



































































































































































































































































































































































































































































































































































































































































































































































Author: Петкович Д.
Tags: компьютерные технологии программное обеспечение базы данных
ISBN: 978-5-9775-0149-1
Year: 2009




Text
Microsoft8 SQL Server" 2008
A BEGINNERS
GUIDE
Dusan Petkovic
New York Chicago San Francisco Lisbon
London Madrid Mexico City Milan
New Delhi Sanjuan Seoul Singapore
Sydney Toronto
Душан Петкович
Microsoft®
SQL Server 2008
Руководство для начинающих
Санкт-Петербург
«БХВ-Петербург»
2009
УДК 681.3.06
ББК 32.973.26-018.2
П29
Петкович Д.
П29 Microsoft® SQL Server™ 2008. Руководство для начинающих:
Пер. с англ. — СПб.: БХВ-Петербург, 2009. — 752 с.: ил.
ISBN 978-5-9775-0149-1
Просто и доступно рассмотрены теоретические основы СУБД SQL Server 2008.
Показана установка, конфигурирование и поддержка MS SQL Server 2008.
Описан язык манипулирования данными Transact-SQL. Рассмотрены создание
базы данных, изменение таблиц и их содержимого, запросы, индексы, представ-
ления, триггеры, хранимые процедуры и функции, определенные пользовате-
лем. Показана реализация безопасности с использованием аутентификации,
шифрования и авторизации. Уделено внимание автоматизации задач с исполь-
зованием SQL Server Agent. Рассмотрено создание резервных копий данных
и выполнение восстановления системы. Описано использование инструментов
для бизнес-анализа (Business Intelligence), разработки и администрирования
СУБД. Подробно рассмотрена технология SQL Server 2008 XML (SQLXML).
Описаны службы Microsoft Analysis Services, Microsoft Reporting Services, вве-
дение в пространственные данные и многое другое.
Для начинающих программистов
Группа подготовки издания:
УДК 681.3.06
ББК 32.973.26-018.2
Главный редактор
Зам.главного редактора
Зав. редакцией
Перевод с английского
Научный редактор
Редактор
Компьютерная верстка
Корректор
Оформление обложки
Зав. производством
Екатерина Кондукова
Игорь Шишигин
Григорий Добин
Александра Бондаря
Сергей Востриков
Анна Кузьмина
Ольги Сергиенко
Зинаида Дмитриева
Елены Беляевой
Николай Тверских
Original edition copyrigjit © 2008 by the McGraw-Hill Companies. All limits reserved.
Russian edition copyrigjit © 2009 year by BHV - Stfttersburg. All rights reserved.
No part of this book may be reproduced or transmitted in any fam or by any means, electronic or mechanical, including photocopying, recording or by
any information storage retrieval system, without permission from the Publisher.
Оригинальное издание выпущено McGraw-Hill Companies в 2008 году. Все права защищены.
Русская редакция издания выпущена издательством БХВ-Петербург в 2009 году. Все права защищены.
Никакая часть настоящей книги не может быть воспроизведена или передана в какой бы то ни было форме и какими бы то ни было
средствами, будь то электронные или механические, включая фотокопирование и запись на магнитный носитель, если на то нет
Лицензия ИД Ne 02429 от 24.07.00. Подписано в печать 02.07.09.
Формат 70x100'/„. Печать офсетная. Усл. печ. л. 60,63.
Тираж 2000 экз. Заказ Ne 1141
"БХВ-Петербург*, 190005, Санкт-Петербург, Измайловский пр„ 29.
Санитарно-эпидемиологическое заключение на продукцию
N. 77.99.60.953.Д.005770.05.09 от 26.05.2009 г. выдано Федеральной службой
Отпечатано с готовых диапозитивов
в ГУП "Типография ’Наука"
199034, Санкт-Петербург, 9 линия, 12
ISBN 978-0-07-154638-6 (англ.)
ISBN 978-5-9775-0149-1 (dvc.)
© 2008 by the McGraw-Hill Companies
© Перевод на русский язык "БХВ-Петербург", 2009
Оглавление
Об авторе............................................................1
О техническом редакторе..............................................1
Благодарности........................................................3
Введение.............................................................5
Цели этой книги......................................................5
Новые возможности SQL Server 2008, описываемые в этой книге..........6
Организация этой книги.............................................. 8
Изменения относительно предыдущей редакции..........................13
Различия в синтаксисе SQL и Transact-SQL............................14
Работа с базами данных примеров.....................................14
ЧАСТЬ I. ОСНОВНЫЕ КОНЦЕПЦИИ И ИНСТАЛЛЯЦИЯ...........................17
Глава 1. Введение в системы реляционных баз данных..................19
Системы баз данных..................................................19
Разнообразные пользовательские интерфейсы.......................20
Физическая независимость данных.................................21
Логическая независимость данных.................................21
Оптимизация запросов............................................21
Целостность данных..............................................21
Управление конкурентным доступом к данным.......................22
Копирование и восстановление данных.............................22
Безопасность базы данных........................................23
Системы реляционных баз данных......................................23
Работа с базой данных примеров в этой книге.....................24
SQL — язык реляционной базы данных.............................. 27
VI
Оглавление
Проектирование базы данных..............................................28
Нормальные формы....................................................29
Первая нормальная форма.......................................29
Вторая нормальная форма.......................................30
Третья нормальная форма.......................................31
Модель "сущность — отношение".......................................31
Соглашения по синтаксису................................................34
Резюме..................................................................35
Упражнения..............................................................35
Глава 2. Планирование инсталляции и инсталляция SQL Server..............37
Планирование инсталляции................................................37
Назначение системы SQL Server.......................................38
Требования к аппаратному обеспечению и к сети.......................38
Требования к аппаратному обеспечению..........................38
Требования к сети.............................................39
Редакции SQL Server.................................................40
Рекомендации по инсталляции.........................................41
Где размещать корневой каталог................................42
Сколько экземпляров Database Engine запускать на выполнение.1.42
Какой выбрать вариант аутентификации......"...................43
Инсталляция SQL Server..................................................43
Перед запуском программы инсталляции................................44
Запуск программы установки и предварительная установка..............44
Установка компонентов SQL Server....................................45
Запуск и останов экземпляра Database Engine.............................53
Выделенное соединение с экземпляром Database Engine.....................54
Резюме..................................................................55
Глава 3. SQL Server Management Studio...................................56
Программная группа SQL Server и Books Online............................56
Введение в SQL Server Management Studio.................................58
Соединение с сервером...............................................59
Зарегистрированные серверы..........................................60
Object Explorer.....................................................61
Организация панелей Management Studio и навигация по панелям........61
Использование Management Studio с Database Engine.......................63
Администрирование серверов базы данных..............................63
Регистрация серверов..........................................63
Соединение с сервером.........................................63
Создание новой серверной группы...............................64
Управление многими серверами..................................64
Запуск и останов серверов.....................................66
Оглавление У7/
Управление базами данных с использованием Object Explorer.........66
Создание баз данных без использования Transact-SQL..........66
Изменение баз данных без использования Transact-SQL.........69
Управление таблицами без использования Transact-SQI.........70
Авторская деятельность с использованием SQL Server Management Studio.75
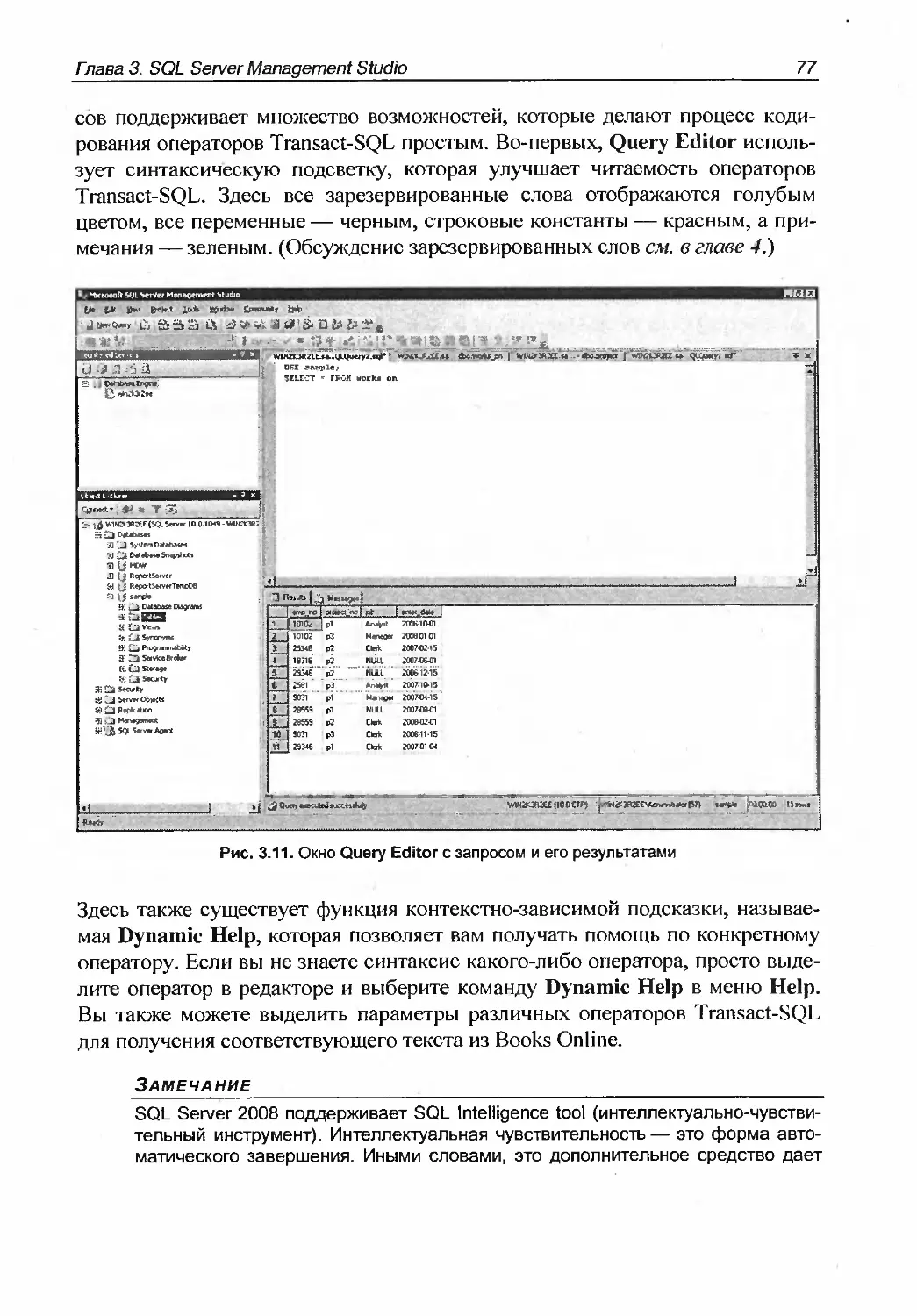
Query Editor................................................75
Solution Explorer...........................................79
Резюме................................................................80
Упражнения............................................................81
ЧАСТЬ II. ЯЗЫК TRANSACT-SQL...........................................83
Глава 4. Основные элементы SQL........................................85
Основные объекты SQL..................................................85
Значения литералов................................................85
Разделители.......................................................87
Комментарии.......................................................87
Идентификаторы....................................................88
Зарезервированные ключевые слова..................................88
Типы данных...........................................................88
Числовые типы данных..............................................89
Символьные типы данных............................................90
Типы данных даты и времени........................................90
Смешанные типы данных.............................................92
Двоичные типы данных и BIT..................................93
Типы данных больших объектов................................93
Тип данных UNIQUEIDENTIFIER.................................95
Тип данных SQL VARIANT......................................95
Тип данных HIERARCHY/D......................................96
Тип данных TIMESTAMP........................................96
Формат хранения VARDECIMAL для DECIMAL............................96
Функции Transact-SQL..................................................98
Агрегатные функции................................................98
Скалярные функции.......................................*.........99
Числовые функции.......................................... 99
Функции даты...............................................101
Строковые функции..........................................102
Системные функции..........................................104
Функции метаданных.........................................106
Скалярные операторы..................................................107
Глобальные переменные............................................108
Значения NULL........................................................109
Резюме...............................................................111
Упражнения...........................................................111
VIII
Оглавление
Глава 5. Язык описания данных.................................................113
Создание объектов базы данных.................................................113
Создание базы данных......................................................114
Создание мгновенного снимка базы данных...................................117
Соединение баз данных и их отсоединение от сервера.................118
CREATE TABLE', основная форма.............................................119
Оператор CREATE TABLE и ограничения декларативной целостности.............122
Предложение UNIQUE.................................................123
11редложение PRIMARY KEY............................................................................ 124
Предложение CHECK..................................................126
Предложение FOREIGN KEY............................................126
Ссылочная целостность..............................................128
Опции ON DELETE и ON UPDATE........................................130
Создание других объектов базы данных......................................132
Ограничения целостности и домены..........................................133
Псевдонимы типов данных............................................134
Типы данных CLR....................................................136
Изменение объектов базы данных................................................136
Изменение базы данных.....................................................136
Добавление или удаление файлов базы данных, файлов протоколов
транзакций или файловых групп.......................................137
Изменение свойств файла или файловой группы........................137
Установка опций базы данных........................................138
Изменение таблиц..........................................................139
Добавление или удаление столбцов...................................139
Изменение свойств столбца..........................................140
Добавление и удаление ограничений целостности......................140
Включение и отключение ограничений.................................141
1 Тереименование объектов базы данных..............................142
Удаление объектов базы данных.................................................143
Резюме........................................................................144
Упражнения....................................................................144
Глава 6. Запросы..............................................................148
Оператор SELECT', основная форма и предложение WHERE.......................148
Предложение WHERE.........................................................150
Логические операторы...............................................152
Операторы IN и BETWEEN.............................................156
Запросы, включающие пустые значения NULL...........................159
Оператор LIKE......................................................160
Подзапросы....................................................................164
Подзапросы и операторы сравнения..........................................164
Подзапросы и оператор IN..................................................165
Подзапросы и операторы ANY и ALL..........................................167
Оглавление
IX
Оператор SELECT: другие предложения и функции...............................168
Предложение GROUP BY...................................................168
Агрегатные функции.....................................................170
Обычные агрегатные функции.......................................170
Статистические агрегатные функции................................175
Агрегатные функции, определенные пользователем...................176
Предложение НА VING....................................................176
Предложение ORDER BY...................................................177
Оператор SELECT и свойство IDENTITY....................................179
Операторы над множествами..............................................181
Оператор над множествами UNION...................................181
Операторы над множествами INTERSECT и EXCEPT.....................184
Выражения CASE.........................................................185
Предложение COMPUTE....................................................187
Временные таблицы..........................................................189
Оператор JCMV..............................................................190
Две синтаксические формы для реализации соединений.....................191
Естественное соединение................................................192
Соединение более чем двух таблиц................................196
Декартово произведение.................................................198
Внешнее соединение.....................................................199
Другие формы операций соединения.......................................202
Тета-соединение..................................................202
Самосоединение. или соединение таблицы самой с собой.............203
11олусоединение..................................................204
Коррелированные подзапросы.................................................204
Подзапросы и функция EXISTS............................................205
Должны вы использовать соединения или подзапросы?......................207
Преимущества подзапросов.........................................207
Преимущества соединений..........................................208
Табличные выражения....................................................... 208
Наследуемые таблицы....................................................209
Общие табличные выражения..............................................210
ОТВ и нерекурсивные запросы......................................211
ОТВ и рекурсивные запросы...................................... 212
Оператор APPLY...................................................217
Резюме.....................................................................217
Упражнения.................................................................217
Глава 7. Изменение содержимого таблиц......................................222
Оператор INSERT............................................................222
Добавление одной строки................................................223
Добавление множества строк.............................................225
Конструкторы значений таблицы и оператор INSERT..........................................227
Оглавление
Оператор UPDATE..........................................................227
Оператор DELETE..........................................................230
Оператор TRUNCATE TABLE.............................................232
Предложение OUTPUT.......................................................232
Оператор MERGE...........................................................233
Резюме...................................................................235
Упражнения...............................................................235
Глава 8. Хранимые процедуры и функции,
определенные пользователем...............................................238
Процедурные расширения...................................................238
Блоки операторов....................................................239
Оператор IF.........................................................239
Оператор WHILE......................................................240
Локальные переменные................................................241
Смешанные процедурные операторы.....................................242
Обработка событий операторами TRY и CATCH...........................243
Хранимые процедуры.......................................................245
Создание выполняемых хранимых процедур..............................246
Изменение структуры хранимых процедур.........................250
Хранимые процедуры и CLR............................................251
Функции, определенные пользователем......................................256
Создание и выполнение функций, созданных пользователем..............257
Вызов функций, определенных пользователем.....................259
Тип данных TABLE..............................................260
Табличные параметры..........................................„261
Табличные функции и оператор APPLY............................262
Изменение структуры UDF.......................................263
Функции, определенные пользователем, и CLR..........................264
Резюме...................................................................265
Упражнения...............................................................266
Глава 9. Системный каталог...............................................267
Общие сведения о системном каталоге......................................267
Общие интерфейсы.........................................................269
Представления просмотра каталога....................................269
Запросы к представлениям просмотра каталогов..................271
Динамически управляемые представления и функции.....................273
Информационная схема................................................273
Informationschema.tables......................................274
Information_schema.columns....................................274
Informationschema.referentialconstraints......................275
Собственные интерфейсы...................................................275
Системные процедуры.................................................276
Системные функции...................................................277
Функции свойств.....................................................278
Оглавление
XI
Резюме................................................................279
Упражнения............................................................279
Глава 10. Индексы.....................................................281
Общие сведения........................................................281
Кластеризованные индексы..........................................284
Некластеризованные индексы........................................285
Transact-SQL и индексы................................................286
Создание индексов.................................................286
Получение информации о фрагментации индекса.......................290
Редактирование информации индекса.................................291
Изменение индексов................................................293
Пересоздание индекса........................................293
Реорганизация индексных страниц листьев......................294
11еревод индекса в неактивное состояние......................294
Удаление и переименование индексов.................................295
Основные направления в создании и использовании индексов...............295
Индексы и условия в предложении WHERE..............................296
Индексы и операция соединения......................................297
Покрывающий индекс.................................................297
Индексы для вычисляемых столбцов.......................................298
Виртуальные вычисляемые столбцы....................................298
Постоянные вычисляемые столбцы.....................................299
Опция PERSISTED..............................................300
Резюме.................................................................300
Упражнения.............................................................301
Глава 11. Представления................................................303
Операторы DDL и представления..........................................303
Создание представления.............................................304
Изменение и удаление представлений................!...............308
Редактирование информации, связанной с представлениями.............309
Операторы DML и представления..........................................309
Представление поиска................................................310
Оператор INSERT и представление....................................311
Оператор UPDATE и представление....................................313
Оператор DELETE и представление....................................315
Индексированные представления..........................................317
Создание индексированного представления............................317
Изменение структуры индексированного представления.................320
Редактирование информации, связанной с индексированными
представлениями....................................1..............320
Преимущества индексированных представлений........................321
Резюме................................................................323
Упражнения............................................................324
XII
Оглавление
Глава 12. Система безопасности Database Engine.......................................326
Аутентификация.......................................................................327
Реализация режима аутентификации................................................328
Шифрование данных...............................................................329
Симметричные ключи.......................................................330
Асимметричные ключи......................................................331
Сертификаты..............................................................33 1
Представления просмотра каталога шифрования..............................333
Улучшения шифрования в SQL Server 2008...................................333
Установка системы безопасности с использованием DDL.............................334
Управление подключениями с использованием Management Studio.....................336
Схемы................................................................................337
Разделение пользователей и схем.................................................337
Операторы DDL, связанные со схемой..............................................338
Оператор CREATE SCHEMA...................................................338
Оператор ALTER SCHEMA....................................................340
Оператор DROP SCHEMA.....................................................340
Безопасность базы данных.............................................................341
Установка учетных записей пользователей для базы данных.........................341
Добавление пользователей при помощи операторов Transact-SQL..............341
Добавление пользователей с применением SQL Server Management Studio......342
Схемы базы данных по умолчанию..................................................343
Роли.................................................................................344
Фиксированные серверные роли....................................................344
Учетная запись sa............................................................................................345
Назначение учетной записи фиксированной серверной роли...................346
Фиксированные роли базы данных..................................................346
Роль public..............................................................347
Назначение пользователя фиксированной роли базы данных...................348
Роли приложений.................................................................348
Создание, модификация и удаление ролей приложений........................349
Активация роли приложения................................................349
Управление ролями приложений с помощью Management Studio.................350
Определенные пользователем роли базы данных.....................................350
Создание и удаление определенных пользователем ролей.....................351
Роли и системные процедуры...............................................351
Управление определенными пользователем ролями с помощью Management
Studio...................................................................352
Авторизация..........................................................................352
Оператор GRANT...................................................................................................... 353
Оператор DENY...................................................................358
Оператор REVOKE.................................................................360
Управление полномочиями с использованием Management Studio......................360
Отслеживание изменений...............................................................363
Оглавление XIII
Безопасность данных и представления..................................366
Резюме...............................................................368
Упражнения...........................................................368
Глава 13. Управление параллельной работой............................371
Модели конкурентного доступа.........................................372
Транзакции...........................................................373
Свойства транзакций..............................................374
Операторы Transact-SQL и транзакции..............................375
Протокол транзакций..............................................378
Блокировка...........................................................379
Режимы блокировки................................................380
Гранулярность блокировок.........................................382
Укрупнение блокировок............................................383
Влияние блокировок...............................................384
Подсказки блокировки.......................................384
Опция LOCK TIMEOUT.........................................385
Отображение информации блокировки................................385
Взаимная блокировка..............................................386
Уровни изоляции......................................................387
Проблемы конкурентного доступа...................................388
Database Engine и уровни изоляции................................388
READ UNCOMMITTED...........................................389
READ COMMUTED..............................................389
REPEA TABLE READ...........................................390
SERIALIZABLE...............................................390
Установка и редактирование уровней изоляции................391
Контроль версий строк................................................391
Уровень изоляции READ COMMITTED SNAPSHOT.........................392
Уровень изоляции SNAPSHOT.................,......................393
READ COMMITTED SNAPSHOT в сравнении c SNAPSHOT.............393
Резюме...............................................................394
Упражнения...........................................................394
Глава 14. Триггеры...................................................397
Общие сведения.......................................................397
Создание триггера DML............................................398
Модификация структуры триггера.................................:.399
Использование таблиц удаления и добавления.......................399
Области приложений для DML-триггеров.................................400
Триггеры AFTER...................................................400
Создание контрольного журнала..............................401
Реализация бизнес-правил...................................402
Поддержание ограничений целостности........................403
XIV
Оглавление
Триггеры INSTEAD OF........,.................................................404
Первый и последний триггеры..................................................406
Триггеры DDL.....................................................................407
Триггеры уровня базы данных..................................................408
Триггеры уровня сервера......................................................409
Триггеры и CLR...................................................................410
Резюме...........................................................................414
Упражнения.......................................................................415
ЧАСТЬ III. SQL SERVER: СИСТЕМНОЕ
АДМИНИСТРИРОВАНИЕ................................................................417
Глава 15. Системное окружение и сервер базы данных...............................419
Системные базы данных............................................................419
База данных master...........................................................419
База данных model............................................................420
База данных tempdb...........................................................420
База данных msdb.............................................................421
Хранение данных на диске.........................................................421
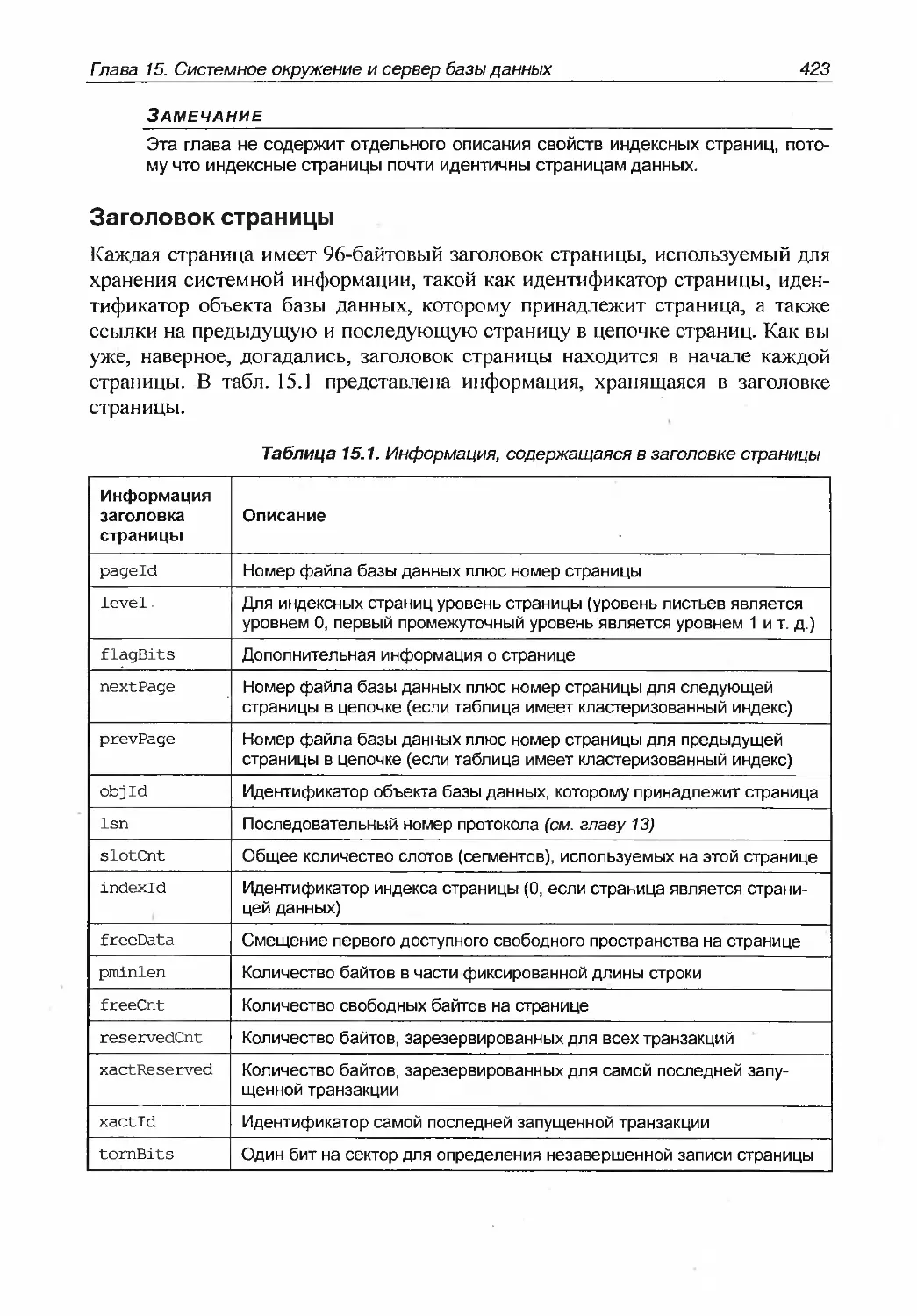
Свойства страниц данных......................................................422
Заголовок страницы....................................................423
Зарезервированное пространство для данных.............................424
Таблица смещений строк................................................424
Типы страниц данных..........................................................425
Страницы данных последовательных строк................................425
Страницы данных переполнения строк....................................425
Параллельное выполнение задач................................................427
Утилиты и команда DBCC...............................................................................................428
Утилита Ьср..................................................................428
Утилита sqlcmd...............................................................430
Команда DBCC.................................................................432
Команды проверки......................................................433
Резюме...........................................................................434
Упражнения.......................................................................434
Глава 16. Управление экземплярами сервера и поддержка
баз данных.......................................................................435
Declarative Management Framework.................................................435
Ключевые термины. .............................................................435
Использование Declarative Management Framework...............................436
Maintenance Plan Wizard..........................................................438
Резюме...........................................................................441
Упражнения.......................................................................441
Оглавление
XV
Глава 17. Копирование и восстановление...........................................442
Методы резервного копирования....................................................443
Полное копирование базы данных..............................................444
Дифференцированное резервное копирование....................................444
Резервное копирование протокола транзакций..................................444
Резервное копирование файла или файловой группы.............................446
Выполнение резервного копирования................................................447
Резервное копирование с помощью операторов Transact-SQL.....................447
Типы устройств для резервного копирования............................447
Оператор BACKUP DATABASE.............................................448
Оператор BACKUP LOG...................................................................450
Резервное копирование с помощью Management Studio...........................451
Создание расписания резервного копирования в Management Studio.......454
Какие базы данных копировать?...............................................454
Резервное копирование базы данных master.............................454
Резервное копирование производственных баз данных....................455
Восстановление базы данных.......................................................456
Автоматическое восстановление...............................................456
Ручное восстановление.......................................................457
Является ли мой набор резервной копии готовым к восстановлению?.....457
Восстановление баз данных и протоколов с использованием операторов
Transact-SQL.........................................................'...459
Восстановление баз данных и протоколов с использованием Management
Studio...............................................................461
Восстановление до отмегки............................................464
Восстановление базы данных master...........................................................465
Восстановление других системных баз данных...........................466
Модели восстановления.......................................................466
Модель полного восстановления........................................467
Модель восстановления с неполным протоколированием...................467
Простая модель восстановления........................................468
. Изменение и редактирование модели восстановления....................469
Высокая доступность..............................................................470
Использование резервного сервера............................................470
Использование технологии RAID...............................................471
Расслоение дисков....................................................472
Зеркальное отображение...............................................472
Контроль по четности.................................................473
Отказоустойчивая кластеризация..............................................474
Зеркальное отображение базы данных..........................................474
Улучшения зеркального отображения базы данных в SQL Server 2008......475
Пересылка протокола.........................................................476
Резюме...........................................................................476
Упражнения.......................................................................477
XVI
Оглавление
Глава 18. Система автоматизации задач администрирования...............479
Запуск и конфигурирование SQL Server Agent............................480
Создание заданий и операторов.........................................481
Создание задания и его шагов......................................48!
Создание расписания задания.......................................485
Операторы уведомлений о состоянии задания.........................486
Просмотр протокола истории задания................................488
11реду преждающие сообщения...........................................489
Сообщения об ошибках..............................................489
Протокол ошибок SQL Server Agent..................................491
Протокол приложений Windows.......................................491
Определение предупреждающих сообщений для обработки ошибок........492
Создание предупреждающих сообщений для системных ошибок.....492
Создание предупреждающих сообщений для группы ошибок с одинаковым
уровнем ошибки..............................................493
Создание предупреждающих сообщений для ошибок, определенных
пользователем...............................................495
Резюме................................................................497
Упражнения............................................................497
Глава 19. Репликация данных...........................................499
Распределенные данные.................................................499
Методы распределения данных.......................................500
Выбор метода распределения данных.................................501
Общие сведения о репликации...........................................501
Издатели, распространители и подписчики...........................502
Публикации и статьи...............................................503
Типы репликации...................................................504
Репликация транзакций.......................................505
Репликация мгновенного снимка...............................505
Репликация слияния..........................................506
Одноранговая репликация транзакций..........................508
Модели репликации.................................................510
Центральный издатель с распространителем....................510
Центральный подписчик с множеством издателей................511
Множество издателей с множеством подписчиков................511
Управление репликацией................................................512
Конфигурирование распределяющего и публикующего серверов..........512
Настройка публикаций..............................................514
Конфигурирование серверов подписки................................515
Резюме................................................................517
Упражнения............................................................518
Глава 20. Оптимизатор запросов........................................519
Фазы обработки запроса................................................519
Как работает оптимизация запроса......................................521
Анализ запроса....................................................521
Оглавление
XVII
Выбор индекса............................................................522
Селективность выражения с индексированным столбцом................522
Статистические данные индекса.....................................524
Статистические данные столбца.....................................525
Выбор порядка соединения.................................................526
Техники обработки соединения.............................................526
Вложенные циклы...................................................526
Слияние соединения................................................527
Хеширование соединения............................................528
Инструменты для редактирования стратегии оптимизатора........................529
Оператор SET.............................................................529
Текстовая форма планов выполнения.................................529
Планы выполнения XML.............................................53 1
Другие опции оператора SET........................................532
Management Studio и графические планы выполнения.........................533
Примеры планов выполнения................................................535
Представления динамического управления и оптимизатор запросов............539
sys.dm exec query optimizer Jnfo..................................539
sys.dm exec query_plan............................................540
sys.dm exec_querystats............................................541
sys.dmexecsqltext u sys.dm exectextquery_plan ...................................^Я 541
sys.dm exec_procedure stats.......................................541
Подсказки оптимизатора.......................................................542
Зачем использовать подсказки оптимизатора................................542
Типы подсказок оптимизации...............................................543
Подсказки таблицы.................................................543
Подсказки соединения..............................................545
Подсказки запроса.................................................548
Структуры планов..................................................549
Резюме.......................................................................550
Глава 21. Настройка производительности.......................................552
Факторы, влияющие на производительность......................................553
Приложения базы данных и производительность..............................553
Эффективность кода приложения.....................................553
Физическое проектирование.........................................554
Database Engine и производительность.....................................556
Оптимизатор.......................................................556
Блокировки........................................................556
Системные ресурсы и производительность...................................556
Дисковые операции ввода/вывола....................................558
Память............................................................560
Мониторинг производительности................................................562
Обзор Performance Monitor................................................562
Мониторинг процессора....................................................564
Мониторинг памяти........................................................566
XVIII
Оглавление
Мониторинг дисковой системы.........................................567
Мониторинг сетевого интерфейса......................................569
Выбор подходящего инструмента...........................................570
SQL Server Profiler.................................................571
Database Engine Tuning Advisor......................................571
Предоставление информации для Database Engine Tuning Advisor..572
Работа c Database Engine Tuning Advisor..............:........574
Инструменты производительности SQL Server 2008..........................579
Performance Data Collector..........................................579
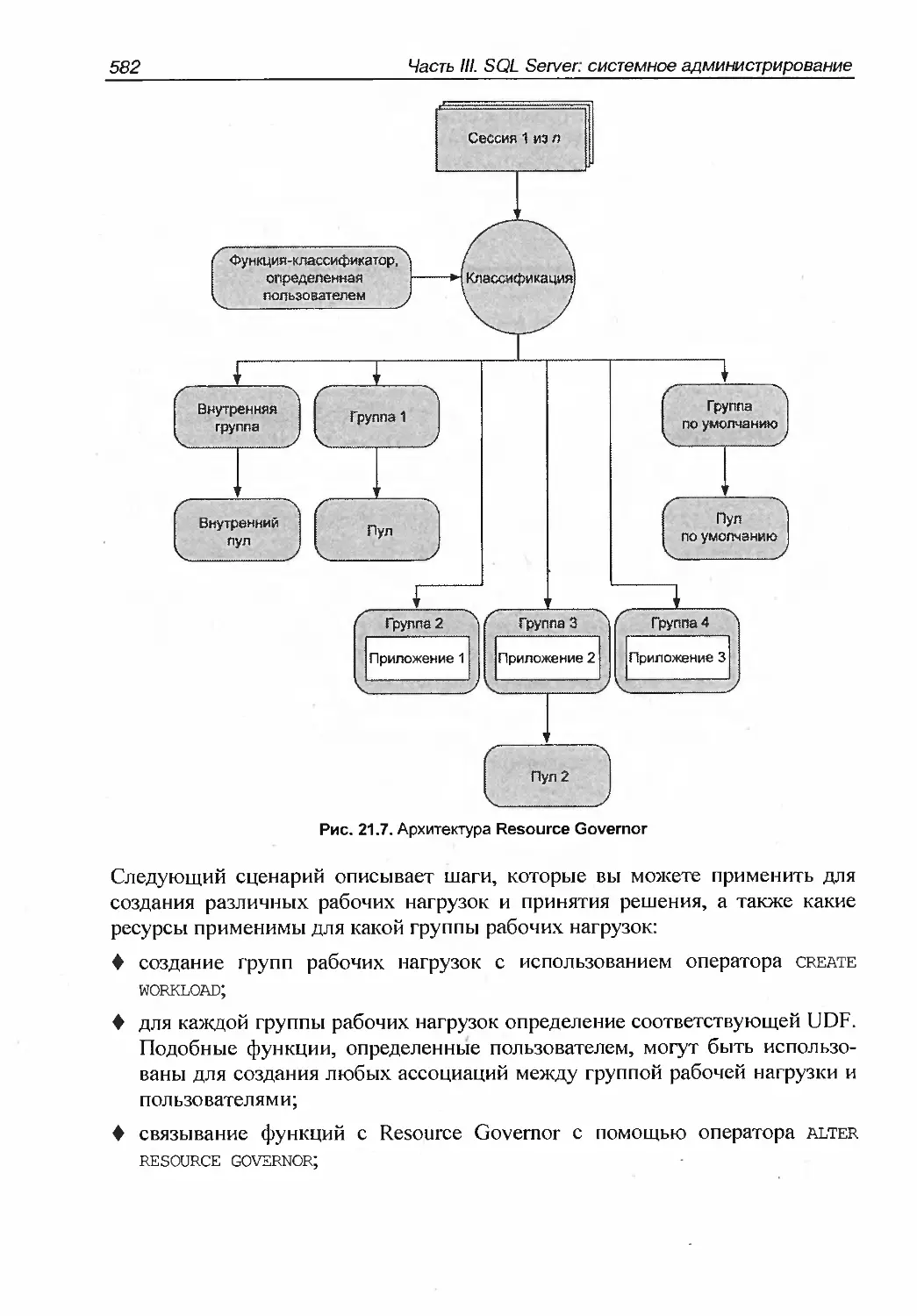
Resource Governor...................................................581
Резюме..................................................................583
Упражнения..............................................................583
ЧАСТЬ IV. SQL SERVER И BUSINESS INTELLIGENCE............................585
Глава 22. Введение в Business Intelligence..............................587
Online Transaction Processing в сравнении c Business Intelligence.......587
Online Transaction Processing.......................................588
Системы Business Intelligence.......................................589
Хранилище данных и киоск данных.........................................590
Проектирование хранилища данных с использованием пространственной модели.. 593
Кубы и их архитектура...................................................596
Агрегаты............................................................597
Сколько можно агрегировать?.........................................598
Физическое хранение кубов...........................................600
Доступ к данным.........................................................601
Резюме..................................................................602
Упражнения..............................................................603
Глава 23. Microsoft Analysis Services___________________________________604
Business Intelligence Development Studio................................605
Создание нового проекта.............................................605
Создание источника данных...........................................607
Создание представления источника данных.............................608
Analysis Services и кубы................................................610
Создание куба.......................................................611
Проектирование агрегата хранения и обработка куба...................612
Просмотр куба.......................................................615
Резюме..................................................................616
Глава 24. Business Intelligence и Transact-SQL..........................617
Введение в SQL/OLAP.....................................................617
Конструкция окна........................................................618
Разбиение на разделы................................................620
Упорядочение........................................................622
Оглавление XIX
Расширения предложения GROUP BY.........................................624
Оператор CUBE.......................................................624
Оператор ROLLUP.....................................................627
Функция GROUPING....................................................627
Оператор GROUPING SETS..............................................628
Функции запросов OLAP....................................'.............629
Функции упорядочения................................................629
Статистические агрегатные функции...................................632
Нестандартные аналитические функции.....................................633
Предложение ТОР.....................................................633
Функция NTILE.......................................................636
Операторы PIVOT и UNPIVOT...........................................637
Резюме..................................................................639
Упражнения..............................................................639
Глава 25. Microsoft Reporting Services..................................641
Введение в Microsoft Reporting Services.................................641
Report Manager......................................................642
Report Server.......................................................642
Report Catalog......................................................643
Создание отчетов........................................................644
Создание отчетов при помощи мастера Report Server Project Wizard....645
Выбор источника данных.......................................645
Проектирование запроса.......................................646
Выбор типа отчета............................................648
Проектирование данных в таблице..............................648
Задание схемы размещения данных в отчете.....................650
Выбор стиля отчета........•..................................650
Предварительный просмотр результирующего набора.. 651
Создание параметризованных отчетов..................................652
Обработка и управление отчетами.........................................654
Организация доступа и распространение отчетов...........................655
Отчеты по запросам..................................................655
Подписка на отчет...................................................656
Персональные подписки........................................656
Подписки, управляемые данными................................657
Резюме..................................................................657
Упражнения..............................................................658
Глава 26. Техники оптимизации для бизнес-аналитики......................659
Распределение данных по разделам........................................659
Способы распределения ваших данных по разделам......................660
Шаги для создания разделенных таблиц................................661
Цели задания разделений......................................661
Определение разделяющего ключа и количества разделов.........662
XX
Оглавление
Создание файловой группы для каждого раздела.....................662
Создание функции разделения и схемы разделения...................664
Создание разделенного индекса....................................667
Совместное размещение таблиц............................................667
SQL Server 2008 и разделение данных.........................................668
Новые операции поиска к разделенным данным.......................668
Параллельное выполнение запросов.................................669
Улучшения, связанные с информацией разделения....................670
Основные правила для разделенных таблиц и индексов......................670
Оптимизация запроса схемы "звезда"..........................................671
Резюме......................................................................673
ЧАСТЬ V. ЗА ПРЕДЕЛАМИ РЕЛЯЦИОННЫХ ДАННЫХ....................................675
Глава 27. Обзор XML.........................................................677
Всемирная паутина...........................................................677
Языки, связанные с XML......................................................678
Базовые концепции XML.......................................................679
Атрибуты XML............................................................681
Пространства имен XML...................................................682
Определение типа документа DTD..........................................683
Схема XML...............................................................685
Резюме......................................................................686
Глава 28. SQL Server и XML..................................................687
Методы хранения документов XML в реляционных базах данных...................687
Хранение документов XML в SQL Server........................................689
Хранение документов XML с использованием типа данных XML................690
Индексирование столбца XML.......................................................................... 692
Типизированные в сравнении с нетипизированными XML............. 694
Хранение документов XML с использованием декомпозиции...................696
Поиск сохраненных документов XML и фрагментов...............................697
Представление реляционных данных в качестве документов XML..................698
Режим RAW...............................................................698
Режим A UTC)............................................................699
Режим EXPLICIT..........................................................700
Режим PATH..............................................................702
Директивы...............................................................703
Директива TYPE...................................................703
Директива ELEMENTS...............................................704
Директива ROOT...................................................704
Методы XQuery в SQL Server..................................................705
SQL Server 2008 и улучшения XML.............................................706
Резюме......................................................................707
Оглавление XXI
Глава 29. Введение в пространственные данные.......................708
Представление пространственных данных..............................708
Модели геодезического пространства.............................709
Модели плоского пространства...................................709
Пространственные типы данных.......................................709
Тип данных GEOMETRY............................................710
Статические геометрические методы........................710
Пространственное индексирование..........................711
Запрос данных GEOMETRY...................................713
Различия между типами данных GEOMETRY и GEOGRAPHY..............715
Резюме.............................................................716
Предметный указатель...............................................717
Об авторе
Душан Петкович — профессор в Отделе компьютерных наук в Политех-
никуме в Розенхейме, Германия. Он является автором книг "SQL Server 7:
A Beginner's Guide", "SQL Server 2000: A Beginner's Guide" и "Microsoft SQL
Server 2005: A Beginner's Guide" и часто пишет статьи для журнала "SQL
Server Magazine".
О техническом редакторе
Тодд Мейстер (Todd Meister) использует технологии Microsoft более десяти
лет. Он был техническим редактором публикаций более 40 наименований в
направлениях от SQL Server до .NET Framework. Помимо этого, Тодд являет-
ся заместителем директора по компьютерным сервисам в Ball State University
в Манси, штат Индиана. Он живет со своей женой Кимберли и четырьмя
детьми в центральной Индиане. С Тоддом можно связаться по адресу:
tmeister@sycamoresolutions.com.
Благодарности
Во-первых, я хочу поблагодарить моего редактора-заказчика Венди Ринальди
(Wendy Rinaldi). С 1998 года Венди была руководителем по созданию всех
четырех книг, которые я опубликовал в издательстве "McGraw-Hill". Я очень
признателен ей за необыкновенную поддержку в течение всех этих лет.
Я также хочу поблагодарить за большое участие Менди Каналес (Mandy
Canales) и Тодда Мейстера.
Введение
Существует множество причин, по которым SQL Server, система, включаю-
щая в себя Database Engine, сервисы анализа (Analysis Services), сервисы от-
четов (Reporting Services) и сервисы интеграции (Integration Services), являет-
ся лучшим выбором для широкого спектра конечных пользователей и про-
граммистов баз данных, создающих бизнес-приложения.
♦ SQL Server является, несомненно, лучшей системой для операционных
систем Windows по причине тесной интеграцией с этими системами
(и низкой цены). Поскольку количество установленных систем Windows
огромно и по-прежнему продолжает быстро расти, SQL Server является
широко используемой системой.
♦ Database Engine в качестве компонента системы реляционной базы данных
является самой простой в использовании системой баз данных. В допол-
нение к популярному интерфейсу Microsoft предоставляет некоторое ко-
личество различных инструментов, помогающих вам создавать объекты
базы данных, настраивать ваши приложения баз данных и управлять зада-
чами системного администрирования.
Вообще, SQL Server не является лишь системой баз данных. Это платформа,
которая не только управляет структурированными, частично структуриро-
ванными и вовсе неструктурированными данными, но также предоставляет
всеобъемлющее, операционно-интегрированное и обладающее средствами
анализа программное обеспечение, которое дает возможность организациям
надежно управлять критически важной информацией.
Цели этой книги
Данной книге предшествуют предыдущие издания, которые посвящены вер-
сиям SQL Server 7, 2000 и 2005.
Введение
Вообще говоря, все пользователи SQL Server, которые хотят получить хоро-
шие знания по этой системе баз данных и научиться успешно с нею работать,
найдут эту книгу весьма полезной для себя. (Если вы пользователь-новичок
в SQL Server, но знакомы с языком SQL, прочтите разд. "Различия в синтак-
сисе между SQL и Transact-SQL" далее в этом введении.)
Эта книга адресована пользователям любых компонентов SQL Server. По
этой причине она разделена на несколько частей: пользователи, которые хо-
тят лучше изучить компонент реляционной базы данных, называемый
Database Engine, найдут для себя наиболее полезными части 1—III. Часть IV
книги предназначена пользователям, занимающимся средствами бизнес-
аналитики (business intelligence), которые используют либо сервисы анализа
(Analysis Services), либо реляционные расширения, связанные с анализом де-
ловых данных. Последняя часть книги дает начальные знания пользователям,
которые собираются использовать данные XML и/или пространственные,
многомерные данные.
Новые возможности SQL Server 2008,
описываемые в этой книге
SQL Server 2008 имеет множество новых возможностей, и почти все они рас-
сматриваются в данной книге. Для каждой возможности предоставляется, по
меньшей мере, один пример для того, чтобы вы лучше поняли эту возмож-
ность. В табл. В1 перечислены главы книги, в которых описываются новые
возможности системы, и дается краткая сводка по каждой новой возможно-
сти, введенной в каждой главе.
Таблица В1. Описание глав
Глава Описание
3 Функциональность InteiliSense в редакторе запросов SQL Server Management Studio описывается в этой главе. InteiliSense предоставляет список опций, кото- рые делают более доступными языковые ссылки. В SQL Server 2008 поддержи- ваются часто используемые элементы Transact-SQL
4 В этой главе описываются некоторые новые возможности, наиболее важной из которых является поддержка новых временных типов данных date, time, datetime2 и datetimeoffset. Также рассматриваются два других типа дан- ных — filestream и hierarchyid. В деталях обсуждается формат хранения VARDECIMAL. Этот формат хранения был введен в Service Pack 2 для SQL Server 2005
5 В этой главе показано создание определенных пользователем типов таблиц. Их практическое использование в параметрах, связанных со значениями таб- лиц, можно найти в главе 8
Введение
Таблица В1 (продолжение)
Глава Описание
6 В этой главе вы найдете синтаксис и примеры использования улучшенной формы предложения group by: group by ()
7 Эта глава описывает оператор merge и конструктор значения строки в операто- ре INSERT. Оператор merge соединяет последовательность условных команд insert и update в один атомарный оператор в зависимости от условия сущест- вования записи. Конструктор значения строки позволяет вам'упростить написа- ние операторов insert
8 Параметры типа значений таблиц, которые позволяют вам упростить задачу передачи множества параметров подпрограммам, описываются в этой главе
12 Эта глава описывает расширенное управление ключами (Extensible Key Management) и прозрачное кодирование данных (Transparent Data Encryption), которые улучшают возможности кодирования данных по сравнению с преды- дущей версией. Здесь также представлен новый механизм трассировки, на- званный CDC (Change Data Capture, отслеживание изменения данных), и пока- зано его практическое использование
13 Улучшения, связанные с расширением блокировок, описываются в этой главе
16 Эта глава описывает два инструмента, из которых Declarative Management Framework (DMF) является новым. DMF — это основа для управления экземп- лярами Database Engine. Он позволяет вам создавать политики, которые в дальнейшем могут быть использованы для всего экземпляра Database Engine или только для его части
17 В этой главе описываются способы сжатия содержимого оперативной копии и вводится несколько улучшений, связанных с зеркалированием (зеркальным копированием) базы данных
19 Одноранговая транзактная репликация, которая поддерживает новую форму определения конфликтов, описывается в этой главе
20 Новая подсказка, называемая forceseek, и новое динамически управляемое представление (sys.dm_exec_procedure_stats) описываются здесь. Также показана новая форма дружественного к пользователю отображения планов выполнения запросов
21 В этой главе, помимо других вещей, рассматриваются два новых и очень важ- ных инструмента производительности — Performance Data Collection и Resource Governor
24 SQL Server 2008 реализует функции ROLLUP и CUBE co стандартизованным син- таксисом, которые описываются здесь. Обе эти функции существовали и в пре- дыдущих версиях, однако поддерживался только внутренний, частный, синтак- сис. В главе также рассматривается новая функция GROUPING SETS
26 Первая часть этой главы описывает параллелизм в декомпозиции данных. Вто- рая часть этой главы является абсолютно новой и описывает замечательную схему оптимизации запросов
28 В конце этой главы описываются незначительные улучшения, касающиеся схемы XML и типа данных xml
Введение
Таблица В1 (окончание)
Глава Описание
29 Это совершенно новая глава, описывающая пространственные данные и два НОВЫХ типа данных — GEOMETRY И GEOGRAPHY
Организация этой книги
Книга состоит из 29 глав и разделена на пять частей.
Часть /, "Основные концепции и инсталляция", описывает понятие системы
баз данных, в общем, и ядро базы данных (именно реляционной системы баз
данных SQL Server), в частности, а также процесс инсталляции. Эта часть
включает следующие главы.
♦ Глава I, "Введение в системы реляционных баз данных", описывает, в об-
щем, базы данных и ядро базы данных, в частности. Здесь же представле-
ны понятия нормальных форм и пример базы данных sample. В главе так-
же вводятся синтаксические соглашения, которые будут использоваться во
всей оставшейся части книги.
♦ Глава 2, "Планирование инсталляции и инсталляция SQL Server", описыва-
ет первую задачу системного администрирования — полную инсталляцию
системы. Несмотря на то, что инсталляция SQL Server является простой
задачей, существуют некоторые шаги, которые требуют объяснения.
♦ Глава 3, "SQL Server Management Studio", описывает компонент, который
называется SQL Server Management Studio. Этот компонент присутствует и
ранее в этой книге в тех случаях, когда вам нужно создавать объекты базы
данных и запросы к данным без предварительных знаний языка SQL.
Часть II, "Язык Transact-SQL", предназначена для конечных пользователей и
разработчиков приложений базы данных. Она содержит следующие главы.
♦ Глава 4, "Основные элементы SQL", описывает основы наиболее важной
части системы реляционных баз данных — язык базы данных. Для всех
подобных систем существует только один язык, который называется SQL.
В этой главе описаны все основные элементы собственного языка базы
данных SQL Server, называемого Transact-SQL. В этой главе вы можете
найти базовые концепции языка, а также описания типов данных. Под ко-
нец описываются системные функции и операции Transact-SQL.
♦ Глава 5, "Язык описания данных", описывает операторы языка определе-
ния всех данных в Transact-SQL (DDL, Data Definition Language— язык
описания данных). Операторы DDL, в зависимости от их назначения,
Введение
представлены в трех группах. Первая группа содержит все формы опера-
тора create, который используется для создания объектов базы данных.
Вторая группа содержит все формы оператора alter, который служит для
изменения структуры некоторых объектов базы данных. Третья группа со-
держит все формы оператора drop, который применяется для удаления от-
дельных объектов базы данных.
♦ Глава 6, "Запросы", рассматривает наиболее важный оператор Transact-
SQL — select. Эта глава вводит вас в область поиска данных в базе дан-
ных и описывает использование простых и сложных запросов. Каждое
предложение оператора select отдельно определяется и объясняется с по-
мощью ссылок на базу данных sample.
♦ Глава 7, "Изменение содержимого таблиц", рассматривает четыре опера-
тора Transact-SQL, используемых для изменения данных в базе данных:
insert, update, delete и merge. При объяснении назначения каждого из
этих операторов приводится множество примеров.
♦ Глава 8, "Хранимые процедуры и функции, определенные пользователем",
описывает процедурные расширения, которые могут быть использованы
при создании мощных программ, называемых хранимыми процедурами и
функциями, определенными пользователем (User Defined Function,
UDF) — программ, которые хранятся на сервере и могут использоваться
многократно. Поскольку Transact-SQL— в полной мере вычислительный
язык, то все процедурные расширения являются неотделимой частью это-
го языка. Некоторые хранимые процедуры пишутся пользователем, другие
предоставляются корпорацией Microsoft и называются системными хра-
нимыми процедурами. Реализация хранимых процедур и UDF, исполь-
зующих Common Language Runtime (CLR), также описывается в этой
главе.
♦ Глава 9, "Системный каталог", описывает одну из наиболее важных час-
тей системы баз данных. Системный каталог содержит системные табли-
цы, которые применяются для хранения информации, относящейся к объ-
ектам базы данных и их взаимозависимостям. Основной характеристикой
системных таблиц в Database Engine является то, что к ним невозможен
прямой доступ. Database Engine поддерживает несколько интерфейсов, ко-
торые вы можете использовать для выполнения запросов к системному ка-
талогу.
♦ Глава 10, "Индексы", описывает первый и наиболее мощный метод, кото-
рый может использовать любой пользователь (в особенности програм-
мист, создающий приложения базы данных) для настройки его приложе-
ния с целью получить наилучший ответ системы и, по этой причине, наи-
лучшую производительность. Эта глава описывает роли индексов и дает
10
Введение
основное направление по их созданию и использованию. В конце главы
вводятся специальные типы индексов, поддерживаемых Database Engine.
♦ Глава 11, "Представления", объясняет, как вы можете создавать представ-
ления, описывает практическое применение представлений (используя
многочисленные примеры) и рассматривает специальную форму пред-
ставлений, называемую индексированными представлениями.
♦ Глава 12, "Система безопасности Database Engine", дает ответы на все
ваши вопросы относительно безопасности данных в базе данных. Она по-
священа вопросам, касающимся авторизации (каким пользователям пре-
доставлены какие права доступа к базе данных) и аутентификации (какие
привилегии доступа являются применимыми для отдельных пользовате-
лей). В этой главе рассматриваются три оператора Transact-SQL — grant,
deny и revoke, которые предоставляют привилегии доступа к объектам ба-
зы данных в противоположность неавторизованному доступу. В конце
главы рассказывается о новых возможностях SQL Server, позволяющих
отслеживать изменения данных.
♦ Глава 13, "Управление параллельной работой", подробно рассказывает об
управлении параллельной (одновременной) работой с базой данных. В на-
чале главы обсуждаются две параллельные модели, поддерживаемые сис-
темой Database Engine. Рассматриваются также все операторы Transact-
SQL, связанные с транзакциями. Далее обсуждаются решения проблем,
связанных с блокировкой одновременного обращения к базе данных.
В конце этой главы вы освоите уровни изоляции и варианты взаимной
блокировки.
♦ Глава 14, "Триггеры", описывает реализацию обеспечения ограничения
процедурной целостности данных при использовании триггеров. Каждый
пример в этой главе связан с проблемой целостности данных, которая мо-
жет стоять перед вами в вашей повседневной жизни как разработчика
приложений базы данных. Создание управляемого кода для триггеров
с помощью CLR также представлено в этой главе.
Часть III, "SQL Server: системное администрирование", описывает все цели
системы администрирования Database Engine. Она содержит следующие главы.
♦ В главе 15, "Системное окружение и сервер базы данных", рассматрива-
ются некоторые вопросы, касающиеся Database Engine. Глава содержит
детальное описание хранящихся на диске элементов базы данных, систем-
ных таблиц и утилит.
♦ Глава 16, "Управление экземплярами сервера и поддержка баз данных",
описывает два важных компонента Database Engine — Declarative Manage-
ment Framework и Maintenance Plan Wizard, которые используются для
управления экземплярами сервера и базами данных соответственно.
Введение 1 t
♦ Глава 17, "Копирование и восстановление", содержит обзор отказоустой-
чивых методов, используемых в стратегии резервного копирования с при-
менением как SQL Server Management Studio, так и соответствующих опе-
раторов Transact-SQL.
♦ Глава 18, "Система автоматизации задач администрирования", описы-
вает компонент Database Engine— SQL Server Agent, который дает воз-
можность автоматизировать некоторые работы системного администриро-
вания, такие как оперативное копирование данных, использование средств
диспетчеризации и уведомления о выполняемых операторах. В главе так-
же рассказывается, как создавать задания, операторы и средства уведом-
ления.
♦ Глава 19, "Репликация данных", содержит введение в репликацию данных,
включая такие концепции, как сервер публикаций и подписчик (абонент).
В главе вводятся различные модели репликации, она может служить в ка-
честве учебника по вопросам конфигурирования публикаций и подписок
(ссылок на сервер репликаций) с использованием существующих про-
грамм-мастеров.
♦ Глава 20, "Оптимизатор запросов", описывает роль и работу, выполняе-
мую оптимизатором запросов. В ней детально рассматриваются все инст-
рументы Database Engine (оператор set, SQL Server Management Studio,
различные представления динамического управления), которые могут
быть использованы для изменения планов выполнения, созданных опти-
мизатором. В конце главы содержатся советы по оптимизации.
♦ В главе 21, "Настройка производительности", обсуждаются вопросы
производительности и рассматриваются инструменты для настройки
Database Engine, соответствующие ежедневному администрированию сис-
темы. После вступительных замечаний, касающихся измерения произво-
дительности, в главе описываются факторы, влияющие на производитель-
ность, и инструменты для мониторинга SQL Server.
В части IV, "SQL Server и Business Intelligence", обсуждаются вопросы анали-
за деловых данных (business intelligence, BI) и все соответствующие темы.
В этих главах содержится введение в Microsoft Analysis Services и Microsoft
Reporting Services. Также в деталях описываются SQL/OLAP и существую-
щие техники оптимизации, относящиеся к BI. Эта часть включает следующие
главы.
♦ Глава 22, "Введение в Business Intelligence", вводит понятие информацион-
ного хранилища. В начале главы объясняется различие между оператив-
ной обработкой транзакций и организацией информационного хранилища.
Данные, сохраняемые в информационном хранилище, могут быть либо
данными всего хранилища, либо данными, относящимися к отдельной
2 Зак. 1141
12
Введение
группе данных. Затем обсуждаются оба типа хранимых данных, приводит-
ся список их отличий. В конце главы рассматривается проектирование ор-
ганизации информационного хранилища.
♦ В главе 23, "Microsoft Analysis Services", обсуждается архитектура Analysis
Services и его главного компонента— Business Intelligence Development
Studio.
♦ В главе 24, "Business Intelligence u Transact-SQL", объясняется, как можно
использовать Transact-SQL для решения задач бизнес-аналитики. В главе
рассматриваются все расширения SQL, такие как операторы cube и rollup,
функции ранга, предложение тор п и реляционный оператор pivot.
♦ Глава 25, "Microsoft Reporting Services", описывает средства создания от-
четов. Этот компонент служит для проектирования и использования отче-
тов. В главе рассматривается среда разработки, которую вы применяете
для проектирования и создания отчетов, и показываются различные спо-
собы распространения спроектированного отчета.
♦ В главе 26, "Техники оптимизации для бизнес-аналитики", описываются
две из нескольких специфических техник оптимизации, которые могут
быть использованы, в первую очередь, в области бизнес-аналитики: разде-
ление данных и схема "звезда".
Часть V, "За пределами реляционных данных", посвящена двум "нереляцион-
ным" темам — XML и пространственным данным, поскольку SQL Server,
являясь платформой данных, не обязан обрабатывать только лишь реляцион-
ные данные. В эту часть включены следующие главы.
♦ Глава 27, "Обзор XML", дает нам обзор документов XML, DTD (Document
Type Definition, описание типа документа) и схем XML. Выполняемый
пример используется для демонстрации того, как документы XML могут
быть верифицированы при использовании шаблона DTD или схемы XML.
♦ В главе 28, "SQL Server и XML", обсуждается SQLXML— набор типов
данных и функций от Microsoft, которые поддерживают XML в SQL Server
2008, устраняя разрыв между XML и реляционными данными. В начале
главы вводятся стандартизованные типы данных xml и объясняется, как
хранимые документы XML могут быть выбраны. После этого детально
обсуждается представление реляционных данных в качестве документов
XML.
♦ В главе 29, "Введение в пространственные данные", рассматриваются
пространственные данные и два различных типа данных (geometry и
geography), которые могут быть использованы для создания таких данных.
Здесь также представлено несколько различных стандартизованных функ-
ций, относящихся к пространственным данным.
Введение
13
Почти все главы в конце содержат многочисленные упражнения, которые вы
можете использовать для улучшения понимания содержания главы. Все ре-
шения представленных упражнений можно найти либо на профессиональном
Web-сайте издательства "McGraw-Hill" (www.mhprofessional.coni), либо на
домашней странице автора этой книги (ivww.fh-roseiiheim.de/~petcovic)1.
Изменения
относительно предыдущей редакции
Если вы знакомы с предыдущим изданием этой книги "Microsoft SQL
Server 2005: A Beginner’s Guide", то увидите, что в данной редакции автором
книги сделаны серьезные изменения. Чтобы сделать книгу более простой в
использовании, некоторые темы были разделены и размещены в совершенно
новых главах. Например, глава 20 является абсолютно новой главой, в кото-
рой очень подробно описывается оптимизатор запросов. В предыдущей ре-
дакции эта тема описывалась лишь вскользь, вместе с индексами в главе 9.
В табл. В2 описаны значимые структурные изменения в книге (небольшие
изменения не представлены).
Таблица В2. Значимые структурные изменения в книге
Глава Изменения
2 Глава, полностью посвященная всем аспектам инсталляции SQL Server (ранее это была глава 17), перенесена в начало книги
6 Описание оператора SELECT теперь улучшено и помещено в одну главу. Коли- чество примеров сокращено, однако все равно здесь присутствует 77 примеров и 30 упражнений
9 В этом издании системный каталог описан ранее, чем в предыдущей редакции (ранее это была глава 11). Причина этого в том, что общее обсуждение пред- ставлений динамического управления (dynamic management view, DMV) дается в главе 9, в то время как описание специфик DMV начинается с главы 10 и продолжается до конца этой книги
10 Эта глава теперь посвящена исключительно индексам
13 В главе 13 описываются не только транзакции, как в предыдущей редакции, но здесь также разбираются вопросы управления параллельностью. Например, в разд. "Модели конкурентного доступа" детально обсуждаются обе модели, поддерживаемые сервером Database Engine
14 Теперь триггеры обсуждаются после описания управления параллельностью, потому что они используют механизм версионности строк, который связан с последующими темами и по этой причине был описан в главе 13
1 На момент выхода этой книги данный адрес был недоступен. — Тед.
14
Введение
Таблица В2 (окончание)
Глава Изменения
16 Эта глава является совершенно новой и описывает два компонента, связанных с управлением экземплярами сервера и поддержкой баз данных
20 Эта глава является совершенно новой и в деталях описывает оптимизатор запросов Database Engine. Этот компонент в предыдущей книге описывался в главе 9 вместе с индексами
26 Это частично новая глава, она описывает секционирование данных и оптими- зацию схемы "звезда"
29 Совершенно новая глава, содержащая описание пространственных данных
Различия в синтаксисе SQL и Transact-SQL
Transact-SQL, язык реляционных баз данных SQL Server, имеет некоторые
нестандартизованные свойства, в основном неизвестные тем людям, которые
знакомы только лишь с SQL.
♦ Тогда как точка с запятой (;) используется в SQL для разделения двух
операторов SQL в группе операторов (и вы обычно получаете сообщение
об ошибке, если не включите символ точки с запятой), в Transact-SQL
применение точки с запятой необязательно.
♦ Transact-SQL использует оператор go. Этот нестандартизованный оператор
в основном применяется для отделения друг от друга групп операторов,
хотя некоторые операторы Transact-SQL (такие как create table, create
index и др.) должны быть единственными в группе. Расширенный синтак-
сис этого оператора, go п (где п = 1, 2, 3, ...), означает, что соответствую-
щий групповой оператор будет выполнен п раз.
♦ Оператор use, который очень часто используется в этой книге, изменяет
контекст базы данных, задавая другую базу данных. Например, оператор
use sample означает, что все последующие операторы будут относиться
к базе данных sample.
Работа с базами данных примеров
В отличие от своего предшественника эта редакция использует несколько
примеров баз данных:
♦ собственная база данных этой книги sample;
♦ база данных Мicrosoft AdventureWorks;
♦ база данных Мicrosoft AdventureWorksDW.
Введение 75
В книге для начинающих, вроде этой, требуется пример базы данных, кото-
рую может легко понять каждый читатель. По этой причине я использовал
очень простую концепцию для моей собственной базы данных sample: она
содержит всего лишь четыре таблицы по нескольку строк в каждой. С другой
стороны, ее логика достаточно богатая, чтобы продемонстрировать сотни
примеров, включенных в текст данной книги. База данных sample, которую
вы будете использовать в этой книге, представляет компанию с отделами и
служащими. Каждый служащий относится в точности к одному отделу, а
каждый отдел содержит одного или более служащих. Работа служащих
сосредоточена вокруг проектов: каждый служащий в одно и то же время ра-
ботает с одним или более проектами, а каждый проект занимает одного или
более служащих.
Далее представлены таблицы базы данных sample.
Таблица ВЗ. Таблица department (отдел)
dept_no dept_name location
d1 Research Dallas
d2 Accounting Seattle
d3 Marketing Dallas
Таблица В4. Таблица employee (служащие)
emp_no emp_fname emp Iname dept_no
25384 Matthew Smith d3
10102 Ann Jones d3
18316 John Barrimore d1
29346 James James d2
9031 Elsa Bertoni d2
2581 Elke Hansel d2
28559 Sybill Moser d1
Таблица В5. Таблица project (проекты)
project_no project_name budget
P1 Apollo 120000
P2 Gemini 95000
P3 Mercury 185600
16
Введение
Таблица В6. Таблица works_on (работает над)
emp_no project_no job enter_date
10102 Р1 Analyst 2006.10.1
10102 рз Manager 2008.1.1
25348 Р2 Clerk 2007.2.15
18316 Р2 NULL 2007.6.1
29346 Р2 NULL 2006.12.15
2581 РЗ Analyst 2007 10.15
9031 Р1 Manager 2007.4.15
28559 Р1 NULL 2007.8.1
28559 Р2 Clerk 2008.2.1
9031 РЗ Clerk 2006.11.15
29346 Р1 Clerk 2007.1.4
Вы можете загрузить базу данных sample с профессионального Web-сайта
издательства "McGraw-Hill" (wvtv.nihprofessioiial.com) или с моей собствен-
ной домашней страницы (5V5V5v.fh-rosenheim.tle/~petcovic), Вы также можете
с моей домашней страницы загрузить все примеры этой книги.
Хотя база данных sample может быть использована во многих примерах этой
книги, для некоторых примеров нужны таблицы с большим количеством
строк (например, чтобы показать возможности оптимизации). По этой при-
чине здесь также используются две демонстрационные базы данных от
Microsoft— AdventureWorks И AdventureWorksDW. Обе ОНИ могут быть найдены
на Microsoft CodePlex Web-сайте 5V5V5v.codeplex.coin/MSFTDBProdSainples.
Часть I
Основные концепции
и инсталляция
ГЛАВА 1
Введение в системы
реляционных баз данных
Эта глава содержит общее описание баз данных. Во-первых, в ней определя-
ется, что такое система баз данных и какие компоненты в ней содержатся.
Каждый компонент вкратце описывается со ссылкой на главу, где он рас-
смотрен подробно. Второй основной раздел этой главы посвящен системам
реляционных баз данных. В нем обсуждаются свойства систем реляционных
баз данных и соответствующий язык, используемый в таких системах —
Structured Query Language (SQL, язык структурированных запросов).
Как правило, прежде чем вы будете создавать базу данных, вы должны ее
спроектировать со всеми ее объектами. В третьем основном разделе этой гла-
вы объясняется, как вы можете использовать нормальные формы для улуч-
шения результатов проектирования вашей базы данных, а также вводится
модель "сущность — отношение", которую вы можете использовать для ос-
мысления всех сущностей и их взаимоотношений. Последний раздел пред-
ставляет соглашения по синтаксису, используемые в рамках этой книги.
Системы баз данных
Система баз данных является всеобъемлющей коллекцией различных про-
граммных компонентов. Базы данных содержат следующие части:
♦ программные приложения базы данных;
♦ клиентские компоненты;
♦ сервер (серверы) базы данных;
♦ собственно базы данных.
Программные приложения базы данных являются программным обеспечени-
ем специального назначения, которые спроектированы и реализованы для
20
Часть I. Основные концепции и инсталляция
пользователей или для программных компонентов сторонних организаций.
В отличие от них клиентские компоненты являются программным обеспече-
нием баз данных общего назначения, спроектированные и реализованные для
компаний, использующих базы данных. В процессе применения клиентских
компонентов пользователи могут получать доступ к данным, хранимым на
том же или на удаленном компьютере.
Задачей сервера базы данных является управление данными, хранимыми в
базе данных. Каждый клиент взаимодействует с сервером базы данных, пере-
давая ему пользовательские запросы. Сервер обрабатывает каждый запрос и
отправляет результаты обратно клиенту.
Вообще, базу данных можно рассматривать с двух сторон— со стороны
пользователя и со стороны системы базы данных. Пользователи видят базы
данных как коллекцию данных, которые логически связаны друг с другом.
С точки зрения системы базы данных, база данных является лишь набором
байтов, как правило, хранящихся на диске. Хотя эти две точки зрения на базу
данных совершенно различны, тем не менее, они также имеют и нечто общее:
система базы данных должна не только предоставлять интерфейсы, которые
пользователи могли бы использовать для создания баз данных, поиска и мо-
дификации данных, но также и системные компоненты для управления хра-
нимыми данными. Следовательно, система базы данных должна обеспечи-
вать следующие возможности:
♦ разнообразные пользовательские интерфейсы;
♦ физическую независимость данных;
♦ логическую независимость данных;
♦ оптимизацию запросов;
♦ целостность данных;
♦ управление конкурентным доступом к данным;
♦ копирование и восстановление данных;
♦ безопасность базы данных.
Следующие разделы вкратце описывают эти возможности.
Разнообразные пользовательские интерфейсы
Большинство баз данных спроектировано и реализовано для использования
разными категориями пользователей с различными уровнями знаний. По этой
причине система баз данных должна предоставлять множество разнообраз-
ных пользовательских интерфейсов. Такие интерфейсы, помимо всего проче-
го, должны включать меню и формы для конечных пользователей и интерак-
тивный язык запросов для опытных пользователей.
Гпава 1. Введение в системы реляционных баз данных 21
Физическая независимость данных
Физическая независимость данных означает, что программы приложений ба-
зы данных не зависят от физической структуры хранения данных в базе дан-
ных. Эта важная возможность позволяет вам выполнять изменения в способе
хранения данных без необходимости делать какие-либо изменения в про-
граммах приложений базы данных. Например, если хранимые данные были
ранее упорядочены с помощью одного критерия, и этот порядок был изменен
при использовании другого критерия, то эта модификация физических дан-
ных не должна влиять на существующие приложения базы данных или на
существующую схему базы данных (описание базы данных, сгенерированное
системой базы данных на основании операторов языка определения данных).
Логическая независимость данных
При работе с файлом (при использовании традиционных языков программи-
рования) объявление структуры файла представлено в программах приложе-
ния, следовательно, любые изменения в структуре этого файла обычно тре-
буют внесения изменений во все программы, использующие этот файл. Сис-
темы баз данных предоставляют логическую независимость данных —
другими словами, можно выполнять изменения логической структуры базы
данных без необходимости делать какие бы то ни было изменения в про-
граммах приложений базы данных. Например, если в системе базы данных
существует структура объекта с именем person, и вы хотите добавить новый
атрибут в person (скажем, адрес), вам понадобится изменить только логиче-
скую структуру базы данных, но не существующие программ'ы приложения.
Оптимизация запросов
Каждая система баз данных содержит компонент, называемый оптимизато-
ром, который рассматривает множество возможных стратегий выполнения
запросов к данным и затем выбирает из них наиболее эффективную. Страте-
гия выборки данных называется планом выполнения запроса. Оптимизатор
принимает решение относительно плана, учитывая такие вещи, как: насколь-
ко велики таблицы, вовлеченные в запрос, какие существуют индексы, какой
логический оператор (and, or или not) присутствует в предложении where.
(Эта тема подробно обсуждается в главе 20.)
Целостность данных
Одной из задач системы баз данных является идентификация логической не-
корректности данных и отмена сохранения таких данных в базе данных.
22
Часть I. Основные концепции и инсталляция
(Двумя примерами подобных данных может служить дата 30 февраля или
время 5:77:00.) В дополнение к этому множество задач реальной жизни, ко-
торые решаются при использовании систем баз данных, имеют ограничения
целостности (integrity constraints), которые должны оставаться истинными
для всех данных. (Одним из примеров ограничения целостности может слу-
жить номер служащего компании, который должен быть целым числом, со-
держащим пять цифр.) Задача поддержания целостности данных может быть
реализована пользователем в программах приложения или в СУБД. Насколь-
ко возможно, такая задача должна решаться в СУБД. (Целостность данных
обсуждается в двух главах этой книги: декларативная целостность — в гла-
ве 5, процедурная целостность — в главе 14.)
Управление конкурентным доступом к данным
Система баз данных является многопользовательской программной системой,
это означает, что много пользовательских приложений имеют доступ к базе
данных в одно и то же время. По этой причине каждая система баз данных
обязана иметь некоторый вид механизма управления, который будет обеспе-
чивать выполнение некоторым контролируемым способом попытки отдель-
ных приложений изменять одни и те же данные. Далее приводится пример
проблемы, которая может возникнуть в случае, если система баз данных не
содержит подобных механизмов контроля:
1. Владельцы банковского счета 4711 в банке X имеют баланс счета $2000.
2. Два совладельца этого банковского счета, миссис А и мистер В, подходят
к двум различным банковским служащим и каждый забирает по $1000
в одно и то же время.
3. После этих транзакций сумма денег на банковском счете 4711 должна
быть $0, а не $1000.
Все системы баз данных имеют необходимые механизмы для обработки слу-
чаев, подобных описанным в примере. Управление конкурентным доступом
к данным в деталях обсуждается в главе 13.
Копирование и восстановление данных
Система базы данных должна иметь подсистему, ответственную за восста-
новление данных в случае аппаратных или программных ошибок. Например,
если сбой возникает, когда приложение базы данных изменяет 100 строк таб-
лицы, то подсистема восстановления должна выполнить отмену (откат— roll
back) всех предыдущих выполненных изменений, чтобы гарантировать, что
все соответствующие данные являются непротиворечивыми после возникно-
Глава 1. Введение в системы реляционных баз данных 23
вения этой ошибки. (См главу 17 для дальнейшего обсуждения вопросов ко-
пирования и восстановления.)
Безопасность базы данных
Наиболее важными концепциями безопасности базы данных являются аутен-
тификация и авторизация. Аутентификация — это процесс проверки полно-
мочий пользователя с целью не допустить неавторизованных пользователей
к использованию системы. Аутентификация чаще всего реализуется требова-
нием к пользователю ввести имя (пользователя) и его пароль. Эта информа-
ция обрабатывается в системе с целью определения, возможен ли для этого
пользователя доступ в систему. Этот процесс может быть усилен при исполь-
зовании шифрования.
Авторизация — это процесс, который применяется после того, как пользова-
тель был идентифицирован при аутентификации. Во время этого процесса
система определяет, к каким ресурсам конкретный пользователь может иметь
доступ. Иными словами, информация об отдельных сущностях в структурном
и системном каталогах теперь доступна только для тех принципалов', кото-
рые имеют права доступа к этим сущностям. (В главе 12 эти концепции рас-
сматриваются подробно.)
Системы реляционных баз данных
Компонент Microsoft SQL Server, называемый Database Engine, является сис-
темой реляционных баз данных. Понятие системы реляционных баз данных
впервые было введено И. Ф. Коддом в его статье "Реляционная модель дан-
ных для больших разделяемых банков данных" ("A Relational Model of Data
for Large Shared Data Banks") в 1970 году. В отличие от ранее существовав-
ших систем баз данных (иерархическая и сетевая) системы реляционных баз
данных основываются на реляционной модели данных, которая базируется на
строгой математической теории.
Замечание__________________________________________________
Модель данных является набором концепций, их отношений и их ограничений,
которые используются для представления данных в реальных задачах.
Центральной концепцией реляционной модели данных является отношение,
т. е. таблица. По этой причине с точки зрения пользователя реляционная база
данных содержит таблицы, и ничего кроме таблиц. В таблице содержится
1 Программистский сленг. Принципал — это процесс или пользователь, который имеет учет-
ную запись в данной среде. — Прим. перев.
24 Часть I. Основные концепции и инсталляция
один или более столбцов и ноль или более строк. На пересечении каждой
строки и столбца таблицы всегда существует в точности одно значение дан-
ных.
Работа с базой данных примеров в этой книге
База данных примеров, используемая в этой книге, представляет некую ком-
панию с отделами и служащими. Каждый служащий в этом примере принад-
лежит ровно одному отделу; отдел имеет одного или более служащих. Работа
служащих сосредоточена вокруг проектов: каждый служащий в одно и то же
время работает с одним или более проектами, а каждый проект занимает од-
ного или более служащих.
Данные в базе данных sample могут быть представлены с использованием че-
тырех таблиц:
♦ department;
♦ employee;
♦ project;
♦ works_on.
В табл. 1.1—1.4 представлены все таблицы базы данных sample.
Таблица department представляет все отделы компании. Каждый отдел со-
держит следующие атрибуты:
department (dept_no, dept_name, location)
Здесь dept no — уникальный номер каждого отдела, dept name — его назва-
ние, a location — место размещения соответствующего отдела.
Таблица employee представляет всех служащих, работающих в компании.
Каждый служащий имеет следующие атрибуты:
employee (emp__no, emp_fname, emp_lname, dept_no)
Здесь emp_no— уникальный номер каждого служащего, emp fname и
emp iname— имя и фамилия каждого служащего соответственно. Наконец,
dept по — это номер отдела, к которому относится данный служащий.
Таблица 1.1. Таблица department
dept_no dept_name location
d1 Research Dallas
d2 Accounting Seattle
d3 Marketing Dallas
Глава 1. Введение в системы реляционных баз данных
25
Таблица 1.2. Таблица employee
emp_no emp_fname emp_lname dept_no
25384 Matthew Smith d3
10102 Ann Jones d3
18316 John Barrimore d1
29346 James James d2
9031 Elsa Bertoni d2
2581 Elke Hansel d2
28559 Sybill Moser d1
Таблица 1.3. Таблица project
project_no project_name budget
P1 Apollo 120000
P2 Gemini 95000
P3 Mercury 185600
Таблица 1.4. Таблица works_on
emp_no project_no job enter_date
10102 P1 Analyst 2006.10.1
10102 P3 Manager 2008.1.1
25348 P2 Clerk 2007.2.15
18316 P2 NULL 2007.6.1
29346 P2 NULL 2006.12.15
2581 P3 Analyst 2007.10.15
9031 P1 Manager 2007.4.15
28559 P1 NULL 2007.8.1
28559 P2 Clerk 2008.2.1
9031 рз Clerk 2006.11.15
29346 P1 Clerk 2007.1.4
26 Часть I. Основные концепции и инсталляция
Каждый проект компании представлен в таблице project. Эта таблица имеет
следующие столбцы:
project (project_no, project_name, budget)
Столбец project_no представляет уникальный номер каждого проекта,
project name и budget задают имя и бюджет каждого проекта соответственно.
Таблица works-on задает отношение между служащими и проектами. Она
имеет следующие столбцы:
works on (emp_no, project_no, job, enter date)
Здесь emp_no— номер служащего, project_no— номер проекта, с которым
работает этот служащий. Комбинация значений данных в этих двух столбцах
всегда является уникальной. Столбцы job и enter date задают задачу и дату
начала работы служащего с этим проектом соответственно.
При использовании базы данных sample можно описать некоторые основные
свойства систем реляционных баз данных.
♦ Строки в таблице не имеют какого-либо особого порядка.
♦ Столбцы в таблице не имеют какого-либо специфического порядка.
♦ Каждый столбец должен иметь имя, уникальное в пределах таблицы.
С другой стороны, столбцы из разных таблиц могут иметь одни и те же
имена. (Например, база данных sample имеет столбец dept no в таблице
department И Столбец С тем же именем В таблице employee.)
♦ Каждый одиночный элемент данных в таблице должен иметь одно значе-
ние. Это означает, что каждая позиция в строке и столбце таблицы нико-
гда не получает множества значений.
♦ Для каждой таблицы существует, по меньшей мере, один столбец (или
комбинация столбцов), имеющий такое свойство, что в таблице не суще-
ствует двух строк, содержащих ту же самую комбинацию значений дан-
ных для этого столбца. В реляционной модели данных подобный иденти-
фикатор называется кандидатом в ключи. Если в таблице содержится бо-
лее одного кандидата в ключи, то проектировщик базы данных выбирает
одного из них в качестве первичного ключа таблицы. Например, столбец
dept_no является первичным ключом в таблице department; столбцы empno
и project no— первичные ключи таблиц employee и project соответствен-
но. Наконец, первичным ключом таблицы works on является комбинация
столбцов emp_no И project по.
♦ В таблице никогда не существует двух одинаковых строк. (Это свойство
всего лишь теоретическое; Database Engine и другие системы реляционных
Гпава 1. Введение в системы реляционных баз данных 27
баз данных обычно допускают существование идентичных строк в преде-
лах одной таблицы'.)
SQL — язык реляционной базы данных
Язык реляционной базы данных в SQL Server называется Transact-SQL. Он
является диалектом наиболее важного на сегодняшний день языка баз дан-
ных— Structured Query Language (SQL, язык структурированных запросов).
Происхождение SQL тесно связано с проектом, названным System R, который
разрабатывался и реализовывался компанией IBM в начале 1980-х годов.
Этот проект показал, что возможно, используя теоретические основы работы
И. Ф. Кодда, создать систему реляционной базы данных.
В отличие от традиционных языков, таких как С, C++ и Java, SQL является
языком, ориентированным на множество. (Ранее подобные языки назывались
ориентированными на записи.) Это означает, что SQL может запрашивать
множество строк из одной или более таблиц, используя всего лишь один опе-
ратор. Эта возможность является одним из наиболее важных преимуществ
SQL, что позволяет использовать этот язык на логически более высоком
уровне, чем тот уровень, на котором могли быть использованы традиционные
языки.
Другим важным свойством SQL является его непроцедурность. Каждая про-
грамма, написанная на процедурном языке (С, C++, Java), описывает, как
должна решаться задача— шаг за шагом. В противоположность им SQL, как
и любой другой непроцедурный язык, описывает, что хочет получить поль-
зователь. Следовательно, система является ответственной за нахождение со-
ответствующего способа удовлетворения требований пользователей.
SQL содержит два подъязыка: язык определения данных (Data Definition
Language, DDL) и язык манипулирования данными (Data Manipulation
Language, DML). Операторы DDL используются для описания схемы — таб-
лиц базы данных. Язык DML содержит три обобщенных оператора: create
объект (создание объекта базы данных), alter объект (изменение характери-
стик объекта) и drop объект (удаление существующего .объекта). Эти опера-
торы создают, изменяют и удаляют объекты базы данных, такие как сама база
данных, таблицы, столбцы и индексы. (Эти операторы подробно обсуждают-
ся в главе 5.)
В отличие от DDL язык DML содержит все те операторы, которые манипули-
руют данными. Всегда существуют четыре основные операции манипулиро-
1 На самом деле при наличии в таблице первичного ключа такое дублирование значений
в принципе невозможно. Результат же выборки данных из любой таблицы (набор данных) мо-
жет содержать и полностью дублированные строки. —Прим, перев.
Часть I. Основные концепции и инсталляция
вания базой данных: поиск, добавление, удаление и изменение. Оператор по-
иска данных select описывается в главе 6, в то время как операторы insert,
delete и update подробно рассматриваются в главе 7.
Проектирование базы данных
Проектирование базы данных — очень важная фаза в жизненном цикле базы
данных, которая предшествует всем фазам за исключением сбора и анализа
требований к данным. Если проектирование базы данных выполнено чисто
интуитивно без какого-либо плана, то, скорее всего, результирующая база
данных не будет соответствовать требованиям пользователя, касающимся ее
производительности. Другим последствием плохого проектирования базы
данных является чрезмерная избыточность данных, что само по себе имеет
два неприятных момента: существование аномалий данных и неоправданно
большой объем занимаемого дискового пространства.
Нормализация данных— это процесс, в результате выполнения которого су-
ществующие таблицы базы данных проверяются на наличие зависимостей
между столбцами таблицы. Если такие зависимости существуют, то таблица
реструктурируется, разделяется, на несколько таблиц (обычно две), которые
устраняют любые зависимости между столбцами. Если одна из этих сгенери-
рованных таблиц все еще содержит зависимости данных, то процесс норма-
лизации должен повторяться, пока не будут устранены все зависимости.
Процесс устранения избыточности данных в таблицах основывается на тео-
рии функциональных зависимостей. Функциональная зависимость означает,
что при использовании известного значения одного столбца соответствующее
значение другого столбца всегда может быть однозначно определено. (То же
самое истинно и для групп столбцов.) Функциональная зависимость между
столбцами А и В обозначается какЛ—>/?; это указывает, что значение столбца
А всегда может быть использовано для определения соответствующего зна-
чения столбца В ("В функционально зависит от Л").
Пример 1.1 показывает функциональную зависимость между двумя атрибу-
тами таблицы employee В базе данных sample.
Пример 1.1
emp_no -> emp_lname
При наличии уникального значения номера служащего можно получить фа-
милию служащего (и все другие соответствующие атрибуты). (Такой вид
функциональной зависимости, когда столбец зависит от первичного ключа
таблицы, называется тривиальной функциональной зависимостью.)
Гпава 1. Введение в системы реляционных баз данных 29
Другой вид функциональной зависимости называется многозначной зависи-
мостью. В отличие от только что описанной тривиальной функциональной
зависимости многозначная зависимость задается для многозначных атрибу-
тов. Это означает, что при использовании известного значения одного атри-
бута (столбца) может быть однозначно определен набор значений другого
соответствующего многозначного атрибута'. Многозначная зависимость обо-
значается как
Пример 1.2 демонстрирует многозначную зависимость, которая поддержива-
ется между двумя атрибутами объекта book.
? Пример 1.2
ISBN ->-> Authors
Значение ISBN в книге всегда определяет характеристики всех ее авторов.
Поэтому атрибут Authors многозначно зависит от атрибута isbn.
Нормальные формы
Нормальные формы используются в процессе нормализации данных и, зна-
чит, в проектировании таблиц. Теоретически существует, по меньшей мере,
пять различных нормальных форм, из которых первые три являются наиболее
значимыми для практического использования. Третья нормальная форма для
таблицы может быть получена в процессе проверки на первую и вторую нор-
мальную форму в качестве промежуточных этапов, при этом цель хорошего
проектирования базы данных обычно может быть достигнута, если все таб-
лицы базы данных находятся в третьей нормальной форме.
Замечание____________________________________________________
Многозначные зависимости могут быть использованы для проверки таблиц на
четвертую нормальную форму. По этой причине такой тип зависимостей не бу-
дет использован далее в этой книге.
Первая нормальная форма
Первая нормальная форма (First Normal Form, INF) означает, что таблица не
имеет атрибутов с несколькими значениями (многозначных атрибутов) или
1 Пожалуй, следовало бы несколько расширить это определение, уточнив, что в подобном слу-
чае можно говорить не только о значении одного исходного атрибута (столбца), а о наборе
значений нескольких столбцов. Это относится и к тривиальной функциональной зависи-
мости. — Прим. иерее.
Часть I. Основные концепции и инсталляция
составных атрибутов. (Составной атрибут содержит другие атрибуты и, сле-
довательно, может быть разделен на более мелкие части.) Все реляционные
таблицы определены в первой нормальной форме, потому что значение лю-
бого столбца в строке должно быть атомарным, т. е. иметь единственное
значение.
В табл. 1.5 демонстрируется первая нормальная форма в таблице works_on из
базы данных sample. Строки в таблице works on могут быть сгруппированы
вместе при использовании номера служащего. А вот табл. 1.6 не находится
в первой нормальной форме, потому что столбец project_no содержит мно-
жество значений (pl, рЗ).
Таблица 1.5. Фрагмент таблицы works_on
ешр_по project_no
10102 Р1
10102 РЗ
Таблица 1.6. Эта "таблица" не находится в первой нормальной форме
етр_по project_no
10102 (Р1.РЗ)
Вторая нормальная форма
Таблица находится во второй нормальной форме (2NF), если она находится в
первой нормальной форме и в ней не существует неключевого столбца, зави-
сящего только от части столбцов первичного ключа этой таблицы. Это озна-
чает, что если (А, В) является комбинацией столбцов таблицы, составляющих
первичный ключ, то в этой таблице не существует столбца, зависящего либо
только от А, либо только от В.
Например, в табл. 1.7 показана таблица works_onl, которая идентична таблице
works on за исключением наличия дополнительного столбца dept_no. Первич-
ный ключ этой таблицы является комбинацией столбцов emp_no и project no.
Столбец dept_no зависит от части первичного ключа, emp no (и не зависит от
project_no). Следовательно, эта таблица не находится во второй нормальной
форме. (Настоящая таблица works on находится во второй нормальной
форме.)
Гпава 1. Введение в системы реляционных баз данных
31
Таблица 1.7. Таблица works_onl
empjno project_no job enter_date dept_no
10102 Р1 Analyst 2006.10 1 d3
10102 РЗ Manager 2008.1.1 d3
25348 Р2 Clerk 2007.2.15 d3
18316 Р2 NULL 2007.6.1 d1
Замечание___________________________________________________
Любая таблица, имеющая первичный ключ, состоящий из одного столбца, все-
гда находится во второй нормальной форме.
Третья нормальная форма
Таблица в третьей нормальной форме (3NF) должна находиться во второй
нормальной форме и у нее не должно быть функциональных зависимостей
между неключевыми столбцами. Например, таблица employeel (табл. 1.8),
которая идентична таблице employee за исключением присутствия дополни-
тельного столбца dept name, не находится в третьей нормальной форме, по-
тому что для каждого значения столбца dept_no может быть точно определе-
но значение столбца dept name. (Оригинальная таблица employee, так же,
как и другие таблицы базы данных sample, находится в третьей нормальной
форме.)
Таблица 1.8. Таблица employee!
emp_no emp_fname emp_lname dept_no dept_name
25384 Matthew Smith d3 Marketing
10102 Ann Jones d3 Marketing
18316 John Barrimore d1 Research
29346 James James d2 Accounting
Модель "сущность — отношение"
Данные в любой базе данных проще всего спроектировать при использовании
одной таблицы, которая будет содержать все данные. Основной недостаток
такого подхода к проектированию базы данных— высокая избыточность
32
Часть I. Основные концепции и инсталляция
данных. Например, если ваша база данных содержит данные, относящиеся к
служащим и их проектам (каждый служащий работает в одно и то же время
над одним или более проектами, и каждый проект задействует одного или
более служащих), то хранимые в одной таблице данные будут содержать
большое множество столбцов и строк. Основной недостаток такой таблицы в
том, что сложно будет поддерживать согласованность данных по причине
этой самой избыточности.
Модель "сущность— отношение" (entity-relationship, ER) используется для
проектирования реляционных баз данных с целью удаления всякой избыточ-
ности данных. Базовым объектом модели "сущность — отношение" является
сущность, т. е. объект реального мира. Каждая сущность имеет несколько
атрибутов, которые являются свойствами этой сущности и, следовательно,
ее описывают. Основываясь на этом определении, можно сказать, что атри-
бут может быть:
♦ атомарным (т. е. атрибутом с единственным значением). Атомарный
атрибут всегда представлен единственным значением для конкретной
сущности. Например, супружеский статус человека (женат/замужем) все-
гда является атомарным атрибутом. Большинство атрибутов являются
атомарными;
♦ многозначным. Многозначный атрибут может иметь одно или несколько
значений для конкретной сущности. Например, location (месторасполо-
жение) в качестве атрибута для сущности enterprise (предприятие) явля-
ется многозначным, поскольку каждое предприятие может иметь один или
несколько адресов;
♦ составным. Составные атрибуты не являются атомарными, поскольку они
включают в себя несколько атомарных атрибутов. Типичным примером
составного атрибута является адрес человека, который состоит из атомар-
ных атрибутов, таких как город, почтовый индекс, улица и др.
Сущность person в примере 1.3 имеет несколько атомарных атрибутов, один
составной атрибут — Address И многозначный атрибут College degree.
; Пример 1.3
PERSON (Personal_no, F_name, L_name, Address(City, Zip, Street),
{College_degree))
Каждая сущность имеет один или более ключевых атрибутов, которые явля-
ются атрибутами (или комбинацией двух или более атрибутов), чьи значения
являются уникальными для каждой конкретной сущности. В примере 1.3 ат-
рибут Personai_no является ключевым атрибутом для сущности person.
Гпава 1. Введение в системы реляционных баз данных
Вместе с сущностями и атрибутами отношение — еще одна базовая концеп-
ция в модели ER ("сущность— отношение"). Отношение существует, если
сущность ссылается на одну (или более) других сущностей. Количество при-
сутствующих в отношении сущностей определяет уровень отношения. На-
пример, отношение works on между сущностями employee и project имеет
второй уровень.
Каждое отношение, существующее между двумя сущностями, может иметь
один из следующих трех типов: 1:1, 1:7V или M-.N. (Это свойство отношения
также называется .мощностью отношения.) Например, отношение между
сущностями department и employee — это отношение 1:7V, потому что каждый
служащий принадлежит в точности одному отделу, который, в свою очередь,
содержит одного или более служащих. А отношение между сущностями
project и employee является отношением.M-.N, потому что каждый проект за-
действует одного или более служащих, и каждый служащий работает в одно
и то же время над одним или более проектами.
Отношение в свою очередь может иметь собственные атрибуты. На рис. 1.1
показан пример диаграммы ER. (Диаграмма ER — это графическое представ-
ление, нотация, используемая для описания модели ER.)
Рис. 1.1. Пример ER-диаграммы
В этой нотации сущности представлены прямоугольниками, внутри которых
записано имя сущности. Атрибуты показаны в эллипсах, каждый атрибут
34
Часть I. Основные концепции и инсталляция
связан с конкретной сущностью (или отношением) прямыми линиями. Нако-
нец, отношения моделируются с использованием ромбов, а сущности, участ-
вующие в этом отношении, соединяются с ним прямыми линиями. Мощность
каждой сущности записывается рядом с соответствующей линией.
Соглашения по синтаксису
В этой книге используются соглашения, показанные в табл. 1.9, для описания
синтаксиса операторов Transact-SQL и для выделения фрагментов текста
книги.
Замечание_____________________________________________
В отличие от квадратных и фигурных скобок, которые являются элементами со-
глашения по синтаксису, круглые скобки () относятся к синтаксису операторов и
всегда должны записываться в операторах!
Таблица 1.9. Соглашения по синтаксису
Обозначение Значение
курсив Новые элементы или термины
ПРОПИСНЫЕ СИМВОЛЫ Ключевые слова Transact-SQL, например, create table. Дополни- тельную информацию по ключевым словам в языке Transact-SQL можно найти в главе 5
строчные символы Переменные в операторах Transact-SQL, например, create table имя_таблицы (пользователь должен заменить "имя_таблицы" на фак- тическое имя создаваемой таблицы)
varl | var2 Альтернативное использование элементов varl или var2. (Вы должны выбрать только один из элементов, разделенных символом вертикаль- ной черты)
{ I Альтернативное использование нескольких элементов. Пример: { выражение | user I NULL }
[ ] Необязательные элементы. Пример: [FOR LOAD]
{ } ... Элемент (элементы) может повторяться произвольное количество раз. Пример: {, @paraml typl} ...
полужирный Элементы интерфейса
По умолчанию Значение по умолчанию всегда подчеркнутое. Пример: { ALL I DISTINCT }
Гпава 1. Введение в системы реляционных баз данных 35
Резюме
Все системы баз данных предоставляют следующие возможности:
♦ разнообразные пользовательские интерфейсы;
♦ физическую независимость данных;
♦ логическую независимость данных;
♦ оптимизацию запросов;
♦ целостность данных;
♦ управление конкурентным доступом к данным;
♦ средства резервного копирования и восстановления данных;
♦ средства безопасности базы данных.
В следующей главе показано, как инсталлировать SQL Server 2008.
Упражнения
j Упражнение 1.1
Что означает "независимость данных" и какие две ее формы существуют?
? Упражнение 1.2
Какая главная концепция лежит в основе реляционной модели?
j Упражнение 1.3
Что именно таблица employee представляет в реальном мире? Что представля-
ет строка в этой таблице с данными для Ann Jones?
| Упражнение 1.4 j
Что таблица works on представляет в реальном мире (и в отношении других
таблиц в базе данных sample)?
i Упражнение 1.5
Пусть book — это таблица с двумя столбцами: isbn и title. Предположив, что
столбец isbn является уникальным и что не существует одинаковых названий
(title), ответьте на следующие вопросы:
36 Часть I. Основные концепции и инсталляция
1. Является ли title ключом этой таблицы?
2. Зависит ли isbn от title?
3. Находится ли book в третьей нормальной форме?
; Упражнение 1.6
Пусть order будет таблицей со следующими столбцами: order_no,
customer_no, discount. Если столбец customer_no функционально зависит от
order_no, а столбец discount функционально зависит от customer_no, ответьте
на следующие вопросы и подробно объясните ваши ответы:
1. Является ли order no ключом этой таблицы?
2. Является ли customer_no ключом таблицы?
I Упражнение 1.7
Пусть company— это таблица со следующими столбцами: company_no,
location. Каждая компания имеет один или более адресов (location). В какой
нормальной форме находится таблица company?
j Упражнение 1.8
Пусть supplier будет таблицей со следующими столбцами: suppiier_no,
article, city. Ключ в этой таблице— комбинация первых двух столбцов.
Каждый поставщик (supplier) поставляет несколько товаров (article), а каж-
дый товар поставляется несколькими поставщиками. В каждом городе (city)
находится только один поставщик. Ответьте на следующие вопросы:
1. В какой нормальной форме находится таблица supplier?
2. Как вы можете разрешить существующие функциональные зависимости?
! Упражнение 1.9
Пусть R(A, В, С)— отношение с функциональной зависимостью: В^>С. (Ат-
рибуты А и В вместе составляют ключ, а атрибут С функционально зависит
от В.) В какой нормальной форме находится отношение R?
j Упражнение 1.10
Пусть R(A, В, С)— отношение с функциональной зависимостью: С^>В. (Ат-
рибуты А и В составляют ключ, а атрибут В функционально зависит от С.)
В какой нормальной форме находится отношение RR
ГЛАВА 2
Планирование инсталляции
и инсталляция SQL Server
Эта глава описывает все задачи, включенные в инсталляцию системы SQL
Server. Во-первых, рассматриваются необходимые шаги по планированию
инсталляции. После этого обсуждается собственно инсталляция сервера базы
данных. В конце главы вы узнаете, как устанавливать, запускать и останавли-
вать экземпляры Database Engine. Вы также получите начальные сведения
о выделенном административном соединении, которое может быть использо-
вано для соединения с экземпляром Database Engine.
Планирование инсталляции
Спецификация плана инсталляции всегда должна предшествовать фактиче-
ской инсталляции системы SQL Server. Аккуратное планирование абсолютно
необходимо, потому что отдельные решения должны быть приняты до начала
инсталляции системы. Системный администратор должен иметь четкие отве-
ты на следующие вопросы, до того, как он начнет процесс инсталляции:
♦ Каково назначение системы SQL Server?
♦ Каковы требования к оборудованию и сетевому окружению?
♦ Как много пользователей будет связано с базой данных в одно и то же
время?
Замечание_________________________________________________
Как вы уже знаете, "SQL Server" является обобщенным названием для несколь-
ких различных компонентов, таких как Database Engine, Analysis Services,
Reporting Services и Integration Services. Во время процесса инсталляции вы
можете принимать решения, какие из этих компонентов вы собираетесь уста-
навливать на вашем компьютере. В данной главе "SQL Server" означает все
компоненты этой системы, которые установлены на вашем компьютере.
38
Часть I. Основные концепции и инсталляция
Назначение системы SQL Server
Направлений использования системы SQL Server может быть множество. На-
пример, ваша система может использоваться исключительно в образователь-
ных целях или быть производственной системой. В случае производственной
системы вам нужно принять решения относительно количества пользовате-
лей и объема хранимых данных, поскольку такие системы могут сильно от-
личаться друг от друга. Другим решением, касающимся современных систем
баз данных, является решение о том, где будет использована система —
в оперативных или в аналитических задачах.
Если у вас большая база данных с несколькими сотнями пользователей или
если ваша система имеет тяжелые транзакции загрузки, то может возникнуть
проблема с производительностью операций работы с базой данных. В обоих
случаях использование многопроцессорных компьютеров будет основным
требованием для обеспечения масштабируемости и хорошего времени откли-
ка системы. Если у вас огромная база данных, то может возникнуть проблема
с недостаточным местом на диске. В этом случае система обычно работает
лучше, если вы используете несколько небольших дисков вместо одного или
двух больших.
Вы должны различать системы, используемые для решения оперативных за-
дач (т. е. системы, которые требуют быстрого доступа к данным и коротких
транзакций), и системы, используемые для аналитических задач (системы,
которые используют сложные операции поиска в огромных базах данных),
поскольку обе задачи не могут быть оптимально решены при использовании
только одного сервера базы данных. По этой причине Database Engine ис-
пользуется для оперативных задач, a Analysis Services — для аналитических.
(Более подробную информацию об Analysis Services см. в части IV).
Требования
к аппаратному обеспечению и к сети
Тот факт, что SQL Server, выполняется только под управлением операцион-
ных систем Windows, упрощает решения, связанные с требованиями к аппа-
ратуре и к сети. Системный администратор должен принять решения только
об аппаратном и сетевом обеспечении.
Требования к аппаратному обеспечению
Операционные системы Windows поддерживаются на платформах Intel и со-
вместимом с ними оборудовании. Быстродействие процессора должно быть
как минимум 1 ГГц.
Гпава 2. Планирование инсталляции и инсталляция SQL Server 39
Замечание________________________________________________________
Существуют две группы редакций SQL Server: 32-разрядная и 64-разрядная.
Требования для этих двух групп различны. Поэтому значения, указанные в этом
разделе, являются общими значениями. Для определения точных требований
каждой редакции обратитесь к SQL Server 2008 Books Online (электронная до-
кументация по SQL Server1), к статье "Hardware and Software Requirements for
Installing SQL Server 2008” (в русскоязычном документе — "Требования к обору-
дованию и программному обеспечению для установки SQL Server 2008"), этот
документ вы можете найти на сайте http://msdn2.microsoft.com/en-us/library
/ms143506(SQL.100).aspx.1 2
Официально, минимальные требования к оперативной памяти— 512 Мбайт.
Однако почти все утверждают, что при минимальной конфигурации не уда-
ется получить эффективную работу. Объем памяти на вашем компьютере
должен быть, по меньшей мере, 1 Гбайт или более.
Требования к объему памяти на жестком диске зависят от вашей конфигура-
ции системы и от выбранных вами для инсталляции приложений.
Требования к сети
Для соединения с любым компонентом SQL Server вы должны иметь сетевой
протокол. Система SQL Server одновременно может обслуживать запросы в
нескольких протоколах. Клиенты подключаются к системе, используя только
один конкретный протокол. Если клиентская программа не знает, какие про-
токолы доступны, сконфигурируйте клиента так, чтобы он последовательно
проверял множество протоколов
Будучи клиент-серверной системой, SQL Server позволяет клиентам исполь-
зовать различные сетевые протоколы для обращения к серверу и в обращении
от сервера к клиентам. В процессе инсталляции подключений системный ад-
министратор должен решить, какие сетевые протоколы (библиотеки) должны
быть доступными для предоставления клиентам доступа к системе. На сер-
верной стороне могут быть выбраны следующие сетевые протоколы:
♦ общая память;
♦ Transmission Control Protocol/Internet Protocol (TCP/IP);
♦ именованные каналы (Named Pipes);
♦ протокол адаптера виртуального интерфейса (Virtual Interface Adapter, VIA).
Соединения с системой у клиента, выполняющегося на том же самом компь-
ютере, используют протокол общей памяти. Общая память не имеет конфи-
гурируемых свойств, этот протокол всегда проверяется первым.
1 Документ существует как в английском, так и в русском вариантах. — Прим. персе.
2 На русском языке см. http://msdn.microsoft.com/ru-ru/library/msl43506.aspx. — Ред.
40
Часть I. Основные концепции и инсталляция
Именованные каналы являются альтернативным протоколом для платформ
Windows. После процесса инсталляции вы можете удалить поддержку имено-
ванных каналов и использовать любой другой сетевой протокол для связи
между сервером и клиентами.
Сетевой протокол TCP/IP позволяет системе выполнять связь с использова-
нием стандарта Windows Sockets в качестве метода Internet protocol commu-
nication (IPC) параллельно с протоколом TCP/IP.
Протокол Virtual Interface Adapter (VIA) работает с оборудованием VIA. Для
получения информации о том, как использовать VIA, свяжитесь с вашим по-
ставщиком оборудования.
Замечание________________________________________________________
Общая память не поддерживается в отказоустойчивых кластерах1.
Редакции SQL Server
Поскольку вы планируете инсталляцию, вам необходимо знать, какие суще-
ствуют редакции SQL Server. Помимо двух групп 32- и 64-разрядных редак-
ций Microsoft поддерживает следующие редакции SQL Server 2008.
♦ Express Edition. Облегченная версия SQL Server 2008. Этот продукт мо-
жет быть использован разработчиками приложений. По этой причине про-
дукт включает основную программу Express Manager (ХМ) и поддержива-
ет интеграцию CLR и собственного XML. Вы также можете скачать SQL
Server Management Express для SQL Server Express для управления базой
данных. SQL Server Express можно свободно скачать по адресу:
http://msdn.niicrosoft.com/express.
♦ Workgroup Edition. Версия разработана для малого и среднего бизнеса,
также может быть использована на уровне отделов. Эта редакция предос-
тавляет поддержку реляционных баз данных без бизнес-аналитики и
средств высокой готовности. Эта редакция поддерживает до двух процес-
соров и максимум 2 Гбайт RAM.
♦ Standard Edition. Предоставляет 32-разрядную версию и 64-разрядную
поддержку для систем х64 и Itanium. Также поддерживает до четырех про-
цессоров и включает полный ряд функциональности бизнес-аналитики.
♦ Enterprise Edition. Специальная форма системы SQL Server, которая
предназначена для приложений, критичных к времени выполнения и
1 VIA тоже. — Прим. иерее.
Гпава 2. Планирование инсталляции и инсталляция SQL Server 41
с огромным количеством пользователей. В отличие от Standard Edition эта
редакция содержит дополнительные возможности, которые могут быть
полезными для очень мощных инсталляций на оборудовании с симмет-
ричными мультипроцессорами или кластерами. Наиболее важными до-
полнительными возможностями Enterprise Edition являются секциониро-
вание данных, получение мгновенных снимков базы данных и оператив-
ная поддержка баз данных.
♦ Developer Edition. Дает возможность разработчикам создавать и тестиро-
вать любые типы приложений с SQL Server на 32- и 64-разрядных плат-
формах. Включает всю функциональность Enterprise Edition, но версия ли-
цензирована только для использования в разработке, тестировании и де-
монстрации. Каждая лицензия на Developer Edition дает право одному
разработчику использовать эту систему на таком количестве систем,
сколько ему необходимо; дополнительные разработчики могут использо-
вать этот программный продукт, купив дополнительные лицензии. Для
быстрого перевода в производственную эксплуатацию система базы дан-
ных Developer Edition может быть легко обновлена до Enterprise Edition.
♦ Compact Edition. Скромная версия SQL Server, которую вы можете ис-
пользовать в карманных PC, мобильных телефонах, планшетных и на-
стольных компьютерах. Базы данных Compact Edition обычно использу-
ются в качестве встроенных (внедренных) баз данных.
Рекомендации по инсталляции
В процессе выполнения инсталляции вам придется принимать большое коли-
чество решений. В качестве основной рекомендации можно посоветовать оз-
накомиться со всеми последствиями принятых решений, прежде чем запус-
кать программу установки Setup. Прежде чем начинать процесс установки,
вам следует ответить на следующие вопросы:
♦ Где будет располагаться корневой каталог?
♦ Должно ли быть использовано несколько экземпляров Database Engine?
♦ Какой вариант аутентификации Database Engine должен быть исполь-
зован?
Замечание____________________________________________________
До начала процесса инсталляции вы должны точно знать, какие компоненты
SQL Server 2008 вы собираетесь инсталлировать (см. также рис. 2.4). Если это
вам еще не известно, то, пожалуйста, изучите существующие компоненты и
примите сейчас ваши решения. Большинство из этих компонентов описано
в данной книге. Описания других компонентов можно найти в Books Online.
42
Часть I. Основные концепции и инсталляция
Где размещать корневой каталог
Корневой каталог — это каталог, в который программа инсталляции помеща-
ет все программные файлы и те файлы, которые не изменяются в процессе
вашего использования системы SQL Server. По умолчанию процесс инстал-
ляции сохраняет все программные файлы в подкаталоге Microsoft SQL Server,
хотя вы можете изменить эту установку в процессе выполнения инсталляции.
Рекомендуется использовать имя по умолчанию, потому что это имя уни-
кально задает версию системы.
Сколько экземпляров Database Engine запускать
на выполнение
Вы можете инсталлировать и использовать несколько различных экземпляров
Database Engine. Экземпляр — это сервер базы данных, который не разделяет
использование его системных и пользовательских баз данных с другими
экземплярами (серверами), выполняющимися на том же компьютере.
Существует два типа экземпляров:
♦ по умолчанию (default);
♦ именованный (named).
Экземпляр по умолчанию сервера базы данных выполняет действия тем же
самым образом, что и серверы баз данных предыдущих версий SQL Server,
где существовал только один сервер базы данных без поддержки экземпляров
сервера. Имя компьютера, на котором выполняется экземпляр, задает только
имя экземпляра по умолчанию. Любой экземпляр сервера базы данных, от-
личный от экземпляра по умолчанию, называется именованным экземпляром.
Для идентификации именованного экземпляра вы должны задать его имя, а
также и имя компьютера, на котором этот экземпляр выполняется, например,
NTB119O1\INSTANCE1. На одном компьютере может быть любое количест-
во именованных экземпляров (в дополнение к экземпляру по умолчанию).
Дополнительно вы можете сконфигурировать именованные экземпляры на
компьютере таким образом, что вообще не будет существовать экземпляра по
умолчанию.
Хотя все экземпляры, выполняющиеся на компьютере, не разделяют боль-
шинство системных ресурсов (сервисы SQL Server и SQL Server Agent, сис-
темные и пользовательские базы данных, так же как и ключи в реестре), тем
не менее, существует ряд компонентов, которые используются всеми экземп-
лярами:
♦ программная группа SQL Server;
♦ сервер Analysis Services;
♦ библиотеки разработки.
Гпава 2. Планирование инсталляции и инсталляция SQL Server 43
Существование на компьютере только одной программной группы SQL
Server также означает, что существует только одна копия каждой утилиты,
которая представлена своим значком в программной группе. (Это также от-
носится и к SQL Server Books Online.) Поэтому работа каждой утилиты для
всех экземпляров сервера базы данных конфигурируется на уровне компью-
тера.
Вы должны принять решение об использовании множества экземпляров,
если:
♦ у вас на компьютере существуют различные типы баз данных;
♦ ваш компьютер достаточно мощный для того, чтобы управлять множест-
вом экземпляров.
Основное назначение множества экземпляров заключается в том, чтобы раз-
делить базы данных, которые существуют в вашей организации, на различ-
ные группы. Например, если система управляет базами данных, которые экс-
плуатируются разными пользователями (производственные базы данных,
тестовые базы данных, базы данных примеров), вы должны разделить их для
работы под различными экземплярами сервера базы данных. Таким образом
вы можете скрыть ваши производственные базы данных от баз данных, кото-
рые используются случайными или неопытными пользователями. Машина с
одним процессором не является подходящей аппаратной платформой для за-
пуска нескольких экземпляров Database Engine по причине ограниченности
ресурсов. Поэтому вы должны рассматривать использование многих экземп-
ляров только для многопроцессорных компьютеров.
Какой выбрать вариант аутентификации
В Database Engine существуют два различных варианта аутентификации:
♦ режим Windows;
♦ смешанный режим.
Microsoft рекомендует использовать режим Windows (подробности см. в гла-
ве 12).
Инсталляция SQL Server
Если вы ранее инсталлировали сложный программный продукт, то, вероятно,
помните то ощущение неуверенности, которое присутствует при выполнении
инсталляции в первый раз. Это ощущение появляется по причине сложности
инсталлируемого программного продукта и множества возникающих вопро-
сов, на которые нужно найти ответы в процессе инсталляции. Поскольку вы
3 Зак. 1141
44
Часть I. Основные концепции и инсталляция
(или тот, кто инсталлирует программное обеспечение), возможно, не вполне
понимаете продукт, то не очень уверенно отвечаете на вопросы, которые за-
дает программа инсталляции в процессе установки программного продукта.
Данный раздел поможет вам найти свой способ инсталляции, заранее предос-
тавляя вам ответы на большинство вопросов.
Для начала инсталляции вставьте DVD, содержащий SQL Server 2008, в уст-
ройство чтения DVD. Мастер Install Shield будет запущен и попросит вас ука-
зать место на диске, где будут сохраняться распаковываемые файлы. Когда
вы щелкнете по кнопке Next, мастер Install Shield распакует все необходимые
файлы с DVD и завершит свою работу.
Перед запуском программы инсталляции
Существует несколько задач, которые вы должны завершить до запуска про-
граммы Setup. Лучшим началом является чтение Release Notes (заметок по
реализации1). Преимуществом заметок по реализации является то, что они
содержат самую последнюю информацию, которая не всегда поставляется с
SQL Server Books Online (в главе 3 более подробно описывается документа-
ция Books Online). Внимательно читайте эти сведения для получения полной
картины о возможностях, в которые были внесены изменения до выхода фи-
нальной версии системы. (В Release Notes также содержится список исправ-
ленных ошибок; это тоже может пригодиться вам в работе.)
Web-сайт Microsoft является дополнительным источником информации. Как
и в Release Notes, вы можете найти много интересных документов на Web-
сайте Microsoft. Особенно важными будут технические описания, которые
Microsoft предоставляет в процессе реализации каждой новой версии SQL
Server. На сайте Microsoft вы можете отыскать и загрузить интересные для
вас документы.
Запуск программы установки
и предварительная установка
На странице Installation Prerequisites (рис. 2.1) программа установки SQL
Server 2008 указывает, какие необходимы дополнительные программные
компоненты прежде, чем вы начнете инсталляцию SQL Server 2008. Для на-
чала процесса их установки щелкните по кнопке Install.
1 На русском языке есть документ "Учебные материалы по SQL Server" (http://nisdn.microsoft.com
/ru-ru/library/msl67593.aspx), который содержит много полезной информации, в том числе и
относящейся к инсталляции системы. — Прим. иерее.
Гпава 2. Планирование инсталляции и инсталляция SQL Server
Рис. 2.1. Страница Installation Prerequisites
Установка компонентов SQL Server
После успешного выполнения предварительной установки процесс инсталля-
ции автоматически показывает окно SQL Server Installation Center
(рис. 2.2), где представлен перечень задач для выполнения. Для инсталляции
SQL Server 2008 выберите New Installation. На этом шаге загружается мас-
тер, который проведет вас через весь процесс инсталляции.
На первой странице мастера, System Configuration Check (рис. 2.3), про-
грамма установки сканирует ваш компьютер с целью выявления условий, ко-
торые могут заблокировать процесс инсталляции. Если вы щелкнете по кноп-
ке Show details, то увидите детали процесса проверки. Для продолжения
процесса инсталляции щелкните по кнопке Next.
На странице Feature Selection (рис. 2.4) выберите компоненты для инсталля-
ции, отмечая соответствующие флажки. В нижней части страницы вы также
можете задать каталог, куда нужно устанавливать разделяемые компоненты.
После этого для продолжения инсталляции щелкните по кнопке Next.
46
Часть I. Основные концепции и инсталляция
Замечание_____________________________________________________
Отмеченные компоненты SQL Server будет устанавливать один за другим в том
порядке, в котором они присутствуют в списке на странице Feature Selection.
Процесс инсталляции начинается с установки Database Engine, после которой
выполняется установка Analysis Services и т. д. Устанавливаются только вы-
бранные вами компоненты.
Рис. 2.2. Окно SQL Server Installation Center
Рис. 2.3. Страница System Configuration Check
Гпава 2. Планирование инсталляции и инсталляция SQL Server
Рис. 2.4. Страница Feature Selection
На странице Instance Configuration (рис. 2.5) вы можете выбрать установку
либо экземпляра по умолчанию, либо именованного экземпляра. Для уста-
новки экземпляра по умолчанию выберите Default instance. Если экземпляр
по умолчанию уже установлен, и вы выбрали Default instance, то программа
установки обновит его и предоставит вам возможность инсталлировать до-
полнительные компоненты. (То есть, у вас есть еще одна возможность уста-
новить компоненты, которые вы пропустили при предыдущих процессах ин-
сталляции.)
Для установки нового именованного экземпляра отметьте переключатель
Named instance, а затем наберите имя в текстовом поле. В нижней части этой
страницы предоставлен список экземпляров, уже установленных в вашей
системе. Как вы можете видеть на рис. 2.5, компьютер, на который я устанав-
ливал экземпляр с именем instancei, уже содержит экземпляр по умолчанию.
(mssqlserver — это имя экземпляра по умолчанию для Database Engine). Для
продолжения щелкните по кнопке Next.
Следующая страница, Server Configuration (рис. 2.6), позволяет задать имена
пользователей и соответствующие пароли для сервисов всех компонентов,
которые будут установлены в процессе инсталляции. (Вы можете использо-
вать одну учетную запись для всех сервисов.)
48
Часть I. Основные концепции и инсталляция
Рис. 2.5. Страница Instance Configuration
Рис. 2.6. Страница Server Configuration, вкладка Service Accounts
Гпава 2. Планирование инсталляции и инсталляция SQL Server
Для задания порядка сортировки для вашего экземпляра выберите вкладку
Collation на странице Server Configuration (рис. 2.7). (Порядок сортировки
определяет поведение сортировки в вашем экземпляре.) Вы можете либо вы-
брать порядок сортировки по умолчанию для всех компонентов, которые бу-
дут установлены, либо щелкните по кнопке Customize для выбора другого
порядка сортировки, поддерживаемого системой. Для продолжения щелкните
по кнопке Next.
Рис. 2.7. Страница Server Configuration, вкладка Collation
На странице Database Engine Configuration (рис. 2.8) вы выбираете режим
аутентификации для вашей системы Database Engine. Как вы уже знаете,
Database Engine поддерживает аутентификацию Windows и смешанную. Если
вы выберете переключатель Windows authentication mode, процесс установ-
ки создаст учетную запись sa (system administrator) системного администра-
тора, который отменит значение по умолчанию. (Обсуждение учетных запи-
сей см. в главе 12.) Если вы установите переключатель Mixed Mode, то долж-
ны будете ввести и подтвердить пароль системного администратора.
Щелкните по кнопке Add Current User, если вы хотите добавить одного или
более пользователей, которые будут иметь неограниченный доступ к экземп-
ляру Database Engine.
50
Часть I. Основные концепции и инсталляция
Рис. 2.8. Страница Database Engine Configuration, вкладка Account Provisioning
Замечание________________________________________________________
Вы можете изменить информацию, связанную с учетными записями, и после
инсталляции системы. В этом случае вы должны запустить сервис Database
Engine, называемый mssqlserver.
Вкладка Data Directories (рис. 2.9) на странице Database Engine Configu-
ration позволяет вам задать размещение всех каталогов, где будут храниться
все файлы, связанные с Database Engine. (Новая возможность в SQL Server
2008 состоит в том, что размещение системной базы данных tempdb задается
в процессе инсталляции.) Щелкните по кнопке Next для продолжения.
Что появится на последующих шагах, зависит от того, выбрали вы или нет
установку Analysis Services. (Страница Configuration появляется для всех
выбранных вами для инсталляций компонентов SQL Server.) Если вы выбра-
ли для установки Analysis Services, то появится страница, показанная на
рис. 2.10. Щелкните по кнопке Next для продолжения.
Аналогично, что появится на следующих шагах, зависит от того, приняли ли
вы решение устанавливать Reporting Services. Если вы указали, что Reporting
Services должен устанавливаться, то на экране появляется страница
Reporting Services Configuration. На этом шаге вы можете решить: только
лишь установить сервер отчетов (без его конфигурирования) или его устано-
Гпава 2. Планирование инсталляции и инсталляция SQL Server
Рис. 2.9. Страница Database Engine Configuration, вкладка Data Directories
Рис. 2.10. Страница Analysis Services Configuration
52
Часть I. Основные концепции и инсталляция
вить и конфигурировать. Третьей альтернативой является интеграция сервера
отчетов с Microsoft SharePoint Server (это серверная программа, которая мо-
жет быть использована для упрощения совместной работы, предоставления
средств управления контентом и реализации бизнес-процессов). После этого
щелкните по кнопке Next для продолжения.
На странице Error and Usage Reporting (рис. 2.11) задайте, если желаете,
информацию, которую вы хотели бы автоматически отправлять в Microsoft.
Снимите оба флажка, если вы не хотите принимать участие в этом автомати-
ческом оповещении. Щелкните по кнопке Next.
Рис. 2.11. Страница Error and Usage Reporting
Последней страницей, до того как фактически начнется процесс инсталляции,
является страница Ready to Install. Эта страница позволяет вам просмотреть
итог по всем компонентам SQL Server, которые будут установлены. Для за-
пуска процесса инсталляции щелкните по кнопке Install. Как вы можете ви-
деть на рис. 2.12, программа Setup позволяет отслеживать динамику выпол-
нения процесса инсталляции. Когда процесс инсталляции будет завершен,
щелкните по кнопке Next.
Появляется страница Complete с указанием размещения файла, содержащего
итоговый протокол. Щелкните по кнопке Close для завершения процесса ин-
Гпава 2. Планирование инсталляции и инсталляция SQL Server
сталляции. После этого вы можете использовать все компоненты, которые
установили в процессе инсталляции.
Следующий раздел описывает использование экземпляра Database Engine.
Рис. 2.12. Страница Installation Progress
Запуск и останов экземпляра
Database Engine
Наиболее удобным способом запуска на выполнение экземпляра Database
Engine является его автоматический старт в процессе первоначальной загруз-
ки компьютера. Однако некоторые обстоятельства могут потребовать другого
поведения системы. По этой причине Database Engine предоставляет несколь-
ко режимов для запуска экземпляра:
♦ SQL Server Management Studio (см. главу 3)\
♦ приложение sqlservr;
♦ команду net.
Приложение sqlservr может быть использовано только для запуска экземпля-
ра Database Engine. Это приложение вызывается следующей командой:
sqlservr optlon_list
54
Часть I. Основные концепции и инсталляция
Параметр option list содержит все режимы, которые могут быть заданы при
использовании этого приложения. В табл. 2.1 описаны наиболее важные ре-
жимы.
Таблица 2.1. Наиболее важные режимы приложения sqlservr
Режим Описание
-f Указывает, что экземпляр запускается в минимальной конфигу- рации
-m Указывает, что экземпляр запускается в режиме одного пользова- теля. Используйте эту опцию, если у вас существуют проблемы с системой и вы хотите осуществить ее поддержку, обслуживание (эта опция должна быть использована при восстановлении базы данных master)
-s instance_name Задает экземпляр Database Engine. Если не задано имя экземп- ляра, sqlservr запускает экземпляр Database Engine по умолчанию
Команды net start, net stop и net pause запускают, останавливают и пере-
водят в состояние ожидания экземпляр Database Engine, соответственно.
Команда net в примере 2.1 запускает на выполнение сервис mssqlserver.
i Пример 2.1
net start mssqlserver
Выделенное соединение
с экземпляром Database Engine
После успешного старта экземпляра Database Engine следующим шагом бу-
дет создание с ним соединения. Обычно вы можете выполнить соединение,
используя SQL Server Management Studio (см. главу 3). Однако существуют
некоторые экстраординарные ситуации, при которых "нормальные" пользо-
ватели не могут соединиться с экземпляром. В этом случае вы можете ис-
пользовать назначенное соединение администратора (Dedicated Administrator
Connection, DAC).
DAC является специальным соединением, которое может быть использовано
администратором базы данных в случае чрезвычайного удаления ресурса
сервера. Даже когда не хватает достаточных ресурсов для соединения новых
пользователей, Database Engine попытается освободить ресурсы для DAC.
Замечание________________________________________________
DAC доступен и поддерживается при помощи утилиты sqlcmd с использовани-
ем опции -А. (Описание утилиты sqlcmd см. в главе 15.)
Гпава 2. Планирование инсталляции и инсталляция SQL Server
Резюме
Инсталляция SQL Server также требует некоторой работы в фазах как до ин-
сталляции, так и после инсталляции. На этапе, предшествующем инсталля-
ции, системный администратор выясняет требования к программному обес-
печению и к оборудованию и готовит различные спецификации для процесса
инсталляции.
Инсталляция SQL Server 2008 более простая по сравнению с предыдущими
версиями. Инсталляция разделяется на две фазы. В первой фазе программа
установки собирает от вас всю необходимую информацию, включая список
необходимых вам для инсталляции компонентов, и после этого запускает
процесс фактической инсталляции.
В следующей главе описывается самый важный компонент SQL Server, назы-
ваемый SQL Server Management Studio.
ГЛАВА 3
SQL Server Management Studio
В этой главе вначале вкратце обсуждается программная группа SQL Server и
документация Books Online— оперативный справочный источник со всей
необходимой информацией, относящейся к SQL Server. Затем детально рас-
сматривается SQL Server Management Studio в связи с Database Engine и дея-
тельностью конечных пользователей. Вы также изучите все функции SQL
Server Management Studio, которые необходимы для создания и выполнения
операторов Transact-SQL.
Программная группа SQL Server
и Books Online
Чтобы увидеть программную группу SQL Server, щелкните по кнопке Start
(Пуск), выберите последовательно All Programs | Microsoft SQL Server 2008
(Все программы | Microsoft SQL Server 2008). Программная группа SQL
Server содержит все приложения, которые вы будете использовать в процессе
вашей работы с этой системой. Эта глава рассматривает только два отдель-
ных приложения: SQL Server Books Online, BOL (Электронная документация
no SQL Server), которое вы найдете в каталоге Documentation and Tutorials
(Документация и учебные материалы), и SQL Server Management Studio — на
этом приложении будет сосредоточено основное внимание данной главы.
Books Online здесь будет рассматриваться вкратце.
Books Online является оперативной документацией, которая поставляется и
инсталлируется вместе с другими программными компонентами SQL Server.
Инструментальная панель окна Books Online содержит, помимо других, и
четыре кнопки для следующих возможностей поиска:
♦ содержание;
♦ указатель;
Гпава 3. SQL Server Management Studio
♦ поиск;
♦ отмеченные (избранные) элементы помощи.
Если вы щелкнете по кнопке Contents, то увидите содержание всей опера-
тивной документации, разделенной на отдельные книги. Каждая тема разде-
лена на подтемы, которые можно открыть, щелкнув по соответствующему
символу "плюс" (+) в иерархии. Вы можете просматривать содержание каж-
дого вложенного каталога одинаковым способом— щелкая по символу +
в соответствующих книгах и во всех вложенных каталогах данного каталога.
Панель Index показывает упорядоченный по алфавиту список всех ключевых
слов, которые встречаются в документации. Существуют два способа выбора
одного из ключевых слов: двойным щелчком по ключевому слову в списке
или через ввод начальных букв ключевого слова. В последнем случае система
выбирает (и подсвечивает) первое алфавитное ключевое слово в списке, ко-
торое имеет указанные буквы в своем начале.
Кнопка Search является наиболее используемой кнопкой. Она позволяет вам
набирать фразы (или отдельные слова), которые затем используются в про-
цессе поиска для отображения всех тем, в которых появляются эти фразы или
слова. (SQL Server 2008 использует собственный компонент для полнотек-
стового поиска для поддержки этого процесса.) Помимо локального поиска в
Books Online, SQL Server также отыскивает фразы в MSDN Online и в
Codezone Community. (Codezone Community— это сайт, где находятся сове-
ты, подсказки, образцы кодов и новости от сторонних организаций, создан-
ные независимыми экспертами— специалистами по Microsoft .ПЕТ
Framework и Visual Studio.)
Результаты поиска отображаются в середине панели по умолчанию. После
вашего щелчка по кнопке Search, соответствующий результат появляется в
панели. Каждый результат включает заголовок документа и краткое описание
темы. Общее количество результатов поиска также появляется в правом
верхнем углу панели.
Вкладка Help Favorites дает вам возможность сохранять выбранные ключе-
вые слова (и фразы). Используйте эту вкладку для отображения ссылок на
элементы, такие как темы подсказки и Web-страницы, содержащие важную
информацию, которую вы собираетесь просматривать снова. Это окно также
хранит запросы на поиск, так что вы можете сохранять полную поисковую
информацию для дальнейшего использования. Для создания вкладки по нуж-
ной теме или Web-сайту вначале откройте тему или Web-сайт, которые вы
собираетесь добавить в список избранных. Затем в инструментальной панели
щелкните мышью по пиктограмме Add to Help Favorites. Чтобы снова найти
одну из сохраненных тем, дважды щелкните мышью по элементу из списка
ваших избранных тем.
58 Часть I. Основные концепции и инсталляция
Введение
в SQL Server Management Studio
SQL Server 2008 предоставляет разнообразные инструменты, которые могут
быть использованы для различных целей, таких как инсталляция, конфигури-
рование, ревизия и настройка производительности. Все эти инструменты бу-
дут рассмотрены в различных главах этой книги.
Замечание
Эта глава предназначена для конечных пользователей. По этой причине только
та функциональность SQL Server Management Studio, которая связана с созда-
нием объектов базы данных, описывается в деталях. Все административные
задачи и задачи, имеющие отношение к Analysis Services, а также к другим ком-
понентам, поддерживаемым этим инструментом, описываются, начиная с час-
ти III.
Основным инструментом администратора для работы с системой является
SQL Server Management Studio. И администраторы, и конечные пользователи
могут использовать этот инструмент для администрирования множества сер-
веров, разработки баз данных, копирования данных и для других целей. Что-
бы запустить на выполнение этот инструмент, щелкните по кнопке Start, вы-
берите АП Programs | Microsoft SQL Server 2008 | SQL Server Management
Studio (Все программы | Microsoft Server 20081 SQL Server Management
Studio). Каждый пользователь, который получает доступ к конкретному сер-
веру баз данных, также может использовать SQL Server Management Studio.
SQL Server Management Studio включает в себя несколько различных компо-
нентов, которые используются для подтверждения авторизации, администри-
рования и управления всевозможными системами.
Следующие компоненты используются для реализации этих задач:
♦ регистрируемые серверы (Registered Servers);
♦ Инспектор объектов (Object Explorer);
♦ Редактор запросов (Query Editor);
♦ Инспектор решений (Solution Explorer).
Первые два компонента обсуждаются в этом введении в SQL Server
Management Studio. Редактор запросов и Инспектор решений рассматривают-
ся в разд. "Авторская деятельность с использованием SQL Server Manage-
ment Studio" далее в этой главе. Для получения основного интерфейса вы
должны соединиться с сервером, как описано далее.
Глава 3. SQL Server Management Studio
59
Соединение с сервером
Когда вы запускаете SQL Server Management Studio, он отображает диалого-
вое окно Connect to Server (рис. 3.1), которое позволяет вам задать необхо-
димые параметры для сервера:
♦ Server type (Тип сервера). Для целей этой главы выберите Database
Engine;
Замечание______________________________________________________
В SQL Server Management Studio вы можете управлять объектами Database
Engine и Analysis Server, не считая других. В этой главе показывается исполь-
зование Management Studio только с Database Engine.
♦ Server name (Имя сервера). Выберите или наберите имя сервера, который
вы собираетесь использовать. Вы можете соединять SQL Server Mana-
gement Studio с любым установленным продуктом на любом сервере;
Рис. 3.1. Диалоговое окно Connect to Server
♦ Authentication (Аутентификация). Варианты аутентификации:
• Windows Authentication (Аутентификация Windows). Соединение с
SQL Server при использовании вашей учетной записи Windows. Этот
вариант наиболее простой и рекомендован корпорацией Microsoft для
использования;
• SQL Authentication (Аутентификация Server). Database Engine исполь-
зует собственную систему аутентификации.
Замечание________________________________________________________
Более подробную информацию, относящуюся к SQL Server Authentication, см.
в главе 12.
60
Часть I. Основные концепции и инсталляция
Когда вы щелкаете мышью по кнопке Connect, Database Engine соединяется с
указанным сервером. После соединения с сервером базы данных появляется
окно по умолчанию SQL Server Management Studio (рис. 3.2). Вид окна по
умолчанию похож на окно Visual Studio, следовательно, пользователи могут
достаточно легко переносить их существующий опыт разработки в Visual
Studio и для использования SQL Server Management Studio.
Рис. 3.2. SQL Server Management Studio: окно по умолчанию для выполнения установок
Замечание_____________________________________________________
SQL Server Management Studio предоставляет вам уникальный интерфейс для
управления серверами и создания запросов для всех компонентов SQL Server.
Это означает, что SQL Server Management Studio предоставляет единый ин-
терфейс для Database Engine, Analysis Services, Integration Services и Reporting
Services.
Зарегистрированные серверы
Зарегистрированные серверы представлены в виде панели, которая позволяет
вам поддерживать соединения с уже использованными серверами. Вы можете
обращаться к этим соединениям для проверки статуса серверов или для
управления их объектами. Каждый пользователь имеет отдельный список
зарегистрированных серверов, который сохраняется локально. (Если панель
Registered Servers не видна, выберите ее имя в меню View.)
Вы можете добавлять новые серверы в список всех серверов или удалять
один или более существующих серверов из этого списка. Вы также можете
Гпава 3. SQL Server Management Studio 61
группировать существующие серверы в серверные группы. Каждая группа
должна содержать серверы, которые логически связаны друг с другом. Вы
можете группировать серверы и по типам серверов, таким как Database
Engine, Analysis Services, Integration Services и Reporting Services.
Object Explorer
Панель Object Explorer (Инспектор объектов) содержит в виде дерева все
объекты базы данных на сервере. (Если панель Object Explorer не видна, вы-
берите Object Explorer в меню View.) Дерево показывает иерархию объектов
на сервере. Следовательно, если вы разворачиваете дерево, то будет показана
логическая структура соответствующего сервера.
Для подключения Object Explorer к серверу щелкните правой кнопкой мыши
по имени сервера и выберите пункт Connect. Для отключения щелкните
по кнопке Disconnect на инструментальной панели и выберите функцию
Disconnect.
Object Explorer позволяет соединяться с множеством серверов в одной и той
же панели. Сервер может быть любым из существующих для Database Engine,
Analysis Services, Reporting Services или Integration Services. Это средство
является дружественным к пользователю, потому что позволяет из одного
места управлять всеми серверами одного и того же или различных типов.
Замечание__________________________________________________
Object Explorer имеет и некоторые другие возможности, которые описываются
далее в этой главе.
Организация панелей Management Studio
и навигация по панелям
Вы можете "причалить" или скрыть любую из панелей Management Studio.
Щелкнув правой кнопкой мыши по заголовку в верхней части соответствую-
щей панели, вы можете выбрать любую из следующих предоставленных воз-
можностей.
♦ Floating. Когда состояние окна установлено в Floating (Плавающее), оно
существует в виде отдельного плавающего окна в верхней свободной час-
ти окна SQL Server Management Studio. Такое окно может перемещаться
куда угодно в пределах экрана.
♦ Dockable. Позволяет вам перемещать панели SQL Server Management
Studio и причаливать их в различные части главного окна. Для перемеще-
ния компонента щелкните кнопкой мыши по заголовку панели и перетас-
62
Часть I. Основные концепции и инсталляция
кивайте ее в середину окна документа. Панель будет отстыкована и станет
плавающей, пока вы ее не отпустите.
♦ Tabbed Document. Вы можете создать панель, сгруппированную в виде
таблицы, используя окно Designer. Когда это сделано, панель изменяет
свое состояние и становится документом с вкладками.
♦ Hide. Закрывает окно. (То же самое можно сделать, щелкнув по кнопке х
в правом верхнем углу окна.) Для отображения закрытого окна выберите
имя этого компонента из меню View.
♦ Auto Hide. Минимизирует панель и помещает ее в левую часть экрана.
Для повторного открытия (максимизации) такой панели переместите
мышь на таблицу в левой части экрана и щелкните по фиксирующей
кнопке для закрепления панели в открытой позиции.
Замечание______________________________________________________
Различие между режимами Hide и Auto Hide заключается в том, что первый
режим убирает панель из SQL Server Management Studio, в то время как второй
сворачивает панель.
Для восстановления конфигурации по умолчанию в меню Window выберите
команду Reset Window Layout. Панель Object Explorer появляется в левой
части, а таблица Object Explorer Details — в правой части главного окна
SQL Server Management Studio. (Таблица Object Explorer Details отображает
информацию текущего выделенного узла Object Explorer.)
Замечание______________________________________________________
Вы можете заметить, что довольно часто существует несколько способов вы-
полнить одну и ту же задачу в SQL Server Management Studio. В этой главе ука-
зывается несколько способов выполнения разных действий, в то время как в
последующих главах для каждой задачи будет предложен только один способ.
Разные люди предпочитают различные методы (кто-то любит выполнять двой-
ной щелчок мышью, кто-то предпочитает щелкать мышью по знакам + или
одни любят щелкать правой кнопкой мыши, другие используют контекстное ме-
ню, а кто-то использует комбинации клавиш быстрого доступа, где это только
возможно). Экспериментируйте с различными способами навигации и исполь-
зуйте те методы, которые вы считаете более естественными для вас.
В панелях Object Explorer и Registered Servers объект следующего уровня
появляется, только если вы щелкнули по символу "плюс" (+) у его непосред-
ственного предшественника (родителя) в дереве иерархии. Чтобы просмот-
реть свойства объекта, щелкните по объекту правой кнопкой мыши и в кон-
текстном меню выберите команду Properties. Символ минуса (-) слева от
имени объекта указывает, что объект в настоящий момент раскрыт. Чтобы
свернуть все подчиненные объекты данного объекта, щелкните по этому сим-
волу "минус". (Другой возможностью является двойной щелчок по папке или
нажатие клавиши <<-> в то время, когда эта папка является выделенной.)
Глава 3. SQL Server Management Studio
63
Использование Management Studio
c Database Engine
SQL Server Management Studio имеют два основных назначения:
♦ администрирование серверов базы данных;
♦ управление объектами базы данных.
Следующие разделы описывают эти средства SQL Server Management Studio.
Администрирование серверов базы данных
Задачами администрирования, которые вы можете выполнять, используя SQL
Server Management Studio, помимо прочих, являются следующие:
♦ регистрация серверов;
♦ соединение с сервером;
♦ создание новых серверных групп;
♦ запуск и останов SQL Server.
Следующие подразделы описывают эти задачи администрирования.
Регистрация серверов
SQL Server Management Studio отделяет деятельность по регистрации серве-
ров от анализа баз данных и их объектов. Оба эти действия могут быть вы-
полнены и при использовании Object Explorer. Каждый сервер (локальный
или удаленный) должен быть зарегистрирован до его использования. Любой
сервер может быть зарегистрирован при первом выполнении SQL Server
Management Studio или позже. Для регистрации сервера базы данных щелк-
ните правой кнопкой мыши по папке сервера вашей базы данных в Object
Explorer и выберите пункт Register. (Если панель Object Explorer не появ-
ляется на вашем экране, в меню View выберите команду Object Explorer.)
Появится диалоговое окно New Server Registration (рис. 3.3). Выберите имя
сервера, который вы хотите зарегистрировать, и режим аутентификации
(Windows Authentication или SQL Server Authentication).
Соединение с сервером
SQL Server Management Studio также разделяет задачи регистрации сервера и
соединения с сервером. Это означает, что регистрация сервера не приводит
к автоматическому соединению с этим сервером. Для соединения с сервером
из окна Object Explorer щелкните правой кнопкой мыши по имени сервера и
выберите пункт Connect.
Часть I. Основные концепции и инсталляция
Рис. 3.3. Диалоговое окно New Server Registration
Создание новой серверной группы
Для создания в панели Registered Servers новой серверной группы щелкните
правой кнопкой мыши по Local Server Groups и выберите пункт New Server
Group. В диалоговом окне New Server Group введите (уникальное) имя
группы и, при желании, описание новой группы.
Управление многими серверами
SQL Server Management Studio позволяет администрировать множество сер-
веров баз данных (называемых экземплярами) с одного компьютера при ис-
пользовании Object Explorer. Каждый экземпляр Database Engine имеет соб-
ственный набор объектов баз данных (системных и пользовательских баз
данных), которые не распределяются среди различных экземпляров Database
Engine.
Для управления сервером и его конфигурацией щелкните правой кнопкой
мыши по имени сервера в Object Explorer и выберите пункт Properties. Диа-
логовое окно Server Properties (рис. 3.4) содержит несколько различных
страниц, таких как General, Security и Permissions.
Гпава 3. SQL Server Management Studio
65
Рис. 3.4. Диалоговое окно Server Properties
Страница General показывает общие свойства сервера. Страница Security
содержит информацию, относящуюся к режиму аутентификации на сервере и
режиму аудита учетных записей. Страница Permissions показывает все учет-
ные записи и роли, которые имеют доступ к серверу. В нижней части этой
страницы показаны все полномочия, которые могут быть предоставлены
учетным записям и ролям.
Вы можете заменить имя существующего сервера на новое. Щелкните правой
кнопкой мыши по серверу в окне Object Explorer и выберите пункт Register.
Теперь вы можете переименовать сервер и изменить описание существующе-
го сервера в окне Registered Server.
Замечание____________________________________________________
Не переименовывайте сервер, потому что изменение имени может повлиять на
другие серверы, ссылающиеся на него.
66
Часть I. Основные концепции и инсталляция
Запуск и останов серверов
Сервер Database Engine может запускаться автоматически при старте опера-
ционной системы Windows или же его можно запускать при помощи SQL
Server Management Studio. Для старта сервера с использованием Management
Studio щелкните правой кнопкой мыши по выбранному серверу в панели
Object Explorer и выберите пункт Start в контекстном меню. Это меню так-
же содержит функции Stop и Pause, которые вы можете использовать для
останова и для паузы в активности сервера соответственно.
Управление базами данных
с использованием Object Explorer
Далее перечислены задачи управления, которые вы можете выполнять, ис-
пользуя SQL Server Management Studio:
♦ создание баз данных без использования Transact-SQL;
♦ изменение баз данных без использования Transact-SQL;
♦ управление объектами баз данных и их использование;
♦ генерация и выполнение операторов SQL.
Создание баз данных без использования Transact-SQL
Вы можете создавать базу данных, используя Object Explorer или операторы
языка Transact-SQL. (Создание баз данных с использованием Transact-SQL
рассматривается в главе 5.) Как подсказывает название, вы также можете ис-
пользовать Object Explorer для просмотра объектов сервера. Из панели
Object Explorer вы можете инспектировать все объекты сервера и управлять
вашим сервером и базами данных. Существующее дерево содержит помимо
других папок папку Databases. Эта папка содержит несколько вложенных
папок, включая одну для системных баз данных и одну для каждой новой ба-
зы данных, создаваемой пользователем. (Системные и пользовательские базы
данных подробно обсуждаются в главе 15.)
Для создания базы данных с использованием Object Explorer щелкните пра-
вой кнопкой мыши по Databases и выберите пункт New Database. В диалого-
вом окне New Database (рис. 3.5) наберите имя новой базы данных в поле
Database name, а затем щелкните по кнопке ОК. Каждая база данных имеет
несколько свойств, такие как тип файла, начальный размер и др. Свойства
базы данных могут быть выбраны из левой панели диалогового окна New
Database. Существует несколько различных страниц (групп свойств):
♦ General;
♦ Files (появляется только для существующей базы данных);
Гпава 3. SQL Server Management Studio
67
♦ Filegroups;
♦ Options;
♦ Permissions (появляется только для существующей базы данных);
♦ Extended Properties (появляется только для существующей базы данных);
♦ Mirroring (появляется только для существующей базы данных);
♦ Transaction Log Shipping (появляется только для существующей базы
данных).
Рис. 3.5. Диалоговое окно New Database
Замечание________________________
Система отображает все группы свойств, заданных для существующей базы
данных. Для новой базы данных, как показано на рис. 3.5, существуют только
три различные группы: General, Options и Filegroups.
68
Часть I. Основные концепции и инсталляция
Страница General в диалоговом окне Database Properties (рис. 3.6) отобра-
жает, помимо прочего, имя базы данных, ее порядок сортировки и модель
восстановления. Свойства файлов данных, которые принадлежат отдельной
базе данных, включают в себя имя и начальный размер файла, место, где бу-
дет сохраняться база данных и тип файла (например, primary). База данных
может храниться в нескольких файлах.
Рис. 3.6. Диалоговое окно Database Properties, страница General
Замечание_______________________________________________________
SQL Server динамически управляет дисковым пространством. Это означает, что
для баз данных может быть сделана установка автоматического увеличения
или уменьшения размера на внешнем носителе при необходимости. Если вы
хотите изменить свойство Autogrowth в опции Files, щелкните мышью по
столбцу Autogrowth и в диалоговом окне Change Autogrowth выполните ваши
изменения. Чтобы позволить базе данных автоматически увеличиваться в раз-
мерах, нужно отметить флажок Enable Autogrowth. Каждый раз, когда оказы-
Гпава 3. SQL Server Management Studio
69
вается недостаточно места в файле для добавления данных в базу данных,
сервер будет запрашивать дополнительное пространство на внешнем носителе
у операционной системы. Объем дополнительного пространства (в мегабайтах)
задан числом в панели File Growth этого же диалогового окна. Вы также може-
те решить, будет ли файл увеличиваться в размерах без каких-либо ограниче-
ний (значение по умолчанию) или нет. Если вы ограничиваете увеличение фай-
ла, то должны задать максимальный размер файла.
Страница Filegroups в диалоговом окне Database Properties отображает спи-
сок имен файловых групп, которым принадлежит файл базы данных, раздел
файловой группы (по умолчанию или заданный явно) и допустимые опера-
ции с файловой группой (чтение/запись или только чтение).
Страница Options в диалоговом окне Database Properties дает возможность
отображать и изменять все режимы уровня базы данных. Существует не-
сколько групп этих режимов: Automatic, Cursor, Miscellaneous, Recovery и
State. Например, для State существуют следующие четыре режима:
♦ Database Read-Only. Для базы данных допускает доступ только для чте-
ния. Это запрещает пользователям модифицировать любые данные. Зна-
чением по умолчанию является False;
♦ Database State. Описывает состояние базы данных. Значение по умолча-
нию — normal;
♦ Restrict Access. Ограничивает использование базы данных в каждый
момент времени только одним пользователем. Значением по умолчанию
является multiuser;
♦ Encryption Enabled. Управляет режимом шифрования базы данных. Зна-
чение по умолчанию — False.
Если вы выбираете страницу Permissions, система открывает соответствую-
щее диалоговое окно и отображает всех пользователей и все роли вместе с их
полномочиями. (Обсуждение полномочий см. в главе 12.)
Изменение баз данных без использования Transact-SQL
Object Explorer также может быть использован для изменения существую-
щей базы данных. При помощи этого компонента вы можете изменять файлы
и файловые группы, принадлежащие этой базе данных. Для добавления но-
вых файлов данных щелкните правой кнопкой мыши по имени базы данных и
выберите пункт Properties. В диалоговом окне Database Properties выберите
Files, щелкните мышью по кнопке Add и наберите имя нового файла. (В диа-
логовом окне Add File вы также можете поменять свойство автоматического
изменения размера файла и размещение каждого существующего файла.) Вы
также можете добавить (вторичную) файловую группу для базы данных, вы-
брав Filegroups и щелкнув по кнопке Add.
70 Часть I. Основные концепции и инсталляция
Замечание______________________________________________________
Только системный администратор или владелец базы данных может изменять
только что описанные свойства базы данных.
Для удаления базы данных с использованием Object Explorer щелкните пра-
вой кнопкой мыши по имени базы данных и выберите пункт Delete.
Управление таблицами без использования Transact-SQL
После того как вы создали базу данных, ваша следующая задача — создание
всех таблиц этой базы данных. Опять же, вы можете создавать таблицы, ис-
пользуя либо Object Explorer, либо Transact-SQL. И опять, только Object
Explorer здесь будет рассматриваться.
Для создания таблицы с помощью Object Explorer раскройте папку
Databases, раскройте базу данных, щелкните правой кнопкой мыши по вло-
женной папке Tables, а затем выберите пункт New Table. Создание таблиц
и всех других объектов базы данных с использованием языка Transact-SQL
будет подробно обсуждаться в главе 5.
Для демонстрации создания таблицы при помощи Object Explorer будет ис-
пользована таблица department в базе данных sample. Введите имена всех
столбцов и их свойства. Имена столбцов, их типы данных так же, как и свой-
ство столбцов null, должны быть введены в двумерную матрицу, как показа-
но в правой верхней панели на рис. 3.7.
Все типы данных, поддерживаемые системой, могут быть отображены
(и один из них выбран), если щелкнуть мышью по знаку стрелки в столбце
Data Туре (стрелка появляется, когда ячейка оказывается в фокусе ввода).
После этого вы можете вводить данные в строках Length, Precision и Scale
для выбранного типа данных в таблице Column Properties (см. панель справа
внизу на рис. 3.7). Некоторые типы данных, такие как char, требуют значения
для строки Length, а некоторые, например, как decimal, требуют значений в
строках Precision и Scale. С другой стороны, таким типам данных, как
integer, не нужно задавать никаких значений в этих строках. (Допустимые
значения для выбранных типов данных подсвечиваются в списке всех воз-
можных свойств столбца.)
Флажок в поле Allow Nulls должен быть установлен, если вы хотите разре-
шить вводить в этот столбец таблицы значения null. Похожим образом, если
для столбца существует значение по умолчанию, то его нужно ввести в стро-
ку Default. Value or Binding в таблице Column Properties. (Значение по
умолчанию— это значение, которое будет помещено в столбец таблицы,
если для него явно не задано никакого значения.)
Столбец dept_no является первичным ключом таблицы department. (Обсуж-
дение первичных ключей см. в главе 1.) Для указания того, что столбец явля-
Глава 3. SQL Server Management Studio
ется первичным ключом таблицы, вы должны щелкнуть по столбцу правой
кнопкой мыши и выбрать пункт Set Primary Key. Под конец закройте пра-
вую панель с информацией, относящейся к новой таблице. После этого сис-
тема отобразит диалоговое окно Choose Name, где вы должны ввести имя
таблицы.
Рис. 3.7. Создание таблицы department с использованием SQL Server Management Studio
Для просмотра свойств существующей таблицы дважды щелкните мышью по
папке той базы данных, где находится таблица, дважды щелкните по Tables,
затем щелкните правой кнопкой по имени таблицы и выберите пункт
Properties. На рис. 3.8 показано диалоговое окно Table Properties для табли-
цы employee.
Для переименования таблицы щелкните правой кнопкой мыши по этой таб-
лице в папке Tables и выберите пункт Rename. Для удаления таблицы щелк-
ните правой кнопкой мыши по имени таблицы в папке Tables в той базе дан-
ных, где находится таблица, и выберите пункт Delete.
Замечание
Теперь вы должны создать другие три таблицы базы данных sample.
72
Часть I. Основные концепции и инсталляция
Рис. 3.8. Диалоговое окно Table Properties для таблицы eirployee
После того как вы создали все четыре таблицы базы данных sample (employee,
department, project и works on), вы можете использовать другие средства SQL
Server Management Studio для отображения соответствующих диаграмм
"сущность — отношение" (entity-relationship, ER) базы данных sample. (Про-
цесс конвертирования существующих таблиц базы данных в соответствую-
щие диаграммы ER называется обратным проектированием (reverse
engineering).)
Чтобы просмотреть ER-диаграмму базы данных sample, щелкните правой
кнопкой мыши по вложенной папке Database Diagrams в базе данных sample
и выберите пункт New Database Diagram.
Замечание__________________________________________________________
Если при открытии диалогового окна вас спрашивают, нужно ли создавать под-
держиваемые объекты, щелкните по кнопке Yes.
Первый (и единственный) шаг— это выбор таблиц, которые будут добавле-
ны в диаграмму. После добавления всех четырех таблиц базы данных sample
мастер завершает работу и создает диаграмму (рис. 3.9).
Гпава 3. SQL Server Management Studio
73
Диаграмма на рис. 3.9 не является окончательной диаграммой базы данных
sample, потому что хотя она и показывает все четыре таблицы с их столбцами
(и соответствующие первичные ключи), она не отображает никаких отноше-
ний между таблицами. Отношение между двумя таблицами основывается на
первичном ключе одной таблицы и (возможно) соответствующем столбце
(столбцах) другой таблицы. (Подробное обсуждение таких отношений и ссы-
лочной целостности см. в главе 5.)
Есть ровно три отношения между существующими таблицами базы данных
sample: во-первых, таблицы department и employee имеют отношение 1 :N, по-
тому что для каждого значения столбца первичного ключа таблицы
department (dept_no) существует одно или более соответствующих значений
столбца dept no таблицы employee. Аналогично, существует отношение меж-
ду таблицами employee и works on, потому что только те значения, которые
присутствуют для первичного ключа таблицы employee (emp no), также появ-
ляются в столбце emp no таблицы works on. (Третье отношение — отношение
между таблицами project и works_on, потому что только те значения, которые
74
Часть I. Основные концепции и инсталляция
присутствуют в первичном ключе таблицы project (prno), появляются также
в столбце рг по таблицы works_on.)
Для создания каждого из трех описанных отношений вам нужно перепроек-
тировать диаграмму, указав столбцы, которые соответствуют первичным
ключам других таблиц. Подобные столбцы называются внешними ключами.
Чтобы увидеть, как это делается, используйте таблицу employee и определите
ее столбец dept no в качестве внешнего ключа, ссылающегося на таблицу
department:
1. Щелкните мышью по созданной диаграмме, щелкните правой кнопкой
мыши по графической форме таблицы employee в детализованной панели
и выберите пункт Relationships. В диалоговом окне Foreign Key Rela-
tionships щелкните по кнопке Add.
2. В диалоговом окне раскройте столбец Tables and Columns Specification
и щелкните по кнопке многоточия (...).
3. Выберите таблицу с соответствующим первичным ключом (таблицу
department).
