь используем, взято по аналогии с принятым в математике обозна-
чением композиции операторов. Так, если даны операторы F и G, то математическое обозначе-
ние GF говорит о том, что оператор G следует за оператором F (т.е. G применяется к результату
И&рименения F). Здесь обозначение LH наоборот, показывает, что оператор Н следует за операто-
ром L. К сожалению, это обозначение не совпадает с принятым в литературе по вейвлетам, где
■Такая композиция обычно обозначается HL. Такой выбор был сделан, чтобы использовать мате-
матическое обозначение, так как в следующей главе будут рассмотрены композиции операторов.
Рис. 5.8.2.
Примеры изображении и их лвумерные веивлет преобразования. Иг
кажлом рисунке изображение нахолится слева а соответствующее
ему веивлет-преобразование Хаара - справа Преобразованные изо-
бражения были сформированы путем приравнивания наименьших (по
величине 50°о коэффиииентов нулю и окрашивания пикселов соо
ветствуюших оставшимся ненулевым коэффиииентам, в черный ивет
Рис 5.8 2 (а) состоит только из вертикальных линий, поэтом}
какие-либо изменения деталей могут происходить только при
движении вдоль горизонтальных линий, то есть вдоль строк-
При движении по вертикали - вдоль столбцов - никакой ин-
формации мы не получаем Таким образом, Н-оператор, в°3'
действуя на строки, будет собирать информацию, в то вре^я
как, воздействуя на столбцы, тот же оператор будет уничто-
жать ее. Результат этого становится очевиден из рисунка, И-1
люстрирующего преобразование. Вся информация в ниЖН^*
половине преобразованного изображения - нулевая Это сл№
ствие того, что все коэффициенты соответствующие ниЖН€
Преобразованные изображения были сформированы путем
цимации массива вей влет-коэффициентов: наименьшие (по
личине) 50% коэффициентов были положены равными нуп
Пикселы, соответствующие ненулевым коэффициентам, g.
затем окрашены в черный, а пикселы, соответствуют^ ,„,'
вым коэффициентам, - в белый цвет Так как само всйвлсч
преобразование может создавать более 50% нулевых коэффщ.
ентов то, вероятно, что более 50% пикселов будут белыми.
5. Простые вейвлеты 165
половине изображения, были подвергнуты высокочастотной
фильтрации по столбцам информации. Верхняя половина пре-
образованного изображения отражает детальную информа-
цию, собранную при движении вдоль строк. Только 3% коэф-
фициентов преобразованного изображения отличны от н^ля.
Рис. 5.8.2 (Ь) иллюстрирует противоположную ситуацию, к;
гда у нас есть только вертикальная информация и нет гориз
тальной. Здесь правая сторона преобразованного из бражи я
нулевая. Здесь тоже только 3% коэффициентов не равны пулю
На Рис. 5.8.2 (с) показан сплошной круг, расположенный
внутри концентрических окружностей. Окружности обеспе-
чивают детальную информацию как в горизонтальном, так и
в вертикальном направлении, поэтому ненулевые коэффици-
енты появляются как в левом нижнем, так и в правом верх-
нем блоках преобразования. Заметим, что сам круг не несет
детальной информации, информацию несет только его гра-
ница, и поэтому нет никаких детализирующих коэффициен-
тов, соответствующих закрашенной части круга. Единствен-
ный LL-коэффициент в верхнем квом углу преобразования
обеспечивает всю информацию, необходимую для представ-
ления этой части изображения В этом преобразованном изо-
бражении примерно 9% коэффициентов ненулевые.
И, наконец, на Рис. 5.8.2 (d) представлено более реалистичное
изображение с его двумерным вейвлет-преобразованием. Заме-
тим, что, как и в случае с изображением круга, сплошной чер-
ный фон изображения не несет детальной информации, и это
выражается в нулевых значениях коэффициентов в блоках, уда-
ленных от левого верхнего угла преобразования. В этом преоб-
разованном изображении 50% коэффициентов ненулевые
5.8.2. Упрощенная схема вей влет-сжатия
Упрощенная схема вейвлет-сжатия такова. После вычисл-
ния вейвлст-преобразования, вейвлет коэффициенты сорти
руются. Запоминаются только х% наибольших коэффициен-
тов, а оставшиеся наименьшие (100-л)% коэффициентов по-
лагаются равными нулю. Значение л выбирается пользовате-
лем. Декодирование производится путем применения обрат-
ного вейвлег-преобразования к прореженному массиву ко-
эффициентов. Рис. 5.8.3 показывает результат применения
этой схемы к изображению «Lena» с использованием 10% и
5% вейвлет-коэффициентов. Как вы видите, хорошее качест-
Фракталы и веивлеты лля сжатия изображений в деиствь
во изображения может быть получено при неболы и м с
кращении общего количества вейвлет-коэффициентов. J4
пример, при 5% коэффициентов мы видим выраженную ^
заичность восстановленного изображения. Это особенност
использования вейвлетов Хаара для сжатия изображени
Вейвлеты Добеши, рассматриваемые в следующей главе
уменьшают эту мозаичность.
Хотя в примерах на Рис. 5.8 3 (а) и (Ь) использованы, соот-
ветственно, 10% и 5% вейвлет-коэффициентов эти примеры
не представляют, соответственно, сжатие 10 1 и rjT
происходит потому, что информацию о расположении ос-
тавшихся коэффициентов тоже нужно хранить вместе с са-
мими значениями коэффициентов. Кроме того, вейвлет-
коэффициенты имеют, как правило, значительно более ши-
рокий динамический диапазон по сравнению с исходными
пикселами изображения и поэтому требуют большего коли-
чества бит для их хранения (или квантования, которое риве-
дст к ухудшению качества декодированного изображения)
В главе 7 этот вопрос, а также методы более эффективного
кодирования, обсуждаются более подробно.
Рис. 5.8.3.
Упрошенное веивлет-преобразование изображения «Lena» с исполь-
зованием вейвлетов Хаара (а) Изображение восстановлено с исполь-
ованием только 10% вейвлет-коэффиииентов. (Ь) Изображение вос-
станов ено с использованием 5°о веивлет коэффиииентов СрелИЯЯ
пиксельная ошибка и PSNR составляют лля (а) 2,0376% и 30,9052 Aw
лля (b) 2,8925% и 27,3918 Лб. Коэффиииенты сжатия прелставл иные
злесь, равны не 20:1 (в случае 5%) или 10:1 (в случае 10%), так ка*
нужно хранить информацию о расположении оставшихся коэффиии-
ентов и вейвлет-коэффиниенты требуют более широкого линамиче'
ского лиапазона, чем исхолное изображение
rjlABA 6.
рейвлеты Добеши
В предыдущей главе мы убедились в том, что метод про-
стого усреднения и нахождения разностей приводит к (по-
строению вейвлетов Хаара и что эти вейвлеты могут ис-
пользоваться для сжатия изображений. В этой главе мы
расширим эти понятия, введя взвешенное среднее и
взвешенную разность, и увидим, что определенный выбор
весовых коэффициентов приводит к построению другой
системы вейвлетов. Ингрид Добеши (Ingrid Daubechies) [12]
выбрала коэффициенты, которые приводят к системе вейв-
летов, особенно хорошо подходящих для сжатия опреде-
ленных типов изображений. Методы вейвлет-кодирования
изображений, которыми мы займемся в следующей главе,
сочетают использование вейвлетов Хаара и вейвлетов, рас-
смотренных в этой главе.
6.1. Взвешенные средние и разности
Предположим, что мы имеем последовательность данных
(т.е. изображение): х - {хь *2, *з« • •■> •*«} Для некоторого п > 0.
Вместо простого среднего, которое приводит к построению
вейвлетов Хаара, мы рассмотрим взвешенное среднее:
СоХ\ + С\Хг + ... + Cyv-iXyv
для некоторого множества коэффициентов с0, си •••* Слч,
N>2. Условно мы определим ск = 0 для значений А<0
и к > N. Аналогом простой операции вычитания будет выра-
жение:
С\Х\ - СоХ2 + СзРСЪ - С2Д4 + ...
Заметим, что этот выбор приводит к следующему свойству
ортогональности:
(Ы.1)
(С0,С! ,С2,С3,...)#(С! ,"С0,С3,-С2,...) = 0
168 Фракталы и вей влеты для сжатия изображений в действ
6.1.1. Низкочастотные и высокочастотные
фильтры
Положим п = 2т для некоторого т > О и расширим послед
вательность данных, введя в нее цикл, чтобы получить п
риодическую последовательность:
..., л 1, Л2> • • • у Хп, л J, Л2> • • •» Хп, Х\ > Х2у •»• j Яги • • •
Таким образом, х0 = хт х.{ = хпЛ, хп+{ = хи хп+2 = х2 и так далее
Напомним, что с* = О для к<0 и k>N. Определим оператоп
L„: R" —» R^2 следующим образом:
(LnX)/=2^-2/+l^> / = 1,...A
Оператор L„ называется низкочастотным фильтром.
Определим оператор Н„: R" —» R"72 следующим образом:
(нл),=£(-1Гс2,Л, /-1....Д
;=1
Оператор Н„ называется высокочастотным фильтром. Вме-
сте L„ и Н„ образуют квадратурно-зеркальный фильтр (КЗФ)
(Английская аббревиатура QMF - quadrature mirror filter)
[19].
6.1.2. Матричное представление
Обозначим через L„[/j] элемент ij матричного представления
оператора L„ для последовательности данных с циклом *•
Тогда
L. ['../Н
су-2/+1 'Vм 0<;'-2/ + l<N-l
<j-M*i« пРи j~2i +КО
О ирм j-2i + l>N
6. Вей влеты Аобеши
169
Аналогично, обозначим через Hn[iJ] элемент ij матричного
представления оператора Н„, так что
нЛиН
(-D
ИГ
О
>+1,
"У-2/+1
^n-j+n
при
при
при
Q<2i-j<N-l
2i-j<0
2i-^j>N
L„[ij] и Hn[iJ] определены для i = 1,2,...,п/2 и/= 1,2,...,л, так
что L„ и Н„ являются матрицами размера п/2 х п.
В качестве примера построим матрицы L„ и Н„ для /t = 8 и
N=6 (т.е. с коэффициентами c0,ci,...,c5). Тогда матрицы L8 и
Н8 имеют вид:
Lft =
О 0 с0 с, с2 су
с4 с5 0 0 с0 Cj
О О
:5 0 0 с0
Нй =
с3 с2
с5 -сА
О О
О О
с3 — с2
с5 -с4
О О
Су — Сл
Свойства коэффициентов и условия,
накладываемые на коэффициенты
В главе 5 мы убедились в том, что из определения операто-
ров усреднения и вычитания А„ и D„ вытекают определенные
свойства, такие как ортогональность, а также свойства, зада-
ваемые уравнениями (5.7.10) и (5.7.11). В этой главе мы на-
ложим условия на коэффициенты с0,...,слч> так что анало-
гичные свойства приобретут операторы L„ и Н„.
Из построения матриц L„ и Н„ и свойства ортогональности
(6.1.1) мы получаем следующее свойство ортогональности'.
^Хп ^Ж =0я/2,
170
Фракталы и вейвлеты для сжатия изображений в действии
(6.2,2)
где Ол/2 - это нулевая матрица размером л/2 х л/2 и * означает
транспонирование матрицы. Мы наложим на L„ (а, следова.
тельно на коэффициенты Co,...,Ov-i) следующее условие:
«Л» L.L>I.„,
где \пп - единичная матрица размера л/2 х л/2. Условие
(6.2.1) эквивалентно равенству
N-\
2C*C*+2m=50m> /П = 0,±1,±2,...,
где 5у - это символ Кронекера (Kronecker delta function):
[l, при i = j
8 =
tJ [0, при i Ф j
Условие (6.2.1) также подразумевает следующее:
(6.2.3) Н НФ = I
Заметим, что
н„(ь>л + hX)=(h„l;K +(h„h:K =o„/2l„ +i„/2h„ =h„
и, аналогично,
l„(l;l„+hX)=l„.
Таким образом, оператор L*nL„ + h:h„:R" —> R" является
единичным оператором:
(6.2.4) 1;ПЬЯ+НХ=1И
п п п п п
Свойство (6.2.4) является аналогом свойства (5.7.10).
6. Вейвлеты Лобеши
171
ш.
шшт
Вейвлет-преобразование
Вейвлет-преобразование может быть определено как дерево
низкочастотных и высокочастотных фильтров, как показано на
Рис. 6.3.L Как и в случае с операторами усреднения и вычита-
ния из главы 5, идея здесь достаточно проста. Низкочастотные
фильтры {Ln} уменьшают количество информации сигнала х.
Высокочастотные фильтры {Нл} представляют недостающую
информацию. На Рис. 6.3.1 показан пример вейвлеТ-
преобразования элемента х из пространства R8. Напомним, что
L„,H„:R'!-»R',/2, т.е. фильтры уменьшают размерность входного
вектора наполовину. Вейвлет-преобразование - это элемент
пространства R8 вида {I^LJUx, H2L4L8X, H4L8x, H8x}. Таким
образом, вейвлет-преобразование состоит из конечного взве-
шенного среднего L^LJUx и всех векторов деталей, сохраняе-
мых на каждом шаге процесса преобразования.
:ъ.з.1.
х\
R8\
Ц
~Ъ
->■ L8x —*
- Н8х^
R4
L4
Н4
* L4L8x —-
-H4L8x >
R2
L2
"ЙГ
L2L4L8x 6 R1
H2L4L8xG R1
R1
Вейвлет-преобразование как лерево низкочастотных и высокочас-
тотных фильтров. В этом примере преобразование применяется к
элементу х из пространства R . Результат преобразования - это
состоящий из низкочастотного сигнала L2L4L8X 6 R
Н8хе R4, H4L8eR2 и
>8
элемент R
трех высокочастотных сигналов
и
H2L4L8 e R1
Свойство (6.4.2) дает ключ к построению обратного вейвлет-
преобразования. Обратное преобразование - это всего лишь
обратный порядок шагов прямого преобразования. На
Рис. 6.3.2 показан пример восстановления элемента х б R из
его вейвлет-преобразования. Например,
I^I^I^LgX ^~ "2**2^'4^'8^ = 1^2^*2 ^~ "2"2 Д-*4^8^ — ^4^8^
172
Фракталы и вейвлеты аля сжатия изображений в действии
Здесь мы воспользовались тем, что L*2L2 + H2H2 =12~ едцч
ничный оператор в R
L2L4L8x -►
H2L4L8x -►
R1
Рис. 6.3.2. С
4
н;
Эбрап
! 1
-©-L4L8x->! L*4 ;-*(±)-L8x-»-
•^ j г
Т * /^\
L8 j"*®"* X
/ / 7 Р8
/ H4L8x->h;/ Н8х-
Hs:7
R2 R4
юе вейвлет-преобразование
^^^^^^^^ншяявм
6.4. Масштабирующие функции и вейвлет-функции
Сейчас мы расширим понятия масштабирующих функций и
вейвлет-функций, введенные в предыдущей главе для вейв-
летов Хаара, для более общих вейвлетов. Масштабирующая
функция Хаара 0(f), определенная равенством (5.3.2), удовле-
творяет следующему соотношению:
ф(() = ф(21) + ф(Ъ-1)
Предположим теперь, что имея множество коэффициентов
со,сь...,Слм, мы ищем масштабирующую функцию 0(f) обще-
го вида, удовлетворяющую следующему свойству:
(6.4.1)
0(f) = s*(c0<K2t) + a<K2t-l) + ... + сылф(21 - (N - 1)))
Уравнение (6.4.1) называется масштабирующим уравнением
(dilation equation) [42]. Константа s*Q введена здесь, чтобы
обеспечить некоторую гибкость в обеспечении существова-
ния такой функции 0, которая удовлетворяет равенству
(6.4.1) и другим условиям, которые мы собираемся наложить.
Фактически константа s будет определена этими условиями.
Введем два дополнительных свойства, которым удовлетворя-
ет масштабирующая функция Хаара и которым должна уДОв"
летворять наша масштабирующая функция общего виДа-
Первое из них - это свойство нормированности:
f>. Вейвлеты Лобеши
173
^]ф2№
г/ = 1
Второе свойство - это ортогональность сдвигов (orthogonal-
ity of translates):
]<j>{2t-j)t>{2t-m)dt = 8hm
14)
t.5)
14.6)
Интегрируя масштабирующее уравнение (6.4.1), мы получаем
N~l (\\ N~l
j0(r)* = 5^cj0(2^-y>=|«|s^cj0(W)rfM
откуда
7=0
7=0
Условие (6.4.4) является условием существования функции ф.
Применяя свойства нормированности (6.4.1) и ортогонально-
сти (6.4.3) к масштабирующему уравнению (6.4.1), получаем
/V-1
;=0
= 1
а, подставляя (6.4.2) при т = 0, получаем значение константы s:
5 = V2
Аналогично тому, как вейвлет-функция Хаара определяется с
помощью оператора вычитания, мы можем определить вейв-
лет-функцию общего вида с помощью оператора высокочас-
тотного фильтрования. Например, для 7V = 4 определим вейв-
лет-функцию y/(t) следующим образом:
^(O = ~p(c30(2r)-c20(2r-l)+c10(2r-2)~co0(2r-3))
V2
174 Фракталы и вей влеты для сжатия изображений в дейс».
Таким образом, если нам известны коэффициенты с0усиС
то мы можем найти 0(7) и у/(г), рекурсивно применяя сооти'**
шения (6.4.1) и (6.4.6). Например, если мы знаем, что <v
принимает целочисленные значения, то легко можем най>,
0(1/2), у(1/2),0(1/4),ит.д. Щ
Уравнения (6.2.2) и (6.4.4) дают нам два условия для коэЛ
фициентов с/. Например, при N = 2, мы получаем систему
c%+cf=l, 4l=c0+cx
откуда можем определить со, сх. Получаем
C°~Cl'T2
как коэффициенты для масштабирующей функции Хаара и
вейвлетов Хаара.
При N > 2 нам потребуются дополнительные условия для оп-
ределения коэффициентов cj.
6.5. Вейвлеты Лобеши
Добеши [11] наложила следующие условия на коэффициенты
су: Она выбрала множество коэффициентов W = (с^-сг^и-со)
так, чтобы линейная комбинация с векторами (1,1,1,1) и
(1,2,3,4) была равна нулю:
(6.5.1) с3 - с2 + сх - с0 = О
с3 -2с2 + 3с, -4с0 =0.
Другими словами, условие (6.5.1) исключает нулевые и первые
моменты. Это означает, что постоянная и линейная часть сиг-
нала может быть значительно сжата. Для изображений, боль-
ших по площади и относительно гладких, например таких, как
изображение «Lena», это дает большое преимущество при
сжатии. Поскольку для таких изображений не только умень-
шается общая ошибка декодирования при заданном коэффи*
циенте сжатия, но также существенно уменьшается блочность,
связанная со сжатием с помощью вейвлетов Хаара.
Используя условие (6.5.1) и условия нормирования и ортого-
нальности, вы можете найти коэффициенты Добеши:
1+Уз ^з+Уз
_ з-Уз _1-Уз
С2= 4Л § С3= 4^'
Эти коэффициенты определяют вейвлеты, называемые D4-
вейвлетами Добеши, Исключение высших моментов приво-
дит к системам вейвлетов Добеши с большим количеством
коэффициентов. Например, Бб-вейвлеты Добеши получа-
ются при исключении не только нулевых и первых, но и
вторых моментов:
12с5 - 22с4 + 32с3 - 42с2 + 52с, - 62с0 = О
Существуют и другие системы вейвлетов Добеши, с 12 и
20 коэффициентами.
Существует простой способ построения графиков таких
вейвлет-функций с помощью применения обратного вейвлет-
преобразования к длинному (например, 1024-точечному)
единичному вектору, т.е. вектору с 1 в одной позиции и ну-
лями во всех остальных позициях [33]. На Рис. 6.5.1 показа-
ны графики D4- и Бб-вейвлет-функций, построенные таким
образом.
(а) (Ь)
Р*. 6.5.h D4 (а) и D6 (Ь) вейвлет-функиии Лобеши. Эти графики были построены
с помощью обратного вейвлет-преобразования елиничного вектора
ллиной 1024, в позициях 6 (а) и 11 (Ь) соответственно
176 Фракталы и вейвлсты для сжатия изображений в действь
04-вейвлет-функция, представленная на Рис. 6.5.1, имеет ря
интересных свойств. Она непрерывная, но не диффереццг!
руемая. В точках А/2", где к и п - целые, производная не Cv
щсствуст. В этих точках есть левая производная, а право
производной нет. Функция равна нулю вне интервала 0 31
Функция, ненулевые значения которой лежат в замкцуТо»
интервале, называется функцией с компактным носип vei/
Все вейвлст-функции Добеши имеют компактный нос !пе%
Э4-вей влет-функция фактически является фракталом ,; ТОм
смысле, что точки, где она не дифференцируема, не ъ <исят
от масштаба. Гладкость вейвлетов Добеши увеличива т я с
увеличением значения /; - числа исключаемых моментов
приобретая примерно половину производной с каждым уве-
личением р. П6-всйвлет-функция Добеши имеет непрерыв-
ную первую производную, но производные высших пор;7дков
не существуют.
6.6. Простое сжатие изображения с помошью
вейвлетов Добеши
То, что вейвлеты Добеши обладают свойством исключать
моменты, означает, что они хорошо подойдут для сжатия
изображений, которые имеют большие гладкие области На-
пример, сегменты изображений примерно одинакового тона
или линейно изменяющегося тона будут сжиматься с помо-
щью этих вейвлетов лучше. Рис 6.6.1 - 6.6.2 показывают, что
Б4-вейвлеты Добеши дают хороший результат при сжатии
изображений «Rose» и «Lena». Сравнение с Рис. 6.2.1 - 6 2.2
показывает, что В4-вейвлет-сжатие дает меньшую ошибку.
чем соответствующее сжатие при помощи вейвлетов Хаара
Кроме того, здесь меньше артефактов блочности. Фактиче-
ски ошибки, вносимые сжатием с помощью вейвлетов Добе-
ши создают впечатление естественного, только неско1ько
нечеткого изображения, как если бы смотрели па это изо-
бражение через окно с мутным стеклом. Это менее неприят-
но, чем блочность, появляющаяся при использовании вейвле-
тов Хаара или фрактального сжатия. В таблице 6 6.1 приве-
дены оценки ошибки для изображения «Lena» при использо-
вании вейвлетов Хаара и Добеши. Эти значения графически
представлены па Рис. 6 6.4.
рис 6.6.1.
Сжатие изображения «Rose» с использованием 04-вейвлетов Лобеши.
(а) 10% вейвлет коэффиииентов; срелняя пиксельная ошибка:
1,8929% (31,7549 Аб по шкале PSNR). (Ь) 5% вейвлет коэффиииентов;
срелняя пиксельная ошибка: 2,8264% (28,0999 Лб по шкале PSNR)
Рис. 6.6.2.
Сжатие изображения «Lena» с использованием 04-вейвлетов Лобеши.
(а) 10% вейвлет коэффиииентов; срелняя пиксельная ошибка:
1,7066% (32,5803 Лб по шкале PSNR). (b) 5% вейвлет коэффиииентов;
срелняя пиксельная ошибка: 2,5006% (28,9101 Лб по шкале PSNR)
Хотя для многих изображений вейвлеты Добеши обеспечи-
вают лучшую производительность сжатия. Рис. 6.6.3 и таб-
лица 6.6.2 показывают, что не всегда преимущество может
быть значительным. Изображение «Winter 1» содержит зна-
чительно больше высокочастотной детальной информации.
Оптимальный выбор вейвлетов для сжатия зависит от изо-
бражения. Этот вопрос рассматривается в работе [27]. Авто-
ры этой работы также предлагают определять количество де-
тализирующей информации в изображении, чтобы облегчить
выбор аппроксимирующей системы вейвлетов.
Рис. 6.6.3.
Хаар:
D4:
D6:
Ср. ошибка
PSNR
Ср. ошибка
PSNR
Ср. ошибка
PSNR
10% коэфф.
2.0376%
30.9052 Аб
1.7066%
32.5803 Аб
1.6699 %
32.8309 Аб
5% коэфф.
2.8925 %
26.3918 Аб
2.5006 %
28.9101 Аб
2.4530 %
29.1049 Аб
1 % коэфф.
5.1009 °о
22 2 69 Дб
4 6811 °о
23.4130 Лб
4.7459%
23.3612 Дб
Таблица 6.6.1.
Оценка ошибки сжатия изображения «Lena» с использованием 10%
5% и 1 % веивлет-коэффициентов для веивлетов Хаара, D4 веивлетов
Лобеши и Об-веивлетов Лобеши
Таблица 6.6.2.
Оценка ошибки сжатия изображения «Winter 1» с использование
10%, 5% и 1% веивлет-коэффициентов лля веивлетов Хаара &'
веивлетов Лобеши и Db-веивлетов Лобеши
т
Изображение «Winter 1» (а) и сжатый вариант (Ь), использующей 70%
коэффициентов 04-вейвлетов Лобеши. Срелняя пиксельная ошибка
4 4540% (24,4362 Лб по шкале PSNR). Сжатие того же изображения
с использованием 10% коэффициентов веивлетов Хаара иволит
к 4 5452% срелней пиксельной ошибке (24,2073 Лб PSNR
Хаар:
D4:
D6:
шшшшшшшшшшшшшшшт
Ср. ошибка
PSNR
Ср. ошибка
PSNR
Ср. ошибка
PSNR
10% коэфф.
4.5452 %
24 2073 А6
4 4540 °о
24.4362 Аб
4.4371 %
24.4696 Аб
5% коэфф.
5.7742 %
21.7420Аб
5.6570 %
22.0399 Аб
5.6506 %
22 0911 Аб
1 % коэфф.
8.1284 %
18.3067 Аб
6.8949 %
18.6811 Аб
6 8417°о
18.7611 Дб
Рис. 6.6.4.
Опенка ошибки сжатия при помощи вей влетов Хаара, DA-вейьлетов
Аобеши и Об-веивлетов Аобеши изображений «Lena» и «Winter 1».
Аля изображения «Lena» вейвлеты Аобеши лают очевилное улучшение
качества по сравнению с вейвлетами Хаара. Олнако лля солержашего
большее количество леталей изображения «Winter 1» значение ошиб-
ки фактически олно и то же для всех трех вейвлетов
Ь.7. Другие системы вейвлетов
(6.7.1)
Рассмотренные здесь вейвлеты Хаара и Добеши - это
только маленький пример из огромного множества систем
вейвлетов, используемых в приложениях обработки сиг-
налов и изображений. Как уже говорилось, системы вейв-
летов Хаара и Добеши обладают свойством компактности
носителя, а также ортогональности. Таким образом, мас-
штабирующие функции фк/1 и вейвлет-функции y/kJ удовле-
творяют равенствам:
(6.7.2)
Кроме того, эти функции также удовлетворяют равенству
(0*.;'V*,/) = ° при всех jj.
180 Фракталы и вейвлеты для сжатия изображений в Действие
Системы вейвлетов Добеши, кроме того, обладают свойства
ми гладкости и исключения моментов.
Есть и другие свойства, которые могут быть полезны в сие
темах вейвлетов. Одно из таких свойств - это симметрия, т е
масштабирующие функции и вейвлет-функции симметрична
относительно своих центров. Вейвлеты Хаара удовлетворяв
этому свойству, а вейвлеты Добеши - нет. Фактически вейв*
леты Хаара - это единственные вейвлеты одновременно и
симметричные, и ортогональные, и обладающие компактным
носителем [12].
Поэтому, например, если нам нужны гладкие, симметричные
вейвлеты с компактным носителем, мы должны отказаться от
ортогональности. Многие из более новых систем вейвлетов
используемых в приложениях, не являются ортогональными
в смысле удовлетворения условиям (6.7.1) - (6.7.2), но зато
удовлетворяют некоторым более слабым свойствам ортого-
нальности. Одно такое свойство - это полуортогональность
[43]. Полуортогональные системы вейвлетов удовлетворяют
равенству (6.7.2), но не удовлетворяют (6.7.1).
Другая слабая форма ортогональности - это
биортогональность. Биортогональность относится к концеп-
ции двойственности. Предположим, что {u\9U2,...9un} - это
множество неортогональных базисных функций. Мы можем
представить функцию/в виде линейной комбинации этих ба-
зисных функций:
п
f(xh^aJuj(x)
Отсутствие ортогональности делает более трудным опреде-
ление коэффициентов я,-. Однако существует другой базис
ul9u2i...9un9 такой что
Я, =(/,";)
Функции Uj обладают также свойством
[ukyUj)=Oy если }Фк
6. Вейвлеты Добеши
181
Базис {П ,м2,...,мп} называется двойственным базисом,
соответствующим {и\,иг,*.*,ип}. Биортогональные вейвлет-
системы состоят из четырех множеств функций: базиса мас-
штабирующих функций J0AJ}, двойственного к нему базиса
}j>kj}, базиса вейвлет-функций \j/kJ\, двойственного к нему
базиса \j/kJ\. Условие биортогональности требует, чтобы эти
множества функций удовлетворяли следующему свойству:
/ „ \ > при всех j,kJ-
Кроме того, двойственность влечет за собой
Биортогональные системы веивлетов стали распространен-
ным средством в приложениях по сжатию изображений. Ав-
торы работы [44] насчитали более 4300 биортогональных
систем веивлетов для приложений по сжатию изображений.
ЕВА 7.
нологии вейвлет-сжатия изображений
В двух предыдущих главах мы рассмотрели простые приме-
ры вейвлет-сжатия изображений, которое заключалось в
применении к изображению вейвлет-преобразования, а затем
удалении части информации из массива преобразования. Эти
примеры иллюстрируют потенциал использования вейвлетов
для сжатия изображений. Однако практические технологии
вейвлет-сжатия изображений, применяемые сегодня, исполь-
зуют более сложные методы кодирования информации с ис-
пользованием вейвлетов, чем простые методы сортировки и
децимации, используемые в предыдущих примерах. В этой
главе мы рассмотрим некоторые вопросы, касающиеся вейв-
лет-сжатия изображений. Мы также введем понятие кодиро-
вания с помощью нуль-деревьев (zerotree encoding) и постро-
им основу для наиболее успешно используемых сегодня схем
вейвлет-сжатия.