Рис. 3.10. Окончательная диаграмма базы данных sample
Глава 3. SQL Server Management Studio 75
4. Выберите столбец dept no этой таблицы в качестве первичного ключа и
столбец с тем же именем в таблице employee в качестве первичного ключа.
Щелкните по кнопке ОК, а затем по кнопке Close.
На рис. 3.10 показана измененная диаграмма после создания всех трех отно-
шений в базе данных sample.
Авторская деятельность с использованием
SQL Server Management Studio
SQL Server Management Studio предоставляет вам завершенную среду автор-
ских разработок для всех типов запросов. Вы можете создавать, загружать и
редактировать запросы. SQL Server Management Studio дает вам возможность
работать с запросами без предварительного соединения с конкретным сер-
вером. Этот инструмент также позволяет вам разрабатывать ваши запросы
в различных проектах.
Авторские возможности связаны с Query Editor, так же как и Solution
Explorer. Упомянутый компонент сейчас будет рассматриваться.
Query Editor
Для запуска панели Query Editor щелкните по кнопке New Query на панели
инструментов SQL Server Management Studio. Если вы раскроете ее для ото-
бражения всех возможных запросов, то увидите не только запросы Database
Engine. По умолчанию вы получите новый запрос Database Engine, однако
возможны и другие запросы, такие как MDX, XMLA и др.
Когда вы откроете Query Editor, строка состояния в нижней части панели
будет сообщать вам, находится ли ваш запрос в подключенном или отклю-
ченном состоянии. Если вы не были автоматически соединены с сервером, то
появляется диалоговое окно Connect to SQL Server, где вы можете набрать
имя сервера базы данных, с которым собираетесь соединиться, и выбрать
режим аутентификации.
Замечание____________________________________________________
Редактирование в отсоединенном режиме является более гибким, чем редак-
тирование при соединении с сервером. Вы можете редактировать запросы без
необходимости выбора сервера, а также можете при запущенном на выполне-
ние Query Editor отключиться от одного сервера и соединиться с другим, не от-
крывая нового окна Query Editor. (Вы можете использовать несоединенное ре-
дактирование, если щелкнете по кнопке Cancel в диалоговом окне Connect to
SQL Server.)
4 Зак. 1141
76
Часть I. Основные концепции и инсталляция
Query Editor может быть использован конечным пользователем для решения
следующих задач:
♦ генерация и выполнение операторов Transact-SQL;
♦ сохранение сгенерированных операторов Transact-SQL в файле;
♦ генерация и анализ планов выполнения для сгенерированных запросов;
♦ получение графической иллюстрации плана выполнения для выбранных
запросов.
Query Editor содержит внутренний текстовый редактор и набор кнопок на
панели инструментов. Главное окно разделено на панель запросов (вверху) и
панель результатов (внизу). Пользователи вводят операторы Transact-SQL
(запросы), которые они собираются выполнить, в панели запросов, а после
того, как система выполнит запросы, полученные данные отображаются
в панели результатов.
Пример, показанный на рис. 3.11, демонстрирует запрос, введенный в Query
Editor, и возвращенный результат. Первый оператор в панели запросов, use,
задает базу данных sample в качестве текущей базы данных. Следующий опе-
ратор, select, отыскивает все строки таблицы works on. Щелчок мышью по
кнопке Query на панели инструментов Query Editor, а затем выбор элемента
Execute или нажатие клавиши <F5> возвращает результаты этих операций
с помещением их в панель результатов Query Editor.
Замечание
Вы можете открыть несколько различных окон, т. е. несколько различных со-
единений с одним или более экземплярами Database Engine. Вы создаете но-
вые соединения, щелкая по кнопке New Query на панели инструментов.
Следующая дополнительная информация, связанная с выполнением операто-
ра (операторов), отображается в строке состояния в нижней части окна Query
Editor:
♦ состояние текущей операции (например, "Query executed successfully" —
"Запрос выполнен успешно");
♦ имя сервера базы данных;
♦ имя текущего пользователя и идентификатор серверного процесса;
♦ имя текущей базы данных;
♦ общее время выполнения последнего запроса;
♦ количество найденных строк.
Одно из основных достоинств SQL Server Management Studio — простота ис-
пользования, а также применение компонента Query Editor. Редактор запро-
Глава 3. SQL Server Management Studio 77
сов поддерживает множество возможностей, которые делают процесс коди-
рования операторов Transact-SQL простым. Во-первых, Query Editor исполь-
зует синтаксическую подсветку, которая улучшает читаемость операторов
Transact-SQL. Здесь все зарезервированные слова отображаются голубым
цветом, все переменные — черным, строковые константы — красным, а при-
мечания — зеленым. (Обсуждение зарезервированных слов см. в главе 4.)
Рис. 3.11. Окно Query Editor с запросом и его результатами
Здесь также существует функция контекстно-зависимой подсказки, называе-
мая Dynamic Help, которая позволяет вам получать помощь по конкретному
оператору. Если вы не знаете синтаксис какого-либо оператора, просто выде-
лите оператор в редакторе и выберите команду Dynamic Help в меню Help.
Вы также можете выделить параметры различных операторов Transact-SQL
для получения соответствующего текста из Books Online.
Замечание__________________________________________________________
SQL Server 2008 поддерживает SQL Intelligence tool (интеллектуально-чувстви-
тельный инструмент). Интеллектуальная чувствительность — это форма авто-
матического завершения. Иными словами, это дополнительное средство дает
78
Часть I. Основные концепции и инсталляция
вам возможность получить доступ к описаниям часто используемых элементов
операторов Transact-SQL без применения клавиатуры. (В будущих версиях SQL
Server это средство будет расширено до поддержки дополнительных элементов
Transact-SQL.)
Object Explorer может также помочь вам редактировать запросы. Например,
если вам нужно просмотреть соответствующий оператор create table для
таблицы employee, войдите в этот объект базы данных, щелкните правой
кнопкой мыши по имени этой таблицы, выберите пункт Script Table as, а за-
тем CREATE to New Query Editor Window. На рис. 3.12 показано окно
Query Editor с оператором create table.
Рис. 3.12. Окно Query Editor с оператором CREATE TABLE
Object Explorer будет очень полезным, если вам понадобится отобразить
графический план выполнения для отдельного запроса. (План выполнения —
это план, выбранный оптимизатором для выполнения данного запроса. Эта
тема подробно обсуждается в главе 20.) Если вы выбираете функцию Query и
Display Estimated Execution Plan, система отобразит графический план вме-
сто результирующего набора данного запроса (рис. 3.13).
Гпава 3. SQL Server Management Studio
79
Рис. 3.13. План выполнения для запроса, показанного на рис. 3.11
Solution Explorer
Редактирование запроса в SQL Server Management Studio основано на методе
решений. Если вы начинаете с пустого запроса нажатием кнопки New Query,
запрос вначале будет основан на пустом решении. Вы можете это увидеть,
выбрав компонент Solution Explorer из меню View сразу после открытия ва-
шего пустого запроса.
Решение может иметь ноль, один или более связанных с ним проектов. Пус-
тое решение не содержит никаких проектов. Если вы хотите связать какой-
нибудь проект с решением, закройте ваше пустое решение, Solution Explorer
и окно Query Editor и запустите новый проект, щелкнув по меню File и вы-
брав New, а затем Project. В окне New Project выберите SQL Server Scripts.
Проект — это метод организации файлов в выбранном месте на внешнем но-
сителе. Вы можете выбрать имя проекта и его размещение на диске. Когда вы
создаете новый проект, то по умолчанию запускаете новое решение. Вы
можете добавить проект в существующее решение, используя Solution
Explorer.
80 Часть I. Основные концепции и инсталляция
Как только новый проект и решение будут созданы, Solution Explorer пока-
жет узлы в каждом проекте для Connections, Queries и Miscellaneous. Для
открытия нового окна Query Editor щелкните правой кнопкой мыши по узлу
Query и выберите пункт New Query.
SQL Server Management Studio поддерживает управление версиями, исполь-
зуя интеграцию с Microsoft Visual Source Safe. Будучи уже запущенным,
Solution Explorer позволяет организовывать и сохранять соответствующие
скрипты как часть проекта. Эти скрипты могут быть проверены как в систе-
ме, так и вне системы управления версиями непосредственно из Solution
Explorer.
Резюме
В этой главе был рассмотрен наиболее важный инструмент SQL Server —
SQL Server Management Studio. SQL Server Management Studio одинаково по-
лезен как конечным пользователям, так и администраторам. Во-первых, он
позволяет выполнять множество административных функций. Здесь мы толь-
ко вскользь их коснулись, однако они будут рассмотрены более подробно
далее в этой книге. В этой главе обсуждались наиболее важные функции SQL
Server Management Studio, относящиеся к конечным пользователям, такие как
создание баз данных и таблиц.
SQL Server Management Studio содержит несколько компонентов:
♦ Registered Servers позволяет регистрировать экземпляры SQL Server и
соединяться с ними;
♦ Object Explorer содержит древовидную структуру всех объектов базы
данных на сервере;
♦ Query Editor предоставляет конечным пользователям возможность гене-
рировать, выполнять и сохранять операторы Transact-SQL. Дополнительно
он дает возможность анализировать запросы, отображая план их выполне-
ния;
♦ Solution Explorer позволяет создавать решения. Решение может иметь
ноль или более связанных с ним проектов.
Следующая глава содержит введение в язык Transact-SQL и описывает его
основные компоненты. После введения в базовые концепции и существую-
щие типы данных в главе также описываются системные функции, поддер-
живаемые Transact-SQL.
Глава 3. SQL Server Management Studio
81
Упражнения
; Упражнение 3.1
Используя SQL Server Management Studio, создайте базу данных test. Сохра-
ните эту базу данных в файле с именем testdate a в каталоге C:\tmp и выдели-
те под него 10 Мбайт дискового пространства. Сконфигурируйте этот файл,
в котором хранится база данных, так, чтобы величина приращения была
2 Мбайт, а общий размер не превышал 20 Мбайт.
Упражнение 3.2
Используя SQL Server Management Studio, измените протокол транзакций для
базы данных test. Сделайте для файла начальный размер 3 Мбайт, увеличе-
ние размера 20%. Задайте возможность для файла протокола транзакций ав-
томатически увеличиваться в размерах.
i Упражнение 3.3
Используя SQL Server Management Studio, предоставьте возможность исполь-
зовать базу данных test только ее владельцу и системному администратору.
Существует ли возможность обоим пользователям одновременно обращаться
к этой базе данных?
| Упражнение 3.4
Используя SQL Server Management Studio, создайте все четыре таблицы в ба-
зе данных sample (см. главу 1) со всеми их столбцами.
§ Упражнение 3.5
Используя SQL Server Management Studio, просмотрите, какие таблицы со-
держит база данных AdventureWorks. После этого выберите таблицу
person.address и просмотрите ее свойства.
| Упражнение 3.6
Используя Query Editor, наберите следующий оператор Transact-SQL:
CREATE DATABASE test
Объясните сообщение об ошибке, появившееся в панели результата.
82 Часть I. Основные концепции и инсталляция
: Упражнение 3.7
Сохраните оператор Transact-SQL создания базы данных из упражнения 3.6
в файле C:\tmp\createdb.sql.
I Упражнение 3.8
Как вы можете сделать базу данных test текущей базой данных при исполь-
зовании Query Editor?
' Упражнение 3.9
Используя Query Editor, сделайте базу данных AdventureWorks текущей базой
данных и выполните следующий оператор Transact-SQL:
SELECT * FROM Sales.Customer
Как вы можете остановить выполнение этого оператора?
Упражнение 3.10
Используя Query Editor, измените результат выполнения оператора select
(см. упражнение 3.9) так, чтобы он появлялся в виде текста, а не в виде сетки.
Часть II
Язык Transact-SQL
ГЛАВА 4
Основные элементы SQL
В этой главе вводятся элементарные типы данных и основные операторы,
поддерживаемые в языке Transact-SQL. Во-первых, описываются базовые
элементы языка, включающие константы, идентификаторы и разделители.
Затем, поскольку каждый элементарный объект имеет соответствующий тип
данных, подробно описываются типы данных. В дополнение к этому обсуж-
даются все существующие операторы и функции. В конце этой главы вводят-
ся значения null.
Основные объекты SQL
Языком Database Engine является Transact-SQL, который обладает теми же
самыми базовыми возможностями, что и любой другой язык программиро-
вания:
♦ значения литералов (также называемых константами);
♦ разделители;
♦ комментарии;
♦ идентификаторы;
♦ ключевые слова.
Следующие разделы описывают эти возможности.
Значения литералов
Значением литерала является алфавитно-цифровая, десятично-шестнадцате-
ричная или числовая константа. Строковая константа содержит один или бо-
лее символов из набора символов, заключенных в два одиночных апострофа
(') или в двойные кавычки ("") (одиночные апострофы более предпочти-
86
Часть II. Язык Transact-SQL
тельны, чем двойные кавычки). Если вам нужно включить апостроф в строку,
заключенную в апострофы, используйте два подряд идущих апострофа. Деся-
тично-шестнадцатеричные константы используются для представления
непечатных символов и других двоичных данных. Каждая десятично-шест-
надцатеричная константа начинается с символов 'Ох', за которыми следуют
числа и/или буквы, соответствующие шестнадцатеричным цифрам. Приме-
ры 4.1 и 4.2 иллюстрируют некоторые правильные и ошибочные представле-
ния строковых и десятично-шестнадцатеричных констант.
\ Пример 4.1
Правильные примеры строковых и десятично-шестнадцатеричных констант
(в четвертой строке обратите внимание на два подряд идущих символа апост-
рофов):
'Philadelphia'
"Berkeley, СА 94710"
'9876'
'Apostrophe is displayed like this: can''t'
0x53514C0D
: Пример 4.2
Примеры неправильных строковых констант:
♦ отсутствие повторения апострофа для одиночного апострофа в константе
АВ'С'
♦ любой ограничитель— апостроф или кавычка—должен быть использо-
ван также и в качестве завершающего символа строки
'New York"
Числовые константы включают все целые числа, числа с фиксированной точ-
кой и числа с плавающей точкой, со знаком или без знака (пример 4.3).
• Пример 4.3
Здесь представлены числовые константы:
130
-130.00
-0.357Е5 (научное представление, указывающее, что число -0.35 умножается
на 10 в заданной степени 5)
22.3Е-3
Гпава 4. Основные элементы SQL
87
Константа всегда имеет тип данных и размер, и оба зависят от ее формата.
Дополнительно к этому каждая числовая константа имеет точность и размер-
ность порядка. (Типы данных различных видов значений литералов обсуж-
даются далее в этой главе.)
Разделители
В Transact-SQL двойные кавычки (") имеют два значения. Помимо обрамле-
ния строк, они могут также быть использованы в качестве разделителей для
так называемых идентификаторов с разделителями. Идентификаторы с раз-
делителями являются специальным видом идентификаторов, обычно исполь-
зуемых для того, чтобы дать пользователю возможность использовать заре-
зервированные ключевые слова в качестве идентификаторов, а также чтобы
допустить применение пробелов в именах объектов базы данных.
Замечание________________________________________________
Различия между апострофами и кавычками впервые было введено в стандарте
SQL92. В случае с идентификаторами этот стандарт устанавливает различие
между регулярными идентификаторами и идентификаторами с разделителями.
Два ключевых отличия в том, что идентификаторы с разделителями заключа-
ются в двойные кавычки и являются чувствительными к регистру. (Transact-SQL
также поддерживает использование квадратных скобок вместо кавычек). Ка-
вычки используются только для строк с разделителями. Вообще говоря, иден-
тификаторы с разделителями были введены, чтобы допустить использование в
идентификаторах зарезервированных ключевых слов. Более точно — иденти-
фикаторы с разделителями защищают вас в случае использования имен (иден-
тификаторов, имен переменных), которые могут быть введены в качестве заре-
зервированных ключевых слов в одном из будущих стандартов SQL. Также
идентификаторы с разделителями могут содержать символы (например, про-
белы), которые в обычных условиях недопустимы в именах идентификаторов.
В Transact-SQL использование кавычек задается параметром quoted identifire
в операторе set. Если значение этого параметра установлено в on, что являет-
ся значением по умолчанию, то идентификаторы в кавычках будут определе-
ны в качестве идентификаторов с разделителями. В этом случае кавычки не
могут использоваться для задания строк.
Комментарии
Существуют два различных способа задания комментариев в операторах
Transact-SQL. Использование пар символов /* и */ задает заключенный в них
текст как комментарий. В этом случае комментарий может располагаться на
нескольких строках. Кроме этого символы — (два минуса) указывают, что
оставшаяся часть текущей строки является комментарием. (Два минуса —
соответствуют стандарту ANSI SQL, в то время как символы /* и */ являются
расширением Transact-SQL.)
88
Часть II. Язык Transact-SQL
Идентификаторы
В Transact-SQL идентификаторы используются для определения объектов
базы данных, таких как базы данных, таблицы, индексы. Они представлены
символьными строками, которые могут включать до 128 символов и содер-
жать буквы, цифры, а также следующие символы: # и $. Каждое имя мо-
жет начинаться с буквы или с одного из следующих символов: _, @ или #.
Символ # в начале имени таблицы или хранимой процедуры означает вре-
менный объект, в то время как @ в начале имени используется для объявления
переменных. Как было отмечено ранее, эти правила не применимы к иденти-
фикаторам с разделителями (также известные как идентификаторы, заклю-
ченные в кавычки), которые могут содержать любой символ и начинаться
с любого символа (отличного от самих кавычек).
Зарезервированные ключевые слова
Каждый язык программирования имеет набор имен с зарезервированным
значением, которые должны быть записаны и использованы в определенном
формате. Имена этого вида называются зарезервированными ключевыми сло-
вами. Transact-SQL использует множество подобных имен, которые, как и во
многих других языках программирования, не могут быть использованы в ка-
честве имен объектов, если только для этих объектов не используются иден-
тификаторы с разделителями (идентификаторы, заключенные в кавычки).
Замечание_____________________________________________
В Transact-SQL имена всех типов данных и системных функций, такие как
character или integer, не являются зарезервированными ключевыми слова-
ми. По этой причине они могут быть использованы для именования объектов.
(Не используйте типы данных и имена системных функций в качестве имен
объектов! Подобное применение делает операторы Transact-SQL сложными
для чтения и понимания.)
Типы данных
Все значения данных одного столбца должны быть одного и того же типа
данных. Существует лишь одно исключение для значений типа данных
sql variant. Transact-SQL использует различные типы данных, которые мо-
гут быть объединены по следующим категориям:
♦ числовые типы данных;
♦ строковые типы данных;
♦ временные типы данных (дата и/или время);
Глава 4. Основные элементы SQL
89
♦ смешанные типы данных;
♦ DECIMAL С ТИПОМ ХраНСНИЯ VARDECIMAL.
Далее описываются все эти категории.
Числовые типы данных
Числовые типы данных используются для представления чисел. В табл. 4.1
представлен список всех числовых типов данных.
Таблица 4.1. Числовые типы данных
Тип данных Описание
INTEGER Содержит целочисленные значения, которые могут быть сохранены в 4 байтах. Диапазон значений от -2 147 483 648 До 2 147 483 647. int является сокращенной формой для integer
SMALLINT Представляет целочисленные значения, которые могут быть сохра- нены в 2 байтах. Диапазон значений от -32 768 до 32 767
TINYINT Представляет неотрицательные целочисленные значения, которые могут быть сохранены в 1 байте. Диапазон значений от 0 до 255
BIGINT Представляет целочисленные значения, которые могут быть сохра- нены в 8 байтах. Диапазон значений от -263 до 263 - 1
DECIMAL (p[,S] ) Описывает значения с фиксированной точкой. Аргумент р (precision, точность) задает общее количество цифр, включая дробную часть s (scale, масштаб) — количество цифр после десятичной точки. Зна- чения decimal сохраняются в зависимости от значения р: в диапа- зоне от 5 до 17 байтов, dec является сокращенной формой ОТ DECIMAL
NUMERIC (p[,S) ) СИНОНИМ ДЛЯ DECIMAL
REAL Используется для значений с плавающей точкой. Диапазон положительных значений составляет приблизительно от 1 18x10-38 до 3.40х1038, а диапазон отрицательных значений приблизительно от -1.18х 1 (Г38 до -3.40х 1038 (нулевое значение также может быть сохранено)
FLOAT[ (p) ] Представляет значения с плавающей точкой, как и real. Здесь р определяет точность. Если р < 25, это одинарная точность (4 байта), при р > 25 — двойная точность (8 байтов)
MONEY Используется для представления денежных значений. Значения MONEY соответствуют 8-байтовым значениям DECIMAL и округляются до четырех знаков после десятичной точки
SMALLMONEY Соответствует типу данных money, но хранится в 4 байтах
90
Часть II. Язык Transact-SQL
Символьные типы данных
Для символьных типов данных существуют две общие формы. Это могут
быть строки или однобайтовые символы, это могут быть строки символов
Unicode. (Unicode использует несколько байтов для задания одного символа.)
Далее, строки могут иметь фиксированную или переменную длину. В табл. 4.2
представлен перечень символьных типов данных.
Таблица 4.2. Символьные типы данных
Тип данных Описание
CHAR[(л)] Представляет строки фиксированной длины из однобайтовых симво- лов, где л — количество символов внутри строки. Максимальное зна- чение л равно 8000. character(п) является дополнительным экви- валентом для char (л). Если л опущено, то длина строки предполага- ется равной единице
VARCHAR[(л)] Описывает строку переменной длины из однобайтовых символов (0 < п < 8000). В отличие от типа данных char значения для типа дан- ных varchar сохраняются в их фактической длине. Этот тип данных имеет два синонима: char varying и character varying
NCHAR[(л)] Хранит строки фиксированной длины символов Unicode. Основное отличие между типами данных char и nchar заключается в том, что каждый символ типа данных nchar сохраняется в 2 байтах, в то вре- мя как каждый символ типа данных CHAR использует 1 байт хранимого пространства. По этой причине максимальное количество символов в столбце с типом данных nchar равно 4000
NVARCHAR [ (л)] Хранит строки переменной длины символов Unicode. Основное отличие между типами данных varchar и nvarchar в том, что каждый символ типа данных nvarchar сохраняется в 2 байтах, в то время как каждый символ типа данных VARCHAR использует 1 байт хранимого пространства. Максимальное количество символов в столбце с типом данных NVARCHAR 4000
Замечание
Тип данных varchar идентичен типу данных CHAR за одним исключением: если
содержимое строки CHAR (л) короче, чем л символов, то оставшаяся часть стро-
ки заполняется пробелами. Значение типа данных varchar всегда сохраняется
в соответствии с фактической длиной.
Типы данных даты и времени
Transact-SQL поддерживает следующие типы данных, связанные с датой и
временем:
♦ datetime;
♦ smalldatetime;
Гпава 4. Основные элементы SQL
91
♦ date;
♦ time;
♦ DATETIME2;
♦ DATETIMEOFFSET.
Типы данных datetime и smalldatetime задают дату и время, при этом каждое
значение сохраняется как целое значение в 4 или в 2 байтах соответственно.
Значения datetime и smalldatetime внутренне сохраняются как два отдельных
числовых значения. Значение даты в datetime хранится в диапазоне от
01.01.1753 до 31.12.9999. Аналогичное значение для smalldatetime хранится в
диапазоне от 01.01.1900 до 06.06.2079. Компонент времени сохраняется в се-
кундах в 4-байтовом (или 2-байтовом для smalldatetime) поле как число трех-
сотых долей секунды (datetime) или минут (smalldatetime), прошедших после
полуночи.
Использование datetime и smalldatetime довольно неудобно, если вы соби-
раетесь хранить только дату или только время. По этой причине SQL Server
2008 вводит новые типы данных, date и time, которые сохраняют только ком-
поненты date или time из datetime, соответственно. Тип данных date хранит-
ся в 3 байтах и имеет диапазон от 01.01.0001 до 31.12.9999. Тип данных time
хранится в 3—5 байтах и имеет точность 100 наносекунд.
Тип данных datetime2 также является новым типом данных, который хранит
с высокой точностью данные даты и времени. Этот тип данных может быть
определен с различными размерами в зависимости от ваших требований.
(Размер хранения 6.—8 байтов.) Точность представления времени составляет
100 наносекунд. Этот тип данных не осведомлен о летнем времени.
Все временные типы данных, описанные до сих пор, не поддерживают часо-
вые пояса. Новый тип данных, называемый datetimeoffset, содержит в себе
часть, являющуюся поправкой времени к часовому поясу. По этой причине
он хранится в 6—8 байтах. (Все другие свойства этого типа данных анало-
гичны соответствующим свойствам datetime2.)
Значение даты в Transact-SQL по умолчанию задается в виде строки в форма-
те: 'mmm dd уууу' (например, 'Jan ю 1993') внутри пары апострофов или
двойных кавычек. (Заметьте, что относительный порядок следования месяца,
дня и года может управляться оператором set dateformat. В дополнение к
этому система распознает числовое значение месяца при использовании раз-
делителей / или -.) Значение времени задается в формате 'hlr.mm' и Database
Engine использует 24-часовое время (например, 23:25).
Замечание____________________________________________________________
Transact-SQL поддерживает множество форматов ввода значений datetime.
Как вы уже знаете, оба объекта задаются раздельно; следовательно, значения
92
Часть II. Язык Transact-SQL
даты и времени могут задаваться в любом порядке или поодиночке. Если одно
из значений отсутствует, система использует значение по умолчанию. (Значе-
ние по умолчанию для времени 12:00 AM.)
Примеры 4.4 и 4.5 показывают различные способы, которыми могут быть за-
писаны значения даты и времени при использовании различных форматов.
j Пример 4.4
Могут быть использованы следующие описания даты:
'28/5/1959' (при выполненном операторе SET DATEFORMAT dray)
'May 28, 1959'
4959 MAY 28'
s Пример 4.5
Могут быть использованы следующие выражения для времени:
'8:45 AM'
Смешанные типы данных
Transact-SQL поддерживает несколько типов данных, которые не принадле-
жат ни одной группе типов данных, описанных ранее:
♦ двоичные типы данных;
♦ bit;
♦ типы данных больших объектов.
♦ cursor (см. главу 8)',
♦ iniquidentifire;
♦ SQL-VARIANT;
♦ table (см. главу 8)',
♦ xml (см. главу 28)\
♦ пространственные типы данных, например, geography и geometry (см. гла-
ву 29)-,
♦ HIERARCHYID;
♦ тип данных timestamp;
♦ типы данных, определенные пользователем (см. главу 5).
Следующие разделы описывают каждый из этих типов данных (другие, от-
личные от упомянутых здесь, обсуждаются в другой главе).
Гпава 4. Основные элементы SQL
93
Двоичные типы данных и BIT
Типы данных binary и varbinary— два двоичных типа данных. Они описы-
вают объекты данных, представляемые во внутреннем формате системы. Они
используются для хранения битовых строк. По этой причине их значения
вводятся с использованием десятично-шестнадцатеричных чисел.
Значения типа данных bit сохраняются в одном бите. Поэтому столбцы,
имеющие размер до 8 бит, сохраняются в одном байте. В табл. 4.3 описаны
свойства этих типов данных.
Таблица 4.3. Двоичные типы данных и BIT
Тип данных Описание
BINARY!(Л)] Задает битовую строку, длиной ровно л байтов (0 < л < 8000)
VARBINARY [ (л) ] Задает битовую строку, длиной не более л байтов (0 < л < 8000)
BIT Используется для логического типа данных с тремя допустимыми значениями: false, true и null
Типы данных больших объектов
Большие объекты (Large objects, LOB) — объекты данных с максимальным
размером 2 Гбайт. Эти объекты обычно применяются для хранения больших
текстовых данных, для загрузки модулей и файлов аудио/видео. Transact-SQL
поддерживает два различных способа для задания LOB и доступа к ним:
♦ использование типов данных varchar (мах) , nvarchar (мах) и varbinary (мах) ;
♦ использование так называемых типов данных "текст/изображение".
Рассмотрим эти две формы LOB подробнее.
Спецификатор мах. Начиная с SQL Server 2005, вы можете использовать од-
ну и ту же программную модель для доступа к значениям стандартных типов
данных и к LOB. Иными словами, вы можете использовать подходящие сис-
темные функции и строковые операции для работы с LOB.
Database Engine использует спецификатор мах для задания типам данных
varchar, nvarchar и varbinary определения столбцов с переменной длиной.
Когда вы используете мах по умолчанию (вместо явного значения), система
проверяет длину конкретной строки и принимает решение, сохранять ли эту
строку в обычном варианте или в виде LOB. Спецификатор мах указывает,
что размер значения столбца может достигать максимального размера для
LOB в текущей системе. (В будущей версии SQL Server, возможно, будет так,
что мах будет иметь большую величину для максимального значения длины
строки.)
94
Часть II. Язык Transact-SQL
Хотя система баз данных принимает решения, как будет сохранен объект
LOB, вы можете перекрыть эту спецификацию по умолчанию, используя сис-
темную процедуру sp_tableoption, В ОПЦИИ LARGEJZALUEJIYPESJ3UT_OF_ROW.
Если значение этой опции установлено в 1, то данные, объявленные в столб-
цах с помощью спецификатора мах, будут сохраняться отдельно от других
данных. Если же эта опция установлена в 0, то Database Engine сохраняет все
значения строк с размером строки меньше, чем 8060 байтов, как обычные
строки данных.
В SQL Server 2008 вы можете использовать новый атрибут filestream для
столбца с типом данных varbinary (мах) для сохранения больших двоичных
данных непосредственно в файловой системе NTFS. Основное преимущество
этого атрибута в том, что размер соответствующего LOB ограничивается
только размером тома файловой системы.
Типы данных text, ntext и image. Типы данных text, ntext и image состав-
ляют так называемые типы данных "текст/изображение". Объекты данных в
image могут содержать любой вид данных (загрузочные модули, аудио, ви-
део), в то время как типы данных text и ntext могут содержать любые тексты
(т. е. данные, которые могут быть распечатаны).
Типы данных "текст/изображение" по умолчанию сохраняются в базе данных
отдельно от всех других значений базы данных с использованием структуры
сбалансированного дерева (В-дерева), которая указывает на фрагменты этих
данных. {Структура В-дерева— древоподобная структура данных, в кото-
рой все нижние узлы имеют один и тот же номер уровня по отношению к
корню дерева.) Для столбцов типа данных "текст/изображение" Database
Engine хранит в строке таблицы 16-байтовый указатель, который содержит
сведения, где могут быть найдены сами данные.
Если размер данных "текст/изображение" меньше 32 Кбайт, то указатель
ссылается на корневой узел структуры В-дерева, который имеет размер
84 байта. Корневой узел указывает на физические блоки данных. Если же
размер этих данных превышает 32 Кбайт, то Database Engine создает проме-
жуточные дополнительные узлы между корневым узлом и блоками данных.
Для каждой таблицы, которая содержит более одного столбца с подобным
типом данных, все значения таких столбцов хранятся вместе. Однако одна
физическая страница может содержать только данные "текст/изображение" из
одной таблицы.
Хотя данные "текст/изображение" хранятся отдельно от всех других данных,
вы можете это изменить, использовав системную процедуру sp tabieoption
с опцией text_in_row. Эта опция задает максимальное количество байтов, ко-
торые сохраняются вместе с обычными данными.
Гпава 4. Основные элементы SQL
95
Обсуждаемые здесь типы данных "текст/изображение" имеют некоторые ог-
раничения. Вы не можете использовать их в качестве локальных переменных
(в хранимых процедурах или в группах операторов Transact-SQL). Они также
не могут быть частью индекса или использоваться в следующих предложени-
ях оператора select: where, order by, group by. Самая большая проблема, свя-
занная с типами данных "текст/изображение", заключается в том, что вам не-
обходимо для работы с этими данными использовать специальные операторы
(readtext, writetext и updatetext).
Замечание____________________________________________________
Типы данных "текст/изображение" отмечаются как нежелательные и будут уда-
лены в будущей версии Database Engine. Используйте вместо них varchar(max) ,
NVARCHAR(МАХ) И VARBINARY(МАХ) .
Тип данных UNIQUEIDENTIFIER
Как можно предположить из названия, значением типа данных uniqueidentifier
является уникальное число, сохраняемое в 16-байтовой двоичной строке.
Этот тип данных тесно связан с уникальным глобальным идентификатором
(Globally Unique Identifier, GUID), который гарантирует глобальную уникаль-
ность. Следовательно, используя этот тип данных, вы можете уникально
идентифицировать данные и объекты в распространяемых системах.
Инициализация столбца или переменной с типом uniqueidentifier может
быть выполнена при использовании функций newid и newsequentialid, так же
как и при помощи строковой константы, записанной в специальной форме
с использованием десятично-шестнадцатеричных цифр и дефисов. (Функции
newid и newsequentialid описываются в разд. "Системные функции" далее
в этой главе.)
Столбец с типом данных newsequentialid можно описать при использовании
ключевого слова rowguidcol, чтобы указать, что этот столбец содержит зна-
чения идентификатора. Это ключевое слово не генерирует никаких значений.
Таблица может иметь несколько столбцов типа newsequentialid, однако толь-
ко один из них может иметь ключевое слово rowguidcol.
Тип данных SQL_VARIANT
Тип данных sql variant может быть использован для хранения значений раз-
личных типов данных в одно и то же время, таких как числовые значения,
строки и дата. (Только один тип данных не может здесь храниться —
timestamp.) Каждое значение столбца sql_variant имеет две части: сами дан-
ные и информация, описывающая это значение. (Эта информация содержит
все свойства фактического типа данных, такие как длина, масштаб и точ-
ность.)
96
Часть II. Язык Transact-SQL
Transact-SQL поддерживает функцию sql_variant_property, которая отобра-
жает присоединенную информацию для каждого столбца sql_variant. Ис-
пользование типа данных sql_variant см. в примере 5.5.
Замечание_________________________________________________
Объявляйте столбец таблицы с типом данных SQL_variant, только если это
действительно необходимо. Столбец должен иметь этот тип данных, если его
значения могут иметь различные типы данных или если невозможно опреде-
лить тип данных столбца в процессе проектирования базы данных.
Тип данных HIERARCHYID
Тип данных hierarchyid применяется для хранения полной иерархии. Он реа-
лизован как определенный пользователем тип CLR (Common Language
Runtime, общая среда для выполнения языков), который включает в себя не-
сколько системных функций для создания и выполнения операций над иерар-
хическими узлами. Следующие функции, помимо прочих, принадлежат ме-
тодам ЭТОГО типа данных: GetAncestor (), Get Des cendant (), Read() И Write ().
(Подробное описание этого типа данных выходит за рамки данной книги.)
Тип данных TIMESTAMP
Тип данных timestamp определяет столбец как varbinary(8) или binary(8)
в зависимости от допустимости пустого значения (null) для столбца. Система
поддерживает текущее значение (не дату или время) для каждой базы дан-
ных, увеличивая его каждый раз на единицу, когда любая строка со столбцом
timestamp добавляется или изменяется, и присваивает это значение столбцу
timestamp. Следовательно, столбцы timestamp могут быть использованы для
определения относительного времени, когда строки были в последний раз
изменены. (Синонимом для timestamp является rowversion.)
Замечание_________________________________________________
Значение, сохраненное в столбце timestamp, не является само по себе важ-
ным. Такой столбец обычно используется для указания того, была ли строка
изменена с последнего момента времени обращения к ней.
Формат хранения VARDECIMAL для DECIMAL
Тип данных decimal обычно сохраняется на диске в виде данных фиксиро-
ванной длины. Начиная с SQL Server 2005 SP2, этот тип данных может со-
храняться как столбец с переменной длиной при использовании нового фор-
мата хранения, называемого vardecimal. С помощью vardecimal вы можете
значительно сократить объем внешней памяти для столбца decimal, в котором
данные могут сильно отличаться по их размеру.
Гпава 4. Основные элементы SQL
97
Замечание____________________________________________________
VARDECIMAL является форматом хранения, а не типом данных.
Формат хранения vardecimal является полезным, когда вам нужно задать
максимально возможное значение для поля, в котором обычно хранятся го-
раздо меньшие значения. Табл. 4.4 показывает это.
Замечание_____________________________________________________
Формат хранения vardecimal для типа данных decimal работает таким же об-
разом, как и тип данных varchar работает для алфавитно-цифровых данных.
Таблица 4.4. Количество байтов для хранения vardecimal
и для фиксированной длины
Точность Количество байтов: VARDECIMAL Количество байтов: фиксированная длина
0 ИЛИ NULL 2 5
1 4 5
20 12 13
30 16 17
38 20 17
Чтобы сделать доступным для использования формат хранения vardecimal,
вы вначале должны сделать его доступным для базы данных, а после этого —
доступным для конкретной таблицы этой базы данных. Для первого шага ис-
пользуется системная процедура sp_db_vardecimal_storage_format, как пока-
зано в примере 4.6.
. Пример 4.6
EXEC sp_db_vardecimal_storage_format 'sample', ' ON';
Опция VARDECIMAL STORAGE FORMAT Системной Процедуры sp_table_option
применяется для задания этого формата хранения для указанной таблицы.
В примере 4.7 устанавливается формат хранения vardecimal для таблицы
project.
; Пример 4.7
EXEC sp_tableoption 'project', 'vardecimal storage format', 1
Как вы теперь уже знаете, основной смысл использования формата хранения
vardecimal заключается в уменьшении объема хранимых данных. Если вы
98
Часть II. Язык Transact-SQL
хотите узнать, сколько памяти будет сэкономлено при использовании этого
формата хранения, примените динамически управляемое представление, на-
зываемое sys.sp_estimated_rowsize_reduction_for_vardecimal. Оно даст вам
детальную оценку состояния конкретной таблицы.
Функции Transact-SQL
Функции Transact-SQL могут быть агрегатными или скалярными.
Агрегатные функции
Агрегатные функции применяются к группе значений столбца. Агрегатные
функции всегда возвращают одно значение. Transact-SQL поддерживает не-
сколько групп агрегатных функций:
♦ обычные агрегатные функции;
♦ статистические агрегатные функции;
♦ агрегатные функции, определенные пользователем;
♦ аналитические агрегатные функции.
Статистические и аналитические агрегатные функции обсуждаются в гла-
ве 24. Агрегатные функции, определенные пользователем, выходят за рамки
этой книги. У нас остаются только обычные агрегатные функции:
♦ avg. Вычисляет среднее арифметическое значение данных, содержащихся
в столбце. Столбец должен содержать числовые значения;
♦ мах и min. Вычисляют максимальное и минимальное значения данных
в столбце, соответственно. Столбец может содержать числовые, строковые
значения, а также значения даты/времени;
♦ sum. Рассчитывает сумму всех значений столбца. Столбец должен иметь
числовые значения;
♦ count. Подсчитывает количество (непустых) значений столбца. Есть толь-
ко одна агрегатная функция, применяемая ко всем столбцам,— coutn(*).
Эта функция возвращает количество строк таблицы (независимо от того,
имеют ли отдельные столбцы значение null);
♦ count_big. Аналогична функции count с той лишь разницей, что count_big
возвращает значение типа данных bigint.
Использование обычных агрегатных функций в операторе select подробно
описывается в главе 6.
Гпава 4. Основные элементы SQL
99
Скалярные функции
В дополнение к агрегатным функциям Transact-SQL предоставляет несколько
скалярных функций, которые используются в составе скалярных выражений.
(Скалярные функции оперируют одним значением или списком значений в
отличие от агрегатных функций, которые оперируют данными из множества
строк.) Скалярные функции могут быть объединены в категории следующим
образом:
♦ числовые функции;
♦ функции даты;
♦ строковые функции;
♦ системные функции;
♦ функции над метаданными.
Числовые функции
Числовые функции в Transact-SQL являются математическими функциями
для изменения числовых значений (табл. 4.5).
Таблица 4.5. Числовые функции
Функция Описание
АВЗ(л) Возвращает абсолютное значение (т. е. отрицательные значения возвращаются как положительные) числового выражения л. Примеры: SELECT ABS(-5.767) = 5.767 SELECT ABS(6.384) = 6.384
ACOS(л) Вычисляет арккосинус п. Параметр л и результирующее значение относятся к типу данных FLOAT
ASIN(л) Вычисляет арксинус л. Параметр п и результирующее значение относятся к типу данных FLOAT
AT AN (л) Вычисляет арктангенс л. Параметр п и результирующее значение относятся к типу данных float
ATN2(л, ш) Вычисляет арктангенс rJm. Параметры л, m и результирующее зна- чение относятся к типу данных FLOAT
CEILING(л) Возвращает наименьшее целое число, большее или равное задан- ному параметру. Примеры: SELECT CEILING(4.88) = 5 SELECT CEILING(-4.88)' = -4
COS(л) Вычисляет косинус л. Параметр п и результирующее значение от- носятся к типу данных FLOAT
100
Часть II. Язык Transact-SQL
Таблица 4.5 (продолжение)
Функция Описание
СОТ(л) Вычисляет котангенс n. Параметр n и результирующее значение относятся к типу данных FLOAT
DEGREES(п) Преобразует радианы в угловые значения. Примеры: SELECT DEGREES(PI О / 2) = 90.0 SELECT DEGREES(0.75) = 42.97
ЕХР(п) Вычисляет значение en. Пример: SELECT EXP(l) = 2.7183
FLOOR(п) Возвращает наибольшее целое число, которое меньше или равно заданному значению л. Пример: SELECT FLOOR(4.88) = 4
LOG(n) Вычисляет натуральный (т. е. с основанием е) логарифм числа п. Примеры: SELECT LOG(4.67) = 1.54 SELECT LOG(0.12) = -2.12
LOGlO(n) Вычисляет десятичный (с основанием 10) логарифм числа л. Примеры: SELECT LOG10(4.67) = 0.67 SELECT LOGIC(0.12) = -0.92
РК) Возвращает значение числа л (3.14)
POWER(х, у) Вычисляет значение ху. Примеры: SELECT POWER(3.12,5) = 295.65 SELECT POWER(81,0.5) = 9
RADIANS (л) Преобразует градусы в радианы. Примеры: SELECT RADIANS(90.0) =1.57 SELECT RADIANS(42.97) =0.75
RAND Возвращает случайное число в диапазоне от 0 до 1 с типом данных FLOAT
ROUND(л, p, [t]) Округляет значение числа п с точностью р. Используйте положи- тельное значение р для округления справа от десятичной точки (дробной части числа) и отрицательное значение рдля округления слева от десятичной точки (целой части числа). Необязательный параметр t означает, что п должно усекаться (а не округляться). Примеры: SELECT ROUND(5.4567, 3) = 5.4570 SELECT ROUND(345.4567, -1) = 350.0000 SELECT ROUND(345.4567, -1, 1) = 340.0000
Глава 4. Основные элементы SQL
101
Таблица 4.5 (окончание)
Функция Описание
ROWCOUNT_BIG Возвращает количество строк, которые были обработаны в процес- се выполнения последнего оператора Transact-SQL. Значение, воз- вращаемое этой функцией, имеет тип данных bigint
SIGN(л) Возвращает знак значения л в виде числа (+1 для положительного, -1 для отрицательного значения, 0 для нулевого значения)
SIN (л) Вычисляет синус л. Параметр п и результирующее значение отно- сятся к типу данных FLOAT
SQRT(n) Вычисляет квадратный корень л. Пример: SELECT SQRT(9) = 3
SQUARE(л) Возвращает квадрат выражения. Пример: SELECT SQUARE(9) =81
TAN (Л) Вычисляет тангенс л. Параметр п и результирующее значение относятся к типу данных float
Функции даты
Функции даты вычисляют соответствующие части даты или времени в выра-
жении или возвращают значение временного интервала (табл. 4.6).
Таблица 4.6. Функции даты
Функция Описание
GETDATE() Возвращает текущую системную дату и время. Пример: SELECT GETDATE() = 2008-01-01 13:03:31.390
DATEPART(item, date) Возвращает указанную часть, заданную параметром item, даты date в виде целого числа. Примеры: SELECT DATEPART(month, '01.01.2005') = 1 (1 = January) SELECT DATEPART(weekday, '01.01.2005') = 7 (7 = Sunday)
DATENAME(i tern, da te) Возвращает указанную часть, заданную параметром item, даты date в виде строки символов. Пример: SELECT DATENAME(weekday, '01.01.2005') = Saturday
102
Часть II. Язык Transact-SQL
Таблица 4.6 (окончание)
Функция Описание
DATEDIFF(item, datl, dat2) Вычисляет разность между частями двух дат datl и dat2 и возвращает результат в виде целого числа в единицах, заданных значением item. Пример: SELECT DATEDIFF(year, BirthDate, GETDATE(J) AS age FROM employee; Возвращает возраст каждого служащего
DATEADD(i, n, d) Прибавляет число п в единицах, заданных значением 1, к заданной дате d. Пример: SELECT DATEADD(DAY, 3, HireDate) AS age FROM employee; Добавляет три дня к дате начала работы служащего для каждого служащего (см. базу данных sample)
Строковые функции
Строковые функции используются для манипулирования значениями данных
в столбцах, которые обычно имеют символьный тип данных (табл. 4.7).
Таблица 4.7. Строковые функции
Функция Описание
ASCII (character) Преобразует указанный символ в эквивалентный (ASCII) код. Возвращает целое число. Пример: SELECT ASCII('А') = 65
CHAR (integer) Преобразует ASCII-код в эквивалентный символ. Пример: SELECT CHAR(65) = 'А'
CHARINDEX(zl, z2) Возвращает начальную позицию, в которой строка zl впервые встречается в строке z2. Возвращает 0, если zl не присутствует в z2. Пример: SELECT CHARINDEX ('Ы', 'table') = 3
DIFFERENCE(zl, z2) Возвращает целое между 0 и 4, которое является разни- цей между значениями soundex двух строк zl и z2. (soundex возвращает число, которое характеризует зву- чание строки. При помощи этой функции можно опреде- лить строки с похожим звучанием.) Пример: SELECT DIFFERENCE('spelling', 'telling') = 2 Звучание несколько похожее; если же функция возвра- щает 0, то строки не звучат одинаково
Гпава 4. Основные элементы SQL
103
Таблица 4.7 (продолжение)
Функция Описание
LEFT(z, length) Возвращает первые length символов строки z
LEN(z) Возвращает количество символов (но не байтов) в заданном строковом выражении, исключая конечные пробелы
LOWER(zl) Преобразует все прописные буквы строки zl в строчные буквы. Буквы в нижнем регистре, цифры и другие симво- лы не изменяются. Пример: SELECT LOWER('BiG') = 'big'
LTRIM(z) Удаляет начальные пробелы в строке z. Пример: SELECT LTRIMC String') = 'String'
NCHAR(i) Возвращает символ Unicode, заданный целочисленным кодом, как определено в стандарте Unicode
QUOTENAME(char string) Возвращает строку Unicode, к которой добавлены раз- делители (кавычки), чтобы сделать строку допустимым идентификатором с разделителями
PATINDEX(%p%, expr) Возвращает начальную позицию первого вхождения шаблона р в заданном выражении ехрг или ноль, если шаблон в строке не найден. Примеры: SELECT PATINDEX('%gs%', 'longstring') = 4; SELECT RIGHT(ContactName, LEN(ContactName) - PATINDEX('% %', ContactName)) AS First_name FROM Customers; Второй запрос возвращает все имена из столбца customers
REPLACE(strl, str2, str3) Заменяет все вхождения строки str2 в строке strl на значение str3. Пример: SELECT REPLACE('shave', 's', 'be') = 'behave'
REPLICATE(z, i) Повторяет i раз строку z. Пример: SELECT REPLICATE('a', 10) = 'aaaaaaaaaa'
REVERSE(z) Отображает строку z в реверсированном, обратном, порядке. Пример: SELECT REVERSE('calculate') = 'etaluclac'
RIGHT(z, length) Возвращает последние length символов строки z. Пример: SELECT RIGHT('Notebook', 4) = 'book'
RTRIM(z) Удаляет конечные пробелы в строке z. Пример: SELECT RTRIM('Notebook ') - 'Notebook'
104
Часть II. Язык Transact-SQL
Таблица 4.7 (окончание)
Функция Описание
SOUNDEX(а) Возвращает четырехсимвольный код soundex, исполь- зуемый для определения похожести звучания двух строк. Пример: SELECT SOUNDEX('spelling') = S145
SPACE(length) Возвращает пробельную строку с длиной, заданной па- раметром length. Пример: SELECT SPACE = ' '
STR(f[, len[, ct]]) Преобразует заданное выражение с плавающей точкой f в строку. Параметр 1еп — длина строки, включая деся- тичную точку, знак числа, цифры и пробелы (по умолча- нию 10), d— количество цифр справа от десятичной точки. Пример: SELECT STR(3.45678, 4, 2) = '3.46'
STUFF(zl, a, length, z2) Заменяет часть строки zl на строку z2, начиная с пози- ции а, заменяя length символов строки zl. Примеры: SELECT STUFF('Notebook', 5, 0, ' in а ') = 'Note in a book' SELECT STUFF('Notebook', 1, 4, 'Hand') = 'Handbook'
SUBSTRING (z, a, length) Выделяет подстроку строки z, начиная с позиции а, длиной length. Пример: SELECT SUBSTRING('wardrobe’, 1, 4) = 'ward'
UNICODE (z) Возвращает целое значение, как определено стандар- том Unicode, для первого символа исходного выраже- ния Z
UPPER (z) Преобразует все строчные буквы строки z в прописные. Прописные буквы и цифры не изменяются. Пример: SELECT UPPER ('loWer') = 'LOWER'
Системные функции
Системные функции в Transact-SQL предоставляют обширную информацию
об объектах базы данных. Большинство системных функций использует
внутренний числовой идентификатор (ID), который назначается системой
каждому объекту базы данных при его создании. Используя этот идентифи-
катор, система может однозначно идентифицировать каждый объект базы
данных. Системные функции предоставляют информацию о системе базы
данных. В табл. 4.8 описаны некоторые системные функции. Полный список
всех системных функций см. в Books Online.
Гпава 4. Основные элементы SQL
105
Таблица 4.8. Системные функции
Функция Описание
CAST(a AS type [(length) ]) Преобразует выражение а в заданный тип данных type (если это возможно). Параметр а может быть любым допустимым выражением. Пример: SELECT CAST(3000000000 AS BIGINT) = 3000000000
COALESCE(al, a2, ...) Для заданного списка выражений al, а2,... возвраща- ет значение первого выражения, которое не является NULL
COL_LENGTH(obj, col) Возвращает длину столбца col, принадлежащего объекту базы данных (таблице или представлению) obj. Пример: SELECT COL-LENGTH('customers', 'CUSt_ID') = 10
CONVERT(type[(length)], a) Эквивалентна cast, но аргументы задаются иным образом. Функция convert может быть использована с любым типом данных
CURRENT_TIMESTAMP Возвращает текущую дату и время. Пример: SELECT CURRENT-TIMESTAMP = 2008-01-01 17:22:55.670'
CURRENT_USER Возвращает имя текущего пользователя
DATALENGTH (z) Вычисляет длину (в байтах) результата, полученного из выражения z. Пример: SELECT DATALENGTH(ProductName) FROM products Этот запрос возвращает длину каждого поля
GETANSINULL( 'dbname') Возвращает 1, если использование значений null в базе данных dbname соответствует стандарту ANSI SQL. (См. также обсуждение значений NULL в конце этой главы.) Пример: SELECT GETANSINULL('AdventureWorks1) = 1
ISNULL (expr, value) Возвращает значение выражения ех.рг, если оно не является NULL, иначе возвращает значение value. (См. пример 5.22)
ISNUMERIC(expression) Определяет, является ли выражение expression допустимым числовым выражением
NEWID() Создает уникальный номер ID, который состоит из 16-байтовой двоичной строки, предназначенной для хранения значений типа данных uniqueidentifier
NEWSEQUENTIALID() Генерирует GUID, который больше любого сгенериро- ванного ранее этой функцией на данном компьютере GUID. (Эта функция может быть использована только в качестве значения по умолчанию для столбца)
106
Часть II. Язык Transact-SQL
Таблица 4.8 (окончание)
Функция Описание
NULLIF(exprl, ехрг2) Возвращает NULL, если значения выражений exprl и ехрг2 равны. Пример: SELECT NULLIF(project—no, 'pl') FROM projects Запрос возвращает NULL для проекта, у которого столбец project_no = 'pl'
SERVERPROPERTY [propertyname) Возвращает информацию о конкретном свойстве сер- вера базы данных
SYSTEM_USER Возвращает id учетной записи текущего пользовате- ля. Пример: SELECT SYSTEM-USER = LTB13942\dusan
USER_ID( [user_name]) Возвращает идентификатор пользователя user_name. Если имя пользователя не задано, то возвращается идентификатор текущего пользователя. Пример: SELECT USER_ID('guest') = 2
USER_NAME ( [id] ) Возвращает имя пользователя с идентификатором id. Если идентификатор не указан, возвращается имя текущего пользователя. Пример: SELECT USERJ'IAME = 'guest'
Все строковые функции могут быть вложены друг в друга. Например:
REVERSE(CURRENT_USER)
Функции метаданных
Функции метаданных обычно возвращают информацию, касающуюся ука-
занной базы данных и объектов базы данных. В табл. 4.9 описаны некоторые
функции метаданных. Полный список всех функций метаданных см. в Books
Online.
Таблица 4.9. Функции метаданных
Функция Описание
COL-NAME (tab-id, col_id) Возвращает имя столбца с идентификатором col_id из таблицы, имеющей идентификатор tab_id Пример: SELECT COL_NAME(OBJECT_ID('employee'), 3) = ' emp_Iname'
COLUMNPROPERTY(id, col, property) Возвращает информацию о столбце, заданном своим идентификатором. Пример: SELECT COLUMNPROPERTY(Obj ect_id('project'), 'project—no', 'PRECISION') = 4
Гпава 4. Основные элементы SQL
107
Таблица 4.9 (окончание)
Функция Описание
DATABASEPROPERTY(da tabase, property) Возвращает значение свойства с именем, заданным в параметре property, из базы данных с именем, задан- ным в параметре database. Пример: SELECT DATABASEPROPERTY (' sample ', 'IsNullConcat') = 0 Свойство IsNullConcat соответствует опции CONCAT_NULL_YIELDS_NULL, Которая ОПИСЫВЭетСЯ В КОНЦе этой главы
DB_ID([db_name]) Возвращает идентификатор базы данных с именем db_name. Если имя не задано, возвращает идентификатор текущей базы данных. Пример: SELECT DB_ID('AdventureWorks') = 6
DB_NAME ( [db_ld] ) Возвращает имя базы данных с идентификатором db_id. Если идентификатор не задан, возвращается имя теку- щей базы данных. Пример: SELECT DB_NAME(6) = 'AdventureWorks'
INDEX_COL( table, i, no) Возвращает имя индексированного столбца в таблице table. Столбец определяется по идентификатору индекса 1 и позиции столбца по в этом индексе
INDEXPROPERTY (obj_id, index_name, property) Возвращает именованный индекс или значение статисти- ческого свойства таблицы, заданной идентификационным номером, именем индекса или статистики и именем свой- ства
OBJECT_NAME (obj_id) Возвращает имя объекта базы данных, заданного своим идентификатором obj_id Пример: SELECT OBJECT_NAME(453576654) = 'products'
OB JECT_ID (obj_name) Возвращает идентификатор объекта базы данных, задан- ного именем obj_name. Пример: SELECT OBJECT_ID('products') = 453576654
OBJECTPROPERTY (obj_id, property) Возвращает информацию об объектах текущей базы дан- ных
Скалярные операторы
Скалярные операторы используются для оперирования скалярными величи-
нами. Transact-SQL поддерживает числовые и логические операции, а также
операцию конкатенации.
5 Зак. 1141
108
Часть II. Язык Transact-SQL
Существуют унарные и бинарные арифметические операции. Унарные опе-
рации: + и - (как знаки числа, выражения). Бинарными арифметическими
операциями являются +, -, *, / и %. (Первые четыре бинарных оператора име-
ют обычное математическое значение, % — остаток от деления.)
Логические операции имеют две различные формы в зависимости от того,
применяются они к битовым строкам или к другим типам данных. Операторы
not, and и t>R применяются ко всем типам данных (за исключением bit). Они
подробно описываются в главе 6.
Побитовые операторы для манипулирования битовыми строками описывают-
ся далее, а пример 4.8 демонстрирует их использование:
♦-----дополнение (т. е. not);
♦ & — конъюнкция битовых строк (т. е. and);
♦ | —дизъюнкция битовых строк (т. е. or);
♦ л — исключающая дизъюнкция (т. е. xor или исключающее or).
| Пример 4.8
-(1001001) = (0110110)
(11001001) | (10101101) = (11101101)
(11001001) & (10101101) = (10001001)
(11001001) л (10101101) = (01100100)
Оператор конкатенации + может быть использован для конкатенации (соеди-
нения) двух символьных или битовых строк.
Глобальные переменные
Глобальные переменные являются специальными системными переменными,
которые могут быть использованы, как если бы они были скалярными кон-
стантами. Transact-SQL поддерживает множество глобальных переменных,
именам которых предшествует префикс @@. В табл. 4.10 описаны некоторые
глобальные переменные. Полный список всех глобальных переменных см.
в Books Online.
Таблица 4.10. Гповальные переменные
Переменная Описание
@@CONNECTIONS Возвращает номер попытки соединения с момента старта системы
@@CPU_BUSY Возвращает общее время занятости центрального процессора (в единицах миллисекунд), прошедшее с момента старта системы
Гпава 4. Основные элементы SQL
109
Таблица 4.10 (окончание)
Переменная Описание
@@ERROR Содержит информацию о возвращенном значении последнего выполненного оператора Transact-SQL
@@IDENTITY Возвращает последнее добавленное значение в столбец, описанный со свойством identity (см. главу 6)
@@LANGID Возвращает идентификатор языка, который в настоящий момент используется для системы базы данных
@@LANGUAGE Возвращает название языка, который в настоящий момент используется для системы базы данных
@ @MAX_CONNECTIONS Возвращает максимальное количество фактических соединений с системой
@@PROCID Возвращает идентификатор хранимой процедуры, выполняющейся в настоящий момент
@@ROWCOUNT Возвращает количество строк, обработанных в последнем операторе Transact-SQL, выполненном в системе
@@SERVERNAME Отыскивает информацию, связанную с локальным сервером базы данных. Эта информация содержит, помимо всего прочего, имя сервера и имя экземпляра сервера
@@SPID Возвращает идентификатор серверного процесса
(AVERSION Возвращает текущую версию программного обеспечения системы базы данных
Значения NULL
Значение null является специальным значением, которое может быть при-
своено столбцу. Это значение обычно используется, когда информация в
столбце неизвестна или неприменима. Например, в случае, когда не известен
номер домашнего телефона у служащего компании, рекомендуется присваи-
вать значение NULL столбцу home telephone.
Любое арифметическое выражение будет возвращать значение null, если лю-
бой операнд в этом выражении имеет значение null. Поэтому в унарных
арифметических операциях (если А— выражение, возвращающее значение
null) оба +а и -а возвращают null. В бинарных выражениях, если один или
оба операнда а или в имеют значение null, то результатом выражений а+в,
a-в, а*в, a/в и а%в также будет null. Операнды айв должны быть числовыми
выражениями.
Если выражение содержит операторы сравнения и один оператор (или оба)
имеет (имеют) значение null, то результатом этой операции будет null. Сле-
110
Часть II. Язык Transact-SQL
довательно, каждое из выражений а = в, а о в, а < в и а > в также вернет
NULL.
В логических выражениях and, or, not поведение значений null определяется
таблицами истинности (табл. 4.11—4.13), где т означает истину, в— ложь, а
и — неизвестное значение (null). В этих таблицах в строках и столбцах по-
следовательно представлены истинностные значения логических выражений,
с которыми выполняются операторы, а на пересечениях строк и столбцов да-
ны значения результата.
Таблица 4.11. Оператор AND
AND Т и F
Т т и F
и и и F
F F F F
Таблица 4.12. Оператор OR
OR Т и F
Т Т т Т
и Т и и
F Т и F
Таблица 4.13. Оператор NOT
NOT Значение
т F
и и
F Т
Любое значение null в аргументе агрегатной функции avg, sum, max, min и
count исключается из вычислений соответствующей функции (за исключени-
ем функции count(*)). Если все обрабатываемые столбцы содержат значение
null, то функция возвращает null. Агрегатная функция count(*) обрабатыва-
ет все значения null так же, как и непустые значения. Если все столбцы со-
держат только значения null, то результатом функции count (distinct
имя__столбца) будет 0.
Гпава 4. Основные элементы SQL
111
Значения null отличаются от всех других значений. Для числовых типов дан-
ных есть различие между нулевым значением и значением null. То же самое
справедливо в отношении пустой строки и значением null для символьных
типов данных.
Столбец в таблице допускает значение null, если при его объявлении явно
было указано null. С другой стороны, значения null не разрешены, если в
объявлении столбца явно указано not null. Если пользователь не указывает
ни null, ни not null при задании типа данных столбца (за исключением
timestamp), то применяются следующие значения:
♦ null, если опция ansi_null_dflt_on в операторе set установлена в on;
♦ not null, если опция ansi_null_dflt_off в операторе set установлена в ON.
Если оператор set не активирован, то столбец будет иметь свойство not null
по умолчанию. (Столбцы типа данных timestamp могут быть объявлены толь-
ко как столбцы not null.)
Существует также другая опция в операторе set: concat_null_yields_null.
Эта опция влияет на операцию конкатенации со значением null, так что лю-
бая конкатенация со значением null даст результат null. Например:
'San Francisco' + NULL = NULL
Резюме
Основные особенности Transact-SQL— типы данных, предикаты и функ-
ции. Типы данных соответствуют типам данных стандарта ANSI SQL92.
Transact-SQL поддерживает множество полезных системных функций.
Следующая глава содержит введение в операторы Transact-SQL, связанные с
языком определения данных SQL. Эта часть Transact-SQL включает в себя
все операторы, необходимые для создания, изменения и удаления объектов
базы данных.
Упражнения
Упражнение 4.1
В чем разница между числовыми типами данных int, smallint и tinyint?
j Упражнение 4.2
В чем разница между типами данных char и varchar? Когда вы должны ис-
пользовать последний (вместо первого) и наоборот?
112
Часть II. Язык Transact-SQL
j Упражнение 4.3
Как вы можете задать формат для столбца с типом данных date, чтобы его
значения могли бы вводиться в виде 'yyyylmtnldd^
В следующих двух упражнениях используйте оператор select в окне Query
Editor в SQL Server Management Studio для отображения всех системных
функций и глобальных переменных. Например, select host_id() отображает
все номера 1D текущего хоста.
Упражнение 4.4
Используя системные функции, найдите номера ID базы данных test (см. уп-
ражнение 2.1).
! Упражнение 4.5
Используя системные переменные, отобразите текущую версию программно-
го обеспечения системы базы данных и язык, который используется в этом
программном обеспечении.
i Упражнение 4.6
Используя битовые операторы s, I и Л, вычислите следующие операции над
битовыми строками:
(11100101) & (01010111)
(10011011) | (11001001)
(10110111) Л (10110001)
j Упражнение 4.7
Что является результатом следующих выражений? (а— числовое, а в— ло-
гическое выражение.)
А + NULL
NULL = NULL
В OR NULL
В AND NULL
Упражнение 4.8
Где вы можете одновременно использовать апострофы и кавычки для опре-
деления строк и временных констант?
j Упражнение 4.9
Что такое идентификатор с разделителями и когда вам нужно его использовать?
ГЛАВА 5
Язык описания данных
Эта глава описывает все операторы Transact-SQL, связанные с языком опре-
деления данных DDL (Data Definition Language). Операторы DDL разделены
на три группы, которые рассматриваются по порядку. Первая группа включа-
ет операторы, которые создают объекты, вторая группа включает операторы,
которые изменяют структуру объектов, а третья группа включает операторы,
которые удаляют объекты базы данных.
Создание объектов базы данных
Организационная структура базы данных включает множество различных
объектов. Все объекты базы данных могут быть физическими или логически-
ми. Физические объекты относятся к организации данных на физических но-
сителях (дисках). Физические объекты Database Engine являются файлами и
группами файлов. Логические объекты являются пользовательскими пред-
ставлениями базы данных. Базы данных, таблицы, столбцы и представления
(виртуальные таблицы) — это экземпляры логических объектов.
Объект базы данных, который должен быть создан в первую очередь, — это
сама база данных. Database Engine управляет как системными, так и пользо-
вательскими базами данных. Авторизованный пользователь может создавать
базы данных пользователя, в то время как системные базы данных генериру-
ются в процессе инсталляции системы баз данных. Системными базами дан-
ных являются:
♦ master;
♦ tempdb;
♦ model;
114
Часть II. Язык Transact-SQL
♦ msdb;
♦ resource.
Эта глава описывает создание, изменение и удаление пользовательских баз
данных, а все системные базы данных будут подробно рассмотрены в гла-
ве 15.
Создание базы данных
Для создания базы данных используются два основных метода. Первый ме-
тод использует Object Explorer в среде SQL Server Management Studio (см.
главу 3). Второй метод заключается в использовании оператора Transact-SQL
create database. Этот оператор имеет следующий синтаксис, детали которого
рассматриваются далее:
CREATE DATABASE db_name
[ON [PRIMARY] { file_specl) ,...]
[LOGON [file_spec2] , ...]
[COLLATE collation_name]
[FOR { ATTACH | ATTACH_REBUILD_LOG } ]
Замечание________________________________________________________
По поводу синтаксиса операторов Transact-SQL: используемые соглашения
описаны в разд. "Синтаксические соглашения" главы 1. В соответствии с эти-
ми соглашениями необязательные элементы заключаются в квадратные скобки
[ ]. Элементы, записанные в фигурных скобках {[ и следующие за символами
многоточия .... являются элементами, которые могут повторяться произволь-
ное количество раз.
Параметр аь_пате— имя базы данных. Максимальным размером для имени
базы данных являются 128 символов. Правила для идентификаторов, описан-
ные в главе 4, применяются и к именам базы данных. Максимальное количе-
ство баз данных, управляемых в одной системе, равно 32 767.
Все базы данных хранятся в файлах. Эти файлы могут быть явно указаны в
системе администратора или неявно предоставлены системой. Если опция
on присутствует в операторе create database, то все файлы, содержащие дан-
ные базы данных, задаются явно.
Замечание
Database Engine использует дисковые файлы для хранения данных. Каждый
дисковый файл содержит данные одной базы данных. Сами файлы могут быть
организованы в файловые группы. Файловые группы предоставляют возмож-
ность распределять данные между различными дисковыми устройствами и вы-
полнять копирование и восстановление подмножеств базы данных (полезно
для очень больших баз данных).
Глава 5. Язык описания данных
115
Параметр file_specl в синтаксисе оператора представляет спецификацию
файла, которая включает дополнительные опции, такие как логическое имя
файла, физическое имя и размер. Опция primary задает первый (и наиболее
важный) файл, который содержит системные таблицы и другую важную
внутреннюю информацию, относящуюся к базе данных. Если опция primary
отсутствует, то первый файл в списке спецификаций используется в качестве
первичного файла.
Пользователь со своей учетной записью, который используется в Database
Engine при создании базы данных, называется владельцем базы данных. База
данных может иметь только одного владельца, который соответствует учет-
ной записи. Учетная запись, принадлежащая владельцу базы данных, имеет
специальное имя аьо. Это имя всегда используется в отношении базы данных,
которой владеет пользователь.
dbo использует опцию log on для определения в качестве физического носи-
теля одного или более файлов, предназначенных для размещения протокола
транзакций этой базы данных. Если опция log on не задана, протокол тран-
закций все равно будет создан, потому что каждая база данных должна иметь,
по меньшей мере, один файл для протокола транзакций. Database Engine со-
храняет запись о каждом изменении, выполненном над базой данных. Систе-
ма хранит все такие записи, в частности значения до и после изменения,
в одном или более файлах, называемых протоколом транзакций. Каждая база
данных системы имеет собственный протокол транзакций. Протоколы тран-
закций подробно обсуждаются в главе 13.
В опции collate вы можете задать порядок сортировки по умолчанию для
базы данных. Если опция collate не задана, то базе данных назначается по-
рядок сортировки по умолчанию из базы данных model, который является тем
же самым, что и порядок сортировки по умолчанию для баз данных системы.
Опция for attach указывает, что база данных создается за счет подключения
уже существующего набора файлов операционной системы. Если использу-
ется эта опция, то вы получаете явно заданный первичный файл. Опция for
attach_rebuild_log указывает, что база данных создана путем присоединения
существующего набора файлов операционной системы1. (Присоединение
базы данных и ее отсоединение описывается позже в этой главе.)
В процессе создания новой базы данных Database Engine использует базу
данных model в качестве шаблона. Свойства базы данных model могут быть
изменены, чтобы соответствовать персональным концепциям системного
администратора.
1 Если у базы данных в этом варианте отсутствует файл протокола транзакций, то он создается
заново. — Прим. перев.
116
Часть II. Язык Transact-SQL
Замечание_____________________________________________________
Если у вас есть объект базы данных, который должен существовать в каждой
пользовательской базе данных, вы предварительно должны создать этот объ-
ект в базе данных model.
В примере 5.1 создается простая база данных без дополнительных специфи-
каций. Для выполнения этого оператора наберите его текст в окне Query
Editor в SQL Server Management Studio и нажмите клавишу <F5>.
j Пример 5.1
USE master;
CREATE DATABASE sample;
В примере 5.1 создается база данных sample. Такая сокращенная форма опе-
ратора create database возможна, потому что почти все опции этого опера-
тора имеют значение по умолчанию. Система по умолчанию создает два фай-
ла. Логическое имя файла данных— sample, а его начальный размер —
2 Мбайт. Аналогично, логическим именем протокола транзакции будет
sample log, а его начальный размер — I Мбайт. Оба значения размеров, так
же, как и другие свойства новой базы данных, зависят от спецификаций в ба-
зе данных model.
В примере 5.2 создается база данных с явными спецификациями для файлов
базы данных и протокола транзакций.
| Пример 5.2
USE master;
CREATE DATABASE projects
ON (NAME = projects_dat,
FILENAME = 'C:\projects.mdf,
SIZE = 10,
MAXSIZE = 100,
FILEGROWTH = 5)
LOG ON
(NAME = prcjectslcg,
FILENAME = 'C:\projects.ldf,
SIZE = 40,
MAXSIZE = 100,
FILEGROWTH = 10);
В примере 5.2 создается база данных projects. Поскольку опция primary от-
сутствует, то предполагается, что первый файл является первичным файлом.
Глава 5. Язык описания данных
117
Этот файл имеет логическое имя projects_dat, он сохраняется в файле
projects.mdf. Начальный размер этого файла— 10 Мбайт. Дополнительное
приращение в 5 Мбайт дискового пространства выделяется системой при не-
обходимости. Если опция maxsize не задана или установлена в unlimited,
файл будет увеличиваться в размерах, пока не заполнит весь диск. (Суффик-
сы КВ, ТВ или МВ могут быть использованы для указания килобайт, тера-
байт или мегабайт соответственно. Значение по умолчанию — МВ.)
Здесь также присутствует единственный файл протокола транзакций с логи-
ческим именем projects log и физическим именем projects.ldf. Все опции спе-
цификации файла протокола транзакций имеют те же имена и тот же смысл,
что и соответствующие опции спецификации файла данных.
Используя язык Transact-SQL, вы можете применить оператор use для изме-
нения контекста базы данных на контекст указанной базы данных. (Альтер-
нативный способ — выбрать имя базы данных из выпадающего меню
Database в панели инструментов SQL Server Management Studio.)
Системный администратор может назначить для пользователей базу данных
по умолчанию, выполнив оператор login или оператор alter login (см. так-
же главу 12). В этом случае пользователям не нужно выполнять оператор use,
если они хотят использовать эту базу данных по умолчанию.
Создание
мгновенного снимка базы данных
Оператор create database может также быть использован для создания мгно-
венного снимка (snapshot) существующей базы данных (исходной базы дан-
ных). Мгновенный снимок базы данных является согласованной с точки зре-
ния завершенных транзакций копией исходной базы данных в том состоянии,
которое соответствует моменту создания мгновенного снимка.
Синтаксис создания мгновенного снимка:
CREATE DATABASE database_snapshot_name
ON (NAME = logical_file_name,
FILENAME = 'os_file_name’} [ , ...n ]
AS SNAPSHOT OF source_database_name
Как вы можете видеть, если вам нужно создать мгновенный снимок базы
данных, вы должны добавить предложение as snapshot of в оператор create
database. В примере 5.3 создается мгновенный снимок базы данных
AdventureWorks, и он сохраняется в каталоге C:\temp. Вы должны создать этот
каталог до того, как запустите пример на выполнение.
118
Часть II. Язык Transact-SQL
। Пример S.3
USE master;
CREATE DATABASE AdventurWorks_snapshot
ON (NAME = 'AdventureWorks_Data' ,
FILENAME = 'C:\temp\snapshot_DB.mdf')
AS SNAPSHOT OF AdventureWorks;
Мгновенный снимок существующей базы данных является копией только для
чтения соответствующей базы данных, которая отображает момент времени,
когда база данных копируется. По этой причине вы можете иметь множество
мгновенных снимков существующей базы данных. Файл мгновенного снимка
(в примере 5.3 C:\temp\snapshot_DB.mdf) содержит только данные, которые
были изменены для исходной базы данных. Поэтому процесс создания мгно-
венных снимков должен включать логическое имя каждого файла данных
исходной базы данных, так же как и соответствующие физические имена (см.
пример 5.3).
Так как мгновенный снимок содержит только измененные данные, дисковое
пространство, необходимое для каждого мгновенного снимка, много меньше,
чем общий объем памяти, требуемой для соответствующей исходной базы
данных.
Замечание_______________________________________________________
Для создания мгновенного снимка базы данных вам нужен дисковый том NTFS,
потому что только такие тома поддерживают технологию разреженных файлов,
которая используется для сохранения мгновенных снимков.
Мгновенные снимки базы данных обычно используются в качестве механиз-
ма защиты данных от ошибок пользователя.
Соединение баз данных и их отсоединение от сервера
Все данные базы данных могут быть отсоединены от сервера базы данных, а
затем соединены с тем же самым или другим сервером базы данных. Отсо-
единение и соединение должно быть сделано, если вы собираетесь перемес-
тить базу данных.
Вы можете отсоединить базу данных от сервера баз данных, используя сис-
темную процедуру sp_detach_db. Отсоединяемая база данных должна быть
в режиме одного пользователя.
Для соединения базы данных используйте либо оператор create database,
либо системную процедуру sp_attach_db. Когда вы соединяетесь с базой дан-
ных, все файлы данных должны быть доступны. Если какой-нибудь файл
Гпава 5. Язык описания данных
119
данных имеет путь, отличный от того, который был задан при первоначаль-
ном создании базы данных, вы должны задать текущий путь к файлу.
CREATE TABLE', основная форма
Оператор create table создает новую таблицу в базе данных со всеми соот-
ветствующими столбцами и их типами данных. Основная форма оператора
CREATE TABLE’.
CREATE TABLE table_name
(col_namel typel [NOT NULL | NULL]
[{, col_name2 type2 [NOT NULL I NULL]} ...])
Замечание_______________________________________________________
Помимо базовых таблиц существует еще несколько специальных видов таблиц,
таких как временные таблицы и представления (см. главы 6 и 11 соответст-
венно).
Параметр tabie_name— это имя создаваемой базовой таблицы. Максималь-
ное количество таблиц в базе данных ограничивается количеством объектов в
этой базе данных (в базе данных может быть более 2 миллиардов объектов,
включая таблицы, представления, хранимые процедуры, триггеры и ограни-
чения). coi_namei, coi_name2, ... являются именами столбцов таблицы, typel,
type2,... -—типы данных соответствующих столбцов (см. главу 4).
Замечание_______________________________________________________
Имя объекта базы данных в общем случае может содержать четыре части в
следующей форме:
[server_name.[db_name.[schema_name.]]]object_name
Здесь object_name— имя объекта базы данных, schema_name— имя схемы,
которой принадлежит объект, server_name и db_name— имена сервера и базы
данных, которым принадлежит объект базы данных. Имена таблиц, соединен-
ные с помощью символа точки с именем схемы, должны быть уникальными
в базе данных. Аналогично, имена столбцов должны быть уникальными в пре-
делах одной таблицы.
Первое ограничение, которое будет рассматриваться в данной книге, — это
существование или отсутствие значений null в столбце. Если задано not
null, то присваивание значений null для этого столбца недопустимо. В этом
случае столбец не может содержать пустых значений, и при попытке помес-
тить в такой столбец значение null система вернет сообщение об ошибке.
Как уже было сказано, объект базы данных (в данном случае таблица) всегда
создается в схеме базы данных. Пользователь может создавать таблицу толь-
ко в схеме, для которой он имеет полномочия alter. Любой пользователь
120
Часть II. Язык Transact-SQL
с ролью sysadmin, dbddladmin или db owner может создавать таблицы в
любой схеме. (Полномочия alter, а также роли базы данных и сервера под-
робно обсуждаются в главе 12.)
Создатель таблицы не обязан быть ее владельцем. Это означает, что вы мо-
жете создать таблицу, которая принадлежит кому-то другому. Аналогично,
таблица, созданная оператором create table, не обязательно будет принад-
лежать текущей базе данных, если в имени таблицы задается префикс неко-
торой другой (существующей) базы данных вместе с именем схемы.
Схема, которой принадлежит таблица, имеет два возможных имени по умол-
чанию. Если таблица задана без явного указания имени схемы, то система
ищет для имени этой таблицы соответствующую схему по умолчанию. Если
имя объекта не может быть найдено в схеме по умолчанию, то система вы-
полняет поиск в схеме цьо.
Замечание________________________________________________________
Вы должны всегда задавать имя таблицы вместе с именем соответствующей
схемы. В этом случае вы можете уменьшить возможность двусмысленности.
Временные таблицы являются специальным видом базовых таблиц. Они со-
храняются в базе данных tempdb и автоматически удаляются в конце сессии.
Свойства временных таблиц и примеры их использования даны в главе 6.
В примере 5.4 показано создание всех таблиц базы данных sample. (База дан-
ных sample должна быть текущей базой данных.)
= Пример 5.4
USE sample;
CREATE TABLE employee (emp_no INTEGER NOT NULL,
emp_fname CHAR(20) NOT NULL,
emp_lname CHAR(20) NOT NULL,
dept_no CHAR(4) NULL);
CREATE TABLE department(dept_no CHAR(4) NOT NULL,
dept_name CHAR(25) NOT NULL,
location CHAR(30) NULL);
CREATE TABLE project (project_no CHAR(4) NOT NULL,
project_name CHAR(15) NOT NULL,
budget FLOAT NULL);
CREATE TABLE works_on (emp_no INTEGER NOT NULL,
project_no CHAR(4) NOT NULL,
job CHAR (15) NULL,
enter_date DATE NULL);
Глава 5. Язык описания данных 121
Помимо типа данных и допустимости пустого значения спецификация столб-
ца может содержать следующие опции:
♦ предложение default;
♦ СВОЙСТВО IDENTITY.
Предложение default в определении столбца задает значение по умолчанию
для столбца, т. е. когда новая строка добавляется в таблицу, значение по
умолчанию для столбца будет использовано, если для него не задано никако-
го значения. В качестве значения по умолчанию могут быть использованы,
помимо прочих, константные значения, такие как системные функции user,
CURRENT USER, SESSIONJJSER, SYSTEM_USER, CURRENTJTIMESTAMP И NULL.
Столбец co свойством identity допускает только целочисленные значения,
которые обычно неявно задаются системой. Каждое значение, которое долж-
но быть помещено в столбец, вычисляется путем увеличения на единицу по-
следнего помещенного в такой столбец значения. Поэтому объявление столб-
ца со свойством identity содержит (неявно или явно) начальное значение и
инкремент. Это свойство будет подробно рассматриваться в следующей главе
(см. пример 6.41).
Замечание_________________________________________________________
Поскольку Database Engine генерирует значения для столбцов со свойством
identity, эти значения всегда будут различными, даже если несколько пользо-
вателей добавляют строки в одно и то же время. Эта особенность является
очень важной для многопользовательской среды, где для обычной программы
довольно сложно генерировать уникальные числовые значения.
Для завершения этого раздела в примере 5.5 показано создание таблицы со
столбцом, имеющим тип данных sql variant.
j Пример 5.5
USE sample;
CREATE TABLE Item_Attributes (
item_id INT NOT NULL,
attribute NVARCHAR(30) NOT NULL,
value SQL_VARIANT NOT NULL,
PRIMARY KEY (item_id, attribute));
В примере 5.5 таблица содержит столбец value, который имеет тип данных
sql variant. Как вы уже знаете из главы 4, тип данных sql variant может
быть использован для хранения в одно и то же время различных типов дан-
ных, таких как числовые значения, строки и значения даты. Обратите внима-
ние, что тип данных sql variant в примере 5.5 используется для значений
столбца, потому что различные значения атрибутов могут присутствовать для
122
Часть II. Язык Transact-SQL
различных типов данных. Например, атрибут размера сохраняется в виде
целочисленного значения, а атрибут имени — в виде строки символов.
Оператор CREATE TABLE
и ограничения декларативной целостности
Одним из наиболее важных свойств является то, что СУБД должна предос-
тавлять способы поддержания целостности данных. Эти ограничения, кото-
рые используют проверку изменения и добавления данных, называются огра-
ничениями целостности. Задача поддержания ограничений целостности мо-
жет быть выполнена пользователем в программах приложения или системой
управления базами данных. Наиболее важными преимуществами обработки
ограничений целостности самой СУБД являются следующие:
♦ повышается надежность данных;
♦ уменьшается время на программирование;
♦ становится проще поддержка.
Использование СУБД для поддержания ограничений целостности повышает
надежность данных, потому что здесь не существует возможности, что про-
граммист забудет о необходимости следить за ограничениями целостности.
Если ограничение целостности обрабатывается в программе приложения, то
все программы, связанные с этим ограничением, должны включать соответ-
ствующий код. Если код опущен в одной из программ приложения, то согла-
сованность данных подвергается риску.
Ограничение целостности, не обрабатываемое СУБД, должно быть определе-
но в каждой программе приложения, которая использует данные, включен-
ные в это ограничение. В противоположность этому то же самое ограничение
целостности должно быть объявлено только один раз, если оно обрабатыва-
ется СУБД. В дополнение к этому, ограничения, поддерживаемые приложе-
нием, обычно более сложны в кодировании, чем ограничения, поддерживае-
мые базой данных.
Если ограничение целостности обрабатывается СУБД, то изменение структу-
ры ограничения (если такое потребуется) должно быть выполнено только
один раз — в СУБД. Это же изменение структуры в программах приложения
требует изменения каждой программы, которая содержит соответствующий
код.
Существуют две группы ограничений целостности, обрабатываемых СУБД:
♦ декларативные ограничения целостности;
♦ процедурные ограничения целостности, которые обрабатываются тригге-
рами (определение триггеров см. в главе 13).
Гпава 5. Язык описания данных 123
Декларативные ограничения объявляются с использованием операторов DDL
create table и alter table. Они могут быть ограничениями на уровне столб-
ца и ограничениями на уровне таблицы. Ограничения на уровне столбца вме-
сте с типом данных и другими свойствами столбца помещаются в объявление
столбца, в то время как ограничения на уровне таблицы всегда размещаются
в конце операторов create table или alter table после объявления всех
столбцов.
Замечание_____________________________________________________
Это только одно отличие ограничений на уровне столбца и ограничений на
уровне таблицы. Ограничение на уровне столбца может применяться только
к одному столбцу, в то время как ограничение на уровне таблицы может ка-
саться одного или более столбцов таблицы.
Каждое декларативное ограничение имеет имя. Имя ограничения может быть
задано явно с использованием опции constraint в операторе create table или
alter table. Если опция constraint отсутствует, Database Engine присваивает
неявное имя этому ограничению.
Замечание_____________________________________________________
Использование явных имен ограничений очень рекомендуется. Поиск нужного
ограничения пройдет много быстрее, если используется явное имя ограниче-
ния. ,
Все декларативные ограничения могут быть разделены на несколько групп:
♦ предложение default;
♦ предложение unique;
♦ предложение primary key;
♦ предложение check;
♦ предложение foreign key и ссылочную целостность.
Определение значения по умолчанию с использованием предложения default
было рассмотрено ранее в этой главе (см. также пример 5.6). Все остальные
ограничения подробно описываются в следующих разделаах.
Предложение UNIQUE
Иногда несколько столбцов или групп столбцов таблицы имеют уникальные
значения и поэтому могут быть использованы в качестве первичного ключа.
Все столбцы или группы столбцов, которые могут рассматриваться как пер-
вичные ключи, называются кандидатами в ключи. Каждый кандидат в ключи
определяется с использованием предложения unique в операторе create table
ИЛИ ALTER TABLE.
124
Часть II. Язык Transact-SQL
Предложение unique имеет следующую форму:
[CONSTRAINT c_name]
UNIQUE [CLUSTERED | NONCLUSTERED] ({ col_namel] ,...)
Опция constraint в предложении unique назначает явное имя кандидату в
ключи. Опция clustered или nonclustered соответствует тому факту, что
Database Engine всегда генерирует индекс для каждого кандидата в ключи
таблицы. Индекс может быть кластеризованным, т. е. физический порядок
строк в индексе соответствует порядку значений столбцов индекса. Если по-
рядок не задан, индекс является некластеризованным (см. также главу 10).
Значение по умолчанию— nonclustered. Параметр coi_namel — имя столбца,
который входит в состав кандидата в ключи. Максимальное количество
столбцов для кандидата в ключи равно 16.
Пример 5.6 демонстрирует использование предложения unique.
i Пример 5.6
USE sample;
CREATE TABLE projects (project_no CHAR(4) DEFAULT 'pl*,
project_name CHAR(15) NOT NULL,
budget FLOAT NULL
CONSTRAINT unique_no UNIQUE (project_no));
Каждое значение столбца project_no в таблице projects является уникаль-
ным, включая значение null. (Точно так же, как и любое другое значение в
ограничении unique, если значения null допустимы для соответствующего
столбца, то в таблице может присутствовать не более одной строки со значе-
нием null для данного столбца.) Если значение, которое уже присутствует
в таблице, будет помещаться в столбец project_no, то система отвергнет эту
операцию. Ограничение, которое определено в примере 5.6, имеет явное имя
unique_no.
Предложение PRIMARY KEY
Первичный ключ в таблице — это столбец или группа столбцов, чьи значения
отличаются для каждой строки. Каждый первичный ключ определяется с ис-
пользованием предложения primary key в операторе create table или alter
TABLE.
Предложение primary key имеет следующую форму:
[CONSTRAINT c_name]
PRIMARY KEY [CLUSTERED | NONCLUSTERED] ({col_namel} ,...)
Гпава 5, Язык описания данных 125
Все опции в предложении primary key имеют то же самое значение, что и со-
ответствующие опции с теми же именами в предложении unique. В отличие
ОТ столбцов UNIQUE СТОлбцЫ PRIMARY KEY ДОЛЖНЫ быть NOT NULL И ИХ реЖИМ ПО
умолчанию CLUSTERED.
В примере 5.7 показано задание первичного ключа для таблицы employee
базы данных sample.
Замечание_______________________________________________________
Вы должны удалить таблицу employee (DROP TABLE employee), прежде чем вы-
полнять следующий пример.
[ Пример 5.7
USE sample;
CREATE TABLE employee (emp_no INTEGER NOT NULL,
emp_fname CHAR(20) NOT NULL,
emp_lname CHAR(20) NOT NULL,
dept_no CHAR(4) NULL,
CONSTRAINT priin_empl PRIMARY KEY (emp_no) ) ;
Таблица employee пересоздается, и ее первичный ключ определяется в приме-
ре 5.7. Первичный ключ этой таблицы задается с использованием деклара-
тивного ограничения целостности, которому присваивается имя prim empl.
Это ограничение целостности является ограничением на уровне таблицы, по-
тому что задается после определения всех столбцов таблицы employee.
Пример 5.8 эквивалентен примеру 5.7, за исключением того, что первичный
ключ таблицы employee создается как ограничение на уровне столбца.
Замечание__________________________________________________________
Опять же, вы должны удалить таблицу employee (DROP TABLE employee), пре-
жде чем будете выполнять следующий пример.
j Пример 5.8
USE sample;
CREATE TABLE employee
(emp_no INTEGER NOT NULL CONSTRAINT prim_empl PRIMARY KEY,
emp_fname CHAR(20) NOT NULL,
emp_lname CHAR(20) NOT NULL,
dept_no CHAR(4) NULL);
В примере 5.8 предложение primary key принадлежит объявлению соответст-
вующего столбца вместе с его типом данных и указанием о недопустимости
126
Часть II. Язык Transact-SQL
пустого значения. По этой причине это ограничение называется ограничени-
ем на уровне столбца.
Предложение CHECK
Ограничение check задает условия для данных, помещаемых в столбец. Каж-
дая строка, добавляемая в таблицу, или каждое значение, изменяющее значе-
ние столбца, должно соответствовать этим условиям. Это предложение мо-
жет быть задано в операторе create table или alter table. Синтаксис пред-
ложения check:
[CONSTRAINT c_name]
CHECK [NOT FOR REPLICATION] expression
Выражение expression должно давать логическое значение (true или false),
оно может ссылаться на любой столбец текущей таблицы (или только на те-
кущий столбец, если определяется как ограничение на уровне столбца), но не
на другие таблицы. Если присутствует опция not for replication, то условие
в предложении check не проверяется в процессе репликации данных. Для ба-
зы данных или ее части должна выполняться репликация, если база хранится
более чем на одном сайте. Репликация может быть использована для улучше-
ния доступности данных. Глава 20 описывает репликацию данных.
В примере 5.9 показано, как может быть использовано предложение check.
Пример 5.9
USE sample;
CREATE TABLE customer
(cust_no INTEGER NOT NULL,
cust_group CHAR(3) NULL,
CHECK (cust_group IN ('cl', 'c2', 'clO')));
Таблица customer, которая создается в примере 5.9, содержит столбец
cust_group с соответствующим ограничением check. Система базы данных
вернет ошибку, если столбец cust_group после изменения существующего
значения или после добавления новой строки будет содержать значение, от-
личное от значения в заданном множестве: (' cl', ' с2', ' cio').
Предложение FOREIGN KEY
Внешний ключ — это столбец или группа столбцов таблицы, которые содер-
жат значения, соответствующие значениям первичного ключа той же самой
или другой таблицы. Каждый внешний ключ объявляется с использованием
предложения foreign key, объединенного с предложением references.
Гпава 5. Язык описания данных
127
Предложение foreign key имеет следующую форму:
[CONSTRAINT c_name]
[[FOREIGN KEY] ({col_namel}, ...)]
REFERENCES table_name ({col_name2}, . ..)
[ON DELETE {NO ACTION I CASCADE I SET NULL I SET DEFAULT}]
[ON UPDATE {NO ACTION I CASCADE I SET NULL I SET DEFAULT}]
Предложение foreign key явно определяет все столбцы, которые принадлежат
внешнему ключу. Предложение references задает имя таблицы со всеми
столбцами, которые входят в состав первичного ключа. Количество и типы
данных столбцов в предложении foreign key должны соответствовать коли-
честву и соответствующим типам данных столбцов в предложении
references (и, разумеется, все они должны соответствовать количеству и ти-
пам данных столбцов первичного ключа таблицы, на которую осуществляет-
ся ссылка).
Таблица, которая содержит внешний ключ, называется дочерней таблицей, а
таблица, содержащая соответствующий первичный ключ, называется роди-
тельской таблицей или главной таблицей. Пример 5.10 показывает специфи-
кацию внешнего ключа в таблице works on базы данных sample.
Замечание__________________________________________________________
Вы должны удалить таблицу works_on, прежде чем станете выполнять сле-
дующий пример.
i Пример 5.10
USE sample;
CREATE TABLE works_on (emp_no INTEGER NOT NULL,
project_no CHAR(4) NOT NULL,
job CHAR (15) NULL,
enter_date DATE NULL,
CONSTRAINT prim_works PRIMARY KEY(emp_no, project_no),
CONSTRAINT foreign_works FOREIGN KEY(emp_no)
REFERENCES employee (emp_no));
Таблица works on в примере 5.10 задана с двумя декларативными ограниче-
ниями целостности: prim works и foreign_works. Оба ограничения являются
ограничениями на уровне таблицы, где вначале задается первичный ключ, а
затем внешний ключ таблицы works on. Далее, ограничение foreign_works
определяет таблицу employee как родительскую таблицу, а ее столбец emp_no
как первичный ключ, соответствующий столбцу с тем же именем в таблице
works_on.
128
Часть II. Язык Transact-SQL
Предложение foreign key может быть опущено, если внешний ключ опреде-
ляется как ограничение на уровне столбца, потому что столбец, для которого
создается ограничение, является неявным столбцом в "списке" для внешнего
ключа, а ключевое слово references является достаточным для указания того,
какой тип имеет это ограничение. Максимальное количество ограничений
внешнего ключа для одной таблицы — 63.
Объявление внешних ключей в таблицах базы данных дополняется наличием
другого важного ограничения целостности: ссылочной целостности, описы-
ваемой далее.
Ссылочная целостность
Ссылочная целостность усиливает правила добавления и изменения данных
в таблице при помощи внешнего ключа и соответствующего ограничения
первичного ключа. В примерах 5.7 и 5.10 задаются два таких ограничения:
prim_empi и foreign_works. Предложение references в примере 5.10 определя-
ет таблицу employee в качестве родительской таблицы.
Возможные проблемы, связанные со ссылочной целостностью
Существуют четыре случая, когда изменение значения внешнего или первич-
ного ключа могут вызвать проблемы. Все эти случаи будут рассмотрены
с использованием базы данных sample. Первые два случая влияют на измене-
ния дочерней таблицы, тогда как последние два связаны с изменениями роди-
тельской таблицы.
Случай 1
Добавление новой строки в таблицу works on с номером служащего 11111.
Добавление новой строки в дочернюю таблицу works on вводит новый номер
служащего, для которого нет соответствующего служащего в родительской
таблице (employee). Если ссылочная целостность для обеих таблиц задана так,
как это сделано в примерах 5.7 и 5.10, то Database Engine отменяет добавле-
ние новой строки. Для читателя, знакомого с языком SQL, соответствующим
оператором Transact-SQL будет
USE sample;
INSERT INTO works_on (emp_no, ...)
VALUES (11111, ...);
Случай 2
Изменение номера служащего 10102 во всех строках таблицы works on. Новое
значение номера — 11111.
В этом случае существующее значение внешнего ключа в таблице works_on
должно быть изменено на новое значение, для которого нет соответствующе-
Гпава 5. Язык описания данных
129
го значения в родительской таблице employee. Если ссылочная целостность
для обеих таблиц задана так, как это сделано в примерах 5.7 и 5.10, то систе-
ма базы данных отменит изменение этих строк в таблице works_on. Соответ-
ствующий оператор Transact-SQL:
USE sample;
UPDATE works_on
SET emp_no = 11111 WHERE emp_no = 10102;
Случай 3
Изменение номера служащего 10102 в соответствующей строке таблицы
employee. Новое значение номера 22222.
В этом случае изменяется только существующее значение первичного ключа
родительской таблицы, но не меняется соответствующее значение внешнего
ключа в дочерней таблице. По этой причине система отменяет изменение
строки в таблице employee с номером служащего 10102. Ссылочная целост-
ность требует выполнения условия, что ни одна строка в дочерней таблице
(с учетом предложения foreign key) не может присутствовать, если в роди-
тельской таблице нет соответствующей строки (предложение primary key).
В противном случае строки в дочерней таблице станут "осиротевшими". Если
бы модификации, описанные выше, были разрешены, то строки в таблице
works_on, имеющие номер служащего 10102, стали бы осиротевшими. Систе-
ма должна отменить это изменение. Соответствующий оператор Transact-
SQL:
USE sample;
UPDATE employee
SET emp_no = 22222 WHERE emp_no = 10102;
Случай 4
Удаление строки из таблицы employee с номером служащего 10102.
Случай 4 похож на случай 3. Это удаление требует удаления служащего для
каждой существующей строки из дочерней таблицы. В примере 5.11 показано
объявление таблиц базы данных sample со всеми существующими ограниче-
ниями первичных и внешних ключей. Если таблицы employee, department,
project и works on уже существуют, то удалите их, используя оператор drop
имя_ та блицы.
; Пример 5.11
USE sample;
CREATE TABLE department(dept_no CHAR(4) NOT NULL,
dept__name CHAR (25) NOT NULL,
130
Часть II. Язык Transact-SQL
location CHAR(30) NULL,
CONSTRAINT prim_dept PRIMARY KEY (dept_no));
CREATE TABLE employee (emp_no INTEGER NOT NULL,
emp_fname CHAR(20) NOT NULL,
emp_lname CHAR(20) NOT NULL,
dept_no CHAR(4) NULL,
CONSTRAINT prim_emp PRIMARY KEY (emp_no),
CONSTRAINT foreign_emp FOREIGN KEY(dept_no) REFERENCES
department(dept_no));
CREATE TABLE project (project_no CHAR(4) NOT NULL,
project_name CHAR(15) NOT NULL,
budget FLOAT NULL,
CONSTRAINT prim_proj PRIMARY KEY (project_no));
CREATE TABLE works_on (emp_no INTEGER NOT NULL,
project_no CHAR(4) NOT NULL,
job CHAR (15) NULL,
enter_date DATE NULL,
CONSTRAINT prim_works PRIMARY KEY(emp_no, project_no),
CONSTRAINT foreignl_works FOREIGN KEY(emp_no) REFERENCES
employee(emp_no),
CONSTRAINT foreign2_works FOREIGN KEY(project_no) REFERENCES
project(project_no));
Опции ON DELETE и ON UPDATE
Database Engine может по-разному реагировать на удаление или изменение
первичного ключа таблицы. Если вы постараетесь изменить значение внеш-
него ключа, и это изменение повлечет несогласованность с соответствующим
первичным ключом (см. случаи 1 и 2 в предыдущем разделе), система базы
данных всегда будет отменять такое изменение и выдаст сообщение вроде
следующего:
Server: Msg 547, Level 16, State 1, Line 1
UPDATE statement conflicted with COLUMN FOREIGN KEY constraint
'FKemployee'. The conflict occurred in database 'sample', table
'employee',
column 'dept_no'. The statement has been terminated.
(Оператор изменения конфликтует с ограничением внешнего ключа для
столбца 'FKemployee'. Конфликт появился в базе данных 'sample', в таблице
'employee', в столбце 'dept no'. Выполнение оператора завершено.)
Однако если вы пытаетесь изменять первичный ключ, и это изменение при-
водит к несогласованности соответствующего внешнего ключа (см. случаи 3
и 4 в предыдущем разделе), то система базы данных может реагировать очень
Гпава 5. Язык описания данных 131
гибко. Существуют четыре опции, определяющие, как система базы данных
может реагировать.
♦ no action. Позволяет вам модифицировать (изменять или удалять) только
те значения в родительской таблице, которые не имеют соответствующих
значений внешнего ключа в родительской таблице.
♦ cascade. Позволяет вам модифицировать (update или delete) все значения
в родительской таблице. Если указана эта опция, то строки будут измене-
ны (update) или удалены (delete) из дочерней таблицы, если соответст-
вующее значение первичного ключа родительской таблицы было измене-
но или вся строка удалена из родительской таблицы.
♦ set null. Опять же позволяет вам изменять и удалять значения в родитель-
ской таблице. Если вы собираетесь изменить значение в родительской
таблице, и это изменение приводит к несогласованности данных в дочер-
ней таблице, то система базы данных устанавливает все соответствующие
значения внешнего ключа дочерней таблицы в null. Аналогично, если вы
собираетесь удалить строку из родительской таблицы, и это удаление зна-
чения первичного ключа приводит к несогласованности данных, то систе-
ма базы данных устанавливает все соответствующие значения внешнего
ключа в null. Таким образом устраняются все несогласованности данных.
♦ set default. Аналогично опции set null за одним исключением: все соот-
ветствующие значения внешнего ключа устанавливаются в значение по
умолчанию. (Очевидно, что значение по умолчанию должно все-таки
существовать в первичном ключе одной из строк родительской таблицы.)
Замечание_________________________________________________________
Язык Transact-SQL поддерживает все четыре альтернативы.
Пример 5.12 показывает использование опций on delete и cm update.
Пример 5.12
USE sample;
CREATE TABLE works_onl
(emp_no INTEGER NOT NULL,
project_no CHAR (4) NOT NULL,
job CHAR (15) NULL,
enter_date DATE NULL,
CONSTRAINT prim_worksl PRIMARY KEY (emp_no, project_no),
CONSTRAINT foreignl_worksl FOREIGN KEY (emp_no)
REFERENCES employee (emp_no) ON DELETE CASCADE,
CONSTRAINT foreign2_worksl FOREIGN KEY (project_no)
REFERENCES project( project_no) ON UPDATE CASCADE);
132
Часть II. Язык Transact-SQL
В примере 5.12 создается таблица works_onl, которая использует опции on
delete cascade и on update cascade. Если вы загружаете таблицу works_oni с
содержимым, показанным в табл. 1.4, то каждое удаление строки в таблице
employee приведет к дополнительному удалению всех тех строк таблицы
works onl, которые имеют соответствующее значение в столбце emp_no. Ана-
логично, каждое изменение значения в столбце project_no в таблице project
приведет к таким же изменениям всех соответствующих значений столбца
project_no таблицы works_onl.
Создание других объектов базы данных
Реляционная база данных содержит не только базовые таблицы, которые су-
ществуют со своими привилегиями, но также и представления, которые яв-
ляются виртуальными таблицами. Данные базовых таблиц существуют физи-
чески, т. е. они сохранены на диске, в то время как представление является
производным от одной или более базовых таблиц. Оператор create view соз-
дает новое представление из одной или более существующих таблиц (или
представлений), используя оператор select, который является неотъемлемой
частью оператора create view. Так как в создании представления всегда при-
сутствует запрос, то оператор create view относится к языку манипулирова-
ния данными (DML), а не к языку определения данных (DDL). По этой при-
чине создание и удаление представлений обсуждается в главе 11 после опи-
сания всех операторов Transact-SQL, выполняющих модификацию данных.
Оператор create index создает новый индекс для указанной таблицы. Индек-
сы в первую очередь используются для повышения эффективности доступа
к данным на диске. Существование индекса может сильно ускорить доступ
к данным. Индексы вместе с оператором create index подробно обсуждаются
в главе 10.
Хранимые процедуры являются дополнительным объектом базы данных, ко-
торые создаются с использованием оператора create procedure. Хранимая
процедура — это специальный вид последовательности операторов, написан-
ных на языке Transact-SQL с использованием SQL и языка расширения для
процедур. В главе 8 хранимые процедуры рассматриваются в подробностях.
Триггеры являются объектами базы данных, которые задают действия как
результат операции с базой данных. Это означает, что когда происходит кон-
кретное действие по изменению данных отдельной таблицы (модификация,
добавление или удаление), Database Engine автоматически выполняет одно
или более действий. Оператор create trigger создает новый триггер. Тригге-
ры подробно описываются в главе 14.
Синоним является локальным объектом базы данных, который предоставляет
связь между самим собой и другим объектом, управляемым тем же или свя-
Глава 5. Язык описания данных
133
занным сервером базы данных. Используя оператор create synonym, вы може-
те создавать синоним для конкретного объекта. Пример 5.13 показывает ис-
пользование этого оператора.
I Пример 5.13
USE sample;
CREATE SYNONYM prod
FOR AdventureWorks.Production.Product;
В примере 5.13 создается синоним для таблицы Product в схеме Production
базы данных AdventureWorks. Этот синоним может быть использован в опера-
торах DML, таких как select, insert, update и delete.
Замечание_____________________________________________________
Основная причина использования синонимов— это возможность не вводить
длинные имена в операторах DML. Как вы уже знаете, имя объекта базы дан-
ных в общем случае может содержать четыре части. Добавление синонима
(содержащего только одну часть) к объекту, который имеет в имени три или че-
тыре части, может сократить ваше время при наборе его имени.
Схема является объектом базы данных, который включает операторы для
создания таблиц, представлений и привилегий пользователя. Вы можете ду-
мать о схеме как о конструкции, которая собрала вместе несколько таблиц,
представлений и привилегий пользователя.
Замечание_____________________________________________________
Database Engine трактует понятие схемы тем же самым образом, что и стандарт
ANSI SQL. В стандарте SQL схема определяется как коллекция объектов базы
данных, которой владеет один хозяин и которая создает единое пространство
имен. Пространство имен (namespace) — это множество объектов, которые не
могут иметь дублирующих имен. Например, две таблицы могут иметь одинако-
вые имена, только если они находятся в различных схемах. В версиях, предше-
ствующих SQL Server 2005, пользователи и схемы базы данных были неявно
объединены; т. е. каждый пользователь базы данных являлся владельцем схе-
мы, которая имела то же самое имя, что и пользователь. Также существовал
оператор create schema, но он фактически не создавал схему. Схема является
очень важной концепцией в модели безопасности Database Engine. Поэтому вы
можете найти детальное описание схемы в главе 12.
Ограничения целостности и домены
Домен — множество всех возможных допустимых значений, которые может
принимать столбец таблицы. Почти все СУБД используют базовые типы дан-
ных, такие как int, char и date, для определения множества возможных зна-
чений столбца. Этот метод усиления "целостности домена" является непол-
ным, как можно увидеть из следующего примера.
134
Часть II. Язык Transact-SQL
Таблица person имеет столбец zip, который задает ZIP-код (почтовый индекс)
города, в котором живет человек. Этот столбец может быть объявлен с типом
данных smallint или char(5). Объявление с типом данных smallint является
неточным, потому что тип данных smallint содержит все положительные и
отрицательные целые числа в диапазоне между -215 и 215- 1. Объявление с
использованием char (5) является даже еще более неточным, потому что в
этом случае здесь могут присутствовать все символы и специальные знаки.
По этой причине правильное определение ZIP-кодов требует задание интер-
вала положительных целых чисел в диапазоне между 00601 и 99950 и назна-
чение его столбцу zip1.
Ограничения check (определяемые в операторах create table и alter table)
могут более точно усилить целостность домена, потому что их выражения
являются гибкими, и они всегда выполняются при добавлении нового значе-
ния или при изменении значения в столбце.
Язык Transact-SQL обеспечивает поддержку доменов путем создания псевдо-
нимов типов данных при использовании оператора create type. Следующие
два раздела описывают псевдонимы и типы данных clr.
Псевдонимы типов данных
Псевдоним типа данных является специальным видом типа данных, который
определяется пользователем при использовании существующих базовых ти-
пов данных. Такие типы данных могут быть использованы в операторе create
table для определения одного или более столбцов в базе данных.
Оператор create type обычно применяется для создания псевдонима типа
данных. Синтаксис этого оператора имеет следующий вид:
CREATE TYPE [type_schema_name.] type_name
{ [ FROM base_type [ ( precision [, scale ] ) ] [ NULL | NOT NULL ] ]
I [ EXTERNAL NAME assembly_name [. class_name ] ]}
В примере 5.14 показано создание типа данных "псевдоним" с использовани-
ем оператора create type.
1 Пример 5.14
USE sample;
CREATE TYPE zip
FROM SMALLINT NOT NULL;
1 Эти рассуждения относятся к почтовым индексам, принятым в США. Подобное решение
можно применить с небольшими поправками и к России. — Прим, перев.
Гпава 5. Язык описания данных 135
В примере 5.14 создается псевдоним типа zip, основанный на стандартном
типе данных smallint. Этот определенный пользователем тип данных теперь
может быть использован для столбца таблицы, как показано в примере 5.15.
Замечание___________________________________________________________
Опять же, вы должны удалить таблицу customer (drop table customer), пре-
жде чем выполнять следующий пример.
j Пример 5.15
USE sample;
CREATE TABLE customer
(cust_no INT NOT NULL,
cust_name CHAR(20) NOT NULL,
city CHAR(20),
zip_code ZIP,
CHECK (zip_code BETWEEN 601 AND 99950));
В примере 5.15 используется тип данных zip для задания столбца таблицы
customer. Значения этого столбца ограничены диапазоном от 601 до 99950.
Как можно увидеть в примере 5.15, это можно сделать, используя предложе-
ние CHECK.
Замечание___________________________________________________________
Обычно Database Engine выполняет неявное преобразование между столбцами
с различными совместимыми типами данных. Это также верно и для псевдони-
мов типов данных.
SQL Server 2008 дополнительно поддерживает создание типов таблиц, опре-
деленных пользователем. В примере 5.16 показано, как вы можете использо-
вать оператор create type для создания подобного типа таблицы.
j Пример 5.16
USE sample;
CREATE TYPE person_table_t AS TABLE
(name VARCHAR(30),
salary DECIMAL(8,2));
Определенный пользователем тип таблицы, названный person table_t, имеет
два столбца: name и salary. Подобные типы таблиц обычно используются
в отношении параметров типа "таблица" (см. главу 8).
136
Часть II. Язык Transact-SQL
Типы данных CLR
Оператор create type может быть также применен для создания определен-
ного пользователем типа данных с использованием .NET. В этом случае реа-
лизация определенного пользователем типа данных будет определяться в
классе сборки Common Language Runtime (CLR). Это означает, что вы можете
использовать один из языков .NET, типа C# или Visual Basic для реализации
нового типа данных. Дальнейшее обсуждение определенных пользователем
типов данных выходит за рамки тематики данной книги.
Изменение объектов базы данных
Язык Transact-SQL поддерживает изменение структуры следующих объектов
базы данных, помимо других:
♦ база данных;
♦ таблица;
♦ хранимая процедура;
♦ представление;
♦ схема;
♦ триггер.
Следующие два раздела описывают по порядку, как вы можете изменять базы
данных и таблицы. Модификация структуры каждого из четырех последних
объектов базы данных описывается в главах 8,11,12 и 14 соответственно.
Изменение базы данных
Оператор alter database изменяет физическую структуру базы данных. Язык
Transact-SQL позволяет модифицировать следующие свойства базы данных:
♦ изменение имени базы данных с использованием хранимой процедуры
sp rename (см. разд. "Изменение таблиц" далее в этой главе)-,
♦ добавление или удаление одного или более файлов базы данных;
♦ добавление или удаление одного или более файлов протоколов тран-
закций;
♦ добавление или удаление файловых групп;
♦ изменение свойств файла или файловой группы;
♦ установка опций базы данных.
Гпава 5. Язык описания данных 137
Добавление или удаление файлов базы данных,
файлов протоколов транзакций или файловых групп
Оператор alter database позволяет добавлять и удалять файлы базы данных.
Предложения add file и remove file задают добавление нового файла или
удаление существующего файла соответственно. (В дополнении к этому но-
вый файл может быть включен в существующую файловую группу при по-
мощи ОПЦИИ ТО FILEGROUP.)
В примере 5.17 показано, как новый файл базы данных может быть добавлен
к базе данных projects.
j Пример 5.17
USE master;
GO
ALTER DATABASE projects
ADD FILE (NAME=projects_datl,
FILENAME = 'C:\projectsl.mdf, SIZE = 10,
MAXSIZE = 100, FILEGROWTH = 5);
Оператор alter database в примере 5.17 добавляет новый файл с логическим
именем projects_dati. Его начальный размер равен 10 Мбайт; этот файл бу-
дет увеличиваться в размерах с приращением 5 Мбайт, пока не достигнет
верхней границы 100 Мбайт.
Предложение remove file удаляет один или более файлов, которые принад-
лежат существующей базе данных. Этот файл может быть файлом данных
или файлом протокола. Файл не может быть удален, если он непустой.
Файлы протоколов добавляются тем же путем, что и файлы базы данных.
Единственным отличием является то, что вы используете предложение add
log file вместо add file.
Предложение create filegroup создает новую файловую группу, в то время
как delete filegroup удаляет из системы существующую файловую группу.
Наконец, вы не можете удалить файловую группу, если она непустая.
Изменение свойств файла или файловой группы
Вы можете использовать предложение modify file для изменения следующих
свойств файла:
♦ изменение логического имени файла с использованием опции newname
в предложении modify file;
♦ увеличение значения свойства size;
138
Часть II. Язык Transact-SQL
♦ изменение свойств filename, maxsize и filegrowth;
♦ отметка файла как offline.
Похожим образом вы можете использовать предложение modify filegroup
для изменения следующих свойств файловой группы:
♦ изменение имени файловой группы с использованием опции name в пред-
ложении MODIFY filegroup;
♦ установка признака, что файловая группа является файловой группой по
умолчанию при использовании опции default;
♦ установка признака, что файловая группа является только для чтения или
для чтения и записи при использовании опций readonly или readwrite.
Установка опций базы данных
Предложение set в операторе alter database используется для установки раз-
личных опций базы данных. Некоторые опции должны быть установлены в
on или off, однако большинство из них имеют список возможных значений.
Каждая опция базы данных имеет значение по умолчанию, которое установ-
лено в базе данных model. Поэтому вы можете внести изменения в базу дан-
ных model для изменения значений по умолчанию указанных опций.
Все опции, которые вы можете устанавливать, разделены на несколько групп.
Наиболее важными группами являются:
♦ опции состояния;
♦ автоматические опции;
♦ опции SQL.
Опции состояния управляют следующим:
♦ доступом пользователя к базе данных (это опции single_user, restricted_
user и multiuser);
♦ статусом базы данных (опции online, offline и emergency);
♦ статусом чтения/записи (опции read_only и read_write).
Автоматические опции вместе с другими элементами управляют способами
останова (shutdown) базы данных (опция auto_close) и тем, как создавать ста-
тистику индекса (опции auto_create_statistics и auto_update_statistics).
Опции SQL управляют соответствием стандарту ANSI базы данных и ее объ-
ектов. Все опции SQL могут быть отредактированы при использовании
функции databaseproperty и изменены с помощью системной процедуры
sp_dboption. Опции восстановления full, bulk_logged и simple влияют на
процесс восстановления базы данных.
Гпава 5. Язык описания данных 139
Изменение таблиц
Оператор alter table изменяет схему таблицы. Язык Transact-SQL позволяет
выполнять следующие виды изменений:
♦ добавлять или удалять один или более столбцов;
♦ изменять свойства столбца;
♦ добавлять или удалять ограничения целостности;
♦ включать или отключать ограничения;
♦ переименовывать таблицы и другие объекты базы данных.
Добавление или удаление столбцов
Вы можете использовать предложение add в операторе alter table для добав-
ления нового столбца в существующую таблицу. В каждом операторе alter
table может быть добавлен только один столбец. В примере 5.18 показано
использование предложения add.
\ Пример 5.18
USE sample;
ALTER TABLE employee
ADD telephone no CHAR(12) NULL;
Оператор alter table в примере 5.18 добавляет столбец telephone_no к табли-
це employee. Database Engine заполняет новый столбец значениями null,
identity или значением, которое было задано в качестве значения по умолча-
нию. По этой причине новый столбец или должен допускать пустые значе-
ния, или должен иметь ограничение значения по умолчанию.
Замечание
Не существует способа добавить столбец в конкретную позицию в таблице.
Столбец, который добавляется с использованием предложения add, всегда до-
бавляется в конец таблицы.
Предложение drop column предоставляет возможность удалить существую-
щий столбец в таблице, как показано в примере 5.19.
j Пример 5.19
USE sample;
ALTER TABLE employee
DROP COLUMN telephone_no;
6 Зак. 1141
140
Часть II. Язык Transact-SQL
Оператор alter table в примере 5.19 удаляет столбец teiephone no, который
был добавлен к таблице employee оператором alter table в примере 5.18.
Изменение свойств столбца
Язык Transact-SQL поддерживает предложение alter column в операторе
alter table, что позволяет изменять свойства существующего столбца. Мо-
гут быть изменены следующие свойства столбца:
♦ тип данных;
♦ допустимость пустого значения null.
В примере 5.20 показано использование предложения alter column.
| Пример 5.20
USE sample;
ALTER TABLE department
ALTER COLUMN location CHAR(25) NOT NULL;
Оператор alter table в примере 5.20 изменяет существующие свойства
(char (30) null) столбца location таблицы department на новые значения
(CHAR (30) NOT null).
Добавление и удаление ограничений целостности
Новое ограничение целостности может быть добавлено в таблицу при ис-
пользовании оператора alter table и его опции, называемой add constraint.
В примере 5.21 показано, как вы можете использовать предложение add
constraint в связи с ограничением check.
| Пример 5.21
USE sample;
CREATE TABLE sales
(order_no INTEGER NOT NULL,
order_date DATE NOT NULL,
ship_date DATE NOT NULL);
ALTER TABLE sales
ADD CONSTRAINT order_check CHECK(order_date <= ship_date);
В примере 5.21 оператор create table создает таблицу sales с двумя столб-
цами, имеющими тип данных date: order_date и ship_date. Следующий
за ним оператор alter table задает ограничение целостности с именем
order check, в котором сравниваются два значения и отображается сообще-
Глава 5. Язык описания данных 141
ние об ошибке, если дата отгрузки (ship_date) меньше даты заказа
(order_date).
В примере 5.22 показано, как вы можете использовать оператор alter table
для последующего определения первичного ключа таблицы.
i Пример 5.22
USE sample;
ALTER TABLE sales
ADD CONSTRAINT primaryk_sales PRIMARY KEY(order_no);
Оператор alter table в примере 5.22 объявляет первичный ключ для таблицы
sales.
Каждое ограничение целостности может быть удалено при использовании
предложения drop constraint оператора alter table (пример 5.23).
: Пример 5.23
USE sample;
ALTER TABLE sales
DROP CONSTRAINT order_check;
Оператор alter table в примере 5.23 удаляет ограничение check с именем
order_check, созданное в примере 5.21.
Замечание_________________________________________________________
Вы не можете использовать оператор alter TABLE для изменения определе-
ния ограничения целостности. В этом случае ограничение должно быть пере-
создано, т. е. удалено, а затем вновь добавлено с новым определением.
Включение и отключение ограничений
Как было ранее установлено, ограничение целостности всегда имеет имя, ко-
торое может быть явно задано с использованием опции constraint или неяв-
но создано системой. Имена всех объявленных (явно или неявно) ограниче-
ний таблицы могут быть просмотрены с использованием системной процеду-
ры spjhelpconstraint.
Ограничение применяется по умолчанию в процессе выполнения новых опе-
раций добавления и изменения данных. В дополнение к этому существующие
значения столбца (столбцов) проверяются при помощи этого ограничения.
В противоположность этому ограничение, которое было создано с опцией
with nocheck, не будет использовано во втором случае. Иными словами, если
142
Часть II. Язык Transact-SQL
вы используете опцию with nocheck, ограничение будет применяться только
к новым операциям добавления и изменения. Обе опции with check и with
nocheck могут быть применены только к ограничениям check и foreing key.
В примере 5.24 показано, как вы можете отключить все существующие огра-
ничения таблицы.
: Пример 5.24
USE sample;
ALTER TABLE sales
NOCHECK CONSTRAINT ALL;
Здесь ключевое слово all служит для отключения всех ограничений в табли-
це sales.
Замечание________________________________________________________
Использование опции nocheck не рекомендуется. Любое нарушение ограниче-
ния, которое было проигнорировано, может привести к тому, что дальнейшие
изменения будут приводить к ошибкам.
Переименование объектов базы данных
Системная процедура sp_rename изменяет имя существующей таблицы (и лю-
бого другого существующего объекта базы данных, такого как база данных,
представление, хранимая процедура). В примерах 5.25 и 5.26 демонстрирует-
ся использование этой системной процедуры.
I Пример 5.25
USE sample;
EXEC sp_rename @objname = department, @newname = subdivision
Пример 5.25 переименовывает таблицу department в subdivision.
Пример 5.26
USE sample;
EXEC sp_rename @objname I 'sales.order_no', @newname = ordernumber
Пример 5.26 переименовывает столбец order_no таблицы sales. Если пере-
именовываемый объект является столбцом таблицы, то его спецификация
должна быть задана в форме имя_таблицы. имя_столбца.
Гпава 5. Язык описания данных 143
Замечание_________________________________________________________
Не используйте системную процедуру sp_rename, потому что изменение имен
объектов может повлиять на другие объекты базы данных, которые на них ссы-
лаются. Удалите объект и пересоздайте его с новым именем.
Удаление объектов базы данных
Все операторы Transact-SQL, которые используются для удаления объектов
базы данных, имеют следующий общий формат:
DROP тип_о&ьекта имя_объекта;
Каждый оператор создания объекта (create тип_о&ьекта) имеет соответст-
вующий оператор удаления (drop) объекта. Оператор
DROP DATABASE databasel {, ...(
удаляет одну или более баз данных. Это означает, что все следы этой базы
данных удаляются из вашей системы баз данных.
Одна или более таблиц могут быть удалены из базы данных следующим опе-
ратором:
DROP TABLE table_namel {, ...}
Все данные, индексы и триггеры, связанные с удаляемой таблицей, будут
также удалены. В противоположность этому, все представления, которые бы-
ли определены с использованием удаленной таблицы, удалены не будут.
Только пользователь с соответствующими привилегиями может удалять таб-
лицу.
В дополнение к database и table, объектами в операторе drop могут быть, по-
мимо других, следующие объекты:
♦ type;
♦ synonym;
♦ procedure;
♦ index;
♦ view;
♦ trigger;
♦ SCHEMA.
Операторы drop type и drop synonym удаляют, соответственно, тип и сино-
ним. Оставшиеся операторы рассматриваются в различных главах: drop
procedure в главе 8, drop index в главе 10, drop view в главе И, drop schema
в главе 12 и drop trigger в главе 14.
144
Часть II. Язык Transact-SQL
Резюме
Язык Transact-SQL поддерживает множество операторов определения дан-
ных, которые создают, изменяют и удаляют объекты базы данных. Следую-
щие объекты базы данных, помимо других, могут быть созданы и удалены
при использовании операторов create объект и drop объект соответственно:
♦ база данных;
♦ таблица;
♦ схема;
♦ представление;
♦ триггер;
♦ хранимая процедура;
♦ индекс.
Структура всех объектов базы данных в предыдущем списке может быть из-
менена с использованием оператора alter объект. Обратите внимание, что
только оператор alter table является стандартизованным оператором в этом
списке. Все другие операторы alter объект являются расширениями Transact-
SQL стандарта SQL.
Следующая глава адресована оператору манипулирования данными select.
Упражнения
| Упражнение 5.1
Используя оператор create database, создайте базу данных test db с явным
заданием файла базы данных и файла протокола транзакций. Файл базы дан-
ных с логическим именем test_db_dat сохраняется в файле C:\tmp\test_db.mdf,
его начальный размер равен 5 Мбайт, максимальный размер не ограничен,
приращение— 8%. Файл протокола с именем test db log хранится в файле
C:\tmp\test_db_log.ldf, начальный размер— 2 Мбайт, максимальный раз-
мер — 10 Мбайт, приращение размера — 500 Кбайт.
. Упражнение 5.2
Используя оператор alter database, добавьте новый файл протокола в базу
данных test db. Файл протокола хранится в файле C:\tmp\emp_log.ldf, на-
чальный размер этого файла — 2 Мбайт, приращение — 2 Мбайт, макси-
мальный размер не ограничен.
Глава 5. Язык описания данных
145
j Упражнение 5.3
Используя оператор alter database, измените размер файла базы данных
test_db до 10 Мбайт.
] Упражнение 5.4
В примере 5.4 в четырех создаваемых таблицах есть некоторые столбцы, объ-
явленные со спецификацией not null. Для каких столбцов эта спецификация
действительно требуется, а для каких не является обязательной?
• Упражнение 5.5
Почему столбцы dept_no и project_no в примере 5.4 объявлены как значения
char (а не как числовые значения)?
i Упражнение 5.6
Создайте таблицы customer и order со следующими столбцами (не объявляйте
соответствующие первичные и внешние ключи).
customer order
customerid char(5) not null orderid integer not null
companyname varchar(40) not null customerid char(5) not null
contactname char(30) null orderdate date null
address varchar(60) null shippeddate date null
city char(15) null freight money null
phone char(24) null shipname varchar(40) null
fax char(24) null shipaddress varchar(60) null
quantity integer null
| Упражнение 5.7
Используя оператор alter database, добавьте новый столбец с именем
shipregion в таблицу order. Поле должно допускать пустое значение и со-
держать целые числа.
146
Часть II. Язык Transact-SQL
i Упражнение 5.8
Используя оператор alter database, измените тип данных столбца shipregion
с integer на character с размером 8. Поле может содержать null.
j Упражнение 5.9
Удалите ранее созданный столбец shipregion (из таблицы order).
\ Упражнение 5.10
Опишите точно, что произойдет, если таблица будет удалена оператором drop
table.
\ Упражнение 5.11
Пересоздайте таблицы customer и orders, добавив в их определения все необ-
ходимые первичные и внешние ключи.
, Упражнение 5.12
Используя SQL Server Management Studio, постарайтесь добавить новую
строку со следующими значениями в таблицу orders:
(10, 'ordOl', getdateO, getdateO, 100.0, 'Windstar', 'Ocean', 1).
Почему это не работает?
; Упражнение 5.13
Используя оператор alter table, добавьте текущую системную дату и время
как значение по умолчанию для столбца orderdate таблицы orders.
; Упражнение 5.14
Используя оператор alter table, создайте ограничение целостности, которое
лимитирует допустимые значения столбца quantity в таблице orders значе-
ниями от 1 до 30.
[ Упражнение 5.15
Отобразите все ограничения целостности данных для таблицы orders.
Глава 5. Язык описания данных 147
; Упражнение 5.16
Удалите первичный ключ в таблице customers. Почему это не работает?
Упражнение 5.17
Удалите ограничение целостности с именем prim_empl, определенное в при-
мере 5.7.
i Упражнение 5.18
Переименуйте столбец city в таблице customers. Новое имя — town.
ГЛАВА 6
Запросы
В этой главе вы изучите, как использовать оператор select для выполнения
поиска данных. Здесь описывается каждое предложение этого оператора и
даются многочисленные примеры с использованием базы данных sample для
демонстрации практического использования каждого предложения. После
этого рассматриваются агрегатные функции, множество операторов, вычис-
ляемые столбцы и временные таблицы. Затем рассказывается более подробно
о сложных запросах. Вводится оператор соединения таблиц. В дополнение к
рассмотрению всех форм оператора соединения, который является наиболее
важным оператором для реляционных систем баз данных, в главе рассматри-
ваются коррелированные подзапросы и функция exists. В конце главы опи-
сываются общие табличные выражения вместе с оператором apply.
Оператор SELECT: основная форма
и предложение WHERE
Язык Transact-SQL имеет один основной оператор для поиска информации в
базе данных: оператор select. При помощи этого оператора можно запраши-
вать информацию из одной, или более таблиц базы данных (или даже из не-
скольких баз данных). Результатом выполнения оператора select является
другая таблица, также известная как результирующий набор'.
Самая простая форма оператора select содержит список select с предложе-
нием from. (Все другие предложения являются необязательными.) Эта форма
оператора select имеет следующий синтаксис:
1 В литературе по системам управления базами данных для результата выборки данных также
используется термин "набор данных". — Прим. персе.
Глава 6. Запросы 149
SELECT [ ALL | DISTINCT ] column_list
FROM {tablel [tab_aliasl] }
Здесь tablel — имя таблицы, из которой выбирается информация. Параметр
tab_ailasi задает псевдоним (алиас) соответствующей таблицы. Псевдоним
является другим именем соответствующей таблицы, он может быть исполь-
зован в качестве сокращенного названия при ссылках на таблицу или при
ссылках на два логических экземпляра одной и той же физической таблицы.
Нс волнуйтесь, все это станет ясным, когда будут рассматриваться примеры.
Параметр coiumn_ilst содержит одну или более из следующих специфи-
каций:
♦ символ звездочки (*), который задает все столбцы таблицы, указанной
в предложении from (или из одной из таблиц, когда задается квалификатор
в виде table2.*);
♦ явное задание имен извлекаемых столбцов;
♦ спецификация вида column_name [AS] colunrn_heading, которая дает воз-
можность заменить имя столбца или задать новое имя выражению;
♦ выражение;
♦ системная или агрегатная функция.
Замечание________________________________________________________
В дополнение к предыдущим спецификациям существуют и другие опции, кото-
рые будут представлены позже в этой главе.
Оператор select может извлекать из таблицы отдельные столбцы или строки.
Первая операция называется списком выбора (или проекцией), вторая — вы-
боркой. Комбинация обеих операций также возможна в операторе select.
Замечание________________________________________________________
Перед тем как вы начнете выполнять запросы этой главы, полностью пересоз-
дайте базу данных sample.
В примере 6.1 показана простейшая форма выборки данных оператором
SELECT.
< Пример 6.1
Получение полных данных из всех отделов:
USE sample;
SELECT dept_no, dept_name, location
FRCM department;
150
Часть II. Язык Transact-SQL
Результатом будет:
dept_no dept_name location
dl Research Dallas
d2 Accounting Seattle
d3 Marketing Dallas
Оператор select в примере 6.1 извлекает все строки и все столбцы в таблице
department. Если вы включаете все столбцы таблицы в список выбора (как это
сделано в примере 6.1), то можете использовать сокращенный вариант *, но
такая нотация не рекомендуется. Имена столбцов служат в качестве заголов-
ков столбцов в результирующем выводе.
Предложение WHERE
Простейшая форма оператора select, описанная в предыдущем разделе, не
является очень полезной для запросов. На практике всегда существует боль-
ше предложений в операторе select, чем в операторе, показанном в приме-
ре 6.1. Далее показан синтаксис оператора select, обращающегося к таблице,
с (почти что) всеми возможными предложениями:
SELECT select_list
[INTO new_table]
FROM table
[WHERE search__condition]
[GROUP BY group_by_expression]
[HAVING searchcondition]
[ORDER BY order_expression [ASC I DESC] ];
Замечание________________________________________________________
Предложения в операторе SELECT должны быть записаны в том синтаксическом
порядке, который показан в предыдущем синтаксисе. Например, предложение
group BY должно следовать после предложения where и перед предложением
having. Предложение INTO не является настолько важным, как другие предло-
жения. Поэтому оно будет обсуждаться позже.
Этот раздел начинается с определения предложения where. Часто бывает не-
обходимым определить одно или более условий, которые ограничивают ко-
личество выбираемых строк. Предложение where задает логическое выраже-
ние (выражение, которое возвращает значение true или false), которое про-
веряется для каждой (потенциально) возвращаемой строки. Если это
выражение истинное, то строка возвращается (помещается в результирующий
набор), если ложное, то строка отбрасывается.
Гпава 6. Запросы 151
В примере 6.2 показано использование предложения where.
| Пример 6.2
Получение имен и номеров всех отделов, размешенных в Далласе:
USE sample;
SELECT dept_name, dept_no
FROM department
WHERE location = 'Dallas';
Результатом будет:
dept_name dept_no
Research dl
Marketing d3
В дополнение к знаку равенства предложение where может содержать другие
операторы сравнения, включая следующие:
♦ <>(или!=) — неравно;
♦ < — меньше чем;
♦ > — больше чем;
♦ >= — больше или равно;
♦ <= — меньше или равно;
♦ 1> — не больше;
♦ !<—не меньше.
В примере 6.3 показано использование оператора сравнения в предложении
WHERE.
i Пример 6.3
Получение фамилии и имени для всех сотрудников с номером служащего,
большим или равным 15 000:
USE sample;
SELECT emp_lname, emp_fname
FRCM employee
WHERE emp_no >= 15000;
Результат:
emp_lname emp_fname
Smith
Matthew
152
Часть II. Язык Transact-SQL
Barrimore John
James James
Moser Sybill
Выражение также может быть частью условия предложения where (при-
мер 6.4).
| Пример 6.4
Получение имен проектов для всех проектов для всех бюджетов, больших,
чем 60 000 фунтов стерлингов. При текущем курсе за 1 доллар 0.51 фунта
стерлингов.
USE sample;
SELECT project_name
FROM project
WHERE budget * 0.51 > 60000;
Результат:
proj ect_name
Apollo
Mercury
Сравнения строк (т. e. значений с типами данных char, varchar, nchar и
nvarchar) выполняются в соответствии с порядком сортировки (с учетом по-
рядка сортировки, заданного при инсталляции Database Engine). Если две
сравниваемые строки используют код ANSI (или любой другой код), то срав-
ниваются каждые последующие символы (первый, второй, третий и т. д.).
Один символ считается меньшим в последовательности, чем другой, если он
появляется в кодовой таблице раньше второго. Две строки разной длины
сравниваются при добавлении к меньшей строке справа пробелов, так что
длина обеих сравниваемых строк одинакова. Числа сравниваются алгебраи-
чески. Значения типов данных даты и времени (такие как date, time и
datetime) сравниваются в хронологическом порядке.
Замечание______________________________________________________
Столбцы с типами данных text и image не могут быть использованы в предло-
жении where за исключением операторов like и is null.
Логические операторы
Условия в предложении where могут быть либо простыми, либо содержать
множество условий. Множественные условия могут быть созданы с помощью
операторов and, or и not. Поведение этих операторов было описано в главе 4
с использованием таблиц истинности.
Гпава 6. Запросы 153
Если два условия соединяются оператором and, то выбираются строки, соот-
ветствующие обоим условиям. Если два условия соединены оператором or,
то выбираются все строки таблицы, для которых истинны либо первое усло-
вие, либо второе, либо оба вместе, как показано в примере 6.5.
! Пример 6.5
Получение номеров служащих, для тех служащих, которые работают над
проектом pl или над проектом р2 (или над обоими):
USE sample;
SELECT project_no, emp_no
FROM works_on
WHERE project_no = 'pl'
OR project_no = 'p2';
Результат:
project_no emp_no
Pl
p2
p2
p2
Pl
Pl
P2
Pl
10102
25348
18316
29346
9031
28559
28559
29346
Результат примера 6.5 содержит некоторые дубликаты значений столбца
eitp_no. Если лишнюю информацию нужно устранить, то должна быть ис-
пользована опция distinct, как показано здесь:
USE sample;
SELECT DISTINCT emp_no
FROM works_on
WHERE project_no = 'pl'
OR project_no = 'p2';
В этом случае результатом будет:
emp_no
9031
10102
18316
25348
154
Часть II. Язык Transact-SQL
28559
29346
Замечание__________________________________________________________
Столбцы с типами данных text и image не могут быть использованы в случае
применения опции distinct.
Заметьте, что опция distinct может быть использована только один раз в
списке оператора select, и она должна предшествовать всем именам столб-
цов в этом списке. Поэтому пример 6.6 ошибочен.
i Пример 6.6
USE sample;
SELECT emp_fname, DISTINCT emp_no
FROM employee
WHERE emp_lname = 'Moser';
Результатом будет сообщение:
Server: Msg 156, Level 15, State 1, Line 1
Incorrect syntax near the keyword 'DISTINCT'.
(Неверный синтаксис возле ключевого слова 'DISTINCT') .
Замечание__________________________________________________________
Когда присутствует более одного столбца в списке выбора оператора select,
то предложение distinct отображает все строки с отличными значениями вы-
бранных столбцов.
Предложение where может включать любое количество одних и тех же или
различных логических операций. Вы должны помнить, что все три логиче-
ские операции имеют различные приоритеты выполнения: операция not име-
ет наивысший приоритет, and вычисляется следующей, а операция or имеет
самый низший приоритет. Если вы не можете запомнить все эти отличия
приоритетов логических операций, то можете получить неожиданный резуль-
тат, как показано в примере 6.7.
; Пример 6.7
USE sample;
SELECT emp_no, emp_fname, emp_lname
FROM employee
WHERE emp_no = 25348 AND emp_lname = 'Smith'
OR emp_fname = 'Matthew' AND dept_no = 'dl';
SELECT emp__no, emp_fname, emp_lname
FROM employee
Гпава 6. Запросы 155
WHERE ( (emp_no = 25348 AND eirp_lname = 'Smith')
OR emp_fname = 'Matthew') AND dept_no = 'dl';
Результатами будут:
emp_no emp_fname emp_lname
25348 Matthew Smith
emp_no emp_fname etnp_lname
Здесь два оператора select отображают два различных набора данных ре-
зультатов. В первом операторе select система вычисляет в первую очередь
оба оператора and (слева направо), затем вычисляется оператор or. Во втором
операторе select использование скобок изменяет порядок выполнения опе-
раций: все выражения внутри круглых скобок выполняются первыми в по-
рядке слева направо. Как вы можете видеть, первый оператор возвращает од-
ну строку, в то время как второй возвращает ноль строк.
Существование нескольких логических операций в предложении where ус-
ложняет соответствующий оператор select и делает его подверженным
ошибкам. В таких случаях очень рекомендуется использовать круглые скоб-
ки, даже если в них и нет особой необходимости. Читаемость таких операто-
ров select будет сильно улучшена, а вероятность ошибок уменьшится. Вот
первый оператор select из примера 6.7, измененный с использованием реко-
мендованной формы:
USE sample;
SELECT emp_no, emp_fname, emp_lname
FROM employee
WHERE (emp_no = 25348 AND emp_lname = 'Smith')
OR (emp_fname = 'Matthew' AND dept_no = 'dl');
Третий логический оператор, not, изменяет логическое значение соответст-
вующего условия. Таблица истинности для not в главе 4 показывает, что от-
рицание истинного значения дает ложь и наоборот. Отрицание значения null
дает также null.
В примере 6.8 показано использование оператора отрицания.
j Пример 6.8
Получение номеров и фамилий всех служащих, кто не работает в отделе d2:
USE sample
SELECT emp_no, emp_lname
FROM employee
WHERE NOT dept no = 'd2';
156
Часть II. Язык Transact-SQL
Результат:
emp_no emp_lname
25348 Smith
10102 Jones
18316 Barrimore
28559 Moser
В этом случае оператор not может быть заменен оператором сравнения о (не
равно).
Замечание
В этой книге используется оператор о (вместо !=), чтобы сохранить соответст-
вие стандарту ANSI SQL.
Операторы IN и BETWEEN
Оператор in дает возможность использовать два или более выражений в за-
просе на поиск. Результатом этого условия будет истина, если значение соот-
ветствующего столбца равняется одному из выражений, указанных в преди-
кате in (пример 6.9).
| Пример 6.9
Получение всех столбцов для каждого служащего, чей номер равен 29346,
28559 или 25348:
USE sample;
SELECT emp_no, emp_fname, empIname
FROM employee
WHERE emp_no IN (29346, 28559, 25348);
Результат:
emp_no emp_fname emp_lname
25348 Matthew Smith
29346 James James
28559 Sybill Moser
Оператор in эквивалентен серии условий, связанных одним или более опера-
торами or. Количество операторов or равняется количеству выражений в опе-
раторе in минус единица.
Оператор in может быть использован вместе с логическим оператором not,
как показано в примере 6.10. В этом случае запрос отыскивает строки, в ко-
торых не присутствуют значения, заданные в списке, среди значений указан-
ного столбца.
Глава 6. Запросы
157
| Пример 6.10
Получение всех столбцов каждого служащего, чей номер не равняется ни
10102, ни 9031:
USE sample;
SELECT emp_no, emp_fname, emp_lname, dept_no
FROM employee
WHERE emp_no NOT IN (10102, 9031);
Результат:
emp__no emp_fname emp_lname dept_no
25348 Matthew Smith d3
18316 John Barrimore dl
29346 James James d2
2581 Elke Hansel d2
28559 Sybill Moser dl
В отличие от оператора in, который задает каждое индивидуальное значение,
оператор between задает диапазон, в котором указывается нижняя и верхняя
границы значений. Использование оператора иллюстрируется в примере 6.11.
{Пример 6.11
Получение названий и бюджетов всех проектов с бюджетом, находящимся
в диапазоне от $95 000 до $120 000, включительно:
USE sample;
SELECT project_name, budget
FROM project
WHERE budget BETWEEN 95000 AND 120000;
Результат:
project_name budget
Apollo 120000.0
Gemini 95000.0
Оператор between выполняет поиск среди всех значений диапазона, включая
граничные значения; т. е. значения могут находиться между граничными зна-
чениями или равняться им.
Оператор between логически эквивалентен двум индивидуальным сравнени-
ям, которые соединены логическим оператором and. Пример 6.11 эквивален-
тен примеру 6.12.
158
Часть II. Язык Transact-SQL
Пример 6.12
USE sample;
SELECT project_name, budget
FROM project
WHERE budget >= 95000 AND budget <= 120000;
Как и оператор between, оператор not between может быть использован для
поиска значений столбца, которые не находятся в заданном диапазоне. Опе-
ратор between может быть также применен и к столбцам, имеющим строко-
вый тип данных и тип данных даты.
В примере 6.13 показаны два оператора select, по-разному записанных, но
выполняющих один и тот же поиск данных.
= Пример 6.13
Получение названий всех проектов с бюджетом, меньшим, чем $100 000 и
большим, чем $150 000:
USE sample;
SELECT projectname
FROM project
WHERE budget NOT BETWEEN 100000 AND 150000;
Результат:
project_name
Gemini
Mercury
При использовании операторов сравнения запрос будет выглядеть иначе:
USE sample;
SELECT project_name
FROM project
WHERE budget < 100000 OR budget > 150000;
Замечание.
Хотя фраза на обычном языке "Получение названий всех проектов с бюджетом,
меньшим, чем $100 000 и большим, чем $150 000" предполагает использование
оператора and в операторе select, представленном в примере 6.13, все-таки
логический смысл запроса требует использование оператора OR, потому что
если бы вы использовали AND вместо OR, то вообще не получили бы никакого
результата. (Причина здесь в том, что не может быть бюджета, который в одно
и то же время меньше $100 000 и больше $150 000). В связи с этим второй за-
прос в примере демонстрирует возможную проблему различия между фразой
на естественном языке при описании примера и ее логическим смыслом.
Гпава 6. Запросы 759
Запросы, включающие пустые значения NULL
Фраза null в операторе create table указывает, что специальное значение,
называемое null (которое обычно представляет неизвестное или непримени-
мое значение), допустимо для описываемого столбца. Такие значения отли-
чаются от всех других значений в базе данных. Предложение where в опера-
торе select обычно позволяет вернуть строки, для которых сравнение в ре-
зультате дает истину. Вопрос при рассмотрении запросов заключается в том,
как сравнения, содержащие значения null, должны быть вычислены в пред-
ложении WHERE?
Все сравнения со значениями null вернут значение "ложь" (даже если им
предшествует отрицание not). Для поиска строк со значениями в столбцах
null язык Transact-SQL включает в себя оператор is null. Эта спецификация
в предложении where оператора select имеет следующую общую форму:
столбец IS [NOT] NULL
Пример 6.14 демонстрирует использование оператора is null.
\ Пример 6.14
Получение номеров служащих и соответствующих номеров проектов для не-
известных работ, связанных с проектом р2:
USE sample;
SELECT emp_no, projectjno
FROM workson
WHERE project_no = 'p2' AND job IS NULL;
Результат:
emp_no project_no
18316 p2
29346 p2
Поскольку все сравнения, содержащие значения null, возвращают значение
"ложь", в примере 6.15 показано синтаксически корректное, но логически не-
верное использование null.
\ Пример 6.15
USE sample;
SELECT project_no, job
FROM works_on
WHERE job О NULL;
160
Часть II. Язык Transact-SQL
Результат:
project_no job
Условие
столбец IS NOT NULL
эквивалентно условию
NOT столбец IS NULL
Системная функция isnullo позволяет отобразить заданное в ней значение в
качестве замены значения null (пример 6.16).
Пример 6.16
USE sample;
SELECT emp_no, ISNULL(job, 'Job unknown') AS task
FROM works_on
WHERE project_no = 'pl';
Результат:
emp_no task
10102 Analyst
9031 Manager
28559 Job unknown
29346 Clerk
В примере 6.16 используется заголовок столбца с именем task для столб-
ца job.
Оператор LIKE
like — это оператор, который используется для проверки соответствия шаб-
лону; т. е. он сравнивает значения столбца с заданным шаблоном. Тип дан-
ных такого столбца может быть любым символьным типом или датой. Общая
форма оператора like:
column [NOT] LIKE 'pattern'
Параметр pattern может быть константой типа строки или даты, либо это
может быть выражение (включающее и столбцы таблиц), которое должно
быть совместимым с типом данных соответствующего столбца. Для заданно-
го столбца сравнение между значением в строке и шаблоном вычисляется
в истину, если значение столбца соответствует выражению шаблона.
Гпава 6. Запросы 161
Некоторые символы в шаблоне, называемые шаблонными или групповыми
символами, имеют специфическую интерпретацию. Два из этих символа:
♦ % (знак процента) задает любую последовательность из нуля или более
символов;
♦ _ (подчеркивание) задает любой одиночный символ.
В примере 6.17 показано использование шаблонных символов % и
' Пример 6.17
Получение имен, фамилий и номеров всех служащих, чье имя содержит бук-
ву "а" в качестве второго символа:
USE sample;
SELECT emp_fname, emp_lname, empjno
FROM employee
WHERE emp_fname LIKE '_a%';
Результат:
emp_fname emp_lname emp_no
Matthew Smith 25348
James James 29346
В дополнение к символам процента и подчеркивания Transact-SQL поддер-
живает и другие символы, которые имеют специальное значение при исполь-
зовании в операторе like. Эти символы ([, ] и ') демонстрируются в приме-
рах 6.18 и 6.19.
I Пример 6.18
Получение всех сведений обо всех подразделениях, чье местоположение на-
чинается с символа в диапазоне от С до F:
USE sample;
SELECT *
FROM department
WHERE location LIKE '[C-F]%';
Результат:
dept_no dept_name Location
dl Research Dallas
d3 Marketing Dallas
162
Часть II. Язык Transact-SQL
Как показано в примере 6.18, квадратные скобки [] заключают в себе диапа-
зон или список символов. Порядок, в котором символы появляются в диапа-
зоне, определяется порядком сортировки, который был задан при инсталля-
ции системы.
Символ Л задает отрицание диапазона или списка символов. Этот символ
имеет такое значение только при паре квадратных скобок, как показано в
примере 6.19.
1 Пример 6.19
Получение номеров, имен и фамилий всех служащих, чьи фамилии не начи-
наются с букв J, К, L, М, N или О и чьи имена не начинаются с букв Е или Z:
USE sample;
SELECT emp_no, emp_fname, emp_lname
FROM employee
WHERE emp_lname LIKE '[AJ-O]%'
AND emp_fname LIKE '[~EZ]%';
Результат:
emp_no emp_fname emp_lnama
25348 Matthew Smith
18316 John Barrimore
Условие
column NOT LIKE 'pattern'
эквивалентно условию
NOT (column LIKE ’pattern')
В примере 6.20 показано использование оператора like (вместе с not).
[ Пример 6.20
Получение полных сведений обо всех служащих, чьи имена не заканчиваются
символом "п":
USE sample;
SELECT emp_no, emp_fname, emp_lname
FROM employee
WHERE emp_fname NOT LIKE '%n';
Гпава 6. Запросы 163
Результат:
emp_no emp_fname emp_lname
25348 Matthew Smith
29346 James James
2581 Elke Hansel
9031 Elsa Bertoni
28559 Sybill Moser
Любой из шаблонных символов (%, _, [, ] или л), заключенный в квадратные
скобки, остается обычным символом. Такая же возможность существует при
использовании опции escape. Исходя из этого, оба оператора select в приме-
ре 6.21 имеют одно и то же значение.
j Пример 6.21
USE sample;
SELECT project_no, project_name
FROM project
WHERE proj ect_name LIKE '%[_]%';
SELECT project_no, project_name
FROM project
WHERE project_name LIKE '%!_%' ESCAPE
Результатами будут:
project_no project_name
project_no project_name
Оба оператора select отыскивают символ подчеркивания как фактический
символ в столбце project name. В первом операторе select этот поиск задает-
ся заключением символа подчеркивания в квадратные скобки. Второй опера-
тор select использует некий символ (в примере 6.21 это символ 1) в качестве
escape-символа. Escape-символ перекрывает значение символа подчеркивания
как шаблонного символа и возвращает его интерпретацию как обычного сим-
вола. (Результат содержит ноль строк, потому что не существует проекта,
в имени которого присутствовал бы символ подчеркивания.)
Замечание________________________________________________________
Стандарт SQL поддерживает только использование шаблонных символов _ и
оператора escape. По этой причине, если нужно, чтобы шаблонный символ оз-
начал обычный символ, рекомендуется использование оператора escape вме-
сто пары квадратных скобок.
164
Часть II. Язык Transact-SQL
Подзапросы
Все предыдущие примеры этой главы содержат сравнения значений столбцов
с выражениями, константами или множеством констант. В дополнение к это-
му язык Transact-SQL предоставляет возможность сравнения значений столб-
цов с результатами выполнения другого оператора select. Подобная конст-
рукция, где один или более операторов select являются вложенными в пред-
ложение where в другом операторе select, называется подзапросом. Самый
первый оператор select в подзапросе называется внешним запросом, в отли-
чие от внутреннего запроса, который обозначает операторы select, исполь-
зуемые в сравнениях. Внутренний запрос будет выполняться первым, а
внешний запрос получает значения от внутреннего запроса.
Замечание____________________________________________________
Внутренний запрос может быть также вложенным в оператор insert, update
или delete. Такие запросы будут обсуждаться позже в этой книге.
Существуют два типа подзапросов:
♦ замкнутый;
♦ коррелированный.
В замкнутом подзапросе внутренний запрос логически выполняется в точно-
сти один раз. Коррелированный подзапрос отличается от замкнутого тем, что
его значение зависит от переменной из внешнего запроса. Поэтому внутрен-
ний запрос в коррелированном подзапросе логически выполняется каждый
раз, когда система отыскивает новую строку из внешнего запроса. Этот раз-
дел содержит примеры замкнутых подзапросов. Коррелированные подзапро-
сы будут рассматриваться позже в этой главе вместе с операцией соединения.
Замкнутый подзапрос может быть использован в следующих операторах:
♦ операторы сравнения;
♦ оператор in;
♦ операторы any и all.
Подзапросы и операторы сравнения
В примере 6.22 показан замкнутый подзапрос, который используется с опера-
тором =.
j Пример 6.22
Получение имен и фамилий сотрудников, работающих в отделе Research:
USE sample;
SELECT emp_fname, emp_lname
Гпава 6. Запросы
165
FROM employee
WHERE dept_no = (SELECT dept_no
FROM department
WHERE dept_name = 'Research');
Результат:
emp_fname
emp_lname
Sybill
Barrimore
Moser
Внутренний запрос в примере 6.22 логически выполняется первым. Этот за-
прос возвращает номер отдела Research (dl). Следовательно, после выполне-
ния внутреннего запроса этот подзапрос в примере 6.22 может быть пред-
ставлен в виде следующего эквивалентного запроса:
USE sample
SELECT emp_fname, emp_lname
FROM employee
WHERE dept_no = 'dl' ;
Подзапрос может быть использован также и с другими операторами сравне-
ния. Любой оператор сравнения может быть использован с условием, что
внутренний запрос возвращает в точности одну строку. Это очевидно, потому
что сравнения между значениями отдельного столбца внешнего запроса и
множеством значений (как результат выполнения внутреннего запроса) не-
возможны. В следующем разделе показано, как вы можете обрабатывать слу-
чай, когда результат выполнения внутреннего запроса содержит набор значе-
ний.
Подзапросы и оператор IN
Оператор in позволяет использовать задание множества выражений (или
констант), которые последовательно используются в запросе на поиск. Этот
оператор может быть применен для подзапроса по той же причине, т. е. когда
результат внутреннего запроса содержит набор значений.
В примере 6.23 показано использование оператора in в подзапросе.
‘ Пример 6.23
Выбор полных данных всех служащих, чей отдел расположен в Далласе:
USE sample;
SELECT *
FROM employee
166
Часть II. Язык Transact-SQL
WHERE dept_no IN
(SELECT dept_no
FROM department
WHERE location = 'Dallas');
Результат:
emp_no empjfname emp_lname dept_no
25348 Matthew Smith d3
10102 Ann Jones d3
18316 John Barrimore dl
28559 Sybill Moser dl
Каждый внутренний запрос может содержать другие запросы. Такой тип под-
запросов называется многоуровневым вложенным подзапросом. Максималь-
ное количество внутренних запросов в подзапросе зависит от объема памяти,
которую имеет Database Engine для каждого оператора select. В случае под-
запросов с множеством уровней вложенности система вначале выполняет са-
мый внутренний запрос и возвращает результат запросу следующего уровня
вложенности и т. д. Под конец выполняется самый внешний запрос.
В примере 6.24 показан запрос с множественными уровнями вложенности.
. Пример 6.24
Получение фамилий всех служащих, работающих над проектом Apollo:
USE sample;
SELECT einp lname
FROM employee
WHERE emp_no IN
(SELECT emp_no
FROM works_on
WHERE project_no IN
(SELECT project no
FROM project
WHERE proj ect_name = 'Apollo'));
Результат:
emp_lname
Jones
James
Bertoni
Moser
Гпава 6, Запросы 167
Самый внутренний запрос в примере 6.24 получает значение столбца
project no, равное pl. Средний внутренний запрос сравнивает это значение
со всеми значениями столбца project no в таблице works on. Результатом это-
го запроса является множество номеров служащих: (10102, 29346, 9031,
28559). Под конец самый внешний запрос отображает соответствующие фа-
милии для выбранных номеров служащих.
Подзапросы и операторы ANY и ALL
Операторы any и all всегда используются в комбинации с одним или не-
сколькими операторами сравнения. Общий синтаксис обоих операторов:
columnyiarrie operator [ANY | ALL] query
Здесь operator— обычный оператор сравнения, a query— внутренний за-
прос.
Оператор any возвращает значение "истина", если результат выполнения со-
ответствующего внутреннего запроса содержит, по меньшей мере, одну стро-
ку, соответствующую сравнению. Ключевое слово some является синонимом
для any. В примере 6.25 показано использование оператора any.
, Пример 6.25
Получение номеров служащих, номеров проектов и названий работ для слу-
жащих, которые не затратили больше всего времени для работы над одним из
этих проектов:
USE sample
SELECT DISTINCT emp_no, project_no, job
FROM works_on
WHERE enter_date > ANY
(SELECT enter_date
FROM workson);
Результат:
emp_no project_no job
2581 p3 Analyst
9031 pl Manager
9031 p3 Clerk
10102 p3 Manager
18316 p2 NULL
25348 p2 Clerk
168
Часть II. Язык Transact-SQL
28559
28559
29346
29346
Pl
р2
Pl
р2
NULL
Clerk
Clerk
NULL
Каждое значение столбца enter_date в примере 6.25 сравнивается со всеми
значениями этого же столбца. Для всех дат этого столбца, за исключением
самой ранней, сравнение возвращает истину как минимум один раз. Строка
с самой ранней датой не принадлежит результату, потому что сравнение не
возвращает истину в этом случае. Другими словами, выражение enter date >
any (select enter_date from works_on) является истинным, если существуют
любые (одна или более) строк в таблице works on со значением столбца
enter date, меньшим, чем значение enter date текущей строки. Это будет
истинным для всех, кроме самого раннего значения столбца enter date.
Оператор all возвращает истину, если вычисление столбца таблицы во внут-
реннем запросе возвращает все значения этого столбца.
Замечание_____________________________________________________
Не используйте операторы ANY и all! Каждый запрос, использующий операто-
ры any и all, может быть лучше сформулирован с функцией exists, которая
объясняется в разд. "Подзапросы и функция EXISTS" далее в этой главе. До-
полнительно семантика оператора any может быть легко спутана с семантикой,
относящейся к оператору ALL, и наоборот.
Оператор SELECT:
другие предложения и функции
Следующие подразделы описывают другие предложения, которые могут
быть использованы в запросах, а также агрегатные функции и наборы опера-
торов. Во-первых, мы рассмотрим предложение group by и предоставим не-
которые примеры с этим предложением и агрегатными функциями, которые
поддерживаются в Transact-SQL. После этого будут рассмотрены предложе-
ния having и order by. В этом разделе также рассматривается свойство
identity и существующий набор операторов (union, intersect и except).
Предложение GROUP BY
Предложение group by задает один или более столбцов в качестве группы,
в которой все строки данной группы имеют одно и то же значение этих
столбцов. В примере 6.26 показано простое использование предложения
GROUP BY.
Гпава 6. Запросы 169
\ Пример 6.26
Получение всех работ служащих:
USE sample;
SELECT job
FROM works_on
GROUP BY job;
Результат:
job
NULL
Analyst
Clerk
Manager
В примере 6.26 предложение group by создает различные группы для всех
возможных значений (в том числе и null), появляющихся в столбце job.
Замечание__________________________________________________________
Существует ограничение относительно использования столбцов в предложении
group by. Каждый столбец, появляющийся в списке select запроса, должен
также появиться и в предложении group by. Это ограничение не применяется к
константам и столбцам, которые являются частью агрегатных функций. (Агре-
гатные функции объясняются в следующем разделе.) Это действительно имеет
смысл, поскольку только столбцы в предложении group by являются гарантами
того, что каждая группа будет иметь единственное значение.
Таблица может быть сгруппирована по любой комбинации ее столбцов.
В примере 6.27 показана группировка строк таблицы works on с использова-
нием двух столбцов.
| Пример 6.27
Группирование всех служащих с использованием номеров их проектов и работ:
USE sample;
SELECT project_no, job
FROM works_on
GROUP BY project_no, job;
Результат:
project_no job
pl Analyst
170
Часть II. Язык Transact-SQL
Pl
Pl
pl
p2
p2
p3
p3
p3
Clerk
Manager
NULL
NULL
Clerk
Analyst
Clerk
Manager
Результат примера 6.27 показывает, что существует девять групп с различ-
ными комбинациями номеров проектов и работ. И только две группы, содер-
жащие более одной строки, которыми являются:
р2 Clerk 25348, 28559
р2 NULL 18316, 29346
Последовательность имен столбцов в предложении group by не обязательно
должна соответствовать последовательности имен в списке select.
Замечание
Столбцы с типом данных text (или image) не могут быть использованы в пред-
ложении GROUP BY.
Агрегатные функции
Агрегатные функции являются функциями, которые используются для полу-
чения обобщенных значений. Все агрегатные функции могут быть разделены
на несколько групп:
♦ обычные агрегатные функции;
♦ статистические агрегатные функции;
♦ агрегатные функции, определенные пользователем;
♦ аналитические агрегатные функции.
Первые три типа описываются в следующих разделах, а аналитические агре-
гатные функции подробно рассматриваются в главе 24.
Обычные агрегатные функции
Язык Transact-SQL поддерживает шесть обычных агрегатных функций:
♦ min;
♦ мах;
♦ sum;
Глава 6. Запросы
171
♦ avg;
♦ count;
♦ COUNT_BIG.
Все агрегатные функции оперируют одним аргументом, который может быть
либо столбцом, либо выражением. Существует только исключение во второй
форме функций count и count_big: count(*) и count_big(*). Результатом каж-
дой агрегатной функции является константное значение, которое отображает-
ся в отдельном столбце результата.
Агрегатные функции появляются в списке выбора оператора select, который
может включать предложение group by. Если в операторе select нет предло-
жения group by, а в списке выбора присутствует хотя бы одна агрегатная
функция, то никакой простой столбец не может быть включен в список выбо-
ра (кроме как в качестве аргумента агрегатной функции). По этой причине
пример 6.28 ошибочен.
Пример 6.28
USE sample;
SELECT emp_lname, MIN(emp_no)
FROM employee;
Столбец етр iname таблицы employee не должен присутствовать в списке вы-
бора select в примере 6.28, потому что он не является аргументом агрегатной
функции. С другой стороны, все имена столбцов, которые не являются аргу-
ментами агрегатной функции, могут присутствовать в списке выбора select,
если они используются для группирования результата.
Аргументу агрегатной функции может предшествовать одно из двух ключе-
вых слов:
♦ all. Указывает, что должны использоваться все значения столбца (all —
значение по умолчанию);
♦ distinct. Устраняет дублирующие значения столбца перед применением
агрегатной функции.
Агрегатные функции min и мах. Агрегатные функции min и мах вычисляют,
соответственно, наименьшее и наибольшее значение в столбце. Если в опера-
торе присутствует предложение where, то функции min и мах возвращают
наименьшее или наибольшее значение в выбранных строках. В примере 6.29
показано использование агрегатной функции min.
7 Зак. 1141
172
Часть II. Язык Transact-SQL
i Пример 6.29
Получение наименьшего номера служащего:
USE sample;
SELECT MIN(emp_no) AS min_employee_no
FROM employee;
Результат:
min_employee_no
2581
Результат примера 6.29 не является дружественным к пользователю. Напри-
мер, нам не известно имя служащего с наименьшим номером. Как было пока-
зано, явное задание столбца emp name в списке выбора select недопустимо.
Для поиска имени служащего с наименьшим номером используется подза-
прос, как показано в примере 6.30, где внутренний запрос содержит оператор
select из предыдущего примера.
i Пример 6.30
USE sample;
SELECT emp_no, enp_lname
FROM employee
WHERE emp_no = (SELECT MIN(enpno)
FROM employee) ;
Результат:
emp_no emp_lname
2581 Hansel
В примере 6.31 показано использование агрегатной функции мах.
\ Пример 6.31
Получение номера служащего с должностью менеджера, который последним
получил эту должность. Выбор данных из таблицы works_on.
USE sample;
SELECT emp_no
FROM works_on
WHERE enter_date = (SELECT MAX(enter_date)
FROM works_on
WHERE job = 'Manager');
173
Гпава 6. Запросы
Результат:
ешр_по
10102
Аргументом функций min и мах может быть также строковое значение и дата.
Если аргументом является строковое значение, то сравнение всех значений
будет осуществляться с использованием фактического порядка сортировки.
Для всех аргументов типа данных "дата/время" более ранняя дата означает
меньшее значение, а более поздняя дата — большее значение в столбце.
Опция distinct не может быть использована в агрегатных функциях min и
мах. Все значения null в столбце, который является аргументом функций min
или мах, всегда исключаются перед использованием функций min и мах.
Агрегатная функция sum. Агрегатная функция sum вычисляет сумму значе-
ний столбца. В примере 6.32 показано использование функции sum.
\ Пример 6.32
Вычисление суммы всех бюджетов всех проектов:
USE sample;
SELECT SUM (budget) sum__of_budgets
FROM project;
Результат:
sum_of_budgets
401500
Агрегатная функция в примере 6.32 группирует все значения бюджетов про-
ектов и определяет их общую сумму. По этой причине запрос в примере 6.32
(как и любой аналогичный запрос) неявно содержит функцию группировки.
Запустив SQL Server 2008, вы можете явно записать функцию группирования
в запросе, показанном в примере 6.32, использовав предложение group by
(примера 6.33).
j Пример 6.33
SELECT SUM (budget) sum_of_budgets
FROM project
GROUP BY();
Рекомендуется использование нового синтаксиса предложения group by, по-
тому что в этом случае явно задается группирование. (В главе 25 описывают-
174
Часть II. Язык Transact-SQL
ся некоторые другие возможности group by, которые являются новыми в SQL
Server 2008.)
Опция distinct исключает все дубликаты значений в столбце перед приме-
нением функции sum. Аналогично, все значения null всегда исключаются до
применения sum.
Агрегатная функция avg. Агрегатная функция avg вычисляет среднее значе-
ние столбца. Аргументом функции avg может быть только число. Все значе-
ния null исключаются перед применением функции avg. Пример 6.34 пока-
зывает использование агрегатной функции avg.
; Пример 6.34
Вычисление среднего значения всех бюджетов, превышающих $100 000:
USE sample;
SELECT AVG(budget) avg_budget
FROM project
WHERE budget > 100000;
Результат:
avg_budget
153250
Агрегатные функции count и count_big. Агрегатная функция count имеет
две различные формы:
COUNT ([DISTINCT] col_name}
COUNT (*)
Первая форма вычисляет количество значений в столбце col_name. Если ис-
пользуется ключевое слово distinct, то исключаются все дубликаты значе-
ний перед применением count. Эта форма count' не подсчитывает значения
null в столбце.
В примере 6.35 показано использование первой формы агрегатной функции
COUNT.
j Пример 6.35
Подсчет всех различных значений работ в каждом проекте:
USE sample;
SELECT project_no, COUNT(DISTINCT job) job_count
FROM works_on
GROUP BY project_no;
Гпава 6. Запросы
175
Результат:
project_no job_count
pl 4
р2 1
рЗ 3
Как можно увидеть из результата примера 6.35, все значения null исключены
до применения функции count (distinct job). Получена сумма всех значений
столбца 8 вместо 11.
Вторая форма функции count, count(*), подсчитывает количество строк в
таблице. Или, если в операторе select присутствует предложение where,
функция возвращает количество строк, для которых условие в where истинно.
В отличие от первой формы функции count вторая форма не исключает зна-
чения null, потому что эта функция оперирует строками, а не со столбцами.
Пример 6.36 показывает использование count(*).
, Пример 6.36
Получение количества работ во всех проектах:
USE sample;
SELECT job, COUNT(*) job_count
FROM works_on
GROUP BY job;
Результат:
job job_count
NULL 3
Analyst 2
Clerk 4
Manager 2
Функция count big аналогична функции count. Единственное между ними
различие заключается в возвращаемом значении: count big всегда возвращает
значение типа данных bigint, а функция count — значение типа данных
INTEGER.
Статистические агрегатные функции
Следующие агрегатные функции принадлежат к группе статистических агре-
гатных функций:
♦ var вычисляет дисперсию для всех значений, представленных в столбце
или в выражении;
176
Часть II. Язык Transact-SQL
♦ varp вычисляет дисперсию для всех значений популяции, представленных
в столбце или в выражении;
♦ stdev вычисляет среднеквадратичное отклонение (СКО) всех значений
столбца или выражения (СКО вычисляется как квадратный корень из со-
ответствующей дисперсии);
♦ stdevp вычисляет СКО популяции всех значений столбца или выражения.
Примеры, связанные со статистическими агрегатными функциями, будут
представлены в главе 24.
Агрегатные функции,
определенные пользователем
Database Engine также поддерживает использование определенных пользова-
телем агрегатных функций. Используя такие функции, вы можете создавать и
распространять агрегатные функции, которые не принадлежат агрегатным
функциям, поддерживаемым системой. Такие функции являются специаль-
ным случаем определенных пользователем функций, которые будут подроб-
но описаны в главе 8.
Предложение HAVING
Предложение having определяет условие, которое затем применяется к груп-
пам строк. Следовательно, это предложение имеет тот же смысл для группы
строк, что и предложение where в отношении содержимого соответствующей
таблицы. Синтаксис предложения having:
HAVING condition
Здесь condition содержит агрегатные функции или константы.
Пример 6.37 демонстрирует использование предложения having с агрегатной
функцией count(*).
1 Пример 6.37
Получение номеров проектов для всех проектов, обслуживаемых меньше,
чем четырьмя сотрудниками:
USE sample;
SELECT project_no
FROM works_on
GROUP BY project_no
HAVING COUNT(*) < 4;
Глава 6. Запросы 177
Результат:
project_no
рз
В примере 6.37 система использует предложение group by для группирования
всех строк в соответствии с существующими значениями в столбце
project_no. После этого она подсчитывает количество строк в каждой группе
и выбирает те группы, которые содержат три и менее строк.
Предложение having может быть также использовано и без агрегатных функ-
ций, как показано в примере 6.38.
Пример 6.38
Группирование строк таблицы works_on по работам и исключение тех работ,
которые не начинаются с буквы М.
USE sample;
SELECT job
FROM works_on
GROUP BY job
HAVING job LIKE 'M%';
Результат:
job
Manager
Предложение having может быть также использовано и без предложения
group by, хотя такое использование является исключением из обычной прак-
тики. В подобном случае все строки целой таблицы принадлежат только од-
ной группе.
Замечание______________________________________________________
Столбцы с типом данных TEXT (или image) не могут быть использованы в пред-
ложении HAVING.
Предложение ORDER BY
Предложение order by определяет конкретный порядок строк в полученном
результате выполнения запроса. Это предложение имеет следующий син-
таксис:
ORDER BY { [col__narie I col_number [ASC | DESC]]}, ...
178
Часть II. Язык Transact-SQL
Столбец col_name определяет упорядочивание. Параметр col_number является
альтернативной спецификацией, которая задает столбец по его позиции в по-
следовательности всех столбцов в списке выбора select (I для первого
столбца, 2 для второго и т. д.). asc задает возрастающий порядок, a desc —
убывающий. При этом asc является значением по умолчанию.
Замечание________________________________________________________
Столбцы в предложении ORDER by не обязательно должны появляться в списке
выбора select. Однако столбцы order by обязаны присутствовать в списке
выбора select, если задано select distinct. Это предложение не может так-
же ссылаться на столбцы из таблиц, которые не указаны в списке предложения
FROM.
Как показывает синтаксис предложения order by, критерии упорядочения
могут содержать более одного столбца (пример 6.39).
j Пример 6.39
Получение номеров отделов и имен служащих для тех служащих, у кого но-
мера меньше, чем 20 000, при упорядочении по возрастанию фамилий и
имен:
USE sample;
SELECT emp_fname, emp_lname, dept_no
FROM employee
WHERE empno < 20000
ORDER BY ernp_lname, emp_fname;
Результат:
John
Elsa
Elke
Ann
emp_lname dept_no
Barrimore dl
Bretoni d2
Hansel d2
Jones d3
В предложении order by также можно указывать столбцы по последователь-
ному номеру столбца в списке выбора select. Предложение order by в приме-
ре 6.39 может быть записано в следующей форме:
ORDER BY 2, 1
Использование номеров столбцов вместо их имен является альтернативным
решением, если критерии упорядочения содержат агрегатные функции. (Дру-
гим способом является использование заголовков столбцов, которые затем
появляются в предложении order by.) Однако рекомендуется использовать
Гпава 6. Запросы 779
имена столбцов вместо их номеров в предложении order by для сокращения
сложностей, которые могут возникнуть в запросе, если потребуется добавить
некоторые столбцы в список выбора select или удалить из этого списка.
В примере 6.40 показано использование номеров столбцов.
Пример 6.40
Для каждого номера проекта получение номера проекта и номеров всех слу-
жащих в убывающем порядке номеров служащих:
USE sample;
SELECT project_no, COUNT(*) emp_quantity
FROM works_on
GROUP BY project_no
ORDER BY 2 DESC;
Результат:
project_no ernp_quantity
pl 4
p2 4
p3 3
Язык Transact-SQL помещает значения null в начало списка, если упорядочи-
вание выполняется по возрастанию, и в конце списка, если задан убывающий
порядок.
Замечание__________________________________________________________
Столбцы с типом данных TEXT (или image) не могут быть использованы в пред-
ложении ORDER BY.
Оператор SELECT и свойство IDENTITY
Столбцы с числовым типом данных, таким как tinyint, smallint, integer или
bigint, могут иметь свойство identity. Database Engine генерирует значения
для подобных столбцов последовательно, начиная с заданного начального
значения. По этой причине вы можете использовать свойство identity, чтобы
дать системе возможность генерировать уникальные числовые значения для
столбца таблицы по вашему выбору.
Каждая таблица может иметь только один столбец со свойством identity.
Владелец таблицы может задавать начальный номер и значение приращения
(пример 6.41).
180
Часть II. Язык Transact-SQL
Пример 6.41
USE sample;
CREATE TABLE product
(product no INTEGER IDENTITY(10000,1) NOT NULL,
product_name CHAR(30) NOT NULL,
price MONEY);
SELECT IDENTITYCOL
FROM product
WHERE product_name = 'Soap';
Результатом может быть:
product_no
10005
В примере 6.41 вначале создается таблица product. Эта таблица имеет стол-
бец product по с заданным свойством identity. Значения столбца product_no
автоматически генерируются системой, начиная с номера 10 000 и увеличи-
ваясь на единицу для каждого последующего значения: 10 000, 10 001, 10 002
ит. д.
Некоторые системные функции и переменные имеют отношение к свойству
identity. В примере 6.41 используется переменная identitycol. Как можно
увидеть по набору результатов примера 6.41, эта переменная автоматически
ссылается на столбец со свойством identity.
Для того чтобы найти начальное значение и величину приращения для столб-
ца со свойством identity, вы можете использовать функции ident_seed и
ident_incr соответственно:
SELECT IDENTSEED('product'), IDENT_INCR(’product)'
Как вы уже знаете, система автоматически устанавливает значения столбца
identity. Если вы хотите установить ваши собственные значения для отдель-
ных строк, вы должны установить опцию identity insert в значение on перед
тем, как явно задавать добавляемое значение:
SET IDENTITY_INSERT table_narne ON
Замечание___________________________________________________________
Поскольку опция identity_insert может быть использована для задания лю-
бых значений для столбца со свойством identity, то свойство identity в об-
щем случае не поддерживает уникальность значений. Для подобных задач ис-
пользуйте ограничения unique или primary key.
Если вы добавляете значения после того, как опция identity insert была
установлена в on, система предполагает, что следующее значение должно
Гпава 6. Запросы
131
быть получено увеличением максимального значения, которое существует
в таблице на данный момент.
Операторы над множествами
В дополнение к операторам, описанным в предыдущих разделах, существуют
три оператора над множествами, поддерживаемых языком Transact-SQL:
♦ union;
♦ intersect;
♦ EXCEPT.
Оператор над множествами UNION
Результатом объединения (union) двух множеств является множество всех
элементов, присутствующих в одном или обоих наборах. Соответственно,
объединение двух таблиц является новой таблицей, содержащей все строки,
присутствующие в одной или В обеих таблицах.
Общая форма оператора union:
select_l UNION [ALL] select_2 {[UNION [ALL] select_3]}...
Параметры seiect_i, seiect_2, ... — операторы select, которые составляют
объединение. Если используется опция all, то все результирующие строки,
включая дубликаты, будут отображаться. Опция all имеет в операторе union
такое же значение, что и в списке выбора select. Существует только одно
отличие: опция all в операторе select используется по умолчанию, а в опе-
раторе union для отображения всех результирующих строк, включая дублика-
ты, она должна задаваться явно.
База данных sample в ее первоначальной форме не подходит для демонстра-
ции оператора union. По этой причине в данном разделе вводится новая таб-
лица employee enh, которая идентична таблице employee с добавлением в нее
нового столбца domicile. Столбец domicile содержит место проживания каж-
дого служащего.
Новая таблица employee_enh имеет следующую форму:
emp__no emp_fname emp_lname dept_no domicile
25348 Matthew Smith d3 San Antonio
10102 Ann Jones d3 Houston
18316 John Barrimore dl San Antonio
29346 James James d2 Seattle
9031 Elke Bertoli d2 Portland
182
Часть II. Язык Transact-SQL
2581 Elisa Kim d2 Tacoma
28559 Sybill Moser dl Houston
Создание таблицы employee_enh предоставляет возможность показать исполь-
зование предложения into в операторе select. Оператор select into имеет
две различные части. Во-первых, он создает новую таблицу со столбцами,
соответствующими столбцам, перечисленным в списке выбора select. Во-
вторых, он добавляет существующие строки из исходной таблицы в новую
таблицу. (Имя новой таблицы появляется в предложении into, а имя исход-
ной таблицы присутствует в предложении from оператора select.)
В примере 6.42 показано создание таблицы employee_enh.
Пример 6.42
USE sample;
SELECT emp_no, emp_fname, emp_lname, dept_no
INTO employee_enh
FROM employee;
ALTER TABLE employee_enh
ADD domicile CHAR(25) NULL;
В примере 6.42 оператор select into генерирует таблицу employee_enh и до-
бавляет в нее все строки из исходной таблицы (employee). Под конец оператор
ALTER TABLE добавляет столбец domicile В таблицу employee_enh.
После выполнения примера 6.42 столбец domicile не содержит никаких зна-
чений. Значения могут быть добавлены при использовании SQL Server
Management Studio (см. главу 3) или при помощи следующих операторов
update:
USE sample;
UPDATE employee_enh SET domicile = ’San Antonio'
WHERE emp_no = 25348;
UPDATE employee_enh SET domicile = 'Houston'
WHERE emp_no = 10102;
UPDATE employee_enh SET domicile = 'San Antonio'
WHERE emp_no = 18316;
UPDATE employee_enh SET domicile = 'Seattle'
WHERE emp_no = 29346;
UPDATE employee_enh SET domicile = 'Portland'
WHERE emp_no = 9031;
UPDATE employee_enh SET domicile = 'Tacoma'
WHERE emp_no = 2581;
UPDATE employee_enh SET domicile = 'Houston'
WHERE emp_no = 28559;
Глава 6. Запросы 183
В примере 6.43 показано объединение таблиц employee_enh И department.
j Пример 6.43
USE sample;
SELECT domicile
FROM employee_enh
UNION
SELECT location
FROM department;
Результат:
domicile
San Antonio
Houston
Portland
Tacoma
Seattle
Dallas
Две таблицы могут быть соединены при помощи оператора union, если они
совместимы друг с другом. Это означает, что оба списка выбора select
должны иметь одно и то же количество столбцов и соответствующие столбцы
должны иметь совместимые типы данных. Например, integer и smallint
являются совместимыми типами данных.
Упорядочение результата объединения может быть выполнено, только если
предложение order by используется в последнем операторе select, как пока-
зано в примере 6.44. Предложения group by и having могут быть использова-
ны в отдельных операторах select, но не в самом объединении.
I Пример 6.44
Получение номеров служащих для тех служащих, которые либо относятся
к отделу dl, либо приступили к работе над проектом до 01.01.2007. Упорядо-
чивание производится по возрастанию номеров служащих:
USE sample;
SELECT emp_no
FROM employee
WHERE dept_no = 'dl'
UNION
184
Часть II. Язык Transact-SQL
SELECT emp_no
FROM works_on
WHERE enterdate < '01.01.2007'
ORDER BY 1;
Результат:
етр no
9031
10102
18316
28559
29346
Замечание_____________________________________________________
Оператор UNION поддерживает опцию all. union вместе c all означает, что
дубликаты не удаляются из результирующего набора.
Вместо оператора union можно использовать оператор or, если все операторы
select, связанные с одним или более операторами union, ссылаются на одну и
ту же таблицу. В этом случае множество операторов select заменяется одним
оператором select с множеством операторов or.
Операторы над множествами
INTERSECT и EXCEPT
Двумя другими операторами над множествами являются оператор intersect,
который задает пересечение, и except, который определяет операцию разно-
сти множеств. Пересечением двух таблиц является множество строк, которые
одновременно принадлежат обеим таблицам. Разность двух таблиц— мно-
жество строк, которые принадлежат первой таблице и не присутствуют во
второй таблице. В примере 6.45 показано использование оператора intersect.
i Пример 6.45
USE sample;
SELECT emp_no
FROM employee
WHERE dept_no = 'dl'
INTERSECT
SELECT emp_no
FROM works_on
WHERE enter date < '01.01.2008';
Глава 6. Запросы 185
Результат:
етр по
18316
28559
Замечание____________________________________________________________
Transact-SQL не поддерживает оператор intersect с опцией all. Это верно и
для оператора except.
В примере 6.46 показано использование оператора над множествами except.
: Пример 6.46
USE sanple;
SELECT ernp__no
FROM employee
WHERE dept_no = 'd3'
EXCEPT
SELECT emp_no
FROM works_on
WHERE enter_date > '01.01.2008';
Результат:
emp no
10102
25348
Замечание______________________________________________________
Вы должны знать, что эти три оператора над множествами имеют различные
приоритеты выполнения: оператор intersect имеет наивысший приоритет,
except вычисляется следующим, а оператор union имеет наименьший приори-
тет. Если вы не будете учитывать эти различия в приоритетах, то получите не-
ожиданные результаты при использовании нескольких операторов над множе-
ствами в одном операторе.
Выражения CASE
При программировании приложений баз данных иногда бывает необходимы-
ми изменять представление данных. Например, род (gender) человека может
быть кодирован с использованием значений 1, 2 и 3 (для женщины, мужчины
и ребенка соответственно). Такие программные техники позволяют сократить
186
Часть II. Язык Transact-SQL
время на реализацию программы. Выражение case в языке Transact-SQL де-
лает подобный тип кодирования простым в реализации.
Замечание________________________________________________________
case является не оператором (как в большинстве языков программирования),
а выражением. Поэтому выражение case может быть использовано (почти)
везде, где язык Transact-SQL позволяет использовать выражения.
Выражение case имеет две различные формы:
♦ простое выражение case;
♦ поисковое выражение case.
Синтаксис простого выражения case:
CASE expression_l
{WHEN expression 2 THEN result—!} _
[ELSE result—n]
END
Оператор Transact-SQL с простым выражением case отыскивает первое вы-
ражение в списке всех предложений where, которое соответствует выражению
expression_i, и выполняет соответствующее предложение then. Если соот-
ветствие не найдено, то выполняется предложение else.
Синтаксис поискового выражения case:
CASE
{WHEN condition! THEN result_l} ...
[ELSE result—n]
END
Оператор Transact-SQL с поисковым выражением case отыскивает первое
выражение, которое при вычислении дает истину. Если никакое условие when
не дает истину, то возвращается значение выражения else. В примере 6.47
показано использование поискового выражения case.
Пример 6.47
USE sample;
SELECT project_name,
CASE
WHEN budget > 0 AND budget < 100000 THEN 1
WHEN budget >= 100000 AND budget < 200000 THEN 2
WHEN budget >= 200000 AND budget < 300000 THEN 3
ELSE 4
END budget_weight
FRCM project;
Гпава 6. Запросы
187
Результат:
project_name budget_weight
Apollo 2
Gemini 1
Mercury 2
В примере 6.47 бюджеты всех проектов взвешиваются, и отображаются все
весовые коэффициенты (вместе с именами соответствующих проектов).
В примере 6.48 показан другой вариант с выражением case, где предложение
when содержит внутренний запрос как часть выражения.
; Пример 6.48
SELECT project_name,
CASE
WHEN pl.budget < (SELECT AVG(p2.budget) FROM project p2)
THEN 'below average'
WHEN pl.budget = (SELECT AVG(p2.budget) FROM project p2)
THEN 'on average'
WHEN pl.budget > (SELECT AVG(p2.budget) FROM project p2)
THEN 'above average'
END budget_category
FROM project pl;
Результат (below average — ниже среднего, above average — выше среднего):
proj ect_name
budget_category
Apollo
Gemini
Mercury
below average
below average
above average
Предложение COMPUTE
Предложение compute использует агрегатные функции (min, max, sum, avg и
count) для вычисления итоговых значений, которые появляются как дополни-
тельные строки в результате выполнения запроса. Агрегатные функции, ис-
пользуемые в предложении compute, рассматриваются как строки агрегатных
функций.
Агрегатные функции обычно применяются к строкам таблицы для вычисле-
ния скалярных величин, которые затем появляются в результате выполнения
запроса в виде дополнительной строки (см. пример 6.49). Запрос, исполь-
188
Часть II. Язык Transact-SQL
зующий такую форму агрегатных функций, возвращает строку в качестве ре-
зультата.
Замечание_____________________________________________________
Результатом предложения compute не является таблица: это отчет. Поэтому
предложение compute, в отличие от всех других описанных операторов и пред-
ложений, не принадлежит реляционной модели.
Предложение compute имеет необязательную опцию by, которая определяет
форму группирования результата. Если by опущено, строка агрегатной функ-
ции применяется ко всем строкам результата запроса. Опция by имя_столбца
указывает, что значения столбца имя_столбца используются для создания
группы. Предложение order by требуется, если предложение compute приме-
няется вместе с by.
Замечание_____________________________________________________
Не используйте предложения compute и compute by, потому что они отмечены
как недопустимые в следующих версиях Database Engine. Вместо этого приме-
няйте оператор group by rollup (см. главу 24).
В примере 6.49 показано использование предложения compute вместе с оп-
цией BY.
; Пример 6.49
USE sample;
SELECT emp_no, project_no, enterdate
FROM works_on
WHERE project_no = 'pl' OR project_no = 'p2'
ORDER BY project_no
COMPUTE MIN(enter_date) BY project_no;
Результат:
emp_no project_no
enterdate
10102 pl
9031 pl
28559 pl
29346 pl
2006-10-01
emp_no project_no
2006-10-01
2007-04-15
2007-08-01
2007-01-04
enter_date
25348 p2
2007-02-15
Гпава 6. Запросы 189
18316 р2 2007-06-01
29346 р2 2006-12-15
28559 р2 2008-02-01
2006-12-15
Предложение compute может иметь множество вариантов использования
в операторе select. Пример 6.49 может быть записан с помощью одного опе-
ратора select и следующих операторов compute:
COMPUTE MIN (enter_date} BY project_no
COMPUTE Niti (enter_date)
Существует несколько ограничений относительно предложения compute:
♦ не допускается использование select into (потому что результат предло-
жения compute не является таблицей);
♦ все столбцы в предложении compute должны присутствовать в списке вы-
бора select;
♦ имя каждого столбца в предложении compute by должно появиться в пред-
ложении order by;
♦ порядок столбцов в предложениях compute by и order by должен быть
одинаковым.
Временные таблицы
Временные таблицы являются объектом базы данных, которые временно
хранятся и управляются системой базы данных. Временные таблицы могут
быть локальными и глобальными. Локальные временные таблицы имеют
физическое представление — они хранятся в системной базе данных tempdb.
Они задаются с префиксом # (например, # tabie_name).
Локальными временными таблицами владеет сессия, которая их создала; они
видимы только для этой сессии. Соответственно, такие таблицы автоматиче-
ски удаляются, когда завершается создавшая их сессия. (Если вы определяете
временную локальную таблицу внутри хранимой процедуры, то таблица бу-
дет удалена, когда завершится выполнение соответствующей процедуры.)
Глобальные временные таблицы видимы любому пользователю и каждому
новому соединению, выполненному после их создания. Они удаляются, когда
все пользователи, обращающиеся к этим таблицам, отключаются от сервера
базы данных. В отличие от локальных временных таблиц глобальные табли-
цы задаются с префиксом ##.
В примерах 6.50 и 6.51 показано, как временная таблица project terrp может
быть создана с использованием двух различных операторов Transact-SQL.
190
Часть II. Язык Transact-SQL
Пример 6.50
USE sample;
CREATE TABLE #project_temp
(project_no CHAR(4) NOT NULL,
project_name CHAR(25) NOT NULL);
Пример 6.51
USE sample;
SELECT project_no, project_name
INTO #project_temp
FROM project;
Примеры 6.50 и 6.51 похожи. Они используют два различных оператора
Transact-SQL для создания локальной временной таблицы #project_temp. При
этом в примере 6.51 временная таблица заполняется данными из таблицы
project, в то время как в примере 6.50 таблица остается пустой.
Оператор JOIN
Предыдущие разделы этой главы демонстрировали использование оператора
select для выборки данных из одной таблицы базы данных. Если бы язык
Transact-SQL поддерживал только такие простые операторы select, то под-
ключение двух и более таблиц для выборки данных было бы невозможным.
Следовательно, все данные базы данных должны были бы храниться в одной
таблице. Хотя хранение всех данных базы данных внутри одной таблицы в
принципе возможно, оно имеет один главный недостаток — хранимые дан-
ные будут весьма избыточны.
Transact-SQL предоставляет оператор соединения, который выбирает данные
более чем из одной таблицы. Этот оператор, возможно, является одним из
наиболее важных операторов для систем реляционных баз данных, потому
что позволяет распределять данные среди множества таблиц и таким образом
обеспечивать жизненно важное свойство систем баз данных— отсутствие
избыточности данных.
Замечание___________________________________________________
Оператор union также объединяет две или более таблиц. При этом оператор
union всегда включает два или более оператора select, в то время как опера-
тор join "соединяет" две или более таблицы с использованием только лишь
одного оператора select. Более того, оператор union объединяет строки таб-
лиц, тогда как, и вы увидите это далее в этом разделе, оператор join "соеди-
няет" столбцы таблиц.
Глава 6. Запросы 191
Оператор join применим к базовым таблицам и представлениям. В этой главе
рассматриваются соединения, выполняемые между базовыми таблицами, а
соединения, связанные с представлениями, будут обсуждаться в главе 11.
Существует несколько различных форм оператора join. В этом разделе рас-
сматриваются следующие фундаментальные типы:
♦ естественное соединение;
♦ декартово произведение (перекрестное соединение);
♦ внешнее соединение;
♦ тета-соединение, рефлексивное соединение (самосоединение) и полусо-
единение.
Прежде чем рассматривать различные формы соединений, в этом разделе
описываются различные синтаксические формы оператора join.
Две синтаксические формы
для реализации соединений
Для соединения таблиц вы можете использовать две различные формы:
♦ явный синтаксис соединения (синтаксис соединения ANSI SQL: 1992);
♦ неявный синтаксис соединения ("старый стиль" синтаксиса соединения).
Синтаксис соединения ANSI SQL: 1992 был введен стандартом SQL92, он яв-
но определяет операции соединения, т. е. с использованием соответствующих
имен для каждого типа операции соединения. Ключевыми словами, связан-
ными с явным заданием соединения, являются:
♦ cross join;
♦ [INNER] JOIN;
♦ LEFT [OUTER] JOIN;
♦ RIGHT [OUTER] JOIN;
♦ FULL [OUTER] JOIN.
cross join задает декартово произведение двух таблиц, inner join определя-
ет естественное соединение двух таблиц, a left outer join и right outer
join задают, соответственно, операции левого и правого соединения. Нако-
нец, full outer join определяет объединение правого и левого соединения.
Все эти операции соединения объясняются в следующих разделах.
Синтаксис неявного соединения является синтаксисом "старого стиля"; здесь
каждая операция соединения определяется неявно через предложение where,
используя так называемые столбцы соединения (см. пример 6.52).
192
Часть II. Язык Transact-SQL
Замечание_____________________________________________________
Рекомендуется использовать явный синтаксис соединения. Этот синтаксис по-
вышает читаемость запросов. По этой причине все примеры в данной главе,
связанные с операциями соединения, созданы с использованием явных синтак-
сических форм. В небольшом количестве представленных примеров вы также
сможете увидеть и синтаксис "старого стиля".
Естественное соединение
Естественное соединение лучше всего объяснить через использование при-
мера, так что см. пример 6.52.
Замечание_____________________________________________________,
Термины "естественное соединение" и "самосоединение" часто используют как
синонимы, однако между ними существует тонкое различие. В операции само-
соединения всегда присутствует одна или более пар столбцов, которые имеют
одинаковые значения в каждой строке. Операция, которая удаляет такие
столбцы из самосоединения, называется естественным соединением.
। Пример 6.52
Получение всех детальных сведений о каждом служащем, т. е. помимо полу-
чения номера служащего, его имени, фамилии и соответствующего номера
отдела, также выбирается название его (или ее) отдела с размещением этого
отдела. Отображаются дубликаты столбцов.
Явный синтаксис соединения:
USE sample;
SELECT employee.*, department.*
FROM employee INNER JOIN department
ON employee.dept_no = department.dept_no;
Список выбора select в примере 6.52 включает все столбцы таблиц employee
и department. Предложение from в операторе select задает соединяемые таб-
лицы и явное название формы соединения (inner join). Предложе-
ние on также является частью предложения from; оно задает столбцы со-
единения в обеих таблицах. Условие employee.dept_no = departmenL.dept_no
в примере 6.52 определяет условие соединения, а оба столбца называются
столбцами соединения.
Эквивалентным решением будет следующее:
Синтаксис"старого стиля":
USE sample;
SELECT employee.*, department.*
Глава 6. Запросы 193
FROM employee, department
WHERE employee.dept_no = department.dept_no;
Синтаксис "старого стиля" имеет два существенных отличия: предложение
from в запросе содержит список соединяемых таблиц, а соответствующие
условия соединения задаются в предложении where с использованием соеди-
няемых столбцов.
Результатом будет:
emp_no emp_fname einp-lnarre dept_no dept_no dept_name location
25348 Matthew Smith d3 d3 Marketing Dallas
10102 Ann Jones d3 d3 Marketing Dallas
18316 John Barrimore dl dl Research Dallas
29346 James James d2 d2 Accounting Seattle
9031 Elsa Bertoni d2 d2 Accounting Seattle
2581 Elke Hansel d2 d2 Accounting Seattle
28559 Sybill Moser dl dl Research Dallas
Замечание________________________________________________________
Очень рекомендуется, чтобы вы применяли символ * в списке выбора select
только в том случае, когда вы используете интерактивный SQL, и исключили бы
его из программ приложения.
Пример 6.52 может быть использован только для демонстрации того, как ра-
ботает операция соединения. Обратите внимание, что это всего лишь иллю-
страция того, что вы можете думать о процессе соединения. Фактически,
Database Engine имеет несколько стратегий, среди которых он осуществляет
выбор реализации оператора соединения. Представьте каждую строку табли-
цы employee, объединенную с каждой строкой таблицы department. Результа-
том такой комбинации будет таблица с семью столбцами (4 из таблицы
employee И 3 ИЗ таблицы department) И 21 строкой (табл. 6.1).
На втором шаге все строки из табл. 6.1, которые не соответствуют условию
соединения employee.dept_no = department.dept_no, будут удалены. Такие
строки помечены в табл. 6.1 символом *. Оставшиеся строки представляют
результат примера 6.52.
Таблица 6.1. Результат декартова произведения таблиц employee и department
emp_no erap_fname emp_lname dept_no dept_no dept_name location
*25348 Matthew Smith d3 d1 Research Dallas
*10102 Ann Jones d3 d1 Research Dallas
18316 John Barrimore d1 d1 Research Dallas
194
Часть II. Язык Transact-SQL
Таблица 6.1 (окончание)
ешр_по emp_fname emp_lname dept_no dept_no dept_name location
*29346 James James d2 d1 Research Dallas
*9031 Elsa Bertoni d2 d1 Research Dallas
*2581 Elke Hansel d2 d1 Research Dallas
28559 Sybill Moser d1 d1 Research Dallas
*25348 Matthew Smith d3 d2 Accounting Seattle
*10102 Ann Jones d3 d2 Accounting Seattle
*18316 John Barrimore d1 d3 Accounting Seattle
29346 James James d2 d2 Accounting Seattle
9031 Elsa Bertoni d2 d2 Accounting Seattle
2581 Elke Hansel d2 d2 Accounting Seattle
*28559 Sybill Moser d1 d2 Accounting Seattle
25348 Matthew Smith d3 d3 Marketing Dallas
10102 Ann Jones d3 d3 Marketing Dallas
*18316 John Barrimore d1 d3 Marketing Dallas
*29346 James James d2 d3 Marketing Dallas
*9031 Elsa Bertoni d2 d3 Marketing Dallas
*2581 Elke Hansel d2 d3 Marketing Dallas
*28559 Sybill Moser d1 d3 Marketing Dallas
Семантика соответствующих столбцов соединения должна быть идентичной.
Это означает, что оба столбца должны иметь один и тот же логический
смысл. Не требуется, чтобы соответствующие столбцы соединения имели
одно и то же имя (или даже один и тот же тип данных), хотя часто так и бы-
вает.
Замечание__________________________________________
Система базы данных не в состоянии проверить логический смысл столбца.
(Например, номер проекта и номер служащего не имеют ничего общего, хотя
оба определены как целочисленные типы данных). По этой причине система
базы данных может только проверить тип данных и размер строкового типа
данных. Database Engine требует, чтобы корреспондирующие столбцы соеди-
нения имели совместимые типы данных, например, такие как integer и
SMALLINT.
Гпава 6. Запросы 195
База данных sample содержит три пары столбцов, где каждый столбец в паре
имеет один и тот же логический смысл (они также имеют одни и те же име-
на). Таблицы employee и department могут быть соединены с использованием
столбцов employee. dept no И department. dept_no. Столбцами для соединения
таблиц employee И works_on ЯВЛЯЮТСЯ столбцы employee. emp_no И works_
on.emp_no. Наконец, таблицы project и works_on могут быть соединены
при использовании столбцов соединения project.project_no и works_
on.project_no.
Имена столбцов в операторе select могут быть уточнены, т. е. могут иметь
квалификацию. "Квалификация" имени столбца означает исключение всякой
возможной двусмысленности относительно того, какой таблице принадлежит
столбец; имени столбца предшествует имя его таблицы (или псевдоним таб-
лицы), отделенное точкой: table_name. column_name.
В большинстве операторов select имена столбцов не требуют обязательной
квалификации, хотя использование квалифицированных имен обычно реко-
мендуется для читаемости текста оператора. Если имена столбцов в операто-
ре SELECT являются двусмысленными (как столбцы employee. dept no и
department.dept_no в примере 6.52), то квалификация имен столбцов обяза-
тельно должна быть использована.
В операторе select, содержащем соединение, предложение where в дополне-
ние к условию соединения может содержать и другие условия, как показано
в примере 6.53.
' Пример 6.53
Получение полных подробностей обо всех служащих, кто работает над про-
ектом Gemini.
Явный синтаксис соединения:
USE sample;
SELECT emp_no, project.project_no, job, enter_date, project_name, budget
FROM works_on JOIN project
ON project.project_no = works_on.project_no
WHERE project_name = 'Gemini';
"Старый стиль" синтаксиса соединения:
USE sample;
SELECT emp_no, project.project_no, job, enter_date, project_name, budget
FROM works_on, project
WHERE project.project_no = works_on.project_no
AND proj ect_name = 'Gemini';
196
Часть II. Язык Transact-SQL
Замечание_______________________________________________________
Квалификация имен столбцов emp_no, project_name, job и budget в приме-
ре 6.53 не является необходимой, потому что не существует никакой двусмыс-
ленности в отношении этих столбцов.
Результат:
einp_no project_no job enter_date project_name budget
25348 p2 Clerk 2007-02-15 Gemini 95000.0
18316 p2 NULL 2007-06-01 Gemini 95000.0
29346 p2 NULL 2006-12-15 Gemini 95000.0
28559 p2 Clerk 2008-02-01 Gemini 95000.0
Начиная с этого момента, все остальные примеры будут реализованы только
с использованием явного синтаксиса соединения.
В примере 6.54 показано другое использование внутреннего соединения.
! Пример 6.54
Получение номера отдела для всех служащих, которые приступили к работе
над проектами 15 октября 2007 г.:
USE sample;
SELECT dept_no
FROM employee JOIN works_on
ON employee.emp no = works_on.emp_no
WHERE enter_date = 40.15.2007’;
Результат:
dept_no
d2
Соединение более чем двух таблиц
Теоретически не существует верхней границы на количество таблиц, которые
могут быть соединены с использованием оператора select. (Одно условие
соединения всегда комбинирует две таблицы!) Однако Database Engine имеет
реализационные ограничения: максимальное количество таблиц, которые мо-
гут быть соединены в операторе select, равно 64.
Замечание__________________________________________________
Обычно в одном операторе select соединяется от восьми до десяти таблиц.
Если у вас есть необходимость соединять более десяти таблиц в операторе
select, то, возможно, проектирование вашей базы данных не является опти-
мальным.
Гпава 6. Запросы 197
В примере 6.55 соединяются три таблицы базы данных sample.
j Пример 6.55
Получение имен и фамилий всех аналитиков (job = 'analyst'), чьи отделы
располагаются в Сиэтле (Seattle):
USE sample;
SELECT emp_fname, emp_lname
FROM works_on
JOIN employee ON works_on.emp_no=employee.emp_no
JOIN department ON employee.dept_no=department.dept_no
AND location = 'Seattle'
AND job = 'analyst';
Результат:
Elke Hansel
Результат примера 6.55 может быть получен лишь в том случае, если вы со-
единяете как минимум три таблицы: works on, employee И department. Эти таб-
лицы могут быть соединены с использованием двух пар столбцов соедине-
ния:
(works_on.emp_no, employee.emp_no)
(employee.dept_no, department.dept_no)
Пример 6.56 использует все четыре таблицы базы данных sample для получе-
ния результирующего набора данных.
| Пример 6.56
Получение названий проектов (с удалением избыточных дубликатов), с ко-
торыми работают служащие из отдела бухгалтерского учета (dept name =
'Accounting'):
USE sample;
SELECT DISTINCT project_name
FROM project
JOIN works_on
ON project.project_no = works_on.project_no
JOIN employee ON works_on.emp_no = employee.emp_no
JOIN department ON employee.dept_no = department.dept_no
WHERE dept_name = 'Accounting';
198
Часть II. Язык Transact-SQL
Результат:
project_name
Apollo
Gemini
Mercury
Обратите внимание, что при соединении трех таблиц для получения естест-
венного соединения вы используете два условия соединения (каждое связы-
вает две таблицы). Когда вы соединяете четыре таблицы, то используете три
таких условия. Вообще, если вы соединяете и таблиц, вам нужно п - 1 усло-
вие соединения, чтобы исключить декартово произведение. Разумеется, мо-
жет понадобиться более чем п - 1 условий соединения и совершенно другие
(безусловно, допустимые) условия соединения для дальнейшего сокращения
результирующего набора данных.
Декартово произведение
В предыдущем разделе иллюстрировались возможные методы получения
естественного соединения. На первом шаге этого процесса каждая строка
таблицы employee комбинировалась с каждой строкой таблицы department.
Этот промежуточный результат был получен при помощи операции, назы-
ваемой декартовым произведением. В примере 6.57 демонстрируется получе-
ние декартова произведения из таблиц employee и department.
i Пример 6.57
USE sample;
SELECT employee.*, department.*
FROM employee CROSS JOIN department;
Результат примера 6.57 показан в табл. 6.1. Декартово произведение комби-
нирует каждую строку первой таблицы с каждой строкой второй таблицы.
Вообще, декартово произведение двух таблиц, где первая таблица содержит
п строк, а у второй таблицы m строк, создаст результат с количеством строк,
равным п х т. Следовательно, результирующий набор данных примера 6.57
содержит 7x3=21 строку.
На практике декартово произведение используется крайне редко. Иногда
пользователи генерируют декартово произведение двух таблиц, когда они
забывают включить условие соединения в предложение where при использо-
вании синтаксиса соединения "старого стиля". В этом случае выходной набор
данных не будет соответствовать ожидаемому результату, потому что содер-
Гпава 6. Запросы 199
жит слишком много строк. (Наличие очень большого количества неожидае-
мых строк в результате выборки данных является подсказкой, что было полу-
чено декартово произведение двух таблиц вместо ожидаемого естественного
соединения).
Внешнее соединение
В предыдущих примерах естественного соединения результирующий набор
данных включал только строки одной таблицы, которые имели соответст-
вующие строки из другой таблицы. Иногда бывает необходимым получать в
дополнение к строкам, имеющим такое соответствие, строки, не имеющие
никакого соответствия, из одной или обеих таблиц. Подобная операция назы-
вается внешним соединением.
В примерах 6.58 и 6.59 показаны различия между естественным соединением
и соответствующим ему внешним соединением. (Все примеры этого раздела
используют таблицу employee_enh.)
I Пример 6.58
Получение полных сведений обо всех служащих, включая местоположение
их отделов, тех служащих, которые живут и работают в одном и том же го-
роде:
USE sample;
SELECT employee_enh.*, department.locat ion
FROM employeejenh JOIN department
ON domicile = location;
Результат:
emp_no emp_fname emp_lname dept_no domicile location
29346 James James d2 Seattle Seattle
В примере 6.58 используется естественное соединение для получения резуль-
тирующего набора строк. Если вы хотите узнать все другие места прожива-
ния служащих, вам нужно использовать (левое) внешнее соединение. Оно
называется левым внешним соединением, потому что возвращаются все стро-
ки таблицы с левой стороны оператора, независимо от того, есть ли соответ-
ствующая строка в таблице справа. Другими словами, если нет соответст-
вующих строк в таблице с правой стороны, внешнее соединение все равно
вернет строку из таблицы с левой стороны со значениями null для каждого
столбца второй таблицы (см. пример 6.59). Database Engine использует опера-
тор left outer join для задания левого внешнего соединения.
200
Часть II. Язык Transact-SQL
Правое внешнее соединение похоже на левое, только оно возвращает все
строки таблицы в правой части выражения. Database Engine использует опе-
ратор right outer join для задания правого внешнего соединения.
| Пример 6.59
Получение подробностей для всех служащих плюс местоположение их отде-
лов для всех городов, в которых они либо живут, либо живут и одновременно
работают:
USE sample;
SELECT employee_enh.*, department.location
FROM employee_enh
LEFT OUTER JOIN department
ON domicile = location;
Результат: dept_no domicile location
emp_no emp_fname emp_lname
25348 Matthew Smith d3 San Antonio NULL
10102 Ann Jones d3 Houston NULL
18316 John Barrimore dl San Antonio NULL
29346 James James d2 Seattle Seattle
9031 Elsa Bertoni d2 Portland NULL
2581 Elke Hansel d2 Tacoma NULL
28559 Sybill Moser dl Houston NULL
Как вы можете видеть, когда не существует соответствующих строк в табли-
це с правой стороны (в данном случае department), левое внешнее соединение
все равно возвращает строки из таблицы с левой стороны (employee enh), а
столбцы второй таблицы заполняются значениями null. В примере 6.60 пока-
зано использование операции правого внешнего соединения.
| Пример 6.60
Получение подробных данных обо всех отделах, так же как и о местожитель-
стве их сотрудников для всех городов, которые расположены там же, где и
отделы:
USE sample;
SELECT employee_enh.domicile, department.*
FROM employee_enh RIGHT OUTER JOIN department
ON domicile = location;
Глава 6. Запросы 201
Результат:
domicile dept_no dept_name location
Seattle d2 Accounting Seattle
NULL dl Research Dallas
NULL d3 Marketing Dallas
В дополнение к левому и правому внешнему соединению существует также и
полное внешнее соединение, которое определяется как объединение левого и
правого внешнего соединения. Другими словами, все строки из обеих таблиц
представлены в результирующем наборе данных. Если нет соответствующей
строки для одной из таблиц, ее столбцы будут возвращены с пустыми значе-
ниями null. Эта операция задается при помощи оператора full outer join.
Database Engine поддерживает внутренний синтаксис для левого и правого
внешних соединений, *= и =* только с целью обратной совместимости. Для
использования этого нестандартного синтаксиса вам нужно изменить режим
совместимости базы данных для SQL Server 2008, который равен 80.
Замечание__________________________________________________________
Изменение режима совместимости не рекомендуется, потому что вы не сможе-
те использовать некоторые новые возможности более поздних версий. По этой
причине, если вы хотите использовать все возможности внешнего соединения,
применяйте стандартизованный синтаксис соединения.
Каждый оператор внешнего соединения может быть смоделирован при ис-
пользовании оператора using плюс функция not exists. Пример 6.61 эквива-
лентен примеру с левым внешним соединением (см. пример 6.59).
| Пример 6.61
Получение подробностей для всех служащих плюс местоположение их отде-
лов для всех городов, в которых они либо живут, либо живут и одновременно
работают:
USE sample;
SELECT employee_enh.*, department.location
FROM employee_enh JOIN department
ON domicile = location
UNION
SELECT employee_enh.*, 'NULL'
FROM employee_enh
WHERE NOT EXISTS
(SELECT *
FROM department
WHERE location = domicile);
202
Часть II. Язык Transact-SQL
Первый оператор select в объединении задает естественное соединение таб-
лиц employee_enh И department СО столбцами соединения domicile И location.
Этот оператор select отыскивает все города, которые в одно и то же время
являются и местом проживания, и местом работы каждого служащего. Вто-
рой оператор select в объединении дополнительно отыскивает все строки из
таблицы empioyee enh, которые не соответствуют условию естественного со-
единения.
Другие формы операций соединения
В предыдущих разделах обсуждались наиболее важные формы соединений.
В данном разделе будут рассмотрены три другие формы:
♦ тета-соединение;
♦ самосоединение;
♦ полусоединение.
Тета-соединение
Соединяемые столбцы не обязательно должны сравниваться с помощью
только знака равенства. Операция соединения, использующая общие условия
соединения, т. е. операторы, отличные от оператора равенства, называется
тета-соединением. В примере 6.62, где используется таблица empioyee enh,
показана операция тета-соединения.
| Пример 6.62
Получение всех комбинаций информации о служащем и информации об от-
деле, где место проживания служащего в алфавитном порядке предшествует
местоположению отдела, в котором работает этот служащий:
USE sample;
SELECT emp_fname, emp_lname, domicile, location
FROM employee_enh JOIN department
ON domicile < location;
Результат:
emp_fname emp Inaine domicile location
Matthew Smith San Antonio Seattle
Ann Jones Houston Seattle
John Barrimore San Antonio Seattle
Elsa Bertoni Portland Seattle
Sybill Moser Houston Seattle
Гпава 6. Запросы
203
В примере 6.62 сравниваются соответствующие значения в столбцах domicile
и location. В каждой строке результата значение столбца domicile сравнива-
ется в алфавитном порядке со значением столбца location.
Самосоединение,
или соединение таблицы самой с собой
В дополнение к соединению двух или более различных таблиц операция
естественного соединения может быть также применена к одной таблице.
В этом случае таблица соединяется сама с собой, столбец таблицы сравнива-
ется с тем же столбцом из той же таблицы'. Сравнение столбцов с самими
собой в одной и той же таблице означает, что имя таблицы появляется дваж-
ды в предложении from оператора select. По этой причине у вас должна быть
возможность ссылаться на имя одной и той же таблицы дважды. Это можно
сделать, используя, по меньшей мере, один псевдоним для таблицы. То же
самое верно и для имен столбцов в условии соединения оператора select.
Для различения имен двух столбцов вы используете квалифицированные
имена. В примере 6.63 таблица department соединяется с собой.
! Пример 6.63
Получение полных данных обо всех отделах, размещенных в том же месте,
что и хотя бы один другой отдел:
USE sample;
SELECT tl.dept_no, tl.dept_name, tl.location
FROM department tl JOIN department t2
ON tl.location = t2.location
WHERE tl.dept—no <> t2.dept_no;
Результат:
dept_no dept_name location
d3 Marketing Dallas
dl Research Dallas
Предложение from в примере 6.63 содержит два псевдонима для таблицы
department: tl и t2. Первое условие в предложении where задает столбцы со-
единения, в то время как второе условие удаляет ненужные дубликаты, ука-
зывая, что каждый отдел сравнивается с другим отделом.
1 На самом деле в подобных видах соединения сравниваемые столбцы вовсе не обязательно
должны быть одними и теми же. — Прим. перев.
8 Зак. 1141
204
Часть II. Язык Transact-SQL
Полусоединение
Полусоединение похоже на естественное соединение, однако результатом
полусоединения является лишь множество строк одной таблицы, где найдено
одно или более соответствий во второй таблице. В примере 6.64 показана
операция полусоединения.
I Пример 6.64
USE sample;
SELECT emp_no, emp_lname, e.dept_no
FROM employee e JOIN department d
ON e.dept_no = d.dept_no
WHERE location = 'Dallas';
Результат:
emp_no emp_lname dept_no
25348 Smith d3
10102 Jones d3
18316 Barrimore dl
28559 Moser dl
Как можно видеть из примера 6.64, список выбора select в полусоединении
содержит только столбцы таблицы employee. Это именно то, что характеризу-
ет операцию полусоединения. Подобная операция обычно применяется
в распределенных запросах для минимизации передачи данных. Database
Engine использует операцию самосоединения для реализации возможности,
называемой запросом Star Join (см. главу 26).
Коррелированные подзапросы
Подзапросы называются коррелированными подзапросами, если внутренний
запрос зависит от внешнего запроса для всех его значений. В примере 6.65
показан коррелированный подзапрос.
I Пример 6.65
Получение фамилий всех служащих, работающих над проектом рЗ:
USE sample;
SELECT emp_lname
FROM employee
Гпава 6. Запросы
WHERE 'рЗ' IN
(SELECT project_no
FROM works_on
WHERE works_on.emp_no = employee.emp_no);
Результат:
emp—lname
Bertoni
Hansel
Внутренний запрос в примере 6.65 должен логически выполняться много раз,
потому что он содержит столбец emp no, который принадлежит таблице
employee во внешнем запросе, и значение столбца emp no изменяется каждый
раз, когда Database Engine проверяет другую строку таблицы employee во
внешнем запросе.
Давайте посмотрим, как система может обрабатывать запрос в примере 6.65.
Во-первых, система отыскивает первую строку в таблице employee (для
внешнего запроса) и сравнивает номер служащего в этом столбце (25 348) со
значениями столбца works_on.emp_no во внутреннем запросе. Так как
project_no для этого служащего имеет только одно значение и равен р2,
внутренний запрос возвращает р2. Это единственное значение во множестве
не равно значению рЗ во внешнем запросе, следовательно, условие внешнего
запроса (where 'рЗ' in ...) не выполнено, и ни одна строка не возвращается
внешнему запросу для этого служащего. Затем система отыскивает следую-
щую строку в таблице employee и повторяет сравнение номеров служащих в
обеих таблицах. Второй служащий имеет две строки в таблице works on со
значениями pl и рЗ столбца project no, следовательно, результирующим
множеством внутреннего запроса является (pl, р2). Один из элементов ре-
зультирующего набора равен значению рЗ, так что условие возвращает ис-
тинное значение, и отображается соответствующее значение столбца
emp lname из второй строки (Jones). Тот же процесс применяется ко всем
строкам таблицы employee; окончательным результатом будет набор из трех
найденных строк.
Другие примеры коррелированных подзапросов будут приведены в следую-
щем разделе.
Подзапросы и функция EXISTS
Функция exists принимает внутренний запрос в качестве аргумента и воз-
вращает истину, если внутренний запрос возвращает одну или более строк, и
206
Часть II. Язык Transact-SQL
возвращает ложь, если запрос вернет ноль строк. Эта функция будет рассмот-
рена с использованием примеров.
= Пример 6.66
Получение фамилий всех служащих, работающих над проектом pl:
USE sample;
SELECT emp_lname
FROM employee
WHERE EXISTS
(SELECT *
FROM works_on
WHERE employee.emp_no = works_on.emp_no
AND project_no = 'pl');
Результат:
Jones
James
Bertoni
Moser
Внутренний запрос в функции exists почти всегда зависит от переменной из
внешнего запроса. По этой причине функция exists обычно задает коррели-
рованный подзапрос.
Давайте посмотрим, как Database Engine может обрабатывать запрос в при-
мере 6.66. Во-первых, внешний запрос просматривает первую строку табли-
цы employee (Smith). Затем выполняется функция exists для определения то-
го, существуют ли строки в таблице works_on, для которых номер служащего
соответствует текущей строке из внешнего запроса и у которых project_no
равняется pl. Поскольку мистер Smith не работает над проектом pl, результа-
том внутреннего запроса будет пустое множество, и функция exists вернет
ложь. Поэтому служащий с фамилией Smith не принадлежит результирую-
щему набору. Используя этот процесс, проверяются все строки таблицы
employee, а затем отображается результат.
В примере 6.67 показано использование функции not exists.
! Пример 6.67
Получение фамилий всех служащих, которые работают в отделах, не распо-
ложенных в Сиэтле:
Глава 6. Запросы 207
USE sample;
SELECT emp_lname
FROM employee
WHERE NOT EXISTS
(SELECT *
FROM department
WHERE employee.dept_no = department.dept_no
AND location = 'Seattle');
Результат:
emp_lname
Smith
Jones
Barrimore
Moser
Для списка выбора оператора select, который является внешним запросом,
включающим функцию exists, не рекомендуется использовать форму select *,
как было в предыдущем примере. Альтернативной формой является форма
select список_столбцов, где список_столбцов — один или более столбцов таб-
лицы. Обе формы эквивалентны, потому что функция exists проверяет толь-
ко лишь существование (в данном случае отсутствие) строк в результирую-
щем наборе. По этой причине использование select * в данном случае явля-
ется более защищенным.
Должны вы использовать соединения
или подзапросы?
Почти что все операторы select, в которых выполняется соединение таблиц
и используется оператор join, могут быть переписаны в виде подзапросов и
наоборот. Написание оператора select, использующего оператор соединения,
обычно является более простым для чтения и восприятия, а также может по-
мочь Database Engine в поиске наиболее эффективной стратегии выборки
нужных данных. Однако существует несколько проблем, которые проще мо-
гут быть решены при использовании подзапросов. Также могут существовать
иные проблемы, которые проще решить при помощи соединений.
Преимущества подзапросов
Подзапросы имеют преимущество относительно соединений, когда вам нуж-
но быстро вычислять агрегатные значения и использовать их во внешних за-
просах для выполнения сравнения. Пример 6.68 демонстрирует это.
208
Часть II. Язык Transact-SQL
j Пример 6.68
Получение номеров служащих и дат начала работы для всех служащих, у ко-
торых дата начала работы равна самой ранней дате:
USE sample
SELECT emp_no, enter_date
FROM works_on
WHERE enter_date = (SELECT min(enter_date)
FROM works_on);
Эта проблема не может быть просто решена при использовании соединения,
потому что вам нужно написать агрегатную функцию в предложении where, а
это недопустимо. (Вы можете решить эту проблему, используя два раздель-
ных запроса к таблице works on.)
Преимущества соединений
Соединения имеют преимущества над подзапросами, если список выбора
select в запросе содержит столбцы более чем из одной таблицы (при-
мер 6.69).
; Пример 6.69
Получение номеров служащих, фамилий и работ для всех служащих, которые
приступили к работе над проектами 15 октября 2007 г.:
USE sample;
SELECT employee.emp_no, emp_lname, job
FROM employee, works_on
WHERE employee.emp_no = works_on.emp_no
AND enter_date = '10.15.2007';
Список выбора select в запросе примера 6.69 содержит столбцы emp no и
emp_lname из таблицы employee и столбец job из таблицы works_on. По этой
причине эквивалентное решение при использовании подзапроса приведет
к выдаче сообщения об ошибке, потому что подзапросы могут отображать
информацию только из внешней таблицы.
Табличные выражения
Табличные выражения являются подзапросами, которые используются там,
। где ожидается появление таблицы.
Глава 6. Запросы
209
Существуют два типа табличных выражений:
♦ наследуемые таблицы;
♦ общие табличные выражения.
Наследуемые таблицы
Наследуемая таблица является выражением для таблицы, которое появляется
в предложении from запроса. Вы можете обращаться к наследуемым табли-
цам, когда использование псевдонимов столбцов невозможно по той причи-
не, что другое предложение обрабатывается транслятором SQL до того, как
станут известны псевдонимы имен. В примере 6.70 демонстрируется попытка
использования псевдонима столбца, где другое предложение обрабатывается
до того, как станет известным псевдоним этого имени.
i Пример 6.70. Пример неверного оператора
Получение всех существующих групп месяцев из значений столбца
enter_date таблицы works_on:
USE sample;
SELECT MONTH(enter_date) as enter_month
FROM works_on
GROUP BY enter_month;
Результатом будет сообщение:
Message 207: Level 16, State 1, Line 4
The invalid column 'enter_month'
(Неверный столбец 'enterjmonth')
Причина появления этого сообщения об ошибке заключается в том, что пред-
ложение group by обрабатывается до обработки соответствующего списка
select, и имя псевдонима enter_month не известно во время процесса группи-
рования. ’
При использовании наследуемой таблицы, которая содержит предыдущий
запрос (без предложения group by), вы должны решить эту проблему, потому
что предложение from выполняется перед предложением group by (при-
мер 6.71).
j Пример 6.71
USE sample;
SELECT enter_month
210
Часть II. Язык Transact-SQL
FROM (SELECT MONTH(enter_date) as enterjnonth
FROM works_on) AS m
GROUP BY enter_month;
Результат:
enter_month
2
6
8
10
11
12
Как правило, допустимо записывать табличное выражение в любом месте
оператора select, где может появиться имя таблицы. Результатом табличного
выражения всегда является таблица или, в особом случае, выражение. В при-
мере 6.72 показано использование табличного выражения в списке выбора
SELECT.
1 Пример 6.72
USE sample;
SELECT w.job, (SELECT e.emp_lname
FROM employee e WHERE e.emp_no = w.emp_no) AS name
FROM works_on w
WHERE w.job IN ('Manager', 'Analyst');
Результат:
job name
Analyst Jones
Manager Jones
Analyst Hansel
Manager Bertoni
Общие табличные выражения
Общее табличное выражение (ОТВ— Common Table Expression, СТЕ) яв-
ляется именованным выражением таблицы, которое поддерживается Tran-
sact-SQL.
Гпава 6. Запросы 211
Существуют два типа запросов, которые используют СТЕ:
♦ нерекурсивные запросы;
♦ рекурсивные запросы.
Следующие разделы описывают оба типа запросов.
Замечание____________________________________________________
Этот раздел также описывает оператор apply, потому что его использует СТЕ
в некоторых нерекурсивных и рекурсивных запросах.
ОТВ и нерекурсивные запросы
Нерекурсивная форма ОТВ может быть использована как альтернатива на-
следуемым таблицам и представлениям. Обычно ОТВ определяются с ис-
пользованием оператора with и дополнительного запроса, который ссылается
на имя, используемое в with (см. пример 6.74).
Замечание____________________________________________________
Ключевое слово with является двусмысленным в языке Transact-SQL. Для уст-
ранения двусмысленности вы должны использовать точку с запятой (;) для за-
вершения оператора, предшествующего оператору with.
Примеры 6.73 и 6.74 используют базу данных AdventureWorks для демонстра-
ции того, как ОТВ могут быть использованы в нерекурсивных запросах.
Пример 6.73 использует "подходящие" средства, в то время как пример 6.74
решает ту же самую проблему через нерекурсивный запрос.
Замечание____________________________________________________
Если у вас нет в вашей системе базы данных AdventureWorks, вы можете за-
грузить ее cwww.codeplex.com/MSFTDBProdSamples.
i Пример 6.73
USE AdventureWorks;
SELECT SalesOrderlD
FROM Sales.SalesOrderHeader
WHERE TotalDue > (SELECT AVG(TotalDue)
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = '2002')
AND Freight > (SELECT AVG(TotalDue)
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = '2002') / 2.5;
212
Часть II. Язык Transact-SQL
Запрос в примере 6.73 отыскивает общие суммы, чьи значения больше, чем
среднее значение всех сумм, и чьи величины превышают 40% средних значе-
ний всех сумм.
Основное свойство этого запроса в том, что он убирает пустые значения, по-
тому что внутренний запрос записан дважды. Одним из способов сокращения
синтаксиса запроса является создание представления, содержащего внутрен-
ний запрос, но это слишком запутано, поскольку вам нужно создавать пред-
ставление, а потом удалять его, когда вы выполните запрос. Лучшим спосо-
бом является создание ОТВ. В примере 6.74 показано использование нере-
курсивного ОТВ, которое сокращает определение запроса в примере 6.73.
\ Пример 6.74
USE AdventureWorks;
WITH price_calc(year_2002) AS
(SELECT AVG(TotalDue)
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = ’2002')
SELECT SalesOrderlD
FROM Sales.SalesOrderHeader
WHERE TotalDue > (SELECT year_2002 FROM price_calc)
AND Freight > (SELECT year_2002 FROM price_calc) / 2.5;
Синтаксис предложения with при нерекурсивном запросе:
WITH cte_name (columnlist) AS
(inner_query)
outer_query
Здесь cte_name — имя ОТВ, которое задает результирующую таблицу. Спи-
сок столбцов, которые принадлежат табличному выражению, записан в скоб-
ках. (ОТВ в примере 6.74 называется price calc и имеет один столбец,
year 2002.) inner query в синтаксисе ОТВ определяет оператор select, кото-
рый задает результирующий набор соответствующего табличного выраже-
ния. После этого вы можете использовать определенное табличное выраже-
ние во внешнем запросе. Внешний запрос в примере 6.74 использует ОТВ,
называемое price_calc, и его столбец уеаг_2002 для упрощения внутреннего
запроса, который появляется дважды.
ОТВ и рекурсивные запросы
Материал в этом подразделе довольно сложен. Поэтому рекомендуется про-
пустить его при первом чтении книги.
Глава 6. Запросы 213
Вы можете использовать ОТВ для реализации рекурсии, потому что ОТВ мо-
гут содержать ссылки на самих себя. Основной синтаксис ОТВ для рекурсив-
ных запросов:
WITH ctename (column_list) AS
(anchor_member
UNION ALL
recursive_member)
outer query
Здесь cte name и column list имеют то же самое значение, что и ОТВ для не-
рекурсивных запросов. Тело предложения with содержит два запроса, кото-
рые связаны с оператором union all. Первый запрос будет вызван только
один раз, он запускается для аккумулирования результата рекурсии. Первый
операнд в union all не ссылается на ОТВ (см. пример 6.75). Этот запрос на-
зывается опорным запросом или источником.
Второй запрос содержит ссылку на ОТВ и представляет рекурсивную часть.
По этой причине он называется рекурсивным членом. При первом вызове ре-
курсивной части ссылка на ОТВ представляет результат опорного запроса.
Рекурсивный член использует результат запроса первого вызова. После этого
система повторяет вызовы рекурсивной части. Вызов рекурсивного члена за-
вершается, когда результат предыдущих вызовов будет пустым множеством.
Оператор union all соединяет аккумулированные строки до тех пор, пока
дополнительные строки добавляются в текущие вызовы. (Включение union
all означает, что дубликаты строк будут удалены из результата.)
Под конец outer query задает спецификацию запроса, который использует
ОТВ для отыскания всех вызовов объединения обоих членов.
Определение таблицы в примере 6.75 будет использовано для демонстрации
рекурсивной формы ОТВ.
; Пример 6.75
USE sanpie;
CREATE TABLE airplane
(containing_assembly VARCHAR(10),
contained_assembly VARCHAR(10),
quantity_contained INT,
unit_cost DECIMAL (6, 2) ) ;
insert into airplane values ( 'Airplane', 'Fuselage', 1, 10);
insert into airplane values ( 'Airplane', 'Wings', 1, 11);
insert into airplane values ( 'Airplane', 'Tail', 1, 12);
insert into airplane values ( 'Fuselage', 'Cockpit', 1, 13);
insert into airplane values ( ’Fuselage', 'Cabin', 1, 14);
214
Часть II. Язык Transact-SQL
insert into airplane values ( 'Fuselage', 'Nose', 1, 15);
insert into airplane values ( 'Cockpit', NULL, 1, 13);
insert into airplane values ( 'Cabin', NULL, 1, 14);
insert into airplane values ( 'Nose', NULL, 1, 15);
insert into airplane values ( 'Wings', NULL, 2, 11);
insert into airplane values ( 'Tail', NULL, 1, 12);
Таблица airplane содержит четыре столбца. Столбец containing_assenibly за-
дает сборку, тогда как столбец contained_assembly содержит части (одна за
другой), которые составляют соответствующую сборку. На рис. 6.1 дано гра-
фическое представление самолета с его составными частями.
| Airplane~j
Рис. 6.1. Представление самолета и его частей
Предположим, что таблица airplane содержит 11 строк, которые показаны
в табл. 6.2. Оператор insert добавляет эти строки в таблицу airplane.
Таблица 6.2. Содержимое таблицы airplane
Airplane Fuselage 1 10
Airplane Wings 1 11
Airplane Tail 1 12
Fuselage Cockpit 1 13
Fuselage Cabin 1 14
Fuselage Nose 1 15
Cockpit NULL 1 13
Cabin NULL 1 14
Nose NULL 1 15
Wings NULL 2 11
Tail NULL 1 12
В примере 6.76 показано использование предложения with для задания запро-
са, который вычисляет общую стоимость каждой сборки.
Гпава 6. Запросы
215
• Пример 6.76
USE sample;
WITH list_of_parts(assembly!, quantity, cost) AS
(SELECT containing_assembly, quantity_contained, unit_cost
FROM airplane
WHERE contained_assembly IS NULL
UNION ALL
SELECT a.containing_assembly, a.quantity_contained,
CAST (1. quantity * l.cost AS DECIMALS, 2))
FROM list_of_parts 1, airplane a
WHERE 1.assembly! = a.contained_assembly)
SELECT * FROM list_of_parts;
Предложение with определяет ОТВ с именем listofjparts, которое содер-
жит три столбца: assembly, quantity и cost. Первый оператор select в приме-
ре 6.76 будет вызван только один раз для аккумулирования результатов пер-
вого шага в рекурсивном процессе.
Оператор select в последней строке примера 6.76 отображает следующий
результат:
Assembly Quantity Costs
Cockpit 1 13,00
Cabin 14.00
Nose 1 16.500
Wings 2 11.00
Tail 1 12.00
Airplane 12.00
Airplane 1 22.00
Fuselage 16.500
Airplane 1 16.500
Fuselage 14.00
Airplane 1 14.00
Fuselage 13.00
Airplane 1 13.00
Первые пять строк в этом наборе показывают результирующий набор первого
вызова опорного члена запроса в примере 6.67. Все остальные строки явля-
ются результатом рекурсивного члена (вторая часть) запроса в том же приме-
ре. Рекурсивный член запроса будет вызван дважды: первый раз для сборки
фюзеляжа, а второй раз для самого самолета.
Запрос в примере 6.77 будет использован для получения стоимости каждой
сборки со всеми ее составными элементами.
216
Часть II, Язык Transact-SQL
j Пример 6.77
USE sample;
WITH list ofjparts(assembly, quantity, cost) AS
(SELECT containing_assembly, quantity_contained, unit_cost
FROM airplane
WHERE contained_assembly IS NULL
UNION ALL
SELECT a.containingassembly, a.quantity_contained,
CAST(1.quantity * l.cost AS DECIMAL(6, 2))
FROM list_of_parts 1, airplane a
WHERE 1.assembly = a.contained__assembly )
SELECT assembly, SUM(quantity) parts, SUM(cost) sum_cost
FROM list_of_parts
GROUP BY assembly;
Результат выполнения запроса примера 6.77 будет следующим:
Assembly Parts Sum_cost
Airplane 5 76.00
Cabin 1 14.00
Cockpit 1 13.00
Fuselage 3 42.00
Nose 1 16.500
Tail 1 12.00
Wings 2 11.00
Существует несколько ограничений для ОТВ в рекурсивных запросах:
♦ определение ОТВ должно содержать как минимум два оператора select
(опорный член и один рекурсивный член), совмещенные с оператором
UNION all;
♦ количество столбцов в опорном и рекурсивном члене должно быть одним
и тем же (это является прямым следствием использования оператора union
all);
♦ тип данных столбца в рекурсивном члене должен быть тем же самым, что
и тип данных соответствующего столбца в опорном члене;
♦ предложение from рекурсивного члена должно ссылаться только один раз
на имя ОТВ;
♦ следующие опции недопустимы в определении части рекурсивного члена:
select distinct, group by, having, агрегатные функции, top, подзапросы.
(Кроме того, оператором соединения, который допустим в определении
запроса, является только оператор внутреннего соединения.)
Гпава 6. Запросы
217
Оператор APPLY.
Оператор apply похож на рекурсивные запросы, потому что он использует
ОТВ тем же самым образом. Этот оператор позволяет вам вызывать функ-
цию, принимающую в виде параметров таблицу, для каждой строки, возвра-
щенной выражением внешней таблицы или запросом. Функция с параметра-
ми в виде таблицы действует как правый ввод, а выражение внешней табли-
цы— как левый ввод. Правый ввод обрабатывается для каждой строки
левого ввода, и полученные строки комбинируются для окончательного вы-
вода. Список столбцов, созданных оператором apply, является множеством
столбцов левого ввода, за которым следует список столбцов, возвращенных
правым вводом. Подробное описание оператора apply см. в главе 8.
Резюме
В этой главе рассматривались все возможности оператора select, касающие-
ся поиска данных в одной или более таблицах. Каждый оператор select, ко-
торый отыскивает данные в таблице, должен содержать, по меньшей мере,
список выбора и предложение from. Предложение from задает таблицу (таб-
лицы), в которой отыскиваются данные. Наиболее важным является необяза-
тельное предложение where, содержащее одно или более условий, которые
могут комбинироваться с использованием логических операторов and, or, not.
Следовательно, условия в предложении where задают ограничения на выби-
раемые строки.
Упражнения
i Упражнение 6.1
Получите все строки таблицы works on.
I Упражнение 6.2
Получите номера служащих для всех клерков (Clerk).
| Упражнение 6.3
Получите номера служащих, работающих над проектом р2 и имеющих номер
служащего меньше 10 000. Решите эту задачу при помощи двух различных,
но эквивалентных операторов select.
218 Часть II. Язык Transact-SQL
TTTZZZ.... .... . .........._........___----------------------_
; Упражнение 6.4
Получите номера служащих, которые не приступили к работе над их проек-
J том в 2007 г.
\ Упражнение 6.5
Получите номера служащих, которые имеют должности лидеров (т. е. Analyst
или Manager) в проекте pl.
| Упражнение 6.6
Получите даты работы над проектом р2 для всех служащих, у которых пока
еще не определена должность (job).
j Упражнение 6.7
Получите номера и фамилии всех служащих, чьи имена содержат две бук-
вы "t".
• Упражнение 6.8
Получите номера и имена всех служащих, чьи фамилии содержат букву "о"
или "а" в качестве второго символа и заканчиваются буквами "es".
j Упражнение 6.9
Найдите номера всех служащих, чьи отделы находятся в Сиэтле (Seattle).
( Упражнение 6.10
Найдите имена и фамилии всех служащих, кто приступил к работе с их про-
ектами 04.01.2007.
г——тужаия;жмр
Упражнение 6.11
Сгруппируйте все отделы с использованием их местоположения.
I Упражнение 6.12
В чем разница между предложениями distinct и group by?
Глава 6. Запросы 219
Упражнение 6.13
Как предложение group by обрабатывает значения null? Соответствует ли это
общей трактовке таких значений?
| Упражнение 6.14
В чем разница между count (*) и count (столбец)? । ( (io iq |\) L'
i Упражнение 6.15
Найдите наибольший номер служащего.
= Упражнение 6.16
Получите должности (job), которые были назначены более чем двоим слу-
жащим.
Упражнение 6.17
Найдите номера всех служащих, которые являются клерками (Clerk) или ра-
ботают в отделе d3.
1 Упражнение 6.18
Почему следующий оператор является ошибочным?
SELECT project_name
FROM project
WHERE project_no =
(SELECT project_no FROM workson WHERE Job = 'Clerk')
Напишите корректную синтаксическую форму для этого оператора.
Упражнение 6.19
Каково практическое использование временных таблиц?
i Упражнение 6.20
В чем отличие между глобальными и локальными временными таблицами?
Напишите все решения, связанные с упражнениями, которые используют
операцию соединения при явном задании синтаксиса соединения.
220
Часть II. Язык Transact-SQL
I Упражнение 6.21
Для таблиц project и works_on создайте операторы для получения следую-
щего:
♦ естественное соединение;
♦ декартово произведение.
; Упражнение 6.22
Если вы собираетесь соединить несколько таблиц в запросе (скажем, п таб-
лиц), сколько условий соединения вам потребуется?
' Упражнение 6.23
Получите номера служащих и названия их должностей (job) для всех служа-
щих, работающих над проектом Gemini.
। Упражнение 6.24
Получите имена и фамилии всех служащих, которые работают в отделе
Research или Accounting.
I Упражнение 6.25
Получите даты начала работы для всех клерков (Clerk), которые принадлежат
отделу dl.
, Упражнение 6.26
Получите названия проектов, в которых работают два или более клерка.
= Упражнение 6.27
Получите имена и фамилии всех служащих, являющихся менеджерами и ко-
торые работают над проектом Mercury.
; Упражнение 6.28
Получите имена и фамилии всех служащих, которые приступили к работе над
проектом в то же время, что и как минимум еще один служащий.
Гпава 6. Запросы 221
; Упражнение 6.29
Получите номера тех служащих, которые живут в том же самом месте и ра-
ботают в том же самом отделе, что и кто-то из других служащих. (Совет: ис-
пользуйте расширенную базу данных sample.)
j Упражнение 6.30
Получите номера всех служащих, работающих в отделе Marketing. Найдите
два эквивалентных решения при использовании:
♦ оператора join;
♦ коррелированного подзапроса.
ГЛАВА 7
Изменение
содержимого таблиц
В дополнение к оператору select, который был описан в главе 6, существуют
три других оператора DML: insert, update и delete. Как и оператор select,
эти три оператора модификации оперируют либо таблицами, либо представ-
лениями. В данной главе обсуждаются эти операторы в работе с таблицами и
даются примеры их использования. Дополнительно рассматриваются два
других оператора: truncate table и merge. В то время как оператор truncate
table является расширением в языке Transact-SQL стандарта SQL, оператор
merge— новая и стандартизованная возможность в SQL Server 2008. В конце
главы рассматривается предложение output и приводится несколько приме-
ров его использования.
Оператор INSERT
Оператор insert добавляет строки (или части строк) в таблицу. Он имеет две
различные формы:
INSERT [INTO] tab_name I <,col_list) ]
DEFAULT VALUES | VALUES ({DEFAULT | NULL | expression} [, ...]);
INSERT INTO tab_name I view_name [(col_list)]
[оператор_выборки I выполняемый_оператор}
При использовании первой формы только одна строка (или ее часть) добавля-
ется в таблицу tab_name. Во второй форме оператор insert добавляет резуль-
тирующий набор, полученный от оператора select или от хранимой процеду-
ры, которая выполняется при использовании оператора execute. Хранимая
процедура должна вернуть данные, которые затем добавляются в таблицу.
Оператор select может выбирать значения из другой или той же самой таб-
Гпава 7. Изменение содержимого таблиц
лицы в качестве источника данных для оператора insert, если типы данных
столбцов совместимы.
В обеих формах оператора каждое добавляемое значение должно иметь тип
данных, совместимый с типом данных соответствующего столбца таблицы.
Для обеспечения совместимости все символьные значения и данные да-
ты/времени должны заключаться в апострофы, в то время как числовые зна-
чения не требуют никаких апострофов.
Добавление одной строки
В обеих формах оператора insert явное задание списка столбцов не является
обязательным. Это означает, что отсутствие списка столбцов эквивалентно
заданию списка всех столбцов таблицы.
Опция default values позволяет добавить значения по умолчанию во все
столбцы таблицы. Если столбец имеет тип данных timestamp или содержит в
описании свойство identity, то в него будет добавлено значение, автоматиче-
ски созданное системой. Для других типов данных столбец устанавливается в
непустое значение по умолчанию, если в описании столбца таблицы задано
значение по умолчанию, или в null, если такое значение не задано. Если
столбец не допускает пустого значения и для него не указано значение
default, то оператор insert выполнен не будет, выдается ошибка.
В примерах 7.1—7.4 добавляются строки в четыре таблицы базы данных
sample. Эти действия демонстрируют использование оператора insert для
загрузки небольшого объема данных в базу данных.
' Пример 7.1
Загрузка данных в таблицу employee:
USE sample;
INSERT INTO employee VALUES
INSERT INTO employee VALUES
INSERT INTO employee VALUES
INSERT INTO employee VALUES
INSERT INTO employee VALUES
INSERT INTO employee VALUES
INSERT INTO employee VALUES
(25348, 'Matthew', 'Smith', 'd3’J
(10102, 'ton', 'Jones', 'd3');
(18316, 'John', 'Barrimore', ’dl’
(29346, 'James', 'James', 'd2');
(9031, 'Elsa', 'Bertoni', 'd2');
(2581, 'Elke', 'Hansel', 'd2');
(28559, 'Sybill', 'Moser', 'dl');
I Пример 7.2
Загрузка данных в таблицу department:
USE sample;
INSERT INTO department VALUES ('dl', 'Research', 'Dallas');
224
Часть II. Язык Transact-SQL
INSERT INTO department VALUES Cd2', 'Accounting', 'Seattle');
INSERT INTO department VALUES ('d3'. 'Marketing', 'Dallas');
l Пример 7.3
Загрузка данных, в таблицу project:
USE sample;
INSERT INTO project VALUES ('pl', 'Apollo', 120000.00);
INSERT INTO project VALUES Cp2', 'Gemini', 95000.00);
INSERT INTO project VALUES ('p3', 'Mercury', 186500.00);
J Пример 7.4
Загрузка данных в таблицу works_on:
USE sample;
INSERT INTO works_on VALUES (10102,'pl', 'Analyst', '2006.10.1');
INSERT INTO works_on VALUES (10102, 'p3', 'Manager', '2008.1.1');
INSERT INTO works_on VALUES (25348, 'p2', 'Clerk', '2007.2.15');
INSERT INTO works_on VALUES (18316, 'p2', NULL, '2007.6.1');
INSERT INTO works_on VALUES (29346, 'p2', NULL, '2006.12.15');
INSERT INTO works_on VALUES (2581, 'p3', 'Analyst', '2007.10.15');
INSERT INTO works_on VALUES (9031, 'pl', 'Manager', '2007.4.15');
INSERT INTO works_on VALUES (28559, 'pl', 'NULL', '2007.8.1');
INSERT INTO works_on VALUES (28559, 'p2', 'Clerk', '2008.2.1');
INSERT INTO works_on VALUES (9031, 'p3', 'Clerk', '2006.11.15');
INSERT INTO works_on VALUES (29346, 'pl','Clerk', '2007.1.4');
Существует несколько отличающихся способов добавления значений в новые
строки. Примеры 7.5—7.7 показывают такие возможности.
( Пример 7.5
USE sample;
INSERT INTO employee VALUES (15201, 'Dave', 'Davis', NULL) ;
Оператор insert в примере 7.5 соответствует операторам insert в приме-
рах 7.1—7.4. Явное использование ключевого слова null позволяет добавить
пустое значение в соответствующий столбец.
Добавление значения в некоторые (но не во все) столбцы таблицы обычно
требует явного задания имен соответствующих столбцов. Опущенные столб-
цы либо должны допускать пустое значение, либо должны иметь значение по
умолчанию.
Гпава 7. Изменение содержимого таблиц
225
Пример 7.6
USE sample;
INSERT INTO employee (emp_no, emp_fname, emp_lname)
VALUES (15201, 'Dave', 'Davis');
Примеры 7.5 и 7.6 эквивалентны. Столбец dept_no является единственным
столбцом, допускающим пустые значения в таблице employee, потому что все
другие столбцы таблицы employee были объявлены с предложением not null в
операторе create table.
Порядок имен столбцов в предложении value оператора insert может отли-
чаться от оригинального порядка столбцов, который был определен в опера-
торе create table. В этом случае абсолютно необходимо задать список
столбцов в новом порядке.
; Пример 7.7
USE sample;
INSERT INTO employee (emp_lname, emp_fname, dept_no, emp_no)
VALUES ('Davis', 'Dave', 'dl', 15201);
Добавление множества строк
Вторая форма оператора insert добавляет одну строку или несколько строк,
полученных из подзапроса.
В примере 7.8 показано, как множество строк может быть добавлено в табли-
цу при использовании второй формы оператора insert.
I Пример 7.8
Получение всех номеров и названий подразделений, расположенных в Далла-
се, и загрузка выбранных данных в новую таблицу:
USE sample;
CREATE TABLE dallas_dept
(deptno CHAR(4) NOT NULL,
dept_name CHAR(20) NOT NULL);
INSERT INTO dallas_dept (dept_no, dept_name)
SELECT dept_no, dept_name
FROM department
WHERE location = 'Dallas';
226
Часть II. Язык Transact-SQL
Новая таблица daiias_dept, создаваемая в примере 7.8, имеет те же самые
столбцы, что и таблица department, за исключением столбца location. Подза-
прос в операторе insert выбирает все строки со значением Dallas в столбце
location. Выбранные строки последовательно добавляются в новую таблицу.
Содержимое таблицы daiias_dept может быть получено при помощи сле-
дующего оператора select:
SELECT * FROM dallas_dept;
Результат:
dept_no dept_name
dl Research
d3 Marketing
Пример 7.9 тоже показывает, как может быть добавлено множество строк с
использованием второй формы оператора insert.
= Пример 7.9
Получение номеров служащих, номеров проектов и даты начала работы над
проектом для всех клерков (job = 'Clerk'), которые работают в проекте р2, и
помещение выбранных данных в новую таблицу:
USE sample;
CREATE TABLE clerk_t
(emp_no INT NOT NULL,
proj ect_no CHAR(4),
enter_date DATE);
INSERT INTO clerk_t (emp_no, project_no, enter_date)
SELECT emp_no, project_no, enter_date
FROM works_on
WHERE job = 'Clerk'
AND project_no = 'p2';
Новая таблица cierk t содержит следующие строки:
ernp_no project_no enter_date
25348 p2 2007-02-15
28559 p2 2008-02-01
Таблицы daiias_dept и cierk_t (примеры 7.8 и 7.9) были пустыми до того,
как оператором insert в них были добавлены строки. Однако если бы табли-
цы уже существовали, и в них содержались бы данные, новые строки были
бы добавлены к существующим.
Гпава 7. Изменение содержимого таблиц 227
Замечание_____________________________________________________
Вы можете переместить оба оператора (create table и insert) в пример 7.9
вместе с оператором select и предложением into (см. пример 6.42).
Конструкторы значений таблицы
и оператор INSERT
SQL Server 2008 вводит новую возможность, называемую конструктором
значения таблицы (или столбца), которая позволяет вам присваивать отдель-
ные кортежи (строки) оператору DML, такому как insert или delete. В при-
мере 7.10 показано, как вы можете присваивать отдельные строки, используя
подобный конструктор с оператором insert.
j Пример 7.10
USE sample;
INSERT INTO department
VALUES ('d4', 'Human Resources', 'Chicago'),
Cd5'
Cd6'
'Distribution', 'New Orleans'),
'Sales', 'Chicago');
Оператор insert в примере 7.10 за один раз добавляет три строки в таблицу
department, используя конструктор значения таблицы. Как вы можете видеть
из этого примера, синтаксис конструктора достаточно простой. Для исполь-
зования конструктора значения таблицы задайте список значений каждой
строки, заключенных в круглые скобки, и отделяя один список от другого
запятой.
Оператор UPDATE
Оператор update изменяет значения в строках таблицы. Этот оператор имеет
следующую общую форму:
UPDATE tab_name
{ SET column_l = (expression I DEFAULT I NULL}} [, . ..n]
[FROM tab_namel [, ...n]]
[WHERE condition]
Строки в таблице tab name изменяются в соответствии с предложением where.
Для каждой изменяемой строки оператор update изменяет значения столбцов
в предложении set, присваивая соответствующим столбцам константы (или,
228
Часть II. Язык Transact-SQL
в общем случае, выражения). Если предложение where отсутствует, оператор
update изменяет все строки таблицы. (Предложение from будет рассматри-
ваться позже в этом разделе.)
Замечание______________________________________________________
Оператор update может изменять данные только в одной таблице.
Рассмотрим пример 7.11.
^Пример 7.11
Установление должности служащему с номером 18 316, работающему над
проектом р2, в значение Manager:
USE sample;
UPDATE works_on
SET job = 'Manager'
WHERE emp_no = 18316
AND project_no = 'p2';
Здесь оператор update изменяет в точности одну строку таблицы works_on,
потому что комбинация столбцов emp_no и project no является первичным
ключом этой таблицы, и по этой причине она уникальна. Этот пример изме-
няет должность служащего, которая до этого была неизвестна (значение было
установлено в null).
Пример 7.12 заменяет строки таблицы на значения, представленные выраже-
нием.
I Пример 7.12
Изменение бюджета всех проектов для представления сумм в британских
фунтах стерлингов. Текущий курс обмена — 0.51 € за $ I.
USE sample;
UPDATE project
SET budget = budget * 0.51;
В этом примере будут изменены все строки таблицы project, потому что
в операторе отсутствует предложение where. Измененные строки таб-
лицы project могут быть отображены с помощью следующего оператора
Transact-SQL:
SELECT * FROM project;
Гпава 7. Изменение содержимого таблиц
229
Результат:
project_no proj ect_name budget
Pl Apollo 61200
Р2 Gemini 48450
РЗ Mercury 95115
| Пример 7.13
В связи с болезнью миссис Джонс устанавливаются в null все ее должности
для всех проектов:
USE sample;
UPDATE works_on
SET job = NULL
WHERE emp_no IN (SELECT emp_no
FROM employee
WHERE emp_lname = 'Jones');
Пример 7.13 использует внутренний запрос в предложении where оператора
update. По причине использования оператора in результат данного запроса
может содержать более одной строки.
Результаты примера 7.13 могут быть также получены при помощи предложе-
ния from в операторе update. Предложение from содержит имена таблиц, ко-
торые включены в оператор update. Все эти таблицы должны быть последо-
вательно соединены (join). В примере 7.14 показано использование предло-
жения from. Этот пример идентичен предыдущему.
Замечание_______________________________________________________
Предложение FROM является расширением в языке Transact-SQL стандарта
ANSI SQL
г Пример 7.14
USE sample;
UPDATE works_on
SET job = NULL
FROM works_on, employee
WHERE emp_lname = 'Jones'
AND works__on.emp_no = employee.emp_no;
Пример 7.15 иллюстрирует использование выражения case в операторе
update. Подробное обсуждение этого выражения см. в главе 6.
230
Часть II. Язык Transact-SQL
j Пример 7.15
Бюджет каждого проекта должен быть увеличен на несколько процентов
(20, Ю или 5) в зависимости от его предыдущего денежного значения. Проек-
ты с меньшим бюджетом будут увеличены на большее количество про-
центов.
USE sample;
UPDATE project
SET budget = CASE
WHEN budget > 0 and budget < 100000 THEN budget * 1.2
WHEN budget >= 100000 and budget < 200000 THEN budget * 1.1
ELSE budget * 1.05
END;
Оператор DELETE
Оператор delete удаляет из таблицы строки. Этот оператор имеет две раз-
личные формы:
DELETE FROM table_name
[WHERE predicate];
DELETE table__name
FROM table_name [, ...]
[WHERE condition];
Все строки, которые удовлетворяют условию в предложении where, будут
удалены. Нет необходимости (и не требуется) явно указывать столбцы в опе-
раторе delete, потому что оператор delete оперирует строками, а не столб-
цами.
Рассмотрим пример 7.16.
'^Пример 7.16.............. _ ..............
Удаление всех менеджеров из таблицы works_on:
USE sample;
DELETE FROM works_on
WHERE job = 'Manager';
Предложение where в операторе delete может содержать внутренний запрос
(пример 7.17).
Гпава 7. Изменение содержимого таблиц
231
j Пример 7.17
Миссис Мозер в отпуске. Удаление в базе данных всех строк, связанных
с ней:
USE sample;
DELETE FROM works_on
WHERE emp_no IN
(SELECT emp__no
FROM employee
WHERE emp_lname = 'Moser');
DELETE FROM employee
WHERE emp_lname = 'Moser';
Пример 7.17 также может быть переформулирован с использованием пред-
ложения from, как показано в примере 7.18. Это предложение имеет ту же се-
мантику, что и предложение from в операторе update.
! Пример 7.18
USE sample;
DELETE works on
FROM workson, employee
WHERE works_on.empno = employee.emp_no
AND emp—Iname = 'Moser';
DELETE FROM employee
WHERE emp_lname = 'Moser';
Использование предложения where в операторе delete является необязатель-
ным. Если предложение where отсутствует, то удаляются все строки таблицы
(пример 7.19).
Пример 7.19
USE sample;
DELETE FROM works_on;
Замечание______________________________________________________
Есть существенная разница между операторами delete и drop table. Опера-
тор delete удаляет (частично или полностью) содержимое таблицы, тогда как
оператор drop table удаляет и содержимое, и схему таблицы. Следовательно,
после выполнения оператора delete таблица продолжает существовать в базе
данных (хотя, возможно, с нулевым количеством строк), однако после выполне-
ния drop table таблицы больше не существует.
232
Часть II. Язык Transact-SQL
Оператор TRUNCATE TABLE
Язык Transact-SQL также поддерживает оператор truncate table. Этот опе-
ратор предоставляет "быстрое выполнение" версии оператора delete, не со-
держащего предложения where. Оператор truncate table удаляет все строки
таблицы гораздо быстрее, чем это сделает оператор delete, потому что он
удаляет содержимое таблицы страница за страницей, в то время как delete
удаляет содержимое строка за строкой.
Замечание____________________________________________________
Оператор truncate table является расширением в языке Transact-SQL стан-
дарта SQL.
Оператор truncate table имеет следующую форму:
TRUNCATE TABLE table_name
Замечание____________________________________________________
Если вам нужно удалить все строки таблицы, используйте оператор truncate
table. Этот оператор выполняется значительно быстрее, чем delete, потому
что у него минимальное количество подключений к базе данных и помещается
очень мало записей в протокол транзакций в процессе его выполнения. Под-
ключения детально обсуждаются в главе 13.
Предложение OUTPUT
Результат выполнения операторов insert, update или delete всегда содержит
только текст, в котором присутствуют только сведения о количестве изме-
ненных строк (например, "3 rows deleted"— "Удалено 3 строки"). Если со-
держимое такого результата вас не устраивает, вы можете использовать
предложение output, которое позволяет явно отображать строки, которые бы-
ли добавлены, изменены в таблице или удалены из нее.
Предложение output использует таблицы inserted и deleted (см. главу 14) для
отображения соответствующего результата.
В примере 7.20 показано, как работает предложение output с оператором
DELETE.
. Пример 7.20
USE sample;
DECLARE @del_table TABLE (emp_no INT, emp_lname CHAR(20));
DELETE employee
OUTPUT DELETED.emp_no, DELETED.emp_lname INTO @del_table
WHERE emp_no > 15000;
SELECT * FROM @del table;
Гпава 7. Изменение содержимого таблиц 233
Результат:
егар_по emp_lname
25348 Smith
18316 Barrimore
29346 James
28559 Moser
Во-первых, здесь объявляется переменная типа таблицы @del_tabie с двумя
столбцами: ешр по и emp iname. Эта таблица будет использована для хранения
удаленных строк. Синтаксис оператора delete расширен опцией output:
OUTPUT DELETED. emp__no, DELETED.emp_lname INTO @del_table
Используя эту опцию, система сохраняет удаляемые строки в таблице
deleted, которая затем копируется в табличную переменную @dei table.
В примере 7.21 показано использование опции output в операторе update.
I Пример 7.21
USE sample;
DECLARE @update_table TABLE
(emp_no INT, project_no CHAR(20) ,old_job CHAR(20), new_job CHAR(20));
UPDATE workson
SET job = NULL
OUTPUT DELETED.emp_no, DELETED.project_no,
DELETED.job, INSERTED.job INTO @update_table
WHERE job = 'Clerk';
SELECT * FROM @update_table;
Результат:
emp_no project_no old_job new_job
25348 p2 Clerk NULL
28559 p2 Clerk NULL
9031 p3 Clerk NULL
29346 pl Clerk NULL
Оператор MERGE
SQL Server 2008 вводит SQL-оператор merge. Этот оператор объединяет по-
следовательность условных команд insert и update в одном атомарном опе-
раторе в зависимости от существования записи.
Основной областью приложения оператора merge является хранилище данных
(см. часть IV), где нужно периодически обновлять таблицы с учетом вновь
234
Часть II. Язык Transact-SQL
приходящих данных от систем оперативной обработки транзакций (OLTP,
online transaction processing). Эти новые данные могут содержать изменения
для существующих строк таблиц и/или новые строки, которые нужно доба-
вить. Если строка в новых данных соответствует элементу, который уже су-
ществует в таблице, то выполняется оператор update. В противном случае
выполняется оператор insert.
В версиях, предшествующих SQL Server 2008, эти операции выполнялись
либо как последовательность операторов insert и update, либо как пакеты
(см. главу 8), где для каждой строки принималось решение, добавлять или
изменять данные. Применение обеих этих техник имеет недостатки произво-
дительности: первой требуется множественное сканирование данных, а вто-
рая оперирует по принципу "запись за записью". При расширении Transact-
SQL новым оператором SQL Server 2008 преодолевает недостатки предыду-
щих подходов и упрощает реализацию приложений хранения данных.
Примеры 7.22 и 7.23 демонстрируют использование оператора merge.
j Пример 7.22
USE sample;
CREATE TABLE bonus
(pr_no CHAR(4),
bonus SMALLINT DEFAULT 100) ;
INSERT INTO bonus (pr_no) VALUES ('pl');
В примере 7.22 создается таблица bonus, которая содержит одну строку (pl,
100). Эта таблица может быть использована для слияния.
’ Пример 7.23
MERGE INTO bonus В
USING (SELECT project_no, budget
FROM project) E
ON (B.pr_no = E.project_no)
WHEN MATCHED THEN
UPDATE SET B.bonus = E.budget * 0.1
WHEN NOT MATCHED THEN
INSERT (B.pr_no, B.bonus)
VALUES (E.project_no, E.budget * 0.05);
Оператор merge в примере 7.23 изменяет данные в таблице bonus в зависимо-
сти от существования значений в столбце ргпо. Если значение столбца
project no таблицы project появляется в столбце рг_по таблицы bonus, ветвь
Гпава 7. Изменение содержимого таблиц 235
matched будет выполнена и существующее значение будет изменено. В про-
тивном случае будет выполняться ветвь not matched и соответствующий опе-
ратор insert добавит новую строку в таблицу bonus.
Содержимое таблицы bonus после выполнения оператора merge будет сле-
дующим:
pr_no bonus
pl 12000
р2 4750 '
рЗ 9325
В результирующем наборе вы можете видеть, что значение столбца bonus
представляет 10% от начального значения в случае оператора update и 5%
в случае оператора insert.
Резюме
Вообще, существуют только три оператора SQL, которые могут быть исполь-
зованы для изменения таблицы: insert, update и delete. Они являются основ-
ными для главных операций работы с данными: для добавления строки вы
используете только один оператор — insert. То же самое верно относительно
изменения столбцов или удаления строк при помощи операторов update и
delete соответственно.
Нестандартный оператор truncate table является всего лишь другой формой
оператора delete, однако удаление строк выполняется быстрее при использо-
вании truncate table, чем при delete. Оператор merge является, скорее всего,
оператором "upsert" (update + insert): он объединяет операторы update и
insert в одном операторе.
Главы 5—7 содержат все операторы, которые принадлежат DDL и DML.
Большинство этих операторов может быть сгруппировано вместе для созда-
ния последовательности операторов Transact-SQL. Подобные последователь-
ности являются основой хранимых процедур, которые будут рассмотрены в
следующей главе.
Упражнения
i Упражнение 7.1
Добавьте данные нового служащего с именем Julia Long, у которой номер
служащего 11 111. Номер ее отдела пока не известен.
9 Зак. 1141
236
Часть II. Язык Transact-SQL
Упражнение 7.2
Создайте новую таблицу с именем emp_di_d2 со всеми служащими, которые
работают в отделе dl или d2, и загрузите соответствующие строки из табли-
цы employee. Найдите два различных, но эквивалентных по результатам ре-
шения.
' Упражнение 7.3
Создайте новую таблицу для всех служащих, которые приступили к работе
над их проектами в 2007 году, и загрузите их строки из соответствующих
строк таблицы employee.
‘ Упражнение 7.4
Измените работы всех служащих проекта pl, которые являются менеджера-
ми. Теперь они должны работать в должности клерков (job = 'clerk').
i Упражнение 7.5 V
Бюджеты всех проектов с этого момента не определены. Назначьте всем
бюджетам значения null.
j Упражнение 7.6
Измените должность служащей с номером 28 559. С этого момента она ста-
новится менеджером во всех ее проектах.
1 Упражнение 7.7
Увеличьте бюджет проекта, где менеджером является служащий с номером
10 102. Увеличение составляет 10%.
5 Упражнение 7.8
Измените название отдела, в котором работает сотрудник с именем James.
Новое название отдела — Sales.
j Упражнение 7.9
Измените дату начала работы над проектом для тех служащих, которые рабо-
тают над проектом pl и принадлежат отделу Sales. Новая дата— 12.12.2007.
Гпава 7. Изменение содержимого таблиц 237
j Упражнение 7.10
Удалите все отделы, которые располагаются в Сиэтле (Seattle).
j Упражнение 7.11
Проект рЗ должен быть завершен. Удалите всю информацию, связанную с
этим проектом из базы данных sample.
Упражнение 7.12
Удалите информацию из таблицы works on для всех служащих, которые ра-
ботают в отделах, располагающихся в Далласе (Dallas).
ГЛАВА 8
Хранимые процедуры и функции,
определенные пользователем
В этой главе вводятся описания пакетов и подпрограмм. Пакеты являются
последовательностью операторов Transact-SQL и процедурных расширений.
Подпрограммы могут быть либо хранимыми процедурами, либо функциями,
определенными пользователем (User Defined Function, UDF). В начале главы
вводятся все процедурные расширения, поддерживаемые Database Engine.
После этого процедурные расширения используются вместе с операторами
Transact-SQL, чтобы продемонстрировать, как могут быть реализованы паке-
ты. Пакет может быть сохранен как объект базы данных в виде хранимой
процедуры или UDF. Одни процедуры написаны- пользователями, другие
предоставляются корпорацией Microsoft, они называются системными хра-
нимыми процедурами. В отличие от пользовательских хранимых процедур
функции, написанные пользователем, возвращают вызвавшей программе не-
которое значение. Все подпрограммы могут быть написаны либо на Transact-
SQL, либо на любом языке программирования, таком как C# или Visual Basic.
В конце главы вводится новая возможность SQL Server 2008 — параметры
типа таблицы.
Процедурные расширения
В предыдущих главах описывались операторы Transact-SQL, которые при-
надлежат языку определения данных DDL или языку манипулирования дан-
ными DML. Большинство из этих операторов может быть сгруппировано
вместе для создания пакета. Как было сказано, пакет является последова-
тельностью операторов Transact-SQL и процедурных расширений, которые
отправляются в систему баз данных для совместного выполнения. Количест-
во операторов в пакете ограничивается размером скомпилированного пакет-
Глава 8. Хранимые процедуры и функции, определенные пользователем 239
лого объекта. Основным преимуществом пакета перед группой одиночных
операторов является то, что выполнение за один раз всех операторов дает
значительный выигрыш в производительности.
Существует много ограничений, связанных с использованием различных
операторов Transact-SQL внутри пакета. Наиболее важное заключается в том,
что операторы определения данных create view, create procedure и create
trigger должны быть единственными операторами в пакете.
Замечание______________________________________________________
Для отделения операторов DDL от остальных используйте оператор GO.
Следующие разделы описывают по отдельности каждое процедурное расши-
рение языка Transact-SQL.
Блоки операторов
Блок позволяет создавать программную единицу из одного или более опера-
торов Transact-SQL. Каждый блок начинается с оператора begin и заканчива-
ется оператором end, как показано в следующем примере:
BEGIN
оператор 1
оператор 2
END
Блок может быть использован внутри оператора if, чтобы предоставить воз-
можность выполнения более одного оператора в зависимости от некоторого
условия (см. пример 8.1).
Оператор IF
Оператор if в языке Transact-SQL соответствует оператору с тем же названи-
ем, который поддерживается почти всеми языками программирования. Опе-
ратор if выполняет один оператор Transact-SQL (или несколько операторов,
составляющих блок), если логическое выражение, которое следует за ключе-
вым словом if, возвращает значение "истина". Если оператор if содержит
оператор else, то вторая группа операторов будет выполняться, если логиче-
ское выражение возвращает ложь.
Замечание______________________________________________________
Прежде чем вы запустите на выполнение пакет, хранимую процедуру или UDF
в этой главе, полностью пересоздайте базу данных sample.
240
Часть II. Язык Transact-SQL
| Пример 8.1
USE sample;
IF (SELECT CCUNT(*)
FROM works_on
WHERE project_no = 'pl'
GROUP BY project_no ) > 3
PRINT 'The number of employees in the project pl is 4 or more'
ELSE BEGIN
PRINT 'The following employees work for the project pl'
SELECT emp_fname, emp_lname
FROM employee, works_on
WHERE employee.emp_no = works_on.emp_no
AND project_no = 'pl'
END
Пример 8.1 демонстрирует использование блока внутри оператора if. Логи-
ческое выражение в операторе if
IF (SELECT COUNT(*)
FROM works_on
WHERE project_no = 'pl'
GROUP BY project_no ) > 3
возвращает истину для базы данных sample. Поэтому выполняется одиноч-
ный оператор print в части if. Обратите внимание, что этот пример исполь-
зует подзапрос для определения количества строк (с помощью агрегатной
функции count), которые соответствуют условию в предложении where
(project no = 'pl'). Результатом выполнения примера 8.1 будет:
The number of employees in the project pl is 4 or more
(Количество служащих в проекте pl 4 или более.)
Замечание_________________________________________________________
Фрагмент ELSE в операторе if из примера 8.1 содержит два оператора: print и
select. Поэтому здесь требуется блок из операторов begin и end, которые об-
рамляют два оператора. Оператор print является еще одним оператором, ко-
торый принадлежит процедурным расширениям; он возвращает сообщение,
определенное пользователем.
Оператор WHILE
Оператор while многократно выполняет один оператор Transact-SQL (или
более операторов, заключенных в блок), пока логическое выражение возвра-
щает значение "истина". Другими словами, если выражение истинно, то вы-
Гпава 8. Хранимые процедуры и функции, определенные пользователем 241
полняется оператор (или блок операторов), после чего опять вычисляется ло-
гическое выражение, чтобы определить, должен ли снова выполняться опера-
тор (или блок операторов). Этот процесс повторяется, пока выражение не
станет ложным.
Блок в операторе while может содержать один из двух операторов, исполь-
зуемых для управления выполнением операторов в блоке: break или continue.
Оператор break останавливает выполнение операторов внутри блока и начи-
нает выполнять оператор, следующий сразу за этим блоком. Оператор
continue останавливает выполнение только текущего оператора и начинает
выполнение блока с его самого начала.
В примере 8.2 показано использование оператора while.
i Пример 8.2
USE sample;
WHILE (SELECT SUM(budget)
FROM project) < 500000
BEGIN
UPDATE project SET budget = budget * 1.1
IF (SELECT MAX(budget)
FROM project) > 240000
BREAK
ELSE CONTINUE
END
В примере 8.2 бюджет всех проектов будет увеличиваться на 10%, пока об-
щая сумма всех бюджетов не превысит $500 000. При этом, повторное вы-
полнение будет остановлено, если бюджет одного из проектов превысит
$240 000. Выполнение примера 8.2 приведет к выдаче следующих сообщений:
(3 rows affected)
(3 rows affected)
(3 rows affected)
Локальные переменные
Локальные переменные являются важным процедурным расширением языка
Transact-SQL. Они используются для хранения значений (любых типов) в па-
кетах или подпрограммах. Они являются "локальными" потому, что на них
можно сослаться только в том же пакете, в котором они определены. Database
Engine также поддерживает глобальные переменные, которые описываются
в главе 4.
Каждая локальная переменная должна быть определена с использованием
оператора declare. Синтаксис оператора declare см. в примере 8.3. Опреде-
242
Часть II. Язык Transact-SQL
ление каждой переменной содержит ее имя и соответствующий тип данных.
К переменным всегда выполняется обращение с использованием префикса
Присваивание значений локальным переменным выполняется с помощью
следующих конструкций:
♦ специальной формы оператора select;
♦ оператором set.
Использование обоих операторов для назначения значений демонстрируется
в примере 8.3.
| Пример 8.3
USE sample;
DECLARE @avg_budget MONEY, @extra_budget MONEY
SET @extra_budget = 15000
SELECT @avg_budget = AVG(budget) FROM project
IF (SELECT budget
FROM project
WHERE project_no = 'pl') < @avg_budget
BEGIN
UPDATE project
SET budget = budget + @extra__budget
WHERE project_no = 'pl'
PRINT 'Budget for pl increased by @extra_budget'
END
ELSE PRINT 'Budget for pl unchanged';
Результатом будет:
Budget for pl increased by @extra_budget
(Бюджет проекта pl увеличен на @extra_budget.)
Пакет в примере 8.3 вычисляет среднее значение всех бюджетов проектов и
сравнивает это значение с бюджетом проекта pl. Если это последнее значе-
ние меньше, чем вычисленное значение, то бюджет проекта pl увеличивается
на значение локальной переменной @extra_budget.
Смешанные процедурные операторы
Процедурное расширение языка Transact-SQL также содержит следующие
операторы:
♦ return;
♦ goto;
Гпава 8. Хранимые процедуры и функции, определенные пользователем 243
♦ raiseerror;
♦ WAITFOR.
Оператор return имеет ту же функциональность внутри пакета, что и опера-
тор break внутри while. Это означает, что оператор return приводит к завер-
шению выполнения пакета, после чего будет выполняться первый оператор,
следующий сразу после пакета.
Оператор goto передает управление на метку, которая стоит перед операто-
ром Transact-SQL в этом же пакете. Оператор raiseerror генерирует сообще-
ние об ошибке, созданное пользователем, и устанавливает флаг системной
ошибки. Номер ошибки, определенной пользователем, должен быть больше
чем 50 000. (Все номера ошибок, меньше или равные 50 000, определены
в системе и резервируются для Database Engine.) Значение кода ошибки со-
храняется в глобальной переменной @@error.
Оператор waitfor либо определяет временной интервал (если используется
опция delay), либо задает время (если указана опция time), в течение которо-
го система должна перейти в состояние ожидания, прежде чем выполнить
следующий оператор в пакете. Синтаксис этого оператора:
WAITFOR { DELAY 'time' | TIME 'time' | TIMEOUT 'timeout' }
Опция delay сообщает системе базы данных, что следует подождать, пока не
пройдет заданный промежуток времени, time задает время в одном из приня-
тых форматов даты. (Пример 13.5 показывает использование оператора
waitfor.) timeout задает время в миллисекундах ожидания появления сооб-
щения из очереди сообщений.
Обработка событий операторами TRYи CATCH
Версии SQL Server, предшествующие SQL Server 2005, требовали написание
кода обработки ошибок после каждого оператора Transact-SQL, который мо-
жет вызывать ошибки. (Вы можете обрабатывать ошибки, используя гло-
бальную переменную @@error. В примере 13.1 показано использование этой
переменной.) Начиная с SQL Server 2005, вы можете перехватить и обрабо-
тать исключения, используя два оператора— try и catch. В этом разделе
вначале объясняется, что означает "исключение", затем обсуждается работа
этих двух операторов.
Исключение— это проблема (обычно ошибка), которая препятствует про-
должению выполнения программы. При наличии такой проблемы вы не мо-
жете продолжать обработку, потому что у вас нет достаточной информации,
необходимой для решения проблемы. По этой причине существующая про-
блема будет направлена другой части программы, которая обработает это ис-
ключение.
244
Часть II. Язык Transact-SQL
Роль оператора try заключается в перехватывании исключения. (Поскольку
этот процесс, как правило, заключает в себе несколько операторов, то обычно
используется термин "блок try" вместо термина "оператор try"). Если ис-
ключение появляется внутри блока try, то часть системы, называемая обра-
ботчиком исключений, направляет это исключение другой части программы,
которая обработает исключение. Эта часть программы объявляется ключе-
вым словом catch и поэтому называется блоком catch.
Замечание________________________________________________________
Обработка исключений с использованием операторов try и catch является
общим методом, который используют современные языки программирования
типа C# и Java для обработки ошибок.
Обработка исключений с использованием блоков try и catch дает програм-
мисту множество преимуществ, например, таких:
♦ исключения предоставляют ясный способ обнаружения ошибок без ис-
пользования хаотичного кода;
♦ исключения предоставляют механизм прямой сигнализации об ошибке, а
не при помощи каких-то посторонних эффектов;
♦ исключения могут быть обнаружены программистом и проверены в про-
цессе компиляции программного кода.
В примере 8.4 демонстрируется, как работает обработка ошибок при исполь-
зовании конструкции try/catch. В нем показано, как вы можете использовать
обработку ошибок при помещении всех операторов в пакет и как выполнить
отмену действия всех операторов в группе при появлении ошибок. Этот при-
мер основан на ссылочной целостности данных между таблицами department
и employee. Поэтому вы должны создать обе таблицы, используя ограничения
primary key и foreign key, как это было сделано в примере 5.11.
! Пример 8.4
USE sample;
BEGIN TRY
BEGIN TRANSACTION
insert into employee values(11111, 'Ann', 'Smith', 'd2');
insert into employee values(22222, 'Matthew', 'Jones', 'd4');
referential integrity error
insert into employee values(33333, 'John', 'Barrimore', 'd2');
COMMIT TRANSACTION
PRINT 'Transaction committed'
END TRY
245
Глава 8. Хранимые процедуры и функции, определенные пользователем
BEGIN CATCH
ROLLBACK
PRINT 'Transaction rolled back'
END CATCH;
После выполнения пакета в примере 8.4 все три оператора в пакете не будут
выполнены, а выводом этого примера будет:
'Transaction rolled back'
(Выполнен откат транзакции.)
Работа примера 8.4 выполняется следующим образом. Первый оператор
insert выполняется успешно. После этого выполнение второго оператора
приводит к нарушению ссылочной целостности данных. Поскольку все три
оператора записаны внутри блока try, выдается исключение, и обработчик
исключений запускает блок catch, catch выполняет отмену всех операторов и
выводит соответствующее сообщение. По этой причине содержимое таблицы
employee не меняется.
Замечание______________________________________________________
Операторы begin transaction, commit transaction и rollback являются
операторами Transact-SQL, связанными с транзакциями. Эти операторы запус-
кают, подтверждают и отменяют транзакции соответственно. Обсуждение этих
операторов и вообще транзакций см. в главе 13.
Хранимые процедуры
Хранимая процедура является специальным видом пакета, написанного на
Transact-SQL с использованием языка SQL и его процедурных расширений.
Основным отличием между пакетом и хранимой процедурой является то, что
процедура сохраняется как объект базы данных. Другими словами, хранимая
процедура сохраняется на серверной стороне для улучшения производитель-
ности и согласованности повторяющихся задач.
Database Engine поддерживает хранимые процедуры и системные процедуры.
Хранимые процедуры создаются тем же самым способом, что и все другие
объекты базы данных, т. е. при помощи языка DDL. Системные процедуры
предоставляются через Database Engine и могут быть использованы для дос-
тупа и изменения информации в системных каталогах. Этот раздел описывает
хранимые процедуры (определяемые пользователем), в то время как систем-
ные процедуры рассматриваются в различных главах этой книги (см., напри-
мер, главы 14 и 22).
При создании хранимой процедуры можно задать (необязательный) список ее
параметров. Процедура принимает соответствующие аргументы каждый раз.
246
Часть II. Язык Transact-SQL
когда осуществляется ее вызов. Хранимые процедуры могут возвращать зна-
чение, которое отображает заданную пользователем информацию или, в слу-
чае возникновения ошибки, соответствующее сообщение об ошибке.
Перед помещением хранимой процедуры в качестве объекта в базу данных
она предварительно компилируется. Эта компилированная форма сохраняет-
ся в базе данных и используется каждый раз при вызове хранимой процедуры
на выполнение. Это свойство хранимых процедур предоставляет важное пре-
имущество: повторная компиляция процедуры (почти всегда) исключается,
поэтому возрастает производительность. Это же свойство хранимых про-
цедур дает еще одно преимущество, связанное с объемом данных, которые
должны быть отправлены системе базы данных и получены от этой системы.
Может потребоваться менее 50 байтов для вызова хранимой процедуры, ко-
торая содержит несколько тысяч байтов операторов. Общий эффект от такой
экономии, когда множество пользователей выполняют повторяющиеся зада-
чи, может быть весьма значительным.
Хранимые процедуры также могут быть использованы в следующих целях:
♦ для управления авторизацией доступа;
♦ для создания контрольного журнала о действиях с таблицами базы дан-
ных.
Использование хранимых процедур обеспечивает управление безопасностью
более высокого уровня, чем использование операторов grant и revoke (см.
главу 12), которые определяют различные привилегии доступа для пользова-
телей. Это происходит потому, что авторизация на выполнение хранимой
процедуры не зависит от авторизации на модификацию объектов, которые
содержит хранимая процедура (как описано в следующем разделе).
Хранимые процедуры, которые отслеживают операции записи и/или чтения,
связанные с таблицами, являются дополнительным средством обеспечения
безопасности базы данных. При использовании подобных процедур админи-
стратор базы данных может отслеживать изменения, выполненные пользова-
телями или прикладными программами.
Создание выполняемых хранимых процедур
Хранимые процедуры создаются при помощи оператора create procedure,
который имеет следующий синтаксис:
CREATE PROCEDURE] [schema_nanie. ]ргос_пате
[({@paraml} typel [ VARYING] [= defaultl] [OUTPUT])] {, ...}
[WITH { RECOMPILE | ENCRYPTION | EXECUTE AS 'userename' )]
[FOR REPLICATION]
AS batch | EXTERNAL NAME method_name;
Гпава 8. Хранимые процедуры и функции, определенные пользователем 247
Здесь schema_name— имя схемы, которой назначается создаваемая хранимая
процедура; proc_name— имя новой хранимой процедуры; Qparaml-— это имя
параметра, a typel задает его тип данных. Параметр в хранимой процедуре
имеет тот же самый логический смысл, что и локальная переменная в пакете.
Параметры являются значениями, передаваемыми от вызвавшего объекта
хранимой процедуре и используемыми в хранимой процедуре. Параметр
defaultl задает необязательное значение по умолчанию соответствующего
параметра. (Значением по умолчанию может быть также и null.)
Опция output указывает, что параметр является выходным параметром и мо-
жет быть возвращен вызывающей процедуре или системе (см. пример 8.8).
Как вы уже знаете, предварительно скомпилированная форма хранимой про-
цедуры хранится в базе данных и используется при вызове хранимой про-
цедуры. Если же вы хотите генерировать компилированную форму каждый
раз, когда вызывается хранимая процедура, используйте опцию with recompile.
Замечание________________________________________________________
Использование опции with recompile разрушает наиболее важное преимуще-
ство хранимых процедур: выгода в производительности достигается при одно-
кратной компиляции. По этой причине опция with recompile должна быть ис-
пользована только в том случае, когда объекты, используемые в хранимой про-
цедуре, часто изменяются или параметры, используемые в хранимой
процедуре, изменчивы.
Предложение execute as задает контекст безопасности, под которым выпол-
няется хранимая процедура после доступа к ней. Задавая этот контекст, под
которым хранимая процедура выполняется, вы можете управлять тем, какую
учетную запись пользователя можно применять для проверки полномочий
объектов, ссылающихся на данную хранимую процедуру.
По умолчанию оператор create procedure могут использовать только участ-
ники с фиксированной серверной ролью sysadmin и участники с фиксиро-
ванными ролями базы данных db owner и db ddladmin. Однако пользовате-
ли с этими ролями могут назначать эти привилегии другим пользователям
с помощью оператора grant create procedure. (Обсуждение полномочий
пользователя, фиксированных серверных ролей и фиксированных ролей базы
данных см. в главе 12.)
В примере 8.5 показано создание простой хранимой процедуры для таблицы
project.
| Пример 8.5
USE sample;
GO
CREATE PROCEDURE increase_budget (@percent INT = 5)
248
Часть II. Язык Transact-SQL
AS UPDATE project
SET budget = budget + budget * @percent I 100;
Замечание__________________________________________________________
Оператор GO используется для разделения двух пакетов. Оператор create
PROCEDURE должен быть первым оператором в этом пакете.
Хранимая процедура increase_budget увеличивает бюджеты всех проектов на
заданный процент, который указывается с использованием параметра
@percent. В процедуре также определяется значение по умолчанию (5), кото-
рое будет использовано, если во время выполнения процедуры ей не переда-
ется никакой аргумент.
Замечание__________________________________________________________
Допустимо создание хранимых процедур, которые ссылаются на несуществую-
щие таблицы. Эта возможность позволяет вам отлаживать код процедуры без
предварительного создания соответствующих таблиц или даже без соединения
с сервером.
В отличие от "базовых" хранимых процедур, которые размещаются в теку-
щей базе данных, возможно создание и временных хранимых процедур, ко-
торые всегда помещаются во временную системную базу данных tempdb. Вы
можете создавать временную хранимую процедуру для исключения повтор-
ного выполнения группы операторов при соединении с базой данных. Вы
можете создавать локальные или глобальные временные процедуры, задав
перед именем процедуры одиночный символ # (#proc_name) для локальной
временной процедуры и два символа # (например, ##proc_name) для глобаль-
ной временной процедуры. Локальная временная хранимая процедура может
быть выполнена только пользователем, ее создавшим, и только во время того
же соединения. Глобальная временная процедура может выполняться всеми
пользователями, но только пока не завершилось последнее соединение, в ко-
тором она выполняется (обычно создателем процедуры).
Жизненный цикл хранимой процедуры имеет две фазы: ее создание и ее вы-
полнение. Каждая процедура создается однажды, а выполняется многократ-
но. Оператор execute выполняет существующую процедуру. Выполнение
хранимой процедуры допустимо для любого пользователя, который либо
является ее владельцем, либо имеет привилегию execute к этой процедуре
(см. главу 12). Оператор execute имеет следующий синтаксис:
[[EXEC[UTE]] [@return_status = ] {proc_name | Qproc_name_var)
{[[@parameterl =] value
I [Qparameterl = ] ^variable [OUTPUT]] | DEFAULT}...
[WITH RECOMPILE];
Глава 8. Хранимые процедуры и функции, определенные пользователем 249
Все опции оператора execute, за исключением return status, имеют то же
логическое значение, что и опции с теми же именами в операторе create
procedure. Опция retum_sta tus является необязательной целочисленной пе-
ременной, которая хранит возвращаемый статус процедуры. Значение пара-
метру может быть присвоено с использованием либо значения (value), либо
локальной переменной (^variable). Порядок задания параметров безразличен,
если используются именованные параметры, однако, если параметры не
имеют имен, значения параметров должны быть представлены точно в том
порядке, в каком они были указаны в операторе create procedure.
Предложение default указывает на значение по умолчанию для параметра,
которое было определено в процедуре. Если процедура ожидает получение
параметра, для которого не определено значение по умолчанию, а параметр
отсутствует или указано предложение default, то возникает ошибка.
Замечание________________________________________________________
Если оператор execute является первым в пакете, то ключевое слово execute
может быть опущено в операторе. Несмотря на это, вам все же следует вклю-
чать это слово в каждый написанный вами пакет.
В примере 8.6 показано использование оператора execute.
I Пример 8.6
USE sample;
EXECUTE increase_budget 10;
Оператор execute в примере 8.6 выполняет хранимую процедуру increase_
budget (см. пример 8.5) и увеличивает бюджеты всех проектов на 10%.
В примере 8.7 показано создание процедуры, которая ссылается на таблицы
employee и works_on.
| Пример 8.7
USE sample;
GO
CREATE PROCEDURE modify_empno (@old_no INTEGER, @new_no INTEGER)
AS UPDATE employee
SET emp_no = @new_no
WHERE emp_no = @old_no
UPDATE works_on
SET emp_no = @new_no
WHERE emp_no = @old_no;
250
Часть II. Язык Transact-SQL
Процедура modify_empno в примере 8.7 демонстрирует использование храни-
мых процедур в виде части средств поддержки ссылочной целостности дан-
ных (в данном случае между таблицами employee и works on). Подобная хра-
нимая процедура может быть использована внутри определения триггера,
который фактически обеспечивает ссылочную целостность (см. пример 14.3).
В примере 8.8 показано использование предложения output.
j Пример 8.8
USE sample;
GO
CREATE PROCEDURE delete_emp @employee_no INT, @counter TNT OUTPUT
AS SELECT Gcounter = COUNT!*)
FROM works_on »
WHERE emp_no = @employee_no
DELETE FROM employee
WHERE emp_no = @employee no
DELETE FROM works_on
WHERE emp_no = @employee_no;
Эта хранимая процедура может быть выполнена с использованием следую-
щих операторов:
DECLARE @quantity INT
EXECUTE delete_emp @employee__no = 28559, @counter = @quantity OUTPUT
Предыдущий пример содержит операторы создания процедуры delete emp и
ее выполнения. Эта процедура вычисляет количество проектов, над которыми
работает служащий (с номером служащего @employee_nc). Вычисленное зна-
чение затем присваивается параметру @counter. После удаления всех строк
с указанным номером служащего из таблиц employee и works_on полученное
значение будет присвоено переменной @quantity.
Замечание_________________________________________________________
Значение параметра будет возвращено вызвавшей процедуре, если была ис-
пользована опция output. В примере 8.8 процедура delete emp передает па-
раметр @counter вызвавшему оператору, таким образом процедура возвраща-
ет значение системе. Поэтому параметр @counter должен быть объявлен с оп-
цией output в процедуре, так же как и в операторе execute.
Изменение структуры хранимых процедур
Database Engine также поддерживает и оператор alter procedure, который
изменяет структуру хранимой процедуры. Оператор alter procedure обычно
Гпава 8. Хранимые процедуры и функции, определенные пользователем 251
используется для изменения операторов Transact-SQL внутри процедуры. Все
опции оператора alter procedure соответствуют опциям с теми же названия-
ми в операторе create procedure. Основным назначением этого оператора
является исключение переназначения существующих привилегий для храни-
мой процедуры.
Замечание____________________________________________________
Database Engine поддерживает тип данных cursor. Вы используете этот тип
данных для объявления курсоров внутри хранимой процедуры. Курсор являет-
ся программной конструкцией, которая служит для хранения результата запро-
са (обычно набор строк) и для предоставления возможности приложениям ко-
нечного пользователя отображать строки запись за записью. Детальное обсуж-
дение курсоров выходит за рамки данной книги.
Хранимая процедура (или группа хранимых процедур с тем же именем) уда-
ляется при использовании оператора drop procedure. Только владелец храни-
мой процедуры или участники фиксированных ролей db_owner и sysadmin мо-
гут удалять процедуру.
Database Engine содержит несколько представлений каталогов, относящихся
к хранимым процедурам. Наиболее важными представлениями являются
sys.objects и sys.procedures. Все строки в sys.objects, для которых значение
столбца type равно Р, относятся к хранимым процедурам. Представление
sys.procedures наследует некоторые столбцы sys.objects и содержит допол-
нительную информацию, связанную с их автоматическим выполнением.
Хранимые процедуры и CLR
В версиях, предшествующих SQL Server 2005, вы могли использовать для
создания хранимых процедур только операторы Transact-SQL. SQL Server
2005 вводит новую возможность Common Language Runtime (CLR), которая
позволяет вам разрабатывать различные объекты базы данных (хранимые
процедуры, функции, определенные пользователем, триггеры, определенные
пользователем агрегаты и определенные пользователем типы) с помощью C#
и Visual Basic. CLR также позволяет выполнять эти объекты, используя об-
щую систему выполнения.
Замечание____________________________________________________
Вы можете разрешать и запрещать использование CLR при помощи опции
clr_enabled системной процедуры sp_configure. Выполните оператор
reconfigure для изменения конфигурации выполнения.
В примере 8.9 показано, как вы можете разрешить использование CLR.
252
Часть II. Язык Transact-SQL
\ Пример 8.9
USE sample;
EXEC sp_configure 'clr_enabled', 1
RECONFIGURE
Для реализации, компиляции и сохранения процедур при использовании CLR
вы должны выполнить следующие четыре шага в указанном порядке:
1. Напишите хранимую процедуру на языке C# (или Visual Basic) и скомпи-
лируйте программу, используя соответствующий компилятор.
2. Используйте оператор create assembly для создания соответствующего
выполняемого файла.
3. Сохраните процедуру как серверный объект посредством оператора create
procedure.
4. Выполните процедуру, используя оператор execute.
Замечание______________________________________________________
Microsoft советует использовать Transact-SQL в качестве языка по умолчанию
для создания объектов на серверной стороне.
На рис. 8.1 показано, как работает CLR. Вы используете среду разработки,
подобную Visual Studio, для реализации вашей программы. После ее создания
р Исходныйкод
CLR-компилятор
I Объектный код
Оператор
CREATE
ASSEMBLY
[ Выполняемый код
Оператор
CREATE
PROCEDURE
Процедура как объект
I базы данных [
Рис. 8.1. Диаграмма последовательности действий
для выполнения под CLR хранимой процедуры
Гпава 8. Хранимые процедуры и функции, определенные пользователем 253
запускаете компилятор C# или Visual Basic для генерации объектного кода.
Этот код будет сохранен в dll-файле, который является исходным для опера-
тора create assembly. После выполнения этого оператора вы получаете про-
межуточный код. На следующем шаге вы используете оператор create
procedure для сохранения выполняемого файла в качестве объекта базы дан-
ных. И, наконец, хранимая процедура может быть выполнена с использова-
нием уже хорошо известного оператора execute.
Примеры 8.10—8.14 демонстрируют только что описанный процесс. В при-
мере 8.10 показана программа на С#, которая будет использована для демон-
страции того, как вы применяете CLR для создания и распространения хра-
нимых процедур.
i Пример 8.10
using System;
using System.Data;
using System.Data.Sql;
using System.Data.SqlClient;
using Microsoft.SqlServer.Server;
using System.Data.SqlTypes;
public partial class StoredProcedures
{ [SqlProcedure]
public static int GetEmployeeCount()
{
int iRows;
SqlConnection conn = new SqlConnection("Context Connection=true");
conn.Open();
SqlCommand sqlCmd = conn.CreateCommandO ;
sqlCmd.CommandText = "select count]*) as 'Employee Count' " +
"from employee";
iRows = (int)sqlCmd.ExecuteScalarO;
conn.Close();
return iRows;
1
);
Эта программа использует запрос для вычисления количества строк в табли-
це employee. Директивы using в начале программы задают пространства имен,
такие как System. Data. Эти директивы позволяют вам задавать имена классов
в исходном тексте программы без указания соответствующих имен про-
странств. Затем определяется класс StoredProcedures, который описывается
с атрибутом [SqlProcedure]. Этот атрибут сообщает компилятору, что данный
класс является хранимой процедурой. Внутри этого класса определяется ме-
254
Часть II. Язык Transact-SQL
тод GetEmployeeCount(). Соединение с базой данных устанавливается с ис-
пользованием экземпляра conn класса SQLConnection. Метод Open () применя-
ется к этому экземпляру для открытия соединения. Метод CreateCommand(),
примененный к conn, позволяет вам получить доступ к экземпляру
SqlCommand, названному sqlCmd.
Следующие строки кода:
sqlCmd.CommandText =
"select count(*) as 'Employee Count' " + "from employee";
iRows = (int)sqlCmd.ExecuteScalar();
используют оператор select для поиска количества строк в таблице employee
и для отображения результата. В этой команде указанный текст служит для
задания значения свойства CommandText экземпляра sqicmd, полученного при
вызове метода CreateCommand ().
Затем вызывается метод ExecuteScalarО экземпляра SqlCommand. Он возвра-
щает скалярное значение, которое преобразуется в тип данных int и присваи-
вается переменной iRows.
В примере 8.11 показан первый шаг по развертыванию хранимой процедуры
при использовании CLR.
Пример 8.11
esc /target: library GetErnployeeCount.es
/reference:"С:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\
MSSQL\Binn\sqlaccess.dll"
Пример 8.11 демонстрирует, как нужно скомпилировать в C# метод
GetEmployeeCount (см. пример 8.Ю). Фактически, эта команда может быть ис-
пользована вообще для компиляции любой программы С#, если вы зададите
соответствующее имя для исходной программы, esc— команда, которая ис-
пользуется для вызова компилятора С#. Вы вызываете команду esc в команд-
ной строке Windows. Прежде чем вызвать эту команду, вы должны указать
размещение компилятора, используя переменную окружения path. На момент
написания этой книги компилятор C# (файл csc.exe) можно было найти в ка-
талоге: C:\WINDOWS\Microsoft.NET\Framework\v2.050727. (Вы должны вы-
брать подходящую версию компилятора.)
Опция /target задает имя программы С#, а опция /reference определяет
dll-файл, который необходим для процесса компиляции.
В примере 8.I2 показан следующий шаг в создании хранимой процедуры.
(Используйте SQL Server Management Studio для выполнения этого опера-
тора.)
Глава 8. Хранимые процедуры и функции, определенные пользователем 255
j Пример 8.12
USE sample;
GO
CREATE ASSEMBLY GetEmployeeCount
FROM 'C:\GetEnployeeCount.dll’ WITH PERMISSIONSET = SAFE
Оператор create assembly использует управляемый код в качестве исходных
данных для создания соответствующего объекта, вместе с которым должны
быть созданы CLR хранимые процедуры, UDF и триггеры. Этот оператор
имеет следующий синтаксис:
CREATE ASSEMBLY assemblyname [ AUTHORIZATION owner_name ]
FROM {dllfile}
[WITH PERMISSION_SET = { SAFE I EXTERNAL_ACCESS I UNSAFE }]
assembiy_name— имя сборки. Необязательное предложение authorization за-
дает имя роли в качестве владельца этой сборки. Предложение from задает
путь, где будет размещаться загружаемая сборка. (В примере 8.12 dll-файл,
сгенерированный из исходной программы, скопирован из каталога Framework
в корневой каталог диска С:.)
Предложение with permission set является очень важным предложением
оператора create assembly и должно быть задано всегда. Оно содержит набор
кодов доступа, предоставленных сборке. Значение safe определяет наиболее
ограниченные полномочия. Код, выполняемый в сборке с этими полномо-
чиями, не может иметь доступ к внешним системным ресурсам, таким как
файлы. Значение external_access открывает сборкам доступ к некоторым
внешним системным ресурсам, в то время как unsafe предоставляет неогра-
ниченный доступ к ресурсам, в том числе и к тем, которые находятся вне сис-
темы базы данных. #
Замечание_________________________________________________________
При сохранении информации, имеющей отношение к коду сборки, пользователь
должен иметь право на выполнение оператора create assembly. Пользова-
тель (или роль), выполняющий этот оператор, становится владельцем сборки.
Существует возможность назначить сборку другому пользователю при приме-
нении предложения authorization в операторе create schema.
Database Engine также поддерживает операторы alter assembly и drop
assembly. Вы можете использовать оператор alter assembly для обновления
системного каталога до последних модулей, поддерживаемых в реализации
.NET. Этот оператор также добавляет или удаляет файлы, связанные с данной
сборкой. Оператор drop assembly удаляет указанную сборку и все связанные
с ней файлы из текущей базы данных.
256
Часть II. Язык Transact-SQL
В примере 8.13 создаются хранимые процедуры, основанные на управляемом
коде, реализованном в примере 8.10.
1 Пример 8.13
USE sample;
GO
CREATE PROCEDURE GetEmployeeCount
AS EXTERNAL NAME GetEmployeeCount.StoredProcedures.GetEmployeeCount
Оператор create procedure в примере 8.13 отличается от такого же оператора,
используемого в примерах 8.5 и 8.7, потому что он содержит опцию external
name. Эта опция указывает, что код сгенерирован с использованием CLR. Имя
в этом предложении состоит из трех частей:
assembly_name.class_name.method_name
Здесь:
♦ assembly_name-—- ИМЯ сборки (см. пример 8.12);
♦ class name — имя класса public (см. пример 8.10);
♦ method_name— необязательная часть имени; это имя метода, который за-
дан внутри класса.
Пример 8.14 используется ДЛЯ выполнения процедуры GetEmployeeCount.
I Пример 8.14
USE sample;
DECLARE @ret INT
EXECUTE @ret = GetEmployeeCount
PRINT @ret
Оператор print возвращает текущее количество строк таблицы employee.
Функции, определенные пользователем
В языках программирования обычно существуют два типа подпрограмм:
♦ хранимые процедуры;
♦ функции, определенные пользователем (User Defined Functions, UDF).
Как было сказано в предыдущих разделах этой главы, хранимые процедуры
содержат несколько операторов, могут иметь ноль или несколько входных
параметров, но обычно не возвращают выходных параметров. В противопо-
Гпава 8. Хранимые процедуры и функции, определенные пользователем 257
ложность этому функции всегда имеют одно возвращаемое значение. Этот
раздел описывает создание и использование функций, определенных пользо-
вателем (UDF).
Создание и выполнение функций,
созданных пользователем
UDF создаются при помощи оператора create function, который имеет сле-
дующий синтаксис:
CREATE FUNCTION [scftema name.]function_name
[({@param } type [= default]) {, ...}
RETURNS {scalar_type | [@variable] TABLE}
[WITH {ENCRYPTION | SCHEMABINDING}
[AS] {block I RETURN (select_statement)}
Здесь schema_name— имя схемы, которой назначено владение созданной
UDF; function name— имя новой функции; @param— имя входного парамет-
ра, a type задает его тип данных. Параметрами являются значения, переда-
ваемые вызвавшими программами для UDF, они используются в функции.
Опция default задает необязательное значение по умолчанию для соответст-
вующего параметра. (Значением по умолчанию может быть также пустое
значение null.)
Предложение returns задает тип данных значения, возвращаемого UDF. Это
может быть любой стандартный тип данных, поддерживаемый системой базы
данных, включая тип данных table. (Только одним стандартным типом дан-
ных, который вы не можете здесь использовать, является тип данных
TIMESTAMP.)
Функции, определенные пользователем, могут быть скалярными или таблич-
ными. Скалярная функция возвращает атомарное (скалярное) значение. Это
означает, что в предложении returns скалярной функции вы задаете один из
стандартных типов данных. Функции являются табличными, если предложе-
ние returns возвращает набор строк (см. следующий подраздел).
Опция with ENCRiPTiON кодирует информацию в системном каталоге, который
содержит текст оператора create function. В этом случае вы не можете про-
сматривать текст, использованный для создания этой функции. (Используйте
эту опцию для повышения защищенности вашей системы базы данных.)
Альтернативное предложение with schemabinding связывает UDF с объектами
базы данных, на которые она ссылается. Любая попытка изменения структу-
ры объекта базы данных, на который ссылается данная функция, оканчивает-
ся неудачей. (Связывание функции с объектами базы данных, на которые она
258
Часть II. Язык Transact-SQL
ссылается, может быть удалено только в том случае, когда функция изменя-
ется, так что в этом случае опция schemabinding больше не действует).
Объекты базы данных, на которые ссылается функция, должны соответство-
вать следующим условиям, если вы хотите использовать предложение
schemabinding при создании этой функции:
♦ все представления и UDF, на которые ссылается функция, должны быть
ограничены схемой;
♦ все объекты базы данных (таблицы, представления, UDF) должны быть
в той же самой базе данных, что и функция.
block является блоком begin/end, который содержит реализацию функции.
Последним оператором блока должен быть оператор return с аргументом.
(Значение аргумента — это значение, возвращаемое данной функцией.) В те-
ле блока begin/end допустимы только следующие операторы:
♦ операторы назначения, такие как set;
♦ операторы управления потоком выполнения, такие как while и if;
♦ операторы declare, определяющие локальные переменные данных;
♦ операторы select, содержащие списки выбора с выражениями, которые
присваиваются в качестве значений переменным, являющимся локальны-
ми в этой функции;
♦ операторы insert, update и delete, изменяющие переменные типа данных
table, которые являются локальными в этой функции.
По умолчанию только участники фиксированной серверной роли sysadmin,
а также участники фиксированных ролей базы данных dbowner и
db_ddladmin могут использовать оператор create function. Однако участни-
ки этих ролей могут назначать подобные привилегии другим пользователям
при использовании оператора grant create function (см. главу 12).
В примере 8.15 показано создание функции compute cost.
• Пример 8Л5
— Эта функция вычисляет дополнительную появляющуюся стоимость,
— если увеличиваются бюджеты проектов
USE sample;
GO
CREATE FUNCTION compute_costs (@percent INT = 10)
RETURNS DECIMAL(16, 2)
BEGIN
DECLARE Gadditional_costs DEC (14, 2), @sum_budget dec(16, 2)
Гпава 8. Хранимые процедуры и функции, определенные пользователем
259
SELECT @sum_budget = SUM (budget) FRCM project
SET @additional_costs = @sum_budget * @percent / 100
RETURN @additional_costs
Функция compute_cost вычисляет дополнительные затраты, которые появля-
ются, если увеличиваются бюджеты проектов. Входная переменная Spercent
задает процент увеличения бюджетов. Блок begin/end объявляет две локаль-
ные переменные: @additional_cost и @sum_budget. Затем функция присваивает
переменной @sum_budget сумму всех бюджетов, используя специальную фор-
му оператора select. После этого функция вычисляет общие дополнительные
затраты и возвращает это значение с помощью оператора return.
Вызов функций, определенных пользователем
Каждая UDF может быть вызвана в операторах Transact-SQL, таких как
select, insert, update или delete. Для вызова функции задается ее имя, за ко-
торым следуют круглые скобки. В этих скобках вы можете задать один или
более аргументов. Аргументы являются значениями или выражениями, пере-
даваемыми входным параметрам, которые заданы сразу после имени функ-
ции. Если вы вызываете функцию, и все входные параметры не имеют значе-
ния по умолчанию, вы должны предоставить значения для каждого парамет-
ра, а также должны указать значения аргументов в том же порядке, в котором
эти параметры определены в операторе create function.
В примере 8.16 показано использование функции compute_cost (см. при-
мер 8.15) в операторе select.
= Пример 8.16
USE sample;
SELECT project_no, project_name
FROM project
WHERE budget < dbo.compute_costs(25)
Результат:
project_no project_name
p2 Gemini
Оператор select в примере 8.16 отображает имена и номера всех проектов,
где бюджет меньше, чем общая дополнительная стоимость всех проектов при
заданном проценте.
260
Часть II. Язык Transact-SQL
Замечание_____________________________________________________
Каждая функция, используемая в операторе Transact-SQL, должна быть задана
с использованием имени из двух частей, т. е. имя_схемы.имя_функции.
Тип данных TABLE
Как вы уже знаете, функции являются табличными, если предложение
returns возвращает набор строк. В зависимости от того, как определено тело
функции, табличные функции могут быть классифицированы как линейные
или как многооператорные функции. Если предложение returns задает table
без указания списка столбцов, то эта функция является линейной. Линейные
функции возвращают результат выполнения оператора select в виде пере-
менной типа данных table (см. пример 8.17). Многооператорная табличная
функция включает имя, следующее за table. Имя задает внутреннюю пере-
менную типа table. Вы можете использовать эту переменную для добавления
в нее строк, а затем вернуть эту переменную в качестве возвращаемого зна-
чения функции.
В примере 8.17 показана функция, которая возвращает переменную типа дан-
ных table.
j Пример 8.17
USE sample;
GO
CREATE FUNCTION employees_in_preject (@pr_number CHAR(4))
RETURNS TABLE
AS RETURN (SELECT emp_fname, emp_lname
FROM works_on, employee
WHERE employee.emp_no = works_on.empno
AND project_no - Gpr_number)
Функция employees_in_project используется для отображения имен всех слу-
жащих, которые связаны с конкретным проектом. Входной параметр
@pr_nurrber задает номер проекта. Поскольку функция в общем случае воз-
вращает набор строк, предложение returns содержит тип данных table. Об-
ратите внимание, что блок begin/end в примере 8.17 должен быть опущен,
потому что предложение return содержит оператор select.
В примере 8.18 показано использование функции employees_in_project.
' Пример 8.18
USE sample;
SELECT *
FROM employees_in_project('p3')
Глава 8. Хранимые процедуры и функции, определенные пользователем 261
Результат:
emp_fname emp_lname
Ann Jones
Elsa Bertoni
Elke Hansel
Табличные параметры
Во всех версиях, предшествующих SQL Server 2008, было сложно передавать
много параметров подпрограмме. В подобных случаях вам нужно было ис-
пользовать временные таблицы, добавлять в них значения, а затем вызывать
вашу подпрограмму. Начиная с SQL Server 2008, вы можете использовать
табличные параметры для упрощения этой задачи. Эти параметры использу-
ются для передачи результирующего набора соответствующей подпро-
грамме.
В примере 8.19 показано использование табличного параметра.
Пример 8.19
CREATE TYPE departmentType AS TABLE
(dept_no CHAR(4), dept_name CHAR(25), location CHAR(30));
GO
CREATE TABLE tfdallasTable
(dept_no CHAR(4), dept_name CHAR(25) , location CHAR(30));
GO
CREATE PROCEDURE insertProc
@Dallas departmentType READONLY
AS SET NOCOUNT ON
INSERT INTO SdallasTable (dept_no, dept_name, location)
SELECT * FROM @Dallas
GO
DECLARE GDallas AS departmentType;
INSERT INTO @Dallas( dept_no, dept_name, location)
SELECT * FROM department
WHERE location = 'Dallas’
EXEC insertProc @Dallas;
В примере 8.19 вначале объявляется пользовательский тип departmentType в
качестве таблицы. Это означает, что данный тип является типом данных
TABLE, следовательно, в него можно помещать строки. В процедуре insertProc
задана переменная @Dalias типа данных departmentType. Предложение
readonly указывает, что содержимое этой табличной переменной не может
262
Часть II. Язык Transact-SQL
быть изменено. В последующем пакете данные добавляются в табличную пе-
ременную, после чего выполняется процедура. Процедура при своем выпол-
нении добавляет строки из табличной переменной во временную таблицу
#daliasTable. Содержимое временной таблицы будет следующим:
dept_no dept_name location
dl Research Dallas
d3 Marketing Dallas
Использование табличных параметров дает вам такие преимущества:
♦ это упрощает программную модель подпрограммы;
♦ это уменьшает объем данных, передаваемых на сервер, и данных, полу-
чаемых с сервера;
♦ результирующая таблица может иметь произвольное количество строк.
В следующем разделе показано, как табличная функция может быть исполь-
зована с оператором apply.
Табличные функции и оператор APPLY
Оператор apply может быть объединен с табличной функцией для получения
результата, похожего на результирующий набор операции соединения двух
таблиц. Примеры 8.20 и 8.21 показывают, как вы можете использовать apply.
| Пример 8.20
— генерирующая функция
CREATE FUNCTION dbo.fn_getjob(@empid AS INT)
RETURNS TABLE AS
RETURN
SELECT job
FROM works_on
WHERE emp_no = @empid
AND job IS NOT NULL AND project_no = 'pl';
Функция fn_getjob() в примере 8.20 возвращает набор строк из таблицы
works_on. Результирующий набор "соединяется" в следующем примере с со-
держимым таблицы employee.
[ Пример 8.21
— использование предложения CROSS APPLY
SELECT E.emp_no, emp_fname, emp_lname, job
Гпава 8. Хранимые процедуры и функции, определенные пользователем 263
FROM employee as Е
CROSS APPLY dbo.fn_getjob(E.emp_no) AS A
— использование предложения OUTER APPLY
SELECT E.emp_no, einp_fname, emp_lname, job
FROM employee as E
OUTER APPLY dbo.fn_getjob(E.emp_no) AS A
Результат:
emp_no emp_fname emp_lname job
10102 Ann Jones Analyst
29346 James James Clerk
9031 Elsa Bertoni Manager
28559 Sybill Moser NULL
emp_no emp fname emp_lname job
25348 Matthew Smith NULL
10102 Ann Jones Analyst
18316 John Barrimore NULL
29346 James James Clerk
9031 Elsa Bertoni Manager
2581 Elke Hansel NULL
28559 Sybill Moser NULL
В первом запросе примера 8.21 результирующий набор табличной функции
fn_getjob() "соединяется" с содержимым таблицы employee за счет использо-
вания оператора cross apply. Табличная функция fn_getjob() выступает в
качестве правого ввода, а таблица employee— в качестве левого ввода. Пра-
вый ввод вычисляется для каждой строки из левого ввода, и полученные
строки комбинируются, создавая окончательный вывод.
Второй запрос похож на первый, но использует outer apply, который соот-
ветствует операции внешнего соединения двух таблиц.
Изменение структуры UDF
Язык Transact-SQL также поддерживает оператор alter function, который
изменяет структуру UDF. Этот оператор обычно используется для удаления
существующего связывания со схемой. Все опции оператора alter function
соответствуют опциям с теми же названиями в операторе create function.
UDF удаляется при использовании оператора drop function. Только владелец
этой функции (или участник фиксированных ролей базы данных dbowner и
sysadmin) может удалять функцию.
264
Часть II. Язык Transact-SQL
Представление отображения каталогов sys.objects отображает информацию
о существующих UDF. (См. значения 'FN' [for scalar functions], 'FS' [for CLR
functions], 'FT' [for table-valued functions] и 'IF' [for inline table-valued functions]
в столбце type.) Системная процедура sp helptext также предоставляет соот-
ветствующую информацию о UDF.
Функции, определенные пользователем,
и CLR
Обсуждение в разд. "Хранимые процедуры и CLR" ранее в этой главе также
применимо и к UDF. С одной только разницей — вы должны использовать
оператор create function (вместо create procedure) для сохранения UDF в
качестве объекта базы данных. Кроме того, UDF применяется в контексте,
отличном от использования хранимых процедур, потому что UDF всегда воз-
вращают значение.
В примере 8.22 показана программа на С#, используемая для демонстрации
того, как компилируются и устанавливаются UDF.
' Пример 8.22
using System;
using System.Data.Sql;
using System.Data.SqlTypes;
public class budgetPercent
{ private const float percent = 10;
public static SqlDouble computeBudget(float budget)
{ float budgetNew;
budgetNew = budget * percent;
return budgetNew;
}
Исходная программа на C# в примере 8.22 показывает UDF, которая вычис-
ляет новый бюджет проекта на основе старого бюджета и заданного процента
увеличения. Описание программы C# опущено, потому что эта программа
является аналогом программы в примере 8.10. В примере 8.23 показан опера-
тор create assembly, который необходим, если вы собираетесь создавать объ-
ект базы данных.
j Пример 8.23
USE sample;
GO
Гпава 8. Хранимые процедуры и функции, определенные пользователем 265
CREATE ASSEMBLY computeBudget
FRCM 'C:\computeBudget.dll'
WITH PERMISSION_SET = SAFE
Оператор create function в примере 8.24 сохраняет сборку computeBudget как
объект базы данных. В дальнейшем он может быть использован в операторах
манипулирования данными, такими как select, что показано в примере 8.25.
\ Пример 8.24
USE sample;
GO
CREATE FUNCTION ReturncomputeBudget (@budget Real)
RETURNS FLOAT
AS EXTERNAL NAME computeBudget.budgetPercent.computeBudget
; Пример 8.25
USE sample;
SELECT dbo.ReturncomputeBudget (321.50)
Результатом будет 3215.
Замечание________________________________________________________
Вы можете поместить существующую функцию UDF в различные места опера-
тора select. В примере 8.16 показано ее использование в предложении where,
в примере 8.18— в предложении FROM, а в примере 8.25— в списке выбора
оператора select.
Резюме
Хранимая процедура является специальным видом пакета, написанного либо
на языке Transact-SQL, либо на языке программирования с помощью CLR.
Хранимые процедуры используются со следующими целями:
♦ для управления авторизацией доступа;
♦ для создания контрольного журнала деятельности с таблицами базы дан-
ных;
♦ для поддержания согласованности и бизнес-правил при изменении дан-
ных;
для повышения производительности повторяющихся задач.
266 Часть II. Язык Transact-SQL
Функции, определенные пользователем, имеют много общего с хранимыми
процедурами. Основное отличие в том, что UDF не используют параметры,
но возвращают значение, которое может быть как одиночным элементом
данных, так и таблицей.
Microsoft рекомендует использовать язык Transact-SQL как язык по умолча-
нию для создания объектов на стороне сервера. CLR рекомендуется как аль-
тернатива только в том случае, когда ваша программа содержит большой
объем вычислений.
В следующей главе рассматривается системный каталог Database Engine.
Упражнения
| Упражнение 8,1
Создайте пакет, который добавляет 3000 строк в таблицу employee. Значения
столбца emp no должны быть уникальными и находиться в диапазоне от 1
до 3000. Все значения В столбцах emp_lname, emp fname и dept_no должны быть
установлены в Jane, Smith и dl соответственно.
; Упражнение 8.2
Измените пакет упражнения 8.1 так, чтобы значения столбца emp no генери-
ровались случайным образом с использованием функции rand. Подсказка:
используйте системные функции времени datepart и getdate для генерации
случайных значений.
ГЛАВА 9
Системный каталог
В этой главе рассматривается системный каталог Database Engine. За общими
сведениями следует описание представлений для просмотра структуры неко-
торых каталогов; представления позволяют вам просматривать метаданные.
В начале главы также рассматривается использование динамически управ-
ляемых представлений и динамически управляемых функций. А затем обсу-
ждаются четыре альтернативных способа поиска информации метаданных:
системные хранимые процедуры, системные функции, функции свойств и
информационная схема.
Общие сведения о системном каталоге
Системный каталог содержит таблицы, которые описывают структуру таких
объектов, как базы данных, базовые таблицы, представления и индексы. Эти
таблицы называются системными базовыми таблицами. Database Engine час-
то обращается к системному каталогу за информацией, которая является ос-
новной для правильного функционирования системы.
Database Engine отличает системные базовые таблицы в базе данных master
от таблиц, описанных в любой базе данных, созданной пользователем. Сис-
темные таблицы из базы данных master находятся в системном каталоге, в то
время как системные таблицы конкретной базы данных располагаются в ка-
талоге базы данных. Поэтому системные базовые таблицы существуют толь-
ко в одном экземпляре во всей системе (если они принадлежат исключитель-
но базе данных master), тогда как другие таблицы присутствуют в каждой
базе данньгх, включая и базу данных master.
Во всех реляционных системах баз данных системные базовые таблицы име-
ют одну и ту же структуру, что и пользовательские таблицы баз данных. Как
результат, одни и те же операторы Transact-SQL, используемые для поиска
10 Зак. 1141
268
Часть II. Язык Transact-SQL
информации в таблицах баз данных, могут быть использованы и для поиска
информации в системных базовых таблицах.
Замечание______________________________________________________
Начиная с SQL Server 2005, использование системных базовых таблиц карди-
нально изменилось. В основном, к системным базовым таблицам больше не-
возможен прямой доступ: вы должны использовать существующий интерфейс
для получения информации из системного каталога. Единственный способ по-
лучения прямого доступа к системной информации в системных базовых таб-
лицах — выполнить соединение, используя выделенное соединение админист-
ратора (см. главу 2).
Существует несколько различных интерфейсов, которые вы можете исполь-
зовать для доступа к информации в системных базовых таблицах.
♦ Представления каталогов. Является первичным интерфейсом для мета-
данных, хранящихся в системных базовых таблицах. Метаданные — это
данные, которые описывают атрибуты объектов в системе базы данных.
♦ Динамически управляемые представления (Dynamic Management
Views, DMV) и функции (Dynamic Management Functions, DMF).
Обычно используются для просмотра активных процессов и содержимого
памяти.
♦ Информационная схема. Стандартизованное решение для доступа к ме-
таданным, которое предоставляет вам общий интерфейс не только для
Database Engine, но и для всех существующих систем реляционных баз
данных (предполагая, что такая система поддерживает информационную
схему).
♦ Функции системы и свойств. Позволяет отыскивать системную инфор-
мацию. Отличия между этими двумя типами функций в основном отно-
сятся к их структуре. Кроме того, функции свойств могут вернуть больше
информации, чем функции системы.
♦ Системные процедуры. Некоторые системные процедуры могут быть
использованы для доступа к системным таблицам и изменения их содер-
жимого.
На рис. 9.1 показана упрощенная форма системной информации Database
Engine и различные интерфейсы, которые вы можете использовать для досту-
па к этой информации.
Замечание______________________________________________________
В этой главе представлен лишь общий обзор системного каталога и показаны
способы, при помощи которых вы можете получить доступ к метаданным. От-
дельные представления для каталогов, так же как и другие интерфейсы, спе-
цифичные для различных задач (такие как индексы, безопасность и др.), опи-
сываются в соответствующих главах.
Гпава 9. Системный каталог
269
Рис. 9.1. Графическое представление различных интерфейсов
для системного каталога
Эти интерфейсы могут быть собраны в две группы: общие интерфейсы (пред-
ставления для каталогов, DMV, DMF и информационная схема) и собствен-
ные интерфейсы, относящиеся к Database Engine (системные процедуры, сис-
темные функции и функции систем).
Замечание_________________________________________________
"Общие" означает, что все соответствующие системы баз данных поддержива-
ют такой интерфейс, но используют различную терминологию. Например,
в терминологии Oracle представления для каталогов и DMV называются "пред-
ставлениями для просмотра данных словаря" и "представлениями для V$" со-
ответственно.
Следующий раздел описывает общие интерфейсы. Собственные интерфейсы
рассматриваются позже в этой главе.