Введение
Вейвлет-преобразование легко реализуется и быстро вычис-
ляется. Поэтому неудивительно, что этапы процесса обра-
ботки изображения, не связанные с самим вейвлет-
преобразованием, преобладают в реализации схем вейвлет-
сжатия изображений. Например, в простой схеме сжатия, ис-
пользуемой в предыдущих двух главах, процесс получения
информации о достаточно большом количестве коэффициен-
тов, необходимый для того, чтобы решить, какие коэффици-
енты можно удалить, занимает большую часть времени ко-
дирования. На Рис. 7.1.1 представлено время кодирования
изображения 256 х 256, с использованием различных про-
центов вейвлет-коэффициентов Хаара. Время на вычисление
вейвлет-преобразования в каждом случае остается постоян-
ным и равным 3 сек. С увеличением процента сохраняемых
вейвлет-коэффициентов время, требуемое на выбор этих ко-
эффициентов, увеличивается и занимает большую часть от
общего времени кодирования.
На первый взгляд может показаться, что вейвлет-сжатие изо-
бражения с использованием 10% вейвлет-коэффициентов
обеспечивает степень сжатия 10:1. Однако все не так просто.
Проблема в том, что вдобавок к значениям коэффициент
мы должны знать, какие именно 10% коэффициентов д0л *
ны быть использованы для представления сжатого изобр^ "
ния. Например, если мы хотим сохранить строки и столб?
информации изображения 256 х 256, нам понадобятся
полнительные 2 байта на каждый коэффициент. Кроме тог *
коэффициенты 8-битового изображения потребуют боле'
8 битов для их представления. Например, вейвлет
коэффициенты изображения «Rose» имеют диапазон от -2979
до 22737 и поэтому потребуют полные 2 байта для хранения
Значит, нам нужно примерно 4 байта на хранение каждого
коэффициента (если мы не применяем какие-либо специаль-
ные методы кодирования). 10%-ное вейвлет-сжатие изобра-
жения 256x256 будет иметь 6554 коэффициентов, на каж-
дый из которых требуются 4 байта, и при этом мы получим
степень сжатия приблизительно 2.5:1, а не 10:1. 5%-ное
вейвлет-сжатие изображения обеспечивает степень сжатия
5:1. Использование более 25% вейвлет-коэффициентов не да-
ет вообще никакого сжатия.
Рис. 7.1.1.
Время сжатия (лля PC Pentium 200 МГц) лля изображения 256 х25б
использованием преобразования Хаара. Когла процент леииШ^и
увеличивается, время вейвлет-преобразования остается постоянным
хотя время, требуемое на выбор сохраняемых коэффициент
(«Время леиимаиии»), преоблалает в обшем времени сжатия
7. Технологии вей влет-сжатия изображений
185
Существуют два направления, в которых можно действовать,
чтобы улучшить коэффициент сжатия при вейвлет-
кодировании изображения. Первое - это хранение самих ко-
эффициентов, а второе - это кодирование информации о раз-
мещении коэффициентов.
Методы сжатия значений коэффициентов включают:
• скалярное квантование (scalar quantization), как однородное,
так и неоднородное;
• приравнивание наименьших х% коэффициентов нулю и
квантование оставшихся коэффициентов. Это форма неодно-
родного квантования. К нулевым коэффициентам может
быть применено кодирование длин последовательностей
(runlength coding);
• энтропийное кодирование (entropy coding) коэффициентов.
Методы сжатия информации о размещении коэффициентов
* включают:
• квантование коэффициентов на месте. Сжатие происходит за
счет более низкого битрейта квантования. Этот метод может
сочетаться с кодированием длин последовательностей;
• хранение информации о размещении (т.е. номера строк и
столбцов) вместе со значениями коэффициентов. Это воз-
можно только если количество оставшихся коэффициентов
мало;
• использование двоичной карты значимостей (binary signifi-
cance map). Это структура с 1 битом на каждый коэффици-
ент. Значение «1» показывает значимый коэффициент, а зна-
чение «О» показывает коэффициент, который был квантован
до значения 0. Размер карты значимостей зависит только от
размера изображения, он не зависит от количества значимых
коэффициентов;
• использование структуры нуль-дерева вейвлета (wavelet ze-
rotree structure).
Последний из этих методов, использующий структуру нуль-
дерева вейвлета, - это направление в вейвлет-сжатии изо-
бражений, в котором проводится наибольшее количество со-
временных исследований.
7.2. Нуль-деревья вейвлетов
В главе 5 мы убедились в том, что двумерное вейвлет.
преобразование можно представить как последовательность
вертикальных и горизонтальных высокочастотных и низко-
частотных операторов, применяемых к изображению. Суще^
ствуют четыре варианта композиции операторов: композиция
вертикального высокочастотного и горизонтального высоко
частотного (ННХ); композиция вертикального высокочастот-
ного и горизонтального низкочастотного (LHX), композиция
вертикального низкочастотного и горизонтального высоко-
частотного (HLX); и, наконец, композиция вертикального
низкочастотного и горизонтального низкочастотного (LLX)\
Схема на Рис. 7.2.1 показывает размещение результатов дей-
ствия этих операторов в массиве вейвлет-преобразования.
Эти блоки могут быть структурированы в дерево, как пока-
зано на Рис. 7.2.2. Каждый коэффициент в блоке имеет четы-
ре «дочерних» в соответствующих блоках следующего уров-
ня. Например, на Рис. 7.2.1 представлено вейвлет-
преобразование изображения 8x8, где LL3, ННз, НЬз и LH3 -
это блоки 1 х 1, НН2, HL2 и LH2 - блоки 2 х 2 и ННЬ НЦ и
LHi - блоки 4x4.
Рис. 7.2.1. Структура вейвлет-поллерева. Шх обозначает композицию верти-
кального высокочастотного и горизонтального низкочастотного
операторов, a HLX- композицию вертикального низкочастотного и
горизонтального высокочастотного операторов
Еще раз остановимся на обозначении композиции операторов: LHX, например, означает, что
первым применятся оператор Нх, а затем к результату - оператор L.
Смысл введения структуры дерева в том, что, как правило,
коэффициентыив блоках на различных уровнях обладают
3jjawrejibHOH(_ст^ен]у^ подо^щ. То есть дочерние коэффи-
циенты на некотором уровне, вероятно, будут похожими на
своих «родителей», находящихся на предыдущем уровне. Это
очевидно из примеров, представленных на Рис. 5.8.2 в главе
5 и на Рис. 7.2.3, показанном ниже. В частности, довольно
распространен случай, что если коэффициент квантуется до
нуля, то и его дочерние коэффициенты тоже квантуются до
нуля. Это наблюдение легло в основу так называемого
вейвлет-кодирования с нуль-деревом (wavelet zerotree encod-
ing), впервые примененного Льюисом и Ноулесом (Lewis и
Knowles) [25].
7.2,2.
Блоки вейвлет-поллерева с Рис. 7.2.1 упорялочены злесь в структуру
лерева. Кажлый коэффициент в блоке имеет четыре лочерних,
располагающихся в соответствующих блоках слелуюшего уровня.
Например, если Рис. 7.2.1 прелставляет вейвлет-преобразование
изображения 8x8, то LL3, НН3, HL3 и LH3 - это блоки 1x1, НН2,
HL2, и Ш2 - блоки 2x2 и ННЬ HL, и LHt - блоки 4x4. «Верх» и
«низ» отмечены, поскольку эти термины используются в алгоритме
ну ль-лерева, описанном ниже
Изображение «Lena» (а) и его вейвлет-преобразование (h). Изображе-
ние на Рис. (Ь) состоит из 50% наибольших вейвлет-коэффицнентов
Хаара, прорисованных черным иветом. На нем нанесена структура
вейвлет-поллерева с обозначенными на ней некоторыми высокочас-
тотными и низкочастотными операторами. Обратите внимание на
полобие соответствующих блоков на соселних уровнях
В оригинальной реализации вейвлст нуль-дерева Льюиса и
Ноулеса [25] 0 сопоставляется всем потомкам коэффициен-
тов, квантуемых до нуля. Этот метод можно рассматривать,
как вид кодирования длин последовательностей (runlength
coding). Фактически он гораздо эффективнее традиционного
кодирования длин последовательностей, так как в нем не
требуется кодирования длины последовательности нулей.
Однако, хотя действительно, что те коэффициенты в струк-
туре поддерева, которые квантуются до нуля, вероятно, будут
иметь потомков, которые тоже квантуются до нуля, так же
вероятно и что они будут иметь значимых ненулевых потом-
ков. Эта возможность привносит ошибки в метод нуль-дерева
Льюиса и Ноулеса. Шапиро (Shapiro) [41] предложил моди-
фицированный метод кодирования с нуль-деревом, которь"1
учитывает возможность изолированных нулей. Сеид и П№
ман (Said и Pearlman) [36] и [37] предложили усовершенство-
ванный вариант кодирования с нуль-деревом, названный
«разбиение множества в иерархических деревьях» (Set Part**
tioning in Hierarchical Trees - SPIHT). В следующей главе мы
подробно рассмотрим реализацию кодирования с ну-ПЬ"
деревом, подобную методам, предложенным Шапиро и Спи-
дом и Пилманом.
7. Технологии вей влет-сжатия изображении 189
7.2.1. Реализация вейвлет-кодирования
с нуль-деревом
В этом разделе мы рассмотрим алгоритм кодирования, ис
пользующий преимущество структуры вейвлет-поддер
показанной на Рис 7.2.2 и 7.2.3. Этот алгоритм бы тр
ет хорошие степень сжатия и качество декодирова- -
бражения и имеет важное свойство обеспечивать пр р
иую передачу (progressive transmission). Прогрессивная пер
дача означает, что закодированная информация сохраняется,
а, следовательно, передается таким образом, что промежу-
точный вариант передаваемого изображения содержит пол-
ное приближение к конечному изображению. Это ценм.е
свойство для приложений, таких как Интернет, где нетерпе-
ливые пользователи могут видеть промежуточные изображе-
ния и решать, сюит ли ждать, пока изображение загрузится
полностью, или перейти к чему-то более интересному.
Та конкретная реализация, которая рассматривается здесь,
основывается на идее нуль дерева, использованной Льюисом
и Ноулесом [25], Шапиро [41] и Сеидом и Пилманом [36].
Однако детали реализации принадлежат автору книги, и все
приведенные здесь оценки производительности относятся
только к данной реализации и не должны браться в качестве
показателей самих алгоритмов с нуль еревом. Данная реа-
лизация предназначена только для иллю рации обсуждае-
мых вопросов, а не для использования в качестве завершен
ной системы сжатия. Например, энтропийное кодирование
символов, полученных в результате работы алгоритма, вклю-
ченного во все упомянутые алгоритмы, сюда не в
7.2.1.1. Терминология: Как правильно?
Прежде всего мы должны определить некоторые терми
чтобы описать структуру дерева на Рис 7.2 2. «Верх» от
сится к верху Рис. 7.2.2, т.е. отмечает вейвлет-коэффициенты
наименьшего разрешения. «Низ» относится к части дерева
внизу рисунка, где расположены значения коэффициентов
высокого разрешения. Мы будем работать с огмеченными на
рисунке поддиапазонами дерева LH, НН и HL. Низкочастот-
ные (LL) элементы сосредоточиваются в области наиботь-
ших по модулю коэффициентов. Мы будем просто записы-
вать значения этих выражений как есть, а не кодировать их.
Рис. 7.2.4.
Кажлый
коэффициент
в кажлом блоке,
кроме блоков
самого нижнего
уровня, имеет
четырех потомков
на слелуюшем,
более низком,
уровне
Важным понятием в реализации кодирования с нуль-деревом
является понятие «значимости» коэффициента. Коэффициент
является значимым относительно данной пороговой величи-
ны, если его абсолютное значение превышает этот порог.
Следовательно, возникает вопрос, как выбрать эту порого-
вую величину. В представленной здесь реализации мы будем
получать двоичное представление каждого вейвлет-
коэффициента, поэтому будем выбирать последовательность
пороговых значений, являющихся степенями двойки.
Чтобы отслеживать этап обработки изображения, мы созда-
дим символьный массив того же размера, что и изображение.
Каждый элемент символьного массива перед началом каЖД°*
го сравнения с пороговым значением мы будем полагать ряв*
ным нулю, чтобы показать, что этот элемент еще не обраба-
тывался. Чтобы обозначить обрабатываемый элемент, мы бу*
дем использовать множество из пяти символов. Вот они:
Технологии вей влет-сжатия изображений
191
POS (positive): соответствующий вейвлет-коэффициент после
прохождения порога является значимым и положительным;
NEG (negative): соответствующий вейвлет-коэффициент после
прохождения порога является значимым и отрицательным;
IZ (isolated zero): изолированный ноль, т.е. соответствующий
вейвлет-коэффициент после прохождения порога является
незначимым, но имеет значимых потомков где-то в поддере-
ве под ним;
ZR (zerotree root): корень нуль-дерева, т.е. соответствующий
вейвлет-коэффициент после прохождения порога является
незначимым, и все поддерево потомков этого коэффициента
содержит только незначимые коэффициенты;
ZT (zerotree): незначимый потомок коэффициента, являющегося
корнем нуль-дерева.
В выходной файл записываются только четыре символа: POS,
NEG, IZ и ZR. При декодировании символы ZT раскрываются,
чтобы заполнить свои нулевые поддеревья, поэтому записы-
вать их в файл нет необходимости. Таким образом, мы можем
использовать по два бита на каждый из четырех символов (ра-
зумеется, в завершенной системе использовалось бы энтро-
пийное кодирование в целях достижения более низкого бит-
рейта). Использование двумерного массива символов отлича-
ется от подхода, выбранного Шапиро [41] и Сеидом и Пилма-
ном [36], которые использовали дополнительный список, что-
бы отслеживать значимые коэффициенты. Так как мы не про-
изводим энтропийное кодирование, то мы можем выписывать
символы после каждого прохождения порога, и, таким обра-
зом, нам нужно хранить в памяти всего один символьный мас-
сив, а не по массиву для каждого порогового значения.
7.2.1.2. Работа с незначимыми коэффициентами
Значимые коэффициенты обрабатываются легко: если абсо-
лютное значение коэффициента превышает порог, мы просто
записываем символ POS или NEG в зависимости от знака ко-
эффициента. Незначимые коэффициенты представляют со-
бой более сложную проблему. Прежде чем выберем один из
символов IZ, ZR или ZT для незначимого коэффициента, мы
должны знать все обо всех его потомках, а также его родите-
лях. Это значит, что нам нужна информация о коэффициен-
тах, расположенных как выше, так и ниже текущего коэффи-
циента в дереве.
Мы получаем эту информацию, делая два прохода по коэгК
фициентам: снизу вверх, чтобы обнаружить родителей зц
чимых потомков, и сверху вниз, чтобы обнаружить коп
нуль-дерева. Внутри поддиапазона (LH, НН или HL) сначап
осуществляется проход снизу вверх. На Рис. 7.2.5 предста
лена блок-схема этого процесса. Начиная с нижнего блока
поддиапазоне, мы выявляем значимые коэффициенты и ппи
сваиваем соответствующим элементам в символьном массив
символы POS или NEG. Одновременно мы получаем инфоп
мацию о родителях этих коэффициентов: ни один из родите.
лей этих значимых коэффициентов не может быть корнем
нуль-дерева (ZR) или потомком корня нуль-дерева (ZT); все
они могут быть закодированы символами POS, NEG или 12
В этой точке помечаем всех предков этих значимых коэффц,
циентов как IZ. Таким образом, мы сопоставляем символ 12
всем элементам в символьном массиве, соответствующим
предкам этих коэффициентов. Затем, по мере того как мы
будем подниматься по дереву, эти элементы могут сами ока-
заться соответствующими значимым коэффициентам, и тогда
символы IZ мы заменим символами POS или NEG. В листин-
ге 7.2.1 прилагаемой программы, написанной на C++, пред-
ставлена функция-член mark_j>arents класса tzerotree
Рис 7.2.5.
ПрОХОА
«снизу вверх»
в алгоритме
с нуль-леревом
чг 7.2.1. Функиия-член mark__parents класса tzerotree из прилагаемой
к книге программы на языке C++
void tzerotree::mark__parents (int row,int col,short symbol) {
// Mark the parents of this position (row,col) as having a
// significant child.
// The four "children" of position (i,j) in the subtree
// are: <2i-l,2j-1), (2i-l,2j), <2i,2j-1) and <2i,2j).
// Here, we need to move "backward", or up the tree, and
// determine the parent of a given (row, col) position,
int ichild = row,jchild = col;
int iparent = ichild,jparent = jchild;
while ((iparent > 1)&&(jparent > 1)) {
if ((ichild/2)*2 == ichild) // even
iparent = ichild/2;
else // odd
iparent - (ichild+1)/2;
if ((jchild/2)*2 = jchild) // even
jparent = jchild/2;
else // odd
jparent = (jchild+l)/2;
set(iparent,jparent,symbol);
ichild = iparent;
jchild — jparent;
} // end while
return;
}
В конце прохода снизу вверх для данного диапазона все зна-
чимые коэффициенты будут определены и закодированы
символами POS или NEG и все изолированные нули будут
определены и закодированы символами IZ. Все оставшиеся
коэффициенты - это или корни нуль-дерева (ZR), или потом-
ки корней нуль-дерева (ZT). Чем именно они являются, опре-
деляет проход сверху вниз. Начиная с верха поддиапазона,
мы проверяем массив символов, чтобы узнать, какие коэф-
фициенты были закодированы. Так как мы начинаем сверху,
то любой коэффициент, который еще не закодирован, должен
являться корнем нуль-дерева. Это справедливо для всех ко-
эффициентов, за исключением коэффициентов самого ниж-
него блока. Коэффициенты в нижнем блоке не имеют потом-
ков и поэтому по определению не могут быть корнями нуль-
дерева. Не закодированным коэффициентам из этого блока
сопоставляется символ IZ, а не ZR. Когда корень нуль-дерева
найден, все его потомки в поддереве ниже его отмечаются
символом ZT. В листинге 7.2.2 представлен код для функции-
члена mark_children класса tzerotree, которая работает
здесь.
Проход сверху вниз также записывает символы в двоичны^
выходной файл. Когда встречается символ POS, NEG, 12 или
он записывается с соответствующим 2-битным кодо^
Символ ZT не записывается в выходной файл. На Рис. 7.2,6
показана блок-схема прохода сверху вниз.
Рис. 7.2.6.
Прохол сверху
вниз в алгоритме
с нуль-леревом
Листинг 7.2.2.
Функиия-член mark_children класса class tzerotree из прила-
гаемой к книге программы на языке C++
void tzerotree::mark__children (int row,int col,int nrows,
int ncole,short symbol) {
int child_end_row,child_end_col,child^rows,child^cols;
// The four "children" of position (i,j) in the subtree
// are: <2i-l,2j-1) , <2i-l,2j) , (2i,2j-1) and <2i,2j).
child_end__row - 2*row;
child^end^col = 2*col;
child^rows - 2;
child^cols = 2;
while ((child__end_row<=nrows)&&(child__end_col<=ncols)) I
for (int i=child__end_row-child_rows+l;
i<=child_end_row;i++)
for (int j=child_end_col-child_cols+l;
j<=child_end__col;j++)
7.2.1.3. Алгоритм кодирования с нуль-деревом
Соединим теперь все части алгоритма кодирования. На
Рис. 7.2.7 изображена блок-схема алгоритма. Очевидно, пер-
вый шаг алгоритма - это применение к изображению дву-
мерного вейвлет-преобразования. В прилагаемой к книге
программе может быть выбран любой из трех видов вейвле-
тов, которые мы будем рассматривать в дальнейшем: вейвле-
ты Хаара, Б4-вейвлеты Добеши и Бб-вейвлеты Добеши.
Данный алгоритм может использовать и другие виды вейвле-
тов. Затем задаем начальный порог Г, равный наибольшей
степени 2, но меньший максимального значения вейвлет-
коэффициентов. В программе, прилагаемой к книге, этот
максимум отслеживается автоматически по ходу вычисления
вейвлет-преобразования. Часто наибольшую величину в мас-
сиве преобразования имеет низкочастотный коэффициент LL
(единственный коэффициент в левом верхнем углу массива
преобразования). Этот коэффициент не входит в три поддиа-
пазона LH, HH и HL и поэтому исключается из рассмотрения
при определении максимального коэффициента преобразо-
вания. Он записывается в выходной файл как есть. Кроме то-
го, в выходной файл (в его начало) записывается некоторая
дополнительная информация, необходимая декодеру: вид
вейвлетов (Хаара, D4, D6), размер, т.е. количество строк (ал-
горитм работает только с квадратными изображениями),
и log2(7).
Далее алгоритм входит в цикл. В начале каждого цикла сим-
вольный массив инициализируется нулями. Для каждого
поддиапазона алгоритм выполняет проход снизу вверх и
сверху вниз, как было описано выше. Поддиапазоны обраба-
тываются в следующем порядке: LH, HH, HL. Напомним, что
символы записываются в выходной файл при проходе сверху
вниз. В конце цикла пороговое значение Т вычитается из зна-
чений всех значимых коэффициентов (т.е. всех коэффициен-
тов, которым сопоставлены символы POS или NEG). После
этого порог уменьшается наполовину, и новое пороговое
инг 7.2.2.
юлжение
set(i,j,symbol);
child_end_row *= 2/
child_end_col *= 2;
child_rows *= 2;
child_cols *= 2;
} // end while
return;
}
значение составляет 772. Следующий проход цикла ср^ь
вает новые вейвлет-коэффициенты с этим новым порог ^
Получившиеся в результате символы записываются в вЬГх
ной файл. Цикл повторяется до тех пор, пока Т не станет п
ным 1. Кроме того, существует опция, позволяющая оста
вить цикл еще до выполнения этого условия; о ней мы п
скажем ниже.
Рис. 7.2.7.
Алгоритм
колирования
с нуль-леревом,
рассматриваемый
в ланном разлеле
7.2.1.4. Битовые плоскости
Исследование описанного выше алгоритма показывает, что
при кодировании фактически строятся последовательные
представления вейвлет-преобразования изображения в виде
битовых плоскостей. Заметим, что на каждом пороговом
уровне мы нигде не сохраняем явной информации о фактиче-
ских значениях значимых коэффициентов (кроме их знака).
Но, путем вычитания степеней 2 из коэффициентов, алгоритм
получает двоичное представление значений этих коэффици-
ентов. В результате каждый проход цикла, представленного
на Рис. 7.2.7, создает битовую плоскость, начинающуюся с
наиболее значимых битов и заканчивающуюся наименее зна-
чимыми битами, как показано на Рис. 7.2.8.
Реальные примеры символьно закодированных битовых
плоскостей показаны на Рис. 7.2.9. Эти битовые плоскости
получены при кодировании изображения «Lena» с нуль-
деревом и использованием Б4-вейвлетов Добеши. Изображе-
ния, представленные на Рис, 7.2,9, построены таким образом,
что четырем символам (POS, NEG, IZ, ZR), закодированным
и записанным в выходной файл, на рисунке соответствуют
различные оттенки серого, а символу ZT - белый цвет. Заме-
тим, что большая часть битовых плоскостей 1 - 7 белая, что
означает, что для хранения этих битовых плоскостей не тре-
буется большой объем памяти. Фактически первые три бито-
Битовые плоскости. Алгоритм колирования с нуль-леревом строит
послеловательность битовых плоскостей, соответствующих лвоичному
прелставлению вейвлет-преобразования изображения. Наиболее
значимые биты колируются первыми, а наименее значимые биты
колируются послелними
Ш.2.8.
198 Фракталы и вейвлеты для сжатия изображений в Аейсть
_— jj^
вые пюскости вместе занимают менее 30 байтов, а пепь
семь требуют только 1 Кб памяти. Это хорошо для схе ^
сжатия, так как эти первые битовые плоскости соле^. *
г г г ^Р*ат
большую часть значимых битов и, следовательно, больш
часть значимой информации изображения. Следующие би"
вые плоскости, например, 13 и 14, компактно упаковывают *
с помощью закодированных символов. Однако эти плоское
содержат меньше значимых битов, и поэтому их можно
учитывать в схеме сжатия. Для того, чтобы увидеть результа
удаления части этой информации, нам нужно декодировать
закодированное изображение.
7.2.2. Декодирование изображения,
закодированного с помошью нудь-дерева
Декодировать изображение, закодированное с помощью
путь-дерева, проще, чем закодировать исходное Блок-схема
процесса декодирования представлена на Рис. 7.2.10. Заголо-
вок файла содержит следующую информацию' вид вейвле-
тов, количество строк (которое равно количеству столбцов и,
таким образом, является размером изображения), низкочас-
тотное значение N = log2(nopor) и количество битовых плос-
костей, использование которых будет объяснено ниже. Как и
для кодирования, для хранения символов мы используем
здесь символьный массив такого же размера, как и изобра-
жение. Символьный массив - это реализация того же C++
класса tzerotree, который использовался для кодирования.
Символьный массив инициализируется нулями при каждом
пороговом проходе. Для каждого порогового значения мы
считывает символы для поддиапазонов LH, НН и HL сверх)
вниз из символьного массива. Всякий раз, когда встречается
символ корня нуль-дерева ZR, он распространяется на все
нулевое поддерево путем сопоставления символа ZT всем его
потомкам в символьном массиве. Это распространение пр0"
ИЗВОДИТСЯ С ПОМОЩЬЮ ТОЙ Же фуНКЦИИ-ЧЛена mark_children
класса tzerotree (листинг 7.2.2), которая использовалась ДЛ
кодирования.
Битовые плоскости 1 -- 14 в процессе колирования изображения
Lena» с нуль-леревом с помощью 04-вейвлетов Лобеши
^7.2.9.
Алгоритм леколирования с нуль-леревом
Значения коэффициентов вейвлет-преобразования содержат-
ся в отдельном массиве. В начале процедуры декодирования
этот массив вейвлет-преобразования инициализируется ну-
лями. Коль скоро символьный массив был весь заполнен Р
данного значения порога, значения в массиве вейвЛ^
преобразования обновляются путем добавления пороговог
значения Т к каждому элементу массива, соответствуют^
символу POS, и вычитанием Т из каждого элемента массй
соответствующего символу NEG. Таким образом, значен
коэффициентов вейвлет-преобразования реконструируй
по их двоичным представлениям, причем вначале задейсТ *
ются наиболее значимые биты, а затем менее значимые, h
Рис. 7.2.10.
Технологии вейвлет-сжатия изображений
201
кодированное изображение получают путем применения об-
ратного вейвлет-преобразования, после того как построена
последняя битовая плоскость.
Именно такой порядок битовых плоскостей преобразованно-
го изображения, от более значимых битовых плоскостей к
менее значимым, дает декодирование с нуль-деревом,
обладающее свойством прогрессивной передачи. Чтобы
увидеть, сколько информации передается с каждой битовой
плоскостью, рекомендуется применять обратное
преобразование после построения каждой битовой
плоскости. На Рис. 7.2.11 показан пример использования
такой техники. Изображения на Рис. 7.2.11 были построены с
использованием обратного 04-вейвлет-преобразования
Добеши к битовым плоскостям, изображенным на Рис. 7.2.9.
На Рис. 7.2.12 показаны (a) PSNR и (Ь) пиксельная ошибка
как функции количества битовых плоскостей для изобра-
жений, показанных на Рис. 7.2.11. Заметим, что когда все
битовые плоскости объединены, описанный здесь алгоритм
кодирования-декодирования с нуль-деревом гораздо ближе
к алгоритмам без потерь. Дело в том, что алгоритм пытает-
ся закодировать все двоичное представление коэффициен-
тов преобразования полностью, без отбрасывания какой-
либо информации. Однако получается так, что небольшая
ошибка квантования возникает из-за того, что вейвлет-
коэффициенты являются значениями с плавающей точкой, а
алгоритм кодирует только целую часть этих значений. Кро-
ме того, возникает небольшая ошибка при применения опе-
раторов прямого и обратного вейвлет-преобразования. Это
приводит к пиксельной ошибке (0.99%; 36.4 PSNR), которая
остается после декодирования, примененного ко всем бито-
вым плоскостям.
Рис .2 7 7.
Прогрессивное леколирование изображения «Lena», которое было &'
колировано с помошью алгоритма с нуль-леревом с 04-вейвлетаМи
Лобеши. Кажлое изображение злесь - это результат леколирова^
соответствуюшей битовой плоскости с Рис. 7.2.9
Прогрессии о
лекодиров нис
зображсния «Lena
(Ь) Зависимость пиксельной ошибки и количества битов на пиксел
от битовой плоскости
р*с. 7.2.12.
Значения погрешностей и коэффициента сжатия в зависимости от ко
личества битовых плоскостей. Числа привеленные злесь, соответст-
вуют изображению Lena размером 256x256 заколировтнному с
помощью алгоритма с нуль-леревом с использованием 04-веивлетов
Лобеши, как показано на Рис 7.2 9 и 7 2 11
(а) Зависимость PSNR и коэффиииен а окатия о битовой плоскости
204 Фракталы и вейвлеты для сжатия изображений в действ
7.2.3. Где же сжатие?
На Рис. 7.2.12 также представлен фактический коэффицИей
сжатия на каждом уровне декодирования битовых плоек
стей. К сожалению, реализованный здесь алгоритм без
w эн-
тропийного кодирования символов при использовании все
битовых плоскостей не дает существенного сжатия. Но если
мы исключим несколько последних битовых плоскостей т
при умеренном сжатии мы можем получить очень хорошее
качество декодированного изображения. Например, на 1(Ц
битовой плоскости декодированное изображение будет иметь
2.0% пиксельную ошибку (31.4 PSNR) с коэффициентом
сжатия 5.16:1 (1.5 бита на пиксел). Поэтому количество би-
товых плоскостей включается в заголовочную информацию
сохраненного закодированного изображения. Декодер может
остановиться на желаемой битовой плоскости для достиже-
ния лучшего сжатия.