Общие интерфейсы
Как уже было сказано, следующие интерфейсы являются общими интерфей-
сами:
♦ представления просмотра каталога;
♦ DMVhDMF;
♦ информационная схема.
Представления просмотра каталога
SQL Server 2005 вводит представления просмотра каталога, как новый ин-
терфейс для поиска системной информации в системном каталоге. Представ-
270
Часть II. Язык Transact-SQL
ления просмотра каталога являются наиболее общим интерфейсом для мета-
данных и предоставляют наиболее эффективный способ получения настраи-
ваемых форм для этой информации (см. примеры 9.1—9.3).
Представления просмотра каталога принадлежат схеме sys, следовательно,
вы должны использовать имя схемы при доступе к объектам. В этом разделе
описываются три наиболее важных представления просмотра каталога:
♦ sys. objects;
♦ sys.columns;
♦ sys.database_principals.
Замечание__________________________________________________________
Вы можете найти описания других представлений либо в различных главах
этой книги, либо в документе Books Online.
Представление просмотра каталога sys.objects содержит одну строку для
каждого объекта, определенного пользователем в схеме пользователя. Суще-
ствуют два других представления просмотра каталогов, которые предостав-
ляют похожую информацию: sys.system_objects и sys.all_objects. Первое
содержит строку для каждого системного объекта, а второе показывает объ-
единение всех объектов, определенных пользователем, и системных объектов
в пределах схемы. Все три представления просмотра каталогов имеют одина-
ковую структуру. В табл. 9.1 дан список и описание наиболее важных столб-
цов представления просмотра каталогов sys.objects.
Таблица 9.1. Избранные столбцы представления просмотра каталогов sys. objects
Имя столбца Описание
name Имя объекта
object_id Идентификационный номер объекта. Уникален в базе данных
schema_id Идентификатор схемы, в которой расположен объект
type Тип объекта
Представление просмотра каталога sys.columns содержит одну строку для
каждого столбца объектов, которые содержат столбцы таких объектов, как
таблицы и представления. В табл. 9.2 приведен список и описание наиболее
важных столбцов представления просмотра каталогов sys.columns.
Представление просмотра каталога sys.database_principals содержит одну
строку для каждого владельца доступа безопасности (т. е. для пользователя,
группы или роли в базе данных). Подробное обсуждение владельцев доступа
Глава 9. Системный каталог
271
см. в главе 12. В табл. 9.3 содержится список и описание наиболее важных
столбцов представления просмотра каталогов sys. database principals.
Таблица 9.2. Избранные столбцы представления просмотра каталогов sys. columns
Имя столбца Описание
object_id Идентификационный номер объекта, которому принадлежит столбец
name Имя столбца
column_id Идентификатор столбца (уникальный в объекте)
Таблица 9.3. Избранные столбцы представления просмотра каталогов
sys.database_principals
Имя столбца Описание
name Имя владельца доступа
principal_id Идентификатор владельца доступа (уникальный в объекте)
type Тип владельца доступа
Замечание__________________________________________________
SQL Server 2008 поддерживает так называемую обратную совместимость с SQL
Server 2000. Каждое совместимое представление имеет то же самое имя (и ту
же самую структуру), что и соответствующая системная базовая таблица в сис-
теме SQL Server 2000. Совместимые представления являются нежелательны-
ми возможностями и будут исключены в будущих версиях SQL Server.
Запросы к представлениям просмотра каталогов
Как уже было сказано в этой главе, все системные таблицы имеют ту же
структуру, что и базовые таблицы. Так как к системным таблицам невозмож-
но обращение напрямую, вы должны использовать запросы к представлениям
просмотра каталогов, которые соответствуют отдельным системным табли-
цам. В примерах 9.1—9.3 используются существующие представления про-
смотра каталогов для демонстрации того, как можно запросить информацию,
связанную с объектами базы данных.
\ Пример 9.1
Получение идентификатора таблицы, идентификатора пользователя и типа
таблицы из таблицы employee:
272
Часть II. Язык Transact-SQL
USE sample;
SELECT object_id, principal_id, type
FROM sys.objects
WHERE name = 'employee';
Результат:
object_id principal_id type
530100929 NULL U
Столбец object_id из представления просмотра каталога sys.objects отобра-
жает уникальный идентификационный номер соответствующего объекта ба-,
зы данных. Значение null в столбце principal_id говорит о том, что владель-
цем объекта является владелец схемы, и в столбце type означает пользователя
(таблица).
j Пример 9.2
Получение имен всех таблиц базы данных sample, которые содержат столбец
proj ect_no:
USE sample;
SELECT sys.objects.name
FROM sys.objects INNER JOIN sys.columns
ON sys.objects.object_id = sys.columns.object_id
WHERE sys.objects.type = 'U'
AND sys.columns.name = 'project_no';
Результат:
project
works_on
[ Пример 9.3
Кто является владельцем таблицы employee?
SELECT sys.database_principals.name
FROM sys.database_principals INNER JOIN sys.objects
ON sys.database_principals.principal_id = sys.objects.schema_id
WHERE sys.objects.name = 'employee'
AND sys.objects.type = 'U';
Гпава 9. Системный каталог
273
Результат:
dbo
Динамически управляемые представления
и функции
Динамически управляемые представления (DMV) и динамически управляе-
мые функции (DMF) возвращают информацию о состоянии сервера, которая
может быть использована для просмотра активных процессов и, соответст-
венно, для настройки производительности системы или для мониторинга ак-
туального состояния системы. В отличие от представлений просмотра ката-
логов DMV и DMF базируются на внутренних структурах системы.
Замечание_________________________________________________
Основное отличие представлений просмотра каталогов от DMV в их примене-
нии: представления просмотра каталогов отображают статическую информа-
цию о метаданных, в то время как DMV (и DMF) используются для доступа к ди-
намическим свойствам системы. Другими словами, вы используете DMV для
получения глубокой внутренней информации о базе данных, об индивидуаль-
ных запросах или об отдельных пользователях.
DMV и DMF принадлежат схеме sys, а их имена начинаются с префикса dm_,
за которым следует текстовая строка, определяющая категорию, к которой
принадлежит конкретный элемент DMV или DMF.
Следующий список идентифицирует и описывает некоторые из этих кате-
горий:
♦ dm_db_* содержит информацию о базе данных и ее объектах;
♦ dm_tran_* содержит информацию относительно транзакций;
♦ dm io * содержит информацию о действиях по вводу/выводу;
♦ dm_exec_* содержит информацию, относящуюся к выполняемому пользо-
вательскому коду.
Замечание_________________________________________________
Многие из DMV и DMF обсуждаются в последующих главах этой книги. Напри-
мер, связанные с индексами DMV и DMF, которые принадлежат к категории
db_db_*, обсуждаются в следующей главе, связанные с транзакциями DMV и
DMF, рассматриваются в главе 13.
Информационная схема
Информационная схема состоит из представлений только для чтения, кото-
рые предоставляют информацию обо всех таблицах, представлениях и столб-
274
Часть II. Язык Transact-SQL
цах Database Engine, к которым вы имеете доступ. По сравнению с систем-
ным каталогом, который управляет метаданными применительно к системе
как единому целому, информационная схема главным образом управляет ок-
ружением базы данных.
Замечание______________________________________________________
Информационная схема первоначально была введена в стандарте SQL92.
Database Engine предоставляет представления просмотра информационной
схемы, так что приложения, разработанные для других систем баз данных, мо-
гут получить данные из этого системного каталога без необходимости исполь-
зовать его напрямую. Эти стандартные представления используют различную
терминологию, следовательно, когда вы интерпретируете имена столбцов,
помните, что "каталог = база данных", а "домен = тип данных", определенный
пользователем.
Следующие разделы дают описание наиболее важных представлений для ин-
формационной схемы.
Information_schema.tables
Представление information_schema.tables содержит одну строку для каждой
таблицы в текущей базе данных, к которой пользователь имеет доступ. Это
представление отыскивает информацию из системного каталога, используя
представление просмотра каталогов sys.objects. В табл. 9.4 содержится спи-
сок и описание четырех столбцов этого представления.
Таблица 9.4. Представление lnformation_schema. tables
Столбец Описание
TABLE_CATALOG Имя каталога (базы данных), которому принадлежит это представление
TABLE_SCHEMA Имя схемы, которой принадлежит это представление
TABLE_NAME Имя таблицы
TABLE_TYPE Тип таблицы (может быть base table или view)
lnformation_schema.columns
Представление information schema.columns содержит одну строку для каждо-
го столбца текущей базы данных, доступной пользователю. Это представле-
ние отыскивает информацию из представлений просмотра каталогов
sys.columns и sys.objects. В табл. 9.5 приведены список и описание шести
наиболее важных столбцов этого представления.
Гпава 9. Системный каталог
275
Таблица 9.5. Представление Information_schema. columns
Столбец Описание
TABLE_CATALOG Имя каталога (базы данных), которому принадлежит этот столбец
TABLE_SCHEMA Имя схемы, которой принадлежит этот столбец
TABLE-NAME Имя таблицы, которой принадлежит столбец
COLUMN—NAME Тип столбца
ORDINAL_POSITION Идентификационный номер столбца
DATAJTYPE Тип данных столбца
lnformation_schema.referential_constraints
Представление Information_schema.referential_constraints содержит одну
строку для каждого ограничения ссылочной целостности данных, которым
владеет текущий пользователь и которое определено в текущей базе данных.
В табл. 9.6 содержится список и описание наиболее важных столбцов этого
представления.
Таблица 9.6. Представление lnformation_schema. referential_constraints
Столбец Описание
CONSTRAINT_CATALOG Имя каталога (базы данных), которому принадлежит это ограни- чение целостности
CONSTRAINT-SCHEMA Имя схемы, которой принадлежит это ограничение целостности
CONSTRAINT-NAME Имя ограничения целостности
DELETE_RULE То действие, которое будет выполняться, если оператор delete нарушает ссылочную целостность, заданную этим ограничением (может быть NO ACTION, CASCADE, SET NULL ИЛИ SET DEFAULT)
UPDATE_RULE Действие, которое будет выполняться, если оператор update нарушает ссылочную целостность, заданную данным ограниче- нием (может быть NO ACTION, CASCADE, SET NULL ИЛИ SET DEFAULT)
Собственные интерфейсы
Предыдущие разделы описывали использование основных интерфейсов для
доступа к системным базовым таблицам. Вы также можете отыскивать сис-
темную информацию, один из следующих собственных механизмов Database
Engine:
276
Часть II. Язык Transact-SQL
♦ системные хранимые процедуры;
♦ системные функции;
♦ функции свойств.
Системные процедуры
Системные процедуры используются для решения многих задач администра-
тора и конечного пользователя, таких как переименование объектов базы
данных, идентификация пользователей, мониторинг авторизации и ресурсов.
Почти что все существующие системные процедуры имеют доступ к систем-
ным базовым таблицам для поиска и изменения системной информации.
Замечание____________________________________________________
Наиболее важным свойством системных процедур является то, что они могут
быть использованы для простого и надежного изменения системных базовых
таблиц.
Этот раздел описывает две системные процедуры: sp heip и sp depends. По
поводу предмета рассмотрения данной главы можно сказать, что некоторые
системные процедуры были описаны в предыдущих главах, другие же про-
цедуры будут рассмотрены в следующих главах этой книги.
Системная процедура sp heip отображает информацию об одном или более
объектов базы данных. Имя любого объекта базы данных или тип данных мо-
гут быть использованы в качестве параметра этой процедуры. Если процеду-
ра sp heip выполняется без каких бы то ни было параметров, то отображается
информация обо всех объектах текущей базы данных.
Системная процедура sp_depends отображает информационные зависимости
между таблицами, представлениями, триггерами и хранимыми процедурами.
В примере 9.4 отображаются информационные зависимости для хранимой
процедуры modify empno. Эта процедура, определенная пользователем, была
создана в примере 8.7.
; Пример 9.4
USE sample;
EXEC sp_depends Gobjname = 'modify_empno';
Результат:
name
dbo.works_on
dbo.employee
type updated selected column
user table yes yes errp_no
user table yes yes emp_no
Глава 9. Системный каталог
277
Системная процедура sp_depends в примере 9.4 отображает информационные
зависимости процедуры modify_empno (созданной в примере 8.7). Эта инфор-
мация содержит имена таблиц, на которые ссылается эта процедура (works on
И employee).
Системные функции
Системные функции описаны в главе 5. Некоторые из них могут быть ис-
пользованы для доступа к системным базовым таблицам. В примере 9.5 пока-
заны два оператора select, которые отыскивают одну и ту же информацию
при использовании различных интерфейсов.
Пример 9.5
USE sample;
SELECT object_id
FROM sys.objects
WHERE name = 'employee';
SELECT obj ect_id('employee');
Второй оператор select в примере 9.5 использует системную функцию
object id для поиска идентификатора таблицы employee. Эта информация
может быть сохранена в переменной, а затем использована при вызове
команды или системной процедуры как идентификатор объекта в качестве
параметра.
Следующие системные функции, помимо других, дают доступ к системным
базовым таблицам:
♦ OBJECT_ID(object—name);
♦ OBJECT_NAME (ojbject_id);
♦ USER—ID([user_name]);
♦ USER_NAME ([ user__id]);
♦ DB_ID ([db_name]);
♦ DB_NAME ([db_ id]);
♦ INDEX—COL(table, index_id, col_id).
Пример 9.6 демонстрирует использование системной функции index col, ко-
торая является более простым вариантом, чем, например, поиск той же ин-
формации с использованием соответствующих представлений выборки дан-
ных в каталогах. Функция index_col отображает имя столбца, на котором ос-
нован индексный ключ.
278
Часть II. Язык Transact-SQL
. Пример 9.6
SELECT INDEX_COL('employee', 1, 1) AS index_col_l
Если этот индекс является кластеризованным для столбца emp no таблицы
employee, то результатом будет следующее:
index_col_l
emp_no
Пример 9.6 отыскивает кластеризованный индекс (index_id = 1) в первом
столбце (col id = 1) таблицы employee.
Функции свойств
Функции свойств возвращают свойства объектов базы данных, типов данных
или файлов. Обычно функции свойств могут возвращать больше информа-
ции, чем могут вернуть системные функции, потому что функции свойств
поддерживают дюжины свойств (в качестве параметров), которые вы можете
задавать явно.
Почти что все функции свойств возвращают одно из следующих трех значе-
ний: 0, 1 или null. Если значением является 0, то объект не имеет соответст-
вующего свойства. Если значение 1, то объект имеет указанное свойство.
Аналогично, значение null указывает, что существование заданного свойства
для данного объекта является неизвестным в системе.
Database Engine помимо других поддерживает следующие функции свойств:
♦ OBJECTPROPERTY(id, property);
♦ COLUMNPROPERTY (id, column, property)',
♦ FILEPROPERTY(filename, property);
♦ TYPEPROPERTY(type, property).
Функция objectproperty возвращает информацию об объектах текущей базы
данных (см. пример 9.2). Функция columnproperty возвращает информацию
о столбце или параметре процедуры. Функция fileproperty возвращает ука-
занное имя файла и значение свойства для заданного имени файла и названия
свойства.
Функция typeproperty возвращает информацию о типе данных. (Описание
существующих свойств для каждого свойства функции можно найти в доку-
менте Books Online.) Использование некоторых функций свойств будет про-
демонстрировано в различных главах этой книги.
Гпава 9. Системный каталог
279
Резюме
Системный каталог является коллекцией системных базовых таблиц, принад-
лежащих базе данных master и существующим пользовательским базам дан-
ных. Обычно к системным базовым таблицам не может быть осуществлен
прямой доступ пользователя. Database Engine поддерживает несколько раз-
личных интерфейсов, которые вы можете использовать для доступа к инфор-
мации в системных каталогах. Представления просмотра каталогов являются
наиболее общим интерфейсом, который вы можете использовать для получе-
ния системной информации. Динамически управляемые представления
(DMV) и динамически управляемые функции (DMF) похожи на представле-
ния просмотра каталогов, при этом вы их используете для доступа к динами-
ческим свойствам системы. Системные хранимые процедуры предоставляют
простой и надежный доступ к системным базовым таблицам. Очень рекомен-
дуется применять исключительно системные процедуры для изменения сис-
темной информации.
Информационная схема является коллекцией представлений, определенных
для системных базовых таблиц, что обеспечивает унифицированный доступ к
системным каталогам для всех приложений баз данных, создаваемых в дру-
гих системах баз данных. Использование информационной схемы рекомен-
довано, если вам нужно переносить вашу систему с одной базы данных на
другую.
Следующая глава содержит введение в индексы базы данных.
Упражнения
| Упражнение 9.1
Используя представление просмотра каталогов, найдите путь в операционной
системе и имя файла базы данных sample.
\ Упражнение 9.2
Используя функцию свойств objectproperty, найдите, где располагается кла-
стеризованный индекс для таблицы employee базы данных sample.
j Упражнение 9.3
Используя представление просмотра каталогов, найдите, сколько ограниче-
ний целостности определено для таблицы employee базы данных sample.
280 Часть II. Язык Transact-SQL
: Упражнение 9.4
Используя представление просмотра каталогов, выясните, существуют ли
ограничения целостности для столбца dept_no таблицы employee.
j Упражнение 9.5
Используя информационную схему, отобразите всех пользователей таблиц,
принадлежащих базе данных AdventureWorks.
| Упражнение 9.6
Используя информационную схему, найдите все столбцы таблицы employee
с их порядковыми номерами и соответствующими типами данных.
ГЛАВА 10
Индексы
В этой главе описываются индексы и их роль в оптимизации времени отклика
запросов. В первой части главы рассматриваются вопросы хранения индексов
и существующие для этого формы. В основном глава содержит описание трех
операторов Transact-SQL, имеющих отношение к индексам: create index,
alter index и drop index. После этого рассматривается фрагментация индек-
сов и ее влияние на производительность системы. Затем приводятся некото-
рые общие рекомендации по созданию индексов. В конце главы описываются
индексы для вычисляемых столбцов.
Общие сведения
Системы баз данных обычно используют индексы для обеспечения быстрого
доступа к реляционным данным. Индекс является отдельной физической
структурой данных, которая предоставляет ускоренный доступ запросов к
одной или нескольким таблицам. Правильная настройка индексов является
ключевым моментом для улучшения производительности запросов.
У индекса есть много сходного с предметным указателем книги. Когда вы
отыскиваете необходимую тему в книге, то используете ее предметный ука-
затель для определения номера страницы (страниц), где описывается эта те-
ма. Аналогично этому, когда вы осуществляете поиск строки в таблице,
Database Engine использует индекс для нахождения ее физического размеще-
ния. Однако существуют два основных отличия предметного указателя от
индекса базы данных.
♦ Как читатель книги, вы можете решить, будете ли использовать предмет-
ный указатель книги. Такой возможности практически не существует, ко-
гда вы используете систему базы данных: компонент этой системы, назы-
ваемый оптимизатором запросов, принимает решение, нужно ли исполь-
282
Часть II. Язык Transact-SQL
зовать существующий индекс. Пользователь может манипулировать ин-
дексом при помощи индексных советов. Однако их использование реко-
мендовано только в небольшом количестве особых случаев. Оптимизатор
и индексные советы описаны в главе 20.
♦ Конкретный предметный указатель книги редактируется вместе с самой
книгой и в принципе не изменяется. Это означает, что вы можете найти
тему точно на той странице, где ее определяет указатель. В противопо-
ложность этому индекс базы данных может изменяться каждый раз, когда
меняются соответствующие данные.
Если таблица не имеет подходящего индекса, система баз данных для поиска
строки применяет метод сканирования таблицы. Сканирование таблицы оз-
начает, что последовательно (от первой до последней) отыскивается и прове-
ряется каждая строка и эта строка помещается в результирующий набор дан-
ных в том случае, если условие поиска в предложении where возвращает зна-
чение "истина". Поэтому в память загружаются все строки в соответствии с
их физическим размещением во внешней памяти. Этот метод менее эффекти-
вен, чем доступ при помощи индексов, как объясняется далее.
Индексы сохраняются в дополнительных структурах данных, называемых
индексными страницами. (Структура индексных страниц очень похожа на
структуру страниц с данными, как вы увидите в главе 15.) Для каждой индек-
сируемой строки существует индексная запись, которая сохраняется на ин-
дексной странице.
Каждая индексная запись содержит индексный ключ плюс указатель. Поэто-
му каждая индексная запись значительно короче, чем соответствующая стро-
ка. Следовательно, количество индексных записей на (индексной) странице
много больше, чем количество строк на странице (данных). Это свойство ин-
дексов играет очень важную, роль, потому что количество операций вво-
да/вывода, требуемых для перемещения по структуре индекса, значительно
меньше, чем количество операций ввода/вывода, требуемых для перемеще-
ния по соответствующим станицам данных. Иными словами, сканирование
таблицы потребует, вероятно, много больше операций ввода/вывода, чем
доступ к данным через соответствующий индекс.
Индексы Database Engine сконструированы с использованием структуры дан-
ных в виде В-дерева (сбалансированного двоичного дерева). Как предполага-
ет само название, В-дерево имеет древоподобную структуру, в которой все
самые нижние узлы (узлы-листья) имеют одинаковый номер уровня по отно-
шению к верхнему (корневому) узлу дерева. Это свойство поддерживается,
даже если добавляются новые данные или удаляются индексируемые столбцы.
На рис. 10.1 иллюстрируется структура В-дерева и прямой доступ к строке
таблицы employee со значением 25 348 в столбце emp no. Предполагается, что
Глава 10. Индексы
283
таблица employee имеет индекс по столбцу emp no. Вы также можете видеть,
что каждое В-дерево состоит из корневого узла, узлов листьев и нуля или бо-
лее промежуточных узлов.
18316
29346
Рис. 10.1. В-дерево для столбца emp_no таблицы employee
Поиск данных со значением 25 348 может быть выполнен следующим обра-
зом: начиная с корневого узла В-дерева, поиск продолжается по наименьшим
ключевым значениям, большим или равным отыскиваемому значению. Сле-
довательно, в корневом узле отыскивается значение 29 346; затем загружает-
ся значение 28 559 в качестве промежуточного уровня, и искомое значение
25 348 отыскивается на уровне листа. С помощью соответствующих указате-
лей отыскивается нужное значение. Альтернативным, но эквивалентным ва-
риантом метода поиска может быть поиск по условию "меньше или равно".
Поиск по индексу обычно является более предпочтительным и, очевидно,
более эффективным методом доступа к множеству строк таблицы. При ис-
пользовании доступа по индексу требуется немного операций ввода/вывода
для поиска любой строки таблицы за очень короткое время, в то время как
-последовательный перебор требует гораздо больше времени для поиска стро-
ки, физически находящейся в конце таблицы.
Замечание______________________________________________________
Помимо удобных индексов в виде В-деревьев и индексов для вычисляемых
столбцов, которые будут описаны в этой главе, SQL Server поддерживает дру-
гие виды индексов, такие как секционированные, индексы XML и полнотексто-
вые индексы. Секционированные индексы используются для секционированных
284
Часть II. Язык Transact-SQL
таблиц и будут описаны в главе 26. Индексы XML подробно рассматриваются
в главе 28. Полнотекстовые индексы выходят за пределы тем данной книги.
Далее обсуждаются два существующих типа индексов, кластеризованные и
некластеризованные, после чего вы узнаете, как создавать индексы.
Кластеризованные индексы
Кластеризованный индекс определяет физический порядок данных в таблице.
Database Engine позволяет создавать один кластеризованный индекс для таб-
лицы, потому что строки в таблице не могут быть физически упорядочены
более чем одним способом. При использовании кластеризованных индексов
система выполняет навигацию от корневого узла структуры В-дерева вниз до
узлов листьев, которые связаны вместе в список двойной связи, называемой
цепочкой страниц. Самым важным свойством кластеризованных индексов
является то, что их страницы листьев содержат страницы данных. Все другие
уровни структуры кластеризованных индексов составлены из индексных
страниц. Если кластеризованный индекс (явно или неявно) определен для
таблицы, то таблица называется кластеризованной таблицей. На рис. 10.2
показана структура В-дерева для кластеризованного индекса.
Кластеризованный индекс создается по умолчанию для каждой таблицы, для
которой вы определяете первичный ключ с использованием ограничения
первичного ключа. Каждый кластеризованный индекс также является уни-
кальным по умолчанию, т. е. каждое значение данных может появиться толь-
ко однажды в столбце, для которого определен кластеризованный индекс.
Если кластеризованный индекс создан для неуникального столбца, система
базы данных будет форсировать уникальность, добавляя четырехбайтовый
идентификатор к строке, которая имеет дубликаты значений.
Глава 10. Индексы 285
Замечание_____________________________________________________
Кластеризованные индексы позволяют сильно ускорить доступ в случае, когда
запрос осуществляет поиск в диапазоне значений (см. главу 20).
Некластеризованные индексы
Некластеризованный индекс имеет точно такую же структуру, что и класте-
ризованный индекс, но с двумя важными отличиями:
♦ некластеризованный индекс не изменяет физический порядок строк в таб-
лице;
♦ страницы листьев в некластеризованном индексе состоят из индексных
ключей и закладок.
Физический порядок строк в таблице не изменяется, если для этой таблицы
определяется один или более некластеризованных индексов. Для каждого
некластеризованного индекса Database Engine создает дополнительную ин-
дексную структуру, которая сохраняется в индексных страницах. .
Закладка в некластеризованном индексе показывает, где находится строка,
соответствующая индексному ключу. Закладка, как часть индексного ключа,
может иметь две формы, в зависимости от формы таблицы, т. е. таблица мо-
жет быть в кластеризованной форме или находиться в куче. (В терминологии
SQL Server куча — это таблица без кластеризованного индекса.) Если суще-
ствует кластеризованный индекс, то закладка некластеризованного индекса
указывает на структуру В-дерева кластеризованного индекса таблицы. Если в
таблице нет кластеризованного индекса, то закладка идентична идентифика-
тору строки (Row IDentifier, RID), который содержит три части: адрес файла,
в котором располагается соответствующая таблица, адрес физического блока
(страницы), в котором хранится строка, и смещение, которое является пози-
цией строки внутри страницы.
Как видно из предыдущих обсуждений, поиск данных с использованием не-
кластеризованного индекса может осуществляться одним из двух различных
способов в зависимости от формы таблицы:
♦ куча— проход по некластеризованной индексной структуре, за которым
следует поиск строки с использованием RID;
♦ кластеризованная таблица— проход по некластеризованной индексной
структуре, за которым следует проход по соответствующему кластеризо-
ванному индексу.
В обоих случаях количество операций ввода/вывода достаточно велико, так
что вам при проектировании некластеризованного индекса нужно проявлять
осторожность, и его следует использовать, только если вы уверены, что это
286
Часть II. Язык Transact-SQL
значительно повысит производительность. На рис. 10.3 показана структура
В-дерева для непастеризованного индекса.
Рис. 10.3. Физическая структура некластеризованного индекса
Transact-SQL и индексы
Теперь, когда вы знакомы с физической структурой индексов, в этом разделе
будет рассмотрено, как вы можете создавать, изменять и удалять индексы,
получать данные о фрагментации индексов и редактировать информацию ин-
дексов — все это поможет вам в дальнейшем обсуждении использовать ин-
дексы для увеличения производительности системы.
Создание индексов
Оператор create index создает индекс для конкретной таблицы. Общая фор-
ма этого оператора:
CREATE [UNIQUE] [CLUSTERED [NONCLUSTERED] INDEX index_name
ON table_name (columnl [ASC | DESC] , ...)
[ INCLUDE ( column_name [,...])]
[WITH
[FILLFACTOR=n]
[[, ] PAD_INDEX = {ON | OFF)]
[[, ] DROP_EXISTING = {ON [ OFF}]
[[, ] SORT_IN_TEMPDB = {ON | OFF}]
[[, ] IGNORE_DUP_KEY = {ON | OFF}]
[[, ] ALLOW_ROW_LOCKS = {ON | OFF}]
[[, ] ALLOW_PAGE_LOCKS = {ON | OFF}]
[[, ] STATISTICSJJORECOMPUTE = {ON | OFF}]
Глава 10. Индексы 287
[[, ] ONLINE = {ON | OFF}]]
[ON file_group I "default"]
Здесь index_name задает имя создаваемого индекса. Индекс может быть соз-
дан для одного или более столбцов ОДНОЙ таблицы (table name), columnl —
имя столбца, для которого создается индекс. Как вы можете видеть в форме
оператора create index, вы можете создавать индекс для нескольких столб-
цов таблицы. Database Engine также поддерживает индексы и для представ-
лений. Подобные представления, называемые индексированными представ-
лениями, обсуждаются в следующей главе.
Замечание_______________________________________________________
Любой столбец таблицы, за исключением столбцов с типом данных "текст/изо-
бражение", может быть индексирован. Это означает, что столбцы с типом дан-
ных varbinary (мах) и sql_variant также могут быть индексированы.
Индекс может быть простым или составным. Простой индекс имеет один
столбец, в то время как составной индекс создан более чем для одного столб-
ца. Каждый составной индекс имеет некоторые ограничения, связанные с его
длиной и количеством столбцов. Максимальный размер индекса— 900 бай-
тов, при этом индекс может содержать не более 16 столбцов.
Опция unique указывает, что каждое значение данных может появляться
только один раз в индексированном столбце. Для уникального составного
индекса комбинация значений данных во всех столбцах каждой строки долж-
на быть уникальной. Если unique не задано, допустимы дубликаты в индек-
сируемом столбце (столбцах).
Опция clustered задает кластеризованный индекс. Опция nonclustered (зна-
чение по умолчанию) указывает, что индекс не изменяет порядок строк в таб-
лице. Database Engine допускает максимум 249 некластеризованных индексов
для одной таблицы.
Database Engine имеет улучшенную поддержку индексов, которые упорядо-
чены по убыванию значений столбца. Опция asc после имени столбца указы-
вает, что индекс создается с возрастающим порядком значений столбца, тогда
как desc задает убывающий порядок. Это дает вам больше гибкости в плане
использования индексов. Убывающие индексы должны быть созданы, когда
вы создаете составной индекс для столбцов, которые имеют противополож-
ные направления сортировки.
Опция include позволяет вам задавать неключевые столбцы, которые добав-
ляются в страницы листьев некластеризованного индекса. Имена столбцов не
могут повторяться в списке include и не могут быть одновременно использо-
ваны в качестве ключевых и неключевых столбцов. Чтобы понять преимуще-
ства опции include, вам нужно знать, что такое покрывающий индекс. Суще-
288
Часть II. Язык Transact-SQL
ственное повышение производительности может быть достигнуто, когда все
столбцы в запросе включены в индекс, потому что оптимизатор запросов мо-
жет локализовать все значения столбцов в индексных страницах без необхо-
димости доступа к данным таблицы. Эта возможность называется покры-
вающим индексом или покрывающим запросом. Следовательно, если вы
включаете дополнительные неключевые столбцы в страницы листьев некла-
стеризованного индекса, может быть покрыто большее количество запросов,
а их производительность может быть значительно более высокой. (Дальней-
шее обсуждение этой темы, равно как и пример того, как оптимизатор запро-
сов обрабатывает покрывающие индексы, см. в разд. "Покрывающий индекс"
далее в этой главе).
Опция пььеастон=л определяет процент заполнения каждой индексной стра-
ницы во время создания индекса. Вы можете задать значение fillfactor в
диапазоне от 1 до 100. Если значение п установлено в 100, то каждая индекс-
ная страница будет заполнена на 100%, т. е. существующая страница листа
индекса так же, как и страница, не относящаяся к листу, не будет иметь места
для добавления новых строк. По этой причине такое значение рекомендуется
использовать только для статических таблиц. Значение по умолчанию 0 так-
же указывает на то, что страница листа индекса будет заполнена полностью и
каждая промежуточная страница содержит место для одной записи.
Если вы установите значение опции fillfactor в значение между 1 и 99, то
новая индексная структура будет создана со страницами листьев, которые не
будут заполнены полностью. Чем больше значение fillfactor, тем меньше
объем памяти, который остается свободным на индексной странице. Напри-
мер, установка опции fillfactor в значение 60 означает, что 40% на каждой
странице листа индекса остается свободным для дальнейшего добавления
строк индекса. (Индексная строка будет добавлена, когда вы выполняете ли-
бо оператор insert, либо оператор update.) По этой причине значение 60 бу-
дет разумным решением для таблиц с довольно частым изменением данных.
Для всех значений опции fillfactor между 1 и 99 все промежуточные стра-
ницы, не относящиеся к листьям, будут содержать свободное место для од-
ной записи.
Замечание_______________________________________________________
Значение fillfactor не является постоянно поддерживаемым, т. е. оно зада-
ет, какой объем памяти существующих данных резервируется в момент зада-
ния этого процента. Если вам нужно переустановить начальное значение опции
FILLFACTOR, то следует использовать оператор ALTER index, который описы-
вается далее в этой главе.
Опция pad_index тесно с вязан а с опцией fillfactor. Опция fillfactor в пер-
вую очередь задает процент свободного места, которое остается на странице
Глава 10. Индексы
289
листьев индекса. С другой стороны, опция pad index указывает, что установ-
ка fillfactor должна быть применена как к индексным страницам, так и
к страницам данных, имеющим отношение к этому индексу.
Опция drop existing позволяет увеличить производительность при пересоз-
дании кластеризованного индекса для таблицы, которая также имеет некла-
стеризованный индекс. Подробности см. в разд. "Пересоздание индекса" да-
лее в этой главе.
Опция sort in tempdb служит для помещения в системную базу данных
tempdb промежуточных данных сортировки, используемой при создании ин-
декса. Это может дать преимущество, если база данных tempdb располагается
на дисковом носителе, отличном от того, где находятся сами данные. (Опция
drop existing обсуждается в разд. "Пересоздание индекса" далее в этой главе.)
Опция ignore_dup_key указывает системе, что она должна игнорировать по-
пытки добавления дубликатов значений в индексный столбец (столбцы). Эта
опция должна быть использована только для того, чтобы исключить завер-
шение длинной транзакции в случае, когда оператор insert добавляет дубли-
каты данных в индексируемый столбец (столбцы). Если активирована эта оп-
ция, и оператор insert пытается добавить строки, которые нарушат уникаль-
ность индекса, то система базы данных вернет предупреждение вместо того,
чтобы выдавать ошибку для всего оператора. Database Engine не добавит
строки, которые пытаются создать дубликаты ключевых значений, он просто
проигнорирует такие строки и добавит все оставшиеся. (Если такая опция не
установлена, то все операторы будут отменены.)
Опция allcw_row_locks задает, что система использует блокировку строк, ко-
гда активирована эта опция (установлена в on). Аналогично, опция
allow_page_locks задает, что система использует блокировку страниц, когда
эта опция установлена в on. (Описание блокировок страниц и строк см. в гла-
ве 13.)
Опция statistics_norecompute указывает, что статистика по указанному ин-
дексу не должна вычисляться заново автоматически. Опция on создает ука-
занный индекс либо для файловой группы по умолчанию ("default"), либо для
указанной файловой группы (file group).
Если вы активируете опцию online, то можете создавать, пересоздавать или
удалять индекс в диалоговом режиме. Эта опция допускает параллельные мо-
дификации индексируемой таблицы или данных кластеризованного индекса,
а также ассоциированных индексов в процессе выполнения изменений ин-
декса. Например, в то время как пересоздается кластеризованный индекс, вы
можете продолжать выполнение изменений данных в таблице и выполнять
запросы к этим данным. (Это означает, что исключительные блокировки дан-
290
Часть II. Язык Transact-SQL
ных соответствующей таблицы не используются в процессе пересоздания
индекса).
Замечание______________________________________________________
Прежде чем запускать на выполнение запросы этой главы, полностью пересоз-
дайте базу данных sample.
В примере 10.1 показано создание некластеризованного индекса.
Пример 10.1
Создание индекса для столбца emp_no таблицы employee:
USE sample;
CREATE INDEX i_empno ON employee (emp_no);
В примере 10.2 показано создание уникального составного индекса.
i Пример 10.2
Создание составного индекса для столбцов emp no и project no таблицы
works on. Составные значения в обоих столбцах должны быть уникальными.
Должны быть заполнены 80% каждой индексной страницы листа.
USE sample;
CREATE UNIQUE INDEX i_empno_prno
ON works_on (emp_no, project_no)
WITH FILLFACTOR = 80;
Создание уникального индекса для столбца, который уже содержит дублика-
ты значений, невозможно. Создание уникального индекса возможно, если
каждое существующее значение данных (в том числе значение null) появля-
ется лишь один раз. Точно так же любая попытка добавить или изменить су-
ществующее значение данных в столбец, включенный в существующий уни-
кальный индекс, будет отвергнуто системой в случае дублирования значения.
Получение информации о фрагментации индекса
В процессе жизненного цикла индекса он может стать фрагментированным,
что означает неэффективное хранение его данных на страницах. Существуют
две формы фрагментации индекса: внутренняя и внешняя. Внутренняя фраг-
ментация определяет объем данных, который хранится на каждой странице.
Внешняя фрагментация появляется, когда нарушается логический порядок
страниц.
Глава 10. Индексы 291
Для получения информации о внутренней фрагментации индекса вы можете
использовать либо динамически управляемое представление (DMV), назы-
ваемое sys.dm_db_index_physical_stats, либо команду DBCC SHOWCONTIG.
В этом разделе обсуждается только DMV, потому что dbcc showcontig не
является рекомендуемой возможностью.
Представление sys.dm_db_index_physicai_stats возвращает размер и инфор-
мацию о фрагментации для данных и индексов указанной таблицы. Для каж-
дого индекса возвращается одна строка для каждого уровня В-дерева. Ис-
пользуя это DMV, вы можете получить информацию о степени фрагментации
строк на страницах данных. Вы можете использовать эту информацию для
принятия решения о необходимости реорганизации данных.
В примере 10.3 показано, как вы можете использовать представление
sys.dm_db_index_physical_stats. Вам нужно удалить существующие индексы
таблицы works on перед выполнением этого пакета.
\ Пример 10.3
DECLARE @db_id INT;
DECLARE @tab_id INT;
DECLARE @ind_id INT;
SET @db_id = DB_ID (’sample') ;
SET @tab_id = OBJECT_ID('employee') ;
SELECT avg_fragmentation_in_percent, avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats
(@db_id, @tab_id, NULL, NULL, NULL)
Итак, представление sys.dm_db_index_physical_stats имеет пять параметров.
Первые три задают идентификаторы текущей базы данных, таблицы и индек-
са соответственно. Четвертый задает частичный идентификатор (см. главу 26),
а последний — уровень сканирования, который должен быть использован для
получения статистики. (Вы всегда можете использовать значение null для
задания значения по умолчанию для конкретного параметра.)
Это представление имеет несколько столбцов, из которых наиболее важными
ЯВЛЯЮТСЯ avg_fragmentation_in_percent И avg_page_space_used_in_percent.
Первый содержит среднее значение фрагментации в процентах, а второй —
процент используемой внешней памяти.
Редактирование информации индекса
После того как вы просмотрели информацию о фрагментации индекса, как
обсуждалось в предыдущем разделе, вы можете использовать следующие
292
Часть II. Язык Transact-SQL
системные средства для редактирования как этой информации, так и другой
информации индекса:
♦ представление просмотра каталогов sys. indexes;
♦ представление просмотра каталогов sys. index columns;
♦ системная процедура sp_heipindex;
♦ функция свойств objectproperty;
♦ SQL Server Management Studio;
♦ DMV sys.dm_db_index_usage_stats;
♦ DMV sys.dm_db_missing_index_details.
Представление просмотра каталогов sys. indexes содержит строку для каждо-
го индекса и строку для каждой таблицы без кластеризованного индекса.
Наиболее важными столбцами этого представления являются object id, name
и index_id. object id— имя объекта базы данных, которому принадлежит
индекс, a name и index id— имя и идентификатор этого индекса соответст-
венно.
Представление просмотра каталогов sys. index_coiumns содержит строку для
столбца, который является частью индекса или кучи. Эта информация может
быть использована вместе с информацией, полученной из представления про-
смотра каталогов sys.indexes, для просмотра других свойств заданного ин-
декса.
sp heipindex отображает индексы таблицы вместе со столбцами статистики.
Синтаксис этой процедуры:
sp_helpindex [@db_object = ] 'name'
Здесь db_object— имя таблицы.
Функция свойств objectproperty имеет два связанных с индексами свойства:
isindexed и isindexabie. Первое информирует вас, имеет ли таблица или
представление индекс, а второе указывает, может ли таблица или представ-
ление быть индексированным.
Для редактирования информации, связанной с существующим индексом при
использовании SQL Server Management Studio, выберите базу данных в папке
Databases, а затем Tables. Разверните папку Indexes. Будет показан список
всех индексов для данной таблицы. После двойного щелчка мышью по одно-
му из индексов система отобразит диалоговое окно Index Properties со всеми
свойствами этого индекса. (Вы также можете использовать SQL Server
Management Studio для создания нового индекса или удаления существую-
щего.)
Представление sys.dm_db_index._usage_stats возвращает количество различ-
ных типов операций с индексами и время, в течение которого выполнялась
Глава 10. Индексы
293
последняя операция каждого типа. Каждый индивидуальный выбор, поиск
или изменение указанного индекса в рамках выполнения одного запроса под-
считывается как факт использования данного запроса, и происходит увеличе-
ние соответствующего счетчика в этом представлении.
Представление sys.dm_db_missing_index_detaiis возвращает детальную ин-
формацию об отсутствующих индексах. Наиболее важными столбцами этого
DMV являются index handie и object id. Первый идентифицирует отсутст-
вующий индекс, второй задает таблицу, где индекс отсутствует.
Изменение индексов
Database Engine является одной из немногих систем баз данных, которая реа-
лизует оператор alter index. Этот оператор может быть использован для
поддержки деятельности с индексами. Синтаксис оператора alter index
очень похож на синтаксис оператора create index. Иными словами, этот опе-
ратор позволяет вам изменять установки следующих опций: allow_row_locks,
ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY И STATISTICS JTORECOMPUTE.
В дополнение к перечисленным опциям оператор alter index поддерживает
три других действия:
♦ пересоздание индекса с использованием опции rebuild;
♦ реорганизацию страниц листьев индекса при использовании опции
reorganize;
♦ перевод индекса в неактивное состояние с использованием опции disable.
Замечание______________________________________________________
Оператор alter index заменяет набор команд и системных процедур, которые
использовались в версиях, предшествующих SQL Server 2005, для поддержки
индексов.
Пересоздание индекса
Существуют три способа, которые можно использовать для пересоздания ин-
декса:
♦ опция rebuild в операторе alter index;
♦ опция drop_existing в операторе create index;
♦ команда dbcc dbreindex.
С опцией rebuild вы можете пересоздавать индекс. Если вы задаете all вме-
сто имени индекса, все индексы указанной таблицы будут пересозданы.
(Предоставляя возможность динамически пересоздавать индексы, вам не
нужно будет их удалять и создавать заново.)
294
Часть II. Язык Transact-SQL
Опция drop existing в операторе create index позволяет улучшить произво-
дительность, когда пересоздается кластеризованный индекс для таблицы, ко-
торая также содержит и некластеризованный индекс. Опция указывает, что
существующий кластеризованный или некластеризованный индекс должен
быть удален и заданный индекс создан заново. Как вы уже знаете, каждый
некластеризованный индекс в кластеризованной таблице содержит в своих
страницах листьев соответствующие значения кластеризованного индекса
таблицы. По этой причине все некластеризованные индексы должны быть
созданы заново, когда удаляется кластеризованный индекс таблицы. Исполь-
зуя опцию drop_existing, вы можете исключить повторное пересоздание не-
кластеризованных индексов.
Замечание_____________________________________________________
Опция drop_existing является более мощной, чем rebuild, потому что она
более гибкая и предоставляет несколько опций, такие как изменение столбцов,
которые включены в состав индекса, и преобразование некластеризованного
индекса в кластеризованный.
Команда dbcc dbreindex пересоздает один или более индексов для таблицы
в указанной базе данных. (Опция dbreindex является нерекомендуемой воз-
можностью и будет удалена в следующих версиях SQL Server.)
Реорганизация индексных страниц листьев
Опция reorganize оператора alter index указывает, что страницы листьев
соответствующей индексной структуры будут реорганизованы таким обра-
зом, чтобы физический порядок этих страниц соответствовал логическому
порядку слева направо для узлов-листьев. Таким образом, эта опция удаляет
фрагментацию индекса, повышая производительность, (reorganize заменяет
команду dbcc dbreindex.)
Перевод индекса в неактивное состояние
Опция disable делает существующий индекс неактивным. Каждый неактив-
ный индекс является недоступным для использования, пока вы снова не пе-
реведете его в активное состояние. Обратите внимание, что неактивный ин-
декс не изменяется при изменении соответствующих данных таблицы. По
этой причине такие индексы должны быть полностью пересозданы, если вы
хотите их снова использовать. Для активации неактивного индекса исполь-
зуйте опцию rebuild оператора alter table.
Замечание_____________________________________________________
Если вы сделали неактивным кластеризованный индекс таблицы, данные таб-
лицы будут недоступными, потому что все страницы данных хранятся на уровне
листьев кластеризованного индекса.
Глава 10. Индексы 295
Удаление и переименование индексов
Оператор drop index удаляет один или более индексов из текущей базы дан-
ных. Обратите внимание, что удаление кластеризованного индекса может
оказаться затратной по ресурсам операцией, потому что потребуется пересоз-
давать все некластеризованные индексы. (Все некластеризованные индексы
используют индексные ключи кластеризованного индекса в качестве указате-
ля в их индексных страницах листьев.) В примере 10.4 показано, как может
быть удален индекс i_empno.
\ Пример 10.4
USE sample;
DROP INDEX i_empno ON employee;
Оператор drop index имеет дополнительную опцию move to, которая является
аналогом опции on в операторе create index. Другими словами, вы можете
использовать эту опцию для указания места, куда нужно помещать строки
данных, которые размещаются в страницах листьев кластеризованного ин-
декса. Эти данные перемещаются на новое место в форме кучи. В качестве
нового размещения вы можете задать либо значение по умолчанию, либо
именованную файловую группу.
Замечание_________________________________________________
Оператор drop index не может быть использован для удаления индексов, ко-
торые неявно генерируются системой для ограничений целостности, таких как
primary key или unique. Для удаления таких индексов вы вначале должны
удалить эти ограничения.
Системная процедура sp_rename, которая обсуждалась в главе 5, может быть
использована для переименования индекса.
Основные направления
в создании и использовании индексов
Хотя Database Engine практически не имеет никаких ограничений, связанных
с количеством индексов, все же рекомендуется ограничить их число по цело-
му ряду причин. Во-первых, каждый индекс использует определенное коли-
чество дисковой памяти, следовательно, существует вероятность того, что
общее количество индексных страниц может превысить количество страниц
данных в базе данных. Во-вторых, в отличие от преимуществ использования
индексов при поиске данных, добавления и изменения данных имеют прямое
воздействие на поддержку индексов. Чем больше индексов в таблице, тем
296
Часть II. Язык Transact-SQL
больше требуется реорганизаций индексов для таких операций. Практическое
правило — выбирайте индексы разумно для часто выполняемых запросов, а
позже оценивайте использование индексов.
Этот раздел дает несколько рекомендаций по созданию и использованию ин-
дексов.
Замечание_____________________________________________________
Следующие рекомендации являются общими практическими правилами. Они,
в конечном счете, зависят от того, как ваша база данных будет применяться
в производстве и какие запросы будут использованы наиболее часто. Индекс
для столбца, который никогда не будет использоваться в операциях выборки
данных, является контрпродуктивным решением.
Индексы и условия в предложении WHERE
Если предложение where в операторе select содержит условие поиска с од-
ним столбцом, вы должны создать индекс для этого столбца. Использование
индекса в особенности рекомендуется, если селективность условия является
высокой. Селективность условия определяется как отношение количества
строк, удовлетворяющих условию, к общему количеству строк в таблице.
(Высокая селективность соответствует меньшему значению этого отноше-
ния.) Наиболее успешная обработка поиска с использованием индексирован-
ного столбца может быть достигнута, если селективность условия составляет
5% или менее.
Столбец не должен быть индексирован, если селективность условия равна
80% или более. В таких случаях для существующих индексных страниц бу-
дут нужны дополнительные операции ввода/вывода, что уменьшает любую
экономию времени, достигаемую за счет использования индексов. В подоб-
ных конкретных случаях последовательное сканирование таблицы будет бо-
лее быстрым, и оптимизатор запросов обычно выбирает использование ска-
нирования таблиц, игнорируя бесполезный индекс.
Если условие поиска в часто используемом запросе содержит одну или более
операций and, то лучше всего создать составной индекс, который включает
все столбцы таблицы, указанные в предложении where оператора select.
В примере 10.5 показано создание составного индекса, который включает все
столбцы, указанные в предложении where оператора select.
1 Пример 10.5
USE sample;
CREATE INDEX i_works ON works_on(emp_no, enter_date) ;
SELECT emp no, project no, enter ‘date
Глава 10. Индексы 297
FROM works_on
WHERE emp_no = 2934 6 AND enter_date = '1.4.2006';
Оператор and в этом запросе содержит два условия. По существу, оба столб-
ца, появляющиеся в каждом условии, должны быть индексированы с исполь-
зованием составного некластеризованного индекса.
Индексы и операция соединения
В случае использования операции соединения рекомендуется индексировать
каждый соединяемый столбец. Соединяемые столбцы обычно представляют
первичный ключ одной таблицы и соответствующий внешний ключ другой
или той же самой таблицы. Если вы задаете ограничения целостности primary
key и foreign key для соответствующих соединяемых столбцов, то должен
быть создан только некластеризованный индекс для столбца внешнего ключа,
поскольку система неявно создает кластеризованный индекс для столбца
PRIMARY key.
В примере 10.6 показано создание индексов, которые будут использованы,
если у вас есть запрос с операцией соединения и с дополнительным фильт-
ром.
; Пример 10.6
USE sample;
SELECT emp_lname, emp_fname
FROM employee, works__on
WHERE employee.emp_no = works_on.emp_no
AND enter_date = '10.15.2007';
Для примера 10.6 рекомендуется создание двух отдельных индексов: для
столбца emp_no в обеих таблицах employee и works_on. Также должен быть
создан дополнительный индекс для столбца enter_date.
Покрывающий индекс
Как вы уже знаете, значительное повышение производительности может
быть достигнуто, когда все столбцы запроса включены в индекс. В примере
10.7 показан покрывающий индекс.
’ Пример 10.7
USE AdventureWorks;
GO
DROP INDEX Person.Address.IX_Address_StateProvinceID;
298
Часть II. Язык Transact-SQL
GO
CREATE INDEX i_address_zip
ON Person.Address (PostalCode)
INCLUDE (City, StateProvincelD);
GO
SELECT city, stateprovincelD
FROM Person.Address
WHERE PostalCode = 84407;
В примере 10.7 в первую очередь из таблицы Address удаляется существую-
щий индекс ix_Address_stateProvinceiD. На следующем шаге создается но-
вый индекс, который дополнительно включает два других столбца, помимо
столбца PostalCode. В заключение оператор select в конце примера демонст-
рирует запрос, покрываемый индексом. Для этого запроса системе нет необ-
ходимости отыскивать данные в страницах данных, потому что оптимизатор
может найти все значения столбцов в страницах листьев некластеризованного
индекса.
Замечание_____________________________________________________
Рекомендуется использовать покрывающие индексы, потому что индексные
страницы, как правило, содержат много больше записей, чем соответствующие
страницы данных. Для использования этого метода также требуется, чтобы
фильтрованные столбцы были первыми ключевыми столбцами в этом индексе!
Индексы для вычисляемых столбцов
Database Engine позволяет создавать следующие специальные типы индексов:
♦ индексы для вычисляемых столбцов;
♦ индексы для представлений.
В этой главе обсуждаются вычисляемые столбцы; индексированные пред-
ставления будут рассматриваться в следующей главе.
Вычисляемый столбец— это столбец таблицы, который используется для
хранения результата вычисления данных таблицы. Такой столбец может быть
виртуальным или постоянным. В следующем подразделе описываются обе
эти формы вычисляемых столбцов.
Виртуальные вычисляемые столбцы
Вычисляемый столбец без соответствующего кластеризованного индекса яв-
ляется логическим, т. е. он физически не хранится на жестком диске. Следо-
вательно, он вычисляется каждый раз, когда к строке осуществляется доступ.
Глава 10. Индексы
299
В примере 10.8 демонстрируется использование виртуальных вычисляемых
столбцов.
i Пример 10.8
USE sample;
CREATE TABLE orders
(orderid INT NOT NULL,
price MONEY NOT NULL,
quantity INT NOT NULL,
orderdate DATETIME NOT NULL,
total AS price * quantity,
shippeddate AS DATEADD (DAY, 7, orderdate));
Таблица orders в примере 10.8 имеет два вычисляемых столбца: total и
shippeddate. Столбец total вычисляется с использованием двух других
столбцов: price и quantity, тогда как столбец shippeddate вычисляется при
использовании функции даты dateadd и столбца orderdate.
Постоянные вычисляемые столбцы
Database Engine позволяет создавать индексы для детерминированных вы-
числяемых столбцов, где столбцы имеют точные типы данных. (Вычисляе-
мый столбец называется детерминированным, если одни и те же значения
всегда возвращаются для одних и тех же данных таблицы.)
Индексированный вычисляемый столбец может быть создан, только если
следующие опции в операторе set установлены в значение on (эти опции га-
рантируют детерминированность столбца):
♦ quoted_identifier;
♦ concat_null_yields_null;
♦ ANSI_NULLS;
♦ ansi_padding;
♦ ANSIWARNINGS.
Также должна быть установлена в off опция numeric_roundabort.
Замечание_______________________________________________________
Столбцы, используемые для индексированных представлений, должны удовле-
творять тем же самым условиям, что и индексируемые вычисляемые столбцы.
Раздел об индексированных представлениях в следующей главе показывает,
как вы можете проверить, что перечисленные только что опции установлены
соответствующим образом.
II Зак. 1141
300
Часть II. Язык Transact-SQL
Если вы создаете кластеризованный индекс для вычисляемого столбца, то
значения этого столбца будут физически присутствовать в соответствующих
строках таблицы, потому что страницы листьев кластеризованного индекса
содержат соответствующие строки данных (см. разд. "Кластеризованные ин-
дексы" ранее в этой главе).
В примере 10.9 показано создание кластеризованного индекса для вычисляе-
мого столбца total из примера 10.8.
Пример 10.9
CREATE CLUSTERED INDEX il ON orders (total);
После выполнения оператора create clustered index в примере 10.9 вычис-
ляемый столбец total станет физически присутствовать в таблице. Это озна-
чает, что все изменения соответствующих столбцов, которые включены в вы-
числение этого столбца, будут приводить к модификации и значения самого
вычисляемого столбца.
Опция PERSISTED
Начиная с SQL Server 2005, можно явно отмечать вычисляемый столбец как
постоянный, используя опцию persisted. Эта опция позволяет указать, что
вычисляемый столбец будет физически существовать в соответствующих
строках таблицы, даже если не будет создан корреспондирующий кластери-
зованный индекс. Эта возможность необходима для вычисляемых столбцов,
созданных из приближенных типов данных (float и real). (Как вы уже знае-
те, вы можете создавать индекс для вычисляемых столбцов только в том слу-
чае, если используемые в вычислении столбцы имеют точные типы данных.)
Резюме
Индексы используются для более эффективного доступа к данным. Они мо-
гут оказать влияние не только на оператор select, но и на производитель-
ность операторов insert, update и delete'. Индекс может быть кластеризо-
ванным и некластеризованным, уникальным и неуникальным, одинарным
или составным. Кластеризованный индекс физически сортирует строки таб-
лицы в порядке указанного столбца (столбцов). Уникщщный индекс указыва-
ет, что каждое значение может появиться только один раз в этом столбце
(столбцах) таблицы. Составной индекс состоит более чем из одного столбца.
1 Чаще всего в худшую сторону. — Прим, перев.
Глава 10. Индексы 301
Прекрасным средством, относящимся к индексам, является Database Engine
Tuning Advisor (DTA), который будет, наряду с другими средствами, анали-
зировать экземпляр вашей фактической рабочей нагрузки (поставляемый ли-
бо через файл скрипта, либо из вашего файла трассировки, полученного от
SQL Server Profiler) и рекомендовать, добавлять или удалять индексы, осно-
вываясь на этой рабочей нагрузке. Очень рекомендуется в вашей работе ис-
пользовать DTA. Более подробную информацию о SQL Server Profiler и DTA
см. в главе 21.
В следующей главе обсуждается понятие представления.
Упражнения
; Упражнение 10.1
Создайте некластеризованный индекс для столбца enter_date таблицы
works on. Должно быть заполнено 60% каждой индексной страницы листьев.
\ Упражнение 10.2
Создайте уникальный составной индекс для столбцов 1_паше и fname табли-
цы employee. Будет ли разница, если вы измените порядок столбцов в состав-
ном индексе?
| Упражнение 10.3
Как вы можете удалить индекс, который был неявно создан для первичного
ключа таблицы?
; Упражнение 10.4
Объясните преимущества и недостатки индексов.
В следующих шести упражнениях создайте индексы, которые будут повы-
шать производительность указанных запросов. Предполагается, что все таб-
лицы базы данных sample, которые используются в следующих упражнениях,
имеют очень большое количество строк.
\ Упражнение 10.5
SELECT emp__no, emp_fname, emp_lname
FROM employee
WHERE emp—lname = 'Smith'
302 Часть II. Язык Transact-SQL
; Упражнение 10.6
SELECT emp_no, emp_fname, emp_lname
FROM employee
WHERE emp_lname = 'Hansel'
AND emp_fname = 'Elke'
Упражнение 10.7
SELECT job
FROM works_on, employee
WHERE employee.emp_no = works_on.emp_no
i Упражнение 10.8
SELECT emp_lname, emp_fname
FROM employee, department
WHERE employee.dept_no = department.dept_no
AND dept_name = 'Research';
&
ГЛАВА 1 1
Представления
Эта глава посвящена исключительно объектам базы данных, называемым
представлениями (view). Структура этой главы соответствует структуре
глав 5 и 7, в которых были описаны операторы DDL и DML для базовых таб-
лиц. В первом разделе этой главы рассматриваются операторы DDL, связан-
ные с представлениями: create view, alter view и drop view. Затем описыва-
ются операторы DDL для представлений: select, insert, update и delete.
Оператор select будет рассмотрен отдельно от других трех операторов.
В отличие от базовых таблиц представления не могут быть использованы для
операций модификации без некоторых ограничений. Эти ограничения опи-
сываются в конце каждого соответствующего раздела.
Альтернативная форма представления, называемая индексированным пред-
ставлением, обсуждается в последнем основном разделе этой главы. Этот тип
индекса материализует соответствующий запрос и позволяет достичь значи-
тельной производительности выполнения запросов с агрегатными данными.
Операторы DDL и представления
В предыдущих главах базовые таблицы описывались с использованием опе-
раторов DDL и DML. Базовая таблица содержит данные, хранимые на диске.
В отличие от них представления по умолчанию не существуют физически,
т. е. их содержимое не хранится на диске. Это неверно для так называемых
индексированных представлений, которые обсуждаются позже в этой главе.
Представления являются объектами базы данных, которые всегда наследуют
одну или более базовых таблиц (или представлений), используя информацию
метаданных. Эта информация (включая имя представления и тот способ, ко-
торый используется для выборки строк из базовых таблиц) является единсг-
304
Часть II. Язык Transact-SQL
венной информацией представления, которая сохраняется физически. Поэто-
му представления также часто называют виртуальными таблицами.
Создание представления
Представление создается при использовании оператора create view. Общая
форма этого оператора:
CREATE VIEW view_name [ (.colvmn_list) ]
[WITH {ENCRYPTION | SCHEMABINDING | VIEWMETADATA}]
AS select_statement
[WITH CHECK OPTION]
Замечание________________________________________________________
Оператор create view должен быть единственным оператором в пакете. Это
означает, что вы должны использовать оператор go для отделения этого опе-
ратора от других операторов в группе операторов.
Здесь view_name— имя определяемого представления; column_list— список
имен, которые будут использованы для столбцов в представлении. Если эта
необязательная спецификация опущена, то будут использованы имена столб-
цов из таблиц, лежащих в основе представления. select_statement задает
оператор select, который отыскивает строки и столбцы из одной или более
таблиц (и/или представлений). Опция with encryption кодирует оператор
select, повышая, таким образом, безопасность системы баз данных.
Предложение schemabinding связывает представление со схемой таблицы, ле-
жащей в основе представления. Когда задано schemabinding, то объекты, на
которые ссылается оператор select, должны иметь имена, состоящие из двух
частей В форме: владелец. о&ъект_базы_данных, где о&ъект_базы_данных может
быть именем таблицы, представления или функцией, определенной пользова-
телем.
Любая попытка изменить структуру представлений или таблиц, на которые
ссылается представление, созданное с этим предложением, будет ошибочной.
Вы должны удалить представление или изменить его так, чтобы оно не со-
держало предложения schemabinding, если вам нужно применить операторы
drop или alter для объектов, на которые осуществляются ссылки. (Предло-
жение with check option подробно обсуждается в разд. "Оператор INSERT
и представление" далее в этой главе.)
Когда представление создается с опцией view metadata, все его столбцы (за
исключением столбцов с типом данных timestamp) могут изменяться, если
представление имеет триггеры insert или update instead of. Триггеры обсу-
ждаются в главе 14.
Глава 11. Представления 305
Замечание_____________________________________ ___________________
Оператор select в представлении не может включать предложения order by,
into или compute. В дополнение к этому нельзя в запросе использовать ссылки
на временные таблицы.
Представления могут применяться для различных целей.
♦ Для ограничения использования отдельных столбцов и/или строк таблицы.
По этой причине представления могут быть использованы для управления
доступом к отдельным частям одной или более таблиц (см. главу 12).
♦ Чтобы скрыть детали сложных запутанных запросов. Если приложениям
базы данных нужны запросы, которые включают сложные операции со-
единения, то создание соответствующих представлений может упростить
использование подобных запросов.
♦ Для ограничения добавляемых или изменяемых значений некоторым диа-
пазоном.
В примере 11.1 показано создание представления.
5 Пример 11.1
USE sample;
GO
CREATE VIEW v_clerk
AS SELECT emp no, project_no, enter_date
FROM works_on
WHERE job = 'Clerk';
Запрос в примере 11.1 отыскивает строки в таблице works on, для которых
истинным является условие job = 'Clerk'. Представление v clerk определе-
но как строки и столбцы, возвращаемые этим запросом. В табл. I l.l пред-
ставлены строки таблицы works on; строки, принадлежащие преставлению
v cierk, выделены полужирным шрифтом.
Таблица 11.1. Базовая таблица workson
emp_no project_no job enter_date
10102 Р1 Analyst | 2006.10.1 00:00:00
10102 p3 Manager 2008.1.1 00:00:00
25348 P2 Clerk 2007.2.15 00:00:00
18316 P2 NULL 2007.6.1 00:00:00
29346 P2 NULL 2006.12.15 00 00:00
2581 P3 Analyst 2007.10.15 00:00:00
306
Часть II. Язык Transact-SQL
Таблица 11.1 (окончание)
emp_no project_no job enter_date
9031 p1 Manager 2007.4.15 00:00:00
28559 p1 NULL 2007.8.1.00:00:00
28559 P2 Clerk 2008.2.1 00:00:00
9031 p3 Clerk 2006.11.15 00:00:00
29346 p1 Clerk 2007.1.4 00:00:00
Пример I l.l задает выборку строк, т. е. он создает горизонтальное подмно-
жество из базовой таблицы works_on. Также можно создавать представления,
которые наряду со строками ограничивают и столбцы, включаемые в пред-
ставление. В примере 11.2 показано создание подобного представления.
f Пример 11.2
USE sample;
GO
CREATE VIEW v_without_budget
AS SELECT project_no, project_name
FROM project;
Представление v_without_budget в примере 11.2 содержит все столбцы табли-
цы project за исключением столбца budget.
Как уже было сказано, задание имен столбцов в представлении в общем фор-
мате оператора create view является необязательным. С другой стороны, су-
ществуют два случая, когда требуется явное задание имен столбцов:
♦ если столбец представления является наследуемым из выражения или
агрегатной функции;
♦ если два или более столбцов имеют одинаковые имена в таблицах, лежа-
щих в основе представления.
В примере 11.3 показано явное задание имен столбцов в представлении.
| Пример 11.3 I
USE sample;
GO
CREATE VIEW v_count(project_no, count_project)
AS SELECT project_no, COUNT(*)
FROM works_on
GROUP BY project_no;
Глава 11. Представления
307
Имена столбцов представления v_count в примере 11.3 должны быть заданы
явно, потому что оператор select содержит агрегатную функцию count;*).
Все столбцы в этом представлении должны быть именованы.
Вы можете избежать явного задания имен столбцов в операторе create view,
если используете заголовки столбцов, как показано в примере 11.4.
I Пример 11.4
USE sample;
GO
CREATE VIEW v_countl
AS SELECT project_no, COUNT(*) count_project
FROM works_on
GROUP BY projectno;
Представление может быть наследуемым из другого существующего пред-
ставления, как показано в примере 11.5.
I Пример 11.5
USE sample;
GO
CREATE VIEW v_project_p2
AS SELECT erap_no
FROM v_clerk
WHERE proj ect_no = 'p2';
Представление v_project_p2 в примере 11.5 наследуется из представления
v_cierk (см. пример 11.1). Каждый запрос, использующий представление
v_project_p2, конвертируется в эквивалентный запрос к базовой таблице
works_on.
Вы также можете создавать представление, используя Object Inspector из
SQL Server Management Studio. Выберите базу данных, для которой собирае-
тесь создавать представление, щелкните правой кнопкой мыши по Views и
выберите пункт New View. Появится соответствующий редактор. Используя
этот редактор, вы можете:
♦ выбрать для создаваемого представления таблицы и столбцы из этих таб-
лиц;
♦ присвоить представлению имя и определить условия в предложении where
соответствующего запроса.
308
Часть II. Язык Transact-SQL
Изменение и удаление представлений
Язык Transact-SQL поддерживает нестандартный оператор alter view, кото-
рый используется для изменения запроса в представлении. Синтаксис опера-
тора alter view аналогичен синтаксису оператора create view.
Вы можете использовать оператор alter view для исключения переназначе-
ния привилегий для представления. Изменение существующего представле-
ния с использованием этого оператора также не влияет на объекты базы дан-
ных (обычно хранимые процедуры), которые зависят от данного представле-
ния. В противном случае, если вы используете операторы drop view и create
view для удаления и пересоздания представления, любые объекты базы дан-
ных, которые используют данное представление, не будут работать правиль-
но, по крайней мере, в промежуток времени, когда представление удаляется и
создается заново.
В примере 11.6 показано использование оператора alter view.
1 Пример 11.6
USE sample;
GO
ALTER VIEW v_without_budget
AS SELECT project_no, project_name
FROM project
WHERE project_no >= 'p3';
Оператор alter view в примере 11.6 расширяет оператор select в представ-
лении v_without_budget (см. пример 11.2), добавляя новое условие в предло-
жение WHERE.
Замечание_______________________________________________________
Оператор alter view может быть также применен и к индексированному пред-
ставлению. Этот оператор удаляет все индексы, существующие для индексиро-
ванного представления.
Оператор drop view удаляет определение указанного представления из сис-
темных таблиц. В примере 11.7 показано использование оператора drop view.
I Пример 11.7
USE sample;
GO
DROP VIEW v_count;
Гпава 11. Представления 309
Если оператор drop view удаляет представление, то все другие наследуемые
от него представления также удаляются, как показано в примере 11.8.
| Пример 11.В
USE sample;
GO
DROP VIEW v_clerk;
Оператор drop view в примере 11.8 также неявно удаляет и представление
y_project_p2 (см. пример 11.5). Например, если вы попытаетесь обратиться к
представлению v_project_p2, то получите сообщение об ошибке: "Invalid
object name: 'vclerk'" ("Неверное имя объекта: 'vclerk'").
Замечание_______________________________________________________
Представление не будет автоматически удалено, если удаляется таблица, ис-
пользуемая в представлении. Это означает, что любое представление, обра-
щающееся к таблице, которая удаляется, должно быть явно удалено при по-
мощи оператора drop view. С другой стороны, если впоследствии создается
таблица с той же логической структурой, что и удаляемая таблица, то данное
представление может быть снова использовано.
Редактирование информации,
связанной с представлениями
Представление sys.objects является наиболее важным представлением про-
смотра каталогов, имеющим отношение к представлениям. Как вы уже знае-
те, это представление просмотра каталогов содержит информацию, связан-
ную со всеми объектами текущей базы данных. Все строки этого представле-
ния, которые имеют значение v для столбца type, являются представлениями.
Другое представление просмотра каталогов sys.views отображает дополни-
тельную информацию о существующих представлениях. Наиболее важным
столбцом этого представления является with_check_option, который сообща-
ет, была ли задана опция with check option.
Используя системную процедуру sp_helptext, вы можете отобразить запрос,
принадлежащий конкретному представлению.
Операторы DML и представления
Представления отыскиваются и модифицируются при помощи тех же самых
операторов Transact-SQL, которые используются для поиска и модификации
310
Часть II. Язык Transact-SQL
базовых таблиц. В следующих подразделах описываются все четыре операто-
ра DML, имеющие отношение к представлениям.
Представление поиска
Представление используется точно так же, как и любая базовая таблица базы
данных. Вы можете думать о выборке данных из представления, как если бы
оператор выборки был бы преобразован в эквивалентный оператор выборки
данных из базовых таблиц, лежащих в основе представления. Пример Н.9
демонстрирует это.
j Пример 11.9
USE sample;
GO
CREATE VIEW v_d2
AS SELECT emp_no, emp_lname
FROM employee
WHERE dept_no = 'd2';
GO
SELECT emp_lname
FROM v_d2
WHERE emp_lname LIKE 'J%';
Результат:
emp_lname
Оператор select из примера 11.9 трансформируется в следующую эквива-
лентную форму с использованием базовой таблицы из представления v_d2:
SELECT emp_lname
FROM employee
WHERE emp_lname LIKE 'J%'
AND dept_no = 'd2';
Следующие три раздела описывают использование представлений с тремя
другими операторами DML: insert, update и delete. Изменение данных эти-
ми операторами трактуется в виде, аналогичном выборке данных. Единст-
венным отличием является только то, что существуют некоторые ограниче-
ния для представлений при использовании добавлений, изменений и удале-
ний данных из таблиц, связанных с представлениями.
Глава 11. Представления
311
Оператор INSERT и представление
Представление может быть использовано с оператором insert, как если бы
оно было обычной базовой таблицей. Когда представление используется для
добавления строк, строки фактически добавляются в соответствующую базо-
вую таблицу.
iipMMep'HJO
USE sample;
GO
CREATE VIEW v_dept
AS SELECT dept_no, dept_name
FROM department;
GO
INSERT INTO v_dept
VALUES('d4 ', 'Development');
Представление v_dept, которое было создано в примере 11.10, содержит пер-
вые два столбца таблицы department. Последующий оператор insert добавля-
ет строку в таблицу, связанную с представлением, используя значения 'd4' и
'Development'. Столбцу location, который не описан в представлении v_dept,
присваивается значение null.
При использовании представления обычно допустимо добавлять в представ-
ление новую строку, которая не удовлетворяет условиям в предложении
where запроса в представлении. Опция with check option используется для ог-
раничения добавления только тех строк, которые удовлетворяют условиям в
запросе. Если используется эта опция, Database Engine проверяет каждую до-
бавляемую строку, чтобы убедиться, что условия в предложении where воз-
вращают значение "истина". Если же эта опция опущена, то не выполняются
никакие проверки соответствия условиям в предложении where, поэтому лю-
бая строка будет добавлена в исходную таблицу. Это может приводить к за-
путанной ситуации, когда строка с использованием представления добавлена
в таблицу, но впоследствии она не может быть найдена при помощи операто-
ра select представления, потому что предложение where ограничивает воз-
вращаемые select строки. Опция with check option также применяется и в
операторе update.
В примерах 11.11 и 11.12 показана разница применения и не использования
опции with check option, соответственно.
312
Часть II. Язык Transact-SQL
) Пример 11.11
USE sample;
GO
CREATE VIEW v_2006check
AS SELECT emp_noz project_no, enter_date
FROM works_on
WHERE enterdate BETWEEN '01.01.2006' AND 42.31.2006’
WITH CHECK OPTION;
GO
INSERT INTO v_2006_check
VALUES (22334, 'p2', '1.15.2007');
В примере 11.11 система проверяет, дает ли добавляемое в столбец
enter_date значение "истина" при вычислении условия в предложении where
оператора select. Эта попытка при добавлении в следующем операторе но-
вой строки завершится неудачно, потому что добавляемая строка не соответ-
ствует условию.
; Пример 11.12
USE sample;
GO
CREATE VIEW v_2006_nocheck
AS SELECT emp_no, project_no, enter_date
FROM works_on
WHERE enter_date BETWEEN '01.01.2006' AND '12.31.2006';
GO
INSERT INTO v_2006_nocheck
VALUES (22334, >p2', 4.15.2007');
SELECT *
FROM v_2006_nocheck;
Результат:
emp_no project_no enter_date
10102 pl 2006-10-01
29346 p2 2006-12-15
9031 p3 2006-11-15
Поскольку в примере 11.12 не используется опция with check option, опера-
тор insert будет выполнен и строка будет добавлена в основную таблицу
Гпава 11. Представления
313
works_on. Заметьте, что последующий оператор select не отображает добав-
ленную строку, потому что она не может быть найдена с использованием
представления v_2006_nocheck.
Добавление строк в таблицы, лежащие в основе представления, нельзя вы-
полнить, если соответствующее представление содержит любую из следую-
щих возможностей:
♦ предложение from в определении представления включает две или более
таблиц, и список столбцов содержит столбцы более чем из одной таблицы;
♦ столбец в представлении наследуется из агрегатной функции;
♦ оператор select в представлении содержит предложение group by или
опцию distinct;
♦ столбец в представлении наследуется от константы или выражения.
В примере 11.13 показано представление, которое не может быть использо-
вано для добавления строк в базовую таблицу, лежащую в основе представ-
ления.
j Пример 11,13
USE sample;
GO
CREATE VIEW v_sum(sum_of_budget)
AS SELECT SUM(budget)
FROM project;
GO
SELECT *
FROM v_sum;
В примере 11.13 создается представление v sum, которое в операторе select
содержит агрегатную функцию. Поскольку представление в примере возвра-
щает результат агрегирования многих строк (а не одной строки из таблицы
project), то нет оснований пытаться добавлять строку в таблицу, лежащую
в основе этого представления, используя это представление.
Оператор UPDATE и представление
Представление может быть использовано с оператором update, как если бы
этот оператор применялся к базовой таблице. Когда представление использу-
ется для модификации строк, содержимое лежащей в основе базовой таблицы
изменяется фактически.
В примере 11.14 создается представление, которое затем используется для
изменения таблицы works_on.
314
Часть II. Язык Transact-SQL
i Пример 11.14
USE sample;
GO
CREATE VIEW vpl
AS SELECT emp_no, job
FROM works_on
WHERE proj ect_no = ' pl';
GO
UPDATE vpl
SET job = NULL
WHERE job- 'Manager';
Вы можете рассматривать обновление представления в примере 11.14, как
если бы оператор update был преобразован к следующему эквивалентному
оператору:
UPDATE workson
SET job = NULL
WHERE job = 'Manager'
AND projectno = 'pl'
Опция with check option имеет то же самое логическое значение для операто-
ра UPDATE, что и для оператора insert. В примере 11.15 показано использова-
ние опции with check option в операторе update.
\ Пример 11.15
USE sample;
GO
CREATE VIEW v_100000
AS SELECT project_no, budget
FROM project
WHERE budget > 100000
WITH CHECK OPTION;
GO
UPDATE vJLOOOOO
SET budget = 93000
WHERE project_no = 'p3';
В примере 11.15 Database Engine проверяет, будет ли измененное значение
столбца budget давать истину в условии предложения where оператора select.
Эта попытка изменения будет неудачной, потому что условие не выполняет-
ся — значение 93 000 не является большим, чем значение 100 000.
Глава 11. Представления 315
Изменение столбцов, лежащих в основе представления таблиц, нельзя выпол-
нить, если соответствующее представление содержит одну из следующих
возможностей:
♦ предложение from в определении представления включает две или более
таблиц, и список столбцов содержит столбцы более чем из одной таблицы;
♦ столбец в представлении наследуется из агрегатной функции;
♦ оператор select в представлении содержит предложение group by или оп-
цию distinct;
♦ столбец в представлении наследуется от константы или выражения.
В примере 11.16 показано представление, которое не может быть использо-
вано для изменения значений строк в базовой таблице представления.
1 Пример 11.16
USE sample;
GO
CREATE VIEW v_uk_pound (project_number, budget_in_pounds)
AS SELECT project_no, budget * 0.65
FROM project
WHERE budget > 100000;
GO
SELECT *
FROM v_uk_pound;
Результат:
project_number budget_in_pounds
pl 78000
p3 121225
Представление v_uk_pound в примере 11.16 не может использоваться с опера-
тором update (так же, как и с оператором insert), потому что столбец
budget_in_pounds является вычисляемым с помощью арифметического выра-
жения и не представляет оригинального столбца лежащей в основе представ-
ления таблицы.
Оператор DELETE и представление
Представление может быть использовано для удаления строк из таблицы
представления, как показано в примере 11.17.
316
Часть II. Язык Transact-SQL
| Пример 11.17
USE sample;
GO .
CREATE VIEW v_project_pl
AS SELECT emp no, job
FROM works_on
WHERE proj ect_no = 'pl';
GO
DELETE FROM v_project_pl
WHERE job = ’Clerk';
В примере 11.17 создается представление, которое затем используется для
удаления строк из таблицы works_on.
Удаление строк из лежащих в основе представления таблиц нельзя выпол-
нить, если соответствующее представление содержит любую из следующих
возможностей:
♦ предложение from в определении представления включает две или более
таблиц, и список столбцов содержит столбцы более чем из одной таблицы;
♦ столбец в представлении наследуется из агрегатной функции;
♦ оператор select в представлении содержит предложение group by или оп-
цию DISTINCT.
В отличие от операторов insert и update оператор delete допускает сущест-
вование в столбце константы или выражения в представлении, которое ис-
пользуется для удаления строк из лежащей в его основе базовой таблицы.
В примере 11.18 показано представление, которое может быть использовано
для удаления строк, но не для добавления строк или изменения значений
столбцов.
^Пример 11.18
USE sample;
GO
CREATE VIEW v_budget (budget_reduction)
AS SELECT budget * 0.9
FROM project;
GO
DELETE FROM v_budget;
Оператор delete в примере 11.18 удаляет все строки из таблицы project, на
которую ссылается представление vbudget.
Глава 11. Представления 317
Индексированные представления
Как вы уже знаете из предыдущей главы, существуют два специальных типа
индексов: индексы для вычисляемых столбцов и индексы для представлений.
В этой главе описываются индексы для представлений.
Представление всегда содержит запрос, который работает как фильтр. При
отсутствии индексов, созданных для конкретного представления, Database
Engine динамически создает результирующий набор при каждом запросе,
ссылающемся на представление. ("Динамически" означает, что если вы изме-
няете содержимое таблицы, соответствующее представление всегда вернет
новую информацию.) Если представление содержит вычисления, основанные
на одном или более столбцов таблицы, это вычисление будет выполняться
каждый раз, когда вы обращаетесь к представлению.
Динамическое создание результирующего набора для запроса может снизить
производительность, если представление в своем операторе select обрабаты-
вает много строк из одной или более таблиц. Если такое представление часто
используется в запросах, вы можете значительно повысить производитель-
ность при помощи создания кластеризованного индекса для этого представ-
ления (см. следующий раздел). Создание кластеризованного индекса означает,
что система материализует динамические данные в страницах листьев ин-
дексной структуры.
Database Engine позволяет создавать индексы для представлений. Такие пред-
ставления называются индексированными или материализованными пред-
ставлениями. Когда для представления создается уникальный кластеризо-
ванный индекс, то при выполнении представления результирующий набор
сохраняется в базе данных таким же образом, как сохраняется таблица с кла-
стеризованным индексом. Это означает, что узлы листьев В-дерева кластери-
зованного индекса содержат страницы данных (см. также описание кластери-
зованных таблиц в главе 10).
Замечание_______________________________________________
Индексированные представления реализуются через синтаксические расшире-
ния операторов create index и create view. В операторе create index вы за-
даете имя представления вместо имени таблицы. Синтаксис оператора create
view расширяется предложением schemabinding. Более подробную информа-
цию о расширениях этих операторов см. в описании в начале этой главы.
Создание индексированного представления
Создание индексированного представления является процессом, состоящим
из двух шагов.
318
Часть II. Язык Transact-SQL
1. Создайте представление, используя оператор create view с предложением
WITH SCHEMABINDING.
2. Создайте соответствующий кластеризованный индекс.
В примере 11.19 показан первый шаг создания типичного представления, ко-
торое может быть индексировано для улучшения производительности. Этот
пример предполагает, что таблица works_on имеет очень большой размер.
Пример 11.19
USE sample;
GO
CREATE VIEW v_enter_month
WITH SCHEMABINDING
AS SELECT emp_no, DATEPART(MONTH, enter_date) AS enter_month
FROM dbo.works_on;
Таблица works_on в базе данных sample содержит столбец enter_date, который
представляет дату начала работы служащего с проектом. Если вам нужно
найти всех служащих, которые начали работать с их проектами в конкретном
месяце, вы можете использовать представление в примере 11.19. Для поиска
подобного результирующего набора с использованием доступа через индекс
Database Engine не может применить индекс таблицы, потому что индекс для
столбца enter_date может локализовать значения этого столбца только по
полной дате, а не по месяцу. В таком случае может помочь индексированное
представление, как показано в примере 11.20.
{Пример 11.20
USE sample;
GO
CREATE UNIQUE CLUSTERED INDEX
c_workson_deptno ON v_enter_month (enter_month, emp_no);
Для того чтобы сделать представление индексированным, вы должны создать
уникальный кластеризованный индекс для столбца (столбцов) представления.
(Как ранее уже было сказано, кластеризованный индекс является только лишь
типом индекса, который содержит значения данных в своих страницах листь-
ев.) После того как вы создадите такой индекс, система базы данных выделит
память для этого представления, а затем вы можете создавать любое количе-
ство некластеризованных индексов, потому что теперь это представление
трактуется как (базовая) таблица.
Глава 11. Представления
319
Индексированное представление может быть создано только в том случае,
если установлены в on следующие опции оператора set (потому что пред-
ставление всегда должно отображать тот же самый результирующий набор):
♦ QUOTEDIDENTIFIER;
♦ concat_null_yields_null;
♦ ansi_nulls;
♦ ansi_padding;
♦ ANSI_WARNINGS.
Также и опция numericjudundabort должна быть установлена в off.
Есть несколько способов проверить, имеют ли опции из предыдущего списка
нужные значения, как обсуждалось в разд. "Редактирование информации,
связанной с представлениями"ранее в этой главе.
Для создания индексированного представления определение представления
должно отвечать следующим требованиям.
♦ Все ссылки на функции (системные или определенные пользователем),
используемые в представлении, должны быть детерминированными —
они всегда должны возвращать один и тот же результат для одних и тех же
аргументов.
♦ Представление должно ссылаться на одну базовую таблицу.
♦ Представление и базовая таблица (таблицы) должны иметь одного и того
же владельца и принадлежать одной и той же базе данных.
♦ Представление должно быть создано с опцией schemabinding. Эга опция
связывает представление со схемой, содержащей базовые таблицы, лежа-
щие в основе представления.
♦ Определенные пользователем функции, на которые осуществляется ссыл-
ка, должны быть созданы с опцией schemabinding.
♦ Оператор select в представлении не может содержать следующие пред-
ложения, функции и опции: DISTINCT, union, compute, top, order by, min, max,
count, sum (для выражений, допускающих пустые значения), подзапросы,
наследуемые таблицы или outer.
Язык Transact-SQL дает вам возможность проверять все эти требования, ис-
пользуя параметр isindexable в функции objectproperty, как показано в при-
мере 11.21. Если значением функции является 1, то все требования выполне-
ны, и вы можете создавать кластеризованный индекс.
I Пример 11.21
USE sample;
SELECT objectproperty(object_id('v_enter_month'), 'Isindexable');
320
Часть II. Язык Transact-SQL
Изменение структуры
индексированного представления
Для удаления уникального кластеризованного индекса в индексированном
представлении вам также нужно удалить все некластеризованные индексы
этого представления. После того как вы удалите кластеризованный индекс,
представление будет трактоваться системой как обычное представление.
Замечание_______________________________________________
Если вы удаляете индексированное представление, удаляются все индексы
этого представления.
Если вы хотите изменить стандартное представление на индексированное, вы
должны для него создать уникальный кластеризованный индекс. Чтобы сде-
лать это, вы должны, во-первых, задать опцию schemabinding для этого пред-
ставления. Вы можете удалить представление и создать его заново, задав
предложение schemabinding в операторе create schema, или же вы можете соз-
дать другое представление, которое имеет тот же самый текст, но другое имя.
Замечание_______________________________________________
Если вы создаете новое представление с другим именем, то должны быть уве-
рены, что новое представление соответствует всем требованиям для индекси-
рованного представления, как было описано в предыдущих разделах.
Редактирование информации,
связанной с индексированными представлениями
Вы можете использовать функцию свойств sessionproperty для проверки то-
го, что опции оператора set являются активированными (список опций см. в
предыдущем разделе). Если функция возвращает 1, то опция установлена
в on. В примере 11.22 показано использование этой функции для проверки,
установлена ли опция quoted_identifier.
\ Пример 11.22
SELECT sessionproperty ('QUOTED_IDENTIFIER');
Наиболее простым способом является применение динамически управляемо-
го представления sys.dm_exec_sessions, потому что вы можете найти все зна-
чения, используя только один запрос. (Опять же, если значением столбца яв-
ляется 1, то соответствующая опция установлена в on.) Пример 1 Е23 возвра-
щает значение первых четырех опций оператора set из списка в разд. "Соз-
Глава 11, Представления
321
danue индексированного представления" ранее в этой главе. (Глобальная пе-
ременная @@spid описана в главе 4.)
Пример 11.23
USE sample;
SELECT quoted_identifier, concat_null_yields_null, ansi_nulls,
ansi_padding
FROM sys.dm_exec_sessions
WHERE session_id = @@spid;
Системная процедура sp spaceused позволяет вам проверить, является ли
представление материализованным, т. е. использует ли оно дисковое про-
странство. Результат примера 11.24 показывает, что представление v_enter_
month использует внешнюю память не только для данных, но и для заданного
индекса.
Пример 11.24
USE sample;
EXEC sp_spaceused 'v_enter_month';
Результат:
name rows reserved data index_size unused
v_enter_month 11 16KB 8KB 8KB 0KB
Преимущества
индексированных представлений
Помимо возможного увеличения производительности при использовании
сложных представлений, которые обычно присутствуют в запросах, приме-
нение индексированных представлений имеет два других преимущества:
♦ индекс представления может быть использован, даже если в представле-
нии явно не указана ссылка на предложение from;
♦ все изменения данных отражаются в соответствующих индексированных
представлениях.
Возможно, наиболее важным свойством индексированных представлений
является то, что у запроса в представлении нет явного указания на использо-
вание индекса в этом представлении. Иными словами, если запрос содержит
ссылку на столбцы базовой таблицы (таблиц), которые также существуют в
322
Часть II. Язык Transact-SQL
индексированных представлениях, и оптимизатор принимает решение, что
использование этого индексированного представления является лучшим вы-
бором, то он выбирает индексы представления точно тем же способом, каким
он выбирает индексы таблицы, когда они явно не указаны в запросе.
Когда вы создаете индексированное представление, результирующий набор
этого представления (в момент создания индекса) сохраняется на диске. По-
этому все данные, которые изменяются в базовой таблице (таблицах), также
будут изменяться в соответствующем результирующем наборе индексиро-
ванного представления.
Помимо всех преимуществ, которые вы можете получить при использовании
индексированных представлений, также существуют и (возможные) недос-
татки: поддержка индексов в индексированных представлениях является бо-
лее сложной, чем индексов в базовых таблицах, потому что структура уни-
кального кластеризованного индекса в индексированном представлении бо-
лее сложная, чем структура соответствующего индекса для базовой таблицы.
Следующие типы запросов могут иметь значительные преимущества в про-
изводительности, если представление, которое используется в соответствую-
щем запросе, является индексированным:
♦ запросы, которые обрабатывают множество строк и содержат операторы
соединения или агрегатные функции;
♦ операции соединения и агрегатные функции, которые часто выполняются
в одном или нескольких запросах.
Если запрос ссылается на стандартное представление, и система баз данных
должна обработать много строк с помощью операции соединения, то оптими-
затор обычно использует субоптимальный метод соединения. Однако если вы
определяете кластеризованный индекс для такого представления, то произво-
дительность запроса может быть значительно улучшена, потому что оптими-
затор может использовать подходящий метод. То же самое истинно и для аг-
регатных функций.
Если запрос, который ссылается на стандартное представление, не обрабаты-
вает много строк, то использование индексированного представления все
равно может дать преимущества, если запрос используется достаточно часто.
То же самое истинно и для групп запросов, которые применяют соединения
этих таблиц или используют те же типы агрегатов.
Если ограничения на типы представлений, которые могут быть индексирова-
ны, не дают вам возможности использовать индексированное представление
в конкретном запросе, постарайтесь создать частичные решения— каждое
с соответствующим индексированным представлением — и после этого объ-
едините все частичные решения в единое. Например, вы не можете спроекти-
Глава 11. Представления 323
ровать индексированное представление для обработки агрегатов данных в
таблицах из разных баз данных с последующим соединением их результатов,
потому что индексированное представление не может ссылаться на таблицы
из нескольких баз данных. Вы можете, тем не менее, создать индексирован-
ное представление для каждой базы данных, которое выполняет агрегирова-
ние данных. Если оптимизатор может найти соответствующее индексирован-
ное представление для частичных запросов, то, по крайней мере, процессы
агрегирования будут выполняться быстрее. Хотя обработка соединения не
будет выполняться быстрее, общий запрос будет выполнен быстрее, потому
что он использует агрегатные данные, сохраненные в индексированном пред-
ставлении.
Резюме
Представления могут быть использованы для различных целей:
♦ для ограничения использования отдельных столбцов и/или строк таблиц,
т. е. для управления доступом к отдельным частям одной или более таб-
лиц;
♦ для сокрытия деталей усложненных запросов;
♦ для ограничения добавляемых или изменяемых значений некоторым диа-
пазоном.
Представления создаются, отыскиваются и изменяются при помощи тех же
самых операторов Transact-SQL, которые используются для создания, поиска
и модификации базовых таблиц. Запрос к представлению всегда трансформи-
руется в эквивалентный запрос к лежащей в основе представления базовой
таблице. Операция изменения трактуется таким же образом, что и поиск. Су-
ществует только одно отличие — имеются некоторые ограничения для пред-
ставлений при выполнении добавлений, изменений и удалений данных из
соответствующей таблицы. Несмотря на это, способ, которым Database
Engine выполняет модификацию строк и столбцов, является гораздо более
систематичным, чем те способы, которыми другие системы реляционных баз
данных осуществляют подобную модификацию.
Индексированные представления используются для повышения производи-
тельности некоторых запросов. Когда для представления создается уникаль-
ный кластеризованный индекс, представление становится индексированным,
т. е. его результирующий набор физически сохраняется точно таким же обра-
зом, как и базовые таблицы.
В следующей главе в деталях рассматриваются вопросы безопасности Data-
base Engine.
324
Часть II. Язык Transact-SQL
Упражнения
j Упражнение 11.1
Создайте представление, которое содержит данные всех служащих, рабо-
тающих в отделе d I.
[ Упражнение 11.2
Для таблицы project создайте представление, которое может быть использо-
вано теми служащими, которым разрешено просматривать все данные из этой
таблицы за исключением столбца budget.
| Упражнение 11.3
Создайте представление, которое содержит имена и фамилии всех служащих,
которые начали работать над их проектами во второй половине 2007 года.
I Упражнение 11.4
Измените результат упражнения 11.3 таким образом, чтобы оригинальные
столбцы f name и I name таблицы получили бы новые имена в представлении:
first и last соответственно.
i Упражнение 11.5
Используя представление в упражнении 1 1.1, отобразите все данные каждого
служащего, чья фамилия начинается с буквы М.
] Упражнение 11.6
Создайте представление, которое содержит полные данные обо всех проек-
тах, над которыми работает служащий по фамилии Smith.
i Упражнение 11.7
Используя оператор alter view, измените условие в представлении из упраж-
нения 11.1. Модифицированное представление должно содержать данные обо
всех служащих, которые работают либо в отделе dl, либо в d2, либо в обоих.
Гпава 11. Представления
325
= Упражнение 11.8
Удалите представление, созданное в упражнении Н.З. Что произойдет с
представлением, созданным в упражнении 11.4?
J Упражнение 11.9
Используя представление из упражнения 11.2, добавьте данные о новом про-
екте с номером проекта р2 и названием Moon.
j Упражнение 11.10
Создайте представление (с предложением with check option), которое содер-
жит имена и фамилии всех служащих, у которых номер служащего меньше,
чем 10 ООО. После этого используйте данное представление для добавления
данных о новом служащем с фамилией Kohn и номером 22 123, который
работает в отделе d3.
j Упражнение 11.11
Используйте представление из упражнения 11.10 без предложения with check
option и найдите разницу в отношении добавления данных.
[ Упражнение 11.12
Создайте представление (с предложением with check option) со всеми под-
робностями из таблицы works_on для всех служащих, которые приступили
к работе над проектами в период с 2007 по 2008 годы. После этого измените
дату начала работы над проектом у служащего с номером 29 346. Новая дата
должна быть 06/01/2006.
Упражнение 11.13
Используйте представление из упражнения 11.12 без предложения with check
option и найдите разницу в отношении изменения данных.
ГЛАВА 12
Система безопасности
Database Engine
Эта глава начинается с краткого обзора наиболее важных концепций безо-
пасности базы данных. Затем обсуждаются специфические особенности сис-
темы безопасности Database Engine.
Наиболее важные концепции безопасности базы данных:
♦ аутентификация;
♦ шифрование;
♦ авторизация;
♦ отслеживание изменений.
Аутентификация требует ответа на следующий вопрос: "Имеет ли этот поль-
зователь легитимные права на доступ в систему?" Следовательно, эта кон-
цепция безопасности задает процесс проверки полномочий для предотвраще-
ния использования системы неавторизованными пользователями. Аутен-
тификация может быть проверена посредством запроса пользователя предос-
тавить, например, следующее:
♦ что-то, что знает пользователь (обычно пароль);
♦ что-нибудь, чем пользователь владеет — магнитная карта или жетон;
♦ физические характеристики пользователя, такие как подпись или отпечат-
ки пальцев.
Наиболее общий способ подтверждения аутентификации— использование
имени и пароля. Эта информация оценивается системой для определения, яв-
ляетесь ли вы допустимым пользователем. Этот процесс может быть усилен
при использовании шифрования.
Шифрование данных— это процесс кодирования информации таким обра-
зом, что она становится непонятной, пока не будет дешифрована для кон-
кретного пользователя. Для шифрования данных могут быть использованы
Глава 12. Система безопасности Database Engine 327
различные методы, как будет рассказано в разд. "Шифрование" далее в этой
главе.
Авторизация — это процесс, который применяется после проверки того, что
пользователь соответствует аутентификации. В течение этого процесса сис-
тема определяет, какие ресурсы может использовать данный пользователь.
Иными словами, информация из структурного и системного каталога о кон-
кретной сущности теперь доступна лишь доверенным лицам — тем людям,
которые имеют полномочия доступа к данной сущности.
Отслеживание изменений означает, что действия неавторизованных пользо-
вателей отслеживаются и документируются на вашем компьютере. Этот про-
цесс полезен для защиты системы от пользователей, которые имеют повы-
шенные привилегии.
В следующих разделах подробно описываются все определенные здесь кон-
цепции безопасности. В дополнение к этому в конце главы описывается, как
представления могут быть использованы для безопасности данных.
Аутентификация
Система безопасности Database Engine включает две различные подсистемы
безопасности:
♦ безопасность Windows;
♦ безопасность SQL Server.
Безопасность Windows задает безопасность на уровне операционной системы,
т. е. метод, при помощи которого пользователи соединяются с операционной
системой, используя учетную запись пользователя Windows. Аутентифика-
ция, которая используется в этой подсистеме, также называется доверенной
аутентификацией, потому что система доверяет операционной системе, кото-
рая уже проверила учетную запись и соответствующий пароль.
Безопасность SQL Server задает дополнительную необходимую безопасность
на уровне системы, т. е. когда пользователь, который уже вошел в операци-
онную систему, может после этого соединяться с сервером базы данных.
Служба безопасности SQL Server определяет учетную запись SQL Server
(также часто называемую логином), которая создается системой и связана с
паролем. Некоторые учетные записи SQL Server идентичны учетным записям
пользователя Windows. Аутентификация, которая используется в этой под-
системе, называется аутентификацией SQL Server.
Замечание_____________________________________________________
В дополнение к учетной записи пользователя Windows и логину существуют
также группы Windows и роли SQL Server (также называемые просто "роли").
328
Часть II. Язык Transact-SQL
Группа Windows является коллекцией учетных записей пользователей Windows.
Назначение учетной записи пользователя членства в группе дает этому поль-
зователю все привилегии, предоставленные группе. Аналогично, роли являются
коллекцией логинов. Роли обсуждаются подробно позже в этой главе.
Основываясь на этих двух системах безопасности, Database Engine может ра-
ботать в одном из следующих режимов аутентификации:
♦ режим Windows;
♦ смешанный режим.
Режим Windows требует учетную запись пользователя Windows исключи-
тельно для соединения с системой. Система принимает учетную запись поль-
зователя, предполагая, что она уже проверена на уровне операционной сис-
темы. Этот вид соединения с системой базы данных называется доверитель-
ным соединением, потому что система доверяет тому, что операционная
система уже проверила эту учетную запись и соответствующий ей пароль.
Смешанный режим дает пользователям возможность соединяться с Database
Engine, используя аутентификацию Windows или аутентификацию SQL
Server. Это означает, что некоторые учетные записи пользователя могут быть
установлены для использования и в подсистеме безопасности SQL Server, и в
подсистеме безопасности Windows.
Замечание_____________________________________________________
Аутентификация SQL Server предоставляется только для обратной совмести-
мости версий. По этой причине вместо нее используйте аутентификацию
Windows.
Реализация режима аутентификации
Вы используете SQL Server Management Studio для выбора одного из сущест-
вующих режимов аутентификации. (В главе 3 весьма подробно обсуждается
интерфейс SQL Server Management Studio.) Чтобы установить режим
Windows, щелкните правой кнопкой мыши по серверу и выберите пункт
Properties. В диалоговом окне Server Properties выберите страницу Security
и щелкните по Windows Authentication Mode. Для выбора смешанного ре-
жима вам нужно только щелкнуть по Server and Windows Authentication
Mode в диалоговом окне Server Properties.
После того как пользователь будет успешно соединен с Database Engine, дос-
туп пользователя к объектам базы данных становится независимым от того,
какой режим аутентификации используется — Windows Authentication или
SQL Server Authentication.
Прежде чем изучать, как устанавливать безопасность сервера базы данных,
вам нужно понять политики и механизмы шифрования, которые описаны
далее.
Глава 12. Система безопасности Database Engine
Шифрование данных
Database Engine защищает данные при помощи иерархических уровней шиф-
рования и инфраструктуры управления ключами. Каждый уровень защищает
следующий за ним уровень шифрования, используя комбинацию сертифика-
тов, асимметричных и симметричных ключей (рис. 12.1).
Рис. 12.1. Database Engine: уровни иерархического шифрования
Главный сервисный ключ на рис. 12.1 задает ключ, который управляет всеми
другими ключами и сертификатами. Сервисный главный ключ создается ав-
томатически, когда вы инсталлируете Database Engine. Этот ключ зашифро-
ван с использованием Windows Data Protection API (DPAPI).
Важным свойством сервисного главного ключа является то, что он управля-
ется системой. Хотя системный администратор может выполнять некоторые
задачи обслуживания, существует только одна задача, которая должна быть
выполнена— копирование сервисного главного ключа, так что вы можете
восстановить ключ при его разрушении.
Как вы можете видеть на рис. 12.1, главный ключ базы данных является кор-
невым объектом шифрования для всех ключей, сертификатов и данных на
уровне базы данных. Каждая база данных имеет один главный ключ базы
данных, который создается при использовании оператора create master key.
Поскольку главный ключ базы данных защищен главным сервисным ключом,
330
Часть II. Язык Transact-SQL
для системы есть возможность автоматически дешифровать главный ключ
базы данных.
Так как существует главный ключ базы данных, пользователи могут его ис-
пользовать для создания пользовательских ключей, которые создаются и
поддерживаются пользователями. Существуют три формы пользовательских
ключей: симметричные ключи, асимметричные ключи и сертификаты. Сле-
дующие подразделы описывают пользовательские ключи.
Симметричные ключи
Система шифрования, которая использует симметричные ключи, — это та, в
которой отправитель и получатель сообщения используют общий ключ. Сле-
довательно, этот единственный ключ применяется как для шифрования, так и
для дешифрования данных.
Использование симметричных ключей имеет несколько преимуществ и один
недостаток. Одним из преимуществ использования симметричных ключей
является то, что они могут защищать значительно больший объем данных,
чем два других типа пользовательских ключей. Этот тип ключей также обра-
батывается значительно быстрее, чем асимметричные ключи
С другой стороны, в распределенных системах использование этого типа
ключей может сделать почти что невозможным сохранение безопасности
шифрования, т. к. один и тот же ключ служит для дешифрования и шифрова-
ния данных в обоих концах системы. Следовательно, основной рекомендаци-
ей является то, что симметричные ключи должны использоваться только
в приложениях, где данные сохраняются в виде зашифрованного текста в од-
ном месте.
Язык Transact-SQL поддерживает некоторые операторы и системные функ-
ции, относящиеся к симметричным ключам. Оператор create symmetric key
создает новый симметричный ключ, а оператор drop symmetric key удаляет
существующий симметричный ключ. Каждый симметричный ключ должен
быть открыт, прежде чем вы сможете его использовать для шифрования дан-
ных или защищать другой новый ключ. Для открытия ключа используется
оператор open symmetric key.
После того как вы откроете симметричный ключ, вам нужно использовать
системную функцию EncryptByKey для шифрования. Она имеет два входных
параметра: идентификатор ключа и текст, который должен быть зашифрован.
Для дешифрования используйте системную функцию DecryptByKey.
Замечание_____________________________________________________
Подробные описания всех операторов Transact-SQL, связанных с симметрич-
ными ключами, а также системных функций EncryptByKey И DecryptByKey
см. в документе Books Online.
Глава 12. Система безопасности Database Engine
331
Асимметричные ключи
Если у вас распределенная система или симметричные ключи не поддержи-
вают безопасность вашего шифрования, то используйте асимметричные клю-
чи. Асимметричный ключ состоит из двух частей: личного ключа и соответ-
ствующего общего ключа. Каждый из ключей может дешифровать данные,
зашифрованные другим ключом. По причине существования личного ключа
асимметричное шифрование обеспечивает более высокий уровень безопасно-
сти, чем это делает симметричное шифрование.
Язык Transact-SQL поддерживает некоторое количество операторов и сис-
темных функций, связанных с асимметричными ключами. Оператор create
asymmetric key создает новый асимметричный ключ, а оператор alter
asymmetric key изменяет свойства асимметричного ключа. Оператор drop
asymmetric key удаляет существующий асимметричный ключ.
После того как вы создали асимметричный ключ, используйте системную
функцию EncryptByAsymKey для шифрования данных. Эта функция имеет
два входных параметра: идентификатор ключа и текст, который должен
быть зашифрован. Для дешифрования используйте системную функцию
DecryptByAsymKey.
Замечание____________________________________________________
Подробные описания всех операторов Transact-SQL, связанных с асимметричными
ключами, а также системных Функций EncryptByAsymKey И DecryptByAsymKey
см. в документе Books Online.
Сертификаты
Общий ключ сертификата, обычно называемый просто сертификатом, явля-
ется двоичной подписью, связывающей значение общего ключа с идентифи-
кацией человека, устройства или сервиса, который содержит соответствую-
щий личный ключ. Сертификаты вызываются и обозначаются при помощи
авторизации сертификации (Certification Authority, СА). Сущность, которая
получает сертификат от СА, является субъектом этой сертификации. Серти-
фикаты содержат следующую информацию:
♦ значение общего ключа субъекта;
♦ информацию, идентифицирующую субъекта;
♦ издателя идентифицирующей информации;
♦ двоичную подпись издателя.
Основное преимущество сертификатов в том, что они освобождают хосты от
необходимости поддерживать наборы паролей для индивидуальных субъек-
12 Зак. 1141
332
Часть II. Язык Transact-SQL
тов. Когда хост, например Web-сервер безопасности, определяет запраши-
вающую сторону, как доверенного пользователя, хост неявно доверяет тому,
что эта запрашивающая сторона проверила идентичность сертифицированно-
го субъекта.
Замечание_____________________________________________________
Сертификаты предоставляют наивысший уровень шифрования в модели безо-
пасности Database Engine. Алгоритмы шифрования для сертификатов дают
большую нагрузку на процессоры. По этой причине используйте сертификаты
при реальной необходимости.
Наиболее важным оператором, связанным с сертификатами, является опера-
тор create certificate (примеры 12.1 и 12.2).
. Пример 12.1
USE sample;
CREATE MASTER KEY
ENCRYPTION BY PASSWORD = 'pls4w9dl6'
GO
CREATE CERTIFICATE certOl
WITH SUBJECT = 'Certificate for dbo';
Если вы хотите создать сертификат без опции encryption by, то должны в
первую очередь создать главный ключ базы данных. Каждый оператор create
certificate, который не включает эту опцию, защищается главным ключом
базы данных. По этой причине первым оператором в примере 12.1 является
оператор create master key. После этого оператор create certificate ис-
пользуется для создания нового сертификата certoi, которым владеет dbo
в базе данных sample, если текущим пользователем является dbo.
• Пример 12.2
USE sample;
CREATE CERTIFICATE cert02
ENCRYPTION BY PASSWORD = 'pGDFD4bb92DGvbd2439587y'
WITH SUBJECT = 'SQL Server 2008';
В примере 12.2 создается новый сертификат с именем cert02. Опция
encryption by password задает пароль, который будет использован при шиф-
ровании личного ключа.
Глава 12. Система безопасности Database Engine 333
Представления просмотра каталога шифрования
Наиболее важными представлениями просмотра каталога шифрования явля-
ются следующие:
♦ sys. syinmetric_keys;
♦ sys .asyiumetric_keys;
♦ sys.certificates;
♦ sys.databasejprincipals.
Первые три представления просмотра каталога предоставляют информацию
о симметричных ключах, всех асимметричных ключах и всех сертификатах,
установленных в текущей базе данных, соответственно. Представление про-
смотра каталогов sys.database_principals дает информацию о каждом поль-
зователе в текущей базе данных. Вы можете соединить последнее представ-
ление просмотра каталога с любым из трех других для просмотра информа-
ции о том. кто владеет конкретным ключом, сертификатом.
Улучшения шифрования в SQL Server 2008
SQL Server 2008 поддерживает две новые возможности шифрования:
♦ расширенное управление ключами — Extensible Key Management (EKM);
♦ прозрачное шифрование данных — Transparent Data Encryption (TDE).
EKM позволяет сторонним производителям регистрировать их объекты в
Database Engine. После того как эти элементы будут зарегистрированы, SQL
Server logins может использовать ключи шифрования, хранящиеся в этих мо-
дулях, как и средства улучшения возможностей шифрования, которые эти
модули поддерживают. ЕКМ также осуществит защиту данных от админист-
раторов базы данных (за исключением членов группы sysadmin). Таким спо-
собом вы можете защитить систему и от пользователей с повышенным уров-
нем привилегий. Данные могут быть зашифрованы и дешифрованы с по-
мощью криптографических операторов Transact-SQL, a SQL Server использу-
ет внешние элементы ЕКМ в качестве хранилища ключа.
Следующие операторы Transact-SQL поддерживают ЕКМ:
♦ create cryptographic provider создает криптографический провайдер
в Database Engine от стороннего производителя ЕКМ;
♦ drop cryptographic provider удаляет существующий провайдер.
Замечание________________________________________________________
Только редакции Enterprise и Developer в SQL Server 2008 поддерживают ЕКМ.
Прозрачное шифрование данных вводит новую опцию базы данных, которая
шифрует файлы базы данных автоматически без необходимости вносить
334
Часть II. Язык Transact-SQL
какие-либо изменения в существующие приложения. При этом способе вы
можете предотвратить доступ к базе данных неавторизованных людей, даже
если у них есть файлы базы данных или файлы резервной копии базы дан-
ных.
Шифрование файла базы данных осуществляется на уровне страницы. Стра-
ницы в зашифрованной базе данных шифруются до их помещения на диск и
дешифруются, когда они считываются в оперативную память. Прозрачное
шифрование данных не увеличивает размер зашифрованной базы данных.
Установка системы безопасности
с использованием DDL
Безопасность Database Engine может быть установлена либо с использовани-
ем операторов Transact-SQL, либо при помощи системных процедур. В этом
разделе описываются только операторы Transact-SQL, потому что все соот-
ветствующие системные процедуры (sp_addlogin и sp droplogin) являются
нерекомендуемыми средствами и будут удалены в одной из следующих вер-
сий SQL Server. Применяются три оператора Transact-SQL: create login,
ALTER LOGIN И DROP LOGIN.
Оператор create login создает новую учетную запись в SQL Server. Синтак-
сис оператора:
CREATE LOGIN login_name
{ WITH option_listl |
FROM {WINDOWS [ WITH option_list2 [, ...] ]
I CERTIFICATE certname | ASYMMETRIC KEY key_name }}
Здесь iogin_name задает имя создаваемой учетной записи. Как видно из син-
таксиса этого оператора, вы можете использовать предложение with для за-
дания одной или более опций для учетной записи или использовать предло-
жение from для определения сертификата, асимметричного ключа или учет-
ной записи пользователя Windows, связанных с соответствующей учетной
записью.
option_iistl содержит некоторые опции. Наиболее важной из них является
опция password, которая задает пароль для учетной записи (пример 12.3).
(ДРУГИМИ ДОПУСТИМЫМИ ОПЦИЯМИ ЯВЛЯЮТСЯ DEFAULT_DATABASE, DEFAULT_
LANGUAGE И CHECK_EXPIRATION.)
Как вы можете видеть из синтаксиса оператора create login, предложение
from содержит одну из следующих опций:
♦ опция windows указывает, что учетная запись будет отображаться в суще-
ствующем списке учетных записей Windows (пример 12.4). Это предложе-
Гпава 12. Система безопасности Database Engine
335
ние может быть задано вместе с другими вложенными опциями, такими
Как DEFAULT_DATABASE И DEFAULT_LANGUAGE;
♦ опция certificate задает имя сертификата, который должен быть связан
с этой учетной записью;
♦ опция ASYMMETRIC key задает имя асимметричного ключа, который должен
быть связан с этой учетной записью. Сертификат так же, как и асиммет-
ричный ключ, должен уже существовать в базе данных master.
В следующих примерах показано создание различных форм учетных записей.
В примере I2.3 создается учетная запись с именем тагу и паролем
youlknow4it9.
j Пример 12.3
USE sample;
CREATE LOGIN тагу WITH PASSWORD = 'youlknow4it9';
В примере 12.4 создается учетная запись с именем pete, которая будет ото-
бражаться в списке учетных записей пользователей Windows с тем же име-
нем.
i Пример 12.4
USE sample;
CREATE LOGIN [NTB11901\pete] FROM WINDOWS;
Замечание
Здесь вы должны изменить имя пользователя и имя компьютера в соответствии
с вашим окружением.
Вторым оператором безопасности, поддерживаемым Transact-SQL, является
alter login, который изменяет свойства отдельной учетной записи. Исполь-
зуя оператор alter login, вы можете изменить текущий пароль и срок исте-
чения его действия, полномочия, базу данных по умолчанию и язык по умол-
чанию. Вы также можете сделать доступным или недоступным указанную
учетную запись.
Наконец, оператор drop login удаляет существующую учетную запись. Учет-
ная запись не может быть удалена, если она ссылается на другие объекты
(владеет другими объектами).
336
Часть II. Язык Transact-SQL
Управление подключениями
с использованием Management Studio
Для создания новой учетной записи с использованием SQL Server
Management Studio раскройте сервер, раскройте Security, щелкните правой
кнопкой мыши по Logins и выберите пункт New Login. Появится диалоговое
окно Login (рис. 12.2). Во-первых, вы должны сделать выбор между аутенти-
фикацией Windows и аутентификацией SQL Server. Если вы выбираете
аутентификацию Windows, то имя учетной записи должно быть правильным
именем Windows, которое записывается в форме доменХимяпользователя.
Если вы выбираете аутентификацию SQL Server, то должны набрать новое
имя учетной записи и соответствующий пароль. Дополнительно вы также
можете задать базу данных по умолчанию и язык для новой учетной записи.
(Базой данных по умолчанию является база данных, с которой пользователь
автоматически соединяется сразу же после соединения с Database Engine.)
После этого пользователь может соединяться с системой под новой учетной
записью.
Рис. 12.2. Диалоговое окно соединения с сервером
Глава 12. Система безопасности Database Engine 337
Схемы
В своей модели безопасности Database Engine использует схемы для упроще-
ния отношений между пользователями и объектами; поэтому схемы имеют
очень большое влияние на то, как вы взаимодействуете с Database Engine.
В этом разделе описывается роль схем в безопасности Database Engine.
В первом подразделе описываются отношения между схемами и пользовате-
лями; во втором подразделе обсуждаются все три оператора Transact-SQL,
связанные с созданием и изменением схемы.
Разделение пользователей и схем
Схема является коллекцией объектов базы данных, которыми владеет один
человек, и множеством форм одного пространства имен. (Две таблицы в од-
ной схеме не могут иметь одинаковых имен.) Начиная с SQL Server 2005,
жесткая связь между пользователями и схемами была отменена. Теперь
Database Engine поддерживает именованные схемы, используя понятие прин-
ципала (администратора доступа), который имеет право доступа к объектам.
Принципал может быть:
♦ индивидуальным;
♦ групповым.
Индивидуальный принципал представляет одного пользователя, например,
в виде учетной записи (логин) или учетной записи пользователя Windows.
Групповой принципал может быть группой пользователей, например, ролью
или группой Windows. Принципалы являются владельцами схем, однако вла-
дение схемой может быть легко передано другому принципалу без изменения
имени схемы.
Отделение пользователей базы данных от схем дает большие преимущества,
например, такие:
♦ один принципал может владеть несколькими схемами;
♦ несколько индивидуальных принципалов могут владеть одной схемой
через их членство в роли или группе Windows;
♦ удаление пользователя базы данных не требует переименования объектов,
содержащихся в схеме этого пользователя.
Каждая база данных содержит схему по умолчанию, используемую для раз-
решения имен объектов, на которые осуществляются ссылки без указания их
полностью квалифицированных имен. Схема по умолчанию указывает пер-
вую схему, которая будет отыскиваться сервером базы данных, когда он раз-
338
Часть II. Язык Transact-SQL
решает имена объектов. Схема по умолчанию может быть установлена и из-
менена с использованием опции defaultjschema оператора create user или
alter user. Если схема по умолчанию default_schema оставлена необъявлен-
ной, пользователю базы данных будет предоставлена схема dbo в качестве его
схемы по умолчанию. Все схемы по умолчанию подробно описываются
в разд. "Схемы базы данных по умолчанию" далее в этой главе.
Операторы DDL, связанные со схемой
Существуют три оператора Transact-SQL, связанные со схемой:
♦ create schema;
♦ ALTER SCHEMA;
♦ DROP SCHEMA.
Оператор CREATE SCHEMA
В примере 12.5 показано, как схемы могут быть созданы и использованы для
управления безопасностью базы данных.
Замечание
Прежде чем выполнять пример 12.5, вы должны создать пользователей базы
данных peter и тагу. Для этого вначале выполните операторы Transact-SQL из
примера 12.8.
j Пример 12.5
USE sample;
GO
CREATE SCHEMA my_schema AUTHORIZATION peter
GO
CREATE TABLE product
(product_no CHAR(IO) NOT NULL UNIQUE,
product_name CHAR(20) NULL,
price MONEY NULL);
GO
CREATE VIEW product_info
AS SELECT product_no, product_name
FROM product;
GO
GRANT SELECT TO mary;
DENY UPDATE TO mary;
Гпава 12. Система безопасности Database Engine 339
В примере 12.5 создается схема my_schema, которая содержит в себе таблицу
product и представление product info. Пользователь базы данных с именем
peter является принципалом на уровне базы данных, который владеет схе-
мой. (Вы используете опцию authorization для определения принципала
схемы. Принципал может владеть и другими схемами, а может и не исполь-
зовать текущую схему как его или ее схему по умолчанию.)
Замечание________________________________________________________
Два других оператора, связанные с полномочиями к объектам базы данных,
GRANT и deny, подробно обсуждаются в конце этой главы, grant предоставляет
полномочия к оператору SELECT для всех объектов, созданных в этой схеме, а
deny отменяет полномочия update для всех объектов схемы.
Оператор create schema может создавать схему, создавать таблицы и пред-
ставления, которые содержит эта схема, а также предоставлять или отменять
полномочия по управлению безопасностью в одном операторе.
Замечание
Управления безопасностью являются ресурсами, для которых система автори-
зации SQL Server регулирует доступ. Существуют три основные области управ-
ления безопасностью: сервер, база данных и схема, которые содержат другие
средства управления безопасностью, такие как логины, пользователи базы
данных, таблицы и хранимые процедуры.
Оператор create schema является атомарным. Иными словами, если в процес-
се выполнения оператора create schema возникает любая ошибка, то ни один
из операторов Transact-SQL, заданных в этой схеме, не будет выполнен.
Объекты базы данных, которые создаются в операторе create schema, могут
быть заданы в любом порядке за одним исключением: представление, кото-
рое ссылается на другое представление, должно быть создано после того
представления, на которое оно ссылается.
Принципал на уровне базы данных может быть пользователем базы данных,
ролью или ролью приложения. (Роли и роли приложений обсуждаются в
разд. "Роли" далее в этой главе.) Принципал, который задается в предложе-
нии authorization оператора create schema, является владельцем всех объек-
тов, созданных в схеме. Владение объектами, содержащимися в схеме, может
быть перенаправлено любому другому принципалу уровня базы данных при
использовании оператора alter authorization (см. пример 12.7).
Пользователь должен иметь полномочие базы данных create schema для вы-
полнения оператора create schema. Для создания объектов, указанных в опе-
раторе create schema, пользователь также должен иметь соответствующие
ПОЛНОМОЧИЯ CREATE.
340
Часть II. Язык Transact-SQL
Оператор ALTER SCHEMA
Оператор alter schema перенаправляет объект между различными схемами
в одной и той же базы данных. Синтаксис оператора alter schema имеет сле-
дующий вид:
ALTER SCHEMA schema_name TRANSFER object_name
В примере 12.6 показано использование оператора alter schema.
! Пример 12.6
USE AdventureWorks;
ALTER SCHEMA humanresources TRANSFER person.address;
В примере 12.6 изменяется схема humanresources базы данных AdventureWorks.
В эту схему перемещается таблица address из схемы person той же самой ба-
зы данных.
Оператор alter schema может быть использован только для перемещения объ-
ектов между разными схемами в одной и той же базе данных. (Одиночные
объекты в схеме могут быть изменены при помощи операторов alter table
ИЛИ ALTER VIEW.)
Оператор DROP SCHEMA
Оператор drop schema удаляет схему из базы данных. Вы можете успешно вы-
полнить оператор drop schema для схемы только лишь в том случае, если эта
схема не содержит никаких объектов. Если же схема содержит какие-либо
объекты, то оператор drop schema будет отменен системой.
Как ранее было сказано, система позволяет изменять владение схемой при
использовании оператора alter authorization, который изменяет владение
для любой сущности.
Замечание_______________________________________________•________
Язык Transact-SQL не поддерживает операторы create authorization или
drop Authorization. Вы задаете владение для любой сущности при использо-
вании оператора create schema.
В примере 12.7 показано использование оператора alter authorization для
изменения владельца схемы my_schema.
| Пример 12.7
USE sample;
ALTER AUTHORIZATION ON SCHEMA ::my_schema TO mary;
Глава 12. Система безопасности Database Engine 341
Безопасность базы данных
Учетная запись пользователя Windows, или логин, дает возможность пользо-
вателю соединяться с системой. Пользователь, который впоследствии соби-
рается получить доступ к отдельной базе данных системы, также должен
иметь учетную запись для этой базы данных для работы с базой данных. По-
этому пользователи должны иметь учетную запись базы данных для каждой
базы данных, которую они собираются использовать. Учетная запись пользо-
вателя для базы данных может отображаться в существующем списке учет-
ных записей пользователя Windows, в группах Windows (членом которых яв-
ляется этот пользователь), в логинах или ролях.
Установка учетных записей пользователей
для базы данных
Полномочия безопасности базы данных могут быть установлены при исполь-
зовании операторов Transact-SQL, Management Studio или системных про-
цедур. В этом разделе не рассматривается создание учетных записей пользо-
вателей с использованием системных процедур, потому что все соответст-
вующие системные процедуры (sp_grantdbaccess И sp_revokedbaccess) будут
удалены в будущих версиях SQL Server.
Добавление пользователей
при помощи операторов Transact-SQL
Оператор create user добавляет пользователя в текущую базу данных. Син-
таксис этого оператора:
CREATE USER user_name
[FOR {LOGIN login I CERTIFICATE cert_name I ASYMMETRIC KEY key_name)]
[ WITH DEFAULT_SCHEMA = scbema_name ]
Здесь user_name— имя, которое будет применяться для идентификации поль-
зователя внутри базы данных; login задает логин, под которым создается
пользователь; cert name и key_name задают сертификат и асимметричный
ключ соответственно. Наконец, опция with default schema задает первую
схему, которая будет отыскиваться на сервере при разрешении имен объектов
для этого пользователя базы данных.
В примере 12.8 демонстрируется использование оператора create user.
= Пример 12.8
USE sample;
CREATE USER peter FOR LOGIN [NTB11901\pete];
342
Часть II. Язык Transact-SQL
CREATE USER тагу FOR LOGIN тагу
WITH DEFAULT_SCHEMA = my_schema;
Замечание____________________________________________________
Для успешного выполнения первого оператора создайте учетную запись Win-
dows с именем pete и измените имя сервера.
Первый оператор create user создает пользователя базы данных с именем
peter для учетной записи Windows с именем pete. Пользователь pete будет
использовать dbo в качестве схемы по умолчанию, потому что опущена
опция default schema. (Схемы по умолчанию описаны в разд. "Схемы базы
данных по умолчанию" далее в этой главе}.
Второй оператор create user создает нового пользователя базы данных
с именем тагу. Этот пользователь в качестве схемы по умолчанию имеет
схему my_schema. (Опция defaultjschema может задавать схему, которая в те-
кущий момент еще не существует в базе данных.)
Замечание____________________________________________________
Каждая база данных имеет собственных заданных пользователей. Поэтому
оператор create user должен быть однократно выполнен для каждой базы
данных, где должна существовать эта учетная запись пользователя. При этом
логин SQL Server должен иметь только одного соответствующего пользователя
базы данных для этой базы данных.
Оператор alter user модифицирует имя пользователя базы данных, изменяет
его схему по умолчанию или перемещает отображение пользователя в другой
логин. Аналогичным образом и в случае оператора create user допустимо
назначать пользователю схему по умолчанию до создания этой схемы.
Оператор drop user удаляет пользователя из текущей базы данных. Пользова-
тели, владеющие объектами безопасности (т. е. объектами базы данных), не
могут быть удалены из базы данных.
Добавление пользователей
с применением SQL Server Management Studio
Для добавления пользователей с применением SQL Server Management Studio
разверните сервер, разверните папку Databases, разверните нужную базу
данных и раскройте узел Security. Щелкните правой кнопкой мыши по Users
и выберите пункт New User. В диалоговом окне Database User (рис. 12.3)
введите имя пользователя и выберите соответствующее имя учетной записи.
В дополнение к этому вы можете выбрать для пользователя участие в роли
базы данных, а также схемы, которыми владеет этот пользователь.
Глава 12. Система безопасности Database Engine
Схемы базы данных по умолчанию
Каждая база данных в системе имеет следующие схемы базы данных по
умолчанию:
♦ guest (ГОСТЬ);
♦ dbo;
♦ information_schema;
♦ sys.
Database Engine дает возможность пользователям, не имеющим учетной запи-
си пользователя, получить доступ к базе данных с использованием схемы
guest. (После создания каждая база данных содержит такую схему.) Вы мо-
жете назначать привилегии схеме guest теми же способами, что и любым
другим схемам. Вы также можете удалять и добавлять схему guest в любой
базе данных за исключением системных баз данных master и tempdb.
344
Часть II. Язык Transact-SQL
Каждый объект базы данных может принадлежать одной и только одной схе-
ме, которая является схемой по умолчанию для этого объекта. Схема по
умолчанию может быть объявлена явно или неявно. Если схема по умолча-
нию не была объявлена явно в процессе создания объекта, то этот объект бу-
дет принадлежать схеме dbo. Логин, который является владельцем базы дан-
ных, всегда имеет специальное имя dbo при использовании базы данных, ко-
торой он владеет.
Схема information schema содержит всю информацию о представлениях схе-
мы. Схема sys, как вы уже, наверное, догадались, содержит системные объек-
ты, такие как представления просмотра каталогов.
Роли
Когда нескольким пользователям нужно выполнять похожие действия с от-
дельной базой данных (и для них нез соответствующей группы Windows), вы
можете добавить роль базы данных, которая задает группу пользователей ба-
зы данных, имеющих доступ к одним и тем же объектам базы данных.
Участниками роли базы данных могут быть любые следующие представите-
ли:
♦ группы Windows и учетные записи пользователей Windows;
♦ учетные записи SQL Server;
♦ другие роли.
Архитектура безопасности в Database Engine включает несколько "систем"
ролей, которые имеют специальные неявные полномочия. Существуют два
типа предварительно определенных ролей (в дополнение к ролям, определен-
ным пользователем):
♦ фиксированные серверные роли;
♦ фиксированные роли базы данных.
Помимо этих двух в следующих разделах также описываются такие типы
ролей:
♦ роли приложений;
♦ роли, определенные пользователем.
Фиксированные серверные роли
Фиксированные серверные роли определены на уровне сервера и поэтому
существуют вне баз данных, принадлежащих базам данных сервера. В табл. 12.1
содержится список фиксированных серверных ролей.
Гпава 12. Система безопасности Database Engine
345
Таблица 12.1. Фиксированные серверные роли
Фиксированная серверная роль Описание
sysadmin Выполняет любые действия в системе баз данных
serveradmin Конфигурирует серверные установки
setupadmin Инсталлирует репликацию и управляет расширенными процедурами
securityadmin Управляет учетными записями и полномочиями create database, проверяет отчетность
processadmin Управляет системными процессами
dbcreator Создает и изменяет базы данных
diskadmin Управляет дисковыми файлами
Системные процедуры sp_addsrvrolemember И sp_dropsrvrolemember исполь-
зуются, соответственно, для добавления членов и удаления членов из фикси-
рованных серверных ролей.
Замечание_______________________________________________________
Вы не можете добавлять или удалять фиксированные серверные роли. Допол-
нительно к этому только члены фиксированных серверных ролей могут выпол-
нять системные процедуры для добавления или удаления учетных записей из
ролей.
Каждая фиксированная серверная роль имеет собственные неявные полномо-
чия к системной базе данных. Вы можете просмотреть полномочия у каж-
дой фиксированной серверной роли, используя системную процедуру
sp_srvroiepermission. Для получения более полной информации о фиксиро-
ванных серверных ролях и их полномочиях см. документацию Books Online.
Учетная запись sa
Учетная запись sa является учетной записью системного администратора.
В версиях, предшествующих SQL Server 2005, где отсутствовали роли, учет-
ной записи sa были предоставлены все возможные полномочия по задачам
системного администрирования. Теперь учетная запись sa включена лишь
для обратной совместимости с предыдущими версиями. Эта учетная запись
всегда является членом фиксированной серверной роли sysadmin и не может
быть удалена из этой роли.
Замечание_______________________________________________________
Используйте учетную запись sa, только если нет другой возможности соеди-
ниться с системой базы данных.
346
Часть II. Язык Transact-SQL
Назначение учетной записи
фиксированной серверной роли
Для назначения учетной записи фиксированной серверной роли с использо-
ванием SQL Server Management Studio разверните сервер, разверните узлы
Security и Server Roles. Щелкните правой кнопкой мыши по роли, в которую
вы хотите добавить новую учетную запись, а затем выберите пункт
Properties. На странице General диалогового окна Server Role Properties
(рис. 12.4) щелкните по кнопке Add. Найдите учетную запись, которую вы
хотите добавить. Эта учетная запись теперь становится членом выбранной
роли и наследует все права, которые были назначены этой роли.
Рис. 12.4. Диалоговое окно Server Role Properties
Фиксированные роли базы данных
Фиксированные роли базы данных определяются на уровне базы данных и
поэтому существуют в каждой базе данных, принадлежащей этому серверу.
Гпава 12. Система безопасности Database Engine 347
В табл. 12.2 содержится список всех фиксированных ролей базы данных.
Члены фиксированной роли базы данных могут выполнять различные дейст-
вия. Для получения информации о том, какие действия допустимы для каж-
дой фиксированной роли базы данных, см. документацию Books Online.
Таблица 12.2. Фиксированные роли базы данных
Фиксированная роль базы данных Описание
db_owner Пользователи, которые могут выполнять почти все действия с базой данных
dbaccessadmin Пользователи, которые могут добавлять и удалять пользователей
db_data reader Пользователи, которые могут просматривать данные из всех таблиц пользователей базы данных
db_datawriter Пользователи, которые могут добавлять, изменять и удалять данные во всех таблицах пользователей базы данных
db_ddladmin Пользователи, которые могут выполнять все операции DDL в базе данных
dbsecurityadmin Пользователи, которые могут выполнять все действия, связанные с полномочиями безопасности в базе данных
db_backupoperator Пользователи, которые могут выполнять резервное копирование базы данных
db_denydata reader Пользователи, которые не могут просматривать любые данные в базе данных
dbdenydatawriter Пользователи, которые не могут изменять никакие данные в базе данных
Помимо фиксированных ролей базы данных, указанных в табл. 12.2. сущест-
вуют специальные фиксированные роли базы данных, называемые public,
которые прямо сейчас и будут рассмотрены.
Роль public
Роль public является специальной фиксированной ролью базы данных, кото-
рой принадлежит каждый легитимный пользователь базы данных. Она вклю-
чает в себя все полномочия по умолчанию для пользователей базы данных.
Это дает механизм по предоставлению всем пользователям без соответст-
вующих полномочий набор (обычно ограниченных) полномочий. Роль public
поддерживает все полномочия по умолчанию для пользователей базы данных
и не может быть удалена. Эта роль не может иметь назначенных ей пользова-
телей, групп или ролей, потому что они принадлежат роли по умолчанию.
(В примере 12.19 далее в этой главе показано использование роли public.)
348
Часть II. Язык Transact-SQL
По умолчанию роль public дает возможность пользователям выполнять сле-
дующее:
♦ просматривать системные таблицы и отображать информацию системной
базы данных master при использовании некоторых системных процедур;
♦ выполнять операторы, которые не требуют полномочий, например, print.
Назначение пользователя
фиксированной роли базы данных
Для назначения учетной записи пользователя фиксированной роли базы дан-
ных с использованием SQL Server Management Studio разверните сервер, раз-
верните узел Databases, разверните нужную базу данных, разверните узлы
Security | Roles | Database Roles. Щелкните правой кнопкой мыши по роли,
в которую вы хотите добавить нового пользователя, а затем выберите пункт
Properties. В диалоговом окне Database Role щелкните по кнопке Add и про-
смотрите список пользователей, чтобы найти того пользователя, которого вы
хотите добавить. Его учетная запись теперь станет членом этой роли и будет
наследовать все полномочия, которые были назначены данной роли.
Роли приложений
Роли приложений позволяют вам усилить уровень безопасности для конкрет-
ного приложения. Другими словами, роли приложений позволяют самому
приложению получить доступ к средствам ответственности за аутентифика-
цию пользователей, вместо того, чтобы рассчитывать на средства системы
базы данных. Например, если клерки в вашей компании имеют право изме-
нять данные о ваших служащих только при использовании существующего
приложения (а не операторами Transact-SQL или любыми другими инстру-
ментами), вы можете создать роль приложения для этого конкретного прило-
жения.
Роли приложений сильно отличаются от других типов ролей. Во-первых, ро-
ли приложений не имеют членов, потому что они используют только прило-
жения, и им не нужно явно предоставлять полномочия пользователям. Во-
вторых, вы должны использовать пароль для активации роли приложения.
Когда активируется роль приложения для существующей сессии приложения,
эта сессия теряет все полномочия, примененные к текущему соединению,
учетным записям пользователей, группам, ролям и всем базам данных теку-
щей сессии. Поскольку эти роли применимы только к тем базам данных, где
они существуют, сессия может получить доступ к другой базе данных только
через полномочия, предоставленные учетной записи пользователя guest дру-
Глава 12. Система безопасности Database Engine 349
гой базы данных. По этой причине, если в базе данных нет учетной записи
пользователя guest, сессия не может получить доступ к этой базе данных.
Создание, модификация и удаление
ролей приложений
Вы можете создавать, изменять и удалять роли приложений, используя либо
язык Transact-SQL, либо системные процедуры. Поскольку все системные
процедуры, связанные с этой темой (sp addapprole, spsetapprole и
sp_dropapproie), не рекомендуются к использованию и будут удалены в од-
ной из следующих версий SQL Server, в этом разделе рассматриваются лишь
соответствующие операторы Transact-SQL.
Оператор create application role создает роль приложения для текущей базы
данных. Этот оператор имеет две опции: одна задает пароль, а другая опреде-
ляет схему по умолчанию, т. е. первую схему, которая будет отыскиваться на
сервере при разрешении имен объектов для этой роли.
В примере 12.9 добавляется новая роль с именем weekly_report в базу дан-
ных sample.
\ Пример 12.9
USE sample;
CREATE APPLICATION ROLE weekly_reports
WITH PASSWORD = 'xly2z3w4',
DEFAULT_SCHEMA = my_schema;
Вы можете изменять или удалять роли приложений, используя операторы
ALTER APPLICATION ROLE ИЛИ DROP APPLICATION ROLE соответственно.
Оператор alter application role изменяет имя, пароль или схему по умолча-
нию у существующей роли приложения. Синтаксис этого оператора похож на
синтаксис оператора create application role. Для выполнения оператора
ALTER APPLICATION ROLE вам нужны ПОЛНОМОЧИЯ ALTER К ЭТОЙ рОЛИ.
Оператор drop application role удаляет роль приложения из текущей базы
данных. Если роль приложения владеет какими-нибудь объектами, она не
может быть удалена.
Активация роли приложения
После того как установлено соединение, вы должны выполнить системную
процедуру sp setapprole для активации полномочий, связанных с ролью
приложения. Эта процедура имеет следующий синтаксис:
350
Часть II. Язык Transact-SQL
sp_setapprole [@rolename = ] 'role',
[^password = ] 'password'
[, [@encrypt = ] 'encrypt_style']
Здесь role— имя роли приложения, определенной в текущей базе данных;
password задает соответствующий пароль; encrypt_style определяет стиль
шифрования, заданный для пароля.
Когда вы активируете роль приложения, используя процедуру sp setapproie,
вам нужно знать следующее:
♦ после активации роли приложения вы не можете деактивировать ее в те-
кущей базе данных, пока сессия не отсоединится от системы;
♦ роль приложения всегда ограничена базой данных, т. е. ее областью види-
мости является текущая база данных. Если вы в сессии изменяете теку-
щую базу данных, у вас появляется возможность выполнять другие дейст-
вия, основанные на полномочиях в этой базе данных.
Замечание___________________________________________________
Проектирование ролей приложения в SQL Server 2008 является субоптималь-
ным, потому что эта деятельность не является унифицированной. Для создания
и удаления ролей приложений вы используете Transact-SQL. После этого акти-
вация ролей приложений выполняется в системной процедуре.
Управление ролями приложений
с помощью Management Studio
Для создания роли приложения с использованием SQL Server Management
Studio разверните сервер, разверните папку Databases, а затем разверните
вашу базу данных и ее узел Security. Щелкните правой кнопкой мыши по
узлу Roles, выберите пункт New, а затем— пункт New Application Role.
В диалоговом окне Application Role введите имя новой роли. Дополнительно
вы должны ввести пароль и можете ввести схему по умолчанию для новой
роли.
Определенные пользователем роли базы данных
Обычно определенные пользователем роли базы данных применяются, когда
группе пользователей базы данных нужно выполнять общий набор действий
с базой данных, а подходящей группы Windows не существует. Такие роли
создаются (и удаляются) с помощью операторов Transact-SQL или системных
процедур. В этом разделе обсуждаются только операторы Transact-SQL, по-
тому что системные процедуры, относящиеся к ролям, определенным поль-
зователем (sp_addrole и sp_droprole), не рекомендуются к использованию.
Глава 12. Система безопасности Database Engine 351
Создание и удаление определенных пользователем ролей
Оператор create role создает новую определенную пользователем роль базы
данных в текущей базе данных. Синтаксис этого Оператора:
CREATE ROLE role_name [AUTHORIZATION oi-/ner_name]
Здесь roie_name— имя создаваемой роли, определенной пользователем;
owner_name задает пользователя или роль базы данных. Если никакой пользо-
ватель не задан, ролью будет владеть тот пользователь, который выполняет
оператор create role.
Оператор alter role изменяет имя определенной пользователем роли базы
данных. Аналогично, оператор drop role удаляет роль из базы данных. Роли,
которые владеют объектами базы данных, не могут быть удалены из базы
данных. Для удаления такой роли вы должны вначале изменить владельца
этих объектов.
Роли и системные процедуры
Все еще существует несколько системных процедур, которые вы должны ис-
пользовать, если вам нужно добавлять или удалять членов определенных
пользователем ролей:
♦ sp_addrolemember;
♦ sp_droprolemember;
♦ sp_helprole.
После того как вы добавили роль в текущую базу данных, вы можете исполь-
зовать системную процедуру sp_addroiemember для добавления членов в эту
роль. Членом роли может быть любой правильный логин, учетная запись
пользователя или группа Windows либо другая роль. Только члены базы дан-
ных ролей db_owner могут выполнять эту системную процедуру. Владельцы
роли могут также выполнять процедуру sp_addrolemember для добавления
членов в любую роль, которой они владеют.
Системная процедура spjdroprolemember удаляет существующего члена из
роли. Эту системную процедуру невозможно использовать для удаления су-
ществующей учетной записи пользователя Windows из группы Windows.
Системная процедура sp_helprole отображает информацию (идентификатор и
имя роли) о конкретной роли или обо всех ролях в текущей базе данных, если
имя роли не указано. Только члены ролей db owner или db securityadmin
могут выполнять эту системную процедуру.
Замечание________________________________________________________
Процесс проектирования ролей (в данном случае ролей базы данных, опреде-
ленных пользователем) в SQL Server 2008 не является ни унифицированным,
352
Часть II. Язык Transact-SQL
ни оптимальным. Для создания и удаления определенных пользователем ро-
лей вы используете Transact-SQL, в то время как для добавления этих ролей
в текущую базу данных вы должны использовать системные процедуры.
В примере 12.10 показано, как можно создать определенную пользователем
роль и добавить в нее членов.
1 Пример 12.10
USE sample;
CREATE ROLE marketing AUTHORIZATION peter;
GO
exec sp_addrolemember @rolename = 'marketing', @membername = 'peter';
exec sp_addrolemember @rolename = 'marketing', Smembername = 'mary';
В примере 12.10 вначале создается определенная пользователем роль с име-
нем marketing, а затем при использовании системной процедуры
sp addroiemember в эту роль добавляются два члена: peter и шагу.
Управление определенными пользователем ролями
с помощью Management Studio
Для создания определенной пользователем роли с помощью SQL Server
Management Studio разверните сервер, разверните папку Databases, а затем —
вашу базу данных и ее узел Security. Щелкните правой кнопкой мыши по
узлу Roles, выберите пункт New | New Database Role. В диалоговом окне
Database Role (рис. 12.5) введите имя новой роли. Щелкните по кнопке Add
для добавления членов в новую роль. Выберите членов (пользователей и/или
другие роли) для новой роли и щелкните по кнопке ОК.
Авторизация
Только авторизованные пользователи имеют возможность выполнять опера-
торы и осуществлять операции над сущностями. Если неавторизованный
пользователь попытается выполнить оператор Transact-SQL или операцию
с объектом базы данных, такое действие будет отменено системой.
Существуют три оператора Transact-SQL, связанные с авторизацией:
♦ grant;
♦ deny;
♦ revoke.
Прежде чем вы приступите к чтению об этих трех операторах, вы должны
знать об одном из наиболее важных свойств безопасности Database Engine: он
поддерживает множество областей и полномочий, чтобы помочь системному
Гпава 12. Система безопасности Database Engine
353
Рис. 12.5. Диалоговое окно Database Role
администратору обрабатывать полномочия. Модель авторизации разделяет
мир на принципалов и объекты безопасности. Каждый объект безопасности
имеет связанные с ним полномочия, которые могут быть предоставлены
принципалу. Принципалы, такие как индивидуальности, группы или прило-
жения, имеют доступ к сущностям. Сущности являются ресурсами, к кото-
рым подсистема авторизации регулирует доступ. Как ранее было сказано,
существуют три области объектов безопасности: сервер, база данных и схема,
которые содержат другие объекты безопасности, такие как учетные записи,
пользователи базы данных, таблицы и хранимые процедуры.
Оператор GRANT
Оператор grant предоставляет полномочия к объектам безопасности. Синтак-
сис оператора grant:
GRANT {ALL [PRIVILEGES]} | permission_list
[ON [class::] securable] TO principal_list [WITH GRANT OPTION]
[AS principal ]
354
Часть II. Язык Transact-SQL
Предложение all указывает, что все полномочия, применимые к данному
объекту безопасности, будут назначены указанному принципалу. (Список
объектов безопасности см. в документации Books Online.) Параметр
permission_list задает операторы или объекты (разделенные запятыми), ко-
торым предоставляются полномочия; class задает или класс безопасности,
или имя объекта безопасности, которому предоставляются полномочия, on
securable задает объект безопасности, которому предоставляются полномо-
чия (см. пример 12.15). principallist задает список всех учетных записей
(разделенных запятыми), которым предоставляются полномочия, principal и
компоненты principai_iist могут быть учетными записями пользователя
Windows, логинами или учетными записями, отображенными в сертификате,
логинами, отображенными в асимметричном ключе, пользователем базы дан-
ных, ролью базы данных или ролью приложения.
В табл. 12.3 содержится список и описание всех полномочий, а также список
объектов безопасности, им соответствующих.
Таблица 12.3. Полномочия с соответствующими объектами безопасности
Полномочие Применяется Описание
SELECT Таблицы и столбцы, синонимы, представления и столбцы, функции с табличными значениями Предоставляет возможность выби- рать (читать) строки. Вы можете ограничить это полномочие одним или более столбцами, задав их спи- сок. (Если такой список отсутствует, то могут выбираться все столбцы этой таблицы)
INSERT Таблицы и столбцы, синонимы, представления и столбцы Предоставляет возможность добав- лять строки
UPDATE Таблицы и столбцы, синонимы, представления и столбцы Предоставляет возможность изме- нять значения столбцов. Вы можете ограничить это полномочие одним или более столбцами, задав их спи- сок. (Если такой список отсутствует, то могут изменяться все столбцы этой таблицы)
DELETE Таблицы и столбцы, синонимы, представления и столбцы Предоставляет возможность удалять строки
REFERENCES Функции, определенные пользователем (SQL и CLR), таблицы и столбцы, синонимы, представления и столбцы Предоставляет возможность во внешнем ключе ссылаться на столб- цы родительской таблицы, когда пользователь не имеет полномочий select к таблице, на которую осу- ществляется ссылка
Глава 12. Система безопасности Database Engine
355
Таблица 12.3 (окончание)
Полномочие Применяется Описание
EXECUTE Хранимые процедуры (SQL и CLR), функции, опреде- ленные пользователем (SQL и CLR), синонимы Предоставляет возможность выпол- нять указанную хранимую процедуру или функцию, определенную пользо- вателем
CONTROL Хранимые процедуры (SQL и CLR), функции, опреде- ленные пользователем (SQL и CLR), синонимы Предоставляет полномочия анало- гичные владению. Получатель имеет все определенные права к данному объекту безопасности. Принципал, которому были предоставлены права CONTROL, также имеет право предос- тавлять полномочия к этому объекту безопасности. Полномочие CONTROL к конкретной области видимости неявно включает полномочия CONTROL ко всем объектам безопас- ности этой области видимости (см. пример 12.16)
ALTER Хранимые процедуры (SQL и CLR), функции, опреде- ленные пользователем (SQL и CLR), таблицы, представ- ления Предоставляет возможность изме- нять свойства (за исключением прав владения) конкретного объекта безопасности. Если права предос- тавляются области видимости, то также дается возможность ALTER, CREATE и drop любому объекту безо- пасности, находящемуся в этой об- ласти видимости
TAKE OWNERSHIP Хранимые процедуры (SQL и CLR), функции, опреде- ленные пользователем (SQL и CLR), таблицы, представ- ления, синонимы Дает возможность объекту безопас- ности получить право владения все- ми объектами безопасности
VIEW DEFINITION Хранимые процедуры (SQL и CLR), функции, опреде- ленные пользователем (SQL и CLR), таблицы, представ- ления, синонимы Управляет возможностью получате- ля полномочий просматривать мета- данные объекта безопасности (см. пример 12.15)
create (безопас- ность сервера) Не применяется Предоставляет право создавать объект безопасности сервера
create (безопас- ность базы данных) Не применяется Предоставляет право создавать объект безопасности базы данных
Замечание________________________________________________________
В табл. 12.3 показаны только наиболее важные полномочия. Модель безопас-
ности в Database Engine является иерархической. Следовательно, существует
356
Часть II. Язык Transact-SQL
множество детальных полномочий, которые не представлены в этой таблице.
Вы можете найти описания этих полномочий в документации Books Online.
Следующие примеры демонстрируют использование оператора grant. Внача-
ле пример 12.11 демонстрирует использование полномочия create.
1 Пример 12.11
USE sample;
GRANT CREATE TABLE, CREATE PROCEDURE
TO peter, mary;
В примере 12.11 пользователи с именами peter и тагу могут выполнять опе-
раторы Transact-SQL create table и create procedure. (Как вы можете видеть
в этом примере, оператор grant с полномочием create не содержит оп-
цию ON.)
В примере 12.12 пользователю тагу предоставляется возможность создавать
определенные пользователем функции в базе данных sample.
i Пример 12.12
USE sample;
GRANT CREATE FUNCTION TO mary;
Пример 12.13 показывает использование полномочия select в операторе
GRANT.
Пример 12.13
USE sample;
GRANT SELECT ON employee
TO peter, mary;
В примере 12.13 пользователи с именами peter и тагу могут читать строки
из таблицы employee.
Замечание__________________________________________________________
Когда полномочие предоставляется учетной записи пользователя Windows, то
это полномочие влияет лишь на эту учетную запись. С другой стороны, если
полномочие предоставляется группе или роли, то это полномочие влияет на
всех пользователей, принадлежащих этой группе (роли).
Пример 12.14 показывает использование полномочия update в операторе
GRANT.
Глава 12. Система безопасности Database Engine 357
j Пример 12.14
USE sample;
GRANT UPDATE ON works_on (emp_no, enter_date) TO peter;
В примере 12.14 пользователь peter может изменять два столбца таблицы
works on: emp_no И enter date.
Пример 12.15 показывает использование полномочия view definition.
= Пример 12.15
USE sample;
GRANT VIEW DEFINITION ON OBJECT::employee TO peter;
GRANT VIEW DEFINITION ON SCHEMA::dbo TO peter;
В примере 12.15 показаны два оператора grant для полномочий view
definition. Первый позволяет пользователю peter просматривать метаданные
таблицы employee базы данных sample, (object — один из объектов безопас-
ности базы данных, вы можете использовать это предложение для предостав-
ления полномочий указанным объектам, таким как таблицы, представления и
хранимые процедуры.) Поскольку объекты безопасности имеют иерархиче-
скую структуру, вы можете использовать объект безопасности "высшего"
уровня, чтобы расширить ПОЛНОМОЧИЯ VIEW definition (или любой другой
базы). Второй оператор в примере 12.15 предоставляет пользователю peter
полномочия доступа к метаданным всех объектов схемы dbo базы данных
sample.
Замечание_________________________________________________________
В версиях, предшествующих SQL Server 2005, была возможность запрашивать
информацию обо всех объектах базы данных, даже если этими объектами вла-
дел другой пользователь. Полномочия view definition теперь дают вам воз-
можность разрешать или отменять доступ к отдельным частям ваших метадан-
ных и, следовательно, принимать решения, какая часть метаданных будет вид-
на другим пользователям.
В примере 12.16 показано использование полномочия control.
' Пример 12.16 .
USE sample;
GRANT CONTROL ON DATABASE::sample TO peter;
В примере 12.16 пользователь peter имеет все определенные полномочия
к объектам безопасности (в данном случае к объектам базы данных sample).
358
Часть II. Язык Transact-SQL
Принципал, которому были предоставлены полномочия control, также неяв-
но получает возможность предоставлять полномочия и другим участникам
безопасности, иными словами, полномочие control включает предложение
with grant option (см. пример 12.17). Полномочие control является полно-
мочием наивысшего уровня в отношении отдельных объектов безопасности
базы данных. По этой причине control для отдельной области видимости не-
явно включает control для всех объектов безопасности, находящихся ниже
этой области видимости. Поэтому полномочие control для пользователя
peter к базе данных sample предполагает все полномочия к этой базе данных,
все полномочия ко всем сборкам этой базы данных, все полномочия ко всем
схемам базы данных sample и все полномочия к объектам базы данных
sample.
По умолчанию если пользователь А предоставляет полномочия пользователю
В, то пользователь В может использовать эти полномочия только для выпол-
нения операторов Transact-SQL, описанных в операторе grant. Предложение
with grant option дает пользователю В дополнительную возможность пре-
доставлять эти привилегии другим пользователям (пример 12.17).
• Пример 12.17
USE sample;
GRANT SELECT ON works_on TO mary
WITH GRANT OPTION;
В примере 12.17 пользователь тагу может использовать оператор select для
выборки строк из таблицы works on, а также предоставлять эту привилегию
другим пользователям базы данных sample.
Оператор DENY
Оператор deny не дает пользователям возможности выполнять действия. Это
означает, что такой оператор удаляет существующие полномочия у учетных
записей пользователей или не разрешает пользователям применять полномо-
чия от их участия в группах/ролях, которые могут быть получены в будущем.
Этот оператор имеет следующий синтаксис:
DENY {ALL [PRIVILEGES] } I permissionlist
[ON [class::] securable] TO principallist
[CASCADE] [ AS principal ]
Все опции оператора deny имеют то же логическое-значение, что и опции
с теми же самыми именами в операторе grant, deny имеет дополнительную
Глава 12. Система безопасности Database Engine 359
опцию cascade, которая указывает, что полномочия не будут применяться для
пользователя А и для любого пользователя, которому пользователь А пере-
даст эти полномочия. (Если опция CASCADE не указана в операторе deny и со-
ответствующие полномочия к объекту задаются с with grant option, то воз-
вращается ошибка.)
Оператор deny запрещает пользователю, группе или роли получать доступ
к полномочиям, полученным через их участие в группе или роли. Это означа-
ет, что если пользователь принадлежит группе (или роли) и предоставленные
группе полномочия отменяются для этого пользователя, то этот пользователь
будет единственным в группе, кто не сможет использовать эти полномочия.
С другой стороны, если полномочия отменяются для всей группы, то эти
полномочия отменяются для всех членов этой группы.
Замечание__________________________________________________________
Вы можете рассматривать оператор grant как "позитивную", a deny как "нега-
тивную" авторизацию. Обычно оператор deny используется для отмены уже
существующих для группы (роли) полномочий для небольшого количества чле-
нов этой группы.
В примерах 12.18 и 12.19 показано использование оператора deny.
[ Пример 12.18
USE sample;
DENY CREATE TABLE, CREATE PROCEDURE
TO peter;
Оператор deny в примере 12.18 отменяет два ранее назначенных полномочия
к операторам для пользователя peter.
:• Пример 12.19
USE sample;
GRANT SELECT ON project
TO PUBLIC;
DENY SELECT ON project
TO peter, mary;
В примере 12.19 показана негативная авторизация для некоторых пользовате-
лей базы данных sample. Вначале предоставляется право чтения всех строк из
таблицы project для всех пользователей базы данных sample. Затем это право
отменяется для двух пользователей: peter и тагу.
360
Часть II. Язык Transact-SQL
Оператор REVOKE
Оператор revoke удаляет одно или. более из ранее предоставленных или отме-
ненных полномочий. Этот оператор имеет следующий синтаксис:
REVOKE [GRANT OPTION FOR]
{ [ALL [PRIVILEGES] ] | permission_list ]}
[ON [class'.: ] securable ]
FROM principal_list [CASCADE] [ AS principal ]
В операторе revoke есть только одна новая опция — grant option for. (Все
другие опции имеют то же самое логическое значение, что и опции с теми же
именами в операторах grant или deny.) grant option for используется для
удаления эффекта with grant option в соответствующем операторе grant.
Это означает, что пользователь продолжает иметь ранее полученные полно-
мочия, но больше не может предоставлять указанное полномочие другим
пользователям.
Замечание___________________________________________________
Оператор revoke отменяет как "позитивные" полномочия, предоставленные
оператором grant, так и "негативные" полномочия, сгенерированные операто-
ром deny. Поэтому его функцией является нейтрализация указанных полномо-
чий (позитивных или негативных).
В примере 12.20 показано использование оператора revoke.
• Пример 12.20
USE sample;
REVOKE SELECT ON project
FROM PUBLIC;
Оператор revoke в примере 12.20 отменяет предоставленное полномочие вы-
борки данных для роли public. В то же время, существующие "негативные"
полномочия для пользователей peter и тагу не отменяются (как в приме-
ре 12.19), потому что операция отмены полномочий для ролей или групп не
оказывает никакого влияния на явно предоставленные или отмененные для
них полномочия.
Управление полномочиями
с использованием Management Studio
Пользователи базы данных могут выполнять предоставленные им действия.
В этом случае существует соответствующая запись в представлении про-
смотра каталога sys.database_permissions (т. е. значение столбца state уста-
Глава 12. Система безопасности Database Engine
новлено в g). Негативная запись в таблице не дает возможности пользовате-
лям осуществлять деятельность. Значение D (deny, отменить) в столбце state
перекрывает полномочие, которое было предоставлено пользователю явно
или неявно с помощью роли, которой принадлежит пользователь. Поэтому в
любом случае пользователь не может выполнять такую деятельность. И в по-
следнем случае (значение r) пользователь не имеет явно установленных при-
вилегий, но может осуществлять некую деятельность, если роль, которой
принадлежит этот пользователь, имеет соответствующие полномочия.
Для управления полномочиями пользователя или роли с использованием
Management Studio разверните сервер и папку Databases. Щелкните правой
Рис. 12.6. Управление оператором полномочий с использованием Management Studio
362
Часть II. Язык Transact-SQL
кнопкой мыши по нужной базе данных и выберите пункт Properties. Выбери-
те страницу Permissions и щелкните по кнопке Add. В диалоговом окне
Database Properties (рис. 12.6) вы можете выбрать один или более типов
объектов (пользователи и/или роли), для которых вы собираетесь устанавли-
вать или отменять полномочия. Для предоставления полномочий отметьте
соответствующий флажок в столбце Grant и щелкните по кнопке ОК. Для
отмены полномочий отметьте соответствующий флажок в столбце Deny.
(Столбец With Grant указывает, что пользователь имеет дополнительную
возможность предоставлять привилегию другим пользователям.) Пробел
в этих столбцах означает отсутствие полномочия.
Для управления полномочиями объекта одной базы данных с использованием
Management Studio разверните сервер, разверните Databases, разверните базу
данных, а затем разверните Tables, Views или Synonyms в зависимости от
того объекта, чьими полномочиями вы хотите управлять. Щелкните правой
кнопкой мыши по объекту, выберите пункт Properties и перейдите на стра-
ницу Permissions. (На рис. 12.7 показано диалоговое окно Table Properties
Рис. 12.7. Управление полномочиями объекта
с использованием SQL Server Management Studio
Гпава 12. Система безопасности Database Engine 363
для таблицы employee.) Щелкните по кнопке Add для открытия диалогового
окна Select Users or Roles. Щелкните no Object Types и выберите один или
более типов объектов (пользователи, роли базы данных, роли приложений).
После этого щелкните по кнопке Browse и отметьте все объекты, которым
должны быть предоставлены полномочия. Для предоставления полномочия
отметьте соответствующий элемент в столбце Grant. Для отмены полномо-
чия отметьте соответствующий элемент в столбце Deny.
Отслеживание изменений
Отслеживание изменений означает документирование всех действий по до-
бавлению, изменению и удалению данных применительно к таблицам базы
данных. Задокументированные изменения затем могут быть просмотрены для
выяснения того, кто обращался к данным и когда были выполнены эти обра-
щения. Существуют два способа, при помощи которых вы можете выполнять
отслеживание изменений:
♦ использование триггеров;
♦ применение средств перехвата, отслеживающих изменения данных
(change data capture, CDC).
Вы можете использовать триггеры для создания контрольного журнала, со-
держащего сведения о действиях с одной или более таблицами базы данных.
В разд. "Триггеры AFTER" главы 14 в примере 14.1 показано, как могут быть
использованы триггеры для отслеживания подобных изменений. По этой
причине настоящий раздел фокусируется на CDC.
CDC является механизмом отслеживания, который вы можете использовать
для просмотра изменений в порядке их появления. Основной целью CDC яв-
ляется фиксация того, кто выполнял изменения, с какими данными и когда,
однако средства CDC могут быть также использованы и для поддержки па-
раллельных изменений. (Если приложение собирается модифицировать стро-
ку, CDC может проверить информацию в списке изменений, чтобы убедиться
в том, что эта строка не была изменена с момента последнего изменения этой
строки данным приложением. Такая проверка называется "параллельным об-
новлением".)
Замечание___________________________________________________
Средства CDC доступны только в SQL Server 2008 редакций Enterprise и
Developer.
Перед перехватом действия экземпляр должен быть создан для индивидуаль-
ных таблиц; база данных, которая содержит эти таблицы, должна стать дос-
тупной для CDC, что можно сделать при помощи системной хранимой про-
13 Зак. 1141
364
Часть II. Язык Transact-SQL
цедуры sys. sp_cdc_enabie_db, как показано в примере 12.21. (Только члены
фиксированной серверной роли sysadmin могут выполнять эту процедуру.)
i Пример 12.21
USE sample;
EXECUTE sys.sp_cdc_enable_db
Для определения, является ли база данных sample доступной для CDC, вы
можете отыскать значение столбца is cdc enabied в представлении просмот-
ра каталога sys.databases. Значение 1 указывает, что средства CDC активи-
рованы для конкретной базы данных.
Если база данных доступна для CDC, то схема cdc, пользователь cdc, таблицы
метаданных и другие системные объекты будут созданы для базы данных.
Схема cdc содержит таблицы метаданных CDC так же, как и индивидуальные
таблицы трассировки, которые служат в качестве репозитария для CDC.
Когда база данных стала доступной для CDC, вы можете создавать целевые
таблицы, которые будут хранить изменения для отдельной исходной табли-
цы. Вы делаете таблицу доступной при использовании хранимой процедуры
sys. sp cdc enabie tabie. (Только члены фиксированной роли базы данных
db owner могут выполнять эту процедуру.) В примере 12.22 показано исполь-
зование этой системной хранимой процедуры.
Замечание__________________________________________________________
Сервис SQLServerAgent должен быть запущен, прежде чем вы сделаете дос-
тупными для CDC ваши таблицы.
1 Пример 12.22
USE sample;
EXECUTE sys.sp_cdc_enable_table
@source_schema = N'dbo', @source_name '= N'works_on',
@role_name = N'cdc_admin';
Системная процедура sys. sp_cdc_enabie_tabie в примере 12.22 делает дос-
тупным CDC для указанной исходной таблицы в текущей базе данных. Когда
таблица доступна для CDC, все операторы DML читаются из протокола тран-
закций и помещаются в ассоциированную таблицу изменений. Параметр
@source_schema задает имя схемы, в которой находится исходная таблица.
@source_name является именем исходной таблицы, для которой вы делаете
доступным CDC. Параметр @roie name задает имя роли базы данных, исполь-
зуемой для предоставления доступа к данным.
Глава 12. Система безопасности Database Engine
365
При создании экземпляра перехвата также создается таблица отслеживания,
которая соответствует исходной таблице. Вы можете указать до двух экземп-
ляров перехвата для одной исходной таблицы. В примере 12.23 выполняется
изменение содержимого исходной таблицы (works on).
; Пример 12.23
USE sample;
INSERT INTO works_on VALUES (10102, 'p2', 'Analyst', NULL);
INSERT INTO works_on VALUES (9031, 'p2', 'Analyst', NULL);
INSERT INTO workson VALUES (29346, 'p3', 'Clerk', NULL);
По умолчанию, по крайней мере, одна функция с табличными значениями
создается для доступа к данным в ассоциированной таблице изменений. Эта
функция позволяет вам запрашивать все изменения, которые появляются в
указанном интервале. Именем этой функции является конкатенация текста
cdc.fn_cdc_get_aii_changes_ и значения, присвоенного параметру
Gcapture instance. В этом случае параметр имеет значение dbo_works_on, как
показано в примере 12.24.
| Пример 12.24
' USE sample;
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_works_on
(sys.fn_cdc_get_min_lsn('dboworkson'), sys.fn_cdc_get_max_lsn(),
'all') ;
Результат:
$start_lsn $update mask ernp_no project_no job enter_date
Ox0000001C000001EF0003 OxOF 10102 p2 Analyst NULL
0x0000001D000000100003 OxOF 9031 p2 Analyst NULL
0x0000001D000000110003 OxOF 29346 p3 Clerk NULL
В примере 12.24 показаны все изменения, которые произошли после выпол-
нения трех операторов insert. Если вы хотите задокументировать все изме-
нения в конкретном временном интервале, то можете использовать пакет,
аналогичный тому, который представлен в примере 12.25.
j Пример 12.25
USE sample;
DECLARE @from_lsn binary(10), @to_lsn binary(lO);
366
Часть II. Язык Transact-SQL
SELECT @from_lsn =
sys.fn_cdc_mapi_time_to_lsn('smallest greater than', GETDATEO — 1) ;
SELECT @to_lsn =
sys.fn_cdc_map time_to_lsn('largest less than or equal', GETDATEO);
SELECT * FROM
cdc.fn_cdc_get_all_changes_dbo_works_on (@from_lsn, @to_lsn, 'all');
Единственным отличием примера 12.25 от примера 12.24 является то, что
пример 12.25 использует два параметра (@from_isn и @to_isn) для определе-
ния начала и завершения интервала времени. (Назначение границ времени
выполняется с ПОМОЩЬЮ функции sys. fn_cdc_map_time_to_lsn О.)
Безопасность данных и представления
Как было сказано в главе 11, представления могут быть использованы:
♦ для ограничения использования отдельных столбцов и/или строк таблицы;
♦ для сокрытия деталей сложных, запутанных запросов;
♦ для ограничения значений добавляемых или изменяемых значений задан-
ным диапазоном.
Ограничение использования отдельных столбцов и/или строк означает, что
механизм представлений обеспечивает управление доступом к данным. На-
пример, если таблица employee также содержит заработные платы каждого
сотрудника, то доступ к этим зарплатам может быть ограничен при использо-
вании представления, которое предоставляет доступ ко всем столбцам этой
таблицы за исключением столбца salary. В итоге, выборка данных из этой
таблицы может быть предоставлена всем пользователям базы данных, ис-
пользующим это представление, тогда как только небольшое количество
(привилегированных) пользователей будет иметь те же привилегии ко всем
данным этой таблицы.
Примеры 12.26—12.28 демонстрируют использование представлений для
ограничения доступа к данным.
: Пример 12.26
USE sample;
GO
CREATE VIEW v_without_budget
AS SELECT project_no, project_name
FROM project;
При использовании представления v_without_budget можно разделить поль-
зователей на две группы: на группу привилегированных пользователей, кото-
Гпава 12. Система безопасности Database Engine 367
рые получают доступ к бюджетам всех проектов, и общую группу пользова-
телей, которые имеют доступ ко всем строкам таблицы projects, кроме дан-
ных столбца budget.
i Пример 12.27
USE sample;
GO
ALTER TABLE employee
ADD user_name CHAR(60) DEFAULT SYSTEMJJSER;
GO
CREATE VIEW v_my_rows
AS SELECT erap_no, emp_fname, emp__lname, dept_no
FROM employee
WHERE user_name = SYSTEMJJSER;
Замечание____________________________________________________________
Операторы Transact-SQL в примере 12.27 должны выполняться отдельно, по-
тому что оператор create view должен быть первым оператором в пакете.
Именно по этой причине используется оператор GO (чтобы отметить заверше-
ние первого пакета).
Схема таблицы employee в примере 12.27 изменяется путем добавления ново-
го столбца user_name. Каждый раз, когда новая строка добавляется в таблицу
employee, системная учетная запись добавляется в столбец user name. После
создания соответствующего представления каждый пользователь может про-
сматривать только те строки, которые были добавлены в эту таблицу. (То же
самое верно и для оператора update.)
i Пример 12.28
USE sample;
GO
CREATE VIEW v_analyst
AS SELECT employee.emp_no, empfname, emp_lname
FROM employee, works_on
WHERE employee.emp_no = works_on.emp_no
AND job = 'Analyst';
Представление v_analyst дает горизонтальное и вертикальное подмножество
(другими словами, оно ограничивает найденные строки и столбцы) таблицы
employee.
368
Часть II. Язык Transact-SQL
Резюме
Существуют следующие наиболее важные концепции системы безопасности
баз данных:
♦ аутентификация;
♦ шифрование;
♦ авторизация;
♦ отслеживание изменений.
Аутентификация является процессом проверки полномочий пользователей
для предотвращения неавторизованного доступа пользователей к использо-
ванию системы. Наиболее общим способом выполнения этого является тре-
бование предоставления имени пользователя и его пароля. Шифрованием
данных является процесс кодирования информации так, чтобы она не была
понятной, пока ее не дешифрует соответствующий получатель. Для шифро-
вания данных могут быть использованы различные методы.
В процессе выполнения авторизации система определяет, какие ресурсы мо-
жет использовать конкретный пользователь. Database Engine поддерживает
авторизацию при помощи следующих операторов Transact-SQL: grant, deny и
revoke. Отслеживание изменений означает, что действия неавторизованных
пользователей отслеживаются и документируются в вашей системе. Этот
процесс полезен для защиты системы от пользователей с расширенными при-
вилегиями.
В следующей главе рассматриваются возможности Database Engine по работе
с системами многопользовательских программ и обсуждаются вопросы, свя-
занные с оптимистическими и пессимистическими стратегиями работы
в многопользовательском параллельном режиме.
Упражнения
j Упражнение 12.1
В чем разница между режимом Windows и смешанным режимом?
= Упражнение 12.2
В чем разница между учетной записью (логином) SQL Server и учетной
записью базы данных?
Гпава 12. Система безопасности Database Engine
369
Упражнение 12.3
Создайте три учетные записи с именами ann, burt и chuck. Соответствую-
щими паролями являются: alb2c3d4e5, <l4e3f2glhO и fl02gh285. Базой дан-
ных по умолчанию является база данных sample. После создания учетных
записей проверьте их существование при использовании системного каталога.
I Упражнение 12.4
Создайте три новых имени пользователей базы данных для учетных записей
из упражнения 12.3. Новыми именами будутsann, sburt и scharles.
j Упражнение 12.5
Создайте новую определенную пользователем роль базы данных с именем
managers и добавьте три члена в эту роль (см. упражнение I2.4). После этого
отобразите информацию об этой роли и о трех ее членах.
5 Упражнение 12.6
Используя оператор grant, предоставьте пользователю s_burt возможность
создавать таблицы, а пользователю s ann создавать хранимые процедуры
в базе данных sample.
; Упражнение 12.7
Используя оператор grant, предоставьте пользователю s charles возможность
изменять значения столбцов Iname И fname таблицы sample.
! Упражнение 12.8
Используя оператор grant, предоставьте пользователям s burt и s_ann воз-
можность читать значения столбцов emp_lname И emp_fname таблицы employee.
Подсказка: сначала создайте соответствующее представление.
Упражнение 12.9
Используя оператор grant, предоставьте определенной пользователем роли
managers добавлять новые строки в таблицу project.
= Упражнение 12.10
Отмените право select у пользователя s_burt.
370 Часть II. Язык Transact-SQL
ё Упражнение 12.11
Используя Transact-SQL, не давайте возможности пользователю s ann добав-
лять новые строки в таблицу project ни явно, ни опосредованно (используя
роли).
S Упражнение 12.12
Объясните разницу между использованием представлений и операторов
Transact-SQL grant, deny и revoke в отношении вопросов безопасности.
j Упражнение 12.13
Отобразите существующую информацию о пользователе s_ann в отноше-
нии базы данных sample. Подсказка: используйте системную процедуру
sp_helpuser.
©
ГЛАВА 13
Управление
параллельной работой
Как вы уже знаете, данные в базе данных обычно используются многими
программами пользовательских приложений. Ситуация, при которой не-
сколько программ пользовательских приложений читают и пишут одни и те
же данные в одно и то же время, называется конкурентным доступом. Сле-
довательно, каждая СУБД должна иметь некоторый механизм управления
для разрешения проблем конкурентного доступа.
Высокий уровень конкурентного доступа возможен в системе базы данных,
которая может управлять многими активными пользовательскими приложе-
ниями без их влияния друг на друга. И наоборот, система базы данных, где
различные активные приложения влияют друг на друга, поддерживает низкий
уровень конкурентного доступа.
Эта глава начинается с описания двух моделей управления конкурентным
доступом, которые поддерживает Database Engine. В следующем разделе объ-
ясняется, как проблемы конкурентного доступа могут быть решены с исполь-
зованием транзакций. Это обсуждение включает вводные сведения в четыре
свойства транзакций, известные как свойства ACID (Atomicity, Consistency,
Isolation, Durability— атомарность, согласованность, изолированность, ус-
тойчивость), обсуждаются связанные с транзакциями операторы Transact-
SQL,’ вводится понятие протокола транзакции. Затем рассматривается блоки-
ровка и три основных свойства блокировки: модели блокировки, ресурсы
блокировки, длительность блокировки. Также вводится важное понятие вза-
имной блокировки, которая может возникать как результат обычной блоки-
ровки.
Поведение транзакций зависит от выбранного уровня изоляции. Вводятся
пять форм уровней изоляции с учетом принадлежности каждой формы к пес-
симистической или оптимистической модели конкурентного доступа. Кроме
372
Часть II. Язык Transact-SQL
этого объясняются различия между существующими уровнями изоляции, а
также их практическое значение.
В конце главы вводится понятие контроля версий строк, который использует-
ся в Database Engine для реализации оптимистической модели конкурентного
доступа. Обсуждаются два уровня изоляции, связанные с этой моделью —
snapshot и read committed snapshot, — а также использование системной ба-
зы данных tempdb в качестве истории версий.
Модели конкурентного доступа
Database Engine поддерживает две различные модели конкурентного доступа:
♦ пессимистический конкурентный доступ;
♦ оптимистический конкурентный доступ.
Пессимистический конкурентный доступ применяет замки для блокировки
доступа к данным, которые используются другим процессом в то же самое
время. Иными словами, система базы данных, которая использует пессими-
стический конкурентный доступ, предполагает, что конфликт между двумя
или более процессами может появиться в любое время, и поэтому блокирует
ресурсы (строки, страницы, таблицы), как только они потребуются, на все
время выполнения транзакции. Как вы увидите в разд. "Блокировка", песси-
мистический конкурентный доступ устанавливает совместно используемые
замки на прочитанные записи, так что никакой другой процесс не может из-
менять эти данные. Пессимистический конкурентный доступ также устанав-
ливает эксклюзивные замки для изменяемых данных, и никакой другой про-
цесс не может ни читать, ни изменять эти данные.
Оптимистический конкурентный доступ работает в предположении, что
транзакция вряд ли модифицирует данные, которые изменяются в другой
транзакции в то же самое время. Database Engine поддерживает оптимистиче-
ский конкурентный доступ, здесь сохраняются старые версии строк данных,
и любой процесс, который читает эти же данные, использует версию строки,
которая была активной на момент начала чтения данных. По этой причине
процесс, изменяющий данные, может это делать без каких-либо ограничений,
потому что все другие процессы, которые читают те же данные, получают
доступ к сохраненным версиям данных. Конфликтная ситуация возникает
только в том случае, когда две или более операций записи используют одни и
те же данные. В этом случае система генерирует ошибку, так что клиентское
приложение может ее обработать.
Замечание__________________________________________________
Понятие оптимистического конкурентного доступа обычно определяется в са-
мом широком смысле. Управление оптимистическим конкурентным доступом
Глава 13. Управление параллельной работой
373
работает в предположении, что конфликт ресурсов для множества пользовате-
лей маловероятен, и дает возможность транзакциям выполняться без исполь-
зования замков. И только когда пользователь пытается изменить данные, ре-
сурсы проверяются для определения возможности возникновения конфликта.
Если конфликт возник, то приложение должно быть (повторно) запущено.
Транзакции
Транзакцией является последовательность операторов Transact-SQL, которые
используются программистами базы данных для объединения операций чте-
ния и записи таким образом, что система гарантирует согласованность дан-
ных. Существуют две формы транзакций.
♦ Неявная. Определяет любой одиночный оператор insert, update или
delete как единицу транзакции.
♦ Явная. Обычно это группа операторов Transact-SQL, где начало и конец
такой группы отмечается операторами begin transaction, commit и
ROLLBACK.
Понятие транзакции лучше всего объяснить на примере. В базе данных
sample служащей Ann Jones должен быть назначен новый номер служащего.
Этот номер служащего должен быть изменен в двух различных таблицах од-
новременно. Строка в таблице employee и все соответствующие строки в таб-
лице works on должны быть изменены в одно и то же время. (Если будут вы-
полнены изменения только в одной из этих таблиц, то данные в базе данных
sample станут несогласованными, потому что значения первичного ключа
в таблице employee и соответствующие значения внешнего ключа в таблице
works on для миссис Jones не будут соответствовать друг другу.)
В примере 13.1 показано, как вы можете разрешить только что рассмотрен-
ную задачу с использованием операторов Transact-SQL.
. Пример 13.1
USE sample;
BEGIN TRANSACTION /* Начало транзакции */
UPDATE employee
SET emp_no = 39831
WHERE emp_no = 10102
IF (terror <> 0)
ROLLBACK /* Откат транзакции */
UPDATE works_on
SET emp_no = 39831
WHERE emp_no = 10102
374
Часть II. Язык Transact-SQL
IF (@@error О 0)
ROLLBACK
COMMIT /* Завершение транзакции */
Согласованное состояние данных, используемых в примере 13.1. может быть
достигнуто, только если либо будут выполнены оба оператора update, либо
ни один из них выполнен не будет. Глобальная переменная @@еггог служит
для проверки результатов выполнения каждого оператора Transact-SQL. Если
возникает ошибка, то @@еггог устанавливается в отрицательное значение, а
выполнение всех операторов отменяется. (Операторы Transact-SQL begin
transaction, commit и rollback определяются в разд. "Операторы Transact-
SQL и транзакции" далее в этой главе.)
Замечание________________________________________________________
Язык Transact-SQL поддерживает исключения. Вместо использования перемен-
ной @@еггог, как это было сделано в примере 13.1, вы можете использовать
операторы try и catch для обработки исключений в транзакции. Использова-
ние этих операторов обсуждалось в главе 8.
В следующем разделе рассматриваются свойства транзакции АСЮ. Эти
свойства гарантируют, что данные, используемые программами приложения,
будут согласованными.
Свойства транзакций
Транзакции имеют следующие свойства, которые известны под аббревиату-
рой ACID:
♦ атомарность (Atomicity);
♦ согласованность (Consistency);
♦ изолированность (Isolation);
♦ устойчивость (Durability).
Свойство атомарности гарантирует неделимость набора операторов, которые
изменяют данные в базе данных и являются частью транзакции. Это означает,
что или выполняются все изменения данных в транзакции, или в случае лю-
бой ошибки все уже выполненные изменения отменяются.
Согласованность гарантирует, что транзакция не даст возможности базе дан-
ных содержать несогласованные данные. Другими словами, трансформация
данных в рамках одной транзакции переводит базу данных из одного согла-
сованного состояния в другое согласованное состояние.
Свойство изолированности разделяет все одновременно выполняющиеся
транзакции. Другими словами, ни одна активная транзакция не может видеть
Гпава 13. Управление параллельной работой
375
изменения данных, выполненные в параллельной, но не завершенной тран-
закции. Это означает, что для обеспечения изолированности для некоторых
транзакций может быть выполнен откат.
Устойчивость представляет одну из наиболее важных концепций базы дан-
ных: живучесть данных. Это свойство гарантирует, что эффект от выполне-
ния любой транзакции сохраняется, даже если возникают системные ошибки.
По этой причине, если возникает ошибка в процессе активности транзакции,
действия всех операторов этой транзакции будут отменены.
Операторы Transact-SQL и транзакции
Существует шесть операторов Transact-SQL, связанных с транзакциями:
♦ BEGIN transaction;
♦ BEGIN DISTRIBUTED TRANSACTION;
♦ commit [work];
♦ rollback [work];
♦ SAVE transaction;
♦ SET IMPLICIT_TRANSACTIONS.
Оператор begin transaction запускает транзакцию. Он имеет следующий
синтаксис:
BEGIN TRANSACTION [ (transaction_name I Qtrans_var }
[WITH MARK ['description']]]
Здесь transaction_name— имя, назначаемое транзакции. Оно может быть ис-
пользовано только в самой внешней паре вложенных операторов begin
transaction/commit или begin transaction/rollback. @trans_var— имя опре-
деленной пользователем переменной, содержащей допустимое имя транзак-
ции. Опция with mark указывает, что транзакция должна быть отмеченной в
протоколе транзакций, description является строкой, которая описывает эту
отметку. Если используется with mark, то имя транзакции обязательно долж-
но быть указано. (Более подробную информацию о протоколе транзакций и
об отметках для восстановления см. в главе 177)
Оператор begin distributed transaction задает старт распределенной тран-
закции, которая управляется Microsoft Distributed Transaction Coordinator (MS
DTC, координатор распределенных транзакций Microsoft). Распределенная
транзакция — это транзакция, которая использует базы данных более чем на
одном сервере. Сервер, выполняющий оператор begin distributed transaction,
является координатором транзакции и поэтому управляет завершением рас-
пределенной транзакции. (Обсуждение распределенных транзакций см. в гла-
ве 197)
376
Часть II. Язык Transact-SQL
Оператор commit work успешно завершает транзакцию, запущенную операто-
ром begin transaction. Это означает, что все изменения, выполненные в этой
транзакции, сохраняются на диске. Оператор commit work является стандарти-
зованным оператором SQL. (Предложение work является необязательным.)
Замечание______________________________________________________
Язык Transact-SQL также поддерживает оператор commit transaction, который
функционально эквивалентен оператору commit work, за одним исключени-
ем — первый оператор допускает использование определенного пользовате-
лем имени транзакции, commit transaction является расширением Transact-
SQL, соответствующим стандарту SQL.
В противоположность оператору commit оператор rollback work сообщает
о неуспешном завершении транзакции. Программисты используют этот опе-
ратор, когда они предполагают, что база данных может оказаться в несогла-
сованном состоянии. В этом случае все выполненные операции по модифи-
кации данных внутри транзакции отменяются. Оператор rollback work явля-
ется стандартизованным оператором SQL. (Предложение work является
необязательным.)
Замечание______________________________________________________
Язык Transact-SQL также поддерживает оператор rollback transaction, кото-
рый функционально эквивалентен оператору rollback work, за одним исклю-
чением — первый оператор допускает использование определенного пользова-
телем имени транзакции.
Оператор save transaction устанавливает точку сохранения транзакции. Точ-
ка сохранения отмечает заданную точку в транзакции, в этом случае все по-
следующие изменения данных могут быть отменены без отмены действий
всей транзакции. Для отмены всей транзакции используйте оператор
rollback.
Замечание______________________________________________________
Оператор save transaction на самом деле не подтверждает какие-либо опе-
рации модификации данных; он лишь создает отметку для последующего опе-
ратора rollback, который будет иметь то же самое имя, что и заданное в опе-
раторе SAVE TRANSACTION.
В примере 13.2 показано использование оператора save transaction.
; Пример 13.2
BEGIN TRANSACTION;
INSERT INTO department (dept_no, dept_name)
VALUES ('d4', ’Sales');
Глава 13. Управление параллельной работой
377
SAVE TRANSACTION а;
INSERT INTO department (dept_no, dept_name)
VALUES ('d5', 'Research');
SAVE TRANSACTION b;
INSERT INTO department (dept_no, dept_name)
VALUES ('d6', 'Management');
ROLLBACK TRANSACTION b;
INSERT INTO department (dept_no, dept_name)
VALUES ('d7', 'Support');
ROLLBACK TRANSACTION a;
COMMIT TRANSACTION;
В примере 13.2 будет выполнен только лишь первый оператор insert. Для
третьего оператора insert будет выполнен откат в операторе rollback
transaction ь, а для двух других операторов insert будет выполнена отмена
оператором rollback transaction а.
Замечание__________________________________________________________
Оператор save transaction в комбинации с оператором if или while является
полезной возможностью использования транзакций для выполнения отдельных
частей полной транзакции. С другой стороны, использование этого оператора
противоречит принципу работы с базами данных, который рекомендует делать
транзакцию настолько короткой, насколько это возможно, поскольку длинные
транзакции обычно уменьшают доступность данных.
Как вы уже знаете, каждый оператор Transact-SQL всегда явно или неявно
принадлежит транзакции. Database Engine предоставляет неявные транзакции
для совместимости со стандартом SQL. Когда сессия работает в режиме не-
явных транзакций, выполняемые операторы неявно выдают оператор begin
transaction. Это означает, что вам ничего не нужно делать для старта неяв-
ных транзакций. Тем не менее, завершение каждой неявной транзакции
должно быть явно подтверждено или отменено при использовании оператора
commit или rollback. Если вы явно не подтвердите транзакцию, то транзакция
и все данные, измененные в ней, будут отменены, когда пользователь отсо-
единится от базы данных.
Для возможности использования неявных транзакций вы должны установить
разрешающее значение в предложении implicit_transaction оператора set.
Этот оператор устанавливает режим неявных транзакций в текущей сессии.
Когда выполняется соединение в режиме неявных транзакций и это соедине-
ние не находится в данный момент в рамках транзакции, то выполнение лю-
бого из следующих операторов запускает на выполнение транзакцию:
♦ ALTER TABLE; ♦ REVOKE;
♦ FETCH; ♦ CREATE TABLE;
378
Часть II. Язык Transact-SQL
♦ grant;
♦ select;
♦ delete;
♦ insert;
♦ TRUNCATE table;
♦ DROP table;
♦ open;
♦ UPDATE.
Иными словами, если у вас есть последовательность операторов из предыду-
щего списка, то каждый оператор будет представлять одну транзакцию.
Начало явно объявленной транзакции отмечается оператором begin
transaction. Завершение явно объявленной транзакции отмечается операто-
рами commit или rollback. Явные транзакции могут быть вложенными. В этом
случае каждая пара операторов begin transaction/commit или begin
transaction/rollback используется внутри одной или большего количества
таких пар. (Вложенные транзакции обычно применяются в хранимых про-
цедурах, которые сами используют транзакции и внутри себя вызывают дру-
гие транзакции.) Глобальная переменная @@trancount содержит количество
активных транзакций для текущего пользователя.
Операторы begin transaction, commit и rollback могут использоваться с име-
нем заданной транзакции. (Имя в операторе rollback может соответствовать
либо именованной транзакции, либо оператору save transaction с тем же
именем.) Вы можете использовать именованные транзакции только в самой
внешней паре вложенных операторов begin transaction/commit или begin
transaction/rollback.
Протокол транзакций
Системы реляционных баз данных сохраняют каждое изменение записи, ко-
торое они выполнили в базе данных в течение транзакции. Это необходимо в
случае появления ошибки в процессе выполнения операторов транзакции.
В этой ситуации все ранее выполненные операторы в рамках данной транзак-
ции должны быть отменены. Если система определяет наличие ошибки, она
должна использовать сохраненные записи для возврата базы данных к согла-
сованному состоянию, которое имела база данных на момент старта этой
транзакции.
Database Engine сохраняет все записанные записи, их значения до и после из-
менения, в одном или более файлах, называемых протоколом транзакций.
Каждая база данных имеет собственный протокол транзакций. Следователь-
но, если нужно отменять одну или более операций изменения данных в таб-
лицах текущей базы данных, Database Engine использует записи в протоколе
транзакций для восстановления значений столбцов, которые были в базе дан-
ных до начала старта транзакции.
Гпава 13. Управление параллельной работой
379
Протокол транзакций служит для отмены или восстановления транзакции.
Если возникает ошибка и транзакция не выполнена полностью, то система
использует все существующие до этого значения из протокола транзакций
(называемых образами до) для отмены изменений до того момента, когда бы-
ла запущена транзакция. Процесс, при котором образ в протоколе транзакции
до начала ее выполнения используется для отката всех изменений, выполнен-
ных в рамках этой транзакции, называется действием по ее отмене.
Протоколы транзакций также сохраняют так называемые образы после. Об-
разы после все являются значениями, которые используются для внесения
всех модификаций, выполненных после старта транзакции. Этот процесс на-
зывается повторным выполнением действий, он применим к процессу вос-
становления базы данных. (Дальнейшие подробности, связанные с протоко-
лами транзакций и восстановлением базы данных, см. в главе 17.)
Каждая запись, помещенная в протокол, уникально идентифицируется с ис-
пользованием последовательного номера протокола (log sequence number,
LSN). Все записи протокола, являющиеся частью отдельной транзакции, свя-
заны вместе, так что все части транзакции могут быть локализованы для от-
мены или для повторного выполнения действий.
Блокировка
Конкурентный доступ может приводить к некоторым негативным эффектам,
таким как чтение несуществующих данных или потеря модифицированных
данных. Рассмотрим такой пример из реальной жизни, который иллюстриру-
ет один из этих негативных эффектов, называемый грязным чтением. Поль-
зователь U\ в отделе кадров получил сведения об изменении адреса у служа-
щего Jim Smith. U{ выполнил изменение адреса, однако потом, просматривая
банковский счет у Smith в следующем диалоговом окне, он обнаружил, что
изменил адрес не тому человеку. (В организации работают два человека по
имени Jim Smith.) К счастью, приложение дает возможность пользователю
отменить это изменение щелчком по кнопке. U\ щелкает мышью по этой
кнопке, зная, что он подтвердил верные данные.
В то же самое время пользователь Ui из технического отдела находит данные
о втором сотруднике Smith, чтобы отправить ему домой последнюю техниче-
скую документацию, потому что этот служащий редко бывает в офисе. Так
как адрес был ошибочно изменен непосредственно перед тем, как U2 отыскал
этот адрес, U2 распечатывает ошибочный адрес и отправляет документ не то-
му человеку.
Для предотвращения проблем, подобных этой, в пессимистической модели
конкурентного доступа каждая СУБД должна иметь механизм, который
управлял бы доступом к данным для всех пользователей в одно и то же вре-
380
Часть II. Язык Transact-SQL
мя. Database Engine, как и все реляционные СУБД, использует замки для га-
рантии согласованности данных в базе данных в случае многопользователь-
ского к ней доступа. Каждая программа приложения блокирует нужные ей
данные, гарантируя этим, что никакая другая программа не может изменять
те же самые данные. Когда другая программа приложения запрашивает мо-
дификацию заблокированных данных, система или останавливает эту про-
грамму, выдавая ошибку, или переводит программу в состояние ожидания.
Блокировка имеет несколько различных аспектов:
♦ длительность блокировки;
♦ режим блокировки;
♦ гранулярность блокировки.
Длительность блокировки задает период времени, в течение которого забло-
кированы ресурсы. Длительность блокировки зависит от некоторых других
вещей: режима блокировки и выбранного уровня изоляции.
Следующие два раздела описывают режимы блокировки и гранулярность
блокировки.
Замечание_____________________________________________________
Следующее обсуждение относится к пессимистической модели конкурентного
доступа. При оптимистической модели конкурентного доступа обработка вы-
полняется с использованием контроля версий строк. Она будет рассмотрена
в конце этой главы.
Режимы блокировки
Режимы блокировки определяют различные виды замков. Выбор того, какой
режим блокировки нужно применить, зависит от того ресурса, который нуж-
но блокировать. Следующие три типа замков используются для блокирования
на уровне строк и на уровне страниц:
♦ разделяемый (shared, S);
♦ исключительный (exclusive, Е);
♦ обновление (update, LJ).
Разделяемая блокировка резервирует ресурс (страницу или строку) только
для чтения. Другие процессы не могут изменять заблокированный ресурс,
пока блокировка не будет снята. С другой стороны, отдельные процессы мо-
гут устанавливать разделяемую блокировку для этого ресурса в то же самое
время, т. е. другие процессы могут читать ресурс, заблокированный при по-
мощи разделяемой блокировки.
Исключительная блокировка резервирует страницу или строку для исключи-
тельного использования в одной транзакции. Она используется для операто-
Гпава 13. Управление параллельной работой 381
ров DML (insert, update или delete), которые изменяют ресурс. Исключи-
тельная блокировка не может быть установлена, если некоторый другой про-
цесс сохраняет разделяемую или исключительную блокировку на этот ресурс,
т. е. для ресурса может существовать только одна исключительная блокиров-
ка. Как только на страницу (или строку) устанавливается исключительная
блокировка, никакая другая блокировка не может быть установлена на тот же
самый ресурс.
Замечание________________________________________________________
Блокировка на уровне страницы также допускает целевую блокировку, которая
описывается далее в этом разделе.
Блокировка обновления может быть установлена, только если не существует
другой блокировки обновления или исключительной блокировки. При этом
она может быть установлена на объекты, которые уже имеют разделяемую
блокировку. В этом случае блокировка обновления получает и другую разде-
ляемую блокировку на тот же объект. Если транзакция, которая изменяет
объект, подтверждается, блокировка обновления заменяется на исключитель-
ную блокировку, если для объекта не существует других блокировок.
Замечание________________________________________________________
Блокировка обновления предотвращает некоторые общие типы взаимных бло-
кировок. (Взаимные блокировки описываются в конце этого раздела.)
В табл. 13.1 показана матрица совместимости разделяемых, исключительных
блокировок и блокировок обновления. Эта матрица интерпретируется сле-
дующим образом: предположим, транзакция Т\ имеет блокировку, как пока-
зано в первом столбце матрицы; предположим также, что некоторая другая
транзакция Ti запрашивает блокировку, как задано в соответствующем заго-
ловке столбца. В этом случае "Да" означает, что блокировка для Тг возможна,
в то время как "Нет" указывает на конфликт с существующей блокировкой.
Таблица 13.1. Матрица совместимости разделяемых,
исключительных блокировок и блокировок обновления
Разделяемая Обновление Исключительная
Разделяемая Да Да Нет
Обновление Да Нет Нет
Исключительная Нет Нет Нет
Замечание_______________________________________________________
Database Engine также поддерживает и другие формы блокировок, такие как
блокировка-защелка и взаимная блокировка.
382
Часть II. Язык Transact-SQL
На уровне таблицы существуют пять различных типов блокировок:
♦ разделяемая (shared, S);
♦ исключительная (exclusive, X);
♦ разделяемая блокировка с намерением (intent shared, IS);
♦ исключительная блокировка с намерением (intent exclusive, IX);
♦ разделяемая блокировка с намерением исключительного доступа (shared
with intent exclusive, SIX).
Разделяемые и исключительные блокировки соответствуют блокировкам на
уровне строки (или страницы) с тем же именем. Как правило, блокировка
с намерением показывает намерение установить блокировку на ресурс более
низкого уровня в иерархии объектов базы данных. Поэтому блокировки с на-
мерением помещаются в иерархии объектов на один уровень выше того объ-
екта, который этот процесс намеревается заблокировать. Это эффективный
способ выяснить, возможна ли подобная блокировка, здесь также устанавли-
вается запрет другим процессам блокировать более высокий уровень до того,
как нужная блокировка будет достигнута.
В табл. 13.2 показана матрица совместимости всех видов блокировок таблиц.
Интерпретация этой матрицы в точности соответствует интерпретации мат-
рицы в табл. 13.1.
Таблица 13.2. Матрица совместимости всех видов блокировок таблиц
s X IS SIX IX
S Да Нет Да Нет Нет
X Нет Нет Нет Нет Нет
IS Да Нет Да Да Да
SIX Нет Нет Да Нет Нет
IX Нет Нет Да Нет Да
Гранулярность блокировок
Гранулярность блокировок указывает, какой блокируется ресурс в одной
попытке блокирования. Database Engine может блокировать такие ресурсы,
как:
♦ строка;
♦ страница;
♦ индексный ключ или диапазон индексных ключей;
Глава 13. Управление параллельной работой 383
♦ таблица;
♦ экстент;
♦ сама база данных.
Замечание______________________________________________________
Система автоматически выбирает гранулярность блокировки.
Строка является наименьшим ресурсом, который может быть заблокирован.
Поддержка блокировки на уровне строки включает и данные строк, и записи
индексов. Блокировка на уровне строки означает, что блокируется только та
строка, к которой осуществляется доступ приложения. Следовательно, все
другие строки, принадлежащие той же странице, являются свободными и мо-
гут использоваться другими приложениями. Database Engine также может
блокировать страницу, на которой хранится строка, которая должна быть за-
блокирована.
Замечание______________________________________________________
Если таблица является кластеризованной, то страницы данных хранятся на
уровне листьев (кластеризованной) индексной структуры и поэтому блокируют-
ся именно они вместе с индексными ключами, а не строки.
Блокировка также выполняется для участков диска, называемых экстентами,
которые имеют размер 64 Кбайт (см. главу 15). Блокировка экстента устанав-
ливается автоматически, когда растет таблица (или индекс) и требуется до-
полнительное дисковое пространство.
Гранулярность блокировок влияет на конкурентный доступ. Обычно, чем
больше гранулярность блокировки, тем больше сокращается возможность
одновременного доступа к данным. Это означает, что блокировка на уровне
строки максимизирует конкурентный доступ, потому что она блокирует
только одну строку, оставляя все другие свободными. С другой стороны, на-
кладные расходы системы увеличиваются, потому что каждая заблокирован-
ная строка требует одного замка. Блокировка на уровне страницы (и блоки-
ровка на уровне таблицы) ограничивает доступность данных, но уменьшает
накладные расходы системы.
Укрупнение блокировок
Если установлено много блокировок с одной и той же гранулярностью в про-
цессе выполнения транзакции, Database Engine автоматически преобразует
эти блокировки в блокировку таблицы. Этот процесс конвертирования мно-
жества блокировок уровней страницы, строки или индекса в блокировку
уровня таблицы называется укрупнением блокировки. Начало укрупнения оп-
384
Часть II. Язык Transact-SQL
ределяется системой динамически и не требует конфигурирования. (В на-
стоящий момент значением границы укрупнения является 5000 блокировок.)
Основной проблемой, связанной с укрупнением блокировки, является то, что
сервер базы данных принимает решение, когда следует укрупнять конкрет-
ную блокировку, а это решение может не быть оптимальным для приложений
с различными потребностями. По этой причине SQL Server 2008 расширяет
синтаксис оператора alter table, предоставляя вам возможность изменять
механизм укрупнения блокировок. Этот оператор теперь поддерживает оп-
цию table со следующим синтаксисом:
SET ( LOCK_ESCALATION = { TABLE | AUTO | DISABLE } )
Опция table является значением по умолчанию; она задает, что укрупнение
блокировки будет устанавливаться на уровне грануляции таблицы. (Это по-
ведение точно такое же, как и в SQL Server 2005.) Опция auto позволяет
Database Engine выбрать гранулярность укрупнения блокировки, которая бу-
дет лучше подходить для таблицы схемы. Наконец, опция disable позволяет
вам отменить в большинстве случаев укрупнение блокировки. (Это тот же
самый случай, когда Database Engine должен выбрать блокировку таблицы
для защиты целостности данных.)
В примере 13.3 запрещается укрупнение блокировки для таблицы employee.
| Пример 13.3
USE sample;
ALTER TABLE employee SET (LOCK_ESCALATION = DISABLE);
Влияние блокировок
Для воздействия на блокировки вы можете использовать или подсказки бло-
кировок, или опцию lock timeout в операторе set.
Подсказки блокировки
Подсказки блокировки задают тип блокировки, используемый Database
Engine для блокировки данных таблицы. Подсказки блокировки на уровне
таблицы могут быть использованы, когда запрашивается точная регулировка
типов блокировки для требуемого ресурса. (Подсказки блокировки перекры-
вают текущий уровень изоляции транзакции для данной сессии.)
Все подсказки блокировки записываются как часть предложения from в опе-
раторе select. Вы можете использовать следующие подсказки блокировки:
♦ updlock устанавливает блокировку обновлений для каждой строки табли-
цы в процессе операций чтения. Все блокировки обновлений сохраняются
до завершения транзакции;
Глава 13. Управление параллельной работой 385
♦ . tablock (tablockx) устанавливает разделяемую (или исключительную)
блокировку таблицы для всей таблицы. Все блокировки сохраняются до
завершения транзакции;
♦ rowlock заменяет существующую разделяемую блокировку таблицы на
разделяемые блокировки строк для каждой указанной строки таблицы;
♦ paglock заменяет разделяемую блокировку таблицы на разделяемые бло-
кировки страниц для каждой страницы, содержащей указанные строки;
♦ nolock— синоним для readuncommitted (см. описание подсказок уровней
изоляции далее в этой главе);
♦ HOLDLOCK- СИНОНИМ ДЛЯ REPEATABLEREAD (СМ. ОПИСЭНИе ПОДСКЭЗОК уровней
изоляции далее в этой главе);
♦ xlock указывает, что исключительные блокировки будут установлены
и сохранены до завершения транзакции. Если xlock указано вместе с
rowlock, paglock или tablock, то применяется исключительная блокировка
для соответствующего уровня гранулярности;
♦ readpast указывает, что Database Engine не читает строки, заблокирован-
ные другими транзакциями.
Замечание___________________________________________________
Все эти опции могут быть объединены в произвольном порядке, если такая
комбинация имеет смысл. (Например, комбинация tablock и paglock бессмыс-
ленна, потому что эти опции применяются к различным ресурсам.)
Опция LOCK-TIMEOUT
Опция lock timeout оператора set может быть использована для задания ко-
личества миллисекунд, в течение которых транзакция будет ожидать снятия
блокировки. Значение -1 (значение по умолчанию) указывает на отсутствие
времени ожидания, иными словами, транзакция вообще не будет ожидать.
Подсказка блокировки readpast предоставляет альтернативу этой опции set.
Отображение информации блокировки
Информация о блокировке может быть отображена либо при использовании
системной процедуры sp iock, либо динамически управляемым представле-
нием, называемым sys. dm_tran_iocks. Поскольку sp_iock является нереко-
мендуемым средством и не будет поддерживаться в следующих версиях
SQL Server, в этом разделе описывается только представление sys.dm_
tran locks.
386
Часть II. Язык Transact-SQL
Представление sys.dm_tran_locks возвращает информацию о текущей актив-
ной блокировке менеджера ресурсов. Каждая строка отображает активный в
настоящий момент запрос на блокировку, которая была предоставлена или
предоставление которой ожидается. Столбцы этого представления соответст-
вуют двум группам: ресурсам и запросам. Группа ресурсов описывает ресур-
сы, которым предоставлена блокировка на основании запросов, а группа за-
просов описывает запросы на блокировку. Наиболее важными столбцами
этого представления являются следующие:
♦ resource type указывает тип ресурса;
♦ resource_database_id задает идентификатор базы данных, в которой нахо-
дится этот ресурс;
♦ request mode задает режим запроса; .
♦ request status задает текущее состояние запроса.
В примере 13.4 отображаются все блокировки, которые находятся в состоя-
нии ожидания.
; При.мер 13.4
SELECT resource_type, DB_NAME(resource_database_id) as db_name,
request_session_id, request_mode, request_status
FROM sys.dm_tran_locks
WHERE request_status = 'WAIT;'
Взаимная блокировка
Взаимная блокировка является особой проблемой одновременной работы с
базой данных, при которой две транзакции блокируют выполнение друг дру-
га. Первая транзакция имеет блокировку на некоторый объект базы данных,
к которому другая транзакция ожидает доступа, и наоборот. (Обычно не-
сколько транзакций могут вызвать взаимную блокировку, когда они создают
циклические зависимости.) В примере 13.5 показана ситуация взаимной бло-
кировки между двумя транзакциями.
Замечание
Параллельность работы не может быть достигнута естественным образом при
использовании маленькой по размерам базы данных sample, потому что каж-
дая транзакция в ней выполняется очень быстро. По этой причине в приме-
ре 13.5 используется оператор waitfor для приостановки выполнения обеих
транзакций на десять секунд для симуляции взаимной блокировки.
Гпава 13. Управление параллельной работой 387
i Пример 13.5
BEGIN TRANSACTION
BEGIN TRANSACTION
UPDATE works_on
SET job = 'Manager'
WHERE emp_no = 18316
AND project_no = 'p2'
UPDATE employee
SET dept_no = 'd2'
WHERE emp_no = 9031
WAITFOR DELAY '00:00:10'
WAITFOR DELAY '00:00:10'
UPDATE employee
SET emp_lname = 'Green'
WHERE emp_no = 9031
DELETE FROM works_on
WHERE emp_no = 18316
COMMIT
AND project_no = 'p2'
COMMIT
Если обе транзакции в примере 13.5 будут выполняться в одно и то же время,
возникнет взаимная блокировка, и система вернет следующее сообщение:
Server: Msg 1205, Level 13, State 45
Transaction (Process id 56) was deadlocked with another process and has been
chosen as deadlock victim. Rerun your command.
(Транзакция (процесс с идентификатором 56) находится во взаимной блоки-
ровке с другим процессом и выбрана в качестве потерпевшей. Выполните
заново вашу команду.)
Из этого сообщения примера 13.5 видно, что система базы данных обрабаты-
вает взаимную блокировку, выбрав одну из транзакций в качестве "жертвы",
"victim" (фактически ту, которая закрыла цикл в запросах на блокировку), и
выполнив ее откат. (Другая транзакция после этого будет выполнена.) Про-
граммист может обрабатывать взаимные блокировки, используя условный
оператор, который проверяет возвращаемый номер ошибки (1205), а затем
заново выполняя отмененную транзакцию.
Вы можете повлиять на то, какая транзакция будет выбрана в качестве "жерт-
вы", используя опцию deadlock_priority в операторе SET. Существует 21 уро-
вень приоритетов: значения от -10 до 10. Значение low соответствует -5, зна-
чение normal (значение по умолчанию) соответствует 0, a high соответству-
ет 5. "Жертва" сессии выбирается в соответствии с установленными в сессии
приоритетами взаимных блокировок.
Уровни изоляции
В теории каждая транзакция должна быть полностью изолирована от всех
других транзакций. Однако в подобном случае объем доступных данных зна-
чительно сокращается, потому что операции чтения в транзакции блокируют-
388
Часть II. Язык Transact-SQL
ся операциями записи в других транзакциях, и наоборот. Если доступность
данных является важным требованием, это свойство должно быть ослаблено
с использованием уровней изоляции. Уровни изоляции задают степень, в ко-
торой отыскиваемые в транзакции данные будут защищены от изменений в
других транзакциях. Прежде чем начать рассмотрение существующих уров-
ней изоляции, в следующем разделе мы вкратце рассмотрим сценарии, кото-
рые могут возникнуть при отсутствии блокировок и, следовательно, не суще-
ствует никакой изоляции между транзакциями.
Проблемы конкурентного доступа
Если не используется блокировка и, следовательно, не существует изоляции
между транзакциями, то могут возникнуть следующие четыре проблемы:
♦ потеря обновлений;
♦ грязное чтение (обсуждавшееся в разд. "Блокировка"ранее в этой главе)',
♦ неповторяемое чтение;
♦ фантомные записи.
Проблема потери обновлений при одновременном доступе появляется, когда
не существует изолированности одной транзакции от всех других транзак-
ций. Это означает, что несколько транзакций могут читать одни и те же дан-
ные и изменять их. Изменения данных, выполненные всеми транзакциями за
исключением транзакции, выполнившей эти изменения последней, будут по-
теряны.
Проблема неповторяемого чтения при одновременном доступе появляется,
когда один процесс читает данные несколько раз, а другой процесс изменяет
те же данные между двумя операциями чтения в первом процессе. По этой
причине данные, прочитанные в различных операциях, будут разными.
Проблема фантомных записей при одновременном доступе похожа на про-
блему неповторяемого чтения, потому что две последовательные операции
чтения могут получать различные значения, однако в данном случае смысл
такого поведения заключается в различном количестве строк, прочитанных в
первый раз и во второй раз. (Дополнительные строки, называемые фантом-
ными, были добавлены другими транзакциями.)
Database Engine и уровни изоляции
Используя уровни изоляции, вы можете определить, какие проблемы конку-
рентного доступа могут появиться, а каких можно избежать. Database Engine
Гпава 13. Управление параллельной работой 389
поддерживает следующие пять уровней изоляции, которые управляют тем,
как будут выполнены ваши операции чтения данных:
♦ read uncommitted;
♦ READ COMMITTED;
♦ REPEATABLE READ;
♦ serializable;
♦ SNAPSHOT.
Уровни ИЗОЛЯЦИИ READ UNCOMMITTED, REPEATABLE READ И SERIALIZABLE ДОСТуПНЫ
только в пессимистической, модели конкурентного доступа, в то время как
уровень snapshot доступен только в оптимистической модели конкурентного
доступа. Уровень изоляции read committed доступен в обеих моделях. Далее
описываются четыре уровня изоляции, которые доступны в пессимисти-
ческой модели конкурентного доступа. Уровень snapshot описывается в
разд. "Контроль версий строк" далее в этой главе.
READ UNCOMMITTED
Уровень изоляции read uncommitted предоставляет наипростейшую форму
изоляции транзакций, потому что он вообще не изолирует операции чтения
других транзакций. Когда транзакция этого уровня изоляции отыскивает
строку, она не запрашивает блокировки и не признает никаких существую-
щих блокировок. Данные, которые читаются этой транзакцией, могут быть
несогласованными. В этом случае транзакция читает данные, которые были
изменены какой-нибудь другой активной транзакцией. Если для второй тран-
закции позже будет выполнен откат, то значит, что первая транзакция прочла
данные, которые никогда реально не существовали.
Из четырех проблем одновременного доступа к данным, рассмотренных
в предыдущем разделе, read uncommitted допускает грязное чтение, неповто-
ряемое чтение и фантомные записи.
Замечание_____________________________________________________
Уровень изоляции read UNCOMMITTED обычно является весьма нежелательным
и должен быть использован, только когда не требуется точности чтения данных
или когда данные изменяются редко.
READ COMMITTED
Как вы уже знаете, уровень изоляции read committed имеет две формы. Пер-
вая форма применяется для пессимистической модели конкурентного досту-
па, а вторая форма —- для оптимистической модели конкурентного доступа.
В этом разделе рассматривается первая форма. Вторая форма read committed
snapshot обсуждается в разд. "Контроль версий строк" далее в этой главе.
390
Часть II. Язык Transact-SQL
Транзакция, которая читает строку и использует уровень изоляции read
committed, проверяет только лишь, установлена ли исключительная блоки-
ровка на эту строку. Если такая блокировка отсутствует, транзакция загружа-
ет строку. (Это выполняется при использовании разделяемой блокировки.)
Это действие не дает транзакции возможности читать неподтвержденные из-
менения данных, которые впоследствии могут быть отменены. После чтения
значений данных эти данные могут быть изменены любой другой тран-
закцией.
Разделяемые блокировки, устанавливаемые на читаемые данные транзакцией
этого уровня изоляции, немедленно отменяются сразу после того, как данные
будут обработаны. (Обычно все блокировки отменяются после завершения
транзакции.) По этой причине доступ к одновременно используемым данным
улучшен, однако неповторяемое чтение и фантомные записи все еще воз-
можны.
Замечание_________________________________________________
Уровень изоляции read committed является уровнем изоляции по умолчанию
для Database Engine.
REPEATABLE READ
В отличие от уровня ИЗОЛЯЦИИ READ committed уровень ИЗОЛЯЦИИ REPEATABLE
read устанавливает разделяемую блокировку на все данные, которые читают-
ся, и сохраняет эту блокировку, пока транзакция не будет подтверждена или
отменена. Следовательно, в этом случае выполнение запроса несколько раз
внутри транзакции всегда вернет один и тот же результат. Недостатком тако-
го уровня изоляции является то, что одновременный доступ ухудшается,
потому что временной интервал, в течение которого другие транзакции не
могут обновлять те же данные, значительно больше, чем в случае read
COMMITTED.
Этот уровень изоляции не запрещает другим транзакциям добавлять новые
строки, которые появляются в последующих чтениях, следовательно, могут
появиться фантомные записи.
SERIALIZABLE
serializable является наиболее строгим уровнем изоляции, потому что он не
допускает все четыре ранее рассмотренные проблемы конкурентного досту-
па. Он получает ряд блокировок на все данные, которые читаются в соответ-
ствующей транзакции. Этот уровень изоляции также не допускает добавле-
ния новых строк другими транзакциями, пока первая транзакция не будет
подтверждена или отменена.
Глава 13. Управление параллельной работой 391
Замечание______________________________________________________
Уровень изоляции serializable реализован с использованием метода блоки-
ровки диапазона ключей. Этот метод блокирует индивидуальные строки и упо-
рядочивает их. Метод блокировки диапазона ключей устанавливает блокировки
на записи индексов, а не на отдельные страницы или на всю таблицу. В этом
случае никакая операция модификации данных в другой транзакции не может
быть выполнена, потому что невозможны необходимые изменения индексных
записей.
Каждый из ранее описанных уровней изоляции снижает степень параллель-
ности менее чем самый последний. Следовательно, уровень изоляции read
uncommitted меньше всего уменьшает степень параллельности. С другой сто-
роны, он также менее всего изолирует транзакцию от конкурентных транзак-
ций. Уровень serializable наиболее сильно снижает степень параллельности,
однако гарантирует полную изоляцию от всех других конкурентных транзак-
ций.
Установка и редактирование уровней изоляции
Вы можете установить уровень изоляции, используя следующее:
♦ предложение transaction isolation level оператора set.
♦ подсказки уровня изоляции.
Предложение transaction isolation level в операторе set предоставляет пять
постоянных значений, которые имеют те же имена и те же значения, что и
только что описанные стандартные уровни изоляции. Предложение from опе-
ратора select поддерживает несколько подсказок для уровней изоляции:
♦ readuncommitted;
♦ readcommitted;
♦ repeatableread;
♦ serializable.
Эти подсказки соответствуют уровням изоляции с теми же самыми именами
(но при наличии пробелов в именах). Задание уровней изоляции в предложе-
нии from оператора select перекрывает текущее значение, установленное
оператором set transaction isolation level.
Оператор dbcc useroptions возвращает, помимо другой информации, инфор-
мацию об уровне изоляции. Посмотрите на опцию значения уровня изоляции
в этом операторе, чтобы увидеть уровень изоляции вашего процесса.
Контроль версий строк
Database Engine поддерживает механизм оптимистического управления па-
раллельной работы, основанный на контроле версий строк. Когда данные из-
392
Часть II. Язык Transact-SQL
меняются с использованием контроля версий строк, то для всех изменяемых
данных в базе данных поддерживаются логические копии. Каждый раз, когда
изменяется строка, система базы данных сохраняет ее образ до изменения
подтвержденной строки в системной базе данных tempdb. Каждая версия от-
мечается последовательным номером транзакции (XSN) той транзакции, ко-
торая выполнила это изменение. (XSN используется для уникальной иденти-
фикации транзакций.) Самая последняя версия строки всегда сохраняется в
базе данных и соединяется через список связей с соответствующей версией,
сохраненной в tempdb. Старая версия строки в базе данных tempdb может со-
держать указатели на другую, еще более старую версию этой строки. Каждая
версия строки сохраняется в базе данных tempdb до тех пор, пока существуют
операции, которым она может потребоваться.
Контроль версий строк изолирует транзакции от эффектов модификаций, вы-
полненных другими транзакциями, без необходимости запроса разделяемых
блокировок для строк, которые были прочитаны. Значительное сокращение
общего количества требуемых блокировок для этого уровня изоляции сильно
увеличивает доступность данных. Однако исключительные блокировки все
еще необходимы: транзакции, использующие оптимистический уровень изо-
ляции, называемый snapshot, требуют блокировок, когда они модифицируют
строки.
Контроль версий строк, помимо прочего, используется для:
♦ поддержки уровня изоляции read committed snapshot;
♦ поддержки уровня изоляции snapshot;
♦ создания в триггерах таблиц inserted и deleted.
Далее описаны уровни изоляции read committed snapshot и snapshot, а в гла-
ве 14 подробно рассматриваются таблицы inserted И deleted.
Уровень изоляции READ COMMITTED SNAPSHOT
read committed snapshot является облегченным вариантом уровня изоляции
read committed, обсуждавшегося в предыдущем разделе. Это изоляция на
уровне оператора, которая означает, что любая другая транзакция может чи-
тать подтвержденные значения, которые существовали на момент начала
данного оператора. В случае изменений этот уровень изоляции возвращает
версии строк в актуальные данные для выборки строк для их изменения и
использует блокировки обновления для выбранных строк данных. Актуаль-
ные строки данных, которые должны быть изменены, получают исключи-
тельные блокировки.
Основное преимущество уровня изоляции read committed snapshot в том, что
операции чтения не блокируют обновления, а обновления не блокируют one-
Гпава 13. Управление параллельной работой 393
рации чтения. С другой стороны, обновления блокируют другие обновления,
потому что устанавливается исключительная блокировка до начала выполне-
ния операции обновления.
Для задания уровня изоляции read committed snapshot вы используете пред-
ложение set оператора alter database. После активации в дальнейшем не
требуются никакие изменения. Любая транзакция, заданная с уровнем изоля-
ции READ COMMITTED, Не будет ВЫПОЛНЯТЬСЯ ПОД READ COMMITTED SNAPSHOT.
Уровень изоляции SNAPSHOT
Уровень изоляции snapshot является изоляцией на уровне транзакции. Это
означает, что любая другая транзакция будет читать подтвержденные изме-
нения, которые существовали непосредственно перед стартом транзакции
snapshot. Транзакция snapshot также будет возвращать первоначальные зна-
чения данных, пока она не будет завершена, даже если другая транзакция из-
менила эти данные в течение этого времени. Поэтому другая транзакция мо-
жет читать измененные данные только после завершения транзакции
SNAPSHOT.
Транзакции, выполняющиеся под уровнем изоляции snapshot, получают ис-
ключительные блокировки данных перед выполнением модификаций только
для поддержания ограничений. В противном случае блокировки на данные не
устанавливаются, пока не будут изменены данные. Если данные строки соот-
ветствуют критериям обновления, то транзакция snapshot проверяет, не были
ли изменены и подтверждены изменения данных этой строки в конкурентной
транзакции после того, как была запущена текущая транзакция. Если данные
в строке были модифицированы в конкурентной транзакции, то возникает
конфликт, и транзакция snapshot завершается. Конфликт обновления обраба-
тывается системой базы данных, поэтому не существует способа отмены про-
явления конфликта обновления.
Реализация уровня изоляции snapshot является процессом, состоящим из
двух шагов. Во-первых, нужно установить опцию для базы данных
allow_snapshot_isolation. Во-вторых, для каждой сессии, которая будет ис-
пользовать этот уровень изоляции, нужно задать для оператора set
transaction isolation level значение snapshot. Когда установлены эти оп-
ции, будут создаваться версии для всех строк, изменяемых в базе данных.
READ COMMITTED SNAPSHOT в сравнении с SNAPSHOT
Наиболее важным отличием этих двух оптимистических уровней изоляции
является то, что транзакция snapshot может вызывать конфликты обновле-
ний, когда процесс просматривает те же данные во время выполнения тран-
394
Часть II. Язык Transact-SQL
закции и не является заблокированным. В противоположность этому уровень
изоляции Read committed snapshot не использует свой собственный XSN при
выборе версий строки. Каждый раз при старте оператора подобная транзак-
ция читает самый последний XSN, созданный для этого экземпляра системой
базы данных, и выбирает строку с этим номером.
Другим отличием является то, что уровень изоляции read committed snapshot
позволяет другим транзакциям выполнять модификацию данных до того, как
будет завершена транзакция контроля версий строк. Это может привести к
конфликту, если другая транзакция изменяет данные в промежутке времени,
когда транзакция контроля версий строк выполнит чтение с последующей
попыткой выполнения соответствующей операции записи. (Для приложения,
базирующегося на уровне изоляции snapshot, система проверяет возможность
возникновения конфликта и отправляет соответствующее сообщение об
ошибке.)
Резюме
Конкурентный доступ в многопользовательских системах баз данных может
приводить к некоторым негативным эффектам, таким как чтение несущест-
вующих данных или потеря изменений данных. Database Engine, как и все
другие СУБД, решает эти проблемы при использовании транзакций. Тран-
закция является последовательностью операторов Transact-SQL, которые
объединяются вместе. Все операторы внутри транзакции составляют атомар-
ную единицу. Это означает, что либо выполняются все операторы, либо
в случае ошибок все операции отменяются.
Для реализации транзакций используется механизм блокировки. Задачей
блокировки является недопущение изменений заблокированных объектов
другими транзакциями. Блокировка имеет следующие аспекты: режим бло-
кировки, гранулярность блокировки и длительность блокировки. Режим бло-
кировки определяет различные типы блокировок, выбор которых зависит от
того ресурса, который нужно заблокировать. Длительность блокировки зада-
ет временной период, в течение которого ресурс будет заблокирован.
Database Engine предоставляет механизм, называемый триггером, который
среди прочих поддерживает общие ограничения целостности. Этот механизм
детально рассматривается в следующей главе.
Упражнения
| Упражнение 13.1
Каково назначение транзакций?
Глава 13. Управление параллельной работой 395
; Упражнение 13.2
В чем разница между локальной и распределенной транзакциями?
| Упражнение 13.3
В чем разница между неявным и явным видом транзакции?
i Упражнение 13.4
Какие виды блокировок совместимы с исключительной блокировкой?
| Упражнение 13.5
Как вы можете проверить успешность выполнения каждого оператора
Transact-SQL?
j Упражнение 13.6
Где вы должны использовать оператор save transaction?
I Упражнение 13.7
Объясните разницу между блокировкой на уровне строки и на уровне стра-
ницы.
| Упражнение 13.8
Может ли пользователь явно влиять на поведение системы при блокировках?
| Упражнение 13.9
В чем разница между базовыми типами блокировок (разделяемая и исключи-
тельная) и блокировкой с намерениями?
: Упражнение 13.10
Что означает укрупнение блокировки?
i Упражнение 13.11
Объясните разницу между уровнями изоляции read uncommitted и serializable.
. 14 Зак. 1141
Часть II. Язык Transact-SQL
S Упражнение 13.12
Что такое взаимная блокировка?
[ Упражнение 13.13
Какой процесс используется в качестве "жертвы" в ситуации взаимной бло-
кировки? Может ли пользователь повлиять на процесс принятия системой
решения по этому поводу?
ГЛАВА 14
Триггеры
Эта глава посвящена механизму, называемому триггерами. В начале главы
описываются операторы Transact-SQL для создания, удаления и изменения
триггеров. После этого даются примеры из различных областей приложений
для этого объекта базы данных. Каждый пример создается с использованием
одного из операторов insert, update или delete. Во второй части этой главы
рассматриваются триггеры DDL, которые базируются на таких операторах,
как create table. Опять же, даются примеры из различных областей прило-
жений, связанных с триггерами DDL. В конце этой главы обсуждается реали-
зация триггеров с использованием CLR (Common Language Runtime).
Общие сведения
Триггер является механизмом, который выполняется, когда происходит кон-
кретное действие с отдельной таблицей. Каждый триггер имеет три основные
части:
♦ имя;
♦ действие;
♦ исполнение.
Максимальный размер имени триггера— 128 байтов. Действием триггера
может быть либо оператор DML (insert, update или delete), либо оператор
DDL. Поэтому существуют две формы триггеров: триггеры DML и триггеры
DDL. Исполнительная часть триггера обычно содержит хранимую процедуру
или пакет.
Замечание____________________________________________________
Database Engine позволяет создавать триггеры, используя либо язык Transact-
SQL, либо языки программирования CLR, такие как C# или Visual Basic. В этом
398
Часть II. Язык Transact-SQL
разделе для создания триггеров описывается использование языка Transact-
SQL. Реализация триггеров с помощью языков программирования CLR показа-
на в конце этой главы.
Создание триггера DML
Триггер создается посредством оператора create trigger, который имеет
следующий синтаксис:
CREATE TRIGGER [schema_name.]trigger_name
ON (table_name I view_name}
[WITH dntl_ trigger'option [, ...]]
{FOR I AFTER | INSTEAD OF} { [INSERT] [,] [UPDATE] [,] [DELETE]}
[WITH APPEND]
{AS sqI statement I EXTERNAL NAME method_name}
Замечание
Предыдущий синтаксис описывает только лишь триггеры DML. Триггеры DDL
имеют небольшие отличия в синтаксисе, которые будут показаны далее в этой
главе.
Здесь schema_name— ИМЯ схемы, которой принадлежит триггер; trigger_
name— имя триггера; table_name— имя таблицы, для которой задается триг-
гер. Для представлений также поддерживаются триггеры, как показано в ва-
рианте view_name.
ОПЦИИ AFTER И INSTEAD OF ЯВЛЯЮТСЯ ДВуМЯ ДОПОЛНИТеЛЬНЫМИ ОПЦИЯМИ, КОТО-
рые вы можете задать в триггере. (Предложение for является синонимом для
after.) Триггеры after вызываются после появления действий, обрабатывае-
мых в триггерах. Триггеры instead of выполняются вместо заданных в триг-
гере действий. Триггеры after могут создаваться только для таблиц, в то
время как триггеры instead of могут создаваться как для таблиц, так и для
представлений. Примеры, показывающие использование этих двух типов
триггеров, будут даны далее в этой главе.
Опции insert, update и delete задают действия триггера. (Действием триггера
является тип оператора Transact-SQL, который активирует этот триггер.) Эти
три оператора могут быть записаны в любой допустимой комбинации.
Оператор delete недопустим, если используется оператор if update (имя
столбца).
Как вы можете видеть в синтаксисе оператора create trigger, спецификация
as sql statement используется для задания действия (действий) триггера. (Вы
также можете использовать опцию external nane, которая рассматривается
далее в этой главе.)
Глава 14. Триггеры 399
Замечание__________________________________________________
Database Engine позволяет создавать множество триггеров для каждой таблицы
и для каждого действия (insert, update и delete). По умолчанию не существу-
ет определенного порядка, в котором выполняется несколько триггеров для
данной модификации действия. (Вы можете определить такой порядок, исполь-
зуя первый и последний триггеры, как показано далее в этой главе.)
Только владелец базы данных, администраторы DDL и владелец таблицы,
для которой определяется триггер, имеют право создавать триггер для теку-
щей базы данных. (В отличие от полномочий для других операторов create
это полномочие не может быть передано другим пользователям.)
Модификация структуры триггера
Transact-SQL также поддерживает оператор alter trigger, который изменяет
структуру триггера. Данный оператор обычно используется для изменения
тела триггера. Все предложения и опции оператора alter trigger соответст-
вуют предложениям и опциям с теми же именами в операторе create trigger.
Полномочия для alter trigger по умолчанию предоставлены членам фикси-
рованных ролей базы данных db_owner и db_ddiadmin, а также владельцу таб-
лицы.
Оператор drop trigger удаляет один или более существующих триггеров из
текущей базы данных.
В следующем разделе описываются удаляемые и добавляемые таблицы, ко-
торые играют значительную роль в действиях триггеров.
Использование таблиц удаления и добавления
При создании синхронизирующего действия в триггере вы обычно должны
указать, на какое значение столбца вы ссылаетесь— на значение, которое
столбец имел до выполненного изменения или после изменения. По этой
причине для проверки нужных значений создаются две виртуальные таблицы
со специальными именами:
♦ deleted содержит копии строк, которые были удалены из таблицы;
♦ inserted содержит копии строк, которые были добавлены в таблицу.
Структура этих таблиц эквивалентна тем таблицам, для которых задан триг-
гер.
Таблица deleted используется, если в операторе create trigger задано пред-
ложение delete или update. Таблица inserted используется, если в операторе
create trigger задано предложение insert или update. Это означает, что для
каждого оператора delete, выполняемого в действиях триггера, создается
400
Часть II. Язык Transact-SQL
таблица deleted. Аналогично, для каждого оператора insert, выполняемого в
действиях триггера, создается таблица inserted.
Оператор update трактуется как оператор delete, за которым следует опера-
тор insert. Поэтому для каждого оператора update, выполняемого в действи-
ях триггера, создаются таблицы deleted и inserted (именно в этом порядке).
Материализация таблиц deleted и inserted осуществляется с использованием
средств контроля версий строк, которые подробно обсуждались в главе 13.
Когда операторы DML, такие как insert, update и delete, выполняются для
таблицы, соответствующей триггеру, все изменения таблицы всегда фикси-
руются в виде версий строк. Когда триггеру требуется информация из табли-
цы deleted, он выбирает данные из истории версий. В случае таблицы
inserted триггер выбирает данные из самой последней версии строки.
Замечание_________________________________________________
Средства контроля версий строк используют базу данных tempdb в качестве ис-
тории версий. По этой причине вы должны ожидать значительного роста раз-
мера этой системной базы данных, если ваша база данных содержит много
триггеров, которые часто используются.
Области приложений
для DML-триггеров
В первой части этой главы было сказано, как вы можете создавать триггеры
DML и изменять их структуру. Такая форма триггеров может быть использо-
вана для решения многих проблем. В данном разделе описываются некото-
рые области приложений для триггеров DML (триггеры after и instead of).
Триггеры AFTER
Как вы уже знаете, триггеры after вызываются после того, как будут выпол-
нены действия. Вы можете задать триггер after, используя ключевое слово
after или for. Триггеры after могут быть созданы только для базовых таб-
лиц.
Триггеры after могут быть использованы, помимо прочего, для выполнения
следующих действий:
♦ создание контрольного журнала выполненных действий для одной или
более таблиц базы данных (см. пример 14.1);
♦ реализация бизнес-правил (см. пример 14.2);
♦ поддержание ссылочной целостности данных (см. примеры 14.3 и 14.4).
Глава 14. Триггеры 401
Создание контрольного журнала
В главе 12 рассказано, как вы можете перехватывать изменения данных, ис-
пользуя механизм, называемый CDC (change data capture, перехват изменения
данных). Триггеры DML также могут быть использованы для решения той же
задачи. В примере 14.1 показано, как триггеры могут создавать контрольный
журнал, содержащий сведения о действиях с одной или более таблиц базы
данных.
i Пример 14.1
/* Таблица audit_budget используется в качестве контрольного журнала
о действиях с таблицей project */
USE sample;
GO
CREATE TABLE audit_budget
(project_no CHAR(4) NULL,
user_name CHAR(16) NULL,
date DATETIME NULL,
budget_old FLOAT NULL,
budget_new FLOAT NULL);
GO
CREATE TRIGGER modify_budget
ON project AFTER UPDATE
AS IF UPDATE(budget)
BEGIN
DECLARE @budget_old FLOAT
DECLARE @budget_new FLOAT
DECLARE @project_number CHAR(4)
SELECT @budget_old = (SELECT budget FROM deleted)
SELECT @budget_new = (SELECT budget FROM inserted)
SELECT @project_number = (SELECT project_no FROM deleted)
INSERT INTO audit_budget VALUES
(@project number, USER_NAME(), GETDATE(), @budget_old, @budget_new)
END
В примере 14.1 показано, как триггеры могут быть использованы для реали-
зации контрольного журнала о действиях с таблицей. В этом примере созда-
ется таблица audit budget, которая сохраняет все изменения в столбце budget
таблицы project. Запись всех изменений в этом столбце будет выполнена при
использовании триггера modify_budget.
Любое изменение столбца budget с помощью оператора update активизирует
данный триггер. В процессе выполнения триггера строкам таблиц deleted и
402
Часть II. Язык Transact-SQL
inserted присваиваются значения соответствующих переменных @budget_old,
@budget_new и @project number. Присвоенные значения вместе с именем
пользователя и текущей датой будут после этого добавлены в таблицу
audit_budget.
Замечание__________________________________________________________
В примере 14.1 предполагается, что за один раз будет изменена только одна
строка. Этот пример является упрощенным вариантом общего случая, когда
триггер обрабатывает обновления множества строк. Реализация такого наибо-
лее общего (и довольно запутанного) триггера выходит за рамки вводного
уровня данной книги.
Если выполнить следующий оператор Transact-SQL
UPDATE project
SET budget = 200000
WHERE proj ect_no = ' p2';
то содержимое таблицы audit_budget будет таким:
project_no username date budget_old budget_new
p2 Dbo 2008-01-31 14:00:05 95000 200000
Реализация бизнес-правил
Триггеры могут быть использованы для создания бизнес-правил приложений.
В примере 14.2 показано создание подобного триггера.
, Пример 14.2
— Триггер total_budget является примером использования
— триггера для реализации бизнес-правил
USE sample;
GO
CREATE TRIGGER total_budget
ON project AFTER UPDATE
AS IF UPDATE (budget)
BEGIN
DECLARE @sum_oldl FLOAT
DECLARE @sum_old2 FLOAT
DECLARE @sum_new FLOAT
SELECT @sum_new = (SELECT SUM(budget) FROM inserted)
SELECT @sum_oldl = (SELECT SUM(p.budget)
FROM project p WHERE p.project_no
NOT IN (SELECT d.project_no FROM deleted d))
Глава 14. Триггеры 403
SELECT @sum_old2 = (SELECT SUM(budget) FROM deleted)
IF @sum_new > (@sum_oldl + @sum_old2) * 1.5
BEGIN
PRINT 'No modification of budgets'
ROLLBACK TRANSACTION
END
ELSE
PRINT 'The modification of budgets executed'
END
В примере 14.2 создается правило, управляющее изменениями бюджета про-
ектов. Триггер totai_budget проверяет каждое изменение бюджета и выпол-
няет только такие операторы update, в которых изменения не увеличивают
сумму всех бюджетов более чем на 50%. В противном случае для оператора
update выполняется откат с использованием оператора rollback transaction.
Поддержание ограничений целостности
Как было сказано в главе 5, СУБД обрабатывают два типа ограничений це-
лостности:
♦ декларативные ограничения целостности, определенные с помощью опе-
раторов CREATE TABLE И ALTER TABLE;
♦ процедурные ограничения целостности (обрабатываемые триггерами).
Использование триггеров для поддержания ограничений целостности имеет
одно значительное преимущество: триггеры являются более гибкими, чем
декларативные ограничения, потому что каждое ограничение может быть
реализовано при помощи триггеров. (То же утверждение не является верным
для декларативных ограничений.)
В примере 14.3 показано, как вы можете поддерживать ссылочную целост-
ность ДЛЯ таблиц employee И works_on.
| Пример 14.3
USE sample;
GO
CREATE TRIGGER works'on_integrity
ON workson AFTER INSERT, UPDATE
AS IF UPDATE(emp_no)
BEGIN
IF (SELECT employee.emp_no
FROM employee, inserted
WHERE employee.emp_no = inserted.emp_no) IS NULL
404
Часть II. Язык Transact-SQL
BEGIN
ROLLBACK TRANSACTION
PRINT 'No insertion/modification of the row'
END
ELSE PRINT 'The row inserted/modified'
END
Триггер workson_integrity в примере 14.3 проверяет ссылочную целостность
для таблиц employee и works on. Это означает, что проверяется каждое изме-
нение значения в столбце emp_no таблицы works_on, и любое нарушение этого
ограничения отменяет операцию. (То же самое верно и для добавления ново-
го значения в столбец emp_no.) Оператор rollback transaction во втором бло-
ке begin отменяет оператор insert или update в случае нарушения ссылочно-
го ограничения.
Триггер в примере 14.3 проверяет случай 1 и случай 2 для ссылочной целост-
ности между таблицами employee и works on (см. определение ссылочной це-
лостности в главе 5). В примере 14.4 создается триггер, который проверяет
нарушение ссылочной целостности между теми же самыми таблицами в слу-
чае 3 и случае 4.
1 Пример 14.4
USE sample;
GO
CREATE TRIGGER refint_workson2
ON employee AFTER DELETE, UPDATE
AS IF UPDATE (emp_no)
BEGIN
IF (SELECT COUNT(*)
FROM WORKSJDN, deleted
WHERE works_on.emp_no = deleted.emp_no) > 0
BEGIN
ROLLBACK TRANSACTION
PRINT 'No modification/deletion of the row'
END
ELSE PRINT 'The row is deleted/modified'
END
Триггеры INSTEAD OF
Триггер с предложением instead of заменяет соответствующее действие, за-
данное для триггера. Он выполняется после создания соответствующих таб-
Глава 14. Триггеры 405
лиц deleted и inserted, но до того, как будут выполнены ограничения цело-
стности данных и любые другие действия.
Триггеры instead of могут быть созданы как для таблиц, так и для представ-
лений. Когда оператор Transact-SQL ссылается на представление, у которого
существует триггер instead of, система базы данных выполняет этот триггер,
вместо выполнения любых других действий. Триггер всегда использует ин-
формацию таблиц deleted и inserted, созданных для представления, чтобы
создавать любые операторы, необходимые для создания запрашиваемых со-
бытий.
Существуют некоторые требования к значениям столбцов, поставляемым
триггерам instead of:
♦ значения не могут быть заданы для вычисляемых столбцов;
♦ значения не могут быть заданы для столбцов с типом данных timestamp;
♦ значения не могут быть заданы для столбцов со свойством identity, если
опция identity_insert не установлена В ON.
Эти требования применимы только к операторам insert и update, которые
ссылаются на базовую таблицу. Оператор insert, ссылающийся на представ-
ление, которое имеет триггер instead of, должен поставлять все значения для
столбцов этого представления, не допускающих пустые значения. (То же са-
мое истинно и для оператора update: оператор update, который ссылается на
представление, имеющее триггер instead of, должен поставлять значения для
каждого столбца представления, который не допускает пустых значений и на
который осуществляется ссылка в предложении set.)
В примере 14.5 показана разница в поведении в процессе добавления значе-
ний в вычисляемые столбцы при использовании таблицы и ее соответствую-
щего представления.
' Пример 14.5
CREATE view all_orders
AS SELECT orderid, price, quantity, orderdate, total, shippeddate
FROM orders;
GO
CREATE TRIGGER tr_orders
CN all_orders INSTEAD OF INSERT
AS BEGIN
INSERT INTO orders
SELECT orderid, price, quantity, orderdate
FROM inserted
END
406
Часть II. Язык Transact-SQL
В примере 14.5 используется таблица orders из главы 10, потому что эта таб-
лица содержит два вычисляемых столбца (см. пример 10.8). Представление
all orders выбирает все строки из этой таблицы. Это представление исполь-
зуется для задания значения столбца представления, который является вы-
числяемым столбцом базовой таблицы. Это способ применения триггера
instead of, который в случае оператора insert заменяет пакет, добавляющий
значения в базовую таблицу через представление all orders. (Оператор
insert, который ссылается напрямую на базовую таблицу, не может постав-
лять значение вычисляемому столбцу.)
Первый и последний триггеры
Database Engine дает возможность создавать множество триггеров для каждой
таблицы или представления и для каждого действия с ними (insert, update и
delete). Дополнительно к этому вы можете задавать порядок для нескольких
триггеров, определенных для конкретного действия. Используя системную
хранимую процедуру sp settriggerorder, вы можете указать, что один из
триггеров after, связанных с таблицей, будет либо первым триггером after,
либо последним выполняемым триггером after для каждого обрабатываемо-
го триггерами действия. Эта системная процедура имеет параметр @order,
который принимает три значения:
♦ first указывает, что данный триггер является первым триггером after,
который будет выполняться для модифицирующего действия;
♦ last указывает, что данный триггер является последним триггером after,
вызываемым для соответствующего действия;
♦ попе указывает, что для триггера не существует какого-нибудь порядка, в
котором он будет выполняться. Это значение обычно используется для
отмены ранее установленного для триггера значения first или last.
Замечание______________________________________________________
Если вы используете оператор alter trigger для изменения структуры триг-
гера, то порядок для этого триггера (first или last) будет отменен.
В примере 14.6 показано использование системной хранимой процедуры
sp_settriggerorder.
| Пример 14.6
EXEC sp_settriggerorder @triggername = 'modify_budget',
@order = 'first', @stmttype = 'update'
Глава 14. Триггеры 407
Замечание________________________________________________________
Для таблицы может быть только один AFTER-триггер first и только один last.
Последовательность, в которой выполняются остальные AFTER-триггеры, не
определена.
Для отображения порядка, в котором выполняются триггеры, вы можете ис-
пользовать следующее:
♦ хранимую процедуру sp_helptrigger;
♦ функцию OBJECTPROPERTY.
Системная процедура sp_helptrigger имеет столбец order, который содержит
порядковый номер указанного триггера. Используя функцию objectproperty,
ВЫ можете указать либо ExecIsFirstTrigger, либо ExecIsLastTrigger В качест-
ве второго параметра этой функции. Первый параметр всегда является иден-
тификационным номером объекта базы данных. Функция objectproperty ото-
бражает 1, если конкретное свойство истинно.
Замечание________________________________________________________
Поскольку триггер instead of вызывается до того, как будут выполнены изме-
нения в соответствующей таблице, триггеры instead of не могут быть заданы
как триггеры first или last.
Триггеры DDL
В первой части этой главы описывались триггеры DML, задающие действия,
которые выполняются сервером при модификации данных таблицы в процес-
се выполнения оператора insert, update или delete. Database Engine позволя-
ет вам определять триггеры и для операторов DDL, таких как create
database, drop table и alter table. Синтаксис для триггеров DDL:
CREATE TRIGGER [schema name.]trigger_name
ON { ALL SERVER | DATABASE )
[WITH {ENCRYPTION | EXECUTE AS clause_name]
{ FOR I AFTER } { event^group I event_type I LOGON }
AS { batch | EXTERNAL NAME method_name }
Как видно из предыдущего синтаксиса, триггеры DDL создаются тем же са-
мым образом, что и триггеры DML. Операторы alter trigger и drop trigger
также используются для изменения и удаления триггеров DDL. По этой при-
чине в данном разделе описываются только те опции оператора create
trigger, которые являются новыми в синтаксисе для триггеров DDL.
Когда вы определяете триггер DDL, вы в первую очередь должны принять
решение об области видимости вашего триггера. Предложение database ука-
408
Часть II. Язык Transact-SQL
зывает, что областью видимости триггера DDL является текущая база дан-
ных. Предложение all server указывает, что областью видимости триггера
DDL является текущий сервер.
После задания области видимости триггера вы должны принять решение, бу-
дет ли триггер вызываться для одного оператора DDL или для группы опера-
торов. Параметр event type задает оператор DDL, после выполнения которо-
го вызывается триггер. Параметр event_group определяет имя предварительно
определенной группы событий в языке Transact-SQL. Триггер DDL вызыва-
ется после появления любого события языка Transact-SQL, принадлежащего
группе event group. Вы можете найти весь список событий группы в доку-
ментации Books Online. Ключевое слово logon задает триггер начала сеанса
(см. пример 14.8).
Помимо похожестей, которые присутствуют у триггеров DML и DDL, у них
существуют и некоторые серьезные отличия. Основным различием между
этими двумя формами триггеров является то, что триггер DDL может быть
использован для задания его области видимости не только в его базе данных,
но и в сервере, не только в отдельном объекте. При этом триггеры DDL не
поддерживают триггеры instead of. Как вы, наверное, догадались, таблицы
inserted и deleted здесь не нужны, потому что триггеры DDL не меняют со-
держимого таблиц.
Далее рассматриваются две различные формы триггеров DDL: триггеры
уровня базы данных и триггеры уровня сервера.
Триггеры уровня базы данных
В примере 14.7 показано, как вы можете реализовать триггер DDL, у которо-
го областью видимости является текущая база данных.
: Пример 14.7
USE sample;
GO
CREATE TRIGGER prevent_drop_triggers
ON DATABASE FOR DROP_TRIGGER
AS PRINT 'You must disable "prevent_drop_triggers" to drop any trigger'
ROLLBACK
Триггер в примере 14.7 запрещает пользователям удалять любой триггер, ко-
торый принадлежит базе данных sample. Предложение database указывает,
что триггер prevent _drop_triggers является триггером уровня базы данных.
Ключевое слово drop_trigger является предварительно определенным типом
события, задающим событие удаления любого триггера.
Глава 14. Триггеры 409
Триггеры уровня сервера
Триггеры уровня сервера отвечают на события изменения на сервере. Вы ис-
пользуете предложение all server для реализации триггеров уровня сервера.
В зависимости от указанного действия существуют две разновидности триг-
геров уровня сервера: условные триггеры DDL и триггеры входа в систему.
События условных триггеров DDL основываются на операторах DDL, тогда
как триггеры входа в систему обрабатывают событие подключения к системе.
В примере 14.8 показан триггер уровня сервера, который является в то же
самое время и триггером входа в систему.
: Пример 14.8
USE master;
GO
CREATE LOGIN login test WITH PASSWORD = 'login_test§$',
CHECK_EXPIRATION = ON;
GO
GRANT VIEW SERVER STATE TO login_test;
GO
CREATE TRIGGER connection_limit_trigger
ON ALL SERVER WITH EXECUTE AS 4ogin_test’
FOR LOGON AS
BEGIN
IF ORIGINAL_LOGIN() = 'login_test' AND
(SELECT COUNT(*) FROM sys.dm_exec_sessions
WHERE is_user_process = 1 AND
original_login_name = 'login_test') > 1
ROLLBACK;
END;
В примере 14.8 вначале создается учетная запись SQL Server с именем
login_test. Эта учетная запись впоследствии исйользуется в триггере уровня
сервера. По этой причине ей требуется полномочие view server state, кото-
рое ей предоставляется при помощи оператора grant. После этого создается
триггер connection_limit_trigger, который принадлежит к триггерам уровня
сервера, потому что используется ключевое слово logon. Использование
представления sys.dm_exec_sessions дает вам возможность проверить, уста-
новлена ли уже сессия с помощью учетной записи login test. В этом случае
выполняется оператор rollback. Таким способом можно устанавливать в одно
и то же время только одну сессию с учетной записью login test.
410
Часть II. Язык Transact-SQL
Триггеры и CLR
Триггеры, так же как и хранимые процедуры и определенные пользователем
функции, могут быть реализованы посредством CLR (Common Language
Runtime). Если вам нужно реализовать, скомпилировать и сохранить тригге-
ры CLR, выполните следующие шаги:
1. Создайте триггер с использованием C# или Visual Basic и скомпилируйте
эту программу с помощью соответствующего компилятора (см. примеры 14.9
и 14.10). Используйте оператор create assembly для создания соответст-
вующего исполняемого файла (см. пример 14.11).
2. Создайте триггер посредством оператора create trigger (см. пример 14.12).
Следующие примеры демонстрируют эти шаги. В примере 14.9 показан ис-
ходный текст программы на языке С#, которая будет использоваться для реа-
лизации триггера из примера 14.1.
Замечание__________________________________________________________
Перед тем как создавать триггер CLR из следующего примера, вам нужно уда-
лить триггер prevent_drop_triggers (см. пример. 14.7), а затем удалить триг-
гер modify_budget (см. пример 14.1), используя оператор drop trigger.
Пример 14.9
using System;
using System.Data;
using System.Data.SqlClient;
using Microsoft.SqlServer.Server;
public class StoredProcedures
(
public static void Modify Budget()
{
SqlTriggerContext context = SqlContext.Triggercontext;
if(context.IsUpdatedColumn(2)) // Budget
{
float budget_old;
float budget_new;
string project_number;
SqlConnection conn = new SqlConnection("context connection=true");
conn. Open () ;
SqlCommand cmd = conn. CreateCoiumand () ;
cmd.CommandText = "SELECT budget FROM DELETED";
budget_old = (float)Convert.ToDouble(cmd.ExecuteScalar()) ;
Глава 14. Триггеры 411
and.CommandText = "SELECT budget FROM INSERTED";
budget new = (float)Convert.ToDouble(and.ExecuteScalar()) ;
and.CommandText = "SELECT project_no FROM DELETED";
project_number = Convert.ToString (and.-ExecuteScalar ()) ;
and.CornmandText = INSERT INTO audit budget
VALUES(@project_number, USER_NAME(), GETDATEO,
@budget_old, @budget_new)";
and.Parameters.AddWithValue("@project_number", project_number);
and.Parameters.AddWithValue("@budget_old", budget_old);
and.Parameters.AddWithValue("@budget_new", budget_new);
and.ExecuteNonQuery();
}
Пространство имен Microsoft.SqlServer.Server ВКЛЮЧавТ все клиентские
классы, нужные программе на С#. SqlTriggerContext и SglFunction являются
экземплярами классов, которые принадлежат этому пространству имен. Про-
странство имен System. Data. Sglciient содержит такие классы, как
SQLConnection и SQLCommand, которые используются для установления соеди-
нения и связи между клиентом и сервером базы данных. Соединение уста-
навливается при использовании строки соединения "context connection=true":
SqlConnection conn = new SqlConnection("context connection=true");
После этого определяется класс storedProcedure, который служит для реали-
зации триггеров. Метод Modify_Budget () реализует триггер с тем же именем.
Экземпляр класса sQLTriggerContext с именем context предоставляет про-
грамме доступ к виртуальной таблице, которая была создана в процессе вы-
полнения этого триггера. Таблица хранит данные, которые приводят к вы-
полнению триггера. Метод isupdatedcolumn() класса SQLTriggerContext дает
возможность определить, был ли изменен указанный столбец таблицы.
Программа на языке C# содержит два других важных класса: SQLConnection и
SQLCommand. Экземпляр класса SQLConnection обычно используется для уста-
новления соединения с базой данных, а экземпляр SQLCommand позволяет вы-
полнять оператор SQL.
Следующие операторы используют СВОЙСТВО Parameters класса SQLCommand
для отображения параметров, а метод AddWithValue () — для добавления зна-
чения в указанный параметр:
and.Parameters.AddWithValue("@project_number”, projectnumber);
and.Parameters.AddWithValue("Sbudget old", budget_old);
and.Parameters.AddWithValue("@budget_new", budget_new);
412
Часть II. Язык Transact-SQL
В примере 14.10 показано выполнение команды esc. С помощью этой коман-
ды вы можете скомпилировать программу на C# из примера 14.9.
! Пример 14.10
esc /target:library Examplel4_9.cs
/reference:"с:\Program Files\Microsoft SQL Server\MSSQL.l\MSSQL\Binn\
sqlaccess.dll"
Подробное описание команды esc см. в главе 8.
Замечание_________________________________________________________
Вы можете включать и отключать использование CLR через опцию clr_enabled
системной процедуры sp_configure. Выполните оператор reconfigure для
изменения текущего значения конфигурации (см. пример 8.9).
В примере 14.11 показаны последующие два шага по созданию триггера
modify budget. Используйте SQL Server Management Studio для выполнения
этих операторов.
i Пример 14.11
CREATE ASSEMBLY Examplel4_9 FROM
'C:\Programs\Microsoft SQL Server\assemblies\Examplel4_9.dll'
WITH PERMISSION_SET=EXTERNAL_ACCESS
Оператор create assembly использует управляемый код в качестве источника
для создания соответствующего объекта вместе с создаваемым триггером
CLR. Предложение with permission set в этом примере указывает, что пол-
номочия доступа установлены в значение external access, которое не позво-
ляет сборкам осуществлять доступ к внешним системным ресурсам, а только
некоторым из них.
В примере 14.12 создается триггер modify budget посредством оператора
CREATE trigger.
: Пример 14.12
CREATE TRIGGER modify_budget ON project
AFTER UPDATE AS
EXTERNAL NAME Examplel4_9.StoredProcedures.Modify_Budget
Оператор create trigger в примере 14.12 отличается от оператора, приме-
ненного в примерах 14.1—14.5, т. к. он использует опцию external name. Эта
Глава 14. Триггеры 413
опция указывает, что код сгенерирован с помощью CLR. Имя в этом предло-
жении является именем, состоящим из трех частей. Первая часть является
именем соответствующей сборки, вторая часть (storedProcedures)— имя
класса public, определенного в примере 14.9, а третья часть (Modify_Budget)
является именем метода, который указан внутри класса.
В примере 14.13 показано, как триггер из примера 14.3 может быть реализо-
ван с использованием языка С#.
Замечание____________________________________________________________
Вам нужно удалить триггер с именем workson_integrity (см. пример 14.3), ис-
пользуя оператор drop trigger, прежде чем вы создадите триггер CLR из
примера 14.13.
Пример 14.13
using System;
using System.Data;
using System.Data.SqlClient;
using Microsoft.SqlServer.Server;
public class StoredProcedures
{
public static void WorksOn_Integrity()
I
SqlTriggerContext context = SqlContext.TriggerContext;
if(context.IsUpdatedColumn(0)) // Emp_No
{
SqlConnection conn = new SqlConnection("context connection=true");
conn.Open () ;
SqlCommand cmd = conn. CreateCoiumand () ;
cmd.CommandText = "SELECT employee.emp_no
FROM employee, inserted
WHERE employee.emp_no = inserted.emp_no";
SqlPipe pipe = SqlContext.Pipe;
if (cmd.ExecuteScalar() == null)
{ System.Transactions.Transaction.Current.RollbackO;
pipe.SendCNo insertion/modification of the row”);
1
pipe.Send("The row inserted/modified");
414
Часть II. Язык Transact-SQL
Всего лишь две новые возможности, использованные в примере 14.13, тре-
буют объяснения. Класс SqiPipe принадлежит пространству имен
Microsoft.SqiServer.Server и дает вам возможность отправлять сообщения
вызвавшей программе, подобные следующему:
pipe.Send("The row inserted/modified");
(Строка добавлена/изменена.)
Для задания (или получения) текущей транзакции в триггере используется
свойство current класса Transaction. В примере 14.13 применяется метод
Rollback () для отката всей транзакции при нарушении ограничения целост-
ности.
В примере 14.14 показано создание сборки и соответствующего триггера, ос-
нованного на программе C# из примера 14.13. (Необходима компиляция про-
граммы на языке C# с помощью команды esc в качестве промежуточного ша-
га, однако здесь это опущено по причине того, что является аналогом той же
команды в примере 14.10.)
: Пример 14.14
CREATE ASSEMBLY Exaniplel4_13 FROM
'C:\Programs\Microsoft SQL Server\assemblies\Exainplel4_13.dll'
WITH PERMISSION_SET=EXTERNAL_ACCESS
GO
CREATE TRIGGER workson_integrity ON works_on
AFTER INSERT, UPDATE AS
EXTERNAL NAME Exairplel4_13.StoredProcedures.WorksOn_Integrity
Резюме
Триггер является механизмом, который размещается на сервере базы данных
и имеет две разновидности: триггеры DML и триггеры DDL. Триггеры DML
задают одно или более действий, которые автоматически выполняются сер-
вером базы данных при осуществлении изменений таблицы, выполненных
посредством операторов insert, updare или delete. (Триггеры DML не могут
быть использованы в операторах select.) В другом варианте триггеры DDL
основаны на операторах DDL. Они существуют в двух разновидностях в за-
висимости от области действия такого триггера — база данных или текущий
сервер. Предложение database указывает, что областью видимости триггера
DDL является текущая база данных. Предложение all server указывает, что
областью видимости триггера DDL является текущий сервер.
Эта глава является последней главой части 7/этой книги. В следующей части
обсуждается системное окружение Database Engine.
Гпава 14. Триггеры.415
Упражнения
i Упражнение 14.1
Используя триггеры, определите ссылочную целостность данных для пер-
вичного ключа таблицы department, столбца dept_no, который является внеш-
ним ключом таблицы works_on.
; Упражнение 14.2
При помощи триггеров задайте ссылочную целостность данных для первич-
ного ключа таблицы project, столбца project_no, который является внешним
ключом таблицы works on.
j Упражнение 14.3
Используя CLR, создайте триггер для примера 14.4.
Часть III
SQL Server:
системное администрирование
ГЛАВА 15
Системное окружение
и сервер базы данных
В этой главе описываются некоторые возможности Database Engine, которые
относятся к системному окружению. Во-первых, в главе дается подробное
описание системных баз данных, которые инсталлируются при установке
всей системы. Другой темой, связанной с системой, является хранение дан-
ных. В этой главе рассматриваются некоторые типы дисковых страниц, также
как и способы сохранения на диске различных типов данных. Под конец
объясняется использование системных утилит Ьср и sqicmd, а также систем-
ной команды DBCC.
Системные базы данных
В процессе инсталляции Database Engine генерируются следующие систем-
ные базы данных:
♦ master;
♦ model;
♦ tempdb;
♦ msdb.
Замечание___________________________________________________
Существует также "скрытая" база данных resource, которая используется для
хранения системных объектов, таких как системные процедуры и функции. Со-
держимое этой базы данных обычно используется для системных обновлений.
База данных master
База данных master является одной из наиболее важных баз данных Database
Engine. Она содержит все системные таблицы, необходимые для вашей рабо-
420
Часть III. SQL Server, системное администрирование
ты. Например, база данных master содержит информацию обо всех других
базах данных, управляемых Database Engine, о клиентских соединениях с
системой и об авторизациях пользователей.
По причине важности этой системной базы данных вы должны всегда сохра-
нять копию этой базы данных (см. главу 17). База данных master изменяется
каждый раз, когда вы выполняете различные системные операции. По этой
причине вы должны осуществлять ее резервное копирование после выполне-
ния каждой такой операции.
База данных model
База данных model применяется в качестве шаблона при создании баз данных,
определяемых пользователем. Она содержит подмножество всех системных
таблиц базы данных master, которые нужны каждой базе данных, создавае-
мой пользователем. Системный администратор может изменять свойства ба-
зы данных model для адаптации ее к специфическим требованиям системы.
Замечание_____________________________________________________
Поскольку база данных model используется в качестве модели каждый раз, ко-
гда вы создаете новую базу данных, вы можете расширять ее, добавляя объек-
ты базы данных и/или полномочия. После этого все новые базы данных будут
наследовать эти новые свойства. Используйте оператор alter database для
расширения или модификации базы данных model.
База данных tempdb
База данных tempdb предоставляет место для хранения временных таблиц и
других необходимых временных объектов. Система, например, сохраняет
промежуточные результаты вычислений сложных выражений в базе дан-
ных tempdb. База данных tempdb используется всеми базами данных, принад-
лежащими системе. Ее содержимое уничтожается каждый раз при рестарте
системы.
Система хранит три различных элемента в базе данных tempdb:
♦ пользовательские объекты;
♦ внутренние объекты;
♦ историю версий.
Личные и глобальные временные таблицы, которые создаются пользователя-
ми, сохраняются в базе данных tempdb. Другими объектами, сохраняемыми в
этой системной базе данных, являются переменные таблиц и функции с таб-
личными значениями. Все пользовательские объекты в tempdb трактуются
-' как и любые другие объекты базы данных. Это озна-
Гпава 15. Системное окружение и сервер базы данных 421
чает, что записи, соответствующие временным объектам, сохраняются в сис-
темном каталоге, и вы можете отыскивать о них информацию, используя
представление просмотра каталога sys.objects.
Внутренние объекты аналогичны пользовательским объектам за исключени-
ем того, что они не видимы при использовании представлений просмотра ка-
талогов или других инструментов поиска метаданных. Существуют три типа
внутренних объектов: рабочие файлы, рабочие таблицы и элементы сорти-
ровки. Рабочие файлы создаются, когда система отыскивает информацию,
используя некоторые операторы. Рабочие таблицы создаются системой, когда
выполняются некоторые операции типа буферизации памяти (спулинг) и вос-
становление баз данных и таблиц при использовании команды dbcc. Наконец,
элементы сортировки создаются при выполнении операций сортировки.
Оптимистический конкурентный доступ (см. главу 13) использует базу дан-
ных tempdb как место для хранения версий строк. По этой причине база дан-
ных tempdb растет каждый раз, когда система помимо других выполняет сле-
дующие операции:
♦ выполняется триггер;
♦ выполняется оператор insert, update или delete для базы данных, которая
допускает уровень изоляции snapshot.
Замечание___________________________________________________
Из-за оптимистического конкурентного доступа база данных tempdb использу-
ется системой довольно активно. По этой причине убедитесь, что объем памяти
для tempdb достаточно большой, регулярно отслеживайте ее память.
База данных msdb
База данных msdb используется компонентом SQL Server Agent для протоко-
лирования сообщений (alert) и заданий (см. главу 18). Эта системная база
данных содержит сведения о планировании задач, обработку исключений,
управление сообщениями и информацию системных операторов; например,
база данных msdb содержит информацию для всех операторов, таких как
адреса электронной почты, номера страниц, историю обо всех операциях ре-
зервного копирования и восстановления баз данных.
Хранение данных на диске
Архитектура хранения данных в Database Engine содержит две основные еди-
ницы для хранения объектов базы данных:
♦ страницу;
♦ экстент.
422
Часть III. SQL Server: системное администрирование
Замечание____________________________________________________
Существуют также и другие единицы хранения, такие как файлы и файловые
группы, которые будут рассматриваться в следующей главе.
Основной единицей хранения данных является страница. Размер страницы
всегда составляет 8 Кбайт. Каждая страница имеет 96-байтовый заголовок,
используемый для хранения системной информации. Строки данных распо-
лагаются на странице сразу после заголовка.
Database Engine поддерживает различные типы страниц, наиболее важные из
них:
♦ страницы данных;
♦ индексные страницы.
Замечание____________________________________________________
Страницы данных и индексов являются физической частью базы данных, где
сохраняются соответствующие таблицы и индексы. Содержимое базы данных
хранится в одном файле или в нескольких файлах, каждый файл разделен на
страницы. Поэтому каждая страница таблицы или индекса (как физическая
единица базы данных) может быть уникально определена с использованием
идентификатора базы данных, идентификатора файла и номера страницы.
При создании таблицы или индекса система выделяет фиксированный объем
внешней памяти для хранения данных таблицы или индекса. Когда это про-
странство заполняется, то должна быть выделена дополнительная память.
Физическая единица памяти, которая выделяется для таблицы (индекса), на-
зывается экстентом. Экстент содержит восемь последовательно располо-
женных страниц, или 64 Кбайт. Существуют два типа экстентов:
♦ однородные экстенты;
♦ смешанные экстенты.
Однородные экстенты содержат данные только одной таблицы или индекса,
тогда как смешанные экстенты могут содержать данные до восьми таблиц
или индексов. Система первоначально всегда выделяет страницы для сме-
шанных экстентов. После этого, если размер таблицы (индекса) превышает
восемь страниц, осуществляется переключение на однородные экстенты.
Свойства страниц данных
Все типы страниц данных имеют фиксированный размер (8 Кбайт), страницы
содержат следующие три части:
♦ заголовок страницы;
♦ пространство для данных;
♦ таблицу смещений строк.
Гпава 15. Системное окружение и сервер базы данных
423
Замечание______________________________________________________
Эта глава не содержит отдельного описания свойств индексных страниц, пото-
му что индексные страницы почти идентичны страницам данных.
Заголовок страницы
Каждая страница имеет 96-байтовый заголовок страницы, используемый для
хранения системной информации, такой как идентификатор страницы, иден-
тификатор объекта базы данных, которому принадлежит страница, а также
ссылки на предыдущую и последующую страницу в цепочке страниц. Как вы
уже, наверное, догадались, заголовок страницы находится в начале каждой
страницы. В табл. 15.] представлена информация, хранящаяся в заголовке
страницы.
Таблица 15.1. Информация, содержащаяся в заголовке страницы
Информация заголовка страницы Описание
pageld Номер файла базы данных плюс номер страницы
level. Для индексных страниц уровень страницы (уровень листьев является уровнем 0, первый промежуточный уровень является уровнем 1 и т. д.)
flagBits Дополнительная информация о странице
nextPage Номер файла базы данных плюс номер страницы для следующей страницы в цепочке (если таблица имеет кластеризованный индекс)
prevPage Номер файла базы данных плюс номер страницы для предыдущей страницы в цепочке (если таблица имеет кластеризованный индекс)
objld Идентификатор объекта базы данных, которому принадлежит страница
Isn Последовательный номер протокола (см. главу 13)
slotCnt Общее количество слотов (сегментов), используемых на этой странице
indexld Идентификатор индекса страницы (0, если страница является страни- цей данных)
freeData Смещение первого доступного свободного пространства на странице
pminlen Количество байтов в части фиксированной длины строки
freeCnt Количество свободных байтов на странице
reservedCnt Количество байтов, зарезервированных для всех транзакций
xactReserved Количество байтов, зарезервированных для самой последней запу- щенной транзакции
xactld Идентификатор самой последней запущенной транзакции
tornBits Один бит на сектор для определения незавершенной записи страницы
424
Часть III. SQL Server, системное администрирование
Зарезервированное пространство для данных
Часть страницы, зарезервированная для данных, имеет переменную длину,
которая зависит от количества и размера строк, хранящихся на этой странице.
Для каждой строки, хранимой на странице, есть запись в зарезервированном
для данных пространстве и запись в таблице смещения строк в конце страни-
цы. (Данные строки не могут размещаться на двух и более страницах за ис-
ключением значений данных varchar(max) и varbinary(max), которые хранят-
ся в собственных специфических страницах.)
Каждая новая строка сохраняется после уже сохраненных строк, пока стра-
ница не будет заполнена. Если на странице нет достаточного места для раз-
мещения новой строки той же таблицы, строка сохраняется на следующей
странице в цепочке страниц.
Для всех таблиц, которые имеют только столбцы фиксированной длины, одно
и то же количество строк хранится на каждой странице. Если же таблица
имеет хотя бы один столбец переменной длины (например, столбец varchar),
то количество строк на страницах может отличаться, и система помещает на
страницу столько строк, сколько эта страница может вместить.
Таблица смещений строк
Последняя часть страницы тесно связана с зарезервированным для данных
пространством, потому что каждая строка, хранящаяся на странице, имеет
соответствующую запись в таблице смещений строк (рис. 15.1). Таблица
Рис. 15.1. Структура страницы данных
Гпава 15. Системное окружение и сервер базы данных 425
смещений строк содержит двухбайтовые записи, состоящие из номера строки
и байта смещения адреса этой строки на странице. (Записи таблицы смеще-
ния строк имеют инвертированный порядок относительно порядка самих
строк на странице.) Предположим, что каждая строка таблицы имеет фикси-
рованную длину 36 байтов. Первая строка таблицы будет сохранена на стра-
нице со смещением 96 байтов (сразу после заголовка страницы). Соответст-
вующая запись в таблице смещения строк будет записана в последних двух
байтах страницы, указывая номер строки (в первом байте) и смещение строки
(во втором байте). Следующая строка будет сохраняться последовательно
в следующих 36 байтах этой страницы. Соответствующая запись в таблице
смещения строк будет располагаться в третьем и четвертом байтах от конца
страницы, указывая опять номер строки (1) и смещение строки (132).
Типы страниц данных
Страницы данных используются для хранения данных таблицы. Существуют
два типа страниц данных, каждый из которых используется для хранения
данных в различных форматах:
♦ страницы данных последовательных строк (in-row data pages);
♦ страницы данных переполнения строк (row-overflow data pages).
Замечание__________________________________________________
Обсуждение в предыдущем разделе касалось всех этих типов страниц данных.
Особые свойства страниц данных переполнения строк рассматриваются в этом
разделе.
Страницы данных последовательных строк
Ничего особенного нельзя сказать про страницы данных последовательных
строк: они являются удобными страницами, в которых хранятся данные и
индексная информация. Все данные, не относящиеся к LOB, всегда сохра-
няются в страницах последовательных строк. Значения типов данных
VARCHAR (MAX), NVARCHAR (МАХ), VARBINARY (МАХ) И XML Также МОГуТ ХрЭНИТЬСЯ В
последовательных страницах, если в системной процедуре sp tableoption
опция large value types out of row установлена в 0. В этом случае все такие
значения хранятся непосредственно в строке данных, не превышая ограниче-
ния 8000 байтов, и если значение умещается в записи. Если значение не мо-
жет поместиться в записи, то в строке сохраняется указатель, а само значение
размещается вне строки в области хранения LOB.
Страницы данных переполнения строк
Значения столбцов varchar(max), nvarchar(мах) и varbinary(мах) могут быть
сохранены вне текущей страницы базы данных. Как вы уже знаете, 8 Кбайт
Часть III. SQL Server: системное администрирование
является максимальным размером строки на странице данных, но вы можете
расширить это ограничение размера, если используете столбцы столь боль-
ших типов данных. В таком случае система сохраняет значения этих столб-
цов в дополнительных страницах, которые называются страницами перепол-
нения строк.
Хранение данных в страницах переполнения строк выполняется только при
соблюдении некоторых условий. Первичным фактором является размер стро-
ки: если строка требует более 8060 байтов, то значения некоторых столбцов
будут сохраняться на страницах переполнения. (Значение одного столбца не
может размещаться и на текущей странице, и на странице переполнения
строк.)
Рассмотрим пример 15.1, демонстрирующий, как сохраняется содержимое
таблицы с большими размерами. В этом примере создается таблица, и в нее
добавляется строка.
I Пример 15.1
USE sample;
CREATE TABLE mytable
(coll VARCHAR(1000),
col2 VARCHAR(3000),
col3 VARCHAR(3000),
col4 VARCHAR(3000));
INSERT INTO mytable
SELECT REPLICATE('a', 1000), REPLICATE('b', 3000),
REPLICATE('c', 3000), REPLICATE('d', 3000);
Запрос в примере 15.2 использует некоторые представления просмотра ката-
логов для отображения информации, связанной с описанием типа страниц.
(Пример 15.2
USE sample;
SELECT rows, type_desc AS page_type, total_pages AS pages
FROM sys.partitions p JOIN sys.allocation_units a ON
p. partitioned = a. container_id
WHERE object_id = object_id('mytable');
Результат:
rows page_type pages
1 IN_ROW_DATA 2
1 ROWJ3VERFLOW_DATA 2
Глава 15. Системное окружение и сервер базы данных 427
В примере 15.2 выполняется соединение двух представлений просмотра ка-
талогов sys.partitions и sys.allocaticn_units для отображения информации,
связанной с таблицей mytabie и хранением ее строк. Представление
sys.partitions содержит одну строку для каждой части каждой таблицы или
индекса. (Неразделенные таблицы, например mytabie, имеют только одну
часть.)
Набор страниц одного конкретного типа данных страницы называется выде-
ленной единицей (allocation unit). Различные выделенные единицы можно
отобразить, используя столбец type_desc представления просмотра каталогов
sys.aiiocation_units. Как вы можете видеть из результата выполнения при-
мера 15.2, для одной строки таблицы mytabie системой выделяются (или ре-
зервируются) две обычные страницы плюс две страницы переполнения строк.
Замечание_______________________________________________________
Производительность системы может значительно снизиться, если вашим за-
просам требуется доступ к множеству страниц данных переполнения строк.
Параллельное выполнение задач
Database Engine может одновременно выполнять различные задачи базы дан-
ных. Следующие задачи могут выполняться параллельно:
♦ массовая загрузка данных;
♦ резервное копирование;
♦ выполнение запроса;
♦ индексы.
Database Engine позволяет одновременно загружать данные посредством ути-
литы Ьср. (Описание утилиты Ьср см. в следующем разделе.) Таблица, в кото-
рую загружаются данные, не должна иметь никаких индексов, а операция за-
грузки не должна быть зарегистрированной. Только приложения, исполь-
зующие ODBC или OLE DB API, могут выполнять параллельную загрузку
данных в одну таблицу.
Database Engine может выполнять резервное копирование баз данных или
транзакций на множество устройств (лента или диск), используя параллель-
ное "расслоенное" копирование. В этом случае страницы базы данных чита-
ются множеством потоков, по одному экстенту за раз.
Database Engine предоставляет возможность параллельного выполнения за-
просов для улучшения выполнения целого запроса. При этой возможности
независимые части оператора select могут выполняться с использованием
нескольких собственных потоков компьютера. Каждый запрос, запланиро-
15 Зак. 1141
428 Часть III. SQL Server: системное администрирование
ванный для параллельного выполнения, содержит оператор обмена в плане
выполнения этого запроса. (Оператор обмена является оператором в плане
выполнения запроса, который осуществляет управление процессом, распре-
деление данных и управление потоком). Для запроса такого вида система ге-
нерирует план параллельного выполнения запроса. Параллельные запросы
значительно увеличивают производительность операторов select, которые
обрабатывают очень большой объем данных.
На компьютерах, имеющих несколько процессоров, Database Engine автома-
тически использует много процессоров для выполнения индексных операций,
таких как создание и пересоздание индексов. Количество процессоров, ис-
пользуемых при выполнении одного оператора, связанного с индексом, опре-
деляется опцией конфигурации max degree of parallelism, а также текущей
нагрузкой. Если система базы данных определяет, что система перегружена,
то степень параллелизма снижается перед выполнением оператора.
Утилиты и команда DBCC
Утилиты являются компонентами, которые предоставляют различные воз-
можности, такие как достоверность данных, определение данных и функции
сохранения статистики. Все утилиты Database Engine имеют два основных
свойства:
♦ они вызываются при использовании команд операционной системы;
♦ каждая утилита имеет несколько необязательных параметров.
В этом разделе описываются утилиты Ьср и sqicmd.
Команды являются операторами Transact-SQL, которые оказывают влияние
на содержимое систем базы данных. В отличие от утилит, команды выпол-
няются при использовании SQL Server Management Studio. Из всех команд
в этой главе обсуждается только DBCC.
Утилита Ьср
Утилита Ьср (Bulk Copy Program, программа массового копирования) являет-
ся полезной утилитой, которая выполняет копирование данных базы данных
в файл данных (или из файла данных в базу данных). Поэтому Ьср часто ис-
пользуется для преобразования большого объема данных в базу данных
Database Engine из других реляционных СУБД при использовании текстового
файла (или наоборот).
Синтаксис утилиты Ьср:
Ьср [[db_name.]schema_name}table_name {IN | OUT | QUERYOUT I FORMAT}
file_name [{-option parameter} ...]
Гпава 15. Системное окружение и сервер базы данных 429
Здесь db_name— имя базы данных, которой принадлежит таблица (tabie_
name). Ключевые слова in и out указывают направление преобразования дан-
ных. Опция IN копирует данные ИЗ файла file_jiame В таблицу table_name,
а опция OUT копирует строки из таблицы table name в файл file name. Опция
format создает формат файла, основанный на указанных далее опциях. Если
используется данная опция, то и опция -f также должна быть использована.
Замечание_______________________________________________________
Опция in добавляет содержимое файла в содержимое таблицы базы данных,
тогда как опция оит перезаписывает содержимое файла.
Данные могут быть скопированы как специфический текст для SQL Server
или как текст ASCII. Копирование данных в виде текста, специфичного для
SQL Server, означает работу в режиме сервера базы данных, тогда как копи-
рование данных в качестве текста ASCII означает работу в режиме символов.
Параметр -п означает режим сервера базы данных, а параметр -с указывает
символьный режим. Режим сервера базы данных ("родной" режим) использу-
ется для экспорта и импорта данных из одной системы, управляемой Database
Engine, в другую систему, также управляемую Database Engine, а символьный
режим обычно применяется для преобразования данных между экземпляром
Database Engine и другими системами баз данных.
В примере 15.3 показано использование утилиты ьср. (Вы должны выполнить
этот оператор из командной строки.)
I Пример 15.3
Ьср AdventureWorks.Person.Address out "address.txt" -T -с
Команда Ьср в примере 15.3 экспортирует данные из таблицы address базы
данных AdventureWorks в выходной файл address.txt. (В точности 19 614 строк
преобразуется в этот файл.) Опция -т указывает, что используется довери-
тельное соединение. (Доверительное соединение означает, что система ис-
пользует общую безопасность вместо информации о пользователе и его
пароле.) Опция -с задает символьный режим, следовательно, здесь данные
сохраняются в файле ASCII.
Замечание__________________________________________________________
Помните, что оператор bulk insert является альтернативой Ьср. Он поддер-
живает все опции Ьср (хотя имеет несколько отличный синтаксис) и предостав-
ляет намного большую производительность. Оператор bulk insert был опи-
сан в главе 7.
430
Часть III. SQL Server: системное администрирование
Для импорта данных из файла в таблицу базы данных вы должны иметь пол-
номочия insert и select к этой таблице. Для экспорта данных из таблицы
в файл вы должны иметь только полномочия select к этой таблице.
Утилита sqlcmd
Утилита sqlcmd позволяет вам вводить операторы Transact-SQL, вызывать
системные процедуры и файлы скриптов из подсказки командной строки.
Общий синтаксис этой утилиты:
sqlcmd {option {parameter]} ...
Здесь option является основной опцией утилиты, a parameter задает значение
указанной опции. Утилита sqlcmd имеет множество опций, наиболее важные
из которых описаны в табл. 15.2.
Таблица 15.2. Наиболее важнее опции утилиты sqlcmd
Опция Описание
—S server_name[\instance_name] Задает имя сервера базы данных и используемый его экземпляр. Если эта опция отсутствует, то уста- новка соединения с сервером базы данных выпол- няется с помощью переменной окружения SQLServer. Если эта переменная окружения не оп- ределена, то соединение устанавливается с ло- кальной машиной
-U login_id Задает учетную запись SQL Server Login. Если эта опция опущена, то используется значение перемен- ной окружения SQLCMDUSER
-Р password Задает пароль, соответствующий имени пользова- теля. Если не заданы ни опция -и, ни опция -р, то sqlcmd пытается соединиться в режиме аутентифи- кации Windows. Аутентификация основывается на учетной записи того пользователя, который выпол- няет sqlcmd
-с command_end Задает завершающий символ пакета. Значением по умолчанию является GO. Эта опция может быть ис- пользована для установления терминатора команды в символ точка с запятой (;), который, как правило, является терминатором по умолчанию для боль- шинства систем управления данными
-i input_file Задает имя файла, который содержит пакет или имя хранимой процедуры. Этот файл должен содержать (как минимум одну) команду терминатора. Знак < может быть использован вместо -1
Глава 15. Системное окружение и сервер базы данных
431
Таблица 15.2 (окончание)
Опция Описание
-о output_file Задает имя файла, который получает результаты выполнения этой утилиты. Знак > может быть ис- пользован вместо -о
-E Использует доверительное соединение (см. гла- ву 12) вместо требования задания пароля
-e Выводит каждый оператор, который появляется во вводе
-L Отображает список всех экземпляров базы данных, найденных в сети
-t seconds Задает количество секунд. Этот интервал времени определяет, как долго должна ждать утилита, пока не примет решения, что соединение с сервером не состоялось
-? Задает стандартный запрос всех опций утилиты sqicmd
-d dbname Задает базу данных, которая будет текущей при старте sqicmd
В примере 15.4 показано использование утилиты sqicmd.
| Пример 15.4
sqicmd -S NTB11901 -i C:\ms0510.sql -о C:\ms0510.rpt
В примере 15.4 пользователь системы базы данных с именем 1ЧТВП901 вы-
полняет пакет, хранящийся в файле ms05l0.sql, и сохраняет результат в вы-
ходном файле ms051O.rpt. В зависимости от режима аутентификации система
выдает подсказку для имени пользователя и пароля (аутентификация SQL
Server) или просто выполняет этот оператор (аутентификация Windows).
Утилита sqicmd поддерживает несколько специфических команд, которые
могут быть использованы в утилите в дополнение к операторам Transact-SQL.
В табл. 15.3 описываются наиболее важные команды утилиты sqicmd.
В примере 15.5 показано использование команды exit в утилите sqicmd.
Пример 15.5
1>USE sample;
2>SELECT * FROM project
3>:EXIT(SELECT @@rowcount)
432
Часть III. SQL Server: системное администрирование
В этом примере отображаются все строки таблицы project и число 3, если
таблица project содержит три строки.
Таблица 15.3. Наиболее важные команды утилиты sqlcmd
Команда Описание
:ED Запускает текстовый редактор. Этот редактор может быть ис- пользован для редактирования текущего пакета или последнего выполненного пакета. Редактор определяется в переменной окружения SQLCMDEDITOR. Например, если вы хотите устано- вить в качестве текстового редактора Microsoft WordPad, то должны выполнить SET SQLCMDEDITOR=wordpad
:! ! Выполняет команды операционной системы. Например, :! ! dir дает список всех файлов и каталогов в текущем каталоге
:r filename Выполняет синтаксический анализ дополнительных операторов Transact-SQL и команд sqlcmd из файла filename и помещает их в кэш операторов. Допустимо выполнение множества команд : г. Следовательно, вы можете использовать эту команду для связывания скриптов с утилитой sqlcmd
:List Выводит содержимое кэша операторов
:QUIT Завершает сессию, запущенную sqlcmd
:EXIT [(statement)] Дает возможность использовать результат выполнения опера- тора SELECT в качестве возвращаемого значения утилиты sqlcmd
Команда DBCC
Язык Transact-SQL поддерживает оператор dbcc (Database Console Commands,
консольные команды базы данных), который работает как команда Database
Engine. В зависимости от опций, используемых с dbcc, команды dbcc могут
быть разделены на такие группы, как:
♦ поддержка;
♦ информация;
♦ проверка;
♦ смешанные.
Замечание
В этом разделе описываются только команды проверки. Другие команды будут
рассматриваться в соответствии с их применением. Например, т. к. команда
dbcc show_statistics связана с оптимизацией запроса, то она будет рассмат-
риваться в главе 20.
Глава 15. Системное окружение и сервер базы данных 433
Команды проверки
Команды проверки осуществляют проверку согласованности базы данных.
Следующие команды принадлежат этой группе:
♦ DBCC CHECKALLOC;
♦ DBCC checktable;
♦ DBCC CHECKCATALOG;
♦ DBCC CHECKDB.
Команда dbcc checkalloc проверяет, для каждого ли экстента, указанного в
системе, выделена память, а также существуют ли выделенные экстенты, ко-
торые не отмечены в системе. Таким образом эта команда выполняет провер-
ку экстентов.
Команда dbcc checktable проверяет целостность всех страниц и структур, ко-
торые составляют таблицу или индексируемое представление. Все выпол-
няемые проверки осуществляются физически и логически. Физические про-
верки контролируют целостность физической структуры страницы. Логиче-
ские проверки контролируют, помимо всего прочего, имеет ли каждая строка
таблицы базы данных соответствующую строку в каждом некластеризован-
ном индексе и наоборот, а также имеют ли индексы правильный порядок сор-
тировки. Используя опцию PHisiCAL ONLY, вы можете проверять только физи-
ческую структуру страниц. Эта опция приводит к тому, что время выполне-
ния команды сильно сокращается, поэтому рекомендуется часто выполнять
такую команду в промышленных работающих системах.
Команда dbcc checkcatalog проверяет согласованность каталога указанной
базы данных. Она выполняет множество перекрестных проверок между таб-
лицами и системным каталогом.
Если вы хотите проверить выделение памяти, а также структурную и логиче-
скую целостность всех объектов в заданной базе данных, используйте коман-
ду dbcc checkdb. (На самом деле эта команда выполняет все описанные выше
проверки в том же порядке.)
Замечание
Все команды dbcc, которые проверяют систему, используют технологию мгно-
венного снимка— snapshot (см. главу 13), для обеспечения согласованности
транзакций. Иными словами, операции проверки не влияют на другие выпол-
няющиеся в тот же момент времени операции базы данных, потому что для
проверок они используют текущие версии строк.
434 Часть III. SQL Server: системное администрирование
Резюме
В этой главе были описаны некоторые возможности системного окружения
Database Engine:
♦ системные базы данных;
♦ хранение данных на диске;
♦ утилиты и команды.
Системные базы данных содержат системную информацию и информацию
высокого уровня обо всей системе базы данных. Наиболее важной из них
является база данных master.
Основной единицей дисковой памяти является страница. Размер страниц —
8 Кбайт. Наиболее важным типом страниц являются страницы данных. (Фор-
ма индексной страницы почти идентична структуре страницы данных.)
Database Engine поддерживает множество утилит и команд. В этой главе бы-
ли рассмотрены две утилиты (sqicmd и Ьср) и команды проверки dbcc.
В следующей главе рассматриваются вопросы управления экземплярами баз
данных и поддержки баз данных.
Упражнения
j Упражнение 15.1
Когда вы создаете временную базу данных, где будут храниться ее данные?
I Упражнение 15.2
Измените свойства базы данных model так, чтобы ее размер был 4 Мбайт.
ГЛАВА 16
Управление
экземплярами сервера
и поддержка баз данных
В этой главе описываются средства для управления экземплярами Database
Engine (Declarative Management Framework) и мастер для создания планов
поддержки базы данных (Maintenance Plan Wizard). Declarative Management
Framework (DMF) является новым средством в SQL Server 2008, которое ис-
пользуется для управления всеми экземплярами его баз данных. Maintenance
Plan Wizard обеспечивает некоторое количество задач, которые, помимо все-
го другого, проверяют, правильно ли выполняется ваша база данных и нахо-
дятся ли ваши таблицы и индексы в согласованном состоянии.
Declarative Management Framework
Новое средство Declarative Management Framework (DMF) является системой,
основанной на политике управления одним или более экземплярами сервера,
базами данных или другими объектами базы данных. Прежде чем вы присту-
пите к изучению работы DMF, вам нужно хотя бы какое-то понимание неко-
торых ключевых терминов и концепций DMF.
Ключевые термины
DMF управляет сущностями, называемыми управляемыми объектами, кото-
рые могут быть экземплярами сервера базы данных, базами данных, табли-
цами или индексами. Все управляемые объекты, принадлежащие экземпляру,
представляют иерархию. Набор объектов— это множество управляемых
объектов, которые являются результатом применения фильтров к иерархии
объектов. Например, если вашим управляемым объектом является таблица,
набором объектов будут все индексы, которые принадлежат этой таблице.
436
Часть III. SQL Server: системное администрирование
Основным аспектом является множество логических свойств, которые моде-
лируют поведение некоторых характеристик управляемых объектов. Количе-
ства и характеристики свойств создаются в аспектах и могут быть добавлены
или удалены только создателем аспекта. Некоторые аспекты могут быть при-
менимы только для отдельных типов управляемых объектов.
Условие является логическим выражением, которое задает множество допус-
тимых для управления состояний объектов в соответствии с аспектом. От-
дельные условия могут быть применимы только к некоторым типам управ-
ляемых объектов.
Политика является условием DMF вместе с соответствующим поведением.
Политика может содержать только одно условие. Политики могут быть сде-
ланы доступными или недоступными. Они управляются пользователями, ис-
пользующими категоризации. Любая политика принадлежит одной и только
одной категории политики. Владельцы базы данных могут подписывать базу
данных набору категорий политик. Только политики подписанных категорий
базы данных могут управлять этой базой данных. Все базы данных неявно
подписываются на категорию политики по умолчанию.
Использование Declarative Management Framework
В данном разделе демонстрируется использование DMF для создания поли-
тики. В этом примере будет создана политика, чьим условием является то,
что степень заполнения индексов будет 60% для всех баз данных конкретного
экземпляра. Описание опции fillfactor см. в главе 10.
Для создания политики запустите на выполнение SQL Server Management
Studio, разверните сервер, а в нем разверните последовательно узлы
Management и Policy Management. Первым шагом является создание усло-
вия. Щелкните правой кнопкой мыши по Conditions и выберите пункт New
Condition. В диалоговом окне Create New Condition (рис. 16.1) в поле Name
наберите имя условия Set Fillfactor и в раскрывающемся списке Facet выбе-
рите Server Configuration. (Установка степени заполнения для всех баз дан-
ных экземпляра осуществляется в границах сервера и поэтому принадлежит
конфигурации сервера.) В столбце Field таблицы Expression из раскрываю-
щегося списка выберите @FiIlFactor, а в качестве оператора (столбец
Operator) выберите =. Наконец, введите число 60 в поле Value. Щелчком
мышью по кнопке ОК будет создано условие.
Следующим шагом является создание политики на базе этого условия. В узле
Policy Management щелкните правой кнопкой мыши по пункту Policies и вы-
берите команду New Policy. В поле Name диалогового окна Create New
Policy (рис. 16.2) наберите имя новой политики — Policy Fillfactor 60. В рас-
крывающемся списке Check condition выберите созданное вами условие
Глава 16. Управление экземплярами сервера и поддержка баз данных
Fillfactor. (Это условие может быть найдено в узле Server Configurations.)
Из раскрывающегося списка Execution Mode выберите On Demand (по за-
просу) и щелкните по кнопке ОК.
Рис. 16.1. Диалоговое окно Create New Condition
Рис. 16.2. Диалоговое окно Create New Policy
438
Часть III. SQL Server: системное администрирование
Замечание_____________________________________________________
Политики администраторов могут выполняться политиками по запросу. Можно
также установить возможность автоматического выполнения политики при ис-
пользовании одного из существующих режимов выполнения.
Для проверки политики раскройте узел Policies, щелкните правой кнопкой
мыши по этой политике и выберите пункт Test Policy. Диалоговое окно Run
Now (рис. 16.3) проинформирует вас, где нарушается эта политика в сущест-
вующих базах данных.
Рис. 16.3. Диалоговое окно Run Now
Описанный только что процесс тем же самым образом может быть применен
к другим политикам, относящимся к серверам, базам данных и объектам баз
данных.
Maintenance Plan Wizard
Мастер Maintenance Plan Wizard предоставляет вам набор базовых задач, не-
обходимых для поддержания баз данных. Он позволяет проверить, что ваша
база данных работает правильно, для нее регулярно выполняется резервное
копирование и база данных свободна от несогласованностей.
Замечание_______________________________________________
Для создания плана выполнения поддержки вы должны быть членом серверной
фиксированной роли sysadmin.
Глава 16. Управление экземплярами сервера и поддержка баз данных 439
Для запуска на выполнение Maintenance Plan Wizard разверните сервер, раз-
верните узел Management, щелкните правой кнопкой мыши по узлу
Maintenance Plans и выберите пункт Maintenance Plan Wizard. На старто-
вой странице Maintenance Plan Wizard будет указано, что вы можете выпол-
нять следующие задачи администрирования:
♦ проверка целостности базы данных;
♦ выполнение поддержки индекса;
♦ обновление статистических данных базы данных;
♦ выполнение резервного копирования базы данных.
.Замечание________________________________________________________
Недостатком этого мастера является то, что он не реализует все те задачи, ко-
торые доступны для использования в плане поддержки.
Когда на стартовой странице вы щелкаете по кнопке Next, следующая стра-
ница мастера, Select Plan Properties, предоставляет возможность выбрать
свойства для вашего плана (рис. 16.4), ввести имя плана и при желании его
описание. Здесь вы также можете выбрать между раздельным получением
отчетов по каждой задаче и созданием единого отчета для всего плана. Этот
пример будет проверять целостность базы данных sample, так что назовите
план Integrity-Sample и отметьте переключатель Single schedule.... Поле
Рис. 16.4. Страница мастера Select Plan Properties
440
Часть III. SQL Server, системное администрирование
Schedule дает вам возможность создавать расписание для отчета о выполне-
нии вашего плана или формировать отчет по запросу. В главе 18 подробно
описывается создание такого расписания. (Для целей этого примера оставьте
поле Schedule установленным в значение No schedule (On Demand).)
После того как вы щелкнете по кнопке Next, отметьте флажок Check
database integrity на странице мастера Select Plan Properties. Теперь вы мо-
жете задать порядок, в котором должны выполняться задачи. В данном слу-
чае не существует никакого порядка, потому что есть только одна выполняе-
мая задача.
Следующие две страницы мастера дают вам возможность задать базу (базы)
данных, для которой должна выполняться задача, и выбрать опции отчета
(рис. 16.5). Страница Select Report Options позволяет записывать отчет в
указанный файл и/или отправлять по электронной почте.
Рис. 16.5. Страница мастера Select Report Options
Замечание___________________________________________________
Сообщение электронной почты может быть отправлено только существующему
оператору. В главе 18 подробно описывается, как вы можете создавать опера-
тор.
Последняя страница мастера предоставляет итоговые данные по всем выпол-
ненным шагам. Щелкните по кнопке Next, мастер выполнит эту задачу и соз-
даст соответствующий отчет.
Глава 16. Управление экземплярами сервера и поддержка баз данных 441
Для просмотра истории существующего расписания поддержки раскройте
узлы Management | Maintenance Plans, щелкните правой кнопкой мыши по
имени расписания и выберите пункт View History. Будет запущен Log File
Viewer с историей выбранного расписания.
Резюме
В этой короткой главе было описано, как вы можете использовать Declarative
Management Framework и Maintenance Plan Wizard. Declarative Management
Framework является основанной на политике системой управления одним или
более экземплярами сервера, баз данных или другими объектами базы дан-
ных. Это очень мощный инструмент, потому что он может управлять чем
угодно: начиная с целой системы базы данных и заканчивая отдельными объ-
ектами, такими как таблицы или индексы. С другой стороны, этот мастер
может быть использован только для одной задачи — для создания планов
поддержки базы данных.
В следующей главе рассматривается, как вы можете предотвратить потерю
данных, используя резервное копирование и восстановление.
Упражнения
Упражнение 16.1
Назовите все ключевые термины Declarative Management Framework, объяс-
ните их роли, а также как они связаны друг с другом.
j Упражнение 16.2
Перечислите все группы, для которых вы можете задать условие.
, Упражнение 16.3
Сгенерируйте политику, которая запрещает использование Common Language
Runtime (CLR).
i Упражнение 16.4
Назовите план поддержки базы данных, который не может быть сгенериро-
ван при использовании мастера Maintenance Plan Wizard.
ГЛАВА 17
Копирование и восстановление
В этой главе рассматриваются две из наиболее важных задач, связанные
с системой администрирования: резервное копирование и восстановление.
Резервное копирование (backup) означает процесс создания копии базы дан-
ных (баз данных) и/или протоколов транзакций для разделения устройств,
которые в дальнейшем при необходимости могут быть использованы для
восстановления данных. Восстановление (recovery)— это процесс использо-
вания устройства резервной копии для замены неподтвержденных, несогла-
сованных или потерянных данных.
Выполнение резервного копирования— это мера предосторожности, кото-
рую вы должны осуществлять для предотвращения потери данных. Причины
потери данных можно разделить наследующие группы:
♦ программные ошибки;
♦ ошибки администратора (человеческий фактор);
♦ выход из строя компьютера (сбой системы);
♦ отказ дискового накопителя;
♦ катастрофы (пожар, наводнение, землетрясение) или кража.
В процессе выполнения программы могут возникать условия, при которых
программа аварийно завершается. Подобные программные ошибки связаны
только с приложениями баз данных и обычно не оказывают влияния на всю
систему базы данных. Поскольку такие ошибки основываются на дефектах
программной логики, система базы данных не может выполнить восстанов-
ления в подобных ситуациях. Поэтому восстановление должен выполнить
сам программист, который обязан выполнить обработку таких исключений с
использованием операторов commit и rollback (см. главу 13).
Глава 17. Копирование и восстановление
443
Другим источником потери данных являются человеческие ошибки. Пользо-
ватель с большими полномочиями (DBA, например) может неумышленно
потерять или разрушить данные (люди могут удалить таблицы, некорректно
изменять или удалять данные и т. д.). Разумеется, в идеале этого никогда не
должно происходить, и вы можете создать такой режим работы, который сде-
лает маловероятным, что производственные данные будут разрушены таким
образом, однако вы должны помнить, что люди совершают ошибки, и данные
могут быть разрушены. Лучшее, что вы можете сделать, — это постараться
исключить такую ситуацию и быть готовыми к восстановлению данных, если
подобное произойдет.
Выход из строя компьютера может произойти в результате различных оши-
бок в оборудовании и программном обеспечении. Сбой оборудования являет-
ся примером отказа системы. В этом случае содержимое основной памяти
компьютера может быть потеряно. Отказ дискового накопителя появляется,
когда ломается головка чтения/записи дискового накопителя или когда сис-
тема ввода/вывода обнаруживает разрушение дисковых секторов при выпол-
нении операций ввода/вывода.
В случае катастрофы или кражи система должна иметь достаточно доступной
информации для восстановления данных. Это можно нормально выполнить,
если устройство, содержащее необходимую для восстановления данных ин-
формацию, будет храниться отдельно от другого оборудования и поэтому не
будет разрушено или потеряно в результате катастроф или краж.
Для большинства только что описанных ошибок резервное копирование,
описываемое далее, может быть решением по восстановлению данных.
Методы резервного копирования
Резервное копирование базы данных является процессом выгрузки данных
(из базы данных, протокола транзакций или из файла) на устройства резерв-
ной копии, которые создаются и поддерживаются системой. Устройство ре-
зервной копии может быть дисковым файлом или магнитной лентой.
Database Engine обеспечивает статические и динамические резервные копии.
Статическая резервная копия означает, что в процессе копирования только
одна активная сессия, поддерживаемая системой, является той сессией, кото-
рая создает резервную копию. Иными словами, недопустимы пользователь-
ские процессы во время выполнения копирования. Динамическое резервное
копирование означает, что копирование базы данных может выполняться без
останова сервера базы данных, удаления пользователей или даже закрытия
файлов. (Пользователи даже не будут знать, что выполняется процесс резерв-
ного копирования.)
444 Часть III. SQL Server: системное администрирование
Database Engine предоставляет четыре различных метода резервного копиро-
вания:
♦ полное копирование базы данных;
♦ дифференцированное резервное копирование;
♦ резервное копирование протокола транзакций;
♦ резервное копирование файла или файловой группы.
Полное копирование базы данных
Полное копирование базы данных захватывает то состояние базы данных,
которое она имеет на момент начала копирования. В процессе полного копи-
рования базы данных система копирует данные, а также схему всех таблиц
базы данных и соответствующие файловые структуры. Если полное копиро-
вание базы данных выполняется динамически, то система базы данных запи-
сывает любые действия, которые имеют место в процессе выполнения ре-
зервного копирования. Поэтому даже все неподтвержденные транзакции в
протоколе транзакций будут записаны на устройство резервной копии.
Дифференцированное резервное копирование
Дифференцированное резервное копирование создает копию только частей
базы данных, которые изменялись с момента последнего полного копирова-
ния базы данных. (Как и в случае полного копирования базы данных любые
действия, имеющие место в процессе дифференцированного резервного ко-
пирования, также копируются.) Преимуществом дифференцированного ре-
зервного копирования является скорость. Этот тип резервного копирования
минимизирует время, требуемое для копирования, потому что количество
копируемых данных значительно меньше, чем в случае полного резервного
копирования. Помните, что полное копирование базы данных включает ко-
пии всех страниц базы данных.
Резервное копирование протокола транзакций
Резервное копирование протокола транзакций учитывает только изменения,
записанные в протокол. Поэтому такая форма резервного копирования не
основывается на физических частях (страницах) базы данных, а только на
логических операциях, т. е. на изменениях, выполненных операторами DML:
insert, update и delete. Опять же, поскольку объем данных достаточно мал,
этот процесс может быть выполнен значительно быстрее, чем полное или
дифференцированное резервное копирование.
Глава 17. Копирование и восстановление
Замечание______________________________________________________
Нет смысла выполнять копирование протокола транзакций без полного копиро-
вания базы данных, выполненного хотя бы однажды.
Существуют две основные причины, по которым следует выполнять копиро-
вание протокола транзакций: во-первых, это сохранение данных, которые
были изменены с момента последнего копирования протокола транзакций
или базы данных на защищенное устройство; во-вторых (что является более
важным), это правильное закрытие протокола транзакций перед началом но-
вой порции действий с этим протоколом. (Активная часть протокола тран-
закций содержит все неподтвержденные транзакции.)
Используя результаты полного резервного копирования базы данных и на-
дежную цепочку всех закрытых протоколов транзакций, можно распростра-
нять копию базы данных на другие компьютеры. Эта копия базы данных за-
тем может быть использована для замещения оригинальной базы данных в
случае сбоев. Такой же сценарий может быть применен и при использовании
полной копии базы данных и последней копии дифференциального копиро-
вания.
Database Engine не дает вам возможности сохранять протокол транзакций
в том же файле, в котором сохраняется сама база данных. Одной из причин
этого является то, что при разрушении этого единственного файла использо-
вание протокола транзакций для восстановления всех изменений с момента
последнего копирования не будет возможным.
Использование протокола транзакций для записи изменений в базе данных
является общим приемом почти для всех существующих реляционных СУБД.
Несмотря на это, могут быть ситуации, когда становится полезным отключе-
ние такой возможности. Например, выполнение тяжелой загрузки данных в
базу данных может занять несколько часов. Такая программа будет выпол-
няться много быстрее, если отключить протоколирование. С другой стороны,
отключение процесса создания протокола может быть опасным, т. к. это раз-
рушает существующие цепочки в протоколе транзакций. Чтобы обеспечить
надежность базы данных, строго рекомендуется выполнить полное резервное
копирование базы данных после успешного завершения такой загрузки дан-
ных.
Одна из наиболее общих ошибок системы возникает, когда переполняется
протокол транзакций. Имейте в виду, что подобная проблема может привести
к полному останову системы. Если память, используемая для протокола тран-
закций, заполняется на 100%, то система должна остановить все выполняю-
щиеся транзакции, пока память для протокола транзакции не будет освобож-
дена. Эта проблема может быть устранена только при частом выполнении
резервного копирования протокола транзакций: каждый раз вы "закрываете"
порцию существующего протокола транзакции и сохраняете протокол на
446
Часть III. SQL Server: системное администрирование
другом внешнем устройстве, эта порция протокола становится повторно ис-
пользуемой, следовательно, система восстанавливает дисковое пространство.
Замечание___________________________________________________
Дифференцированное резервное копирование и копирование протокола тран-
закций минимизируют время, требуемое для резервного копирования базы
данных. Однако между ними существует значительное различие: копирование
протокола транзакций содержит все изменения строки, которые выполнялись
несколько раз с момента последнего копирования, в то время как дифференци-
рованное резервное копирование содержит только последнюю выполненную
модификацию такой строки.
Некоторые различия между копированием протокола и дифференцирован-
ным копированием не имеют особого значения. Преимуществом дифферен-
цированного копирования является то, что вы экономите время в процессе
восстановления, потому что для полного восстановления базы данных вам
нужна полная копия базы данных и только лишь последняя дифференциро-
ванная копия. Если вы используете копию протокола в таком сценарии, вы
должны использовать полную копию базы данных и все существующие ко-
пии протоколов транзакций для приведения базы данных в согласованное
состояние. Недостатком дифференцированного копирования является то, что
вы не можете использовать такую копию для восстановления базы данных на
конкретный момент времени, потому что не существует истории промежу-
точных изменений базы данных.
Резервное копирование файла
или файловой группы
Резервное копирование файла (или файловой группы) дает вам возможность
копировать указанные файлы базы данных (или файловые группы) вместо
копирования всей базы данных. В этом случае Database Engine копирует
только заданные вами файлы. Отдельные файлы (или файловые группы) мо-
гут быть восстановлены из копии базы данных, позволяя выполнить восста-
новление после сбоя, который повлиял лишь на небольшое подмножество
файлов базы данных. Для восстановления отдельных файлов или файловых
групп вы можете использовать или копию базы данных, или копию файловой
группы. Это означает, что вы можете использовать копии базы данных и про-
токола транзакций в качестве вашей процедуры резервного копирования и в
то же время иметь возможность восстанавливать отдельные файлы (и файло-
вые группы) из копий базы данных.
Замечание___________________________________________________
Копирование файла базы данных рекомендуется выполнять только когда база
данных, которая должна быть скопирована, является очень большой, и нет дос-
таточно времени для полного копирования базы данных.
Глава 17. Копирование и восстановление
447
Выполнение резервного копирования
Вы можете выполнить резервное копирование, используя следующие средства:
♦ операторы Transact-SQL;
♦ SQL Server Management Studio.
Резервное копирование
с помощью операторов Transact-SQL
Все типы операций резервного копирования могут быть выполнены при ис-
пользовании двух операторов Transact-SQL:
♦ backup database;
♦ BACKUP LOG.
Прежде чем я начну описывать эти два оператора Transact-SQL, я расскажу
про существующие типы устройств для резервного копирования.
Типы устройств для резервного копирования
Database Engine позволяет вам копировать базы данных, протоколы транзак-
ций и файлы на такие устройства резервного копирования, как:
♦ диск;
♦ магнитная лента.
Дисковые файлы чаще всего используются для хранения резервных копий.
Дисковое устройство копии может размещаться на локальном жестком диске
на сервере или на удаленном диске на общем сетевом ресурсе. Database
Engine позволяет добавлять новые копии в файл, который уже содержит ко-
пии той же самой или другой базы данных. При добавлении нового набора
копий на существующий носитель предыдущее содержимое носителя остает-
ся нетронутым, а новая копия записывается после последней копии на этом
носителе. (Набор копий включает все сохраненные данные объектов, которые
вы выбираете для копирования.) По умолчанию Database Engine всегда до-
бавляет новые копии на дисковые файлы.
Внимание!___________________________________________________
Не выполняйте резервное копирование файлов на тот же физический диск, на
котором хранится база данных или протокол транзакций! Если диск с базой
данных будет разрушен, то резервная копия, которая хранится на том же самом
диске, также будет неработоспособной.
Магнитная лента в качестве устройства для хранения резервной копии обыч-
но используется таким же образом, что и дисковое устройство. Однако когда
448
Часть III. SQL Server: системное администрирование
вы выполняете резервное копирование на ленту, это ленточное устройство
должно быть локально подсоединено к системе. Преимуществом ленточных
устройств по сравнению с дисковыми устройствами является простота их ад-
министрирования и операций над ними.
Оператор BACKUP DATABASE
Оператор backup database используется для полного копирования базы дан-
ных или дифференцированного резервного копирования. Этот оператор име-
ет следующий синтаксис:
BACKUP DATABASE {dbnairie | @variable}
TO device list
[MIRROR TO device_list2]
[WITH | optionlist]
Здесь db_name является именем базы данных, для которой должно быть вы-
полнено резервное копирование. Имя базы данных также может быть задано
переменной ^variable. Параметр device_list задает одно или более имен
устройств, где будет сохраняться копия базы данных. Параметр device_iist
может быть списком имен дисковых файлов или магнитных лент. Синтаксис
для этих устройств таков:
( logical_device_name | @logical_device_name_var }
[ { DISK | ТАРЕ } = { 'physical_device_name'
I @physical_device_name_var }
Здесь имя устройства может быть либо логическим именем (или перемен-
ной), либо физическим именем, начинающимся с ключевых слов disk или
ТАРЕ.
Опция mirror то указывает, что сопровождающий набор устройств является
отображением зеркального набора устройств. Такие устройства копии долж-
ны быть идентичными по типу и по количеству устройствам, заданным в
предложении то. В отзеркалированном наборе устройств все устройства ре-
зервной копии должны иметь одни и те же свойства. (См. также описание
зеркалируемого устройства в разд. "Зеркальное отображение базы данных"
далее в этой главе.)
Параметр option list содержит несколько опций, которые могут быть зада-
ны для различных типов резервных копий. Наиболее важными опциями яв-
ляются следующие:
♦ differential;
♦ noskip/skip;
♦ noinit/init;
Глава 17. Копирование и восстановление
449
♦ noformat/format;
♦ unload/nounload;
♦ MEDIANAME, MEDIADESCRIPTION И MEDIAPASSWORD;
♦ blocksize;
♦ COMPRESSION.
Первая опция, differential, задает дифференцированное резервное копиро-
вание. Все другие предложения в этом списке относятся к полному копиро-
ванию базы данных.
Опция skip отменяет проверку завершения и имени набора копии, которая
обычно выполняется в backup database для предотвращения перезаписи на-
боров резервных копий. Опция noskip, которая является опцией по умолча-
нию, указывает оператору backup, что должна быть выполнена проверка дат
завершения и имен всех наборов резервных копий до их перезаписи.
Опция init используется для перезаписи любых существующих данных на
устройстве резервной копии. Эта опция не перезаписывает заголовок устрой-
ства, если он существует. Если существует резервная копия, которая еще не
закончена, то операция копирования отменяется. В этом случае используйте
комбинацию опций skip и init для перезаписи устройства резервной копии.
Опция noinit, которая задается по умолчанию, добавляет резервную копию к
существующим копиям на устройстве.
Опция format служит для записи заголовков для всех файлов (или ленточных
томов), которые используются для резервного копирования. По этой причине
применяйте эту опцию для инициализации устройства копирования. Когда вы
используете опцию format для выполнения копирования на устройство маг-
нитной ленты, то предполагается присутствие опций init и skip. Аналогично
предполагается опция init, если для файла устройства задана опция format.
Опция noformat, являющаяся опцией по умолчанию, указывает, что операция
копирования обрабатывает существующий заголовок устройства и набор ко-
пий на томах устройства.
ОПЦИИ UNLOAD И NOUNLOAD ВЫПОЛНЯЮТСЯ, ТОЛЬКО еСЛИ УСТРОЙСТВОМ КОПИроВЭНИЯ
является магнитная лента. Опция unload, которая является опцией по умолча-
нию, указывает, что магнитная лента автоматически перематывается и дан-
ные выгружаются с ленточного устройства после завершения резервного ко-
пирования. Используйте опцию nounload, если система базы данных не долж-
на перематывать (и разгружать) магнитную ленту автоматически.
MEDIANAME, MEDIADESCRIPTION И MEDIAPASSWORD ЗЭДЭЮТ Описание, ИМЯ И ПарОЛЬ
для набора внешних устройств соответственно. Опция blocksize задает физи-
ческий размер блока в байтах. Поддерживаемыми размерами являются 512,
450 Часть III. SQL Server: системное администрирование
1024, 2048, 4096, 8192, 16384, 32 768 и 65 536 (64 Кбайт) байтов. Значением
по умолчанию для ленточных устройств является 65 536 байтов и 512 байтов
для всех других устройств.
SQL Server 2008 поддерживает сжатый вариант резервной копии. Для задания
копирования в сжатом формате используйте опцию compression в операторе
backup database. В примере 17.1 выполняется резервное копирование базы
данных sample и сжатие файла резервного копирования.
I Пример 17.1
USE master;
BACKUP DATABASE sample
TO DISK = 'C:\sample.bak'
WITH INIT, COMPRESSION;
Замечание_________________________________________________________
Если вы получаете сообщение об ошибке "Access Denied" ("Доступ запрещен")
для каталога на устройстве С:, измените размещение хранения для файла
sample.bak на другой каталог (например, tmp).
Если вы хотите узнать, сжимается ли конкретный файл копии, используйте
вывод оператора restore headeronly, который описан позже в этой главе.
Оператор BACKUP LOG
Оператор backup log применяется для создания резервной копии протокола
транзакций. Этот оператор имеет следующий синтаксис:
BACKUP LOG {db_name | @variable}
ТО device_list
[MIRROR ТО device_list2]
[WITH option_list]
Здесь db_name, ^variable, device_iist и device_iist2 имеют те же самые зна-
чения, что и параметры с теми же именами в операторе backup database. Па-
раметр option_iist имеет те же опции, что и в операторе backup database,
кроме того, он поддерживает специфические опции протокола no truncate,
NORECOVERY И STANDBY.
Вы должны использовать опцию no truncate, если хотите выполнять копиро-
вание протокола без его усечения, т. е. эта опция не очищает подтвержденные
транзакции в протоколе. После выполнения этой опции система записывает
все последние действия с базой данных в протокол транзакций. Поэтому оп-
ция no truncate позволяет вам восстанавливать данные прямо до той точки,
когда произошел сбой базы данных.
Глава 17. Копирование и восстановление
Опция norecovery копирует остаток протокола и оставляет базу данных в со-
стоянии восстановления. Значение norecovery будет полезным, когда сбой
происходит во вторичной базе данных (базе данных — получателе) и при со-
хранении остатка протокола перед операцией восстановления. Опция standby
копирует остаток протокола и оставляет базу данных в режиме только для
чтения и в состоянии standby. (Операция восстановления и состояние standby
описываются позже в этой главе.)
Резервное копирование
с помощью Management Studio
Прежде чем вы начнете выполнять резервное копирование базы данных или
протокола транзакции, вы должны указать (или создать) устройства копиро-
вания. SQL Server Management Studio позволяет создавать дисковые и лен-
точные устройства одним и тем же образом. В обоих случаях разверните сер-
Рис. 17.1. Диалоговое окно Backup Device
452
Часть III. SQL Server: системное администрирование
вер, разверните узел Server Objects, щелкните правой кнопкой мыши по узлу
Backup Devices и выберите пункт New Backup Device. В диалоговом окне
Backup Device (рис. 17.1) введите имя дискового устройства (если вы устано-
вили переключатель File) или ленточного устройства (если вы установили
переключатель Таре). В первом случае вы можете щелкнуть по кнопке мно-
готочия ... в правой части поля для отображения размещения существующих
устройств для резервных копий. Во втором случае, если устройство Таре не
может быть активировано, то это означает, что не существует никаких лен-
точных устройств на локальном компьютере.
После того как вы укажете устройство для резервного копирования, вы може-
те выполнять резервное копирование базы данных. Разверните сервер, раз-
верните узел Databases, щелкните правой кнопкой мыши по нужной базе
данных. После выделения Tasks выберите Back Up. Появится диалоговое
окно Back Up Database (рис. 17.2). На странице General этого диалогового
Рис. 17.2. Диалоговое окно Back Up Database, страница General
Глава 17. Копирование и восстановление
453
окна из раскрывающегося списка Backup type выберите тип резервной ко-
пии: Full (Полная), Differential (Дифференцированное) или Transaction Log
(Протокол транзакции), в поле Name введите имя набора резервных копий и,
при желании, в поле Description — описание этого набора копий. В том же
диалоговом окне вы можете выбрать срок хранения для этой резервной
копии.
В области Destination выберите существующее устройство, щелкнув по
кнопке Add. Кнопка Remove позволяет удалить одно или более устройств
резервных копий из списка используемых устройств.
Чтобы на странице Options (рис. 17.3) добавить копию к существующему
набору копий на выбранном устройстве, отметьте переключатель Append to
the existing backup set. Выбор переключателя Overwrite all existing backup
sets в том же поле перезаписывает все существующие резервные копии на
выбранном устройстве резервных копий.
Рис. 17.3. Диалоговое окно Back Up Database, страница Options
454 Часть III. SQL Server: системное администрирование
Для верификации копии базы данных установите флажок Verify backup
when finished в разделе Reliability. На странице Options вы также можете
выбрать копирование на новый набор внешних устройств, отметив переклю-
чатель Back up to a new media set, and erase all existing backup sets, а затем
введя имя и описание набора устройств.
Для создания и верификации дифференцированной копии базы данных или
протокола транзакции выполняйте те же действия, только выберите соответ-
ствующий тип резервной копии в поле Backup type на странице General.
После того как все опции будут выбраны, щелкните по кнопке ОК. Будет
создана резервная копия базы данных или протокола транзакции. Имя, физи-
ческое размещение и тип устройств резервного копирования могут быть по-
казаны, если вы выберете сервер, развернете папку Server Objects и под ко-
нец развернете папку Backup Devices.
Создание расписания резервного копирования
в Management Studio
Хорошо спланированный график по срокам операций резервного копирова-
ния позволит вам избежать недостатков в работе системы в процессе дея-
тельности пользователей. SQL Server Management Studio поддерживает такое
планирование, предоставляя простой в использовании графический интер-
фейс для создания расписания резервного копирования. Создание расписания
резервного копирования с использованием SQL Server Management Studio
подробно описывается в следующей главе.
Какие базы данных копировать?
Следующие базы данных должны копироваться регулярно:
♦ база данных master;
♦ все производственные базы данных.
Резервное копирование базы данных master
База данных master является наиболее важной базой данных системы, потому
что она содержит информацию обо всех базах данных в этой системе. По
этой причине вы должны выполнять резервное копирование базы данных
master на регулярной основе. Помимо этого, вы должны копировать базу
данных master каждый раз, когда выполняются операторы или хранимые
процедуры, потому что Database Engine автоматически изменяет базу данных
master.
Глава 17. Копирование и восстановление 455
Замечание_____________________________________________________
Вы можете выполнять только полное резервное копирование базы данных
master. Система не поддерживает дифференцированное резервное копирова-
ние, копирование протокола транзакций или копирование файлов для базы
данных master.
Многие действия приводят к модификации базы данных master. Вот некото-
рые из них:
♦ создание, изменение и удаление базы данных;
♦ изменения протокола транзакций.
Замечание_____________________________________________________
Если не выполнять резервного копирования базы данных master, вам придется
полностью пересоздавать системные базы данных, потому что при разрушении
базы данных master будут потеряны все существующие созданные пользова-
телем базы данных, на которые она ссылается.
Резервное копирование производственных баз данных
Вы должны выполнять резервное копирование производственных баз данных
на регулярной основе. Дополнительно, вы должны выполнять резервное ко-
пирование любых производственных баз данных, после того как с базами
данных были выполнены следующие действия:
♦ после их создания;
♦ после создания индексов;
♦ после создания протокола транзакций;
♦ после выполнения ^протоколируемых операций.
Всегда выполняйте полное резервное копирование баз данных после их соз-
дания для случая, когда возникает сбой в период между созданием базы дан-
ных и ее первым регулярным копированием. Помните, что копирование про-
токола транзакций не может быть использовано без полного резервного ко-
пирования базы данных.
Резервное копирование базы данных после создания одного или более индек-
сов экономит время процесса восстановления, потому что структуры индек-
сов копируются вместе с данными. Резервное копирование протокола тран-
закций после создания индексов вовсе не экономит время при восстановле-
нии, потому что в протокол транзакций записывается только лишь сам факт,
что индекс был создан (и не записывается изменение структуры индекса).
Резервное копирование базы данных после очистки протокола транзакций
необходимо, потому что протокол транзакций более не содержит записей
о действиях с базой данных, которые используются для восстановления базы
456 Часть III. SQL Server: системное администрирование
данных. Все операции, которые не записываются в протокол транзакций, на-
зываются непротоколируемыми операциями. По этой причине все действия,
выполненные этими операциями, не могут быть восстановлены во время
процесса восстановления базы данных.