Существует и другой путь достижения лучшего сжатия. Мы
можем скомбинировать метод децимации из предыдущих
двух глав с алгоритмом нуль-дерева. Децимация применяется
к вейвлет-коэффициентам перед кодированием с нуль-
деревом. Если сохраняются все битовые плоскости, то ре-
зультат получается примерно такой же, как для базового ал-
горитма децимации - и по ошибке декодированного изобра-
жения, и по коэффициенту сжатия. Например, если сохраня-
ются 10% коэффициентов преобразования изображения
«Lena» с помощью Б4-вейвлетов Добеши, любой из алгорит-
мов дает коэффициент сжатия приблизительно равный 2.5:1
и 31-32 Дб PSNR. Мы можем улучшить коэффициент сжатия
изображения, закодированного алгоритмом с нуль-деревом,
за счет внесения небольшой ошибки в декодированное изо-
бражение путем сохранения только 10 битовых плоскостей.
На Рис. 7.2.13 сравниваются базовый алгоритм децимации с
алгоритмом с нуль-деревом, использующим децимацию и
10 битовых плоскостей. При сохранении 10 битовых плоско-
стей и 10% вейвлет-коэффициентов коэффициент сжатия со-
ставляет 7.35:1, a PSNR - 30.3 Дб.
Ш2.13.
Сравнение PSNR и коэффициента сжатия лля алгоритма леиимаиии и
алгоритма с нуль-леревом, использующего леиимаиию и 10 битовых
плоскостей. Алгоритм с нуль-леревом лает лучшее сжатие, при этом
внося меньшее значение PSNR. Используется изображение «Lena»
256 х 256 и D4-вей влеты Лобеши
7.2.4. Скорость кодирования
Важное преимущество алгоритма с нуль-деревом, особенно
по сравнению с фрактальным алгоритмом, это скорость ко-
дирования. На Рис. 7.2.14 сравнивается время кодирования
для алгоритма с нуль-деревом и базового алгоритма децима-
ции. Сжатие достигается только за счет сокращения числа
битовых плоскостей. Процесс децимации включает опера-
цию сортировки, на которую приходится большая часть вре-
мени кодирования. Само вейвлет-преобразование изображе-
ния 256 X 256 занимает приблизительно 3 секунды. Алгоритм
с нуль-деревом без децимации занимает всего секунду или
две, прибавляемые ко времени преобразования. Это время
включает время записи символов в файл. Время децимации
увеличивается с увеличением процента сохраняемых коэф-
фициентов. Для 1% сохраняемых коэффициентов (коэффи-
циент сжатия 25:1) это время незначительно, и поэтому об-
щее время кодирования приблизительно равно времени вейв-
лет-преобразования, т.е. 3 секундам. Для 10% сохраняемых
коэффициентов (коэффициент сжатия 2.5:1) время децима-
Рис. 7.2.14.
Зависимость времени колирования от коэффициента сжатия лля
колирования с нуль-леревом без леиимаиии и базового алгоритма
леиимаиии (npoueccop Pentium 200 МГц). Леиимаиия включает в
себя операиию сортировки, на которую прихолится большая часть
времени колирования лля этого алгоритма
7.3. Смешанное фрактально-вейвлетное кодирование
Самоподобие при любом масштабе - это определяющее
свойство фракталов. Вейвлеты с их способностью выделять
информацию, зависящую от масштаба, являются естествен-
ным инструментом анализа фракталов. Поэтому неудиви-
тельно, что в последнее время исследовательская деятель-
ность сконцентрировалась на комбинировании вейвлетных И
фрактальных методов сжатия изображения. Дэвис [13, 14, 1-М
предложил подход, который использует элементы как фраК*
тального, так и вейвлетного сжатия изображений и предо0'
тавляет основу, которая связывает эти два подхода вместе-
Асгари (Asgari) и др. [1] используют вейвлет-преобразованИ
при построении неаффинного преобразования для схемь
сжатия, основанной на системах итерируемых функций. Xе'
берт и Саундарарян (Hebert, Soundararajan) [21] предлагаю?
ции увеличивается до 15 секунд и составляет большую ца
общего времени кодирования, равного 18 секундам. ^
7. Технологии вей влет-сжатия изображений
207
доменно-ранговое сопоставление в вейвлет-преобразовании
доменов, дающее очень высокий коэффициент сжатия.
Идея, лежащая в основе большинства смешанных фракталь-
но-вейвлетных методов кодирования, состоит в применении
к изображению вейвлет-преобразования с последующим
применением фрактальных методов к вейвлет-образу изо-
бражения, Однако распределение и динамический диапазон
значений вейвлет-коэффициентов может создавать проблемы
при использовании этого подхода. Те самые свойства, кото-
рые делают вейвлет-преобразование выгодным для сжатия
изображений, создают трудности при обращении с вейвлет-
образом изображения. Напомним, что мы можем отбросить
90% и более коэффициентов вейвлет-преобразования, при
этом получая качественную прорисовку исходного изобра-
жения после применения обратного преобразования. Это го-
ворит о том, что основная часть информации об изображении
концентрируется в небольшом числе коэффициентов преоб-
разования. Мы убедились, что значимые коэффициенты в
массиве вейвлет-преобразования сосредоточены главным об-
разом в левом верхнем углу среди низкочастотных значений.
Это очевидно, например, из Рис, 7.2.9, где первые 6 битовых
плоскостей значимых коэффициентов почти все нулевые, за
исключением нескольких значений в левом верхнем углу.
На Рис. 7.3.1 показаны два различных вида квантования
вейвлет-преобразования изображения «Lena». На рисунке
(а) — это равномерное квантование (256 градаций серого).
Почти все изображение квантуется до одного и того же уров-
ня (соответствующего нулевому значению коэффициента
преобразования - преобразование содержит как отрицатель-
ные, так и положительные значения). Это происходит вслед-
ствие широкого динамического диапазона вейвлет-значений,
а также потому, что много значений концентрируется около
нуля (именно благодаря этому вейвлет-преобразование обес-
печивает столь хорошее сжатие!). Динамический диапазон
растет приблизительно как степени 2 на каждом вейвлет-
уровне. На рисунке (Ь) каждый вейвлет-уровень квантовался
независимо, для того чтобы получить большее количество
деталей в преобразованном изображении. Здесь видно боль-
ше деталей, но все еще преобладают вейвлет-значения, кото-
рые квантуются до нуля на каждом уровне.
(а) (Ь)
Рис. 7.3.1. Веивлет преобразование Хаарв изображения Lena (а) Равномерное
квантование (Ь) Отлельное квантование кажлото веивлет-уровня
Проблема с применением фрактального сжатия к веивлет-
преобразованному изображению такому как па показано на
Рис. 7.3.1 (а) или (Ь), в том, что вейвлет-преобразованное
изображение содержит недостаточно информации для фрак-
тального алгоритма. Процесс доменно-рангового сопостав-
ления при фрактальном кодировании не может выделить ка-
кую-либо область изображения для более тщательной обра-
бочки. Поэтом) стандартный фрактальный алгоритм н бес-
печивает достаточную точность кодирования значимой ин-
формации в левом верхнем углу массива вейвлет-
преобразования.
7.3.1. Операторный подход к смешанному
фрактально-вейвлетному кодированию
Дэвис (Davis) [13, 14, 15] предложил смешанный по д, ос~
нованный на построении операторной схемы вейвле образа
изображения Эта операторная схема подобна операторном)
представлению фрактального кодирования, которую 1Ы рас-
сматривали в главе 3 Однако вместо оперирования на блоч-
ных подызображениях, как было в случае фрактального ко-
дирования, Дэвис ввел операторы извлечения поддерева (ge
subtree) и вставки поддерева (put subtree), которые действ)Ют
на поддеревьях в вейвлетной области (Рис 7.3.2).
Рис. 7.3.2.
(7.3.1)
Фрактальное колирование отображает ломенные блоки в ранговые
блоки (а), Лэвис [13, 14, 15] прелложил аналогичную операцию в
вейвлетнои области, отображающую поллерево в поллерево (Ь)
Имея заданное изображение F Е 3 и вейвлет-
преобразование W(F), алгоритм отображает доменное подде-
рево в ранговое поддерево, чтобы получить оператор G вида
W(F)~G(W(F)) + H
Решение уравнения (7.3,1) дается выражением
(7.3.2)
i--\v1(i-g)\h)
Существование решения обеспечивается выполнением усло-
вия ||G|| < 1. Обратите внимание, что данное операторное вы-
ражение подобно стандартному операторному выражению во
фрактальном кодирование Как и в случае фрактального ко-
дирования, уравнение (7.3.2) решается следующим образом:
сначала мы итеративно получаем w(f), а затем применяем
обратное вейвлет-преобразование VV"1
Сведем воедино шаги смешанного алгоритма Дэвиса
Чтобы закодировать изображение F:
1. Применяем вейвлет-преобразование F —> W(F). Реорганизуем
коэффициенты W(F) в вейвлет-поддервья.
2. Устанавливаем систему доменных поддеревьев и отделяем
ранговые поддеревья (аналогично фрактальным доменным и
ранговым блокам). Определяем составной оператор G, ото-
бражающий доменные поддеревья в ранговые поддеревья
так, чтобы минимизировать ошибку в вейвлетнои области.
210 Фракталы и вей влеты для сжатия изображений в Аейсг»
3. Применяем квантование и энтропийное кодирование
Чтобы декодировать изображение:
1. Выделяем оператор G и дополнение Н из квантованных
энтропийно закодированных значений коэффициентов.
2. Начинаем с произвольного изображения У<0) и проводим
итерации:
У00 = (/(У0*0) + Н
3. Применяем обратное вейвлет-преобразование:
F = W~\Y)
Работа с вейвлет-поддеревьями, а не с самими блоками изо-
бражения, позволяет устранить артефакты блочности из де-
кодированного изображения. В результате декодированное
изображение получается более приемлемым с точки зрения
зрительного восприятия, даже когда стандартные оценки
ошибки сравнимы с оценками для стандартных методов. Дэ-
вис [15] достиг достаточно хороших результатов, используя
свой метод самоквантования поддеревьев или метод SQS
(SQS - self-quantization of subtrees). Он сообщает о коэффи-
циенте сжатия 65:1 для изображения 512x512 «Lena» с
PSNR около 30 Дб. С другой стороны, вычислительная слож-
ность этого метода такова, что кодирование этого изображе-
ния занимает более часа на Pentium 133.
7.3.2. Другие смешанные подходы
Хеберт и Саундарарян [21] использовали специальный поря-
док сканирования для преобразования двумерного изображе-
ния в одномерный вектор. Этот вектор затем подразделялся
на ранговые подвекторы фиксированной равной длины. Так-
же устанавливалась система перекрывающихся доменных
подвекторов, длина каждого из которых равна удвоенной
длине рангового вектора. Затем выполнялось одномерное
вейвлет-преобразование каждого доменного и рангового век-
тора. Доменные и ранговые области сравниваются на основе
их вейвлет-преобразований. Скорость достигается за счет то-
го, что вначале сравниваются коэффициенты низкого разре*
шения и исключаются сопоставления, не прошедшие порого-
вый тест. (Авторы сообщают, что кодирование изображения
256 X 256 в градациях серого заняло несколько минут на Р^
7. Технологии вейвлет-сжатия изображений
211
Pentium). Когда наилучшее доменно-ранговое соответствие
найдено, доменные области отображаются в ранговые с ис-
пользованием аффинного преобразования, которое сжимает
доменные области по степеням 2 и применяет оптимальные
масштабирующие и детализирующие значения, определяе-
мые методом наименьших квадратов. Алгоритм достигает
высокого коэффициента сжатия (более 100:1) благодаря его
относительной жесткости. Например, в нем отсутствует
адаптация ранговых областей. Количество ранговых облас-
тей фиксировано, поэтому количество преобразований тоже
фиксировано. Место преобразования в списке определяет
ранговую область, к которой оно применяется. Количество
доменов относительно невелико (в своем примере авторы ис-
пользуют 255 доменов), поэтому доменный индекс занимает
небольшое количество битов. Из всей информации преобра-
зования сохранять нужно только индекс доменов, а также
масштабирующие и детализирующие значения. Ценой этой
жесткости, как можно предположить, является относительно
низкое значение PSNR для декодированных изображений
(порядка 21 Дб). Однако метод, основанный на порядке ска-
нирования, устраняет артефакты блочное™, что приводит к
визуально приемлемым декодированным изображениям, не-
смотря на низкое значение PSNR.
Кавнение фрактального и вейвлетного
входов к сжатию изображений
В предыдущих главах мы рассмотрели способы сжатия изо-
бражения, использующие фрактальный и вейвлетный подхо-
ды. В этой, заключительной, главе, мы сравним эти два подхо-
да и обсудим относительные преимущества каждого. Пред-
ставленные здесь результаты были получены с помощью при-
лагаемой к книге программы. Как мы уже упоминали, эта про-
грамма разрабатывалась только для иллюстрирования изло-
женного в книге материала и не предназначена для непосред-
ственного применения. Системы, сравниваемые здесь, также
не являются законченными системами сжатия. В частности,
здесь отсутствует энтропийное кодирование на выходе фрак-
тального и вейвлетного алгоритмов. При энтропийном коди-
ровании результаты могут отличаться от результатов, пред-
ставленных здесь. Например, те или иные алгоритмы при эн-
тропийном кодировании могут давать большее сжатие. Приве-
денные здесь результаты нужны нам для сравнения относи-
тельных достоинств фрактальных и вейвлетных алгоритмов,
представленных здесь, и не должны сопоставляться с резуль-
татами исследовательских и коммерческих программ.
р. Степень искажения
Степень искажения (rate distortion) сравнивает соотношение
между сжатием и искажением в алгоритмах с потерями.
Оценка определяется как среднее значение числа бит, необ-
ходимого для представления каждого пиксела [40]. Измеря-
ется в битах на пиксел (bpp - bits per pixel). Искажение
обычно измеряется с помощью PSNR, хотя это и не всегда
удобная оценка для воспринимаемого качества изображения.
Кривые оценки искажения обычно представляют собой зави-
симость PSNR от bpp. Однако в литературе по фрактальному
кодированию степень искажения чаще описывают в терми-
нах зависимости PSNR от коэффициента сжатия. Возможно,
причина в том, что фрактальное кодирование не связано с
размером изображения в пикселах, как другие методы коди-
рования. В нашем дальнейшем изложении мы тоже будем
описывать степень искажения в терминах зависимости PSNR
от коэффициента#сжатия. Размер кодируемого изображен^
во фрактальных методах определяется путем сопоставлени
4 байтов каждому ранговому блоку. Коэффициент сжати
определяется путем деления размера исходного растровог
изображения в байтах на количество байтов закодированног
изображения. Искажение, измеряемое через PSNR, определи
ется с помощью декодирования изображения того же разме
ра, что и исходное растровое изображение, и сравнения п^
кодированного изображения с исходным. Для вейвлет*
методов размер кодируемого изображения - это размер дв0„
ичного нуль-дерева, как описывалось в главе 7.
На Рис. 8.1.1 представлен график зависимость PSNR от ко-
эффициента сжатия для различных фрактальных и вейвлет-
ных методов сжатия, применяемых к изображению «Lena»
256 х 256. Эти графики изображают зависимость от коэффи-
циента сжатия качества изображения, выраженного через
PSNR. Наиболее благоприятный участок этого графика - это
правый верхний квадрант, где сочетаются высокий коэффи-
циент сжатия и хорошее качество изображения. В действи-
тельности все алгоритмы кодирования располагаются в ле-
вом нижнем углу, где они должны управлять соотношением
между коэффициентом сжатия и качеством изображения.
Рис. 8.1.1.
Графики зависимости PSNR от коэффициента сжатия лля фракталь^1
и вейвлетных метолов сжатия, примененных к изображению «Len**
(256x256)
8. Сравнение фрактального и вейвлетного подходов к сжатию изображений 215
Существует принципиальное отличие в том, как для фрак-
тальных и вейвлетных алгоритмов, описанных в этой книге,
можно управлять соотношением качества изображения и ко-
эффициента сжатия. Фрактальные методы используют схемы
адаптивных квадродеревьев, которые управляются заранее
определенной допустимой ошибкой. Чем меньше допустимая
ошибка, тем лучше качество декодированного изображения.
Однако это приводит к увеличению числа ранговых блоков,
а следовательно, к ухудшению сжатия. Таким образом, поль-
зователь заранее определяет качество изображения и вынуж-
ден мириться с той степенью сжатия, которая при этом мо-
жет быть достигнута. Можно построить неадаптивные схемы
разбиения, в которых пользователь заранее определяет раз-
биение на ранговые блоки (обычно используется равномер-
ное распределение). Это позволяет пользователю управлять
процессом сжатия, однако для большинства изображений
равномерное распределение приводит к плохому качеству
декодированного изображения.
С другой стороны, вейвлет-методы дают пользователю воз-
можность управлять процессом сжатия, позволяя ему выби-
рать битовые плоскости и/или процент децимации. В этом
случае пользователь заранее определяет степень сжатия и
вынужден мириться с таким качеством декодированного
изображения, которое при этом достигается. Следует пом-
нить об этом отличии между фрактальными и вейвлетными
алгоритмами сжатия при сравнении графиков степени иска-
жения для этих алгоритмов.
Для данного сравнения использовались три фрактальных алго-
ритма: «базовый метод» из главы 3, а также методы классифи-
кации доменов с выделением особенностей FE (FE - feature ex-
traction) и метод самоорганизации SO (SO - self-organizing) из
главы 4. Во всех трех случаях были использованы 1186 доме-
нов (два уровня, горизонтальное и вертикальное перекрывание
равно 0.5). Опция Search for the best domain? (Искать наилуч-
ший домен?) была включена, и это улучшило качество изо-
бражения (за счет времени сжатия, как мы увидим далее). Что-
бы получить различные варианты коэффициентов сжатия и
качества изображения, использовались пять комбинаций глу-
бины квадродерева и допустимой ошибки:
1. Глубина квадродерева 5; допустимая ошибка 0.05;
2. Глубина квадродерева 6; допустимая ошибка 0.05;
216 Фракталы и вейвлеты для сжатия изображений в действи
3. Глубина квадродерева 7; допустимая ошибка 0.05;
4. Глубина квадродерева 6; допустимая ошибка 0.025,
5. Глубина квадродерева 7; допустимая ошибка 0.025.
Как и следовало ожидать, сочетание наименьшей допусти
мой ошибки (0.025) с наибольшей глубиной квадродерева П\
обеспечивает наилучшее качество изображения, но не очень
хорошее сжатие.
Вейвлет-алгоритм - это алгоритм нуль-дерева из главы 7, ис-
пользующий 04-вейвлеты Добеши и реализованный в двух
вариантах: без удаления коэффициентов («без дец.») и с уда-
лением 90% коэффициентов («10% дец.»).
В данном случае базовый фрактальный алгоритм работает
лучше, чем вей влет-алгоритмы или фрактальные FE- и SO-
ал го ритмы, обеспечивая лучшее качество изображения при
приблизительно одинаковых коэффициентах сжатия. На вто-
ром месте находятся вей влет-алгоритмы. Заметим, что для
получения коэффициента сжатия примерно 10:1 или более,
два вейвлет-алгоритма соединяются, обеспечивая, по
существу, одинаковую производительность. Таким образом,
выполнять трудоемкую операцию децимации на этом этапе
сжатия не имеет смысла, так как это не дает никакого выиг-
рыша в степени сжатия (а также, очевидно, и в плане качест-
ва изображения). Алгоритм нуль-дерева без децимации - это,
по-существу, алгоритм без потерь, если используется боль-
шое количество битовых плоскостей. Таким образом неуди-
вительно, что график кривой зависимости PSNR от коэффи-
циента сжатия для этого алгоритма поднимается вдоль оси
PSNR выше остальных графиков. Загвоздка, конечно, в том,
что эта кривая асимптотически приближается к вертикальной
линии, на которой коэффициент сжатия равен 1.
Наихудшую производительность показывают фрактальные
FE- и SO-алгоритмы. Эти алгоритмы разрабатывались как
наиболее быстрые, и скорость достигается за счет некоторого
ухудшения сжатия и качества изображения, как показывает
Рис. 8.1.1. Расхождение между кривыми зависимости PSNK
от коэффициента сжатия для этих алгоритмов и для базового
фрактального алгоритма показывает, что улучшение может
быть достигнуто за счет выбора свойств, используемых в
этих алгоритмах. Никаких попыток оптимизировать выбор
этих свойств сделано не было. Другими исследователям11
рассматривались возможности Фурье [291 и вейвлетов Г211-
8. Сравнение фрактального и вейвлетного подходов к сжатию изображений 217
В качестве второго примера зависимости PSNR от коэффи-
циента сжатия мы рассмотрим результаты, полученные для
изображения «Leaves». Это изображение, а также его фрак-
тальная версия представлены на Рис. 8.1.2. Как показывают
графики зависимости PSNR от коэффициента сжатия, пред-
ставленные на Рис. 8.1.3, это изображение представляет
сложности для кодирования с помощью наших алгоритмов
сжатия.
(а) (Ь)
Рис. 8.1.2. Сложное изображение «Leaves» (256 х256). (а) Исхолное изображение.
(Ь) Изображение, сжатое с помошью базового фрактального алгоритма
с коэффиииентом сжатия 3.8:1 с пиксельной ошибкой 3.1% (25.9
PSNR)
Сравнение с Рис. 8.1.1 показывает, что для этого изображе-
ния все алгоритмы работают значительно хуже по сравнению
с изображением «Lena». Вейвлет-алгоритм нуль-дерева без
децимации дает высокое значение PSNR в тех случаях, когда
используется большое количество битовых плоскостей, но
сжатие при этом практически отсутствует. Заметим, что про-
изводительность этого алгоритма очень близка к производи-
тельности базового фрактального алгоритма. В действитель-
ности графики зависимости степени сжатия от PSNR для
этих алгоритмов пересекаются при степени сжатия около 5:1
при том, что график качества изображения для вейвлет-
алгоритма выше соответствующего графика для фрактально-
го алгоритма при степени сжатия левее точки пересечения.
Фрактальные FE- и SO-алгоритмы ведут себя здесь несколь-
ко лучше, превышая по производительности вейвлет-
алгоритм 10% децимации для небольших степеней сжатия.
Кривые зависимости PSNR от коэффициента сжатия лля фрактальных
и вейвлетных алгоритмов сжатия, примененных к изображению
«Leaves » (256 х 256)
8.2. Скорость кодирования
Кроме коэффициента сжатия и качества изображения, суще-
ствует третий параметр, а именно скорость кодирования, ко-
торый должен приниматься во внимание при сравнении ал-
горитмов сжатия. Именно здесь базовый фрактальный алго-
ритм, который весьма успешно выдерживал конкуренцию со
стороны вейвлетных алгоритмов в предыдущем разделе, по-
видимому должен быть исключен из дальнейшего рассмот-
рения. На Рис. 8.2.1 сравниваются коэффициенты сжатия и
время кодирования (на Pentium 200 МГц). Временная шкала
на вертикальной оси является логарифмической, иначе гра-
фик времени кодирования для базового фрактального алго-
ритма будет слишком отличаться от всех остальных графи-
ков. Значения времени здесь соответствуют параметрам ко-
дирования для изображения «Lena», представленного на
Рис. 8.1.1.
Напомним, что все фрактальные алгоритмы, проиллюстриро-
ванные на Рис. 8.1.1, использовали опцию Search for the best
domain? (Искать наилучший домен?). Когда эта опция включе-
на, процедуры доменно-рангового сопоставления проверяют
все домены, даже если соответствие уже найдено, т.е. находит-
ся в пределах допустимой ошибки. Это обеспечивает несколь-
ко лучший показатель оценки искажения, но приводит к уве-
личению времени кодирования. Как мы видели из табл. 3.3.2 в
главе 3, эта опция может втрое увеличить время работы базо-
вого фрактального алгоритма. В отношении FE- и SO-
алгоритмов положение не столь удручающее - включение этой
опции увеличивает их время работы только в два раза.
На Рис. 8.2.2 показано время кодирования для базового алго-
ритма с включенной опцией Search for the best domain? (Ис-
кать наилучший домен?) («Базовый фракт.») и отключенной
опцией («Базовый фракт. - без поиска»). Кроме того, в по-
следнем случае количество преобразований пространствен-
ной ориентации уменьшено с 8 до 4, чтобы достичь даль-
нейшего сокращения времени кодирования. Эти модифика-
ции в 5 раз уменьшают время кодирования, но, в то же время,
на 2 Дб уменьшают PSNR.
he. 8.2.1. Зависимость времени колирования (на Pentium 200 МГи) лля изобра-
жения «Lena» (256 х 256)
Рис. 8.2,2.
(Ь) Зависимость PSNR от коэффиииента сжатия
(а) Зависимость времени колирования от коэффиииента сжатия
лля изображения «Lena» (256x256). На этом рисунке лля сравнения
привелен результат использования опции Search for the best do-
main? (Искать наилучший ломен?), а также сокращения числа преоб-
разований пространственной ориентаиии с 8 ло 4. (Ь) Зависимость
PSNR от коэффиииента сжатия лля тех же случаев
8. Сравнение фрактального и вейвлетного подходов к сжатию изображений 221
В, Большие изображения
Во всех рассмотренных нами примерах мы имели дело с изо-
бражениями 256 х 256. Такие небольшие изображения удоб-
ны для обработки. Однако во многих статьях по сжатию изо-
бражений приводятся результаты для изображений, стан-
дартный размер которых 512x512. Изображения большего
размера обычно легче сжимаются. Особенно это справедливо
в тех случаях, когда они представляют собой увеличенный
вариант того же изображения, например, когда сравнивается
изображение «Lena» размером 512x512 с тем же изображе-
нием размером 256 х 256. Это неудивительно, так как при
увеличении размера изображения его информационное со-
держимое увеличивается очень незначительно. Фрактальные
методы, в частности, могут использовать преимущество та-
кого незначительного увеличения количества информации
для достижения значительно большей степени сжатия для
больших изображений.
На Рис. 8.3.1 сравниваются графики степени искажения для
фрактального кодирования изображений «Lena» размером
512x512 и 256x256. Заметим, что для изображения боль-
шего размера кривые значительно сдвигаются вправо, пока-
зывая большую степень сжатия при том же уровне PSNR.
Фактически, если мы проведем горизонтальную линию через
некоторое значение PSNR, то увидим, что она пересекает
графики зависимости PSNR от коэффициента сжатия для
большего изображения в точке, соответствующей значению
коэффициента сжатия приблизительно в 4 раза большему,
чем те же графики для меньшего изображения. Пунктирная
линия на Рис. 8.3Л показывает один их таких примеров. Го-
ризонтальная линия на уровне PSNR примерно 26 Дб пересе-
кает кривые FE и SO для изображения 256 х 256 при степени
сжатия 10:1 и пересекает кривые для изображения 512 х 512
при степени сжатия 40:1.
Рис. 8.3.1. Графики зависимости PSNR от коэффициента сжатия для фрактального
колирования изображения «Lena» размером 512x512 и 256x256.
Пунктирная линия показывает пример/ когла лля ланного значения
PSNR коэффициент сжатия приблизительно в 4 раза больше лля
большего изображения
Фактически при одной и той же глубине квадродерева и до-
пустимой ошибке методы фрактального кодирования дают
приблизительно одинаковое количество ранговых блоков для
изображений любого размера. Это видно из Рис. 8.3.2, на ко-
тором представлены графики зависимости PSNR от количе-
ства ранговых блоков для изображений обоих размеров. Раз-
ница в количестве ранговых блоков для этих изображений
очень мала.
Тот факт, что количество ранговых блоков не увеличивается
с увеличением размера изображения - это то же явление,
благодаря которому возникает свойство независимости от
разрешения во фрактальном кодировании, описанное в гла-
ве 3. Фрактальное кодирование ищет в изображении инфор-
мацию. Размер изображения не имеет значения.
к
83.2.
Зависимость PSNR от количества ранговых блоков при фрактальном
колировании изображения «Lena» размером 512 х 512 и 256 х 256
В вейвлет-кодировании ситуация похожая. Здесь, как и для
фрактальных методов, коэффициент сжатия приблизительно
в 4 раза больше для изображения 512x512 по сравнению с
изображением 256 х 256 (Рис. 8.3.3). Примеры на Рис. 8.3.3 -
это вейвлет-кодирование изображения «Lena» с использова-
нием Б4-вейвлетов Добеши без децимации. Пунктирная ли-
ния показывает, что коэффициент сжатия при зафиксирован-
ном уровне PSNR для меньшего изображения равен 20:1,
а для большего - приблизительно 80:1.
8.33.
Графики зависимости PSNR от коэффициента сжатия лля вейвлет-колиро-
вания с нуль-леревом изображения «Lena» размером 512 х512 и 256 х256
Фракталы и вейвлеты для сжатия изображений в лейст^н
Увеличение коэффициента сжатия для больших изображена
не обходится даром - кодирование больших изображена
требует большего времени. Для фрактальных методов врем
кодирования изображения 512x512 приблизительно в дг>
раза больше, чем изображения 256 х 256. Но это не так у^
плохо, если учесть, что большее изображение содержит
4 раза больше пикселов. Для вейвлет-метода с нуль-деревом
без децимации время кодирования большего изображения
фактически увеличивается в 5-6 раз, хотя общее время кодц,
рования остается порядка 30 сек. (на Pentium 200 МГц). При
децимации время кодирования значительно увеличивается
так как добавляется операция сортировки.
8.4. Итоги
В этой книге мы рассмотрели фрактальные и вейвлетные ме-
тоды сжатия изображений. Перед автором книги не стояла
цель «продать» тот или иной метод, каждый сравнивался с
остальными или со стандартными методами, которые ис-
пользуются в настоящее время. Скорее, целью было воору-
жить читателя средствами и информацией для дальнейшего
самостоятельного изучения этих методов.
Фрактальные и вейвлетные методы представляют собой аль-
тернативу технологиям, основанным на преобразованиях
Фурье, таким как JPEG. Как мы уже упоминали в главе 1,
стандарты, такие как JPEG и MPEG, не должны стать тормо-
зом на пути развития дальнейших исследований в области
сжатия изображений. Более того, благодаря успешному ис-
пользованию цифровых изображений в средствах коммуни-
кации эти стандарты помогают находить новые сферы при-
менения технологий сжатия. Новые технологии, такие как
фрактальные и вейвлетные, должны рассматриваться не как
конкуренты, а как союзники в установлении новых стандар-
тов. Фактически вейвлеты являются основой нового стандар-
та JPEG 2000. Комитет по стандарту JPEG (JPEG Committee)
Международной организации по стандартизации (ISO
International Standards Organization) в сотрудничестве с груп'
пой DIG (DIG - Digital Imaging Group) поняли необходимость
обновления оригинального стандарта JPEG в свете роста
объемов цифровых изображений благодаря сети Интернет»
а также в свете возрастающих требований тех, кто создает И
8. Сравнение фрактального и вейвлетного полхолов к сжатию изображений 225
использует цифровые изображения. За последние три года
они разработали стандарт JPEG 2000 как новый стандарт
сжатия цифровых изображений. В соответствии с белой кни-
гой стандарта DIG JPEG 2000 (DIG JPEG 2000 white paper)
[17], вейвлет-технология JPEG 2000 может обеспечивать 20%
улучшение эффективности сжатия по сравнению с предыду-
щими методами сжатия JPEG DCT. JPEG 2000 также исполь-
зует свойство прогрессивной передачи вейвлетов, описанное
в главе 7, чтобы обеспечить конечного пользователя изобра-
жения прогрессивным доступом к качеству разрешения и
глубине цвета. Выпуск JPEG 2000 планируется в начале 2000,
а принятие его в качестве международного стандарта - в том
же году позднее.
Базовый фрактальный метод кодирования может обеспечи-
вать лучшую по степени искажения производительность, т.е.
лучшее сжатие и качество изображения. Однако эта произво-
дительность достигается за счет значительного увеличения
времени кодирования. Более высокая производительность
может быть достигнута за счет использования большего ко-
личества доменов, но это обостряет проблему времени. Мы
предлагаем решить проблему времени с помощью выделения
особенностей и классификации доменов. Это сокращает вре-
мя кодирования до уровня, сравнимого с вейвлет-методами,
но за счет ухудшения степени искажения. Как уже упомина-
лось выше, это предполагает, что используемые особенности,
которые не были каким-либо образом оптимизированы, мо-
гут быть улучшены в дальнейшем. Преимущество процесса
фрактального кодирования в том, что он может быть полно-
стью распараллелен. Доменно-ранговое сопоставление может
производиться одновременно на множестве фрагментов изо-
бражения параллельно в нескольких процессах обработки, не
требующих взаимодействия. Поэтому специализированное
оборудование для параллельной обработки может значитель-
но снизить время кодирования. Такое оборудование обычно
используется компанией Iterated Systems, Inc.
В текущей реализации, такой как описана в этой книге, фрак-
тальные методы, возможно, лучше всего приспособлены для
приложений архивирования, таких как цифровые энциклопе-
дии, где изображение кодируется лишь однажды, а декоди-
руется множество раз. Вейвлет-методы больше подходят для
приложений, требующих быстрого кодирования, например в
226 Фракталы и вей влеты для сжатия изображений в дейсть.^
Интернет-приложениях, или в приложениях от обнаружен
летящих целей до наземного контроля.
Наше понимание изображений как источника информацй
является далеко не полным. Фрактальные методы являют
шагом в новом направлении, ведущем к дальнейшему пои
манию изображений. В отличие от методов вейвлет
преобразований или преобразований Фурье, которые, По
существу, отбрасывают информацию для достижения ежа
тия, фрактальные методы пытаются перестроить изображу
ние, используя взаимоотношения между фрагментами изо-
бражения. Метод доменно-рангового сопоставления, кото-
рый является основой большинства фрактальных методов
далеко не оптимальным образом воплощает теорию фрак-
тального представления изображений. Напомним пример
изображения «лист папоротника» из главы 2, который явля-
ется классическим примером ИФС-изображения. Это изо-
бражение построено с использование всего 4 аффинных пре-
образований. Что получится, если мы применим фрактальное
кодирование к растровому изображению такого же листа па-
поротника? Нам понадобятся сотни и тысячи преобразова-
ний, а декодированное изображение будет не столь хорошим,
как сгенерированное с использованием 4 исходных преобра-
зований. Однако этот простой пример приведен не для того,
чтобы продемонстрировать непригодность фрактальных ме-
тодов, а чтобы подчеркнуть необходимость дальнейшего ис-
следования этих методов для раскрытия их потенциала.
ЛОЖЕНИЕ А.
ользование прилагаемого
граммного обеспечения
Программы, прилагаемые к данной книге, предназначены
для того, чтобы проиллюстрировать изложенные в ней идеи.
Эти программы можно найти на сайте
http://www.spie.org/bookstore/tt40/. Несмотря на то, что было
сделано все возможное для того, чтобы создать стабильную
программу с удобным пользовательским интерфейсом, в ней
отсутствуют многие возможности, которыми обладают ком-
мерческие программы. Также прилагаются и исходные коды,
что дает вам возможность изменить программу и провести
самостоятельное исследование фрактальных и вейвлетных
методов сжатия. При написании программ не ставилась зада-
ча оптимизировать исходный код по скорости, целью было
сделать его простым и ясным для понимания программ и за-
ложенных в них идей. Более подробно исходный код обсуж-
дается в приложениях В и С.
Системные требования. Программное обеспечение разрабо-
тано для работы на PC Pentium под управлением операцион-
ных систем Win32, таких как Windows 95, Windows 98 или
Windows NT; можно также использовать Windows 3.1 с до-
полнением WIN32S. Исполняемые файлы (\ехе) работают без
каких-либо дополнительных динамических библиотек (DLL),
кроме тех, которые входят в стандартную конфигурацию
Windows.
Системы программного обеспечения. Предоставляются три
системы программного обеспечения:
• Система IFS: создает и вычисляет системы итерируемых
функций
• Система IMG: осуществляет фрактальное сжатие изобра-
жений
• Система WAV: осуществляет вейвлет-сжатие изображений и
распечатывает результат
Рис.А.1.1. Основное окно системы IFS с открытым основным меню огш^
окном IFS
А.1. Система IFS
Система IFS создает системы итерируемых функций (Тро
используя отмеченные точки и аффинные преобразова
между множествами точек. На Рис. АЛЛ показано основ *
окно системы IFS с открытым меню, содержащим опции ^
крытия окон различных типов. Программа дает возможное
размещать точки на двумерной сетке и использовать эти то
ки для задания аффинного преобразования. Аффинные пп
образования определяют IFS. Программа вычисляет коэффи
циенты аффинного преобразования и сохраняет их в файле
Этапы построения изображения, являющегося аттрактором
IFS, следующие:
1. Определение точек.
2. Определение аффинного преобразования.
3. Сохранение коэффициентов в файле.
4. Открытие файла коэффициентов и запуск IFS.
В следующих разделах эти шаги обсуждаются более подробно.
ие прилагаемого программного обеспечения 229
АЛЛ. Окно точек
Окно точек содержит сетку для определения координат
точек, которые определят аффинное преобразование. Про-
грамма позволяет импортировать растровое изображение
(меню Image (Изображение)), которое накладывается на
сетку для того, чтобы определить координаты точек. На
Рис. 2.4.1 показан пример сетки с наложенным импорти-
рованным изображением. Вы можете определить коорди-
наты х и у выделяющихся точек изображения, таких как
кончики листьев или углы прямоугольников, ограничи-
вающих букву. Вам необходимо знать заранее, какими бу-
дут ваши преобразования и какие точки будут задавать эти
преобразования. Не забывайте, что здесь должна приме-
няться теорема коллажа (см. раздел 2.3.2). Ваше преобра-
зование должно быть сжимающим (т.е. таким преобразо-
ванием, которое переводит большие области в меньшие)
и должно достаточно точно покрывать изображение
(т.е. стремиться не перекрывать его и не оставлять непо-
крытых участков). Чем более точным будет ваше преобра-
зование-коллаж, тем лучше получится результирующее
IFS-изображение.
Для того чтобы добавить новую точку, выберите команду
меню Edit ♦ Add New Points (Редактирование ♦ Добавить но-
вые точки), затем щелкните на сетке приблизительно в том
месте, где хотите разместить точку. На экране появится диа-
лог X-Y Point (Координаты X-Y точки) (Рис. А. 1.2), позво-
ляющий точно задать координаты точки. После того, как вы
нажмете в диалоге кнопку ОК, на сетке появится точка с при-
своенной ей числовой меткой. Вы будете оставаться в режи-
ме Add New Points (Добавить новые точки) до тех пор, пока
этот пункт меню остается выбранным.
Рис.А.1.2.
Окно точек с открытым меню Edit (Релактирование) и Аналогом лля
релактирования списка точек
Чтобы отредактировать существующие точки, выберите
пункт меню Edit Points (Редактировать точки), а затем щелк-
ните на точке, которую вы хотите отредактировать. Теперь
точку можно перетащить в нужное место. Можно также от-
редактировать точку, выбрав команду меню Edit ♦ Browse
Points List (Редактирование ♦ Просмотреть список точек), ко-
торый вызывает диалог с прокручивающимся списком теку-
щих точек. Двойной щелчок мышью на элементе этого спи-
ска вызывает диалог X-Y Point (Координаты X-Y точки) для
редактирования координат точки. На Рис. А. 1.2 показано ок-
но точек с открытым меню Edit (Редактирование), диалог X-Y
Point (Координаты X-Y точки) и диалог с прокручивающимся
списком точек.
Когда вы будете удовлетворены вашим списком точек, со-
храните список в файл, используя или команду меню File ♦
Save Points File (Файл ♦ Сохранить файл точек), или команДУ
меню File ♦ Save Points File as... (Файл ♦ Сохранить файл то-
чек как...). (Многоточие («...») в пункте меню означает, чТ°
этот пункт меню вызывает диалог. Это соглашение сушесТ'
вует со времен программного обеспечения для самых ранних
компьютеров Macintosh). После этого закройте окно точек.
А.1.2. Окно преобразования
Окно преобразования предназначено для создания, редакти-
рования и сохранения аффинного преобразования по создан-
ному ранее файлу точек. Для того чтобы открыть окно пре-
образования, выберите команду меню Run ♦ New Transforma-
tion Window (Выполнить ♦ Окно нового преобразования), если
хотите создать новые преобразования, или Run ♦ Open Trans-
formation File... (Выполнить ♦ Открыть файл преобразования),
чтобы отредактировать существующий список преобразова-
ний. И в том, и в другом случае на экране появится диалог,
запрашивающий имя файла со списком точек, по которым
будет задано данное преобразование.
А'1.3. Окно преобразования, с открытым меню Edit (Релактирование)
и Аналогом лля реАактирования преобразований
В окне преобразования точки отображаются на такой же сет-
ке, как та, которая использовалась для их создания в окне то-
чек. Но редактировать эти точки в окне преобразования нель-
зя. На Рис. А. 1.3 показано окно преобразования с открытым
232 Фракталы и вейвлеты для сжатия изображений в дейсть
меню Edit (Редактирование) и диалог для редактировали
преобразований. Как и в окне точек, здесь можно импопт
ровать растровое изображение, наложить его на сетку, цТог *
помочь создать преобразования.
Выберите команду меню Edit ♦ Create New Transformation
(Редактирование ♦ Создать новое преобразование), чтоб
начать создавать новое преобразование. Аффинное npeofi
разование задается шестью точками; первую тройку точек
оно переводит во вторую тройку. Точки выделяются левой
кнопкой мыши, а снимается выделение - правой. После то-
го, как вы выбрали точки, они соединяются линиями, а на
первых трех точках и на последних трех точках строится
треугольник. Как мы уже говорили в предыдущем разделе
следует помнить о том, что вы пытаетесь применить теоре-
му коллажа (см. раздел 2.3.2). Второй треугольник должен
быть меньше первого, так как отображение является сжати-
ем, и совокупность вторых треугольников всех преобразо-
ваний должна достаточно точно покрывать изображение,
оставляя как можно меньше непокрытых участков и незна-
чительно перекрывая его. После того, как вы выберете по-
следнюю, шестую точку, определяющую преобразование,
выберите команду меню Edit ♦ Accept New Transformation...
(Редактирование ♦ Сохранить новое преобразование...). На
экране появится диалог Transformation Points (Точки преоб-
разования), как показано на Рис. А. 1.3. Этот диалог позво-
ляет изменить ваш выбор точек, а также определить цвет
для преобразования, используя стандартный диалог Win-
dows для выбора цвета. Выбор цвета определяет цвет диа-
пазона преобразования (т.е. области, ограниченной вторым
треугольником преобразования) в конечном IFS-
изображении.
Вы можете отредактировать ваш список преобразовании с
помощью команды меню Edit ♦ Edit Transformations... (Pe*
дактирование ♦ Редактирование преобразований), которая
вызывает диалог, показанный на Рис. А. 1.3. Этот диалог
можно также использовать для просмотра преобразовании,
выбирая их из списка. При этом на сетке отобразятся Дв
треугольника для выбранного преобразования, причем вто-
рой треугольник будет закрашен цветом, выбранным Дл
этого преобразования.
233
После того как вы завершите создание и редактирование ва-
шего списка преобразований, сохраните список в файле, ис-
пользуя одну из команд меню File ♦ Save Transformation File
(Файл ♦ Сохранить преобразования) или File ♦ Save Transfor-
mation File as... (Файл ♦ Сохранить преобразования как.,.).
Теперь, когда точки и преобразования определены, вы гото-
вы построить свою LFS. Выберите команду меню File ♦ Create
Coeff File... (Файл ♦ Создать файл коэффициентов...) для то-
го, чтобы создать файл коэффициентов IFS. Вам будет пред-
ложено ввести имя файла (*.cff). Затем программа вычислит
аффинные коэффициенты ваших преобразований. Программа
проверит, действительно ли каждое из преобразований явля-
ется сжатием. Если она обнаружит преобразование, не яв-
ляющееся сжатием, то выведет на экран предупреждающее
сообщение, в котором будет указано, какое из преобразова-
ний неверно. Тем не менее, она вычислит аффинные коэф-
фициенты и сохранит их в указанном файле. Когда вы попы-
таетесь вывести на экран LFS-изображение, то система, в ко-
торой присутствует несжимающее преобразование, вероятно,
окажется расходящейся.
А.1.3. Окно IFS
В окне IFS запускается итерационный процесс и выводится
на экран конечное изображение-аттрактор. Изображение мо-
жет быть сгенерировано как с использованием детермини-
стического алгоритма, описанного в разделе 2.4.3.1, так и ве-
роятностного алгоритма, описанного в разделе 2.4.3.2. На
Рис. А. 1.4 показано окно IFS, в котором выведены и вероят-
ностное, и детерминистическое изображения. Команда меню
Run ♦ Run IFS (Выполнить ♦ Выполнить IFS) запускает итера-
ционный процесс, и на экран выводится результирующее
изображение-аттрактор. Остановить итерационный процесс
можно, щелкнув левой кнопкой мыши в любом месте окна
или нажав клавишу [[Езс|, По умолчанию выполняется веро-
ятностный алгоритм. Для того чтобы выбрать детерминисти-
ческий алгоритм, выберите команду меню Run ♦ Use Determi-
nistic System (Выполнить ♦ Использовать детерминистиче-
скую систему). Выберите команду меню Run ♦ Change Det
Start Image... (Выполнить ♦ Изменить детерминистическое
стартовое изображение) и в открывшемся диалоге выберите в
качестве начального изображения квадрат, окружность или
точку.
Рис. Л. 1.4. Окно IFS, в котором прелставлены изображения листа папоротника,
построенные с использованием вероятностного (справа) и летермини-
стического (слева) алгоритма. Начальным изображением лля летерш-
нистического алгоритма в ланном примере была окружность
Для определения различных параметров графики, таких как
координаты х-у окна и цвет фона, служит диалог Graph Setup
(Установки графики), вызываемый при выборе команды ме-
ню Image ♦ Setup Image... (Изображение ♦ Установки изобра-
жения...). Изменение координат х-у окна позволяет рассмот-
реть изображение-аттрактор более подробно (Рис. А. 1.5) (это
свойство доступно только для вероятностного IFS-
атграктора). Команда меню Image ♦ Copy Image to Clipboard
(Изображение ♦ Копировать изображение в буфер обмена)
позволяет напрямую импортировать изображение в дрУг°е
Windows-приложение для печати или просмотра.
{А.1.5.
Аналог Graph Setup (Установки графики) может быть использован лля
изменения коорлинат х-у окна и ивета фона
236 Фракталы и вейвлеты для сжатия изображений в действ.,
А.2. Система IMG: фрактальное сжатие изображений
Система IMG осуществляет фрактальное сжатие изображ
ний, описанное в главах 3 и 4. Она выполняет следующи
действия:
• Кодирование изображения в градациях серого с использова
нием:
i. стандартного фрактального квадродерева кодирования;
п. фрактального квадродерева кодирования с выделением осо-
бенностей;
iii. фрактального квадродерева кодирования с выделением осо-
бенностей и самоорганизующейся нейронной сетью для
классификации доменов.
• Хранение закодированного изображения как в виде текстово-
го так и в виде бинарного ранговых файлов;
• Декодирование изображения, сохраненного в виде текстово-
го или бинарного рангового файла;
• Сравнение декодированного изображения с исходным и вы-
числение ошибки путем вычитания изображений;
• Вывод изображения в градациях серого как двумерной по-
верхности в трехмерном пространстве.
На Рис. А.2.1 показаны пункты меню File (Файл), позволяю-
щие открыть различные типы окон. Закодированное изобра-
жение находится в файле изображения в формате Windows
bitmap (BMP). Существует множество утилит, которые преоб-
разовывают другие форматы изображений, такие как TIFF,
GIF или JPEG, в формат BMP (т.к. мы здесь занимаемся сжа-
тием изображений, то нам не имеет смысла начинать с уже
сжатых изображений, таких как GIF или JPEG). Программа
может считывать и выводить на экран цветные BMP-
изображения. Перед кодированием такие изображения будУ1
преобразованы в изображения в градациях серого.
жение А. Использование прилагаемого программного обеспечения
237
4.2.7. Система IMG лля фрактального колирования изображений. Система
может колировать изображения в гралаииях серого, используя
фрактальные метолы, описанные в главе 3 и 4, и может леколиро-
вать изображения, записанные в ранговых файлах. В окне вычитания
изображений вычисляется ошибка изображения
А.2.1. Окно кодирования
В окне кодирования осуществляется базовое фрактальное ко-
дирование методом квадродерева. Доменно-ранговое сопос-
тавление может основываться на выделении особенностей
(features) или на непосредственном сравнении пикселов. Когда
вы открываете окно кодирования, то на экране появляется
диалог, запрашивающий имя BMP-файла, который должен
быть закодирован. На Рис. А.2.2 показано окно кодирования и
два его меню. Меню Image (Изображение) содержит информа-
цию об изображении, такую как его размер (пункт Bitmap Info...
(Сведения об изображения...))) и все значения характеристик
(Show Image Features... (Показать характеристики изображе-
ния...)). Это именно те характеристики, которые извлекаются
для каждой доменной и ранговой области (см. главу 4) при
Рис. А.2.2.
Окно колирования, меню Run (Выполнить), меню Image (Изображен»
и лиалог image Features (Характеристики изображения)
выбранном режиме выделения особенностей. Команда Мен
Stretch Bitmap (Растянуть изображение) увеличивает или ом,*0
мает изображение в соответствие с размерами окна. Коман
Copy Image to Clipboard (Копировать изображение в буфер 0^
мена) копирует содержимое окна (как растровое изображены \
в буфер обмена Windows, чтобы импортировать его в друГй
Windows-приложения. Меню Run (Выполнить) запускает пои
ложение. Команда меню Run ♦ Gray Image (Выполнить ♦ pD
дации серого) преобразует растровое изображение, отобпа
женное на экране, во внутренний массив значений градации
серого (даже если исходное изображение цветное). Команда
меню Run ♦ Encode Image (Выполнить ♦ Кодирование изобра-
жения) выполняет такое преобразование автоматически перед
началом кодирования. Сравнение изображений (например, в
окне вычитания изображений) осуществляется именно по это-
му массиву, поэтому иногда бывает нужно выполнить команду
Run ♦ Gray Image (Выполнить ♦ Градации серого) и без процес-
са кодирования. Команда меню Run ♦ Remove Redundant Do-
mains (Выполнить ♦ Удалить избыточные домены) сравнивает
домены и удаляет избыточные домены из списка. Домен счи-
тается избыточным, если он может быть отображен в другой
домен с погрешностью, не выходящей за выбранную допусти-
мую погрешность.
Аналог Encode Setup (Установки колирования) - это пример объект-
но-ориентированного Аналога лля релактирования списка. Лвойной
щелчок на пункте списка вызывает соответствующий Аналог лля
релактирования параметра
А.2.1 Л. Установки кодирования
Команда меню Setup ♦ Setup Image Encoding... (Установки ♦
Установки кодирования изображения,..) вызывает диалог
Encode Setup (Установки кодирования) (Рис. А.2.3). Это при-
мер объектно-ориентированного диалога для редактирования
списка. Двойной щелчок на пункте этого списка вызовет
диалог, предназначенный для редактирования значения соот-
ветствующего параметра. Есть, например, числовые пункты,
которые редактируются с помощью диалога, допускающего
только числовые значения и осуществляющего проверку на
максимум-минимум. Пункты Yes-No (Да-Нет) редактируются
с помощью диалога, в котором есть только кнопки Yes (Да) и
No (Нет). Есть также пункты, содержащие имя файла, и пунк-
ты, содержащие значение цвета, которые редактируются с
помощью стандартных диалогов Windows для выбора имени
файла или цвета. Преимущество такого диалога со списком в
том, что он позволяет разработчику (а вы теперь, кроме всего
прочего, еще и разработчик!) добавлять пункты, не изменяя
при этом пользовательский интерфейс.
. А.2.3.
240 Фракталы и вейвлеты для сжатия изображений в дейсть
Параметры в диалоге Encode Setup (Установки кодировани
позволяют управлять выполнением фрактального кодиро*
ния (как скоростью, так и качеством декодированного из "
бражения). Значения, принятые по умолчанию, обеспечивав
приемлемую производительность для изображения в град
циях серого размером 256 х 256. Ниже приведен список па
раметров и зависящих от них показателей:
Domain Rows, Columns (Количество доменов в строке
в столбце). Определяет базовый размер доменного блока'
По умолчанию 8x8.
Domain Levels (Уровни доменов). На каждом уровне базовый
размер домена уменьшается наполовину. Если базовый раз-
мер домена 8x8, то на уровне 2 будут домены размером
8 х 8 и 4 х 4.
Horizontal and Vertical Overlap Delta (Горизонтальное и верти-
кальное перекрывание). Этот параметр определяет степень
наложения доменов, причем чем меньше его значение, тем
больше доменов. Значение 1.0 означает отсутствие наложе-
ния, а значение 0.0 - полное перекрывание (программа тре-
бует, чтобы как минимум 1 пиксел оставался неперекрытым,
иначе мы получим бесконечное количество доменов).
Error Threshold (Допустимая погрешность). Это параметр
предварительного контроля качества. Разница при доменно-
ранговом сопоставлении должна быть меньше этого значе-
ния, чтобы соответствие было приемлемым. Чем меньше
значение этого параметра, тем лучше качество изображе-
ния, но за счет ухудшения сжатия и увеличения времени
кодирования.
Gray Levels (Градации серого). Количество градаций серого,
используемых при преобразовании экранного изображения
во внутренний массив значений градаций серого.
Use Domain Features? (Использовать характеристики доме-
нов?). Эта опция включает или отключает процедуру вычис-
ления характеристик доменов. Когда она отключена (нахо-
дится в состоянии No (Нет)), то доменно-ранговое сопостав-
ление происходит на основе попиксельного сравнения
(т.е. осуществляется базовое фрактальное кодирование)-
В этом случае будьте готовы к тому, что кодирование займет
не один час.
жжение А. Использование прилагаемого программного обеспечения
241
Feature Tolerance (Допустимое отклонение характеристики).
Этот параметр, описанный в главе 4, выполняет функции
стражника. При выбранной опции вычисления характеристик
первая доменно-ранговая проверка осуществляется на основе
значений характеристик. Если расстояние в пространстве ха-
рактеристик меньше допустимого отклонения, то начинается
попиксельное сравнение, использующее параметр допусти-
мой погрешности. Малое значение этого параметра сокраща-
ет время кодирования, но может привести к отбрасыванию
слишком многих доменов. Большое значение сводит на нет
преимущество от использования сравнения характеристик.
Search for the Best Domain? (Искать наилучший домен?). Если
этот параметр имеет значение No (Нет), то доменно-ранговое
сопоставление для данного рангового блока прекращается,
как только соответствие оказывается в пределах допустимой
погрешности. Если он имеет значение Yes (Да), то проверя-
ются все домены и наилучший из них запоминается (и если
соответствие оказывается в пределах допустимой погрешно-
сти, то дальнейшее ветвление квадродерева для данного ран-
гового блока не производится).
Quadtree Depth (Глубина квадродерева). Этот параметр опреде-
ляет максимальную глубину квадродерева для ранговых блоков.
Большие значения (например, 7 для изображения 256 х 256) да-
ют хорошее качество изображения, но плохое сжатие,
S Мах: Максимальный возможный коэффициент контрастно-
сти в аффинном преобразовании. Он должен быть близким к
I. Значения больше 1 могут быть использованы, но есть риск,
что преобразование при этом может перестать быть сжи-
мающим. Слишком маленькое значение увеличивает количе-
ство итераций, требуемых для декодирования.
Number of Transformations (Количество преобразований). Коли-
чество допустимых комбинаций поворотов и отражений для
аффинных преобразований. Максимальное значение, равное 8,
допускает 4 поворота для каждого из 2 отражений. Кодирова-
ние может быть ускорено за счет сокращения этого числа
с 4 до 2, на степень сжатия это повлияет незначительно.
Display graphics during encoding? (Отображать графику в про-
цессе кодирования?). Включает или отключает отображение
графики. Программа выводит на экран дисплея квадродерево
разбиения изображения, отображая его по мере построения в
процессе кодирования. Это позволяет наблюдать за процес-
сом кодирования. Использование этой опции увеличивает
время кодирования всего на 1-2 сек., но если вы хотите полу
чить абсолютный рекорд по скорости, отключите эту опцию
Write features to file? (Записать характеристики в файл?), у Ва
есть опция сохранения векторов характеристик, вычисленных
для каждого доменного блока. Программа запишет семь ха-
рактеристик, представленных в Таблице 4.1.1 (и в диалоге на
Рис. А.2.2) в текстовый файл; семь столбцов данных и одну
строку текста для каждого доменного блока (например, если
всего у нас 320 доменов, то будет записано 320 строк инфор-
мации о векторах характеристик). Заметим, что в действитель-
ности при доменно-ранговом сопоставлении используются
только 5 характеристик, так как вместо горизонтального и вер-
тикального градиентов используется максимальный градиент.
Write features to file? (Имя файла характеристик). Имя файла
характеристик. Этот пункт вызывает диалог обзора файлов.
А.2.1.2. Запуск процесса кодирования изображения
После того как вы выбрали подходящие параметры установ-
ки, можно начинать кодирование изображения. Команда ме-
ню Run ♦ Encode Image (Выполнить ♦ Кодировать изображе-
ние) запускает фрактальное кодирование. Кодирование мо-
жет занять от нескольких секунд - если вы выберете кодиро-
вание с выделением особенностей, до нескольких часов, если
пойдете по пути классического фрактального кодирования.
Построение квадродерева в процессе кодирования отобража-
ется на экране, давая зримую обратную связь с работой алго-
ритма. Вы можете прервать кодирование в любой момент,
нажав клавишу |[ Esc |.
Рис. А.2А.
Это сообщение,
солержашее
статистику,
появляется
по окончании
процесса
колирования
А.2.2. Окно кодирования метолом
самоорганизации
В окне кодирования методом самоорганизации реализуется
фрактальное кодирование, использующее самоорганизую-
щуюся нейронную сеть для классификации доменов, опи-
санную в главе 4. Это окно включает все опции кодирова-
ния, которые есть в обычном окне кодирования плюс опции
для задания и обучения самоорганизующейся нейронной
сети. На Рис. А.2,5 показано это окно с открытым меню
Weights (Веса) и диалогом для установок самоорганизую-
щейся нейронной сети.
. А.2.5. Окно колирования метолом самоорганизаиии солержит меню лля обу-
чения и сохранения весов нейронной сети и лиалог лля залания
параметров, связанных с обучением нейронной сети
244 Фракталы и вей влеты для сжатия изображений в действии
А.2.2.1. Задание самоорганизующейся сети
Первый шаг в задании самоорганизующейся сети - это уста.
новка параметров, которые показаны в диалоге на Рис. А,2 5
Здесь приведены значения, установленные по умолчанию
и они подходят для большинства ситуаций. Ниже приведен
список параметров и их назначение, если вы хотите поэкспе-
риментировать с их изменением:
Lattice Rows, Cols (Количество строк, столбцов решетки). Ко-
личество строк и столбцов весовой решетки. Их произведе-
ние равняется количеству узлов решетки, которое соответст-
вует максимальному числу классов доменов. Между количе-
ством узлов в решетке и количеством доменов в каждом
классе необходим баланс, так как алгоритм должен осущест-
влять поиск как по всем узлам решетки, так и по всем доме-
нам внутри выбранного класса. Большее количество узлов
означает меньшее их количество в каждом классе; меньшее
количество узлов ускоряет поиск по решетке, но зато доме-
нов в каждом классе будет больше.