Восстановление базы данных
Каждый раз, когда транзакция запускается на выполнение, Database Engine
становится ответственным за выполнение транзакции до ее завершения и за
запись ее изменений в базу данных или за гарантию того, что транзакция не
оказала совсем никакого влияния на базу данных. Такой подход гарантирует,
что база данных остается согласованной в случае сбоя, потому что сбои не
разрушают саму базу данных, а вместо этого лишь влияют на транзакции,
которые были активными в момент сбоя. Database Engine поддерживает как
автоматическое, так и ручное восстановление, что далее и будет обсуждаться.
Автоматическое восстановление
Автоматическое восстановление является средством, позволяющим сохра-
нить работоспособность системы при возникновении ошибок. Database
Engine выполняет автоматическое восстановление каждый раз после его пе-
резапуска после возникновения ошибки или после его останова. Процесс ав-
томатического восстановления проверяет, требуется ли восстановление базы
данных. Если да, то каждая база данных возвращается в ее последнее согла-
сованное состояние при использовании протокола транзакций.
В процессе автоматического восстановления Database Engine проверяет про-
токол транзакций от последней контрольной точки до точки, в которой про-
изошел отказ системы или был выполнен останов Database Engine. (Кон-
трольная точка— это самая последняя точка, при которой все изменения
данных были записаны в базу данных из оперативной памяти. По этой при-
чине контрольная точка обеспечивает физическую согласованность данных.)
Протокол транзакций содержит подтвержденные транзакции (транзакции,
которые были успешно выполнены, но их изменения пока еще не записаны в
базу данных) и неподтвержденные транзакции (транзакции, которые не были
успешно выполнены до появления сбоя или останова системы). Database
Engine повторяет все подтвержденные транзакции, следовательно, делает из-
менения в базе данных постоянными и отменяет часть неподтвержденных
транзакций, которые выполнялись до контрольной точки.
Database Engine вначале выполняет автоматическое восстановление базы
данных master, после этого восстанавливаются все другие системные базы
данных. Затем восстанавливаются базы данных, созданные пользователями.
Гпава 17. Копирование и восстановление
457
Ручное восстановление
Ручное восстановление базы данных задает приложение полного копирова-
ния вашей базы данных и приложение для всех протоколов транзакций в по-
следовательности их создания. (Альтернативно вы можете использовать пол-
ную резервную копию базы данных вместе с последней дифференцированной
резервной копией базы данных.) После этого база приводится в то же (согла-
сованное) состояние, которое она имела в тот момент времени, когда в по-
следний раз выполнялось резервное копирование протокола транзакций.
Когда вы восстанавливаете базу данных с использованием полной резервной
копии базы данных, Database Engine вначале пересоздает все файлы базы
данных и размещает их на соответствующих физических устройствах. После
этого система пересоздает все объекты базы данных.
Database Engine может выполнять некоторые формы восстановления динами-
чески (пока выполняется экземпляр системы базы данных). Динамическое
восстановление улучшает доступность системы, потому что в этом случае
недоступны только данные, подлежащие восстановлению. Динамическое
восстановление позволяет восстановить либо целый файл базы данных, либо
файловую группу. (Microsoft называет динамическое восстановление "вос-
становлением в режиме онлайн".)
Является ли мой набор резервной копии
готовым к восстановлению?
После выполнения оператора backup выбранное устройство (магнитная лента
или диск) содержит все данные того объекта, который вы выбрали для ре-
зервного копирования. Сохраненные данные называются набором резервной
копии. Прежде чем вы запустите на выполнение процесс восстановления, вы
должны быть уверены, что:
♦ набор резервной копии содержит те данные, которые вы хотите восстанав-
ливать;
♦ набор резервной копии является пригодным к восстановлению.
Database Engine поддерживает множество операторов Transact-SQL, которые
позволяют вам определить, что набор резервной копии является пригодным
к восстановлению и содержит нужные данные. Следующие четыре опции,
помимо других, принадлежат этому множеству.
♦ restore labelonly. Этот оператор используется для отображения инфор-
мации заголовка внешнего устройства (диска или магнитной ленты), при-
меняется в процессе резервного копирования. Выводом оператора restore
labelonly является единственная строка, которая содержит итоговую ин-
458
Часть III. SQL Server: системное администрирование
формацию о заголовке (имя внешнего устройства, описание процесса ре-
зервного копирования и дату этого процесса).
♦ restore headeronly. В то время как оператор restore labelonly дает крат-
кую информацию о заголовке файла вашего устройства резервной копии,
оператор restore headeronly дает информацию о резервных копиях, кото-
рые хранятся на устройстве резервных копий. Этот оператор отображает в
одной строке итоговые данные по каждой резервной копии на устройстве
резервных копий. По сравнению с restore labelonly использование
restore headeronly может потребовать много большего времени, если уст-
ройство содержит несколько резервных копий.
Вывод restore headeronly содержит столбец Compressed, который сооб-
щает вам, является ли файл резервной копии сжатым (значение 1) или нет.
♦ restore filelistonly. Данный оператор возвращает результирующий на-
бор, который отображает базу данных и протоколы транзакций, содержа-
щиеся в наборе резервной копии. Вы можете отображать информацию
только об одном наборе резервной копии за один раз. По этой причине,
если указанное устройство резервной копии содержит несколько резерв-
ных копий, вам нужно задавать обрабатываемую позицию набора резерв-
ной копии.
Используйте restore filelistonly, если точно не знаете, существуют ли
наборы резервных копий, или где располагаются файлы конкретного на-
бора резервной копии. В обоих случаях вы можете проверить все или
только часть устройств для создания общей картины существующих ре-
зервных копий.
♦ restore verifyonly. После того как вы нашли ваш результат резервного
копирования, вы можете выполнить следующее действие: проверить ре-
зервную копию без ее использования в процессе восстановления. Вы мо-
жете выполнить эту верификацию с оператором restore verifyonly, кото-
рый проверяет существование всех устройств резервного копирования
(магнитных лент или дисков) и может ли быть прочитана существующая
информация.
Замечание________________________________________________________
restore labelonly читает лишь заголовок файла, следовательно, используй-
те этот оператор, если вам нужно получить краткий обзор того, что содержит
ваш набор резервной копии.
По сравнению с тремя предыдущими операторами оператор restore
verifyonly поддерживает две особые опции:
• loadhistory выполняет добавление информации резервного копирова-
ния к таблице историй резервных копирований;
Глава 17. Копирование и восстановление
459
• stats отображает каждый раз сообщение, когда считывается новая пор-
ция информации. Используется в качестве масштаба процесса (значе-
нием по умолчанию является 10).
Восстановление баз данных и протоколов
с использованием операторов Transact-SQL
Все операции восстановления могут быть выполнены с помощью двух опера-
торов Transact-SQL:
♦ RESTORE database;
♦ RESTORE log.
Оператор restore database используется для выполнения процесса восста-
новления для базы данных. Общий синтаксис этого оператора:
RESTORE DATABASE {db_name I @variable}
[FROM device_list]
[WITH option_list]
Здесь db_name— имя базы данных, которая будет восстанавливаться. Имя ба-
зы данных может задаваться и с использованием переменной ^variable. Па-
раметр device_list задает одно или более имен устройств, на которых распо-
лагается резервная копия базы данных. (Если вы не задаете предложение
from, то будет иметь место только процесс автоматического восстановления, а
не процесс восстановления с резервной копии, и в этом случае вы должны
задать одну из опций recovery, norecovery или standby. Это действие воз-
можно, если вы хотите переключиться на резервный сервер.) Параметр
device_list может быть списком имен дисковых файлов или магнитных лент.
Параметр option_iist содержит несколько опций, которые могут быть зада-
ны для различных форм резервных копий. Наиболее важными опциями яв-
ляются:
♦ recovery/norecovery/standby;
♦ checksum/no_checksum;
♦ replace;
♦ partial;
♦ stopat;
♦ stopatmark;
♦ STOPBEFOREMARK.
Опция recovery инструктирует Database Engine о том, что необходимо про-
пускать любые подтвержденные транзакции и отменять неподтвержденные
транзакции. После применения опции recovery база данных будет находиться
16 Зак. 1141
460 Часть III. SQL Server: системное администрирование
в согласованном состоянии и будет готовой для использования. Эта опция
является опцией по умолчанию.
Замечание________________________________________________________
Используйте опцию recovery при восстановлении с использованием последне-
го протокола транзакций или при восстановлении с полной резервной копии
базы данных без последующей резервной копии протокола транзакций.
При опции norecovery Database Engine не выполняет откат неподтвержден-
ных транзакций, потому что вы будете применять следующие резервные ко-
пии. После применения опции norecovery база данных будет недоступной для
использования.
Замечание________________________________________________________
Используйте опцию NORECOVERY при восстановлении с последним протоколом
транзакций.
Опция standby является альтернативой для опций recovery и norecovery, она
используется с резервным сервером. (Резервный сервер обсуждается в
разд. "Использование резервного сервера" далее в этой главе.) При доступе к
данным, хранящимся на резервном сервере, вы обычно восстанавливаете базу
данных после восстановления протокола транзакций. С другой стороны, если
вы восстанавливаете базу данных на резервном сервере, вы не можете для
процесса восстановления применять дополнительные журналы с производст-
венного сервера. В этом случае вы используете опцию standby для того, что-
бы разрешить пользователям обращаться к резервному серверу. Дополни-
тельно вы позволяете системе выполнять восстановление с дополнительных
протоколов транзакций. Опция standby предполагает существование файлов
отмены, которые служат для отката изменений при восстановлении дополни-
тельных протоколов.
Опция checksum инициирует верификацию контрольных сумм резервной ко-
пии и контрольных сумм страниц, если они присутствуют. Если контрольные
суммы отсутствуют, операция restore выполняется без верификации. Опция
no checksum явно отменяет проверку контрольных сумм в операции восста-
новления.
Опция replace заменяет существующую базу данных данными из резервной
копии другой базы данных. В этом случае сначала удаляется существующая
база данных, а различия между именами файлов базы данных и именем базы
данных игнорируются. (Если вы не используете опцию replace, то система
базы данных выполняет безопасную проверку, которая гарантирует, что су-
ществующая база данных не будет заменяться, если имена файлов базы дан-
ных или имя самой базы данных отличаются от соответствующих имен в на-
боре резервной копии.)
Глава 17. Копирование и восстановление
461
Опция partial задает операцию частичного восстановления. С этой опцией
вы можете восстанавливать-часть базы данных, присутствующую в ее пер-
вичной файловой группе и в одной или более вторичных файловых групп,
которые задаются в дополнительной опции под названием filegroup. (Опцию
partial нельзя применять в операторе restore log.)
Опция stopat позволяет восстанавливать базу данных в том состоянии, кото-
рое она имела на конкретный момент времени до возникновения сбоя, при
помощи задания точного времени. Database Engine восстанавливает все под-
твержденные транзакции, которые были записаны в протокол транзакций до
заданного момента времени. Если вы хотите восстанавливать базу данных,
указывая момент времени, выполните оператор restore database с использо-
ванием предложения norecovery. После этого выполните оператор restore
log для применения всех резервных копий протокола транзакций, указав имя
базы данных, устройство резервной копии, с которой будет восстанавливать-
ся резервная копия протокола транзакций, и задав предложение stopat.
Опции stopatmark и stopbeforemark задают восстановление до отметки. Эта
тема описывается в разд. "Восстановление до отметки" далее в этой главе.
Оператор restore database также используется для восстановления базы дан-
ных с дифференцированной резервной копии. Синтаксис и опции для восста-
новления базы данных с дифференцированной резервной копии такие же, как
и для восстановления с полной резервной копии базы данных. В процессе
восстановления с дифференцированной резервной копии Database Engine
восстанавливает только часть базы данных, которая была изменена с момента
последнего полного резервного копирования базы данных. Поэтому восста-
навливайте полную резервную копию базы данных до того, как вы будете
восстанавливать дифференцированную резервную копию!
Оператор restore log используется для выполнения процесса восстановления
протокола транзакций. Этот оператор имеет ту же самую синтаксическую
форму и те же самые опции, что и оператор restore database.
Восстановление баз данных и протоколов
с использованием Management Studio
Для восстановления базы данных с полной резервной копии базы данных
разверните сервер, выберите узел Databases и щелкните правой кнопкой
мыши по базе данных. Затем щелкните по Tasks, выберите Restore, а затем
Database. Появится диалоговое окно Restore Database (рис. 17.4). На стра-
нице General выберите базы данных, в которые и из которых вы хотите вы-
полнять восстановление. Затем отметьте тип резервной копии, которую вы
собираетесь обрабатывать (в данном случае Full Database Backup).
462
Часть III. SQL Server: системное администрирование
Рис. 17.4. Диалоговое окно Restore Database, страница General
Замечание______________________________________________________
Если вы выполняете восстановление из резервной копии протокола транзак-
ций, не забывайте, что последовательность в восстановлении отличается от
резервного копирования. Сначала восстановите полную резервную копию базы
данных. Затем восстанавливайте все соответствующие протоколы транзакций
в последовательности их создания.
Для задания подходящих опций восстановления выберите страницу Options
(рис. 17.5) в диалоговом окне Restore Database. В верхней части этого окна
выберите один или несколько типов восстановления. В нижней части этого
окна вы можете выбрать одну из трех существующих опций. Выбор первой
опции, Leave the database ready to use by rolling back uncommitted
transactions, указывает Database Engine, что нужно пройти по всем подтвер-
жденным транзакциям и отменить все неподтвержденные транзакции. После
применения этой опции база данных будет находиться в согласованном со-
Глава 17. Копирование и восстановление
463
стоянии и будет готовой для использования. Эта опция эквивалентна опции
recovery в операторе restore database.
Рис. 17.5. Диалоговое окно Restore Database, страница Options
Замечание_________________________________________________________
Применяйте эту опцию, только когда восстанавливается последний протокол
транзакций или при полном восстановлении базы данных, когда нет необходи-
мости использовать никаких последующих протоколов транзакций.
Если вы щелкнете по второй опции, Leave the database non-operational, and
do not roll back uncommitted transactions, Database Engine не выполнит от-
кат неподтвержденных транзакций, потому что вы будете использовать
последующие резервные копии. После того как вы примените эту опцию,
база данных не будет доступной для использования, нужно будет восстано-
вить дополнительные протоколы транзакций. Эта опция эквивалентна опции
norecovery в операторе restore database.
464 Часть III. SQL Server: системное администрирование
Замечание_____________________________________________________
Используйте эту опцию с восстановлением всех самых последних протоколов
транзакций или с восстановлением дифференцированной резервной копии.
Выбор третьей опции, Leave the database in read-only mode, задает файл
(в диалоговом окне Standby file), который впоследствии будет использован
для отмены эффектов восстановления. Эта опция эквивалентна опции standby
в операторе restore database..
Процесс восстановления базы данных из дифференцированной резервной
копии базы данных эквивалентен процессу восстановления из полной резерв-
ной копии базы данных. В этом случае вы должны отметить Differential
Database Backup в качестве типа резервной копии в диалоговом окне Restore
Database. Единственным отличием от восстановления полной резервной
копии базы данных является то, что только первая опция в нижней поло-
вине страницы Options (Leave the database ready to use by rolling back
uncommitted transactions) может быть использована для восстановления из
дифференцированной резервной копии.
Замечание_____________________________________________________
Если вы выполняете восстановление из дифференцированной резервной ко-
пии, вначале выполните восстановление из полной резервной копии базы дан-
ных, прежде чем осуществлять восстановление соответствующей дифферен-
цированной резервной копии. В отличие от резервной копии протокола тран-
закций, применяется только лишь последняя дифференцированная резервная
копия, потому что она включает в себя все изменения, выполненные после
полного резервного копирования.
Для восстановления базы данных с новым именем разверните Databases и
щелкните правой кнопкой мыши по базе данных. После щелчка по Tasks
выберите Restore, а затем Database. В странице Generals диалогового окна
Restore Database в раскрывающемся списке То database введите имя базы
данных, которую вы собираетесь создать, а в раскрывающемся списке From
database введите имя базы данных, чья резервная копия будет использована.
Восстановление до отметки
Database Engine позволяет вам использовать протокол транзакций для вос-
становления до заданной отметки. Отметки в протоколе соответствуют ука-
занной транзакции и добавляются только в том случае, если транзакция под-
тверждается. Это позволяет отметкам быть связанными с заданной деятель-
ностью и предоставляет возможность выполнять восстановление на ту точку,
которая включает или исключает такую деятельность. Это дает возможность
таким отметкам быть связанными с заданной деятельностью и предоставляет
средства для восстановления с той точки, которая включает или исключает
такую деятельность.
Глава 17. Копирование и восстановление 465
Замечание_______________________________________________________
Если отмеченная транзакция использует несколько баз данных на том же сер-
вере базы данных, то отметки записываются во все протоколы используемых
баз данных.
Оператор begin transaction выполняет поддержку отметки в протоколах
транзакций. Используйте предложение with mark для вставки отметок в про-
токолы. Поскольку имя отметки является тем же самым, что и имя ее тран-
закции, требуется задание имени транзакции. (Опция description задает тек-
стовое описание отметки.)
В протокол транзакций записывается информация об имени отметки, описание,
база данных, пользователь, дата и время и последовательный номер протоко-
ла (log sequence number, LSN). Не требуется уникальность имен транзакций,
чтобы дать возможность повторно их использовать. Информация даты и вре-
мени вместе с этим именем служит для уникальной идентификации отметки.
Для задания восстановления до отметки вы можете использовать опера-
тор restore log (вместе с предложением stopatmark или с предложением
stopbeforemark). Предложение stopatmark указывает процессу восстановле-
ния, что нужно пропустить все до заданной отметки и включить транзакцию,
которая содержит эту отметку. Если вы задаете предложение stopbeforemark,
то процесс восстановления исключает транзакцию, которая содержит эту от-
метку.
Оба предложения просто описывают поддержку необязательного предложе-
ния after datetime. Если это предложение опущено, то восстановление оста-
навливается на первой отметке с указанным именем. Если предложение зада-
но, то восстановление останавливается на первой отметке с указанным име-
нем и с временем, равным или большим, чем datetime.
Восстановление базы данных master
Разрушение системной базы данных master может обернуться крахом всей
системы, потому что эта база данных содержит все системные таблицы, ко-
торые необходимы для работы с системой базы данных. Процесс восстанов-
ления базы данных master сильно отличается от такого же процесса для баз
данных, определенных пользователем.
Поврежденная база данных master сама порождает различные сбои. Такими
сбоями являются следующие:
♦ невозможность запуска процесса MSSQLSERVER;
♦ ошибки ввода/вывода;
♦ выполнение команды dbcc указывает на подобные сбои.
466
Часть III. SQL Server: системное администрирование
Существуют два различных способа восстановления базы данных master. Са-
мым простым способом является тот, при котором вы можете запустить на
выполнение вашу систему базы данных. В этом случае вы просто восстанав-
ливаете базу данных master из полной резервной копии базы данных. Более
сложный способ придется использовать тогда, когда вы не можете запустить
вашу систему. В этом случае применяйте команду sglserver.
Для восстановления вашей базы данных master запустите ваш экземпляр в
режиме одного пользователя. Как вы уже знаете, существует несколько спо-
собов это сделать. Моим любимым способом является использование коман-
ды Windows и выполнение приложения sglserver (из командной строки)
с опцией -т. На следующем шаге вы восстанавливаете базу данных master со
всеми другими базами данных, используя последнюю полную резервную ко-
пию базы данных.
Замечание___________________________________________________
Если были сделаны какие-либо изменения в базе данных master после по-
следнего полного резервного копирования этой базы данных, вам придется
восстановить эти изменения вручную.
Восстановление других системных баз данных
Процесс восстановления всех системных баз данных, отличных от master,
аналогичен. Поэтому я объясню этот процесс на основе базы данных msdb.
Базу данных msdb нужно восстанавливать из резервной копии в том случае,
когда либо пересоздается база данных master, либо когда сама база данных
msdb оказывается разрушенной. Если база данных msdb разрушена, восстано-
вите ее, используя существующие резервные копии. Если выполнялись лю-
бые изменения после того, как для базы данных msdb было выполнено резерв-
ное копирование, сделайте заново эти изменения вручную.
Замечание___________________________________________________
Вы не можете восстанавливать базу данных, к которой обращаются пользова-
тели. Поэтому при восстановлении базы данных msdb сервис SQL Server Agent
должен быть остановлен. (SQL Server Agent обращается к базе данных msdb.)
Модели восстановления
Модель восстановления позволяет вам управлять тем объемом данных, кото-
рые вы рискуете потерять в подтвержденных транзакциях при разрушении
базы данных. Она также определяет скорость использования и размер вашей
резервной копии протокола транзакций. В дополнение к этому, выбор модели
восстановления оказывает влияние на размер протокола транзакций и поэто-
Глава 17. Копирование и восстановление 467
му на период времени, необходимый для выполнения резервного копирова-
ния протокола. Database Engine поддерживает три модели восстановления:
♦ полную;
♦ с неполным протоколированием;
♦ простую.
Следующие разделы описывают эти модели восстановления.
Модель полного восстановления
В процессе полного восстановления все операции записываются в протокол
транзакций. Поэтому эта модель предоставляет полную защиту против сбоев
внешних устройств. Это означает, что вы можете восстанавливать вашу базу
данных с последней подтвержденной транзакции, которая была сохранена в
файле протокола. В дополнение к этому вы можете восстанавливать данные
на любой момент времени (предшествующий моменту сбоя). Чтобы обеспе-
чить это, также полностью протоколируются такие операции, как select
into, и выполнение утилиты Ьср.
Помимо возможности восстановления на момент времени, модель полного
восстановления позволяет также выполнять восстановление на отметку в
протоколе. Отметки в протоколе соответствуют заданной транзакции и до-
бавляются в протокол, только если эта транзакция подтверждается.
Модель полного восстановления также протоколирует все операции, связан-
ные с оператором create index, подразумевая, что процесс восстановления
данных теперь включает и создание индекса. В этом случае пересоздание ин-
дексов выполняется быстрее, потому что вам не нужно отдельно создавать их
заново.
Недостатком этой модели восстановления является то, что соответствующий
протокол транзакций может быть очень большим по объему, и файлы на дис-
ке, содержащие этот протокол, могут быть заполнены очень быстро. Кроме
того, для такого объемного протокола вам потребуется значительно больше
времени на резервное копирование.
Замечание_____________________________________________________
Если вы используете модель полного восстановления, протокол транзакций
должен быть защищен от сбоев внешних устройств. По этой причине использо-
вание RAID 1 для защиты протокола транзакций строго рекомендуется. (RAID 1
объясняется в разд. "Высокая доступность" далее е этой главе.)
Модель восстановления с неполным протоколированием
Восстановление с неполным протоколированием поддерживает протоколы
резервных копий при использовании минимального пространства в протоко-
468
Часть III. SQL Server: системное администрирование
ле транзакций для некоторых крупномасштабных или объемных операций.
Протоколирование следующих операций является минимальным и не может
управляться по принципу "операция за операцией":
♦ SELECT into;
♦ create index (включая индексируемые представления);
♦ утилита Ьср и bulk insert.
Хотя объемные операции и не являются полностью запротоколированными,
вам не нужно выполнять полное резервное копирование базы данных после
завершения подобной операции. В процессе восстановления с неполным про-
токолированием резервные копии протокола транзакций содержат и прото-
кол, и результат объемной операции. Это упрощает переход между полной
моделью и моделью восстановления с неполным протоколированием.
Модель восстановления с неполным протоколированием позволяет восста-
навливать базу данных до конца резервной копии протокола транзакций (т. е.
до самой последней подтвержденной транзакции). Дополнительно вы можете
восстанавливать вашу базу данных на любой момент времени, если вы не вы-
полняли объемных операций. То же самое верно и для операции восстанов-
ления до именованной отметки в протоколе.
Преимуществом модели восстановления с неполным протоколированием
является то, что объемные операции выполняются много быстрее, чем под
моделью полного восстановления, потому что они не протоколируются пол-
ностью. С другой стороны, Database Engine выполняет резервное копирова-
ние всех экстентов вместе с собственно протоколом. Поэтому для резервной
копии протокола требуется гораздо меньше памяти, чем в случае полного
восстановления. Время восстановления с резервной копии протокола также
значительно увеличивается.
Простая модель восстановления
В простой модели восстановления протокол транзакций усекается, если появ-
ляется точка сохранения. Поэтому вы можете выполнять восстановление раз-
рушенной базы данных только при использовании полной резервной копии
базы данных или дифференцированной резервной копии, потому что они не
требуют резервной копии протокола. Стратегия резервного копирования для
этой модели является очень простой: выполнение восстановления базы дан-
ных с существующей резервной копии базы данных и, если существуют
дифференцированные резервные копии, применение самой последней ее вер-
сии.
Замечание_____________________________________________________
Простая модель восстановления не означает, что вообще не существует прото-
колирования. Содержимое протокола не будет использовано для целей ре-
Глава 17. Копирование и восстановление 469
зервного копирования, однако оно используется во время создания контроль-
ной точки, где все транзакции протокола подтверждены или для них выполнен
откат.
Преимуществом простой модели восстановления является то, что производи-
тельность всех объемных операций очень высокая, а требования к объему
памяти протокола очень невысокие. С другой стороны, эта модель требует
больше ручной работы, поскольку все изменения с момента самого последне-
го резервного копирования базы данных (или получения дифференцирован-
ной резервной копии) должны быть восстановлены. В этой модели восста-
новления не допустимы восстановления на конкретный момент времени или
восстановление страниц. Кроме того, восстановление файлов допустимо
только для вторичных файловых групп только для чтения.
Замечание_________________________________________________________
Не используйте простую модель восстановления для производственных баз
данных.
Изменение и редактирование модели восстановления
Вы можете изменить модель восстановления, используя опцию recovery опе-
ратора alter database. Частью синтаксиса оператора alter database, связан-
ного с моделями восстановления, является:
SET RECOVERY [FULL | BULK_LOGGED | SIMPLE]
Существуют два способа, которыми вы можете редактировать текущую мо-
дель восстановления вашей базы данных:
♦ С ПОМОЩЬЮ функции свойств databasepropertyex;
♦ с помощью представления просмотра каталогов sys.databases.
Если вы хотите отобразить текущую модель восстановления вашей базы дан-
ных, используйте предложение recovery функции databaseproperty. В приме-
ре 17.2 показан запрос, который отображает модель восстановления базы
данных sample. Эта функция отображает одно из значений full, bulk logged
или SIMPLE.
j Пример 17.2
SELECT databasepropertyex('sample', 'recovery')
Столбец recovery_model_desc в представлении просмотра каталогов
sys. databases отображает ту же информацию, что и функция
databasepropertyex (пример 17.3).
470
Часть III. SQL Server: системное администрирование
' Пример 17.3
SELECT name, database_id, recovery_model_desc AS model
FROM sys.databases
WHERE name = 'sample'
Результат:
name database_id model
sample 7 FULL
Высокая доступность
Обеспечение доступности вашей системы базы данных и самих баз данных
является сегодня одним из наиболее важных вопросов. Существует несколько
техник, которые вы можете использовать для обеспечения их доступности,
которые можно разделить на две группы: те, которые являются компонента-
ми Database Engine, и те, которые не реализованы в сервере базы данных.
Следующие две техники не являются частью Database Engine:
♦ использование резервного сервера;
♦ использование технологии RAID.
Следующие техники принадлежат системе базы данных:
♦ отказоустойчивая кластеризация;
♦ зеркальное отображение базы данных;
♦ пересылка протокола;
♦ репликация.
Следующие разделы описывают все эти компоненты, кроме репликации, ко-
торая обсуждается в главе 19.
Использование резервного сервера
Резервный сервер является именно тем, что предполагается в его названии —
другой сервер, который резервируется на случай, если что-нибудь произойдет
с производственным сервером (также называемым первичным сервером). Ре-
зервный сервер содержит файлы, базы данных (определенные системой и
пользователем) и учетные записи пользователей, идентичные тем, что распо-
лагаются на производственном сервере.
Резервный сервер реализован для начального восстановления базы данных
с полной резервной копии базы данных и применения резервных копий про-
Гпава 17. Копирование и восстановление
471
токолов транзакций для поддержания базы данных на резервном сервере в
синхронном состоянии по отношению к производственному серверу. Для
установки резервного сервера установите опцию базы данных read only в
значение true. Эта опция запрещает пользователям любые операции записи
в базу данных.
Основными шагами по использованию копии производственной базы данных
являются следующие:
♦ восстановление производственной базы данных при использовании опера-
тора restore database с предложением standby;
♦ применение каждого протокола транзакций для резервного сервера при
использовании оператора restore log с предложением standby;
♦ при применении последней резервной копии протокола транзакции ис-
пользуйте оператор restore log с предложением recovery. Этот финаль-
ный оператор восстанавливает базу данных без создания файла с преды-
дущими образами, делая также базу данных доступной для операций
записи.
После того как база данных и резервные копии протоколов транзакций будут
восстановлены, пользователи могут работать с точной копией производст-
венной базы данных. Будут навсегда потеряны только лишь неподтвержден-
ные транзакции, которые существовали на момент возникновения сбоя.
Замечание_____________________________________________________
Если на производственном сервере происходит сбой, то пользовательские про-
цессы не переходят автоматически на резервный сервер. В этом случае всем
пользовательским процессам нужно перезапустить те задачи, которые имели
неподтвержденные транзакции на момент сбоя производственного сервера.
Использование технологии RAID
RAID (избыточный массив из независимых дисков) является специальной
дисковой конфигурацией, в которой множество дисковых устройств создает
единый элемент. Этот процесс дает возможность файлам распределять мно-
жество дисковых устройств. Технология RAID предоставляет повышенную
надежность при небольшой стоимости выполнения. Существует шесть уров-
ней RAID, с 0 до 5. Только три из этих уровней О, I и 5 являются значимыми
для систем баз данных.
Технология RAID может быть основана на оборудовании или на программ-
ном обеспечении. Основанная на оборудовании технология RAID является
более затратной (потому что требует приобретения дополнительных диско-
вых контроллеров), но обычно выполняется быстрее. Основанная на про-
граммном обеспечении технология RAID может поддерживаться либо опера-
472
Часть III. SQL Server: системное администрирование
ционной системой, либо самой системой базы данных. Операционные систе-
мы Windows предоставляют RAID уровней 0, 1 и 5. Технология RAID имеет
влияние на следующие свойства:
♦ устойчивость к ошибкам;
♦ производительность.
Преимущества и недостатки каждого уровня RAID в отношении этих двух
свойств рассматриваются далее.
RAID обеспечивает защиту от сбоев жестких дисков и следующей за этим
потери данных при помощи трех методов: расслоение дисков, зеркальное
отображение и контроль по четности. Эти три метода соответствуют RAID
уровней 0, 1 и 5 соответственно.
Расслоение дисков
RAID уровня 0 определяет расслоение дисков без контроля по четности. При
использовании RAID уровня 0 данные записываются на несколько дисковых
устройств в порядке, допускающем наиболее простой доступ к данным, а все
операции чтения и записи могут быть выполнены наиболее быстро. По этой
причине RAID уровня 0 является самой быстрой конфигурацией RAID. Не-
достатком расслоения дисков является то, что эта конфигурация вообще не
обеспечивает устойчивости к ошибкам. Это означает, что если на одном дис-
ке происходит сбой, то все данные этого массива становятся недоступными.
Зеркальное отображение
Зеркальное отображение является специальной формой расслоения дисков,
которое использует пространство на дисковом устройстве для поддержания
дубликатов копий некоторых файлов. По этой причине конфигурация RAID
уровня I, которая задает зеркальное отображение дисков, защищает данные
от сбоев внешних устройств при помощи создания и поддержания копни ба-
зы данных (или ее части) на другом диске. Если устройство, на котором раз-
мещается зеркальная копия, разрушается, файлы с такого разрушенного уст-
ройства могут быть созданы заново. Конфигурация оборудования для зер-
кального отображения является более дорогостоящей, однако она
обеспечивает высокую скорость. Преимуществом зеркального отображения
Windows (т. е. основанном на программном обеспечении) является то, что
оно может быть сконфигурировано как зеркальное отображение на разделе
диска, в то время как зеркальное отображение на основе оборудования обыч-
но реализуется на целом диске.
В отличие от RAID О, RAID 1 является более медленным, однако его надеж-
ность много выше. К тому же RAID 1 стоит много больше, чем RAID 0, по-
скольку каждый зеркальный диск должен быть дублирован. Эта конфигура-
Глава 17. Копирование и восстановление
473
ция может поддерживать, по меньшей мере, одно поврежденное устройство и
выдержать разрушение более половины дисковых устройств в множестве
зеркалируемых дисков без необходимости администратору системы останав-
ливать систему и восстанавливать базу данных с резервных копий. (RAID 1
является опцией RAID с наилучшим исполнением, когда требуется устойчи-
вость к ошибкам.)
Зеркальное отображение также сильно влияет на производительность в от-
ношении операций чтения и записи. Когда используется зеркальное отобра-
жение, операции записи снижают производительность, потому что каждая
такая операция требует использования наборов операций ввода/вывода к
двум дискам— один набор к оригинальному дисковому устройству, дру-
гой — к зеркальному. С другой стороны, зеркальное отображение повышает
производительность операций чтения, потому что Database Engine имеет воз-
можность читать с любого дискового устройства в зависимости от того, кото-
рый из них является менее загруженным в данное время.
Контроль по четности
Контроль по четности (RAID уровня 5) реализован при помощи вычисления
информации восстановления относительно данных, записанных на диск, и
записывающих эту информацию о контроле четности на другие устройства,
которые формируют массив RAID. Если устройство дает сбой, то новое уст-
ройство добавляется в массив RAID, и данные с этого сбойного устройства
восстанавливаются, получая информацию для восстановления (контроль по
четности), записанную на других устройствах. Эта информация используется
для регенерации данных со сбойного устройства.
Преимуществом контроля по четности является то, что вам нужно одно до-
полнительное дисковое устройство для защиты любого количества сущест-
вующих дисковых устройств. Недостатки контроля по четности связаны с
производительностью и устойчивостью к ошибкам. Помимо дополнительных
затрат, связанных с вычислением и записью контрольных сумм, требуются
дополнительные дисковые операции ввода/вывода. (Стоимость операций
ввода/вывода при поиске данных является одинаковой для зеркального ото-
бражения и для контроля по четности.) Также при использовании контроля
по четности вы можете поддерживать только одно отказавшее дисковое уст-
ройство до того, как весь массив должен быть переведен в недоступное со-
стояние и будет выполнено восстановление устройства с резервной копии.
Поскольку расслоение дисков с контролем по четности требует дополнитель-
ных затрат, связанных с вычислением и записью контрольных значений,
RAID 5 требует пяти операций ввода/вывода в то время, как RAID 0 требует
только одной операции, a RAID 1 —только двух.
474
Часть III. SOL Server: системное администрирование
Отказоустойчивая кластеризация
Отказоустойчивая кластеризация является, пожалуй, наиболее важной техно-
логией, поддерживаемой Database Engine для достижения высокой готовно-
сти. Это процесс, при котором операционная система и система базы данных
работают вместе для обеспечения работоспособности в случае возникновения
сбоя. Отказоустойчивый кластер из группы резервных серверов, называемых
узлами, которые совместно используют внешнюю дисковую систему. Когда
узел в кластере дает сбой, экземпляр Database Engine на этой машине пре-
кращает работу, останавливается. Microsoft Cluster Service автоматически пе-
ремещает ресурсы с отказавшей машины на таким же образом сконфигури-
рованный другой узел. Перемещение ресурсов с одного узла на другой узел
в кластере происходит довольно часто.
Преимуществом отказоустойчивой кластеризации является то, что она защи-
щает вашу систему от аппаратных сбоев, потому что предоставляет механизм
автоматического перезапуска систем базы данных на другом узле кластера.
(Это единственная технология высокой надежности в Database Engine, кото-
рая поддерживает подобную избыточность серверов.) С другой стороны, эта
технология имеет возможность отказа в случае набора дисков, которые со-
вместно используют узлы кластера, и не может исключить ошибку в данных.
Другим недостатком этой технологии является то, что она не улучшает про-
изводительность или масштабируемость. Другими словами, приложение не
может осуществлять масштабирование до возможностей кластера, а только
в пределах одного узла.
Зеркальное отображение базы данных
Как вы уже знаете из предыдущих разделов, отказоустойчивая кластеризация
предоставляет избыточный сервер, но она не предоставляет избыточности
файла данных. Технология Database Engine, называемая зеркальным ото-
бражением базы данных, не предоставляет избыточного сервера, но предос-
тавляет и избыточность базы данных, и избыточность файла данных.
Для установки зеркального отображения базы данных используются два сер-
вера с базой данных, которая будет зеркалироваться с одного сервера на дру-
гой. Первый называется главным (основным) сервером, второй —зеркальным
сервером. Копия базы данных на зеркальном сервере называется зеркальной
базой данных.
Зеркальное отображение базы данных позволяет выполнять непрерывную
передачу протокола транзакций с главного сервера на зеркальный сервер.
Копия действий протокола транзакций записывается в протокол зеркалируе-
мой базы данных, и в ней выполняются эти транзакции. Если главный сервер
становится недоступным, приложения могут соединиться с базой данных на
Глава 17. Копирование и восстановление
475
зеркальном сервере, не ожидая завершения процесса восстановления. В от-
личие от отказоустойчивой кластеризации, зеркальный сервер полностью
кэширован и готов выполнять задания по причине его синхронизированного
состояния. Можно создавать до четырех наборов зеркальных резервных ко-
пий. Для реализации зеркального отображения используйте опцию mirror то
в операторе backup database или в операторе backup log.
Существует также третий сервер, называемый следящим сервером. Он опре-
деляет, какой сервер является главным сервером, а какой— зеркальным.
Этот сервер необходим только в том случае, если требуется автоматическая
отказоустойчивость. Чтобы установить режим автоматической отказоустой-
чивости, вы должны включить синхронный оперативный режим, т. е. в опе-
раторе ALTER DATABASE уСТЭНОВИТЬ Значение ОПЦИИ SAFETY В FULL.
Улучшения зеркального отображения базы данных
в SQL Server 2008
SQL Server 2008 содержит следующие улучшения зеркального отображения
базы данных:
♦ сжатие потока данных;
♦ улучшенное использование буферов отправляемых протоколов;
♦ опережающее чтение в процессе выполнения фазы отмены;
♦ опережающую запись во входной поток зеркального сервера.
Database Engine сжимает поток данных, если по крайней мере может быть
достигнут процент сжатия 12.5. Таким способом система сокращает объем
данных протокола, которые пересылаются от главного сервера зеркальному
серверу (серверам).
В предыдущих версиях каждая операция пересылки протокола на главном
сервере резервировала отправляемый буфер для зеркального протокола для
всей базы данных. В SQL Server 2008, если самый последний используемый
кэш протокола содержит достаточно свободной памяти для записей протоко-
ла для следующей операции пересылки протокола, то эти записи будут до-
бавляться к данному кэшу протокола.
После перехвата сбоя новый зеркальный сервер должен отменить каждое из-
менение данных, для которого страница была записана на диск локально, но
для которого запись в протокол, возможно, не была сделана на новом глав-
ном сервере. Для отмены подобных измененных страниц новый зеркальный
сервер должен вначале запросить и получить соответствующие страницы с
нового главного сервера. Производительность этой фазы отмены изменений
улучшена в SQL Server 2008, потому что новый зеркальный сервер отправля-
ет подсказки опережающего чтения новому главному серверу для указания
того, какие страницы будут запрошены позже.
476 Часть III. SQL Server: системное администрирование
При получении записей входного протокола зеркальный сервер записывает
их на диск асинхронно. В то же самое время зеркальный сервер обрабатывает
записи протокола, которые уже были записаны на диск.
Пересылка протокола
Пересылка протокола позволяет протоколам транзакций из одной базы дан-
ных постоянно пересылаться и использоваться в другой базе данных. Это да-
ет возможность иметь горячий резервный сервер, а также предоставляет спо-
соб для загрузки данных с исходной машины на другие компьютеры только
для чтения. База данных — получатель является точной копией первичной
базы данных, потому что целевая база данных получает все изменения от
первичной базы данных. У вас есть возможность сделать целевую базу дан-
ных новой первичной базой данных, если первичный сервер, который владеет
оригинальной базой данных, становится недоступным.
Пересылка протокола не поддерживает автоматическую обработку сбоев. По-
этому, если сервер исходной базы данных дает сбой, вы должны сами восста-
новить целевую базу данных либо вручную, либо при помощи пользователь-
ского кода.
Замечание__________________________________________________
Пересылка протокола похожа на зеркальное отображение базы данных в том,
что она дает избыточность базы данных. С другой стороны, зеркальное ото-
бражение базы данных значительно расширяет возможности пересылки прото-
кола, потому что оно позволяет обновлять целевую базу данных через прямое
соединение и в реальном времени.
Резюме
Системный администратор или владелец базы данных должны периодически
выполнять резервное копирование базы данных и ее протокола транзакций
для обеспечения возможностей восстановления в случае системной ошибки,
сбоя оборудования или различных бедствий (таких как пожар или кража).
Database Engine позволяет выполнять два вида резервного копирования базы
данных: полное и дифференцированное. Полное резервное копирование ис-
пользует состояние базы данных на момент времени, когда выдается опера-
тор, и выполняет копирование на устройство резервной копии (файл или лен-
точное устройство). В случае дифференцированного резервного копирования
копируются те части базы данных, которые были изменены с момента по-
следнего полного резервного копирования базы данных. Преимуществом
дифференцированного резервного копирования является то, что оно выпол-
няется быстрее, чем полное резервное копирование базы данных для той же
Глава 17. Копирование и восстановление
477
базы данных. (Существует также резервное копирование протокола транзак-
ций, которое выполняет резервное копирование протоколов транзакций на
устройства копии.)
Database Engine выполняет автоматическое восстановление каждый раз, когда
происходит системный сбой, который не приводит к сбою любого оборудо-
вания хранения данных. (Автоматическое восстановление также выполняет-
ся, когда система запускается после каждого останова системы.) В процессе
автоматического восстановления каждая подтвержденная транзакция, обна-
руженная в протоколе транзакций, записывается в базу данных, а каждая не-
подтвержденная отменяется. После любого сбоя внешнего устройства может
потребоваться ручное восстановление базы данных с доступной копии и ее
протокола транзакций. Для восстановления базы данных должны быть ис-
пользованы полная резервная копия базы данных и только самая последняя
дифференцированная резервная копия. Если для восстановления базы данных
вы используете протоколы транзакций, вначале используйте полную резерв-
ную копию базы данных, а затем применяйте все существующие протоколы
транзакций в порядке их создания для приведения базы данных в согласован-
ное состояние, которое она имела на момент, когда была создана последняя
резервная копия протокола транзакций.
Database Engine поддерживает несколько собственных технологий, которые
служат для повышения доступности систем баз данных и самих баз данных:
♦ отказоустойчивая кластеризация;
♦ зеркальное отображение базы данных;
♦ пересылка протокола.
Отказоустойчивая кластеризация является наиболее важной технологией
Database Engine по отношению к высокой доступности. Только эта техноло-
гия предоставляет избыточный сервер. Зеркальное отображение базы данных
не предоставляет избыточности сервера, но дает избыточность базы данных.
Пересылка протокола похожа на зеркальное ртображение базы данных, но
поддерживает только подмножество его возможностей.
В следующей главе описываются все возможности системы, которые позво-
ляют автоматизировать системные административные задачи.
Упражнения
Упражнение 17.1
Обсудите разницу между дифференцированным резервным копированием и
резервным копированием протокола транзакций.
478
Часть III. SQL Server: системное администрирование
I Упражнение 17.2
Куда вы должны выполнять резервное копирование производственной базы
данных?
§ Упражнение 17.3
Как вы можете выполнить дифференцированное резервное копирование базы
данных master?
; Упражнение 17.4
Обсудите использование различных технологий RAID с точки зрения устой-
чивости к ошибкам базы данных и ее протокола транзакций.
’ Упражнение 17.5
Какие основные различия между ручным и автоматическим восстановле-
нием?
I Упражнение 17.6
Какой оператор вы должны использовать для проверки вашей резервной ко-
пии без его применения для процесса восстановления?
\ Упражнение 17.7
Обсудите преимущества и недостатки трех моделей восстановления.
j Упражнение 17.8
Обсудите сходство и различие между отказоустойчивой кластеризацией, зер-
кальным отображением базы данных и пересылкой протокола.
ГЛАВА 18
Система автоматизации
задач администрирования
Одним из наиболее важных преимуществ Database Engine по сравнению
с другими реляционными СУБД является его автоматическое администриро-
вание задач, а это снижает затраты. Вот примеры некоторых важных, часто
выполняемых задач, которые должны быть автоматизированы:
♦ резервное копирование базы данных и протокола транзакций;
♦ преобразование данных;
♦ удаление и пересоздание индексов;
♦ проверка целостности данных.
Вы можете автоматизировать все эти задачи, так что они появятся в регуляр-
ном расписании. Например, вы можете установить, что задача резервного ко-
пирования базы данных появляется каждую пятницу в 20:00, а задача резерв-
ного копирования протокола транзакций — ежедневно в полночь.
Компоненты Database Engine, которые используются в процессах автомати-
зации, включают следующие:
♦ сервис SQL Server (MSSQLSERVER);
♦ протокол приложения Windows;
♦ сервис SQL Server Agent.
Зачем для Database Engine нужны эти три компонента для автоматизации
процессов? В связи с автоматизацией задач администрирования сервис
MSSQLSERVER нужен для записи событий в протокол приложений
Windows. Некоторые события записываются автоматически, а другие должны
быть вызваны администратором (подробные объяснения см. далее в этой главе).
Протокол приложений Windows содержит все сообщения операционной сис-
темы Windows и сообщения ее компонентов. Роль протокола приложений
480
Часть III. SQL Server: системное администрирование
Windows в процессе автоматизации заключается в информировании SQL
Server Agent о существующих событиях.
SQL Server Agent является еще одним сервисом, который соединяется с про-
токолом приложений Windows и с сервисом MSSQLSERVER. Роль SQL
Server Agent в процессе автоматизации заключается в выполнении действия
после информирования через протокол приложений Windows. Такое действие
может быть выполнено при соединении с сервисом MSSQLSERVER или с
некоторым другим приложением. На рис. 18.1 показано, как работают вместе
эти три компонента.
Рис. 18.1. Компоненты автоматизации SQL Server
Запуск и конфигурирование
SQL Server Agent
SQL Server Agent выполняет задания и выдает сообщения. Как вы увидите в
следующих разделах, задания и сообщения определяются отдельно и могут
быть выполнены независимо. Тем не менее, задания и сообщения могут быть
также взаимодополняющими процессами, поскольку задание может вызывать
сообщение, и наоборот.
Рассмотрим пример. Задание А выполняется для информирования админист-
ратора системы о неожиданном заполнении протокола транзакций, что пре-
вышает допустимый лимит. Когда происходит это событие, вызывается свя-
занное с ним сообщение и в качестве реакции системный администратор мо-
жет быть проинформирован по электронной почте или сообщением на
пейджер.
Другим критическим событием является сбой при выполнении резервного
копирования протокола транзакций. Когда это происходит, то связанное со-
общение может вызывать задание, которое усекает протокол транзакций. Это
Глава 18. Система автоматизации задач администрирования 481
может быть подходящей реакцией, если причиной сбоя резервного копирова-
ния является переполнение (полное заполнение) протокола транзакций.
В других случаях (например, когда полностью заполняется устройство, на
которое осуществляется резервное копирование) подобное усечение не даст
никакого эффекта. Этот пример показывает тесную связь, которая может су-
ществовать между событиями, которые имеют похожие симптомы.
SQL Server Agent позволяет вам автоматизировать различные администра-
тивные задачи. Прежде чем вы сможете это сделать, должен быть запущен
этот процесс. SQL Server Agent может быть запущен тем же образом, что и
сервис MSSQLSERVER. Более подробную информацию см. в главе 2.
Как уже было сказано, вызов сообщения также может включать передачу
сведений об одном или более операторах по электронной почте с использова-
нием Database Mail. Database Mail является решением на уровне предприятия,
позволяющим отправлять сообщения по электронной почте от Database
Engine. Используя Database Mail, ваши приложения могут отправлять пользо-
вателям сообщения по электронной почте. Эти сообщения могут содержать
результаты запросов, а также включать файлы любого ресурса вашей локаль-
ной сети.
Создание заданий и операторов
Обычно существуют три действия, которые вы используете, если собираетесь
создать задание:
1. Создайте задание и его шаги.
2. Создайте расписание выполнения задания, если задание не должно выпол-
няться по запросу.
3. Сообщите операторам о статусе этого задания.
В следующих разделах объясняются эти действия с использованием примера.
Создание задания и его шагов
Задание может содержать один или более шагов. Существуют различные
способы, которыми можно определить шаг задания. Следующий список со-
держит некоторые из них.
♦ Использование операторов Transact-SQL. Многие из шагов задания со-
держат операторы Transact-SQL. Например, если вам нужно автоматизи-
ровать резервное копирование базы данных или протокола транзакций, вы
используете оператор backup database или оператор backup log соответст-
венно.
482 Часть III. SQL Server, системное администрирование
♦ Операционная система (CmdExec). Некоторые другие задания могут по-
требовать выполнения утилиты SQL Server, которая обычно запускается
вместе с соответствующей командой. Например, если вы собираетесь ав-
томатизировать перемещение данных из вашего сервера базы данных в
файл данных или наоборот, вы можете использовать утилиту Ьср.
♦ Вызов программы. В качестве еще одной альтернативы может быть нуж-
ным выполнение программы, которая была разработана с использованием
Visual Basic или любого другого языка программирования. В этом случае
вы всегда должны включать в путь букву устройства в текстовом поле
Command при запуске такой программы. Это необходимо, потому что
SQL Server Agent должен найти выполняемый файл.
Если задание содержит несколько шагов, важно определить, какие действия
должны быть выполнены в случае сбоя. Обычно Database Engine запускает
следующий шаг задания, если предыдущий шаг был успешно выполнен. Од-
нако если шаг задания был выполнен со сбоем, любые следующие шаги этого
задания не будут выполняться. Поэтому; вы всегда должны указывать, как
часто каждый шаг должен повторяться в случае возникновения сбоя. И, разу-
меется, необходимо устранить причину ненормального завершения шага за-
дания (очевидно, что повторное выполнение задания всегда будет приводить
к той же самой ошибке, если ее не исправить).
Замечание________________________________________________________
Количество попыток зависит от типа и содержания выполняемого шага задания
(пакет, команда или программа приложения).
Вы можете создавать задание, используя:
♦ SQL Server Management Studio;
♦ системные хранимые процедуры (sp_add_job или sp_add_jobstep).
SQL Server Management Studio используется в данном примере, где создается
задание, которое выполняет резервное копирование базы данных sample. Для
создания этого задания соединитесь с экземпляром Database Engine в Object
Explorer, а затем разверните этот экземпляр. Разверните узел SQL Server
Agent, щелкните правой кнопкой мыши по узлу Jobs, а затем выберите пункт
New Job. (SQL Server Agent должен быть запущен.) Появится диалоговое ок-
но New Job (рис. 18.2). На странице General введите имя задания в поле
Name. Как вы можете видеть на рис. 18.2, для задания резервного копирова-
ния базы данных sample указано имя backup_sample.
В поле Owner щелкните мышью по кнопке с многоточием (...) и выберите
владельца, ответственного за выполнение этого задания. Из раскрывающего-
ся списка Category выберите категорию, которой принадлежит задание.
Глава 18. Система автоматизации задач администрирования
В примере на рис. 18.2 задание backup_sample не имеет категории, а вла-
дельцем является пользователь, который создал это задание. При желании вы
можете добавить описание задания в поле Description.
Рис. 18.2. Диалоговое окно New Job
Замечание_____________________________________________________
Если вы должны управлять несколькими заданиями, рекомендуется указывать
для них категории. Это особенно полезно, если ваши задания выполняются в
многосерверном окружении.
Установите флажок Enabled, чтобы сделать задание доступным для выпол-
нения.
Замечание_____________________________________________________
Все задания являются доступными по умолчанию. SQL Server Agent делает за-
дания недоступными, если расписание задания было определено в момент
времени, которое уже прошло, или для повторяющегося выполнения с датой
484
Часть III. SQL Server: системное администрирование
завершения, которая также прошла. В обоих случаях вы должны вручную за-
дать доступность задания.
Каждое задание должно иметь один или более шагов. Поэтому в дополнение
к указанию свойств задания вы должны создать, по меньшей мере, один шаг
прежде, чем сохраните это задание. Для определения одного или более шагов
щелкните по странице Steps в диалоговом окне New Job и нажмите кнопку
New. Появится диалоговое окно New Job Step (рис. 18.3). Введите имя для
шага задания. В данном примере шаг называется backup. В раскрывающемся
списке Туре выберите Transact-SQL script (T-SQL), потому что резервное
копирование базы данных sample будет выполняться с помощью оператора
Transact-SQL backup database.
Рис. 18.3. Диалоговое окно New Job Step, страница General
В раскрывающемся списке Database выберите базу данных master, потому
что эта системная база данных должна быть текущей базой данных, если вы
хотите выполнять резервное копирование любой базы данных.
Глава 18. Система автоматизации задач администрирования 485
Вы можете вручную ввести оператор Transact-SQL в поле Command или вы-
звать его из файла. В первом случае введите следующие операторы:
EXEC sp_addumpdevice 'disk', 'backup_filel', 'C:\sample_backup'
BACKUP DATABASE sample TO backupfilel
Как вы, вероятно, догадались, системная процедура sp_addumpdevice добавля-
ет устройство для резервной копии в экземпляр Database Engine. Для вызова
оператора Transact-SQL из файла нажмите кнопку Open и выберите файл.
Синтаксис оператора (операторов) может быть проверен, если нажать кнопку
Parse.
Создание расписания задания
Каждое созданное задание может быть выполнено по запросу (т. е. вручную
пользователем) или при использовании одного или более расписаний. Зада-
ние из расписания может появиться в указанное время или с заданной перио-
дичностью.
Замечание______________________________________________________
Каждое задание может иметь множество расписаний. Например, резервное ко-
пирование протокола транзакций производственной базы данных может выпол-
няться в двух различных расписаниях в зависимости от времени дня. Это озна-
чает, что во время пика деловой активности вы можете выполнять резервное
копирование чаще, чем в другое время дня.
Чтобы создать расписание для существующего задания с использованием
SQL Server Management Studio, выберите страницу Schedules в диалоговом
окне Job Properties и нажмите кнопку New. (Диалоговое окно Job Properties
является тем же самым диалоговым окном, что и на рис. 18.2.) Если диалого-
вое окно Job Properties неактивно, разверните узел SQL Server Agent, а за-
тем — узел Jobs и щелкните по заданию, с которым вы собираетесь работать.
Замечание______________________________________________________
Если вы получите предупреждение "The On Access action of the last step will be
changed from Get Next Step to Quit with Success" ("Действие On Access послед-
него шага будет изменено с Get Next Step на Quit with Success"), нажмите кноп-
ку Yes.
Появится диалоговое окно New Job Schedule (рис. 18.4).
Для базы данных sample укажите в расписании, что резервное копирование
выполняется каждую пятницу в 20:00. Чтобы это сделать, введите имя в поле
Name и выберите значение Recurring в раскрывающемся списке Schedule
type. В разделе Frequency в раскрывающемся списке Occur выберите значе-
ние Weekly и отметьте флажок Friday. В разделе Daily frequency установите
переключатель Occurs once at и введите время (20:00:00). В разделе Duration
486
Часть III. SQL Server: системное администрирование
выберите начальную дату из раскрывающегося списка Start date, а затем ус-
тановите переключатель End date и из соответствующего раскрывающегося
списка выберите конечную дату. (Если в расписании задания не должно быть
конечной даты, установите переключатель No end date.)
Рис. 18.4. Диалоговое окно New Job Schedule
Операторы уведомлений о состоянии задания
Когда задание завершается, возможно использование некоторых методов
формирования уведомлений. Например, вы можете указать системе о необ-
ходимости записать соответствующее сообщение в протокол приложения
Windows, рассчитывая на то, что системный администратор время от времени
читает этот протокол. Лучшим выбором является явное использование одно-
го или более операторов для отправки уведомлений по электронной почте
или на пейджер и/или использование команды net send.
Прежде чем назначать оператор заданию, вы должны создать для него запись.
Для создания оператора с использованием SQL Server Management Studio
Глава 16. Система автоматизации задач администрирования 487
разверните узел SQL Server Agent, щелкните правой кнопкой мыши по узлу
Operators, а затем — по New Operator. Появится диалоговое окно New
Operator (рис. 18.5). На странице General в поле Name введите имя операто-
ра. Укажите один или более методов выполнения этим оператором уведомле-
ний (через электронную почту, на пейджер или адрес net send). В разделе
Pager on duty schedule введите рабочие часы оператора.
Рис. 18.5. Диалоговое окно New Operator
Для извещения одним или более операторами после завершения задания
(успешного или неуспешного) вернитесь к диалоговому окну задания Job
Properties, выберите страницу Notifications (рис. 18.6) и отметьте соответст-
вующие флажки. Помимо извещения по электронной почте, пейджеру и ис-
пользования команды net send в этом диалоговом окне вы также найдете оп-
ции для записи сообщения в протокол приложения Windows и/или удаления
задания.
488
Часть III. SQL Server: системное администрирование
Рис. 18.6. Диалоговое окно Job Properties, страница Notifications
Просмотр протокола истории задания
Система базы данных хранит информацию, связанную со всеми действиями
задания, в системной таблице sysjobhistory системной базы данных msdb.
Поэтому данная таблица представляет протокол истории заданий вашей сис-
темы. Вы можете просматривать информацию в этой таблице, используя SQL
Server Management Studio. Чтобы это сделать, разверните узел SQL Server
Agent, затем — узел Jobs, щелкните правой кнопкой мыши по заданию и вы-
берите пункт View History. Диалоговое окно Log File Viewer покажет прото-
кол истории задания.
Каждая строка протокола истории задания отображается в детальной панели,
которая содержит, помимо прочего, следующую информацию:
♦ дату и время выполнения шага задания;
♦ завершился ли шаг задания успешно или неудачно;
Гпава 18. Система автоматизации задач администрирования
♦ операторы, которым было передано уведомление;
♦ длительность задания;
♦ ошибки или сообщения, связанные с шагом задания.
По умолчанию максимальный размер протокола истории заданий составляет
1000 строк, тогда как количество строк для конкретного задания имеет огра-
ничение 100. (Протокол истории задания автоматически очищается, когда
достигается максимальное количество строк.) Если вы хотите хранить ин-
формацию о каждом задании, и ваша система имеет несколько заданий, уве-
личьте размер протокола истории заданий и/или количество строк на одно
задание. Используя SQL Server Management Studio, щелкните правой кнопкой
мыши по узлу SQL Server Agent и выберите пункт Properties. В диалоговом
окне SQL Server Agent Properties выберите страницу History и введите но-
вые значения для максимального размера протокола истории заданий и мак-
симальное количество строк истории заданий для одного задания. Вы также
можете отметить Automatically remove agent history и выбрать интервал
времени, когда протоколы должны быть удалены.
Предупреждающие сообщения
Информация о выполнении заданий и сообщения об ошибках системы сохра-
няются в протоколе приложений Windows. SQL Server Agent читает этот про-
токол и сравнивает хранимые сообщения с предупреждающими сообщения-
ми (alert), определенными для системы. Если найдено соответствие, SQL
Server Agent выдает предупреждающее сообщение. Поэтому предупреждаю-
щие сообщения могут быть использованы для ответа на потенциальные про-
блемы (такие как переполнение протокола транзакций), различные системные
ошибки или ошибки, определенные пользователем. Прежде чем объяснять,
как вы можете создавать предупреждающие сообщения, в этом разделе рас-
сматриваются сообщения о системных ошибках и два протокола - - протокол
ошибок SQL Server Agent и протокол приложений Windows, которые исполь-
зуются для перехвата всех системных сообщений (и, следовательно, боль-
шинства ошибок).
Сообщения об ошибках
Системные ошибки объединяются в четыре отдельные группы. Database
Engine предоставляет обширную информацию о каждой ошибке. Эта инфор-
мация структурирована и включает:
♦ уникальный номер сообщения об ошибке;
♦ дополнительный номер в диапазоне от 0 до 25, который представляет сте-
пень уровня ошибки;
490 Часть III. SQL Server: системное администрирование
♦ номер строки, который указывает строку, в которой произошла ошибка;
♦ текст ошибки.
Замечание________________________________________________________
Текст ошибки не только описывает обнаруженную ошибку, он также может со-
держать рекомендации, как разрешить проблему, что может оказаться очень
полезным пользователю.
В примере 18.1 выдается запрос к таблице, которая не существует в базе дан-
ных sample.
j Пример 18.1
USE sample;
SELECT * FROM authors;
Результат:
Msg 208, Level 16, State 1, Line 2
Invalid object name 'authors'. (Неверное имя объекта 'authors')
Все сообщения об ошибках хранятся в системной таблице sysmessages базы
данных master. Для просмотра информации из этой таблицы используйте
представление просмотра каталогов sys.messages. Тремя наиболее важными
столбцами ЭТОГО представления ЯВЛЯЮТСЯ message_id, severity И text.
Каждый уникальный номер ошибки имеет соответствующее сообщение об
ошибке. (Текст сообщения хранится в столбце text, а соответствующий но-
мер ошибки помещается в столбец message id представления просмотра ката-
логов sys.messages.) В примере 18.1 сообщение, связанное с несуществую-
щим или неправильно записанным объектом базы данных, соответствует но-
меру ошибки -208.
Степень уровня ошибки (столбец severity представления просмотра катало-
гов sys.messages) представлена в форме числа в диапазоне от 0 до 25. Уровни
между 0 и 10 являются просто информационным сообщением, где ничего не
нужно исправлять. Все уровни от 11 до 16 указывают на различные про-
граммные ошибки и могут быть разрешены пользователем. Значения 17 и 18
указывают на ошибки программного обеспечения и оборудования, которые
обычно не завершают выполнение процесса. Все ошибки со степенью уровня
от 19 и выше являются фатальными системными ошибками. Соединение про-
граммы, сгенерировавшей подобную ошибку, закрывается, а ее процесс будет
затем удален.
Сообщения, связанные с программными ошибками (т. е. с уровнем между 11
и 16), отображаются только на экране. Все системные ошибки (ошибки со
степенью 19 и выше) также записываются и в протокол.
Гпава 18. Система автоматизации задач администрирования 491
В порядке разрешения ошибки вам обычно нужно прочесть подробное опи-
сание соответствующей ошибки. Вы также можете найти детальные описания
ошибок в документе Books Online.
Сообщения системных ошибок записываются в протокол ошибок SQL Server
Agent и в протокол приложений Windows. Следующие два раздела описыва-
ют эти два компонента.
Протокол ошибок SQL Server Agent
SQL Server Agent создает протокол ошибок, в который по умолчанию запи-
сываются предупреждения и ошибки. Следующие предупреждения и ошибки
отображаются в этом протоколе:
♦ предупреждающие сообщения, которые предоставляют информацию о по-
тенциальных проблемах;
♦ сообщения об ошибках, которые обычно требуют вмешательства систем-
ного администратора.
Система поддерживает до девяти протоколов ошибок SQL Server Agent. Те-
кущий протокол называется Current, тогда как другие протоколы имеют
расширение, которое указывает относительный возраст протокола. Например,
Archive #1 определяет самый последний архив протокола ошибок.
Протокол ошибок SQL Server Agent является важным источником информа-
ции для системного администратора. С помощью этого протокола он может
отслеживать использование системы и определять, какие корректирующие
действия следует выполнить.
Для просмотра протокола ошибок SQL Server Agent из SQL Server
Management Studio разверните экземпляр в Object Explorer, разверните узлы
SQL Server Agent и Error Logs. Щелкните мышью по одному из файлов,
чтобы просмотреть желаемый протокол. Появятся подробности протокола
в детальной панели диалогового окна Log File Viewer.
Протокол приложений Windows
Database Engine также записывает системные сообщения в протокол прило-
жений Windows. Протокол приложений Windows является местом для всех
сообщений для операционных систем Windows, он располагается там, где
хранятся все сообщения приложения. Вы можете просмотреть протокол при-
ложений Windows, используя Windows Event Viewer.
Просмотр ошибок в протоколе приложений Windows имеет несколько пре-
имуществ по сравнению с их просмотром в протоколе ошибок SQL Server
Agent. Наиболее важным является то, что протокол приложений Windows
предоставляет дополнительный компонент для поиска нужных строк.
17 Зак. 1141
492 Часть III. SQL Server: системное администрирование
Для просмотра информации, хранящейся в протоколе приложений Windows,
щелкните мышью по Start | Control Panel | Administrative Tools | Event
Viewer. В окне Event Viewer вы можете выбирать сообщения системы, служ-
бы безопасности и приложений.
Определение предупреждающих сообщений
для обработки ошибок
Предупреждающее сообщение (alert) может быть определено в качестве отве-
та на конкретный номер ошибки или на группу ошибок, которые принадле-
жат заданной степени ошибки кода. Кроме того, определение предупреж-
дающего сообщения для конкретной ошибки отличается от определения для
системных ошибок и ошибок, определенных пользователем. (Создание пре-
дупреждающих сообщений для определенных пользователем ошибок описы-
вается далее в этой главе.)
В оставшейся части этого раздела показано, как вы можете создавать преду-
преждающие сообщения, используя SQL Server Management Studio.
Создание предупреждающих сообщений
для системных ошибок
Пример 13.5, где одна транзакция имела взаимную блокировку с другой тран-
закцией, был использован для того, чтобы показать, как создать предупреж-
дающее сообщение о номере системной ошибки. Если транзакция входит во
взаимную блокировку с другой транзакцией, то пострадавшая транзакция
должна быть выполнена снова. Это можно сделать, помимо других способов,
и при помощи предупреждающих сообщений.
Для создания предупреждающего сообщения о взаимной блокировке (и для
любой другой ситуации) разверните узел SQL Server Agent, щелкните пра-
вой кнопкой мыши по узлу Alerts и выберите пункт New Alert. В диалоговом
окне New Alert (рис. 18.7) в поле Name введите имя сообщения, выберите
тип сообщения (SQL Server event alert) и из раскрывающегося списка
Database name выберите все базы данных— <all databases>. Установите
переключатель Error number и введите 1205. (Этот номер ошибки указывает
на проблему взаимной блокировки, где текущий процесс был выбран в каче-
стве "потерпевшей стороны").
Второй шаг определяет реакцию на предупреждающее сообщение. В том же
диалоговом окне щелкните по странице Response (рис. 18.8). Вначале от-
метьте флажок Execute job, а затем выберите задание, которое будет выпол-
няться при появлении предупреждающего сообщения. (Здесь в примере оп-
ределяется новое задание с именем deadlock_all_db, которое заново запуска-
493
Глава 18. Система автоматизации задач администрирования
ет неудачную транзакцию.) Установите флажок Notify operators, а затем в
списке Operator list выберите операторы и методы для извещения (электрон-
ная почта, пейджер и/или команда net send).
Рис. 18.7. Диалоговое окно New Alert, страница General
Замечание_______________________________________________
В предыдущем примере предполагается, что "потерпевший" процесс будет за-
вершен. Фактически, после получения ошибки взаимной блокировки 1205 про-
грамма заново запускает сбойную транзакцию по своему усмотрению.
Создание предупреждающих сообщений
для группы ошибок с одинаковым уровнем ошибки
Вы также можете определить предупреждающее сообщение, которое будет
возникать в качестве ответа на уровень ошибки. Каждая системная ошибка
имеет соответствующий уровень, который является числом между 0 и 25.
494
Часть III. SQL Server: системное администрирование
Рис. 18.8. Диалоговое окно New Alert, страница Response
Чем выше уровень, тем серьезнее ошибка. Ошибки с уровнем от 20 до 25
являются фатальными ошибками. Ошибки с уровнем от 19 до 25 записыва-
ются в протокол приложения Windows.
Замечание____________________________________________________
Всегда определяйте уведомляющий оператор при возникновении фатальной
ошибки.
В качестве примера того, как вы можете создавать предупреждающие сооб-
щения для различных степеней ошибки, рассмотрим использование SQL
Server Management Studio для создания конкретного предупреждающего со-
общения для степени 25. Вначале разверните узел SQL Server Agent, щелк-
ните правой кнопкой мыши по узлу Alerts, а затем выберите пункт New
Alert. В поле Name введите имя этого предупреждающего сообщения (на-
пример, Severity 25 errors). В поле Туре выберите SQL Server event alert. Из
раскрывающегося списка Database name выберите базу данных sample. Уста-
новите переключатель Severity и выберите 025 — Fatal Error.
Гпава 18. Система автоматизации задач администрирования 495
На странице Response введите один или более операторов для уведомлений
по электронной почте, пейджеру и/или командой net send при появлении
ошибки со степенью 25.
Создание предупреждающих сообщений для ошибок,
определенных пользователем
В дополнение к предупреждающим сообщениям для системных ошибок вы
можете создавать предупреждающие настраиваемые сообщения об ошибках
для отдельных приложений базы данных.
Если вы хотите создать предупреждающие сообщения для определенных
пользователем ошибок, вам нужно выполнить следующие шаги:
1. Создать сообщение об ошибке.
2. Вызвать ошибку в приложении базы данных.
3. Определить предупреждающее сообщение на сообщение об ошибке.
Пример является лучшим способом иллюстрации создания подобного преду-
преждающего сообщения: сообщение выдается, если дата отгрузки про-
дукции указана более ранняя, чем дата заказа. (Определение таблицы sales
см. в главе 5.)
Замечание___________________________________________________
Здесь описаны только два первых шага, потому что предупреждающие сооб-
щения для сообщений, определенных пользователем, задаются аналогично
предупреждающим сообщениям для системных ошибок.
Создание сообщения об ошибке. Для создания определенного пользовате-
лем сообщения об ошибке вы можете использовать SQL Server Management
Studio или хранимую процедуру sp_addmessage. В примере 18.2 создается со-
общение об ошибке для данного примера с помощью хранимой процедуры
sp__addmessage.
\ Пример 18.2
sp_addmessage @msgnum=50010, @severity=16,
@msgtext= "The shipping date of a product is earlier than the order date',
@lang='us_english', @with_log='true'
Хранимая процедура sp_addmessage создает определенное пользователем со-
общение об ошибке с номером ошибки 50010 (параметр @msgnum) и уровнем 16
(параметр gseverity). Все определенные пользователем сообщения об ошиб-
ках хранятся в системной таблице sysmessages базы данных master и могут
быть просмотрены с использованием представления просмотра каталогов
496
Часть III. SQL Server: системное администрирование
sys.messages. Номер ошибки в примере 18.2 задан значением 50010, потому
что все определенные пользователем ошибки должны иметь номер больше
чем 50000. (Все номера сообщений об ошибках, меньшие, чем 50000, резерви-
руются для системы.)
Для каждого определенного пользователем сообщения об ошибке вы можете
при желании задать язык, в котором отображается это сообщение, используя
параметр @1апд. Эта спецификация может быть необходимой, если на вашем
компьютере выполнена инсталляция с несколькими языками. (Когда язык не
указан, языком сессии будет язык по умолчанию.)
По умолчанию определенные пользователем сообщения не записываются
в протокол приложений Windows. С другой стороны, вы должны записы-
вать сообщения в этот протокол, если хотите для него вызывать предупреж-
дающее сообщение. Если вы в системной процедуре sp_addmessage установи-
те параметр @with_log в true, то сообщение будет записываться в этот про-
токол.
Вызов ошибки с помощью триггера. Для вызова ошибки из приложения
базы данных вы используете оператор raiserror. Этот оператор возвращает
определенное пользователем сообщение об ошибке и устанавливает систем-
ный флаг в глобальной переменной @@еггог. Вы также можете обработать со-
общения об ошибках, используя блоки try/catch.
В примере 18.3 создается триггер t date comp, который возвращает опреде-
ленную пользователем ошибку 50010, если дата отгрузки продукции более
ранняя, чем дата заказа.
Замечание___________________________________________________________
Для выполнения примера 18.3 должна существовать таблица sales (см. при-
мер 5.21).
| Пример 18.3
USE sample;
GO
CREATE TRIGGER t_date_comp
ON sales
FOR INSERT AS
DECLARE @order_date DATE
DECLARE @shipped_date DATE
SELECT @order_date = order_date, @shipped_date = ship_date
FROM INSERTED
IF @order_date > @shipped_date
RAISERROR (50010, 16, -1)
Глава 18. Система автоматизации задач администрирования 497
Теперь если вы добавляете следующую строку в таблицу sales, где дата от-
грузки продукции более ранняя, чем дата заказа
INSERT INTO sales VALUES (1, '01.01.2007', '01.01.2006')
то система вернет определенное пользователем сообщение об ошибке:
Msg 50010, Level 16, State 1, Procedure t_date_comp. Line 8
Резюме
Database Engine позволяет вам автоматизировать и ускорить многие админи-
стративные задачи, такие как резервное копирование базы данных, пересылка
данных, поддержка индексов. Для выполнения таких задач должен быть за-
пущен на выполнение SQL Server Agent.
Для автоматизации задачи вы должны выполнить несколько шагов:
♦ создать задание;
♦ создать операторы;
♦ создать предупреждающие сообщения.
Задание и задача являются синонимами, так что, когда вы создаете задание,
вы создаете конкретную задачу, которую хотите автоматизировать. Самым
простым способом создания задания является использование SQL Server
Management Studio, который позволяет вам определять один или более шагов
задания и создавать расписание их выполнения.
Когда задание завершается (успешно или неудачно), вы можете отправить
сообщения одному человеку или большему количеств}' людей, используя со-
ответствующие операторы. Точно так же общим способом создания операто-
ров является использование SQL Server Management Studio.
Предупреждающие сообщения определяются отдельно и могут также выпол-
няться независимо от заданий. Предупреждающее сообщение может обраба-
тывать отдельные системные ошибки, ошибки, определенные пользователем,
или группы ошибок, принадлежащих одному из 25 уровней ошибок.
В следующей главе рассматривается репликация данных.
Упражнения
{ Упражнение 18.1
Назовите несколько задач администрирования, которые могут быть автома-
тизированы.
498 Часть III. SQL Server: системное администрирование
j Упражнение 18.2
Вы хотите выполнять резервное копирование протокола транзакций вашей
базы данных каждый час во время пика деловой активности и каждые четыре
часа в остальное время. Что вы должны сделать?
I Упражнение 18.3 .
Вы собираетесь тестировать производительность вашей производственной
базы данных относительно блокировок и хотите знать, бывает ли так, что
время ожидания завершения блокировки превышает 30 секунд. Как автома-
тически вы можете получить сообщение, когда происходит это событие?
i Упражнение 18.4
Определите все части сообщения об ошибке SQL Server.
j Упражнение 18.5
Какие столбцы являются наиболее важными в представлении отображения
каталогов sys.messages, которые относятся к ошибкам?
ГЛАВА 19
€b
Репликация данных
Кроме распределенных транзакций, средства репликации данных являются
еще одним способом получения доступа к окружению распределенных дан-
ных. Общее обсуждение этих двух методов проводится в начале этой главы.
После этого вводятся элементы репликации и описываются существующие
типы репликации. Последняя часть этой главы посвящена, различным аспек-
там управления репликациями.
Распределенные данные
Сегодня рынок усиливает требования к большинству компаний, заставляя их
сделать так, чтобы их компьютеры (и выполняющиеся на них приложения)
фокусировались на бизнесе и на их покупателях. Как результат, данные, ис-
пользуемые этими приложениями, должны быть доступны в любом месте и в
любое время. Подобная среда для данных может быть предоставлена не-
сколькими базами данных, которые включают множество копий одной и той
же информации.
Переезжающие с места на место продавцы представляют прекрасный пример
того, как используется среда распределенных данных. В течение дня прода-
вец обычно использует дорожный компьютер для запроса всей необходимой
информации из базы данных (цены и существование продуктов, например)
для информирования на месте покупателей. Позже, в номере отеля, продавец
снова использует дорожный компьютер — на этот раз для пересылки данных
(о проданных продуктах) в штаб-квартиру фирмы.
По этому сценарию вы можете видеть, что среда распределенных данных
имеет несколько преимуществ по сравнению с централизованной обработкой
данных:
500
Часть III. SQL Server: системное администрирование
♦ данные непосредственно доступны людям, которым они нужны, и тогда,
когда эти данные нужны;
♦ система позволяет локальному пользователю автономно оперировать дан-
ными; 4
♦ система сокращает сетевой трафик;
♦ система делает безостановочный процесс дешевле.
С другой стороны, среда распределенных данных является гораздо более
сложной, чем соответствующая централизованная модель, и поэтому требует
больше сил на планирование и администрирование.
Методы распределения данных
Существуют два основных метода распределения данных на множество сер-
веров базы данных:
♦ распределенные транзакции;
♦ репликация данных.
Распределенная транзакция — это транзакция, где все изменения во всех раз-
мещениях (где хранятся распределенные данные) собираются вместе и вы-
полняются синхронно. Системы распределенных баз данных используют ме-
тод, называемый двухфазовым подтверждением для реализации распреде-
ленных транзакций.
Каждая база данных, вовлеченная в распределенную транзакцию, имеет соб-
ственную технику восстановления, которая используется в случае ошибки.
(Помните, что все операторы внутри транзакции либо выполняются в своей
неделимости, либо вместе отменяются.) Менеджер глобального восстановле-
ния (называемый координатором) координирует обе фазы распределенного
процесса.
На первой фазе этого процесса координатор проверяет, все ли участвующие
сайты готовы выполнять их часть распределенной транзакции. Вторая фаза
состоит из фактического выполнения транзакции на всех участвующих сай-
тах. В течение этого процесса любая ошибка на любом сайте приводит к то-
му, что координатор останавливает транзакцию. В этом случае он отправляет
сообщение каждому менеджеру локального восстановления, чтобы он отме-
нил ту часть транзакции, которая уже была выполнена на этом сайте.
Замечание______________________________________________________
Microsoft Distributed Transaction Coordinator (DTC) поддерживает распределен-
ные транзакции с использованием двухфазового подтверждения.
В течение процесса репликации данных копии данных распределяются от
исходной базы данных к одной или более целевым базам данных, размещен-
Глава 19. Репликация данных
501
ным на отдельных компьютерах. По этой причине репликация данных отли-
чается от распределенных транзакций в двух аспектах: промежутком времени
и задержкой по времени.
В отличие от метода распределенных транзакций, где все данные являются
одними и теми же на всех участвующих сайтах, репликация данных позволя-
ет сайтам иметь различные данные в одно и то же время. Кроме.того, репли-
кация данных является асинхронным процессом. Это означает, что существу-
ет некоторая задержка по времени, когда все копии данных становятся оди-
наковыми на всех участвующих в процессе сайтах. (Эта задержка может
изменяться в диапазоне от единиц секунд до нескольких дней или недель.)
Выбор метода распределения данных
Репликация данных в большинстве случаев является лучшим решением, чем
использование распределенных транзакций, потому что она дешевле и на-
дежнее. Эксперименты с двухфазовым подтверждением транзакций показали,
что администрирование становится более сложным при увеличении участ-
вующих в этом процессе сайтов. Кроме того, увеличение участвующих сай-
тов уменьшает надежность, потому что вероятность того, что локальная часть
распределенной транзакции завершится со сбоем, увеличивается при увели-
чении количества узлов. (Если одна локальная часть дает сбой, то вся распре-
деленная транзакция также даст сбой.)
Другой причиной использования репликации данных вместо централизации
данных является производительность: клиенты сайта, где проверялась репли-
кация данных, имели повышенную производительность, потому что у них
была возможность получать доступ к данным локально, а не при использова-
нии сети для соединения с центральным сервером базы данных.
Общие сведения о репликации
Вообще, репликация основывается на двух различных концепциях;
♦ использование протокола транзакций;
♦ использование триггеров.
Как уже было сказано в главе 13, Database Engine хранит все значения изме-
ненных строк (значения как "до", так и "после") в системных файлах, назы-
ваемых протоколами транзакций. Если для выбранных строк нужно выпол-
нить репликацию, система запускает новый процесс, который читает данные
из протокола транзакций и отправляет их одной или более целевым базам
данных.
Другой метод основан на триггерах. Изменение таблицы, содержащей дан-
ные, для которых должна быть выполнена репликация, вызывает соответст-
502
Часть III. SQL Server: системное администрирование
вуюший триггер, который по порядку создает новую таблицу с данными и
запускает процесс репликации.
Обе концепции имеют как преимущества, так и недостатки. Репликация, ос-
нованная на протоколе, характеризуется улучшенной производительностью,
поскольку процесс, который читает данные из протокола транзакций, выпол-
няется асинхронно и оказывает очень небольшое влияние на производитель-
ность всей системы. С другой стороны, реализация репликации, основанной
на протоколе транзакций, является весьма сложной для компаний, создаю-
щих системы баз данных, потому что система базы данных должна не только
управлять дополнительными процессами и буферизацией, но и разрешать
проблемы одновременного доступа между системой и процессами реплика-
ции, которые обращаются к протоколу транзакций.
Замечание____________________________________________________
Database Engine использует обе концепции: метод протокола транзакции для
процесса репликации на основе транзакций и триггеры для слияния обработан-
ных репликаций. Обработка транзакций и слияние репликаций подробно опи-
сываются далее в этой главе.
Издатели, распространители и подписчики
Репликация Database Engine основывается на так называемой метафоре изда-
тель-подписчик. Эта метафора описывает различные роли, которые могут
играть серверы в процессе репликации.
Один или более серверов публикуют данные, на которые могут подписывать-
ся другие серверы. Между ними существует распространитель, который со-
храняет изменения и передает их дальше (подписчикам). Следовательно, узел
может иметь три роли в сценарии репликации.
♦ Издатель (или публикующий сервер). Поддерживает свои исходные ба-
зы данных, делает данные доступными для репликации и отправляет из-
мененные данные распространителю.
♦ Распространитель (или распределяющий сервер). Получает от издателя
все изменения для данных, подлежащих репликации, сохраняет и отправ-
ляет их соответствующим подписчикам.
♦ Подписчик (или получающий сервер). Получает и сохраняет опублико-
ванные данные.
Сервер базы данных может играть несколько ролей в процессе репликации.
Например, сервер в одно и то же время может работать как издатель и как
распространитель. Этот сценарий подходит для случая с небольшими репли-
Глава 19. Репликация данных 503
кациями и с небольшим количеством подписчиков. Если же существует мно-
жество подписчиков для информации издателя, то распространитель должен
размещаться на собственном сервере. На рис. 19.1 показан сложный сцена-
рий, в котором существует множество издателей и множество подписчиков
(см. разд. "Моделирепликации" далее в этой главе).
Замечание___________________________________________________
Вы можете выполнять репликацию только для баз данных, определенных поль-
зователем.
Публикации и статьи
Единица публикуемых данных называется публикацией. Статья содержит
данные из таблицы и/или одной или более хранимых процедур. Таблица
статьи может быть целой таблицей или подмножеством данных таблицы.
Хранимая процедура статьи может содержать одну или более хранимых про-
цедур, которые существуют в базе данных на момент публикации.
Публикация содержит одну или более статей. Каждая публикация может со-
держать данные только из одной базы данных.
Замечание_______________________________________________
Публикация является основой подписки. Это означает, что вы не можете под-
писываться напрямую к статье, потому что статья всегда является частью пуб-
ликации.
504
Часть III. SQL Server: системное администрирование
Фильтр является процессом, который ограничивает информацию, создавая
подмножество. По этой причине публикация содержит один или более сле-
дующих элементов, которые задают типы статей таблицы:
♦ таблица;
♦ вертикальный фильтр;
♦ горизонтальный фильтр;
♦ комбинация вертикальных и горизонтальных фильтров.
Замечание_____________________________________________________
Существуют некоторые ограничения фильтрации данных в отношении слияния
репликаций.
Вертикальный фильтр содержит подмножество столбцов таблицы. Горизон-
тальный фильтр содержит подмножество строк таблицы.
Подписка может быть инициализирована двумя различными способами:
♦ через принудительную подписку;
♦ через подписку по запросу.
При принудительной подписке все управление созданными подписками вы-
полняется издателем в процессе определения публикации. Принудительные
подписки упрощают и централизуют управление, потому что обычный сце-
нарий репликации содержит одного издателя и множество подписчиков.
Преимуществом принудительной подписки является высокий уровень безо-
пасности, потому что процесс инициализации управляется из одного места.
С другой стороны, производительность распространителя может пострадать,
потому что полное распространение подписок выполняется немедленно.
При подписке по запросу подписчик инициализирует подписку. Подписка по
запросу является более избирательной, чем принудительная подписка, пото-
му что подписчик может выбирать публикации для подписки. В отличие от
принудительной подписки подписка по запросу должна быть использована
для публикаций с низким уровнем секретности и большим количеством под-
писчиков.
Замечание_____________________________________________________
Загрузка данных через Интернет является типичным примером подписки по за-
просу.
Типы репликации
Database Engine предоставляет следующие типы репликации, такие как:
♦ репликация транзакций;
♦ репликация мгновенного снимка;
Гпава 19. Репликация данных
505
♦ репликация слияния;
♦ одноранговая репликация.
Репликация транзакций
В репликации транзакций для репликации данных используется протокол
транзакций системы. Все транзакции, которые содержат данные, подлежащие
репликации, отмечаются как транзакции для репликации. Компонент с име-
нем Log Reader Agent отыскивает отмеченные транзакции и копирует их из
протокола транзакций издателя в баз}' данных distribution (см. далее). Дру-
гой компонент— Distribution Agent — перемещает транзакции подписчику,
где они применяются для целевых таблиц в подписанных базах данных.
Замечание____________________________________________________
Все таблицы, опубликованные с использованием репликации транзакций,
должны явно содержать первичный ключ. Первичный ключ требуется для уни-
кальной идентификации строк в опубликованной таблице, потому что строка
является единицей перемещения в репликации транзакций.
Репликация транзакций может выполнять репликацию таблиц (или части
таблиц) и одной или более хранимых процедур. Использование хранимых
процедур в репликации транзакций повышает производительность, потому
что объем данных, пересылаемых через сеть, обычно бывает значительно
меньше. Вместо репликации данных подписчику пересылаются только хра-
нимые процедуры, где они и выполняются. Вы можете сконфигурировать
время задержки синхронизации между издателем с одной стороны и подпис-
чиком с другой стороны в процессе выполнения репликации транзакций. (Все
эти изменения распространяются компонентами Log Reader Agent и Distribu-
tion Agent.)
База данных distribution является системной базой данных, которая инстал-
лируется на распределяющий сервер, когда запускается процесс репликации.
Эта база данных содержит все реплицированные транзакции из публикаций и
издателей, которые должны быть отправлены подписчикам. Это интенсивно
используется только в репликации транзакций.
Замечание____________________________________________________
Прежде чем репликация транзакций может начаться, каждому подписчику
должна быть направлена копия полной базы данных. Это осуществляется при
выполнении мгновенного снимка.
Репликация мгновенного снимка
Самый простой тип репликации (репликация мгновенного снимка) копирует
опубликованные данные от издателя всем подписчикам. (Различием между
506 Часть III. SQL Server: системное администрирование
репликацией мгновенного снимка и репликацией транзакций является то, что
в первом случае подписчику пересылаются все опубликованные данные, а во
втором случае — только измененные данные).
Репликация мгновенного снимка тесно связана с компонентом, называемым
Snapshot Agent. Этот компонент генерирует схему и данные из опубликован-
ных таблиц и сохраняет их в файлах. Схема таблицы и соответствующий
файл данных создают синхронизированный набор, который представляет
мгновенный снимок таблицы в конкретный момент времени. Создает ли
агент новые файлы мгновенных снимков каждый раз при его выполнении,
зависит от типа репликации и выбранных опций.
Замечание______________________________________________________
Репликация транзакций и репликация мгновенного снимка являются однона-
правленными репликациями, это означает, что изменения реплицируемых дан-
ных создаются только на публикующем сервере. Поэтому данные на всех полу-
чающих серверах являются данными только для чтения за исключением тех,
изменения которых были выполнены в процессе репликации.
В отличие от репликации транзакций репликация мгновенного снимка не
требует для таблиц присутствия первичного ключа. Причина очевидна: еди-
ницей пересылки в репликации мгновенного снимка является файл мгновен-
ной копии, а не строка таблицы. Другим отличием между этими двумя типа-
ми репликации является задержка во времени: репликация мгновенного
снимка выполняется периодически, что означает значительную задержку во
времени, потому что все публикуемые данные (измененные и неизмененные)
пересылаются от издателя к подписчикам.
Замечание______________________________________________________
Репликация мгновенного снимка не использует напрямую базу данных
distribution. Однако база данных distribution содержит информацию со-
стояния и другие детали, которые применяются в репликации мгновенного
• снимка.
Репликация слияния
В репликации транзакций и в репликации мгновенного снимка издатель от-
правляет данные, а подписчик их получает. (Не существует такой возможно-
сти, чтобы подписчик отправлял реплицированные данные издателю.) Репли-
кация слияния позволит издателю и подписчикам изменять реплицируемые
данные. По этой причине могут возникать конфликты в процессе репликации.
После создания публикации на публикующем сервере Snapshot Agent подго-
тавливает файлы, содержащие схему таблицы и данные, и сохраняет их в ра-
бочем каталоге на существующем распределяющем сайте. (В процессе слия-
ния репликации база данных distribution содержит только лишь состояние
Глава 19. Репликация данных
507
процесса репликации.) Затем используется синхронизирующее задание для
другого компонента— Merge Agent, который отправляет все измененные
данные на другой сайт. Помните, что Merge Agent может отправлять репли-
цированные данные как подписчикам, так и издателям. Перед тем как старту-
ет процесс пересылки, Merge Agent также сохраняет соответствующую ин-
формацию, которая позволяет отслеживать конфликты изменений.
Когда вы используете сценарий слияния репликаций, система выполняет три
важных изменения в схеме для публикуемой базы данных:
♦ она идентифицирует уникальный столбец для каждой реплицируемой
строки;
♦ добавляет несколько системных таблиц;
♦ создает триггеры для таблиц, для которых выполняется репликация дан-
ных.
Database Engine создает или находит уникальный столбец в таблице для реп-
лицируемых данных. Если базовая таблица уже содержит столбец с типом
данных uniqueidentifier и со свойством rowguidcol, то система использует
этот столбец для идентификации каждой реплицируемой строки. Если в таб-
лице не существует подобного столбца, то система добавляет столбец rowguid
с типом данных UNIQUEIDENTIFIER и свойством rowguidcol.
Замечание_______________________________________________________
Столбец uniqueidentifier может содержать множество экземпляров значе-
ний. Свойство rowguidcol дополнительно указывает, что значение столбца с
типом данных uniqueidentifier уникально идентифицирует строку в таблице.
Поэтому столбец с типом данных uniqueidentifier со свойством rowguidcol
содержит уникальное значение для каждой строки среди всех компьютеров в
сети во всем мире и поэтому гарантирует уникальность реплицируемой строки
среди множества копий таблицы издателя и подписчиков.
Добавление новых системных таблиц предоставляет способ определения и
разрешения любых конфликтов обновления. Для разрешения конфликта
Database Engine сохраняет все изменения, связанные с реплицируемыми дан-
ными, в системных таблицах слияния msmerge_contents и msmerge_tombstone И
соединяет их (используя свойство rowguid существующего столбца с типом
данных uniqueidentifier) с таблицей, которая содержит реплицируемые дан-
ные.
Database Engine для всех таблиц, содержащих реплицируемые данные, созда-
ет триггеры на всех сайтах для отслеживания изменения данных в каждой
реплицируемой строке. Эти триггеры определяют, какие были выполнены
изменения в таблице и записывают их в системные таблицы msmerge_contents
И msmerge_tombstone.
Часть III. SQL Server: системное администрирование
Выявление конфликта выполняется Merge Agent при использовании проис-
хождения столбца в системной таблице msmerge_contents. Разрешение кон-
фликта может быть выполнено на основе приоритета или на основе пользова-
теля.
Разрешение конфликта на основе приоритета означает, что любой конфликт
между новым и старым значениями в реплицируемой строке разрешается ав-
томатически на основе назначенных приоритетов. (Особым случаем метода
на основе приоритета является метод "первый побеждает", при котором пер-
вое по времени изменение реплицируемой строки становится победителем.)
Метод на основе приоритета является методом по умолчанию. Метод на ос-
нове пользователя применяет пользовательский триггер, основанный на биз-
нес-правилах, определенных администратором базы данных для разрешения
конфликтов.
Одноранговая репликация транзакций
Одноранговая репликация является еще одной формой репликации транзак-
ций, при которой каждый сервер в одно и то же время является издателем,
распространителем и подписчиком одних и тех же данных. Иными словами,
все серверы содержат одни и те же данные, но каждый сервер ответственный
за изменение собственной части данных.
Одноранговую репликацию лучше всего объяснить через пример. Предполо-
жим, что компания имеет несколько офисов филиалов в различных городах, и
каждый офисный сервер имеет такой же набор данных, что и все другие сер-
веры. С другой стороны, все данные разделены на подмножества, и каждый
офисный сервер может изменять только собственное подмножество данных.
Когда данные изменяются на одном офисном сервере, эти изменения репли-
цируются на все другие серверы (подписчики) в одноранговой сети. (Пользо-
ватели в каждом офисе могут читать данные без каких-либо ограничений.)
Преимуществами этой формы репликации являются:
♦ вся система хорошо масштабируется;
♦ вся система предоставляет высокую доступность.
Система, которая поддерживает одноранговую репликацию, хорошо масшта-
бируется, потому что каждый сервер обслуживает только локальных пользо-
вателей. (Пользователи могут изменять только те части данных, которые
принадлежат их локальному серверу. Для операций чтения все данные также
хранятся локально.)
Высокая доступность основывается на том факте, что если один или более
серверов отключаются от сети, все другие серверы могут продолжать работу,
поскольку все данные, необходимые им для операций чтения и записи, хра-
Глава 19. Репликация данных 509
нятся локально. Когда отключенный сервер снова включается в сеть, заново
стартует процесс репликации, и сервер получает все модификации данных,
которые были выполнены на других сайтах.
Определение конфликтов в одноранговой репликации. В случае одноран-
говой репликации вы можете изменять данные на любом узле. Поэтому из-
менения данных на разных узлах могут конфликтовать друг с другом. (Если
строка изменяется более чем на одном узле, то это может привести к кон-
фликту.)
Одноранговая репликация в SQL Server 2008 вводит опцию для возможности
определения конфликта в одноранговой топологии. При включенной такой
опции конфликтное изменение данных трактуется как критическая ошибка,
которая приводит к завершению Distribution Agent. В случае конфликта сце-
нарий остается в несогласованном состоянии, пока конфликт не будет разре-
шен и данные не будут приведены в согласованное состояние на всех участ-
вующих серверах.
Замечание_______________________________________________________
Вы можете включить определение конфликтов, используя системные процеду-
ры sp_addpublication или sp_configure_peerconflictdetection.
Конфликты в одноранговой репликации определяются хранимыми процеду-
рами, которые применяют изменения к каждому узлу, основываясь на скры-
том столбце в каждой опубликованной таблице. Этот скрытый столбец хра-
нит идентификатор, комбинируемый вместе с идентификатором, который вы
указываете для каждого узла, и с версией строки. Эти процедуры выполняют-
ся из Distribution Agent, они применяют операции добавления, изменения и
удаления с других участников сети. Если одна из процедур определяет кон-
фликт при чтении значений скрытого столбца, то она вызывает ошибку
22 815.
Замечание_______________________________________________________
Скрытый столбец может быть доступен только тому пользователю, который со-
единился через Dedicated Administrator Connection (см. главу 2).
Когда появляется конфликт одноранговой репликации, то выдается преду-
преждающее сообщение "Peer-to-peer conflict detection alert". Вы должны
сконфигурировать это предупреждающее сообщение так, чтобы вы были со-
ответствующим образом проинформированы при появлении конфликта.
(В предыдущей главе объяснялось, как может быть сконфигурировано пре-
дупреждающее сообщение, и обсуждалось использование операторов инфор-
мирования.) В документации Books Online описывается несколько подходов
для обработки возникших конфликтов.
510 Часть III. SQL Server: системное администрирование
Замечание____________________________________________________
Вы должны стараться исключить конфликты в одноранговой репликации, даже
если включено определение конфликтов.
Модели репликации
В предыдущих разделах были описаны различные типы репликации, которые
использует Database Engine для распределения данных между различными
узлами. Типы репликации (транзакционная, мгновенный снимок, слияние и
одноранговая) предоставляют функциональность для обработки реплицируе-
мых данных. С другой стороны, репликационные модели используются в
компании для проектирования их собственной репликации данных. (Каждая
модель репликации может быть реализована с использованием одного или
более типов репликации). Тип репликации и репликационная модель обычно
определяются в одно и то же время.
В зависимости от требований может быть использовано несколько моделей
репликации. Тремя базовыми моделями репликации являются следующие:
♦ центральный издатель с распространителем;
♦ центральный подписчик с множеством издателей;
♦ множество издателей с множеством подписчиков.
Центральный издатель с распространителем
В модели центрального издателя с распространителем существует один изда-
тель и обычно один распространитель. Издатель создает публикации, кото-
рые распространитель распределяет нескольким подписчикам. Эта модель
является стандартной моделью.
Если объем публикуемых данных не является слишком большим, то издатель
и распространитель могут располагаться на одном сервере. В противном слу-
чае рекомендуется использование двух отдельных серверов для повышения
производительности. Если есть большой объем публикуемых данных, то рас-
пространитель обычно является узким местом в процессе. На рис. 19.2 пока-
зана модель репликации с центральным издателем и отдельным распростра-
нителем.
Публикации, созданные в этой модели и полученные подписчиком, обычно
бывают только для чтения. По этой причине в большинстве случаев реплика-
ция транзакций является предпочтительным типом репликации для этой мо-
дели, хотя здесь может быть также использована и репликация мгновенного
снимка.
Глава 19. Репликация данных
511
Центральный подписчик с множеством издателей
Сценарий, описанный в начале этой главы про путешествующего продавца,
который передает данные в главный офис, является типичным примером цен-
трального подписчика с множеством издателей. Данные собираются на цен-
тральном подписчике, и несколько издателей направляют туда свои данные.
Для этой модели вы можете использовать тип репликации транзакций или
слияния в зависимости от использования реплицируемых данных. Если изда-
тель публикует (и, значит, изменяет) одни и те же данные для подписчика, то
должна быть использована репликация слияния. Если каждый издатель имеет
для публикации собственные данные, то должна быть использована реплика-
ция транзакций или одноранговая репликация. (В этом случае опубликован-
ные таблицы будут отфильтровываться горизонтально, а каждый издатель
будет исключительным владельцем отдельного фрагмента таблицы.)
Множество издателей с множеством подписчиков
Модель репликации, в которой несколько серверов или все серверы, участ-
вующие в репликации данных, играют роль издателей, а также подписчиков,
известна как модель множества издателей с множеством подписчиков.
В большинстве случаев эта модель включает несколько распространителей,
которые обычно располагаются на каждом издателе (см. рис. 19.1).
Эта модель может быть реализована только при использовании репликации
слияния, потому что публикации изменяются на сервере издателя. Только
512 Часть III. SQL Server: системное администрирование
единственным другим способом реализации этой модели является использо-
вание распределенных транзакций с двухфазным подтверждением.
Управление репликацией
Все серверы, являющиеся участниками репликации, должны быть зарегист-
рированы. (Регистрация сервера описана в главе 3.) После регистрации серве-
ров распределяющий сервер, сервер (серверы) издателя и сервер (серверы)
подписчика должны быть настроены. Следующие разделы описывают конфи-
гурирование этих процессов с помощью соответствующих мастеров.
Конфигурирование
распределяющего и публикующего серверов
Прежде чем устанавливать публикуемые базы данных, вы должны устано-
вить распределяющий сервер и сконфигурировать распределяемые базы дан-
ных. Вы можете настроить распределяющий сервер, используя мастер
Configure Distribution Wizard. Этот мастер позволяет сконфигурировать рас-
пространитель и распределяемую базу данных и сделать доступным издателя
(издателей). При помощи этого мастера вы можете:
♦ сконфигурировать ваш сервер в качестве распространителя так, чтобы его
могли использовать другие издатели;
♦ сконфигурировать ваш сервер в качестве издателя так, чтобы он мог рабо-
тать и как собственный распространитель;
♦ сконфигурировать ваш сервер в качестве издателя, чтобы он использовал
другой сервер как распространителя.
В этом разделе показан сценарий репликации данных базы данных sample с
использованием двух экземпляров на одном и том же компьютере: NTB01112
и NTB01112MNSTANCE1. Первый будет использован в качестве издателя и
распространителя, тогда как второй будет подписчиком.
Первым шагом будет использование мастера Configure Distribution Wizard
для настройки сервера NTB01112 в качестве издателя, который в то же самое
время работает и как собственный распространитель. (Дополнительно мастер
будет создавать и базу данных distribution.)
Замечание
Для настройки распределяющего сервера и базы данных distribution вы
также можете использовать системные процедуры sp adddistributor и
sp_adddistributiondb. Процедура spadddistributor настраивает распре-
деляющий сервер путем создания новой строки в системной таблице sysservers.
Глава 19. Репликация данных
513
Процедура sp_adddistributiondb создает новую распространяемую базу дан-
ных и инсталлирует схему распространения.
Для запуска на выполнение мастера запустите SQL Server Management Studio,
разверните экземпляр, щелкните правой кнопкой мыши по узлу Replication и
выберите пункт Configure Distribution. Появится мастер Configure
Distribution Wizard. На первой странице выберите распределяющий сервер и
щелкните по кнопке Next. После этого выберите папку, где будет сохранять-
ся мгновенный снимок, полученный от издателя (издателей), которые ис-
пользуют распределяющий сервер, и щелкните по Next. На третьей странице
выберите имя распределяемой базы данных и файлы протоколов. На сле-
дующей странице включите издателя (издателей) (в этом примере — сервер
NTB01112) и выберите, нужно ли будет завершить процесс конфигурирова-
ния немедленно или требуется сгенерировать файл скрипта, который будет
запущен позже для конфигурирования распределения. Щелкните по Next. На
рис. 19.3 показан итог всех шагов, которые вы выполнили для конфигуриро-
вания сервера NTB01112 в качестве распространителя и издателя.
Рис. 19.3. Завершающая страница мастера по конфигурированию
распространителя и издателя (издателей)
Замечание______________________________________________________
Существующие на сервере издатель и распространитель могут быть отключены
при использовании Disable Publishing и Distribution Wizard. Для запуска мастера
514
Часть III. SQL Server: системное администрирование
щелкните правой кнопкой мыши по узлу Replication и выберите пункт Disable
Publishing and Distribution.
После того как вы сконфигурировали распределяющий и издательский серве-
ры, вы должны настроить процесс публикации. Это делается при помощи
мастера New Publication Wizard, о котором рассказывается в следующем раз-
деле.
Настройка публикаций
Вы можете использовать мастер New Publication Wizard для:
♦ выбора данных и объектов базы данных, для которых вы хотите выпол-
нять репликацию;
♦ фильтрации опубликованных данных таким образом, что подписчики бу-
дут получать только те данные, которые им требуются.
Предположим, что вы хотите опубликовать данные таблицы employee с сер-
вера NTB01112 на экземпляр NTB01112\1N STANCE 1, используя тип репли-
кации "мгновенный снимок". В этом случае единицей публикации является
ВСЯ таблица employee.
Для создания публикации разверните узел сервера в публикующем сервере
(NTB01112), разверните папку Replication, щелкните правой кнопкой мыши
по папке Local Publications и выберите пункт New Publication. Запустится
мастер New Publication Wizard. На первых двух страницах выберите базу
данных для издания (sample) и тип публикации (в данном случае издание
мгновенного снимка) и щелкните по кнопке Next. Затем для публикации вы-
берите, по меньшей мере, один объект и щелкните по кнопке Next (в этом
примере выберите всю таблицу employee). Мастер New Publication Wizard
также позволяет фильтровать (горизонтально или вертикально) данные, кото-
рые вы собираетесь издавать. (Этот пример будет реплицировать всю табли-
цу employee). Мгновенный снимок выбранных данных может быть инициали-
зирован немедленно и/или для него может быть создано расписание периоди-
ческого выполнения. Вы также можете завершить процесс конфигурирования
немедленно или сгенерировать файл скрипта для более позднего выполнения
создания публикации.
На следующей странице задайте установки безопасности для Snapshot Agent.
Чтобы это сделать, щелкните мышью по кнопке Security Settings и наберите
имя учетной записи пользователя Windows, под которой будет выполняться
процесс Snapshot Agent. Учетная запись должна быть введена в форме
шгя_домена\имя_учетной_ записиполъзователя. На рис. 19.4 показан итог
всех шагов, выполненных для настройки таблицы employee в качестве едини-
цы публикации.
Гпава 19. Репликация данных
515
Рис. 19.4. Завершающая страница мастера для единицы публикации
Последним шагом является конфигурирование серверов подписки, что рас-
сматривается в следующем разделе.
Конфигурирование серверов подписки
Это задача, которая связана с подписчиками, но должна быть выполнена на
издателе, имеющем возможность подписки. Используйте SQL Server
Management Studio для включения подписчика на сервере издателя. Во-
первых, разверните публикующий сервер, разверните узел Replication, щелк-
ните правой кнопкой мыши по узлу Local Subscriptions и выберите пункт
New Subscriptions. Появится мастер New Subscription Wizard. Вы можете ис-
пользовать этот мастер для:
♦ создания для публикации одного или более подписчиков;
♦ указания, где и когда будут запускаться агенты для синхронизации под-
писки.
На первой странице выберите публикацию, для которой вы собираетесь соз-
дать одного или более подписчиков, и щелкните по кнопке Next. (В этом
примере выберите публикацию employee_tab2, которая уже была сгенериро-
вана в мастере New Publication Wizard.)
516
Часть III. SQL Server: системное администрирование
На следующей странице, Distribution Agent Location, вы должны выбрать
между принудительной подпиской и подпиской по запросу (рис. 19.5). При-
нудительная подписка означает, что синхронизация подписок администра-
тивно централизована. Для этого вида репликации отметьте переключатель
Run all agents at the Distributor. Для указания распространения по запросу
отметьте переключатель Run each agent at its Subscriber. Щелкните no
кнопке Next.
Рис. 19.5. Выбор между принудительной подпиской
и подпиской по запросу
На следующей странице вы должны указать все получающие серверы. Если
получающие серверы еще не были добавлены, щелкните по Add SQL Server
Subscriber и выберите все серверы, на которые будет выполняться реплика-
ция данных. Щелкните по кнопке Next. Прежде чем вы завершите этот про-
цесс, мастер покажет вам итоговые данные, связанные с конфигурацией под-
писки (рис. 19.6).
Замечание_______________________________________________________
На рис. 19.6 используется локальная учетная запись администратора. Вместо
нее для репликации вы должны создать специально предназначенную для это-
го учетную запись.
Гпава 19. Репликация данных
517
Рис. 19.6. Завершающая страница мастера для подписчика
Резюме
Репликация данных является предпочтительным методом распределения
данных, потому что она дешевле, чем использование распределенных тран-
закций. Database Engine позволяет выбрать один из четырех возможных ти-
пов репликации (репликация мгновенного снимка, репликация транзакции,
слияние и одноранговая репликация), в зависимости от используемой вами
физической модели. Теоретически в любой модели репликации можно ис-
пользовать любой тип репликации, хотя каждая (базовая) модель имеет соот-
ветствующий тип, который используется в большинстве случаев.
Публикация является наименьшей единицей репликации. Одна база данных
может иметь множество публикаций с различными типами репликации. Од-
нако каждая публикация соответствует только одной базе данных.
Для конфигурирования процесса репликации вы должны в первую очередь
настроить распределяющий сервер и систему распределения базы данных, а
также сконфигурировать публикующий сервер (серверы). Database Engine
поддерживает эти шаги при помощи трех различных мастеров: Configure
Distribution Wizard, New Publication Wizard и New Subscription Wizard.
518 Часть III. SQL Server: системное администрирование
В следующих двух главах рассматриваются общие характеристики системы.
В главе 20 объясняется, как работает оптимизатор запросов в Database Engine,
а в главе 27 обсуждается настройка производительности. Эти главы заверша-
ют часть 77/данной книги.
Упражнения
; Упражнение 19.1
Почему вам нужен первичный ключ для репликации данных? Какой тип реп-
ликации требует наличия первичного ключа?
j Упражнение 19.2
Как вы можете ограничить сетевой трафик и/или размер базы данных?
j Упражнение 19.3
Конфликты изменений не рекомендуются. Как вы можете их минимизиро-
вать?
\ Упражнение 19.4
Когда система использует Log Reader Agent, Merge Agent и Snapshot Agent
соответственно?
ГЛАВА 20
Оптимизатор запросов
Вопросом, который обычно возникает, когда Database Engine (или любая дру-
гая система реляционной базы данных) выполняет запрос, является вопрос,
как доступ к необходимым данным и обработка этих данных в запросе может
быть выполнена с максимальной эффективностью. Компонент системы базы
данных, ответственный за такую деятельность, называется оптимизатором
запросов.
Задачей оптимизатора запросов (или просто оптимизатора) является рассмот-
рение множества возможных стратегий выполнения поиска требуемых в за-
просе данных и выбор наиболее эффективной стратегии. Выбранная страте-
гия называется планом выполнения запроса. Оптимизатор принимает свои
решения с учетом таких факторов, как: насколько велики по размерам табли-
цы, вовлеченные в запрос, какие существуют индексы и какие логические
операции (and, or, not) используются в предложении where. Обычно такие
факторы называются статистическими данными.
В начале главы вводятся фазы обработки запроса, а затем подробно объясня-
ется, как работает третья фаза — оптимизация запроса. Это составляет осно-
ву практических примеров, представленных в последующих разделах. Сле-
дом за этим вам будут представлены различные инструменты, которые вы
можете использовать для редактирования работы оптимизатора запросов.
В конце главы даются подсказки оптимизации, которые вы можете давать
оптимизатору в особых ситуациях, когда он не может найти оптимального
решения.
Фазы обработки запроса
Задачей оптимизатора является разработка наиболее эффективного плана вы-
полнения для заданного запроса. Эта задача решается с использованием сле-
дующих четырех фаз (рис. 20.1).
520
Часть III. SQL Server: системное администрирование
SELECT empjname, emp_fname
FROM employee
WHERE empno = 28559
Фаза 1: синтаксический разбор
Фаза 2: компиляция запроса
Фаза 3: оптимизация запроса
Фаза 4: выполнение запроса
emp_lname empfname
Moser Sybill
Рис. 20.1. Фазы в обработке запроса
Замечание________________________________________________________
В этой главе рассматривается оптимизатор запросов для запросов оператора
select. Оптимизатор запросов также используется для операторов insert,
update и delete. Оператор insert может содержать подзапрос, а операторы
update и delete часто содержат предложение where, которое должно быть об-
работано.
1. Синтаксический разбор (parsing). Проверяется синтаксис запроса, сам
запрос преобразуется в дерево. После этого выполняется проверка всех-
объектов базы данных, на которые в запросе приводятся ссылки. (Напри-
мер, проверяется существование всех столбцов, на которые ссылается за-
прос, и определяются их идентификаторы.) После процесса проверки
формируется окончательное дерево запроса.
2. Компиляция запроса (query compilation). Дерево запроса компилируют-
ся оптимизатором запросов.
3. Оптимизация запроса (query optimization). В качестве входных данных
оптимизатор запросов получает скомпилированное дерево запроса, кото-
рое было сгенерировано на предыдущем шаге, и рассматривает различные
стратегии доступа, прежде чем принять решение, как следует обрабаты-
вать данный запрос. Для поиска наиболее эффективного плана выполне-
ния запроса оптимизатор запросов вначале выполняет анализ запроса, в
процессе которого он отыскивает аргументы поиска и операции соедине-
ния. Затем оптимизатор выбирает индексы, которые будут использоваться.
Под конец, если существуют операции соединения, оптимизатор выбирает
Глава 20. Оптимизатор запросов 521
порядок соединений и выбирает одну из техник обработки соединений.
(Эти фазы оптимизации детально рассматриваются в следующем разделе.)
4. Выполнение запроса (query execution). После того как будет сгенериро-
ван план выполнения, он сохраняется и запрос выполняется.
Замечание____________________________________________________
Для некоторых операторов исключается синтаксический разбор и оптимизация,
если Database Engine знает, что существует только один жизнеспособный план.
(Такой процесс называется тривиальным планом оптимизации). Примером опе-
ратора, для которого может быть использован тривиальный план оптимизации,
может служить оператор insert в его простой форме.
Как работает оптимизация запроса
Как вы уже знаете из предыдущего раздела, фаза оптимизации запроса может
быть разделена на следующие фазы:
♦ анализ запроса;
♦ выбор индекса;
♦ выбор порядка операций соединения;
♦ выбор техники (техник) для обработки операций соединения.
Анализ запроса
В процессе анализа запроса оптимизатор проверяет запрос на аргументы по-
иска, использование оператора or и существование критериев соединения —
именно в этом порядке. Поскольку использование оператора or и существо-
вание критериев соединения не требуют объяснения, здесь обсуждаются
только аргументы поиска.
Аргумент поиска является частью запроса, которая ограничивает промежу-
точный результирующий набор запроса. Основным назначением аргументов
поиска является то, что они позволяют использовать существующие индексы
применительно к конкретному выражению. Вот примеры аргументов поиска:
♦ emp_fname = 'Moser';
♦ salary >= 50000;
♦ emp_fname = 'Moser' AND salary >= 50000.
Существует несколько форм выражений, которые не могут быть использова-
ны оптимизатором в качестве аргументов поиска. К первой группе принад-
лежат выражения с оператором отрицания (not, о). Точно так же, если вы
522
Часть III. SQL Server: системное администрирование
используете выражение в левой части оператора, существующее выражение
не может быть использовано в качестве аргумента поиска.
Вот примеры выражений, которые не являются аргументами поиска:
♦ NOT IN ('dl', 'd2');
♦ emp_no <>. 9031;
♦ budget * 0.59 > 55000.
Основным недостатком выражений, которые не могут быть использованы в
качестве аргументов поиска, является то, что оптимизатор не может исполь-
зовать существующие индексы в отношении выражения, чтобы повысить
производительность соответствующего запроса. Иными словами, в этом слу-
чае единственным способом доступа к данным может быть только последо-
вательное сканирование таблицы.
Выбор индекса
Идентификация аргументов поиска позволяет оптимизатору принять решение
о том, можно ли использовать один или более существующих индексов. На
этой фазе оптимизатор проверяет каждый аргумент поиска на предмет, суще-
ствуют ли подходящие индексы для соответствующего выражения. Если та-
кой индекс существует, оптимизатор принимает решение, использовать его
или нет. Это решение зависит от селективности соответствующего выраже-
ния. Селективность выражения определяется как отношение количества
строк, удовлетворяющих условию, к общему количеству строк в таблице.
Оптимизатор проверяет селективность выражения с индексированным столб-
цом, используя статистические данные, которые создаются для распределе-
ния значений в столбце. Оптимизатор запросов учитывает эту информацию
для определения оптимального плана запроса, оценивая стоимость использо-
вания индекса для выполнения запроса.
Следующие разделы подробно описывают селективность выражений с ин-
дексированным столбцом и статистическими данными. (Поскольку статисти-
ческие данные существуют как для индексов, так и для столбцов, они рас-
сматриваются отдельно в двух разделах.)
Замечание____________________________________________________
Database Engine автоматически создает (для индекса и столбца) статисти-
ческие данные, если для базы данных активирована опция auto_create_
STATISTICS. Эта опция описывается позже в данной главе.
Селективность выражения с индексированным столбцом
Как вы уже знаете, оптимизатор использует индексы для повышения скоро-
сти выполнения запроса. Когда вы обращаетесь к таблице, у которой нет ин-
Гпава 20. Оптимизатор запросов 523
дексов, или если оптимизатор принимает решение не использовать сущест-
вующий индекс, система выполняет последовательное сканирование табли-
цы. В процессе сканирования таблицы Database Engine последовательно чи-
тает страницы данных таблицы для поиска строк, которые принадлежат ре-
зультирующему набору данных. Доступ по индексу является методом
доступа, при котором система базы данных читает и записывает страницы
данных с использованием индекса. Так как доступ по индексу значительно
сокращает количество операций ввода/вывода, он обычно выполняется го-
раздо быстрее, чем сканирование таблицы.
Как вы уже знаете из главы 10, Database Engine использует некластеризован-
ный индекс для поиска данных одним из двух способов. Если у вас есть куча
(таблица без кластеризованного индекса), то система вначале исследует
структуру некластеризованного индекса, а затем отыскивает строку, исполь-
зуя идентификатор этой строки. Однако если у вас кластеризованная таблица,
то проход по некластеризованной индексной структуре выполняется вслед за
проходом по индексной структуре кластеризованного индекса таблицы.
С другой стороны, использование кластеризованного индекса для поиска
данных всегда уникально: Database Engine начинает поиск с корневого узла
соответствующего В-дерева и обычно после трех или четырех операций чте-
ния достигает узла листа, где хранятся данные. По этой причине проход по
индексной структуре кластеризованного индекса почти всегда выполняется
значительно быстрее, чем проход по индексной структуре соответствующего
некластеризованного индекса.
Из вышеприведенных рассуждений вы можете видеть, что ответ на вопрос,
какой метод доступа (сканирование индекса или сканирование таблицы) яв-
ляется наиболее быстрым, не является простым и зависит от селективности и
типа индекса.
Тесты, которые я выполнял, показали, что сканирование таблицы часто вы-
полняется быстрее, чем доступ к некластеризованным индексам, когда выби-
рается, по меньшей мере, 10% строк. В этом случае решение оптимизатора,
когда переключаться от доступа к некластеризованному индексу к сканиро-
ванию таблицы, может быть некорректным. (Если вы считаете, что оптимиза-
тор собирается выполнять сканирование таблицы без особых оснований, вы
можете использовать в запросе подсказку index для изменения этого реше-
ния, как описывается позже в этой главе.)
По некоторым причинам кластеризованный индекс обычно выполняется бы-
стрее, чем некластеризованный индекс. Когда система сканирует кластеризо-
ванный индекс, нет необходимости покидать структуру В-дерева для скани-
рования страниц данных, потому что такие страницы уже присутствуют на
уровне листьев этого дерева. Некластеризованный индекс также требует
18 Зак. 1141
524 Часть III. SQL Server: системное администрирование
больше операций ввода/вывода, чем соответствующий кластеризованный ин-
декс. Непастеризованному индексу нужно читать страницы данных после
просмотра В-дерева либо, если существует кластеризованный индекс для
другого столбца (столбцов) таблицы, некластеризованному индексу нужно
читать структуру В-дерева кластеризованного индекса.
Поэтому вы можете ожидать, что кластеризованный индекс будет выпол-
няться значительно быстрее, чем сканирование таблицы, даже если его селек-
тивность довольно плохая (т. е. процент возвращенных строк велик, потому
что запрос возвращает много строк). Тесты, которые я выполнял, показали,
что когда селективность выражения 75% или меньше, доступ к кластеризо-
ванному индексу, как правило, выполняется быстрее, чем сканирование таб-
лицы.
Статистические данные индекса
Статистические данные индекса обычно создаются, когда создается индекс
для конкретного столбца (столбцов). Создание статистических данных ин-
декса означает, что Database Engine создает гистограмму, основанную более
чем на 200 значениях столбца. (По этой причине создается более 199 интер-
валов.) Гистограмма указывает, помимо других вещей, как много строк в
точности соответствует каждому интервалу, среднее количество строк с раз-
личными значениями внутри интервала и плотность значений.
Замечание_______________________________________________________
Статистические данные индекса всегда создаются для одного столбца. Если
ваш индекс является составным индексом (состоит из нескольких столбцов), то
система генерирует статистические данные для первого столбца в этом ин-
дексе.
Если вы хотите явно создать статистические данные индекса, то можете ис-
пользовать следующие инструменты:
♦ системную процедуру sp_createstats;
♦ SQL Server Management Studio.
Системная процедура sp createstats создает статистические данные по оди-
ночному столбцу для всех столбцов всех пользовательских таблиц текущей
базы данных. Новые статистические данные имеют те же имена, что и имена
столбцов, для которых они создаются.
Чтобы использовать SQL Server Management Studio для создания статистиче-
ских данных индекса, разверните сервер, разверните папку Databases, раз-
верните базу данных, разверните папку Tables, раскройте таблицу, щелкните
правой кнопкой мыши по узлу Statistics и выберите пункт New Statistics.
Глава 20. Оптимизатор запросов
525
В диалоговом окне New Statistics on Table задайте имя статистических дан-
ных и щелкните по кнопке ОК.
Как только данные в столбце изменяются, статистические данные индекса
становятся устаревшими. Устаревшие статистические данные могут значи-
тельно повлиять на производительность при выполнении запроса. Database
Engine может автоматически обновлять статистические данные индекса, если
активизирована опция базы данных auto update statistics (установлена
в on). В этом случае любые статистические данные, требуемые для оптимиза-
ции запроса, будут автоматически обновляться в процессе оптимизации за-
проса.
Также существует еще одна опция базы данных, auto create statistics, ко-
торая создает любые отсутствующие статистические данные, требуемые для
оптимизации запроса. Обе опции могут быть активированы (или деактивиро-
ваны) при использовании оператора alter database или SQL Server Manage-
ment Studio.
Статистические данные столбца
Как вы уже знаете из предыдущих разделов, Database Engine создает стати-
стические данные для каждого существующего индекса. Система также мо-
жет создавать статистические данные и для неиндексированных столбцов.
Эти статистические данные называются статистическими данными столб-
ца. Вместе со статистическими данными индекса статистические данные
столбца используются для оптимизации плана выполнения запроса.
Database Engine создает статистические данные даже для неиндексированно-
го столбца, который является частью условия в предложении where.
Существует несколько ситуаций, при которых наличие статистических дан-
ных столбца может помочь оптимизатору принять правильное решение. Од-
ной из них является ситуация, когда у вас есть составной индекс из двух или
более столбцов. Как вы уже знаете, для такого индекса система генерирует
статистические данные только для первого столбца индекса. Существование
статистических данных столбца для второго столбца (и для всех других
столбцов) составного индекса может помочь оптимизатору выбрать опти-
мальный план выполнения.
Database Engine поддерживает два представления просмотра каталогов, ис-
пользуемых для статистических данных столбца (эти представления также
могут быть использованы для редактирования информации, связанной со ста-
тистическими данными индекса):
♦ sys.stats;
♦ sys.stats_columns.
526 Часть III. SQL Server: системное администрирование
Представление sys. stats содержит одну строку для каждого статистического
данного таблицы или представления. Помимо столбца name, который задает
имя статистических данных, это представление имеет, помимо прочих, два
других столбца:
♦ auto_created — статистические данные созданы оптимизатором запросов;
♦ user created — статистические данные явно созданы пользователем.
Представление sys.stats_columns содержит дополнительную информацию
относительно столбцов, которые являются частью представления sys.stats.
(Для определения этой дополнительной информации вы должны выполнить
соединение этих двух представлений.)
Выбор порядка соединения
Обычно порядок, в котором две или более соединяемые таблицы записыва-
ются в предложении from оператора select, не оказывает влияния на реше-
ние, принимаемое оптимизатором относительно порядка их обработки.
Как вы увидите в следующем разделе, множество различных факторов влияет
на решение оптимизатора, касающееся того, к какой таблице в первую оче-
редь будет выполняться обращение. С другой стороны, вы можете повлиять
на выбор порядка соединения, используя подсказку force order (рассматри-
вается позже в этой главе).
Техники обработки соединения
Операция соединения является операцией, больше всего забирающей время
при обработке запроса. Database Engine поддерживает следующие три раз-
личные техники обработки соединения, так что оптимизатор может выбрать
одну из них в зависимости от статистических данных в каждой из таблиц:
♦ вложенные циклы;
♦ слияние соединения;
♦ хеширование соединения.
Вложенные циклы
Использование вложенных циклов является техникой обработки, которая ра-
ботает как "грубая сила". Другими словами, для каждой строки внешней таб-
лицы отыскивается и сравнивается каждая строка из внутренней таблицы.
Псевдокод в примере 20.1 демонстрирует технику выполнения вложенных
циклов для двух таблиц.
Глава 20. Оптимизатор запросов
527
j Пример 20.1
айв являются двумя таблицами.
for each row in the outer table A do:
read the row
for each row in the inner table В do:
read the row
if A.join_column = B.join_column then
accept the row and add it to the resulting set
end if
end for
end for
Здесь для каждой строки, выбранной из внешней таблицы (таблица а), осу-
ществляется доступ ко всем строкам внутренней таблицы (таблица в). После
этого выполняется сравнение значений, и строка добавляется в результи-
рующий набор, если значения в обоих столбцах равны.
Метод вложенных циклов является очень медленным, если не существует
индекса для одного из соединяемых столбцов. При отсутствии индекса
Database Engine должен выполнять сканирование внешней таблицы один раз,
а внутренней и раз, где п — количество выбранных строк внешней таблицы.
По этой причине оптимизатор запросов обычно выбирает этот метод в том
случае, когда соединяемый столбец во внутренней таблице индексирован, так
что для внутренней таблицы не нужно выполнять сканирование для каждой
строки внешней таблицы.
Слияние соединения
Техника слияния соединения предоставляет рентабельную альтернативу соз-
дания индекса вложенным циклам. Строки соединяемых таблиц должны быть
физически упорядочены с использованием значений столбца соединения. Обе
таблицы затем сканируются в порядке столбцов соединения, отыскивая соот-
ветствующие строки с теми же значениями столбцов соединения. Псевдокод
в примере 20.2 демонстрирует технику обработки процесса соединения для
двух таблиц.
j Пример 20.2
Внешняя таблица А отсортирована в возрастающем порядке с использованием
столбца соединения. Внутренняя таблица в отсортирована в возрастающем
порядке с использованием столбца соединения.
528
Часть III. SQL Server: системное администрирование
for each row ip the outer table A do:
read the row
for each row from the inner table В with a value
less than or equal to the join column
do:
read the row
if A.join_column = B.join_column then
accept the row and add it to the resulting set
end if
end for
end for
Техника выполнения слияния соединения будет иметь высокие накладные
расходы, если строки в обеих таблицах неотсортированы. Однако этот метод
является предпочтительным, когда для значений обоих столбцов соединения
выполнена предварительная сортировка. (Это всегда тот случай, когда оба
соединяемых столбца являются первичными ключами в соответствующих
таблицах, потому что Database Engine по умолчанию создает кластеризован-
ный индекс для первичного ключа таблицы.)
Хеширование соединения
Техника хеширования соединения обычно используется, когда не существует
никаких индексов для соединяемых столбцов. В случае техники хеширования
соединения обе таблицы, которые должны быть соединены, рассматриваются
как два потока ввода: компонуемый ввод и контрольный ввод. (Наименьшая
таблица обычно представляет компонуемый ввод.) Этот процесс работает
следующим образом:
1. Значение соединяемого столбца строки из компонуемого ввода сохраняет-
ся в хешированном сегменте памяти в зависимости от количества, полу-
ченного от алгоритма хеширования.
2. Как только все строки из компонуемого ввода будут обработаны, начина-
ется обработка строк из контрольного ввода.
3. Каждое значение соединяемого столбца строки из контрольного ввода об-
рабатывается с использованием того же алгоритма хеширования.
4. Отыскиваются соответствующие строки из хешированного сегмента памя-
ти и используются для создания результирующего набора.
Замечание___________________________________________________
Техника хеширования соединения не требует никакого индекса. Поэтому дан-
ный метод хорошо применим в первую очередь для тех запросов, где не пред-
полагается наличие индексов. При этом если оптимизатор использует в работе
Глава 20. Оптимизатор запросов 529
данную технику, то это может служить вам подсказкой, что нужно создать до-
полнительные индексы для одного или более соединяемых столбцов.
Инструменты для редактирования
стратегии оптимизатора
Database Engine поддерживает несколько инструментов, которые позволяют
редактировать конкретные действия оптимизатора запросов. Помимо прочих
вы можете использовать следующие инструменты:
♦ оператор set (для отображения в виде текста или в формате XML планов
выполнения);
♦ Management Studio (для отображения планов выполнения в графическом
виде);
♦ представления динамического управления (Dynamic management views,
DMV) и функции;
♦ SQL Server Profiler (подробно обсуждается в главе 21).
В следующих разделах описываются первые три инструмента.
Замечание____________________________________________________
Все примеры в этой главе используют базу данных Adventurework. Если ваша
система не содержит эту базу данных, во введении описывается, как вы можете
ее скачать.
Оператор SET
Для понимания различных опций оператора set вам нужно знать, что суще-
ствуют три различные формы, в которых может отображаться план выполне-
ния запроса:
♦ текстовая форма;
♦ использование XML;
♦ графическая форма.
Первые две формы используют оператор set, так что эти две формы обсуж-
даются в следующих подразделах. Графическая форма плана выполнения
обсуждается в разд. "Management Studio и графические планы выполнения"
далее в этой главе.
Текстовая форма планов выполнения
Результат текстовой формы плана выполнения возвращается в форме строк.
Database Engine использует вертикальную полосу для отображения зависи-
530
Часть III. SQL Server: системное администрирование
мостей между существующими операциями. Текстовая форма планов выпол-
нения может отображаться с использованием следующих опций оператора
set:
♦ showplan_text;
♦ SHOWPLAN_ALL.
Пользователи, выполняющие запрос, могут отображать текстовый план вы-
полнения запроса при помощи активации (установив значение опции в on)
либо у опции оператора showplan_text, либо у опции showplan_all до того,
как они введут соответствующий оператор select. Опция showplan_all ото-
бражает ту же детальную информацию относительно плана выполнения за-
проса, что и showplan_text с дополнительной оценкой требуемых ресурсов
для этого оператора.
В примере 20.3 показано использование опции set showplan_text.
Замечание
Как только вы активируете опцию set showplan_text, все последующие опера-
торы Transact-SQL не будут выполняться, пока вы не деактивируете эту опцию
С ПОМОЩЬЮ SET SHOWPLAN_TEXT OFF. Оператор SET SHOWPLAN_XML ЯВЛЯвТСЯ
другим оператором с тем же самым свойством.
: Пример 20.3
SET SHOWPLAN_TEXT ON
GO
USE AdventureWorks;
SELECT * FROM HumanResources.Employee e JOIN
HumanResources.EmployeeAddress a
ON e.EmployeelD = a.EmployeelD
AND e.EmployeelD = 10;
GO
SET SHCWPLAN_TEXT OFF.
Следующий текстовый план показывает результат плана примера 20.3.
StmtText
|—Nested Loops(Inner Join)
I—Clustered Index Seek(OBJECT:([AdventureWorks].[HumanResources].
[Employee].
[PK_Employee_EmployeeID] AS [e]), SEEK:([e].[EmployeelD]=(10)) ORDERED
FORWARD)
I—Clustered Index
Гпава 20. Оптимизатор запросов
531
Seek(OBJECT:([AdventureWorks].[HumanResources].[EmployeeAddress].
[PK_EmployeeAddress_EmployeeID_AddressID] AS [a]), SEEK:([a].
[ErnployeeID] = (10) ) ORDERED FORWARD)
Если вы посмотрите на результаты примера 20.3, то увидите, что есть три
оператора, Nested Loops и clustered index Seek (дважды). (Все операторы от-
мечены на панели как |.) Nested Loops выполняет внутреннее соединение таб-
лиц employee И employeeaddress. Каждый оператор Clustered Index Seek ОТЫ-
скивает строки, используя соответствующие кластеризованные индексы в
обеих таблицах. Отступы в описании операторов определяют порядок вы-
полнения операторов: оператор с отступом выполняется первым. Если есть
два или более операторов с одинаковым отступом, то их обработка выполня-
ется сверху вниз. Это означает, что в примере 20.3 поиск кластеризованного
индекса для таблицы employee выполняется первым. После этого тот же са-
мый оператор применяется к таблице employeeaddress, а затем обе таблицы
соединяются при помощи техники обработки вложенных циклов.
Замечание_______________________________________________________
Доступ к индексу имеет две формы: сканирование индекса и поиск по индексу.
Сканирование индекса обрабатывает весь уровень листьев индексного дерева,
в то время как поиск по индексу возвращает значения индекса (или строки) для
одного или более диапазонов индекса.
Планы выполнения XML
Фраза "план выполнения XML" означает, что план выполнения запроса
отображается в документе XML. (Более подробную информацию об XML
см. в главе 27.) Наиболее важным преимуществом использования планов вы-
полнения XML является то, что такие планы могут быть перенесены с одной
системы на другую, позволяя использовать их в другом программном окру-
жении.
Оператор set имеет две опции, связанные с XML:
♦ SHOWPLAN-xml;
♦ STATISTICS XML.
Опция showplan_xml возвращает информацию в виде набора документов
XML. Другими словами, если вы активируете эту опцию, то Database Engine
возвращает детальную информацию о том, как операторы будут выполняться
в форме хорошо созданного документа XML без их фактического выполне-
ния. Каждый оператор отображается в результирующем выводе в виде одного
документа. Каждый документ содержит текст оператора, за которым следуют
подробные описания шагов выполнения.
В примере 20.4 показано, как может быть использована опция showplan xml.
532 Часть III. SQL Server: системное администрирование
i Пример 20.4
SET SHOWPLAN_XML ON
GO
USE AdventureWorks;
SELECT * FROM HumanResources.Employee e JOIN
HumanResources.EmployeeAddress a
ON e.EmployeelD = a.EmployeelD
AND e.EmployeelD = 10;
GO
SET SHOWPLAN_XML OFF
Основное отличие между опциями showplan xml и statistics xml заключает-
ся в том, что вывод второго генерируется во время выполнения. По этой при-
чине statistics xml включает результат опции showplan_xml так же, как и до-
полнительную информацию времени выполнения.
Каждый план выполнения XML может быть сохранен в файле. При исполь-
зовании расширения по умолчанию sqlplan план будет автоматически ото-
бражаться в графической форме, когда вы используете SQL Server Manage-
ment Studio. Таким способом вы можете легко переносить планы выполнения
с одного компьютера на другой без сохранения образов соответствующих
планов выполнения.
Замечание________________________________________________________
В SQL Server 2008 вы можете легко открывать сохраненный план выполнения
при двойном щелчке по нему мышью. После этого план будет открыт в SQL
Server Management Studio и будет отображена его графическая форма.
Другие опции оператора SET
Оператор set имеет много других опций, которые используются по отноше-
нию к блокировке, транзакции и операторам даты-времени. В связи со стати-
стическими данными Database Engine поддерживает следующие три опции
оператора set:
♦ statistics io;
♦ statistics time;
♦ STATISTICS profile.
В случае задания опции statistics io система отображает статистическую
информацию, связанную со степенью активности по отношению к диску,
сгенерированную запросом — например, количество операций ввода/вывода,
обработанных в запросе. При задании опции statistics time система ото-
бражает время обработки, оптимизации и выполнения запроса.
Глава 20. Оптимизатор запросов
Когда активирована опция statistics profile, каждый выполняемый запрос
возвращает его обычный результирующий набор, за которым следует допол-
нительный результирующий набор, возвращающий набор параметров выпол-
нения запроса. (Иными словами, результирующий набор содержит вывод
опции showplan all плюс дополнительный результирующий набор.)
В примере 20.5 показано использование опции statistics profile в операто-
ре SET.
I Пример 20.5
SET STATISTICS PROFILE ON
GO
USE AdventureWorks;
SELECT * FROM HumanResources.Employee e JOIN
HumanResources.EmployeeAddress a
ON e.EmployeelD = a.EmployeelD
AND e.EmployeelD = 10;
GO
SET STATISTICS PROFILE OFF
Результат примера 20.5, который здесь не показан, потому что он слишком
большой, содержит вывод оператора set statistics io, а также вывод опера-
тора SET SHOWPLAN_ALL.
Management Studio
и графические планы выполнения
Графический план выполнения является лучшим способом отображения пла-
на выполнения запроса, если вы пока еще начинающий или просто хотите
быстро просмотреть разные планы в короткое время. Эта форма отображения
использует пиктограммы для представления операторов в плане запроса.
В качестве примера того, как графические планы выполнения могут быть за-
пущены и как они выглядят, посмотрите на рис. 20.2, который показывает
графический план выполнения запроса из примера 20.3. Для отображения
плана выполнения в графической форме запишите запрос в окне Query
Editor утилиты SQL Server Management Studio и щелкните мышью по кнопке
Display Estimated Execution Plan в панели инструментов Management Studio.
Альтернативным способом является выбор меню Query | Display Estimated
Execution Plan.
Если вы посмотрите на рис. 20.2, то увидите, что существует одна пикто-
грамма для каждого оператора в плане выполнения. Если вы переместите
534
Часть III. SQL Server: системное администрирование
мышь на одну из этих пиктограмм, то появится детальная информация по
этому оператору, включая предполагаемые затраты на операции вво-
да/вывода и загрузку центрального процессора, ожидаемое количество строк
и их размер, затраты на оператор. Стрелки между пиктограммами представ-
ляют потоки данных. (Вы также можете щелкнуть мышью по стрелке, в этом
случае будет отображаться такая информация, как ожидаемое количество
строк и ожидаемый размер строки.)
Рис. 20.2. Графический план выполнения запроса из примера 20.3
Замечание_____________________________________________________
Толщина стрелок в графическом плане выполнения зависит от количества
строк, возвращаемых соответствующим оператором. Чем толще стрелка, тем
больше строк будет возвращаться.
Как и предполагает это название, щелчок мышью по кнопке Display
Estimated Execution Plan отображает предполагаемый план выполнения за-
проса без его фактического выполнения. Там есть еще одна кнопка — Include
Actual Execution Plan, которая позволяет выполнить запрос и дополнительно
Гпава 20. Оптимизатор запросов 535
отобразить его план выполнения. Фактический план выполнения содержит
дополнительную информацию относительно ожиданий этого плана, таких как
фактическое количество обрабатываемых строк и фактическое количество
выполнений каждого оператора.
Примеры планов выполнения
В этом разделе представлено несколько запросов, связанных с базой данных
AdventureWorks вместе с их планами выполнения. Эти примеры демонстри-
руют уже рассмотренные темы, предоставляя вам возможность увидеть, как
оптимизатор запросов работает на практике.
В примере 20.6 вводится новая таблица (new_addresses) в базу данных sample.
Пример 20.6
USE sample;
SELECT * into new_addresses
FROM AdventureWorks.Person.address;
GO
CREATE INDEX i_stateprov on new_addresses(StateProvincelD)
Пример 20.6 копирует содержимое таблицы address из схемы Person базы
данных AdventureWorks в новую таблицу базы данных sample. Это необходи-
мо, потому что первая таблица содержит несколько индексов, которые пре-
пятствуют прямому использованию таблицы address из базы данных
AdventureWorks для демонстрации специфических свойств оптимизатора за-
просов. Кроме этого, в примере создается индекс для столбца StateProvincelD
этой таблицы.
В примере 20.7 показаны запрос с высокой селективностью и план, который
выбирает оптимизатор в данном случае.
. Пример 20.7
— высокая селективность
USE sample;
SELECT * FROM new_addresses a
WHERE a.StateProvincelD = 32;
Текстовым выводом примера 20.7 будет:
I—Nested Loops(Inner Join, OUTER REFERENCES:([BmklOOO]))
I—Index Seek(OBJECT:([sample].[dbo].[new_addresses].[i_stateprov]
AS [a]).
536 Часть III. SQL Server системное администрирование
SEEK:([a].[StateProvinceID]=(32)) ORDERED FORWARD)
I—RID Lookup(OBJECT:([sample].[dbo].[newaddresses] AS [a]),
SEEK:([Bmkl000]=[Bmkl000]) LOOKUP ORDERED FORWARD)
Замечание___________________________________________________________
Оператор Nested Loops в выводе отображается, даже если запрос в примере 20.7
осуществляет доступ только к одной таблице. Начиная с SQL Server 2005, этот
оператор отображается всегда, когда существуют два оператора, которые "со-
единены" вместе (как и операторы RID Lookup и Index Seek в примере 20.7).
Фильтр в примере 20.7 выбирает только одну строку из таблицы new_
addresses. (Общее количество строк в этой таблице 19614.) Поэтому селек-
тивность выражения в предложении where является очень высокой (1/19614).
В этом случае, как вы можете видеть из результатов примера 20.7, опти-
мизатором будет использоваться существующий индекс для столбца
StateProvincelD.
В примере 20.8 показан тот же запрос, что и в примере 20.8, но с другим
фильтром.
’ Пример 20.8
— низкая селективность
USE sample;
SELECT * FROM new addresses a
WHERE a.StateprovincelD = 9;
Текстовым выводом примера 20.8 будет:
I—Table Scan(OBJECT:([sample].[dbo].[new_addresses] AS [a]),
WHERE:([sample].[dbo].[new_addresses].[StateprovincelD] as [a],
[StateProvincelD]=(9)))
Хотя запрос в примере 20.8 отличается от запроса из примера 20.7 только
значением в правой части условия в предложении where, но план выполнения,
выбранный оптимизатором, отличается значительно. В этом случае сущест-
вующий индекс не будет использован, потому что селективность фильтра
низкая. (Отношение количества строк, удовлетворяющих условию, к общему
количеству строк в таблице будет 4564/19614 = 0.23, или 23%.)
В примере 20.9 показано использование кластеризованного индекса.
j Пример 20.9
USE AdventureWorks;
SELECT * FROM HumanResources.Employee
WHERE HumanResources.Employee.EmployeelD = 10;
Гпава 20. Оптимизатор запросов 537
Текстовым выводом примера 20.7 будет:
|—Clustered Index Seek(OBJECT:([AdventureWorks].[HumanResources].
[Employee].
[PK_Employee_EmployeeID]), SEEK:([AdventureWorks].[HumanResources].
[Employee].[EmpioyeeiD]=CONVERT_IMPLICIT(int, [@1], 0)) ORDERED FORWARD)
Запрос из примера 20.9 использует кластеризованный индекс рк_Етр1оуее_
EmpioyeeiD. Этот кластеризованный индекс неявно создается системой, пото-
му что столбец EmpioyeeiD является первичным ключом таблицы Employee.
В примере 20.10 показано использование техники вложенных циклов.
| Пример 20.10
USE AdventureWorks;
SELECT * FROM HumanResources.Employee e
JOIN HumanResources.EmployeeAddress a
ON e.EmployeelD = a.EmpioyeeiD
AND e.EmployeelD = 10;
Текстовым выводом примера 20.10 является:
I—Nested Loops(Inner Join)
I—Clustered Index
Seek(OBJECT:([AdventureWorks].[HumanResources].[Employee].
[PK_Employee_EmployeeID] AS [e]), SEEK:([e].[EmpioyeeiD]=(10)) ORDERED
FORWARD)
I—Clustered Index
Seek(OBJECT:([AdventureWorks].[HumanResources].[EmployeeAddress].
[PK_EmployeeAddress_EmployeeID_AddressID] AS [a]), SEEK:([a].
[EmployeeID]=(10))
ORDERED FORWARD)
Запрос в примере 20.10 использует метод вложенных циклов, хотя соединяе-
мые столбцы в таблицах являются в то же самое время их первичными клю-
чами. По этой причине кто-то мог ожидать, что будет использован метод
слияния соединения. Оптимизатор запросов принимает решение использо-
вать вложенные циклы, потому что здесь существует дополнительный
фильтр (e.EmployeelD = io), который сокращает результирующий набор этого
запроса до одной строки.
Небольшое изменение запроса из примера 20.10 оказывает влияние на выбор
оптимизатором другой техники обработки соединения (пример 20.11).
538 Часть III. SQL Server: системное администрирование
j Пример 20.11
USE AdventureWorks;
SELECT * FROM HumanResources.Employee e
JOIN HumanResources.EmployeeAddress a
ON e.EmployeelD = a.EmployeelD;
Текстовым выводом примера 20.11 является:
I—Merge Join (Inner Join, MERGE:([e].[EmployeelD]) = ([a].[EmployeelD]),
RESIDUAL:([AdventureWorks].[HumanResources].[EmployeeAddress].
[EmployeelD] as
[a].[EmployeelD]=[AdventureWorks].[HumanResources].[Employee].
[EmployeeID]
as
[e].[EmployeelD]))
|—Clustered Index
Scan(OBJECT:([AdventureWorks].[HumanResources].[Employee].
[PK_Employee_EmployeeID] AS [e]), ORDERED FORWARD)
I —Clustered Index
Scan(OBJECT:([AdventureWorks].[HumanResources].[EmployeeAddress].
[PK_EmployeeAddress_EmployeeID_AddressID] AS [a]), ORDERED FORWARD)
Если вы сравните запросы в примерах 20.10 и 20.11, то вы увидите, что у вто-
рого отсутствует условие е.EmployeelD = io. (Это отличие только в запросах.)
По этой причине результирующий набор примера 20.11 содержит 290 строк.
Поэтому оптимизатор запросов принимает решение, что в данном случае ис-
пользование метода слияния соединения имеет преимущества.
В примере 20.12 показано использование техники хеширования соединения.
. Пример 20.12
USE AdventureWorks?
SELECT * FROM Person.Address a JOIN Person.StateProvince s
ON a.StateProvincelD = s.StateProvincelD;
Текстовым выводом примера 20.12 является:
I—Hash Match(Inner Join,
HASH:([s].[StateProvincelD])=([a].[StateProvincelD]))
I —Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[StateProvince].
[PKStateProvince_StateProvinceID] AS [s]))
I—Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[Address].[PK_Address_AddressID]
AS [a]))
Гпава 20. Оптимизатор запросов
Хотя оба соединяемых столбца в предложении on являются первичными
ключами в каждой таблице (Address и StateProvince), оптимизатор запросов
не выбирает метод слияния соединения. Причиной является то, что все
(19 614) строки таблицы Address принадлежат результирующему набору.
В этом случае использование метода хеширования соединения является более
предпочтительным, чем обе другие техники обработки.
Представления динамического управления
и оптимизатор запросов
Существует много представлений (и функций) динамического управления,
которые напрямую связаны с оптимизатором запросов. В этом разделе рас-
сматриваются следующие DMV (Dynamic Management View, представления
динамического управления):
♦ sys.dm_exec_query_opt imi ze r_info;
♦ sys.dm_exec_query_plan;
♦ sys.dm_exec_query_stats;
♦ sys.dm_exec_sql_text;
♦ sys.dm_exec_text_query_plan;
♦ sys. dm exec_procedure_stats (новое в SQL Server 2008).
sys.dmexecqueryoptimizerinfo
Представление sys.dm ex.ec_query_optimizer_info, пожалуй, является наибо-
лее важным DMV в плане работы оптимизатора запросов, потому что оно
возвращает детальную статистику об операции оптимизатора. Вы можете
использовать это представление при настройке рабочей нагрузки для опреде-
ления проблем оптимизации запросов или для повышения производитель-
ности.
Представление sys. dm_exec_query_optimizer_info содержит три столбца:
counter, occurrence и value. Столбец counter содержит имя события оптими-
затора, тогда как столбец occurrence отображает накапливаемое количество
появлений этих событий. Значение столбца value содержит дополнительную
информацию, связанную с событием. (Не все события поставляют значение
value.)
Используя это представление, вы можете, например, отобразить общее коли-
чество оптимизаций, общее затраченное время и окончательное значение
стоимости для сравнения оптимизации запросов для текущей нагрузки лю-
бых изменений, обнаруженных в процессе настроек.
540
Часть III. SQL Server: системное администрирование
Использование представления sys. dm exec query optimizer info показано в
примере 20.13.
Пример 20.13
SELECT counter, occurrence, value
FROM sys.dm_exec_query_optimizerinfо
WHERE value IS NOT NULL
AND counter LIKE 'search 1%';
Результат:
Counter
search 1
search 1 time
search 1 tasks
occurrence value
117 1
95 0,0120736842105263
117 513,982905982906
В примере 20.13 исследуется, как много раз выполняется оптимизация фа-
зы 1. Существуют три фазы оптимизации: фаза 0, фаза 1 и фаза 2, которые
задаются в значениях search о, search 1 и search 2 соответственно.
Замечание_____________________________________________________
По причине своей сложности процесс разбивается на три фазы. Первая фаза
(фаза 0) рассматривает только непараллельные планы выполнения. Если
стоимость фазы 0 не является оптимальной, то выполняется фаза 1, в которой
рассматриваются непараллельные планы и параллельные планы. Фаза 2 при-
нимает во внимание только параллельные планы.
sys.dm_exec_query_plan
Как вы уже знаете, хранимая процедура создается однажды и выполняется
много раз. По этой причине план выполнения для хранимой процедуры (или
пакета) размещается в кэше процедур. Таким образом, он может быть ис-
пользован оптимизатором в любое время. Вы можете проверить кэш проце-
дур, используя различные представления динамического управления. Одним
из них является представление sys.dm_exec_query_plan, которое возвращает
все планы выполнения, хранящиеся в кэше процедур вашей системы. (Планы
выполнения отображаются в формате XML.) Документация Books Online
содержит несколько полезных примеров использования этого представле-
ния DMV.
Каждый план выполнения, хранящийся в кэше процедур, определяется
по уникальному идентификатору, называемому дескриптором плана (plan
handle). Представление sys. dm exec query plan требует дескриптор плана для
отыскания плана выполнения для отдельного запроса Transact-SQL или
Гпава 20. Оптимизатор запросов 54 У
пакета. Этот дескриптор можно отобразить, используя представление sys.dm_
exec query stats, которое сейчас будет рассматриваться.
sys.dmexec_querystats
Представление sys. dm_exec_query_stats возвращает общие статистические
данные для кэшированных планов запросов. Это представление содержит
одну строку на один оператор запроса вместе с кэшированным планом, а
время жизни строк связано с самим планом.
В примере 20.14 с помощью оператора cross apply выполняется "соедине-
ние" представлений sys.dm_exec_query_stats И sys.dm exec query plan ДЛЯ
получения планов выполнения всех кэшированных планов. Кроме того, каж-
дый оператор SQL в многооператорной процедуре или пакете будет отобра-
жаться отдельно. (Оператор cross apply подробно обсуждается в главе 8.)
: Пример 20.14
SELECT query_plan
FROM sys.dm_exec_query_stats as qs
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle);
sys.dmexec_sqltext и sys.dm_exec_text_query_plan
Предыдущее представление, sys. dm exec query stats, может быть использо-
вано с некоторыми другими DMV для отображения различных свойств за-
просов. Другими словами, каждое DMV, которому требуется дескриптор
плана для идентификации запроса, будет "соединено" с представлением
sys. dm_exec_query_stats для отображения требуемой информации. Одним из
таких представлений является sys.dm exec sqi text. Это представление воз-
вращает текст пакета SQL, который определяется указанным дескриптором.
В документе Books Online показано множество полезных примеров, где "со-
единяются" представления sys.dm_exec_sql_text И sys. dm_exec_query__stats
для получения текстов запросов SQL, которые были выполнены в пакетах, и
предоставляют о них статистическую информацию.
В отличие ОТ sys.dm_exec_sql_text представление sys.dm_exec_text_query_
plan возвращает план выполнения пакета в формате XML. Аналогично пре-
дыдущим представлениям, план задается дескриптором плана. (План, пред-
ставленный дескриптором плана, может быть кэширован или выполняться
в настоящий момент.)
sys.dm_exec_procedure_stats
Это представление похоже на представление sys. dm_exec_query_stats. Оно
возвращает общие статистические данные для кэшированных хранимых про-
542 Часть III. SQL Server: системное администрирование
цедур. Представление содержит одну строку на каждую хранимую процеду-
ру, время жизни строки продолжается столько времени, пока хранимая про-
цедура остается кэшированной. Когда хранимая процедура удаляется из
кэша, соответствующая строка убирается из этого представления.
Замечание
Представление sys. dm_exec_procedure_stats является одним из нескольких
новых представлений, реализованных в SQL Server 2008. Корпорация Microsoft
добавила около 50 новых DMV и функций в новый релиз.
Подсказки оптимизатора
В большинстве случаев оптимизатор запросов выбирает самый быстрый план
выполнения. Однако существует несколько особых ситуаций, при которых
оптимизатор, по ряду различных причин, не может найти оптимальное реше-
ние. В подобных случаях вы должны применять подсказки (hint) оптимизато-
ра, чтобы заставить его использовать конкретный план выполнения, который
должен работать лучше.
Подсказки оптимизатора являются необязательной частью в операторе
select, которые указывают оптимизатору запросов, что нужно применять
один из специфических вариантов поведения. Другими словами, при исполь-
зовании подсказок оптимизатора вы не позволяете оптимизатору запросов
искать и находить способ выполнения запроса, потому что вы точно говорите
ему, что он должен делать.
Зачем использовать подсказки оптимизатора
Вы должны использовать подсказки оптимизатора только временно и только
для тестирования. Другими словами, исключите их использование в качестве
постоянной части любого запроса. Существуют две причины этого высказы-
вания. Во-первых, если вы заставляете оптимизатор использовать конкрет-
ный индекс, а несколько позже определяете другой индекс, который даст
лучшие результаты производительности при выполнении запроса; здесь за-
прос и приложение, которому принадлежит этот запрос, не смогут использо-
вать преимущества нового индекса. Во-вторых, Microsoft постоянно прилага-
ет усилия, чтобы сделать оптимизатор запросов лучше. Если вы свяжете
запрос с конкретным планом выполнения, то оптимизатор не сможет реали-
зовать преимущества от новых и улучшенных возможностей в последующих
версиях SQL Server.
Глава 20. Оптимизатор запросов 543
Существуют две причины, по которым оптимизатор иногда выбирает не са-
мый быстрый план выполнения:
♦ оптимизатор запросов не является безупречным;
♦ система не предоставляет оптимизатору подходящую информацию.
Замечание_____________________________________________________
Подсказки оптимизатора могут помочь вам только в том случае, если выбран-
ный оптимизатором план не является оптимальным. Если система не предос-
тавляет оптимизатору подходящую для его работы информацию, используйте
опции базы данных auto_create_statistics и autojjpdate_statistics для
создания или изменения существующих статистических данных.
Типы подсказок оптимизации
Database Engine поддерживает следующие типы подсказок оптимизации:
♦ подсказки таблицы;
♦ подсказки соединения;
♦ ' подсказки запроса;
♦ структуры планов.
Замечание_____________________________________________________
Последующие примеры будут демонстрировать использование подсказок опти-
мизатора, однако они не являются рекомендациями по их использованию в лю-
бом конкретном запросе. В большинстве случаев то использование подсказок
оптимизации, что показано в этих примерах, приводит к обратным результатам.
Подсказки таблицы
Вы можете применить подсказки таблицы к одной таблице. Поддерживаются
следующие подсказки таблицы:
♦ index;
♦ noexpand;
♦ forceseek (новое в SQL Server 2008).
Подсказка index служит для указания одного или более индексов, которые
затем будут использованы в запросе. Эта подсказка задается в предложении
from в запросе. Вы можете использовать эту подсказку, чтобы осуществить
доступ к индексу, если оптимизатор по различным причинам выбрал после-
довательное сканирование таблицы для данного запроса. (Подсказка index
также может быть полезной для того, чтобы не позволить оптимизатору ис-
пользовать другой конкретный индекс.)
544.Часть III. SQL Server: системное администрирование
В примерах 20.15 и 20.16 показано использование подсказки index.
i Пример 20.15
USE sample;
SELECT * FROM new_addresses a WITH (INDEX(i_stateprov))
WHERE a.StateProvincelD = 9
Текстовым выводом примера 20.15 является:
I—Nested Loops(Inner Join, OUTER REFERENCES:([BmklOOO],
[Exprl004]) WITH UNORDERED PREFETCH)
|—Index Seek(OBJECT:([sample].[dbo].[new_addresses].[i_stateprov]
AS [a]),
SEEK: ([a].[StateprovincelD] = (9)) ORDERED FORWARD)
|—RID Lookup(OBJECT:([sample].[dbo].[new addresses] AS [a]),
SEEK:([Bmkl000]=[BmklOOO]) LOOKUP ORDERED FORWARD)
Пример 20.15 идентичен примеру 20.8, однако он дополнительно содержит
подсказку index. Эта подсказка заставляет оптимизатор запросов использо-
вать индекс i stateprov. Без этой подсказки оптимизатор выбирает сканиро-
вание таблицы, и это вы можете увидеть в результатах вывода в приме-
ре 20.8.
Другая форма подсказки для запроса index, index (О), требует, чтобы оптими-
затор не использовал никаких существующих индексов. В примере 20.16 по-
казано применение этой подсказки.
Пример 20.16
USE AdventureWorks;
SELECT * FROM Person.Address a
WITH (INDEX(0))
WHERE a.StateprovincelD = 32
Текстовым выводом примера 20.16 является:
I —Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[Address].[PK_Address_AddressID]
AS [a]),
WHERE:([AdventureWorks].[Person].[Address].[StateProvincelD] as
[a].[StateprovincelD]=(32)))
Замечание___________________________________________________________
Если кластеризованный индекс существует, то index(0) требует сканирования
кластеризованного индекса, a index (1) требует сканирования индекса или по-
Гпава 20. Оптимизатор запросов 545
иска по индексу. Если же кластеризованный индекс не существует, то index (0)
требует сканирования таблицы, a index (1) интерпретируется как ошибка.
План выполнения запроса в примере 20.16 показывает, что оптимизатор ис-
пользует сканирование кластеризованного индекса по причине задания под-
сказки index(0). Без этой подсказки оптимизатор запросов должен был вы-
брать сканирование некластеризованного индекса. Вы сами можете это про-
верить, удалив из запроса эту подсказку.
Подсказка noexpand указывает, что не будет раскрываться никакое индекси-
рованное представление для доступа к лежащим в его основе таблицам в то
время, когда оптимизатор запросов обрабатывает запрос. Оптимизатор запро-
сов трактует представление как таблицу без кластеризованного индекса. Об-
суждение индексированных представлений см. в главе 11.