Starting Stepsize (Начальный шаг). Это начальное значение
шага Е, используемое при обучении сети. Оно управляет ско-
ростью адаптации в процессе итераций обучения. Малое зна-
чение замедляет итерации обучения, а слишком большое
значение может нарушить сходимость.
Starting Nbhd (Начальная окрестность). Это начальный радиус
окрестности решетки при обучающей адаптации. Когда узел
решетки выбирается как winner (результирующий) в процессе
итераций обучения, весовой вектор этого узла, как и весовые
векторы, связанные с каждым из узлов из окрестности этого
узла, адаптируются, чтобы быть более похожими на входной
вектор. Если начальный радиус окрестности слишком мал, то
веса решетки могут «завязаться в узел» при кодировании, что
приведет к плохой топологии обучаемой сети (т.е. рядом в ре-
шетке могут оказаться непохожие векторы). Такие примеры
описаны в [45]. Как правило, начальный радиус окрестности
берется равным половине числа строк (или столбцов) решетки.
Iter Blocksize (Размер итерационного блока). Обучающие ите-
рации делятся на блоки. В конце одного итерационного
блока величина шага адаптации и радиус окрестности со-
кращаются, и обучение продолжается со следующим итера-
ционным блоком.
ожение А. Использование прилагаемого программного обеспечения 245
Iter Blocks (Итерационные блоки). Общее количество итера-
ционных блоков. Общее количество обучающих итераций.
Таким образом, это количество блоков, умноженное на раз-
мер блока. Чем больше сеть, тем больше требуется обучаю-
щих итераций.
Max Search Radius (Максимальный радиус поиска). Это пара-
метр, связанный не с обучением, а с поиском. Когда сеть ра-
ботает как классификатор и в нее вводится входной вектор,
алгоритм поиска выбирает тот узел решетки, весовой вектор
которого наиболее близок к входному вектору. Алгоритм бу-
дет осуществлять поиск среди доменов, связанных с этим уз-
лом, а также искать узлы в радиусе поиска, как показано на
Рис. 4.2.2.
Read weights from file? (Прочитать веса из файла?). При коди-
ровании похожих изображений нет необходимости обучать
алгоритм заново. Если вы хотите просмотреть весовой файл,
обученный на другом изображении, то выберите Yes (Да) в
данном пункте и подставьте имя весового файла в следую-
щий пункт в списке. Если эта опция имеет значение No (Нет),
то алгоритм автоматически начнет процесс обучения по это-
му изображению как часть процесса кодирования.
Weights File Name (Имя весового файла): Имя весового файла.
Это файл, который будет читаться, если в предыдущем пунк-
те было выбрано значение Yes (Да), или имя файла, куда бу-
дут записаны веса, если в предыдущем пункте было выбрано
значение No (Нет).
А.2.2.2. Запуск кодирования метолом самоорганиз аиии
Единственное отличие этого окна от предыдущего окна ко-
дирования - в наличии в нем самоорганизующейся нейрон-
ной сети и файла ее весов. Если вы выберете ранее обучен-
ный весовой файл, то программа считает этот файл и про-
должит кодирование. В противном случае программа обучит
веса по изображению, открытому в данный момент в окне.
Вы можете отделить обучение от кодирования, выбрав ко-
манду меню Weights ♦ Train and Save Weights to File... (Веса ♦
Обучить и сохранить веса в файл...)- Когда начинается про-
цесс обучения, на экране появляется строка линейного инди-
катора, которая показывает, на каком этапе процесса обуче-
ния мы находимся.
А.23. Окно декодирования
Открыть окно декодирования можно при помощи команд
меню File ♦ Open Range File.,. (Файл ♦ Открыть ранговый
файл) или File ♦ Open Binary Range File... (Файл ♦ Открыть би-
нарный ранговый файл). На Рис. А.2.6 показано окно деко-
дирования с открытым меню Run (Выполнить). Как показано
на рисунке, в окне отображается квадродерево, которое стро-
ится в процессе кодирования. При пошаговом декодировании
команда меню Decode Image (Декодирование изображения)
выполняет одну итерацию декодирования. Чтобы увидеть ре.
зультирующее изображение, выберите команду Gray Image
(Градации серого). Чтобы процесс декодирования происхо-
дил автоматически, выберите команду Iterate Decoding (Ите-
рационное декодирование). При этом появится диалог, спра-
шивающий о количестве итераций (по умолчанию - 6 итера-
ций). Выполнив указанное количество итераций, программа
будет автоматически возвращаться к началу цикла, выводя
результирующее изображение на экран на каждом шаге.
Рис. А.2.6.
Окно леколирования, отображающее квалролерево и леколированное
изображение
ожение А. Использование прилагаемого программного обеспечения 247
Напомним, что теорема о сжимающих отображениях утвер-
ждает, что итерации будут сходиться к аттрактору системы
независимо от того, какое начальное изображение вы выбе-
рете. Команда меню Image ♦ Setup Image (Изображение ♦ Вы-
бор изображения) вызывает диалог Decode Setup (Установки
декодирования), в котором вы можете выбрать начальное
изображение. По умолчанию начальное изображение одно-
родно серое. Программа будет заполнять внутренний массив
значений градаций серого, используя значение серого, вве-
денное в пункте Starting Image No (Номер стартового изобра-
жения) диалога Decode Setup (Установки декодирования)
(Рис. А.2.7). Вы можете изменить это значение в диалоге. Вы
также располагаете опцией импортирования растрового изо-
бражения в качестве начального Use Starting Bitmap Image...
(Использовать начальное растровое изображение). Эта опция
вызывает диалог для выбора файла растрового изображения,
загружает выбранный файл и отображает изображение на эк-
ране. Выбор начального изображения не оказывает сущест-
венного влияния на скорость декодирования или на качество
декодированного изображения, зато интересно наблюдать
применение теоремы о сжимающих отображениях в дейст-
вии. На Рис. 3.2.4 и Рис. 3.4.1 показаны примеры выбора раз-
ных начальных изображений.
Заметим, что в диалоге Decode Setup (Установки декодирова-
ния) вы можете также выбрать количество строк и столбцов
для декодированного изображения. Декодер не знает разме-
ров исходного изображения, которое было закодировано,
и ему и не нужно знать их. Размер декодированного изобра-
жения, и фактически его форма, не зависят от размеров зако-
дированного изображения. Декодированное изображение
может быть больше или меньше, быть более сжатым или вы-
тянутым по сравнению с исходным изображением. По умол-
чанию размер декодированного изображения 256 х 256. Если
вы хотите, например, получить размер 512x512, то вам не-
обходимо изменить количество строк и столбцов в диалоге
на 512.
Меню Image (Изображение) содержит также команды для ис-
кажения доменов и преобразований. Эти команды предна-
значены для исследования вопросов надежности передачи,
обсуждаемых в главе 3. Опция искажения доменов случай-
ным образом изменяет некоторый процент доменных индек-
сов. Этот процент является одним из устанавливаемых пара-
метров. Аналогично вы можете исказить процент преобраз0
ваний поворота/отражения. После того как искажение был
сделано, его можно отменить только заново загрузив ранго
вый файл. Разумеется, такое искажение не стоит выполнят*
при обычной работе.
Рис. А.2.7. Меню Image (Изображение) и лиалог с установками лля окна колиро-
вания
А.2.4. Окно вычитания изображений
Окно вычитания изображений сравнивает декодированное
изображение с исходным изображением. Для того чтобы
открыть окно вычитания изображений, необходимо открыть
окно кодирования и окно декодирования. Изображение в
окне кодирования должно быть преобразовано во внутрен-
ний массив значений градаций серого. Если это не было
сделано в результате кодирования, вы можете сделать это с
помощью команды меню Gray Image (Градации серого) в
окне кодирования. Чтобы запустить вычитание изображе-
ний, нужно просто выбрать этот пункт в меню Run (Выпол-
нить) в окне вычитания изображений. Здесь нет никаких
параметров установки. На Рис. А.2.8 показан пример окна
вычитания изображений. Программа сообщает среднюю
пиксельную ошибку и пиковое соотношение сигнал/шум
(PSNR), а также выводит на экран дефект изображения.
Дефект изображения здесь отображается в негативе, т.е. ну-
левой ошибке соответствует белый цвет, а чем больше ее
величина, тем темнее цвет изображения. Чем меньше это
изображение похоже на исходное изображение, тем меньше
ошибка. Окно вычитания изображений работает с самыми
последними открытыми окнами кодирования и декодирова-
ния. Во избежание путаницы, лучше всего открыть нужное
окно кодирования и окно декодирования, прежде чем от-
крывать окно вычитания изображений.
:. А.2.8. Окно вычитания изображений вычитает леколированное изображение
из исхолного колируемого изображения и вычисляет срелнюю
пиксельную ошибку и пиковое соотношение сигнал/шум (PSNR)
А.2.5. Графическое окно
Последнее свойство системы IMG - это окно двумерной гпа
фики. В этом окне изображение выводится в виде двумерно ^
поверхности в трехмерном пространстве. Графическое окн
работает совместно с окном кодирования. Чтобы открыть эт
окно, нужно сначала открыть файл растрового изображения в
окне кодирования и преобразовать это изображение в массив
значений градаций серого. На Рис. А.2.9 показано графиче-
ское окно вместе с соответствующим окном кодирования и
диалог с установками.
Рис. А.2.9.
Окно лвумерного графика с открытым Аналогом установки параметров
Параметры установки управляют построением графика. Па-
раметры Elevation angle (Угол наклона) и Rotation angle (Угол
поворота) определяют угол под которым мы видим график.
Параметры Pixel averaging factor (Средний пиксельный коэф-
фициент) и X Decimation (Х-децимация) и Y Decimation (Y-
децимация) управляют плотностью линий сетки на графике
Pixel averaging factor (Средний пиксельный коэффициент)
жениеА. Использование прилагаемого программного обеспечения 251
уменьшает размер массива изображения путем усреднения
соседних пикселов в исходном изображении. Такое умень-
шенное изображение и есть тот массив, по которому строит-
ся график. Коэффициенты х- и у-децимации уменьшают ко-
личество линий сетки по оси х и у соответственно. Таким об-
разом, у нас есть два способа уменьшения плотности линий
сетки. Если мы положим средний пиксельный коэффициент
равным 4, а коэффициенты децимации равными I, или если
положим средний пиксельный коэффициент равным I, а ко-
эффициенты децимации равными 4, то количество линий
сетки в результате будет одинаковым. Однако чем больше
средний пиксельный коэффициент, тем более гладким полу-
чается график.
Проекции координат определяют размещение виртуальной
центральной проецируемой точки. Это точка, в которой на-
ходится виртуальный наблюдатель. Изменение значений
х и у изменяют наклон графика, а значение z задает расстоя-
ние от наблюдателя до графика. Большие значения z (напри-
мер 100) уменьшают рельефность, а маленькие значения (на-
пример 2) увеличивают ее.
А.З. Система WAV: вейвлет-сжатие изображений
Система WAV выполняет вейвлет-сжатие растровых изобпа
жений, используя вейвлеты Хаара и D4- и Бб-вейвлеты Д0
беши. Кроме того, она может распечатывать вейвлет
функции, а также выводить на экран двумерное вейвлет*
преобразование изображений. В системе WAV реализованы
два различных алгоритма сжатия: базовый алгоритм децима^
ции, описанный в главах 5 и 6, и алгоритм нуль-дерева, опи-
санный в главе 7. В окне Wavelet Compression Window (Окна
вейвлет-сжатия) реализуется базовый алгоритм децимации
сжатие и декодирование изображения. Алгоритм нуль-дерева
реализуется в окнах кодирования и декодирования, и система
может сохранять закодированные нуль-деревом изображения
в файл. На Рис. А.3.1 представлено главное окно программы
с открытым меню File (Файл), позволяющим открывать окна
различных типов.
Рис, А,3.1, Главное окно системы WA V
ожеиие А. Использование прилагаемого программного обеспечения 253
А.3.1. Окно вейвлет-сжатия
В окне вейвлет-сжатия может отображаться как сжатое изо-
бражение (команда меню Run ♦ Show Wavelet Compressed Im-
age (Выполнить ♦ Показать вейвлет-сжатое изображение)),
так и вейвлет-преобразование изображения (команда меню
Run ♦ Show Wavelet Transform (Выполнить ♦ Показать вейв-
лет-преобразование)). Вы можете выбрать один из трех типов
вейвлетов: вейвлеты Хаара, 04-вейвлеты Добеши и D6-
вейвлеты Добеши. Вы можете задать процент сжатия с по-
мощью диалога Compression Percent... (Процент сжатия...),
вызываемого из меню Setup (Установки). Это процент коэф-
фициентов вейвлет-преобразования, которые не будут обну-
ляться перед применением обратного преобразования. Таким
образом, если процент сжатия равен 10, то 10% наибольших
по величине коэффициентов вейвлет-преобразования будут
сохранены, а оставшиеся 90% - положены равными нулю.
Однако, если этот процент равен 0, то никакой децимации
вообще не происходит. Напомним, что процент сжатия 10%
не означает сжатие в соотношении 10:1, так как информация
о расположении оставшихся 10% коэффициентов тоже долж-
на быть сохранена. Обработка, которая выполняется при вы-
боре команды меню Run ♦ Show Wavelet Compressed Image
(Выполнить ♦ Показать вейвлет-сжатие изображения) при
проценте сжатия равном х%9 осуществляется следующим об-
разом:
1. К изображению применяется вейвлет-преобразование, ис-
пользующее выбранный тип вейвлетов,.
2. Максимальные по модулю х% коэффициентов преобразова-
ния сохраняются, а оставшиеся (100-х)% полагаются равны-
ми нулю и удаляются из двумерного массива коэффициентов
преобразования.
3. После децимации к массиву применяется обратное вейвлет-
преобразование. Полученное в результате изображение вы-
водится на экран.
Вы можете узнать ошибку выполнения сжатия, открыв окно
вычитания изображений, так же, как и в системе фрактально-
го сжатия изображений. Точно так же для этого необходимо,
чтобы было открыто окно, отображающее исходное изобра-
жение (команда меню File ♦ Open Image BMP file... (Файл ♦
Открыть BMP-файл изображения...)) и окно вейвлет-
Рис. A3.2. В окне вейвлет-преобразования может отображаться как сжатое изо-
бражение (команла меню Run ф Show Wavelet Compressed Image
(Выполнить ф Показать вейвлет-сжатое изображение)), так и вейвлет-
преобразование изображения (команла меню Run ф Show Wavelet
Transform (Выполнить ф Показать вейвлет-преобразование)), На ри~
сунке привелено изображение Leaves, сжатое с помощью вей влетов
Хаара с оставленными 50% коэффициентов. Тип вейвлетов, проиент
сжатия и пороговый проиент преобразования (лля вывола коэффиии~
ентов вейвлет-преобразования) опрелеляются пользователем в соот-
ветствующих лиалогах
преобразования. Каждое окно должно содержать массив зна-
чений градаций серого для этого изображения (команда ме.
ню Run ♦ Gray Image (Выполнить ♦ Изображение в градациях
серого)).
В окне вейвлет-преобразования может также быть отображен
бинарный вариант вейвлет-преобразования изображения, как
показано на Рис. А.3.2. Эта опция отображает х% наиболь-
ших коэффициентов черным цветом, а оставшиеся (100-*)%
коэффициентов белым. Вывод на экран бинарного изображе-
ния обычно занимает минуту или две, так как в выбор коэф-
фициентов входит операция сортировки.
А.3.2. Вейвлет-кодирование с нуль-деревом
Окно вейвлет-кодирования с нуль-деревом кодирует растро-
вое изображение, используя алгоритм кодирования с нуль-
деревом, описанный в главе 7. На Рис. А.3.3 показан пример
такого окна с открытыми меню Setup (Установки) и Run (Вы-
полнить). Как и в окне базового вейвлет-сжатия, вы можете
выбрать один из трех типов вейвлетов, а также процент сжа-
тия. Процент сжатия - это процент вейвлет-коэффициентов,
которые будут сохранены после децимации. Однако при ну-
левом значении, заданном по умолчанию, децимация вообще
не будет происходить. Кроме того, кодирование с нуль-
деревом имеет опцию Set Max Bit Plane... (Установить макси-
мальную битовую плоскость).
'. А.3.3. Окно колирования с нуль-леревом. Это окно имеет опиии выбора
типа вейвлетов, проиента сжатия и максимальной битовой плоско-
сти, используемые при колировании. В процессе колирования в окне
отображается символьный массив лля кажлой битовой плоскости
При кодировании с нуль-деревом сжатие может достигаться
двумя способами. Первый способ - через децимацию коэф-
фициентов, которая регулируется установленным процентом
сжатия. Второй, более эффективный, состоит в ограничении
максимального числа битовых проекций, используемых ко-
256 Фракталы и вейвлеты для сжатия изображений в дейстьн
дером. Когда это значение равно 0, используются все бито
вые плоскости (обычно их бывает 14-16). Когда вводится 0т
личное от нуля число, кодер останавливается как только ко
личество закодированных битовых плоскостей достигает это
го число. Пример пошагового декодирования, приведенный &
главе 7, показывает качество декодированного изображения
на различных битовых плоскостях.
Когда вы будете готовы к кодированию, выберите команду
меню Run ♦ Wavelet Zerotree Encoding... (Выполнить ♦ Вейвлет-
кодирование с нуль-деревом). Окно кодирования с нуль-
деревом сохраняет закодированное изображение в файл с рас-
ширением *.wvz. В диалоге вам будет нужно ввести имя файла
На битовых плоскостях, выводимых на экран, четыре кодовых
символа изображаются четырьмя градациями серого, а символ
ZT - белым цветом, как показано на Рис. А.3.3. Выбор коман-
ды меню Run ♦ Show Bit Planes During Encoding (Выполнить ♦
Отображать битовые плоскости в процессе кодирования) ото-
бражает каждую символьную битовую плоскость в процессе
кодирования. Когда этот пункт не выбран, на экран выводится
только последняя битовая плоскость. Время, затрачиваемое на
вывод этих битовых плоскостей, не учитывается во времени
кодирования, выводимом на экран в итоге кодирования. Как и
окно вейвлет-преобразования, данное окно может отображать
вейвлет-преобразование, используя параметр Transform Thresh-
old Percent... (Пороговый процент преобразования...) (в про-
цессе кодирования это значение не используется).
А.3.3. Вейвлет-декодирование с нуль-деревом
Окно декодирования с нуль-деревом читает файл с расшире-
нием *.wvz, содержащий данные, записанные в процессе ко-
дирования с нуль-деревом. Информация о типе вейвлетов,
размере изображения и количестве битовых плоскостей со-
держится в самом файле, поэтому в окне нет никаких опции,
влияющих на декодированное изображение. Команда меню
Run ♦ Show Progressive Decoding (Выполнить ♦ Показать де-
кодирование по шагам) отображает каждую битовую плос-
кость, построенную в процессе декодирования. Это занимает
много времени, но наблюдать за этим процессом весьма ин-
тересно. Когда эта опция отключена, на экран выводится
только конечное декодированное изображение. На Рис. А.3.4
показан пример окна декодирования с нуль-деревом в про-
цессе пошагового декодирования.
A3 А. Окно леколирования с нуль-леревом. При выбранной опии и Show
Progressive Decoding (Показать леколирование по шагам) в проиес-
се леколирования отображается кажлая битовая плоскость. Когла эта
опиия отключена, на экран выволится только конечное леколирован-
ное изображение
АЗА. Вычитание изображений в системе WAV
Система WAV имеет опцию вычитания изображений, при по-
мощи которой вы можете вычислить ошибку декодированно-
го изображения. Для вычитания изображений нужно, чтобы
исходное изображение было отображено в окне. Это делается
с помощью команды меню File ♦ Open Image BMP File...
(Файл ♦ Открыть BMP-файл изображения). Прежде чем от-
крыть окно вычитания изображений, изображение должно
быть преобразовано во внутренний массив значений града-
ций серого. Декодированное изображение также должно ото-
бражаться в окне. Это может быть или окно базового вейв-
лет-сжатия, или окно декодирования с нуль-деревом. Когда
оба окна - окно исходного изображения и окно декодирован-
ного изображения - открыты, вы можете открыть окно вычи-
тания и выполнить вычитание изображений для вычисления
ошибки. Чтобы избежать путаницы и непредсказуемых ре-
зультатов от несоответствия декодированного и исходного
изображений, следует открывать только одно окно исходного
изображения и одно окно декодированного изображения.
А.3.5. Окно построения вейвлетов
Окно построения вейвлетов графически отображает вейвлет-
функции Хаара, D4- и Бб-вейвлеты Добеши. На Рис. А.3.5 по-
казан пример этого окна с открытыми меню Run (Выполнить)
и Setup (Установки). В основе метода построения графиков
лежит простой алгоритм, взятый из [33], который эффективно
использует код, уже разработанный для вейвлет-сжатия части
системы. Этот алгоритм просто применяет одномерное обрат-
ное вейвлет-преобразование к единичному вектору, все ком-
поненты которого, кроме одной, равны нулю; эта единствен-
ная компонента равна единице. Вы можете определить, какая
компонента будет ненулевой, используя команду меню Setup *
Set Starting Component... (Установки ♦ Установить начальную
компоненту). График на Рис. А.3.5 был построен с помощью
вектора длины 1024 с 1 Iй компонентой, равной единице.
Рис. А.3.5.
Окно построения вейвлетов может отображать вейвлет-фу^каИ
Хаара, Лобеши-04 и Аобеши-06
Почему этот алгоритм создает график вейвлет-функции? На-
помним, что одномерный вектор вейвлет-преобразования
представляет коэффициенты разложения по базису некоторой
функции, используя масштабированные и сдвинутые версии
вейвлет-функции в качестве базисных функций. Какой тип
функции будет иметь разложение с единственным ненулевым
коэффициентом? Это должна быть одна из базисных функций,
т.е. одна из масштабированных и сдвинутых вейвлет-функции.
Если вы зададите больше начальных компонентов, например
50 или 100, вы увидите, что график вейвлет-функции сдвинет-
ся вправо и сожмется, т.е. это дает сдвиг и масштабирование.
А.3.5.1. Установка параметров графика
Диалог установок графика (Рис. А.3.6) управляет построени-
ем графика, позволяя вам включать или выключать различ-
ные опции, такие как линии сетки или элементы разметки
осей. Вы можете изменить область графика х-у, реализовав
грубое масштабирование, если параметр Scale Window from
Data? (Масштабировать окно по данным?) установите в No
(Нет), а затем измените значения параметров X Min (Мини-
мальное X), X Мах (Максимальное X), Y Min (Минимальное Y)
и Y Мах (Максимальное Y).
:. A.3.6.
Аналог установок графика управляет отображением графика, например,
лобавляя линии сетки и элементы разметки осей
ЕИЛОЖЕНИЕ В.
|блиотека утилит Windows
В этом приложении дается краткий обзор программирования
для Windows и описывается библиотека UWL (Utility Win-
dows Library - Библиотека утилит Windows) - объектно-
ориентированная библиотека классов C++, которая стала ос-
новой для разработки программ, прилагаемых к книге.
|1# Программирование для Windows
С точки зрения программирования, среда Windows определя-
ется интерфейсом API (Application Programming Interface -
Интерфейс программирования приложений) для Windows,
который состоит из более чем тысячи определений функций,
а также определений типов, структур и констант. Чтобы про-
граммировать для Windows на языке С, вы можете писать
код, который напрямую обращается к функциям API. Суще-
ствуют также несколько библиотек классов C++, разработан-
ных для облегчения программирования для Windows. Наибо-
лее известная из них - это библиотека MFC (Microsoft Foun-
dation Classes), которая на сегодняшний день эффективно оп-
ределяет Windows-интерфейс языка C++. Программное обес-
печение, прилагаемое к данной книге, использует для обес-
печения интерфейса со средой Windows собственную встро-
енную библиотеку классов, называемую UWL (Utility Win-
dows Library - Библиотека утилит Windows). Эта библиотека
является основой для легкой реализации подмножества
функций Windows API. Полный исходный код UWL содер-
жится в программном обеспечении.
Зачем было разрабатывать новую библиотеку классов, когда
есть MFC? Во-первых, на момент начала разработки данного
программного обеспечения библиотека MFC не была доста-
точно развита. В то время существовало несколько конкури-
рующих библиотек, в том числе ранняя версия MFC и биб-
лиотека OWL (Object Windows Library) компании Borland.
Впоследствии MFC победила. Однако наличие собственной
библиотеки гарантирует возможность компиляции этого кода
любым компилятором, который поддерживает Windows API.
Этот код был скомпилирован и проверен на компиляторах
Borland C++ 3.1 (только 16-разрядный код), Borland C++ 4.5 и
Borland C++ 5.0, а также Symantec C++ 7.2, и Microsoft Visual
262 Фракталы и вейвлеты для сжатия изображений в Действие
C++ 4.1. Другим преимуществом UWL является малый размеп
получающихся исполняемых файлов (обычно меньш
300 Кбайт), для которых не нужны собственные динамиче
ские библиотеки DLL (Dynamic Link Library). Для сравнения-
исполняемые файлы, которые получаются при использовав
нии библиотеки MFC, достигают размера 1,5 Мбайт и более
Везде, где это возможно, код для вычислений отделен от
Windows-зависимого кода. Это позволяет организовать взаи-
модействие вычислительных модулей с другими библиоте-
ками Windows, например MFC, и даже с другими оконными
платформами, такими как X-Windows для UNIX.
Лучший материал по основам программирования для Win-
dows содержится в книге Петцольда (Petzold) выпуска 1992 г.
[46] или в ее обновленной версии для Windows 95 выпуска
1996 г. [47].
UWL обеспечивает две основные возможности, которые тре-
буются программному обеспечению, прилагаемому к данной
книге, от Windows-интерфейса: во-первых, возможность од-
новременного вывода на экран нескольких окон с графиче-
ской информацией; во-вторых, возможность взаимодействия
с пользователем через диалоги. В следующих разделах эти
две возможности рассматриваются более подробно.
В.1.1. Многооконный интерфейс (MDI)
Большинство коммерческих Windows-программ, таких как
Microsoft Word и Visual C++, используют какую-либо разно-
видность многооконного интерфейса MDI (Multiple Docu-
ment Interface). MDI позволяет одновременно открывать не-
сколько окон. Пользователь может свободно переключаться
между окнами. Фрейм MDI управляет меню и определяет об-
ласти экрана, которые содержат окна приложения. Фрейм
MDI управляет открытием новых окон, а также закрывает
приложение, когда пользователь выходит из него. Клиент-
ское окно MDI - это настоящее окно, которое содержится
внутри фрейма (темно-серый фон на Рис, В. 1.1). Функцио-
нально клиентское окно MDI управляет начальным размеще-
нием дочерних окон, а также может автоматически упоряД0-
чивать дочерние окна с помощью команд Tile (Черепица) или
, Cascade (Каскад) меню Window (Окно).
В.1.1. Основные компоненты MDl-системы включают в себя окно фрейма,
клиентское окно, меню и несколько лочерних окон
В большинстве коммерческих MDI-приложений каждое до-
чернее окно имеет одно и то же поведение. Например, в MS
Word каждое окно является окном редактирования для ввода
текста. Однако есть возможность для MDI-приложения иметь
разные типы дочерних окон, и это на самом деле так для ка-
ждого из приложений, сопровождающих эту книгу. Напри-
мер, система IMG имеет несколько типов окон кодирования и
декодирования, а также окна вычитания и прорисовки изо-
бражений.
В.1.2. Диалоги
Диалоги - это основные средства, с помощью которых про-
граммы взаимодействуют с пользователем. Диалоги воспри-
нимают ввод данных от пользователя, а также могут отобра-
жать для него информацию. Диалоги можно отличить как по
их внешнему виду, так и по их функциональности. Файлы
ресурсов определяют внешний вид диалога. Функции обрат-
ного вызова определяют, что диалог делает. На Рис, В. 1.2,
например, файл ресурсов определяет размеры диалога,
а также расположение и вид его компонентов, включая кноги
ки ОК и Cancel (Отмена), рамку с переключателями Yes (Да\
и No (Нет) и текст Use Domain Features? (Использовать свой.
ства домена?). Файлы ресурсов обычно создаются с помо-
щью визуального редактора ресурсов, хотя можно редакти-
ровать текстовые файлы ресурсов и вручную.
После того как для диалога определен файл ресурсов, его
функциональность можно определить с помощью процедуру
обратного вызова. Процедура обратного вызова предназна-
чена в Windows для определения тех действий, которые
должны быть выполнены в ответ на события, связанные с
диалогом. Примерами таких событий могут быть нажатие
пользователем кнопки ОК или установка переключателя. Ка-
ждый компонент диалога имеет идентификатор, т.е. опреде-
ленную связанную с ним константу, так чтобы программа
знала, когда событие воздействует на этот компонент.
Рис.В.1.2.
Файлы ресурсов опрелеляют внешний вил Аналога, в то время как его
повеление опрелеляется проиелурой обратного вызова
В. 1.2,1. Модальные и немодальные диалоги
В Windows существует два типа диалогов. Наиболее часто
используемым типом диалогов являются так называемые
модальные диалоги. Когда открывается модальный диалог,
он требует от пользователя предельного внимания. Пользо-
ватель не может взаимодействовать ни с одним компонен-
том пользовательского интерфейса вне диалога, пока диа-
лог не исчезнет с экрана, обычно после нажатия кнопок ОК
или Cancel (Отмена). С точки зрения программирования с
модальными диалогами очень легко иметь дело. Пока ди^'
265
лог открыт, программа ничего не делает. Поэтому, если у
вас есть строка кода, которая выполняет диалог, то вы мо-
жете быть уверены в том, что следующая строка кода будет
доступна только тогда, когда пользователь закончит ввод в
диалоге.
Другой тип диалогов Windows - это менее распространенные
немодальные диалоги. Немодальные диалоги позволяют
взаимодействовать с другими компонентами приложения при
открытом диалоге. Немодальные диалоги больше похожи на
обычные окна, чем типичные модальные диалоги. Диалог
проверки орфографии в программе MS Word является приме-
ром немодального диалога, поскольку вы можете покидать
диалог и исправлять ошибки непосредственно в текстовом
окне, в то время как диалог остается открытым, С точки зре-
ния программирования с немодальными диалогами иметь де-
ло несколько сложнее. С одной стороны, функция WinMain
должна быть изменена, чтобы перехватывать сообщения,
предназначенные для немодального диалога, и переадресо-
вывать их этому диалогу. С другой стороны, поскольку диа-
лог открыт, вызывающая программа должна проверять диа-
лог в то время, когда ее собственное выполнение продолжа-
ется. Единственное место в прилагаемом программном обес-
печении, где используется немодальный диалог, находится в
системе IMG, где немодальный диалог используется для ото-
бражения линейного индикатора во время процесса обучения
самоорганизующейся сети.
В.1>2.2. Стандартные диалоги Windows
Windows включает в себя набор предопределенных диалогов
для выполнения стандартных операций, таких как выбор
имени файла или выбор цвета. Эти диалоги, называемые
стандартными диалогами Windows, не требуют файла ре-
сурсов или функций обратного вызова. На Рис. В. 1.3 показа-
ны два стандартных диалога: ChooseColor и
GetOpenFileName. Есть также стандартные диалоги для печа-
ти и выбора шрифта. Вы должны пользоваться преимущест-
вами стандартных диалогов Windows везде, где это возмож-
но, при разработке программ для Windows. Хотя бы потому,
что легче использовать их, чем определять ваши собственные
диалоги. Они также автоматически обновляются вместе с но-
выми версиями Windows. Например, файловые диалоги, ко-
торые входят в Windows 95, и более поздние, а также послед-
ние версии Windows NT, имеют возможность иметь дело с
именами файлов длиннее 8 символов, а также имеют новый
внешний вид, как показано на Рис. В. 1.3. Если ваш код
использует файловый диалог Windows, то он пользуется
всеми преимуществами новой функциональности и внешнего
вида даже без перекомпиляции кода, поскольку доступ к
диалогам осуществляется через DLL. Однако, если вы
разработали свой собственный диалог доступа к файлам, то
он останется с той функциональностью, которая была
заложена в него первоначально.
ChooseColor GetOpenFiieName
ChooseColor и GetOpenFiieName - лва станлартных Аналога Windows.
Эти лиалоги не требуют файла ресурсов или функций обратного вы-
зова, и к ним можно обратиться с помошью еАинственного вызова со-
ответствующей функции API
Рис.В.1.3.
?ис. В.2.7. Иерархия классов лля классов окон в UWL
i.2. Библиотека утилит Windows (UWL)
Библиотека утилит Windows UWL (Utility Windows Library) -
это библиотека классов C++, которая осуществляет основное
управление окнами MDI и диалогами. Разработка интерфейса
пользователя для Windows - идеальный кандидат для напи-
сания на объектно-ориентированном языке, таком как C++.
Насущные задачи, которые являются стандартными для всех
окон и диалогов, могут быть связаны с базовыми классами и
к ним не надо потом возвращаться. Некоторые источники,
ссылки на которые приведены в списке литературы в конце
этой книги, содержат более подробную информацию, ка-
сающуюся использованного здесь подхода к управлению ок-
нами MDI [49] и диалогами MDI [48]. На Рис. В.2.1 показана
иерархия классов в UWL, которые имеют дело с управлением
окнами MDI.
268
Фракталы и вей влеты для сжатия изображений в лей
В.2.1. Класс twindow
Класс twindow - это базовый класс окна, от которого проис
ходят все другие окна, включая окно фрейма и дочерние окна
MDI. Этот класс заботится о распределении задач и о пове-
дении всех окон.
Windows - это среда, управляемая событиями. Действия
пользователя, например перемещение мыши или ввод симво-
лов с клавиатуры, генерируют события. Windows реагирует
на эти события, посылая сообщения в программу. Фактиче-
ски основная программа в любых Windows-программах (на-
зываемая winMain) просто выполняет цикл, который отсле-
живает сообщения среды Windows и передает их в окна при-
ложений. Одно приложение отличается от другого только
способом реагирования на эти сообщения.
Базовый класс twindow отвечает на сообщения Windows через
СВОЮ фуНКЦИЮ-ЧЛен handle_message. В Листинге В.2.1 Пред-
ставлен код этой функции. Функции, такие как
respond_wm_j>aint, задают ответ на определенное сообщение
Windows, в данном случае wm_paint. В twindow этот ответ не
является функциональным. Однако в производных классах
окна необходимо лишь переопределить отдельные функции
ответа на сообщение. Во многих случаях нет необходимости
переопределять саму функцию handie_message. Заметим, что
во многих случаях handie_message возвращает 0. Возвраще-
ние 0 в операционную систему Windows заставляет ее про-
должить обработку сообщения, а ненулевое значение пре-
кращает обработку сообщения. Обычно лучше всего позво-
лить Windows продолжить обработку сообщения после того,
как вы сами его обработали, поскольку может существовать
функциональность, о которой вы не знаете (часть которой
может быть введена в более поздних версиях Windows).
Как Сообщения попадают В функцию handle_message?
В Windows с каждым типом окна связана процедур3
(процедура обратного вызова). Это связывание возникает
путем назначения адреса процедуры окну при его регистра-
ции. Регистрация окна происходит в функции winMain.
В идеальном случае нам хотелось бы назначить адрес функ-
ции-члена handle_message. Однако C++ Не ПОЗВОЛЯеТ назна-
чать адреса функций-членов, так как этот адрес не известен
до тех пор, пока определенный объект (экземпляр) класса не
будет создан во время выполнения. Вот почему twindow име-
ет функцию-член set_giobai^ptr. В производных классах
окна эта функция-член переопределяется так, чтобы устано-
вить глобальный указатель на определенный экземпляр клас-
са окна (с помощью указателя класса this). Этот глобальный
указатель затем определяет конкретный экземпляр функции
handle_message, КОТОрая вызывается ИЗ ГЛобалЬНОЙ функции,
чей адрес предоставляется Windows в качестве процедуры
обратного вызова, связанной с этим типом окна.
стинг В.2.1. Функция-член handle_message класса twindow
LRESULT CALLBACK twindow::handle_message (HWND hwnd,
UINT message, WPARAM wParam, LPARAM lParam) {
/* If "respond^. .." procedure actually does
something,then return, otherwise drop through to
default. */
hwindow = hwnd;
switch (message)
{
case WM_CREATE:
if (respond_wm_create (hwnd)) return 0;
break;
case WM_COMMAND:
if (re spond_wm_command (wPa ram, 1 Pa ram))
return 0;
break/
case WM_PAINT:
if (respond_wmj?aint ()) return 0;
break;
case WM_MDIACTIVATE:
if (respond_wm_mdiactivate(hwnd,wParam,lParam))
return 0;
break;
case WM_SIZE:
if (respond_wm_size(lParam)) return 0;
break;
case WM_HSCROLL:
if (respond_wm_hscroll (wParam,lParam))
return 0;
break;
case WM_VSCROLL:
if (respond_wm_yscroll (wParam,lParam))
return 0;
break;
case WM_QUERYENDSESSION:
if (respond_wm_queryendsession()) return 0;
break;
case WM_CLOSE:
if (respond_wm_close()) return 0;
break;
Листинг В.2.1. Функция-член handlejmes sage класса twindow
(прололжение)
case WM_DESTROY:
if (respond__wm_destroy (hwnd)) return 0;
break;
} /* end switch */
return
default_window_proc (hwindow,message,wParam,lParam);
}
B.2.2. Окно фрейма MDI
Класс tmdi_frame_window ЯВЛЯетСЯ ПрЯМЫМ ПОТОМКОМ Класса
twindow, который реализует окно фрейма MDI. Окно фрейма
отображает меню, взаимодействует с пользователем через
команды меню и пересылает команды пользователя в кли-
ентское окно. Клиентское окно либо прямо отвечает на ко-
манды, либо пересылает их дальше соответствующему до-
чернему окну. UWL не модифицирует поведение клиентского
окна по умолчанию, и поэтому не включает в себя класс C++,
соответствующий клиентскому окну.
Листинг В.2.2 содержит определение класса
tmdi_frame_window. Структура связанного списка
tmdi_type_iist_struct предназначена для управления раз-
личными типами дочерних окон с помощью единственного
класса окна фрейма. Эта структура связывает команду меню
type_id с классом окна the_class. Когда окно фрейма полу-
чает команду меню, оно сначала просматривает связанный
список дочерних окон и проверяет соответствует ли команда
идентификатору какого-либо из этих типов. Если соответст-
вует, то фрейм создает новое дочернее окно этого типа. Этот
связанный список позволяет управлять любым количеством
типов дочерних окон без необходимости создавать новый
класс фрейма для каждого приложения. Единственный мо-
мент, когда вам нужно создать новый класс фрейма, это ко-
гда приложению надо выполнить действие, отличное от от-
крытия дочернего окна (например, когда окно фрейма долж-
но управлять вводом данных пользователя в диалоге).
Окно фрейма отвечает на сообщение Windows wm_create с
помощью функции respond_wm_create, которая создает кли-
ентское окно MDI. Затем окно фрейма может отобразить
диалог About (Сведения). Каждое из приложений, включен-
ных сюда, использует диалог About (Сведения).
утилит Windows
271
Выбранная пользователем команда меню пересылается
функции-члену respond_wm_command. Там тип дочернего окна
Проверяется ПО Связанному СПИСКу tmdi_type_list_struct.
Совпадение инициирует создание дочернего окна MDI соот-
ветствующего класса. Если совпадения нет, то фрейм про-
должает проверять другие обычные команды, включая пре-
допределенные команды, определяющие поведение окон
MDI, такие как расположение дочерних окон мозаикой или
каскадом. Заметим, что это базовое поведение MDI реализу-
ется простой посылкой нужного сообщения клиентскому ок-
ну. Определенная здесь структура команд достаточно общая
для большинства приложений MDL Специфические потреб-
ности, такие как взаимодействие с пользователем через диа-
логи, могут быть реализованы с помощью производных клас-
сов фреймов.
Опрелеление класса лая tmdi_f rame_window
typedef struct tmdi_type_list_tag {
UINT type_id;
LPCSTR the_class;
LPCSTR the_title;
tmdi_type_li st_tag *next ;
} tmdi_type_l i s t_s truet /
void free_mdi_type_l i s t_s truet (tmdi_type_l i s t_s truet
*type_list);
LRESULT CALLBACK _export FrameWndProc (HWND hwnd, UINT
message, WPARAM wParam,LPARAM 1 Pa ram) ;
#define NO_ABOUT 0
#define SHOW_ABOUT 1
class tmdi_frame^window: public twindow {
public:
tmdi_frame_window (HINSTANCE hlnstance,
LRESULT CALLBACK window_proc,int window_extra,
LPCSTR menu^name,
LPCSTR title_name,
LPCSTR class_name,LPCSTR icon_name,
tmdi_type_l i s t_s truet * chi ld_types,
int init_show_about);
HWND hwndClient;
CLIENTCREATESTRUCT clientcreate /
LRESULT CALLBACK lpfnEnum ;
HWND hwndChild ;
MDICREATESTRUCT mdicreate ;
tmdi_type_l i s t_s truet *mdi_chi ldren_types;
272
Фракталы и вейвлеты для сжатия изображений в действии
Листинг В.2.2. Опрелеление класса лля tmdi_f rame_window
Прололжение
UINT latest_command;
HMENU frame_menu, frame_submenu ;
int show_about;
virtual void set^mdicreate (LPCSTR the^class,LPCSTR
the_title);
virtual void set__global_ptr (void) ;
virtual int respond_wm_create (HWND hwnd);
virtual int respond__wm_command (WPARAM wParam,LPARAM
1Param);
virtual int respond__wm_queryendsession (void);
virtual int respond_wm_close (void);
virtual int respond_wm_destroy (HWND hwnd);
virtual int respond__wm_about (void) ;
virtual LRESULT CALLBACK default__window_proc (HWND
hwnd,
UINT mess age, WPARAM wParam, LPARAM lParam) ;
void init_menu (HINSTANCE hinst,LPCSTR menu_rc_name,
WPARAM window_submenu__pos) ;
);
B.2.3. Окна MDI
На Листинге B.2.3 представлен класс, который определяет
основное поведение окон MDI. Базовый класс tmdi_window
переопределяет функцию-член defauit_window_j>roc, чтобы
вызывать функцию Windows DefMDichiidProc, которая опре-
деляет поведение MDI по умолчанию.
Windows отслеживает активные дочерние окна MDI через
список идентификаторов hwnd. Когда дочерние окна созда-
ются или удаляются, Windows добавляет или удаляет иден-
тификаторы hwnd, чтобы этот список правильно отображал
текущие окна, открытые в окне фрейма. UWL представляет
каждое дочернее окно MDI посредством потомка класса
tmdi_child_window, ПОЭТОМу ему нуЖНО ПОДДерЖИВаТЬ 0Т-
дельный список указателей для доступа к активным объектам
C++ класса дочерних окон MDI. Назначение класса
tmdi_manager - поддерживать этот список и пересылать со-
общения Windows в активное дочернее окно.
Структура chiid_window_struet связывает идентификатор
Windows hwnd с указателем на объект класса
tmdi_child_window. Это указатель на КЛаСС object_list, КО-
торый является классом для управления массивом указателей
273
на объекты. Класс tmdi_manager имеет виртуальную
функцию new_chiid_window, которая создает новое дочернее
окно. Для того чтобы создать дочерние окна конкретного ви-
да, вам необходимо создать потомок класса управления MDI,
который переопределит эту виртуальную функцию посредст-
вом версии, создающей нужный тип дочернего окна. Обычно
функции new_child_window И set_global_ptr — ЭТО единст-
венные функции-члены, которые вам необходимо переопре-
делить в производных классах управления.
ФуНКЦИЯ-ЧЛен handle_message класса tmdi_manager обраба-
тывает сообщения wm_create и wm_destroy сама, так что она
может постоянно обновлять свой список активных окон. Со-
общения, которые относятся к дочерним окнам, такие как со-
общения о прорисовке окна или о перемещениях мыши, пе-
ресылаются в активное дочернее окно. Все остальные сооб-
щения обрабатываются по умолчанию стандартным образом.
ФуНКЦИИ-ЧЛенЫ init_menu И set_frame_menu устанавливают
меню и подменю в дочерних окнах и их взаимосвязи с меню
окна фрейма. Эти функции вызываются один раз из функции
winMain, сразу после регистрации окна. Идентификатор
menu_rc_name - ЭТО ИМЯ СТроКИ ДЛЯ МеНЮ ОКНа, Как ОНО ВЫГЛЯ-
ДИТ в файле ресурсов. Параметр window_submenu_j?os сообща-
ет Windows, где разместить список открытых дочерних окон
MDI. Вид этого списка в меню - преимущество, которое вы
получаете бесплатно от системы управления MDI Windows.
Класс tmdi_chiid_window является базовым классом для
конкретных типов дочерних окон. Он инкапсулирует поведе-
ние, общее для всех дочерних окон MDI. Наиболее интерес-
ное поведение заключается в том, что меню окна фрейма ме-
няется при активизации нового дочернего окна. Это выпол-
няет функция-член respond_wm_mdiactivate в ответ на со-
общение wm_mdiactivate. Эта функция использует два мак-
роса: ACTIVATE_MDI_CHILD_WINDOW И MDI_SETMENU_MSGPARAMS.
Имеется две версии этих макросов, одна для 16-разрядных
Windows (такой как Windows 3.1) и одна для 32-разрядных
Windows (таких как Windows 95/98/NT). Эти макросы позво-
ляют использовать один и тот же набор исходных кодов,
который может компилироваться как в 16-разрядном, так и в
32-разрядном окружении.
Листинг В.2.3. Опрелеление класса лля окон MDI
class tmdi_window: public twindow {
public:
// Base class for tmdi_manager and tmdi_child__window
tmdi_window (HINSTANCE hlnstance,LRESULT CALLBACK
window_proc, int window^extra, LPCSTR menu^name
LPCSTR title_name,
LPCSTR class^name, LPCSTR icon__name) :
twindow (hlnstance, window__proc, window_extra,
menu_name, title_name, class^name, icon__name)
{);
virtual LRESULT CALLBACK default_window_proc (HWND
hwnd, UINT message,WPARAM wParam,LPARAM lParam) ;
};
#define MAX_NOjDF_ACTIVE_WINDOWS 20
class tmdi_child__window; // Complete declarations given
// below
class tmdi frame__window;
typedef struct {
HWND hwnd;
tmdi_child_window *window;
) child_window^struct;
class tmdi_jnanager: public tmdi^window {
public:
HWND hwndClient,hwndFrame;
HMENU window_jnenu, window_submenu, f rame_jnenu,
frame^submenu;
tmdi_frame^window *parent^frame;
object_list *window_list;
int active_index;
tmdi^joanager (HINSTANCE hlnstance,
tmdi_frame_window *parent,
LRESULT CALLBACK window_proc,
int window_extra,LPCSTR menu^name,
LPCSTR title_name,
LPCSTR class^name,LPCSTR icon^name);
virtual int respond_wm_create (HWND hwnd);
virtual int respond_wm_destroy (HWND hwnd);
virtual HWND get_active_hwnd (void);
virtual int add_child_window (HWND hwnd,
child_window^struct *child);
virtual child__window_struct *get_child_window
(HWND hwnd,int *index);
virtual LRESULT CALLBACK handle_message
(HWND hwnd,UINT message,
WPARAM wParam,LPARAM lParam) ;
тинг В.2.3. Опрелеление класса лля окон MDI
ыолжение
void init_menu (HINSTANCE hinet,LPCSTR menu^rc^name,
HP ARAM window_submenu__pos) ;
void se^frame^jnenu (HMENU the_f rame^jnenu,
HMENU the_f rame_BUbmenu) ;
virtual ~tmdi_manager ();
);
class tmdi_child_window: public tmdi window {
public:
tmdi_manager ^manager;
tmdi_child_window (HWND hwnd,
tmdi_manager *the_manager,
LPCSTR title_name);
virtual int respond_wm_jndiactivate (HWND hwnd,
WPARAM w Pa ram,
LPARAM lParam)/
virtual int respond__wm_queryendsession (void) ;
virtual int respond_wm_close (void);
);
B.2.4. Графическое окно
UWL ВКЛЮЧаеТ В Себя Класс OKHa MDI tmdi_graph_window ДЛЯ
управления основной функциональностью графиков X-Y.
В Листинге В.2.4 приведены две структуры, которые содер-
жат большинство параметров, определяющих графическое
ОКНО. Структура graph_setup_rec СОДерЖИТ Информацию,
заданную пользователем и определяющую внешний вид гра-
фика, такую как название и разметка осей. Вычисляемые
значения в graph_window_struct определяют взаимоотно-
шения между значениями X-Y и пикселами окна. Все функ-
ции вычерчивания графика используют эти структуры в ка-
честве аргументов. Это шаг к переносимости, поскольку ни-
жележащие функции вычерчивания могут быть изменены
для другой оконной операционной системы (такой как X-
Windows) без изменения кода приложения, который вызывает
эти функции.
276 Фракталы и вейвлеты для сжатия изображений в Действие
Листинг В.2.4. Структуры, используемые графическими окнами MDI
/* graph_setup_rec holde items usually specified by the
/* user. If you add fields to graph_setup_rec be sure to /*
change the constant GRAPH_SETUP_ITEMS. */
typedef struct {
float x__min, x_max, y_min, y_max ;
BOOL scale_jwindow__f rom_data, use_nice_numbers;
BOOL label_x_axis,label_y_axis,label^axes,show_title;
ch ar xaxi s_label,y_axi s_label;
char hor_axis_label[GR__LABEL_LEN +1],
vert_axis_label[GR_LABEL_LEN +1],
graph_title [GR_TITLE_LEN + 1] ,
print_header_l [GR__HEADER_FOOTER_LEN+l] ,
print_header_2 [GR_HEADER_FOOTER_LEN+l] ,
print_footer [GR_HEADER_FOOTER_LEN+l]/
BOOL show__x_tic__marks , show_y_tic_marks ,
label_x_tic marks, label_y_tic__marks ;
float x_tic_size,y_tic_size;
BOOL show_x_max_min, show__y__max_min;
int x_len, y_len, x_dec_jpl ace s, y__dec__pl aces;
BOOL show_x__grid_lines , show_y_grid__lines ;
DWORD line__color, text_color, back_color;
} graph^setup_rec;
/* graph_window_struct holds items that are computed as /*
specific for this window */
typedef struct {
HDC hDC;
HWND HWindow;
RECT rect,draw^rect,iter_rect/
SIZE label_extent;
f loat x__min, y_min, x_max, y_max, x^range, y_range ;
int logical_x_max,logical_y__max,start_col,end_col,
title_row,
s tar t__row, end_row,
x_min_col, x__max_col, y_min_row, y_max_row,
no_of_rows, no_of_cols,
iter_row_l, iter_row^2,
i ter__col, done_row,
x^row, x_center_col,
y_col, y_center__row,
tic_cols,tic^rows,
x_space,y_space;
DWORD line^color,text_color,back_color;
} graph window struct;
277
Класс tmdi_graph_window, определенный в Листинге В.2.5,
предоставляет оконную среду для графического вывода, но
на самом деле он ничего не рисует. Это будет делать произ-
водный класс ОКОН Приложения. Класс tmdi_graph_window
обеспечивает интерфейс пользователя для получения значе-
ний структуры graph_setup_rec. Он также преобразует все,
что есть в окне, в растровую картинку, чтобы окно могло
быть быстро перерисовано в ответ на сообщение Windows
для перерисовки окна (которое может возникнуть, например,
при изменении размера окна или его перекрытии другим ок-
ном) без повторного вычисления значений для построения
графика. Он также обеспечивает возможность копировать эту
растровую картинку в буфер обмена Windows (clipboard),
чтобы изображение графика можно было импортировать в
другие приложения Windows.
Опрелеление класса лля окон MDI
class tmdi_graph_window: public tmdi_child__window
{ public:
HDC memory__dc;
HBITMAP hbitmap;
graph_window_struct gr;
graph_setup_rec gr_setup;
tlis t_box_data gr_setup_data;
tmdi_graph_window(HWND hwnd,tmdi_manager * the_manager,
LPCSTR title_name);
virtual int save_image_to_bitmap();
virtual int OnCopyToClipboard ();
virtual int respond_wm_paint();
virtual int respond__wm_print () ;
virtual int respond_wm_create(HWND hwnd);
virtual int respond__wm_graph_setup () ;
virtual int respond_wm_command (WPARAM wParam, LPARAM) ;
virtual int respond__wm_destroy (HWND hwnd);
virtual ^tmdi graph__window () ;
B.2.5. Функция WinMain в приложении UWL
Каждое приложение Windows имеет функцию WinMain.
ФунКЦИЯ WinMain, подобно фуНКЦИИ Main В обычНОМ прИЛО-
жении C/C++, является главной функцией, которая выполня-
ет приложение. Главная работа, которую выполняет
winMain, - диспетчеризация (пересылка) сообщений Windows
в приложение. Поэтому каждая функция WinMain содержит
стинг В.2.5.
278 Фракталы и вей влеты для сжатия изображений в Дейстьи..
цикл обработки сообщений в качестве основного кода. Ос
новная работа, которую выполняет программист при разпа
ботке функции WinMain для приложения, - определить, куп
пересылать приходящие сообщения.
Шаги, которые выполняются при разработке функции
WinMain для приложения UWL, просты и являются общими
для всех приложений UWL В Листинге В.2.6 представлен
код функции winMain для системы IMG, приложения дЛя
фрактального сжатия изображений, которое включено в со-
провождающее книгу программное обеспечение. Одно из
выдающихся качеств библиотеки UWL - это легкость, с ко-
торой она размещает многие типы окон, все с различной
функциональностью, внутри одного приложения MDI. Сис-
тема IMG включает в себя пять различных типов окон. В раз-
делах А.2.1 - А.2.5 показаны примеры этих типов окон и об-
суждается их функциональность.
Следующие шаги являются общими при разработке функции
winMain для всех приложений UWL MDI. Эти шаги выделе-
ны в коде, представленном на Листинге В.2.6.
1. Определение имен классов Windows для фрейма и каждого
типа дочерних окон. Это строки, которые Windows использу-
ет для идентификации типа окна.
2. Определение связанного списка для типов дочерних окон
MDI. Это связанный список указателей на структуры типа
tmdi_type_l i s t_s t rue t.
3. Определение объекта для окна фрейма и объекта для управ-
ления MDI для каждого типа дочернего окна. Это указатели
на соответствующий класс C++ для каждого типа. Для IMG
имеется пять таких классов дочерних окон:
tenc_window_manager для управления основными окнами
фрактального кодирования изображений,
tself_org_enc_windowjnanager ДЛЯ управления фракталь-
ным кодированием изображений с самоорганизующейся до-
менной классификацией, tdec_windowjnanager для управле-
ния окнами, которые декодируют и отображают фрактально
кодированные изображения, tsub_window_manager ДЛЯ
управления окнами вычитания изображений,
tplt2d_window_manager для управления окнами, которые
отображают двухмерную поверхность изображений.
4. Заполнение элементов связанного списка дочерних типов.
Создание одного элемента для каждого типа дочернего окна.
type_id - это идентификатор ресурсов меню для пункта ме-
ню, который открывает это дочернее окно, the_ciass - это
класс строк Windows, определенный выше. Заметим, что IMG
фактически имеет шесть элементов в этом связанном списке,
в то время как тип окна декодирования имеет две различные
команды меню, которые ему соответствуют. Идентификато-
ры меню для IMG следующие: img_open (для основного окна
кодирования), img_open_range и imgjdpen_binary_range
(окно декодирования, соответствующее двум типам ранговых
файлов), img_self_org_open (фрактальное кодирование с са-
моорганизующейся доменной классификацией),
IMG_OPEN_PLOT (ОКНО ПрОрИСОВКи) И IMG_OPEN_SUB (ОКНО ВЫ-
читания).
5. Создание объекта фрейма и объекта управления каждым до-
черним окном MDL Размещение каждого указателя C++ с
помощью конструктора этого класса.
6. Регистрация окна фрейма и каждого типа дочернего окна с
ПОМОЩЬЮ функции-члена класса register_window_class.
Такая регистрация необходима в любом приложении Win-
dows.
7. Создание меню для фрейма и каждого типа дочернего окна.
Каждый класс окна в UWL MDI имеет функцию-член
init_menu. Классы управления окном MDI также имеют
функцию set_frame_menu, которая связывает меню дочерне-
го окна с окном фрейма.
8. Загрузка акселераторов, создание и отображение окна
фрейма, реализация цикла обработки сообщений. Некото-
рые варианты этого кода являются общими для всех при-
ложений windows независимо от того, приложение ли это
UWL или нет.
9. Приборка после завершения работы. Удаление фрейма и
объектов управления MDI, освобождение связанного списка
типов дочерних окон. В приложениях Windows важно осво-
бодить память, поскольку распределяемая под объекты па-
мять может быть вне границ приложения.
Листинг В, 2.6,
Функция WinMain лля системы IMG. Шаги, которые выполняются
фу н кии и WinMain лля типичного приложения UWL, вылелены
// IMGMAIN.CPP WinMain for IMG system: Fractal image
// compression.
#include <stdlib.h>
#include "uwl.h"
#include "imgwin.h"
#include "decwin.h"
#include "encwin.h"
#include "soencwin.h"
#include "subwin.h"
#include "plt2dwin.h"
// For menu position constants:
#include "mdifmids.h"
#include "imgrids.h"
// Step 1: Define Windows class names for the frame
// and each type of child window.
// Step 2: Define the linked list for the MDI child
// window types.
tmdi type list struct *child list,*child type;
// Step 3: Define an object for the frame window, and an object
// for the MDI manager for each child window type.
char szFrameClass [] = "IMGFrame" ;
char szIMGSClass [] = "IMGChild";
char IMG_title [] = "IMG Window";
char szDECSClass [] = "DECChild";
char DEC_title [] = "DEC Window";
char szSUBSClass [] = "SUBChild";
char SUB__title [] = "SUB Window";
char szPLOTSClass [] = "PLOTChild";
char PLOT_title [] = "PLOT Window";
char szSELFORGSClass [] = "SELFORGChild";
char SELF_ORG_title [] = "SELF ORG Window";
HINSTANCE hlnst ;
int WINAPI WinMain (HINSTANCE hlnstance,
HINSTANCE hPrevInstance, LPSTR, int nCmdShow)
{
HACCEL hAccel ;
HWND hwndFrame, hwndClient ;
MSG msg ;
стинг В.2.6. Функция winMain лля системы IMG. Шаги, которые выполняются в
юлолжение функиии WinMain лля типичного приложения UWL, вылелены
tmdi_fг ame_window *img_frame_window ;
tenc_window_manager *enc_jnanager;
tself__org_enc_window_manager *self_org_enc__manager ;
tdec_window_manager *dec_manager;
tsub_window__manager *sub_jnanager ;
tplt2d__window_manager *plt2d_manager ;
int width,height;
// Step 4: Fill the entries in the child type linked list.