Подсказка таблицы forceseek заставляет оптимизатор запросов выполнять
только операцию поиска по индексу в качестве пути доступа к данным в таб-
лице (или представлении), на которую ссылается запрос. Вы можете исполь-
зовать эту подсказку таблицы для того, чтобы перекрыть план по умолчанию,
выбранный оптимизатором запросов, для устранения проблем производи-
тельности, появившихся в результате неэффективного плана выполнения.
Например, если план содержит операторы сканирования таблицы или индек-
са, а соответствующие таблицы требуют большого количества чтений в про-
цессе выполнения запроса, то задание операции выборки по индексу может
дать лучшую производительность запроса. Это в особенности вероятно, когда
неточное определение количества элементов или оценка стоимости приводят
к тому, что оптимизатор предпочитает операции сканирования в качестве
плана во время компиляции.
Замечание________________________________________________________
Подсказка forceseek может применяться как к кластеризованному, так и к не-
кластеризованному индексам. Эта подсказка является новой возможностью в
SQL Server 2008.
Подсказки соединения
Подсказки соединения дают указания оптимизатору запросов, как должны
выполняться операции соединения в запросе. Они заставляют оптимизатор
либо соединять таблицы в том порядке, в каком они указаны в предложении
from оператора select, либо использовать техники выполнения соединения,
явно указанные в операторе. Database Engine поддерживает несколько под-
сказок соединения:
♦ force order;
♦ loop;
546
Часть III. SQL Server: системное администрирование
♦ hash;
♦ MERGE.
Подсказка force order заставляет оптимизатор выполнять соединение таблиц
в том порядке, в котором они указаны в запросе. В примере 20.17 показано
использование этой подсказки соединения.
' Пример 20.17
USE AdventureWorks;
SELECT е.EmployeelD, e.LoginlD, d.DepartmentID
FROM HumanResources.Employee e, HumanResources.Department d,
HumanResources.EmployeeDepartmentHistory h
WHERE d.DepartmentID = h.DepartmentID
AND h.EmployeelD = e.EmployeelD
AND h.EndDate IS NOT NULL
OPTION(FORCE ORDER);
Текстовым выводом примера 20.17 является:
I—Merge Join(Inner Join, MERGE:([d].[DepartmentID],
[e].[EmployeelD])=([h].[DepartmentID], [h].[EmployeelD]),
RESIDUAL:([AdventureWorks].[HumanResources].[Department].[DepartmentID]
as
[d].[DepartmentID]=[AdventureWorks].[HumanResources].
[EmployeeDepartmentHistory].
[DepartmentID] as [h].[DepartmentID] AND
[AdventureWorks].[HumanResources].[EmployeeDepartmentHistory].
[EmployeelD] as
[h].[EmployeelD]=[AdventureWorks].[HumanResources].[Employee].[EmployeelD]
[e] . [EmployeelD]))
I—Sort(ORDER BY:([d].[DepartmentID] ASC, [e].[EmployeelD] ASC))
I |—Nested Loops(Inner Join)
I I — Index
Scan(OBJECT:([AdventureWorks].[HumanResources].[Employee].
[AK Employee_LoginID] AS [e]))
I I —Clustered Index
Scan(OBJECT:([AdventureWorks].[HumanResources].[Department].
[PKDepartment_DepartmentID] AS [d]))
I—Sort(ORDER BY:([h].[DepartmentID] ASC, [h].[EmployeelD] ASC))
I—Clustered Index
Scan(OBJECT:([AdventureWorks].[HumanResources].
[EmployeeDepartmentHistory].
Гпава 20. Оптимизатор запросов 547
[PK_EmployeeDepartmentHistory_EmployeeID_StartDate_DepartmentID] AS [h]),
WHERE:([AdventureWorks].[HumanResources].[EmployeeDepartmentHistory].
[EndDate] as
[h].[EndDate] IS NOT NULL))
Как вы можете видеть, оптимизатор выполняет операцию соединения в том
порядке, в котором таблицы появляются в запросе. Это означает, что таблица
Employee будет обработана первой, затем таблица Department, а под конец
таблица EmployeeDepartmentHistory. Если вы выполняете запрос без подсказки
force order, то оптимизатор запросов будет обрабатывать таблицы в проти-
воположном порядке: вначале EmployeeDepartmentHistory, Затем Department,
ПОТОМ Employee.
Замечание____________________________________________________________
Помните, что это вовсе не означает, что новый план будет выполняться лучше,
чем тот, который выберет оптимизатор.
Подсказки запроса loop, hash и merge заставляют оптимизатор использовать
метод циклического соединения, технику слияния соединений и технику хе-
ширования соединений соответственно. Эти три подсказки соединения могут
применяться только в том случае, когда операция соединения соответствует
стандарту SQL, т. е. когда соединение явно указано при помощи ключевого
слова join в предложении from оператора select.
В примере 20.18 показан запрос, который использует метод слияния соедине-
ния, потому что подсказка с тем же названием (merge join) явно определена
в операторе select. (Вы можете применить другие две подсказки hash и merge
тем же самым образом.)
i Пример 20.18
USE AdventureWorks;
SELECT * FROM Person.Address a JOIN Person.StateProvince s
ON a.StateProvincelD = s.StateProvincelD
OPTION (MERGE JOIN);
Текстовым выводом примера 20.18 является:
I—Merge Join(Inner Join,
MERGE:([s].[StateProvincelD]) = ([a].[StateProvincelD]),
RESIDUAL:([AdventureWorks].[Person].[StateProvince].[StateProvincelD] as
[s].[StateProvincelD]=[AdventureWorks].[Person].[Address].[StateProvincelD]
as
[a].[StateProvincelD]))
|—Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[StateProvince].
548 Часть III. SQL Server: системное администрирование
[PK_StateProvince_StateProvinceID] AS [s]), ORDERED FORWARD)
I—Sort(ORDER BY:([a].[StateProvincelD] ASC))
I —Clustered Index
Scan(OBJECT:([AdventureWorks].[Person].[Address].[PK_Address_AddressID]
AS [a]))
Как вы можете видеть из текстового вывода примера 20.18, оптимизатор за-
просов должен использовать технику обработки слияния соединения. (Если
удалить эту подсказку, то оптимизатор запросов выберет технику хеширова-
ния соединений.)
Выбранная подсказка соединения может быть записана в предложении from
запроса или при использовании предложения option в конце этого запроса.
Если вы собираетесь применять несколько различных подсказок вместе, то
рекомендуется предложение option. Пример 20.19 идентичен примеру 20.18,
только в нем подсказка соединения указана в предложении from запроса. Об-
ратите внимание, что в этом случае требуется ключевое слово inner.
j Пример 20.19
USE AdventureWorks;
SELECT * FROM Person.Address a INNER MERGE JOIN Person.StateProvince s
ON a.StateProvincelD = s.StateprovincelD;
Текстовый вывод примера 20.19 полностью совпадает с выводом приме-
ра 20.18.
Подсказки запроса
Существует несколько подсказок запроса, которые используются для раз-
личных целей. В этом разделе рассматриваются следующие две подсказки
запроса
♦ fast п;
♦ OPTIMIZE FOR.
Список всех других подсказок запроса вы можете найти в документации
Books Online.
Подсказка fast п указывает, что запрос оптимизируется для быстрого поиска
первых п строк. После того как первые г строк будут получены, запрос про-
должит свое выполнение и создаст полный набор результата.
Замечание_________________________________________________________
Эта подсказка может быть очень полезной, если вы имеете очень сложный за-
прос с множеством результирующих строк, требующих большого количества
Гпава 20. Оптимизатор запросов 549
времени для их обработки. Обычно запрос выполняется полностью, а затем
система отображает его результат. Эта подсказка запроса требует, чтобы сис-
тема отображала первые п строк сразу после их обработки.
Подсказка optimize for заставляет оптимизатор запросов использовать кон-
кретное значение для локальной переменной, когда запрос компилируется и
оптимизируется. Это значение используется только в процессе оптимизации
запроса, но не в процессе его выполнения. Эта подсказка запроса может быть
использована, когда вы задаете структуры планов, которые обсуждаются
в следующем разделе.
В примере 20.20 показано использование подсказки запроса optimize for.
: Пример 20.20
DECLARE @city_name nvarchar(30)
SET @city_name = 'Newark'
SELECT * FROM Person.Address
WHERE City = @city_name
OPTION (OPTIMIZE FOR (Gcityname = 'Seattle'));
Хотя значение переменной @city_name установлено в Newark, подсказка
optimize for заставляет оптимизатор использовать значение Seattle для этой
переменной при оптимизации запроса.
Структуры планов
Как вы уже знаете из предыдущего раздела, подсказки явно задаются в опе-
раторе select для оказайия влияния на работу оптимизатора запросов. Иногда
вы не можете или у вас просто нет желания изменять текст в операторе
select напрямую. В этом случае все равно можно повлиять на выполнение
запросов, используя структуры планов. Другими словами, структуры планов
дают вам возможность использовать отдельную подсказку оптимизации каж-
дый раз, когда выполняются ее условия, без изменения синтаксиса оператора.
Структуры планов создаются при помощи системной процедуры sp_create_
plan guide. Эта процедура создает структуру плана для ассоциированных
подсказок запроса или для фактических планов запросов для запросов к базе
данных. Другая системная процедура, sp_control_plan_guide, включает, от-
ключает или удаляет существующую структуру плана.
Замечание_________________________________________________________
Не существует операторов DDL Transact-SQL для создания и удаления структур
планов. Надо надеяться, что последующие версии SQL Server будут поддержи-
вать подобные операторы.
550
Часть III. SQL Server: системное администрирование
Database Engine поддерживает следующие типы структур планов:
♦ SQL. Соответствует запросам, которые выполняются в контексте одиноч-
ных операторов Transact-SQL или пакетам, которые не являются частью
объекта базы данных;
♦ OBJECT. Соответствует запросам, которые выполняются в контексте под-
программ и триггеров DML;
♦ TEMPLATE. Соответствует одиночным запросам, параметризованным к
указанной форме.
Для редактирования информации, связанной со структурой планов, исполь-
зуйте представление просмотра каталогов sys.pian guides. Это представле-
ние содержит одну строку для каждой структуры плана в текущей базе дан-
ных. Наиболее важными Столбцами ЯВЛЯЮТСЯ plan guide id, name и
query_text. Столбец plan_guide_id задает уникальный идентификатор струк-
туры плана, а паше определяет ее имя. Столбец query text задает текст запро-
са, для которого создана структура плана.
Резюме
Оптимизатор запросов является частью Database Engine, которая принимает
решение, как лучше выполнить запрос. Он генерирует несколько планов вы-
полнения запроса для заданного запроса и выбирает план с наименьшей
стоимостью.
Фаза оптимизации запроса может быть разделена на следующие фазы: анализ
запроса, выбор индекса и выбор порядка выполнения соединения. В процессе
выполнения фазы анализа запроса оптимизатор просматривает запрос с
целью определения аргументов поиска, наличия операторов or и существова-
ния критериев соединения — в указанном порядке. Идентификация аргумен-
тов поиска позволяет оптимизатору принять решение, будут ли использо-
ваться один или более существующих индексов.
Порядок, в котором две или более соединяемых таблиц записаны в предло-
жении from оператора select, никак не влияет на решения оптимизатора
относительно порядка их обработки. Database Engine поддерживает три раз-
личные техники обработки соединения, которые могут быть использованы
оптимизатором. То, какую технику выберет оптимизатор, зависит от сущест-
вующих статистических данных для соединяемых таблиц.
Database Engine поддерживает множество инструментов, которые могут быть
использованы для редактирования существующих планов. Наиболее важны-
Гпава 20. Оптимизатор запросов
ми являются инструменты текстового и графического отображения планов
и представления динамического управления (DMV).
Вы можете повлиять на работу оптимизатора, используя подсказки оптими-
зации. Database Engine поддерживает много подсказок оптимизации, которые
могут быть объединены в следующие группы: подсказки таблицы, подсказки
соединения и подсказки запроса.
В следующей главе рассматривается настройка производительности.
ГЛАВА 21
Настройка производительности
Улучшение производительности системы базы данных требует принятия
множества решений, таких как: где хранить данные и как осуществлять дос-
туп к данным. Эта задача отличается от других административных задач, по-
тому что содержит несколько иные шаги, которые связаны со всеми аспекта-
ми программного обеспечения и оборудования. Если система базы данных не
работает оптимально, то системный администратор должен проверить мно-
жество факторов и по возможности настроить программное обеспечение
(операционную систему, систему базы данных, приложения базы данных) так
же, как и оборудование.
Производительность Database Engine (и любой другой реляционной СУБД)
определяется по двум критериям:
♦ время реакции;
♦ пропускная способность.
Время реакции определяет производительность отдельной транзакции или
программы. Время реакции трактуется как длительность во времени от мо-
мента, когда пользователь вводит команду или оператор, до момента, когда
система отмечает, что выполнение команды (оператора) завершено. Для дос-
тижения оптимального времени реакции всей системы почти все сущест-
вующие команды и операторы (80—90%) не должны превышать указанное
ограничение времени реакции.
Пропускная способность измеряет общую работу системы, вычисляя количе-
ство транзакций, которые могут быть обработаны Database Engine в заданный
период времени. Обычно пропускная способность измеряется в количестве
транзакций в секунду. Поэтому существует прямая связь между временем
реакции системы и ее пропускной способностью: когда время реакции ухуд-
Глава 21. Настройка производительности 553
шается (например, потому что много пользователей одновременно использу-
ют систему), то и пропускная способность системы также ухудшается.
В этой главе рассматриваются вопросы производительности и инструменты
для настройки системы базы данных, которые соответствуют ежедневным
задачам администрирования системы. Сначала в главе описываются факторы,
влияющие на производительность. После этого даются некоторые советы, как
выбрать правильный инструмент для задач администрирования. В конце гла-
вы представлены инструменты для мониторинга систем базы данных.
Факторы,
влияющие на производительность
Факторы, влияющие на производительность, разделяются на три общие кате-
гории:
♦ приложения базы данных;
♦ система базы данных; »
♦ системные ресурсы.
Эти факторы могут оказывать влияние на некоторые другие факторы, кото-
рые обсуждаются в следующих разделах.
Приложения базы данных и производительность
Следующие факторы могут влиять на производительность приложений базы
данных:
♦ эффективность кода приложения;
♦ физическое проектирование.
Эффективность кода приложения
Приложения содержат собственный код, используемый системным про-
граммным обеспечением и Database Engine. По этой причине они могут соз-
давать проблемы производительности, если вы задали неправильное исполь-
зование системных ресурсов. Большинство проблем производительности в
программах приложений появляется в результате неправильного выбора опе-
раторов Transact-SQL и их последовательности в программах приложений.
В следующем списке даны некоторые способы, которые могут улучшить об-
щую производительность, если вы измените код в приложении:
♦ использование кластерных индексов;
♦ исключить использование предиката not in.
554
Часть III. SQL Server: системное администрирование
Кластерные индексы обычно улучшают производительность. Производи-
тельность запроса для диапазона значений является наилучшей, если в
фильтре вы используете столбец, для которого существует кластерный ин-
декс. Если же вы отыскиваете только небольшое количество строк, то не су-
ществует разницы между использованием некластеризованного и кластери-
зованного индексов.
Предикат not in не является оптимизируемым, иными словами, оптимизатор
запросов не может использовать его в качестве аргумента поиска (sarg; опре-
деление см. в главе 20). Поэтому выражение с предикатом not in всегда при-
водит к последовательному сканированию таблицы.
Замечание_____________________________________________________
Большинство подсказок о том, как модификации кода могут улучшить общую
производительность, даны в главе 20.
Физическое проектирование
В процессе физического проектирования базы данных вы выбираете кон-
кретные структуры хранения и пути доступа к файлам базы данных. На этом
шаге проектирования иногда рекомендуется выполнять денормализацию не-
которых таблиц базы данных с целью достижения хорошей производитель-
ности для различных приложений базы данных. Денормализация таблиц оз-
начает, что две или более нормализованных таблицы объединяются вместе,
что приводит к некоторой избыточности данных.
Для демонстрации процесса денормализации рассмотрим следующий при-
мер: в табл. 21.1 показаны две таблицы из базы данных sample — department и
employee, которые являются нормализованными. (Более подробную информа-
цию о нормализации данных см. в главе 1.) Данные в этих двух таблицах мо-
гут быть представлены с использованием только одной таблицы dept_emp
(табл. 21.2), которая показывает денормализованную форму данных, храня-
щихся в таблицах department и errployee. В отличие от таблиц department и
employee, которые не содержат никаких избыточных данных, таблица
dept emp содержит много избыточности, потому что два столбца этой табли-
цы (dept_name И location) зависят ОТ столбца dept_no.'
Денормализация данных имеет два преимущества и два недостатка. Первое
преимущество: если у вас есть столбец, который зависит от другого столбца
таблицы (такой как столбец dept_name в таблице dept emp, который зависит от
столбца dept_no) для данных, часто используемых в запросах, вы можете
1 Эта таблица нарушает требования третьей нормальной формы — оба указанных столбца за-
висят не от ключа, а от неключевого столбца. — Прим, перев.
Глава 21. Настройка производительности 555
Таблица21.1. Таблицы employee и department
emp_no emp_fname emp_lname dept no
25348 Matthew Smith d3
10102 Ann Jones d3
18316 John Barrimore d1
29346 James James d2
9031 Elke Hansel d2
28559 Sybill Moser d1
dept_no dept_name location
d1 Research Dallas
d2 Accounting Seattle
d3 Marketing Dallas
Таблица 21.2. Таблица dept_emp
emp_no emp_fname enp_lname dept_no dept_name location
25348 Matthew Smith d3 Marketing Dallas
10102 Ann Jones d3 Marketing Dallas
18316 John Barrimore d1 Research Dallas
29346 James James d2 Accounting Seattle
9031 Elke Hansel d2 Accounting Seattle
28559 Sybill Moser d1 Research Dallas
исключить операцию соединения таблиц, которая оказывает влияние на про-
изводительность приложений. Второе преимущество: денормализованные
данные требуют меньшего количества таблиц, чем нормализованные данные.
С другой стороны, денормализованные таблицы требуют дополнительного
объема дисковой памяти, а изменение данных выполнять сложнее по причине
избыточности данных.
Другим вариантом в физическом проектировании базы данных, который спо-
собствует хорошей производительности, является создание индексов. В гла-
ве 10 даны основные положения по созданию индексов, а далее в данной гла-
ве представлены примеры.
19 Зак. 1141
556
Часть III. SQL Server: системное администрирование
Database Engine и производительность
Database Engine может значительно влиять на производительность всей сис-
темы. Двумя наиболее важными компонентами (механизмами) Database
Engine, которые влияют на производительность, являются:
♦ оптимизатор;
♦ блокировки.
Оптимизатор
Оптимизатор формулирует несколько планов выполнения запросов для чте-
ния строк, которые требуются для обработки запроса, а затем принимает ре-
шение, какой план будет использоваться. Это решение касается выбора наи-
более подходящего плана выполнения, включая то, какие индексы должны
быть использованы, как осуществлять доступ к таблицам и в каком порядке
должны соединяться таблицы. Все эти решения могут значительно повлиять
на производительность приложений базы данных. Оптимизатор подробно
обсуждался в предыдущей главе.
Блокировки
Система базы данных использует блокировки в качестве механизма защиты
одного пользователя от другого. Поэтому блокировки служат для управления
доступом к данным для всех пользователей в одно и то же время и для пре-
дотвращения вероятных ошибок, которые могут возникнуть в результате од-
новременного доступа к одним и тем же данным.
Блокировка влияет на производительность системы через ее гранулярность,
т. е. размер объекта, который будет заблокирован, и уровень изоляции. Бло-
кировка на уровне строки таблицы обеспечивает наилучшую производитель-
ность системы, потому что она оставляет незаблокированным все строки на
странице, кроме одной, и, следовательно, позволяет выполнять больше па-
раллельных действий, чем блокировки на уровне страницы или на уровне
всей таблицы.
Уровни изоляции влияют на длительность блокировки операторов select.
При использовании низких уровней изоляции, таких как read uncommitted и
read committed, может быть улучшена доступность данных и, следовательно,
количество одновременных обращений к данным. Блокировки и уровни изо-
ляции подробно рассматриваются в главе 13.
Системные ресурсы и производительность
Database Engine выполняется под операционной системой Windows, которая
сама использует системные ресурсы. Эти ресурсы имеют значительное влия-
Гпава 21. Настройка производительности
557
ние на производительность операционной системы, так же как и на произво-
дительность системы базы данных. Производительность любой системы базы
данных зависит от четырех основных системных ресурсов:
♦ центральный процессор (central processing unit, CPU);
♦ память;
♦ дисковые операции ввода/вывода;
♦ сетевое окружение.
Центральный процессор вместе с оперативной памятью является ключевым
компонентом, определяющим быстродействие компьютера. Это также ключ к
производительности системы, поскольку центральный процессор управляет
другими ресурсами системы и выполняет все приложения. Он выполняет
пользовательские процессы и взаимодействует с другими ресурсами вашей
системы. Проблемы производительности, связанные с центральным процес-
сором, могут появиться, когда операционная система и пользовательские
программы выполняют слишком много к нему запросов. Обычно, чем более
мощный процессор доступен вашему компьютеру, тем лучше работает вся
система.
Database Engine динамически запрашивает и освобождает память по мере не-
обходимости. Проблемы производительности, связанные с памятью, могут
появиться, если памяти недостаточно для выполнения требуемой работы.
Когда такое происходит, то много страниц памяти записывается в файл стра-
ниц. (Понятие файла страниц подробно объясняется далее в этой главе.)
Если процесс записи в файл страниц происходит слишком часто, то произво-
дительность системы может ухудшаться. Поэтому аналогично правилу цен-
трального процессора можно сказать: чем больше памяти доступно на вашем
компьютере, тем лучше работает вся система.
Существуют два момента, связанных дисковым вводом/выводом: дисковая
скорость и пропускная способность диска. Дисковая скорость определяет, как
быстро выполняются операции чтения и записи для диска. Пропускная спо-
собность диска задает, какой объем данных может быть записан на диск в
единицу времени (время обычно измеряется в секундах). Очевидно, что чем
быстрее диск, тем больший объем данньгх может быть обработан. Так же,
большее количество дисков лучше, чем один диск в случае, когда много
пользователей одновременно обращается к системе базы данных. В этом слу-
чае доступ к данным обычно распределяется между многими дисками, что
улучшает общую производительность системы.
В конфигурации "клиент/сервер" система базы данных иногда выполняется
хуже, если существует множество клиентских соединений. В этом случае
объем данных, которые нужно пересылать по сети, может превышать воз-
558
Часть III. SQL Server: системное администрирование
можности сетевого окружения. Чтобы устранить это узкое место в произво-
дительности, следует принять во внимание следующие общие рекомендации:
♦ если сервер базы данных отправляет приложению некоторые строки, то
нужно отправлять лишь те строки, которые действительно требуются при-
ложению;
♦ если выполняющееся в течение долгого времени пользовательское прило-
жение выполняется строго на клиентской стороне, переместите его на сто-
рону сервера (например, выполняя его как хранимую процедуру).
Все системные ресурсы взаимно зависят друг от друга. Это означает, что
проблемы производительности с одним ресурсом могут привести к пробле-
мам производительности, связанным с другими ресурсами. Аналогично,
улучшения, связанные с одним ресурсом, могут значительно повысить про-
изводительность некоторого другого ресурса (или даже всех). Рассмотрим
примеры.
♦ Если вы увеличиваете количество центральных процессоров, то каждый
CPU может равномерно разделять нагрузку и поэтому способен сгладить
проблемы с дисковым вводом/выводом. С другой стороны, неэффективное
использование центрального процессора часто бывает результатом пред-
шествующей объемной загрузки дисковыми операциями ввода/вывода
и/или оперативной памяти.
♦ Если доступно больше памяти, то существует высокий шанс найти в памя-
ти страницу, требуемую приложению (вместо того, чтобы отыскивать ее
на диске), что приводит к повышению производительности. В отличие от
этого чтение данных с дискового устройства, вместо извлечения их из го-
раздо более быстрой памяти, серьезно замедляет работу системы, особен-
но при наличии большого количества конкурентных процессов.
Дисковые операции ввода/вывода
Одним из назначений базы данных является сохранение, поиск и изменение
данных. Поэтому Database Engine, как и любая другая система базы данных,
должна выполнять множество действий с дисками. В отличие от других сис-
темных ресурсов дисковая подсистема имеет две движущиеся части: сам диск
и дисковые головки. На вращение диска и перемещение дисковых головок
требуется очень много времени, поэтому чтение с диска и запись на диск яв-
ляются двумя высокозатратными операциями, которые выполняет система
базы данных. (Например, доступ к диску обычно медленнее доступа к опера-
тивной памяти на два порядка и более.)
Database Engine сохраняет данные в страницах размером 8 Кбайт. Кэш буфе-
ра оперативной памяти также разделен на страницы по 8 Кбайт. Система
читает данные в единицах страницы. Операции чтения появляются не только
Гпава 21. Настройка производительности
559
при поиске данных, но также и при любых операциях модификации, таких
как update и delete, потому что система должна прочесть данные, прежде чем
она сможет их модифицировать.
Если нужная страница находится в буфере кэша, она будет читаться из памя-
ти. Такая операция ввода/вывода называется логическим вводом/выводом или
логическим чтением. Если страница не находится в памяти, то она читается с
диска и помещается в буфер кэша. Такая операция ввода/вывода называется
физическим вводом/выводом или физическим чтением. Буфер кэша разделя-
ется между всеми пользователями, потому что Database Engine использует
архитектуру только с одним адресным пространством памяти. Поэтому много
пользователей могут обращаться к одной и той же странице. Логическая
запись происходит, когда данные модифицируются в буфере кэша. Анало-
гично, физическая запись происходит, когда страница записывается из буфе-
ра кэша на диск. Поэтому может быть выполнено множество операций логи-
ческой записи для одной страницы, прежде чем она будет записана на диск.
Database Engine имеет несколько компонентов, которые оказывают очень
большое влияние на производительность, потому что они потребляют боль-
шое количество ресурсов ввода/вывода:
♦ упреждающее чтение;
♦ контрольные точки.
Упреждающее чтение описывается в следующем разделе, а контрольные точ-
ки подробно рассматривались в главе 17.
Оптимальным поведением системы базы данных является чтение данные и
без ожидания завершения операции чтения с диска. Лучшим способом реше-
ния такой задачи является тот случай, когда известно несколько страниц, ко-
торые потребуются пользователю, и чтение этих страниц с диска в буферный
пул, прежде чем они будут запрошены пользовательским процессом. Этот
механизм называется упреждающим чтением, он позволяет системе оптими-
зировать производительность, эффективно обрабатывая большой объем дан-
ных.
Компонент Database Engine, называемый Read Ahead Manager, внутренне
управляет процессами упреждающего чтения, так что пользователь не имеет
возможности повлиять на этот процесс. Вместо использования страниц по
8 Кбайт Database Engine использует блоки данных размером 64 Кбайт в каче-
стве единицы чтения для упреждающего чтения. Благодаря этому пропускная
способность для запросов ввода/вывода значительно увеличивается. Меха-
низм упреждающего чтения используется системой базы данных для выпол-
нения сканирования больших таблиц и сканирования индексных диапазонов.
Сканирование таблицы выполняется с использованием информации, которая
560
Часть III. SQL Server: системное администрирование
хранится в страницах схемы размещения индексов (index allocation map, IAM)
для создания последовательного списка дисковых адресов, которые должны
быть прочитаны. (Страницы IAM являются страницами размещения, храня-
щими информацию об экстентах, которые используются таблицами или ин-
дексами.) Это позволяет системе базы данных оптимизировать ее ввод/вывод
путем объемного последовательного чтения с диска. Read Ahead Manager чи-
тает до 2 Мбайт данных за один раз. Каждый экстент читается единственной
операцией.
Замечание________________________________________________________
Database Engine предоставляет множество последовательных операций упре-
ждающего чтения за один раз для каждого файла, включенного в сканирование
таблицы. Эта возможность может дать преимущества для расслоенных набо-
ров дисков.
Для индексного диапазона Database Engine использует информацию из про-
межуточного уровня индексных страниц, непосредственно перед уровнем
листьев, для определения того, какие страницы нужно читать. Система ска-
нирует все эти страницы и создает список страниц листьев, которые должны
быть прочитаны. В процессе этой операции распознаются смежные страницы
и читаются за одну операцию. Если требуется отыскать много страниц,
Database Engine формирует блок чтений в один раз.
Механизм упреждающего чтения также может иметь и негативное влияние на
производительность, если приходится читать слишком много страниц, и бу-
фер кэша излишне переполняется. Единственное, что вы можете сделать
в этом случае, — это создать индексы, которые вам действительно необхо-
димы.
Существует несколько счетчиков производительности и представлений ди-
намического управления, которые связаны с деятельностью упреждающего
чтения. Они рассматриваются позже в этой главе.
Память
Память является ключевым ресурсом не только для выполняющегося прило-
жения, но также и для операционной системы. Когда приложение выполняет-
ся, оно загружается в оперативную память и для него выделяется некоторый
объем памяти. (В терминологии Microsoft общий объем памяти, доступный
приложению, называется его адресным пространством.)
Операционные системы Windows поддерживают виртуальную память. Это
означает, что объем памяти, доступный приложениям, равен объему физиче-
ской памяти (или RAM) компьютера плюс размер специального файла на
дисковом устройстве, называемого файлом страниц (в операционных систе-
мах Windows файл страниц— pagefile.sys). Когда данные выгружаются из
Гпава 21. Настройка производительности 561
оперативной памяти во внешнюю, они размещаются в файле страниц. Если
система запрашивает поиск данных, которые не размещены в RAM, система
загружает эти данные из того внешнего размещения, где они хранятся, и до-
полнительно генерирует так называемую страничную ошибку'.
Замечание_______________________________________________________
Файл pagefile.sys должен размещаться на устройстве, отличном от устройства,
на котором находятся файлы, используемые Database Engine, потому что про-
цесс подкачки страниц может оказывать сильное влияние на дисковые опера-
ции ввода/вывода.
В оперативной памяти чаще всего хранится не все приложение, а только его
часть. Обычно в RAM располагаются страницы, к которым в последнее время
были обращения. Когда нужная приложению информация отсутствует в
RAM, операционная система должна выполнить подкачку (т. е. считать стра-
ницу из файла страниц в RAM). Этот процесс называется подкачкой страниц
по запросу. Чем больше системе требуется выполнять подкачку, тем хуже
производительность системы.
Замечание_______________________________________________________
Когда понадобится страница, отсутствующая в RAM, самая старая страница из
адресного пространства приложения перемещается в файл страниц, чтобы ос-
вободить место для новой страницы. Перемещения страниц всегда ограничены
адресным пространством текущего приложения. По этой причине не существу-
ет непредвиденного случая, когда будут заменены страницы адресного про-
странства других выполняющихся приложений.
Как вы уже знаете, страничная ошибка возникает, когда приложение делает
запрос к информации, а страница данных, содержащая эту информацию, не
находится по указанному адресу в RAM компьютера. Информация может
быть либо перемещена в файл страниц, либо может размещаться где-либо в
другом месте RAM. По этой причине существуют два типа страничных оши-
бок:
♦ ошибка страницы диска— страница была перемещена на внешнее уст-
ройство (в файл страниц) и должна быть загружена в RAM с дискового
устройства;
♦ ошибка программной страницы— страница находится в другом месте
RAM.
Ошибка программной страницы потребляет только ресурсы RAM. Поэтому
она лучше, чем ошибка страницы диска, которая приводит к появлению опе-
раций чтения и записи для диска.
1 Несмотря на принятую терминологию, это не является ошибкой. Система на аппаратном
уровне определяет отсутствие в памяти нужной страницы и выдает аппаратное прерывание,
в результате обработки которого в память подкачивается нужная страница. — Прим. персе.
562
Часть III. SQL Server: системное администрирование
Замечание__________________________________________________
Страничная ошибка является нормальной для окружения операционной систе-
мы Windows, потому что операционная система запрашивает страницы выпол-
няющихся приложений для удовлетворения потребностей в памяти запус-
каемых на выполнение приложений. Однако чрезмерное замещение страниц
(особенно в случае ошибок страниц диска) является серьезной проблемой про-
изводительности, потому что оно может приводить к перегрузке дискового уст-
ройства и к дополнительному расходованию мощности центрального процес-
сора.
Мониторинг производительности
Все факторы, которые влияют на производительность, могут отслеживаться с
использованием различных компонентов. Эти компоненты могут быть сгруп-
пированы по следующим категориям:
♦ счетчики Performance Monitor;
♦ представления динамического управления и представления каталогов;
♦ команда dbcc;
♦ системные хранимые процедуры.
В этом разделе вначале дается обзор Performance Monitor, а затем описыва-
ются все компоненты для мониторинга производительности, связанной с че-
тырьмя факторами: центральный процессор, память, доступ к диску, сетевое
окружение.
Обзор Performance Monitor
Performance Monitor является графическим инструментом Windows, который
позволяет отслеживать активность как системы Windows, так и системы базы
данных. Преимуществом этого инструмента является то, что он надежно ин-
тегрируется с операционными системами Windows и поэтому отображает
достоверные значения различных аспектов производительности. Performance
Monitor предоставляет множество объектов производительности, и каждый
объект производительности имеет несколько счетчиков. Эти счетчики могут
отслеживаться локально или через сетевое окружение.
Performance Monitor поддерживает три различных режима представления ре-
зультатов:
♦ графический режим отображает выбранные счетчики в виде цветных ли-
ний, где ось х представляет время, а ось у — значение счетчика; это режим
отображения по умолчанию;
Гпава 21. Настройка производительности
♦ режим гистограммы отображает выбранные счетчики в виде цветных
горизонтальных полос, которые представляют квантование значений дан-
ных;
♦ режим отчета отображает значения счетчиков в текстовом виде.
Для запуска Performance Monitor щелкните по кнопке Start (Пуск), выберите
Control Panel | Administrative Tools | Performance (Панель управления | Ад-
министрирование | Производительность). Начальное окно Performance Moni-
tor, показанное на рис. 21.1, содержит три счетчика по умолчанию: Pages/sec
(Object — Memory), Avg. Disk Queue Length (Object— PhysicalDisk), % Pro-
cessor Time (Object— Processor). Эти три счетчика являются важными,
однако вам понадобится выполнять отображение значений и некоторых дру-
гих счетчиков.
Рис. 21.1. Performance Monitor
Для добавления счетчика, подлежащего мониторингу, щелкните мышью по
символу + на панели инструментов Performance Monitor, выберите объект
564
Часть III. SQL Server: системное администрирование
производительности, которому принадлежит счетчик, выберите счетчик и
щелкните по кнопке Add. Для удаления счетчика выделите линию в нижней
области и щелкните по кнопке Delete (или нажмите клавишу <Del>).
Мониторинг процессора
В этом разделе описываются некоторые счетчики Performance Monitor, свя-
занные с мониторингом центрального процессора:
♦ % Processor Time (% загруженности процессора), здесь Object (Объ-
ект) — Processor (Процессор);
♦ % Interrupt Time (% времени прерываний), здесь Object — Processor;
♦ Interrupts/sec (Прерываний/сек.), здесь Object — Processor;
♦ Processor Queue Length (Длина очереди процессора), здесь Object —
System (Система).
В этом разделе также описывается одна системная процедура и два представ-
ления, связанные с мониторингом центрального процессора:
♦ sp_monitor;
♦ sys.sysprocesses;
♦ sys.dm_exec_requests.
Счетчик % Processor Time отображает использование процессора в масшта-
бах всей системы и выступает в роли первичного индикатора активности
процессора. Значение этого счетчика должно находиться между 80 и 90. Вы
должны стремиться сократить использование центрального процессора, если
значение этого счетчика постоянно превышает 90. (Использование CPU в
100% допустимо лишь в том случае, если это происходит в короткий проме-
жуток времени.)
Счетчик % Interrupt Time показывает процент времени, которое CPU тратит
на обслуживание прерываний оборудования. Значение этого счетчика являет-
ся важным, если хотя бы один элемент оборудования пытается получить про-
цессорное время. Если только один элемент оборудования вызывает пробле-
мы, то решением может быть обновление такого элемента.
Счетчик Interrupts/sec отображает, сколько раз в секунду процессор получа-
ет прерывания от оборудования для обслуживания запросов от периферий-
ных устройств. Это число обычно может быть большим в окружении с высо-
ким использованием дисков или большим количеством сетевых запросов.
Счетчик Processor Queue Length указывает, как много потоков ожидает вы-
полнения. Если этот счетчик все время превышает 5 в случае, когда исполь-
зование процессора приближается к 100%, то это означает, что активных по-
Глава 21. Настройка производительности 565
токов реально существует больше, чем машинные процессоры в состоянии
обработать.
Системная процедура spjnonitor отображает статистические данные, напри-
мер, количество секунд, при которых CPU осуществлял работу системы, ко-
личество секунд, в течение которых система находилась в состоянии ожида-
ния, количество операций ввода/вывода и количество соединений (или попы-
ток соединения) с системой.
Представление каталога sys.sysprocesses может быть полезным, если вы
хотите идентифицировать процесс, который больше всего использует про-
цессорное время. Это представление содержит информацию о процес-
сах, которые выполняются в экземпляре. Эти процессы могут быть клиент-
скими процессами или системными процессами. Представление принад-
лежит системной базе данных master. По этой причине для доступа к
представлению вы должны использовать имя, состоящее из трех частей
(master.dbo. sysprocesses). Наиболее важными столбцами этого представле-
ния являются spid (идентификатор сессии), dbid (идентификатор текущей
базы данных), uid (идентификатор пользователя, который выполняет теку-
щую команду) и сри (накапливаемое для процесса время CPU).
Представление sys.dm_exec_requests предоставляет ту же информацию, что и
представление каталога sys.sysprocesses, однако имена соответствующих
столбцов отличаются. В примере 21.1 показано использование этих дина-
мических представлений управления. Имена столбцов объясняют свое назна-
чение.
Пример 21.1
SELECT session_id, database_id, user_id, cpu time, sql_handle
FROM sys.dm_exec_requests
order by cpu_time DESC
Столбец sqi_handle в представлении указывает на область, где сохраняется
весь пакет. Если вы хотите уменьшить информацию до одного только опера-
тора, вы должны использовать столбцы statement start offset и statement-
end—offset для сокращения результата.
Замечание___________________________________________________________
Представление динамического управления действительно является полезной
вещью, если вы хотите определять запросы, которые выполняются длительное
время.
Часть III. SQL Server: системное администрирование
Мониторинг памяти
Этот раздел описывает некоторые счетчики Performance Monitor, связанные
с мониторингом памяти:
♦ Buffer Cache Hit Ratio (% использования выделенной памяти), здесь
Object — Memory (Память);
♦ Pages/sec (Обмен страниц в сек.), здесь Object — Memory;
♦ Page Faults/sec (Ошибок страницы/сек.), здесь Object — Memory.
В этом разделе также описывается одна команда и два представления, свя-
занные с мониторингом памяти:
♦ DBCC memorystatus;
♦ sys. dm_os_meinory_clerks;
♦ sys.dm_os_memory_objects.
Счетчик Buffer Cache Hit Ratio отображает процент страниц, которые не
требуется читать с диска. Чем выше это отношение, тем реже система должна
обращаться к жесткому диску для чтения данных, при этом улучшается об-
щая производительность. Обратите внимание, что не существует правильного
значения этого счетчика, потому что оно зависит от приложения.
Замечание________________________________________________________
Этот счетчик отличается от большинства других счетчиков, потому что его зна-
чение не измеряется в реальном времени, а является средним значением за
все дни с момента последнего запуска Database Engine.
Счетчик Pages/sec отображает объем обмена страниц (т. е. количество стра-
ниц, записанных на диск или считанных с диска в секунду). Этот счетчик яв-
ляется важным индикатором наличия ошибок, которые приводят к пробле-
мам производительности. Если значение этого счетчика слишком велико, вы
должны принять решение о дополнительной физической памяти.
Счетчик Page Faults/sec отображает среднее количество ошибок страниц в
секунду. Этот счетчик включает как программные ошибки, так и ошибки
диска. Ошибки страниц появляются, когда системный процесс ссылается на
виртуальную страницу памяти, которая в этот момент не находится в рабочей
области физической памяти. Если запрашиваемая страница находится в спи-
ске простаивающей памяти или страница в настоящий момент разделяется
другими процессами, то генерируется ошибка программной страницы, и
ссылка на память разрешается без физического обращения к диску. Однако
если страница, на которую осуществляется ссылка, находится в файле стра-
ниц, то генерируется ошибка страницы диска, и данные должны быть загру-
жены с диска.
Глава 21. Настройка производительности 567
Команда dbcc memorystatus предоставляет мгновенный снимок текущего со-
стояния памяти Database Engine. Вывод этой команды полезен в процессе ис-
правления ошибок, которые связаны с использованием памяти Database
Engine или со специфическими ошибками памяти (многие из которых авто-
матически отправляют этот вывод в протокол ошибок).
Представление sys. dm_os_memory_cierks возвращает набор всех служб памя-
ти, которые являются активными в текущем экземпляре. Вы можете исполь-
зовать это представление для получения распределения памяти для различ-
ных типов памяти.
Замечание___________________________________________________________
Менеджер памяти Database Engine является трехуровневой иерархией. На
нижнем уровне иерархии располагаются узлы памяти. Следующий уровень со-
стоит из служб памяти, кэша памяти и пула памяти. Последний уровень состоит
из объектов памяти. Эти объекты обычно используют распределение памяти.
Представление sys.dm_os_memory_objects возвращает объекты памяти, кото-
рые в настоящий момент распределены системой базы данных. Это представ-
ление динамического управления в первую очередь служит для анализа ис-
пользования памяти и для анализа возможного недостатка памяти, как пока-
зано в примере 21.2.
\ Пример 21.2
SELECT type, SUM(pages_allocated_count) AS total_memory
FROM sys.dm_os_memory_objects
GROUP BY type
ORDER BY total_memory DESC
Здесь все объекты памяти группируются в соответствии с их типом, а затем
используется значение столбца pages_allocated_count для отображения
объема памяти каждой группы.
Мониторинг дисковой системы
В этом разделе описываются некоторые счетчики Performance Monitor, свя-
занные с мониторингом дисковой системы:
♦ % Disk Time (% активности диска), здесь Object— Physical Disk (Физи-
ческий диск);
♦ Current Disk Queue Length (Текущая длина очереди диска), здесь
Object — Physical Disk;
568
Часть III. SQL Server: системное администрирование
♦ Disk Read Bytes/sec (Скорость чтения с диска (байт/сек)), здесь Object —
Physical Disk;
♦ Disk Write Bytes/sec (Скорость записи на диск (байт/сек)), здесь Object —
Physical Disk;
♦ % Disk Time (% активности диска), здесь Object — Logical Disk (Логиче-
ский диск);
♦ Current Disk Queue Length (Текущая длина очереди диска), здесь
Object — Logical Disk;
♦ Disk Read Bytes/sec (Скорость чтения с диска (байт/сек)), здесь Object —
Logical Disk;
♦ Disk Write Bytes/sec (Скорость записи на диск (байт/сек)), здесь Object —
Logical Disk.
Как вы можете видеть из предыдущего списка, имена счетчиков Performance
Monitor для объектов физического диска и объектов логического диска явля-
ются одинаковыми. (Различие между физическими и логическими объектами
объяснялось в главе 5.) Эти счетчики имеют одно и то же назначение для
каждого объекта, так что следующие описания объясняют счетчики только
для объектов физического диска.
В этом разделе также описывается одно представление, связанное с монито-
рингом ДИСКОВОЙ системы — sys.dm_os_wait_stats.
Счетчик % Disk Time отображает количество времени, в течение которого
жесткий диск фактически работает. Он предоставляет хорошую относитель-
ную меру того, насколько загружен системой ваш диск. Он должен быть ис-
пользован в течение длительного периода времени для определения потенци-
альной потребности в больших возможностях ввода/вывода.
Счетчик Current Disk Queue Length сообщает, как много операций вво-
да/вывода для диска ожидает, когда диск станет свободным. Это количество
должно быть как можно меньшим.
Счетчик Disk Read Bytes/sec показывает скорость, с которой данные пересы-
лаются с жесткого диска в процессе операций чтения, в то время как Disk
Write Bytes/sec дает скорость, с которой данные пересылаются на жесткий
диск в процессе операций записи.
Представление sys. dm_os_wait_stats возвращает информацию об ожиданиях
в выполняемых потоках. Используйте это представление для диагностики
производительности Database Engine, а также заданных запросов и пакетов.
Наиболее важными столбцами этого представления являются wait type и
waiting_tasks_count. Первый отображает имена типов ожидания, а второй —
количество ожиданий соответствующего типа ожидания.
Глава 21. Настройка производительности 569
Мониторинг сетевого интерфейса
В этом разделе описываются некоторые счетчики Performance Monitor, свя-
занные с мониторингом сети:
♦ Bytes Total/sec (Всего байт/сек), здесь Object — Network Interface (Сете-
вой интерфейс);
♦ Bytes Received/sec (Получено байт/сек), здесь Object— Network
Interface;
♦ Bytes Sent/sec (Отправлено байт/сек), здесь Object — Network Interface.
В этом разделе также описывается команда и представление, связанные с мо-
ниторингом сетевого интерфейса:
♦ dbcc perfmon;
♦ sys.dm_exec_connections.
Замечание_______________________________________________________
Системная процедура spjnonitor, описанная в разд. "Мониторинг процессо-
ра" ранее в этой главе, может быть очень полезной для отслеживания данных,
связанных с сетевым интерфейсом, потому что она отображает информацию
об отправленных и полученных пакетах.
Счетчик Bytes Total/sec отображает количество байтов, которые были от-
правлены в секунду по сети. (Данные включают сетевой трафик, как связан-
ный с Database Engine, так и не связанный с ним.) Предположим, что ваш
сервер является назначенным сервером базы данных. Подавляющее боль-
шинство объема трафика, показанного в этом счетчике, будет от Database
Engine. Постоянно низкое значение этого счетчика указывает на то, что сете-
вые проблемы могут быть связаны с вашим приложением.
Чтобы определить, как много данных было отправлено с вашего сервера и
получено сервером из сети, используйте счетчики Bytes Received/sec и Bytes
Sent/sec. Первый отображает скорость, с которой были получены данные из
сети (в байтах), второй фиксирует скорость отправляемых данных. Эти счет-
чики будут вам полезны для определения того, насколько ваш сервер загру-
жен сетевым трафиком.
Команда dbcc perfmon отображает информацию об операциях ввода/вывода,
выполняемых Database Engine, а также сетевые статистические данные. По
отношению к сети эта команда предоставляет вам детальную информацию
о фактическом количестве прочитанных и записанных байтах (опции
Network Bytes Read и Network Bytes Written соответственно).
Замечание_______________________________________________________
Команда dbcc perfmon может быть отменена в одной из следующих версий
SQL Server.
570
Часть III. SQL Server: системное администрирование
Представление sys. dm ezec__conneccions возвращает информацию о соедине-
ниях, установленных с экземпляром Database Engine, и детали каждого со-
единения. Двумя важными столбцами этого представления динамического
управления являются num_reads и num writes. Первый отображает количество
прочитанных пакетов в данном соединении, а второй предоставляет инфор-
мацию о количестве записанных пакетов в данном соединении.
Выбор подходящего инструмента
Выбор соответствующего инструмента зависит от факторов производитель-
ности, которые предполагается отслеживать, и от типа мониторинга. Типами
мониторинга могут быть:
♦ реальное время;
♦ отсроченный мониторинг (информация, например, сохраняется в файле).
Мониторинг реального времени означает, что вопросы производительности
исследуются в процессе их появления. Если вы хотите отображать фактиче-
ские значения одного или нескольких факторов производительности, таких
как количество пользователей или количество попыток соединения, приме-
няйте существующие представления динамического управления по причине
простоты их использования. Фактически DMV могут быть использованы
только для мониторинга в реальном времени. Поэтому, если вы хотите от-
слеживать производительность различных деятельностей в течение опреде-
ленного периода времени, вы должны обратить внимание на такой инстру-
мент, как SQL Server Profiler (см. следующий раздел).
Возможно, наилучшим многоцелевым инструментом мониторинга является
Performance Monitor, потому что он содержит множество опций. Во-первых,
вы можете выбрать производительность той деятельности, которую вы хоти-
те отслеживать и одновременно отображать. Во-вторых, Performance Monitor
позволяет вам устанавливать пороговые значения отдельных счетчиков (фак-
торов производительности) для генерации предупреждающих сообщений,
которые уведомляют операторы. Таким путем вы можете мгновенно реагиро-
вать на любые проблемы с производительностью. В-третьих, вы можете соз-
давать отчет о производительности выполняемых действий и позже исследо-
вать результирующие диаграммы файлов протоколов.
Также очень рекомендуется использовать DMV по причине их простоты.
Первая группа представлений динамического управления была реализована
в SQL Server 2005, и каждая новая версия будет поддерживать все больше и
больше DMV, которые могут быть использованы для различных задач.
Глава 21. Настройка производительности 571
В следующих разделах описываются SQL Server Profiler и Database Engine
Tuning Advisor.
SQL Server Profiler
SQL Server Profiler является графическим инструментом, который позволяет
системным администраторам отслеживать и записывать деятельность базы
данных и сервера, такие как соединение, пользователь, а также информацию
приложения. SQL Server Profiler может отображать информацию о различных
действиях сервера в реальном времени или создавать фильтры, чтобы сфоку-
сироваться на отдельных событиях пользователя, типах команд или типах
операторов Transact-SQL. Помимо прочего, при использовании SQL Server
Profiler вы можете отслеживать следующие события:
♦ соединения, попытки соединения, ошибки соединений и отсоединения;
♦ использование пакетов центрального процессора;
♦ проблемы взаимных блокировок;
♦ все операторы DML (select, insert, update и delete);
♦ запуск и завершение работы хранимой процедуры.
Наиболее важной особенностью SQL Server Profiler является возможность
перехвата деятельностей, связанных с запросами. Эти действия могут быть
использованы в качестве ввода для Database Engine Tuning Advisor, который
позволяет отбирать индексы и индексированные представления для одного
или более запросов. По этой причине в следующем разделе рассматриваются
возможности SQL Server Profiler вместе с Database Engine Tuning Advisor.
Database Engine Tuning Advisor
Database Engine Tuning Advisor является частью общей системы и позволяет
вам автоматизировать физическое проектирование ваших баз данных. Как
уже было сказано, Database Engine Tuning Advisor тесно связан с SQL Server
Profiler, который может отображать информацию о некоторых действиях сер-
вера в реальном времени, он также может создавать фильтры, чтобы сфоку-
сироваться на отдельных событиях пользователя, типах команд или типах
операторов Transact-SQL.
Специфической особенностью SQL Server Profiler, которая используется в
Database Engine Tuning Advisor, является его способность просматривать
и записывать выполняемые пользователями пакеты и предоставлять инфор-
мацию о производительности, такую как использование в пакетах CPU и со-
ответствующие статистические данные по вводу/выводу.
572
Часть III. SQL Server: системное администрирование
Предоставление информации
для Database Engine Tuning Advisor
Database Engine Tuning Advisor обычно используется вместе c SQL Server
Profiler для автоматизации процессов настройки. Вы применяете SQL Server
Profiler для записи в файл трассировки информации о проверяемой деятель-
ности. (В качестве альтернативы файлу деятельности можете использовать
любой файл, который содержит набор операторов Transact-SQL. В этом слу-
чае вам нет необходимости запускать SQL Server Profiler.) Database Engine
Tuning Advisor может затем читать этот файл и давать рекомендации, чтобы
отдельные физические объекты, такие как индексы, индексированные пред-
ставления и схема разбиения, были созданы для данной деятельности.
В примере 21.3 показано, как Database Engine Tuning Advisor оценивает файл,
созданный SQL Server Profiler. Таблицы order и order detail будут использо-
ваны для демонстрации рекомендаций пб физическим объектам, данным
Database Engine Tuning Advisor.
; Пример 21.3
USE sample;
CREATE TABLE orders
(orderid INTEGER NOT NULL,
orderdate DATE,
shippeddate DATE,
freight money);
CREATE TABLE order details
(productid INTEGER NOT NULL,
orderid INTEGER NOT NULL,
unitprice money,
quantity INTEGER);
Для демонстрации использования Database Engine Tuning Advisor требуется
очень много строк в обеих таблицах. Примеры 21.4 и 21.5 добавляют 3000 строк
в таблицу order и 30 000 строк в таблицу order_detail соответственно.
j Пример 21.4
— Эта процедура добавляет 3000 строк в таблицу orders
USE sample;
declare @i int, @order_id integer
declare @orderdate datetime
declare @shipped__date datetime
declare @freight money
Глава 21. Настройка производительности 573
set @i = 1
set @orderdate = getdateO
set @shippeddate = getdateO
set @freight = 100.00
while @i < 3001
begin
insert into orders (orderid, orderdate, shippeddate, freight)
values(@i, @orderdate, @shipped_date, @freight)
set @i = @i+l
• Пример 21.5
— Эта процедура добавляет 30 000 строк в таблицу order_details
— и изменяет некоторые из них
USE sample
declare @i int, @j int
set @i = 3000
set @j = 10
while @j > 0
begin
if @i > 0
begin
insert into order_details (productid, orderid, quantity)
values (@i, Gj, 5)
set @i = @i — 1
end
else begin
set @j = @j - 1
set @i = 3000
end
end
go
update order_details set quantity = 3
where productid in (1511, 2678)
Запрос в примере 21.6 будет использован в качестве входного файла для SQL
Server Profiler. Предположим, что никакие индексы не создавались для
столбцов, которые появляются в операторе select.
| Пример 21.6
USE sample;
SELECT orders.orderid, orders.shippeddate
574
Часть III. SQL Server: системное администрирование
FROM orders
WHERE orders.orderid between 806 and 1600
and not exists (SELECT order_details.orderid
FROM order_details
WHERE order_details.orderid = orders.orderid);
Вначале вызовите SQL Server Profiler, щелкнув по кнопке Start (Пуск), вы-
брав AU Programs | Microsoft SQL Server 2008 | Performance Tools | SQL
Server Profiler (Все программы | Microsoft SQL Server 2008 | Performance
Tools | SQL Server Profiler). В меню File выберите команду New Trace. После
соединения с сервером появляется диалоговое окно Trace Properties. Набе-
рите имя трассировки и выберите выходной trc-файл для информации Profiler
(в поле Save to file). Щелкните по кнопке Run для начала захвата и использо-
вания SQL Server Management Studio для выполнения запроса из приме-
ра 21.6. Под конец остановите SQL Server Profiler, выбрав команду Stop
Trace в меню File, и выберите соответствующую трассировку.
Работа с Database Engine Tuning Advisor
Database Engine Tuning Advisor анализирует рабочую нагрузку и выдает ре-
комендации по физическому проектированию одной или нескольких баз дан-
ных. Анализ будет включать рекомендации по добавлению, удалению или
изменению физических структур баз данных, таких как индексы, индексиро-
ванные представления и разделы диска. Database Engine Tuning Advisor мо-
жет рекомендовать набор физических структур базы данных, которые опти-
мизируют задачи, включенные в рабочую нагрузку.
Для использования Database Engine Tuning Advisor (рис. 21.2) щелкните
мышью по кнопке Start (Пуск), выберите All Programs | Microsoft SQL
Server 2008 | Performance Tools | Database Engine Tuning Advisor (Все про-
граммы | Microsoft SQL Server 2008 | Performance Tools | Database Engine
Tuning Advisor). Альтернативным способом является запуск SQL Server
Profiler и выбор в меню Tools и команды Database Engine Tuning Advisor.
В поле Session name наберите имя сессии, для которой Database Engine
Tuning Advisor будет создавать рекомендации по настройкам. В группе
Workload установите либо переключатель File, либо переключатель Table.
Если вы выбрали File, введите имя файла трассировки. Если вы выбрали
Table, то должно быть введено имя таблицы, созданной SQL Server Profiler.
Используя SQL Server Profiler, вы можете перехватывать и сохранять данные
о каждой деятельности с файлом или с таблицей SQL Server.
В области Select databases and tables to tune выберите одну или более баз
данных и/или одну или более таблиц, которые вы хотите настраивать.
Database Engine Tuning Advisor может настраивать рабочую нагрузку, кото-
Глава 21. Настройка производительности
575
рая относится к нескольким базам данных. Это означает, что данный инстру-
мент может рекомендовать индексы, индексированные представления и схе-
му распределения для любой базы данных рабочей нагрузки.
Рис. 21.2. Database Engine Tuning Advisor, вкладка General
Для выбора опций настройки щелкните мышью по вкладке Tuning Options
(рис. 21.3). Все опции на этой вкладке разделены на три группы:
♦ Physical Design Structures (PDS) to use in database (Физическое проекти-
рование структур для использования в базе данных);
♦ Partitioning strategy to employ (Стратегия выполнения декомпозиции);
♦ Physical Design Structures (PDS) to keep in database (Физическое проек-
тирование структур для хранения в базе данных).
Первая группа опций позволяет вам указать, какие физические структуры
(индексы и/или индексированные представления) должны быть рекомендова-
ны Database Engine Tuning Advisor после настройки существующей рабочей
нагрузки. Опция Evaluate utilization of existing PDS only предписывает
576
Часть III. SQL Server: системное администрирование
Database Engine Tuning Advisor проанализировать существующие физические
структуры и дать рекомендации, какие из них должны быть удалены.
Рис. 21.3. Database Engine Tuning Advisor, вкладка Tuning Options
Группа переключателей Partitioning strategy to employ позволяет выбрать,
будут ли созданы рекомендации по декомпозиции. Если вы выбираете реко-
мендации по декомпозиции, вы также можете выбрать тип декомпозиции —
полный или регулируемый. (Декомпозиция подробно рассматривается в гла-
ве 26.)
Последняя группа переключателей, Physical Design Structures (PDS) to keep in
database, позволяет вам принять решение, какие из существующих структур
должны оставаться в базе данных нетронутыми после выполнения настройки.
Для больших баз данных настройка физических структур обычно требует за-
трат значительного времени и ресурсов. Вместо того чтобы начать затратный
поиск возможных индексов, Database Engine Tuning Advisor предоставляет
(по умолчанию) ограниченное использование ресурсов. Этот режим операции
все еще дает весьма хорошие результаты, хотя количество настраиваемых
ресурсов значительно сокращается.
Глава 21. Настройка производительности
577
В процессе задания опций настройки вы можете указать дополнительные на-
страиваемые опции, щелкнув мышью по Advanced Options, в результате чего
откроется диалоговое окно Advanced Tuning Options (рис. 21.4). Отметив
флажок в верхней части этого диалогового окна^ вы можете определить мак-
симальное пространство рекомендаций. Для больших баз данных выбор фи-
зических структур обычно требует значительного количества ресурсов. Вме-
сто того чтобы начать затратный поиск, Database Engine Tuning Advisor пре-
доставляет опцию для ограничения пространства, используемого для
настройки.
Рис. 21.4. Диалоговое окно Advanced Tuning Options
Из всех опций настройки индекса одной из наиболее интересных является
вторая опция в этом диалоговом окне, которая позволяет определять макси-
мальное количество столбцов в индексе. Индекс, содержащий один столбец,
или составной индекс, созданный из двух столбцов, может быть использован
несколько раз со многими запросами и требует меньше памяти для своего
хранения, чем индекс, созданный из четырех или более столбцов. (Это при-
менимо в случае, когда вы используете собственный файл рабочей нагрузки
вместо трассировки SQL Server Profiler для заданной рабочей нагрузки.)
С другой стороны, составной индекс, созданный из четырех или более столб-
цов, может быть использован в качестве покрывающего индекса для предос-
тавления только индексного доступа в некоторых запросах рабочей нагрузки.
(Более подробную информацию о покрывающих индексах см. в главе 10.)
После того как вы выберите опции в диалоговом окне Advanced Tuning
Options, щелкните по кнопке ОК, чтобы закрыть это окно. Затем вы можете
запустить анализ рабочей нагрузки. Для старта процесса настройки щелкните
на панели инструментов по Actions и выберите Start Analysis. После того как
вы запустите процесс настройки для файла трассировки из примера 21.6,
Database Engine Tuning Advisor создает рекомендации по настройке, которые
вы можете увидеть, щелкнув по вкладке Recommendations (рис. 21.5). Как вы
578
Часть III. SQL Server: системное администрирование
можете видеть, Database Engine Tuning Advisor рекомендует создать два ин-
декса.
Рис. 21.5. Database Engine Tuning Advisor, вкладка Recommendations
Рекомендации Database Engine Tuning Advisor, связанные с физическими
структурами, могут быть просмотрены с помощью набора отчетов, которые
предоставляют информацию об очень интересных опциях. Эти отчеты позво-
ляют вам увидеть, как Database Engine Tuning Advisor обрабатывал рабочую
нагрузку. Для просмотра этих отчетов щелкните по вкладке Reports в диало-
говом окне Database Engine Tuning Advisor после завершения процесса на-
стройки. Помимо прочих, вы можете просматривать следующие отчеты:
♦ Index usage report (current and recommended) (Отчет по использованию
индексов (текущий и рекомендуемый));
♦ Index detail report (current and recommended) (Подробный отчет по ин-
дексам (текущий и рекомендуемый));
♦ Table access report (Отчет доступа к таблицам);
♦ Workload analysis report (Отчет анализа рабочей нагрузки).
Глава 21. Настройка производительности 579
Index usage report (recommended) отображает информацию об ожидаемом
использовании рекомендованных индексов и их предполагаемых размерах.
Index usage report (current) представляет ту же самую информацию для
существующей конфигурации.
Index detail report (recommended) отображает информацию об именах всех
рекомендуемых индексах и их типах. Index detail report (current) представ-
ляет ту же самую информацию для фактической конфигурации, которая су-
ществовала до момента старта процесса настройки.
Table access report отображает информацию о стоимости всех запросов ра-
бочей нагрузки (используя таблицы базы данных).
Workload analysis report предоставляет информацию об относительных час-
тотах всех операторов модификации данных. Стоимости вычисляются отно-
сительно наиболее дорогостоящего оператора в текущей конфигурации ин-
дексов.
Существуют три способа, которыми вы можете применить созданные реко-
мендации: немедленно, по расписанию или после сохранения в файле. Если
вы щелкнете по элементу меню Actions и выберете Apply Recommendations,
то рекомендации будут применены немедленно. Аналогично, если вы выбе-
рите Save Recommendations в том же самом меню, то рекомендации будут
сохранены в файле. (Эта альтернатива полезна, если вы генерируете скрипт
с одной (тестовой) системой, и он предназначен для использования рекомен-
даций настройки в другой (производственной) системе.) Третья опция,
Evaluate Recommendations, служит для проверки рекомендаций, созданных
Database Engine Tuning Advisor.
Инструменты производительности
SQL Server 2008
SQL Server 2008 поддерживает два новых инструмента производительности:
♦ Performance Data Collector;
♦ Resource Governor.
Performance Data Collector
Одной из ситуаций, которая обычно встает перед администратором базы дан-
ных, является тот факт, что проблемы производительности иногда бывают
очень сложны для их отслеживания. Причина этого заключается в том, что
администратор базы данных обычно не находится в нужном месте в нужное
время для того, чтобы определить проблему и отреагировать на нее при пер-
вом же ее обнаружении.
580
Часть III. SQL Server: системное администрирование
В SQL Server 2005 введено средство Performance Dashboard для решения этой
проблемы, однако это не является полным решением. В SQL Server 2008 кор-
порация Microsoft добавила целую инфраструктуру для решения такой про-
блемы. Ключевым компонентом этой новой инфраструктуры является
Performance Data Collector, компонент, который инсталлируется в экземпляре
SQL и может быть сконфигурирован для выполнения либо в соответствии
с расписанием, либо в постоянном режиме. Этот инструмент имеет две задачи:
♦ сбор различных наборов данных, относящихся к производительности;
♦ сохранение этих данных в реляционной базе данных.
Затем эти данные могут быть использованы вместе с уже существующими
данными, которые были собраны ранее. Собранные множества данных могут
быть использованы для исправления ошибок, настроек и для отслеживания
состояния одного или более экземпляров Database Engine. Эти данные затем
могут быть сохранены в Management Data Warehouse (MDW), который явля-
ется еще одним компонентом этого инструмента. MDW является базой дан-
ных, которая используется в качестве репозитария для всех собранных дан-
ных.
Перед тем как использовать Performance Data Collector, вы должны вначале
сконфигурировать MDW. Чтобы это сделать, разверните сервер, разверните
X Configure Management Data Warehouse... |Z~|fo|x
Рис. 21.6. Конфигурирование хранилища MDW при помощи мастера
Глава 21. Настройка производительности
581
узел Management, щелкните правой кнопкой мыши по узлу Data Collection и
выберите пункт Configure Management Data Warehouse. Запустится мастер
Configure Management Data Warehouse Storage. На первом шаге после откры-
тия страницы вы должны выбрать сервер и базу данных для сохранения ва-
ших управляющих данных в информационном хранилище (рис. 21.6). На сле-
дующем шаге выполнения мастера отметьте соединения, пользователей, роли
и группы для помещения в хранилище. Последний шаг завершает работу
мастера и запускает сбор данных.
После того как Performance Data Collector будет сконфигурирован и активи-
рован, система запустит процесс сбора информации по производительности и
помещения данных в MDW.
Resource Governor
Одной из самых больших проблем предыдущих версий SQL Server является
попытка управления ресурсами в конкурентной рабочей нагрузке на разде-
ляемом сервере базы данных. Вы можете решить эту проблему, используя
либо виртуализацию сервера, либо несколько экземпляров сервера. В обоих
случаях для экземпляра не существует возможности определить, используют
ли другие экземпляры (или виртуальные машины) память и центральный
процессор. Новый инструмент Resource Governor управляет подобной ситуа-
цией, предоставляя возможность одному экземпляру резервировать часть
CPU (или другого ресурса) для отдельного процесса.
Обычно Resource Governor позволяет администратору базы данных опреде-
лять ограничения ресурсов и приоритеты для различных рабочих нагрузок.
Таким путем может быть достигнута согласованность производительности
для процессов.
Resource Governor имеет два главных компонента: группы ресурсов и пулы
ресурсов (рис. 21.7). Когда процесс соединяется с Database Engine, он клас-
сифицируется, а затем ему назначается группа ресурсов на основе этой клас-
сификации. (Классификация выполняется либо при помощи встроенного
классификатора, либо с помощью функции, определенной пользователем).
Одна или более ресурсных групп затем назначается заданным ресурсным
пулам.
Как вы можете видеть на рис. 21.7, существуют две различные группы ресурсов:
♦ внутренняя группа;
♦ группа по умолчанию.
Внутренняя группа служит для выполнения некоторых системных функций,
в то время как группа по умолчанию используется, когда процесс не имеет
определенной классификации.
582
Часть III. SQL Server: системное администрирование
Следующий сценарий описывает шаги, которые вы можете применить для
создания различных рабочих нагрузок и принятия решения, а также какие
ресурсы применимы для какой группы рабочих нагрузок:
♦ создание групп рабочих нагрузок с использованием оператора create
workload;
♦ для каждой группы рабочих нагрузок определение соответствующей UDF.
Подобные функции, определенные пользователем, могут быть использо-
ваны для создания любых ассоциаций между группой рабочей нагрузки и
пользователями;
♦ связывание функций с Resource Governor с помощью оператора alter
resource governor;
Глава 21. Настройка производительности 583
♦ определение того, какая группа рабочей нагрузки получает какие ресурсы
при использовании оператора alter workload group;
♦ выполнение оператора alter resource governor с опцией reconfigure для
применения изменений к Resource Governor.
Резюме
Вопросы производительности могут быть разделены на проактивные (упреж-
дающие) и реактивные ответы. Проактивные вопросы касаются всех видов
деятельности, которые влияют на производительность всей системы и кото-
рые повлияют на будущие системы организации. Правильное проектирование
базы данных и правильный выбор форм операторов Transact-SQL в програм-
мах приложений принадлежит области проактивных ответов. Реактивные во-
просы производительности связаны с действиями, которые предпринимаются
после появления проблемы производительности. SQL Server предоставляет
множество инструментов (графические компоненты, операторы Transact-SQL
и хранимые процедуры), которые могут быть использованы для просмотра и
трассировки проблем производительности в системе SQL Server.
Среди всех компонентов Performance Monitor и представления динамического
управления являются лучшими инструментами для мониторинга, потому что
вы можете их использовать для отслеживания, отображения, создания отче-
тов и трассировки любых узких мест в производительности.
Со следующей главы начинается часть этой книги, связанная с Analysis
Services. В ней вводятся общие термины и концепции, которые необходимы
вам, чтобы разбираться в этой важной теме.
Упражнения
j Упражнение 21.1
Обсудите различия между SQL Server Profiler и Database Engine Tuning
Advisor.
Упражнение 21.2
Обсудите различия между Performance Data Collector и Resource Governor.
Часть IV
SQL Server
и Business Intelligence
ГЛАВА 22
Введение
в Business Intelligence
Целью этой главы является ознакомление вас с важной областью технологии
баз данных— интеллектуальными ресурсами (business intelligence, бизнес-
аналитика). Сначала объясняются различия между оперативной обработкой
транзакций (online transaction processing, OLTP), с одной стороны, и бизнес-
аналитикой, с другой стороны. Складом данных для процесса бизнес-
аналитики может быть хранилище данных (data warehouse) или киоск данных
(data mart). Обсуждаются оба типа, а затем описываются их отличия. Проек-
тирование данных в бизнес-аналитике и необходимость создания агрегатных
таблиц объясняются в конце главы.
Online Transaction Processing
в сравнении с Business Intelligence
С самого начала системы реляционных баз данных использовались в основ-
ном для хранения первичных деловых данных, таких как заказы и счета с ис-
пользованием обработки, основанной на транзакциях. Такое фокусирование
внимания на деловых данных имеет свои преимущества и недостатки. Одним
из преимуществ является то, что низкая производительность ранних систем
баз данных была резко улучшена, так что сегодня многие системы баз данных
могут выполнять тысячи транзакций в секунду (при использовании подходя-
щего оборудования). С другой стороны, фокусирование внимания на обра-
ботке транзакций мешает людям, использующим деловые базы данных, ви-
деть другие естественные приложения систем баз данных: использование их
для фильтрации и анализа необходимой информации за пределами сущест-
вующих данных на уровне предприятия или отдела.
20 Зак. 1141
588
Часть IV. SQL Server и Business Intelligence
Online Transaction Processing
Как уже было сказано, производительность является одним из основных во-
просов для систем, которые базируются на обработке транзакций. Такие сис-
темы называются системами оперативной обработки транзакций (online
transaction processing, OLTP). Типичным примером операции, выполняемой
системой OLTP, является получение денег с банковского счета при помощи
банкомата. Системы OLTP имеют несколько важных свойств, таких как:
♦ короткие транзакции, т. е. высокая производительность;
♦ большое количество (возможно, сотни или даже тысячи) пользователей;
♦ постоянные операции чтения и записи, основанные на небольшом количе-
стве строк;
♦ в базе данных хранятся данные небольшого размера.
Производительность системы базы данных будет повышаться, если транзак-
ции в прикладных программах базы данных будут короткими. Причина этому
заключается в том, что транзакции используют блокировки (см. главу 13) для
предотвращения возможных отрицательных эффектов при одновременной
работе нескольких пользователей. Если транзакции имеют большую длитель-
ность, то количество блокировок и их длительность увеличивается, уменьшая
доступность данных для других транзакций и поэтому снижая их производи-
тельность.
Большие системы OLTP обычно имеют много пользователей, одновременно
работающих с системой. Типичным примером является система резервирова-
ния авиационной компании, которая должна обрабатывать тысячи запросов
относительно поездок в одной стране или даже по всему миру почти что од-
новременно. В подобном типе систем большинство пользователей ожидает,
что их требование к времени отклика будет выполнено системой и система
будет доступной для работы в рабочие часы (или 24 часа в день, семь дней
в неделю).
Пользователи системы OLTP выполняют их операторы DML непрерывно,
т. е. они используют операции чтения и записи в одно и то же время и посто-
янно. (Поскольку данные в системе OLTP постоянно изменяются, эти данные
очень динамичны.) Все операции (или их результаты) в базе данных обычно
включают только небольшой объем данных, хотя возможно, что система базы
данных должна обращаться к большому количеству строк в одной или более
таблиц, хранящихся в базе данных.
В последние годы объем данных, хранящихся в оперативных базах данных
(т. е. в базах данных, управляемых системами OLTP), постоянно увеличива-
ется. На сегодняшний день существует множество баз данных, которые хра-
нят несколько гигабайт и даже десятки гигабайт данных. Как вы увидите,
Глава 22. Введение в Business Intelligence
589
этот объем данных все еще относительно мал по сравнению с данными, нахо-
дящимися в хранилищах.
Системы Business Intelligence
Business Intelligence (бизнес-аналитика) является процессом интеграции дан-
ных в масштабе всего предприятия на едином складе данных, к которому ко-
нечные пользователи могут выполнять специальные запросы и формировать
отчеты для анализа существующих данных. Другими словами, целью бизнес-
аналитики является хранение данных, к которым могут обращаться пользова-
тели, принимающие бизнес-решения на основе анализа данных. Такие систе-
мы обычно называются аналитическими или информативными системами,
потому что при обращении к этим данным пользователи получают необхо-
димую информацию для принятия наилучших решений в области бизнеса.
Цели систем бизнес-аналитики отличаются от целей систем OLTP. Следую-
щий запрос является типичным для системы бизнес-аналитики: "Какая
категория продуктов является наилучшей в плане продаж для каждого из
регионов продаж в третьем квартале 2005 года?" Поэтому система бизнес-
аналитики имеет свойства, сильно отличающиеся от тех, которые были пере-
числены для систем OLTP в предыдущем разделе. Наиболее важными свой-
ствами системы бизнес-аналитики являются:
♦ периодические операции записи (загрузки) в результате запросов, осно-
ванных на огромном количестве строк;
♦ небольшое количество пользователей;
♦ большой размер данных, хранимых в базе данных.
Помимо загрузки данных, которая выполняется регулярно (обычно ежеднев-
но), системы бизнес-аналитики являются в основном системами только для
чтения. Поэтому природа данных в подобных системах является статической.
Как будет подробно рассказано далее в этой главе, данные собираются из
различных источников, очищаются (делаются согласованными) и загружают-
ся в базу данных, называемую хранилищем данных (или киоском данных).
Очищенные данные обычно не изменяются, т. е. запросы пользователей ис-
пользуют только операторы select для получения необходимой информации
(а операции модификации применяются крайне редко).
Поскольку системы бизнес-аналитики служат для получения информации,
количество пользователей, которые одновременно работают с подобной сис-
темой, относительно мало по сравнению с количеством пользователей, кото-
рые одновременно используют систему OLTP. Пользователи системы бизнес-
аналитики обычно генерируют отчеты, которые отражают различные факто-
ры, связанные с финансами предприятия (или отдела), или же они выполняют
сложные запросы для сравнения данных.
590
Часть IV. SQL Server и Business Intelligence
Замечание__________________________________________________
Другим отличием систем OLTP от бизнес-аналитики является то, что фактиче-
ски воздействует на поведение пользователей: ежедневное расписание, т. е.
как эти системы используются в течение дня. Система OLTP может работать
постоянно (она спроектирована для такого использования), в то время как сис-
тема бизнес-аналитики может быть использована только тогда, когда данные
приведены в согласованное состояние и загружены в базу данных.
В отличие от систем баз данных OLTP, которые хранят только текущие дан-
ные, системы бизнес-аналитики должны также отслеживать историю данных.
Помните, что системы бизнес-аналитики выполняют сопоставление данных,
собранных в различные периоды времени. По этой причине объем данных,
хранящихся на складе данных, очень велик.
Хранилище данных и киоск данных
Хранилище данных может быть определено как база данных, которая вклю-
чает корпоративные данные и может быть постоянно доступной пользовате-
лям. Это краткое определение; объяснение понятия хранилища данных гораз-
до более сложное. Предприятие обычно имеет большой объем данных, хра-
нящихся в разное время в различных базах данных (или в файлах данных),
которые управляются различными СУБД. Эти системы управления базами
данных не обязательно являются реляционными: на некоторых предприятиях
все еще существуют базы данных, управляемые иерархическими или сетевы-
ми системами баз данных. Особая группа специалистов по программному
обеспечению проверяет исходные базы данных (и файлы данных) и конвер-
тирует их в целевое место сохранения: в хранилище данных. В дополнение к
этому, конвертированные данные в хранилище данных должны быть консо-
лидированы, потому что они хранят информацию, которая является ключевой
для операционной обработки в корпорации. (Консолидация данных означает,
что все эквивалентные запросы к хранилищу данных, выполненные в раз-
личное время, дают один и тот же результат.) Консолидация данных
в хранилище данных выполняется в несколько этапов:
♦ сборка данных из различных источников (также называется выделением
данных);
♦ очистка данных (другими словами — выполнение трансформации дан-
ных);
♦ поддержка качества данных.
Данные должны быть аккуратно собраны из разных источников. В этом про-
цессе данные выделяются из источников, конвертируются в промежуточную
схему и перемещаются во временную рабочую область. Для выделения дан-
Глава 22. Введение в Business Intelligence
ных вам нужны инструменты, которые выделяют в точности именно те дан-
ные, которые должны сохраняться в хранилище данных.
Очистка данных гарантирует целостность данных, которые должны сохра-
няться в целевой базе данных. Например, очистка данных должна быть вы-
полнена для некорректных полей данных, таких как адреса или несовмести-
мые типы данных, используемые для определения дат в различных источни-
ках. Для выполнения этого процесса группе очистки данных требуется
специальное программное обеспечение. Пример поможет более четко объяс-
нить процесс очистки данных. Предположим, что существуют два источника
данных, которые хранят персональные данные о служащих, и эти две базы
данных имеют атрибут Gender (пол). В первой базе данных этот атрибут оп-
ределен как char(6) и значениями данных являются "female" (женский) и
"male" (мужской). Тот же самый атрибут во второй базе данных определен
как char(1) со значениями "f" и "т". Значения в обоих источниках данных
являются корректными, однако для целевой базы данных вы должны выпол-
нить очистку данных, т. е. представить значения этого атрибута в унифици-
рованном виде.
Последняя часть консолидации данных— поддержка качества данных —
включает процесс проверки данных, при котором определяются данные,
к которым конечный пользователь должен иметь доступ. По этой причине
конечный пользователь должен быть тесно вовлечен в этот процесс консоли-
дации. Когда процесс консолидации данных завершается, данные должны
загружаться в хранилище данных.
Замечание_________________________________________________________
Весь процесс консолидации данных называется ETL (extraction, transformation,
loading — выделение, трансформация, загрузка). Корпорация Microsoft предос-
тавляет компонент SQL Server Integration Services (SSIS) для поддержки поль-
зователей в процессе выполнения ETL.
По своей природе (в качестве общего склада для всех данных предприятия)
хранилище данных содержит огромный объем данных. (Некоторые хранили-
ща данных содержат десятки терабайт и даже петабайт1 данных.) Кроме того,
поскольку эти данные охватывают все предприятие, реализация обычно за-
нимает очень много времени, которое зависит от размера предприятия. Из-за
этого недостатка многие компании начинают с меньших решений, которые
называются киоском данных.
Киоск данных— это склад данных, который включает все данные на уровне
отдела и поэтому предоставляет пользователям доступ к данным, относя-
щимся только к одной части их организации. Например, отдел маркетинга
1 Один петабайт равен 1024 терабайтов. — Прим, перев.
592
Часть IV. SQL Server и Business Intelligence
хранит все данные, связанные с маркетингом, в своем собственном киоске
данных, отдел исследований помещает экспериментальные данные в киоск
данных исследований и т. д. В связи с этим киоск данных имеет несколько
преимуществ перед хранилищем данных:
♦ суженная область приложения;
♦ сокращение времени разработки и меньшая стоимость;
♦ простота поддержки данных;
♦ разработка снизу вверх.
Как уже было сказано, киоск данных включает только ту информацию, кото-
рая нужна одной части организации, обычно отделу. Поэтому данные, пред-
назначенные для использования на такой малой единице организации, могут
быть гораздо проще подготовлены для потребностей конечного пользователя.
Время разработки хранилища данных в среднем составляет два года и стоит
5 млн долларов. С другой стороны, стоимость киоска данных в среднем
200 тыс. долларов, и такой проект занимает от трех до пяти месяцев. По этим
причинам разработка киоска данных является предпочтительной, особенно
если это первый проект бизнес-аналитики в вашей организации.
Тот факт, что киоск данных содержит значительно меньший объем данных,
чем хранилище данных, помогает вам сократить и упростить все задачи, та-
кие как выделение данных, очистка данных и поддержка качества данных.
Точно так же в этом случае проще проектировать решения для отдела, чем
для целой организации. (Более подробную информацию о проектировании
бизнес-аналитики и о пространственной модели см. в следующем разделе.)
Если вы проектируете и разрабатываете несколько киосков данных в вашей
организации, то есть возможность со временем объединить их всех в одном
большом хранилище данных. Этот процесс проектирования снизу вверх име-
ет несколько преимуществ перед проектированием "с нуля" хранилища дан-
ных: во-первых, каждый киоск данных может содержать идентичные табли-
цы, которые можно унифицировать на уровне соответствующего хранилища
данных. Во-вторых, некоторые задачи являются логическими задачами на
уровне предприятия, например, такая задача, как сбор финансовой информа-
ции для бухгалтерского отдела. Если существующие киоски данных будут
объединены вместе для создания хранилища данных на уровне предприятия,
то потребуется глобальный репозитарий (т. е. каталог данных, который со-
держит информацию обо всех данных, хранящихся как в исходных базах
данных, так и в целевой базе данных).
Замечание_______________________________________________________
Имейте в виду, что создание хранилища данных путем соединения киоска дан-
ных может оказаться довольно хлопотным занятием по причине возможных
Гпава 22. Введение в Business Intelligence
593
значительных отличий в структуре и в проектах существующих киосков данных.
Разные подразделения предприятия могут использовать различные модели
данных и иметь различные инструкции для представления данных. По этой
причине в начале процесса проектирования снизу вверх рекомендуется сде-
лать единое представление всех данных, которые будут допустимыми на уров-
не предприятия; не следует проектировать данные различных подразделений
отдельно.
Проектирование хранилища данных
с использованием пространственной модели
Только хорошо спланированная и хорошо спроектированная база данных
даст вам возможность достигнуть хорошей производительности. Реляцион-
ные базы данных и хранилища данных имеют множество отличий, которые
требуют разных методов проектирования. Реляционные базы данных проек-
тируются с помощью хорошо известной модели "сущность— отношение"
(entity-relationship, ER), в то время как пространственная модель используется
для проектирования хранилища данных и киоска данных.
При использовании реляционных баз данных избыточность данных устраня-
ется при использовании нормальных форм (см. главу 1). Процесс нормализа-
ции разделяет каждую таблицу базы данных, которая включает избыточные
данные, на две отдельные таблицы. Процесс нормализации должен быть
завершен, когда все таблицы базы данных содержат только неизбыточные
данные.
Хорошо нормализованные таблицы имеют преимущества в OLTP, поскольку
в этом случае все транзакции могут быть максимально простыми и коротки-
ми. С другой стороны, процессы бизнес-аналитики основываются на запро-
сах, которые оперируют огромным количеством данных и никогда не бывают
ни короткими, ни простыми. По этой причине хорошо нормализованные таб-
лицы не подходят для проектирования хранилищ данных, поскольку цель
систем бизнес-аналитики совершенно другая: тут существует мало одновре-
менно выполняющихся транзакций, а каждая транзакция обращается к очень
большому количеству записей. (Представьте огромный объем данных, при-
надлежащих хранилищу данных, содержащихся в сотнях таблиц. В большин-
стве запросов на поиск будут содержаться дюжины соединений больших по
размеру таблиц. Подобные запросы не могут хорошо выполняться, даже если
вы используете оборудование с параллельными процессорами и систему базы
данных с наилучшим оптимизатором запросов.)
Хранилища данных не могут использовать модель ER, потому что эта модель
подходит для проектирования баз данных с неизбыточными данными. Логи-
ческая модель, используемая для проектирования хранилищ данных, называ-
ется пространственной моделью.
594
Часть IV. SQL Server и Business Intelligence
Замечание________________________________________________________
Существует еще одна причина, почему модель ER не является подходящей для
• проектирования хранилищ данных: использование данных в хранилище данных
неструктурировано. Это означает, что запросы выполняются частично, позво-
ляя пользователям анализировать данные совершенно различными способами.
(С другой стороны, системы OLTP обычно используют приложения базы дан-
ных, которые жестко кодированы и поэтому содержат запросы, которые не
очень часто изменяются.)
В пространственном моделировании каждая модель состоит из одной табли-
цы, которая хранит критерии, и нескольких других таблиц, которые описы-
вают это пространство (рис. 22.1). Первая называется таблицей фактов, а
остальные — таблицами измерений. Примеры данных, хранимых в таблице
фактов, включают реестры продаж и расходы. Таблицы измерений обычно
включают время, счета, продукцию и-данные по служащим.
REGION
REGIONJD
ADDRESS
ZIP
Таблица фактов
SALES PERSON
SALES_PERSON_ID
LAST_NAME
FIRST_NAME
ADDRESS
REGIONJD
SALES-PERSONJD
QUARTERJD
TOTAL_SALES
PROFIT
QUARTER
QUARTERJD
MONTH
DAY
Рис. 22.1. Пример пространственной модели: схемы "звезда"
Каждая таблица измерений обычно имеет первичный ключ из одного столбца
и несколько других атрибутов, которые подробно описывают этот элемент.
С другой стороны, первичный ключ таблицы фактов является комбинацией
первичных ключей всех таблиц измерений (см. рис. 22.1). По этой причине
первичный ключ таблицы фактов состоит из нескольких внешних ключей.
(Количество измерений также определяет количество внешних ключей в таб-
лице фактов.) Как вы можете видеть на рис. 22.1, таблицы в пространствен-
ной модели созданы в звездообразной структуре. Поэтому такая модель часто
называется схемой "звезда".
Другим отличием в природе данных в таблице фактов и соответствующих
таблицах измерений является то, что большинство неключевых столбцов в
Гпава 22. Введение в Business Intelligence 595
таблице фактов являются числовыми и аддитивными, потому что подобные
данные могут быть использованы для выполнения необходимых вычислений.
(Помните, что типичный запрос к хранилищу данных считывает тысячи или
даже миллионы строк за один раз, и, единственно полезной операцией по
отношению к такому огромному количеству строк является применение агре-
гатных функций (сумма, максимум, минимум или среднее значение).) На-
пример, столбцы вроде units_of_product_soid (количество единиц проданной
продукции), Total sales (общие продажи), Profit (прибыль), ИЛИ Dollars_
cost (цена в долларах) являются типичными столбцами в таблице фактов. Чи-
словые столбцы в таблице фактов, которые не составляют первичный ключ
этой таблицы, называются измерениями.
С другой стороны, столбцы таблицы измерений являются строками, которые
содержат текстовые описания измерений. Например,, такие столбцы как
Address (адрес), Location (размещение) и Name (имя) часто появляются в таб-
лицах измерений. Такие столбцы обычно используются в качестве заголовков
отчетов. Другим следствием текстовой природы столбцов в таблицах измере-
ний и их использования в запросах является то, что каждая таблица измере-
ний содержит гораздо больше индексов, чем соответствующая таблица фак-
тов. (Таблица фактов обычно содержит только один уникальный индекс, со-
стоящий из всех столбцов, входящих в состав первичного ключа таблицы.)
В табл. 22.1 описываются отличия таблицы фактов от таблицы измерений.
Таблица 22.1. Различия между таблицами фактов и измерений
Таблица фактов Таблица измерений
Обычно одна в пространственной модели Много (12—20)
Содержит много строк хранилища данных Содержит относительно небольшой объем данных
Составной первичный ключ (содержит все первичные ключи таблиц измерений) Обычно один столбец таблицы создает первичный ключ
Столбцы являются числовыми и аддитив- ными Столбцы являются описательными и поэтому текстовыми
Замечание_____________________________________________________
Иногда необходимо иметь много таблиц фактов в хранилище данных, потому
что у вас могут быть различные наборы измерений, и каждый такой набор дол-
жен быть связан с различными таблицами фактов.
Столбцы в таблице измерений обычно являются весьма ненормализованными,
это означает, что множество столбцов зависит друг от друга. Ненормализо-
ванная структура таблицы измерений имеет одно важное назначение: все
столбцы такой таблицы используются в качестве заголовков отчетов. Если
596
Часть IV. SQL Server и Business Intelligence
отсутствие нормализации данных в таблице измерений не является желатель-
ным, то таблица измерений может быть разделена на несколько подчиненных
таблиц. Это обычно бывает необходимым, когда столбцы в таблице измере-
ний составляют иерархию. (Например, измерение product может иметь такие
столбцы, как Product_id, Category Ld и Subcategory_id, которые создают
трехуровневую иерархию с первичным ключом Product id в качестве корня.)
Такая структура, в которой каждый уровень базовой сущности представлен
в своей собственной таблице, называется схемой с контуром снежинки. На
рис. 22.2 показана такая схема измерения product.
Brand code,
Brand name
Brand manager
Brand code
Subcategory code.
Subcategory name
Category code
Category name
Subcategory code
Line manager
Product code
Product name
Product color
Category code
Рис. 22.2. Схема с контуром снежинки
Расширение схемы "звезда" до соответствующей схемы с контуром снежинки
имеет несколько преимуществ (уменьшение используемого дискового про-
странства, например) и один главный недостаток: схема "снежинка" требует
большего количества соединений для получения информации из таблиц, что
негативно влияет на производительность при выборке данных. По этой при-
чине производительность запросов, основанных на схеме "снежинка", обычно
низкая. Поэтому проектирование с использованием схемы "снежинка" реко-
мендуется только в небольшом количестве очень специфических случаев.
Кубы и их архитектура
Системы бизнес-аналитики поддерживают различные типы хранилищ дан-
ных. Некоторые из этих типов хранилищ данных основаны на многомерных
базах данных, которые также называются кубами. Куб является подмножест-
вом данных из хранилища данных, который может быть организован в мно-
гомерные структуры. Для определения куба вы, во-первых, выбираете табли-
цу фактов из пространственной схемы и идентифицируете числовые столбцы
(измерения), которые вам интересны. Затем вы выбираете таблицы измере-
ний, которые предоставляют описания анализируемых наборов данных. Для
демонстрации этого процесса рассмотрим, как может быть определен куб для
Глава 22. Введение в Business Intelligence
597
анализа продаж автомобилей. Например, таблица фактов может включать
измерения Cars_sold, Total sales И Costs, В ТО время как таблицы Models,
Quarters и Regions задают таблицы измерений. Куб на рис. 22.3 показывает
все три измерения: Models, Regions И Quarters.
Models
Falcon
Crow
Eagel
Рис. 22.3. Куб с размерностями Models, Regions и Quarters
В каждом измерении существуют дискретные значения, называемые членами.
Например, измерение Regions может содержать следующие члены: ALL, Се-
верная Америка, Южная Америка и Азия. (Член ALL задает все члены в из-
мерении.)
Дополнительно каждый куб измерения может иметь иерархию уровней, ко-
торая позволяет пользователям задавать вопросы на более детальном уровне.
Например, измерение Regions может включать следующие уровни иерархии:
Country, Province и city. Аналогично, измерение Quarters может включать
Month, week и Day в качестве уровней иерархии.
Замечание_____________________________________________________
Кубы и многомерные базы данных управляются специальными системами, на-
зываемыми многомерными системами баз данных (multidimensional database
system, MDBMS). В SQL Server MDBMS называется Analysis Services.
Физическое хранение кубов описывается после следующего обсуждения
агрегатов.
Агрегаты
Данные сохраняются в таблице фактов в наиболее детализированной форме,
чтобы их могли использовать соответствующие отчеты. С другой стороны
598
Часть IV. SQL Server и Business Intelligence
(как было сказано ранее), типичный запрос к таблице фактов считывает ты-
сячи или даже миллионы строк за один раз, и единственной полезной опера-
цией для такого огромного количества строк является агрегатная функция
(сумма, максимум, минимум или среднее значение). Такое различное исполь-
зование данных может снизить производительность для запросов, если они
выполняются над данными низкого уровня (атомарными данными), потому
что вычисления, затрагивающие время и ресурсы, будут необходимы для вы-
полнения каждой агрегатной функции.
По этой причине данные низкого уровня в таблице фактов должны заранее
суммироваться и сохраняться в промежуточных таблицах. По причине их
"агрегатной" информации такие таблицы называются агрегатными таблица-
ми, а весь процесс — агрегацией.
Замечание____________________________________________________
Агрегируемая строка из таблицы фактов всегда связана с одной или более
строками агрегируемой таблицы измерений. Например, пространственная мо-
дель на рис. 22.1 может содержать следующие агрегатные строки: агрегаты
ежемесячных продаж продавцов по региону и агрегаты ежедневных продаж
уровня регионов по продавцам.
В примере будет показано, как может быть выполнена агрегация данных низ-
кого уровня. Конечный пользователь может захотеть запустить на выполне-
ние незапланированный запрос, который отображает общие продажи органи-
зации за последний месяц. Это может привести к тому, что сервер будет сум-
мировать все продажи для каждого дня последнего месяца. Если в среднем
существует 500 транзакций по продажам в день в каждом из 500 магазинов
организации и данные хранятся на уровне транзакций, то такому запросу мо-
жет потребоваться чтение 7 500 000 строк (500x500x30 дней) и создание со-
ответствующей суммы для получения результата. Теперь рассмотрим, что
произойдет, если данные агрегируются в таблице, которая создается с ис-
пользованием ежемесячных продаж в магазине. В этом случае таблица будет
иметь только 500 строк (итог за месяц для каждого из 500 магазинов), а про-
изводительность резко возрастет.
Сколько можно агрегировать?
Относительно агрегации существуют два экстремальных решения: вообще не
выполнять агрегацию и выполнять агрегацию для каждой возможной комби-
нации запросов, необходимых пользователю. Из предыдущих обсуждений
должно быть ясно, что полное отсутствие агрегации не является вопросом по
причине возможных проблем с производительностью. (Хранилище данных
без каких-либо агрегирующих таблиц вообще не может быть использовано в
Глава 22. Введение в Business Intelligence
599
качестве производственного склада данных.) Противоположное решение
также не является приемлемым по нескольким причинам:
♦ огромный объем дискового пространства, необходимый для хранения до-
полнительных данных;
♦ непомерно сложная поддержка агрегатных таблиц;
♦ начальная загрузка данных будет слишком долгой.
Сохранение дополнительных данных, которые содержат агрегированные
данные на каждом возможном уровне, занимает дополнительный объем дис-
кового пространства, что увеличивает начальное дисковое пространство в
шесть или более раз (в зависимости от объема начального дискового про-
странства и количества необходимых пользователю запросов). Создание таб-
лиц для хранения агрегатов для всех существующих комбинаций является
неподъемной задачей для системного администратора. Наконец, создание
агрегатов при начальной загрузке данных может иметь разрушительный ре-
зультат, если загрузка уже заняла много времени и дополнительное время
просто недоступно.
По результатам этого обсуждения вы должны понимать, что агрегатные таб-
лицы должны быть аккуратно спланированы и созданы. В процессе выполне-
ния фазы планирования помните эти два основных соображения при опреде-
лении того, какие агрегаты создавать:
♦ Где концентрируются данные?
♦ Какие именно агрегаты могут в наибольшей степени улучшить производи-
тельность?
Планирование и создание агрегатных таблиц зависит от концентрации дан-
ных в столбцах базовой таблицы фактов. В хранилище данных, где отсутст-
вует деятельность в течение дня, соответствующая строка вообще не записы-
вается. Следовательно, если система загружает большое количество строк, по
сравнению с количеством всех строк, которые могут быть загружены, то вы-
полнение агрегирования по такому столбцу базовой таблицы фактов резко
увеличивает производительность. В противоположность этому, если система
загружает небольшое количество строк относительно общего количества
строк, которые должны быть загружены, то агрегирование по такому столбцу
не даст никакого эффекта.
Вот еще один пример, который иллюстрирует предыдущее рассуждение. Из
всех продуктов в продуктовом магазине только небольшая их часть (скажем,
процентов 15) фактически продана за текущий день. Если у нас пространст-
венная модель с тремя измерениями Product, store и Time, то будет использо-
вано только 15% комбинаций трех соответствующих первичных ключей для
конкретного дня и конкретного магазина. Ежедневные данные по продаже
600
Часть IV. SQL Server и Business Intelligence
продуктов будут разряженными. В отличие от этого, если в продуктовом ма-
газине в конкретный день были проданы все или большинство продуктов
(например, за счет специального предложения), то данные по ежедневным
продажам продуктов будут плотными.
Для определения того, какие измерения будут плотными, а какие разряжен-
ными, вы должны создать строки из всех возможных комбинаций таблиц и
оценить их. Обычно измерение Time является плотным, потому что всегда
существуют записи для каждого дня. Измерения Product, store и Time в ком-
бинациях с измерениями store и Time являются плотными, потому что для
каждого дня будут некоторые данные, относящиеся к продажам в каждом
магазине. С другой стороны, комбинация измерений store и Product является
разряженным (по причинам, рассмотренным ранее). В этом случае измерение
Product обычно является разряженным, потому что его появление в комбина-
ции с другими измерениями является разряженным.
Выбор агрегатов, которые будут в большей мере увеличивать производи-
тельность, зависит от конечного пользователя. Поэтому в самом начале про-
екта бизнес-аналитики вы должны опросить конечных пользователей для
сбора информации о данных, которые будут запрашиваться, о том, как много
строк будет отыскиваться в этих запросах, и другие критерии.
Физическое хранение кубов
Системы оперативного анализа данных (online analytical processing, OLAP)
обычно используют одну из следующих трех различных архитектур для хра-
нения многомерных данных:
♦ реляционные OLAP (ROLAP);
♦ многомерные OLAP (MOLAP);
♦ гибридные OLAP (HOLAP).
Обычно эти три архитектуры отличаются по тому способу, в котором они
хранятся в'данных на уровне листьев, и наличием предварительно рассчитан-
ных агрегатов. (Данные на уровне листьев являются наилучшей частицей
данных, которая определена в группе измерения куба. Поэтому данные на
уровне листьев соответствуют данным таблицы фактов куба.)
В ROLAP предварительно вычисленные данные не сохраняются. Вместо это-
го запросы обращаются к данным в реляционной базе данных и ее таблицам,
чтобы получить данные, требуемые в качестве ответа на вопрос. MOLAP яв-
ляется типом хранения, при котором данные на уровне листьев и их агрегатов
хранятся с использованием многомерных кубов.
Хотя логическое содержание этих двух типов хранения данных одинаково
для одного и того же хранилища данных, а оба аналитических инструмента
Глава 22. Введение в Business Intelligence 601
ROLAP и MOLAP спроектированы так, чтобы позволить выполнение анализа
через использование пространственной модели данных, между ними сущест-
вуют значительные различия. Преимуществами типа хранения ROLAP явля-
ются следующие:
♦ данные не требуют дублирования;
♦ материализованные (т. е. индексированные) представления могут быть
использованы для получения итоговых данных.
Если данные должны быть также сохранены и в многомерной базе данных, то
некоторый объем данных должен быть дублирован. Поэтому тип хранения
ROLAP не требует дополнительной памяти для копирования данных на уров-
не листьев. Также подведение итогов (см. следующий раздел) может быть вы-
полнено в ROLAP очень быстро, если соответствующие итоговые таблицы
были сгенерированы с использованием материализованных представлений.
С другой стороны, MOLAP также имеет некоторые преимущества по сравне-
нию с ROLAP:
♦ агрегаты сохраняются в многомерной форме;
♦ запросы выполняются обычно быстрее.
При использовании MOLAP многие агрегаты предварительно вычисляются и
сохраняются в многомерном кубе. Этот способ не требует от системы вычис-
лять результаты подобных агрегатов каждый раз, когда они нужны. В случае
MOLAP ядро системы управления базой данных и сама база данных обычно
оптимизированы для совместной работы, так что ответ на запрос может быть
быстрее, чем в случае ROLAP.
Хранение HOLAP является комбинацией типов хранения MOLAP и ROLAP.
Предварительно вычисленные данные сохраняются, как и в случае хранения
MOLAP, в то время как данные на уровне листьев остаются в реляционной
базе данных. (Поэтому в случае запросов, использующих подведение итогов,
HOLAP идентичен MOLAP.) Преимуществом хранения HOLAP является то,
что данные на уровне листьев нс дублируются.
Доступ к данным
К данным, находящимся в хранилище данных, может осуществляться доступ
с использованием трех основных техник:
♦ составление отчета;
♦ OLAP;
♦ извлечение данных.
602
Часть IV. SQL Server и Business Intelligence
Составление отчета является наиболее простой формой доступа к данным.
Отчет является лишь представлением результата запроса в табличной форме.
(Составление отчетов подробно обсуждается в главе 25.) В OLAP вы анали-
зируете данные интерактивно; т. е. это позволяет вам выполнять сравнения
и вычисления среди любых измерений в хранилище данных.
Замечание_____________________________________________________
Transact-SQL поддерживает все стандартизованные функции и конструкции,
относящиеся к SQL/OLAP. Эта тема подробно будет рассматриваться в гла-
ве 24.
Извлечение данных служит для исследования и анализа больших количеств
данных для отыскания значимых шаблонов. Этот поиск не является единст-
венной задачей извлечения данных: используя эту технику, вы должны быть
в состоянии преобразовать существующие данные в необходимую информа-
цию и преобразовать информацию в действия. Иными словами, этого недос-
таточно для анализа данных; вы должны применять результаты извлечения
данных осмысленно и выполнять необходимые действия с полученными ре-
зультатами. (Извлечение данных, как наиболее сложная из всех трех, техник,
не будет подробно рассматриваться в этой книге.)
Резюме
В самом начале проекта бизнес-аналитики основным вопросом является объ-
ект создания: хранилище данных или киоск данных. Возможно, лучшим ре-
шением будет начать с одного или более киосков данных, которые в даль-
нейшем будут объединены в хранилище данных. Большинство из сущест-
вующих инструментов на рынке бизнес-аналитики поддерживают именно эту
альтернативу.
В отличие от операционных баз данных, которые используют модели "сущ-
ность — отношение" при их проектировании, проектирование хранилищ дан-
ных лучше осуществлять с использованием пространственной модели. Эти
две модели имеют значительные различия. Если вы уже знакомы с моделью
"сущность — отношение", то лучшим способом изучить использование про-
странственной модели является забыть все о модели "сущность — отноше-
ние" и начать моделирование с нуля.
После этого вводного обсуждения общего рассмотрения процесса бизнес-
аналитики в следующей главе рассматривается серверная часть Microsoft
Analysis Services.
Глава 22. Введение в Business Intelligence 603
Упражнения
j Упражнение 22.1
Объясните разницу между оперативными и аналитическими системами.
’ Упражнение 22.2
Объясните разницу между моделью "сущность — отношение" и пространст-
венной моделью.
! Упражнение 22.3
В начале разработки проекта хранилища данных существует так называемый
процесс ETL (extracting, transforming, loading— выделение, преобразование,
загрузка). Объясните эти три подпроцесса.
\ Упражнение 22.4
Объясните разницу между таблицей фактов и соответствующими таблицами
измерений.
: Упражнение 22.5
Обсудите преимущества всех трех типов хранения (MOLAP, ROLAP и
HOLAP).
! Упражнение 22.6
Почему необходимо выполнять агрегирование данных, хранимых в таблице
фактов?
ГЛАВА 23
Microsoft Analysis Services
Microsoft Analysis Services является группой сервисов, которые используются
для управления данными, находящимися в хранилище данных или в киоске
данных. Analysis Services преобразует данные из хранилища данных в много-
мерные кубы (см. главу 22) с агрегатами, для того чтобы дать возможность
создавать замысловатые отчеты и сложные запросы. Ключевыми особенно-
стями Analysis Services являются:
♦ простота использования;
♦ гибкость модели данных;
♦ поддержка некоторых API.
Analysis Services предоставляет мастеров для большинства задач, которые
выполняются в процессе проектирования и реализации хранилища данных.
Например, Data Source Wizard позволяет задавать один или более источников
данных, в то время как Cube Wizard используется для создания многомерных
кубов, где хранятся агрегатные данные.
Простота использования гарантируется Business Intelligence Development
Studio. Вы можете использовать этот инструмент для разработки баз данных
и других объектов хранилища данных. Это значит, что Business Intelligence
Development Studio предоставляет единый интерфейс для разработки проек-
тов Analysis Services и проектов SQL Server Integration Services и Reporting
Services.
В отличие от большинства других систем хранилищ данных Analysis Services
позволяет использовать архитектуру, которая больше всего подходит для
системы хранилища данных. Вы можете осуществить выбор между тремя
архитектурами (MOLAP, ROLAP и HOLAP), которые подробно рассматрива-
лись в предыдущей главе.
Глава 23. Microsoft Analysis Services 605
Business Intelligence Development Studio
Главным компонентом Analysis Services является Business Intelligence
Development Studio — инструмент управления, который предоставляет еди-
ную платформу разработки для Integration Services, извлечения данных
Reporting Services и Analysis Services. Созданный в Visual Studio, Business
Intelligence Development Studio поддерживает интегрированную платформу
разработки для системных разработчиков в области бизнес-аналитики. Сред-
ства отладки, управление источниками данных и разработка кода доступны
во всех компонентах приложения бизнес-аналитики.
Вы можете использовать Business Intelligence Development Studio не только
для создания и управления кубами, но и для проектирования возможностей
для SQL Reporting Services и SQL Server Integration Services. (Reporting
Services рассматривает в главе 25, тогда как обсуждение Integration Services
выходит за рамки данной книги.)
Замечание______________________________________________________
Пользовательский интерфейс Business Intelligence Development Studio очень
похож на интерфейс SQL Server Management Studio. Однако эти два инструмен-
та отличаются в их применении: вы должны использовать Business Intelligence
Development Studio для разработки проектов бизнес-аналитики, тогда как SQL
Server Management Studio используется в основном для поддержки и опериро-
вания объектами базы данных бизнес-аналитики.
В этой главе Business Intelligence Development Studio используется для созда-
ния куба, основанного на базе данных AdventureWorkDW, и для работы с ним.
Для запуска Business Intelligence Development Studio щелкните мышью по
кнопке Start, выберите All Programs | Microsoft SQL Server 2008 | SQL
Server Business Intelligence Development Studio.
Создание нового проекта
Первым шагом в создании аналитического приложения является создание
нового проекта. Для создания проекта в меню File выберите New | Project.
В диалоговом окне New Projects (рис. 23.1) в панели Project types щелкните
по папке Business Intelligence Projects. В панели Templates выберите
Analysis Services Project. Наберите имя проекта и его местоположение в тек-
стовых полях Name и Location соответственно. Для целей данного примера
именем проекта будет Project 1. Новый проект будет создан после того, как вы
щелкнете мышью по кнопке ОК.
Новый проект всегда создается в новом решении. Следовательно, решение
является наибольшей единицей управления в Business Intelligence Develop-
ment Studio и всегда содержит один или более проектов. Если панель Solution
606
Часть IV. SQL Server и Business Intelligence
Explorer, которая позволяет вам просматривать и управлять объектами
решения или проекта, невидима, вы можете ее увидеть, выбрав в меню View
команду Solution Explorer.
Рис. 23.1. Диалоговое окно New Project
Посмотрите на панель Solution Explorer с новым созданным проектом. Ниже
узла проекта помимо других присутствуют следующие папки:
♦ Data Sources хранит информацию о соединении с исходной базой данных;
♦ Data Source Views содержит информацию, связанную с подмножеством
таблиц в исходной базе данных;
♦ Cubes содержит все кубы, которые принадлежат данному проекту;
♦ Dimensions содержит все измерения. Analysis Services поддерживает три
типа измерений. Разделяемые измерения (также называемые согласован-
ными измерениями) — это измерения, которые разделяются между двумя
или более кубами базы данных. Типичными разделяемыми измерениями
являются Time, Product и Customer. Личные измерения создаются для инди-
видуального куба. Связанное измерение основано на измерении, которое
хранится в другой базе данных Analysis Services. Исходная база данных
для связанного измерения может быть на том же самом или на другом
сервере;
Гпава 23. Microsoft Analysis Services
607
♦ Mining Structures позволяет вам создавать модель извлекаемых данных
с использованием Data Mining Wizard. Эти модели основываются на суще-
ствующей в кубе информации.
Помимо этих папок существует еще и несколько других папок (Roles,
Assemblies и Miscellaneous). Описания этих папок можно найти в документа-
ции Books Online.
После того как проект будет создан, вы должны создать источник данных.
Создание источника данных
Для создания источника данных щелкните правой кнопкой мыши по папке
Data Source в панели Solution Explorer и выберите пункт New Data Source.
Запустится мастер Data Source Wizard, который проведет вас через процесс
создания источника данных. (В качестве источника данных в этом примере
используется база данных примера SQL Server с именем AdventureWorkDW.)
Вначале на странице Select how to define the connection убедитесь, что отме-
чен переключатель Create a data source based on an existing or new
connection, и щелкните по кнопке New. В диалоговом окне Connection
Manager выберите Native OLE DB/SQL Server Native Client 10.0 и задайте
имя вашего сервера базы данных в качестве имени сервера. В этом же шаге
выберите Use Windows Authentication, а затем в раскрывающемся списке
Select or enter database name выберите базу данных AdventureWorkDW. Прежде
чем щелкнуть мышью по кнопке ОК, щелкните по кнопке Test Connection
для проверки соединения с базой данных.
Под конец на странице Completing the Wizard задайте новое имя источника
данных (для данного примера назовите источник Source 1) и нажмите кнопку
Finish. Новый источник данных появится в панели Solution Explorer в папке
Data Sources (рис. 23.2).
Рис. 23.2. Панель Solution Explorer с новым источником данных
608
Часть IV. SQL Server и Business Intelligence
Следующим шагом является создание представления, которое соответствует
выбранному источнику данных.
Создание представления источника данных
Представление источника данных используется для определения информации
схемы, которую вы хотите использовать в вашем решении. Другими словами,
представление источника данных содержит информацию, связанную с под-
множеством таблиц из заданной исходной базы данных. (Вы должны создать
представление источника данных, когда ваша база данных содержит сотни
таблиц, из которых только небольшое количество является полезным для
приложения бизнес-аналитики.)
Для создания подобного представления на панели Solution Explorer щелкни-
те правой кнопкой мыши по папке Data Source Views и выберите пункт New
Data Source Views. Мастер Data Source Views Wizard проведет вас через все
шаги, необходимые для создания представления источника данных. (В этом
примере создается представление с именем Viewl, которое основывается на
таблицах customer и Project, а также на их связанных таблицах.)
Вначале на странице Select a Data Source выберите существующий реляци-
онный источник данных (для этого примера выберите Source 1) и щелкните по
кнопке Next. На следующей странице — Select Tables and Views — выберите
таблицы, которые'принадлежат вашему кубу в виде таблиц измерений или
таблиц фактов. (Для выбора таблицы отметьте ее имя и щелкните по кнопке >
в средней части окна. Затем щелкните по кнопке Finish. После этого таблица
появится в панели Included objects.) Для этого примера выберите таблицы
DimCustomer И DimProduct ИЗ базы данных AdventureWorkDW, соответственно, И
они будут использованы для создания куба измерений. При щелчке мышью
по кнопке Add Related Tables вы сообщаете системе, что она должна найти
таблицы, имеющие отношение к двум выбранным таблицам. (Чтобы найти
связанные таблицы, система просматривает все отношения "первичный
ключ/внешний ключ", которые существуют в базе данных.)
Добавьте также таблицу DimTime, поскольку измерение времени является
(почти) всегда частью куба. После этого щелкните по кнопке Next. На стра-
нице Completing the Wizard система покажет таблицы, которые вы можете
видеть на рис. 23.3:
♦ DimCustomer;
♦ DimProduct;
♦ FactResellerSales;
♦ DimProductSubcategory;
Гпава 23. Microsoft Analysis Services
609
♦ FactlntemetSales;
♦ DimTime.
Рис. 23.3. Страница Completing the Wizard
Щелкните по кнопке Finish. После того как будут выбраны таблицы, работа
мастера будет завершена, Data Source View Designer покажет выбранные таб-
лицы (рис. 23.4). Data Source View Designer является инструментом, который
показывает в графическом представлении определенную вами схему базы
данных.
Data Source View Designer предоставляет несколько полезных функций. Для
просмотра объектов вы должны в вашем исходном представлении перемес-
тить указатель мыши на пиктограмму с крестиком в правом верхнем углу.
Когда форма указателя изменится на перекрестие, щелкните по этой пикто-
грамме. Появится окно Navigation. Теперь вы можете перемещаться от одной
части диаграммы к другой части. Если вам нужно найти конкретную таблицу,
используйте в меню Data Source View пункт Find Table. Для просмотра дан-
ных таблицы щелкните правой кнопкой мыши по таблице, а затем выберите
пункт Explore Data.
Вы также можете создавать именованные запросы, которые являются запро-
сами постоянно хранимыми и к которым можно обращаться, как и к любой
таблице. Для создания подобного запроса щелкните в меню по функции Data
610
Часть IV. SQL Server и Business Intelligence
Source View и затем выберите New Named Query. Диалоговое окно Create
Named Query позволяет создавать любые запросы к выбранным таблицам.
Рис. 23.4. Data Source View Designer с выбранными таблицами
Analysis Services и кубы
Куб является многомерной структурой, которая содержит все данные или
часть данных из хранилища данных. Каждый куб содержит следующие
компоненты;
♦ измерения;
♦ члены;
♦ иерархии;
♦ ячейки;
♦ уровни;
♦ свойства.
Измерение является множеством логически связанных атрибутов (хранимых
вместе в таблице измерений), которые детально описывают меры (хранящие-
Глава 23. Microsoft Analysis Services 611
ся в таблице фактов). Хотя термин "куб" включает три измерения, многомер-
ные кубы могут иметь гораздо больше измерений. Например, Time, Product и
Customer — типичные измерения, которые являются частью многих моделей.
Замечание________________________________________________________
Одним из важных измерений куба является измерение Measures (Мера), кото-
рое включает все меры, определенные в таблице фактов.
Каждое дискретное значение в измерении называется членом. Например, чле-
нами измерения Product могут быть Компьютеры, Диски, Центральные процессоры.
Каждый член может быть вычисляемым. Это означает, что его значение вы-
числяется во время выполнения при использовании выражения, которое зада-
ется в процессе определения члена. (Поскольку вычисляемые члены не хра-
нятся на диске, они позволяют добавлять новые члены без увеличения разме-
ра соответствующего куба.)
Иерархии задают группировку множества членов в одно измерение. Они ис-
пользуются для уточнения запросов, связанных с анализом данных. Ячейки
являются частью многомерного куба, которые определяются по своим коор-
динатам (координаты X, Y и Z, если- куб является трехмерным). Это означает,
что ячейка является набором, содержащим члены из каждого измерения. На-
пример, рассмотрим трехмерный куб из главы 22 (см. рис. 22.3), который
представляет продажи автомобилей для одного региона за квартал. Ячейки со
следующими координатами помимо прочих принадлежат кубу:
♦ первый квартал, Южная Америка, Falcon;
♦ третий квартал, Азия, Eagle.
Когда вы определяете иерархии, вы их определяете в терминах их уровней.
Другими словами, уровни описывают иерархию от наивысшего (наиболее
обобщенного) уровня до самого нижнего (наиболее детализированного)
уровня данных. Следующий список отображает возможные уровни иерархии
для измерения времени:
♦ квартал (QI, Q2, Q3, Q4);
♦ месяц (январь, февраль,...);
♦ день (день1, день2,...).
Создание куба
Прежде чем создавать куб, вы должны задать один или более источников
данных и создать представление источника данных, как было описано ранее в
этой главе. После этого вы можете использовать Cube Wizard для создания
куба.
612
Часть IV. SQL Server и Business Intelligence
Для создания куба щелкните правой кнопкой мыши по папке Cubes в кон-
кретном проекте в панели Solution Explorer и выберите пункт New Cube.
Запустится мастер Cube Wizard. На странице Select Creation Method выбери-
те Use existing table и щелкните по кнопке Next. На странице Select Measure
Group Tables выберите представление источника данных, щелкните по
кнопке Suggest, а затем по кнопке Next.
На странице Select Measure выберите следующие меры: SalesAmount (из
таблицы фактов FactResellerSales) и TotalProductCost (из таблицы фактов
Factinternetsales). Щелкните по кнопке Next. На странице Select New
Dimensions выберите для создания все три измерения (DimTime, DimProduct и
DimCustomer), основываясь на доступных таблицах. Последняя страница,
Completing the Wizard, показывает общий итог всех выбранных мер и изме-
рений (рис. 23.5). Щелкните по кнопке Finish для завершения работы.
Рис. 23.5. Страница Completing the Wizard
Проектирование агрегата хранения
и обработка куба
Как вы уже знаете, базовые данные из таблицы фактов могут быть предвари-
тельно просуммированы и сохранены в постоянных таблицах. Такой процесс
называется агрегацией, он может значительно улучшить время ответа по за-
Гпава 23. Microsoft Analysis Services
просу, поскольку сканирование миллионов строк для вычисления агрегации
на лету может занять очень много времени.
Существует компромисс между требованиями хранения и процентом воз-
можной агрегации, которая вычисляется и сохраняется. Вычисление всех
возможных агрегатов в кубе и сохранение их на диске приводит к макси-
мально возможной скорости ответа для всех запросов, потому что ответ на
любой запрос является практически непосредственным без промежуточных
этапов. Недостатком такого подхода является то, что время на сохранение и
обработку, требуемое для агрегаций, может быть значительным.
С другой стороны, если никакие агрегации не вычисляются и не сохраняются,
вам не нужно никакого дополнительного дискового пространства, однако
время ответа на запросы, связанные с агрегатными функциями, может быть
велико, потому что каждый агрегат должен быть вычислен на лету.
Analysis Services предоставляет мастер Aggregation Design Wizard для помо-
щи вам в оптимальном проектировании агрегаций. Для запуска этого мастера
щелкните по таблице Partitions в Cube Designer. (На рис. 23.6 показана таб-
лица Partitions ДЛЯ таблицы фактов FactintemetSales.) В таблице, которая
появляется в Cube Designer (FactintemetSales), щелкните по значению
столбца Aggregations. После этого щелкните по кнопке многоточия (...) в том
же поле. Будет запущен мастер Aggregation Design Wizard.
Рис. 23.6. Таблица Partitions в таблице фактов FactintemetSales
На первом шаге выполнения мастера вы просматриваете агрегации с исполь-
зованием установок в окне Review Aggregation. Здесь вы можете добавить
или убрать атрибуты, появляющиеся на этой странице.
Следующим шагом после выбора структуры хранения является задание ко-
личества членов в каждом атрибуте. Это вы делаете на странице Specify
Objects Counts. Для каждого выбранного объекта куба вы должны ввести
предполагаемое количество значений или количество значений сегментов,
прежде чем вы запустите на выполнение мастер. Щелкните мышью по кноп-
614
Часть IV. SQL Server и Business Intelligence
ке Count для запуска мастера, который подсчитает и отобразит найденное
количество счетчиков.
На втором и последнем шаге на странице Set Aggregation Options (рис. 23.7)
выберите одну из четырех опций для задания точки, до которой агрегации
должны быть спроектированы (или вообще не должны проектироваться):
♦ Estimated storage reaches ... МВ задает максимальный объем дисковой
памяти, которая может быть использована для предварительных вычисле-
ний агрегаций. Чем больше объем, тем большее количество предваритель-
но вычисленных агрегаций может быть создано;
♦ Performance gain reaches ... % задает увеличение производительности,
которую вы хотите достигнуть. Чем выше процент предварительно вычис-
ленных агрегаций, тем лучше производительность;
♦ I click Stop позволяет именно вам решить, когда остановить процесс про-
ектирования (когда вы щелкнете по кнопке Stop);
♦ Do not design aggregation (0%) указывает, что не должны создаваться ни-
какие предварительно вычисленные агрегации.
Рис. 23.7. Страница Set Aggregation Options
После того как вы щелкнете по кнопке Start и по кнопке Next, появится
страница Completing the Wizard. На этой странице вы можете выбрать, нач-
Гпава 23. Microsoft Analysis Services
615
нется ли процесс агрегации немедленно (Deploy and process now) или позже
(Save the aggregations but do not process them).
Окно Process Progress показывает прогресс выполнения обработки куба
(рис. 23.8).
Рис. 23.8. Окно Process Progress
Замечание_____________________________________________________
Куб должен быть обработан, когда вы впервые его создаете и каждый раз, ко-
гда вы его изменяете. Если куб содержит очень много данных и предваритель-
но вычисляемых агрегаций, то обработка куба может потребовать очень много
времени.
Просмотр куба
Для просмотра куба щелкните правой кнопкой мыши по имени куба и выбе-
рите пункт Browse. Появится одноименное окно. Вы можете добавить любые
измерения в представление, щелкнув правой кнопкой мыши по имени изме-
рения в левой панели и выбрав пункт Add to Column Area или Add to Row
Area. Вы также можете добавить меру из той же самой панели, если щелкни-
те правой кнопкой мыши по мере и выберите пункт Add to Data Area. На
рис. 23.9 показаны объемы продаж для продаж через Интернет для разных
покупателей и продуктов. Чтобы показать эти объемы, щелкните правой
кнопкой мыши по таблице DimProduct и выберите пункт Add to Column Area.
616
Часть IV. SQL Server и Business Intelligence
Рис. 23.9. Перекрестные табличные данные объемов продаж для продаж через Интернет
Щелкните также правой кнопкой мыши по таблице DimCustomer и выбе-
рите пункт Add to Row Area. Мера SalesAmount из таблицы фактов
Factinternetsales будет удалена аналогичным образом.
Замечание____________________________________________________________
Вы можете использовать комбинацию клавиш <Alt>+<Shift+<Enter> для увели-
чения представления Browse в Cube Designer. Та же самая комбинация клавиш
возвращает представление к нормальному виду.
Резюме
В Analysis Services Microsoft предоставляет набор сервисов для хранилищ
данных, которые могут быть использованы для начального и промежуточно-
го уровней анализа данных. В частности, простота его использования в
Business Intelligence Development Studio, который основывается на Visual
Studio, предоставляет пользователям простой способ проектирования и раз-
работки хранилищ данных и киосков данных.
В следующей главе описываются расширения SQL/OLAP в Transact-SQL.
ГЛАВА 24
Business Intelligence
и Transact-SQL
В части II этой книги была показана вся мощь языка Transact-SQL при
управлении традиционными деловыми данными. До версии SQL Server 2000
язык Transact-SQL не выполнял достаточно хорошо сложный анализ данных.
С самого начала Transact-SQL предоставлял некоторые агрегатные функции,
которые могли быть использованы для вычисления простых обобщений дан-
ных, а также предложение group by, которое позволяло выполнять элемен-
тарную группировку данных.
SQL Server 2000 был первой версией SQL Server, которая предоставляла
сложные возможности анализа данных, такие как оператор cube и предложе-
ние top. SQL Server 2005 значительно расширил эти возможности, введя
функции упорядочения и некоторые реляционные операторы. SQL Server
2008 вводит стандартизованный синтаксис для операторов rollup и cube, а
также для группировки наборов, что позволяет выполнять вычисления для
групп некоторых различных наборов по столбцам группирования.
После короткого введения в SQL/OLAP в этой главе рассматриваются сле-
дующие темы, связанные с аналитическими функциями:
♦ конструкция окна;
♦ расширения предложения group by;
♦ функции аналитических запросов;
♦ нестандартные аналитические функции.
Введение в SQL/OLAP
Пробовали ли вы когда-нибудь писать запрос на Transact-SQL, который вы-
числяет изменения значений в процентах между двумя последними кварта-
618
Часть IV. SQL Server и Business Intelligence
лами? Или запрос, который выполняет накапливаемое суммирование либо
скользящее агрегирование? Если вы пытались это делать, то знаете, насколь-
ко сложные эти задачи. Сегодня вам больше не нужно их выполнять. Стан-
дарт SQL: 1999 был приспособлен к набору функций оперативного анализа
данных (Online Analytical Processing, OLAP), которые позволяют просто вы-
полнять эти вычисления, так же как и множество других вычислений, кото-
рые являются слишком сложными в реализации. Эта часть стандарта SQL
называется SQL/OLAP. SQL/OLAP включает все функции и операторы, кото-
рые используются для анализа данных.
Применение функций OLAP для пользователя имеет несколько преимуществ:
♦ пользователи со стандартными знаниями языка SQL могут легко задавать
нужные им вычисления;
♦ системы баз данных, такие как Database Engine, могут выполнять эти вы-
числения гораздо эффективнее;
♦ поскольку существуют стандартные спецификации на эти функции, сейчас
они стали более экономичными в эксплуатации для продавцов инструмен-
тов и приложений;
♦ почти все аналитические функции, предложенные в стандарте SQL: 1999,
реализованы в системах баз данных предприятий одним и тем же спо-
собом. По этой причине вы можете переносить операторы в форме
SQL/OLAP с одной системы на другую без какого-либо изменения кода.
Database Engine предоставляет множество расширений оператора select, ко-
торые могут быть использованы в первую очередь в аналитических операто-
рах. Некоторые из этих расширений были определены в соответствии со
,стандартом SQL: 1999, а некоторые нет. В следующих разделах описываются
как стандартные, так и нестандартные функции и операторы SQL/OLAP.
Конструкция окна
Наиболее важным расширением языка Transact-SQL, связанным с анализом
данных, является конструкция окна. Окно (в связи с SQL/OLAP) определяет
разделенный набор строк, к которому применяется функция. Количество
строк, принадлежащих окну, динамически определяется в зависимости от
спецификаций пользователя. Конструкция окна задается с использованием
предложения over.
Стандартизованная конструкция окна имеет три основные части:
♦ разбиение на разделы;
♦ упорядочение;
♦ группирование агрегатов.
Гпава 24. Business Intelligence и Transact-SQL
619
Замечание_________________________________________________________
SQL Server 2008 не поддерживает группирование агрегатов, так что эта воз-
можность здесь не рассматривается.
Прежде чем вы начнете разбираться в конструкции окна и ее частей, взгляни-
те на таблицы, которые будут использоваться в примерах. В примере 24.1
создается таблица project_dept, показанная в табл. 24.1, которая использует-
ся в этой главе для демонстрации расширений Transact-SQL, связанных
с SQL/OLAP.
Таблица 24.1. Содержимое таблицы project dept
dept_name emp ent budget date_month
Research 5 50000 01.01.2007
Research 10 70000 02.01.2007
Research 5 65000 07.01.2007
Accounting 5 10000 07.01.2007
Accounting 10 40000 02.01.2007
Accounting 6 30000 01.01.2007
Accounting 6 40000 02.01.2008
Marketing 6 100000 01.01.2008
Marketing 10 180000 02.01.2008
Marketing 3 100000 07.01.2008
Marketing NULL 120000 01.01.2008
; Пример 24.1
USE sanple;
create table project_dept
( dept_name chart 20 ) not null,
enpcnt int null,
budget float,
datejnonth date ) ;
Таблица project_dept содержит несколько отделов и количество их служа-
щих, а также бюджеты проектов, которые управляются каждым отделом.
В примере 24.2 показаны операторы insert, которые используются для до-
бавления строк, показанных в табл. 24.1.
21 Зак. 1141
620
Часть IV. SQL Server и Business Intelligence
. Пример 24.2
INSERT INTO project_dept VALUES
('Research', 5, 50000, '01.01.2007');
INSERT INTO project_dept VALUES
('Research', 10, 70000, '02.01.2007');
INSERT INTO project_dept VALUES
('Research', 5, 65000, '07.01.2007');
INSERT INTO project_dept VALUES
('Accounting', 5, 10000, '07.01.2007');
INSERT INTO project_dept VALUES
('Accounting', 10, 40000, '02.01.2007');
INSERT INTO project_dept VALUES
('Accounting', 6, 30000, '01.01.2007');
INSERT INTO project_dept VALUES
('Accounting', 6, 40000, '02.01.2008');
INSERT INTO project_dept VALUES
('Marketing', 6, 100000, '01.01.2008');
INSERT INTO project_dept VALUES
('Marketing', 10, 180000, '02.01.2008');
INSERT INTO project_dept VALUES
('Marketing', 3, 100000, '07.01.2008');
INSERT INTO project_dept VALUES
('Marketing', NULL, 120000, '01.01.2008');
Разбиение на разделы
Разбиение на разделы позволяет разделить результирующий набор запроса на
группы, так что каждая строка раздела будет отображаться отдельно. Если
разделы не заданы, то весь набор строк будет принадлежать одному разделу.
Хотя разбиение на разделы и выглядит как группирование с использованием
предложения group by, это не является тем же самым. Предложение group by
сворачивает строки раздела в одну строку, в то время как разбиение на раз-
делы в конструкции окна просто организует строки в группы без их сворачи-
вания.
Следующие два примера показывают различия между разбиением на разделы
с использованием конструкции окна и группированием при использовании
предложения group by. Предположим, что вы хотите вычислить некоторые
различные агрегаты, касающиеся служащих в каждом отделе. В примере 24.3
показано, как предложение over вместе с предложением partition by может
быть использовано для создания разделов.
Гпава 24. Business Intelligence и Transact-SQL 621
; Пример 24.3
Используя конструкцию окна, создайте раздел в соответствии со значениями
столбца dept name и вычислите общее количество сотрудников и среднее зна-
чение бюджетов для отделов Accounting и Research:
USE sample;
SELECT dept_name, budget,
SUM( emp_cnt ) OVER( PARTITION BY dept_name ) AS emp_cnt_sum,
AVG( budget ) OVER( PARTITION BY dept_name ) AS budget_avg
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research');
Результат: dept_name budget emp_cnt_sum budget_avg
Accounting 10000 27 30000
Accounting 40000 27 30000
Accounting 30000 27 30000
Accounting 40000 27 30000
Research 50000 20 61666.6666666667
Research 70000 20 61666.6666666667
Research 65000 20 61666.6666666667
В примере 24.3 используется предложение over для определения соответст-
вующего окна. Внутри него опция partition by применяется для задания
разделов. (Разделы группируются при использовании значений столбца
dept name.) Под конец агрегатная (или некоторая другая) функция применя-
ется к разделам. Наконец, как вы можете видеть по результатам данного при-
мера, разбиение на разделы размещает строки по разделам без их сворачи-
вания.
В примере 24.4 показан похожий запрос, который использует предложение
GROUP BY.
; Пример 24.4
Группировка значений в столбце dept name для отделов Accounting и Research
и вычисление суммы и среднего значения для этих двух групп:
USE sample;
SELECT dept_name,
SUM(emp_cnt) AS ent, AVG( budget ) AS budget_avg
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research')
GROUP BY dept__name;
622
Часть IV. SQL Server и Business Intelligence
Результат:
dept_name ent budget_avg
Accounting 27 30000
Research 20 61666.6666666667
Как уже было сказано, когда вы используете предложение group by, каждая
группа сворачивается в одну строку.
Замечание
Существует другое значительное различие между предложениями over и group
by. Как можно видеть из примера 24.2, когда вы используете предложение
OVER, соответствующий список select может содержать любые имена столбцов
таблицы. Это очевидно, поскольку разбиение на разделы организует строки
в группы без их сворачивания.
Упорядочение
Упорядочение в конструкции окна похоже на упорядочение в запросе. Во-
первых, вы используете предложение order by для задания конкретного по-
рядка строк в результирующем наборе. Во-вторых, это предложение включа-
ет список ключей сортировки и указывает, в каком порядке они должны быть
отсортированы — по возрастанию или по убыванию значений. Наиболее
важным отличием является то, что порядок внутри окна применим только
к каждому разделу.
SQL Server 2008 не поддерживает упорядочение внутри конструкции окна
для агрегатных функций. Другими словами, предложение over для агрегат-
ных функций может содержать только предложение partition by. (Назло
этому ограничению упорядочение внутри окна работает для функций ранжи-
рования.) Пример 24.5, который поддерживается стандартом SQL, выдает
ошибку.
: Пример 24.5. Выдает ошибку
Разделение строк таблицы project dept при использовании значений столбца
dept name и сортировка строк в каждом разделе по значениям столбца budget:
USE sample;
SELECT dept_name, budget, emp_cnt
SUM(budget) OVER(PARTITION BY dept_name ORDER BY budget) AS
sum_dept
FROM proj ect_dept;
Глава 24. Business Intelligence и Transact-SQL
623
В примере 24.6 используются обычные средства Transact-SQL для решения
проблемы из примера 24.65, которая называется кумулятивной агрегацией
или в данном случае кумулятивным суммированием. Кумулятивные агрега-
ции аккумулируют данные, начиная с первого значения раздела и заканчивая
текущим значением.
J Пример 24.6
Группирует таблицу project dept, используя значения столбца dept name и
сортируя строки в каждом разделе на основе значений столбца budget:
USE sample;
SELECT pl.dept_name, pl.budget, pl.emp_cnt,
SUM (p2.budget) AS cumulative_budget
FROM project_dept pl JOIN project_dept p2
ON pl.dept_name = p2.dept_name
AND p2.budget <= pl.budget
GROUP BY pl.dept_name, pl.budget, pl.emp_cnt
ORDER BY pl.dept_name, pl.budget, pl.emp_cnt;
Замечание___________________________________________________________
Стандарт SQL определяет дополнительную часть конструкции окна, называе-
мую группировкой агрегации. С группировкой агрегации вы можете определять
набор строк, которыми оперирует агрегатная функция для каждой строки в раз-
деле. Transact-SQL не поддерживает группировку агрегации.
Вы можете использовать несколько столбцов таблицы для создания различ-
ных схем разделов в запросе (пример 24.7).
j Пример 24.7
Создание двух разделов для отделов Accounting и Research: один на основе
значений столбца budget, а другой на основе значений столбца dept_name.
Вычисление сумм для первого раздела и средних значений для второго раз-
дела.
USE sample;
SELECT dept_name, CAST( budget AS INT ) AS budget,
SUM( emp_cnt ) OVER( PARTITION BY budget ) AS emp_cnt_sum,
AVG( budget ) OVER( PARTITION BY dept_name ) AS budget_avg
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research');
624
Часть IV. SQL Server и Business Intelligence
Результат:
dept_name budget emp_cnt_sum budget_avg
Accounting 10000 5 30000
Accounting 30000 6 30000
Accounting 40000 16 30000
Accounting 40000 16 30000
Research 50000 5 61666.6666666667
Research 65000 5 61666.6666666667
Research 70000 10 61666.6666666667
Запрос в примере 24.7 имеет две различные схемы разделов: одна со значе-
ниями столбца budget, другая со значениями столбца dept_name. Первая ис-
пользуется для вычисления количества служащих в отделах с одинаковыми
бюджетами. Вторая — для вычисления среднего значения бюджетов отделов,
сгруппированных по их именам.
Расширения предложения GROUP BY
Transact-SQL расширяет предложение group by следующими операторами:
’♦ cube;
♦ rollup;
♦ GROUPING SETS.
Предложение group by также имеет дополнительную функцию grouping, ко-
торая будет рассмотрена после только что упомянутых операторов.
Оператор CUBE
'В этом разделе будут рассмотрены различия между группированием с ис-
пользованием предложения group by и группированием с применением group
by в комбинации с оператором cube. Основное отличие заключается в том,
что предложение group by определяет один или более столбцов в качестве
группы, где все строки в любой группе имеют те лее значения для тех же
столбцов, cube и rollup предоставляют дополнительные итоговые строки для
группируемых данных. Эти итоговые строки также называются многомер-
ными итогами.
Следующие два примера демонстрируют эти отличия. В примере 24.8 приме-
няется предложение group by для группирования строк таблицы project_dept
на основе двух критериев: столбцов dept name и emp_cnt.
Гпава 24. Business Intelligence и Transact-SQL
625
, Пример 24.8
При использовании предложения group by выполняется группировка строк
таблицы project-dept С ПОМОЩЬЮ столбцов dept_name И emp cnt:
USE sample;
SELECT dept_name, emp_ent, SUM(budget) sum_of_budgets
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research' GROUP BY dept_name, emp_ent; Результат:
dept_name emp ent sum_of_budgets
Accounting 5 10000
Accounting 6 70000
Accounting 10 40000
Accounting NULL 120000
Research 5 115000
Research 10 70000
Research NULL 185000
NULL NULL 305000
NULL 5 125000
NULL 6 70000
NULL 10 110000
В примере 24.9 показано использование оператора cube.
' Пример 24.9
Группировка строк в таблице project dept выполняется для отделов Accoun-
ting и Research с учетом столбцов dept_name и emp cnt. Кроме того, дополни-
тельно выводятся все возможные итоги строк:
USE sample;
SELECT dept—name, emp_cnt, SUM(budget) sum_of_budgets
FROM project—dept
WHERE dept—name IN ('Accounting', 'Research')
GROUP BY CUBE (dept_name, emp_ent);
Результат:
dept_name emp_cnt sum_of_budgets
Accounting 5 10000
Accounting 6 70000
626
Часть IV. SQL Server и Business Intelligence
Accounting 10 40000
Accounting NULL 120000
Research 5 115000
Research 10 70000
Research NULL 185000
NULL NULL 305000
NULL 5 125000
NULL 6 70000
NULL 10 110000
Основным отличием между двумя последними примерами является то, что
результирующий набор примера 24.8 отображает только значения, относя-
щиеся к группам, тогда как результирующий набор примера 24.9 содержит
дополнительно все возможные итоги строк. Заполнитель значений в ненуж-
ных столбцах суммируемых строк отображается в виде null. Например, сле-
дующая строка в результирующем наборе
NULL NULL 305000
дает сумму всех бюджетов всех существующих проектов в этой таблице, то-
гда как строка
NULL 5 125000
показывает сумму всех бюджетов всех проектов, над которыми работает в
точности пять служащих.
Замечание______________________________________________________
Поскольку оператор CUBE отображает каждую возможную комбинацию групп и
итоговых строк, количество строк является тем же самым, независимо от по-
рядка столбцов в предложении group by.
Синтаксис cube в примере 24.9 соответствует стандартизованному синтаксису
этого оператора. Этот синтаксис введен в SQL Server 2008. Пример 24.10
эквивалентен примеру 24.9, однако он использует синтаксис старого стиля.
j Пример 24.10
Группирование строк таблицы project dept, которые принадлежат отделам
Accounting и Research, при использовании столбцов dept_name и emp_cnt при
дополнительном отображении всех возможных итоговых строк:
USE sample;
SELECT dept_name, emp_cnt, SUM(budget) sum_of—budgets
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research')
GROUP BY dept_name, emp_cnt
WITH CUBE;
Гпава 24. Business Intelligence и Transact-SQL 627
Оператор ROLLUP
В отличие от оператора cube, который возвращает любую возможную комби-
нацию групп и итоговых строк, иерархия групп, использующая rollup, опре-
делена в порядке, в котором заданы группируемые столбцы. В примере 24.11
показано использование оператора rollup.
^Пример 24.11
Группирование строк таблицы project dept, которая принадлежит отделам
Accounting и Research, при использовании столбцов dept_name и emp_cnt при
дополнительном отображении итоговых строк для столбца dept_name:
USE sample;
SELECT dept_name, emp_cnt, SUM(budget) sum_of_budgets
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research')
GROUP BY ROLLUP (dept_name, emp_cnt);
Функция GROUPING
Как вы уже знаете, значение null используется в комбинации cube и rollup
для задания заменителя значений ненужных столбцов. В этом случае нельзя
отличить null в отношении cube и rollup от значения null. Transact-SQL под-
держивает стандартизованную функцию grouping, которая позволяет разре-
шить проблему с двусмысленностью null. Функция grouping возвращает 1,
если null в результирующем наборе связан с cube или rollup, и 0, если он
представляет группу значений null.
В примере 24.12 показано использование функции grouping.
= Пример 24.12
Функция grouping выясняет, какие значения null в результате выполнения
следующего оператора select отображают итоговые строки:
USE sample;
SELECT dept_name, emp_cnt, SUM(budget) sum_b, GROUPING(emp_cnt) gr
FROM project_dept
WHERE dept_name IN ('Accounting', 'Marketing')
GROUP BY ROLLUP (dept_name, emp_cnt);
Результат:
dept_name emp_cnt sum_b gr
Accounting
10000
628
Часть IV. SQL Server и Business Intelligence
Accounting 6 70000 0
Accounting 10 40000 0
Accounting NULL 120000 1
Marketing NULL 120000 0
Marketing 3 100000 0
Marketing 6 100000 0
Marketing 10 180000 0
Marketing NULL 500000 1
NULL NULL 620000 1
Если вы посмотрите на сгруппированный столбец (gr), то увидите, что в нем
присутствуют 0 и 1. Значение 1 указывает, что соответствующий null в
столбце emp cnt задает суммарное значение.
Оператор GROUPING SETS
Группирование наборов является расширением предложения group by,.кото-
рое дает возможность пользователям определять несколько групп в одном и
том же запросе. Вы используете оператор grouping sets для реализации
сгруппированных наборов. В примере 24.13 показано использование этого
оператора.
| Пример 24.13
Вычисление суммы бюджетов для отделов Accounting и Research вначале
с помощью комбинации значений столбцов dept_name и emp cnt, после чего —
значений одного столбца dept_name:
USE sample;
SELECT dept_name, emp_cnt, SUM(budget) sum_budgets
FROM project_dept
WHERE dept_name IN ('Accounting', 'Research')
GROUP BY GROUPING SETS ((dept_name, emp_cnt),(dept_name));
Результат: dept_name emp_cnt sum_budgets
Accounting 5 10000
Accounting 6 70000
Accounting 10 40000
Accounting NULL 120000
Research 5 115000
Research 10 70000
Research NULL 185000
Гпава 24. Business Intelligence и Transact-SQL 629
Как вы можете видеть в результирующем наборе примера 24.13, запрос при-
меняет две различные группировки для вычисления суммы бюджетов: внача-
ле выполняется комбинация значений столбцов dept name и emp_cnt, а затем
используются значения одного столбца dept name.
Вы можете использовать серию сгруппированных наборов, заменяя операто-
ры rollup и cube. Например, следующая серия сгруппированных наборов
GROUP BY GROUPING SETS ((dept_name, emp_cnt), (dept_name), ())
эквивалентна предложению rollup:
GROUP BY ROLLUP (deptname, emp_cnt)
Таким же образом выражение
GROUP BY GROUPING SETS ( (dept пме, emp_cnt), (emp_cnt, dept_name),
(dept name), ())
эквивалентно следующему предложению cube:
GROUP BY CUBE (dept_name, emp_cnt)
Функции запросов OLAP
Transact-SQL поддерживает две группы функций, которые являются функ-
циями запросов OLAP:
♦ функции упорядочения;
♦ статистические агрегатные функции.
Следующие подразделы описывают эти функции.
Замечание______________________________________________________
Функция grouping, описанная ранее, также принадлежит к функциям OLAP.
Функции упорядочения
Функции упорядочения возвращают упорядоченное значение каждой строки
в группе раздела. Transact-SQL поддерживает следующие функции упорядо-
чения:
♦ rank;
♦ dense_rank;
♦ R0W_NUMBER.
В примере 24.14 показано использование функции rank.
630
Часть IV. SQL Server и Business Intelligence
1 Пример 24.14
Найти все отделы с бюджетом не более чем 30 000 и отобразить результи-
рующий набор в убывающем порядке:
USE sample;
SELECT RANKO OVER(ORDER BY budget DESC) AS rank_budget,
dept_name, emp_cnt, budget
FROM project_dept
WHERE budget <= 30000;
Результат:
rank_budget dept_name ernp_cnt budget
1 Accounting 6 30000
2 Accounting 5 10000
Пример 24.14 использует функцию rank для получения количества (в первом
столбце результирующего набора), которое задает порядок строки среди дру-
гих строк. Пример использует предложение over для сортировки результи-
рующего набора по столбцу budget в убывающем порядке. В этом примере
опущено предложение partition by. Поэтому весь результирующий набор
будет принадлежать только одному разделу.
Замечание________________________________________________________
Функция rank использует логическое агрегирование. Другими словами, если
две или более строки в результирующем наборе являются связанными (имеют
одно и то же значение в столбце, по которому выполняется упорядочивание),
то они будут иметь одинаковый ранг. Следующая по порядку строка будет
иметь ранг равный единице плюс номер ранга предыдущей строки. По этой
причине функция rank отображает "дыры", если две или более строк имеют од-
но и то же значение ранга.
В примере 24.15 показано использование двух других функций упорядоче-
ния: DENSE_RANK И ROW_NUMBER.
: Пример 24.15
Найти все отделы с бюджетом не более чем 40 000 и отобразить уплотненный
ранг и последовательный номер каждой строки в результирующем наборе:
USE sample;
SELECT DENSE_RANK() OVER( ORDER BY budget DESC ) AS rank_budget,
ROW_NUMBER() OVER( ORDER BY budget DESC ) AS row_number,
dept_name, emp_cnt, budget
Глава 24. Business Intelligence и Transact-SQL
631
FROM project_dept
WHERE budget <= 40000;
Результат:
rank_budget row_number dept_name emp ent budget
Accounting 10 40000
1 2 Accounting 6 40000
2 3 Accounting 6 30000
3 4 Accounting 5 10000
Первые два столбца в результирующем наборе примера 24.15 показывают
значения функций dense_rank и rcw_number соответственно. Вывод функции
DENSE_RANK похож на вывод функции rank (см. пример 24.14). Единственным
отличием является то, что функция dense rank не возвращает "дыры", если
два или более ранжируемых значения равны и, следовательно, имеют один и
тот же ранг.
Использование функции row_number очевидно: она возвращает последова-
тельный номер строки в результирующем наборе, начиная с 1 для первой
строки.
В последних двух примерах предложение over служит для определения по-
рядка результирующего набора. Как вы уже знаете, это предложение также
может быть использовано для разделения результирующего набора, создан-
ного предложением from, на группы (разделы), а затем для применения агре-
гатной или упорядочивающей функции отдельно для каждого раздела.
В примере 24.16 показано, как функция rank может быть применена к раз-
делам.
j Пример 24.16
USE sample;
SELECT date_month, dept_name, emp_cnt, budget,
RANKO OVER(PARTITION BY date_month ORDER ЁУ emp_cnt desc) AS
rank
FROM project_dept;
Результат:
date_month dept_name emp_cnt budget rank
Accounting 6
Research 5
30000
50000
2007-01-01
2007-01-01
632
Часть IV. SQL Server и Business Intelligence
2007-02-01 Research 10 70000
2007-02-01 Accounting 10 40000
2007-07-01 Research 5 65000
2007-07-01 Accounting 5 10000 1
2008-01-01 Marketing 6 100000
2008-01-01 Marketing NULL 120000 2
2008-02-01 Marketing 10 180000
2008-02-01 Accounting 5 40000 2
2008-07-01 Marketing 3 100000 1
Результирующий набор в примере 24.16 разделен (выделен по разделам) на
шесть групп в соответствии со значениями столбца date_month. После того,
как функция rank будет применена к каждому разделу. Если вы внимательно
посмотрите и сравните предыдущий пример с примером 24.5, то вы увидите,
что последний пример работает, тогда как пример 24.5 выдает ошибку, хотя
оба примера используют одну и ту же конструкцию окна. Как ранее было
сказано, в настоящий момент Transact-SQL поддерживает предложение over
для агрегатных функций только с предложением partition by, но в случае
функций упорядочения система поддерживает общий синтаксис стандарта
SQL с предложениями partition by и order by.
Статистические агрегатные функции
В главе 6 рассматривались статистические агрегатные функции:.
♦ var вычисляет дисперсию для всех значений, представленных в столбце
или в выражении;
♦ varp вычисляет дисперсию для всех значений популяции, представленных
в столбце или в выражении;
♦ stdev вычисляет среднеквадратичное отклонение (СКО) всех значений
столбца или выражения. (СКО вычисляется как квадратный корень из со-
ответствующей дисперсии);
♦ stdevp вычисляет СКО популяции всех значений столбца или выражения.
Вы можете использовать статистические агрегатные функции с конструкцией
окна или без нее. В примере 24.17 показано, как могут быть использованы
функции var и stdev в конструкции окна.
Пример 24.17
Используя конструкцию окна, вычислить дисперсию и СКО бюджетов в раз-
делах, сформированных с использованием столбца dept name:
Глава 24. Business Intelligence и Transact-SQL
633
USE sample;
SELECT dept_name, budget,
VAR(budget) OVER(PARTITION BY dept_name) AS budget_var,
STDEV(budget) OVER(PARTITION BY dept_name) AS budget_stdev
FROM project—dept
WHERE dept—name in ('Accounting', 'Research');
Результат:
dept_name budget budget_var budget_stdev
Accounting 10000 200000000 14142.135623731
Accounting 40000 200000000 14142.135623731
Accounting 30000 200000000 14142.135623731
Accounting 40000 200000000 14142.135623731
Research 50000 108333333,333333 10408.3299973306
Research 70000 108333333,333333 10408.3299973306
Research 65000 108333333,333333 10408.3299973306
Нестандартные аналитические функции
SQL Server содержит несколько функций OLAP, которые не входят в стан-
дарт SQL. Следующие функции и операторы принадлежат нестандартному
SQL/OLAP:
♦ тор;
♦ ntile;
♦ pivot и unpivot.
Предложение ТОР
Предложение тор задает первые найденные п строк результата запроса. Это
предложение всегда должно быть использовано с предложением order by, по-
тому что результат такого запроса является всегда хорошо определенным и
может быть использован в табличных выражениях. Табличное выражение
задает экземпляр сгруппированного табличного результата. Запрос с тор, но
без предложения order by является недетерминированным. Это означает, что
многократные выполнения запроса к одним и тем же данным не всегда будет
отображать один и тот же результирующий набор.
В примере 24.18 показано использование этого предложения.
634
Часть IV. SQL Server и Business Intelligence
! Пример 24.18
Выборка четырех проектов с наибольшими бюджетами:
USE sample
SELECT TOP (4) dept_name, budget
FROM project_dept
ORDER BY budget DESC;
Результат:
dept_name budget
Marketing 180000
Marketing 120000
Marketing 100000
Marketing 100000
Как вы можете видеть, предложение тор является частью списка в операторе
select и записывается в начале списка имен всех столбцов.
Замечание________________________________________________________
Начиная с SQL Server 2005, вы должны записывать значение параметра для
ТОР внутри круглых скобок, потому что система поддерживает любые самооп-
ределенные выражения в качестве параметров.
Предложение тор является нестандартной реализацией Transact-SQL, исполь-
зуемой для отображения рангов первых п строк таблицы. Запрос, эквивалент-
ный запросу из примера 24.18, который использует конструкцию окна и
функцию rank, показан в примере 24.19.
1 Пример 24.19
Выборка четырех проектов с наибольшими бюджетами:
USE sample;
SELECT dept_name, budget
FROM (SELECT dept_name, budget,
RANKO OVER (ORDER BY budget DESC) AS rank_budget
FROM project_dept) part_dept
WHERE rank_budget <= 4;
Предложение top также может быть использовано с дополнительной опцией
percent. В этом случае отыскиваются первые п процентов строк из результи-
рующего набора. Дополнительная опция with ties указывает, что дополни-
Глава 24. Business Intelligence и Transact-SQL
тельные строки будут выбраны из результата запроса, если они имеют то же
самое значение в столбце (столбцах) предложения order by, что и последняя
строка, которая принадлежит отображаемому набору. В примере 24.20 пока-
зано использование опций percent и with ties.
; Пример 24.20
Выборка первых 25% строк с наименьшими номерами служащих:
USE sample;
SELECT TOP (25) PERCENT WITH TIES empcnt, budget
FROM project_dept
ORDER BY emp_cnt ASC;
Результат:
emp_cnt budget
NULL 120000
3 100000
5 50000
5 65000
5 10000
Результат примера 24.20 содержит пять строк, потому что существуют три
проекта с пятью служащими.
Начиная с SQL Server 2005, вы можете использовать предложение тор с опе-
раторами update, delete и insert. В примере 24.21 показано использование
этого предложения с оператором update.
i Пример 24.21
Поиск трех проектов с наибольшим размером бюджета и уменьшение этих
бюджетов на 10%:
USE sample
UPDATE TOP (3) project_dept
SET budget = budget * 0.9
, WHERE budget in (SELECT TOP (3) budget
FROM project_dept
ORDER BY budget desc);
В примере 24.22 показано использование предложения тор вместе с операто-
ром DELETE.
636
Часть IV. SQL Server и Business Intelligence
\ Пример 24.22
Удаление четырех проектов с наименьшими значениями бюджетов:
USE sample
DELETE TOP (4)
FROM projectdept
WHERE budget IN (SELECT TOP (4) budget FROM project_dept
ORDER BY budget ASC);
В примере 24.22 предложение top используется вначале в подзапросе для по-
иска проектов с наименьшими значениями бюджетов, а затем в операторе
delete для удаления этих проектов.
Функция NTILE
Функция ntile принадлежит к функциям упорядочения. Она распределяет
строки по разделам с указанным номером группы. Для каждой строки функ-
ция ntile возвращает номер группы, к которой принадлежит эта строка. По
этой причине данная функция обычно применяется для упорядочения строк
в группе.
В примере 24.23 показано использование функции ntile.
1 Пример 24.23
>.................................................................... J
USE sample
SELECT dept_name, budget,
CASE NTILE(3) OVER (ORDER BY budget ASC)
WHEN 1 THEN 'Low'
WHEN 2 THEN 'Medium'
WHEN 3 THEN 'High'
END AS groups
FROM projectdept;
Результат:
dept_name budget groups
Accounting 10000 Low
Accounting 30000 Low
Accounting 40000 Low
Accounting 40000 Low
Research 50000 Medium
Research 65000 Medium
Гпава 24. Business Intelligence и Transact-SQL
637
Research 70000 Medium
Marketing 100000 Medium
Marketing 100000 High
Marketing 120000 High
Marketing 180000 High
Операторы PIVOT и UNPIVOT
pivot и unpivot являются нестандартными реляционными операторами, кото-
рые поддерживаются Transact-SQL. Вы можете их использовать для манипу-
лирования выражением табличного значения в другой таблице, pivot преоб-
разует такое значение, возвращая уникальные значения одного столбца этого
выражения в виде множества столбцов, и выполняет агрегирование любых
остальных значений столбца, которые нужны в результирующем выводе.
В примере 24.24 показано, как работает pivot.
I Пример 24.24
USE sample;
SELECT *, month(date_month) as month, year(date_month) as year
INTO project_dept_pivot
FROM project_dept;
GO
SELECT year, [1] as January, [2] as February, [7] July FROM
(SELECT budget, year, month from project_dept_pivot) p2
PIVOT (SUM(budget) FOR month IN ([1],[2],[7])) AS Р;
Результат:
Year January February July
2007 80000 11000 75000
2008 220000 200000 100000
В первой части примера 24.24 создается новая таблица, project dept pivot,
которая будет использована для демонстрации того, как работает оператор
pivot. Эта таблица идентична таблице project_dept (введенной в приме-
ре 24.1), за исключением двух дополнительных столбцов: month и year. Стол-
бец month таблицы project_dept_pivot содержит годы 2007 и 2008, которые
ПОЯВЛЯЮТСЯ в столбце date_month таблицы project_dept. Также столбцы month
таблицы project dept_pivot (January, February И July) содержат итоговые
значения бюджетов, соответствующие этим месяцам в таблице project dept.
638
Часть IV. SQL Server и Business Intelligence
Второй оператор select содержит внутренний запрос, который встроен в
предложение from внешнего запроса. Предложение pivot является частью
внутреннего запроса. Оно начинается с задания агрегатной функции sum
(суммы бюджетов). Вторая часть задает основной столбец (month) и значения
этого столбца, которые будут использоваться в качестве заголовков столбца
(в примере 24.24 это первый, второй и седьмой месяц года). Значение кон-
кретного столбца в строке вычисляется с использованием заданной агрегат-
ной функции над строками, которые соответствуют заголовку столбца.
Замечание________________________________________________________
Как видно из примера 24.24, использование всех возможных значений основно-
го столбца не требуется.
Оператор unpivot выполняет реверсирование операции pivot путем цикличе-
ского сдвига столбцов в строках. В примере 24.25 показано использование
этого оператора.
j Пример 24.25
CREATE TABLE project_dept_pvt (year int, January float, February float,
July float);
INSERT INTO project_dept_pvt VALUES (2007, 80000, 110000, 75000);
INSERT INTO project_dept_pvt VALUES (2008, 50000, 80000, 30000);
— Таблица UNPIVOT
SELECT year, month, budget
FROM
(SELECT year, January, February, July
FROM project_dept_pvt) p
UNPIVOT (budget FOR month IN (January, February, July)
) AS unpvt
Результат:
year month budget
2007 January 80000
2007 February 110000
2007 July 75000
2008 January 50000
2008 February 80000
2008 July 30000
В примере 24.25 используется таблица project dept part для демонстрации
реляционного оператора.unpivot. Первыми входными данными unpivot явля-
ется имя столбца (budget), который содержит нормализованные значения.
Гпава 24. Business Intelligence и Transact-SQL
639
После этого опция for применяется для определения имени целевого столбца
(month). Под конец в качестве части опции in указываются выбранные значе-
ния целевого столбца.
Замечание___________________________________________________
unpivot не является точным реверсированием pivot, потому что любые зна-
чения null в таблице, которые должны быть преобразованы, не могут быть ис-
пользованы в качестве значений столбца в результирующем выводе.
Резюме
Расширения SQL/OLAP языка Transact-SQL поддерживают возможности
анализа данных. Существуют четыре основные части SQL/OLAP, которые
поддерживаются в SQL Server 2008:
♦ конструкция окна;
♦ расширения предложения group by;
♦ функции аналитических запросов;
♦ нестандартные аналитические функции.