Create
// one entry for each type of child window. The type_id is the
// menu resource id for the menu item that will open this child
// window; the class is the Windows class string defined above.
child_list = (tmdi_type_list_struct *)
malloc ((size_t) sizeof (tmdi_type_list__struct)) ;
child_type = child__list;
child_type->type_id = IMG_OPEN;
child_type->the_class = szIMGSClass;
child_type->the_title = IMG_title;
child_type->next = (tmdi_type_list__struct *)
malloc ( (size_jt) sizeof (tmdi_type_list_struet) ) ;
child_type = child_type->next;
child_type->type_id = IMG_OPEN_RANGE;
child_type->the_class « szDECSClass;
child_type->the_title « DEC_title;
/* Commands IMGJDPENJRANGE and IMG_OPEN_BINARY_RANGE
correspond to the same window type. */
child_type->next = (tmdi_type_list_struct *)
malloc ((size_t) sizeof (tmdi_type_list_struct)) ;
child_type = child_type->next;
child_type->type_id = IMG_OPEN_BINARY_RANGE ;
child_type->the_class = szDECSClass;
child_type->the_title = DEC_title;
child_type->next = (tmdi_type_list__struct *)
malloc ((size_t) sizeof (tmdi__type_list_struet)) ;
child_type = child_jtype->next;
child_type->type_id = IMG_OPEN_SUB ;
child_type->the_class = szSUBSClass;
child_type->the_title = SUB_title;
child_type->next = (tmdi_type__list_struct *)
malloc ( (size_t) sizeof (tmdi_type_list_struct) ) ;
child_type = child_type->next;
child_type->type_id = IMG_OPEN_PLOT ;
child_type->the_class = szPLOTSClass;
child type->the title = PLOT title;
Листинг В. 2,6.
Прололжение
Функция WinMain лля системы IMG. Шаги, которые выполняются
функции WinMain лля типичного приложения UWL, вылелены
child_type->next = (tmdi_type_list_struct *)
malloc < (size_t) sizeof (tmdi_type_list_struct) )
child_type = child_type->next;
child_type->type_id = IMG_SELFJDRGJDPEN ;
child_type->the_class = szSELFORGSClass;
child_type->the_title = SELF_ORG_title;
child type->next = NULL;
hlnst = hlnstance ;
gdlg_instance = hlnstance;
// Step 5: Instantiate the
// child MDI manager object
■ш„1Л.ии.п
and each
img^frame_window = new tmdi_frame_window (hlnstance,
(LRESULT CALLBACK) FrameWndProc,0,"" ,
"IMG System" , szFrameClass, "IFS_ICON" ,
child_list,SHOW_ABOUT) ;
enc^manager = new tenc_window_manager (hlnstance,
img_f rame_window, 0, szIMGSClass, "IFS_ICON") ;
self_org_encjnanager = new tself_org_enc_window_manager
(hlnstance,img_frame^window,0,szSELFORGSClass,
"IFS_ICON") ;
dec_manager = new tdec_window_manager (hlnstance,
img_frame_window,0,szDECSClass,"IFS_ICON");
sub_manager = new tsub_window_manager (hlnstance,
img_frame^window,0,szSUBSClass,"IFS_ICON",
enc_manager, self_org_encjoanager, decjaanager) ;
plt2d_manager = new tplt2d_window_manager
(hlnstance,img_frame_window,
"IFSJECON",szPLOTSClass,"IFSJECON",enc_manager);
!// Step 6: Register the frame window and each child
I// window type, using the class's
* • function.
if (IhPrevInstance)
{
img_frame_window->register__window_class () ;
enc_manager->register__window_class () ;
self_org_encjnanager->register_window_class()
dec_manager->register_window_class () ;
sub_manager->register__window_class () ;
plt2d__manager->register_window_class();
}
// Step 7: Initialize the menus for the frame and
// each child window type.
img_frame_window->init_menu (hlnst, "MainMenu"
INIT MENU POS);
4СТИИГ В.2.6.
рололжение
Функция WinMain лля системы IMG. Шаги, которые выполняются в
функции WinMain лля типичного приложения UWL, вылелены
enc__manager->init_menu (hlnst, "IMGMenu" ,
IMG_MENU_CHILD_POS) ;
enc__manager - >se t_f rame_jnenu
(img_f rame__window->f rame_menu,
img_frame_window->frame_submenu) ;
self_org_enc_manager->init_menu (hlnst, "SLFORGMenu" ,
SOJSNC_MENU_CHILD_POS) ;
se lf__org_encjnanager - >se t_f r ame_menu
(img_f rame_window->f ramejaenu,
img_frame_window->frame_submenu) ;
dec__manager->init_menu (hlnst, "DECMenu",
DEC_MENU_CHILD_POS) ;
decjaanager- >se t_f r ame_jnenu
(img_f rame_window->f rame_menu,
img_f rame_window->f rame^submenu) ;
subjmanager->init_menu (hlnst, "SUBMenu",
SUB_MENU_CHILD_POS) ;
subjnanager- >se t_f r ame_jnenu
(img_f rame_window->frame_menu,
img_frame_window->frame_submenu) ;
plt2d_manager->init_menu(hlnst,"PLOTMenu",
PLOT_MENU_CHILD_POS) ;
pi t2 d__manager->set_f rame_jnenu
(img_f rame_window->f ramejaenu,
img_frame_window->frame_submenu) ;
// Step 8: Set up the Windows code. Load the
// accelerators, create and show the frame window,
[// and implement the message loop. This is standard
// Windows code.
// Load accelerator table
hAccel = LoadAccelerators (hlnst, "MdiAccel") ;
// Create the frame window
width = GetSystemMetries (SM_CXSCREEN);
height = GetSystemMetries (SM_CYSCREEN);
hwndFrame = CreateWindow (szFrameClass, "IMG System11,
WSJDVERLAPPEDWINDOW |
WS_CLI PCHILDREN,
0, 0,
width, height,
NULL,img_frame_window->frame^menu,
hlnstance, NULL) ;
hwndClient « GetWindow (hwndFrame, GW CHILD) ;
ShowWindow (hwndFrame, nCmdShow) ;
UpdateWindow (hwndFrame) ;
Листинг В.2.6.
Прололжение
Функиия WinMain лая системы IMG. Шаги, которые выполняются
функции WinMain лля типичного приложения UWL, вылелены
// Enter the modified message loop
while (GetMessage (&msg, NULL, 0, 0))
{
if ( fg^modeless^dialog I|
!IsDialogMessage
(g__modeless_dialog->hdialog, &msg))
if (ITranslateMDISysAccel (hwndClient, &msg) &&
!TranslateAccelerator (hwndFrame, hAccel, &msg))
{
TranslateMessage (&msg) ;
DispatchMessage (&msg) ;
}
}
// Step 9: Clean up when done. Delete the frame and
// MDI manager objects and free the linked list of
// child types.
delete enc_manager;
delete self org_enc_manager;
delete dec^manager;
delete sub_manager;
delete plt2d_manager;
delete img_frame^window;
f r ee__mdi_type__li s t_s truсt (chi ld_l i s t)
return msg.wParam ;
}
B.2.6. Диалоги UWL
Вдобавок к обеспечению основной функциональности окон
MDI, UWL также предоставляет ряд диалогов для ввода дан-
ных пользователя. На Рис. В.2.2 показана иерархия классов
для классов диалога в UWL. Класс tnum_input__diaiog соби-
рает числовой ввод пользователя. Введенные данные редак-
тируются, чтобы они были действительно числовыми, а так-
же есть специальная опция для проверки вхождения данных
в определенный диапазон max-min. На Рис. В. 1.2 показан
пример диалога, порожденного классом tbooi_diaiog, кото-
рый требует от пользователя ответа yes/no (да/нет) на задан-
ный вопрос. Класс tabout_diaiog является базовым классом
для диалогов приложения About (О программе).
Диалоги с прокручивающимися списками реализуются клас-
сом tiist_diaiog. Windows обеспечивает поддержку элемен-
тов управления с прокручивающимся списком, который ото-
бражает, прокручивает и выбирает пункт из списка тексто-
вых строк. Класс tiist_diaiog вставляет этот элемент
управления в диалог. Этот класс загружает диалог и список
строк и возвращает индекс выбранной пользователем строки
по закрытии диалога. Класс tdata_iist_diaiog идет на шаг
дальше. Здесь диалог со списком отображает строки, связан-
ные с объектами типизированных данных, которые являются
членами класса ttyped_data_obj. Когда пользователь дваж-
ды щелкает мышью на элементе этого списка, на экране по-
является соответствующий диалог для редактирования этого
элемента. Например, если элемент - числовые данные, то на
экране появится диалог для ввода числовых данных, если
элемент - имя файла, то на экране появится стандартный
диалог Windows для ввода имени файла и так далее. В При-
ложении А этот тип диалога со списком был назван диало! ом
со списком объектов данных. Его пример показан на
Рис. А.2.3. С точки зрения программирования преимущество
диалога со списком объектов данных состоит в том, что но-
вые элементы ввода данных могут быть добавлены к списку
без перепроектирования диалога. То есть нет необходимости
изменять файл ресурсов или добавлять дополнительное
управление логикой в класс диалога. Нужно лишь вставить в
список необходимый тип объекта данных, и вы автоматиче-
ски получите диалог для редактирования значения этого объ-
екта. Для более подробной информации о диалоге этого типа
см. [48]. Реализация этой идеи на Java содержится в [50].
Класс tmodeiess_diaiog является базовым классом для не-
модальных диалогов. Функция-член exec_diaiog этого клас-
са вызывает функцию Windows API createDiaiog, которая
создает немодальный диалог (в противоположность функ-
ции-члену exec_dialog класса tdialog, которая вызывает
функцию Windows API DiaiogBox для создания модального
диалога). Функция winMain приложения должна знать, когда
открывается немодальный диалог, для того чтобы она могла
пересылать в него сообщения. Связь с конкретным немо-
дальным диалогом устанавливается через глобальный указа-
тель g_modeiess_diaiog, который устанавливает адрес от-
крытого В текущий момент ПОТОМКа класса tmodeless_dialog
с помощью функции exec__diaiog этого класса. В рамках та-
кого подхода в одном приложении одновременно может быть
открыт только один немодальный диалог.
Класс tprogress_bar_dig является потомком класса
tmodeiess_diaiog, который реализует линейный индикатоп
для графического отображения хода выполнения программ-
ной задачи. Система IMG отображает линейный индикатор Вп
время обучения самоорганизующейся сети. Как упоминалось
ранее, это единственный экземпляр немодального диалога в
сопровождающем книгу программном обеспечении.
Рис. В.2.2.
Иерархия классов Аналога в UWL
В.2.7. Построение UWL
Ниже приведен список файлов исходных кодов для UWL
В именах файлов соблюдаются некоторые соглашения. Фай-
лы, имена которых начинаются на «и», содержат код какой-
либо утилиты. Код определяется как «утилита», если он ис-
пользуется более чем одной системой (таким образом, по оп-
ределению, утилитами в UWL является все), «w», следующая
за «и», означает, что утилита использует Windows-зависимый
код. Большая часть кода UWL написана на C++, хотя есть не-
сколько файлов, написанных на С и содержащих функции
общего назначения, которые было трудно отнести к какому*
нибудь классу C++. Файл заголовков (*.h) для этих файлов
C/C++ приведены в Листинге В.2.6 как часть файла заголов-
ков UWL.h. Приложения, которые используют UWL, должны
включать один файл заголовков UWLh.
• utobjlst.cpp содержит класс object_iist для управления мас-
сивами объектов.
• uwabtdlg.cpp содержит определение класса tabout_diaiog.
• uwcolors.c содержит основные утилиты С для управления
цветами RGB Windows.
• uwdatobjxpp содержит определение класса ttyped_data_obj.
• uwdialgs.cpp содержит ряд самостоятельных функций, кото-
рые создают, инициализируют и выполняют различные клас-
сы диалогов. Эти функции получают пользовательский ввод,
затем уничтожают объект диалога и возвращают введенные
данные вызывающей программе.
• uwdlg.cpp содержит определение классов tdialog,
tinput_dialog, tnum_input_dialog И tbool__dialog.
• uwgrnbrs.c содержит утилиты С для формирования элегант-
ных надписей на осях координат графиков.
• uwgrset.c содержит служебные функции С для прорисовки
графики.
• uwgrsetp.cpp содержит функцию init_graph_setup для ини-
циализации Структуры graph_setup_rec И фуНКЦИЮ
graph_setup_to_coiiection, которая связывает элементы
этой структуры с объектами в массиве object_iist array.
• uwgrwin.cpp содержит определение класса
tmdi_graph_window.
• uwmdichw.cpp содержит определение классов tmdi_manager и
tmdi_child_window.
• uwmdifrm.cpp содержит определение класса
tmdi_f r ame_wi ndow.
• uwmdlsdg.cpp содержит определение класса
tmodeles s_dialog.
• uwprgbar.cpp содержит определение класса
tprogres s_bar_dlg.
288 Фракталы и вей влеты для сжатия изображений в действ^
• uwprtwin.c содержит функции С для печати графического ок
на. Эти функции используют стандартный диалог печати
Windows. Однако логика установлена только для черно-белой
печати. Они не подходят для печати изображений в градами
ях серого. Чтобы напечатать градации серого, скопируй
окно изображения в буфер обмена и импортируйте его в при-
ложение с полными возможностями печати.
• uwwin.cpp содержит определение класса twindow.
Программное обеспечение, прилагаемое к книге, связывает
UWL как статическую 32-разрядную библиотеку GUI Win-
dows. Связывание UWL как статической библиотеки означа-
ет, что исполняемые файлы этих приложений независимы.
Вам не нужно беспокоиться о переносе дополнительных
файлов библиотек, когда вы переносите эти приложения с
одного компьютера на другой. Возможно также компилиро-
вать и связывать UWL как динамическую библиотеку DLL,
Если вы выберете эту возможность, то всякий раз при уста-
новке приложения вам надо будет копировать файл DLL.
Чтобы построить библиотеку UWL, включите все перечис-
ленные выше файлы C/C++ в ваш файл проекта или Makefile.
Тип целевого файла должен быть установлен в статическую
32-разрядную библиотеку GUI Windows. Определите кон-
станты win_32 и strict, strict - это константа Windows, ко-
торая гарантирует совместимость кода с Windows NT.
win__32 - это константа UWL, которая гарантирует, что для
32-разрядной Windows будут выбраны правильные макросы.
Существуют соответствующие макросы для 16-разрядной
Windows (т.е. Windows 3.1), но эти макросы не были исполь-
зованы, поэтому нет никаких гарантий, как будет выполнять-
ся результирующий код при выборе макросов для 16-
разрядной Windows. Также 32-разрядный код выполняется
намного быстрее, чем 16-разрядный код. Если вы собирае-
тесь заняться сжатием изображений, то должны всерьез за-
думаться об обновлении до 32-разрядной Windows, если вы
этого еще не сделали. Наконец, в вашем проекте или файле
Makefile вы должны указать, где расположены стандартные
каталоги include и lib языка С.
тинг В.2.6. Файл заголовков UWL.H. Программы C++, которые используют UWL,
лолжны включать этот елинственный файл. Программы С, которые
используют в UWL только функции С обшего назначения, лолжны
включать только файл заголовков лля этих функций (например,
uwgr.h или messages.h)
II File uwl.h General UWL header. Application programs should
// include this header when using UWL.
#ifndef UWL_H
#define UWL_H
#include "dlgids.h"
#include "grrscids.h"
#include "mdifmids.h"
#include "messages.h"
#include "utobjlst.h"
#include "uwabtdlg.h"
#include "uwcolors.h"
#include "uwdatobj.h"
#include "uwdialgs.h"
#include "uwdlg.h11
#include "uwgr.h"
# include "uwgrnbrs.h"
#include "uwgrwin.h"
#include "uwmdi.h"
#include "uwmdlsdg.h"
#include "uwprgbar.h"
#include "uwprtwin.h"
# include "uwwin.h"
#endif
(ИЛОЖЕНИЕ С.
рганизация прилагаемого исходного
>да программ
В этом приложении обсуждается организация прилагаемого к
книге исходного кода программ.
Система IFS
С.1.1. Классы IFS
На Рис. С.1.1 показана иерархия классов для системы IFS.
Система IFS состоит из трех различных типов окон MDI,
каждый с их собственными менеджерами окна MDI и с
поддержкой диалогов. Есть также некоторые функции-
утилиты С.
Первый тип окна - окно точек, реализованное классом
tpoints_window и его классами менеджера окна MDI
tnew_points_window_manager И topen_points_window_manager.
Оба эти класса управляют окнами точек. Различие в том, что
менеджер open (открыть) открывает предварительно сохра-
ненный файл точек, поэтому использует диалог открытия
файла, чтобы спросить имя файла точек перед тем, как соз-
дать новое окно. На Рис. А. 1.2 в Приложении А1 показаны
окно точек и два его диалога для редактирования точек.
Класс tpoints_window является потомком класса
tmdi_graph_window, который отображает сетку X-Y для то-
го, чтобы определить местонахождение точек, которые оп-
ределяют аффинные преобразования. Он также имеет оп-
цию импортирования и показа растрового изображения на
этой сетке, поэтому он использует утилиту-функцию, чтобы
читать растровый файл. Утилиты-функции для прорисовки
используются, чтобы рисовать сетку и отображать точки.
Класс tpoint_diaiog реализует потомка класса tdialog,
который редактирует значения координат X и Y точки. Он
также имеет опцию удаления этой точки. Класс
tedit_points_diaiog реализует диалог со списком, кото-
рый отображает список точек и позволяет редактировать их
с помощью диалога точек.
Рис. С.1.1.
Иерархия классов лля системы IFS. Сплошные линии указывают насле-
лование, а пунктирные линии указывают, что этот класс используется
Ару г им классом
Следующий тип окна в IFS - окно преобразования, реализо-
ванное классом ttrf_window. Как и в случае для окна точек,
есть два класса менеджера MDI (многодокументального ин-
терфейса): topen_trf_window_manager, который открывает
предварительно сохраненный файл преобразования, и
tnew_trf_window_manager. В любом случае, окно преобразо-
вания оперирует предварительно созданным файлом точек,
так что каждый из этих менеджеров использует диалог от-
крытия файла, чтобы получить имя файла точек перед созда-
нием нового окна преобразования. Окно преобразования ри-
сует ту же самую сетку, как и окно точек, и так же отобража-
ет точки и их метки. Оно также имеет возможность импорти-
рования и отображения на сетке растрового изображения.
Пользователь создает новое аффинное преобразование, опре-
деляя два набора из трех точек. Первый набор точек - это
доменная область преобразования, а второй набор - ранговая
область преобразования. Как только каждый из наборов из
трех точек будет выбран, окно рисует линии, соединяюши6
точки в треугольник, завершая таким образом определение
набора трех выбранных точек. Когда пользователь завершав
выбор точек, класс ttrf_pts_diaiog предоставляет диалог с
точками преобразования для редактирования индексов точек
и для выбора цвета, который будет связан с преобразовани-
ем. Класс tedit_trf_diaiog реализует диалог списка, кото-
рый управляет списком преобразований. Каждое предвари-
тельно созданное преобразование может быть отредактиро-
вано с помощью этого списка и диалога редактирования то-
чек преобразования.
Окно преобразования обеспечивает геометрическое описание
преобразования. Однако выполнение IFS требует, чтобы ка-
ждое преобразование было представлено в терминах его аф-
финных коэффициентов. Окно преобразования предоставля-
ет эти коэффициенты. Когда пользователь выбирает команду
меню File ♦ Create Coeff File (Файл ♦ Создать файл коэффици-
ентов), класс ttrf_window передает управление своей функ-
ции-члену onCreateCoef f, которая, в свою очередь, вызывает
внешнюю функцию create_coeff_fiie. Эта функция вычис-
ляет коэффициенты, используя подход, описанный в Главе 2.
Вычисление включает в себя обращение матрицы 3x3, ис-
пользующее функции из библиотеки матричных утилит UTM,
файлы которой упомянуты ниже.
Третий и последний тип окна - окно IFS, реализованное классом
tifs_window. Это окно, которое фактически отображает изо-
бражение-аттрактор IFS. Внешние функции
if s_random_image_crraph И if s_jdeterministic_image_graph ри-
суют изображение-аттрактор, используя соответственно случай-
ный и детерминированный алгоритмы, чтобы итерационно по-
лучить изображение, как обсуждалось в Главе 2. Внешние
функции используются здесь, чтобы сохранить вычислительную
часть кода отдельно от Windows-зависимых частей кода. Это
делается для более простого переноса вычислительных частей
кода в другие платформы, отличные от Windows. Заметим, что
графические запросы используют здесь графические структуры
UWL, а не параметры, характерные для Windows.
С.1.2. Файлы кода IFS
Вот файлы С/С ++, необходимые для построения системы IFS:
• ifsfiles.cpp: функции для чтения и записи файлов точек и
файлов преобразования и функции для создания
(create_coeff_file) и чтения файлов аффинных коэффициентов.
294 Фракталы и вей влеты для сжатия изображений в действц.,
• ifsmain.cpp: функция winMain для системы IFS.
• ifsproc.cpp: функции для отображения графики IFS, включа
if s_random__image__graph И if s_deterministic_image grar>h
• ifswin.cpp: содержит класс tifs_window для отображения
изображения-аттрактора IFS в графическом окне MDI и класс
менеджера MDI tif s_window_manager.
• ifswprcs.c: графические процедуры Windows для прорисовки
линии координатной сетки и точки в окне графики MDI.
• ptdlalg.Cpp: содержит классы tedit_j>oints_dialog и
tpoint_dialog.
• ptswin.cpp: содержит класс tpoints_window для того, чтобы
создавать наборы точек и отображать их на сетке, а также со-
держит классы менеджера MDI tnew_points_window_manager
И topen_points_window_manager.
• readbmp.cpp: содержит функцию read_BMP_fiie для чтения
файлов растровой графики, используемых классами
tpoints_window И ttrf_window ДЛЯ Импортирования растро-
вых изображений.
• readln.c: содержит функцию общего назначения readin для
чтения строки данных из файла.
• trfptSdg.cpp: содержит классы tedit_trf_dialog И
ttrf_points_dialog.
• trfwin.cpp: содержит класс ttrf_window для создания ряда
преобразований и отображения их на сетке, а также содержит
классы менеджера MDI tnew_ trf_window_manager И
topen_trf_window_manager.
• utofile.c: содержит функции-утилиты общего назначения для
того, чтобы открывать и закрывать текстовые и двоичные
файлы.
• wkeys.c: содержит некоторые функции-утилиты общего на-
значения для управления сообщениями клавиатуры Windows.
Кроме того, вам будут нужны соответствующие файлы заголов-
ков, которые включаются в эти файлы, а также понадобятся
следующие файлы ресурсов, которые включены в ifsapp.rc:
• ifsmenu.rc: меню для окна фрейма и дочерних окон.
• ptdialg.rc: файл ресурсов диалога точек.
• UWLAdlg.rc: файл ресурсов для всех диалогов в UWL (распо-
ложенный в каталоге UWL).
• trfpts.rc: файл ресурсов диалога преобразования точек.
• abifsdg.rc: файл ресурсов диалога About IFS (О IFS), включая
fern.bmp.
• fern.bmp: растровый рисунок изображения папоротника, ис-
пользуемого в диалоге About IFS (О IFS).
• fern.ico: значок папоротника (отображается в верхнем левом
углу окон).
Чтобы построить приложение IFS, вы должны включить в
ваш проект или файл Makefile файлы кода С/С ++, перечис-
ленные здесь, наряду с файлом ресурсов ifsapp.rc. Кроме то-
го, вы будете должны скомпоновать библиотеки UWL32.Iib и
UTM32.Iib. На Рис. С. 1.2 показаны файлы, необходимые для
создания IFS32.exe.
с. С 7.2. Созлание приложения IFS. Ваш проект или файл Makefile лолжны
включить показанные злесь файлы C/C++, RC и библиотечные файлы,
а также лолжны опрелелить константы win__32 и STRICT. Целевая
платформа лля библиотек и исполняемого файла приложения - 32-
разрялный графический интерфейс пользователя (GUI) Windows
С.1.3. Библиотека UTM
Библиотека матричных утилит (UTM - Utility Matrix) - Эт
небольшой набор файлов, которые исполняют матричные и
векторные вычисления и манипуляции. Эта библиотека
включает никакого зависимого от Windows кода, так что она
должна быть переносима на другие платформы. Она компи-
лируется как 32-разрядная библиотека, которая будет связана
с 32 -разрядным приложением GUI Windows. Файлы кода пе-
речислены ниже:
• utintmat.c: код для распределения и освобождения целочис-
ленных матриц.
• utmatinv.c: обращение матрицы с помощью алгоритма ис-
ключения Джордана-Гаусса.
• utmatrix.c: код для распределения и освобождения матриц
(с плавающей точкой).
• utprod.c: произведение матрицы на вектор и скалярное произ-
ведение вектора на вектор.
• utvect.c: код для распределения и освобождения векторов
(целочисленных и с плавающей точкой).
2. Система IMG
С.2.1. Классы IMG
На Рис. С.2.1 показана иерархия классов для системы IMG.
Система IMG отображает пять типов дочерних окон MDI.
Фактически в IMG есть шесть классов дочерних окон MDI,
так как timg_window - базовый класс для четырех классов,
которые ВЫВОДЯТ изображения: tenc_window, tdec_window,
tsub_window, и tseif_org_enc__window. Есть также класс ото-
бражения изображения как двумерной поверхности -
tplt2d_window.
Рис. С.2.1.
Иерархия классов лля системы фрактального сжатия изображений
IMG. Сплошные линии указывают наслелование, а пунктирные линии
указывают, что этот класс используется лругим классом
Вычисления для кодирования и декодирования отделены от
классов окна, инкапсулируя их в их собственные классы C++.
timage - простой класс, который определяет объект изображе-
298 Фракталы и вейвлеты для сжатия изображений в АейстВич
ния. Пикселы изображения содержатся в двумерном массиве
tf ract_image - базовый класс, выполняющий подготовку опе^
раций для управления доменными и ранговыми областями, ко.
торые являются общими для фрактального кодирования и деко.
дирования. Класс tf ract_image имеет три производных класса-
tenc_image реализует основной алгоритм фрактального кодиро.
вания, описанный в Главе 3, а также алгоритм с выделением
особенностей из Главы 4. tseif_org_encode_image реализует
подход к кодированию с помощью самоорганизующейся ней-
ронной сети, описанный в Главе 4. Наконец, tdec_image деко-
дирует фрактально сжатые изображения. Каждый из этих по-
томков класса tf ract_image ИСПОЛЬЗует объекты timage, Чтобы
хранить изображение, с которым они работают.
С.2.2. Файлы кодов IMG
Вот файлы С/С -Н-, необходимые для построения системы IMG:
• binrange.cpp: функции для того, чтобы читать и писать дво-
ичные ранговые файлы.
• decimg.cpp: содержит класс tdec_image для декодирования
фрактально сжатого изображения.
• decwin.cpp: содержит классы tdec_window и
tdec_window_manager для показа изображения во время опе-
рации декодирования.
• encimg.cpp: содержит класс tenc_image для кодирования изо-
бражения с помощью алгоритма фрактального кодирования.
• encwin.cpp: содержит классы tenc_window и
tenc_window_manager для показа изображения во время опе-
рации фрактального кодирования.
• features.с: функции для того, чтобы вычислить ключевые харак-
теристики, используемые во время выделения особенностей.
• frctimag.cpp: содержит базовый класс tfract_image для
управления доменными и ранговыми областями.
• image.cpp: содержит базовый класс timage для хранения изо-
бражения.
• imgmain.cpp: функция WinMain для системы IMG. Цикл обработ-
ки сообщений изменен, чтобы приспособить сообщения для не-
модального диалога, который отображает линейный индикатор
во время обучения самоорганизующейся нейронной сети.
иожениеС. Организация прилагаемого исходного кода программ 299
• imgproc.cpp: различные процедуры.
%/ imgwin.cpp: содержит классы timg__window и
timg_window_manager ДЛЯ показа изображения.
• p1ot_2d.c: функции общего назначения для прорисовки дву-
мерной поверхности в трехмерном пространстве.
• plt2dset.cpp: СОДерЖИТ фуНКЦИЮ plot_2d_setup_to_collection,
которая связывает параметры установки, используемые ко-
дом двумерного рисования со списком объектов
ttyped_data_obj. Допускается изменять значения парамет-
ров в диалоге со списком объектов данных.
• plt2dwin.cpp: содержит классы tpit2d_window и
tplt2d_window_manager для отображения двумерной поверх-
ности.
• slforgw.cpp: код для реализации самоорганизующейся ней-
ронной сети. Включает функции для чтения, записи и обуче-
ния сетевых весов, а также функции, которые используют
обученную сеть как классификатор.
• soencimg.cpp: содержит класс tself_org_encode_image, ко-
торый использует самоорганизующуюся нейронную сеть для
фрактального кодирования изображений.
• SOencwin.cpp: СОДерЖИТ классы tself_org_enc_window И
tself_org_enc_window_manager ДЛЯ отображения изображе-
ния во время фрактального кодирования с помощью самоор-
ганизующейся нейронной сети.
• subwin.cpp: содержит классы tsub_window и
tsub_window_manager для отображения различия изображений,
полученного вычитанием одного изображения из другого.
• utmatrix.c: код для размещения и освобождения матриц.
• utofile.c: содержит функции общего назначения для того, что-
бы открывать и закрывать текстовые и двоичные файлы.
• utscan.c: содержит функции-утилиты общего назначения для
просмотра строки текста.
• utvectc: код для размещения и освобождения векторов.
Кроме того, в файл imgapp.rc включены следующие файлы
ресурсов:
• abimgdg.rc: файл ресурсов для диалога About IMG (О IMG).
• imgmenu.rc: файл ресурсов меню.
• UWLAdlg.rc: файл ресурсов для всех диалогов в UWL
• bill.bmp: растровый файл для изображения «cat» (кот), Ис^
пользуемого в диалоге About IMG (О IMG).
• IFSXfern.ico: значок папоротника из системы IFS (используе.
мый некоторыми окнами).
Построение приложения IMG подобно построению приложе-
ния IFS. Вы должны включить в ваш проект или файл Make-
file перечисленные здесь файлы кода С/С ++ наряду с файлом
ресурсов imgapp.rc и скомпоновать его с библиотекой
UWL32.lib. Поскольку система IMG использует функции раз-
мещения только из utmatrix.c и utvector.c, она включает эти
файлы непосредственно (в качестве альтернативы вы можете
скомпоновать приложение с библиотекой UTM32.lib, как было
сделано для системы IFS). На Рис. С.2.2 показаны файлы,
необходимые для построения IMG32.exe.