Конструкция окна является наиболее важным расширением. Это комбинация
агрегатных функций и функций упорядочения. Конструкция окна позволяет
просто вычислять аналитические функции, такие как кумулятивные функции
и скользящее агрегирование. Существуют три расширения предложения
group by, которые описаны в стандарте SQL и поддерживаются в SQL Server
2008: операторы cube, rollup и grouping sets.
Наиболее важными функциями аналитического запроса являются функции
упорядочения: rank, dense_rank и row number. Transact-SQL поддерживает не-
которые нестандартные аналитические функции и операторы, такие как тор,
NTILE, PIVOT И UNPIVOT.
В следующей главе описывается Reporting Services— компонент бизнес-
аналитики в SQL Server.
Упражнения
| Пример 24.1
Найдите среднее количество служащих в отделе Accounting. Решите эту за-
дачу:
♦ используя конструкцию окна;
♦ используя предложение group by.
640
Часть IV. SQL Server и Business Intelligence
j Пример 24.2
Используя конструкцию окна, найдите отдел с наибольшим бюджетом за
2007 и 2008 годы.
= Пример 24.3
Найдите количество служащих в комбинации значений в отделах и значе-
ниями бюджетов. Также должны отображаться все возможные итоговые
строки.
s Пример 24.4
Решите задачу примера 24.3, используя оператор rollup. Какая разница меж-
ду этим результирующим набором и результирующим набором из приме-
ра 24.3?
j Пример 24.5
Используя функцию rank, найдите три отдела с наибольшим количеством
служащих.
j Пример 24.6
Решите задачу из примера 24.5, используя предложение тор.
j Пример 24.7
Вычислите ранги всех отделов за 2008 год в соответствии с количеством
служащих. Отобразите также значения функций dense_rank и row number.
ГЛАВА 25
Microsoft Reporting Services
В этой главе описывается инструмент создания промышленных отчетов
в SQL Server, называемый Reporting Services. В начале главы обсуждается
общая структура отчета и объясняются основные компоненты Reporting
Services. После этого вы увидите, как можно создавать отчеты с помощью
мастера Report Server Project Wizard. Затем будет рассмотрена обработка от-
чета. Под конец будут показаны различные способы поставки спроектиро-
ванного и развернутого отчета.
Введение в Microsoft Reporting Services
Прежде чем вы начнете изучать компоненты Reporting Services, вы должны
научиться понимать структуру отчетов. Каждый отчет имеет следующие два
набора инструкций, которые вместе определяют содержание отчета:
♦ определение данных задает источники данных и набор данных. Набором
данных является информация, найденная в источниках данных. Содержи-
мое набора данных определяется при использовании Query Designer — ин-
струмента, который создает запрос, используемый в вашем отчете для вы-
борки данных;
♦ схема размещения отчета позволяет представить найденные данные
пользователю. Вы можете задать, какие значения столбцов каким полям
соответствуют, форму и расположение заголовков, номеров страниц.
Когда будет собрана информация, связанная с определением данных и схе-
мой размещения отчета, Reporting Services сохраняет ее, используя язык оп-
ределения отчетов Report Definition Language (RDL). RDL является языком,
основанным на XML, который используется исключительно для хранения
определений отчета. RDL является языком открытой схемы, это означает, что
642
Часть IV. SQL Server и Business Intelligence
разработчик может расширять язык дополнительными атрибутами и элемен-
тами.
Reporting Services включает три основных компонента, которые представля-
ют уровень приложения, уровень сервера и уровень метаданных соответст-
венно:
♦ Report Manager;
♦ Report Server;
♦ 'Report Catalog.
Report Manager
Report Manager является инструментом доступа и управления отчетом, кото-
рый выполняется с использованием Internet Explorer. Вы можете применять
этот инструмент для создания и поддержки иерархии элементов в одном эк-
земпляре сервера отчета. Как администратор сервера отчета, используйте
Report Manager для конфигурирования свойств и значений по умолчанию для
сайта и для создания разделяемых расписаний и разделяемых источников
данных, которые делает расписания и соединения с источником данных более
управляемым. Вы также можете использовать Report Manager для конфигу-
рирования безопасности, основанной на ролях.
Report Server
Report Server является основным компонентом в Reporting Services. Он реали-
зован как Web-сервис, а также как и сервис Windows. Web-сервис содержит
набор интерфейсов, которые может использовать клиентское приложение для
доступа к отчетам через Web-сервер. Сервис Windows предоставляет сервисы
составления расписаний и поставки. Оба сервиса работают вместе и состав-
ляют один экземпляр сервера отчетов.
Как вы можете видеть на рис. 25.1, Report Server включает несколько компо-
нентов:
♦ процессор отчетов;
♦ провайдер данных;
♦ визуализатор (выполняющий построение изображений);
♦ обработчик запросов.
Процессор отчетов управляет выполнением отчета. Он отыскивает определе-
ние отчета, которое представлено в RDL, и определяет, что необходимо для
этого отчета. Процессор отчетов также управляет работой других компонен-
тов, которые используются для создания отчета.
Гпава 25. Microsoft Reporting Services
643
Процессор отчетов также отыскивает данные, которые используются для за-
грузки набора данных. После этого он выбирает провайдер данных, который
знает, как получить информацию из источника данных. Задачей провайдера
данных является соединение с источником данных, получение информации
для отчета и передача ее процессору.
Когда провайдер поставляет данные для отчета, процессор отчетов может
начать процесс создания отчета. Для генерации размещения данных в отчете
процессор должен знать формат отчета (HTML или PDF, например). Визуа-
лизатор используется для создания соответствующего формата.
Обработчик запросов получает запросы на отчеты и отправляет их процессо-
ру отчетов. Он также передает готовый отчет. Различные формы передачи
отчетов будут рассмотрены позже в этой главе.
Report Catalog
Report Catalog содержит две базы данных, которые используются для хране-
ния определений всех существующих отчетов, которые принадлежат кон-
кретному Report Server. Хранимая информация включает имя отчета, описа-
ния, информацию соединения с источником данных, информацию о полно-
мочиях, параметры и свойства выполнения. Report Catalog также хранит
установки безопасности и информацию, связанную с составлением расписа-
ния и передачей данных.
Reporting Services использует две базы данных: базу данных Report Server и
временную базу данных Report Server для отделения постоянно хранимых
данных от требований временного сохранения. Базы данных создаются вме-
сте, они связаны по имени. По умолчанию именами баз данных являются
reportserver и reportservertempdb. Первая используется для хранения Report
Catalog, а вторая — для временного хранения. Временная база данных Report
644
Часть IV. SQL Server и Business Intelligence
Server служит для хранения данных сессии, кэшированных отчетов и рабочих
таблиц, которые были сгенерированы для отчета.
Теперь, когда вы знакомы с компонентами Reporting Services, вы изучите, как
создавать, использовать и поставлять отчеты.
Создание отчетов
Вы используете Business Intelligence Development Studio для создания отчета.
Инструмент BI Development Studio, кратко рассмотренный в главе 23, являет-
ся интегрированной средой разработки, созданной на Visual Studio и спроек-
тированной для разработки систем бизнес-аналитики. Для запуска В1
Development Studio щелкните по кнопке Start, выберите All Programs |
Microsoft SQL Server 2008 | SQL Server Business Intelligence Development
Studio.
Первым шагом в построении отчета является создание нового проекта, кото-
рому будет принадлежать отчет. Для создания проекта в меню File выберите
команды New | Project. В диалоговом окне New Project в панели Project
types выберите папку Business Intelligence Projects. Наберите имя проекта и
его размещение в текстовых полях Name и Location соответственно. Проект
в этом примере называется Report 1 (рис. 25.2).
Рис. 25.2. Диалоговое окно New Project
Глава 25. Microsoft Reporting Services 645
В панели Templates диалогового окна New Project вы увидите три шаблона
проектов, связанных с отчетами. Шаблон Report Server Project создает пустой
отчет и оставляет вас в одиночестве, давая возможность сделать оставшуюся
часть работы. Мастер Report Server Project Wizard проведет вас через фазы
создания нового отчета. Шаблон Report Model Project создает модель данных
для использования в Report Builder.
Замечание____________________________________________________
Обычно отчеты Reporting Services создаются либо с помощью Report Builder,
либо посредством Report Designer. Report Builder позволяет создавать специ-
альные отчеты, без знания чего бы-то ни было относительно структуры базы
данных и создания запросов с использованием языков запросов, таких как SQL.
Компонент Report Designer позволяет вам создавать отчет из рабочей области.
Он предоставляет гораздо больше возможностей для создания отчетов, чем
Report Builder.
В этом разделе вы будете использовать шаблон мастера Report Server Project
Wizard, чтобы увидеть, как нужно создавать отчет. Поэтому выберите пикто-
грамму Report Server Project Wizard и щелкните по кнопке ОК.
Создание отчетов при помощи мастера
Report Server Project Wizard
Страница приветствия мастера Report Server Project Wizard содержит шаги,
которые проведут вас через создание отчета:
1. Выберите источник данных.
2. Спроектируйте запрос.
3. Выберите тип отчета.
4. Спроектируйте данные в таблице.
5. Задайте схему размещения данных в отчете.
6. Задайте стиль отчета.
Следующие разделы описывают эти шаги, а также разъясняют, как можно
выполнить предварительный просмотр созданного отчета.
Выбор источника данных
Источник данных содержит информацию о соединении с исходной базой
данных. Наберите имя нового источника данных на странице Select the Data
Source. (В этом примере назовите источник данных Sourcel).
Замечание____________________________________________________
Reporting Services может создавать отчеты из различных реляционных баз дан-
ных (SQL Server и Oracle) или из многомерных баз данных (Analysis Services).
646
Часть IV. SQL Server и Business Intelligence
Источники данных OLE DB, ODBC и XML могут быть также использованы. Рас-
крывающийся список Туре на странице Select Data Source позволяет выбрать
один из различных типов источников данных.
Щелкните мышью по кнопке Edit. Появится диалоговое окно Connection
Properties (рис. 25.3). Наберите localhost или имя вашего сервера базы дан-
ных в качестве имени сервера. В том же самом диалоговом окне отметьте ли-
бо переключатель Use Windows Authentication, либо переключатель Use
SQL Server Authentication. Установите переключатель Select or enter a
database name и из раскрывающегося списка выберите одну из баз данных
в качестве источника данных. Прежде чем щелкнуть по кнопке ОК, щелкните
мышью по кнопке Test Connection для проверки соединения с базой данных.
На странице Select the Data Source щелкните по кнопке Next.
Рис. 25.3. Диалоговое окно Connection Properties
Проектирование запроса
Следующим шагом является проектирование запроса, который должен быть
выполнен к выбранному источнику данных. На странице Design the Query
вы можете набрать существующий запрос или использовать компонент Query
Builder для создания запроса.
Гпава 25. Microsoft Reporting Services 647
Замечание _________________________________________________________
Query Builder соответствует аналогичному компоненту Access, который вы мо-
жете использовать для проектирования запросов при отсутствии знаний языка
SQL. Этот компонент обычно известен как QBE (query by example).
Для этого первого отчета используйте запрос, представленный в примере 25.1.
Пример 25.1
SELECT dept_name, emp_lname, emp_fname, job, enter_date
FRCM department d JOIN employee e ON d.dept_no = e.dept_no
JOIN works_on w ON w.emp_no = e.emp_no
WHERE YEAR(enter_date) = 2007
ORDER BY dept_name
Этот запрос выбирает данные по служащим, которые приступили к работе
в 2007 году. Результирующий набор этого запроса затем сортируется по име-
нам отделов. После этого щелкните мышью по кнопке Next.
Рис. 25.4. Страница Design the Query с сообщением об ошибке
648
Часть IV. SQL Server и Business Intelligence
Замечание_____________________________________________________
Reporting Services проверяет имена таблиц и столбцов, записанных в запросе.
Если система находит какую-нибудь синтаксическую или семантическую ошиб-
ку, она выдает соответствующее сообщение в нижней части окна (рис. 25.4).
Выбор типа отчета
Следующим шагом в создании отчета является выбор типа отчета. У вас есть
выбор между двумя типами отчета:
♦ табличный создает отчет в табличной форме. Столбцы этой таблицы соот-
ветствуют столбцам списка в операторе select, а количество строк в таб-
лице зависит от результирующего набора оператора запроса;
♦ матричный создает отчет в форме матрицы, которая похожа на табличную
форму, но предоставляет функциональность для перекрестных табличных
данных. В отличие от табличного типа отчета, который имеет статичный
набор столбцов, матричный тип отчета может быть динамическим.
Замечание
Вы должны использовать матричный тип отчета, когда собираетесь использо-
вать запрос, который содержит агрегатные функции, такие как avg или sum.
Запрос в примере 25.1 не содержит никаких агрегатных функций. Поэтому
выберите табличный тип отчета.
Проектирование данных в таблице
После того как вы щелкните мышью по кнопке Next, появится страница
Design the Table. Эта страница позволяет вам принять решения, где выбран-
ные столбцы будут размещаться в вашем отчете. Страница Design the Table
содержит две группы полей:
♦ Available fields (Доступные поля);
♦ Displayed fields (Отображаемые поля).
Страница Design the Table также имеет три представления:
♦ Page (Страница);
♦ Group (Группа);
♦ Details (Детализация).
Доступными полями являются столбцы из списка выбора оператора select
вашего запроса. Каждый столбец может быть перенесен в одно из представ-
лений. Для перемещения поля в представление Page, Group или Details вы-
берите поле, а затем щелкните мышью по кнопке Page, Group или Details
Гпава 25. Microsoft Reporting Services 649
соответственно. Отображаемое поле является доступным полем, которое
назначено одному из существующих представлений.
Представление Page отображает все столбцы, которые появляются на уровне
страницы, а представление Group отображает столбцы, которые используют-
ся для группирования результирующего набора запроса. Представление
Details служит для отображения столбцов, которые появляются в детальном
разделе таблицы. На рис. 25.5 показана страница Design the Table с проекти-
рованием табличного представления результирующего набора. В этом при-
мере столбец dept name будет появляться на уровне страницы, а столбец job
будет использоваться для группирования выбранных строк. После того как
вы выберите порядок группирования данных в таблице, щелкните мышью по
кнопке Next.
Рис. 25.5. Страница Design the Table
Замечание________________________________________________________
Порядок столбцов может быть важным, особенно для представления Group.
Для изменения порядка столбцов выберите столбец и щелкните мышью по
кнопкам-стрелкам вверх или вниз справа от имени столбца.
650
Часть IV. SQL Server и Business Intelligence
Задание схемы размещения данных в отчете
Следующим шагом является задание схемы вашего отчета. Страница Choose
the Table Layout имеет несколько опций:
♦ Stepped;
♦ Block;
♦ Include subtotals;
♦ Enable drilldown.
Если вы выбираете Stepped, то отчет будет содержать один столбец для каж-
дого поля с группировкой полей, появляющихся в заголовках слева от столб-
цов с детальными полями. В этом случае не будет создаваться нижний колон-
титул группы. Если в этом типе размещения вы добавляете подуровни, то
подуровень будет помещаться в строках заголовка группы.
Опция Block создает отчет, который содержит один столбец для каждого по-
ля с группой полей, появляющейся в первой детальной строке каждой груп-
пы. Этот тип размещения имеет нижние колонтитулы групп, только если ак-
тивирована опция Include subtotals.
Опция Enable drilldown скрывает внутренние группы отчета и делает види-
мым переключатель. Вы можете выбрать Enable drilldown, только если вы
выбрали опцию Stepped.
Для продолжения выберите Stepped и Include subtotals и щелкните по кноп-
ке Next.
Выбор стиля отчета
Следующим шагом является выбор стиля вашего отчета. Страница Choose
the Table Style позволяет выбрать шаблон для применения стилей, таких как
шрифт, цвет и стиль рамки отчета. Существует несколько различных шабло-
нов стилей, такие как Forest, Corporate и Bold. Выберите Bold и щелкните
мышью по кнопке Next.
После выбора стиля отчета существует еще один промежуточный шаг, если
вы создаете отчет первый раз. На этом шаге, называемом выбором размеще-
ния использования, вы должны выбрать URL виртуального каталога сервера
отчетов в качестве папки использования для ваших отчетов. Для сервера
отчетов, выполняющегося на собственном узле, используйте путь к сер-
веру отчетов, куда будет помещаться проект, например, http://servername
/ReportServer. Для сервера отчетов, выполняющегося в интегрированном
режиме Sharepoint, используйте URL сайта Sharepoint, на котором располага-
ется проект, например, http://servername.
Гпава 25. Microsoft Reporting Services 651
Замечание______________________________________________________
SQL Server 2008 Reporting Services поддерживает два режима использования
экземпляров сервера отчетов: собственный режим и интегрированный режим
Sharepoint. В собственном режиме, который является режимом по умолчанию,
сервер отчетов является автономной серверной системой, которая предостав-
ляет все представления, управление, обработку и предоставление отчетов.
В интегрированном режиме Sharepoint сервер отчетов становится частью раз-
мещения приложения SharePoint Web. Пользователи SharePoint Server могут
сохранять отчеты в библиотеках SharePoint и иметь к ним доступ через те же
самые сайты SharePoint, которые они используют для доступа к другим дело-
вым документам.
В заключение вы завершаете работу мастера, задавая имя отчета. Вы также
можете посмотреть на итоговые данные отчета, где задокументированы все
предыдущие шаги, выполненные в процессе создания отчета. Щелкните по
кнопке Finish для завершения работы мастера.
Предварительный просмотр результирующего набора
После того как вы завершите создание вашего отчета с использованием мас-
тера, появятся три табличные вкладки в панели Report Designer, которые вы
можете использовать для просмотра созданного отчета в различных формах.
Если панель Report Designer не видна, в меню View выберите команду
Designer. Табличные вкладки соответствуют следующим представлениям:
♦ Layout;
♦ Data;
♦ Preview.
Таблица Layout позволяет просматривать и изменять схему размещения ва-
шего отчета. Представление Layout состоит из следующих разделов: тело,
страница, заголовок и верхний колонтитул страницы. Вы можете использо-
вать окна Toolbox и Properties для управления элементами в отчете. Чтобы
просмотреть эти окна, выберите в меню View команду Toolbox или
Properties Window. Используйте окна Toolbox для выбора элементов, чтобы
разместить их в одном из разделов. Каждый элемент на поверхности спроек-
тированного отчета содержит свойства, которыми можно управлять с по-
мощью окна Properties.
Для просмотра запроса щелкните по вкладке Data. Вы можете использовать
это представление для отображения запроса в двух различных формах: при
использовании общего дизайнера запросов или при использовании графиче-
ского дизайнера запросов. Общий дизайнер запросов состоит из двух панелей
инструментов и двух обычных панелей: панель Query показывает запрос, ко-
торый вы применили для создания отчета, а панель Result показывает резуль-
тирующий набор этого запроса. Графический дизайнер запросов состоит из
22 Зак. 1141
652
Часть IV. SQL Server и Business Intelligence
панели инструментов и четырех обычных панелей: панель Diagram показы-
вает все таблицы, которые используются в запросе с соответствующими ог-
раничениями целостности; панель Grid содержит компонент QBE для ото-
бражения запроса в табличной форме; панель SQL отображает оператор
select, а панель Result показывает результирующий набор оператора.
Для предварительного просмотра отчета щелкните мышью по вкладке
Preview. Отчет будет запущен автоматически с использованием уже задан-
ных свойств. На рис. 25.6 показан предварительный просмотр отчета, кото-
рый был определен предыдущими шагами.
Рис. 25.6. Предварительный просмотр отчета
Создание параметризованных отчетов
Параметризованный отчет — это отчет, который использует входные пара-
метры для осуществления обработки отчета. Параметры затем используются
для выполнения запроса, который предоставляет данные для отчета. Если вы
проектируете или используете параметризованный отчет, вам нужно пони-
мать, как выбранный параметр влияет на отчет.
Гпава 25. Microsoft Reporting Services 653
Параметры в Report Services обычно служат для фильтрации данных. Они
задаются с помощью известного синтаксиса для переменных (@уеаг, напри-
мер). Если параметр задан в запросе, то его значение должно быть предостав-
лено для завершения оператора select или хранимой процедуры, которая
отыскивает данные для отчета.
Для параметра вы можете определить значение по умолчанию. Если все па-
раметры имеют значения по умолчанию, то отчет немедленно отображает
данные при выполнении отчета. Если хотя бы один из параметров не имеет
значения по умолчанию, отчет будет отображаться только после того, как
пользователь введет все значения параметров.
Когда отчет запускается в браузере, параметр отображается в окне в верхней
части отчета. Когда отчет запускается в режиме предварительного просмотра
(Preview), значение параметра отображается в соответствующем окне.
Рассмотрим пример, в котором показано, как создавать параметризованный
отчет. Этот пример описывает только те шаги, которые отличаются от только
что рассмотренных шагов в примере 25.1. Запрос, используемый в этом при-
мере, показанный в примере 25.2, выбирает данные из базы данных
AdventureWorksdw. По этой причине вы должны выбрать и определить новый
источник данных. Спецификация нового источника идентична спецификации
источника с именем Sourcel, за исключением того, что вы выбираете базу
данных AdventureWorksDW вместо базы данных sample.
1 Пример 25.2
USE AdventureWorksDW;
SELECT t.MonthNumberOfYear AS month,
t.CalendarYear AS year,
p.ProductKey AS product_id,
SUM(f.UnitPrice) AS sum_of_sales,
COUNT(f.UnitPrice) AS total_sales
FROM DimTime t, DimProduct p, FactlnternetSales f
WHERE t.TimeKey = f.OrderDateKey AND
p.ProductKey = f.ProductKey
AND CalendarYear = @year
GROUP BY t.CalendarYear, t.MonthNumberOfYear, p.ProductKey
ORDER BY 1;
Запрос в примере 25.2 вычисляет количество единиц продукции и сумму цен.
Он также группирует строки в соответствии со списком имен столбцов в
предложении group by.
654
Часть IV. SQL Server и Business Intelligence
Выражение
CalendarYear = @year
в предложении where этого примера указывает, что входной параметр @уеаг
в этом запросе относится к календарному году, для которого вы хотите вы-
брать данные.
Этот отчет является отчетом типа матрицы. Значения столбца year будут на-
значены представлению Раде, значения столбца month— представлению
Columns, а значения столбца product_id— представлению Rows. Представле-
ние Detail отображает агрегатные значения sum и count.
Для запуска отчета в режиме Preview наберите значение параметра
CalendarYear (2003, например) и щелкните мышью по ViewReport.
Обработка и управление отчетами
Обработка отчета начинается с публикации определения отчета, которая
включает запрос, информацию о схеме размещения и код. Отчет вместе с об-
работкой данных создает набор данных с информацией о размещении, кото-
рая сохраняется в промежуточном формате. После того как обработка завер-
шается, отчеты компилируются в виде сборок CLR и выполняются в сервере
отчетов.
Промежуточный формат отчета используется сервером отчетов для следую-
щих форм отчета:
♦ кэширование отчета;
♦ мгновенный снимок отчета.
Кэширование означает, что отчет генерируется только для первого пользова-
теля, который его открывает, а после этого он отыскивается в кэше данных
для всех последующих пользователей, которые работают с тем же самым от-
четом. Как вы, вероятно, догадались, кэширование сокращает время на поиск
часто используемых отчетов.
Мгновенный снимок отчета содержит данные в указанный момент времени.
Главным отличием между мгновенным снимком отчета и другими отчетами
является то, что другие отчеты обычно содержат информацию запроса, тогда
как мгновенный снимок отчета содержит результирующий набор выполнен-
ного запроса.
Замечание___________________________________________________
Мгновенный снимок отчета обычно используется, если отчет базируется на
долго выполняющемся запросе.
Гпава 25. Microsoft Reporting Services
Обычно для управления отчетами вы используете Report Manager. Report
Manager является инструментом доступа к отчету и управления отчетом, ос-
нованным на технологии Web, который запускает Microsoft Internet Explorer
или другой браузер. Следующие функции управления, помимо других, могут
быть выполнены при помощи Report Manager:
♦ просмотр или изменение определений отчета;
♦ управление соединениями с источниками данных;
♦ просмотр и конфигурирование истории отчета.
Описание всех функций управления, предоставляемых Report Manager, мож-
но найти в документации Books Online.
Организация доступа
и распространение отчетов
Прежде чем вы сможете использовать и распространять отчет, вы должны его
развернуть. Это может быть выполнено при помощи щелчка правой кнопкой
мыши по созданному отчету и выбора пункта Deploy. Процесс развертывания
содержит несколько шагов, которые показаны в панели Output:
----- Build started: Project: Rl, Configuration: Debug --
Build complete — 0 errors, 0 warnings
----- Deploy started: Project: Rl, Configuration: Debug -
Deploying to http://localhost/ReportServer
Deploying data source '/Rl/sample'.
Deploying report '/Rl/Reportl'.
Deploy complete — 0 errors, 0 warnings
========== Build: 1 succeeded or up-to-date, 0 failed, 0 skipped
= —===== Deploy: 1 succeeded, 0 failed, 0 skipped =====
Организацию доступа и распространение отчетов можно выполнять, исполь-
зуя два метода:
♦ по запросу;
♦ на основании подписки.
Отчеты по запросам
Доступ по запросу дает возможность пользователям выбирать отчеты при
помощи инструмента просмотра отчетов. Для просмотра отчета вы можете
использовать Report Manager или браузер. В этом разделе объясняется, как вы
можете просматривать отчеты по запросам, используя браузер.
656
Часть IV. SQL Server и Business Intelligence
Reporting Services является Web-приложением. По этой причине все отчеты
организованы в иерархическом пространстве имен, и к ним осуществляется
доступ через виртуальные каталоги Report Server. Следовательно, в браузере
перейдите к домашней странице SQL Server Reporting Services (http://
localhost/reportserver), которая является виртуальным каталогом по умолча-
нию для Report Server. Виртуальным каталогом по умолчанию для Report
Manager является http://localhost/reports/. (Оба значения по умолчанию мож-
но изменить.)
Для просмотра отчета по запросу выберите отчет из соответствующей иерар-
хии папок. В этом случае Report Server создает временный мгновенный сни-
мок с целью передачи отчета. После передачи мгновенный снимок удаляется.
Существует несколько возможностей для выполнения отчетов по запросу.
В первом случае указывается, что отчет запрашивает соответствующий ис-
точник данных каждый раз, когда пользователь выполняет отчет. Здесь но-
вый экземпляр отчета генерируется каждый раз, когда новый пользователь
выполняет отчет.
Если вы хотите повысить производительность, вашим выбором должно быть
кэширование отчетов. Как уже было сказано, система создает кэшированную
копию отчета для первого пользователя, кто его открывает. Все другие поль-
зователи, которые работают с тем же самым отчетом, выбирают его из кэша.
Подписка на отчет
Использование отчетов по запросу требует выбора отчета каждый раз, когда
вы хотите просмотреть результат отчета. С другой стороны, доступ, основан-
ный на подписке, автоматически генерирует и предоставляет отчеты адре-
сату.
Reporting Services поддерживает два вида подписки:
♦ персональные (стандартные) подписки;
♦ подписки, управляемые данными.
Персональные подписки
Персональная подписка обычно состоит из указанных параметров для пара-
метризованных отчетов, а также опций представления и опций развертыва-
ния. Вы можете использовать различные инструменты для создания персо-
нальных подписок. Вот как в качестве примера вы можете использовать SQL
Server Management Studio для создания файла разделяемой подписки:
1. В Object Explorer раскройте тот отчет, на который вы хотите подписать-
ся. Чтобы это сделать, вы должны вначале соединиться с Reporting
Services. Щелкните мышью по кнопке Connect и выберите Reporting
Глава 25. Microsoft Reporting Services 657
Services. Раскройте соответствующий экземпляр, раскройте папку, где
хранится отчет, и раскройте сам отчет.
2. Щелкните правой кнопкой мыши по папке Subscription и выберите пункт
New Subscription.
3. Выберите Report Server File Share из списка Notify by.
4. В текстовом поле File name наберите имя отчета.
5. В текстовом поле Path наберите путь к папке, которая содержит отчет.
6. Выберите формат и режим из списков Render format и Write mode соот-
ветственно.
7. Наберите имя пользователя (Username) и пароль (Password) в соответст-
вующих текстовых полях.
Замечание____________________________________________________
Создание подписки электронной почты в SQL Server Management Studio выпол-
няется аналогичным образом, за исключением следующих шагов: в списке
Notify by выберите Report Server E-Mail, а в текстовом поле То наберите ад-
рес электронной почты.
Подписки, управляемые данными
Подписки, управляемые данными, поставляют отчеты списку получателей,
определяемых в процессе выполнения. Этот тип подписки отличается от пер-
сональной подписки тем способом, которым подписчик получает подписан-
ную информацию: некоторые установки источника данных задаются во вре-
мя выполнения, а другие установки передаются от определения подписки.
Статические аспекты управляемой данными подписки включают поставляе-
мый отчет, поставляемые расширения, информацию соединения с внешним
источником данных, который содержит подписанные данные и запрос. Дина-
мические установки подписки получаются от множества строк, полученных в
запросе, включая список подписчиков и расширений, связанных с пользова-
телями-получателями или значениями параметров.
Резюме
Reporting Services является инструментом отчетов предприятия, основанным
на SQL Server. Для создания отчета вы можете использовать мастера Report
Server Project Wizard, Report Builder или Report Designer. Определение отчета,
которое содержит соответствующий запрос, информация размещения эле-
ментов отчета и код сохраняются с использованием, в основанном, на XML-
языке Report Definition Language (RDL). Reporting Services обрабатывает
определение отчета в одном из стандартных форматов, таких как HTML
или PDF.
658 Часть IV. SQL Server и Business Intelligence
К отчетам можно обращаться по запросу или по подписке. Когда вы выпол-
няете отчет по запросу, новый экземпляр отчета будет сгенерирован каждый
раз, когда вы выполняете отчет. Отчеты, основанные на подписке, могут быть
либо стандартными, либо управляемыми данными. Отчеты, основанные на
персональной подписке, обычно содержат заданные параметры, так же как и
опции представления отчета и опции поставки. Подписки, управляемые дан-
ными, поставляют отчеты списку получателей, определяемых во время
выполнения.
В следующей главе описываются техники оптимизации для бизнес-анали-
тики.
Упражнения
| Упражнение 25.1
Получить номера служащих и их имена для всех клерков (Clerk). Создать от-
чет типа матрицы с использованием этого запроса. Для просмотра отчета ис-
пользовать Report Manager.
Упражнение 25.2
Используйте базу данных sample и получите бюджеты проектов и имена про-
ектов, выполняющихся для служащих отдела Research, с номерами служа-
щих, меньшими 25 000. Создайте отчет в виде табличного отчета с помощью
этого запроса. Для просмотра отчета используйте браузер.
ГЛАВА 26
Техники оптимизации
для бизнес-аналитики
В этой главе описываются две техники оптимизации, связанные с ROLAP.
Иными словами, эти техники могут быть применены только по отношению к
хранению многомерных данных. В начале этой главы обсуждается, когда
имеет смысл хранить все экземпляры сущности в одной таблице, а когда
лучшим решением с точки зрения производительности — в разделенных таб-
лицах данных. После общего введения даются способы, которые можно
использовать для разделения данных. Помимо общих правил разделения
данных в этой главе описываются улучшения в SQL Server 2008, связанные
с этими техниками.
Затем подробно объясняется техника оптимизации запросов, называемая
схемой "звезда". Будут представлены преимущества этой техники, а также
использование фильтров битовых образов.
Распределение данных по разделам
Самым простым и наиболее естественным способом проектирования сущно-
сти является использование одной таблицы. При этом если все экземпляры
сущности хранятся в одной таблице, от вас не требуется принятия решения,
где физически хранить ее строки, потому что система базы данных сделает
это для вас. По этой причине вам не нужно выполнять никаких задач админи-
стрирования, связанных с хранением данных таблицы, если вы этого не хо-
тите.
С другой стороны, одним из наиболее частых случаев плохой производитель-
ности реляционных систем баз данных является размещение данных на од-
ном устройстве ввода/вывода. Это в особенности верно, если вы имеете одну
или более очень больших таблиц с несколькими сотнями тысяч или миллио-
660
Часть IV. SQL Server и Business Intelligence
нов строк. В этом случае в системах с множеством центральных процессоров
разделение таблиц может привести к лучшей производительности за счет
распараллеливания операций.
Используя средства разделения данных, вы можете разделять очень большие
таблицы (а также индексы) на более мелкие части, которыми проще управ-
лять. Если сделано разделение, то многие операторы могут быть выполнены
параллельно, например, загрузка данных, создание резервной копии и вос-
становление-данных, обработка запросов.
Разделение данных также увеличивает доступность всех данных таблицы.
Размещая каждую часть на отдельном диске, вы все равно можете иметь дос-
туп к отдельным данным, даже если один или более дисков недоступны.
В этом случае все данные из доступных разделов могут быть использованы
для операций чтения и записи. То же самое верно и для поддержки операций.
Если таблица является разделенной, оптимизатор запросов может распознать
ситуацию, когда условия поиска в запросе ссылаются только на строки из
некоторых разделов, и по этой причине можно ограничиться их поиском
только в этих разделах. Таким образом, вы можете достичь значительного
повышения производительности.
Способы распределения ваших данных
по разделам
Таблица может быть разделена с использованием любого столбца таблицы.
Такой столбец называется разделяющим ключом. (Также возможно использо-
вание группы столбцов для отдельного разделяющего ключа.) Значения раз-
деляющего ключа служат для разделения строк таблицы по различным фай-
ловым группам.
Помимо разделяющего ключа существуют два других важных понятия, свя-
занные с разделением: схема разделения и функция разделения. Схема разде-
ления распределяет строки таблицы в одну или несколько файловых групп.
Способ, каким выполняется такое распределение, описывается посредством
функции разделения. Другими словами, функция разделения определяет ал-
горитм, который используется для указания строкам их физическое разме-
щение.
Database Engine поддерживает только одну форму разделения, которая явля-
ется упорядоченным разделением. Упорядоченное разделение разделяет стро-
ки таблицы в различные разделы, основываясь на значении разделяющего
ключа. Следовательно, при применении упорядоченного разделения вы все-
гда должны знать, в каком разделе будет сохраняться конкретная строка.
Глава 26. Техники оптимизации для бизнес-аналитики 661
Замечание______________________________________________________
Помимо упорядоченного разделения существует несколько других форм разде-
ления. Одна из них называется хешированным разделением. В отличие от
упорядоченного разделения хешированное разделение размещает строки в
разделах одна после другой, применяя функцию хеширования к разделяющему
ключу. Эта форма разделения не поддерживается в Database Engine.
Прежде чем определять упорядоченное разделение, мы рассмотрим шаги для
создания разделенных таблиц.
Шаги для создания разделенных таблиц
Прежде чем вы начнете разделять таблицы базы данных, вы должны завер-
шить следующие шаги:
1. Задать цели разделения.
2. Определить разделяющий ключ и количество разделов.
3. Создать файловую группу для каждого раздела.
4. Создать функцию разделения и схему разделения.
5. Создать индексы разделения (если необходимо).
Цели задания разделений
Цели разделений зависят от типа приложений, которые обращаются к табли-
цам, подлежащим разделению. Существует множество различных целей и
каждая из них может быть единственной причиной для разделения таблицы:
♦ увеличение производительности для индивидуальных запросов;
♦ уменьшение конкуренции;
♦ улучшение доступности данных.
Если первичной целью разделения таблицы является увеличение производи-
тельности для индивидуальных запросов, распределите все строки таблицы
равномерно. Причина этого в том, что система базы данных не будет ожидать
больше времени при поиске данных из раздела, имеющего больше строк, чем
другие разделы. Также, если запросы осуществляют доступ к данным путем
сканирования таблицы с большим объемом данных, следует только разделить
строки таблицы. (В данном случае разделение соответствующего индекса
лишь увеличит накладные расходы.)
Разделение данных может уменьшить конкуренцию, когда много одновре-
менных запросов выполняют сканирование индекса для выбора всего лишь
небольшого количества строк таблицы. В этом случае разделите таблицу и
индекс по схеме разделения, которая позволит каждому запросу исключить
ненужные разделы из их сканирования. Для достижения этой цели начните
662
Часть IV. SQL Server и Business Intelligence
с исследования, какие запросы обращаются к частям таблицы. Затем раздели-
те строки таблицы таким образом, чтобы разные запросы обращались к раз-
личным разделам.
Разделение улучшает доступность базы данных. Размещая каждый раздел в
своей файловой группе и помещая файловую группу на свой диск, вы можете
улучшить доступность данных, потому что если один диск дает сбой и стано-
вится недоступным, то недоступными будут данные только в этом разделе.
Пока системный администратор обслуживает сбойный диск, другие пользо-
ватели могут осуществлять доступ к данным других разделов таблицы.
Определение разделяющего ключа
и количества разделов
Таблица может быть разделена с помощью любого столбца таблицы. Значе-
ния разделяющего ключа используются для размещения строк таблицы по
различным файловым группам. Для лучшей производительности каждый
раздел должен сохраняться в отдельной файловой группе, а каждая файловая
группа должна сохраняться на отдельном дисковом устройстве. Размещая
данные на нескольких дисковых устройствах, вы можете сбалансировать
операции ввода/вывода и улучшить производительность, готовность и под-
держку запросов.
Вы должны разделять данные таблицы, используя столбец, значения которо-
го меняются нечасто. Если разделение выполняется по столбцу, который час-
то изменяется, то любые операции изменения этого столбца могут привести
к тому, что система будет перемещать изменяемые строки из одного раздела
в другой, что может потребовать затрат времени.
Создание файловой группы для каждого раздела
Для достижения лучшей производительности, наивысшей доступности дан-
ных и более простой поддержки следует использовать различные файловые
группы для разделения данных таблицы. Количество файловых групп глав-
ным образом зависит от используемого вами оборудования. Если у вас не-
сколько центральных процессоров, разделите ваши данные таким образом,
чтобы каждый CPU мог обращаться к данным на одном дисковом устройстве.
Если Database Engine может обрабатывать несколько разделов параллельно,
то время работы вашего приложения будет значительно сокращено.
Каждый раздел данных должен размещаться в файловой группе. Для созда-
ния файловой группы используйте оператор create database или alter
database. В примере 26.1 показано создание базы данных test_partitioned
с одной первичной файловой группой и двумя другими файловыми группами.
Гпава 26. Техники оптимизации для бизнес-аналитики
663
Замечание______________________________________________________
Прежде чем вы создадите базу данных test partitioned, вы должны изме-
нить физические адреса всех mdf- и ndf-файлов в примере 26.1 в соответствии
с той файловой системой, которая существует на вашем компьютере.
j Пример 26.1
USE master;
CREATE DATABASE test^partiLioned
ON PRIMARY
(NAME='MyDB_Primary',
FILENAME = 'd:\mssql\PT_Test_Partitioned_Range_df.mdf',
SIZE = 2000,
MAXSIZE = 5000,
FILEGROWTH = 1),
FILEGROUP MyDB_FGl
(NAME = 'FirstFileGroup',
FILENAME = 'd:\mssql\MyDB_FGl.ndf',
SIZE = 1000MB,
MAXSIZE = 2500,
FILEGROWTH = 1),
FILEGROUP MyDB_FG2
(NAME = 'SecondFileGroup',
FILENAME = 'f:\mssql\MyDB_FG2.ndf',
SIZE = 1000MB,
MAXSIZE = 2500,
FILEGROWTH = 1 );
В примере 26.1 мы создаем базу данных testpartitioned, которая содержит
первичную файловую группу MyDB_Primary и две другие файловые группы:
MyDB_FGl и MyDB_FG2. Файловая группа MyDB FGi сохраняется на диске D:, а
файловая группа MyDB_FG2 — на дисковом устройстве F:.
В случае, если вы хотите добавить файловую группу к существующей базе
данных, используйте оператор alter database. В примере 26.2 показано, как
создать еще одну файловую группу в базе данных test partitioned.
: Пример 26.2
USE master;
ALTER DATABASE test ^partitioned
ADD FILEGROUP MyDB_FG3
664
Часть IV. SQL Server и Business Intelligence
ALTER DATABASE test_partitioned
ADD FILE
(NAME = 'ThirdFileGroup',
FILENAME = 'G:\mssql\MyDB_FG3.ndf',
SIZE = 1000MB,
MAXSIZE = 2500,
FILEGROWTH = 1)
TO FILEGROUP MyDB_FG3;
В примере 26.2 мы используем оператор alter database для создания допол-
нительной файловой группы MyDB_FG3. Во втором операторе alter database
мы добавляем новый файл в созданную файловую группу. Обратите внима-
ние, что опция то filegroup задает имя файловой группы, в которую будет
добавлен новый файл.
Создание функции разделения и схемы разделения
Следующим шагом после создания файловых групп является создание функ-
ции разделения. Функция разделения создается оператором create partition
function. Существуют две формы этого оператора в зависимости от типа раз-
деления. Синтаксис create partition function, связанный с этими типами
разделения, следующий:
CREATE PARTITION FUNCTION function_name(param_type)
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ , ... n ] ] )
Здесь function_name задает имя функции разделения; param_type определяет
тип данных ключа разделения; boundary_value задает одно или более значе-
ний границ, для каждого раздела разделяемой таблицы или индекса, исполь-
зующего функцию разделения.
Оператор create partition function поддерживает две формы опции range:
RANGE LEFT И RANGE RIGHT. RANGE LEFT указывает, ЧТО уСЛОВИе ГраНИЦЫ ЯВЛЯСТ-
ся верхней границей в первом разделе, range right указывает, что условие
границы является нижней границей в последнем разделе. Если опция не ука-
зана, по умолчанию принимается range left.
Прежде чем определять функцию разделения, вы должны задать таблицу, ко-
торая будет использована для разделения. В примерах этой главы будет ис-
пользована таблица orders. В примере 26.3 создается эта таблица. Вначале
проверьте, не содержит ли ваша база данных sample таблицу orders. Если со-
держит, то удалите ее.
Глава 26. Техники оптимизации для бизнес-аналитики
665
; Пример 26.3
USE sample;
CREATE TABLE orders
(orderid INTEGER NOT NULL,
orderdate DATE,
shippeddate DATE,
freight money);
GO
declare @i int , @order_id integer
declare @orderdate datetime
declare @shipped_date datetime
declare Sfreight money
set @i = 1
set @orderdate = getdateO
set @shipped_date = getdateO
set @freight = 100.00
while @i < 1000001
begin
insert into orders (orderid, orderdate, shippeddate, freight)
vainest @i, @orderdate, @shipped_date, Ofreight)
set @i = @i + 1
end
Оператор create table в примере 26.3 создает таблицу orders, а последующие
операторы загружают миллион строк в эту таблицу.
В примере 26.4 показано определение функции разделения для таблицы
orders с 1 000 000 строк.
i Пример 26.4
USE test_partitioned;
CREATE PARTITION FUNCTION myRangePFl (int)
AS RANGE LEFT FOR VALUES (500000);
Оператор create partition function myRangePFl указывает, что будут два раз-
дела и что значением границы является 500 000. Это означает, что все значе-
ния разделяющего ключа, которые меньше, чем 500 000, будут размещены в
первом разделе, а все значения, большие, чем 500 000, будут сохраняться во
втором разделе. (Заметьте, что значение границы связано со значениями раз-
деляющего ключа, которым в нашем примере является столбец orderid таб-
лицы orders. Как вы увидите, мы задаем имя разделяющего ключа в соответ-
ствующем операторе create table.)
666
Часть IV. SQL Server и Business Intelligence
Созданная функция разделения является бесполезной, пока вы не свяжете ее
с соответствующими файловыми группами. Этот процесс называется схемой
разделения, вы используете оператор create partition scheme для установле-
ния связи между схемой разделения и соответствующими файловыми груп-
пами. В примере 26.5 показано создание схемы разделения для функции раз-
деления из примера 26.4.
| Пример 26.5
USE testjpartitioned;
CREATE PARTITION SCHEME myRangePSl
AS PARTITION myRangePFl
TO (MyDB_FGl, MyDB_FG2);
Здесь создается схема разделения с именем myRangePSl. В соответствии с этой
схемой все значения слева от значения границы (т. е. все значения, меньшие
500 000) будут сохраняться в файловой группе MyDB_FGl. Аналогично, все
значения справа от значения границы будут сохраняться в файловой группе
MyDB_FG2.
Замечание
Когда вы определяете схему разделения, вы должны быть уверены, что задали
файловую группу для каждого раздела, даже если несколько разделов будет
храниться в одной и той же файловой группе.
Создание разделяемой таблицы существенно отличается от создания нераз-
деляемой таблицы. Как вы можете догадаться, оператор create table должен
содержать имя схемы разделения и имя столбца таблицы, который будет ис-
пользоваться в качестве разделяющего ключа. В примере 26.6 показана
улучшенная форма оператора create table, которая используется для разде-
ления таблицы orders.
| Пример 26.6
USE test_partitioned;
CREATE TABLE orders
(orderid INTEGER NOT NULL,
orderdate DATETIME,
shippeddate DATETIME,
freight money)
ON myRangePSl (orderid);
Предложение on в конце оператора create table применяется для задания
уже определенной схемы разделения. Используя эту схему, создаваемая схе-
Гпава 26. Техники оптимизации для бизнес-аналитики 667
ма разделения связывает вместе столбец таблицы (orderid) и функцию разде-
ления, где задан тип данных (int) разделяющего ключа (см. пример 26.4).
Создание разделенного индекса
Когда вы разделяете данные таблицы, индексы, ассоциированные с этой таб-
лицей. также могут быть разделены. Вы можете разделять индексы таблицы с
использованием существующей схемы разделения для этой таблицы или дру-
гую схему. Когда и индексы, и таблица используют одну и ту же функцию
разделения и те же разделяющие столбцы (в том же порядке), то таблица и
индекс называются выровненными. Когда таблица и ее индексы являются вы-
ровненными, система базы данных может перемещать разделы между разде-
ленными таблицами более эффективно, поскольку разделение обоих объек-
тов базы данных выполнено при помощи одного и того же алгоритма. По
этой причине в большинстве практических случаев рекомендуется, чтобы вы
использовали выровненные индексы.
В примере 26.7 показано создание кластерного индекса для таблицы orders.
Индекс является выровненным, т. е. он разделяется с помощью схемы разде-
ления таблицы orders.
| Пример 26.7
USE test_partitioned;
CREATE UNIQUE CLUSTERED INDEX CI_orders
ON orders(orderid)
ON myRangePSl(orderid);
Как вы можете видеть из примера 26.7, создание разделенного индекса для
таблицы orders выполняется с использованием улучшенной формы операто-
ра create index. Эта форма оператора create index содержит дополнительное
предложение on, которое задает схему разделения. Если вы хбтите выровнять
индекс в этой таблице, задайте ту же самую схему разделения, что и для со-
ответствующей таблицы. (Первое предложение on является стандартной
частью синтаксиса оператора create index, второе задает столбец для разде-
ления.)
Совместное размещение таблиц
Помимо разделения таблиц вместе с соответствующими индексами, Database
Engine также поддерживает разделение двух таблиц с использованием одной
и той же функции разделения. Эта форма разделения означает, что строки
обеих таблиц, которые имеют одно и то же значение разделяющего ключа.
23 Зак. 1141
668
Часть IV. SQL Server и Business Intelligence
сохраняются вместе. Эта концепция разделения данных называется совмест-
ным размещением.
Предположим, что помимо таблицы orders существует также таблица
order details, которая содержит ноль, одну или более строк с заказами для
каждого уникального номера заказа в таблице orders. Если вы разбиваете обе
таблицы, используя одну и ту же функцию разбиения для соединения столб-
цов orders. orderid и order_details. orderid, ТО строки обеих таблиц С одина-
ковыми значениями столбцов orderid будут сохраняться на диске вместе.
Предположим, что существует уникальный заказ с идентификационным но-
мером 49 031 в таблице orders и пять соответствующих строк в таблице
order_detaiis. В случае совместного размещения все шесть строк будут со-
хранены на диске одна за другой. Та же самая процедура будет применена ко
всем строкам этих таблиц с одинаковым значением столбца orderid.
SQL Server 2008 и разделение данных
SQL Server 2008 имеет следующие улучшения, касающиеся разделения дан-
ных:
♦ преимущества производительности для многих параллельных планов за-
просов за счет порядка выполнения операций доступа;
♦ параллельное выполнение запросов к разделенным таблицам при исполь-
зовании многих потоков управления;
♦ улучшенное редактирование информации, относящейся к разделенным
данным.
В следующих разделах рассматриваются эти возможности.
Новые операции поиска к разделенным данным
В SQL Server 2008 было изменено внутреннее представление разделенных
таблиц, такая таблица представляется процессору запросов в виде составного
(содержащего несколько столбцов) индекса с разделяемым столбцом в каче-
стве лидирующего столбца. Этот столбец, называемый partitionedro, являет-
ся скрытым вычисляемым столбцом, используемым внутренне для представ-
ления идентификатора раздела, содержащего указанную строку.
Предположим, например, что существует таблица tab с тремя столбцами
coll, со12 и со13. (coll используется для разделения таблицы, а со12 является
кластерным индексом.) В SQL Server 2008 такая таблица внутренне трактует-
ся как неразделенная таблица со схемой
tab (partitionlD, coll, со12 со13)
Гпава 26. Техники оптимизации для бизнес-аналитики 669
и с кластерным индексом с составным ключом (partitioniD, со12). Это по-
зволяет оптимизатору запросов выполнять операции поиска, основанные на
вычисляемом столбце partitioniD, для любой разделенной таблицы или ин-
декса.
Таким способом выполнение значительного количества запросов к разделен-
ным таблицам может быть улучшено, поскольку устранение разделения было
выполнено ранее.
Параллельное выполнение запросов
В SQL Server 2005 один поток был выделен на раздел, когда запрос обращал-
ся к нескольким разделам. Иными словами, каждый запрос, который приме-
нялся к разделенным таблицам, не мог выполняться параллельно. (Определе-
ние параллельных запросов см. в главе 15.) Это может привести к проблемам
производительности в системах с несколькими центральными процессорами,
если схема таблицы содержит меньше разделов, чем существует центральных
процессоров. В этом случае не все CPU будут использованы для обработки
запроса.
SQL Server 2008 предоставляет две стратегии выполнения запросов для па-
раллельных планов запросов к разделенным объектам: стратегия одного по-
тока на раздел и стратегия нескольких потоков на раздел.
В стратегии одного потока на раздел оптимизатор запросов назначает один
поток на каждый раздел для выполнения параллельного плана запроса, кото-
рый обращается к нескольким разделам. (Это соответствует поведению SQL
Server 2005 и является значением по умолчанию для SQL Server 2008.) Один
раздел не разделяется между несколькими потоками, но несколько разделов
могут выполняться параллельно.
Стратегия нескольких потоков на раздел назначает несколько потоков на раз-
дел, независимо от количества разделов, к которым осуществляется доступ.
Иными словами, все доступные потоки запускаются к первому разделу; он
сканируется в первую очередь. Когда раздел достигает конца раздела, он
переключается на следующий раздел и начинает его сканирование. При пере-
ходе на другой раздел поток не ждет, когда другие потоки завершат свою ра-
боту.
Замечание________________________________________________________
Стратегия нескольких потоков на раздел будет доступной при использовании
флага трассировки 2440. Флаги трассировки используются для временного
задания специфических характеристик сервера или для отключения некоторого
поведения. Для установки флага трассировки используйте команду DBCC с оп-
цией traceon. Следующая команда делает доступной флаг трассировки 2440:
DBCC TRACEON (2440)
670
Часть IV. SQL Server и Business Intelligence
Решение о том, какую выбрать стратегию, зависит от вашего оборудования.
Первая стратегия рекомендуется, когда операции ввода/вывода в запросах
ограничены и в них включено больше разделов, чем уровень параллелизма.
Вторая стратегия рекомендуется в следующих случаях:
♦ разделы распределены равномерно среди многих дисков;
♦ ваши запросы используют меньшее количество разделов, чем количество
доступных потоков;
♦ размеры разделов значительно отличаются в пределах одной таблицы.
Улучшения, связанные с информацией разделения
SQL Server 2008 предоставляет следующую улучшенную информацию разде-
ления:
♦ необязательный атрибут, называемый Partitioned, который указывает, что
оператор (поиска, сканирования, добавления, изменения или удаления)
выполняется по отношению к разделенной таблице;
♦ улучшенная информация, связанная с вычисляемым столбцом partitioniD;
♦ итоговая информация, которая предоставляет общее количество обраще-
ний к разделам.
Основные правила для разделенных таблиц
и индексов
Следующие советы являются основными правилами для разделенных таблиц
и индексов.
♦ Не разделяйте каждую таблицу. Разделяйте только те таблицы, к которым
осуществляется обращение наиболее часто.
♦ Размышляйте о разделении таблицы только в том случае, когда она явля-
ется огромной, т. е. если она содержит, по меньшей мере, несколько сотен
тысяч строк.
♦ Для лучшей производительности используйте разделенные индексы для
уменьшения количества конфликтов между сессиями.
♦ Сохраняйте равновесие между количеством разделов и количеством про-
цессоров в вашей системе. Если для вас нет возможности установить от-
ношение 1:1 между количеством разделов и количеством процессоров, за-
дайте количество разделов в виде кратного множителя количества процес-
соров.
♦ Не разделяйте таблицу по столбцу, который часто изменяется. Если вы-
полняется разделение по столбцу, изменяющемуся часто, то любая опера-
Гпава 26. Техники оптимизации для бизнес-аналитики 671
ция изменения по такому столбцу может привести к тому, что система бу-
дет перемещать строки из одного раздела в другой, а это может занять
слишком много времени.
♦ Для оптимальной производительности выполняйте разделение таблиц для
увеличения возможностей параллельности, однако не разделяйте их ин-
дексы. Помещайте индексы в отдельную файловую группу.
Оптимизация запроса схемы "звезда"
Как вы уже знаете из главы 22, схема снежинки является основной формой в
структурах данных хранилища данных. Такая схема обычно имеет одну таб-
лицу фактов, которая связана с несколькими таблицами измерений. Таблица
фактов может иметь 100 млн строк или более, тогда как таблица измерений
содержит гораздо больше миллионов строк. Обычно при решениях поддерж-
ки запросов некоторые размеры таблиц объединяются с соответствующими
таблицами фактов. Можно получить значительное увеличение производи-
тельности, если оптимизатор запросов сможет распознавать эти запросы и
применять для этого особые техники. Использование таких техник в оптими-
заторе запросов обычно называется оптимизацией StarSchema.
Замечание__________________________________________________
Хотя оптимизация StarSchema поддерживалась в SQL Server 2005, основные
улучшения были выполнены в SQL Server 2008.
Давайте используем пример 26.8, где работает схема оптимизации запросов
StarSchema.
Пример 26.8
USE AdventureWorksDW;
SELECT ProductAlternateKey
FROM FactintemetSales f JOIN DimTime t ON f.OrderDateKey = t.TimeKey
JOIN DimProduct d ON d.ProductKey = f.ProductKey
WHERE CalendarYear BETWEEN 2003 AND 2004
MID ProductAlternateKey LIKE 'BK%'
GROUP BY ProductAlternateKey, CalendarYear;
Замечание__________________________________________________________
В примере 26.8 просто показана общая форма запроса, где к запросу
StarSchema может быть применена оптимизация. Здесь не говорится, что опти-
мизатор запросов будет применять такой механизм к этому запросу.
Предыдущий пример является запросом, основанным на одной из схемы
StarSchema для базы данных AdventureWorksDW. Оптимизатор запросов в
672
Часть IV. SQL Server и Business Intelligence
SQL Server 2008 определяет StarSchema и находит таблицу фактов
(Factinternetsales) и соответствующие таблицы размеров (DimTime и
DimProduct). Если результирующие наборы соответствующих операций со-
единения таблицы фактов с каждой таблицей размеров содержат небольшое
или среднее количество строк, то оптимизатор запросов применяет так назы-
ваемые битовые фильтры для применения операции полусоединения в начале
запроса. (Определение полусоединения см. в главе 6.)
Замечание_______________________________________________________
Не путайте битовые фильтры с битовыми индексами! Битовые фильтры явля-
ются структурой в памяти, которая используется для улучшения производи-
тельности в процессе выполнения запроса. Битовые индексы являются посто-
янными структурами, которые используются в бизнес-аналитике в качестве
альтернативы структурам В-дерева. SQL Server не поддерживает битовые ин-
дексы.
Основной ролью битовых фильтров является увеличение скорости парал-
лельных планов за счет полусоединения, выполняющегося прежде, чем стро-
ки будут передаваться между операторами, относящимися к параллельному
выполнению. Битовые фильтры не используются в последовательных планах.
Замечание_______________________________________________________
Битовые фильтры могут быть использованы в двух техниках обработки соеди-
нения: хеширование соединений и слияние соединений.
SQL Server 2008 поддерживает следующие улучшения, связанные с битовы-
ми фильтрами:
♦ для битовых фильтров существуют новые планы запросов;
♦ оптимизатор запросов может динамически изменять позицию битовых
фильтров;
♦ поддержка множества битовых фильтров;
♦ оптимизатор запросов принимает решение, когда и как применять битовые
фильтры.
Битовые фильтры видны в форме XML в плане выполнения (см. главу 20).
В этом случае XML-атрибуты PhisicalOP и LogicalOP содержат значения
"Bitmap" и "Bitmap Create" соответственно. (Об определении атрибутов XML
см. главу 27.)
В отличие от SQL Server 2005, оптимизатор запросов в SQL Server 2008 мо-
жет динамически изменять позицию битового фильтра. (Преимущества про-
изводительности могут быть достигнуты, если битовые фильтры будут пере-
мещены на более низкие уровни дерева запроса.) Также к запросу теперь мо-
жет быть применено несколько битовых фильтров.
Гпава 26. Техники оптимизации для бизнес-аналитики
673
На решения оптимизатора запросов по отношению к оптимизации соедине-
ний не могут влиять пользователи. Иными словами, не существует систем-
ных процедур (или известных флагов трассировки), которые могли бы быть
использованы для деактивации (или активации) этой возможности.
Замечание_____________________________________________________
Решение корпорации Microsoft о создании оптимизации запросов схемы
"звезда" без предоставления возможности для пользователей деактивировать
ее имеет свои преимущества и недостатки. Основным преимуществом являет-
ся то, что полученное решение не увеличивает сложности системы. С другой
стороны, пользователи должны бы иметь альтернативу для деактивации этого
средства в запросе, который не получает выгоды от этой возможности.
Резюме
Database Engine поддерживает упорядоченное разделение данных и индексов,
что является совершенно прозрачным для приложений. Упорядоченное раз-
деление осуществляет разделение строк, основанное на значении разделяю-
щего ключа. Иными словами, данные разделяются при использовании значе-
ний разделяющего ключа.
Если вы хотите разделять ваши данные, вы должны выполнить следующие
шаги:
1. Создать файловую группу для каждого раздела.
2. Создать функцию разделения и схему разделения.
3. Создать разделенные индексы (если необходимо).
Используя различные файловые группы для разделяемых данных, вы дости-
гаете лучшей производительности, большей доступности данных и более
простой поддержки.
Функция разделения служит для размещения строк таблицы или индексов в
разделах, основанных на значениях заданного столбца. Для создания функ-
ции разделения используйте оператор create partition function. Для связы-
вания функции разделения с конкретной файловой группой применяется схе-
ма разделения. Когда вы разделяете данные таблицы, индексы, ассоцииро-
ванные с этой таблицей, могут быть также разделены. Вы можете разделять
индексы таблицы, используя существующую схему разделения для этой таб-
лицы или любую другую схему.
Оптимизация запроса к схеме "звезда" основана на индексе и поддерживает
оптимальное использование индексов в огромных таблицах фактов.
674
Часть IV. SQL Server и Business Intelligence
Главными преимуществами этой техники являются следующие:
♦ значительное улучшение производительности в условии высокой и сред-
ней селективности запросов к схеме "звезда";
♦ не требуется дополнительной памяти. Система не создает никаких допол-
нительных индексов, однако вместо этого использует битовые фильтры.
Эта глава является последней главой части книги, которая посвящена бизнес-
аналитике. Со следующей главы начинается последняя часть этой книги, где
дается введение в XML.
Часть V
За пределами
реляционных данных
ГЛАВА 27
Обзор XML
В этой главе вводится расширенный язык разметки гипертекста (Extended
Markup Language, XML), который становится все более и более важным с
точки зрения формата хранения данных. Вначале в главе описывается Все-
мирная паутина. Затем дается введение в язык разметки XML. В главе также
описываются основные концепции XML, такие как элементы, атрибуты и
пространства имен. В конце главы рассматривается язык определения типа
документа (Document Type Definition, DTD) и язык схемы XML.
Всемирная паутина
Всемирная паутина (World Wide Web) приобрела огромное, важное значение
в качестве среды коммуникации, поскольку она используется для многих ви-
дов деятельности. WWW включает большинство сервисов Интернета (под
одним и тем же пользовательским интерфейсом) и поэтому является наибо-
лее мощным из всех сервисов Интернета. WWW имеет четыре части:
♦ Web-сервер;
♦ Web-браузер;
♦ HTML (Hypertext Markup Language, язык разметки гипертекста);
♦ HTTP (Hypertext Transfer Protocol, протокол передачи гипертекста).
Web-сервер отправляет страницы (обычно страницы HTML) в сеть. Web-брау-
зер получает эти страницы и отображает их на экране компьютера. Microsoft
Internet Explorer является примером Web-браузера.
Вы используете HTML для создания документов для WWW. Этот язык по-
зволяет вам форматировать данные, которые отображаются при использова-
нии Web-браузера. Простота HTML является одной из причин, почему Все-
678
Часть V. За пределами реляционных данных
мирная паутина приобрела такое важное значение. Однако HTML имеет один
главный недостаток: он может вам только сказать, как данные должны
выглядеть. Иными словами, этот язык не позволяет вам узнать смысл этих
данных.
Документы HTML являются текстовыми файлами, которые содержат теги, и
каждый тег записывается в угловых скобках. Наиболее важными тегами
являются гиперссылки. Вы используете гиперссылки для обращения к доку-
ментам, которые обрабатываются Web-сервером. Такие обращения создают
сеть, которая охватывает весь Интернет.
HTTP является протоколом, который "соединяет" Web-браузер с Web-серве-
ром и пересылает доступные страницы от первого ко второму. Если страница
содержит другую гиперссылку, этот протокол применяется для соединения
с Web-сервером на основе полученного адреса.
Языки, связанные с XML
XML является языком, который используется для дискретного представления
документов. Этот язык связан с двумя другими языками:
♦ SGML;
♦ HTML.
Стандартный язык обобщенной разметки документов (Standard General
Markup Language, SGML) является очень мощным языком разметки, который
служит для взаимного обмена между большими и сложными документами.
(В языках разметки текстов задаются специальные знаки, которые использу-
ются либо для форматирования документов, либо для представления логиче-
ской структуры документов. Примером языка разметки форматирования яв-
ляется LaTEX.) SGML используется во многих областях, где есть потреб-
ность в сложных документах, в таких как эксплуатация самолетов. Как вы
сейчас увидите, XML является облегченным вариантом SGML, т. е. он явля-
ется упрощенным подмножеством SGML, который главным образом исполь-
зуется в WWW.
HTML является наиболее важным языком разметки, используемым во Все-
мирной паутине. Каждый документ HTML является документом SGML с
фиксированным типом определения документа (DTD). (Фиксированные типы
документов описываются в следующем разделе.) Поэтому HTML является
лишь экземпляром SGML.
HTML имеет две важные особенности:
♦ он используется только для форматирования документа;
♦ он не является расширяемым языком.
Гпава 27. Обзор XML 679
HTML является языком разметки, который вы можете использовать для того,
чтобы описать, как должны выглядеть данные. С другой стороны, этот язык
предоставляет гораздо больше возможностей, чем простые языки форматиро-
вания, такие как LaTEX, потому что его элементы являются обобщенными и
наглядными.
HTML использует только фиксированное количество элементов. По этой
причине вы не можете использовать HTML подходящим образом для отдель-
ных типов документов.
Базовые концепции XML
XML является HTML-подобным языком, который служит для обмена данны-
ми. В отличие от HTML, в котором существует фиксированное количество
тегов и где каждый тег имеет собственное значение, набор тегов в XML не
является заранее установленным, а смысловое значение не установлено для
любого тега XML.
Пример 27.1 поможет прояснить эти и другие свойства XML. Однако прежде
чем смотреть на различные части документа XML, рассмотрим требования
к хорошо форматированному документу XML:
♦ он имеет корневой элемент;
♦ за каждым открывающим тегом следует соответствующий закрывающий
тег;
♦ элементы документа являются правильно вложенными;
♦ атрибут должен иметь значение, которое заключается в кавычки.
\ Пример 27.1
<?xml version="1.0" encoding="UTF-8"?>
<FersonList Type="Employee">
<Title> Value="Employee List"X/Title>
<Contents>
<Employee>
<Name>Ann Jones</Name>
<No>10102</No>
<Deptno>d3</Deptno>
<Address>
<City>Dallas</City>
<Street>Main St</Street>
</Address>
</Employee>
680
Часть V. За пределами реляционных данных
<Employee>
<Name>John Barrimore</Naine>
<No>18316</No>
<Deptno>dl< / Deptno
<Address>
<City>Seattle</City>
<Street>Abbey Rd</Street>
</Address>
</Employee>
</Contents>
</PersonList>
Как показано в примере 27.1, документ XML содержит общие три части:
♦ необязательная первая строка, которая сообщает программе, которая по-
лучает документ, какова версия XML, с которым программа имеет дело
(в примере 27.1 это версия 1.0);
♦ необязательная схема (обычно записывается с использованием DTD или
XSD; см. разд. "Определение типа документа DTD" далее в этой главе);
♦ корневой элемент — элемент, который содержит все другие элементы.
Вы используете XML для дискретного представления документов. Для пред-
ставления документа вы должны знать его структуру. Например, если вы рас-
сматриваете книгу как документ, она вначале должна быть разбита на главы
(с заголовками). Каждая глава содержит несколько разделов (с их заголовка-
ми и номерами), а каждый раздел имеет один или более абзацев.
Все части документа XML, которые принадлежат его логической структуре,
называются элементами. Поэтому в XML каждый элемент представляет
компонент документа. В примере 27.1 PersonList, Title и Contents являются
примерами элементов XML. Каждый элемент также может содержать другие
элементы. Те части элемента, которые не принадлежат логической структуре
документа, называются символьными данными. Например, слова или пред-
ложения в книге могут трактоваться как символьные данные.
Все элементы документа составляют иерархию, которая называется древо-
видной структурой документа. Каждая структура имеет корневой элемент на
верхнем уровне, который содержит все другие элементы. Такой элемент на-
зывается корневым элементом. Все элементы, которые не содержат никаких
подчиненных элементов, называются листьями.
Замечание________________________________________________________
В отличие от HTML, где правильные теги определяются спецификацией языка,
имена тегов в XML выбираются программистом.
Глава 27. Обзор XML 681
Элементы XML, непосредственно вложенные в другие элементы, называются
дочерними. Например, в примере 27.1 элементы Name, No и Address являются
дочерними для элемента Employee, который является дочерним для contents, а
тот, в свою очередь, является дочерним элементом корневого элемента
PersonList. (Отношения "предок" и "потомок" также определены в языке
XML.)
Каждый элемент может иметь дополнительную информацию, соединенную с
ним. Подобная информация называется атрибутом, она описывает свойства
элемента. Атрибуты используются вместе с элементами для представления
объектов (т. е. типами документа). В теге
<PersonList Type="Employee">
Туре является именем атрибута, который принадлежит элементу PersonList, а
Employee является значением этого атрибута. В следующем разделе подробно
описываются атрибуты.
Атрибуты XML
Атрибуты служат для представления данных. С другой стороны, элементы
также могут быть использованы для той же самой цели. По этой причине ра-
зумно задать вопрос: "Нужны ли нам вообще атрибуты?", потому что почти
все, что вы можете сделать, используя атрибуты, можно также выполнить и
при помощи элементов (или субэлементов). Однако следующие задачи могут
быть сделаны только при использовании атрибутов:
♦ определение уникального значения;
♦ усиление ограничения ссылочной целостности.
Замечание______________________________________________________
Не существует общего правила, как вы должны определять данные. Лучшим
правилом просмотра является использование атрибута, когда свойство эле-
мента является общим, и субэлементов для специфического свойства эле-
мента.
Атрибут может быть задан в виде идентификатора типа атрибута. Значение
идентификатора типа атрибута должно быть уникальным в пределах доку-
мента XML. Поэтому идентификатор атрибута всегда применяется для опре-
деления уникального значения.
Атрибут типа IDREF должен ссылаться на правильный идентификатор, объ-
явленный в том же самом документе. Иными словами, значение атрибута
1DREF должно появляться в документе в качестве значения соответствующе-
го идентификатора атрибута.
682 Часть V. За пределами реляционных данных
Атрибут типа IDREFS задает список строк, разделенных пробелами, которые
ссылаются на значения атрибута ID. Например, следующая строка показыва-
ет фрагмент XML с атрибутом IDREFS:
department Members="10102 18316"/>
В этом примере предполагается, что атрибут No элемента Employee является
идентификатором атрибута, тогда как атрибут Members элемента Department
является типом IDREFS.
Пары ID/IDREF и ID/IDREFS соответствуют отношению "первичный
ключ/внешний ключ" в базе данных с небольшими отличиями. В документе
XML значения различных идентификаторов типов атрибутов должны быть
различными. Например, если у вас есть атрибуты CustomeriD и SaiesOrderiD
в документе XML, то эти значения должны быть различными.
Замечание______________________________________________________
Типы, упомянутые ранее (ID, IDREF и IDREFS), являются частью определений
типа документа (DTD), обсуждаемого позже в этой главе.
Пространства имен XML
При использовании XML вы создаете словарь терминов, который соответст-
вует домену, в котором вы моделируете ваши данные. В этой ситуации раз-
личные словари для различных доменов могут привести к конфликту имен,
если вы надумаете соединить вместе эти домены в документе XML. (Обычно
это происходит, когда вы хотите интегрировать информацию, полученную из
разных доменов.) Эта проблема может быть решена при использовании про-
странства имен XML.
В общем случае имя каждого тега XML должно быть записано в виде
имя_пространства‘.имя, где имя__пространства задает имя пространства XML, а
имя является тегом XML.
Имя пространства всегда представляется в виде уникального URI (unique
resource identifier, унифицированного идентификатора ресурса) Всемирной
паутины, который обычно является URL, однако может быть также и абст-
рактным идентификатором.
В примере 27.2 показано использование двух пространств имен.
; Пример 27.2
<Faculty xmlns="http://www.fh-rosenheim.de/informatik"
xmlns:lib="http:// www.fh-rosenheim.de/library">
<Name>Book</Name>
Гпава 27. Обзор XML 683
<Feature>
<lib:Title>Introduction to Database Systems</lib:Title>
<1ib:Author>A. Finkelstein</1ib:Author>
</Feature>
</Faculty>
Пространства имен определяются с помощью атрибута xmins. В примере 27.2
задаются два имени пространства. Первое из них является пространством
имен по умолчанию, поскольку оно задается только с ключевым словом xmins.
Это пространство имен является краткой записью для пространства имен
http://www.fh-rosenheim.de/informatik. Второе пространство имен задается в
форме xmins:иь. Префикс lib служит в качестве сокращенной записи для
http://www.fh-rosenheim.de/Iibrary.
Теги, принадлежащие второму пространству имен, должны иметь префикс
lib. Теги без какого-либо префикса принадлежат пространству имен по
умолчанию. В примере 27.2 два тега принадлежат второму пространству
имен: Title и Author.
Определение типа документа DTD
В отличие от HTML, который содержит набор фиксированных правил, кото-
рым вы должны следовать при создании документа HTML, XML не имеет
таких правил, поскольку этот язык предназначен для большого количества
различных областей приложений. Следовательно, XML включает язык, кото-
рый используется для задания структуры документа.
Набор правил для структурирования документов XML называется определе-
нием типа документа (document type definition, DTD). DTD может быть задан
как часть документа XML, либо документ XML может содержать унифици-
рованный указатель ресурса (uniform resource locator, URL), указывающий,
где хранится DTD. Документ, который согласован со связанным DTD, назы-
вается достоверным документом.
Замечание_______________________________________________________
XML не обязывает документы иметь соответствующие DTD, однако он требует,
чтобы документ был правильно сформирован.
В примере 27.3 показан DTD для документа XML из примера 27.1.
: Пример 27.3
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE PersonList SYSTEM "C:\tmp\Unbenannt4,dtd">
<1 ELEMENT EmployeeList (Title, Contents)>
684
Часть V. За пределами реляционных данных
<!ELEMENT Title EMPTY>
<!ELEMENT Contents (Employee*)>
<!ELEMENT Employee (Name, No, Deptno, Address)>
<!ELEMENT Name (Fname, Lname)>
<!ELEMENT Fname (#PCDATA)>
<!ELEMENT Lname (#PCDATA)>
<'ELEMENT No (#PCDATA)>
<!ELEMENT Deptno (#PCDATA)>
<!ELEMENT Address (City, Street) >
<!ELEMENT City (#PCDATA)>
<!ELEMENT Street (#PCDATA)>
<!ATTLIST EmployeeList Type CDATA #IMPLIED
Date CDATA #IMPLIED>
<!ATTLIST Title Value CDATA #REQUIRED>
Существует несколько общих компонентов DTD: имя (EmployeeList в приме-
ре 27.3) и набор операторов element и attlist. Имя DTD должно быть согла-
совано с именем тега корневого элемента в документе XML (см. при-
мер 27.1), который для проверки достоверности использует DTD.
Объявления типа элемента должны начинаться с оператора element, за кото-
рым следует имя элемента, для которого определяется тип. (Каждый элемент
в правильном документе XML должен быть согласован с типом элемента,
объявленным в DTD.) В примере 27.3 первый оператор element указывает,
что элемент EmployeeList состоит из элементов Title и Contents в указанном
порядке. Элемент Title не содержит никаких субэлементов.
Знак * в определении элемента Contents указывает, что существует ноль или
более элементов типа Employee. Элементы Fname, Lname, No, Deptno, City и
street объявлены как алфавитно-цифровые, т. е. типа #pcdata.
Замечание__________________________________________________L__
Элементы могут иметь простые или сложные типы. В примере 27.3 Address
представляет сложный тип, a city — простой тип.
Атрибуты объявляются для указанных типов элементов с помощью операто-
ра attlist. Это означает, что каждое объявление атрибута начинается со
строки <!ATTLIST. Сразу после этого идет имя атрибута и его тип данных.
В примере 27.3 элемент EmployeeList может иметь атрибуты Туре И Date, то-
гда как элемент Title может иметь только атрибут value. Все другие элемен-
ты не имеют атрибутов.
Ключевое слово #implied указывает, что соответствующий атрибут является
необязательным, а ключевое слово #required определяет обязательную форму
атрибута.
Гпава 27. Обзор XML 685
Замечание___________________________________________________
Атрибуты могут иметь только простые типы данных.
Помимо определения структуры документа, форматирование документа мо-
жет быть важным моментом для тех из вас, кто не хочет использовать Web-
браузер, вроде Microsoft Internet Explorer, для управления формой документа.
Для такой задачи XML поддерживает другой язык, называемый Extensible
Stylesheet Language (XSL), который позволяет описать, как данные вашего
документа должны быть отформатированы или отображены.
Замечание___________________________________________________
Стиль документа описывается в отдельном объекте. По этой причине каждый
документ без этого дополнительного объекта будет использовать форматиро-
вание по умолчанию Web-браузера.
Схема XML
Схема XML или язык определения схемы XML (XML Schema Definition
Language, XSD) является DDL для документов XML. Этот язык определяет
стандартный набор базовых типов, которые поддерживаются в качестве ти-
пов в XML. Схема XML содержит множество расширенных возможностей и
поэтому является значительно более сложной, чем DTD.
Замечание___________________________________________________
Схема XML в этой книге обсуждается только вкратце по причине своей слож-
ности. (См. также главу 28, где обсуждается поддержка схемы XML в SQL
Server.)
Основными особенностями схемы XML являются следующие:
♦ она использует тот же синтаксис, что и применяемый для документов
XML. По этой причине сами схемы являются хорошо сформированными
документами XML;
♦ она интегрирована с механизмом пространства имен. Хотя может быть
более одной схемы определения документа для пространства имен, схема
определения документа определяет тип только одного пространства имен;
♦ она предоставляет набор базовых типов таким же способом, как и SQL
предоставляет char, integer и другие стандартные типы данных;
♦ она поддерживает ограничения целостности "внешний ключ/первичный
ключ1'.
686
Часть V, За пределами реляционных данных
Резюме
XML является форматом представления данных, основанным на SGML, он
все больше и больше используется в качестве формата хранения данных. До-
кумент XML содержит несколько тегов, которые выбираются человеком,
создающим документ. Все части документа XML, которые принадлежат его
логической структуре, называются элементами. Элементы могут хранить
простые или сложные типы данных. Каждый элемент может иметь дополни-
тельную информацию, которая с ним соединена. Такая информация называ-
ется атрибутом. Атрибуты могут содержать только простые типы данных.
DTD являются набором правил, которые структурируют документ XML. До-
кумент XML, который соответствует ассоциированному DTD, называется
правильным документом. Для проверки документа XML вы вместо DTD
можете использовать XSD. XSD включает операторы определения данных
для XML чаще всего в том же виде, что и язык DDL (см. главу 1), содержа-
щий операторы определения данных для SQL.
В следующей главе рассматривается XML в связи с системой SQL Server.
ГЛАВА 28
SQL Server и XML
В этой главе подробно рассматриваются три основные темы, важные, когда
XML и системы реляционных баз данных объединяются вместе:
♦ хранение документов XML в реляционных базах данных;
♦ поиск сохраненных документов XML;
♦ представление реляционных данных в форме XML.
В начале главы обсуждаются различные способы, при помощи которых до-
кументы XML могут сохраняться в реляционной базе данных. После этого
вводится наиболее важная форма хранения— использование типа данных
XML. Затем показывается выборка сохраненных документов XML с исполь-
зованием системных хранимых процедур и стандартного оператора insert.
Также рассматривается другая проблема— представление реляционных дан-
ных в XML. В конце главы вкратце рассматривается язык XQuery и сущест-
вующие методы XQuery в SQL Server.
Замечание___________________________________________________
В этой главе "XML" имеет два значения. Во-первых, этот термин указывает на
язык Extended Markup Language. Во-вторых, тот же самый термин используется
для задания типа данных XML в SQL Server. Чтобы обеспечить ясность в этом
различии, эта глава использует термин "XML" для указания языка, а выражение
"тип данных xml" — для задания типа данных. (Аналогично, "столбец XML" озна-
чает столбец с типом данных XML.)
Методы хранения документов XML
в реляционных базах данных
Как вы уже знаете из главы 1, модель реляционных данных является лучшей
моделью, если вы должны структурировать данные в соответствующую схе-
688
Часть V. За пределами реляционных данных
му. С другой стороны, если используемые вами данные не полностью струк-
турированы, вы должны знать, как моделировать эти данные. В этом случае
хорошим выбором является XML, поскольку эта модель является независи-
мой от платформы, которая обеспечивает переносимость слабоструктуриро-
ванных данных.
Тесная взаимосвязь существует между системами реляционных баз данных и
документами XML, потому что целью современных систем баз данных явля-
ется хранение данных любого вида. Существуют три основные техники хра-
нения документов XML в реляционных базах данных:
♦ в виде "сырых" документов;
♦ разнесение документа по реляционным столбцам (выполнение декомпози-
ции);
♦ с использованием собственной формы хранения.
Если вы сохраняете документ XML в виде большого объекта (Large Object,
LOB), то сохраняется точная копия данных. В этом случае документы XML
сохраняются в "сыром" виде, т. е. в форме строки символов. "Сырая" форма
позволяет очень просто добавлять документы. Поиск такого документа весь-
ма эффективен, если вы отыскиваете целый документ.
Для распределения документа XML по различным столбцам одной или более
таблиц (выполнение декомпозиции хранения) вы можете использовать анно-
тированный XSD. (XML Schema Definition Language, язык определения схе-
мы XML, вкратце описанный в предыдущей главе, определяет набор стан-
дартных типов данных, которые поддерживаются в документах XML.) В этом
случае сохраняется иерархическая структура документа, тогда как порядок
элементов игнорируется. Как вы уже знаете, реляционная модель не поддер-
живает упорядоченность столбцов в таблице, тогда как элементы в докумен-
тах XML являются упорядоченными. Хранение документов XML в распреде-
ленной форме позволяет много проще выполнять индексирование по элемен-
ту, если он размещается в своем собственном столбце.
Замечание______________________________________________________
Процесс декомпозиции документов XML на отдельные столбцы также известен
как "шрединг”.
Собственная форма хранения означает, что документы XML сохраняются
в форме данных, обработанных синтаксическим анализатором. Иными сло-
вами, документ сохраняется во внутреннем представлении (например, в
Infoset), который сохраняет содержимое данных XML. (Infoset, или XML
Information set, является спецификацией консорциума World Wide Web
Consortium (W3C; www.w3.org), которая предоставляет комплект для исполь-
Гпава 28. SQL Server и XML
689
зования в других спецификациях, которым нужно ссылаться на информацию
в документе XML.)
Использование собственного хранения делает более простым запрос инфор-
мации, основанной на структуре документа XML. С другой стороны, рекон-
струкция оригинальной формы документа XML является сложной, потому
что созданное содержание может не быть точной копией документа. Подроб-
ная информация о значительном пустом пространстве, порядке атрибутов и
префиксах пространства имен в документах XML обычно не сохраняется.
После этого общего введения в модели хранения перейдем к рассмотрению
того, как SQL Server поддерживает эти техники.
Хранение документов XML в SQL Server
SQL Server поддерживает все три общие техники для сохранения документов
XML, рассмотренные в предыдущем разделе.
♦ ’’Сырые” документы. SQL Server использует типы данных’ varchar (мах)
и varbinary (мах) для хранения документов XML в качестве "сырых" доку-
ментов. Этот подход не будет в дальнейшем обсуждаться в этой книге по
причине его сложности.
Замечание____________________________________________________
Реализация XML в SQL Server (называемая SQLXML) не является частью SQL
Server 2008. SQLXML предоставляется корпорацией Microsoft в качестве от-
дельного продукта.
♦ Декомпозиция. SQL Server может выполнять декомпозицию документа
XML на раздельные столбцы таблиц, используя системную процедуру
sp xml preparedocument. Эта процедура выполняет синтаксический анализ
предоставленного документа и представляет его узлы в виде дерева. (По-
лученное дерево может затем сохраняться в столбцах реляционных таблиц
при использовании стандартного оператора insert и функции OpenXML.)
♦ Собственный формат хранения. Тип данных xml позволяет сохранять
документы XML в собственном формате в базе данных, поддерживаемой
Database Engine. Системы базы данных, такие как Database Engine, кото-
рые сохраняют документы XML в полностью преобразованной синтакси-
ческим анализатором форме, называются системами базы данных с собст-
венным форматом XML.
В следующих двух разделах подробно рассматриваются последние две тех-
ники. Поскольку тип данных xml является наиболее важной формой хране-
ния, он рассматривается первым.
690
Часть V. За пределами реляционных данных
Хранение документов XML
с использованием типа данных XML
Тип данных xml является базовым типом данных Transact-SQL. Это означает,
что вы можете использовать тип данных xml таким же образом, каким вы ис-
пользуете любые другие стандартные типы данных, такие как integer или
character. С другой стороны, тип данных xml имеет ряд ограничений, потому
что столбец xml не может быть объявлен с помощью предложений unique,
PRIMARY KEY ИЛИ FOREIGN KEY.
В общем случае вы можете использовать тип данных xml для объявления:
♦ столбцов таблицы;
♦ переменных;
♦ входных или выходных параметров (в хранимых процедурах и в функци-
ях, определенных пользователем).
Замечание__________________________________________________
Далее описывается использование типа данных xml для объявления столбца
таблицы. Использование этого типа для объявления переменных или парамет-
ров аналогично.
В примере 28.1 показано применение типа данных xml для объявления столб-
ца таблицы.
j Пример 28.1
USE sample;
CREATE TABLE xmltab (id INTEGER NOT NULL PRIMARY KEY,
xml_column XML);
Здесь оператор create table создает таблицу с двумя столбцами: id и
xml_column. Столбец id служит для уникальной идентификации каждой стро-
ки в таблице. Столбец xmi_ column является столбцом xml, который будет ис-
пользоваться в следующих примерах для демонстрации того, как документы
XML могут сохраняться, индексироваться и отыскиваться.
Как ранее было сказано, документы XML могут быть сохранены в собствен-
ном формате в столбце с типом данных xml. В примере 28.2 показано исполь-
зование оператора insert для сохранения такого документа.
\ Пример 28.2
USE sample;
INSERT INTO xmltab VALUES (1,
'<?xml version="1.0"?>
Гпава 28. SQL Server и XML
691
<PersonList Type="Employee">
<Title> Value="Employee List"x/Title>
<Contents>
<Employee>
<Name>Ann Jones</Name>
<No>10102</No>
<Deptno> d3 </Dept no>
<Address>
<City>Dallas</City>
<Street>Main St</Street>
</Address>
</Employee>
<Employee>
<Name>John Barrimore</Name>
<No>18316</No>
<Deptno>dl</Deptno>
<Address>
<City>Seattle</City>
<Street>Abbey Rd</Street>
</Address>
</Employee>
</Contents>
</PersonList>');
Оператор insert в примере 28.2 добавляет два значения; значение идентифи-
катора и документ XML. (Добавляемый документ XML является тем же са-
мым документом, который использовался в предыдущей главе; см. при-
мер 27.1.) Прежде чем документ XML будет сохранен, с ним будет проведен
синтаксический анализ при помощи синтаксического анализатора XML, ко-
торый проверит его синтаксис. Фактически синтаксический анализатор про-
веряет, является ли конкретный документ XML правильно форматирован-
ным. Например, если вы опустите последнюю строку в документе XML
(</PersonLlst>), синтаксический анализатор XML выдаст следующее сооб-
щение об ошибке:
Msg 9400, Level 16, State 1, Line 3
XML parsing: line 24, character 0, unexpected end of input
(непредвиденное завершение ввода)
Если вы применяете оператор select для просмотра содержимого таблицы
xmltab, SQL Server Management Studio использует редактор XML для отобра-
жения документов XML. (Для отображения всего содержимого документа
в этом редакторе щелкните мышью по соответствующему значению в резуль-
тирующем наборе.)
692
Часть V. За пределами реляционных данных
Индексирование столбца XML
Database Engine внутренне сохраняет значения xml как большой двоичный
объект. Без индекса для таких объектов во время выполнения запроса осуще-
ствляется декомпозиция, что может занять много времени. Поэтому причи-
ной выполнять индексирование столбцов xml является увеличение произво-
дительности запроса.
Замечание______________________________________________________
Если вы хотите создавать произвольные виды индексов XML, соответствующая
таблица должна включать явное определение первичного ключа.
Система поддерживает первичный индекс xml и три типа вторичных индексов
xml. Первичный индекс xml индексирует все теги, значения и пути в экземп-
лярах XML столбца xml. Запросы используют первичный индекс xml для по-
лучения скалярных значений или вложенных деревьев xml.
В примере 28.3 создается первичный индекс xml.
§ Пример 28.3
USE sample;
GO
CREATE PRIMARY XML INDEX i_xmlcolumn ON xml tab(xml_column);
Как вы можете видеть из примера 28.3, создание первичного индекса xml по-
хоже на создание "нормального" индекса, описанного в главе 10. Первичный
индекс xml использует экземпляр xml для генерации вне его соответствующей
внутренней реляционной формы. Таким путем исключается повторяющаяся
генерация внутренней формы для запросов и обновлений.
Для дальнейшего улучшения производительности выборки данных вы може-
те создавать вторичные индексы xml. Первичный индекс xml должен сущест-
вовать до создания вторичных индексов. Вы можете создавать три типа вто-
ричных индексов xml с использованием различных ключевых слов:
♦ for path создает вторичный индекс xml для структуры документа:
♦ for value создает вторичный индекс xml для значений элемента и атрибута
столбца xml;
♦ for property создает вторичный индекс xml, который отыскивает свойство.
Далее представлены некоторые рекомендации по созданию вторичных ин-
дексов XML.
♦ Если ваши запросы значительно используют выражения путей в столбцах
xml, то, скорее всего, индекс path повысит их скорость. Наиболее общим
Гпава 28. SQL Server и XML
693
случаем является использование метода exist о для столбцов xml в пред-
ложении where в языке Transact-SQL. (Метод exist о обсуждается позже
в этой главе.)
♦ Если ваши запросы отыскивают множество значений из индивидуальных
экземпляров xml с использованием выражений пути, то полезным может
быть индекс PROPERTY.
♦ Если ваши запросы включают поиск значений в экземплярах xml без зна-
ния имен элементов или атрибутов, которые содержат эти значения, то
вам может понадобиться создать индекс value.
В примере 28.4 показано использование ключевого слова for path. (Синтак-
сис создания всех других вторичных индексов хмь аналогичен.)
| Пример 28.4
USE sample;
GO
CREATE XML INDEX i_xmlcolumn_path ON xmltab(xml_column)
USING XML INDEX i_xmlcolumn FOR PATH;
В примере 28.4 показано создание вторичного индекса хмь с ключевым сло-
вом for path. Если вы хотите определить вторичный индекс хмь, вы должны
указать предложение using.
Индексы хмь имеют некоторые ограничения по сравнению с "нормальными"
индексами:
♦ индексы хмь не могут быть составными индексами;
♦ не существует кластерных индексов хмь.
Замечание_______________________________________________________
Причины создания индексов хмь отличаются от причин создания обычных ин-
дексов. Индексы хмь увеличивают производительность запросов XQuery в то
время, как обычные индексы увеличивают производительность запросов SQL.
SQL Server также поддерживает соответствующие операторы: alter index и
drop index. Оператор alter index позволяет изменять структуру существую-
щего индекса XML, а оператор удаляет drop index подобный индекс.
Существует также представление каталога для индексов хмь, называемое
sys.xml indexes. Это представление возвращает одну строку для каждого ин-
декса хмь. Наиболее важными столбцами этого представления являются
using_xml_index_id И secondary type. Первый указывает, является индекс
первичным или вторичным, а второй определяет тип вторичного индекса
694
Часть V. За пределами реляционных данных
("Р" для path, "V" для value и "R" для property вторичных индексов). Помимо
этого, данное представление наследует столбцы из представления каталога
sys.indexes.
Типизированные в сравнении с нетипизированными XML-
Как вы уже знаете из главы 27, документ XML может быть хорошо сформи-
рованным и правильным. Проверяться может только хорошо сформирован-
ный документ. Документ XML, который соответствует одной или более схе-
мам, является достоверным в схеме и называется экземпляром документа
в схеме. Схемы XML используются для выполнения более точных проверок
в процессе компиляции запросов.
Столбцы с типом данных xml, переменные и параметры могут быть типизи-
рованными (соответствуют набору схем) или нетипизированными. Иными
словами, когда типизированный экземпляр xml назначен столбцу типа данных
xml, переменной или параметру, то система проверяет экземпляр.
Рассмотрим использование схем XML, а затем подробно обсудим экземпляры
типизированных XML.
Схемы XML и SQL Server
Схема XML задает набор типов данных, которые существуют в конкретном
пространстве имен. XML Schema (или XML Schema Definition Language)
является языком определения данных для документов XML.
SQL Server использует оператор create xml schema collection для импорта
компонентов схемы в базу данных. В примере 28.5 показано использование
этого оператора.
i Пример 28.5
USE sample;
CREATE XML SCHEMA COLLECTION Employeeschema AS
N'<?xml version="l.0" encoding="UTF-16"?>
<xsd:schema elementFormDefault="unqualified"
attributeFormDefault="unqualified"
xmlns:xsd="http://www.w3.org/2001/XMLSchema" >
<xsd:element name="employees">
<xsd:complexType mixed="false">
<xsd:sequence>
<xsd:element name="fname" type="xsd:string"/>
<xsd:element name="lname" type="xsd:string"/>
<xsd:element name="department" type="xsd:string"/>
<xsd:element name="salary" type="xsd:integer"/>
Гпава 28. SQL Server и XML 695
<xsd:element name-1comments" type="xsd:string”/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>';
В примере 28.5 показано, как оператор create xml schema collection может
быть использован для каталогизации схемы Employeeschema в качестве объек-
та базы данных. Схема XML для примера 28.5 включает атрибуты (элементы)
для служащих, такие как имя, фамилия и зарплата. Подробное обсуждение
схем XML выходит за рамки этой книги.
Обычно коллекция схемы XML имеет имя, у которого может присутство-
вать квалификация с использованием имени реляционной схемы
(dbo.Employeeschema, например). Коллекция схемы состоит из одной или бо-
лее схем, которые определяют типы в одном или более пространстве имен
XML. Если атрибут targetNamespace отсутствует в схеме XML, то такая схема
не имеет ассоциированного пространства имен. (Не более одной такой схемы
может присутствовать внутри коллекции схем XML.)
SQL Server также поддерживает операторы alter xml schema collection и
drop xml schema collection. Первый позволяет добавлять новые схемы в су-
ществующую коллекцию схем XML, а второй удаляет все схемы коллекции.
Типизированные столбцы XML, переменные и параметры
Каждый типизированный столбец xml, переменная или параметр должны
быть заданы с ассоциированными схемами. Чтобы сделать это, имя коллек-
ции схем, которая была создана с использованием оператора create xml
schema collection, должно быть записано внутри пары круглых скобок после
имени экземпляра. В примере 28.6 показано это.
I Пример 28.6
USE sample;
CREATE TABLE xml_persontab (id INTEGER,
xml_person XML(Employeeschema));
Столбец xml person в примере 28.6 ассоциирован с коллекцией схем XML
Employeeschema (см. пример 28.5). Это означает, что используются все специ-
фикации из определенных схем для проверки правильности значения столбца
xml person. Иными словами, когда вы добавляете новое значение в типизиро-
ванный столбец xml (или изменяете существующее значение), проверяются
все ограничения, заданные в схемах.
696 Часть V. За пределами реляционных данных
Спецификация коллекции схем XML для типизированного экземпляра хмь
может быть расширена двумя ключевыми словами:
♦ document;
♦ CONTENT.
Ключевое слово document указывает, что столбец хмь может содержать только
документы XML, а ключевое слово content, значение по умолчанию, указы-
вает, что столбец хмь может содержать или документы, или фрагменты.
(Помните, что документ XML должен иметь один корневой элемент.)
В примере 28.7 показано использование ключевого слова document.
1 Пример 28.7
USE sample;
CREATE TABLE xml_persontab_doc (id INTEGER,
xml_person XML(DOCUMENT Employeeschema));
Представления каталогов схемы XML
SQL Server поддерживает несколько представлений каталогов, связанных
с XML Schema, наиболее важными из которых являются следующие:
♦ sys.xml_schema_attributes возвращает строку для каждого компонента
схемы XML, который является атрибутом;
♦ sys. xml schema elements возвращает строку для каждого компонента схе-
мы XML, который является элементом;
♦ sys.xml_schema_components возвращает строку для каждого компонента
схемы XML.
Хранение документов XML
с использованием декомпозиции
Системная процедура sp_xml_preparedocument читает текст XML, представ-
ленный ей в качестве ввода, выполняет синтаксический анализ и представля-
ет преобразованный документ в виде дерева с различными узлами: элементы,
атрибуты, текст и комментарии.
В примере 28.8 показано использование системной процедуры sp_xmi_
preparedocument.
j Пример 28.8
USE sample;
DECLARE @hdoc int
Глава 28. SQL Server и XML
697
DECLARE @doc varchar(1000)
SET @doc = '<ROOT>
<Employee>
<Name>Ann Jones</Name>
<No>10102</No>
<Deptno>d3 </Deptno>
<Address>Dallas</Address>
</Employee>
<Employee>
<Name>John Barrimore</Name>
<No>18316</No>
<Deptno>dl < / Dept no>
<Address>Seattle</Address>
</Employee>
</RCOT>'
EXEC sp_xml_preparedocument @hdoc OUTPUT, @doc
Документ XML в примере 28.8 сохраняется в виде строки в переменной @doc.
Эта строка дробится системной процедурой sp_xml_preparedocument. Про-
цедура возвращает дескриптор (@hdoc), который затем может быть использо-
ван для доступа к вновь созданному представлению документа XML.
Системная процедура sp_xmi_removedocument удаляет внутреннее представле-
ние документа XML, заданное дескриптором документа, и делает недействи-
тельным этот дескриптор документа.
В следующем разделе показано, как вы можете отыскивать сохраненные дан-
ные XML в реляционной форме.
Поиск сохраненных документов XML
и фрагментов
Вы можете сгенерировать набор строк из документов и фрагментов XML и
запросить его с помощью языка Transact-SQL. Это делается посредством
OpenXML, который позволяет использовать операторы Transact-SQL для вы-
деления данных из документа XML. Используя OpenXML, вы можете оты-
скивать данные из документа XML, как если бы они были реляционной таб-
лицей. (OpenXML является международным стандартом для документов; он
может быть свободно реализован множеством приложений на множестве
платформ.)
В примере 28.9 показано, как вы можете запрашивать документ из примера
28.8 с помощью OpenXML.
698
Часть V. За пределами реляционных данных
Замечание__________________________________________________
Код примера 28.9 должен быть добавлен в код примера 28.8, и оба кода долж-
ны быть выполнены вместе.
I Пример 28.9
SELECT * FROM OPENXML (@hdoc, '/ROOT/Employee', 1)
WITH (name VARCHAR(20) 'Name',
no INT 'No',
deptno VARCHAR(6) 'Deptno',
address VARCHAR(50) ’Address');
Результат:
Name no deptno address
Ann Jones 10102 d3 Dallas
John Barrimore 18316 dl Seattle
Представление реляционных данных
в качестве документов XML
Как вы уже знаете из главы 6, оператор select обращается к одной или более
таблицам и отображает соответствующий результирующий набор. Результи-
рующий набор отображается по умолчанию в виде таблицы. Если вы хотите
отобразить результирующий набор запроса в виде документа XML или фраг-
мента, то можете использовать предложение for xml в вашем операторе
select. В этом предложении вы можете задать один из следующих четырех
режимов:
♦ raw;
♦ auto;
♦ explicit;
♦ PATH.
Замечание
Предложение FOR xml должно быть задано в конце оператора select.
Режим RAW
Опция for xml raw преобразует каждую строку результирующего набора в
элемент XML с идентификатором <row>. Каждое значение столбца преобра-
Гпава 28. SQL Server и XML
699
зуется в атрибут элемента XML, где имя атрибута является тем же самым
именем, что и имя столбца. Это истинно только для непустых столбцов.
В примере 28.10 показано использование опции for xml raw, заданной для
соединения таблиц employee и works_on из базы данных sample.
j Пример 28.10
USE sample;
SELECT employee.emp_no, emp_lname, works_on.job
FRCM employee, works_on
WHERE employee.emp_no <= 10000
AND employee.emp_no = works_on.emp_no
FOR XML RAW;
Пример 28.10 отображает следующий фрагмент документа XML:
<row emp_no="2581'
crow emp_no="9031'
<row emp_no="9031'
emp_lname="Hansel
emp_lname="Bertoni
emp_lname="Bertoni
" job="Analyst
" job="Manager
" job="Clerk
Без опции for xml raw оператор select из примера 28.10 вернет следующие
строки:
emp_no emp_lname job
2581 Hansel Analyst
9031 Bertoni Manager
9031 Bertoni Clerk
Как вы можете видеть из обоих результатов, первый результат создает один
элемент XML для каждой строки в результирующем наборе.
Режим AUTO
Режим auto возвращает результирующий набор запроса в виде простого вло-
женного дерева XML. Каждая таблица в предложении from, из которого, по
меньшей мере, один столбец появляется в списке select, представлена в виде
элемента XML. Столбцы в списке select отображаются в соответствующие
атрибуты элемента.
В примере 28.11 показано использование режима auto.
| Пример 28.11
USE sample;
SELECT employee.emp_no, emp_lname, works_on.job
FROM employee, works_on
24 Зак. 114I
700 Часть V. За пределами реляционных данных
WHERE employee.emp_no <= 10000
AND employee.emp_no = works_on.emp_no
FOR XML AUTO;
Результат:
<employee emp_no="9031" emp_lname="Bertoni ">
cworkson job="Manager " />
<works on job="Clerk />
</employee>
<employee emp_no="2581" emp_lname="Hansel ">
<works_on job-"Analyst " />
</employee>
Результат примера 28.11 значительно отличается от результата предыдущего
примера, хотя операторы select обоих примеров эквивалентны (за исключе-
нием указания режима auto вместо режима raw). Как вы можете видеть из
примера 28.11, результирующий набор отображается в виде иерархии таблиц
employee и works on. Эта иерархия основывается на отношении "первичный
ключ/внешний ключ" обеих таблиц. По этой причине данные из таблицы
employee отображаются первыми, а соответствующие данные из таблицы
works on отображаются следом, на более низком уровне иерархии.
Вложенность элементов в результирующем документе или фрагменте XML
основана на порядке таблиц, указанных столбцами, заданными в предложе-
нии select; поэтому порядок, в котором имена столбцов заданы в предложе-
нии select, является значимым. По этой причине в примере 28.11 значения
столбца emp_no таблицы employee создают верхний элемент результирующего
фрагмента XML. Значения столбца job таблицы works on формируют элемен-
ты, подчиненные верхнему элементу.
Режим EXPLICIT
Как вы можете видеть из примера 28.11, результирующий набор в режиме
auto отображается как простое вложенное дерево XML. Запросы в режиме
auto являются подходящими, если вы хотите генерировать простые иерархии,
поскольку этот режим предоставляет минимальное управление формой доку-
мента XML, сгенерированного из результата запроса.
Если вы хотите указать расширенную форму результирующего набора, то
можете использовать опцию for xml explicit. С этой опцией результирую-
щий набор отображается как универсальная таблица, которая содержит всю
информацию о результирующем дереве XML. Данные в этой таблице верти-
кально разделены на группы. Каждая группа затем становится элементом
XML в результирующем наборе.
Гпава 28. SQL Server и XML
701
В примере 28.12 показано использование режима explicit.
' Пример 28.12
USE sample;
SELECT 1 AS tag, NULL as parent,
emp_lname AS [employee!1!emp_lname],
NULL AS [works_on!2!job]
FROM employee
UNION
SELECT 2, 1, emp_lname, works_on.job
FROM employee, works_on
WHERE employee.emp_no <= 10000
AND employee.emp_no = works_on.emp_no
ORDER BY [employee!l!emp_lname]
FOR XML EXPLICIT;
Результат:
<employee emp_lname="Barrimore
<employee emp_lname="Bertoni
<works_on job="Clerk
<works_on job="Manager
</employee>
<employee emp_lname="Hansel
<works_on job="Analyst
</employee>
<employee emp_lname="James
<employee emp_lname="Jones
<employee emp_lname="Moser
<employee emp_lname="Smith
Как вы можете видеть в операторе select примера 28.12, опция for xml
explicit требует двух дополнительных столбцов метаданных: tag и parent.
(Эти два столбца используются для определения отношения "первичный
ключ/внешний ключ" в дереве XML.) Столбец tag хранит номер тега текуще-
го элемента, в то время как столбец parent хранит номер тега родительского
элемента. Родительская таблица-— это таблица с первичным ключом. Если
родительский тег имеет значение null, то эта строка находится непосредст-
венно под корневым элементом.
Замечание______________________________________________________
Не используйте режим explicit, потому что он является слишком сложным.
Вместо него используйте режим path (см. далее).
702
Часть V. За пределами реляционных данных
Режим PATH
Все три опции for xml, рассмотренные ранее, имеют различные недостатки и
ограничения. Опция for xml raw поддерживает только один уровень вложен-
ности, тогда как опция for xml auto требует, чтобы все столбцы, выбранные
из той же таблицы, появлялись на том же уровне. Также обе опции не позво-
ляют смешивать элементы и атрибуты в одном документе XML. С другой
стороны, опция for xml explicit позволяет смешивать элементы и атрибуты,
однако синтаксис этой опции довольно неуклюжий, как вы можете видеть из
предыдущего примера.
Опция for xml path позволяет реализовать очень простым способом почти
все запросы, которые требуют режима explicit. В режиме path имена столб-
цов или псевдонимы столбцов трактуются как выражения XPath, которые
указывают, как значения распределяются в XML. (Выражение XPath состоит
из последовательности узлов, возможно, разделенных символом наклонной
черты /. Для каждой наклонной черты система создает другой уровень
иерархии в результирующем документе.)
В примере 28.13 показано использование режима path.
i Пример 28.13
USE sample;
SELECT d.dept_name Department",
emp_fname "EmpName/First",
emp_lname "EmpName/Last"
FRCM Employee e, department d
WHERE e.deptno = d.dept_no
AND d.dept no = 'dl'
FOR XML PATH;
Результат:
<row Department="Research
<EmpName>
<First>John </First>
<Last>Barrimore </Last>
</EmpName>
</row>
<row Department="Rese$rch
<EmpName>
<First>Sybill </First>
<Last>Moser </Last>
</EmpName>
</row>
Гпава 28. SQL Server и XML
703
В режиме path имена столбцов используются в качестве пути в конструкции
документа XML. Столбец, содержащий имена отделов, начинается с символа
@. Это означает, что атрибут Department добавлен в элемент <row>. Все другие
столбцы включают символ наклонной черты / в имя столбца, что указывает
на иерархию. По этой причине результирующий документ XML будет иметь
дочерний элемент <EmpName> ниже элемента <row> и элементы <First> и <Last>
на следующем подуровне.
Директивы
SQL Server поддерживает несколько других директив, которые позволяют
создавать различные результаты, когда вы хотите отображать документы и
фрагменты XML. В следующем списке показано несколько таких директив:
♦ type;
♦ ELEMENTS (с XSINIL);
♦ ROOT.
Следующие подразделы описывают эти директивы.
Директива TYPE
SQL Server позволяет хранить результат реляционного запроса в виде доку-
мента или фрагмента XML в типе данных XML при использовании директи-
вы type. Когда указана директива type, запрос с опцией for xml возвращает
результирующий набор с одной строкой и одним столбцом. (Эта директива
является общей директивой; это означает, что вы можете ее использовать во
всех четырех режимах.) В примере 28.14 показано использование директивы
type с режимом auto.
Пример 28.14
USE sample;
DECLARE @х xml;
SET @x = (SELECT * FROM department
FOR XML AUTO, TYPE);
SELECT @x;
Результат:
<department dept_no="dl " dept_name="Research " location="Dallas " />
department dept_no="d2 " dept_name="Accounting " location="Seattle " />
department dept_no="d3 " dept_name="Marketing " location="Dallas " /.>
704
Часть V. За пределами реляционных данных
В примере 28.14 вначале объявляется переменная @х в качестве локальной
переменной типа данных xml, и ей назначается результат выполнения опера-
тора select. Последний оператор select в пакете отображает содержимое
этой переменной.
Директива ELEMENTS
Как вы уже знаете из главы 3, Database Engine поддерживает значения null
для указания неизвестных (или отсутствующих) значений. В отличие от ре-
ляционной модели XML не поддерживает значений null, и такие значения
отсутствуют в результирующих запросах с опцией for xml.
SQL Server позволяет отображать отсутствующие значения в документе XML
при использовании директивы elements с опцией xsinil. В общем, директива
elements создает соответствующий документ XML таким образом, что каж-
дое значение столбца отображается в элемент. Если значением столбца явля-
ется null, то по умолчанию не добавляется никакой элемент. При указании
дополнительной опции xsinil вы можете задать, чтобы также создавался и
элемент со значением null. В этом случае элемент с атрибутом xsinil, уста-
новленным в true, будет возвращен для каждого null значения в столбце.
Директива ROOT
Обычно запросы с опцией for xml создают фрагменты XML — XML без со-
ответствующего корневого элемента. Это может оказаться проблемой, если
API принимает в качестве ввода только документы XML. SQL Server позво-
ляет добавлять корневой элемент с использованием директивы root. При за-
дании директивы root в запросе for xml вы можете запросить один элемент
верхнего уровня из результирующего XML. (Аргумент, указанный в дирек-
тиве, задает корневой элемент.)
В примере 28.15 показано использование директивы root.
I Пример 28.15
USE sample;
SELECT * FROM department
FOR XML AUTO, ROOT ('AllDepartments');
Результат:
<A1lDepartments>
<department dept_no="dl " dept_name="Research " location="Dallas
department dept_no="d2 " dept_name="Accounting " location="Seattle
department dept_no="d3 " dept_name="Marketing " location="Dallas
</AllDepartments>
Гпава 28. SQL Server и XML
705
Запрос в примере 28.15 отображает фрагмент XML со всеми строками из таб-
лицы department. Директива root добавляет в результирующий набор специ-
фикацию корня при помощи параметра AllDepartments в качестве имени
корня.
Методы XQuery в SQL Server
XQuery является новым языком запросов для XML. Этот язык является го-
раздо более сложным, чем XPath. Фактически, XQuery содержит XPath в ка-
честве своего подъязыка. Вы можете конвертировать данные столбцов XML
в экземпляр типа данных XML с помощью опции for xml с директивой type и
запрашивать их посредством XQuery. SQL Server поддерживает пять мето-
дов, которые могут быть использованы для запроса документов XML в
XQuery:
♦ query О принимает оператор XQuery в качестве ввода и возвращает экзем-
пляр типа данных xml;
♦ exist () принимает оператор XQuery в качестве ввода и возвращает 0, 1
или null в зависимости от результата запроса;
♦ value () принимает оператор XQuery в качестве ввода и возвращает един-
ственное скалярное значение;
♦ nodes () полезен, когда вы хотите разделить тип данных xml на реляцион-
ные данные. Это позволяет идентифицировать узлы, которые будут раз-
мещены в новых строках;
♦ modify (). В отличие от стандартизованной версии XQuery, которая в своей
версии 1.0 не имеет спецификаций для операций изменения, SQL Server
поддерживает добавление, модификацию и удаление документов XML
при использовании метода modify ().
Замечание____________________________________________________
Вы можете найти подробное описание XQuery в документации Books Online.
В следующих двух примерах показано использование двух методов XQuery.
В примере 28.16 демонстрируется применение метода query ().
i Пример 28.16
USE sample;
SELECT xml column.query('/PersonList/Title')
FROM xmltab
FOR XML AUTO, TYPE;
706
Часть V. За пределами реляционных данных
Результат:
<xmltab>
<Title> Value="Employee List"></Title>
</xmltab>
Список select запроса в примере 28.16 содержит метод query о с выражени-
ем XPath. (Заметьте, что методы XQuery в SQL Server применяются с исполь-
зованием разделителя "точка".) Выражение '/PersonList/Title' является аб-
солютным выражением, в котором отыскивается значение элемента Title.
Помните, что выражения XPath являются допустимыми операторами XQuery,
поскольку XPath является подъязыком XQuery.
Как вы уже знаете, метод exist () принимает оператор XQuery в качестве
ввода и возвращает 0, 1 или null в зависимости от результата запроса. Если
результатом запроса является пустая последовательность, то возвращаемым
значением будет 0. Последовательность, содержащая, по крайней мере, один
элемент, возвращает 1, a null возвращается, если значение столбца есть null.
В примере 28.17 показано использование метода exist ().
: Пример 28.17
SELECT xml_column.exist('/PersonList/Title/@Value=EmployeeList') AS a
FROM xmltab
FOR XML AUTO, TYPE;
Результат:
<xmltab a="l" />
Список SELECT в данном запросе содержит метод exist () с выражением
XPath, которое проверяет, имеет ли атрибут Value документа XML значение
EmployeeList. Проверка дает в результате истину, поэтому возвращаемое зна-
чение запроса будет 1.
SQL Server 2008 и улучшения XML
SQL Server 2008 имеет следующие минимальные изменения, связанные с
поддержкой XML Schema:
♦ улучшена поддержка временных функций xs:dateTime, xs:date И xs:time
("xs" является префиксом пространства имен, связанного с XML Schema);
♦ улучшена поддержка функций xs: list и xs: union.
Как вы уже знаете из главы 4, SQL Server 2008 поддерживает новые типы
данных date и time. Также поддерживаются соответствующие типы данных
XML Schema.
Гпава 28. SQL Server и XML
Вы можете использовать схемы XML для определения типов данных для ва-
ших данных XML, что позволяет ограничить множество значений, которые
могут присваиваться элементам и атрибутам с несколькими значениями.
Одной из них является xs:list, которая поддерживается в настоящий момент.
В SQL Server 2008 также добавлена поддержка для типов union, содержащих
типы list, которые вы можете использовать для слияния множества опреде-
лений типов списков и ограничений в единый тип.
Помимо этих двух улучшений система поддерживает функции sql.-variable и
sql:column в параметре типа данных хмь.
Резюме
SQL Server содержит полную поддержку XML. Наиболее важной возмож-
ностью является существование типа данных хмь, который позволяет системе
базы данных сохранять документы XML в виде объектов первого класса.
Значениями типа данных хмь может быть проверка схемы, если с этим типом
ассоциирована одна или более схем. Вы можете определять точные типы
данных для элементов и атрибутов, только если соответствующий документ
XML содержит типы, указанные в схемах XML. Определения схем создаются
с использованием оператора create xml schema collection.
XML также содержит собственные языки запросов, наиболее важным из ко-
торых является язык XQuery. SQL Server поддерживает несколько нестан-
дартных методов, которые могут быть использованы в запросах к докумен-
там XML при помощи XQuery.
В следующей главе описываются пространственные данные.
ГЛАВА 29
Введение
в пространственные данные
За последние несколько лет потребности бизнеса включить географические
данные в их базы данных и управлять ими с использованием систем баз дан-
ных значительно возросли. Наиболее важным фактором, который привел к
этому росту, является быстрое увеличение географических сервисов и уст-
ройств, таких как Microsoft Virtual Earth и недорогие устройства GPS (Global
Positioning System, глобальная система навигации).
Обычно поддержка пространственных данных продавцами баз данных помо-
гает пользователям принимать лучшие решения в некоторых сценариях, та-
ких как:
♦ анализ недвижимости ("Найти подходящую собственность в пределах
500 метров от начальной школы");
♦ информация для потребителя ("Найти ближайшие торговые центры с за-
данным почтовым индексом");
♦ анализ рынка ("Определить географию продаж по регионам и выяснить
необходимость создания новых филиалов офисов").
В начале этой главы вводятся две различные пространственные модели. По-
сле этого подробно рассматриваются тип данных geometry и соответствую-
щие методы. Под конец показывается практическое использование этих ме-
тодов в запросах.
Представление пространственных данных
Как правило, существуют две различные группы моделей для представления
пространственных данных:
♦ геодезические модели пространственных данных;
♦ плоские модели пространственных данных.
Глава 29. Введение в пространственные данные 709
Модели геодезического пространства
Планеты являются сложными объектами, которые могут быть представлены с
использованием сплющенной сферы (называемой сфероидом}. Хорошим
приближением для представления Земли (и других планет) является глобус,
где размещение объектов на поверхности описывается с использованием ши-
роты и долготы. (Широта определяет положение места на Земле на север или
на юг от экватора, тогда как долгота определяет положение относительно вы-
бранного меридиана). Модели, которые используют эти измерения, называ-
ются геодезическими моделями. Поскольку эти модели предоставляют хоро-
шее приближение сфероида, они дают наиболее точный способ представле-
ния пространственных данных.
Модели плоского пространства
Модели плоского пространства (или планарные модели) используют карту
с двумя измерениями для представления Земли. В этом случае сфероид дела-
ется плоским и отображается в плане. Процесс уплощения приводит к неко-
торой деформации фигуры и размеров отображаемых (географических) объ-
ектов. Модели плоского пространства лучше работают для небольших облас-
тей поверхности, поскольку чем больше область поверхности представляется,
тем больше появляется деформаций.
Пространственные типы данных
SQL Server 2008 предоставляет два пространственных типа данных:
♦ geography представляет пространственные данные в геодезических про-
странственных моделях;
♦ geometry представляет пространственные данные в плоских пространст-
венных моделях.
Оба типа данных реализованы с помощью CLR и могут быть использованы
для хранения различных видов географических элементов, таких как точки,
линии и полигоны.
В следующих разделах подробно описывается тип данных geometry и даются
некоторые примеры того, как вы можете его использовать. Поскольку тип
данных geography очень похож на тип данных geometry, то только тип данных
geometry описывается в деталях, при этом в одном коротком разделе, который
завершает данную главу, описаны различия между этими двумя типами дан-
ных.
710
Часть V. За пределами реляционных данных
Тип данных GEOMETRY
Пример поможет объяснить использование типа данных geometry. В при-
мере 29.1 создается таблица для рынков безалкогольных напитков в заданном
городе (или штате).
\ Пример 29.1
USE sample;
CREATE TABLE beverage_markets
(id INTEGER IDENTITY (1,1) ,
name VARCHAR(25),
shape GEOMETRY);
INSERT INTO beverage_markets
VALUES ('Coke', geometry::STGeomFromText
('POLYGON ((0 0, 150 0, 150 150, 0 150, 0 0))', 0) ) ;
INSERT INTO beverage_markets
VALUES ('Peps i', geomet ry::STGeomFromText
(’POLYGON ((300 0, 150 0, 150 150, 300 150, 300 0))', 0));
INSERT INTO beverage_markets
VALUES ('7UP', geometry::STGeomFromText
('POLYGON ((300 0, 150 0, 150 150, 300 150, 300 0))', 0)) ;
INSERT INTO beverage_markets
VALUES ('Almdudler', geometry::STGeomFromText
('POINT (50 0)', 0)) ;
Таблица beverage markets имеет три столбца, где первый является просто
столбцом идентификатора, тогда как второй содержит название напитка. Тре-
тий столбец, shape, задает место в области рынка, где конкретный напиток
является наиболее предпочтительным. Первые три оператора insert создают
три области, где конкретный напиток является наиболее предпочтительным.
Все три области представляют полигон. Четвертый оператор insert добавля-
ет точку, поскольку существует только одно место, где конкретный напиток
(Almdudler) может быть куплен.
Как вы можете видеть из примера 29.1, метод STGeomFromText () используется
для добавления координат геометрической фигуры, такой как полигон или
точка. Этот метод принадлежит группе статических географических методов,
обсуждаемых далее. После этого будет рассмотрено в деталях пространст-
венное индексирование.
Статические геометрические методы
Используя тип данных geometry, вы можете задавать пространственные пре-
дикаты для экземпляров пространственной геометрии в стандартных опера-
Гпава 29. Введение в пространственные данные 711
торах SQL. Эти предикаты используют специальные методы для выполнения
пространственных операций, таких как вычисление расстояний между двумя
местоположениями. То же самое верно и для типа данных geography.
SQL Server 2008 поддерживает статические геометрические методы, опреде-
ленные в Open Geospatial Consortium (OGC, открытый картографический
консорциум). ODG является бесприбыльной организацией, которая лидирует
в разработке стандартов для пространственных данных. Целью деятельности
организации является предоставление необходимых спецификаций для
средств, связанных с пространственными данными. Задачей продавцов про-
граммного обеспечения является реализация полных или частичных специ-
фикаций. (Продавцы иногда также реализуют некоторые нестандартные воз-
можности.)
Список статических геометрических методов, определенных OGC и реализо-
ванных в Microsoft, довольно обширен. По этой причине здесь представлены
только четыре метода, которые могут быть применены к типу данных
geometry:
♦ STGeomFromText () возвращает экземпляр типа данных geometry из пред-
ставления Well-Known Text (WKT), дополненный соответствующими зна-
чениями высоты и единицы измерения. WKT — это язык разметки текстов
для представления векторов геометрических объектов;
♦ STPointFromText () возвращает представление WKT экземпляра point;
♦ STLineFronffext () возвращает представление WKT экземпляра linestring,
дополненное соответствующими значениями высоты и единицы измере-
ния;
♦ STPolyFromText () возвращает представление WKT экземпляра multipolygon,
дополненное соответствующими значениями высоты и единицы измере-
ния.
Замечание_____________________________________________________
Помимо статических геометрических методов существуют другие геометри-
ческие методы, которые используются с операторами DML; они объясняются
в разд. "Запрос данных GEOMETRY" далее в этой главе.
Пространственное индексирование
Как вы уже знаете из главы 10, индексирование обычно используется для по-
лучения быстрого доступа к данным. Поэтому пространственное индексиро-
вание необходимо для ускорения операций выборки пространственных дан-
ных.
Пространственный индекс определяется для столбца таблицы с типом дан-
ных geometry или geography. В SQL Server 2008 пространственные индексы
712
Часть V. За пределами реляционных данных
создаются с использованием двоичных деревьев; это означает, что индексы
представляют две размерности в линейном порядке двоичных деревьев. По
этой причине, прежде чем читать данные из пространственного индекса, SQL
Server 2008 реализует иерархическую унифицированную декомпозицию про-
странства. В процессе создания индекса выполняется декомпозиция на четы-
рехуровневую иерархическую структуру.
Замечание________________________________________________________
Существует несколько типов индексов, которые используются специально для
пространственных данных. Наиболее важный из них — индекс R-дерева. Будем
надеяться, что этот тип индекса будет реализован Microsoft в последующих
версиях SQL Server.
Оператор create spatial index служит для создания пространственного ин-
декса. Общая форма этого оператора похожа на соответствующий оператор
create index, но содержит дополнительные опции и предложения, некоторые
из которых перечислены далее.
♦ Предложение geometry_grid задает геометрию координатной сетки моза-
ичной схемы, которую вы используете. (Создание мозаики является про-
цессом, который выполняется после чтения данных из пространственного
объекта. В течение этого процесса объект заполняет иерархическую сетку
в соответствии его связи с набором ячеек сетки.) Предложение
geometry grid может быть указано только для столбца с типом данных
GEOMETRY.
♦ Опция bounding_box задает числовой четырехмерный кортеж, который оп-
ределяет четыре координаты ограничивающего прямоугольника: коорди-
наты X и У левого нижнего угла и координаты X и У правого верхнего
угла. Эта опция применяется только в предложении geometry grid.
♦ Предложение geography grid задает географию координатной сетки моза-
ичной схемы. Это предложение может быть указано только со столбцом
с типом данных geography.
В примере 29.2 показано создание пространственного индекса для столбца
shape таблицы beverage_markets.
\ Пример 29.2
USE sample;
GO
ALTER TABLE beverage_markets
ADD CONSTRAINT prim_key PRIMARY KEY(id);
GO
CREATE SPATIAL INDEX i_spatial shape
Гпава 29. Введение в пространственные данные 713
ON beverage_markets(shape)
USING GEOMETRY_GRID
WITH (
BOUNDING—BOX = ( xmin = 0, ymin = 0, xmax = 500, ушах = 200 ),
GRIDS = (LOW, LOW, MEDIUM, HIGH),
PAD_INDEX = ON ) ;
Пространственный индекс может быть создан, только если для таблицы со
столбцом, хранящим пространственные данные, явно определен первичный
ключ. По этой причине первым оператором в примере 29.2 является оператор
alter table, который определяет это ограничение.
Последующий оператор create spatial index создает индекс с использовани-
ем предложения geometry grid. Опция bounding_bcx задает границы, внутри
которых будет размещаться экземпляр столбца shape. Опция grids указывает
плотность сетки на каждом уровне мозаичной схемы. (Опция pad index была
описана в главе 10.)
SQL Server 2008, помимо прочих, поддерживает два представления катало-
гов, относящихся к пространственным данным:
♦ sys.spatial-indexes;
♦ sys.spatial_index_tessellations.
Представление sys.spatial_indexes возвращает основную индексную ин-
формацию пространственных индексов. При использовании представления
sys. spatial—index—tessellations вы можете отображать информацию о моза-
ичной схеме и о параметрах каждого из существующих пространственных
индексов. В примере 29.3 показано, какую информацию можно получить при
использовании этого представления.
; Пример 29.3
SELECT object-id, name, type_desc
FROM sys.spatial—indexes
Результат:
Object_id name type_desc
914102297 i_spatial—shape SPATIAL
Запрос данных GEOMETRY
К пространственным данным можно выполнять запросы тем же самым обра-
зом, что и к реляционным данным. SQL Server поддерживает множество гео-
714
Часть V. За пределами реляционных данных
метрических методов для запроса пространственных данных. В следующих
примерах показана информация, которая может быть найдена из содержимо-
го столбца shape таблицы beverage_markets.
В примере 29.4 показано использование метода STContains ().
\ Пример 29.4
Расположен ли магазин, который продает Almdudler, в том районе, где пред-
почтительным напитком является "Кока-кола"? •
DECLARE Gg geometry;
DECLARE @h geometry;
SELECT @h = shape FROM beveragemarkets WHERE name ='Almdudler';
SELECT @g = shape FROM beverage_markets WHERE name = 'Coke';
SELECT Gg.STContains(Gh);
Результатом будет 0.
Метод STContains о вернет I, если экземпляр типа данных geometry пол-
ностью содержит другой экземпляр того же типа данных. Результат приме-
ра 29.4 означает, что магазин, который продает Almdudler, не принадлежит
той области, где предпочтительным напитком является "Кока-кола".
В примере 29.5 показано использование метода STLength ().
j Пример 29.5
Найти длину и представление WKT столбца shape для магазина Almdudler.
SELECT id, shape.ToString() AS wkt, shape.STLength() AS length
FRCM beveragemarkets
WHERE name = 'Almdudler' ;
Результат:
id wkt length
4 POINT (50 0) 0
Метод STLength () в примере 29.5 возвращает общую длину элементов типа
данных geometry. (Результат 0, потому что отображаемое значение является
точкой.) Метод ToString () является основным методом, который загружает
полный набор переменных при одном вызове метода. В примере 29.5 этот
метод используется для загрузки всех свойств данной точки и их отображе-
ния с использованием представления WKT.
Глава 29. Введение в пространственные данные
В примере 29.6 показано использование метода STintersects ().
j Пример 29.6
Пересекается ли район, где продается "Кока-кола", с районом, где продается
"Пепси-кола"?
USE sample;
DECIARE @g geometry;
DECIARE @h geometry;
SELECT @h = shape FROM beverage_markets WHERE name = 'Coke';
SELECT @g = shape FROM beverage_markets WHERE name = 'Pepsi';
SELECT @g.STintersects(@h);
Метод STintersects () в примере 29.6 применяется к обоим районам для вы-
яснения того, пересекаются ли районы. (Значение 1 подразумевает, что рай-
оны пересекаются.)
Замечание
Помимо методов, использованных в предыдущих примерах, существует много
других нестатических методов, которые подробно описаны в документации
Books Online.
Различия между типами данных
GEOMETRY w GEOGRAPHY
Как вы уже знаете, тип данных geometry используется в плоских пространст-
венных моделях, тогда как тип данных geography применяется в геодезиче-
ских моделях. Основным отличием между этими двумя группами моделей
является то, что в типе данных geometry расстояния и области даются в тех же
самых единицах измерения, что и координаты экземпляров. (Поэтому рас-
стояние между точками (0, 0) и (3, 4) всегда будет составлять 5 единиц.) Это
не тот случай для типа данных geography, который работает с эллиптически-
ми координатами, которые выражаются в градусах широты и долготы.
Существуют также некоторые ограничения, накладываемые на тип данных
geography. Например, каждый экземпляр типа данных geography должен раз-
мещаться внутри полусферы. Пространственные объекты большего размера
недопустимы и вызывают ошибку.
716
Часть V. За пределами реляционных данных
Резюме
SQL Server 2008 поддерживает два пространственных типа данных: geography
и geometry. Тип данных geography используется для представления простран-
ственных данных в геодезических моделях, а тип данных geometry— в пло-
ских пространственных моделях. Для работы с этими типами данных вам
нужен набор соответствующих операторов (т. е. методов). Корпорация
Microsoft реализовала статические геометрические методы, специфицирован-
ные в OGC. Помимо поддерживаемых статических геометрических методов,
существует и другая группа реализованных методов, которые могут быть ис-
пользованы для поиска пространственных данных.
Предметный указатель
в
Business Intelligence 587
Business Intelligence Development Studio
605
В-дерево 94, 282
c
Common Language Runtime (CLR) 136,
251,410
Common Table Expression (CTE) 210
Configure Distribution Wizard 512
Cube Wizard 604
D
Data Definition Language (DDL) 113
Data Source View Designer 609
Data Source Wizard 604
Database Engine Tuning Advisor 571
Database Mail 481
Declarative Management Framework
(DMF) 435
Distribution Agent 505
Document Type Definition (DTD) 683
E
Event Viewer 491
H
HTML 678
HTTP 677
I
Install Shield, мастер 44
L
Log Reader Agent 505
Log Sequence Number (LSN) 379
M
Maintenance Plan Wizard 438
Management Data Warehouse (MDW) 580
Merge Agent 507
Microsoft Analysis Services 604
Microsoft Cluster Service 474
Microsoft Distributed Transaction
Coordinator 375, 500
Microsoft Reporting Services 641
N
New Publication Wizard 514
New Subscription Wizard 515
NULL, значение 109, 159
О
Object Explorer 61
Online Analytical Processing (OLAP) 600
Online Transaction Processing (OLTP) 588
Open Geospatial Consortium (OGC) 711
OpenXML 697
718
Предметный указатель
р Solution Explorer 79
SQL Server Agent, протокол ошибок 491
Performance Data Collector 579 Performance Monitor 562 Q Query by example (QBE) 647 Query Editor 75 R RAID 471 Read Ahead Manager 559 Report Builder 645 Report Catalog 643 Report Definition Language (RDL) 641 Report Designer 645 Report Manager 642 Report Server 642 Report Server Project Wizard 645 Resource Governor 581 s SGML 678 Snapshot Agent 506 A Авторизация 23, 327, 352 Авторская деятельность 75 Агрегация 598 0 кумулятивная 623 Адресное пространство 560 Анализ запроса 521 Аналитические задачи 38 Аргументы поиска 520 Аспект 436 Атрибут: 0 FILESTREAM 94 0 Атомарный 30 SQL Server Authentication 59 SQL Server Profiler 571 SQL/OLAP617 u URI, унифицированный идентификатор ресурса 682 w Web-браузер 677 Web-сервер 677 Windows Authentication 59 Well-Known Text (WKT) 711 X XML 678 0 атрибуты 681 0 пространство имен 682 XPath 705 XQuery 705 XSD 685 XSL 685 Аутентификация 23, 326, 327 0 Доверительная 327 0 режим Windows 43 0 смешанный режим 43 Б База данных: 0 master 419 0 model 420 0 msdb 421 0 tempdb420 0 безопасность 23
Предметный указатель
719
О восстановление 456
О высокая доступность 470
0 зеркальная 474
0 зеркальное отображение 474
О мгновенный снимок 117
0 многомерная 597
0 модель восстановления 466
0 оперативная 588
0 соединение с сервером 118
0 создание 114
0 физическое проектирование 554
Бизнес-правила 402
Блокировка 379
0 взаимная 386
0 гранулярность 382
0 диапазона ключей 391
0 защелка 381
0 исключительная 380
0 на уровне страниц 380
0 на уровне строки 383
0 на уровне таблицы 383
0 обновления 381
0 разделяемая 380
0 режимы 380
0 с намерением 382
0 укрупнение 383
В
Ввод/вывод:
0 логический 559
0 физический 559
Владение схемой 337
Восстановление базы данных 456
0 master 465
0 автоматическое 456
0 до отметки 464
0 ручное 457
0 системной 466
Выборка 149
Выделенная единица 427
Выделенное соединение 54
0 администратора 268
Выражение CASE 185
Г
Глобальный уникальный идентификатор
GUID 95
Грязное чтение 379
д
Данные:
0 копирование и восстановление 22
0 логическая независимость 21
0 пространственные 708
О распределенные 499
О статистические 519
° индекса 524
° столбца 525
0 физическая независимость 21
Декартово произведение 198
Декомпозиция хранения 688
Денормализация:
0 данных 554
0 таблиц 554
Дескриптор плана 540
Динамическое управление дисковым
пространством 68
Директива 703
0 ELEMENTS 704
0 ROOT 704
0 TYPE 703
Дисковые операции ввода/вывода 557
Документ, достоверный в схеме 694
Долгота 709
Домен 133
3
Заголовок страницы 423
Запрос:
0 внешний 164
0 внутренний 164
0 выполнение 521
0 компиляция 520
0 нерекурсивный 211
0 опорный 213
0 оптимизация 21
О план выполнения 21
0 покрывающий 288
0 рекурсивный 212
Зеркальное отображение 472
720
Предметный указатель
И
Идентификатор 88
О с разделителями 87
Иерархия 611
Издатель 502
Измерение 595, 610
0 личное 606
0 разделяемое 606
0 связанное 606
0 согласованное 606
Именованный экземпляр 42
Индекс:
0 битовый 672
0 выбор 522
0 изменение 293
0 кластеризованный 284
0 некластеризованный 285
0 покрывающий 288, 297
0 простой 287
0 сканирование 531
0 создание 286
0 составной 287
0 фрагментация 290
Индексированные представления 287
Индексированные столбцы 522
Индексная страница 282
Инсталляция SQL Server 43
Интерфейс:
0 общий 269
0 собственный 275
Информационная схема 268
Источник 213
0 данных 607
° представление 608
Исходная таблица 364
К
Кандидат в ключи 26, 123
Каталог:
0 корневой 42
0 системный 267
Киоск данных 591
Класс:
0 SQLCommand 411
0 SQLConnection 411
0 SqIPipe4l4
0 StoredProcedure 411
Ключ:
0 асимметричный 331
0 внешний 74, 126
0 главный 329
0 первичный 26, 124
0 разделяющий 660
О' сертификата, общий 331
0 симметричный 330
Ключевое слово:
0 //IMPLIED 684
0 //REQUIRED 684
0 CONTENT 696
0 DOCUMENT 696
0 FOR РАТИ 692
0 FOR PROPERTY 692
0 FOR VALUE 692
0 ROWGUIDCOL 95
0 ROWVERSION.96
0 зарезервированное 88
Команда:
0 !! 432
0 DBCC 432
° CHECKALLOC 433
- CHECKCATALOG 433
° CHECKDB 433
° CHECKTABLE 433
° DBREINDEX 294
я MEMORYSTATUS 567
° PERFMON569
□ SHOWCONTIG 291
- USEROPTIONS 391
0 net 54
Комментарий 87
Консолидация данных 590
0 ETL 591
Контроль:
0 версий строк 391
0 по четности 473
Контрольная точка 456, 559
Контрольный журнал 401
Криптографические операторы 333
Куб 596,610
0 обработка 612
0 просмотр 615
0 создание 611
Куча 285
Предметный указатель
721
Л
Литерал 85
Логин 327
м
Метаданные 268
Метод:
О Add With Vai ие() 411
О existQ 705
О IsUpdatedColumnQ 411
О modifyQ 705
О nodes() 705
О queryO 705
О STContains() 714
О STGeomFromText() 710
О STIntersectsQ 715
О STLength() 714
О STLineFromText() 711
О STPointFromText() 711
О STPolyFromText() 711
О ToString() 714
О value() 705
Методы XQuery 705
Множество экземпляров 43
Модель:
О конкурентного доступа 372
О пространственных данных:
° геодезические 708
° плоские 708
0 "сущность — отношение" 31
Мониторинг:
0 производительности 562
0 реального времени 570
Мощность отношения 33
н
Набор:
0 объектов 435
0 резервной копии 457
Неповторяемое чтение 388
Нормализация 28
Нормальная форма 29
0 1NF, первая нормальная форма 29
0 2NF, вторая нормальная форма 30
0 3NF, третья нормальная форма 31
О
Обработка событий 243
Обработчик запросов 642
Образы 379
Общее табличное выражение (ОТВ) 210
Ограничение:
0 CHECK 134
0 доступа к данным 366
0 на уровне столбца 123
0 на уровне таблицы 123
0 ссылочной целостности 128
0 целостности 122
Оперативные задачи 38
Оператор:
0 ALL 167
0 ALTER APPLICATION ROLE 349
0 ALTER ASSEMBLY 255
0 ALTER ASYMMETRIC KEY 331
0 ALTER AUTHORIZATION 340
0 ALTER DATABASE 136
0 ALTER FUNCTION 263
0 ALTER INDEX 293
0 ALTER LOGIN 335
0 ALTER PROCEDURE 250
0 ALTER ROLE 351
0 ALTER SCHEMA 340
0 ALTER TABLE 139
0 ALTER TRIGGER 399
0 ALTER USER 338
0 ALTER VIEW 308
0 ALTER XML SCHEMA
COLLECTION 695
0 AND 153
0 ANY 167
0 APPLY 217, 262
0 ATTLIST684
0 BACKUP DATABASE 448
0 BACKUP LOG 450
0 BEGIN 239
0 BEGIN DISTRIBUTED
TRANSACTION 375
0 BEGIN TRANSACTION 375
0 BETWEEN 157
0 BREAK 241
0 BULK INSERT 429
722
Предметный указатель
Оператор (ирод.)-.
О CATCH 244
О COMMIT 375, 442
О CONTINUE 241
О CREATE APPLICATION ROLE 349
О CREATE ASSEMBLY 253, 255
0 CREATE CERTIFICATE 332
0 CREATE DATABASE 114
0 CREATE FUNCTION 257
0 CREATE INDEX 132, 286
0 CREATE LOGIN 334
0 CREATE MASTER KEY 329
0 CREATE PARTITION FUNCTION
664
0 CREATE PARTITION SCHEME 666
0 CREATE PROCEDURE 246
0 CREATE ROLE 351
0 CREATE SCHEMA 338
0 CREATE SPATIAL INDEX 712
0 CREATE SYNONYM 133
0 CREATE TABLE 119
0 CREATE TRIGGER 132,398
0 CREATE TYPE 134
0 CREATE USER 338
0 CREATE VIEW 304
0 CREATE XML SCHEMA
COLLECTION 694
0 CROSS APPLY 541
0 CROSS JOIN 191
0 CUBE 624
0 DECLARE 241
0 DELETE 230
0 DENY 358
0 DROP 143
0 DROP APPLICATION ROLE 349
0 DROP ASSEMBLY 255
0 DROP ASYMMETRIC KEY 331
0 DROP DATABASE 143
0 DROP FUNCTION 263
0 DROP INDEX 295
0 DROP LOGIN 335
0 DROP PROCEDURE 251
0 DROP ROLE 351
0 DROP SCHEMA 340
0 DROP SYMMETRIC KEY 330
0 DROP SYNONYM 143
0 DROP TABLE 143
0 DROP TRIGGER 399
0 DROP TYPE 143
0 DROP USER 342
0 DROP VIEW 308
0 DROP XML SCHEMA COLLECTION
695
0 ELEMENT 684
0 END 239
0 EXECUTE 248
0 FULL OUTER JOIN 191
0 GO 248
0 GOTO 243
0 GRANT 353
0 GRANT CREATE FUNCTION 258
0 GRANT CREATE PROCEDURE 247
0 GROUPING SETS 628
0 IF 239
0 IN 156,165
0 INNER JOIN 191
0 INSERT 222
0 JOIN 190
0 LEFT OUTER JOIN 191 ,
0 LIKE 160
0 MERGE 233
0 NOT 152
0 OR 152
0 PIVOT 637
0 PRINT 240
0 RAISERROR 243
0 RECONFIGURE 251
0 RESTORE DATABASE 459
0 RESTORE LOG 461
0 RETURN 243
0 REVOKE 360
0 RIGHT OUTER JOIN 191
0 ROLLBACK 375, 442
0 ROLLUP 627
0 SAVE TRANSACTION 375
0 SELECT 148
0 SET 242, 529
0 SET DATEFORMAT 91
0 TRUNCATE TABLE 232
0 TRY 244
0 UNPIVOT 637
0 UPDATE 227
Предметный указатель
723
О USE 117
О WAITFOR 243
О WHILE 240
О WITH 211
О логический 152
О над множествами 181
° INTERSECT 184
° UNION 181
° EXCEPT 184
О обмена 428
О скалярный 107
О сравнения 164
Операция:
О бинарная арифметическая 108
О унарная арифметическая 108
Оптимизатор запросов 21
Оптимизация:
О запроса 520
О тривиальный план 521
Опция:
0 -7 431
О ALLOWPAGELOCKS 289
О ALLOW_ROW_LOCKS 289
О ANSI_NULLS 319
О ANSI_PADDING 319
О ANSI_WARNINGS 319
О ASC287
О ASYMMETRIC KEY 335
О AUTO 384
О Auto Hide 62
О BLOCLS1ZE449
О BOUNDING BOX 712
О CERTIFICATE 335
О CHECKSUM 460
О CLUSTERED 287
О COMPRESSION 450
О CONCAT-NULL_YIELDS_NULL
111,319
О DEADLOCK-PRIORITY 387
О DEFAULT VALUES 223
О DELAY 243
О DESC287
О DIFFERENTIAL 449
О DISABLE 294, 384
О DISTINCT 153
О DROP_EXISTING 289
О EXTERNAL NAME 256
О FILEGROUP 461
О FILLFACTOR 288
О FORMAT 449
О GRANT OPTION FOR 360
0 1DENTITYJNSERT 180
0 IGNORE DUP-KEY 289
0 INCLUDE 287
0 INIT 449
0 LOCK_TIMEOUT 385
0 MEDIADESCRIPTION 449
0 MEDIANAME 449
0 MEDIAPASSWORD 449
0 MIRROR TO 448
0 MOVE TO 295
0 NO_CHECKSUM 460
0 NO_TRUNCATE 450
0 NOFORMAT 449
0 NO1NIT 449
0 NONCLUSTERED 287
0 NORECOVERY 460
0 NOSKIP 449
0 NOUNLOAD 449
0 NUMERIC_ROUNDABORT 319
0 ONLINE 289
0 OUTPUT 247
0 PADJNDEX 288
0 PARTIAL 461
0 PERSISTED 300
0 QUOTEDJDENT1FIER 319
0 REBUILD 294
0 RECOVERY 459
0 REORGANIZE 294
0 REPLACE 460
0 SHOWPLAN_ALL 530
0 SHOWPLAN_TEXT 530
0 SHOWPLAN_XML 531
0 SKIP 449
0 SORT IN TEMPDB 289
0 STANDBY 460
0 STATISTICS IO 532
0 STATISTICS PROFILE 532
0 STATISTICS TIME 532
0 STATISTICS XML 531
0 STATISTICS NORECOMPUTE 289
0 STOPAT 461
724
Предметный указатель
Опция (пред.)-.
О STOPATMARK 461
О STOPBEFOREMARK 461
О TABLE 384
О TIME 243
О TIMEOUT 243
О UNIQUE 287
О UNLOAD 449
О VIEW METADATA 304
О WINDOWS 334
О WITH CHECK 142
О WITH CHECK OPTION 311
0 WITH ENCRIPT10N 257
0 WITH GRANT OPTION 358
0 WITH NOCHECK 142
0 WITH RECOPILE 247
0 WITH SCHEMABINDING 257
0 XSINIL 704
Отказ дискового накопителя 442
Отказоустойчивая кластеризация 474
Отмена действий 379
Отслеживание изменений 327, 363
Отчет:
0 кэширование 654
0 матричный 648
0 мгновенный снимок 654
0 параметризованный 652
0 по запросам 655
0 создание 644
0 табличный 648
Очистка данных 591
Ошибка:
0 определенная пользователем 495
0 программной страницы 561
0 системная 489
0 страницы диска 561
п
Пакет 238
Память 557, 560
Параллельное выполнение запросов 669
Параметр QUOTEDJDENTIFIER 87
Переменная:
О ©©CONNECTIONS 108
0 @@CPUJBUSY 108
0 @@ERROR 109,374
0 ©©IDENTITY 109
0 @@LANGID 109
0 ©©LANGUAGE 109
0 @@MAX_CONNECTIONS 109
0 @@PROCID 109
0 @@ROWCOUNT 109
0 @@SERVERNAME 109
0 @@SPID 109
0 @@trancount 378
0 @@VERSION 109
0 глобальная 108
0 локальная 241
Пересылка протокола 476
Перехват изменения данных 363
План выполнения:
0 XML531
0 графический 533
0 запроса 519
0 текстовая форма 529
Планарные модели 709
Повторное выполнение действий 379
Подзапрос 164
0 замкнутый 164
0 коррелированный 164,204
0 многоуровниевый вложенный 166
0 преимущества 207
Подкачка страниц по запросу 561
Подписка:
0 на отчет 656
0 на репликацию 504
0 по запросу 504
0 принудительная 504
Подписчик 502
Подпрограмма 238
Подсказка:
0 FAST 548
0 FORCE ORDER 546
0 FORCESEEK 545
0 HASH 546
0 INDEX 523, 544
0 LOOP 545
0 MERGE 546
0 NOEXPAND 545
0 OPTIMIZE FOR 548
725
Предметный указатель
О блокировки:
° HOLDLOCK 385
- NOLOCK385
о PAGELOCK385
° READPAST 385
= ROWLOCK 385
" TABLOCK (TABLOCKX) 385
□ UPDLOCK384
° XLOCK385
О запроса 548
О оптимизатора 542
О соединения 545
О таблицы 543
Поиск по индексу 531
Полномочия 348
Последовательный номер транзакции
XSN 392
Потеря обновлений 388
Предложение:
О ADD CONSTRAINT 140
0 ADD FILE 137
0 AFTER datetime 465
0 ALL SERVER 408
0 ALTER COLUMN 140
0 AS SNAPSHOT OF 117
0 CHECK 126
0 COMPUTE 187
0 CREATE FILEGROUP 137
0 DATABASE 407
0 DEFAULT 121,249
0 DELETE FILEGROUP 137
0 DROP COLUMN 139
0 DROP CONSTRAINT 141
0 EXECUTE AS 247
0 EXTERNALACCESS 255
0 FOR XML 698
0 FOREIGN KEY 126
0 FROM 313, 315, 334
0 GEOGRAPHY GRID 712
0 GEOMETRY GRID 712
0 GROUP BY 168
0 HAVING 176
0 IMPLICIT TRANSACTION 377
0 MODIFY FILE 137
0 ORDER BY 177
0 OVER 621
0 PARTITION BY 620
0 PRIMARY KEY 124
0 REFERENCES 126
0 REMOVE FILE 137
0 RETURNS 257
0 SCHEMABINDING 304
0 TOP 634
0 TRANSACTION ISOLATION LEVEL
391
0 UNIQUE 123
0 VALUE 225
0 WHERE 150,296
0 WITH MARK 465
0 WITH PERMITION SET 255
Представление 132, 303
0 information_schema.columns 274
0 information_schema.referential_constrai
nts 275
0 informationschema.tables 274
0 sys.allobjects 270
0 sys.columns 270
0 sys.database_permissions 360
0 sys.database_principals 270
0 sys.databases 469
0 sys.dm_db_index_physical_stats 291
0 sys.dm_db_index_usage_stats 292
0 sys.dm db missingjndex details 293
0 sys.dmexecconnections 569
0 sys.dmexecprocedurestats 541
0 sys.dm_exec_query_optimizer_info 539
0 sys.dm_exec_query_plan 540
0 sys.dm exec_query_stats 541
0 sys.dmexecrequests 565
0 sys.dm_exec_sessions 320,409
0 sys.dmexecsqltext 541
0 sys.dm_exec_text_query_plan 541
0 sys.dm os memory clerks 567
0 sys.dm_os_memory objects 567
0 sys.dm_os_wait_stats 568
0 sys.dmtranlocks 386
0 sys.index columns 292
0 sys.indexes 292
0 sys.objects 270
0 sys.plan guides 550
726
Предметный указатель
Представление (прод.):
О sys.procedures 251
О sys.sp_estimated_rowsize_reduction_
for_vardecimal 98
О sys.spatial_indexe_tessellations 713
О sys.spatial indexes 713
О sys.stats 526
О sys.statscolumns 526
О sys.sysprocesses 565
О sys.system.objects 270
О sys.xmlindexes 693
О sys.xml_schema_attributes 696
О sys.xml_schema_components 696
О sys.xmlschemaelements 696
О динамически управляемое 268
О индексированное 317
О каталогов 268
О источника данных 608
Представления совместимые 271
Предупреждающие сообщения 489
Принципал 337
О групповой 337
О индивидуальный 337
Провайдер данных 642
Прозрачное шифрование данных 333
Производительность 553
Пространство имен 133
0 Microsoft.SqlServer.Server 411
0 System.Data.SqlClient 411
0 XML 682
Протокол:
0 TCP/IP 40
0 Virtual Interface Adapter (VIA) 40
0 именованные каналы (Named Pipes)
40
0 общей памяти 39
0 сетевой 39
0 транзакций! 15, 136, 378
Процедура:
0 глобальная временная 248
0 локальная временная 248
0 системная 268
Процедурные расширения 238
Процессор отчетов 642
Псевдоним 149
0 типов данных 134
Публикация 503
Р
Разделение:
0 упорядоченное 660
0 хешированное 661
Разделитель 87
Размерность:
0 плотная 600
0 разряженная 600
Разрешение конфликта:
0 методом пользователя 508
0 методом приоритета 508
Распределение данных по разделам 659
Распространитель 502
Расслоение дисков 472
Расширенное управление
ключами 333
Редакции SQL Server 40
Режим:
0 AUTO 699
0 EXPLICIT 700
0 PATH 702
0 RAW 698
0 аутентификации:
° Windows 328
° смешанный 328
Резервное копирование:
0 базы данных master 454
0 динамическое 443
0 дифференцированное 444
0 полное, базы данных 444
0 производственных баз данных 455
0 протокола транзакций 444
0 с помощью Management Studio 451
0 статическое 443
0 файла 446
О файловой группы 446
Рекурсивные члены 213
Рендерер 642
Репликация:
0 данных 499
0 мгновенного снимка 505
0 модели 510
0 слияния 506
0 транзакций 505
° одноранговая 508
727
Предметный указатель
Роль 344
О public 347
О базы данных 344
° определенная пользователем 350
° фиксированная 346
0 приложений 348
0 сервера, фиксированная 344
С
Сбой оборудования 443
Свойство:
0 IDENTITY 121, 179
0 ROWGUIDCOL 507
Сервер:
О главный 474
0 зарегистрированный 60
0 зеркальный 474
0 регистрация 63
0 резервный 471
Сервис MSSQLSERVER 479
Сертификат 331
Сетевое окружение 557
Сетевой интерфейс 569
Символы Unicode 90
Синоним 132
Синтаксический разбор 520
Система:
0 аналитическая 589
0 информативная 589
Системная процедура 276
0 spaddmessage 495
0 sp addpublication 509
0 sp addrolemember 351
0 sp addumpdevice 485
0 sp_attach_db 118
0 sp_configure_peerconflictdetection 509
0 sp_control_plan guide 549
0 sp_create_plan_guide 549
0 sp createstats 524
0 sp_db_vardecimal_storage_format 97
0 sp_dboption 138
0 sp_depends 276
0 sp detach db 118
О sp_droprolemember 351
О sp_help 276
О sphelpindex 292
О sp helprole 351
О sp_helptext 309
О sp helptrigger 407
О sp lock 385
О sp monitor 565
О sp_rename 142
О sp_setapprole 349
О sp settriggerorder 406
О sp_spaceused 321
О sp_table_option 97
О sp_tableoption 94
О sp_xml_preparedocument 696
О sp xinl removedocument 697
Системная таблица:
О msmerge_contents 507
О msmerge_tombstone 507
Системная функция:
О DecryptByAsymKey 331
О DecryptByKey 330
О EncryptByAsymKey 331
О EncryptByKey 330
Системный администратор 345
Склад данных 587
Собственная форма хранения
документов XML 688
Совместное размещение таблиц 667
Соединение 190
О внешнее 199
О доверительное 328
О естественное 192
О неявный синтаксис 191
О полусоединение 204
О самосоединение 192,203
О слияние 527
О тета-соединение 202
О явный синтаксис 191
Средства управления безопасностью
339
Статья 503
Столбец 139
О вычисляемый 298
О детерминированный 299
Страницы данных:
О переполнения строк 425
О последовательных строк 425
728
Предметный указатель
Стратегия:
О нескольких потоков на раздел 669
О одного потока на раздел 669
Структура плана 549
О OBJECT 550
0 SQL 550
0 TEMPLATE 550
Сфероид 709
Схема 337
0 cdc 364
0 dbo 344
0 guest 343
0 INFORMATION-SCHEMA 344
0 sys 270
О информационная 273
О по умолчанию 344
0 разделения 660
т
Таблица 119
0 deleted 399
О inserted 399
О агрегатная 598
О временная 120,189
° локальная 189
О добавление одной строки 222
О дочерняя 127
О изменение 139
О измерений 594
О кластеризованная 284
О наследуемая 209
О родительская 127
О системная базовая 267
О сканирование 523
О создание 119
О фактов 594
Табличное выражение 208
Тип данных 88
0 B1GINT89
0 BINARY 93
О BIT 93
О CHAR 90
О DECIMAL 89
О FLOAT 89
О GEOGRAPHY 709
О GEOMETRY 709
О HIERARCHYID 96
О IMAGE 94
О INTEGER 89
О LOB93
О MONEY 89
О NCHAR 90
О NTEXT94
О NUMERIC 89
О NVARCHAR 90
О REAL 89
О SMALLINT89
О SMALLMONEY 89
О SQL VARIANT 95
О TABLE 260
О TEXT 94
О TIMESTAMP 96
О TINYINT89
О UNIQUEIDENTIFIER 95
О VARBINARY 93
О VARCHAR 90
О XML690
О даты и времени 90
О символьный 90
О смешанный 92
О числовые 89
Точка сохранения 376
Транзакция 373
О двухфазовое подтверждение 500
О распределенная 500
О свойства 374
О уровень изоляции 392, 387
Требования:
О к оборудованию 38
О к оперативной памяти 39
О к сети 39
Триггер 132
О AFTER 398,400
О connection limit trigger 409
О DDL 407
О DML398, 400
О INSTEAD OF 398, 404
О уровня базы данных 408
О уровня сервера 409
Предметный указатель
729
У
Упорядочение 622
Управление:
О доступом к данным 366
О экземплярами сервера 441
Управляемые объекты 435
Упреждающее чтение 559
Устройства резервного копирования 447
Утилита:
О Ьср428
О sqlcmd 430
Учетная запись:
0 sa345
0 владельца базы данных 115
0 пользователя 341
- guest 348
° Windows 327
Ф
Файловая группа 137
Фантомные записи 388
Фильтр 504
0 битовый 672
0 вертикальный 504
0 горизонтальный 504
Функциональная зависимость 28
0 тривиальная 28
Функция 100
0 ABSQ99
0 ACOS0 99
О ASCI10 102
О AS1N()99
О ATANQ99
О ATN2()99
О CAST() 105
О CEILING0 99
О CHAR() 102
О CHARINDEXO 102
О COALESCE0 105
О COL LENGTH0 105
О COL_NAME() 106
О COLUMNPROPERTY0 106,278
О CONVERT0 105
О COSO 99
О COUNT0307
О CURRENTTIMESTAMPO Ю5
О CURRENT_USERO Ю5
О DATABASEPROPERTY() 107
О DATALENGTHO 105
О DATEADD0 102
О DATED1FF0 102
О DATENAME0101
О DATEPARTO 101
О DBJD() 107
О DB_NAME0 107
О DEGREESO 100
О DENSE RANKO 630
О DIFFERENCEO 102
О EXISTS()205
О EXPO юо
О FILEPROPERTY0 278
О FLOOR0 ЮО
О GetAncestor() 96
О GETANSINULLO 105
О GETDATEO 101
О GetDescendant() 96
О GROUP1NG0 627
О 1NDEX_COL() 107
О INDEXPROPERTYO 107
О ISNULLO 105
О ISNUMERICO Ю5
О LEFT() 103
О LEN() 103
О LOG() 100
О LOG 100 ЮО
О LOWER0103
О LTR1MO 103
О NCHARO 103
О NEW1D0 105
О NEWSEQUENT1ALIDO 105
О NT1LEQ636
О NULL1FO106
О OBJ ЕСТ JD() 107
О OBJECT_NAME0 Ю7
О OBJECTPROPERTY() 107,278
О PATINDEXO 103
О Р1() ЮО
О POWER() 100
О QUOTENAMEO ЮЗ
О RADIANSO ЮО
О RAND0100
730
0 RANKO 630, 634
О Read()96
О REPLACEO 103
О REPLICATE() 103
О REVERSE() 103
О RIGHTO ЮЗ
О ROUNDO ЮО
О ROW_NUMBERO 630
О ROWCOUNT BIGO 101
О RTRIM() 103
О SERVERPROPERTYO 106
О SIGNO 101
О SIN() 101
О SOUNDEXO 104
О SPACEO 104
О SQRTO 101
О SQUAREO 101
О STR() 104
О STUFFO 104
О SUBSTRINGO 104
О SYSTEM USERO 106
О TAN() 101
О TYPEPROPERTYO 278
О UNICODEO 104
О UPPERO 104
О USERJDO 106
О USER_NAME() Ю6
О Write() 96
О агрегатная 98, 170, 307
° обычная 170
° определенная пользователем 176
- STDEV 176
° STDEVP 176
° VAR175
° VARP176
О даты 101
О динамически управляемая 268
О запросов OLAP 629
О метаданных 106
О определенная пользователем 264
О разделения 660
О с табличными параметрами 217
Предметный указатель
О свойств 278
О системная 104, 277
О скалярная 99
О строковая 102
О числовая 99
X
Хеширование соединения 528
Хранилище данных 590
Хранимая процедура 132, 245
О sp rename 136
О sys.spcdcenabledb 364
О sys.sp_cdc_enable_table 364
О системная 238
U
Целостность данных 21
Цепочка страниц 284
Цикл вложенный 526
ш
Широта 709
Шифрование данных 326, 329
О иерархические уровни 329
О прозрачное 333
О с помощью ключей 329
э
Экземпляр:
О документа 694
О по умолчанию 42
Экстент 383
О однородный 422
О смешанный 422
Эффективность кода приложения 553
Я
Язык определения отчетов 641