Построение приложения IMG. Ваш проект или файл Makefile лолжны
включить показанные злесь файлы C/C++, RC и библиотечные файлы,
а также опрелелить константы WIN_32 и STRICT Целевая платформ
лля библиотек и выполняемой программы - 32-разрялный графиче-
ский интерфейс пользователя (GUI) Windows
Рис. С.2.2.
щложение С. Организация прилагаемого исходного кода программ 301
.3. Система WAV
С.3.1. Классы WAV
На Рис. С.3.1 показана иерархия классов для системы WAV.
Система WAV отображает семь типов дочерних окон много-
документального интерфейса (MDI). Класс timg_window - это
тот же самый базовый класс для отображения изображения,
который используется системой IMG. Здесь он используется,
чтобы отобразить первоначальное (оригинальное) изображе-
ние с тем, чтобы сравнить его с вейвлет-сжатой версией.
Сравнение изображений осуществляется с помощью одного
из двух типов окон вычитания, также реализованных тем же
самым классом tsub_window, который используется системой
IMG. Класс twavelet_window отображает вейвлет-сжатое изо-
бражение, используя простой алгоритм сжатия с помощью
децимации. Классы twavelet_zerotree_window и
tdecode_zerotree_window управляют кодированием и деко-
дированием с помощью нуль-дерева. Класс
twavelet__plot__window отображает график вейвлет-функции.
Система WAV обеспечивает работу с тремя типами вейвлетов:
вейвлетами Хаара, Добеши-4 и Добеши-6. Класс twavelet - это
базовый класс для этих вейвлетов. Он включает основной вейв-
лет-фильтр и его транспонированную версию, а также оператор
вейвлет- преобразования и оператор обратного вейвлет- преоб-
разования. Три типа вейвлетов, используемые здесь, отличаются
друг от друга только своими коэффициентами, так что класс
twavelet обеспечивает общие значения коэффициентов, в то
Время как производные классы tHaar_wavelet, tDaub4_wavelet,
и tDaub6_wavelet реализуют характерные для этих классов зна-
чения коэффициентов. Приведенные здесь вейвлет-фильтр и код
преобразования основаны на общедоступном вейвлет-коде из
[33] (обратите внимание, что большая часть кода там не обще-
доступна, однако вейвлет-код на их Web-узле был помещен в
общедоступную область). Класс twavelet_2d_array определяет
вейвлет-преобразование и обратное вейвлет-преобразование для
двумерных массивов, таких как изображения. Этот класс просто
применяет класс одномерного преобразования twavelet к
столбцам и строкам массива, как обсуждалось в Главе 5. Класс
twave_dialog реализует простой диалог с тремя переключате-
лями для выбора из трех типов вейвлетов.
Иерархия классов лля системы вей влет-сжатия изображений WAV.
Сплошные линии указывают наслелование, а пунктирные линии
указывают, что этот класс используется лругим классом
Рис.С.3.1.
С.3.2. Файлы кола системы WAV
Вот файлы С/С ++, необходимые для построения системы
WAV:
• uwplot.c: содержит функцию piot_xy, общую утилиту рисо-
вания графика X-Y.
• wavdzwin.Cpp: СОДерЖИТ КЛасС tdecode_zerotree_window, ПО-
ТОМОК класса twaveiet_window для декодирования изображе-
ния, закодированного с помощью нуль-дерева.
• wave_dlg.cpp: содержит класс twave_dig, диалог с переклю-
чателями для выбора типа вейвлетов.
• wavelet.cpp: содержит все классы вейвлетов (twaveiet,
tHaar^wavelet, tDaub4_wavelet, tDaub6_wavelet И
twavelet_2d__array).
• Waveproc.c: Содержит функцию decimate_array, ИСПОЛЬЗО-
ванную классом twaveiet_2d_array, чтобы удалить все, кро-
ме х% наибольших значений массива (это действительно
функция общего назначения, которая не использует никаких
свойств вейвлета).
• wavmain.cpp: функция winMain для системы WAV.
• Wavplot.cpp: Содержит КЛаССЫ twavelet_plot_window И
twavelet_j?lot_window_manager ДЛЯ отображения вейвлет-
функции в окне.
• wavwin.cpp: содержит классы twaveiet_window и
twaveiet_window_manager для отображения вей влет-сжатого
изображения в окне.
• wavzwin.cpp: содержит класс tencode_zerotree_window, по-
томок класса twaveiet_window для кодирования изображений
с применением алгоритма с нуль-деревом из Главы 7.
• zerotree.cpp: содержит класс tzerotree, потомок класса
tshort_array, который включает функции-члены
mark_children И mark_j?arentB ДЛЯ реализации алгоритма
кодирования с нуль-деревом.
Кроме того, WAV совместно с IMG использует следующие
файлы (обсужденные в предыдущем разделе):
• IMGVimage.cpp
• IMGVimgproc.cpp
• IMGVimgwin.cpp
• IMGXsubwin.cpp
• UTMXutofile.c
• UTMXutShort.cpp: Содержит класс tshort_array.
Кроме того, в wavapp.rc включены следующие файлы
ресурсов:
• abwavdg.rc: файл ресурсов для диалога About WAV (О WAV).
• wave_dlg.rc: файл ресурсов для диалога с переключателями
выбора типа вейвлетов.
• wavmenu.rc: файл ресурсов меню.
• UWLAdlg.rc: файл ресурсов для всех диалогов в UWL.
Рис. С.3.2.
Построение приложения WAV, Ваш проект или файл Makefile лолжны
включить показанные злесь файлы C/C++, RC и библиотечные фаил^
а также лолжны опрелелить константы WIN_32 и STRICT, иеле
платформа лая библиотек и выполняемой программы - 32-разрял
GUI Windows
• daub4wav.bmp: файл растровой графики для изобп
вейвлетов Добеши-4, используемый в диалоге ДЬ е1йв
(О WAV). °Ut WAV
• wavelet.ico: значок вейвлет-функции (используемый и
рыми окнами). Кот°-
Система WAV также включает библиотечные & -
UTM32.lib и UWL32.lib. Подобно системам IFS и IMG, WAV^
ляется 32-разрядным приложением GUI Windows iT
Рис. С.3.2 показаны файлы и параметры настройки, необ а
димые для построения WAV32.exe.
Кисок литературы
1. Asgari, S., T.Q. Nguyen, and W.A. Sethares. 1997. "Wavelet-
Based Fractal Transforms for Image Coding with No Search",
Proc. IEEE International Conf. on Image Processing, (ICIP97).
2. Bani-Eqbal, B. 1995. "Speeding up Fractal Image Compression",
Proc. SPIE Still-Image Compression, Vol. 2418.
3. Bamsley, M. 1993, Fractals Everywhere, 2nd ed,, Boston:
Academic Press.
4. Bamsley, M, and L. Hurd. 1993. Fractal Image Compression,
Wellesley, MA: A.K.Peters, Ltd.
5. Bamsley, M, and A, Sloan. 1988. "A Better Way to Compress
Images", Byte, January:215-223.
6. Bamsley, M., and A. Sloan, 1990, "Method and Apparatus for
Image Compression by Iterated Function System", U.S. Patent
#4,941,193.
7. Bamsley, M., and A. Sloan. 1991. "Method and Apparatus for
Processing Digital Data", U.S. Patent #5,065,447.
8. Bogdan, A., and H. Meadows. 1992. "Kohonen neural network
for image coding based on iteration transformation theory", Proc.
SPIE 1766:425-436.
9. Burrus, C, Gopinath, R., and Guo, H. 1998. Introduction to
Wavelets and Wavelet Transforms, Prentice-Hall, Upper Saddle
River, New Jersey.
10. Chen, Т., ed. 1998. "The Past, Present, and Future of Image and
Multidimensional Signal Processing", IEEE Signal Processing
Magazine, Vol. 15, No. 2, March:21-58.
11. Daubechies, I. 1988. "Orthonormal bases of compactly supported
wavelets", Comm. on Pure and Applied Math, XLI:909-966,
12. Daubechies, I. 1992. Ten Lectures on Wavelets, SIAM,
Philadelphia.
13. Davis, G. 1995. "Adaptive self-quantization of wavelet subtrees:
A wavelet-based theory of fractal image compression", Proc. of
SPIE Conf. on Wavelet Applications in Signal and Image
Processing III, San Diego.
14. Davis, G. 1996. "Implicit Image Models in Fractal
Compression", Proc. of SPIE Conf. on Wavelet Appling1?!*1
Signal and Image Processing IV, Denver. °n^ ^
15. Davis, G. 1998. "A Wavelet-Based Analysis of Fractal I
Compression", IEEE Trans, on Image Proc, Vol. 7 No 2-1 л 11 ^e
16. Davis, G., and A. Nosratinia. 1998. "Wavelet-based I
Coding: An Overview", pre-print, to appear in Applied**8!
Computational Control, Signals, and Circuits, Vol. 1 м ,
(64 pages). ' ' '
17. Digital Imaging Group 1999. "JPEG 2000 White Paper-
available at the JPEG Web site, www.jpeg.org.
18. Fisher, Y., ed. 1995. Fractal Image Compression, New
York: Springer- Verlag.
19. Gopinath, R., and С Burrus. 1993. "A Tutorial Overview of
Filter Banks, Wavelets and Interrelations", Proc. ISCAS-93.
20. Hamzaoui, R. 1995. "Codebook Clustering by Self-Organizing
Maps for Fractal Image Compression", Proc. NATO Advanced
Study Institute Conf. on Fractal Image Encoding and Analysis,
Trondheim, July, 1995, Y. Fisher (ed.), New York.Springer-
Verlag.
21. Hebert, D., and E. Soundararajan. 1998. "Fast Fractal Image
Compression with Triangulation Wavelets", Proc. of SPIE Conf.
on Wavelet Applications in Signal and Image Processing VI, San
Diego.
22. Jacobs, E., R. Boss, and Y. Fisher. 1995. "Method of Encoding a
Digital Image Using Iterated Image Transformations To Form an
Eventually Contractive Map", U.S. Patent #5,416,856.
23. Jacquin, A. 1992. "Image Coding Based on a Fractal Theory of
Iterated Contractive Image Transformations'\ IEEE Trans, о
Image Proc. Vol. 1, No. 1:18-30.
24. Kohonen, T. 1984. Self Organization and Associative Memory,
2nd ed., Berlin:Springer-Verlag.
25. Lewis, A., and G. Knowles. 1992. "Image Compression Using; t «
2-D Wavelet Transform", IEEE Trans, on Image Proc Vol.
No. 2:244-250.
26. Lu, N. 1997. Fractal Imaging, San Diego:Academic Press.
27. Mandal, М., S. Panchanathan and Т. Aboulnasr. 1996. "Choice of
Wavelets for Image Compression", Lecture Notes in Computer
Science, Vol. 1133:239-249, Springer-Verlag.
28. Mandelbrot, B. 1983. The Fractal Geometry of Nature, New
York:W. H. Freeman and Company.
29. McGregor, D., R.J. Fryer, W.P. Cockshott and P. Murray. 1994.
"Fast Fractal Transform Method for Data Compression",
University of Strathclyde Research Report/94/156[IKBS-17-94].
30. Peitgen, H., and D. Saupe, eds. 1988. The Science of Fractal
Images, New York:Springer-Verlag.
3L Polidori, E., and J. Dugelay. 1995. "Zooming Using Iterated
Function Systems", Proc. of NATO Advanced Study Institute
Conf. on Fractal Image Encoding and Analysis, Trondheim,
Norway, July, 1995, Y. Fisher (ed.), New York:Springer-Verlag.
32. Popescu, D., A. Dimca, and H. Yan. 1997. "A Nonlinear Model
for Fractal Image Coding", IEEE Trans, on Image Proc, Vol. 6,
No. 3:373-382.
33. Press, W., S. Teukolsky, W. Vetterling, and B. Flannery. 1992.
Numerical Recipes in C, 2nd ed., Cambridge University Press.
34. Ritter, H., T. Martinez and K. Schulten. 1992. Neural
Computation and Self-Organizing Maps, Reading, MA: Addison-
Wesley.
35. Ruhl, M., and H. Hartenstein. 1997. "Optimal Fractal Coding Is
NP-hard", Proc. DCC97 Data Compression Conference, IEEE
Computer Society Press:261-270.
36. Said, A., and W. Pearlman. 1996. "A New Fast and Efficient
Image Codec Based on Set Partitioning in Hierarchical Trees",
IEEE Trans, on Circuits and Systems for Video Technology,
Vol. 6, June:243-250.
37. Said, A., and W. Pearlman. 1996. "An Image Multiresolution
Representation for Lossless and Lossy Compression", ШЕЕ
Trans, on Image Proc, Vol. 5, No. 9:243-250.
38. Saupe, D. 1994. "Breaking the Time Complexity of Fractal Image
Compression", Tech. Report 53, Institut fur Informatik.
39. Saupe, D. 1996. "The Futility of Square Isometries in Fractal
Image Compression", IEEE International Conference on Image
Processing (ICIP'96), Lausanne.
40. Sayood, К. 1996. Introduction to Data Compressi
Francisco:Morgan Kaufmann Publishers, Inc.
41. Shapiro, J. 1993. "Embedded Image Coding Using Zerot
Wavelet Coefficients", IEEE Trans, on Signal Proc. Vol 1Г$ °f
12:3445-3462. ' *41'N0.
42. Strang, G. 1989. "Wavelets and Dilation Equations' д ft •
Introduction", SIAM Review 31:613-627. ' rief
43. Stollnitz, E., DeRose, Т., Salesin, D. 1996. Wavelets
Computer Graphics, Morgan Kaufmann, San Francisco. Г
44. Villasenor, J., Belzer, В., and Liao, J. 1995. "Wavelet Fik
Evaluation for Image Compression", IEEE Trans, on Image Proc
Vol. 4, No. 8:1053-1060.
45. Welstead, S. 1997. "Self-Organizing Neural Network Domain
Classification for Fractal Image Coding", Proc. of IASTED
International Conference on Artificial Intelligence and Soft
Computing, July, 1997, Banff, Canada, IASTED Press:248-25L
Список литературы по программированию Windows
46. Petzold, С. 1992. Programming Windows 3.1, Microsoft Press.
47. Petzold, С 1996. Programming Windows 95, Microsoft Press.
48. Welstead, S. 1995. "Data Object List Dialog for Windows",
C/C++ Users Journal, Vol. 13, No. 9:23-41 (also appears as
Chapter 8, pp. 115-139, in Windows NT Programming in
Practice, R&D Books, Miller Freeman, Inc., Lawrence, KS,
1997).
49. Welstead, S. 1996. "C++ Classes for MDI Windows
Management", C/C++ Users Journal, Vol. 14, No. 11:41-50.
50. Welstead, S. 1999. "A Java Object List Dialog", C/C^ Users
Journal, Vol. 17, No. 1:21-33.
■авторе
Стефен Уэлстид - ведущий специалист по научным исследо-
ваниям корпорации COLSA, г.Хантсвил, штат Алабама, про-
фессор математики университета Алабама в г.Хантсвиле, где
он преподает курс фрактальной геометрии. Стефен Уэлстид -
автор большого количества книг и работ в области нейрон-
ных сетей, хаоса, динамических систем, фрактального сжа-
тия и обработки сигналов. Стефен Уэлстид является членом
ассоциации инженеров фотооптиков (SPIE) и прикладных
математиков (SIAM), а также института инженеров элек-
тронной и электрической техники (ШЕЕ).
Информация о программном обеспечении
На CD-ROM-диске находятся исполняемые файлы программ
с помощью которых читатель сможет построить и запустить
примеры, иллюстрирующие материал из книги. Эти программы
работают под управлением операционных систем Win32, таких
как Windows XP/2000/NT/98/95.
Представлены три программы:
• IFS32 строит системы итерируемых функций;
• IMG32 сжимает Втр-изображения, используя фрактальные
методы;
• WAV32 сжимает Втр-изображения, используя вейвлет-методы.
Кроме того, на диске находятся файлы с образцами данных для
работающих примеров, а также полные исходные коды
программ на C/C++.
Компилировать файлы с исходными кодами, для того чтобы
запустить программу, не нужно.
Более детально содержимое файлов описано в файле readme.txt.
Предметный указатель
04-вейвлеты Добеши, 175
алгоритм кодирования
без потерь, 20
с потерями, 20
асимметрия, 108
аттрактор, 45
бета, 109
биортогональность, 180
биортогональные вейвлет-системы, 181
вейвлет-кодирование с нуль-деревом, 187
вейвлет-преобразование, 140
взвешенная разность, 167
взвешенное среднее, 167
градиент
вертикальный, 109
горизонтальный, 109
максимальный, 109
двойственный базис, 181
децимация, 24
диалог
модальный, 264
немодальный, 265
замыкание, 39
значимый коэффициент, 190
изолированный ноль, 191
информация, 22
источник, 22
итерация, 42
квадратура, 28
квадродерево, 77
класс
objectjist, 272, 287
tabout_dialog, 284, 287
tbooLdialog, 284, 287
tdataJist_dialog, 285
tDaub4_wavelet, 301, 302
tDaub6_wavelet, 301, 302
tdec_image, 297, 298
tdec_window, 296, 298
tdec_window_manager, 278, 298
tdecode_zerotree_window, 301, 302
tdialog, 285,287,291
tedit_points_dialog, 291, 294
tediUrLdialog, 293, 294
tenc_image, 297, 298
tenc_window, 296, 298
tenc_window_manager, 278, 298
tencode_zerotree_window, 303
tfractjmage, 297, 298
tHaar_wavelet, 301,302
tifs_window, 293, 294
tifs_window_manager, 294
timage, 297, 298
timg^window, 296, 298, 300
timg_window_manager, 298
tinput_dialog, 287
tlisulialog, 284, 285
tmdi_child_window, 272, 273, 287
tmdLframe_window, 270, 287, 291
tmdLgraph_window, 275, 277, 287
312 Форм;
tmdLmanager, 272, 273, 287
tmdi_window, 272
tmodeless^dialog, 285, 287
tnew_ trf_window_manager, 294
tnew_points_windo\v_manager, 291, 294
tnew_trf_window_manager, 292
tnum_input_dialog, 284, 287
topen_points_window_manager, 291, 294
topen_trf_window_manager, 292, 294
tplt2d_window, 296, 298
tplt2d_window_manager, 278, 298
tpoint_dialog, 291,294
tpoints_window, 291, 294
tprogress_bar_dlg, 286, 287
tself_org_enc_window, 296, 299
tself_org_enc_window_manager, 278, 299
tself_org_encode_image, 297, 299
tshort_array, 303
tsub_window, 296, 299, 300
tsub_window_manager, 278, 299
ttrf_points_dialog, 294
ttrf_pts_dialog, 293
ttrf_window, 292, 293, 294
ttyped_data_obj, 285, 287
twave_dialog, 301
twave_dlg, 302
twavelet, 301,302
twavelet_2d_array, 301, 302, 303
twavelet_plot_window, 301, 303
twavelet_plot_window_manager, 303
twavelet_window, 301, 302, 303
ы и алгоритмы сжатия изображений в действии
twavelet_window_manager, 303
twavelet_zerotree_window, 301
twindow, 268, 288
tzerotree, 303
кодовая книга, 25
компактный носитель, 176
контрастность, 73
межпиксельная, 109
корень нуль-дерева, 191
коэффициент сжатия, 41
кратномасштабный анализ, 146
максимальное число преобразований, 95
масштабирование, 141
масштабирующая функция, 141
масштабирующее уравнение, 172
метод квадродерева, 78, 83
метрика, 36, 37
метрическое пространство, 36, 37
полное, 38
Хаусдорфа, 41
множество
компактное, 40
ограниченное, 39
моделирование данных, 24
насыщенность, 28
норма, 151
нормированная функция, 151
носитель, 142
однократное применение, 77
орбита динамической системы, 58
ортогональное дополнение, 148
GetOpenFileName, 265, 266
странные аттракторы, 33
теорема
коллажа, 45
о сжимающих отображениях, 43
точка, 37, 39
неподвижная, 43
предельная, 38
траектория динамической системы, 58
фильтр
высокочастотный, 168
квадратурно-зеркальный, 168
низкочастотный, 168
фрактал, 35
функция
CreateDialog, 285
default_window_proc, 272
DefMDIChildProc, 272
DialogBox, 285
exec_dialog, 285
graph_setup_to_collection, 287
handle_message, 268, 273
init_graph_setup, 287
init_menu,273,279
Main, 277
new_child_window, 273
register_window_class, 279
respond_wm_command, 271
respond_wm_create, 270
respond_wm_mdiactivate, 273
respond_wm_paint, 268
ортогональность, 173
ортогональные функции, 148
отображение, 41
сжимающее, 41
палитра, 25
покрытие, 74
полуортогональность, 180
последовательность, 38
сходящаяся, 37
предел, 37
преобразование, 41
преобразования
аффинные, 47
прогрессивная передача, 189
пространственная составляющая
преобразования, 73
решетка, 122
самоорганизующаяся карта свойств, 122
самоорганизующаяся нейронная сеть, 122
самоподобие, 35
самоподобное изображение, 34
свойство
нормированности, 172
ортогональности, 169
синфазный, 28
система итерируемых
кусочно-определенных функций, 72
система итерируемых функций, 44
среднеквадратическая метрика, 72
стандартное отклонение, 108
стандартный диалог Windows, 265
ChooseColor, 265
set_frame_menu, 273, 279
set_giobai_ptr, 269, 273
WinMain, 265, 268, 273, 277, 294,
298,303
обратного вызова, 268
с компактным носителем, 176
цвет, 28
цветовая карта, 25
энтропия, 22
яркость, 28, 73
удержание
Предисловие 11
Краткий обзор материала книги 13
Благодарности 15
ГЛАВА 1. Введение 17
1.1. Изображения 18
1.2. Проблема сжатия изображения 20
1.3. Информация, энтропия и моделирование данных 22
1.4. Скалярное и векторное квантование 24
1.5. Методы преобразования 26
1.6. Цветные изображения 28
1.7. Основной объект внимания этой книги 29
ЧАСТЬ I. ФРАКТАЛЬНОЕ СЖАТИЕ ИЗОБРАЖЕНИЙ
ГЛАВА 2. Системы итерируемых функций .33
2. L Системы итерируемых функций
как стимул фрактального сжатия изображений 33
2.2. Метрические пространства 36
2.2.1. Основные понятия 36
2.2.2. Компактные множества и пространство Хаусдорфа 39
2.2.3. Сжимающие отображения 41
2.3. Системы итерируемых функций 44
2.3.1. Введение 44
2.3.2. Теорема коллажа 45
2.3.3. О чем говорит теорема коллажа 46
2.3.4. Аффинные преобразования 47
2.4. Применение системы итерируемых функций 48
2.4.1. Точки и преобразования 48
2.4.2. Коэффициенты аффинного преобразования 51
2.4.3. Построение фрактального
изображения-аттрактора с помощью IFS 51
2.5. Примеры 62
2.5.1. Треугольник Серпинского 62
2.5.2. Построение 1FS по реальному изображению 66
2.5.3. Другие примеры 1FS 68
Форматы и алгоритмы сжатия изображений в дей
ГААВА 3. Фрактальное кодирование изображений
в градациях серого
3.1. Метрическое пространство для изображений
в градациях серого
3.2. Системы итерируемых кусочно-определенных функций..
3.2.1. Аффинные преобразования изображений
в градациях серого 7
3.2.2. Сжимающие отображения изображений
в градациях серого 7
3.2.3. Теорема о сжимающих отображениях
для изображений в градациях серого 74
3.2.4. Теорема коллажа для изображений
в градациях серого 76
3.3. Фрактальное кодирование изображений 77
3.3.1. Доменные блоки gj
3.3.2. Разбиение на ранговые блоки методом квадро дерева.... 83
3.3.3. Отображение доменных областей в ранговые 86
3.3.4. Время кодирования 88
3.4. Декодирование изображений 90
3.4.1. Количественная оценка искажений 91
3.5. Хранение закодированного изображения 93
3.5.1. Формат рангового файла 93
3.5.2. Двоичный формат рангового файла 95
3.6. Независимость от разрешения 1W
3.7. Операторное представление фрактального
кодирования изображений ^2
3.7.1. Операторы извлечения блока и вставки блока
«get-block» и «put-block» *
3.7.2. Операторный вид
104
3.7.3. Решение операторного уравнения
3.7.4. Анализ ошибок
ГЛАВА 4. Повышение скорости фрактального
кодирования
107
4.1. Выделение характеристических особенностей
108
4.1.1. Определение характеристик
4.1.2. Алгоритм кодирования, использующий ^ j j
характеристические особенности
4.1.3. Результаты применения алгоритма ц5
с выделением особенностей
>жание 317
4.2. Классификация доменов 120
4.2.1. Самоорганизующиеся нейронные сети 121
4.2.2. Фрактальное кодирование изображений с помощью
самоорганизующейся классификации доменов 125
4.2.3. Примеры результатов использования
самоорганизующейся доменной классификации 127
4.3. Другие пути ускорения фрактального кодирования 132
ЧАСТЬ II. ВЕЙВЛЕТ-СЖАТИЕ ИЗОБРАЖЕНИЙ
ГААВА 5. Простые вейвлеты 135
5.1. Введение 135
5.2. Усреднение и детализация 137
5.3. Масштабирующие функции и вейвлет-функции 140
5.4. Кратномасштабный анализ 146
5.5. Нормирование 151
5.6. Вейвлет-преобразование 152
5.7. Обратное вейвлет-преобразование 156
5.8. Двумерные вейвлет-преобразования 159
5.8.1. На что похоже вейвлет-преобразование 162
5.8.2. Упрощенная схема вейвлет-сжатия 165
ГААВА 6. Вейвлеты Аобеши 167
6.1. Взвешенные средние и разности 167
6.1.1. Низкочастотные и высокочастотные фильтры 168
6.1.2. Матричное представление 168
6.2. Свойства коэффициентов и условия,
накладываемые на коэффициенты 169
6.3. Вейвлет-преобразование 171
6.4. Масштабирующие функции и вейвлет-функции 172
6.5. Вейвлеты Добеши 174
6.6. Простое сжатие изображения
с помощью вейвлетов Добеши 176
6.7. Другие системы вейвлетов 179
ГААВА 7. Технологии вейвлет-сжатия изображений 183
7.1. Введение 183
7.2. Нуль-деревья вейвлетов 186
7.2.1. Реализация вейвлет-кодирования с нуль-деревом 189
318 Форматы и алгоритмы сжатия изображений в действ
7.2.2. Декодирование изображения,
закодированного с помощью нуль-дерева ,Q
7.2.3. Где же сжатие? ~~
7.2.4. Скорость кодирования ~п
7.3. Смешанное фрактально-вейвлетное кодирование 90*
7.3.1. Операторный подход к смешанному
фрактально-вейвлетному кодированию 20r
7.3.2. Другие смешанные подходы 2м
ГААВА 8. Сравнение фрактального и вейвлетного
подходов к сжатию изображений 213
8.1. Степень искажения 213
8.2. Скорость кодирования 218
8.3. Большие изображения 221
8.4. Итоги 224
Приложение А. Использование прилагаемого
программного обеспечения „227
АЛ. Система IFS 228
АЛЛ. Окно точек 229
АЛ .2. Окно преобразования 231
A.1.3.0khoIFS 233
А.2. Система IMG: фрактальное сжатие изображений 236
А.2.1. Окно кодирования 237
А.2.2. Окно кодирования методом самоорганизации 243
А.2.3. Окно декодирования 246
А.2.4. Окно вычитания изображений 248
А.2.5. Графическое окно ^
А.З. Система WAV: вейвлет-сжатие изображений *****
А.3.1. Окно вейвлет-сжатия ^
255
А.З.2. Вейвлет-кодирование с нуль-деревом *
А.3.3. Вейвлет-декодирование с нуль-деревом
257
А.3.4. Вычитание изображений в системе WAV
258
А.З.5. Окно построения вейвлетов
?б1
Приложение В. Библиотека утилит Windows
261
В.1. Программирование для Windows
262
В.1 Л. Многооконный интерфейс (MDI) -
В.1.2. Диалоги
^держание 319
В.2. Библиотека утилит Windows (UWL) 267
B.2.L Класс twindow 268
8.2.2. Окно фрейма MDI 270
8.2.3. Окна MDI 272
8.2.4. Графическое окно 275
8.2.5. Функция WinMain в приложении UWL 277
8.2.6. Диалоги UWL 284
8.2.7. Построение UWL 286
Приложение С. Организация прилагаемого
исходного кола программ 291
C.L Система IFS 291
С. 1.1. Классы IFS 291
С.1.2. Файлы кода 1FS 293
С. 1.3. Библиотека UTM 296
С.2. Система 1MG 297
С.2.1. Классы 1MG 297
С.2.2. Файлы кодов IMG 298
С.З. Система WAV 301
С.3.1. Классы WAV 301
С.3.2. Файлы кода системы WAV 302
Список литературы 305
Список литературы по программированию Windows 308
Об авторе 309
Информация о программном обеспечении 310
Предметный указатель 311
С. Уэлстид
ФРАКТАЛЫ И ВЕЙВЛЕТЫ
ЛАЯ
СЖАТИЯ ИЗОБРАЖЕНИЙ
В ДЕЙСТВИИ
Перевод Л.В. Печникова.
Редактор В.Н. Печников.
Дизайн обложки О.В. Русецкая.
Корректор Е.В. Горбачева.
Верстка О.И. Воробьева.
Подписано в печать с оригинал-макета 14.07.2003 г.
Формат 70x100/16. Печать офсетная. Печ. л. 20.
Заказ № 9978.
Тираж 3 000 экз.
ООО «Издательство ТРИУМФ». 125438, г. Москва, а/я 18.
Лицензия серия ИД № 05434 от 20.07.01 г.
Оптовый отдел: (095) 720-07-65
Отпечатано в полном соответствии с качеством предоставленных
диапозитивов в ОАО «Можайский полиграфический комбинат»
143200, г. Можайск, ул. Мира, 93